

Emotion Recognition with Speech and Facial Images
-
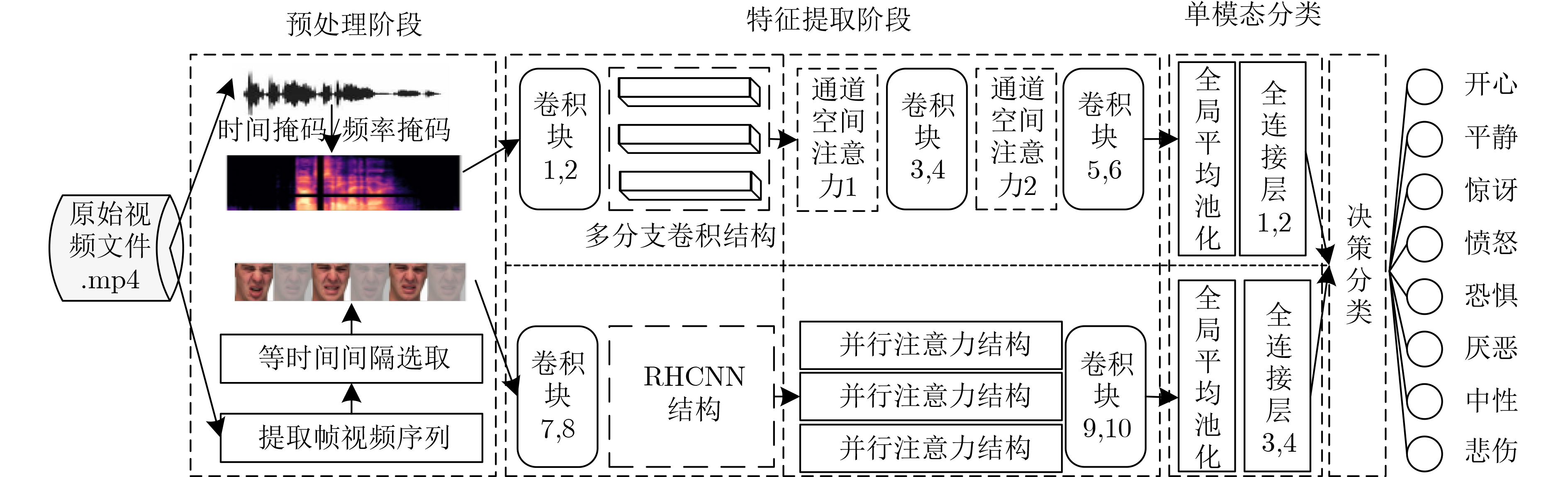
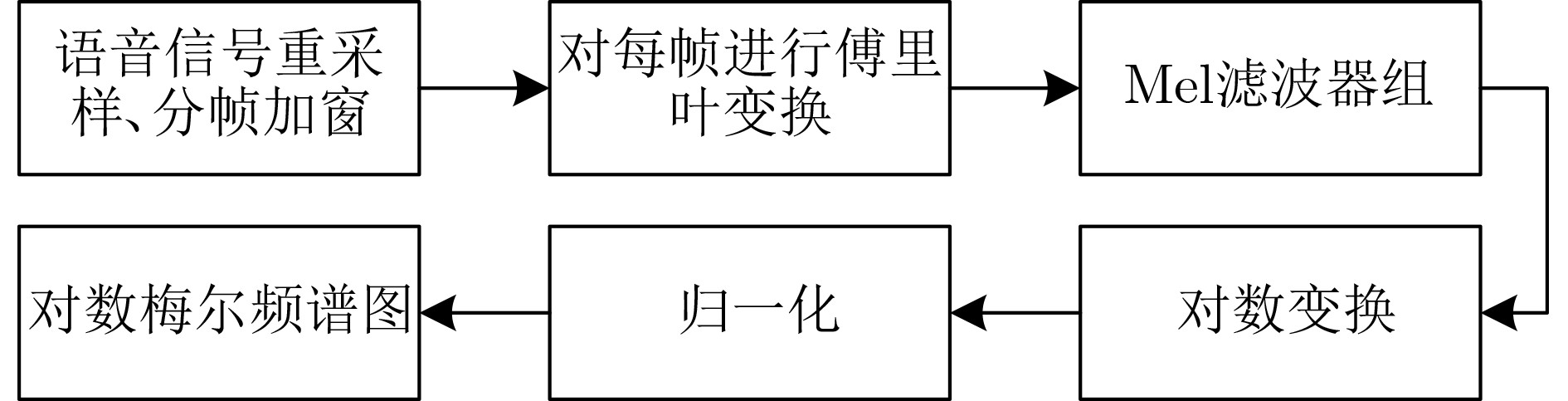
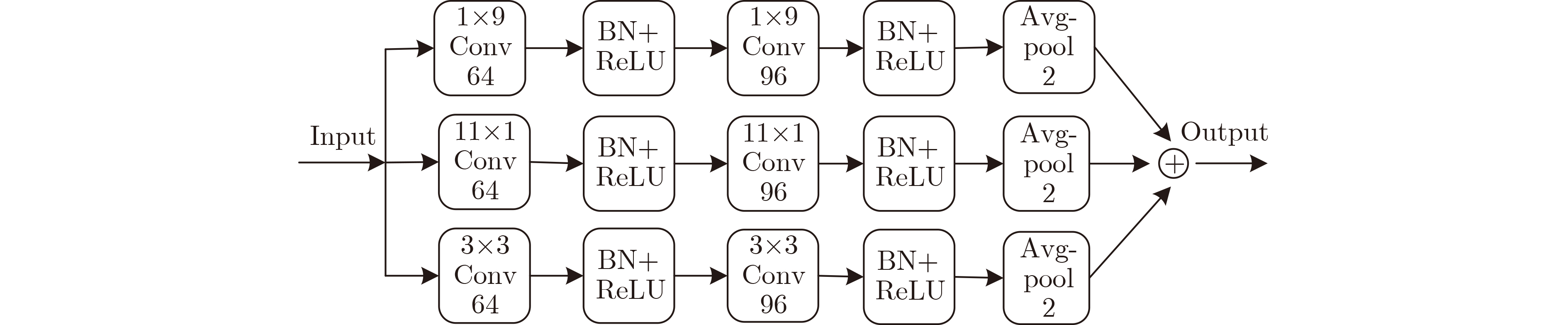
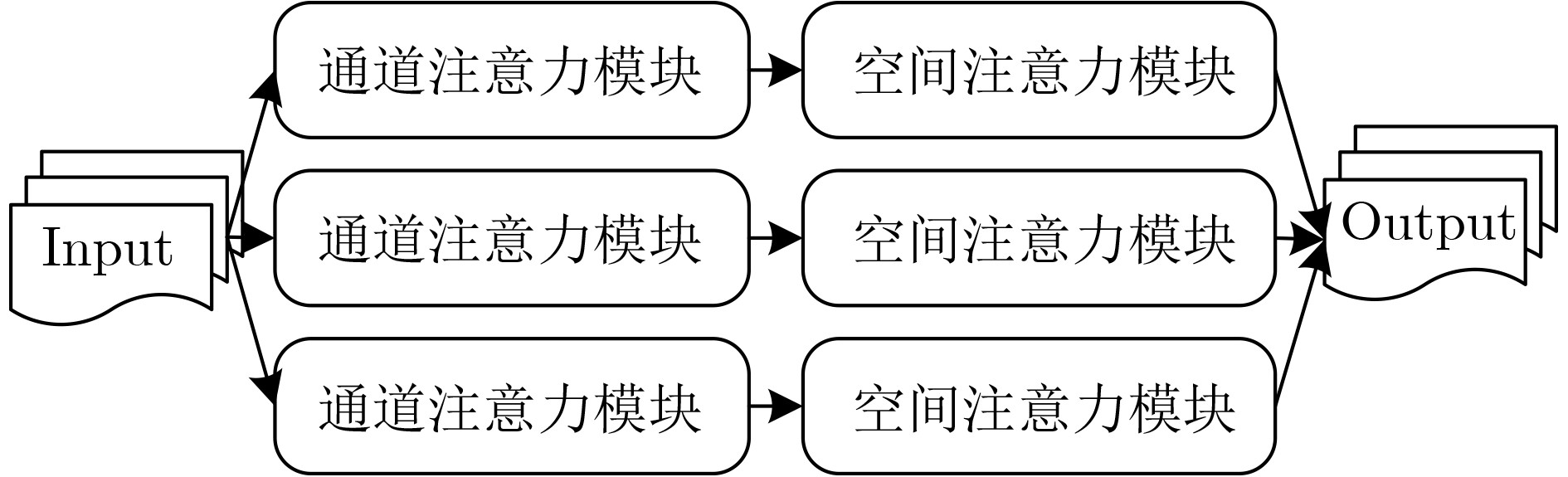
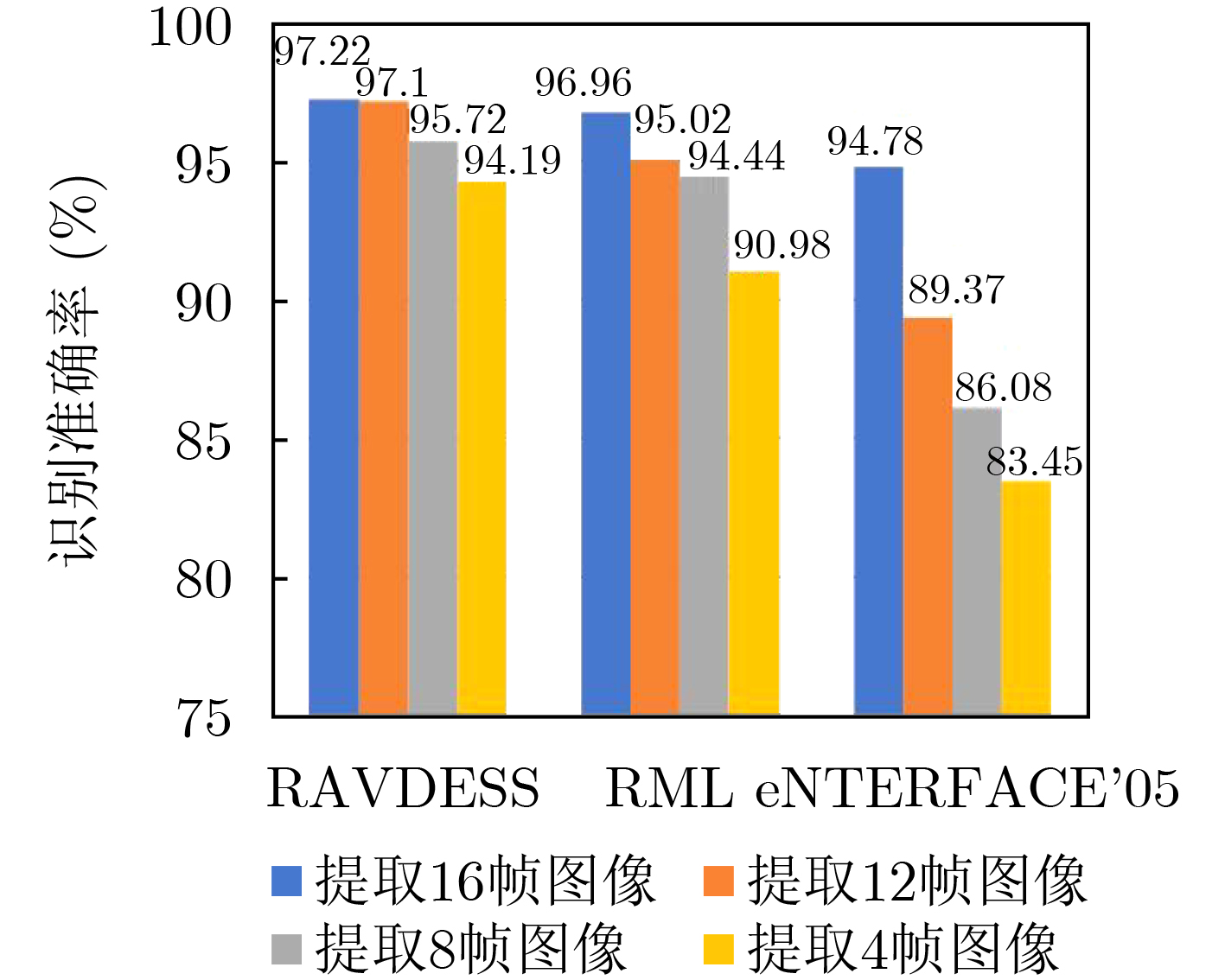
摘要: 为提升情感识别模型的准确率,解决情感特征提取不充分的问题,对语音和面部图像的双模态情感识别进行研究。语音模态提出一种结合通道-空间注意力机制的多分支卷积神经网络(Multi-branch Convolutional Neural Networks, MCNN)的特征提取模型,在时间、空间和局部特征维度对语音频谱图提取情感特征;面部图像模态提出一种残差混合卷积神经网络(Residual Hybrid Convolutional Neural Network, RHCNN)的特征提取模型,进一步建立并行注意力机制关注全局情感特征,提高识别准确率;将提取到的语音和面部图像特征分别通过分类层进行分类识别,并使用决策融合对识别结果进行最终的融合分类。实验结果表明,所提双模态融合模型在RAVDESS, eNTERFACE’05, RML三个数据集上的识别准确率分别达到了97.22%, 94.78%和96.96%,比语音单模态的识别准确率分别提升了11.02%, 4.24%, 8.83%,比面部图像单模态的识别准确率分别提升了4.60%, 6.74%, 4.10%,且与近年来对应数据集上的相关方法相比均有所提升。说明了所提的双模态融合模型能有效聚焦情感信息,从而提升情感识别的准确率。Abstract: In order to improve the accuracy of emotion recognition models and solve the problem of insufficient emotional feature extraction, this paper conducts research on bimodal emotion recognition involving audio and facial imagery. In the audio modality, a feature extraction model of a Multi-branch Convolutional Neural Network (MCNN) incorporating a channel-space attention mechanism is proposed, which extracts emotional features from speech spectrograms across time, space, and local feature dimensions. For the facial image modality, a feature extraction model using a Residual Hybrid Convolutional Neural Network (RHCNN) is introduced, which further establishes a parallel attention mechanism that concentrates on global emotional features to enhance recognition accuracy. The emotional features extracted from audio and facial imagery are then classified through separate classification layers, and a decision fusion technique is utilized to amalgamate the classification results. The experimental results indicate that the proposed bimodal fusion model has achieved recognition accuracies of 97.22%, 94.78%, and 96.96% on the RAVDESS, eNTERFACE’05, and RML datasets, respectively. These accuracies signify improvements over single-modality audio recognition by 11.02%, 4.24%, and 8.83%, and single-modality facial image recognition by 4.60%, 6.74%, and 4.10%, respectively. Moreover, the proposed model outperforms related methodologies applied to these datasets in recent years. This illustrates that the advanced bimodal fusion model can effectively focus on emotional information, thereby enhancing the overall accuracy of emotion recognition.
-
Key words:
- Emotion recognition /
- Attention mechanism /
- Multi-branch convolution /
- Residual mixing /
- Decision fusion
-
表 1 语音模型各类情感识别结果(%)
类别 RAVDESS RML eNTERFACE’05 P R S F1 P R S F1 P R S F1 中性 83.22 87.94 98.84 85.52 – – – – – – – – 平静 86.94 88.35 97.94 87.64 – – – – – – – – 快乐 79.86 97.46 97.20 87.79 78.12 92.59 95.62 84.75 95.66 95.94 99.12 95.80 悲伤 80.46 78.64 97.04 79.56 91.95 78.82 98.47 84.88 94.59 90.27 99.01 92.38 愤怒 87.03 84.62 97.93 85.80 96.09 94.51 99.25 95.29 84.44 87.99 96.85 86.18 恐惧 85.40 91.06 97.65 88.14 83.43 82.51 96.80 82.97 85.15 88.68 96.90 87.36 厌恶 90.66 83.61 98.41 87.00 86.50 87.37 97.07 86.93 91.83 93.68 98.30 92.75 惊讶 94.31 82.30 99.19 87.89 93.30 94.27 98.60 93.78 92.15 85.67 98.47 88.79  下载: 导出CSV
下载: 导出CSV
表 3 面部图像模型各类情感识别结果(%)
类别 RAVDESS RML eNTERFACE’05 P R S F1 P R S F1 P R S F1 中性 91.95 91.33 99.44 91.64 – – – – – – – – 平静 95.22 93.44 99.24 94.32 – – – – – – – – 快乐 94.79 92.54 99.25 93.65 96.84 97.35 99.36 97.10 89.31 88.29 97.82 88.79 悲伤 94.04 92.21 99.10 93.11 93.22 88.24 98.71 90.66 86.62 84.21 97.57 85.40 愤怒 92.41 93.59 98.80 92.99 91.67 95.38 98.42 93.48 87.61 89.68 97.48 88.63 恐惧 87.27 92.13 97.95 89.63 91.35 87.56 98.27 89.42 87.04 87.78 97.29 87.41 沮丧 94.58 96.62 99.09 95.59 93.75 94.74 98.71 94.24 90.42 89.68 97.99 90.81 惊讶 90.39 87.89 98.66 89.12 90.31 94.15 97.96 92.19 87.01 86.75 97.49 86.88
下载: 导出CSV
表 4 面部图像模态经典网络与本文结果对比(%)
数据集 方法 A R S F1 RAVDESS ResNet-34[26] 88.37 88.64 98.34 88.19 ShuffleNetV2[27] 82.03 82.06 97.43 81.60 MobileNetV2[28] 84.03 84.46 97.71 83.86 本文方法 92.62 92.47 98.94 92.51 RML ResNet-34[26] 89.29 89.41 97.86 89.27 ShuffleNetV2[27] 79.55 79.82 95.95 79.24 MobileNetV2[28] 86.07 86.33 97.22 86.05 本文方法 92.86 92.90 98.57 92.85 eNTERFACE’05 ResNet-34[26] 83.30 83.57 96.67 83.28 ShuffleNetV2[27] 82.13 82.17 96.43 82.04 MobileNetV2[28] 83.50 83.68 96.70 83.49 本文方法 88.04 87.98 97.61 87.99
下载: 导出CSV
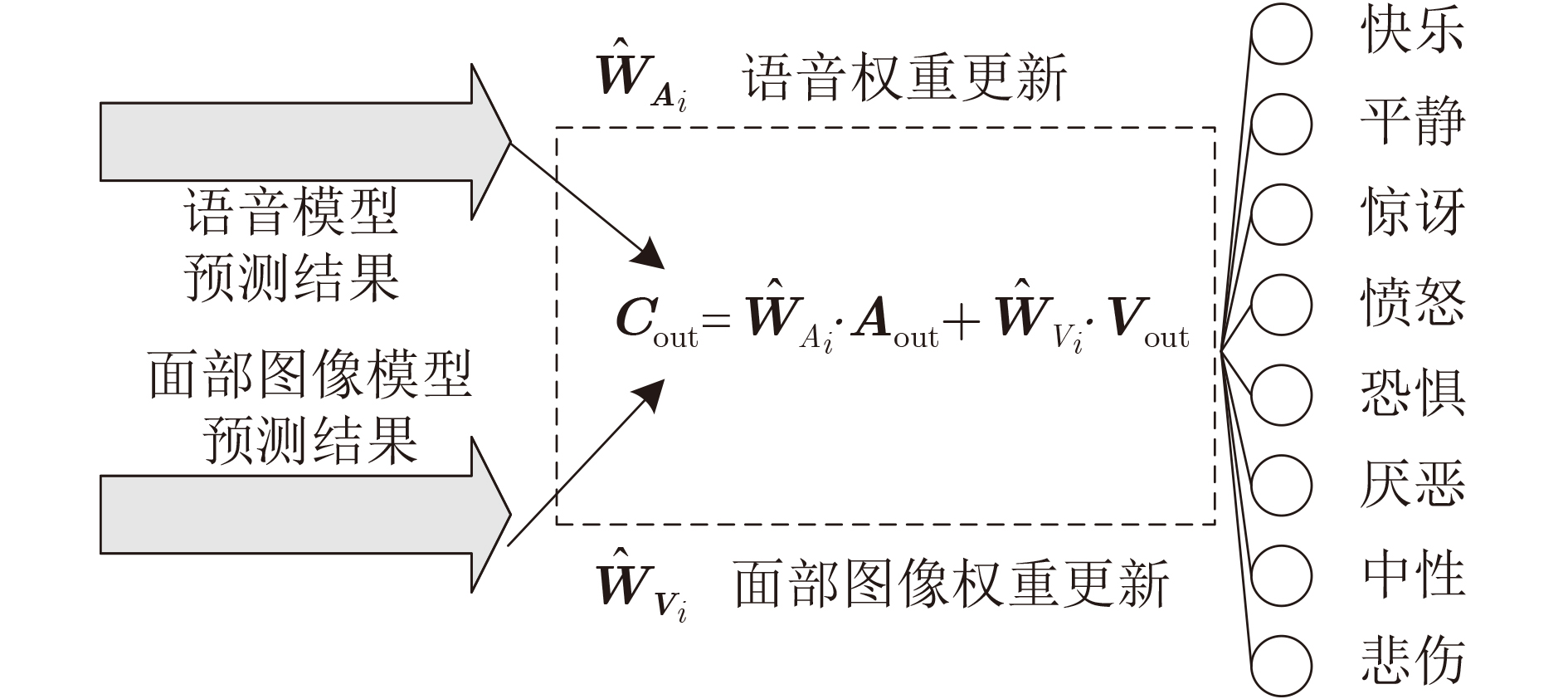
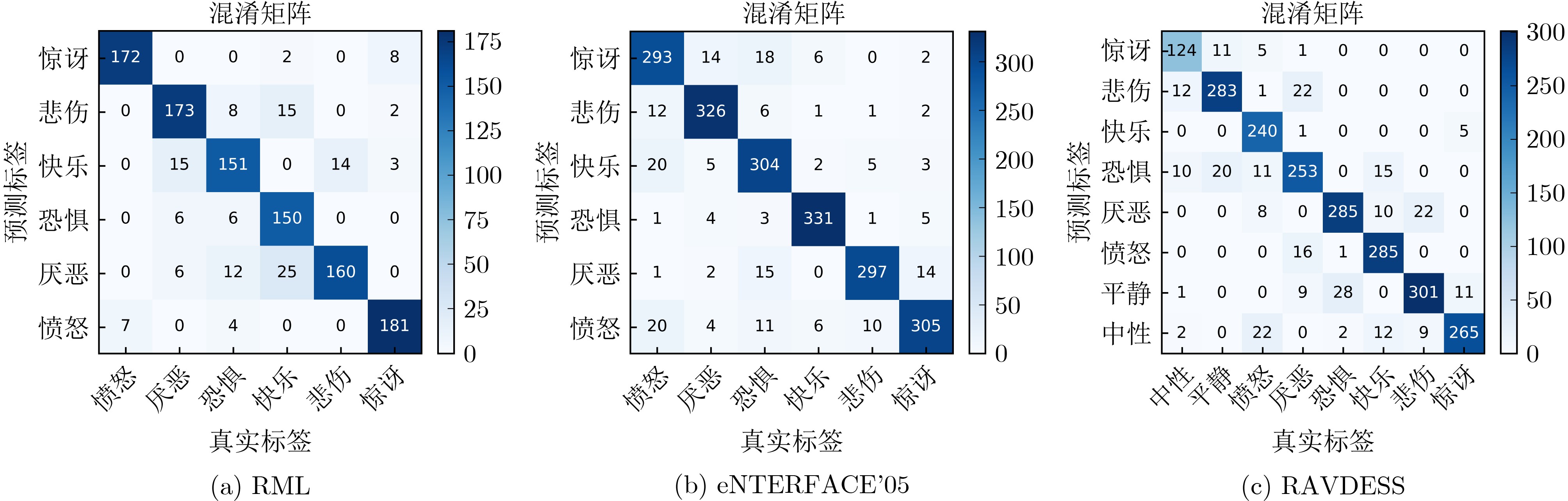
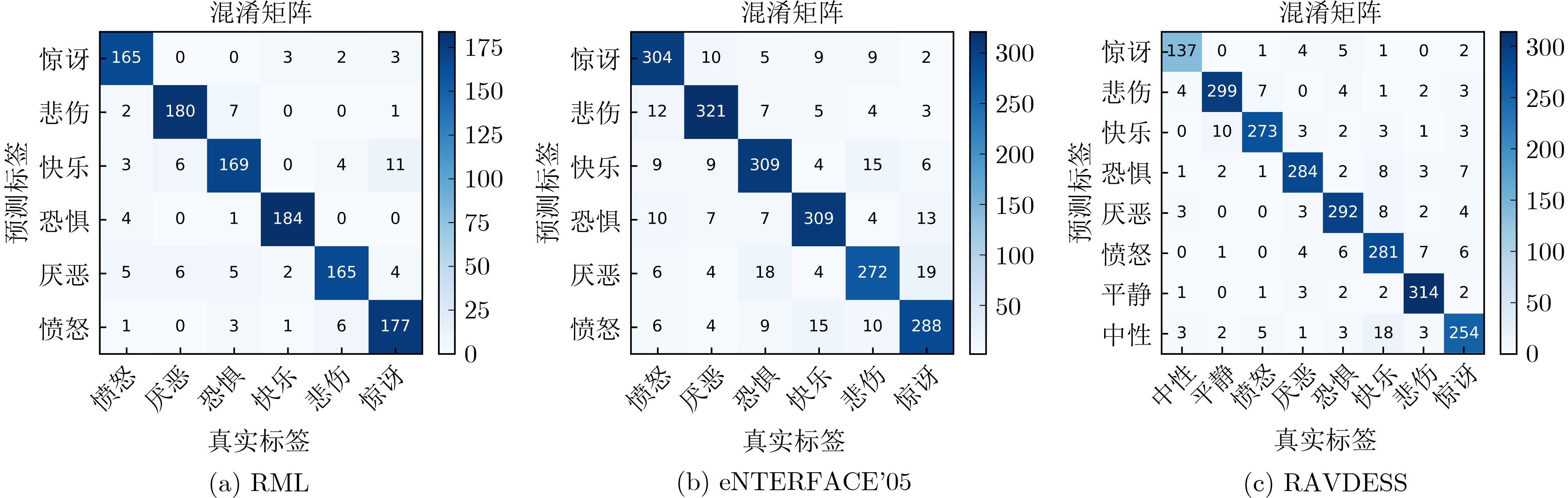
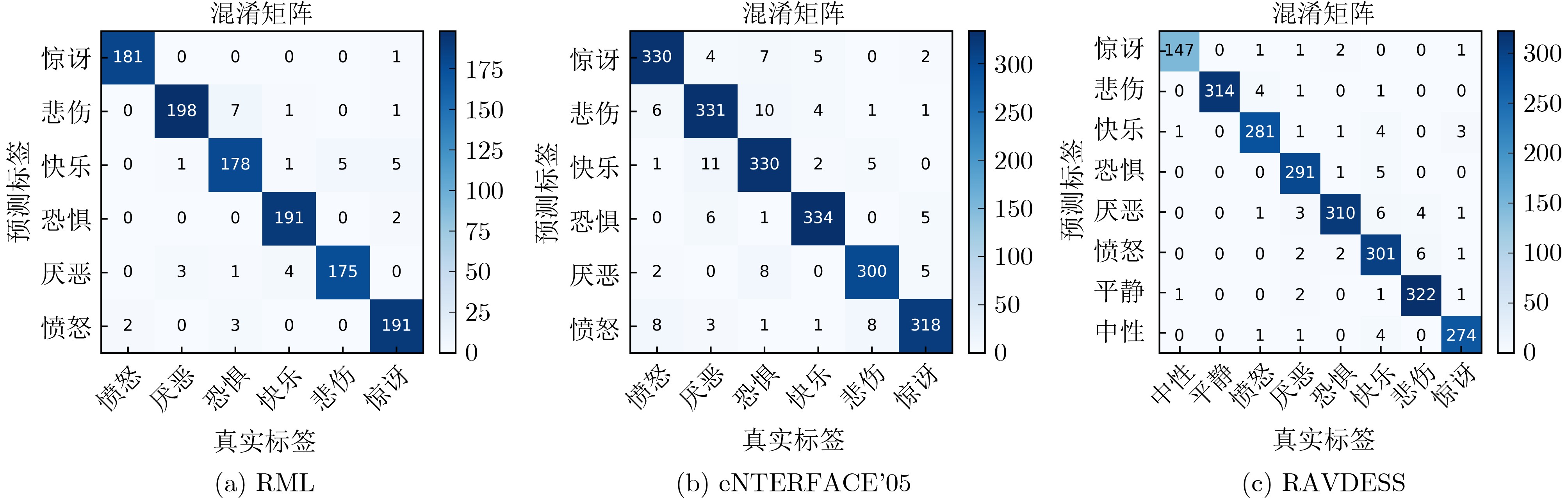
表 5 双模态模型各类情感识别结果(%)
类别 RAVDESS RML eENTERFACE’05 P R S F1 P R S F1 P R S F1 中性 98.66 96.71 99.91 97.67 – – – – – – – – 平静 100.00 98.13 100.00 99.05 – – – – – – – – 快乐 97.57 96.56 99.65 97.06 96.95 98.96 99.37 97.95 96.53 96.53 99.00 96.53 悲伤 96.36 97.98 99.45 97.16 97.22 95.63 99.48 96.42 95.54 95.24 98.59 95.39 愤怒 98.10 95.38 99.70 96.72 98.91 99.45 99.79 99.18 95.18 94.83 98.41 94.96 恐惧 93.48 96.47 98.95 94.95 95.24 93.75 99.06 94.49 92.44 94.56 99.30 93.48 沮丧 96.99 98.47 99.49 97.72 98.02 95.59 99.58 97.30 93.24 93.77 99.19 93.50 惊讶 97.51 97.86 99.65 97.68 95.50 97.45 99.06 96.46 96.07 93.81 99.24 94.93
下载: 导出CSV
-
[1] KUMARAN U, RADHA RAMMOHAN S, NAGARAJAN S M, et al. Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN[J]. International Journal of Speech Technology, 2021, 24(2): 303–314. doi: 10.1007/s10772-020-09792-x. [2] 韩虎, 范雅婷, 徐学锋. 面向方面情感分析的多通道增强图卷积网络[J]. 电子与信息学报, 2024, 46(3): 1022–1032. doi: 10.11999/JEIT230353.HAN Hu, FAN Yating, and XU Xuefeng. Multi-channel enhanced graph convolutional network for aspect-based sentiment analysis[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1022–1032. doi: 10.11999/JEIT230353. [3] CORNEJO J and PEDRINI H. Bimodal emotion recognition based on audio and facial parts using deep convolutional neural networks[C]. Proceedings of the 18th IEEE International Conference On Machine Learning And Applications, Boca Raton, USA, 2019: 111–117. doi: 10.1109/ICMLA.2019.00026. [4] O’TOOLE A J, CASTILLO C D, PARDE C J, et al. Face space representations in deep convolutional neural networks[J]. Trends in Cognitive Sciences, 2018, 22(9): 794–809. doi: 10.1016/j.tics.2018.06.006. [5] CHEN Qiupu and HUANG Guimin. A novel dual attention-based BLSTM with hybrid features in speech emotion recognition[J]. Engineering Applications of Artificial Intelligence, 2021, 102: 104277. doi: 10.1016/J.ENGAPPAI.2021.104277. [6] PAN Bei, HIROTA K, JIA Zhiyang, et al. A review of multimodal emotion recognition from datasets, preprocessing, features, and fusion methods[J]. Neurocomputing, 2023, 561: 126866. doi: 10.1016/j.neucom.2023.126866. [7] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791. [8] HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735. [9] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [10] KIM B K, LEE H, ROH J, et al. Hierarchical committee of deep CNNs with exponentially-weighted decision fusion for static facial expression recognition[C]. Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle Washington, USA, 2015: 427–434. doi: 10.1145/2818346.2830590. [11] TZIRAKIS P, TRIGEORGIS G, NICOLAOU M A, et al. End-to-end multimodal emotion recognition using deep neural networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1301–1309. doi: 10.1109/JSTSP.2017.2764438. [12] SAHOO S and ROUTRAY A. Emotion recognition from audio-visual data using rule based decision level fusion[C]. Proceedings of 2016 IEEE Students’ Technology Symposium, Kharagpur, India, 2016: 7–12. doi: 10.1109/TechSym.2016.7872646. [13] WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11534–11542. doi: 10.1109/CVPR42600.2020.01155. [14] CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1251–1258. doi: 10.1109/CVPR.2017.195. [15] LIVINGSTONE S R and RUSSO F A. The Ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English[J]. PLoS One, 2018, 13(5): e0196391. doi: 10.1371/journal.pone.0196391. [16] WANG Yongjin and GUAN Ling. Recognizing human emotional state from audiovisual signals[J]. IEEE Transactions on Multimedia, 2008, 10(5): 936–946. doi: 10.1109/TMM.2008.927665. [17] MARTIN O, KOTSIA I, MACQ B, et al. The eNTERFACE’ 05 audio-visual emotion database[C]. Proceedings of the 22nd International Conference on Data Engineering Workshops, Atlanta, USA, 2006: 8. doi: 10.1109/ICDEW.2006.145. [18] VIJAYAN D M, ARUN A V, GANESHNATH R, et al. Development and analysis of convolutional neural network based accurate speech emotion recognition models[C]. Proceedings of the 19th India Council International Conference, Kochi, India, 2022: 1–6. doi: 10.1109/INDICON56171.2022.10040174. [19] AGGARWAL A, SRIVASTAVA A, AGARWAL A, et al. Two-way feature extraction for speech emotion recognition using deep learning[J]. Sensors, 2022, 22(6): 2378. doi: 10.3390/s22062378. [20] ZHANG Limin, LI Yang, ZHANG Yueting, et al. A deep learning method using gender-specific features for emotion recognition[J]. Sensors, 2023, 23(3): 1355. doi: 10.3390/s23031355. [21] KANANI C S, GILL K S, BEHERA S, et al. Shallow over deep neural networks: A empirical analysis for human emotion classification using audio data[M]. MISRA R, KESSWANI N, RAJARAJAN M, et al. Internet of Things and Connected Technologies. Cham: Springer, 2021: 134–146. doi: 10.1007/978-3-030-76736-5_13. [22] FALAHZADEH M R, FARSA E Z, HARIMI A, et al. 3D convolutional neural network for speech emotion recognition with its realization on Intel CPU and NVIDIA GPU[J]. IEEE Access, 2022, 10: 112460–112471. doi: 10.1109/ACCESS.2022.3217226. [23] FALAHZADEH M R, FAROKHI F, HARIMI A, et al. Deep convolutional neural network and gray wolf optimization algorithm for speech emotion recognition[J]. Circuits, Systems, and Signal Processing, 2023, 42(1): 449–492. doi: 10.1007/s00034-022-02130-3. [24] HARÁR P, BURGET R, and DUTTA M K. Speech emotion recognition with deep learning[C]. Proceedings of the 4th International Conference on Signal Processing and Integrated Networks, Noida, India, 2017: 137–140. doi: 10.1109/SPIN.2017.8049931. [25] SLIMI A, HAFAR N, ZRIGUI M, et al. Multiple models fusion for multi-label classification in speech emotion recognition systems[J]. Procedia Computer Science, 2022, 207: 2875–2882. doi: 10.1016/j.procs.2022.09.345. [26] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [27] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: Practical guidelines for efficient CNN architecture design[C]. Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 116–131. doi: 10.1007/978-3-030-01264-9_8. [28] SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4510–4520. doi: 10.1109/CVPR.2018.00474. [29] MIDDYA A I, NAG B, and ROY S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities[J]. Knowledge-Based Systems, 2022, 244: 108580. doi: 10.1016/j.knosys.2022.108580. [30] LUNA-JIMÉNEZ C, KLEINLEIN R, GRIOL D, et al. A proposal for multimodal emotion recognition using aural transformers and action units on RAVDESS dataset[J]. Applied Sciences, 2021, 12(1): 327. doi: 10.3390/app12010327. [31] BOUALI Y L, AHMED O B, and MAZOUZI S. Cross-modal learning for audio-visual emotion recognition in acted speech[C]. Proceedings of the 6th International Conference on Advanced Technologies for Signal and Image Processing, Sfax, Tunisia, 2022: 1–6. doi: 10.1109/ATSIP55956.2022.9805959. [32] MOCANU B and TAPU R. Audio-video fusion with double attention for multimodal emotion recognition[C]. Proceedings of the 14th Image, Video, and Multidimensional Signal Processing Workshop, Nafplio, Greece, 2022: 1–5. doi: 10.1109/IVMSP54334.2022.9816349. [33] WOZNIAK M, SAKOWICZ M, LEDWOSINSKI K, et al. Bimodal emotion recognition based on vocal and facial features[J]. Procedia Computer Science, 2023, 225: 2556–2566. doi: 10.1016/j.procs.2023.10.247. [34] PAN Bei, HIROTA K, JIA Zhiyang, et al. Multimodal emotion recognition based on feature selection and extreme learning machine in video clips[J]. Journal of Ambient Intelligence and Humanized Computing, 2023, 14(3): 1903–1917. doi: 10.1007/s12652-021-03407-2. [35] TANG Guichen, XIE Yue, LI Ke, et al. Multimodal emotion recognition from facial expression and speech based on feature fusion[J]. Multimedia Tools and Applications, 2023, 82(11): 16359–16373. doi: 10.1007/s11042-022-14185-0. [36] CHEN Luefeng, WANG Kuanlin, LI Min, et al. K-means clustering-based kernel canonical correlation analysis for multimodal emotion recognition in human-robot interaction[J]. IEEE Transactions on Industrial Electronics, 2023, 70(1): 1016–1024. doi: 10.1109/TIE.2022.3150097. [37] CHEN Guanghui and ZENG Xiaoping. Multi-modal emotion recognition by fusing correlation features of speech-visual[J]. IEEE Signal Processing Letters, 2021, 28: 533–537. doi: 10.1109/LSP.2021.3055755. -

 下载:
下载:



图(11) / 表(6)
计量
- 文章访问数: 993
- HTML全文浏览量: 736
- PDF下载量: 105
- 被引次数: 0
