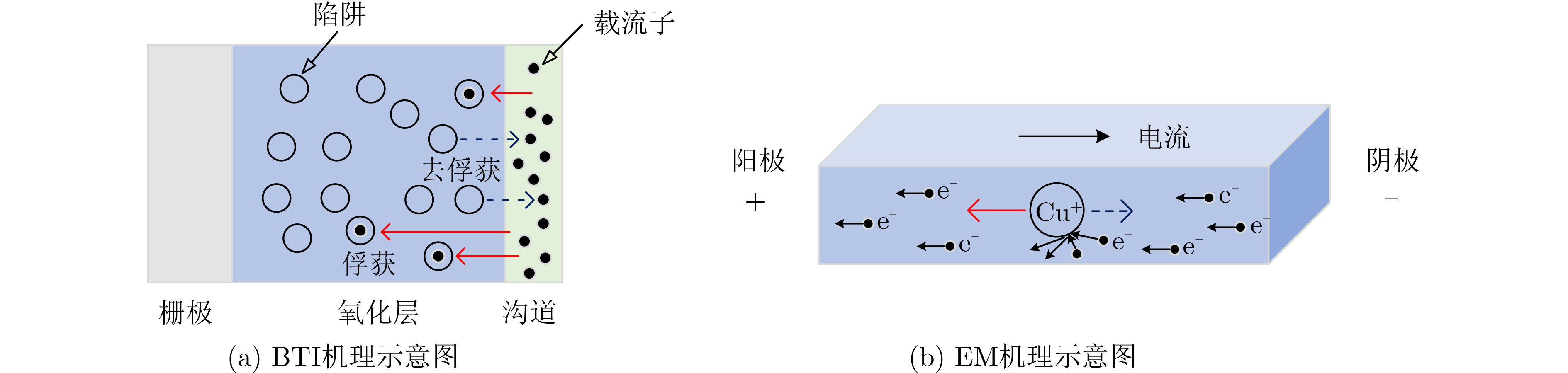
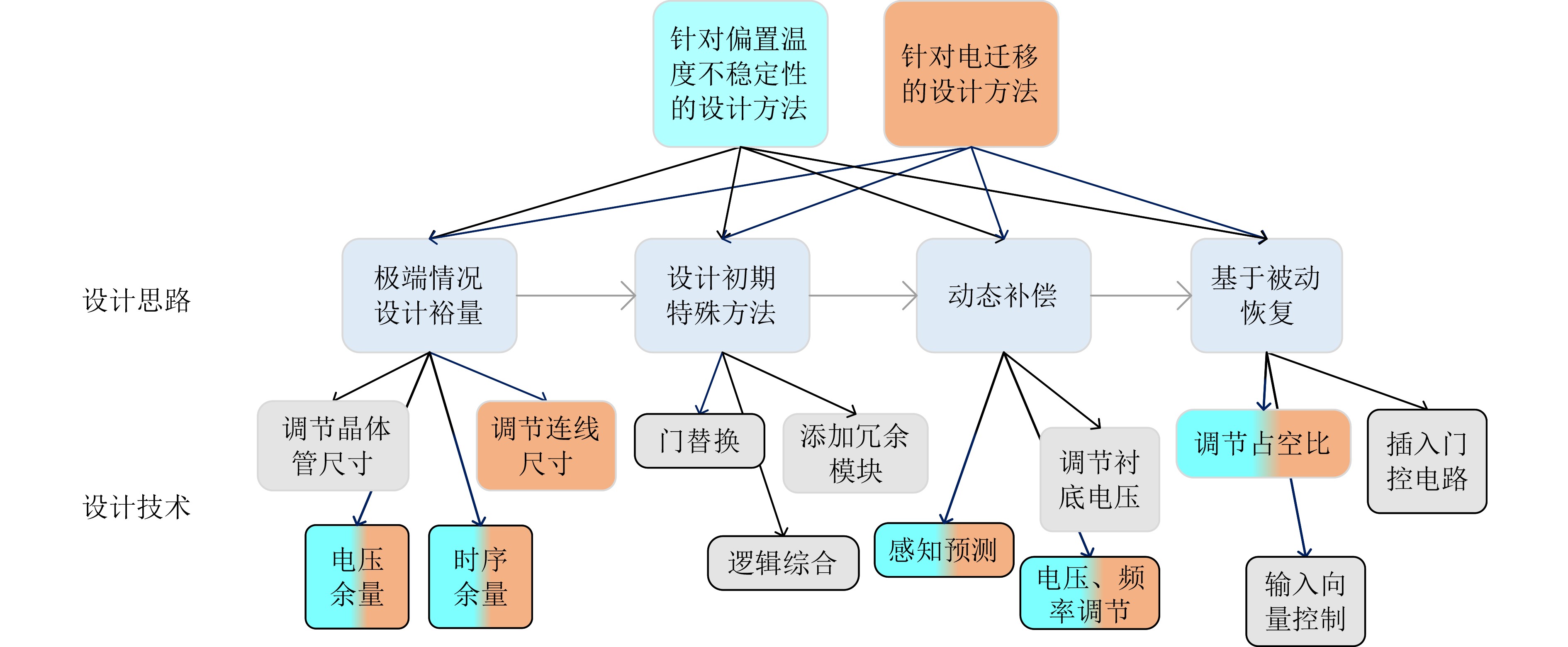
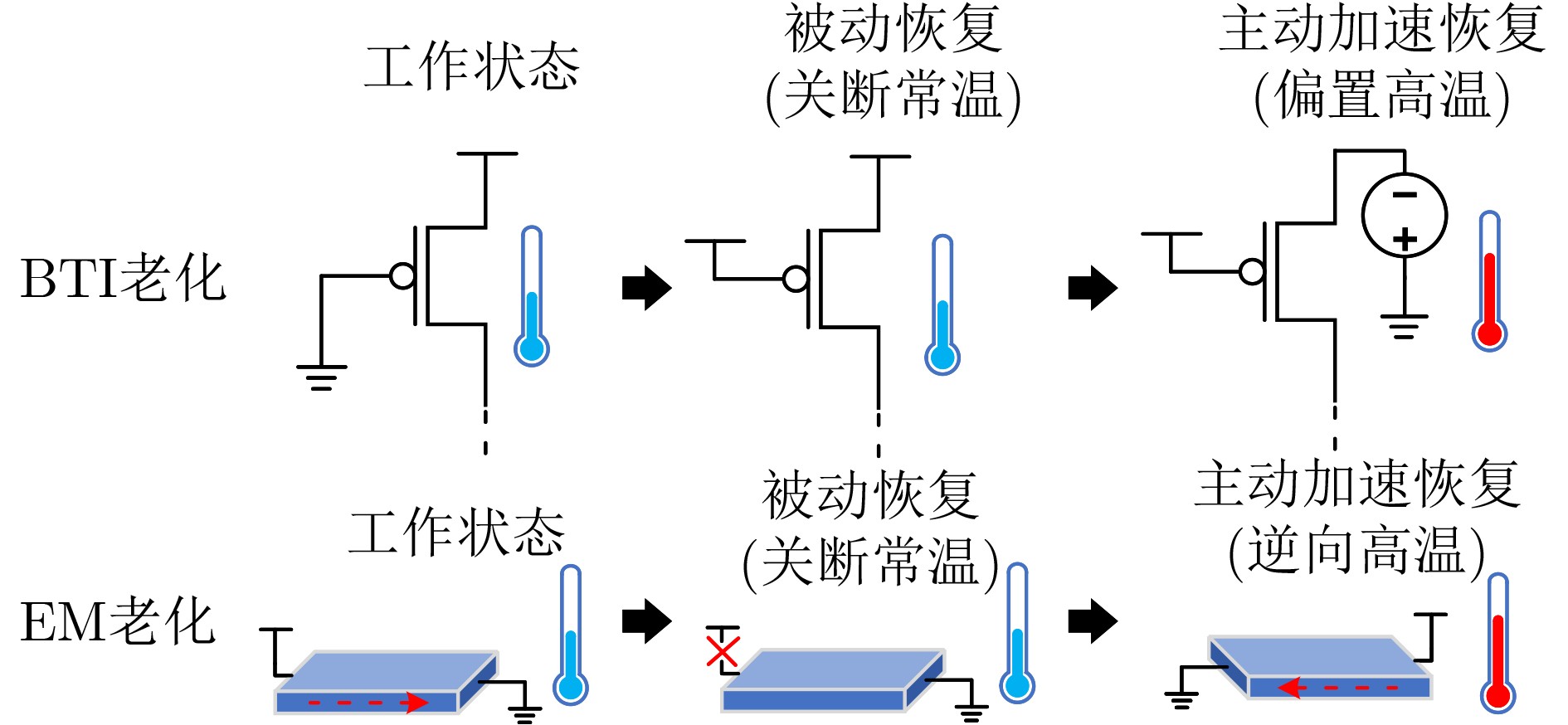
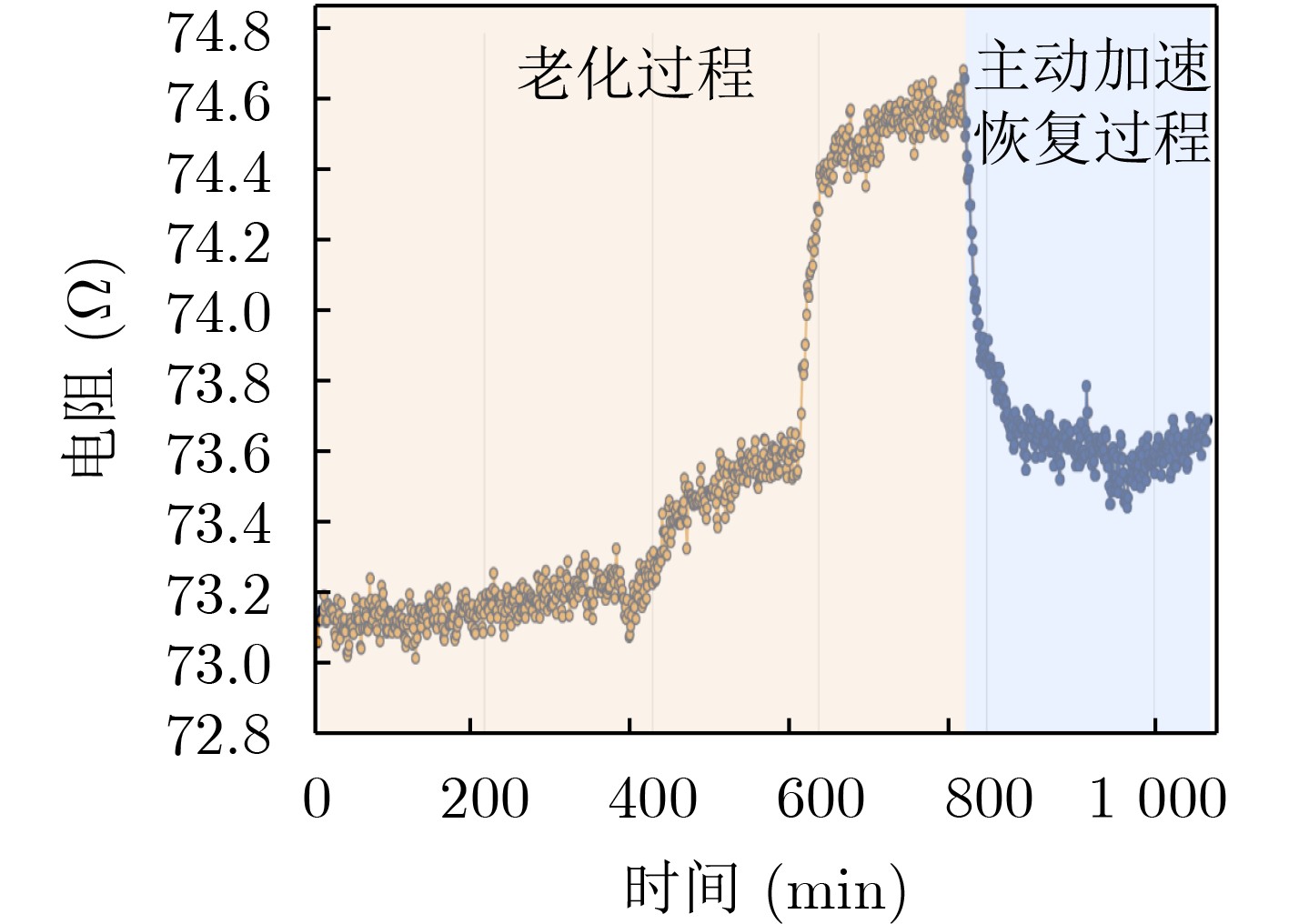
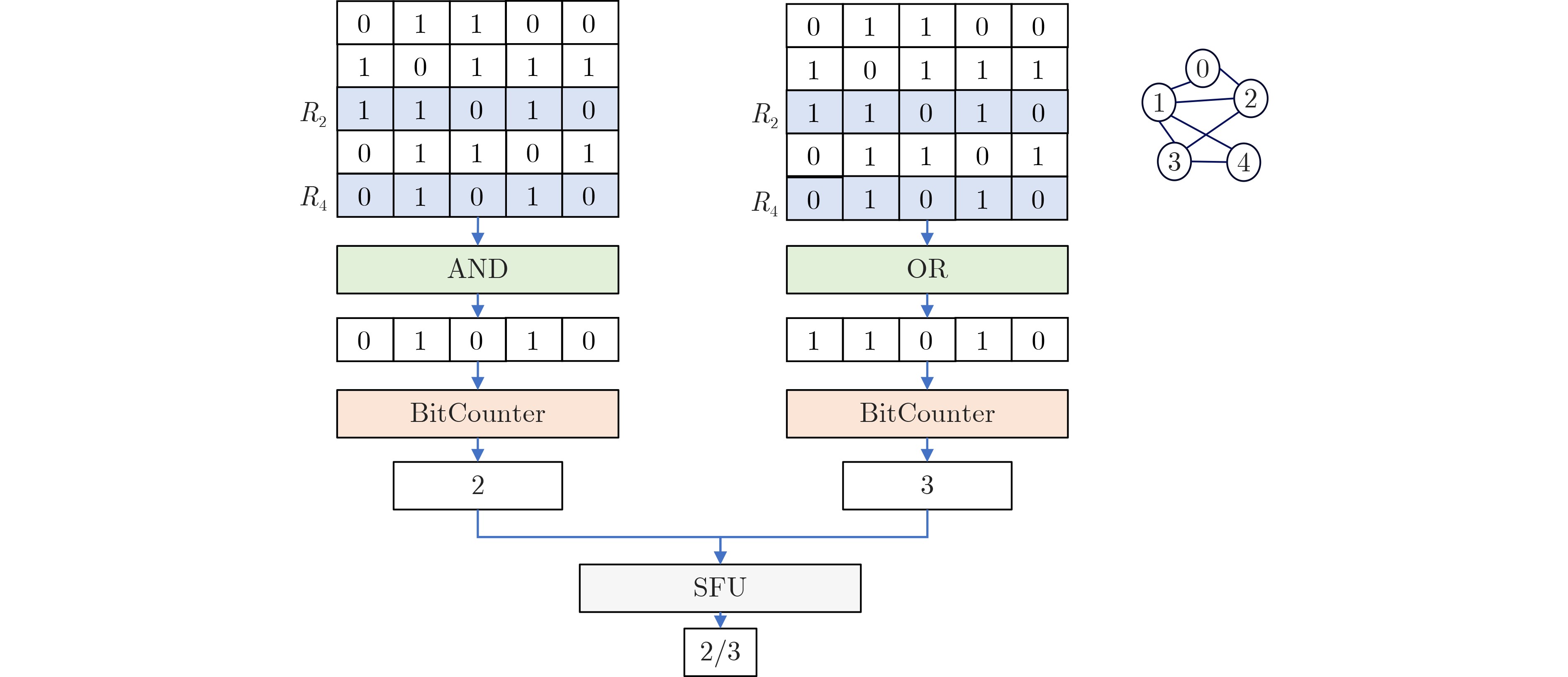
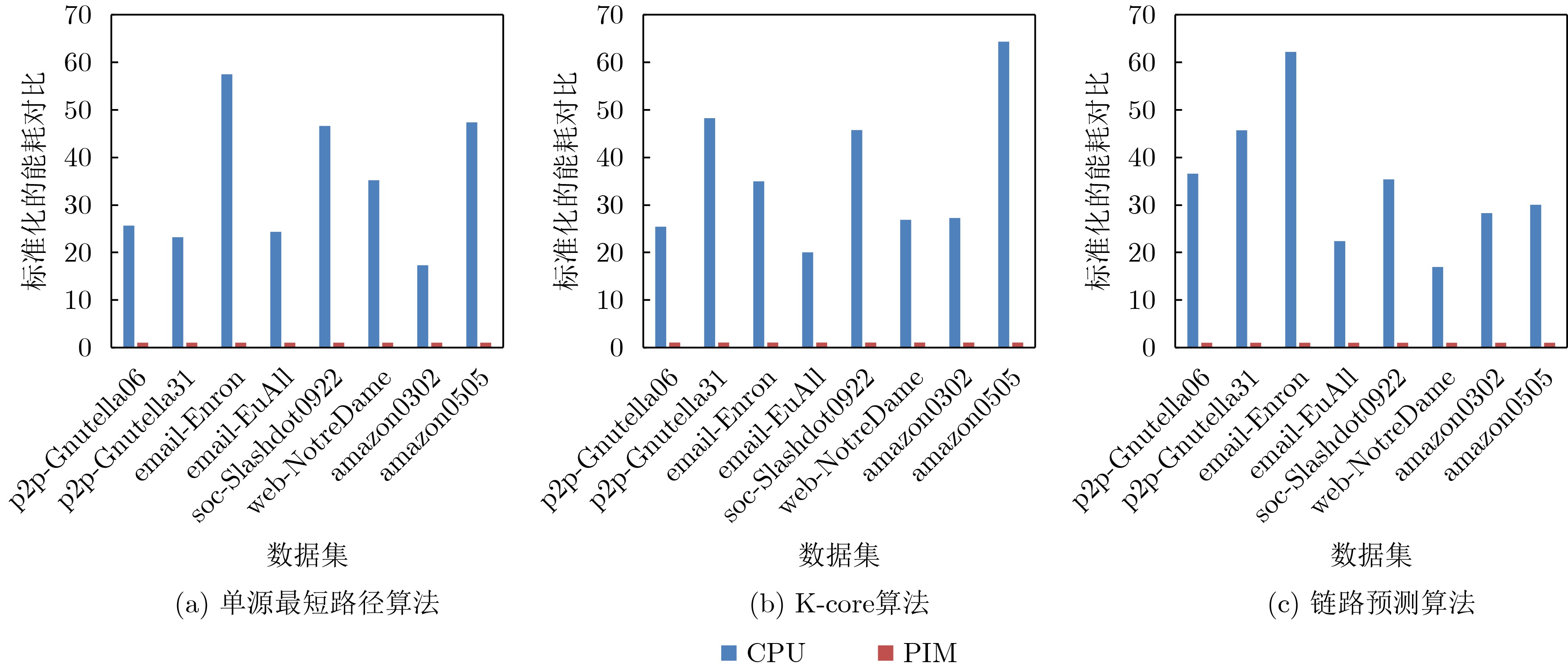
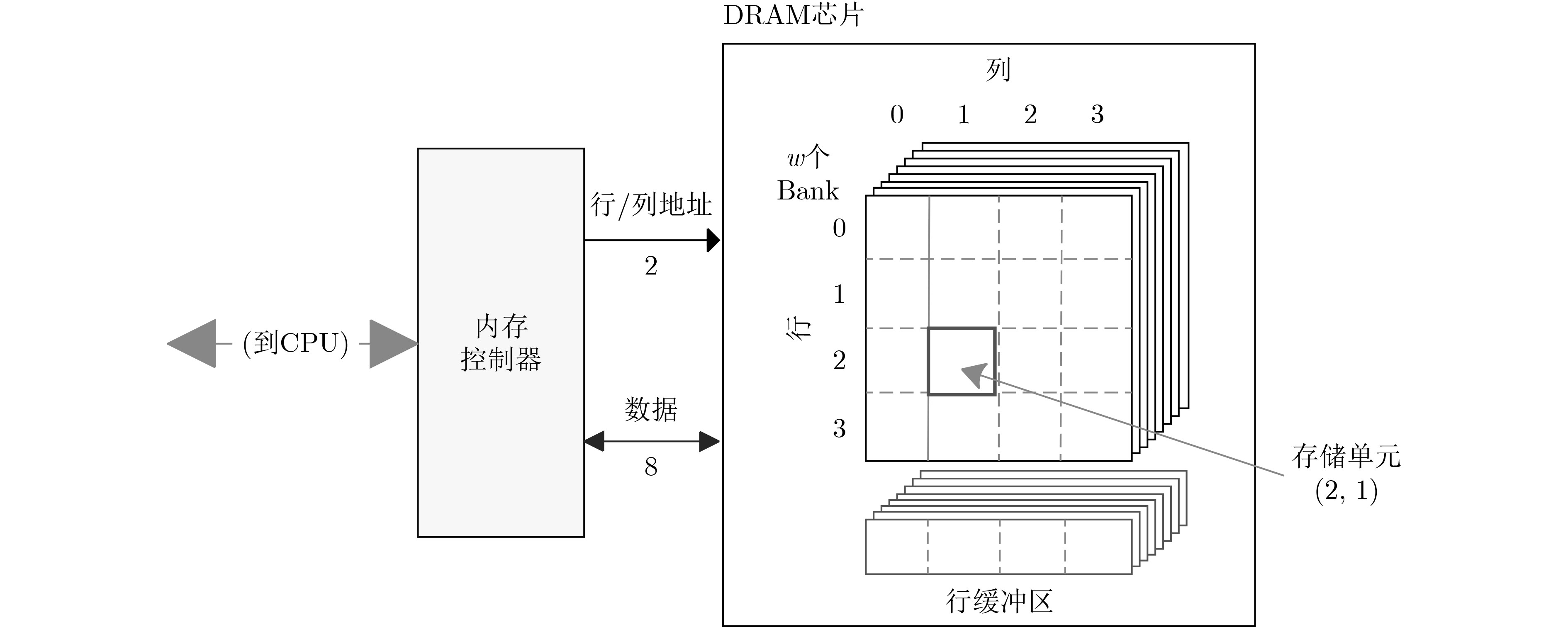
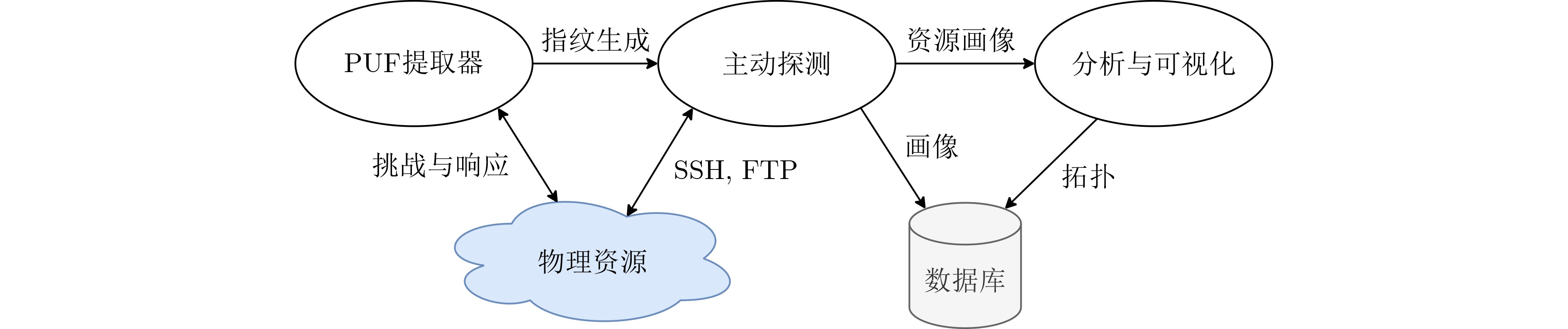
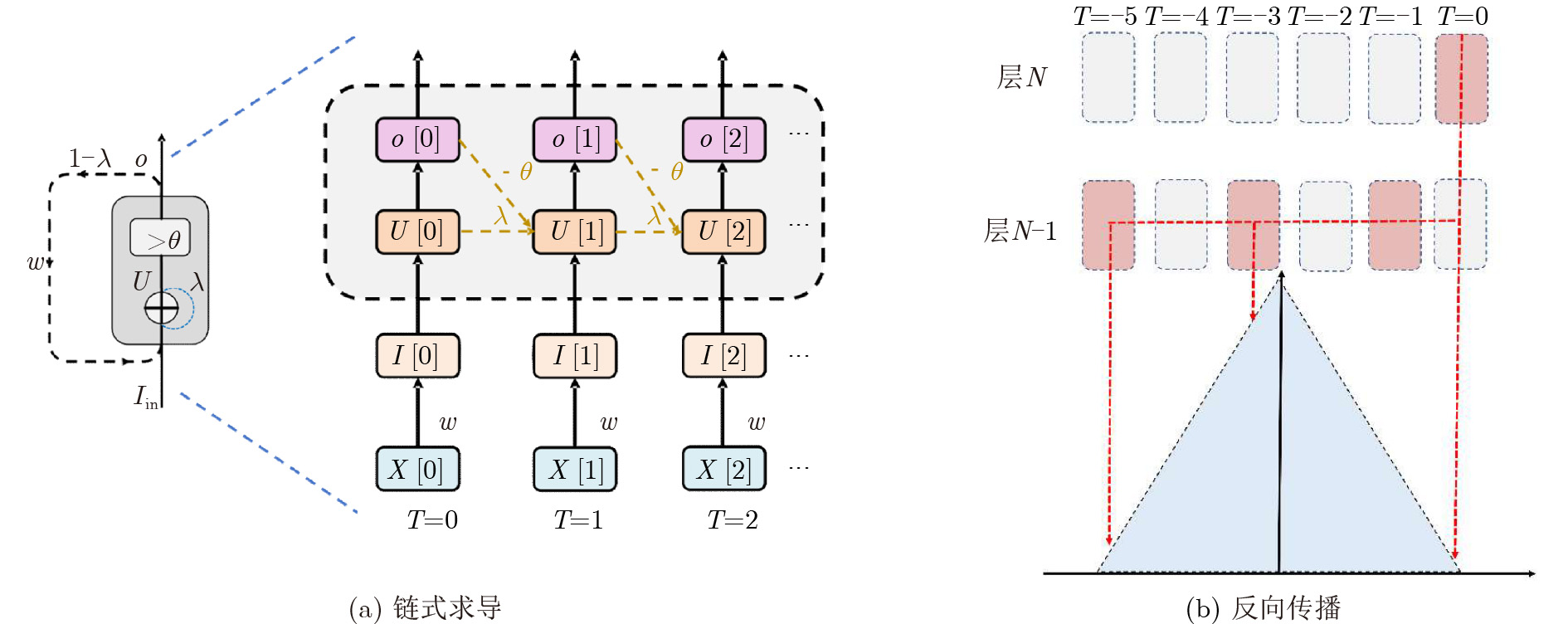
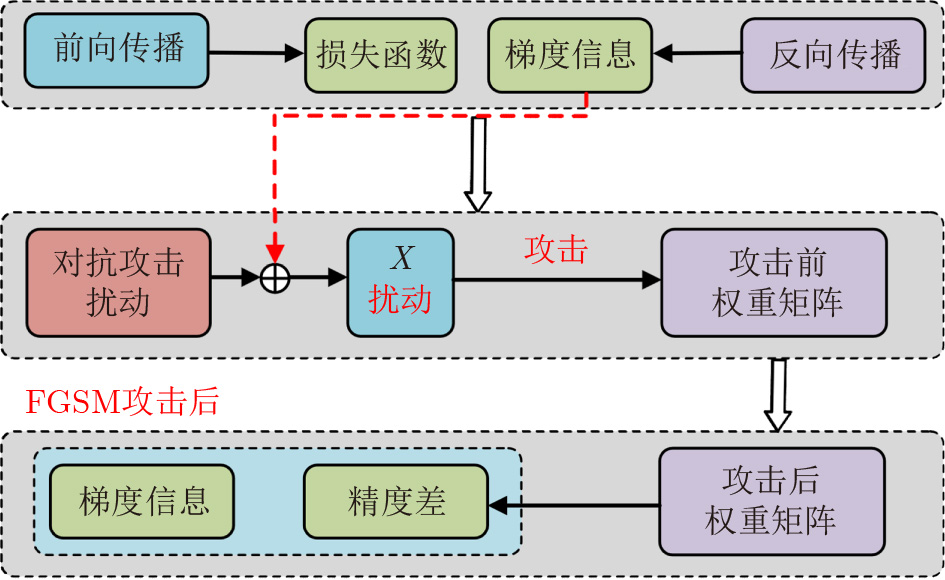
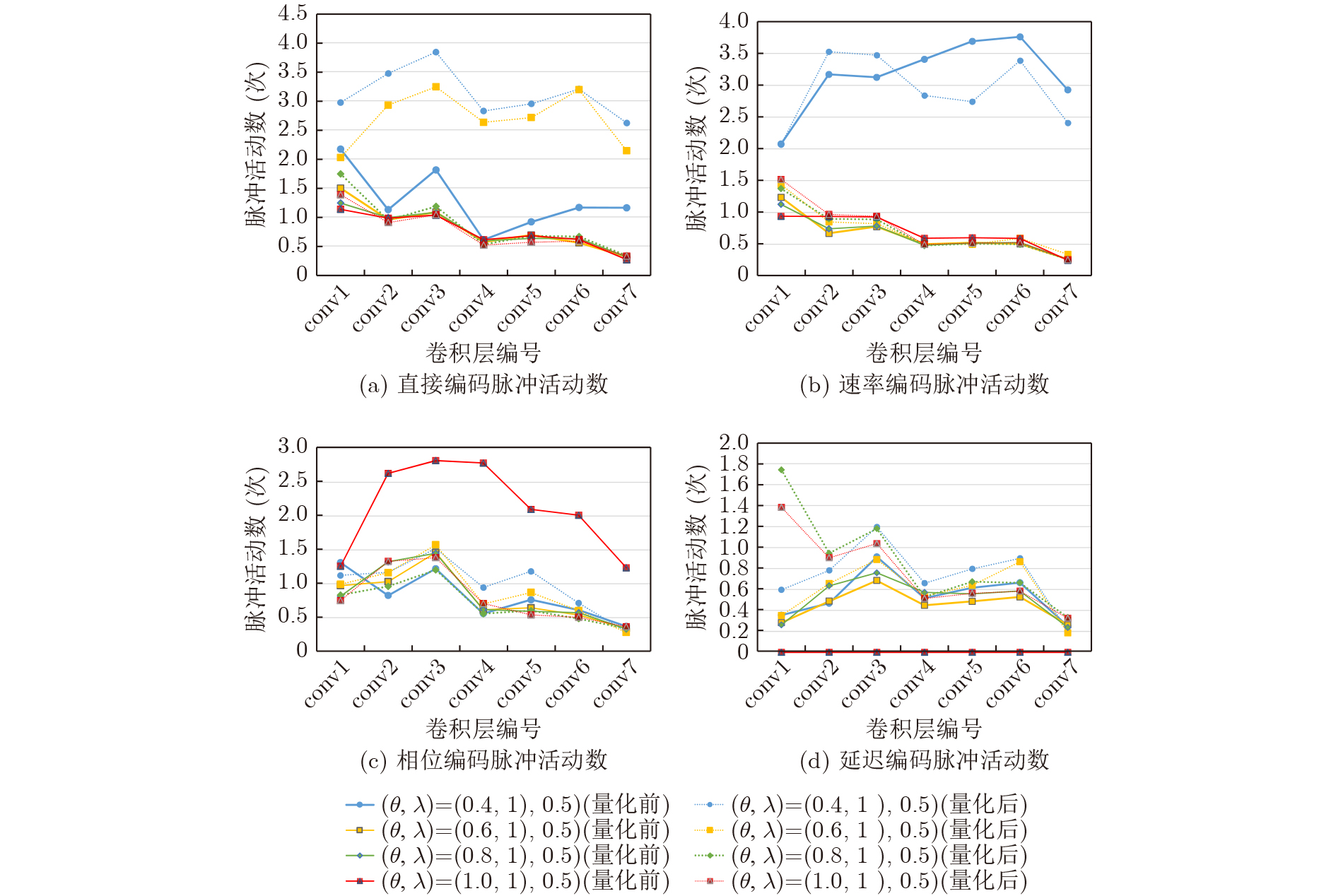
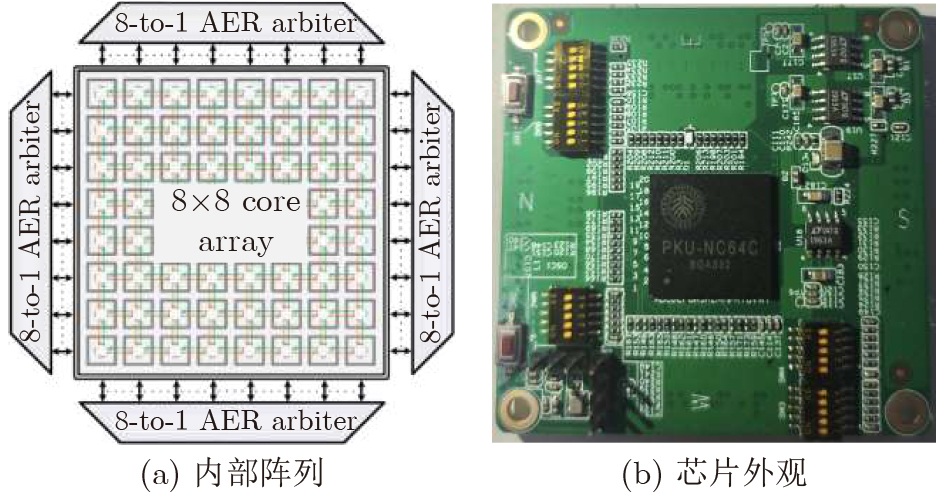
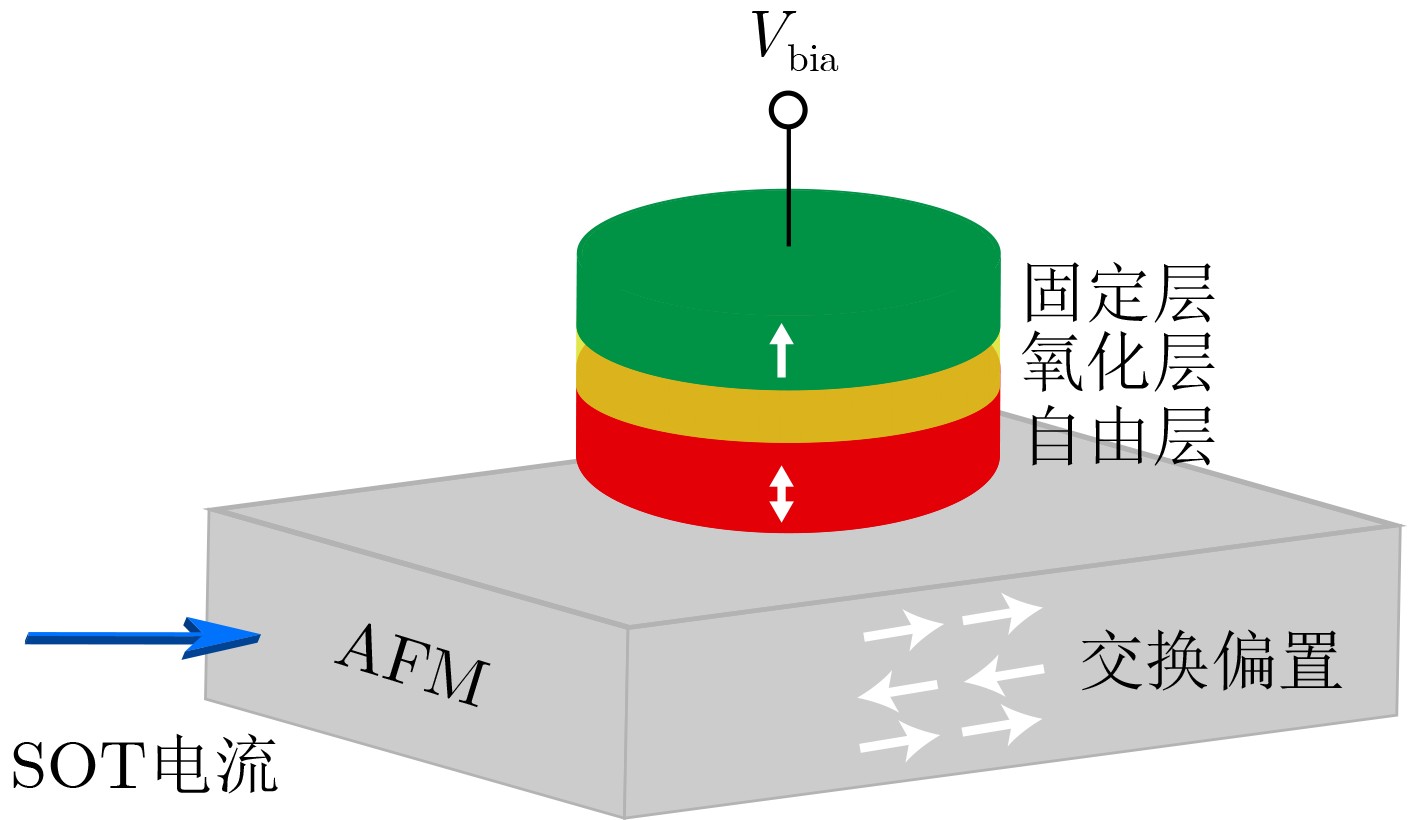
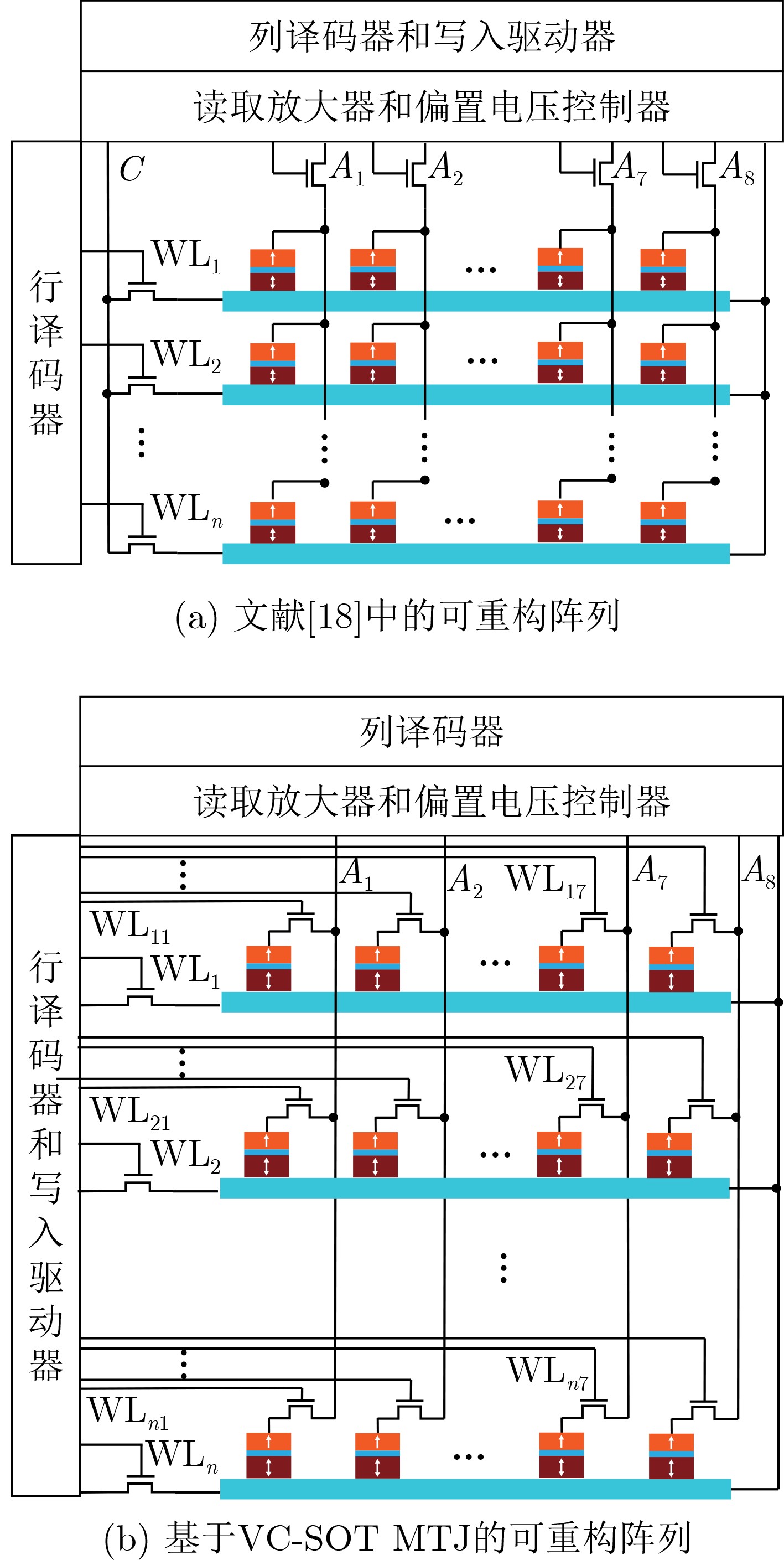
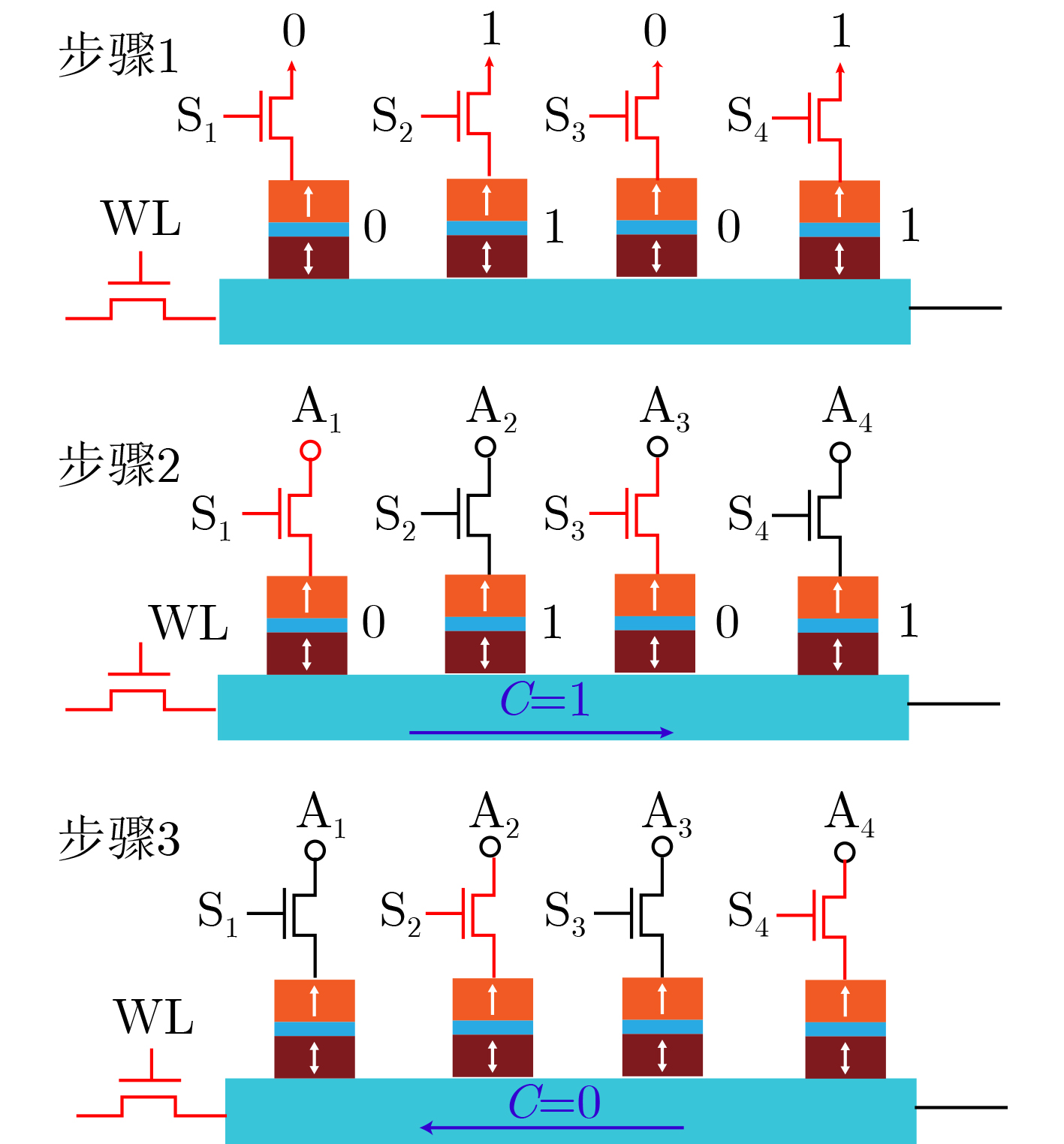
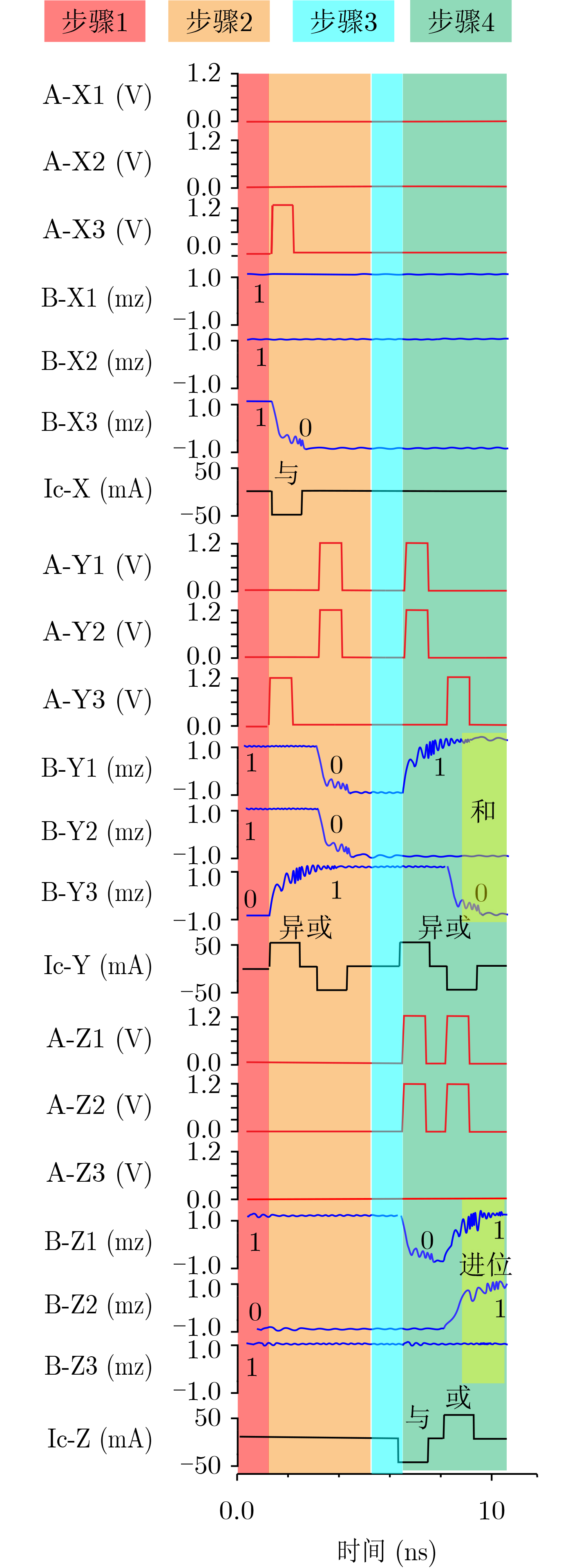
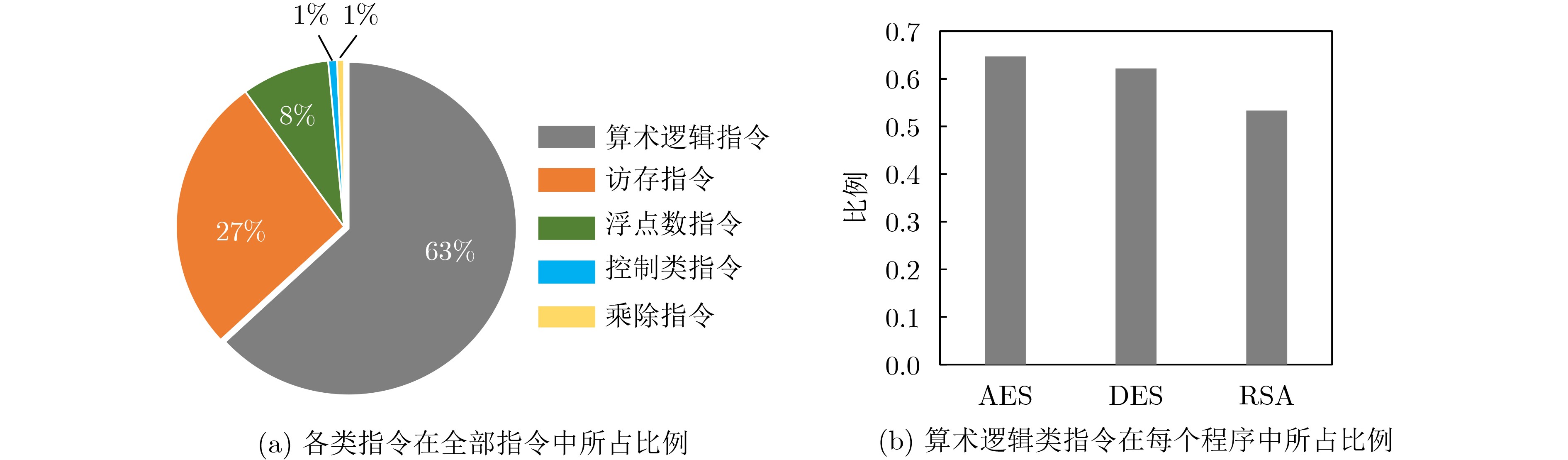
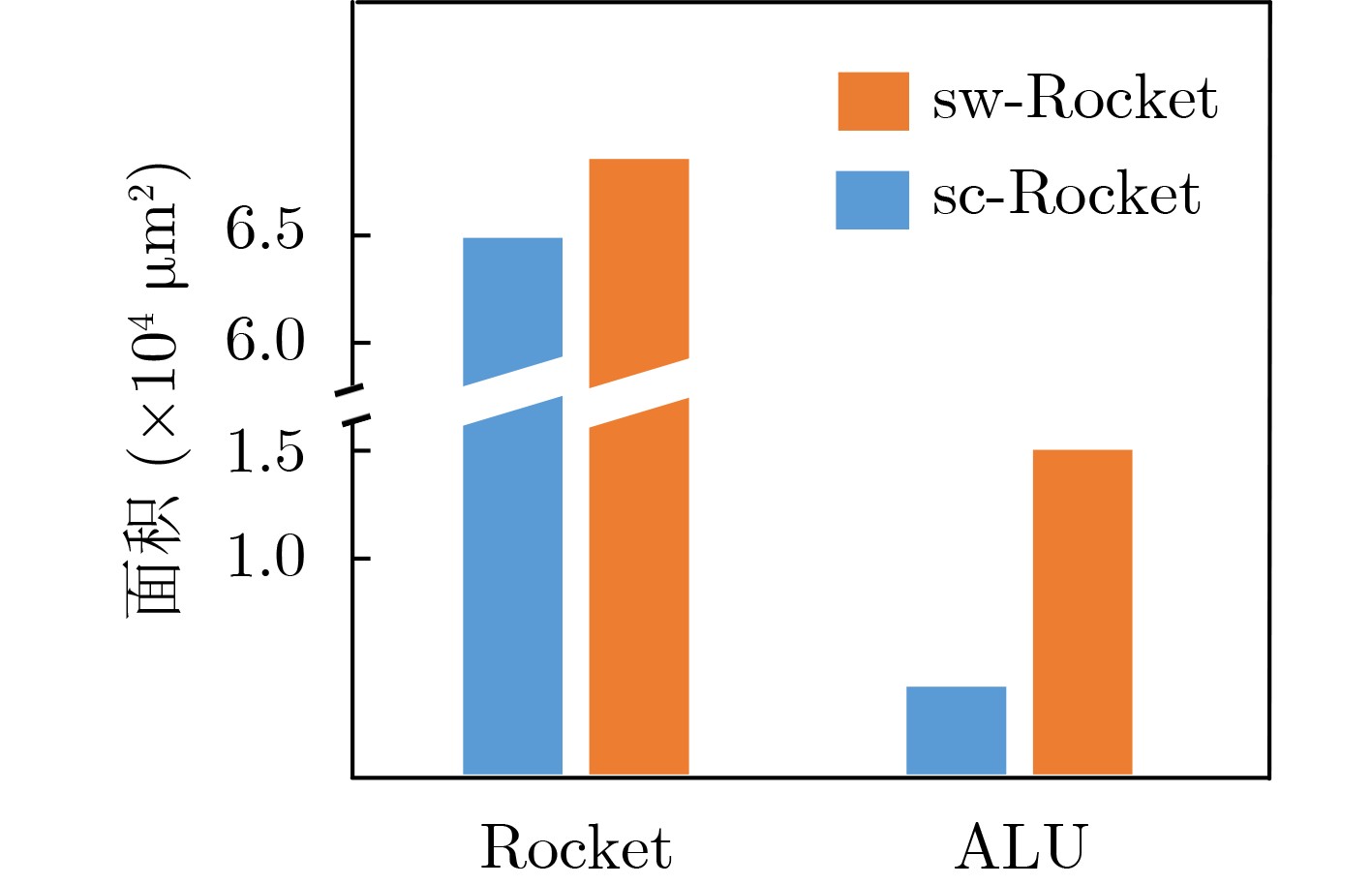
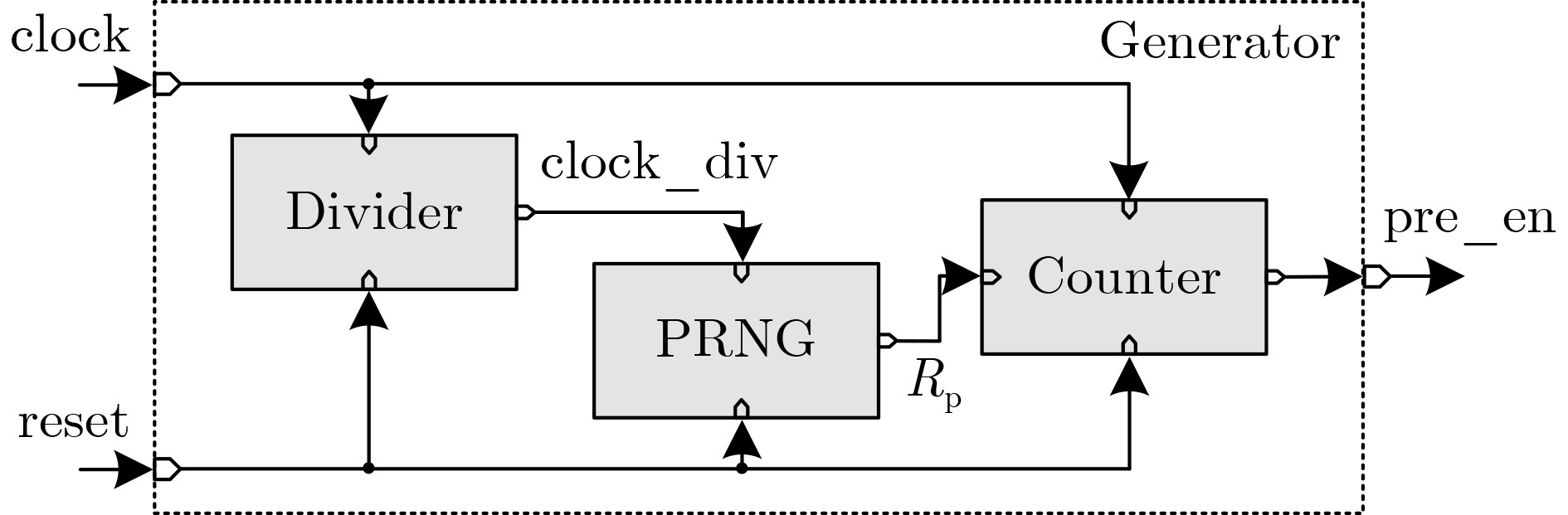
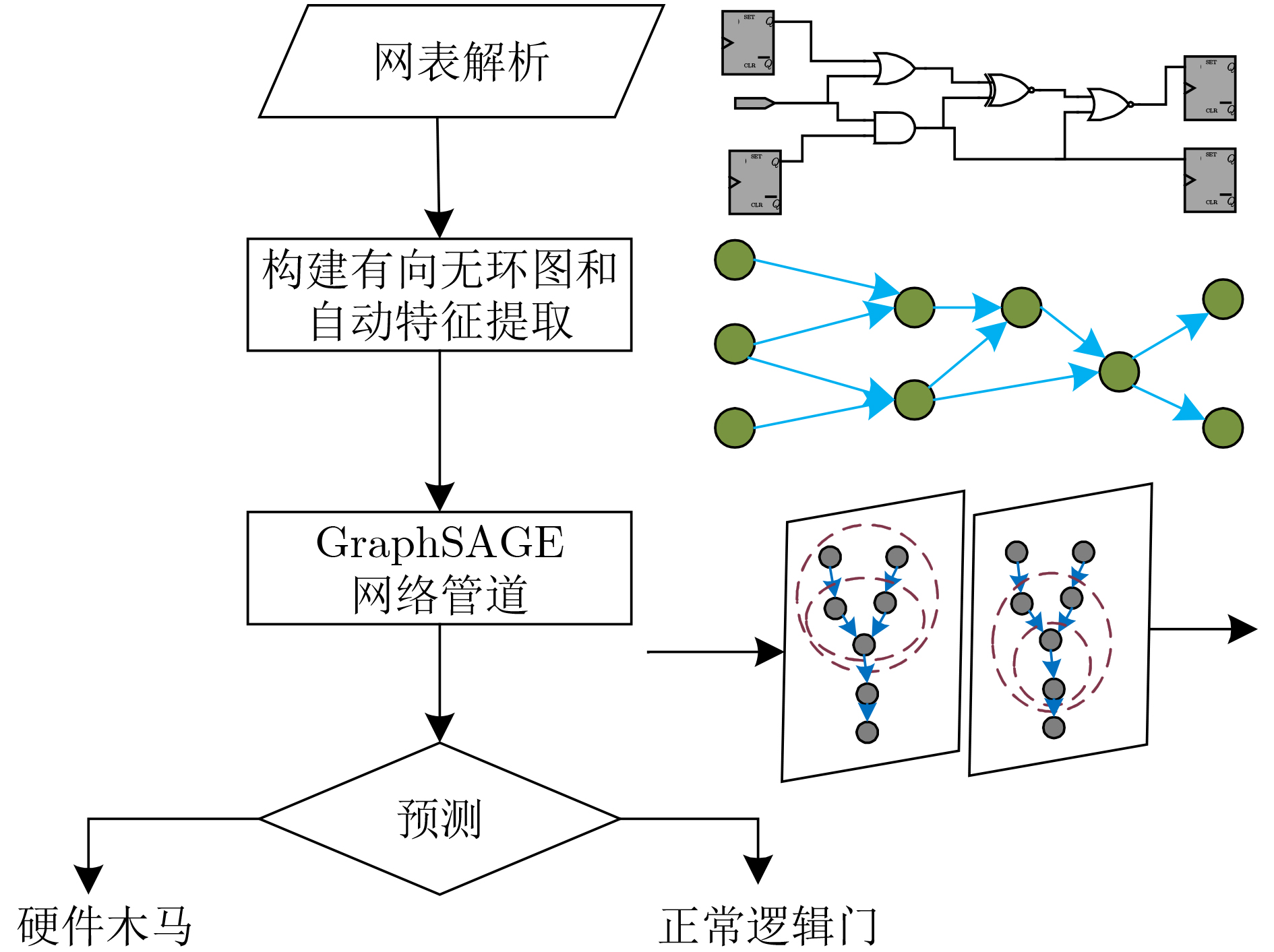
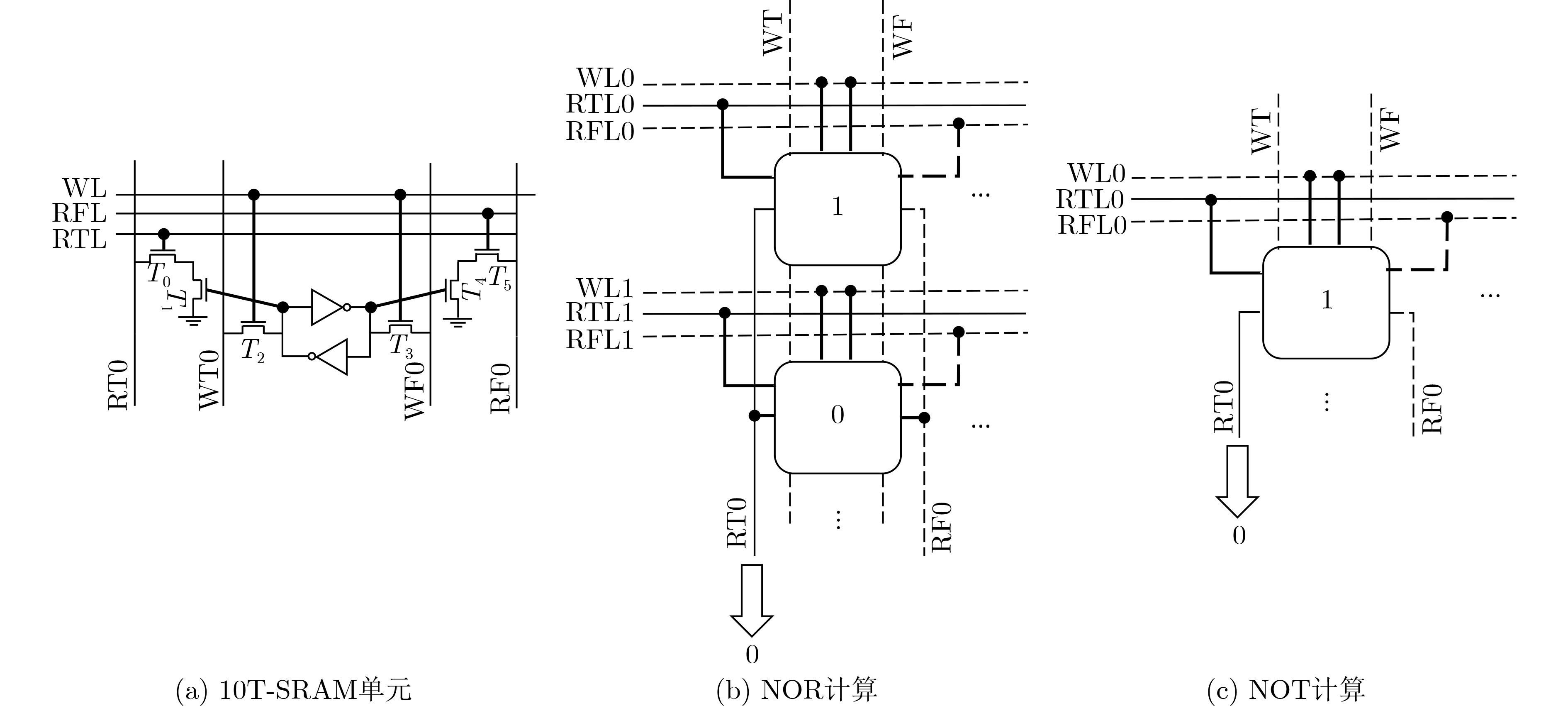
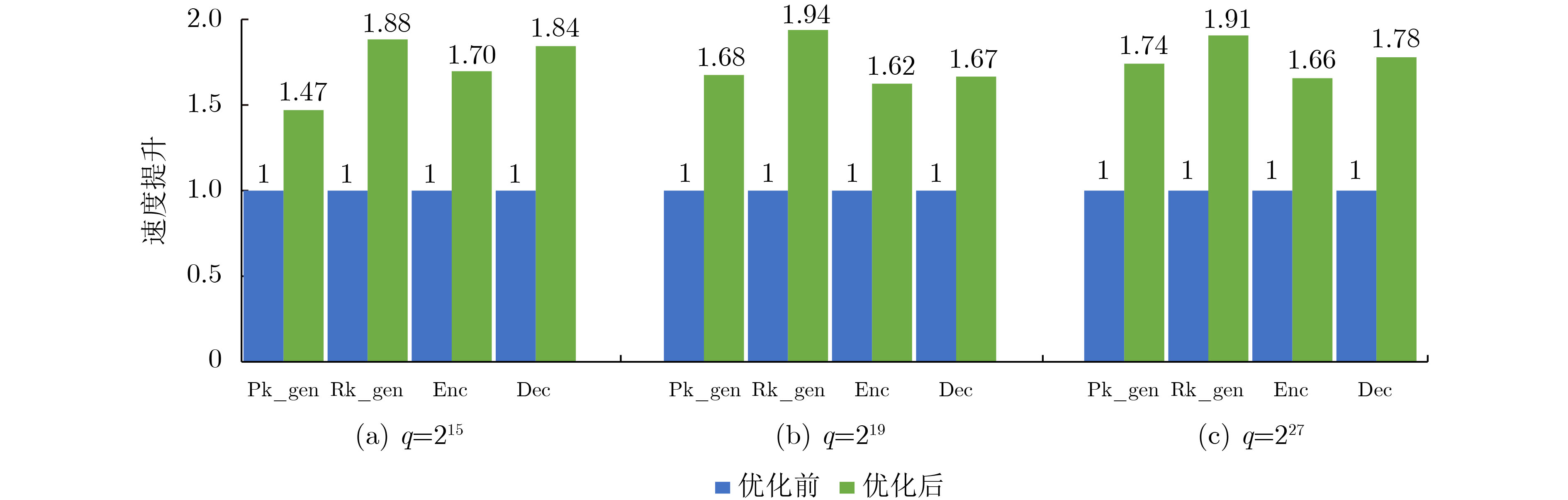
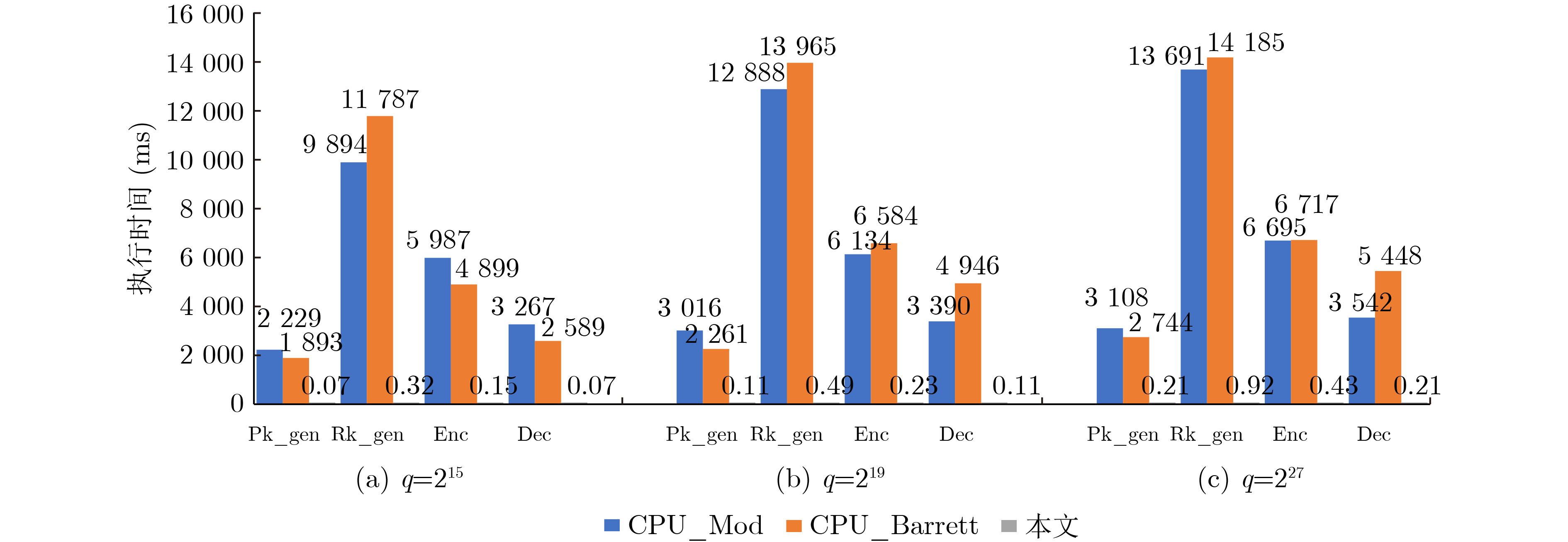
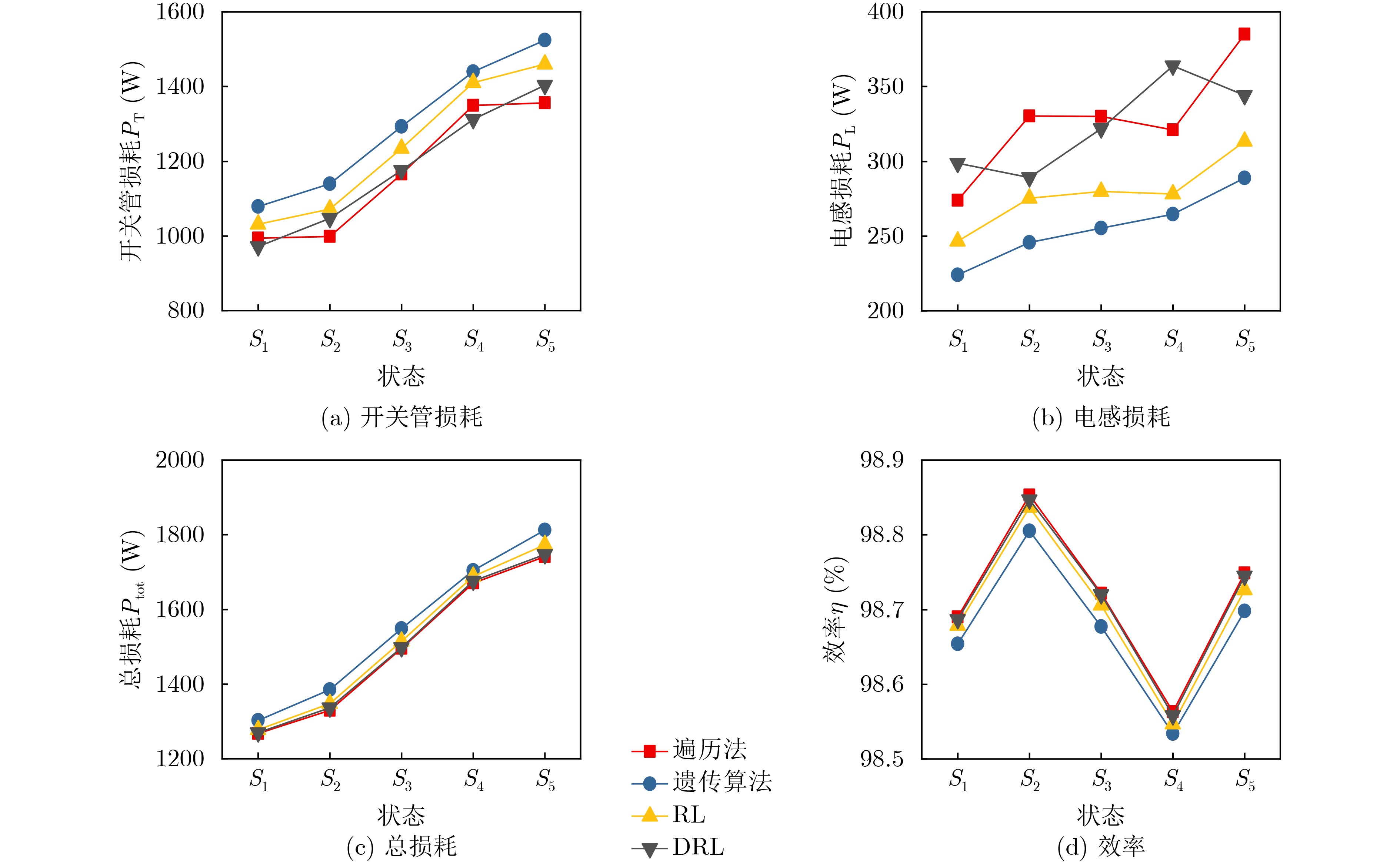
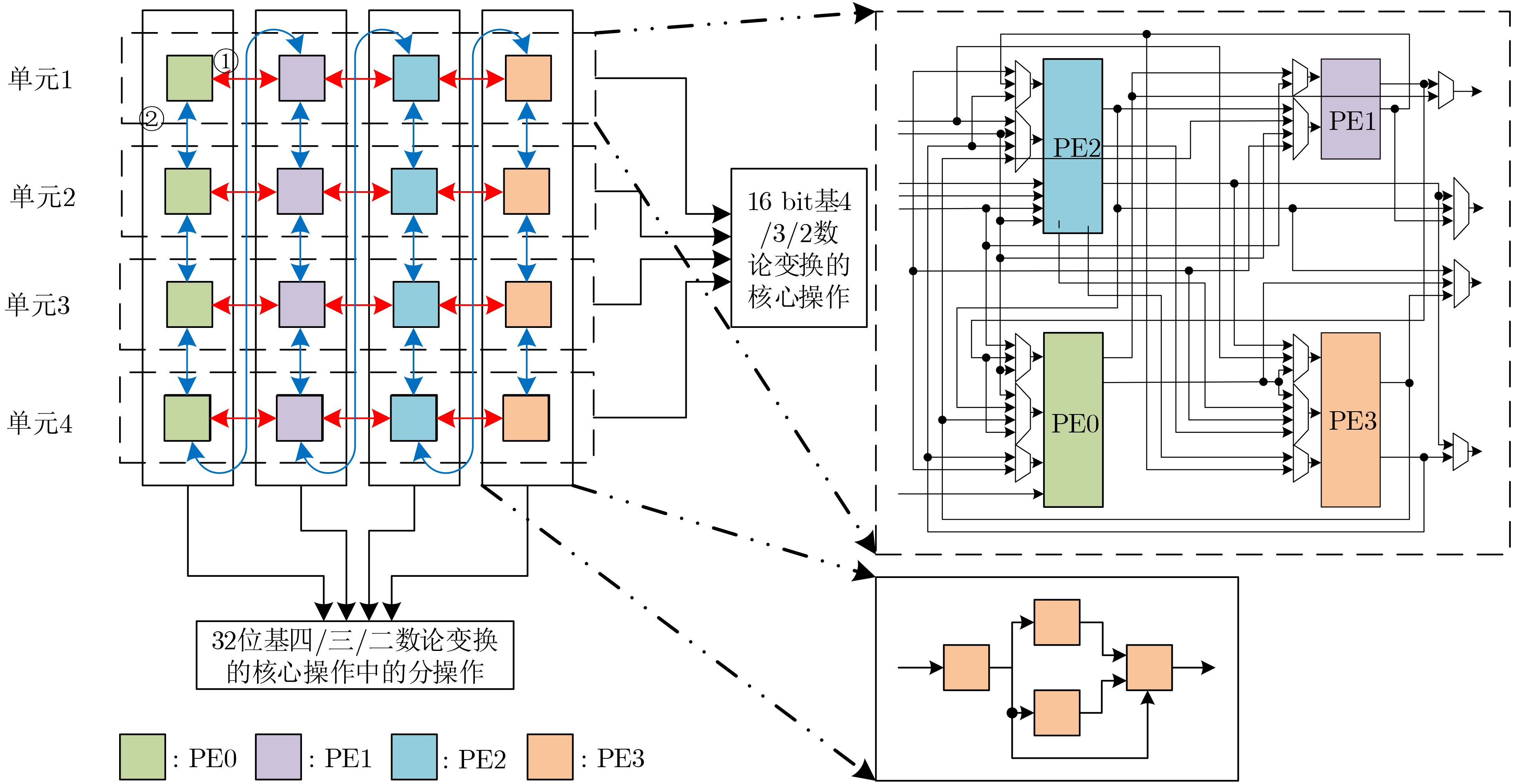
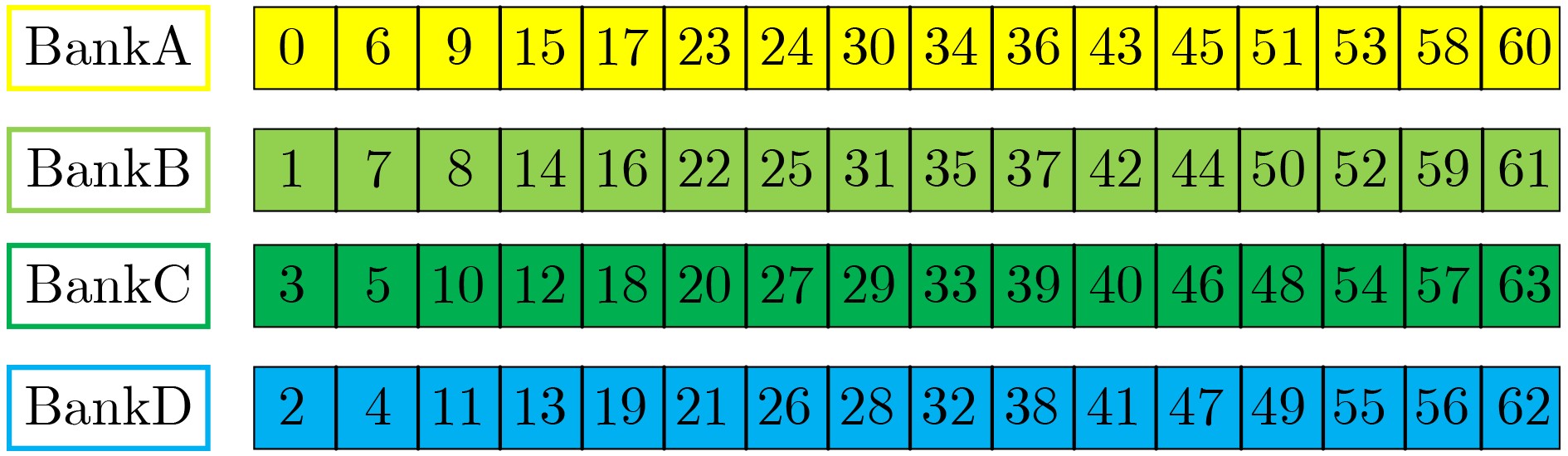
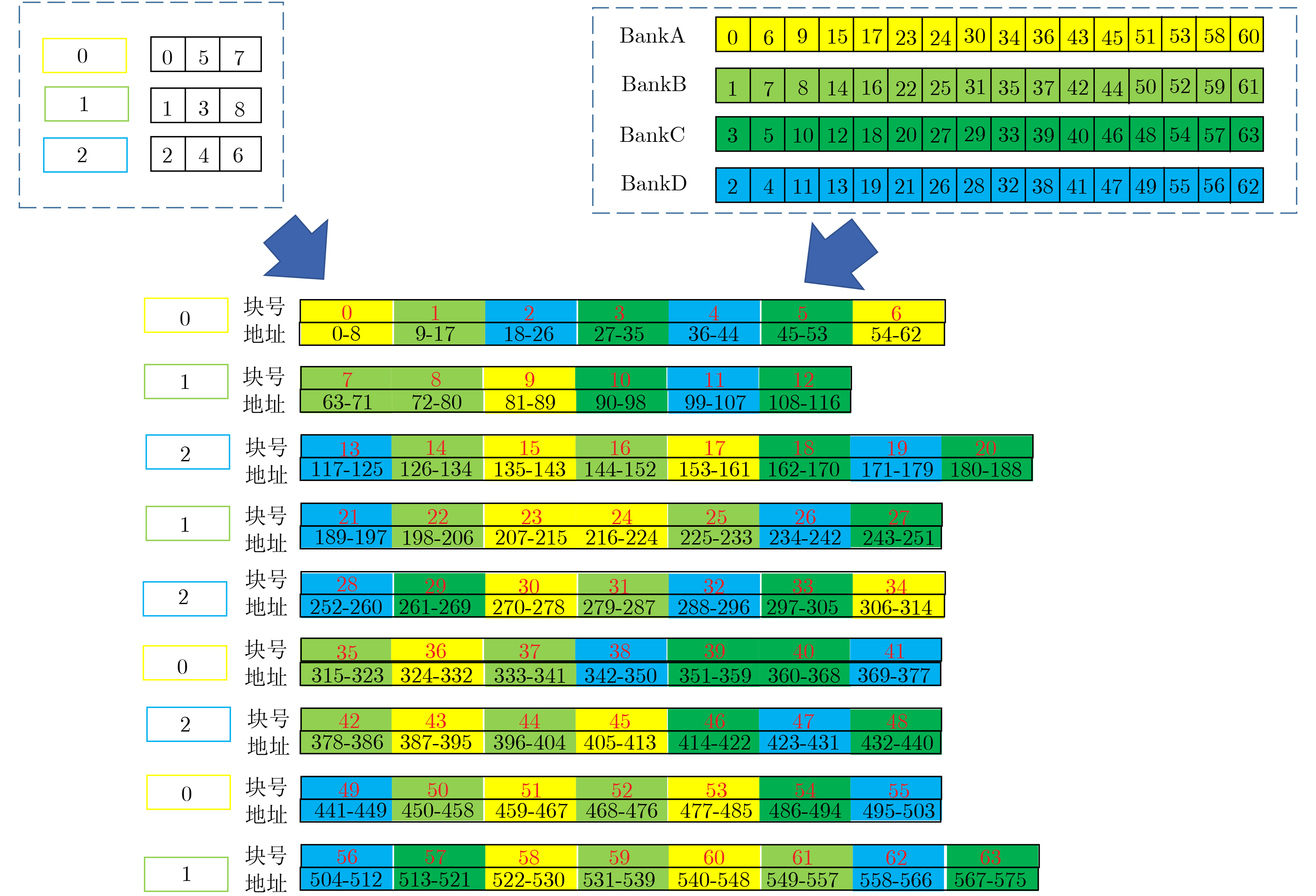
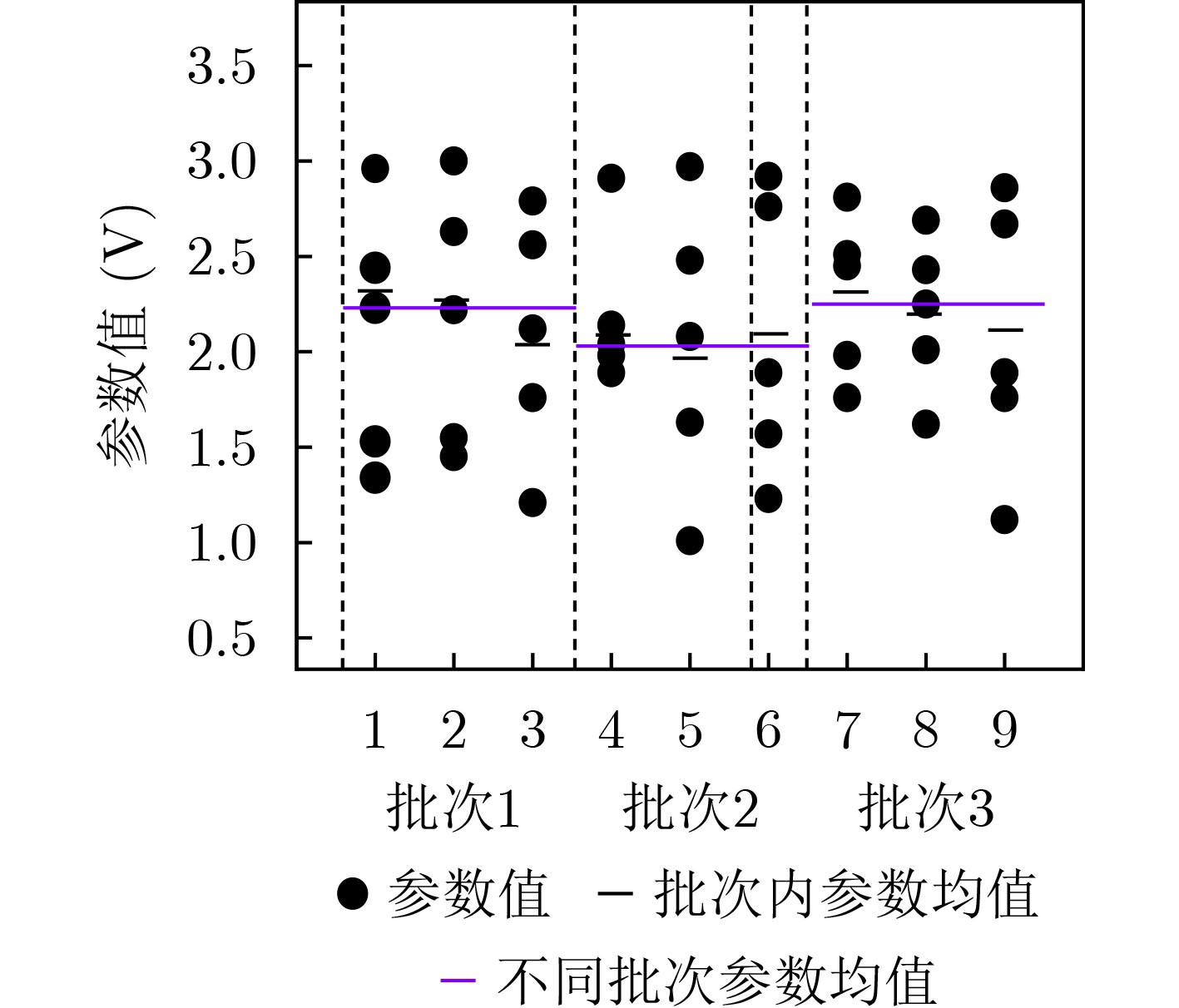
2023, 45(9): 3430-3438.
doi: 10.11999/JEIT221158
摘要:
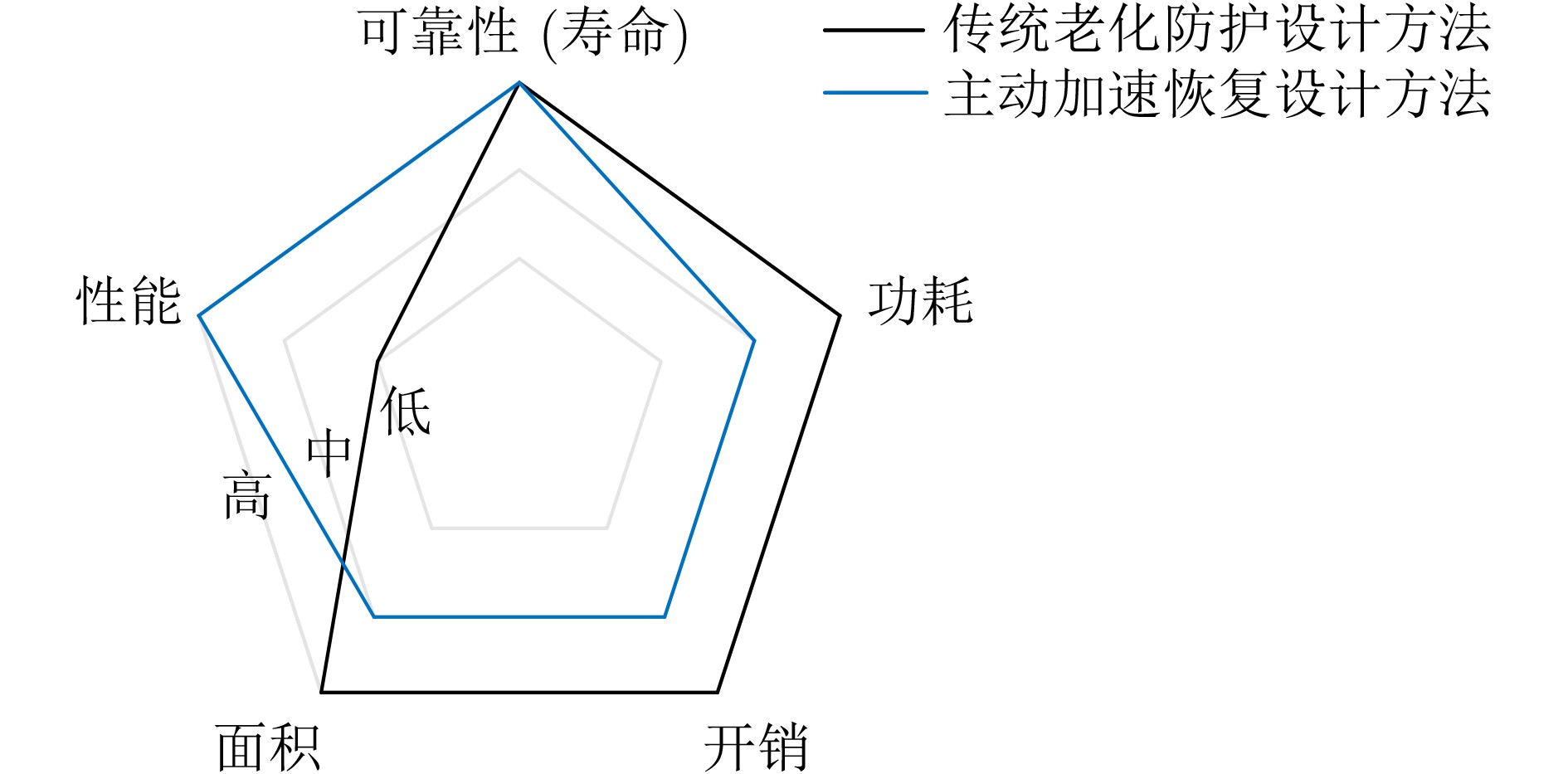
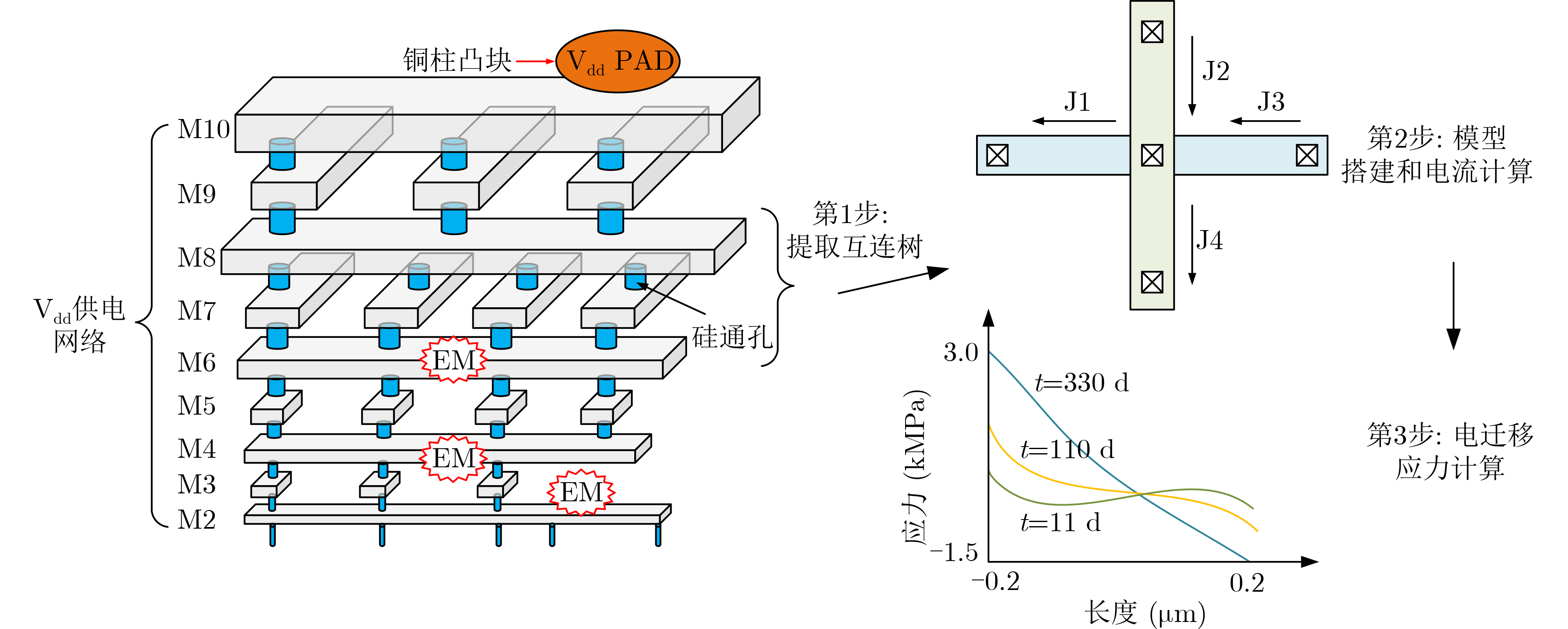
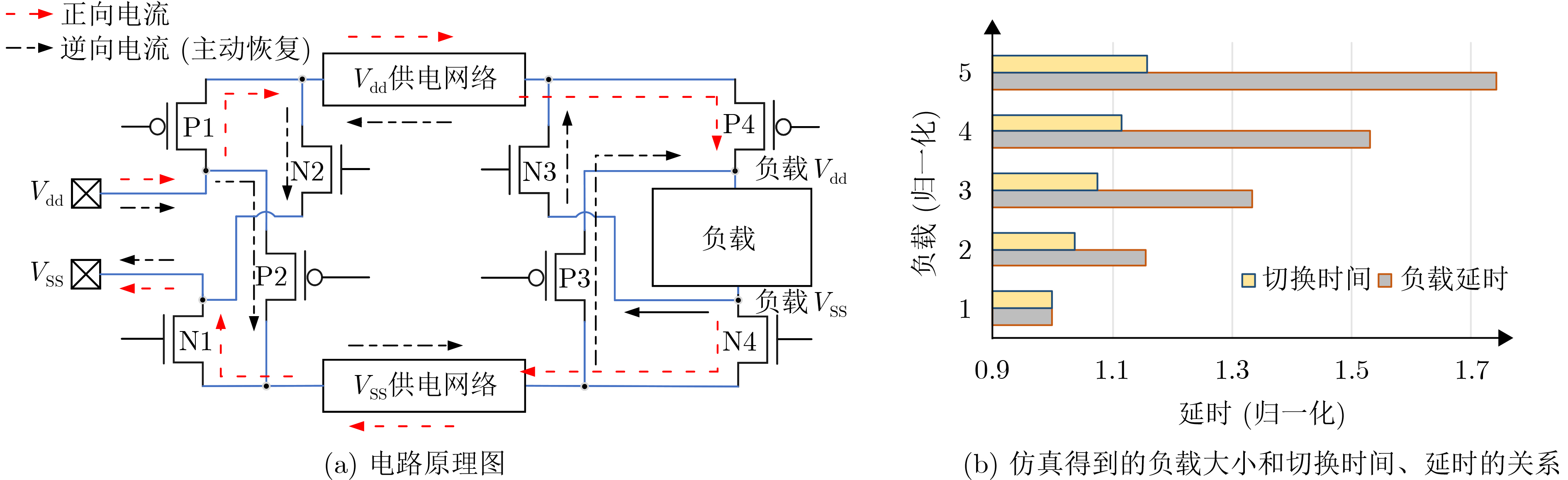
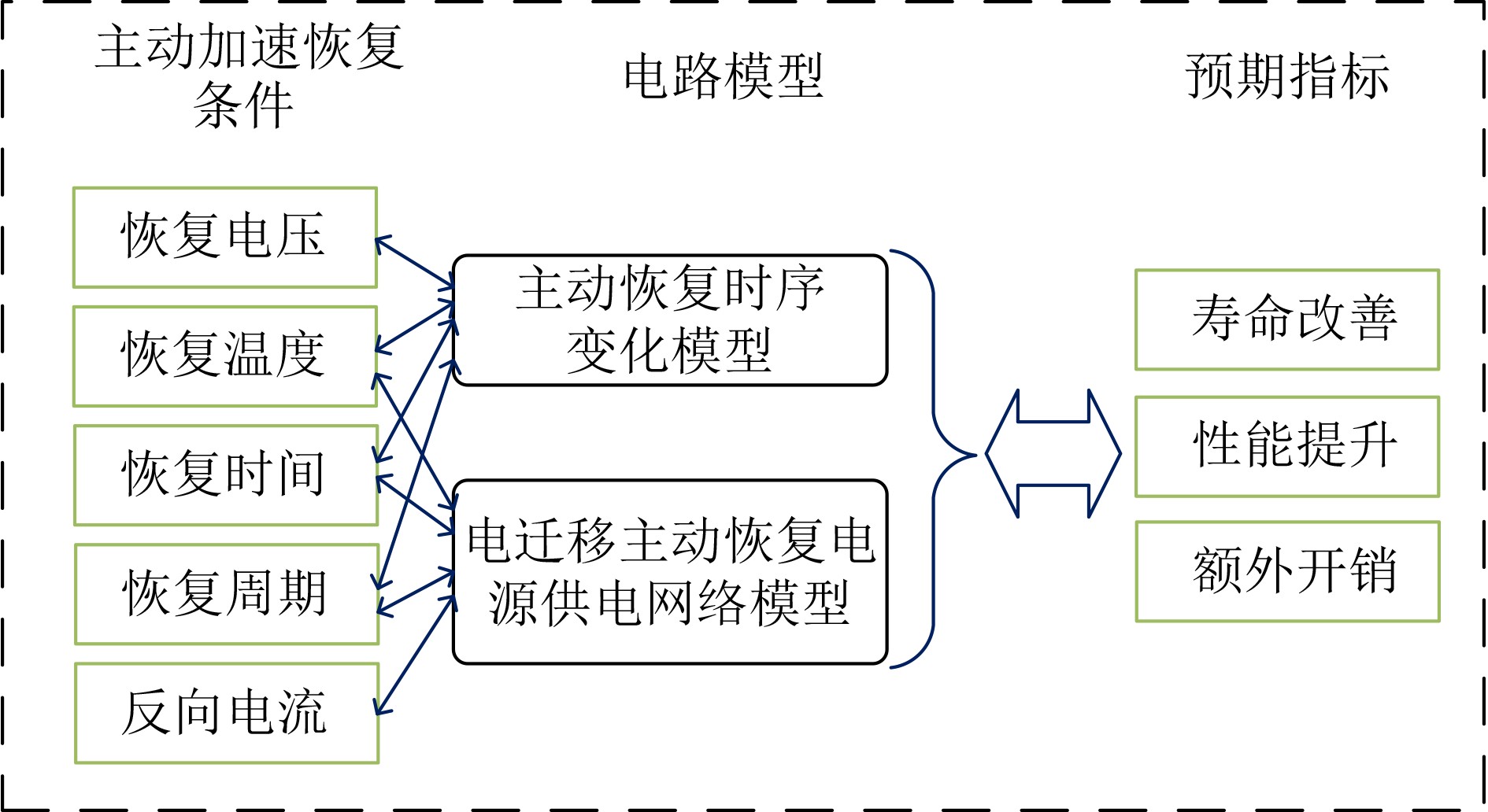
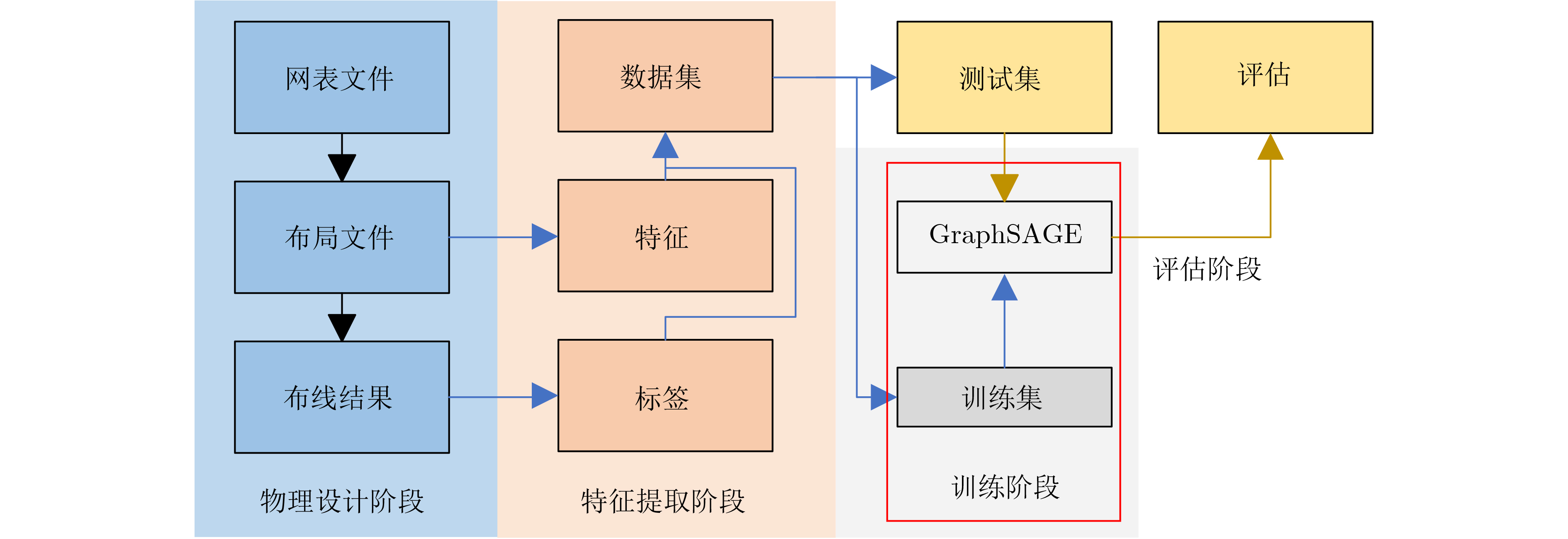
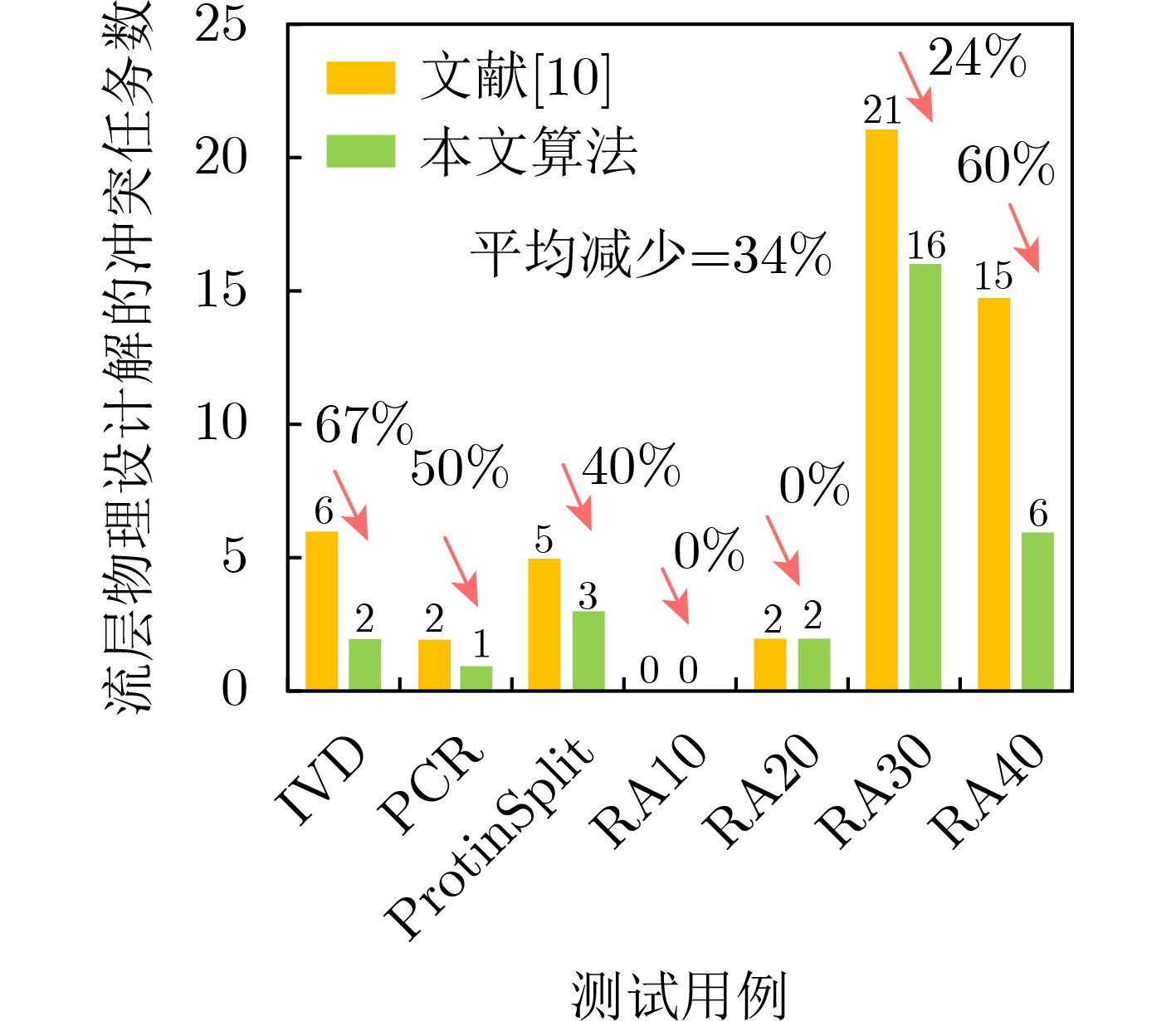
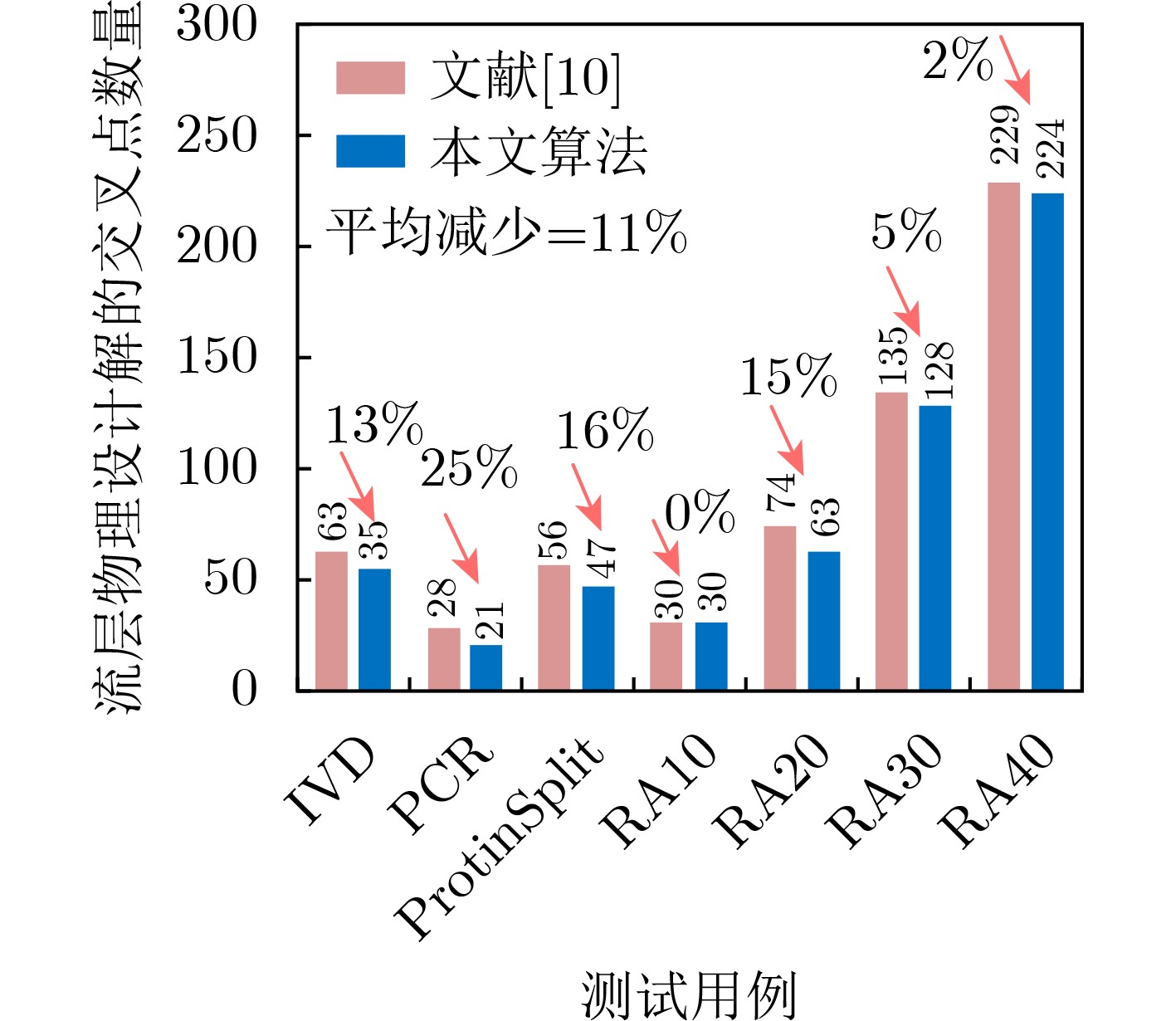
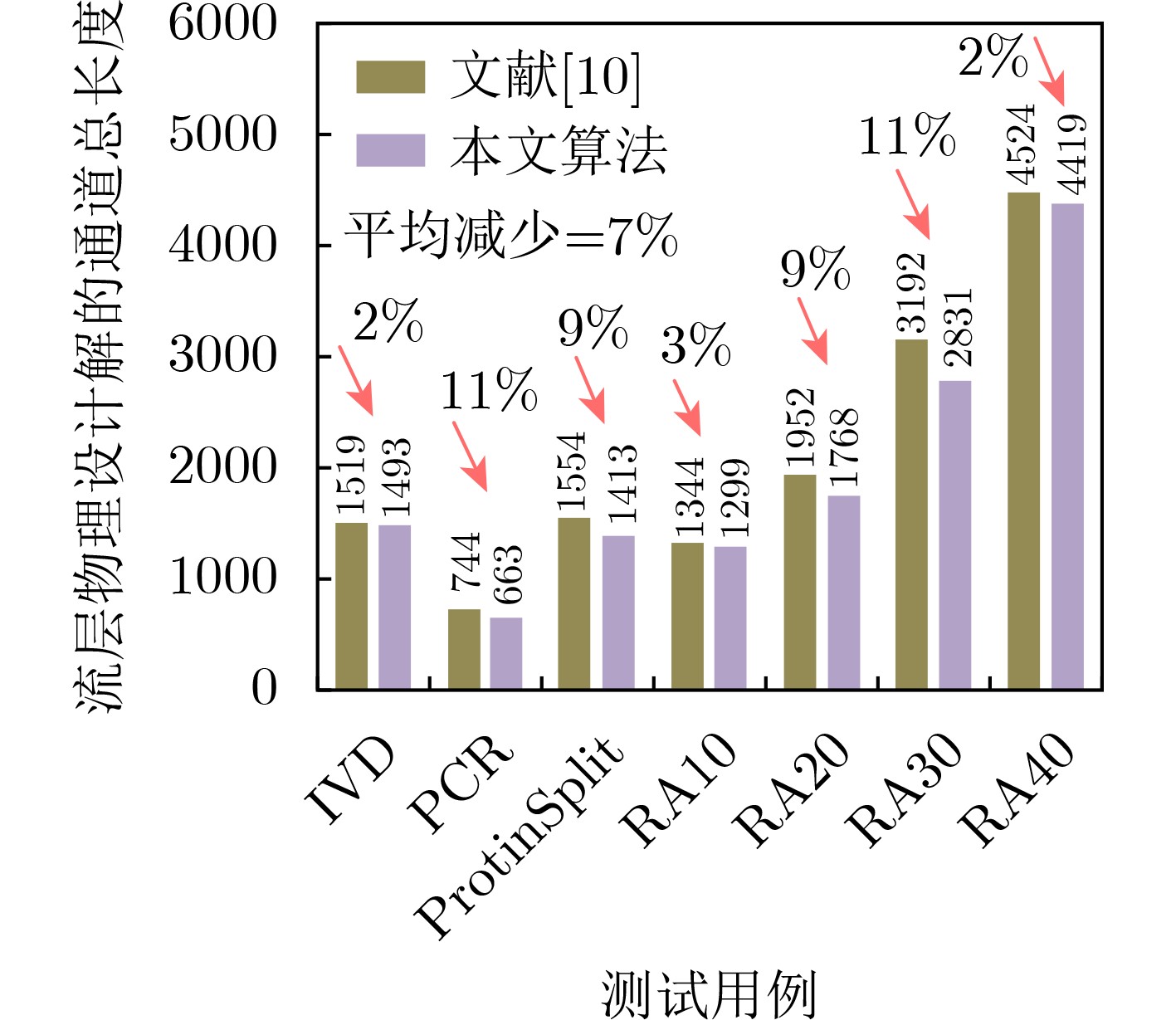
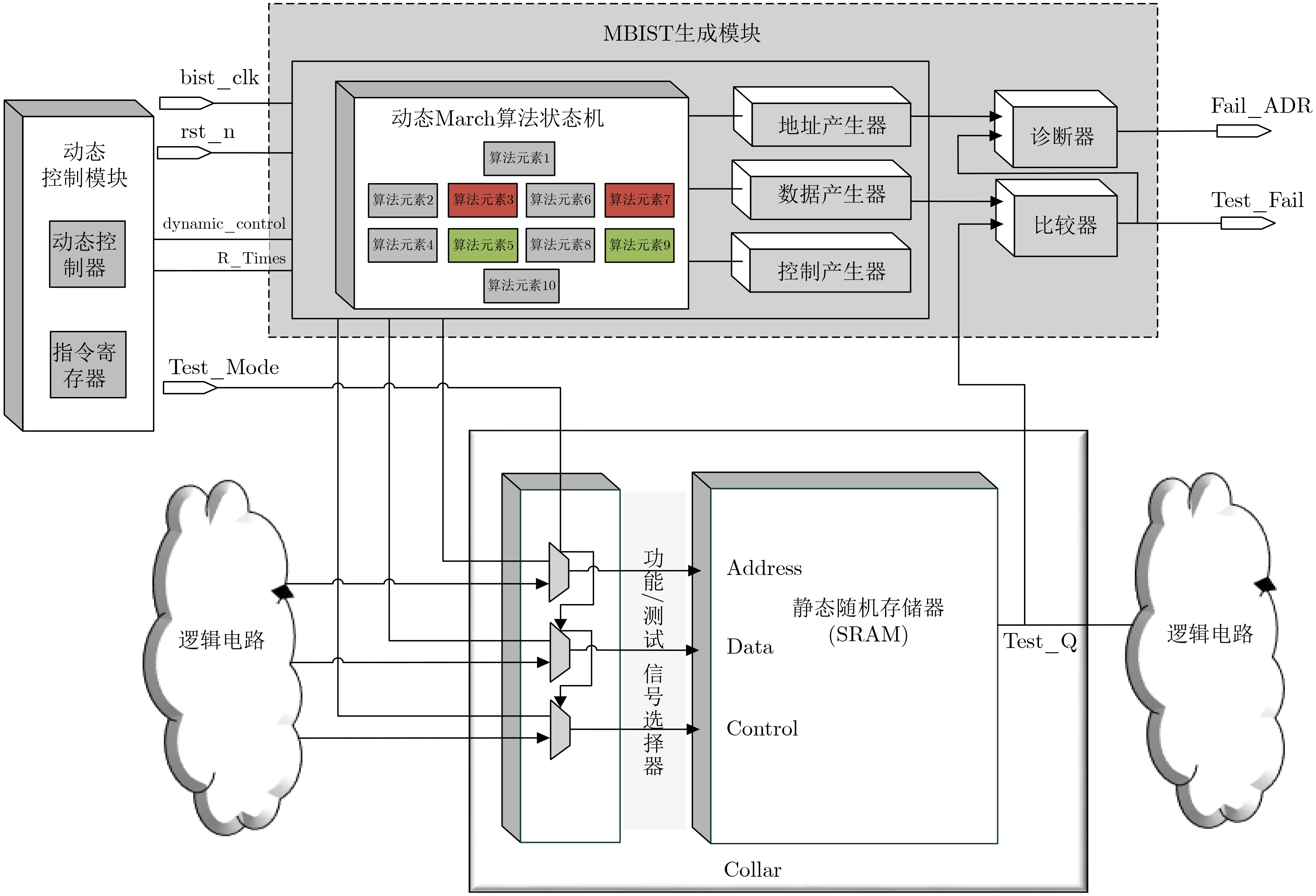
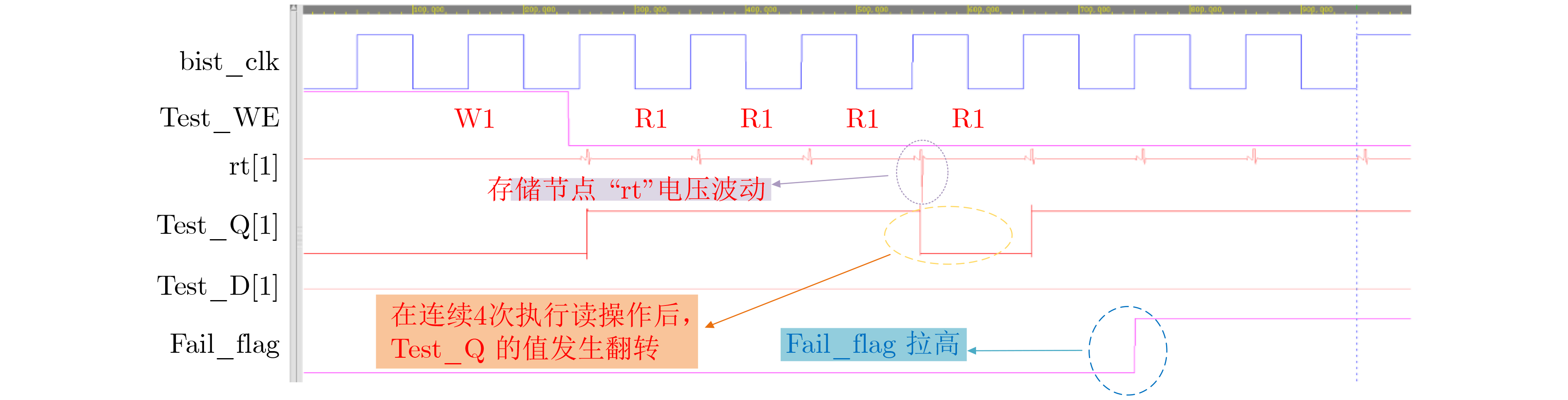
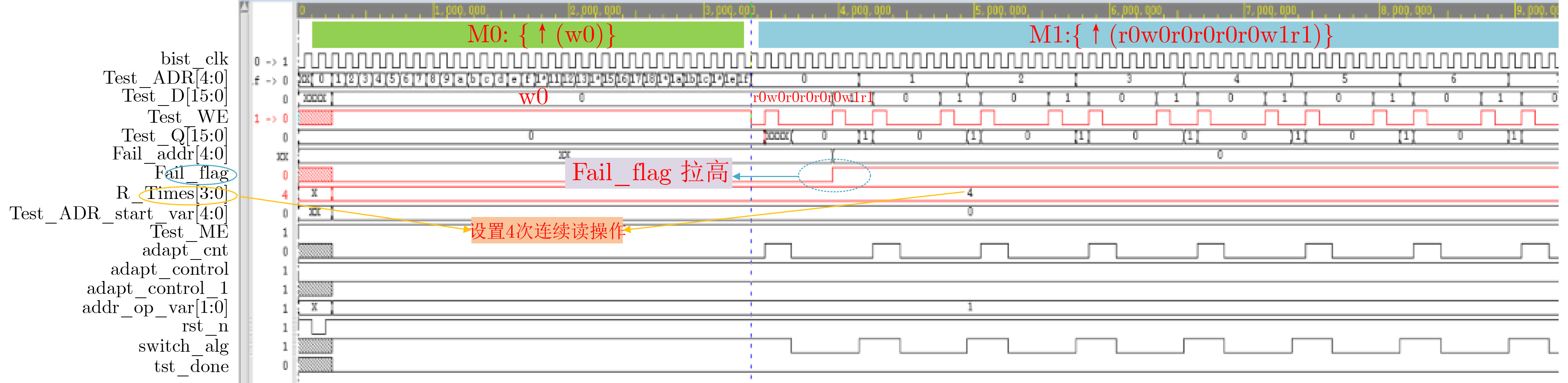
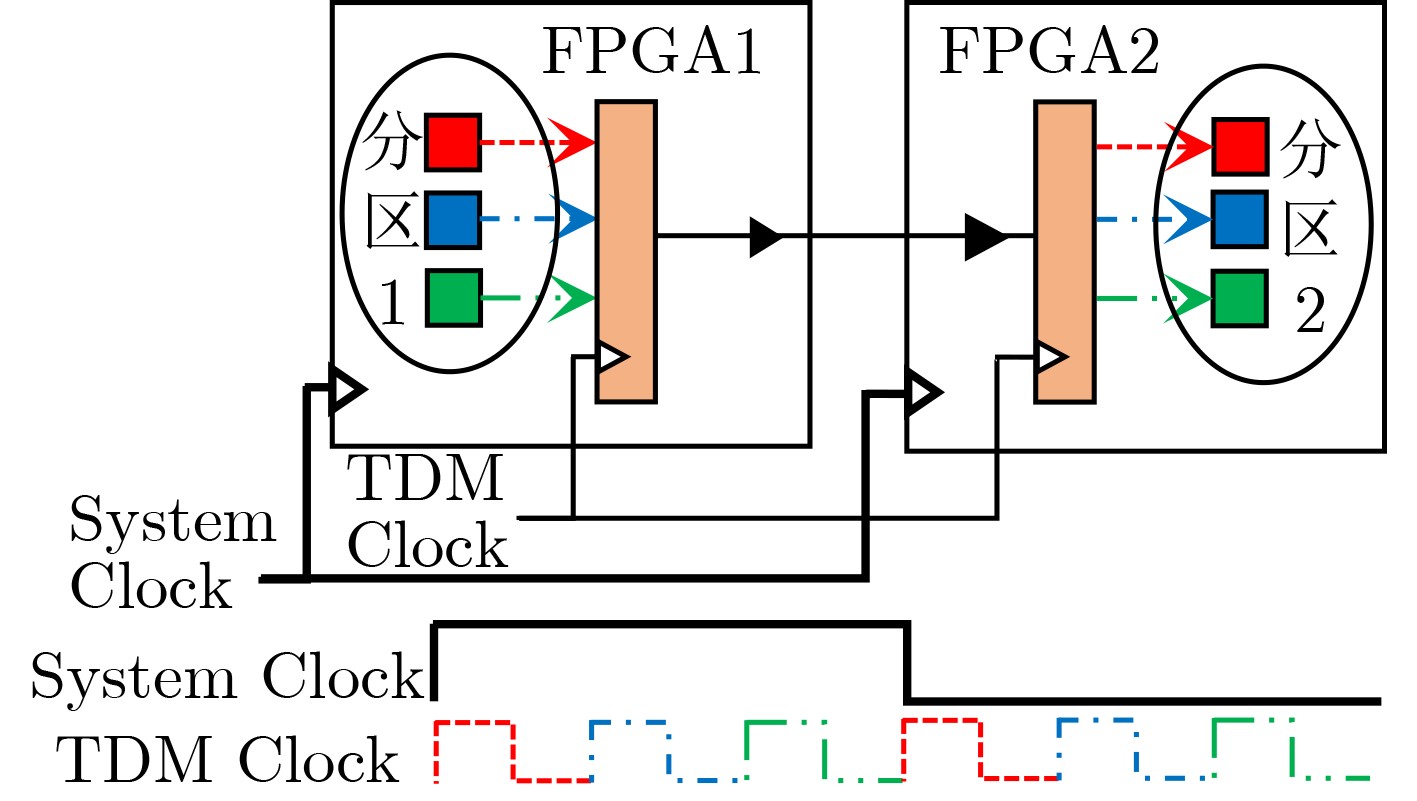
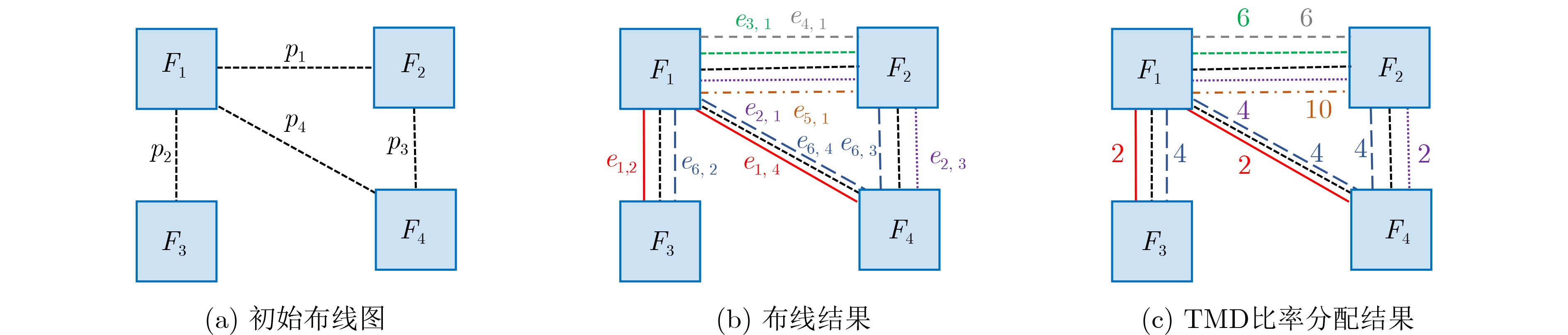
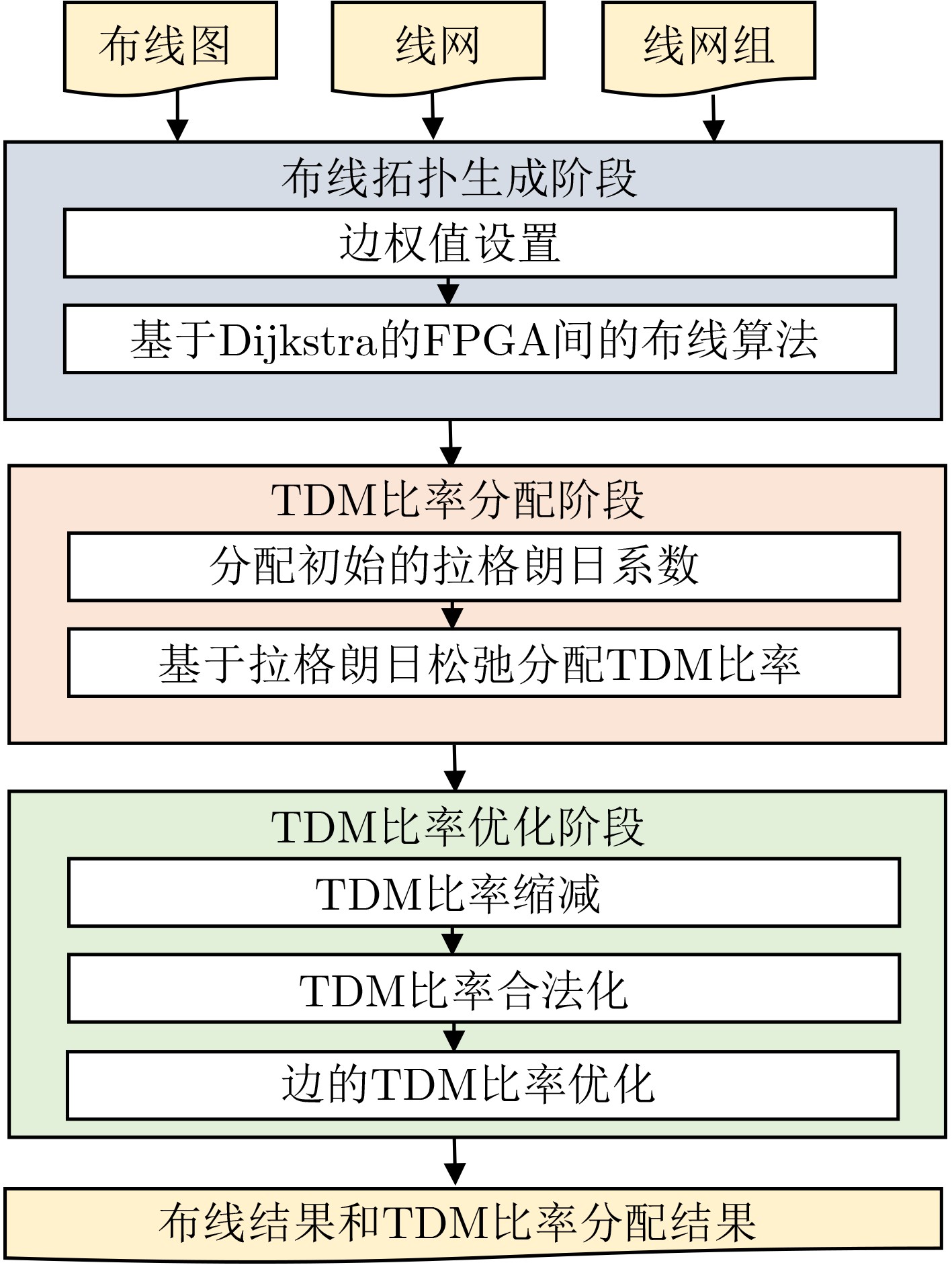
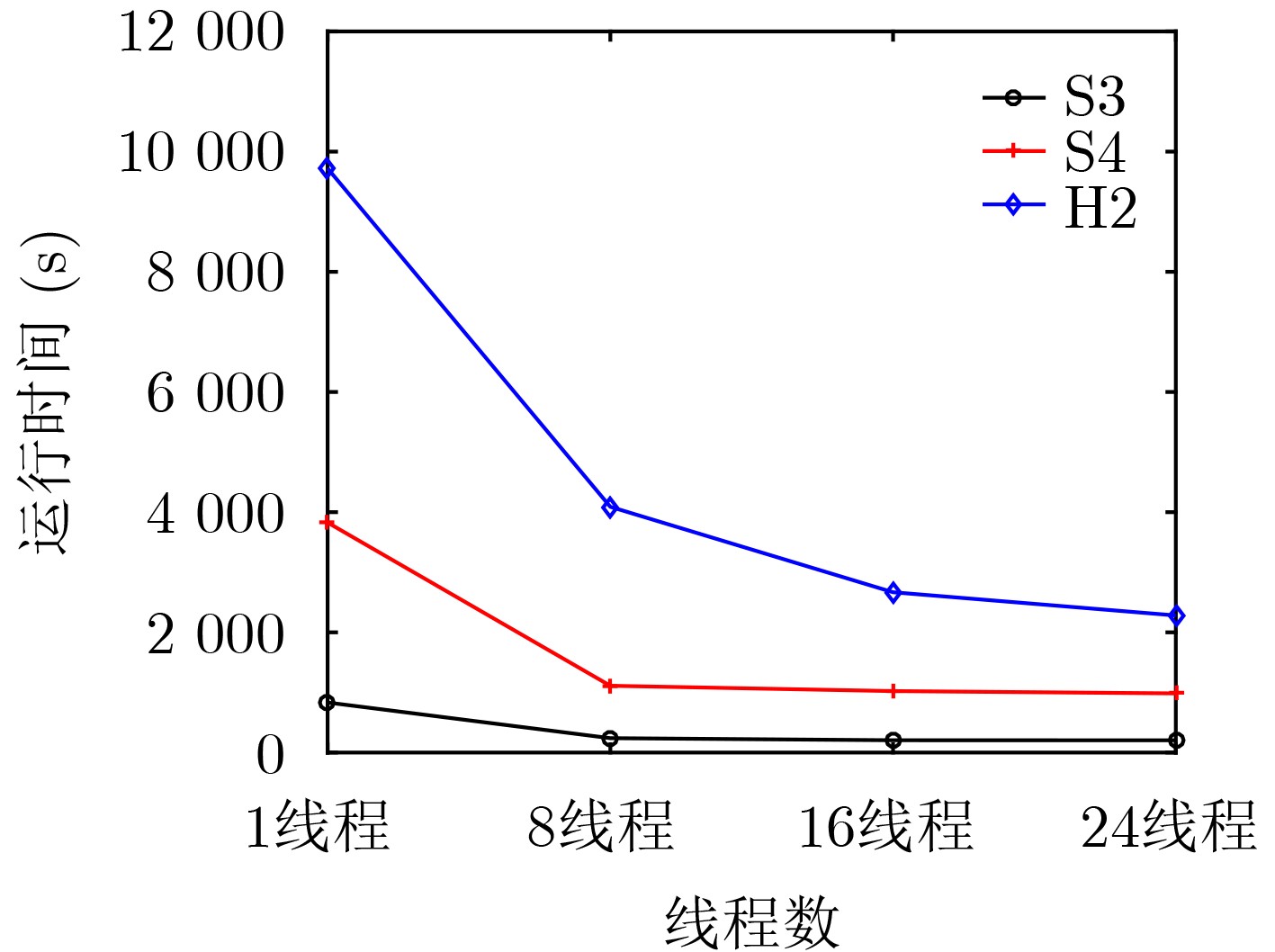
时分复用(Time-Division Multiplexing, TDM)技术被广泛地运用于解决IO瓶颈问题,以提高现场可编程门阵列(Field Programmable Gate Array, FPGA)系统的可布线性,但TDM比率的增大会导致系统时延的显著增加。因此,为了优化FPGA系统时延以及可布线性,该文提出一种用于时分复用技术的多阶段协同优化FPGA布线(Multi-Stage Co-Optimization FPGA Routing, MSCOFRouting)方法。首先,设计自适应布线算法,以减少布线拥塞情况,提高可布线性,解决FPGA间的布线优化问题,为后续的TDM比率分配提供高质量的布线结果。其次,为了避免因大规模线网组的TDM比率过大而导致系统时延劣化的情况,提出基于拉格朗日松弛(Lagrangian Relaxation, LR)的TDM比率分配算法,为布线图的边分配系统时延更小的初始TDM比率。此外,为了进一步减小最大线网组的TDM比率,通过一种多层次的TDM比率优化算法,缩减线网组和FPGA连接对的TDM比率。同时,为了提高MSCOFRouter的运行效率,在上述3个算法中使用多线程并行化方法,有效缩减运行时间。实验结果表明,MSCOFRouting可以获得满足TDM比率约束的结果,取得同类工作中最佳的布线优化结果和TDM比率分配结果。