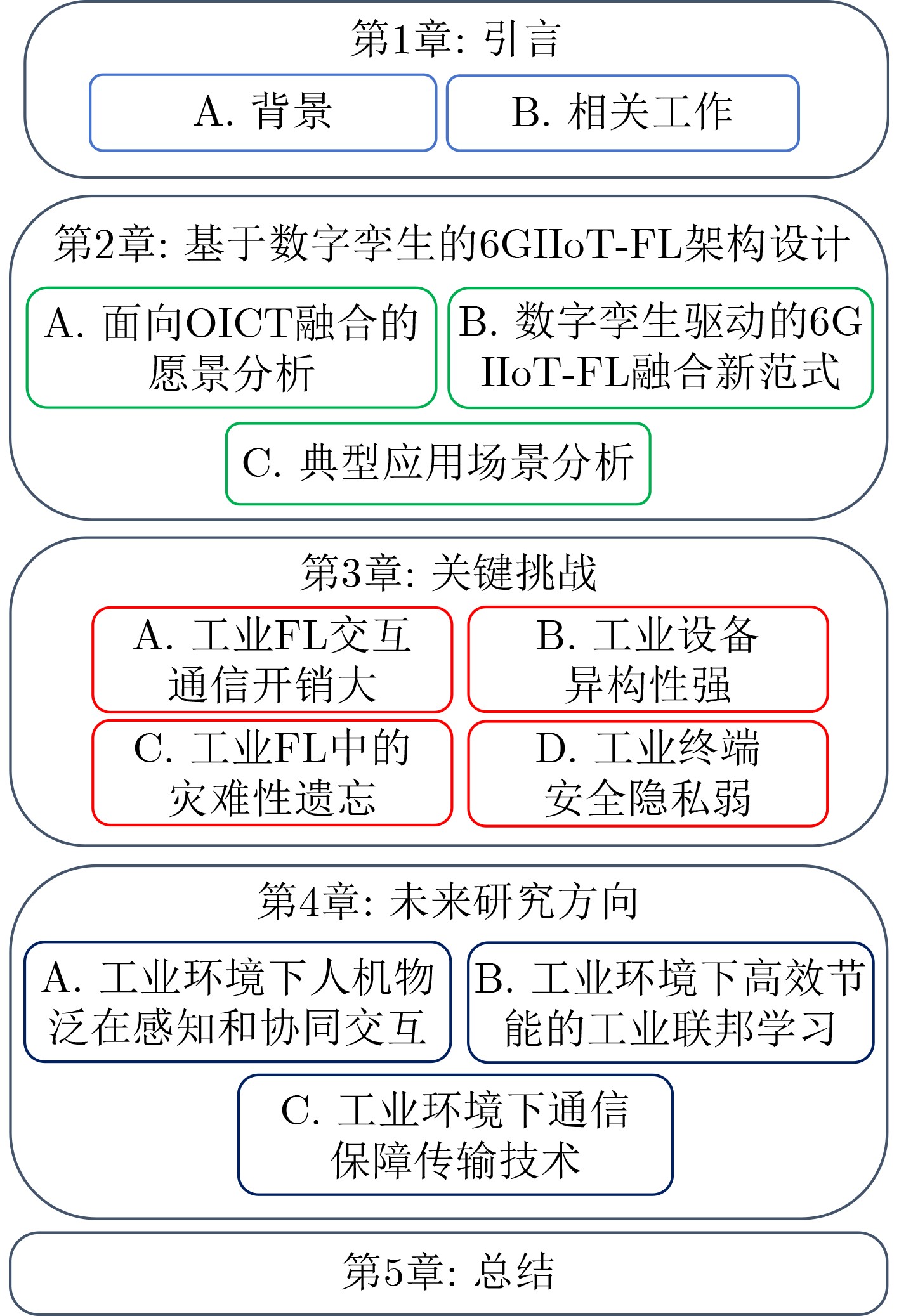
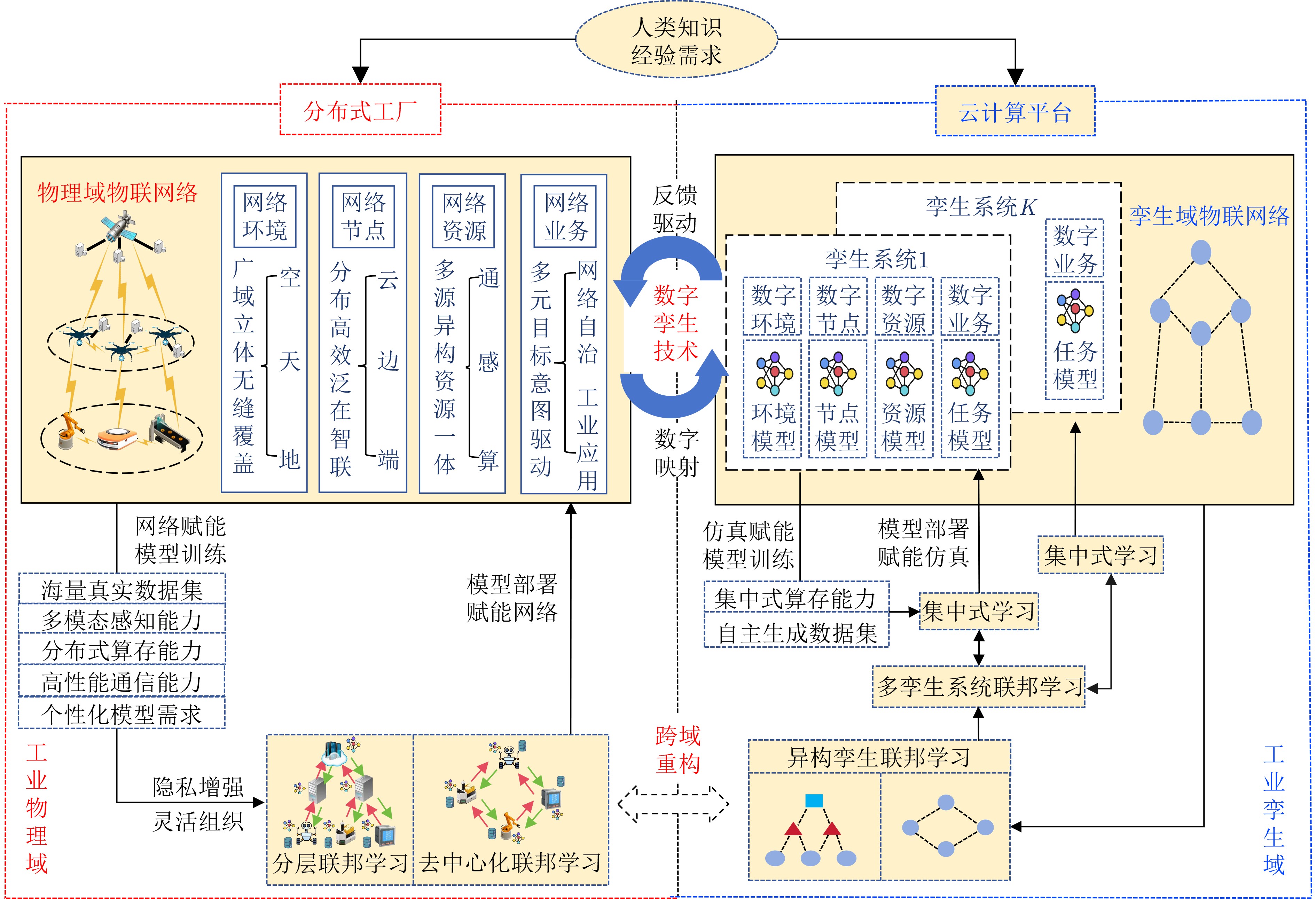
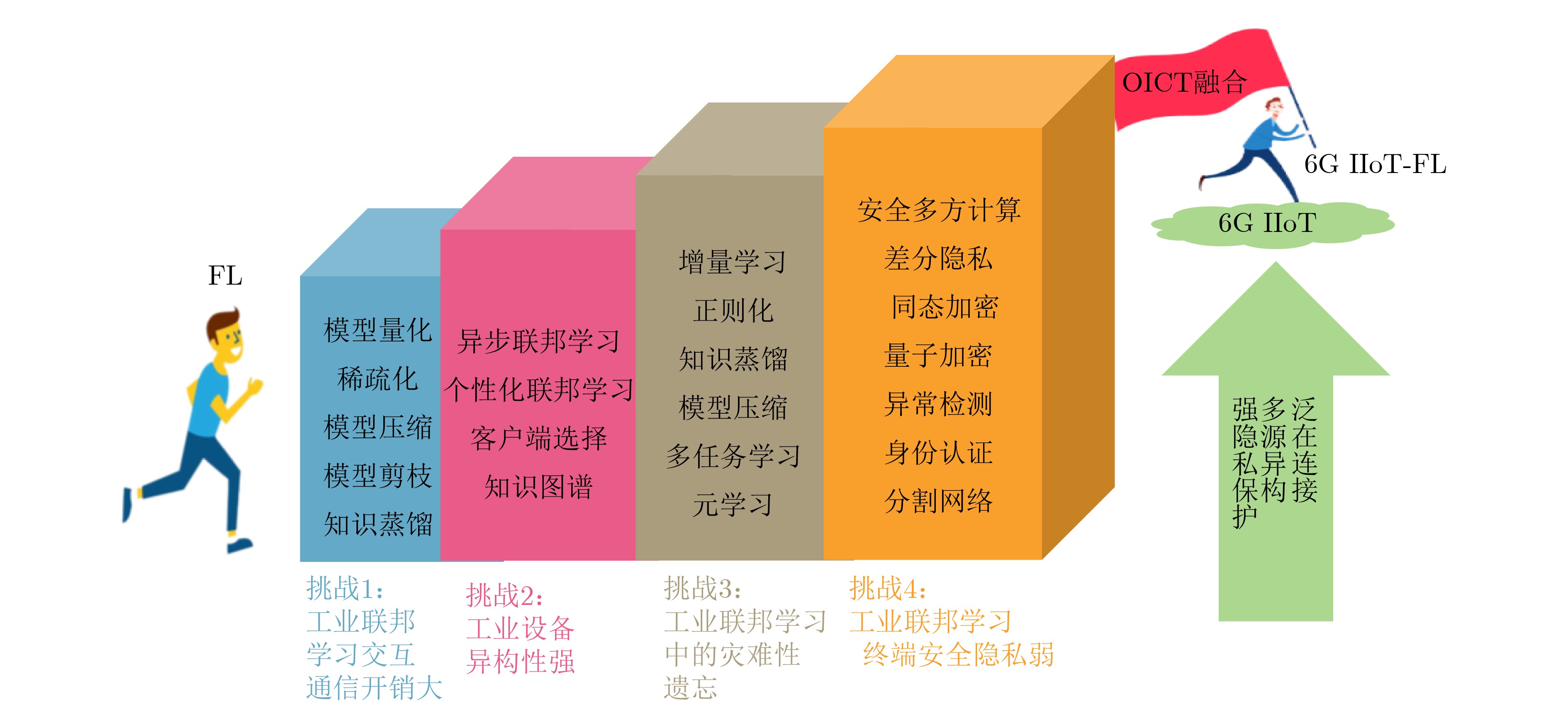
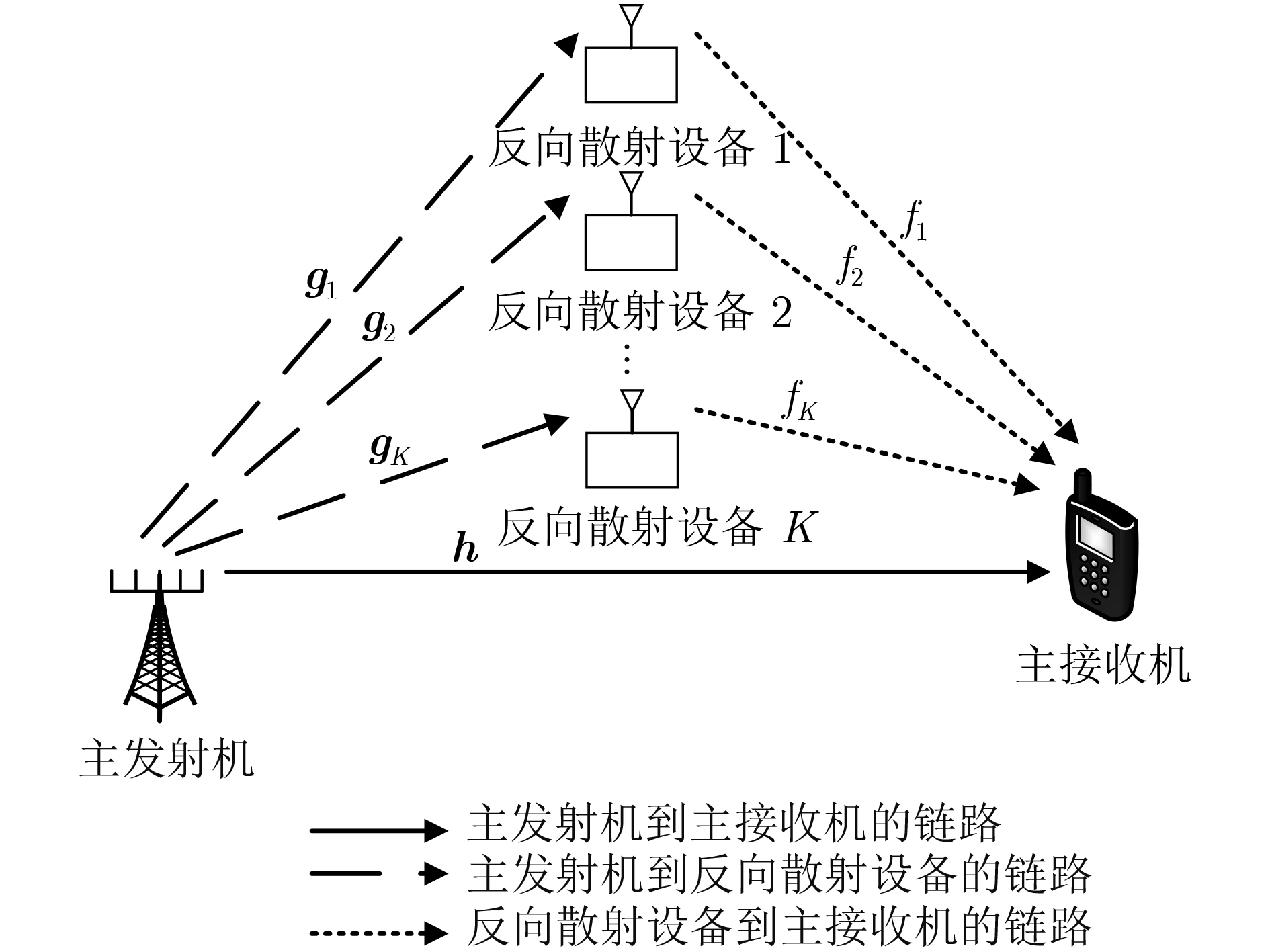
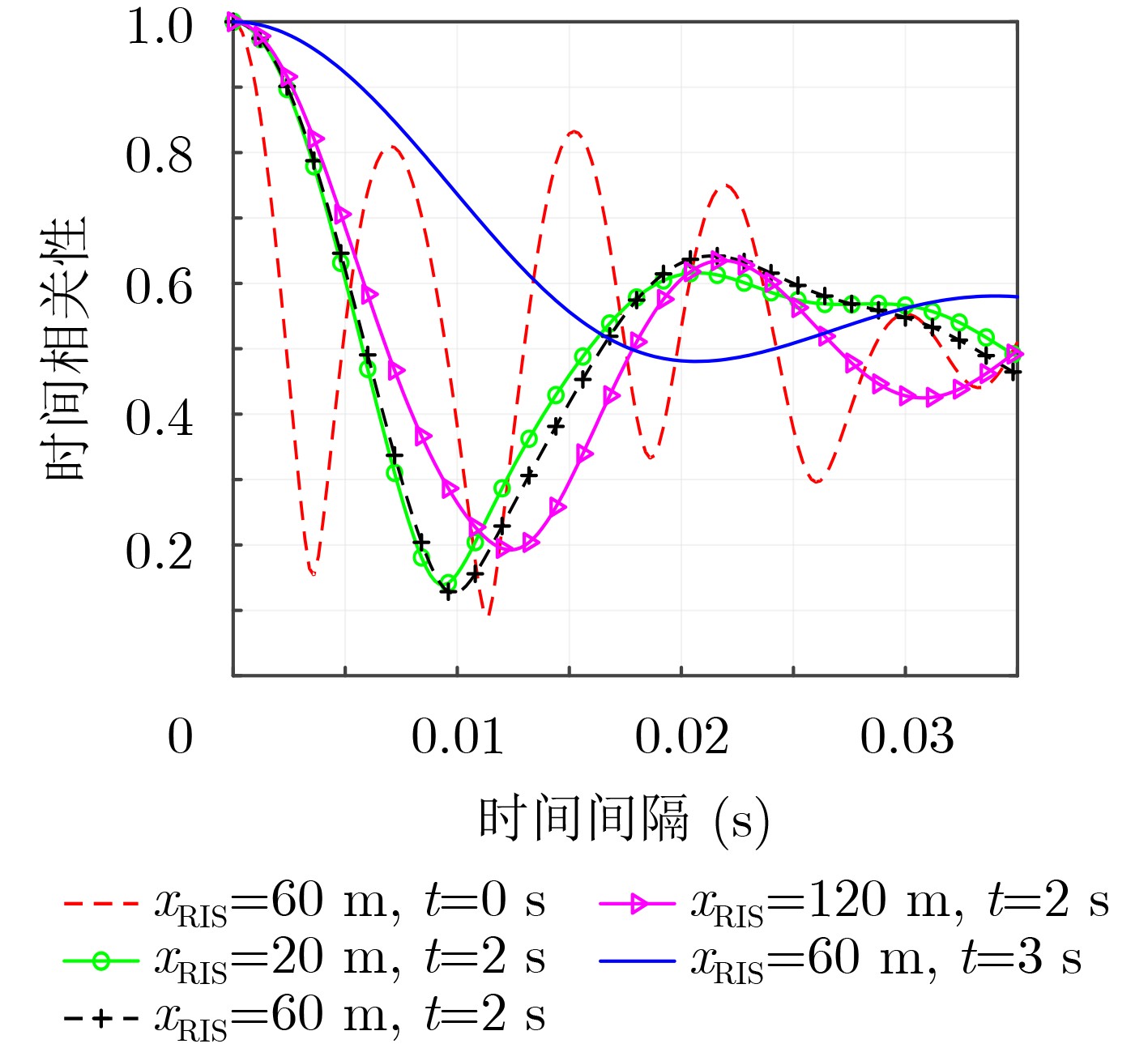
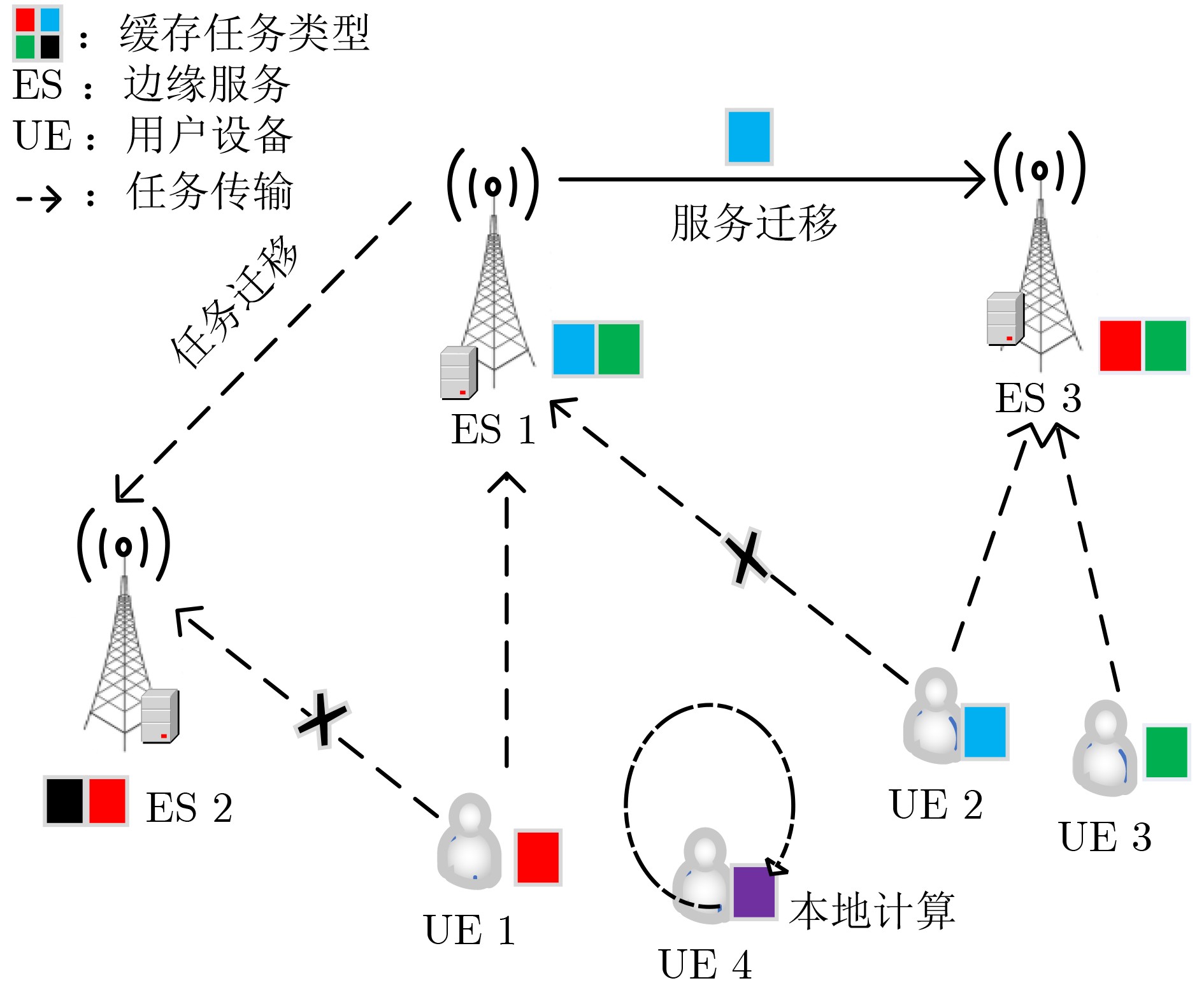
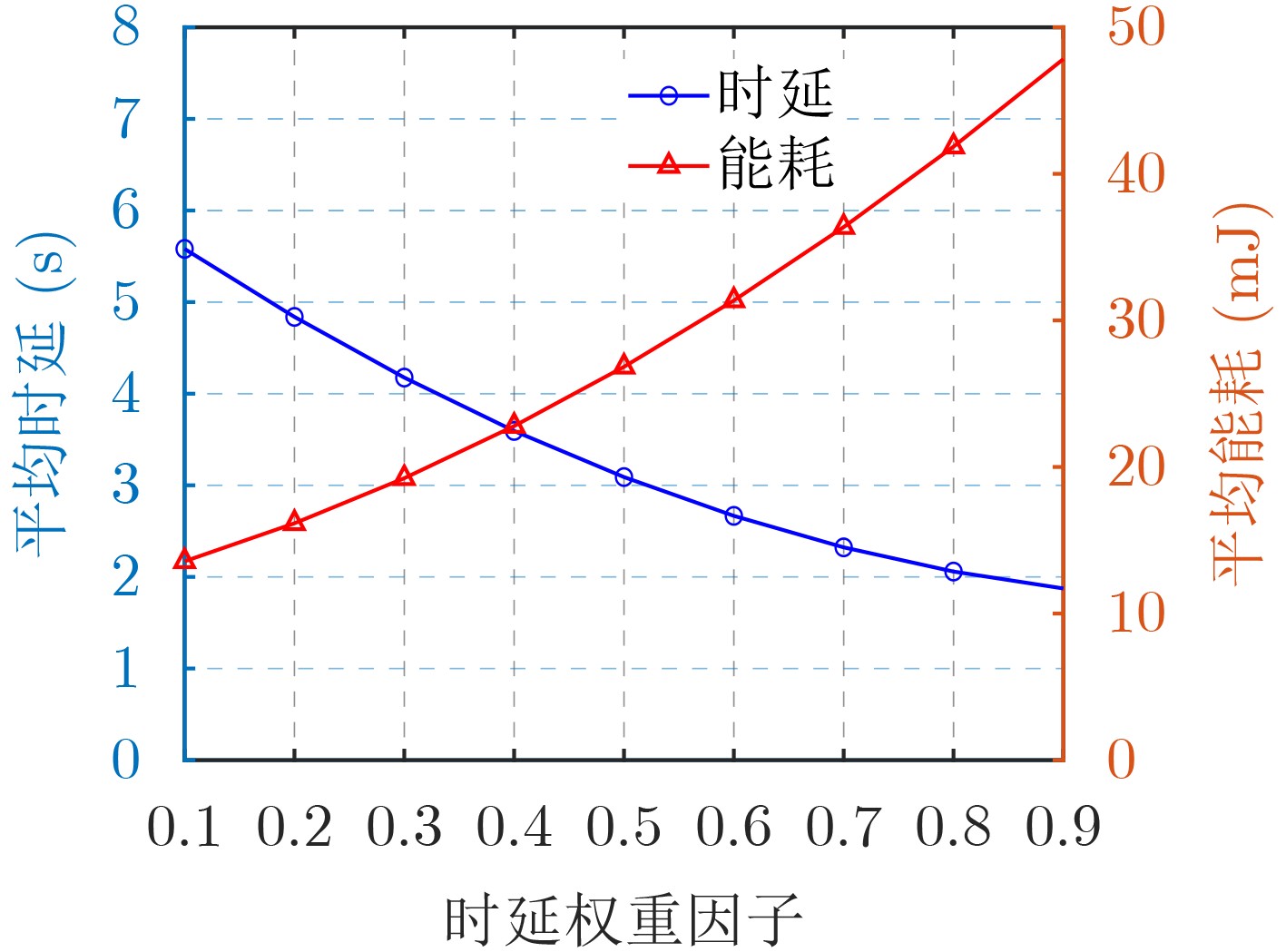
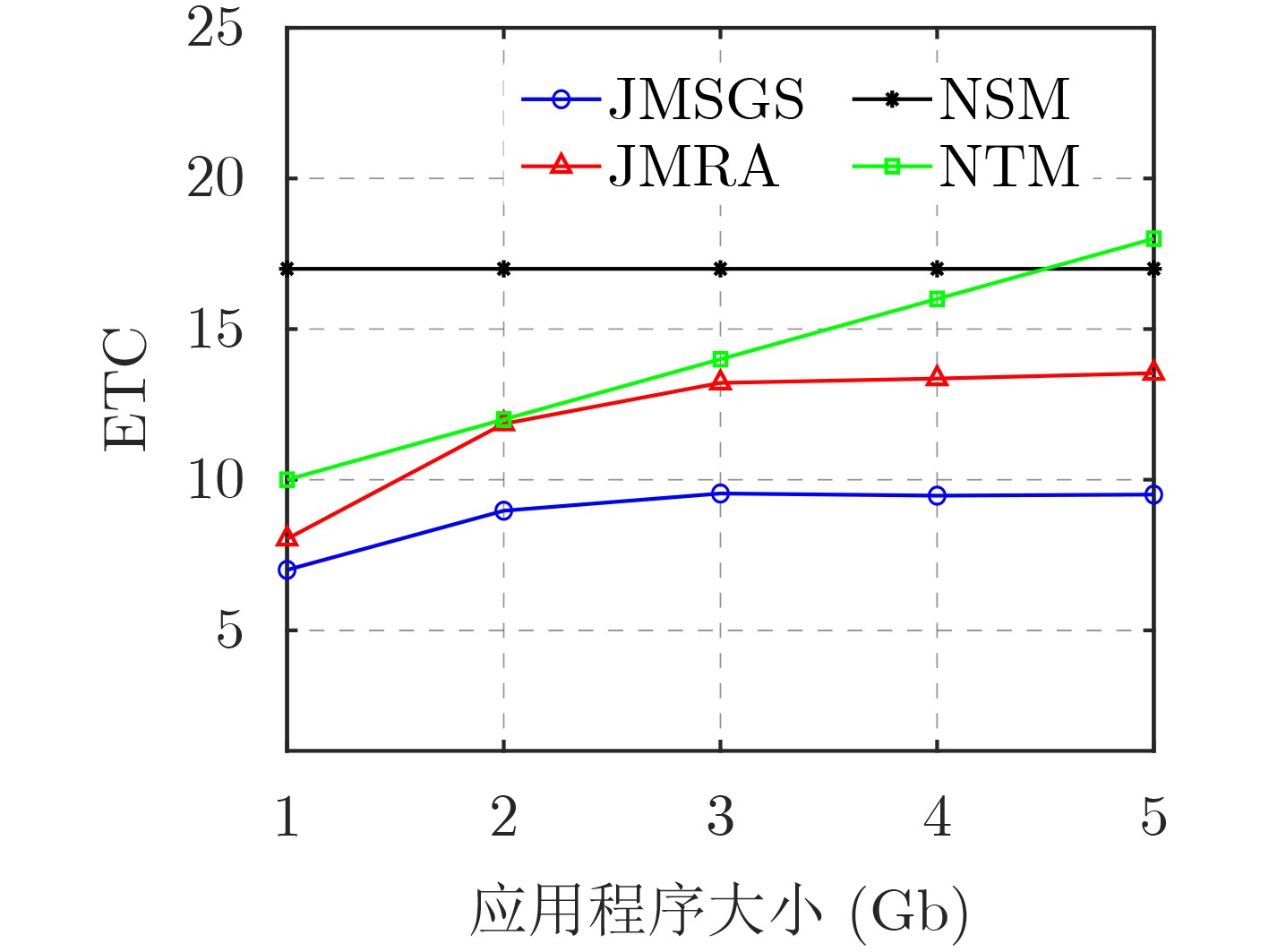
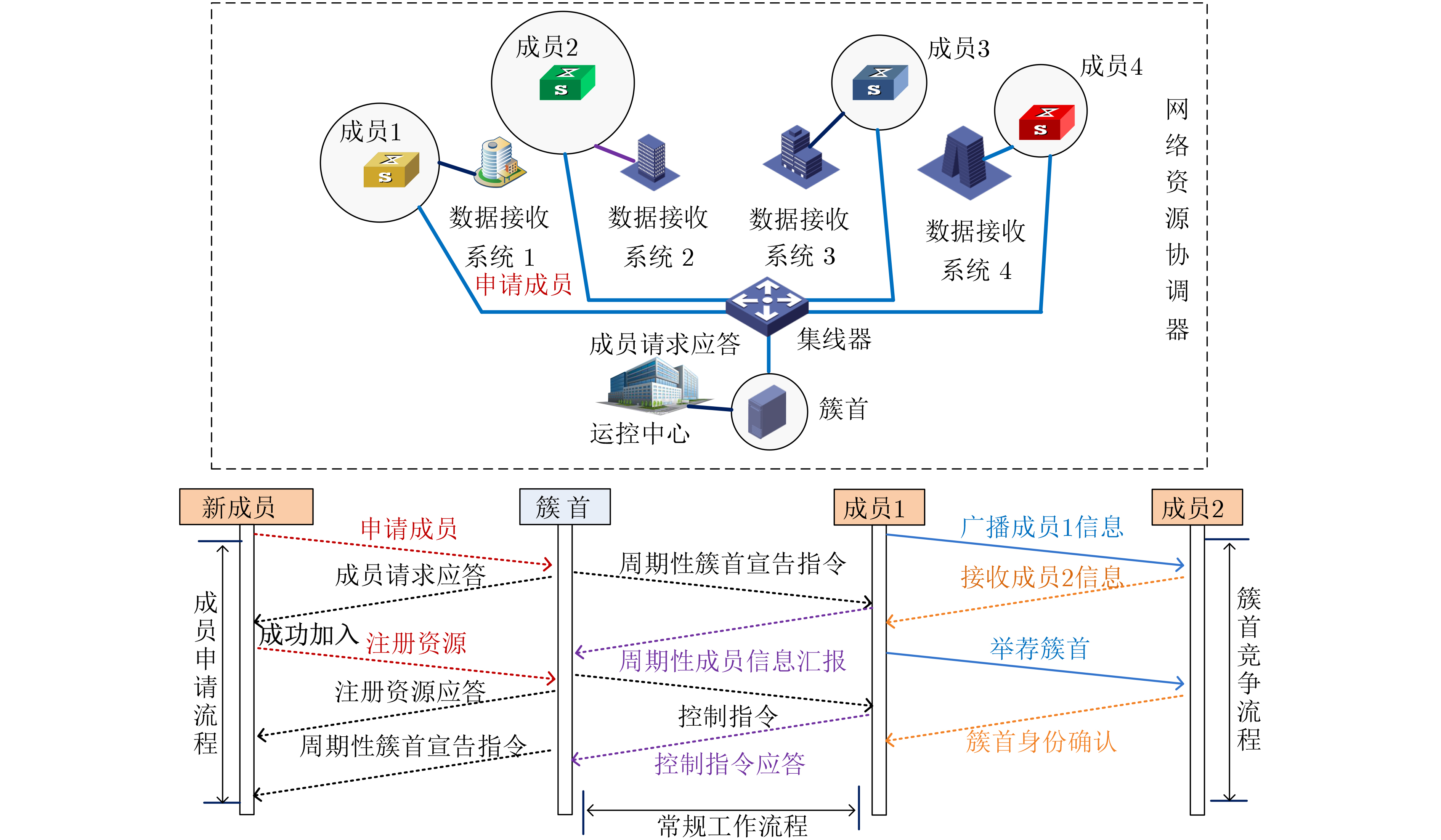
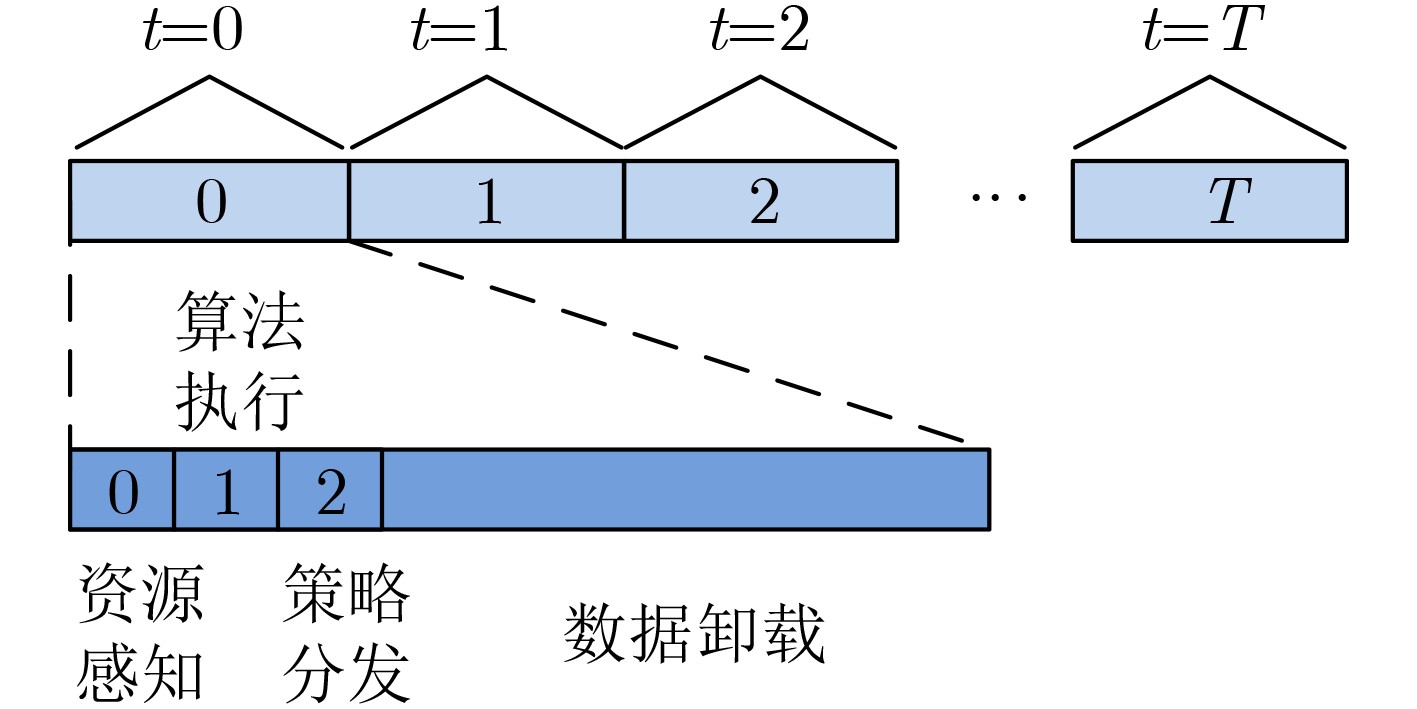
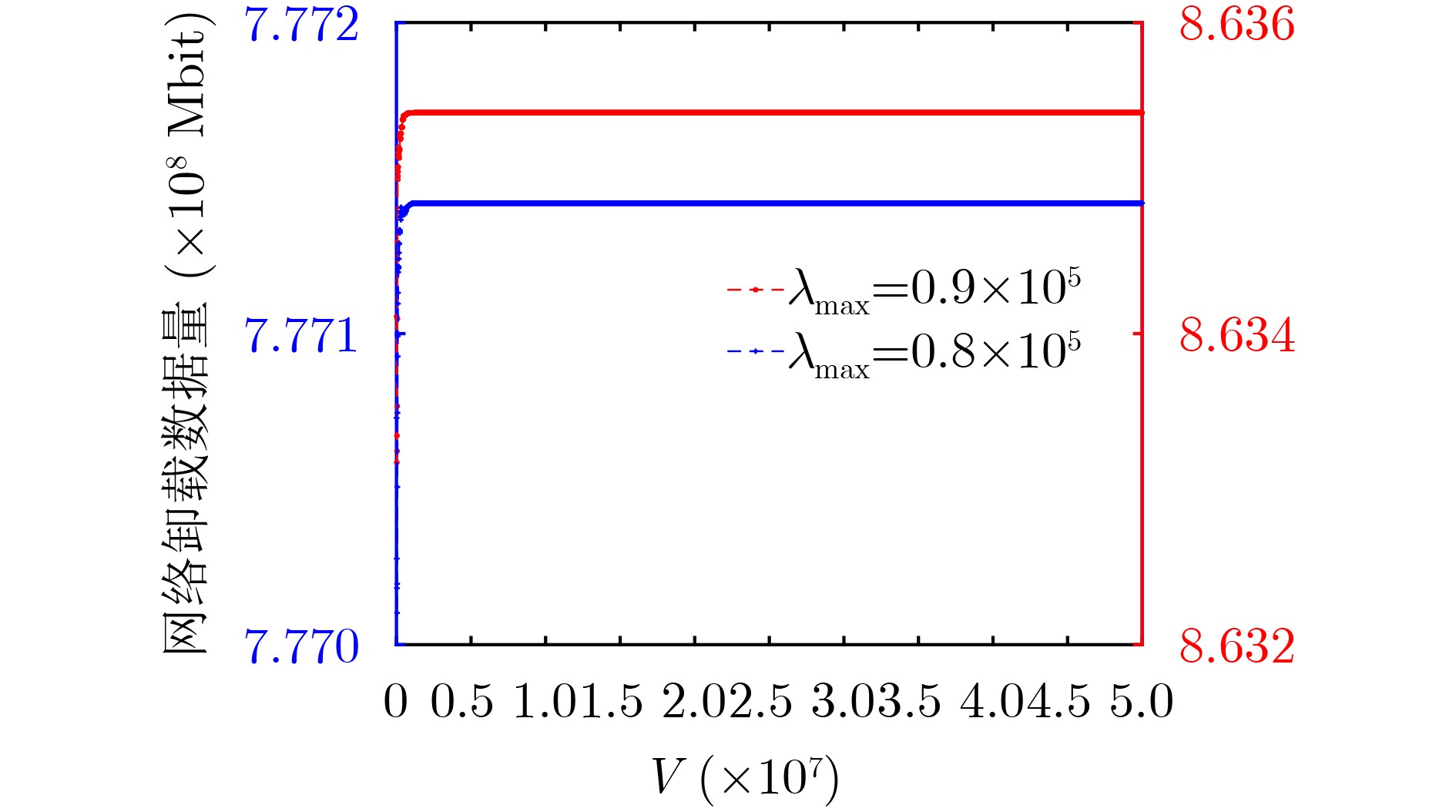
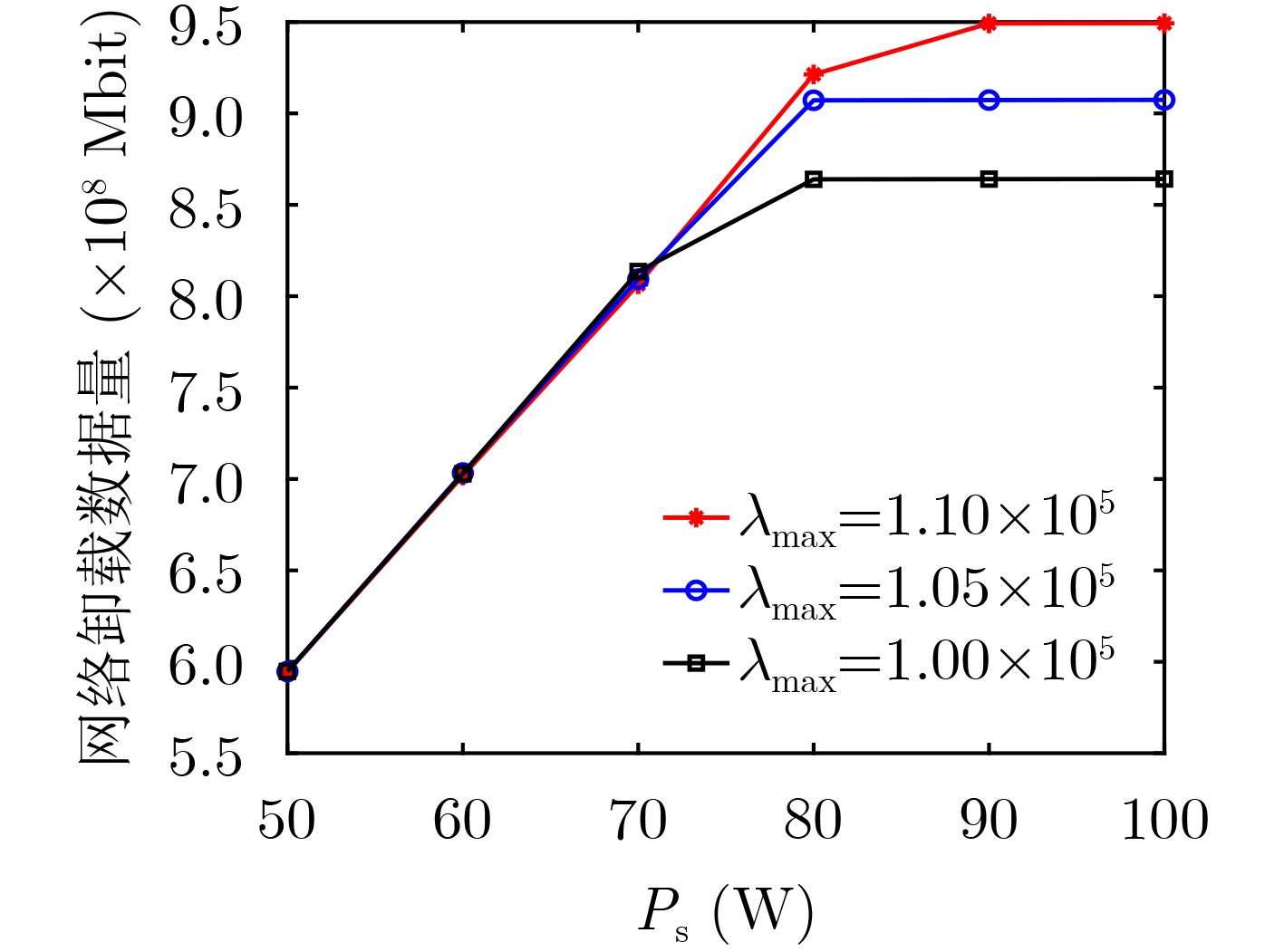
2024, 46(12): 4542-4552.
doi: 10.11999/JEIT240087
摘要:
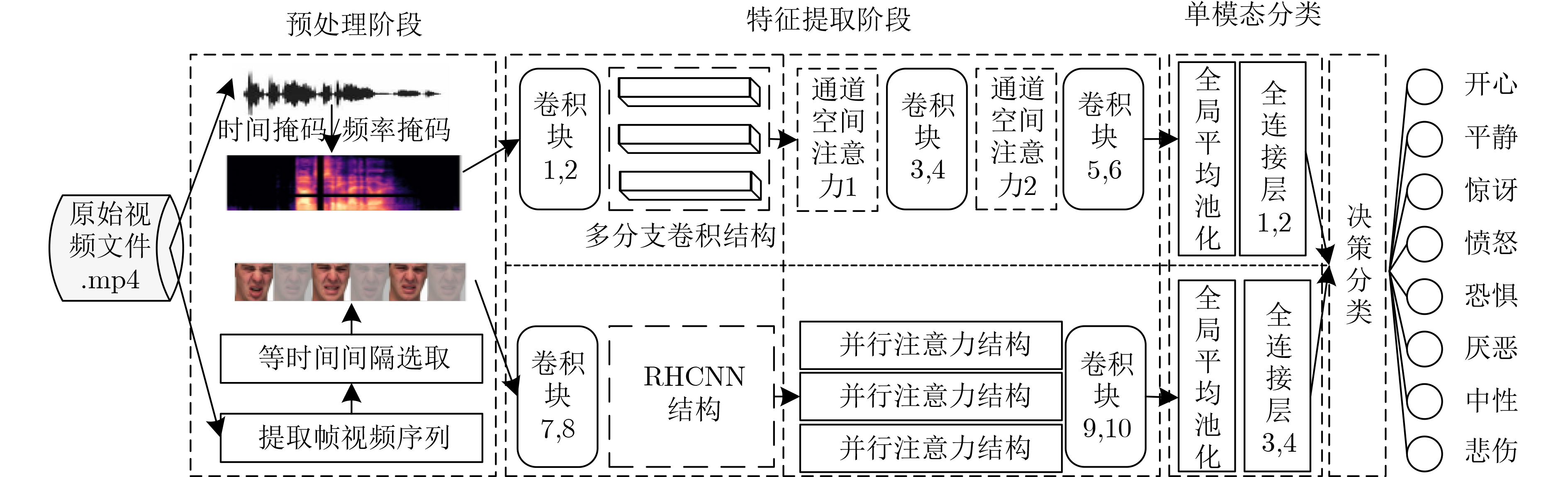
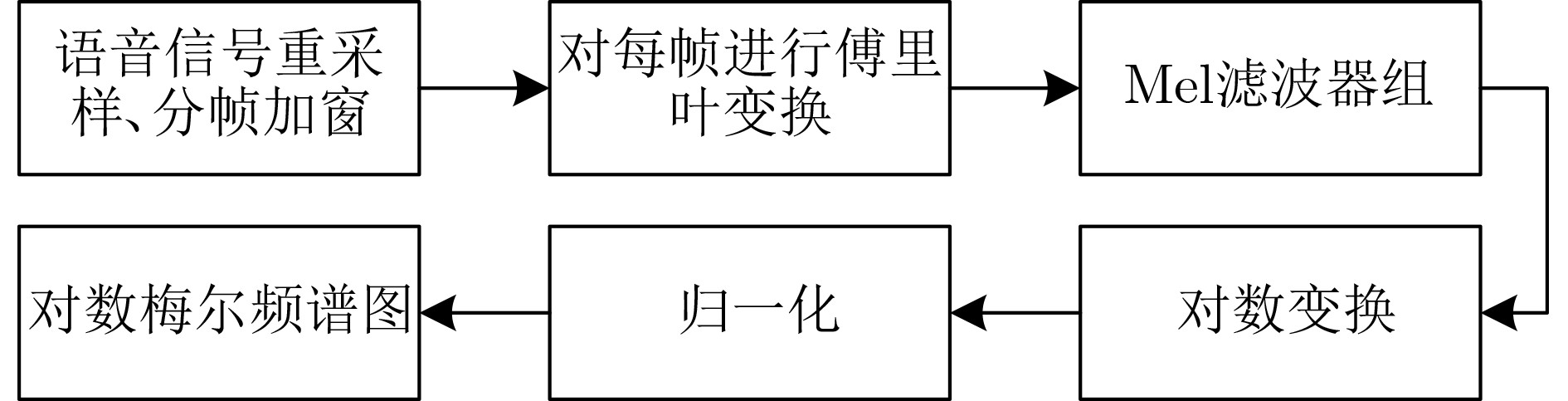
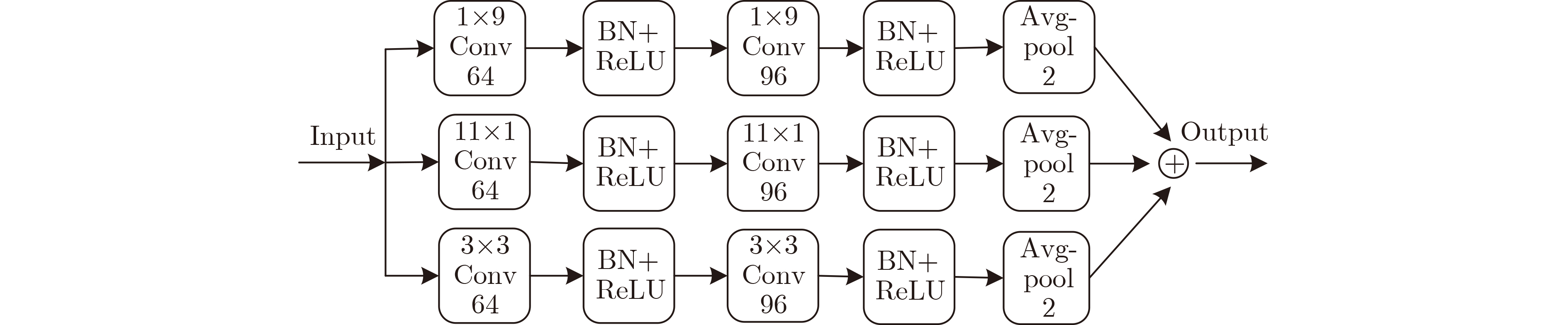
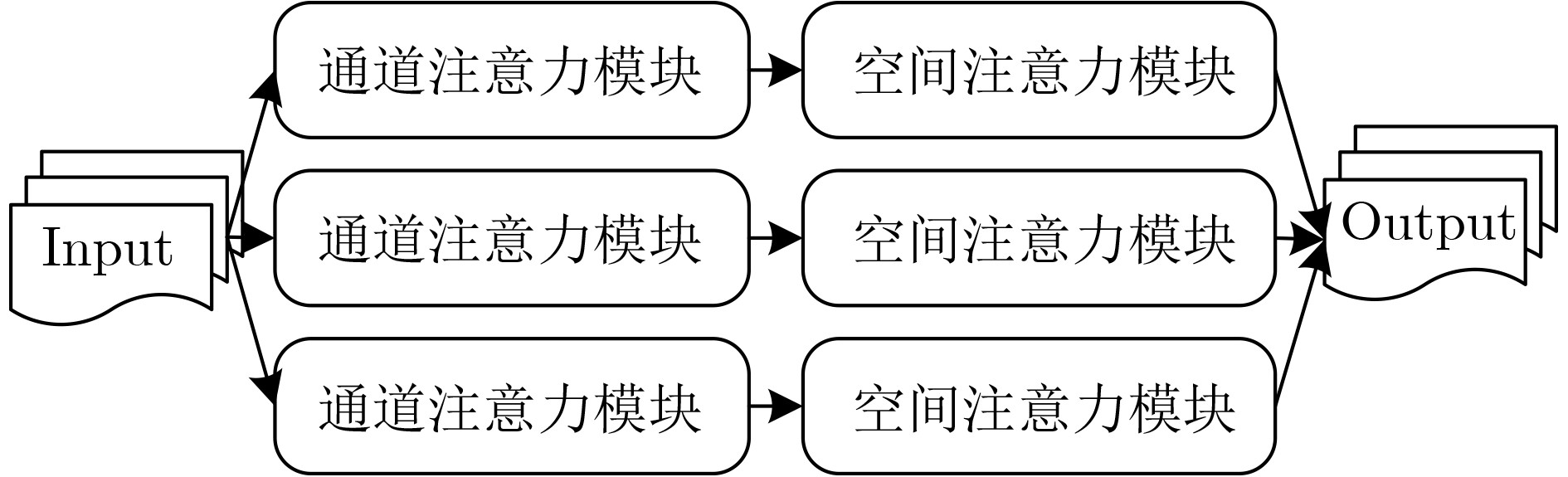
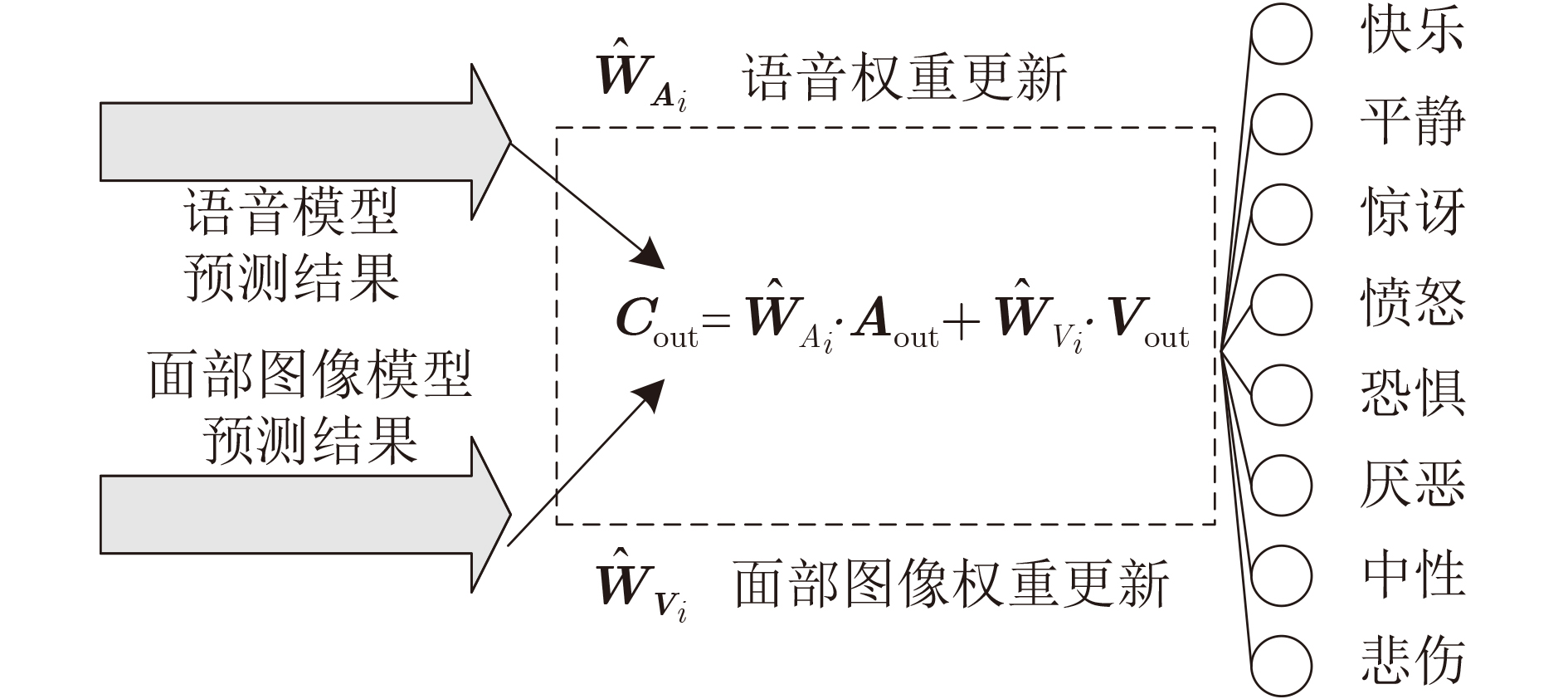
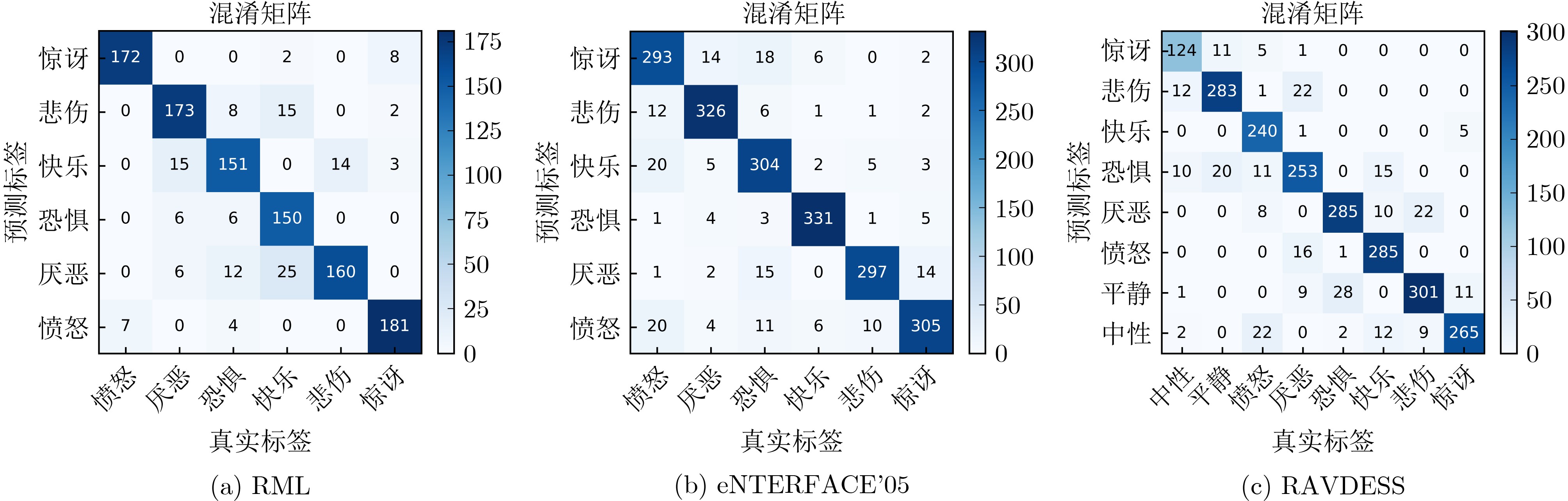
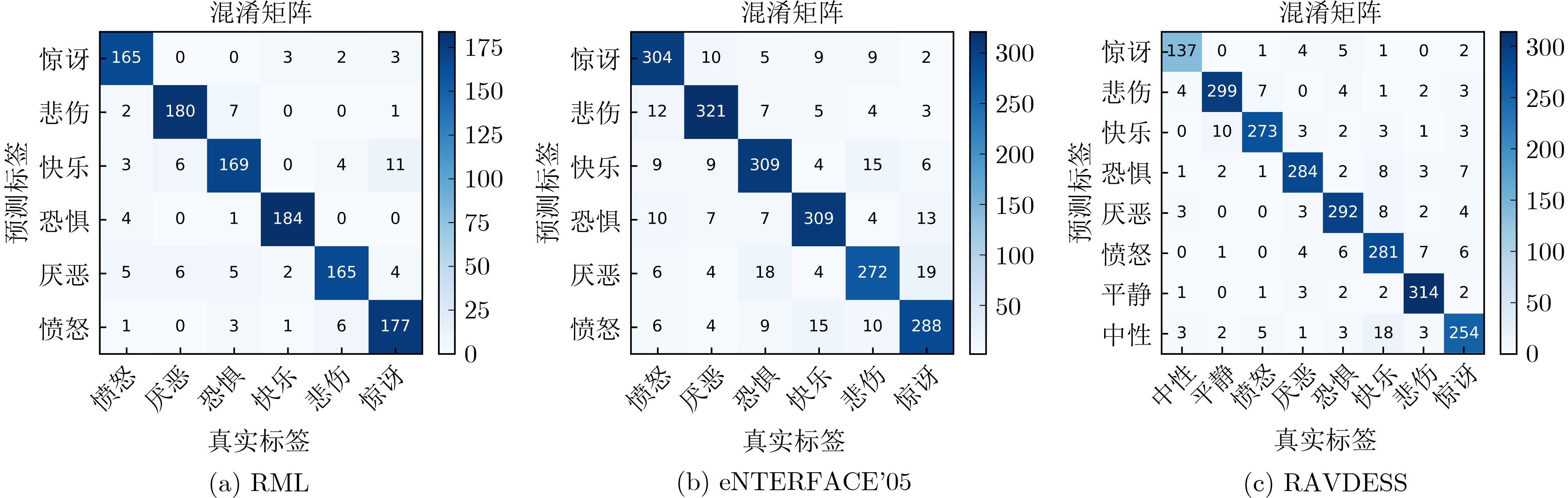
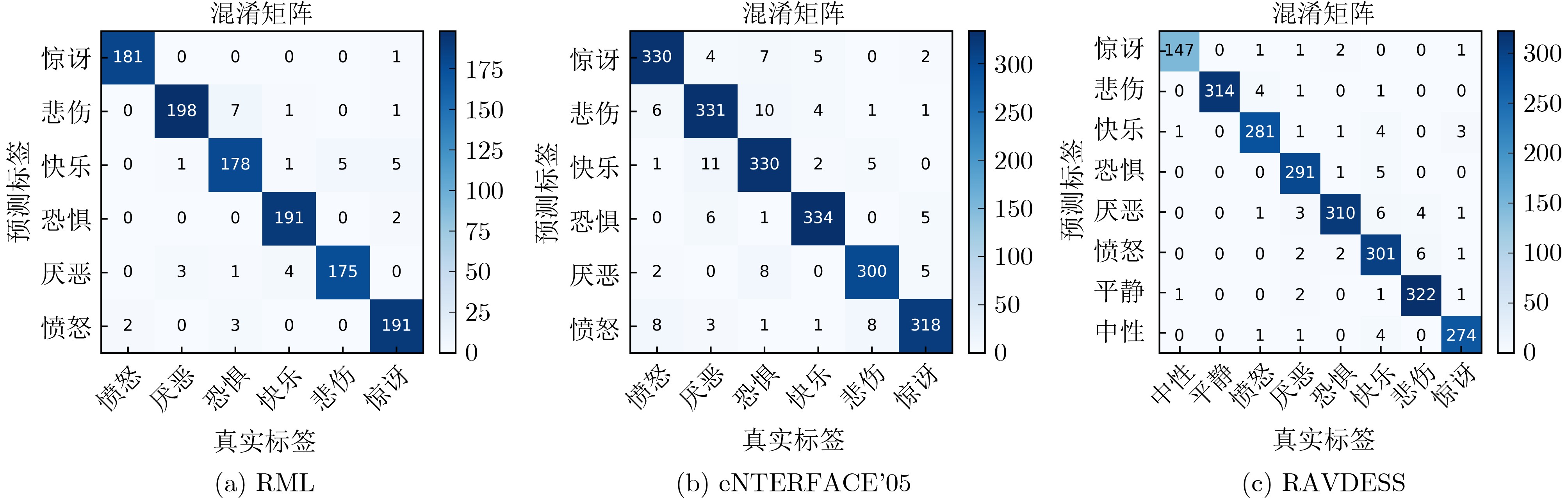
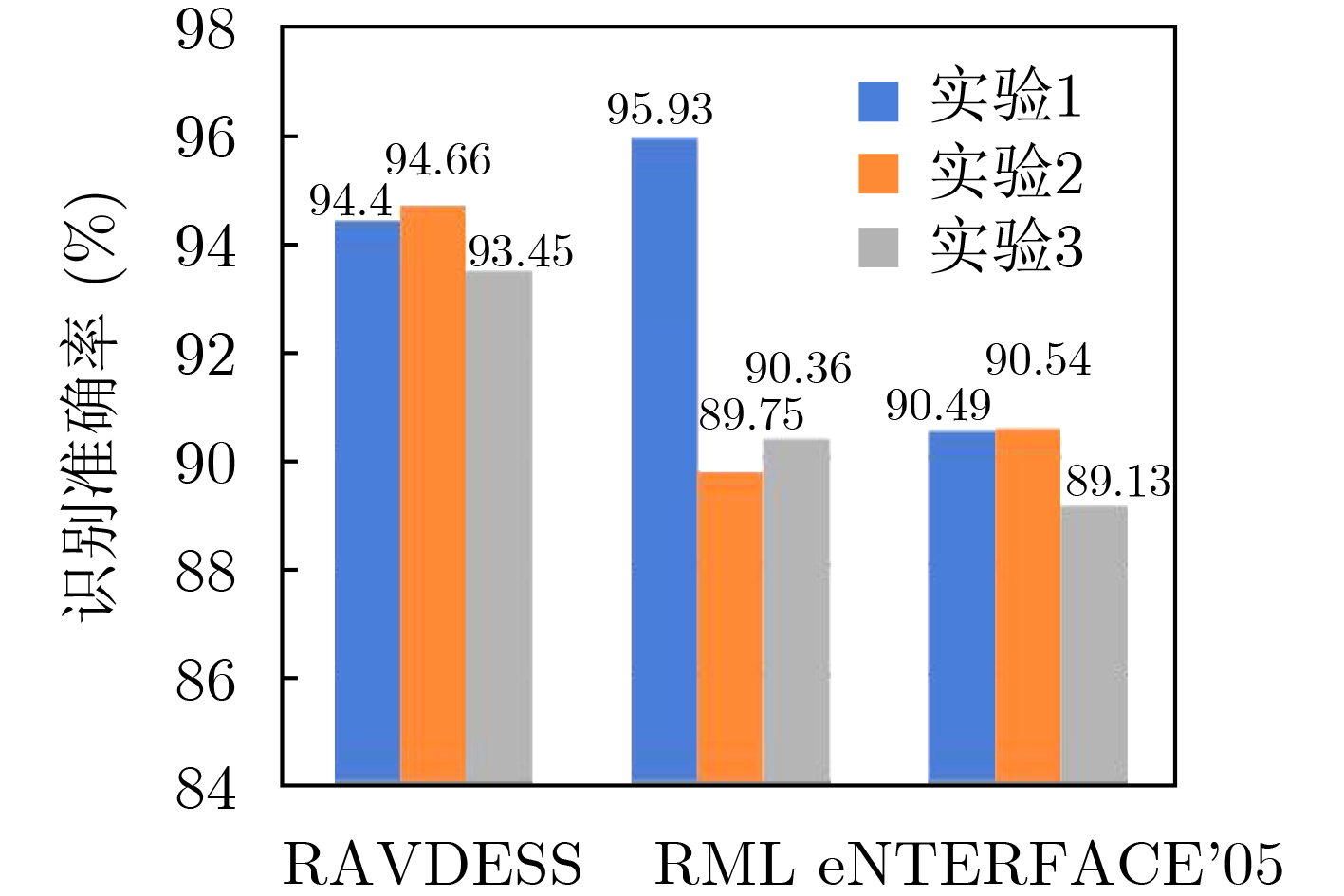
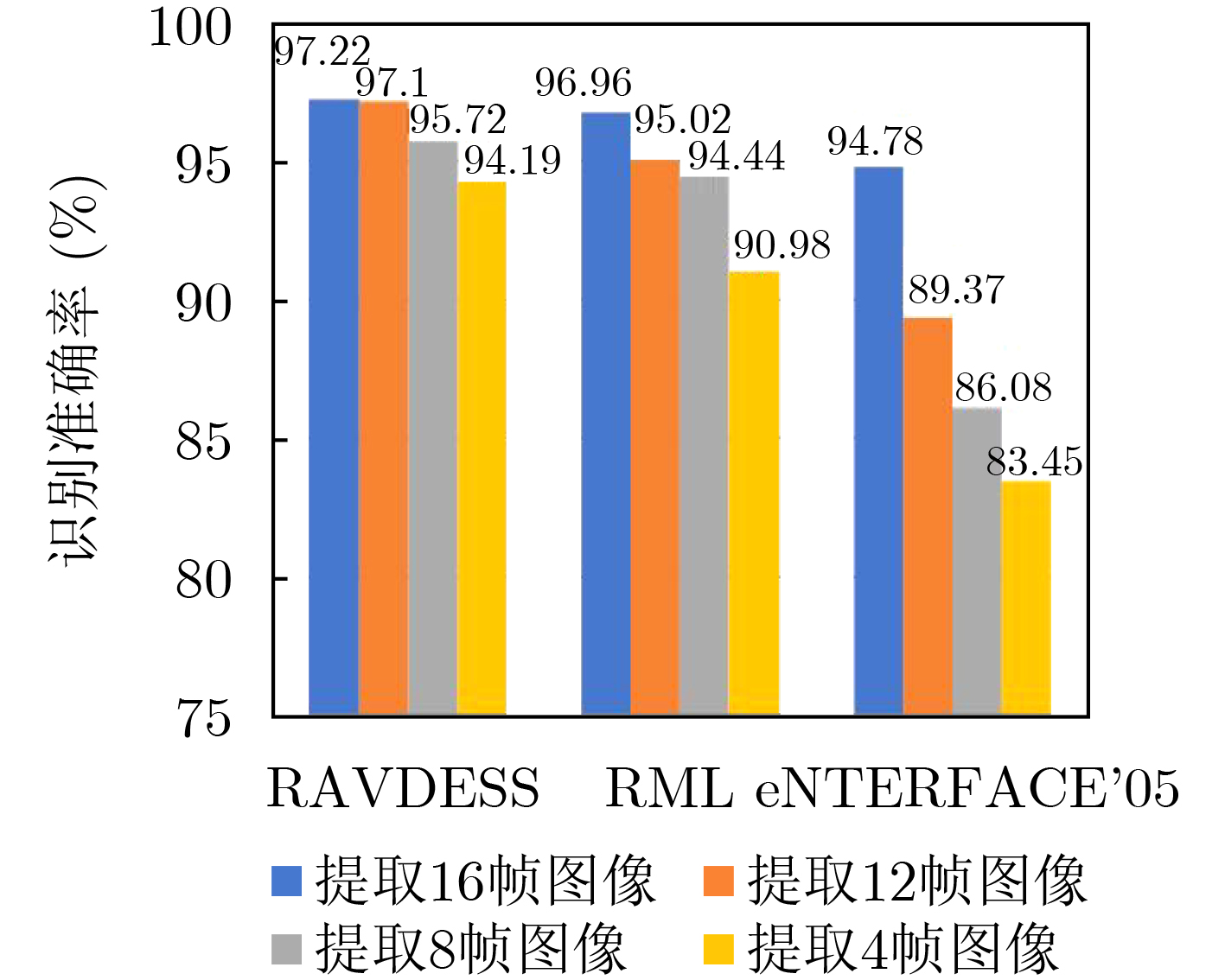
为提升情感识别模型的准确率,解决情感特征提取不充分的问题,对语音和面部图像的双模态情感识别进行研究。语音模态提出一种结合通道-空间注意力机制的多分支卷积神经网络(Multi-branch Convolutional Neural Networks, MCNN)的特征提取模型,在时间、空间和局部特征维度对语音频谱图提取情感特征;面部图像模态提出一种残差混合卷积神经网络(Residual Hybrid Convolutional Neural Network, RHCNN)的特征提取模型,进一步建立并行注意力机制关注全局情感特征,提高识别准确率;将提取到的语音和面部图像特征分别通过分类层进行分类识别,并使用决策融合对识别结果进行最终的融合分类。实验结果表明,所提双模态融合模型在RAVDESS, eNTERFACE’05, RML三个数据集上的识别准确率分别达到了97.22%, 94.78%和96.96%,比语音单模态的识别准确率分别提升了11.02%, 4.24%, 8.83%,比面部图像单模态的识别准确率分别提升了4.60%, 6.74%, 4.10%,且与近年来对应数据集上的相关方法相比均有所提升。说明了所提的双模态融合模型能有效聚焦情感信息,从而提升情感识别的准确率。