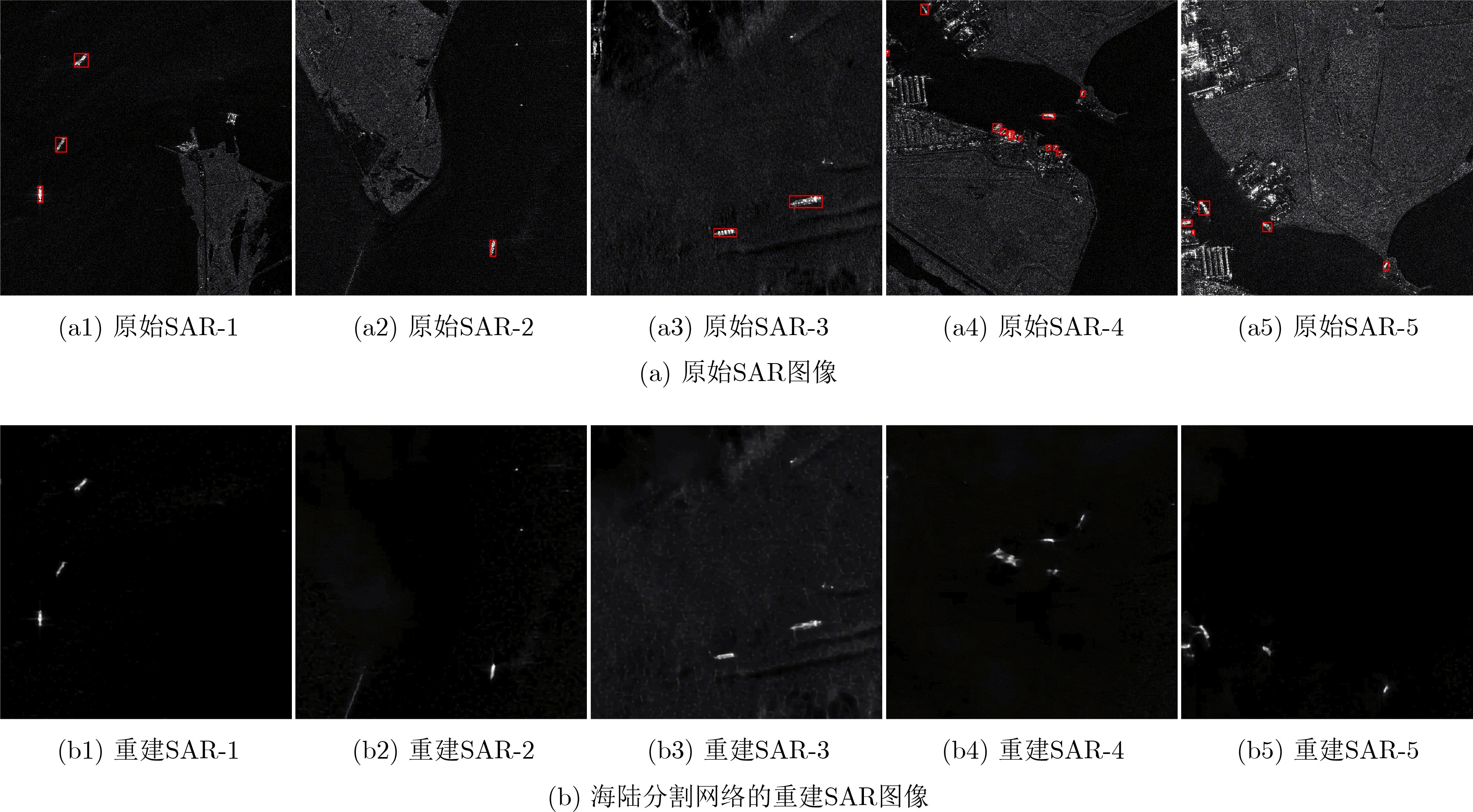
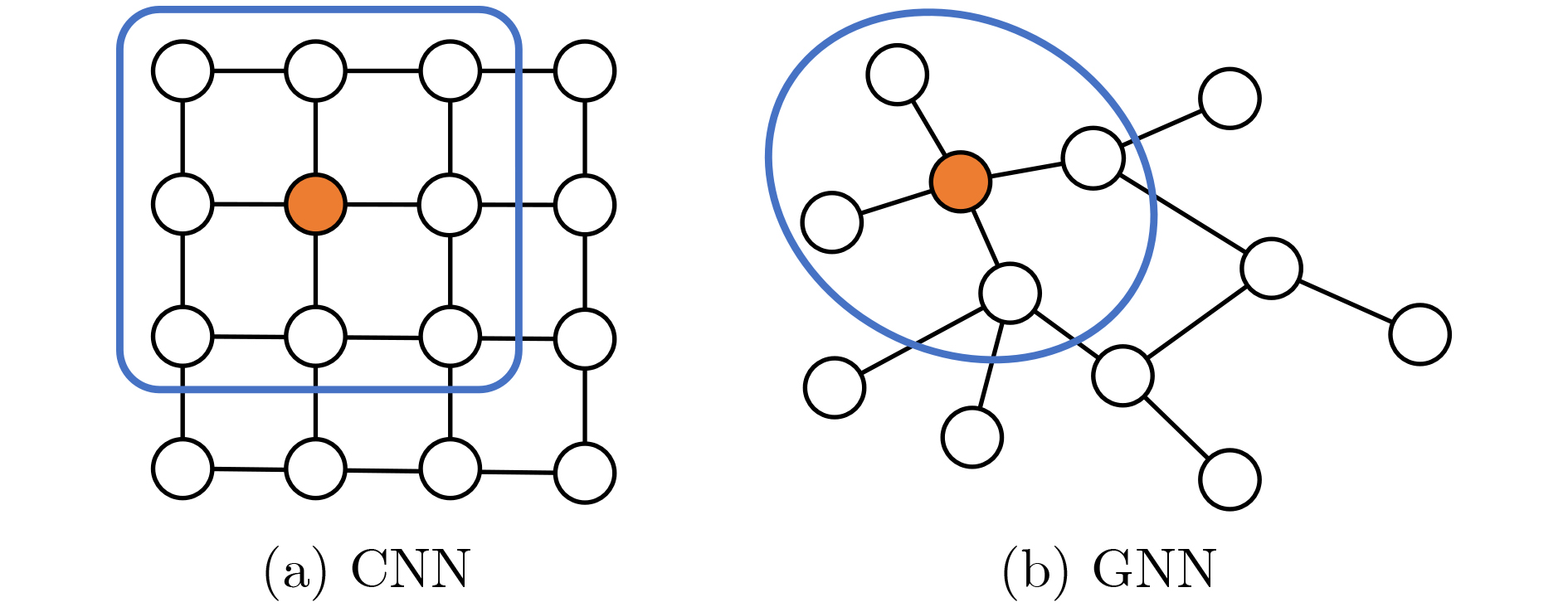
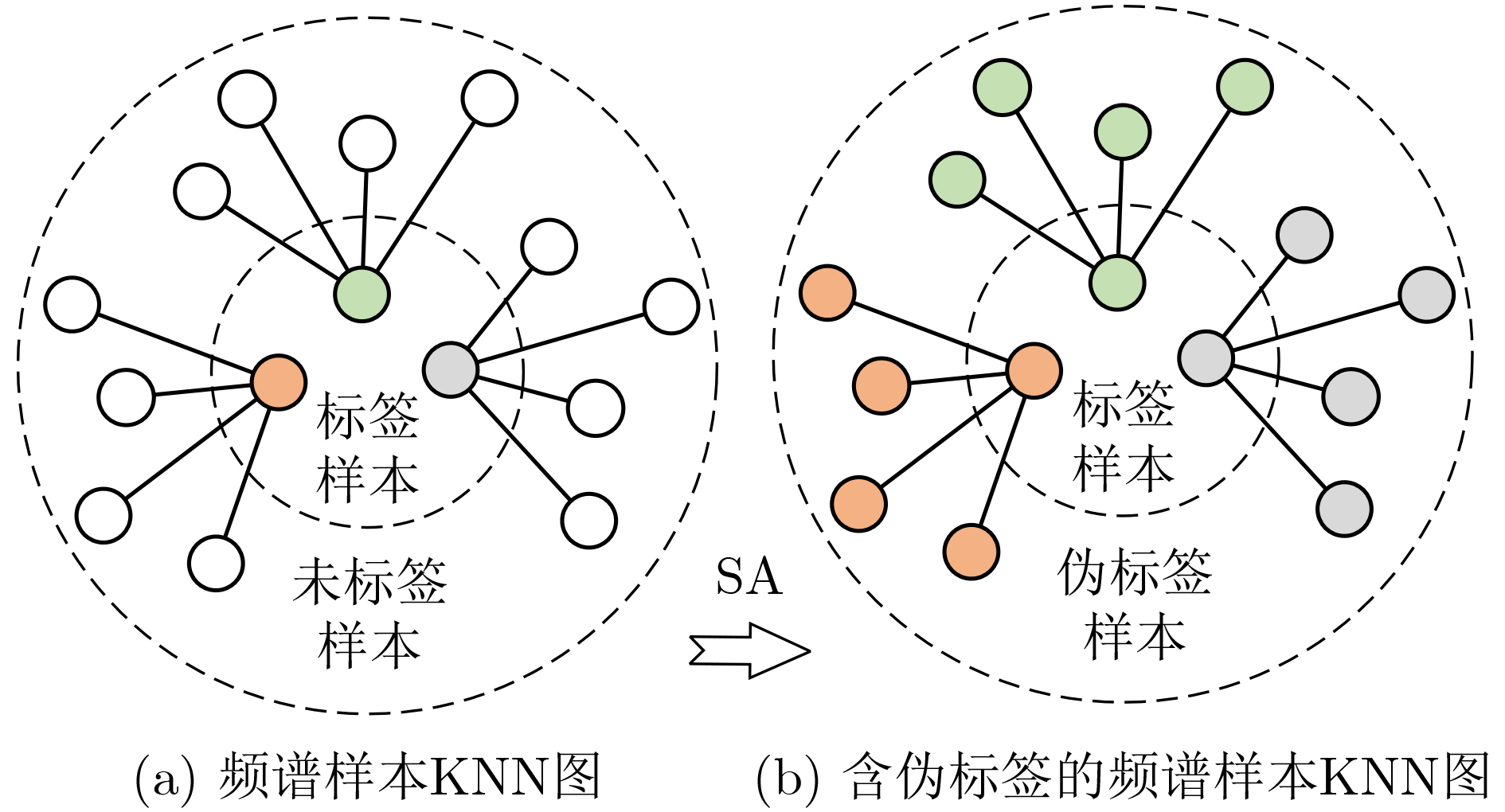
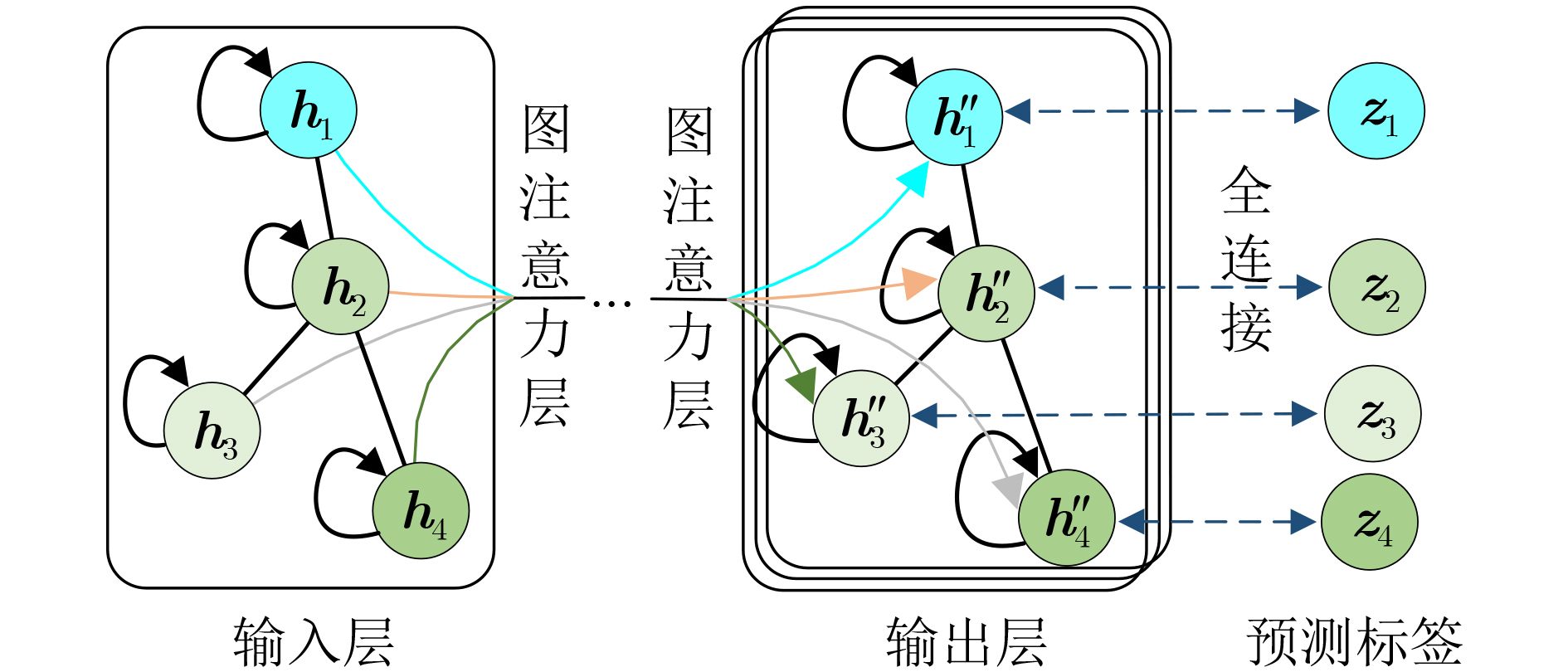
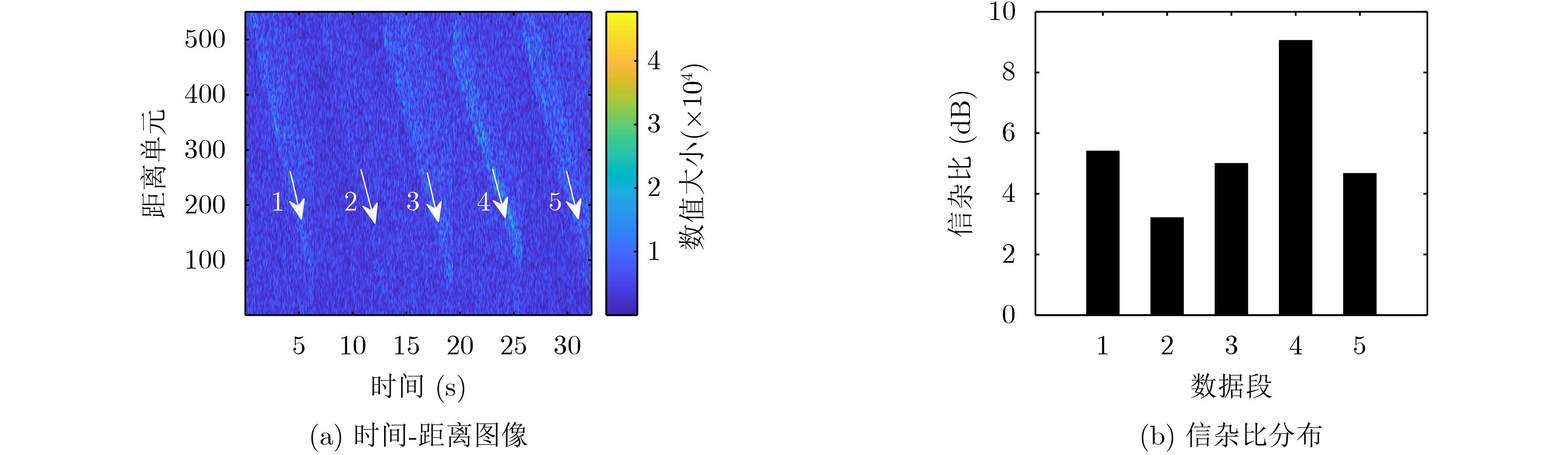
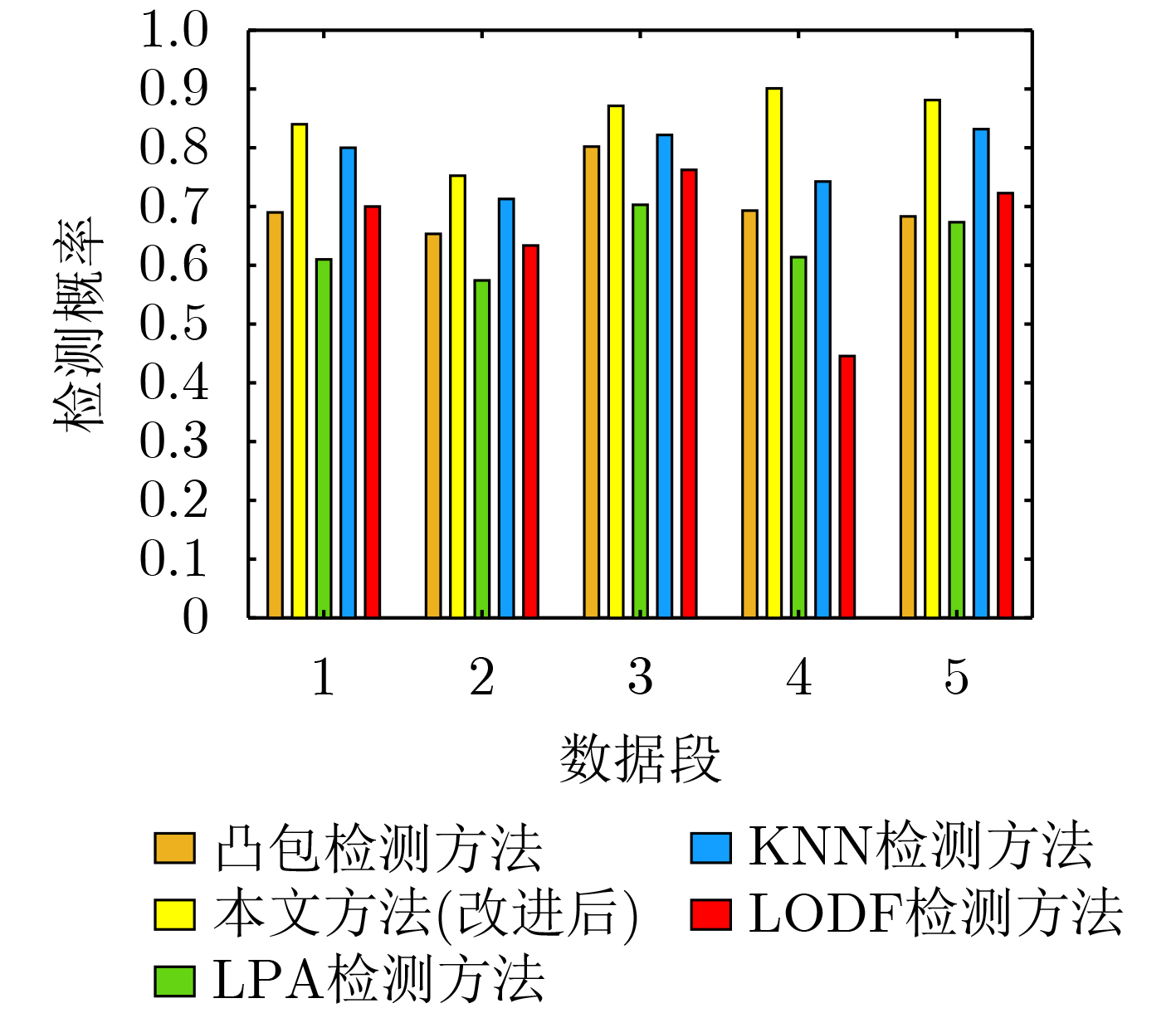
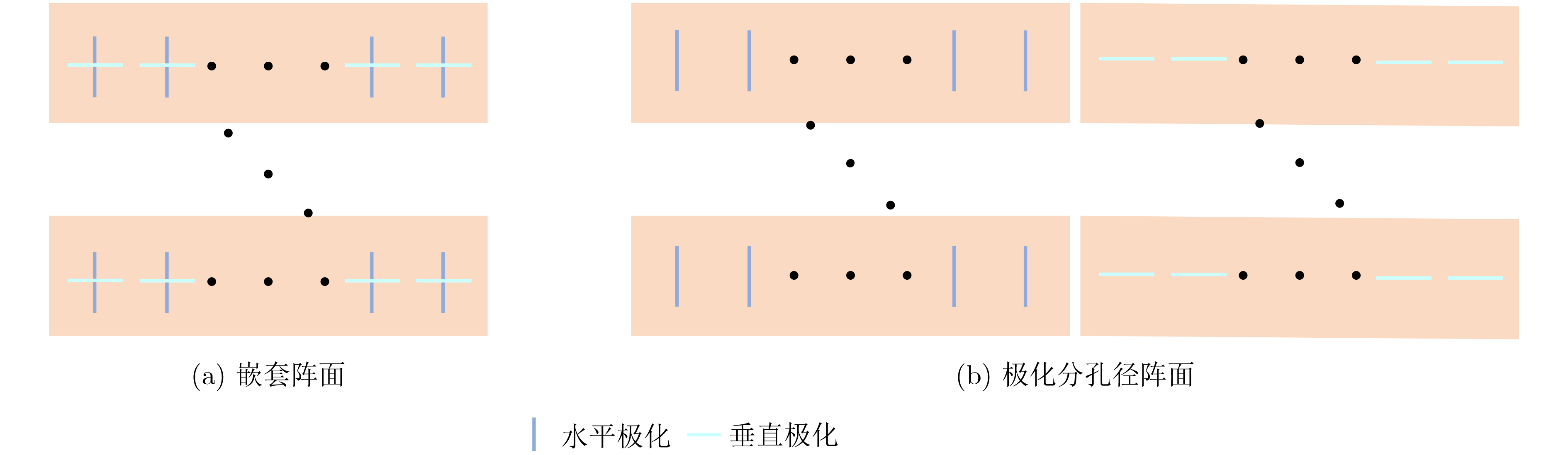
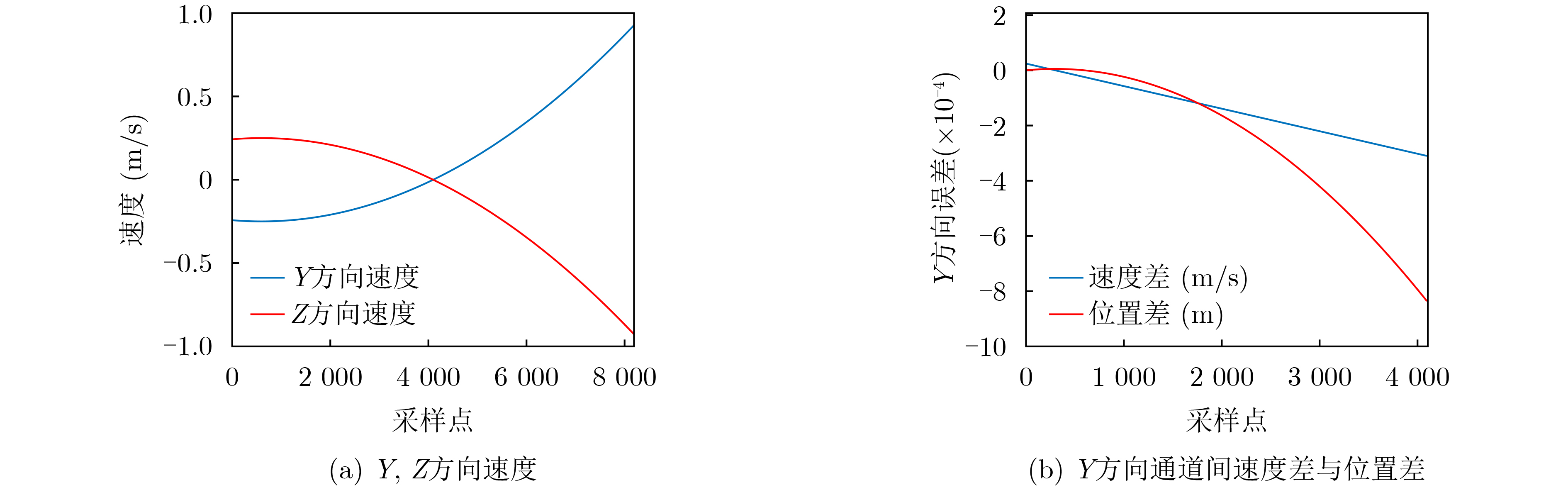
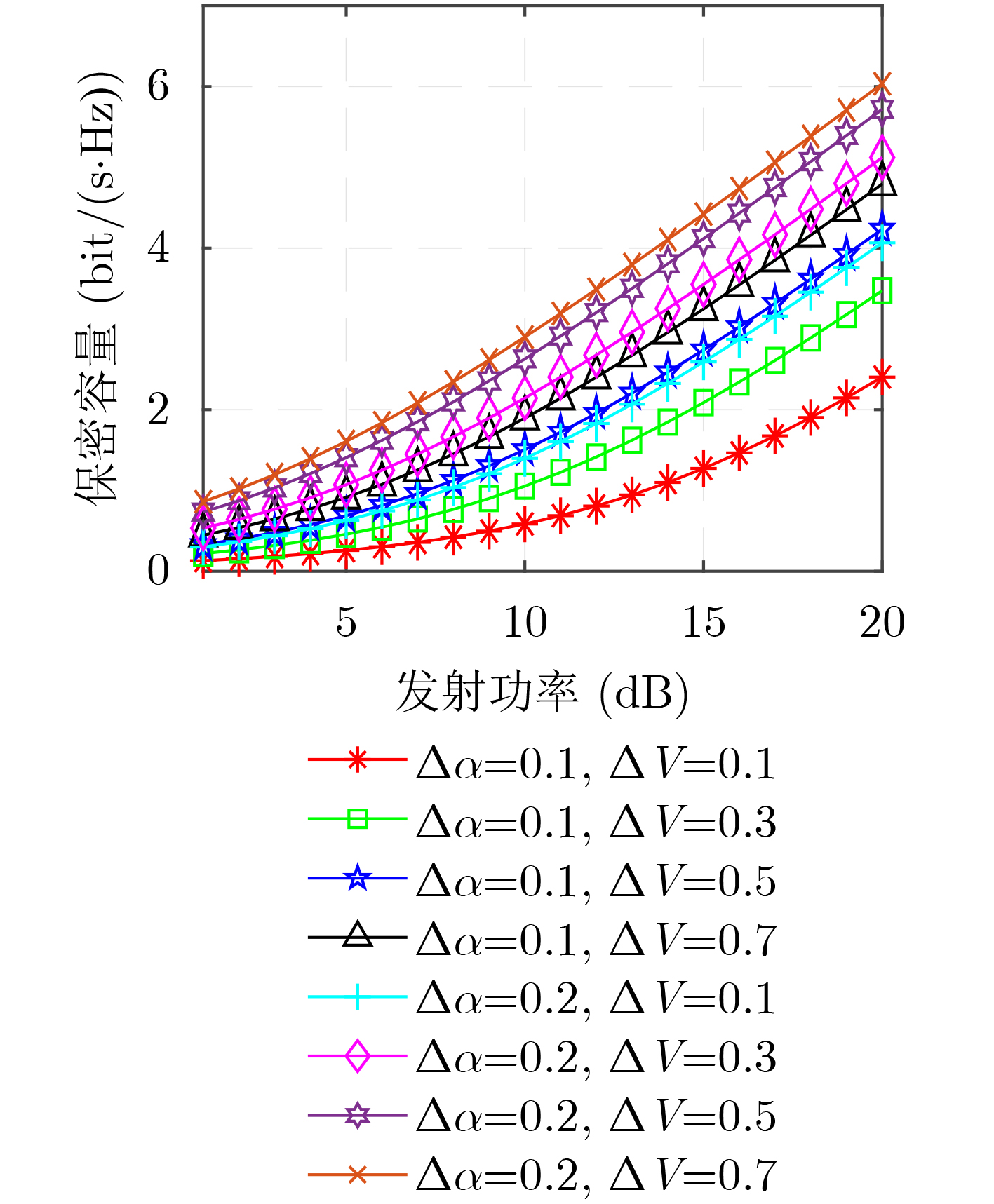
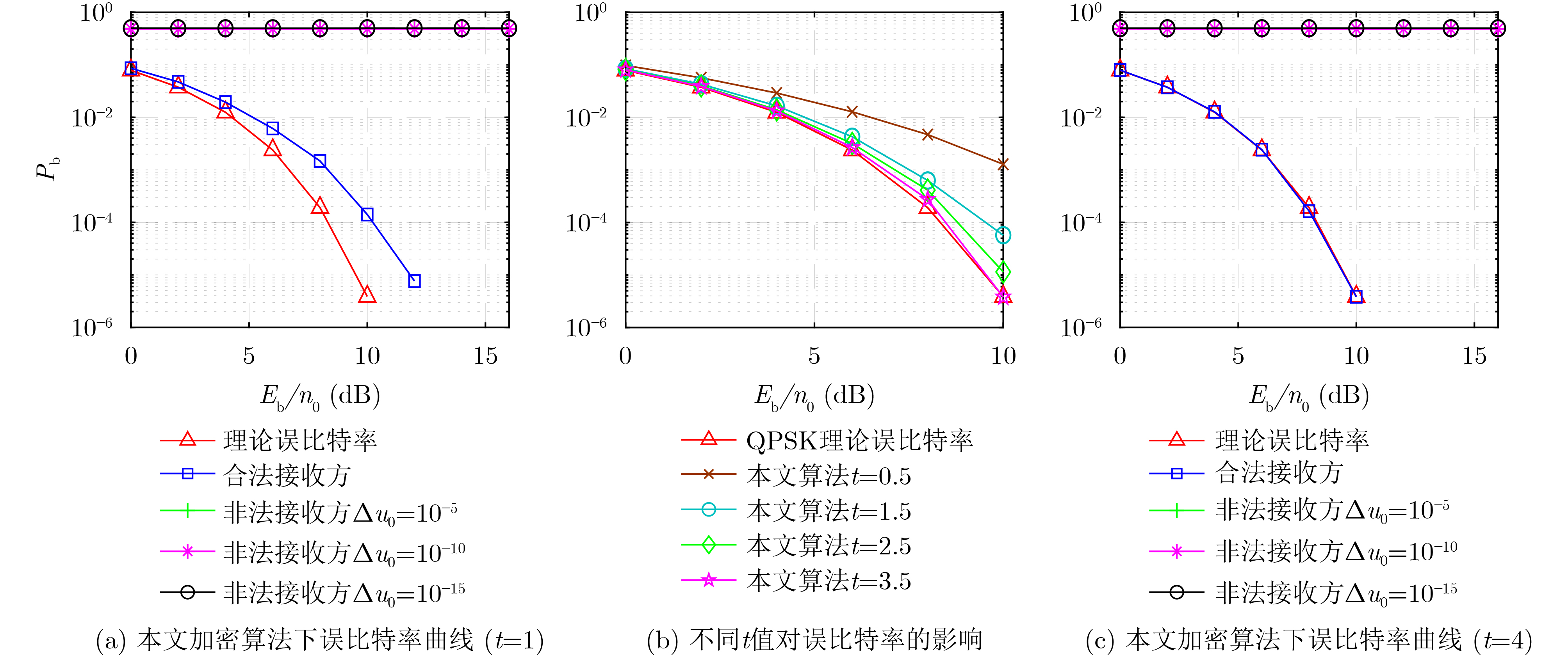
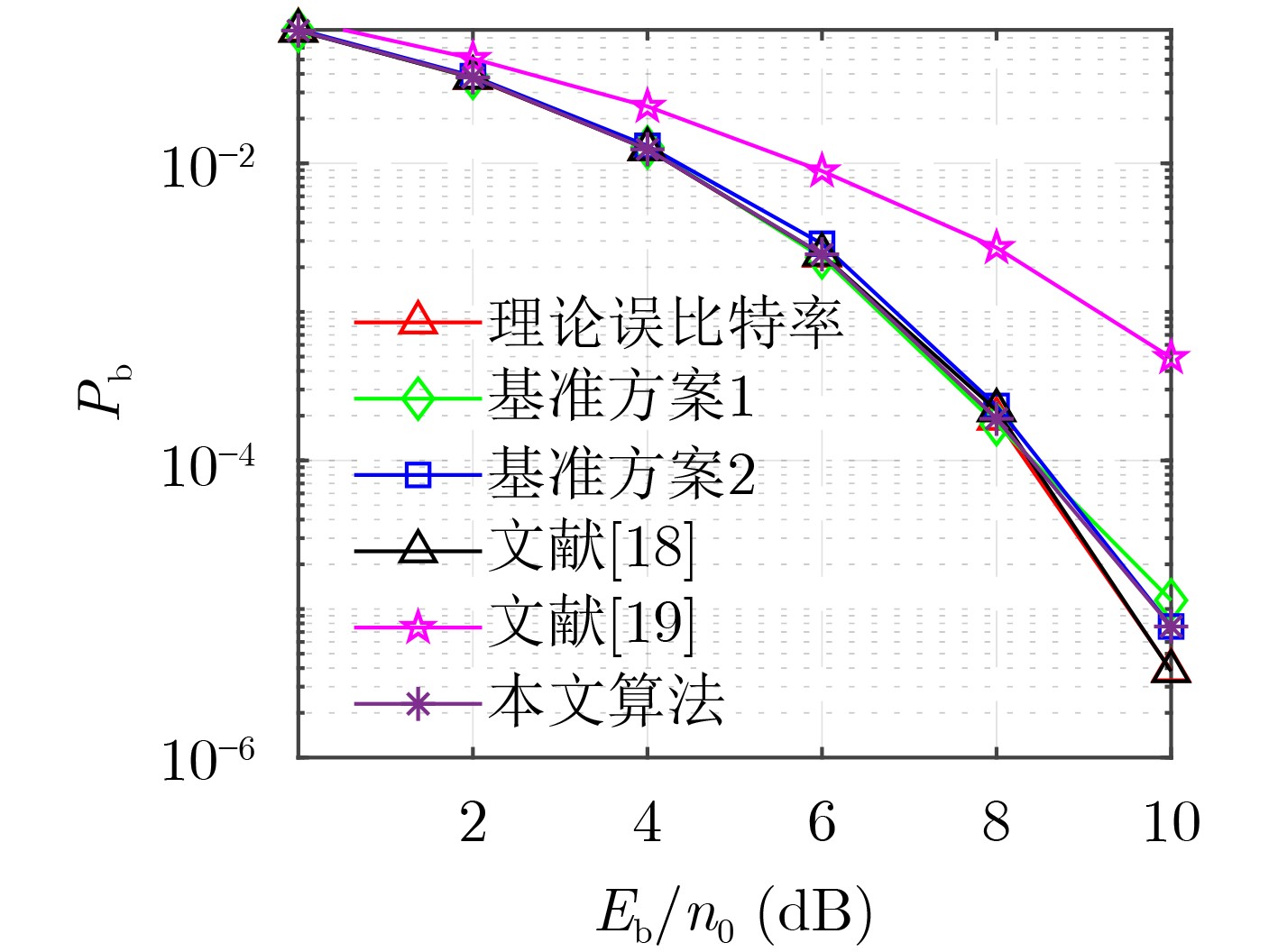
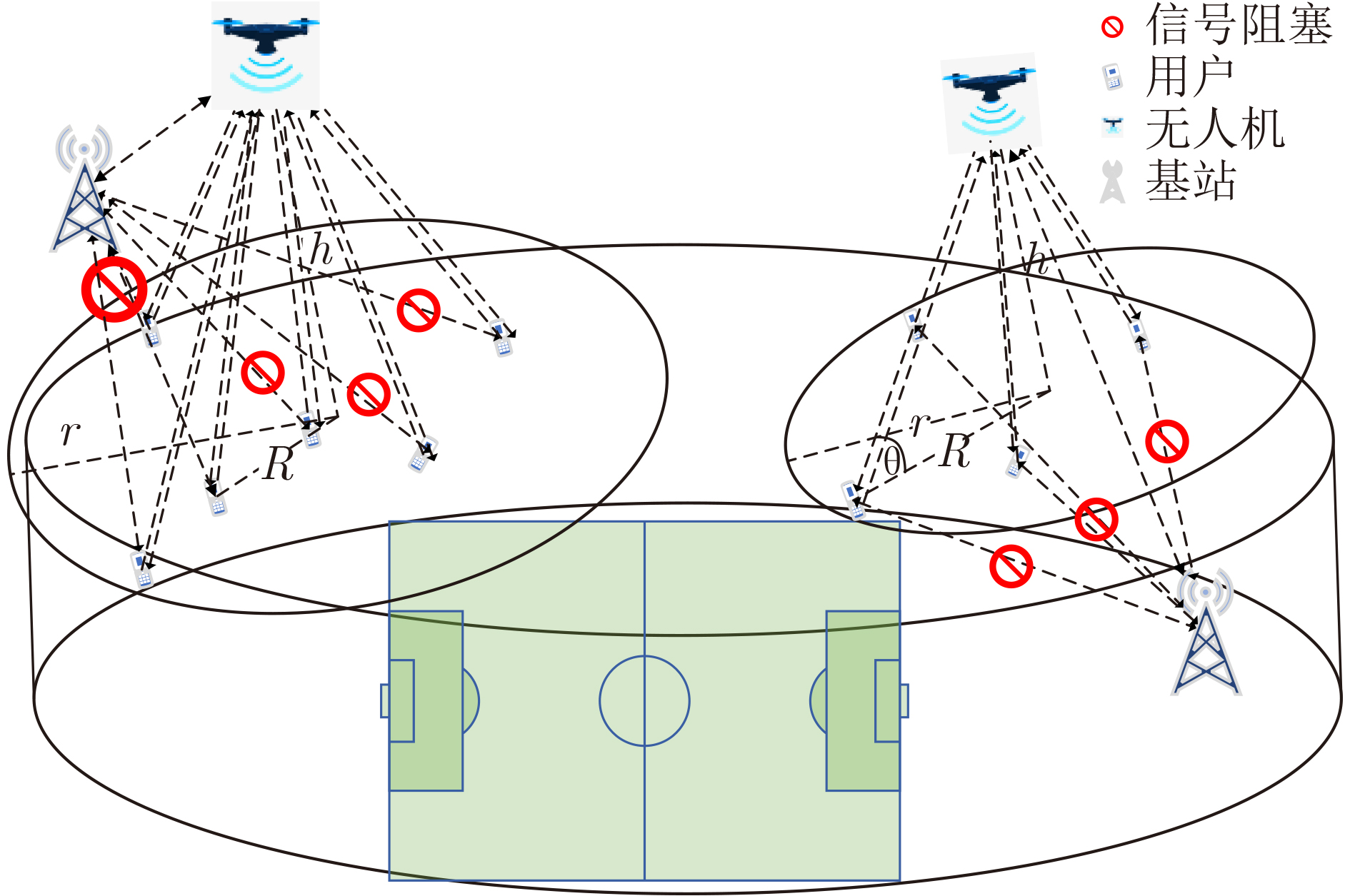
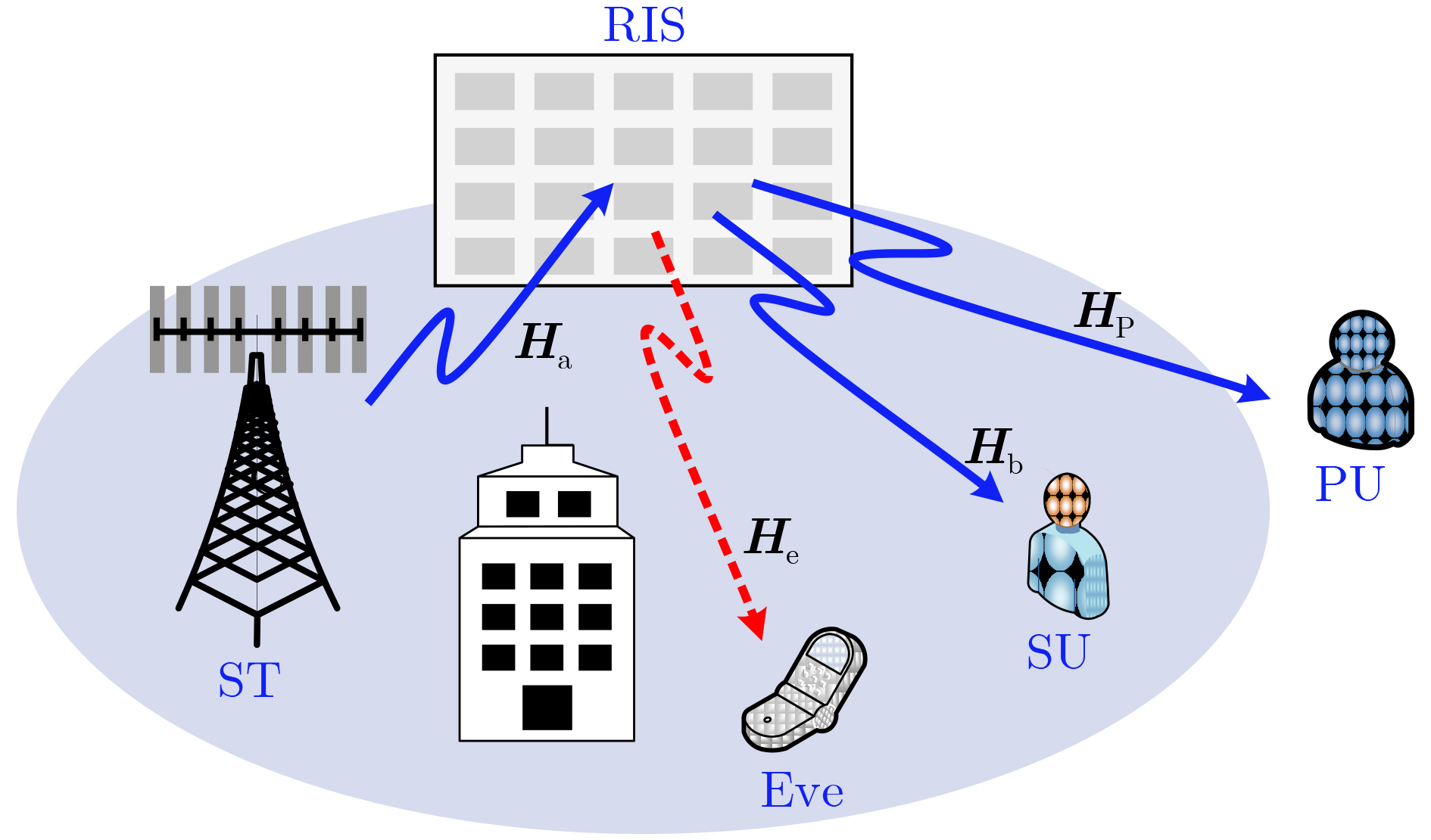
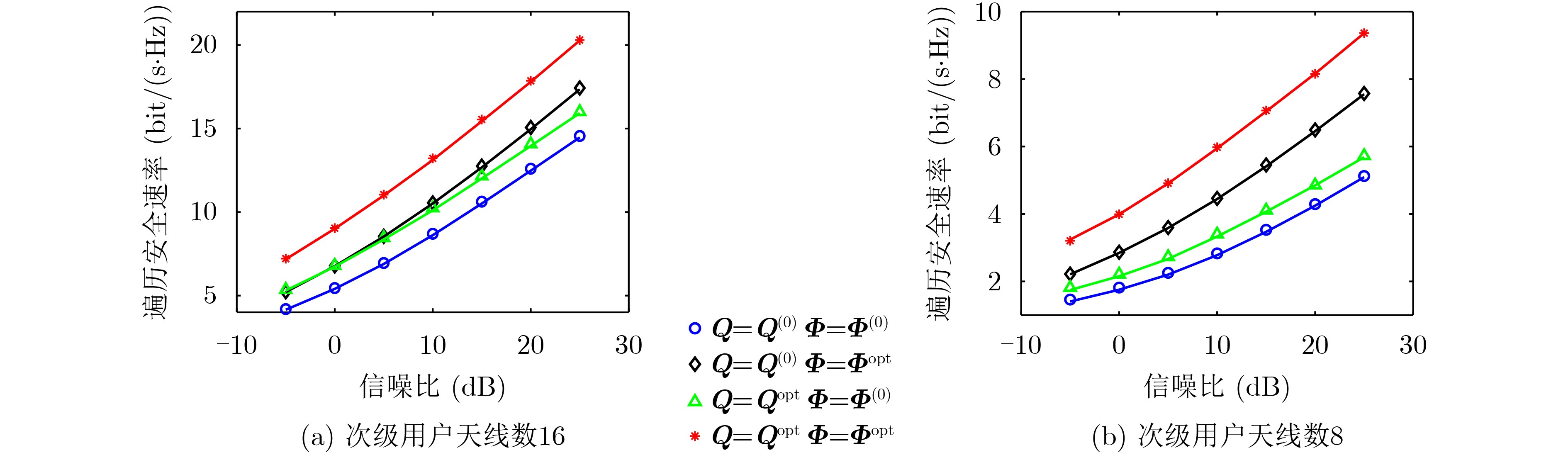
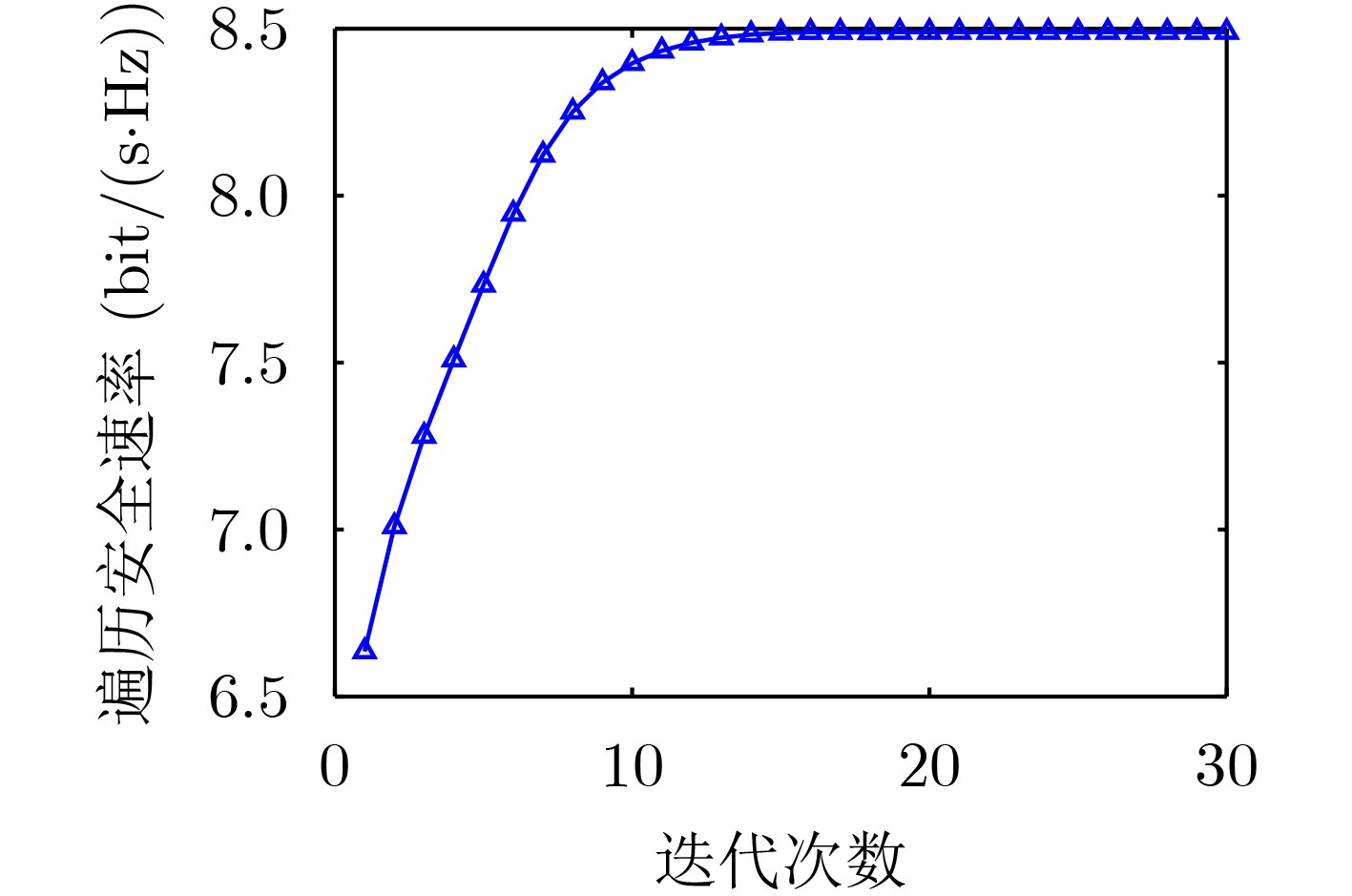
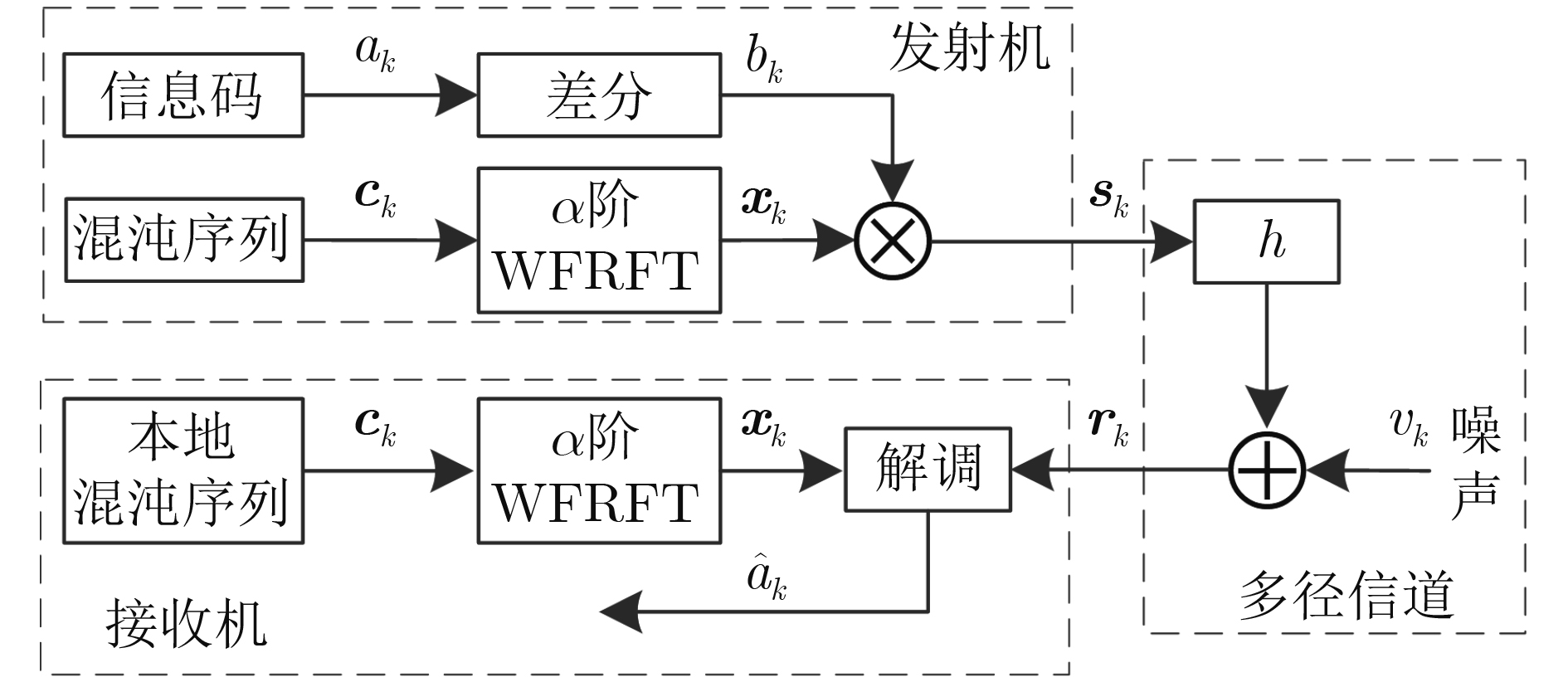
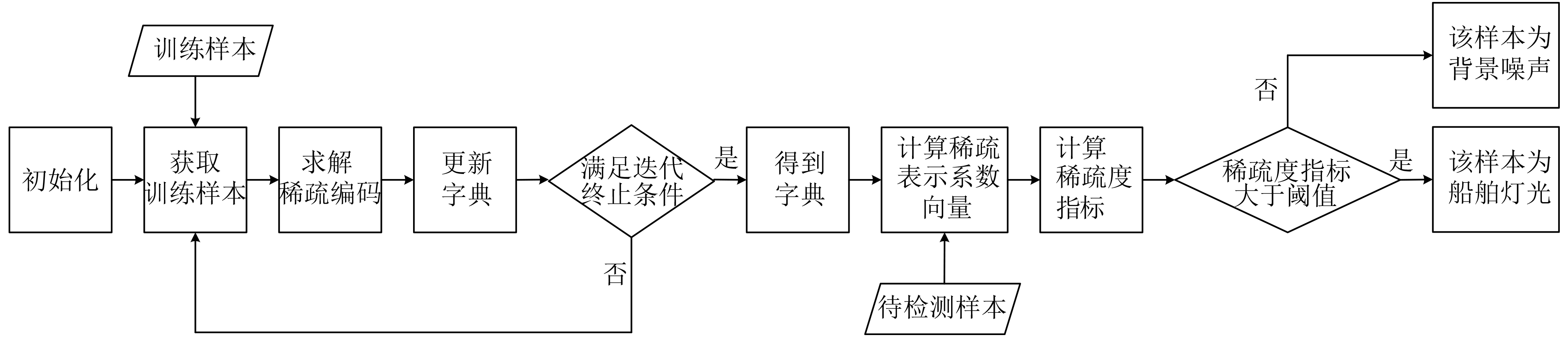
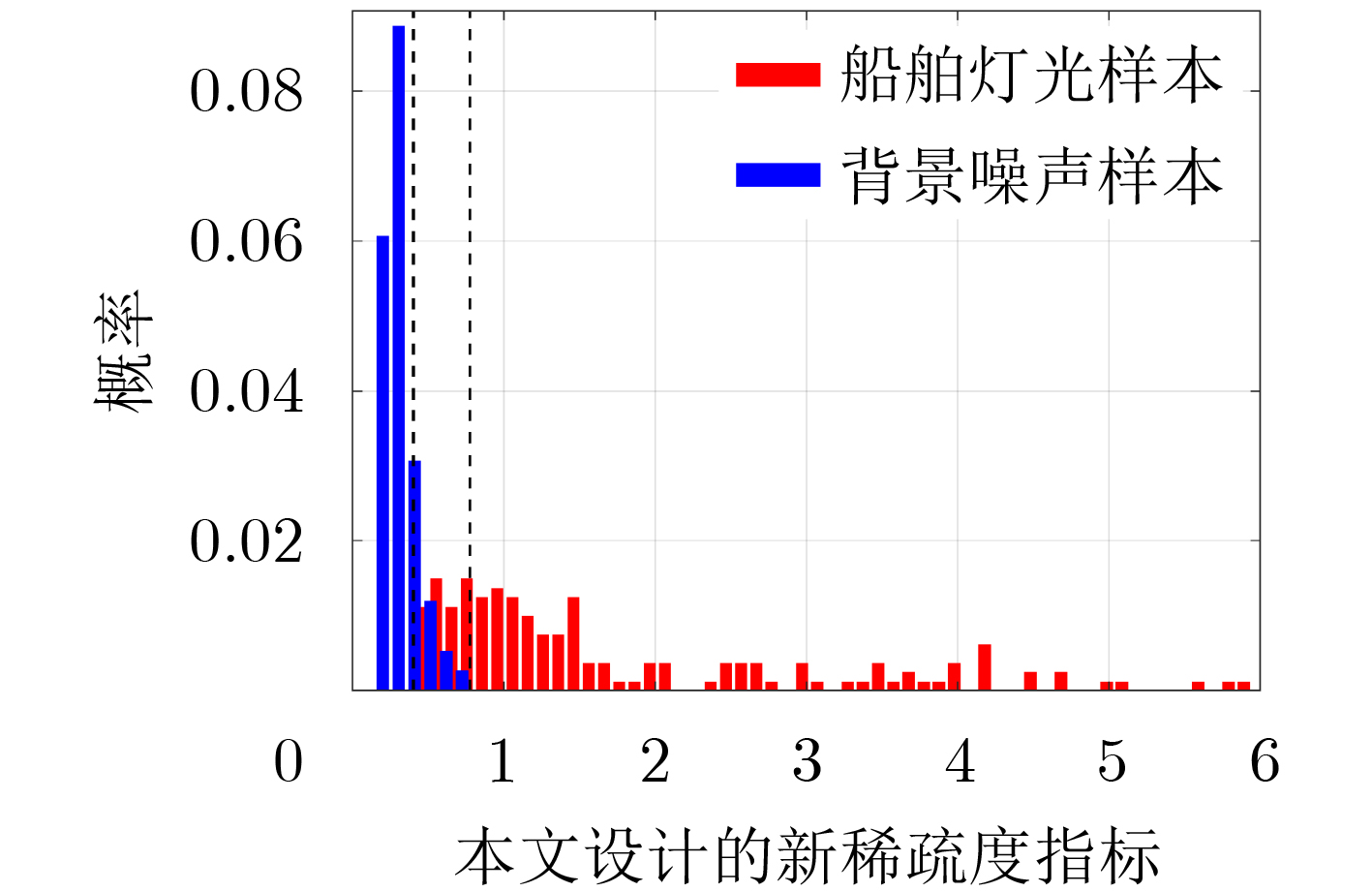
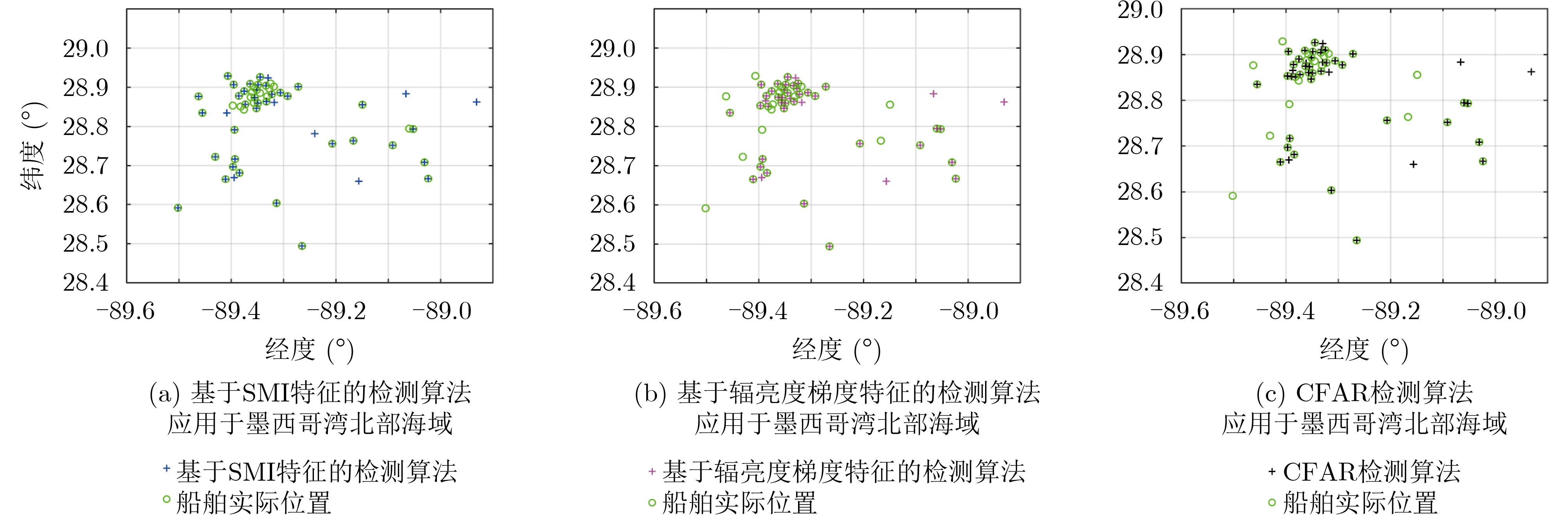
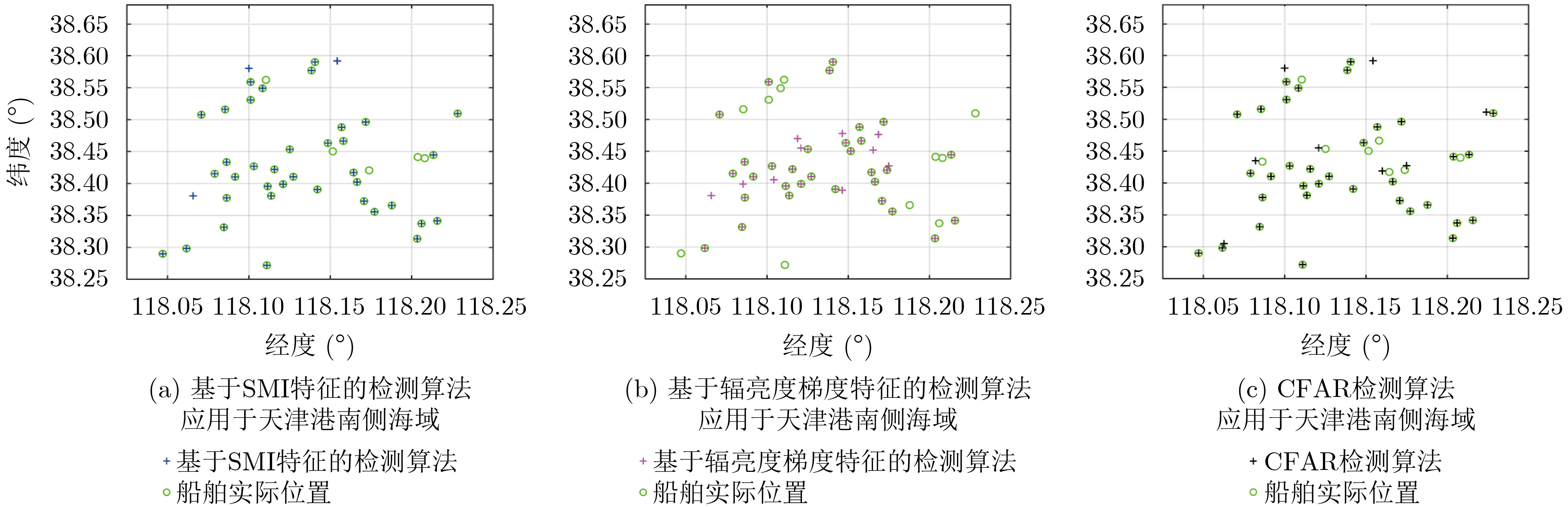
2023, 45(5): 1807-1816.
doi: 10.11999/JEIT220445
Abstract:
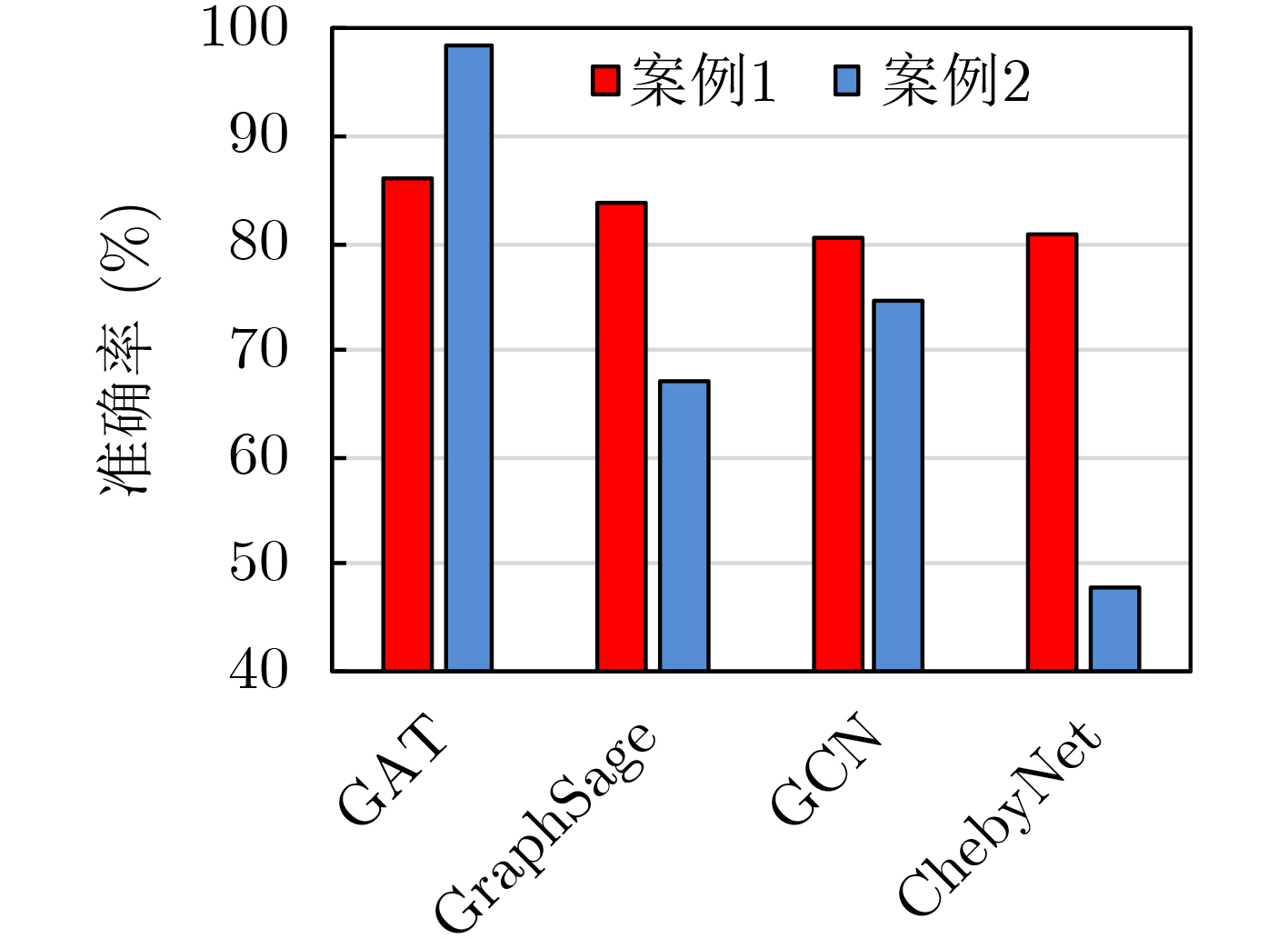
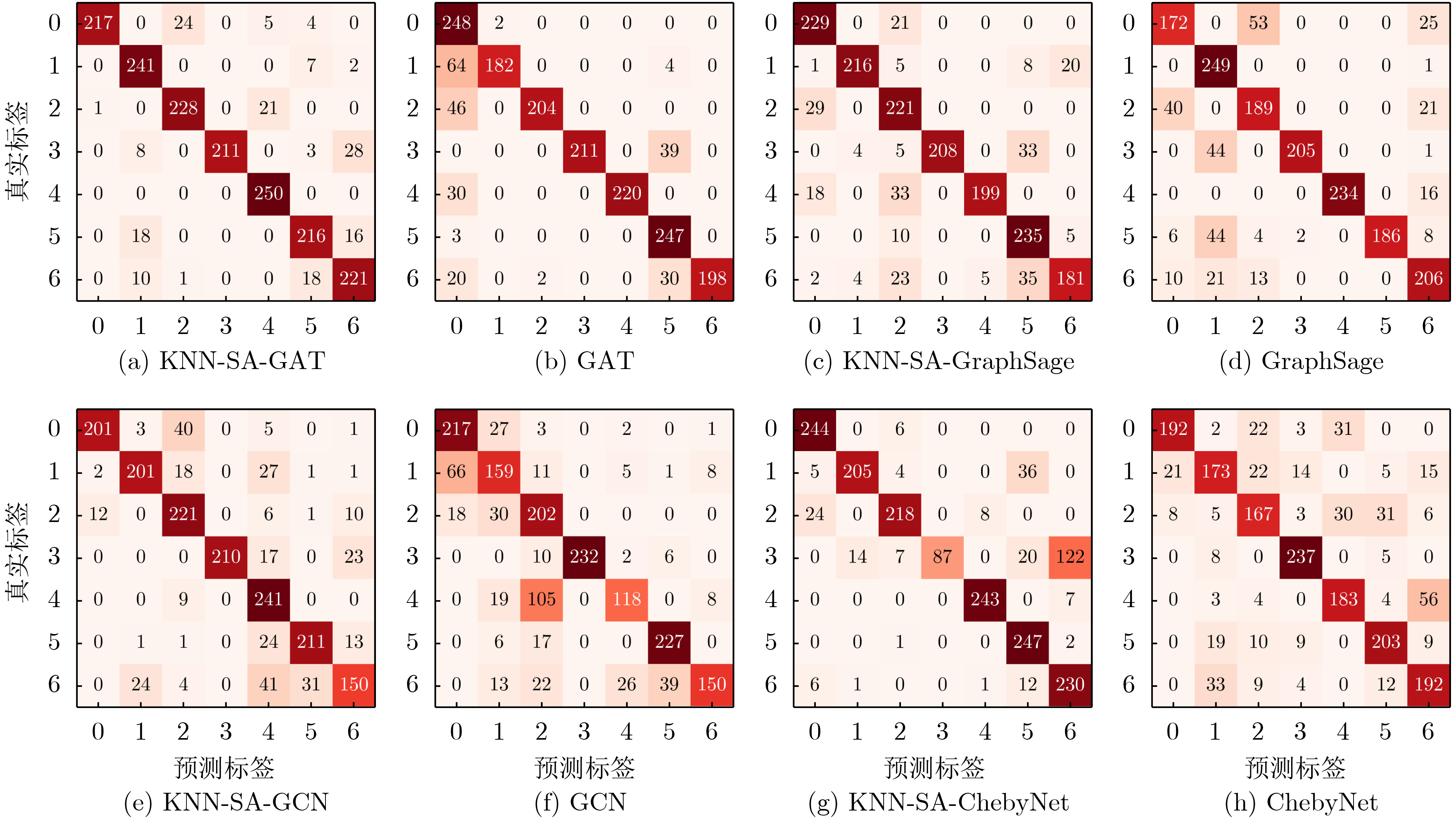
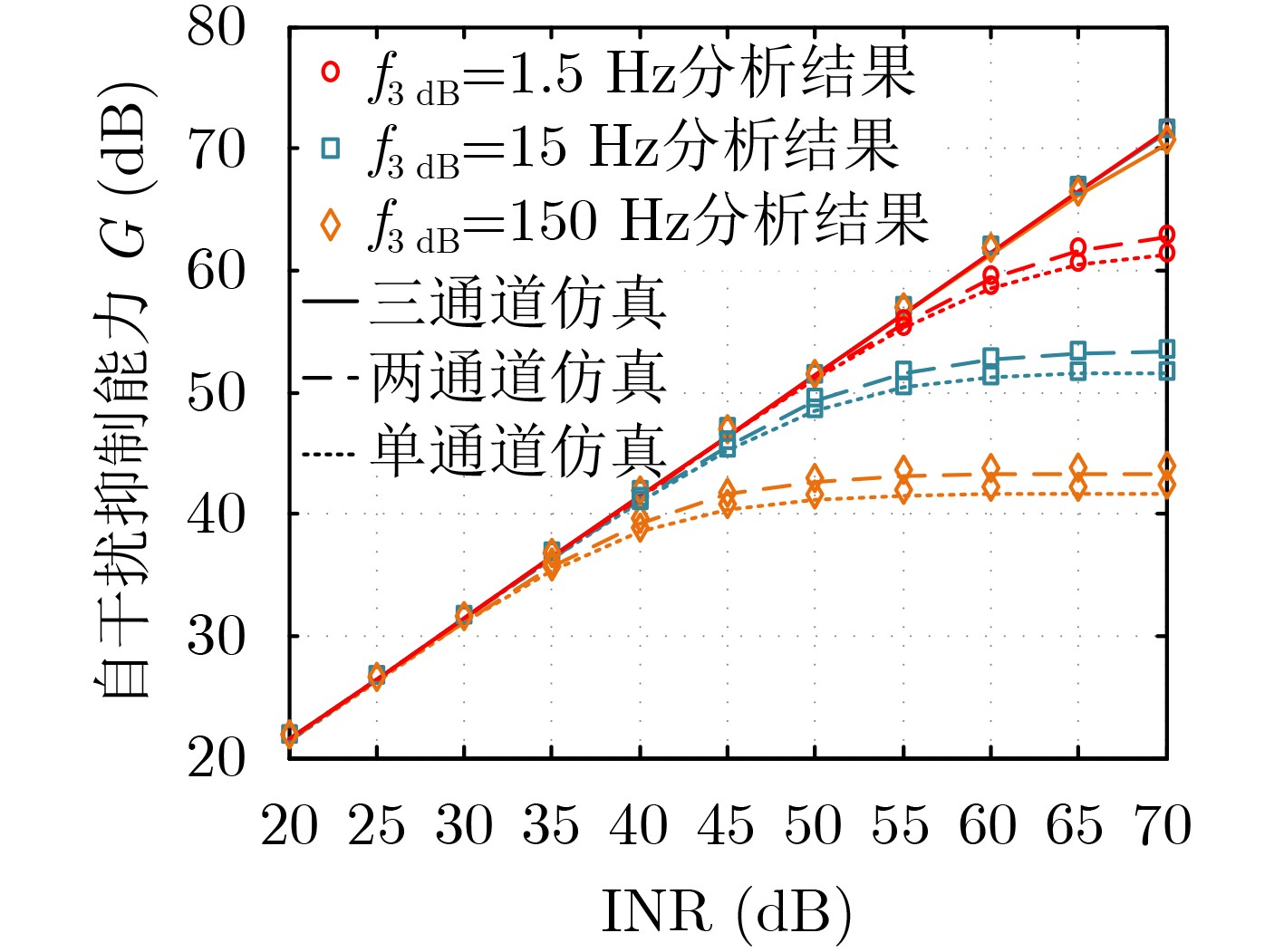
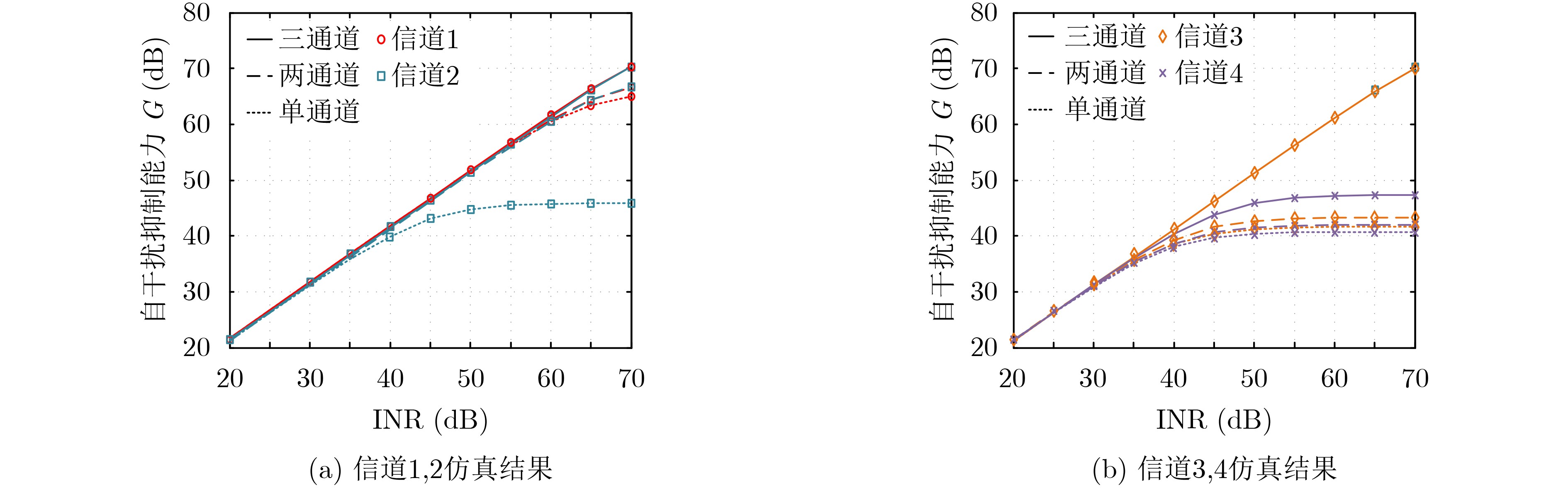
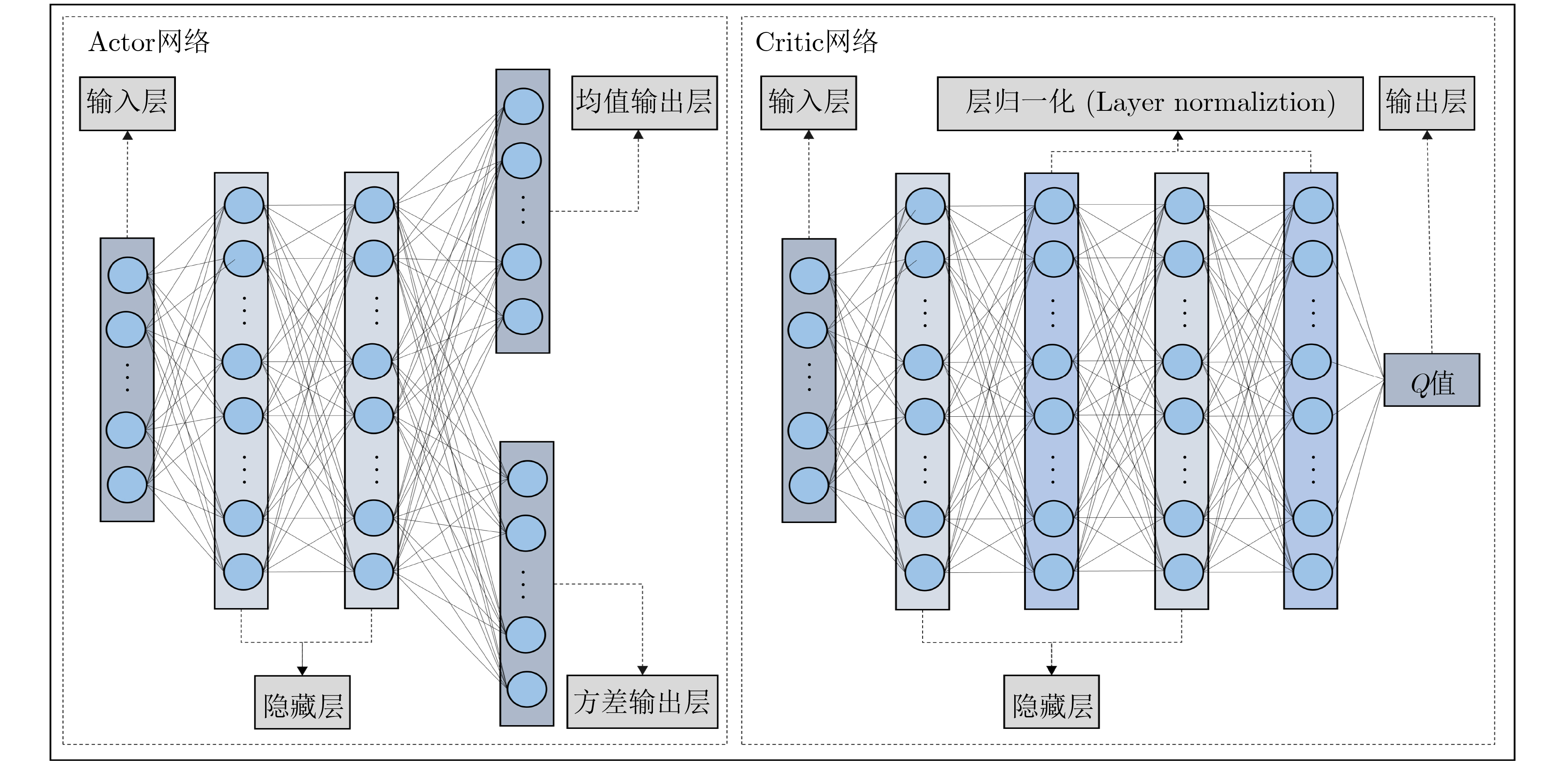
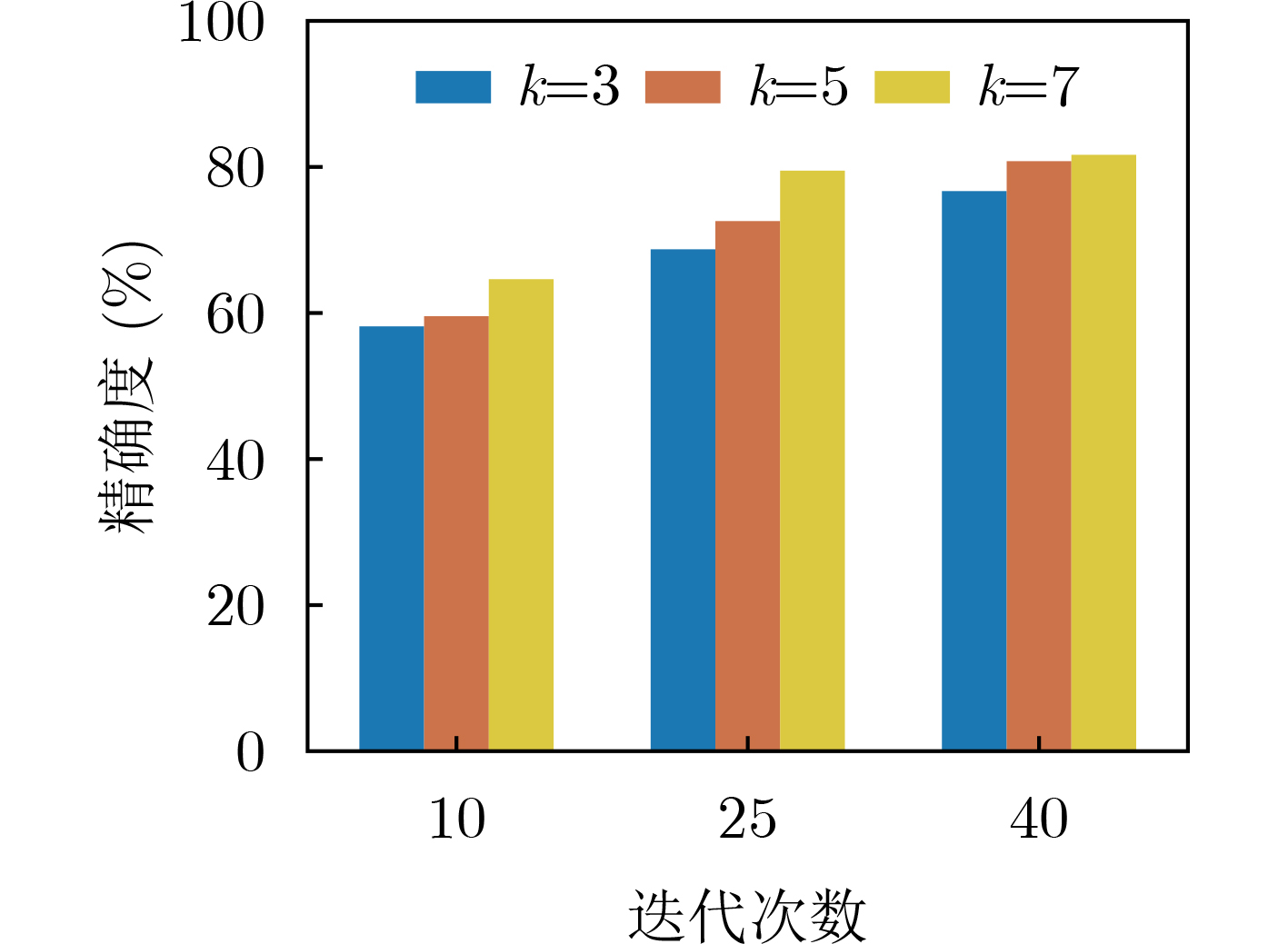
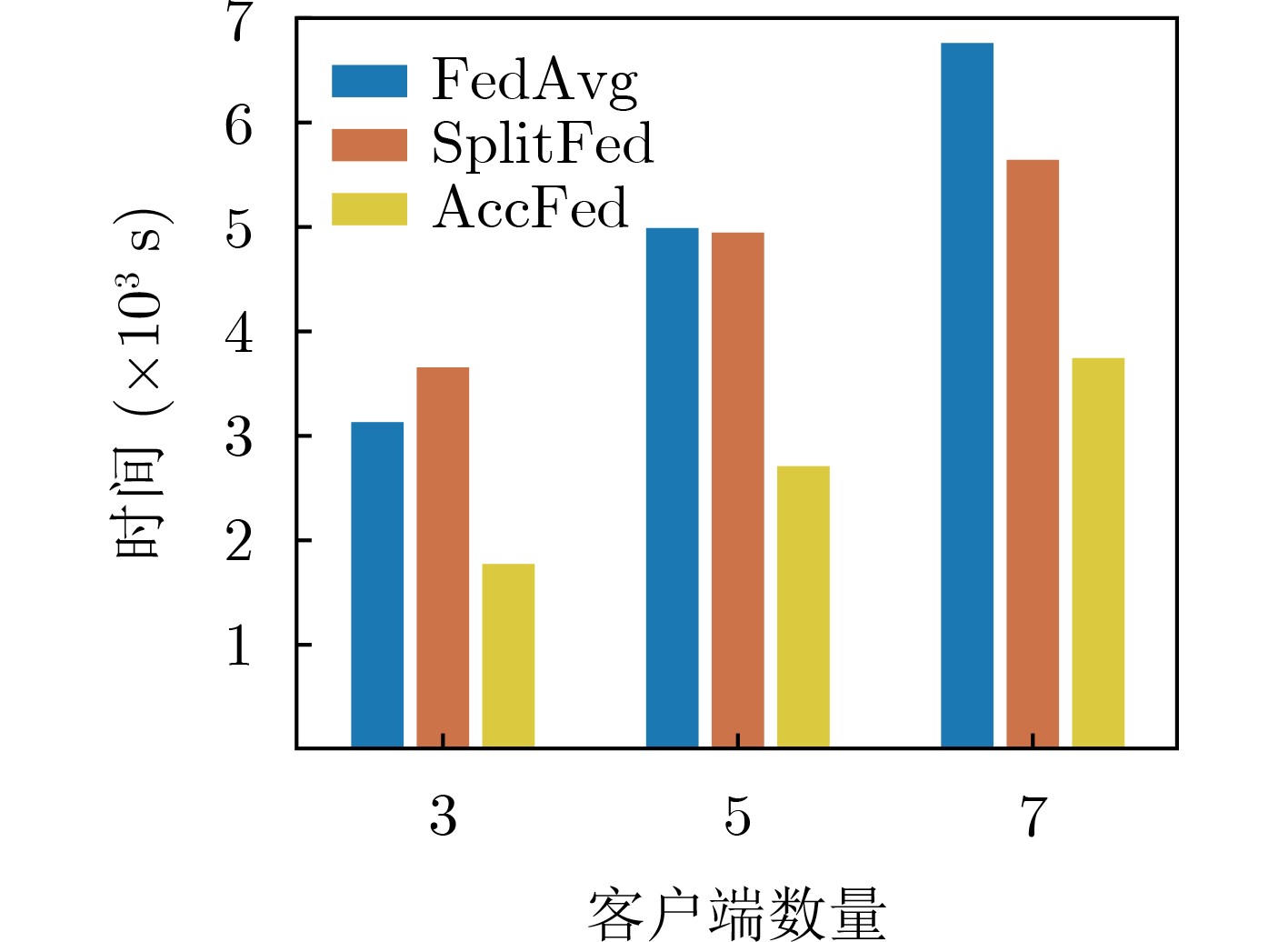
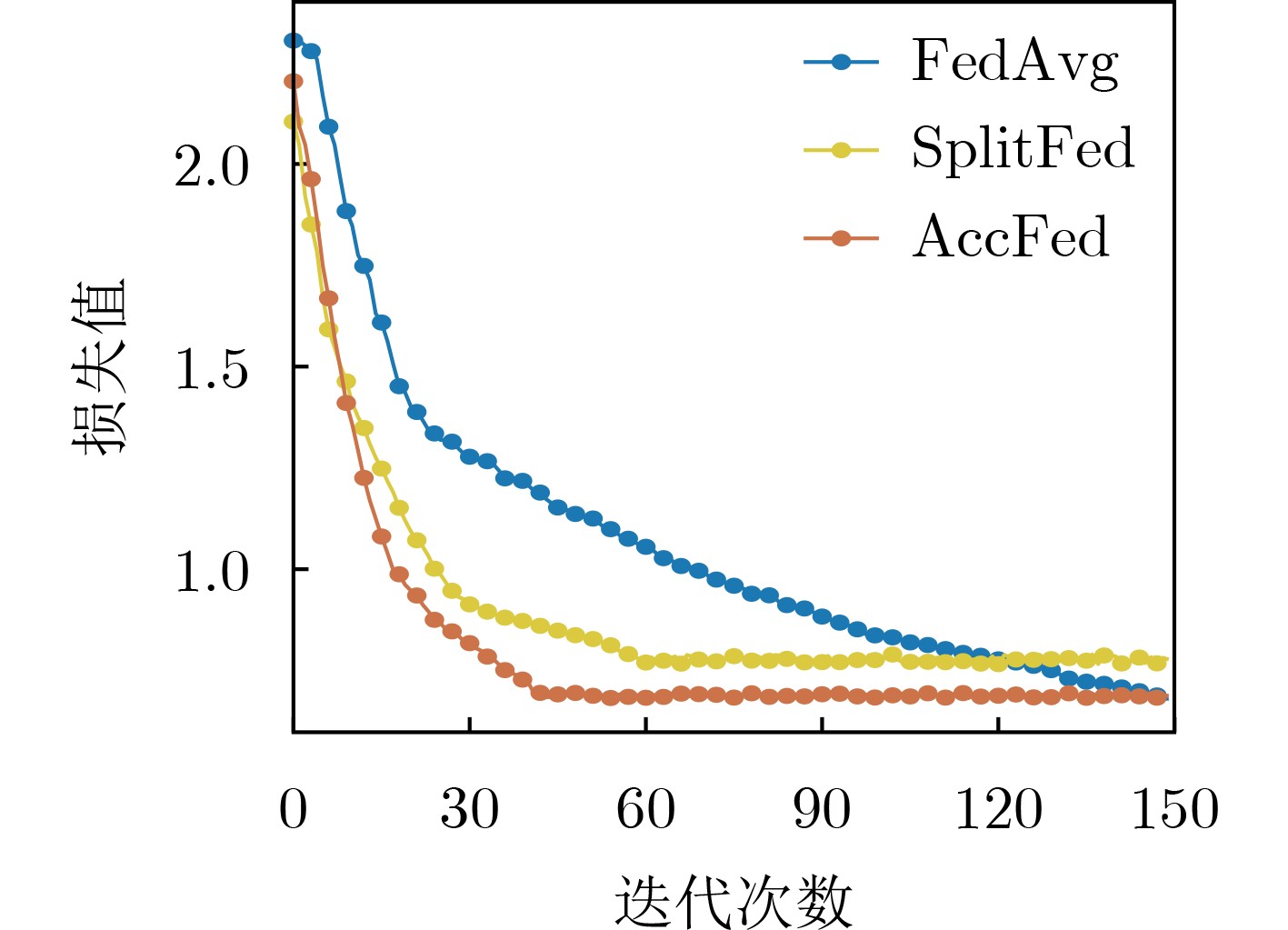
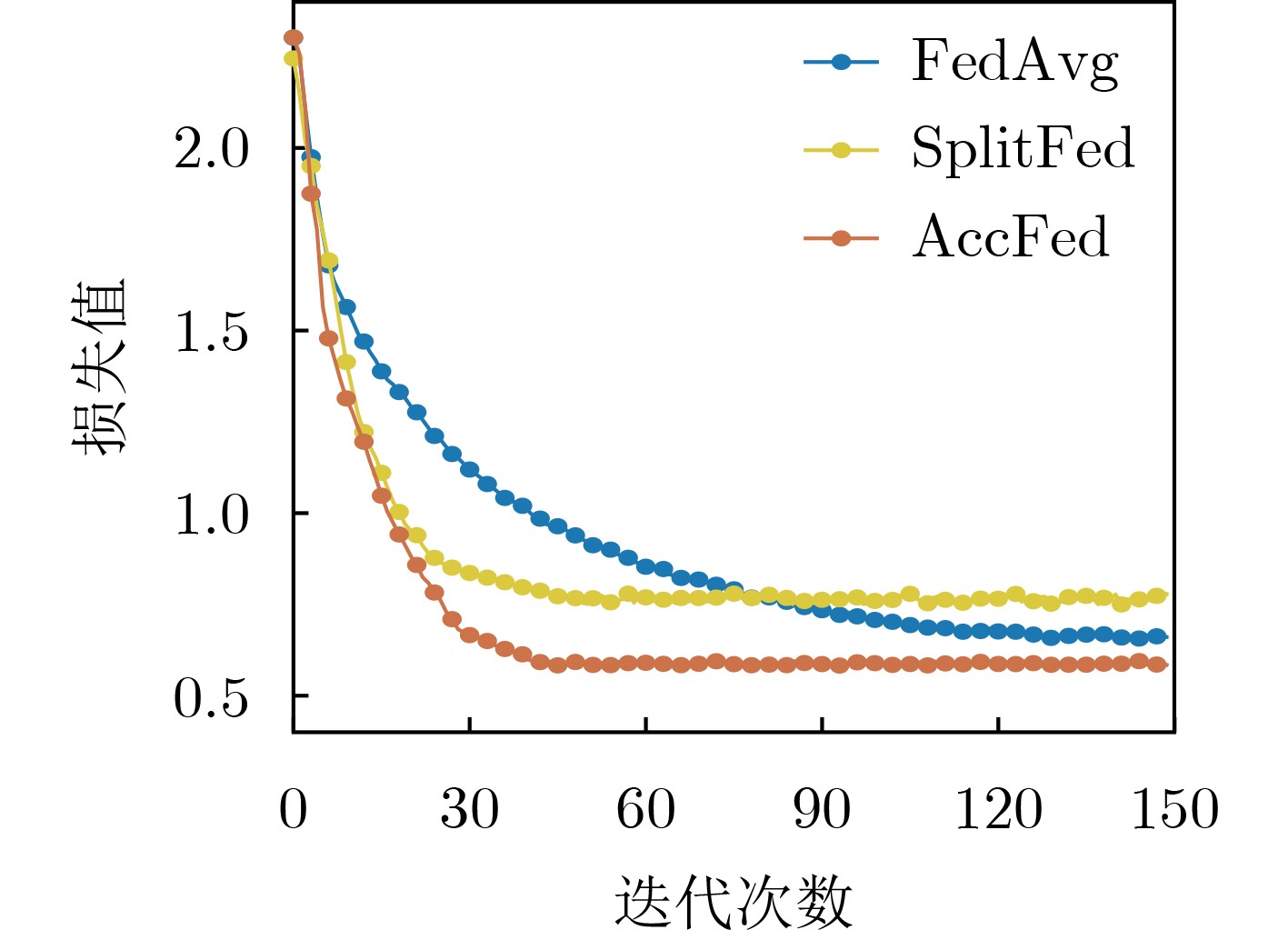
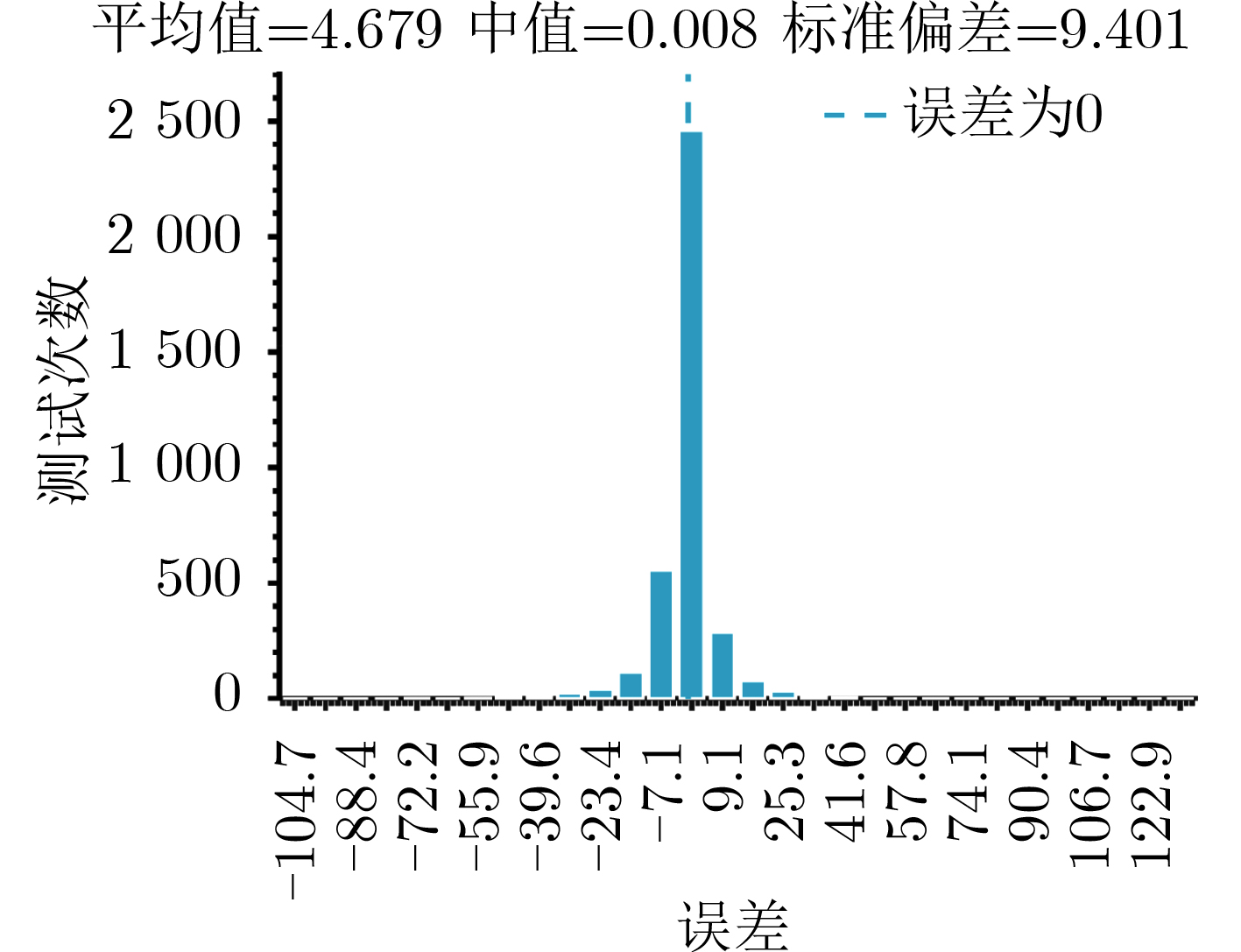
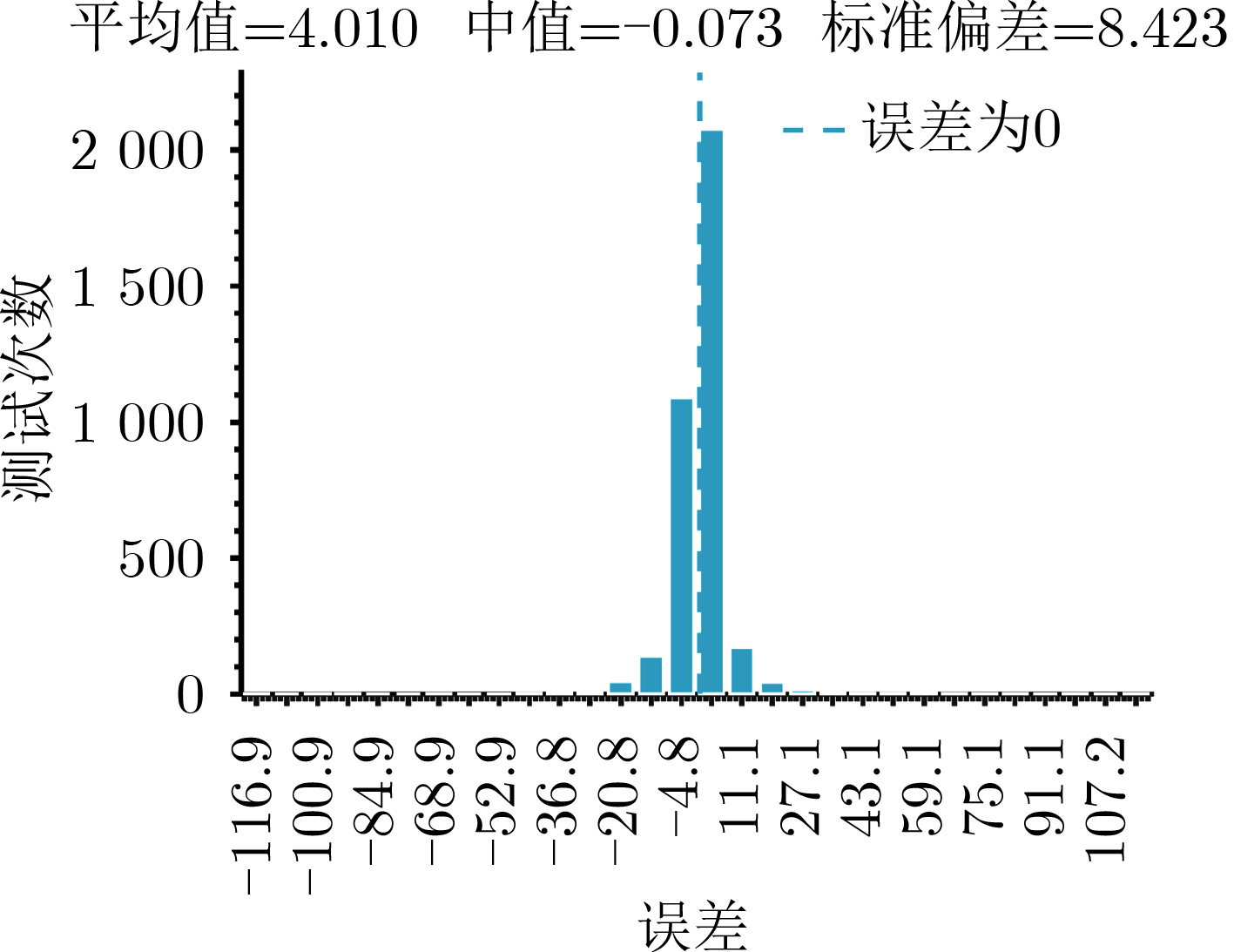
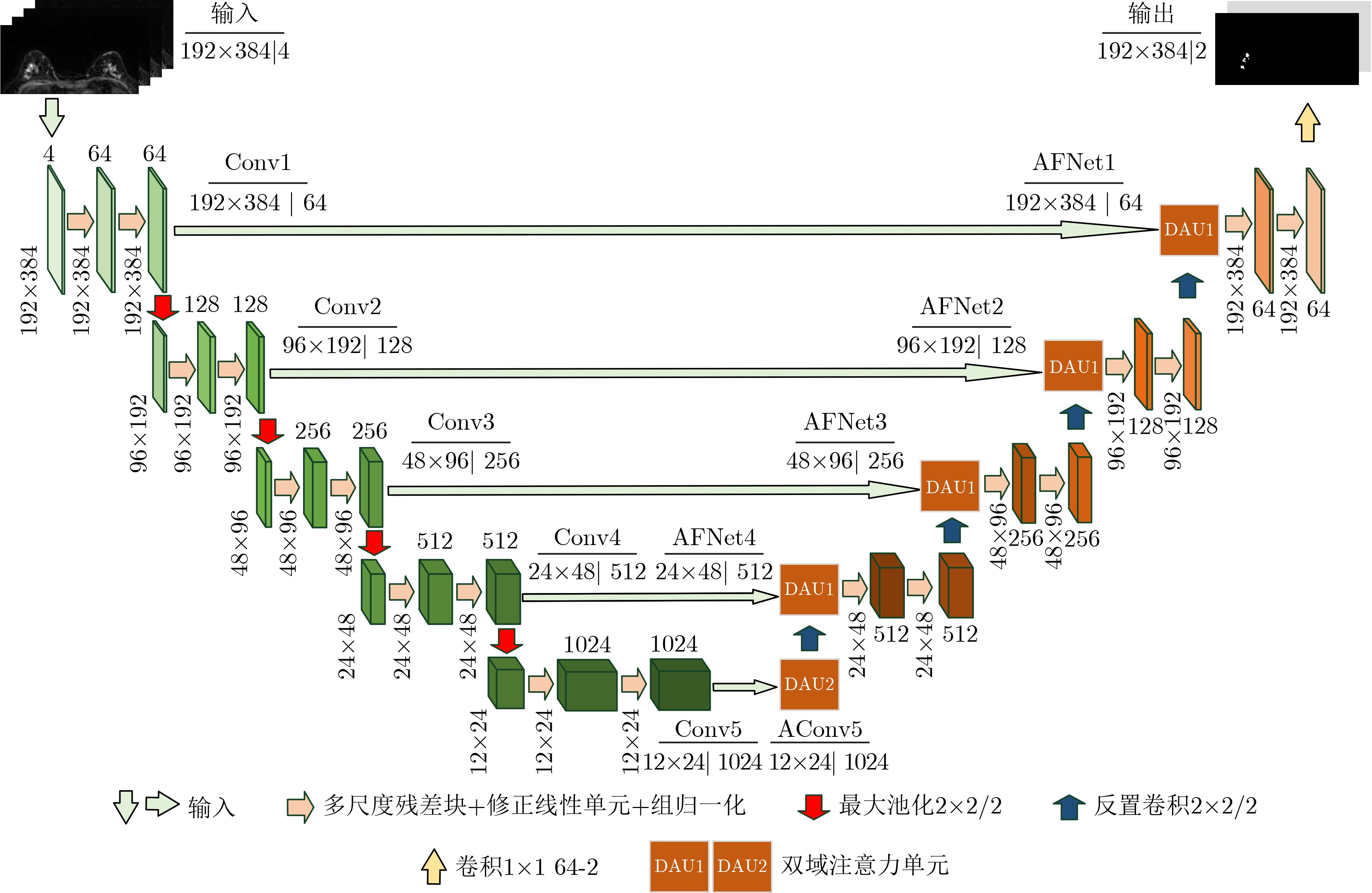
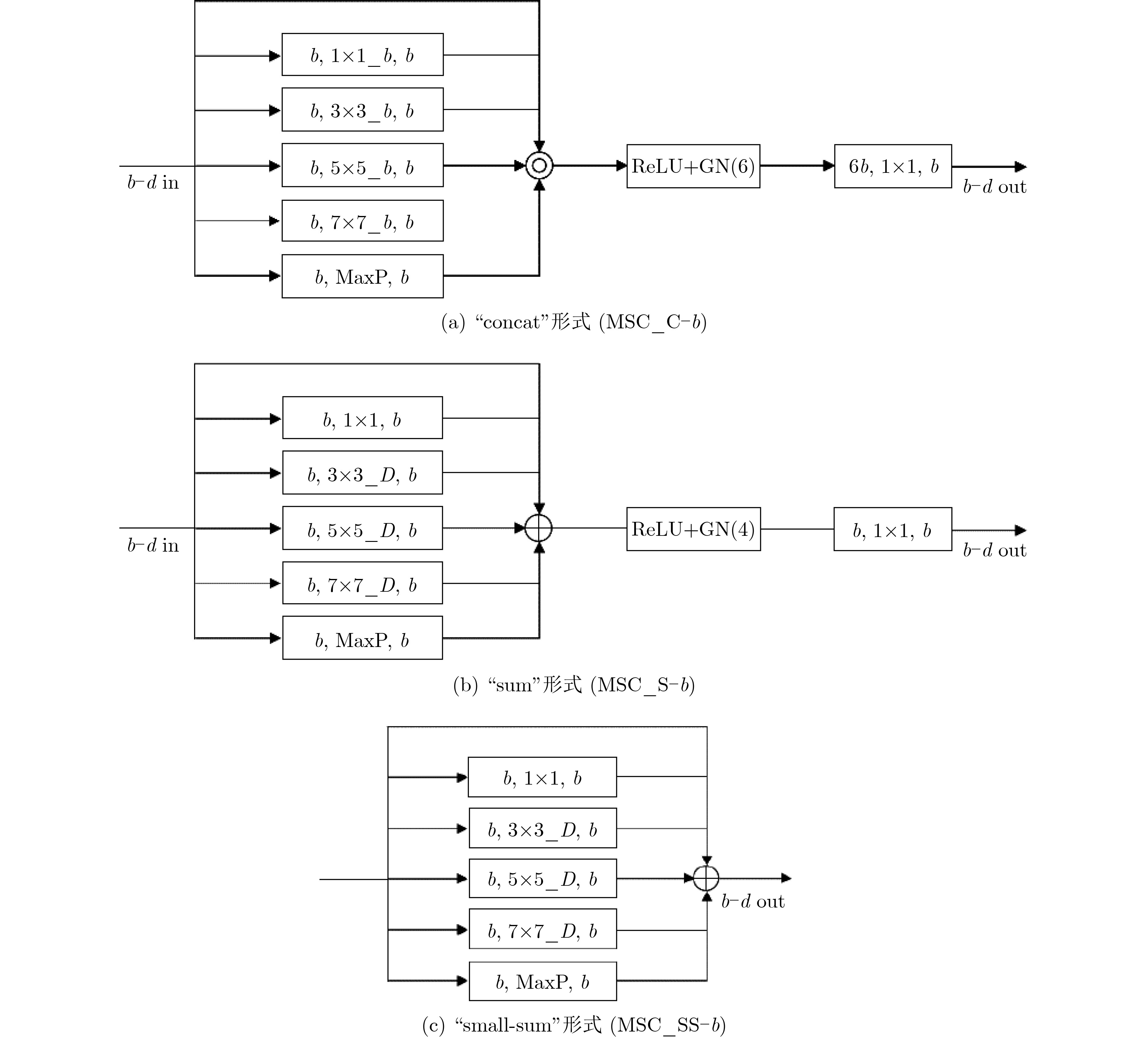
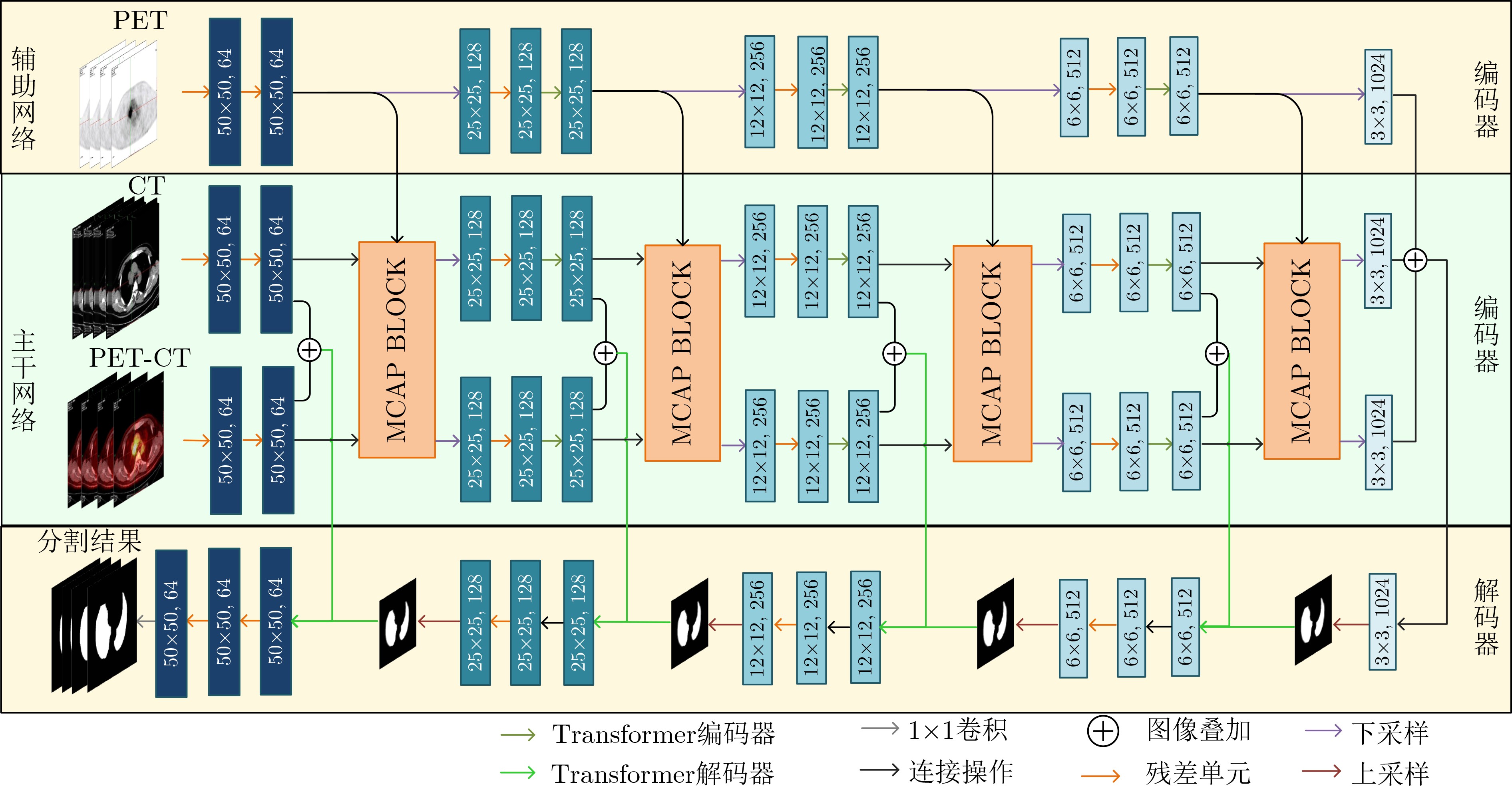
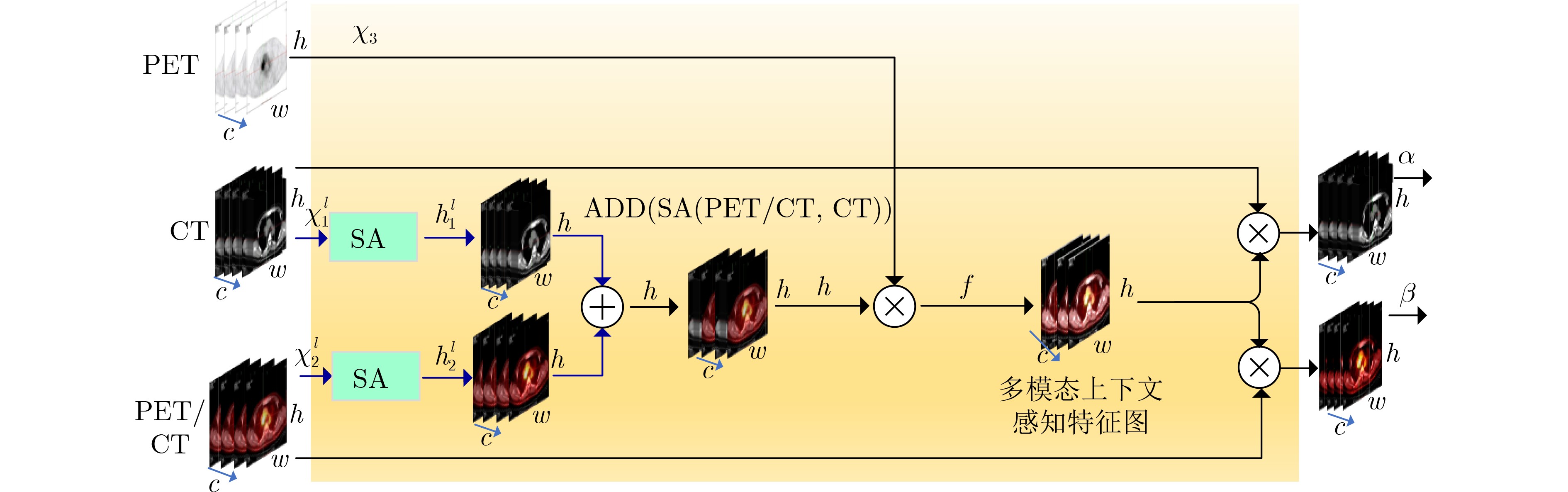
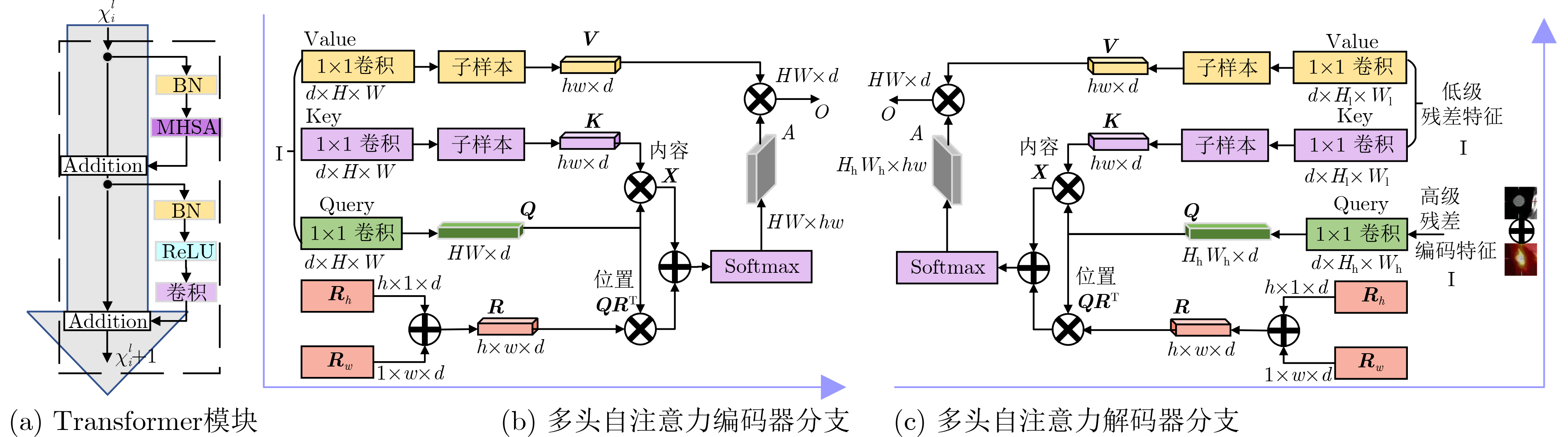
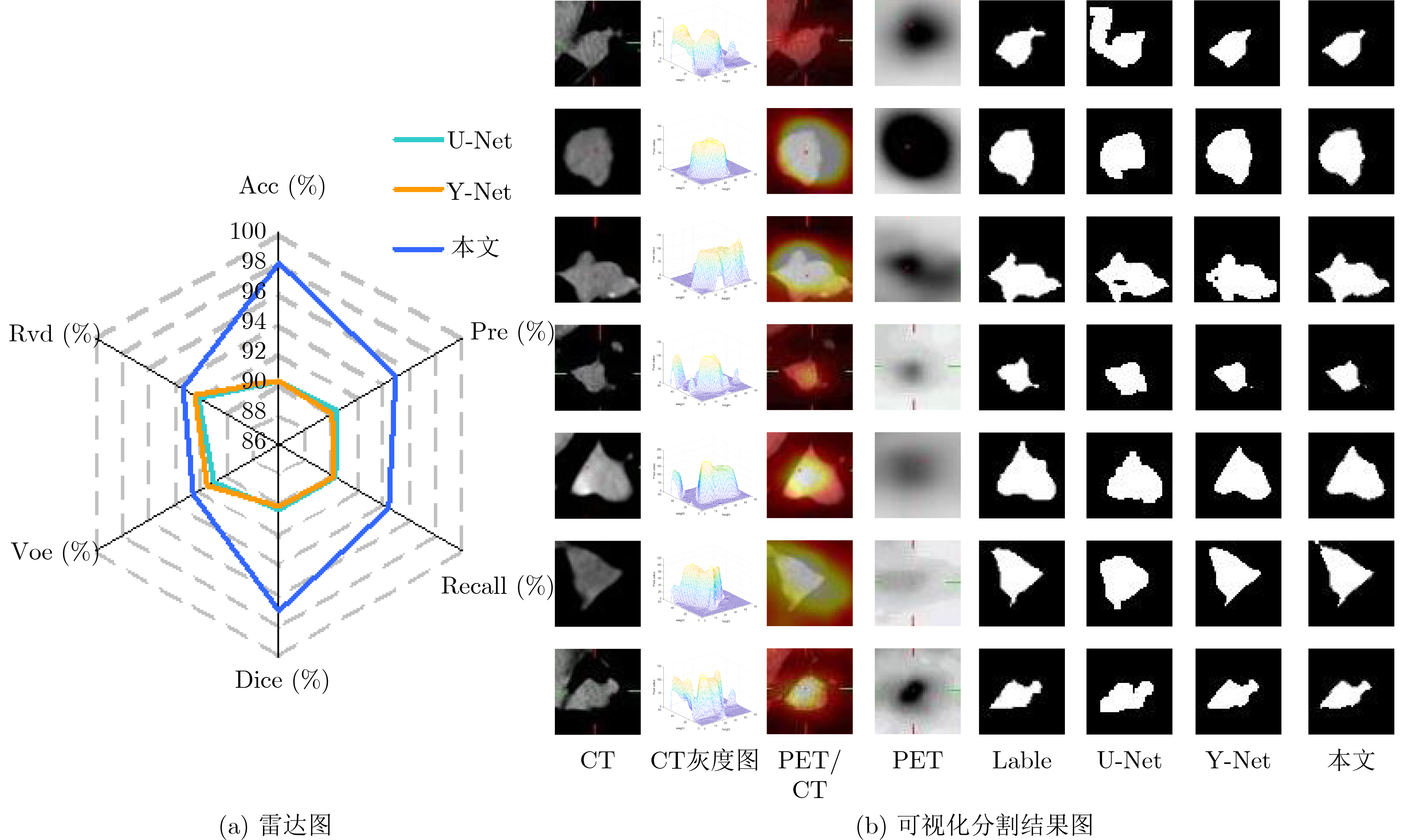
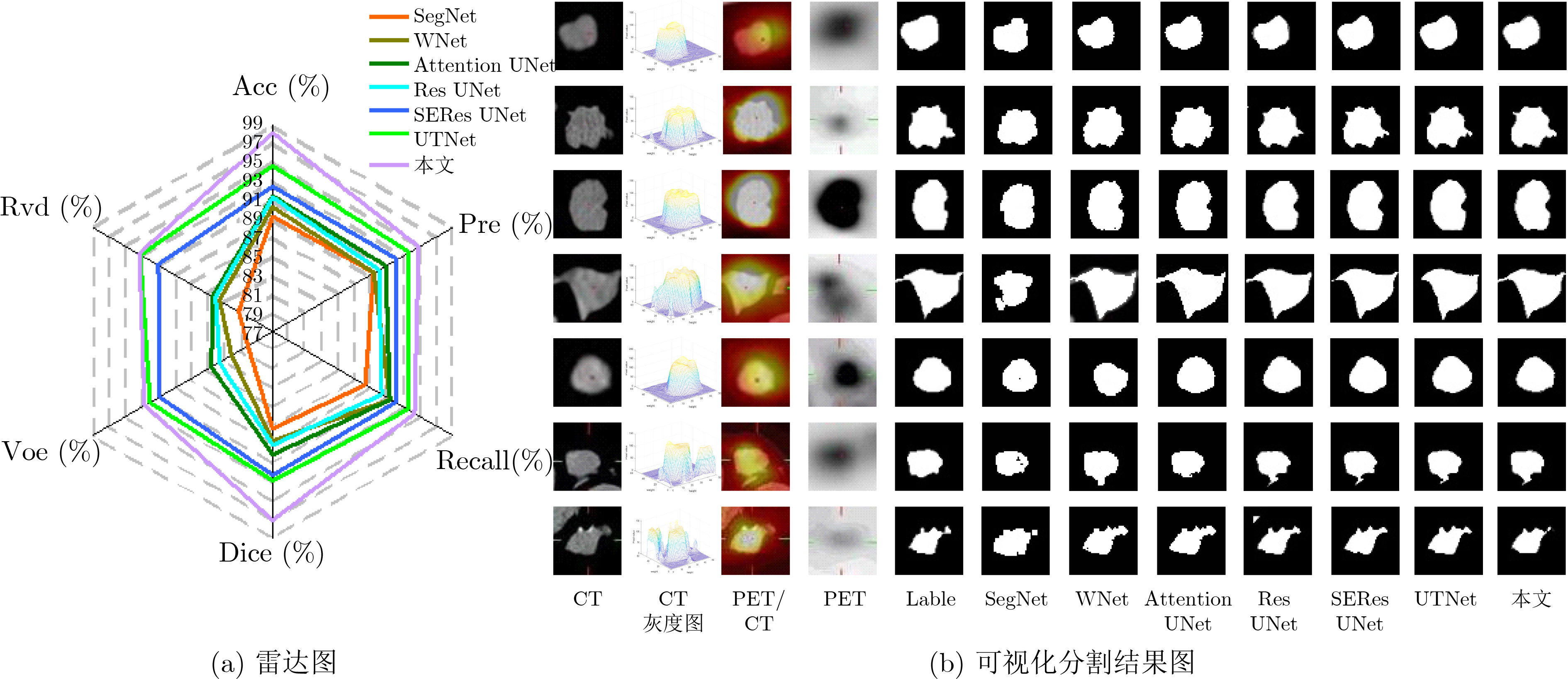
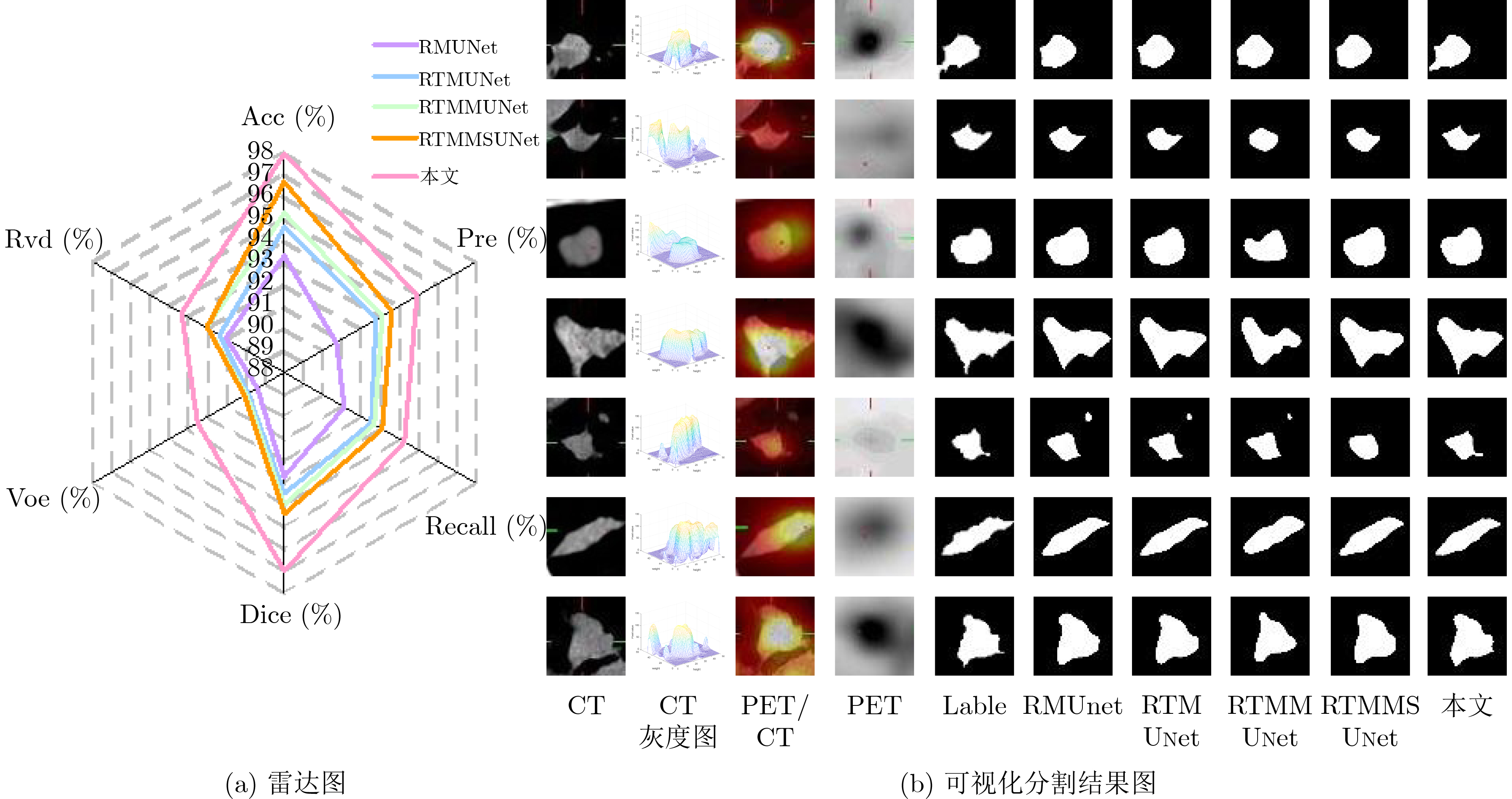
Cross-modal medical images can provide more semantic information at the same lesion. In view of the U-Net network uses mainly single-modal images for segmentation, the cross-modal and contextual semantic correlations are not fully considered. Therefore, a cross-modal and contextual semantic-oriented medical image segmentation C2 Transformer U-Net model is proposed. The main idea of this model is: first, a backbone and auxiliary U-Net network structure is proposed in the encoder part to extract semantic information of different modalities; Then, the Multi-modal Context semantic Awareness Processor (MCAP) is designed to extract effectively the semantic information of the same lesion across modalities. After adding the two modal images using the backbone network in the skip connection, it is passed to the Transformer decoder. This enhances the expression ability of the model to the lesion; Secondly, the pre-activated residual unit and Transformer architecture are used in the encoder-decoder. On the one hand, the contextual feature information of the lesion is extracted, and on the other hand, the network pays more attention to the location information of the lesion when making full use of low-level and high-level features; Finally, the effectiveness of the algorithm is verified by using a clinical multi-modal lung medical image dataset. Comparative experimental results show that the Acc, Pre, Recall, Dice, Voe and Rvd of the proposed model for lung lesion segmentation are: 97.95%, 94.94%, 94.31%, 96.98%, 92.57% and 93.35%. For the segmentation of lung lesions with complex shapes, it has high accuracy and relatively low redundancy. Overall, it outperforms existing state-of-the-art methods.