

A Survey of Continual Learning with Deep Networks: Theory, Method and Application
-
摘要: 自然界中的生物需要在其一生中不断地学习并适应环境,这种持续学习的能力是生物学习系统的基础。尽管深度学习方法在计算机视觉和自然语言处理领域取得了重要进展,但它们在连续学习任务时面临严重的灾难性遗忘问题,即模型在学习新知识时会遗忘旧知识,这在很大程度上限制了深度学习方法的应用。持续学习研究对人工智能系统的改进和应用具有重要意义。该文对深度模型的持续学习进行了全面回顾。首先介绍了持续学习的定义和典型设定,阐述了问题的关键。其次,将现有持续学习方法划分为基于正则化、基于回放、基于梯度和基于网络结构4类,分析了各类方法的优点和局限性。同时,该文强调并总结了持续学习领域的理论分析进展,建立了理论与方法之间的联系。此外,提供了常用的数据集和评价指标,以公正评判不同方法。最后,从多个领域的应用价值出发,讨论了深度持续方法面临的问题、挑战和未来研究方向。Abstract: Biological organisms in nature are required to continuously learn from and adapt to the environment throughout their lifetime. This ongoing learning capacity serves as the fundamental basis for the biological learning systems. Despite the significant advancements in deep learning methods for computer vision and natural language processing, these models often encounter a serious issue, known as catastrophic forgetting, when learning tasks sequentially. This refers to the model’s tendency to discard previously acquired knowledge when acquiring new information, which greatly hampers the practical application of deep learning models. Thus, the exploration of continual learning is paramount for enhancing and implementing artificial intelligence systems. This paper provides a comprehensive survey of continual learning with deep models. Firstly, the definition and typical settings of continual learning are introduced, followed by the key aspects of the problem. Secondly, existing methods are categorized into four main groups: regularization-based, replay-based, gradient-based and structure-based approaches, with an outline of the strengths and weaknesses of each group. Meanwhile, the paper highlights and summarizes the theoretical progress in continual learning, establishing a crucial nexus between theory and methodology. Additionally, commonly used datasets and evaluation metrics are provided to facilitate fair comparisons among these methods. Finally, the paper addresses current issues, challenges and outlines future research directions in deep continual learning, taking into account its potential applications across diverse fields.
-
Key words:
- Deep learning /
- Continual learning /
- Catastrophic forgetting
-
表 1 持续学习的不同任务设定
任务设定 数据分布 任务标识 域增量学习 $ p\left({\mathcal{X}}_{i}\right)\ne p\left({\mathcal{X}}_{j}\right),{\mathcal{Y}}_{i}={\mathcal{Y}}_{j}, \forall i\ne j $ × 任务增量学习 $ p\left({\mathcal{X}}_{i}\right)\ne p\left({\mathcal{X}}_{j}\right),{\mathcal{Y}}_{i}\bigcap {\mathcal{Y}}_{j}=\varnothing , \forall i\ne j $ √ 类别增量学习 $ p\left({\mathcal{X}}_{i}\right)\ne p\left({\mathcal{X}}_{j}\right),{\mathcal{Y}}_{i}\bigcap {\mathcal{Y}}_{j}=\varnothing , \forall i\ne j $ ×  下载: 导出CSV
下载: 导出CSV
表 2 持续学习与相关研究领域的区别
研究领域 训练数据 测试数据 额外限制 监督学习 $ {\mathcal{D}}_{\mathrm{t}\mathrm{r}\mathrm{a}\mathrm{i}\mathrm{n}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{e}\mathrm{s}\mathrm{t}} $ $ p\left({\mathcal{D}}_{\mathrm{t}\mathrm{r}\mathrm{a}\mathrm{i}n}\right)=p\left({\mathcal{D}}_{\mathrm{t}\mathrm{e}\mathrm{s}\mathrm{t}}\right) $ 多任务学习 $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t} $ $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t} $ $ p\left({\mathcal{D}}_{i}\right)\ne p\left({\mathcal{D}}_{j}\right), $ $ i\ne j $ 元学习 $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t-1} $ $ {\mathcal{D}}_{t} $ $ p\left({\mathcal{D}}_{i}\right)\ne p\left({\mathcal{D}}_{t}\right), $ $ i < t $ 迁移学习 $ {\mathcal{D}}_{\mathrm{s}\mathrm{r}\mathrm{c}},{\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $ $ p\left({\mathcal{D}}_{\mathrm{s}\mathrm{r}\mathrm{c}}\right)\ne p\left({\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}}\right) $ 域适应 $ {\mathcal{D}}_{\mathrm{s}\mathrm{r}\mathrm{c}},{\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $无标注信息 域泛化 $ {\mathcal{D}}_{\mathrm{s}\mathrm{r}\mathrm{c}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $ $ {\mathcal{D}}_{\mathrm{t}\mathrm{g}\mathrm{t}} $无法访问 持续学习 $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t} $ $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t} $ $ {\mathcal{D}}_{1},{\mathcal{D}}_{2},\cdots,{\mathcal{D}}_{t-1} $无法访问
下载: 导出CSV
表 3 持续学习方法分类及特点
类别 方法 方法特点 优缺点 基于正则化 参数正则化
数据正则化
任务偏向修正通过参数重要性估计对参数进行保护
保持新旧模型对给定数据的输出一致性
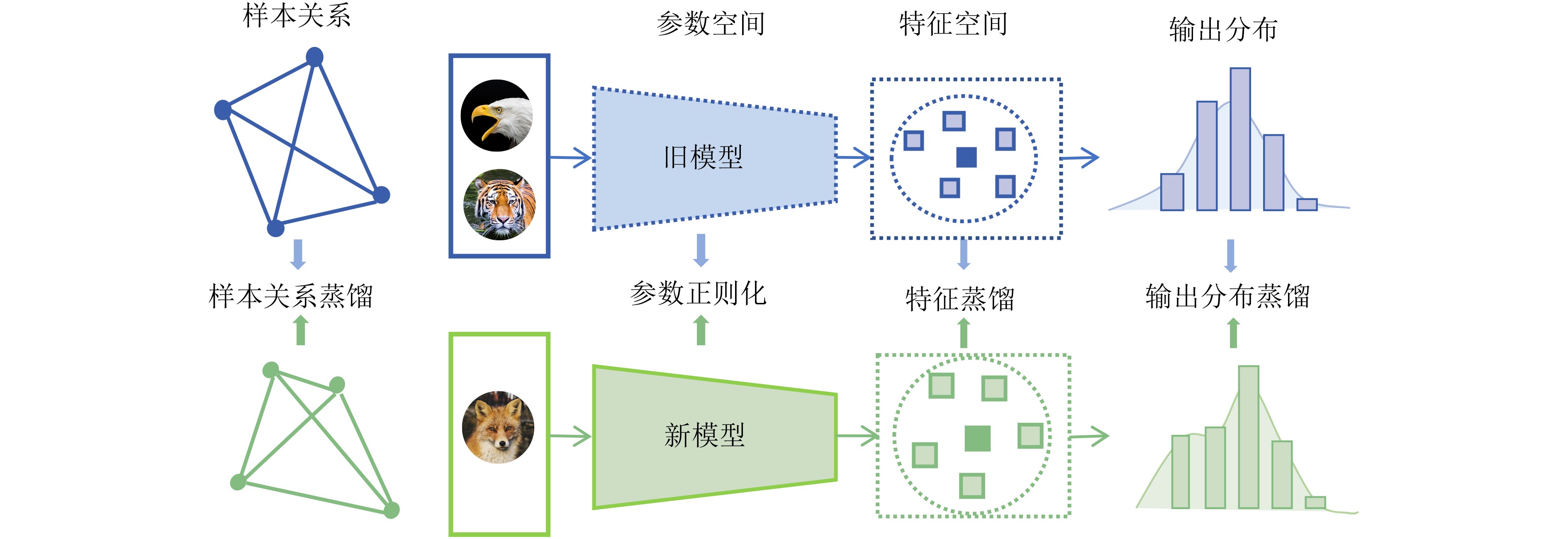
针对网络任务偏向问题提出不同的解决方案无需回放样本,但难以有效估计参数重要性,性能较差
简单有效,但通常需要回放样本或特征以提高性能
需要额外的修正训练,或额外的计算资源基于回放 原始数据回放
原始特征回放
生成式回放回放部分任务的原始样本
回放样本特征或类别原型
使用生成模型进行数据回放简单有效,但回放样本占据空间较大
节省存储空间,面临特征偏移问题
生成数据的质量难以保证基于梯度 梯度情景记忆
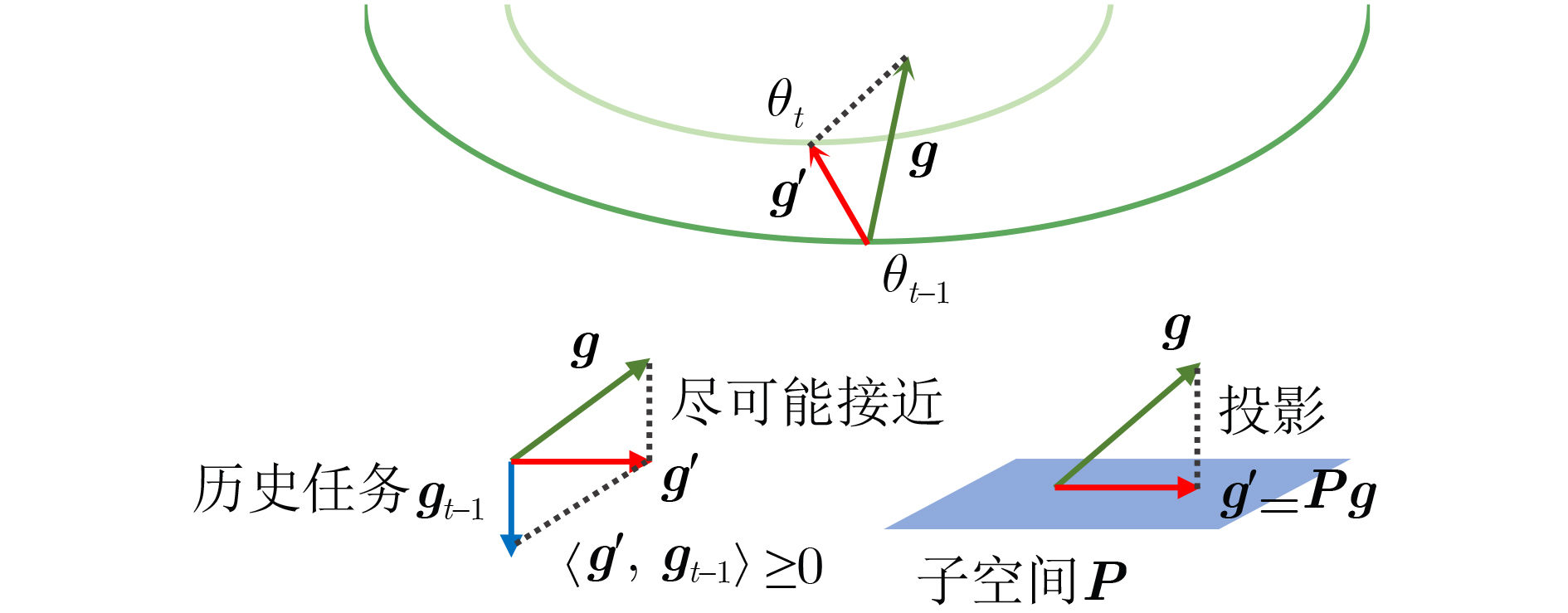
子空间投影
平坦极小点基于历史数据的梯度构建约束
将参数梯度投影到子空间
获取平坦极小点需要回放样本,并计算额外梯度
能有效减缓遗忘,需要存储特征空间
使用额外的技术手段,增加训练成本基于网络结构 静态结构
动态结构
参数高效微调将网络参数分配给任务
动态地扩张网络结构
对预训练模型进行增量式微调模型容量有限,难以解决长序列任务的学习问题
能有效减缓遗忘,但扩张网络带来额外存储和推理负担
能有效减缓遗忘,但获取预训练模型需要成本
下载: 导出CSV
表 4 持续学习理论工作总结
理论工作 主要结果 特点 对应方法 概率模型 $ {\theta }_{t}\approx {\mathrm{argmax}}_{\theta }\mathrm{log}p\left({\mathcal{D}}_{t}|{\boldsymbol{\theta}} \right)-{\left({\boldsymbol{\theta}} -{{\boldsymbol{\theta}} }_{t-1}\right)}^{\mathrm{T}}{\boldsymbol{F}}_{1:t-1}({\boldsymbol{\theta}} -{{\boldsymbol{\theta}} }_{t-1})/2 $ 通过对先前任务进行近似和估计,
得到网络训练的正则损失参数正则化 PAC学习 $ {\varepsilon }_{{\mathcal{D}}_{t}}\left(h\right)\le \dfrac{1}{t-1}{\displaystyle\sum }_{i=1}^{t-1}{\widehat{\varepsilon }}_{{D}_{i}}\left(h\right)+\dfrac{1}{2\left(t-1\right)}{\displaystyle\sum }_{i=1}^{t-1}{d}_{\mathcal{H}\Delta \mathcal{H}}\left({\mathcal{D}}_{i},{\mathcal{D}}_{t}\right)+{\lambda }_{t-1} $ 在PAC学习理论框架下,对网络的
泛化误差进行界定数据正则化
基于回放的方法神经正切核 $ {{\varDelta }}_{t-1}={\left\|\mathcal{{\boldsymbol{K}}}\left({{\boldsymbol{X}}}_{t-1},{{\boldsymbol{X}}}_{t}\right){\left(\mathcal{{\boldsymbol{K}}}\left({{\boldsymbol{X}}}_{t},{{\boldsymbol{X}}}_{t}\right)+\lambda {\boldsymbol{I}}\right)}^{-1}{\tilde{{\boldsymbol{y}}}}_{t}\right\|}_{2}^{2} $ 在神经正切核范式下,
分析神经网络的遗忘问题基于梯度的方法 任务分解 $ p\left({\boldsymbol{x}}\in {{\boldsymbol{X}}}_{t,j}|{\boldsymbol{\theta}} \right)=p\left({\boldsymbol{x}}\in {{\boldsymbol{X}}}_{t,j}|{{\boldsymbol{\theta}} }^{\left(t\right)}\right)p\left({\boldsymbol{x}}\in {{\boldsymbol{X}}}_{t}|{\boldsymbol{\theta}} \right) $ 将类别增量学习问题分解为任务
内预测和任务标识预测两个子问题基于网络结构
的方法
下载: 导出CSV
表 5 持续学习常用数据集
数据集 年份 类别数 数据量 MNIST[212] 1998 10 60,000 CIFAR-10[213] 2009 10 60,000 CIFAR-100[213] 2009 100 60,000 CUB-200[214] 2011 200 11,788 Tiny-ImageNet[215] 2015 200 120,000 Sub-ImageNet[216] 2009 $ 100 $ 60,000 Full-ImageNet[216] 2009 1,000 1,280,000 5-datasets[217] 2020 50 260,000 CORe50[218] 2017 50 15,000 DomainNet[219] 2019 345 590,000 CCDB[220] 2023 2 --
下载: 导出CSV
-
[1] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, USA, 2012: 1097–1105. [2] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [3] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]. 9th International Conference on Learning Representations, Austria, 2021. [4] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, USA, 2017: 6000–6010. [5] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]. The 34th International Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 2020: 159. [6] ABDEL-HAMID O, MOHAMED A R, JIANG Hui, et al. Convolutional neural networks for speech recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(10): 1533–1545. doi: 10.1109/TASLP.2014.2339736. [7] ZHOU Kaiyang, LIU Ziwei, QIAO Yu, et al. Domain generalization: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 4396–4415. doi: 10.1109/TPAMI.2022.3195549. [8] WANG Yi, DING Yi, HE Xiangjian, et al. Novelty detection and online learning for chunk data streams[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(7): 2400–2412. doi: 10.1109/TPAMI.2020.2965531. [9] HOI S C H, SAHOO D, LU Jing, et al. Online learning: A comprehensive survey[J]. Neurocomputing, 2021, 459: 249–289. doi: 10.1016/J.NEUCOM.2021.04.112. [10] FRENCH R M. Catastrophic forgetting in connectionist networks[J]. Trends in Cognitive Sciences, 1999, 3(4): 128–135. doi: 10.1016/s1364-6613(99)01294-2. [11] MCCLOSKEY M and COHEN N J. Catastrophic interference in connectionist networks: The sequential learning problem[J]. Psychology of Learning and Motivation, 1989, 24: 109–165. [12] CICHON J and GAN Wenbiao. Branch-specific dendritic Ca2+ spikes cause persistent synaptic plasticity[J]. Nature, 2015, 520(7546): 180–185. doi: 10.1038/nature14251. [13] ZENKE F, GERSTNER W, and GANGULI S. The temporal paradox of Hebbian learning and homeostatic plasticity[J]. Current Opinion in Neurobiology, 2017, 43: 166–176. doi: 10.1016/j.conb.2017.03.015. [14] POWER J D and SCHLAGGAR B L. Neural plasticity across the lifespan[J]. WIREs Developmental Biology, 2017, 6(1): e216. doi: 10.1002/wdev.216. [15] MCCLELLAND J L, MCNAUGHTON B L, and O'REILLY R C. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory[J]. Psychological Review, 1995, 102(3): 419–457. doi: 10.1037/0033-295x.102.3.419. [16] RATCLIFF R. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions[J]. Psychological Review, 1990, 97(2): 285–308. doi: 10.1037/0033-295x.97.2.285. [17] KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521–3526. doi: 10.1073/pnas.1611835114. [18] HINTON G E and PLAUT D C. Using fast weights to deblur old memories[C]. Proceedings of the 9th Annual Conference of the Cognitive Science Society, Seattle, USA, 1987: 177–186. [19] KAMRA N, GUPTA U, and LIU Yan. Deep generative dual memory network for continual learning[J]. arXiv: 1710.10368, 2017. doi: 10.48550/arXiv.1710.10368. [20] ROBBINS H and MONRO S. A stochastic approximation method[J]. The Annals of Mathematical Statistics, 1951, 22(3): 400–407. doi: 10.1214/aoms/1177729586. [21] LOPEZ-PAZ D and RANZATO M A. Gradient episodic memory for continual learning[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6470–6479. [22] ZENG Guanxiong, CHEN Yang, CUI Bo, et al. Continual learning of context-dependent processing in neural networks[J]. Nature Machine Intelligence, 2019, 1(8): 364–372. doi: 10.1038/s42256-019-0080-x. [23] MALLYA A and LAZEBNIK S. PackNet: Adding multiple tasks to a single network by iterative pruning[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7765–7773. doi: 10.1109/CVPR.2018.00810. [24] YAN Shipeng, XIE Jiangwei, and HE Xuming. DER: Dynamically expandable representation for class incremental learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3013–3022. doi: 10.1109/CVPR46437.2021.00303. [25] DOUILLARD A, RAMÉ A, COUAIRON G, et al. DyTox: Transformers for continual learning with DYnamic TOken eXpansion[C]. IEEE/CVF International Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9275–9285. doi: 10.1109/CVPR52688.2022.00907. [26] WANG Zifeng, ZHANG Zizhao, LEE C Y, et al. Learning to prompt for continual learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 139–149. doi: 10.1109/CVPR52688.2022.00024. [27] HE Junxian, ZHOU Chunting, MA Xuezhe, et al. Towards a unified view of parameter-efficient transfer learning[C]. Tenth International Conference on Learning Representations, 2022. [28] JIA Menglin, TANG Luming, CHEN B C, et al. Visual prompt tuning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 709–727. doi: 10.1007/978-3-031-19827-4_41. [29] HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP[C]. 36th International Conference on Machine Learning, Long Beach, USA, 2019: 2790–2799. [30] HU E J, SHEN Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C]. Tenth International Conference on Learning Representations, 2022. [31] LI X L and LIANG P. Prefix-tuning: Optimizing continuous prompts for generation[C]. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021: 4582–4597. doi: 10.18653/v1/2021.acl-long.353. [32] LESTER B, AL-RFOU R, and CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 3045–3059. doi: 10.18653/v1/2021.emnlp-main.243. [33] PARISI G I, KEMKER R, PART J L, et al. Continual lifelong learning with neural networks: A review[J]. Neural Networks, 2019, 113: 54–71. doi: 10.1016/j.neunet.2019.01.012. [34] DE LANGE M, ALJUNDI R, MASANA M, et al. A continual learning survey: Defying forgetting in classification tasks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3366–3385. doi: 10.1109/tpami.2021.3057446. [35] MASANA M, LIU Xialei, TWARDOWSKI B, et al. Class-incremental learning: Survey and performance evaluation on image classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 5513–5533. doi: 10.1109/tpami.2022.3213473. [36] BELOUADAH E, POPESCU A, and KANELLOS I. A comprehensive study of class incremental learning algorithms for visual tasks[J]. Neural Networks, 2021, 135: 38–54. doi: 10.1016/j.neunet.2020.12.003. [37] 朱飞, 张煦尧, 刘成林. 类别增量学习研究进展和性能评价[J]. 自动化学报, 2023, 49(3): 635–660. doi: 10.16383/j.aas.c220588.ZHU Fei, ZHANG Xuyao, and LIU Chenglin. Class incremental learning: A review and performance evaluation[J]. Acta Automatica Sinica, 2023, 49(3): 635–660. doi: 10.16383/j.aas.c220588. [38] MERMILLOD M, BUGAISKA A, and BONIN P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects[J]. Frontiers in Psychology, 2013, 4: 504. doi: 10.3389/fpsyg.2013.00504. [39] VAN DE VEN G M and TOLIAS A S. Three scenarios for continual learning[J]. arXiv: 1904.07734, 2019. doi: 10.48550/arXiv.1904.07734. [40] BUZZEGA P, BOSCHINI M, PORRELLO A, et al. Dark experience for general continual learning: A strong, simple baseline[C]. The 34th International Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 2020: 1335. [41] MAI Zheda, LI Ruiwen, JEONG J, et al. Online continual learning in image classification: An empirical survey[J]. Neurocomputing, 2022, 469: 28–51. doi: 10.1016/j.neucom.2021.10.021. [42] GOODFELLOW I J, MIRZA M, XIAO Da, et al. An empirical investigation of catastrophic forgetting in gradient-based neural networks[J]. arXiv: 1312.6211, 2013. doi: 10.48550/arXiv.1312.6211. [43] SHMELKOV K, SCHMID C, and ALAHARI K. Incremental learning of object detectors without catastrophic forgetting[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3420–3429. doi: 10.1109/ICCV.2017.368. [44] LI Dawei, TASCI S, GHOSH S, et al. RILOD: Near real-time incremental learning for object detection at the edge[C]. The 4th ACM/IEEE Symposium on Edge Computing, Arlington, USA, 2019: 113–126. doi: 10.1145/3318216.3363317. [45] PENG Can, ZHAO Kun, MAKSOUD S, et al. SID: Incremental learning for anchor-free object detection via Selective and Inter-related Distillation[J]. Computer Vision and Image Understanding, 2021, 210: 103229. doi: 10.1016/j.cviu.2021.103229. [46] 商迪, 吕彦锋, 乔红. 受人脑中记忆机制启发的增量目标检测方法[J]. 计算机科学, 2023, 50(2): 267–274. doi: 10.11896/jsjkx.220900212.SHANG Di, LYU Yanfeng, and QIAO Hong. Incremental object detection inspired by memory mechanisms in brain[J]. Computer Science, 2023, 50(2): 267–274. doi: 10.11896/jsjkx.220900212. [47] CERMELLI F, MANCINI M, BULÒ S R, et al. Modeling the background for incremental learning in semantic segmentation[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9230–9239. doi: 10.1109/CVPR42600.2020.00925. [48] DOUILLARD A, CHEN Yifu, DAPOGNY A, et al. PLOP: Learning without forgetting for continual semantic segmentation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 4039–4049. doi: 10.1109/CVPR46437.2021.00403. [49] YAN Shipeng, ZHOU Jiale, XIE Jiangwei, et al. An EM framework for online incremental learning of semantic segmentation[C]. Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 3052–3060. doi: 10.1145/3474085.3475443. [50] MICHIELI U and ZANUTTIGH P. Continual semantic segmentation via repulsion-attraction of sparse and disentangled latent representations[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1114–1124. doi: 10.1109/CVPR46437.2021.00117. [51] YANG Guanglei, FINI E, XU Dan, et al. Uncertainty-aware contrastive distillation for incremental semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2567–2581. doi: 10.1109/TPAMI.2022.3163806. [52] ZHAI Mengyao, CHEN Lei, TUNG F, et al. Lifelong GAN: Continual learning for conditional image generation[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 2759–2768. doi: 10.1109/ICCV.2019.00285. [53] Zając M, Deja K, Kuzina A, et al. Exploring continual learning of diffusion models[J]. arxiv:2303.15342, 2023. doi: 10.48550/arXiv.2303.15342. [54] ZHAI Mengyao, CHEN Lei, HE Jiawei, et al. Piggyback GAN: Efficient lifelong learning for image conditioned generation[C]. The 17th European Conference on Computer Vision, Glasgow, UK, 2020: 397–413. doi: 10.1007/978-3-030-58589-1_24. [55] WANG Liyuan, YANG Kuo, LI Chongxuan, et al. ORDisCo: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5379–5388. doi: 10.1109/CVPR46437.2021.00534. [56] YOON J, HWANG S J, and CAO Yue. Continual learners are incremental model generalizers[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 40129–40146. [57] HU Dapeng, YAN Shipeng, LU Qizhengqiu, et al. How well does self-supervised pre-training perform with streaming data?[C]. Tenth International Conference on Learning Representations, 2022. [58] COSSU A, CARTA A, PASSARO L, et al. Continual pre-training mitigates forgetting in language and vision[J]. Neural Networks, 2024, 179: 106492. doi: 10.1016/j.neunet.2024.106492. [59] CARUANA R. Multitask learning[J]. Machine Learning, 1997, 28(1): 41–75. doi: 10.1023/A:1007379606734. [60] HOSPEDALES T, ANTONIOU A, MICAELLI P, et al. Meta-learning in neural networks: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5149–5169. doi: 10.1109/TPAMI.2021.3079209. [61] WEISS K, KHOSHGOFTAAR T M, and WANG Dingding. A survey of transfer learning[J]. Journal of Big data, 2016, 3(1): 9. doi: 10.1186/s40537-016-0043-6. [62] PATEL V M, GOPALAN R, LI Ruonan, et al. Visual domain adaptation: A survey of recent advances[J]. IEEE Signal Processing Magazine, 2015, 32(3): 53–69. doi: 10.1109/MSP.2014.2347059. [63] WANG Jindong, LAN Cuiling, LIU Chang, et al. Generalizing to unseen domains: A survey on domain generalization[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(8): 8052–8072. doi: 10.1109/TKDE.2022.3178128. [64] REBUFFI S A, KOLESNIKOV A, SPERL G, et al. iCaRL: Incremental classifier and representation learning[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 5533–5542. doi: 10.1109/CVPR.2017.587. [65] HUSZÁR F. Note on the quadratic penalties in elastic weight consolidation[J]. Proceedings of the National Academy of Sciences of the United States of America, 2018, 115(11): E2496–E2497. doi: 10.1073/pnas.1717042115. [66] LIU Xialei, MASANA M, HERRANZ L, et al. Rotate your networks: Better weight consolidation and less catastrophic forgetting[C]. The 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 2018: 2262–2268. doi: 10.1109/ICPR.2018.8545895. [67] RITTER H, BOTEV A, and BARBER D. Online structured Laplace approximations for overcoming catastrophic forgetting[C]. The 32nd International Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 2018: 3742–3752. [68] ZENKE F, POOLE B, and GANGULI S. Continual learning through synaptic intelligence[C]. The 34th International Conference on Machine Learning (ICML), Sydney, Australia, 2017: 3987–3995. [69] ALJUNDI R, BABILONI F, ELHOSEINY M, et al. Memory aware synapses: Learning what (not) to forget[C]. The 15th European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 144–161. doi: 10.1007/978-3-030-01219-9_9. [70] CHAUDHRY A, DOKANIA P K, AJANTHAN T, et al. Riemannian walk for incremental learning: Understanding forgetting and intransigence[C]. The 15th European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 556–572. doi: 10.1007/978-3-030-01252-6_33. [71] LEE S W, KIM J H, JUN J, et al. Overcoming catastrophic forgetting by incremental moment matching[C]. The 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, USA, 2017: 4655–4665. [72] BENZING F. Unifying importance based regularisation methods for continual learning[C]. The 25th International Conference on Artificial Intelligence and Statistics (ICAIS), 2022: 2372–2396. [73] HINTON G, VINYALS O, and DEAN J. Distilling the knowledge in a neural network[J]. arXiv: 1503.02531, 2015. doi: 10.48550/arXiv.1503.02531. [74] LI Zhizhong and HOIEM D. Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935–2947. doi: 10.1109/TPAMI.2017.2773081. [75] HOU Saihui, PAN Xinyu, LOY C C, et al. Learning a unified classifier incrementally via rebalancing[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 831–839. doi: 10.1109/CVPR.2019.00092. [76] DHAR P, SINGH R V, PENG Kuanchuan, et al. Learning without memorizing[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 5133–5141. doi: 10.1109/CVPR.2019.00528. [77] KANG M, PARK J, and HAN B. Class-incremental learning by knowledge distillation with adaptive feature consolidation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 16050–16059. doi: 10.1109/CVPR52688.2022.01560. [78] DOUILLARD A, CORD M, OLLION C, et al. PODNet: Pooled outputs distillation for small-tasks incremental learning[C]. The 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 2020: 86–102. doi: 10.1007/978-3-030-58565-5_6. [79] SIMON C, KONIUSZ P, and HARANDI M. On learning the geodesic path for incremental learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 1591–1600. doi: 10.1109/CVPR46437.2021.00164. [80] GAO Qiankun, ZHAO Chen, GHANEM B, et al. R-DFCIL: Relation-guided representation learning for data-free class incremental learning[C]. The 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 2022: 423–439. doi: 10.1007/978-3-031-20050-2_25. [81] TAO Xiaoyu, CHANG Xinyuan, HONG Xiaopeng, et al. Topology-preserving class-incremental learning[C]. The 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 2020: 254–270. doi: 10.1007/978-3-030-58529-7_16. [82] TAO Xiaoyu, HONG Xiaopeng, CHANG Xinyuan, et al. Few-shot class-incremental learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 12180–12189. doi: 10.1109/CVPR42600.2020.01220. [83] MARTINETZ T M and SCHULTEN K J. A "neural-gas" network learns topologies[M]. KOHONEN T, MÄKISARA K, SIMULA O, et al. Artificial Neural Networks. Amsterdam: North-Holland, 1991: 397–402. [84] LIU Yu, HONG Xiaopeng, TAO Xiaoyu, et al. Model behavior preserving for class-incremental learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(10): 7529–7540. doi: 10.1109/TNNLS.2022.3144183. [85] ASADI N, DAVARI M R, MUDUR S, et al. Prototype-sample relation distillation: Towards replay-free continual learning[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 1093–1106. [86] ARANI E, SARFRAZ F, and ZONOOZ B. Learning fast, learning slow: A general continual learning method based on complementary learning system[C]. The Tenth International Conference on Learning Representations (ICLR), 2022. [87] VIJAYAN P, BHAT P, ZONOOZ B, et al. TriRE: A multi-mechanism learning paradigm for continual knowledge retention and promotion[C]. The 37th Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 3226. [88] JEEVESWARAN K, BHAT P S, ZONOOZ B, et al. BiRT: Bio-inspired replay in vision transformers for continual learning[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 14817–14835. [89] ZHU Fei, ZHANG Xuyao, WANG Chuang, et al. Prototype augmentation and self-supervision for incremental learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5867–5876. doi: 10.1109/CVPR46437.2021.00581. [90] SZATKOWSKI F, PYLA M, PRZEWIĘŹLIKOWSKI M, et al. Adapt your teacher: Improving knowledge distillation for exemplar-free continual learning[C]. IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024: 1966–1976. doi: 10.1109/WACV57701.2024.00198. [91] LIANG Yanshuo and LI Wujun. Loss decoupling for task-agnostic continual learning[C]. The 37th International Conference on Neural Information Processing Systems (NIPS), New Orleans, USA, 2023: 492. [92] WU Yue, CHEN Yinpeng, WANG Lijuan, et al. Large scale incremental learning[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 374–382. doi: 10.1109/CVPR.2019.00046. [93] ZHAO Bowen, XIAO Xi, GAN Guojun, et al. Maintaining discrimination and fairness in class incremental learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 13205–13214. doi: 10.1109/CVPR42600.2020.01322. [94] GOSWAMI D, LIU Yuyang, TWARDOWSKI B, et al. FeCAM: Exploiting the heterogeneity of class distributions in exemplar-free continual learning[C]. The 37th Conference on Neural Information Processing Systems (NIPS), New Orleans, USA, 2023: 288. [95] XIANG Xiang, TAN Yuwen, WAN Qian, et al. Coarse-to-fine incremental few-shot learning[C]. The 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 2022: 205–222. doi: 10.1007/978-3-031-19821-2_12. [96] AHN H, KWAK J, LIM S, et al. SS-IL: Separated softmax for incremental learning[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 824–833. doi: 10.1109/ICCV48922.2021.00088. [97] YANG Yibo, CHEN Shixiang, LI Xiangtai, et al. Inducing neural collapse in imbalanced learning: Do we really need a learnable classifier at the end of deep neural network?[C]. The 36th Conference on Neural Information Processing Systems (NIPS), New Orleans, USA, 2022: 2753. [98] YANG Yibo, YUAN Haobo, LI Xiangtai, et al. Neural collapse inspired feature-classifier alignment for few-shot class-incremental learning[C]. The 11th International Conference on Learning Representations (ICLR), Kigali, Rwanda, 2023. [99] LYU Yilin, WANG Liyuan, ZHANG Xingxing, et al. Overcoming recency bias of normalization statistics in continual learning: Balance and adaptation[C]. The 37th Conference on Neural Information Processing Systems (NIPS), New Orleans, USA, 2023: 1108. [100] GUO Chengcheng, ZHAO Bo, and BAI Yanbing. DeepCore: A comprehensive library for coreset selection in deep learning[C]. 33rd International Conference on Database and Expert Systems Applications, Vienna, Austria, 2022: 181–195. doi: 10.1007/978-3-031-12423-5_14. [101] FELDMAN D. Introduction to core-sets: An updated survey[J]. arXiv: 2011.09384, 2020. doi: 10.48550/arXiv.2011.09384. [102] CHEN Yutian, WELLING M, and SMOLA A J. Super-samples from kernel herding[C]. 26th Conference on Uncertainty in Artificial Intelligence, Catalina Island, USA, 2010: 109–116. [103] WELLING M. Herding dynamical weights to learn[C]. The 26th Annual International Conference on Machine Learning, Montreal, Canada, 2009: 1121–1128. doi: 10.1145/1553374.1553517. [104] CHAUDHRY A, ROHRBACH M, ELHOSEINY M, et al. On tiny episodic memories in continual learning[J]. arXiv: 1902.10486, 2019. doi: 10.48550/arXiv.1902.10486. [105] YOON J, MADAAN D, YANG E, et al. Online coreset selection for rehearsal-based continual learning[C]. Tenth International Conference on Learning Representations, 2022. [106] ALJUNDI R, CACCIA L, BELILOVSKY E, et al. Online continual learning with maximally interfered retrieval[C]. The 33rd International Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 2019: 1063. [107] BANG J, KIM H, YOO Y J, et al. Rainbow memory: Continual learning with a memory of diverse samples[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8214–8223. doi: 10.1109/CVPR46437.2021.00812. [108] BORSOS Z, MUTNÝ M, and KRAUSE A. Coresets via bilevel optimization for continual learning and Streaming[C]. The 34th International Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 2020: 1247. [109] ZHOU Xiao, PI Renjie, ZHANG Weizhong, et al. Probabilistic bilevel coreset selection[C]. 39th International Conference on Machine Learning, Baltimore, USA, 2022: 27287–27302. [110] TIWARI R, KILLAMSETTY K, IYER R, et al. GCR: Gradient coreset based replay buffer selection for continual learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 99–108. doi: 10.1109/CVPR52688.2022.00020. [111] HAO Jie, JI Kaiyi, and LIU Mingrui. Bilevel coreset selection in continual learning: A new formulation and algorithm[C]. The 37th Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 2220. [112] WANG Tongzhou, ZHU Junyan, TORRALBA A, et al. Dataset distillation[J]. arXiv: 1811.10959, 2018. doi: 10.48550/arXiv.1811.10959. [113] YU Ruonan, LIU Songhua, and WANG Xinchao. Dataset distillation: A comprehensive review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(1): 150–170. doi: 10.1109/TPAMI.2023.3323376. [114] LIU Yaoyao, SU Yuting, LIU Anan, et al. Mnemonics training: Multi-class incremental learning without forgetting[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 12242–12251. doi: 10.1109/CVPR42600.2020.01226. [115] ZHAO Bo, MOPURI K R, and BILEN H. Dataset condensation with gradient matching[C]. The 9th International Conference on Learning Representations, Austria, 2021. [116] ZHAO Bo and BILEN H. Dataset condensation with differentiable Siamese augmentation[C]. The 38th International Conference on Machine Learning, 2021: 12674–12685. [117] YANG Enneng, SHEN Li, WANG Zhenyi, et al. An efficient dataset condensation plugin and its application to continual learning[C]. The 37th Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 2957. [118] CACCIA L, BELILOVSKY E, CACCIA M, et al. Online learned continual compression with adaptive quantization modules[C]. The 37th International Conference on Machine Learning, 2020: 1240–1250. [119] VAN DEN OORD A, VINYALS O, and KAVUKCUOGLU K. Neural discrete representation learning[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6309–6318. [120] WANG Liyuan, ZHANG Xingxing, YANG Kuo, et al. Memory replay with data compression for continual learning[C]. Tenth International Conference on Learning Representations, 2022. [121] KULESZA A and TASKAR B. Determinantal point processes for machine learning[J]. Foundations and Trends® in Machine Learning, 2012, 5(2/3): 123–286. doi: 10.1561/2200000044. [122] LUO Zilin, LIU Yaoyao, SCHIELE B, et al. Class-incremental exemplar compression for class-incremental learning[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 11371–11380. doi: 10.1109/CVPR52729.2023.01094. [123] ZHAI Jiangtian, LIU Xialei, BAGDANOV A D, et al. Masked autoencoders are efficient class incremental learners[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 19047–19056. doi: 10.1109/ICCV51070.2023.01750. [124] HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 15979–15988. doi: 10.1109/CVPR52688.2022.01553. [125] ISCEN A, ZHANG J, LAZEBNIK S, et al. Memory-efficient incremental learning through feature adaptation[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 699–715. doi: 10.1007/978-3-030-58517-4_41. [126] BELOUADAH E and POPESCU A. IL2M: Class incremental learning with dual memory[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 583–592. doi: 10.1109/ICCV.2019.00067. [127] TOLDO M and OZAY M. Bring evanescent representations to life in lifelong class incremental learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16711–16720. doi: 10.1109/CVPR52688.2022.01623. [128] WANG Kai, VAN DE WEIJER J, and HERRANZ L. ACAE-REMIND for online continual learning with compressed feature replay[J]. Pattern Recognition Letters, 2021, 150: 122–129. doi: 10.1016/j.patrec.2021.06.025. [129] PETIT G, POPESCU A, SCHINDLER H, et al. FeTrIL: Feature translation for exemplar-free class-incremental learning[C]. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 3900–3909. doi: 10.1109/WACV56688.2023.00390. [130] ZHU Fei, CHENG Zhen, ZHANG Xuyao, et al. Class-incremental learning via dual augmentation[C]. The 35th International Conference on Neural Information Processing Systems (NIPS), 2021: 1096. [131] ZHU Kai, ZHAI Wei, CAO Yang, et al. Self-sustaining representation expansion for non-exemplar class-incremental learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9286–9395. doi: 10.1109/CVPR52688.2022.00908. [132] SHI Wuxuan and YE Mang. Prototype reminiscence and augmented asymmetric knowledge aggregation for non-exemplar class-incremental learning[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 1772–1781. doi: 10.1109/ICCV51070.2023.00170. [133] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. [134] KINGMA D P and WELLING M. Auto-encoding variational Bayes[C]. 2nd International Conference on Learning Representations, Banff, Canada, 2014. [135] HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574. [136] SHIN H, LEE J K, KIM J, et al. Continual learning with deep generative replay[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 2994–3003. [137] WU Chenshen, HERRANZ L, LIU Xialei, et al. Memory replay GANs: Learning to generate images from new categories without forgetting[C]. The 32nd International Conference on Neural Information Processing Systems, Montreal, Canada, 2018: 5966–5976. [138] HE Chen, WANG Ruiping, SHAN Shiguang, et al. Exemplar-supported generative reproduction for class incremental learning[C]. British Machine Vision Conference 2018, Newcastle, UK, 2018: 98. [139] KEMKER R and KANAN C. FearNet: Brain-inspired model for incremental learning[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1–15. [140] YE Fei and BORS A G. Learning latent representations across multiple data domains using lifelong VAEGAN[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 777–795. doi: 10.1007/978-3-030-58565-5_46. [141] GAO Rui and LIU Weiwei. DDGR: Continual learning with deep diffusion-based generative replay[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 10744–10763. [142] JODELET Q, LIU Xin, PHUA Y J, et al. Class-incremental learning using diffusion model for distillation and replay[C]. 2023 IEEE/CVF International Conference on Computer Vision Workshops, Paris, France, 2023: 3417–3425. doi: 10.1109/ICCVW60793.2023.00367. [143] XIANG Ye, FU Ying, JI Pan, et al. Incremental learning using conditional adversarial networks[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 6618–6627. doi: 10.1109/ICCV.2019.00672. [144] VAN DE VEN G M, SIEGELMANN H T, and TOLIAS A S. Brain-inspired replay for continual learning with artificial neural networks[J]. Nature Communications, 2020, 11(1): 4069. doi: 10.1038/s41467-020-17866-2. [145] LIU Xialei, WU Chenshen, MENTA M, et al. Generative feature replay for class-incremental learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2020: 915–924. doi: 10.1109/CVPRW50498.2020.00121. [146] CHAUDHRY A, RANZATO M A, ROHRBACH M, et al. Efficient lifelong learning with A-GEM[C]. 7th International Conference on Learning Representations, New Orleans, USA, 2019. [147] RIEMER M, CASES I, AJEMIAN R, et al. Learning to learn without forgetting by maximizing transfer and minimizing interference[C]. 7th International Conference on Learning Representations, New Orleans, USA, 2019. [148] FARAJTABAR M, AZIZAN N, MOTT A, et al. Orthogonal gradient descent for continual learning[C]. 23rd International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 2020: 3762–3773. [149] TANG Shixiang, CHEN Dapeng, ZHU Jinguo, et al. Layerwise optimization by gradient decomposition for continual learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 9629–9638. doi: 10.1109/CVPR46437.2021.00951. [150] KAO T C, JENSEN K T, VAN DE VEN G M, et al. Natural continual learning: Success is a journey, not (just) a destination[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 2150. [151] LIU Hao and LIU Huaping. Continual learning with recursive gradient optimization[C]. Tenth International Conference on Learning Representations, 2022. [152] SAHA G, GARG I, and ROY K. Gradient projection memory for continual learning[C]. 9th International Conference on Learning Representations, Austria, 2021. [153] WANG Shipeng, LI Xiaorong, SUN Jian, et al. Training networks in null space of feature covariance for continual learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 184–193. doi: 10.1109/CVPR46437.2021.00025. [154] KONG Yajing, LIU Liu, WANG Zhen, et al. Balancing stability and plasticity through advanced null space in continual learning[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 219–236. doi: 10.1007/978-3-031-19809-0_13. [155] LIN Sen, YANG Li, FAN Deliang, et al. TRGP: Trust region gradient projection for continual learning[C]. Tenth International Conference on Learning Representations, 2022. [156] LIN Sen, YANG Li, FAN Deliang, et al. Beyond not-forgetting: Continual learning with backward knowledge transfer[C]. The 36th Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1176. [157] HOCHREITER S and SCHMIDHUBER J. Flat minima[J]. Neural Computation, 1997, 9(1): 1–42. doi: 10.1162/neco.1997.9.1.1. [158] KESKAR N S, MUDIGERE D, NOCEDAL J, et al. On large-batch training for deep learning: Generalization gap and sharp minima[C]. 5th International Conference on Learning Representations, Toulon, France, 2017. [159] FORET P, KLEINER A, MOBAHI H, et al. Sharpness-aware minimization for efficiently improving generalization[C]. 9th International Conference on Learning Representations, Austria, 2021. [160] HUANG Zhongzhan, LIANG Mingfu, LIANG Senwei, et al. AlterSGD: Finding flat minima for continual learning by alternative training[J]. arXiv: 2107.05804, 2021. doi: 10.48550/arXiv.2107.05804. [161] SHI Guangyuan, CHEN Jiaxin, ZHANG Wenlong, et al. Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima[C]. The 35th Conference on Neural Information Processing Systems, 2021: 517. [162] DENG Danruo, CHEN Guangyong, HAO Jianye, et al. Flattening sharpness for dynamic gradient projection memory benefits continual learning[C]. 35th International Conference on Neural Information Processing System, 2021: 1430. [163] LIU Yong, MAI Siqi, CHEN Xiangning, et al. Towards efficient and scalable sharpness-aware minimization[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12350–12360. doi: 10.1109/CVPR52688.2022.01204. [164] WU Tao, LUO Tie, and WUNSCH II D C. CR-SAM: Curvature regularized sharpness-aware minimization[C]. Proceedings of the 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 6144–6152. doi: 10.1609/aaai.v38i6.28431. [165] MADAAN D, YOON J, LI Yuanchun, et al. Representational continuity for unsupervised continual learning[C]. Tenth International Conference on Learning Representations, 2022. [166] CHA H, LEE J, and SHIN J. Co2L: Contrastive continual learning[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9496–9505. doi: 10.1109/ICCV48922.2021.00938. [167] FINI E, DA COSTA V G T, ALAMEDA-PINEDA X, et al. Self-supervised models are continual learners[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9611–9620. doi: 10.1109/CVPR52688.2022.00940. [168] AHN H, CHA S, LEE D, et al. Uncertainty-based continual learning with adaptive regularization[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 395. [169] GURBUZ M B and DOVROLIS C. NISPA: Neuro-inspired stability-plasticity adaptation for continual learning in sparse networks[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 8157–8174. [170] JIN H and KIM E. Helpful or harmful: Inter-task association in continual learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 519–535. doi: 10.1007/978-3-031-20083-0_31. [171] XUE Mengqi, ZHANG Haofei, SONG Jie, et al. Meta-attention for ViT-backed continual learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 150–159. doi: 10.1109/CVPR52688.2022.00025. [172] JANG E, GU Shixiang, and POOLE B. Categorical reparameterization with gumbel-softmax[C]. 5th International Conference on Learning Representations, Toulon, France, 2017. [173] SERRÀ J, SURIS D, MIRON M, et al. Overcoming catastrophic forgetting with hard attention to the task[C]. 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 4548–4557. [174] WORTSMAN M, RAMANUJAN V, LIU R, et al. Supermasks in superposition[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1272. [175] KANG H, MINA R J L, MADJID S R H, et al. Forget-free continual learning with winning subnetworks[C]. 39th International Conference on Machine Learning, Baltimore, USA, 2022: 10734–10750. [176] YOON J, YANG E, LEE J, et al. Lifelong learning with dynamically expandable networks[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1–15. [177] XU Ju and ZHU Zhanxing. Reinforced continual learning[C]. The 32nd International Conference on Neural Information Processing Systems, Montreal, Canada, 2018: 907–916. [178] RUSU A A, RABINOWITZ N C, DESJARDINS G, et al. Progressive neural networks[J]. arXiv: 1606.04671, 2016. doi: 10.48550/arXiv.1606.04671. [179] FERNANDO C, BANARSE D, BLUNDELL C, et al. PathNet: Evolution channels gradient descent in super neural networks[J]. arXiv: 1701.08734, 2017. doi: 10.48550/arXiv.1701.08734. [180] RAJASEGARAN J, HAYAT M, KHAN S, et al. Random path selection for incremental learning[J]. arXiv: 1906.01120, 2019. doi: 10.48550/arXiv.1906.01120. [181] ALJUNDI R, CHAKRAVARTY P, and TUYTELAARS T. Expert gate: Lifelong learning with a network of experts[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7120–7129. doi: 10.1109/CVPR.2017.753. [182] WANG Fuyun, ZHOU Dawei, YE Hanjia, et al. FOSTER: Feature boosting and compression for class-incremental learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 398–414. doi: 10.1007/978-3-031-19806-9_23. [183] ZHOU Dawei, WANG Qiwei, YE Hanjia, et al. A model or 603 exemplars: Towards memory-efficient class-incremental learning[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023. [184] WANG Zifeng, ZHANG Zizhao, EBRAHIMI S, et al. DualPrompt: Complementary prompting for rehearsal-free continual learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 631–648. doi: 10.1007/978-3-031-19809-0_36. [185] SMITH J S, KARLINSKY L, GUTTA V, et al. CODA-Prompt: COntinual decomposed attention-based prompting for rehearsal-free continual learning[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 11909–11919. doi: 10.1109/CVPR52729.2023.01146. [186] GAO Qiankun, ZHAO Chen, SUN Yifan, et al. A unified continual learning framework with general parameter-efficient tuning[C]. IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 11449–11459. doi: 10.1109/ICCV51070.2023.01055. [187] ZHOU Dawei, CAI Ziwen, YE Hanjia, et al. Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need[J]. arXiv: 2303.07338, 2023. doi: 10.48550/arXiv.2303.07338. [188] WANG Yabin, MA Zhiheng, HUANG Zhiwu, et al. Isolation and impartial aggregation: A paradigm of incremental learning without interference[C]. Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 10209–10217. doi: 10.1609/aaai.v37i8.26216. [189] WANG Liyuan, XIE Jingyi, ZHANG Xingxing, et al. Hierarchical decomposition of prompt-based continual learning: Rethinking obscured sub-optimality[C]. The 37th Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 3022. [190] WANG Yabin, HUANG Zhiwu, and HONG Xiaopeng. S-prompts learning with pre-trained transformers: An Occam’s razor for domain incremental learning[C]. The 36th Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 411. [191] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. 38th International Conference on Machine Learning, 2021: 8748–8763. [192] ZHOU Dawei, ZHANG Yuanhan, NING Jingyi, et al. Learning without forgetting for vision-language models[J]. arXiv: 2305.19270, 2023. doi: 10.48550/arXiv.2305.19270. [193] KHATTAK M U, WASIM S T, NASEER M, et al. Self-regulating prompts: Foundational model adaptation without forgetting[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 15144–15154. doi: 10.1109/ICCV51070.2023.01394. [194] KIM G, XIAO Changnan, KONISHI T, et al. Learnability and algorithm for continual learning[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 16877–16896. [195] TANG Yuming, PENG Yixing, and ZHENG Weishi. When prompt-based incremental learning does not meet strong pretraining[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 1706–1716. doi: 10.1109/ICCV51070.2023.00164. [196] NGUYEN C V, LI Yingzhen, BUI T D, et al. Variational continual learning[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018. [197] KAPOOR S, KARALETSOS T, and BUI T D. Variational auto-regressive Gaussian processes for continual learning[C]. 38th International Conference on Machine Learning, 2021: 5290–5300. [198] RAMESH R and CHAUDHARI P. Model zoo: A growing brain that learns continually[C]. Tenth International Conference on Learning Representations, 2022. [199] WANG Liyuan, ZHANG Xingxing, LI Qian, et al. CoSCL: Cooperation of small continual learners is stronger than a big one[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 254–271. doi: 10.1007/978-3-031-19809-0_15. [200] YE Fei and BORS A G. Task-free continual learning via online discrepancy distance learning[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1720. [201] SHI Haizhou and WANG Hao. A unified approach to domain incremental learning with memory: Theory and algorithm[C]. Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 660. [202] BEN-DAVID S, BLITZER J, CRAMMER K, et al. A theory of learning from different domains[J]. Machine Learning, 2010, 79(1/2): 151–175. doi: 10.1007/s10994-009-5152-4. [203] JACOT A, GABRIEL F, and HONGLER C. Neural tangent kernel: Convergence and generalization in neural networks[C]. 32nd International Conference on Neural Information Processing Systems, Montreal, Canada, 2018: 8580–8589. [204] BENNANI M A, DOAN T, and SUGIYAMA M. Generalisation guarantees for continual learning with orthogonal gradient descent[J]. arXiv: 2006.11942, 2020. doi: 10.48550/arXiv.2006.11942. [205] DOAN T, BENNANI M A, MAZOURE B, et al. A theoretical analysis of catastrophic forgetting through the NTK overlap matrix[C]. 24th International Conference on Artificial Intelligence and Statistics, 2021: 1072–1080. [206] KARAKIDA R and AKAHO S. Learning curves for continual learning in neural networks: Self-knowledge transfer and forgetting[C]. Tenth International Conference on Learning Representations, 2022. [207] EVRON I, MOROSHKO E, WARD R A, et al. How catastrophic can catastrophic forgetting be in linear regression?[C]. 35th Conference on Learning Theory, London, UK, 2022: 4028–4079. [208] LIN Sen, JU Peizhong, LIANG Yingbin, et al. Theory on forgetting and generalization of continual learning[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 21078–21100. [209] GOLDFARB D and HAND P. Analysis of catastrophic forgetting for random orthogonal transformation tasks in the overparameterized regime[C]. 26th International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 2023: 2975–2993. [210] KIM G, XIAO Changnan, KONISHI T, et al. A theoretical study on solving continual learning[C]. Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 366. [211] KIM G, LIU Bing, and KE Zixuan. A multi-head model for continual learning via out-of-distribution replay[C]. 1st Conference on Lifelong Learning Agents, Montreal, Canada, 2022: 548–563. [212] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791. [213] KRIZHEVSKY A and HINTON G. Learning multiple layers of features from tiny images[J]. Handbook of Systemic Autoimmune Diseases, 2009, 1(4): 1–60. [214] WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200-2011 dataset[R]. CNS-TR-2010-001, 2011. [215] LE Ya and YANG Xuan. Tiny ImageNet visual recognition challenge[J]. CS 231N, 2015, 7(7): 3. [216] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [217] EBRAHIMI S, MEIER F, CALANDRA R, et al. Adversarial continual learning[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 386–402. doi: 10.1007/978-3-030-58621-8_23. [218] LOMONACO V and MALTONI D. CORe50: A new dataset and benchmark for continuous object recognition[C]. 1st Annual Conference on Robot Learning, Mountain View, USA, 2017: 17–26. [219] PENG Xingchao, BAI Qinxun, XIA Xide, et al. Moment matching for multi-source domain adaptation[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 1406–1415. doi: 10.1109/ICCV.2019.00149. [220] LI Chuqiao, HUANG Zhiwu, PAUDEL D P, et al. A continual deepfake detection benchmark: Dataset, methods, and essentials[C]. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2023: 1339–1349. doi: 10.1109/WACV56688.2023.00139. [221] XIAO Han, RASUL K, and VOLLGRAF R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms[J]. arXiv: 1708.07747, 2017. doi: 10.48550/arXiv.1708.07747. [222] NETZER Y, WANG Tao, COATES A, et al. Reading digits in natural images with unsupervised feature learning[C]. Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 2011. [223] BULATOV Y. Notmnist dataset[EB/OL]. http://yaroslavvb.blogspot.it/2011/09/notmnist-dataset.html, 2011. [224] YANG Yuwei, HAYAT M, JIN Zhao, et al. Geometry and uncertainty-aware 3D point cloud class-incremental semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 21759–21768. doi: 10.1109/CVPR52729.2023.02084. [225] CAMUFFO E and MILANI S. Continual learning for LiDAR semantic segmentation: Class-incremental and coarse-to-fine strategies on sparse data[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 2447–2456. doi: 10.1109/CVPRW59228.2023.00243. [226] CASTAGNOLO G, SPAMPINATO C, RUNDO F, et al. A baseline on continual learning methods for video action recognition[C]. IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 2023: 3240–3244. doi: 10.1109/ICIP49359.2023.10222140. [227] NAQUSHBANDI F S and JOHN A. Sequence of actions recognition using continual learning[C]. 2022 Second International Conference on Artificial Intelligence and Smart Energy, Coimbatore, India, 2022: 858–863. doi: 10.1109/ICAIS53314.2022.9742866. [228] LI Dingcheng, CHEN Zheng, CHO E, et al. Overcoming catastrophic forgetting during domain adaptation of Seq2seq language generation[C]. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, USA, 2022: 5441–5454. doi: 10.18653/v1/2022.naacl-main.398. [229] MONAIKUL N, CASTELLUCCI G, FILICE S, et al. Continual learning for named entity recognition[C]. Proceedings of the 35th AAAI Conference on Artificial Intelligence, 2021: 13570–13577. doi: 10.1609/aaai.v35i15.17600. [230] LIU Qingbin, YU Xiaoyan, HE Shizhu, et al. Lifelong intent detection via multi-strategy rebalancing[J]. arXiv: 2108.04445, 2021. doi: 10.48550/arXiv.2108.04445. [231] MARACANI A, MICHIELI U, TOLDO M, et al. RECALL: Replay-based continual learning in semantic segmentation[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 7006–7015. doi: 10.1109/ICCV48922.2021.00694. [232] WANG Rui, YU Tong, ZHAO Handong, et al. Few-shot class-incremental learning for named entity recognition[C]. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 2022: 571–582. doi: 10.18653/v1/2022.acl-long.43. [233] GENG Binzong, YUAN Fajie, XU Qiancheng, et al. Continual learning for task-oriented dialogue system with iterative network pruning, expanding and masking[C]. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021: 517–523. doi: 10.18653/v1/2021.acl-short.66. [234] CHEN Wuyang, ZHOU Yanqi, DU Nan, et al. Lifelong language PRETRAINING with distribution-specialized experts[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 5383–5395. [235] LUO Yun, YANG Zhen, MENG Fandong, et al. An empirical study of catastrophic forgetting in large language models during continual fine-tuning[J]. arXiv: 2308.08747, 2023. doi: 10.48550/arXiv.2308.08747. [236] QI Xiangyu, ZENG Yi, XIE Tinghao, et al. Fine-tuning aligned language models compromises safety, even when users do not intend to![C]. Twelfth International Conference on Learning Representations, Vienna, Austria, 2024. [237] SMITH J S, HSU Y C, ZHANG Lingyu, et al. Continual diffusion: Continual customization of text-to-image diffusion with C-LoRA[J]. arXiv: 2304.06027, 2023. doi: 10.48550/arXiv.2304.06027. [238] YANG Xin, YU Hao, GAO Xin, et al. Federated continual learning via knowledge fusion: A survey[J]. arXiv: 2312.16475, 2023. doi: 10.48550/arXiv.2312.16475. [239] LIU Xialei, HU Yusong, CAO Xusheng, et al. Long-tailed class incremental learning[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 495–512. doi: 10.1007/978-3-031-19827-4_29. -


 下载:
下载:





图(6) / 表(5)
计量
- 文章访问数: 3714
- HTML全文浏览量: 3352
- PDF下载量: 682
- 被引次数: 0
