

Optimizing Age of Information in LoRa Networks via Deep Reinforcement Learning
-
摘要: 信息年龄(AoI)是信息新鲜度的衡量指标,针对时间敏感的物联网,最小化AoI显得尤为重要。该文基于LoRa网络的智能交通环境,分析Slot-Aloha协议下的AoI优化策略,建立了Slot-Aloha协议下数据包之间传输碰撞和等待时间的系统模型。通过分析指出,在LoRa上行传输过程中,随着数据包数量增多,AoI主要受到数据包碰撞影响。为克服优化问题中动作空间过大导致难以实现有效求解的问题,该文采用连续动作空间映射离散动作空间的方式,使用柔性动作-评价 (SAC)算法对LoRa网络下的AoI进行优化。仿真结果显示,SAC算法优于传统算法与传统深度强化学习算法,可有效降低网络的平均AoI。Abstract:
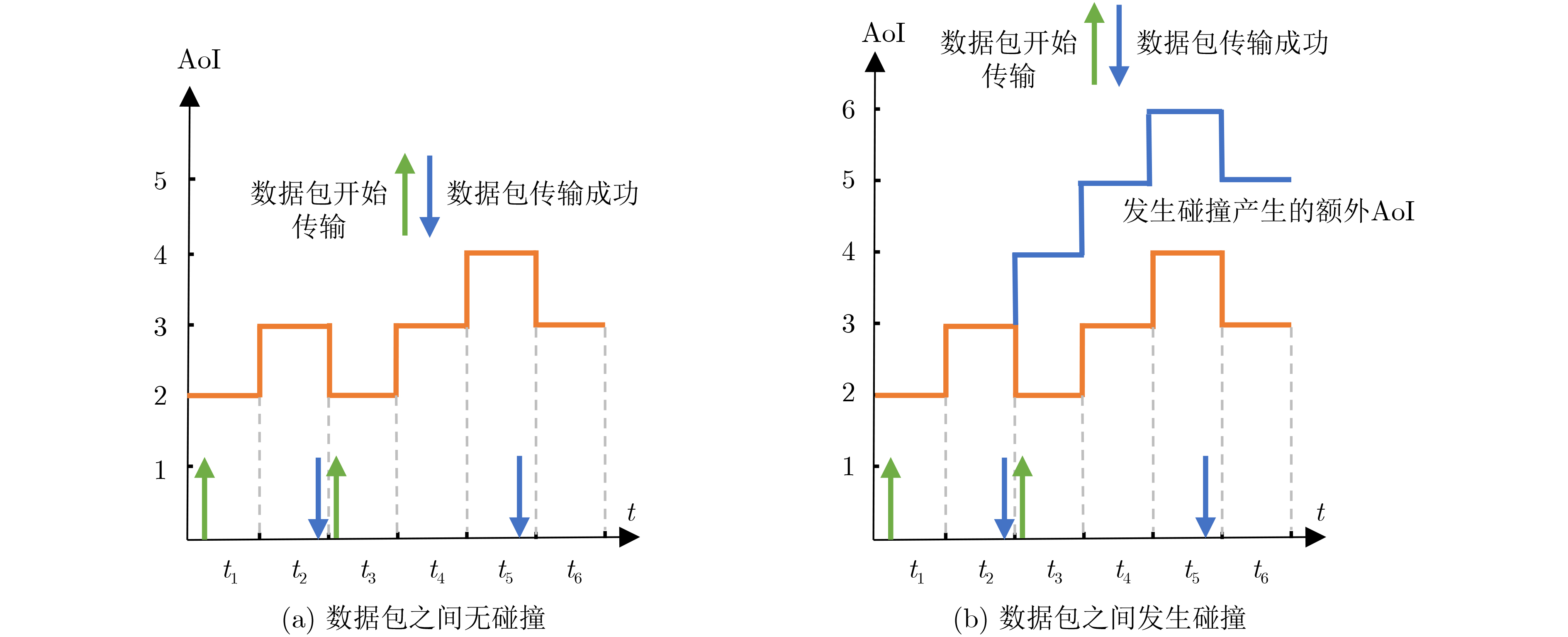
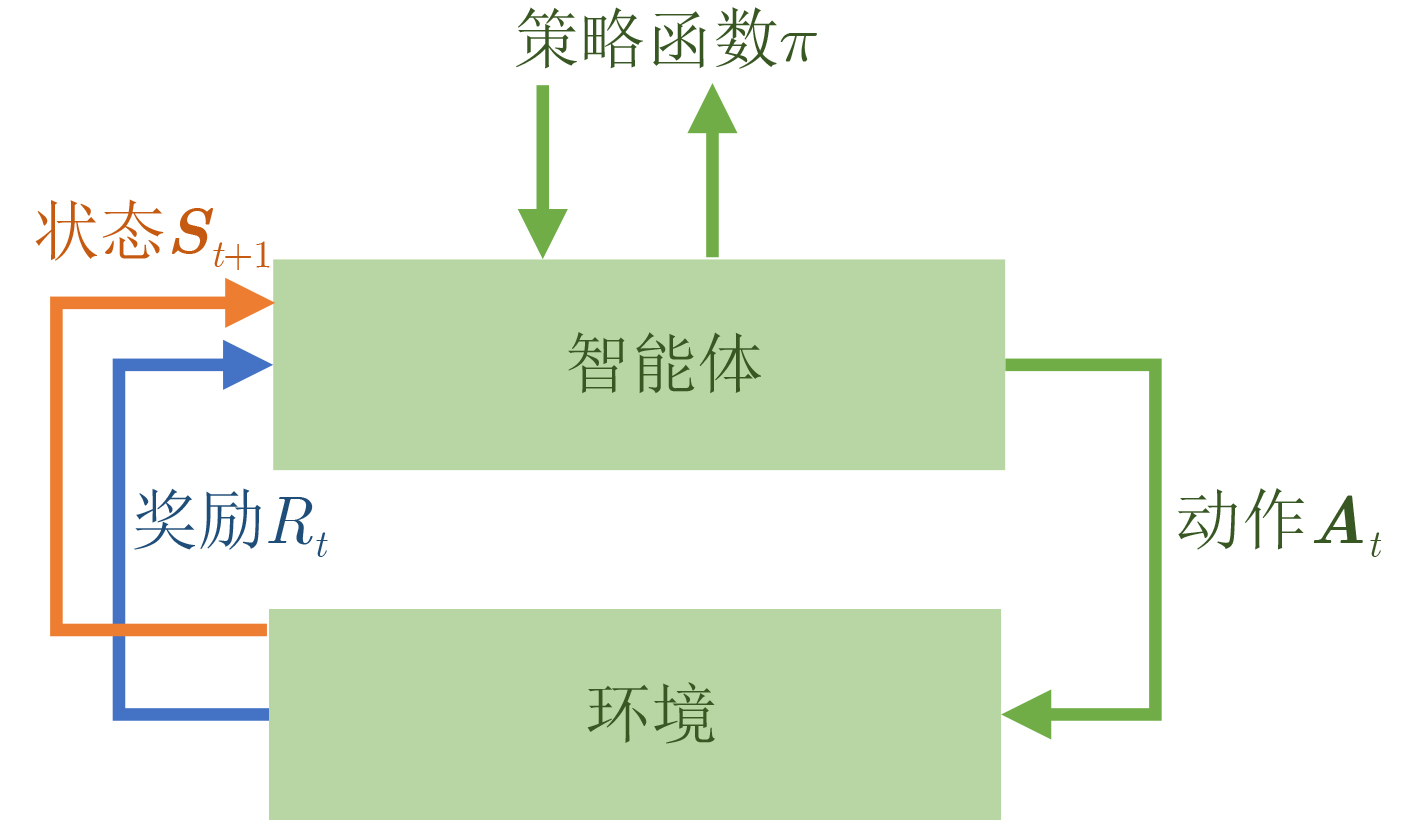
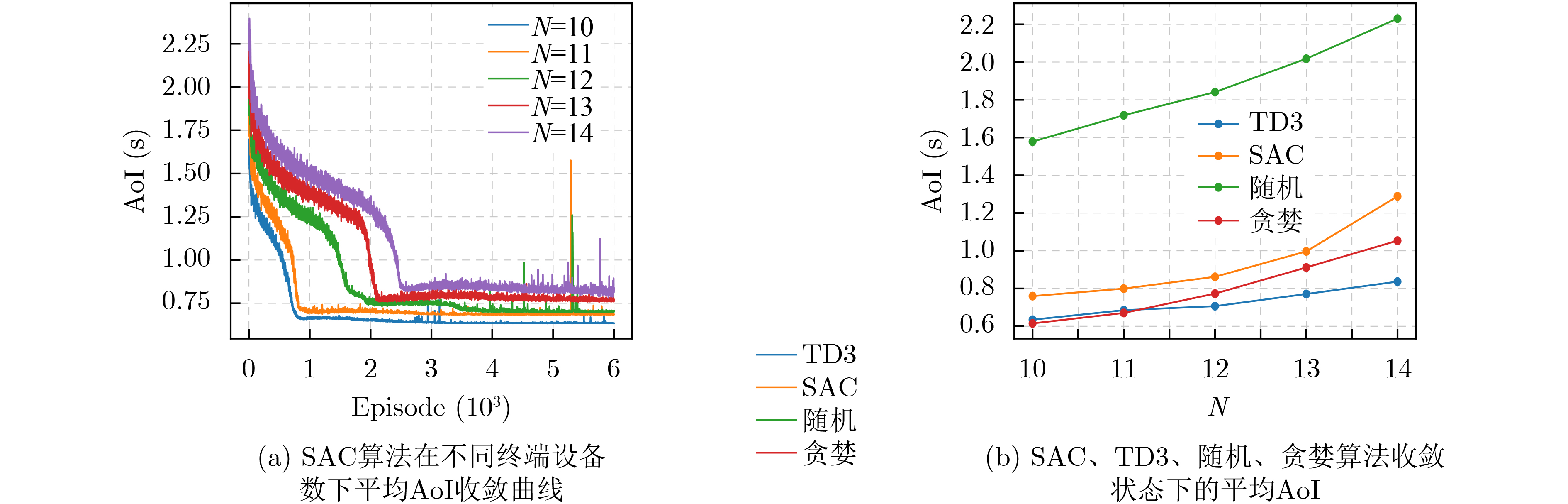
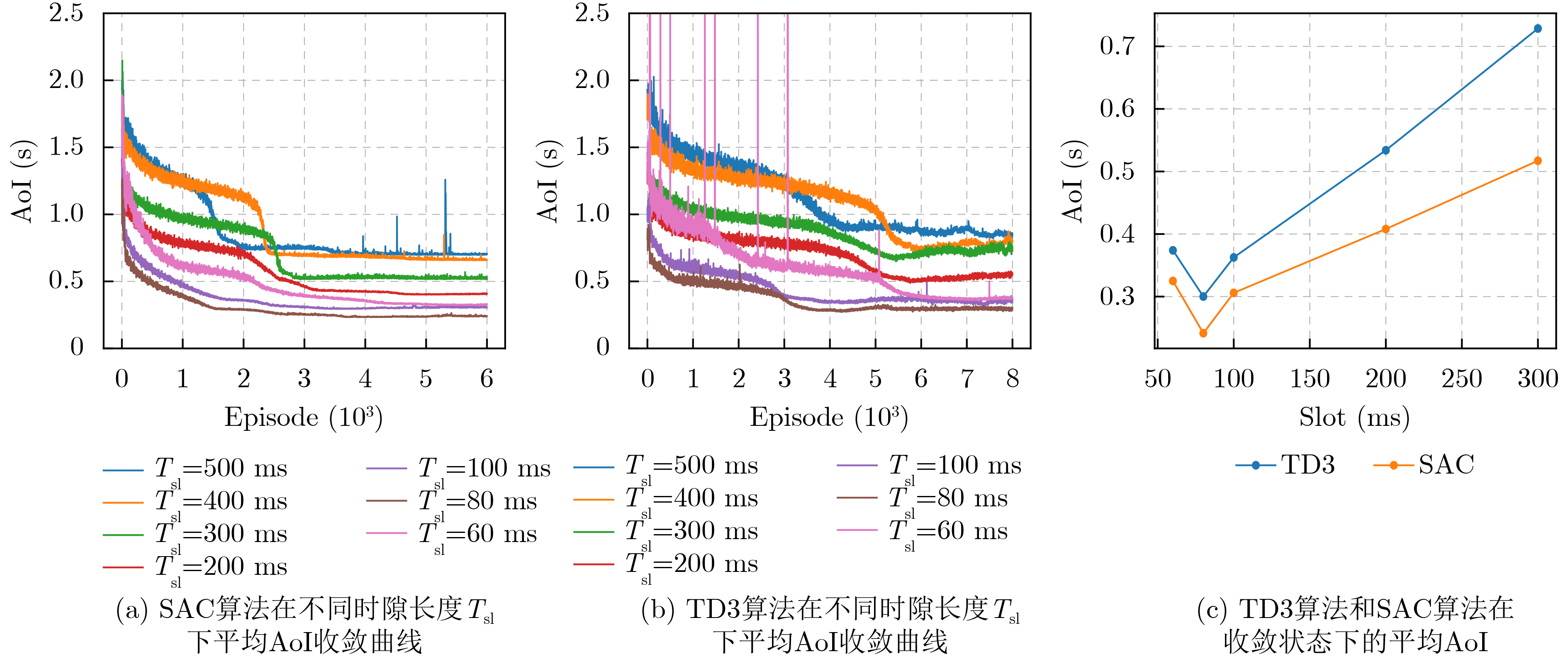
Age of Information (AoI) quantifies information freshness, which is critical for time-sensitive Internet of Things (IoT) applications. This paper investigates AoI optimization in an LoRa network under the Slot-Aloha protocol in an intelligent transportation environment. A system model is established to characterize transmission collisions and packet waiting times. Analytical results indicate that in LoRa uplink transmission, as the number of packets increases, AoI is primarily influenced by packet collisions. To address the challenge of a large action space hindering effective solutions, this study maps the continuous action space to a discrete action space and employs the Soft Actor-Critic (SAC) algorithm for AoI optimization. Simulation results demonstrate that the SAC algorithm outperforms conventional algorithms and traditional deep reinforcement learning approaches, effectively reducing the network’s average AoI. Objective With the rapid development of intelligent transportation systems, ensuring the real-time availability and accuracy of traffic data has become essential, particularly in transmission systems for traffic monitoring cameras and related equipment. Long-range, low-power radio frequency (LoRa) networks have emerged as a key technology for sensor connectivity in intelligent transportation due to their advantages of low power consumption, wide coverage, and long-distance communication. However, in urban environments, LoRa networks are prone to frequent data collisions when multiple devices transmit simultaneously, which affects information timeliness and, consequently, the effectiveness of traffic management decisions. This study focuses on optimizing data packet timeliness in LoRa networks to enhance communication efficiency. Specifically, it aims to improve AoI under the Slotted Aloha protocol by analyzing the effects of packet collisions and over-the-air transmission time. Based on this analysis, an optimization method using deep reinforcement learning is proposed, employing the SAC algorithm to minimize AoI. The goal is to achieve lower latency and a higher data transmission success rate in an intelligent transportation environment with frequent data transmissions, thereby improving overall system performance and ensuring real-time information availability to meet the freshness requirements of intelligent transportation systems. Method To address the requirements for information freshness in intelligent transportation scenarios, this study investigates the optimization of packet AoI in LoRa networks under the Slotted Aloha protocol. A system model is established to analyze packet collisions and over-the-air transmission time, providing theoretical support for enhancing information transmission efficiency. Given the Markovian nature of AoI evolution, the optimization problem is formulated as a Markov Decision Process (MDP) and solved using the SAC algorithm in deep reinforcement learning. Results and Discussions The study examines AoI variations during collisions ( Fig. 2 ) and develops a collision model for data packet transmission (Fig. 4 ). Simulation results indicate that the SAC algorithm outperforms the Temporal Difference (TD) algorithm and conventional methods (Fig. 6 ). As the number of terminals increases, the system’s average AoI also increases (Fig. 7 ). Additionally, the variations in average AoI under different time slots for the SAC and TD3 algorithms are analyzed (Fig. 8 ).Conclusions Given the limited research on AoI in LoRa networks, this study examines the AoI optimization problem in LoRa uplink packet transmission within an intelligent traffic management environment and proposes a packet collision model under the Slotted Aloha protocol. The greedy algorithm and SAC algorithm are employed for AoI optimization. Simulation results demonstrate that the greedy algorithm outperforms conventional deep reinforcement learning algorithms but remains less effective than the SAC algorithm. The SAC algorithm significantly improves AoI optimization in LoRa networks. However, this study focuses solely on AoI optimization without considering energy consumption and packet loss rate. Future research should explore the trade-offs between energy efficiency, packet loss, and AoI optimization to minimize energy consumption and data loss. Additionally, this study does not address heterogeneous network scenarios. In environments where LoRa networks coexist with other communication technologies (e.g., Wi-Fi, Bluetooth, NB-IoT), challenges related to interoperability, data consistency, and network management arise. Investigating AoI optimization in heterogeneous transmission environments could further enhance the performance and reliability of LoRa networks in complex applications such as intelligent traffic management. -
1 贪婪算法
输入:终端集合$ \mathrm{s}\mathrm{e}\mathrm{n}\mathrm{s}\mathrm{o}\mathrm{r}\mathrm{s}=\{{\mathrm{s}\mathrm{e}\mathrm{n}}_{1},{\mathrm{s}\mathrm{e}\mathrm{n}}_{2},\cdots ,{\mathrm{s}\mathrm{e}\mathrm{n}}_{n}\} $ 输出:每个终端分配的SF和信道集合 $ \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t}=\{\left({\mathrm{S}\mathrm{F}}_{1},{C}_{1}\right),\left({\mathrm{S}\mathrm{F}}_{2},{C}_{2}\right),\cdots ,({\mathrm{S}\mathrm{F}}_{n},{C}_{n}\left)\right\} $ (1) $ \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t} \leftarrow \mathrm{\varnothing },\mathrm{s}\mathrm{f}\in \left\{\mathrm{7,8},\cdots ,12\right\},\mathrm{信}\mathrm{道}C\in \{\mathrm{0,1},\cdots, c\} $ (2) $ \bf{f}\bf{o}\bf{r}\;i=\mathrm{1,2},\cdots ,N\;\bf{d}\bf{o} $ (3) $ {\mathrm{S}\mathrm{F}}_{i}\leftarrow \mathrm{随}\mathrm{机}\mathrm{从}{\bf{s}\bf{f}}\mathrm{集}\mathrm{合}\mathrm{中}\mathrm{选}\mathrm{择} $ (4) $ {{C}}_{i}\leftarrow \mathrm{随}\mathrm{机}\mathrm{从}C\mathrm{集}\mathrm{合}\mathrm{中}\mathrm{选}\mathrm{择} $ (5) $ \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t}\leftarrow \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t}\cup ({\mathrm{S}\mathrm{F}}_{i},{C}_{i}) $ (6) $ \bf{e}\bf{n}\bf{d}\;\bf{f}\bf{o}\bf{r} $ (7) $ \bf{f}\bf{o}\bf{r}\;j=\mathrm{1,2},\cdots ,N\;\bf{d}\bf{o} $ (8) 记录第$ j $时隙下最优的SF $ {\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}{\mathrm{SF}}}_{j}=0 $ (9) 记录第$ j $时隙下最优的信道C $ {\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}C}_{j}=0 $ (10) $ \mathrm{m}\mathrm{i}\mathrm{n}\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{a}\mathrm{v}\mathrm{g}\mathrm{A}\mathrm{o}\mathrm{I}=\mathrm{M}\_\mathrm{I}\mathrm{N}\mathrm{T} $ (11) $ \bf{f}\bf{o}\bf{r}\;\mathrm{s}\mathrm{f}\mathrm{ }\leftarrow \mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }7\;\mathrm{t}\mathrm{o}\;12\;\bf{d}\bf{o} $ (12) $ \bf{f}\bf{o}\bf{r}\;C\leftarrow 0\;\mathrm{t}\mathrm{o}\;c\;\bf{d}\bf{o} $ (13) $ \mathrm{a}\mathrm{v}\mathrm{g}\mathrm{A}\mathrm{o}\mathrm{I}=\mathrm{a}\mathrm{v}\mathrm{e}\mathrm{r}\mathrm{a}\mathrm{g}\mathrm{e}\left(\mathrm{A}\mathrm{o}\mathrm{I}\right) $ (14) $ \text{if avgAoI < minavgAoI} $ (15) $ \text{minavgAoI=avgAoI} $ (16) $ {\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}\mathrm{S}\mathrm{F}}_{j}=\mathrm{s}\mathrm{f} $ (17) $ {\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}C}_{j}=C $ (18) $ \bf{end}\;\bf{f}\bf{o}\bf{r} $ (19) $ \bf{e}\bf{n}\bf{d}\;\bf{f}\bf{o}\bf{r} $ (20) $ \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t}\leftarrow \mathrm{r}\mathrm{e}\mathrm{s}\mathrm{u}\mathrm{l}\mathrm{t}\cup ({\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}\mathrm{S}\mathrm{F}}_{i},{\mathrm{b}\mathrm{e}\mathrm{s}\mathrm{t}C}_{i}) $ (21) $ \bf{e}\bf{n}\bf{d}\;\bf{f}\bf{o}\bf{r} $ (22) $ \bf{r}\bf{e}\bf{t}\bf{u}\bf{r}\bf{n}\;\bf{r}\bf{e}\bf{s}\bf{u}\bf{l}\bf{t} $  下载: 导出CSV
下载: 导出CSV
表 2 实验参数值
参数名 值 信道数量($ c $) 2 终端数量($ N $) 12 SF数量 6 编码率($ \mathrm{C}\mathrm{R} $) 4/5 带宽($ \mathrm{B}\mathrm{W} $) 125 kHz 数据包大小($ {L}_{\mathrm{d}} $) 50 Byte step总数($ {T}_{\mathrm{s}\mathrm{t}} $) 500 时隙长度($ {T}_{\mathrm{s}\mathrm{l}} $) 500 ms
下载: 导出CSV
-
[1] KAUL S, YATES R, and GRUTESER M. Real-time status: How often should one update?[C]. IEEE INFOCOM, Orlando, USA, 2012: 2731–2735. doi: 10.1109/INFCOM.2012.6195689. [2] INOUE Y, MASUYAMA H, TAKINE T, et al. A general formula for the stationary distribution of the age of information and its application to single-server queues[J]. IEEE Transactions on Information Theory, 2019, 65(12): 8305–8324. doi: 10.1109/TIT.2019.2938171. [3] BEDEWY A M, SUN Yin, and SHROFF N B. Minimizing the age of information through queues[J]. IEEE Transactions on Information Theory, 2019, 65(8): 5215–5232. doi: 10.1109/TIT.2019.2912159. [4] HE Qing, YUAN Di, and EPHREMIDES A. Optimal link scheduling for age minimization in wireless systems[J]. IEEE Transactions on Information Theory, 2018, 64(7): 5381–5394. doi: 10.1109/TIT.2017.2746751. [5] KADOTA I, SINHA A, UYSAL-BIYIKOGLU E, et al. Scheduling policies for minimizing age of information in broadcast wireless networks[J]. IEEE/ACM Transactions on Networking, 2018, 26(6): 2637–2650. doi: 10.1109/TNET.2018.2873606. [6] WU Beining, CAI Zhengkun, WU Wei, et al. AoI-aware resource management for smart health via deep reinforcement learning[J]. IEEE Access, 2023, 11: 81180–81195. doi: 10.1109/ACCESS.2023.3299340. [7] PENG Kai, XIAO Peiyun, WANG Shangguang, et al. AoI-aware partial computation offloading in IIoT with edge computing: A deep reinforcement learning based approach[J]. IEEE Transactions on Cloud Computing, 2023, 11(4): 3766–3777. doi: 10.1109/TCC.2023.3328614. [8] WANG Hao, LIU Chi, YANG Haoming, et al. Ensuring threshold AoI for UAV-assisted mobile crowdsensing by multi-agent deep reinforcement learning with transformer[J]. IEEE/ACM Transactions on Networking, 2024, 32(1): 566–581. doi: 10.1109/TNET.2023.3289172. [9] WANG Zhuoyao, XU Xiaokang, and ZHAO Jin. Spreading factor allocation and rate adaption for minimizing age of information in LoRaWAN[C]. 2022 IEEE 24th International Conference on High Performance Computing & Communications; 8th International Conference on Data Science & Systems; 20th International Conference on Smart City; 8th International Conference on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Hainan, China, 2022: 482–489. doi: 10.1109/HPCC-DSS-SmartCity-DependSys57074.2022.00092. [10] CUOMO F, CAMPO M, CAPONI A, et al. EXPLoRa: Extending the performance of LoRa by suitable spreading factor allocations[C]. Proceedings of the 13th International Conference on Wireless and Mobile Computing, Networking and Communications, Rome, Italy, 2017: 1–8. doi: 10.1109/WiMOB.2017.8115779. [11] GEORGIOU O and RAZA U. Low power wide area network analysis: Can LoRa scale?[J]. IEEE Wireless Communications Letters, 2017, 6(2): 162–165. doi: 10.1109/LWC.2016.2647247. [12] HAMDI R, QARAQE M, and ALTHUNIBAT S. Dynamic spreading factor assignment in LoRa wireless networks[C]. 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 2020: 1–5. doi: 10.1109/ICC40277.2020.9149243. [13] FARHAD A, KIM D H, STHAPIT P, et al. Interference-aware spreading factor assignment scheme for the massive LoRaWAN network[C]. International Conference on Electronics, Information, and Communications, Auckland, New Zealand, 2019: 1–2. doi: 10.23919/ELINFOCOM.2019.8706416. [14] FARHAD A, KIM D H, and PYUN J Y. Resource allocation to massive internet of things in LoRaWANs[J]. Sensors, 2020, 20(9): 2645. doi: 10.3390/s20092645. [15] BELTRAMELLI L, MAHMOOD A, ÖSTERBERG P, et al. LoRa beyond aloha: An investigation of alternative random access protocols[J]. IEEE Transactions on Industrial Informatics, 2021, 17(5): 3544–3554. doi: 10.1109/TII.2020.2977046. [16] WANG Jiwen, YU Jihong, CHEN Xiaoming, et al. Age of information for frame slotted aloha[J]. IEEE Transactions on Communications, 2023, 71(4): 2121–2135. doi: 10.1109/TCOMM.2023.3244214. [17] CHEIKH I, SABIR E, AOUAMI R, et al. Throughput-delay tradeoffs for slotted-aloha-based LoRaWAN networks[C]. International Conference on Wireless Communications and Mobile Computing, Harbin, China, 2021: 2020–2025. doi: 10.1109/IWCMC51323.2021.9498969. [18] HAMDI R, BACCOUR E, ERBAD A, et al. LoRa-RL: Deep reinforcement learning for resource management in hybrid energy LoRa wireless networks[J]. IEEE Internet of Things Journal, 2022, 9(9): 6458–6476. doi: 10.1109/JIOT.2021.3110996. [19] HONG Shengguang, YAO Fang, ZHANG Fengyun, et al. Reinforcement learning approach for SF allocation in LoRa network[J]. IEEE Internet of Things Journal, 2023, 10(20): 18259–18272. doi: 10.1109/JIOT.2023.3279429. [20] WARET A, KANEKO M, GUITTON A, et al. LoRa throughput analysis with imperfect spreading factor orthogonality[J]. IEEE Wireless Communications Letters, 2019, 8(2): 408–411. doi: 10.1109/LWC.2018.2873705. [21] HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 1856–1865. -

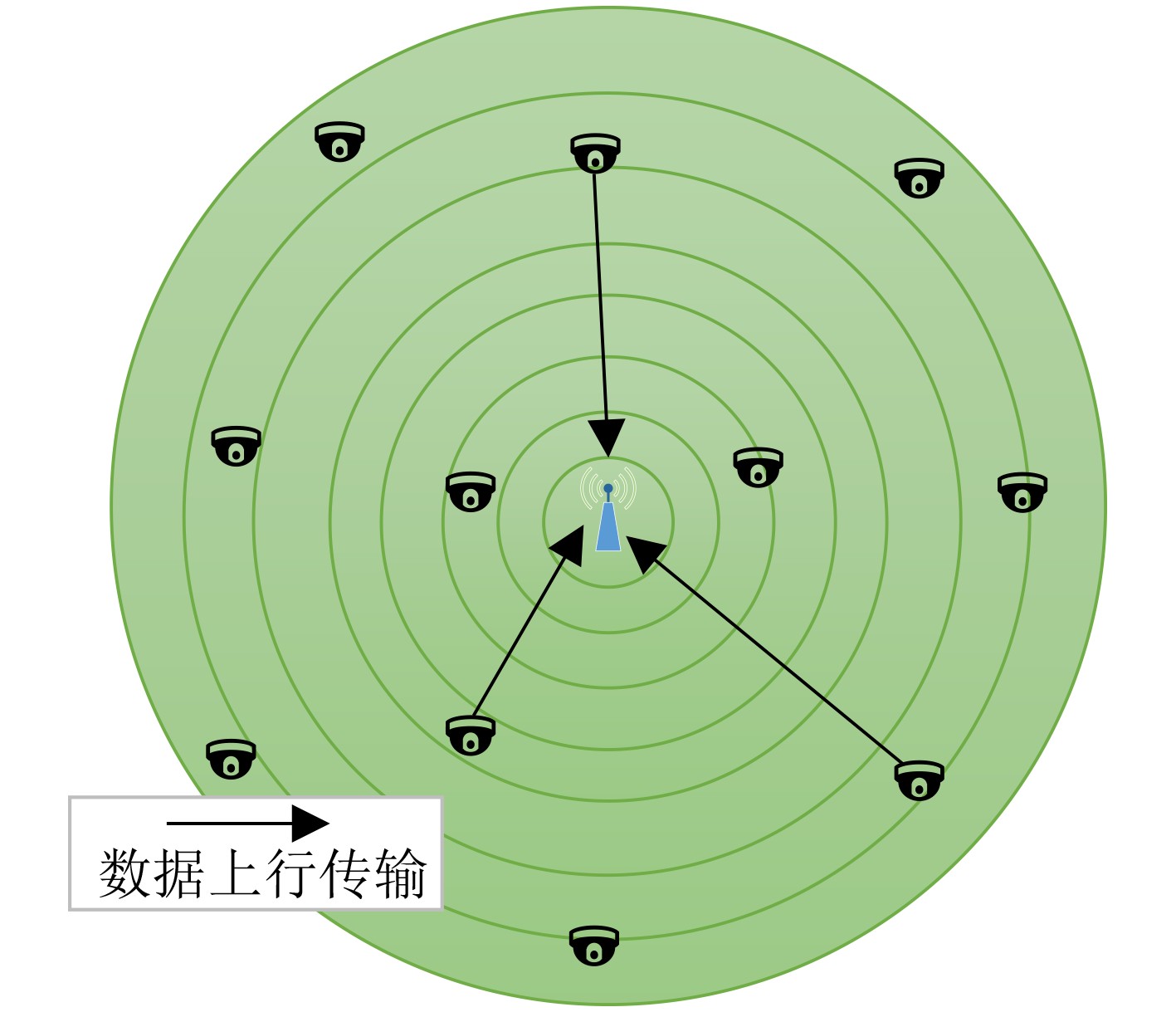
 下载:
下载:





图(8) / 表(3)
计量
- 文章访问数: 1613
- HTML全文浏览量: 858
- PDF下载量: 69
- 被引次数: 0
