

A System-level Exploration and Evaluation Simulator for chiplet-based CPU
-
摘要: 随着摩尔定律的逐步失效,芯片制造工艺的提升愈发困难,芯片性能的提升面临“面积墙”问题,chiplet(芯粒)技术开始被广泛采用来解决此问题。然而,面向chiplet引入的架构设计参数,目前的体系结构模拟器面临新的挑战。为了能够探索chiplet架构的特定设计参数,现有工作通常只会为模拟器增加单一的功能,导致其难以用于探索多个参数对chiplet芯片的整体影响。为了能够较为全面地探索和评估chiplet芯片架构,该文基于现有gem5模拟器实现了面向通用处理器芯粒架构探索和评估的系统级模拟器(SEEChiplet)模拟器框架。首先,总结了现在chiplet芯片设计关注的3类设计参数,包括:(1) 芯片cache系统设计;(2) 封装方式模拟;(3) chiplet间的互连网络。其次,针对上述3类参数:(1)设计并实现了私有末级缓存系统,扩大了cache系统设计空间;(2) 修改了gem5已有的全局目录,以适配私有末级缓存(LLC)系统;(3) 建模了两种常见的chiplet封装方式以及chiplet间互连网络。最后,该文在SEEChiplet框架中进行了系统级的模拟评估,在被测chiplet架构通用处理器上运行操作系统及PARSEC 3.0基准测试程序,验证了SEEChiplet的功能,证明SEEChiplet可以对chiplet设计空间进行探索和评估。Abstract: As Moore’s Law comes to an end, it is more and more difficult to improve the chip manufacturing process, and chiplet technology has been widely adopted to improve the chip performance. However, new design parameters introduced into the chiplet architecture pose significant challenges to the computer architecture simulator. To fully support exploration and evaluation of chiplet architecture, System-level Exploration and Evaluation simulator for Chiplet (SEEChiplet), a framework based on gem5 simulator, is developed in this paper. Firstly, three design parameters concerned about chiplet chip design are summarized in this paper, including: (1) chiplet cache system design; (2) Packaging simulation; (3) Interconnection networks between chiplet. Secondly, in view of the above three design parameters, in this paper: (1) a new private last level cache system is designed and implemented to expand the cache system design space; (2) existing gem5 global directory is modified to adapt to new private Last Level Cache (LLC) system; (3) two common packaging methods of chiplet and inter-chiplet network are modeled. Finally, a chiplet-based processor is simulated with PARSEC 3.0 benchmark program running on it, which proves that SEEChiplet can explore and evaluate the design space of chiplet.
-
Key words:
- Chiplet /
- Design space exploration /
- Computer architecture simulator /
- Cache system
-
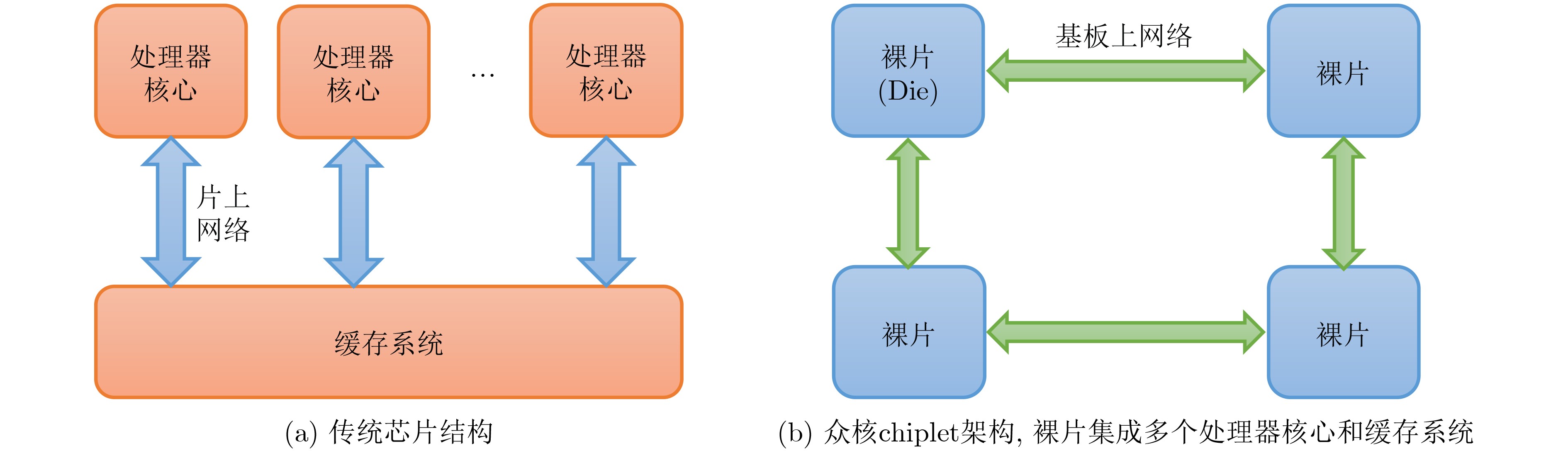
表 1 众核chiplet架构设计空间
设计选项 参数数量 chiplet本身 处理器:指令集架构;顺序执行,乱序执行;核心数量
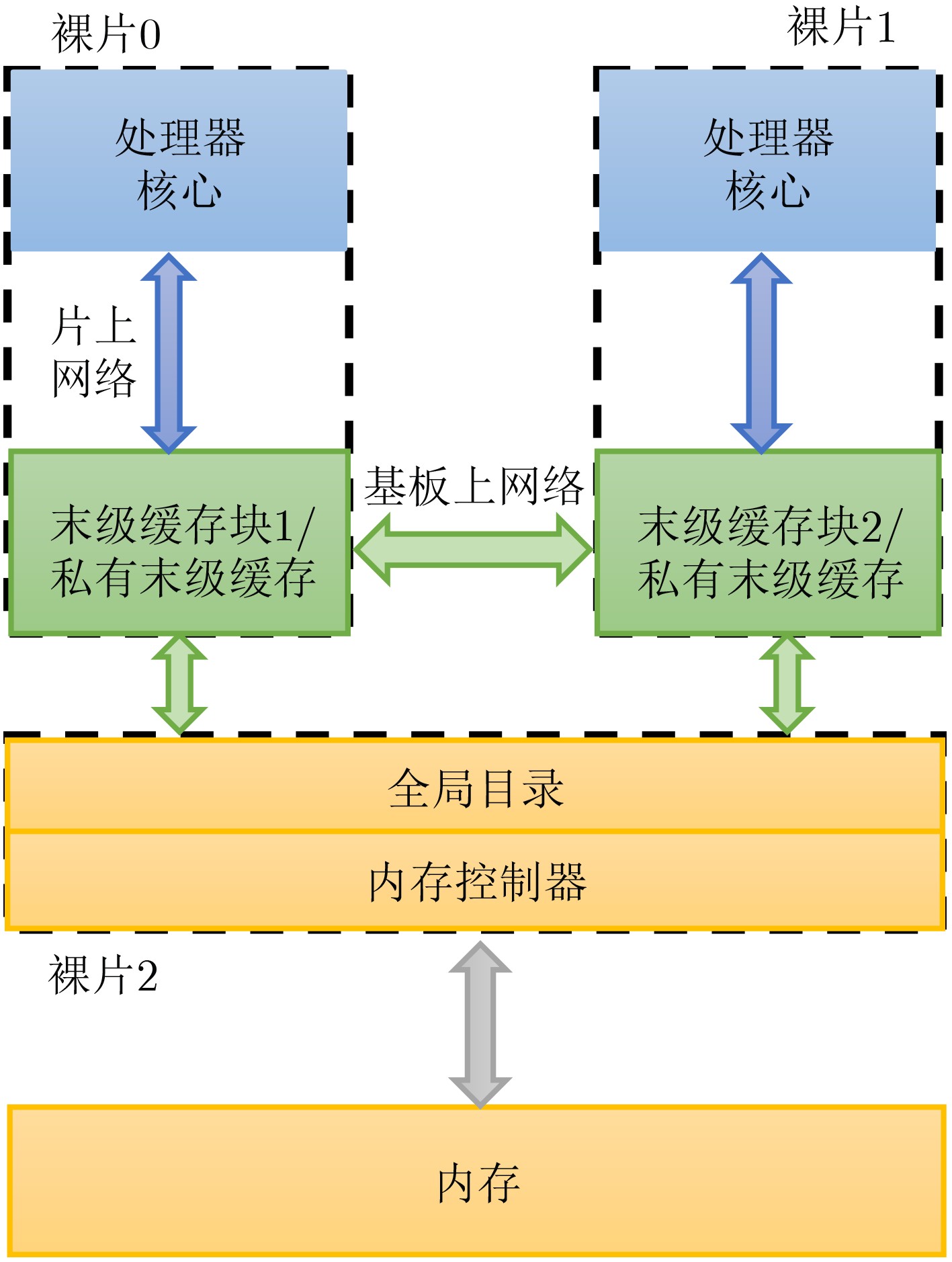
cache系统:cache 块大小;cache容量;cache层级;chiplet私有末级缓存,全局共享末级缓存等
chiplet数量chiplet互连架构 chiplet拓扑:Mesh, IO-die等;路由算法
chiplet互连:连接带宽;连接延迟;Router延迟
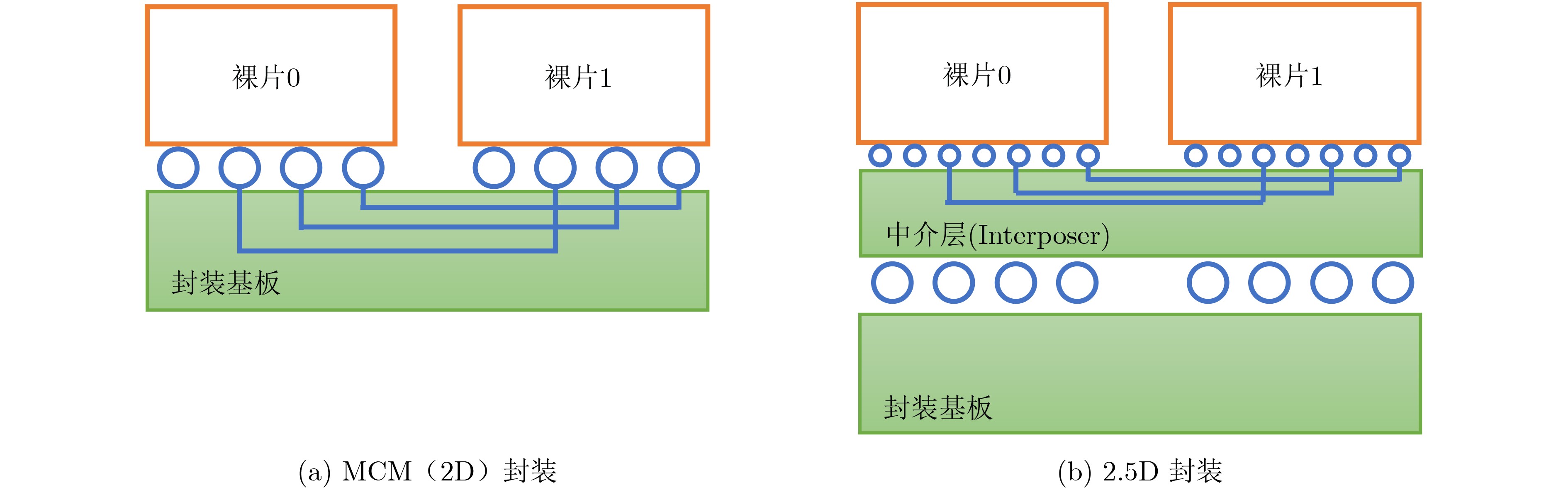
chiplet集成方式:MCM, 2.5D, 3D;chiplet与封装基板或中介层(Interposer)间SERDES配置等 下载: 导出CSV
下载: 导出CSV
表 2 现有chiplet研究工作
研究工作 基于的模拟器或模拟手段 研究内容 chiplet封装方式 是否支持模拟运行操作系统 是否开源 Meduza[16] PriME[24] chiplet cache系统 2.5D 否 否 文献[17] gem5[25] chiplet cache系统 2.5D 否 否 文献[18] Multi2Sim[26] chiplet cache系统 无线连接 否 否 文献[19] gem5-X[27] chiplet cache 系统 无线连接 是 否 1-Update[20] SimFlex[28] chiplet cache系统 3D 否 是 SILO[21] 未提到 chiplet cache系统 3D 否 否 Kite[22] gem5 chiplet 拓扑 2D, 2.5D 是 否 HexaMesh[23] BookSim[29] chiplet 拓扑 2.5D 否 否 文献[30] Swarm[31] chiplet 架构性能 2D, 2.5D 否 否 文献[32] gem5[24] chiplet 架构模拟 无 是 是 DCRA[33] muchiSim[34] chiplet 架构模拟 2D, 2.5D 否 是 文献[35] FPGA chiplet 架构模拟 2D 是 否 SMAPPIC[36] FPGA chiplet 架构模拟 无 是 是
下载: 导出CSV
表 4 SEEChiplet模拟参数配置表
配置项 基本信息 CPU Timing CPU, X86指令集,3 GHz cache层级及相应参数(其中容量等参数可以根据用户需求配置) 3级cache, Inclusive,频率同CPU
L1: 指令cache,数据cache;每个CPU核心一组;均为32 kB, 4路组相连
L2: 每个CPU一组;1MB, 8路组相连
L3:所有chiplet共享/chiplet内部共享;32 MB, 16路组相连封装方式 MCM, 2.5D:SERDES组件增加2个cycle, Router本身3个cycle chiplet拓扑 支持IO Die, Mesh架构 chiplet参数 每个chiplet可以有2, 4, 8, 16个核心 内存 单通道DDR4, 8 GB, 2400 MT/s
下载: 导出CSV
表 5 不同末级缓存架构,chiplet内外部请求分布
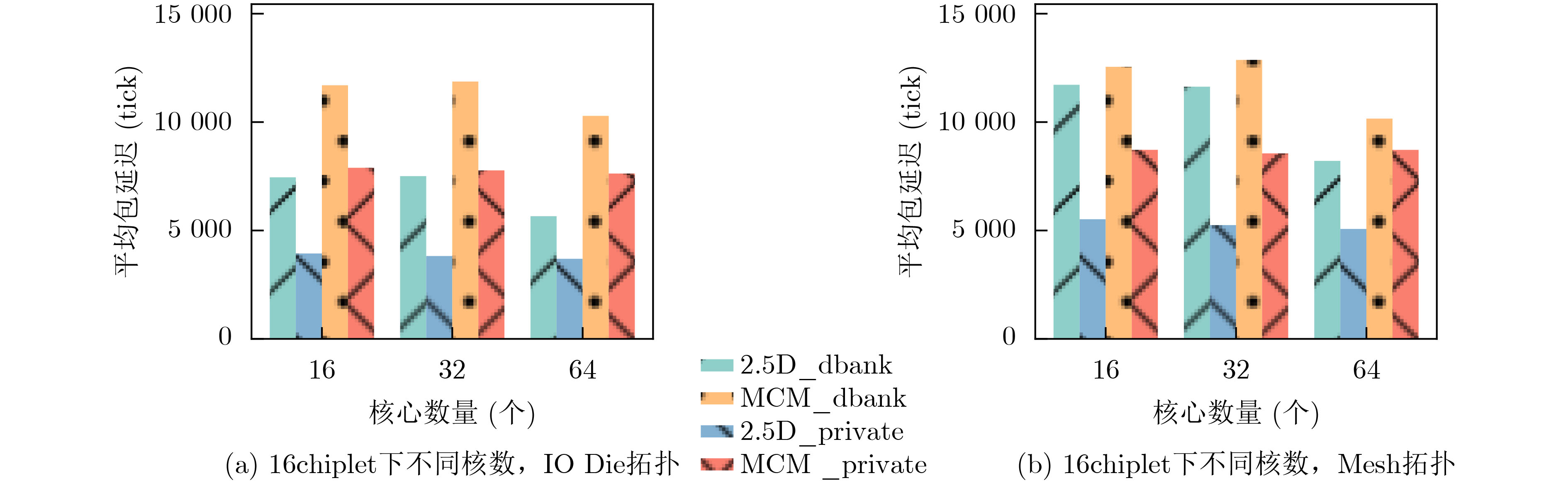
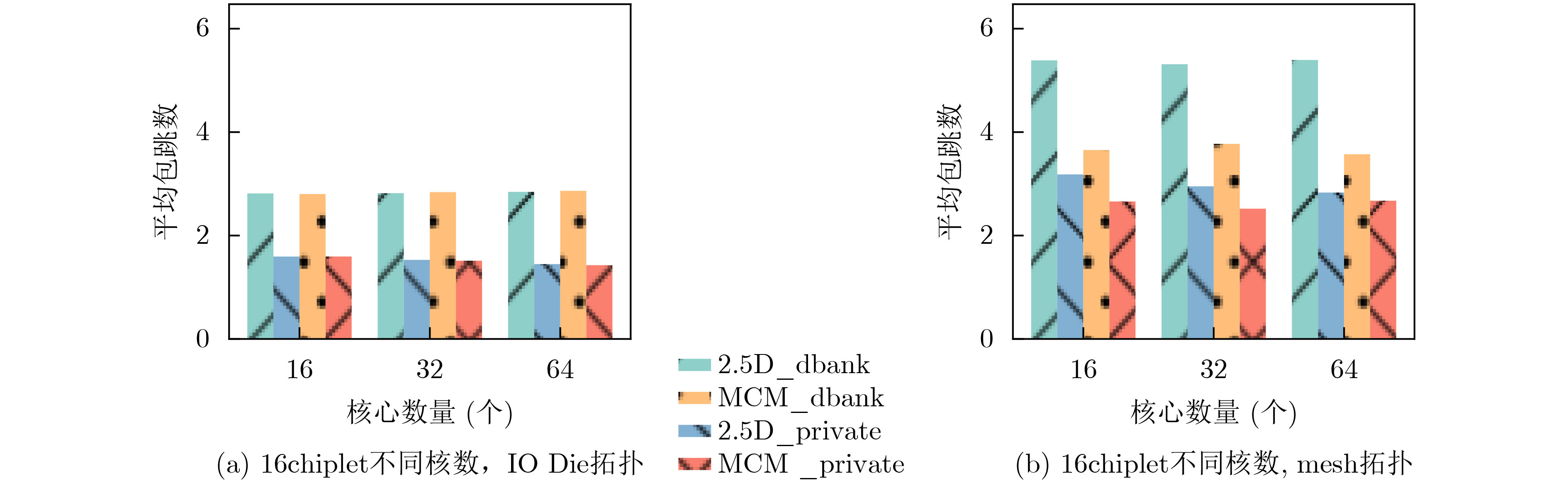
末级缓存组织形式 内部请求比例(%) 外部请求比例(%) 请求总数量 chiplet私有末级缓存 78.4 21.6 458037 全局共享末级缓存 5.8 94.2 404340
下载: 导出CSV
表 6 SEEChiplet建模开销总结
开销来源 开销总结 chiplet私有末级缓存 代码量:~ 1000 行
新增中间状态:12个
新增事件类型:11个
新增状态转移逻辑:30个,和全局目录及其他LLC进行交互
新增虚通道:2个,用于和全局目录进行交互全局目录 代码量:~600行
每行新增bit数:64bit用于存放共享chiplet列表,
8 bit用于存放持有者chiplet ID
新增状态:1个基础状态S, 9个中间状态
修改状态:M状态以及相关处理逻辑
新增事件类型:10个新增状态转移逻辑:18个,全局目录转发请求,响应请求等
新增虚通道:2个,用于和末级缓存进行交互
下载: 导出CSV
-
[1] MOORE G E. Cramming more components onto integrated circuits[J]. Electronics, 1965, 38(8): 114–117. [2] DENNARD R H, GAENSSLE F H, YU H N, et al. Design of ion-implanted MOSFET's with very small physical dimensions[J]. IEEE Journal of Solid-State Circuits, 1974, 9(5): 256–268. doi: 10.1109/JSSC.1974.1050511. [3] HAN Yinhe, XU Haobo, LU Meixuan, et al. The big chip: Challenge, model and architecture[J]. Fundamental Research, 2023, S2667325823003709. doi: 10.1016/j.fmre.2023.10.020. [4] CAI Jingwei, WU Zuotong, PENG Sen, et al. Gemini: Mapping and architecture co-exploration for large-scale DNN Chiplet accelerators[C]. 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Edinburgh, United Kingdom, 2024: 156–171. doi: 10.1109/HPCA57654.2024.00022. [5] 陈云霁, 蔡一茂, 汪玉, 等. 集成电路未来发展与关键问题—第347期"双清论坛(青年)"学术综述[J]. 中国科学: 信息科学, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356.CHEN Yunji, CAI Yimao, WANG Yu, et al. Integrated circuit technology: Future development and key issues–review of the 347th "Shuangqing Forum (Youth)"[J]. Scientia Sinica Informationis, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356. [6] 项少林, 郭茂, 蒲菠, 等. Chiplet技术发展现状[J]. 科技导报, 2023, 41(19): 113–131. doi: 10.3981/j.issn.1000-7857.2023.19.013.XIANG Shaolin, GUO Mao, PU Bo, et al. Overview of the development status of Chiplet technology[J]. Science & Technology Review, 2023, 41(19): 113–131. doi: 10.3981/j.issn.1000-7857.2023.19.013. [7] 厉佳瑶, 张琨, 潘权. Chiplet技术: 拓展芯片设计的新边界[J]. 集成电路与嵌入式系统, 2024, 24(2): 1–9.LI Jiayao, ZHANG Kun, and PAN Quan. Chiplet: Expanding the innovative boundaries of chip design[J]. Integrated Circuits and Embedded Systems, 2024, 24(2): 1–9. [8] MA Xiaohan, WANG Ying, WANG Yujie, et al. Survey on Chiplets: Interface, interconnect and integration methodology[J]. CCF Transactions on High Performance Computing, 2022, 4(1): 43–52. doi: 10.1007/s42514-022-00093-0. [9] SUGGS D, SUBRAMONY M, and BOUVIER D. The AMD “Zen 2” processor[J]. IEEE Micro, 2020, 40(2): 45–52. doi: 10.1109/MM.2020.2974217. [10] NAFFZIGER S, LEPAK K, PARASCHOU M, et al. 2.2 AMD Chiplet architecture for high-performance server and desktop products[C]. 2020 IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, USA, 2020: 44–45. doi: 10.1109/ISSCC19947.2020.9063103. [11] EVERS M, BARNES L, and CLARK M. The AMD next-generation “Zen 3” Core[J]. IEEE Micro, 2022, 42(3): 7–12. doi: 10.1109/MM.2022.3152788. [12] MUNGER B, WILCOX K, SNIDERMAN J, et al. Zen 4: The AMD 5nm 5.7GHz x86-64 microprocessor core[C]. 2023 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, USA, 2023: 38–39. doi: 10.1109/ISSCC42615.2023.10067540. [13] GIANOS C. Architecting for flexibility and value with next gen Intel® Xeon® processors[C]. 2023 IEEE Hot Chips 35 Symposium (HCS), Palo Alto, USA, 2023: 1–15. doi: 10.1109/HCS59251.2023.10254694. [14] ESPOSITO B. Intel Agilex® 9 direct RF-series FPGAs with integrated 64 Gsps data converters[C]. 2023 IEEE Hot Chips 35 Symposium (HCS), Palo Alto, USA, 2023: 1–35. doi: 10.1109/HCS59251.2023.10254707. [15] VENTANA MICRO. Veyron V1 data center-class RISC-V processor[C]. 2023 IEEE Hot Chips 35 Symposium (HCS), Palo Alto, USA, 2023: 1–16. doi: 10.1109/HCS59251.2023.10254710. [16] CHIRKOV G and WENTZLAFF D. Seizing the bandwidth scaling of on-package interconnect in a post-Moore’s law world[C]. Proceedings of the 37th International Conference on Supercomputing, Orlando, USA, 2023: 410–422. doi: 10.1145/3577193.3593702. [17] YANG Chongyi, ZHANG Zhendong, WANG Xiaohang, et al. Adaptive caching policies for Chiplet systems based on reinforcement learning[C]. 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, USA, 2023: 1–5. doi: 10.1109/ISCAS46773.2023.10181966. [18] GADE S H, SINHA M, KUMAR M, et al. Scalable hybrid cache coherence using emerging links for Chiplet architectures[C]. 2022 35th International Conference on VLSI Design and 2022 21st International Conference on Embedded Systems (VLSID), Bangalore, India, 2022: 92–97. doi: 10.1109/VLSID2022.2022.00029. [19] MEDINA R, KEIN J, ANSALONI G, et al. System-level exploration of in-package wireless communication for multi-Chiplet platforms[C]. Proceedings of the 28th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 2023: 561–566. doi: 10.1145/3566097.3567952. [20] ZHU Mingcan, SHAHAB A, KATSARAKIS A, et al. Invalidate or update? Revisiting coherence for tomorrow's cache hierarchies[C]. 2021 30th International Conference on Parallel Architectures and Compilation Techniques (PACT), Atlanta, USA, 2021: 226–241. doi: 10.1109/PACT52795.2021.00024. [21] SHAHAB A, ZHU Mingcan, MARGARITOV A, et al. Farewell my shared LLC! A case for private die-stacked DRAM caches for servers[C]. 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 2018: 559–572. doi: 10.1109/MICRO.2018.00052. [22] BHARADWAJ S, YIN Jieming, BECKMANN B, et al. Kite: A family of heterogeneous interposer topologies enabled via accurate interconnect modeling[C]. 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2020: 1–6. doi: 10.1109/DAC18072.2020.9218539. [23] IFF P, BESTA M, CAVALCANTE M, et al. HexaMesh: Scaling to hundreds of Chiplets with an optimized Chiplet arrangement[C]. 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2023: 1–6. doi: 10.1109/DAC56929.2023.10248006. [24] FU Yaosheng and WENTZLAFF D. PriME: A parallel and distributed simulator for thousand-core chips[C]. 2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Monterey, USA, 2014: 116–125. doi: 10.1109/ISPASS.2014.6844467. [25] LOWE-POWER J, AHMAD A M, AKRAM A, et al. The gem5 simulator: Version 20.0+[EB/OL]. https://arxiv.org/abs/2007.03152, 2020. [26] UBAL R, JANG B, MISTRY P, et al. Multi2Sim: A simulation framework for CPU-GPU computing[C]. Proceedings of the 21st International Conference on Parallel Architectures and Compilation Techniques. Minneapolis, USA, 2012: 335–344. doi: 10.1145/2370816.2370865. [27] QURESHI Y M, SIMON W A, ZAPATER M, et al. gem5-X: A many-core heterogeneous simulation platform for architectural exploration and optimization[J]. ACM Transactions on Architecture and Code Optimization (TACO), 2021, 18(4): 44. doi: 10.1145/3461662. [28] HARDAVELLAS N, SOMOGYI S, WENISCH T F, et al. SimFlex: A fast, accurate, flexible full-system simulation framework for performance evaluation of server architecture[J]. ACM SIGMETRICS Performance Evaluation Review, 2004, 31(4): 31–34. doi: 10.1145/1054907.1054914. [29] JIANG Nan, BECKER U D, MICHELOGIANNAKIS G, et al. A detailed and flexible cycle-accurate network-on-chip simulator[C]. 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Austin, USA, 2013: 86–96. doi: 10.1109/ISPASS.2013.6557149. [30] BRKIĆ I R and JEFFREY M C M. Disintegrating manycores: Which applications lose and why?[C]. Proceedings of the 16th International Workshop on Network on Chip Architectures, Toronto, Canada, 2023: 3–8. doi: 10.1145/3610396.3618090. [31] JEFFREY M C, SUBRAMANIAN S, YAN Cong, et al. A scalable architecture for ordered parallelism[C]. 2015 48th International Symposium on Microarchitecture (MICRO), Waikiki, USA, 2015: 228–241. doi: 10.1145/2830772.2830777. [32] ZHI Haocong, XU Xianuo, HAN Weijian, et al. A methodology for simulating multi-Chiplet systems using open-source simulators[C]. Proceedings of the Eight Annual ACM International Conference on Nanoscale Computing and Communication, New York, NY, USA, 2021: 18. doi: 10.1145/3477206.3477459. [33] ORENES-VERA M, TURECI E, MARTONOSI M, et al. DCRA: A distributed Chiplet-based reconfigurable architecture for irregular applications[EB/OL]. https://arxiv.org/abs/2311.15443, 2024. [34] ORENES-VERA M, TURECI E, MARTONOSI M, et al. MuchiSim: A simulation framework for design exploration of multi-chip Manycore systems[C]. Proceedings of the 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Indianapolis, USA, 2024: 48–60. doi: 10.1109/ISPASS61541.2024.00015. [35] LI Xingyu. High-performance FPGA-accelerated Chiplet modeling[D]. [Master dissertation], University of California, Berkeley, 2022. [36] CHIRKOV G and WENTZLAFF D. SMAPPIC: Scalable multi-FPGA architecture prototype platform in the cloud[C]. Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, Canada, 2023: 733–746. doi: 10.1145/3575693.3575753. [37] ZHAN Xusheng, BAO Yungang, BIENIA C, et al. PARSEC3.0: A multicore benchmark suite with network stacks and SPLASH-2X[J]. ACM SIGARCH Computer Architecture News, 2017, 44(5): 1–16. doi: 10.1145/3053277.3053279. [38] HARDAVELLAS N, FERDMAN M, FALSAFI B, et al. Reactive NUCA: Near-optimal block placement and replication in distributed caches[J]. ACM SIGARCH Computer Architecture News, 2009, 37(3): 184–195. doi: 10.1145/1555815.1555779. [39] AWASTHI M, SUDAN K, BALASUBRAMONIAN R, et al. Dynamic hardware-assisted software-controlled page placement to manage capacity allocation and sharing within large caches[C]. 2009 IEEE 15th International Symposium on High Performance Computer Architecture, Raleigh, USA, 2009: 250–261. doi: 10.1109/HPCA.2009.4798260. [40] KIM C, BURGER D, and KECKLER S W, et al. An adaptive, non-uniform cache structure for wire-delay dominated on-chip caches[C]. Proceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems, San Jose, USA, 2002: 211–222. doi: 10.1145/605397.605420. [41] LI Chengeng, JIANG Fan, CHEN Shixi, et al. Accelerating cache coherence in Manycore processor through silicon photonic Chiplet[C]. Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design (ICCAD'22), San Diego, USA, 2022: 43. doi: 10.1145/3508352.3549338. [42] CUBERO-CASCANTE J, ZURSTRAßEN N, NÖLLER J, et al. Parti-gem5: Gem5’s timing mode parallelised[C]. 23rd International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation, Samos, Greece, 2023: 177–192. doi: 1 0.1007/978-3-031-46077-7_12. -

 下载:
下载:

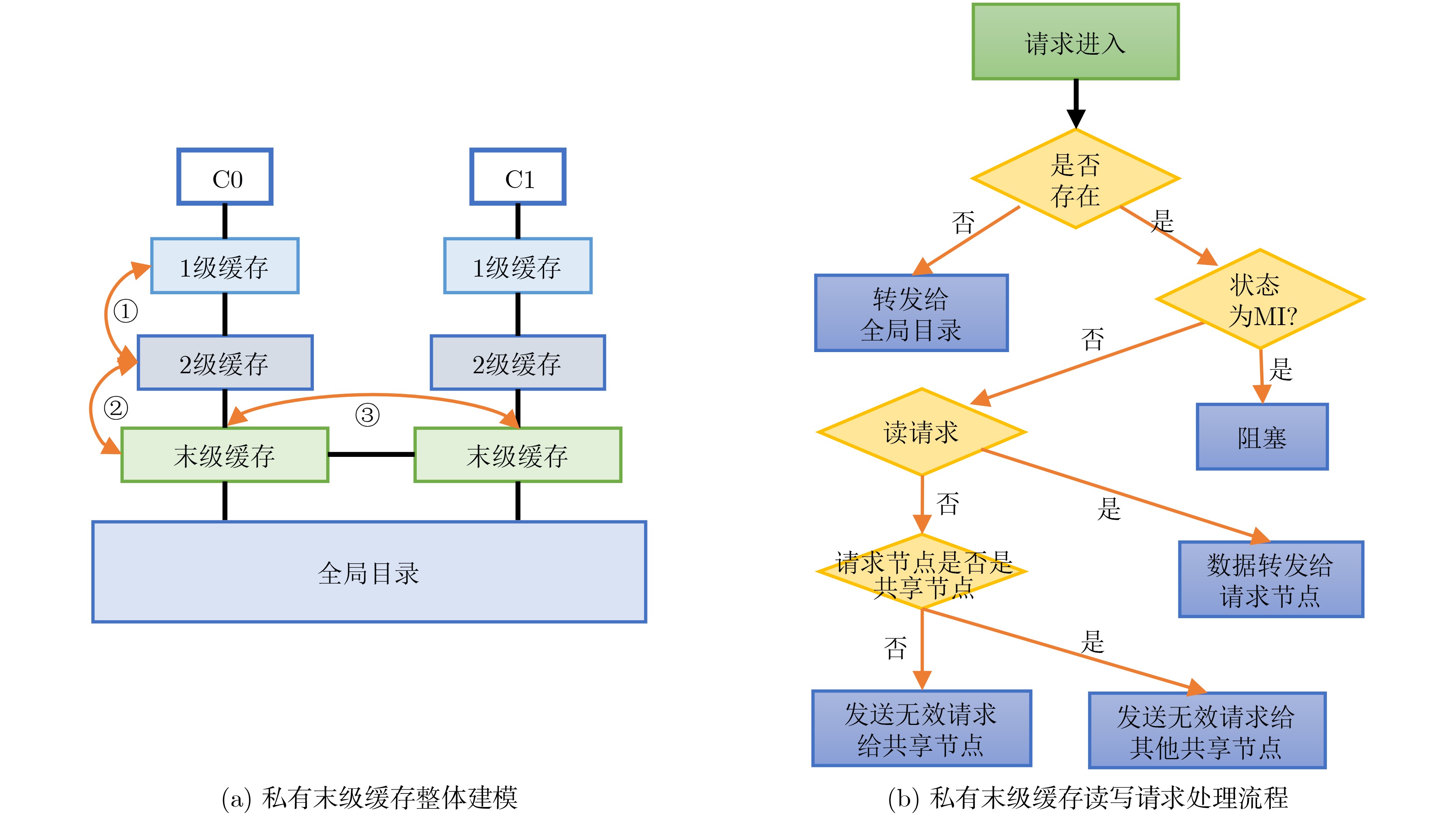
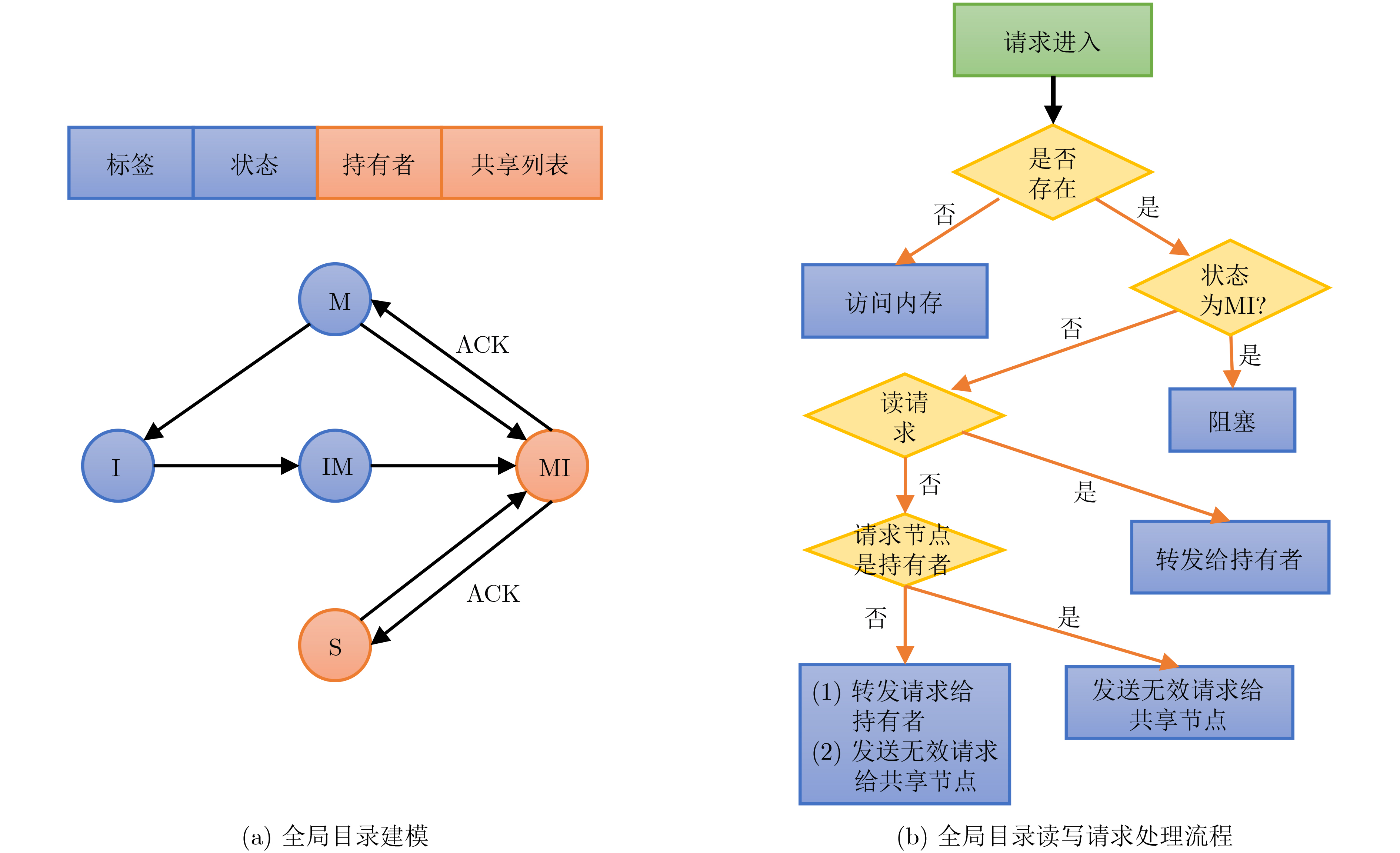
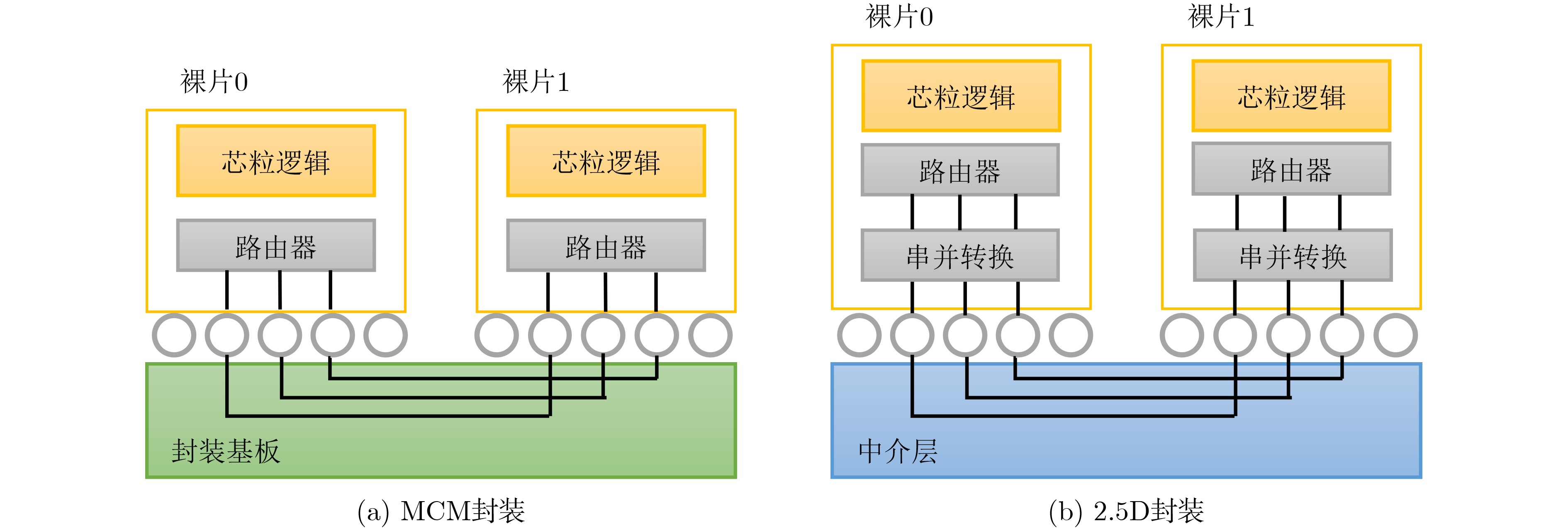
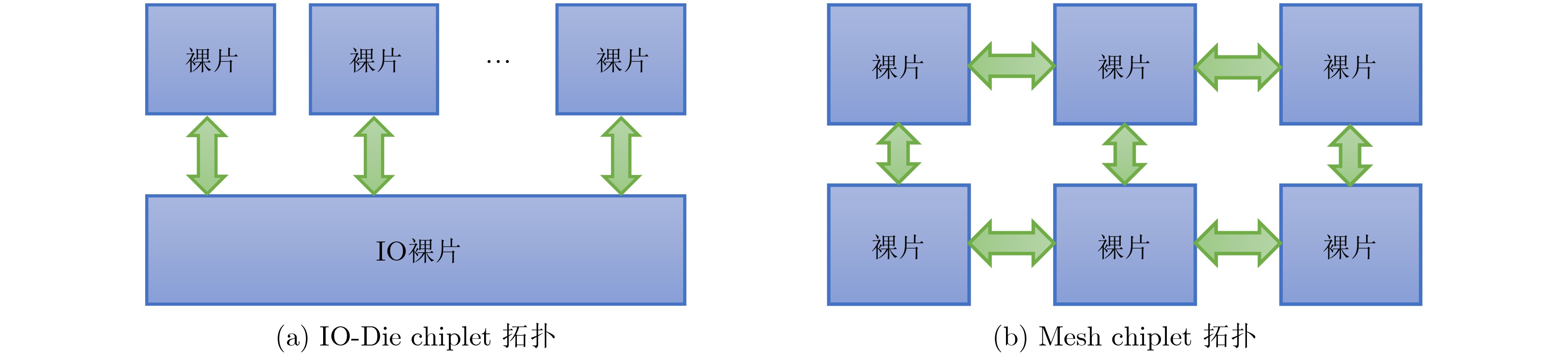



图(12) / 表(6)
计量
- 文章访问数: 1786
- HTML全文浏览量: 1341
- PDF下载量: 186
- 被引次数: 0
