

Intelligent Decision-making for Selection of Communication Jamming Channel and Power
-
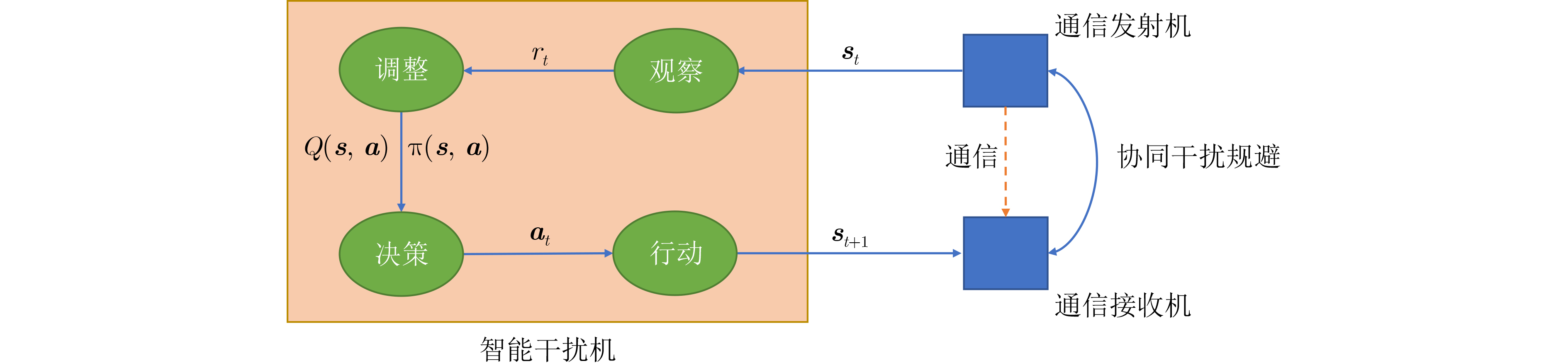
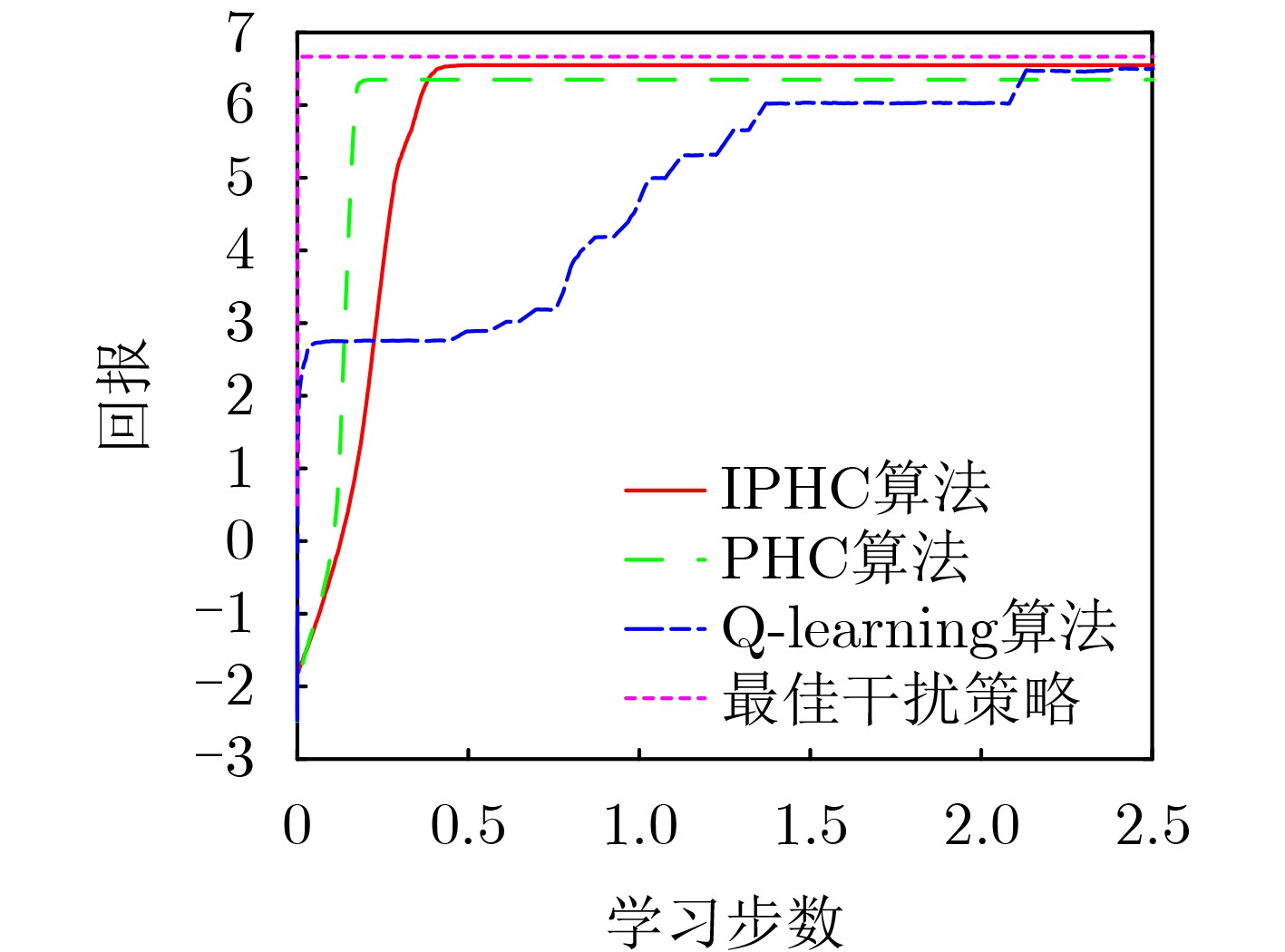
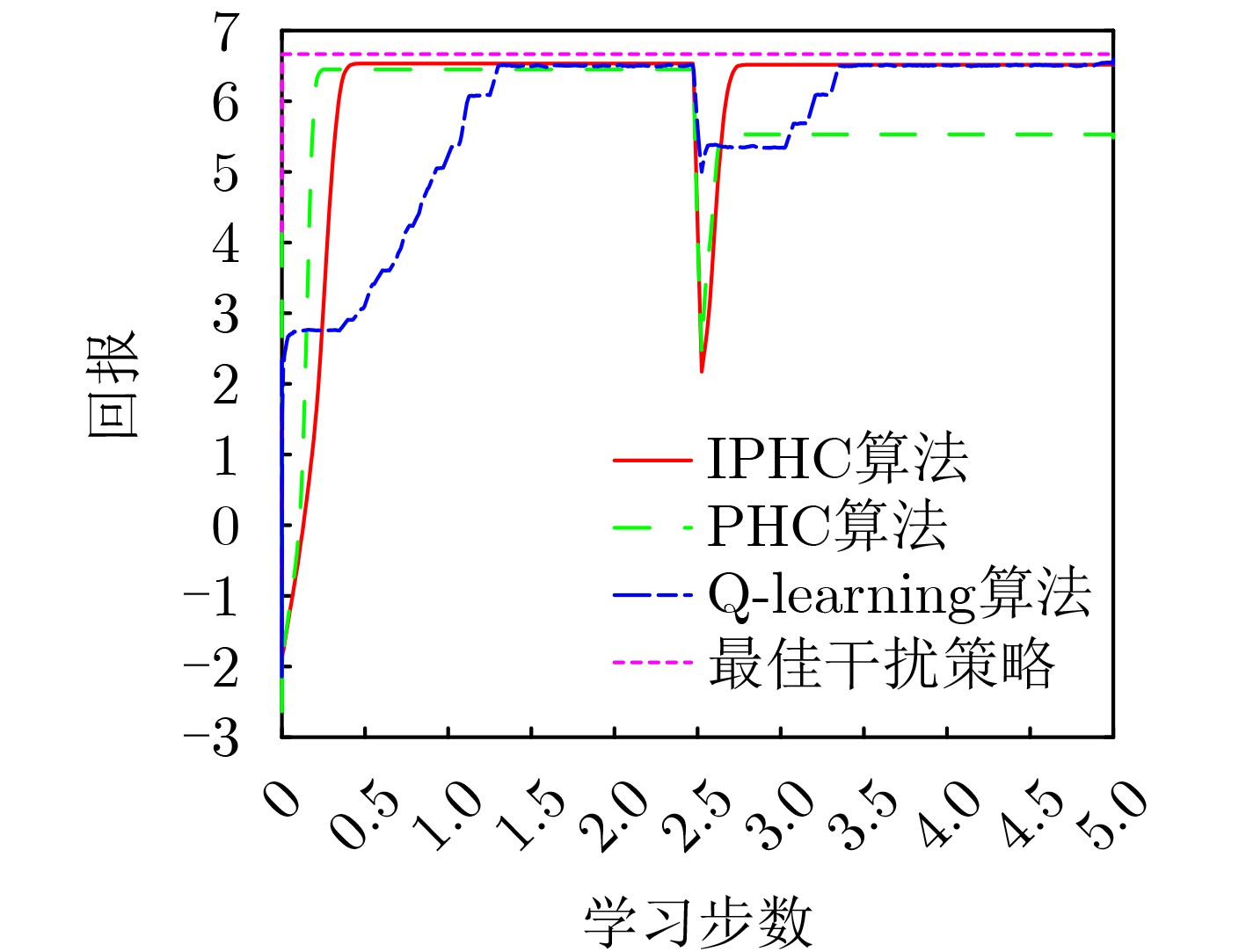
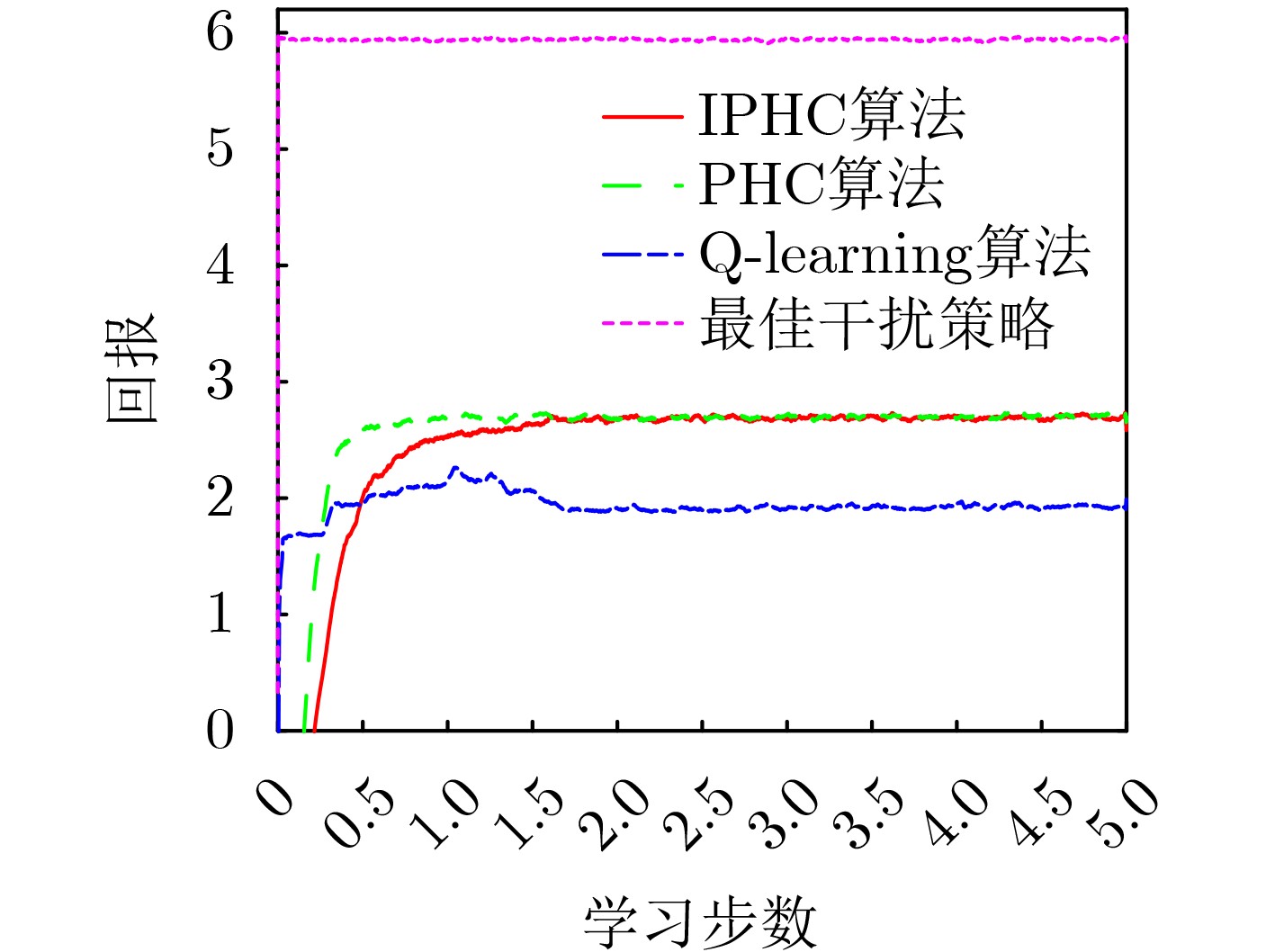
摘要: 智能干扰是一种利用环境反馈自主学习干扰策略,对敌方通信链路进行有效干扰的技术。然而,现有的智能干扰研究大多假设干扰机能够直接获取通信质量反馈(如误码率或丢包率),这在实际对抗环境中难以实现,限制了智能干扰的应用范围。为了解决这一问题,该文将通信干扰问题建模为马尔科夫决策过程(MDP),综合考虑干扰基本原则和通信目标行为变化制定干扰效能衡量指标,提出了一种改进的策略爬山算法(IPHC)。该算法按照“观察(Observe)-调整(Orient)-决策(Decide)-行动(Act)”的OODA闭环,实时观察通信目标变化,灵活调整干扰策略,运用混合策略决策,实施通信干扰。仿真结果表明,在通信目标采用确定性规避策略时,所提算法能够较快收敛到最优干扰策略,并且其收敛耗时较Q-learning算法至少缩短2/3;当通信目标变换策略时,能够自适应学习,重新调整到最优干扰策略。在通信目标采用混合性规避策略时,所提算法也能够快速收敛,取得较优的干扰效果。Abstract: Intelligent jamming is a technique that utilizes environmental feedback information and autonomous learning of jamming strategies to effectively disrupt the communication links of the enemy. However, most existing research on intelligent jamming assumes that jammers can directly access the feedback of communication quality indicators, such as bit error rate or packet loss rate. This assumption is difficult to achieve in practical adversarial environments, thus limiting the applicability of intelligent jamming. To address this issue, the communication jamming problem is modeled as a Markov Decision Process (MDP), and by considering both the fundamental principles of jamming and the dynamic behavior of communication objectives, an Improved Policy Hill-Climbing (IPHC) algorithm is proposed. This algorithm follows an OODA loop of “Observe-Orient-Decide-Act”, continuously observes the changes of communication objectives in real time, flexibly adjusts jamming strategies, and applies a mixed strategy decision-making to execute communication jamming. Simulation results demonstrate that when the communication objectives adopt deterministic evasion strategies, the proposed algorithm can quickly converge to the optimal jamming strategy, and the convergence time is at least two-thirds shorter than that of the Q-learning algorithm. When the communication objectives switch evasion strategies, the algorithm can adaptively learn and readjust to the optimal jamming strategy. In the case of communication objectives using mixed evasion strategies, the proposed algorithm also achieves fast convergence and obtains superior jamming effects.
-
1 基于IPHC的通信干扰信道和功率智能决策算法
参数设置:$ Q\left( {{\boldsymbol{s}},{\boldsymbol{a}}} \right) = 0 $,$ {\pi} \left( {{\boldsymbol{s}},{\boldsymbol{a}}} \right) = {1 \mathord{\left/ {\vphantom {1 {\left| A \right|}}} \right. } {\left| A \right|}} $,更新步长$\alpha $和学习率$\eta $。 学习过程:令$t = 0$,在状态${{\boldsymbol{s}}_t}$,依据$ {\pi} \left( {{{\boldsymbol{s}}_t},{\boldsymbol{a}}} \right) $得到动作${{\boldsymbol{a}}_t}$,并转移到下一状态${{\boldsymbol{s}}_{t + 1}}$。 while $t < T$ 由${{\boldsymbol{s}}_t}$和${{\boldsymbol{s}}_{t + 1}}$之间的关系,评估奖励:$ {r_t} = {w_1}{\varphi _1}\left( {{\text{JNSR}} - {T_{\text{h}}}} \right) + {w_2}\mu \left( {{f_{{\text{c}},t + 1}} - {f_{{\text{c}},t}}} \right) + {w_3}{\varphi _2}\left( {{p_{{\text{c}},t + 1}} - {p_{{\text{c}},t}}} \right) - {w_4}{{{p_{{\text{j}},t + 1}}} \mathord{\left/ {\vphantom {{{p_{{\text{j}},t + 1}}} {{P_{{\text{jMax}}}}}}} \right. } {{P_{{\text{jMax}}}}}} $; 依据奖励$ {r_t} $,调整Q值表:$ Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right) = Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right) + \alpha \left[ {{r_t} + \gamma \mathop {\max }\limits_{\boldsymbol{a}} Q\left( {{{\boldsymbol{s}}_{t + 1}},{\boldsymbol{a}}} \right) - Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right)} \right] $; 依据Q值表调整策略,并进行归一化:$ {\pi} \left({\boldsymbol{s}},{\boldsymbol{a}}\right)={\pi} \left({\boldsymbol{s}},{\boldsymbol{a}}\right)+\eta ,\;\;{\boldsymbol{a}}=\mathrm{arg}\underset{{{\boldsymbol{a}}}^{\prime }}{\mathrm{max}}Q\left({\boldsymbol{s}},{\boldsymbol{{a}}}^{\prime }\right) $,$ {\pi} \left( {{\boldsymbol{s}},{{\boldsymbol{a}}_i}} \right) = {{{\pi} \left( {{\boldsymbol{s}},{{\boldsymbol{a}}_i}} \right)} \Bigr/ {\displaystyle\sum\limits_{i = 1}^{M \times K} {{\pi} \left( {{\boldsymbol{s}},{{\boldsymbol{a}}_i}} \right)} }} $; 转入下一时刻,$t = t + 1$,在状态${{\boldsymbol{s}}_t}$,依据$ {\pi} \left( {{{\boldsymbol{s}}_t},{\boldsymbol{a}}} \right) $得到动作${{\boldsymbol{a}}_t}$,并转移到下一状态${{\boldsymbol{s}}_{t + 1}}$。  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数设置
参数 取值 $\gamma $ 0.5 $\alpha $ 0.1 $\eta $ 0.001 ${T_{\text{h}}}$ 0.3 ${w_1}$ 1 ${w_2}$ 0.5 ${w_3}$ 0.5 ${w_4}$ 1
下载: 导出CSV
表 3 前2个最大Q值对应不同策略选择个数情况
序号 干扰
状态增大
功率切换
信道序号 干扰
状态增大
功率切换
信道1 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 1 11 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 1 1 2 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 1 12 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 2 0 3 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 1 1 13 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 1 4 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 2 0 14 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 1 5 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 0 2 15 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 1 1 6 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 0 2 16 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 2 0 7 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 1 1 17 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 1 8 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 2 0 18 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 1 9 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 0 2 19 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 1 1 10 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 1 20 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 1 1 总次数 21 19
下载: 导出CSV
表 4 不同策略选择概率情况
序号 干扰
状态增大
功率切换
信道序号 干扰
状态增大
功率切换
信道1 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 0 11 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 0.76 0.24 2 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 0 12 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 1 0 3 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 0.89 0.11 13 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 0 4 $ \left( {{f_{{\text{j}},t}} = {F_1},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_1},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 0.77 0.23 14 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 0 5 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 0 15 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 0.93 0.07 6 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 0 16 $ \left( {{f_{{\text{j}},t}} = {F_4},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_4},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 1 0 7 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 0.98 0.02 17 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 0 8 $ \left( {{f_{{\text{j}},t}} = {F_2},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_2},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 0.80 0.20 18 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 0 9 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 2{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 7{\text{ }}{\rm{mW}}} \right) $ 1 0 19 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 6{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 21{\text{ }}{\rm{mW}}} \right) $ 0.87 0.13 10 $ \left( {{f_{{\text{j}},t}} = {F_3},{p_{{\text{j}},t}} = 4{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_3},{p_{{\text{c}},t}} = 14{\text{ }}{\rm{mW}}} \right) $ 1 0 20 $ \left( {{f_{{\text{j}},t}} = {F_5},{p_{{\text{j}},t}} = 8{\text{ }}{\rm{mW}},{f_{{\text{c}},t}} = {F_5},{p_{{\text{c}},t}} = 28{\text{ }}{\rm{mW}}} \right) $ 0.76 0.24 平均概率 0.94 0.06 注:表中有部分结果为0,实际上其值为小于${10^{ - 3}}$的值,对结果的影响极小。为了表述方便,本文将其忽略。
下载: 导出CSV
-
[1] HAN Hao, XU Yifan, JIN Zhu, et al. Primary-User-Friendly Dynamic Spectrum Anti-Jamming Access: A GAN-Enhanced Deep Reinforcement Learning Approach[J]. IEEE Wireless Communications Letters, 2022, 11(2): 258–262. doi: 10.1109/LWC.2021.3125337. [2] NI Gang, HE Chong, JIN Ronghong. Single-Channel Anti-Jamming Receiver With Harmonic-Based Space-Time Adaptive Processing[J]. IEEE Wireless Communications Letters, 2022, 11(4): 776–780. doi: 10.1109/LWC.2022.3143505. [3] ZHU Xinyu, HUANG Yang, WANG Shaoyu, et al. Dynamic Spectrum Anti-Jamming With Reinforcement Learning Based on Value Function Approximation[J]. IEEE Wireless Communications Letters, 2023, 12(2): 386–390. doi: 10.1109/LWC.2022.3228045. [4] 汪志勇, 张沪寅, 徐宁, 等. 认知无线电网络中基于随机学习博弈的信道分配与功率控制[J]. 电子学报, 2018, 46(12): 2870–2877. doi: 10.3969/j.issn.0372-2112.2018.12.008.WANG Zhiyong, ZHANG Huyin, XU Ning, et al. Channel assignment and power control based on stochastic learning game in cognitive radio networks[J]. Acta electronica sinica, 2018, 46(12): 2870–2877. doi: 10.3969/j.issn.0372-2112.2018.12.008. [5] 饶宁, 许华, 蒋磊, 等. 基于多智能体深度强化学习的分布式协同干扰功率分配算法[J]. 电子学报, 2022, 50(6): 1319–1330. doi: 10.12263/DZXB.20210818.RAO Ning, XU Hua, JIANG Lei, et al. Allocation algorithm of distributed cooperative jamming power based on multi-agent deep reinforcement learning[J]. Acta electronica sinica, 2022, 50(6): 1319–1330. doi: 10.12263/DZXB.20210818. [6] 宋佰霖, 许华, 齐子森, 等. 一种基于深度强化学习的协同通信干扰决策算法[J]. 电子学报, 2022, 50(6): 1301–1309. doi: 10.12263/DZXB.20210814.SONG Bailin, XU Hua, QI Ziseng, et al. A collaborative communication jamming decision algorithm based on deep reinforcement learning[J]. Acta electronica sinica, 2022, 50(6): 1301–1309. doi: 10.12263/DZXB.20210814. [7] AMURU S, TEKIN C, SCHAAR M V D, et al. Jamming Bandits—A Novel Learning Method for Optimal Jamming[J]. IEEE Transactions on Wireless Communications, 2016, 15(4): 2792–2808. doi: 10.1109/TWC.2015.2510643. [8] ZHUANSUN Shaoshuai, YANG Junan, LIU Hui, et al. A novel jamming strategy-greedy bandit[C]. Proceedings of the 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN). Guangzhou, China: IEEE, 2017: 1142-1146. doi: 10.1109/ICCSN.2017.8230289. [9] 张君毅, 张冠杰, 杨鸿杰. 针对未知通信目标的干扰策略智能生成方法研究[J]. 电子测量技术, 2019, 42(16): 148–153. doi: 10.19651/j.cnki.emt.1903103.ZHANG Junyi, ZHANG Guanjie, YANG Hongjie. Research on intelligent interference strategy generation method for unknown communication target[J]. Electronic measurement technology, 2019, 42(16): 148–153. doi: 10.19651/j.cnki.emt.1903103. [10] ZHUANSUN Shaoshuai, YANG Junan, LIU Hui. An algorithm for jamming strategy using OMP and MAB[J]. EURASIP Journal on Wireless Communications and Networking, 2019(1): 85–95. doi: 10.1186/s13638-019-1414-4. [11] 颛孙少帅, 杨俊安, 刘辉, 等. 采用双层强化学习的干扰决策算法[J]. 西安交通大学学报, 2018, 52(2): 63–69. doi: 10.7652/xjtuxb201802010.ZHUANSUN Shaoshuai, YANG Junan, LIU Hui, et al. An algorithm for jamming decision using dual reinforcement learning[J]. Journal of Xi’an jiaotong university, 2018, 52(2): 63–69. doi: 10.7652/xjtuxb201802010. [12] ZHOU Cheng, MA Congshan, LIN Qian, et al. Intelligent bandit learning for jamming strategy generation[J]. Wireless Networks, 2023, 29(5): 2391–2403. doi: 10.1007/s11276-023-03286-9. [13] 李芳, 熊俊, 赵肖迪, 等. 基于快速强化学习的无线通信干扰规避策略[J]. 电子与信息学报, 2022, 44(11): 3842–3849. doi: 10.11999/JEIT210965.LI Fang, XIONG Jun, ZHAO Xiaodi, et al. Wireless communications interference avoidance based on fast reinforcement learning[J]. Journal of electronics and information technology, 2022, 44(11): 3842–3849. doi: 10.11999/JEIT210965. [14] 潘筱茜, 张姣, 刘琰, 等. 基于深度强化学习的多域联合干扰规避[J]. 信号处理, 2022, 38(12): 2572–2581. doi: 10.16798/j.issn.1003-0530.2022.12.012.PAN Xiaoqian, ZHANG Jiao, LIU Yan, et al. Multi-domain joint interference avoidance based on deep reinforcement learning[J]. Journal of signal processing, 2022, 38(12): 2572–2581. doi: 10.16798/j.issn.1003-0530.2022.12.012. [15] TOM V. 9 Reinforcement Learning: The Markov Decision Process Approach[M]. MIT Press. 2021: 133-152. [16] 杨鸿杰, 张君毅. 基于强化学习的智能干扰算法研究[J]. 电子测量技术, 2018, 41(20): 49–54. doi: 10.19651/j.cnki/emt.1802113.YANG Hongjie, ZHANG Junyi. Research on intelligent interference algorithm based on reinforcement learning[J]. Electronic measurement technology, 2018, 41(20): 49–54. doi: 10.19651/j.cnki/emt.1802113. [17] MARTIN A, ANDERS H. Reinforcement Learning[M]. Wiley. 2023: 327-349. [18] 裴绪芳, 陈学强, 吕丽刚, 等. 基于随机森林强化学习的干扰智能决策方法研究[J]. 通信技术, 2019, 52(9): 2118–2124. doi: 10.3969/j.issn.1002-0802.2019.09.009.PEI Xufang, CHEN Xueqiang, LV Ligang, et al. Research on jamming intelligent decision-making method based on random forest reinforcement learning[J]. Communications technology, 2019, 52(9): 2118–2124. doi: 10.3969/j.issn.1002-0802.2019.09.009. [19] 张双义, 沈箬怡, 陈学强, 等. 基于强化学习的功率与信道联合干扰方法研究[J]. 通信技术, 2020, 53(8): 1859–1868. doi: 10.3969/j.issn.1002-0802.2020.08.004.ZHANG Shuangyi, SHEN Ruoyi, CHEN Xueqiang, et al. Joint jamming method of channel and power based on reinforcement learning[J]. Communications technology, 2020, 53(8): 1859–1868. doi: 10.3969/j.issn.1002-0802.2020.08.004. [20] BOWLING M, VELOSO M M. Rational and Convergent Learning in Stochastic Games[C]. Proceedings of the International Joint Conference on Artificial Intelligence. Seattle, WA, 2001: 1021-1026. [21] XU B, ZENG W. A Combat Decision Support Method Based on OODA and Dynamic Graph Reinforcement Learning[C]. Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC). Hefei, China: IEEE , 2022: 4872-4878. doi: 10.1109/CCDC55256.2022.10033986. -


 下载:
下载:


图(5) / 表(6)
计量
- 文章访问数: 902
- HTML全文浏览量: 458
- PDF下载量: 84
- 被引次数: 0
