

Energy-Efficient UAV Trajectory Planning Algorithm for AoI-Constrained Data Collection
-
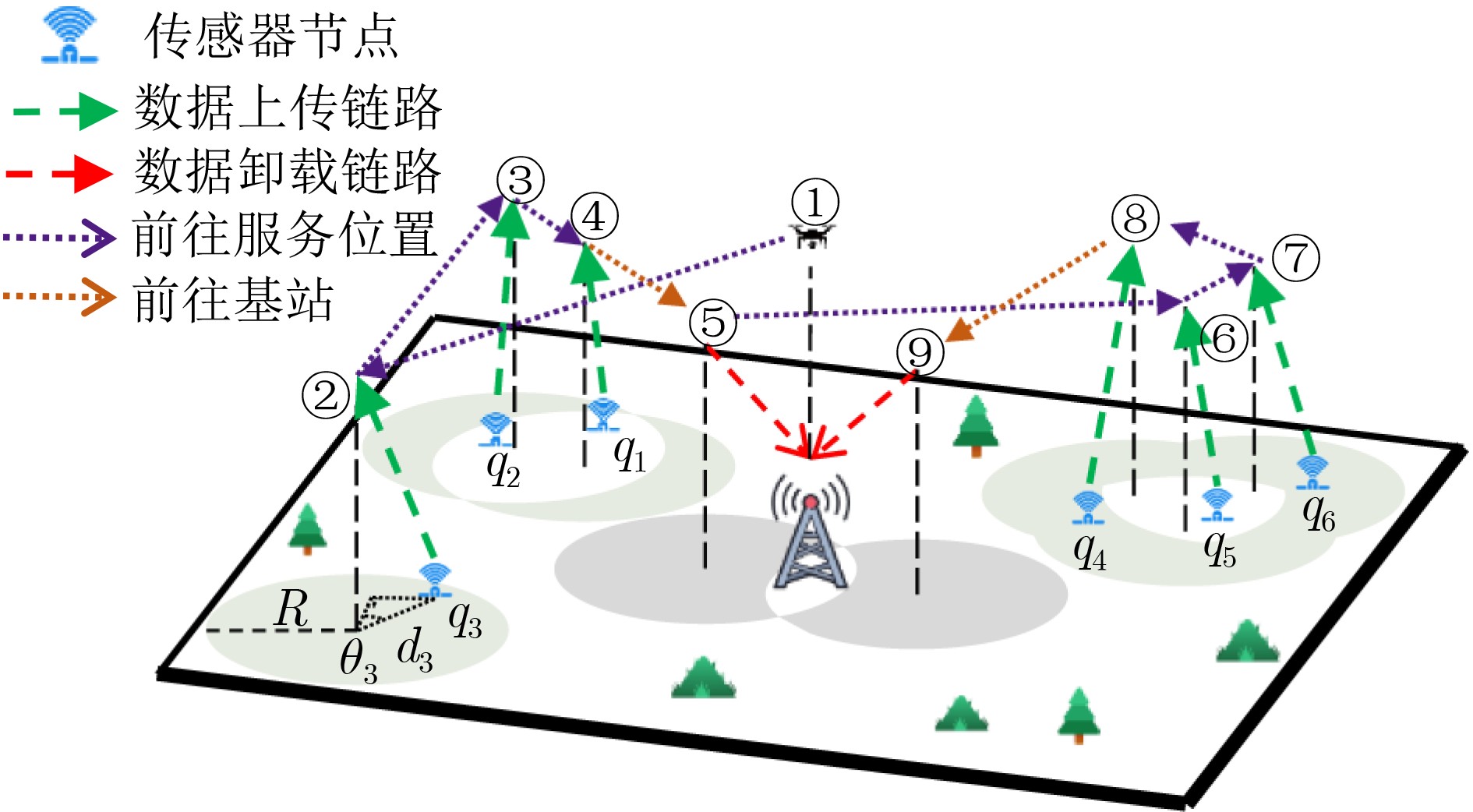
摘要: 信息年龄(AoI)是评价无线传感器网络(WSN)数据时效性的重要指标,无人机辅助WSN数据采集过程中采用优化飞行轨迹、提升速度等运动策略保障卸载至基站的数据满足各节点AoI限制。然而,不合理的运动策略易导致无人机因飞行距离过长、速度过快产生非必要能耗,造成数据采集任务失败。针对该问题,该文首先提出信息年龄约束的无人机数据采集能耗优化路径规划问题并进行数学建模;其次,设计一种协同混合近端策略优化(CH-PPO)强化学习算法,同时规划无人机对传感器节点或基站的访问次序、悬停位置和飞行速度,在满足各传感器节点信息年龄约束的同时,最大限度地减少无人机能量消耗。再次,设计一种融合离散和连续策略的损失函数,增强CH-PPO算法动作的合理性,提升其训练效果。仿真实验结果显示,CH-PPO算法在无人机能量消耗以及影响该指标因素的比较中均优于对比的3种强化学习算法,并具有良好的收敛性、稳定性和鲁棒性。
-
关键词:
- 无线传感器网络 /
- 信息年龄约束 /
- 协同混合近端策略优化算法 /
- 无人机路径规划 /
- 深度强化学习
Abstract: The information freshness is measured by Age of Information (AoI) of each sensor in Wireless Sensor Networks (WSN). The UAV optimizes flight trajectories and accelerates speed to assist WSN data collection, which guarantees that the data offloaded to the base station meets the AoI limitation of each sensor. However, the UAV’s inappropriate flight strategies cause non-essential energy consumption due to excessive flight distance and speed, which may result in the failure of data collection mission. In this paper, firstly a mathematical model is investigated and developed for the UAV energy consumption optimization trajectory planning problem on the basis of AoI-constrained data collection. Then, a novel deep reinforcement learning algorithm, named Cooperation Hybrid Proximal Policy Optimization (CH-PPO) algorithm, is proposed to simultaneously schedule the UAV’s access sequence, hovering position, the flight speed to the sensor nodes or the base station, to minimize the UAV's energy consumption under the constraint of data timeliness for each sensor node. Meanwhile, a loss function that integrates the discrete policy and continuous policy is designed to increase the rationality of hybrid actions and improve the training effectiveness of the proposed algorithm. Numerical results demonstrate that the CH-PPO algorithm outperforms the other three reinforcement learning algorithms in the comparison group in energy consumption of UAV and its influencing factors. Furthermore, the convergence, stability, and robustness of the proposed algorithm is well verified. -
1 CH-PPO算法
(1)输入:训练轮数${\text{EP}}$,参数更新次数$M$,学习率$\eta $,裁剪系数$ \varepsilon $; (2)初始化网络参数:$\theta $,$ {\theta _{{\text{old}}}} $和$\omega $; (3)循环训练:$i = 1,2, \cdots ,{\text{EP}}$: (4) ${\text{done}} \ne 0$时: (5) 计算离散动作${\chi _{\mathrm{d}}}\left( {{{\boldsymbol{s}}_k};{\theta _{{\mathrm{d}},{\mathrm{old}}}}} \right)$; (6) 计算连续动作${\chi _{\mathrm{c}}}\left( {{{\boldsymbol{s}}_k};{\theta _{{\mathrm{c}},{\mathrm{old}}}}} \right)$; (7) 得到混合动作${{\boldsymbol{a}}_k} = \left\{ {i,\left( {l\left( k \right),\theta \left( k \right),{\boldsymbol{v}}\left( k \right)} \right)} \right\}$; (8) 智能体在状态${{\boldsymbol{s}}_k}$下执行动作${{\boldsymbol{a}}_k}$,获得奖励${r_k}$,并进入下
一状态${{\boldsymbol{s}}_{k + 1}}$;(9) 将$\left( {{{\boldsymbol{s}}_k},{{\boldsymbol{a}}_k},{r_k},{{\boldsymbol{s}}_{k + 1}}} \right)$存储在经验池; (10) 直到${\text{done}} = 0$; (11) 循环参数更新:$j = 1,2, \cdots ,M$: (12) 从经验池中获得所有经验$ {\left( {{{\boldsymbol{s}}_k},{{\boldsymbol{a}}_k},{r_k},{{\boldsymbol{s}}_{k + 1}}} \right)_{k \in \{ 1,2, \cdots ,K\} }} $; (13) 计算经验池中所有状态的状态价值${\text{va}}{{\text{l}}_1}, \cdots ,{\text{va}}{{\text{l}}_K}$; (14) 计算优势函数的估计值$ {\hat A_1}, \cdots ,{\hat A_K} $; (15) 分别计算离散策略和连续策略的新旧策略比值:
$ r_k^{\mathrm{d}}\left( {{\theta _{\mathrm{d}}}} \right) = \dfrac{{{\pi _{{\theta _{\mathrm{d}}}}}({\boldsymbol{a}}_k^d|{{\boldsymbol{s}}_k})}}{{{\pi _{{\theta _{{\mathrm{d}},{\text{old}}}}}}({\boldsymbol{a}}_k^{\mathrm{d}}|{{\boldsymbol{s}}_k})}} $,$r_k^c\left( {{\theta _{\mathrm{c}}}} \right) = \dfrac{{{\pi _{{\theta _{\mathrm{c}}}}}({\boldsymbol{a}}_k^{\mathrm{c}}|{{\boldsymbol{s}}_k})}}{{{\pi _{{\theta _{{\mathrm{c}},{\text{old}}}}}}({\boldsymbol{a}}_k^{\mathrm{c}}|{{\boldsymbol{s}}_k})}}$;(16) 分别计算Actor网络和Critic网络的损失:$ {\text{L}}{{\text{A}}_k}\left( \theta \right) $,
${\text{L}}{{\text{C}}_k}{{(\omega )}}$;(17) 分别计算Actor网络和Critic网络的梯度:${\nabla _\theta }l_k^\chi \left( \theta \right)$,
${\nabla _\omega }l_k^V\left( \omega \right)$;(18) 更新参数$ \theta =\theta -\eta \text{ }{\nabla }_{\theta }{l}_{k}^{\chi }\left(\theta \right) $,$\omega = \omega - \eta {\nabla _\omega }l_k^V\left( \omega \right)$; (19) 直到$j = M$; (20) 更新旧Actor网络的参数:$ {\theta }_{\text{old}}=\theta $; (21) 清空经验池; (22)直到$i = {\text{EP}}$,训练结束。  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数
参数 取值 参数 取值 无人机初始能量$ {E_{{\text{init}}}} $ $1 \times {10^5}{\text{ J}}$ 无人机最大飞行速度${v_{\max}}$ $30{\text{ m/s}}$ 无人机飞行高度$H$ $10{\text{ m}}$ 传感器节点的数据量$D$ $5 \times {10^4}{\text{ Byte}}$ 无人机最大连通半径$R$ $30{\text{ m}}$ LoS和NLoS依赖常数$a,b$ $ 10,0.6 $ 带宽$W$ $ 1{\text{ MHz}} $ 信道功率${P_{\mathrm{d}}}$ $ - 20{\text{ dBm}} $ 非视距信道额外衰减系数$\mu $ $ 0.2 $ 单位信道功率增益$\zeta $ $ - 30{\text{ dB}} $ 噪声功率${\sigma ^2}$ $ - 90{\text{ dBm}} $ 通径损失指数$\alpha $ $ 2.3 $
下载: 导出CSV
表 2 网络参数
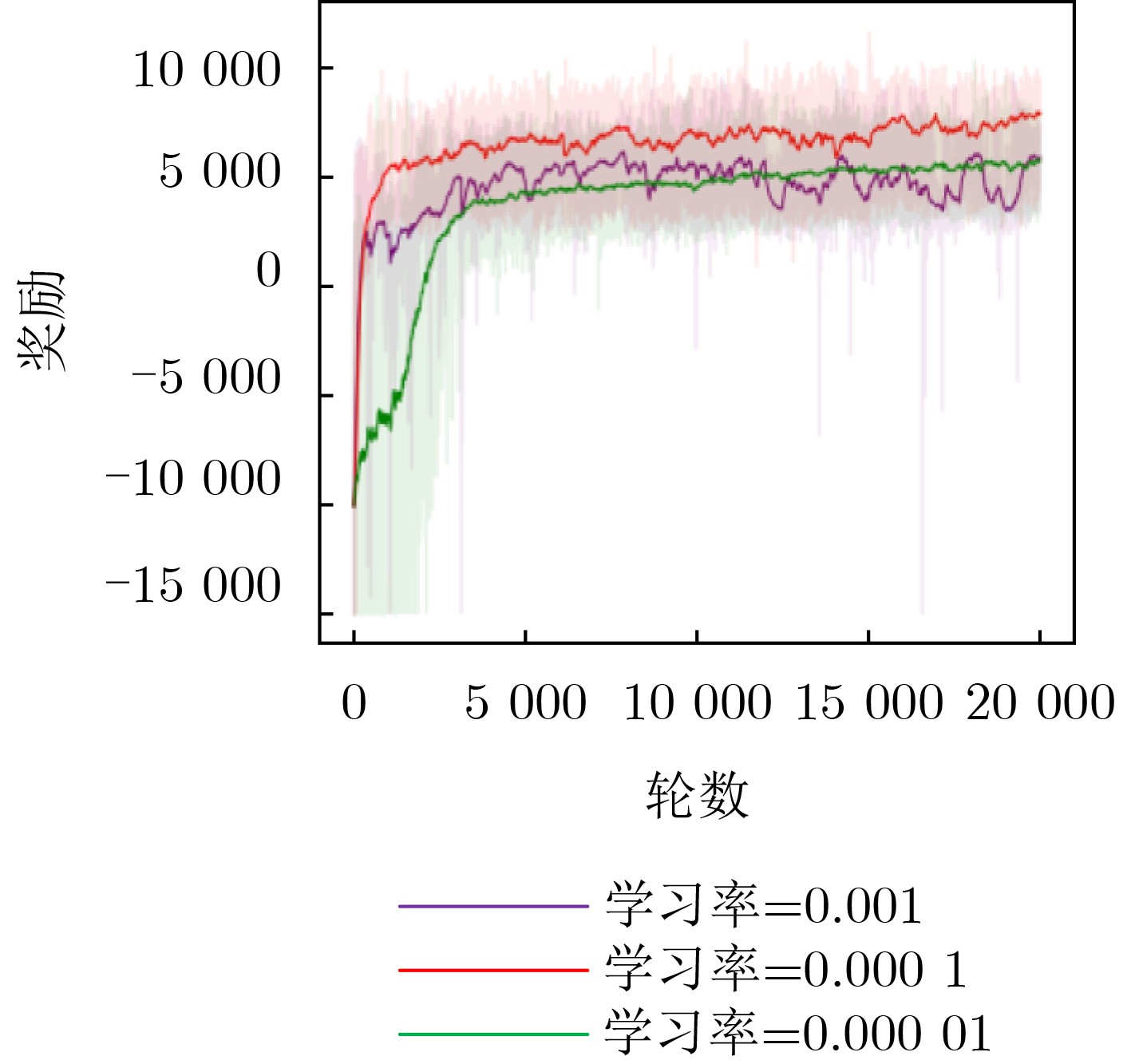
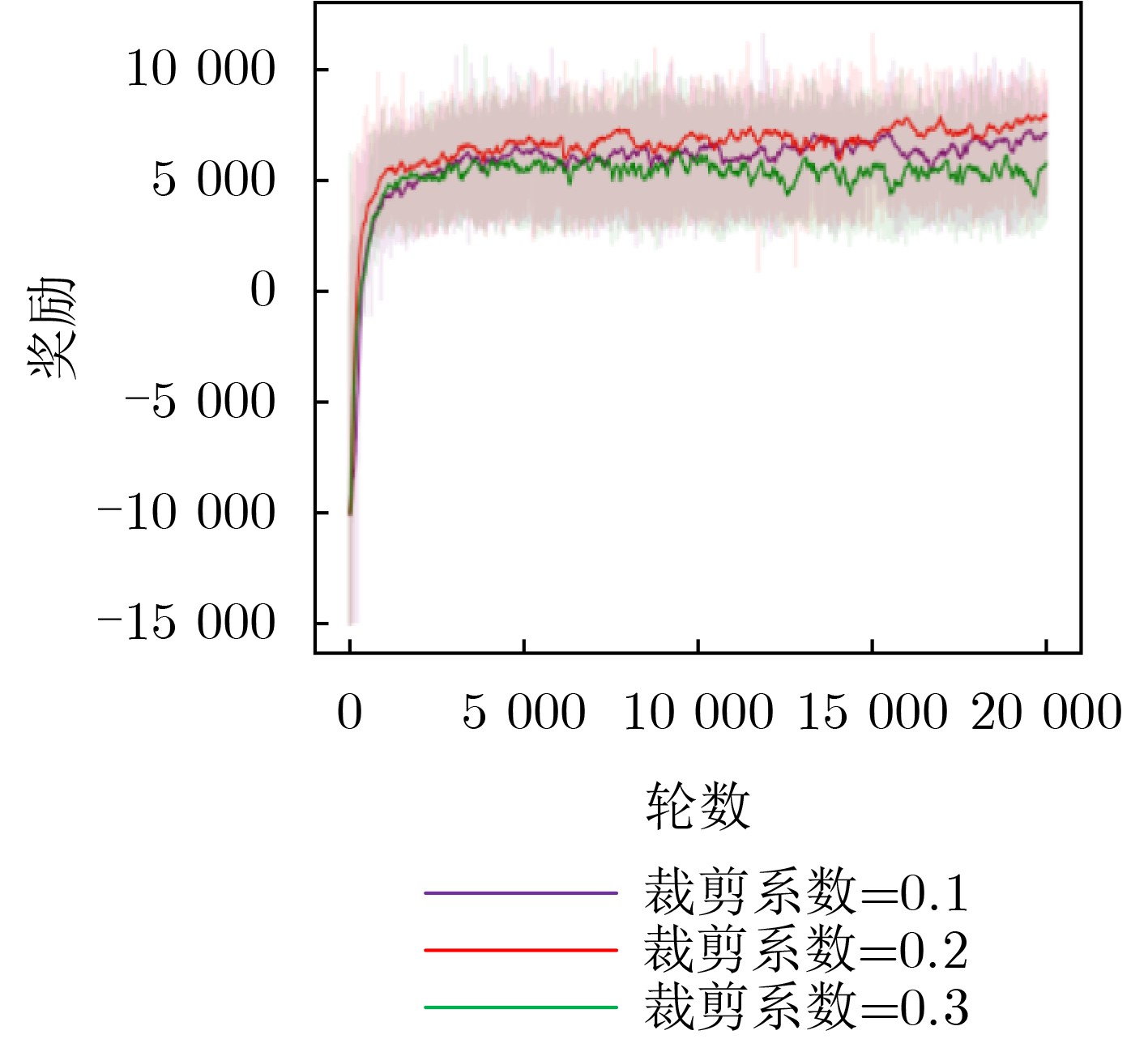
参数 取值 训练轮数${\text{EP}}$ 20000 学习率$\eta $ $1 \times {10^{ - 4}}$ 奖励折扣率$\gamma $ 0.99 裁剪系数$ \varepsilon $ 0.2
下载: 导出CSV
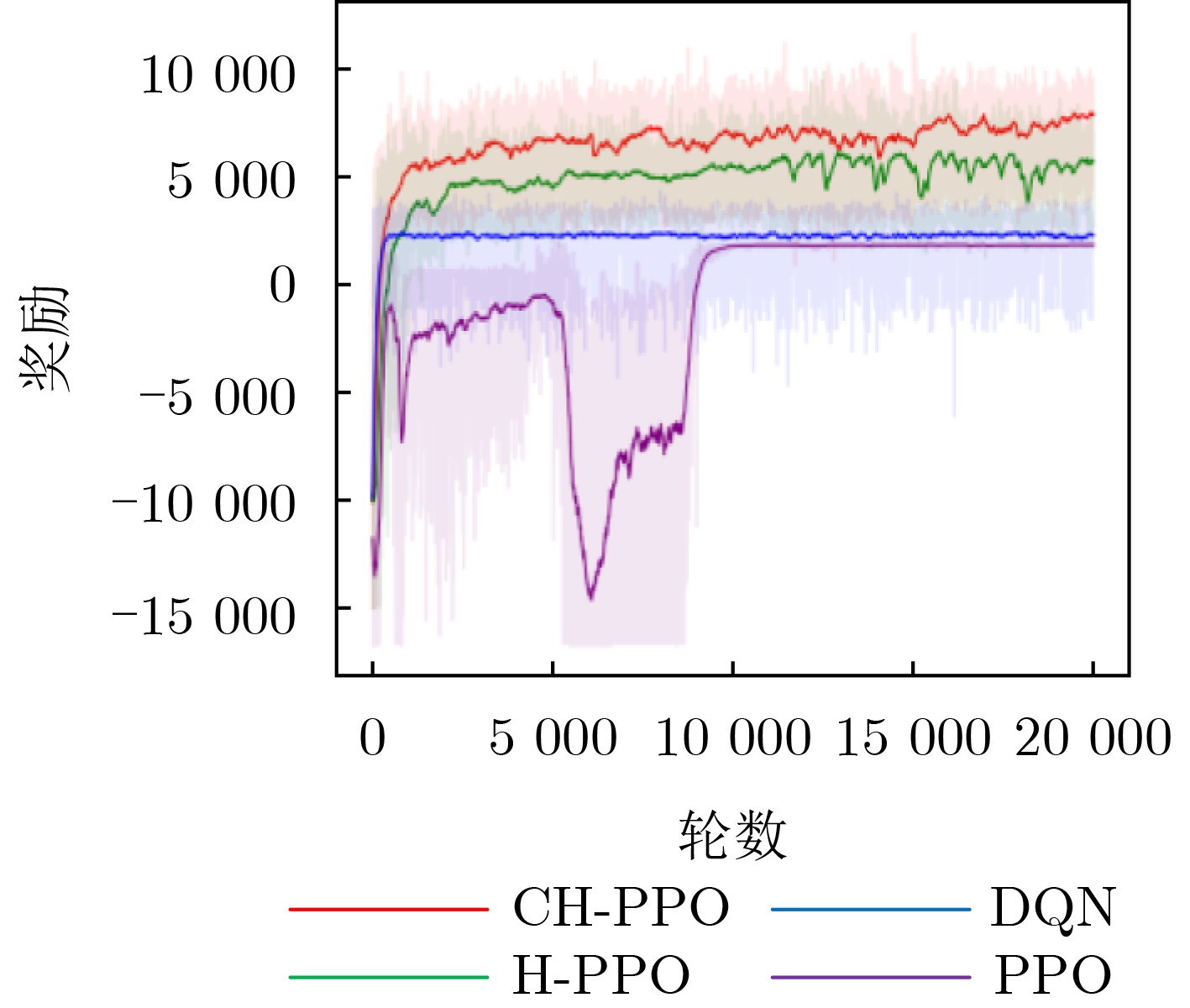
表 3 不同任务规模下的无人机能量消耗($1 \times {10^4}\;{\text{J}}$)
区域边长 网络规模 CH-PPO H-PPO DQN PPO VLC-GA 200 20 1.71 1.75 2.32 2.82 2.18 40 4.01 4.55 4.91 4.73 4.95 60 6.10 6.72 6.82 7.08 6.93 300 20 1.96 2.07 2.61 4.02 2.54 40 4.89 5.21 6.84 9.28 6.91 60 9.18 9.45 11.43 12.59 11.51 400 20 2.02 2.11 2.92 4.46 2.84 40 6.37 7.60 7.62 12.76 7.64 60 10.03 10.70 12.04 14.78 12.13
下载: 导出CSV
表 4 不同任务规模下的无人机飞行距离(m)
区域边长 网络规模 CH-PPO H-PPO DQN PPO VLC-GA 200 20 1488 1560 2398 2805 2249 40 3600 4308 5102 4596 5155 60 5922 6566 7025 6818 7175 300 20 1785 1837 2734 4115 2654 40 4471 4802 7270 9641 7356 60 8483 8785 12173 12526 12322 400 20 1898 1921 3066 4623 2991 40 6001 7242 8121 10767 8177 60 9367 9964 12880 13135 13019
下载: 导出CSV
表 5 不同任务规模下的任务时间(s)
区域边长 网络规模 CH-PPO H-PPO DQN PPO VLC-GA 200 20 100 105 138 172 130 40 241 259 291 293 293 60 323 345 406 440 412 300 20 121 125 154 241 150 40 297 290 399 550 403 60 550 489 669 684 673 400 20 126 131 171 264 167 40 355 424 443 583 445 60 584 549 699 762 704
下载: 导出CSV
表 6 不同任务规模和AoI阈值下的无人机能量消耗($1 \times {10^4}\;{\text{J}}$)
AoI阈值 [60,80] [90,110] [120,140] 区域边长 网络规模
20020 1.90 1.71 1.45 40 5.77 4.01 3.83 60 8.24 6.10 5.89
30020 2.19 1.96 1.55 40 7.79 4.89 4.29 60 10.47 9.18 7.96
40020 2.29 2.02 1.95 40 8.36 6.37 5.80 60 11.34 10.03 9.57
下载: 导出CSV
-
[1] AKYILDIZ I F, SU W, SANKARASUBRAMANIAM Y, et al. Wireless sensor networks: A survey[J]. Computer Networks, 2002, 38(4): 393–422. doi: 10.1016/S1389-1286(01)00302-4. [2] HAYAT S, YANMAZ E, and MUZAFFAR R. Survey on unmanned aerial vehicle networks for civil applications: A communications viewpoint[J]. IEEE Communications Surveys & Tutorials, 2016, 18(4): 2624–2661. doi: 10.1109/COMST.2016.2560343. [3] MOTLAGH N H, BAGAA M, and TALEB T. UAV-based IoT platform: A crowd surveillance use case[J]. IEEE Communications Magazine, 2017, 55(2): 128–134. doi: 10.1109/MCOM.2017.1600587CM. [4] HU Jie, WANG Tuan, YANG Jiacheng, et al. WSN-assisted UAV trajectory adjustment for pesticide drift control[J]. Sensors, 2020, 20(19): 5473. doi: 10.3390/s20195473. [5] 周彬, 郭艳, 李宁, 等. 基于导向强化Q学习的无人机路径规划[J]. 航空学报, 2021, 42(9): 325109. doi: 10.7527/S1000-6893.2021.25109.ZHOU Bin, GUO Yan, LI Ning, et al. Path planning of UAV using guided enhancement Q-learning algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(9): 325109. doi: 10.7527/S1000-6893.2021.25109. [6] ZHOU Conghao, WU Wen, HE Hongli, et al. Delay-aware IoT task scheduling in space-air-ground integrated network[C]. 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, USA, 2019: 1–6. doi: 10.1109/GLOBECOM38437.2019.9013393. [7] LIU Dianxiong, XU Yuhua, WANG Jinlong, et al. Opportunistic utilization of dynamic multi-UAV in device-to-device communication networks[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(3): 1069–1083. doi: 10.1109/TCCN.2020.2991436. [8] 张广驰, 何梓楠, 崔苗. 基于深度强化学习的无人机辅助移动边缘计算系统能耗优化[J]. 电子与信息学报, 2023, 45(5): 1635–1643. doi: 10.11999/JEIT220352.ZHANG Guangchi, HE Zinan, and CUI Miao. Energy consumption optimization of unmanned aerial vehicle assisted mobile edge computing systems based on deep reinforcement learning[J]. Journal of Electronics & Information Technology, 2023, 45(5): 1635–1643. doi: 10.11999/JEIT220352. [9] LUO Chuanwen, CHEN Wenping, LI Deying, et al. Optimizing flight trajectory of UAV for efficient data collection in wireless sensor networks[J]. Theoretical Computer Science, 2021, 853: 25–42. doi: 10.1016/j.tcs.2020.05.019. [10] ZHU Yuchao and WANG Shaowei. Efficient aerial data collection with cooperative trajectory planning for large-scale wireless sensor networks[J]. IEEE Transactions on Communications, 2022, 70(1): 433–444. doi: 10.1109/TCOMM.2021.3124950. [11] ZHAN Cheng and ZENG Yong. Completion time minimization for multi-UAV-enabled data collection[J]. IEEE Transactions on Wireless Communications, 2019, 18(10): 4859–4872. doi: 10.1109/TWC.2019.2930190. [12] KAUL S, YATES R, and GRUTESER M. Real-time status: How often should one update?[C]. 2012 Proceedings IEEE INFOCOM, Orlando, USA, 2012: 2731–2735. doi: 10.1109/INFCOM.2012.6195689. [13] 张建行, 康凯, 钱骅, 等. 面向物联网的深度Q网络无人机路径规划[J]. 电子与信息学报, 2022, 44(11): 3850–3857. doi: 10.11999/JEIT210962.ZHANG Jianhang, KANG Kai, QIAN Hua, et al. UAV trajectory planning based on deep Q-network for internet of things[J]. Journal of Electronics & Information Technology, 2022, 44(11): 3850–3857. doi: 10.11999/JEIT210962. [14] LIAO Yuan and FRIDERIKOS V. Energy and age pareto optimal trajectories in UAV-assisted wireless data collection[J]. IEEE Transactions on Vehicular Technology, 2022, 71(8): 9101–9106. doi: 10.1109/TVT.2022.3175318. [15] SHERMAN M, SHAO Sihua, SUN Xiang, et al. Optimizing AoI in UAV-RIS-assisted IoT networks: Off policy versus on policy[J]. IEEE Internet of Things Journal, 2023, 10(14): 12401–12415. doi: 10.1109/JIOT.2023.3246925. [16] SUN Mengying, XU Xiaodong, QIN Xiaoqi, et al. AoI-energy-aware UAV-assisted data collection for IoT networks: A deep reinforcement learning method[J]. IEEE Internet of Things Journal, 2021, 8(24): 17275–17289. doi: 10.1109/JIOT.2021.3078701. [17] LIU Juan, TONG Peng, WANG Xijun, et al. UAV-aided data collection for information freshness in wireless sensor networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(4): 2368–2382. doi: 10.1109/TWC.2020.3041750. [18] DAI Zipeng, LIU C H, YE Yuxiao, et al. AoI-minimal UAV crowdsensing by model-based graph convolutional reinforcement learning[C]. IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, United Kingdom, 2022: 1029–1038. doi: 10.1109/INFOCOM48880.2022.9796732. [19] LIU Kai and ZHENG Jun. UAV trajectory optimization for time-constrained data collection in UAV-enabled environmental monitoring systems[J]. IEEE Internet of Things Journal, 2022, 9(23): 24300–24314. doi: 10.1109/JIOT.2022.3189214. [20] SUN Yin, UYSAL-BIYIKOGLU E, YATES R D, et al. Update or wait: How to keep your data fresh[J]. IEEE Transactions on Information Theory, 2017, 63(11): 7492–7508. doi: 10.1109/TIT.2017.2735804. [21] YU Yu, TANG Jie, HUANG Jiayi, et al. Multi-objective optimization for UAV-assisted wireless powered IoT networks based on extended DDPG algorithm[J]. IEEE Transactions on Communications, 2021, 69(9): 6361–6374. doi: 10.1109/TCOMM.2021.3089476. [22] ZENG Yong, XU Jie, and ZHANG Rui. Energy minimization for wireless communication with rotary-wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329–2345. doi: 10.1109/TWC.2019.2902559. [23] FAN Zhou, SU Rui, ZHANG Weinan, et al. Hybrid actor-critic reinforcement learning in parameterized action space[C]. Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 2019. [24] HA V P, DAO T K, PHAM N Y, et al. A variable-length chromosome genetic algorithm for time-based sensor network schedule optimization[J]. Sensors, 2021, 21(12): 3990. doi: 10.3390/s21123990. -

 下载:
下载:




图(6) / 表(7)
计量
- 文章访问数: 1098
- HTML全文浏览量: 631
- PDF下载量: 90
- 被引次数: 0
