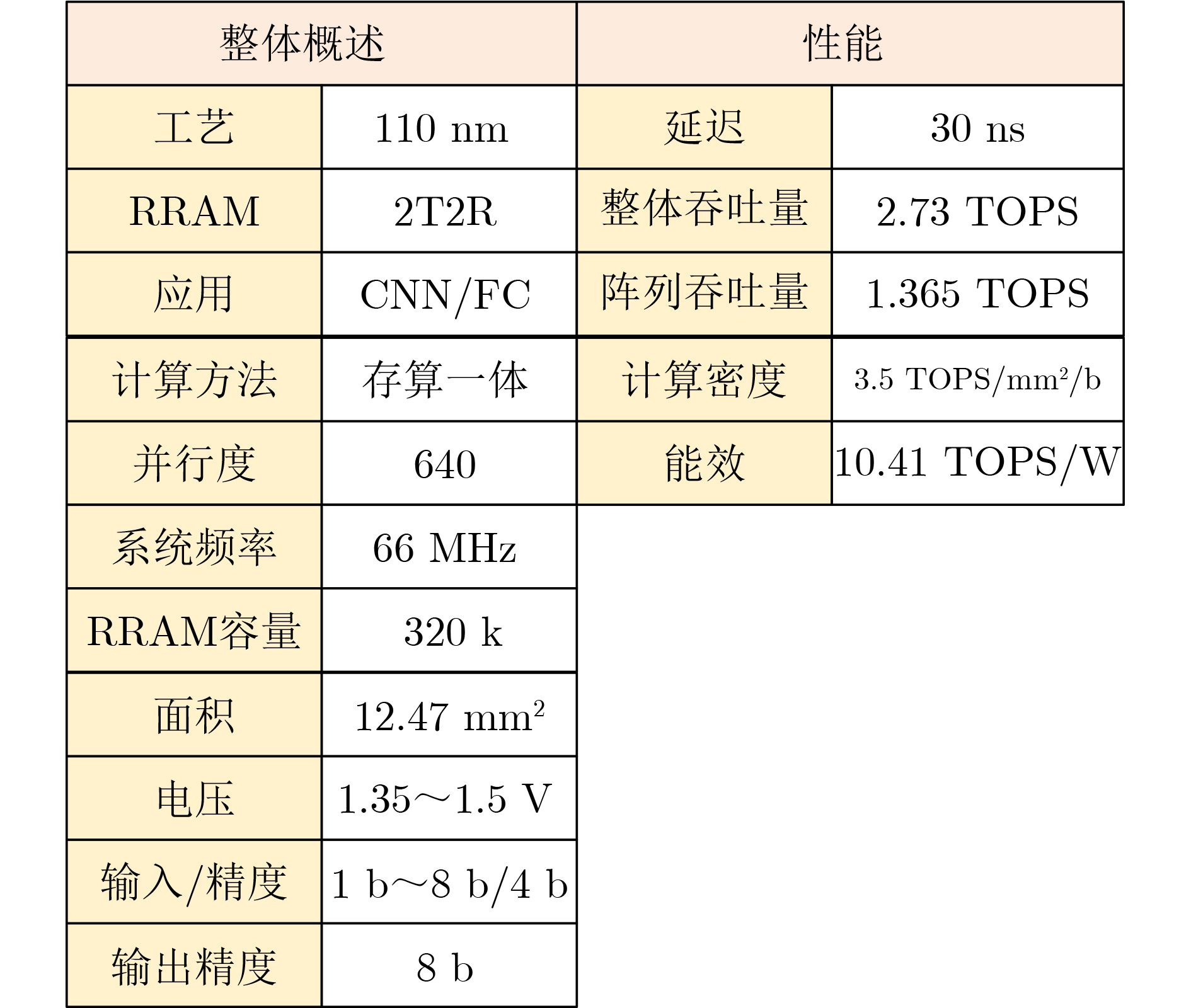
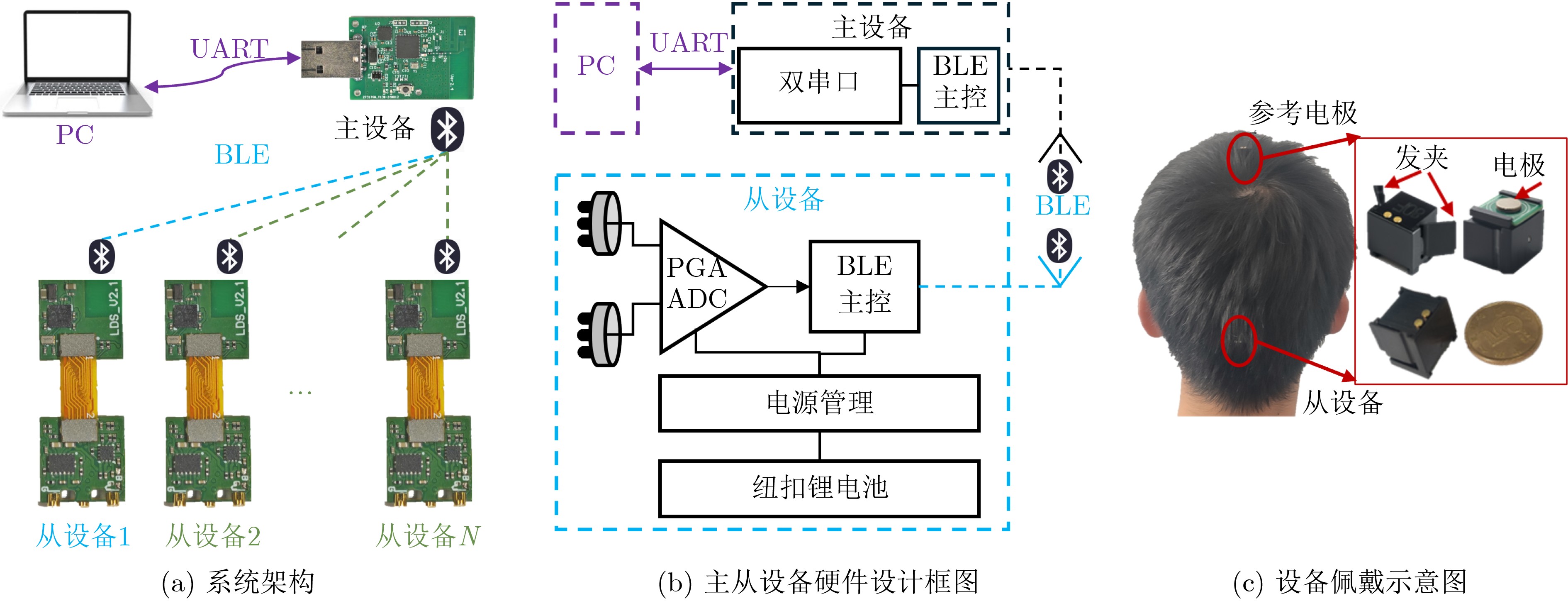
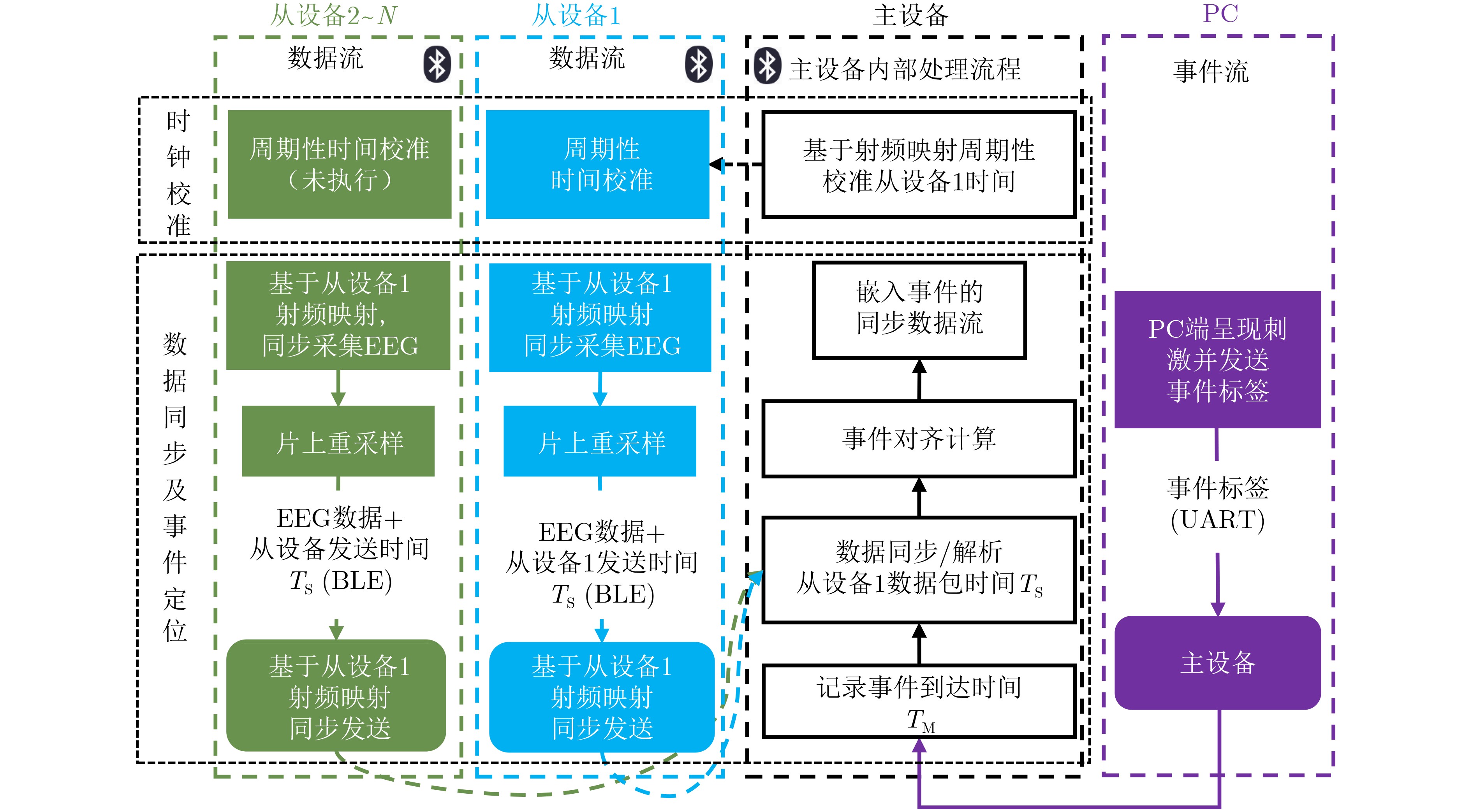
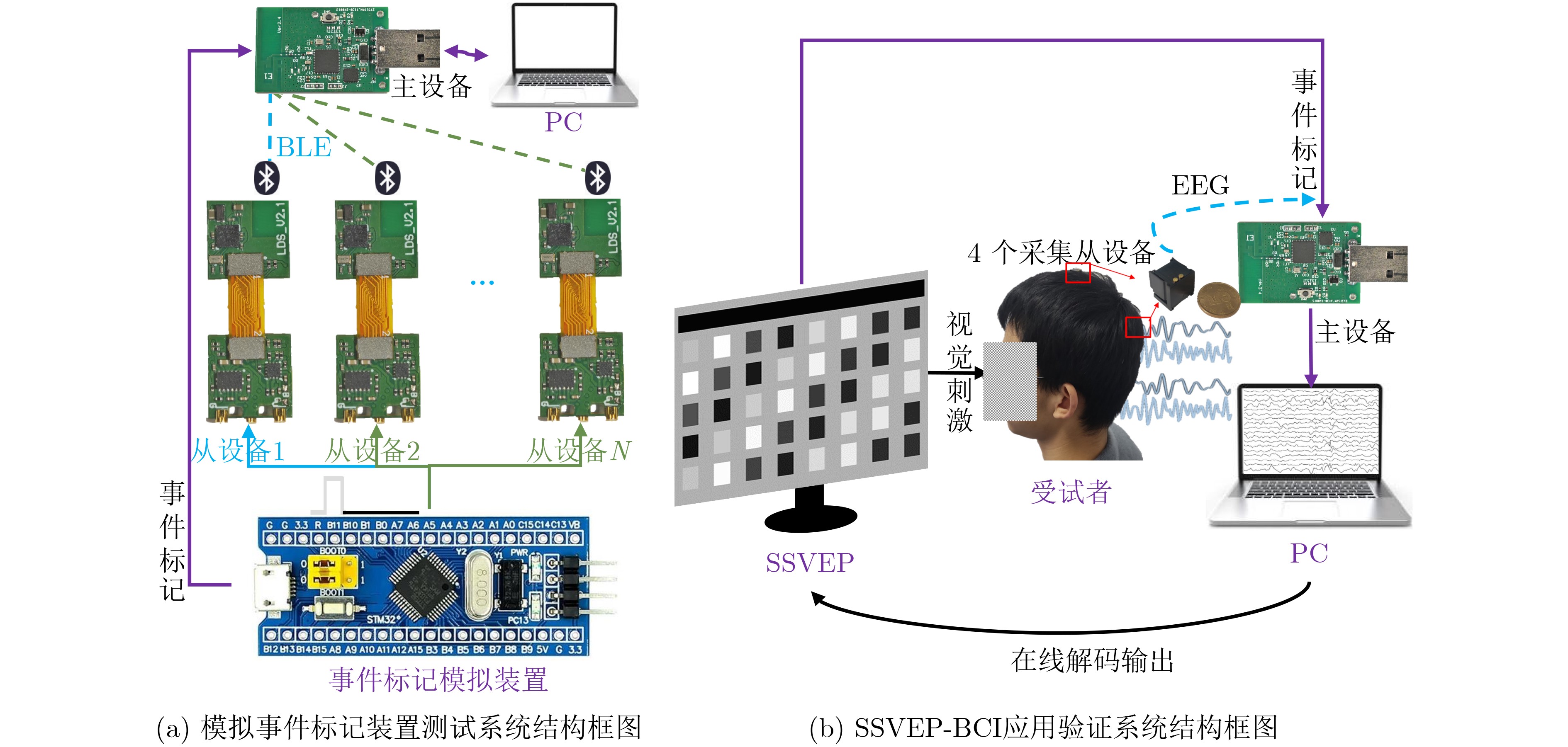
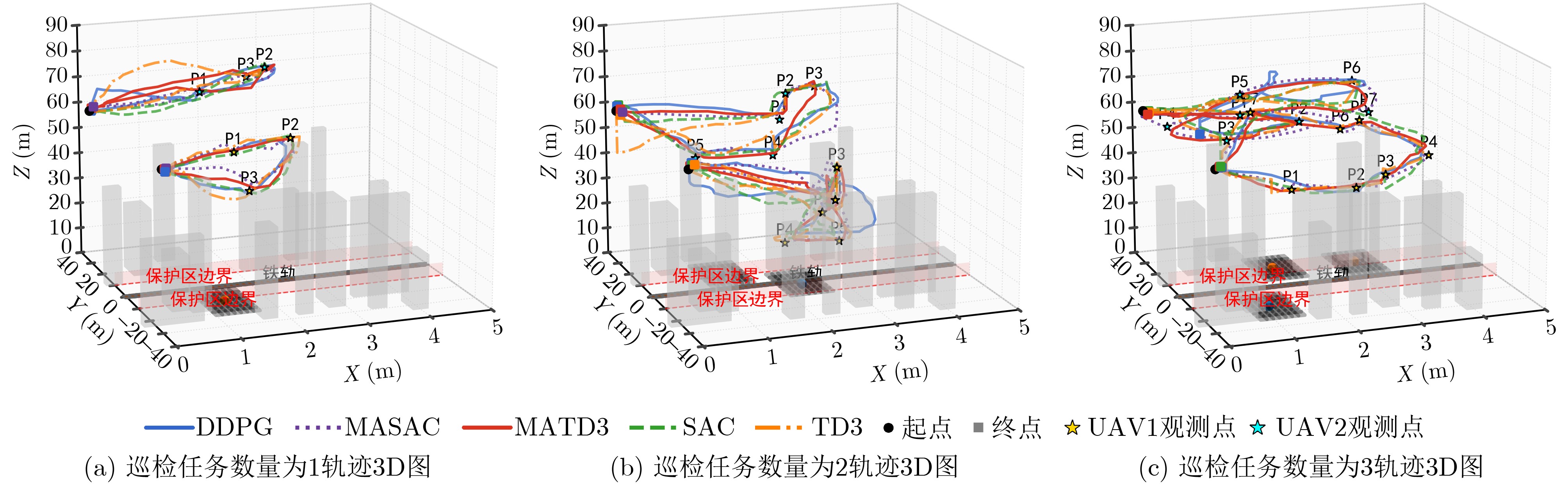
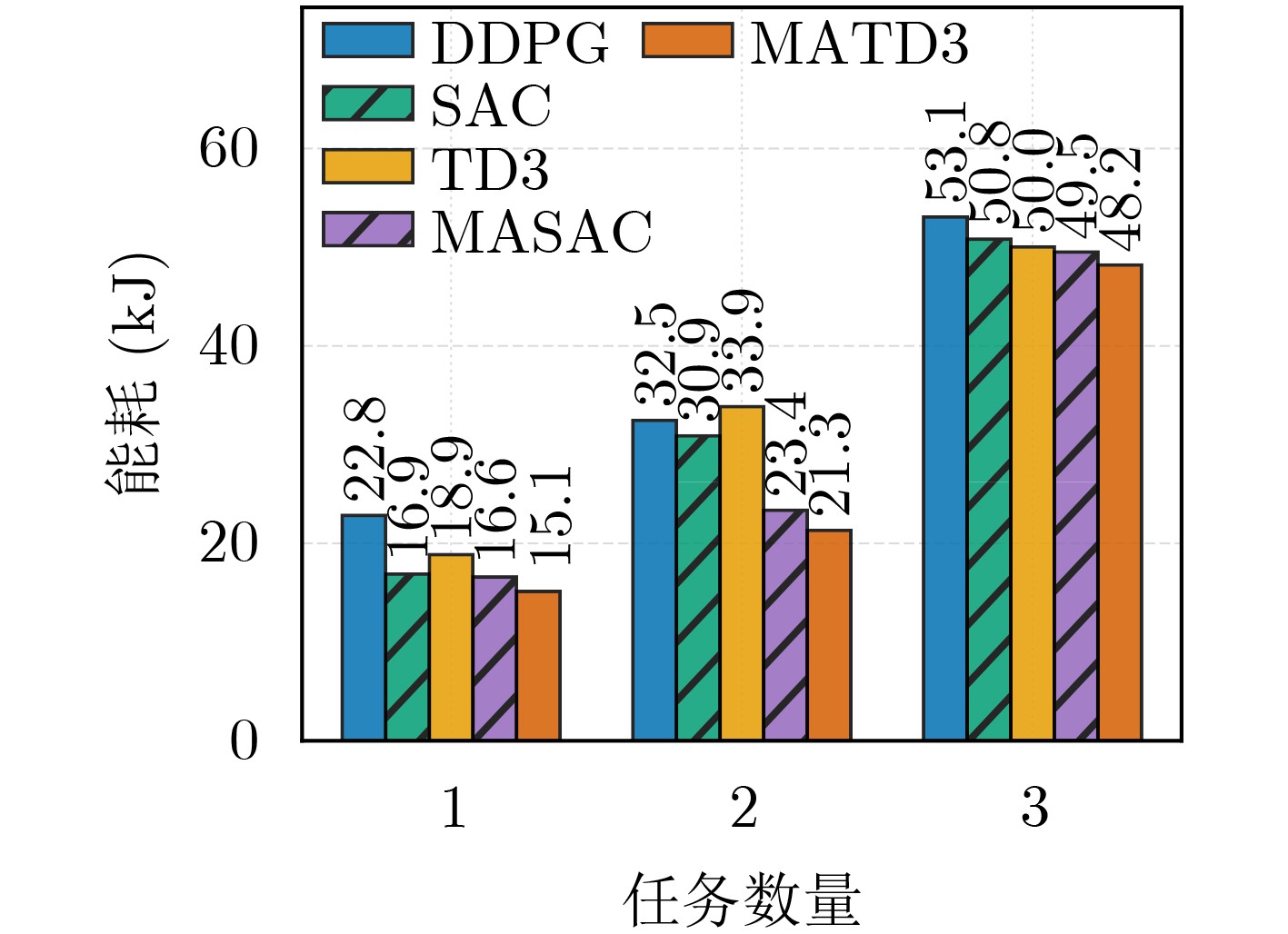
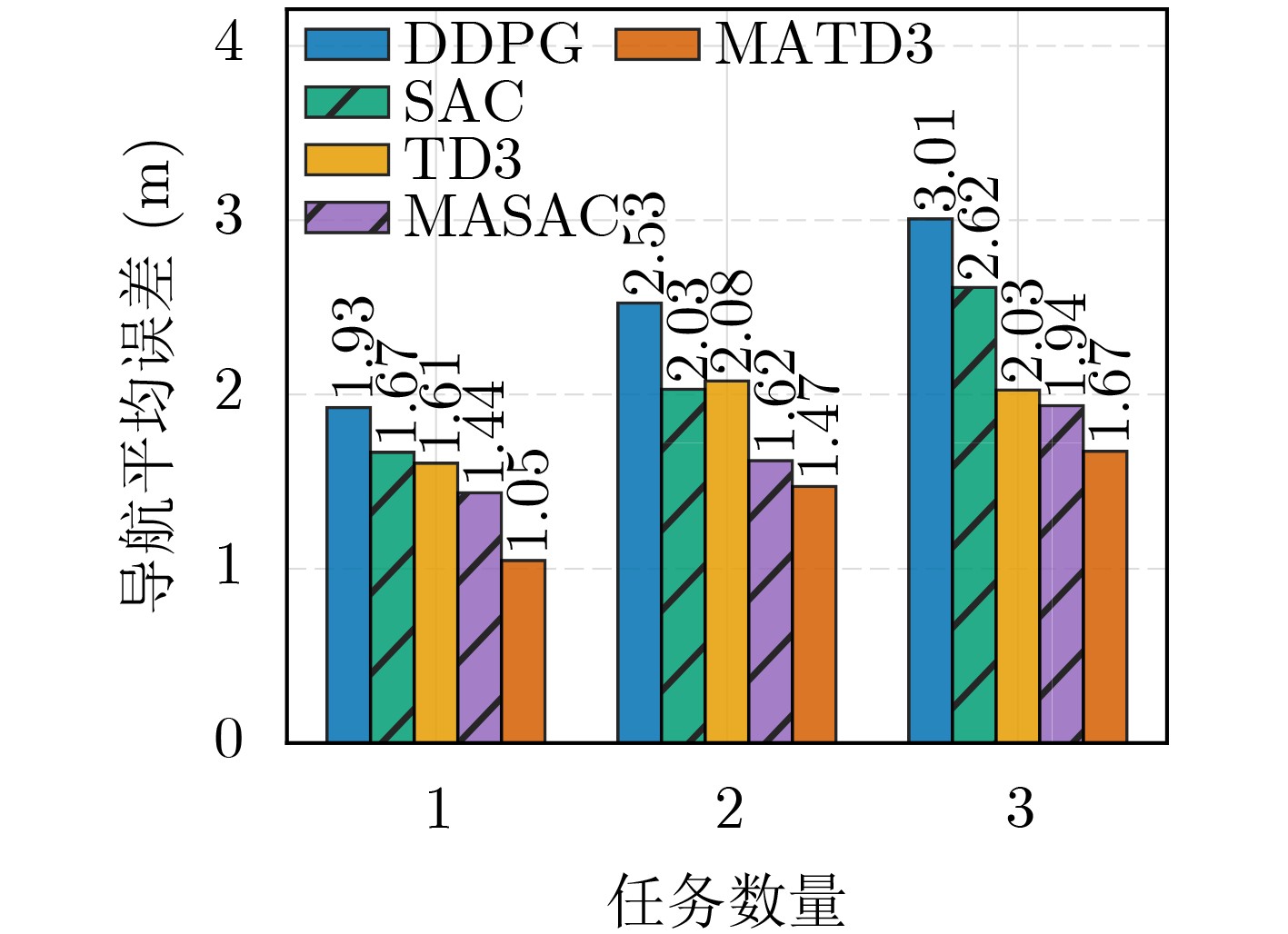
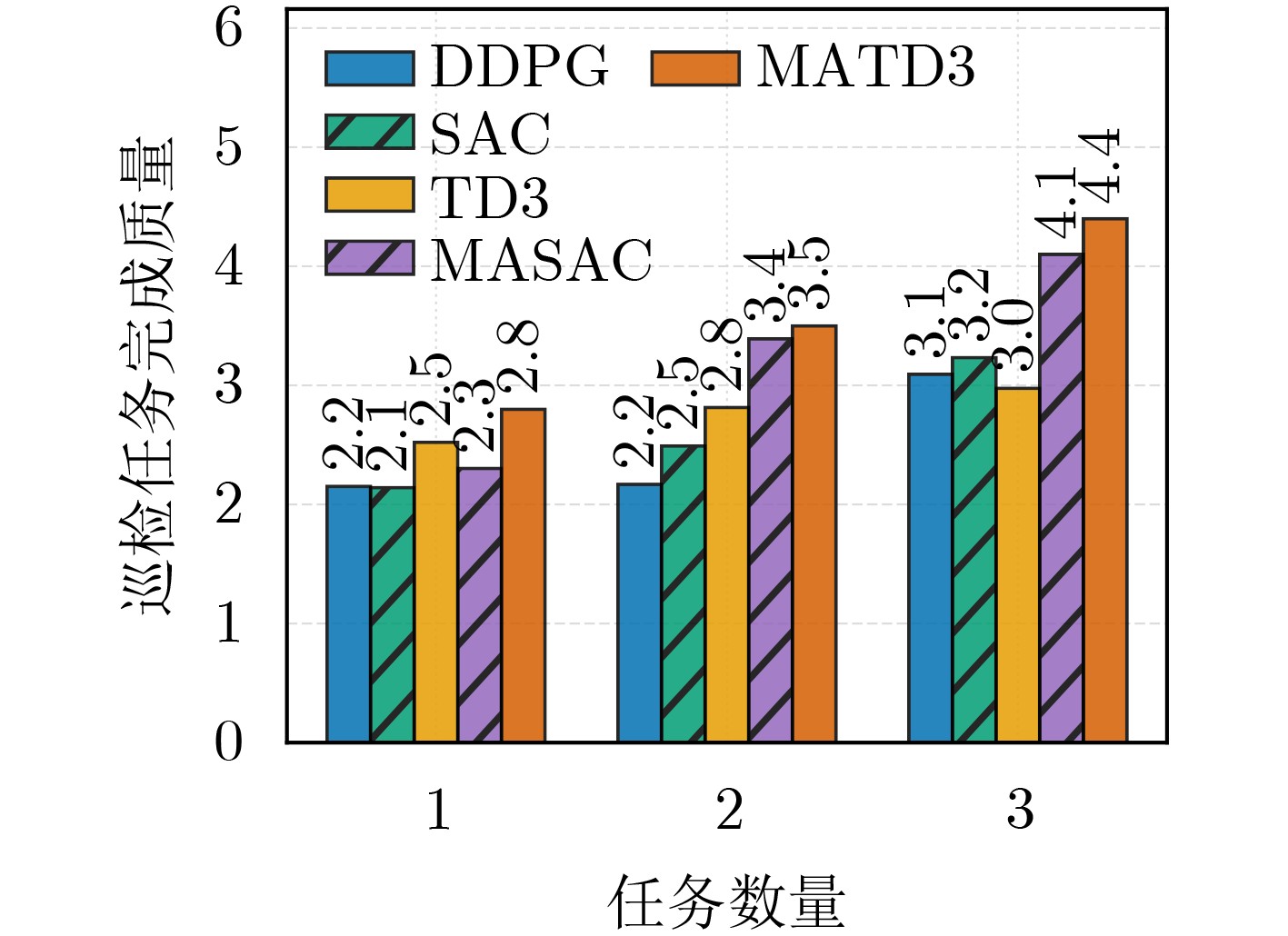
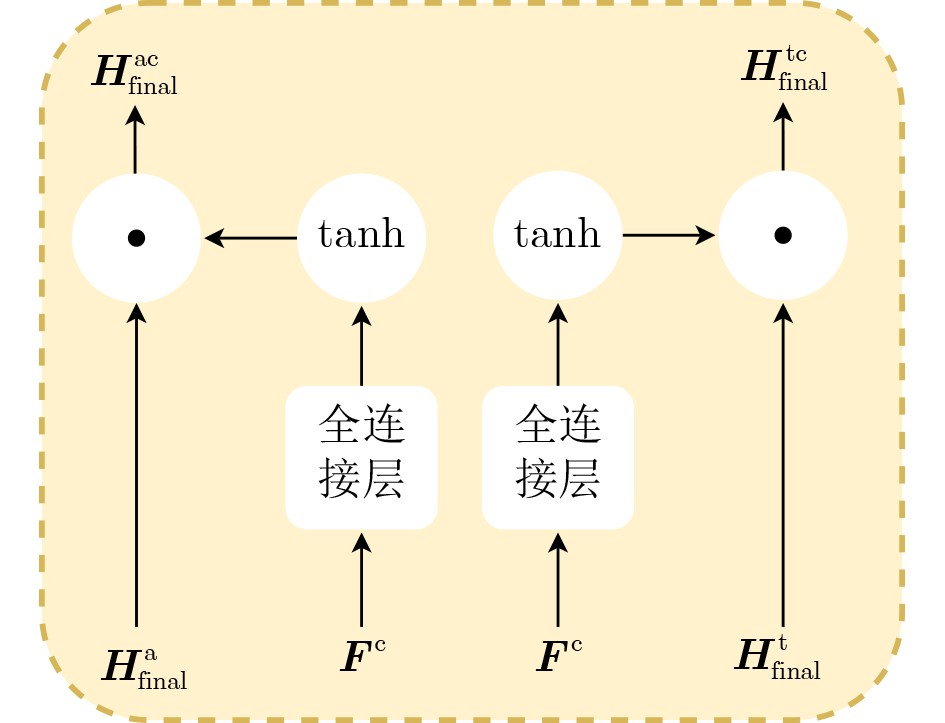
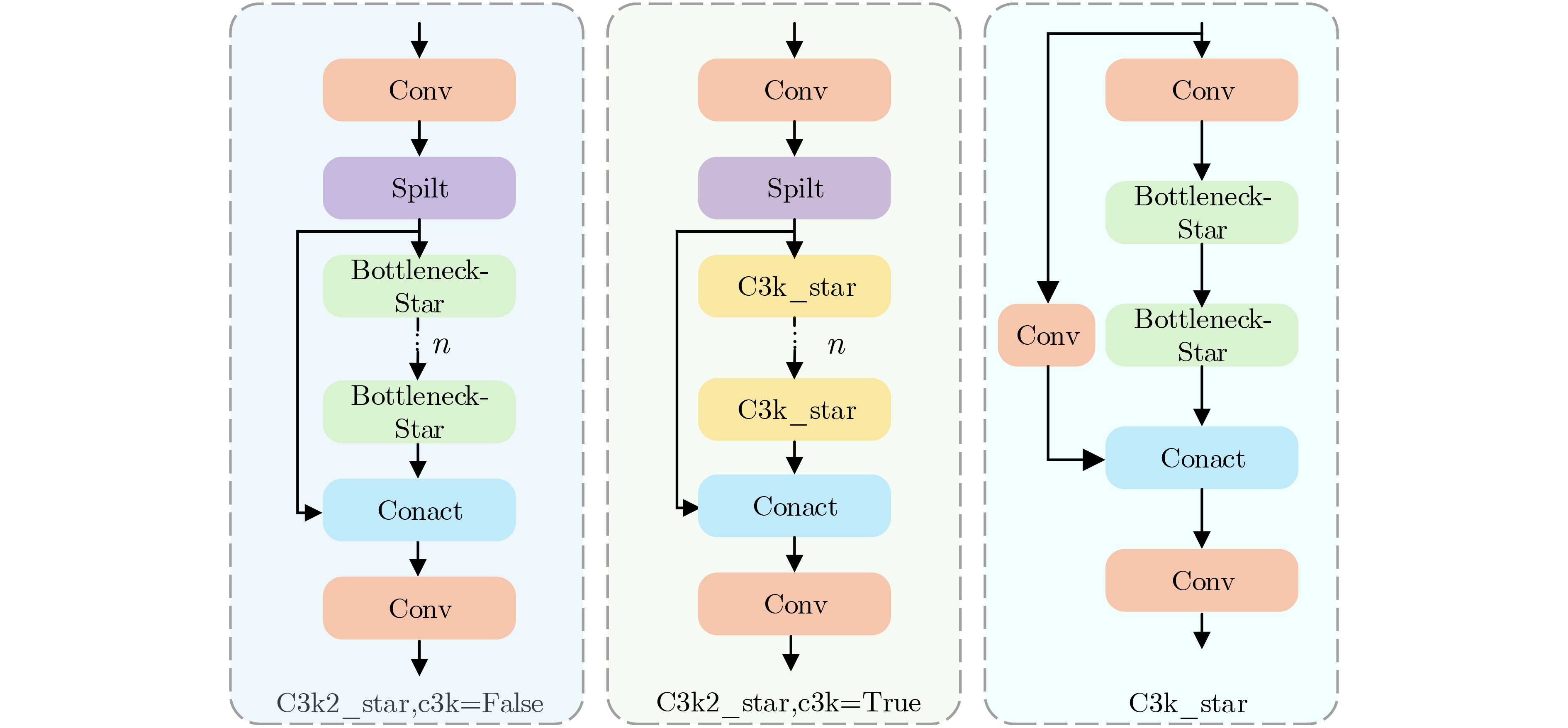
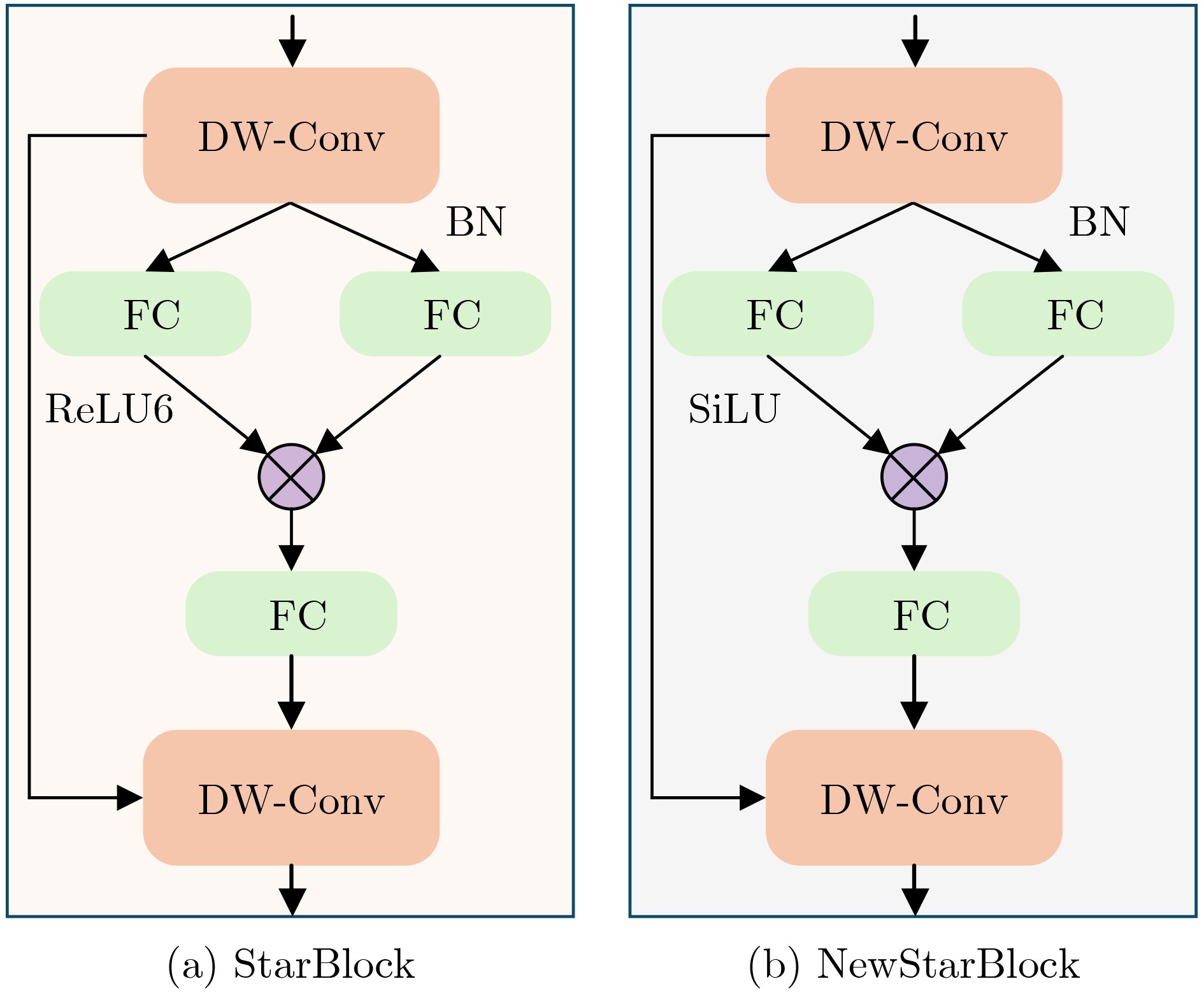
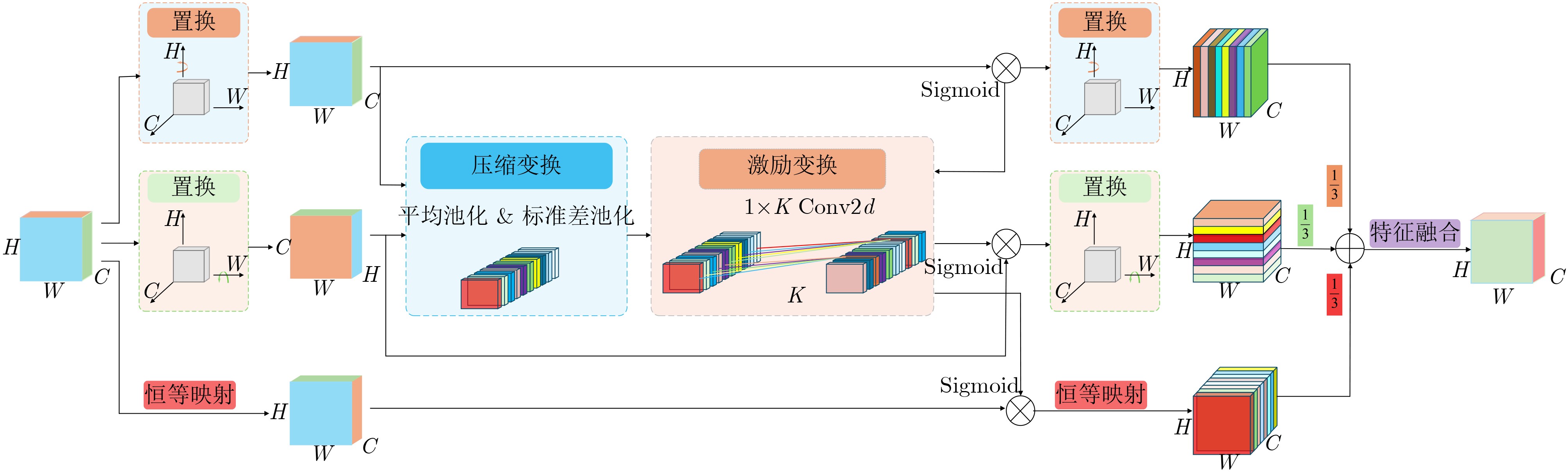
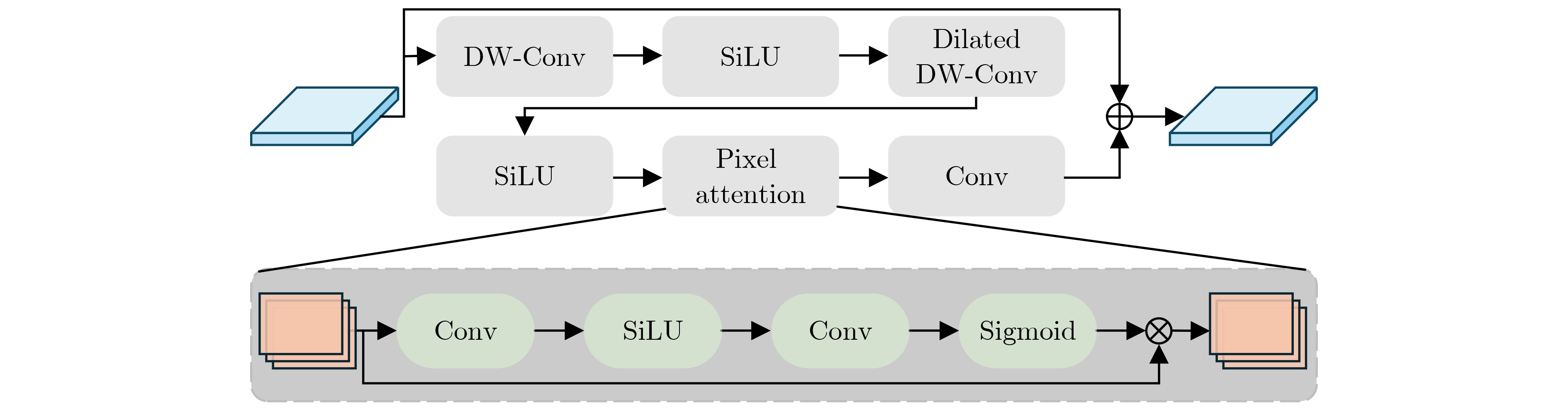
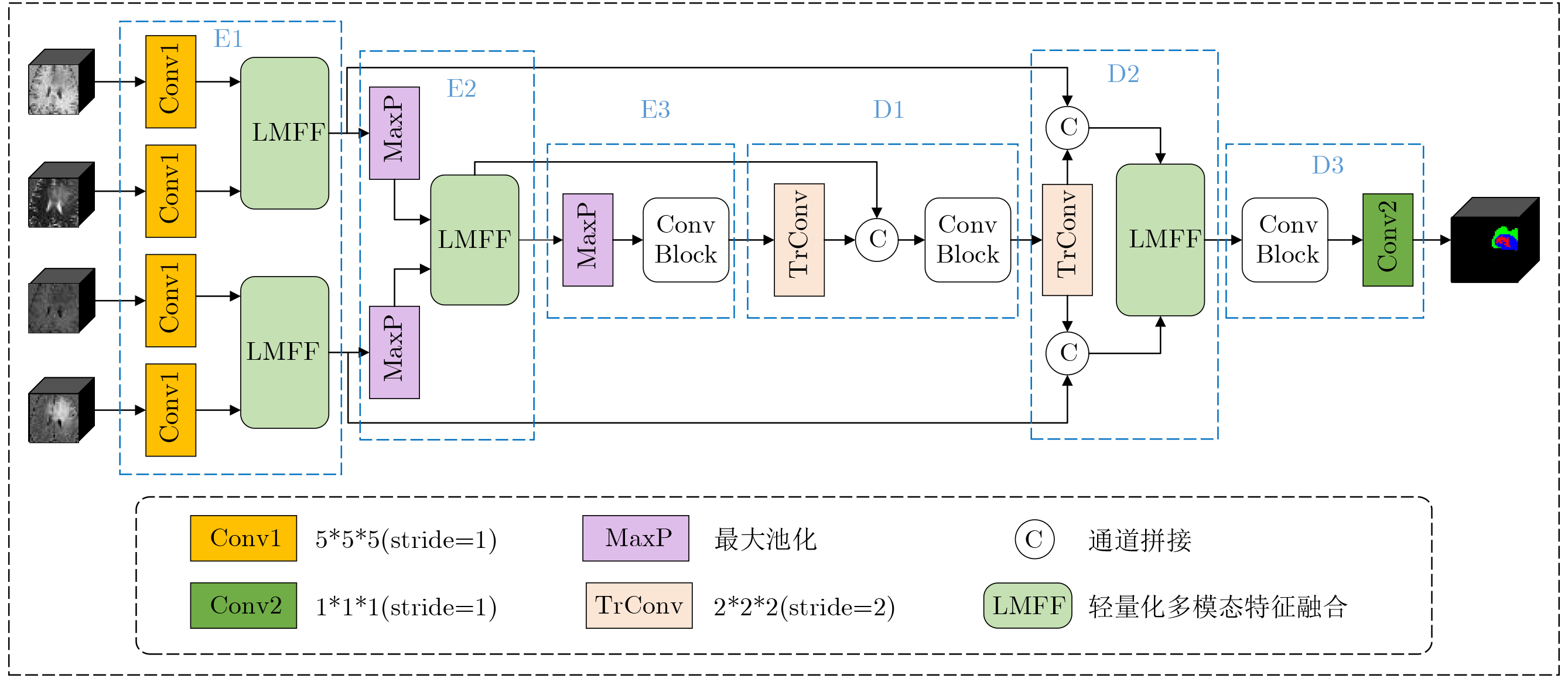
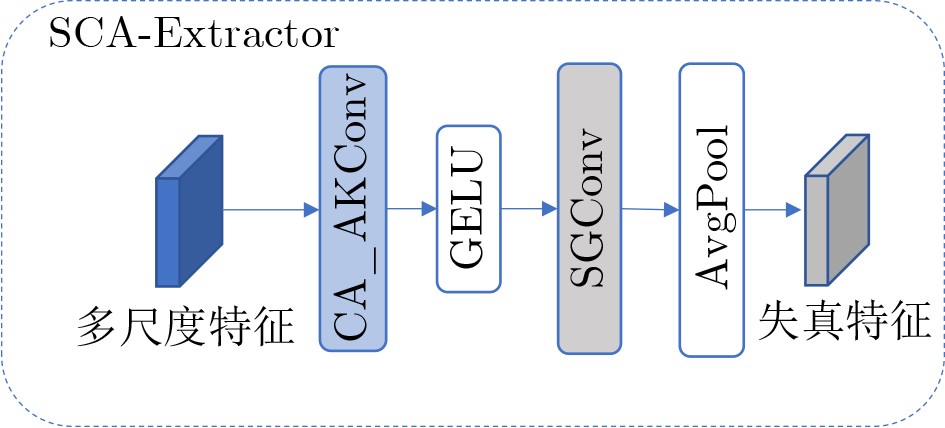
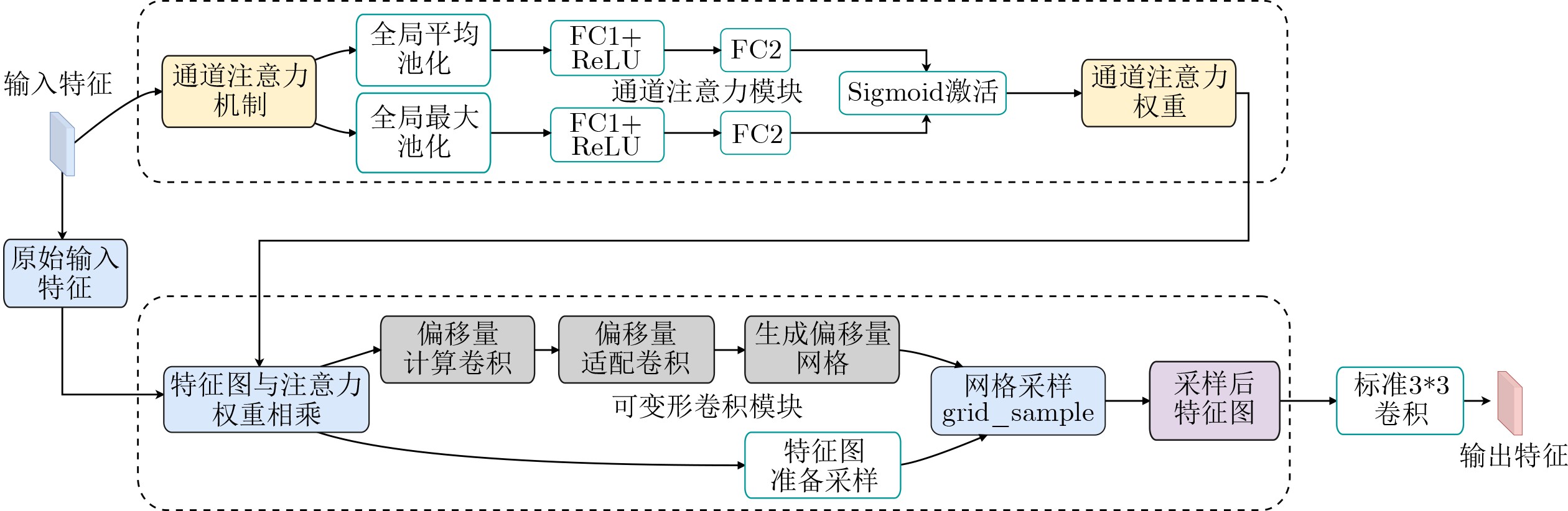
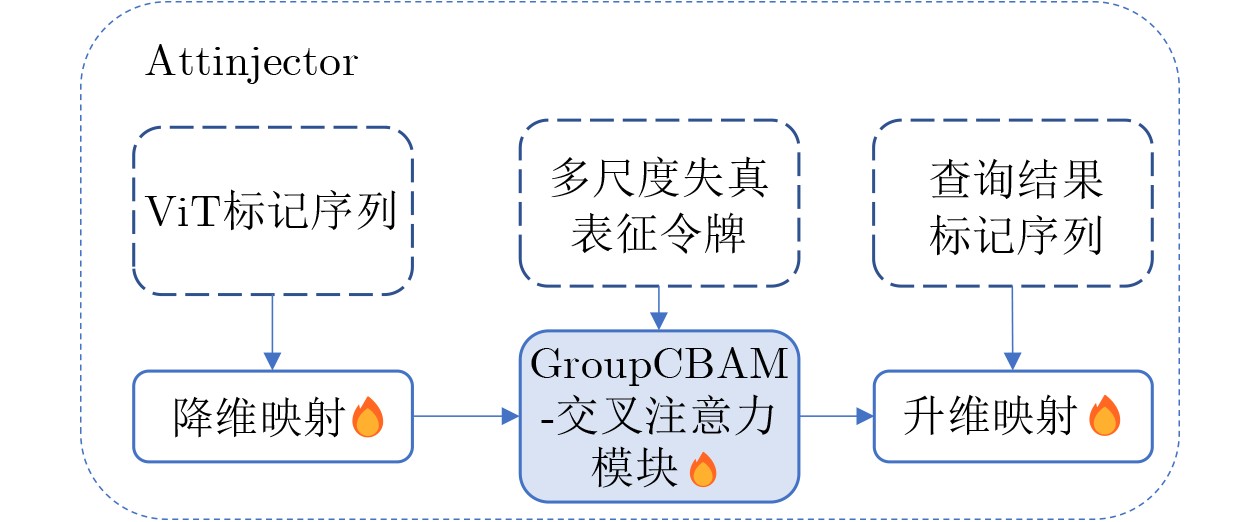
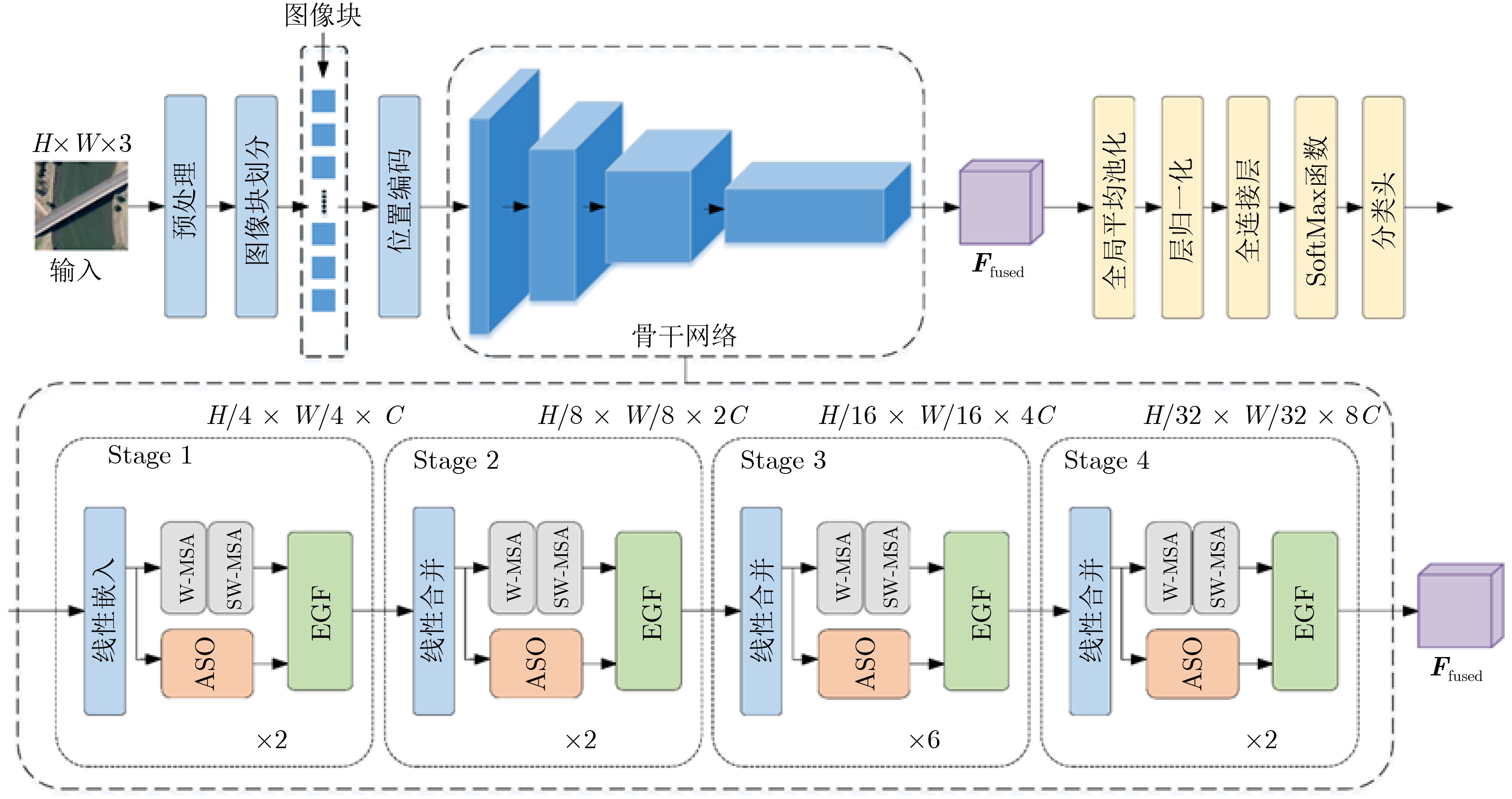
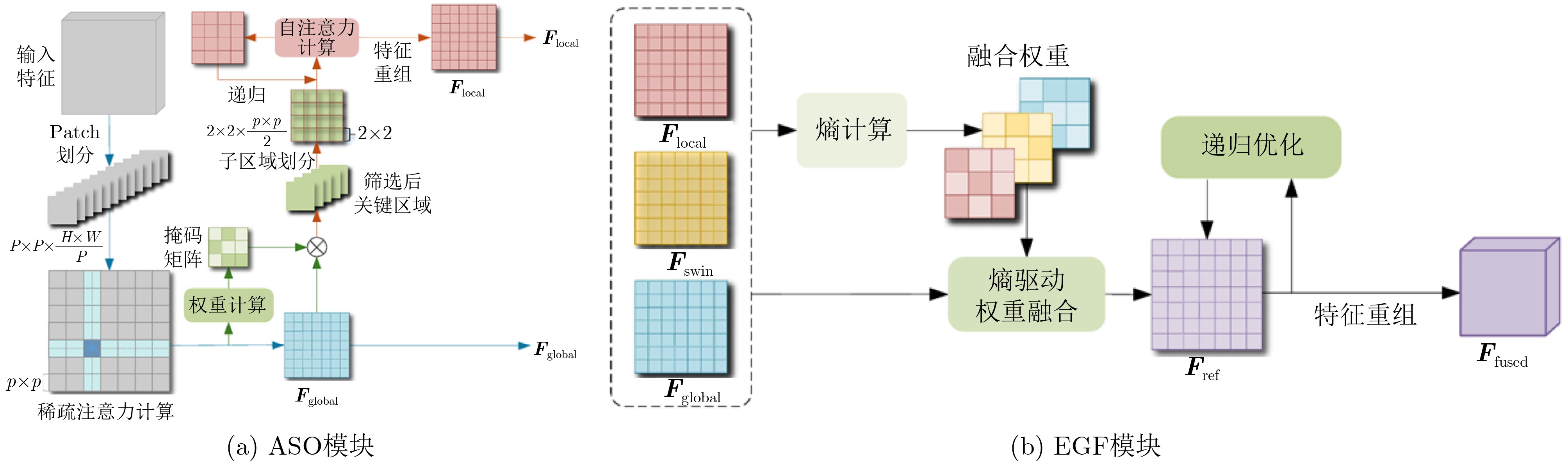
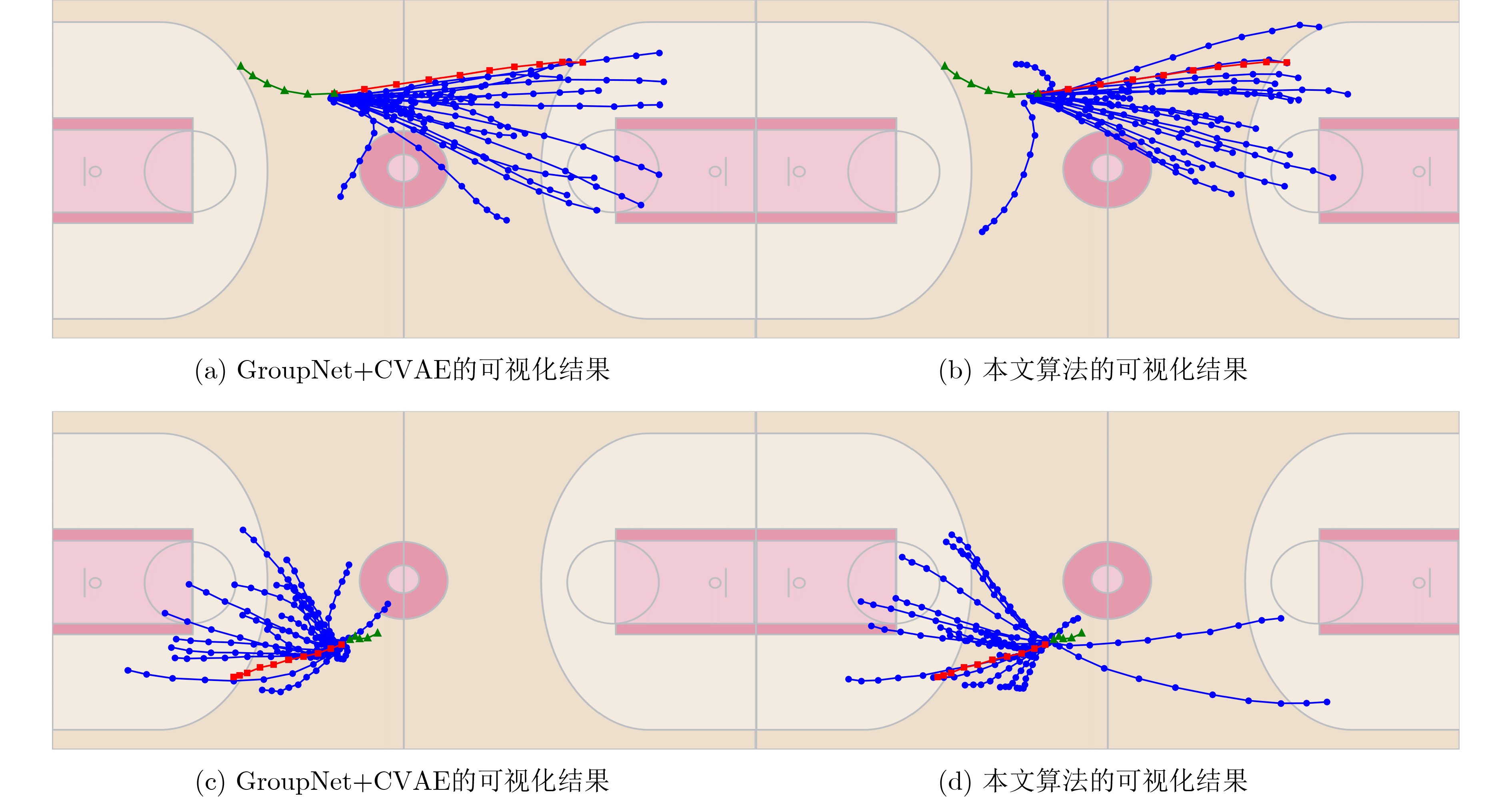
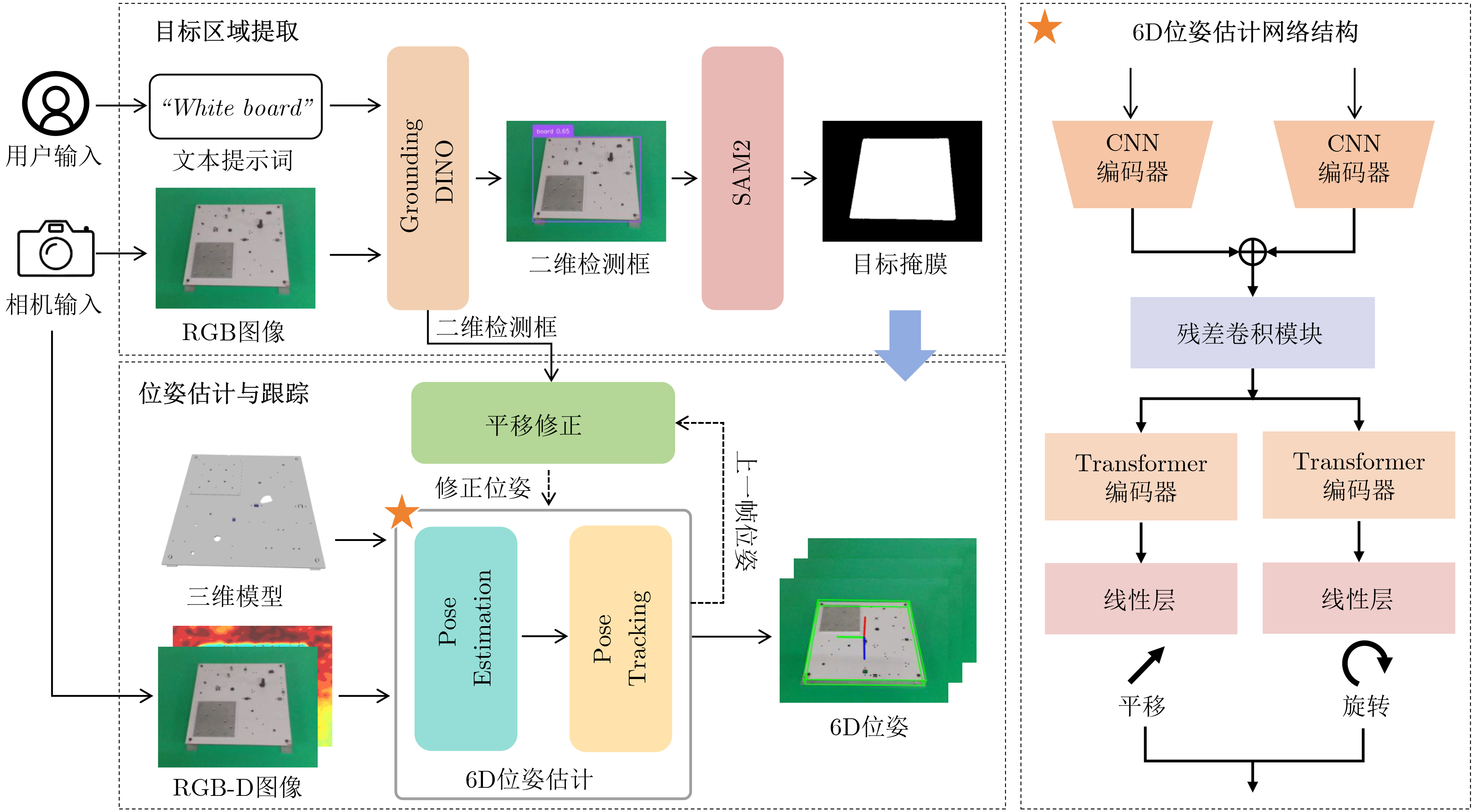
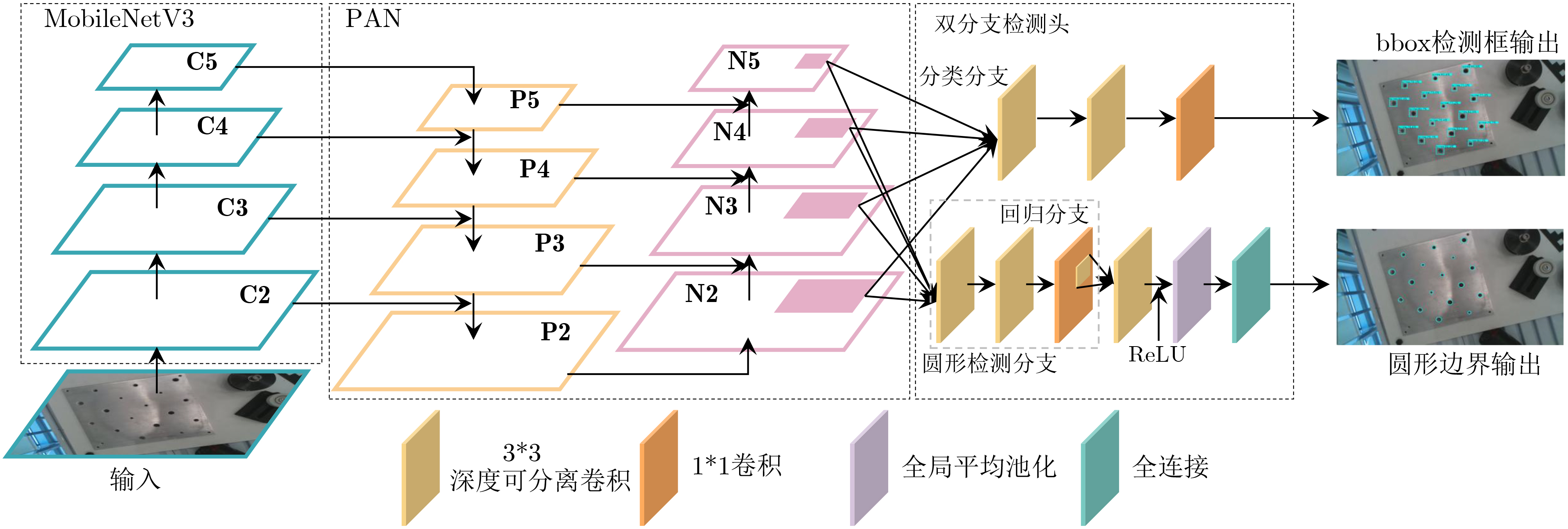
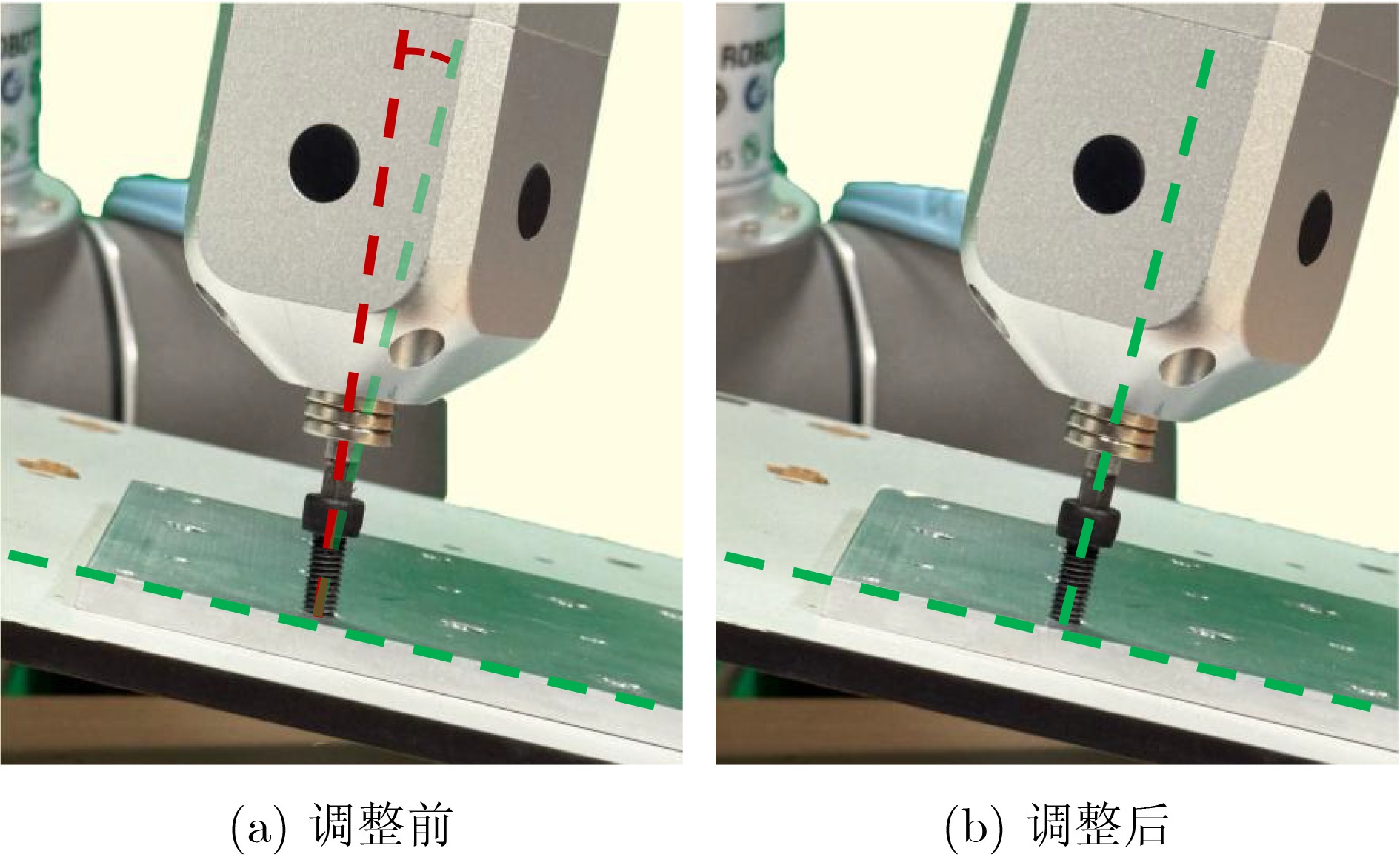
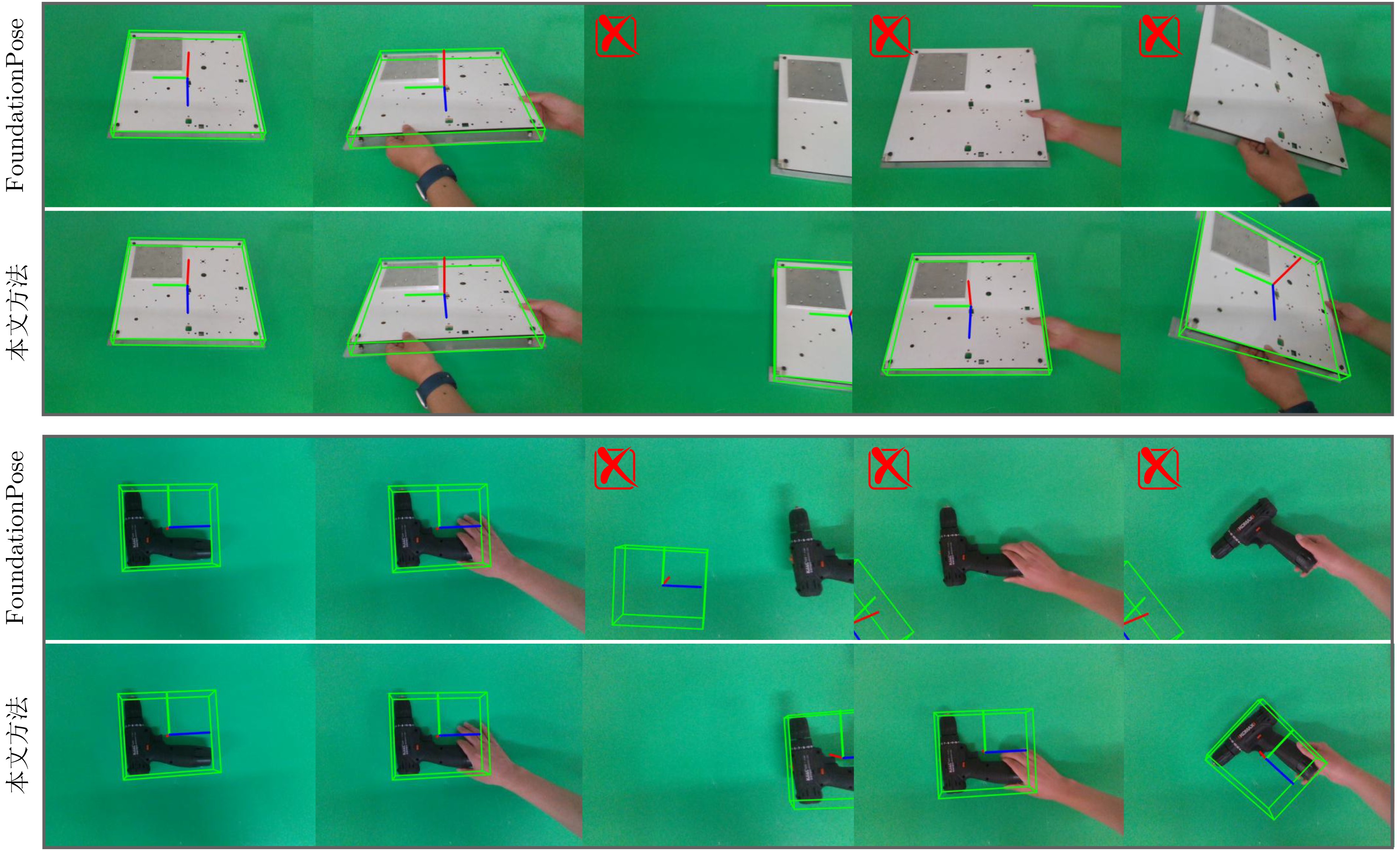
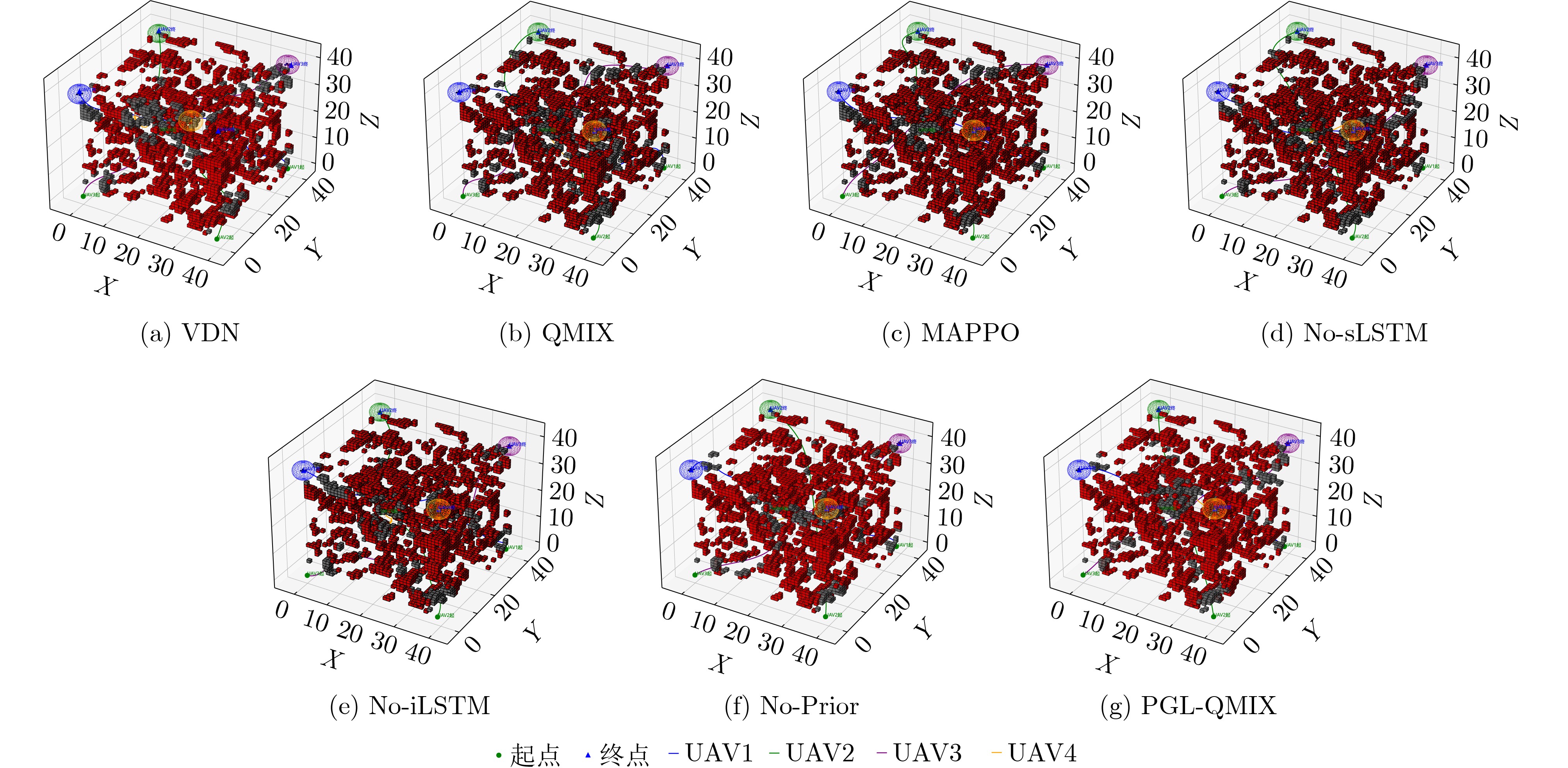
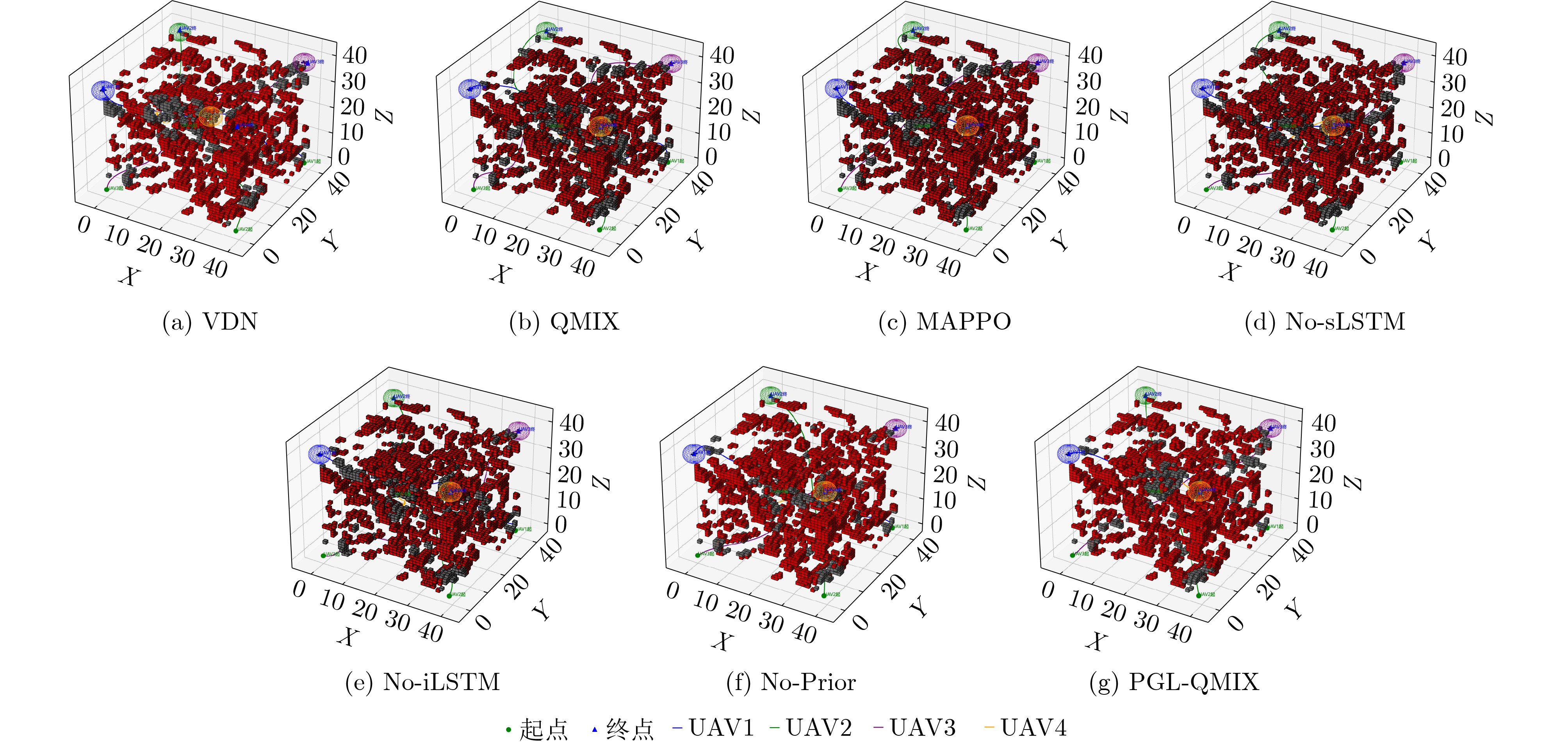
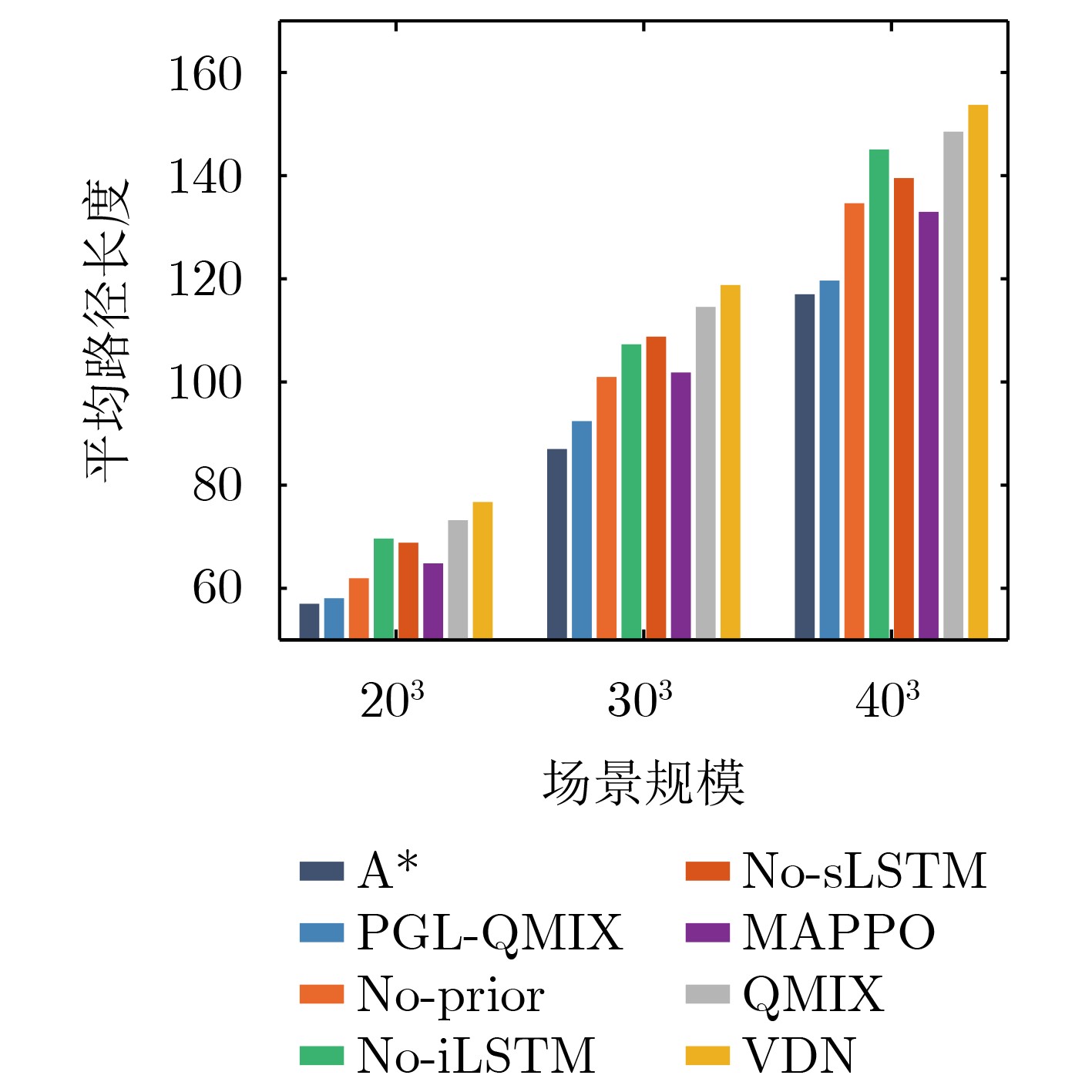
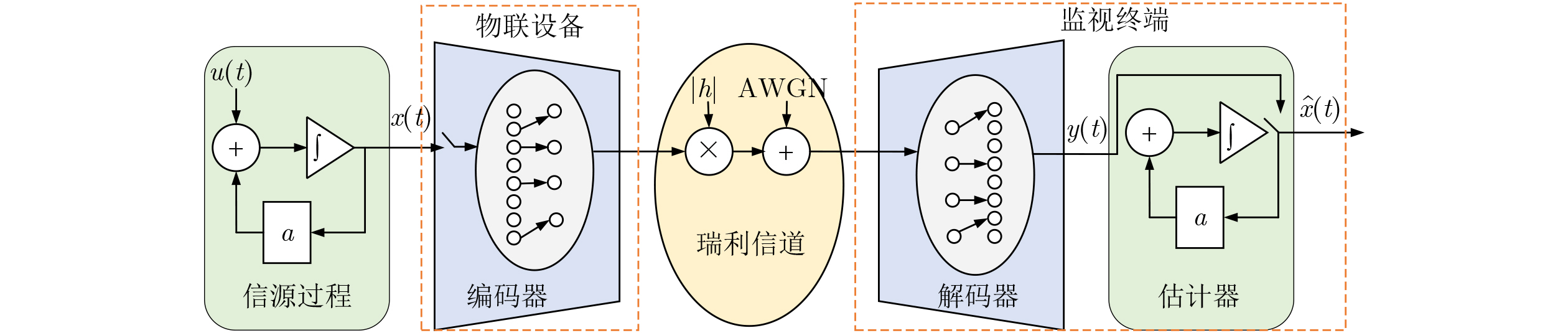
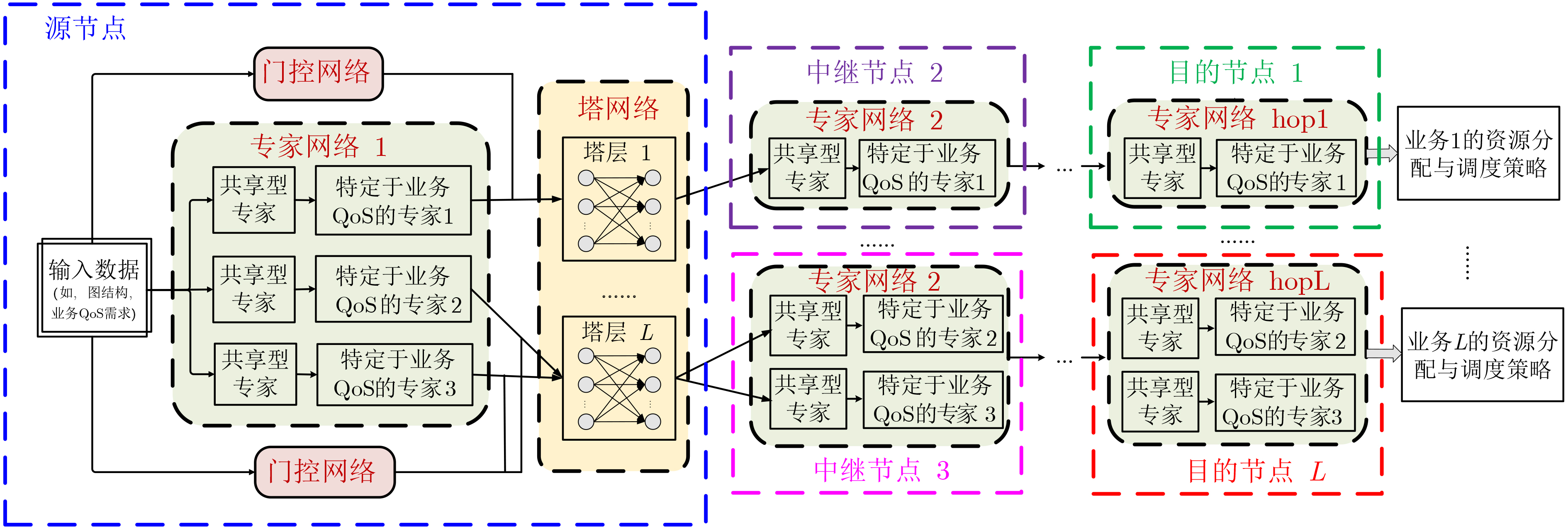
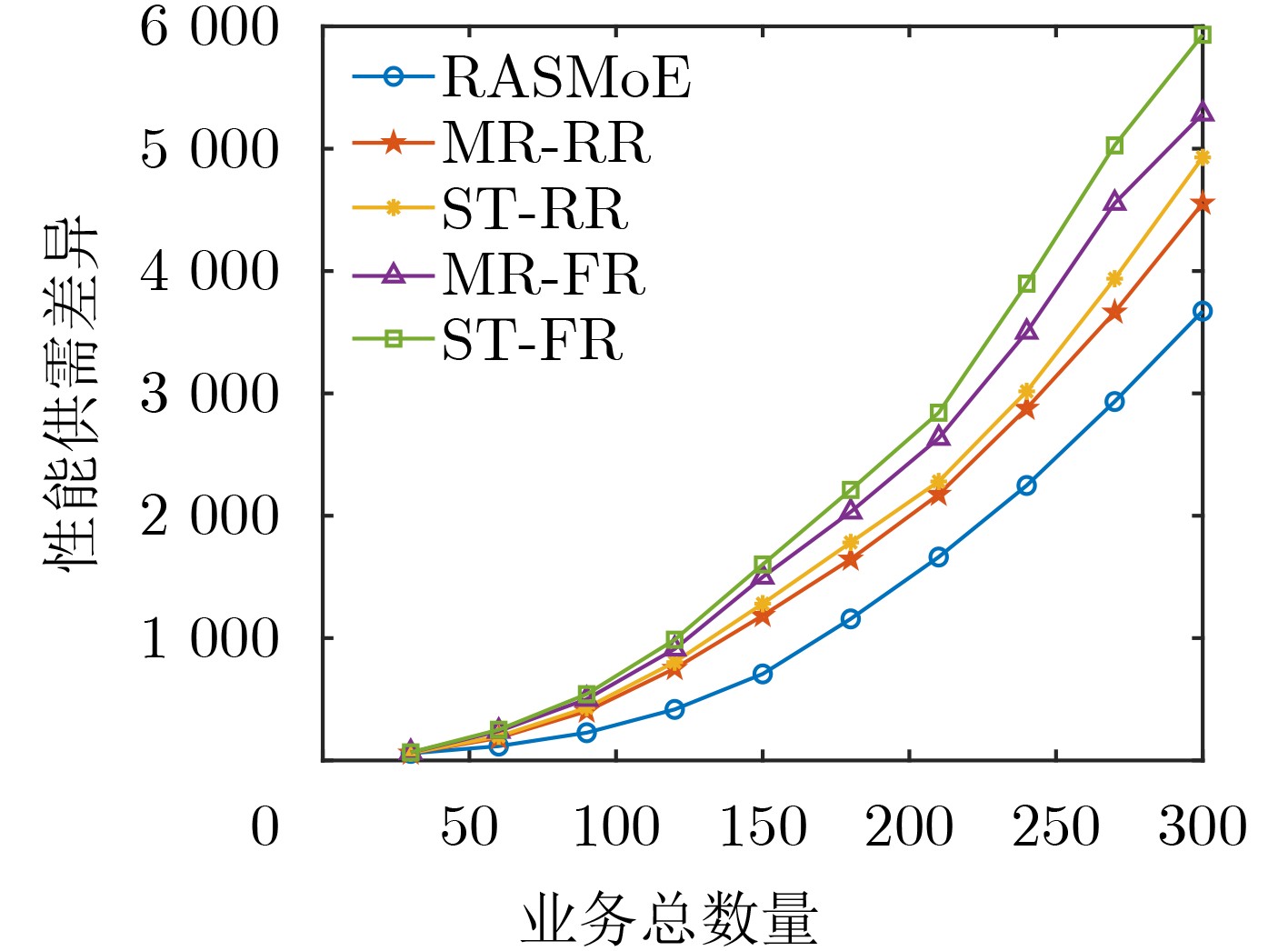
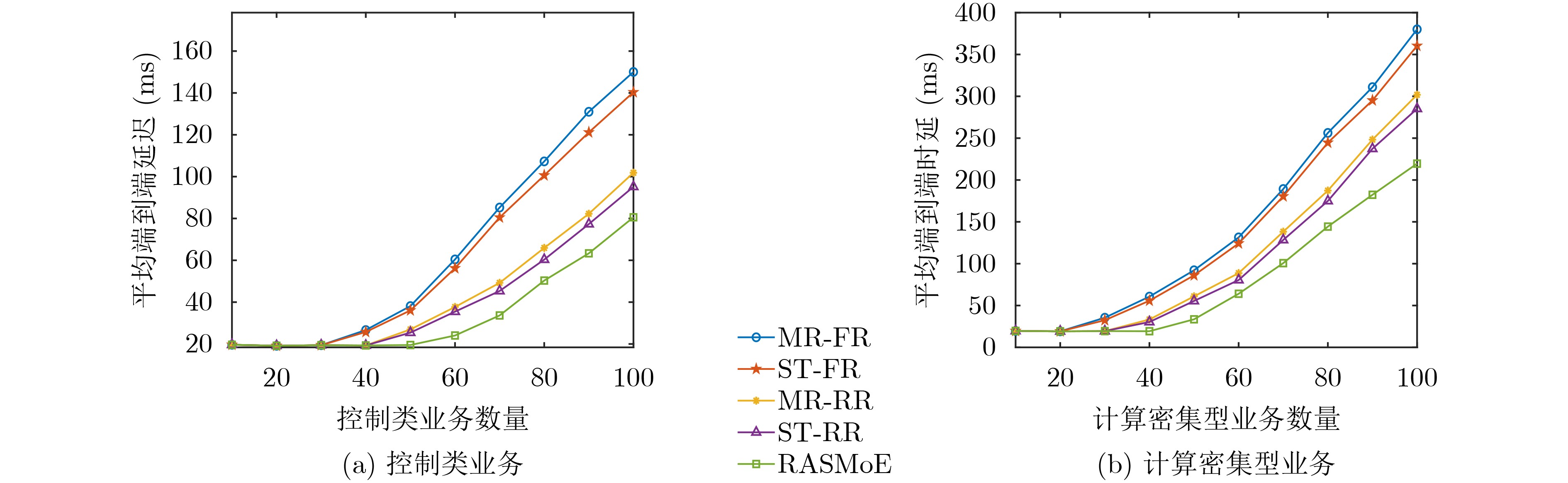
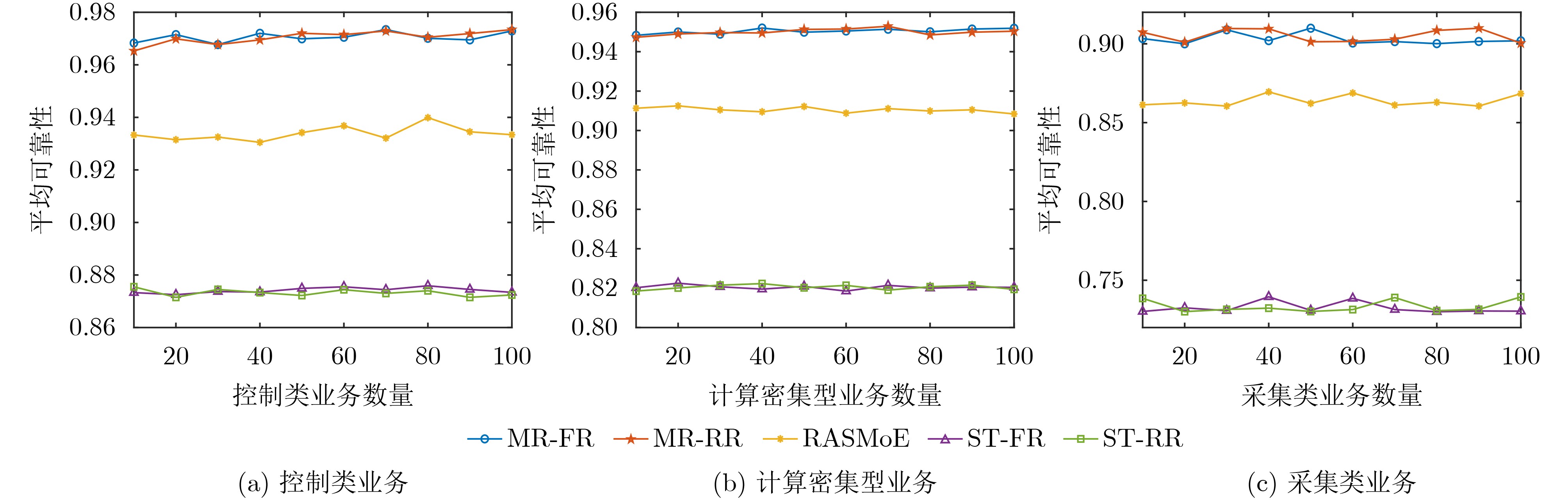
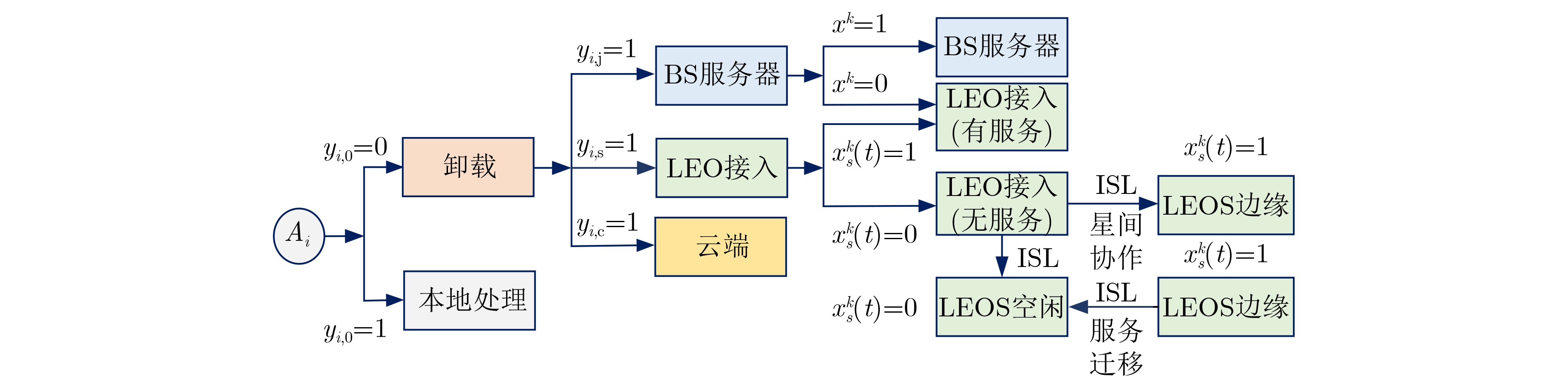
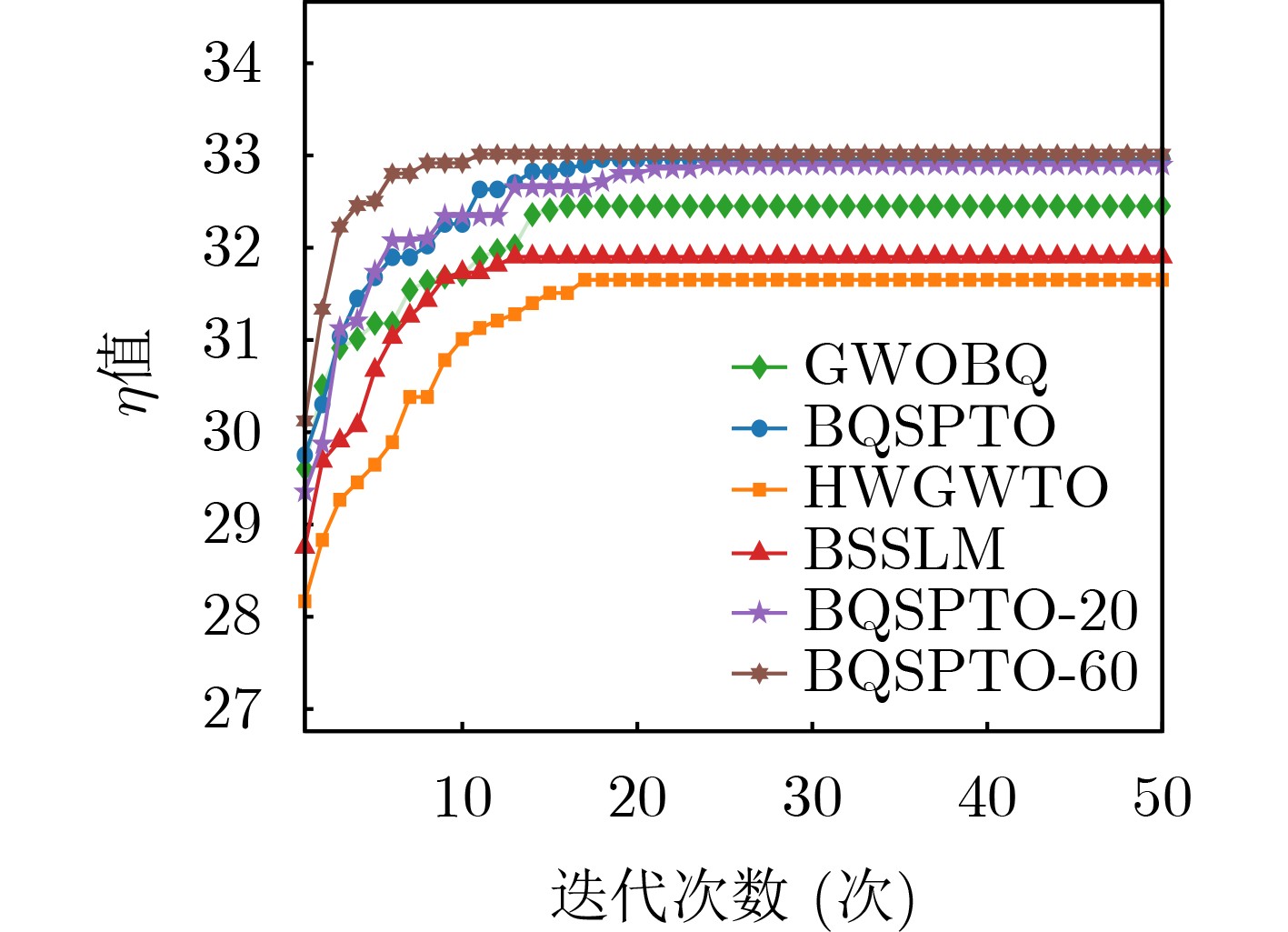
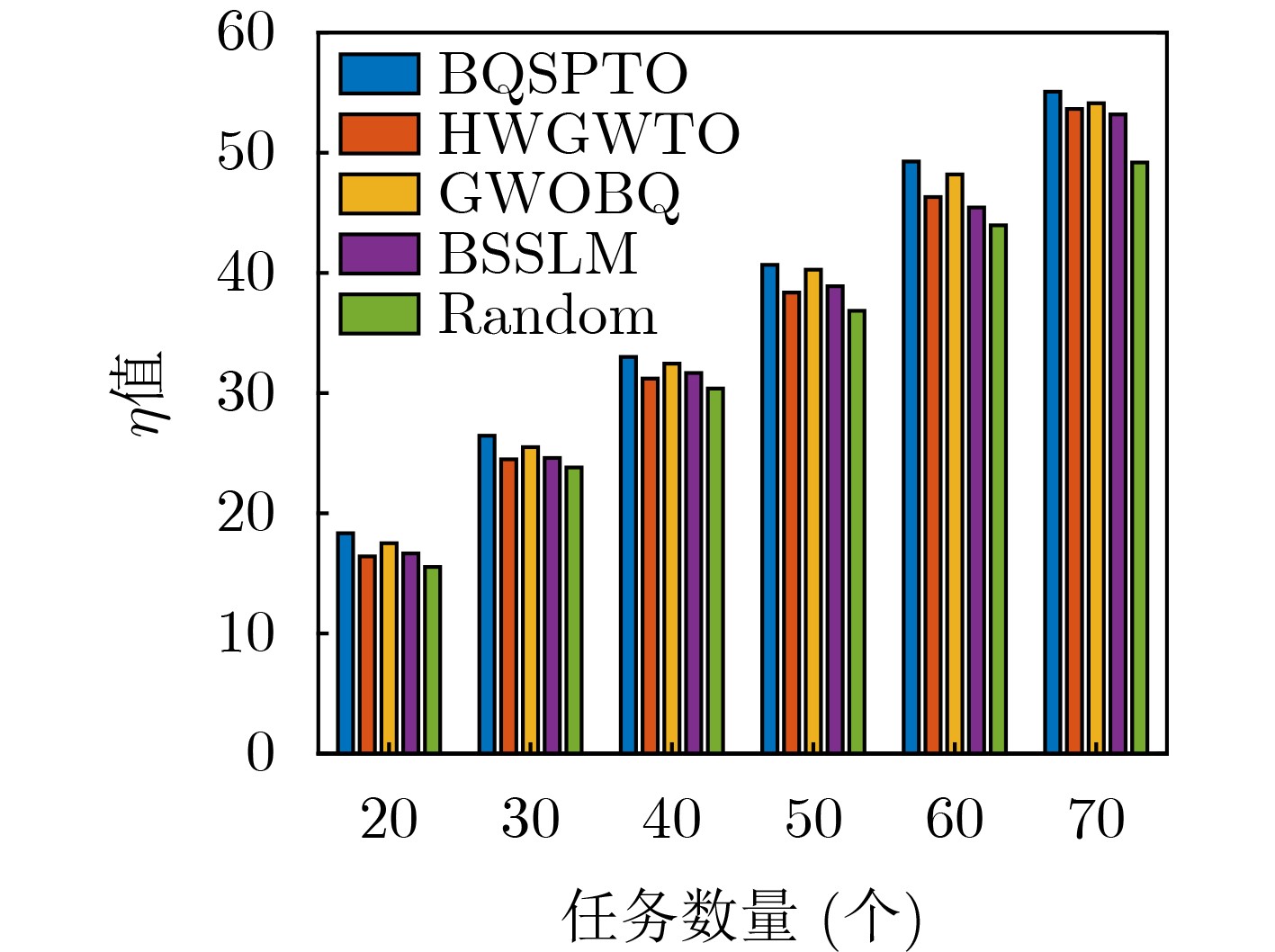
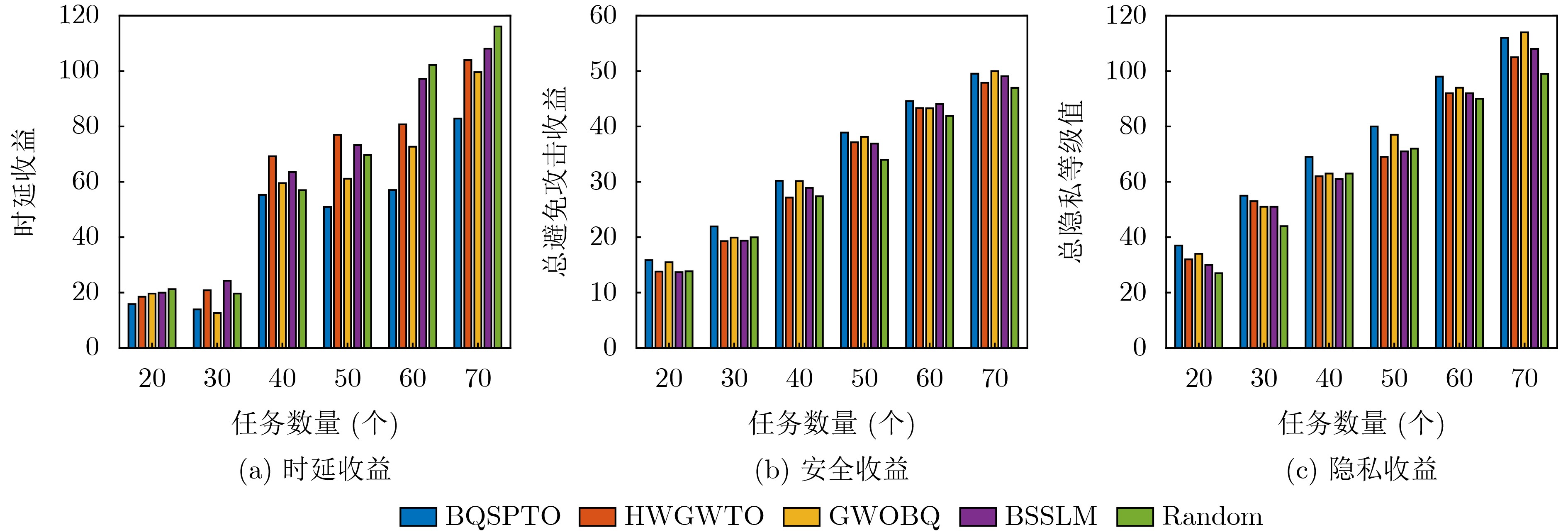
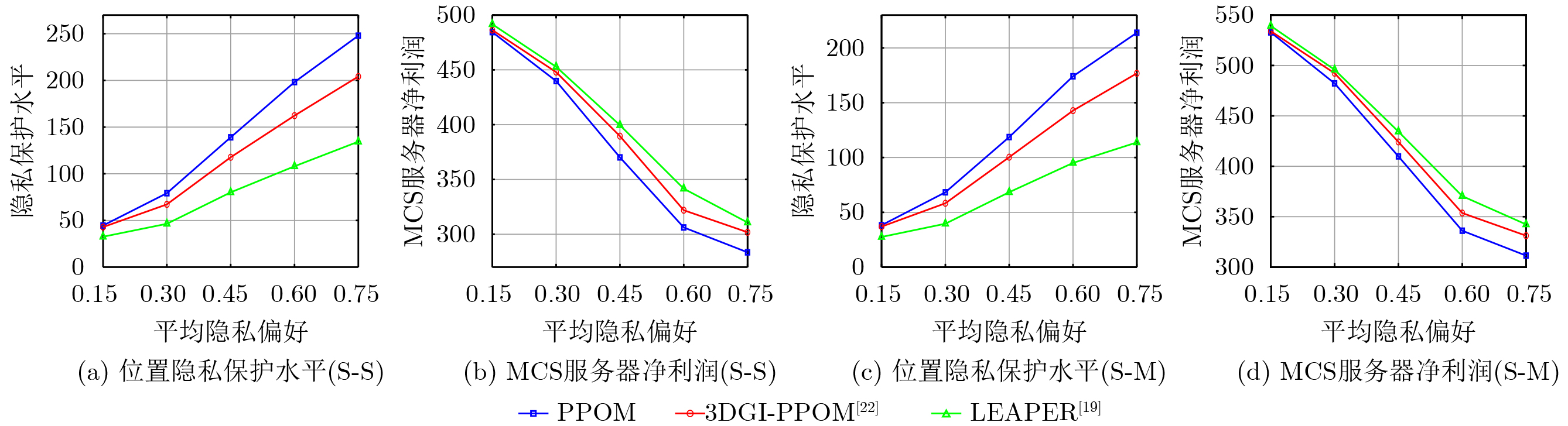
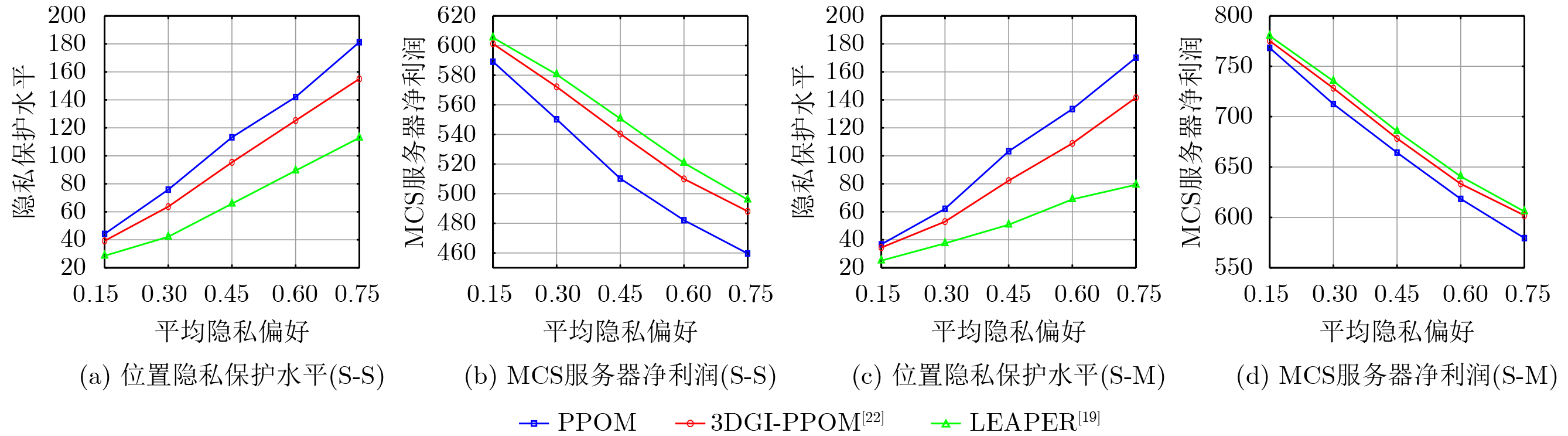
摘要: 针对行人轨迹预测中多模态特征捕捉不足及群体动态关系缺失的问题,该文提出了一种新颖的多模态行人轨迹预测框架——MSGD (Multi-Scale Spatio-Temporal Group Modeling and Diffusion)。首先利用多尺度时空特征,准确构建多尺度时空群体;其次,设计时空交互三元组编码机制,对个体-邻居-群体的时空关系进行联合建模,兼顾局部交互细节与全局动态结构,提升对群体行为演化的表征能力。最后利用扩散模型的逆过程在生成阶段逐步减少可行区域内的不确定性,最终生成多样、合理且逼真的目标轨迹。该文在3个公开数据集(ETH, UCY和NBA数据集)上对所提出的方法进行了广泛评估,并与当前最先进的方法进行了比较。实验结果表明,MSGD框架在预测性能方面取得了显著提升,具体表现为平均偏移误差(ADE)和最终偏移误差(FDE)指标的显著改善,展现了其在建模复杂行人行为方面的有效性。