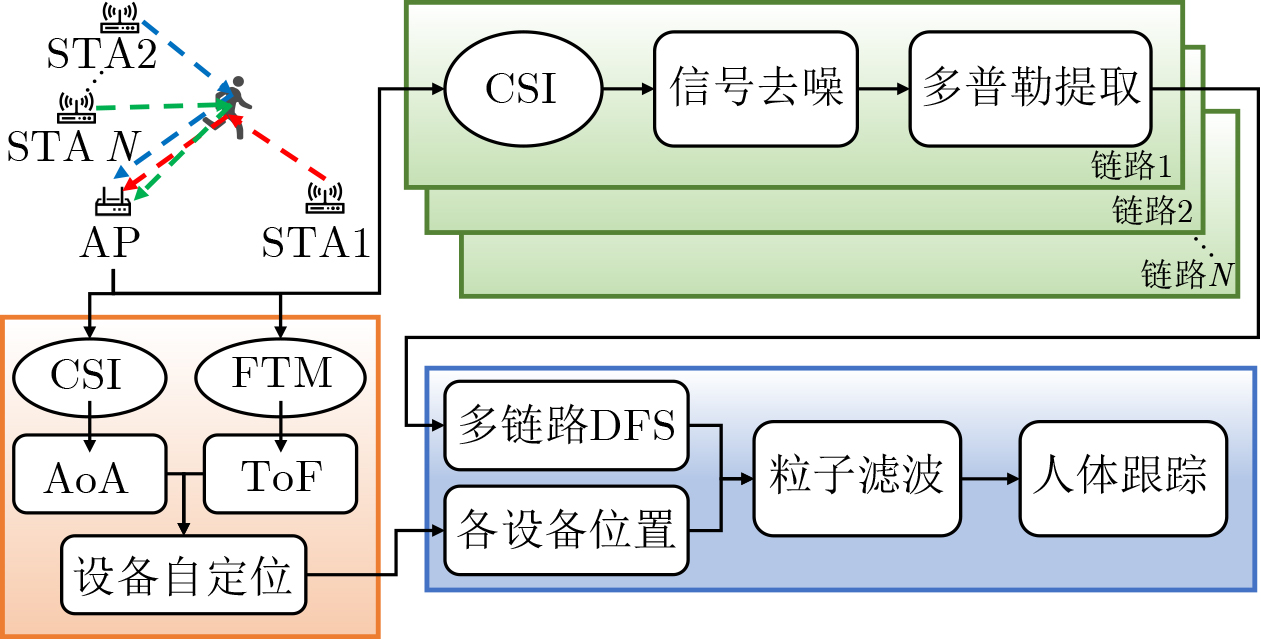
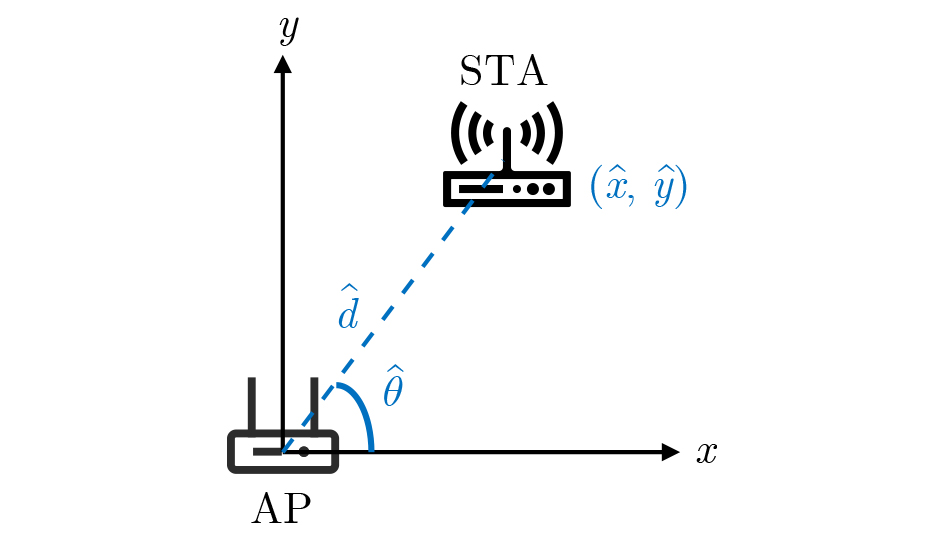
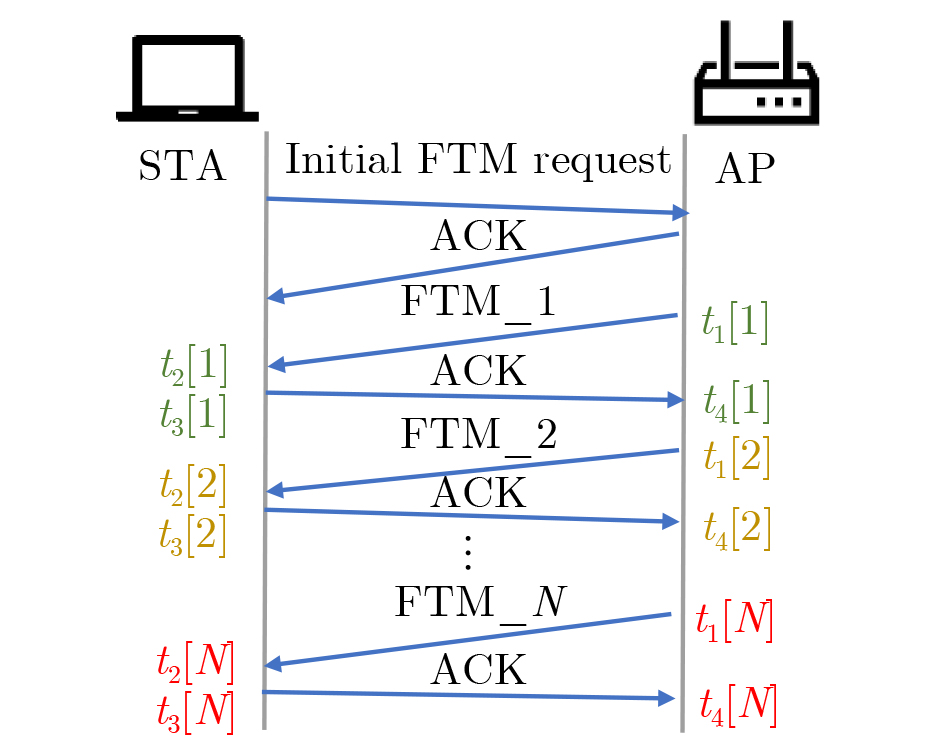
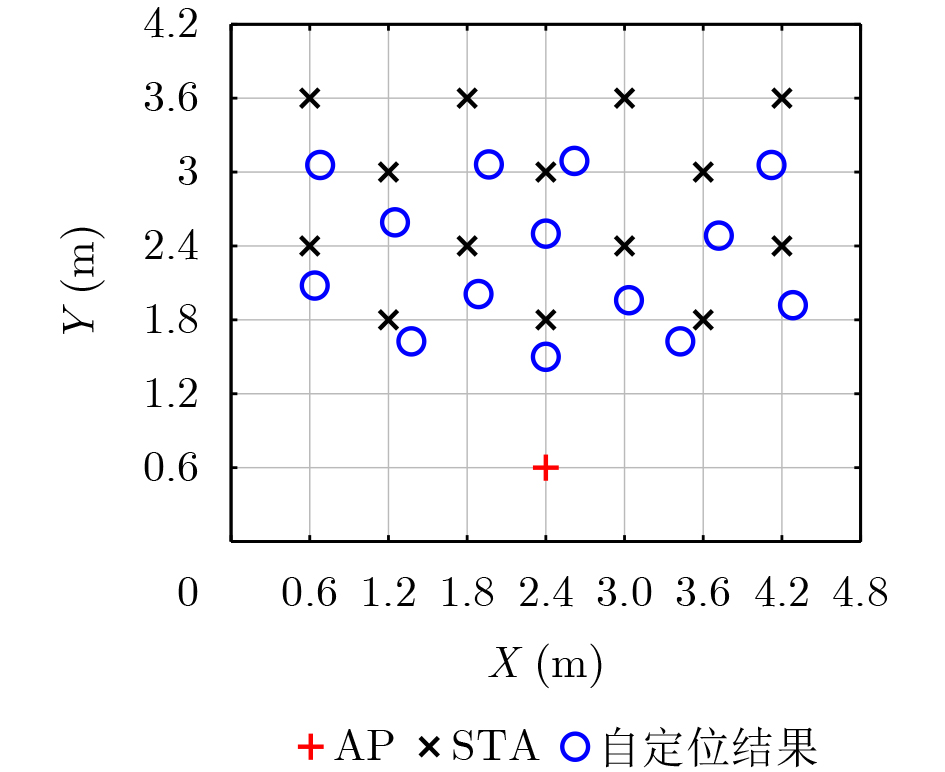
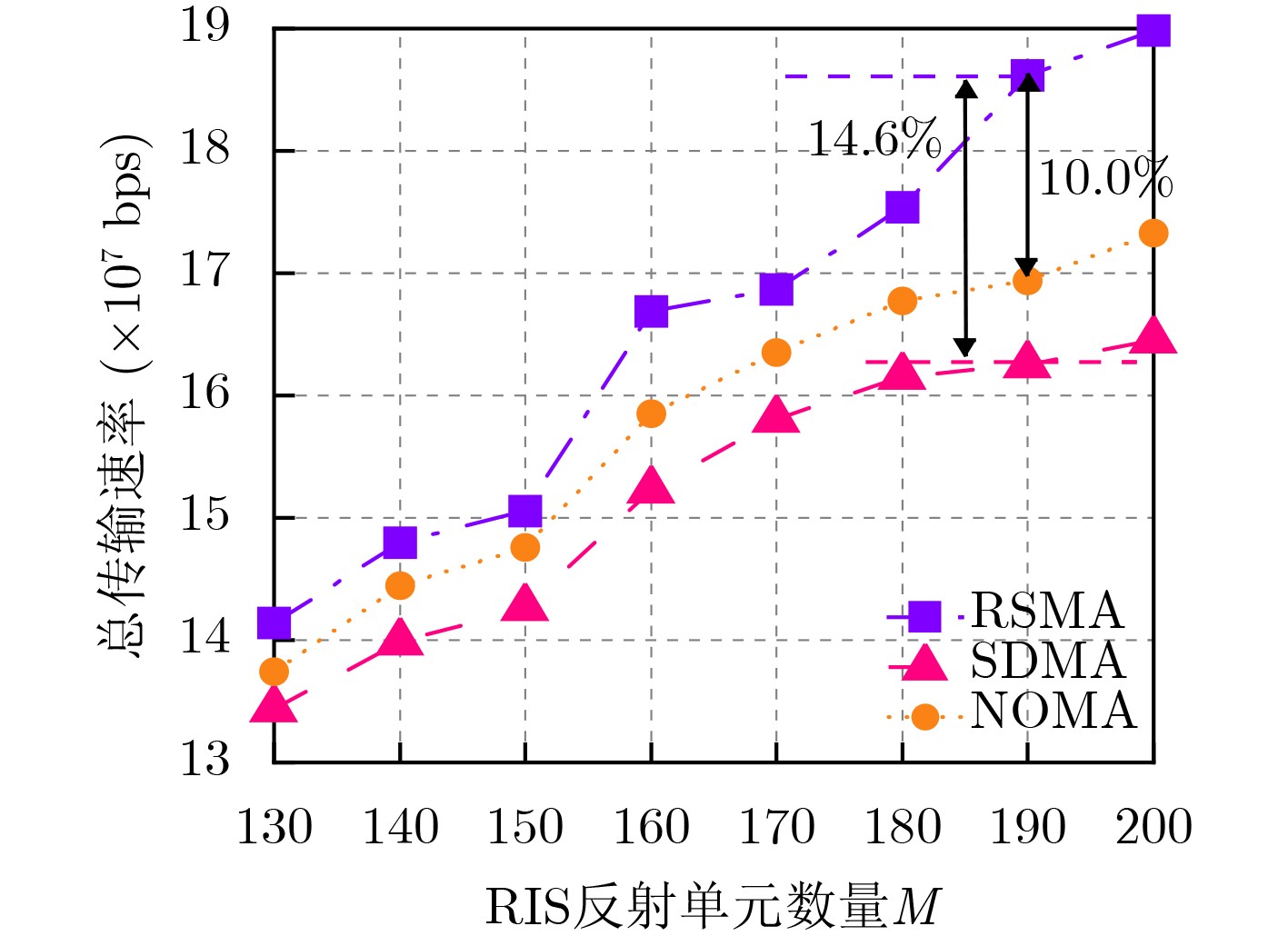
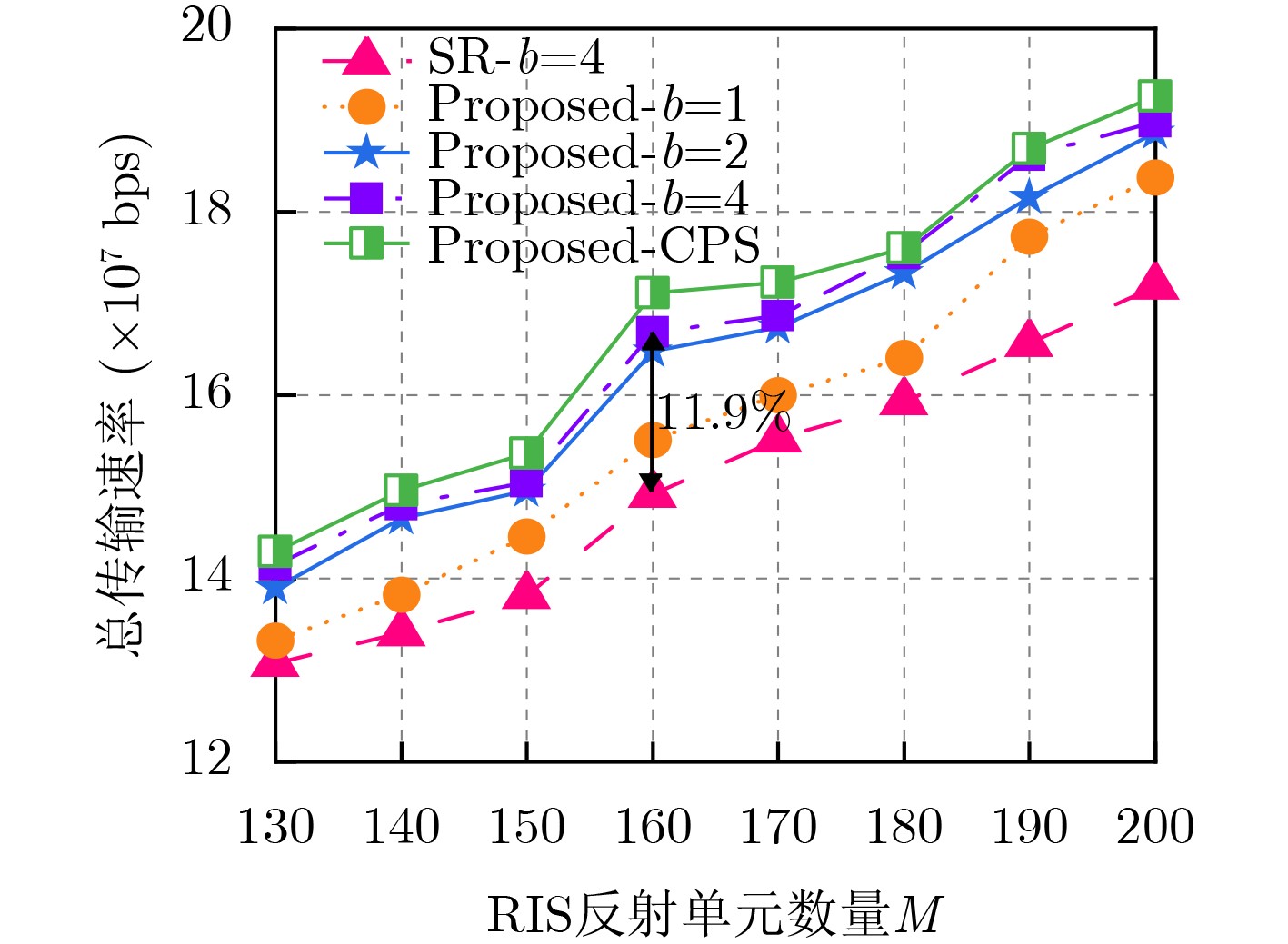
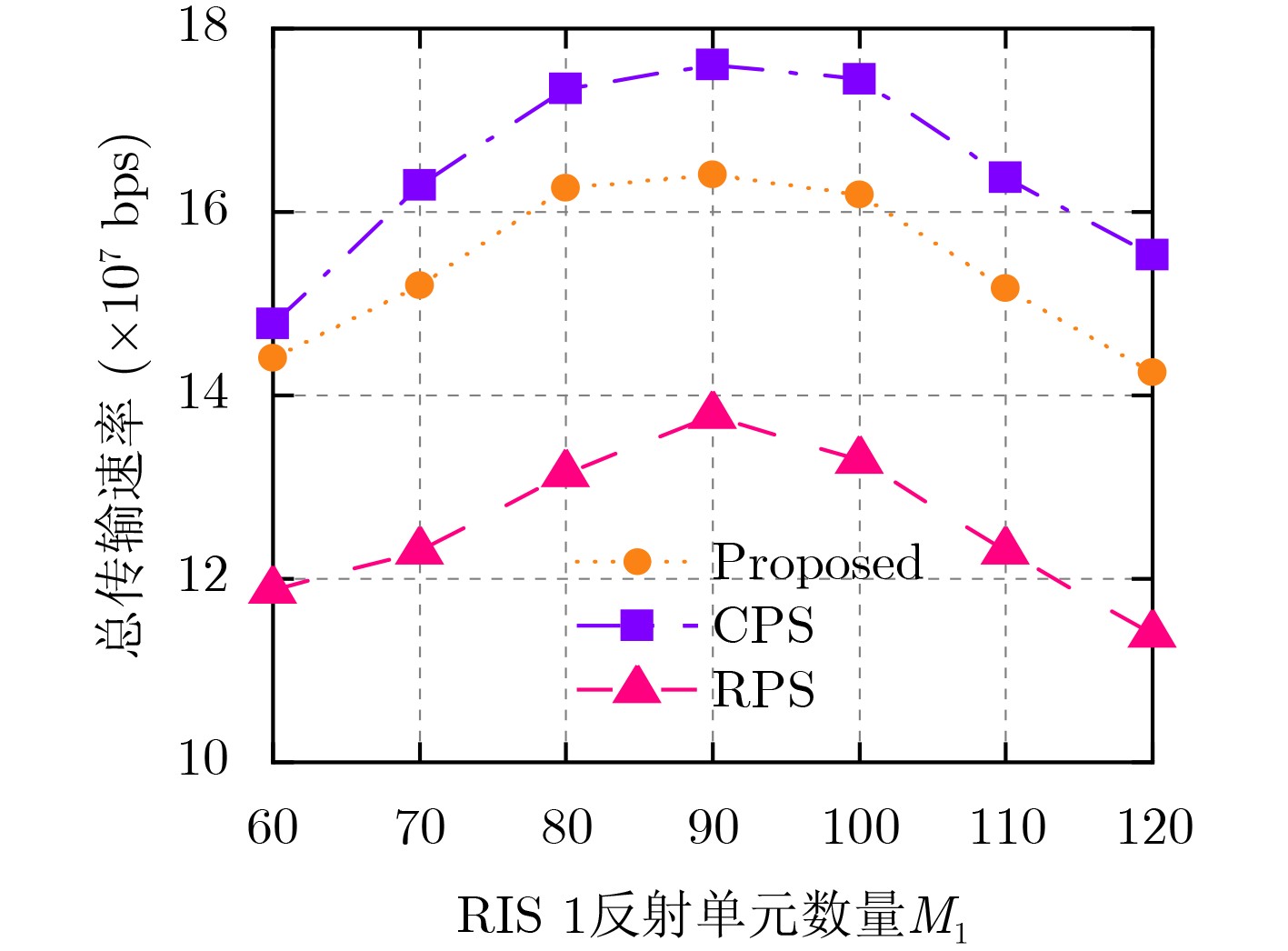
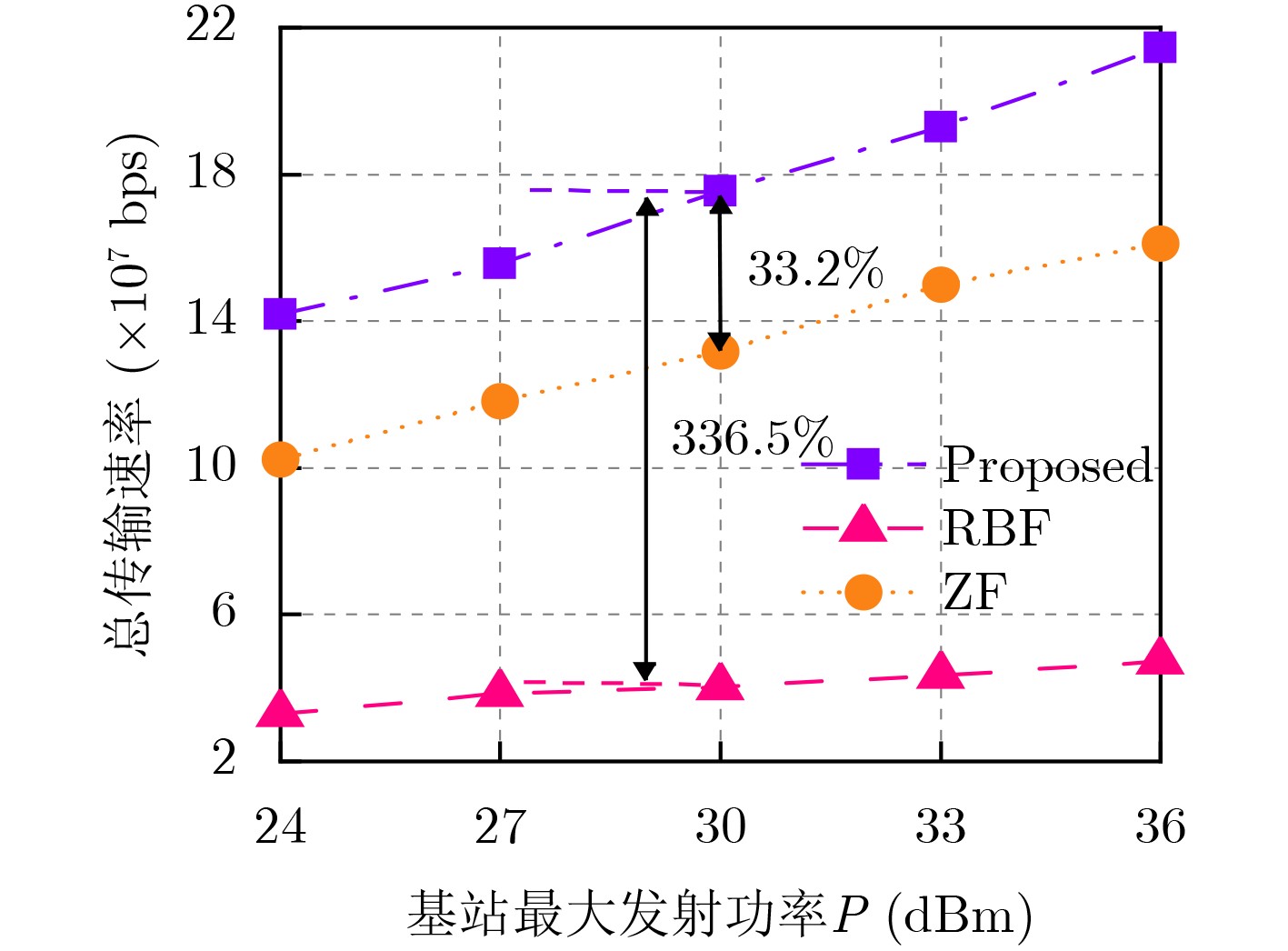
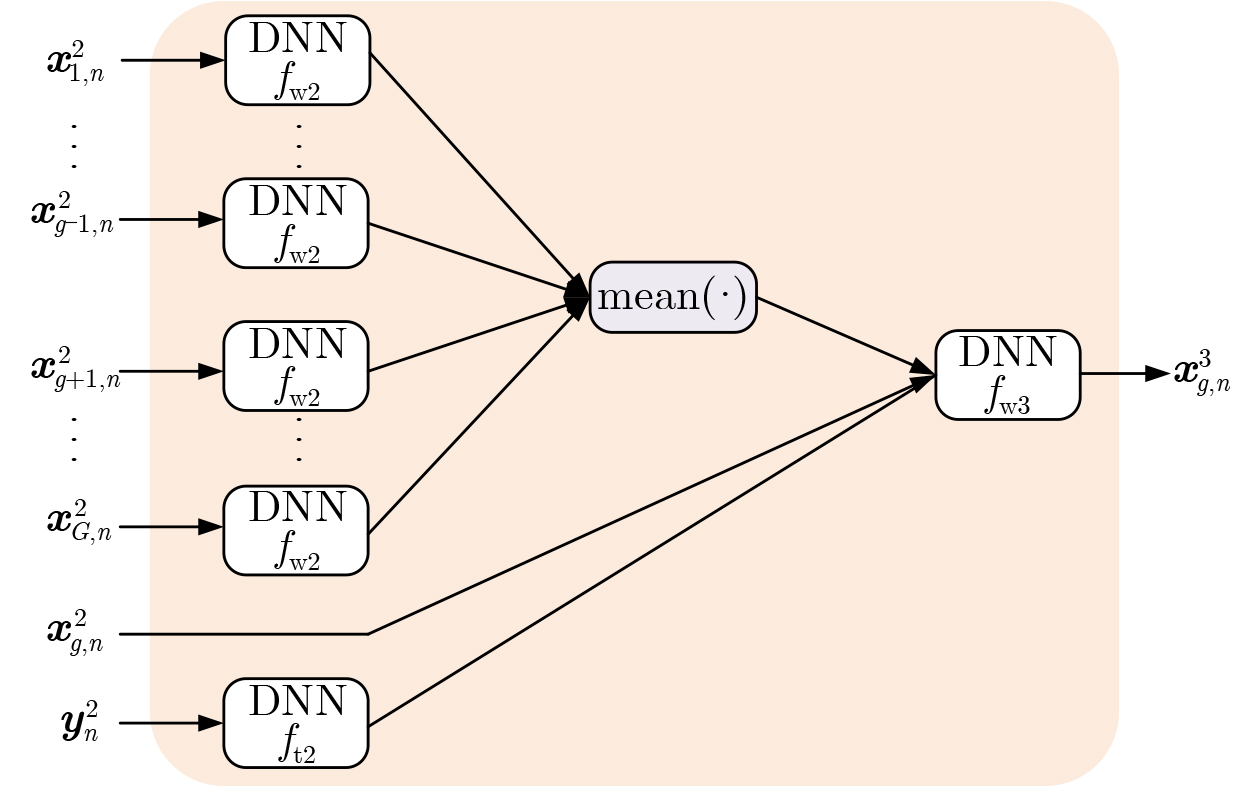
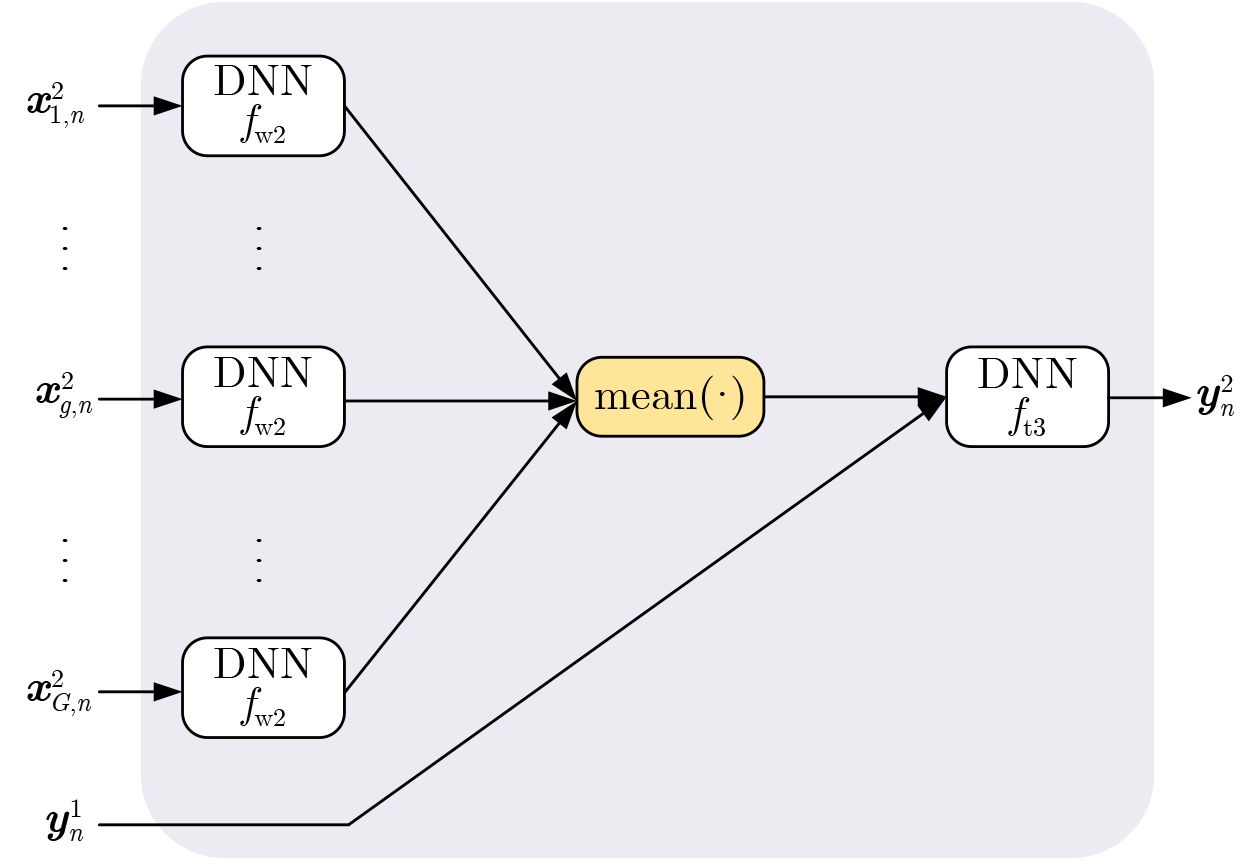
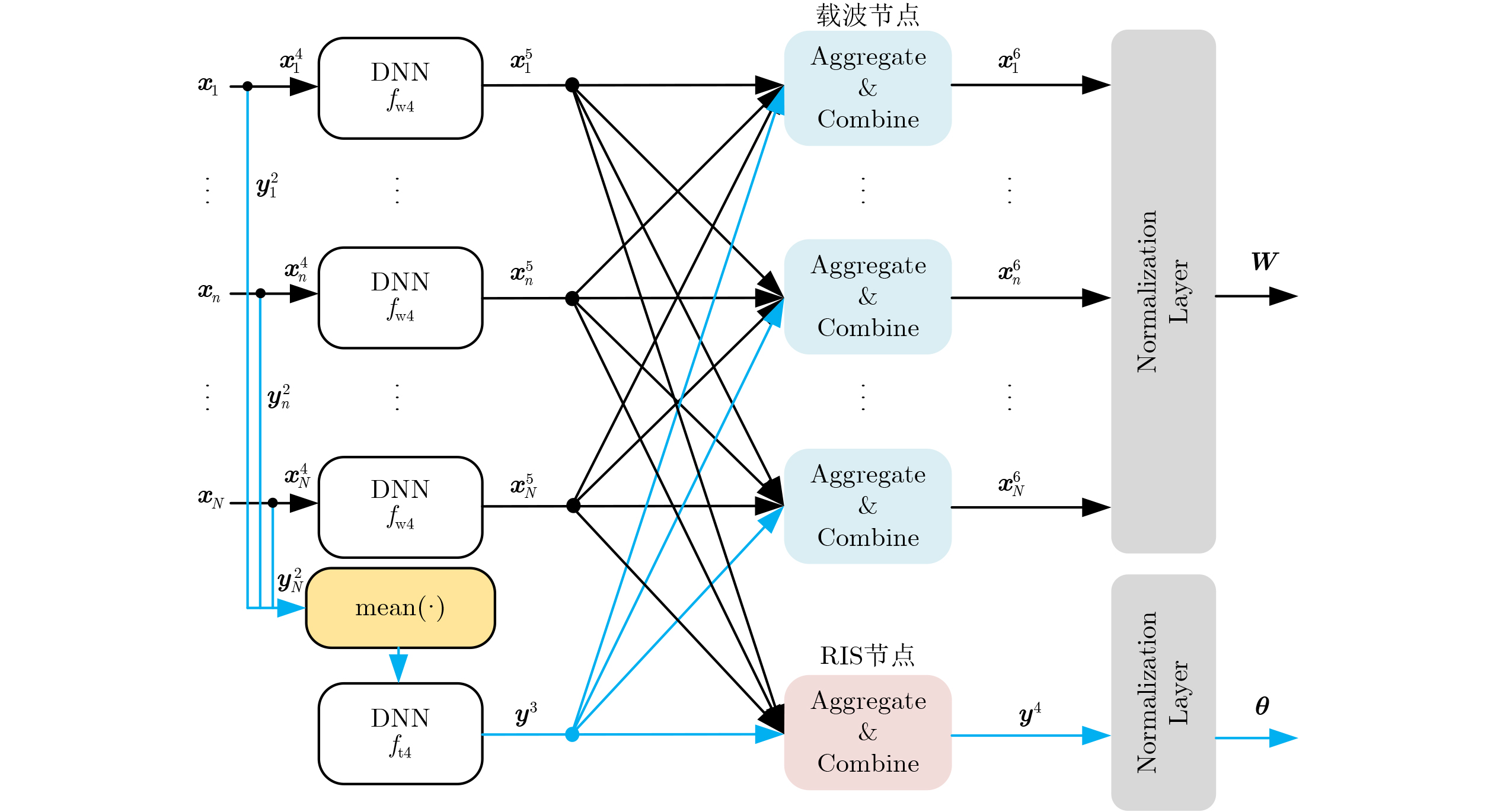
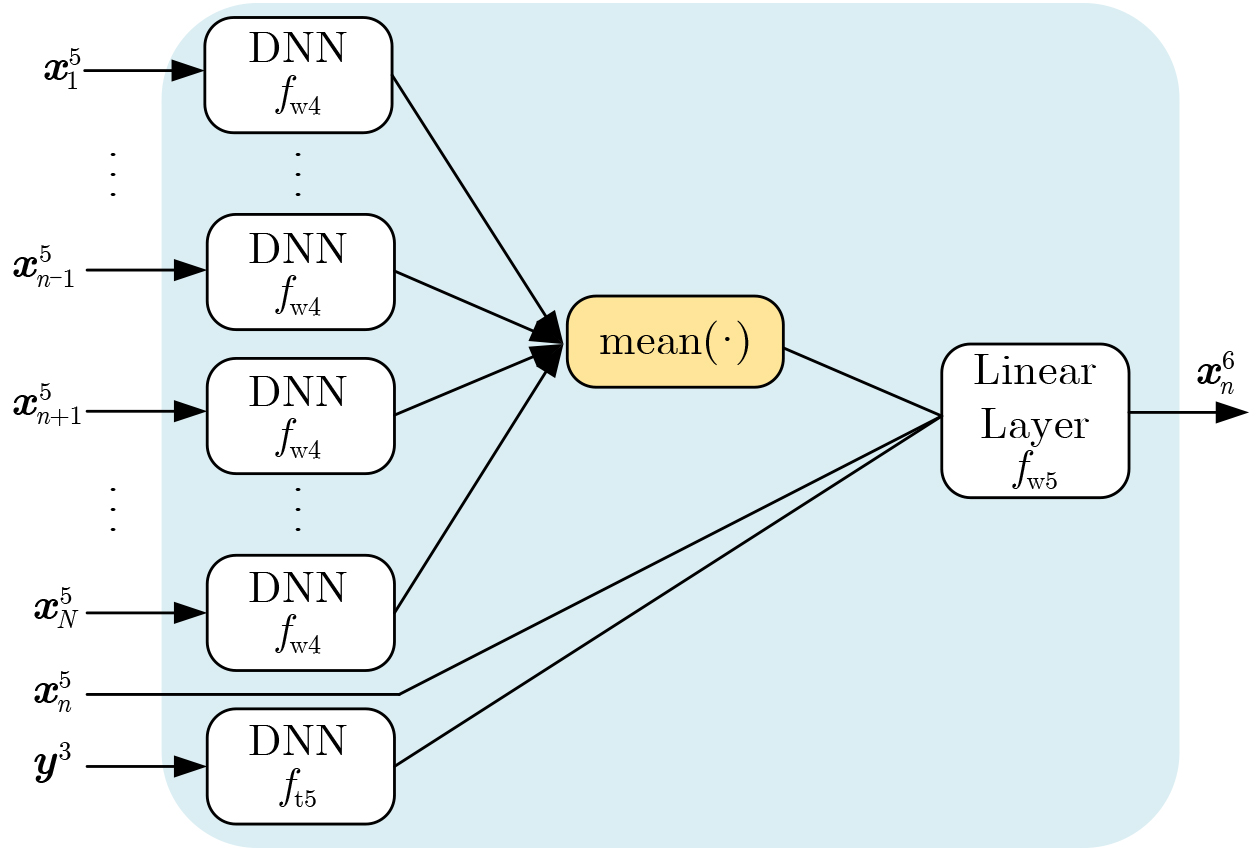
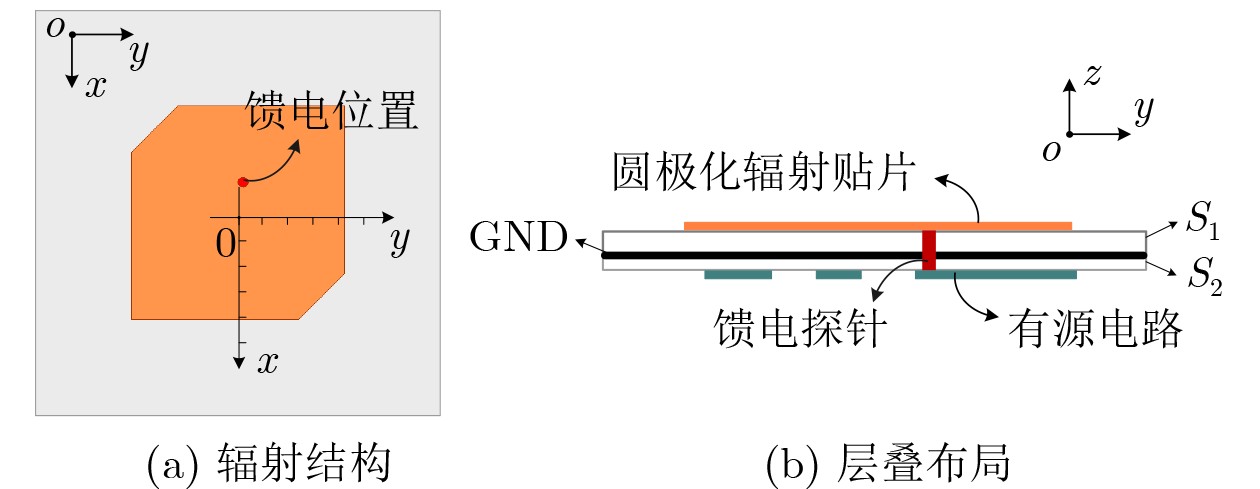
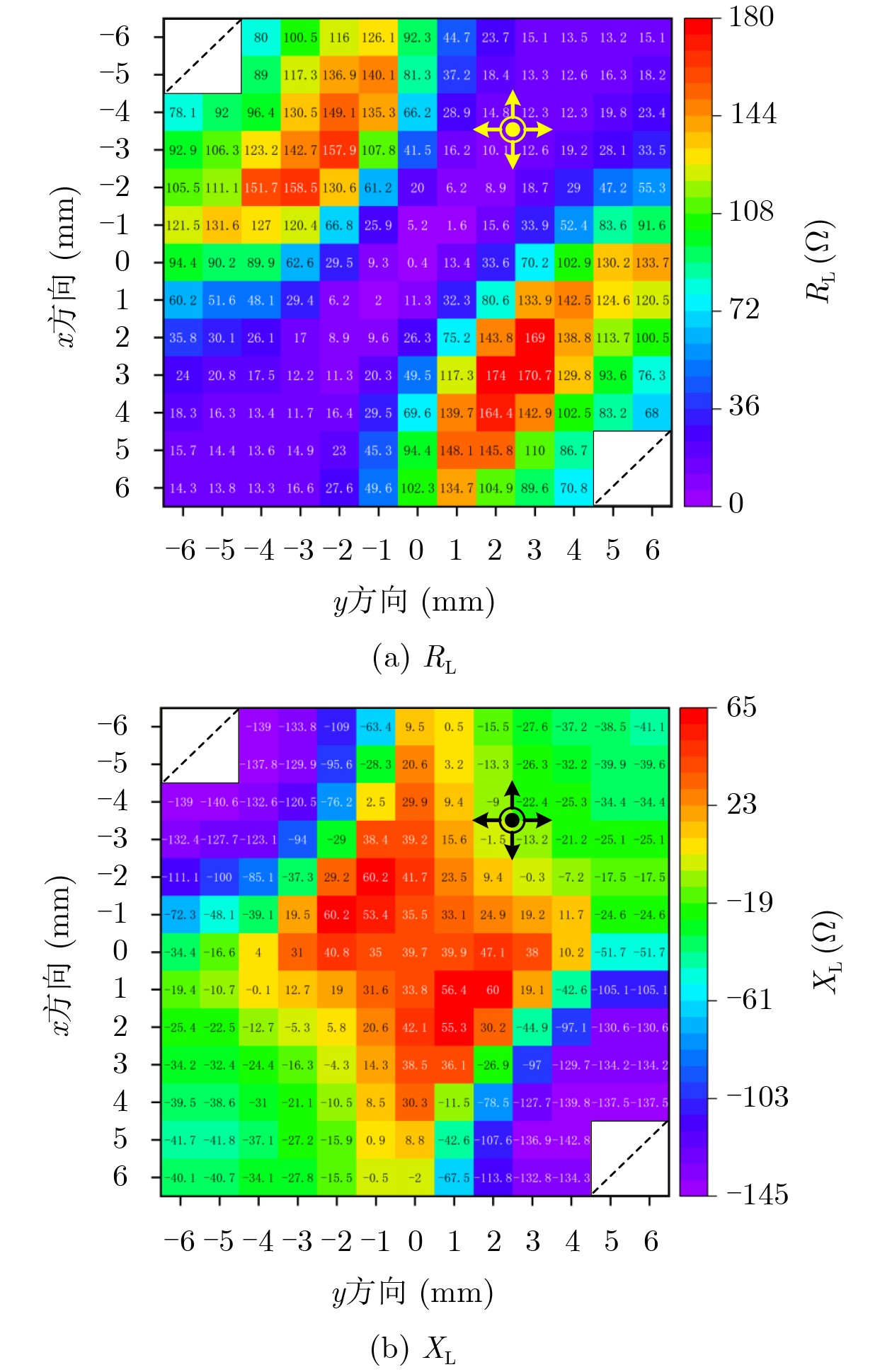
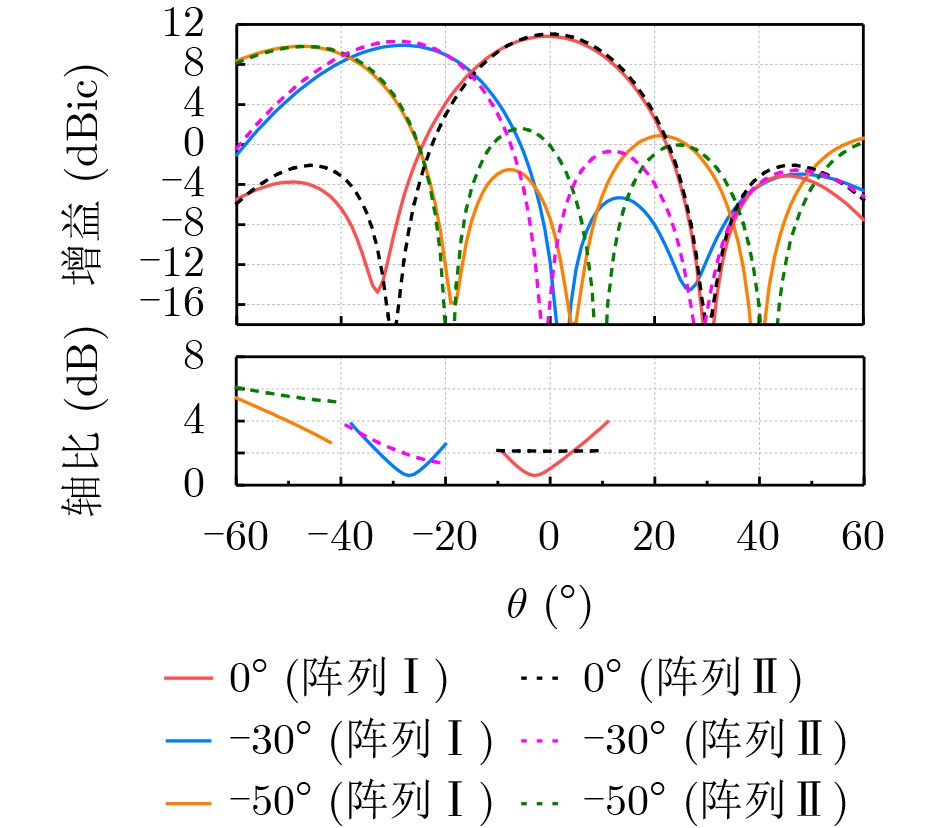
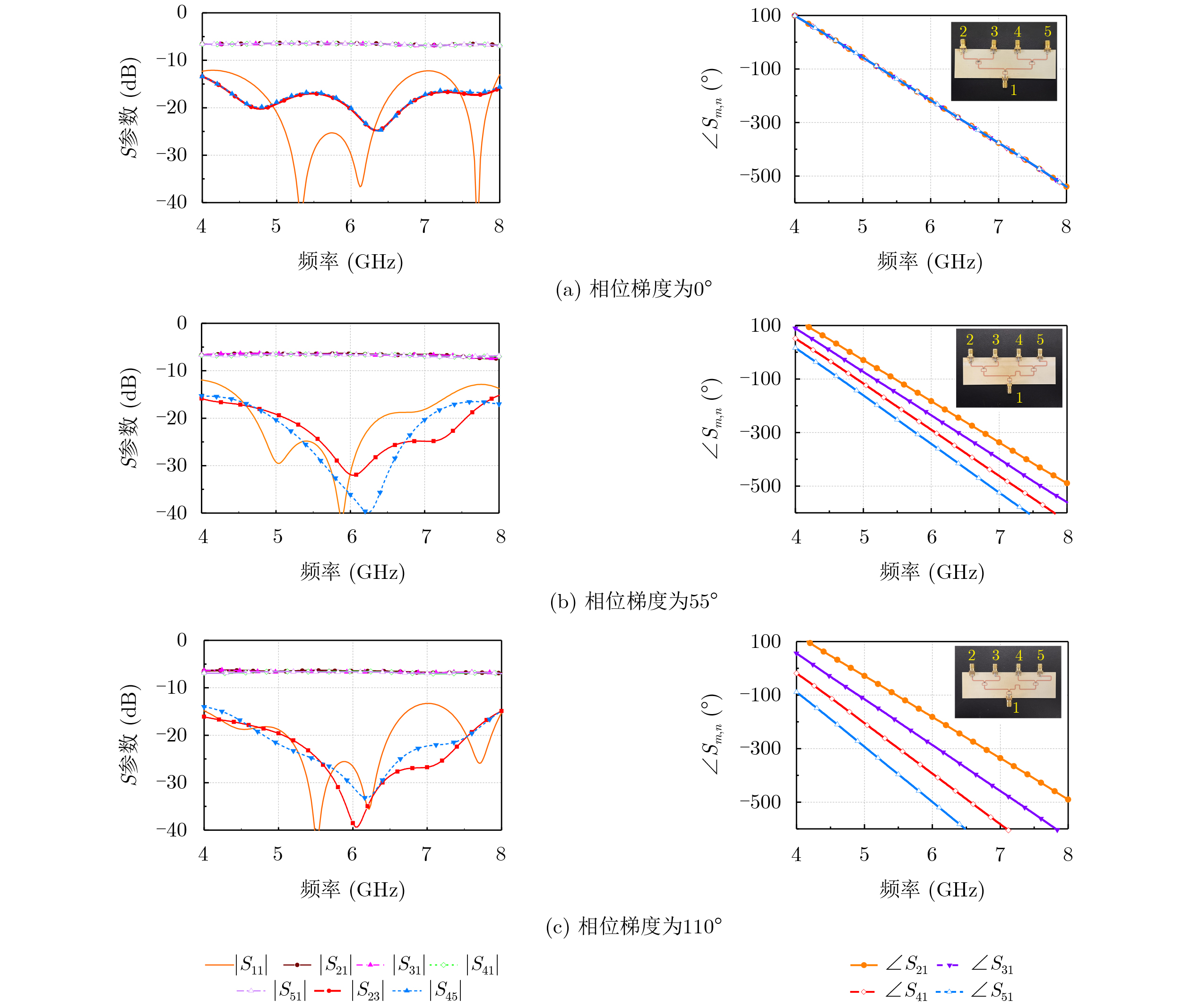
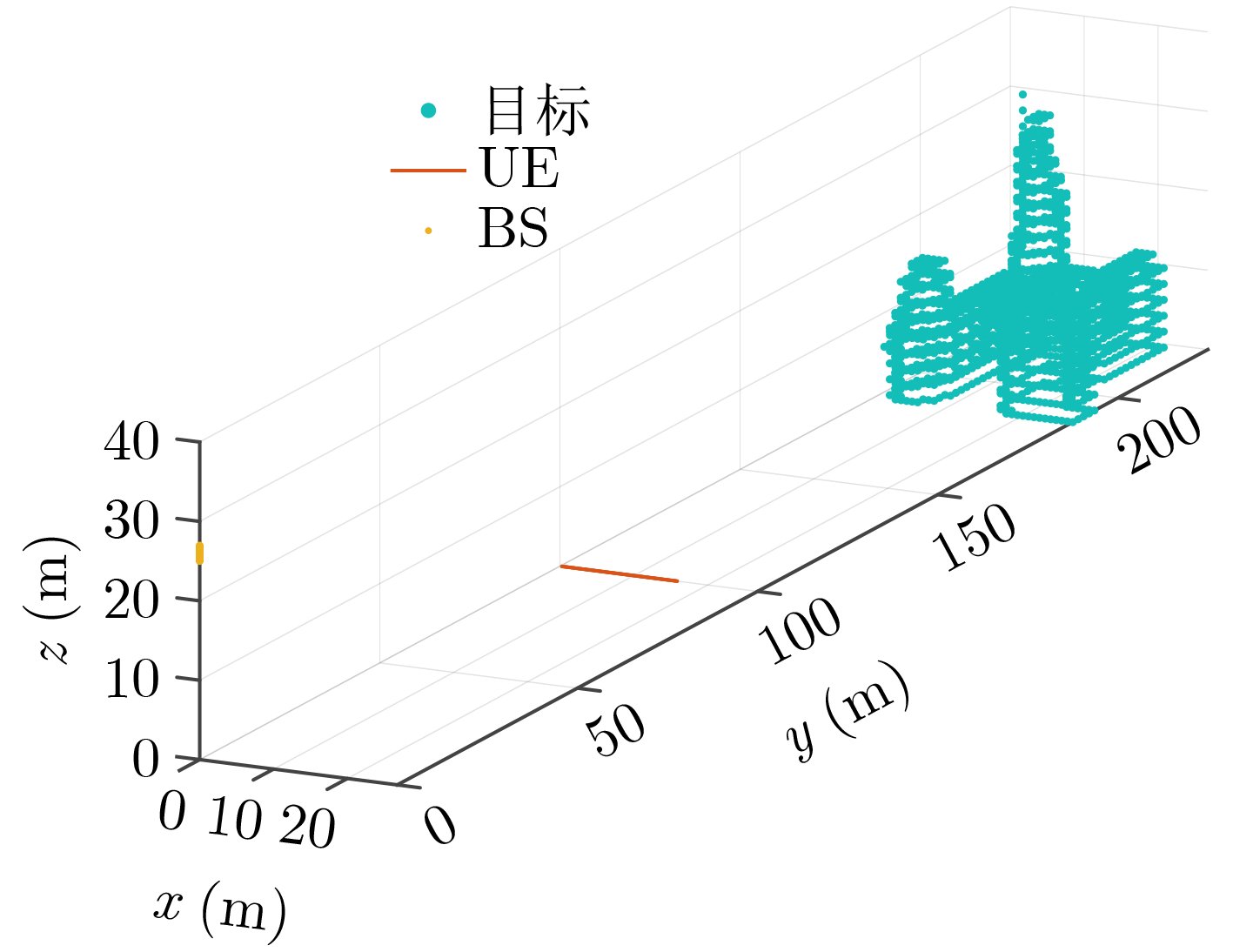
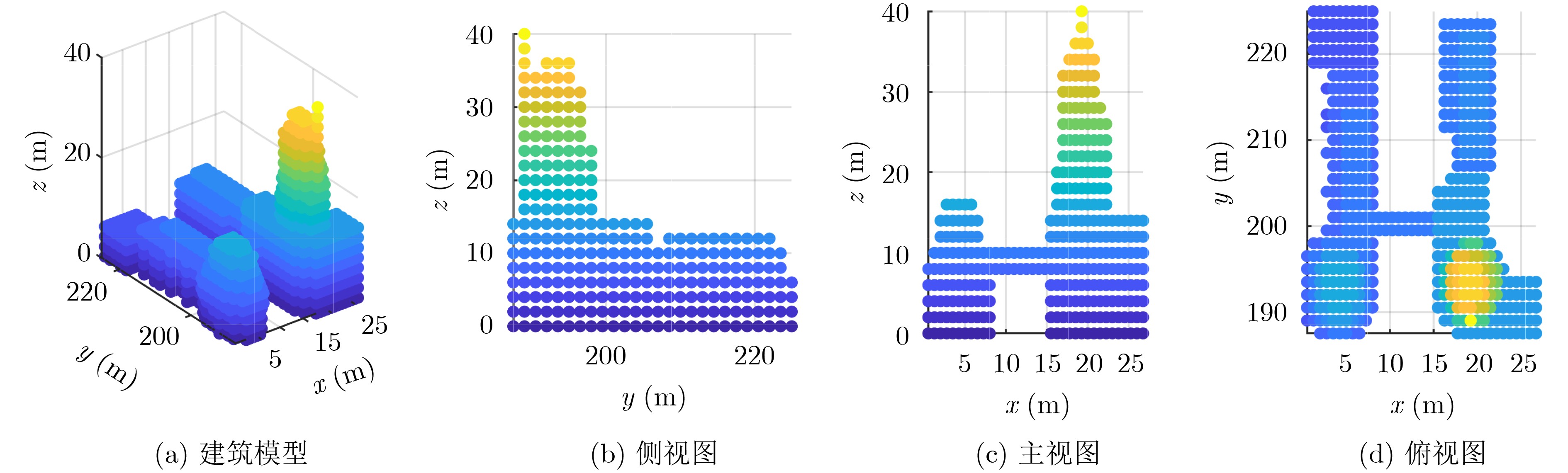
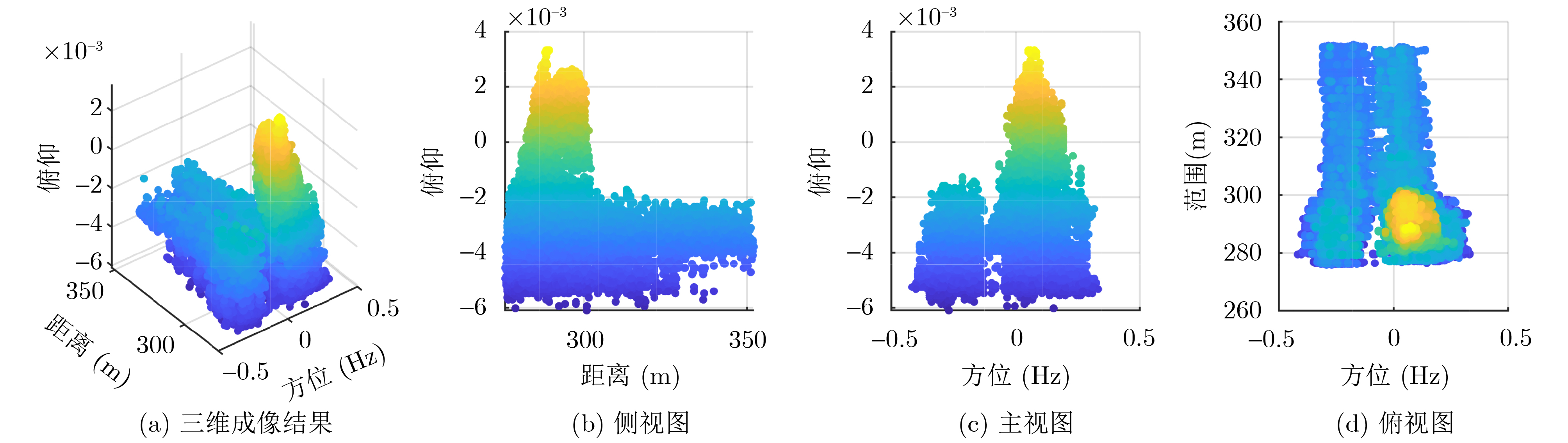
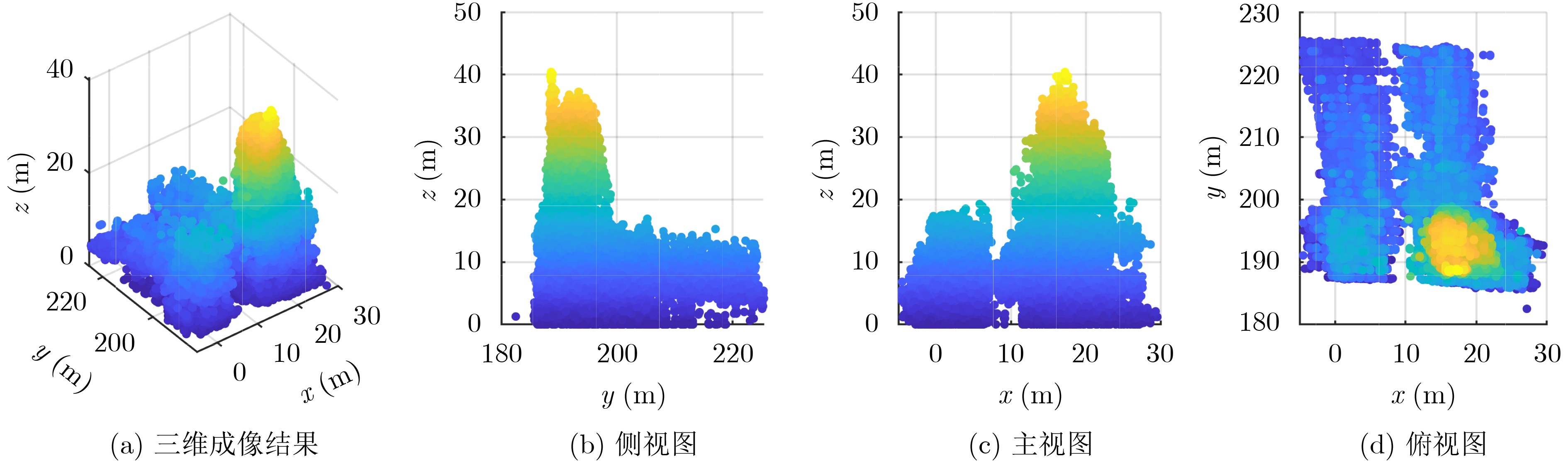
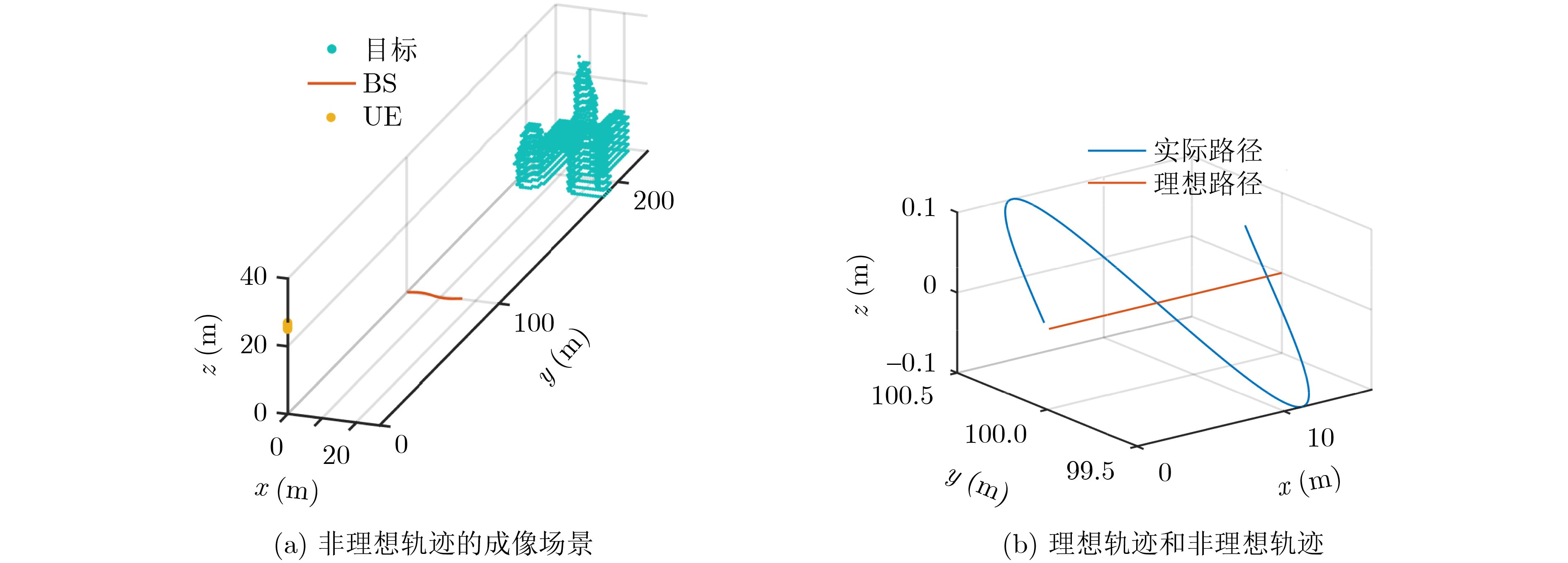
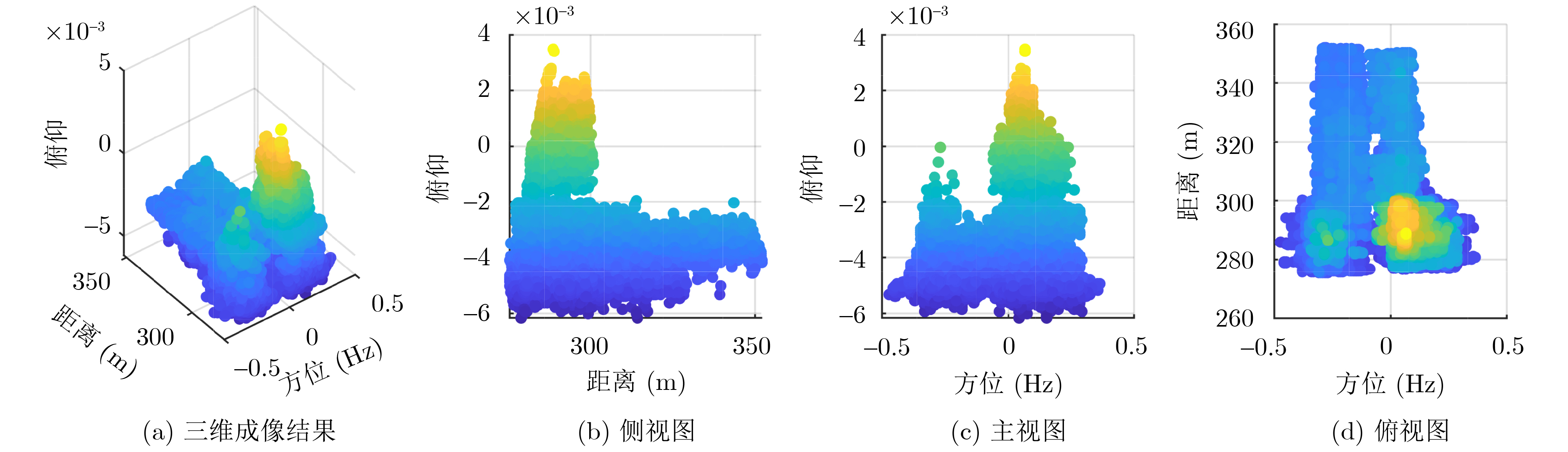
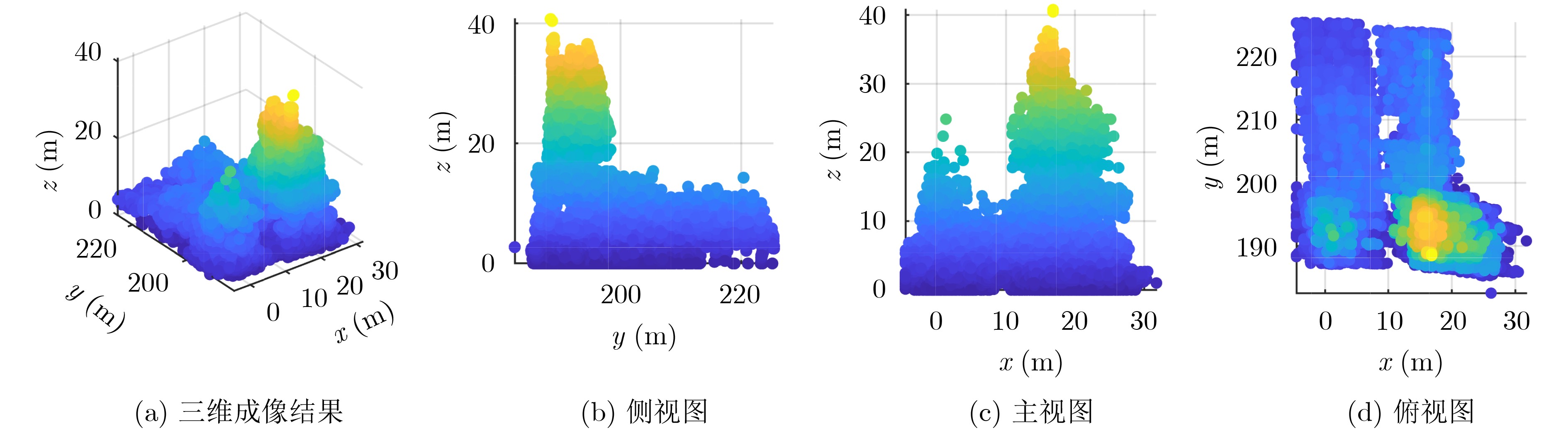
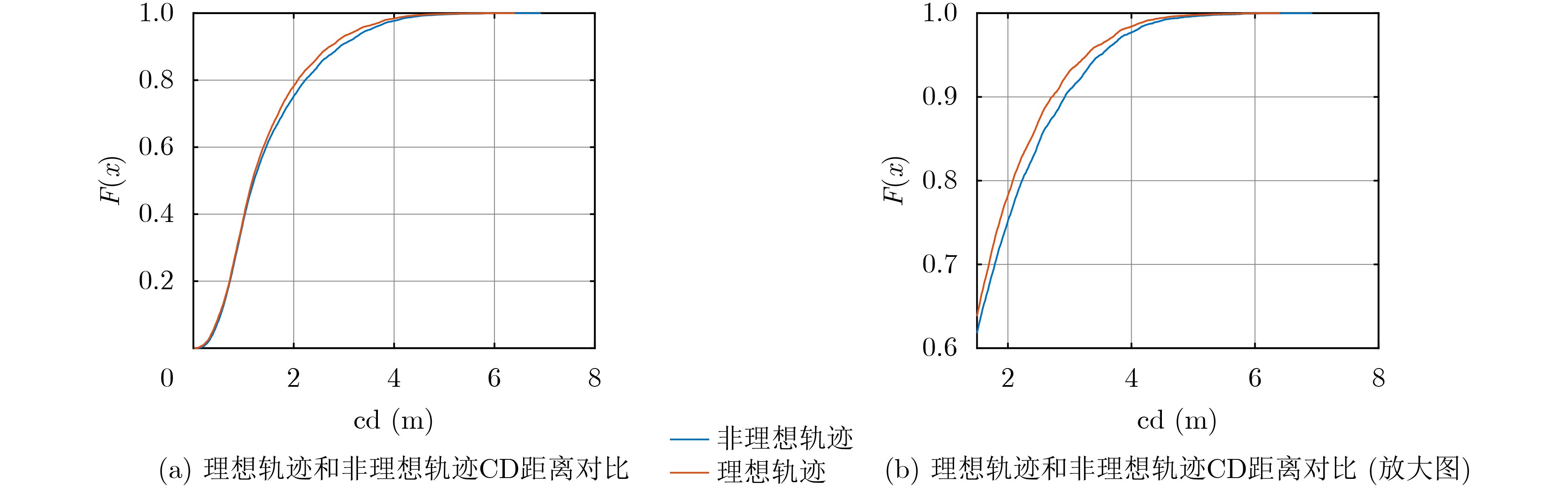
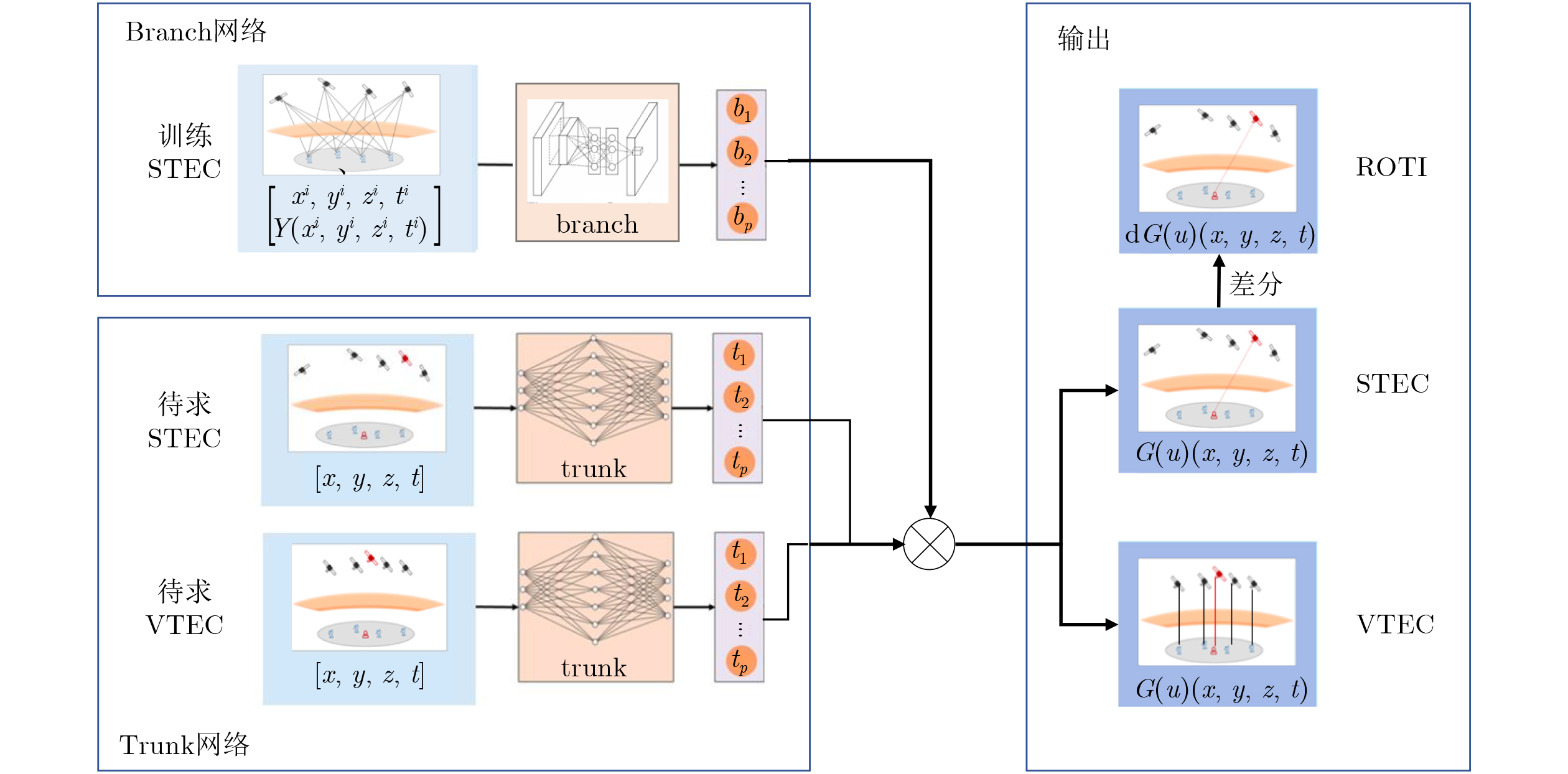
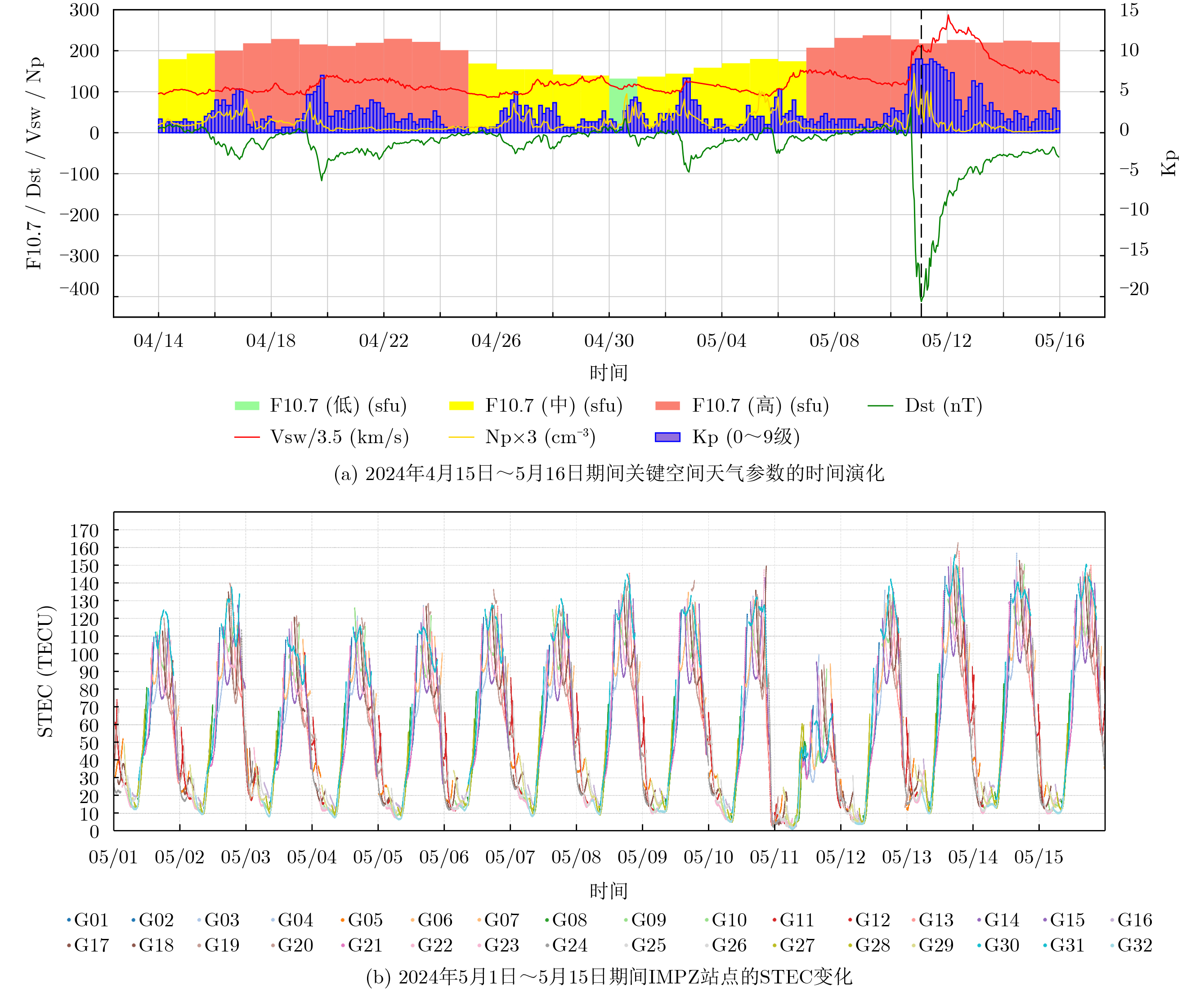
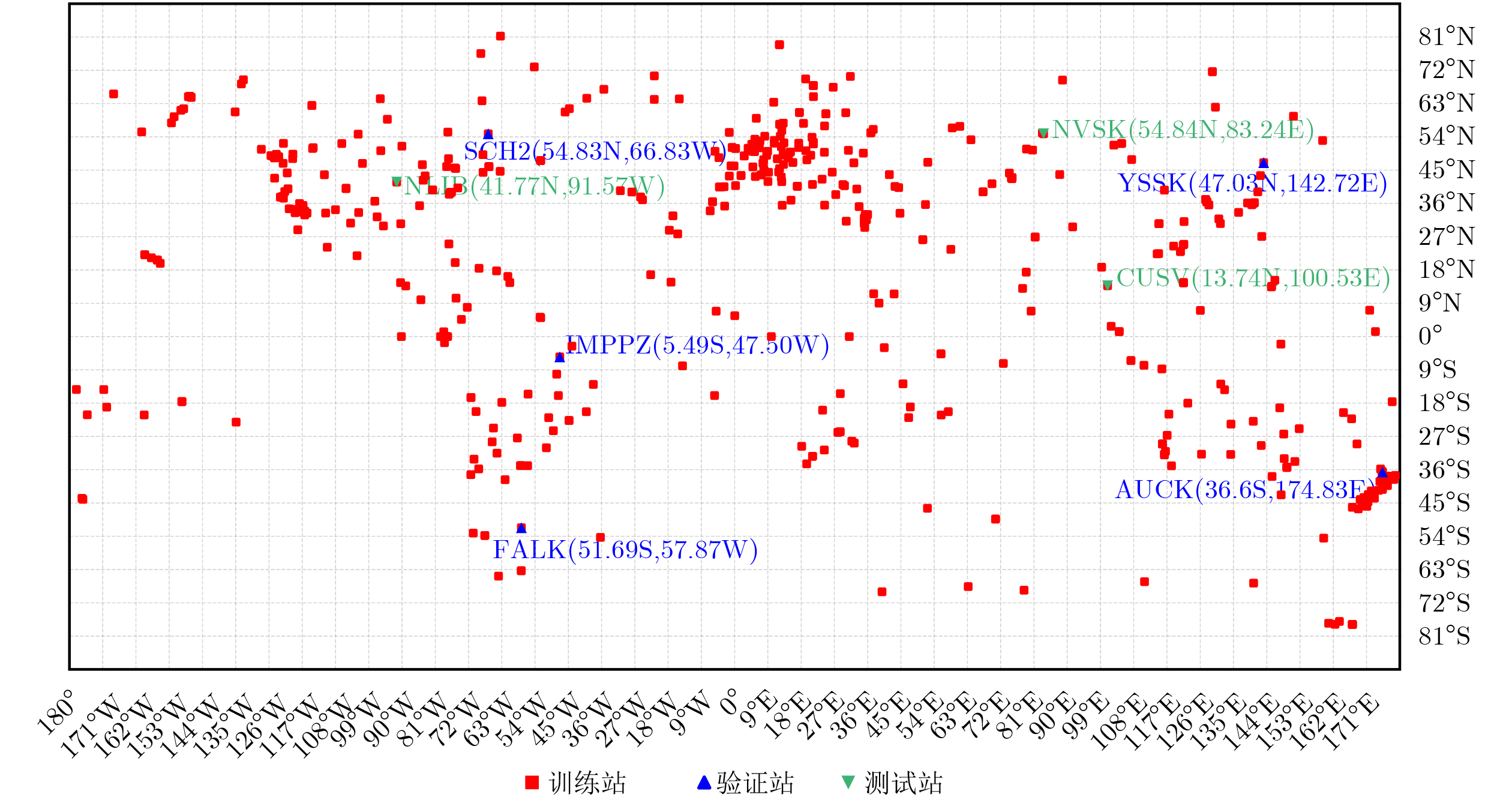
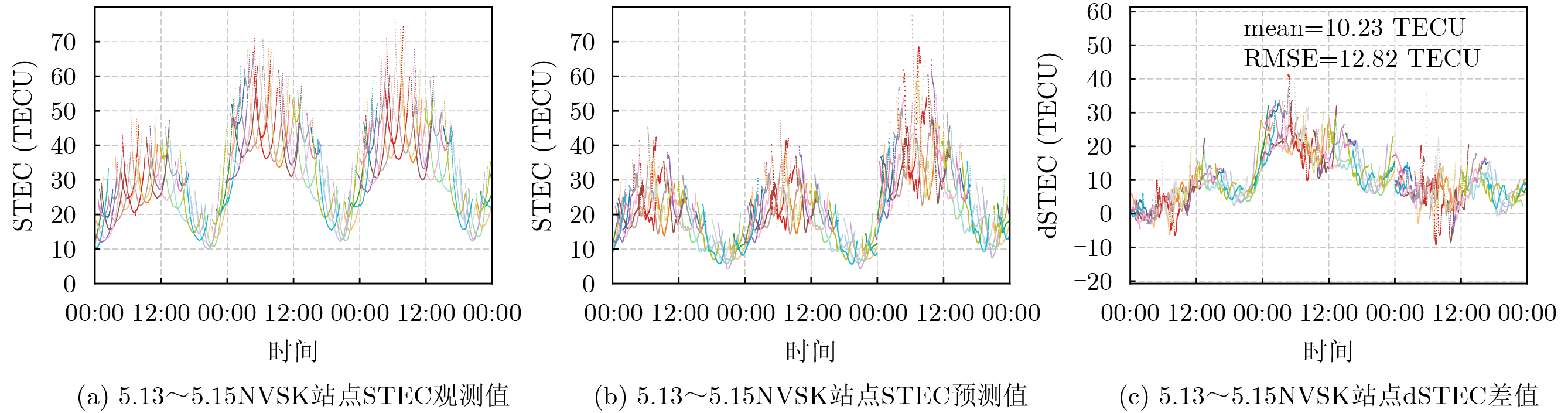
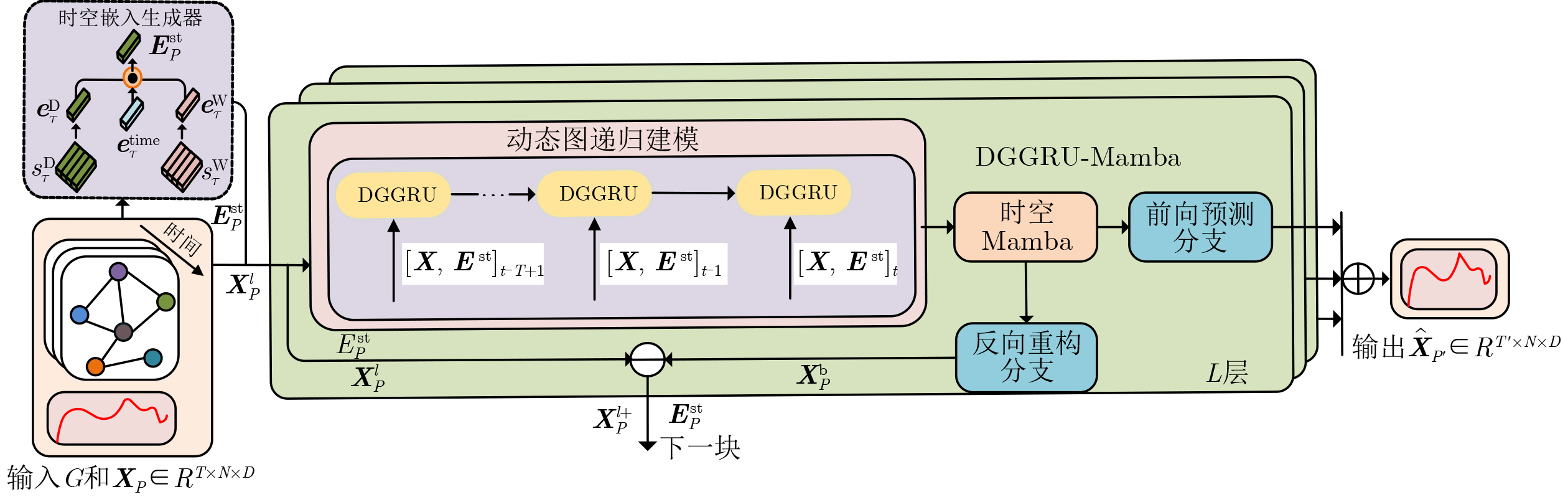
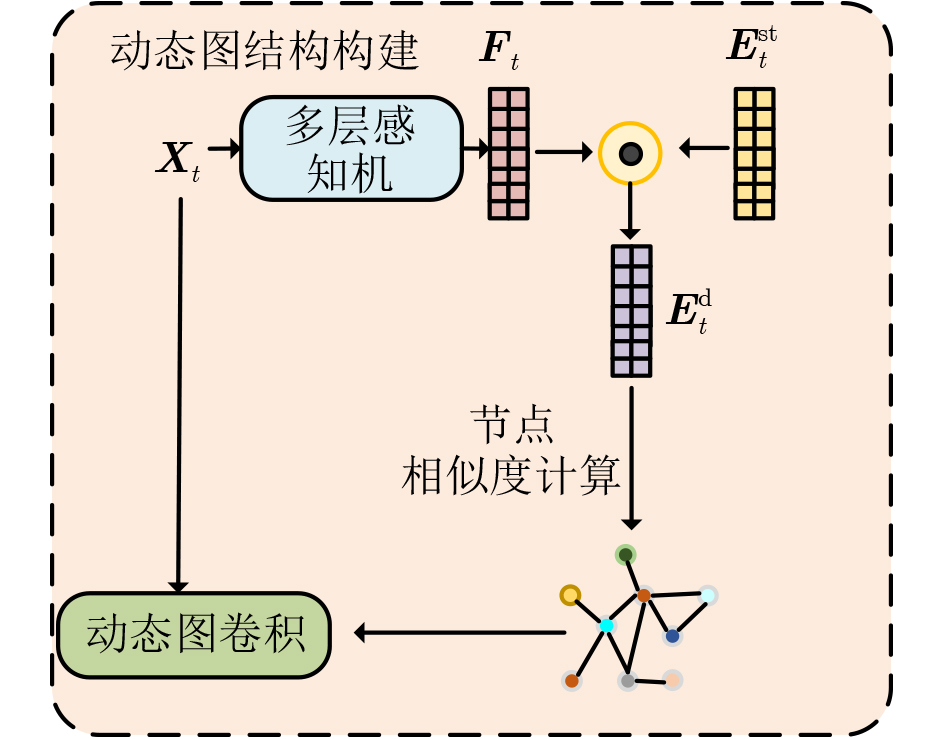
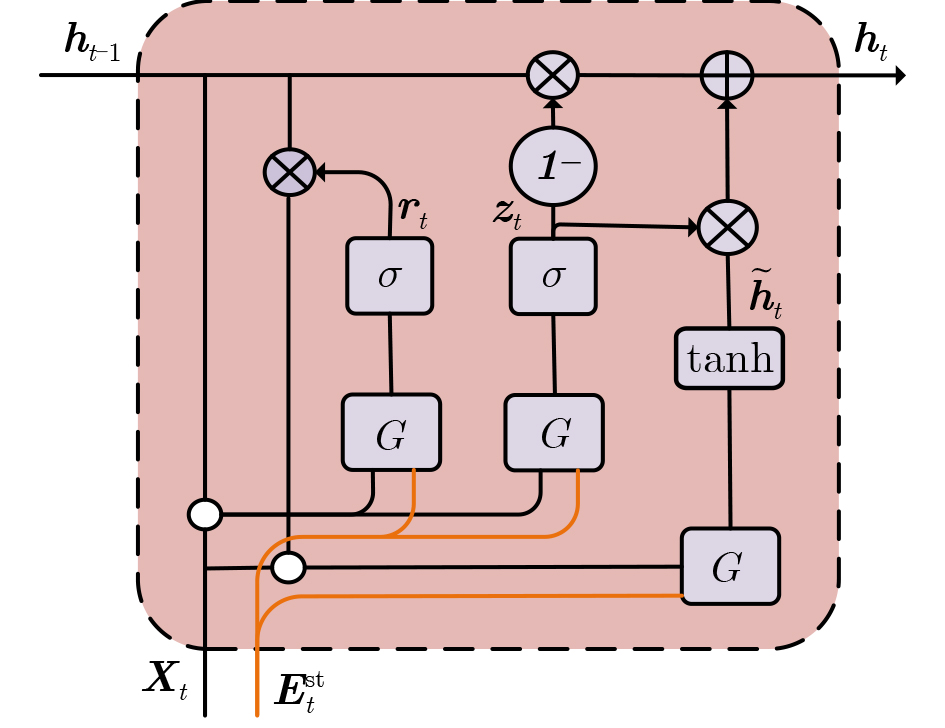
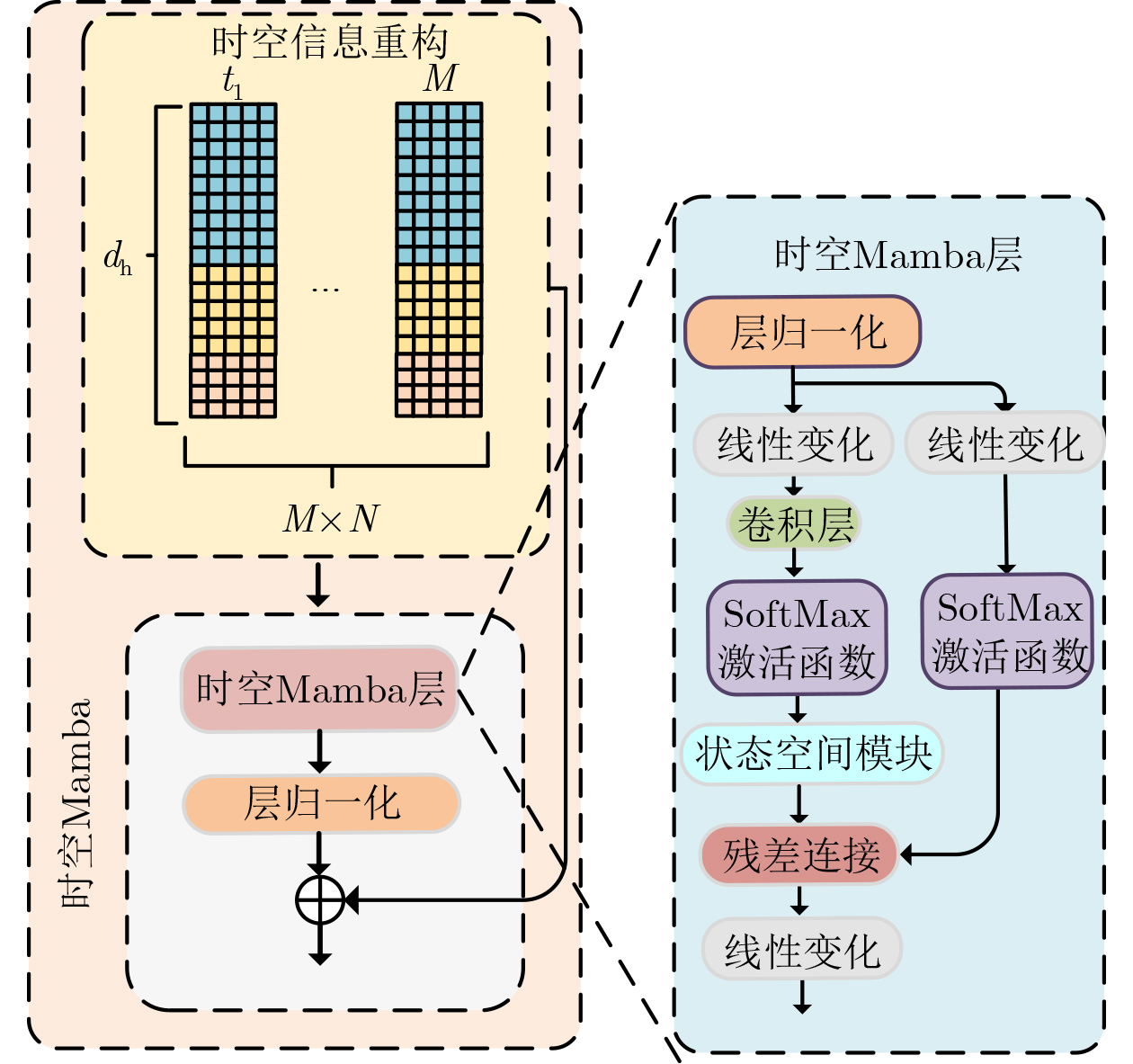
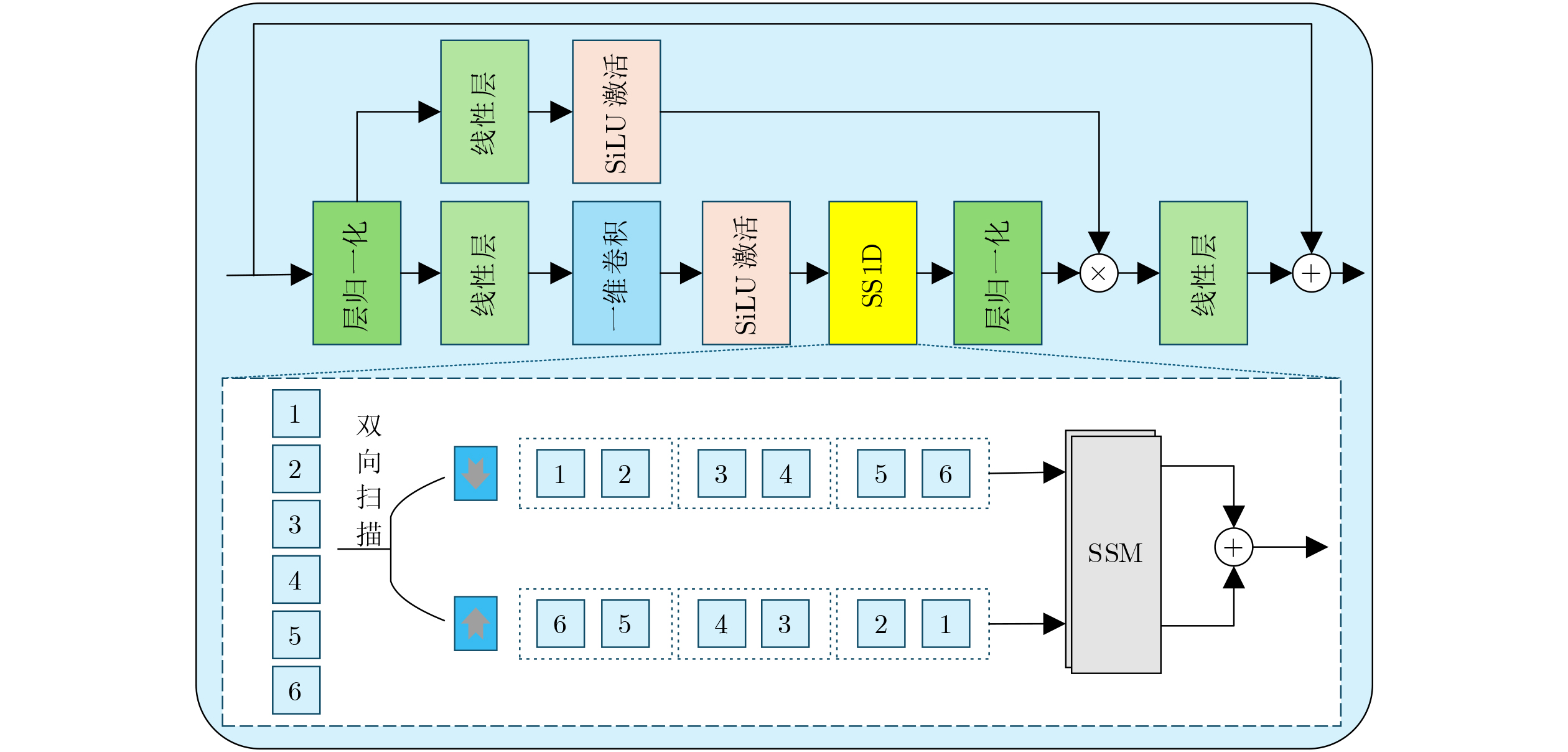
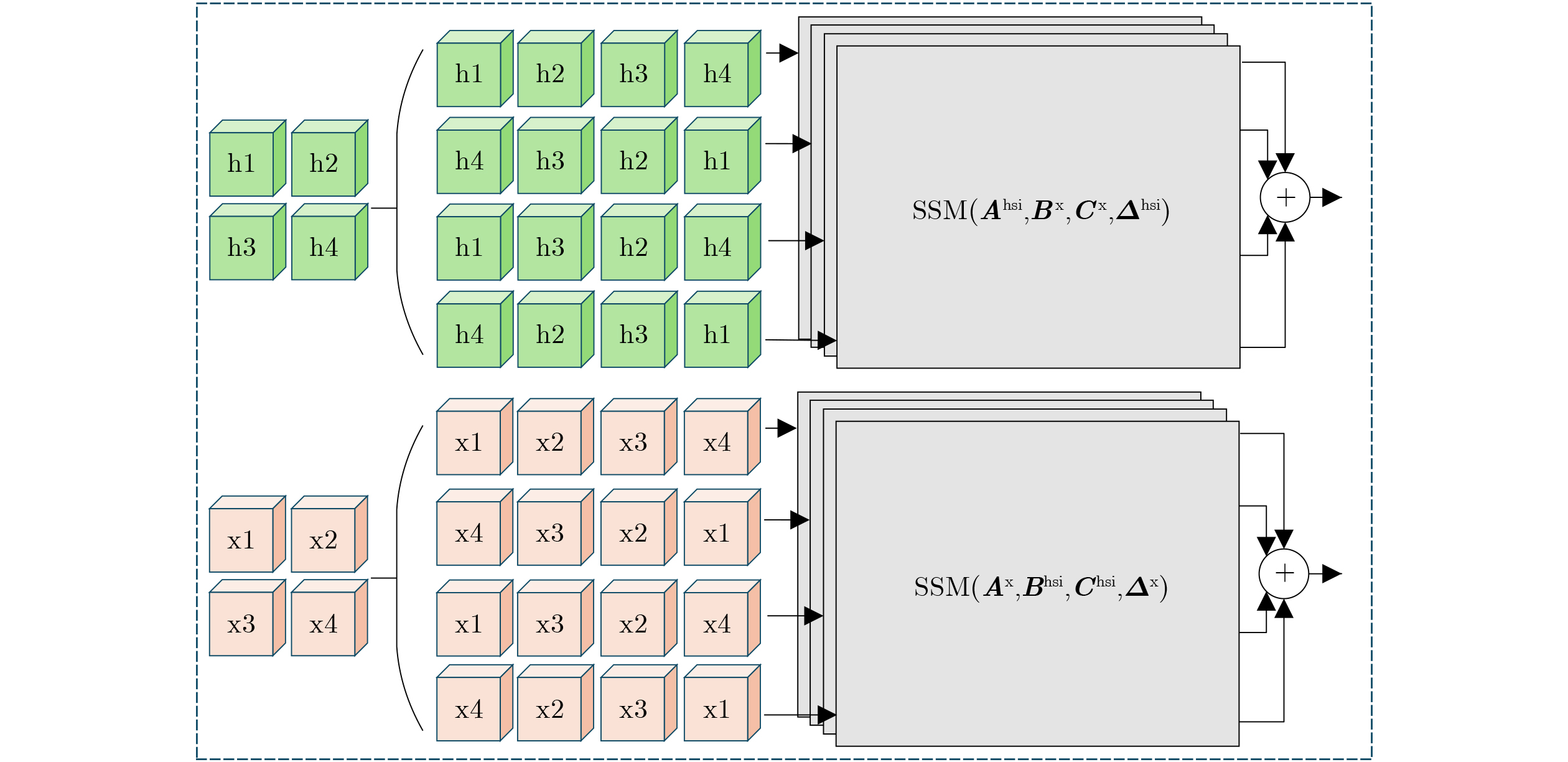
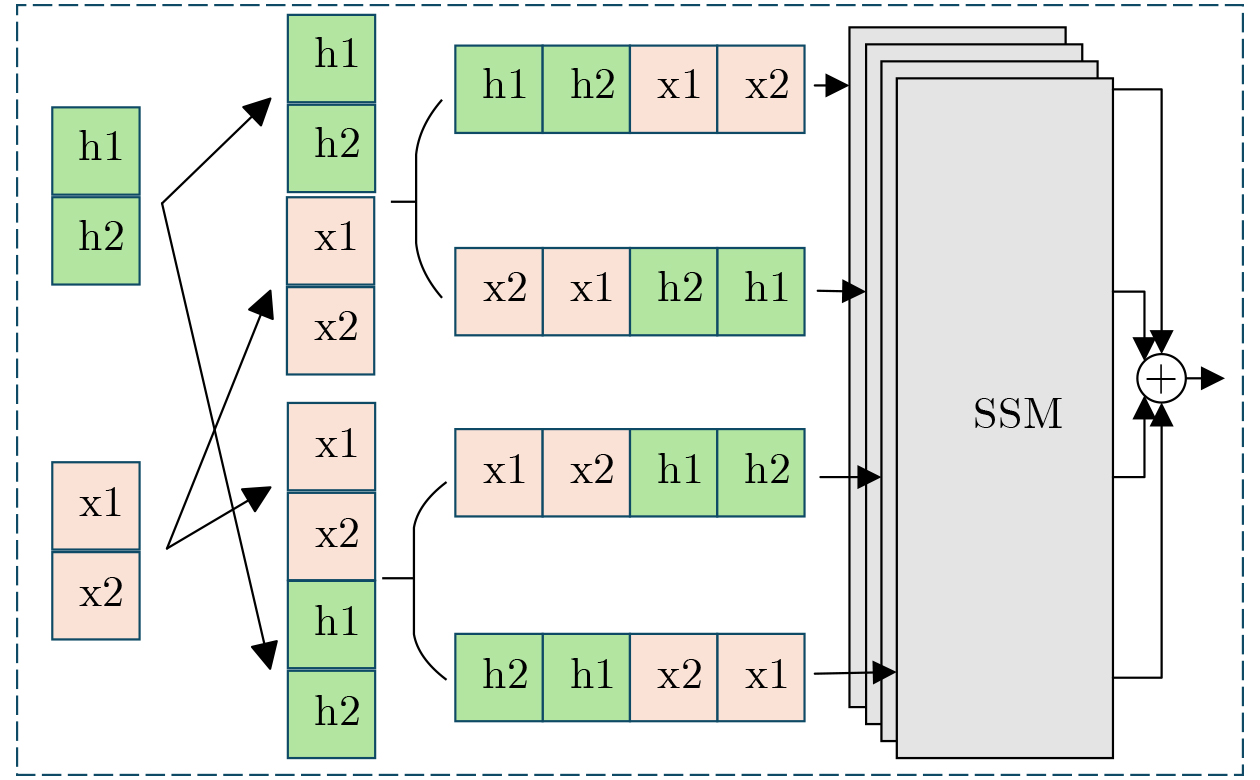
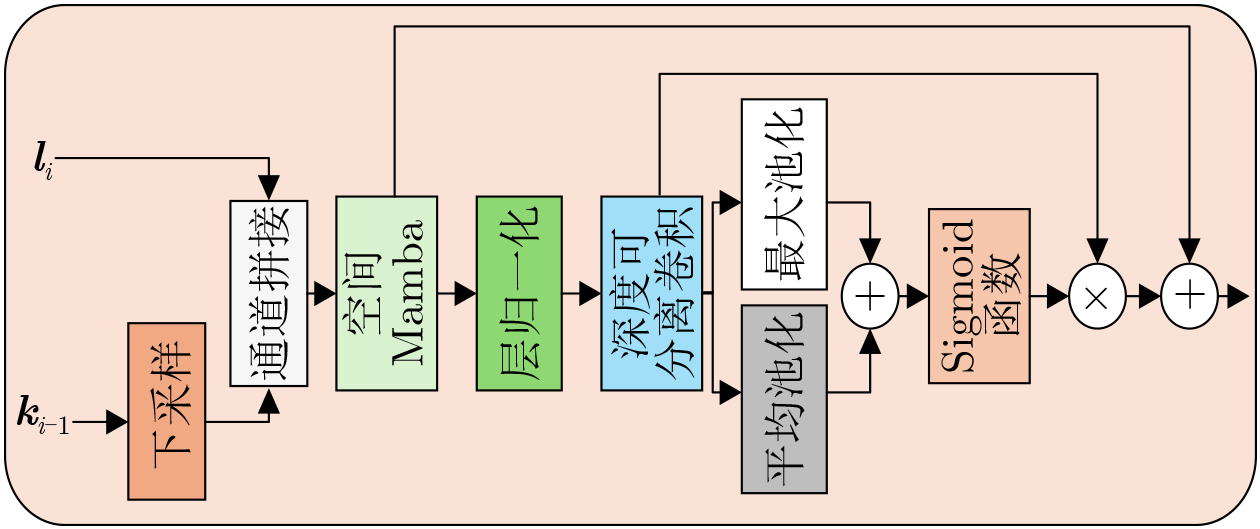
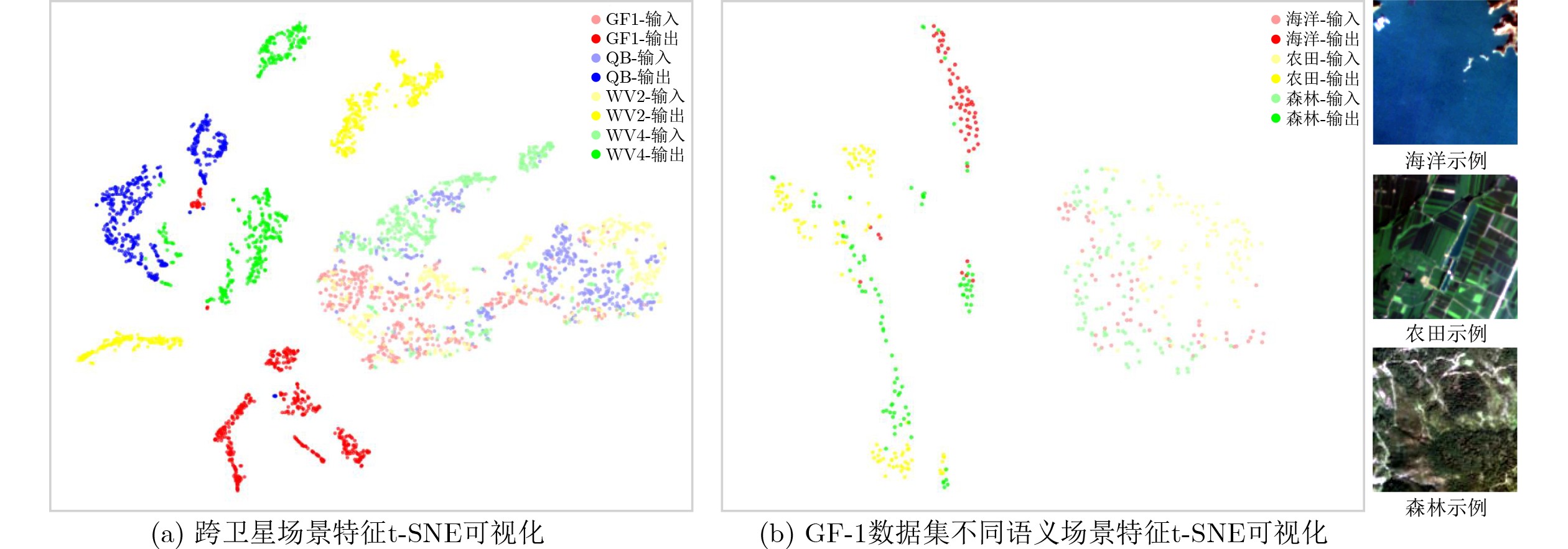
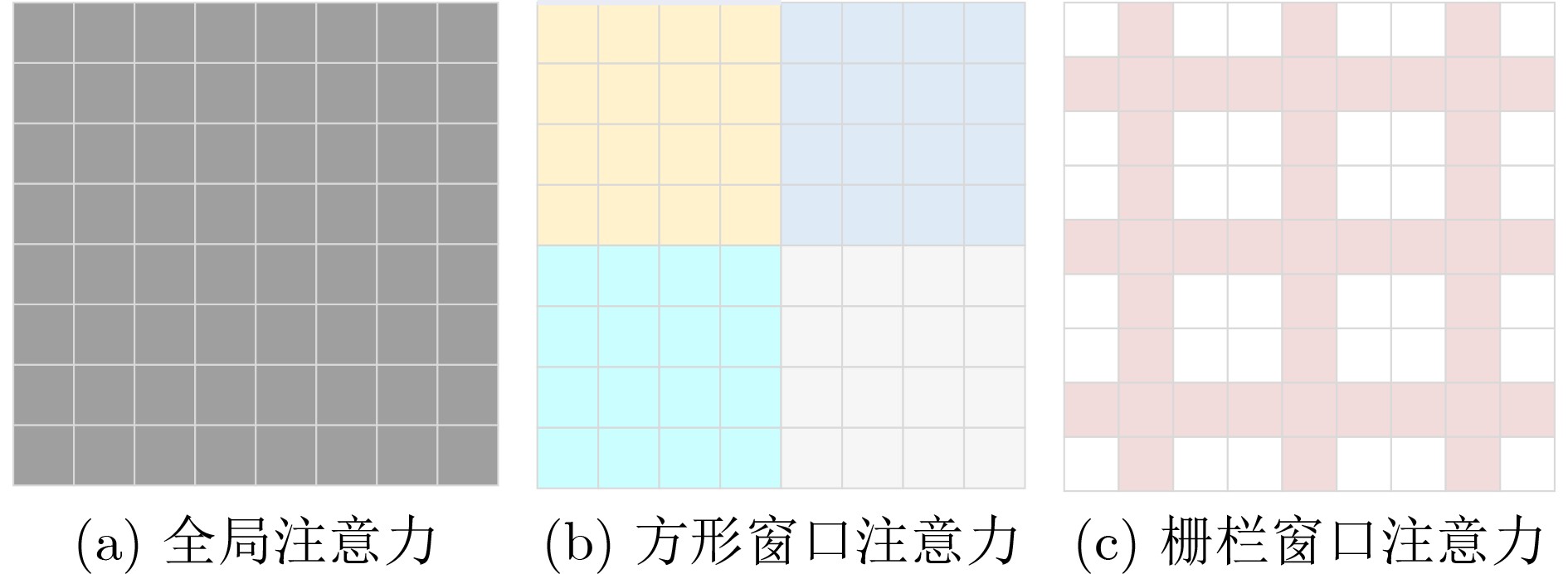
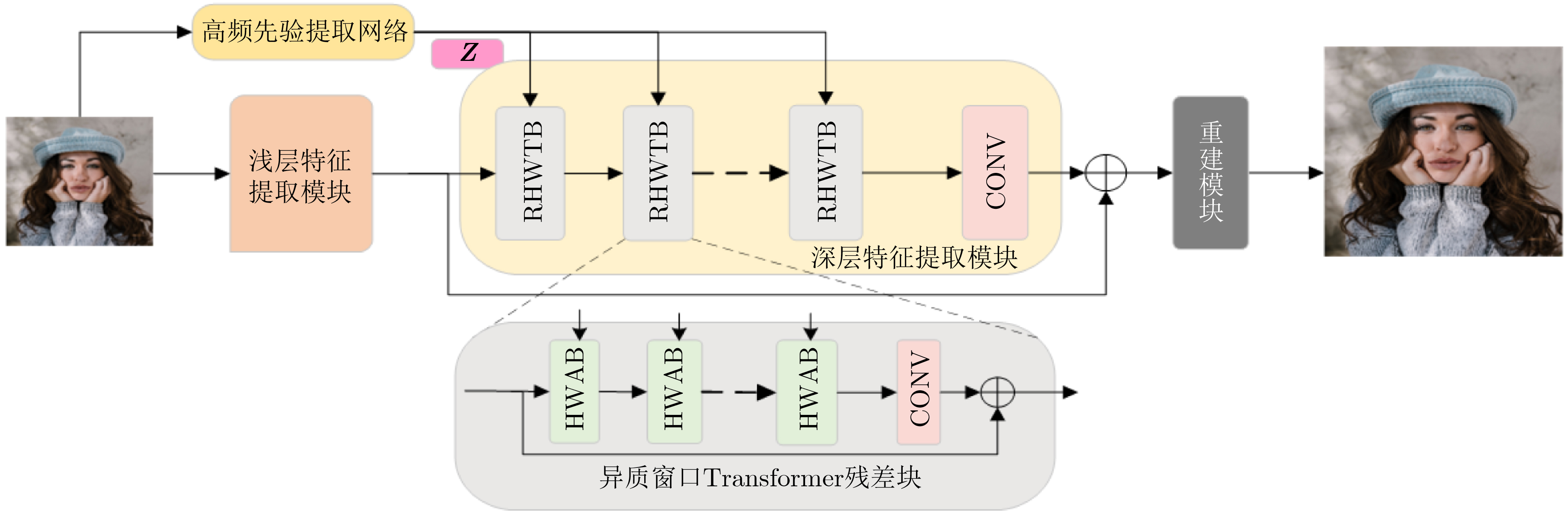
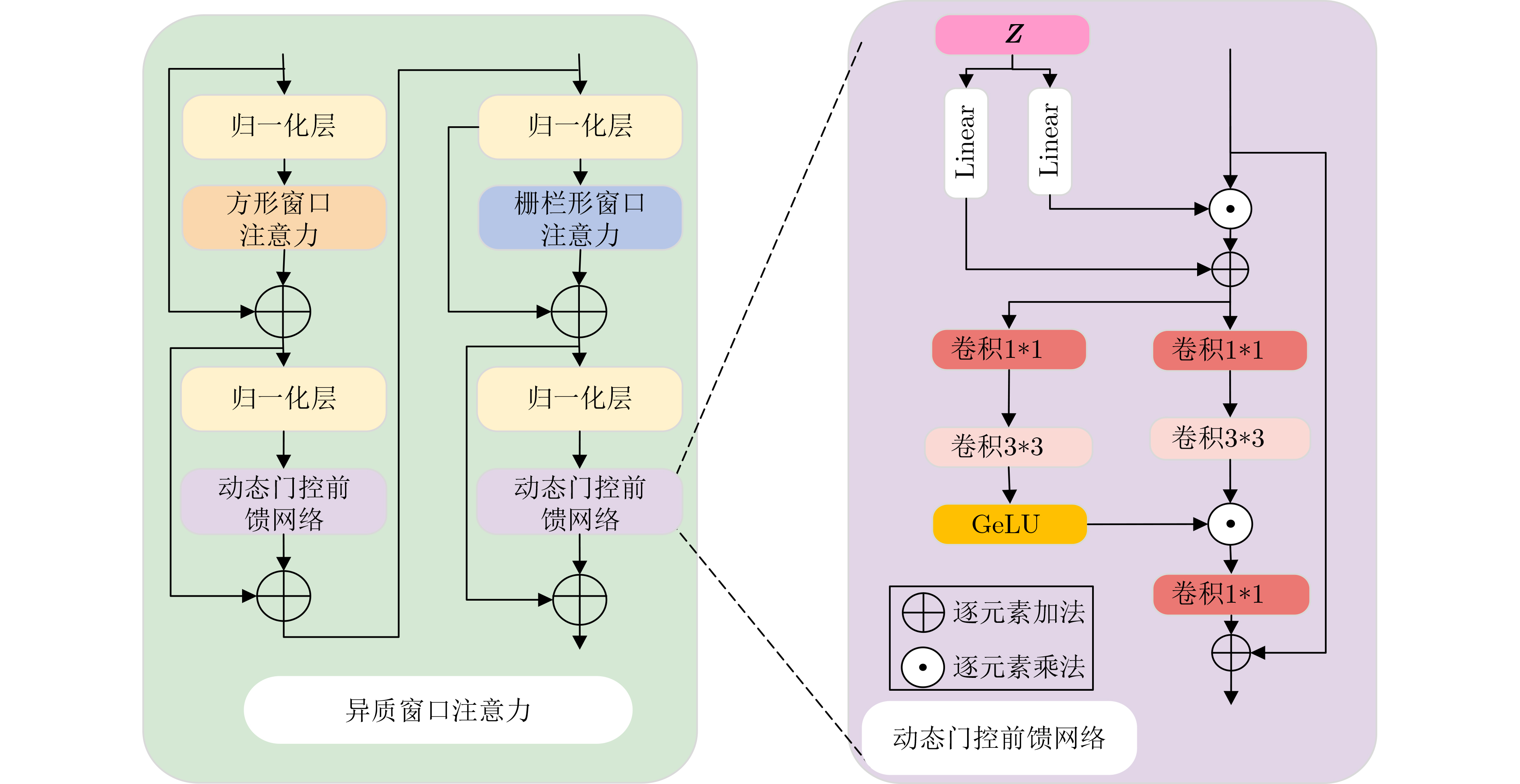
2026, 48(6): 2591-2601.
doi: 10.11999/JEIT250749
Abstract:
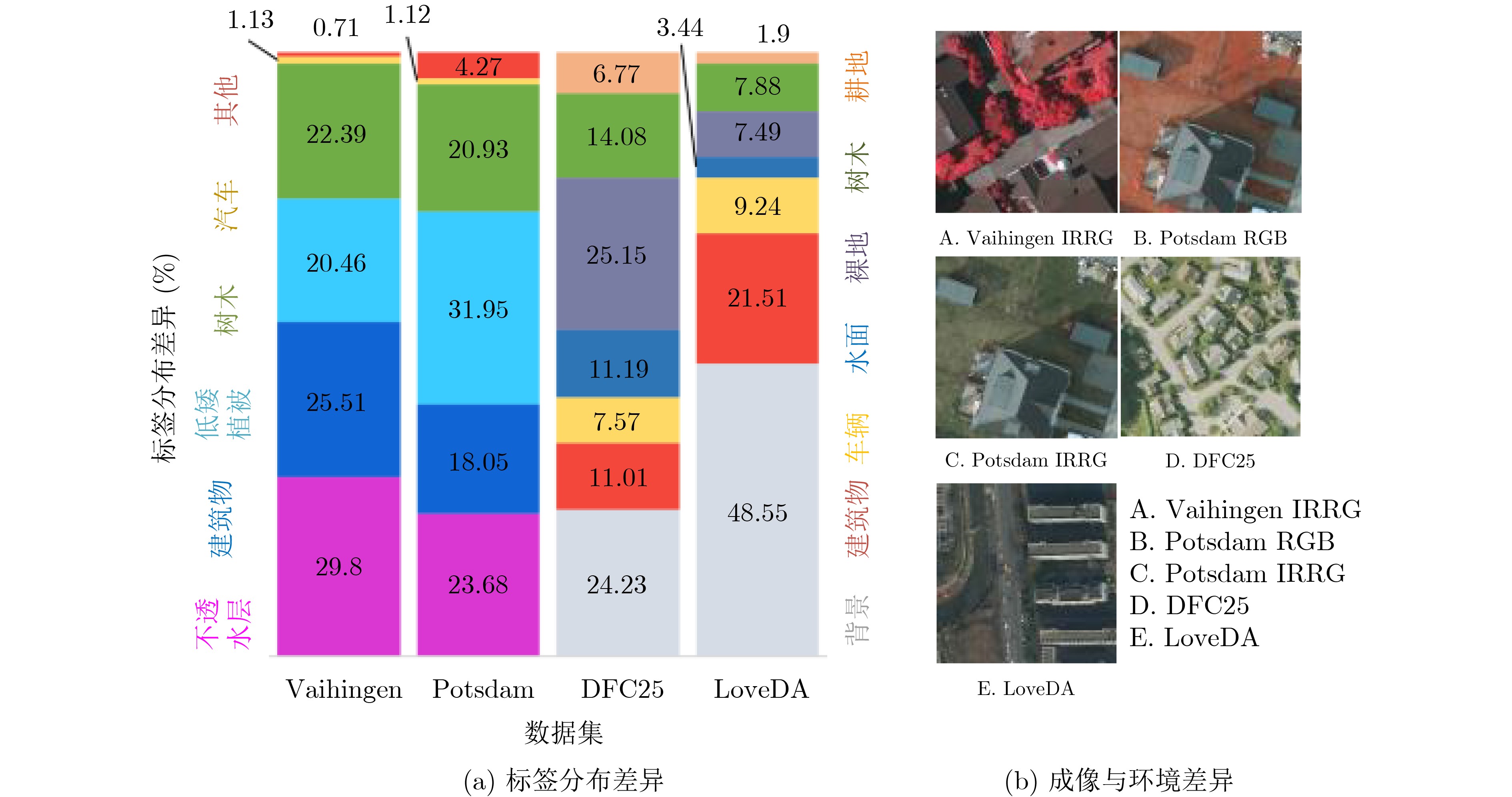
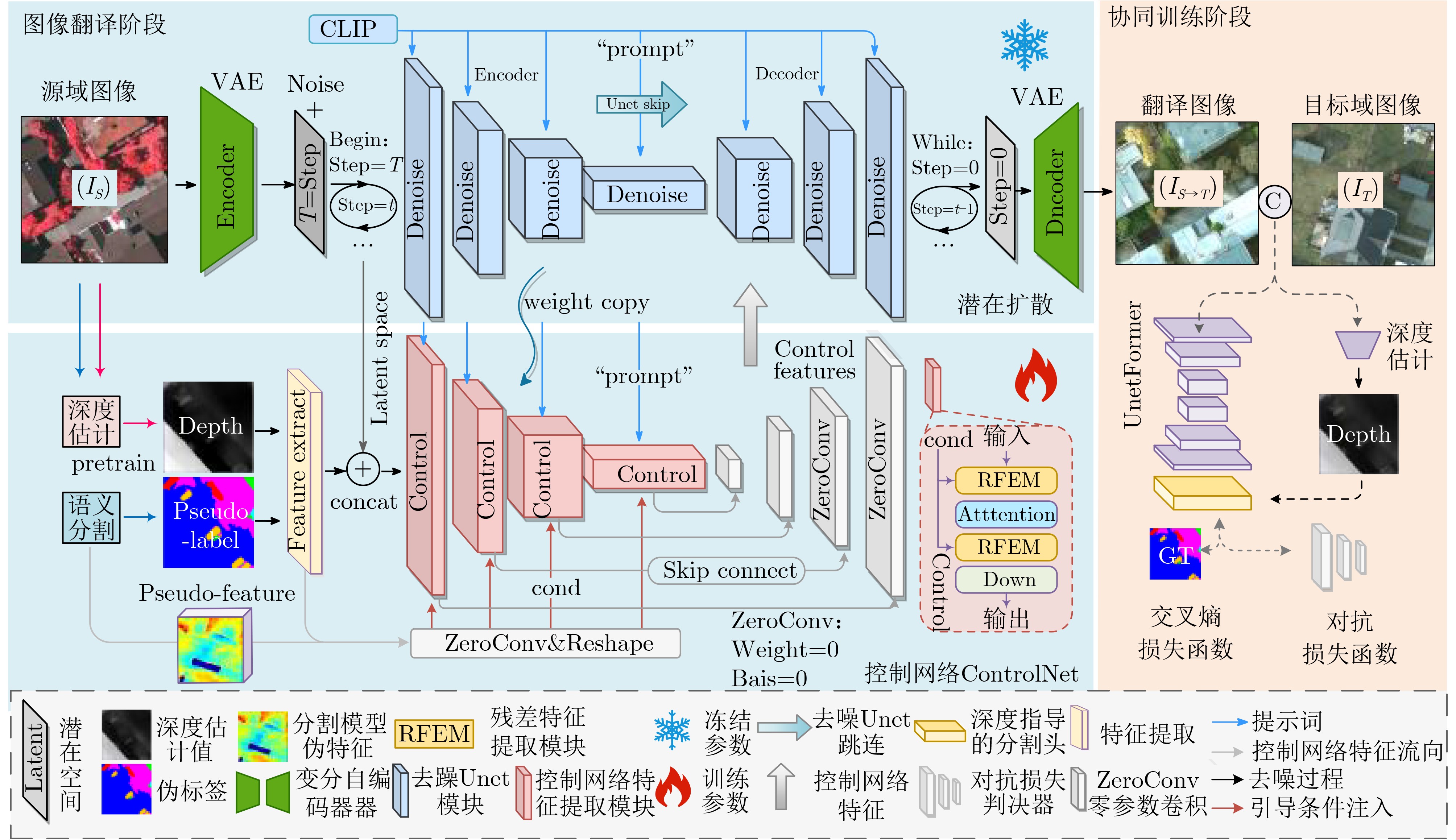
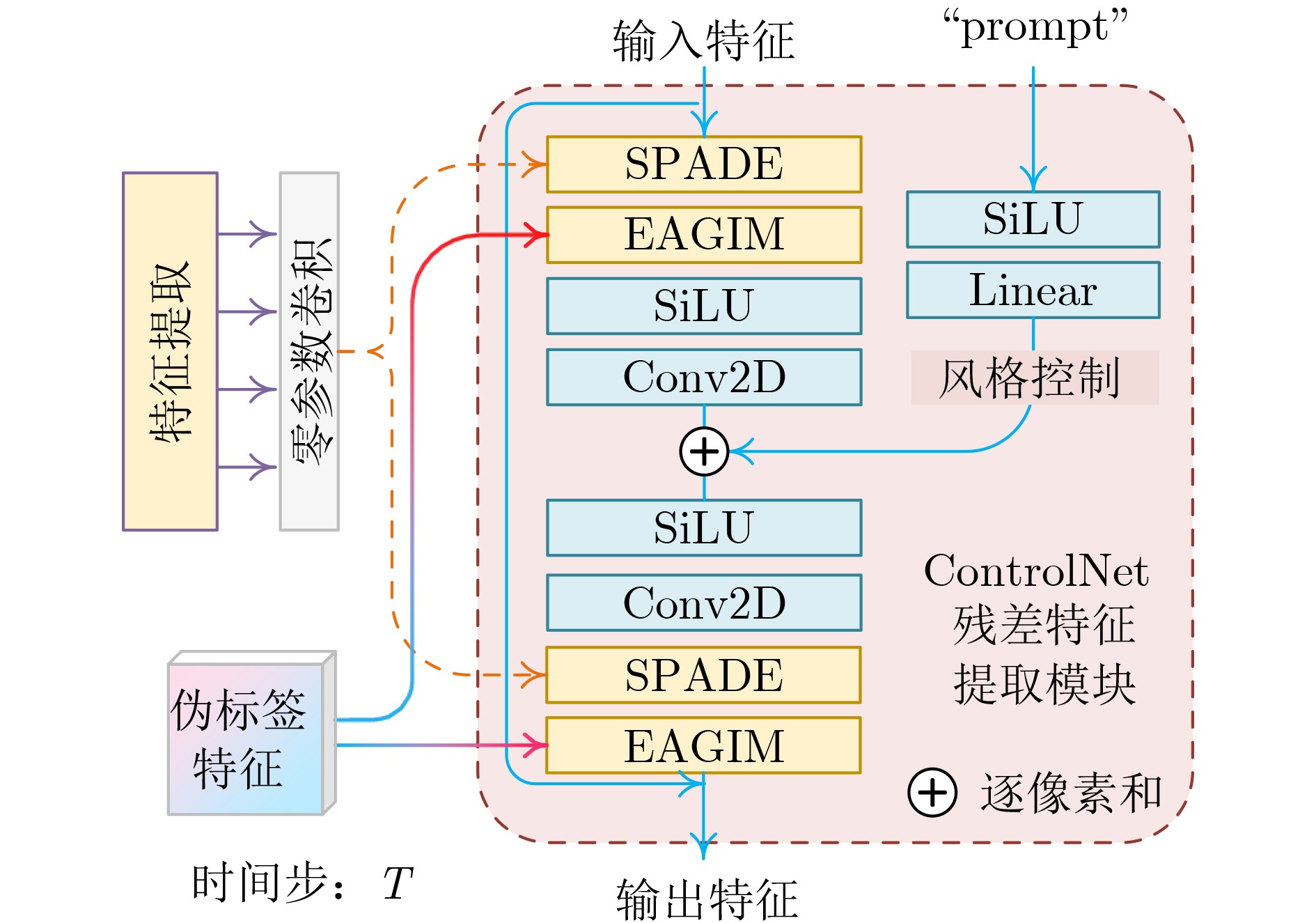
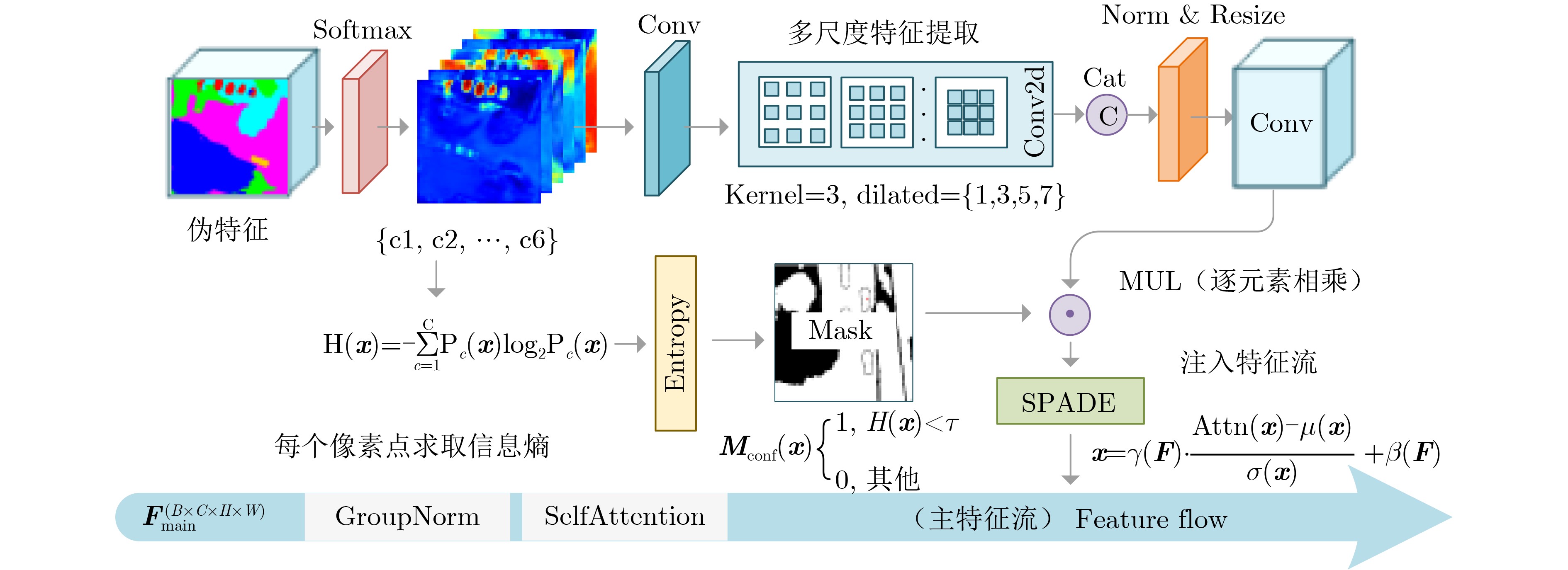
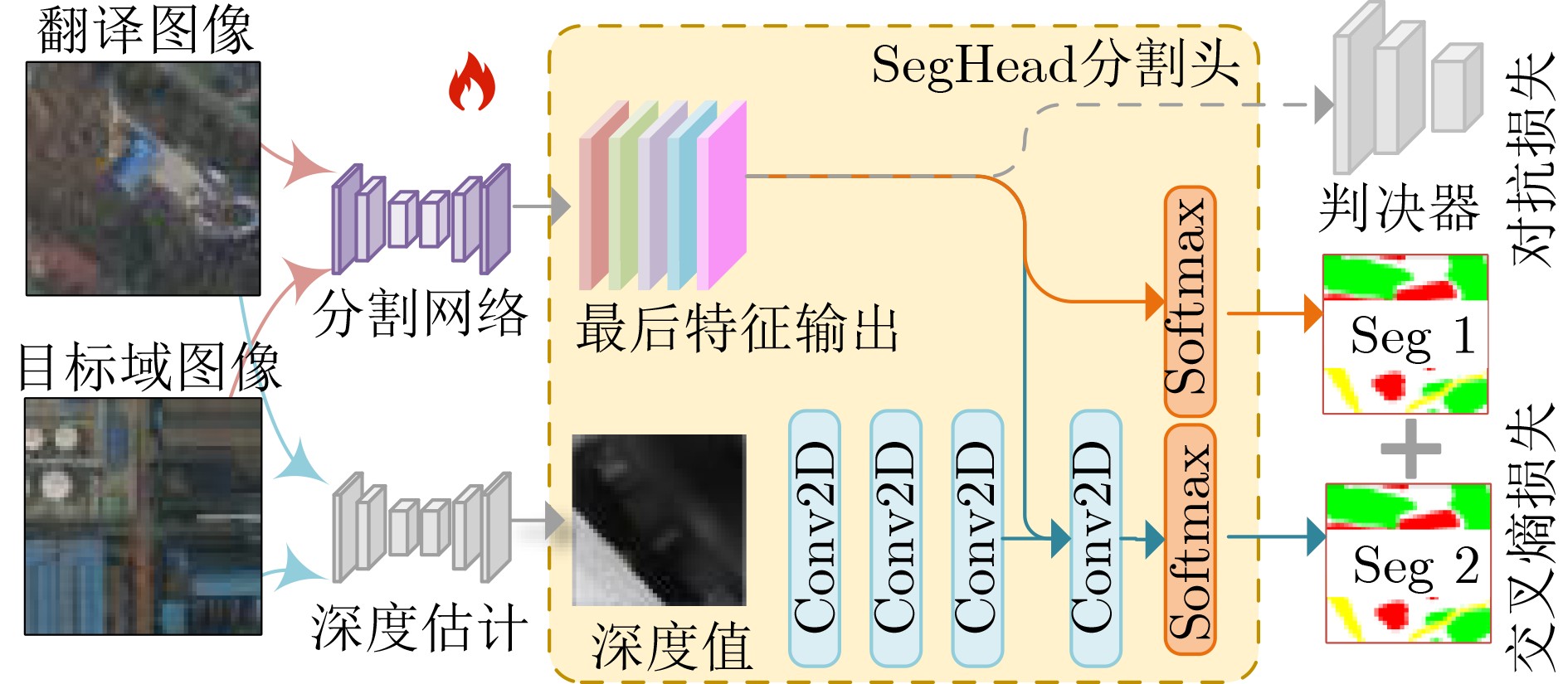
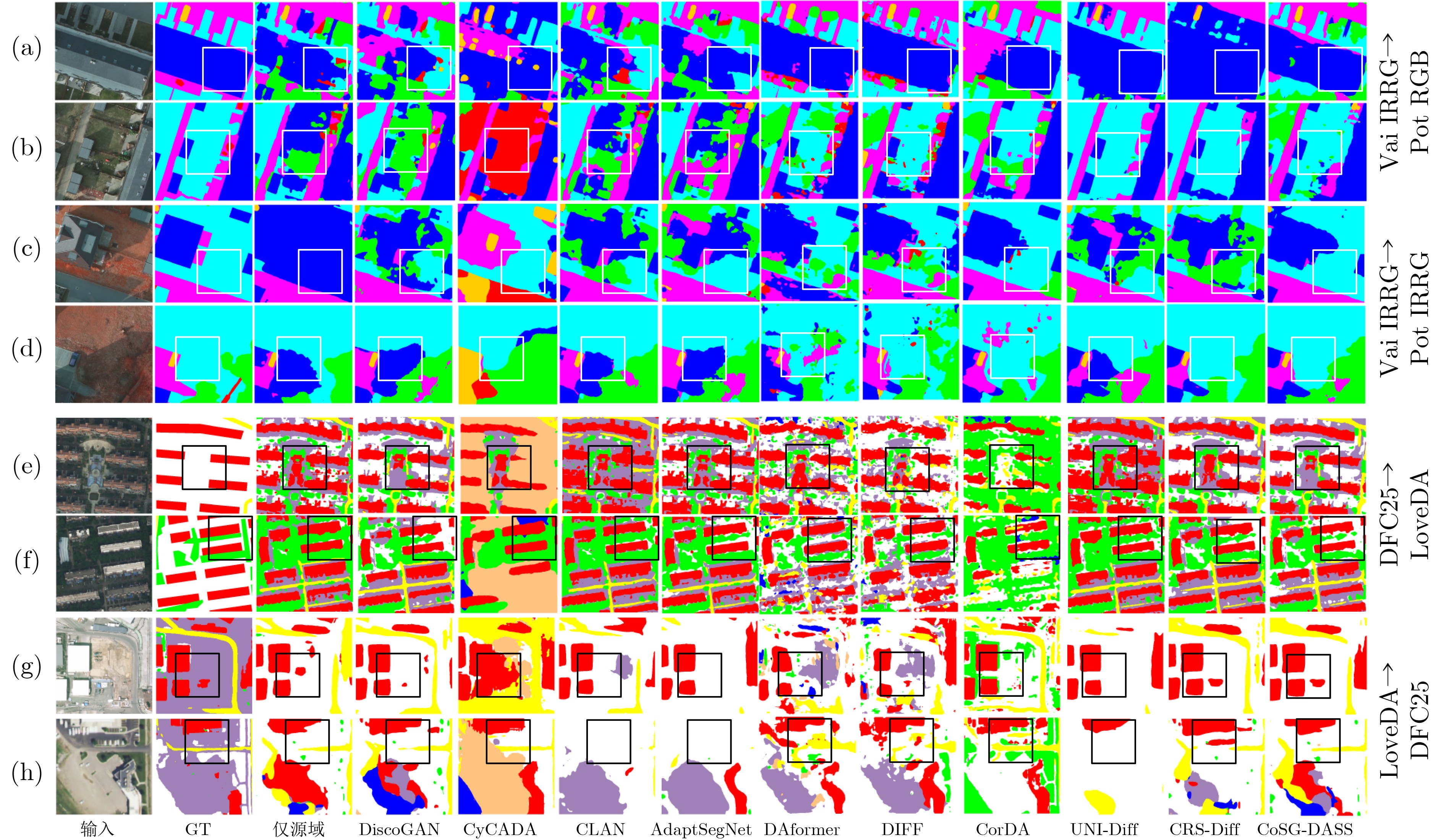
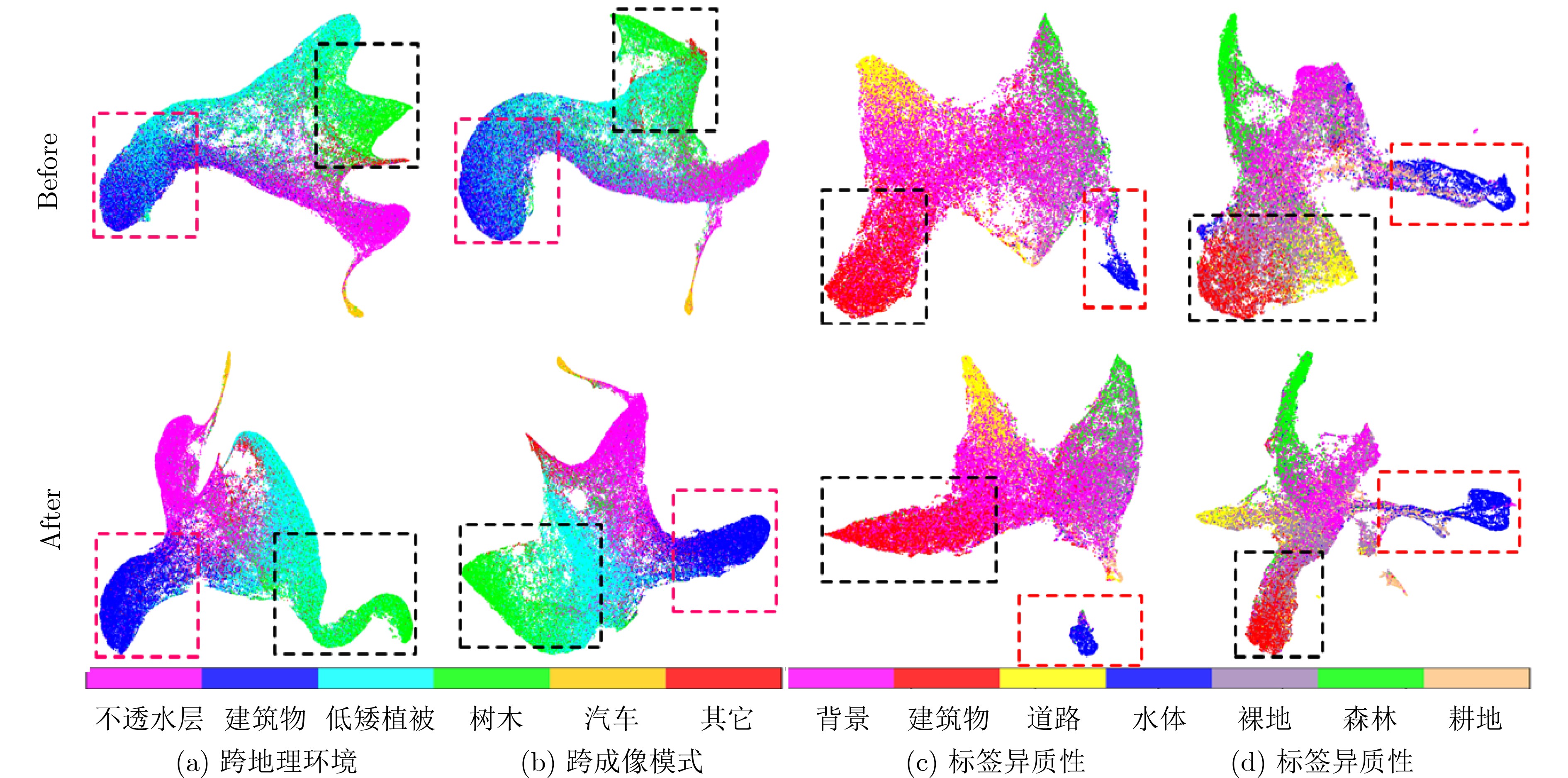
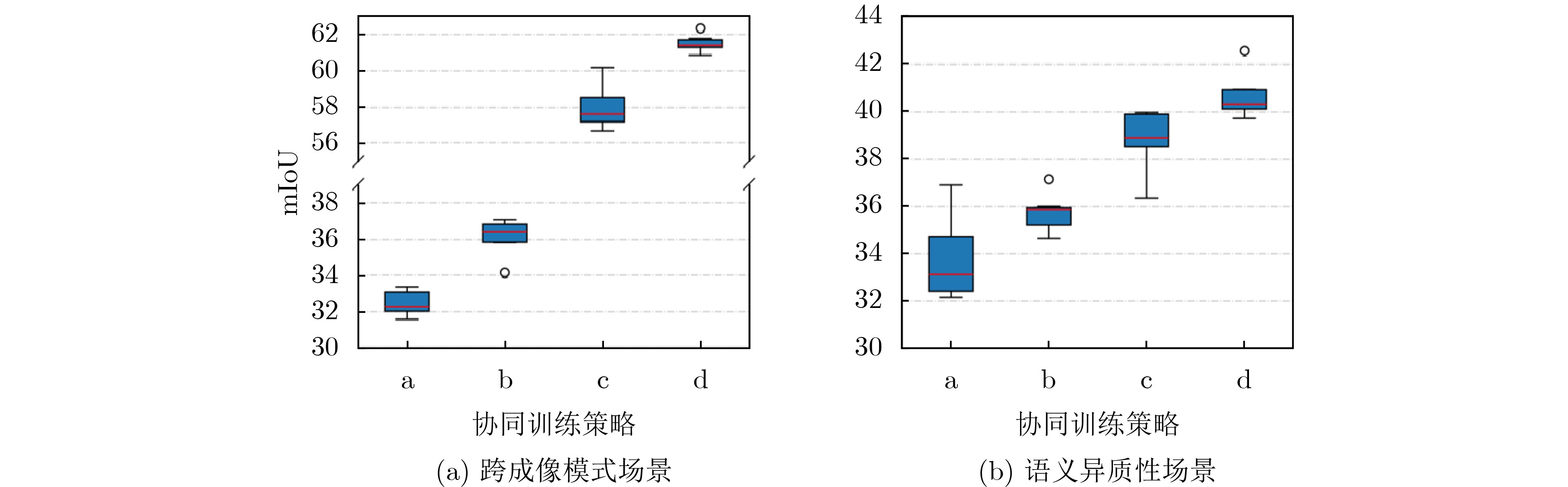
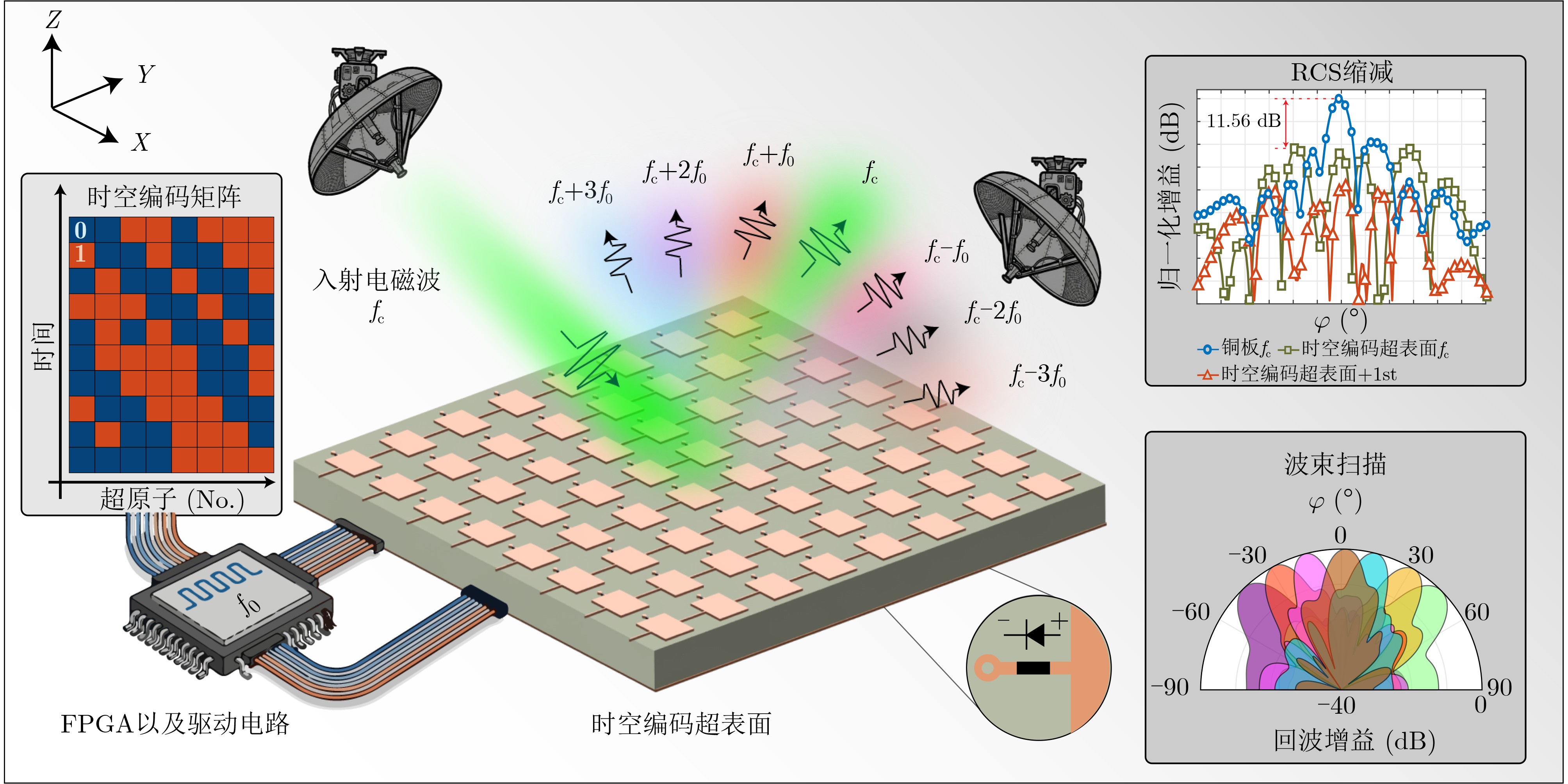
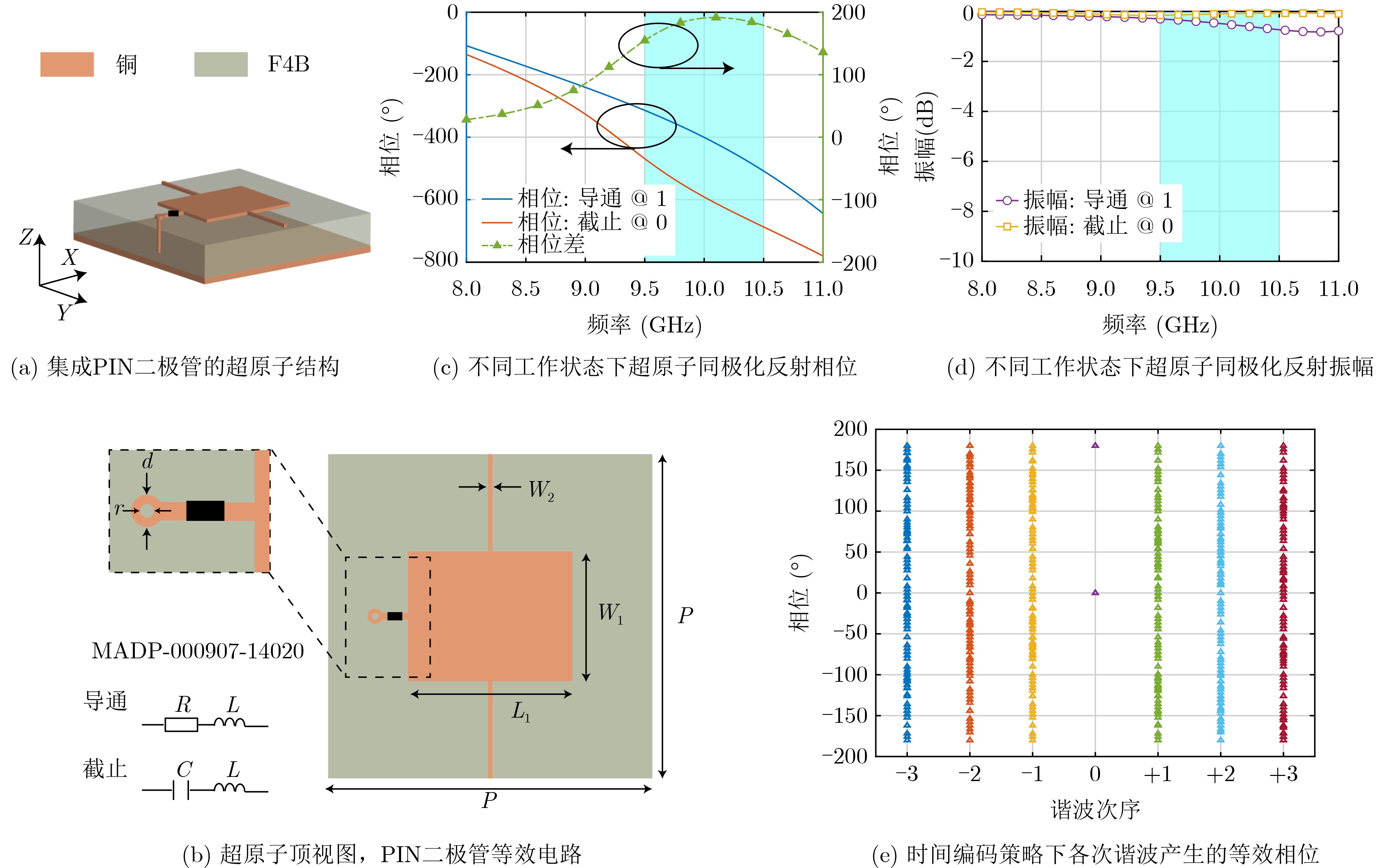
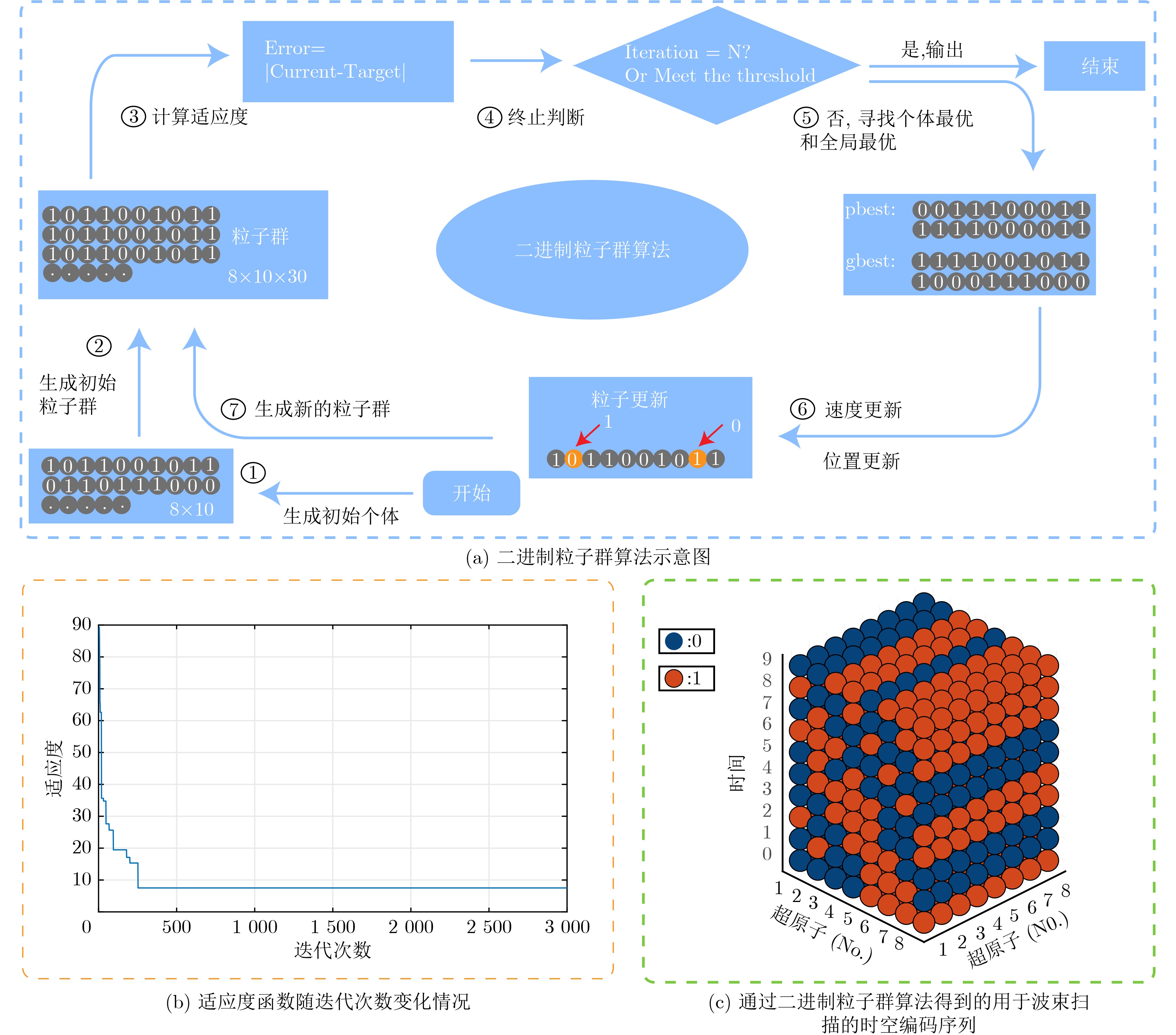
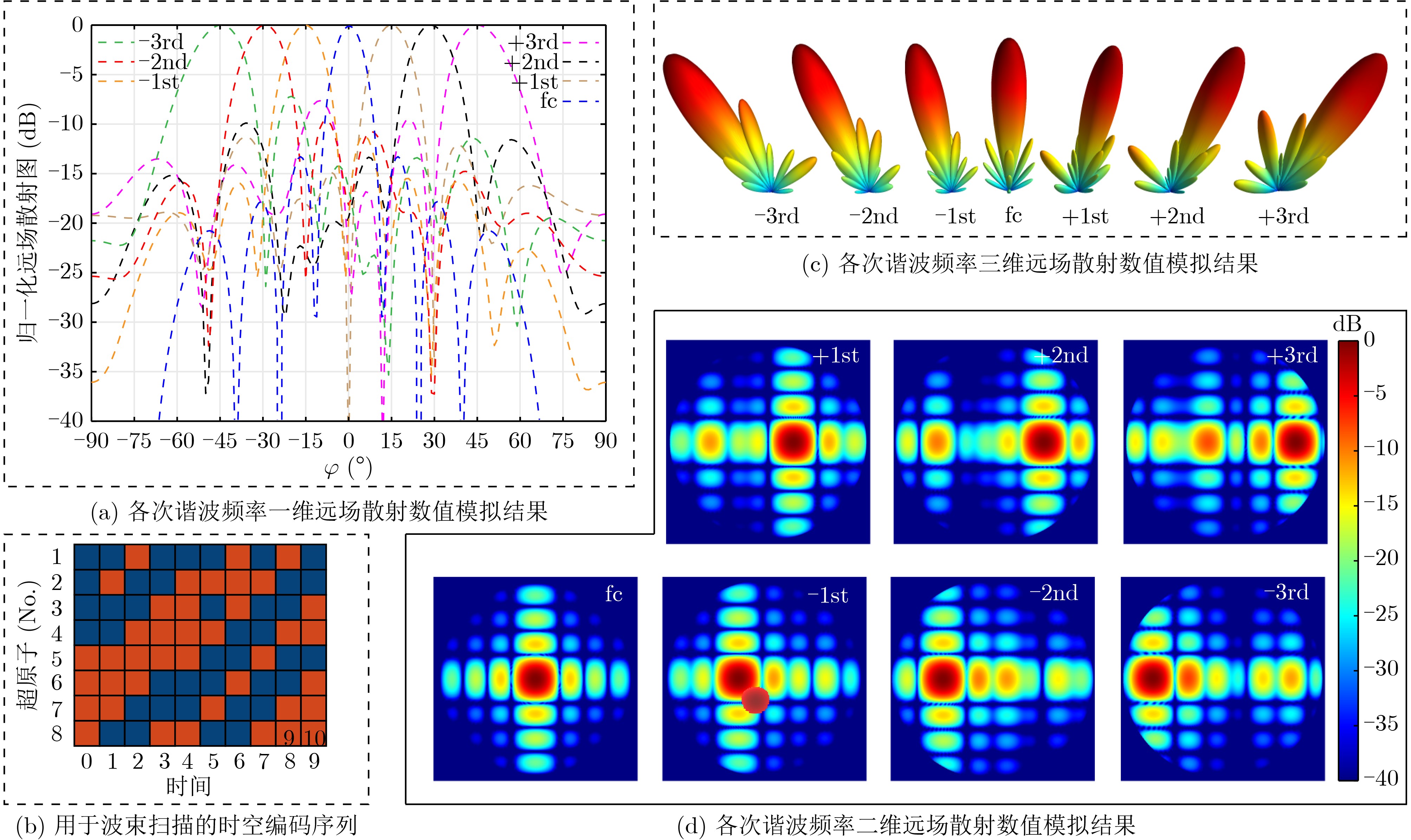
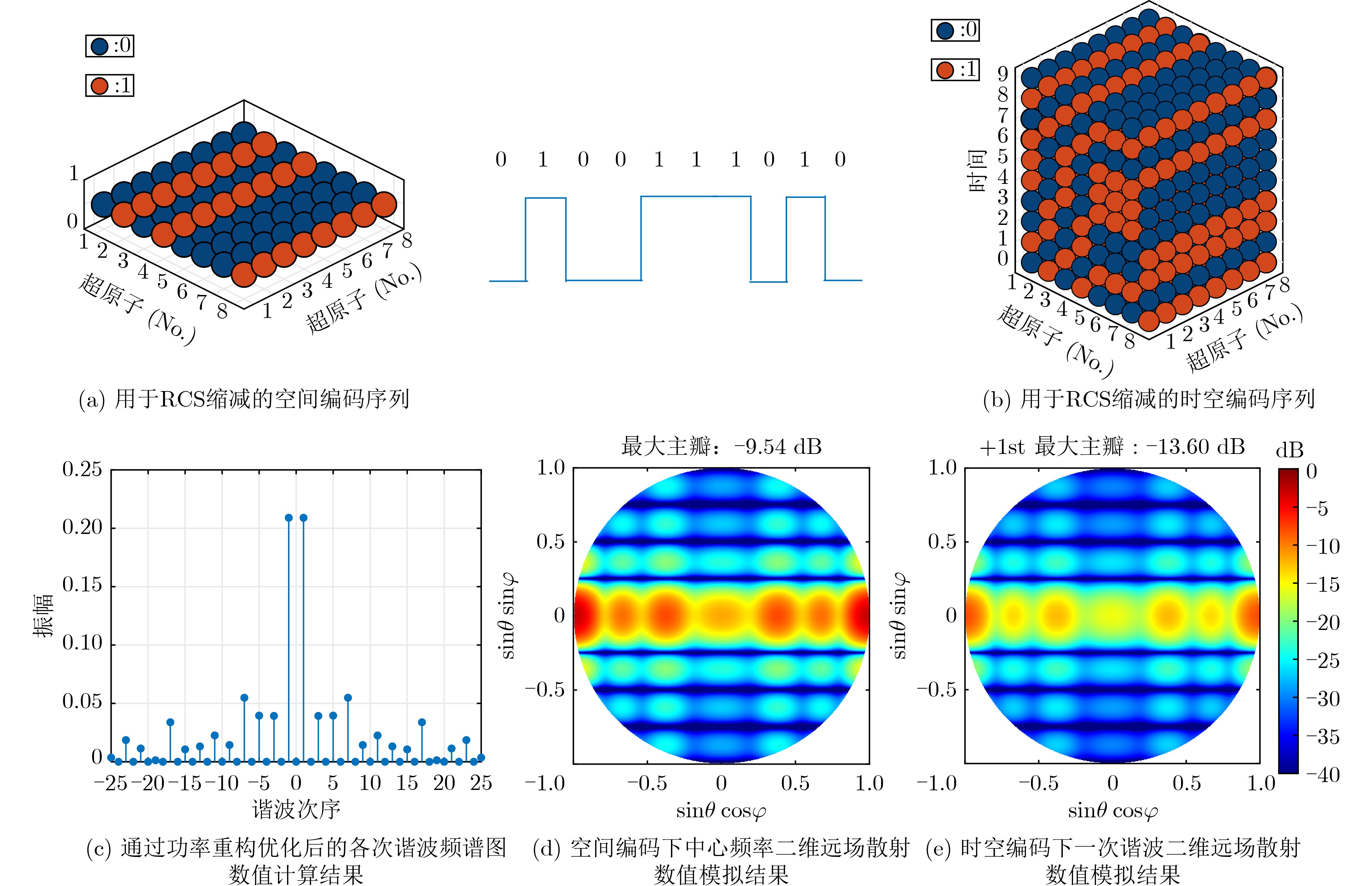
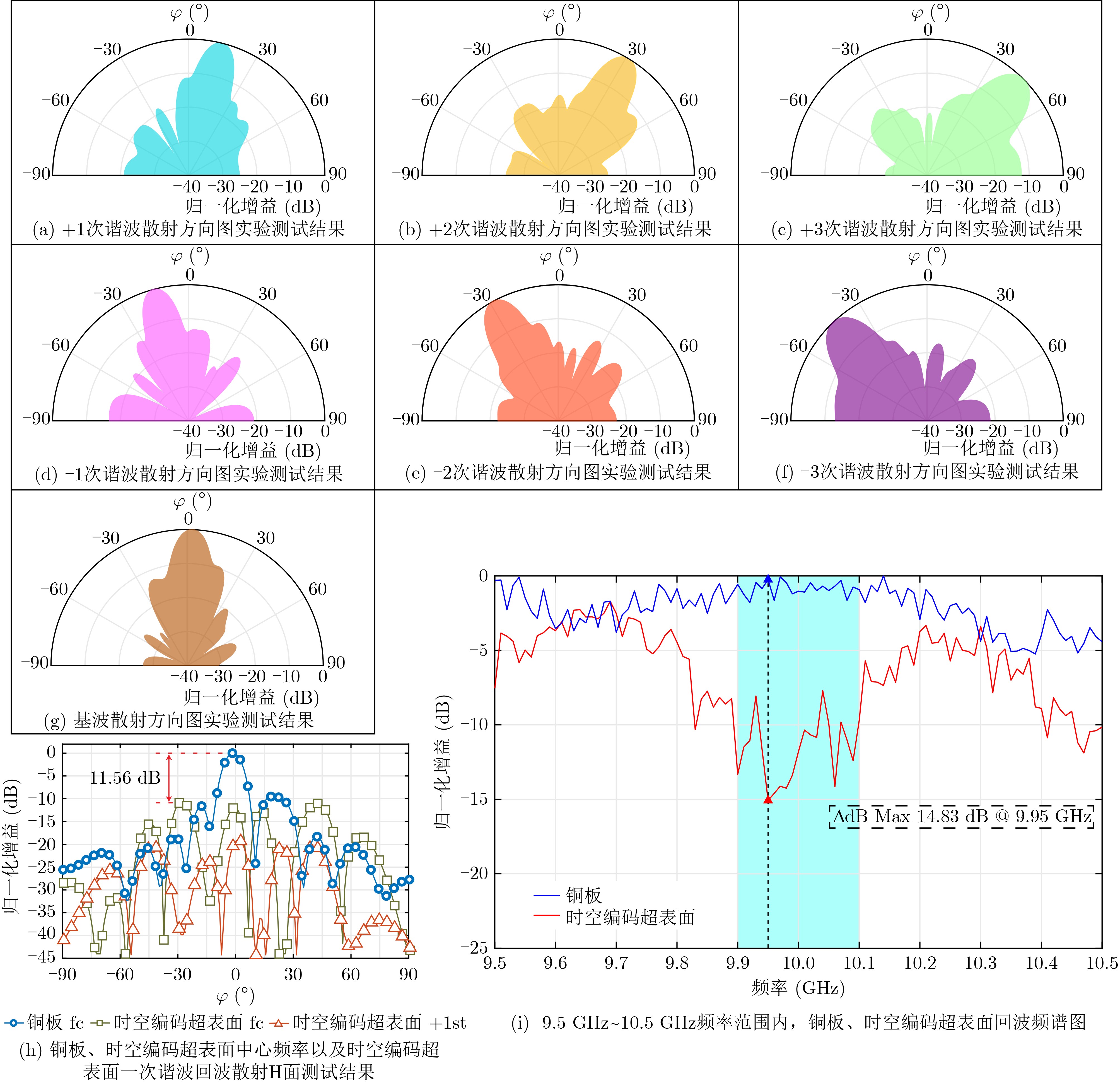
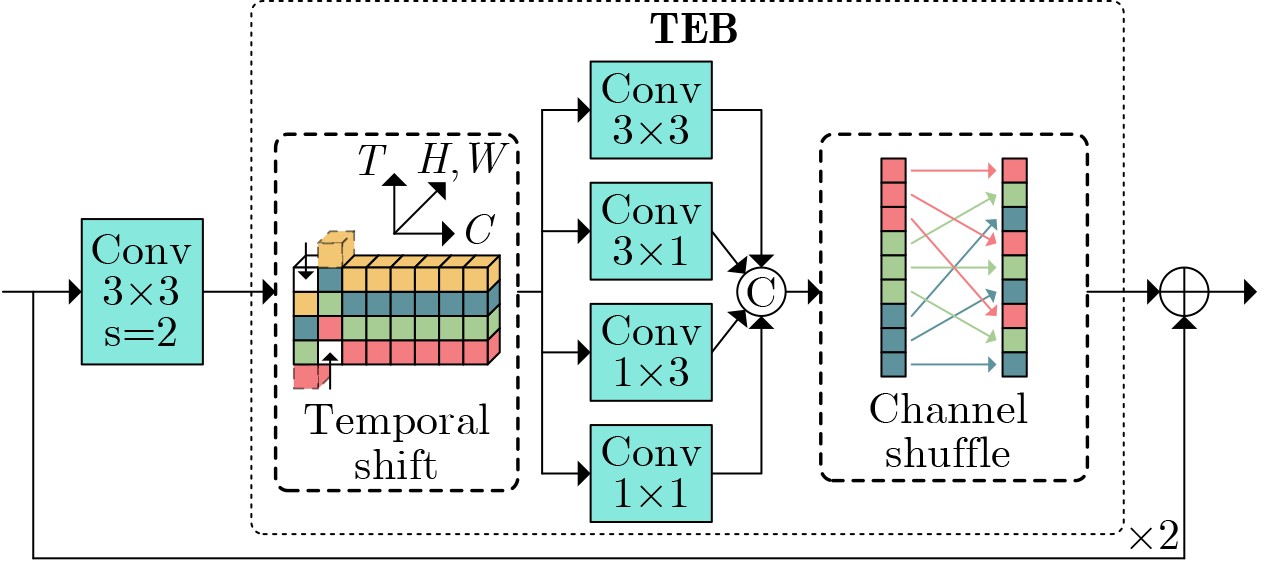
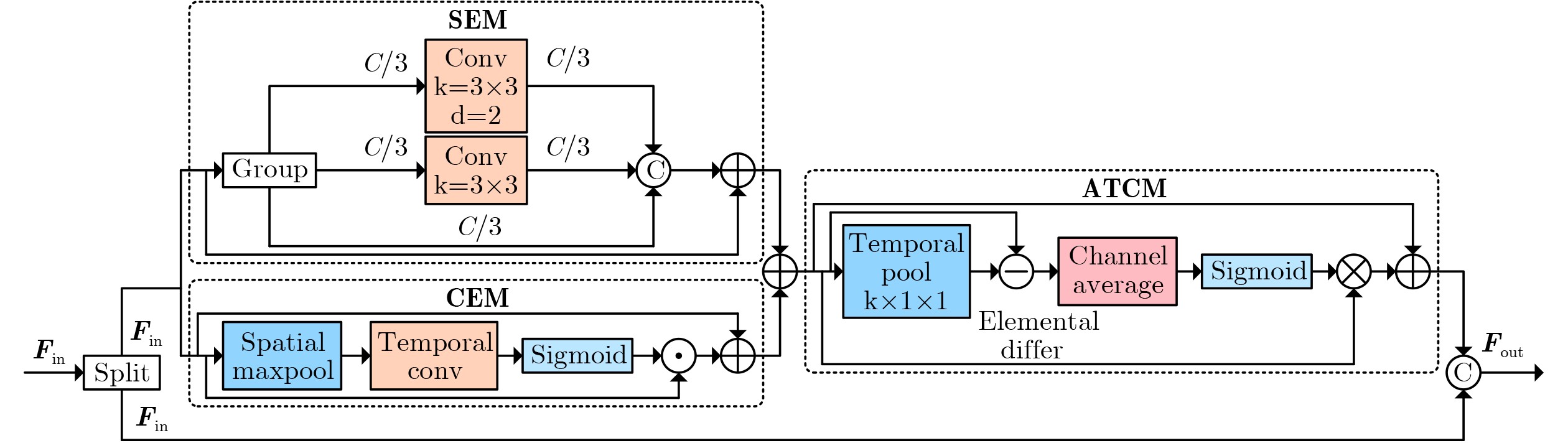
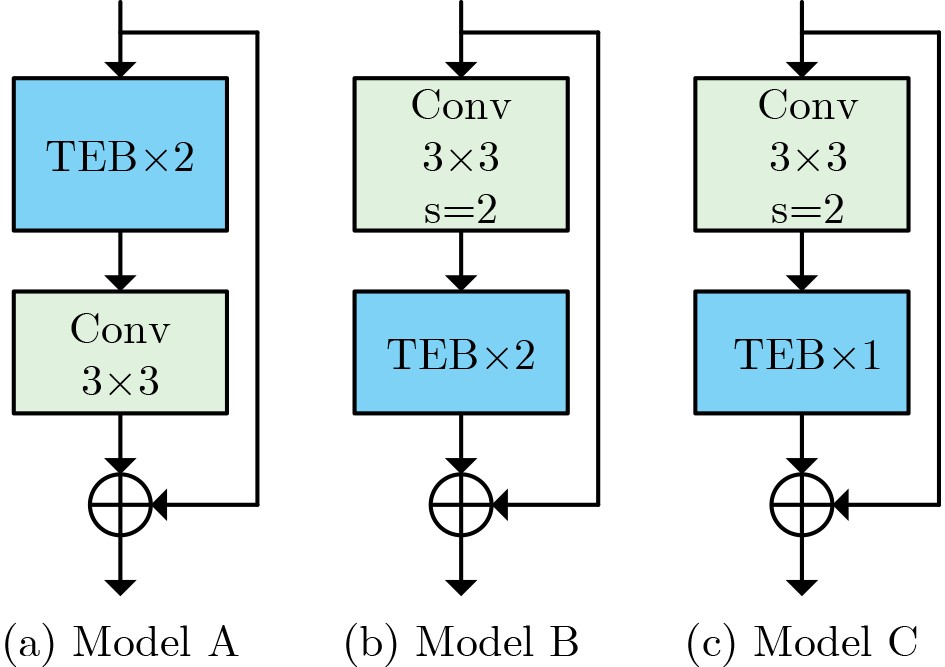
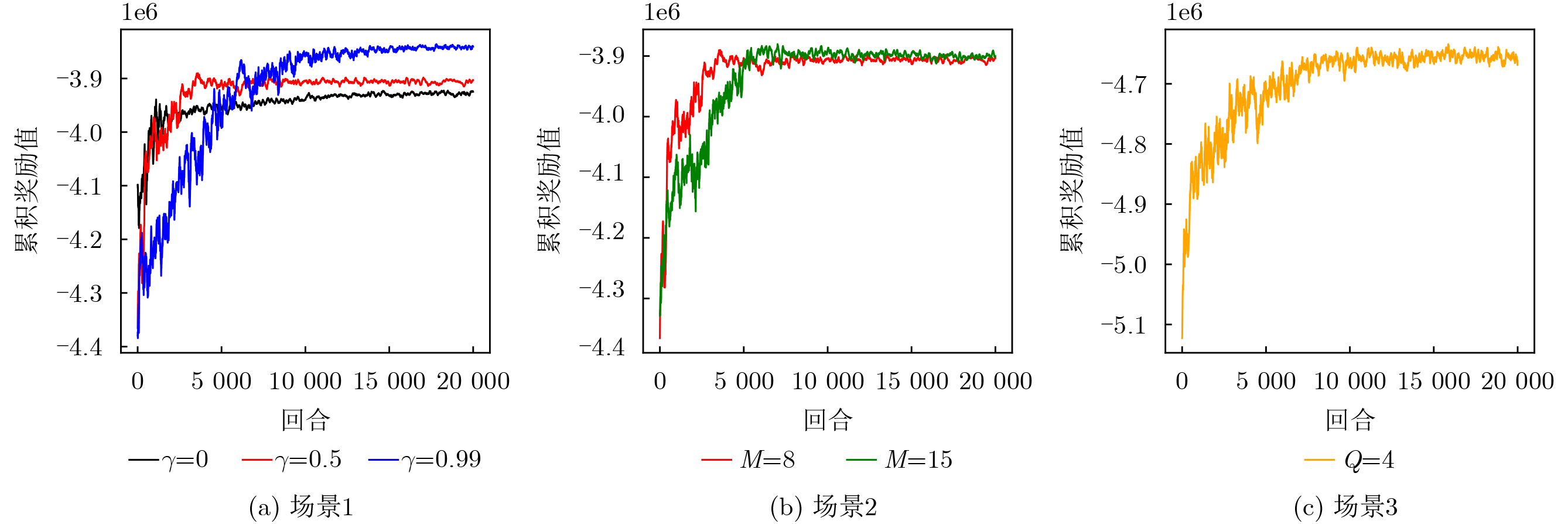
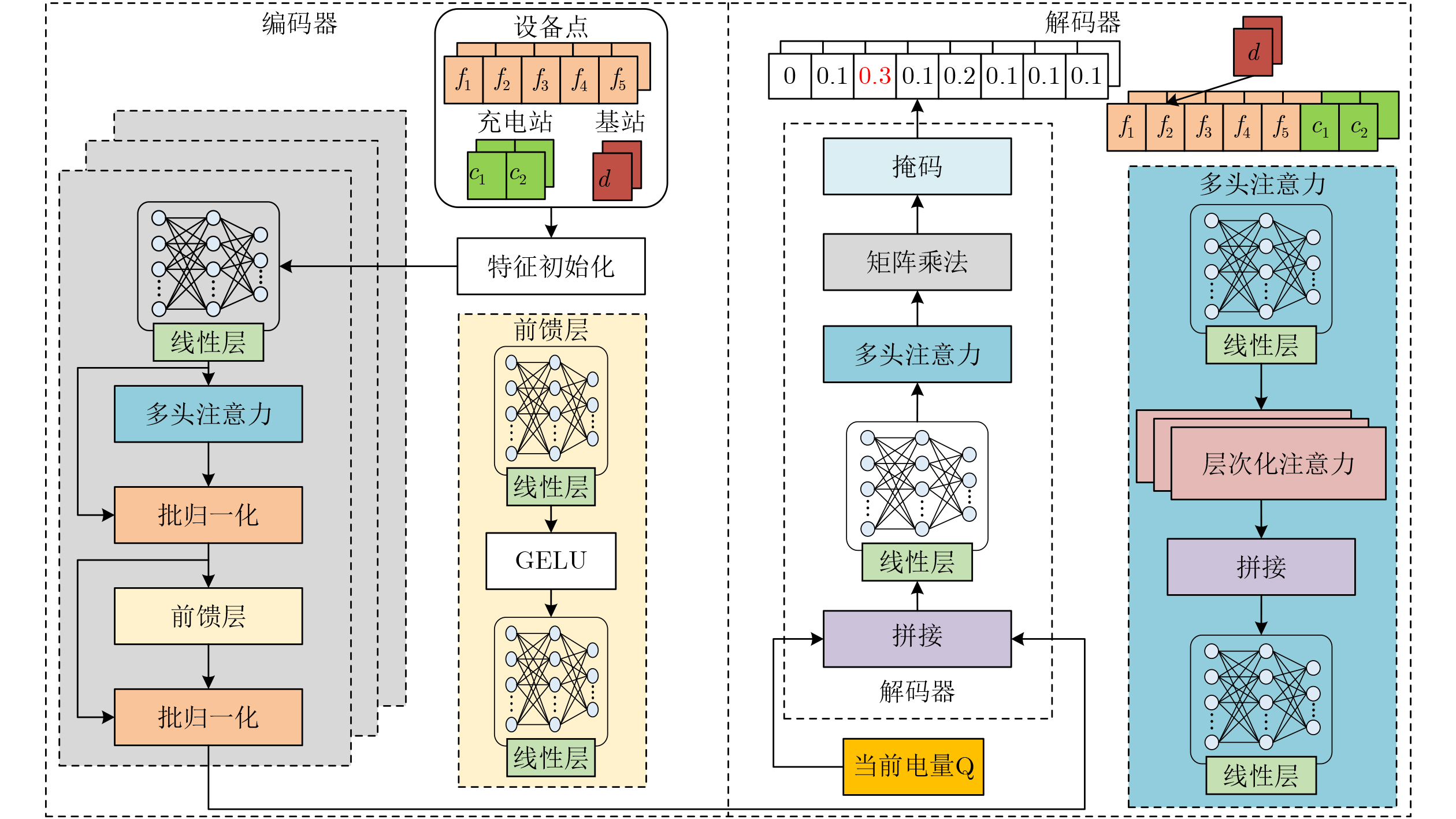
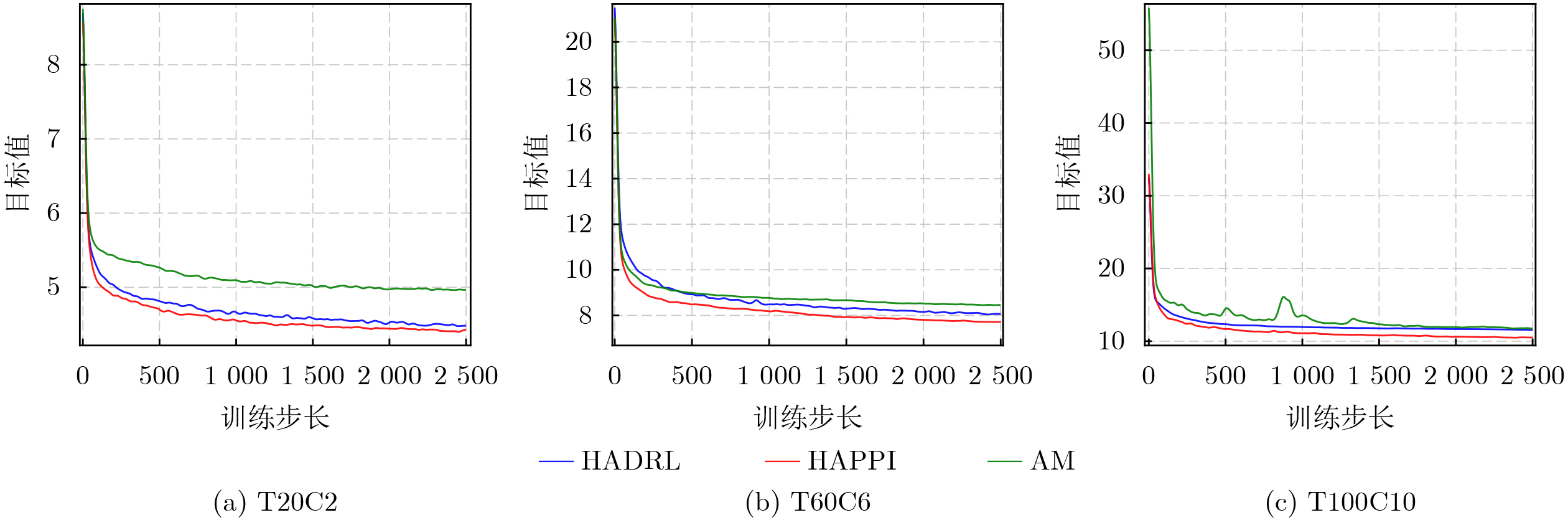
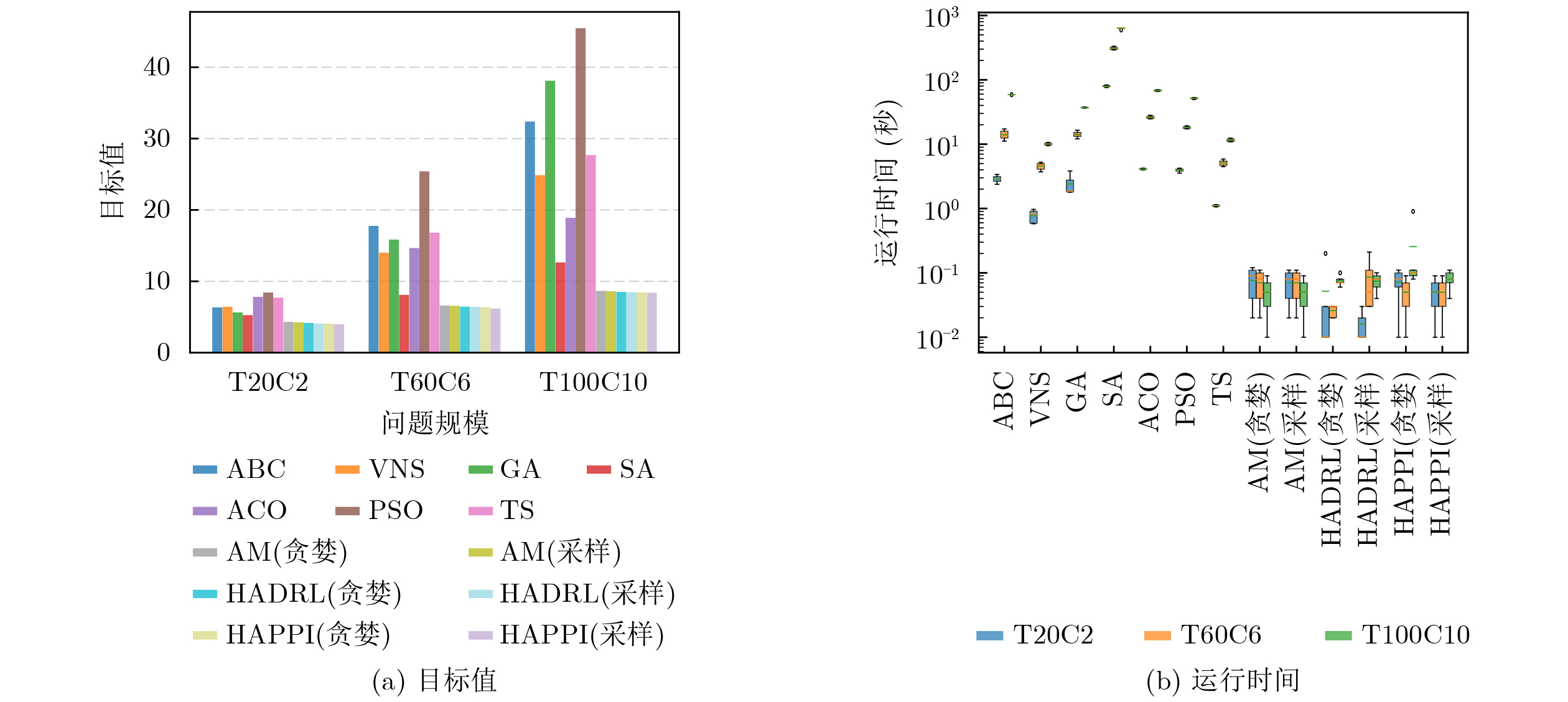
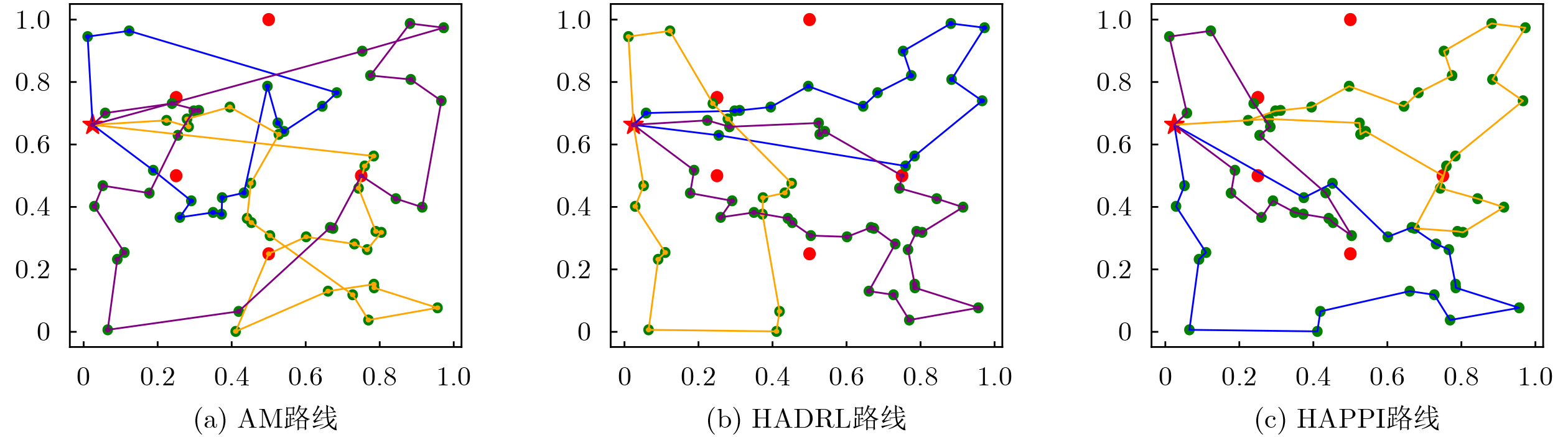
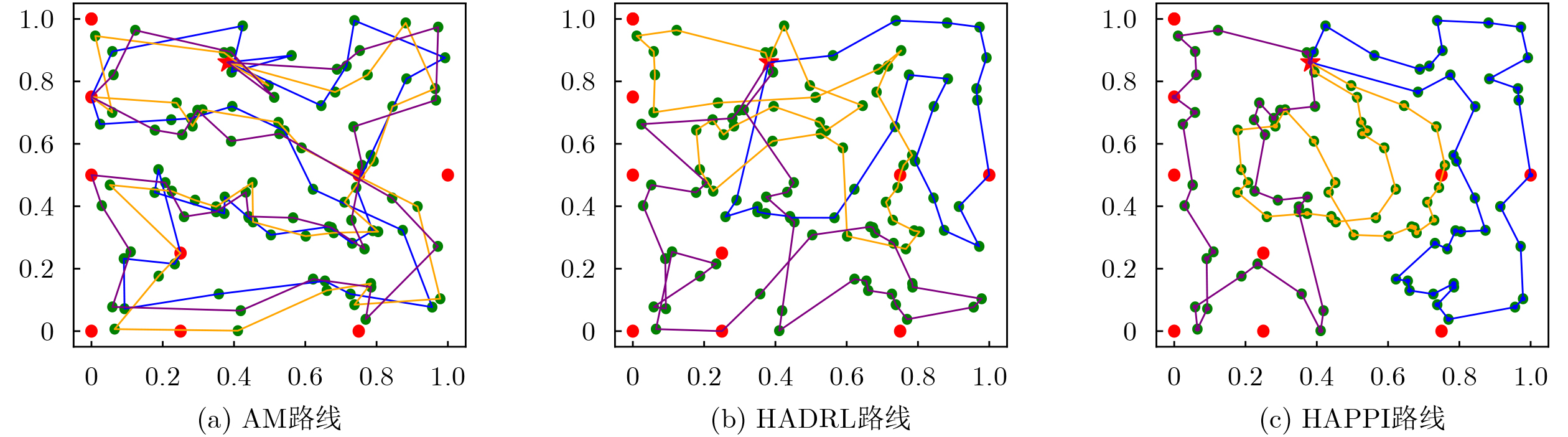
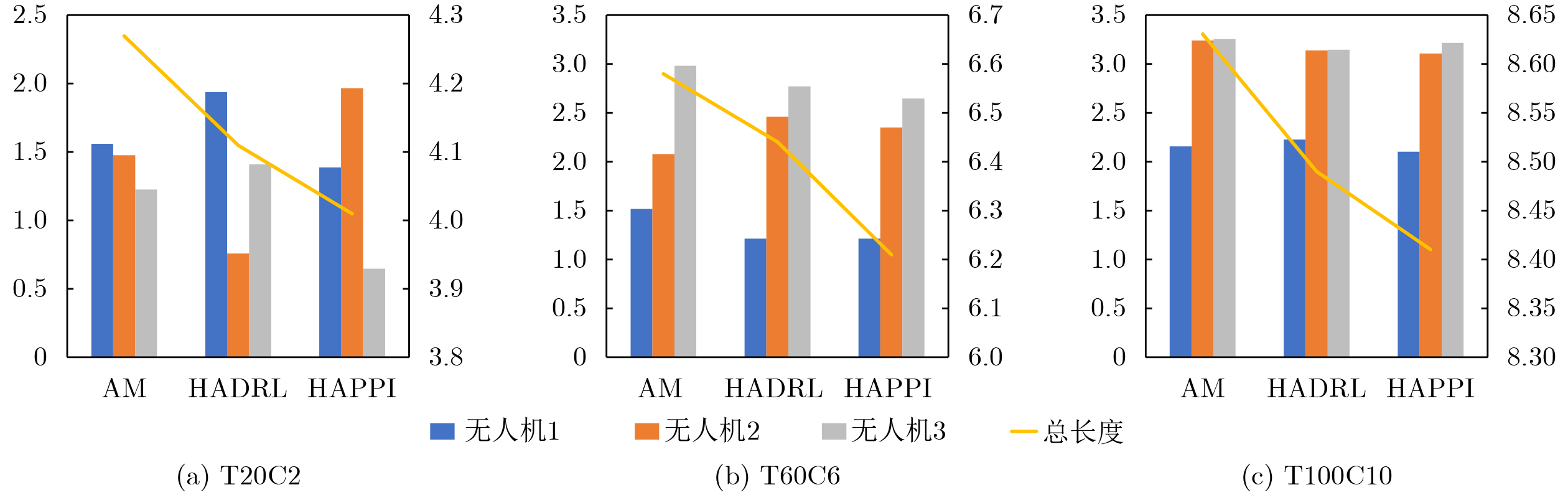
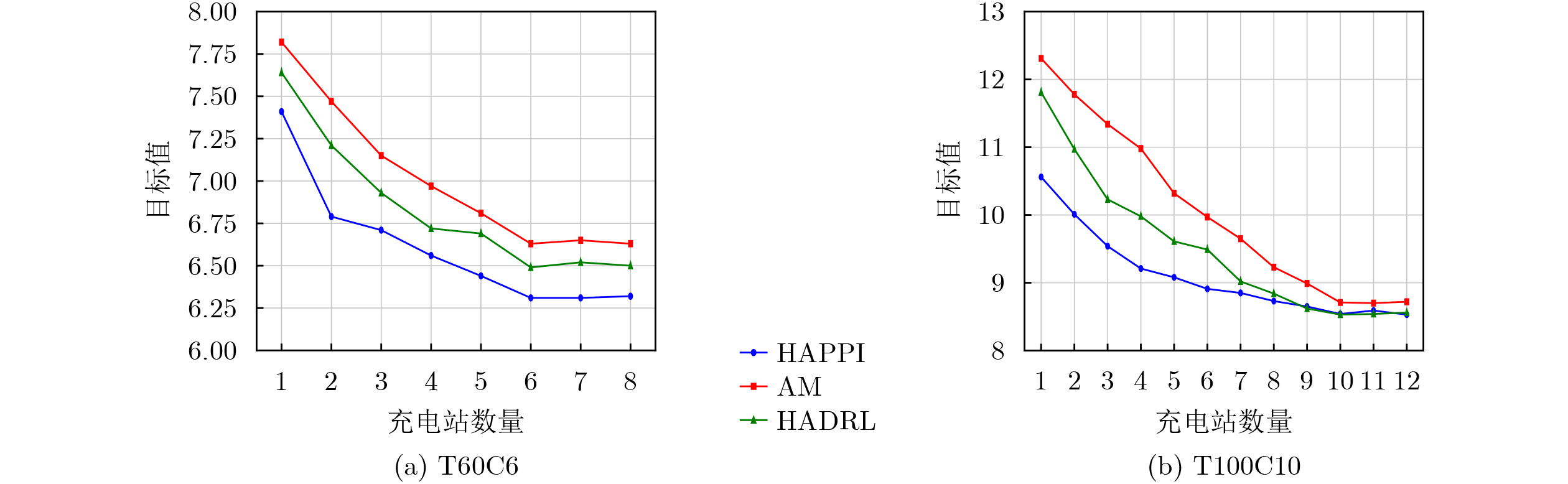
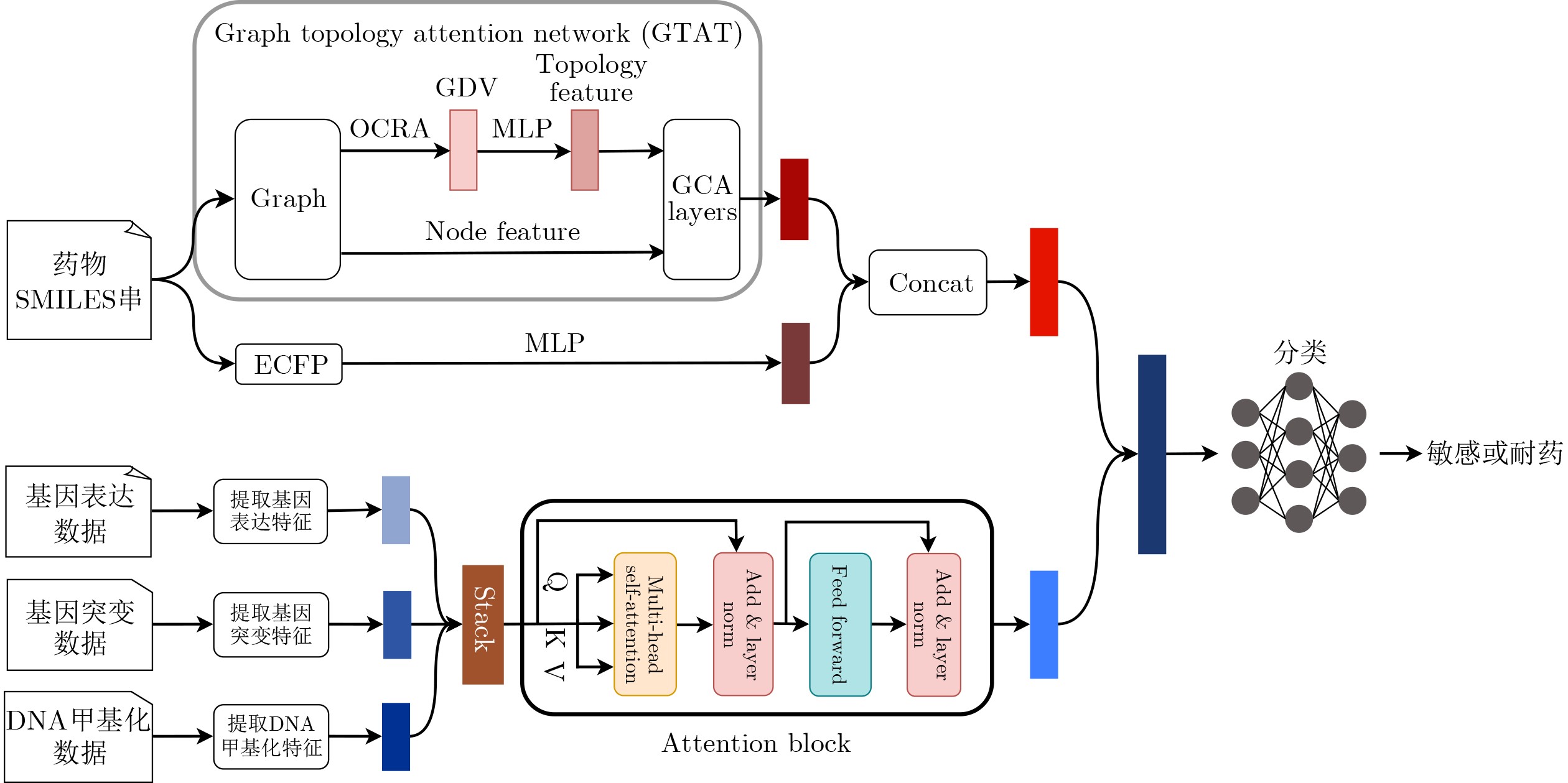
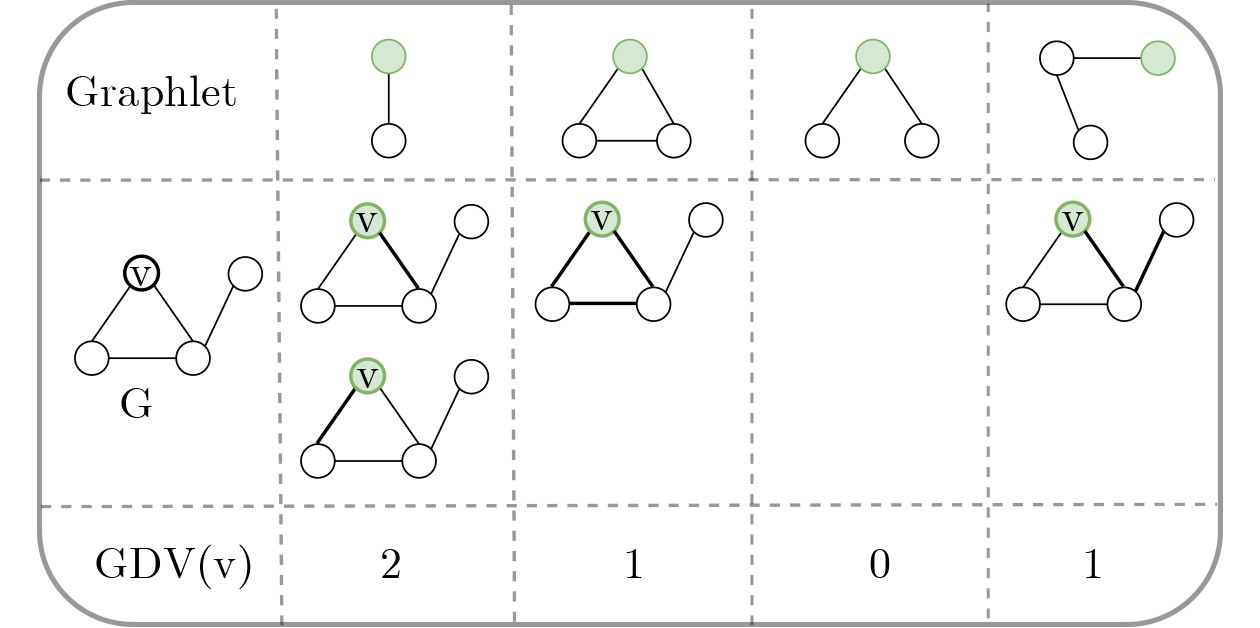
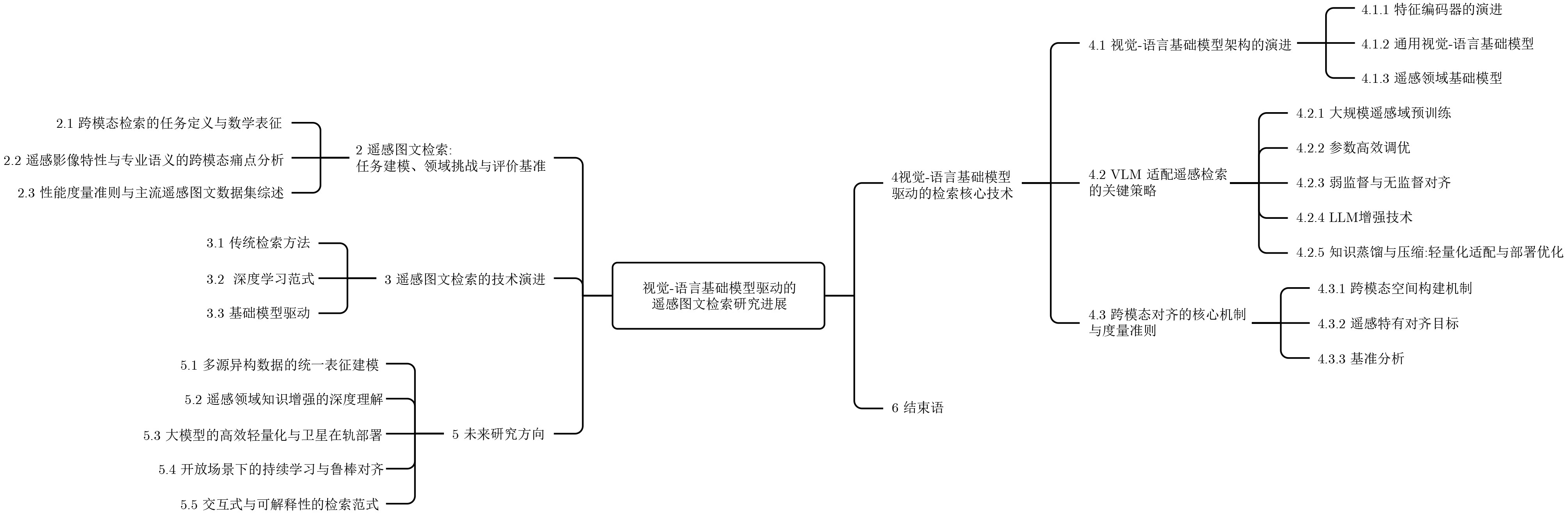
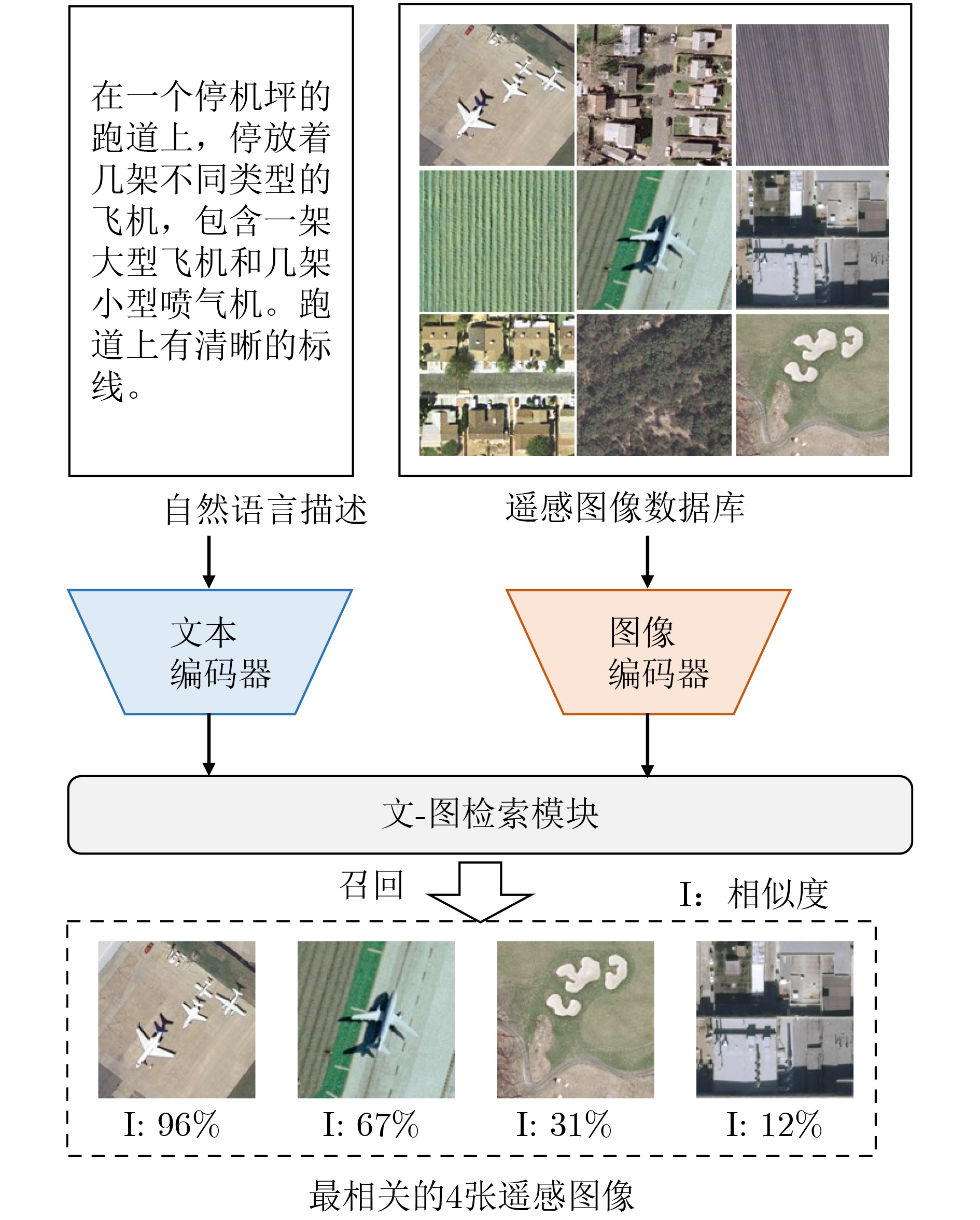
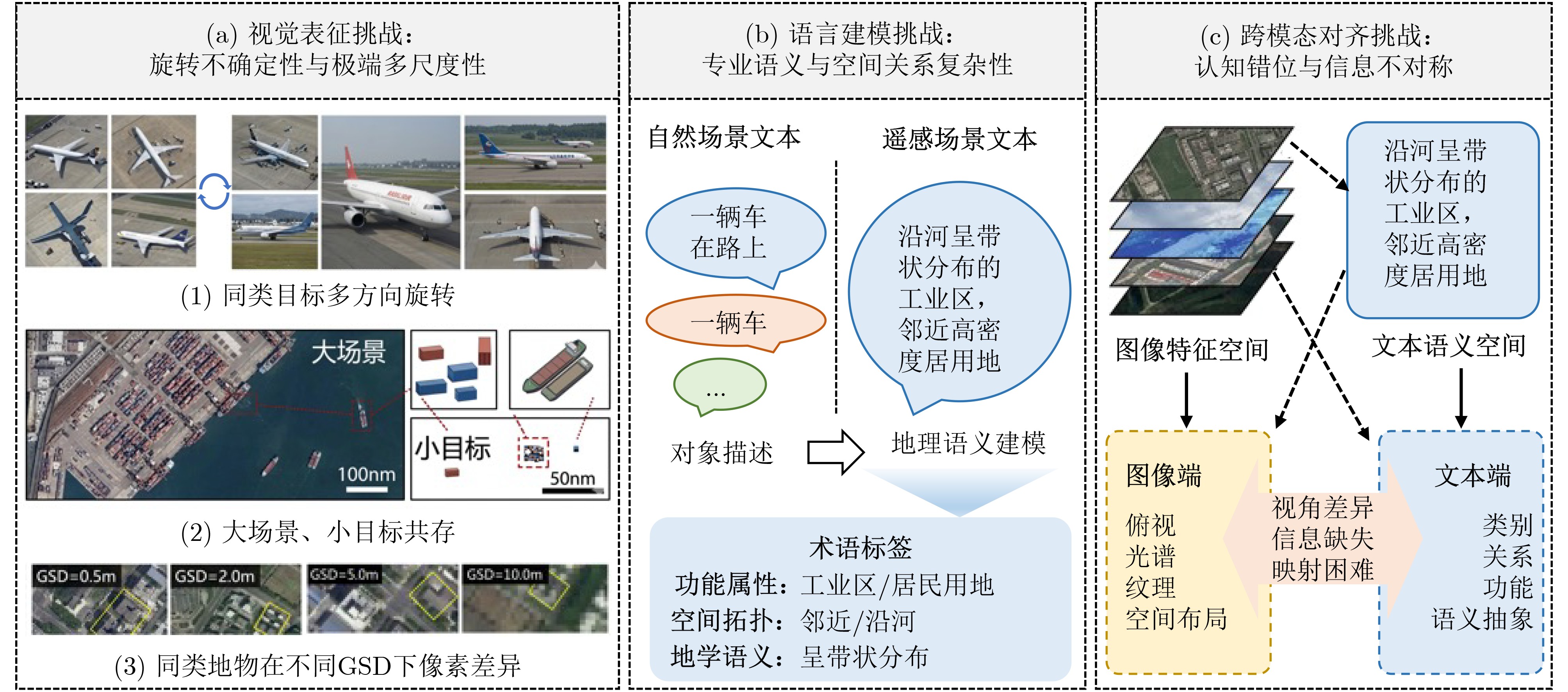
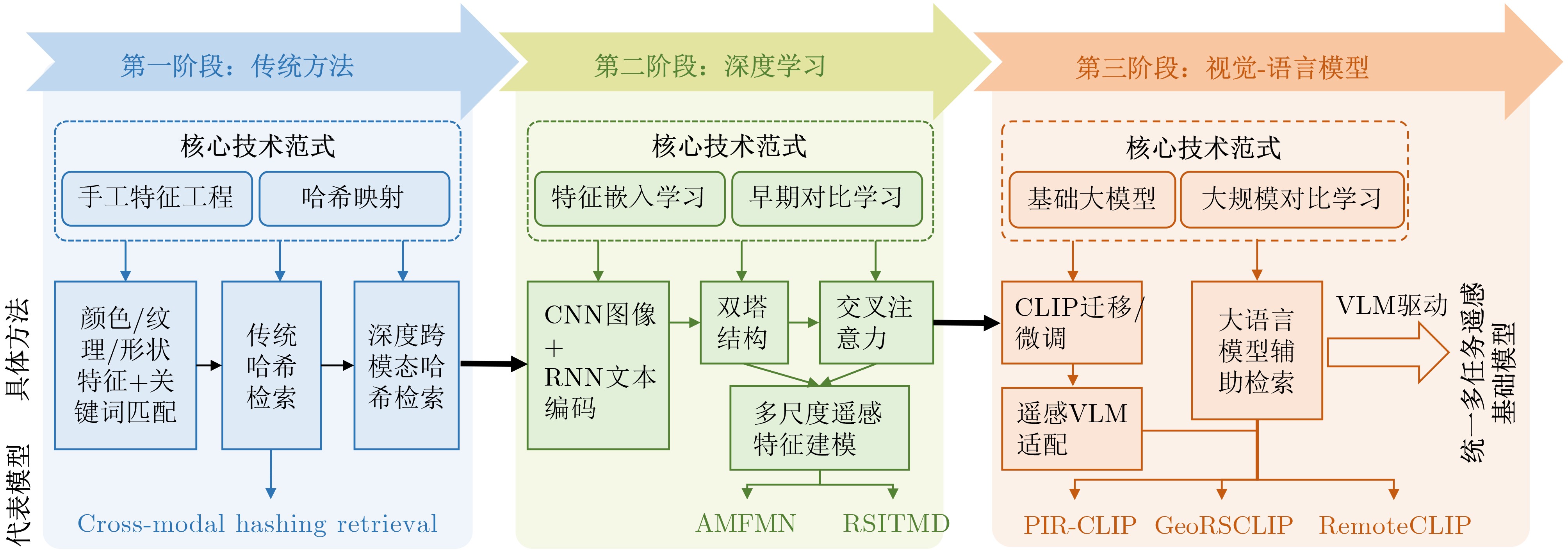
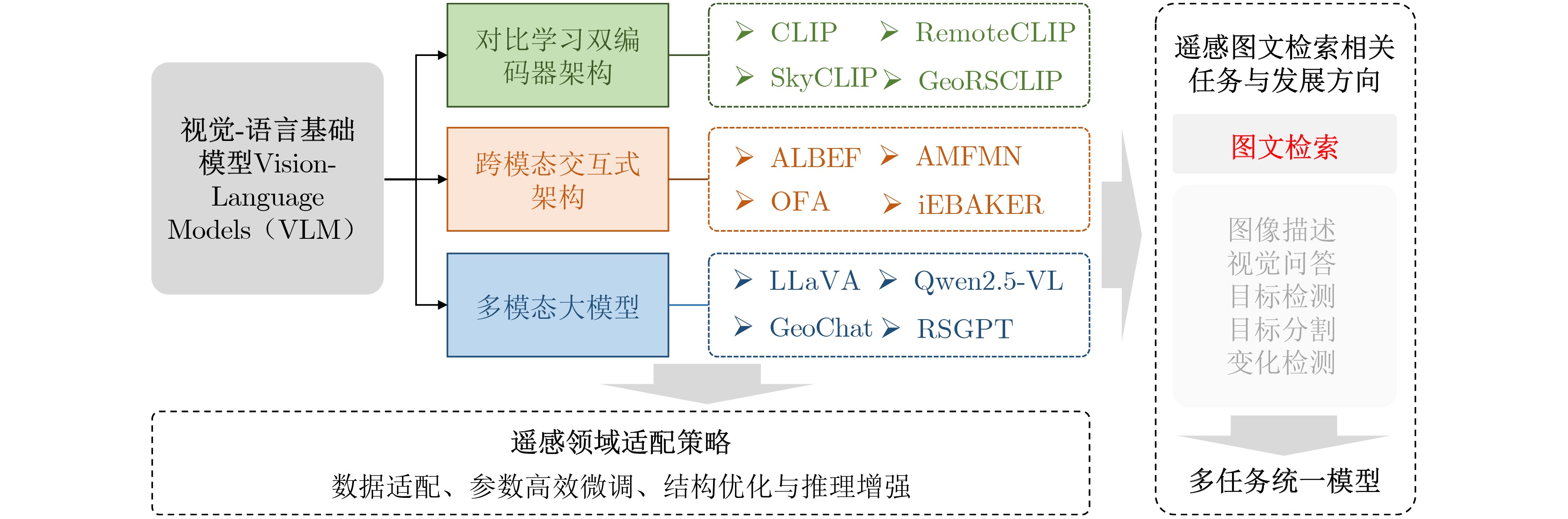
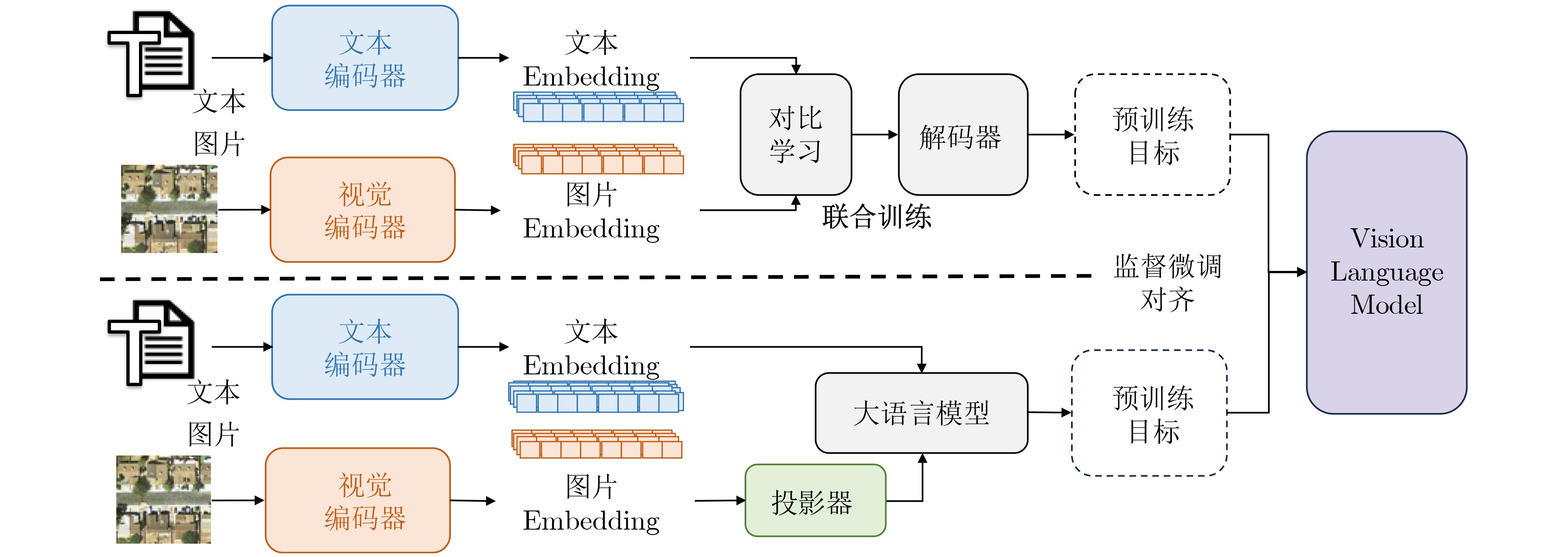
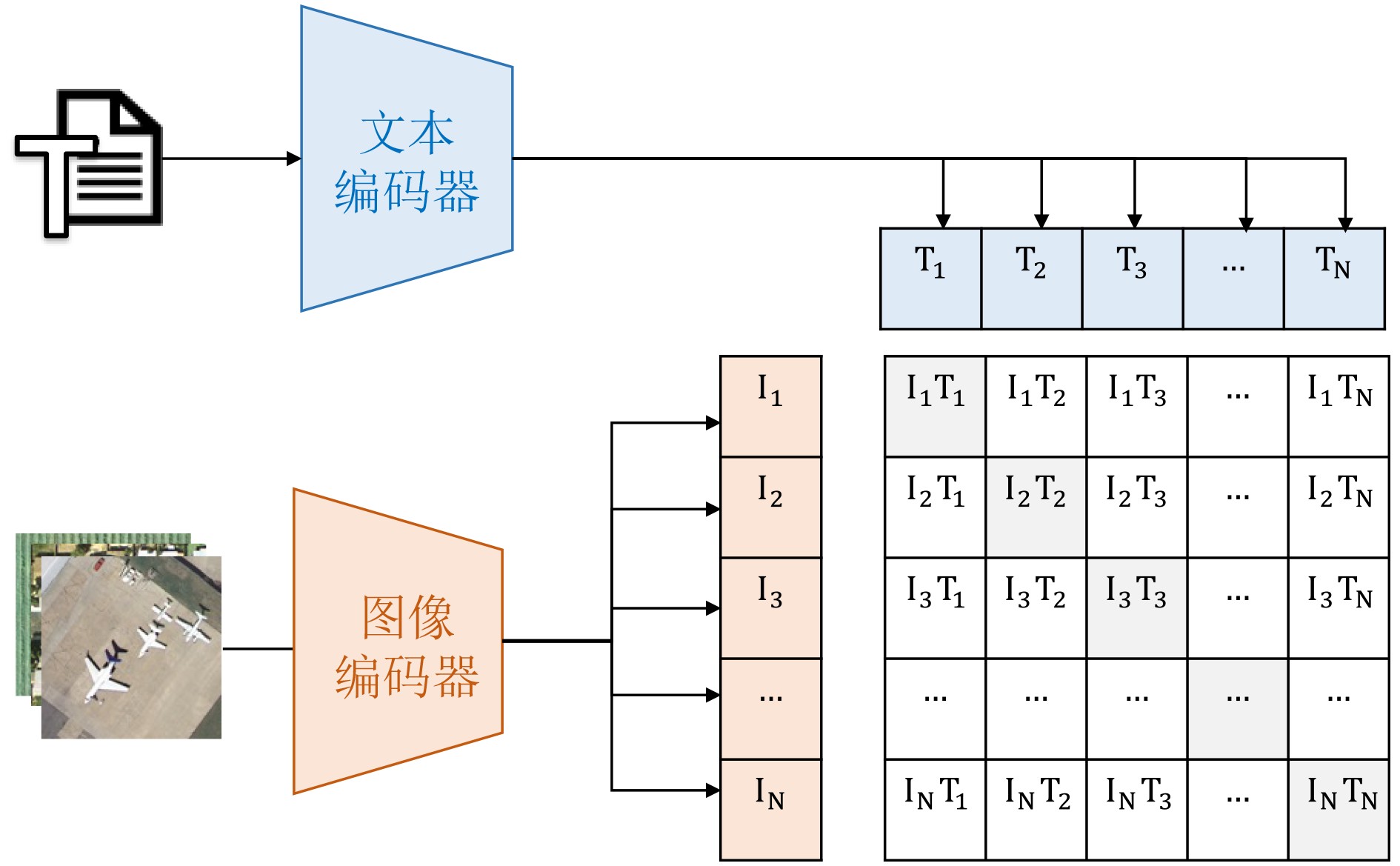
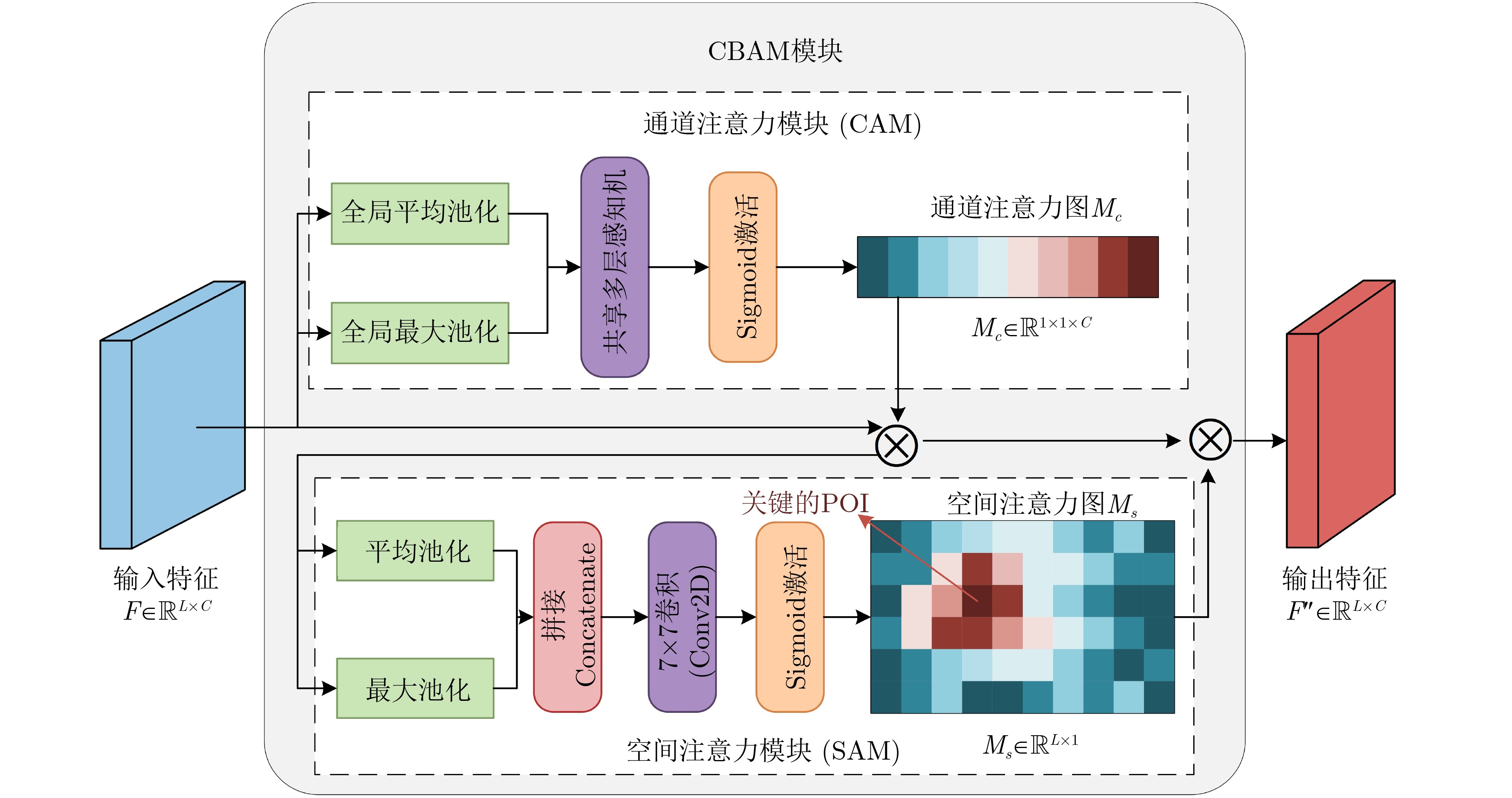
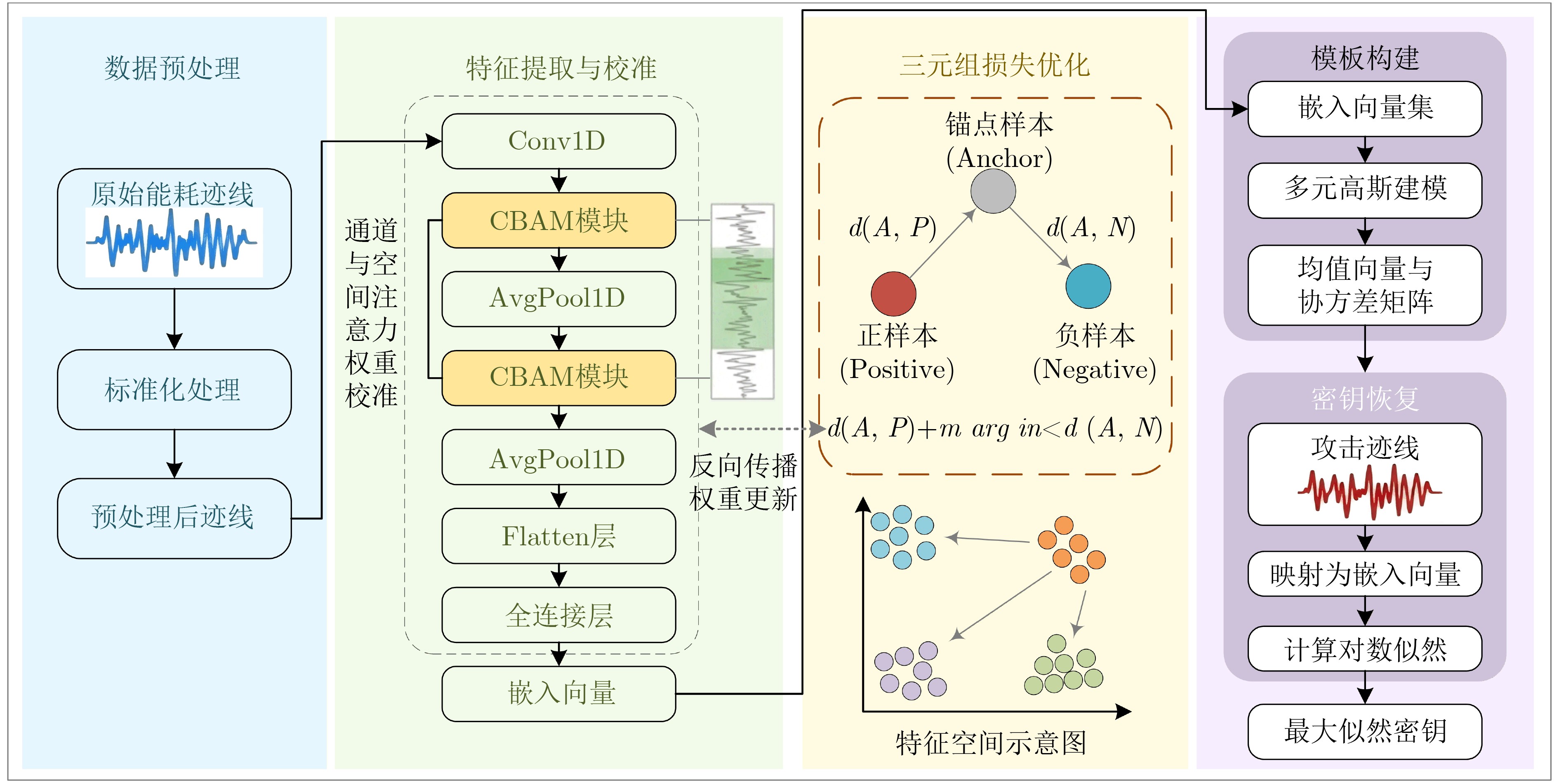
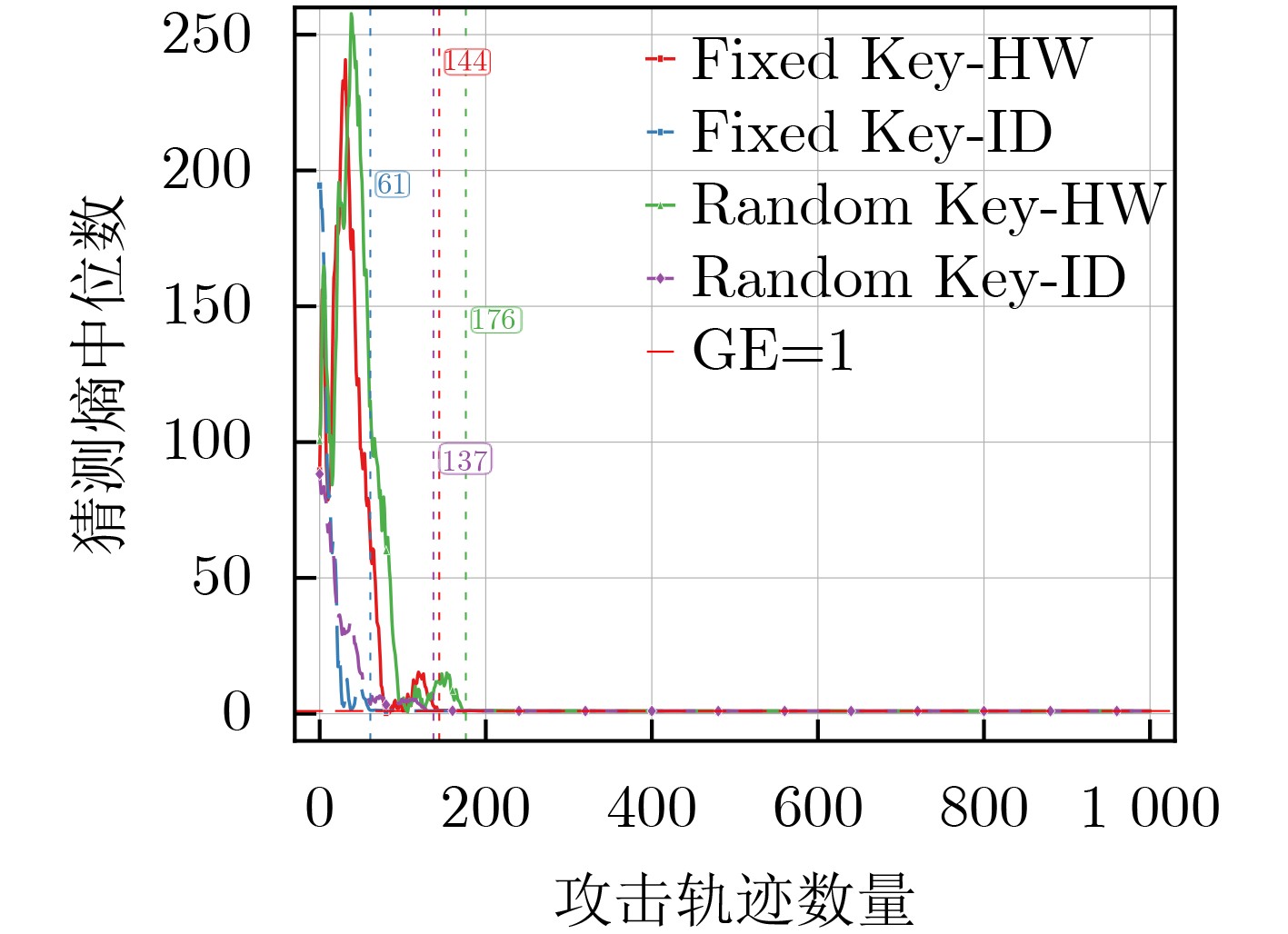
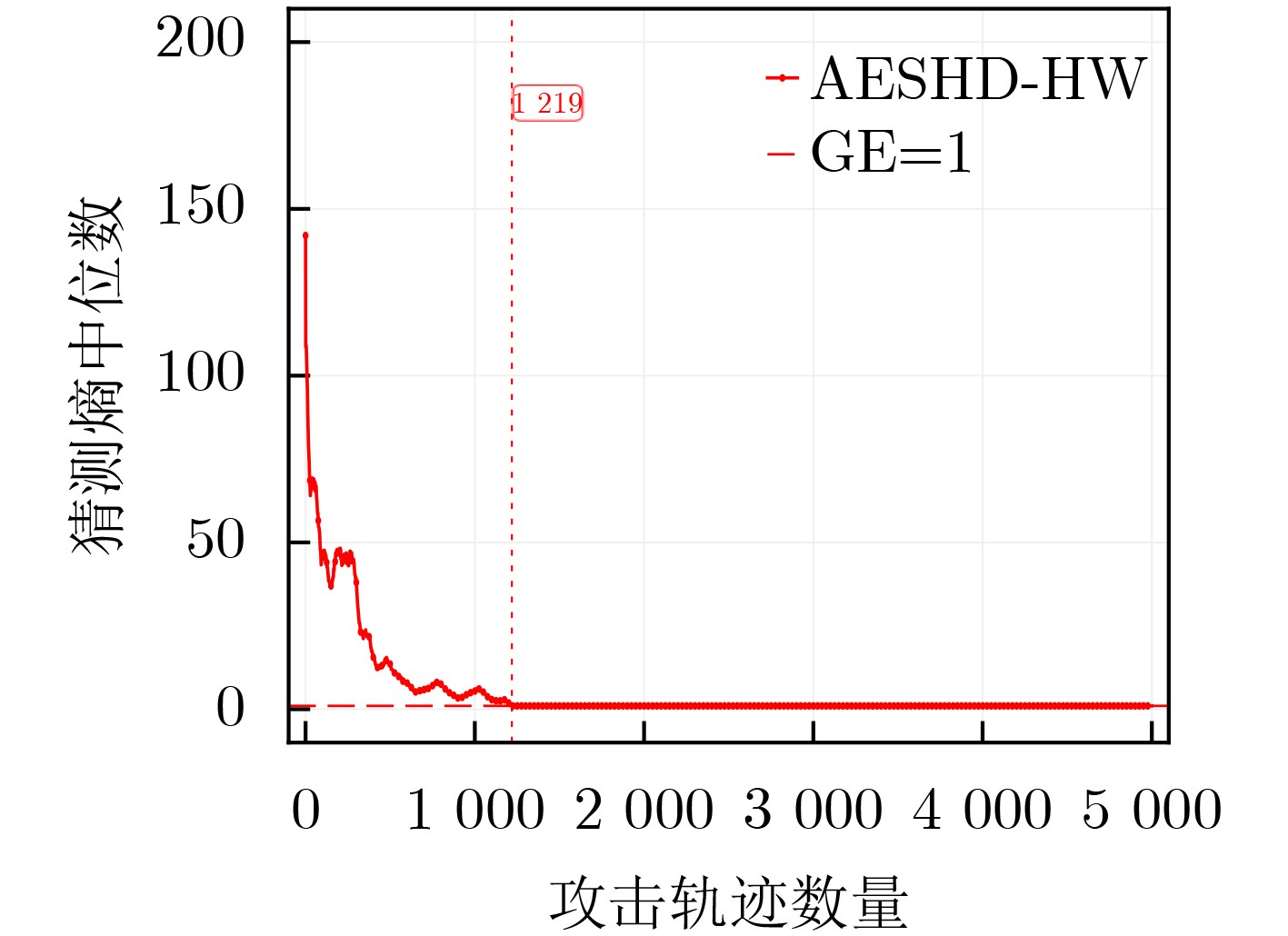
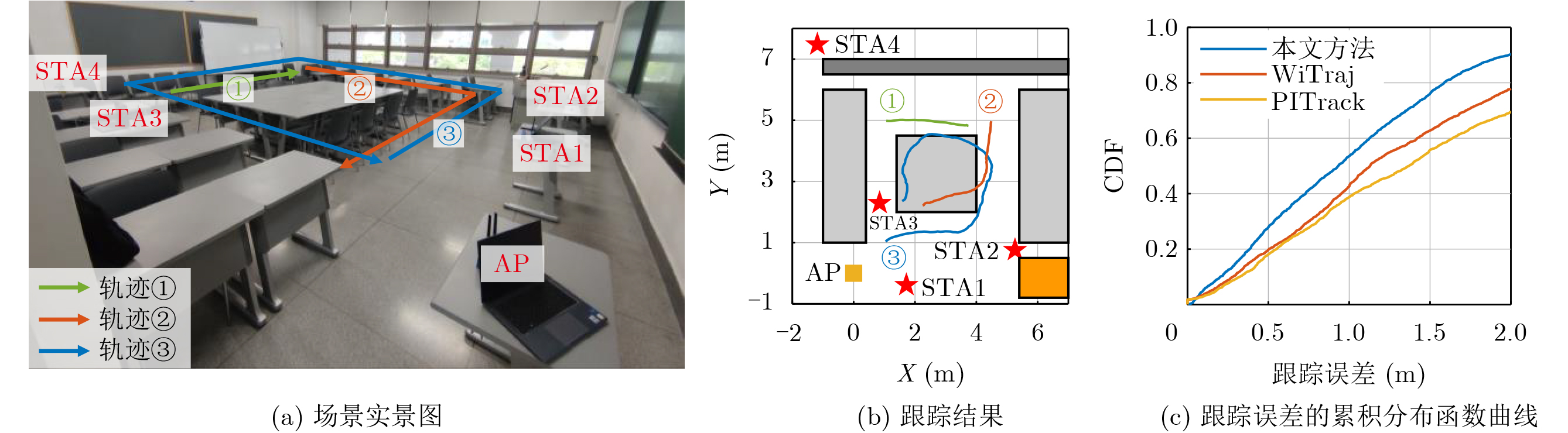
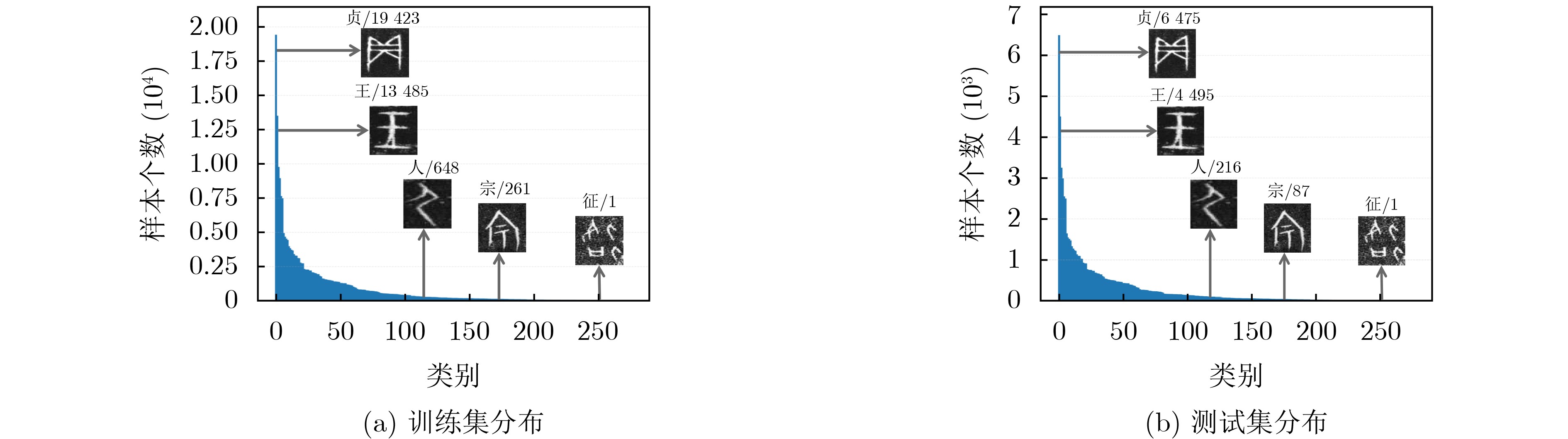
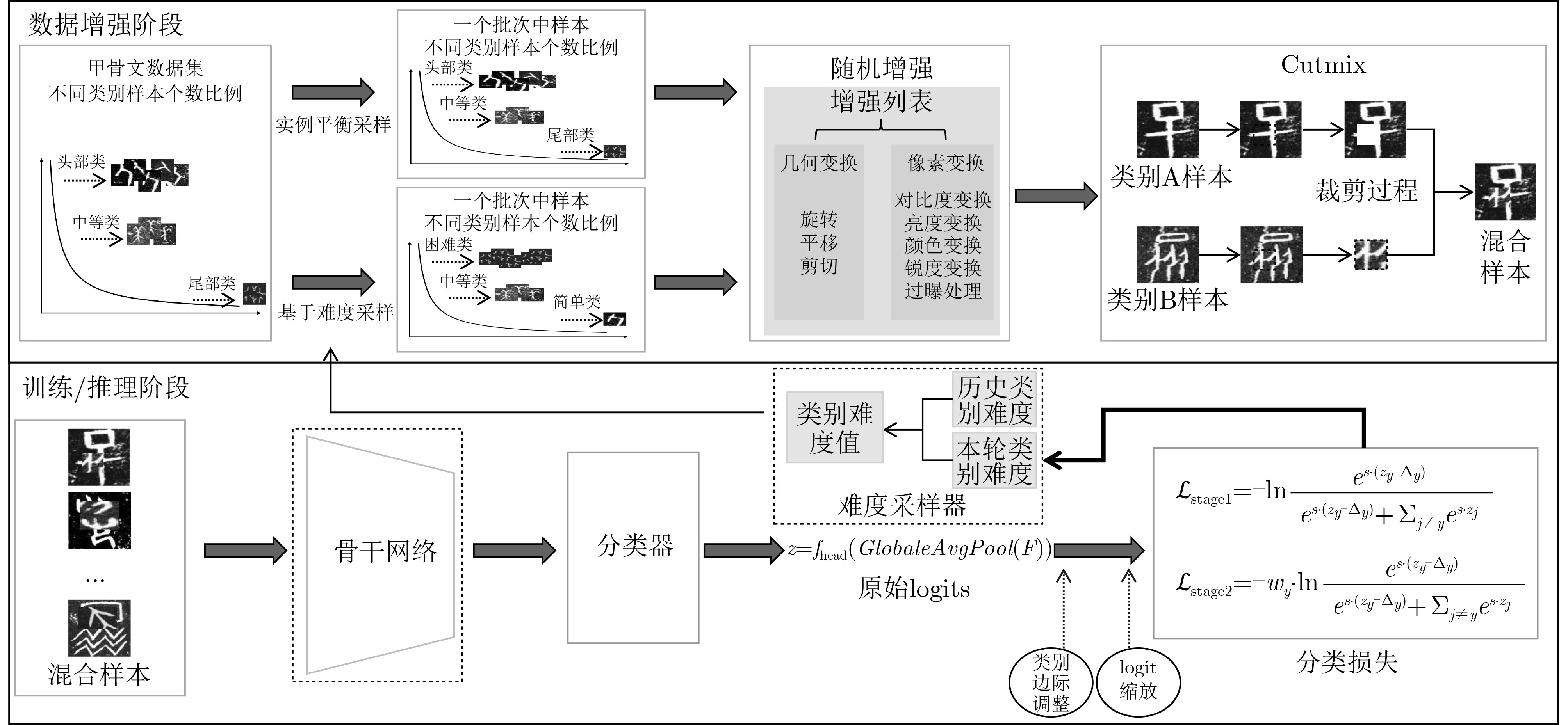
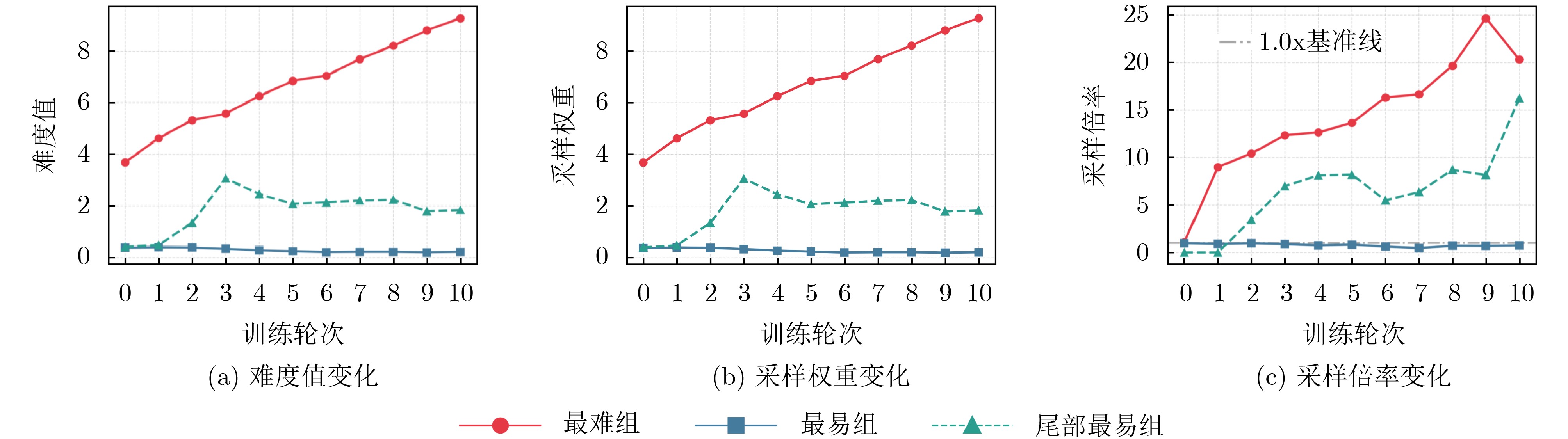
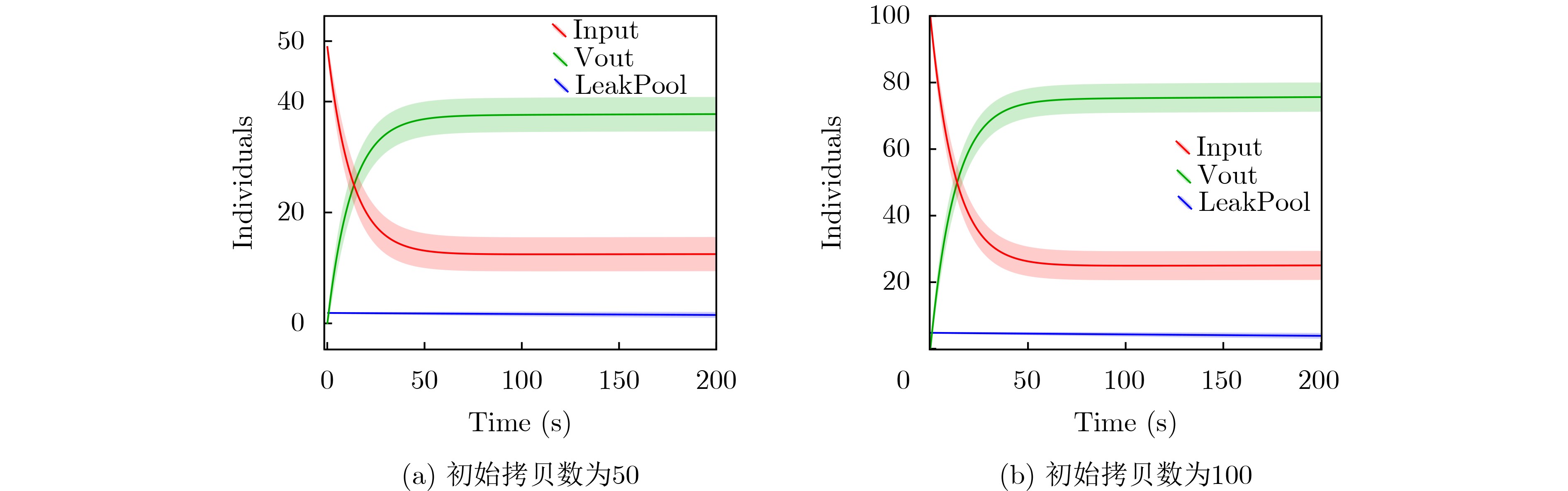
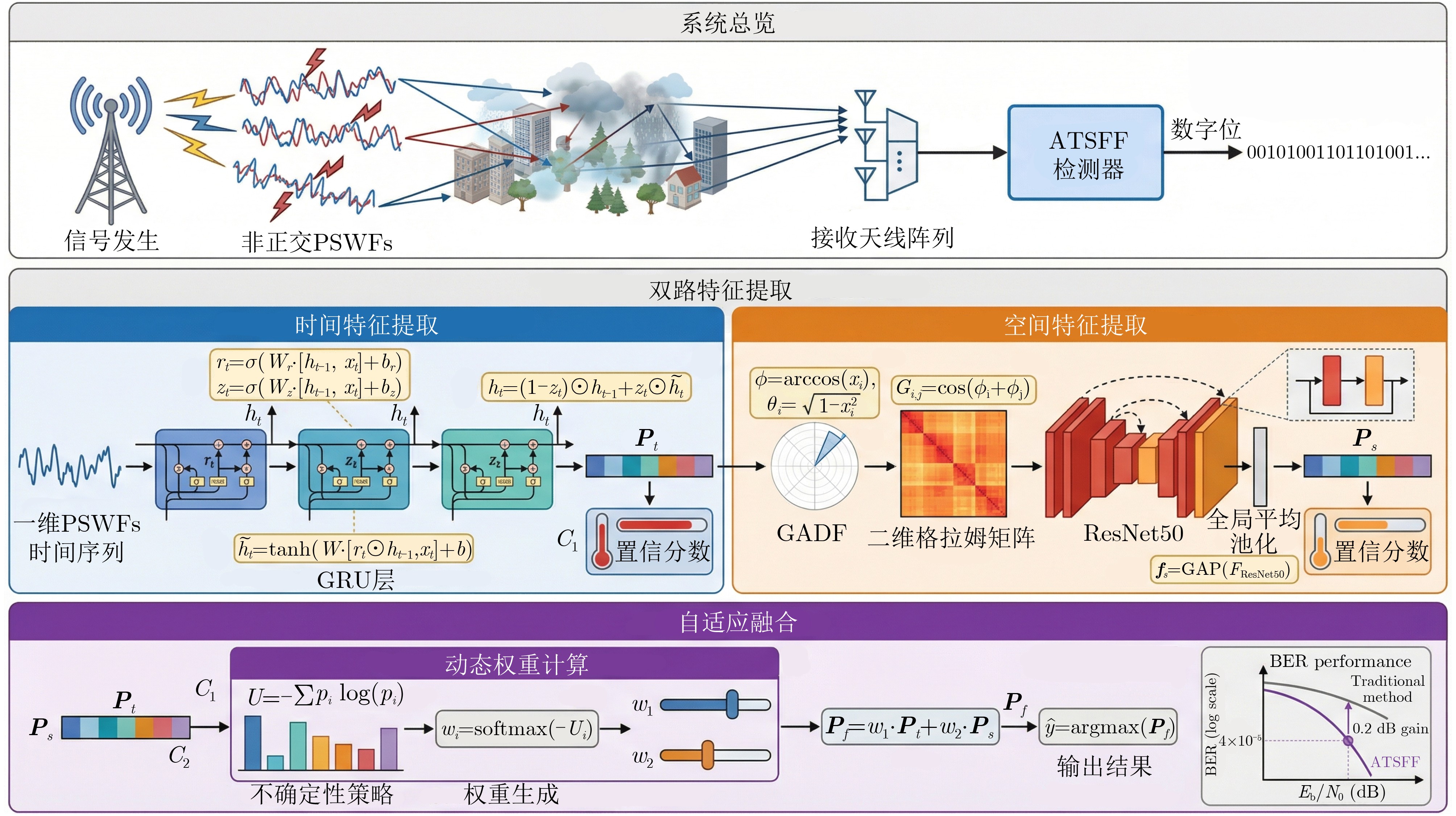
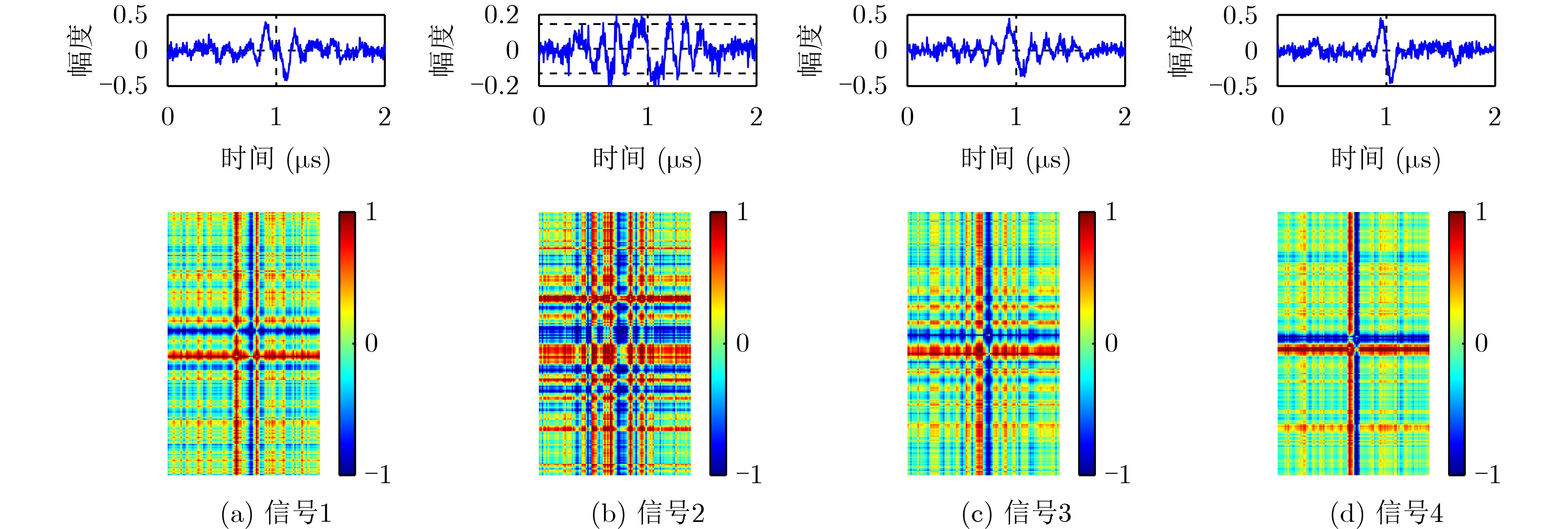
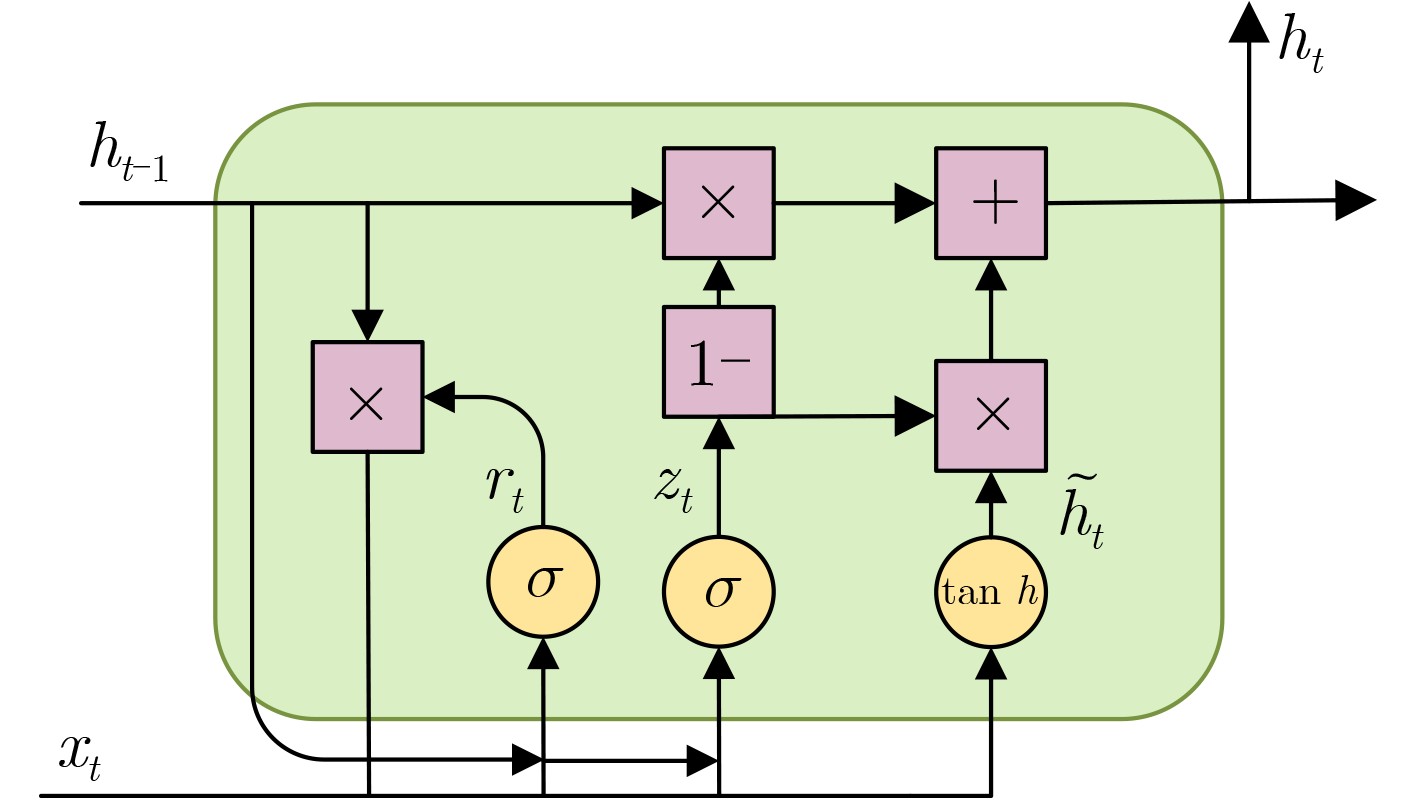
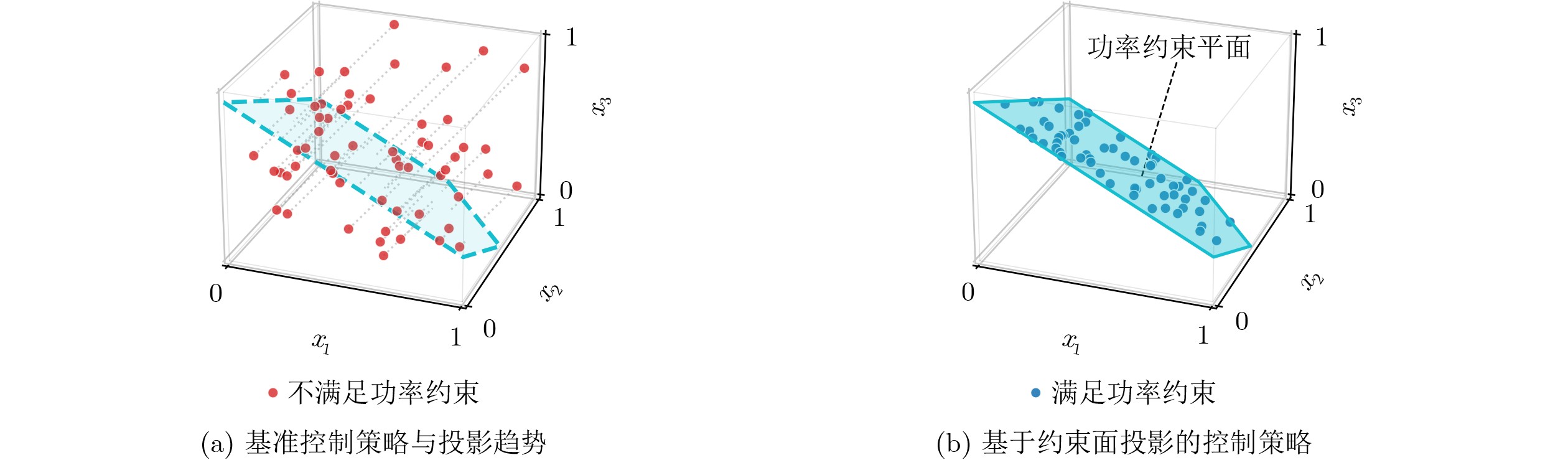
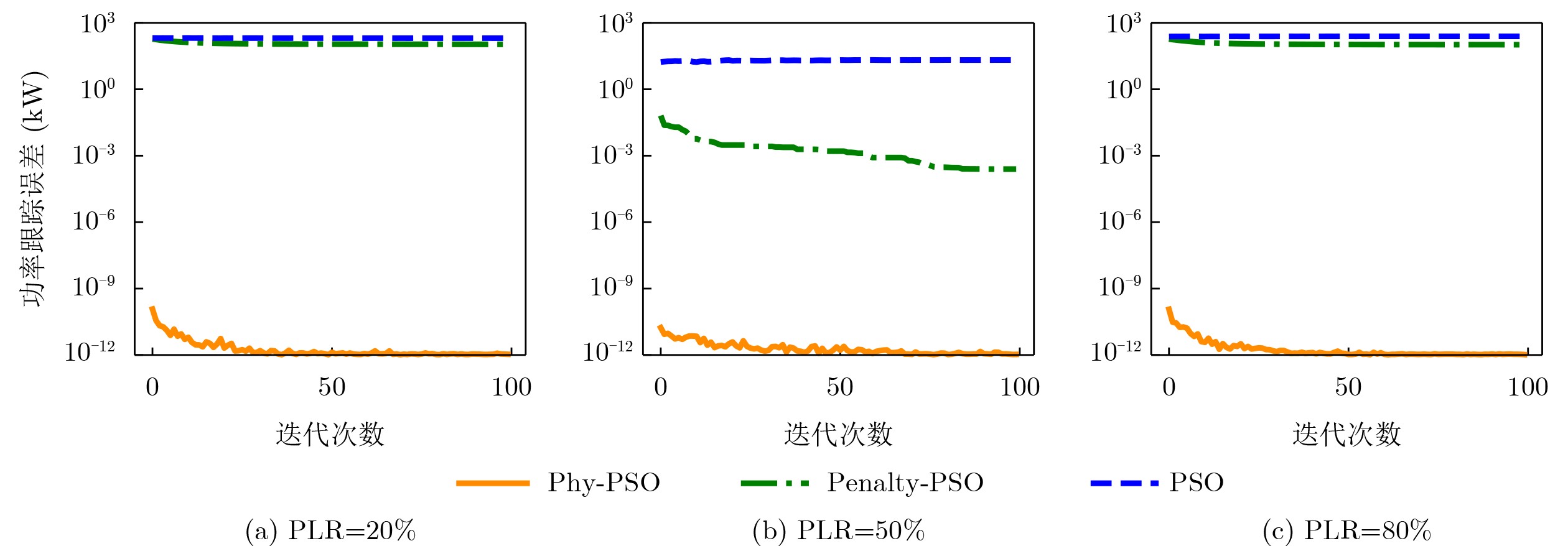
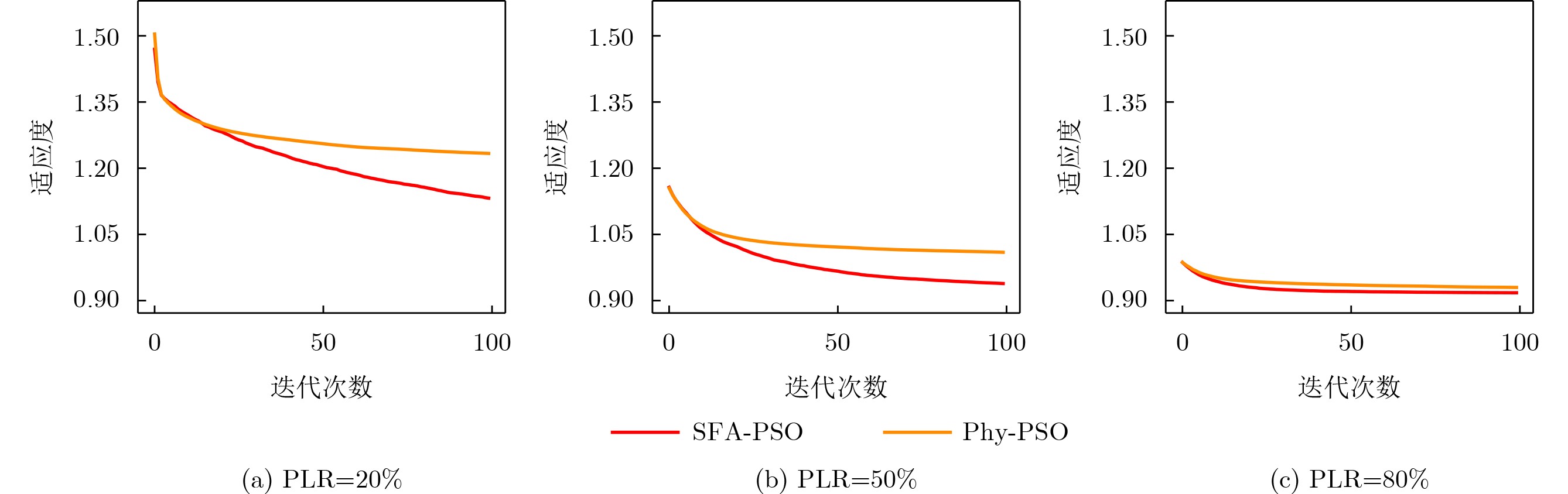
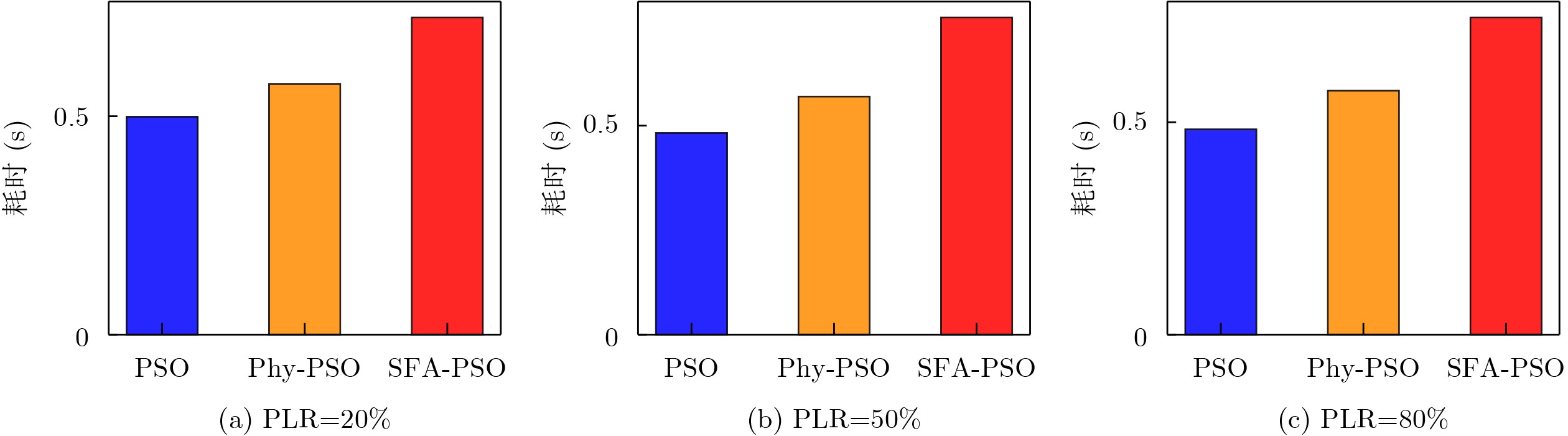
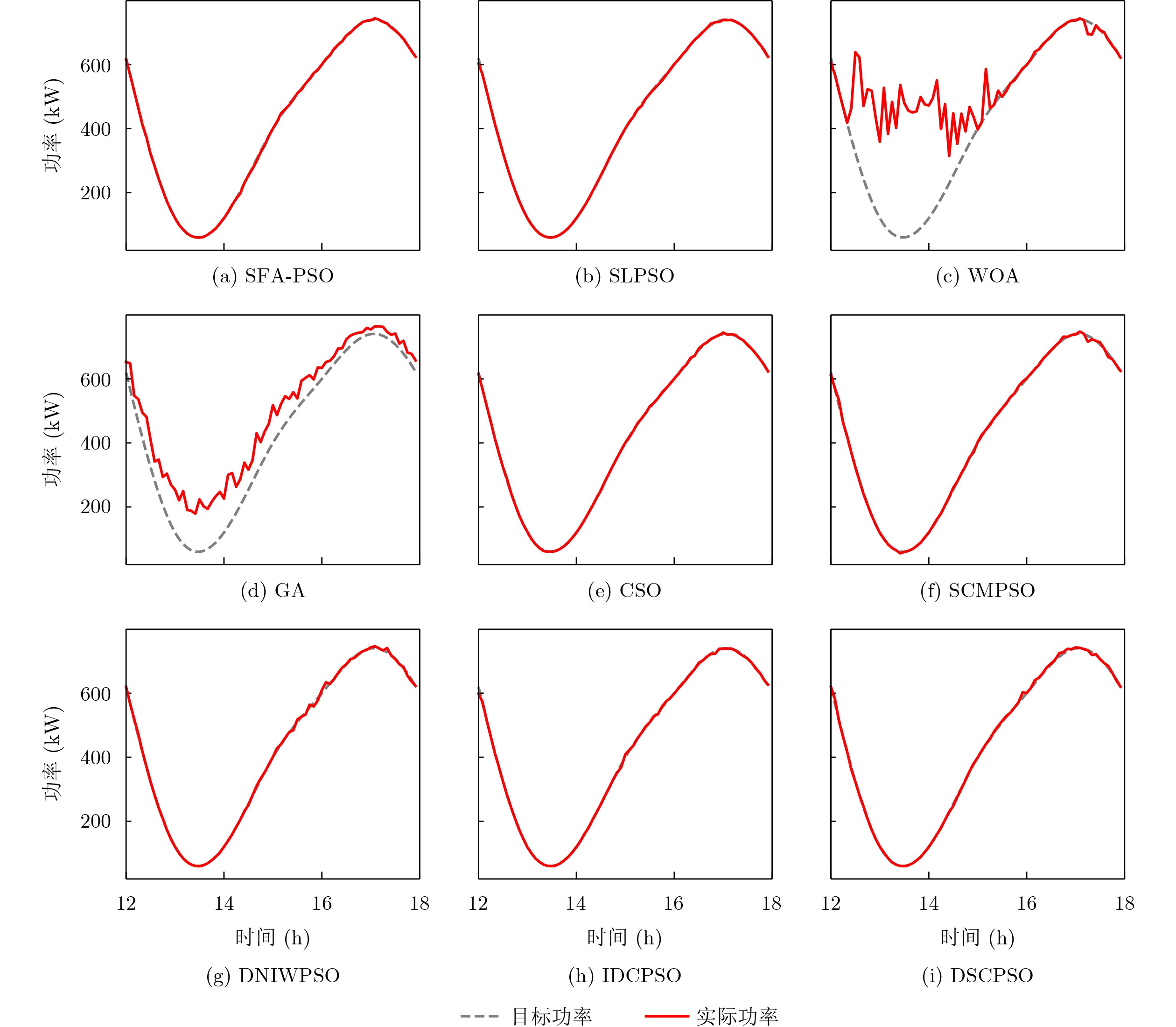
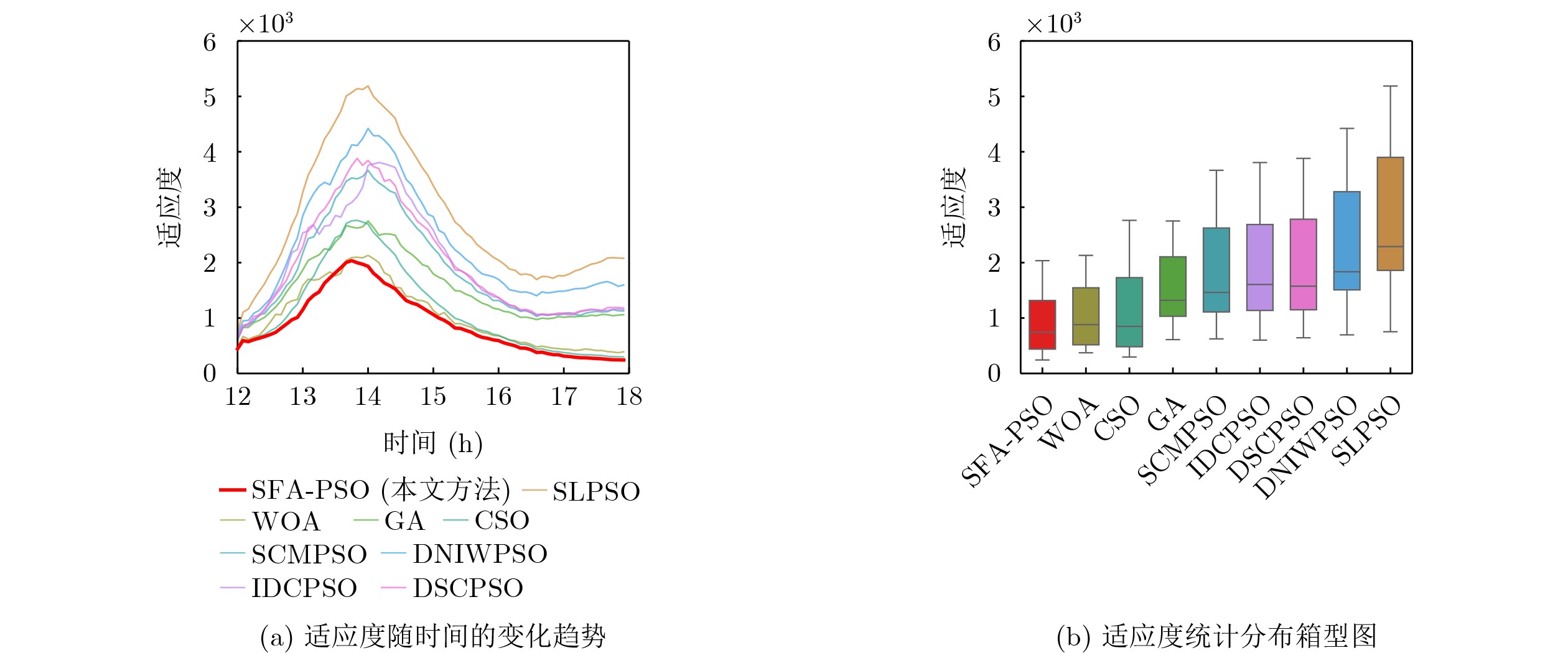
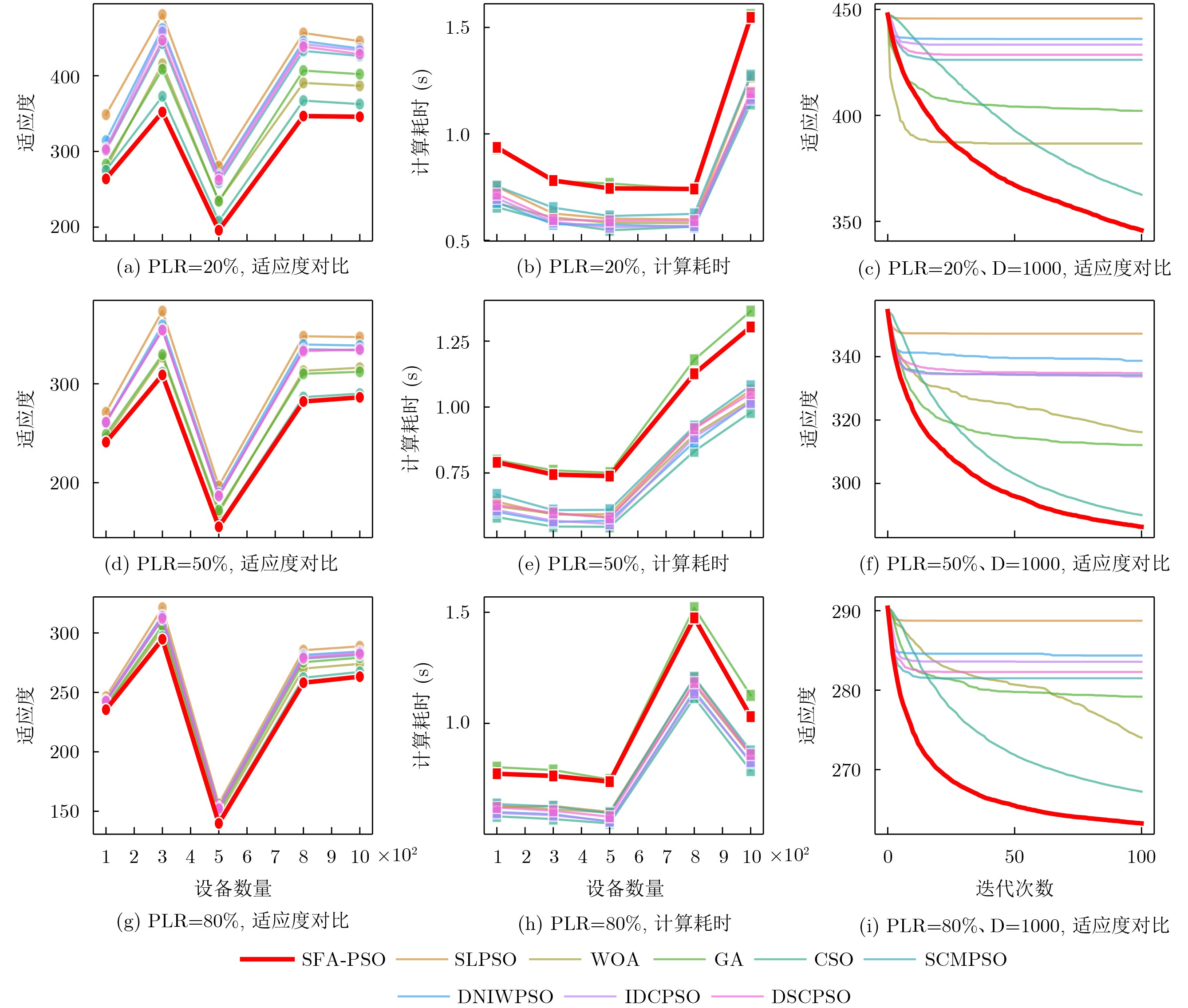
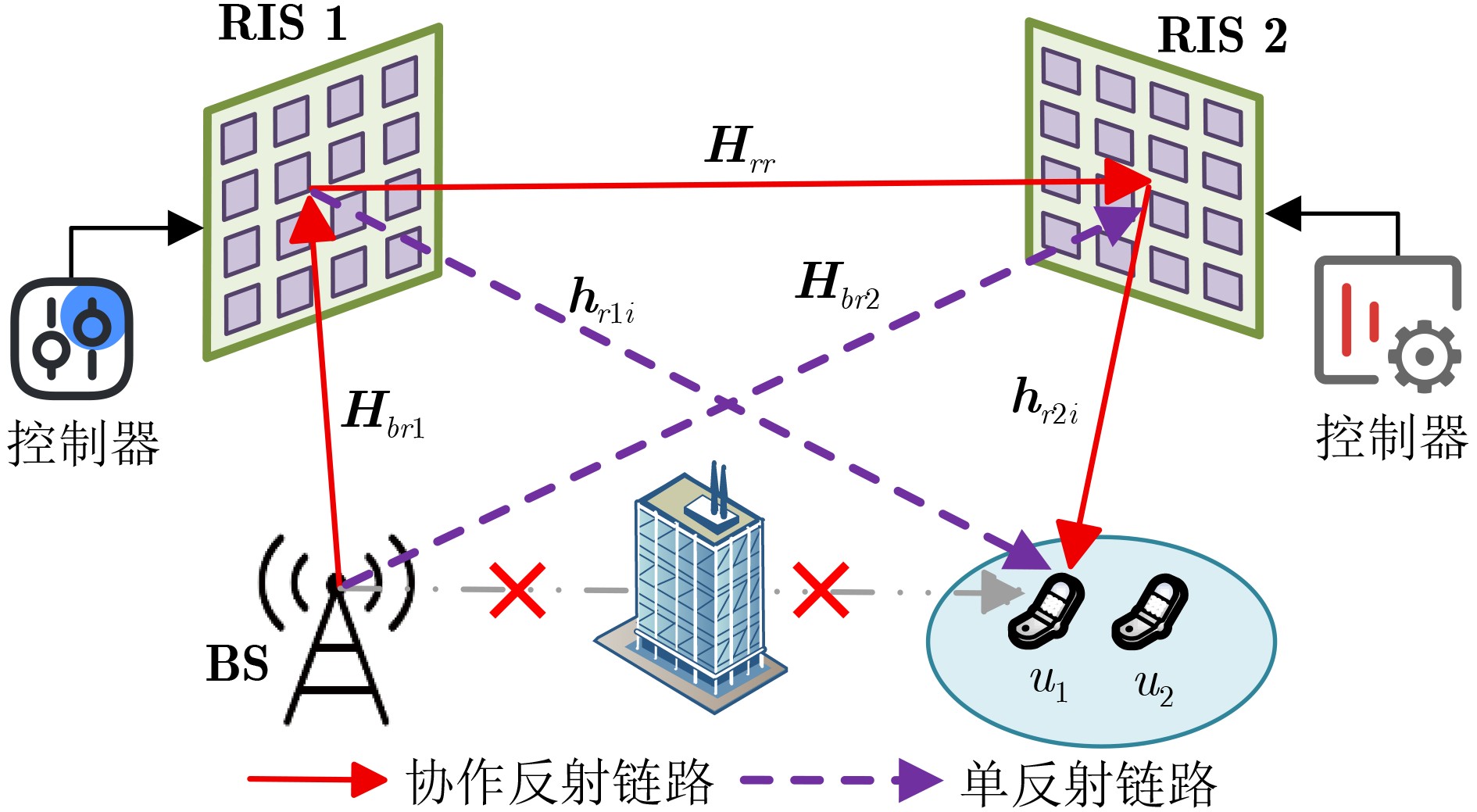
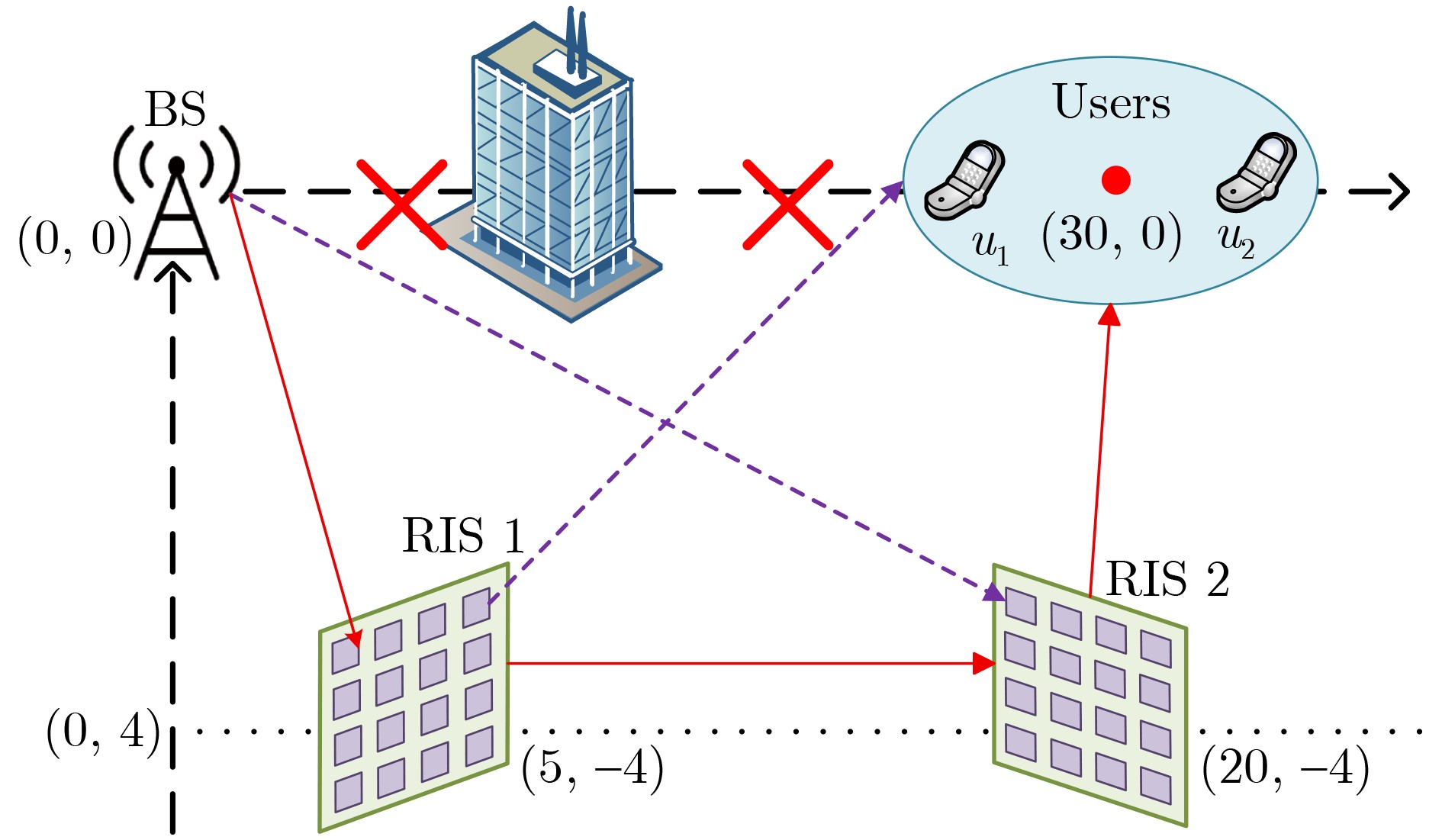
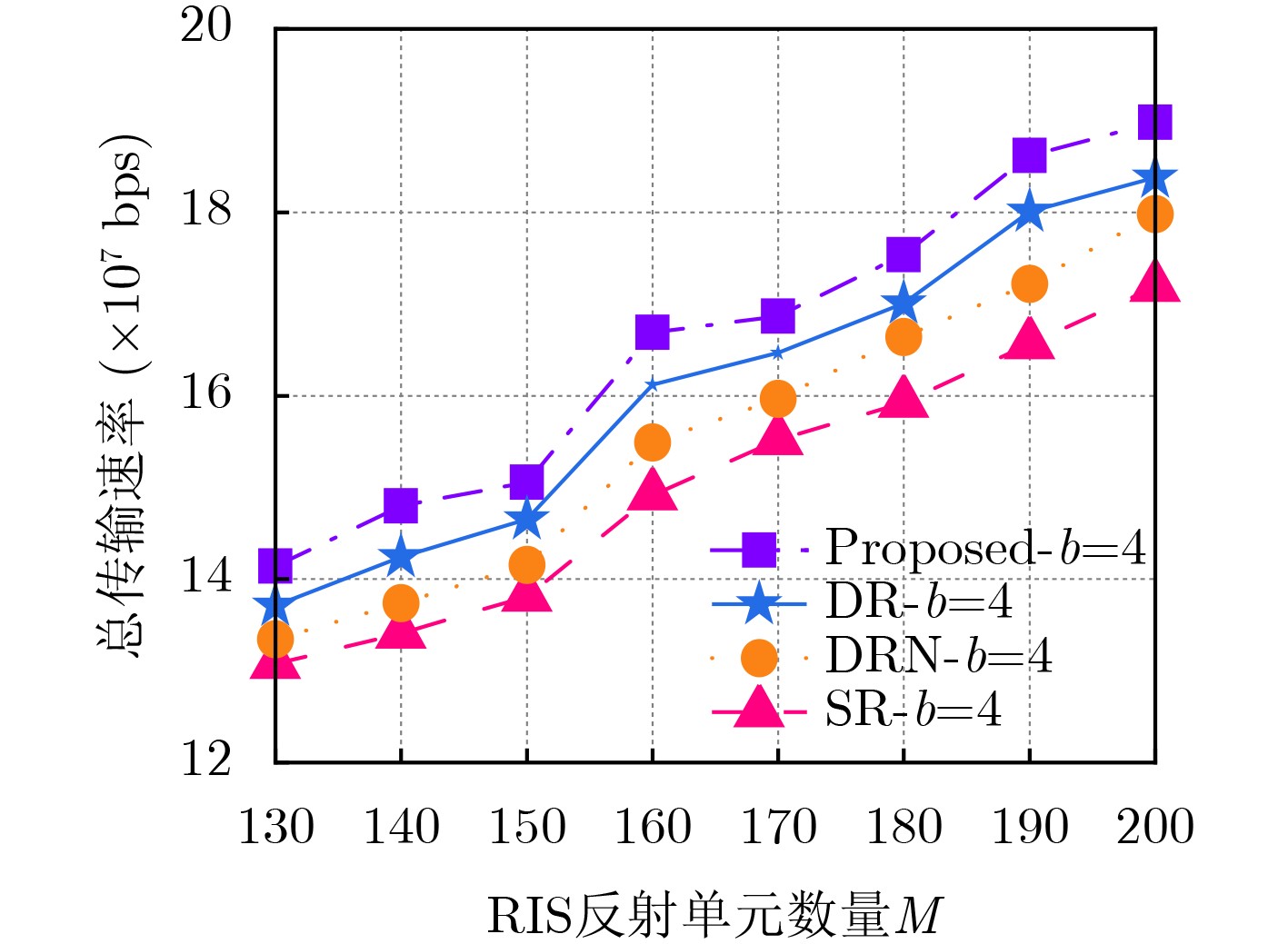
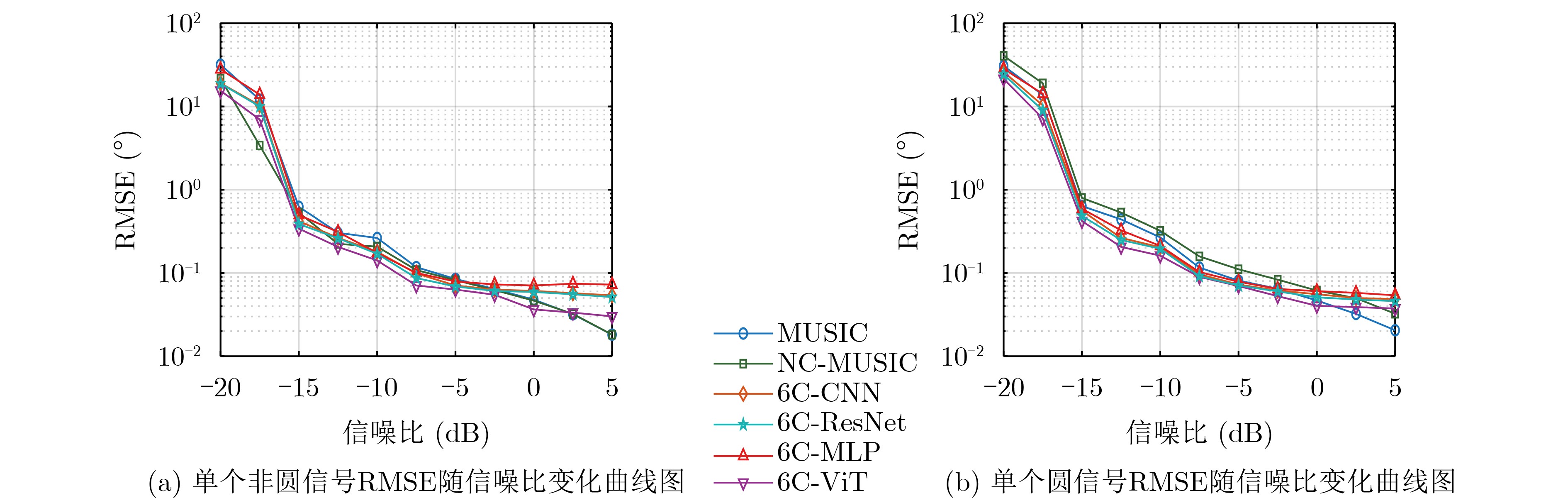
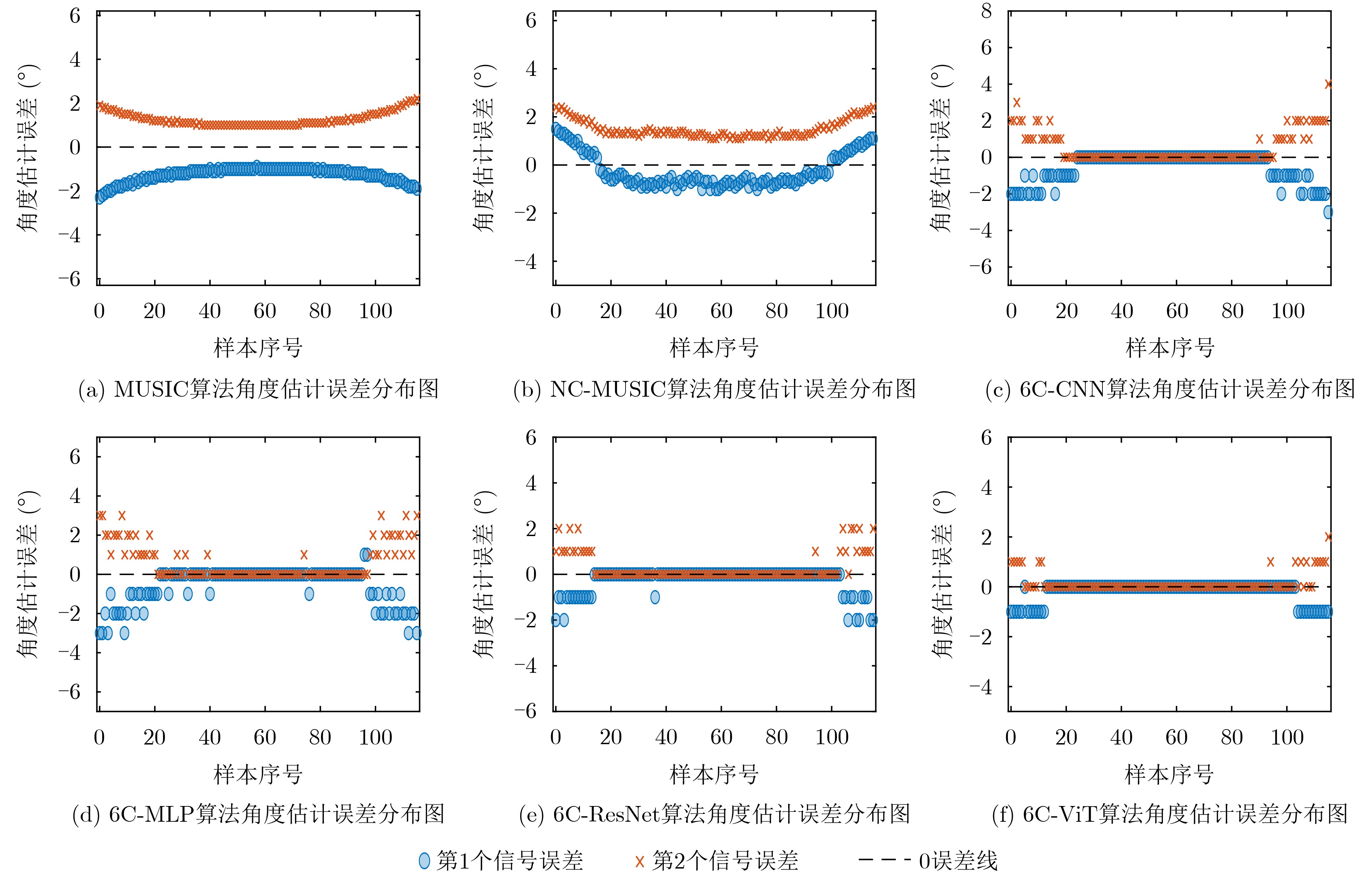
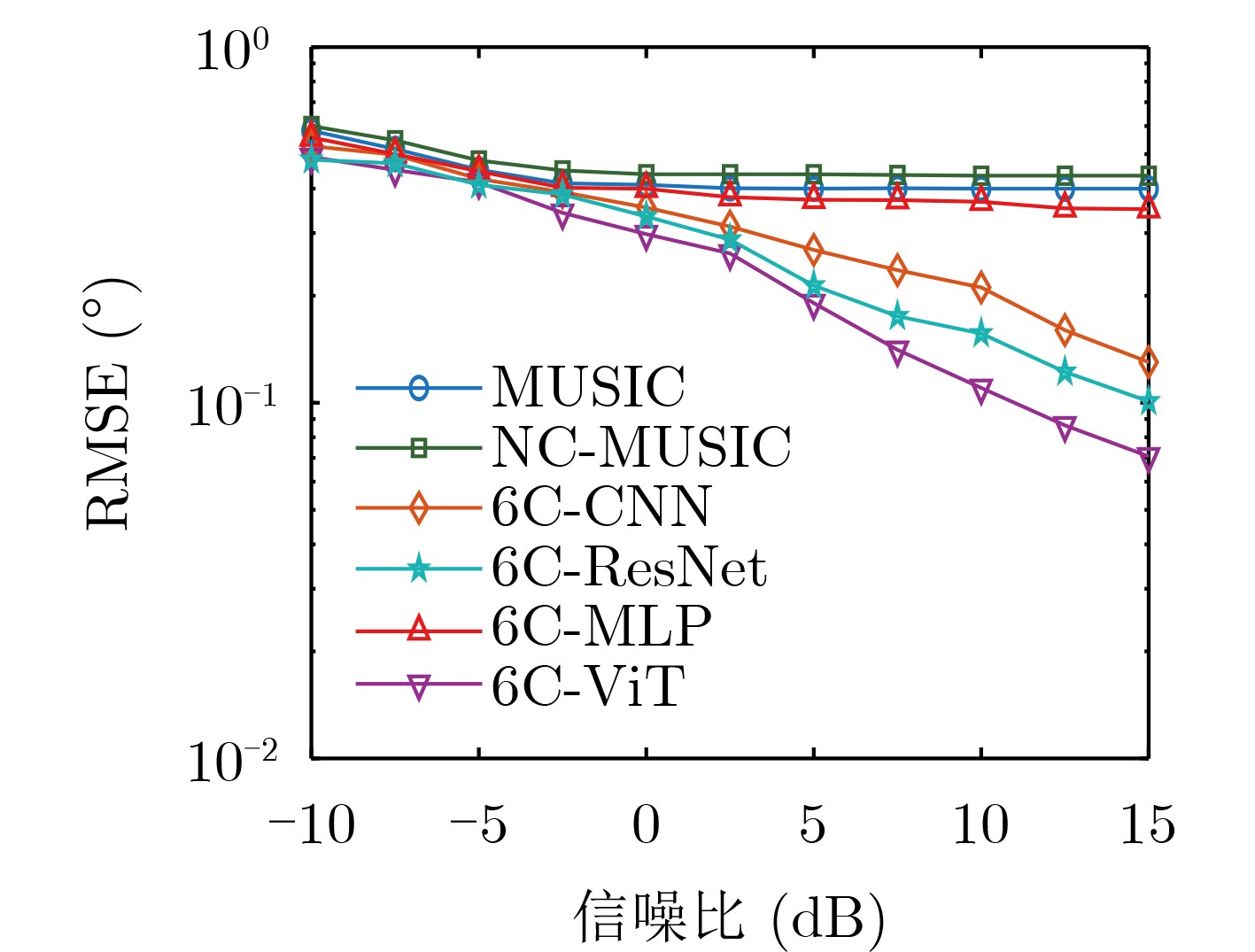
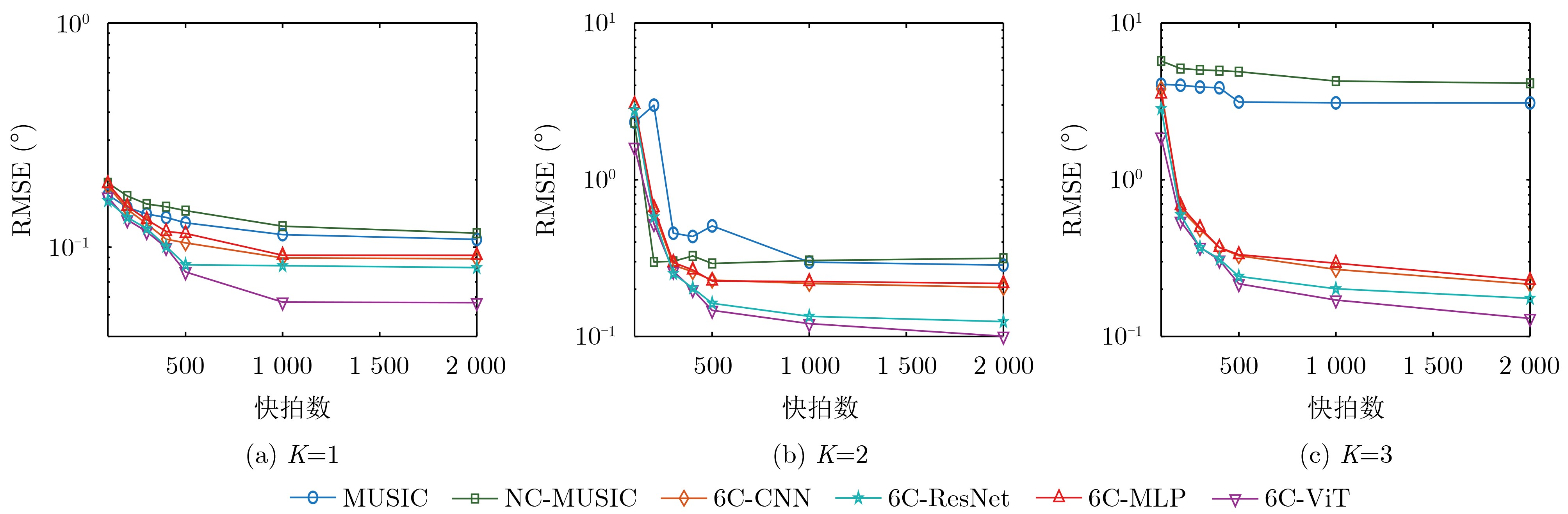
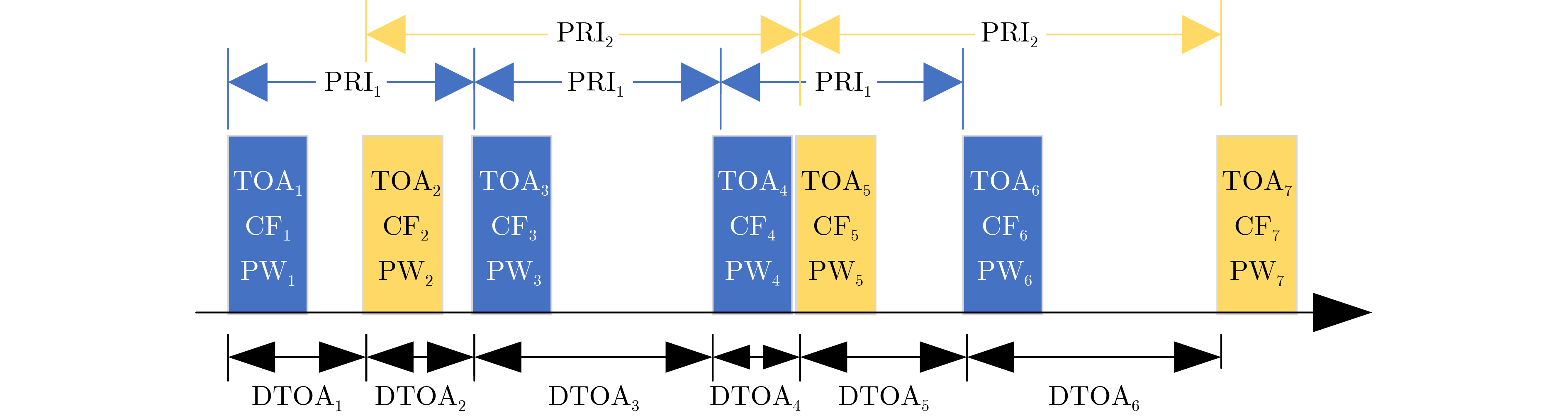
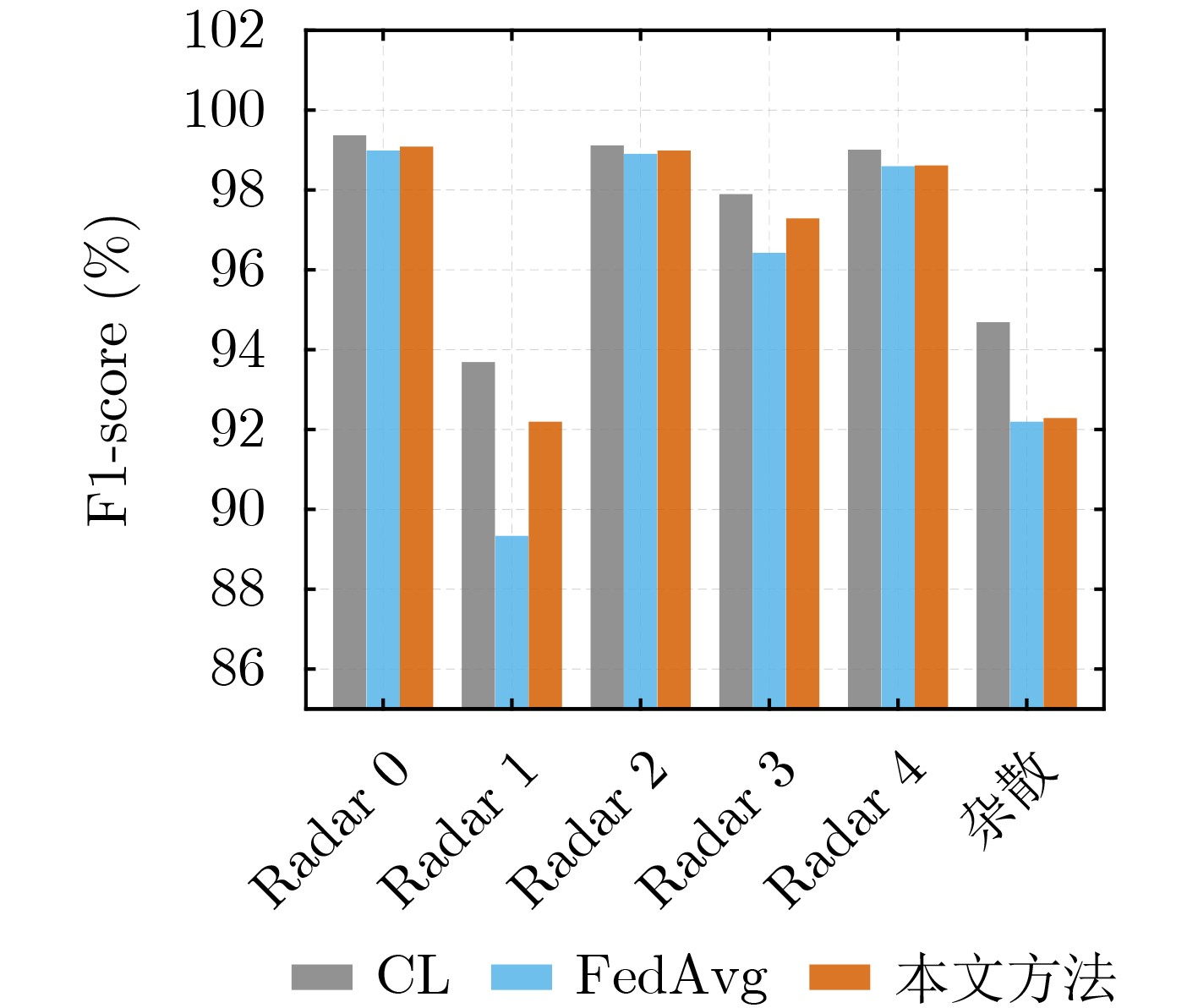
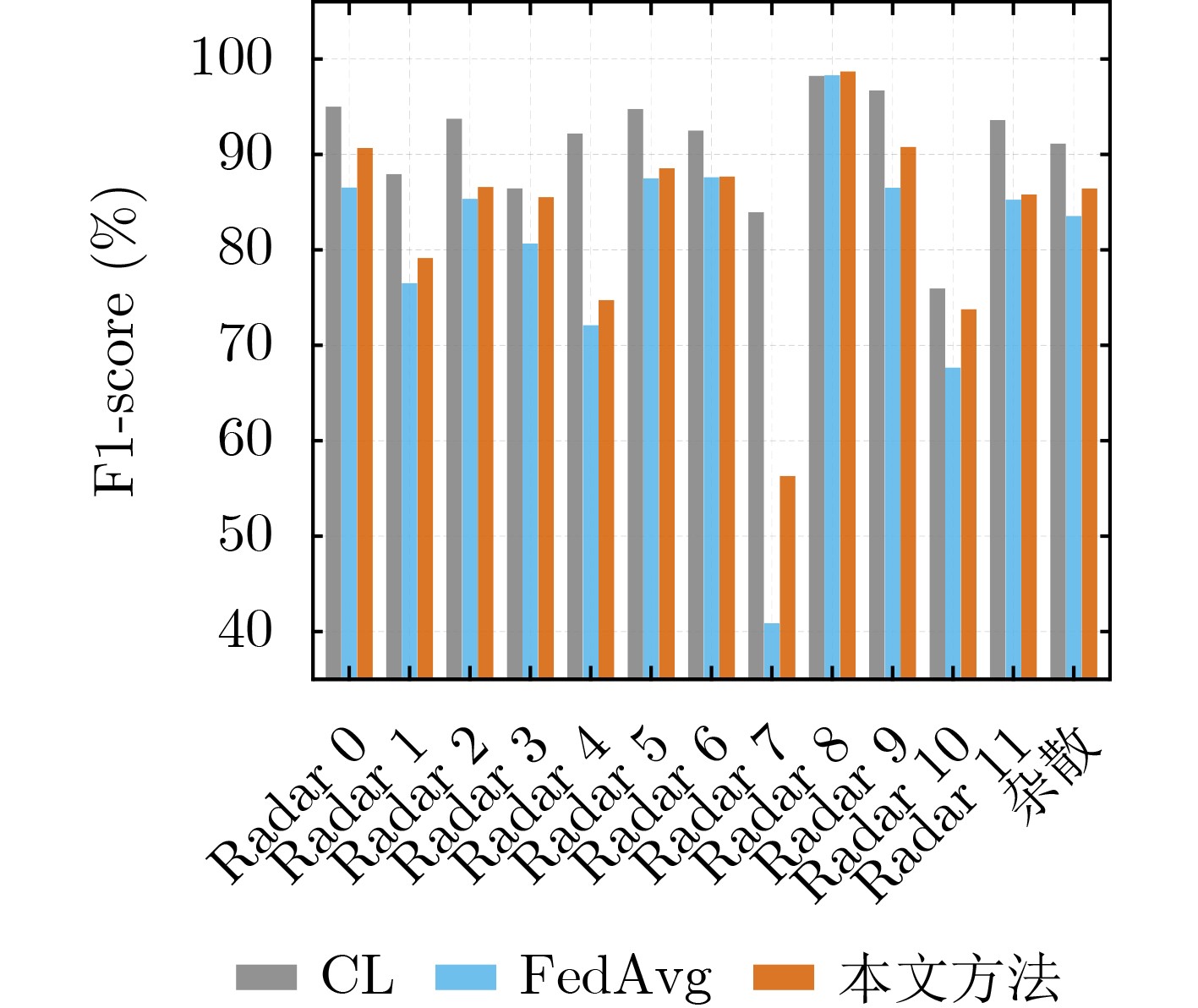
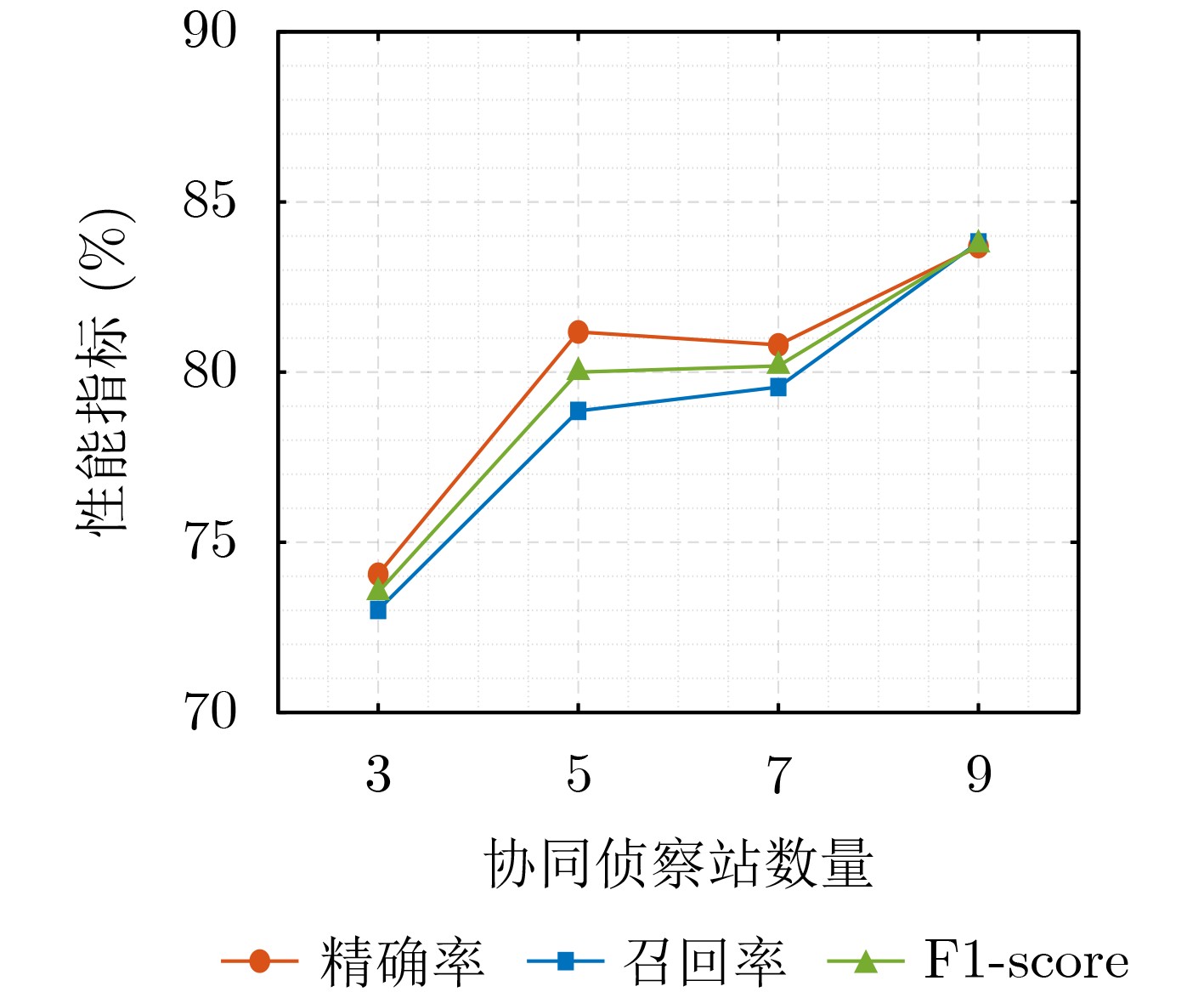
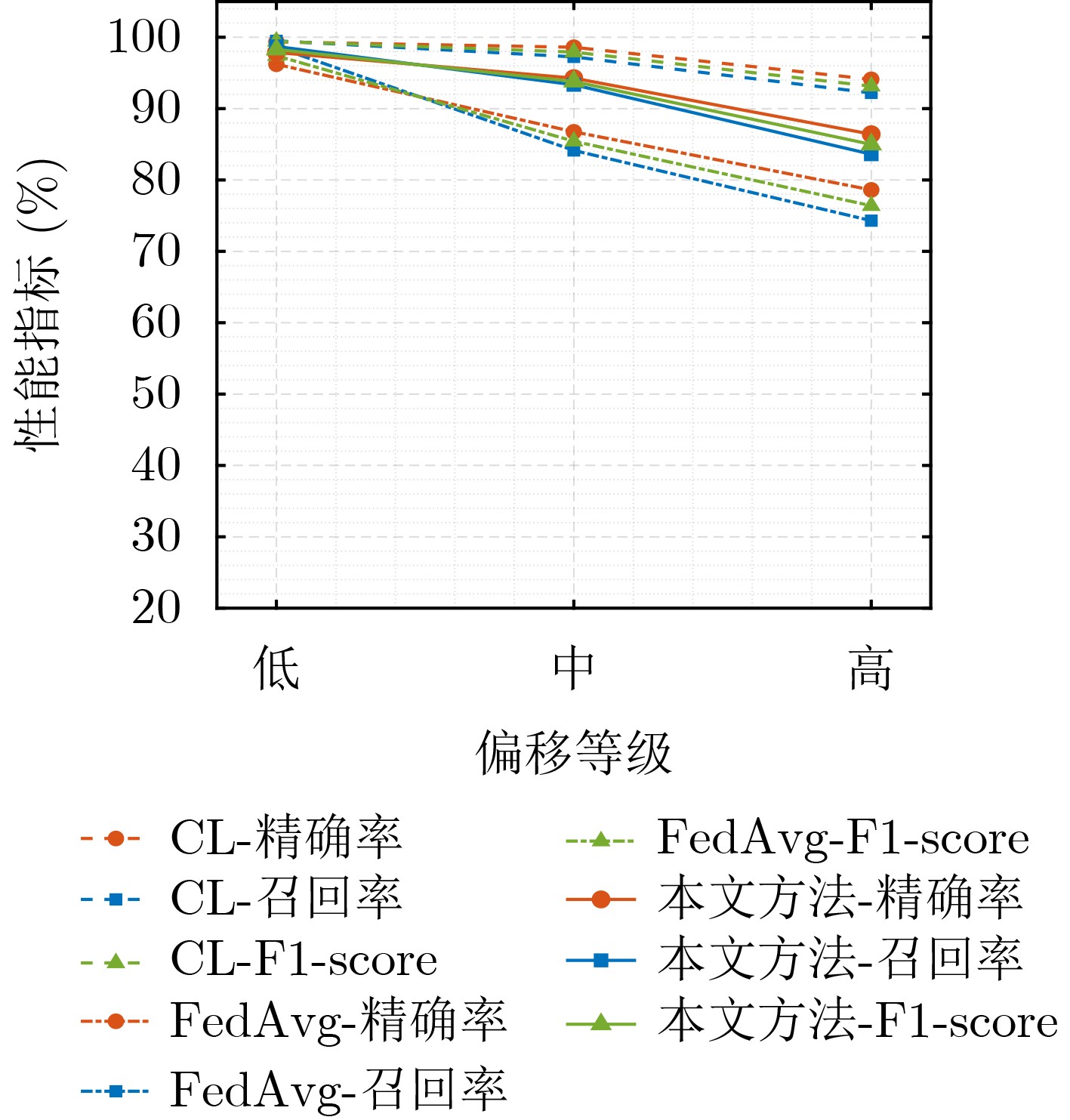
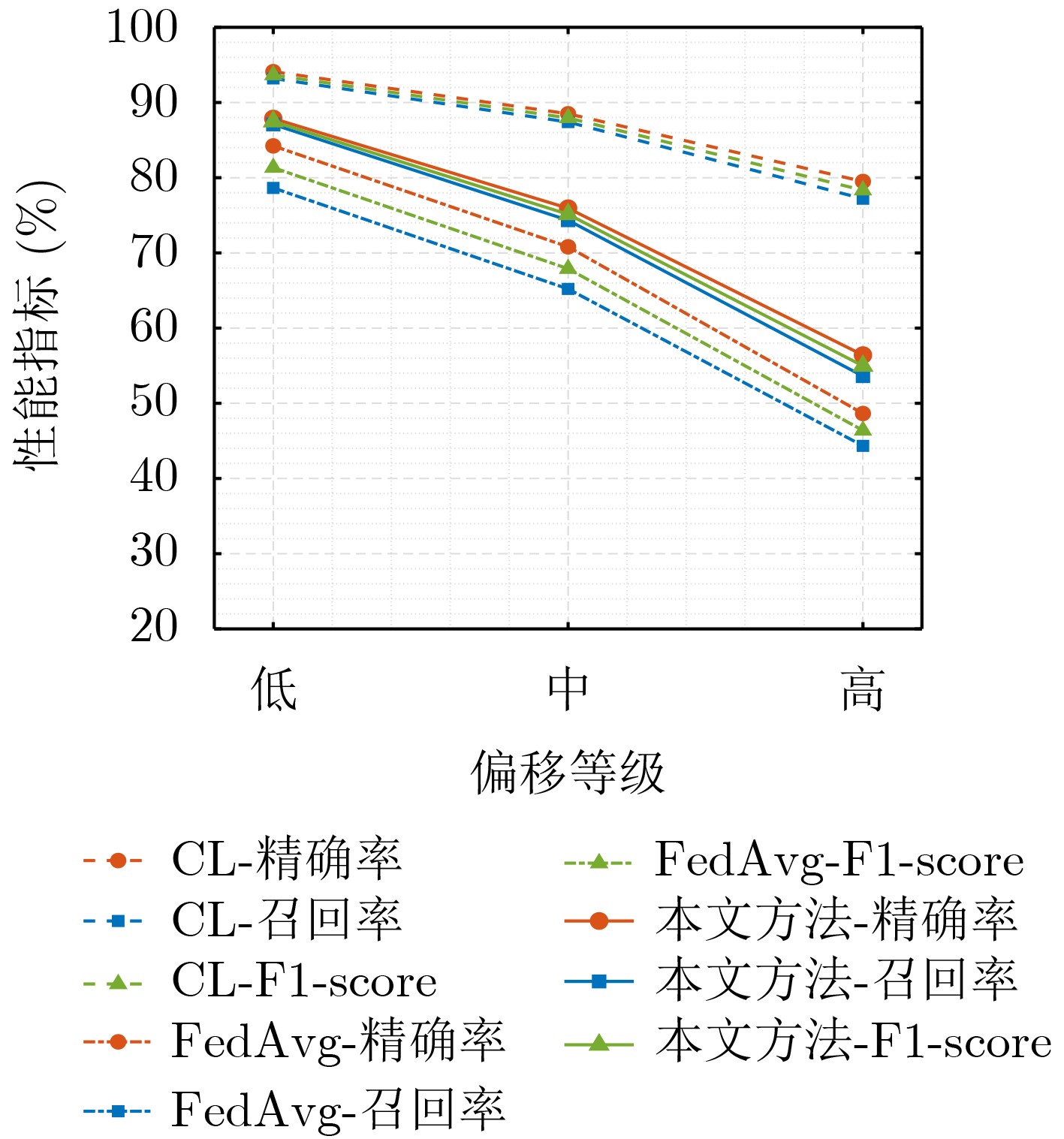
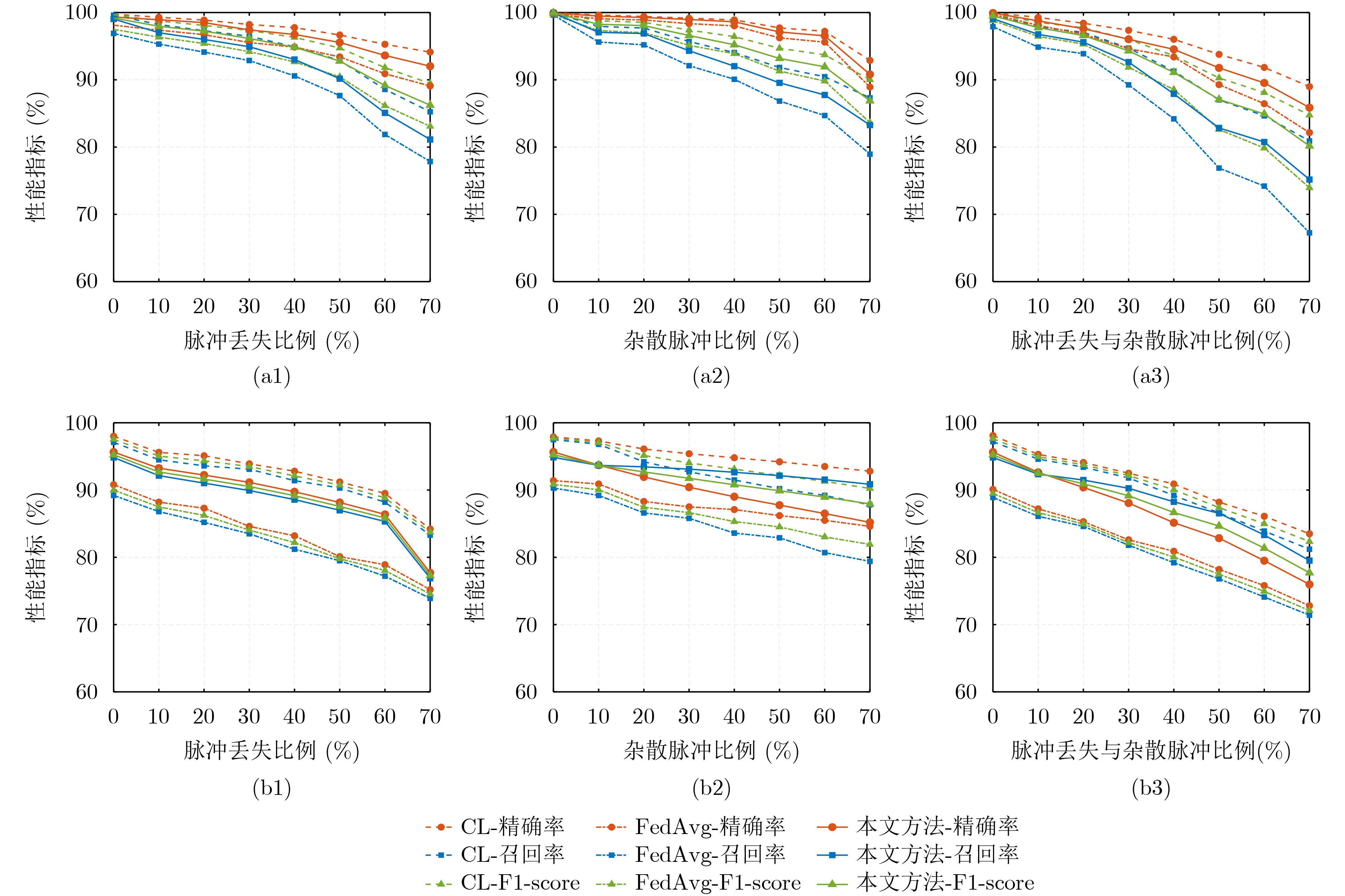
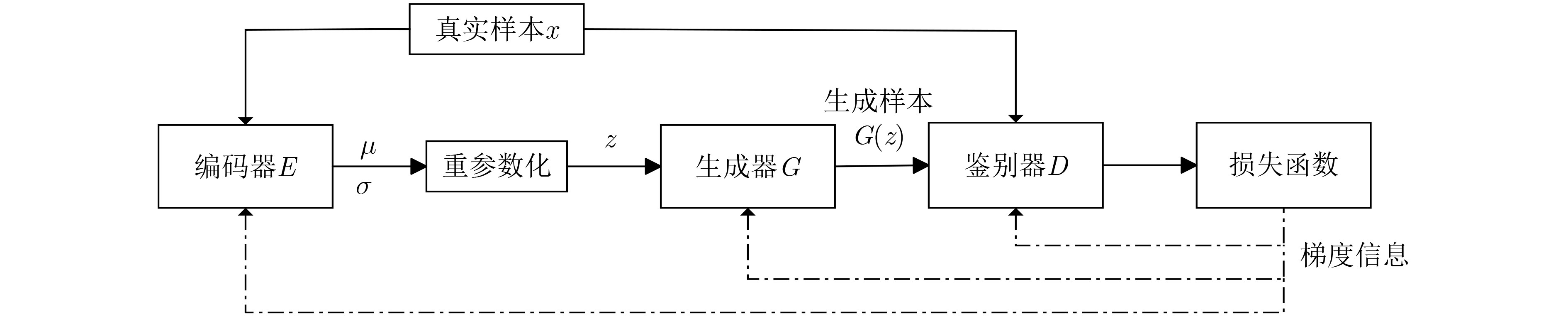
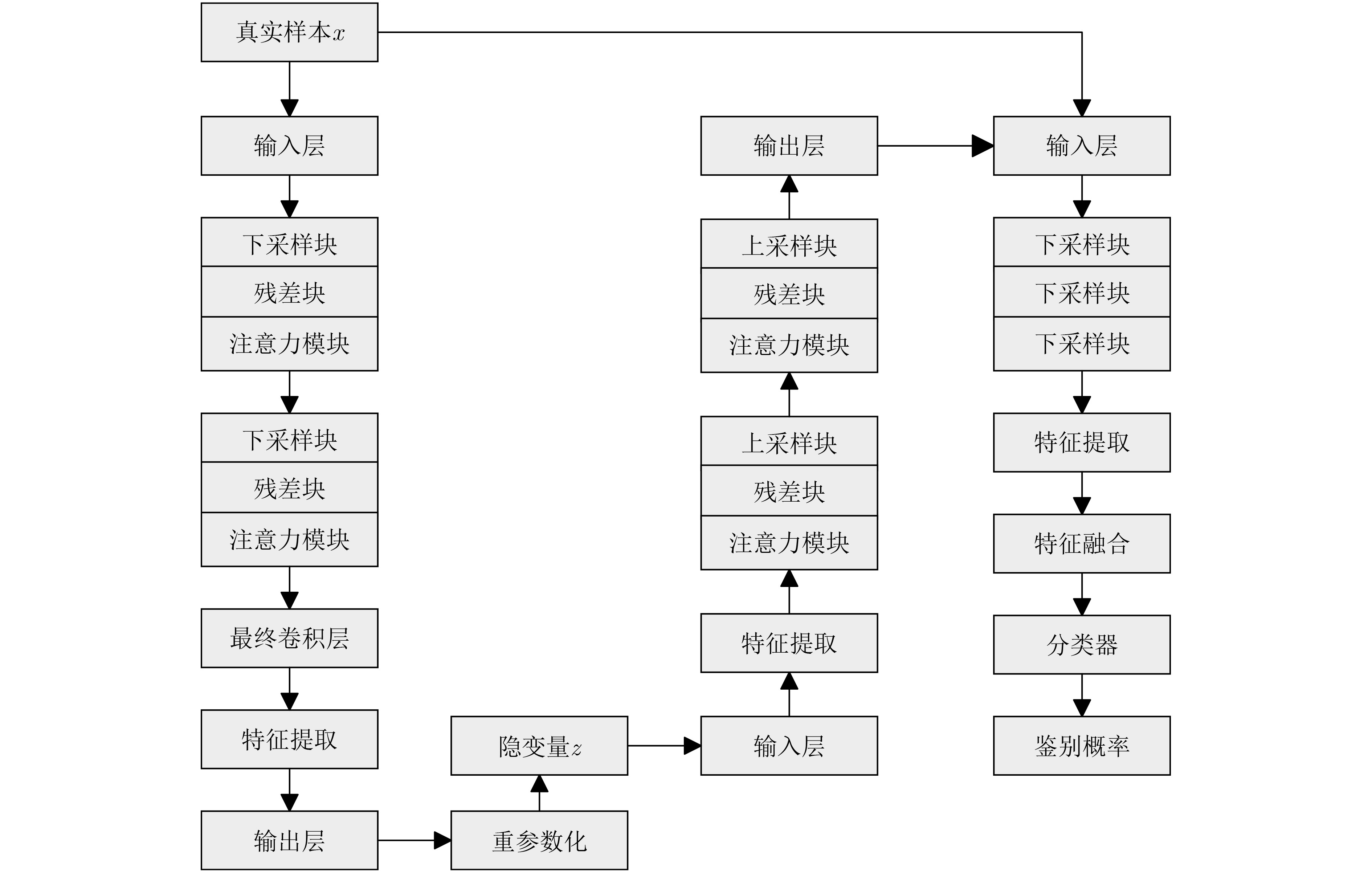
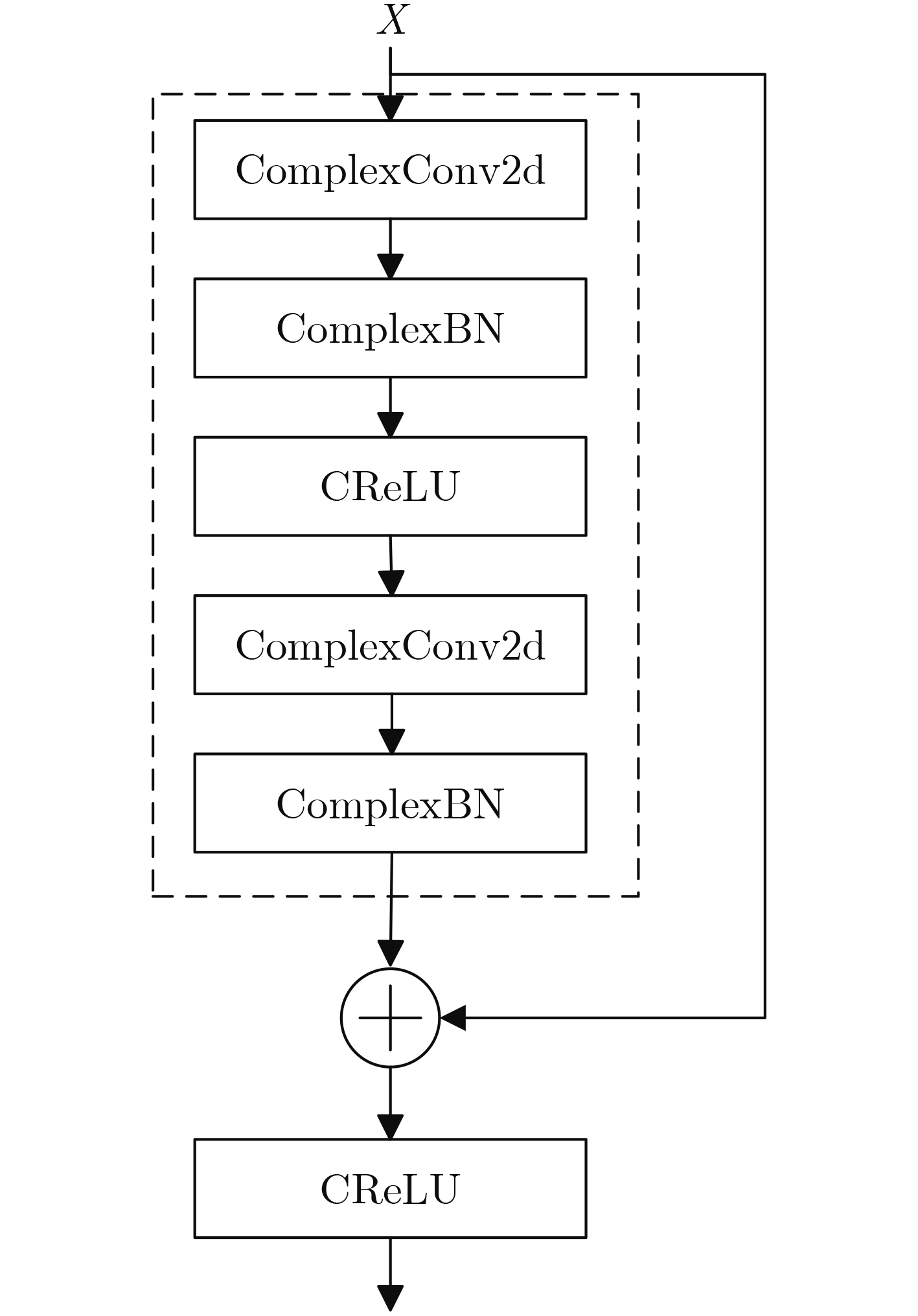
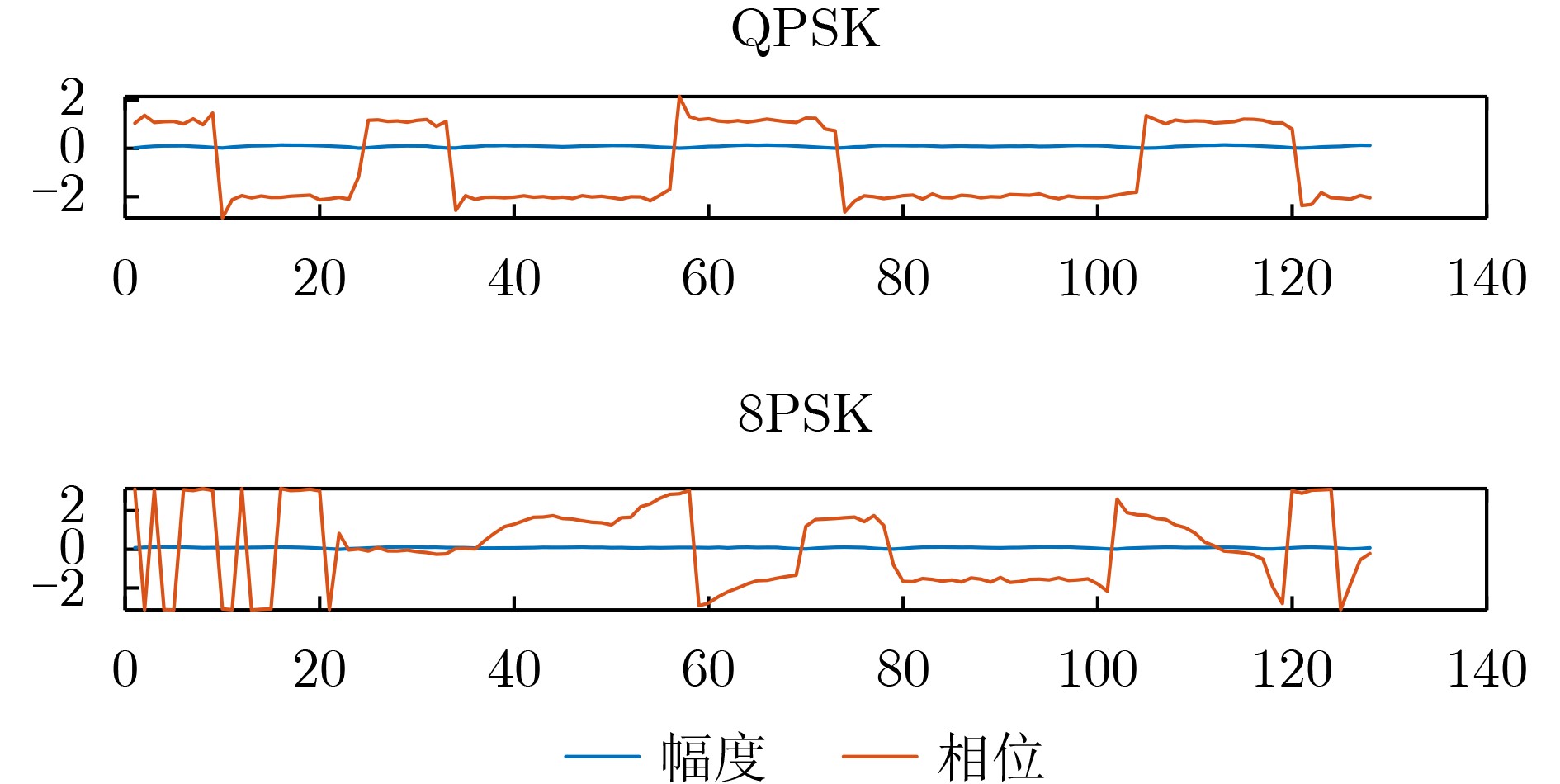
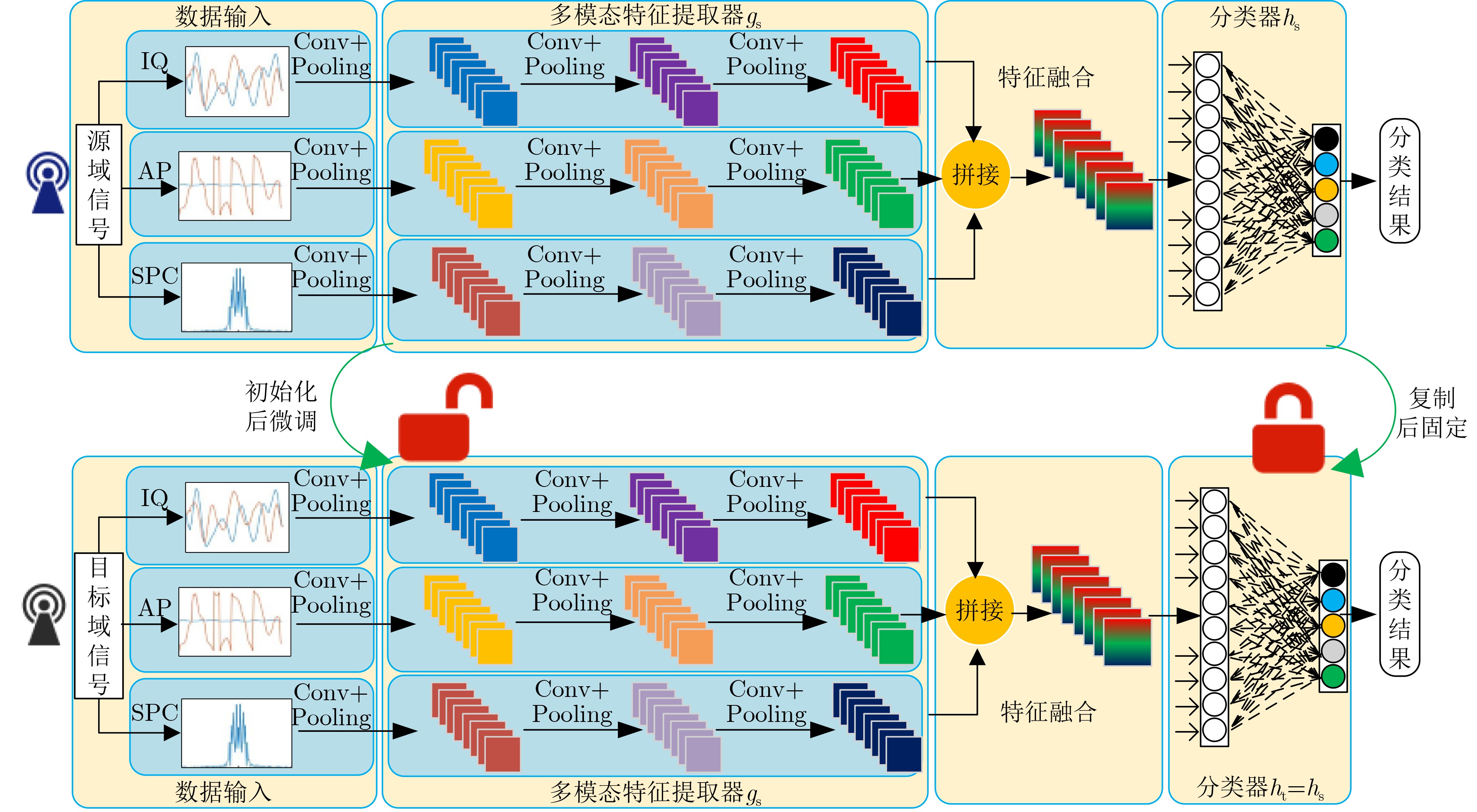
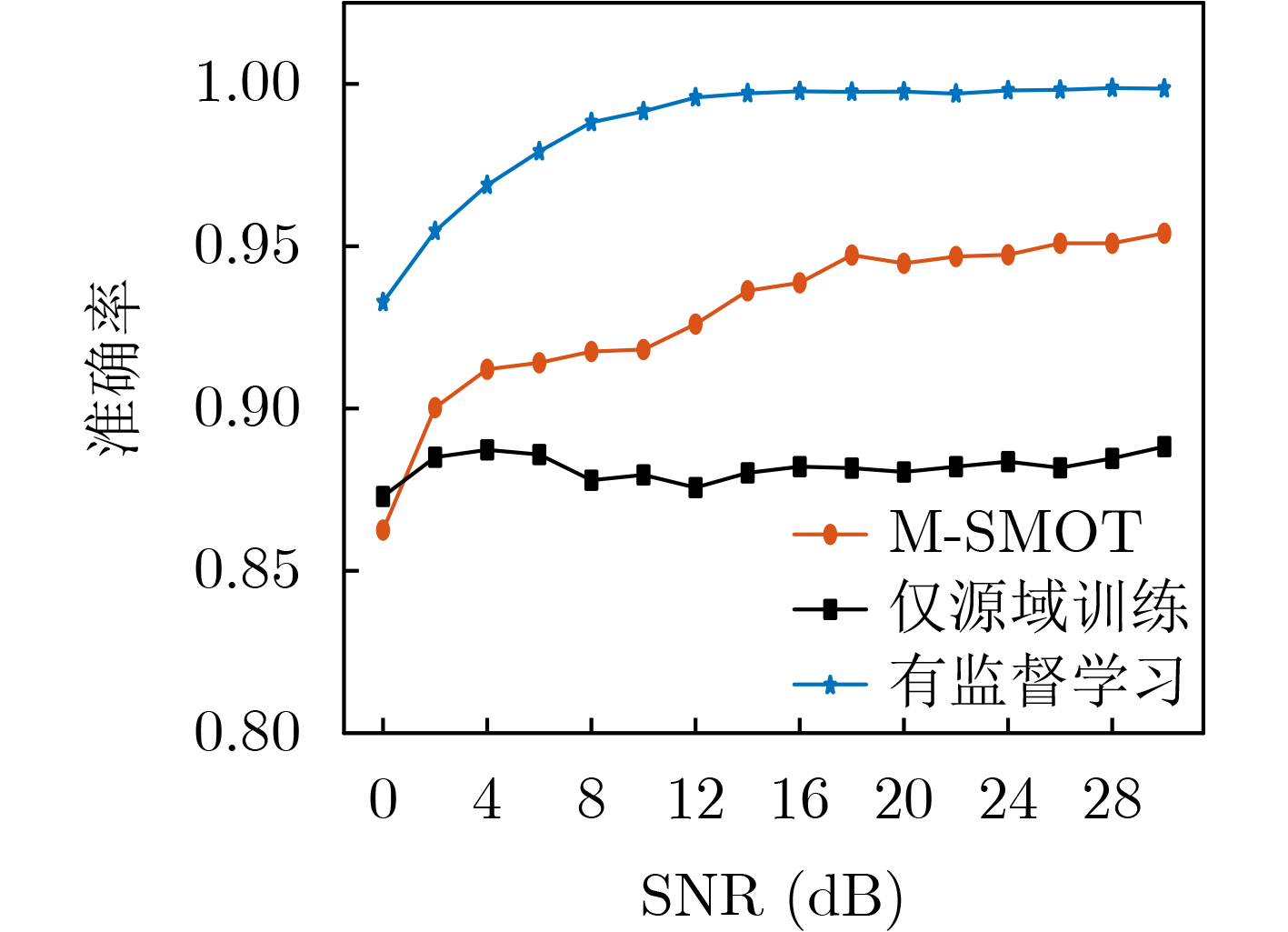
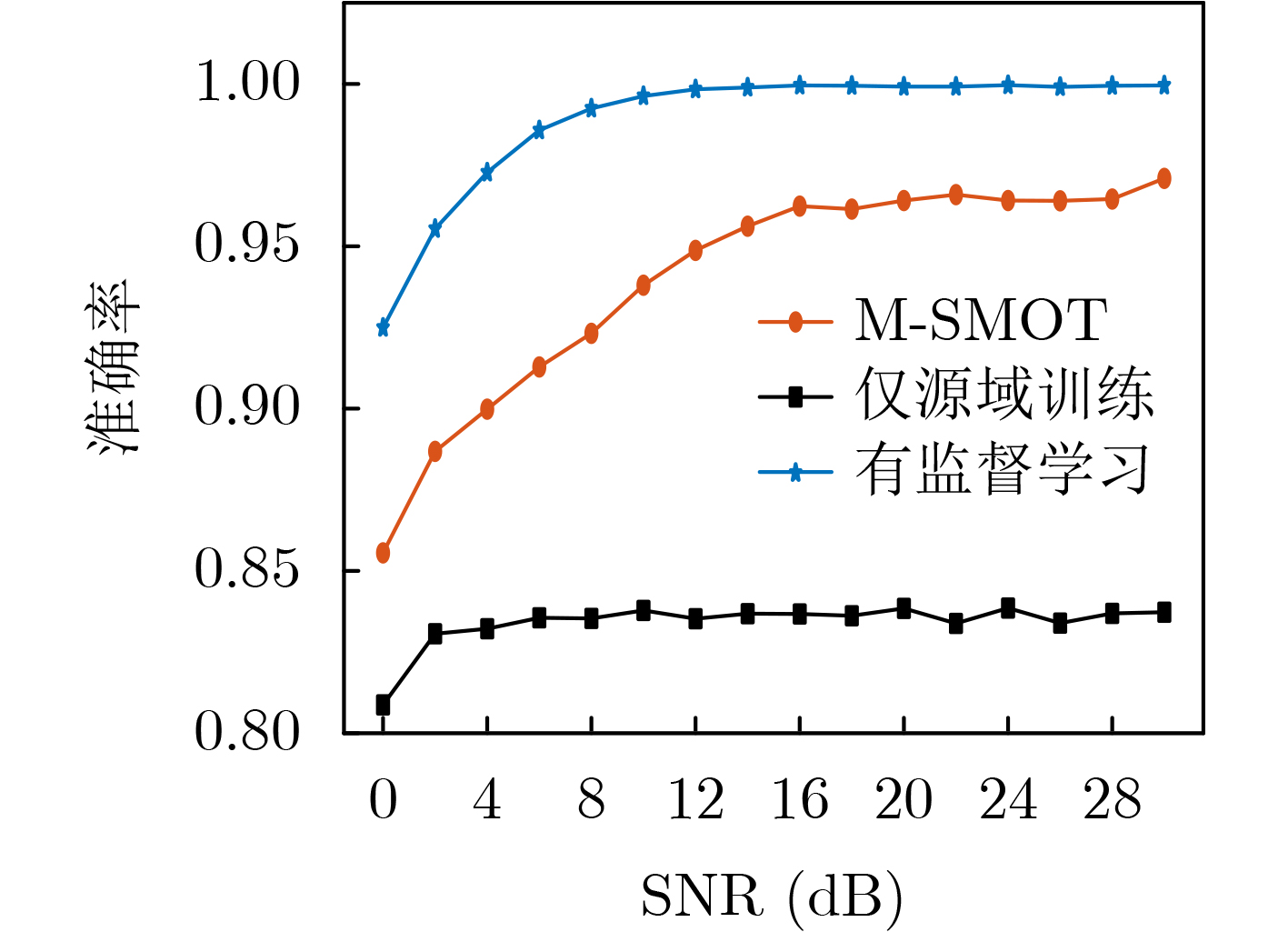
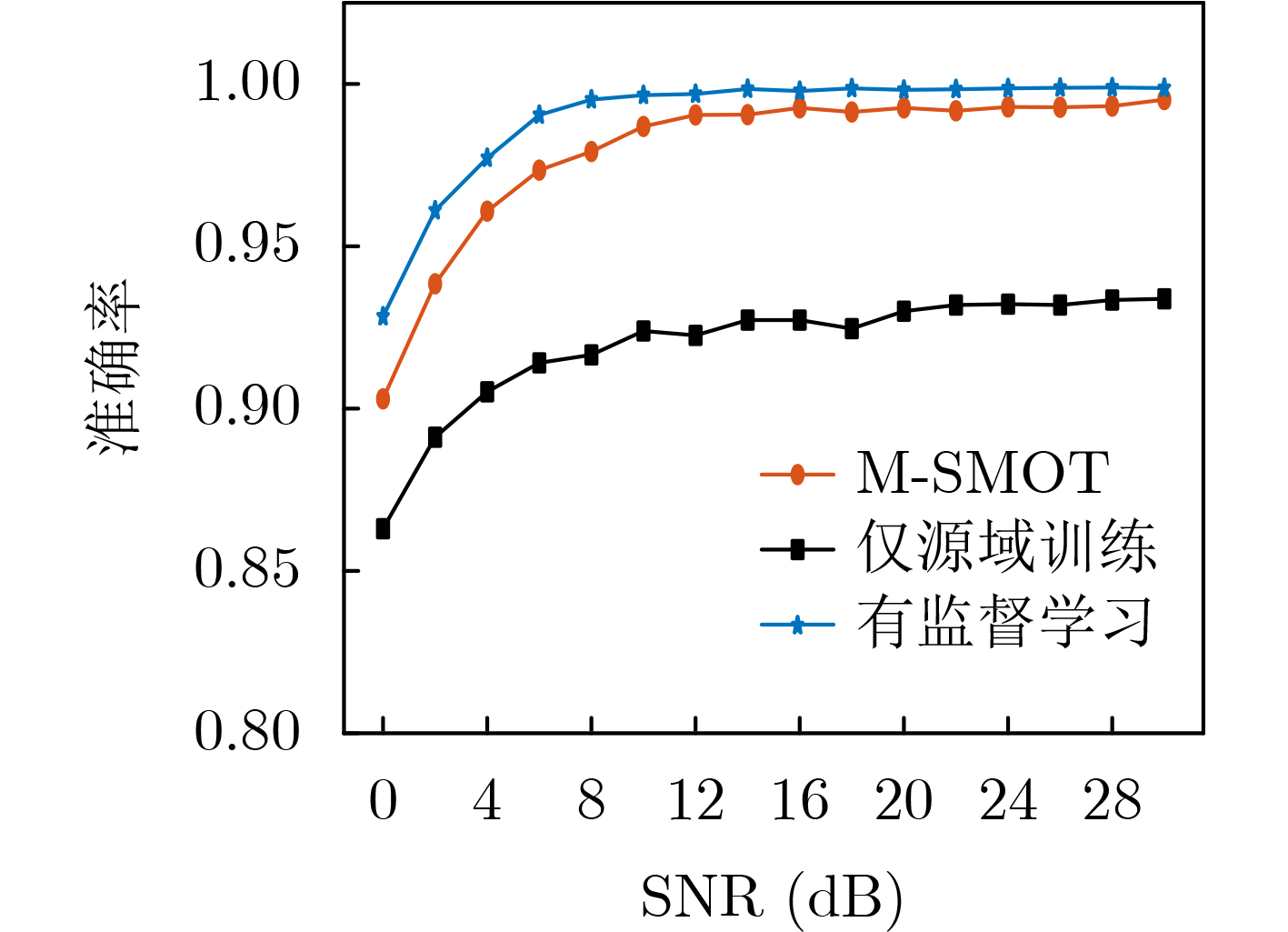
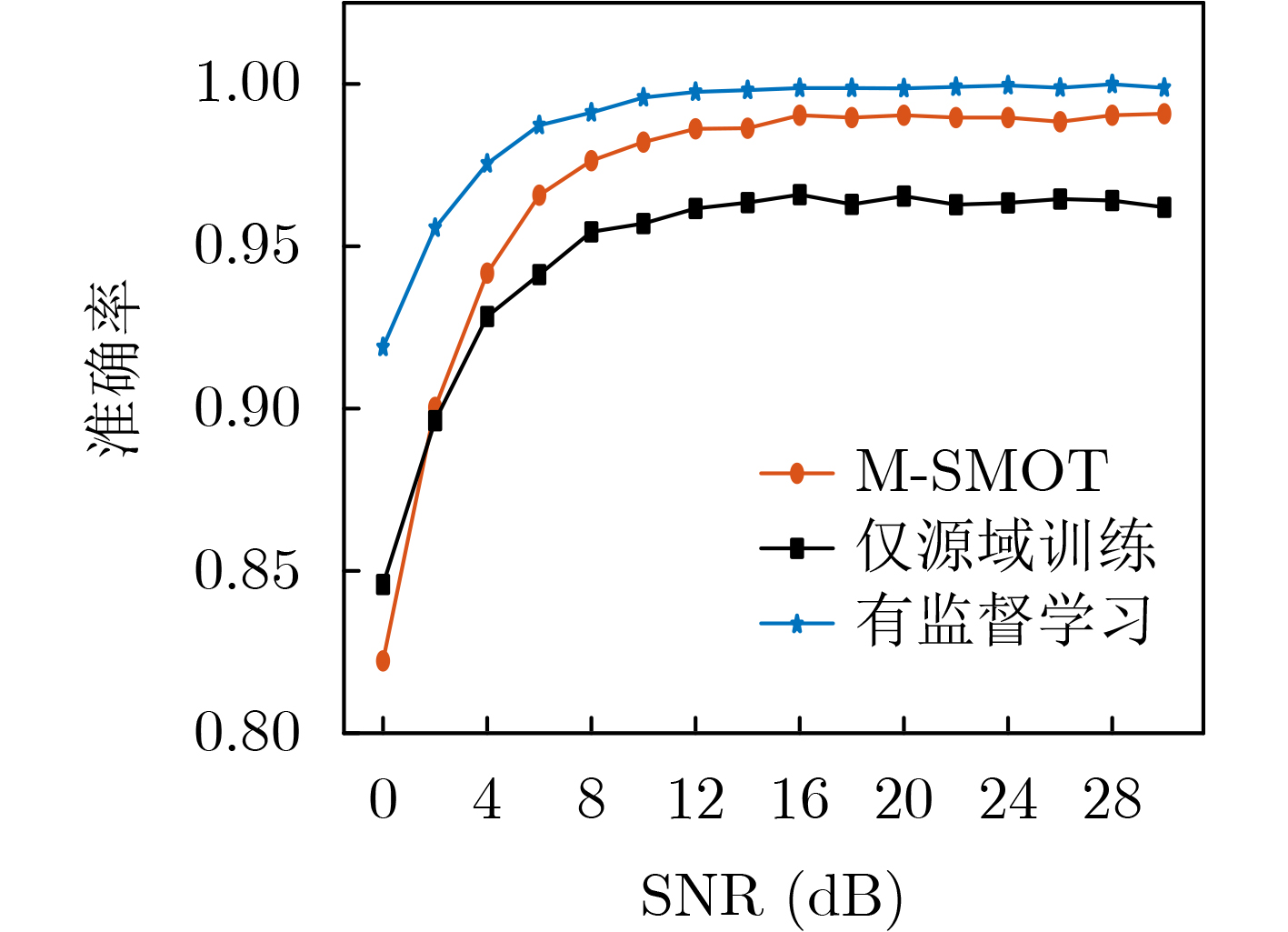
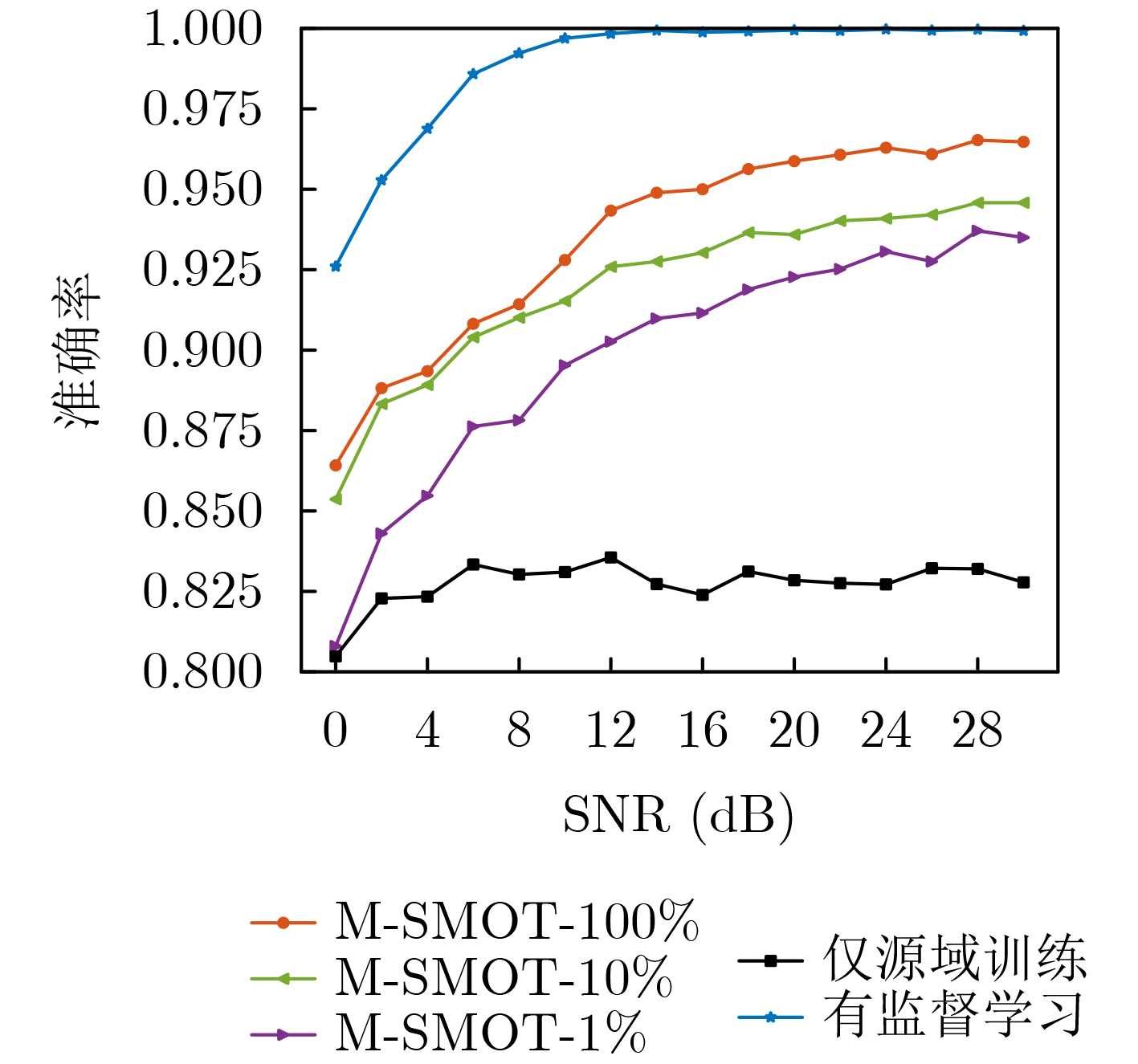
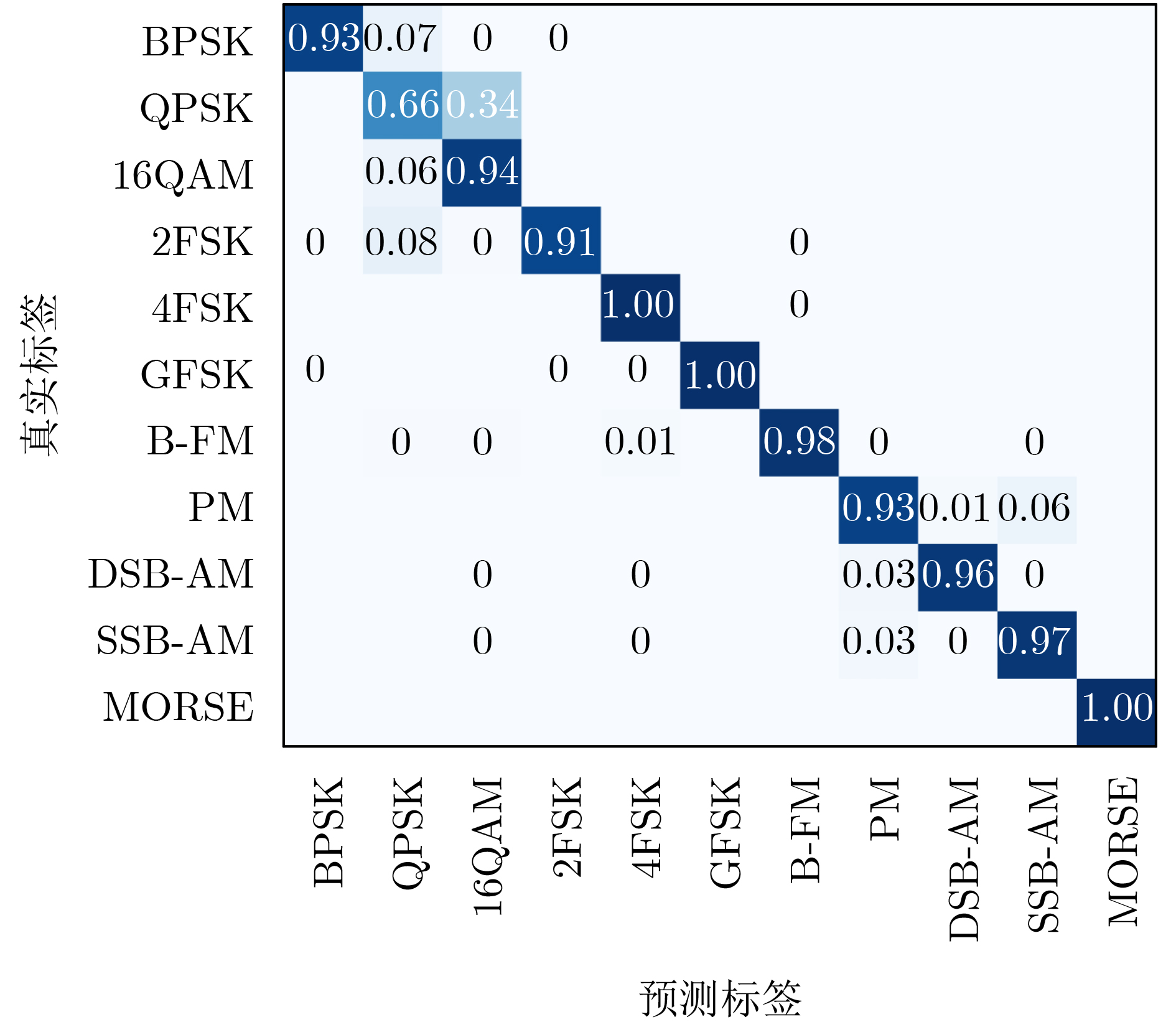
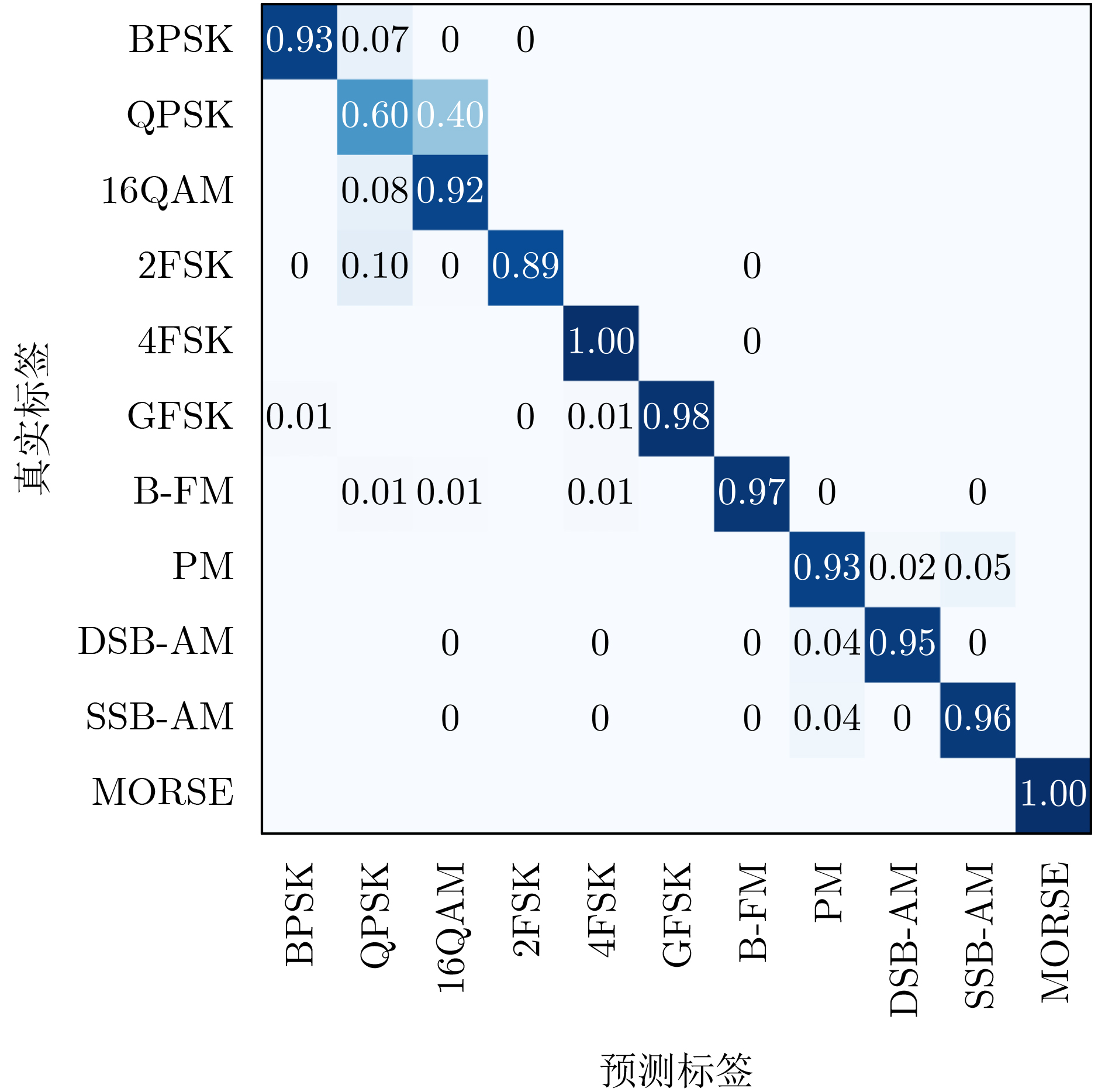
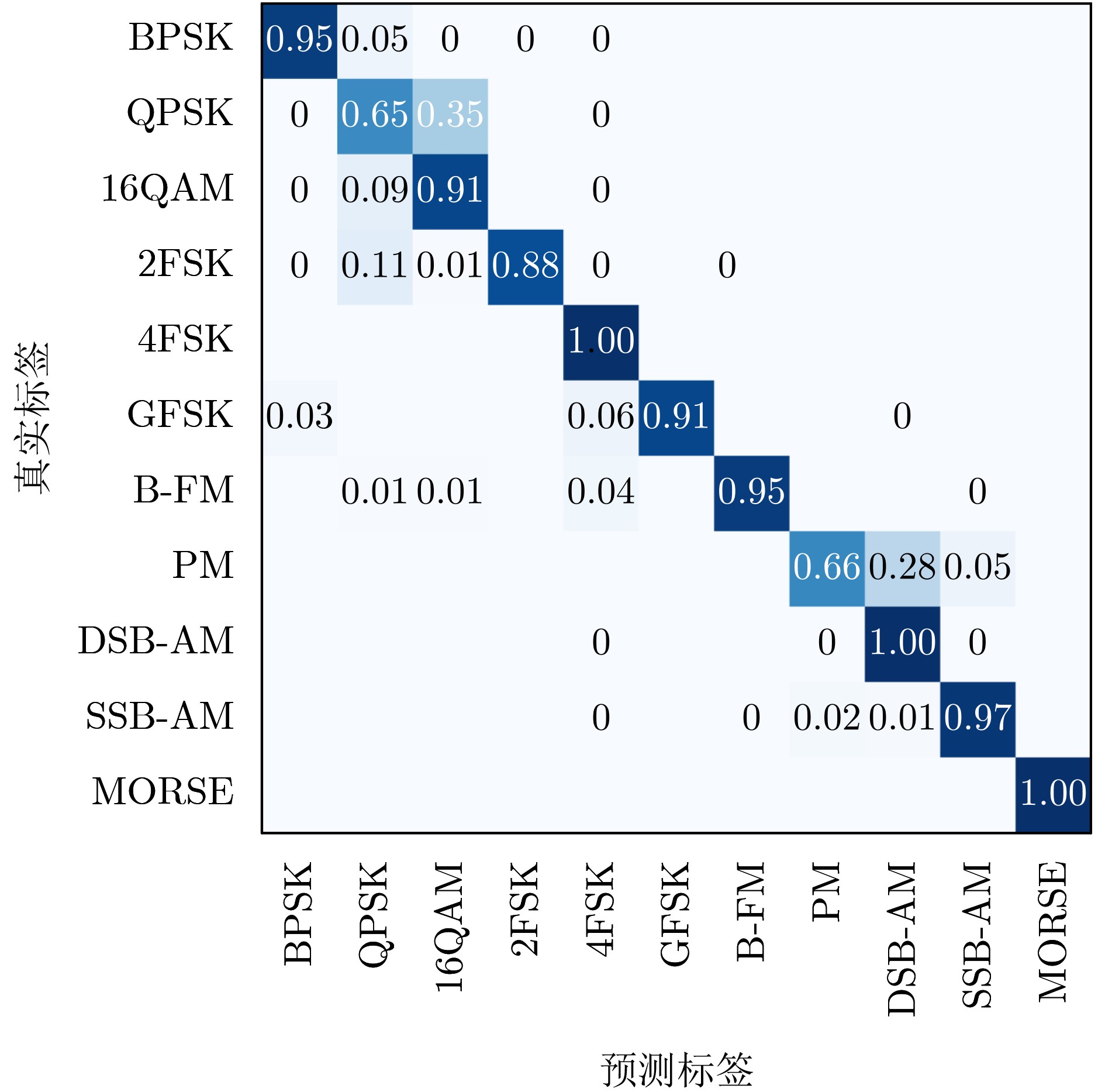
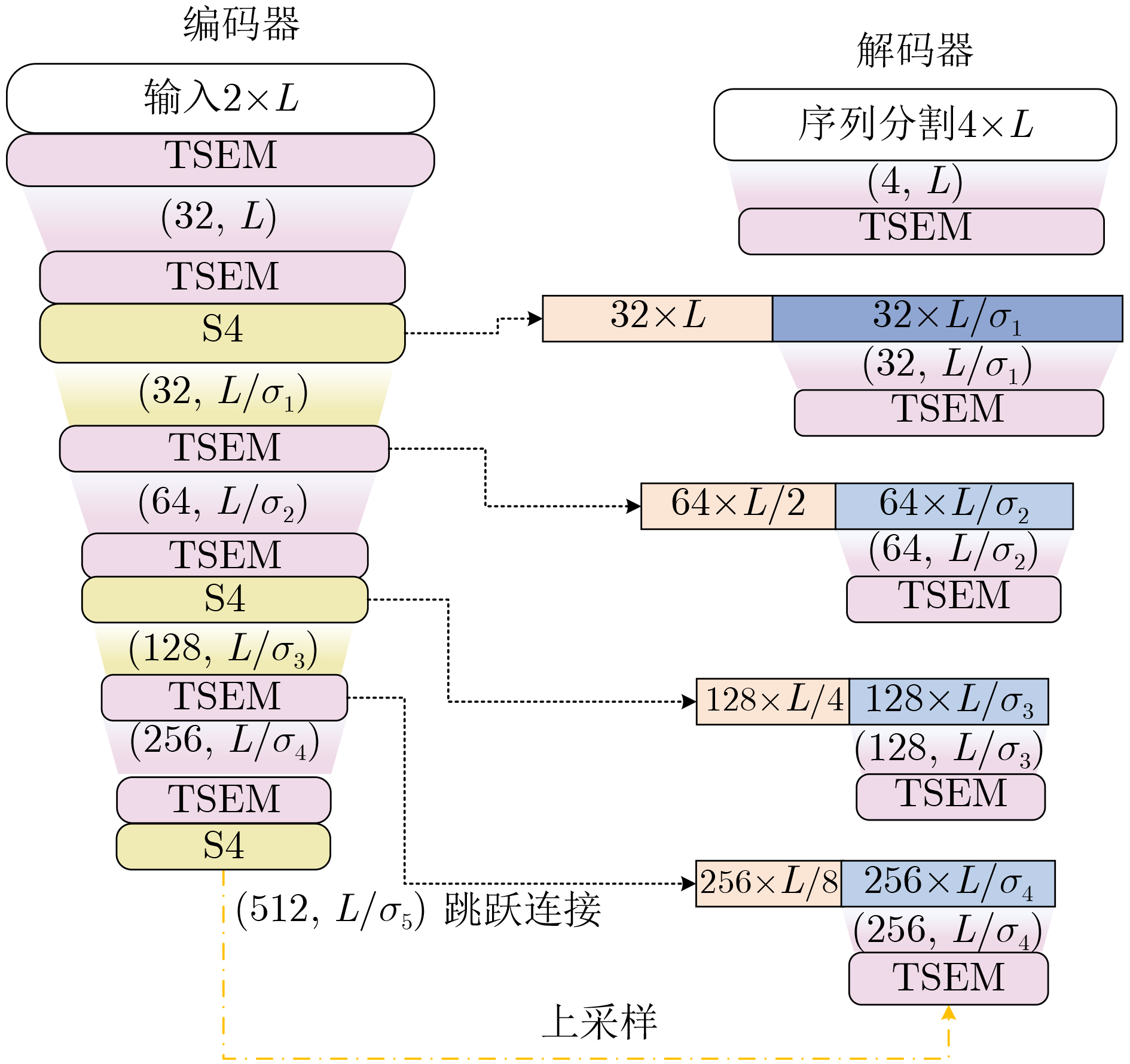
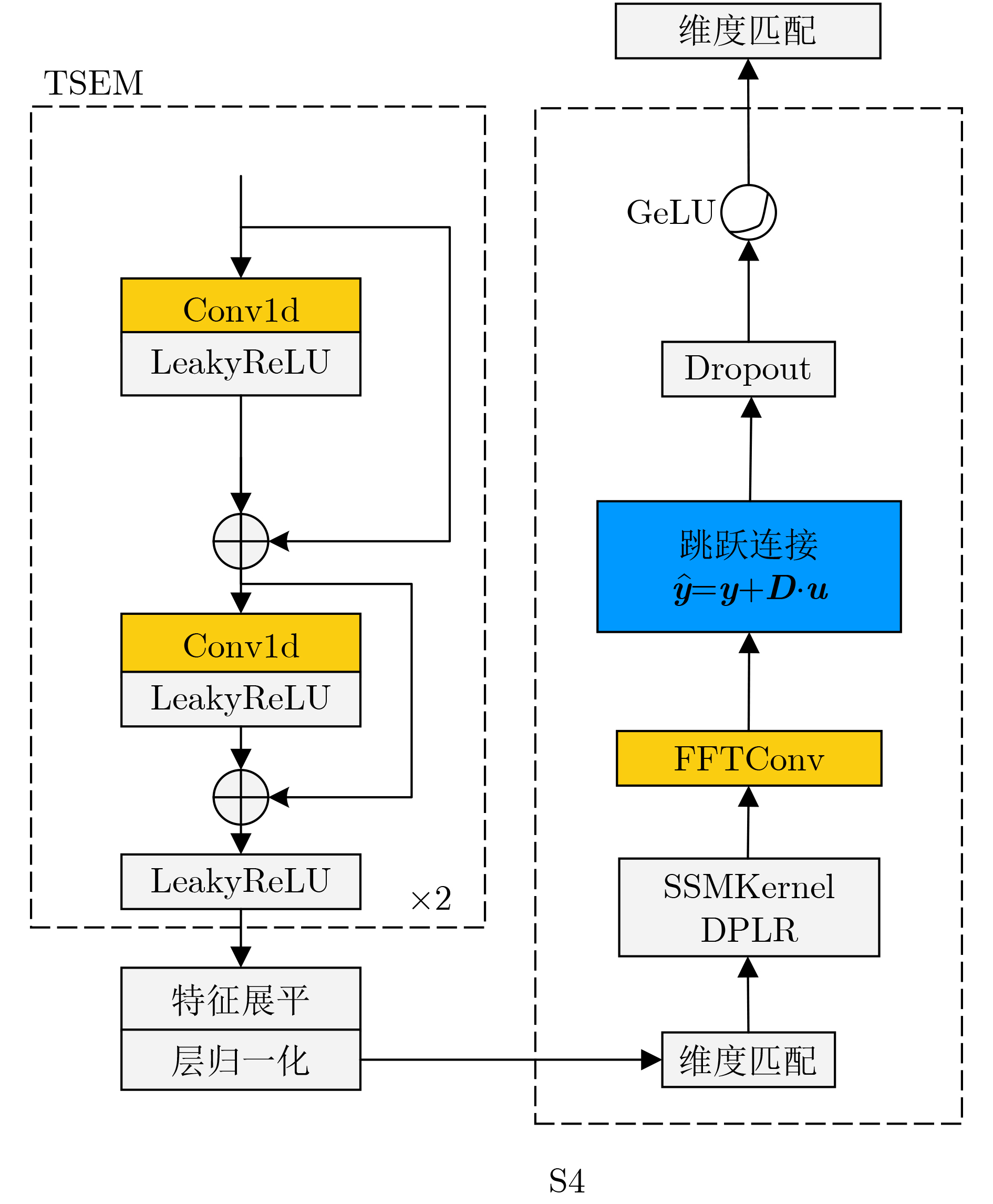
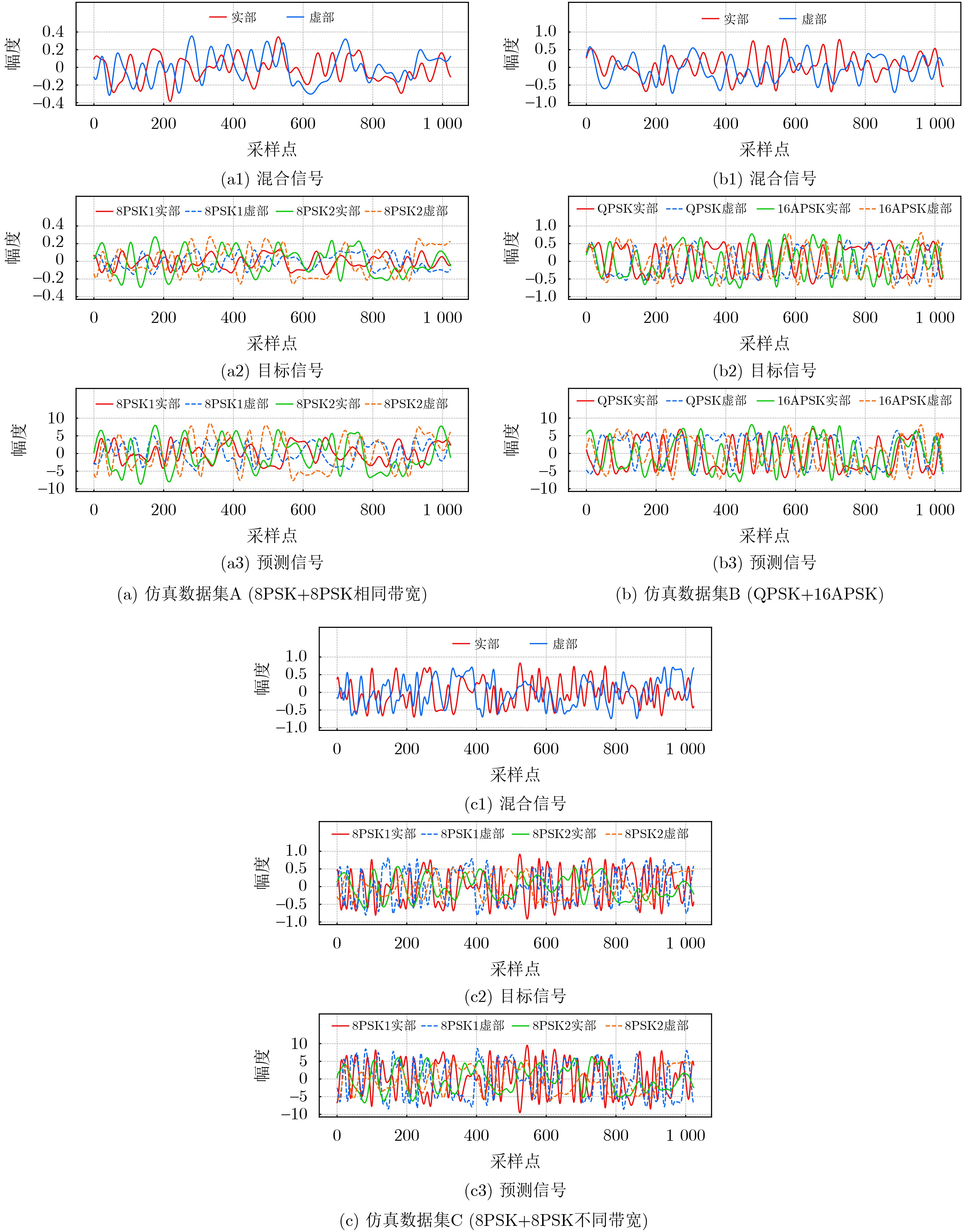
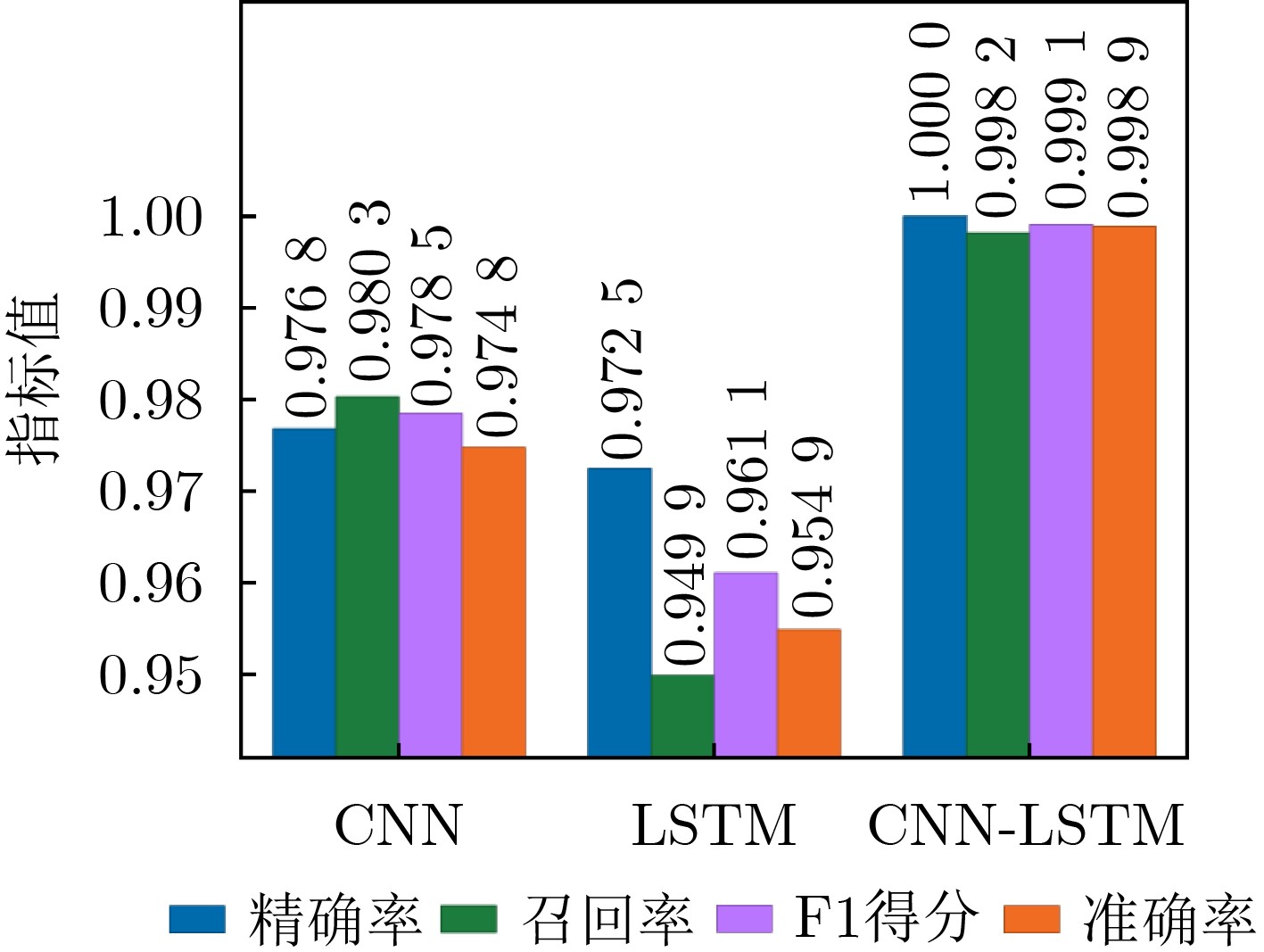
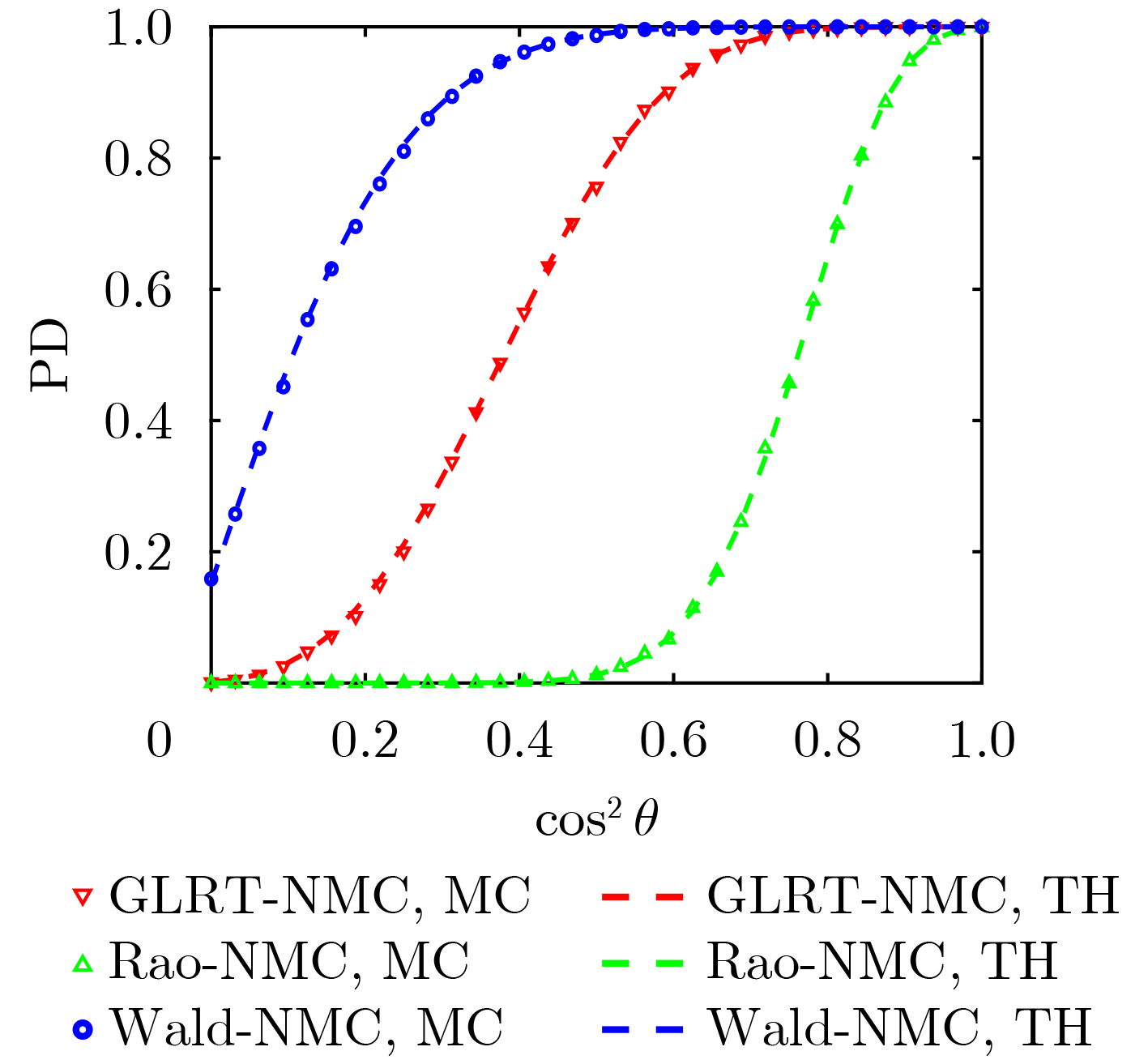
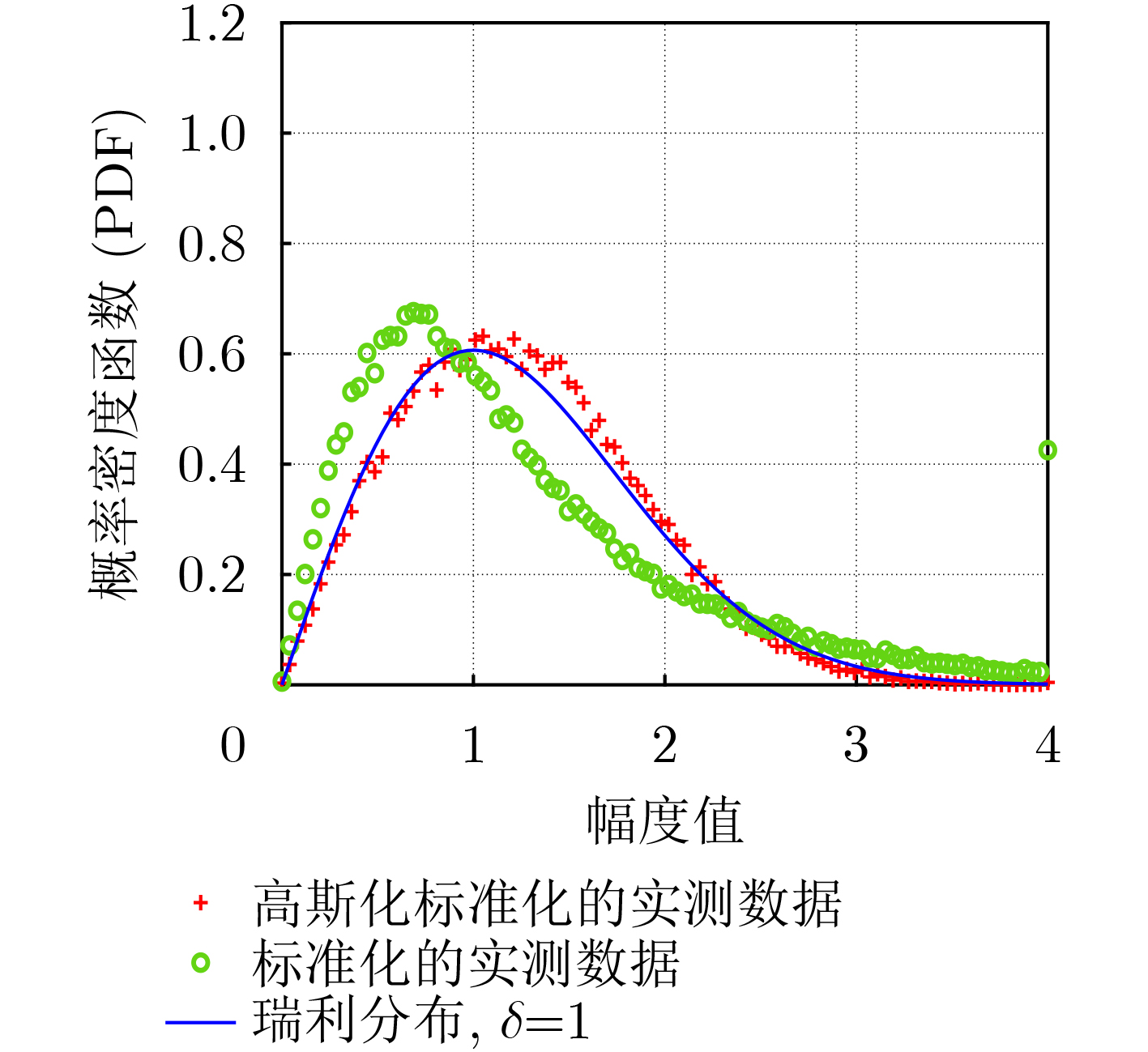
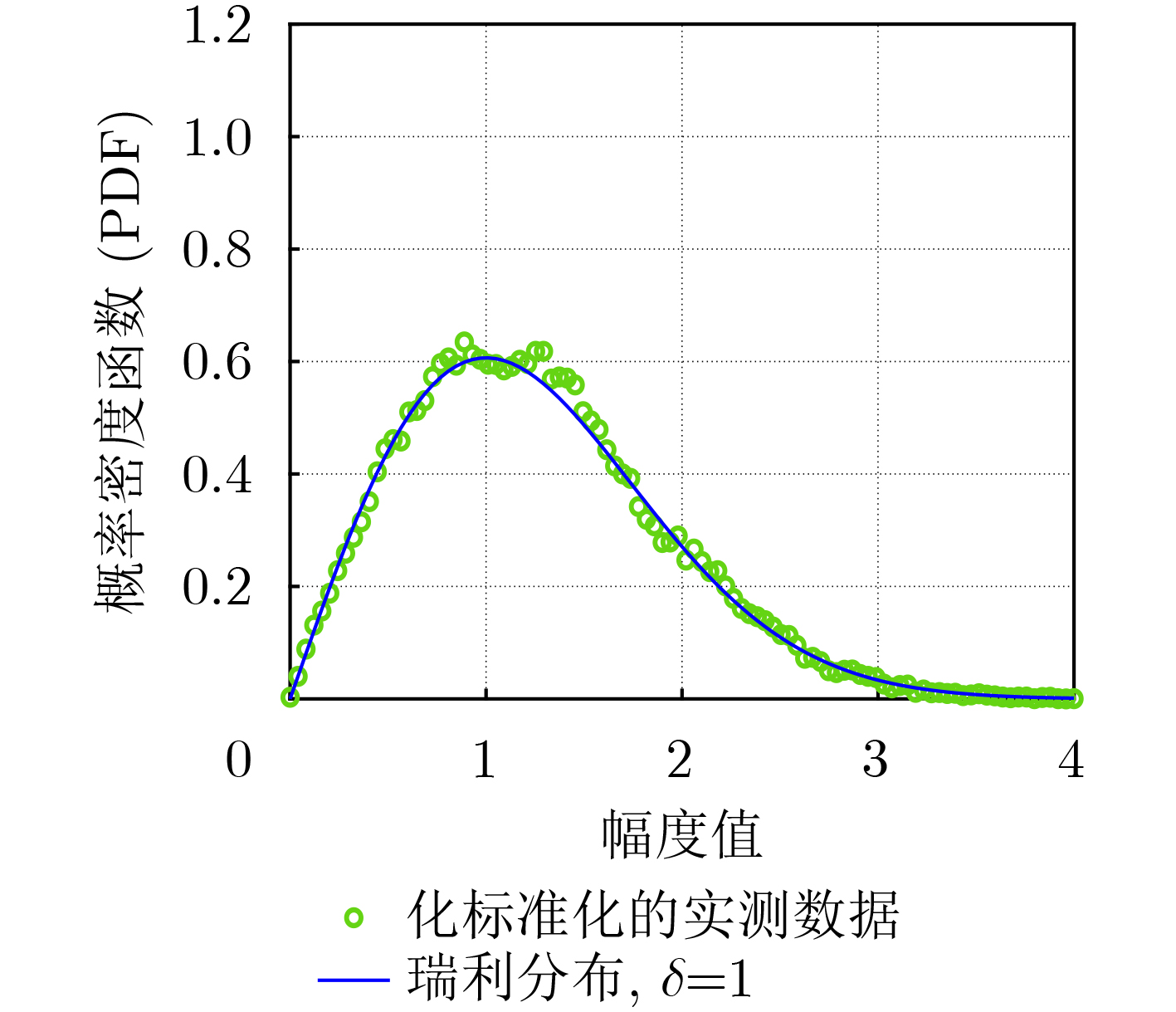
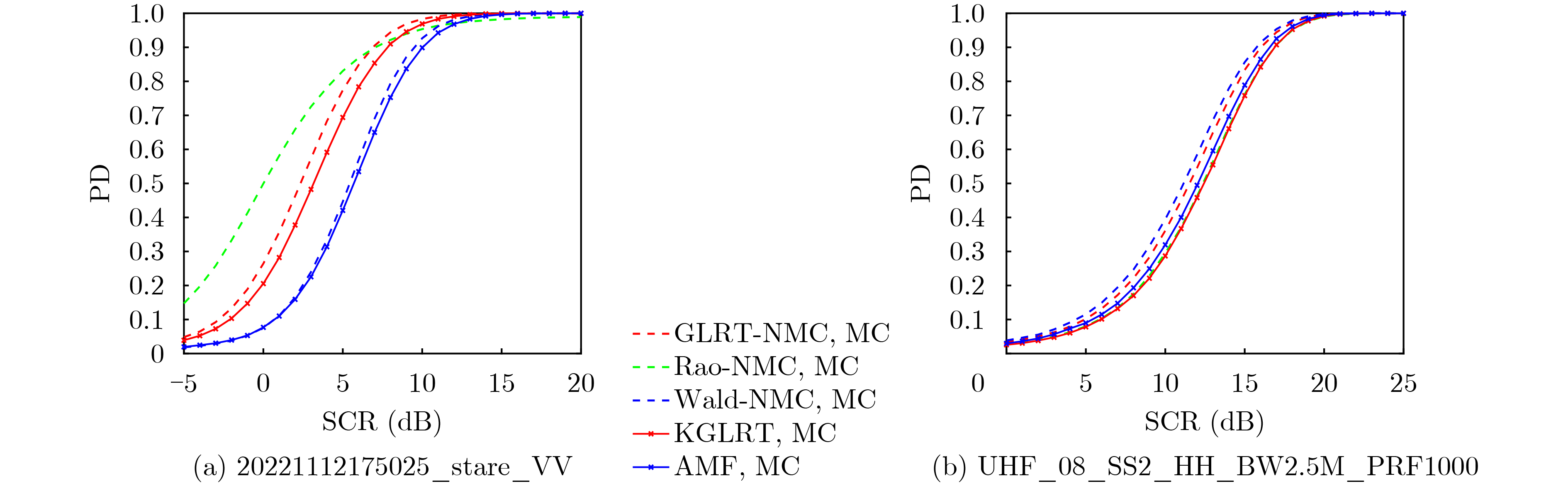
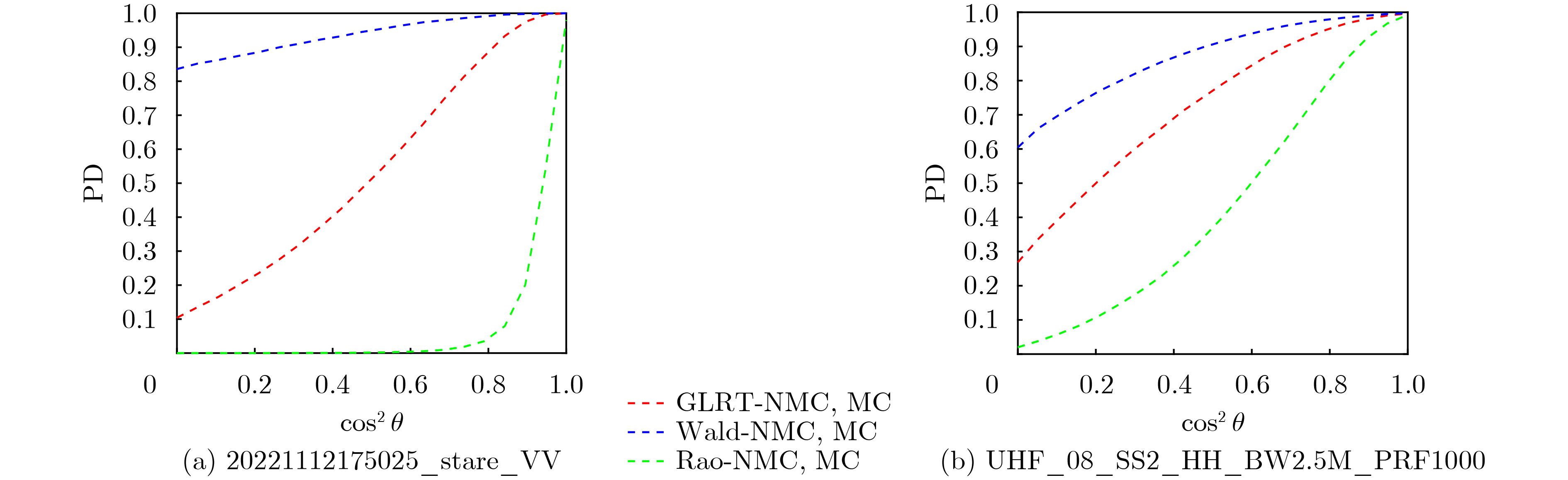
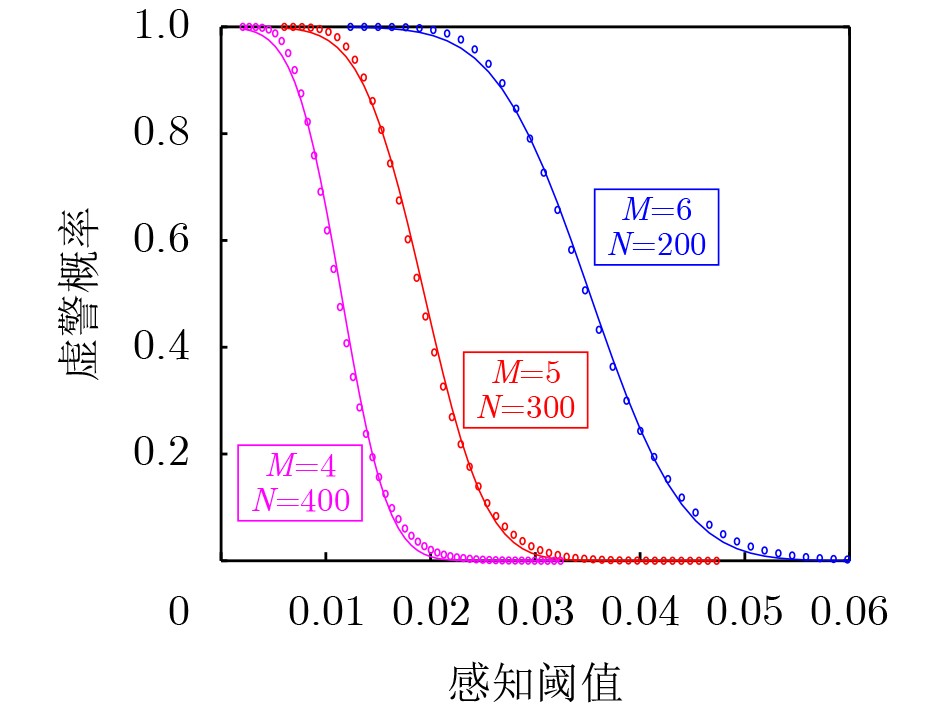
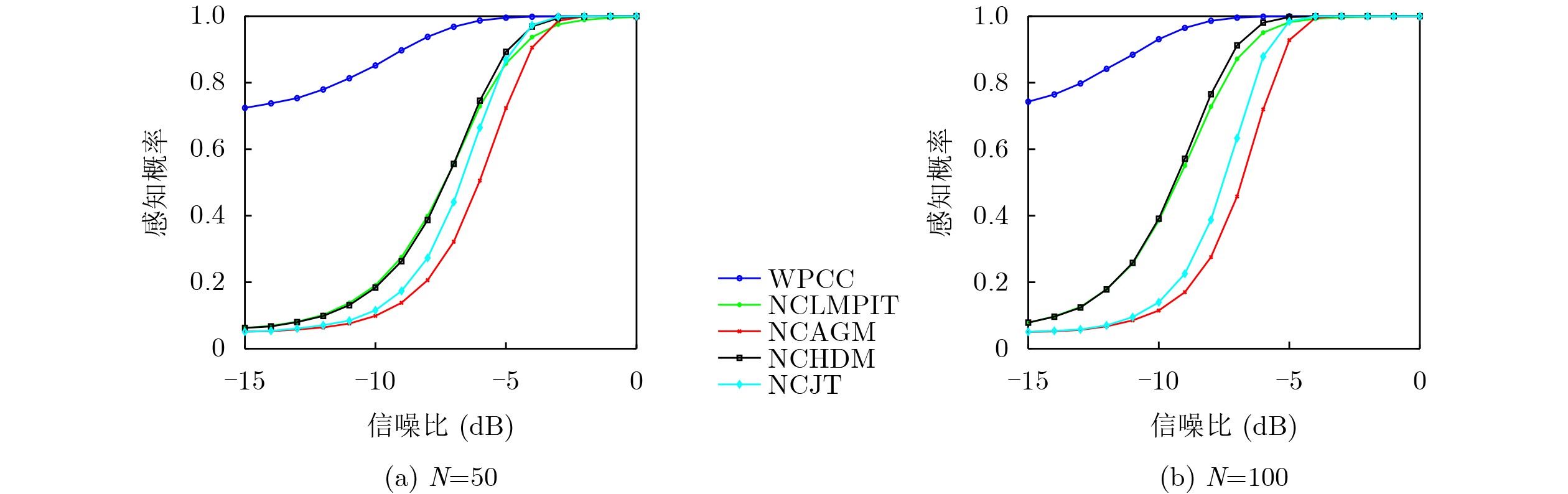
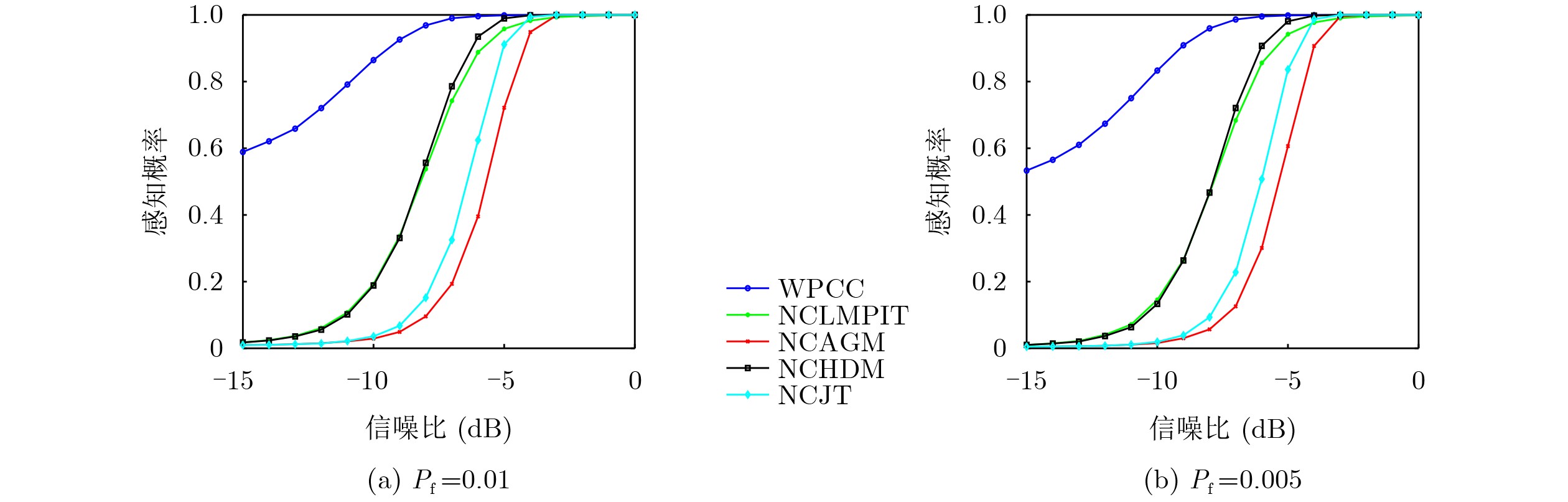
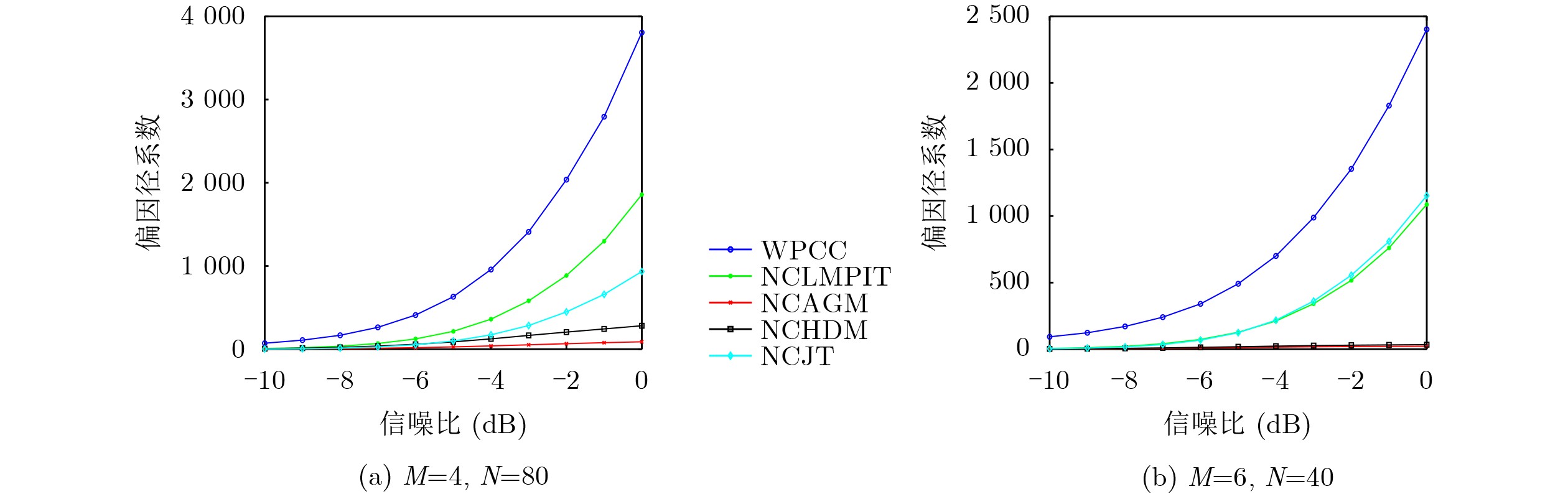
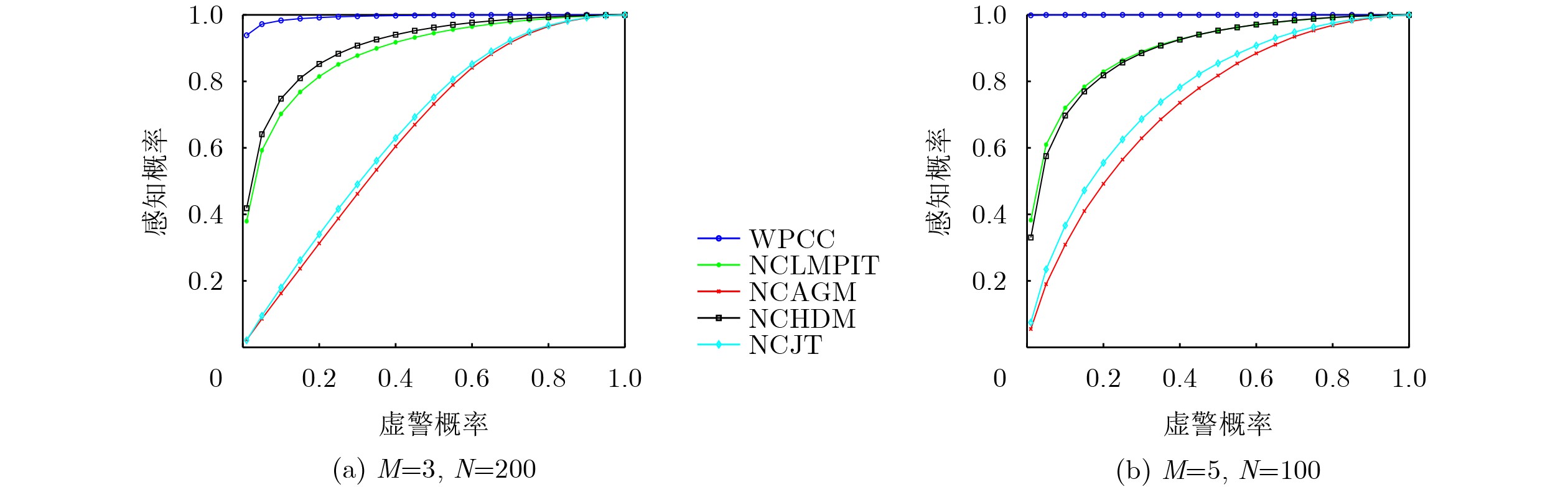
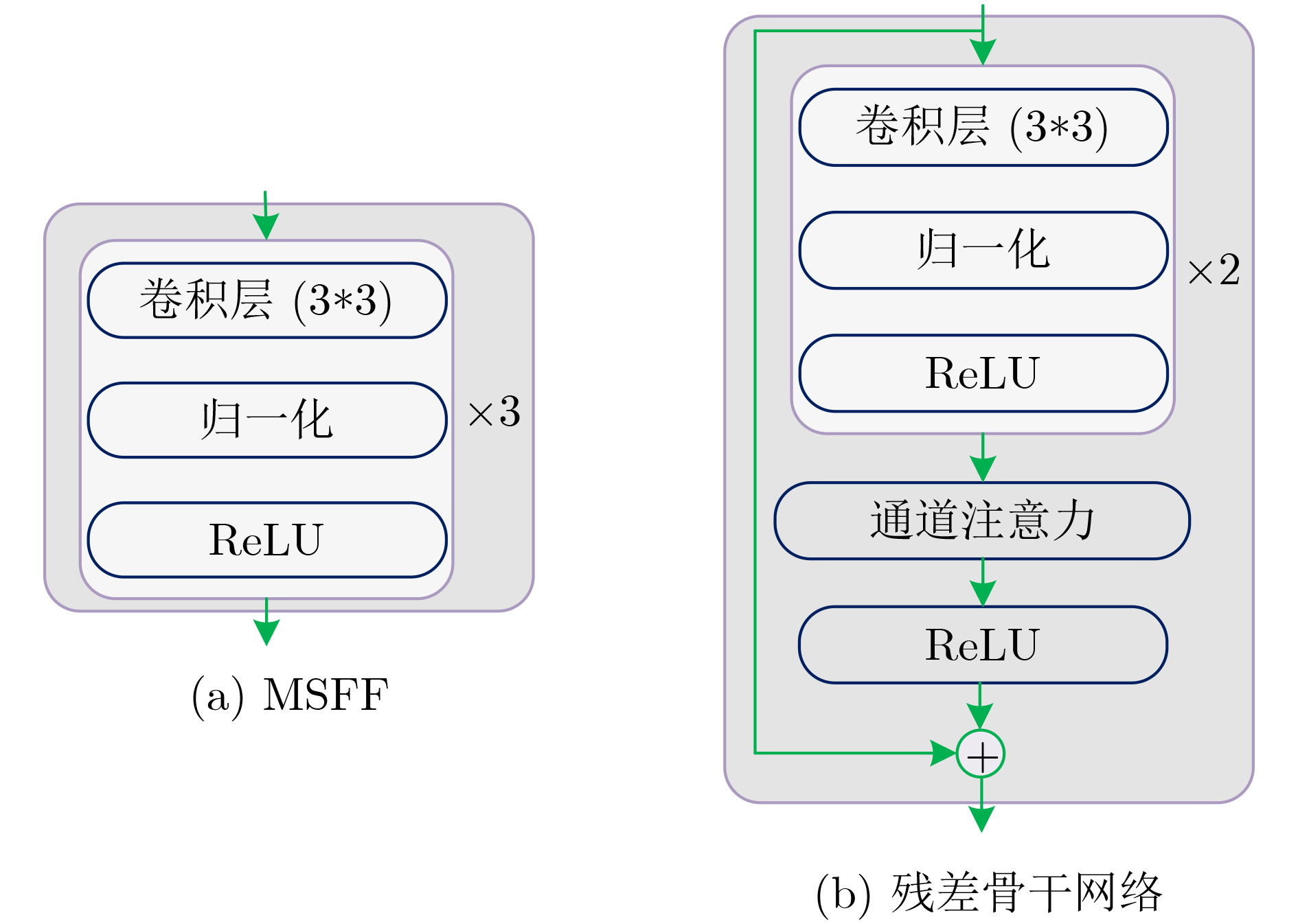
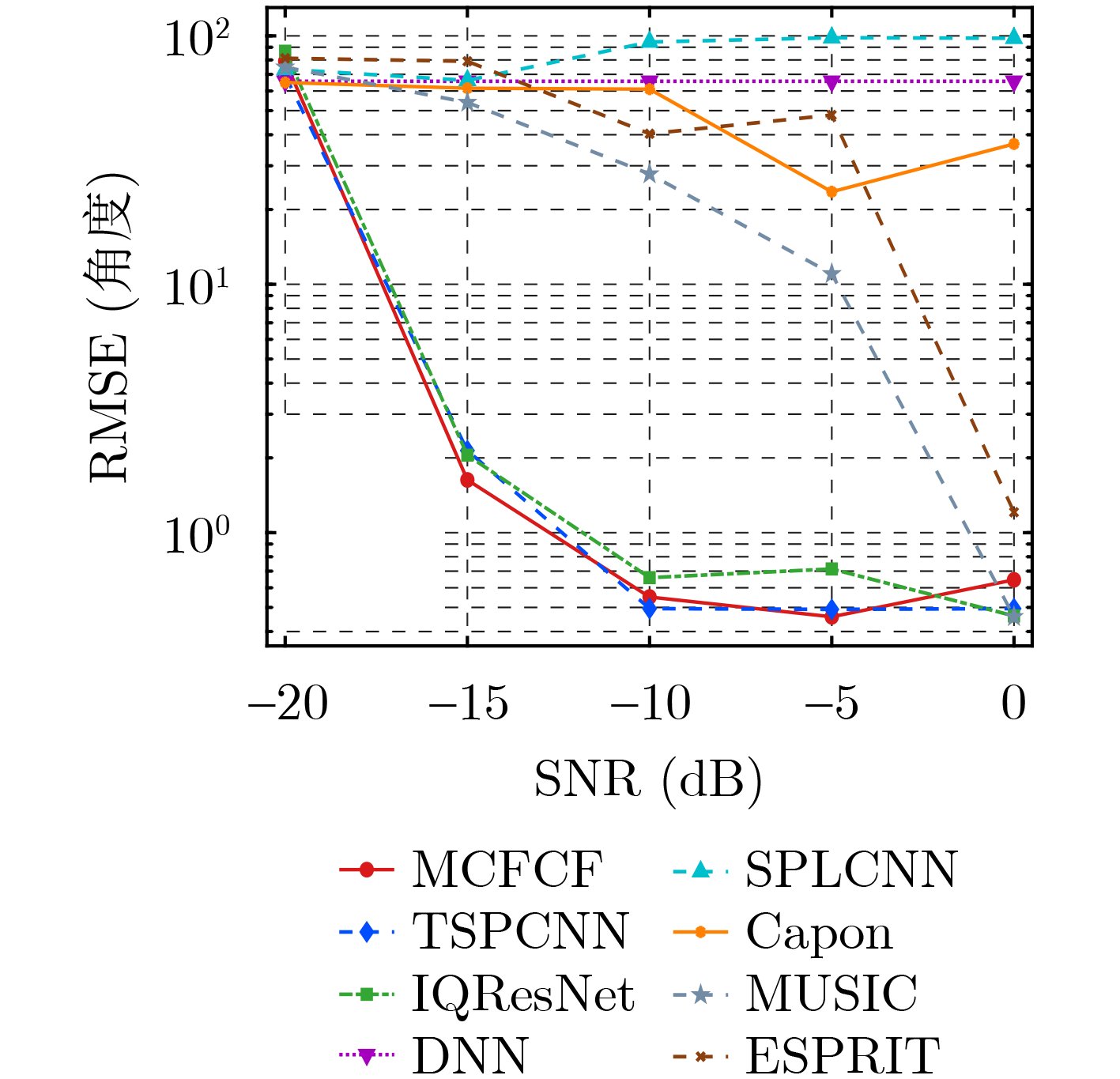
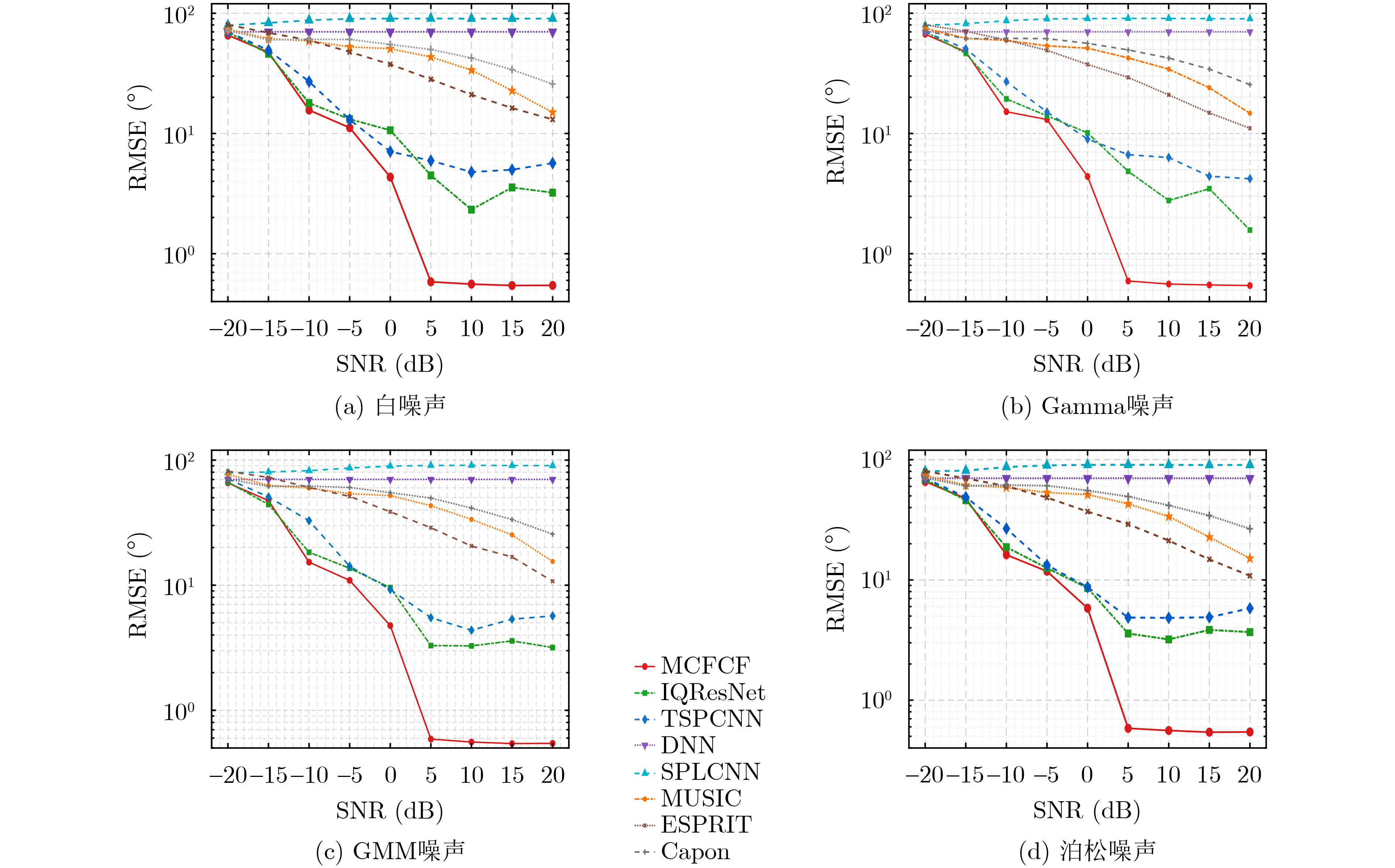
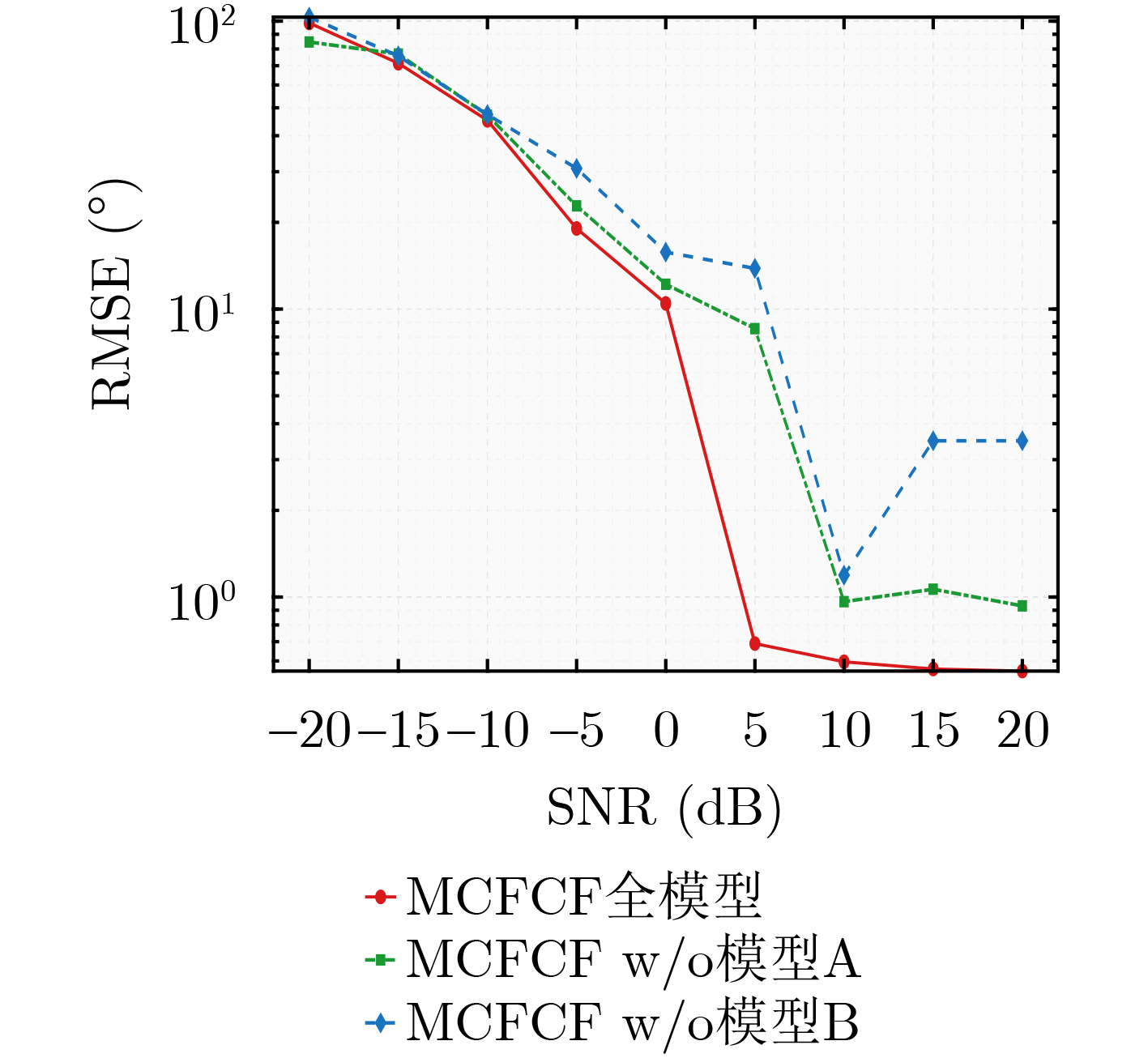
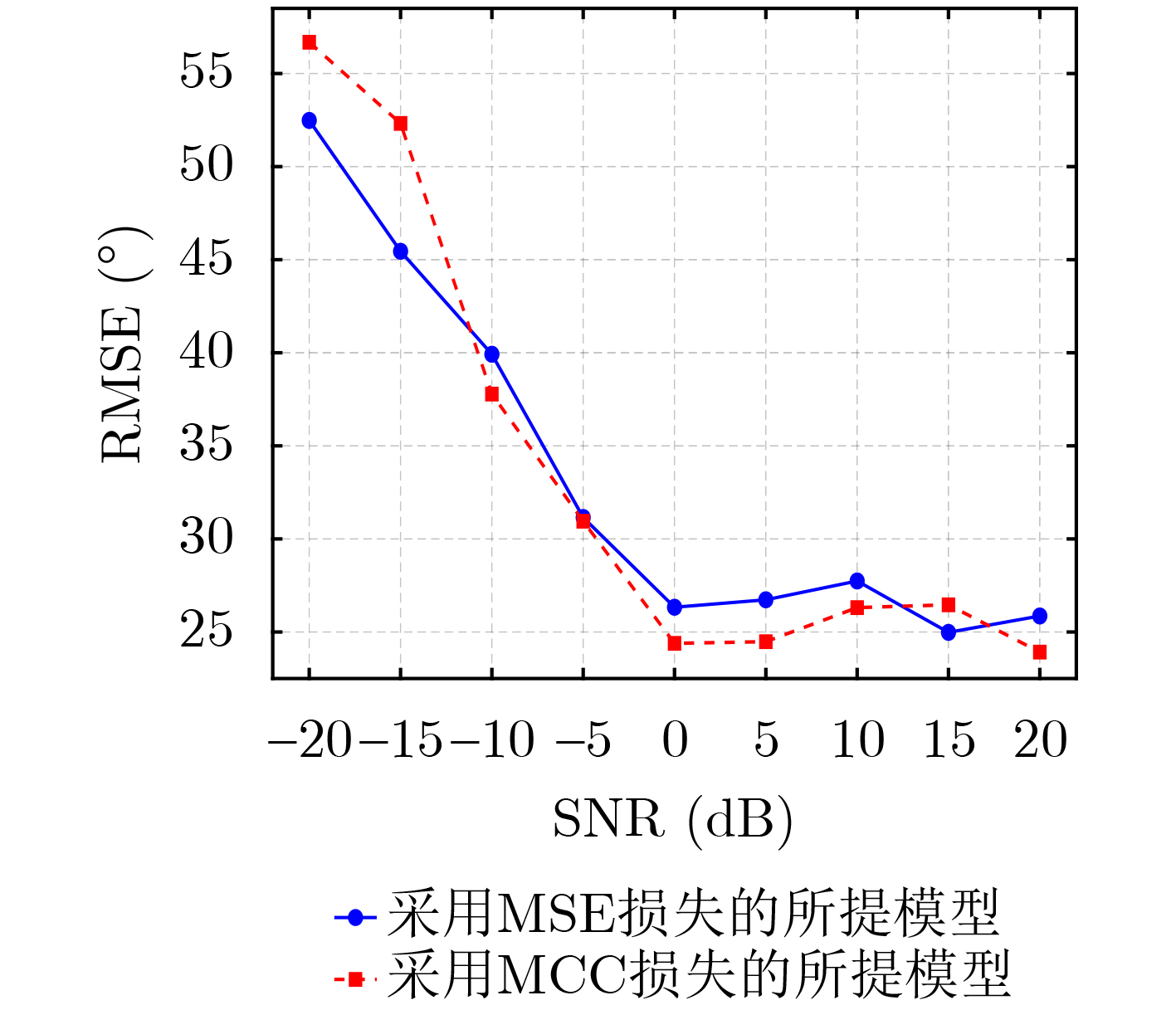
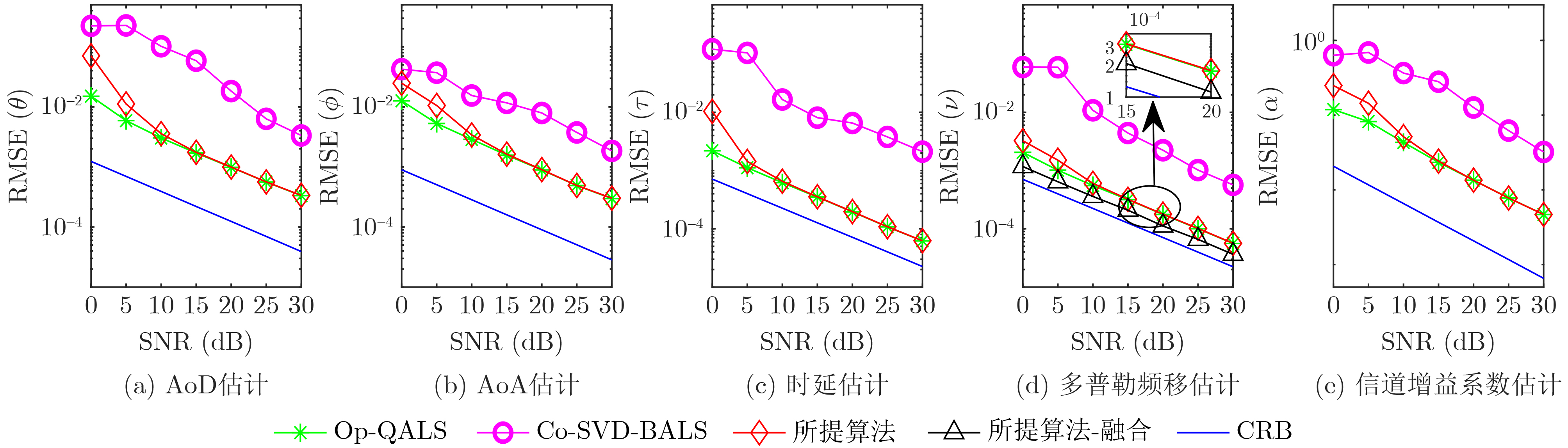
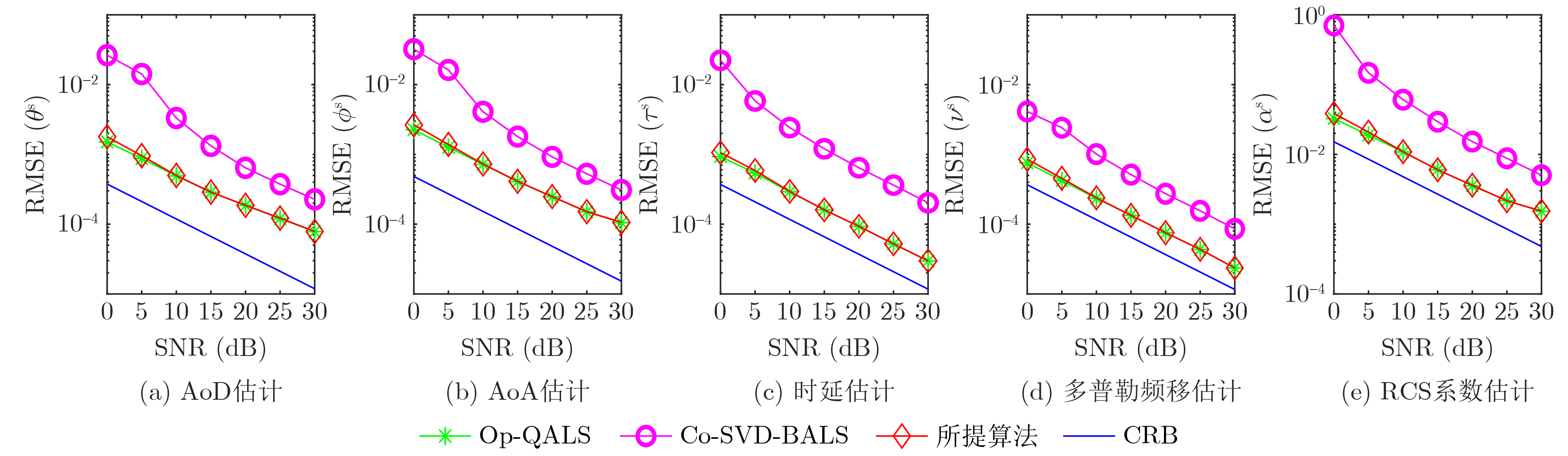
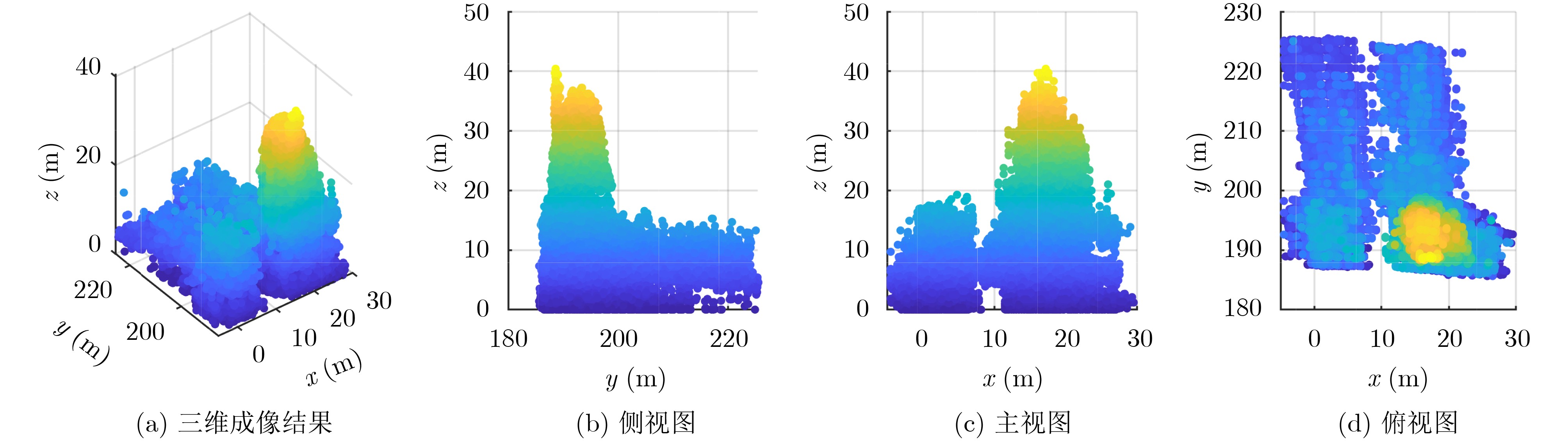
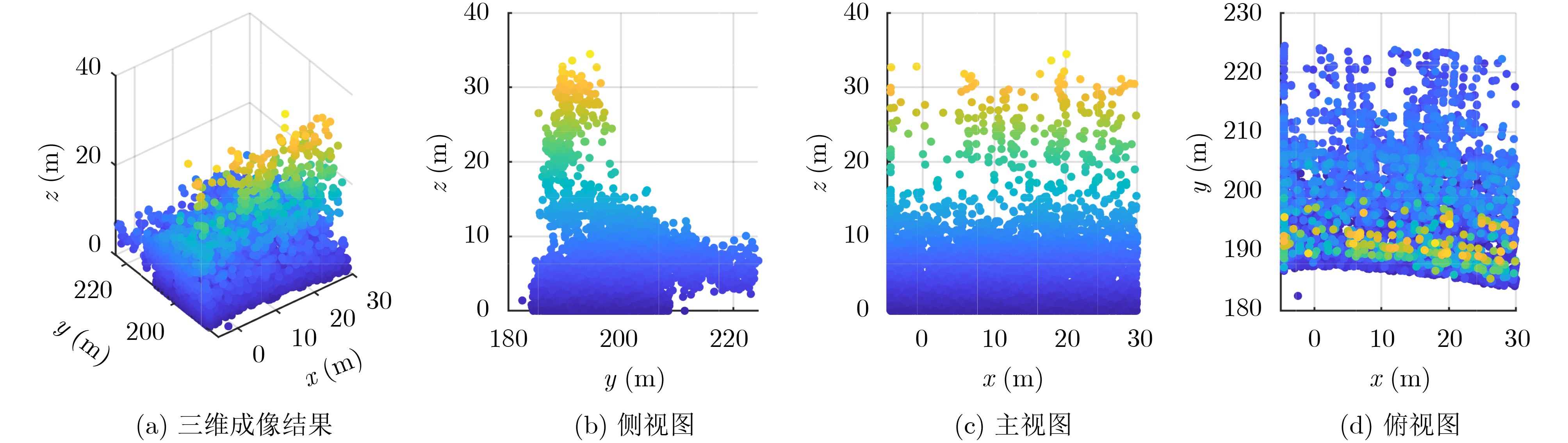
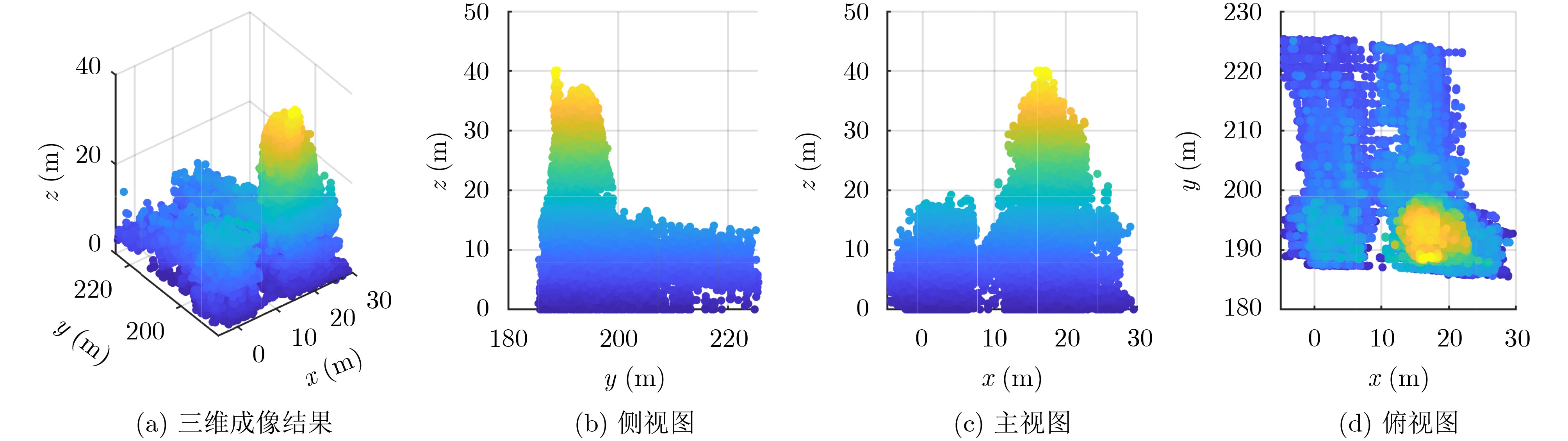
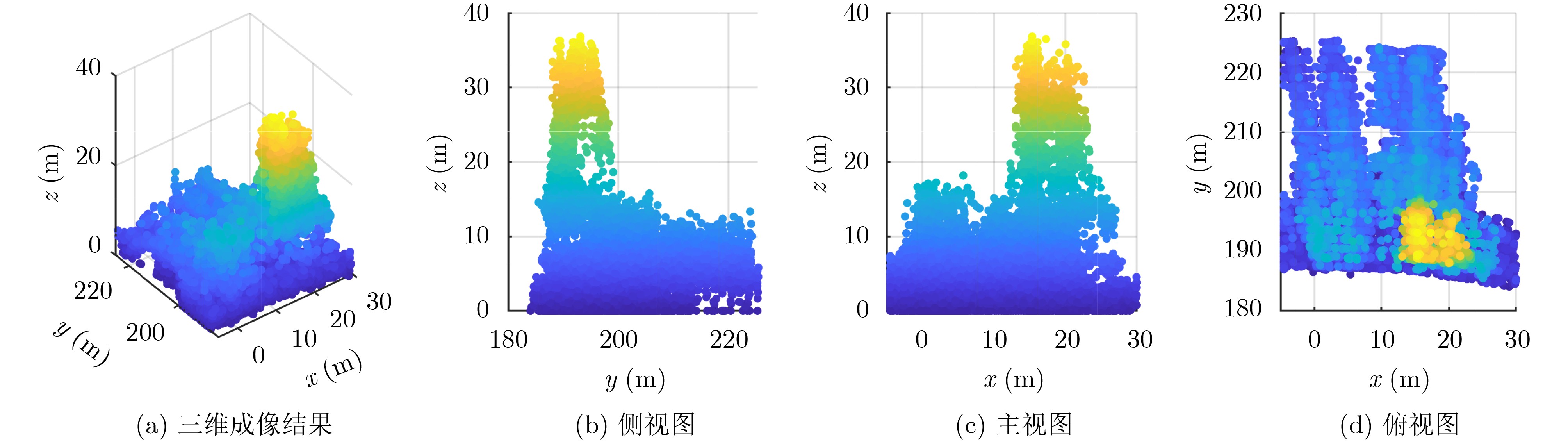
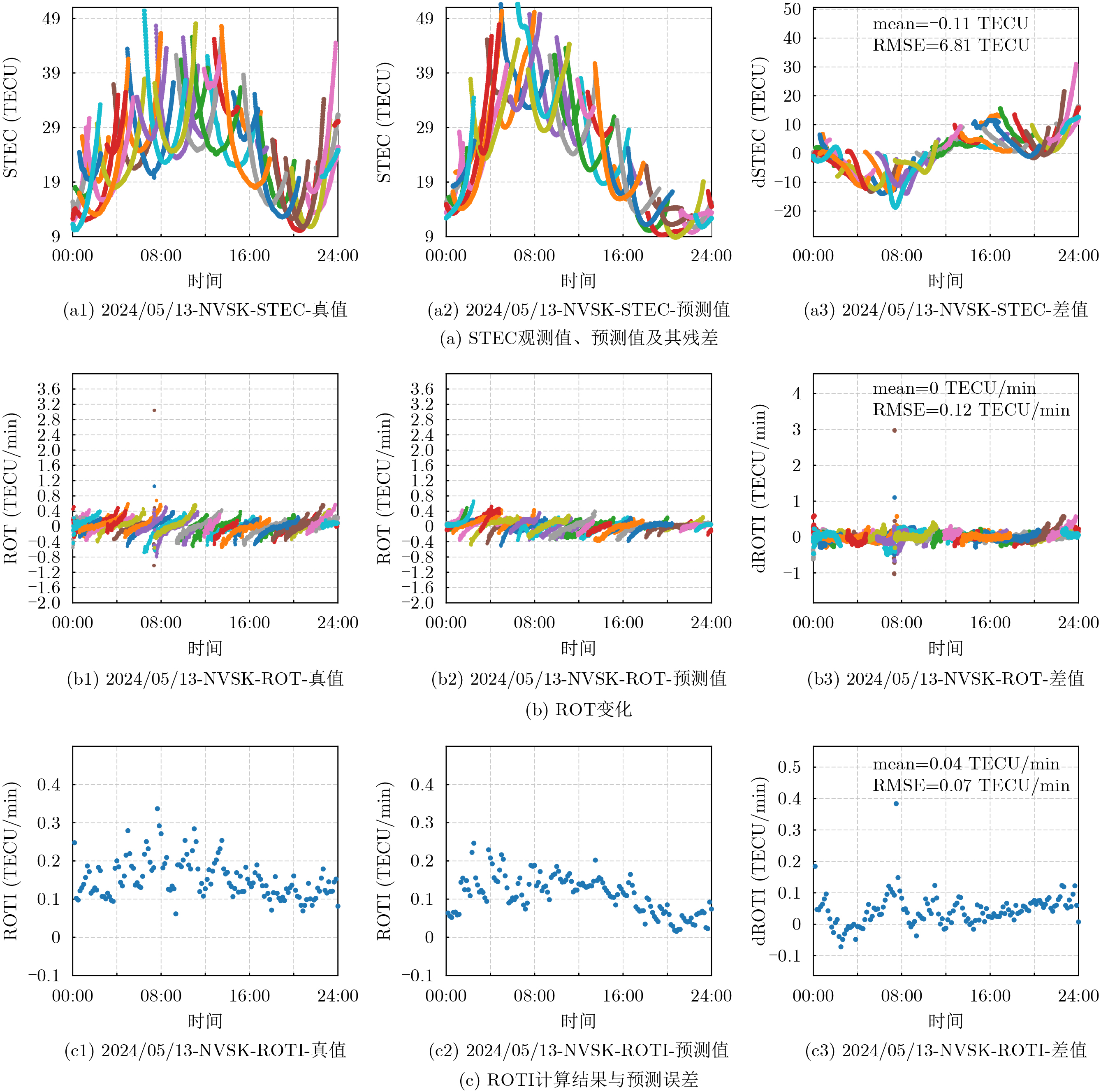
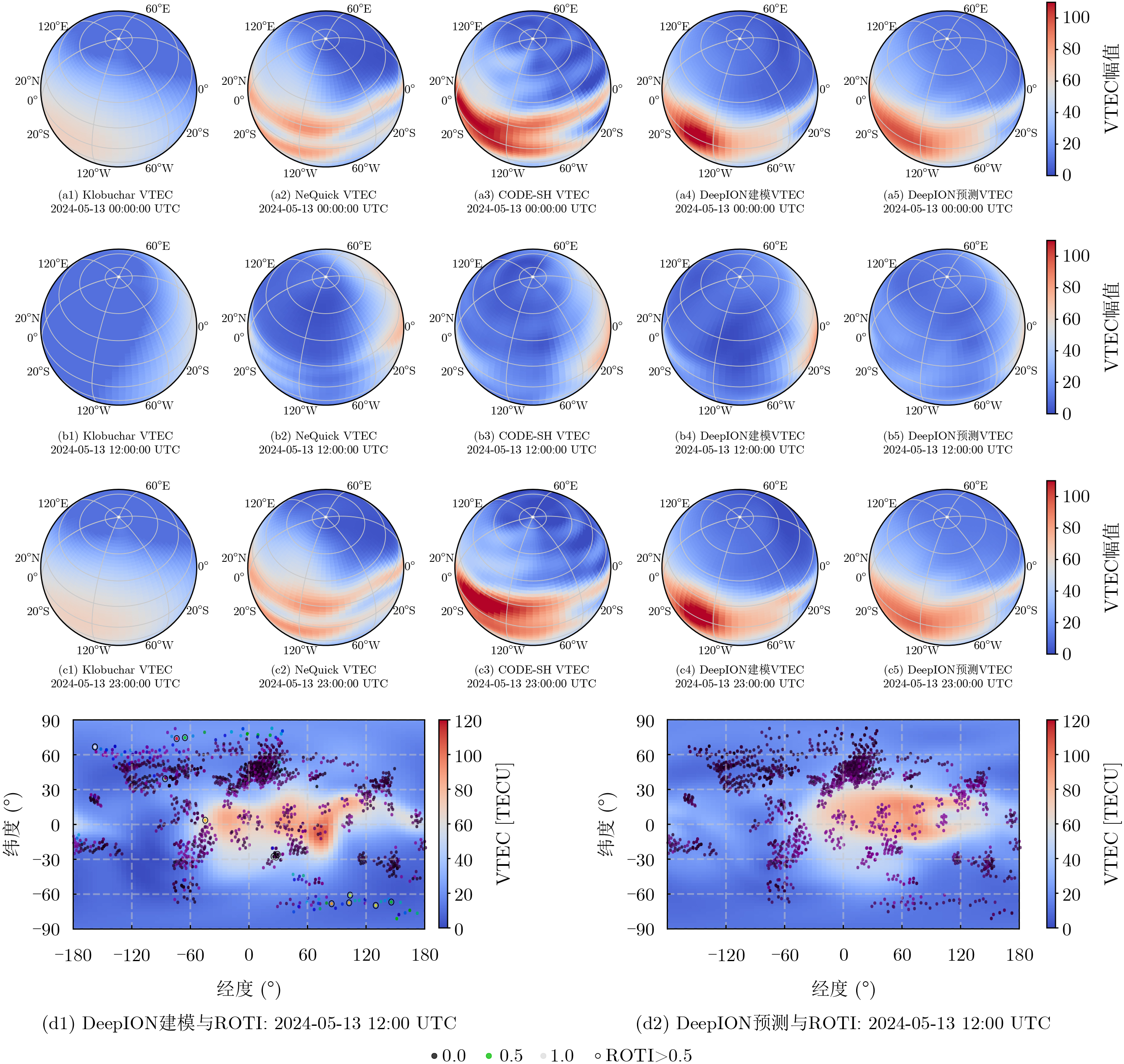
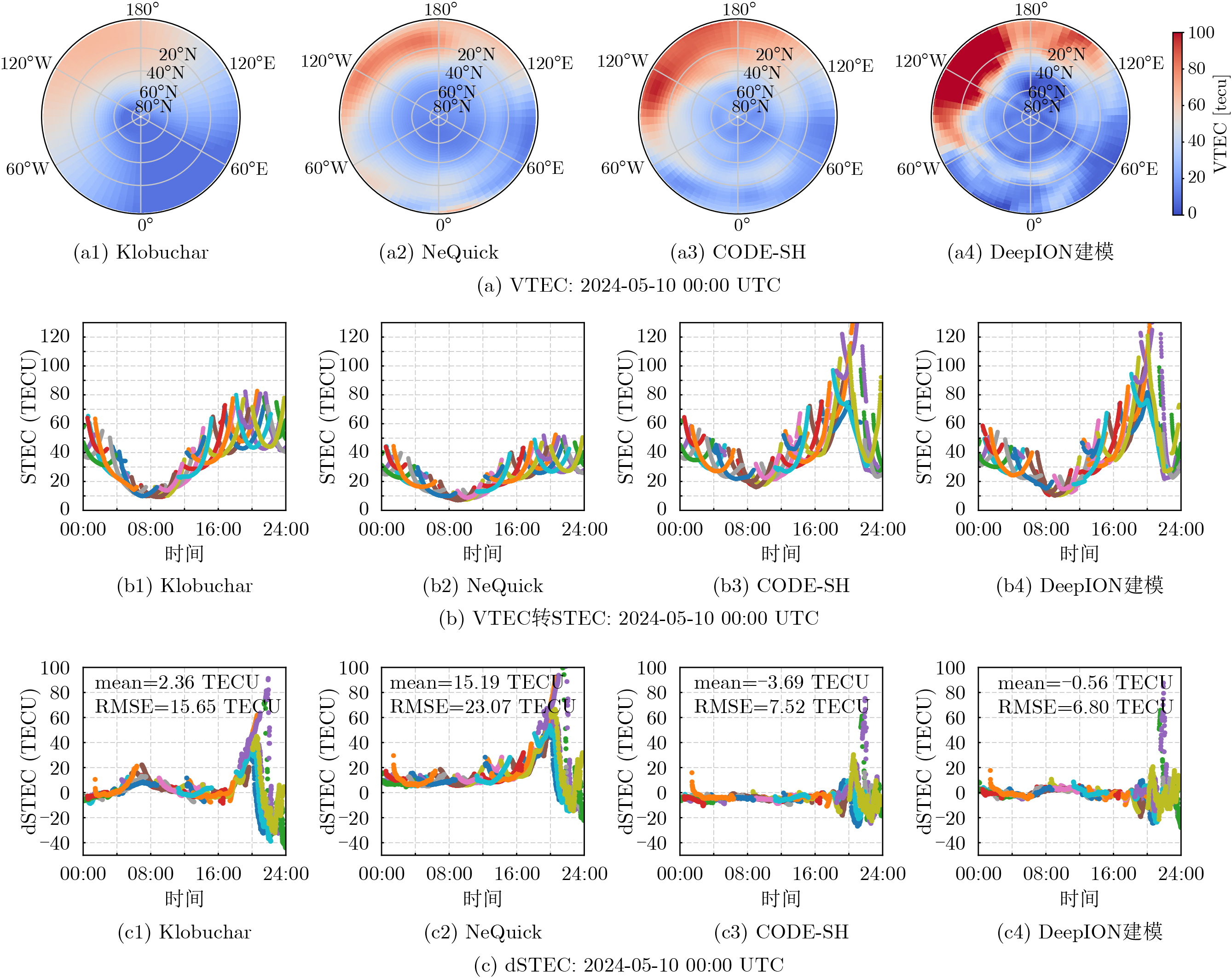
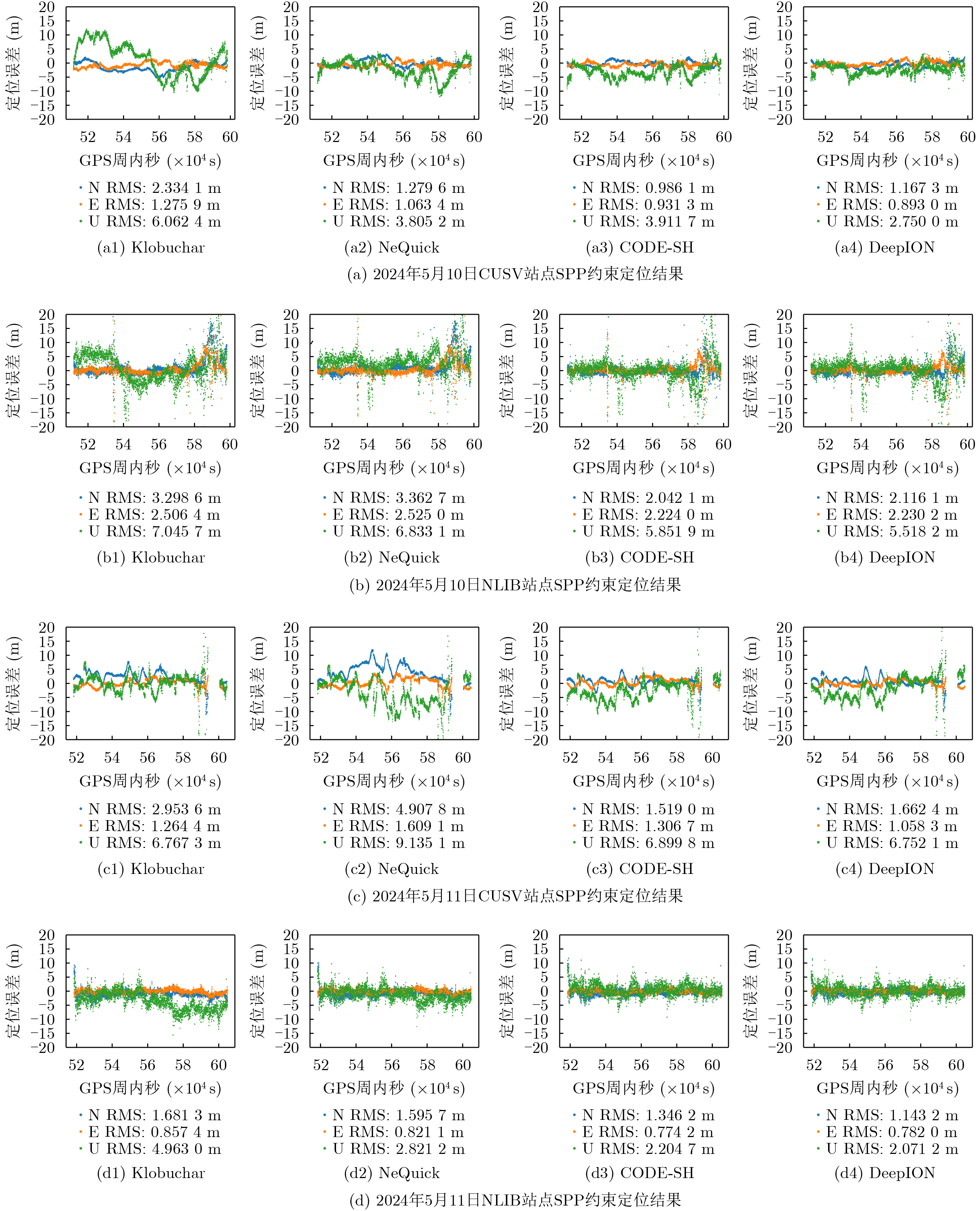
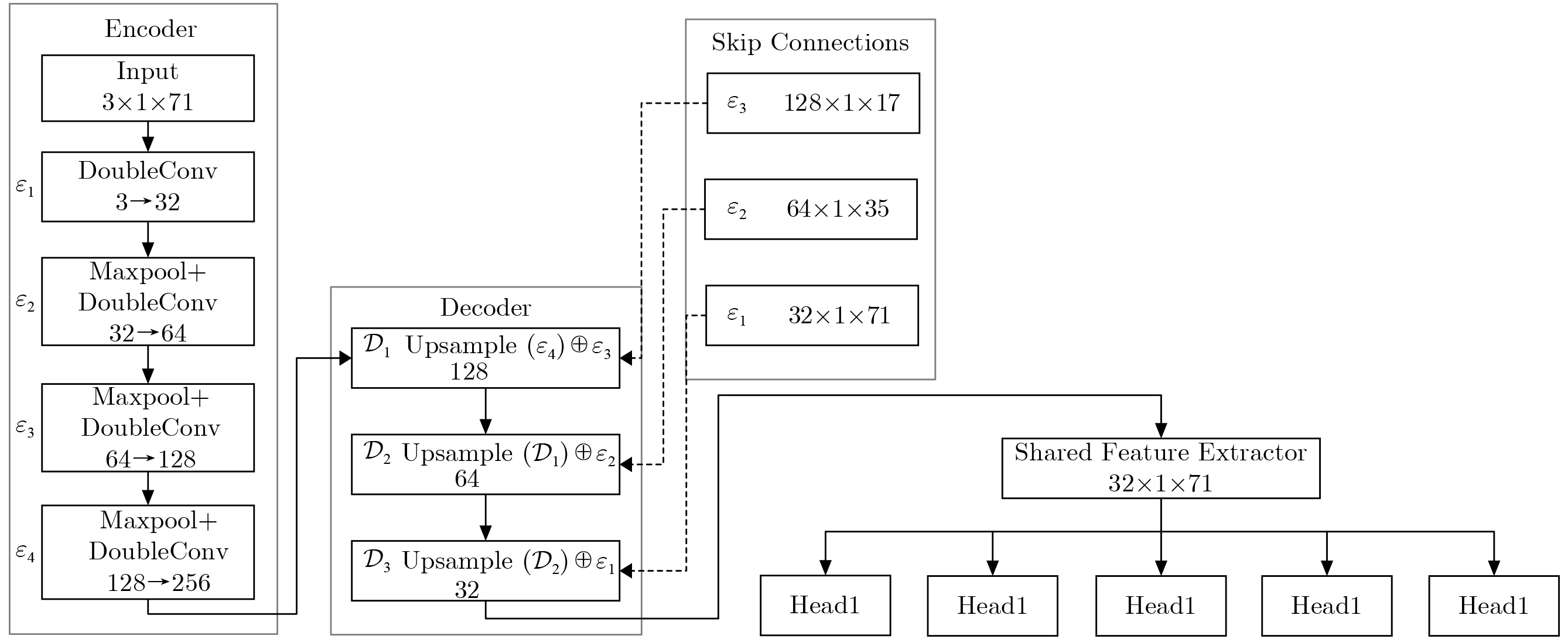
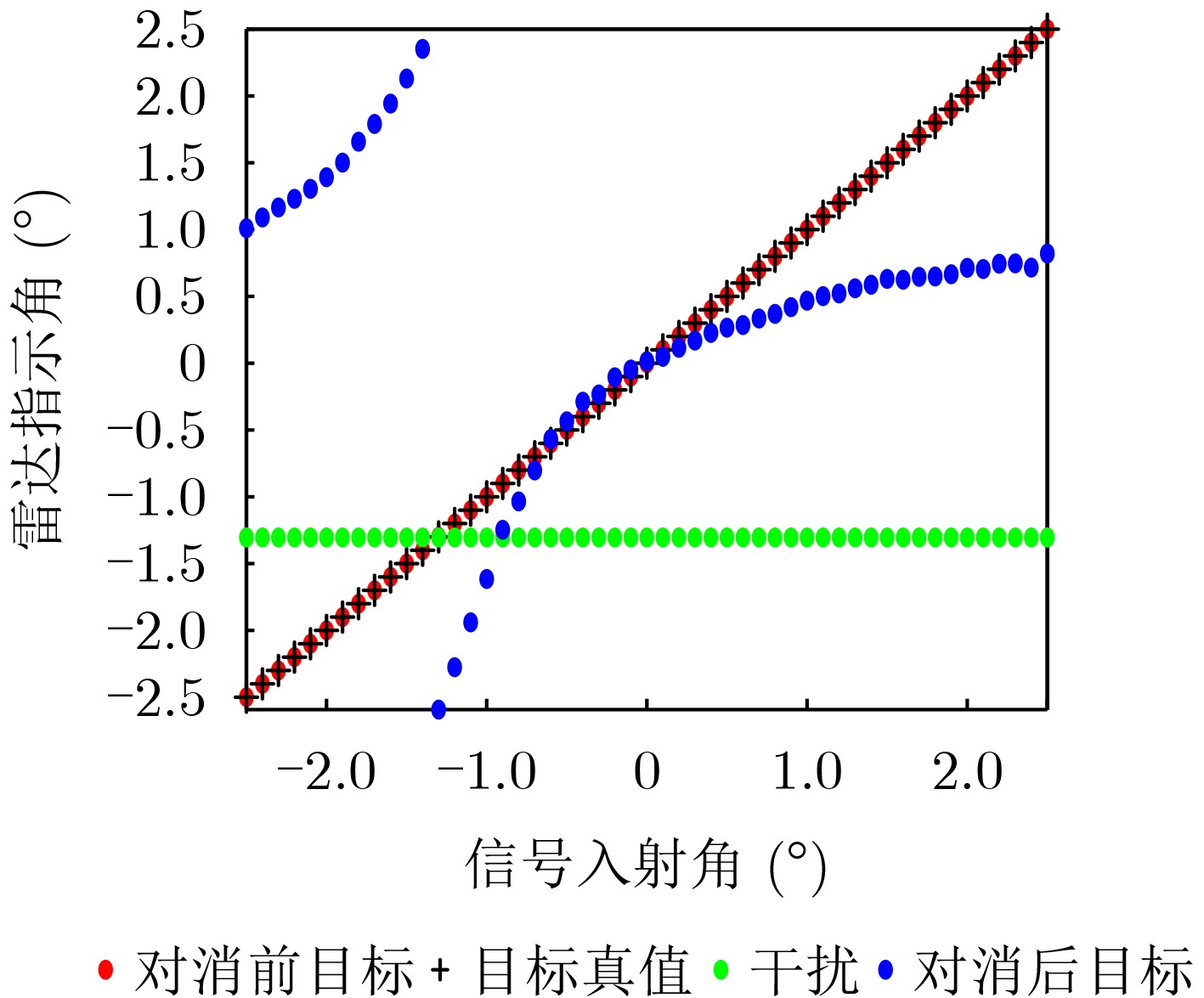
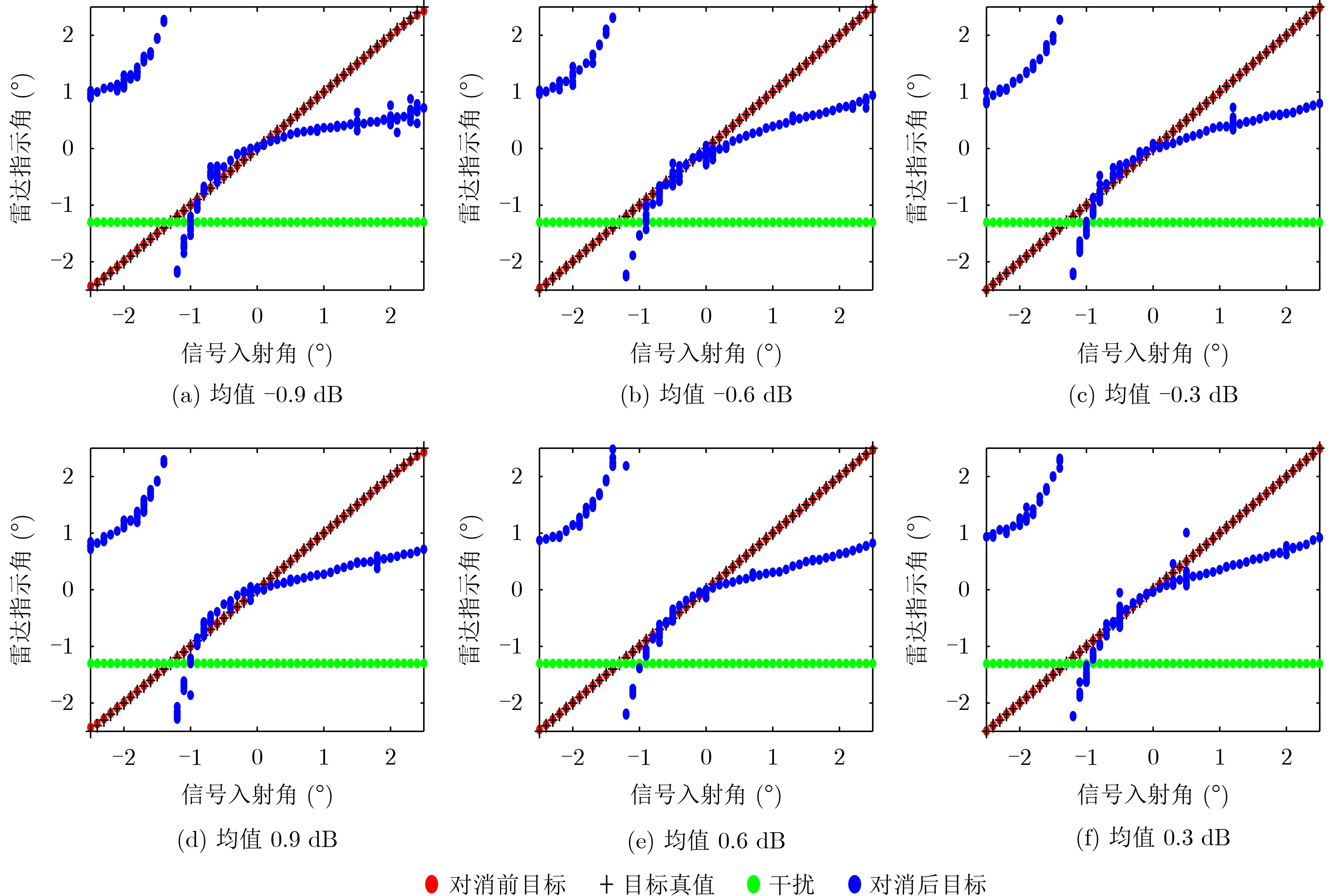
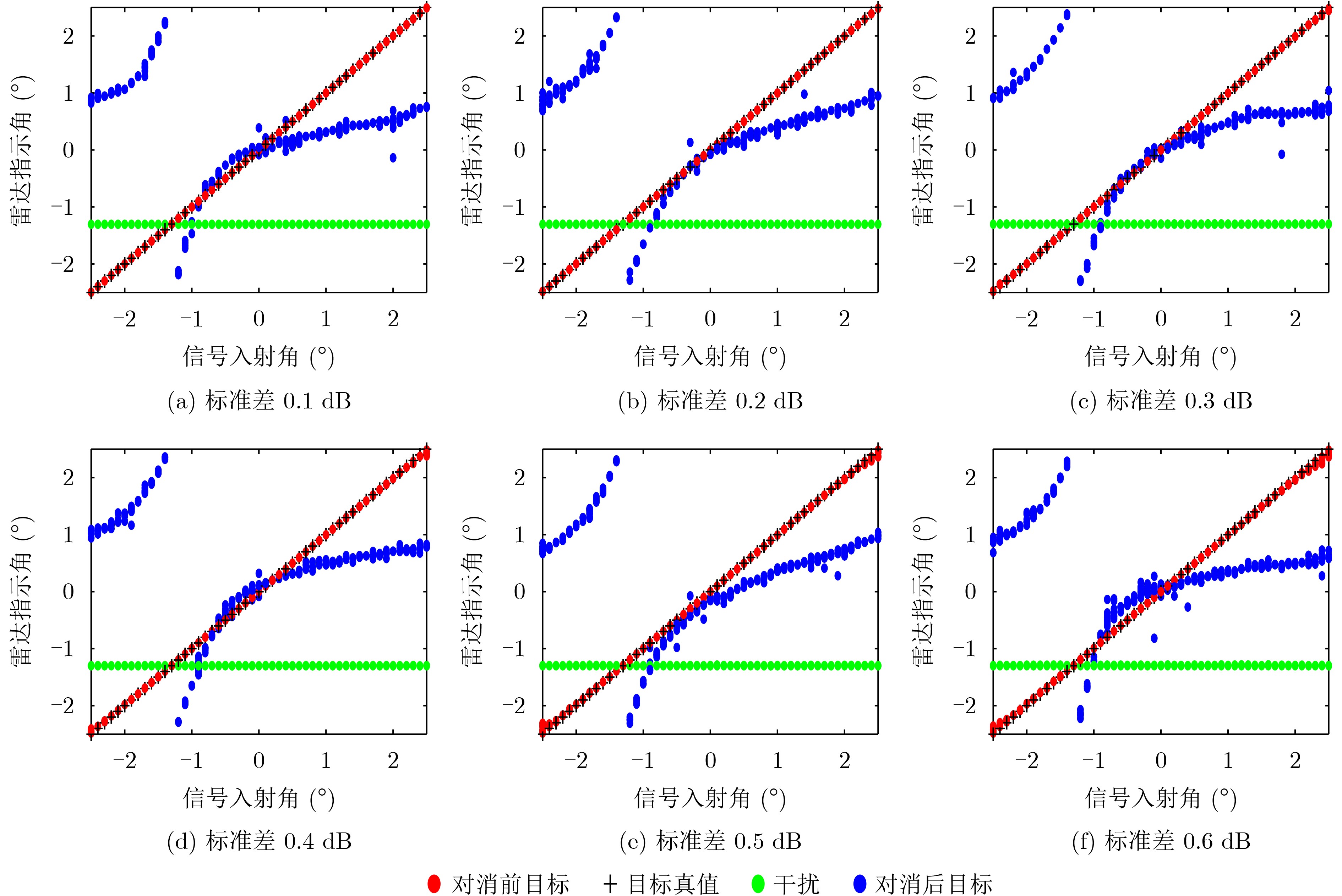
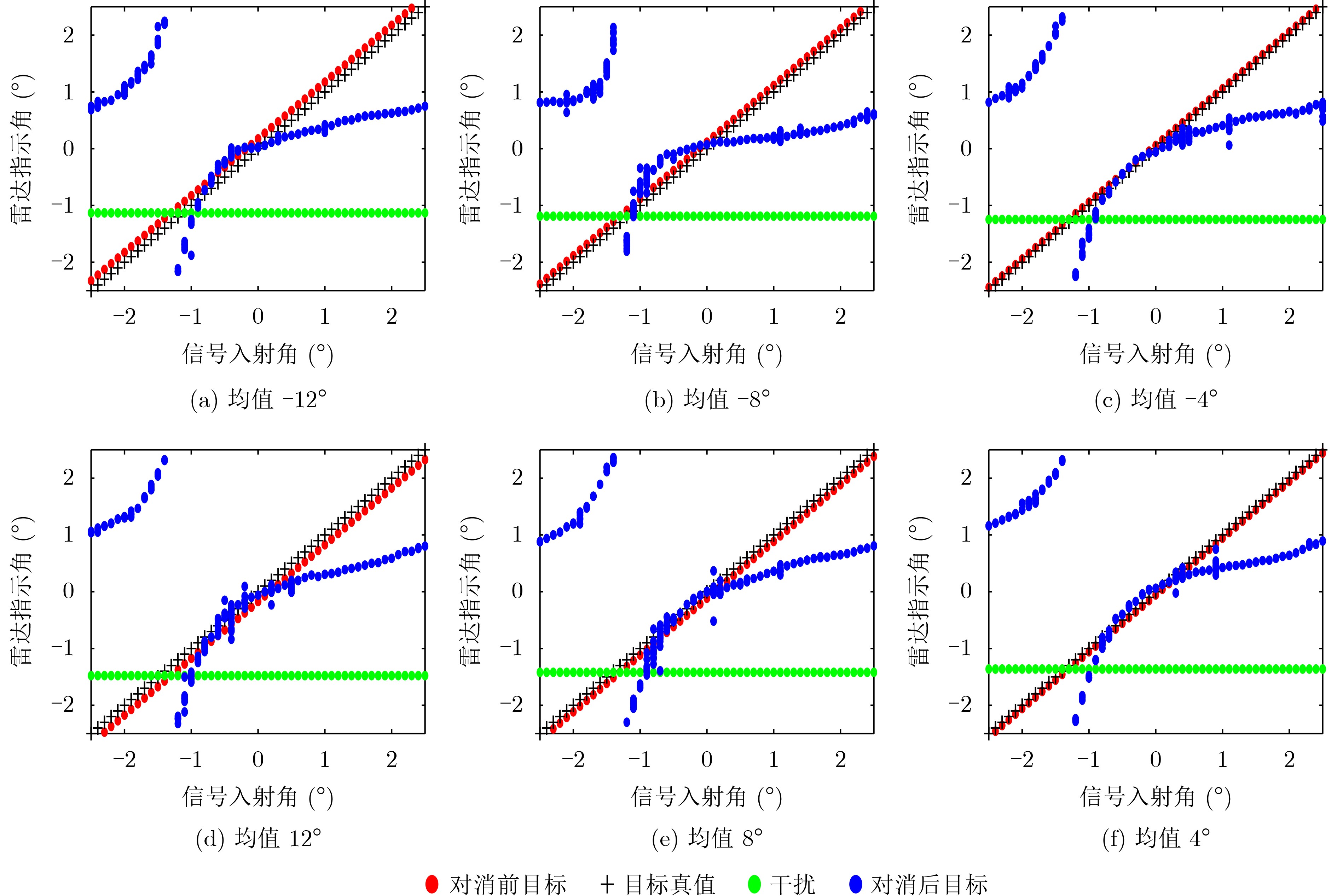
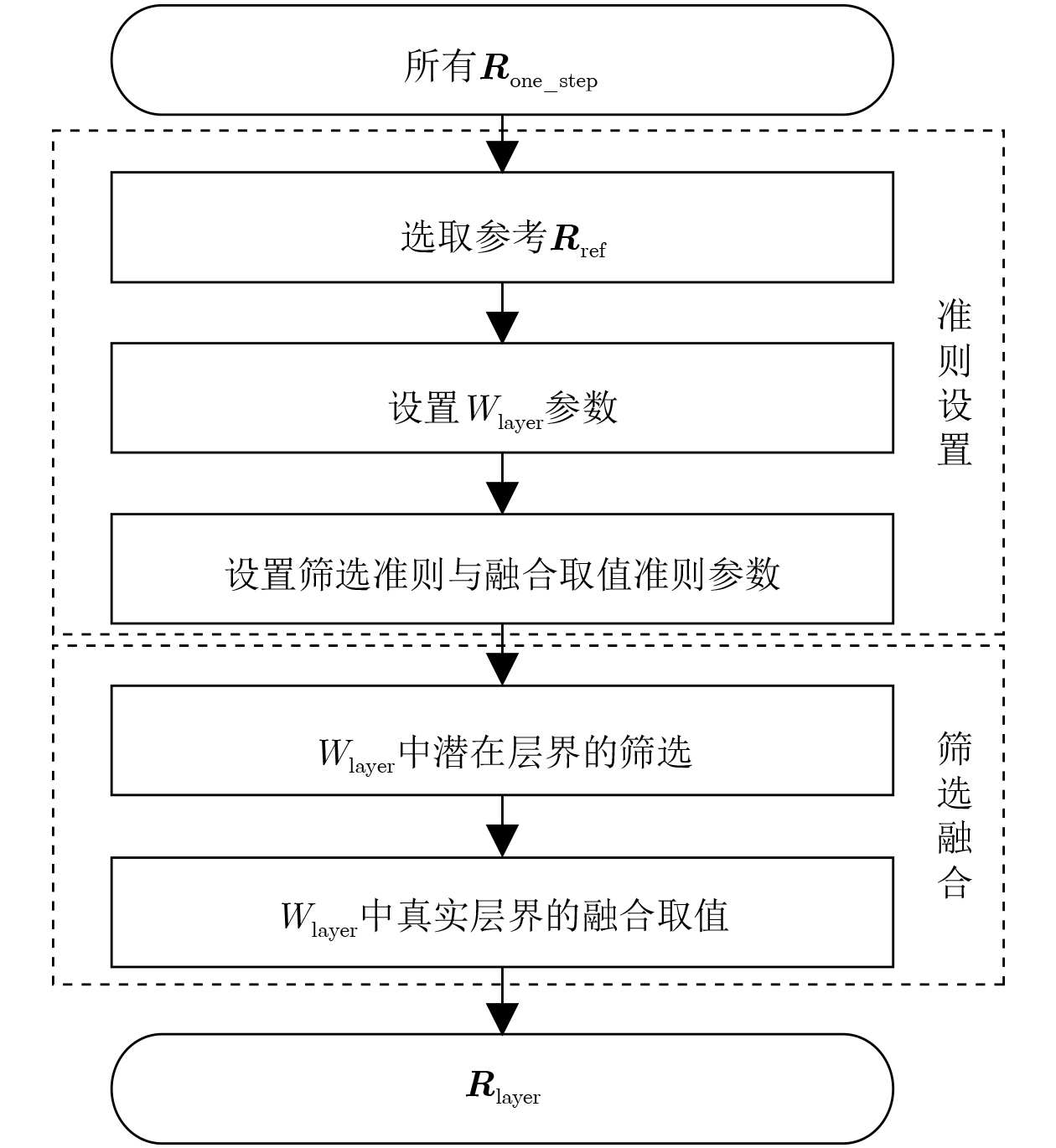
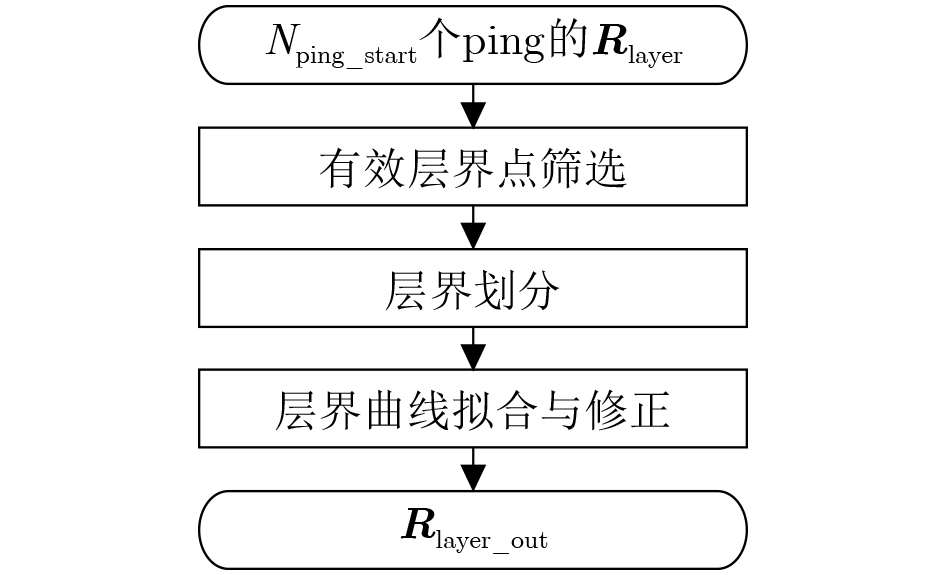
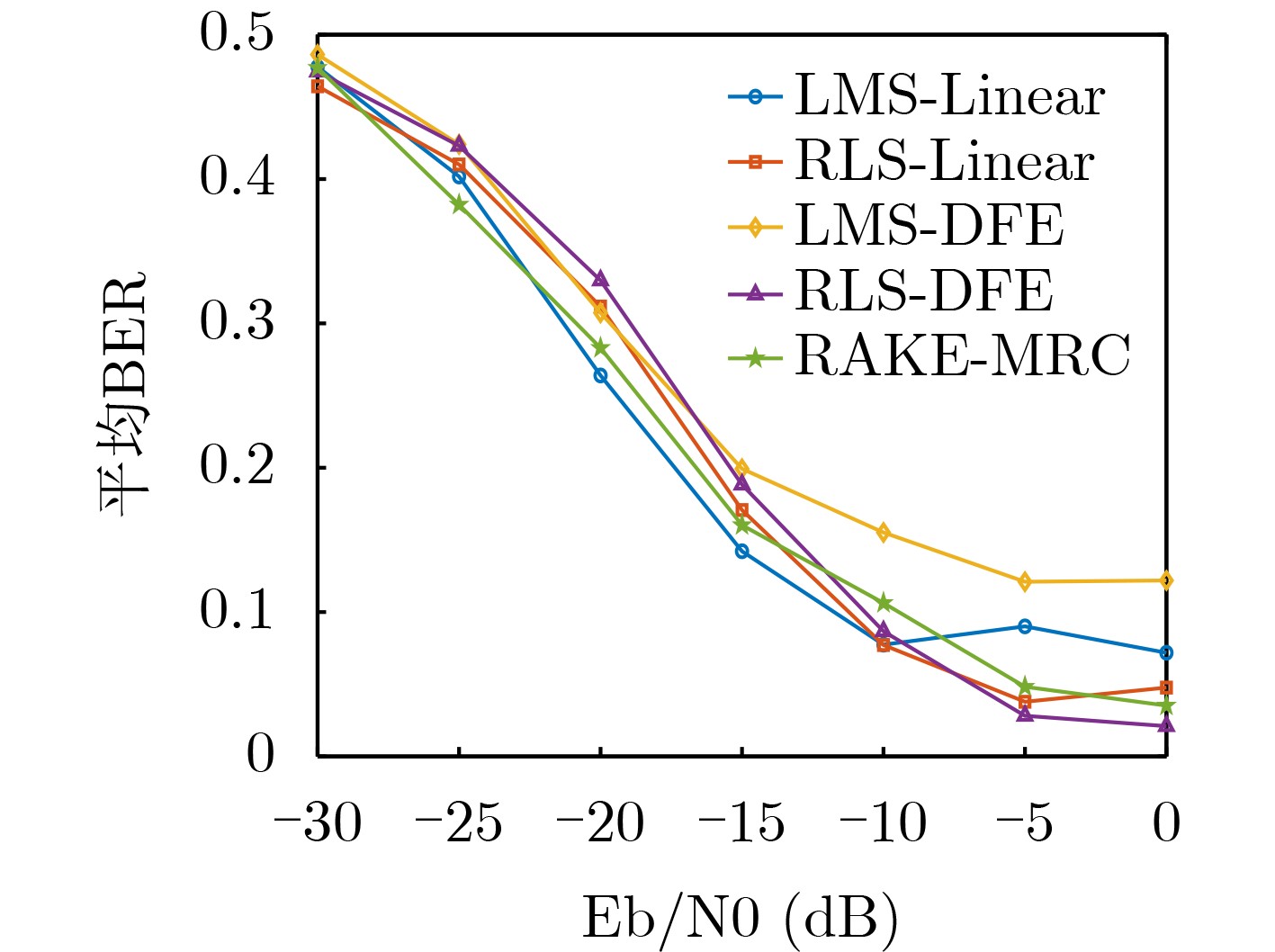
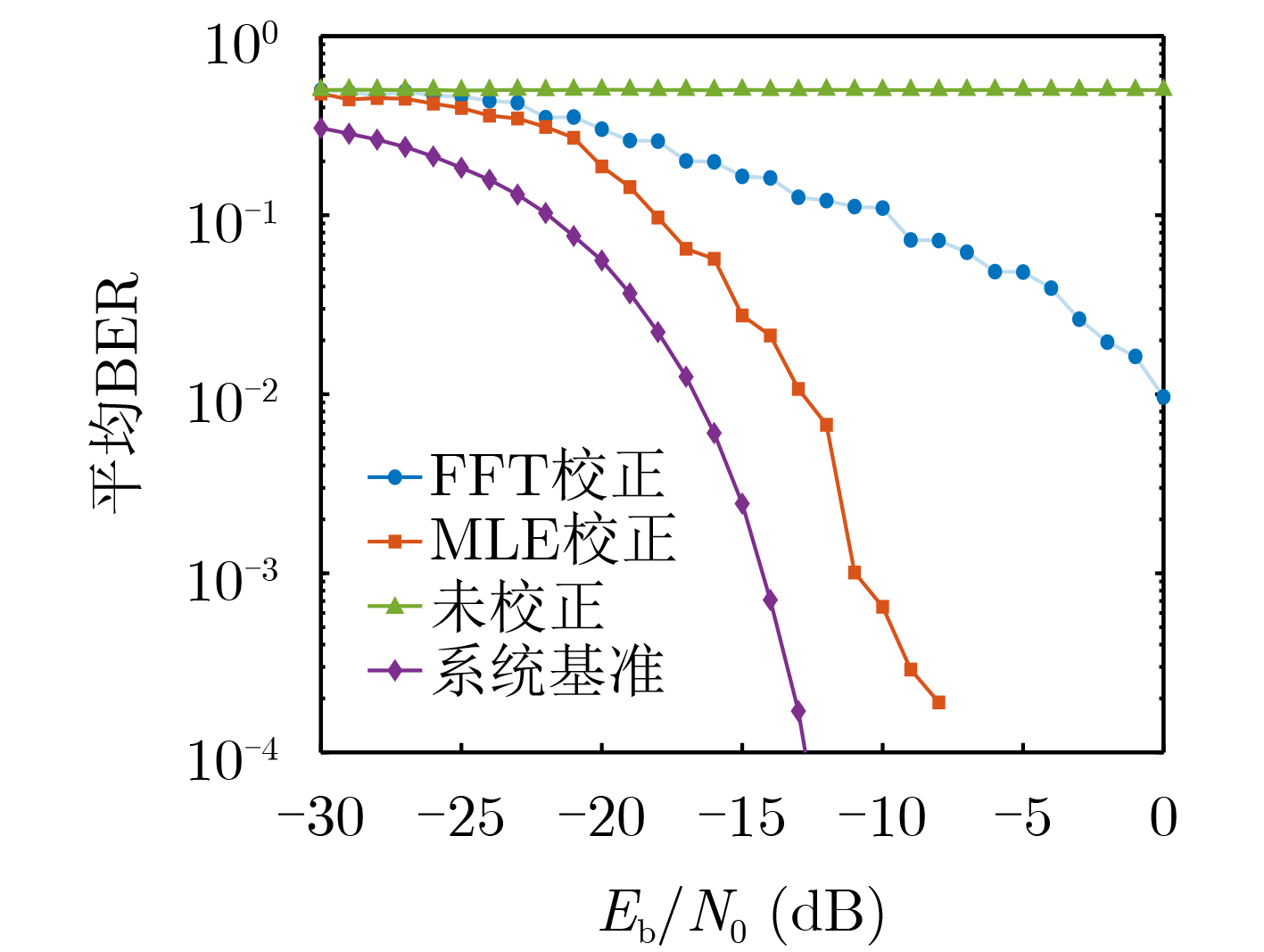
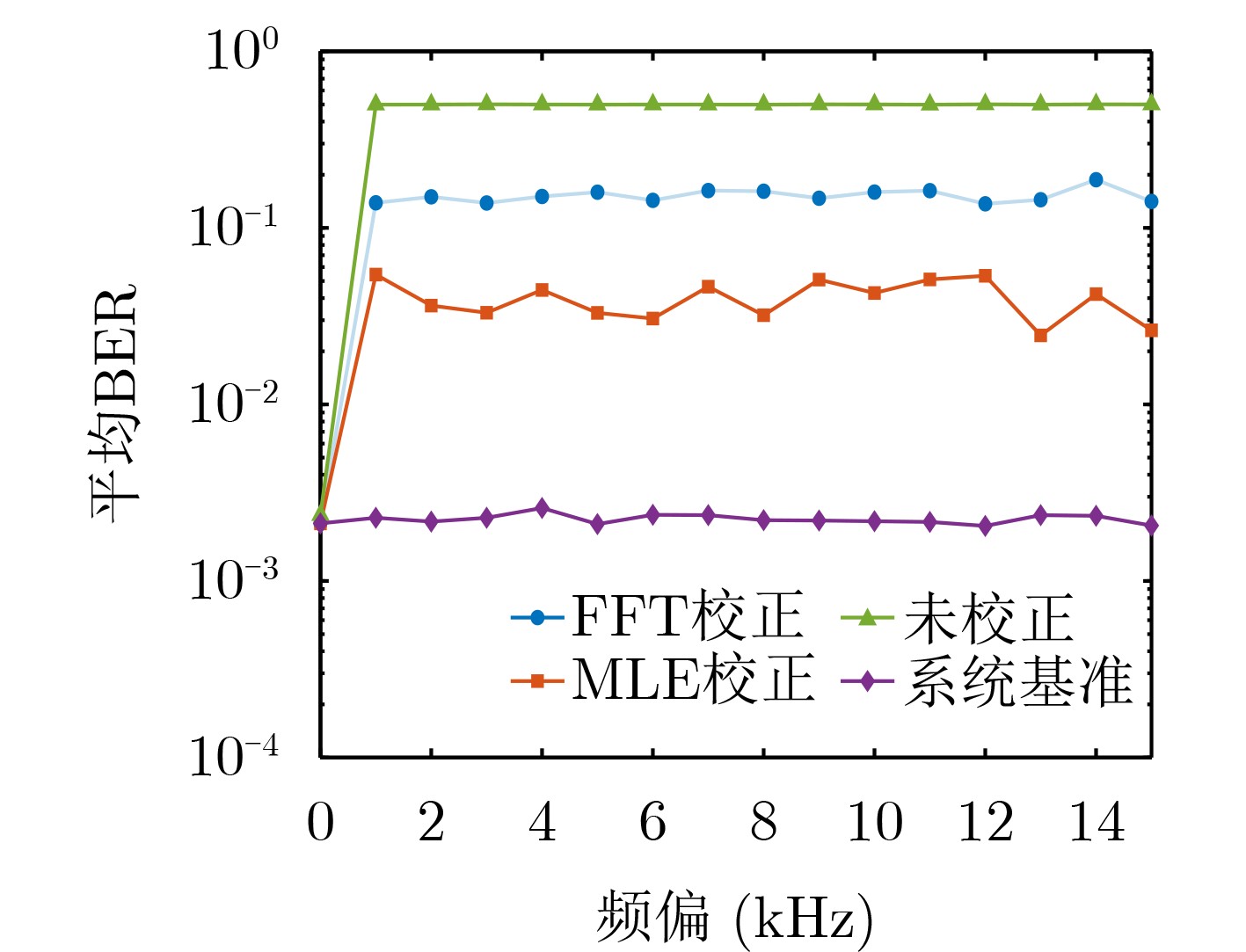
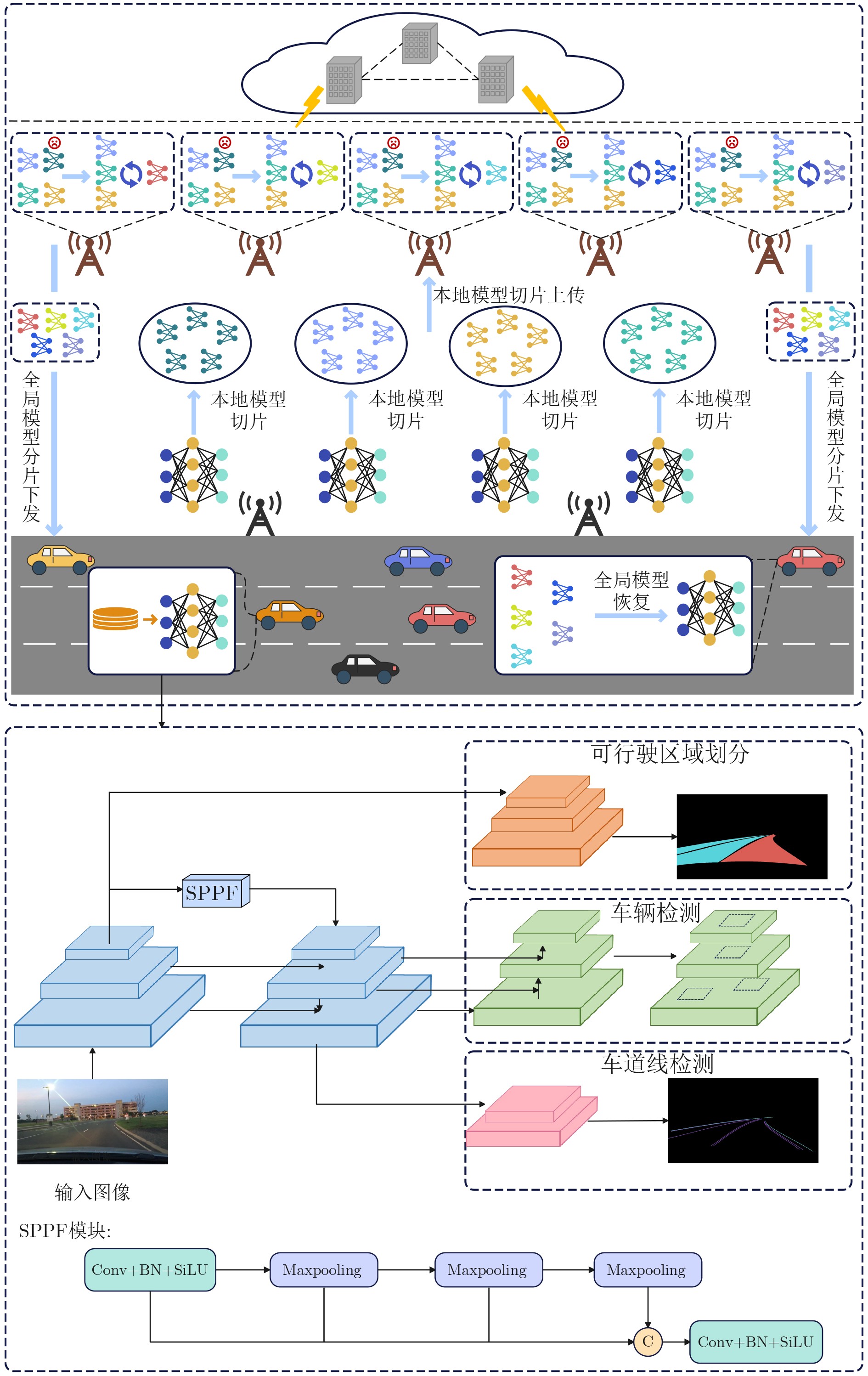
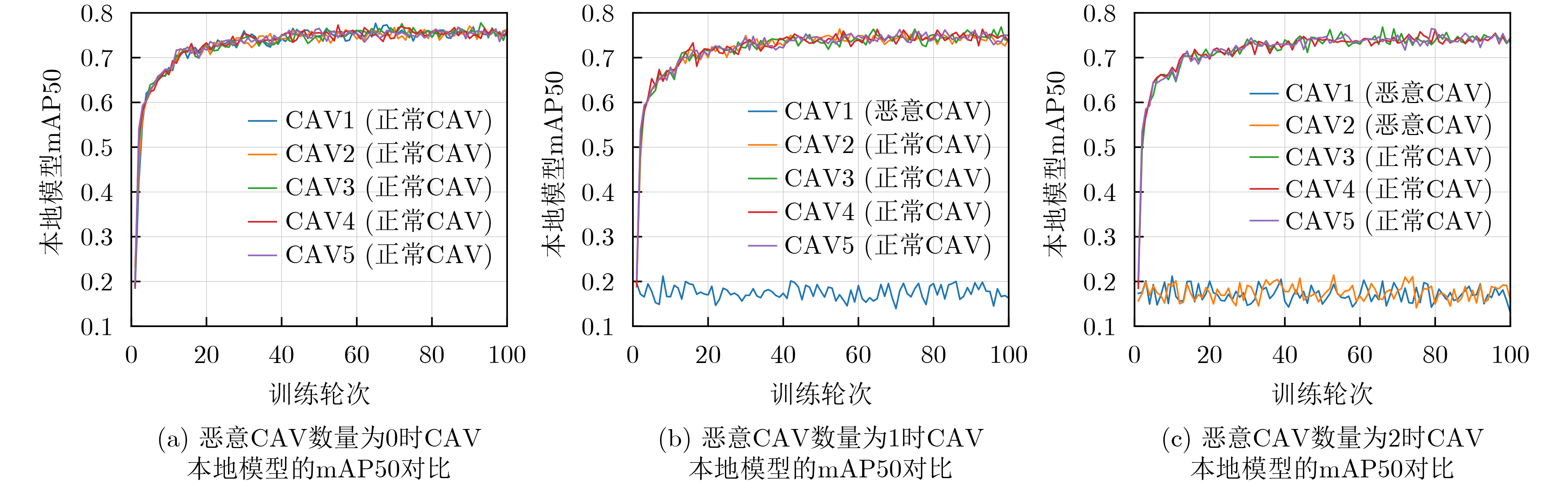
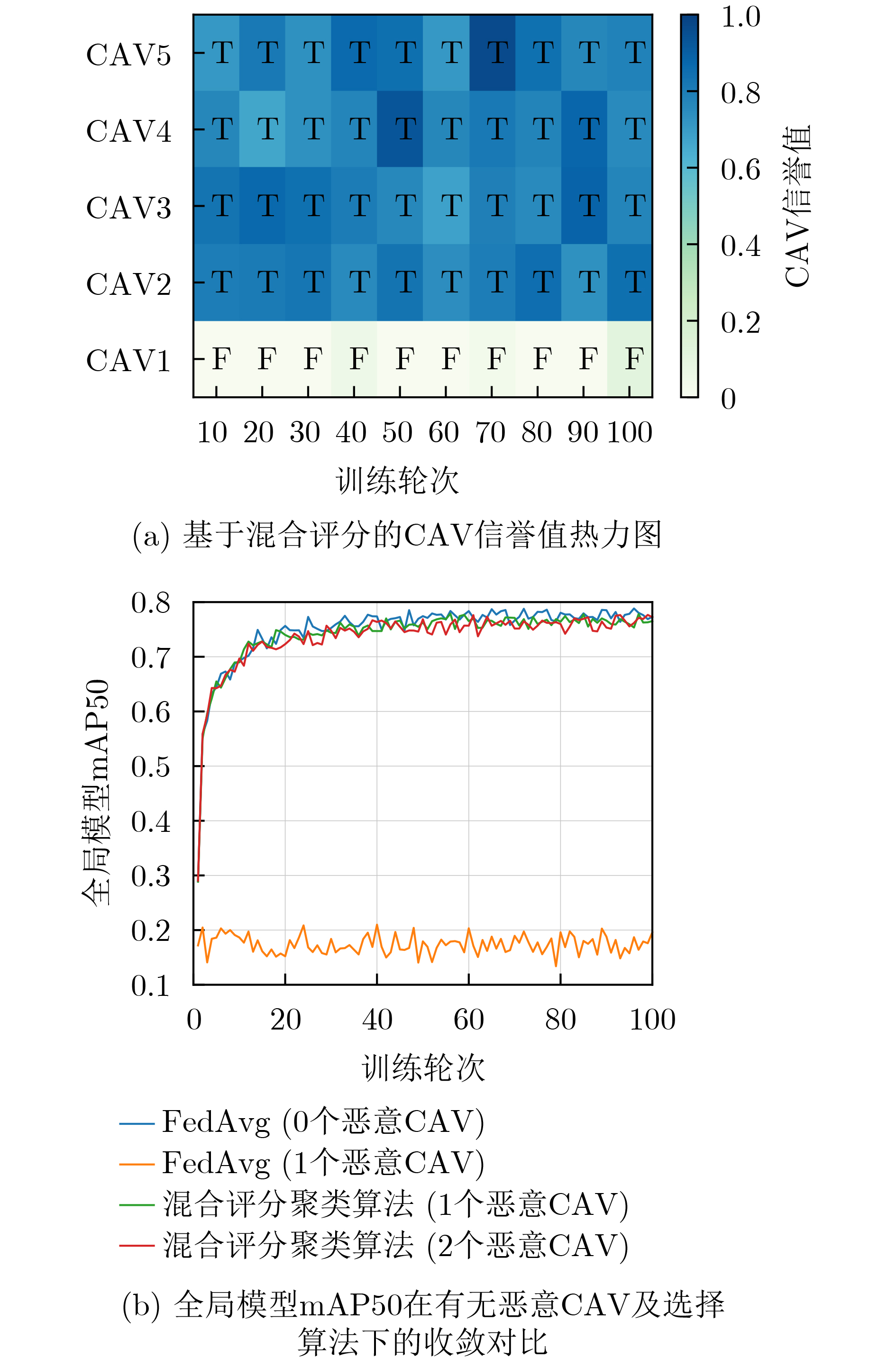
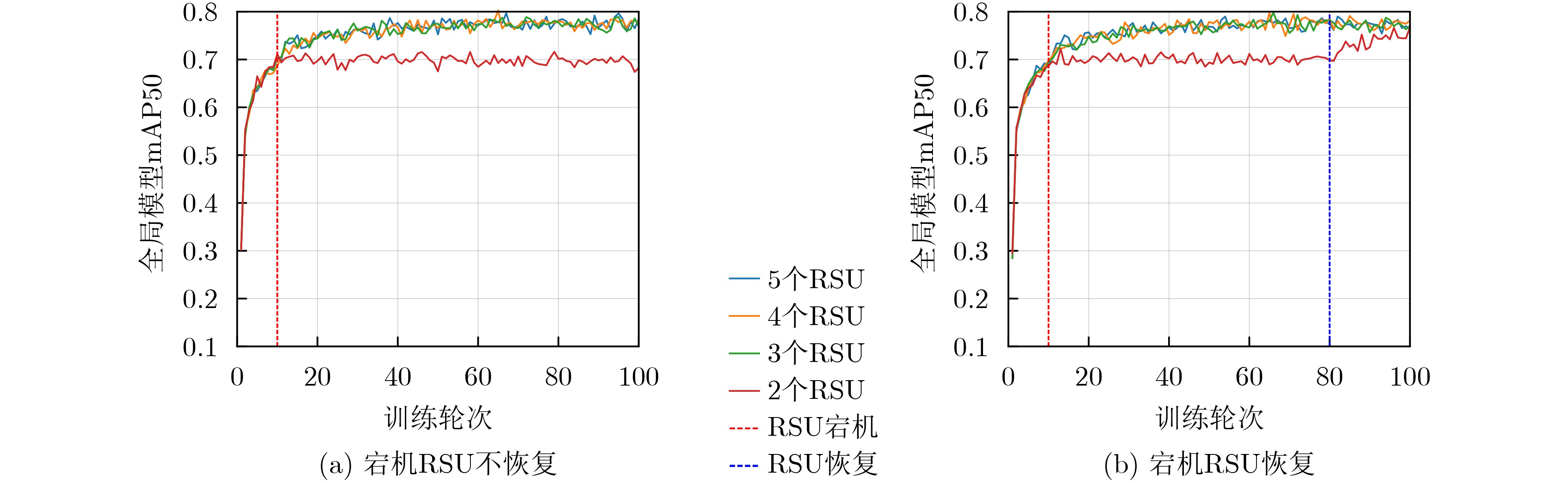
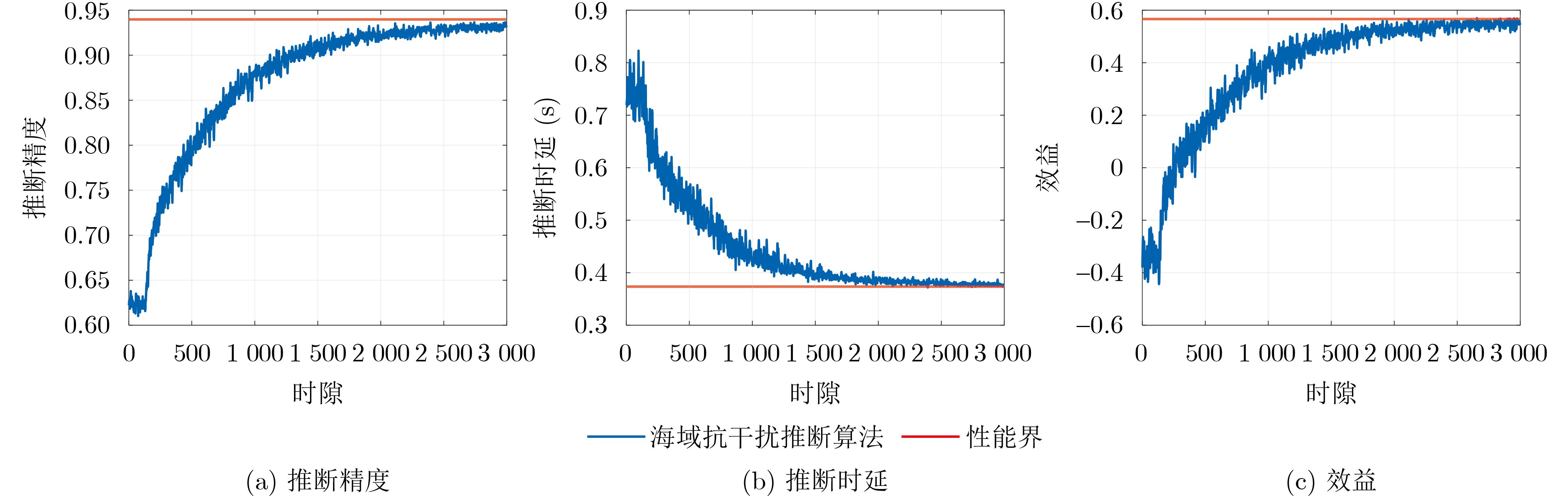
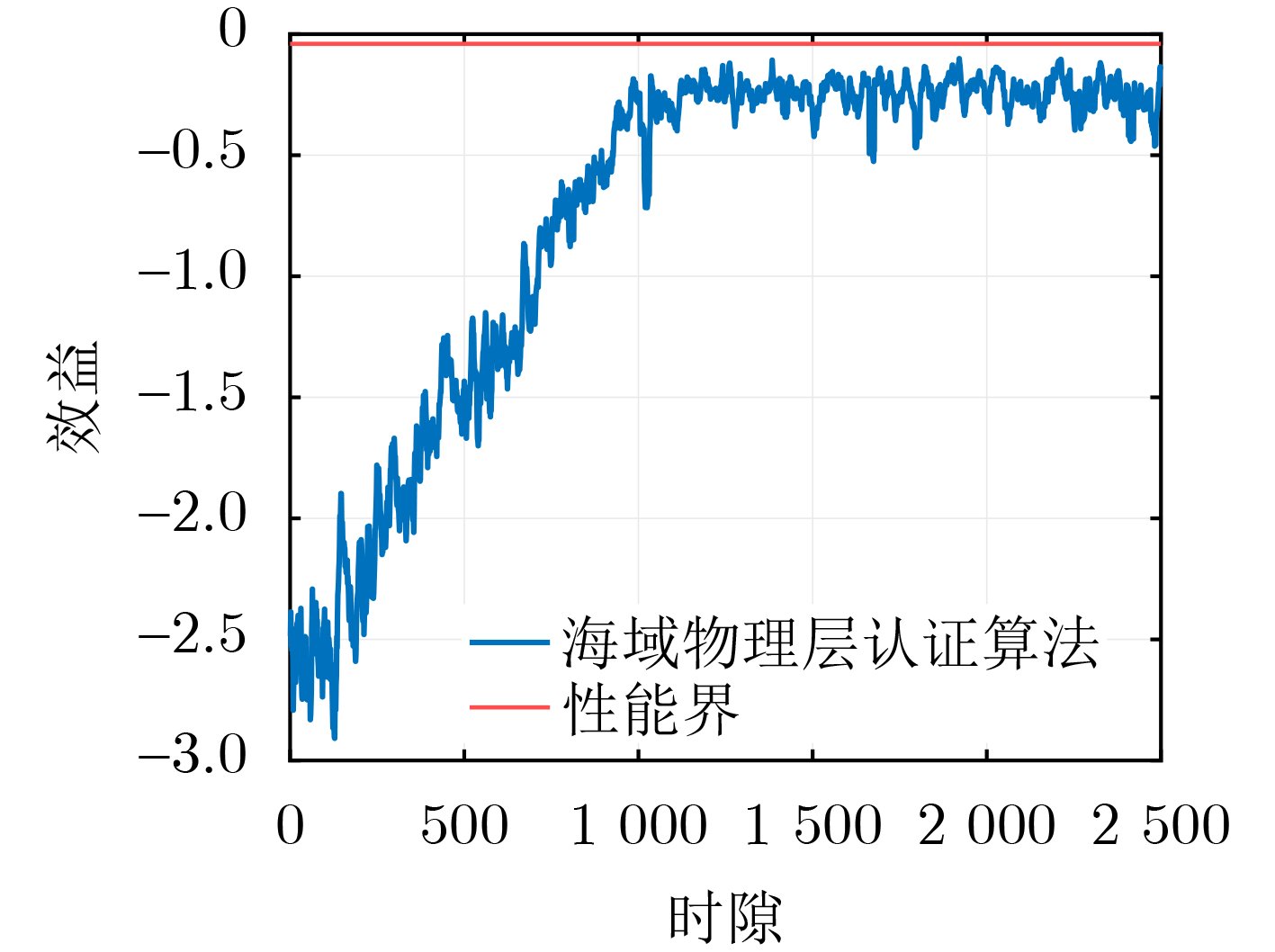
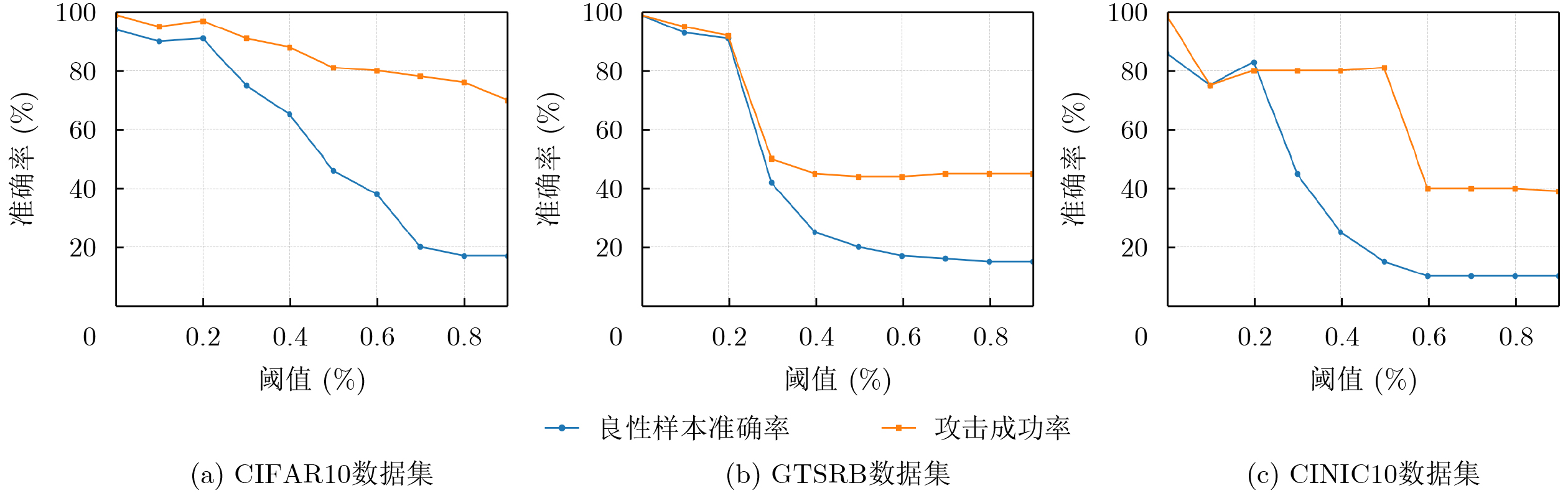
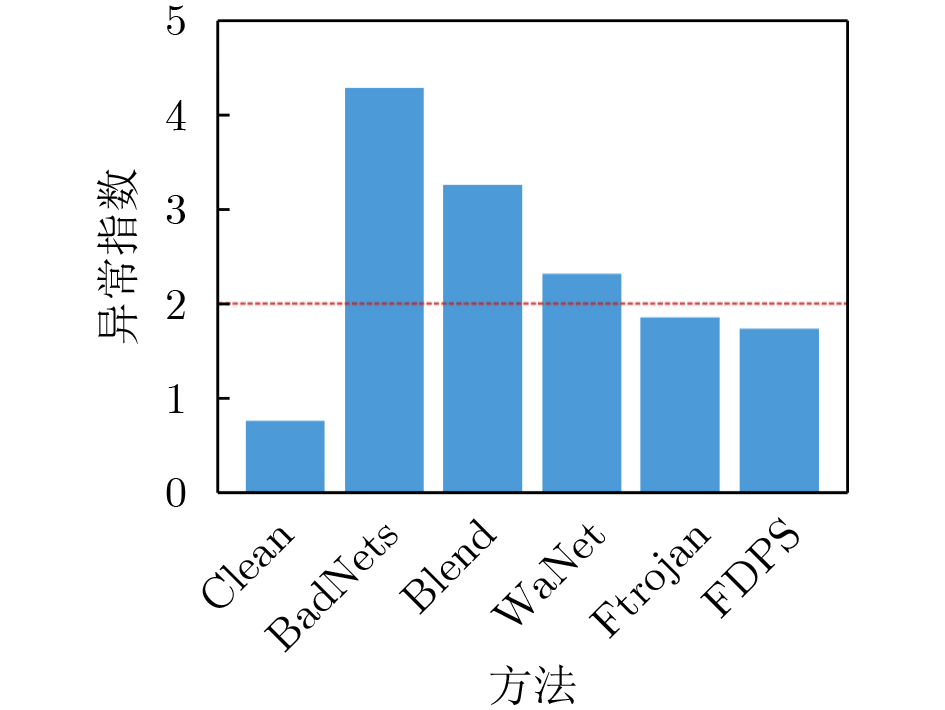
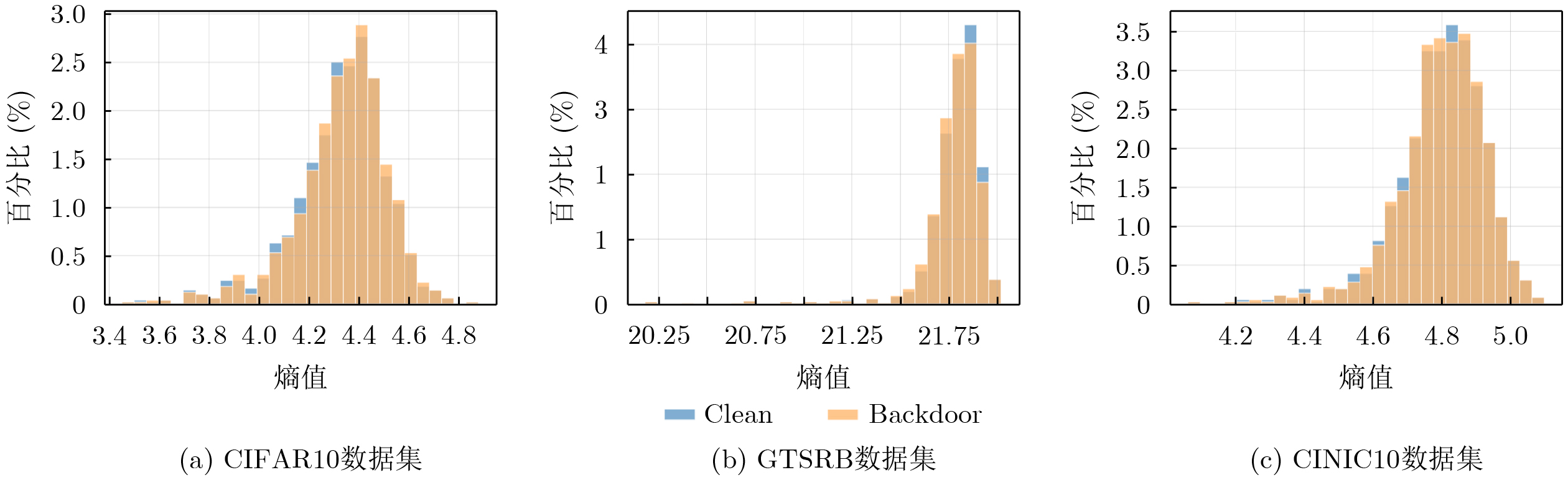
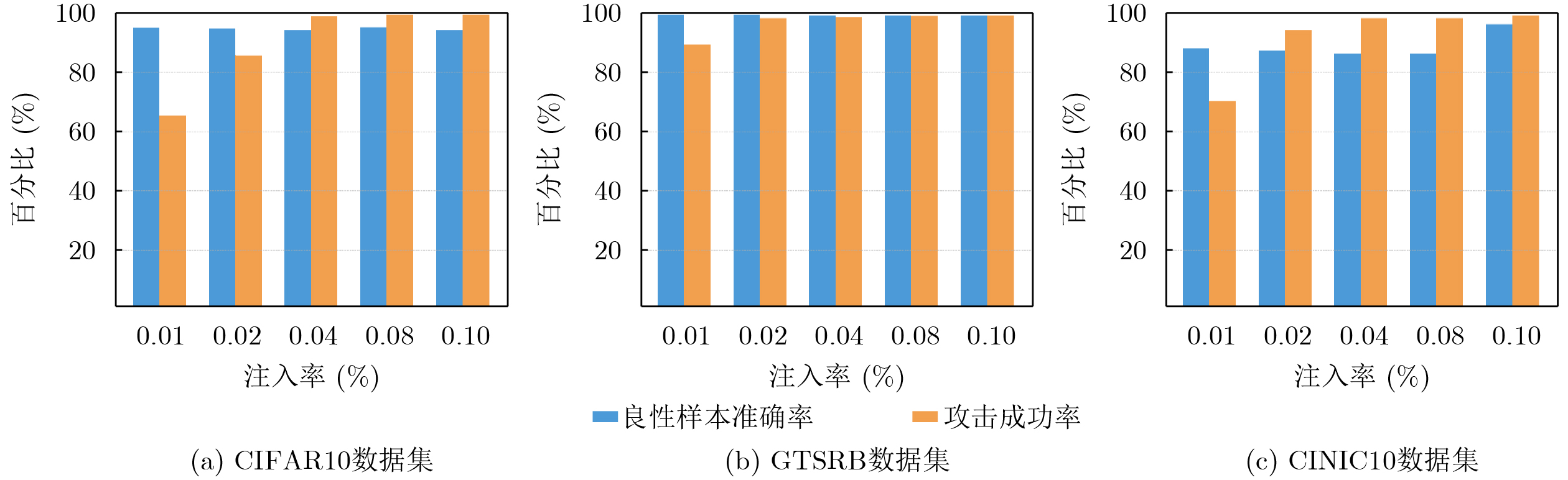
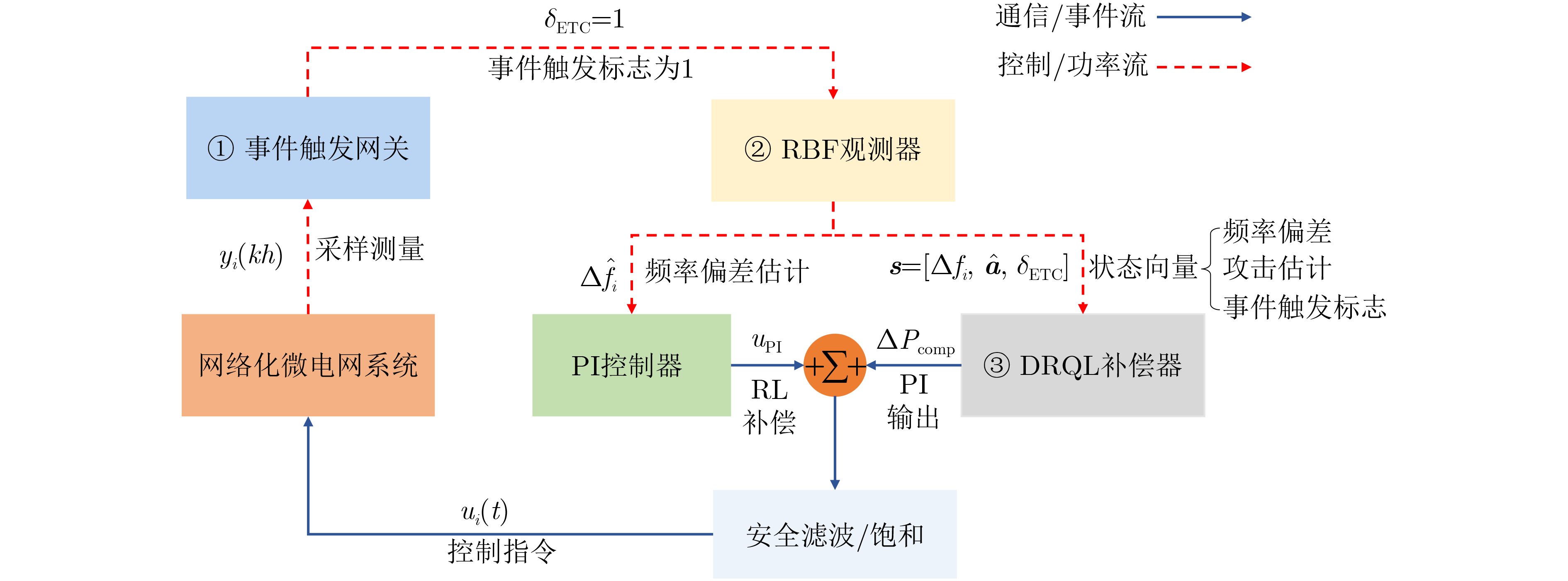
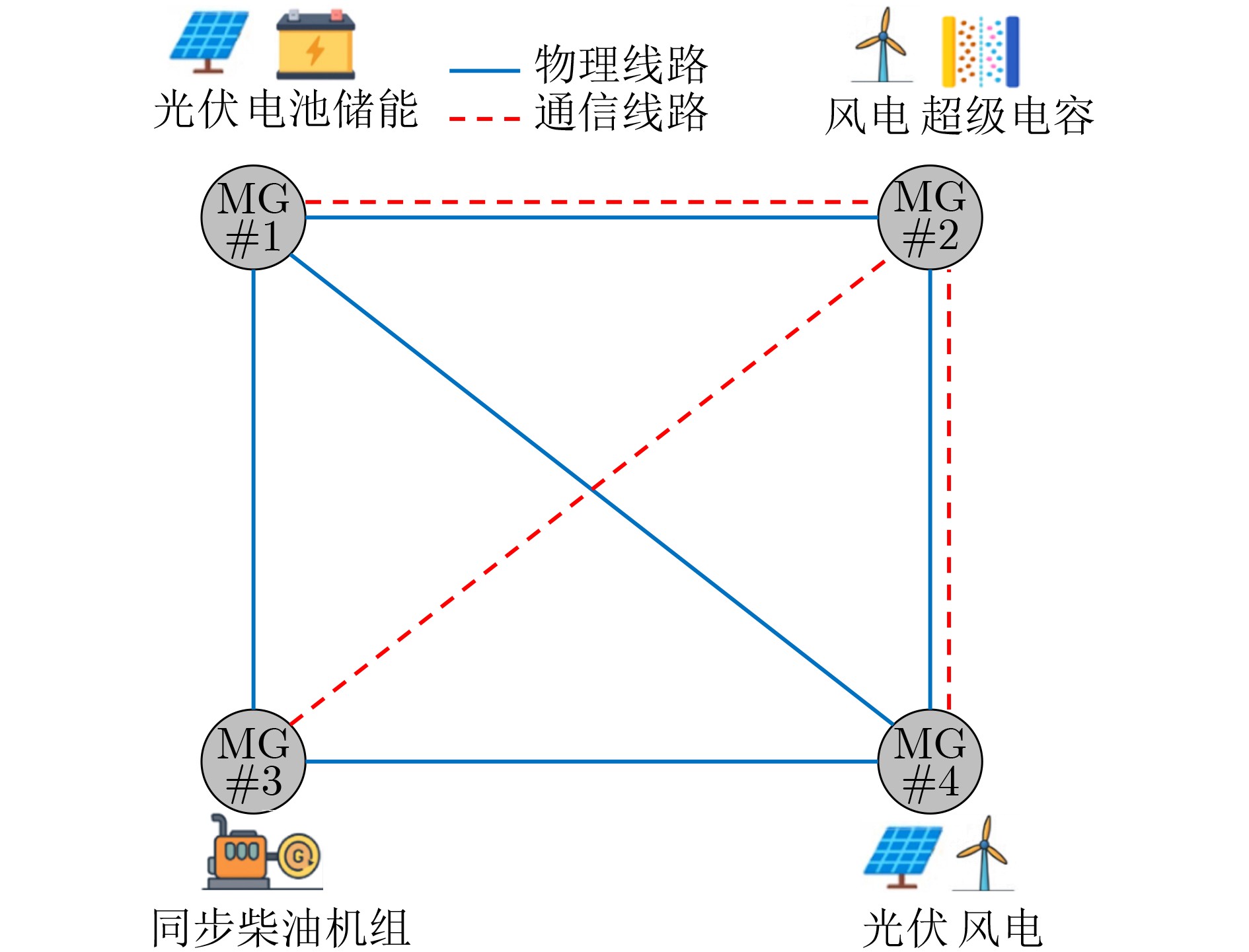
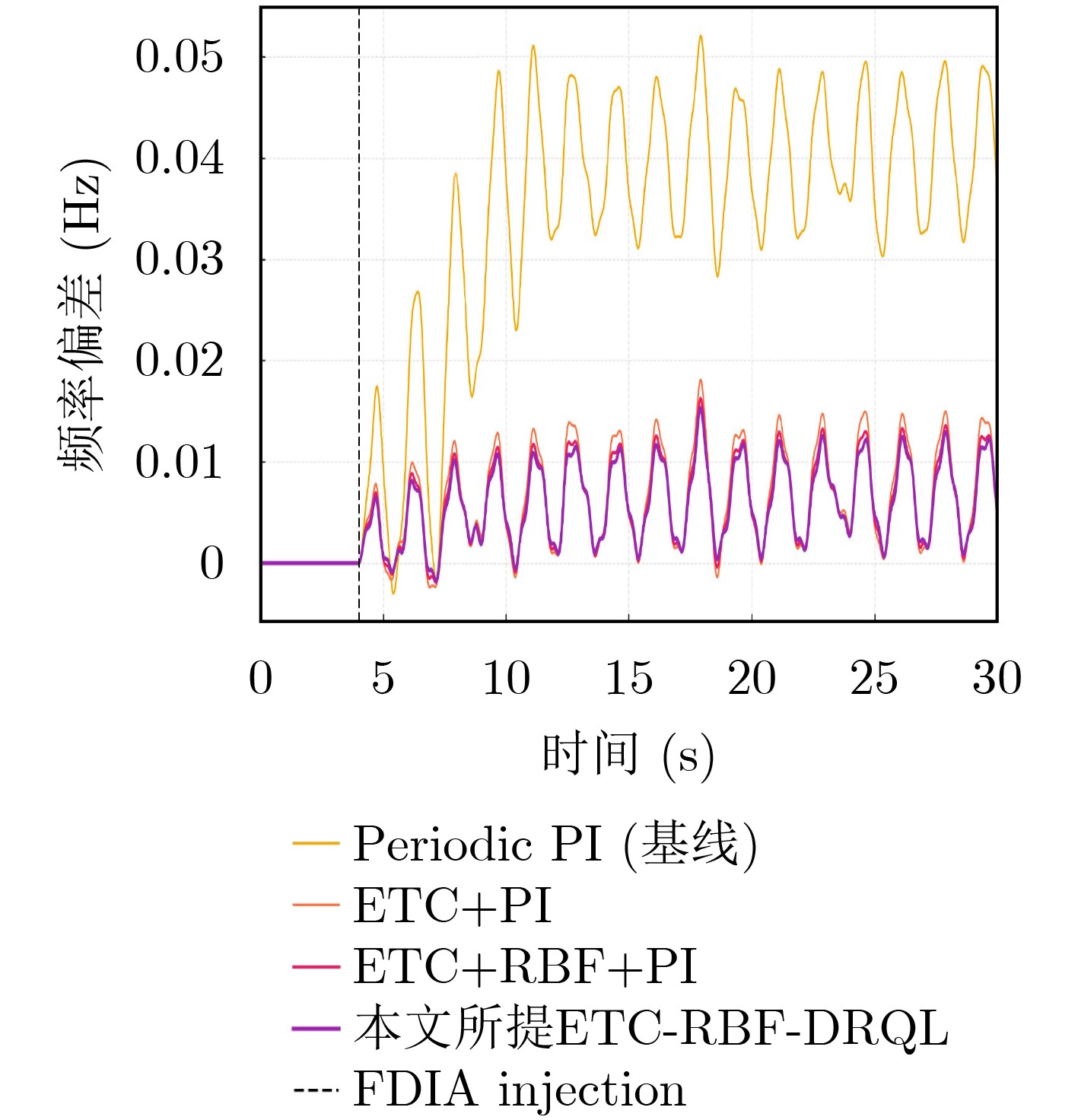
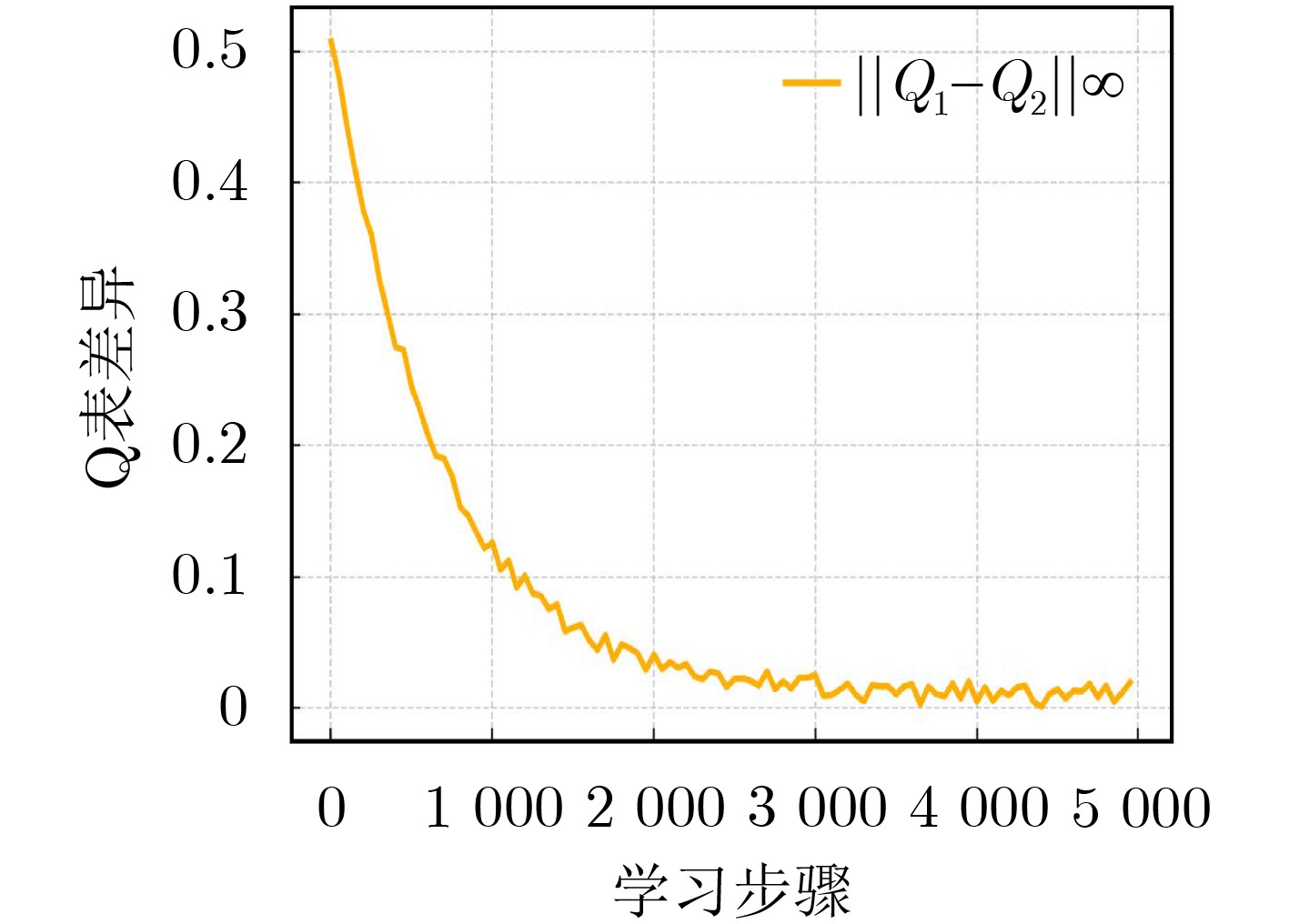
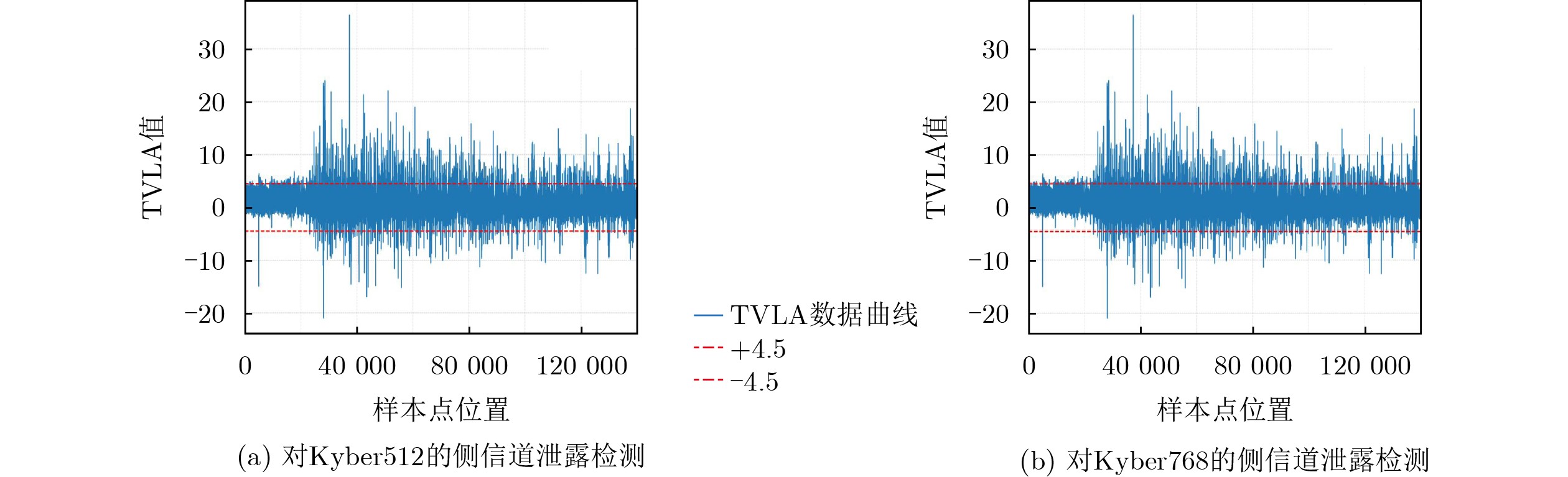
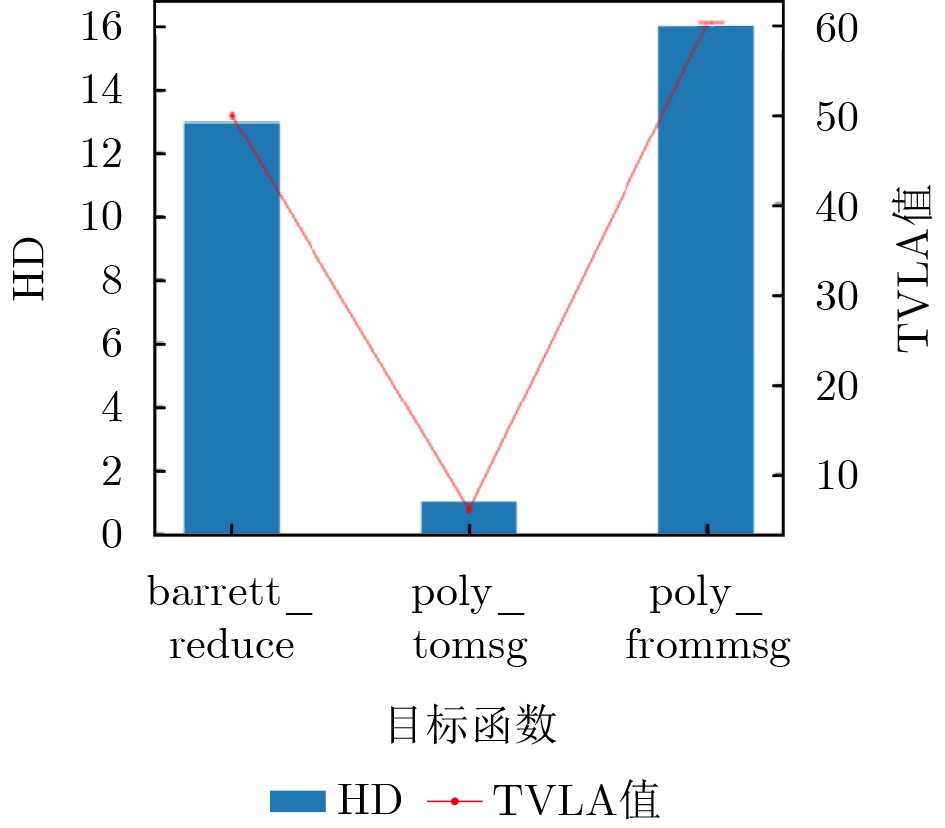
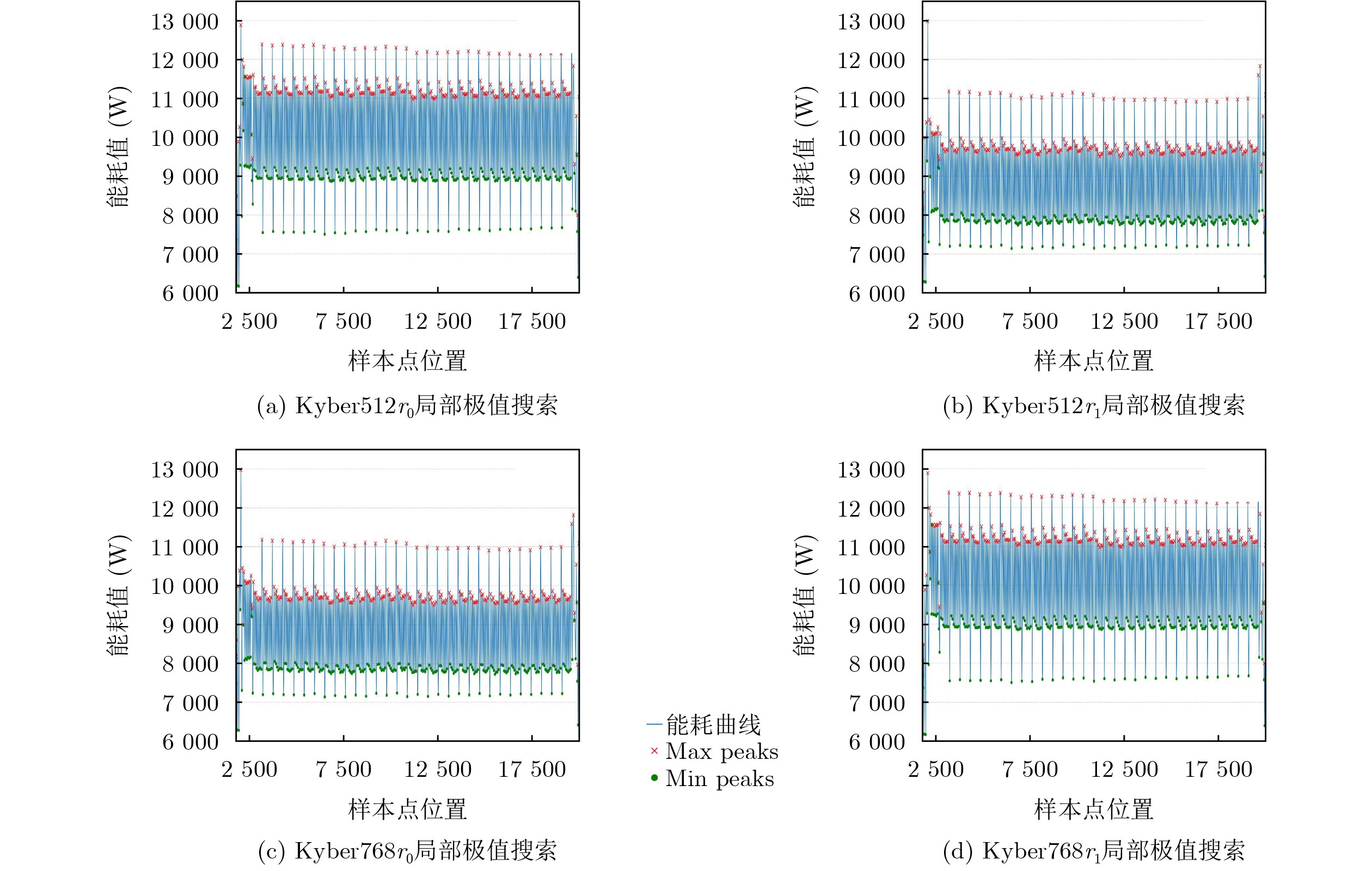
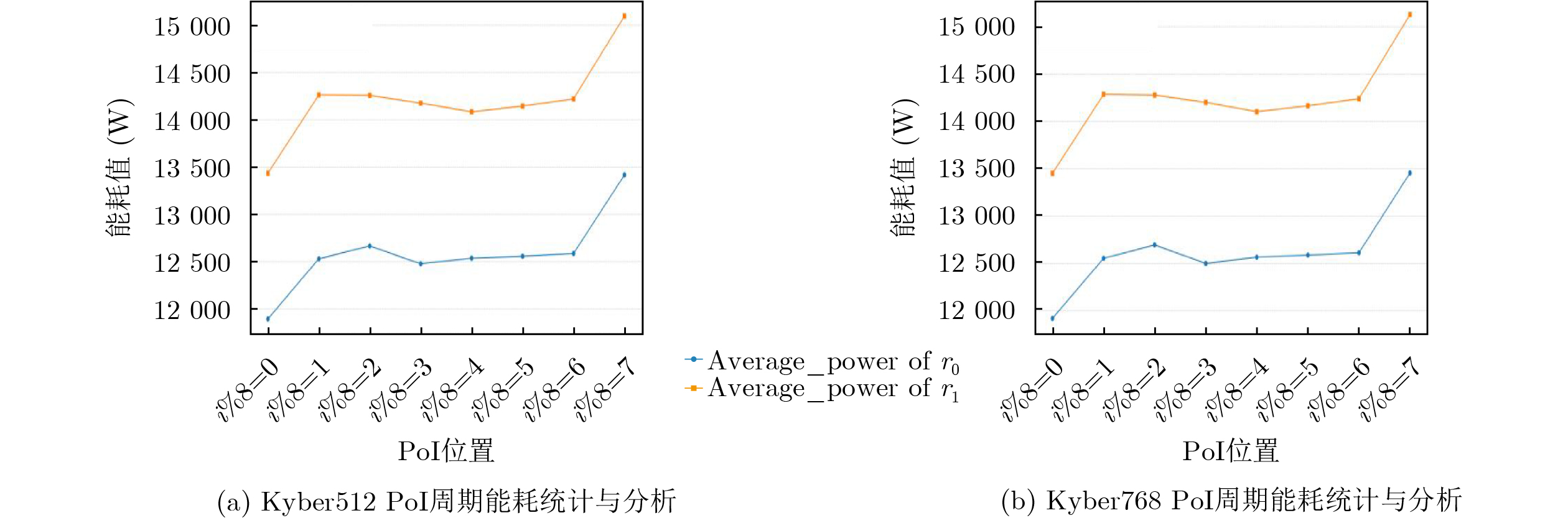
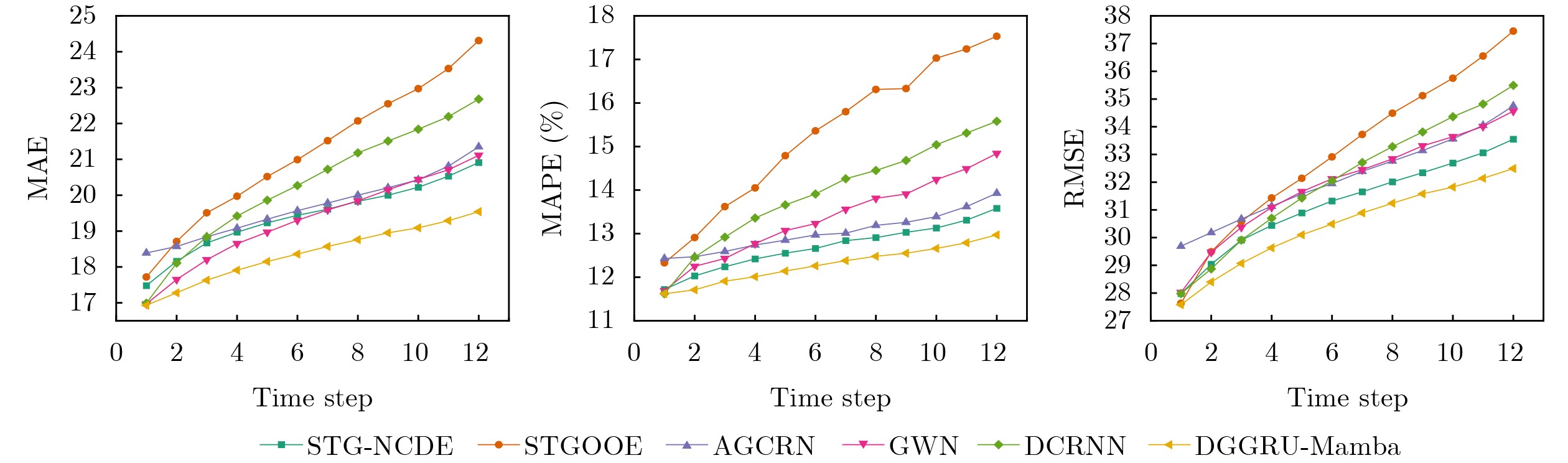
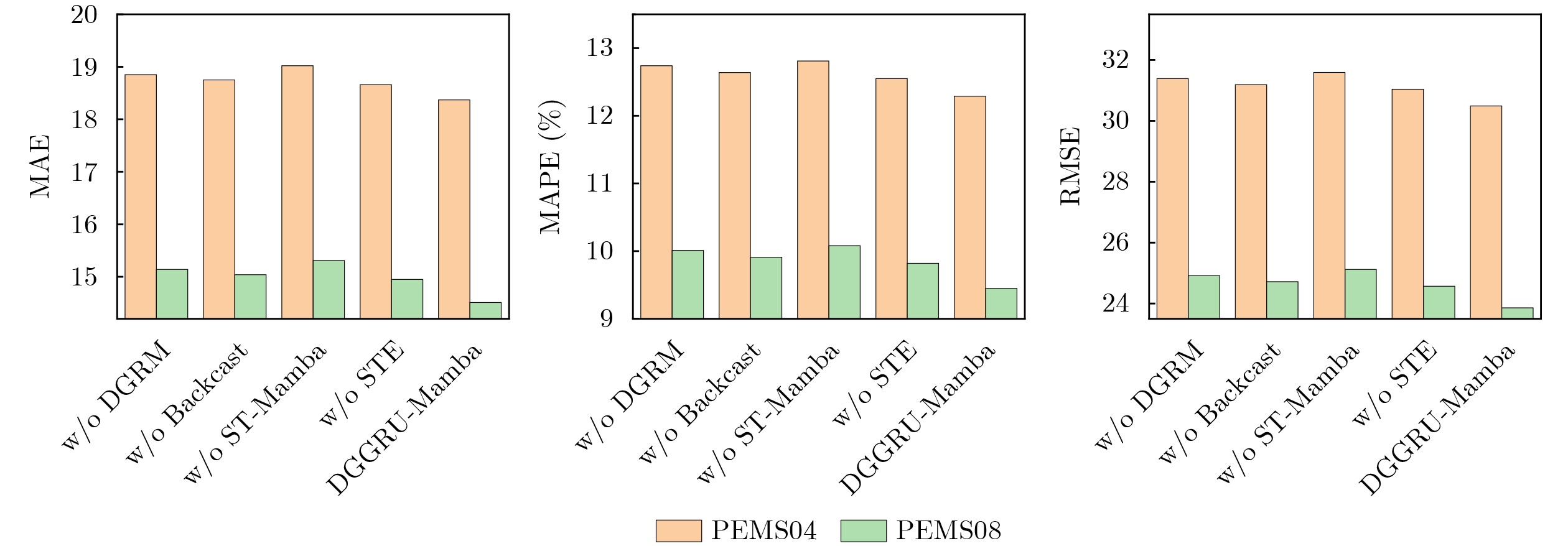
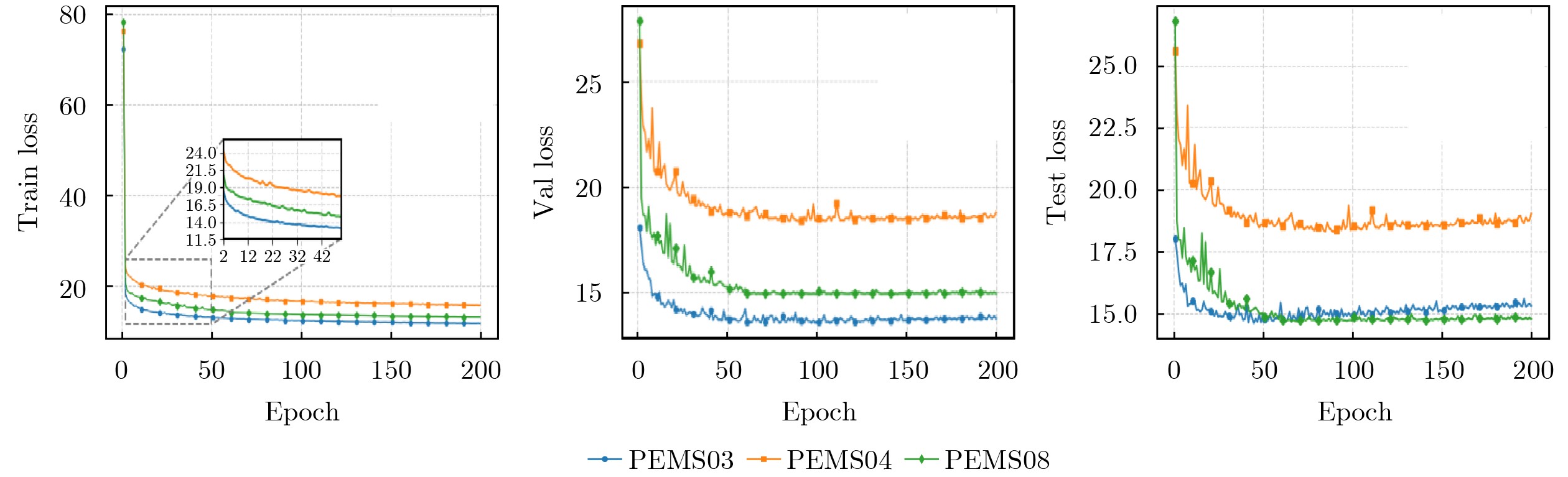
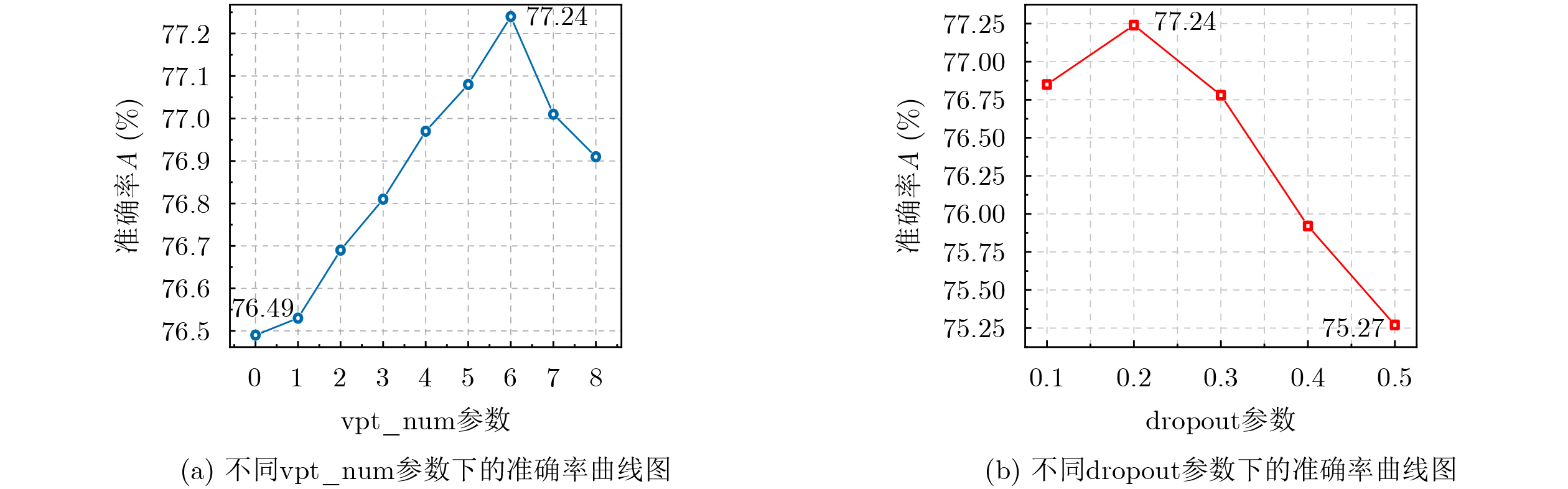
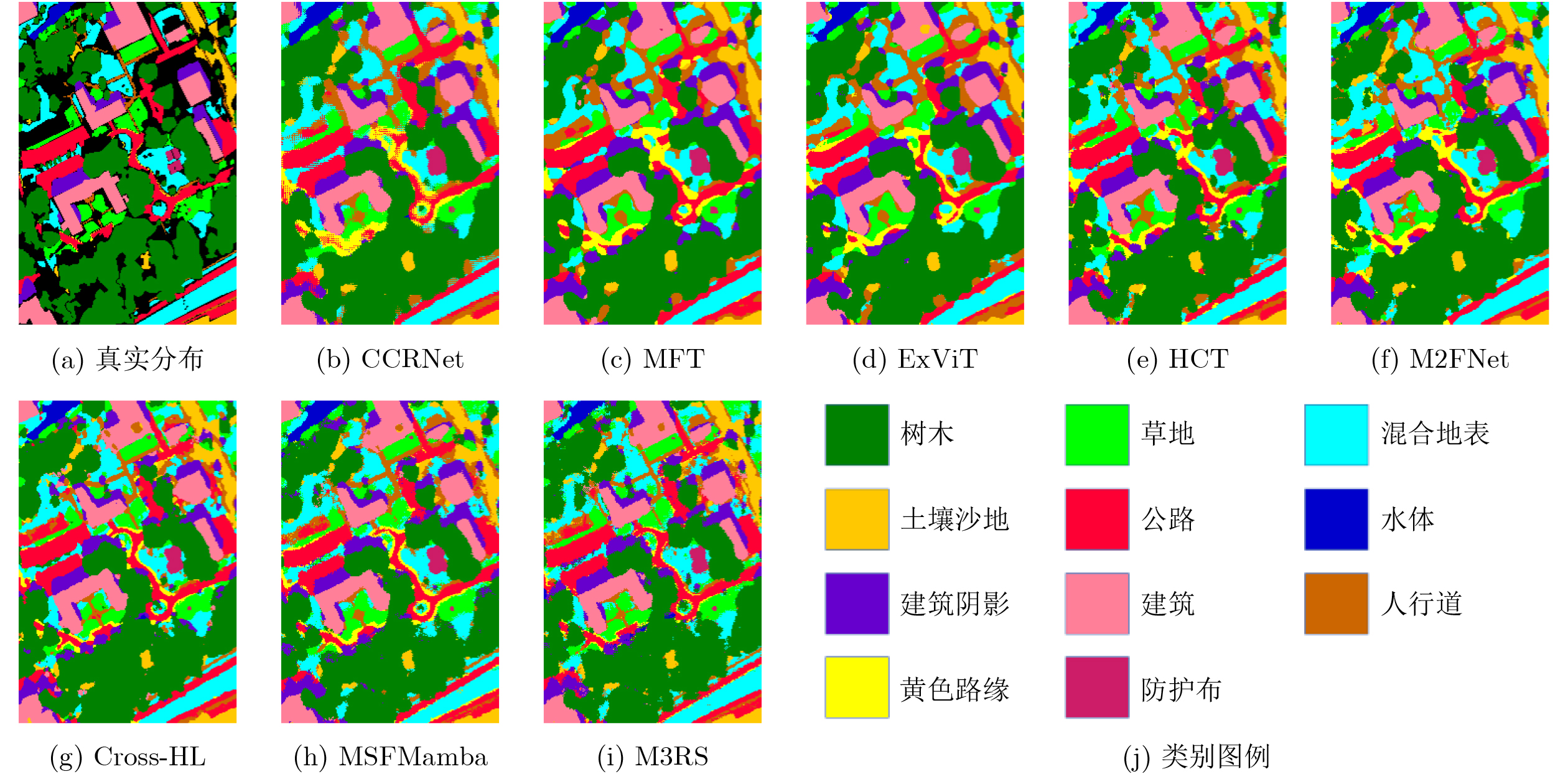
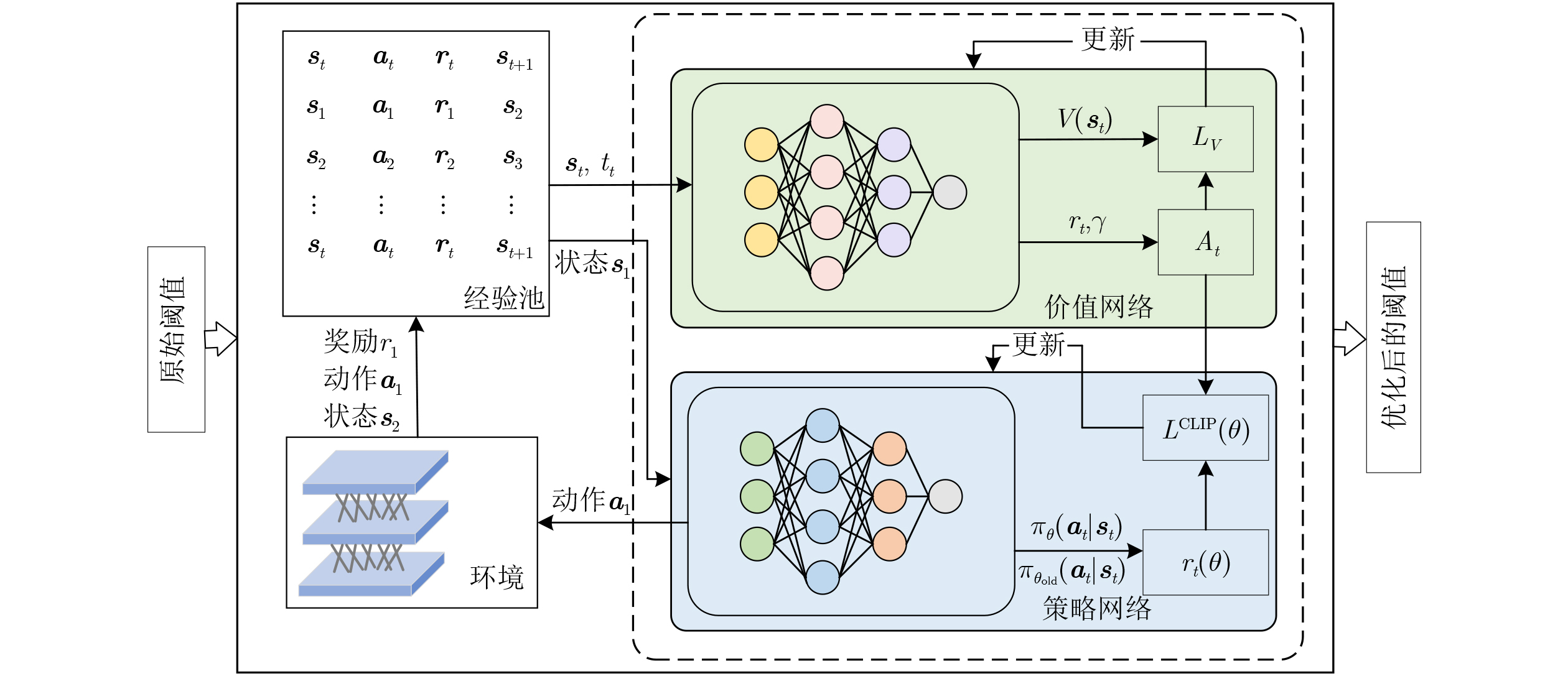
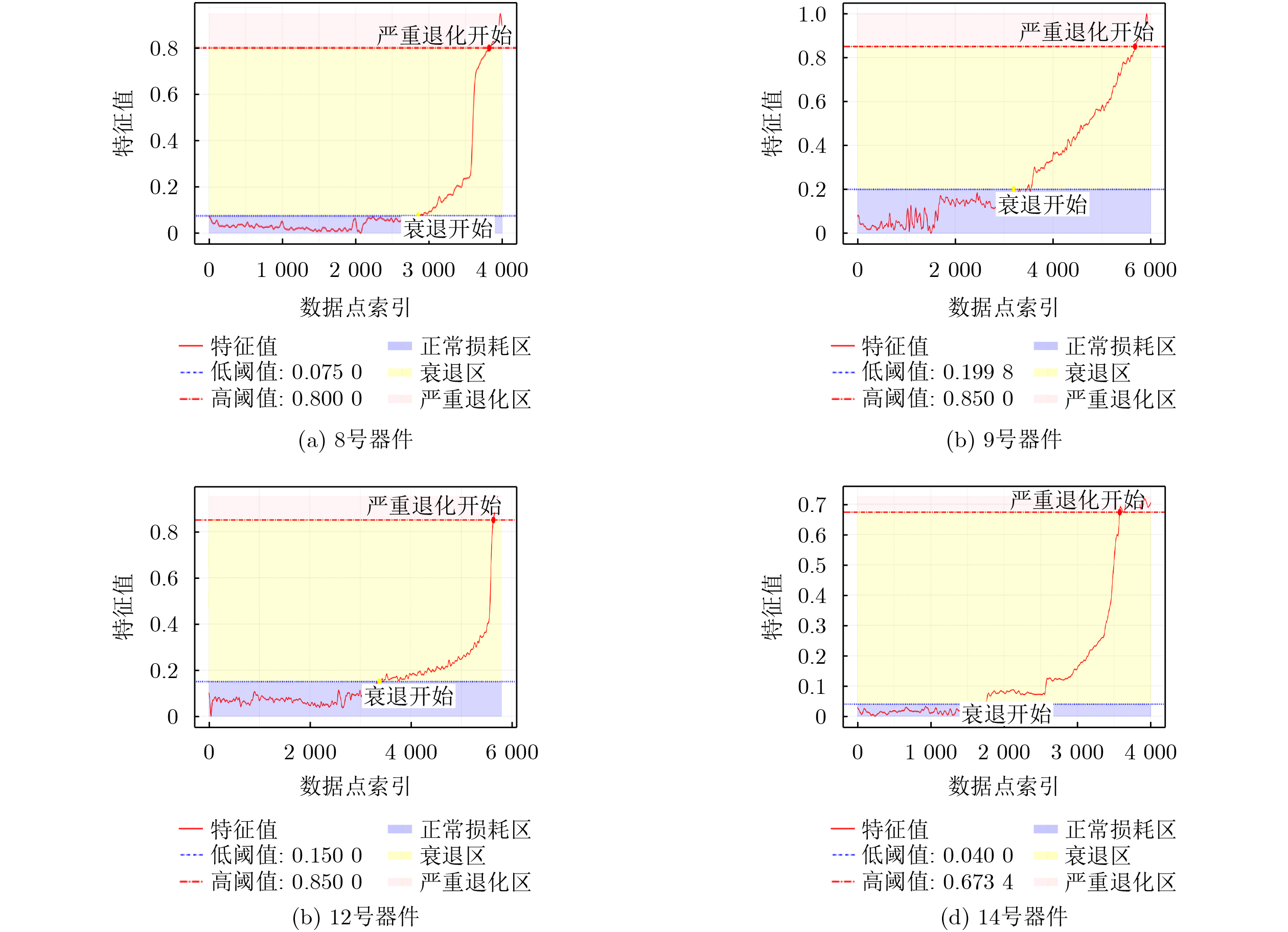
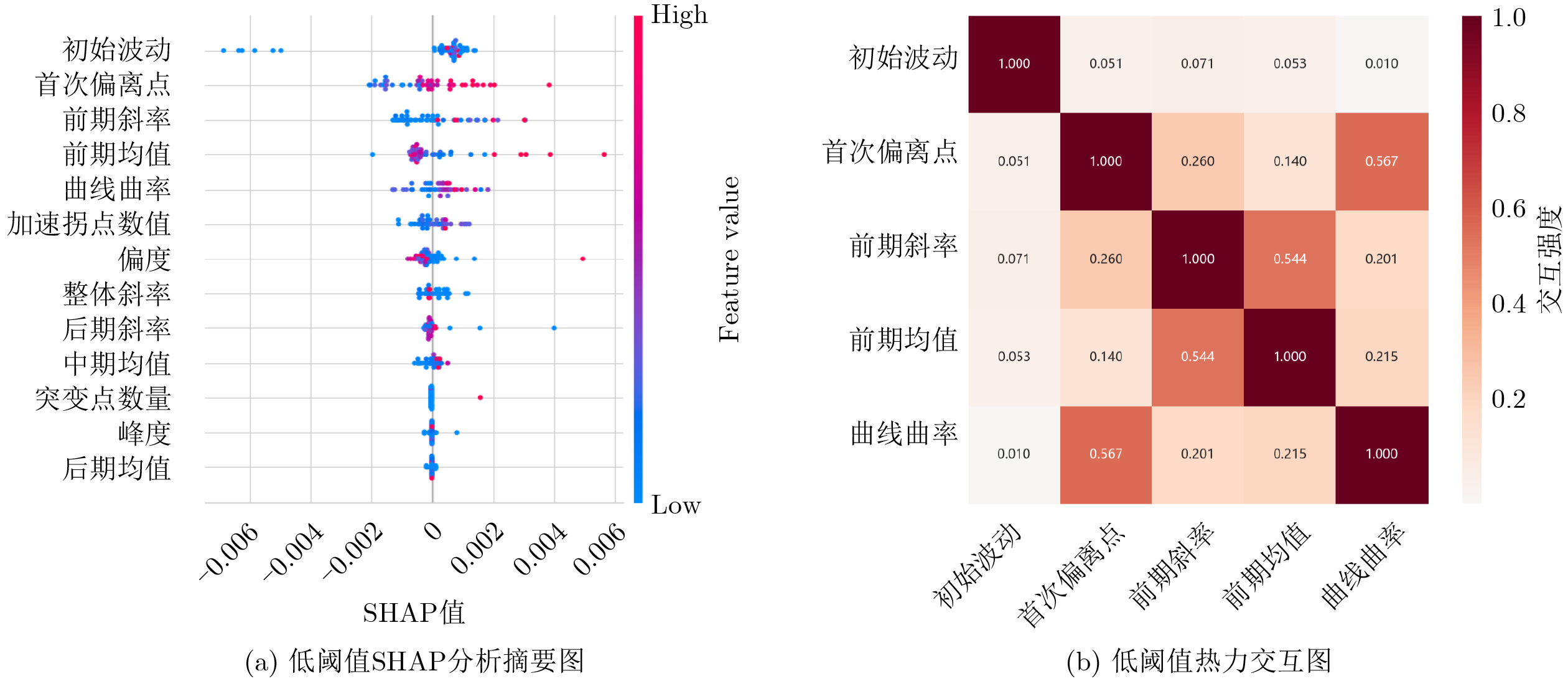
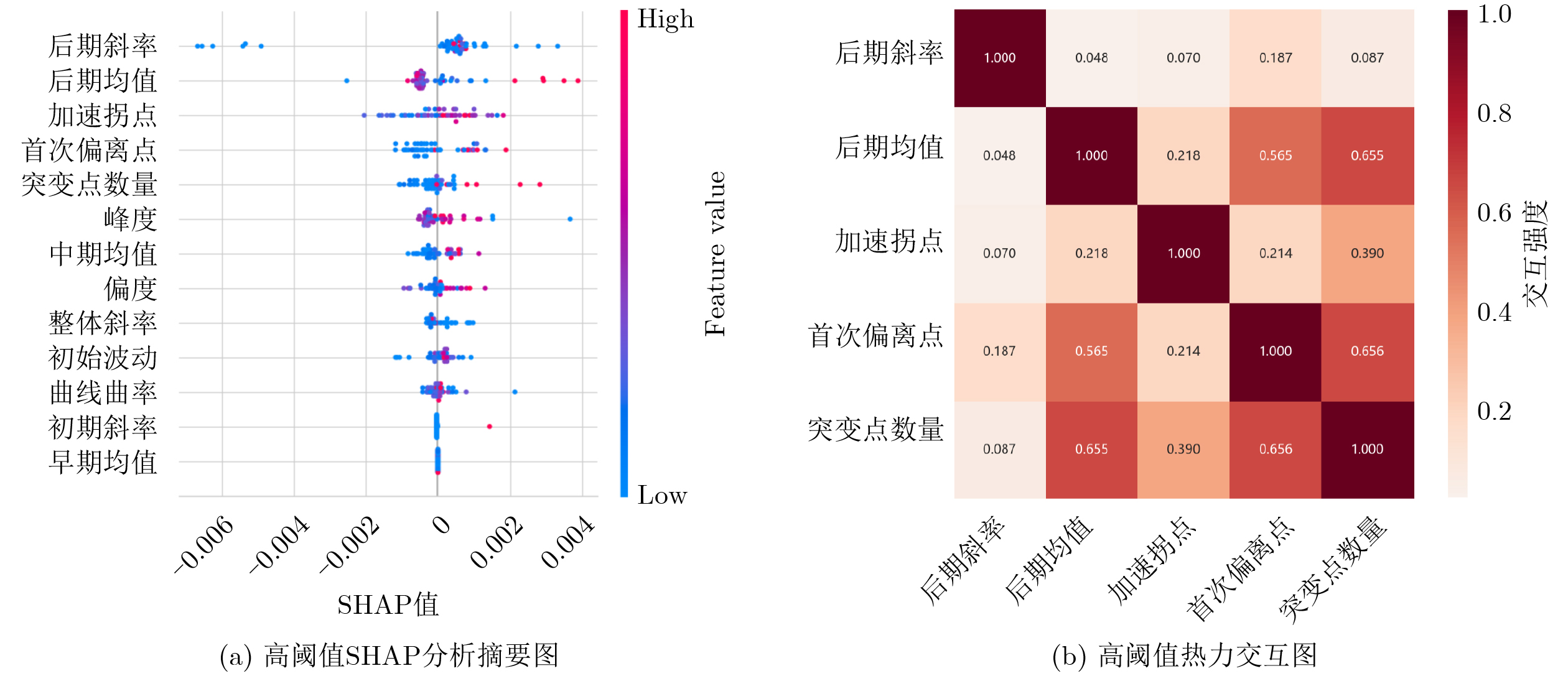
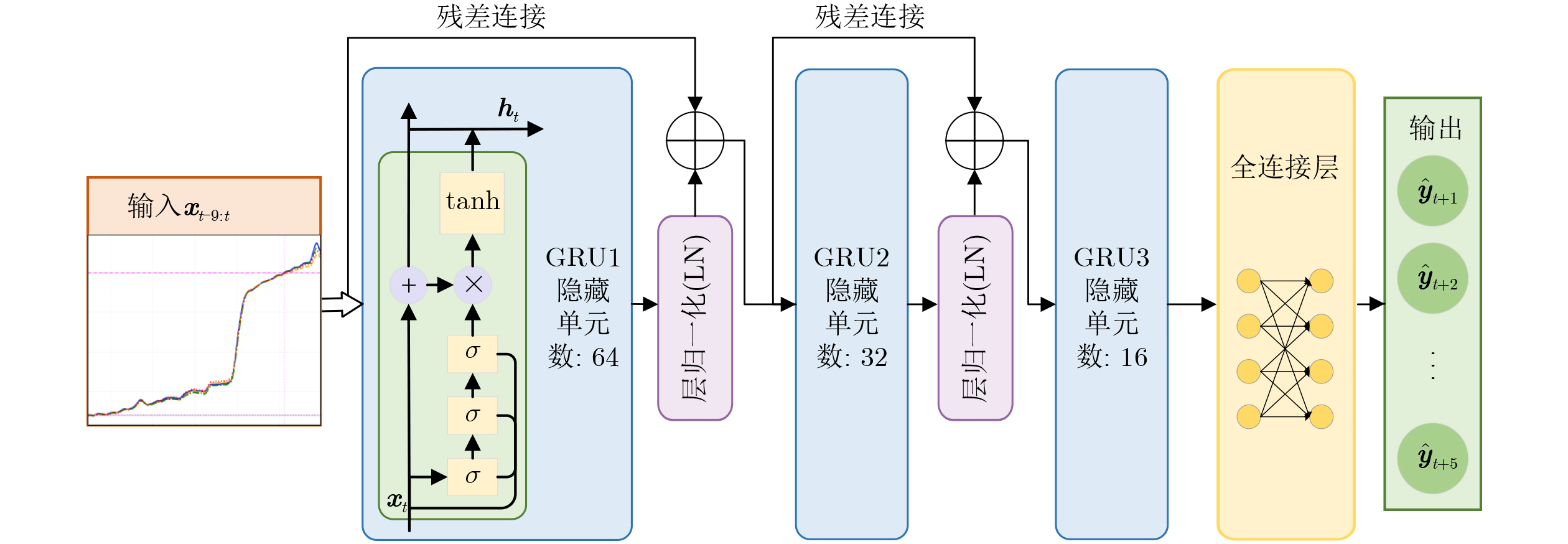
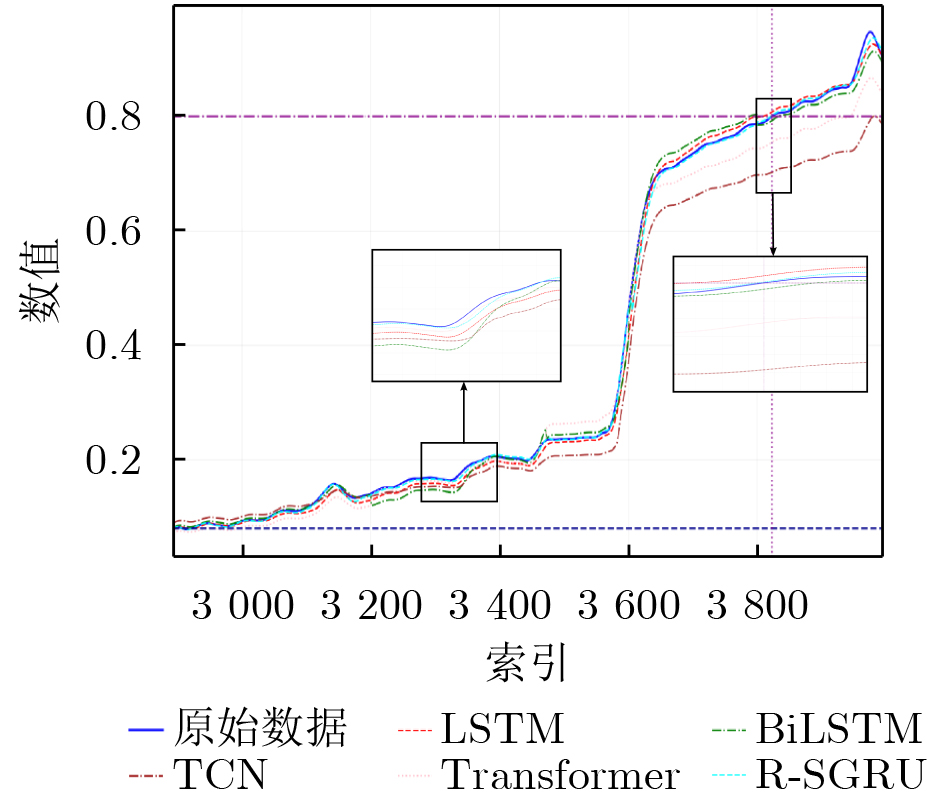
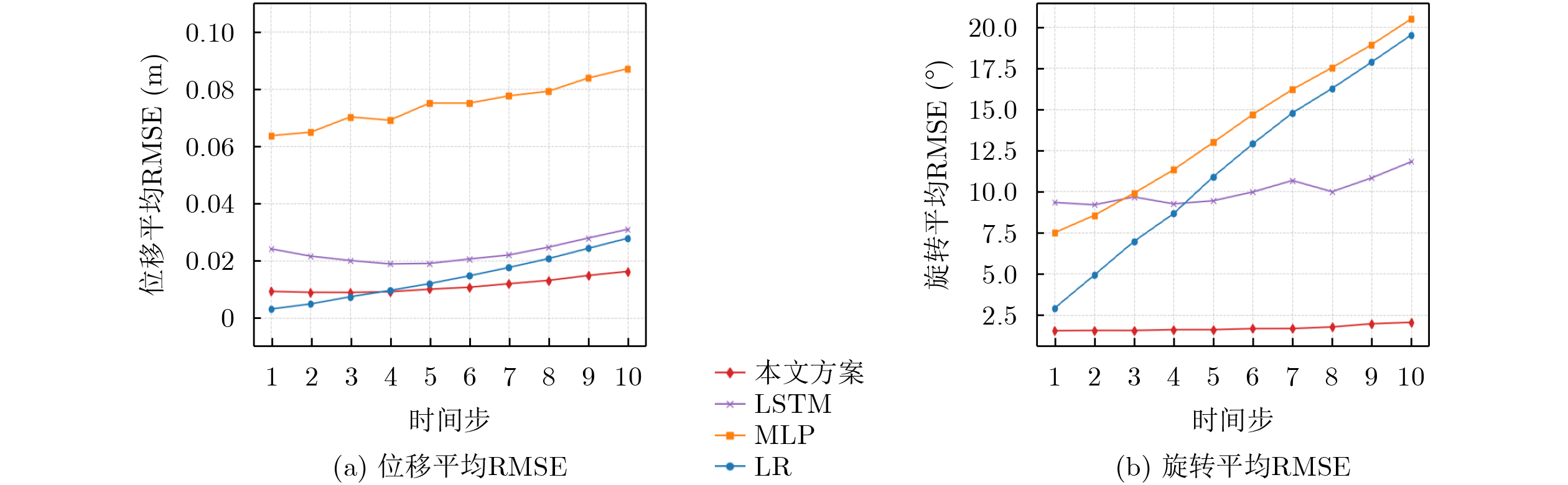
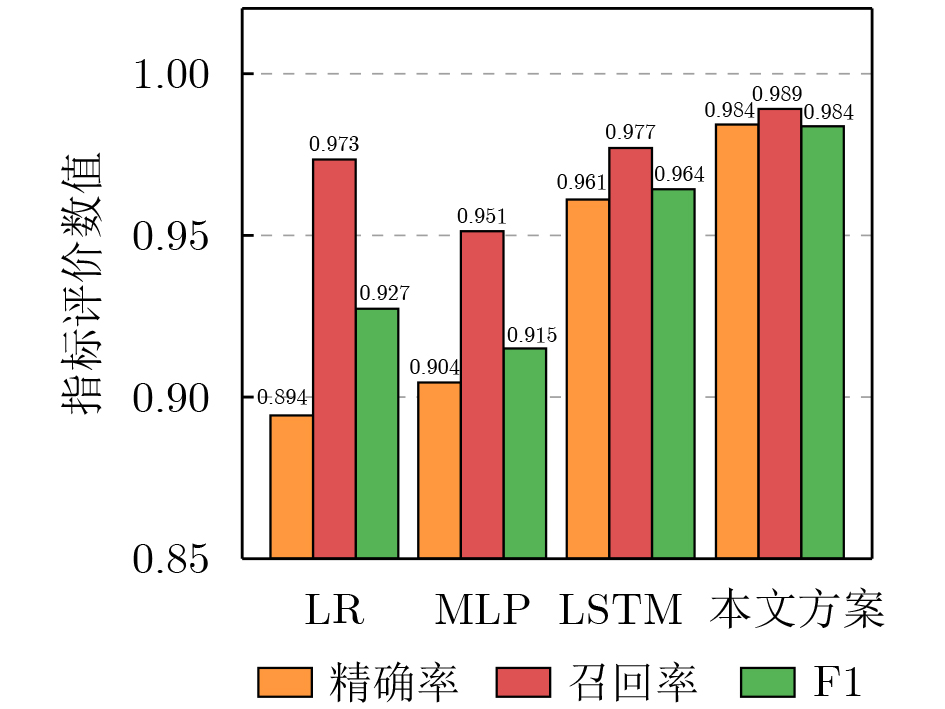
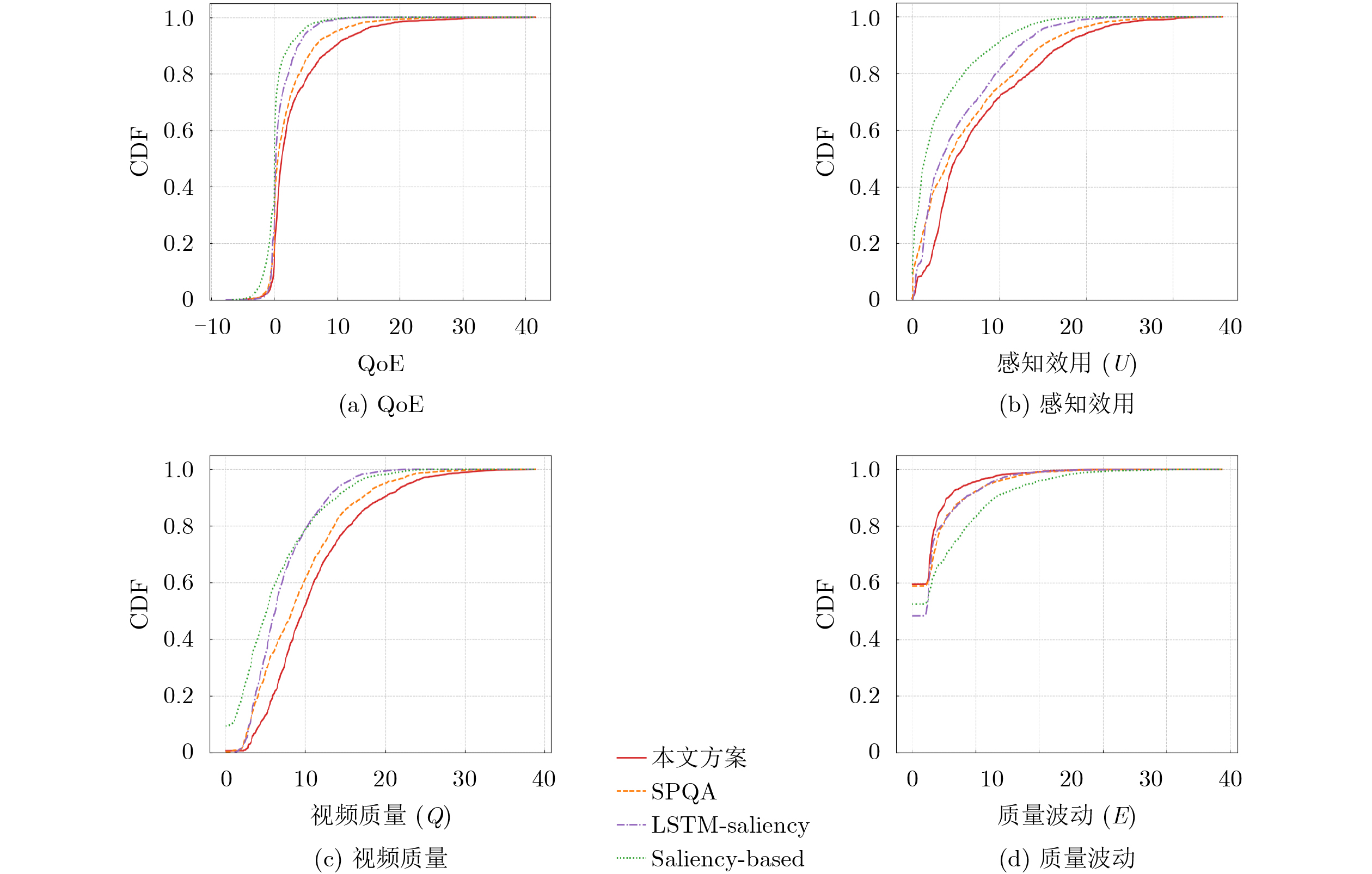
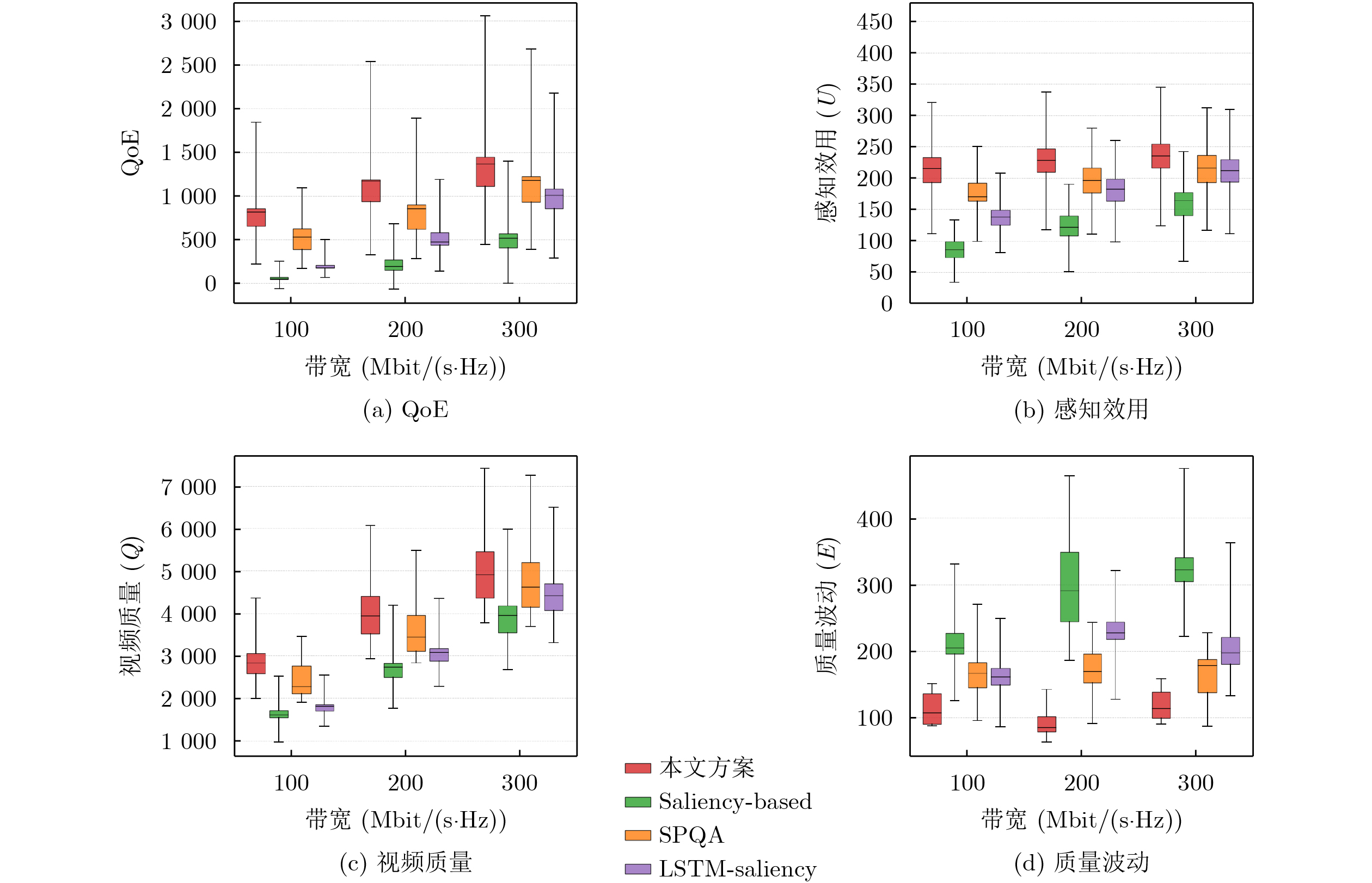
Objective Connected autonomous vehicles (CAVs) need to perceive complex driving environments accurately and in real time, including traffic object detection, drivable-area segmentation, and lane-line detection. Existing single-task perception models are difficult to meet these diverse requirements simultaneously, while running multiple models in sequence increases latency and is unsuitable for safety-critical autonomous driving. In addition, the performance of deep learning models depends heavily on large-scale and diverse training data, whereas the data collected by an individual CAV are usually limited and scenario-specific. Federated learning (FL) provides a feasible way to train a more generalized global model without uploading raw vehicle data. However, conventional FL still faces several challenges in Internet of Vehicles scenarios, including malicious CAVs that upload low-quality or poisoned local models, privacy leakage from uploaded model parameters, and the single point of failure caused by centralized aggregation. To address these problems, this paper proposes a Secure Multi-task Federated Panoptic Perception (SMFPP) algorithm for connected autonomous vehicles. The goal is to achieve efficient multi-task driving perception, reliable collaborative model training, malicious-node resistance, privacy-preserving aggregation, and fault tolerance in a unified framework. Methods The proposed SMFPP framework consists of a cloud layer, an edge layer, and a terminal layer. The cloud layer publishes FL tasks and provides global coordination, the edge layer contains multiple road side units (RSUs) responsible for model aggregation, and the terminal layer consists of CAVs that train local models with their own driving-scene data. First, a YOLO-based multi-task panoptic perception model is designed as the local model. Its backbone network extracts visual features from vehicle images, while the spatial pyramid pooling fast module and feature pyramid network perform multi-scale feature fusion. Three task-specific detection heads are constructed to perform traffic object detection, drivable-area segmentation, and lane-line detection in parallel, thereby reducing perception latency and improving real-time applicability. The overall loss function combines the losses of the three tasks, including object detection losses and segmentation-related losses. Second, to defend against poisoning attacks and low-quality updates in FL, a hybrid-scoring-based CAV selection algorithm is proposed. For direct scoring, each CAV evaluates the cosine similarity between its local model and the previous global model, as well as the update age of its local model. For indirect scoring, RSUs select high-reputation CAVs to conduct encrypted cross-validation of other CAVs’ local models, and the model quality is evaluated according to local validation performance. The direct and indirect scores are normalized and used as the input of K-means clustering to select CAVs with high model quality, good timeliness, and strong consistency. The reputation value of each CAV is then updated for subsequent training rounds. Third, to avoid centralized aggregation risks, a Shamir-secret-sharing-based global model aggregation algorithm is developed. Each selected CAV splits its local model parameters into secret shares and sends them to different RSUs. Each RSU aggregates only the received shares and returns an aggregation share to CAVs. When a CAV receives at least the threshold number of aggregation shares, it reconstructs the global model by Lagrange interpolation. In this way, no single RSU can obtain a complete local model, and the system can still work when some RSUs fail. Results and Discussions Experiments are conducted on the BDD100K dataset, which contains diverse driving scenes from urban roads, suburban areas, and highways. In the basic simulation setting, five CAVs participate in FL training, each CAV uses 20% of the dataset to train its local model, and five RSUs serve as edge aggregation nodes. The effectiveness of the hybrid-scoring-based CAV selection algorithm is first verified under different numbers of malicious CAVs. As shown in Fig. 2, the mAP50 values of normal CAVs increase with training rounds and gradually converge, whereas malicious CAVs maintain low and unstable mAP50 values. Fig.3 further shows that a malicious CAV is excluded from global aggregation throughout training, and the global model achieves better convergence when the proposed selection algorithm is used. Compared with FedAvg, FedCS, and FedAsync, the proposed SMFPP framework obtains the best overall performance, achieving 86.4% Recall, 77.7% mAP50, 89.6% mIoU, 82.4% Accuracy, and 27.2% IoU, as reported in Table 1. For traffic object detection, SMFPP achieves 86.4% Recall and 77.7% mAP50, and its mAP50 is higher than those of MultiNet, DLT-Net, Fast R-CNN, YOLOv8n, YOLOP, A-YOLOM, and YOLOMH, as shown in Table 2. For drivable-area segmentation, SMFPP reaches 89.6% mIoU, outperforming MultiNet, DLT-Net, PSPNet, YOLOv8n(seg), YOLOP, A-YOLOM, and YOLOMH by 20.2%, 18.8%, 2.0%, 12.2%, 0.3%, 0.9%, and 0.4%, respectively, as shown in Table 3. For lane-line detection, SMFPP achieves the best Accuracy of 82.4% and IoU of 27.2%, as shown in Table 4. In both daytime and nighttime scenarios, SMFPP performs better than YOLOP on all evaluation metrics, demonstrating its adaptability to different illumination conditions (Table 5). In terms of efficiency, SMFPP contains only 3.45 million parameters and reaches 52.4 fps, indicating that it is lightweight and suitable for edge deployment (Table 6). The scalability experiment shows that, when the number of CAVs increases from 5 to 20, the global model performance improves consistently, with Recall, mAP50, mIoU, Accuracy, and IoU increasing to 88.6%, 79.5%, 90.4%, 85.2%, and 28.4%, respectively (Table 7). Moreover, the Shamir-secret-sharing-based aggregation scheme remains effective as long as at least three of the five RSUs survive. When the number of available RSUs is below the threshold, the global model cannot be correctly recovered; once enough RSUs recover, model training continues normally (Fig. 5). These results demonstrate that SMFPP improves perception accuracy, robustness against malicious CAVs, privacy protection, fault tolerance, and scalability. Conclusions This paper presents SMFPP, a secure multi-task federated panoptic perception algorithm for connected autonomous vehicles. The proposed method integrates a lightweight YOLO-based multi-task perception model with FL to solve the data-island problem among CAVs and to support collaborative training without exposing raw driving data. The hybrid-scoring-based CAV selection algorithm effectively filters malicious or low-quality local models by jointly considering model quality, update timeliness, and model similarity. The Shamir-secret-sharing-based aggregation scheme further protects local model parameters and removes the single point of failure in centralized FL aggregation. Simulation results on the BDD100K dataset verify that SMFPP achieves competitive or superior performance in object detection, drivable-area segmentation, and lane-line detection, while maintaining high inference efficiency and strong robustness. Future work may consider larger-scale heterogeneous vehicular networks, dynamic communication conditions, adaptive threshold settings, and real-world deployment in edge-assisted intelligent transportation systems.