

Graph Algorithm Optimization for Spintronics-based In-memory Computing Architecture
-
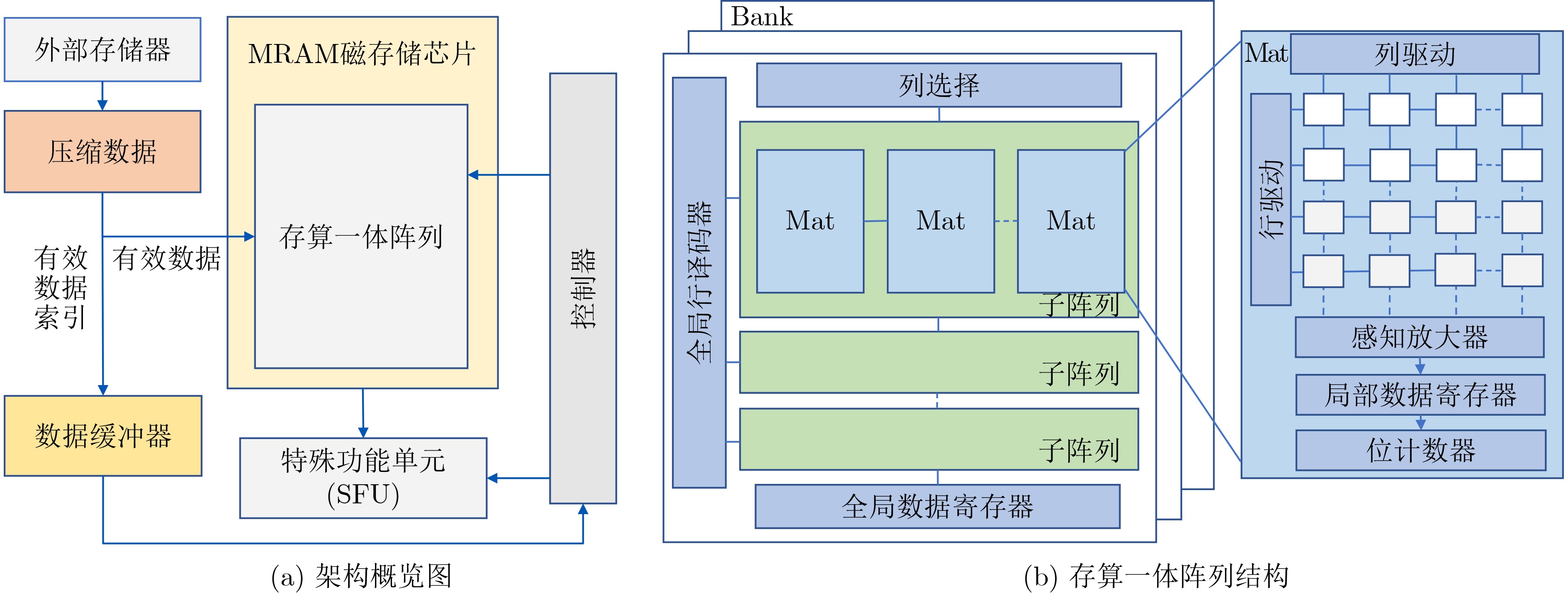
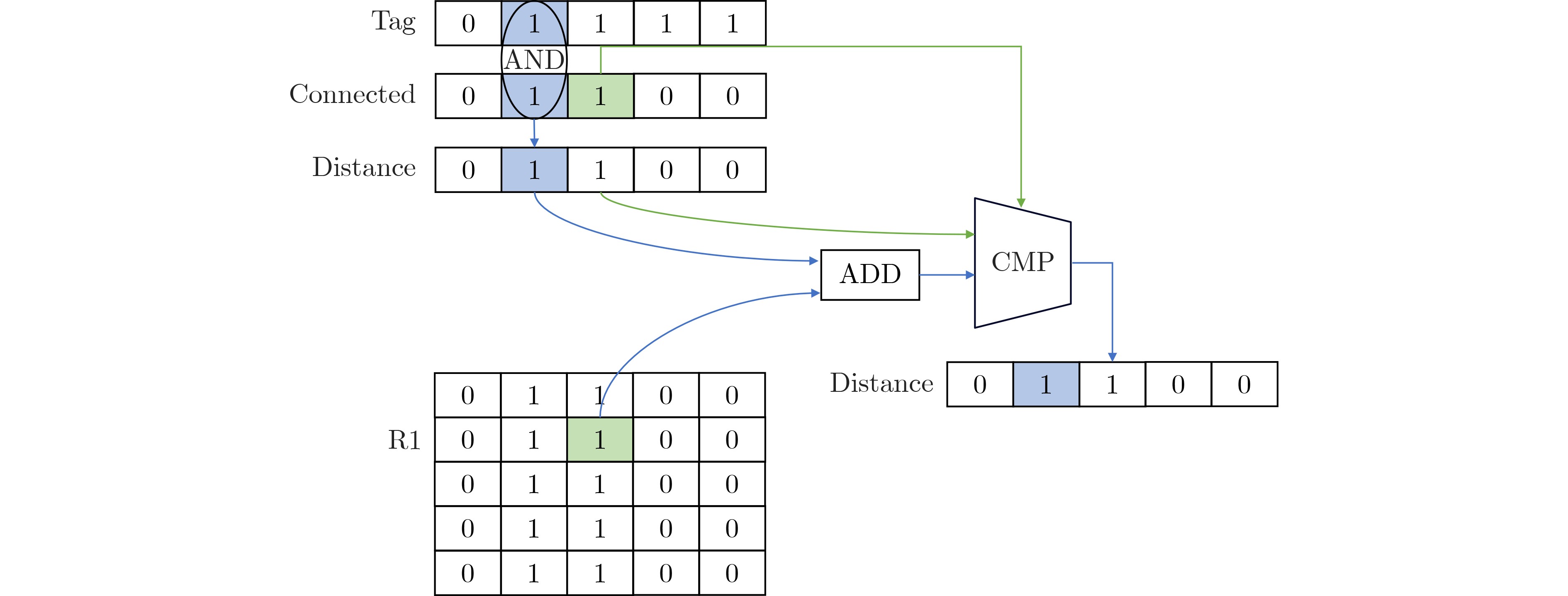
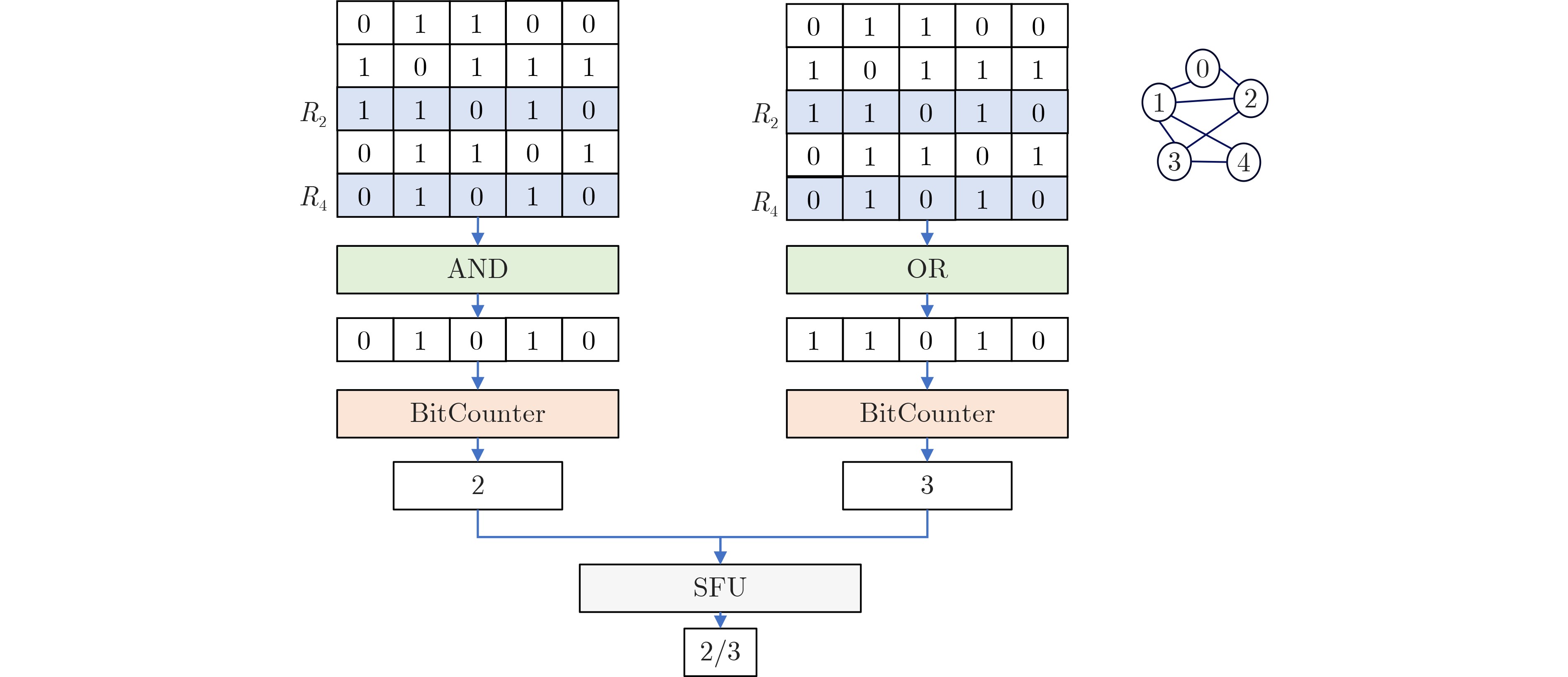
摘要: 图计算广泛应用于社交网络分析、推荐系统等诸多关键领域,然而,传统的大规模图计算系统面临冯诺依曼架构下访存带来的性能瓶颈。新型存内计算架构成为加速大规模图计算非常有前景的方案,尤其是非易失自旋磁存储器(MRAM)具备超高耐擦写性和超快写入等优点,可使图计算的存内实现更为高效。实现这种潜力的关键挑战之一是如何优化存内计算架构下的图算法设计。该文的前期工作表明,三角形计数算法和图连通分量计算算法可以通过按位运算实现,从而高效地部署在自旋存内处理核中加速。该文探索了更多图算法的优化实现,例如单源最短路径、K-core、链路预测,并提出了面向新型存内计算架构的图算法优化设计模型。该研究对于突破冯诺依曼架构下大规模图计算的内存访问瓶颈具有关键意义。Abstract: Graph computing has been widely applied to emerging fields such as social network analysis and recommendation systems. However, large-scale graph computing under the traditional Von-Neumann architecture faces the memory access bottleneck. The newly developed in-memory computing architecture becomes a promising alternative for accelerating graph computing. Due to its ultra-high endurance and ultra-fast writing speed, non-volatile Magnetoresistive Random Access Memory (MRAM) has the potential in building efficient in-memory accelerators. One of the key challenges to achieve such potential is how to optimize the graph algorithm design under the in-memory computing architecture. Our previous work shows that the triangle counting algorithms and graph connected component computing algorithms can be implemented with bitwise operations, which enables efficient spintronics in-memory computations. In this paper, the optimized implementation of more graph algorithms is explored such as single-source shortest path, K-core and link prediction, and an optimized design model of graph algorithms for the new in-memory computing architecture based is proposed. This research is of key significance for the breakthrough of solving the memory access bottleneck in large-scale graph computing under the Von Neumann architecture.
-
表 2 MTJ关键参数
参数 值 参数 值 磁性隧道结表面长度 40 nm 隧道磁电阻 100% 磁性隧道结表面宽度 40 nm 饱和场 106 A/m 自旋霍尔角 0.3 吉尔伯特阻尼常数 0.03 磁性隧道结电阻面积乘积 10–12 Ω·m2 垂直磁各向异性 4.5×105 A/m 氧化物阻挡层厚度 0.82 nm 温度 300 K  下载: 导出CSV
下载: 导出CSV
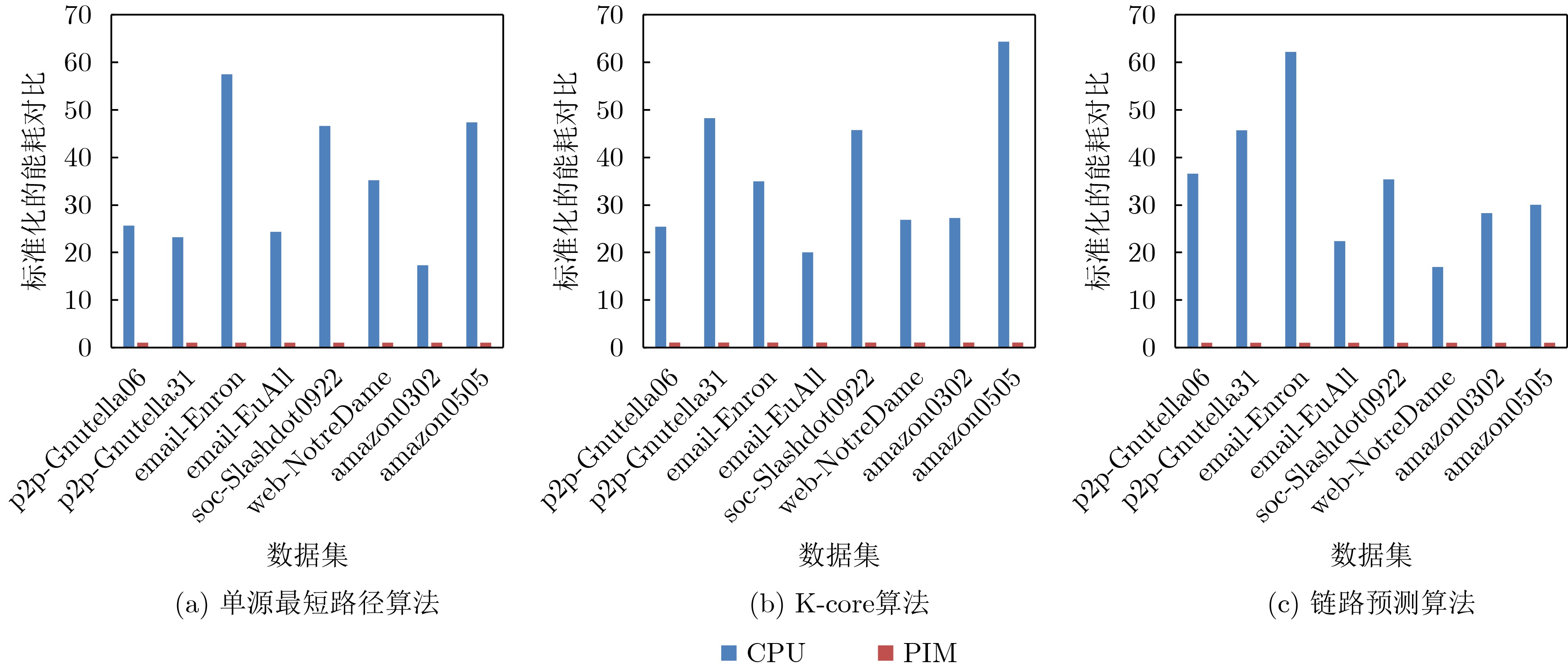
表 3 图计算存内加速架构实现与CPU实现速度对比(s)
图数据集 单源最短路径 K-core 链路预测 CPU PIM CPU PIM CPU PIM p2p-Gnutella06 0.063 0.0014 0.187 0.006 0.001 0.00012 p2p-Gnutella31 1.187 0.021 1.084 0.031 0.002 0.00016 email-Enron 2.972 0.071 1.383 0.056 0.001 0.00010 email-EuAll 2.826 0.081 3.832 0.193 0.003 0.00041 soc-Slashdot0922 10.989 0.203 10.137 0.241 0.002 0.00017 web-NotreDame 12.567 0.184 43.975 0.754 0.005 0.00037 amazon0302 17.837 0.329 14.392 0.381 0.002 0.00013 amazon0505 38.608 0.565 50.632 1.649 0.003 0.00043
下载: 导出CSV
-
[1] CHI Ping, LI Shuangchen, XU Cong, et al. PRIME: A novel processing-in-memory architecture for neural network computation in ReRAM-based main memory[J]. ACM SIGARCH Computer Architecture News, 2016, 44(3): 27–39. doi: 10.1145/3007787.3001140 [2] OZDAL M M, YESIL S, KIM T, et al. Energy efficient architecture for graph analytics accelerators[J]. ACM SIGARCH Computer Architecture News, 2016, 44(3): 166–177. doi: 10.1145/3007787.3001155 [3] HAM T J, WU Lisa, SUNDARAM N, et al. Graphicionado: A high-performance and energy-efficient accelerator for graph analytics[C]. 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, China, 2016: 1–13. [4] KYROLA A, BLELLOCH G, and GUESTRIN C. GraphChi: Large-scale graph computation on just a PC[C]. Proceedings of the 10th USENIX conference on Operating Systems Design and Implementation, Hollywood, USA, 2012: 31–46. [5] LIANG Shengwen, WANG Ying, LIU Cheng, et al. EnGN: A high-throughput and energy-efficient accelerator for large graph neural networks[J]. IEEE Transactions on Computers, 2021, 70(9): 1511–1525. doi: 10.1109/TC.2020.3014632 [6] DAI Guohao, HUANG Tianhao, CHI Yuze, et al. GraphH: A processing-in-memory architecture for large-scale graph processing[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2018, 38(4): 640–653. doi: 10.1109/TCAD.2018.2821565 [7] BEAMER S, ASANOVIC K, and PATTERSON D. Locality exists in graph processing: Workload characterization on an ivy bridge server[C]. 2015 IEEE International Symposium on Workload Characterization, Atlanta, USA, 2015: 56–65. [8] WANG Mengxing, CAI Wenlong, ZHU Daoqian, et al. Field-free switching of a perpendicular magnetic tunnel junction through the interplay of spin-orbit and spin-transfer torques[J]. Nature Electronics, 2018, 1(11): 582–588. doi: 10.1038/s41928-018-0160-7 [9] GUO Zongxia, YIN Jialiang, BAI Yue, et al. Spintronics for energy-efficient computing: An overview and outlook[J]. Proceedings of the IEEE, 2021, 109(8): 1398–1417. doi: 10.1109/JPROC.2021.3084997 [10] JAIN S, RANJAN A, ROY K, et al. Computing in memory with spin-transfer torque magnetic RAM[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2018, 26(3): 470–483. doi: 10.1109/TVLSI.2017.2776954 [11] ANGIZI S, SUN Jiao, ZHANG Wei, et al. GraphS: A graph processing accelerator leveraging SOT-MRAM[C]. 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 2019: 378–383. [12] WANG Xueyan, YANG Jianlei, ZHAO Yinglin, et al. Triangle counting accelerations: From algorithm to in-memory computing architecture[J]. IEEE Transactions on Computers, 2022, 71(10): 2462–2472. doi: 10.1109/TC.2021.3131049 [13] LI Shuangchen, XU Cong, ZOU Qiaosha, et al. Pinatubo: A processing-in-memory architecture for bulk bitwise operations in emerging non-volatile memories[C]. The 53rd ACM/EDAC/IEEE Design Automation Conference, Austin, USA, 2016: 1–6. [14] HAN Lei, SHEN Zhaoyan, LIU Duo, et al. A novel ReRAM-based processing-in-memory architecture for graph traversal[J]. ACM Transactions on Storage, 2018, 14(1): 9. doi: 10.1145/3177916 [15] CHEN Xuhang, WANG Xueyan, JIA Xiaotao, et al. Accelerating graph-connected component computation with emerging processing-in-memory architecture[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2022, 41(12): 5333–5342. doi: 10.1109/TCAD.2022.3163628 [16] PEROZZI B, AL-RFOU R, and SKIENA S. DeepWalk: Online learning of social representations[C]. The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2014: 701–710. [17] LESKOVEC J and KREVL A. SNAP Datasets: Stanford large network dataset collection[EB/OL]. http://snap.stanford.edu/data, 2014. -

 下载:
下载:


图(4) / 表(3)
计量
- 文章访问数: 1229
- HTML全文浏览量: 831
- PDF下载量: 117
- 被引次数: 0
