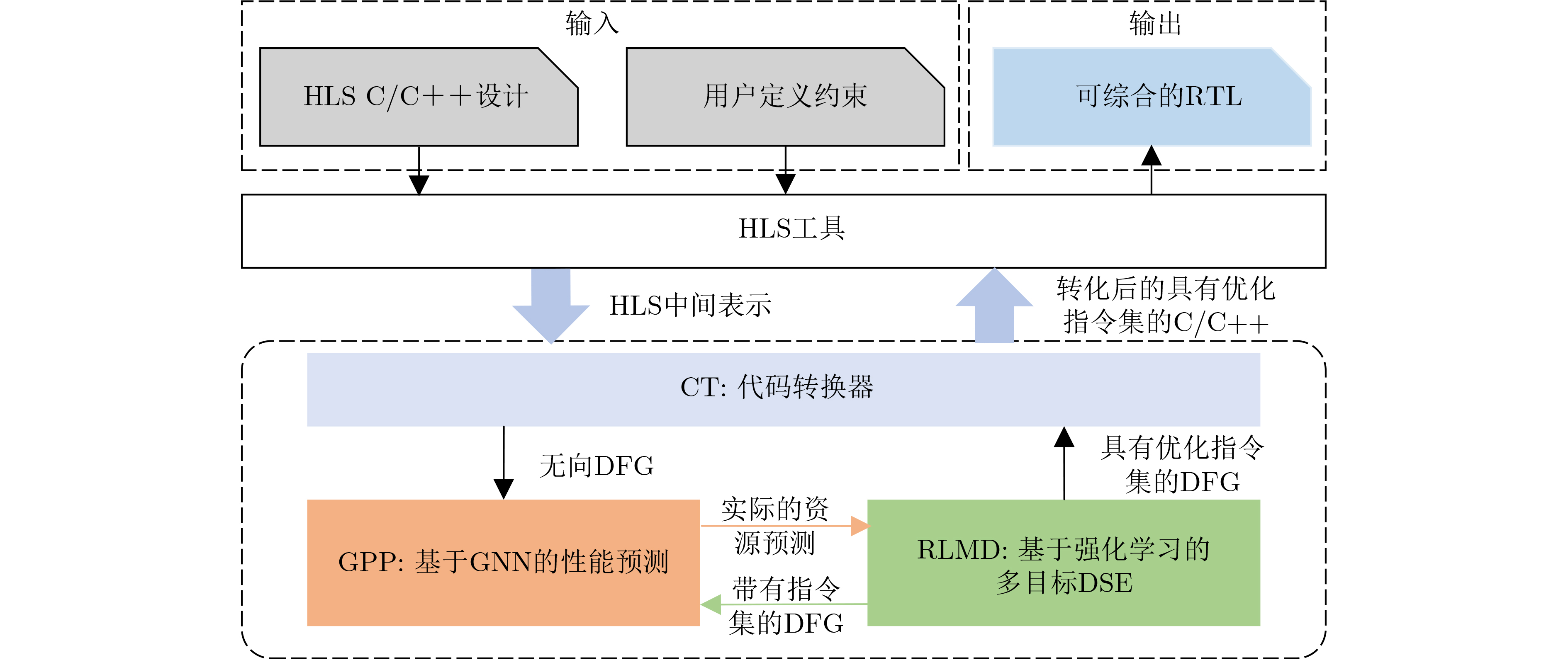
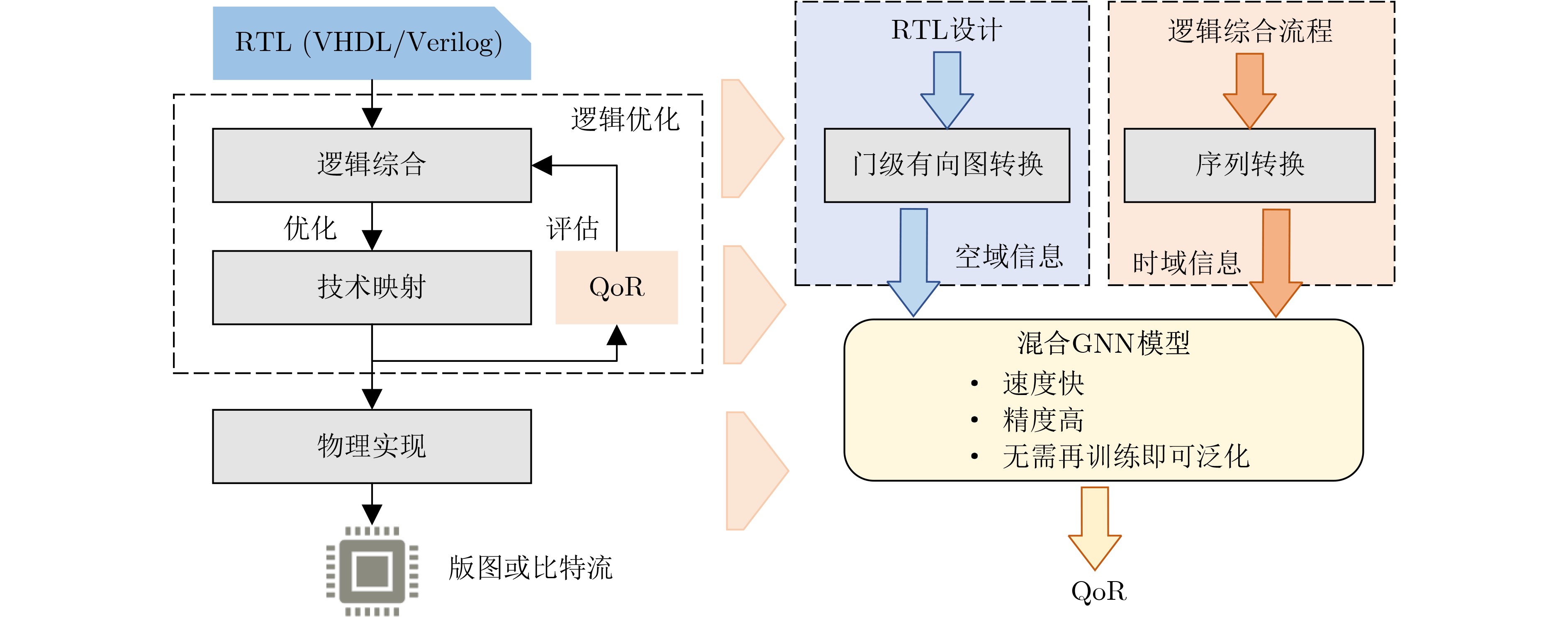
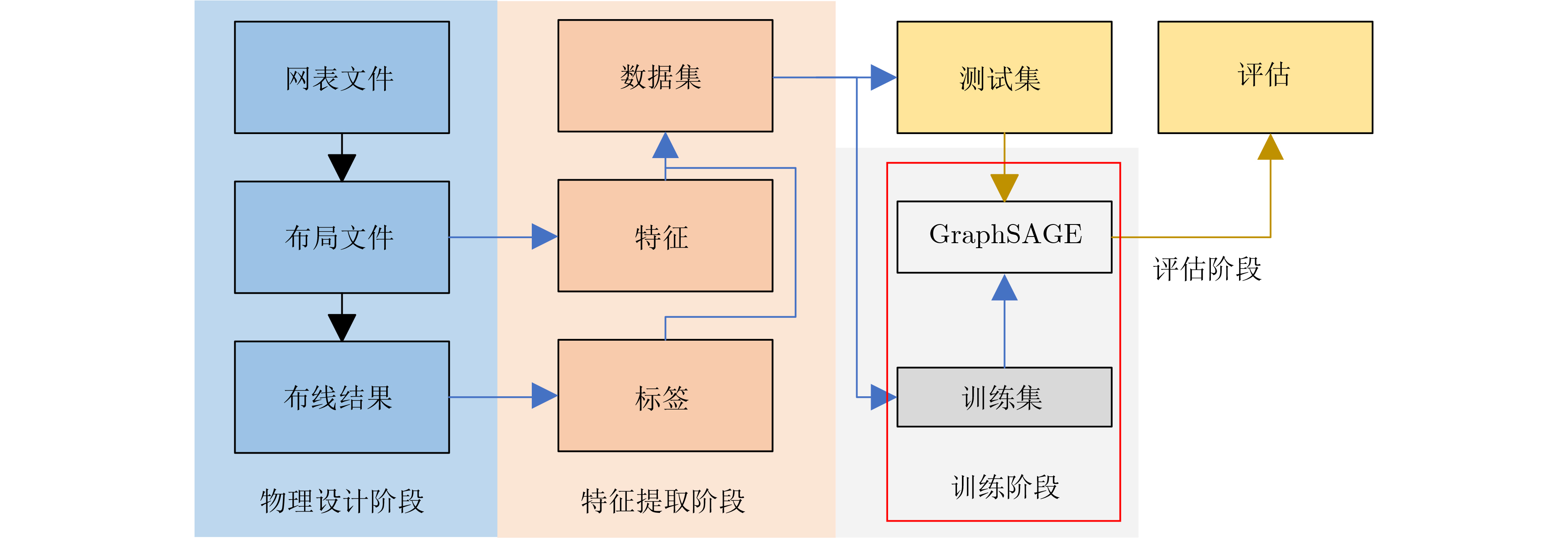
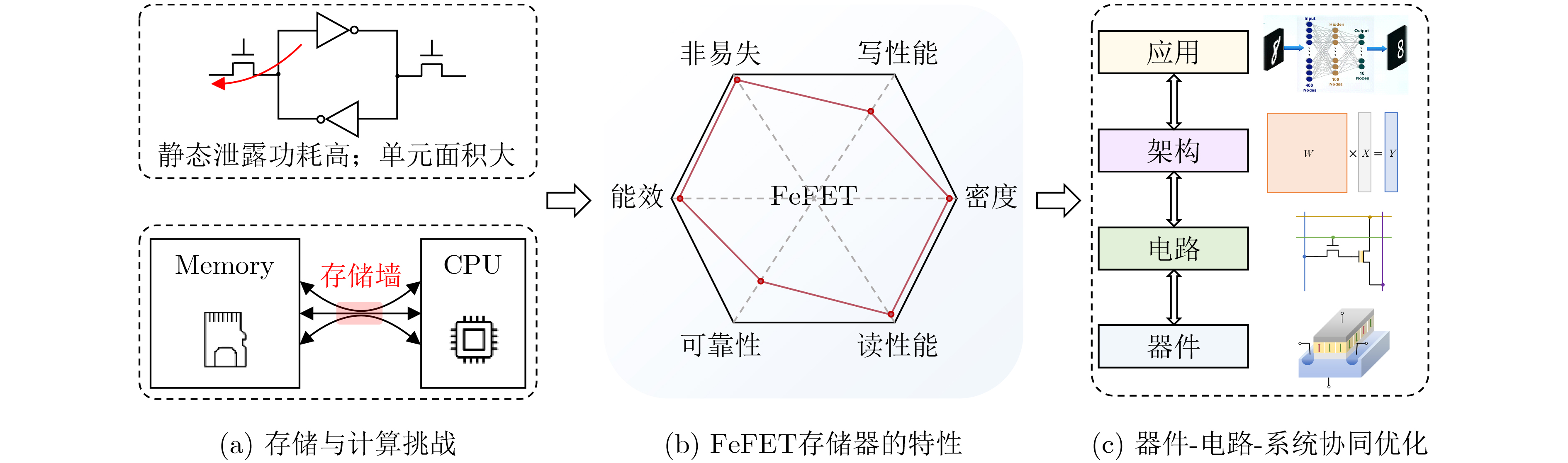
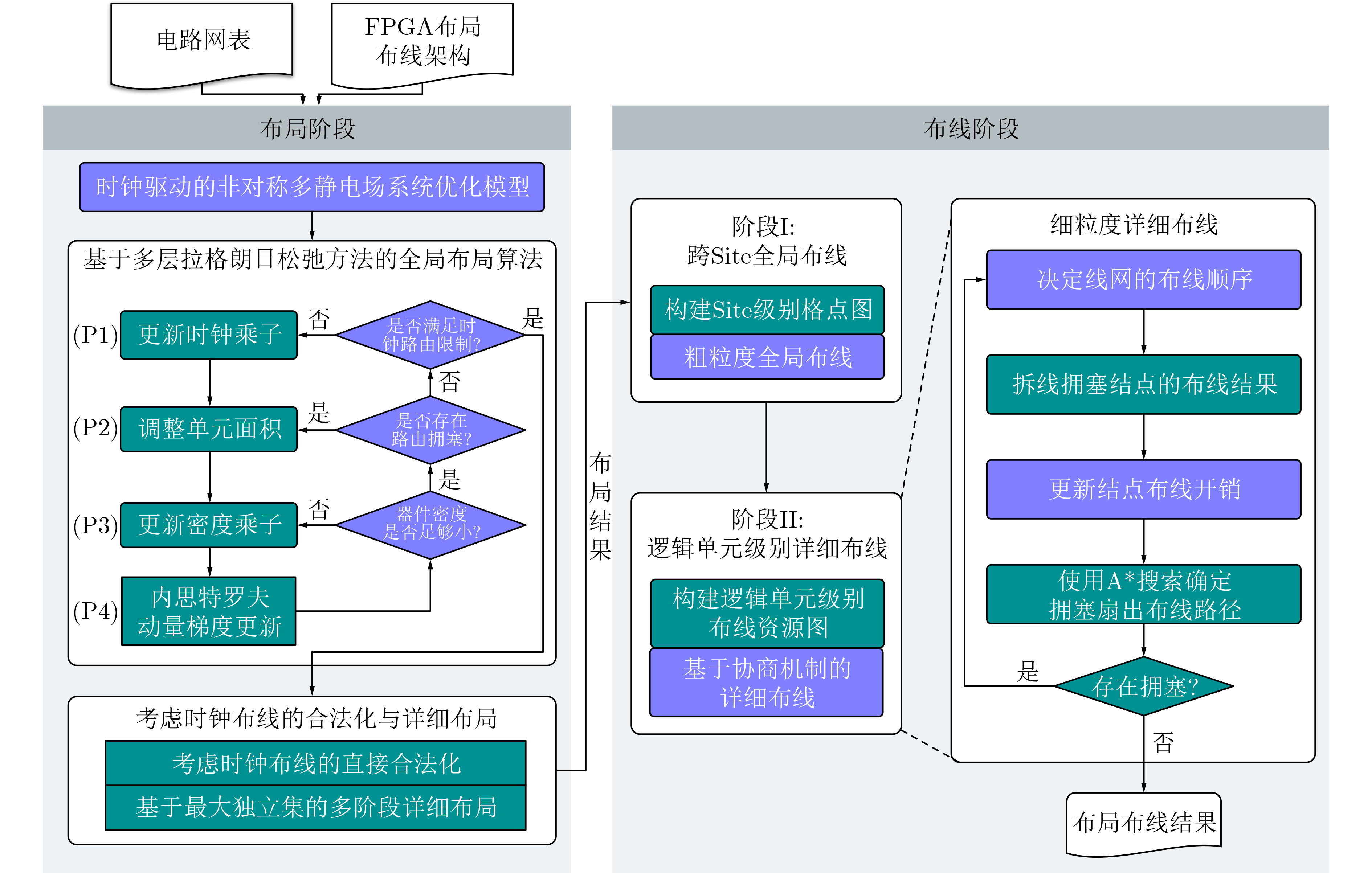
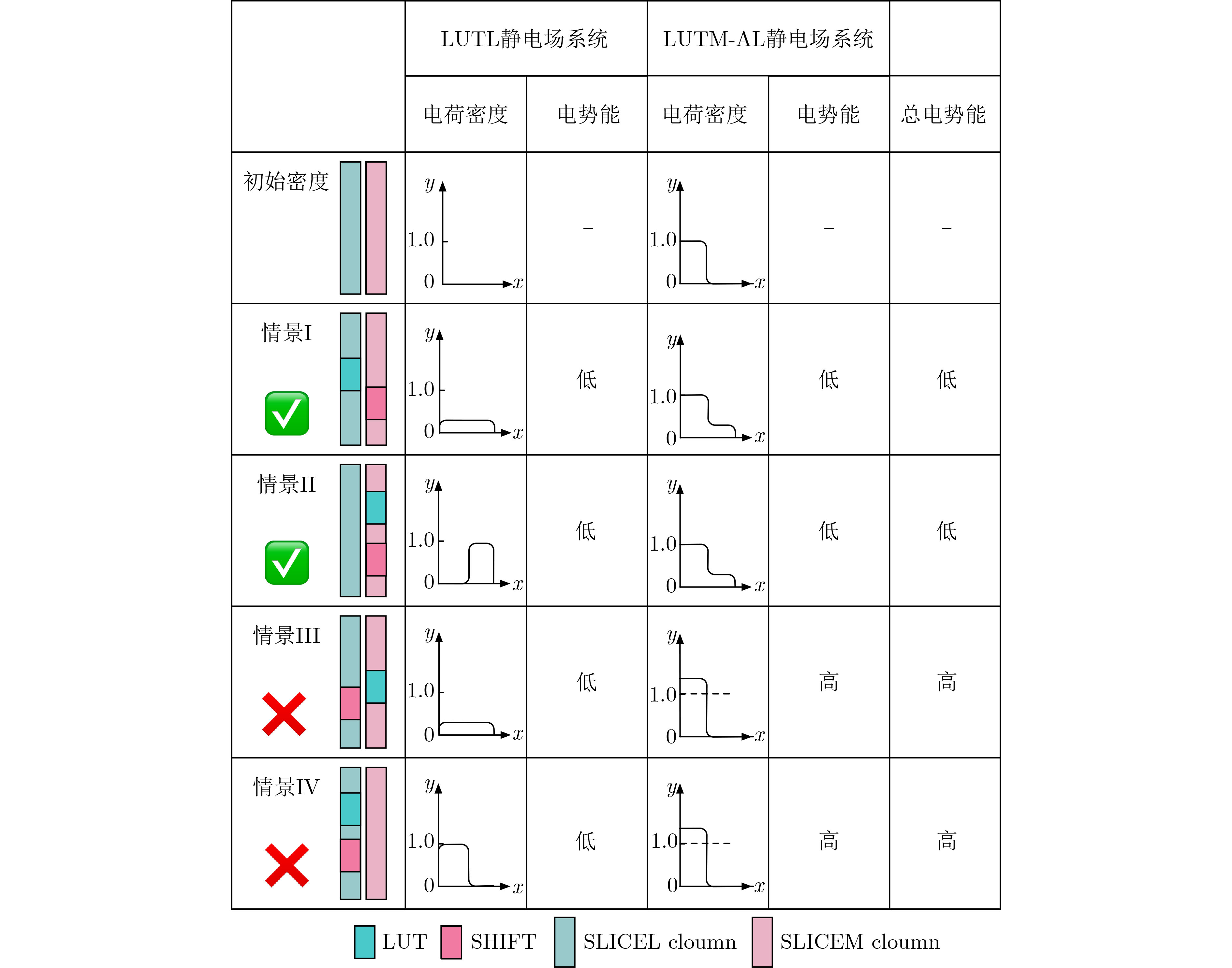
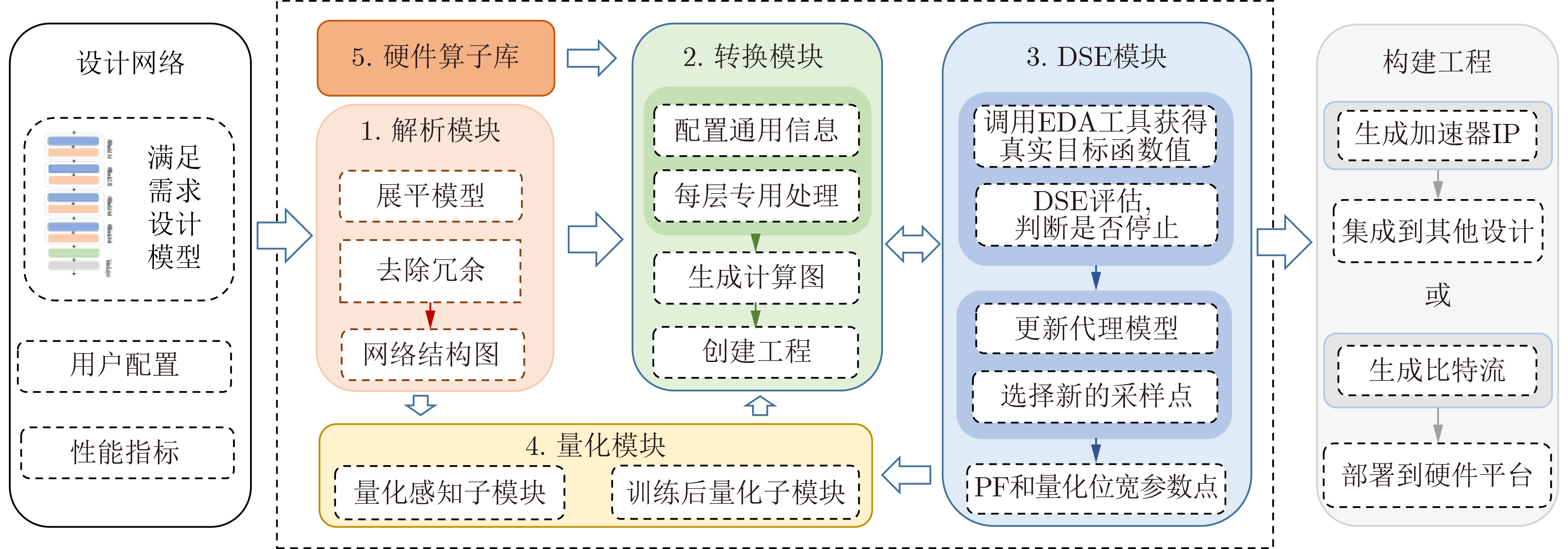
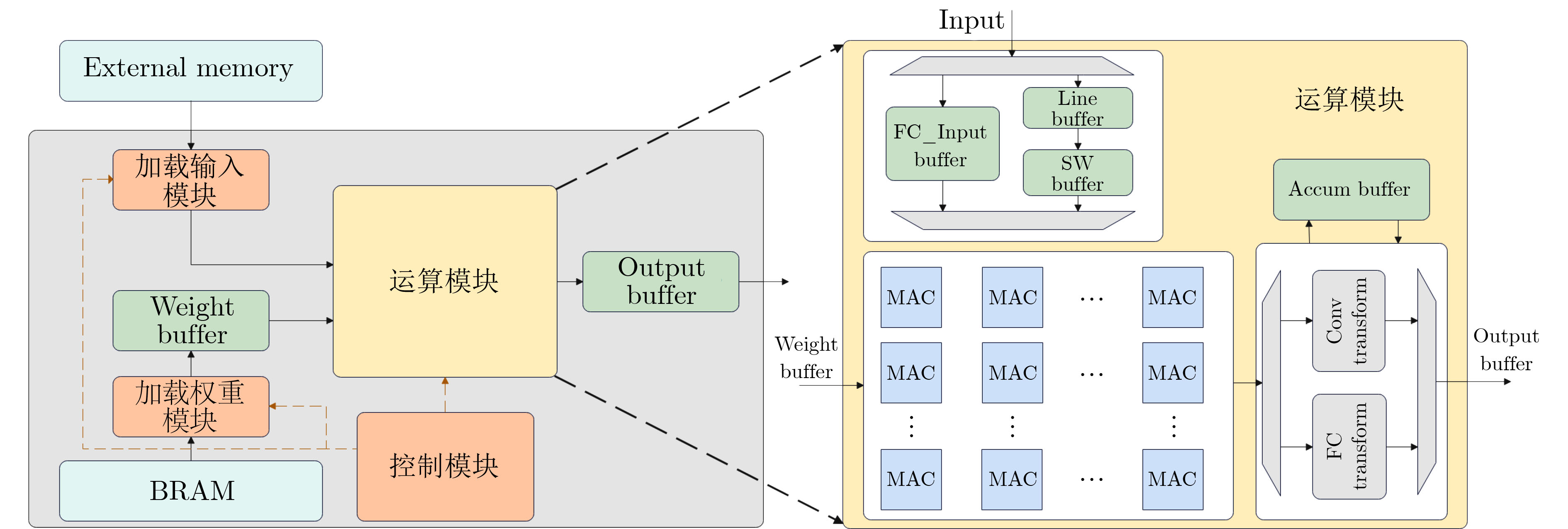
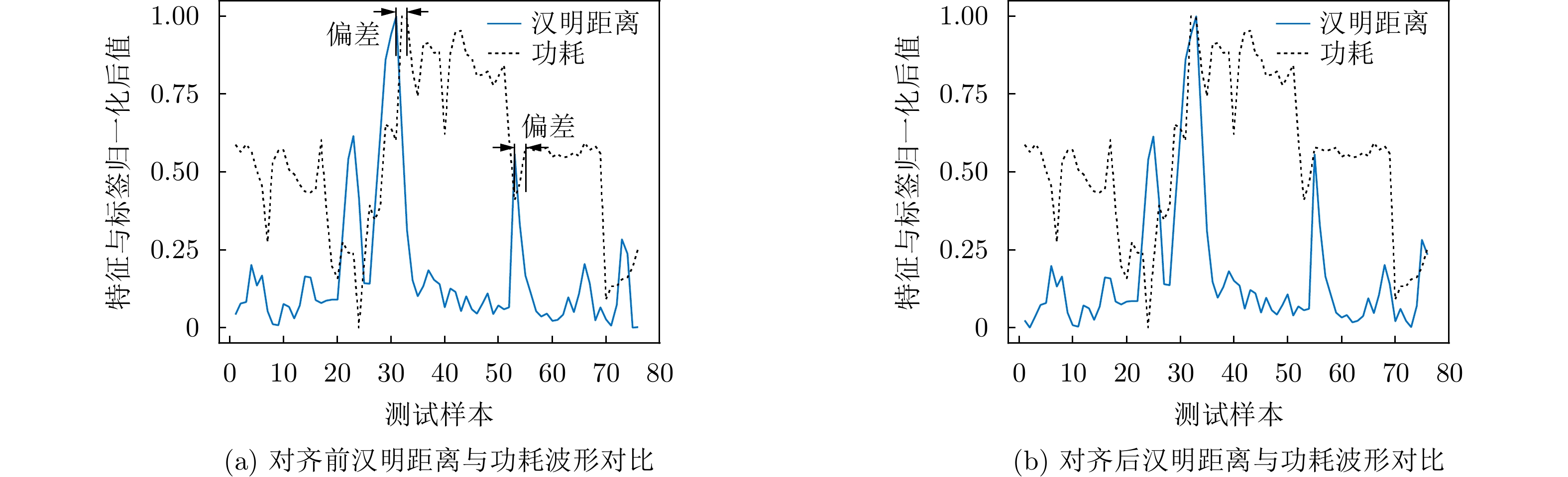
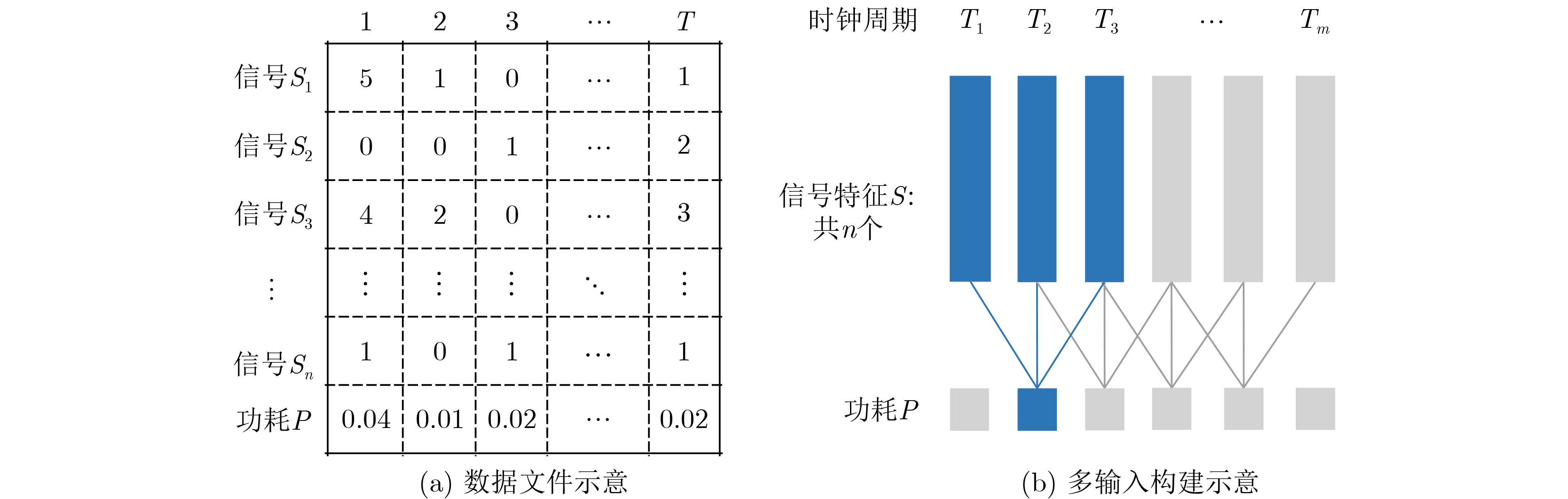
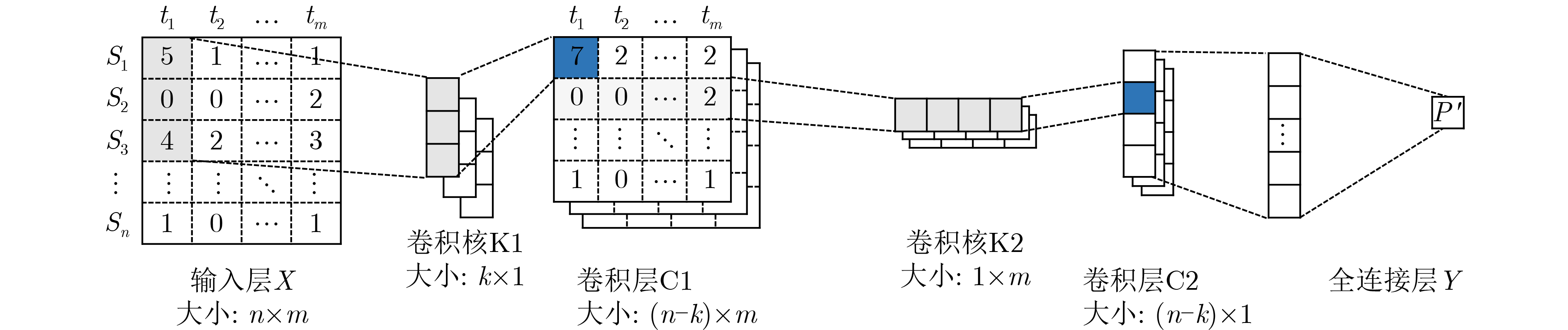
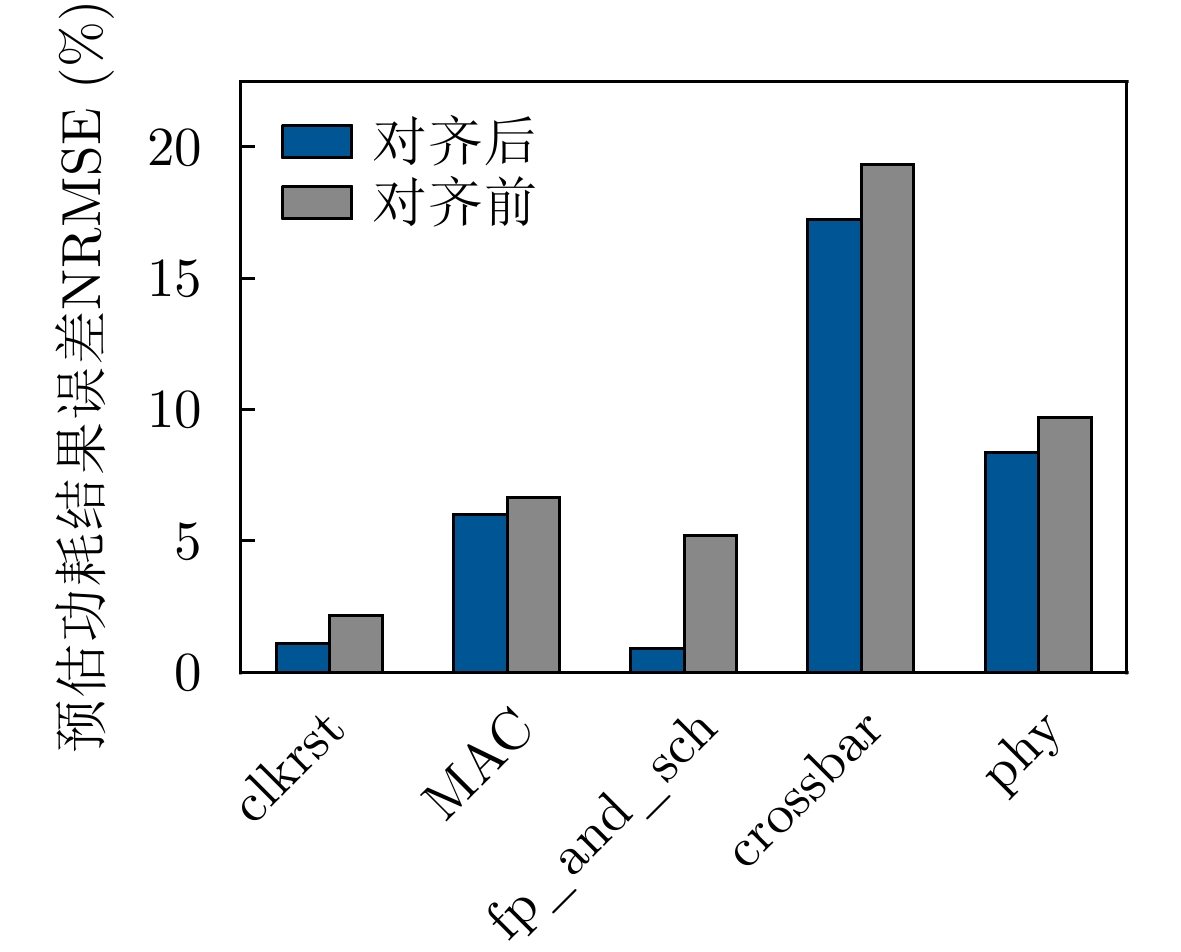
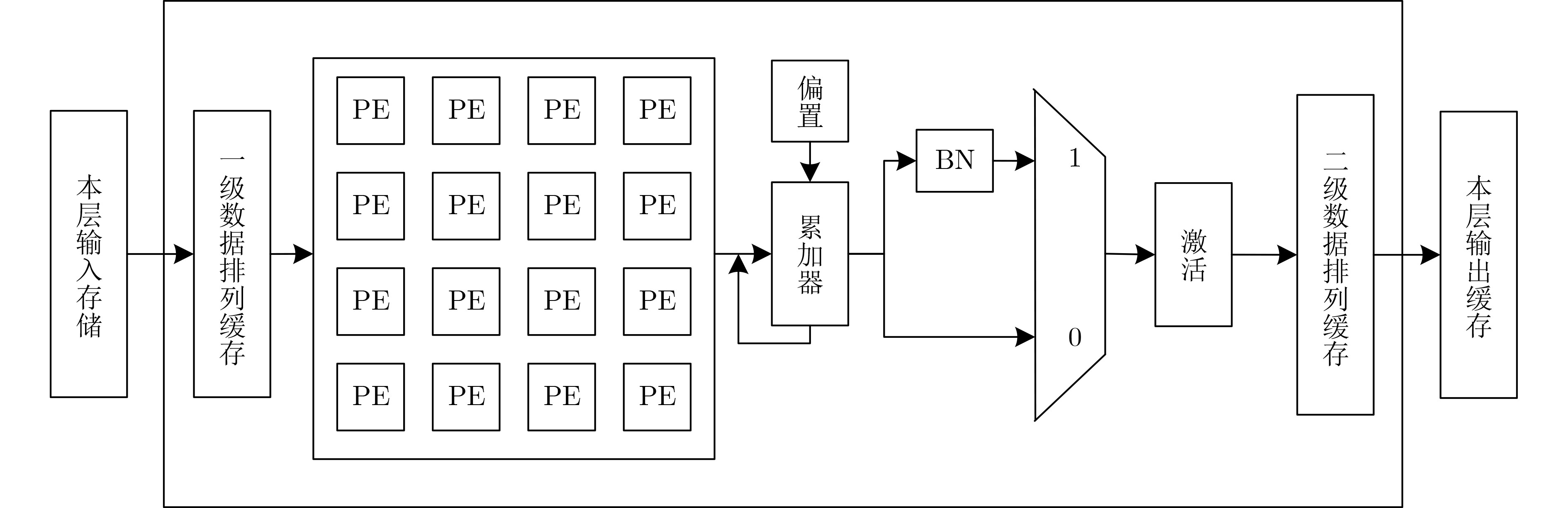
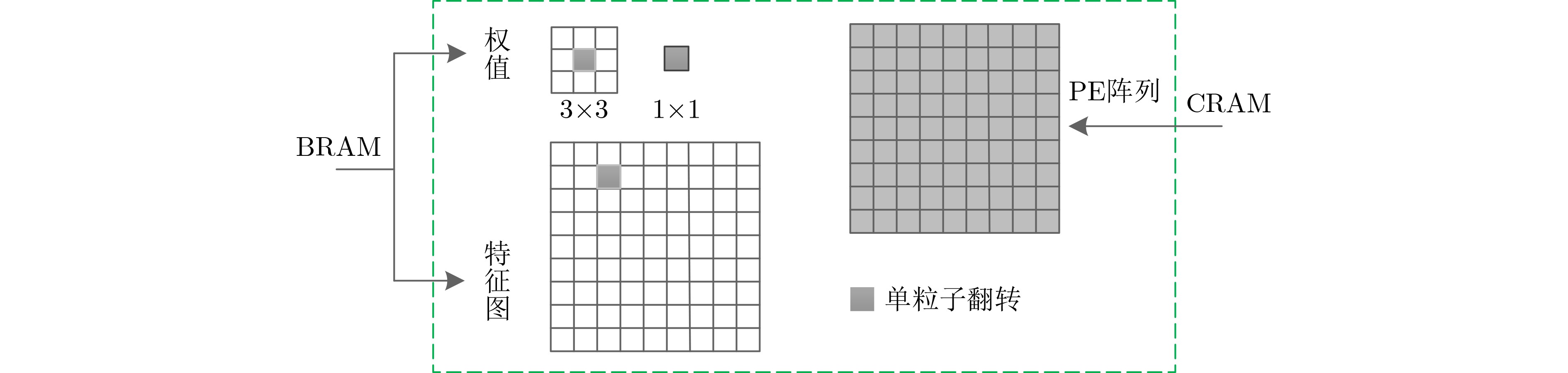
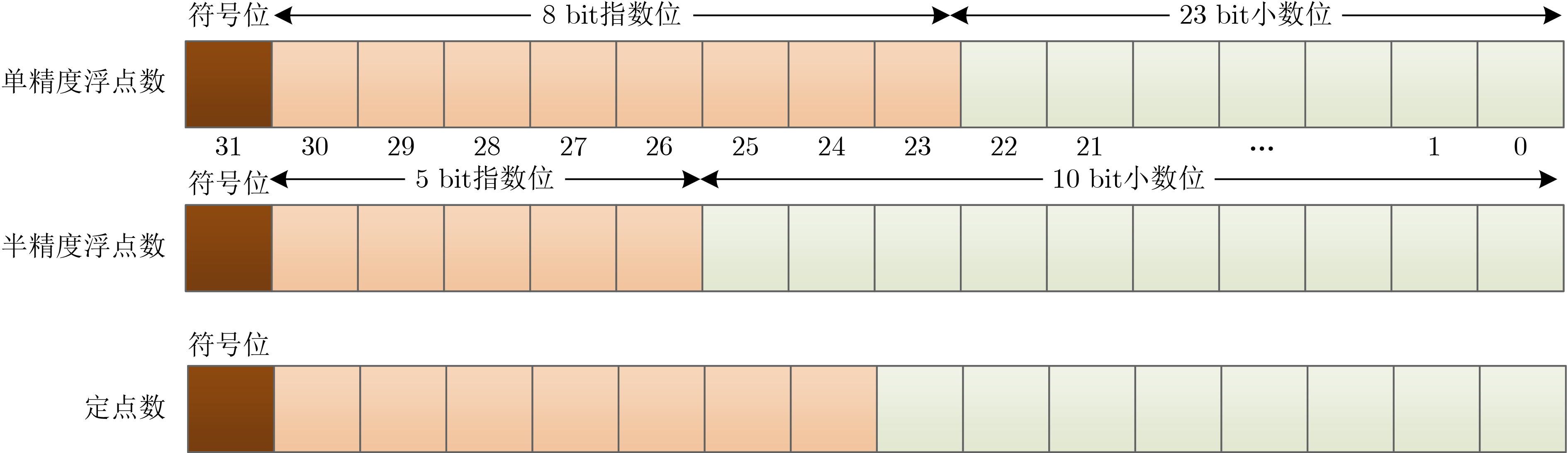
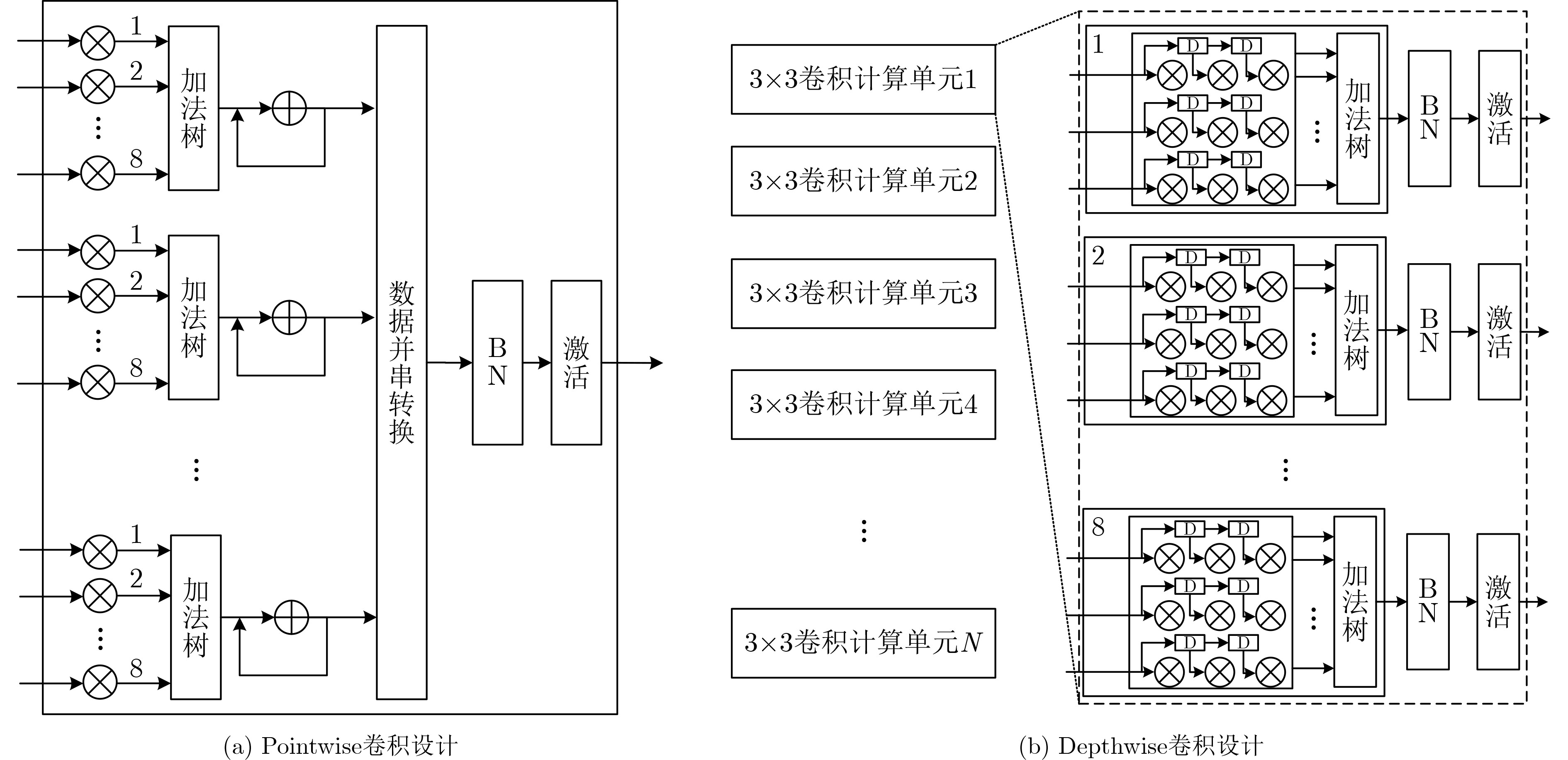
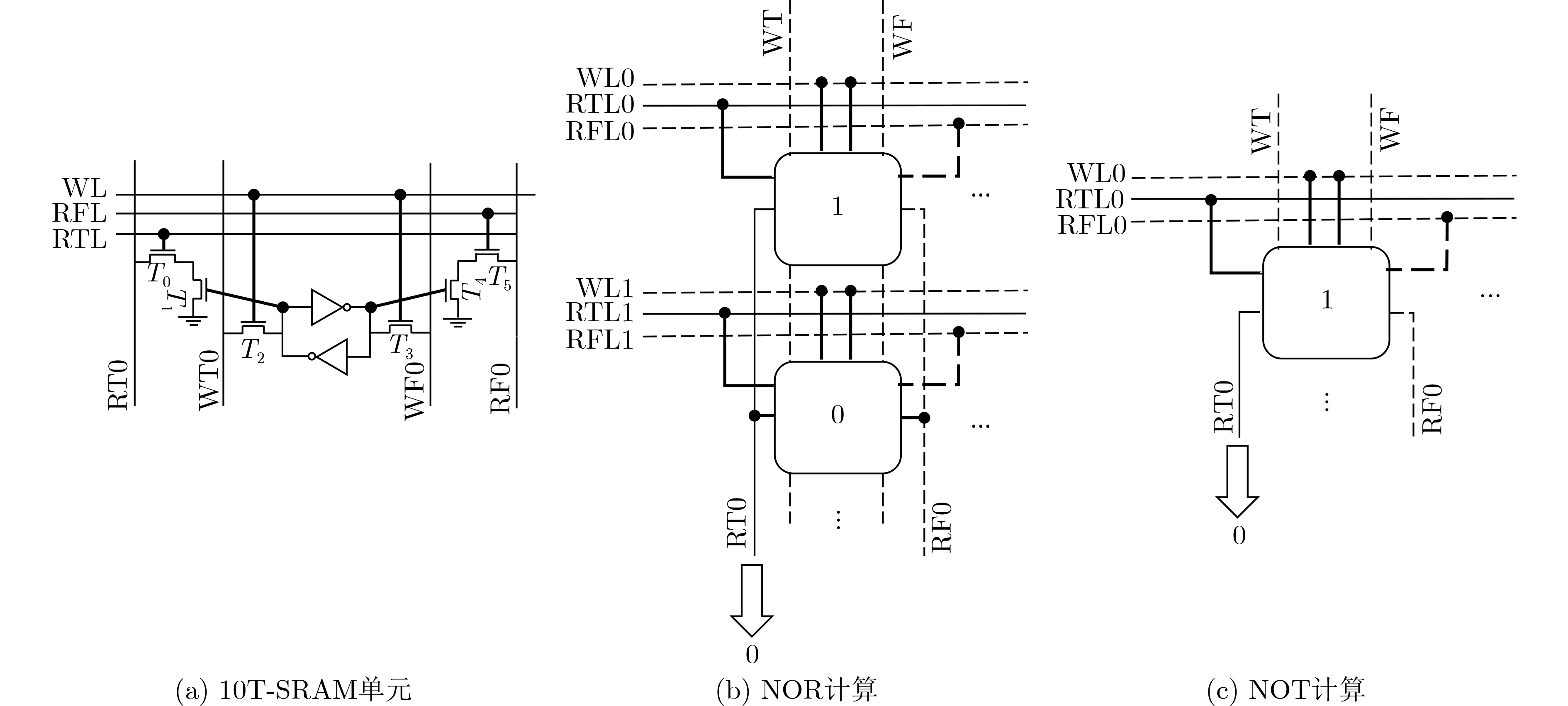
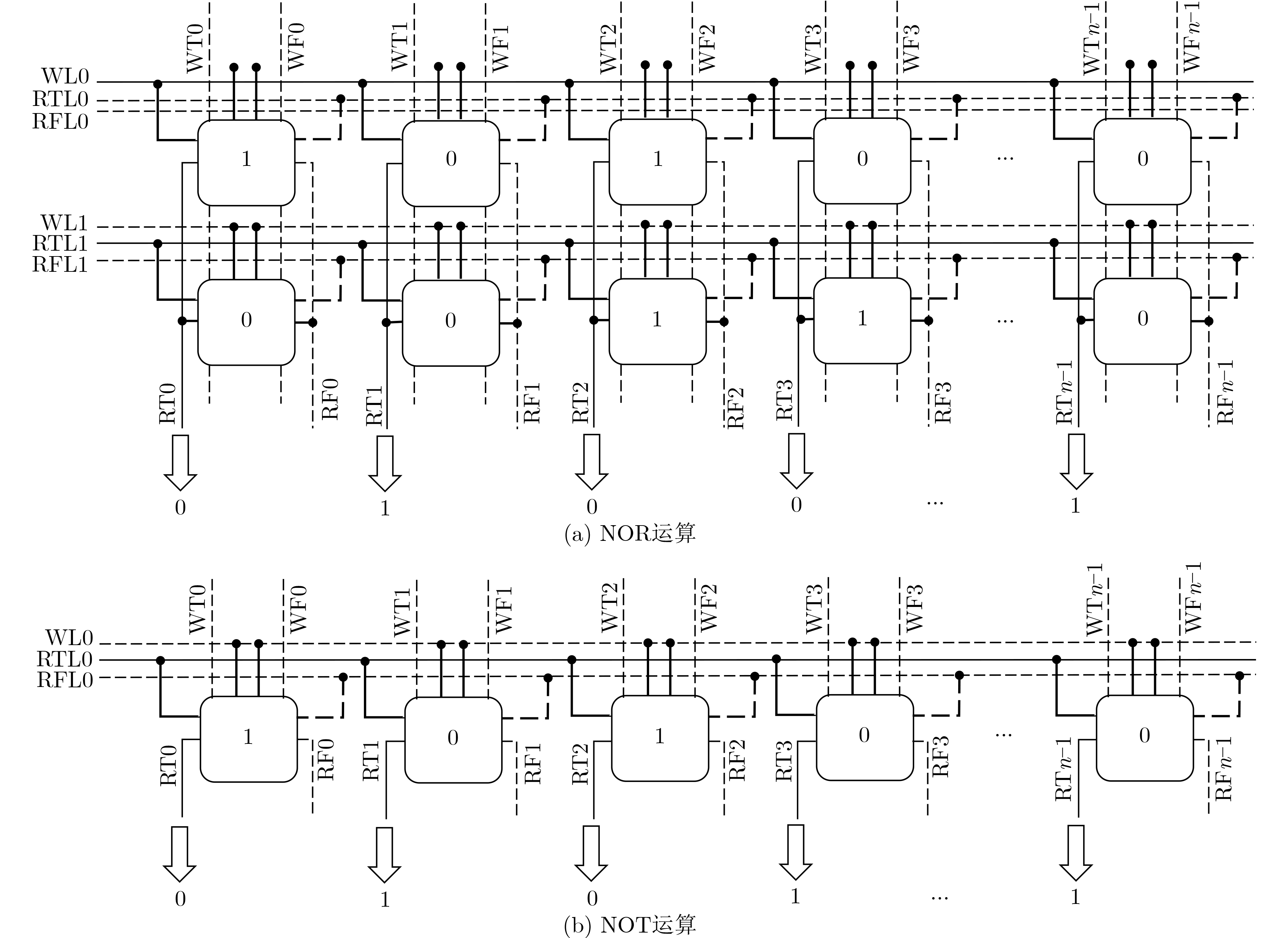
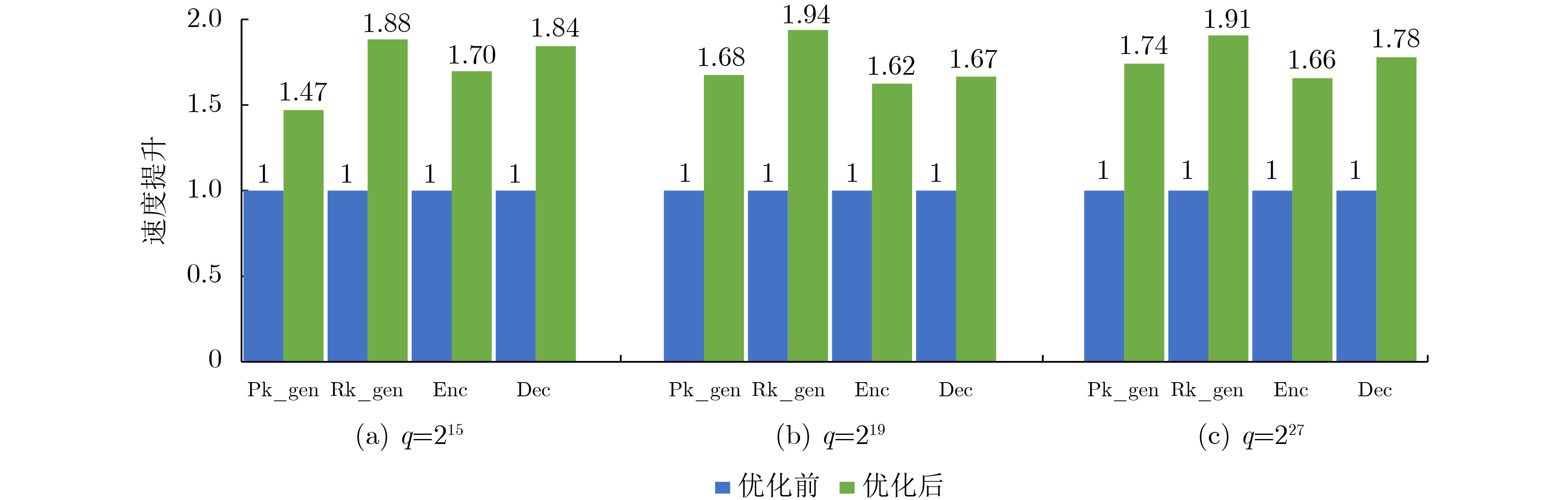
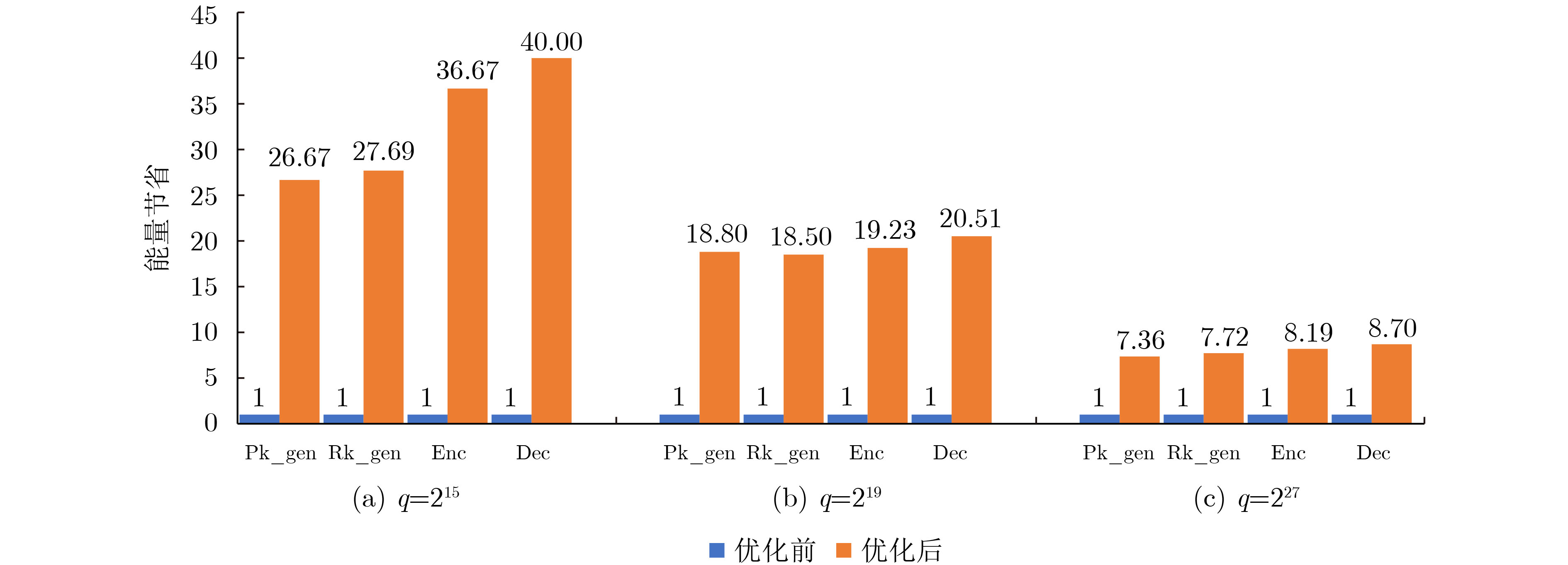
2023, 45(9): 3410-3419.
doi: 10.11999/JEIT221420
Abstract:
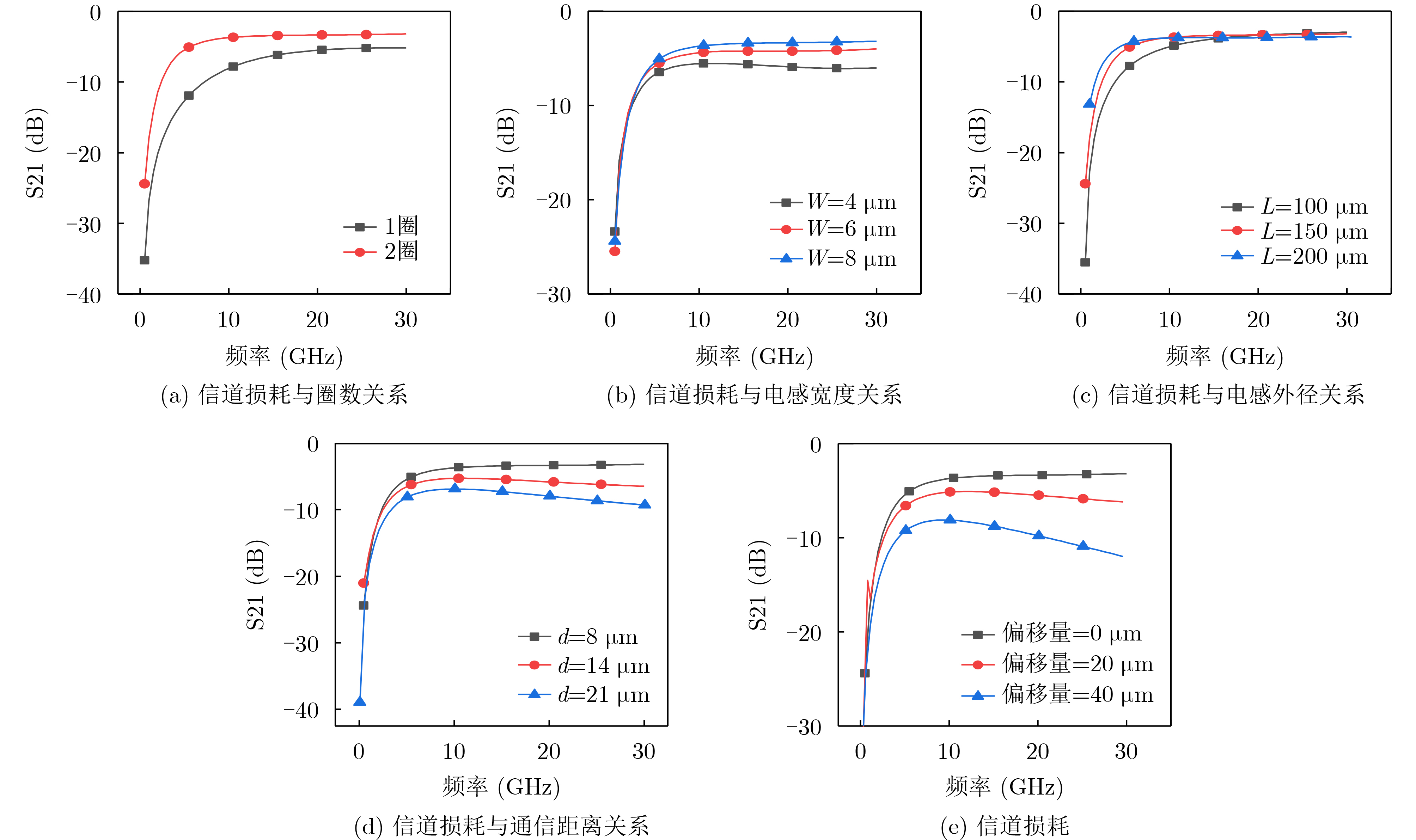
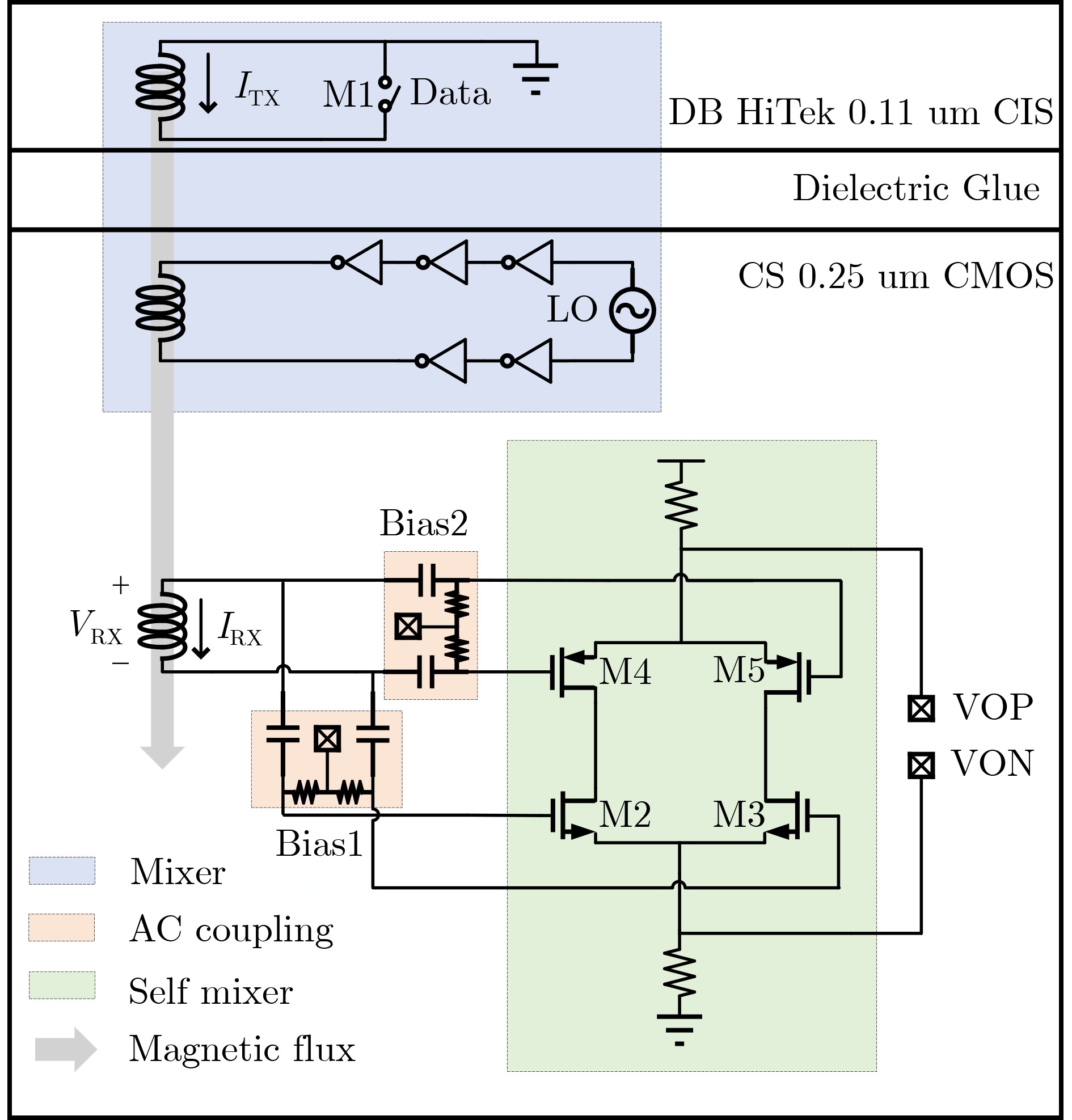
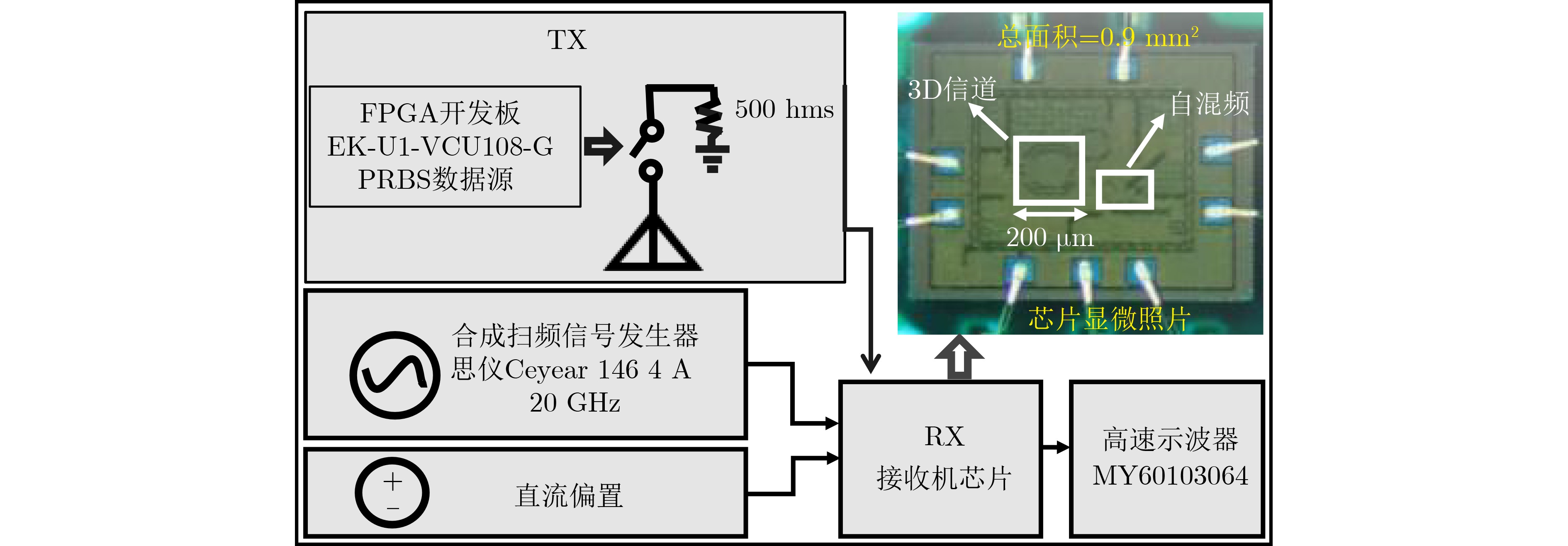
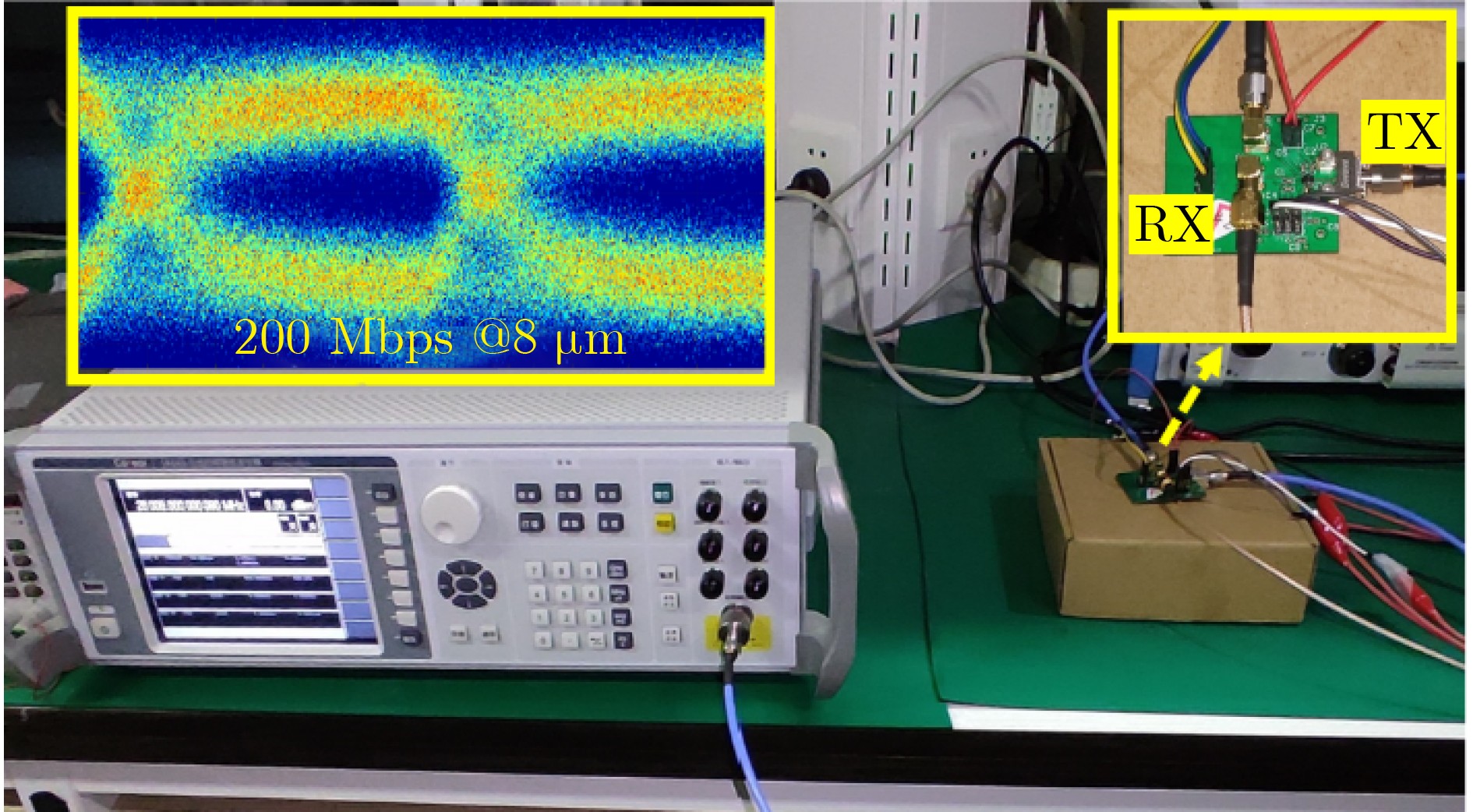
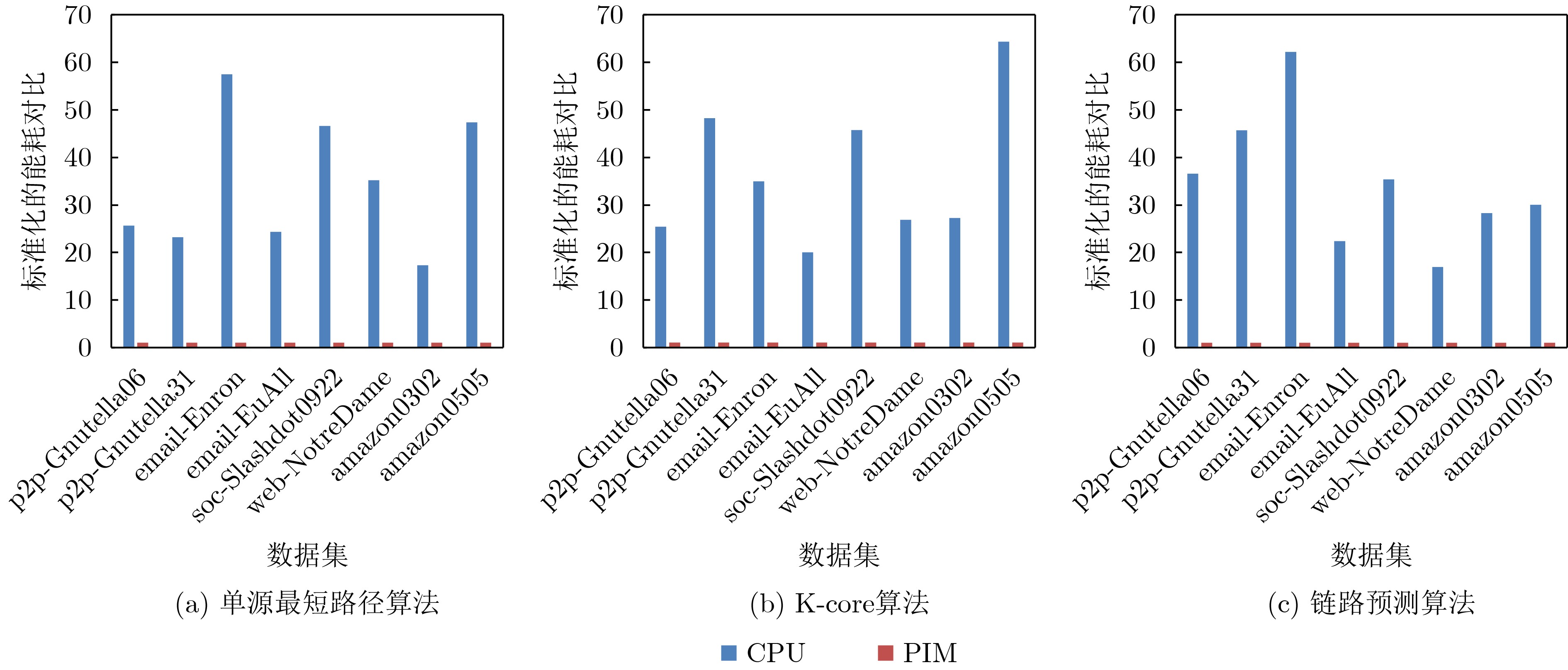
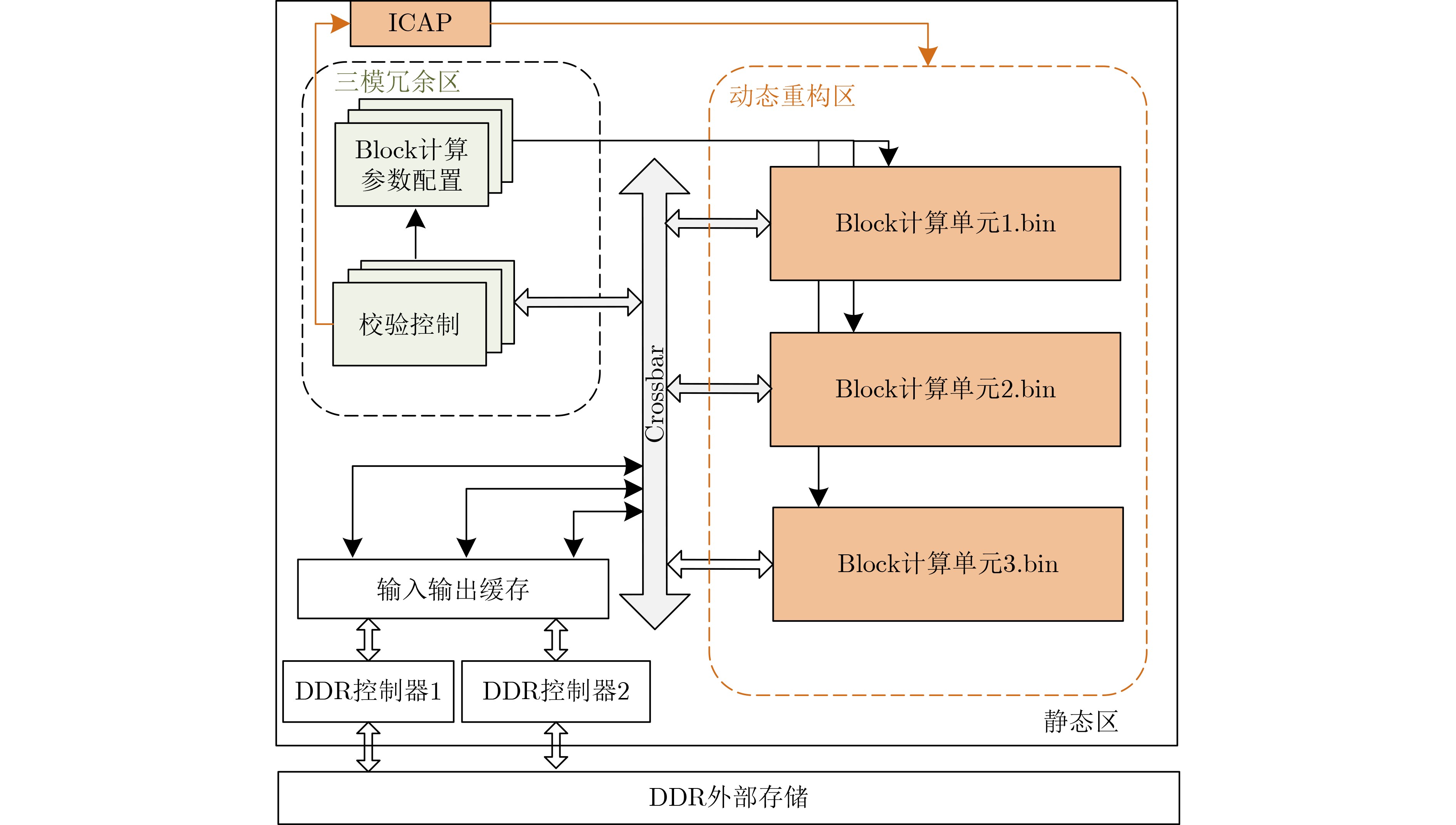
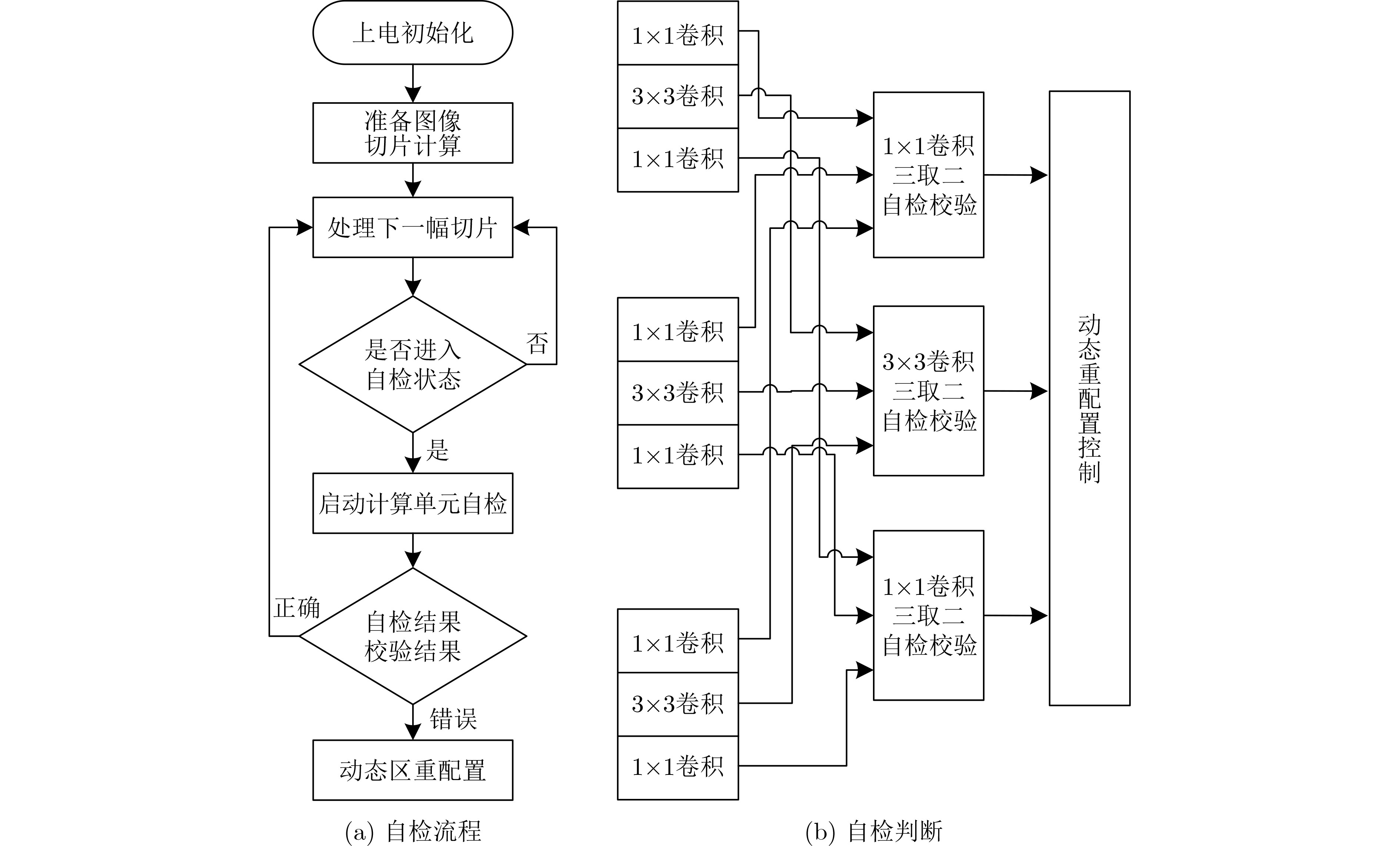
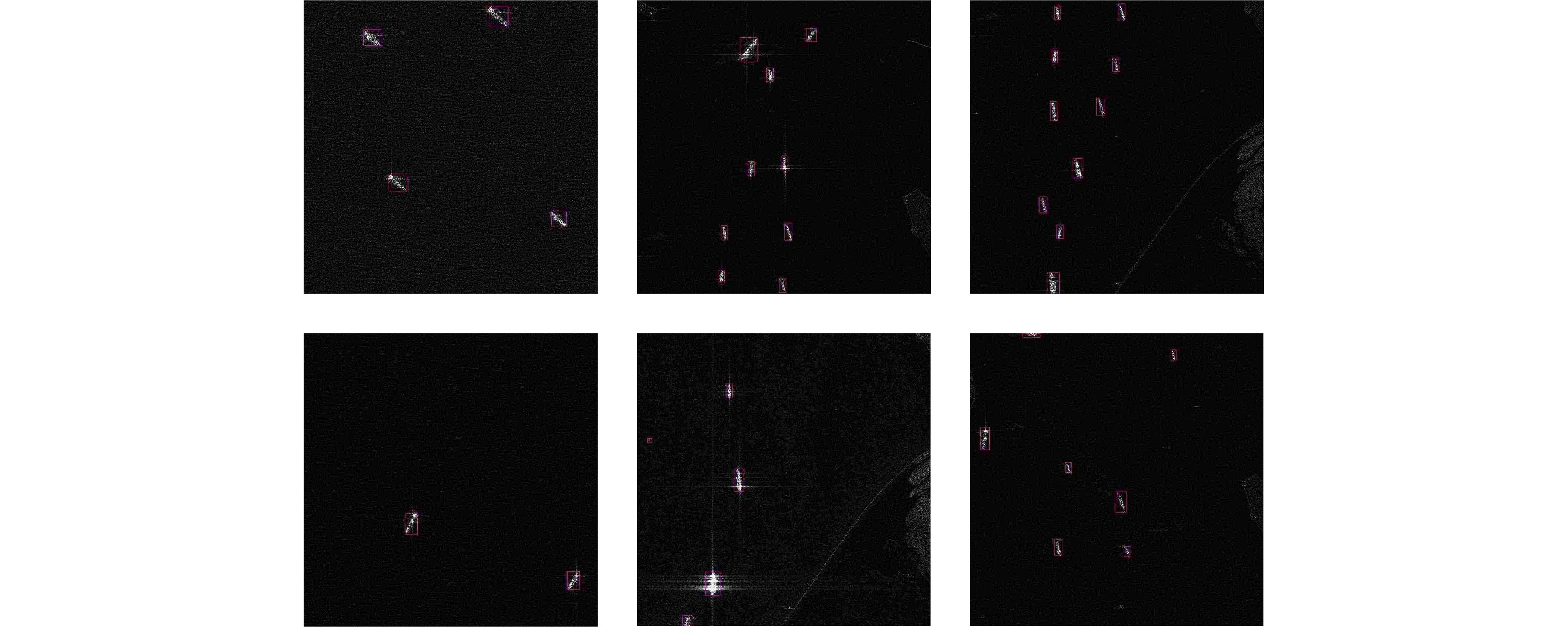
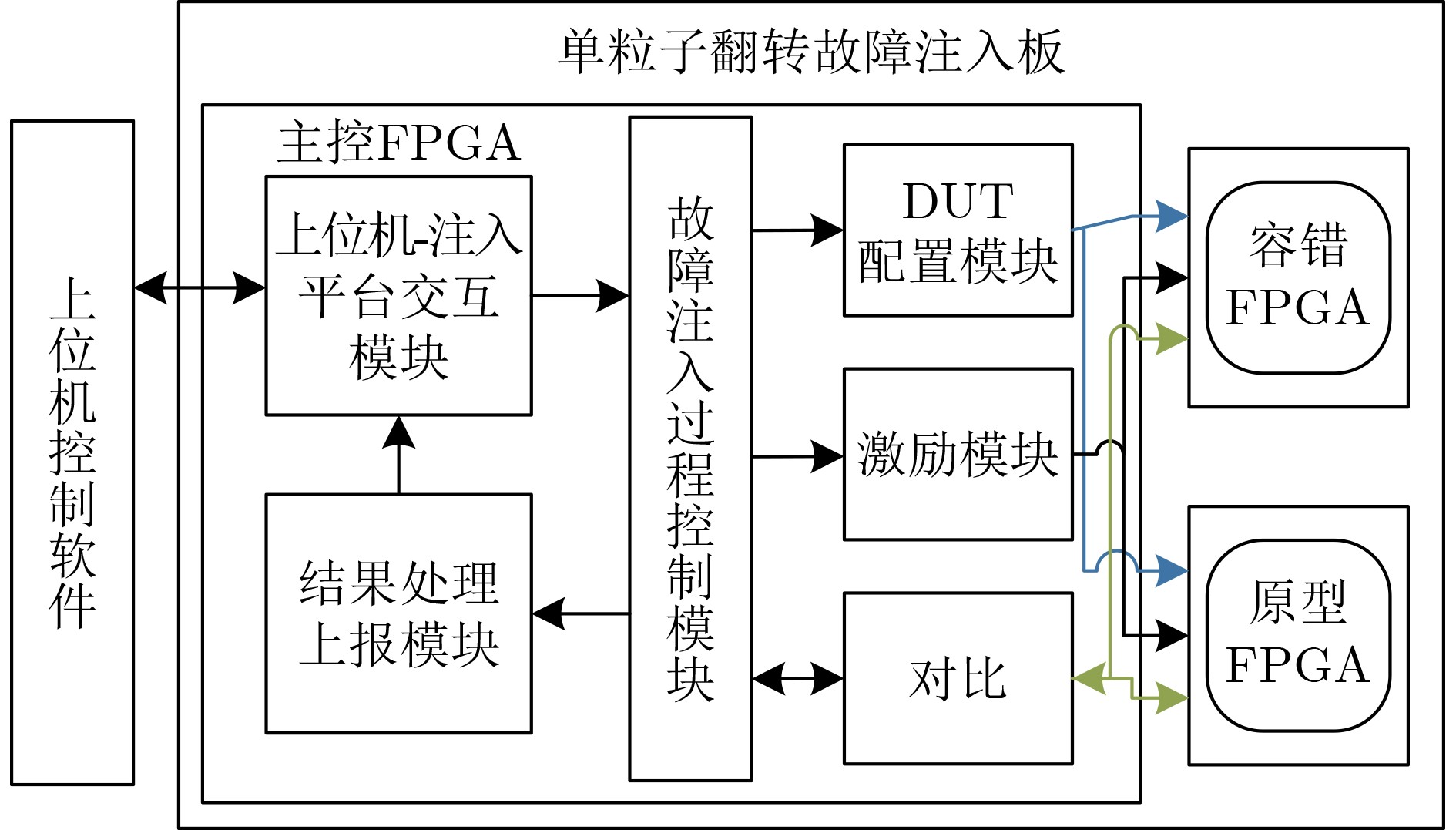
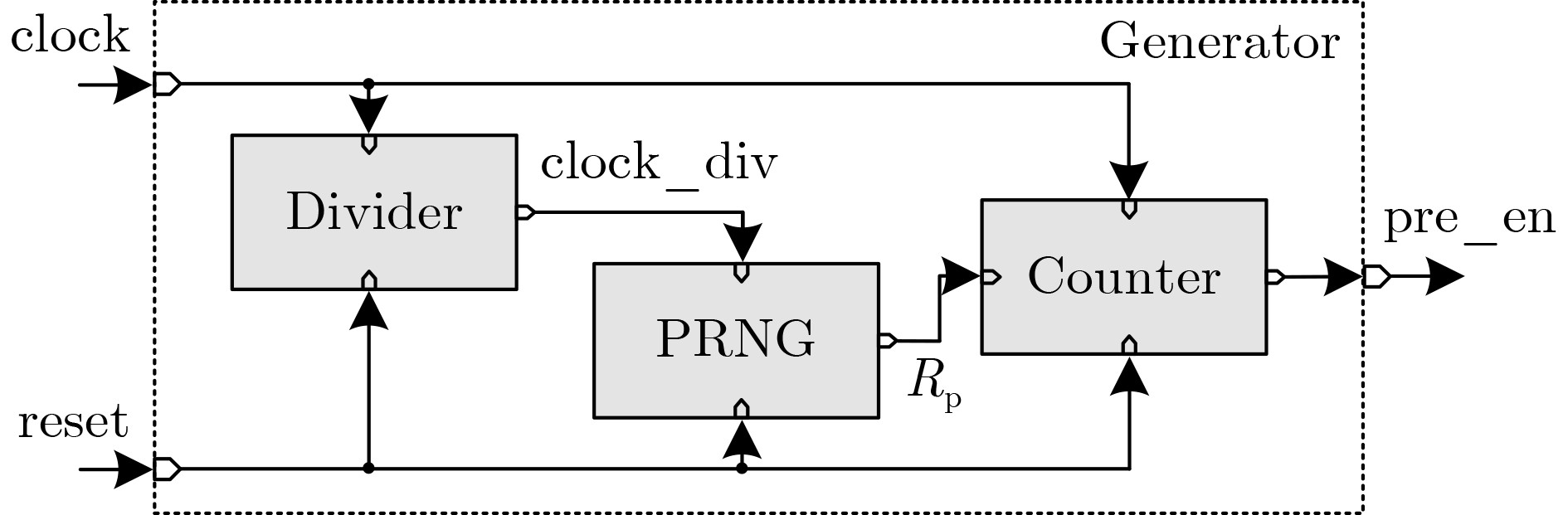
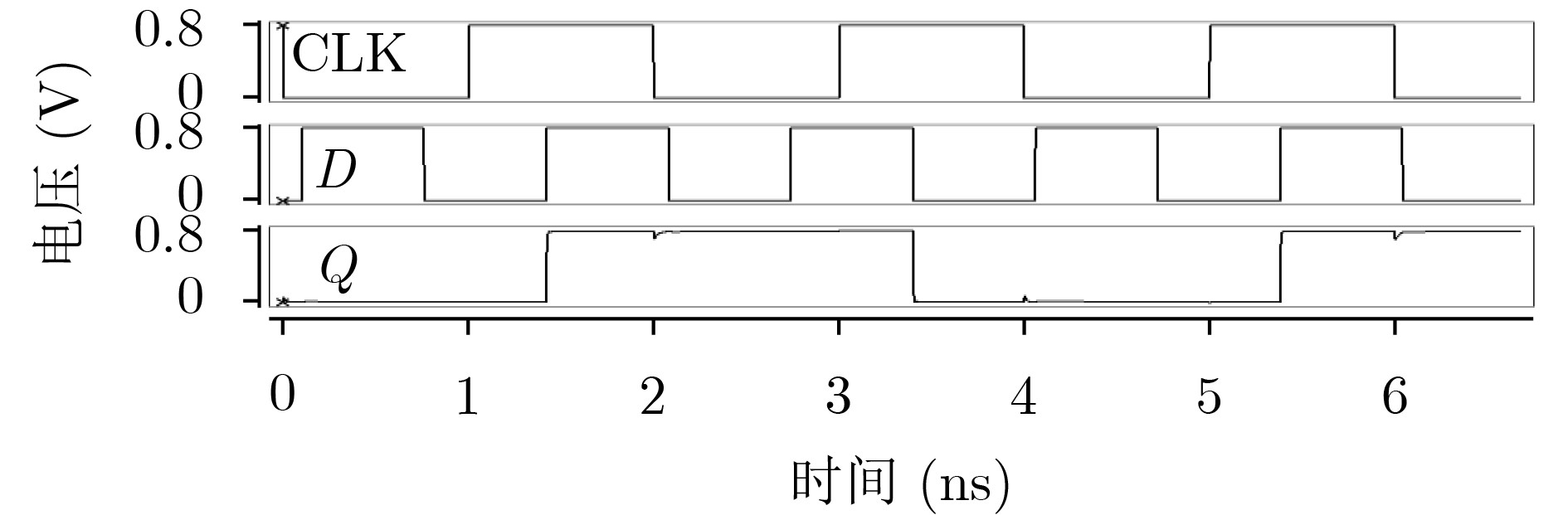
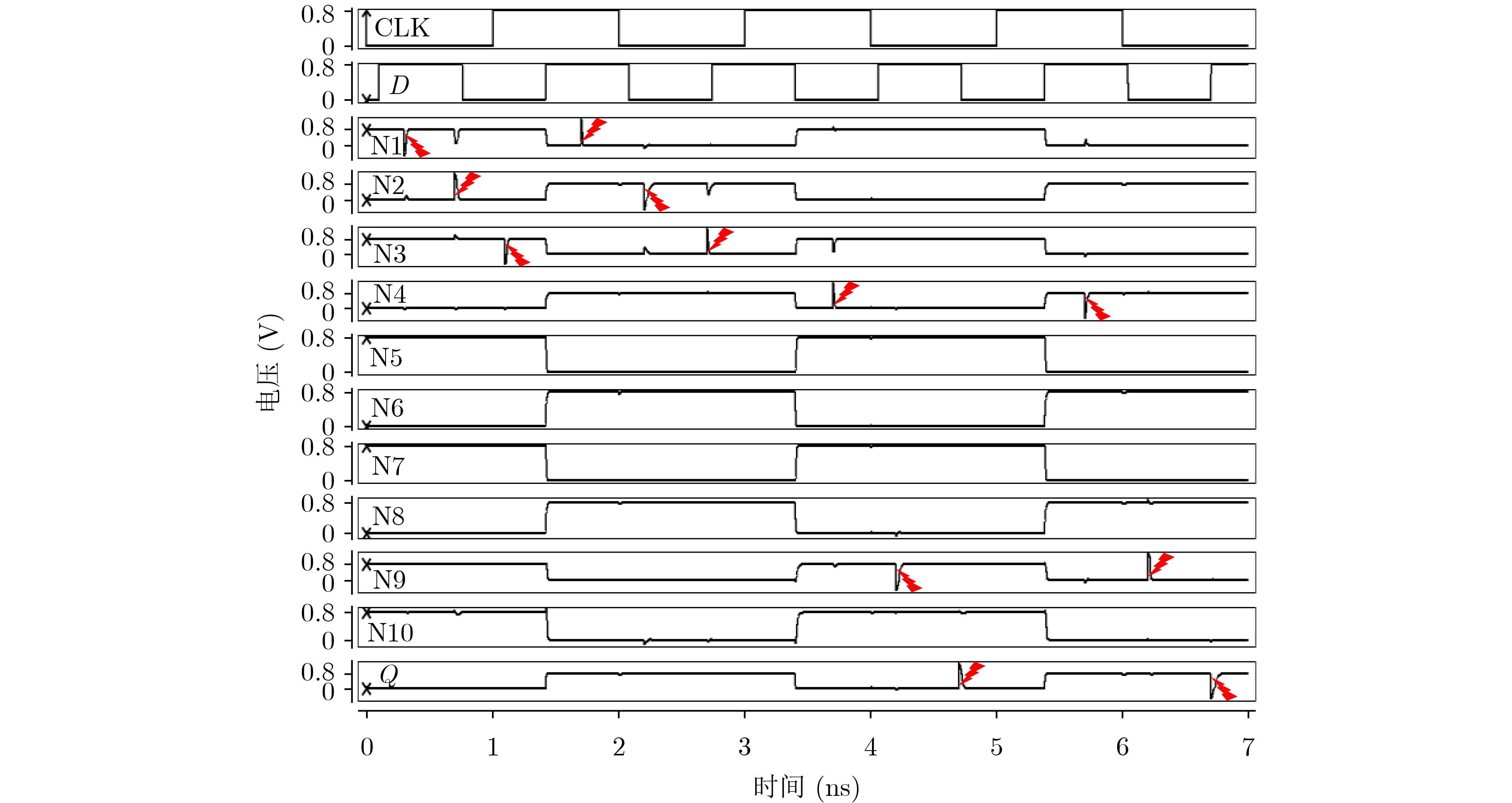
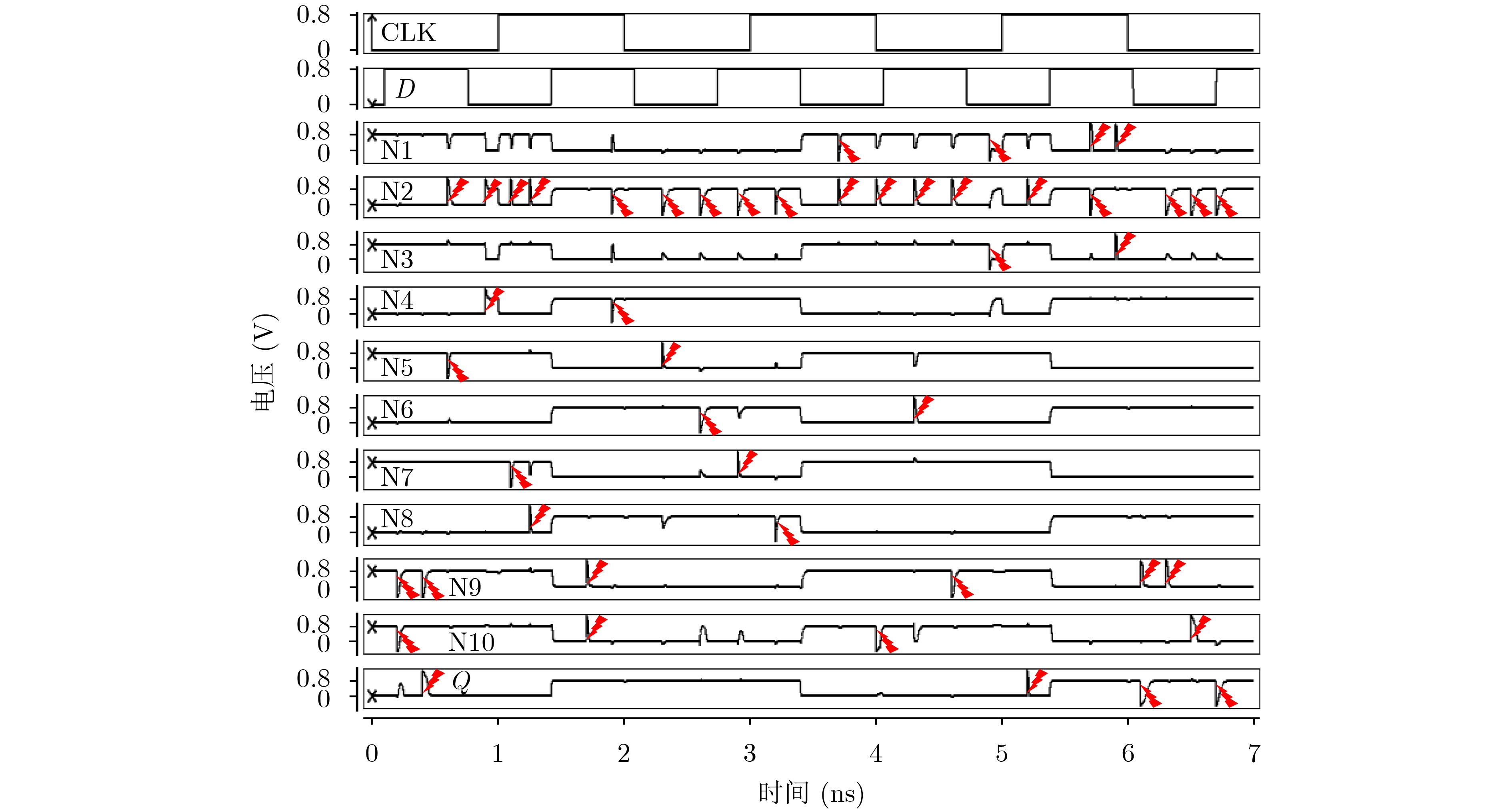
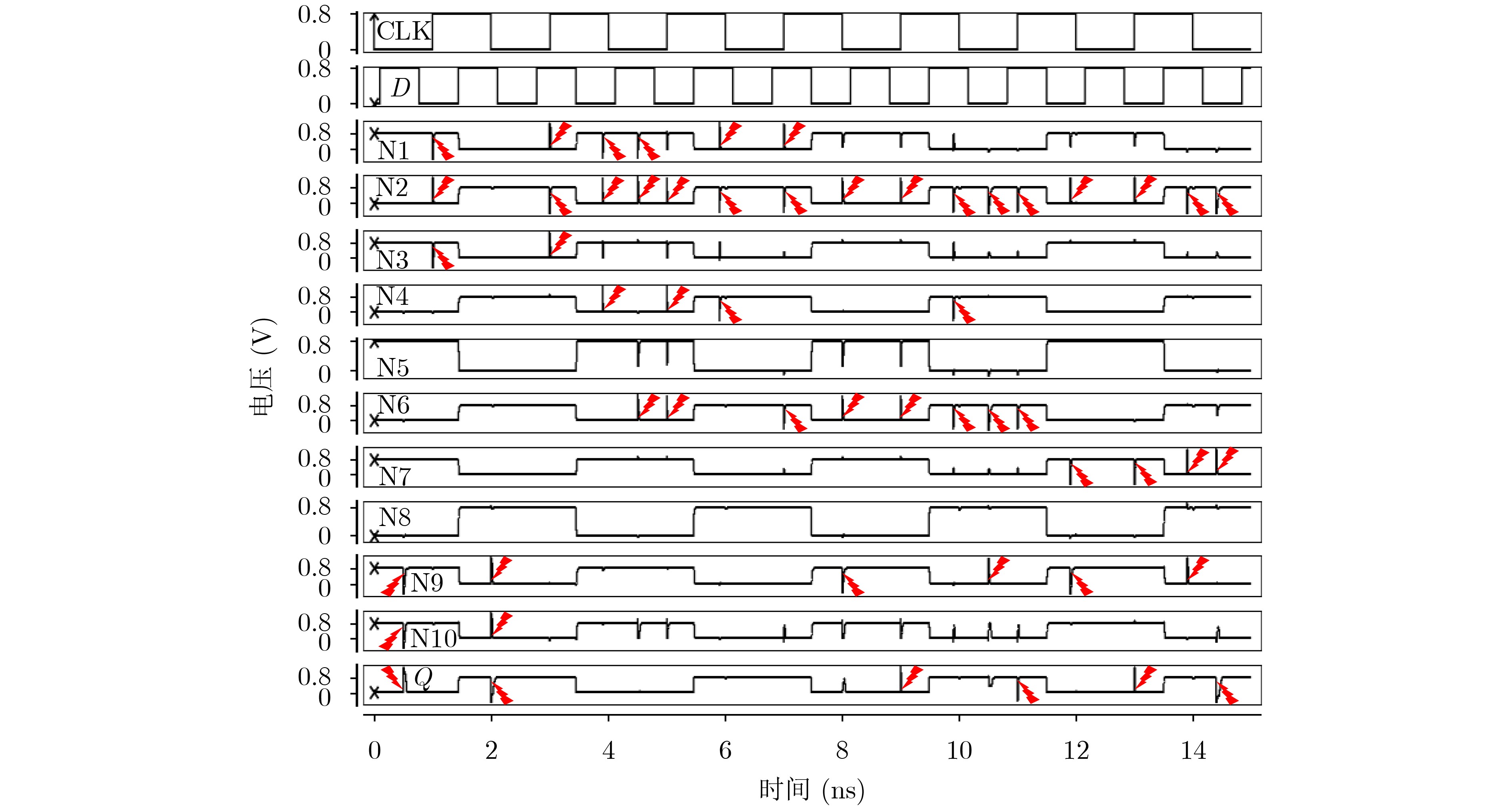
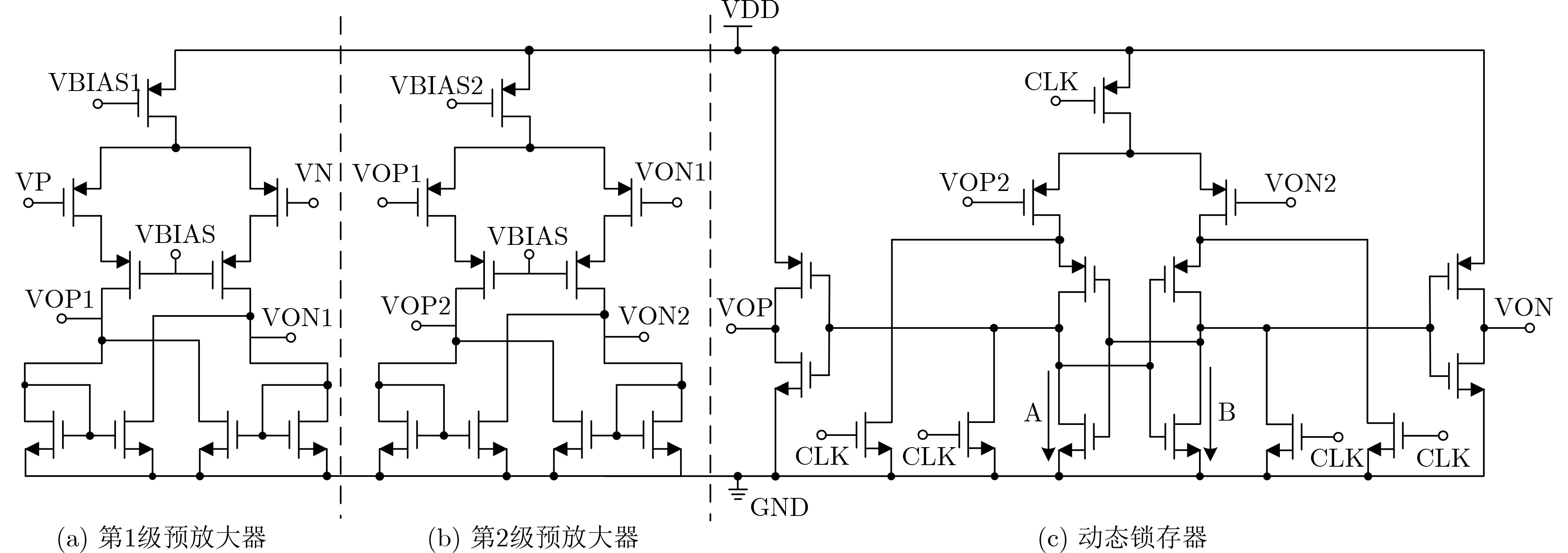
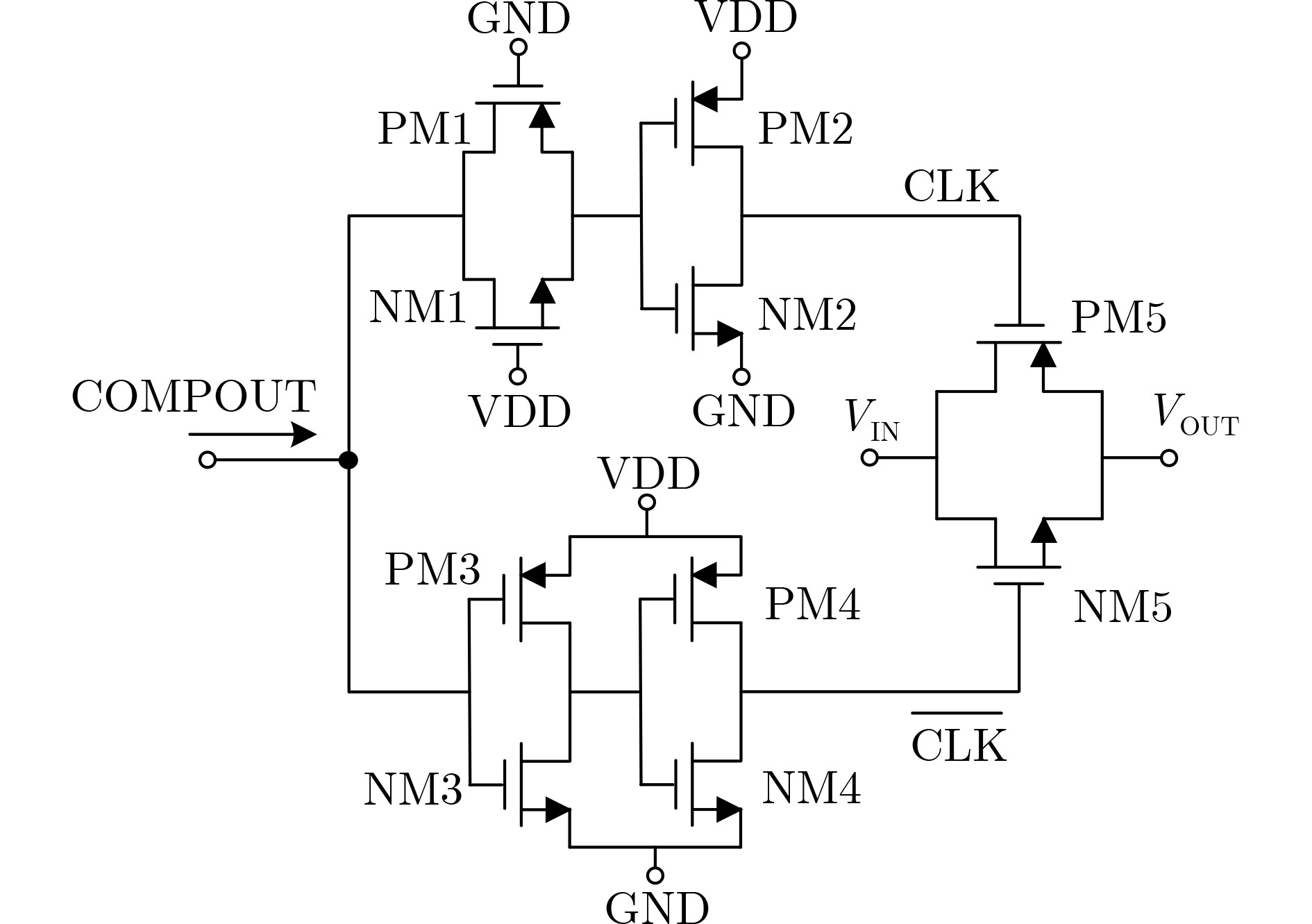
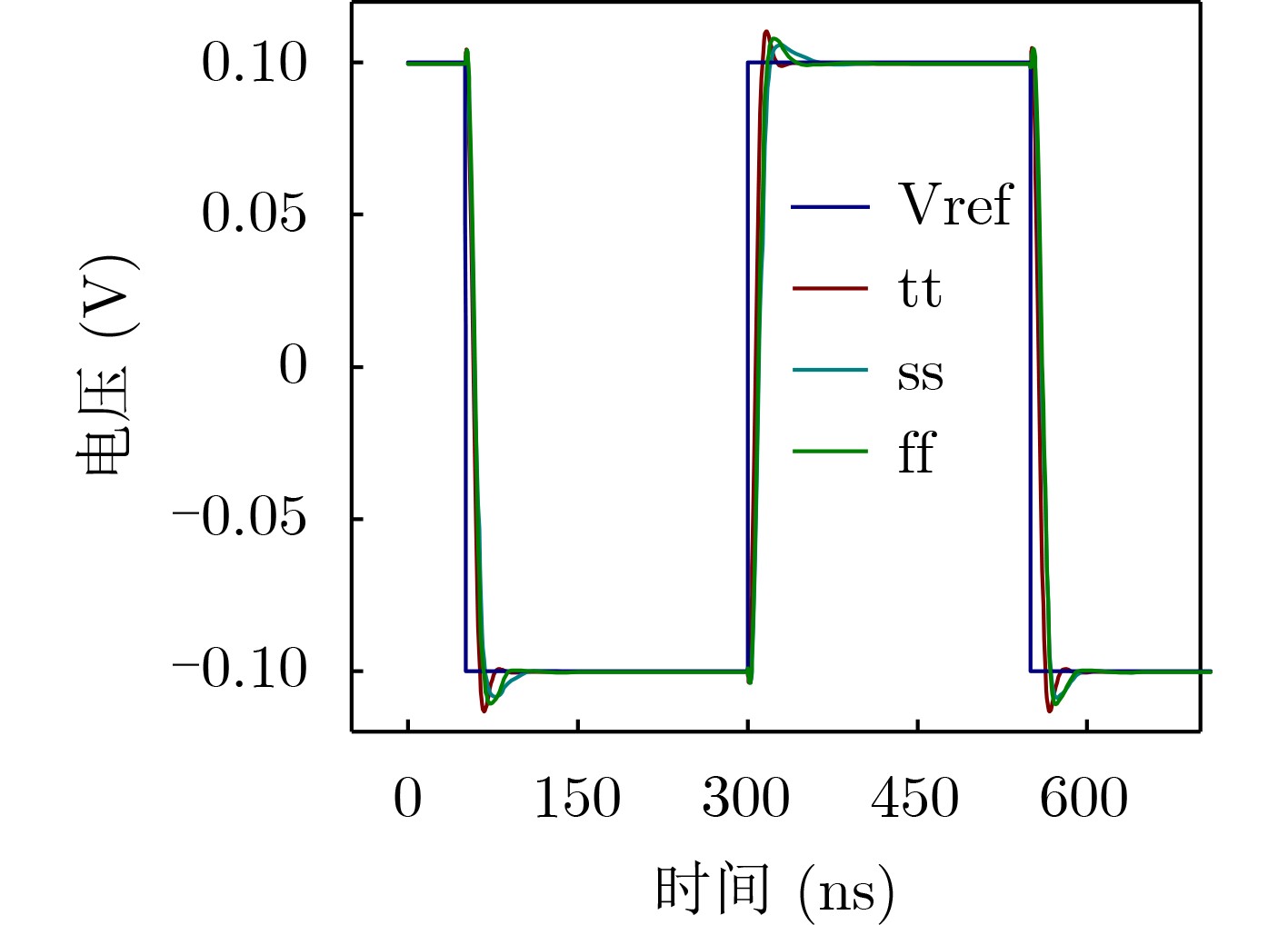
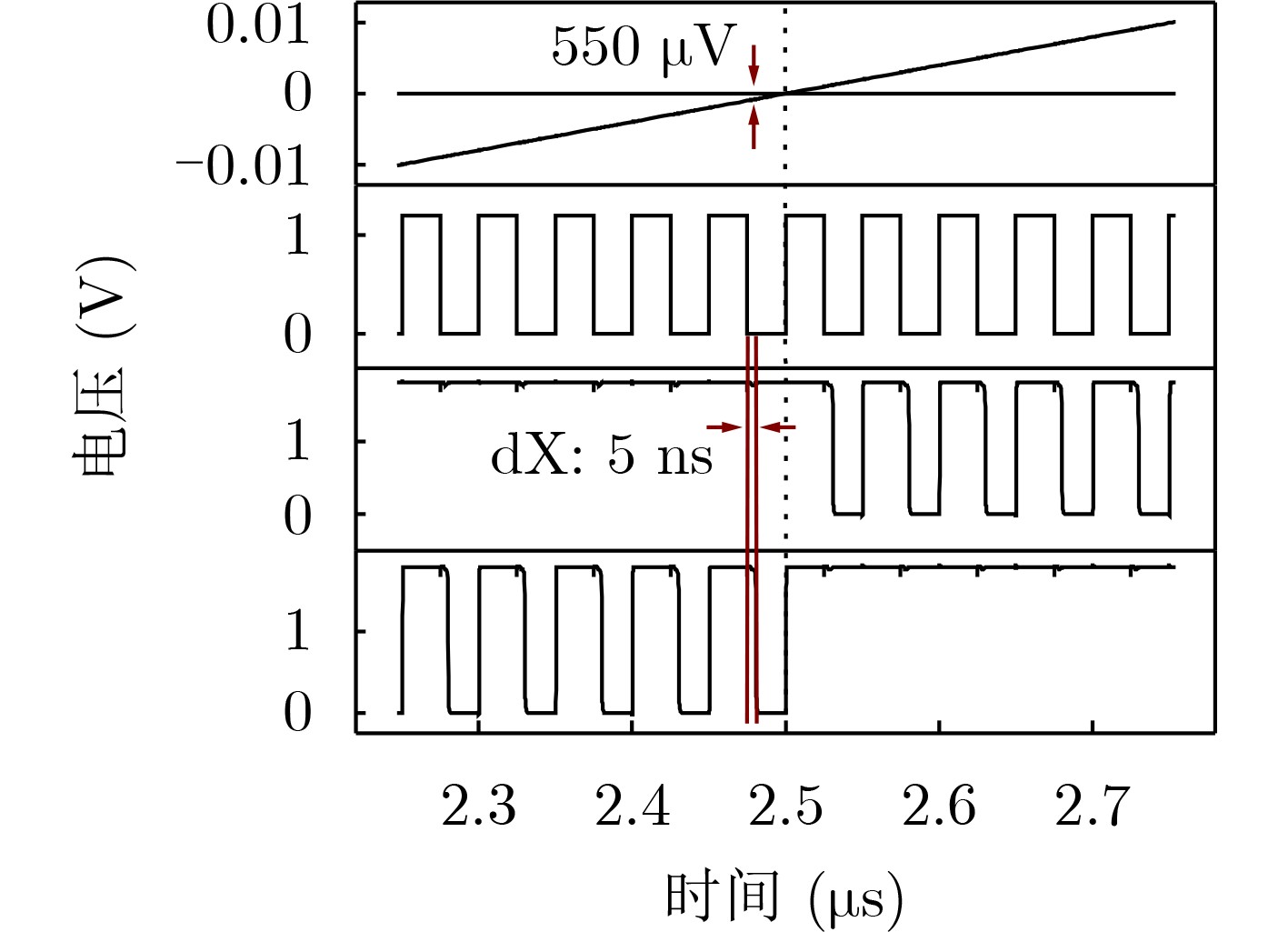
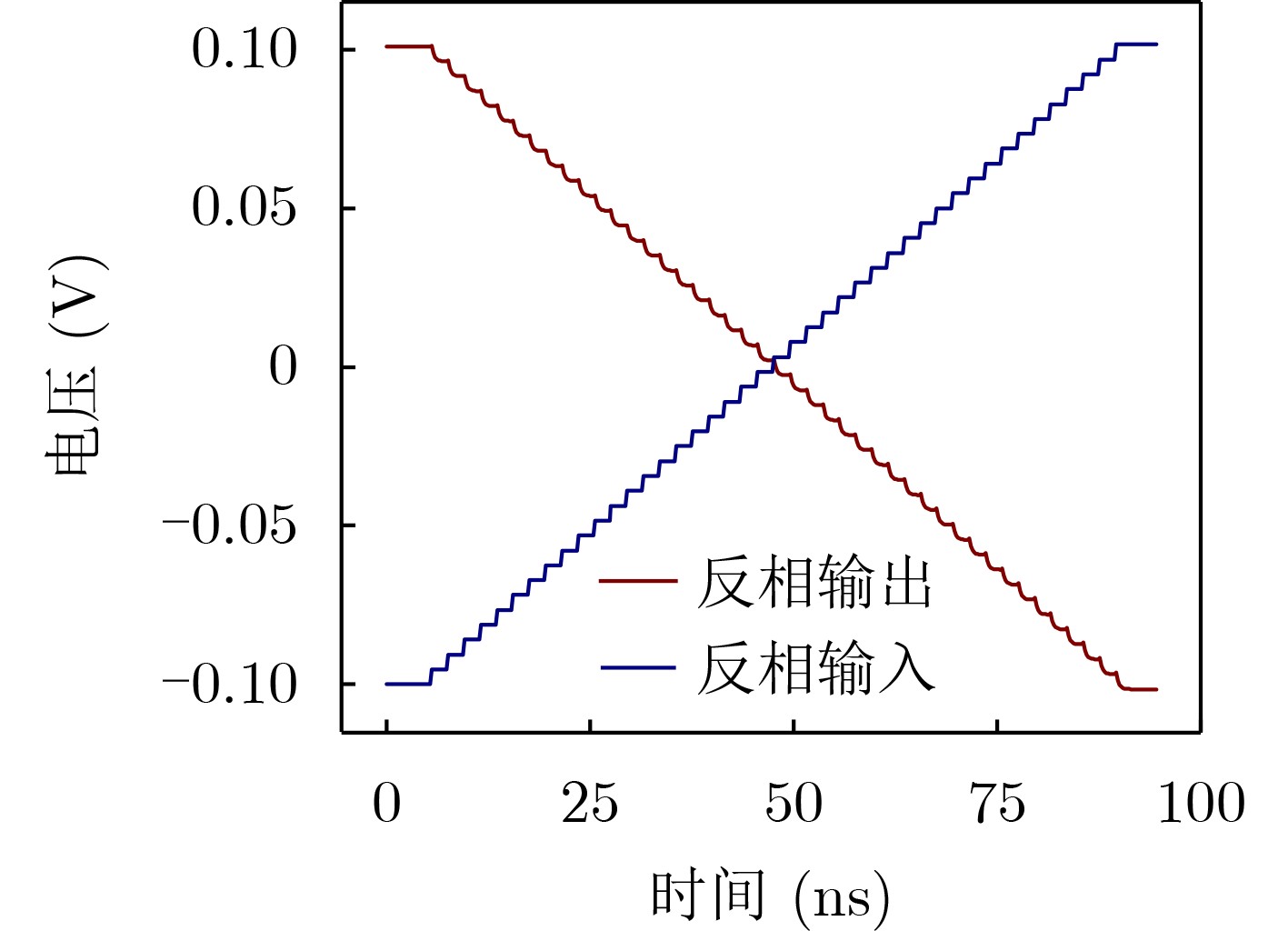
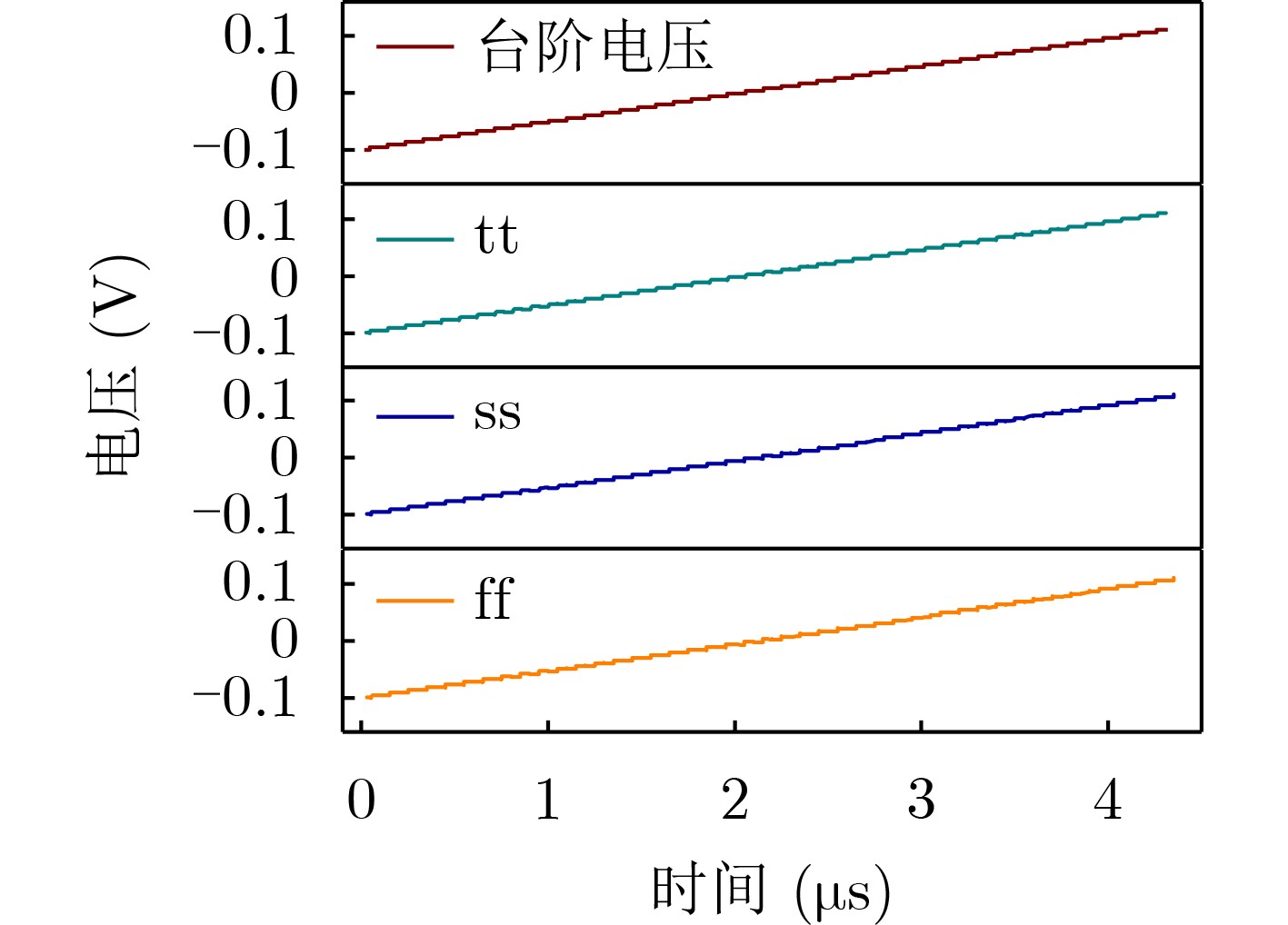
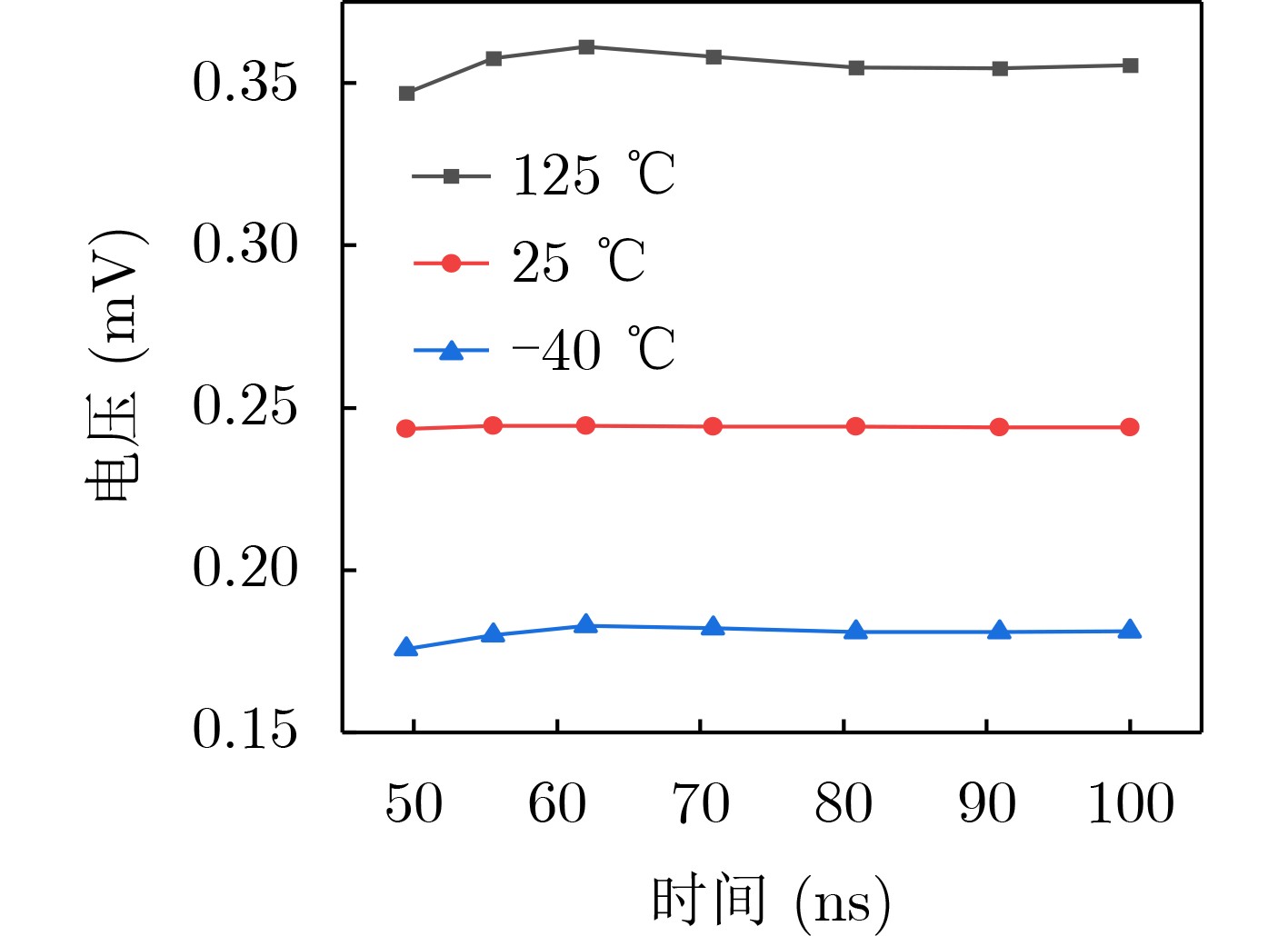
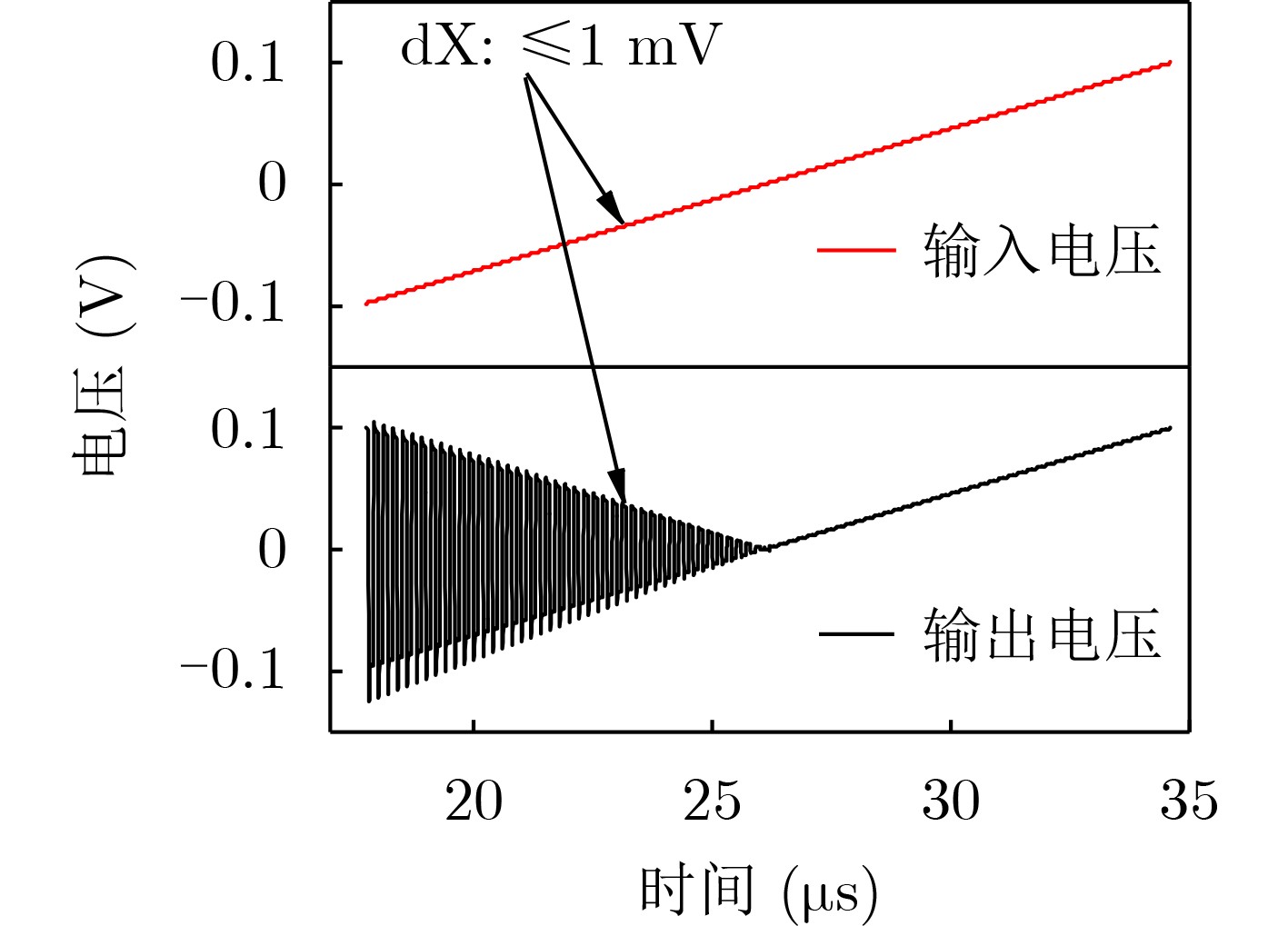
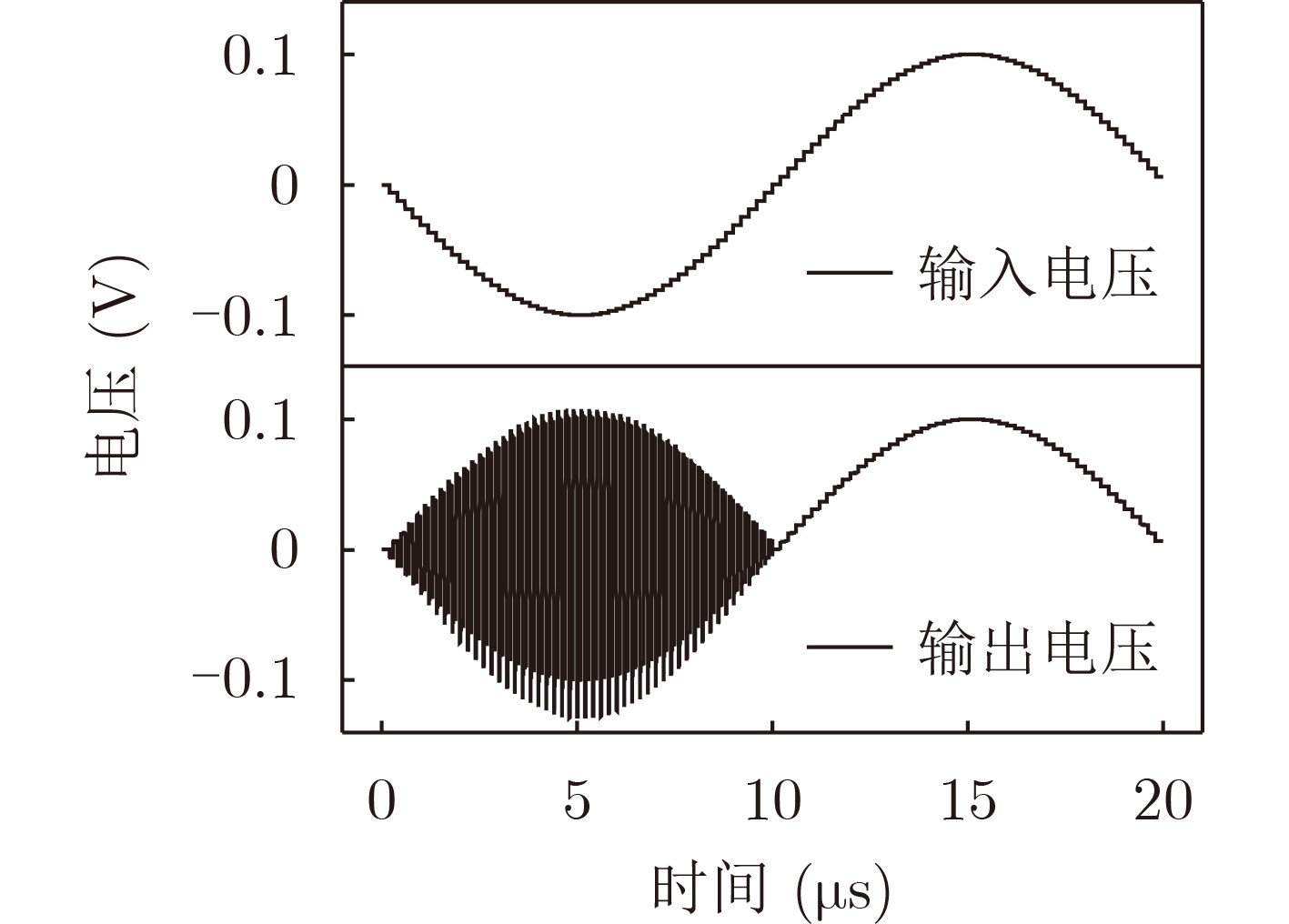
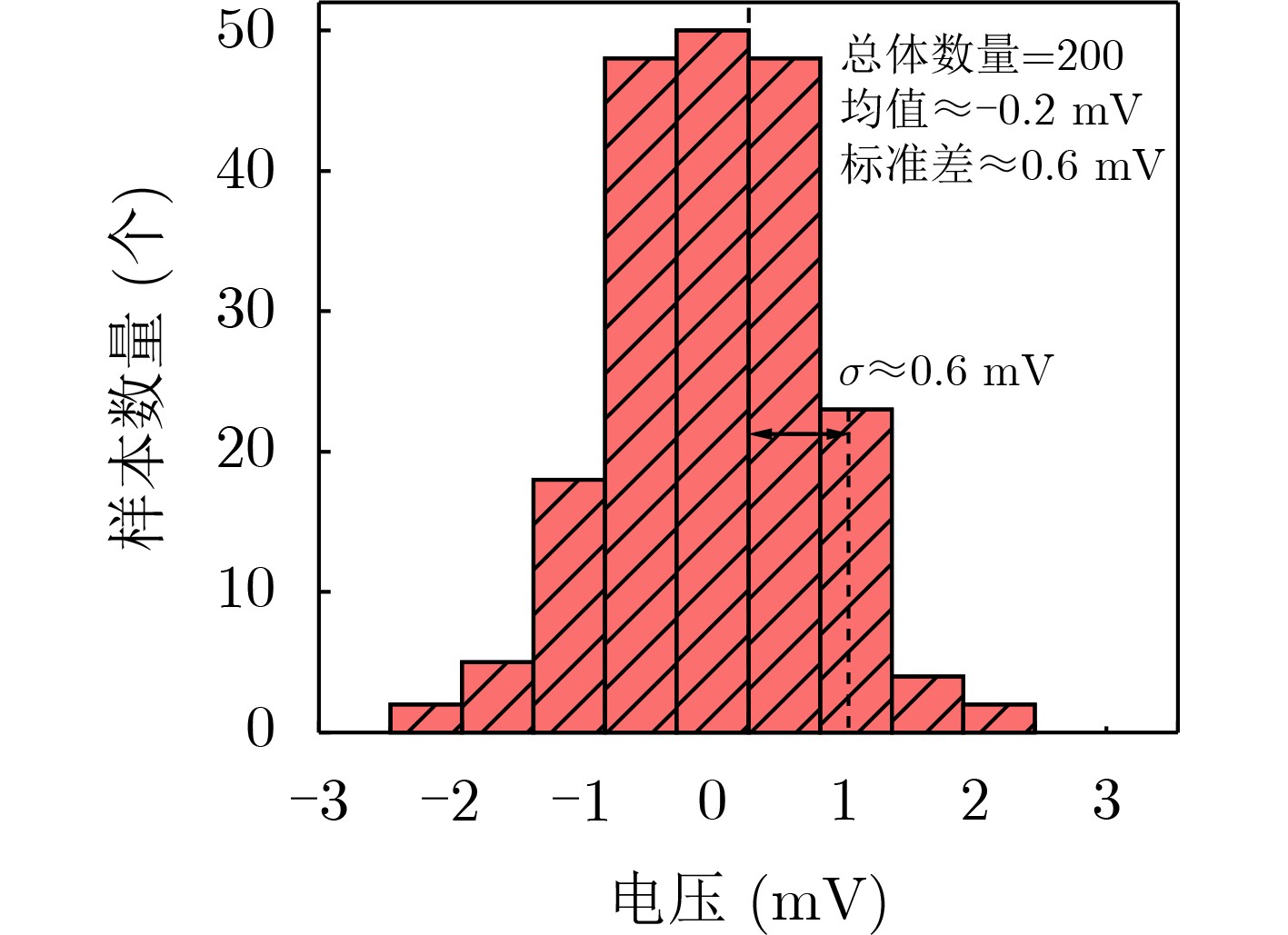
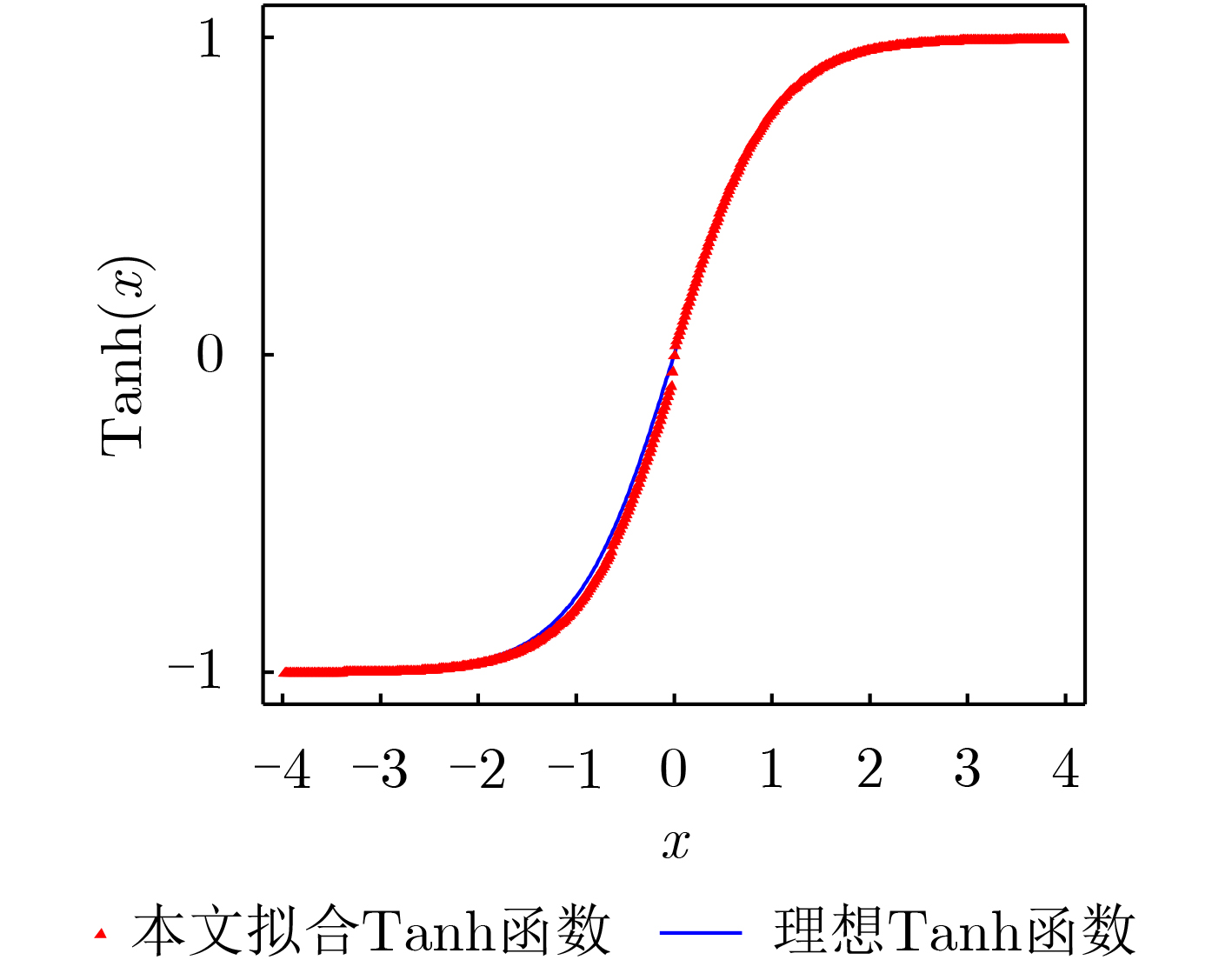
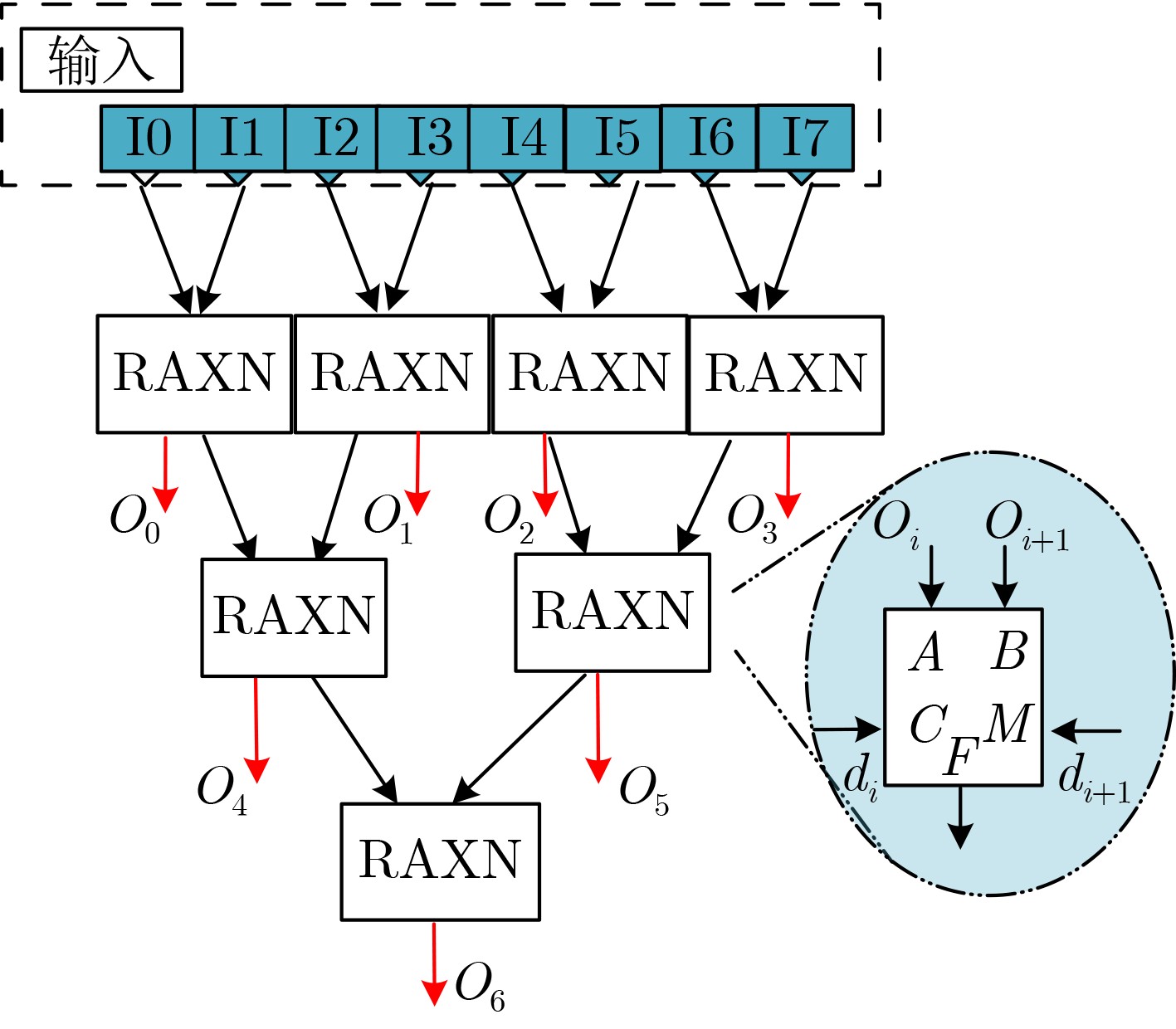
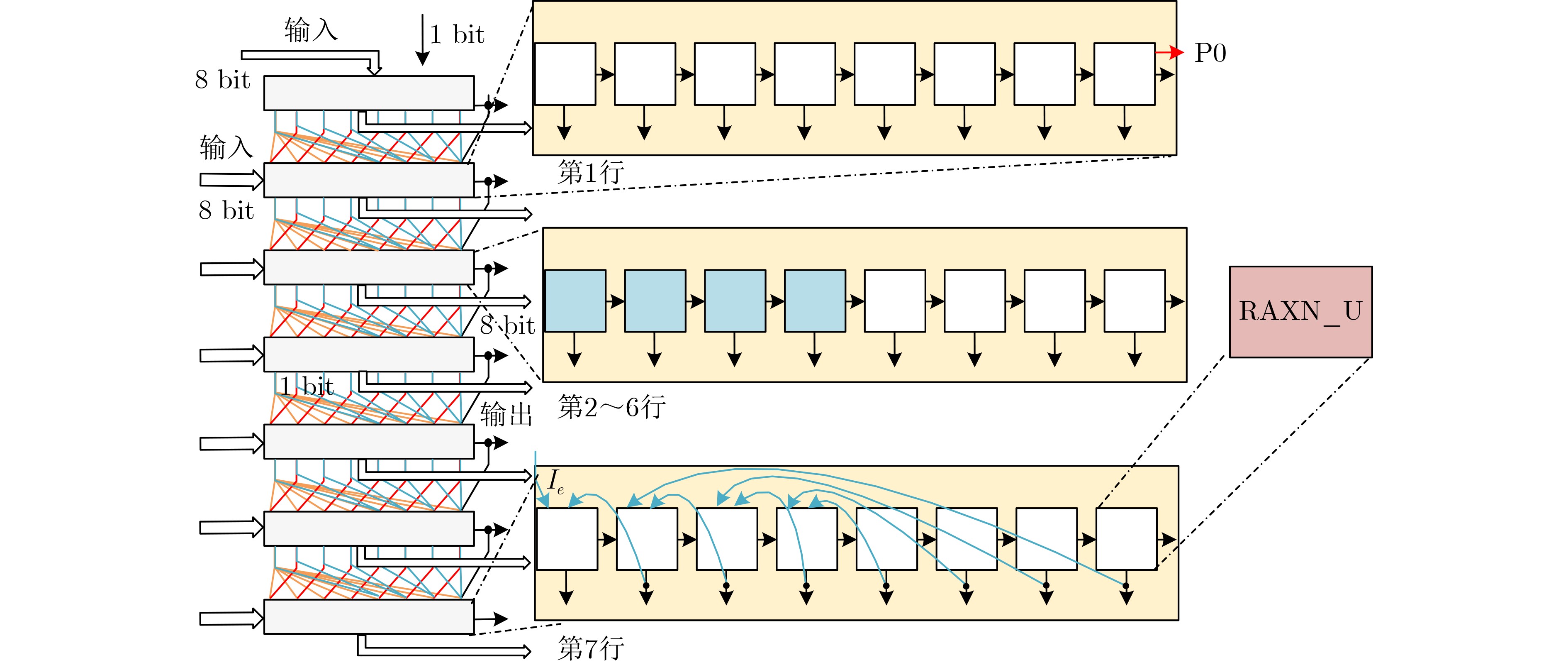
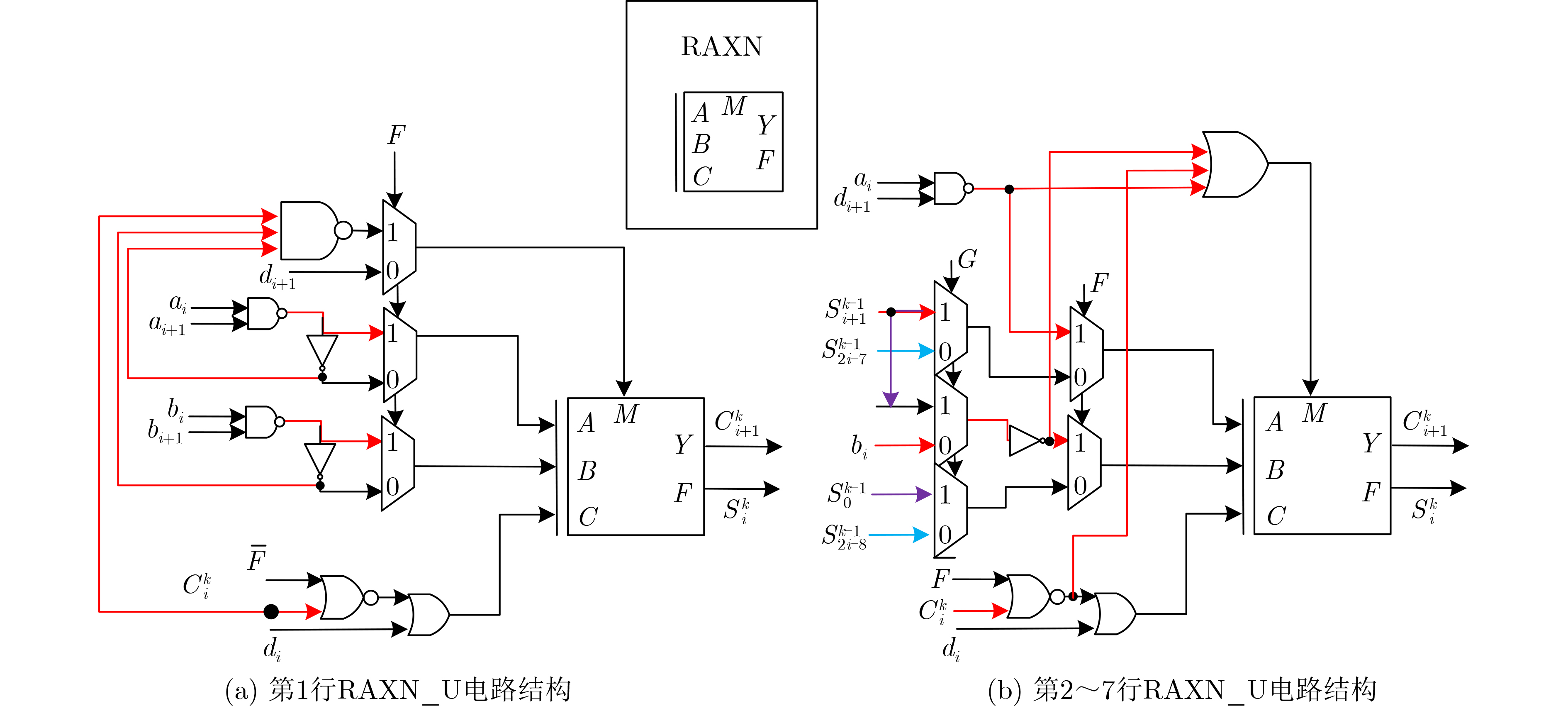
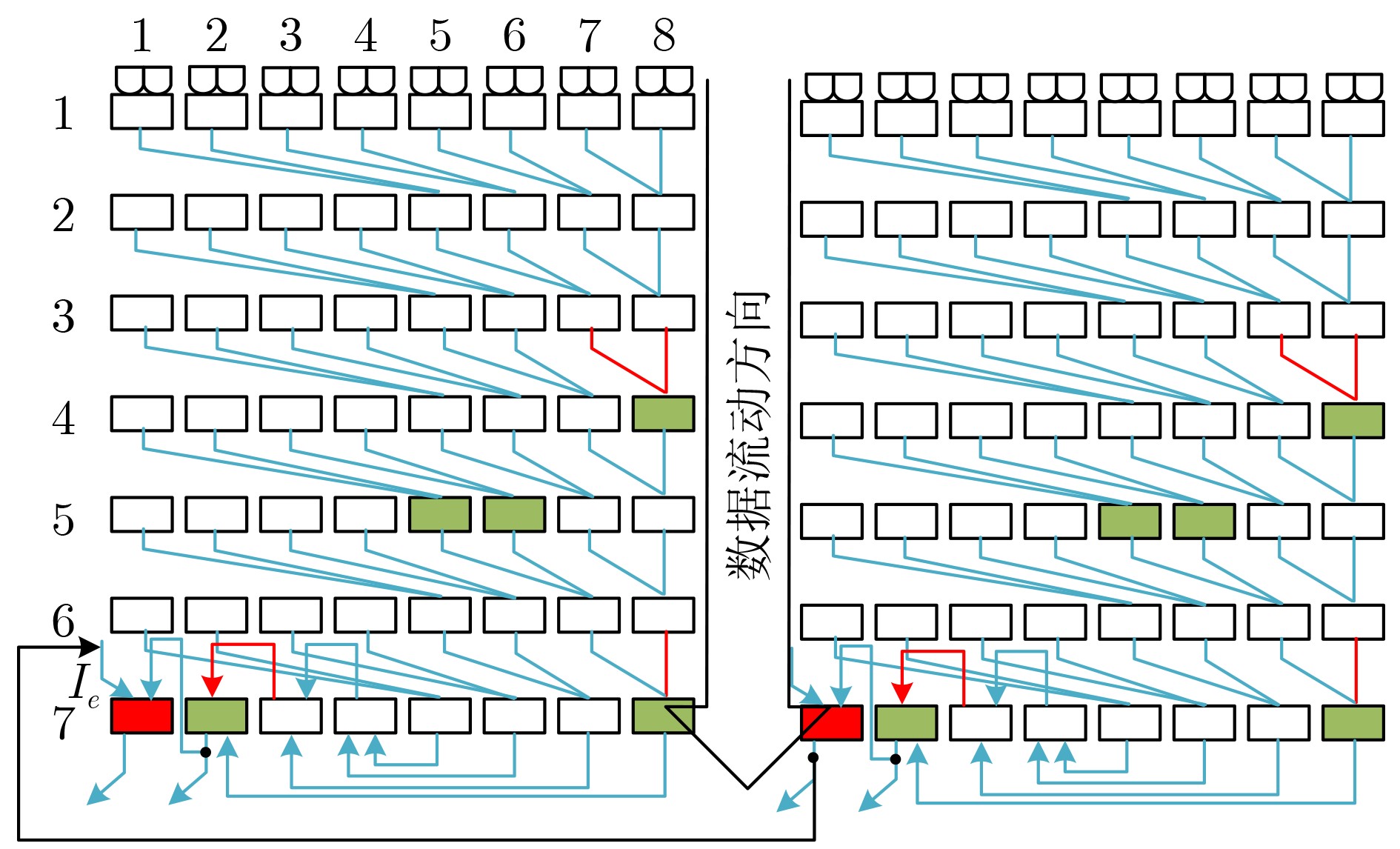
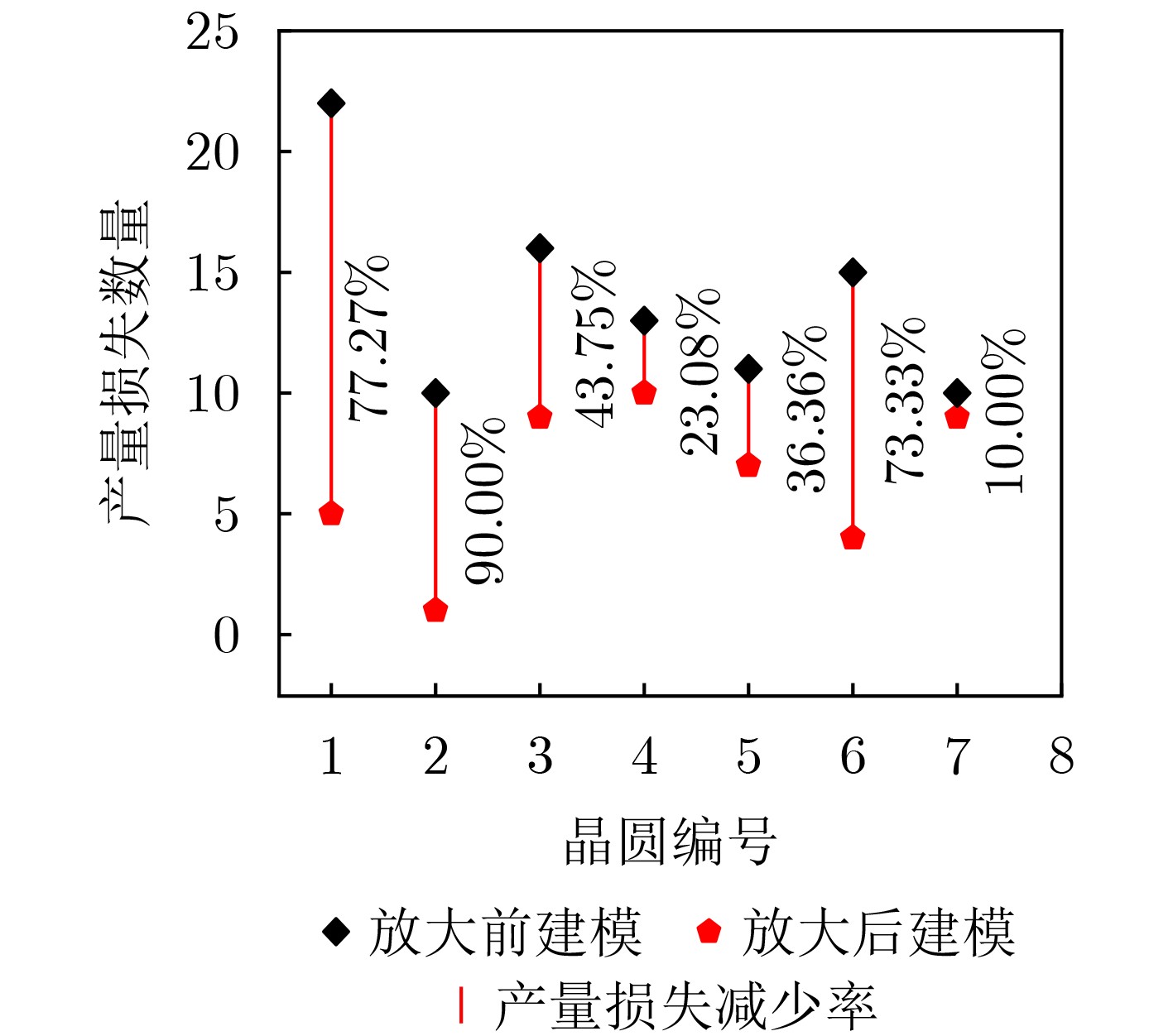
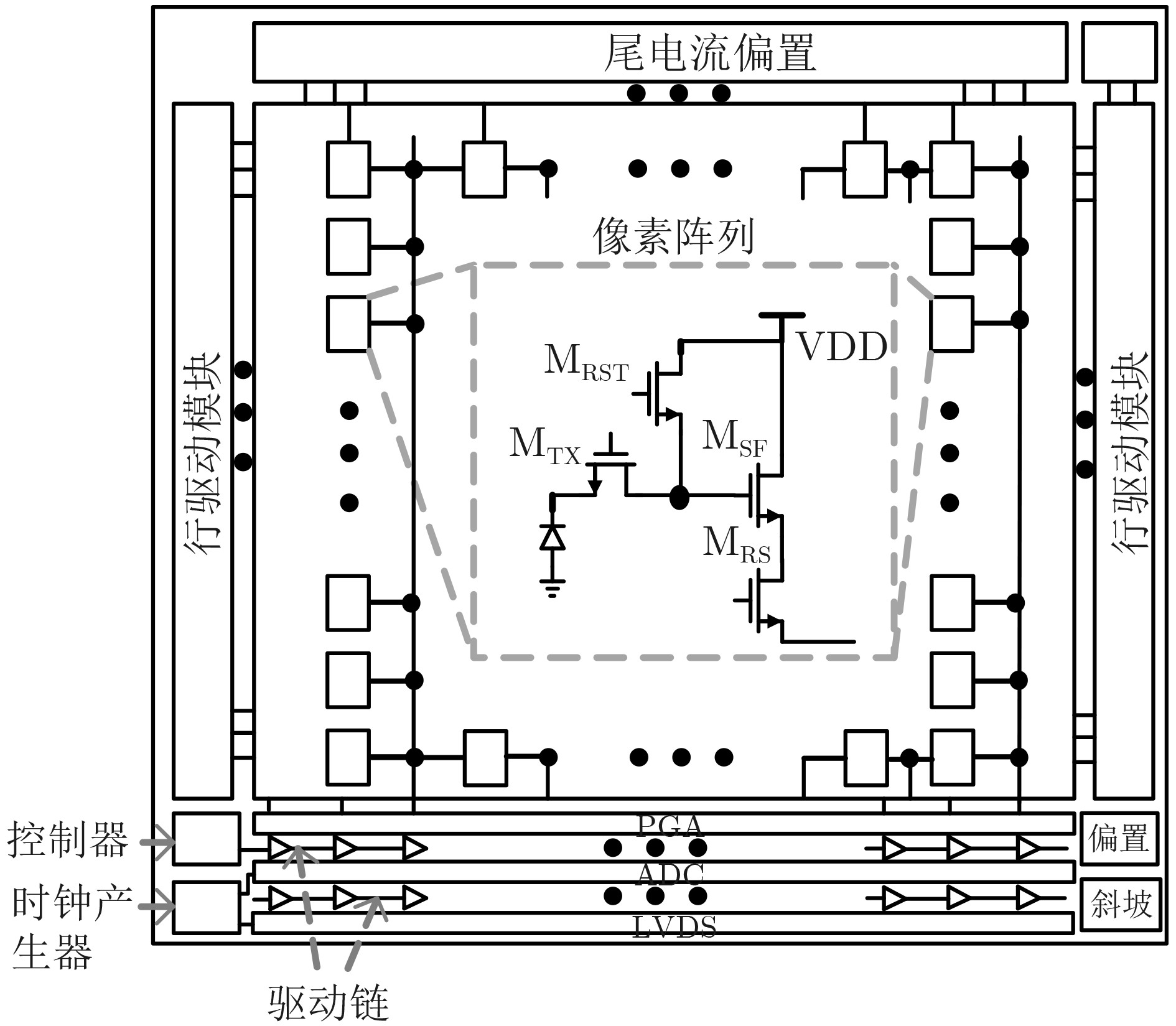
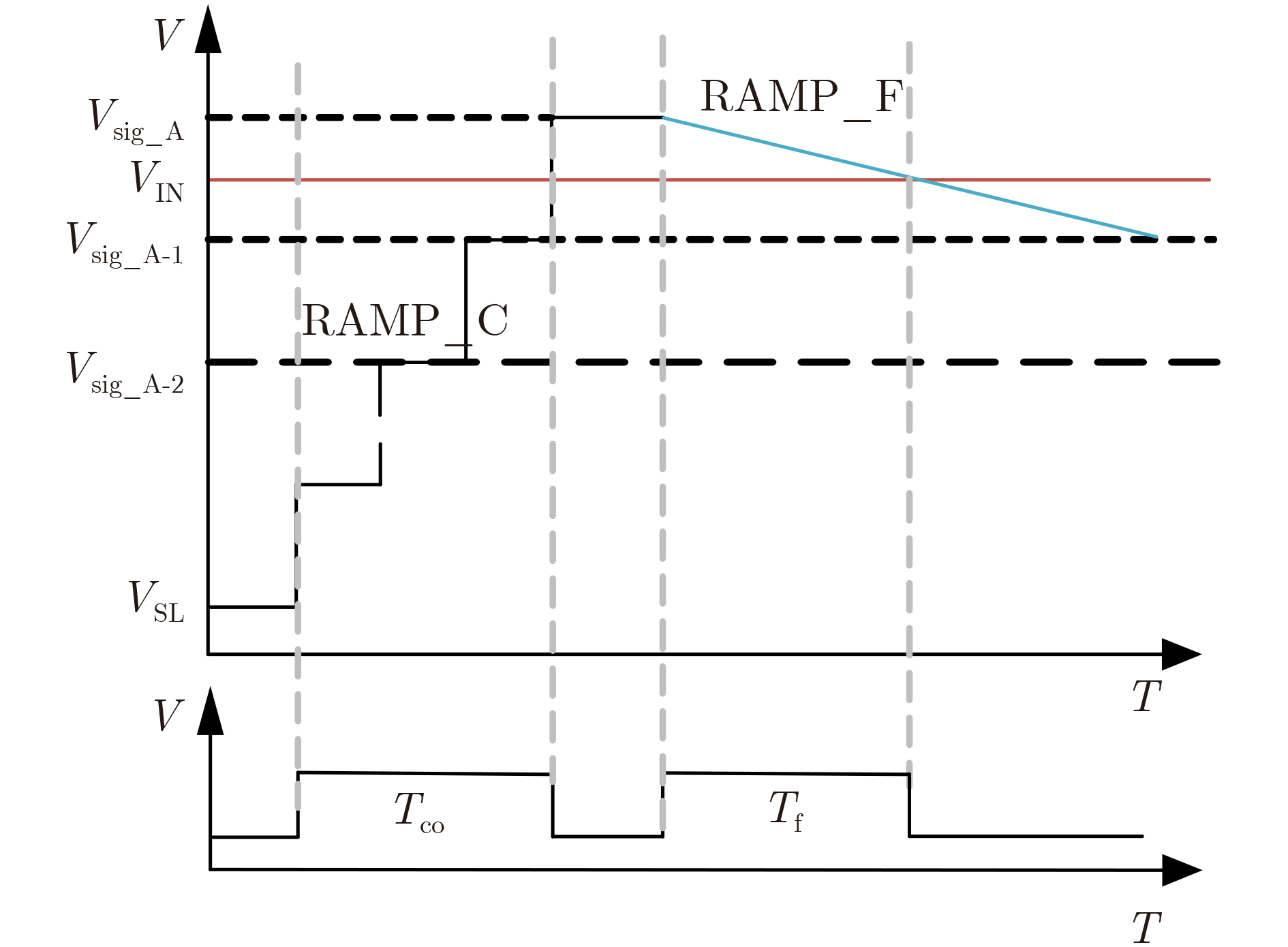
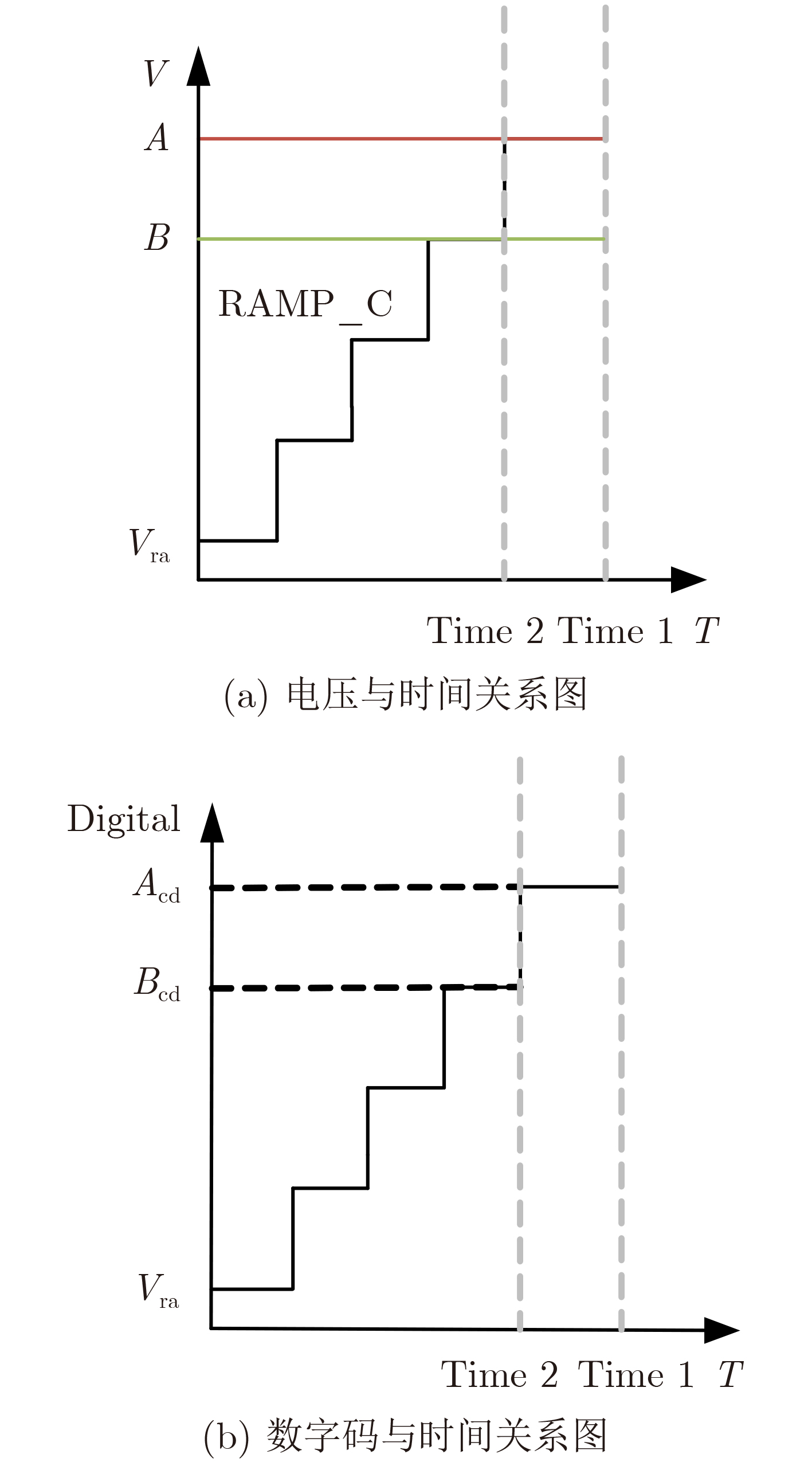
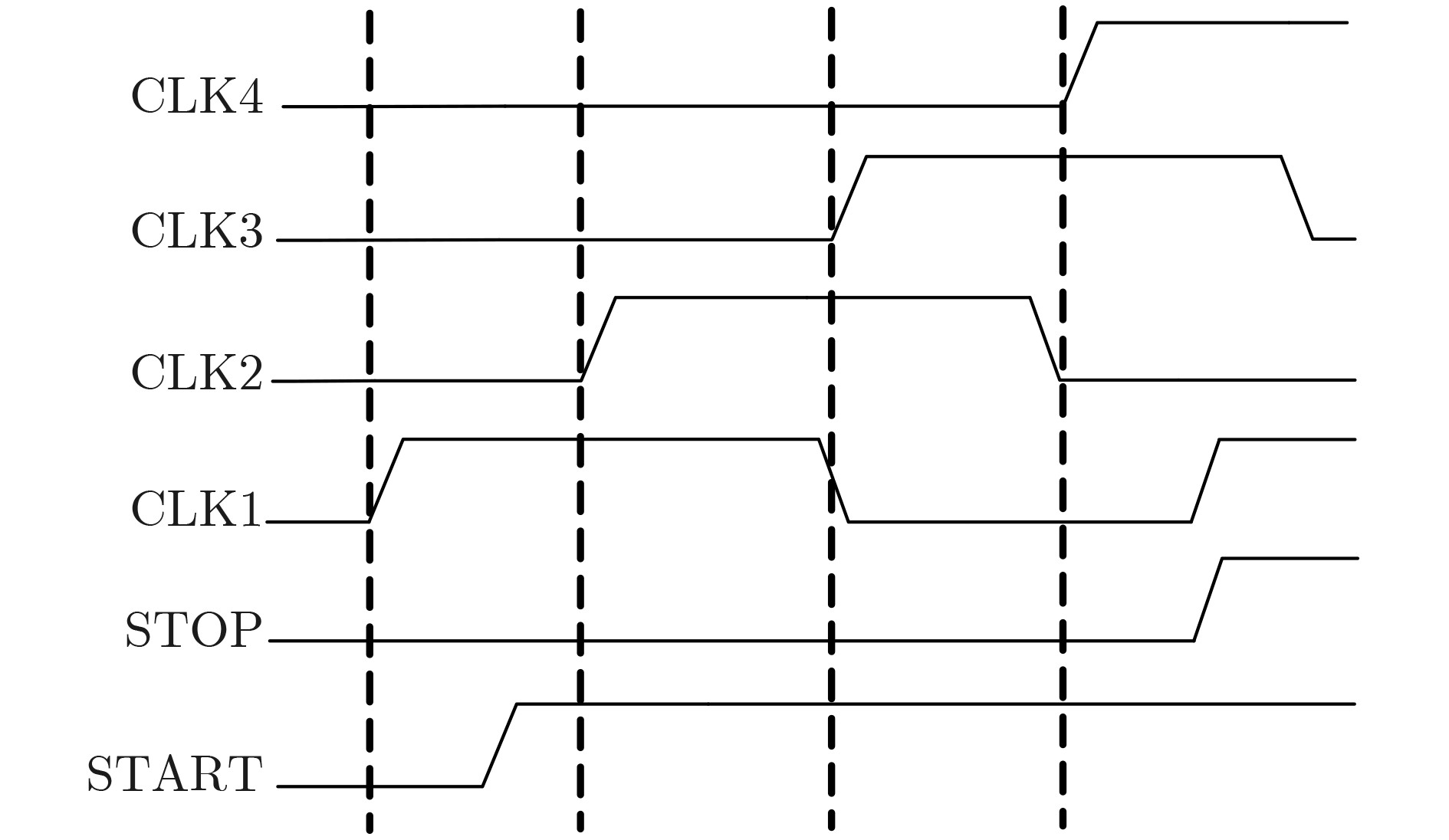
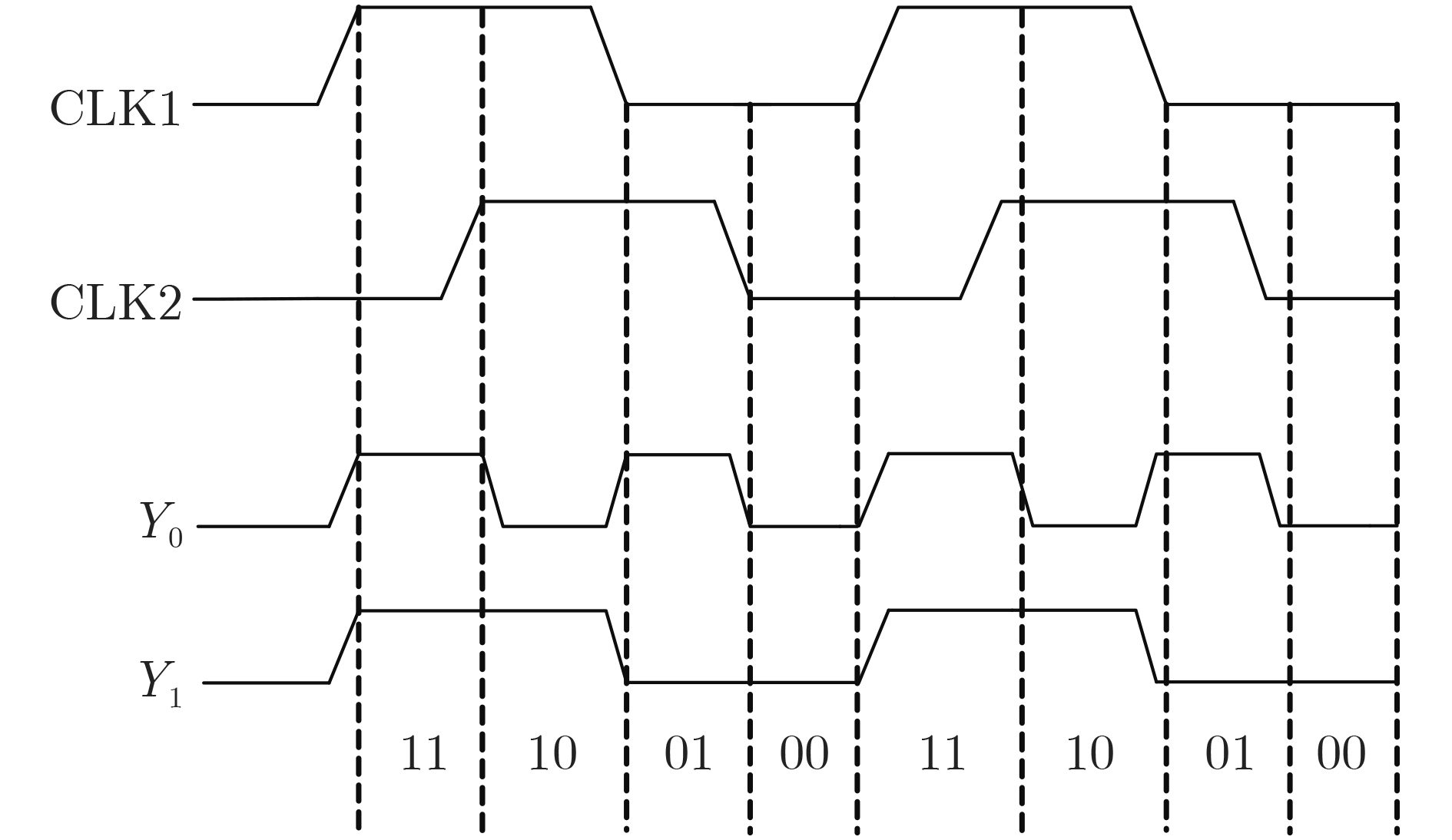
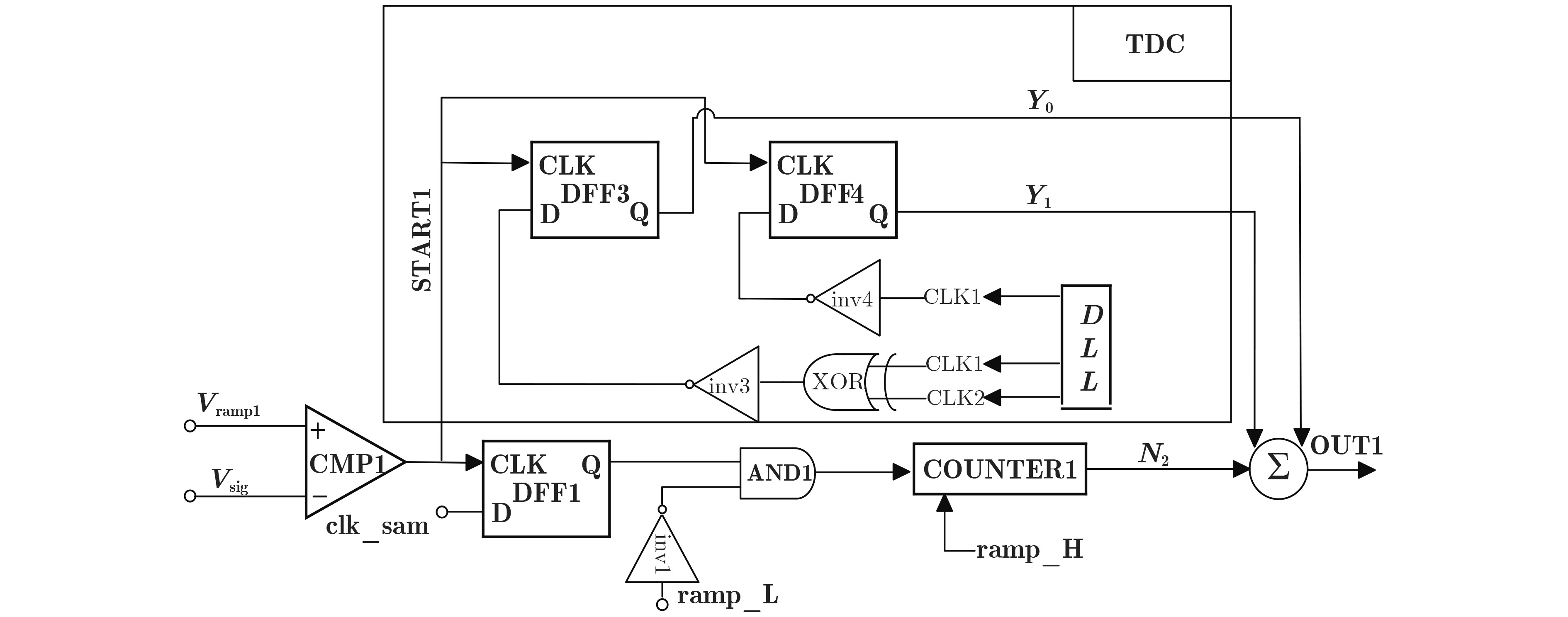
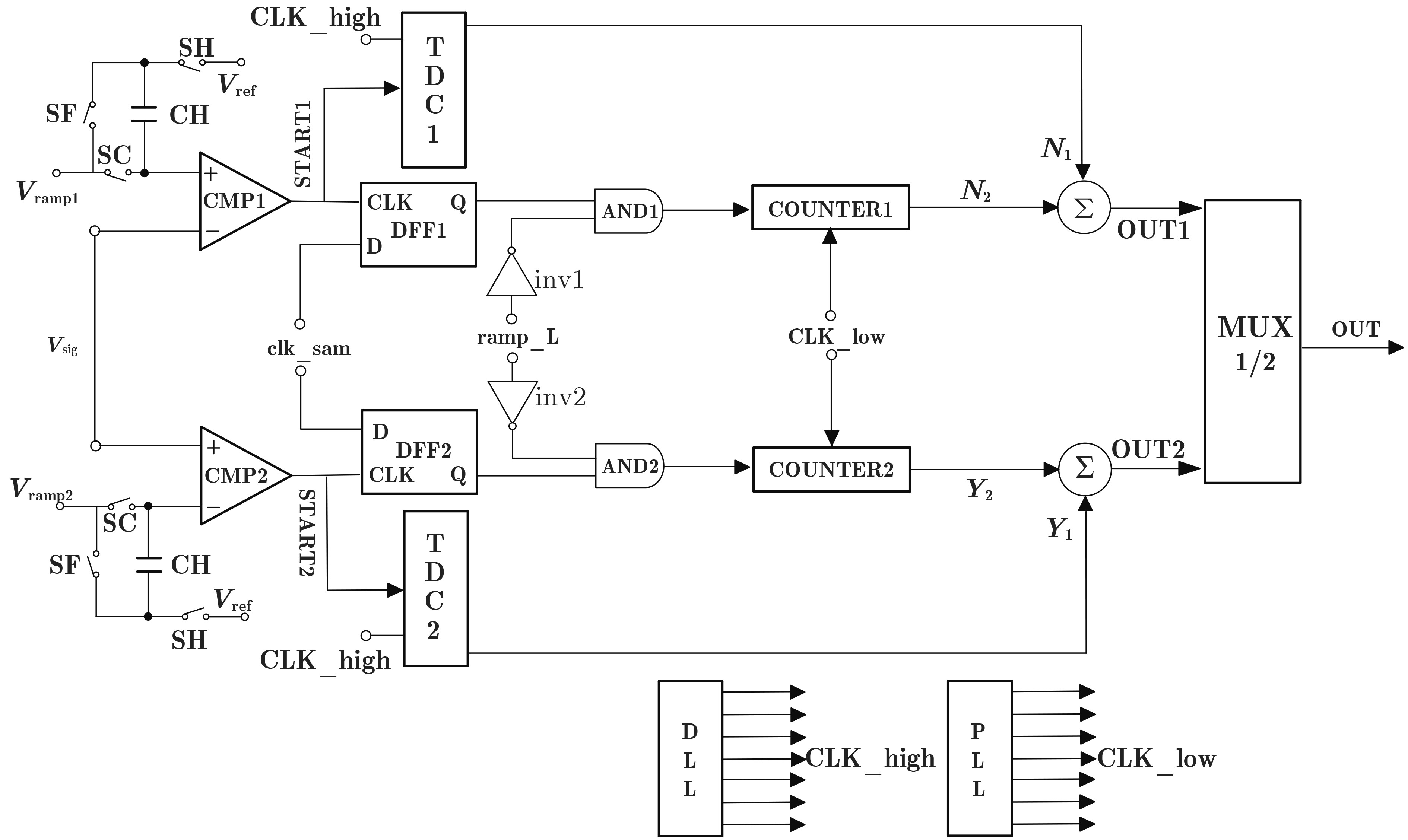
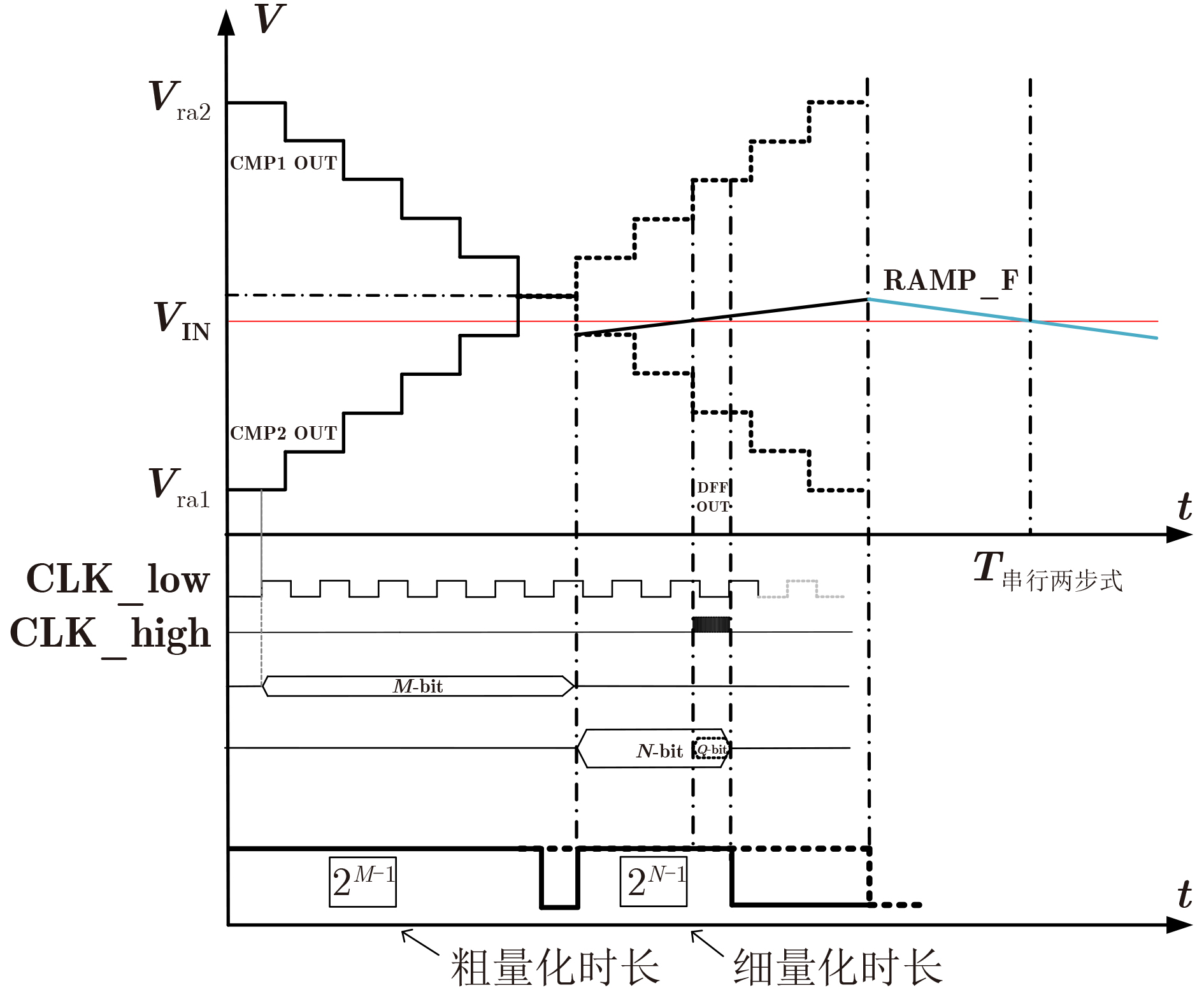
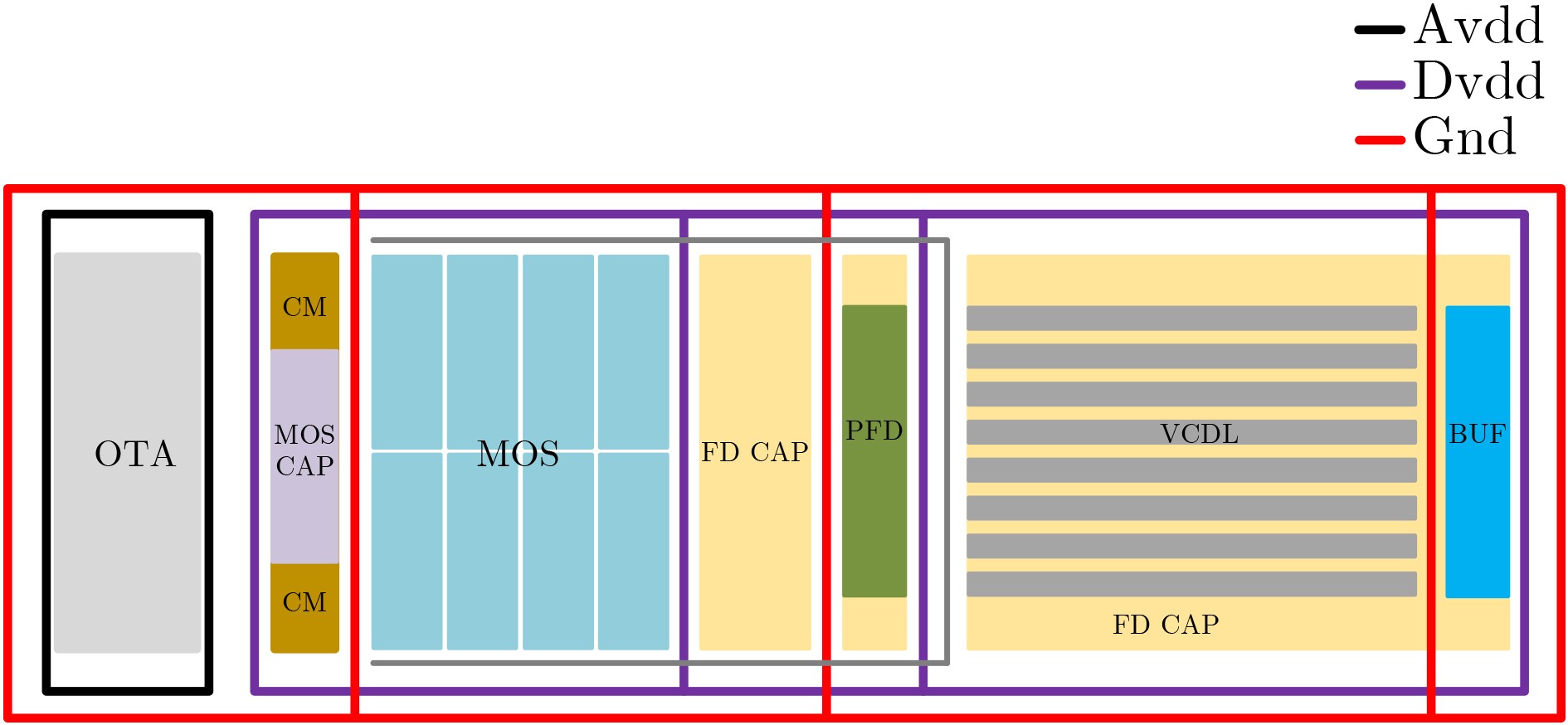
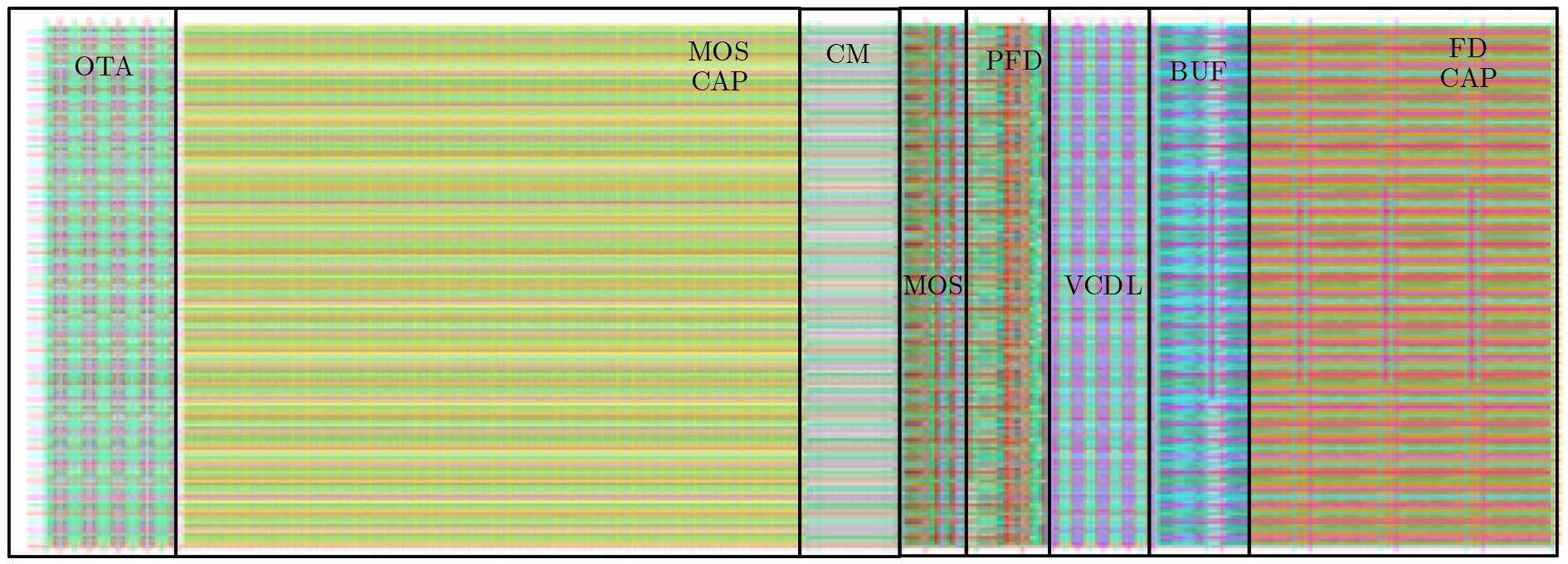
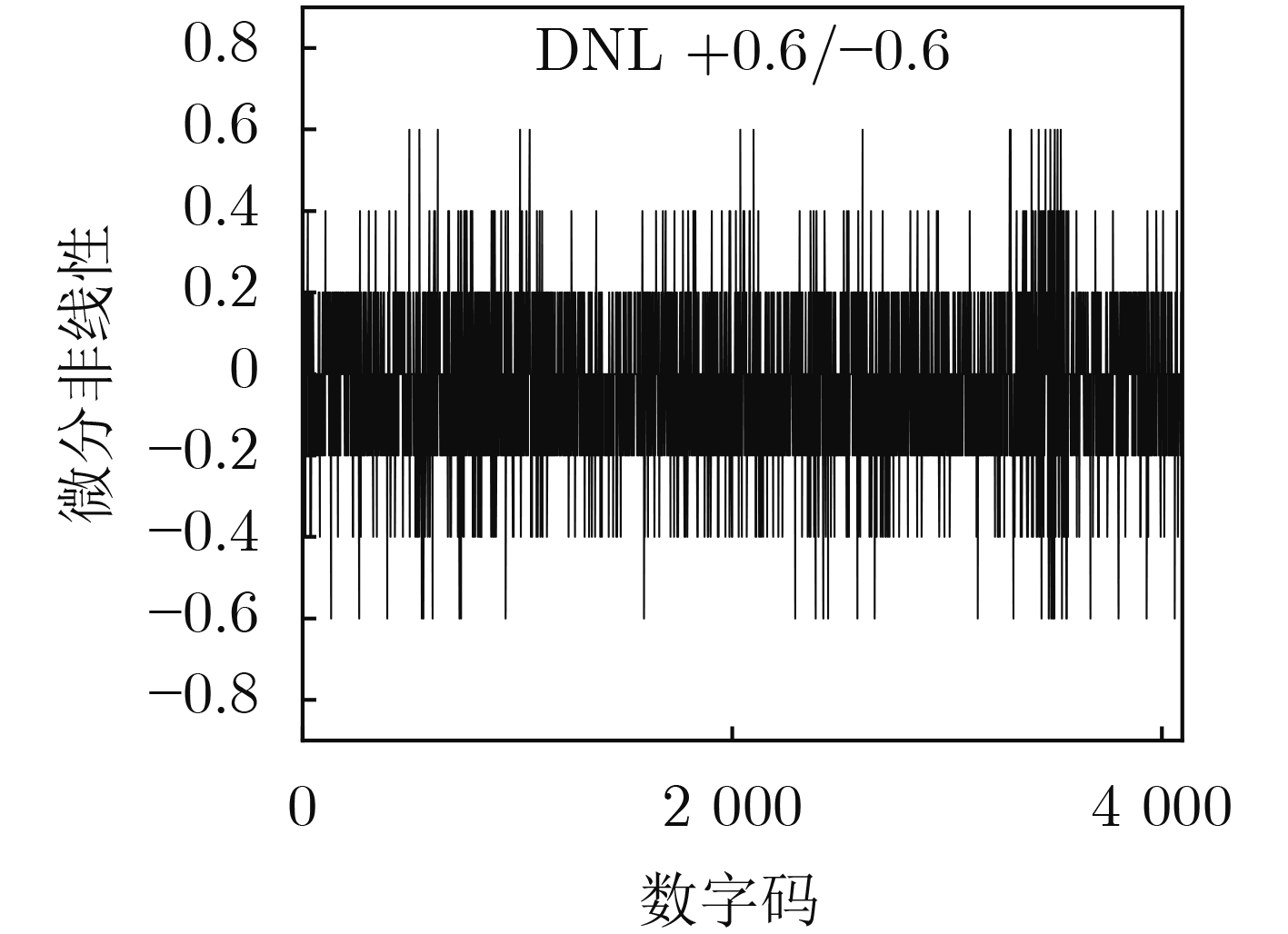
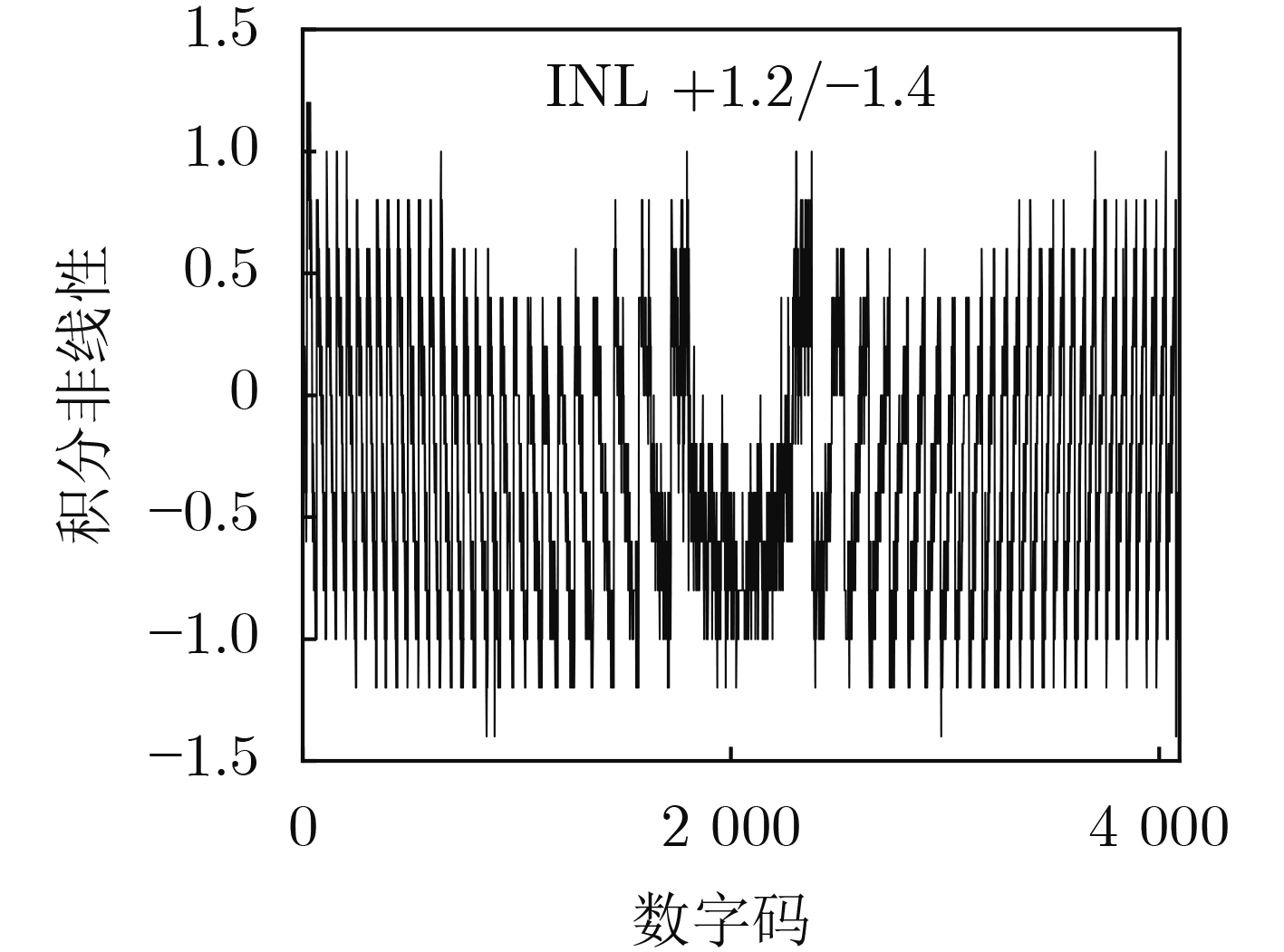
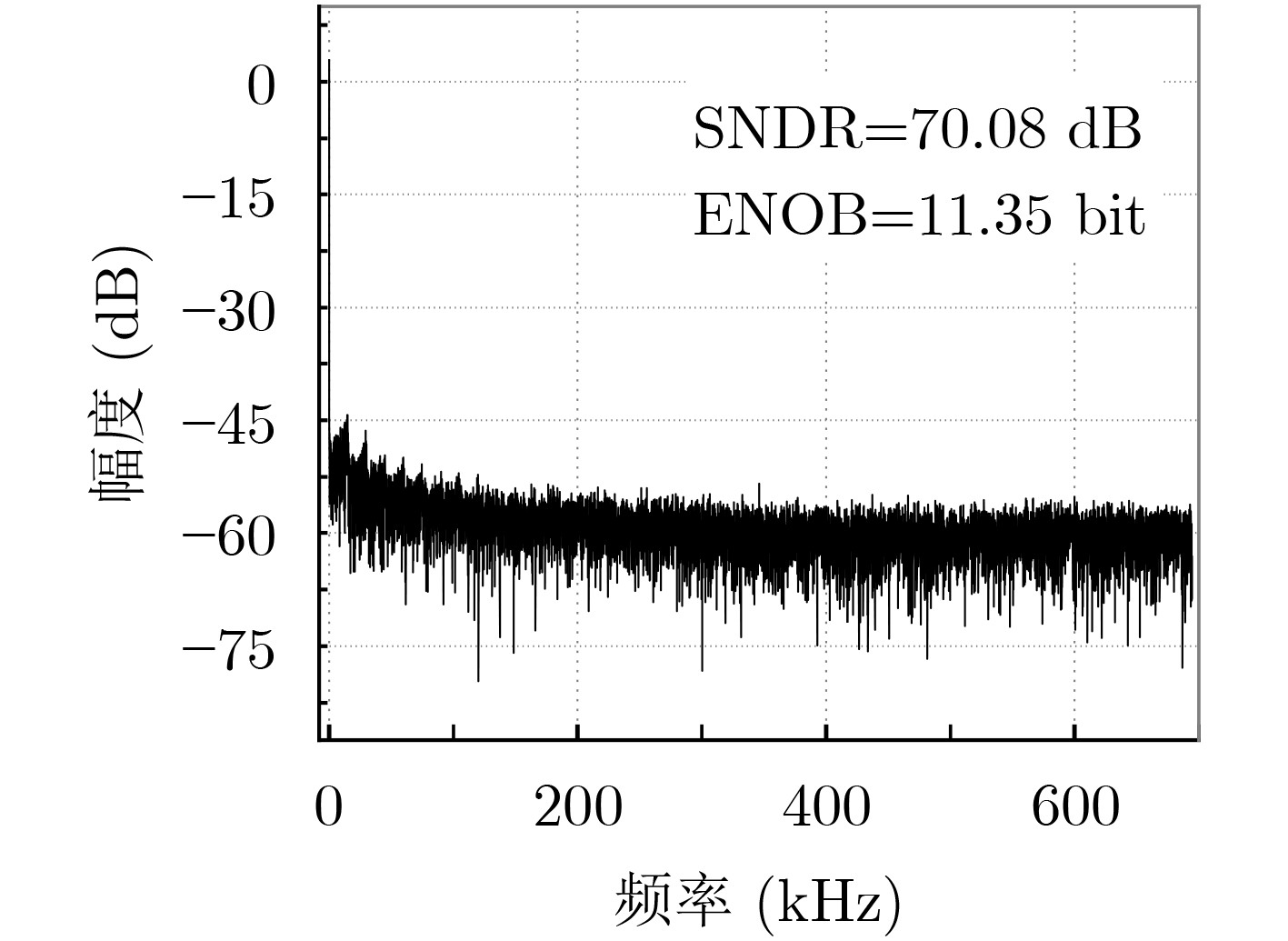
Due to the common speed bottleneck problem of traditional Single-Slope Analog-to-Digital Converter (SS ADC) and serial two-step ADC, the application requirements of high frame rate CMOS Image Sensor (CIS) in the industry have not been met. In this paper, a high-speed fully differential two-step ADC design method for CIS is proposed. The ADC design method is based on differential ramp and Time-to-Digital Conversion (TDC) technology. A parallel conversion mode is formed, which is different from serial conversion, and the robustness of the system is ensured due to the existence of differential ramps. Focusing on the inconsistency between traditional TDC technology and single-slope ADC, a TDC technology based on level coding is proposed, which completes time-to-digital conversion in the last clock cycle of A/D conversion, and realizes a two-step conversion process at another level. Based on the 55 nm 1P4M CMOS experimental platform, this paper completes the circuit design, layout design and test verification of the proposed design method. Under the design environment of analog voltage 3.3 V, digital voltage 1.2 V, clock frequency 100MHz, and dynamic input range 1.6 V, this design is a 12 bit ADC, the conversion time is 480 ns, the column-level power consumption is 62 μW, the DNL (Differential Non-Linearity is measured in the Least Significant Bit) is +0.6/–0.6, the INL (Integral Non-Linearity is measured in the Least Significant Bit) is +1.2/–1.4, and the Signal-to-Noise Distortion Ratio (SNDR) reaches 70.08 dB. Compared with the existing advanced single-slope ADC, the ADC conversion speed is increased by more than 52%, which is a large area array with high frame rate. It provides an effective solution for the implementation of high frame frequency CIS.