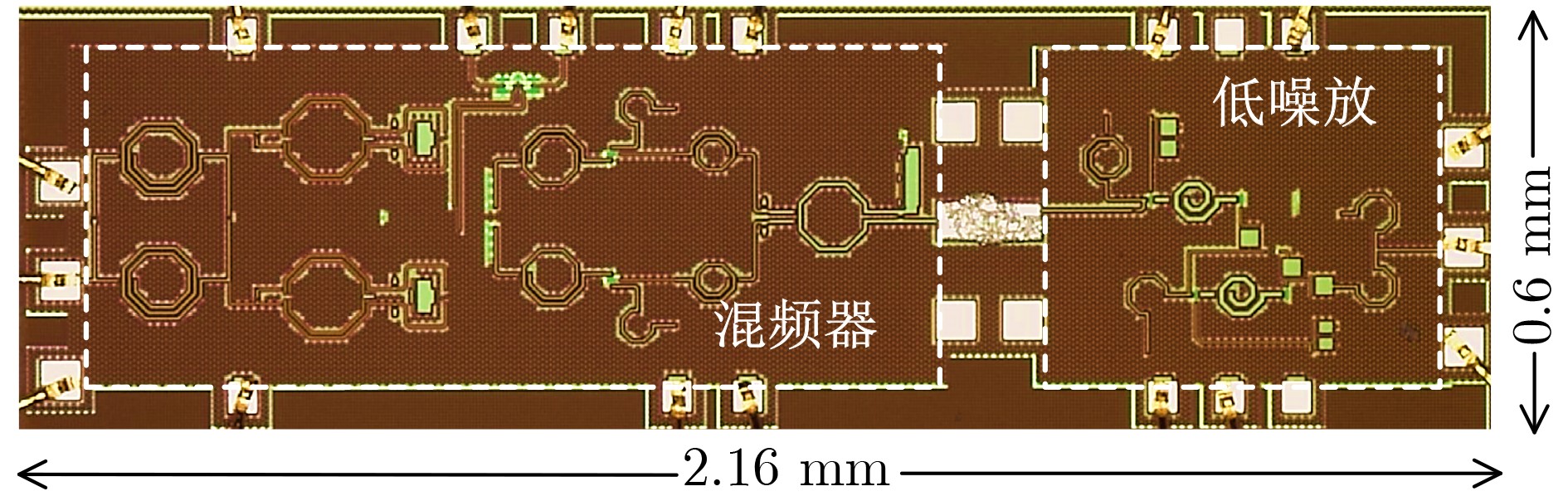
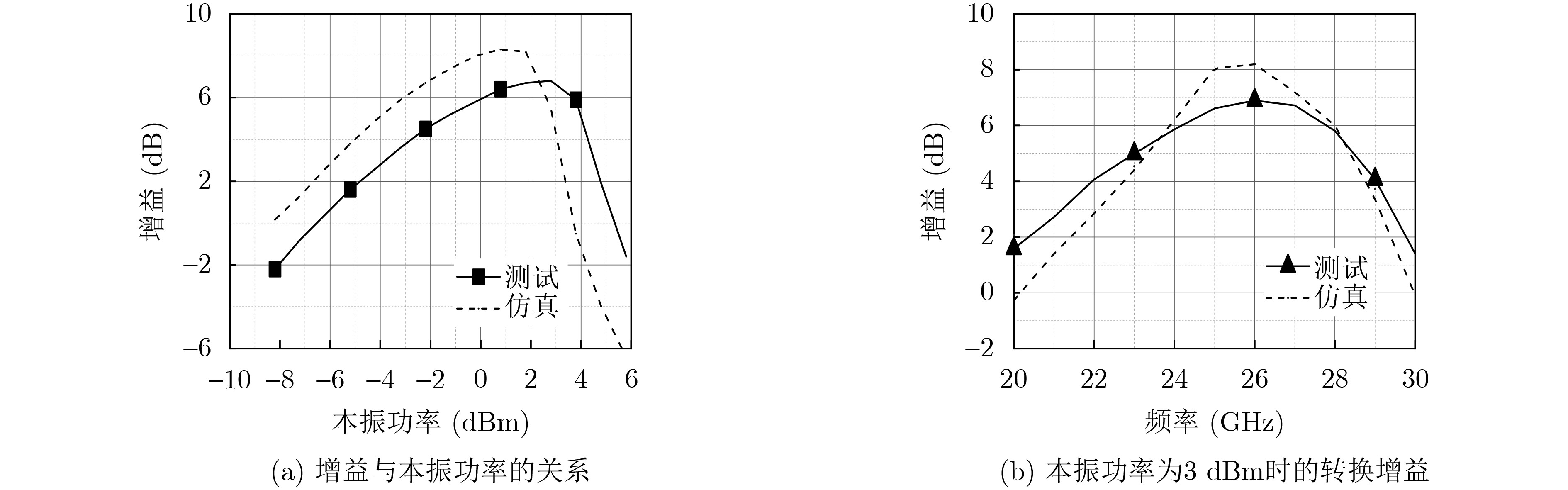
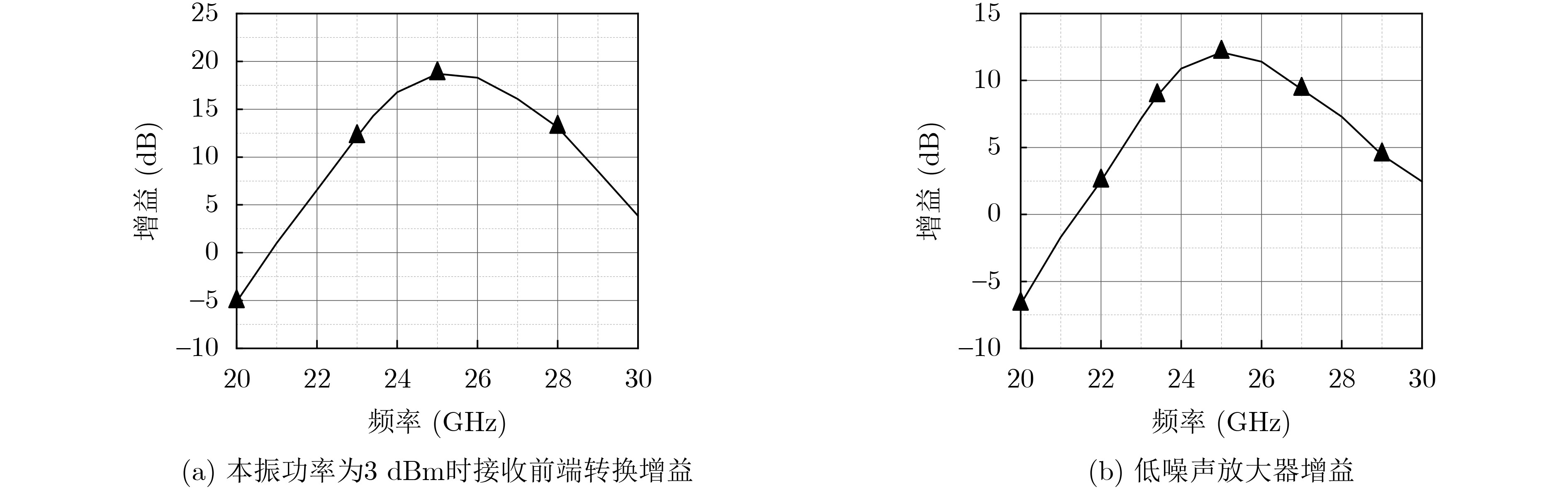
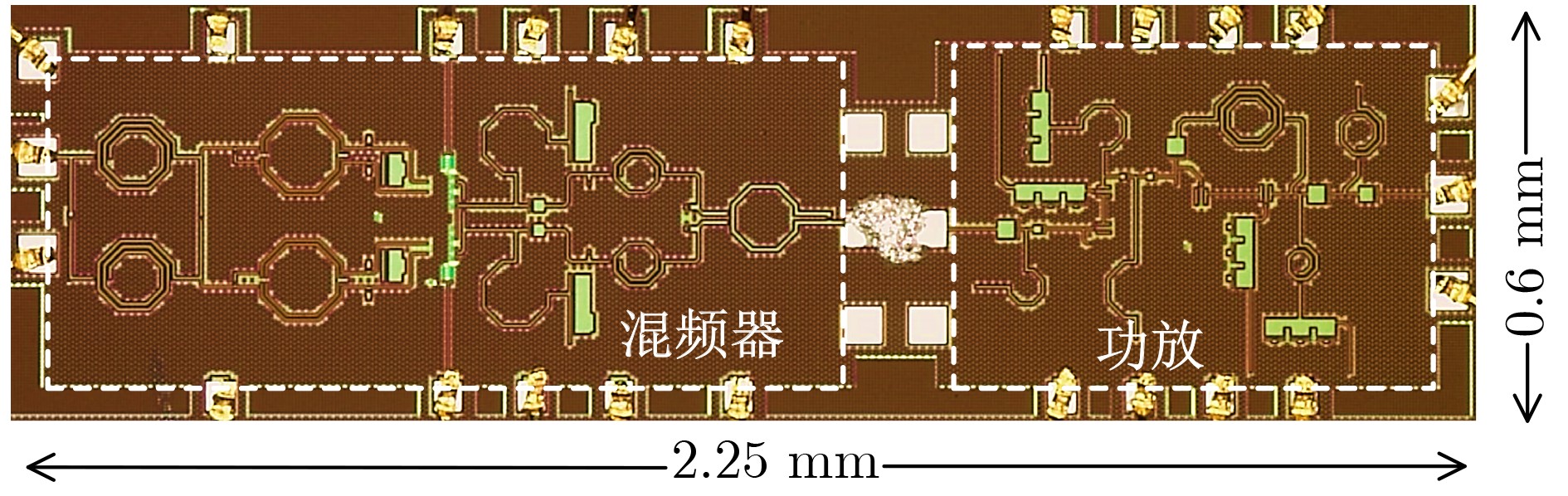
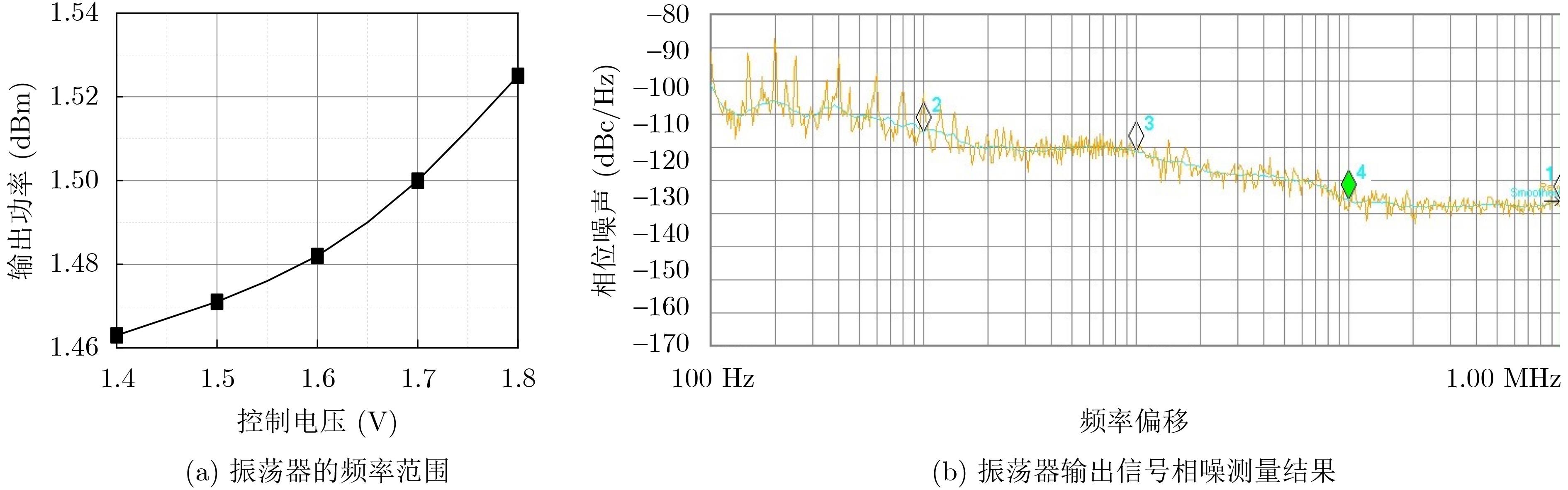
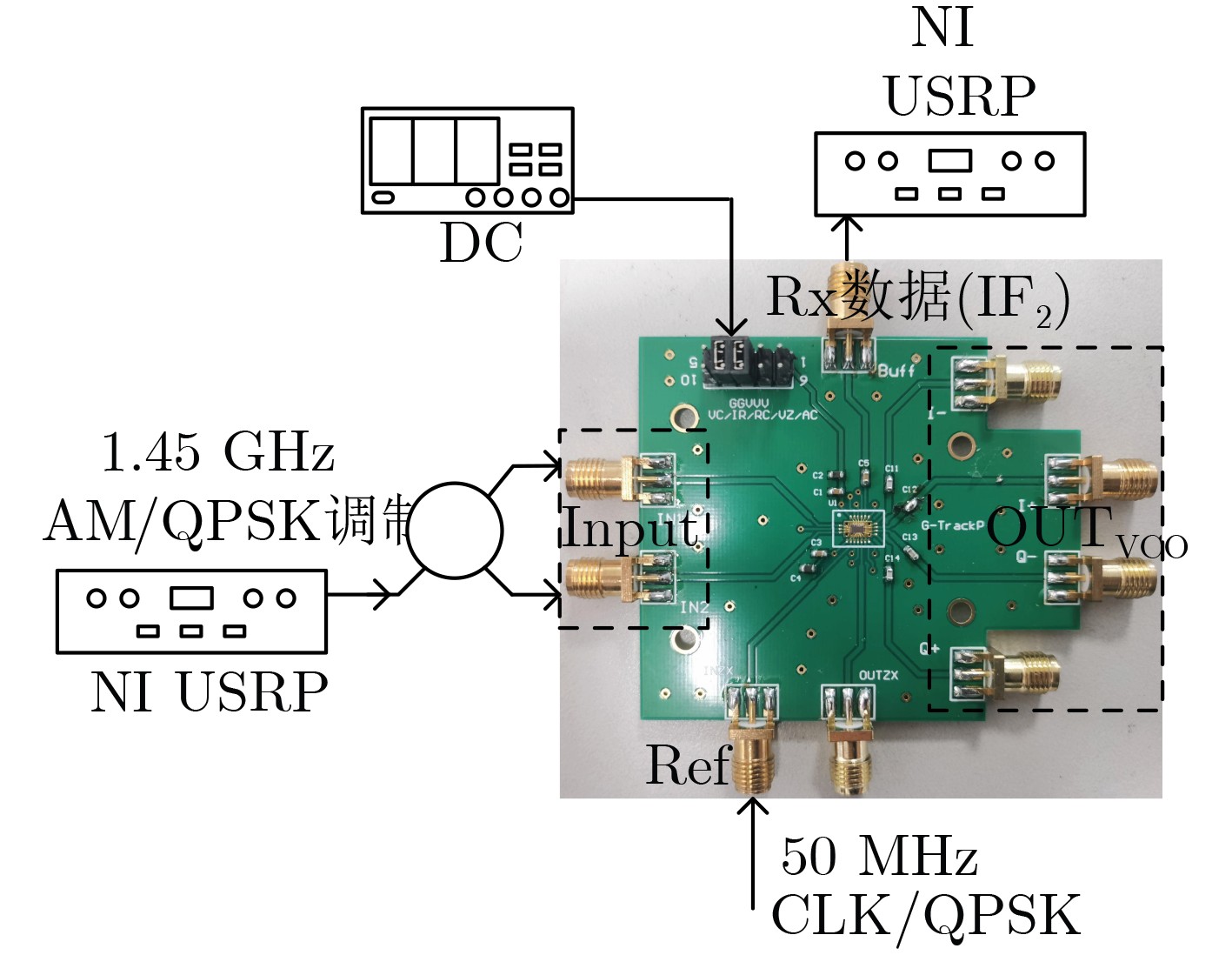
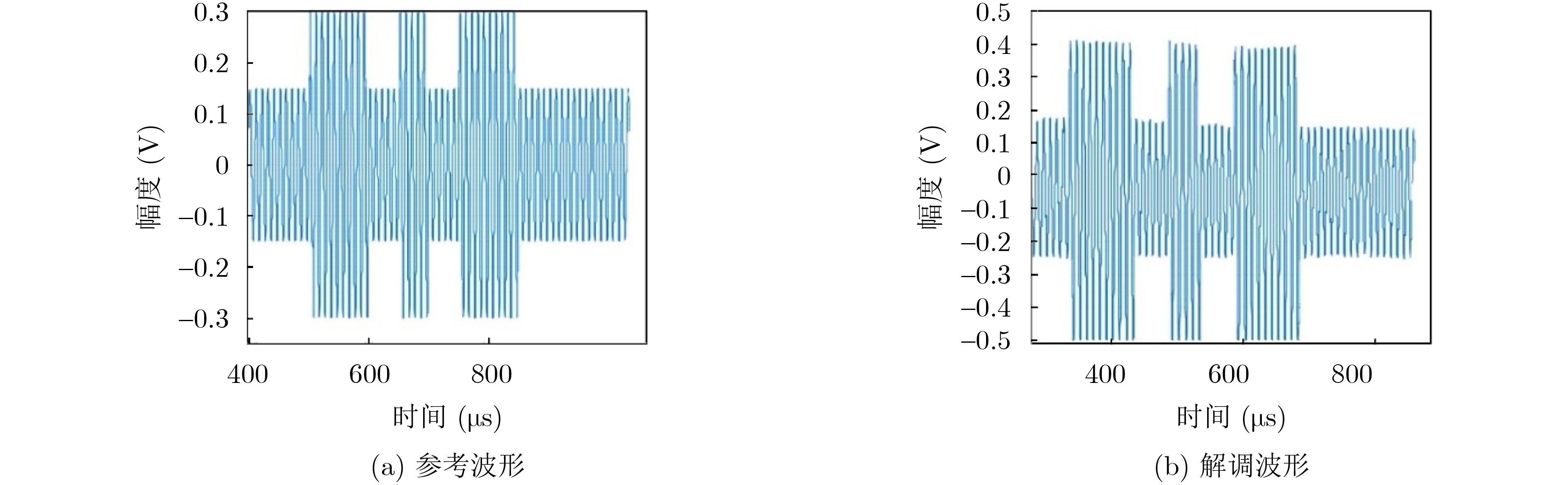
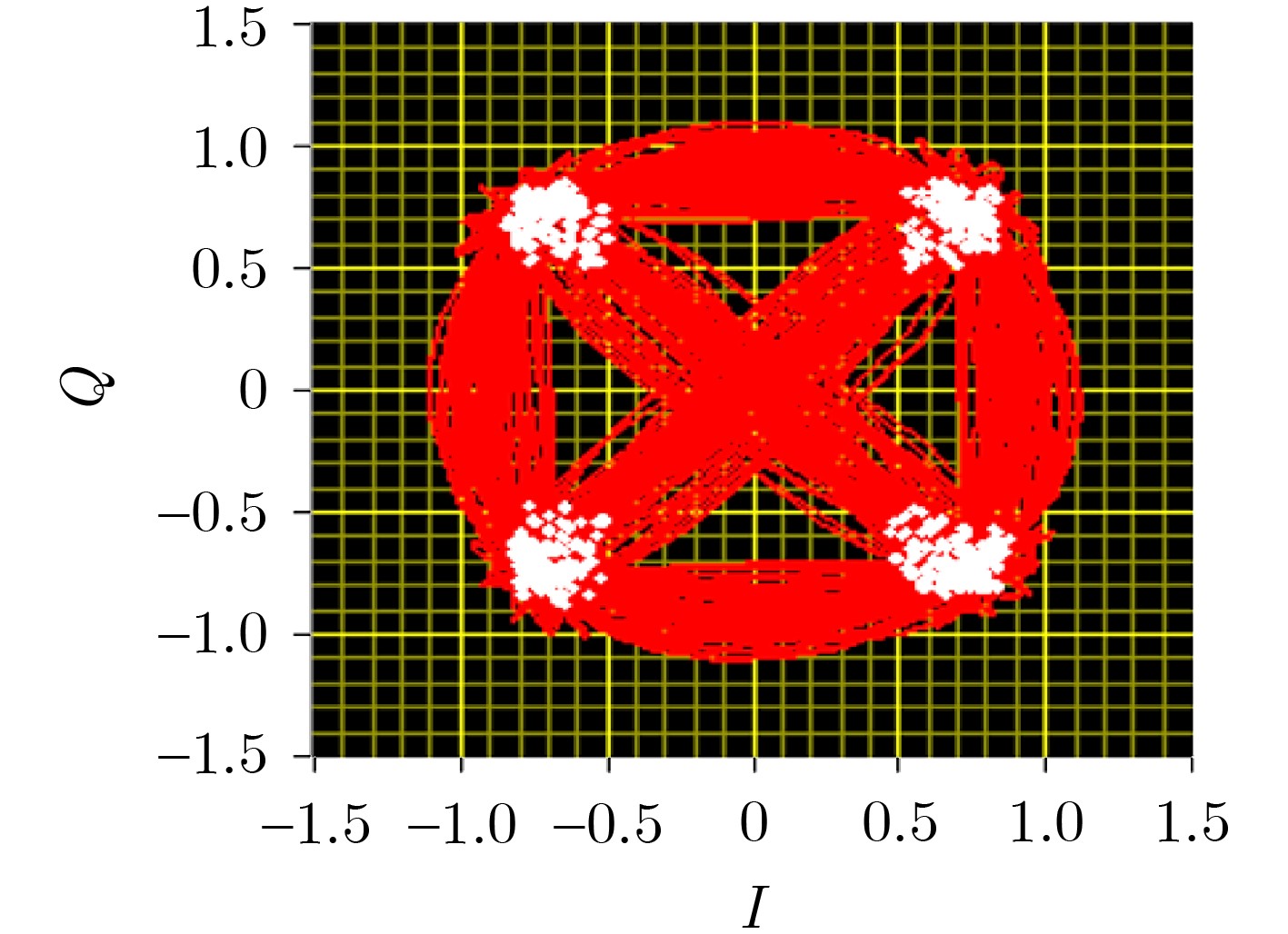
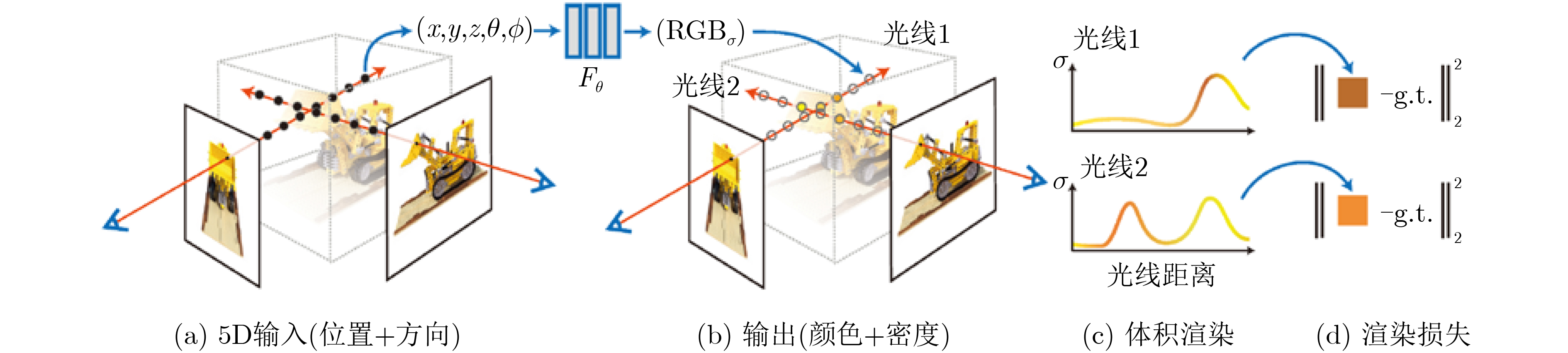
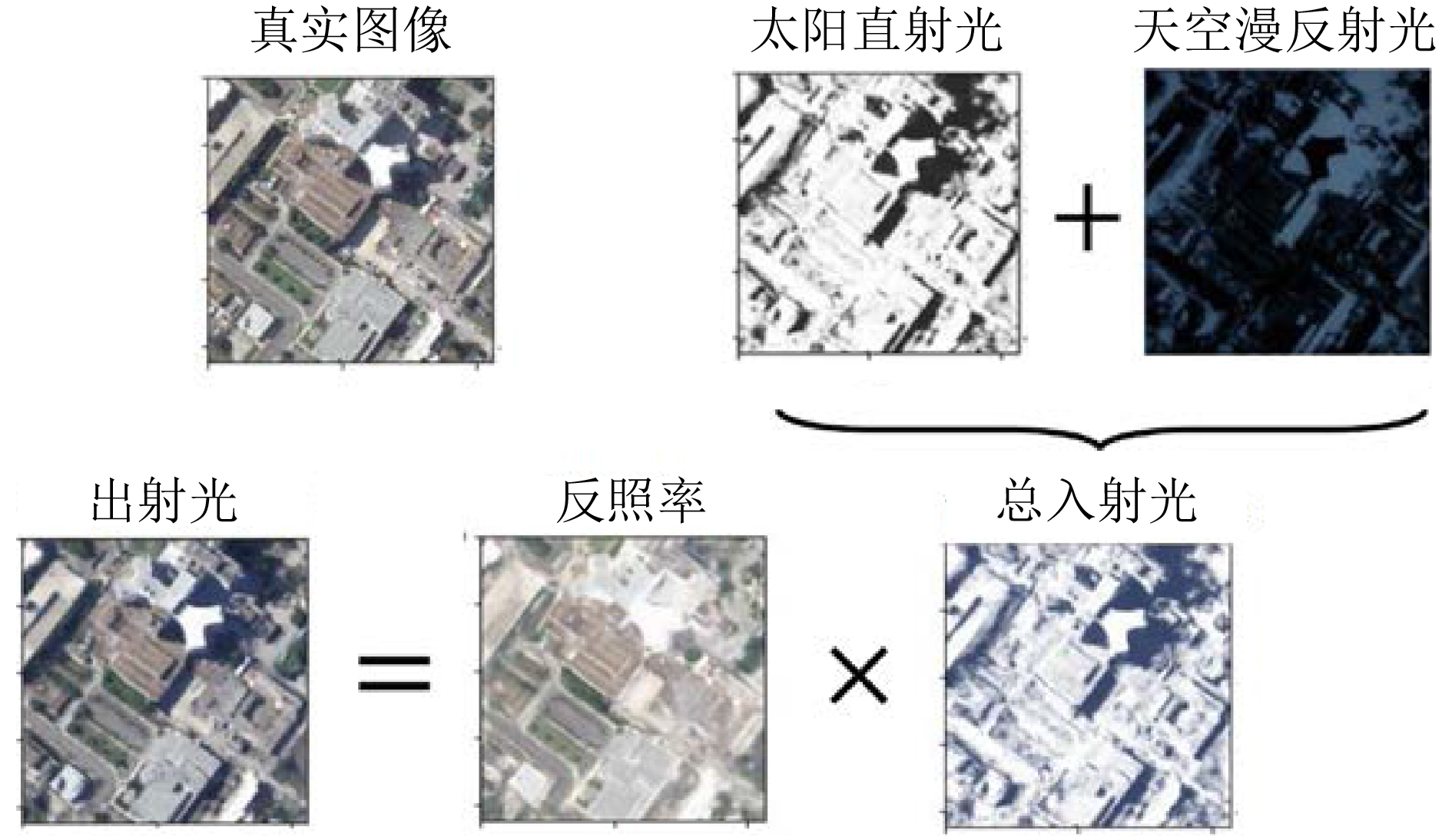
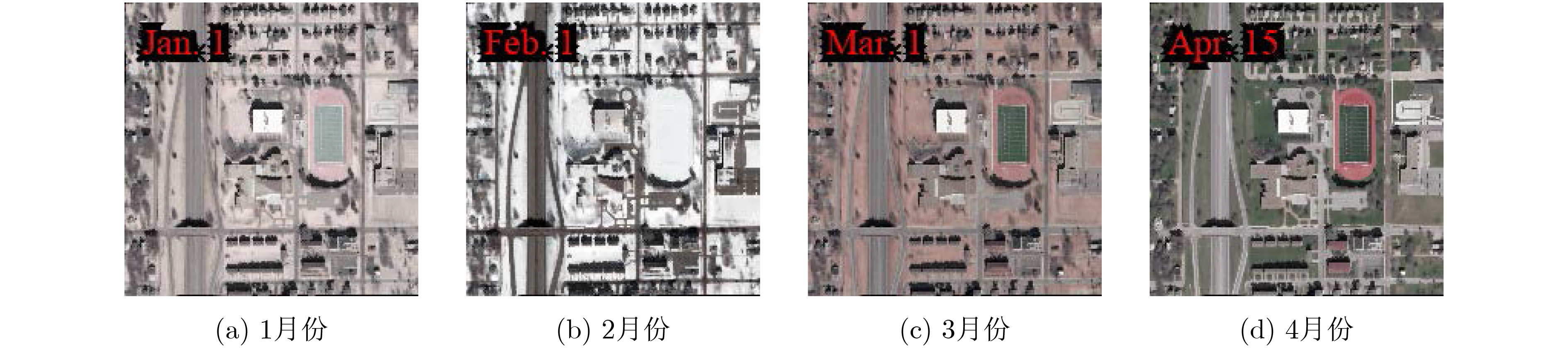
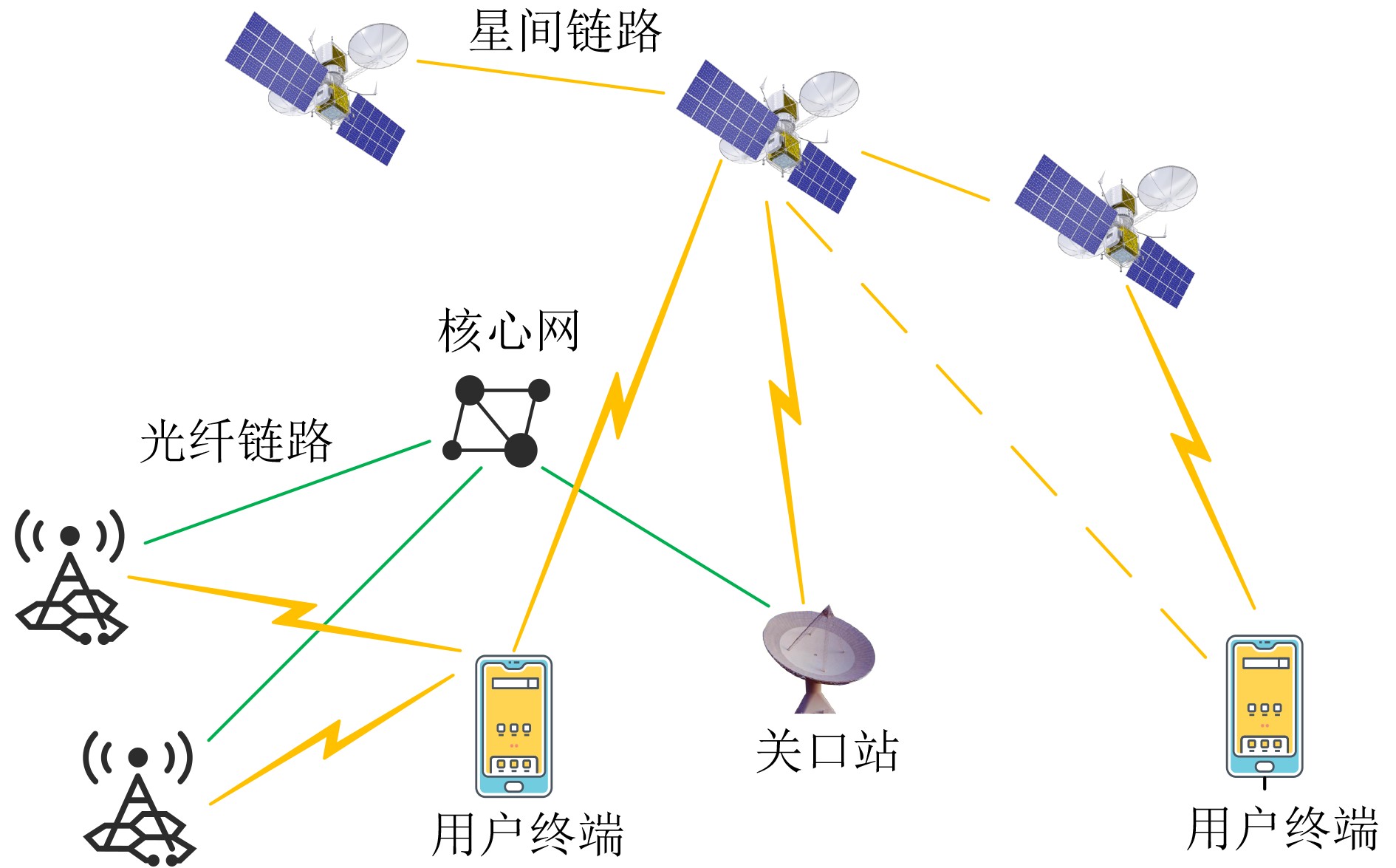
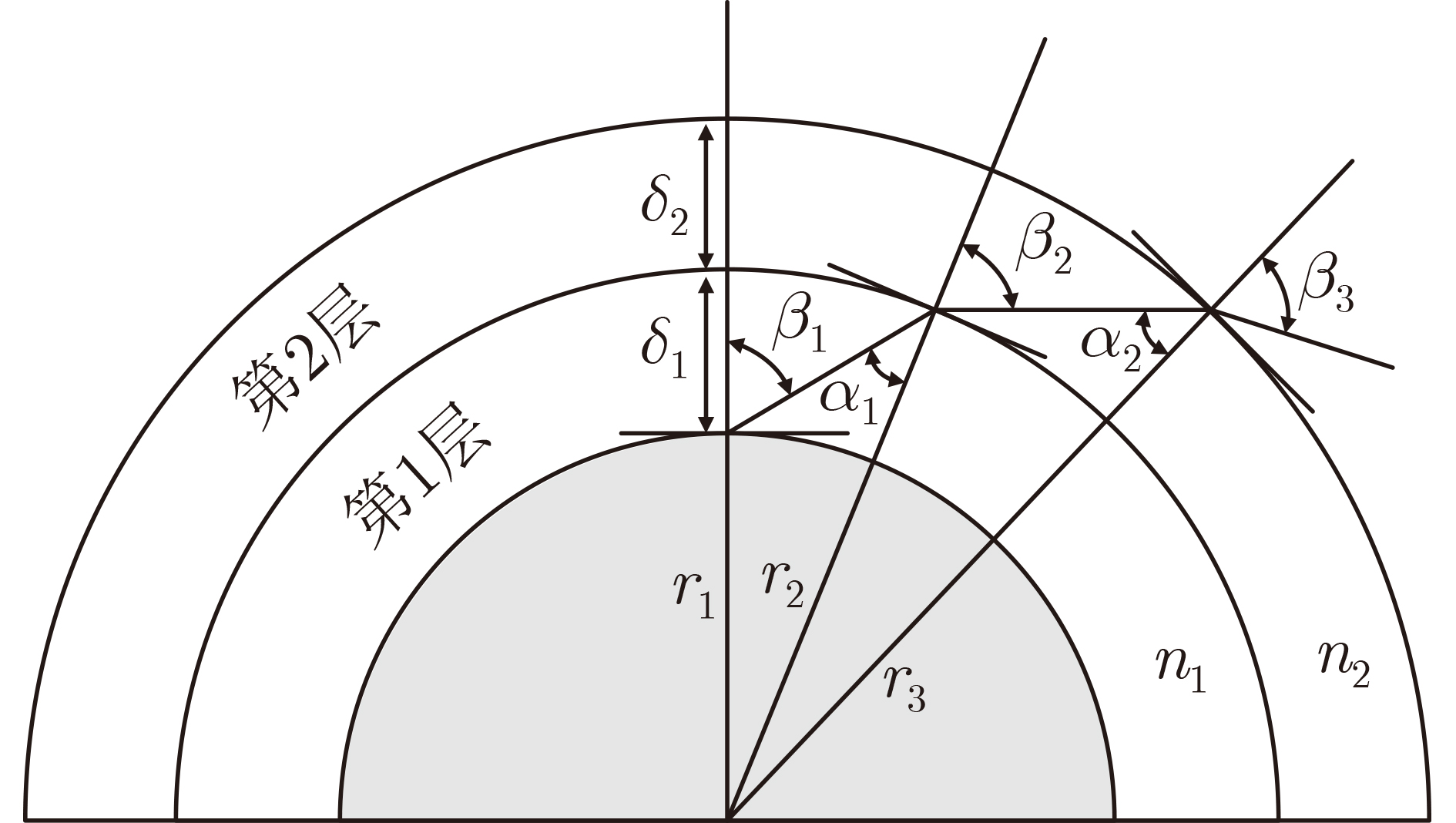
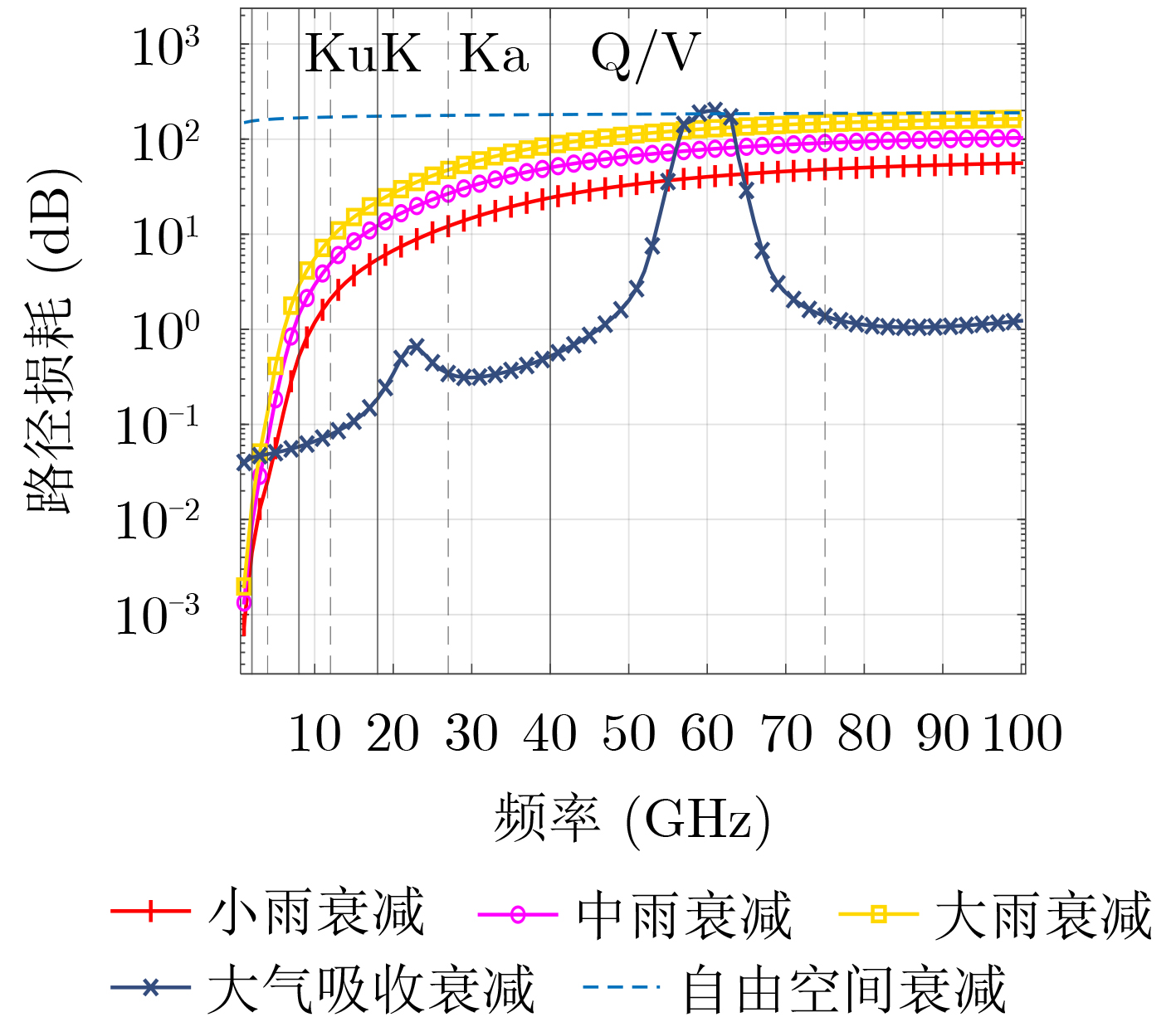
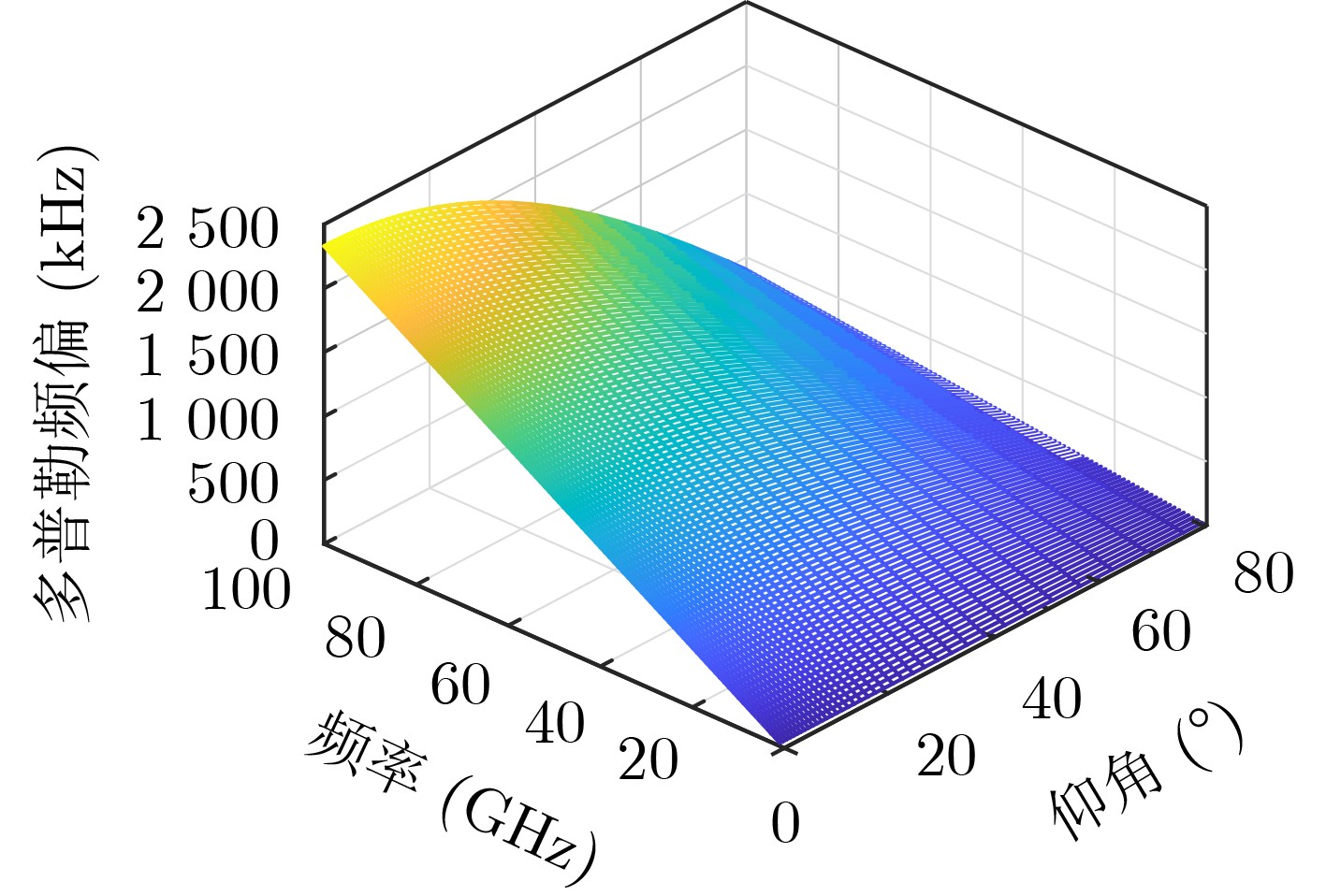
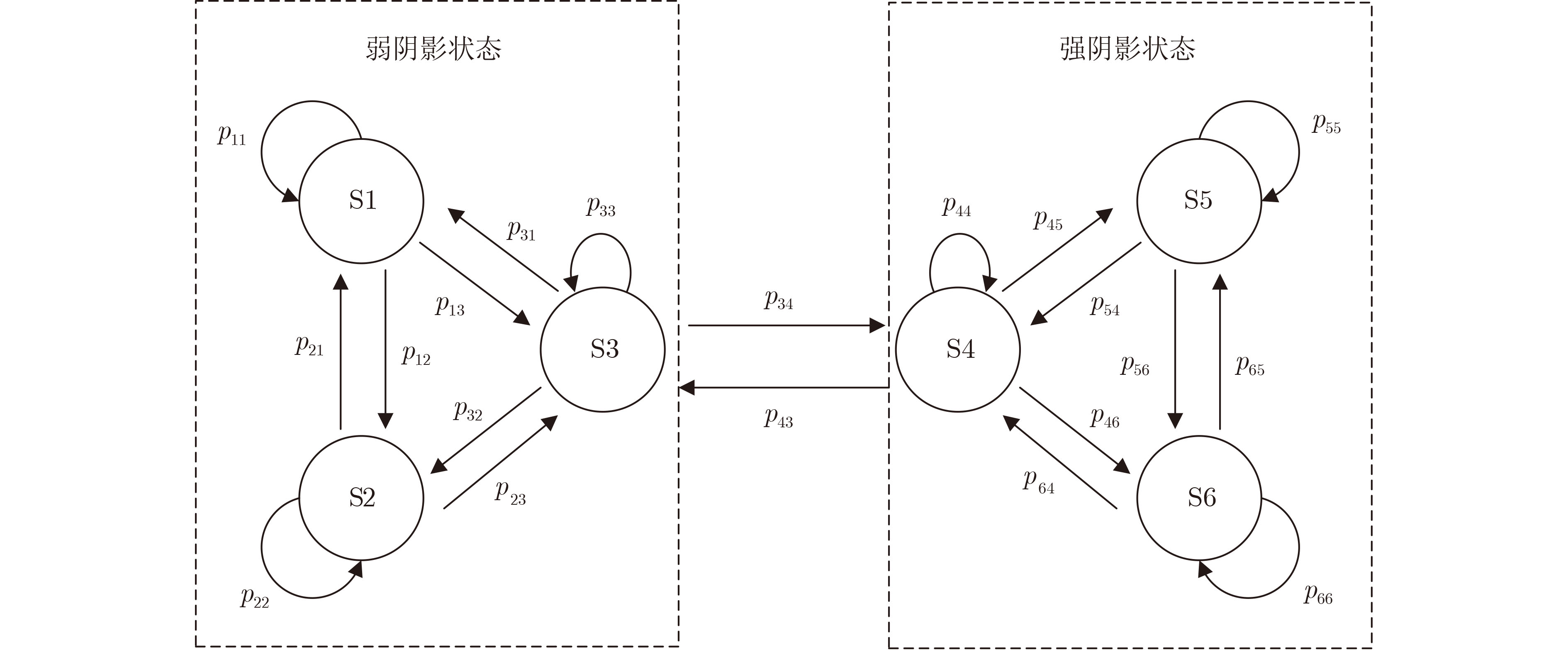
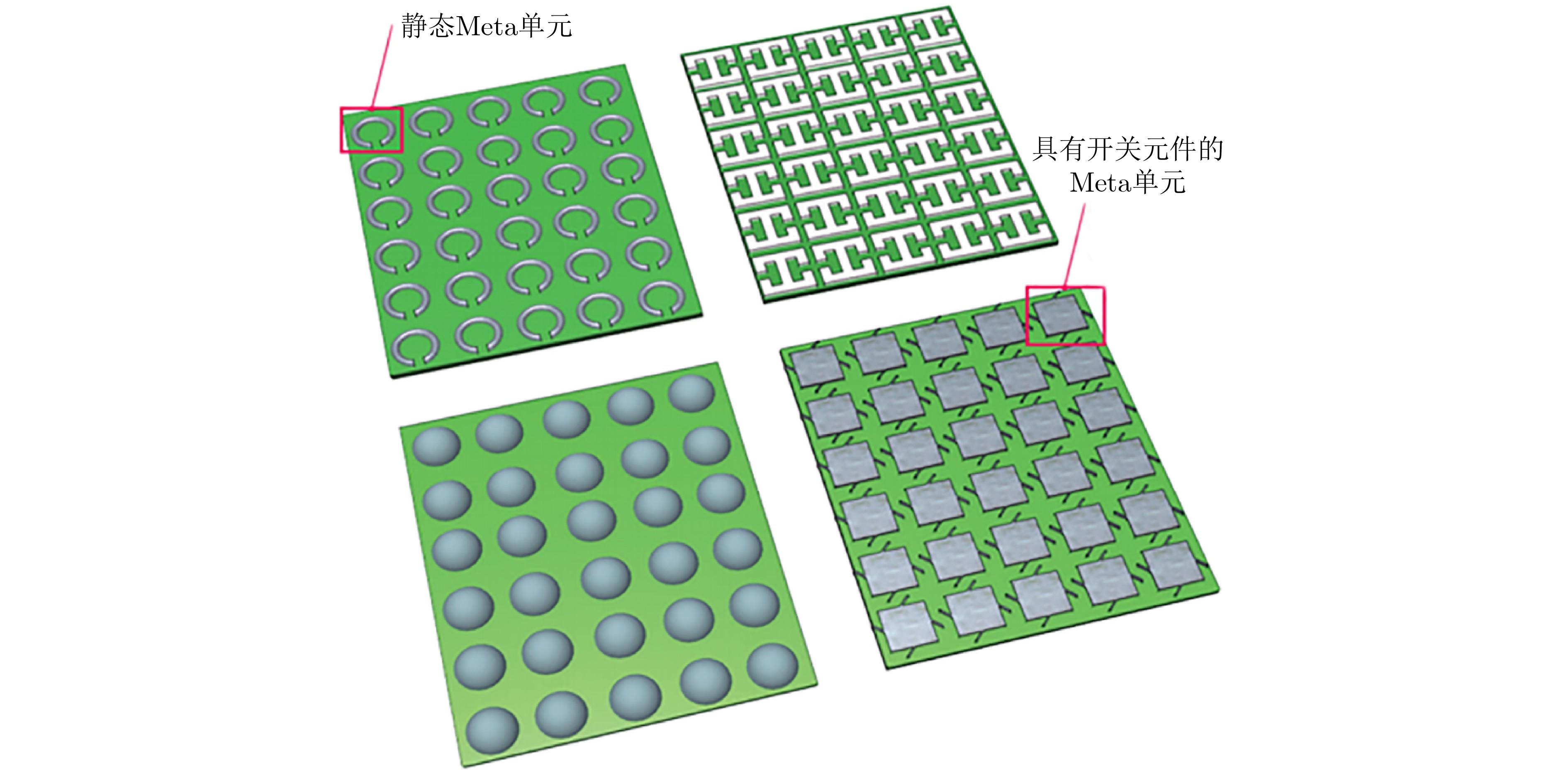
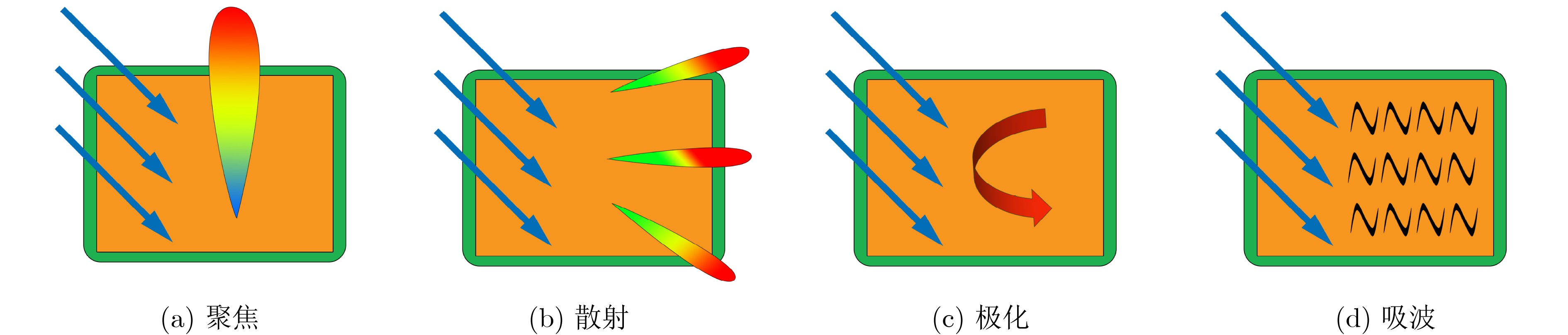
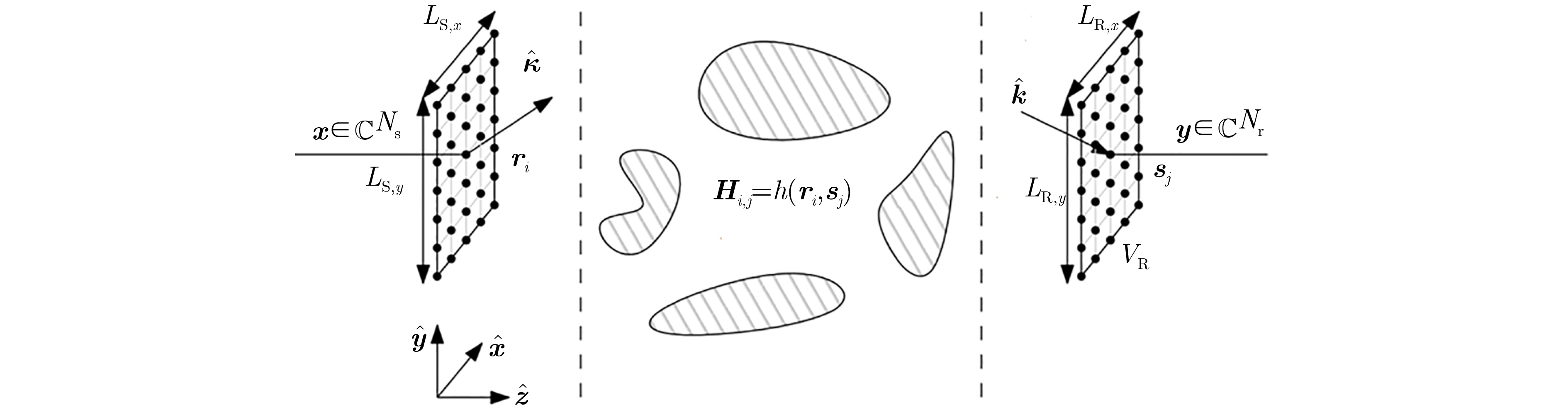
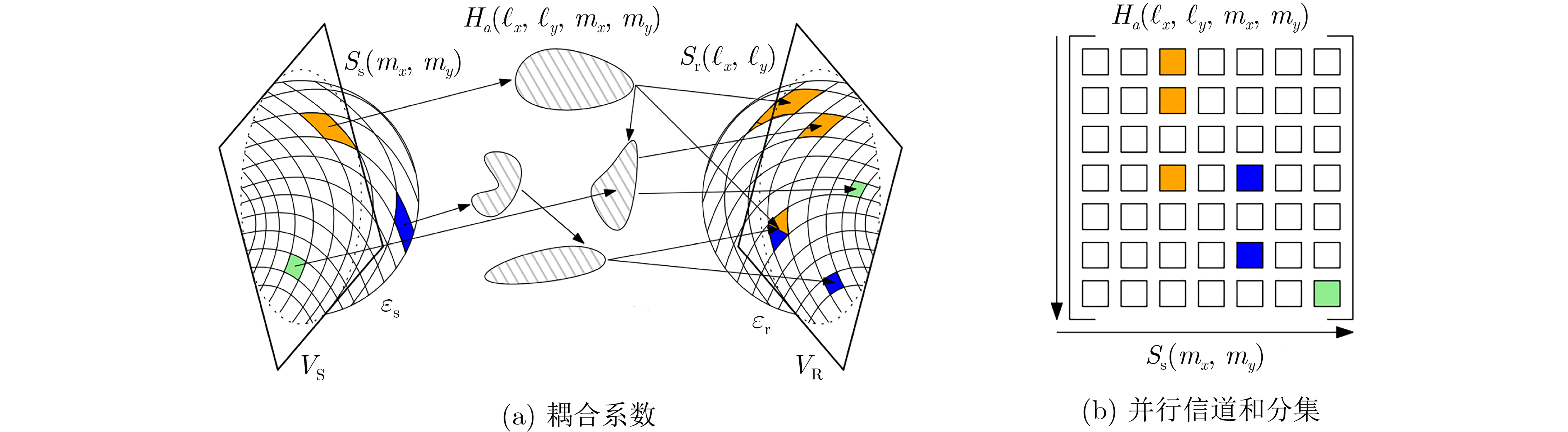
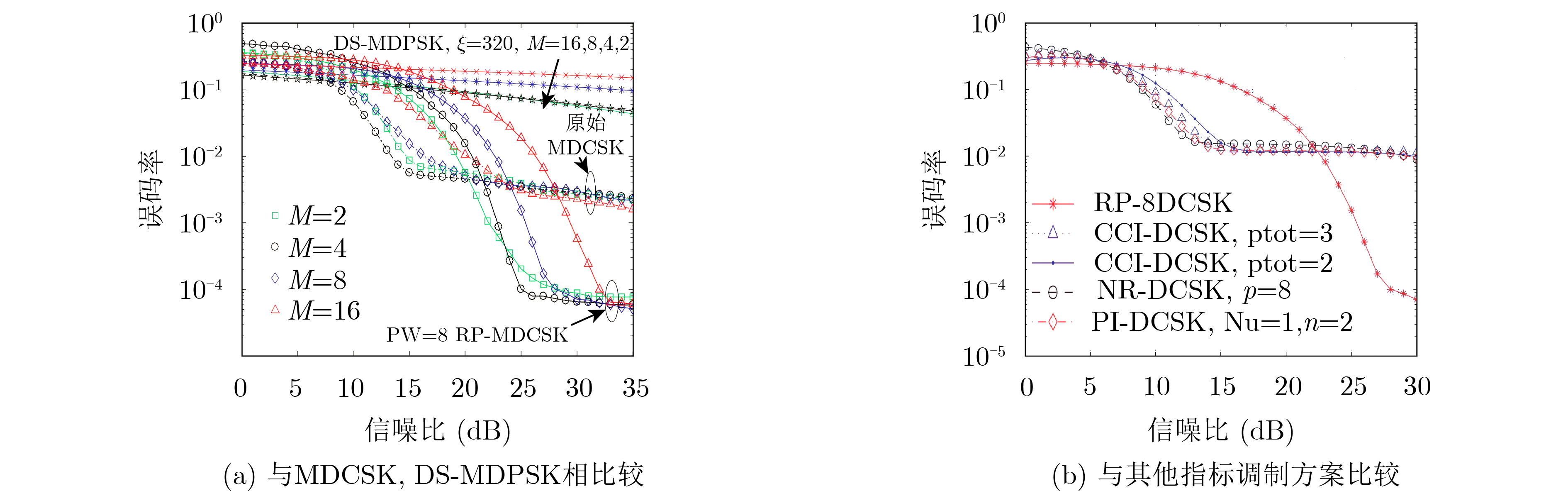
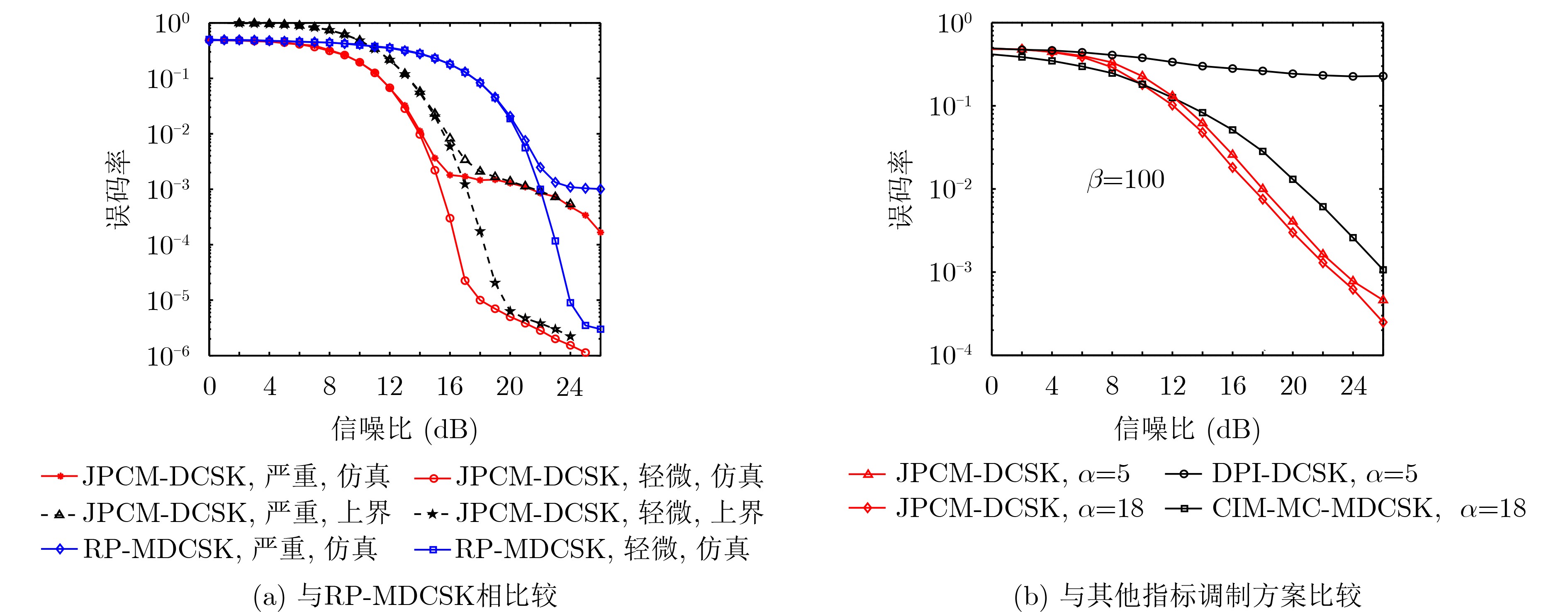
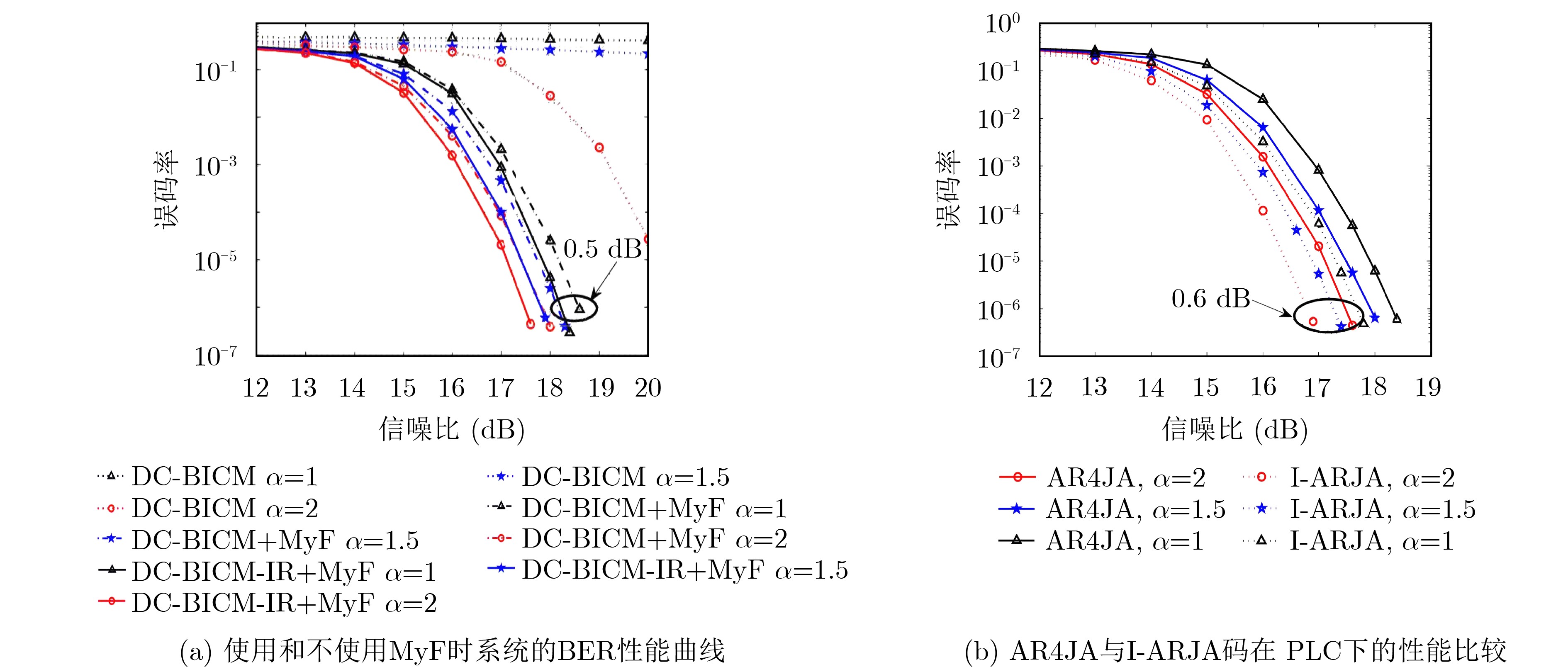
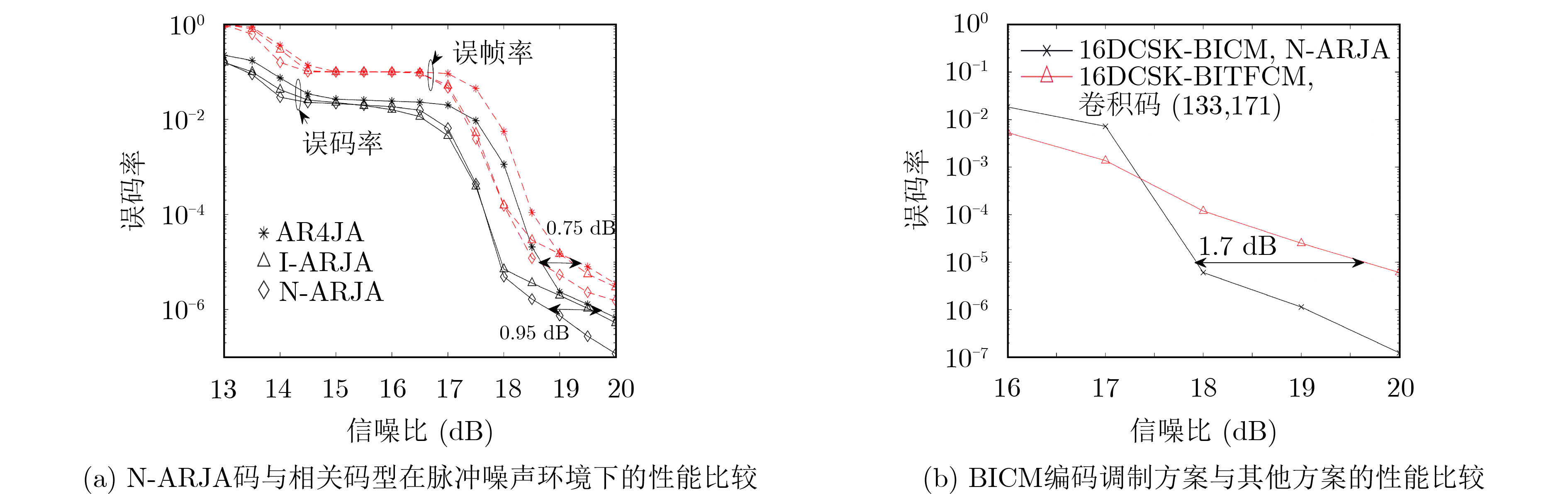
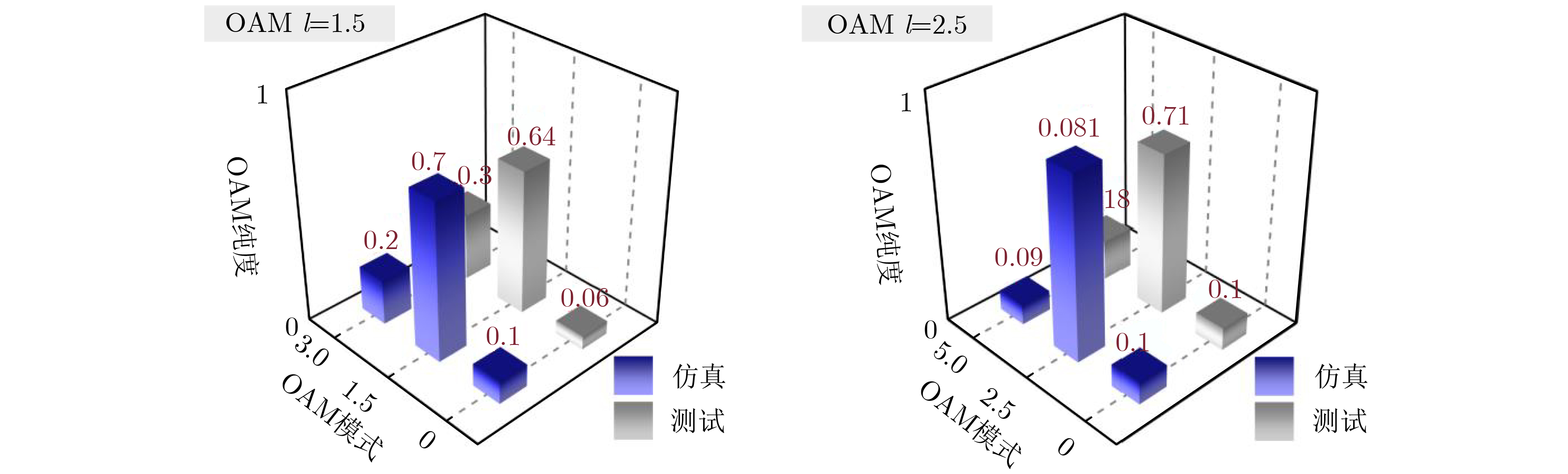
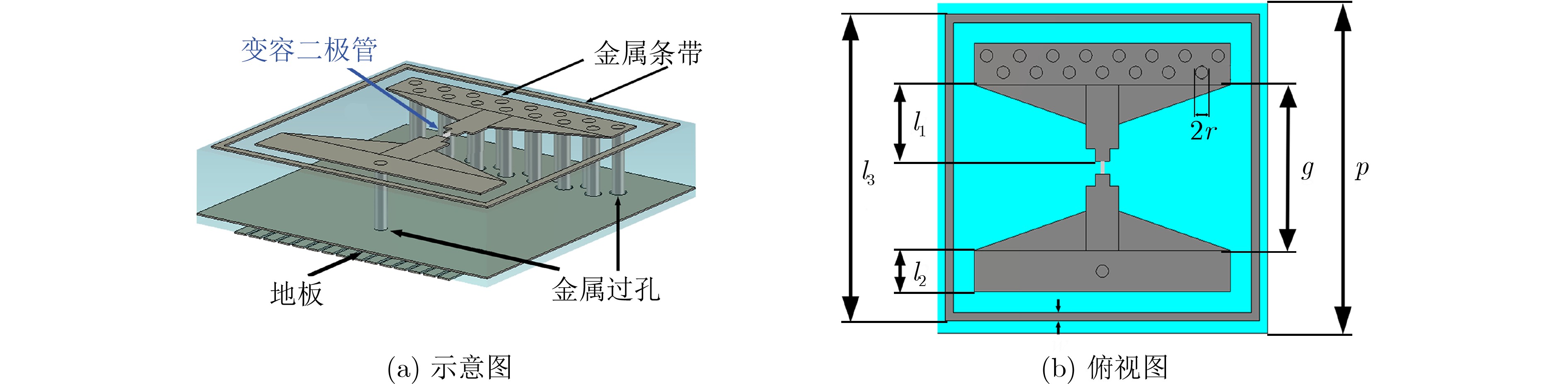
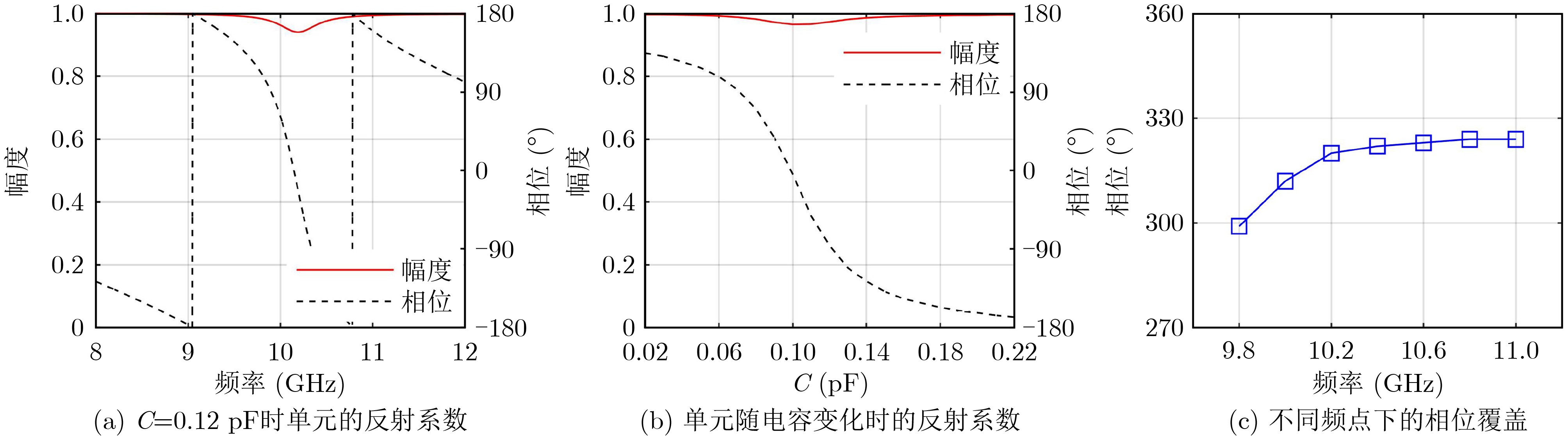
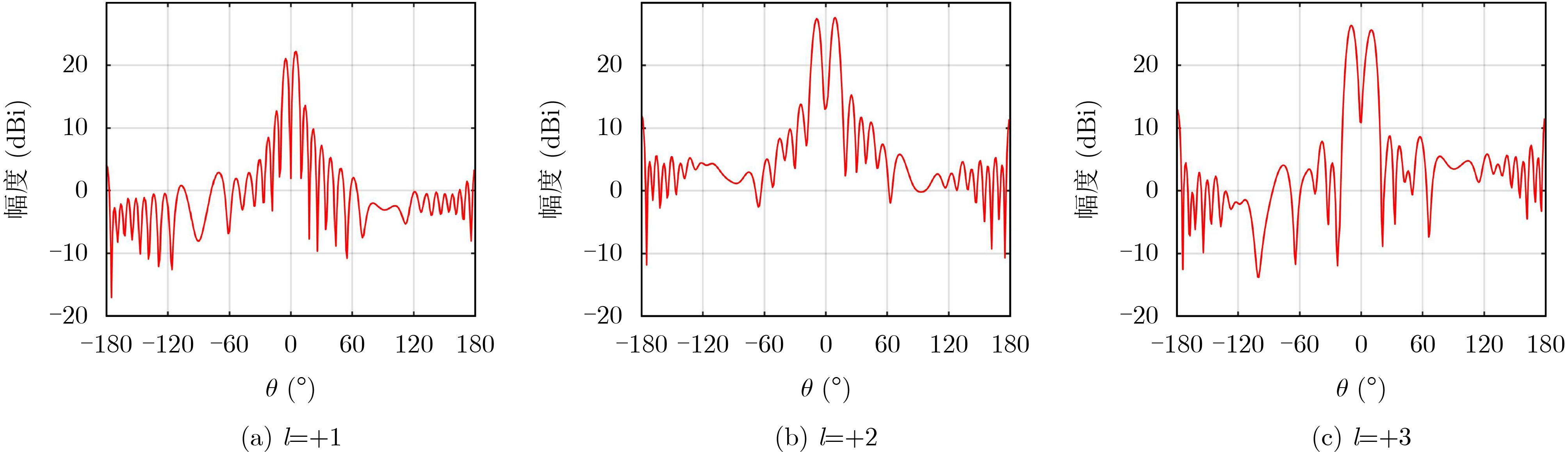
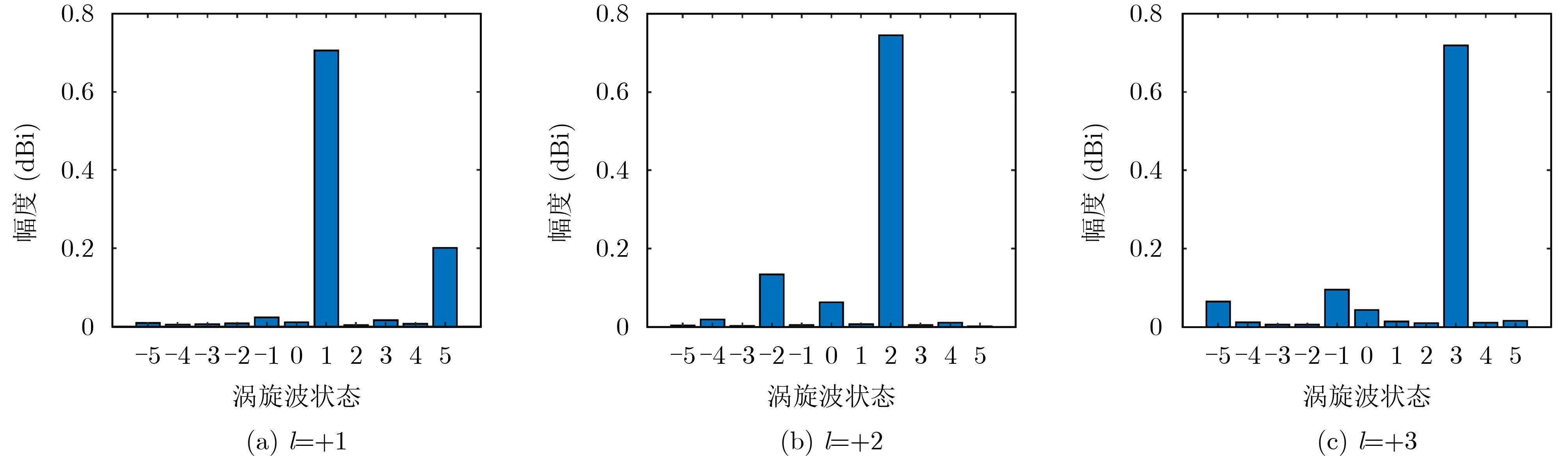
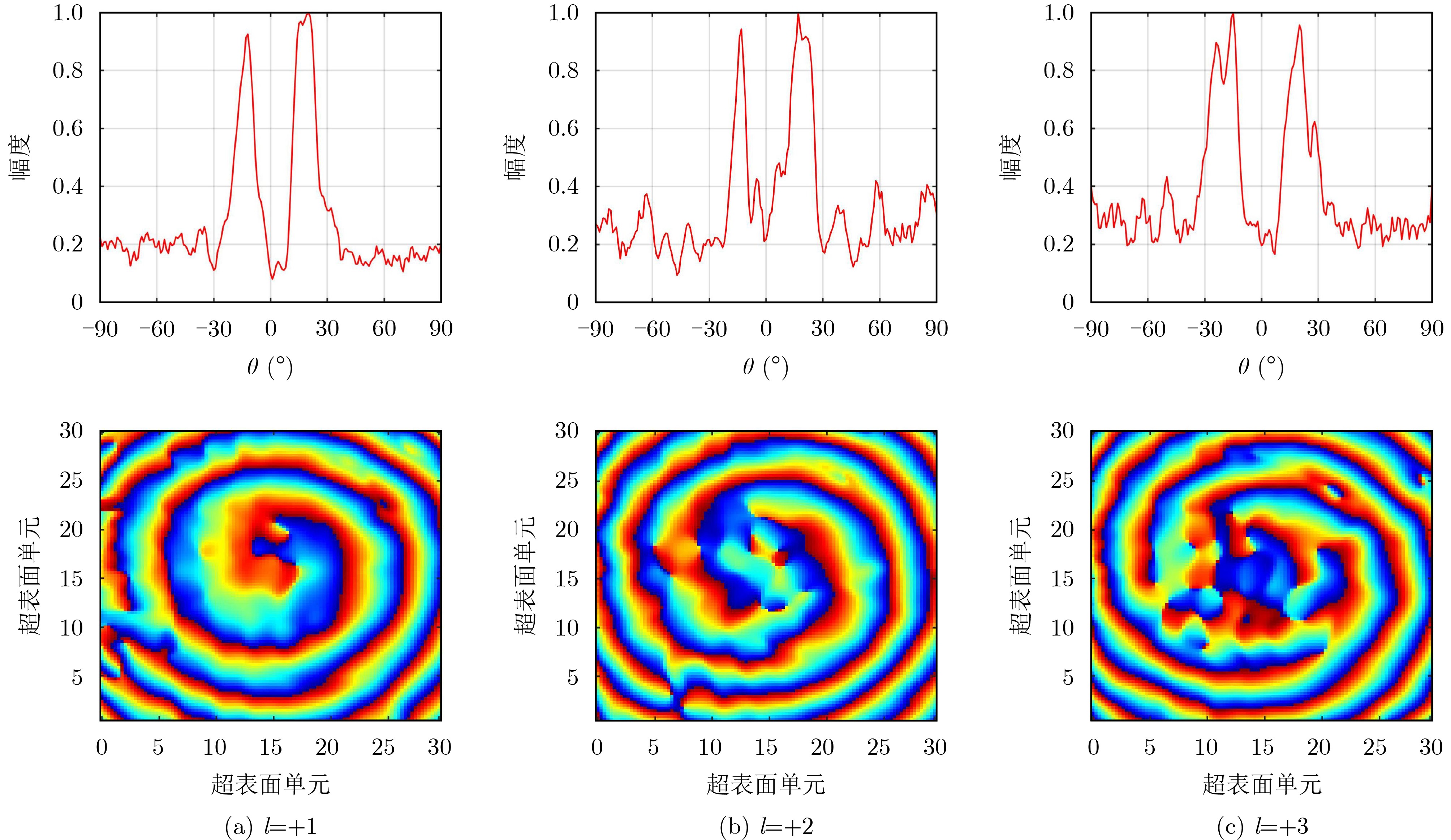
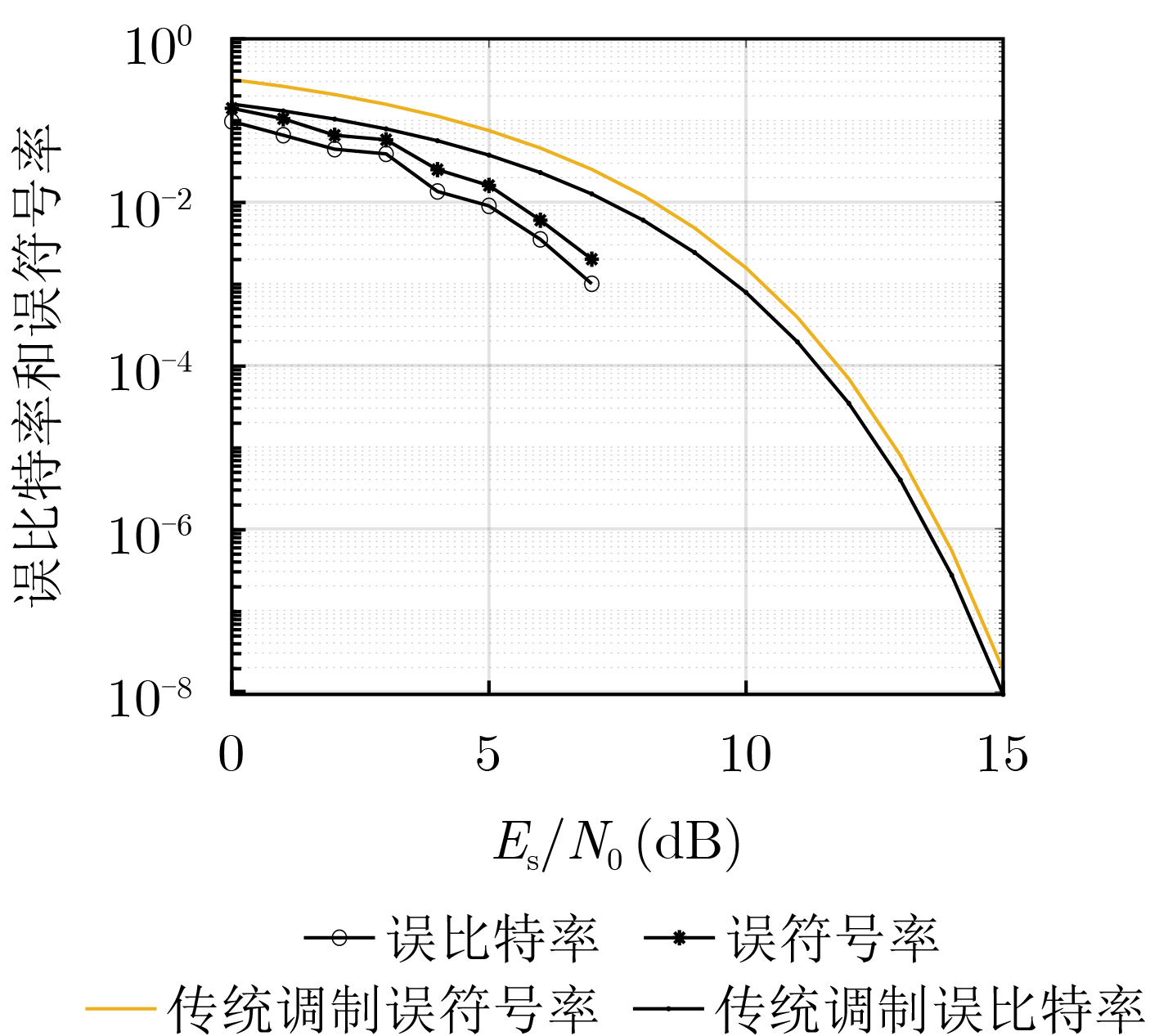
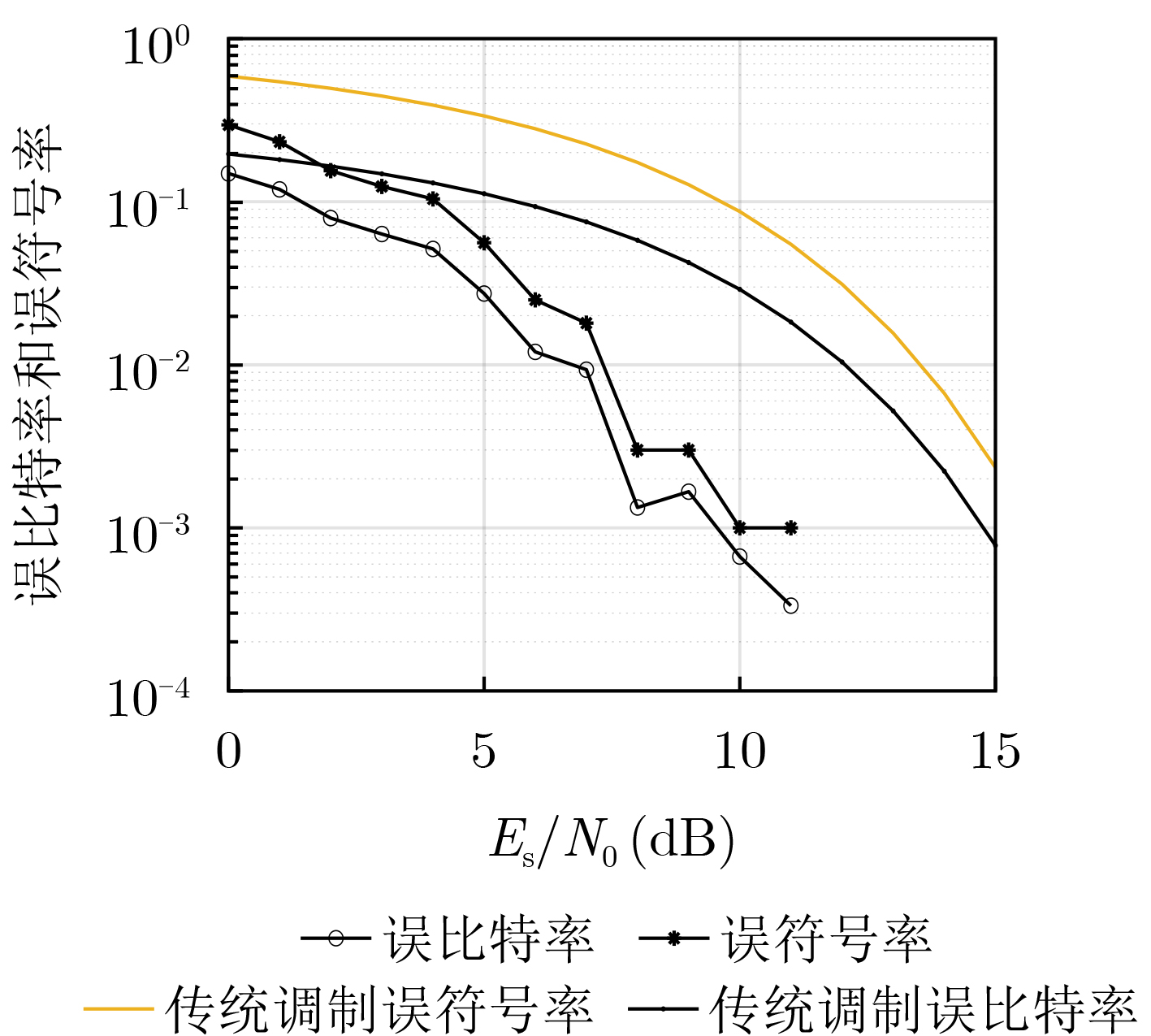
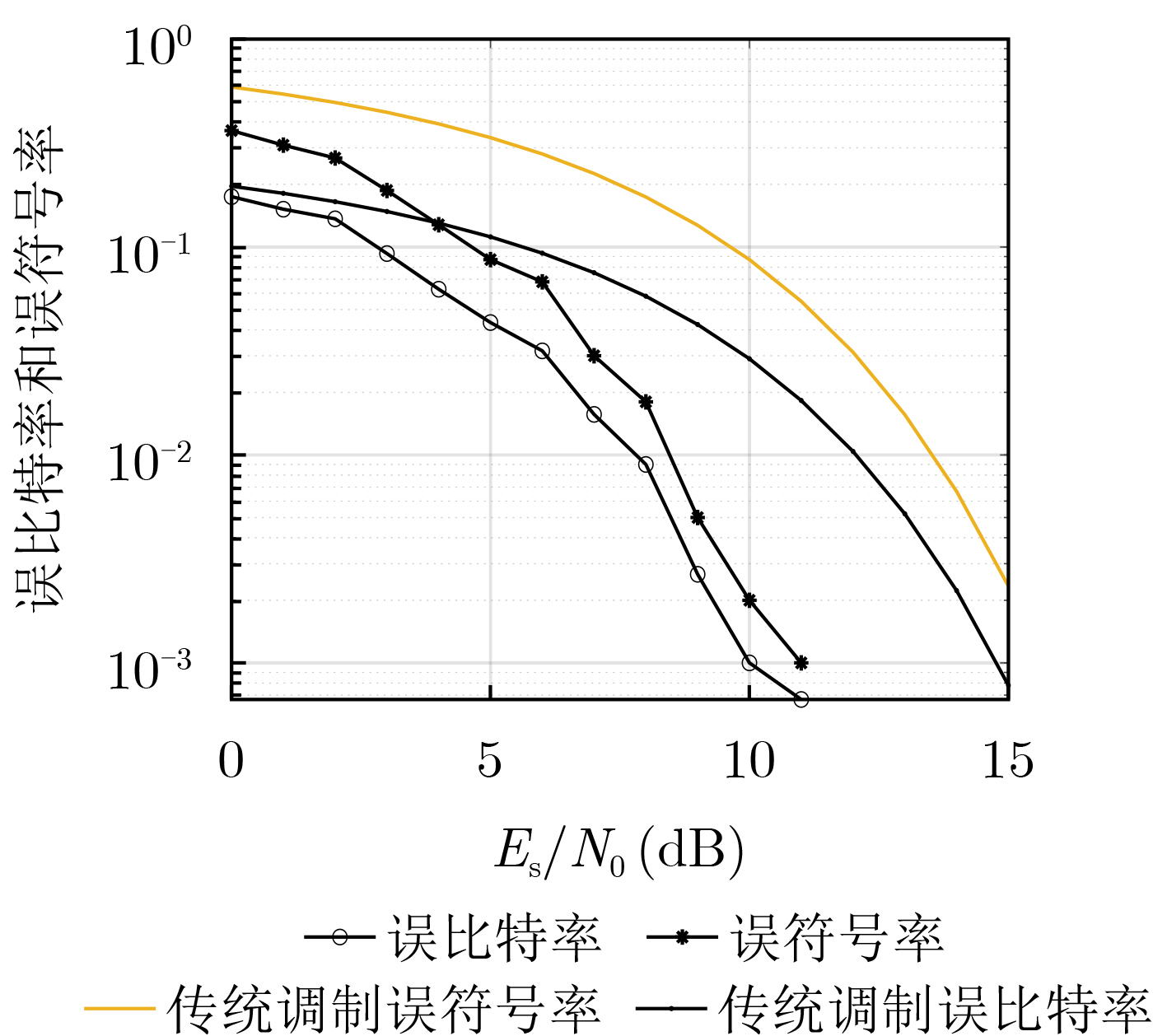
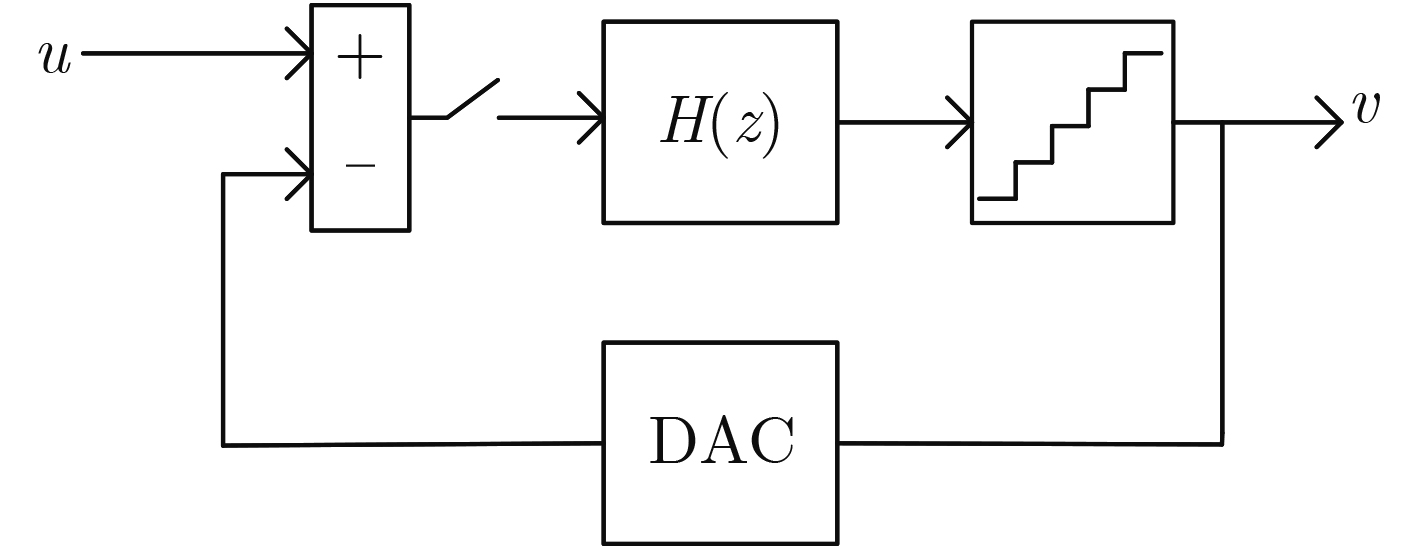
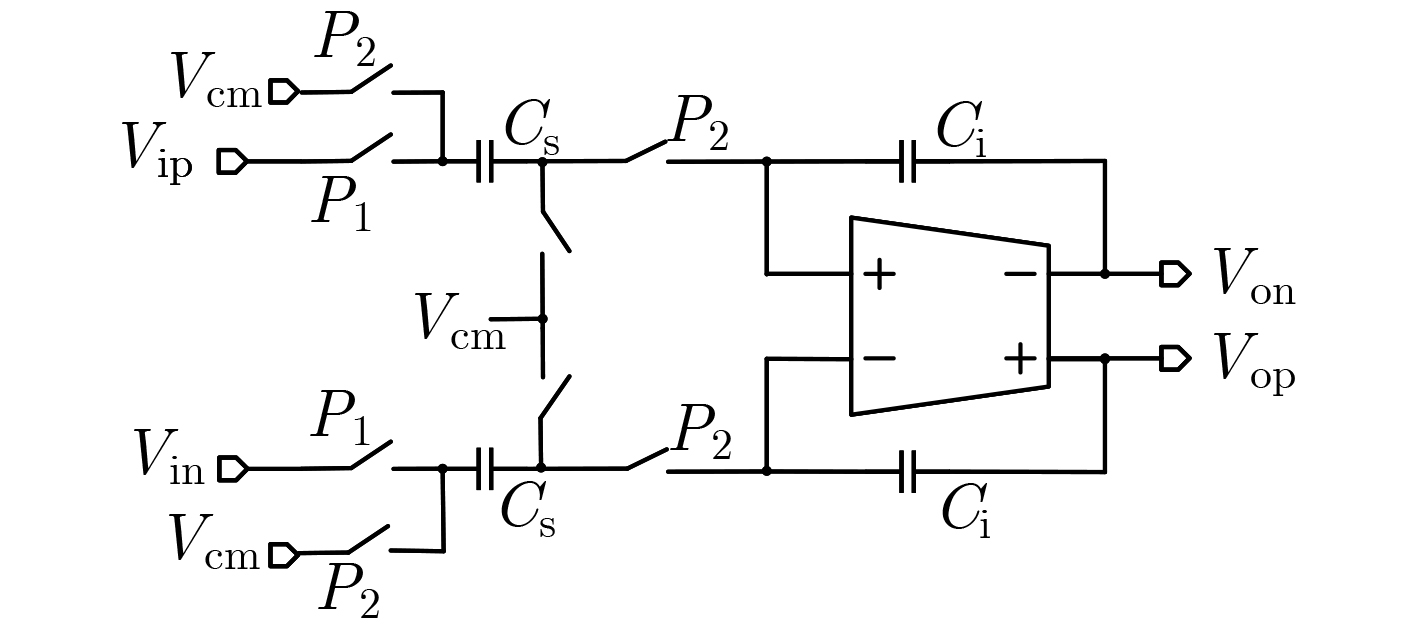
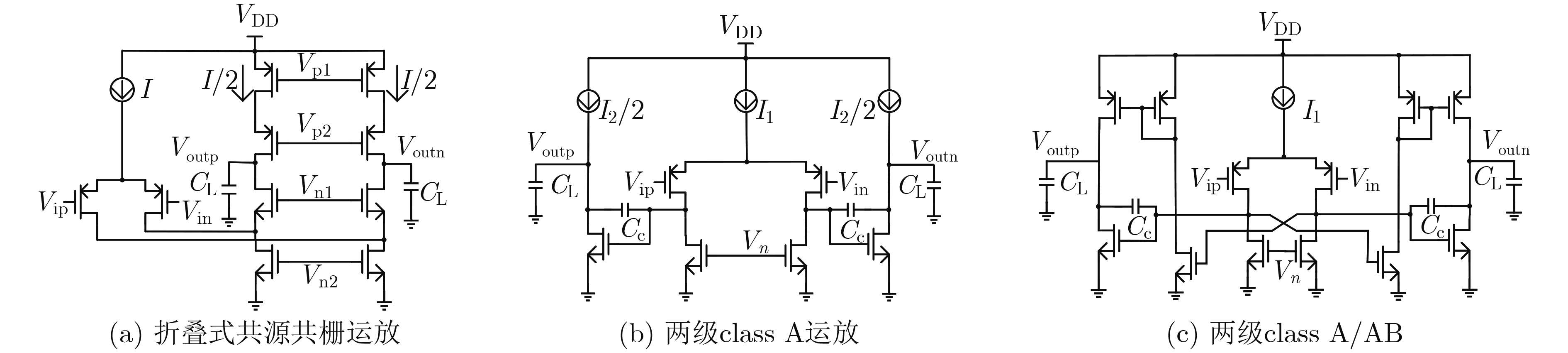
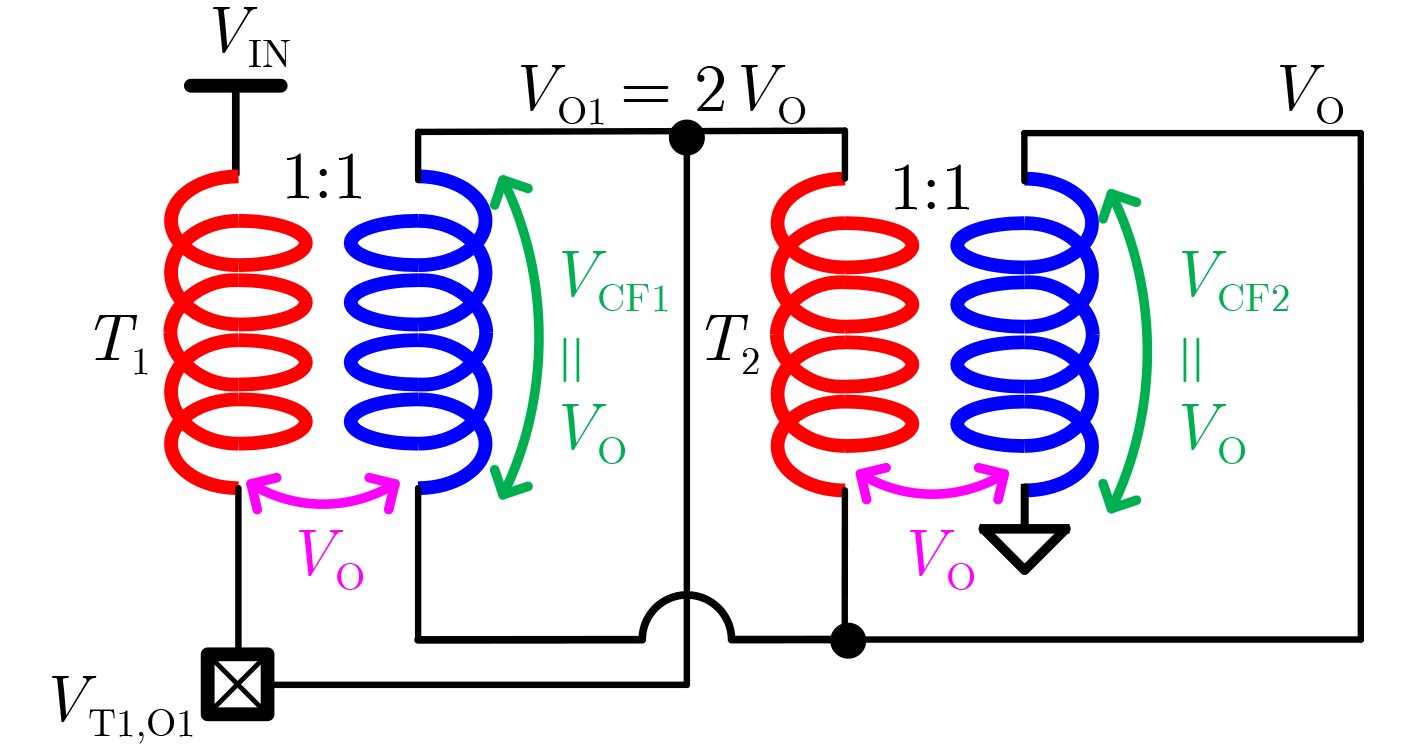
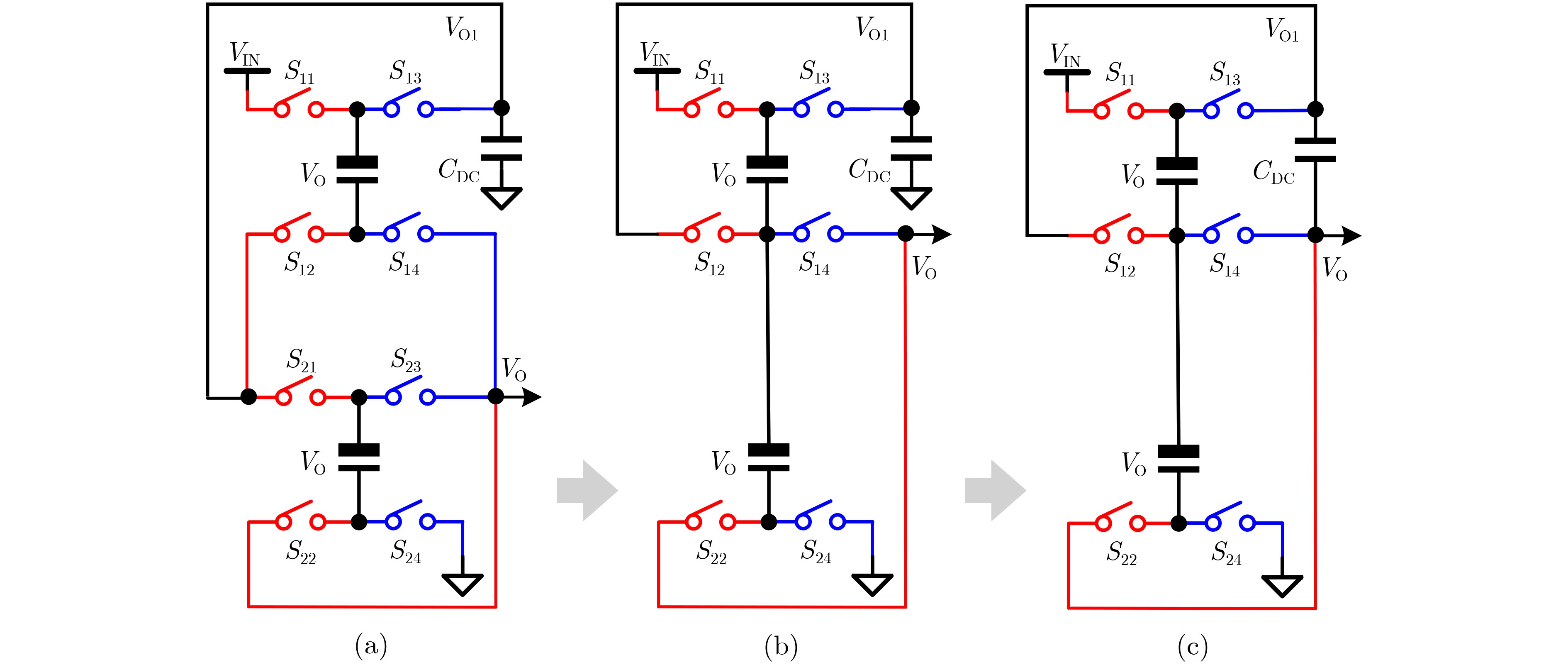
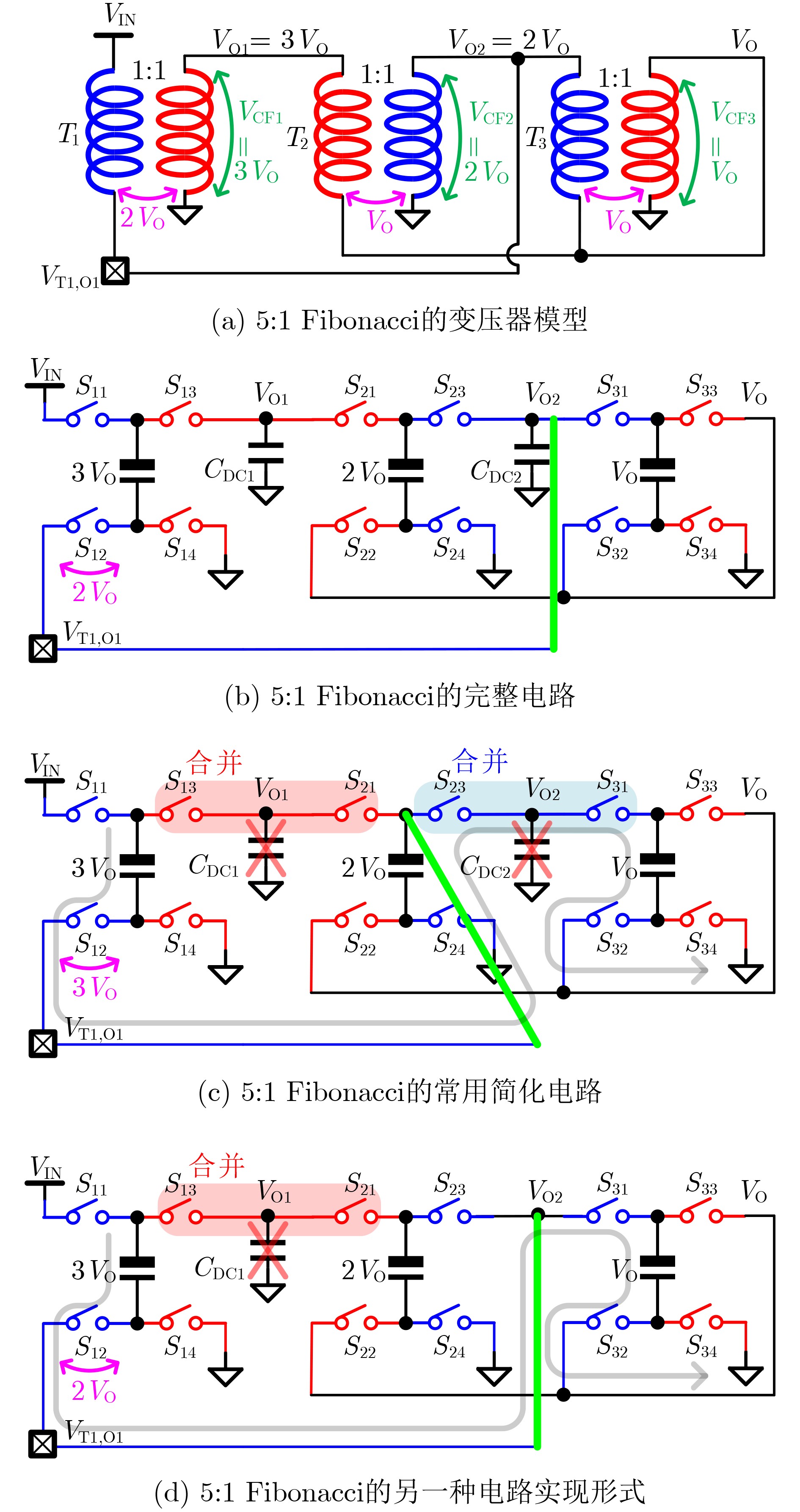
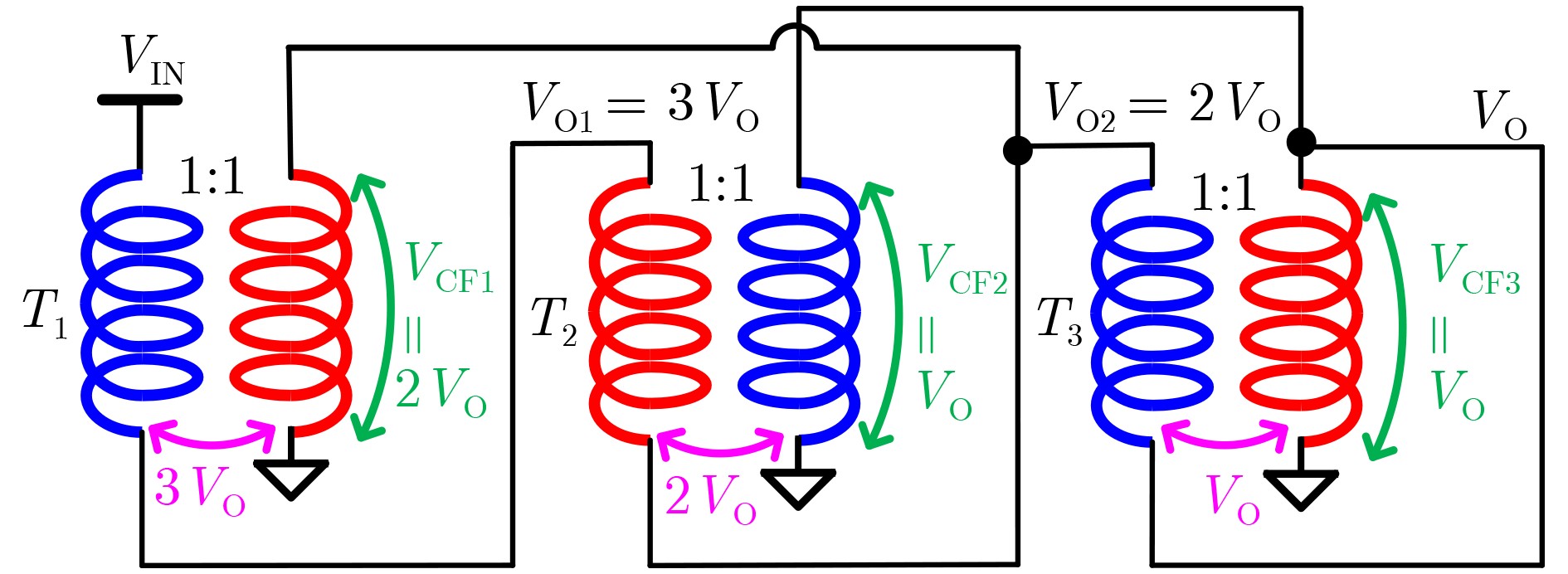
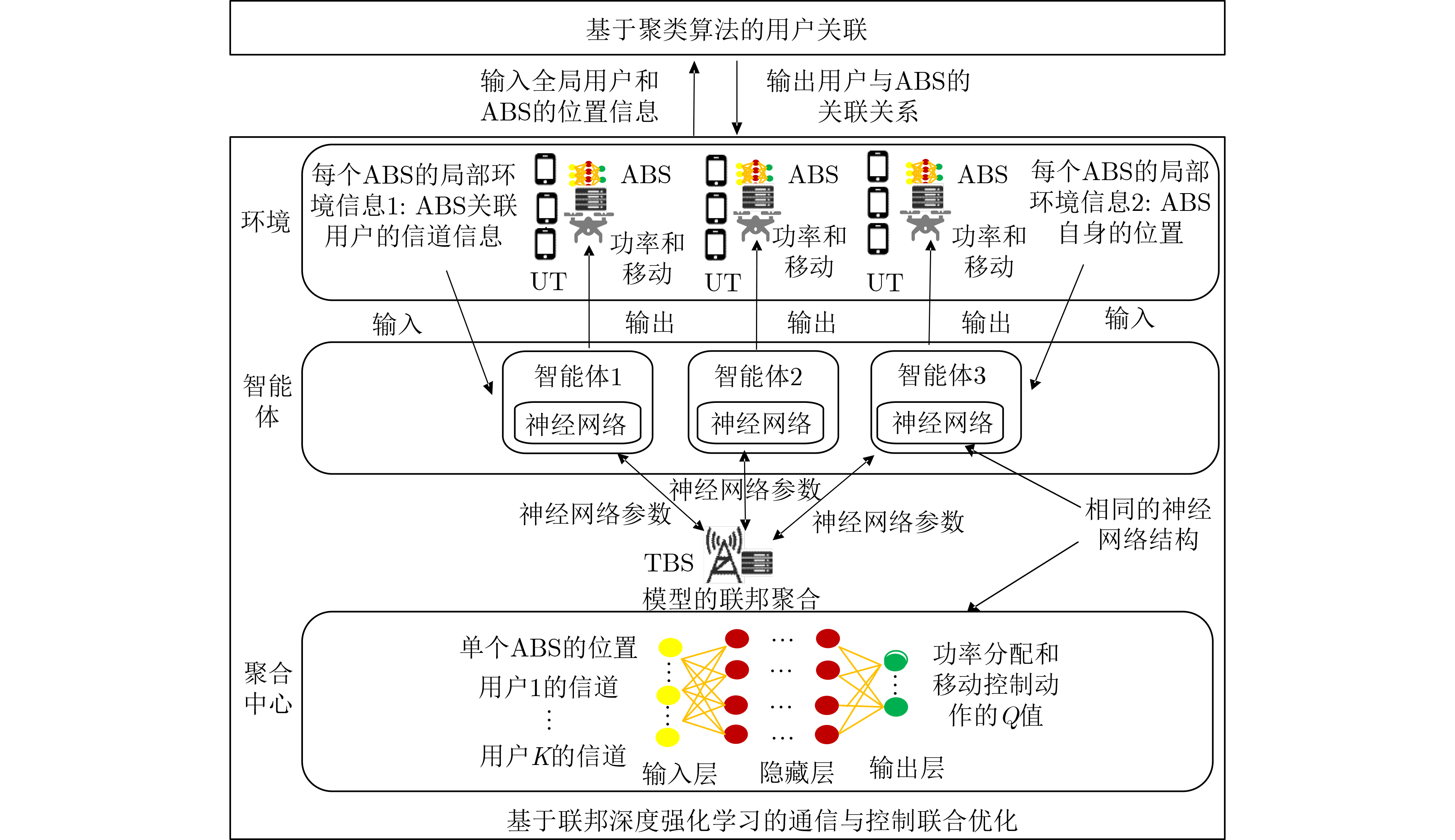
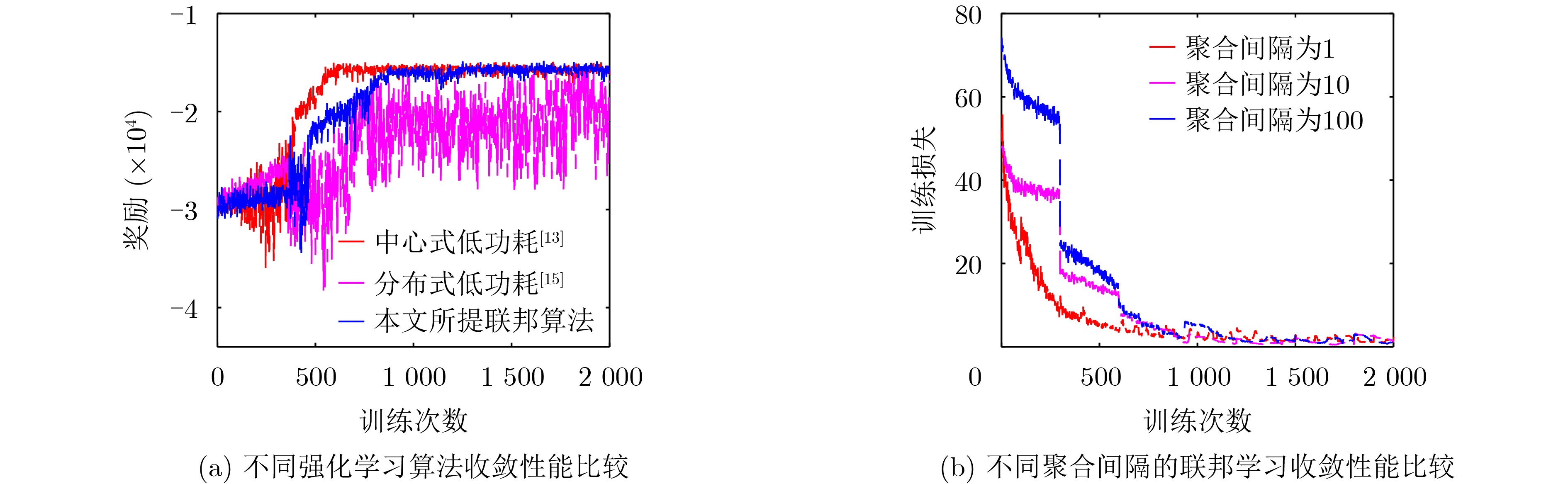
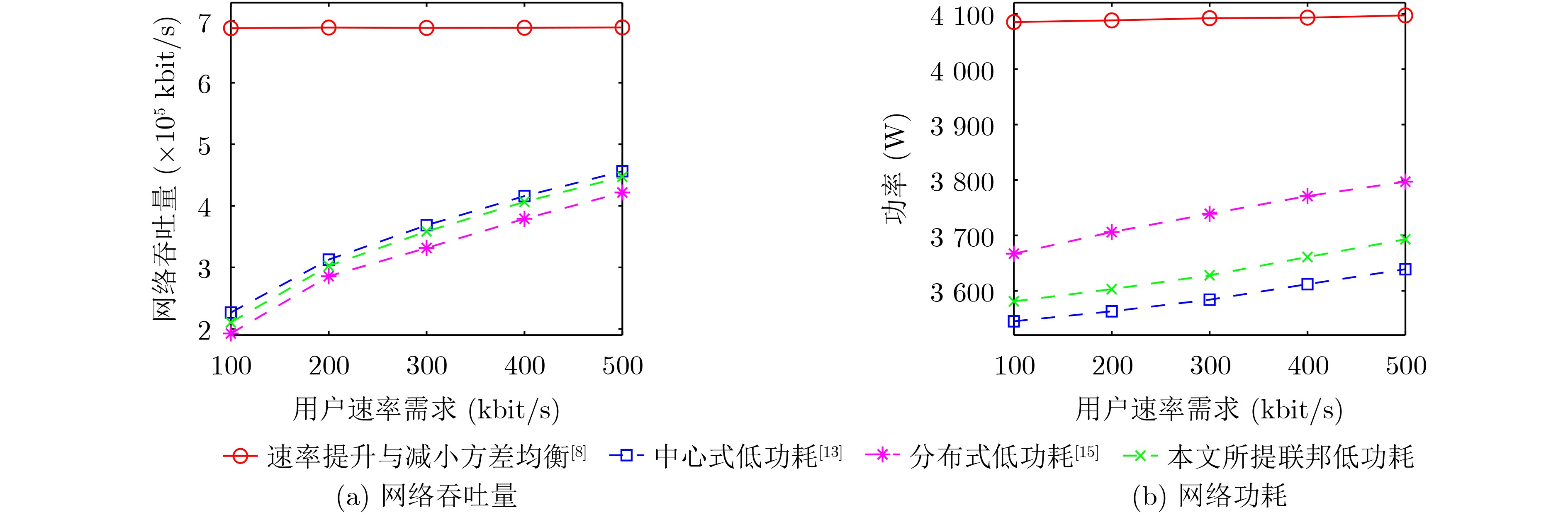
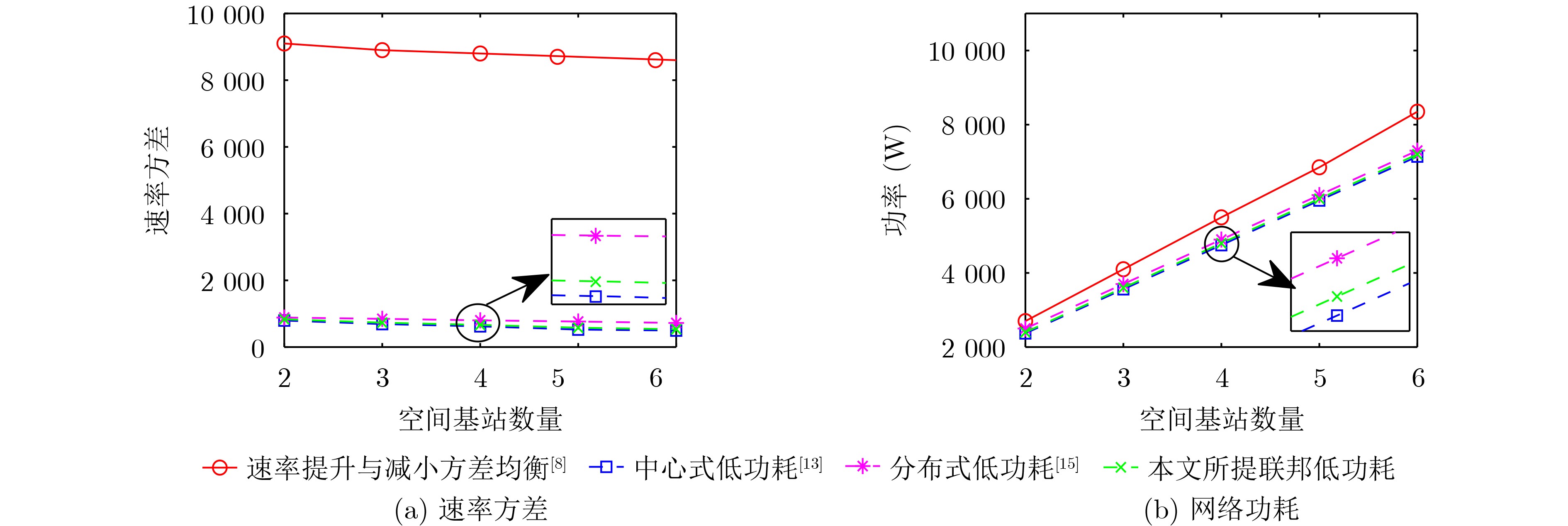
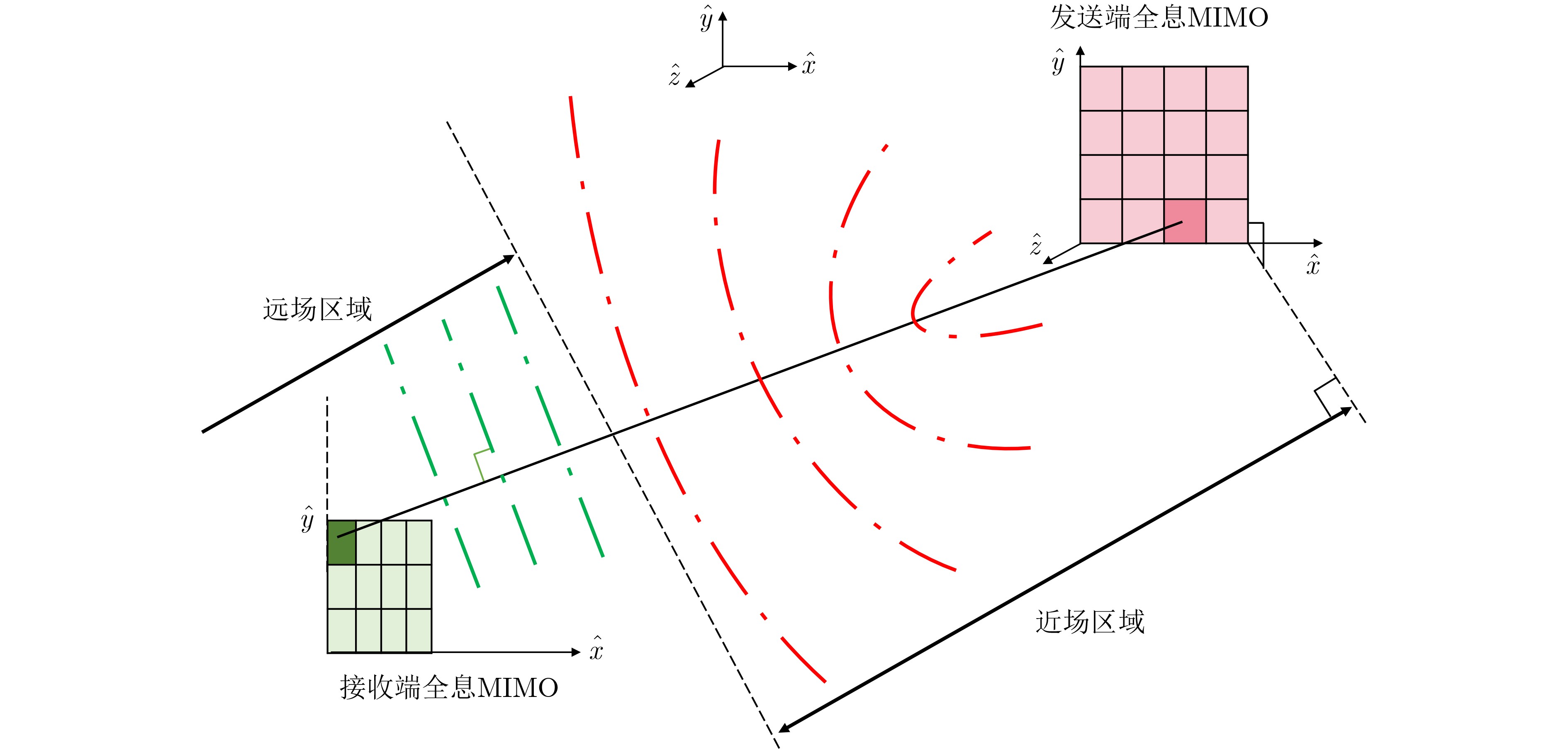
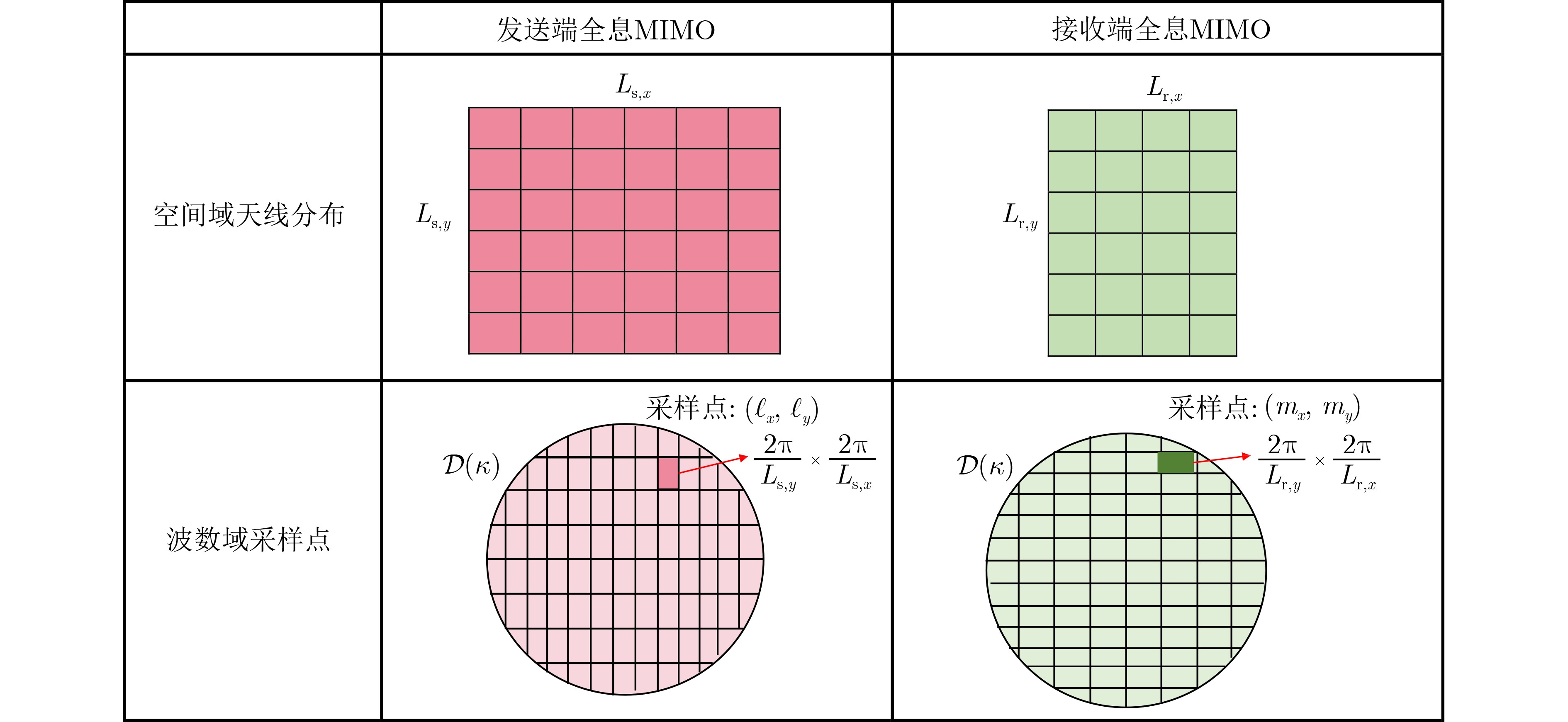
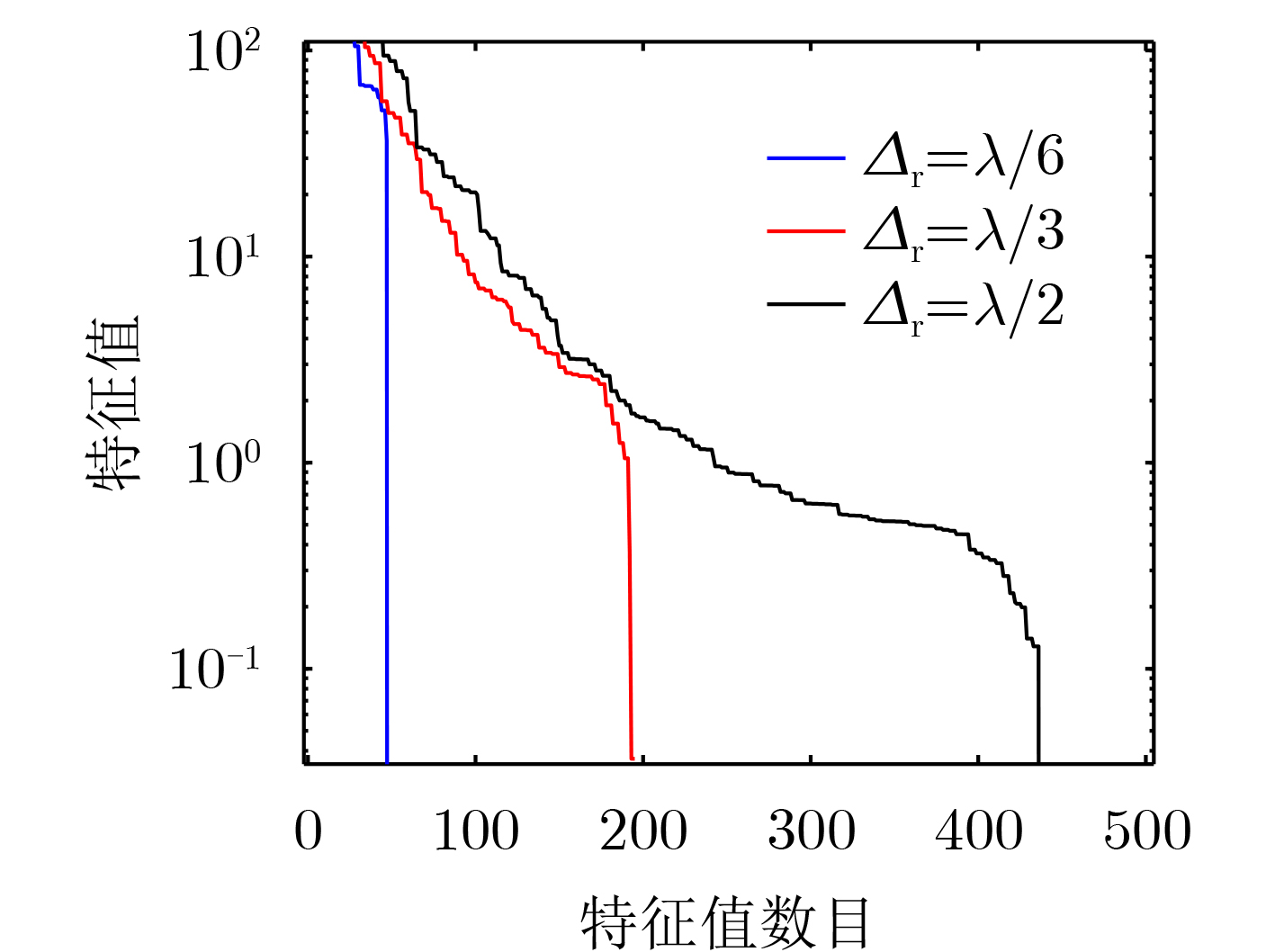
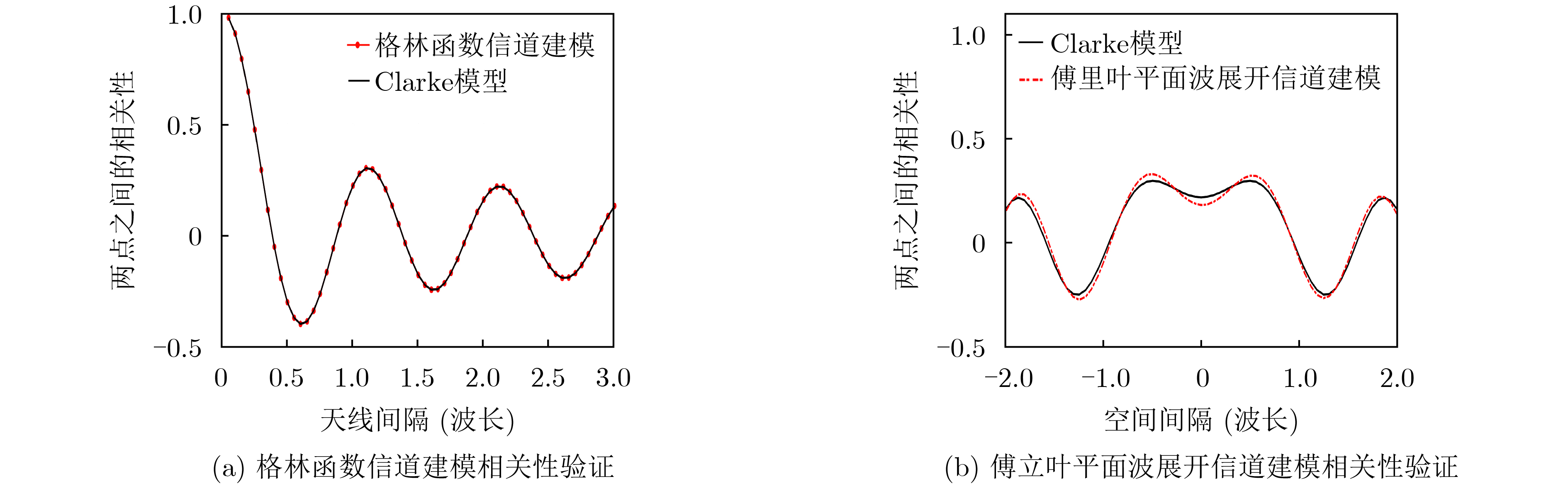
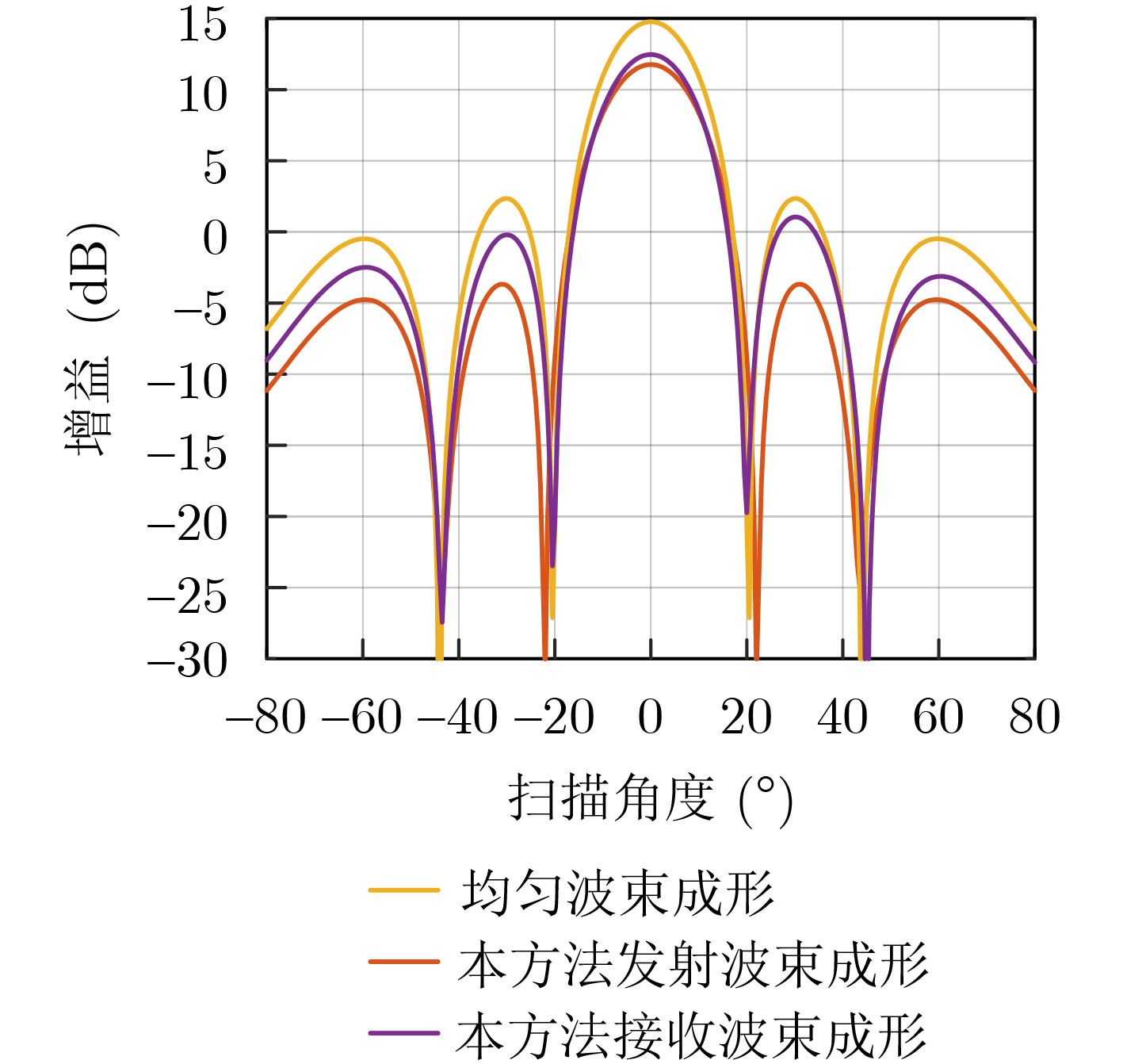
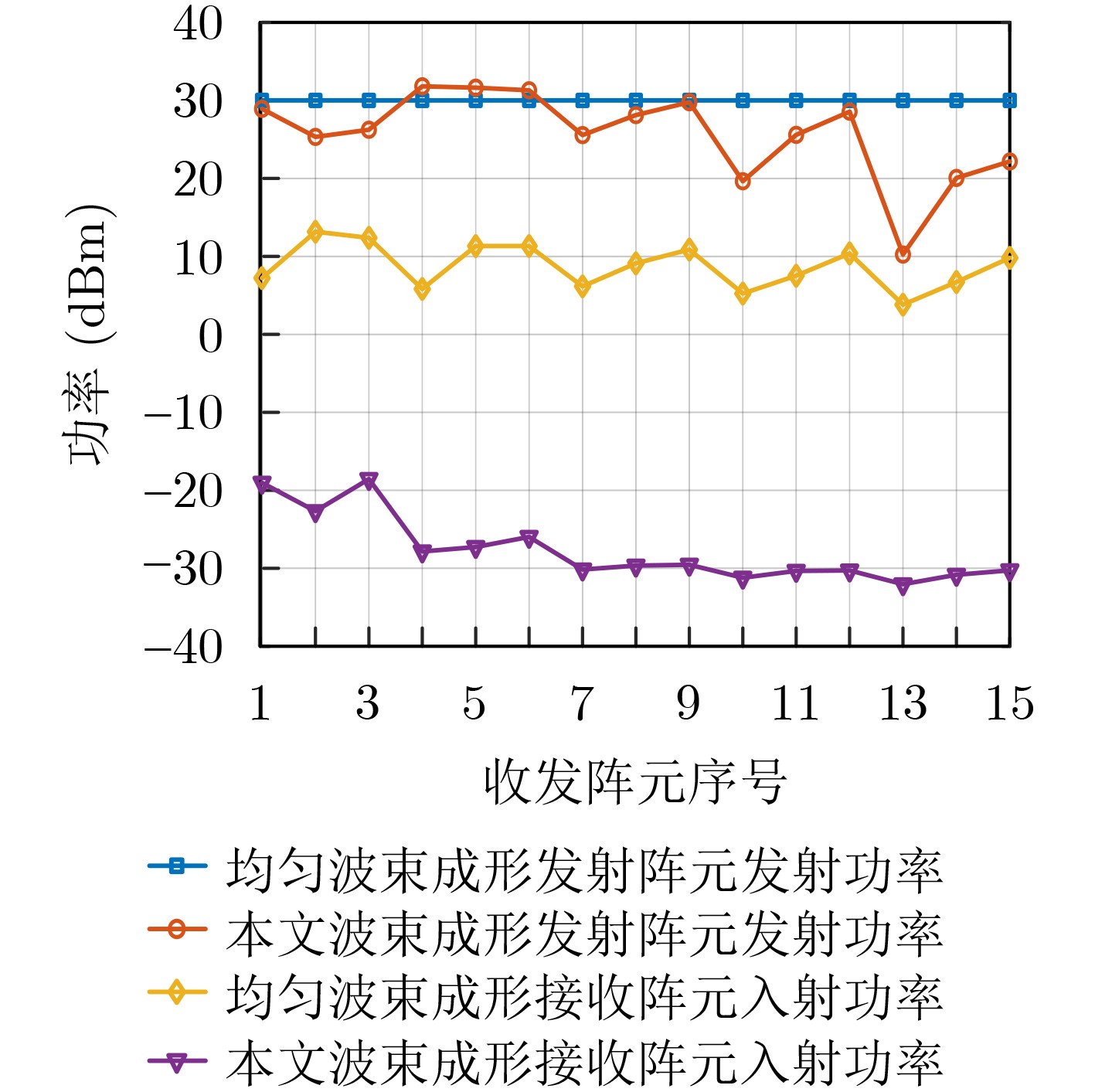
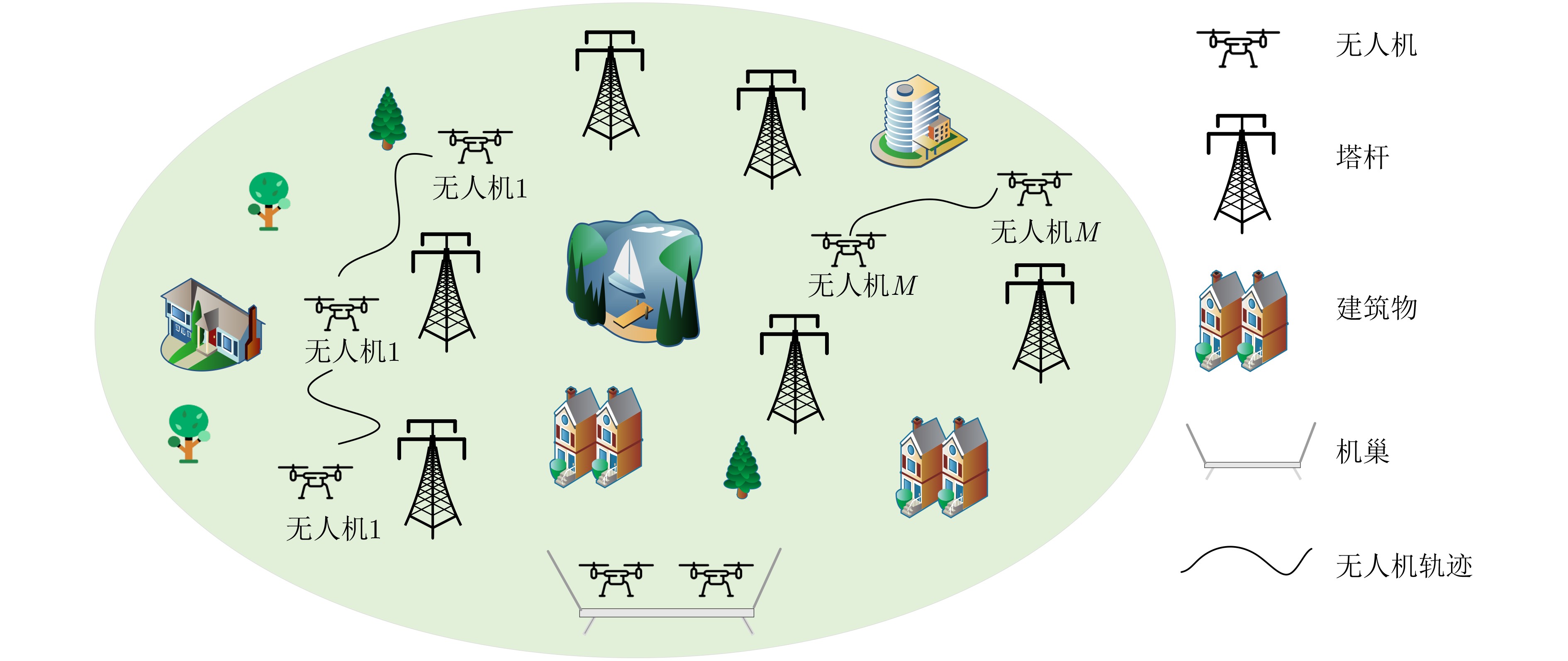
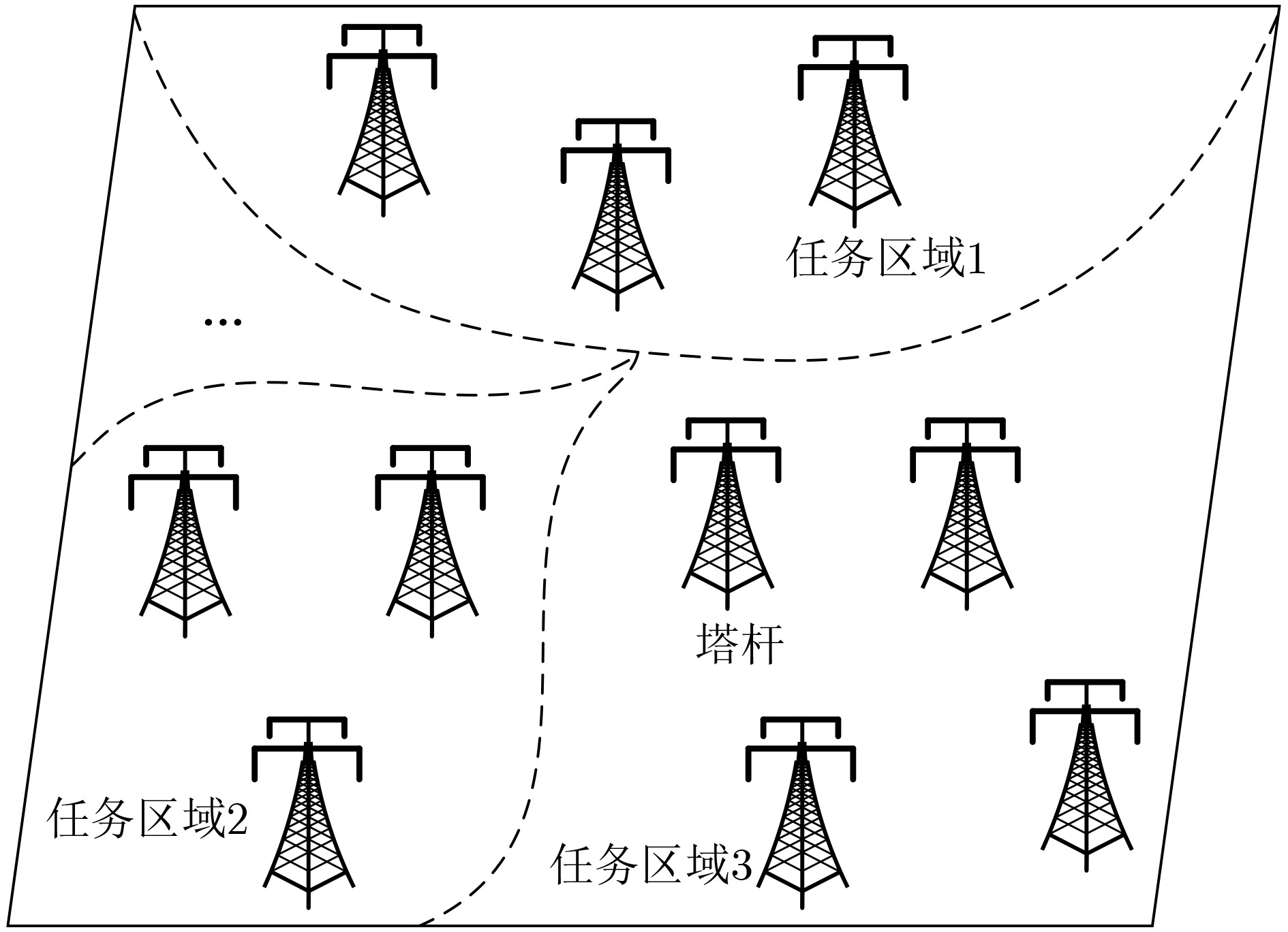
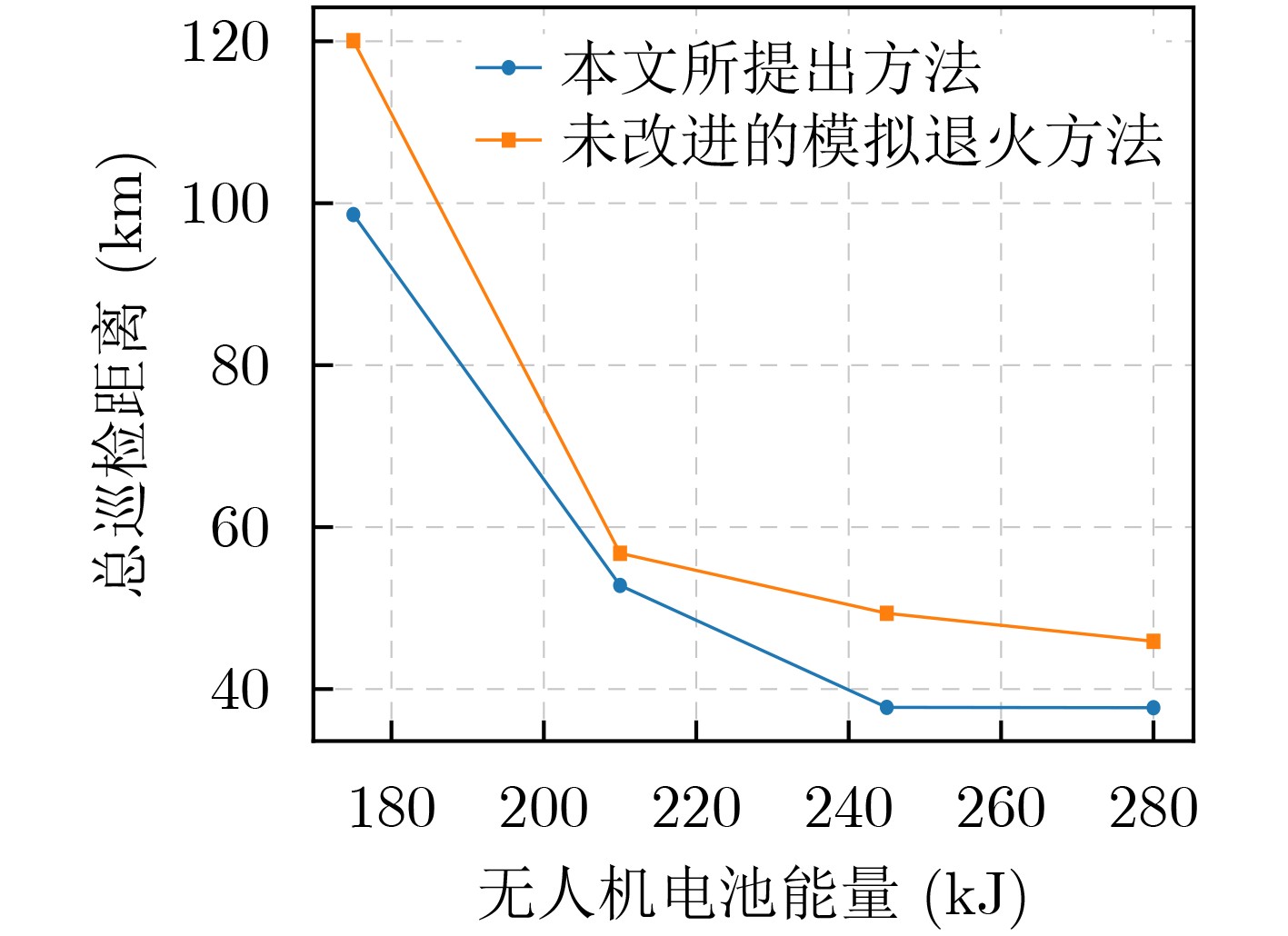
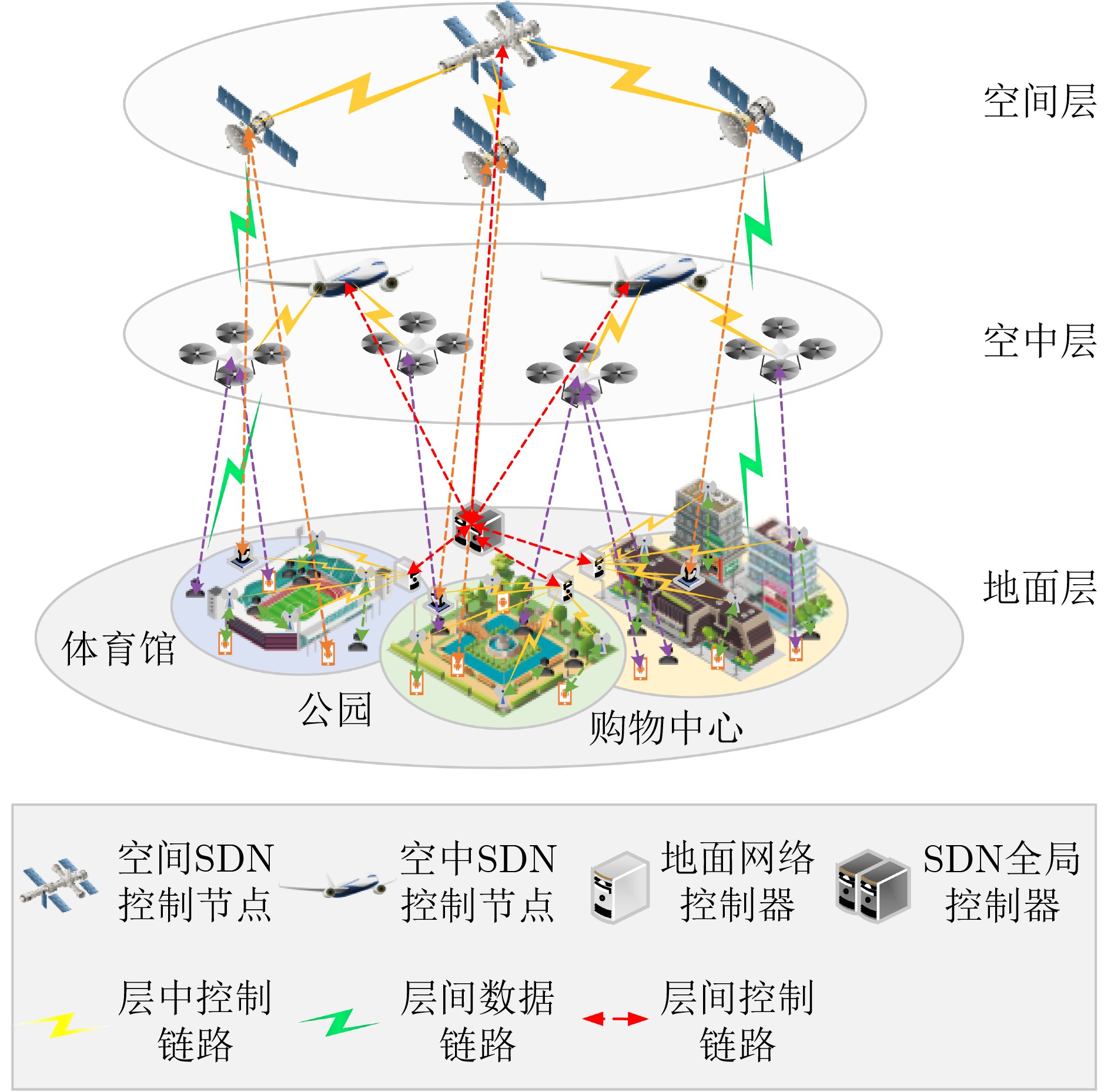
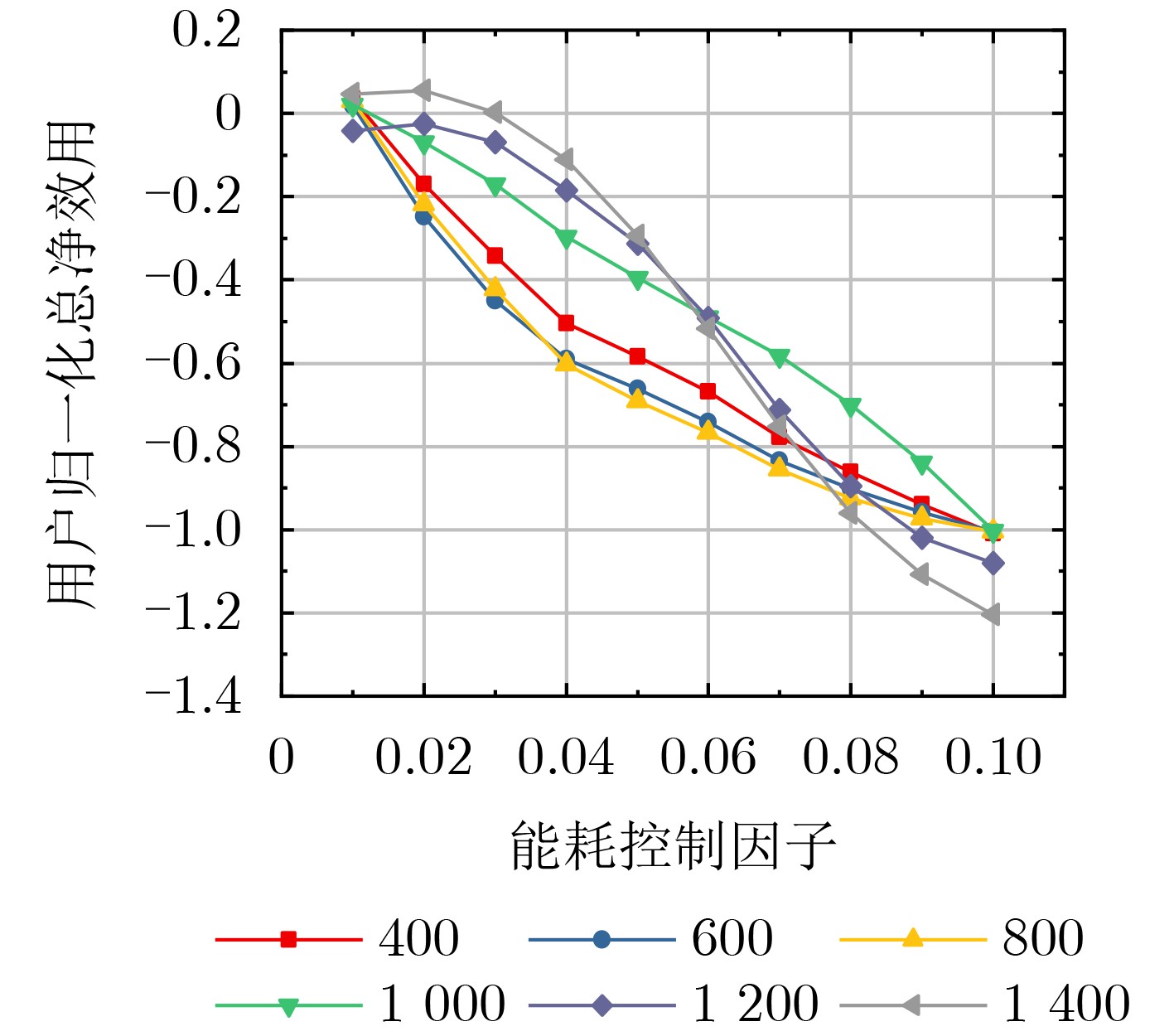
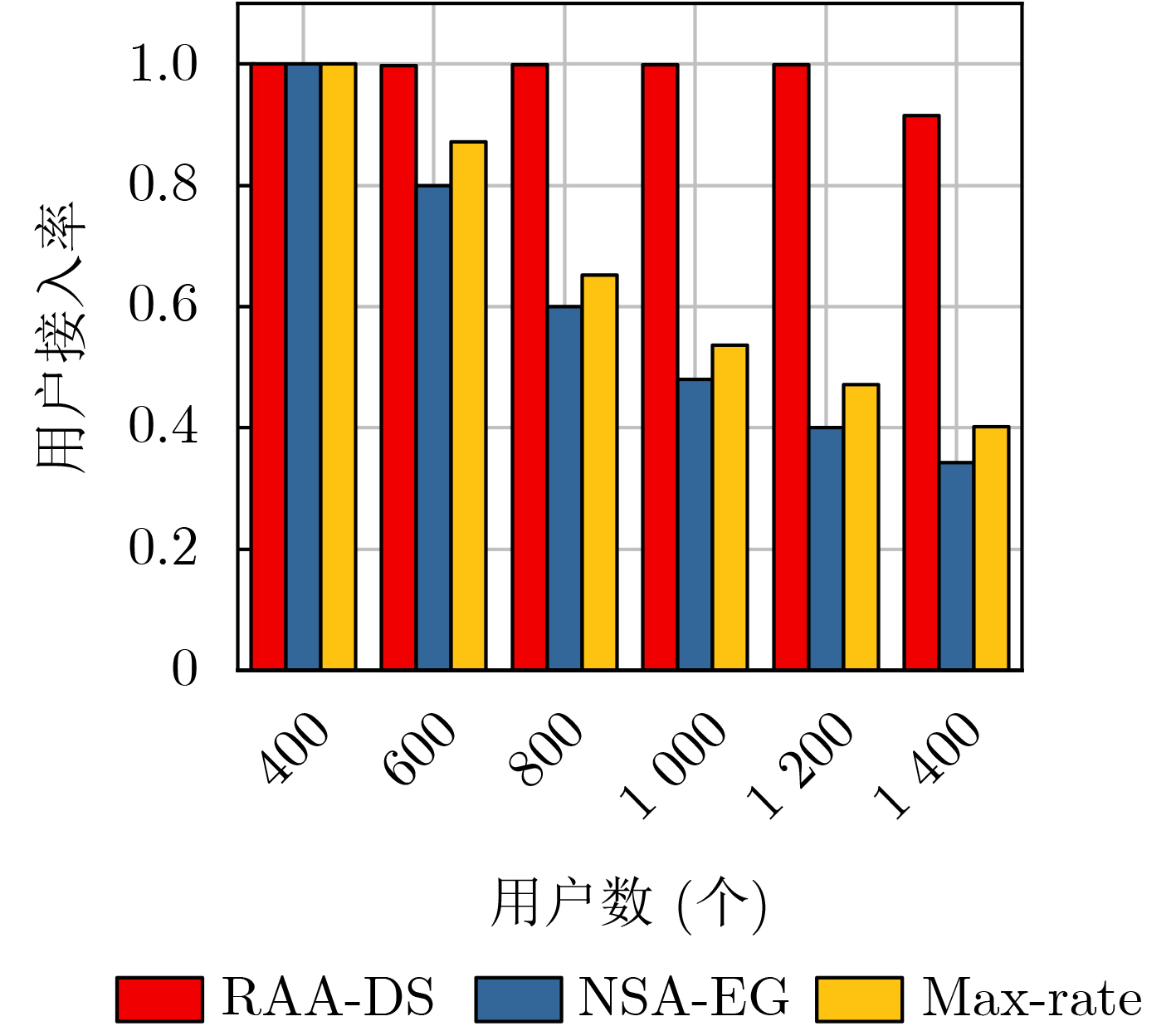
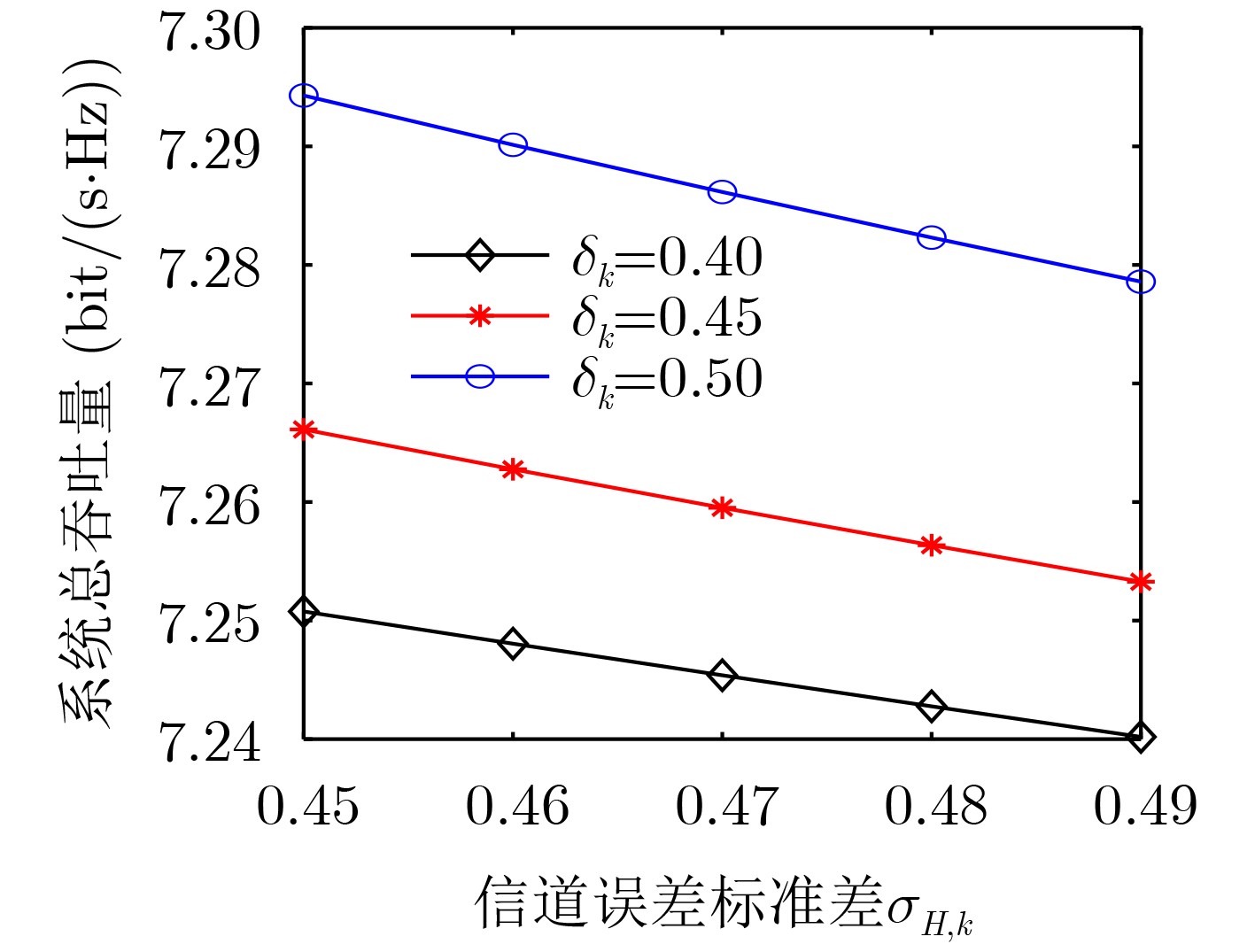
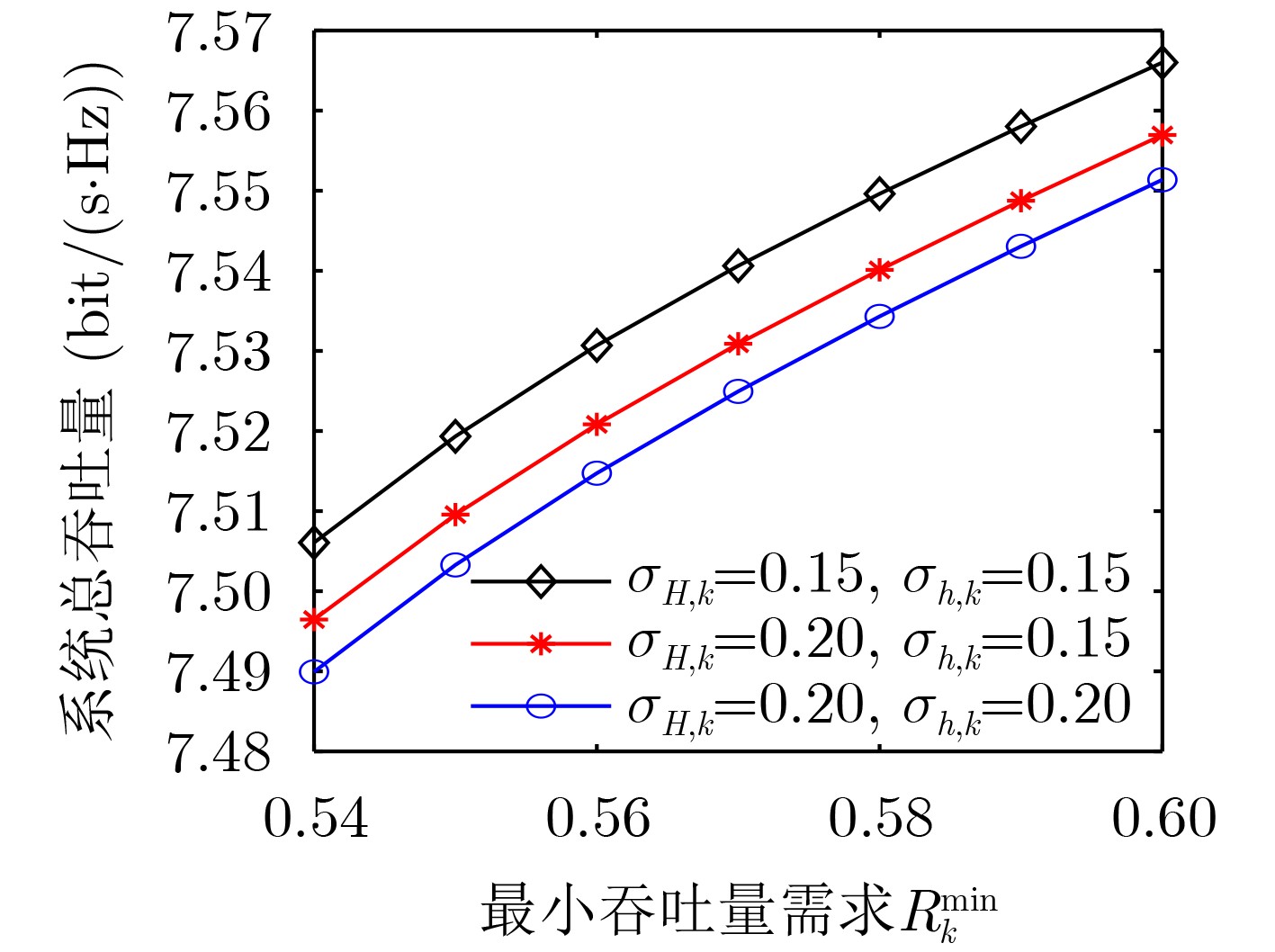
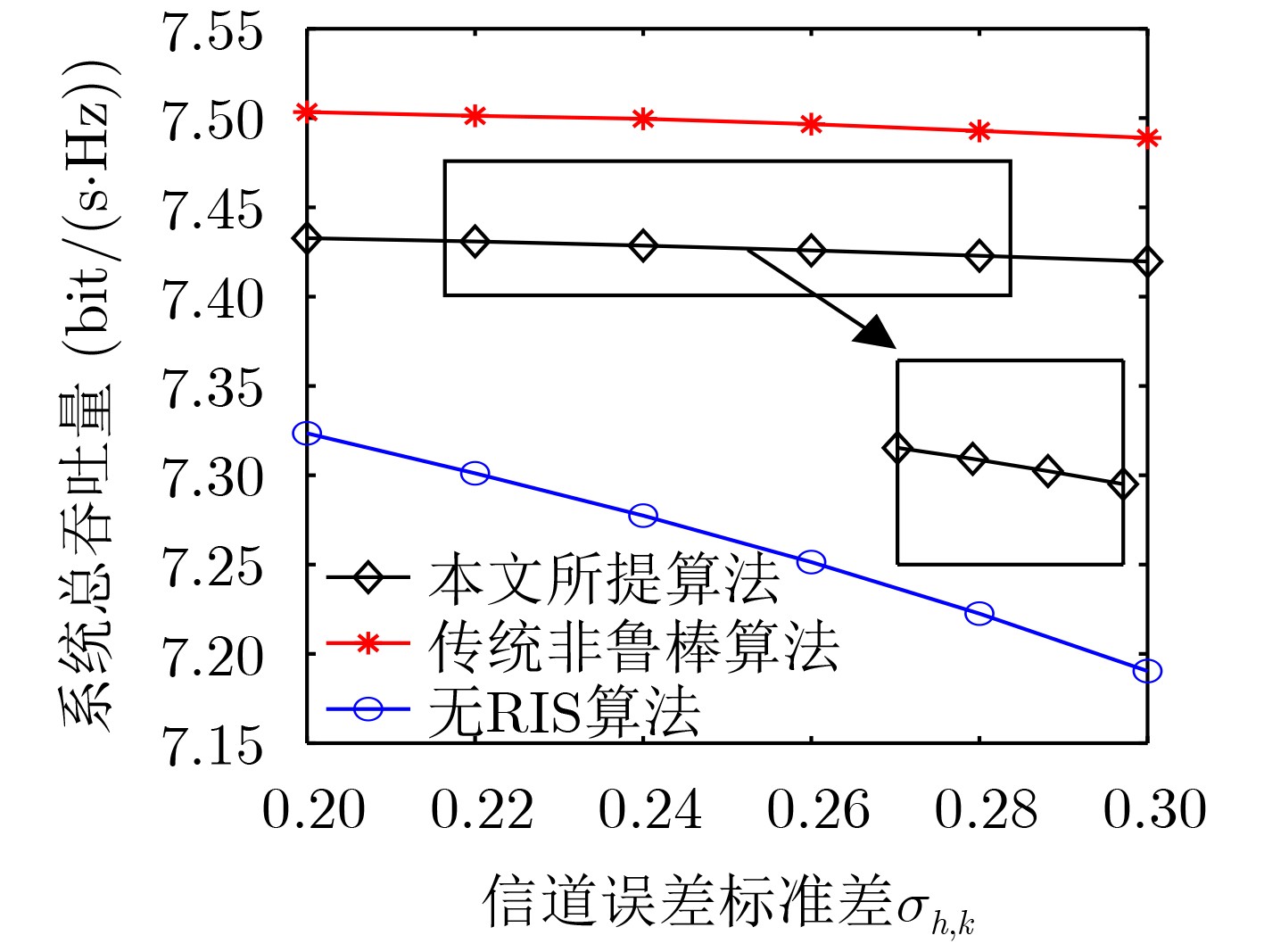
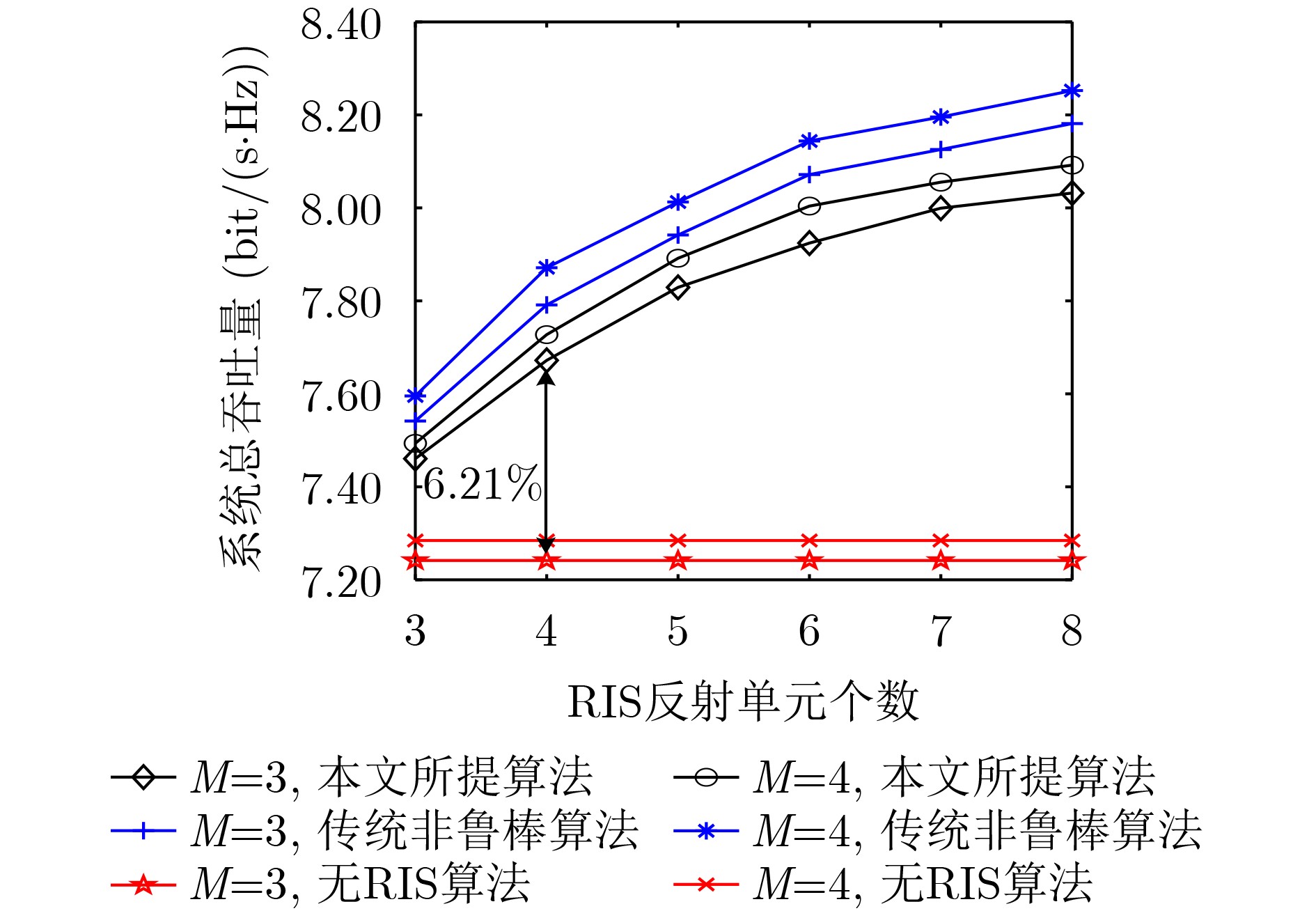
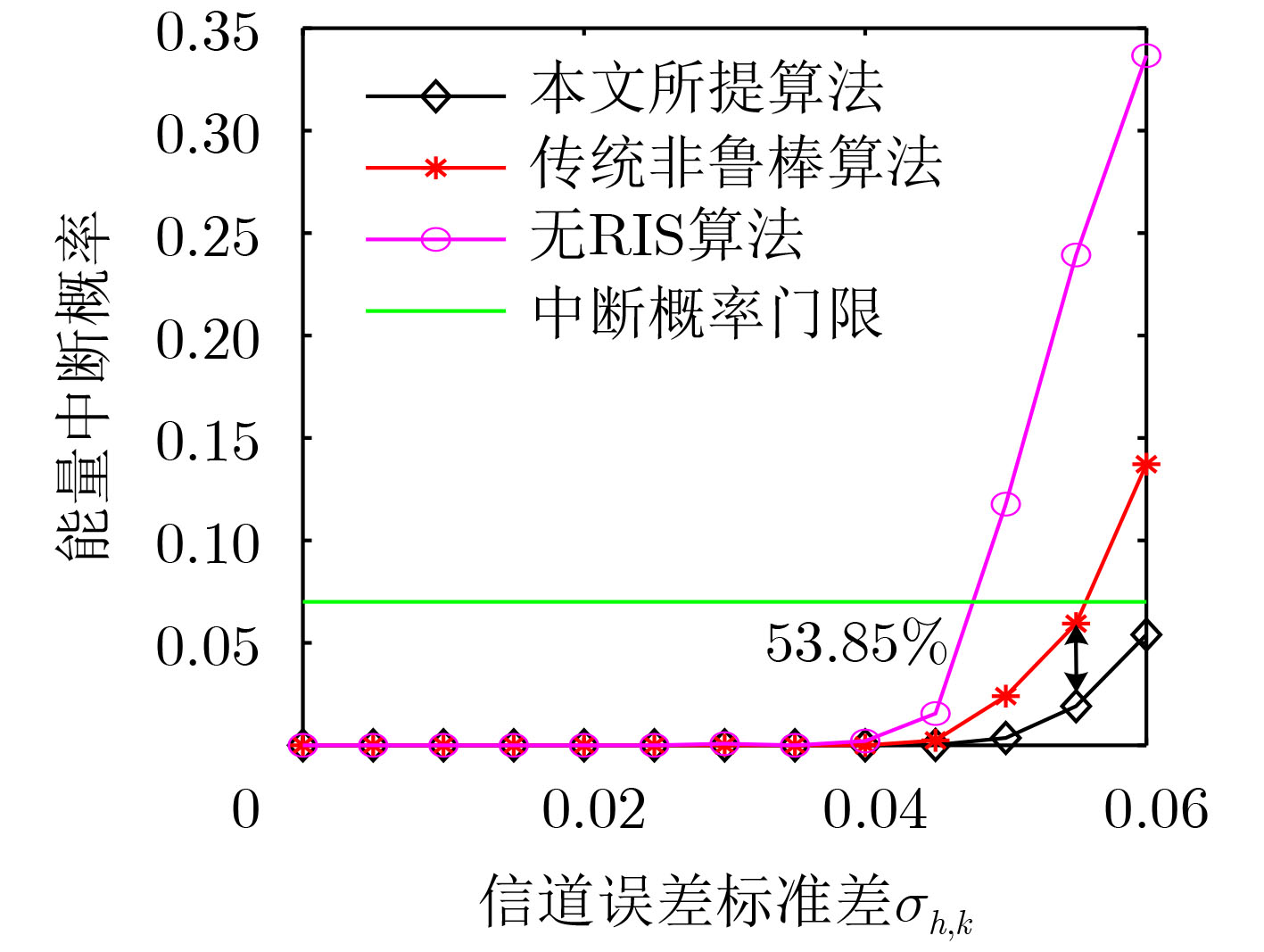
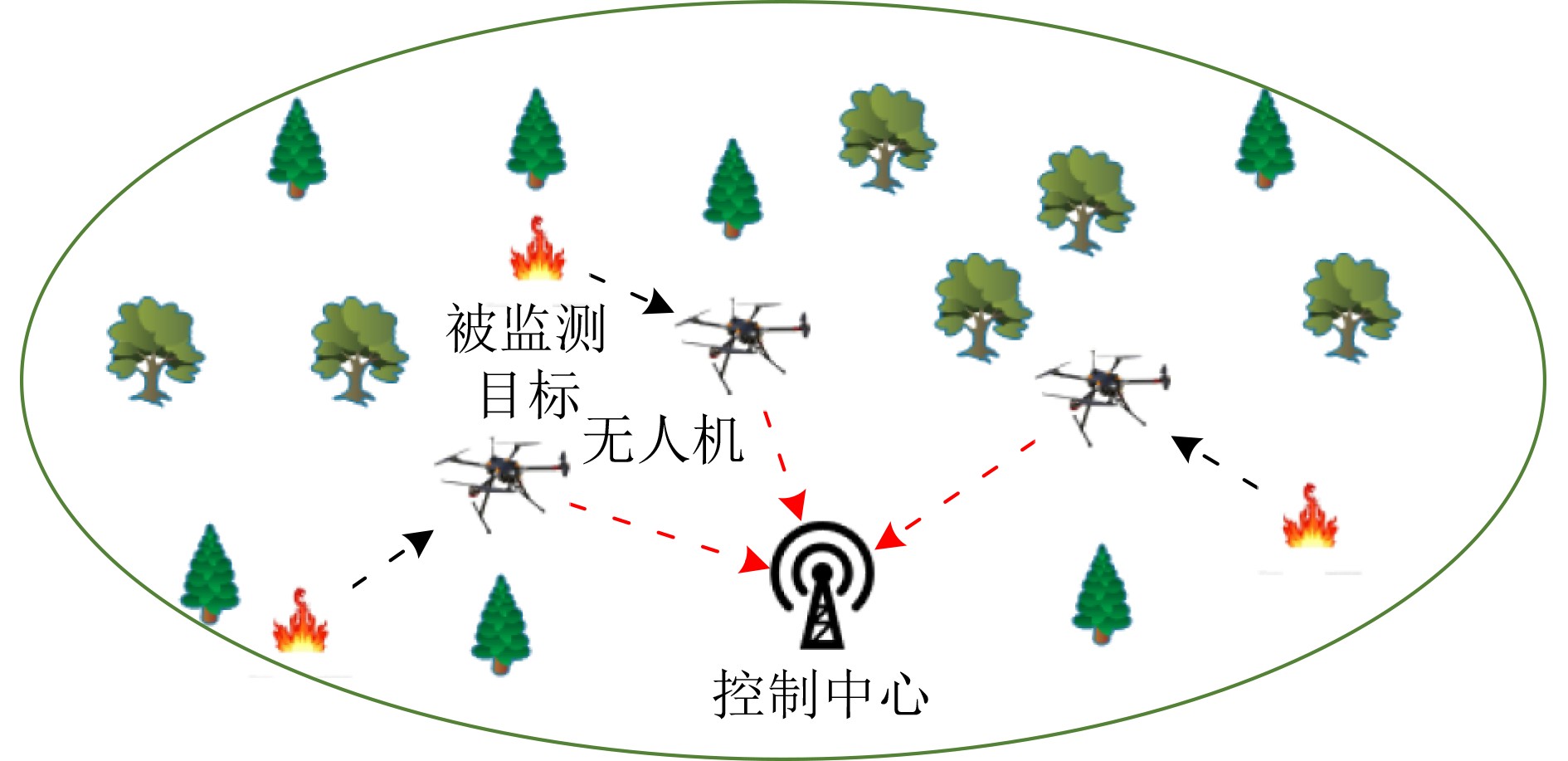
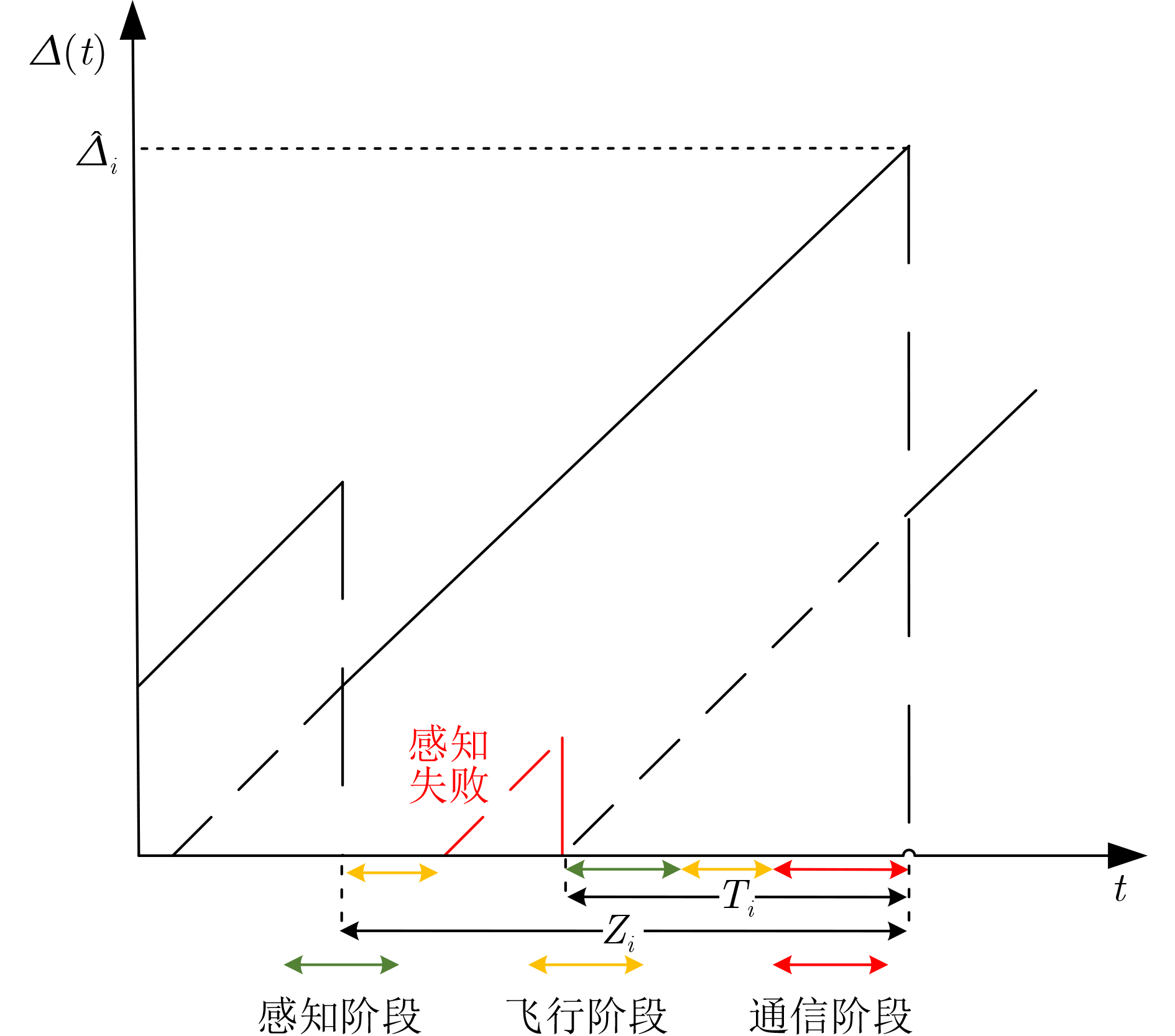
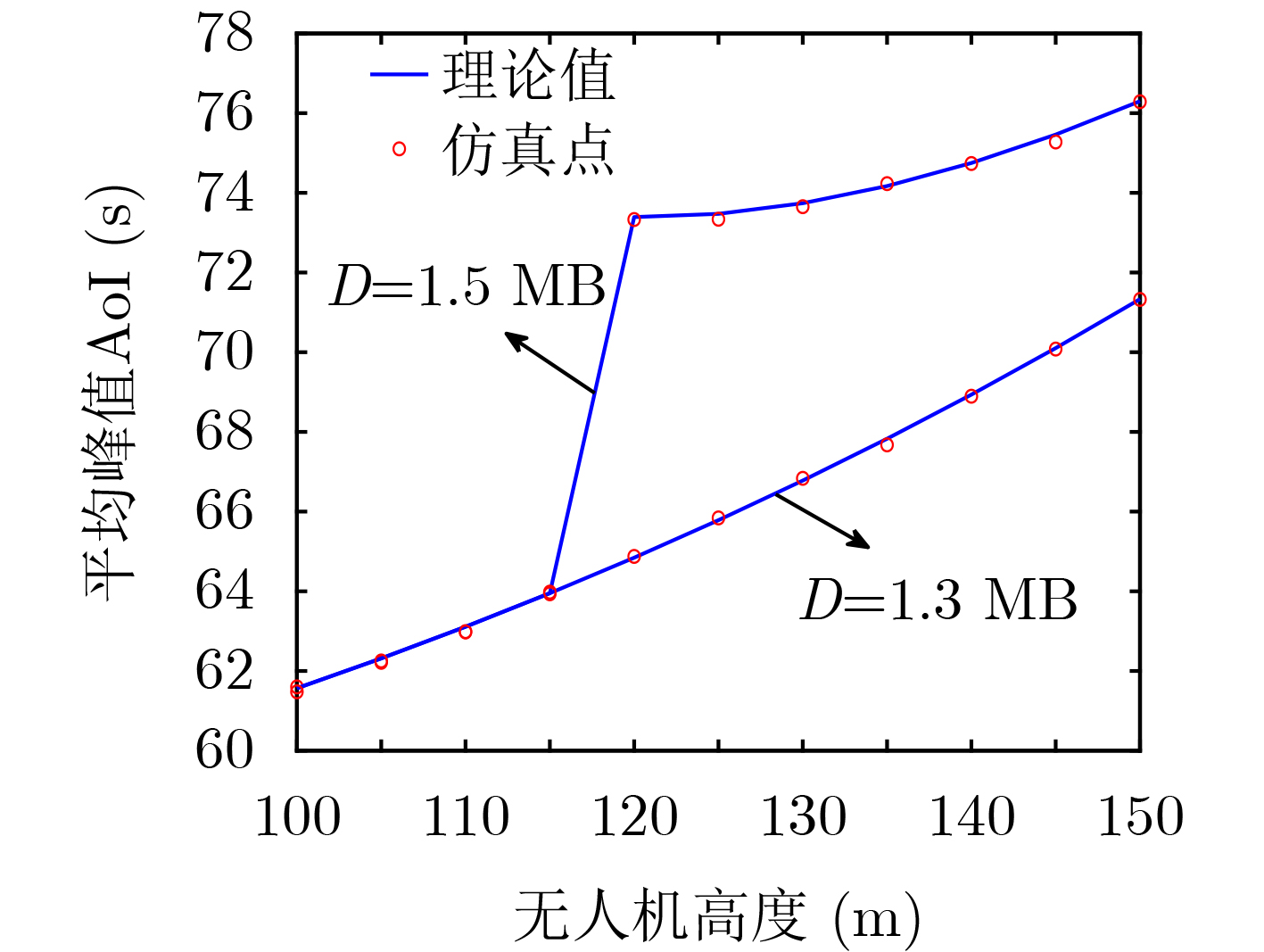
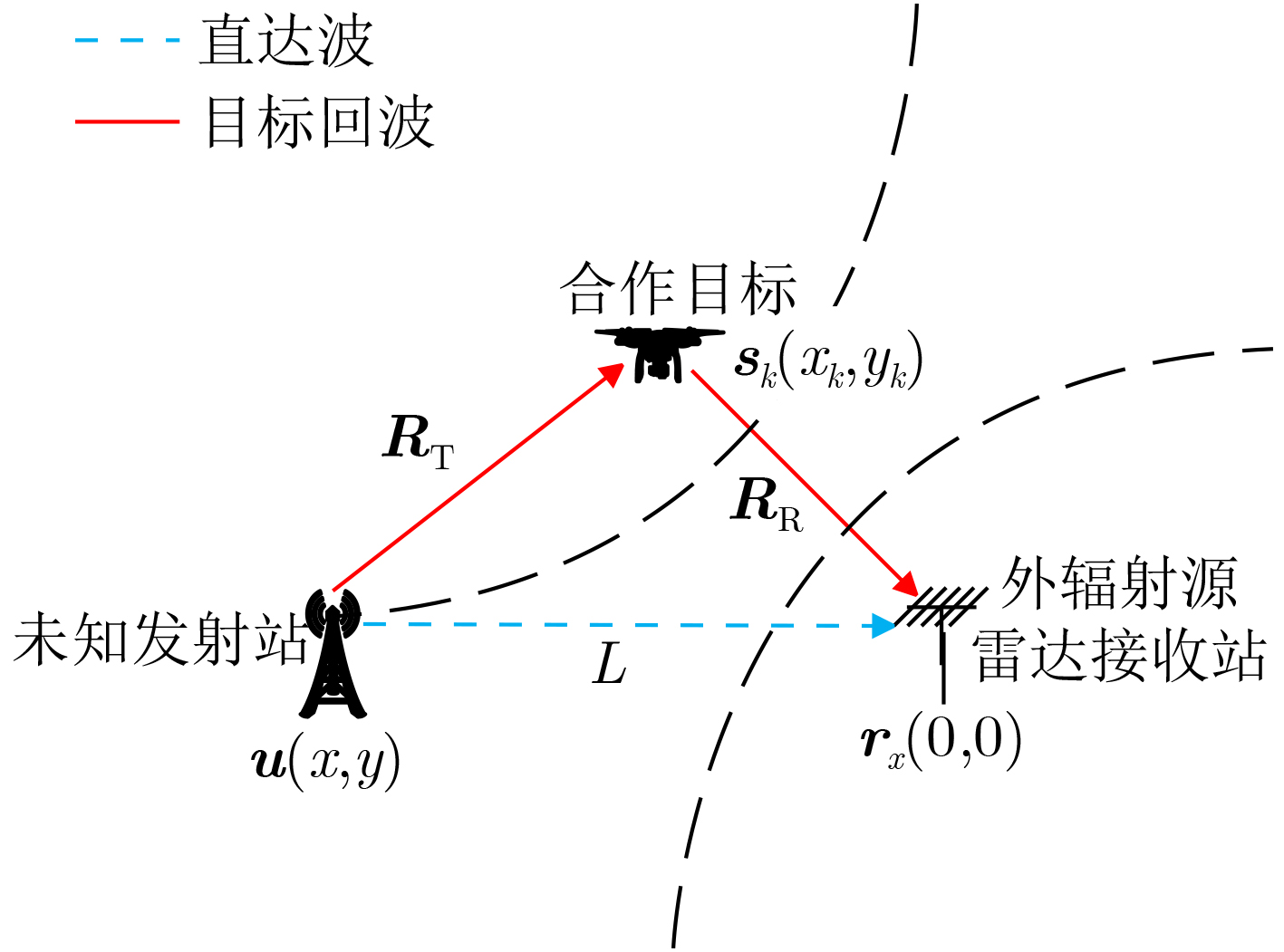
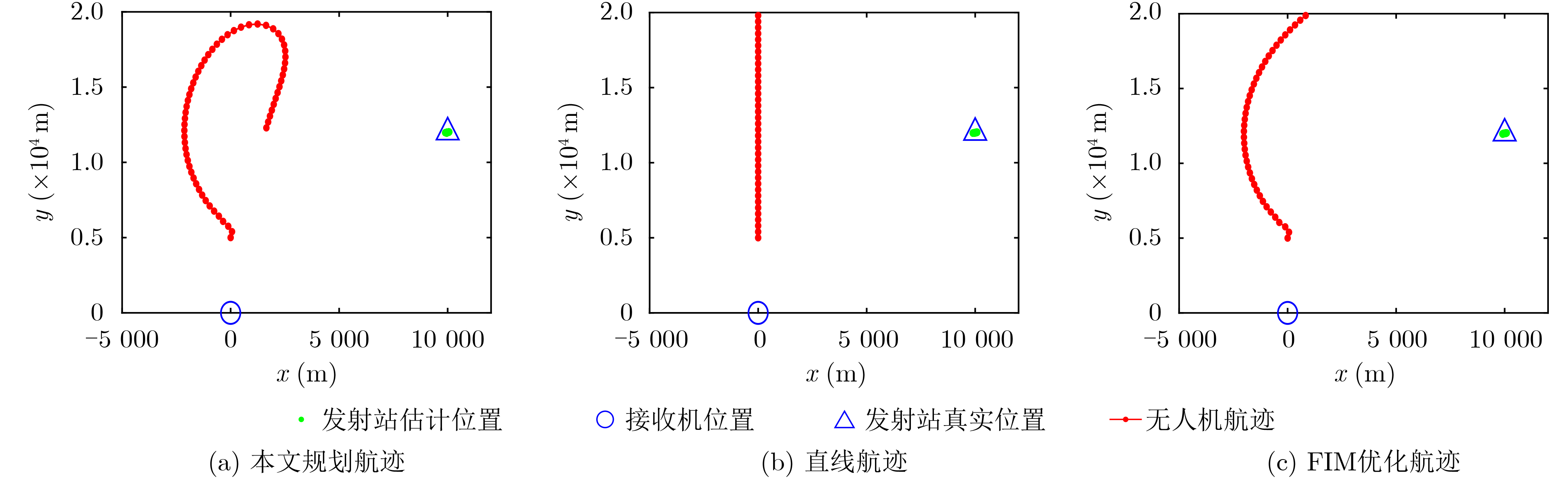
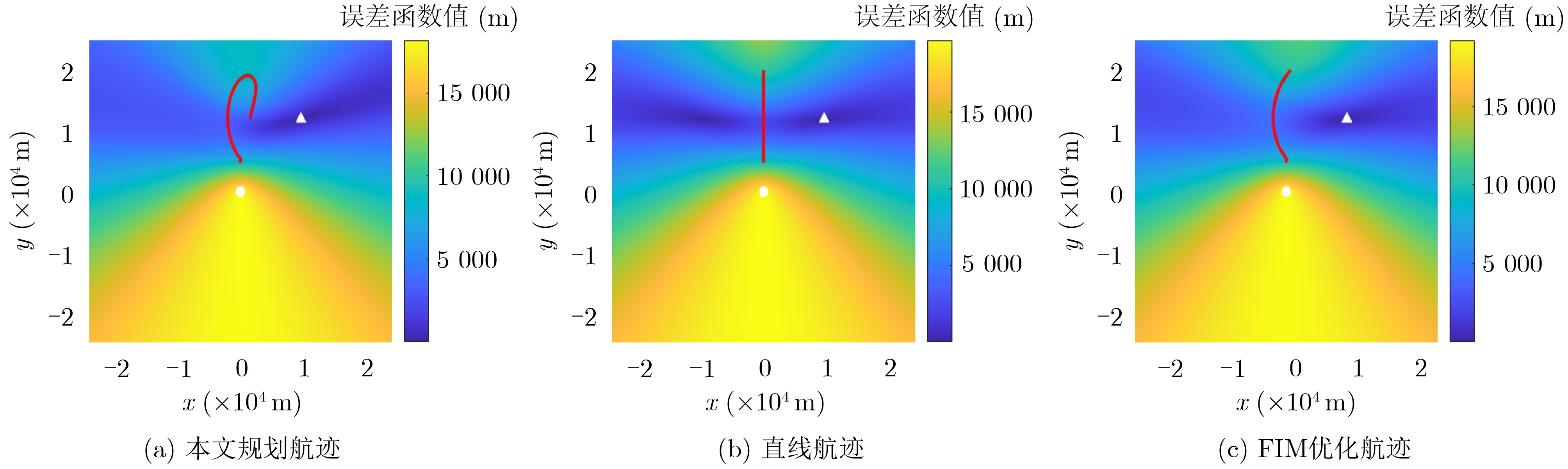
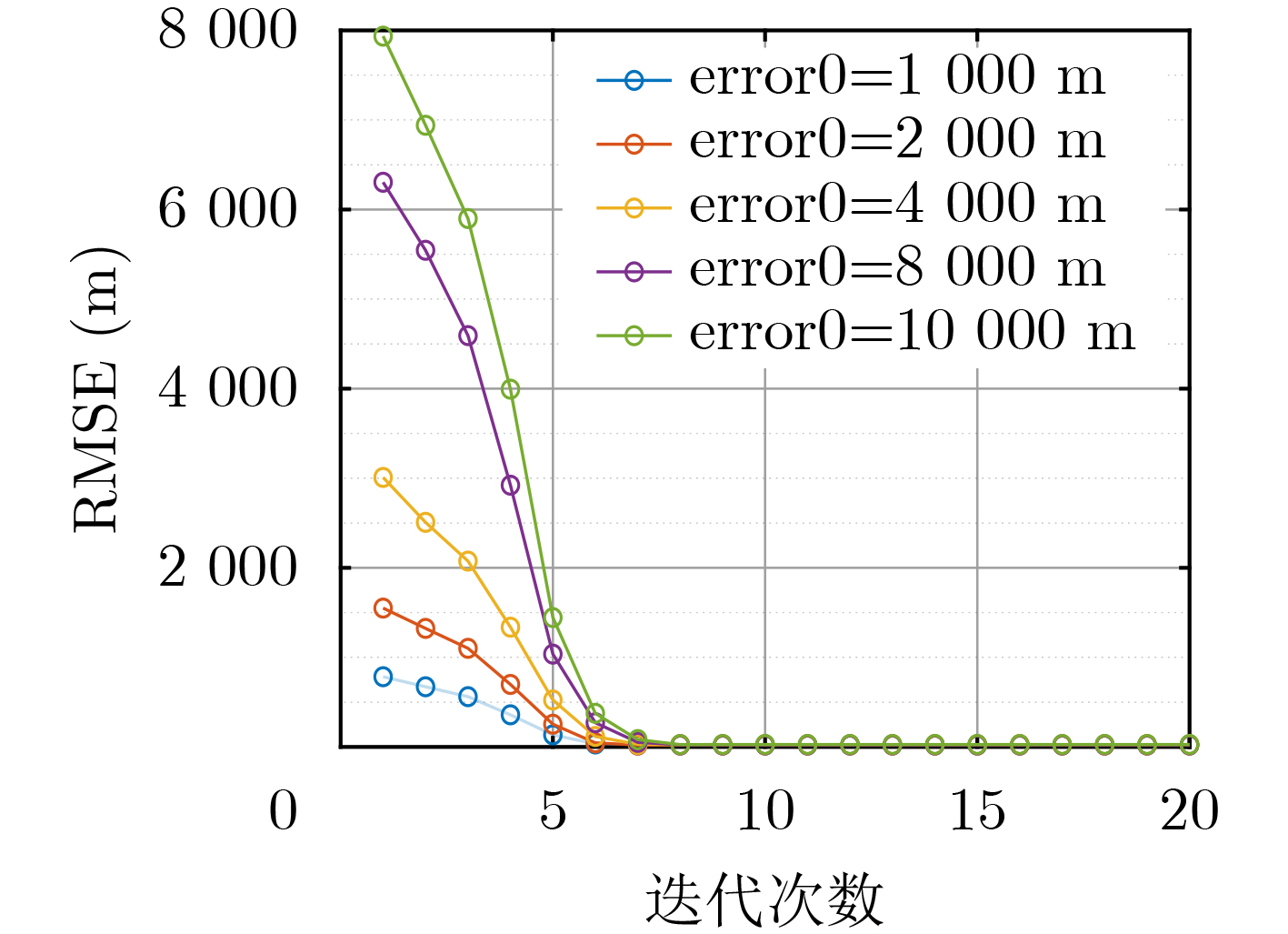
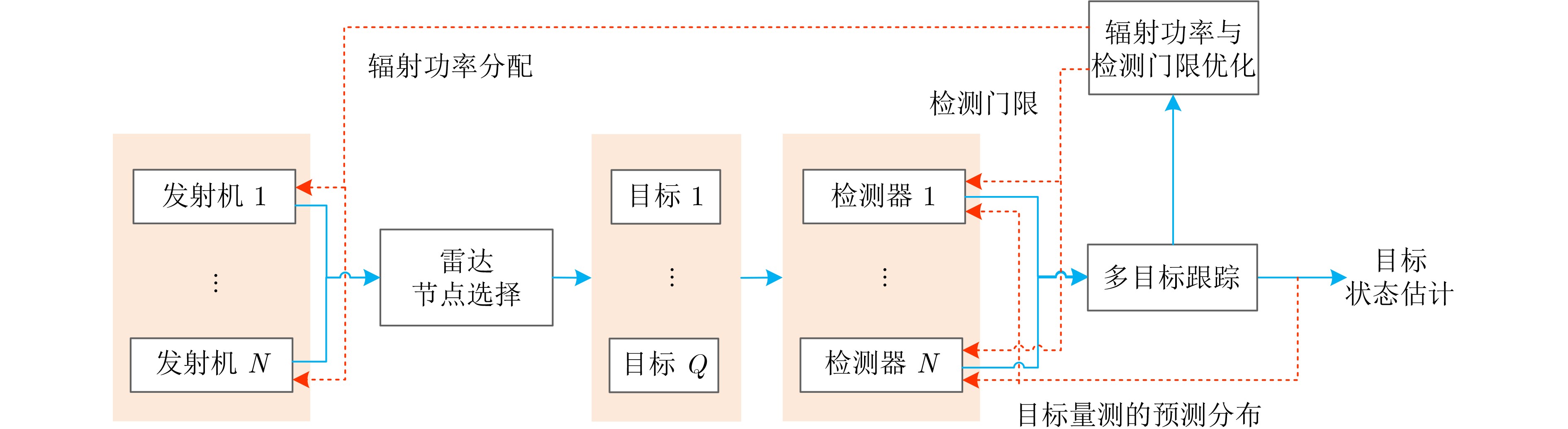
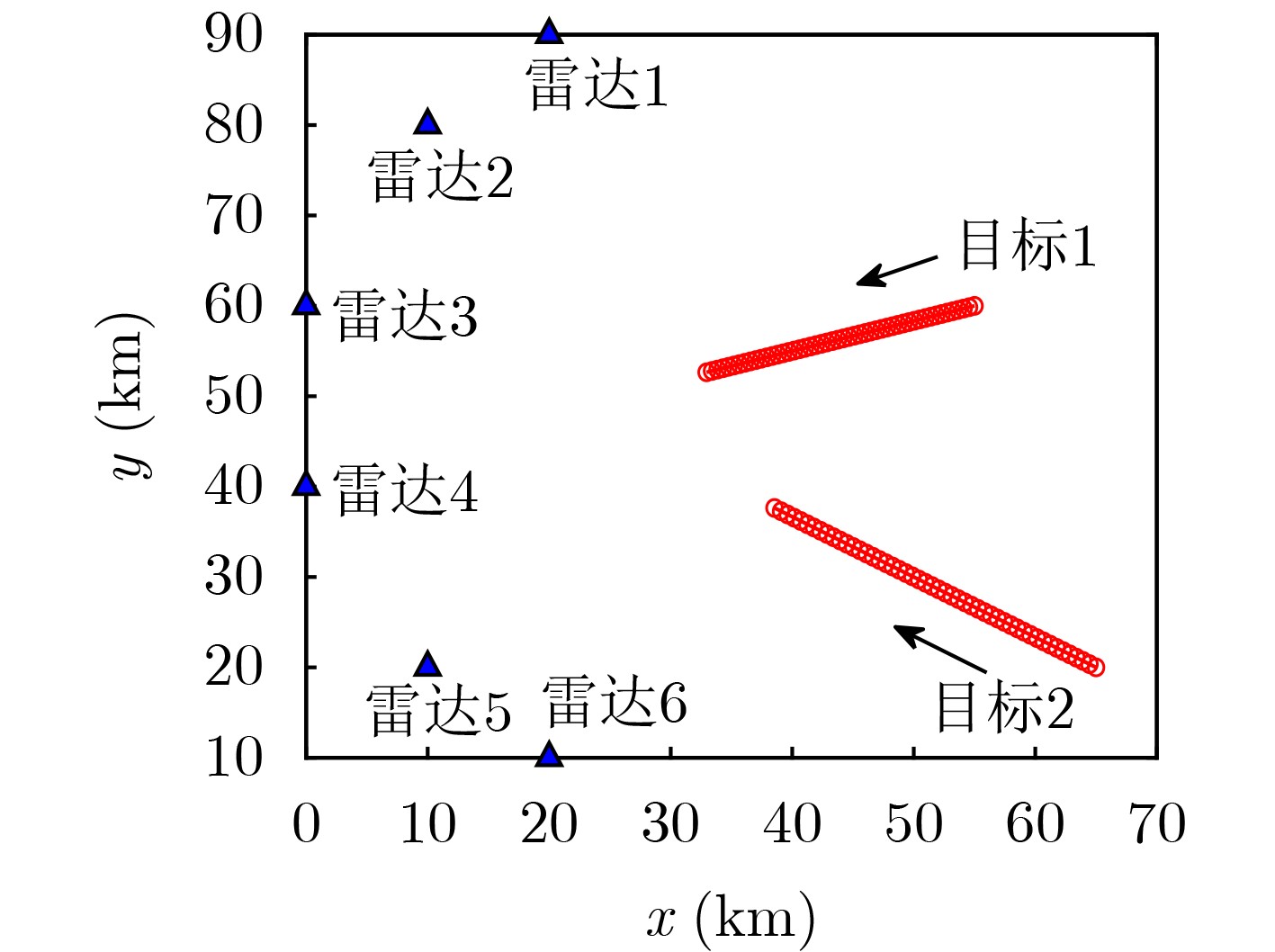
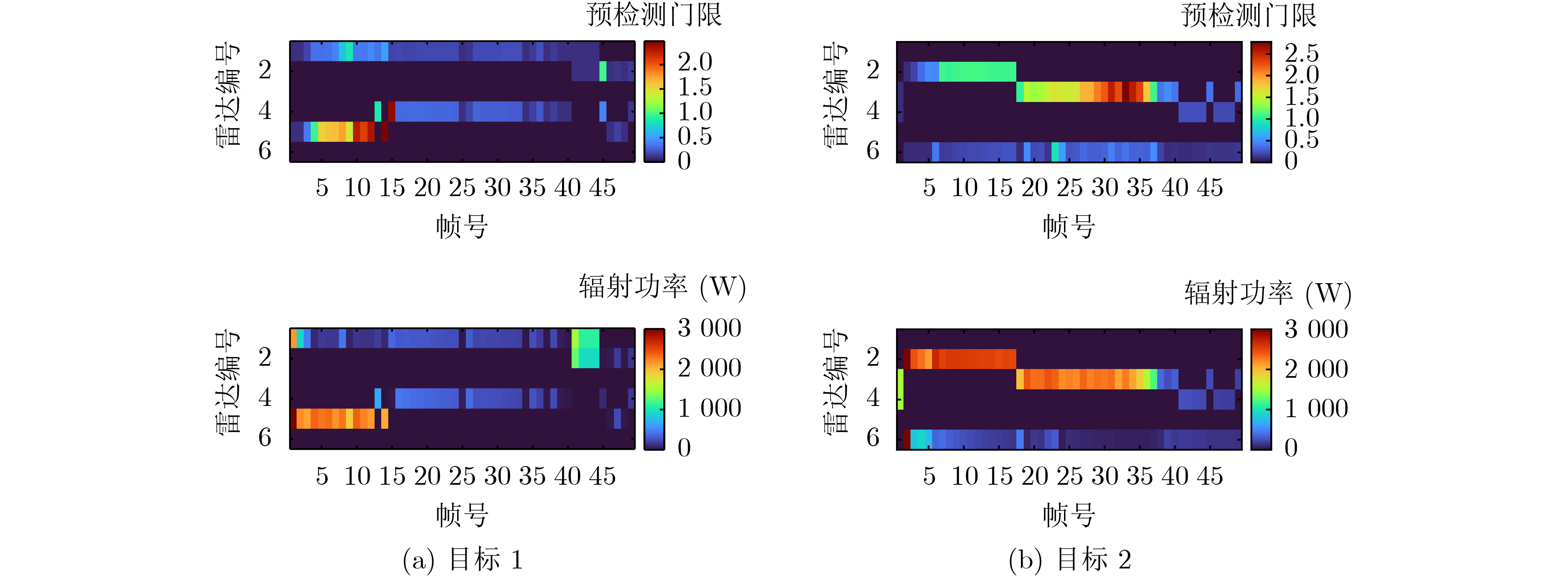
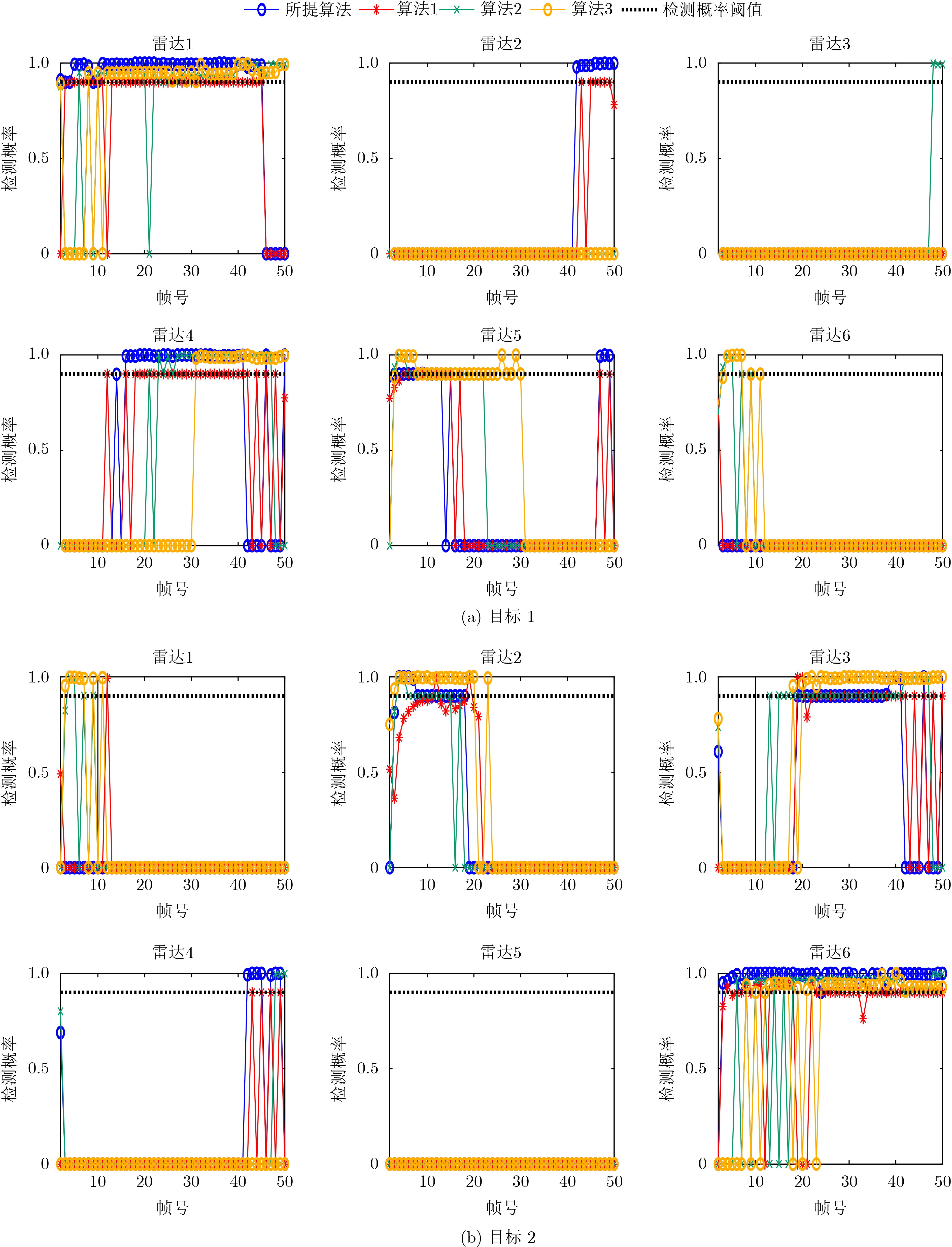
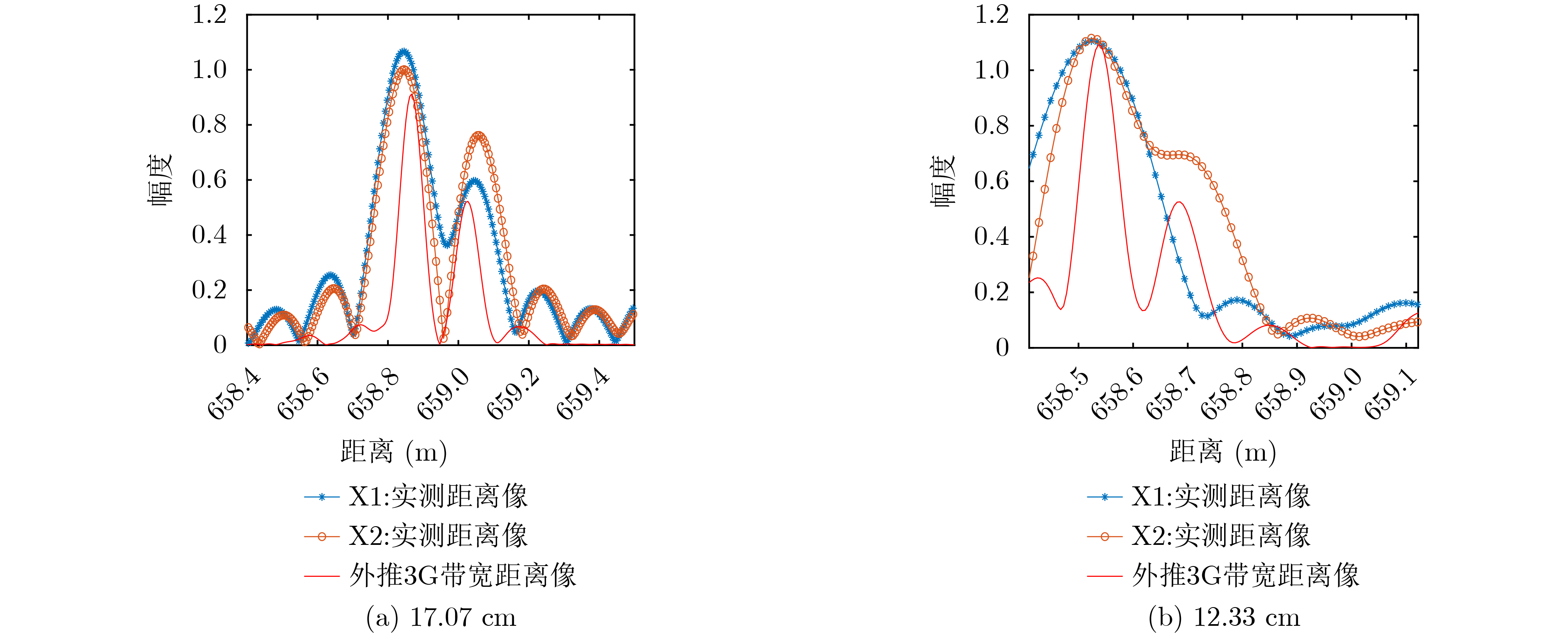
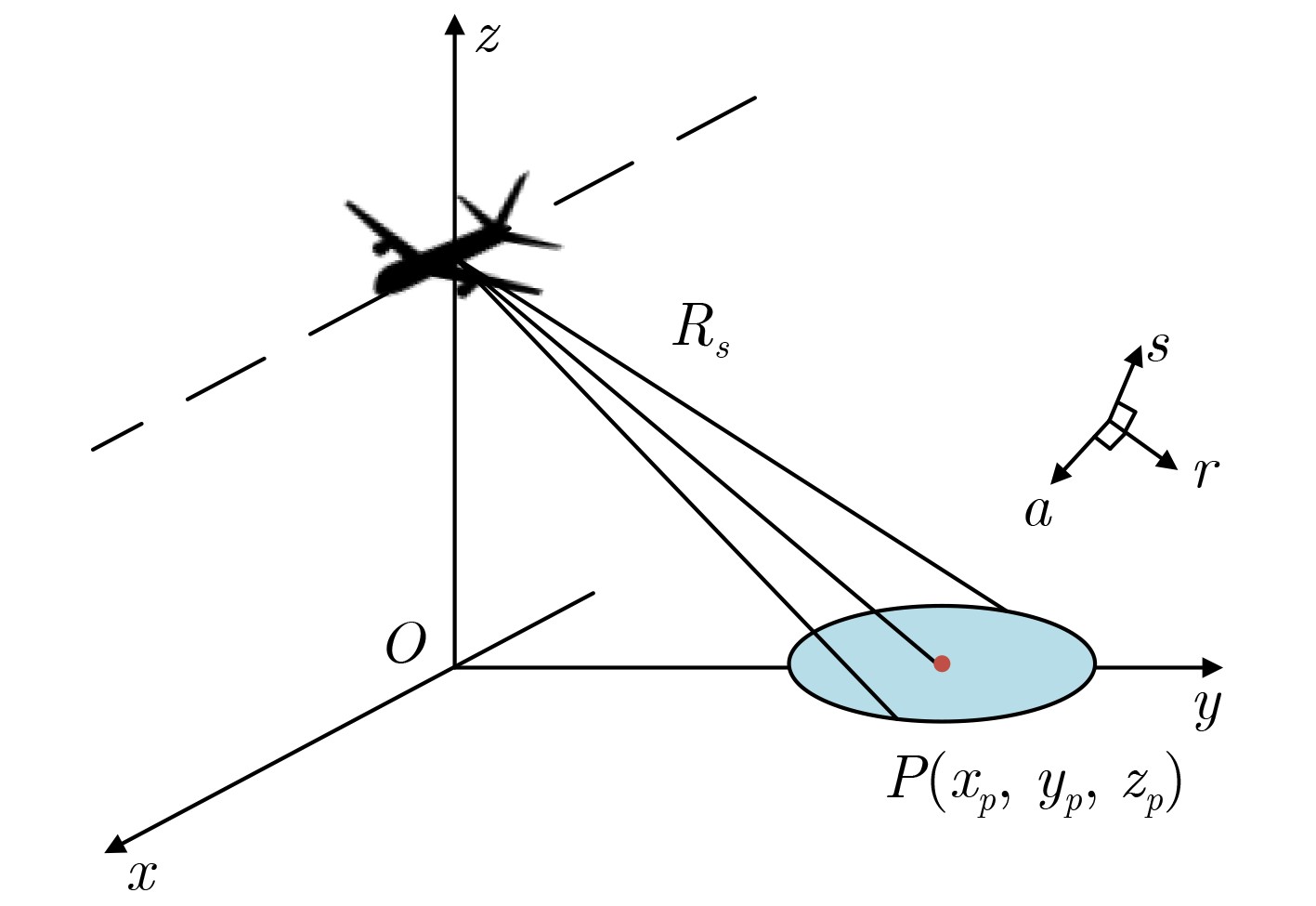
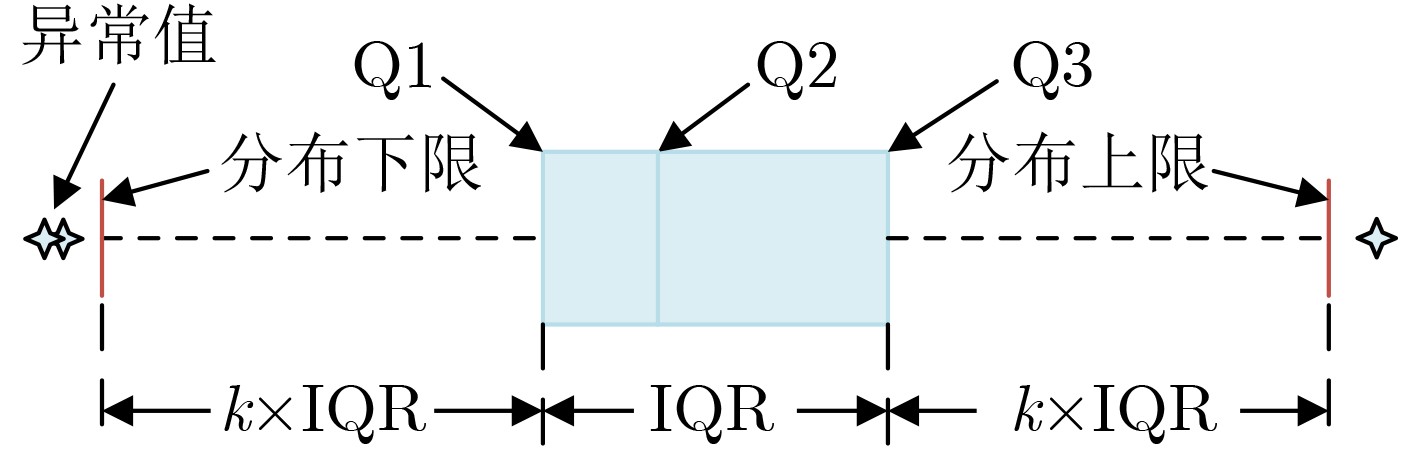
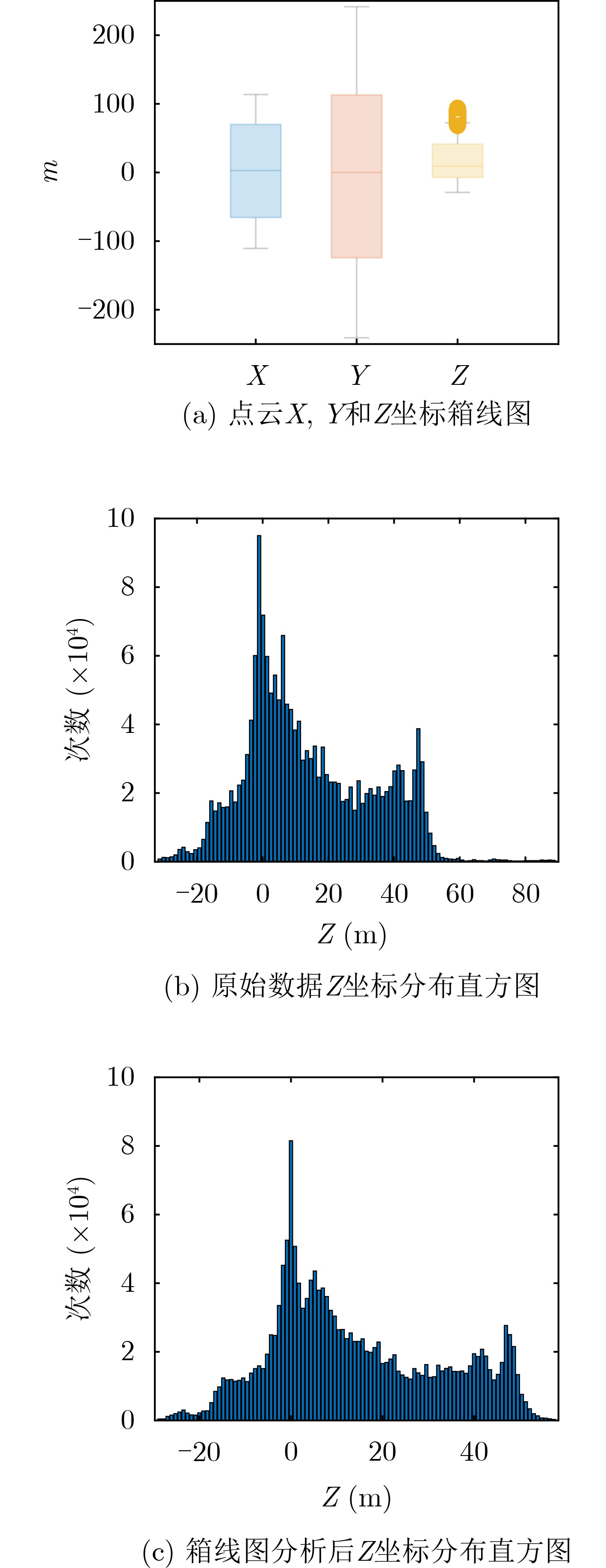
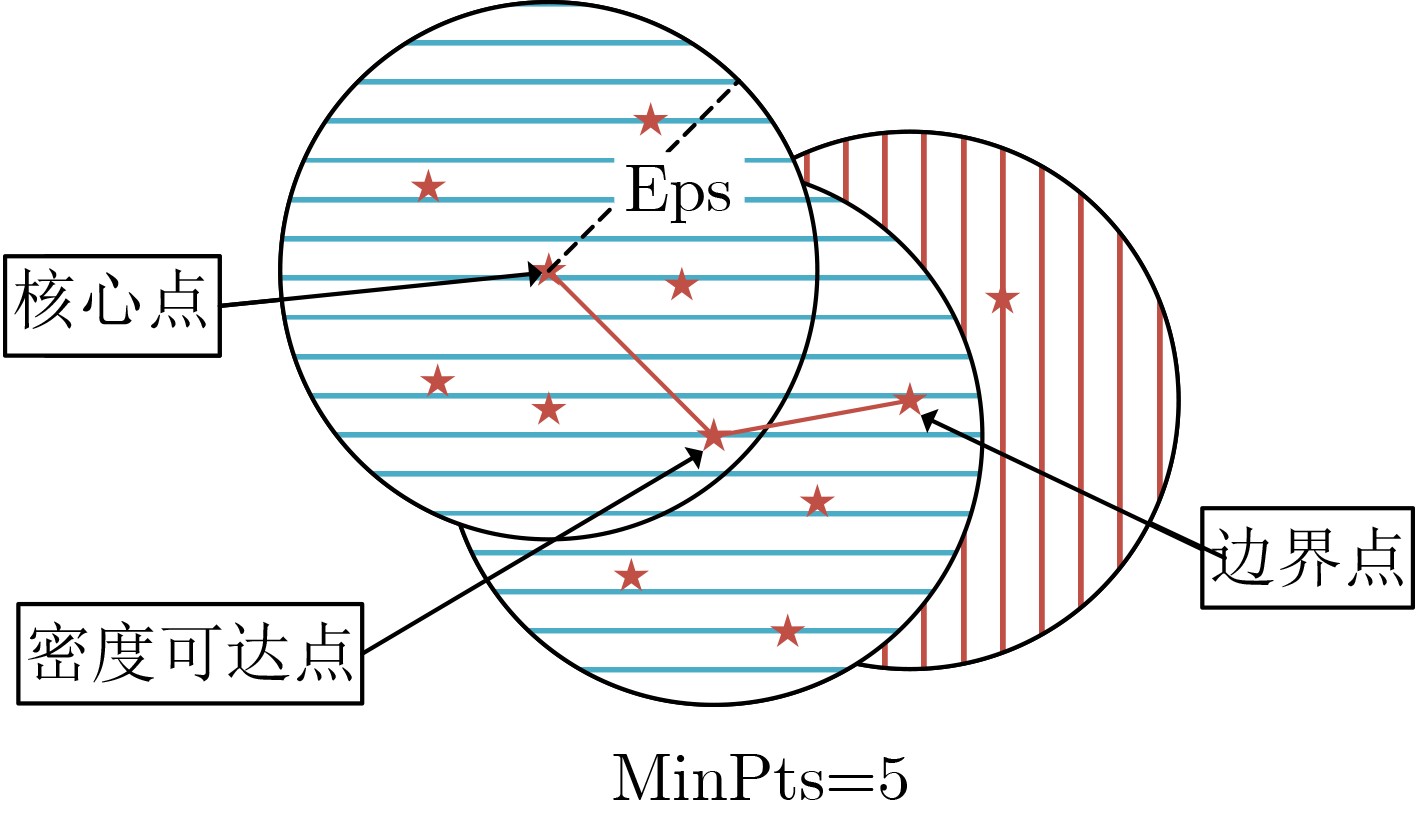
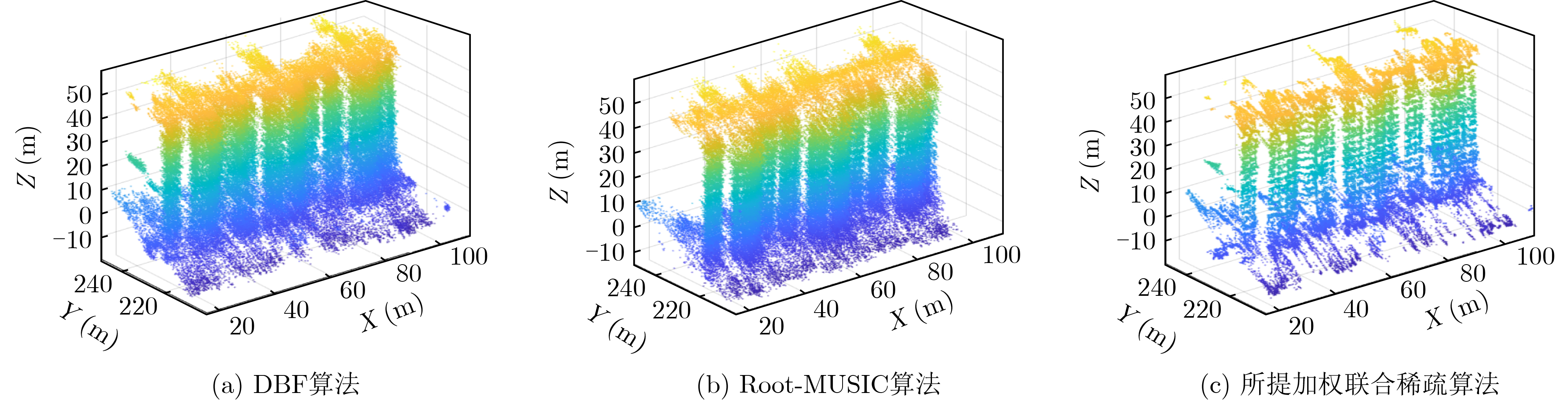
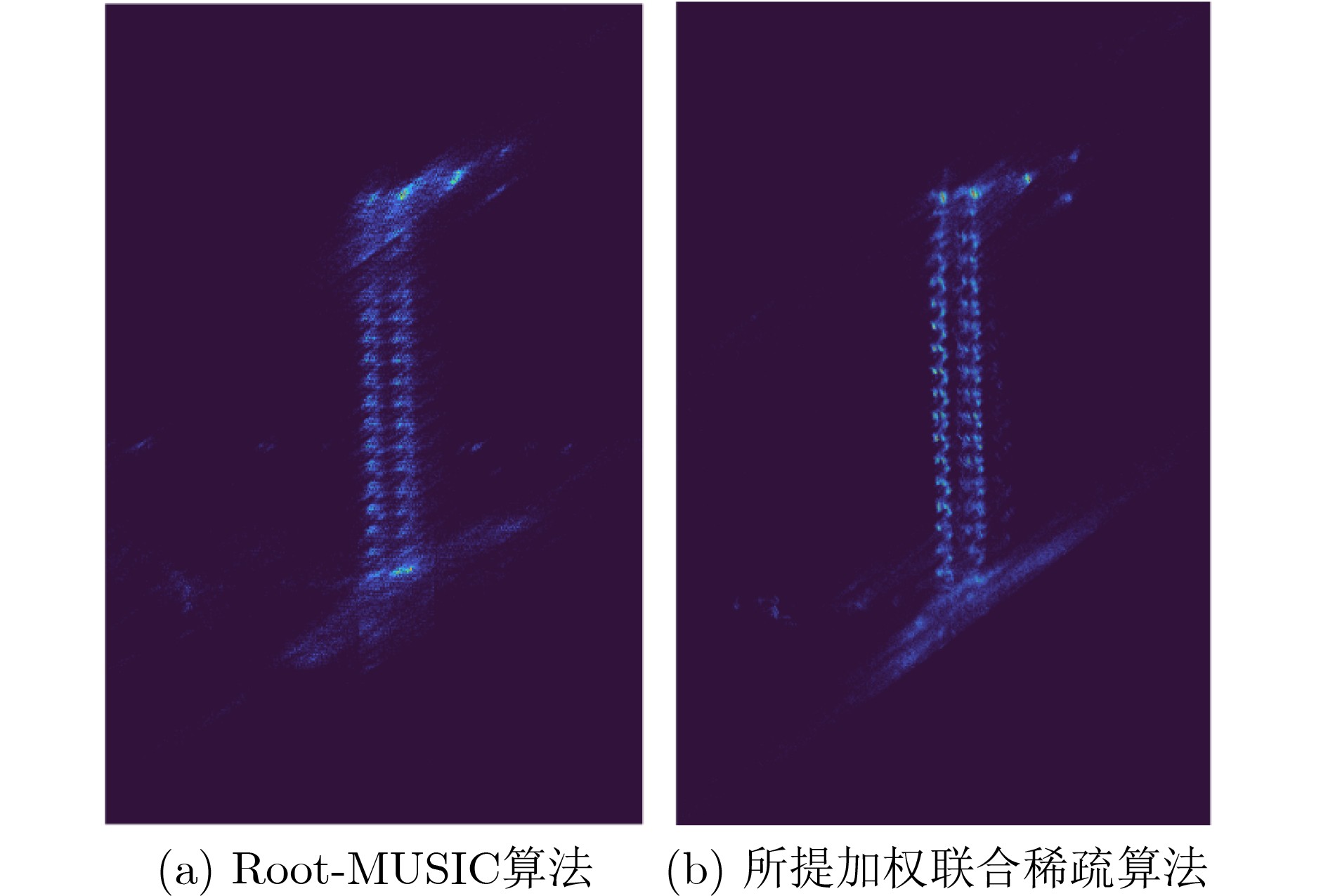
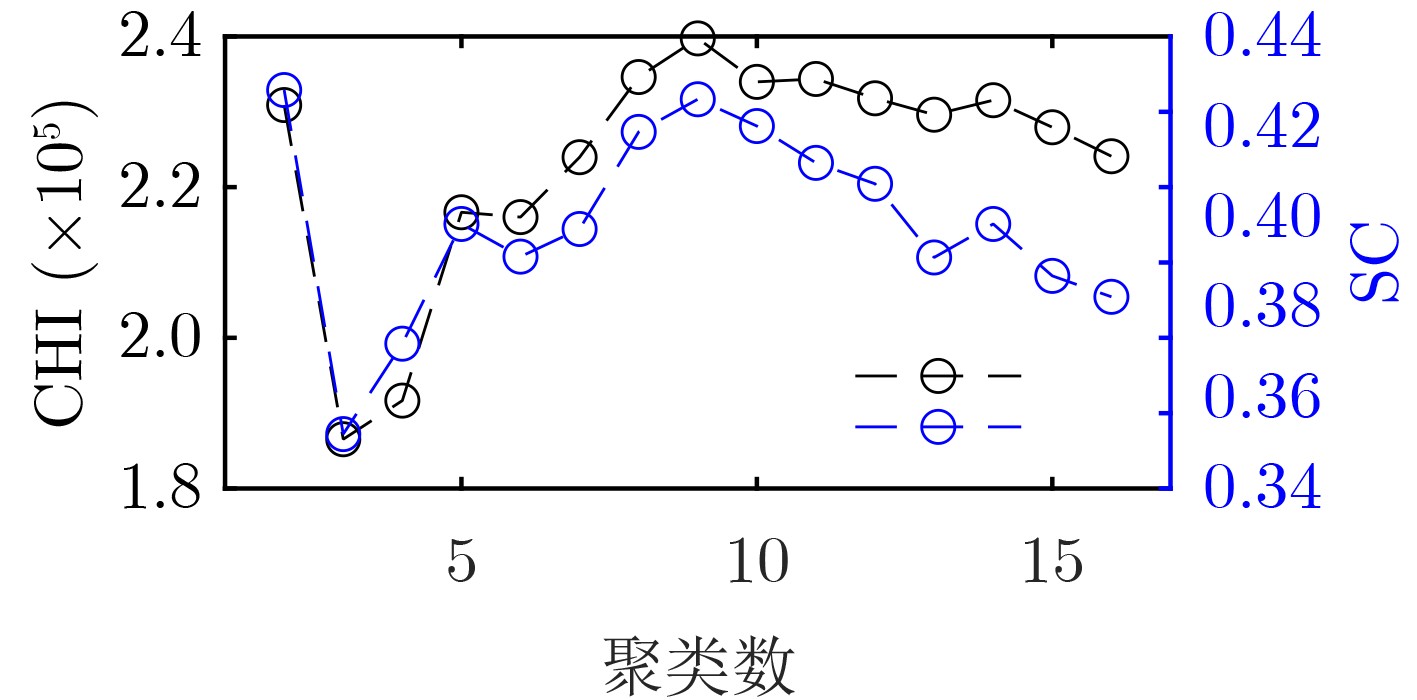
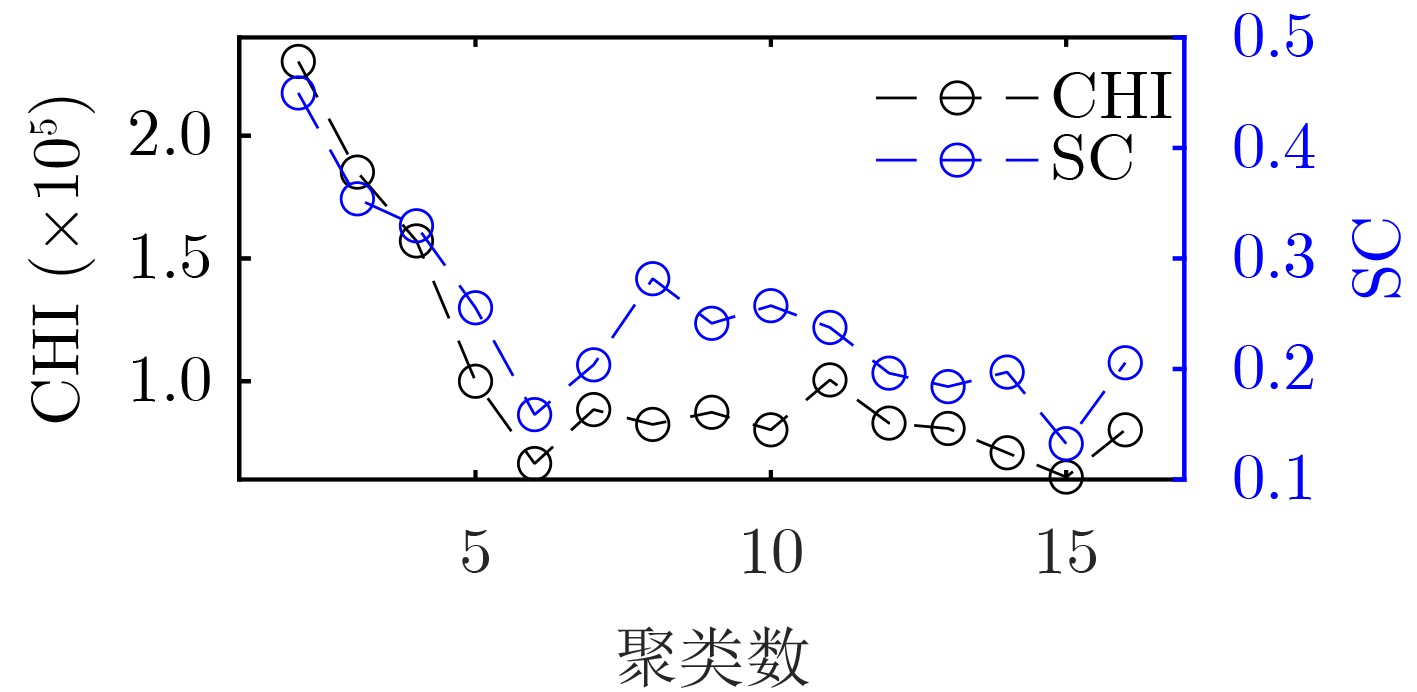
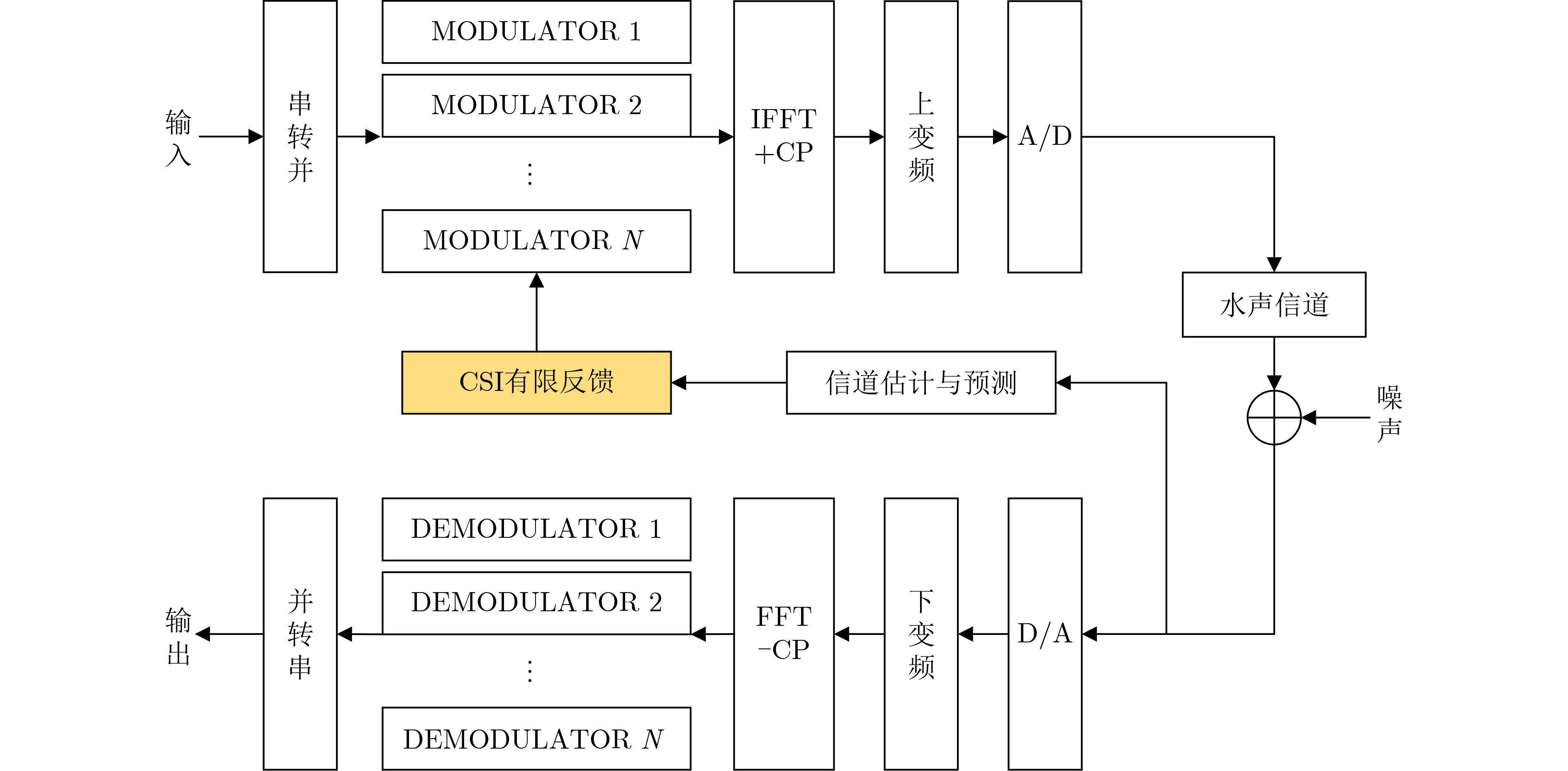
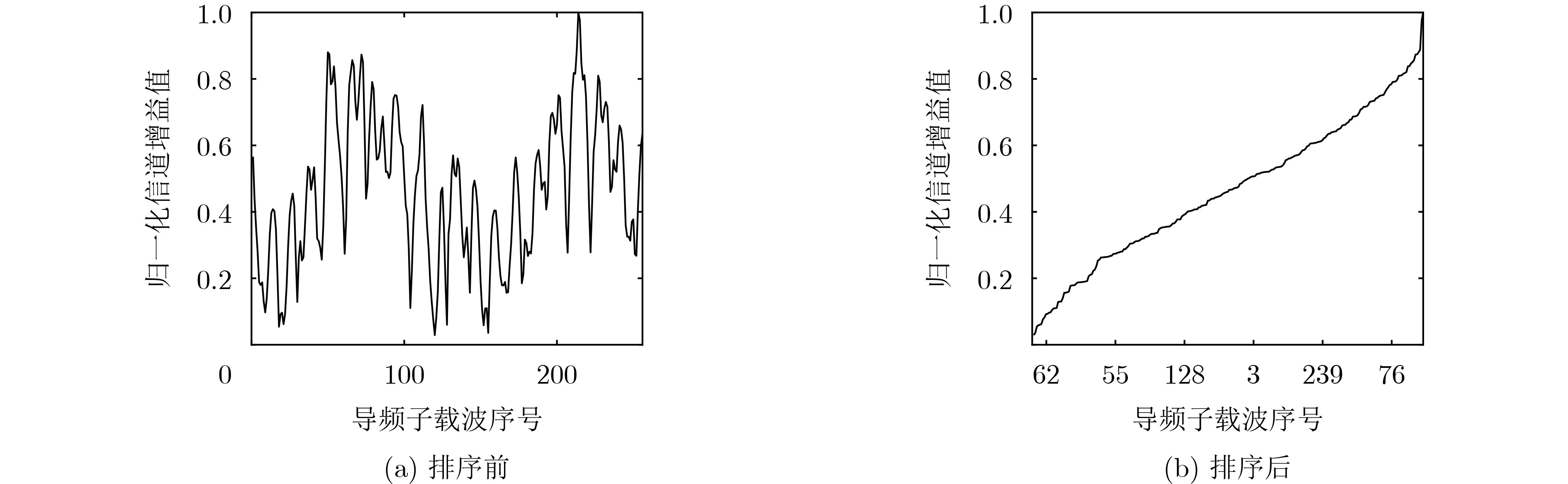
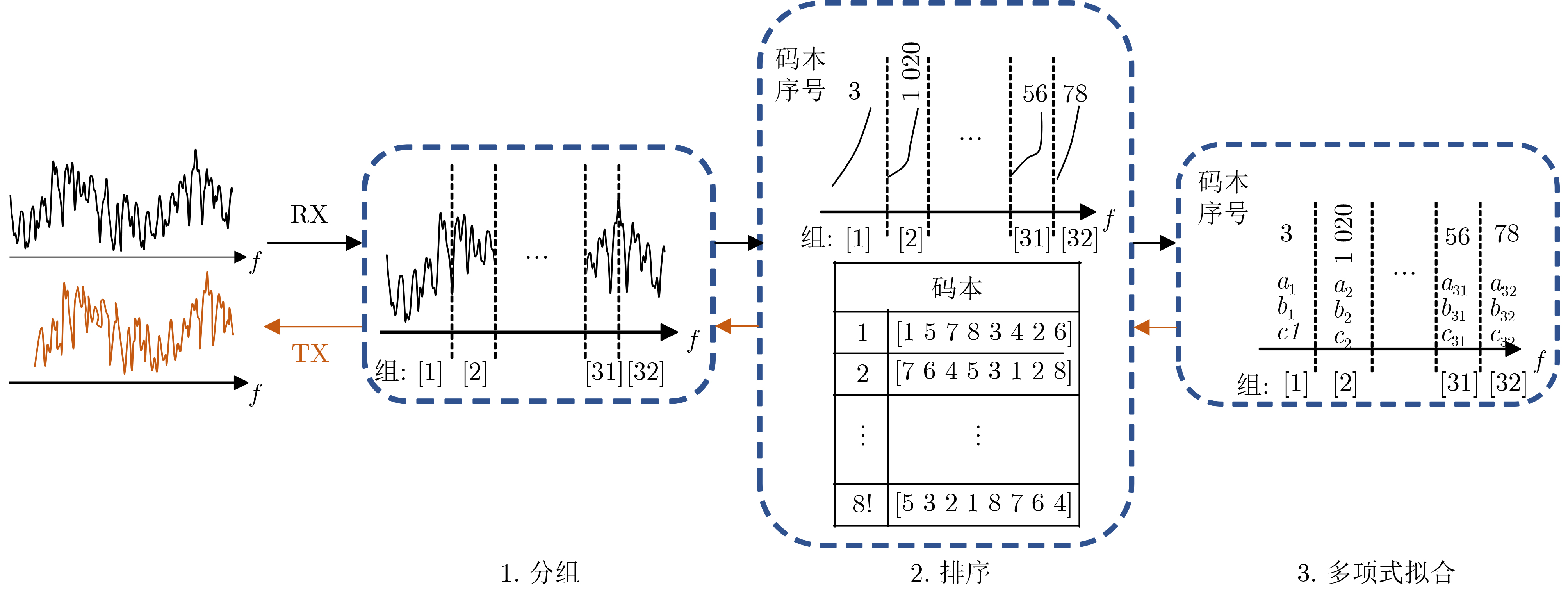
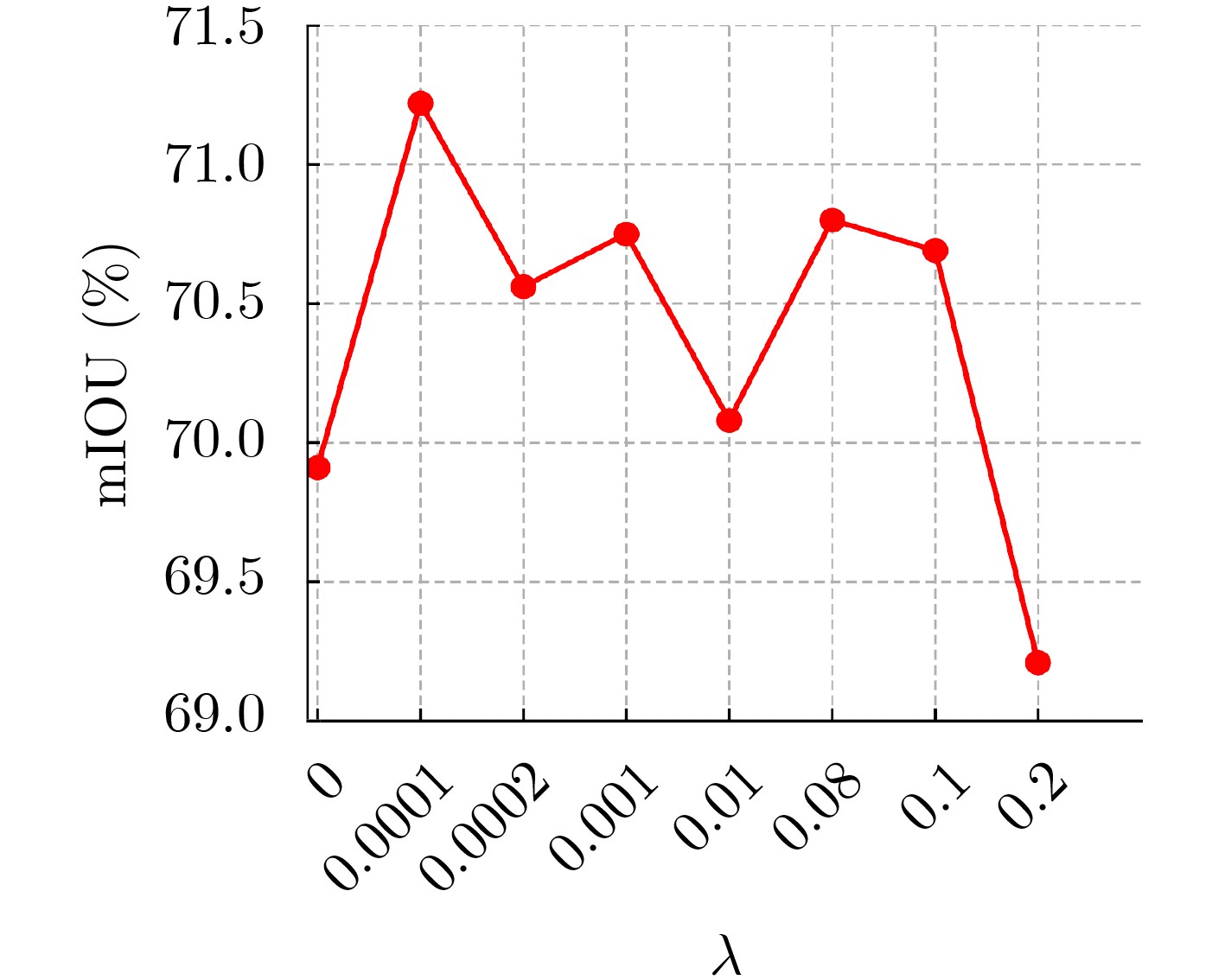
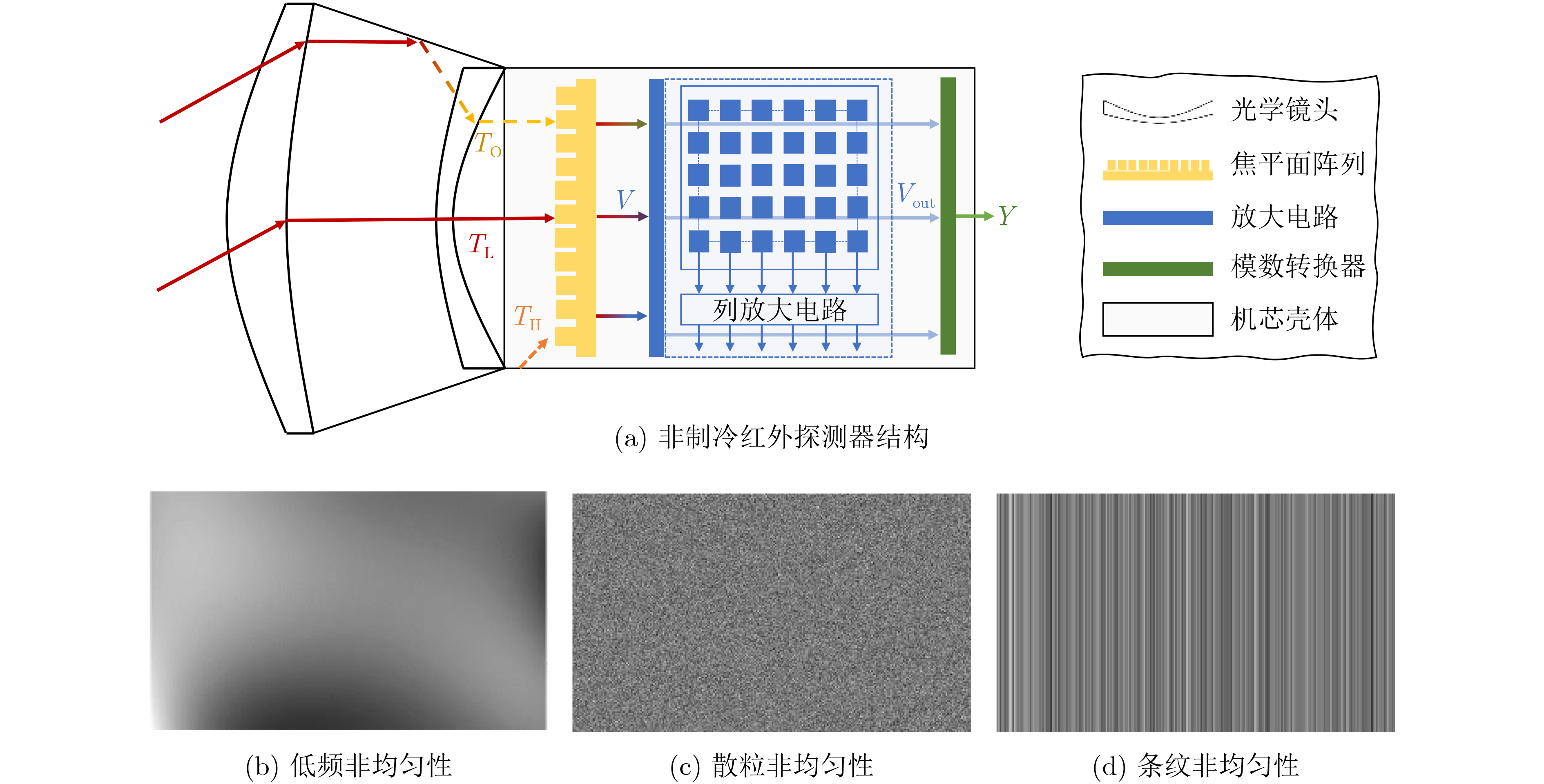
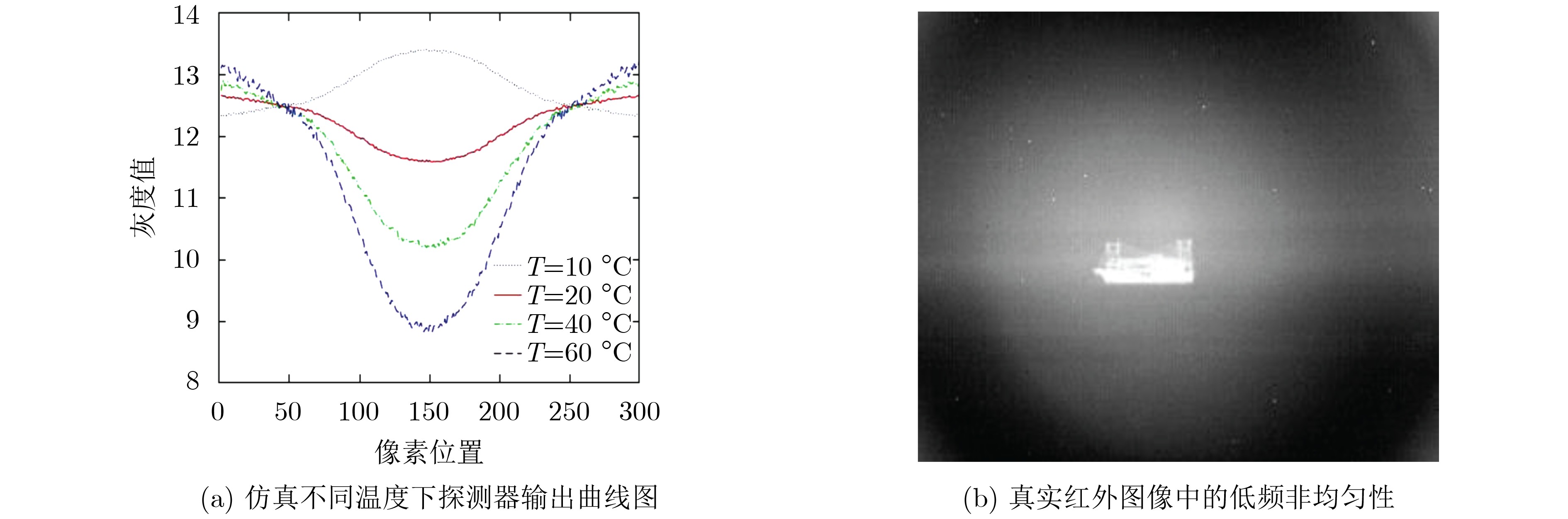
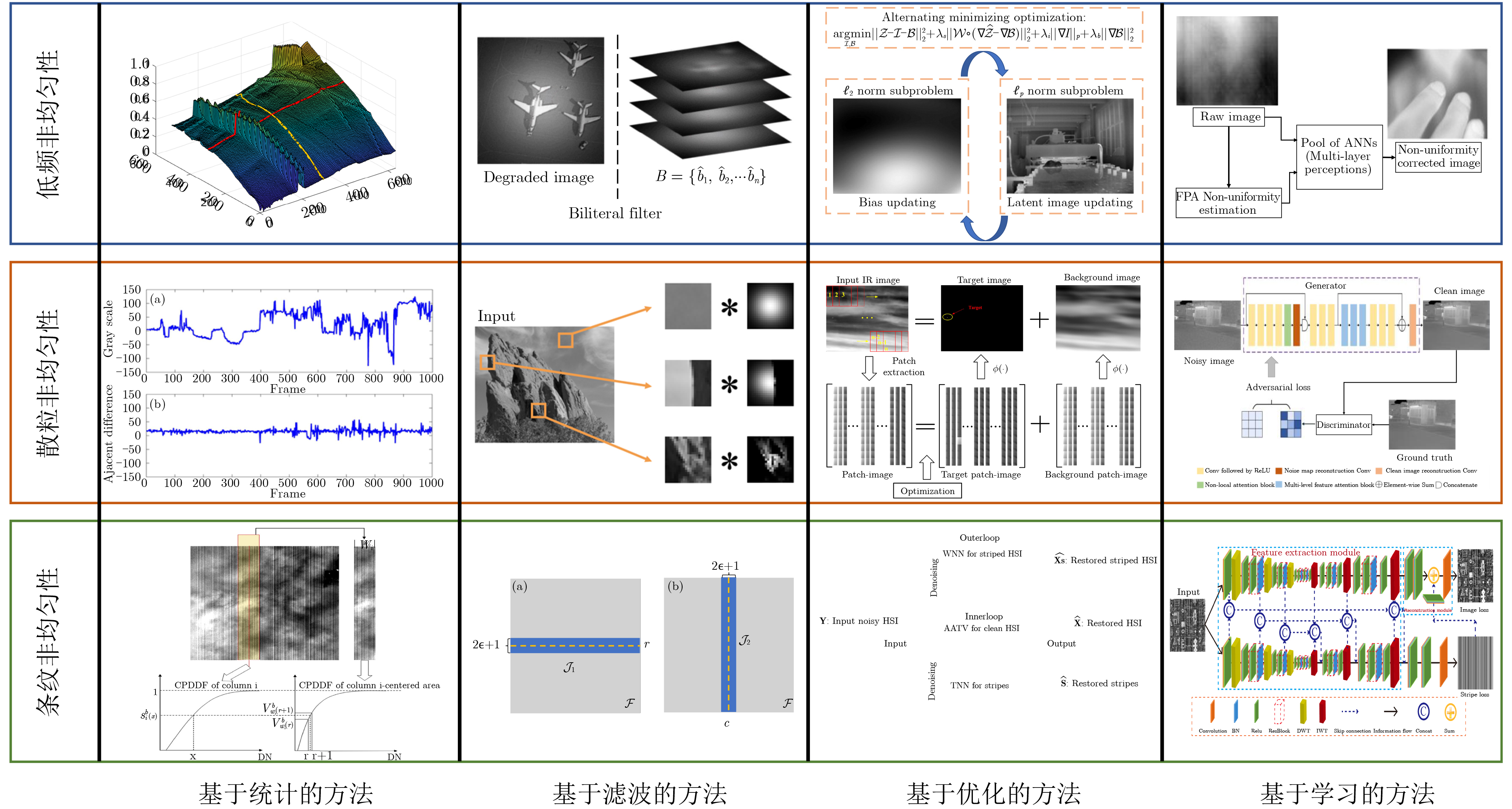
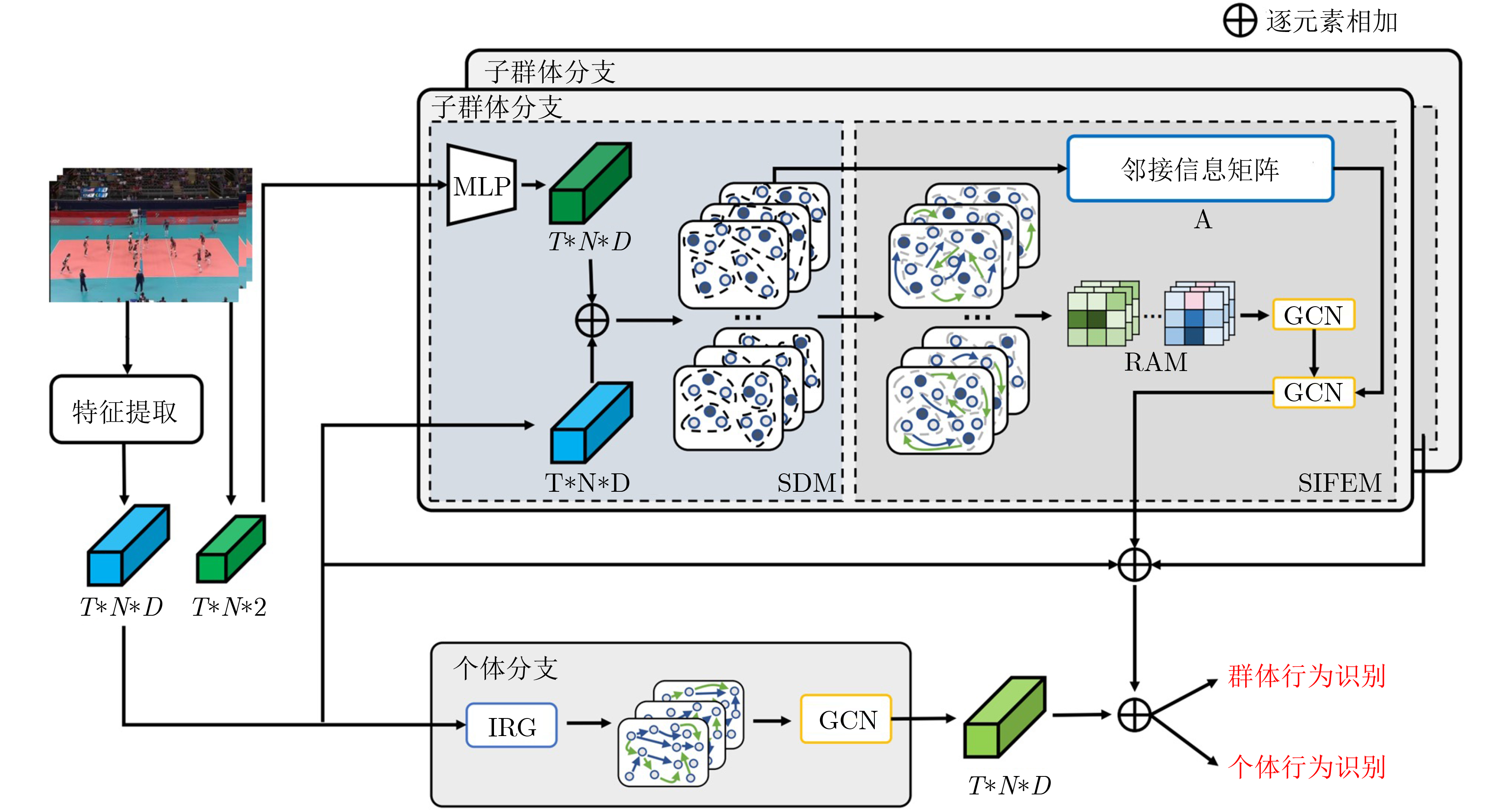
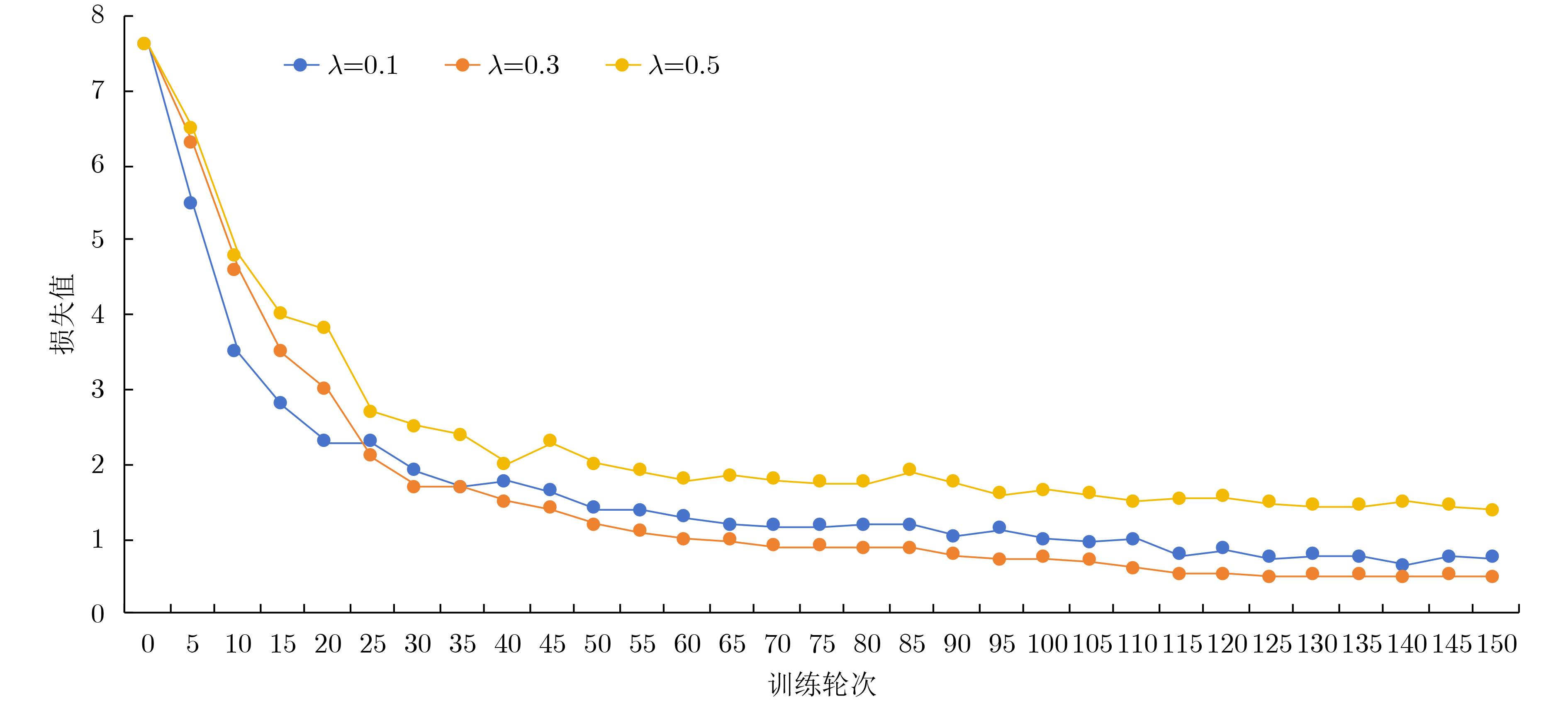
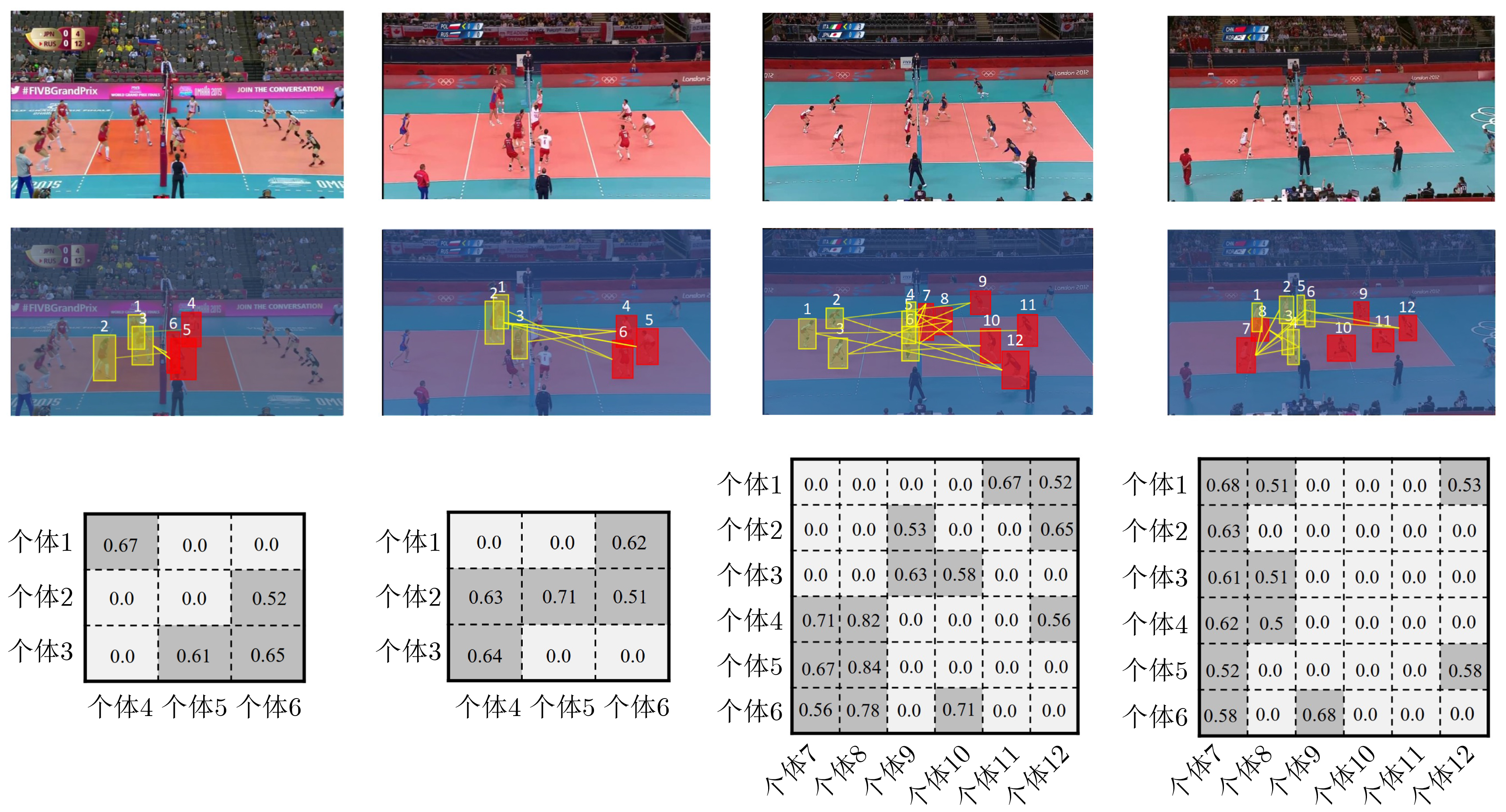
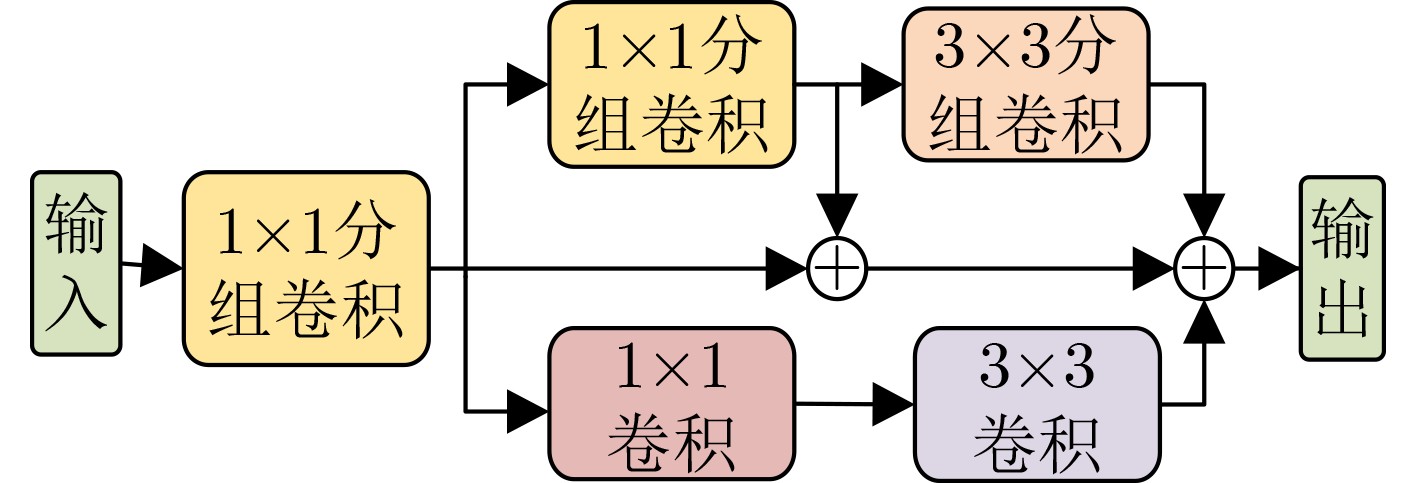
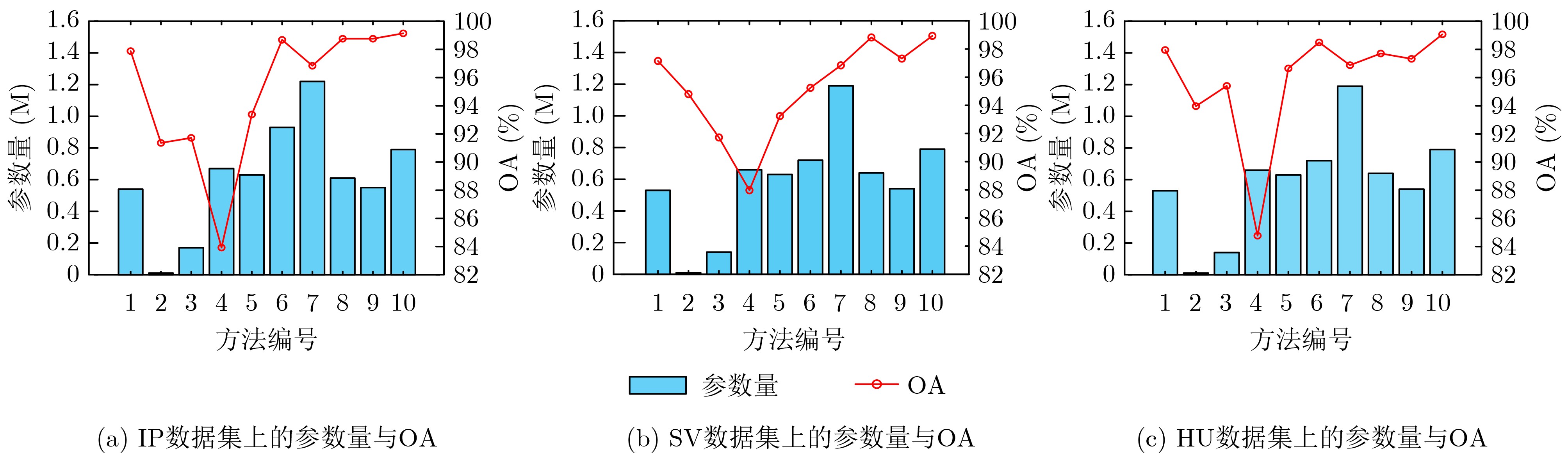
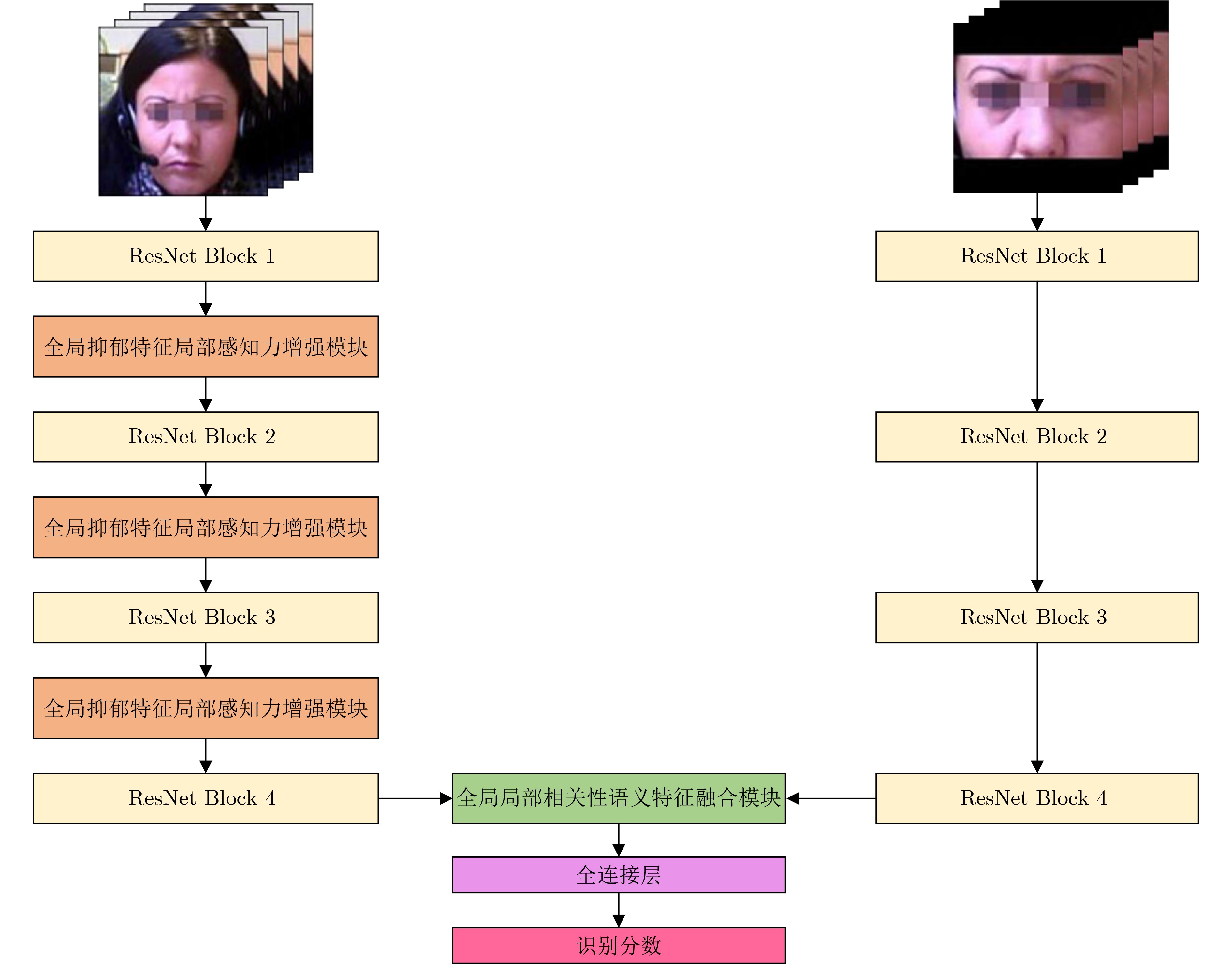
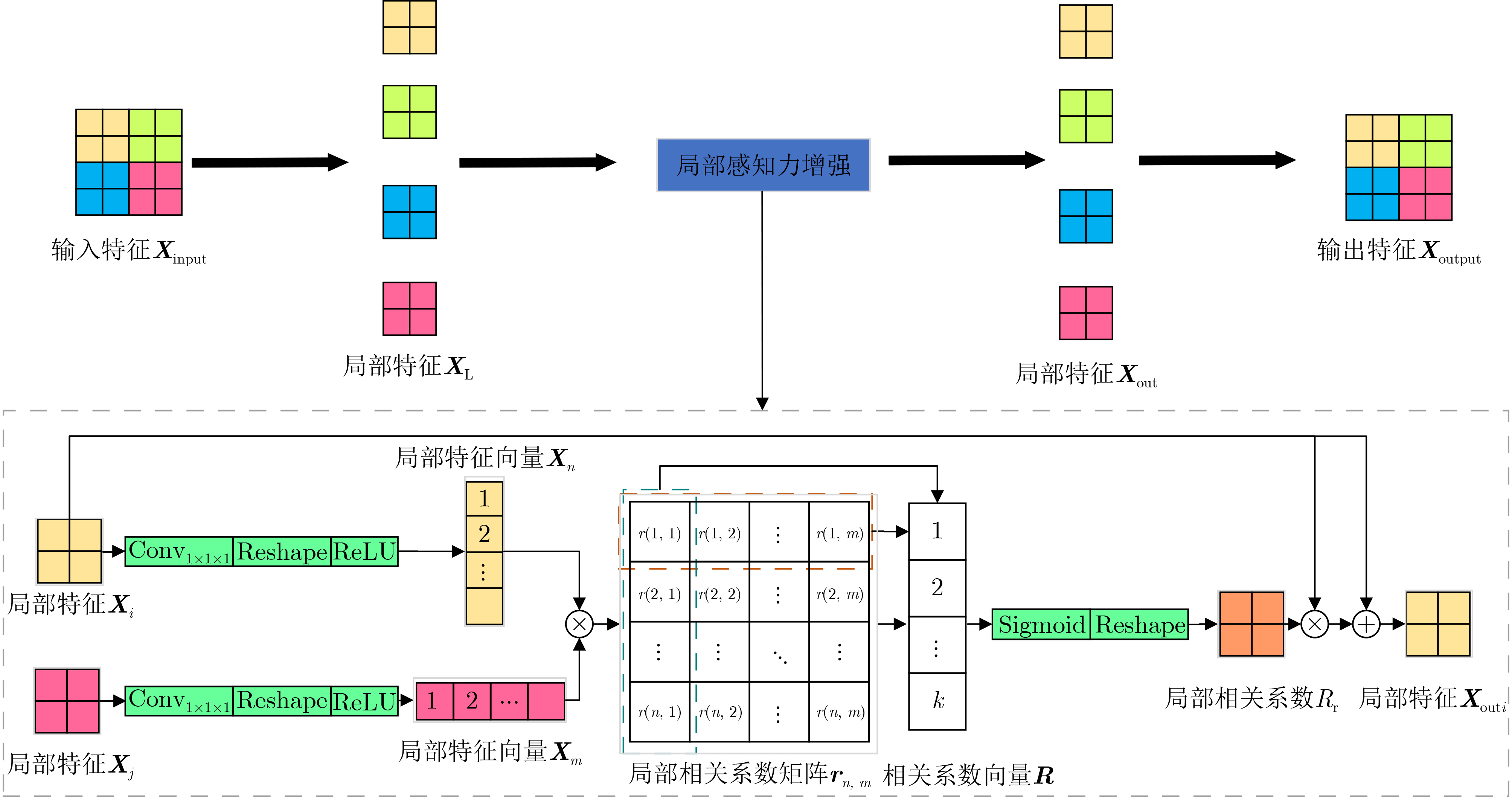
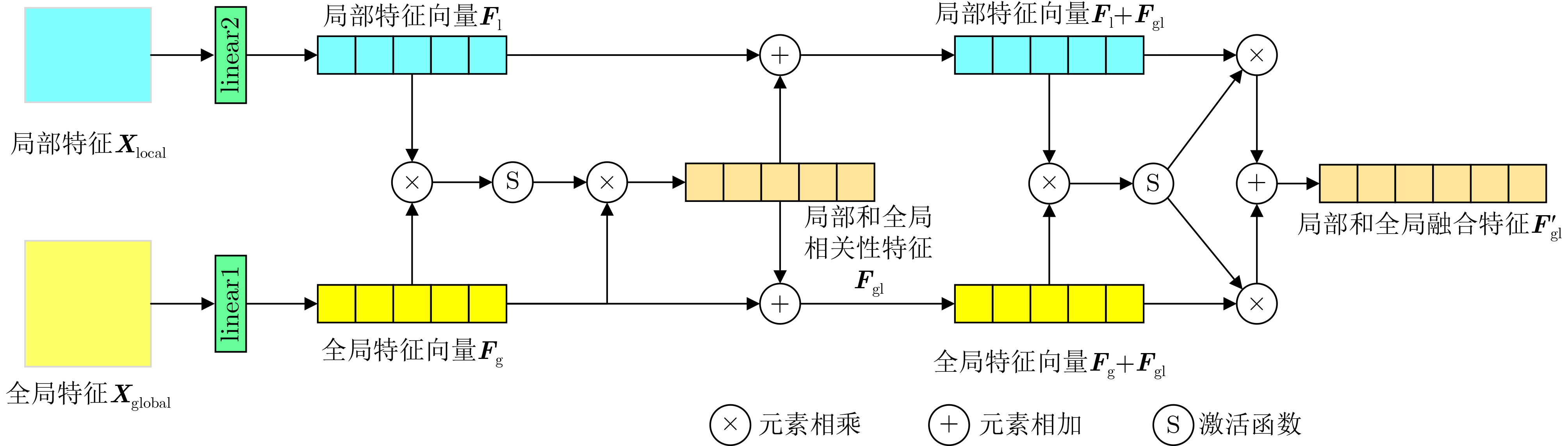
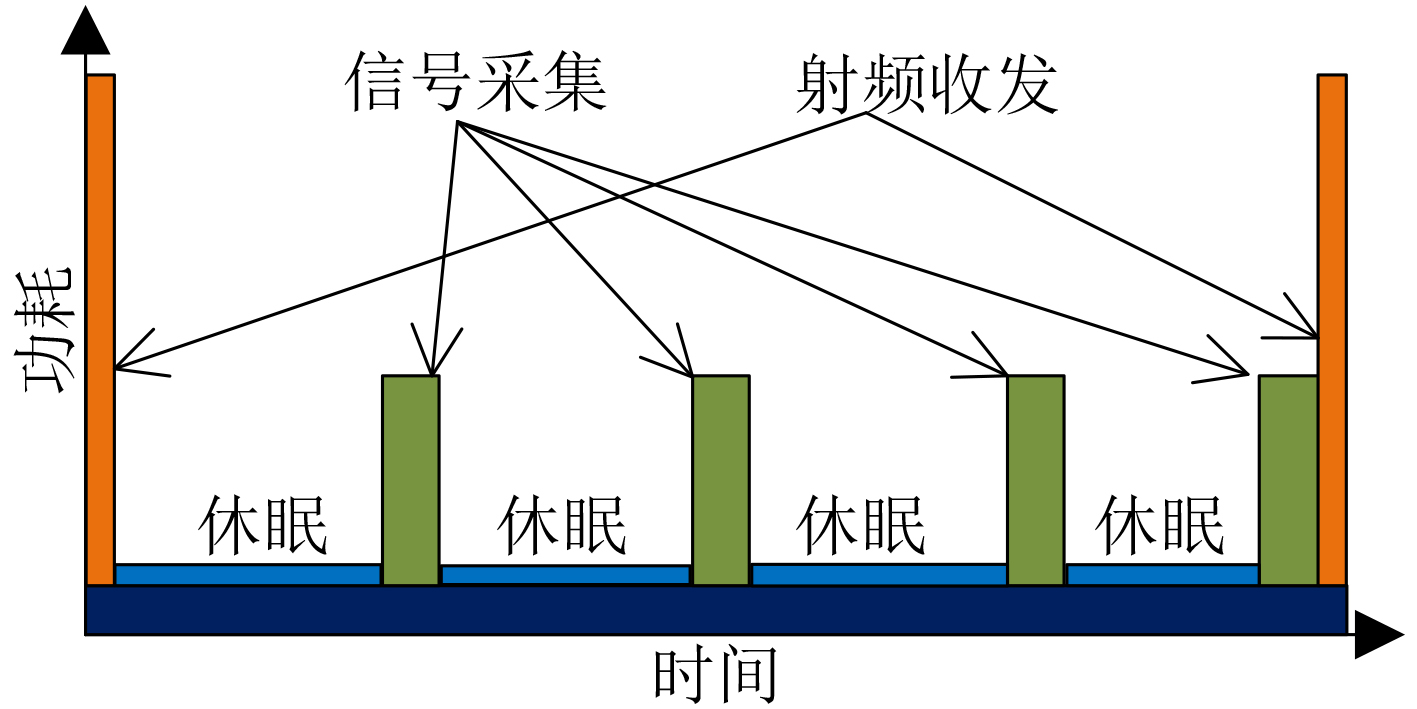
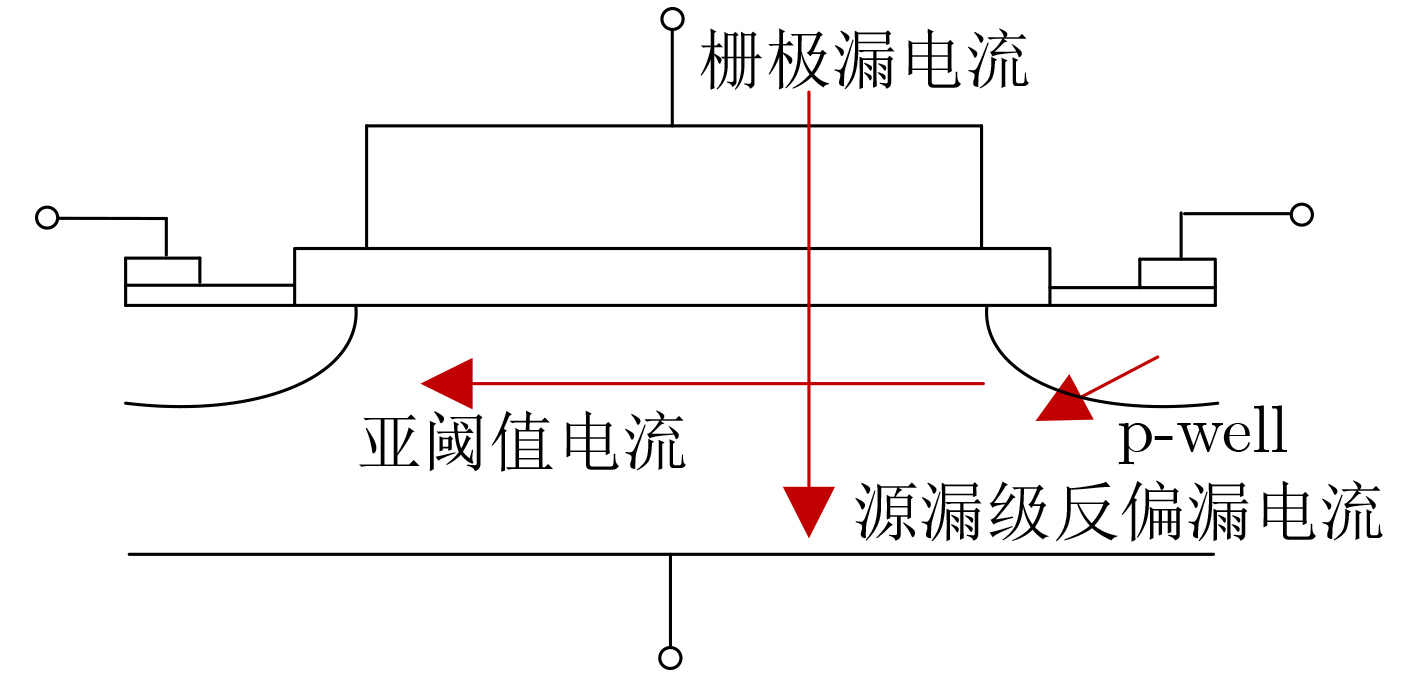
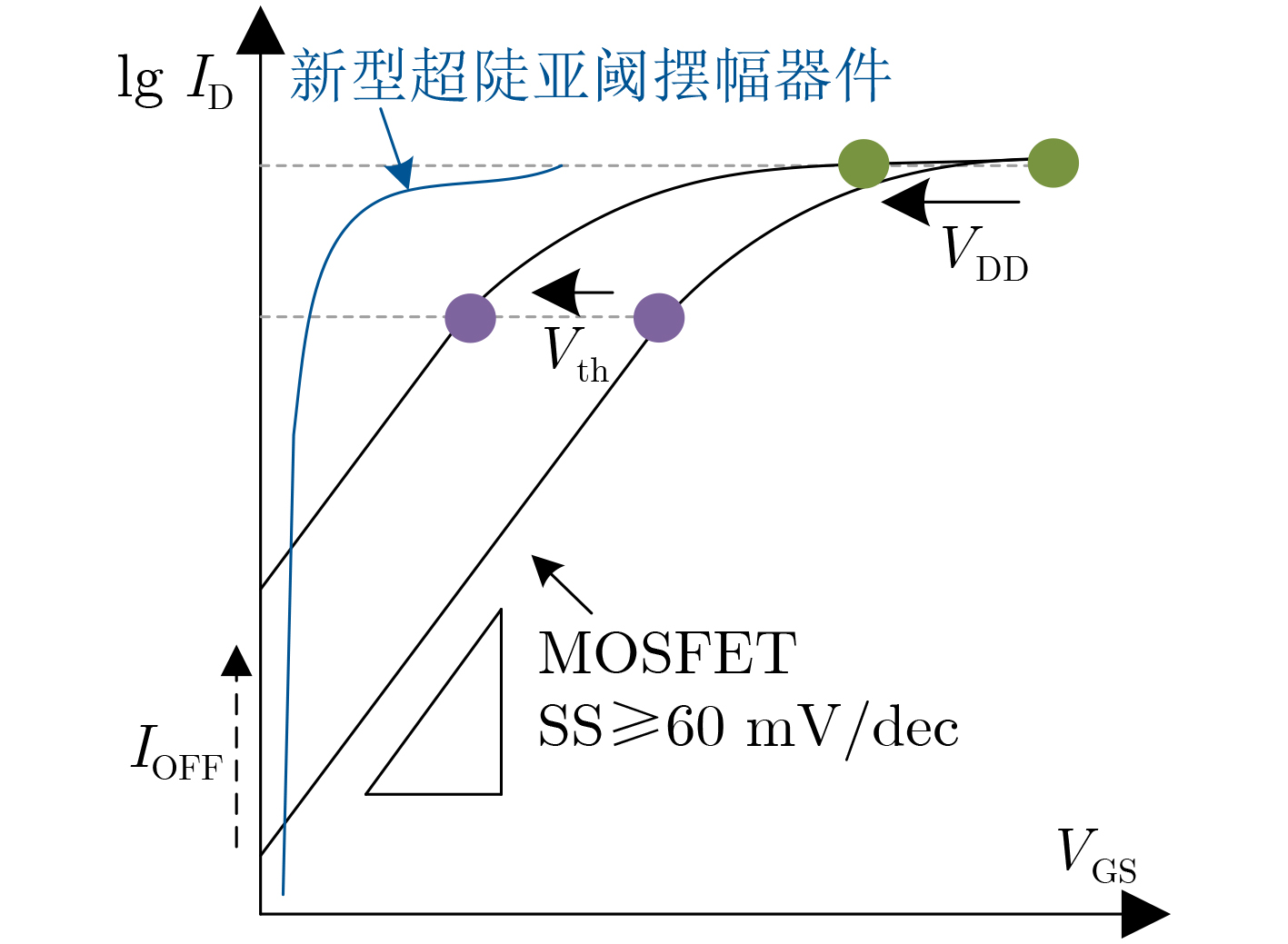
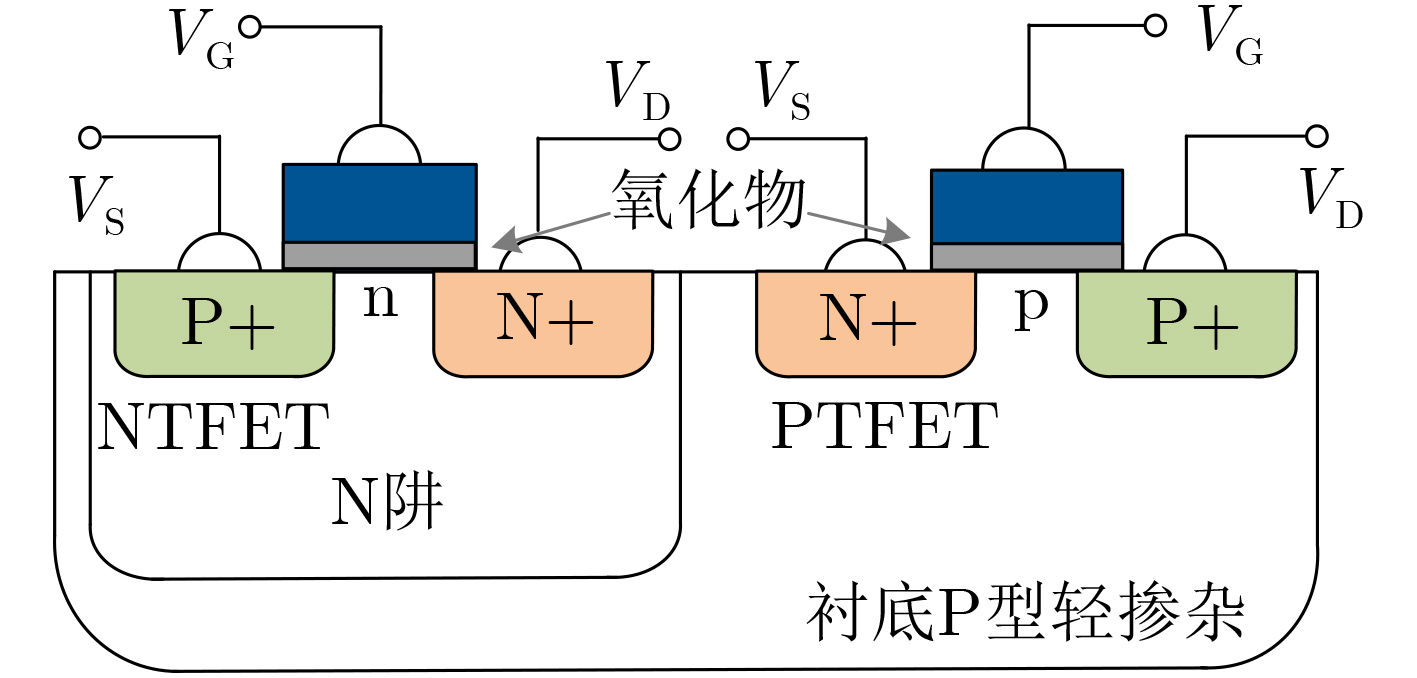
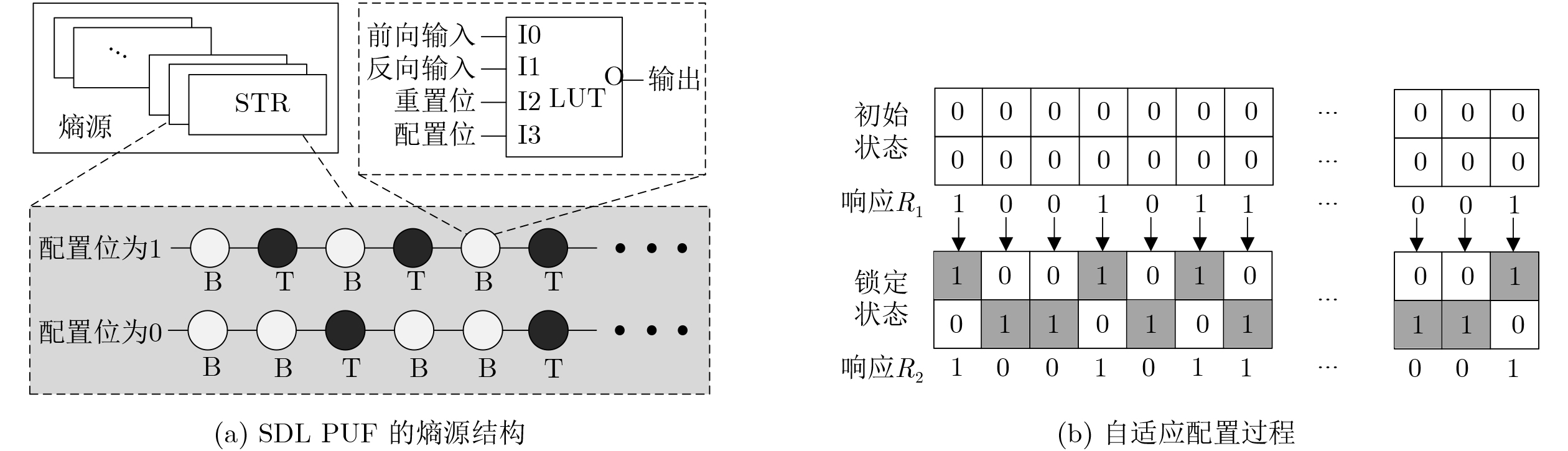
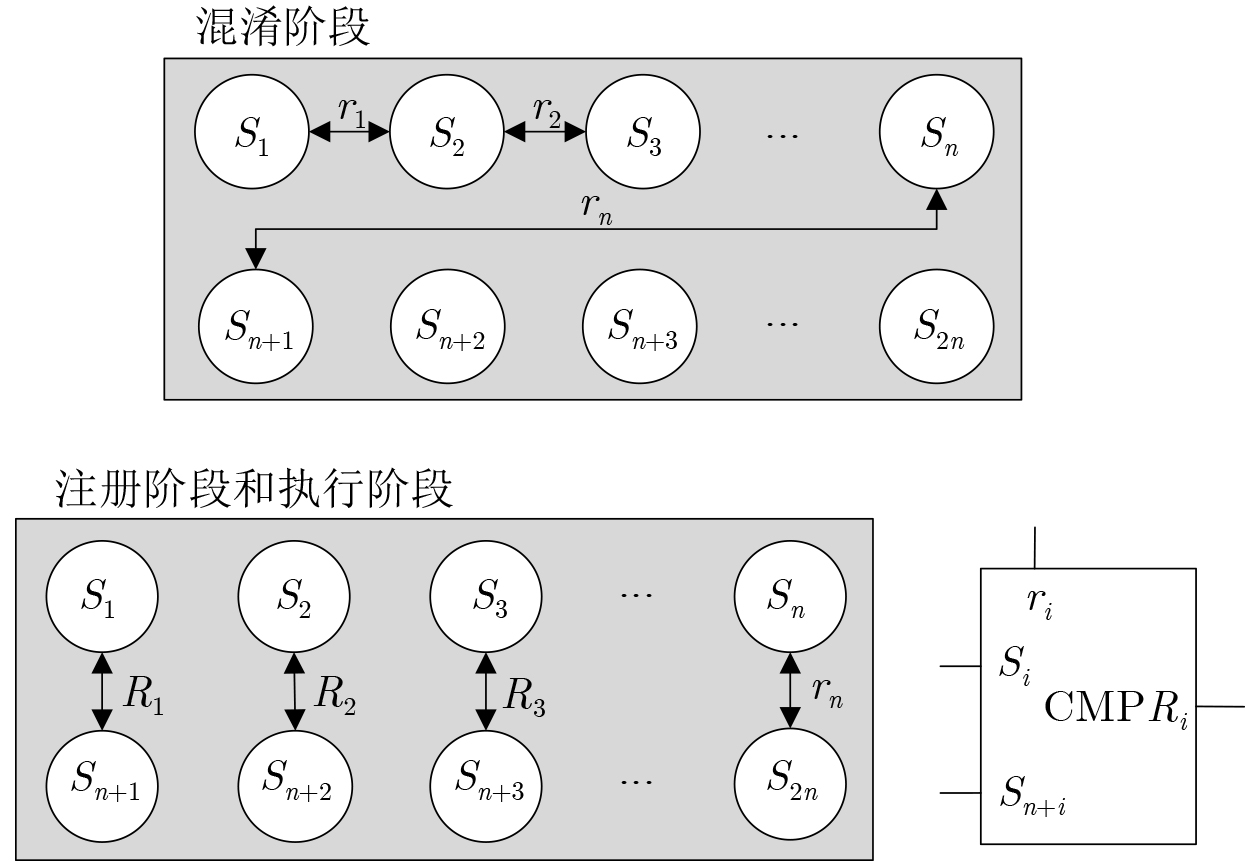
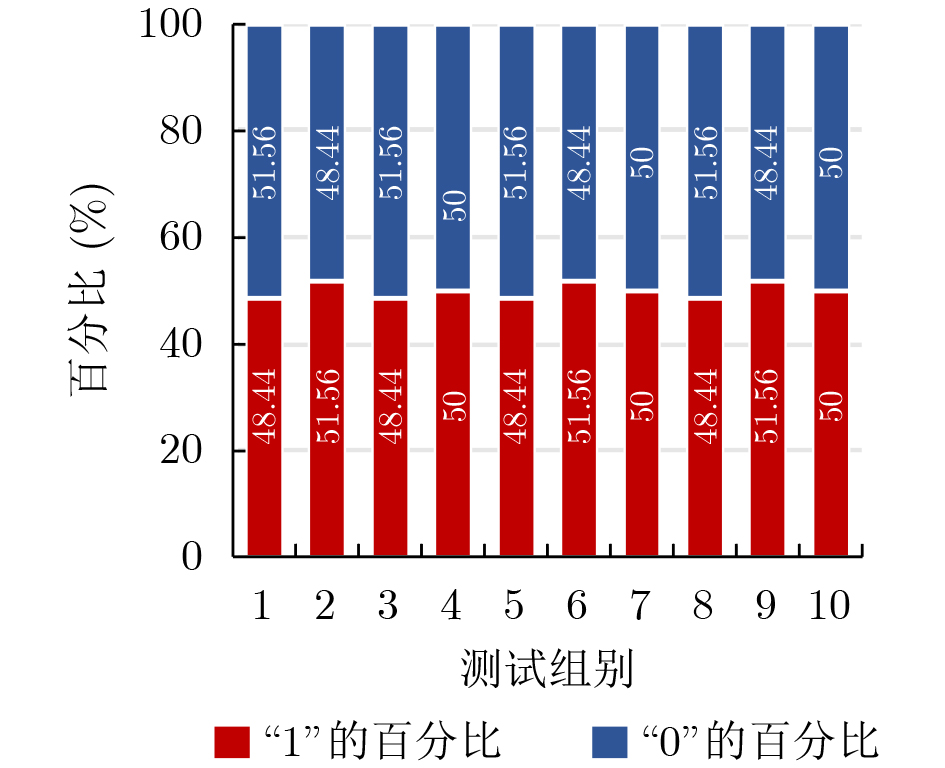
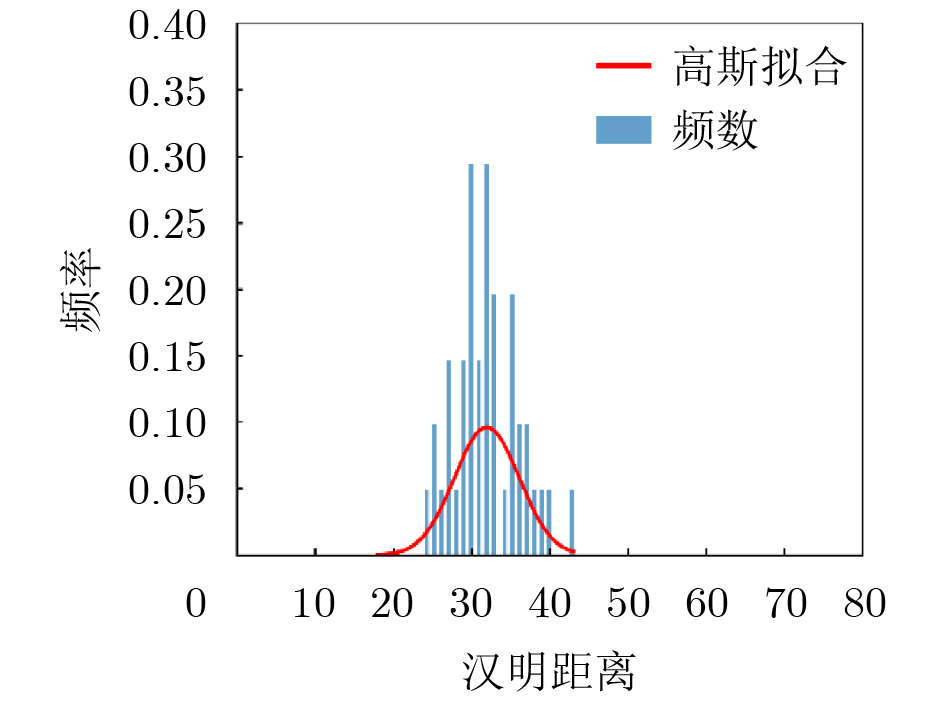
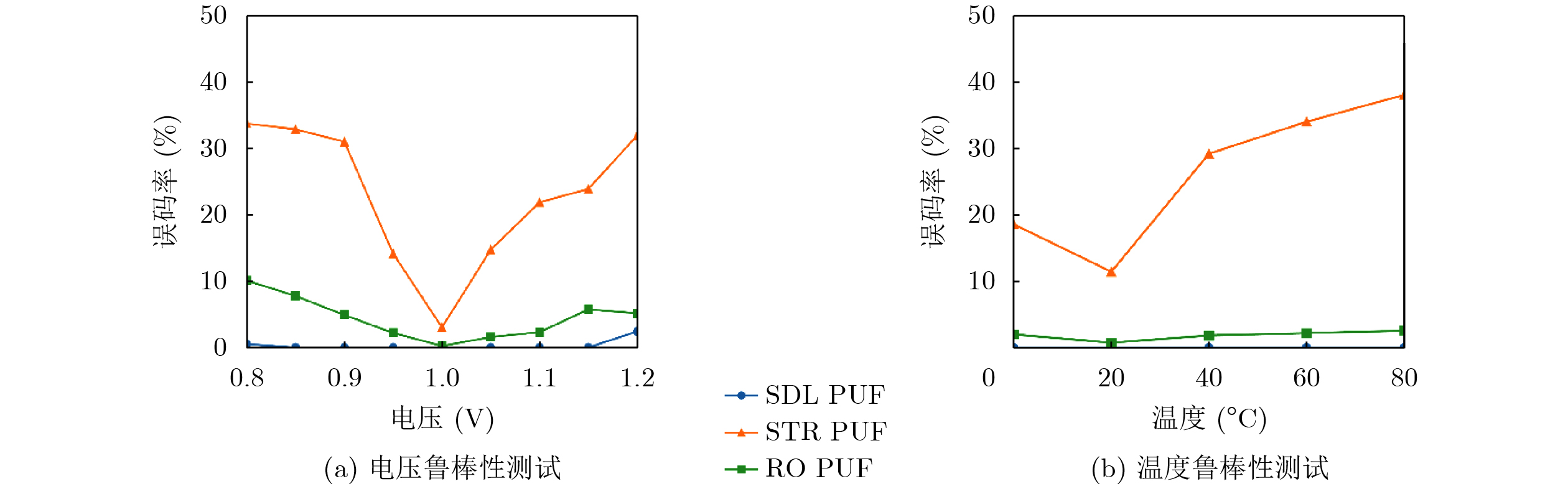
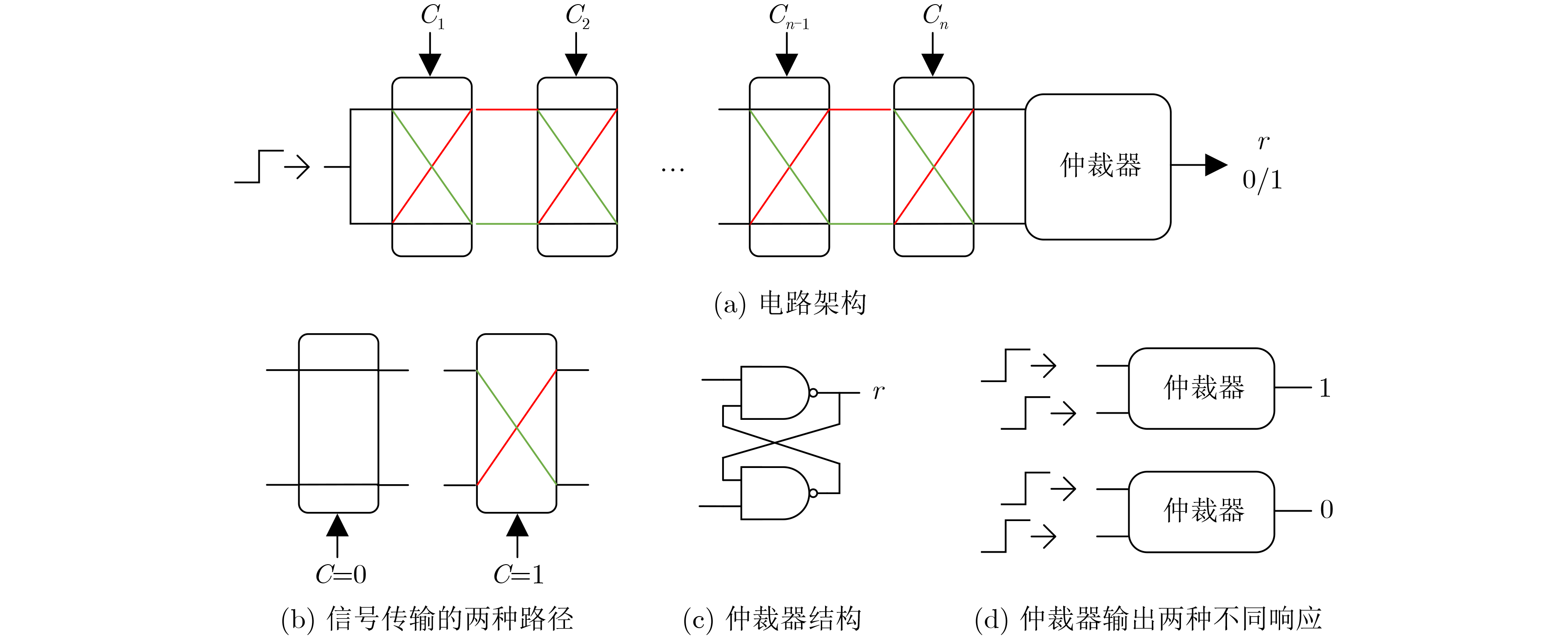
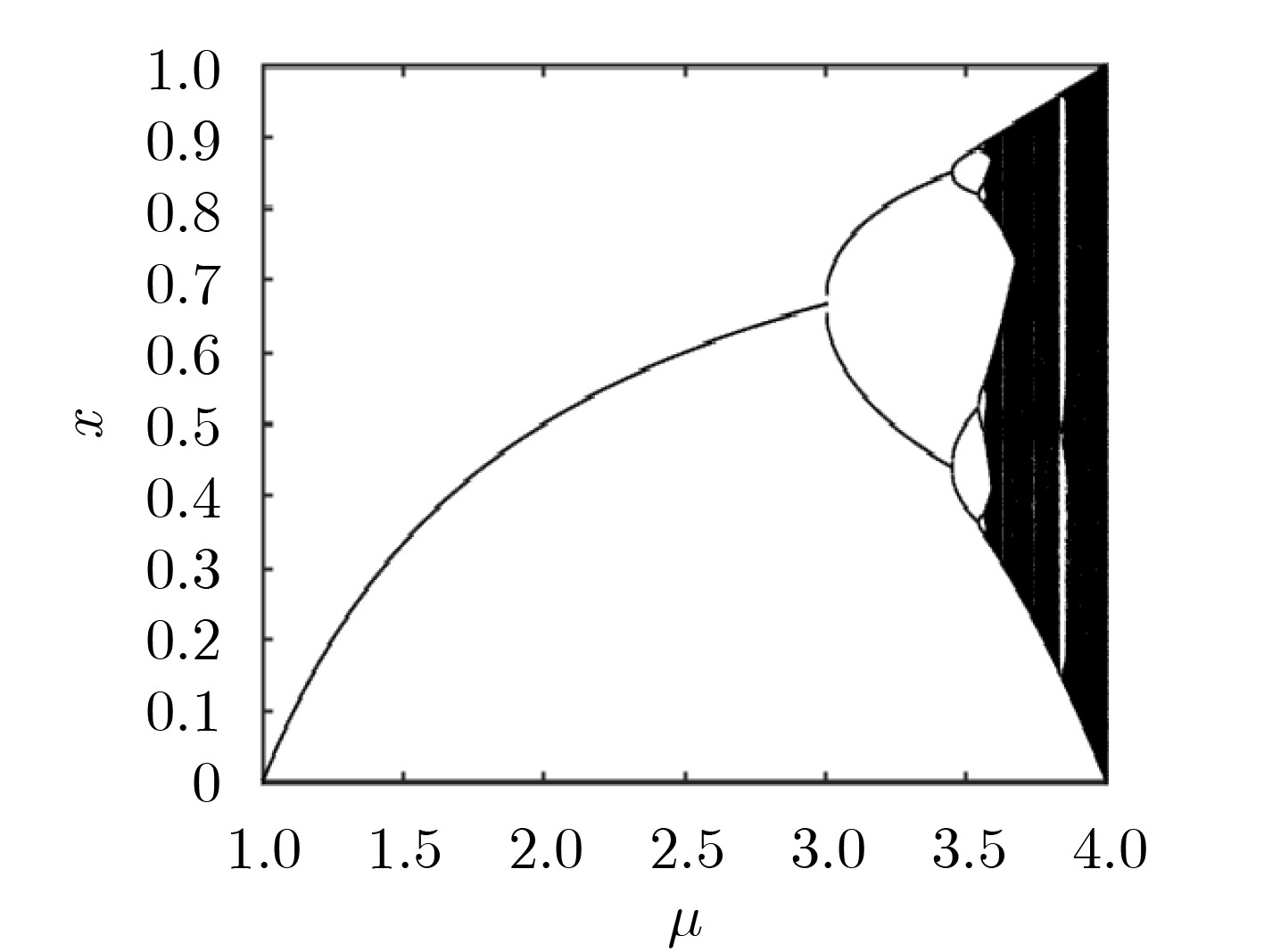
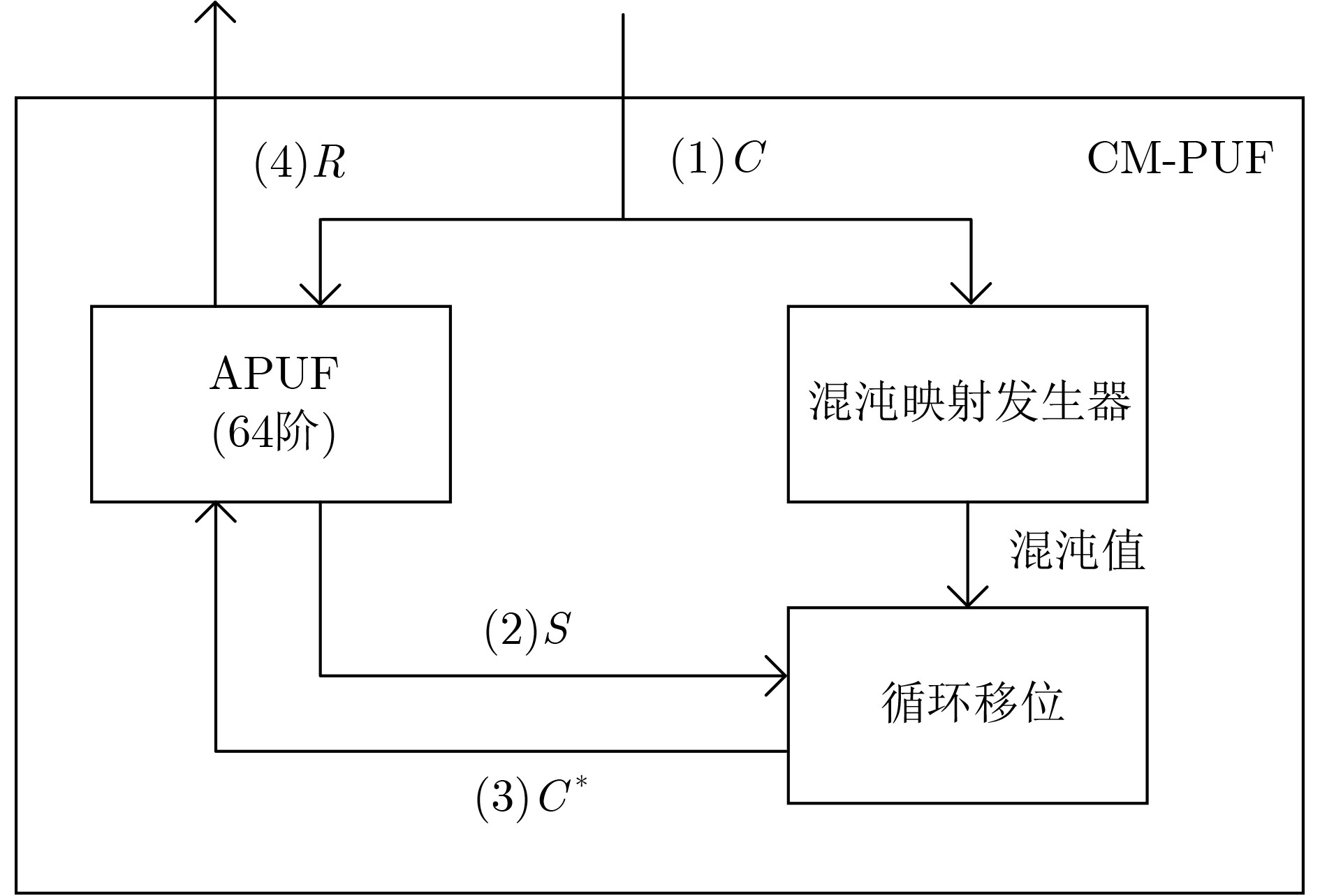
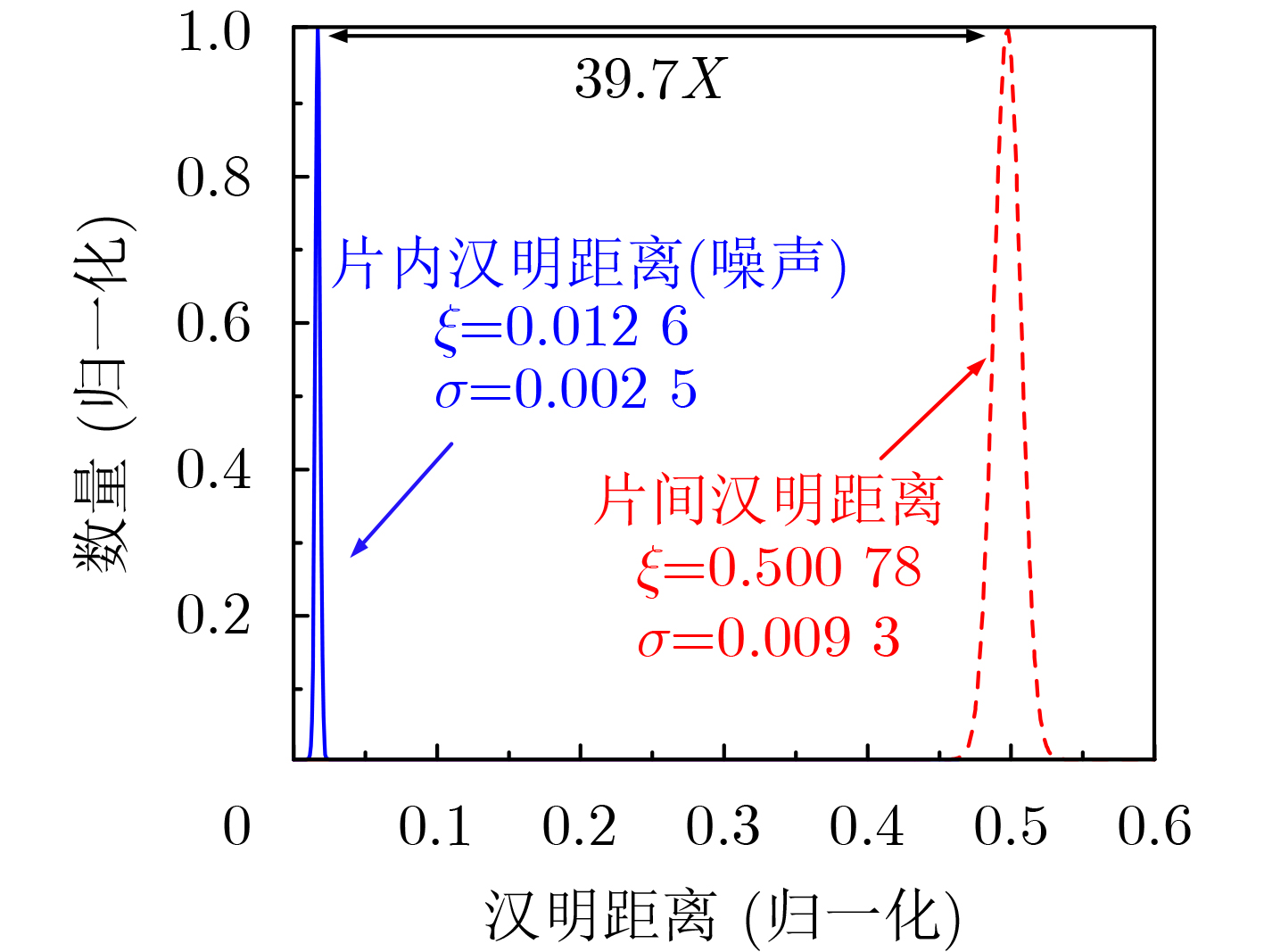
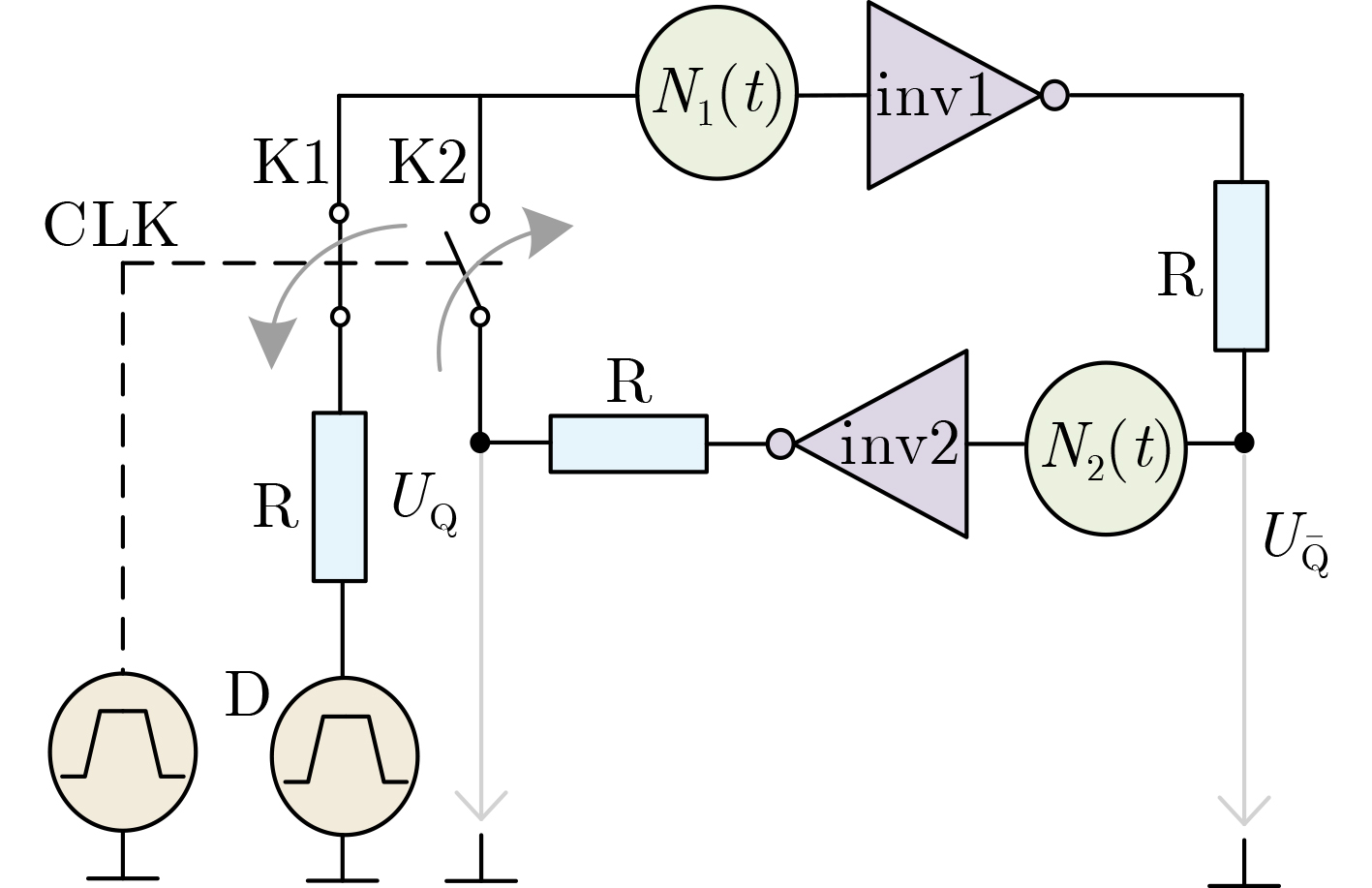
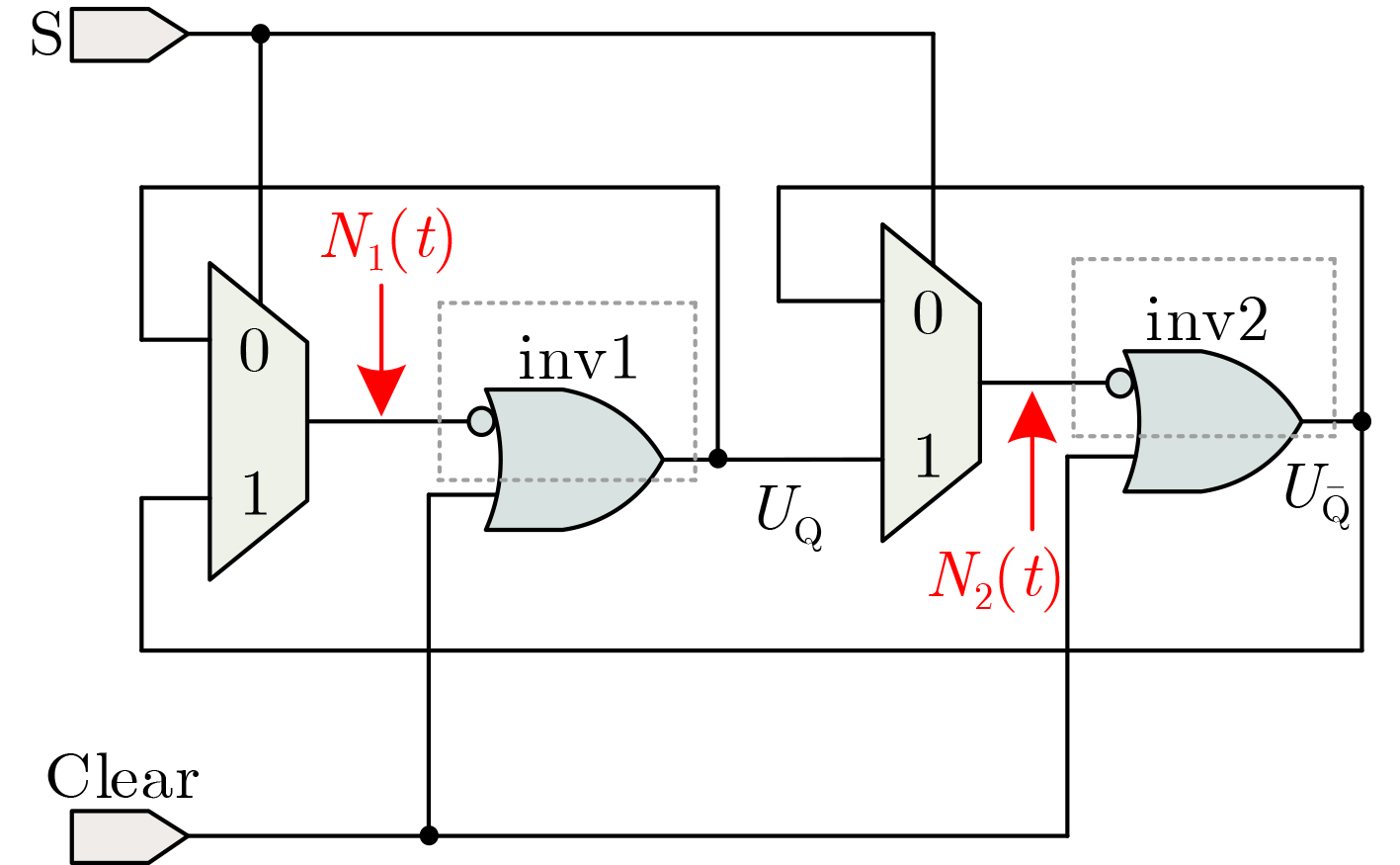
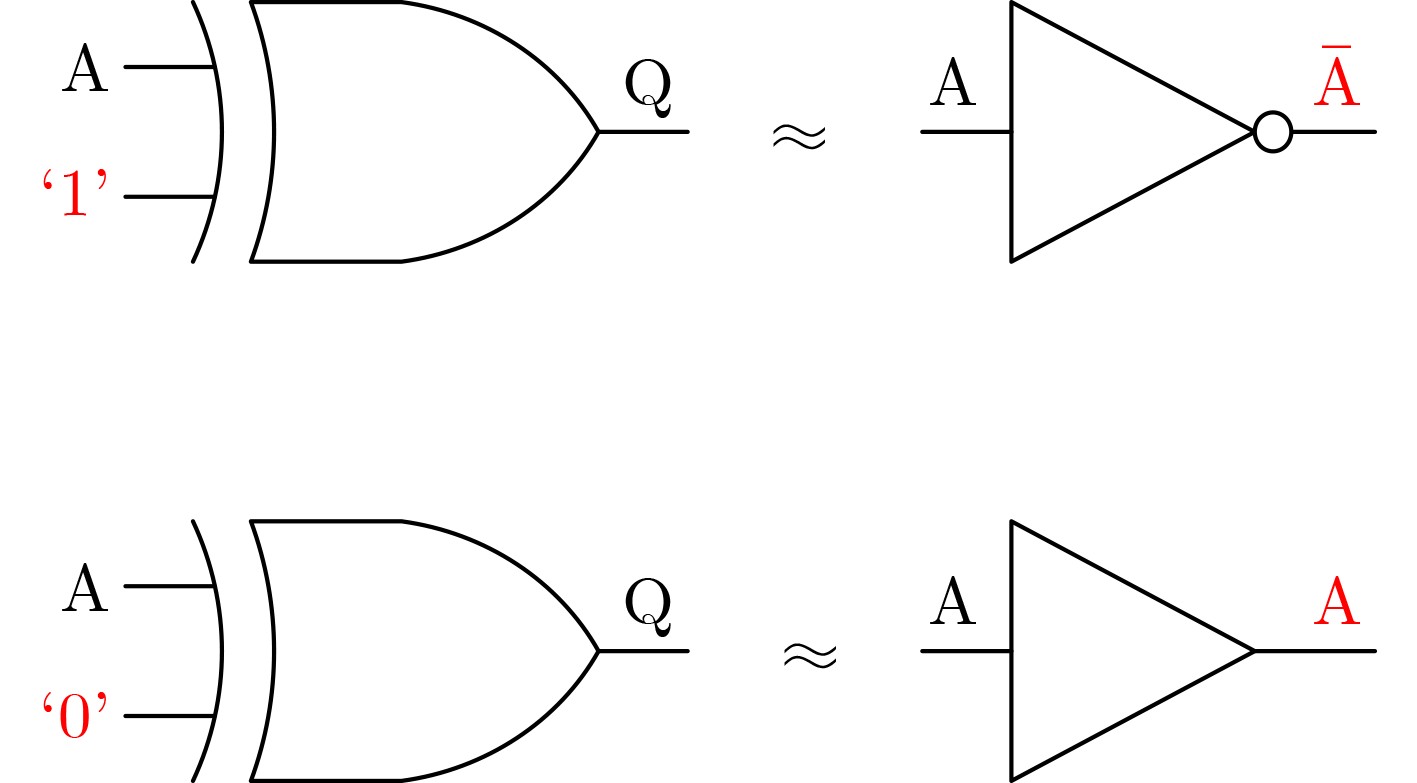
2024, 46(5): 1658-1671.
doi: 10.11999/JEIT231201
Abstract:
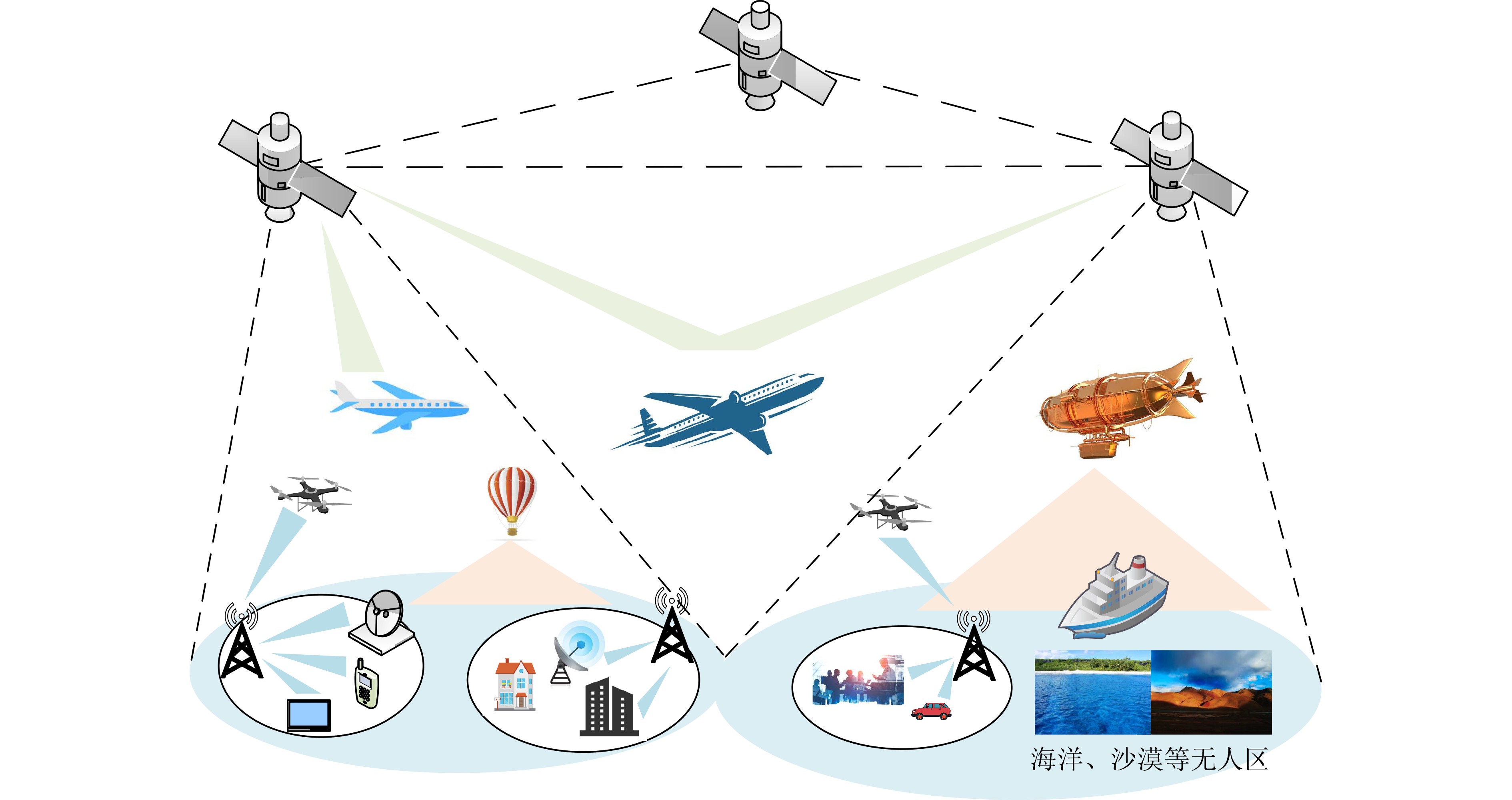
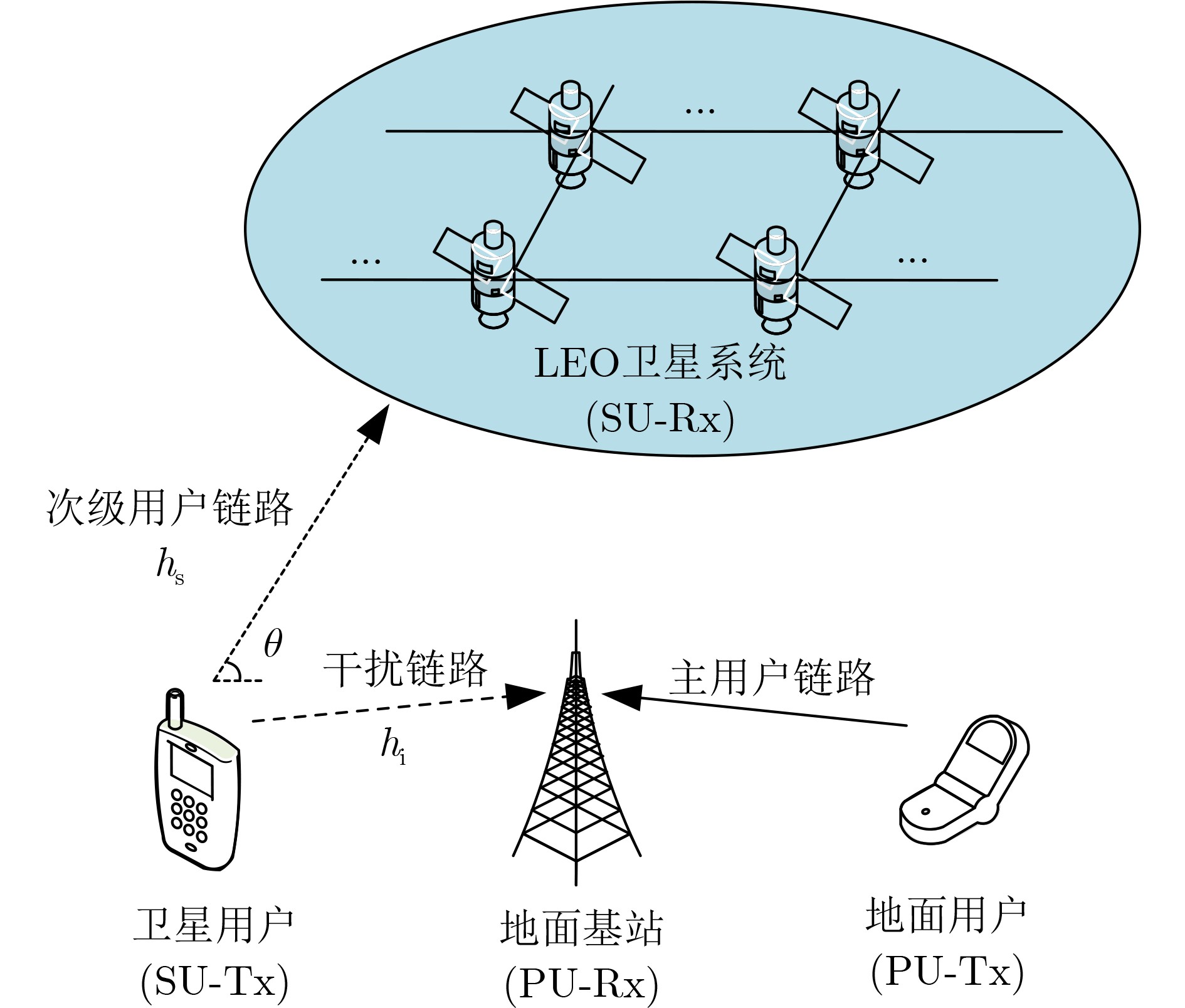
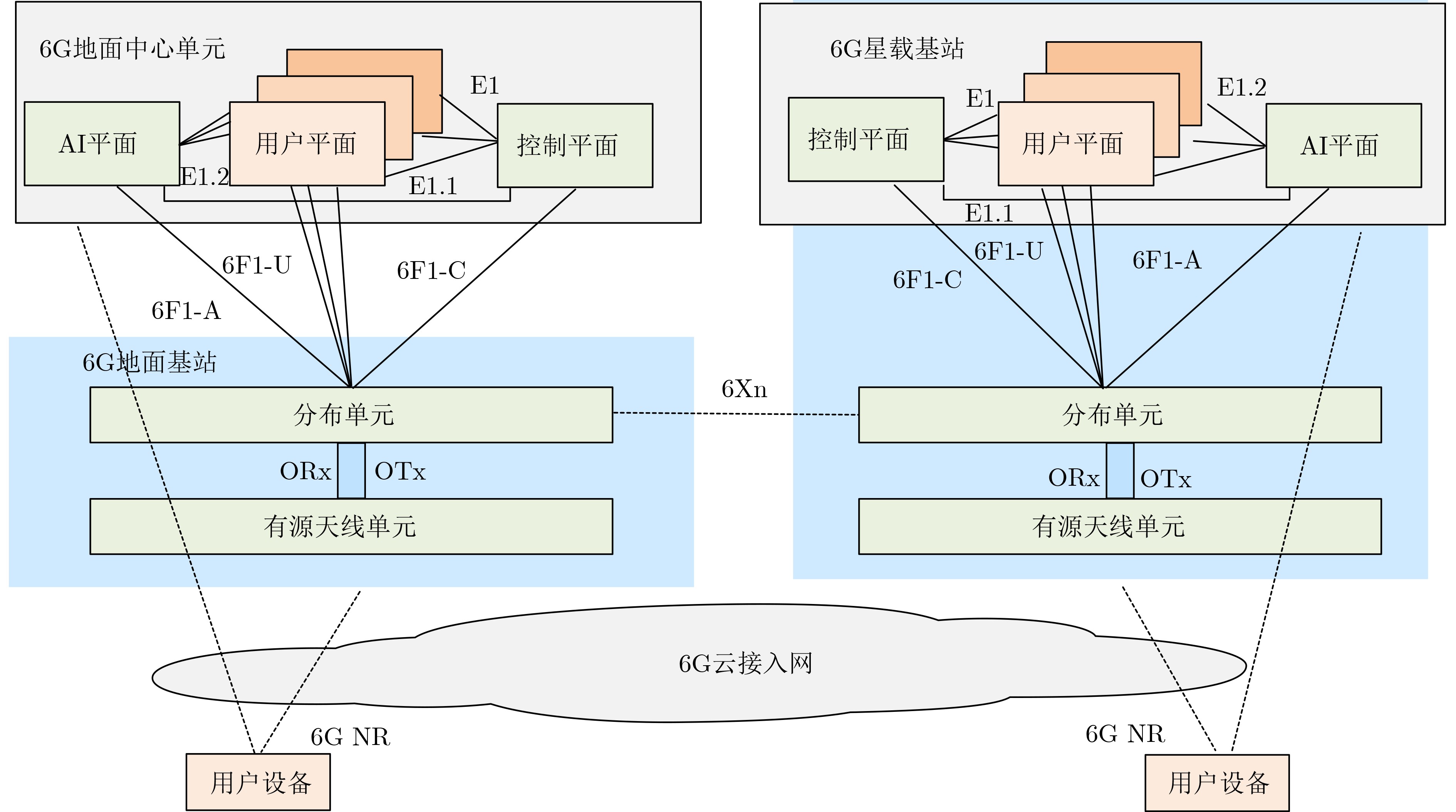
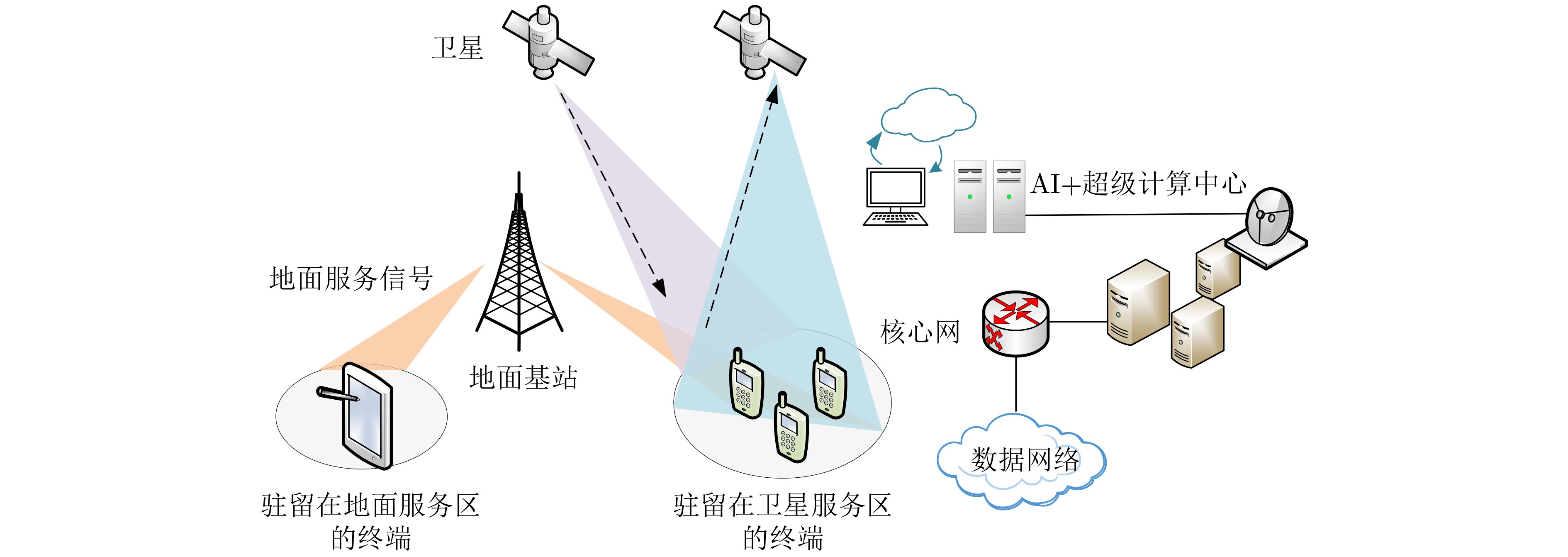
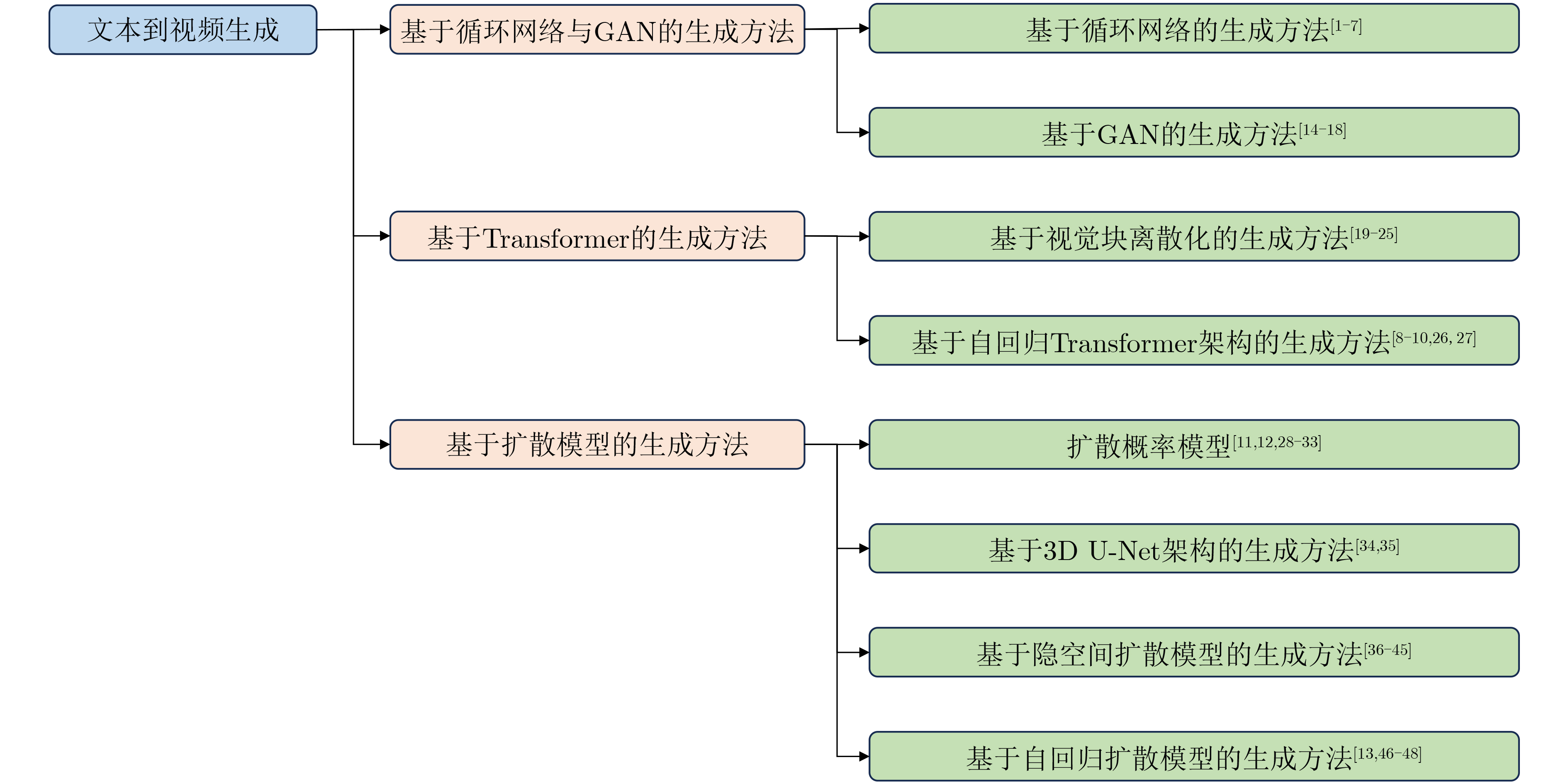
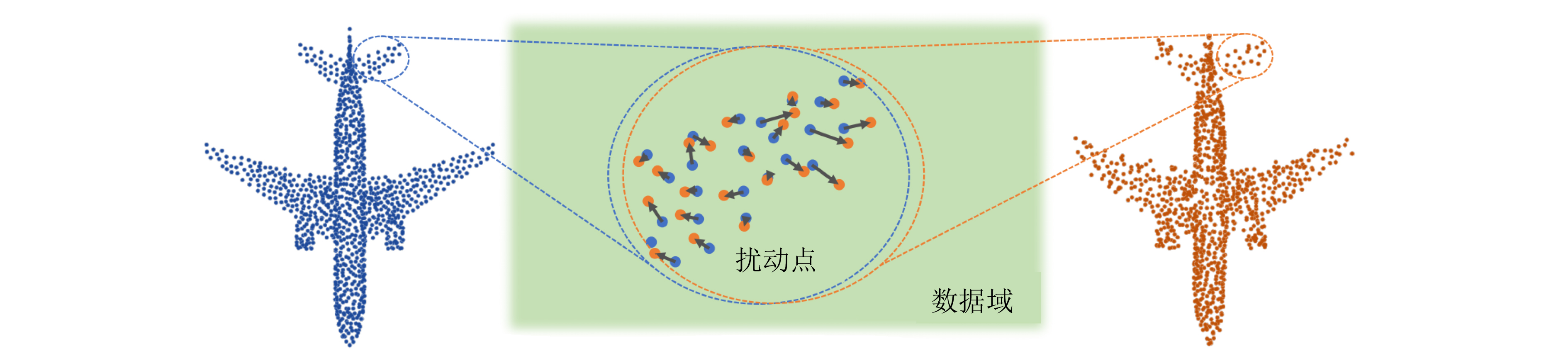
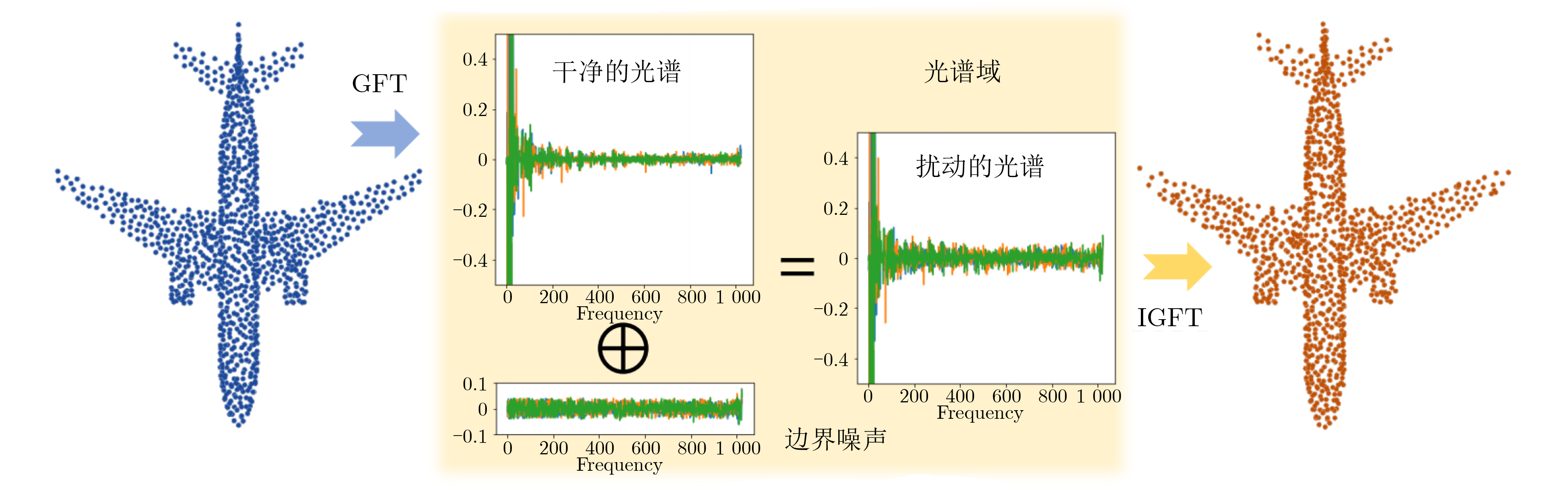
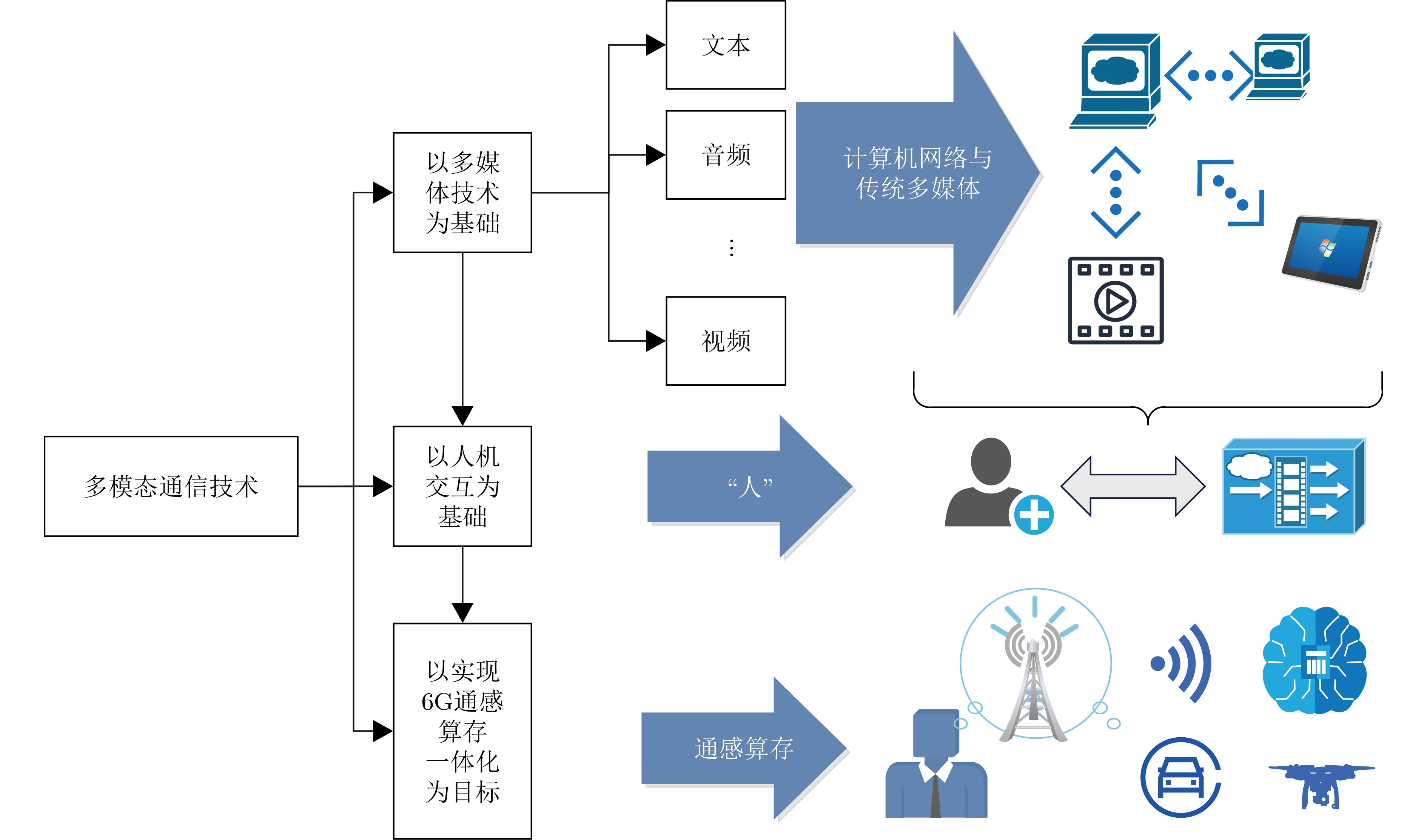
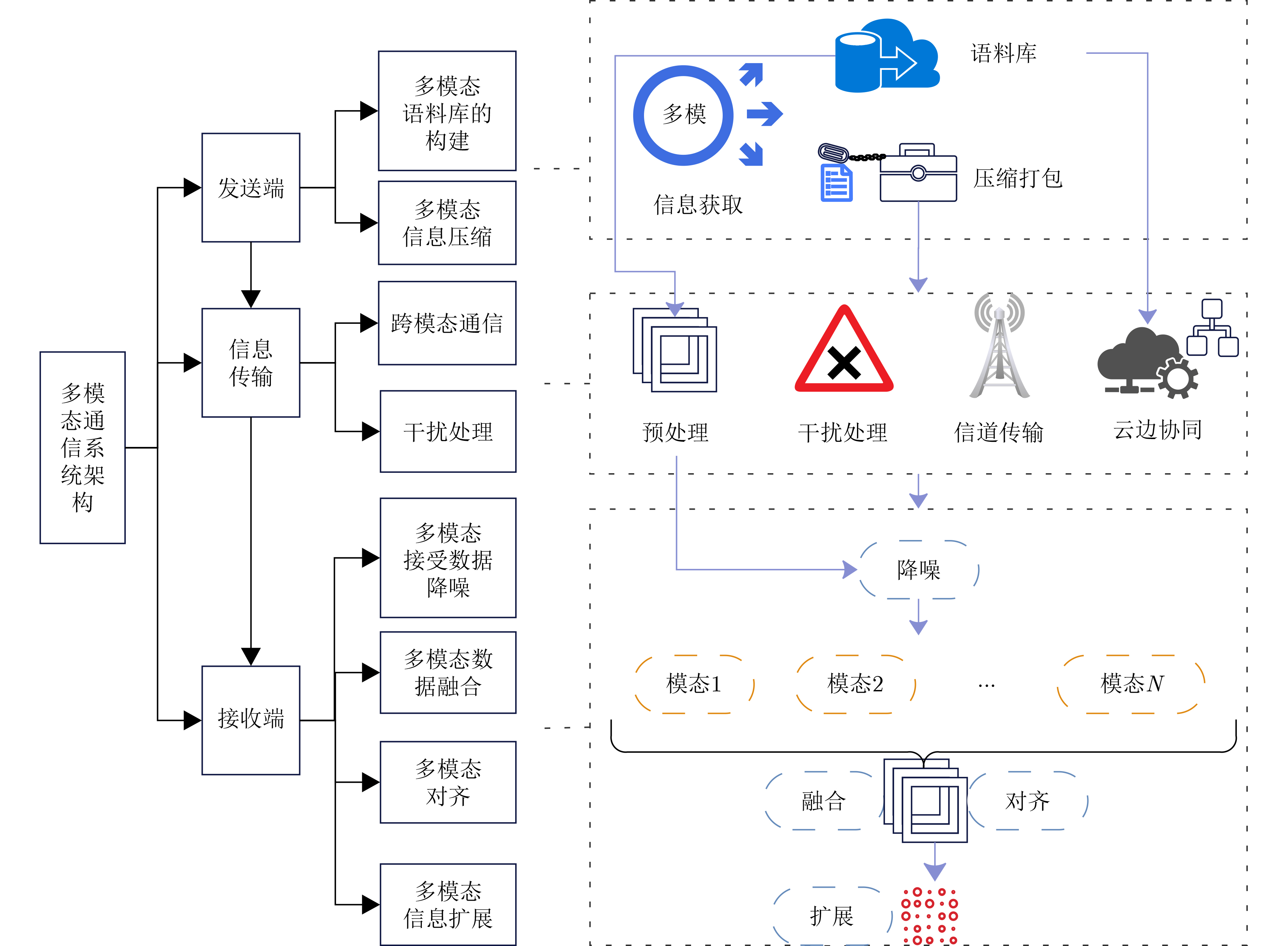
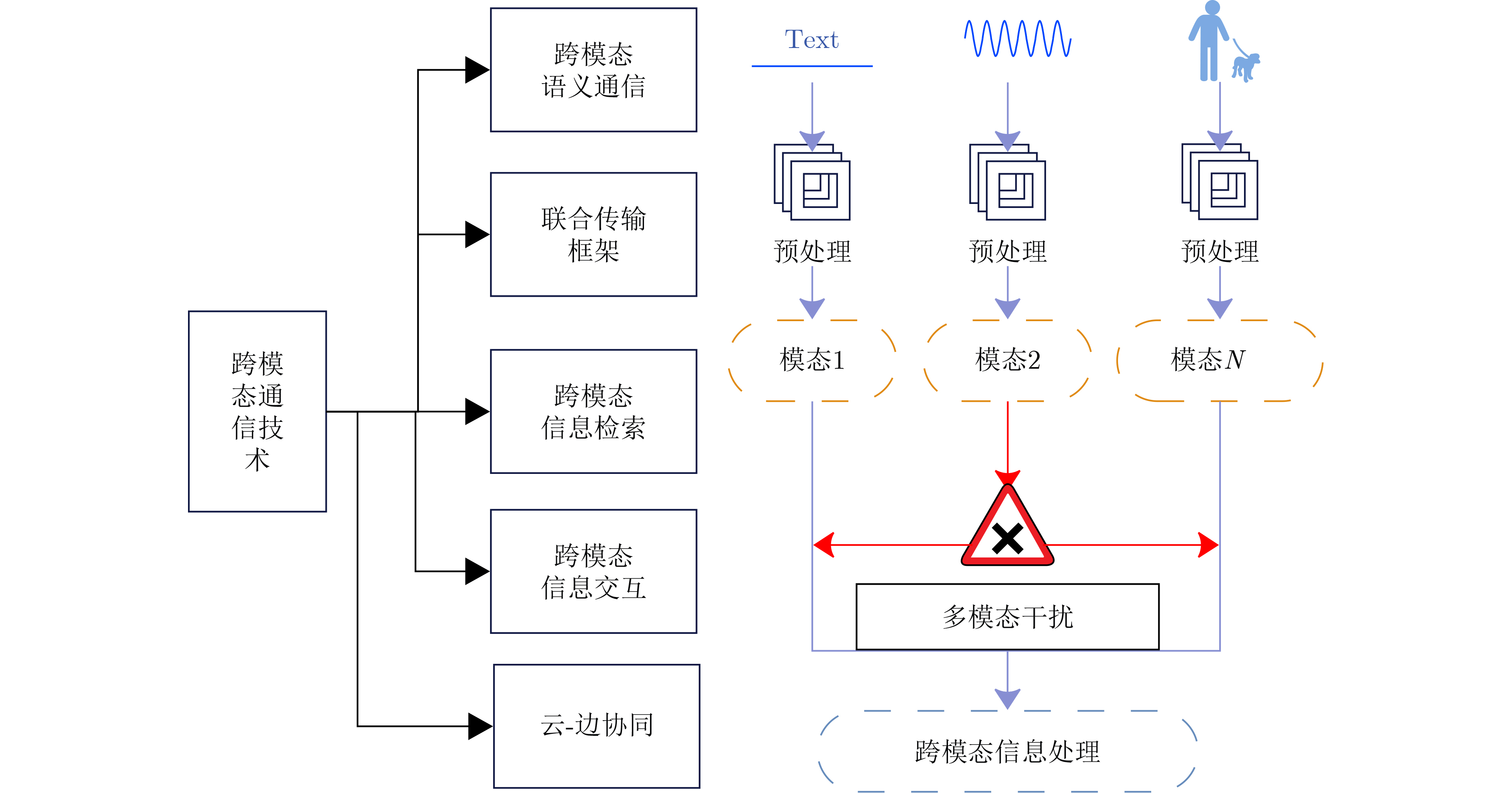
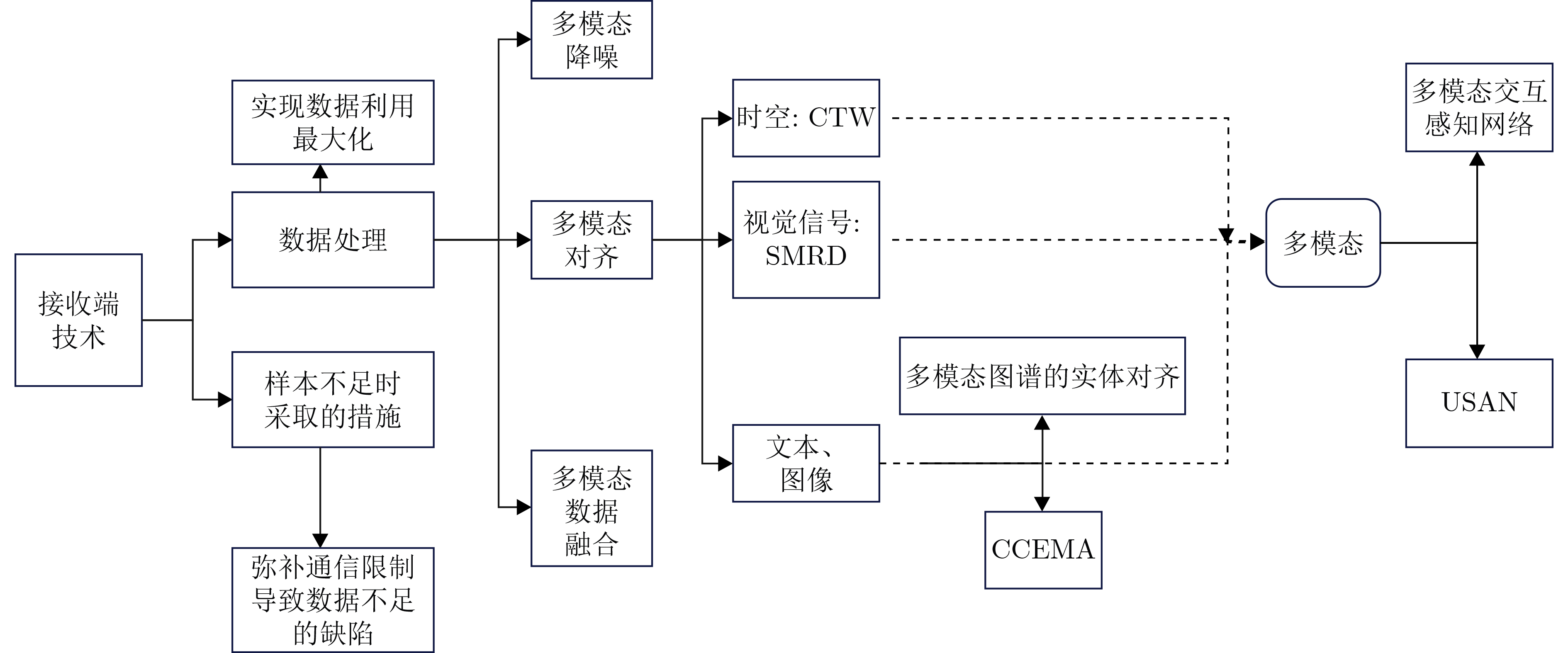
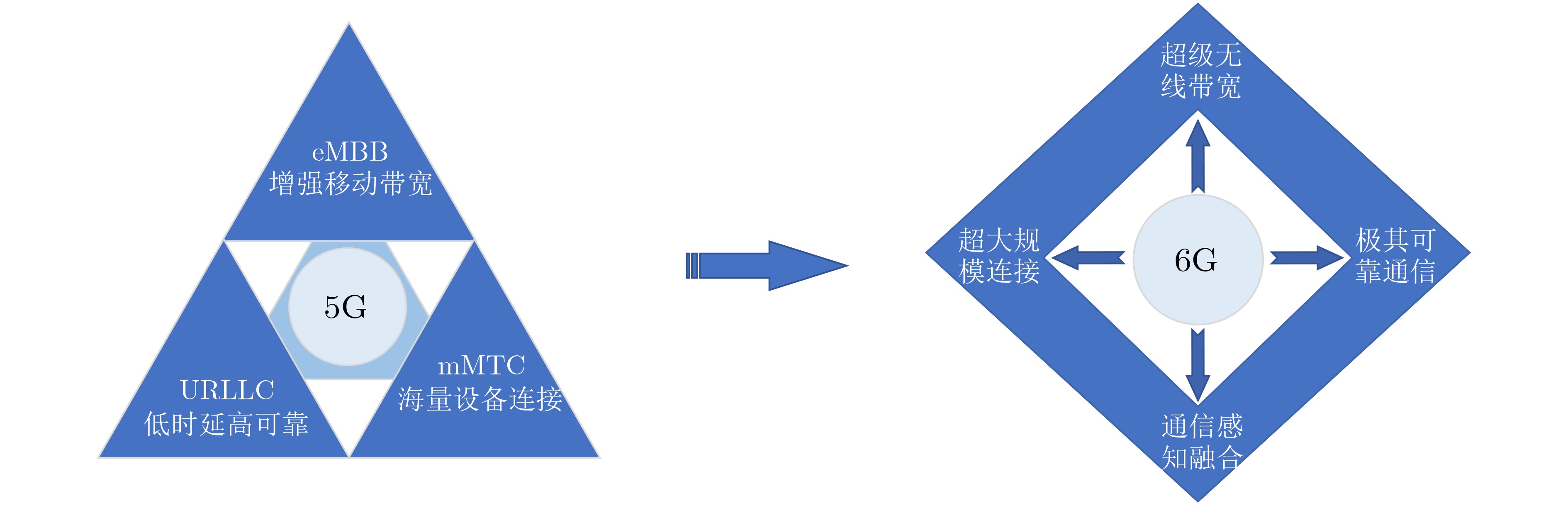
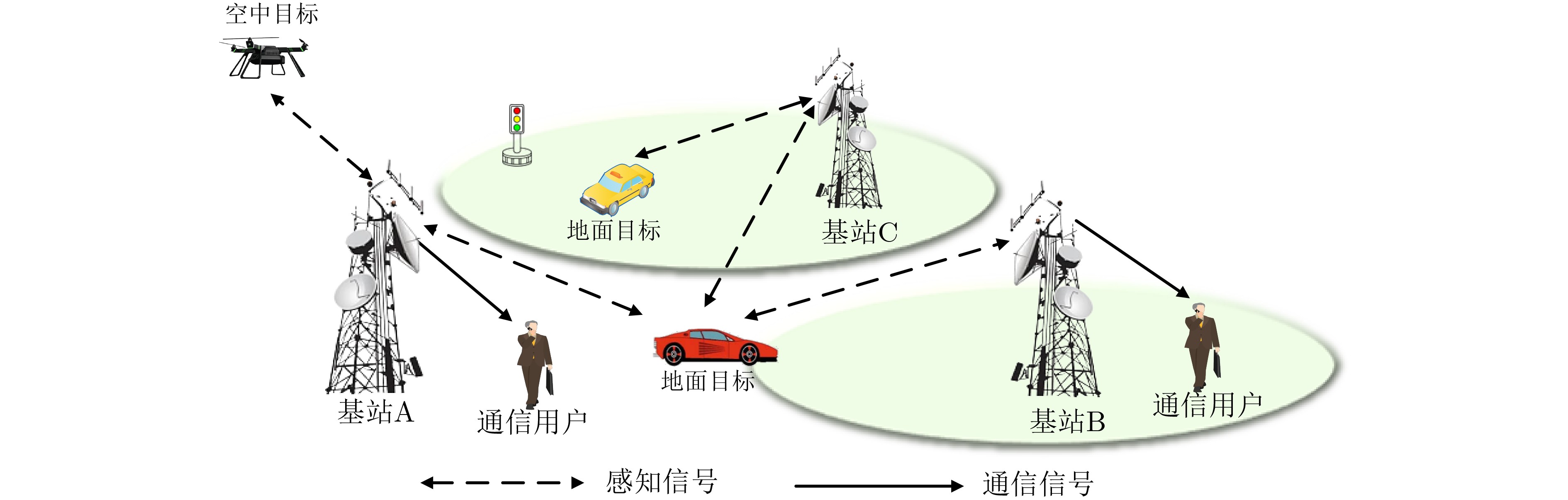
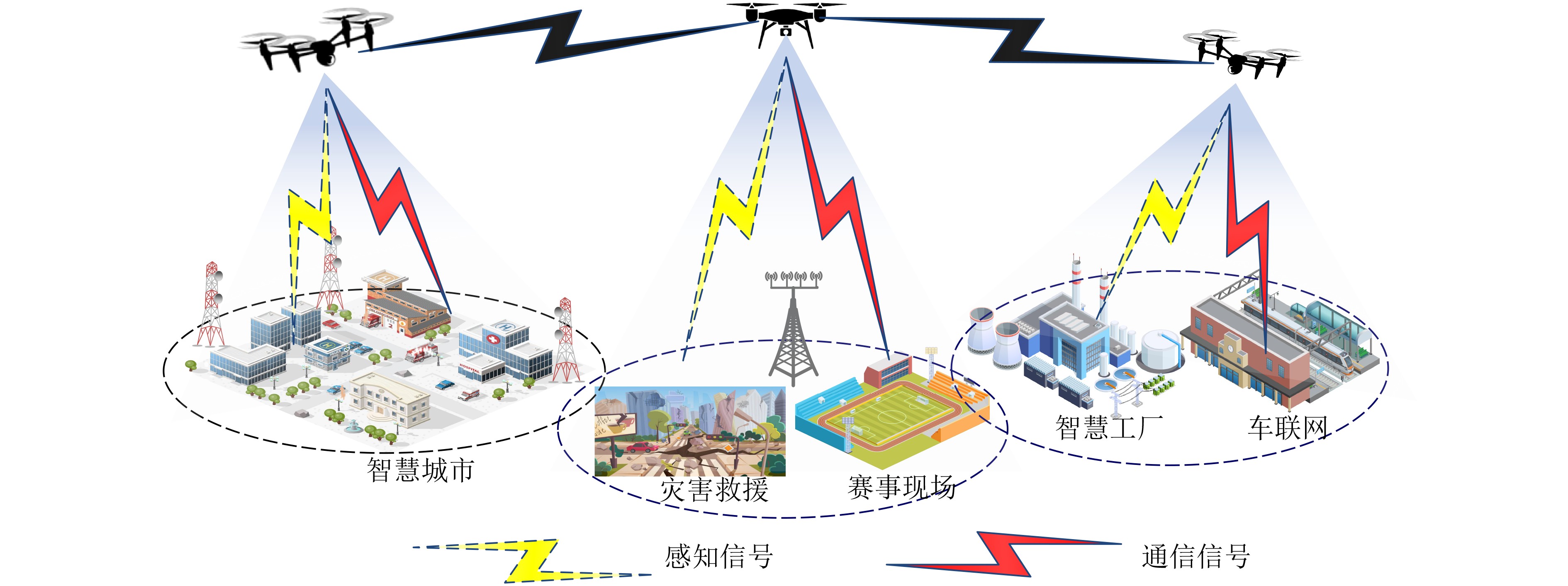
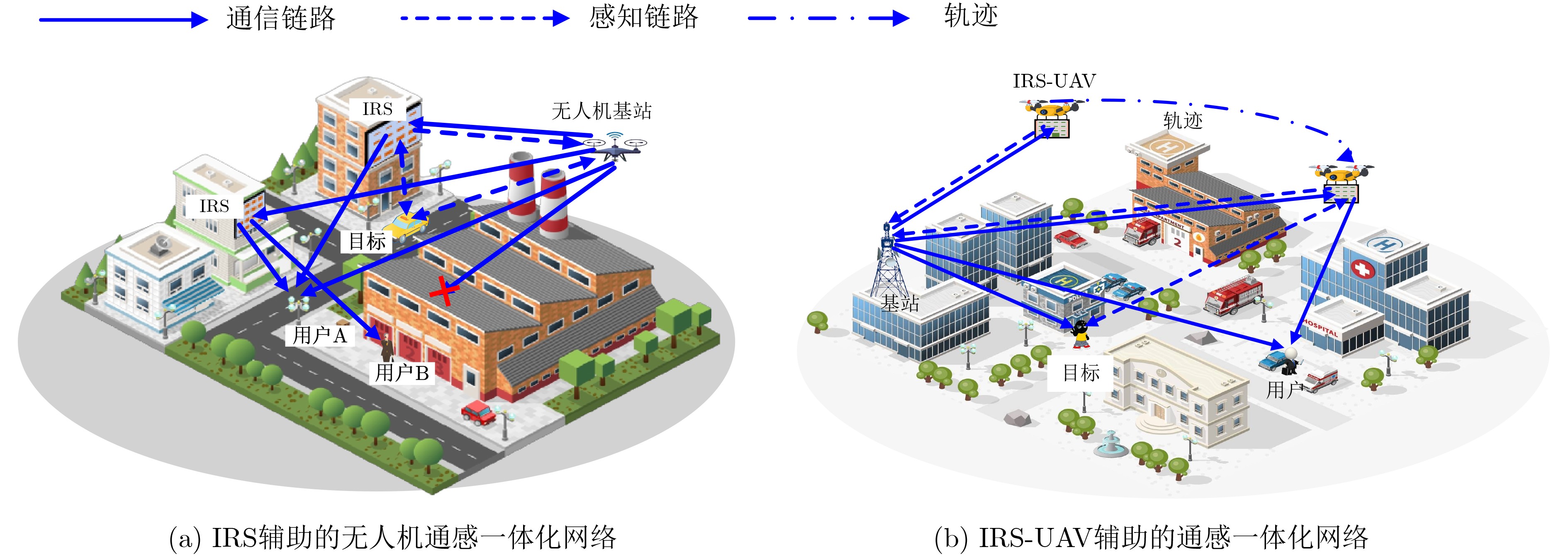
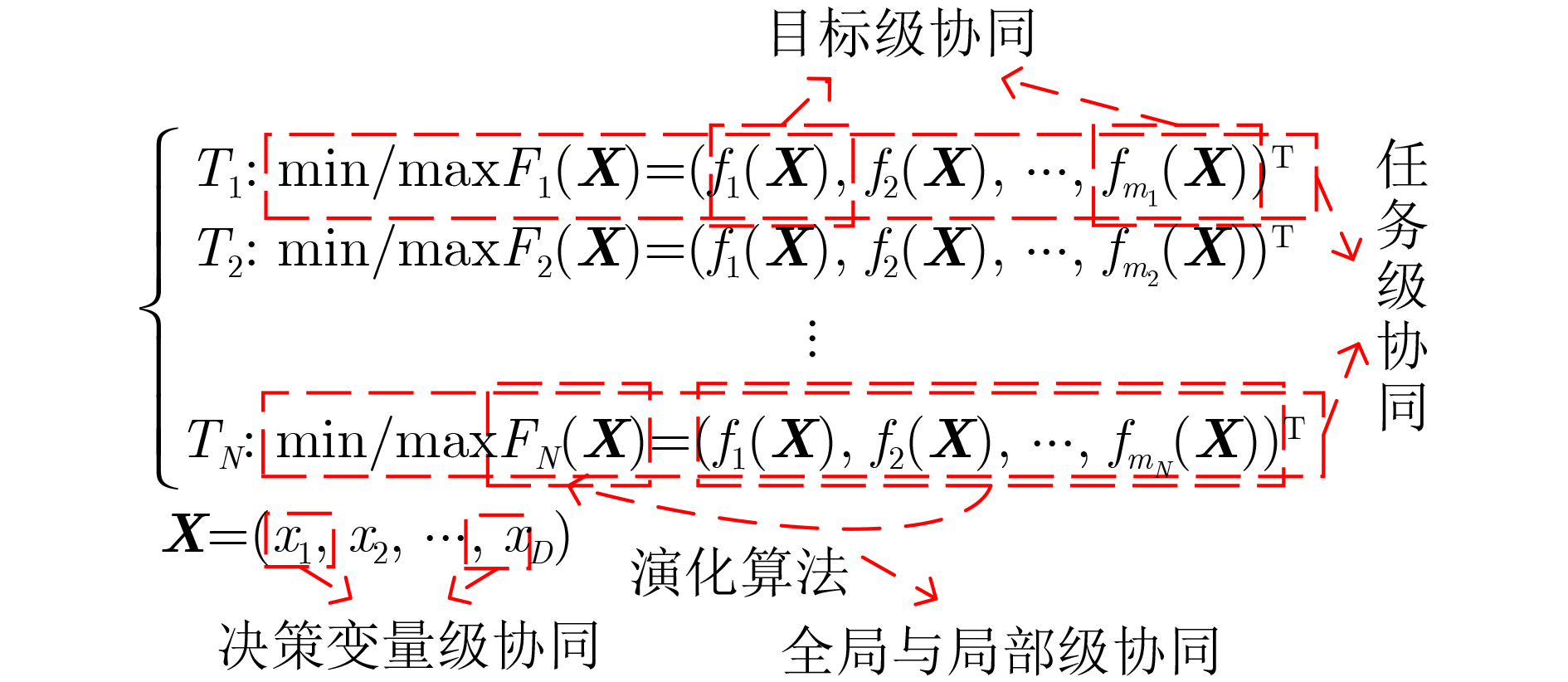
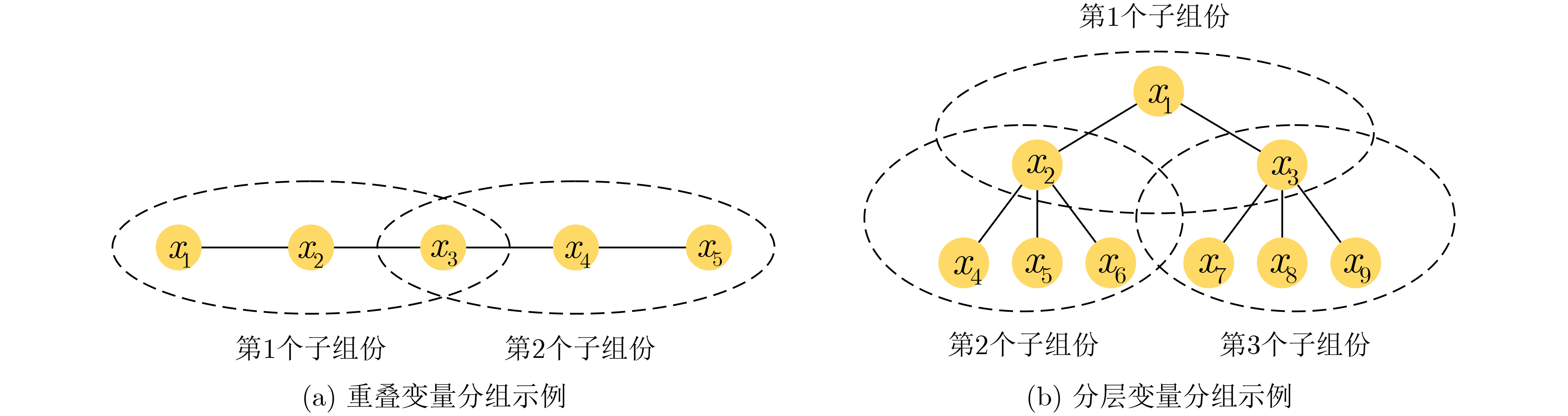
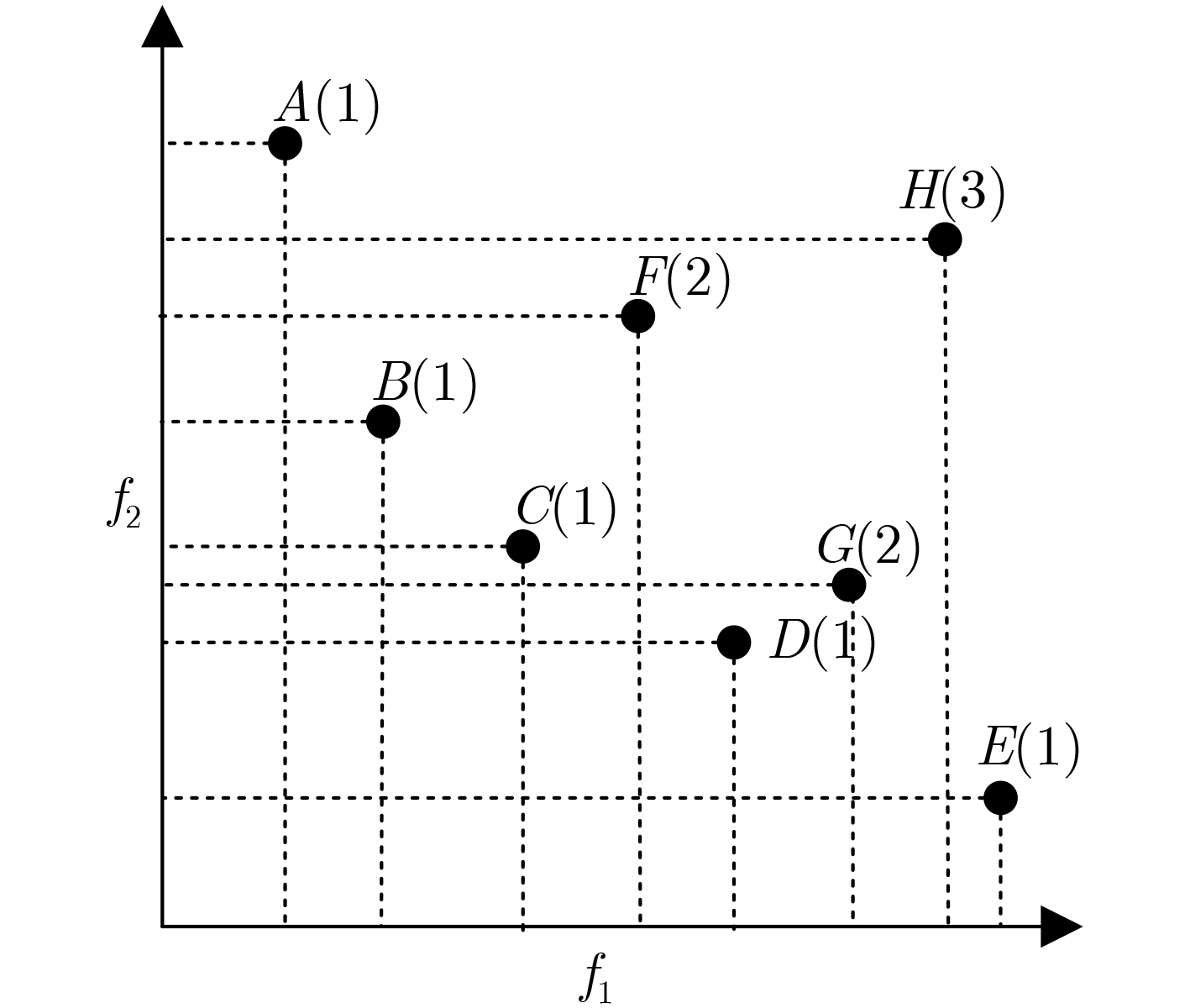
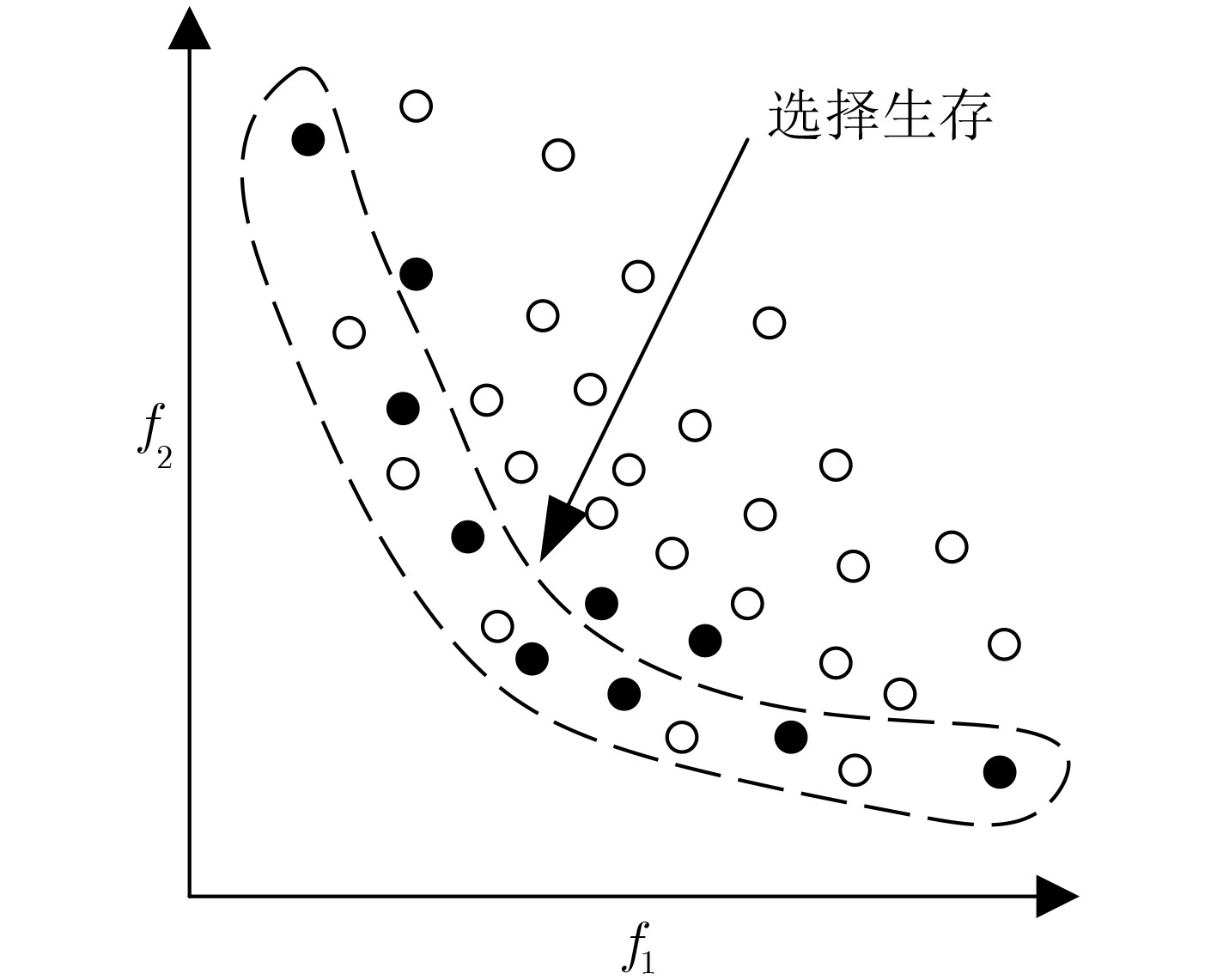
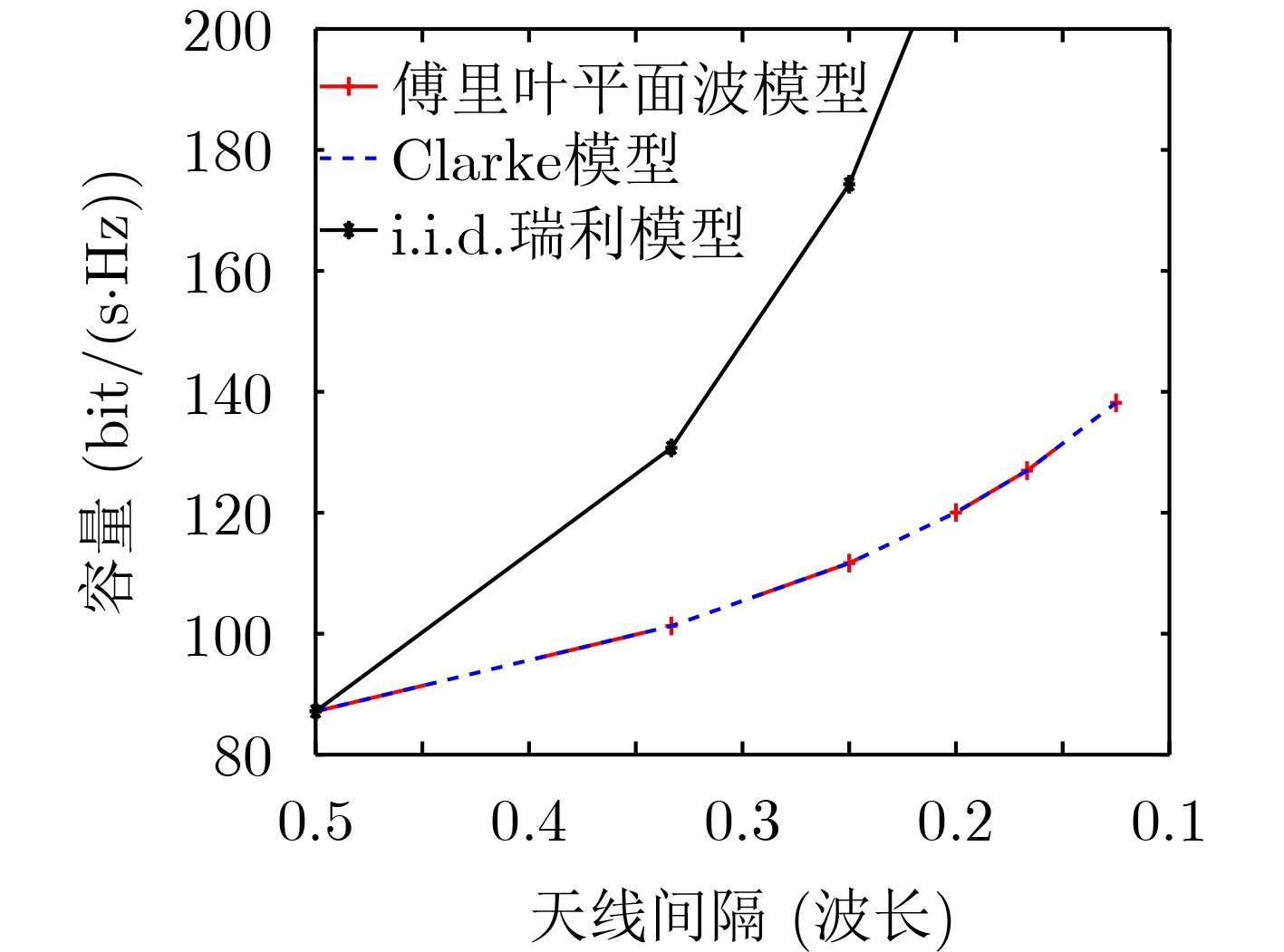
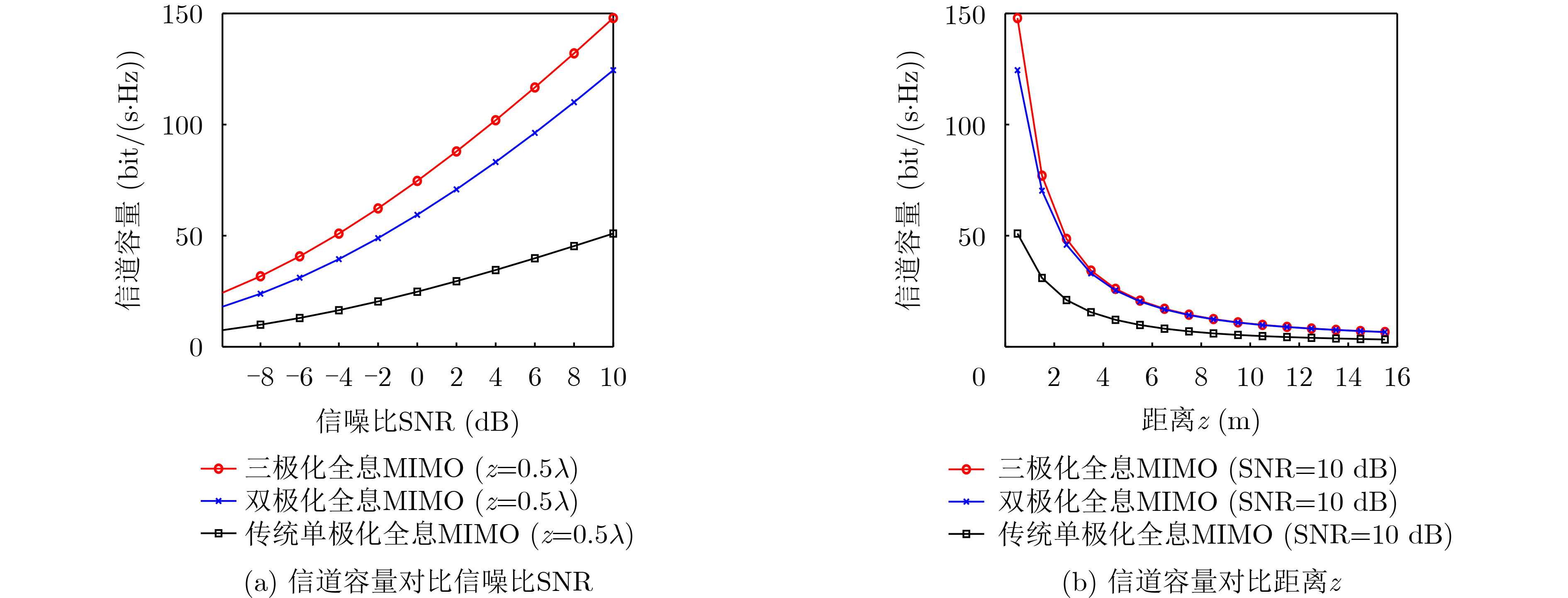
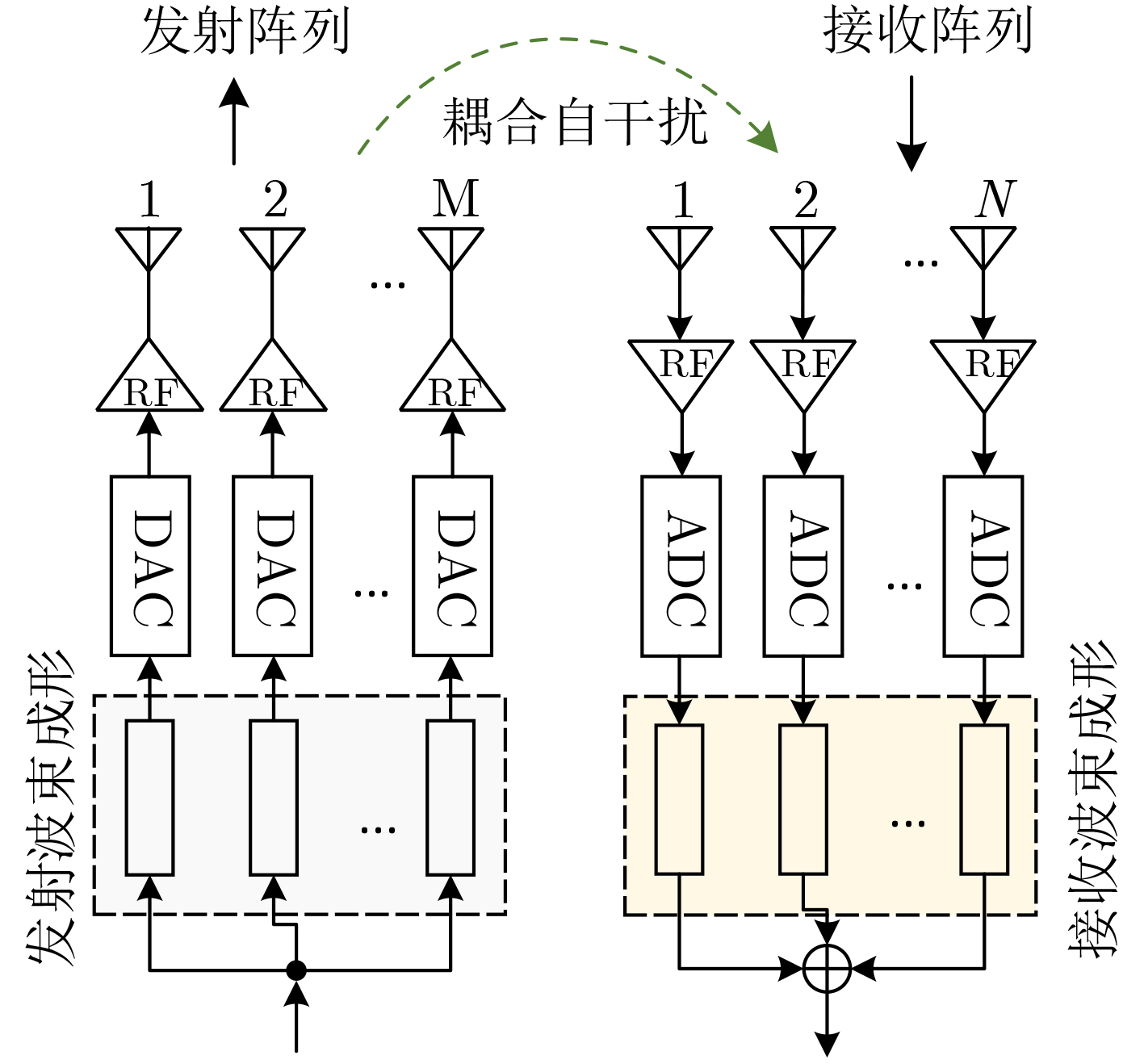
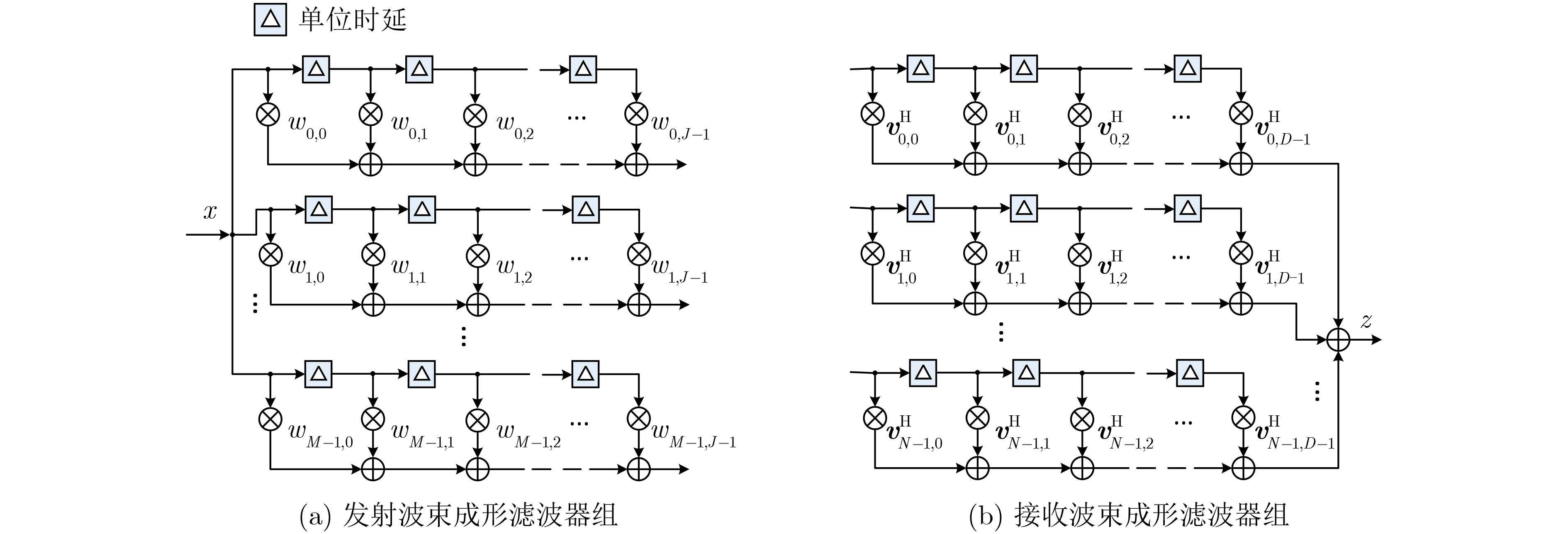
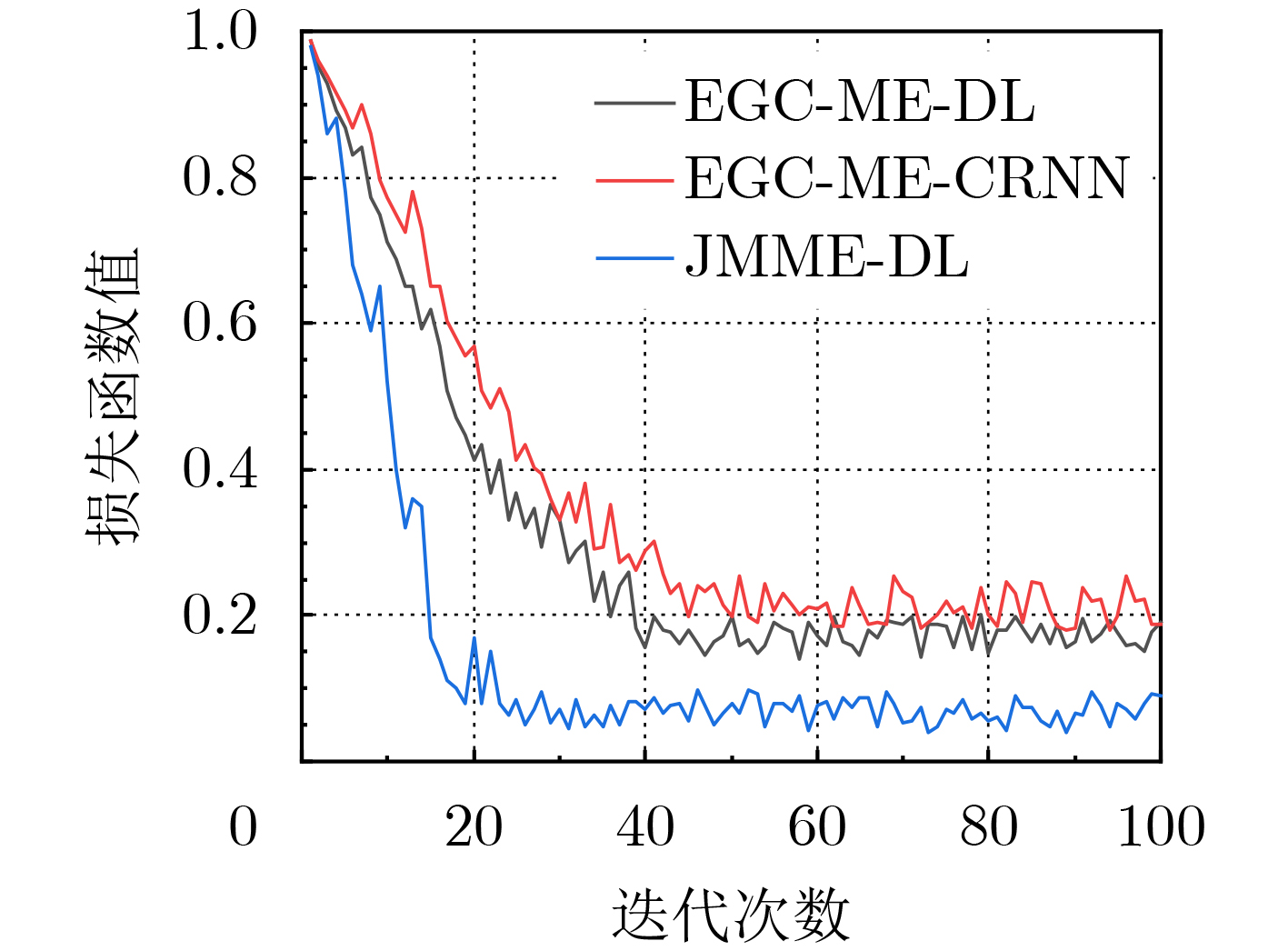
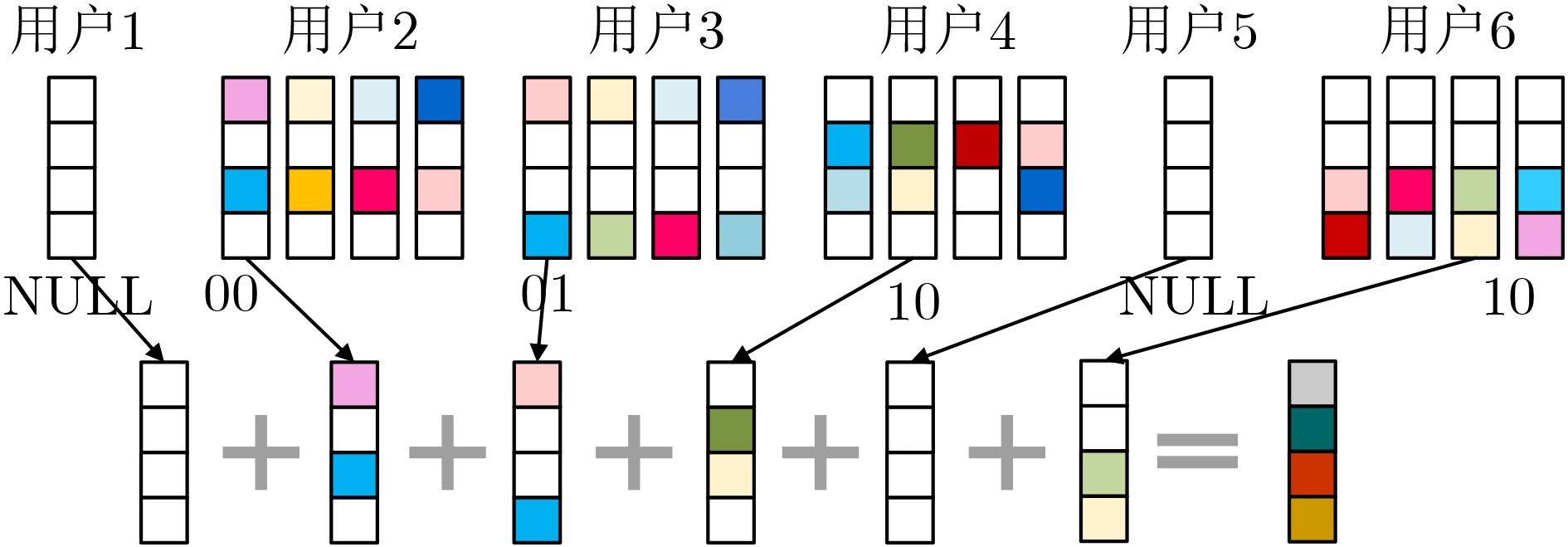
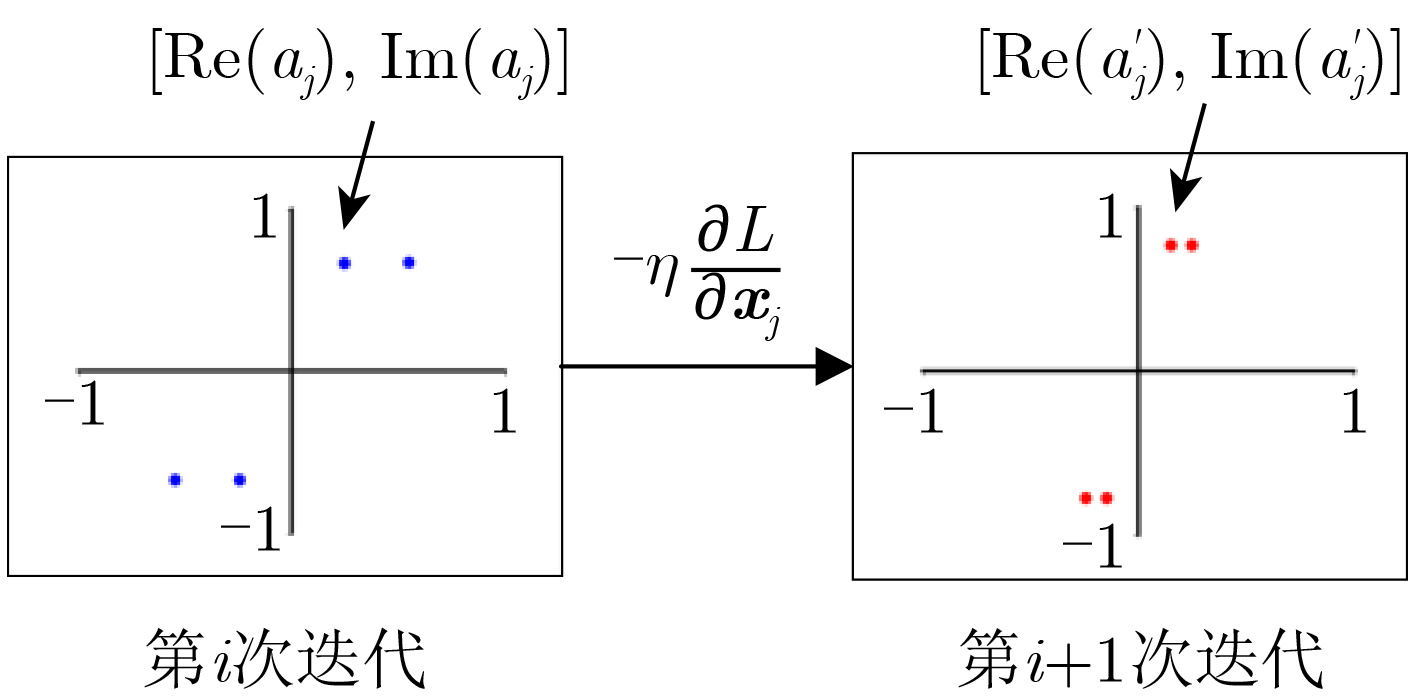
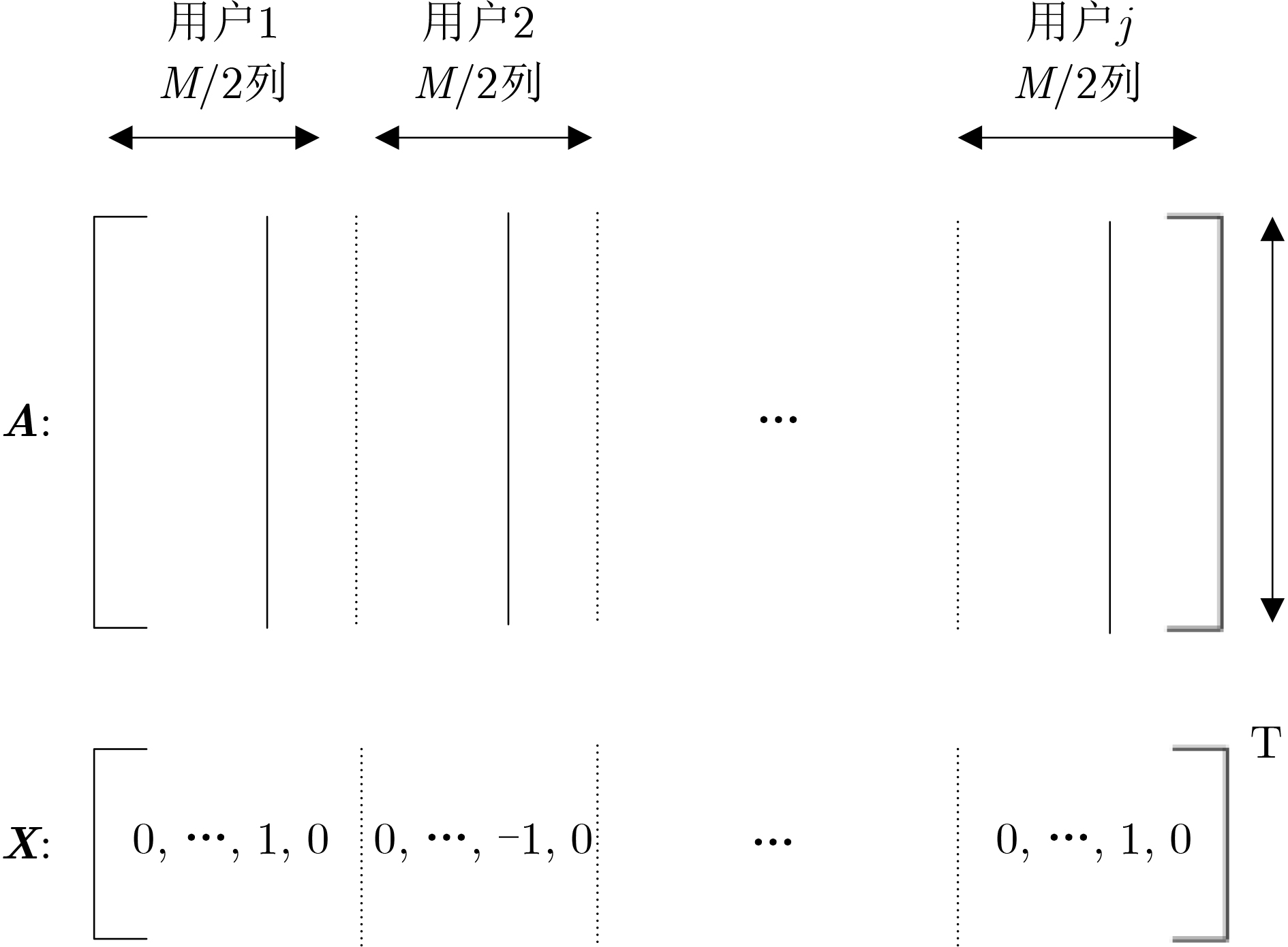
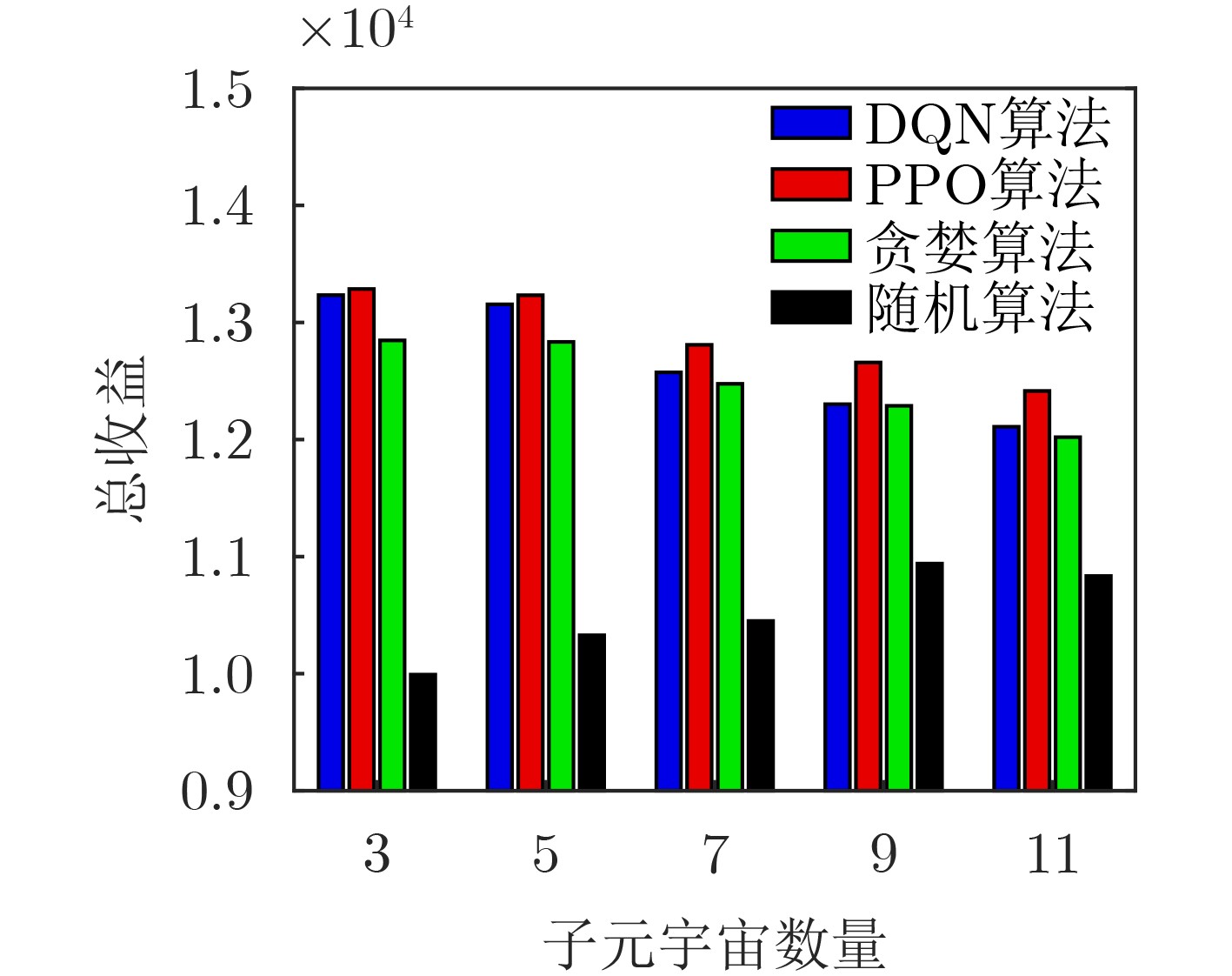
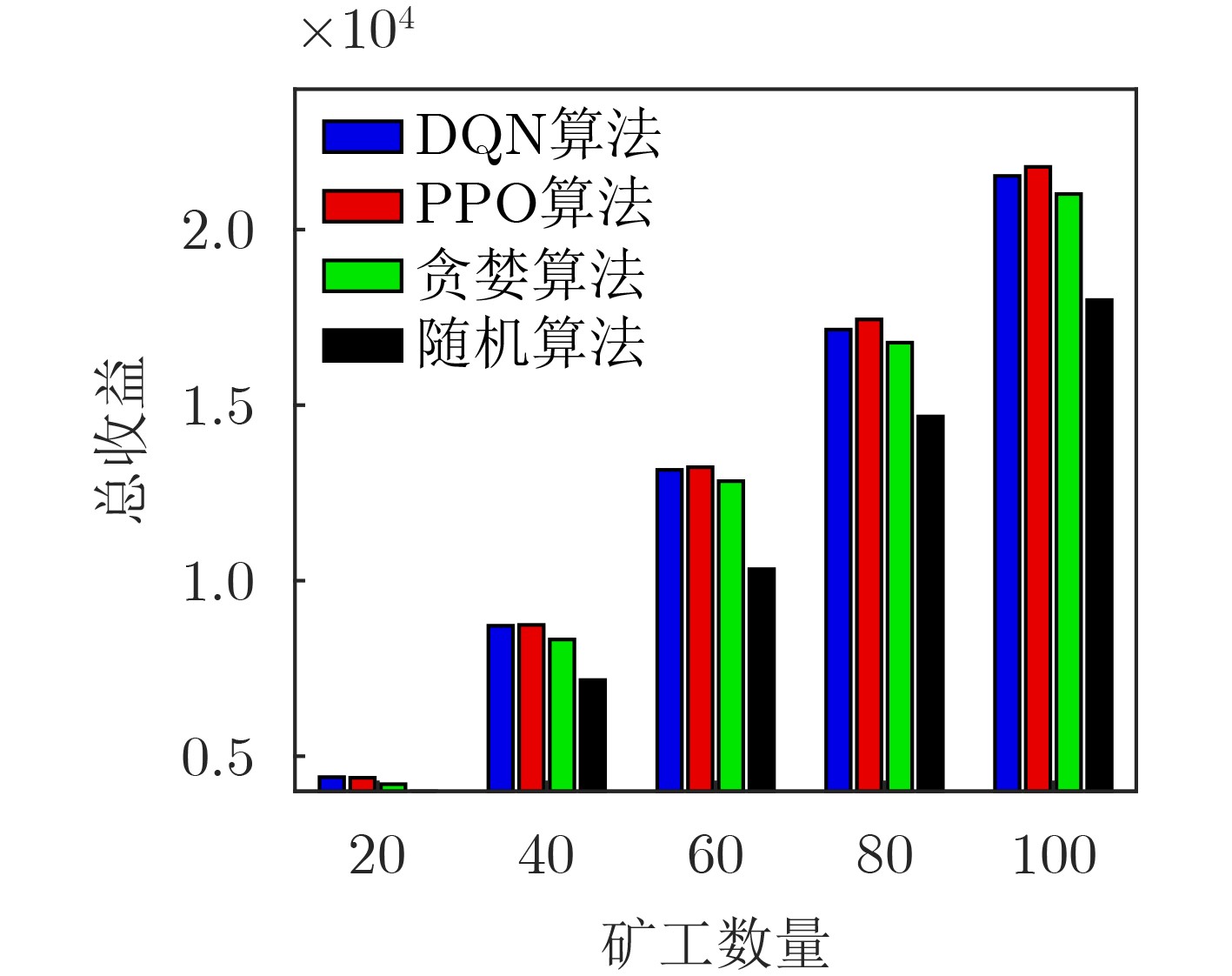
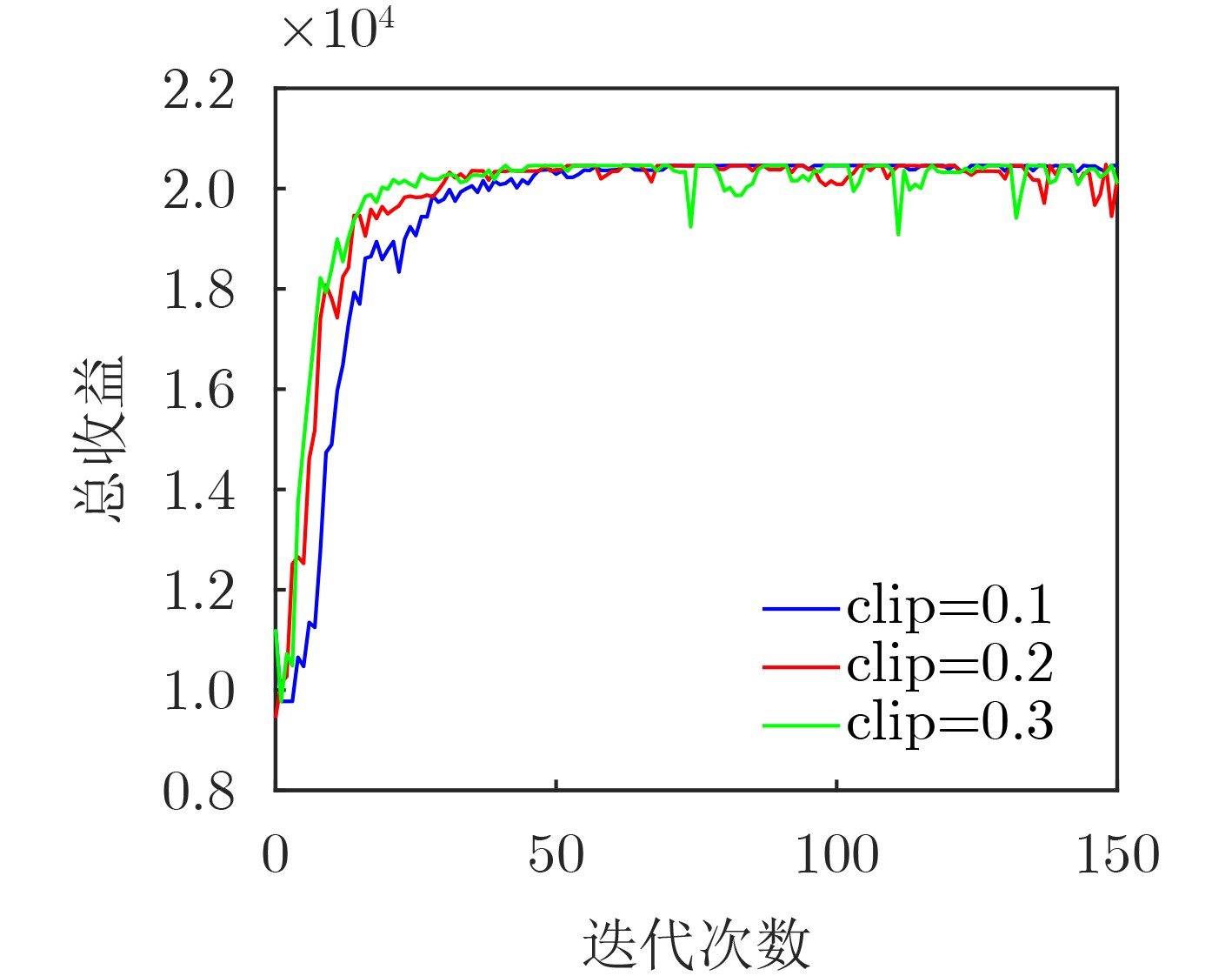
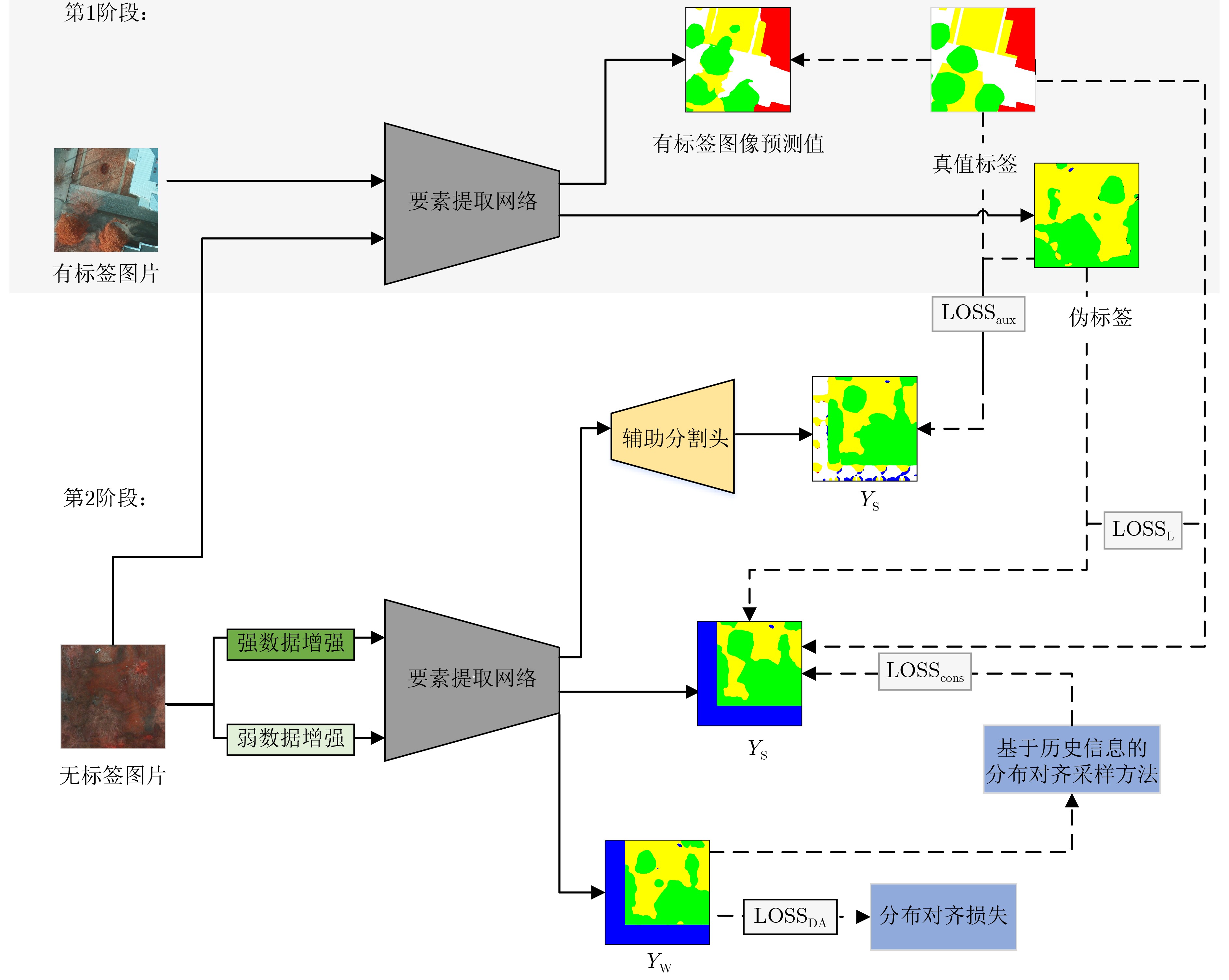
An overview of multimodal communication as an important information transfer mode that can simultaneously interact with multiple modal forms in different application scenarios is proposed in this paper. The future development prospects of multimodal communication in 6G wireless communication technology is also discussed. Firstly, multimodal communication is classified into three categories, and its key roles in these fields are explored. Furthermore, a deep analysis is conducted on the communication, sensation, computation, and storage resource limitations, as well as cross-domain resource management issues that 6G wireless communication systems may face. It points out that future 6G wireless multimodal communication will achieve deep integration of communication perception, computation, and storage, as well as enhance communication capabilities. In the process of implementing multimodal communication, various aspects must be considered, including multi-transmitter processing, transmission technology, and receiver processing, in order to address challenges in multimodal corpus construction, multimodal information compression, transmission, interference handling, noise reduction, alignment, fusion, and expansion, as well as resource management issues. Finally, the importance of cross-domain multimodal information transfer, complementarity, and collaboration in the 6G network is emphasized. This will better integrate and apply a massive amount of heterogeneous information to meet the future communication demands of high-speed, low-latency, and intelligent interconnection.