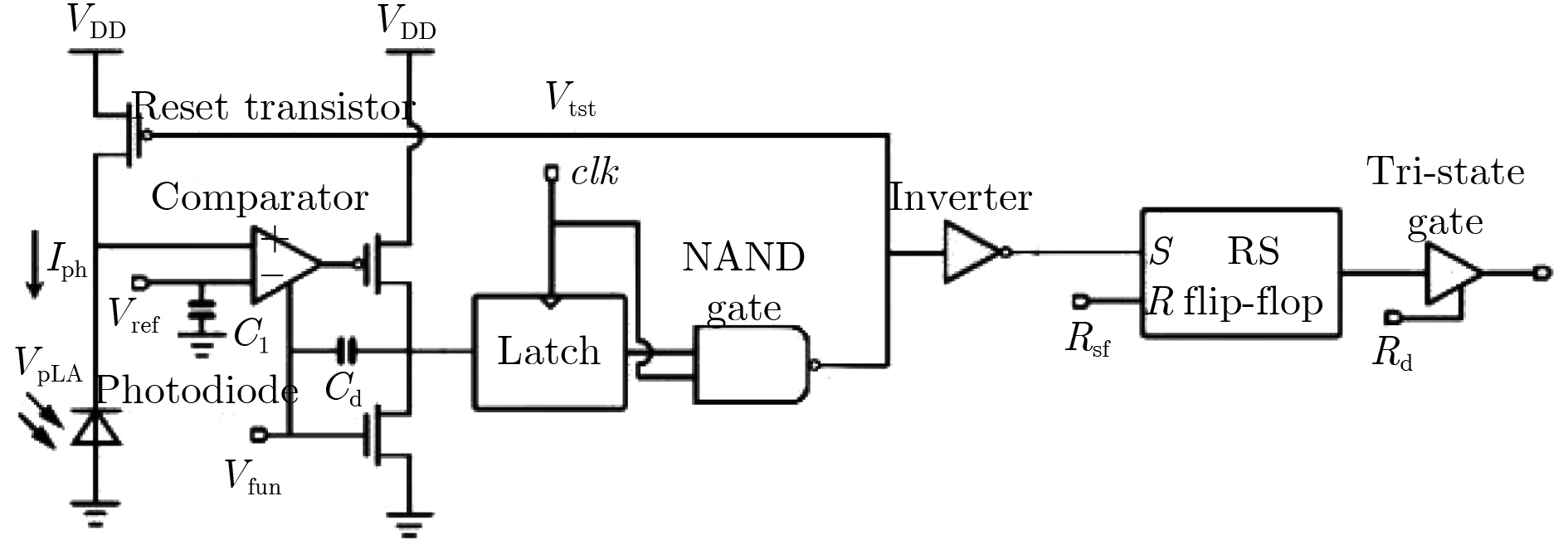
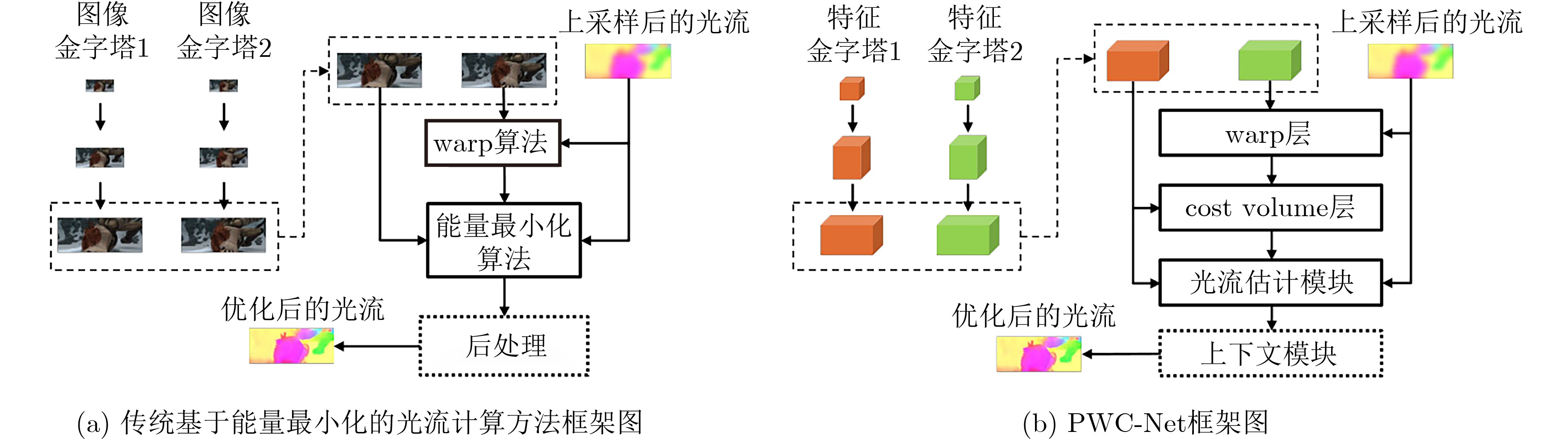
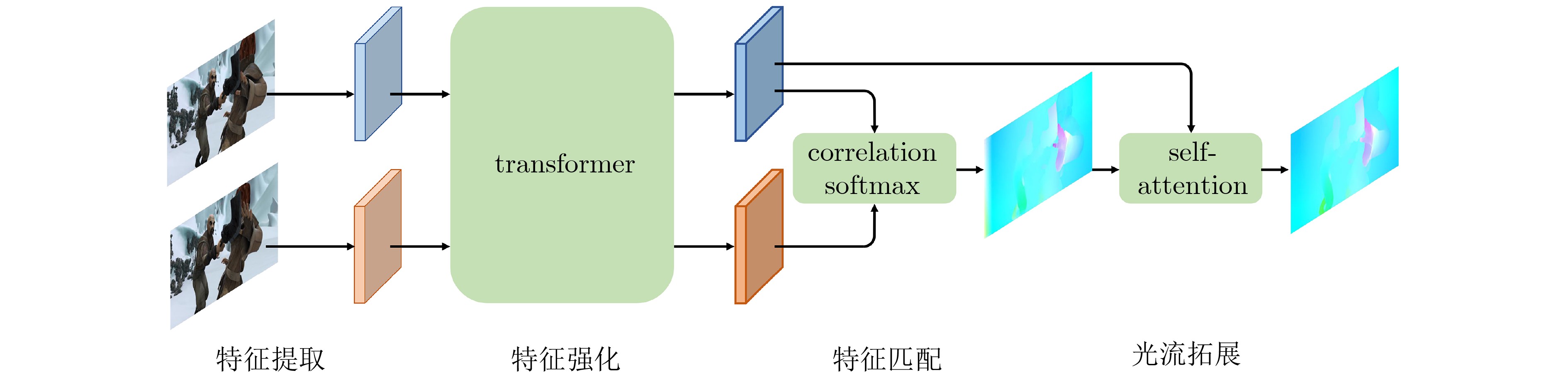
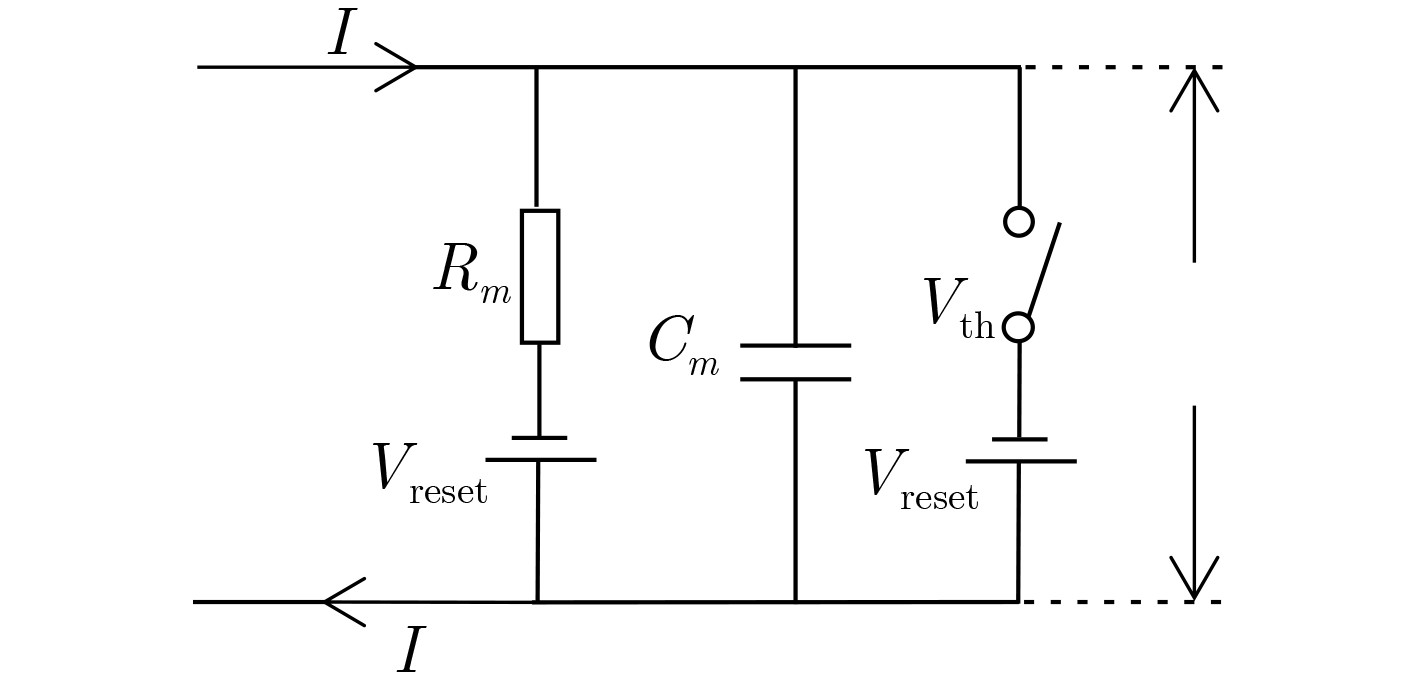
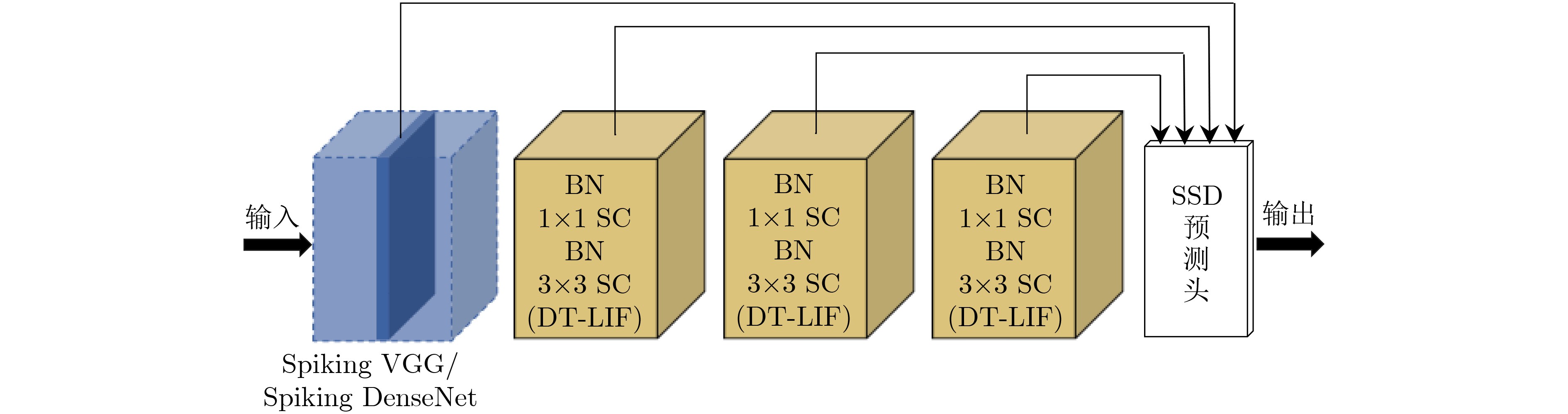
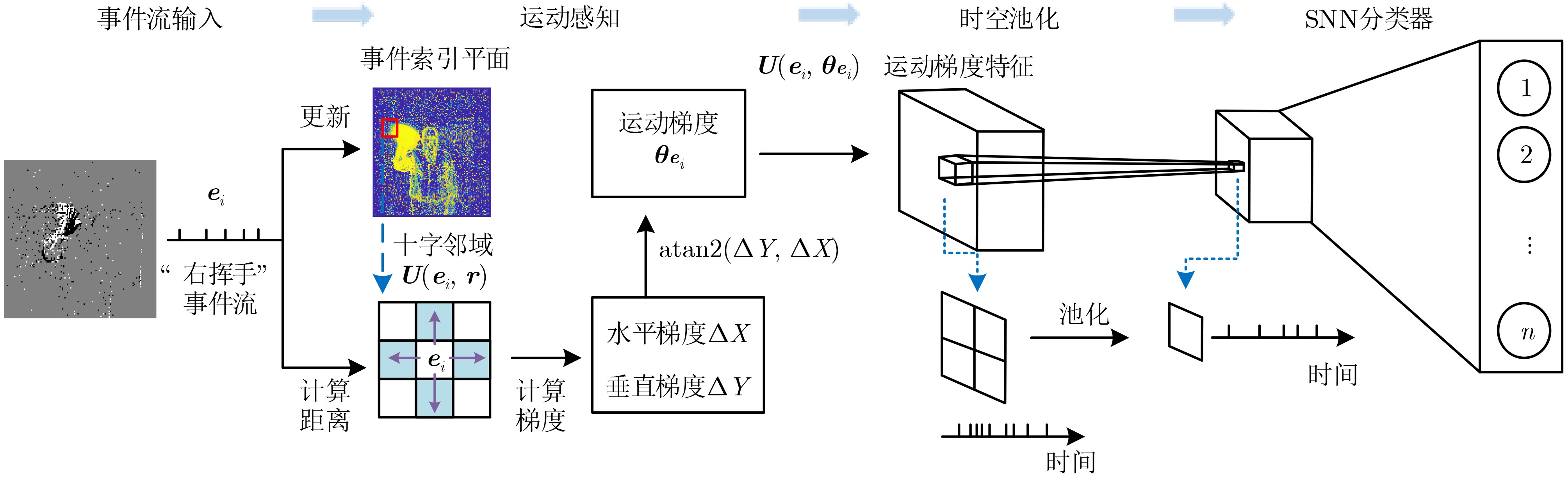
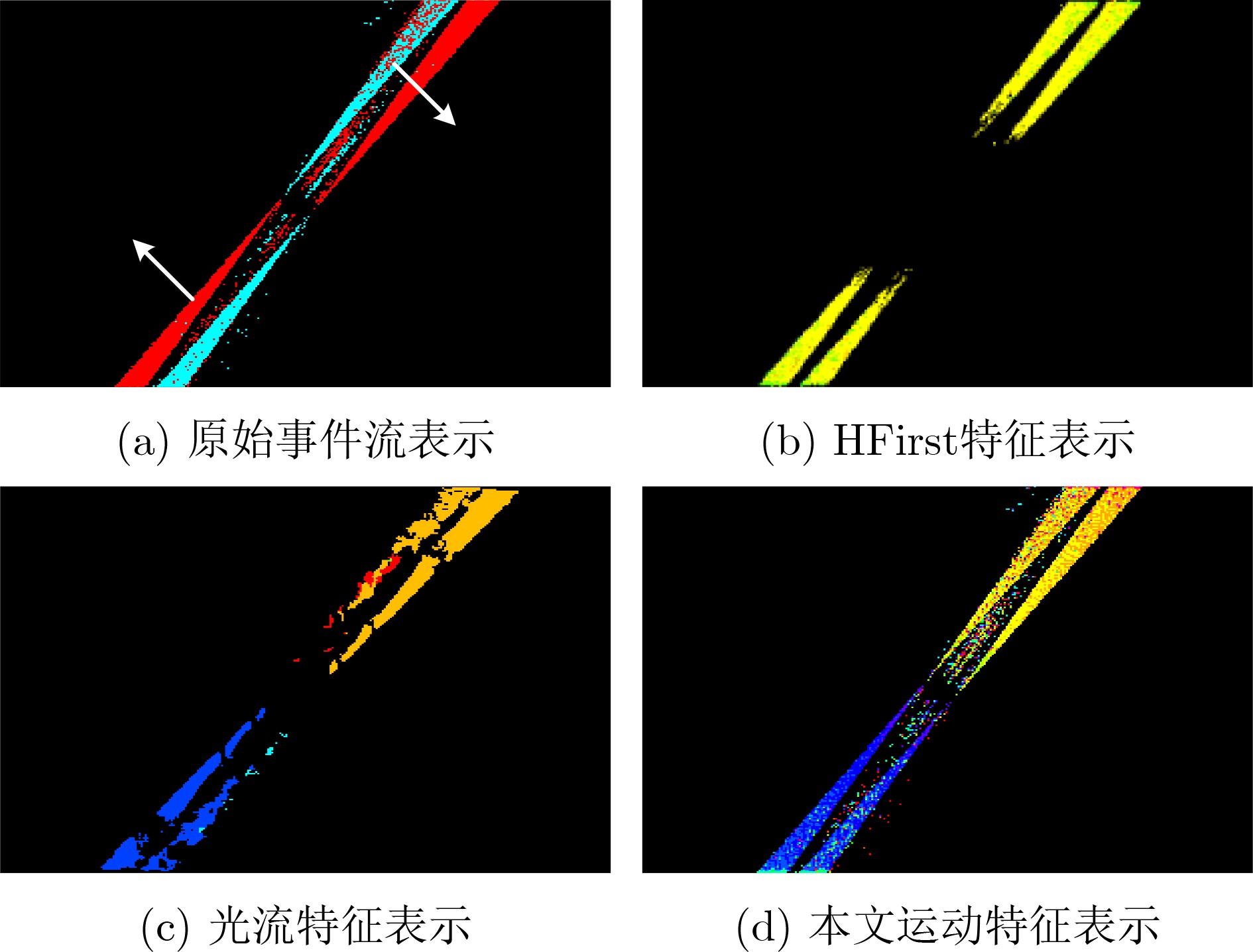
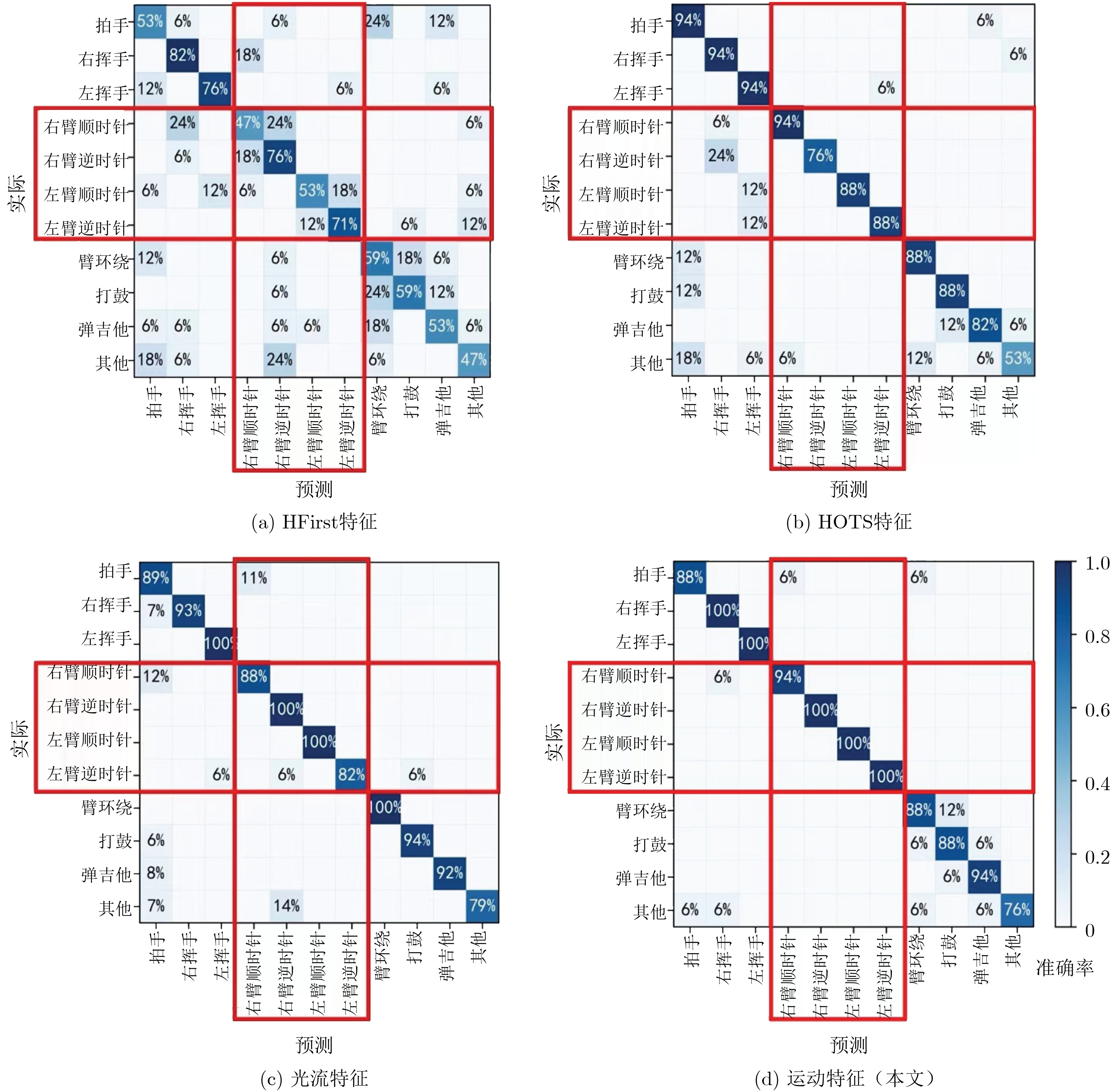
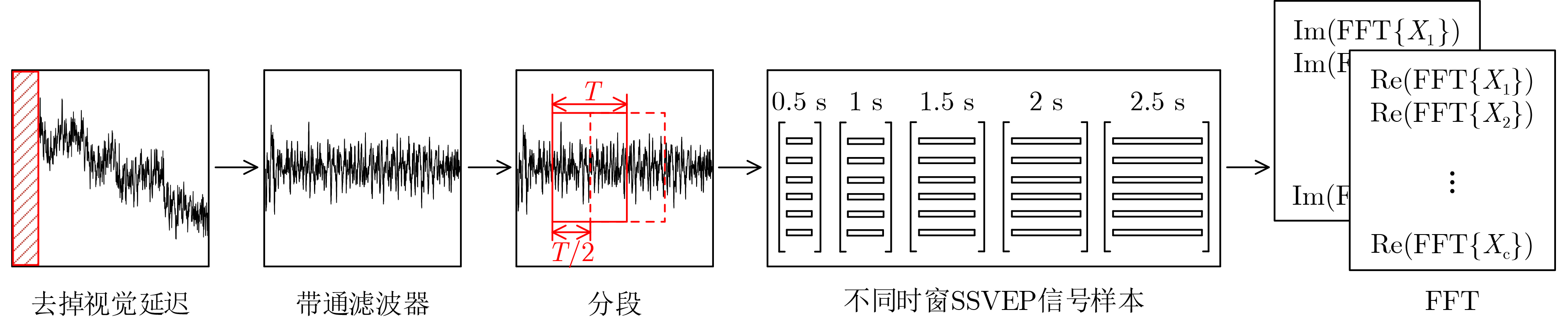
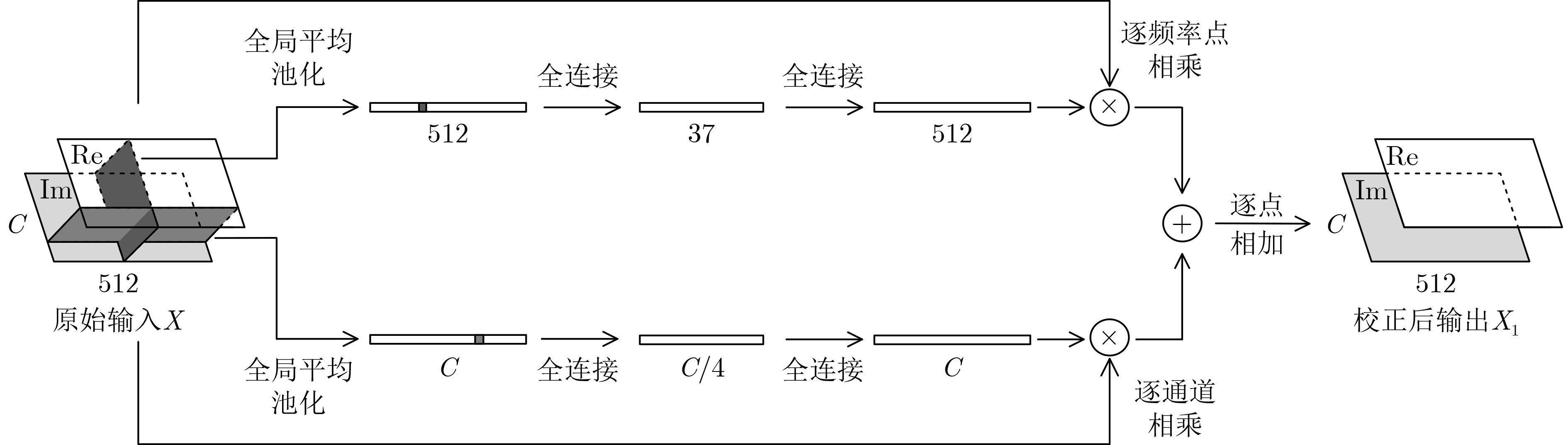
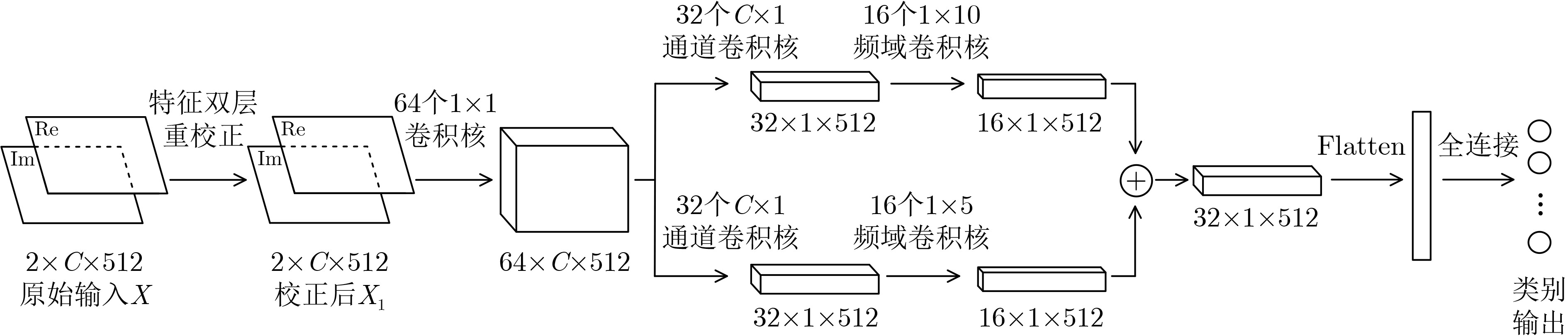
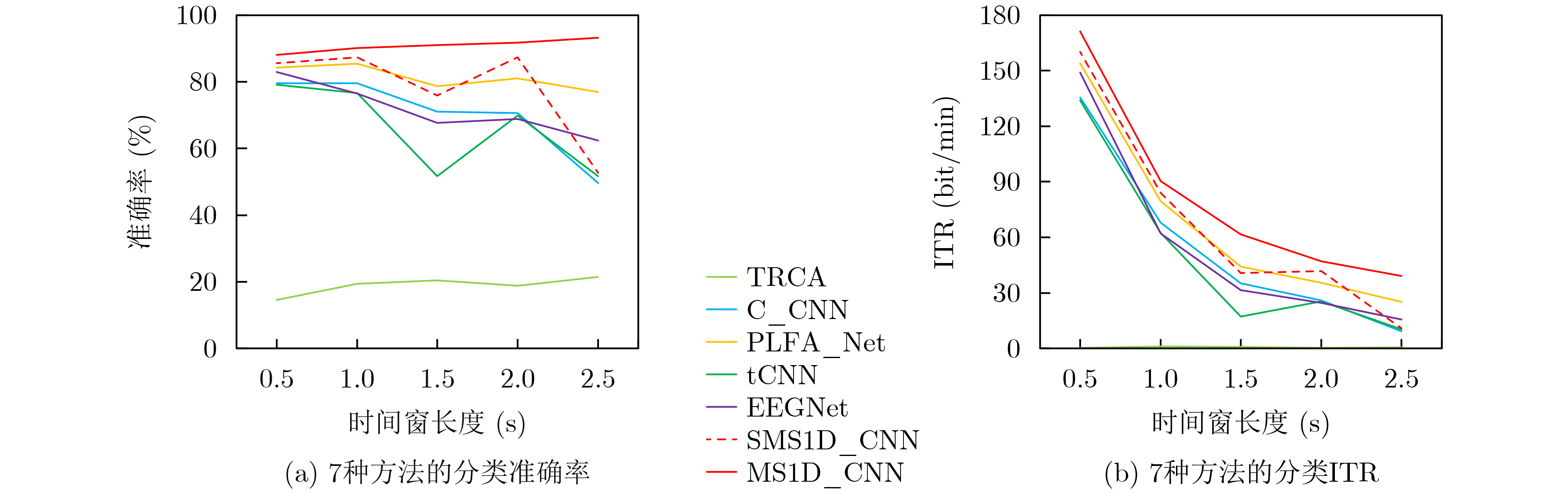
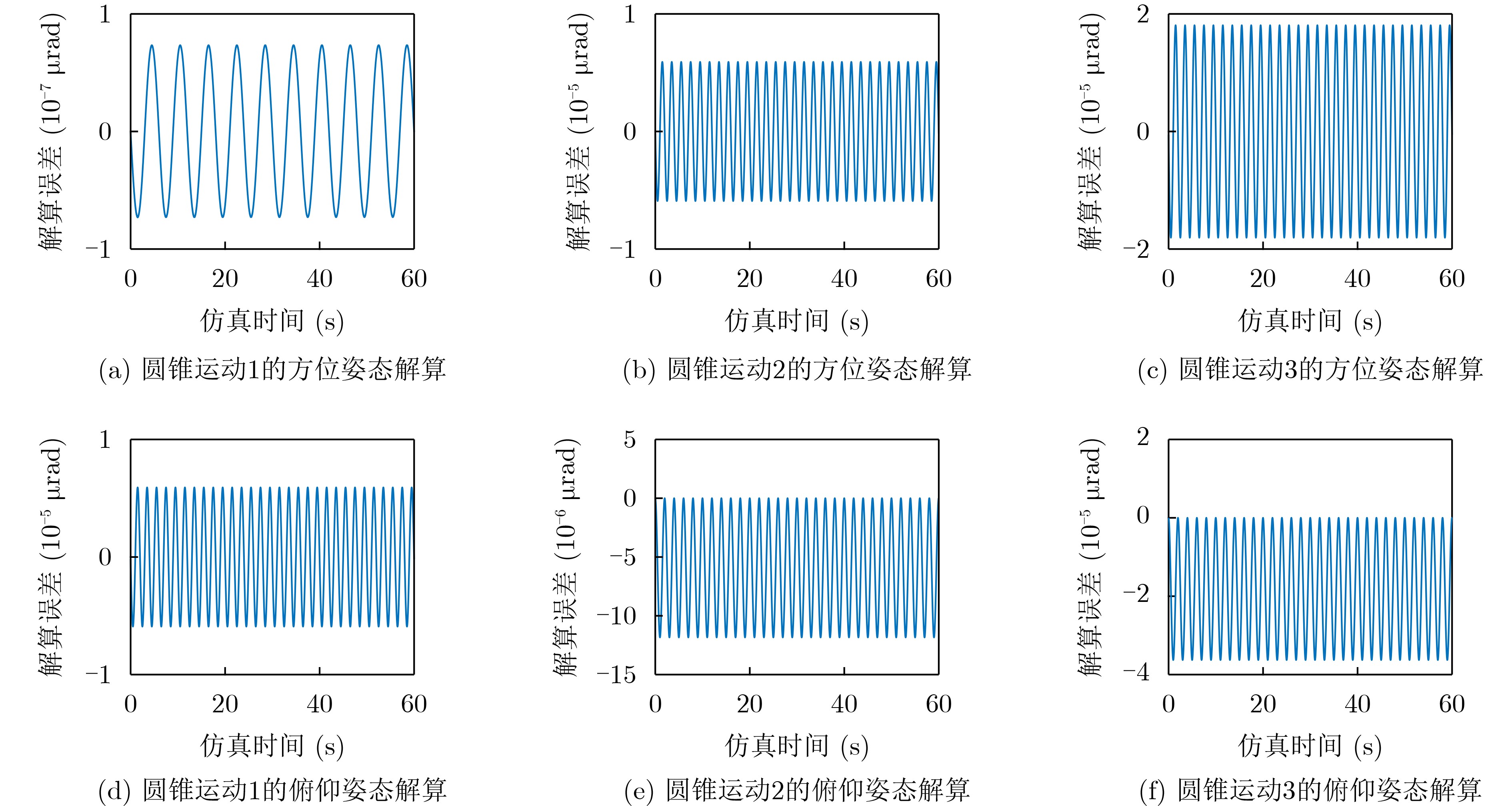
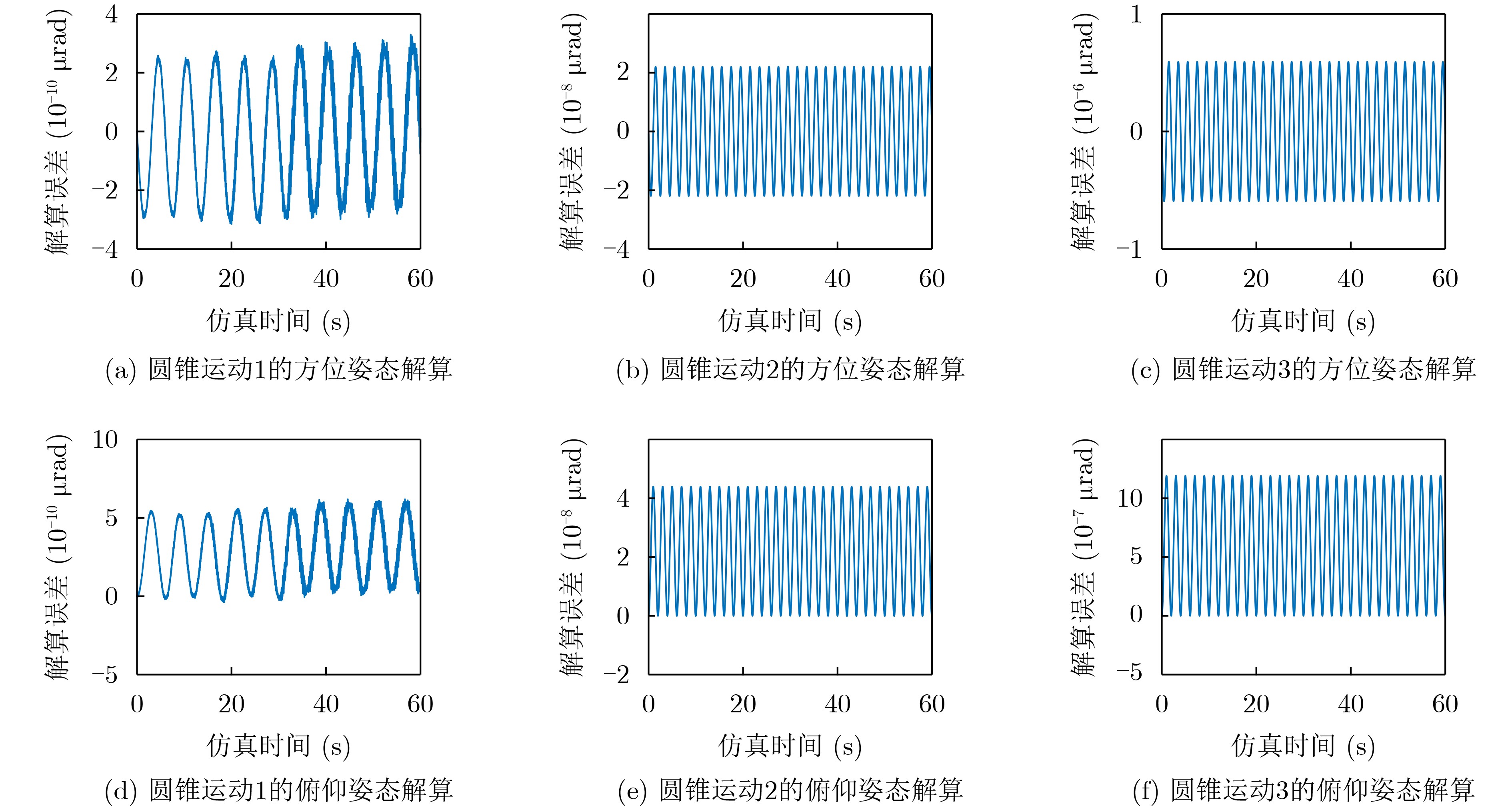
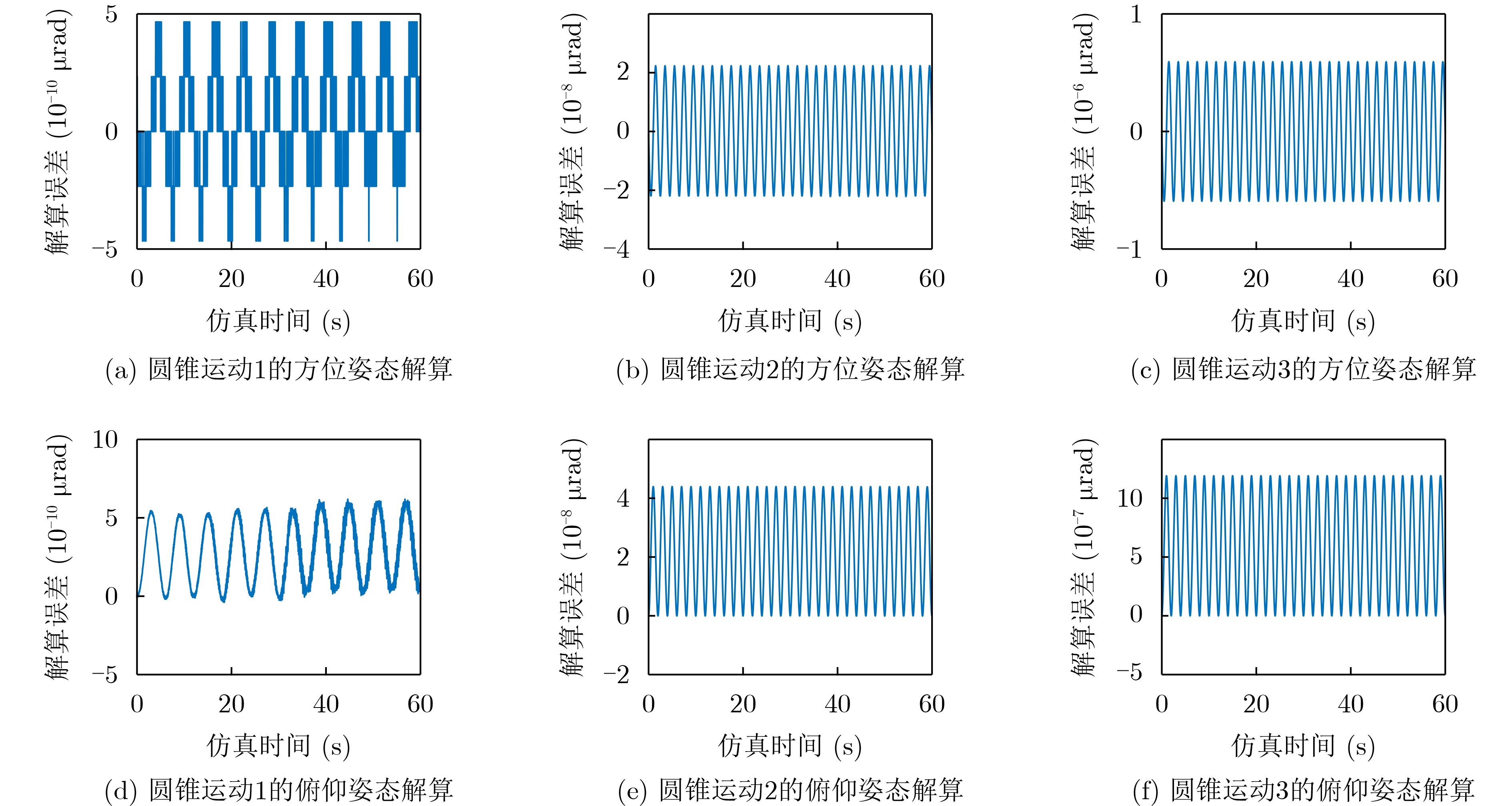
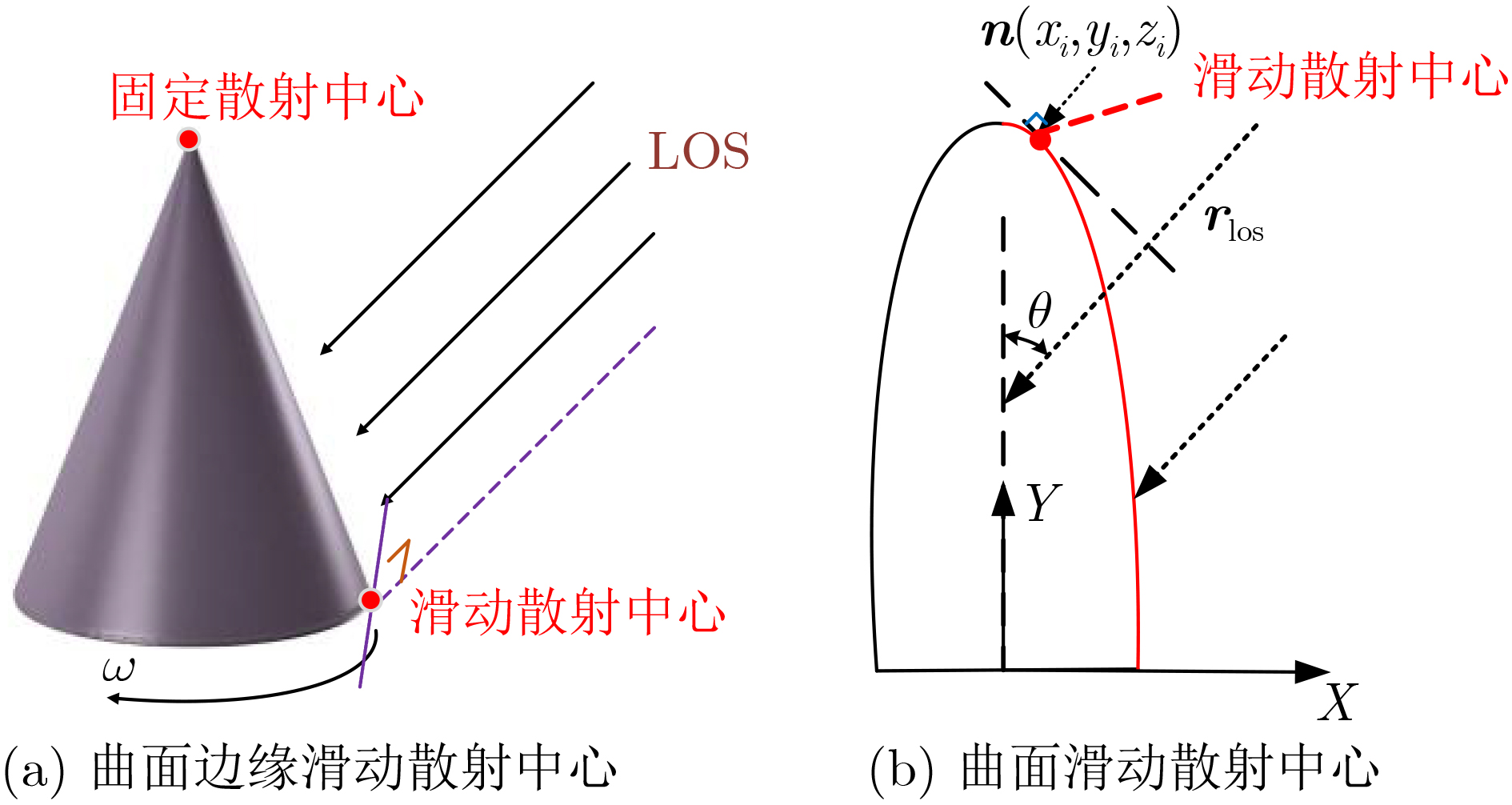
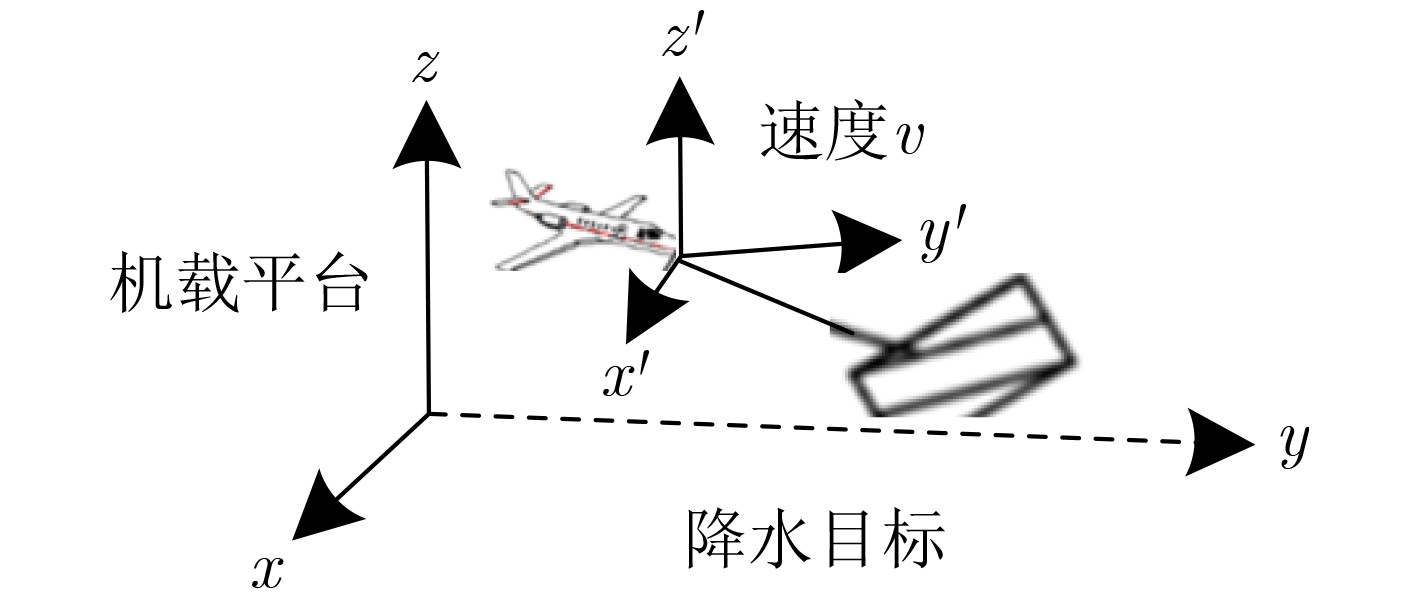
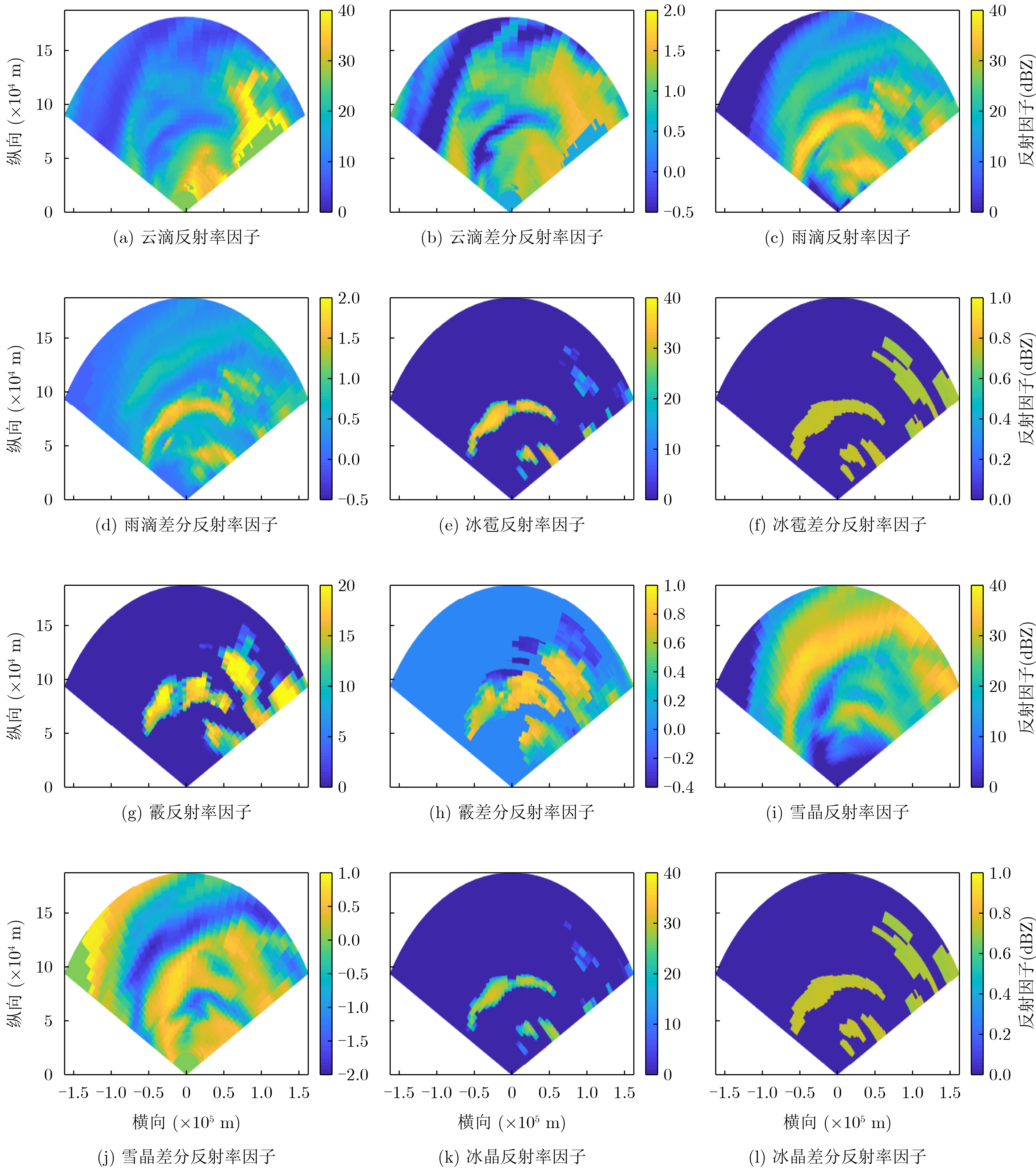
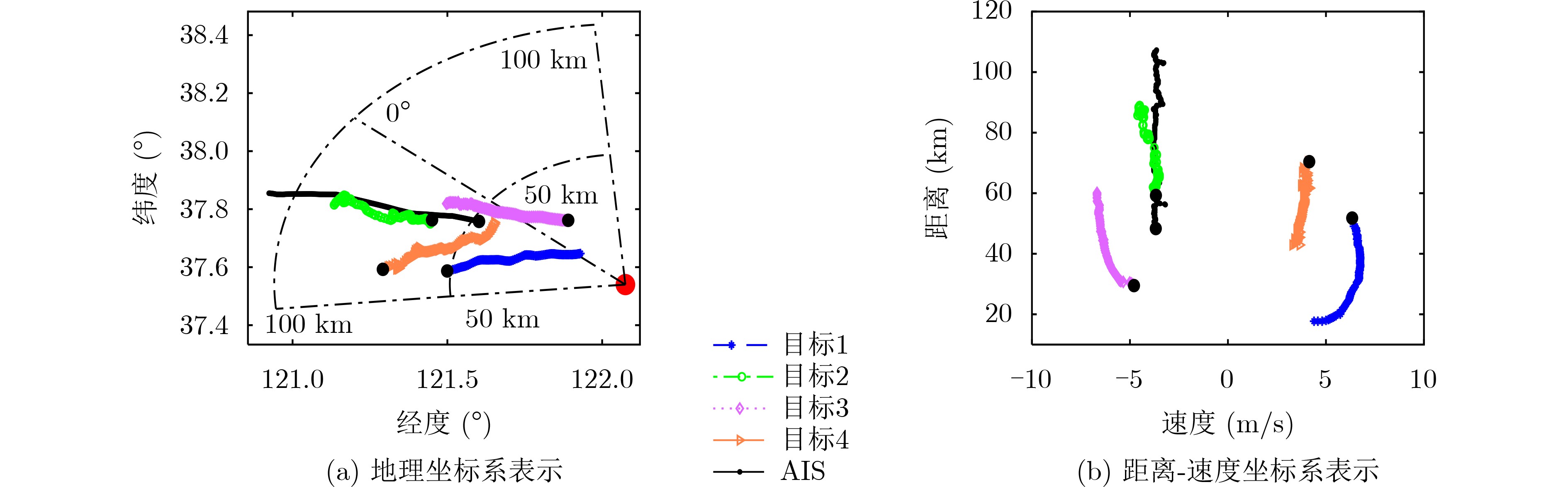
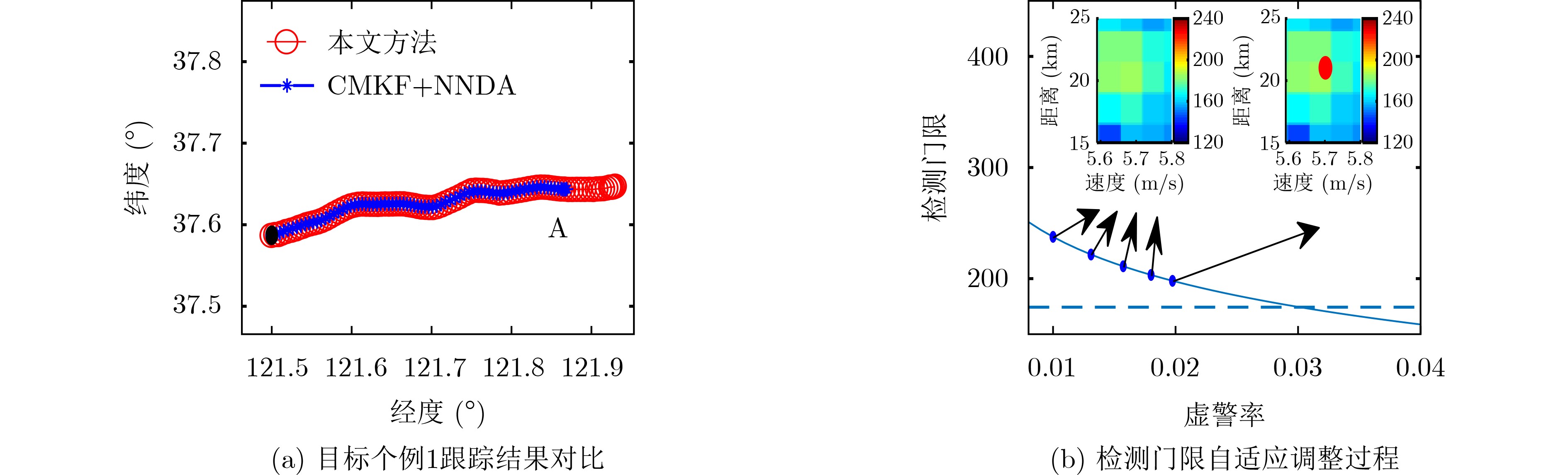
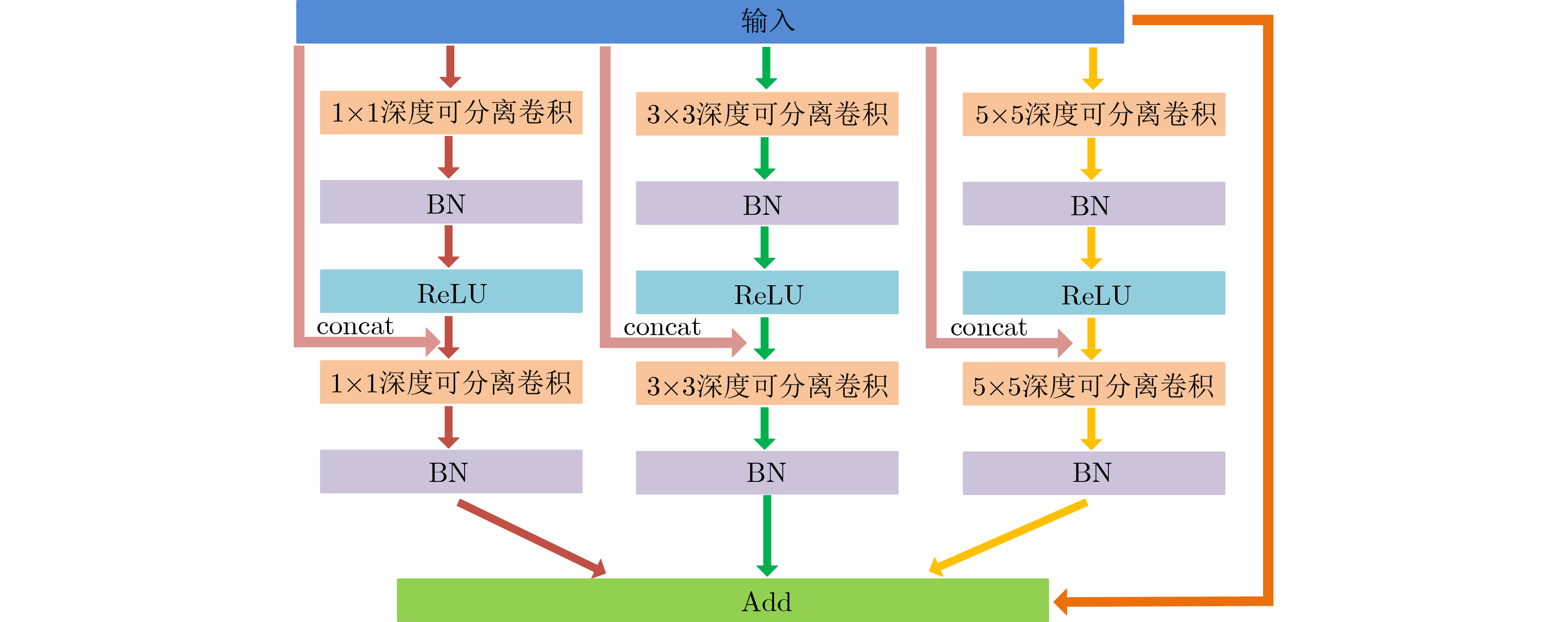
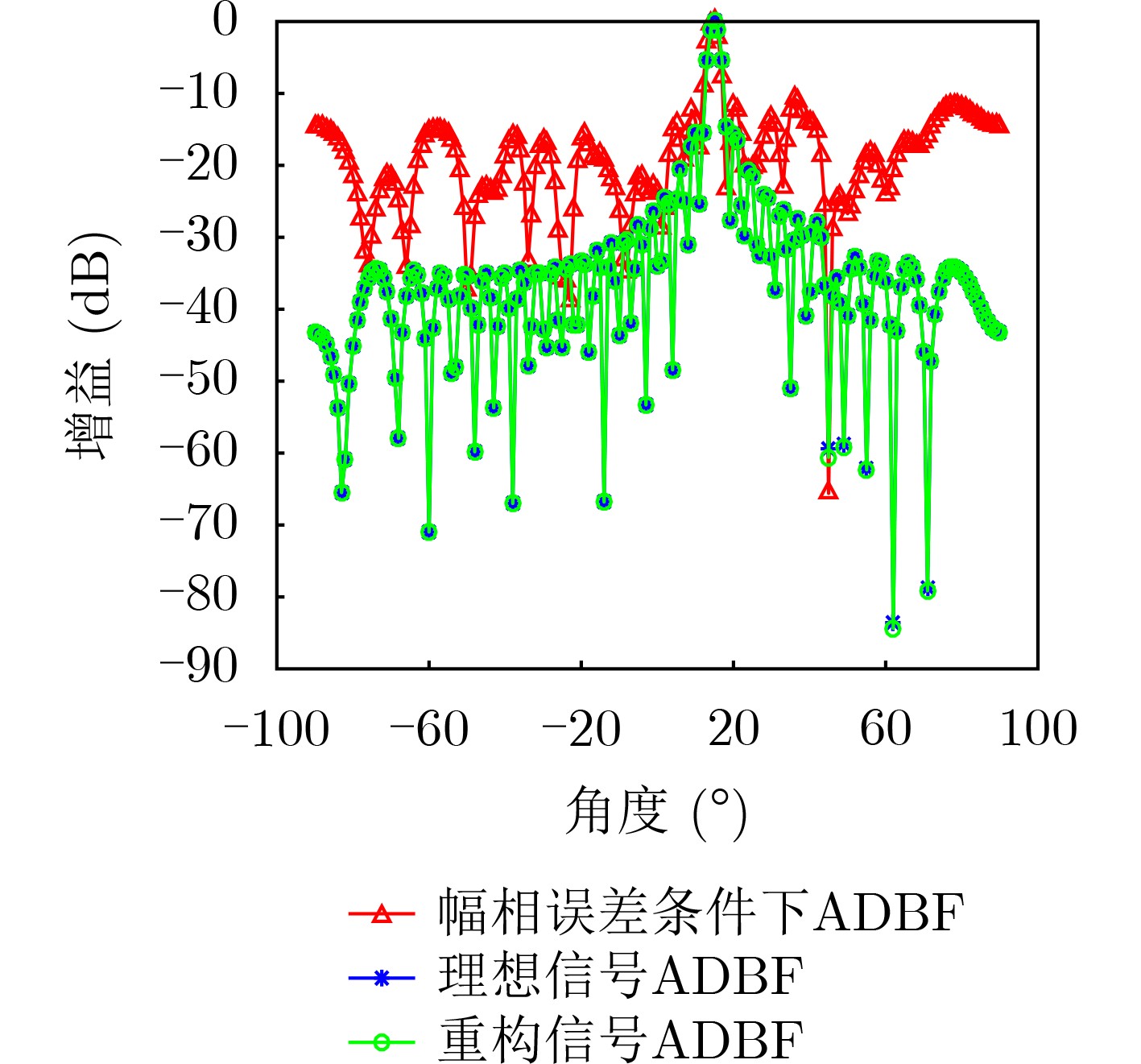
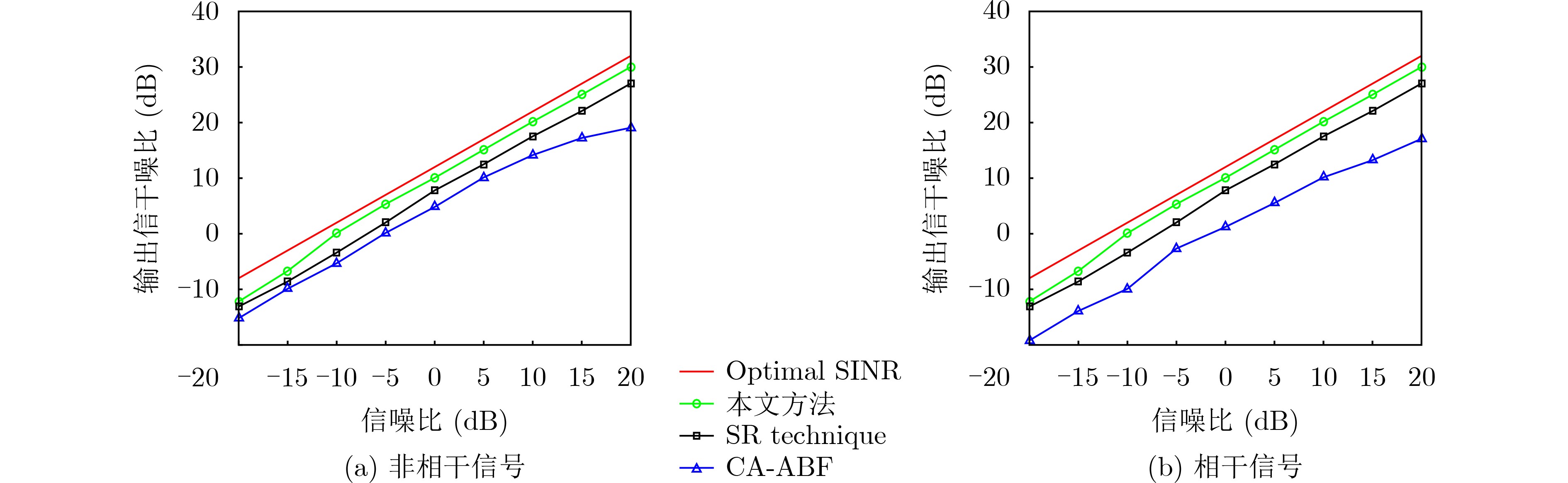
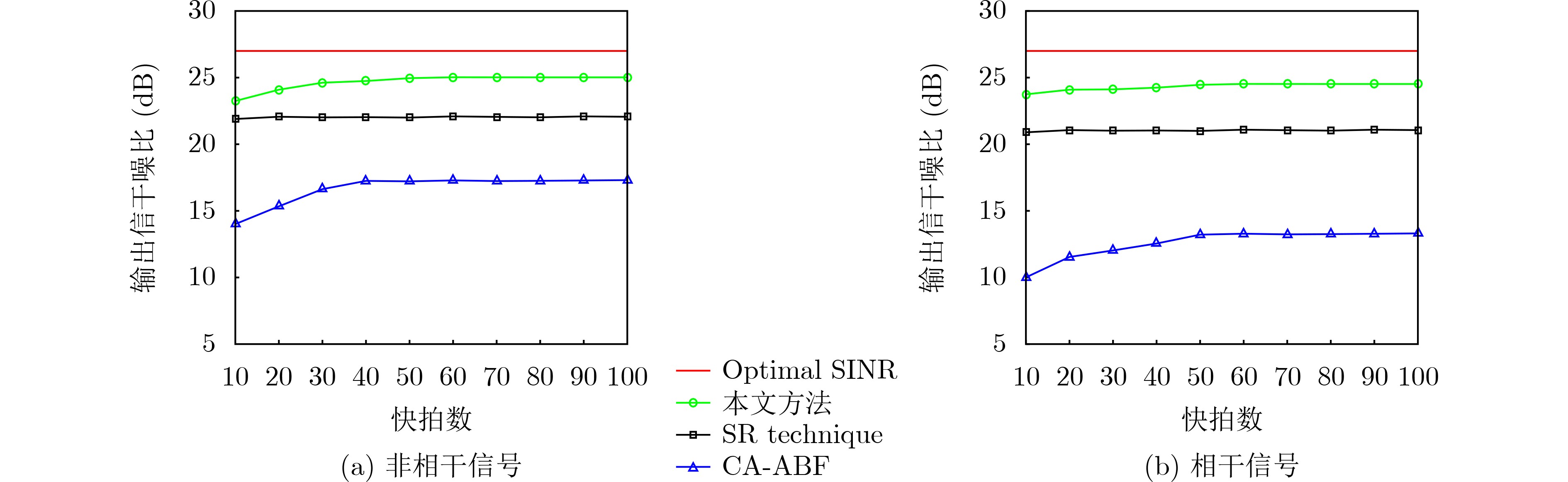
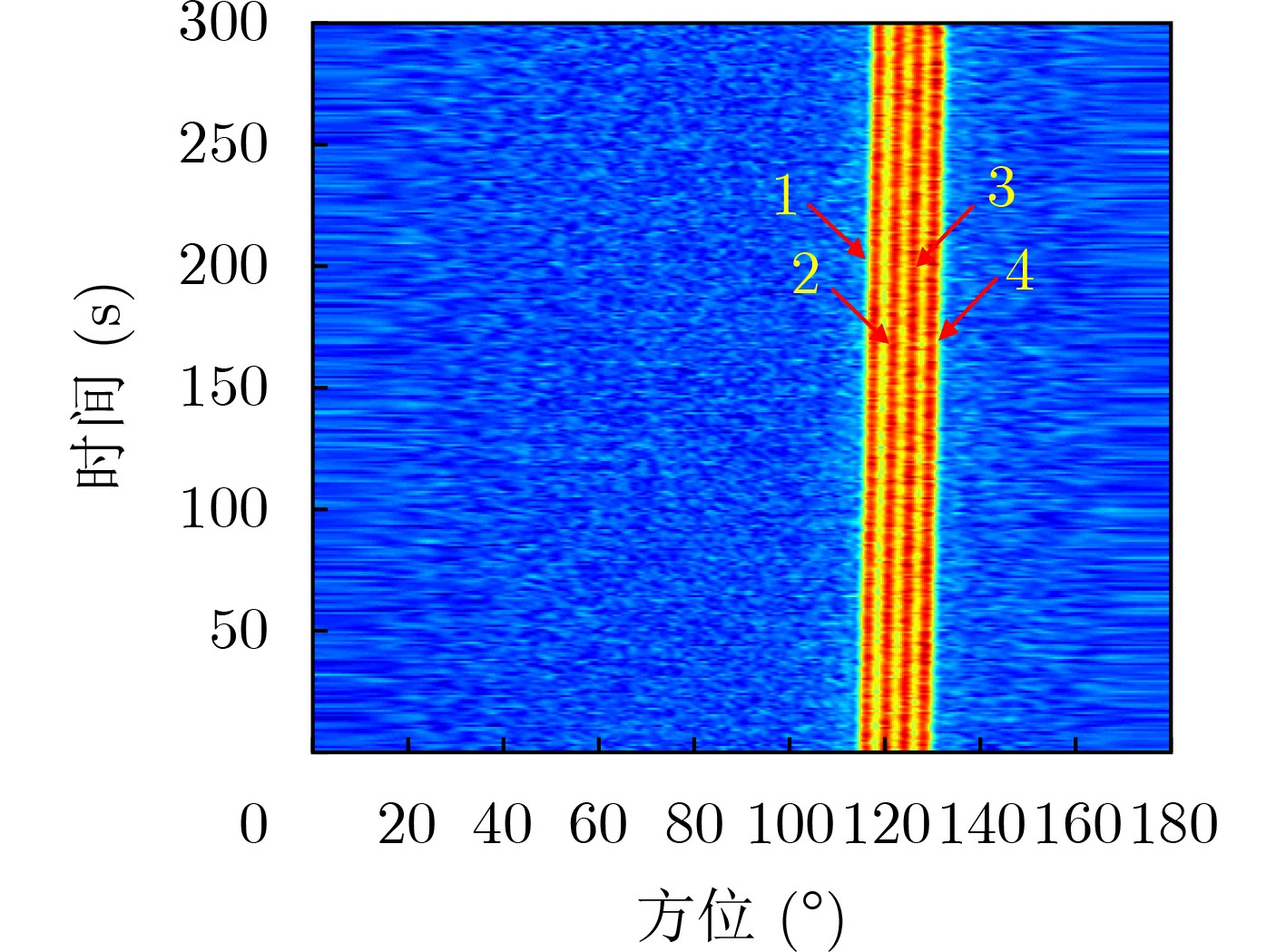
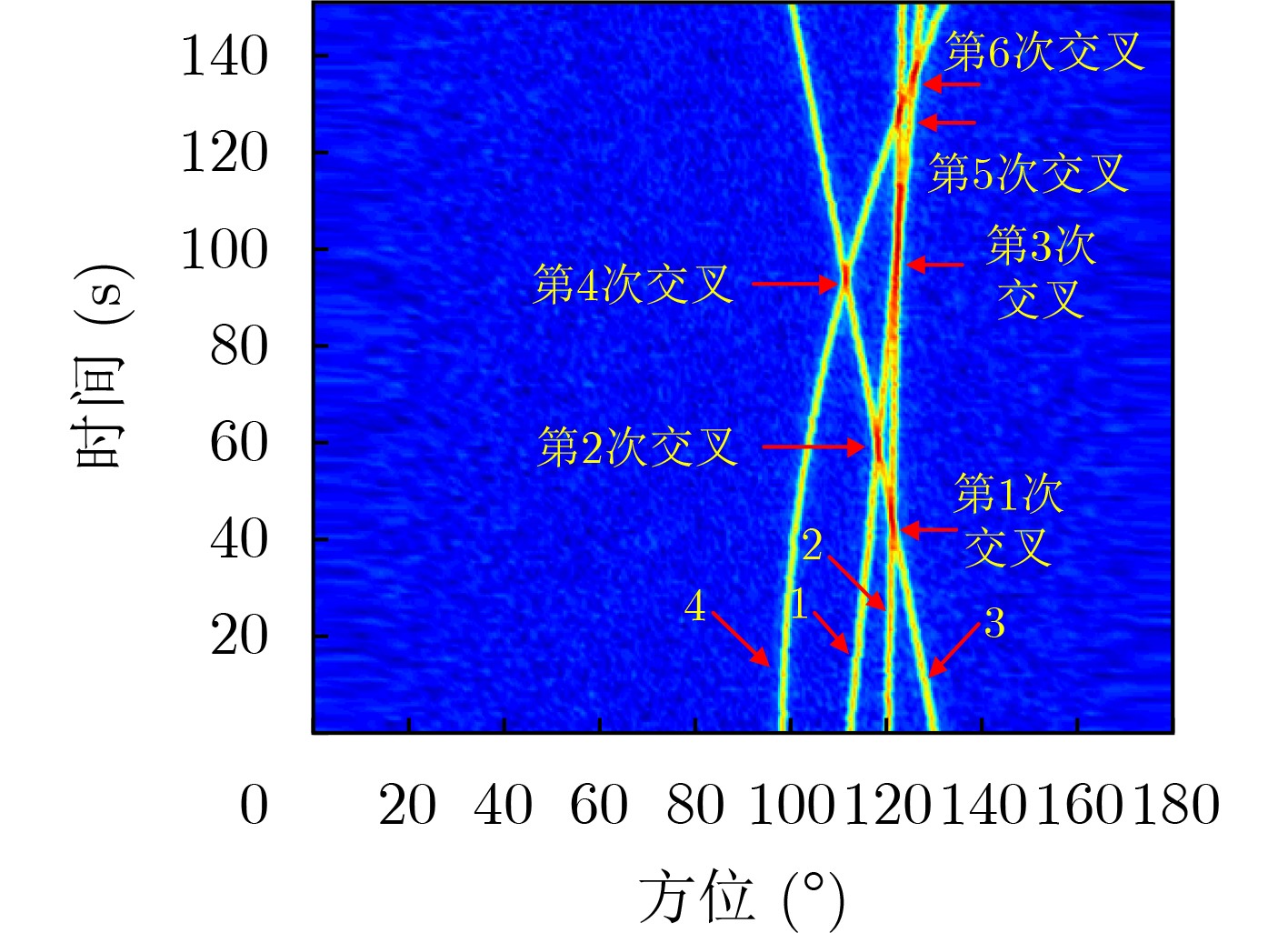
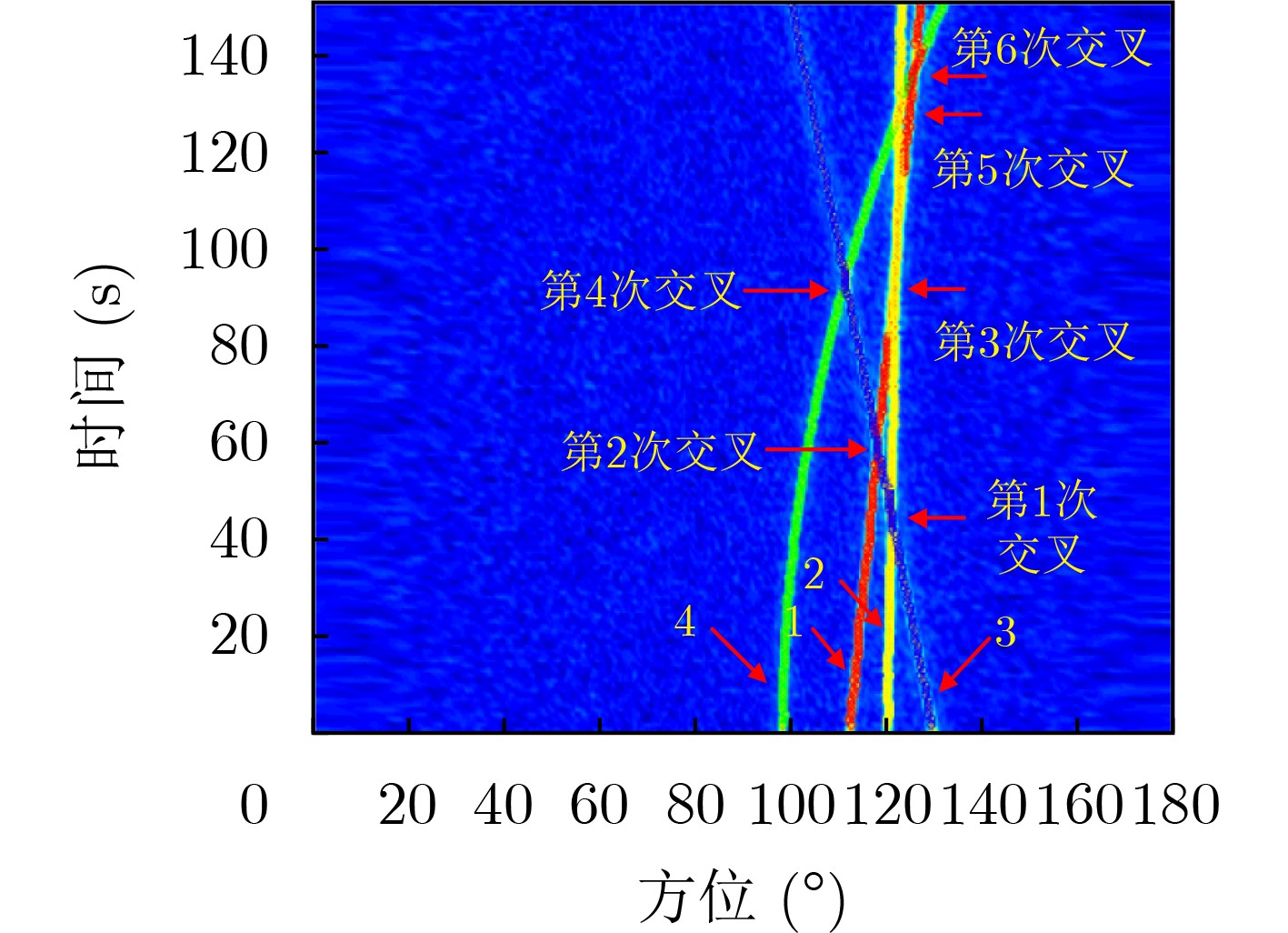
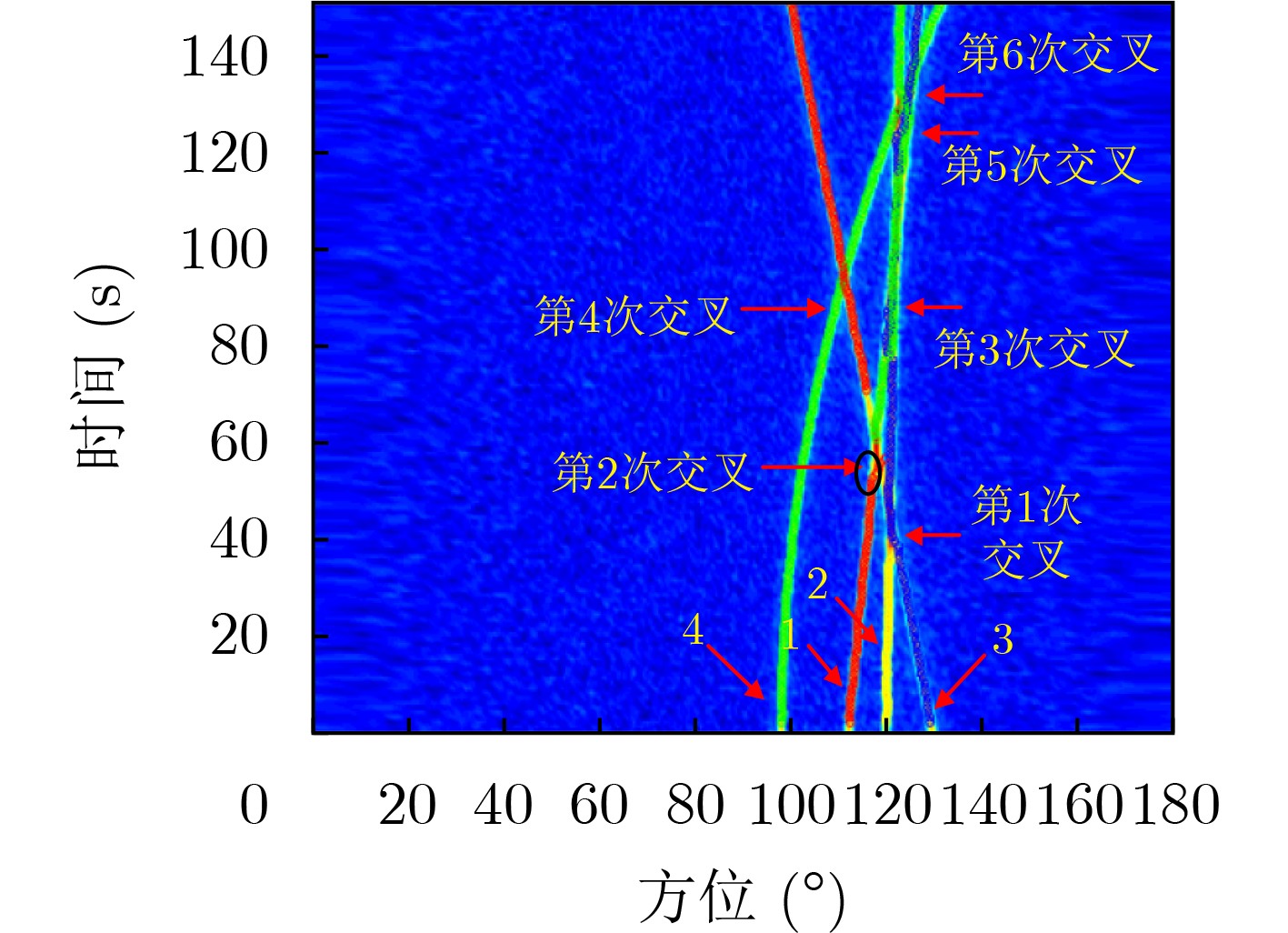
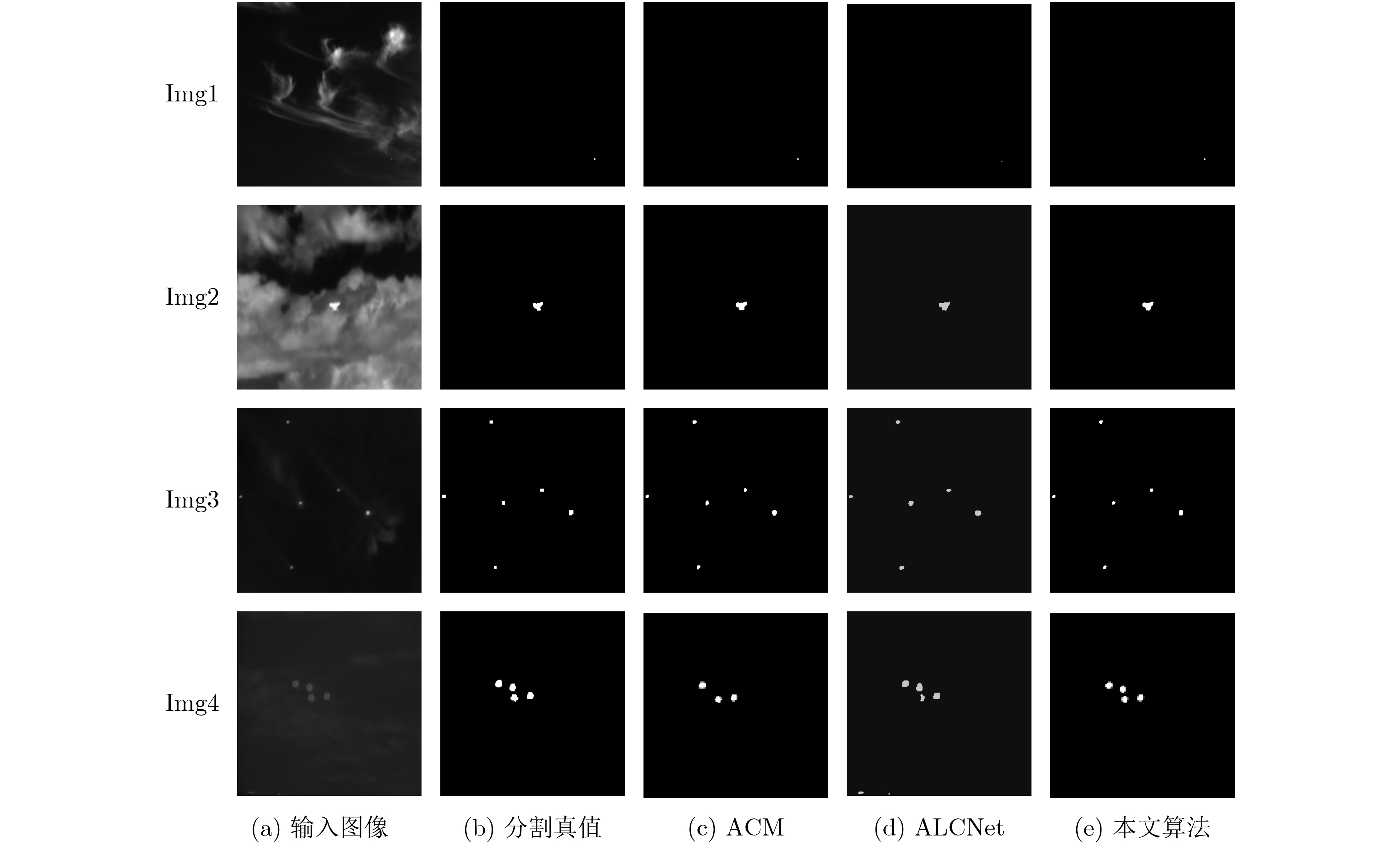
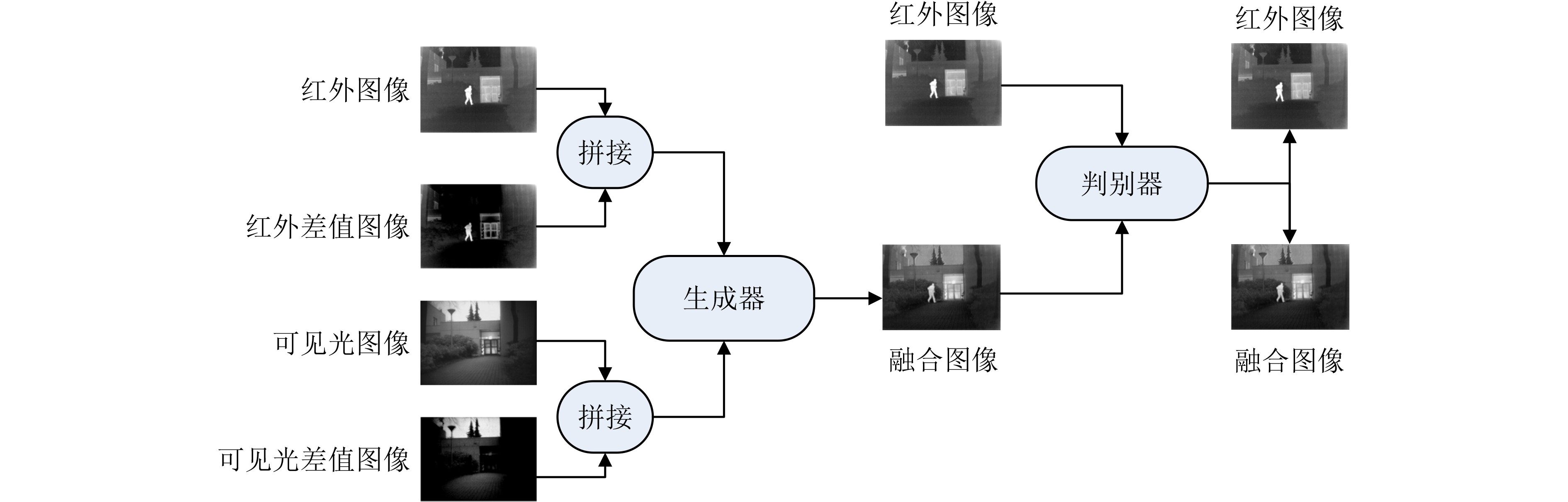
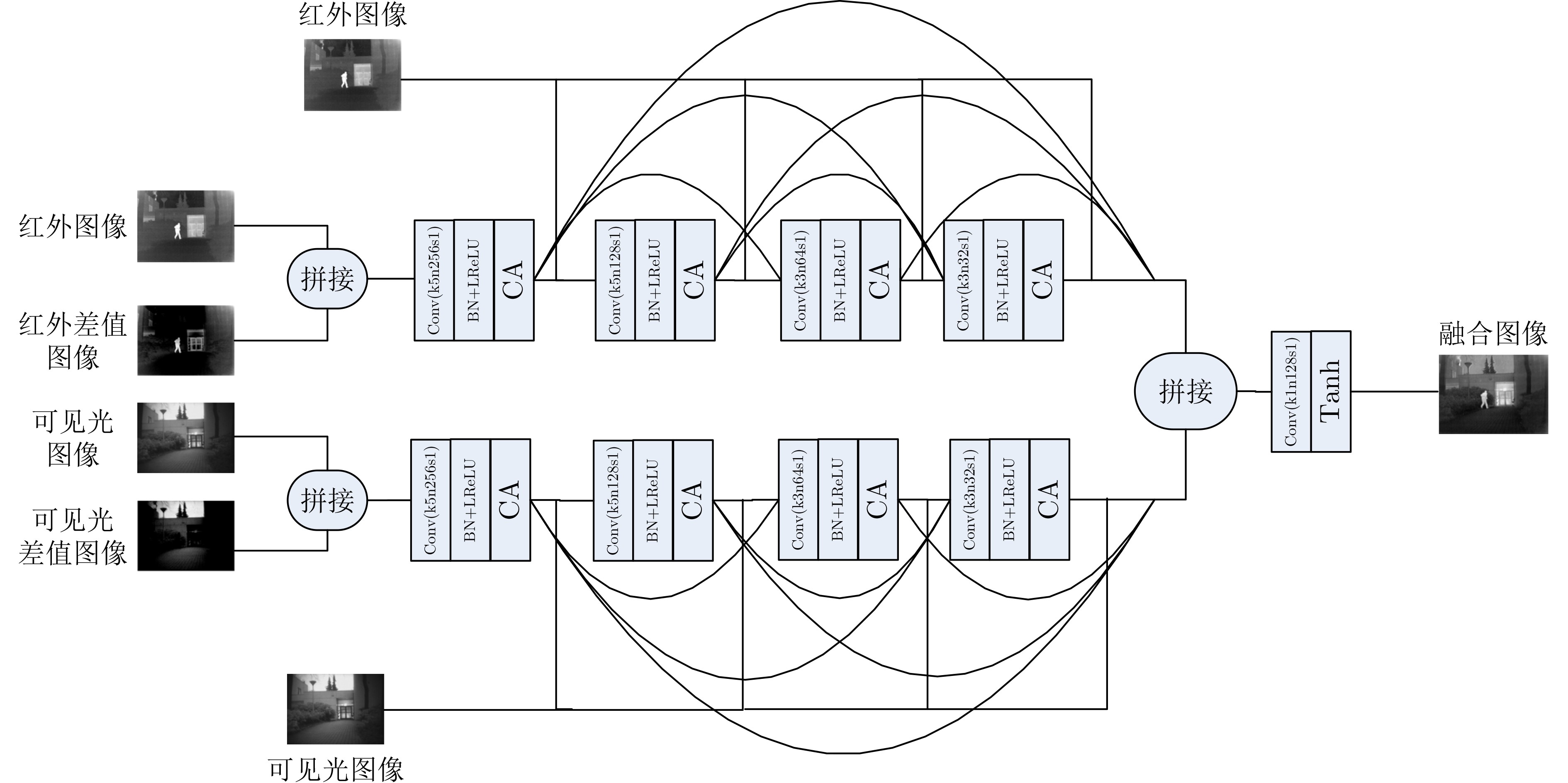
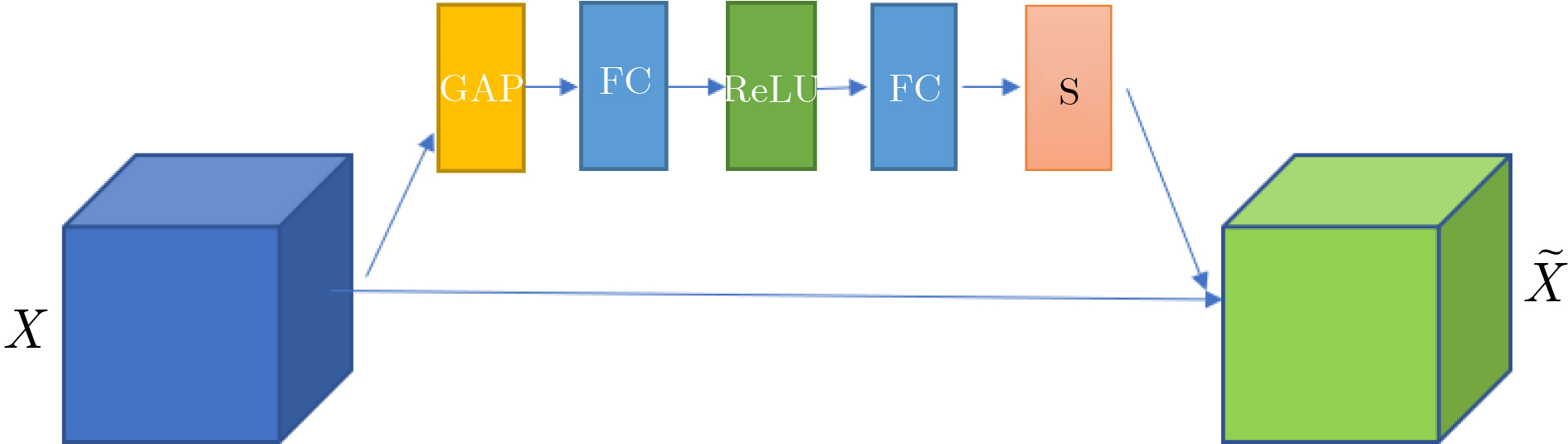
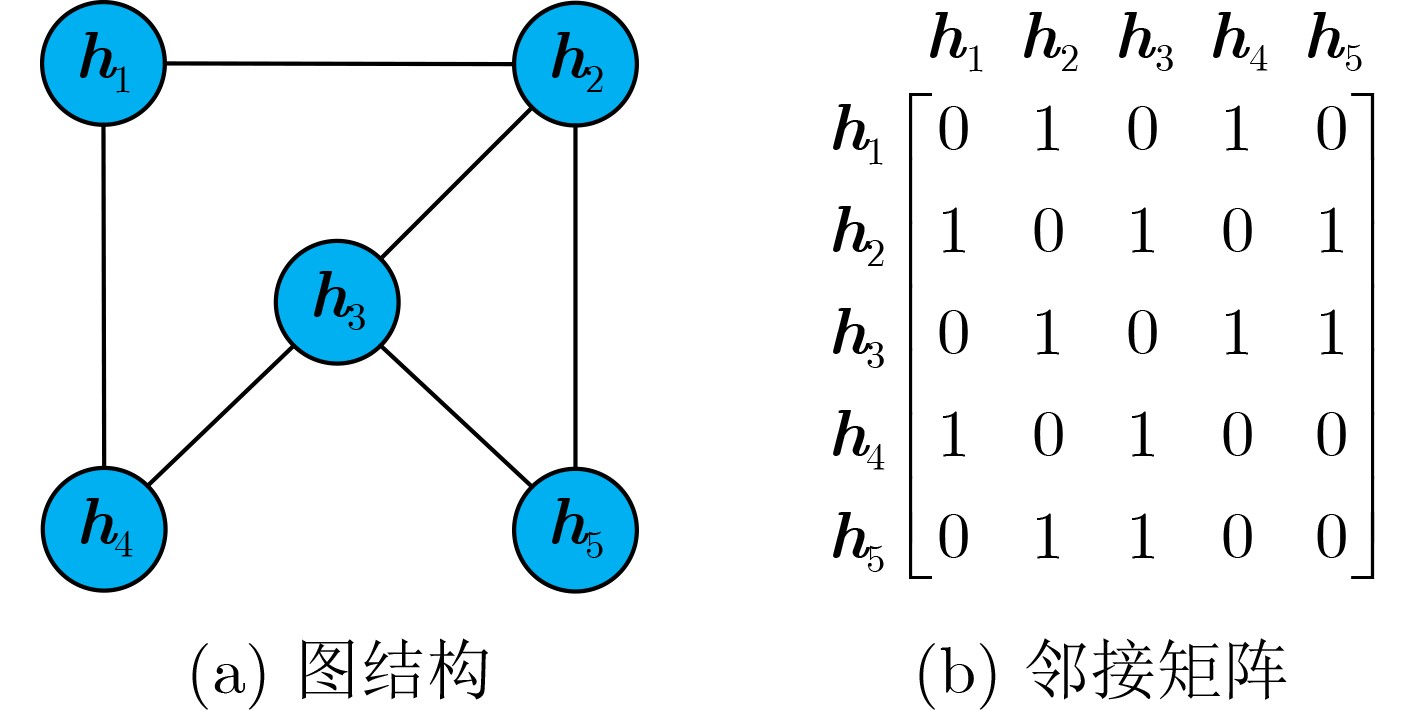
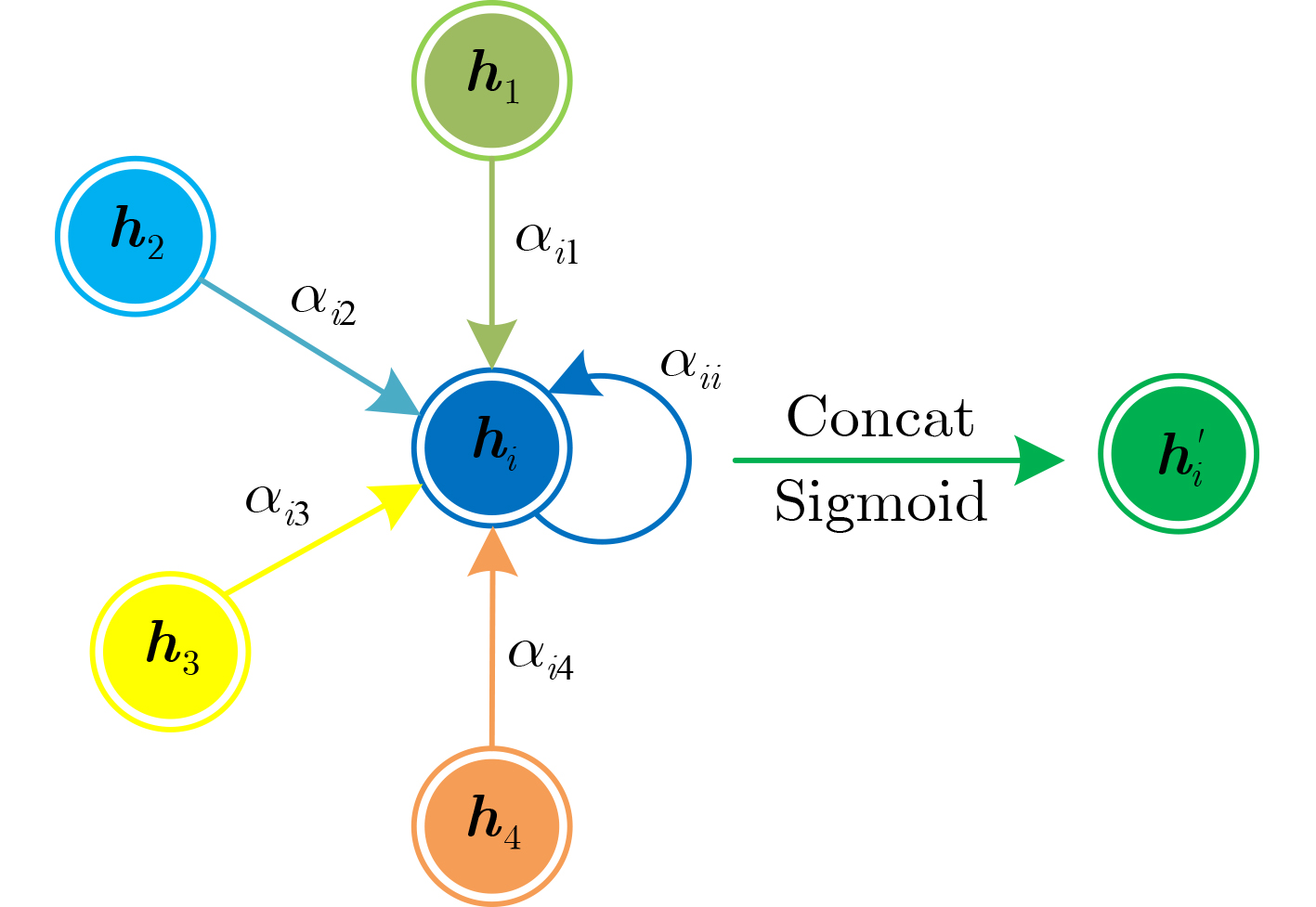
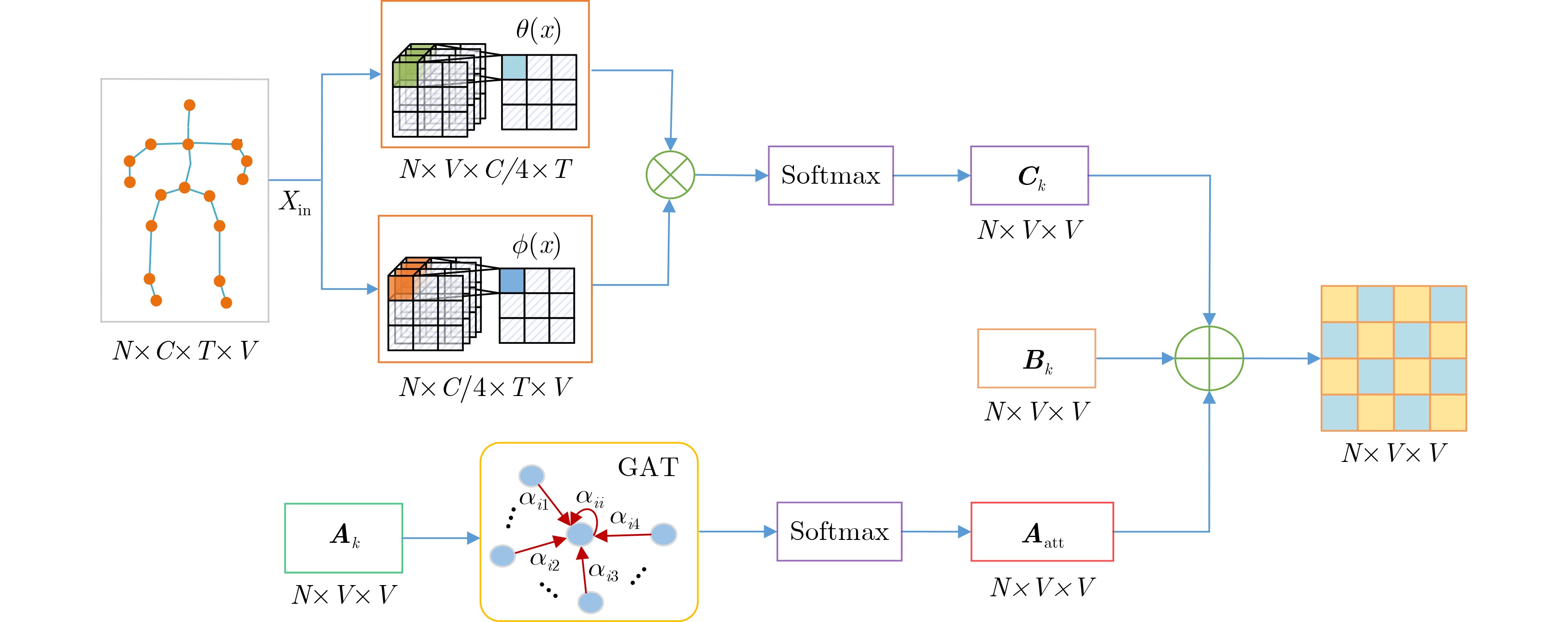
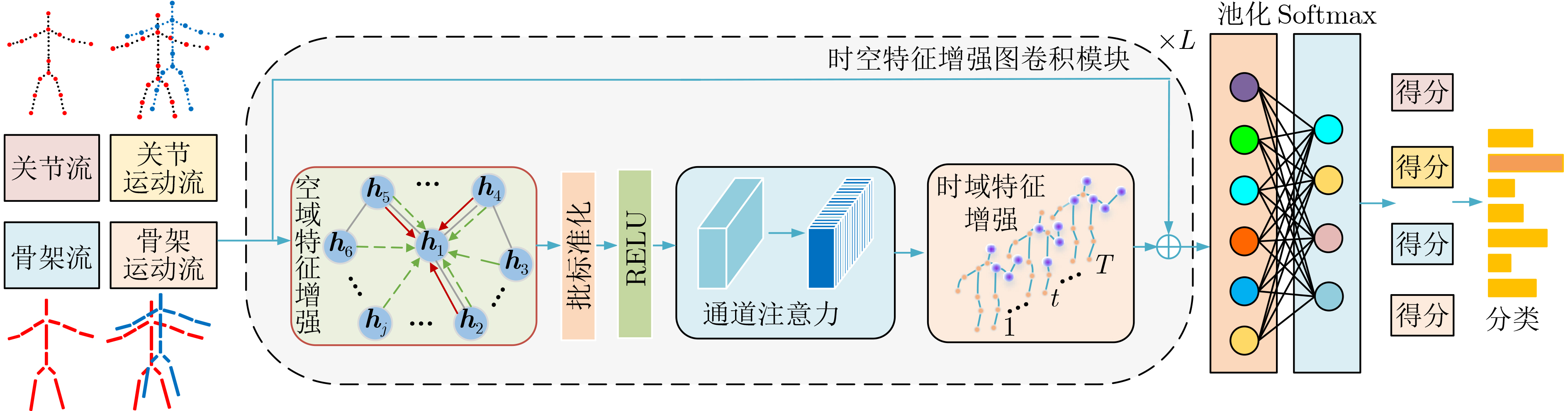
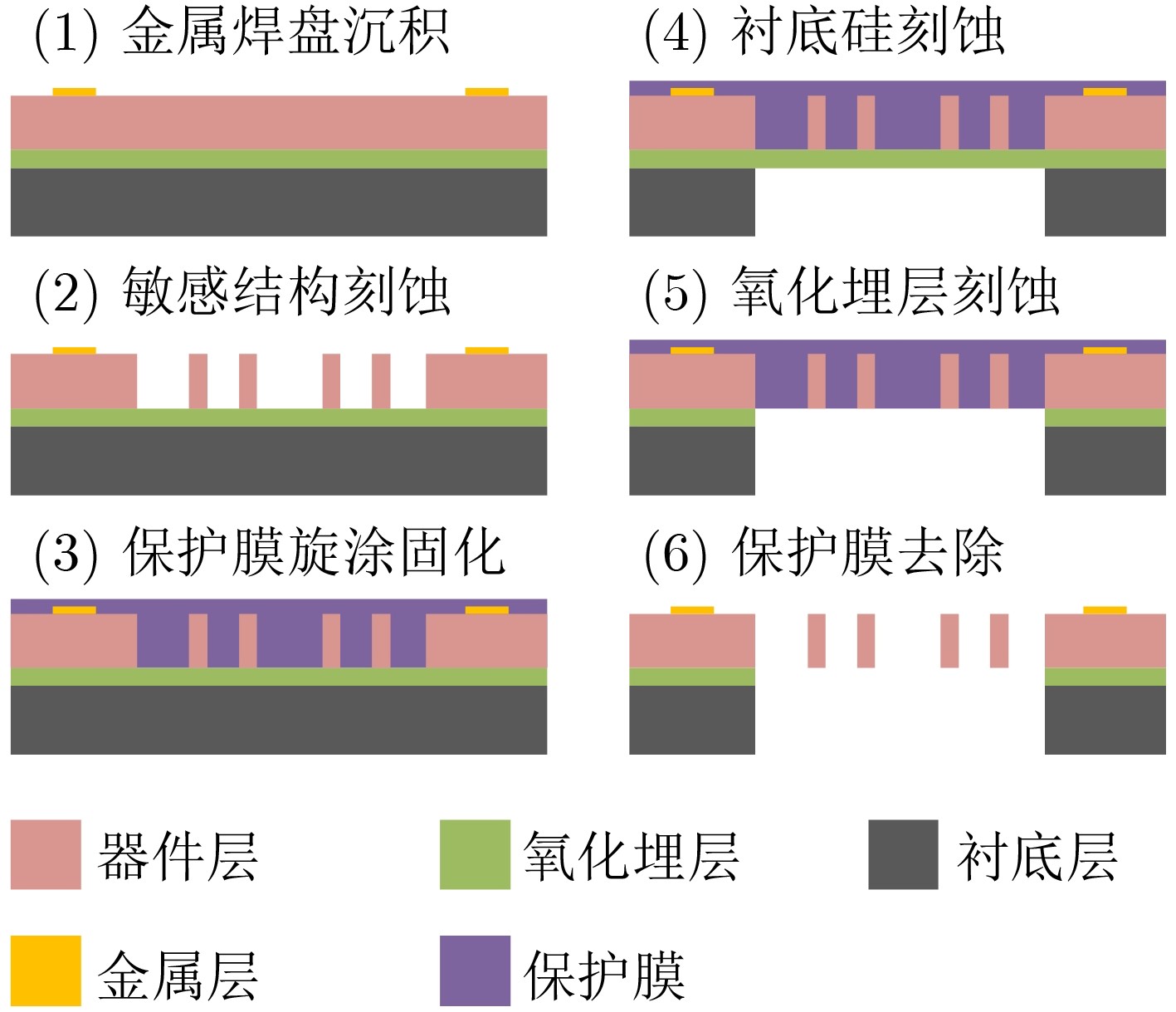
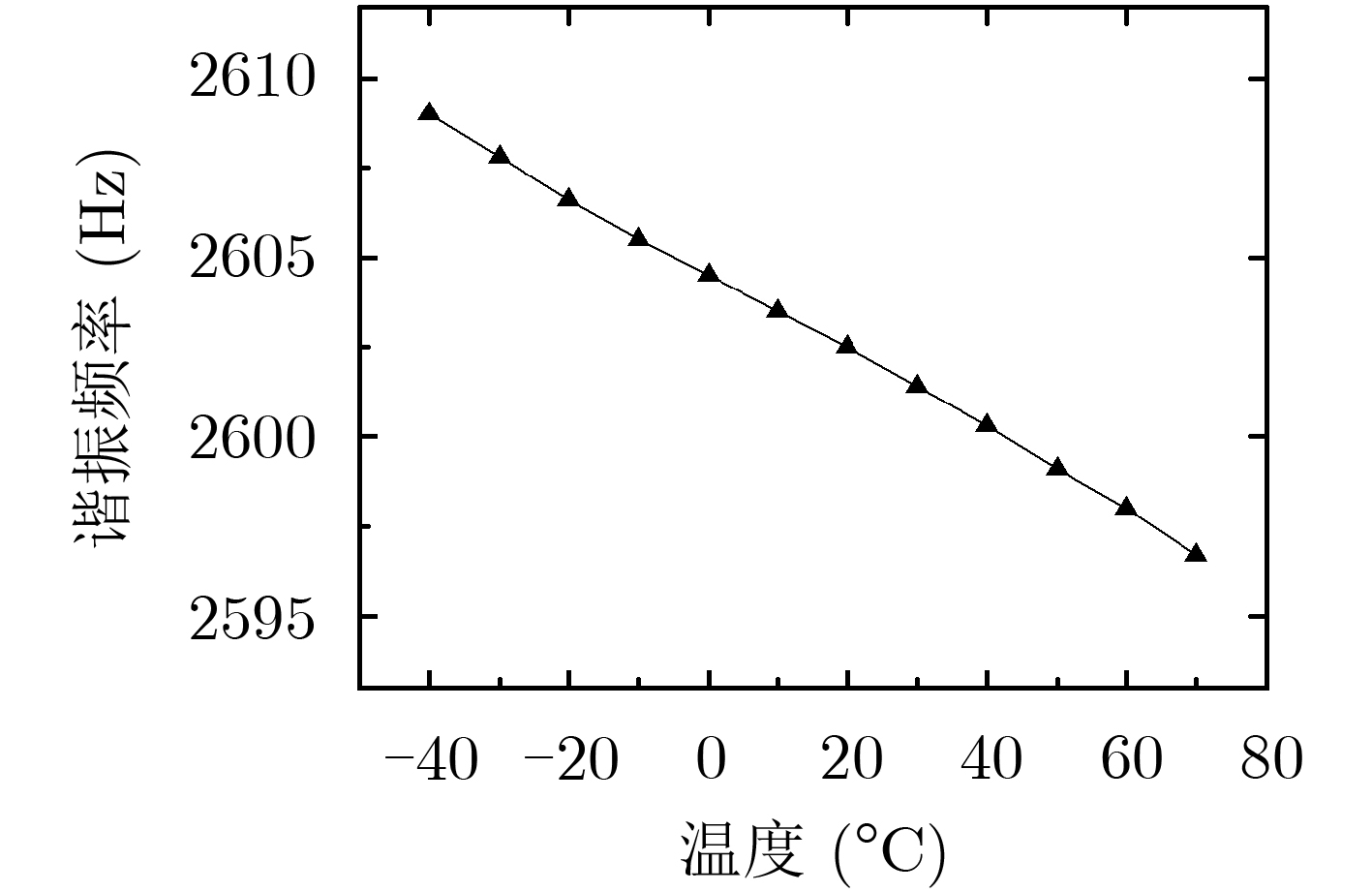
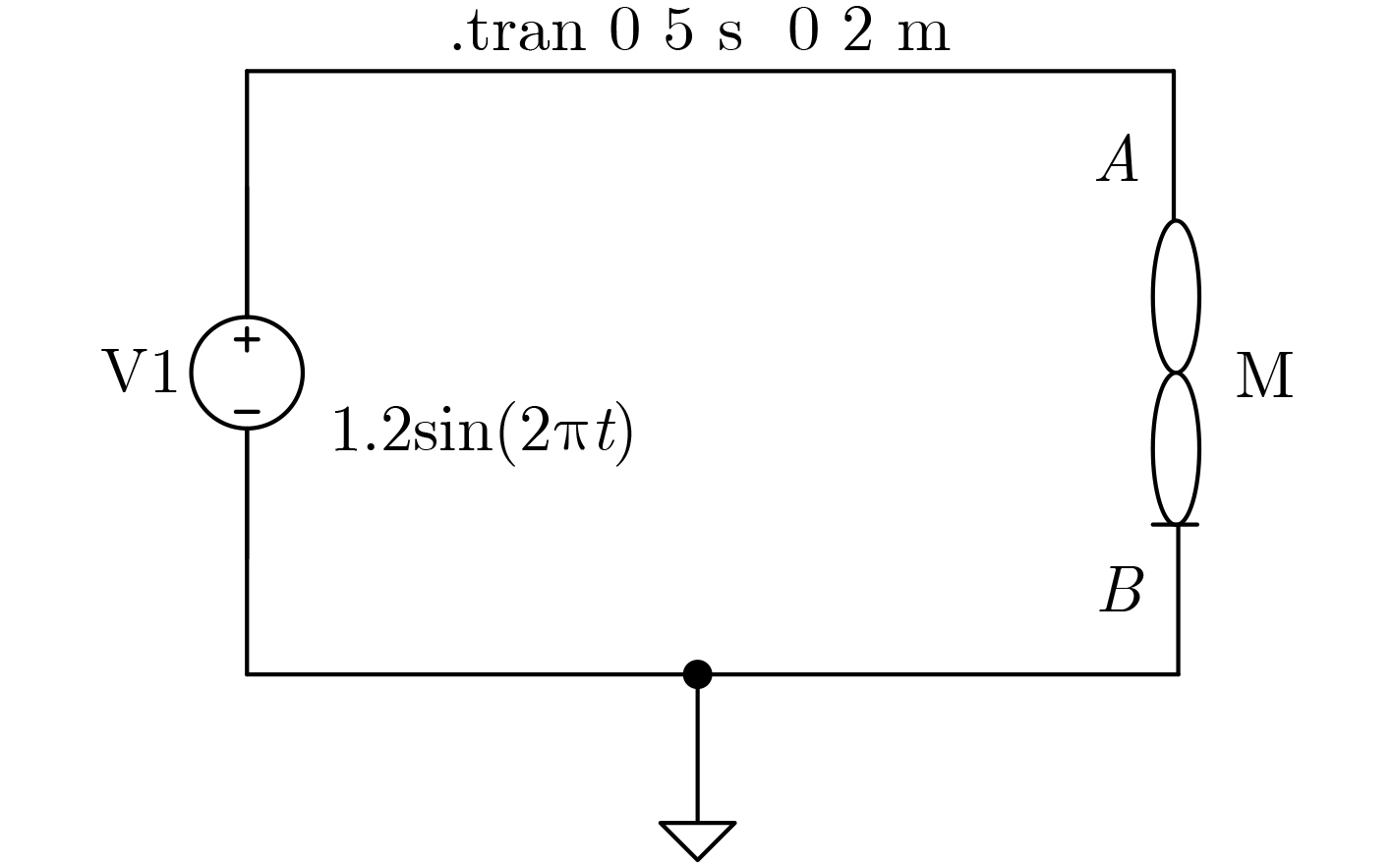
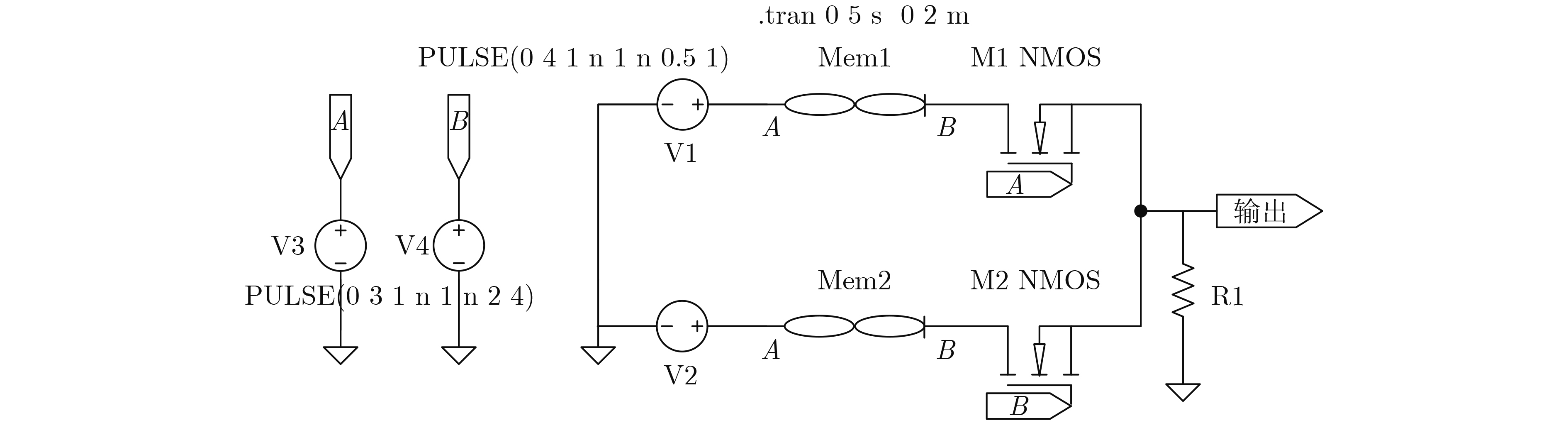
2023, 45(8): 2675-2688.
doi: 10.11999/JEIT221459
Abstract:
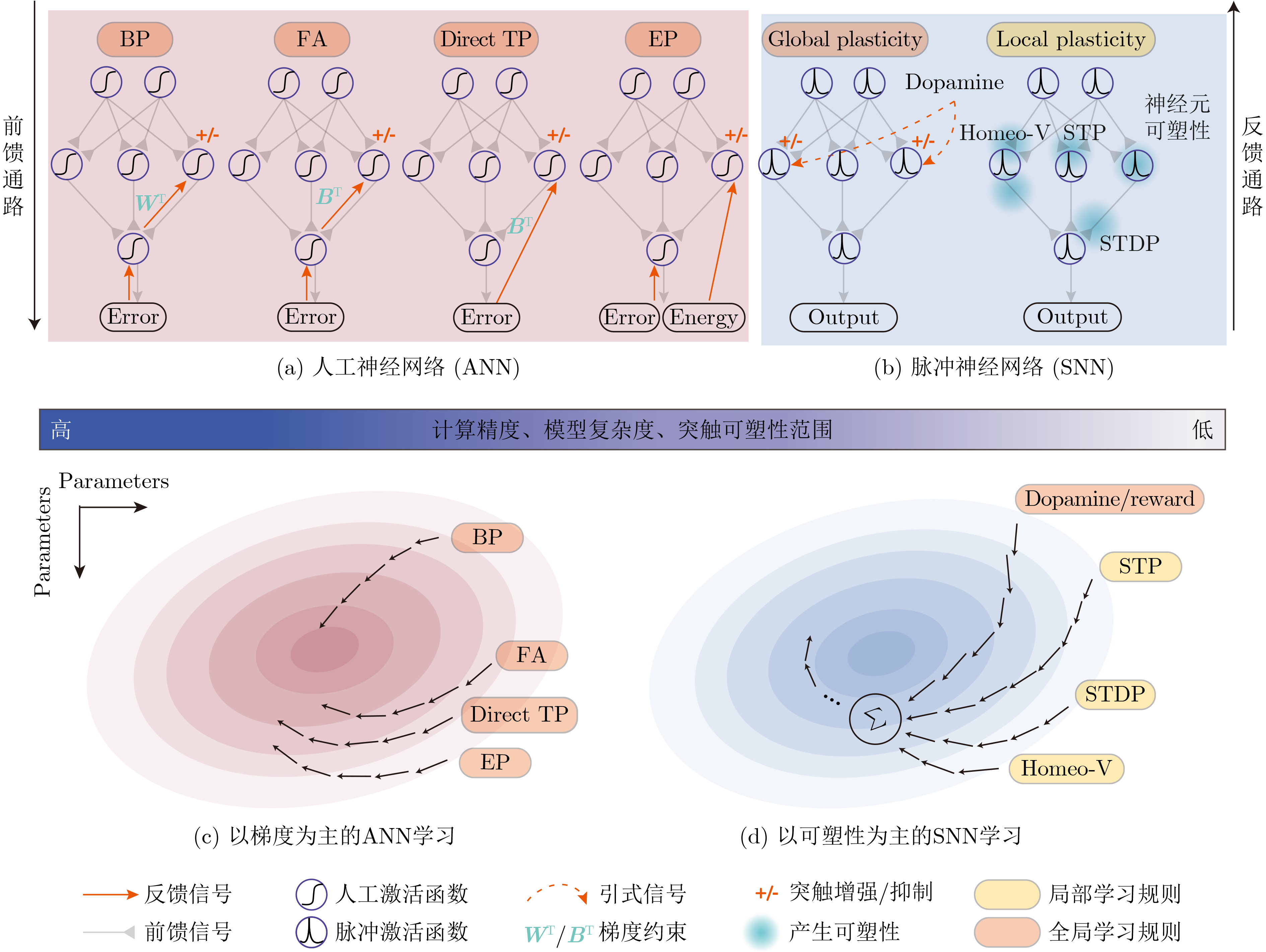
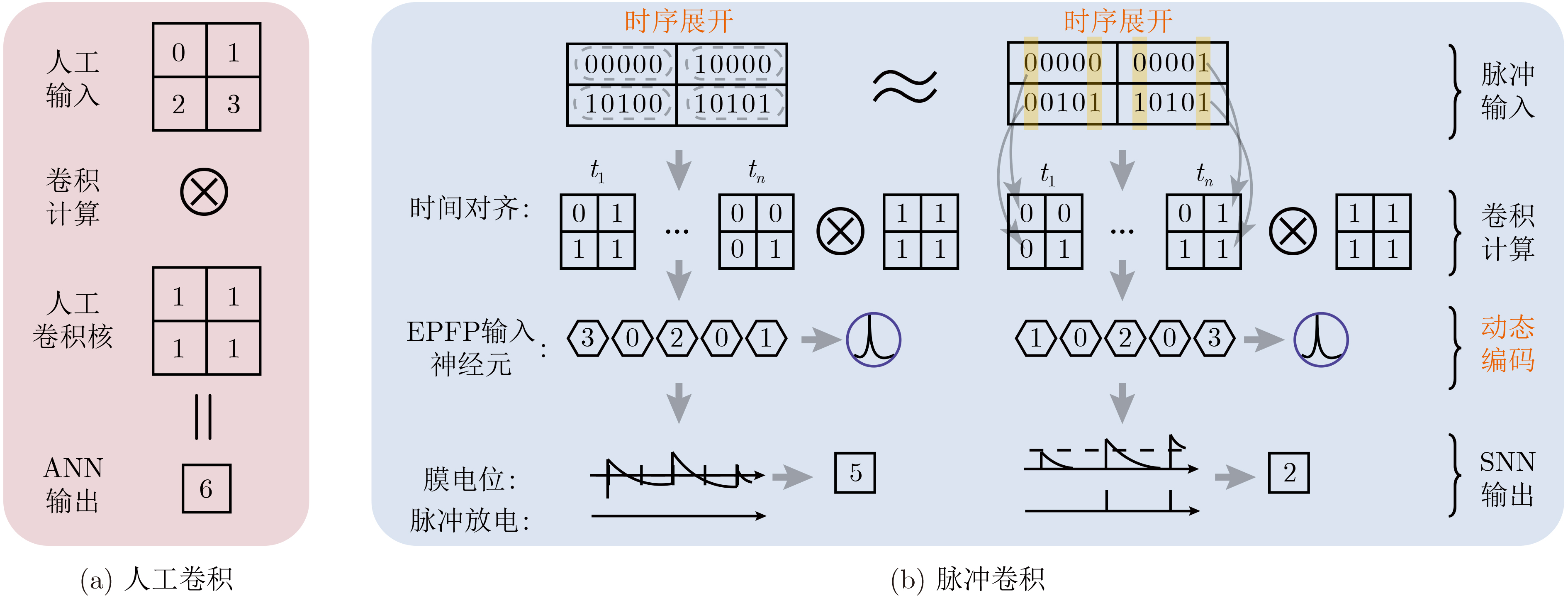
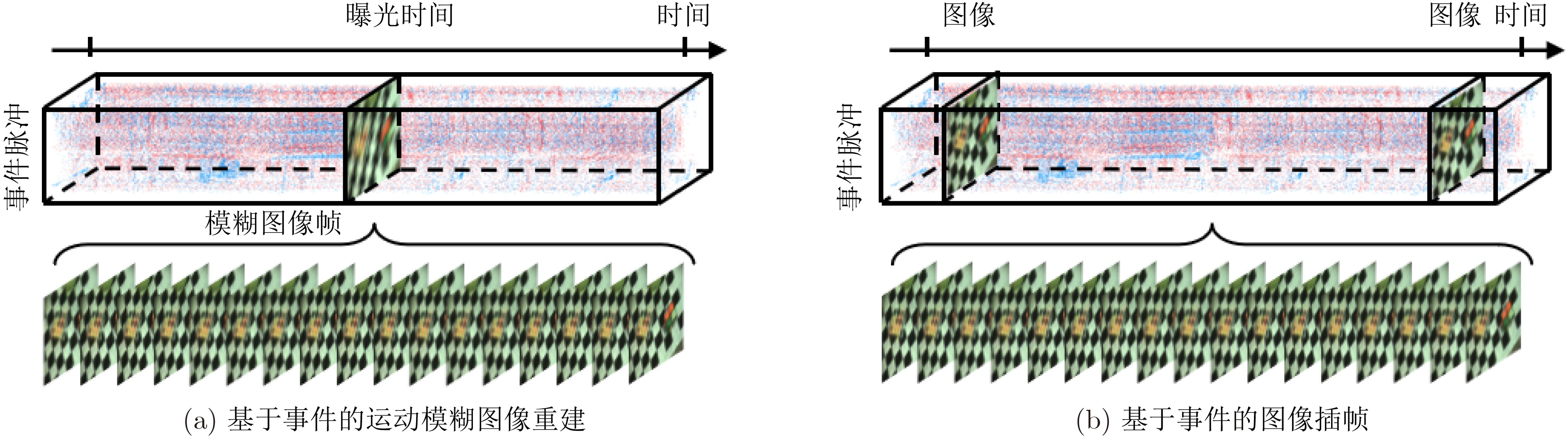
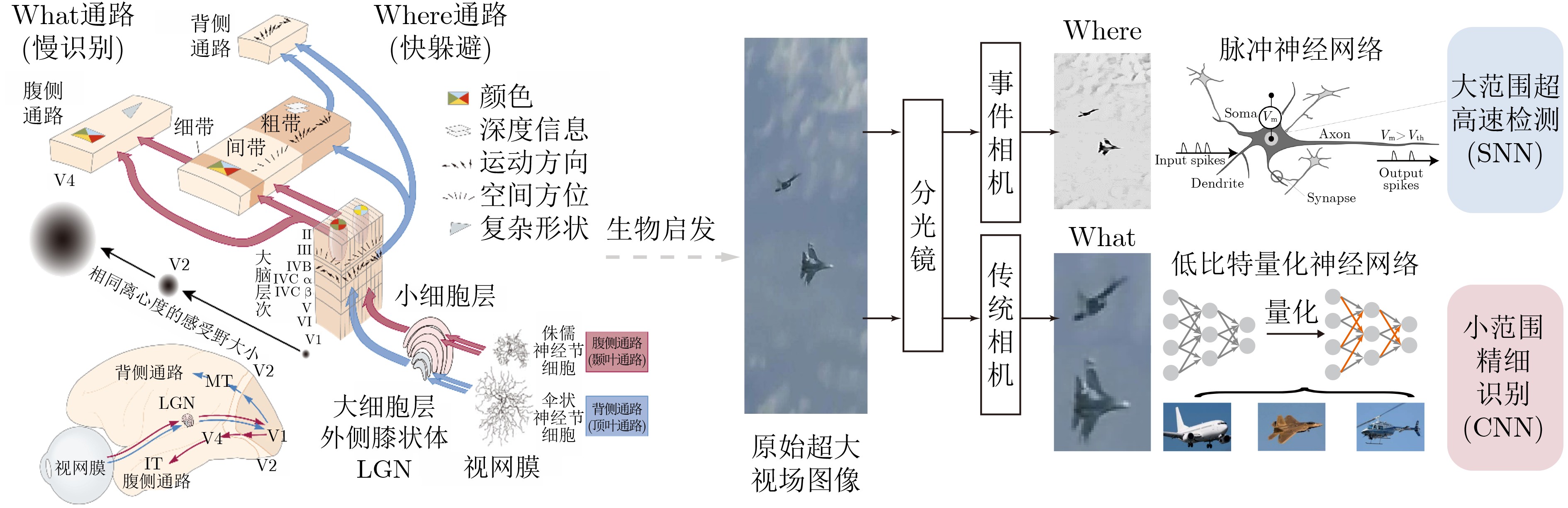
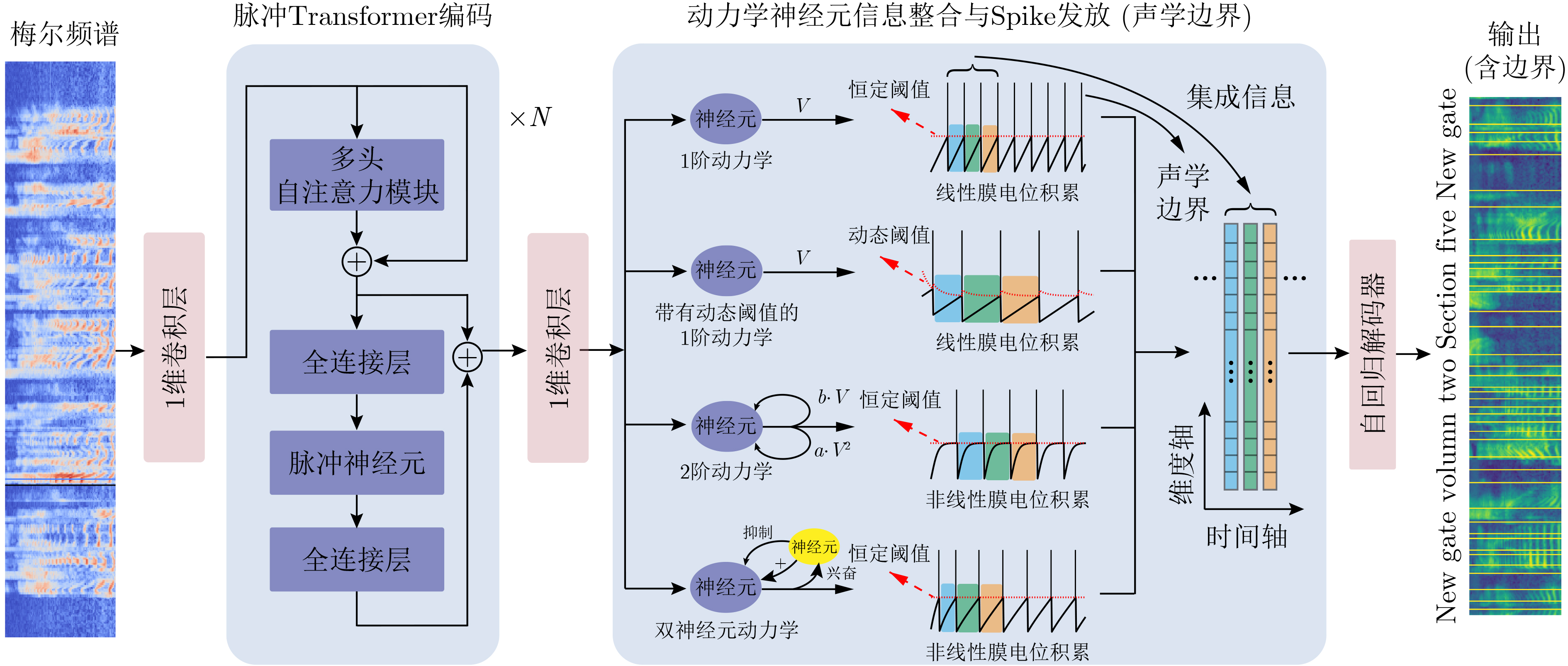
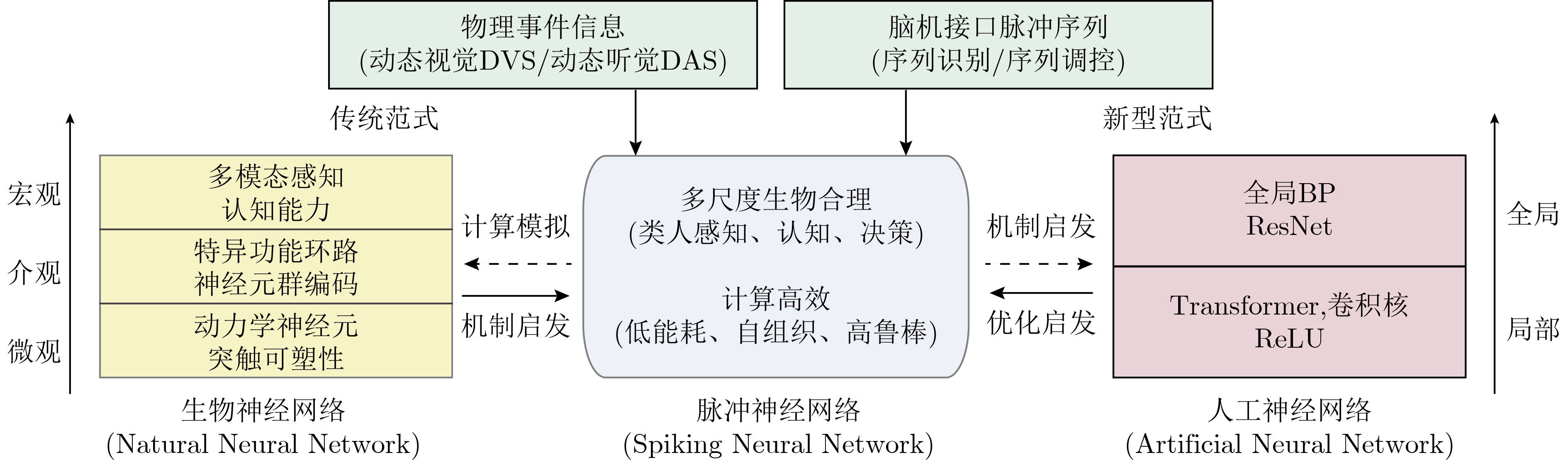
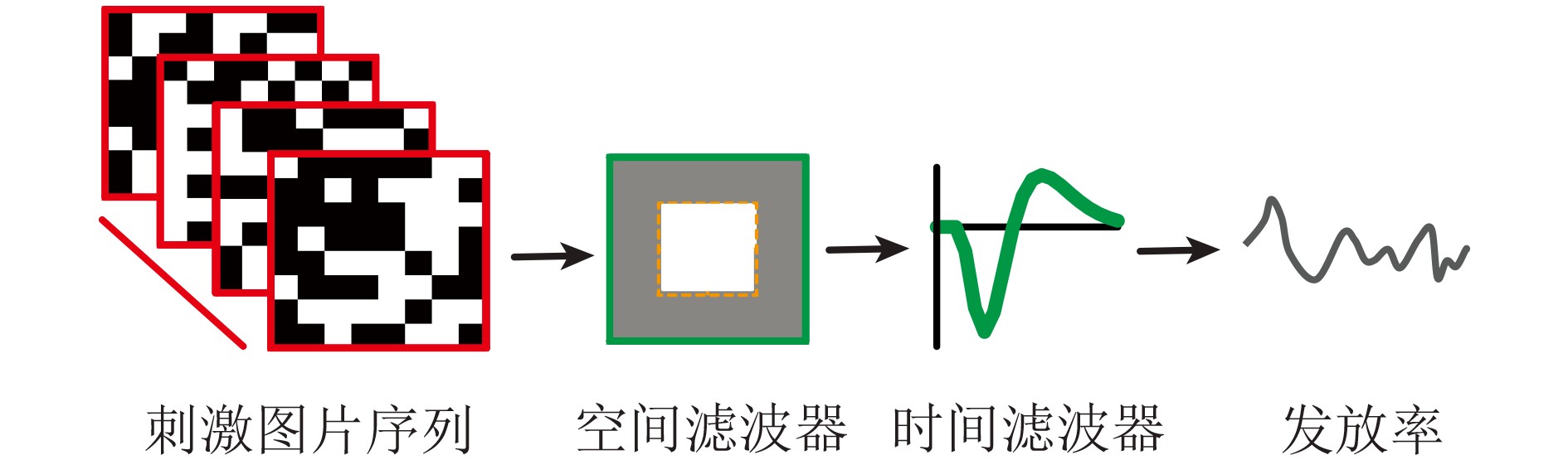
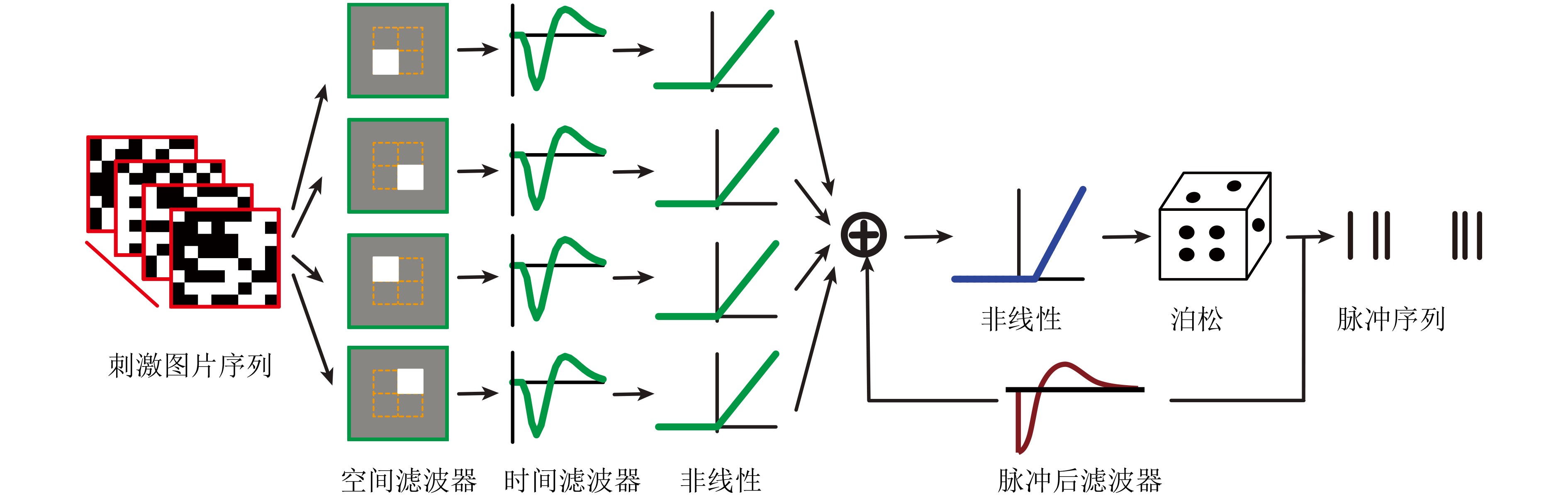
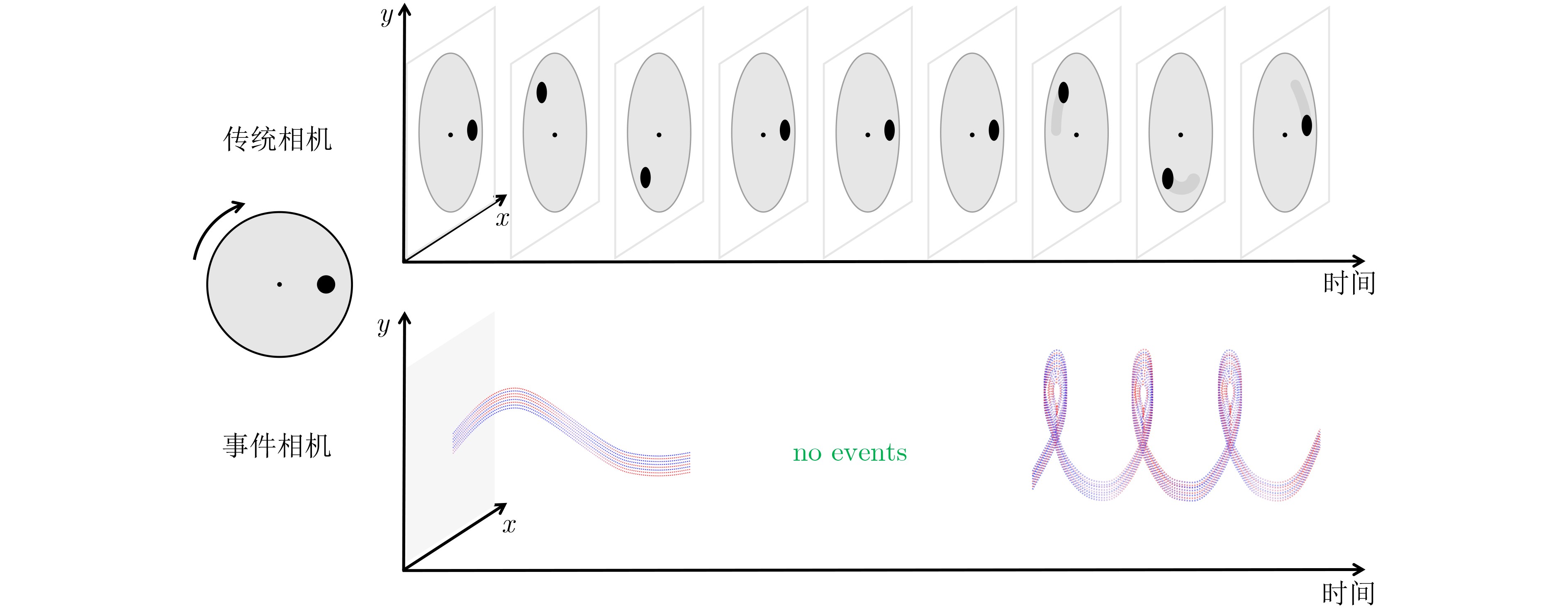
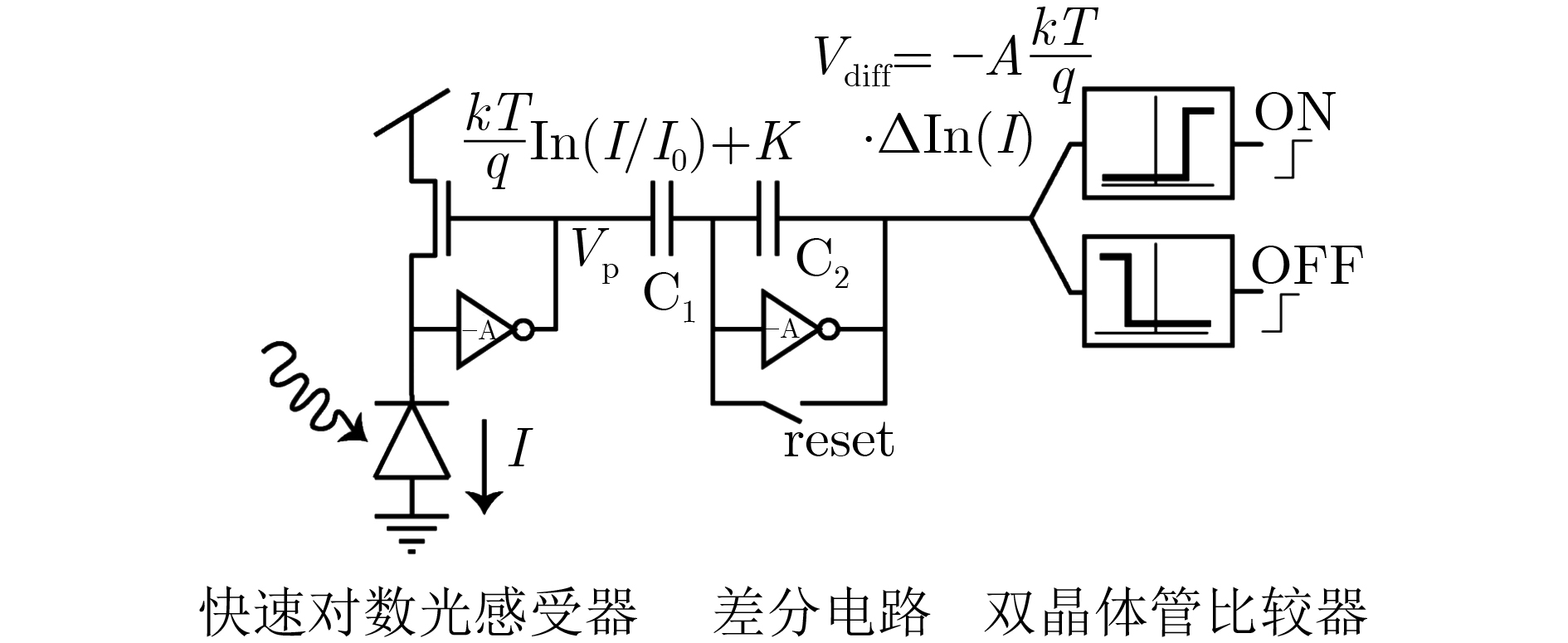
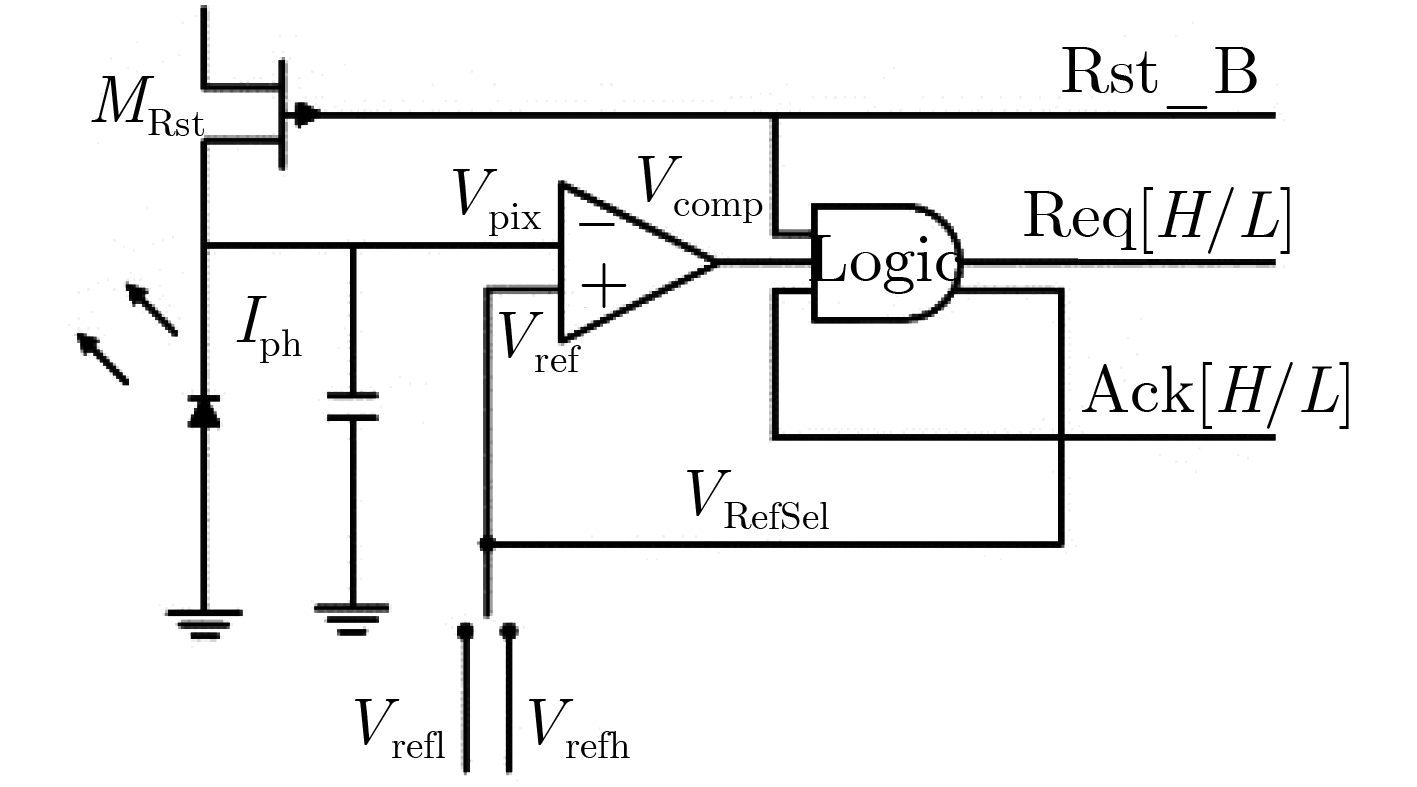
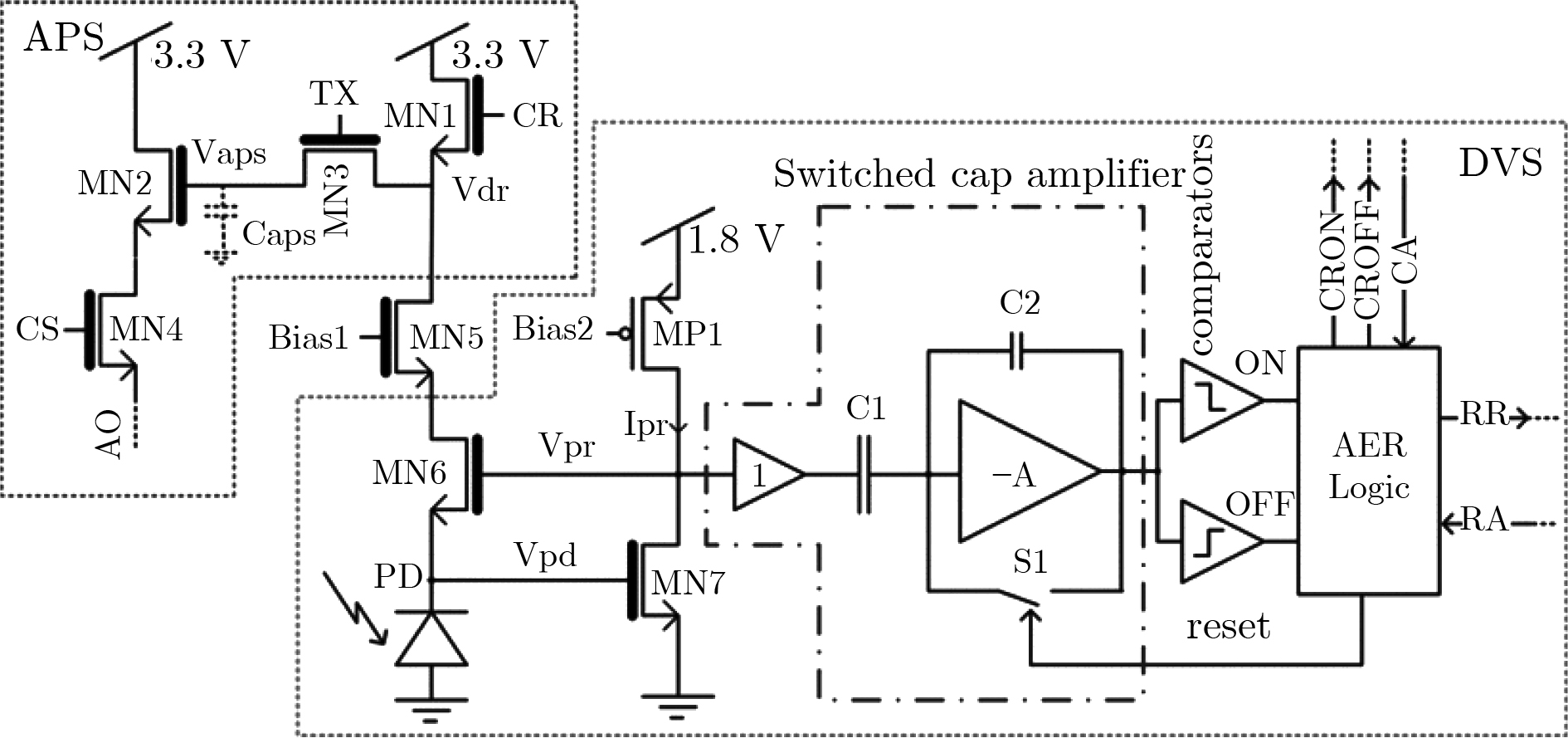
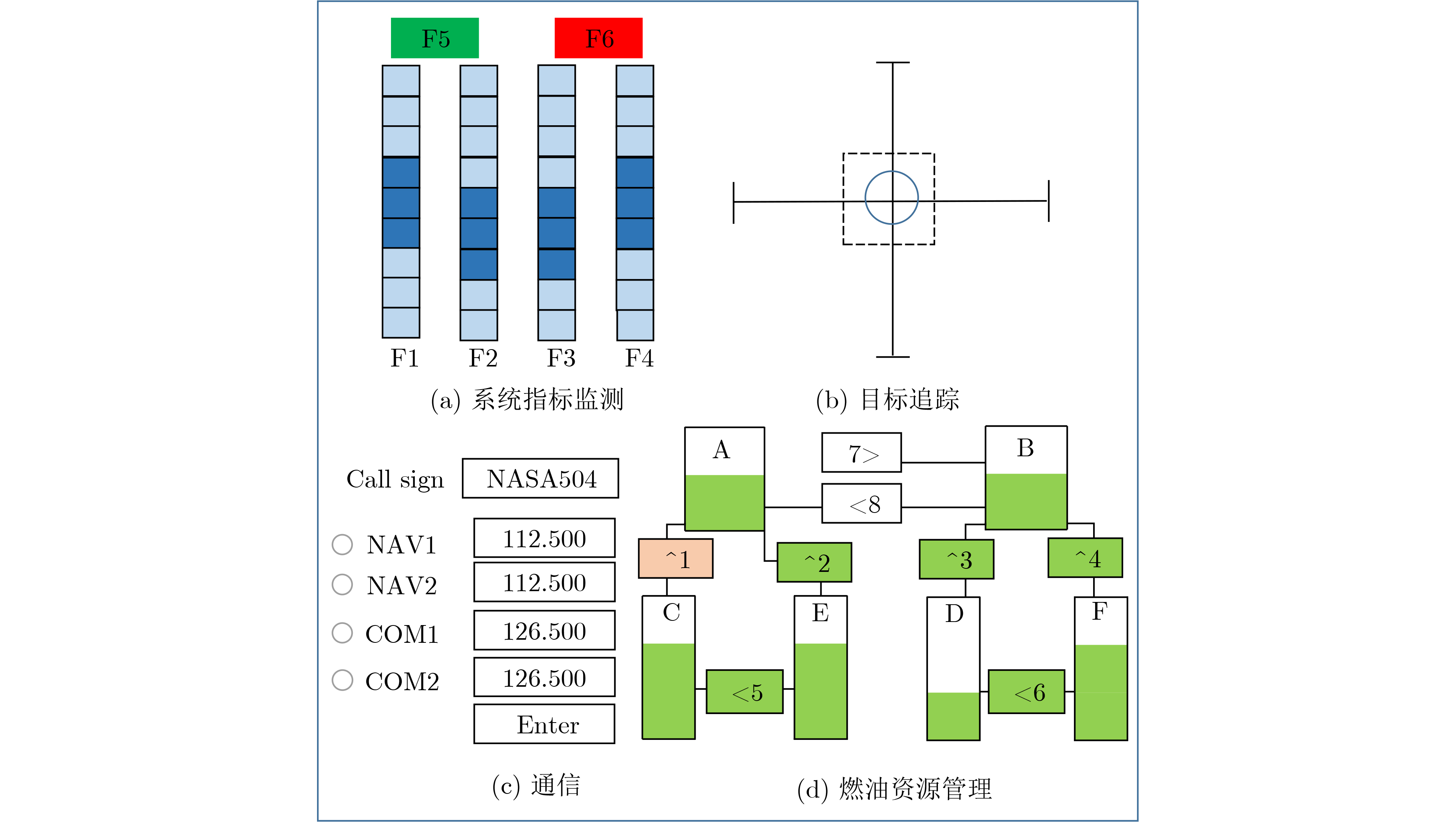
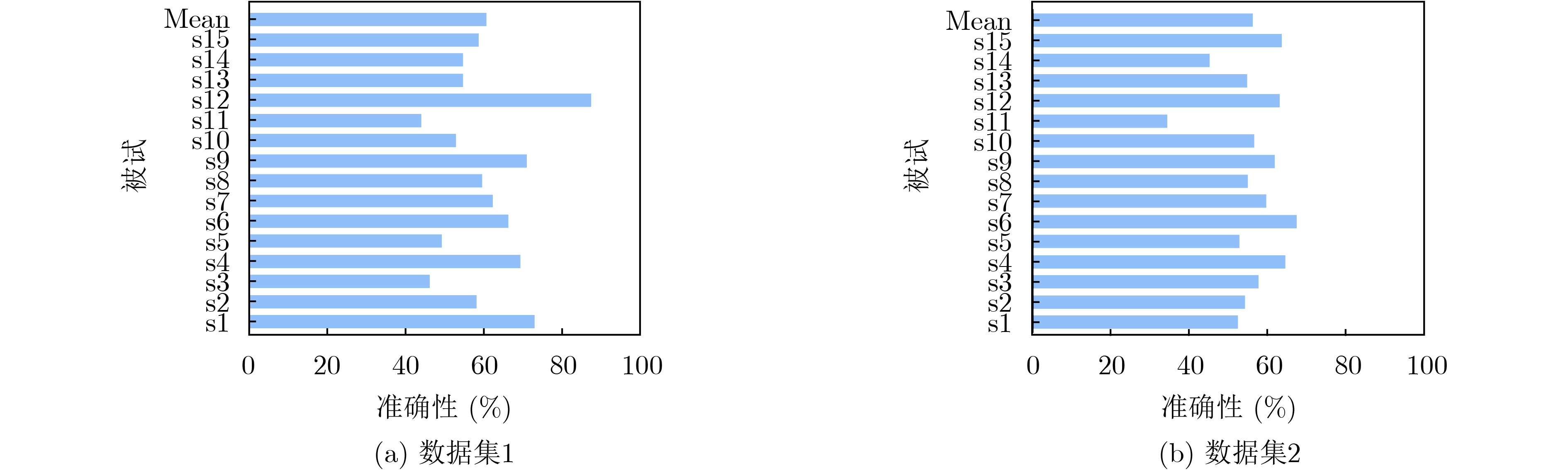
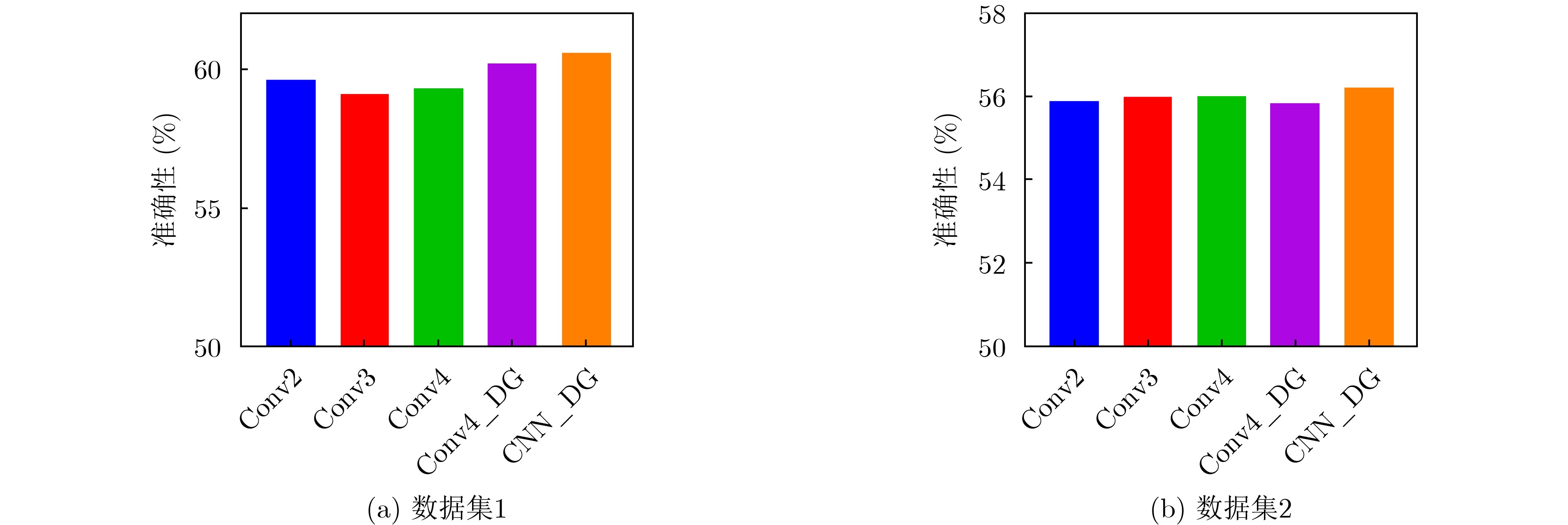
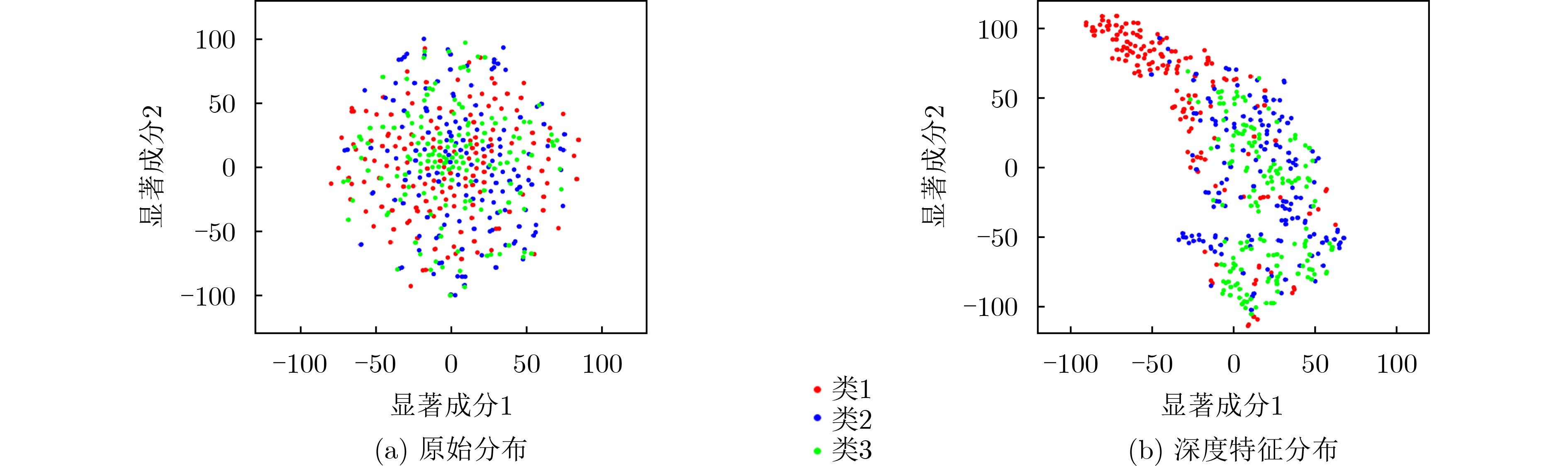
Spiking Neural Networks (SNN) are gaining popularity in the computational simulation and artificial intelligence fields owing to their biological plausibility and computational efficiency. Herein, the historical development of SNN are analyzed to conclude that these two fields are intersecting and merging rapidly. After the successful application of Dynamic Vision Sensors (DVS) and Dynamic Audio Sensors (DAS), SNNs have found some proper paradigms, such as continuous visual signal tracking, automatic speech recognition, and reinforcement learning of continuous control, that have extensively supported their key features, including spiking encoding, neuronal heterogeneity, specific functional circuits, and multiscale plasticity. In comparison to these real-world paradigms, the brain contains a spiked version of the biology-world paradigm, which exhibits a similar level of complexity and is usually considered a mirror of the real world. Considering the projected rapid development of invasive and parallel Brain-computer Interface (BCI), as well as the new BCI-based paradigm, which includes online pattern recognition and stimulus control of biological spike trains, it is natural for SNNs to exhibit their key advantages of energy efficiency, robustness, and flexibility. The biological brain has inspired the present study of SNNs and effective SNN machine-learning algorithms, which can help enhance neuroscience discoveries in the brain by applying them to the new BCI paradigm. Such two-way interactions with positive feedback can accelerate brain science research and brain-inspired intelligence technology.