

A Class Incremental Learning Algorithm with Dual Separation of Data Flow and Feature Space for Various Classes
-
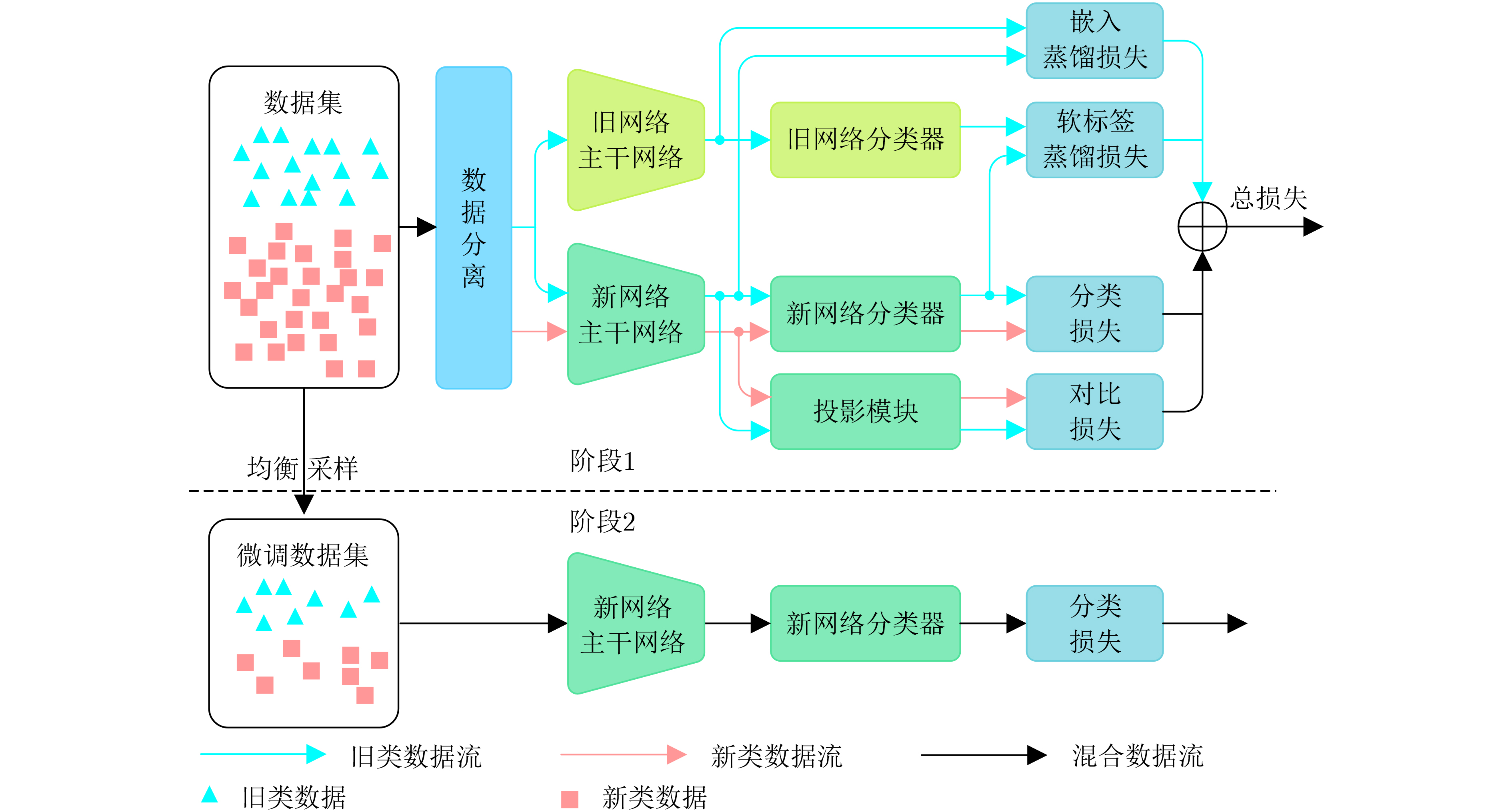
摘要: 针对类增量学习(CIL)中的灾难性遗忘问题,该文提出一种不同类的数据流和特征空间双分离的类增量学习算法。双分离(S2)算法在1次增量任务中包含2个阶段。第1个阶段通过分类损失、蒸馏损失和对比损失的综合约束训练网络。根据模块功能对各类的数据流进行分离,以增强新网络对新类别的识别能力。通过对比损失的约束,增大各类数据在特征空间中的距离,避免由于旧类样本的不完备性造成特征空间被新类侵蚀。第2个阶段对不均衡的数据集进行动态均衡采样,利用得到的均衡数据集对新网络进行动态微调。利用实测和仿真数据构建了一个飞机目标高分辨率距离像增量学习数据集,实验结果表明该算法相比其它几种对比算法在保持高可塑性的同时,具有更高的稳定性,综合性能更优。Abstract: To address the catastrophic forgetting problem in Class Incremental Learning (CIL), a class incremental learning algorithm with dual separation of data flow and feature space for various classes is proposed in this paper. The Dual Separation (S2) algorithm is composed of two stages in an incremental task. In the first stage, the network training is achieved through the comprehensive constraint of classification loss, distillation loss, and contrastive loss. The data flows from different classes are separated depending on module functions, in order to enhance the network’s ability to recognize new classes. By utilizing contrastive loss, the distance between different classes in the feature space is increased to prevent the feature space of old class from being eroded by the new class due to the incompleteness of the old class samples. In the second stage, the imbalanced dataset is subjected to dynamic balancing sampling to provide a balanced dataset for the new network’s dynamic fine-tuning. A high-resolution range profile incremental learning dataset of aircraft targets was created using observed and simulated data. The experimental results demonstrate that the algorithm proposed in this paper outperforms other algorithms in terms of overall performance and higher stability, while maintaining high plasticity.
-
1 新类样本集的构建
输入:任务${T_i}$包含${N_{{\text{NC}}}}$个类别的数据集${{\boldsymbol{D}}^i}$ 输入:每个类别保存样本数$m$ 输入:主干网络$ \text{CONV}(\cdot) $ 1: for $j = 1,2, \cdots ,{N_{{\text{NC}}}}$ 2: 样本嵌入均值$ {{\boldsymbol{\mu }}_j} \leftarrow \frac{1}{{\left| {{{\boldsymbol{D}}_j}} \right|}}\sum\limits_{{\boldsymbol{x}} \in {{\boldsymbol{D}}_j}} {{\text{CONV}}({\boldsymbol{x}})} $ 3: for $k = 1,2, \cdots ,m$ 4: ${{\boldsymbol{z}}_{jk}} \leftarrow \mathop {\arg \min }\limits_{{\boldsymbol{x}} \in {{\boldsymbol{D}}^i}} \left\| {{{\boldsymbol{\mu }}_j} - \dfrac{1}{k}\left[ {{\text{CONV}}({\boldsymbol{x}}) + \displaystyle\sum\limits_{l = 1}^{k - 1} {{\text{CONV}}({{\boldsymbol{z}}_{il}})} } \right]} \right\|$ 5: end for 6: ${{\boldsymbol{Z}}_j} \leftarrow \left( {{{\boldsymbol{z}}_{j1}},{{\boldsymbol{z}}_{j2}}, \cdots ,{{\boldsymbol{z}}_{jm}}} \right)$ 7: end for 输出:$ {{\boldsymbol{Z}}^{{\text{NC}}}} \leftarrow {{\boldsymbol{Z}}_1} \cup {{\boldsymbol{Z}}_2} \cup \cdots \cup {{\boldsymbol{Z}}_{{N_{{\text{NC}}}}}} $  下载: 导出CSV
下载: 导出CSV
2 S2未增量训练过程
输入:新类数据集${{\boldsymbol{D}}^0}$ 输入:每个类别保存样本数$m$ 输入:初始网络参数${\boldsymbol{W}}$ 1: ${\boldsymbol{W}} \leftarrow \mathop {\arg \min }\limits_{\boldsymbol{W}} {\text{los}}{{\text{s}}_{{\text{cls}}}}({{\boldsymbol{D}}^0},{\boldsymbol{W}})$ 2: 利用算法1挑选新类样本${{\boldsymbol{Z}}^{{\text{NC}}}} \leftarrow {{\boldsymbol{D}}^0}$ 3: 回放数据集${{\boldsymbol{Z}}^0} \leftarrow {{\boldsymbol{Z}}^{{\text{NC}}}}$ 输出:${\boldsymbol{W}}$, ${{\boldsymbol{Z}}^0}$
下载: 导出CSV
3 S2增量训练过程
输入:新类数据集${{\boldsymbol{D}}^i}$ 输入:回放数据集${{\boldsymbol{Z}}^{i - 1}}$ 输入:每个类别保存样本数$m$ 输入:当前网络参数${\boldsymbol{W}}$ 1: /*阶段1*/ 2: for $k = 1,2, \cdots ,{\text{epoc}}{{\text{h}}_{{\text{train}}}}$ 3: 随机抽取一个批次的数据
${{\boldsymbol{D}}_{{\text{batch}}}} = {\text{RandomSample}}\left( {{{\boldsymbol{D}}^i} \cup {{\boldsymbol{Z}}^{i - 1}}} \right)$4: 新旧数据分流${\boldsymbol{D}}_{{\text{batch}}}^{\text{O}},{\boldsymbol{D}}_{{\text{batch}}}^{\text{N}} = {\text{separate}}({{\boldsymbol{D}}_{{\text{batch}}}})$,
$\left( {{{\boldsymbol{x}}^{{\text{OC}}}},{y^{{\text{OC}}}}} \right) \in {\boldsymbol{D}}_{{\text{batch}}}^{\text{O}}$, $\left( {{{\boldsymbol{x}}^{{\text{AC}}}},{y^{{\text{AC}}}}} \right) \in {\boldsymbol{D}}_{{\text{batch}}}^{}$5: 特征提取${{\boldsymbol{e}}^{{\text{ONOC}}}} = {\text{CON}}{{\text{V}}^{{\text{ON}}}}({{\boldsymbol{x}}^{{\text{OC}}}})$,
$ {{\boldsymbol{e}}^{{\text{NNOC}}}}{\text{ = CON}}{{\text{V}}^{{\text{NN}}}}({{\boldsymbol{x}}^{{\text{OC}}}}) $, $ {{\boldsymbol{e}}^{{\text{NNAC}}}}{\text{ = CON}}{{\text{V}}^{{\text{NN}}}}({{\boldsymbol{x}}^{{\text{AC}}}}) $6: 计算嵌入蒸馏损失$ {\text{los}}{{\text{s}}_{{\text{ED}}}} $ 7: 分类器输出${{\boldsymbol{l}}^{{\text{ONOC}}}} = {\text{F}}{{\text{C}}^{{\text{ON}}}}({{\boldsymbol{e}}^{{\text{ONOC}}}})$,
${{\boldsymbol{l}}^{{\text{NNOC}}}} = {\text{F}}{{\text{C}}^{{\text{NN}}}}({{\boldsymbol{e}}^{{\text{NNOC}}}})$, ${{\boldsymbol{l}}^{{\text{NNAC}}}} = {\text{F}}{{\text{C}}^{{\text{NN}}}}({{\boldsymbol{e}}^{{\text{NNAC}}}})$8: 计算软标签蒸馏损失$ {\text{los}}{{\text{s}}_{{\text{LD}}}} $ 9: 计算分类损失$ {\text{los}}{{\text{s}}_{{\text{cls}}}} $ 10: 投影$ {{\boldsymbol{p}}^{{\text{NNAC}}}} = {\text{PROJECTION}}({{\boldsymbol{e}}^{{\text{NNAC}}}}) $ 11: 计算对比损失$ {\text{los}}{{\text{s}}_{{\text{SCL}}}} $ 12: 计算总损失$ {\text{los}}{{\text{s}}_{{\text{total}}}} $ 13: 利用$ \nabla {\text{los}}{{\text{s}}_{{\text{total}}}} $更新${\boldsymbol{W}}$ 14: end for 15: /*阶段2*/ 16: for $k = 1,2, \cdots ,{\text{epoc}}{{\text{h}}_{{\text{ft}}}}$ 17: 均衡数据集${{\boldsymbol{D}}^{\text{B}}} \leftarrow {\text{BalanceSample(}}{{\boldsymbol{D}}^i},{{\boldsymbol{Z}}^{i - 1}}{\text{)}}$ 18: 微调${\boldsymbol{W}} \leftarrow \mathop {\arg \min }\limits_{\boldsymbol{W}} {\text{los}}{{\text{s}}_{{\text{cls}}}}({{\boldsymbol{D}}^{\text{B}}},{\boldsymbol{W}})$ 19: end for 20: /*回放数据集管理*/ 21: 挑选旧类样本${{\boldsymbol{Z}}^{{\text{OC}}}} \leftarrow {{\boldsymbol{Z}}^{i - 1}}$ 22: 利用算法1挑选新类样本${{\boldsymbol{Z}}^{{\text{NC}}}} \leftarrow {{\boldsymbol{D}}^i}$ 23: 回放数据集${{\boldsymbol{Z}}^i} \leftarrow {{\boldsymbol{Z}}^{{\text{OC}}}} \cup {{\boldsymbol{Z}}^{{\text{NC}}}}$ 输出:${\boldsymbol{W}}$, ${{\boldsymbol{Z}}^i}$
下载: 导出CSV
表 1 飞机尺寸参数
飞机型号 机长(m) 机宽(m) 机高(m) 多边形数量 飞机1 28.72 30.04 9.10 166 338 飞机2 17.51 15.46 4.84 69 446 飞机3 6.84 15.00 1.74 64 606 飞机4 12.58 7.60 3.33 119 940 飞机5 16.18 7.40 2.44 51 736 飞机6 7.93 9.01 3.09 141 343 飞机7 15.28 13.02 4.99 114 166 飞机8 7.36 9.20 2.89 76 851 雅克42 36.38 34.88 9.83 - 奖状 14.40 15.90 4.57 - 安26 23.80 29.20 9.83 -
下载: 导出CSV
表 3 模块消融实验结果
序号 分类
损失蒸馏
损失数据流
分离对比
损失动态
微调分类器 准确率
(%)NME CNN 1 √ √ √ √ √ √ 97.88 2 √ √ √ √ √ 96.36 3 √ √ √ √ 95.33 4 √ √ √ 94.35 5 √ √ √ 91.94
下载: 导出CSV
-
[1] ZHU Kai, ZHAI Wei, CAO Yang, et al. Self-sustaining representation expansion for non-exemplar class-incremental learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9286–9295. doi: 10.1109/CVPR52688.2022.00908. [2] LI Zhizhong and HOIEM D. Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935–2947. doi: 10.1109/TPAMI.2017.2773081. [3] DOUILLARD A, CORD M, OLLION C, et al. PODNet: Pooled outputs distillation for small-tasks incremental learning[C]. The 16th European Conference, Glasgow, UK, 2020: 86–102. doi: 10.1007/978-3-030-58565-5_6. [4] REBUFFI S A, KOLESNIKOV A, SPERL G, et al. iCaRL: Incremental classifier and representation learning[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 2001–2010. doi: 10.1109/CVPR.2017.587. [5] 曲志昱, 李根, 邓志安. 基于知识蒸馏与注意力图的雷达信号识别方法[J]. 电子与信息学报, 2022, 44(9): 3170–3177. doi: 10.11999/JEIT210695.QU Zhiyu, LI Gen, and DENG Zhian. Radar signal recognition method based on knowledge distillation and attention map[J]. Journal of Electronics & Information Technology, 2022, 44(9): 3170–3177. doi: 10.11999/JEIT210695. [6] ISCEN A, ZHANG J, LAZEBNIK S, et al. Memory-efficient incremental learning through feature adaptation[C]. Proceedings of the 16th European Conference, Glasgow, UK, 2020: 699–715. doi: 10.1007/978-3-030-58517-4_41. [7] PELLEGRINI L, GRAFFIETI G, LOMONACO V, et al. Latent replay for real-time continual learning[C]. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, USA, 2020: 10203–10209. doi: 10.1109/IROS45743.2020.9341460. [8] YIN Hongxu, MOLCHANOV P, ALVAREZ J M, et al. Dreaming to distill: Data-free knowledge transfer via DeepInversion[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 8715–8724. doi: 10.1109/CVPR42600.2020.00874. [9] SHEN Gehui, ZHANG Song, CHEN Xiang, et al. Generative feature replay with orthogonal weight modification for continual learning[C]. 2021 International Joint Conference on Neural Networks, Shenzhen, China, 2021: 1–8. doi: 10.1109/IJCNN52387.2021.9534437. [10] WU Yue, CHEN Yinpeng, WANG Lijuan, et al. Large scale incremental learning[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 374–382. doi: 10.1109/CVPR.2019.00046. [11] LIU Yaoyao, SCHIELE B, and SUN Qianru. Adaptive aggregation networks for class-incremental learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2544–2553. doi: 10.1109/CVPR46437.2021.00257. [12] CHEN Long, WANG Fei, YANG Ruijing, et al. Representation learning from noisy user-tagged data for sentiment classification[J]. International Journal of Machine Learning and Cybernetics, 2022, 13(12): 3727–3742. doi: 10.1007/s13042-022-01622-7. [13] ZHOU Dawei, YE Hanjia, and ZHAN Dechuan. Co-transport for class-incremental learning[C]. The 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 1645–1654. doi: 10.1145/3474085.3475306. [14] WANG Fuyun, ZHOU Dawei, YE Hanjia, et al. FOSTER: Feature boosting and compression for class-incremental learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 398–414. doi: 10.1007/978-3-031-19806-9_23. [15] ZHAO Bowen, XIAO Xi, GAN Guojun, et al. Maintaining discrimination and fairness in class incremental learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 13208–13217. doi: 10.1109/CVPR42600.2020.01322. [16] ZHOU Dawei, WANG Fuyun, YE Hanjia, et al. PyCIL: A python toolbox for class-incremental learning[J]. Science China Information Sciences, 2023, 66(9): 197101. doi: 10.1007/s11432-022-3600-y. -

 下载:
下载:












图(13) / 表(6)
计量
- 文章访问数: 977
- HTML全文浏览量: 825
- PDF下载量: 137
- 被引次数: 0
