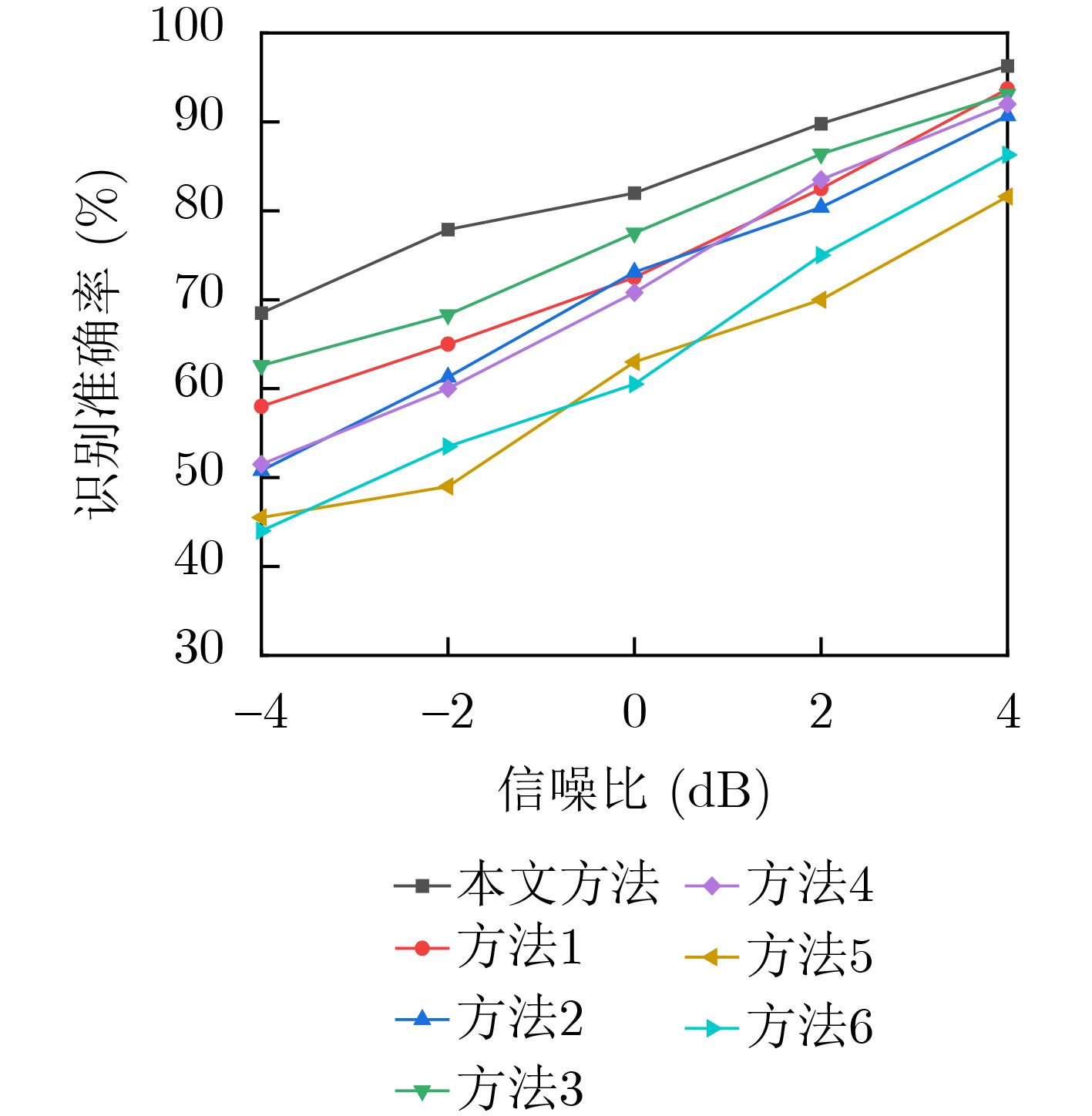
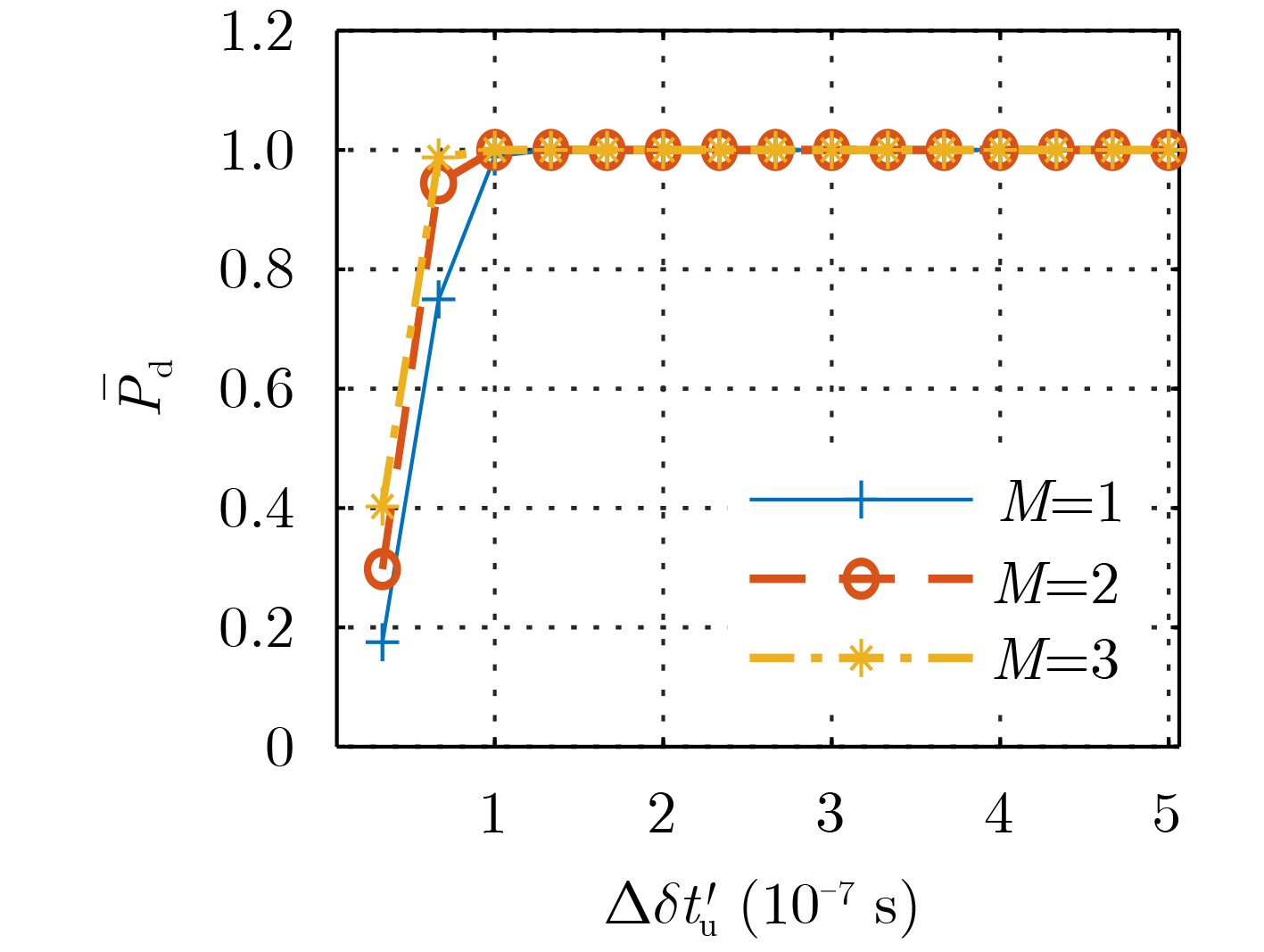
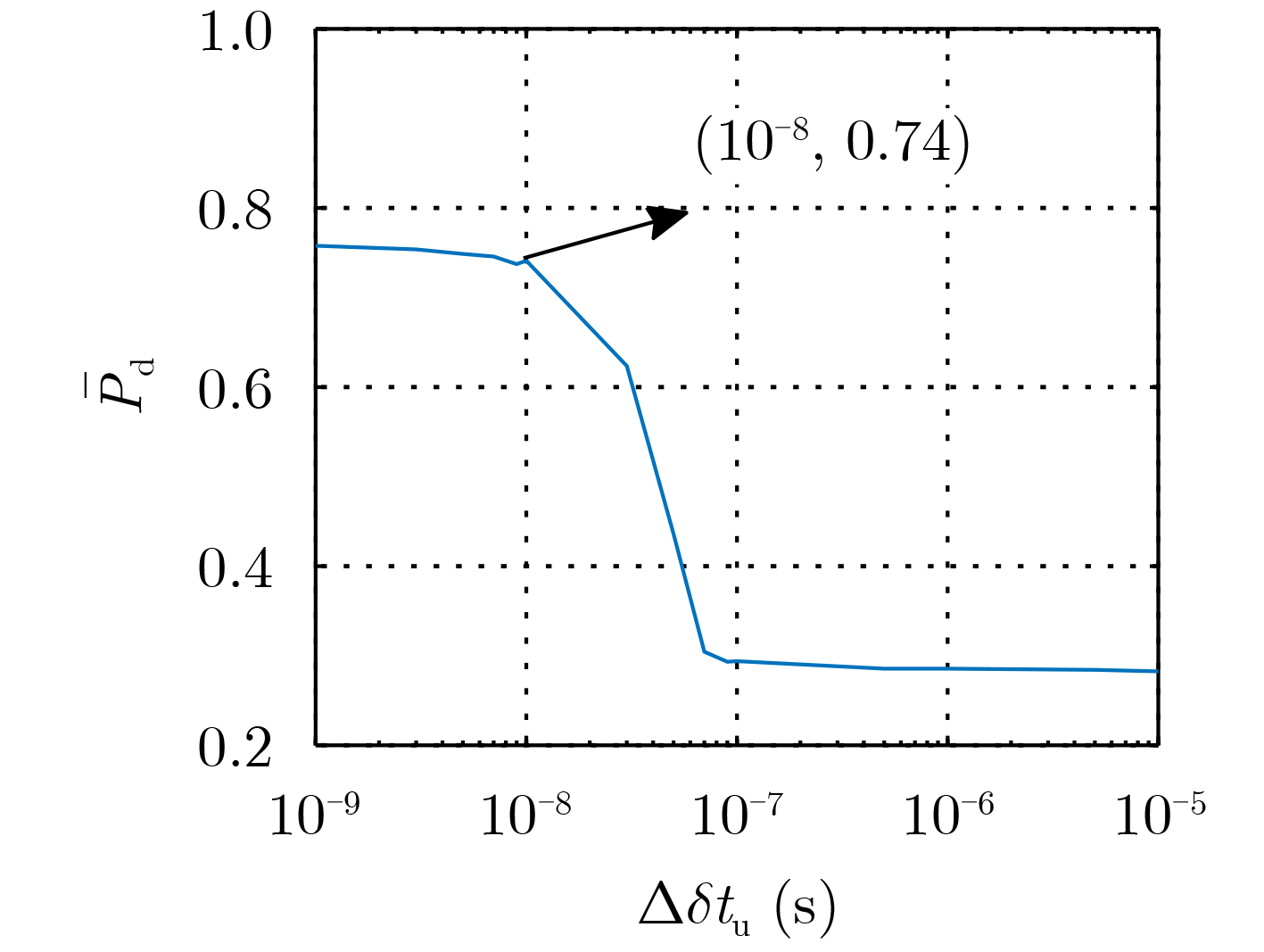
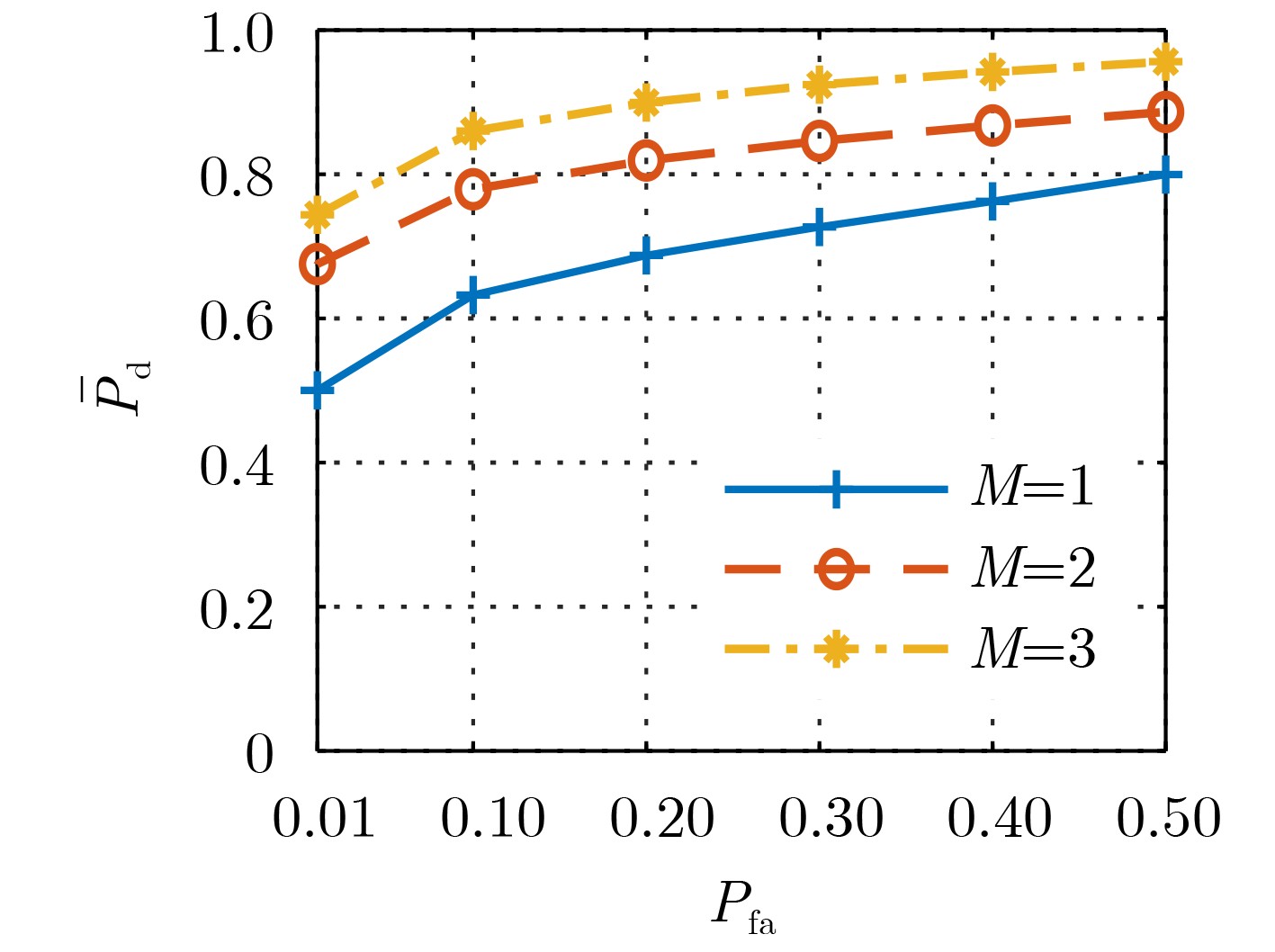
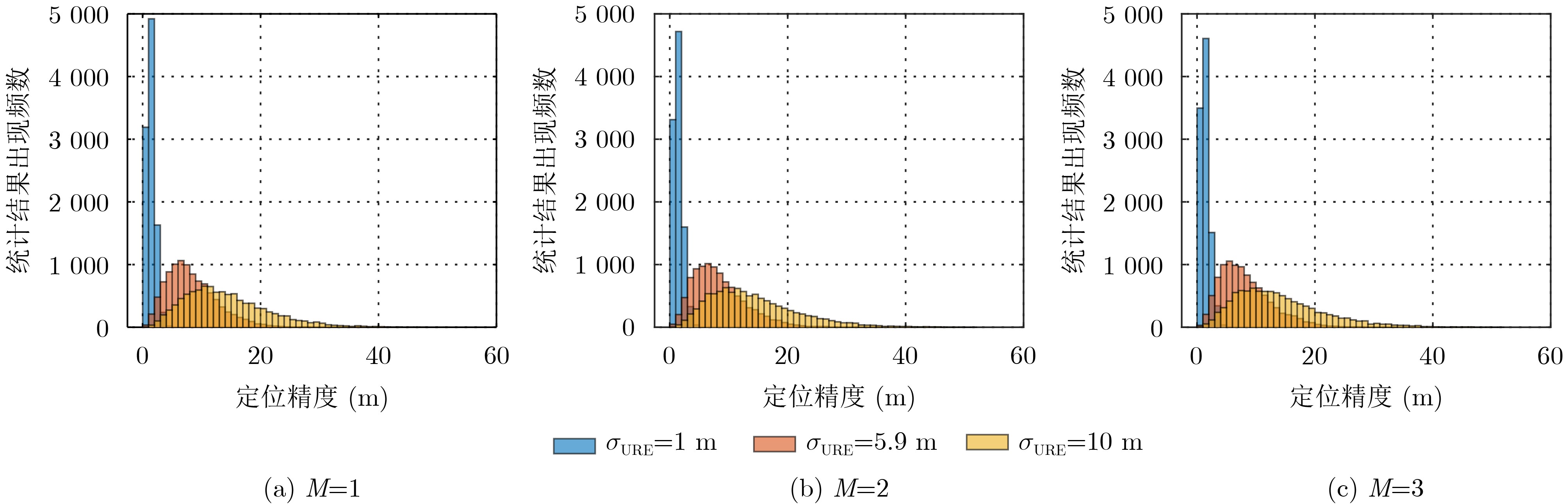
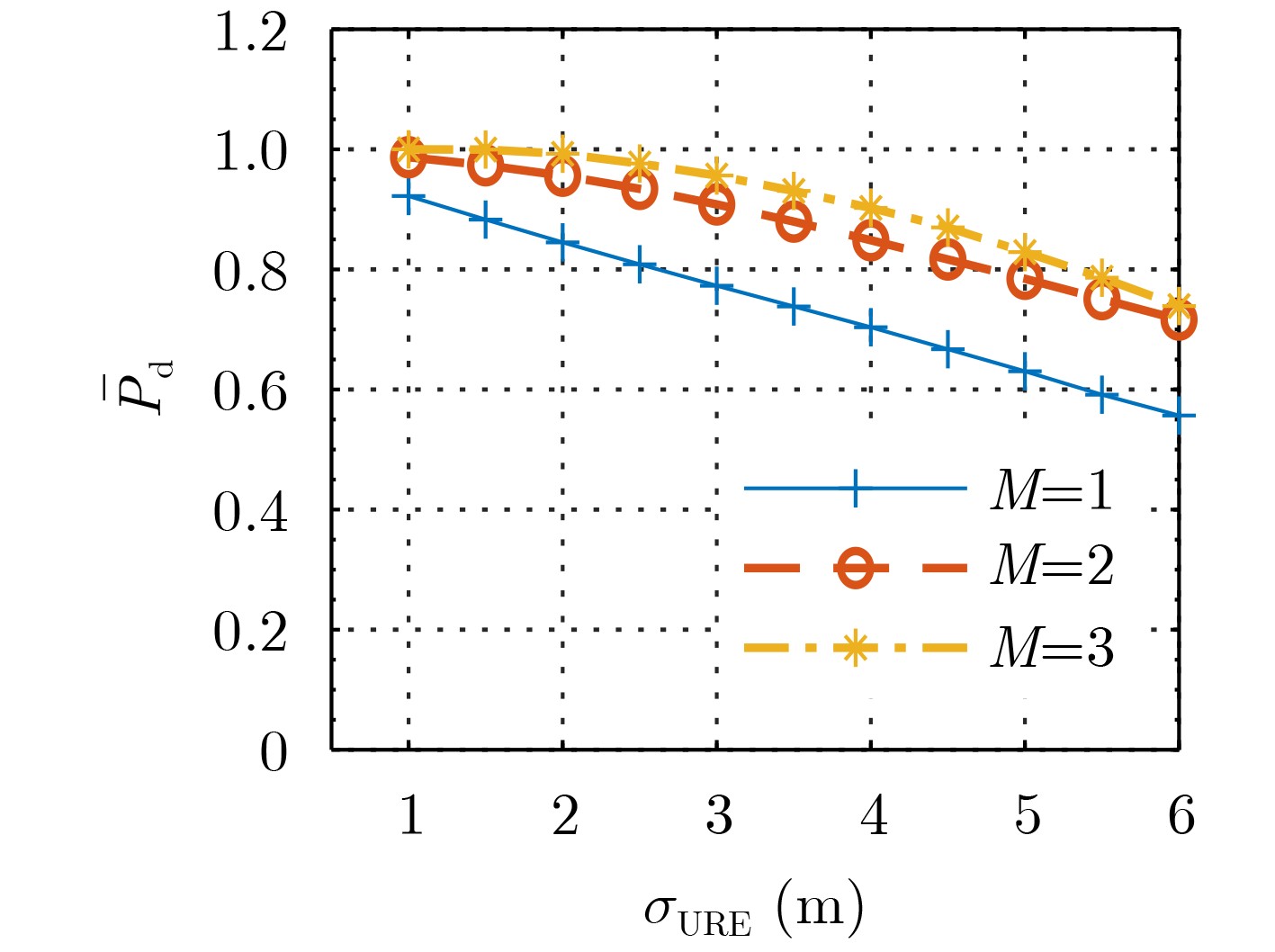
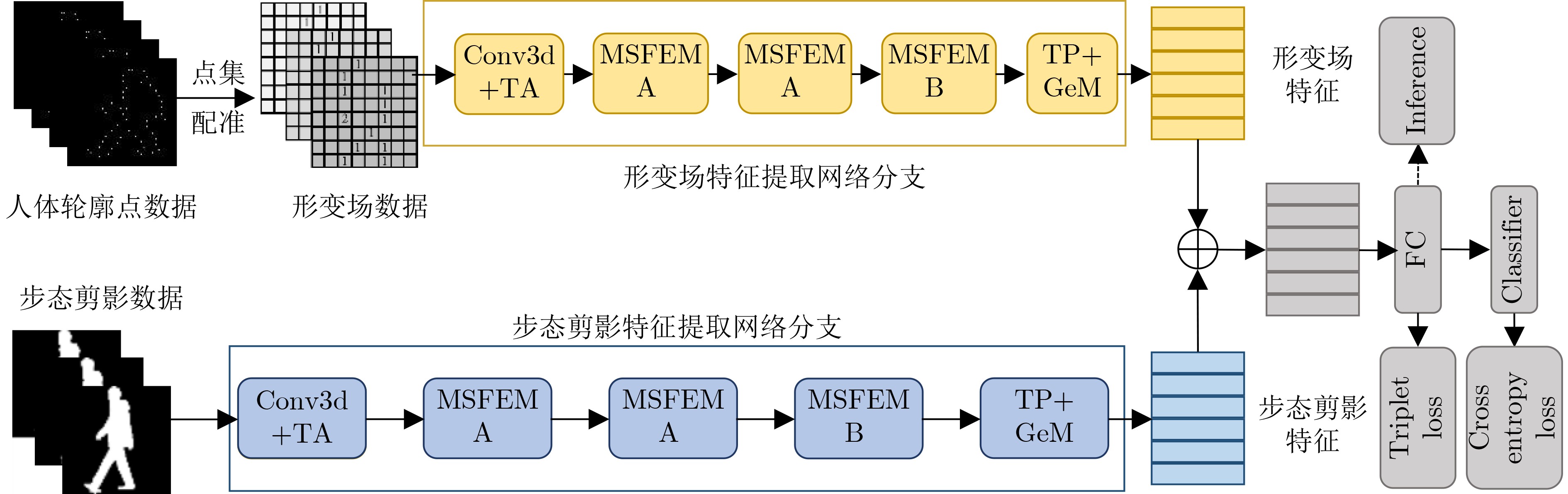
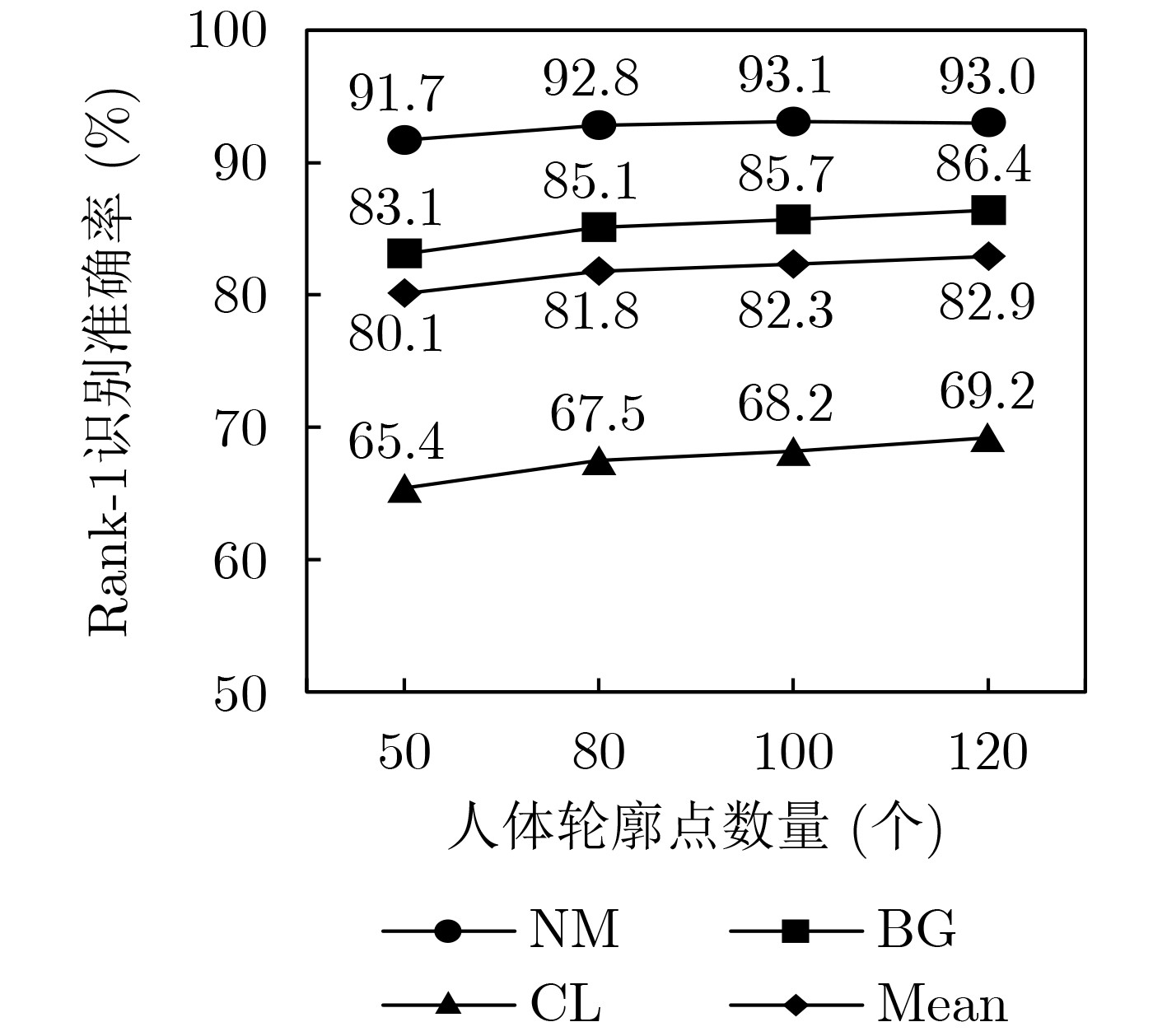
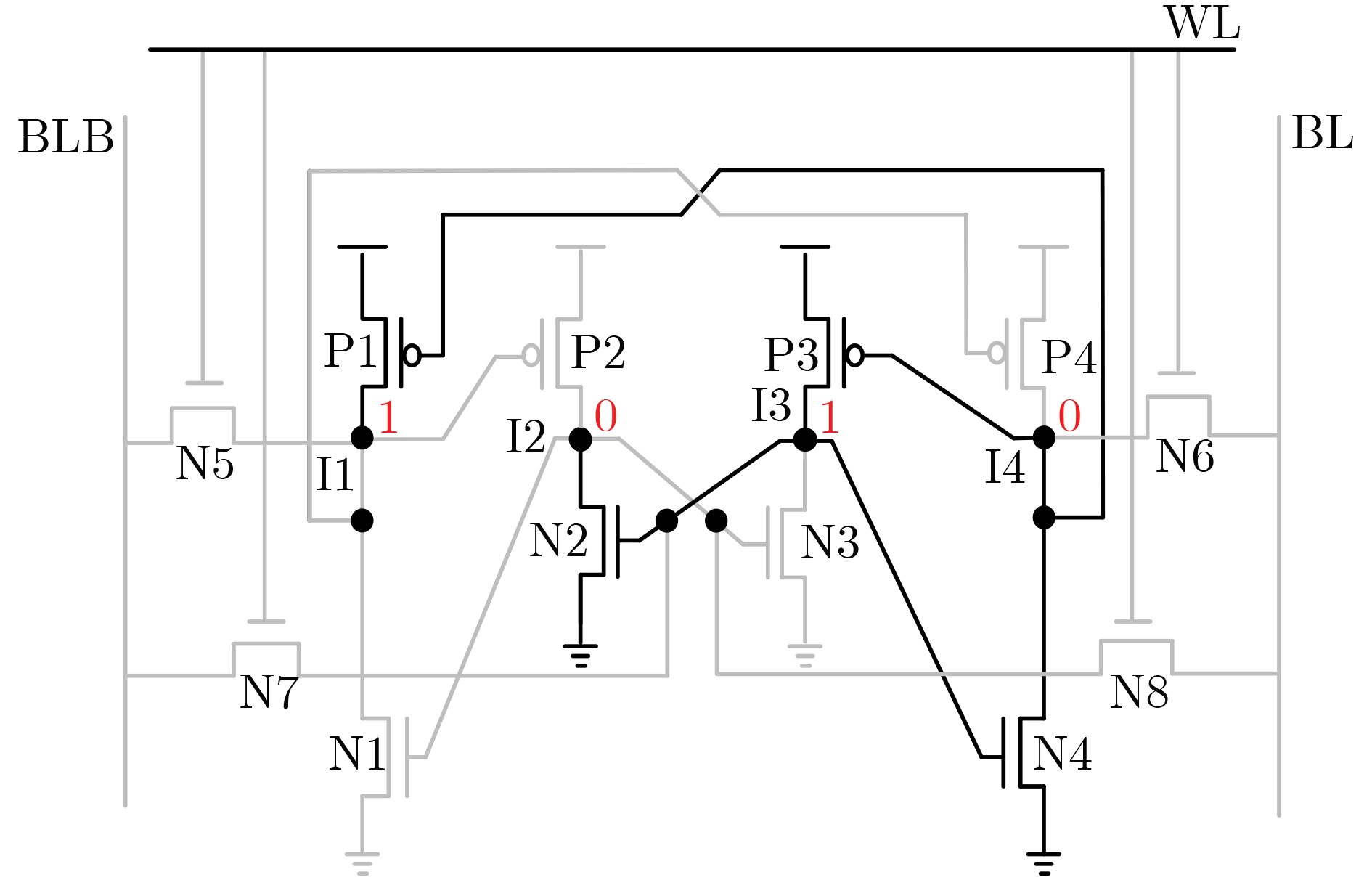
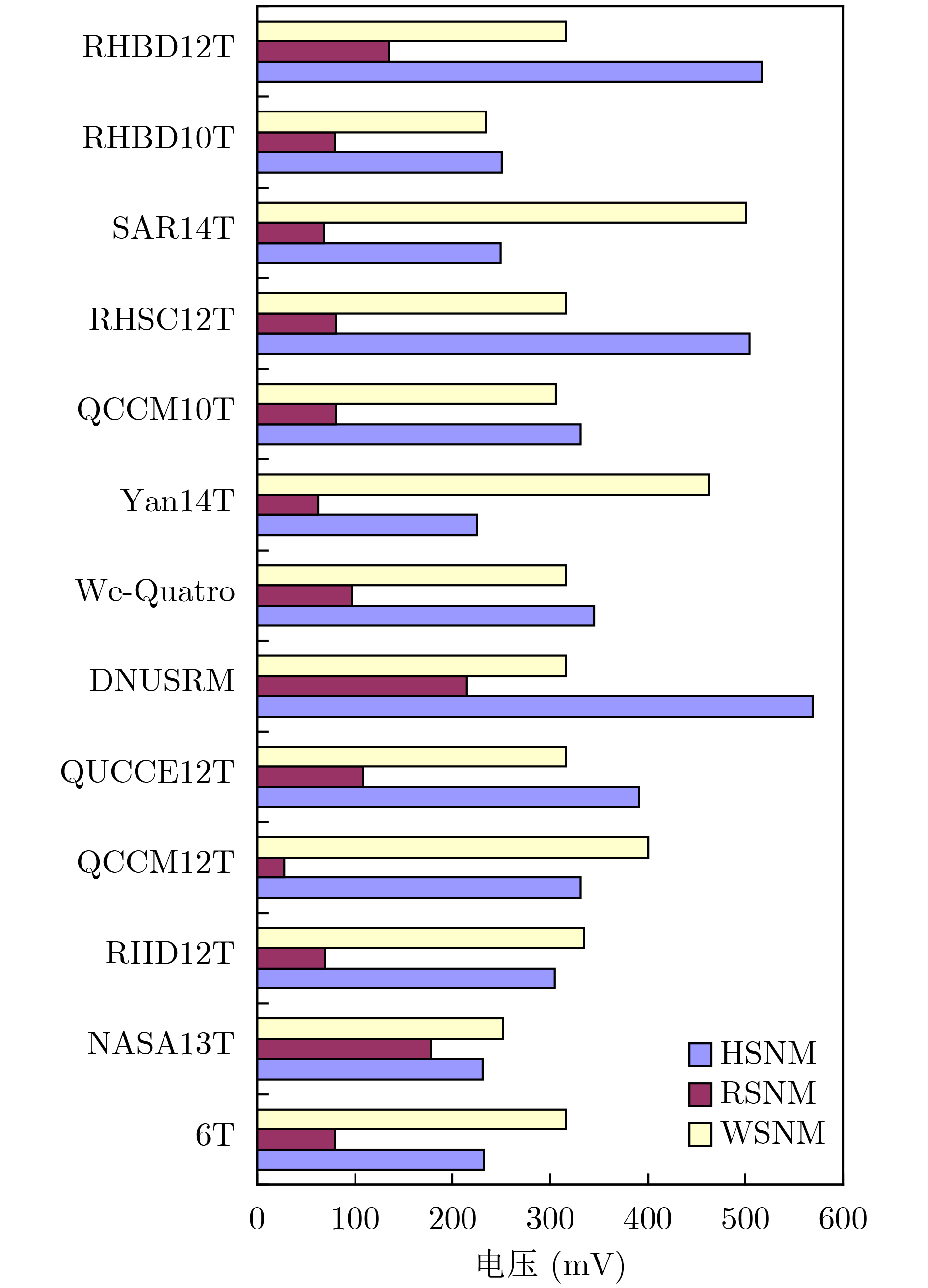
尊敬的读者、作者、审稿人, 关于本刊的投稿、审稿、编辑和出版的任何问题, 您可以本页添加留言。我们将尽快给您答复。谢谢您的支持!
作者中心
审者中心
编者中心
下载中心
1979年创刊 月刊
主管单位:中国科学院
主办单位:中国科学院空天信息创新研究院(原中国科学院电子学研究所)
主 编:付琨
ISSN 1009-5896 CN 11-4494/TN
官方微信,欢迎关注
邮件订阅
RSS
电子与信息学报
微信学术论坛群