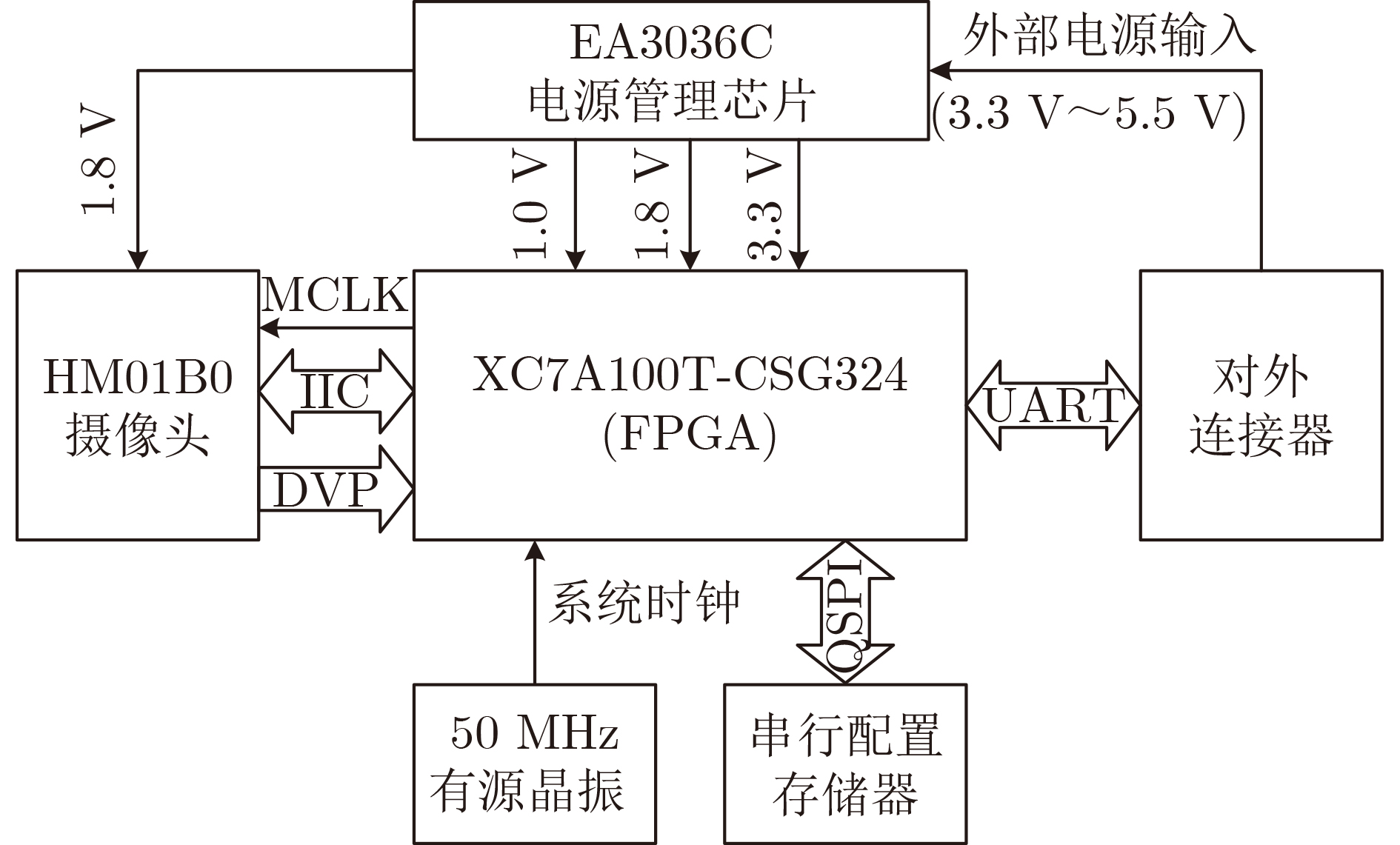
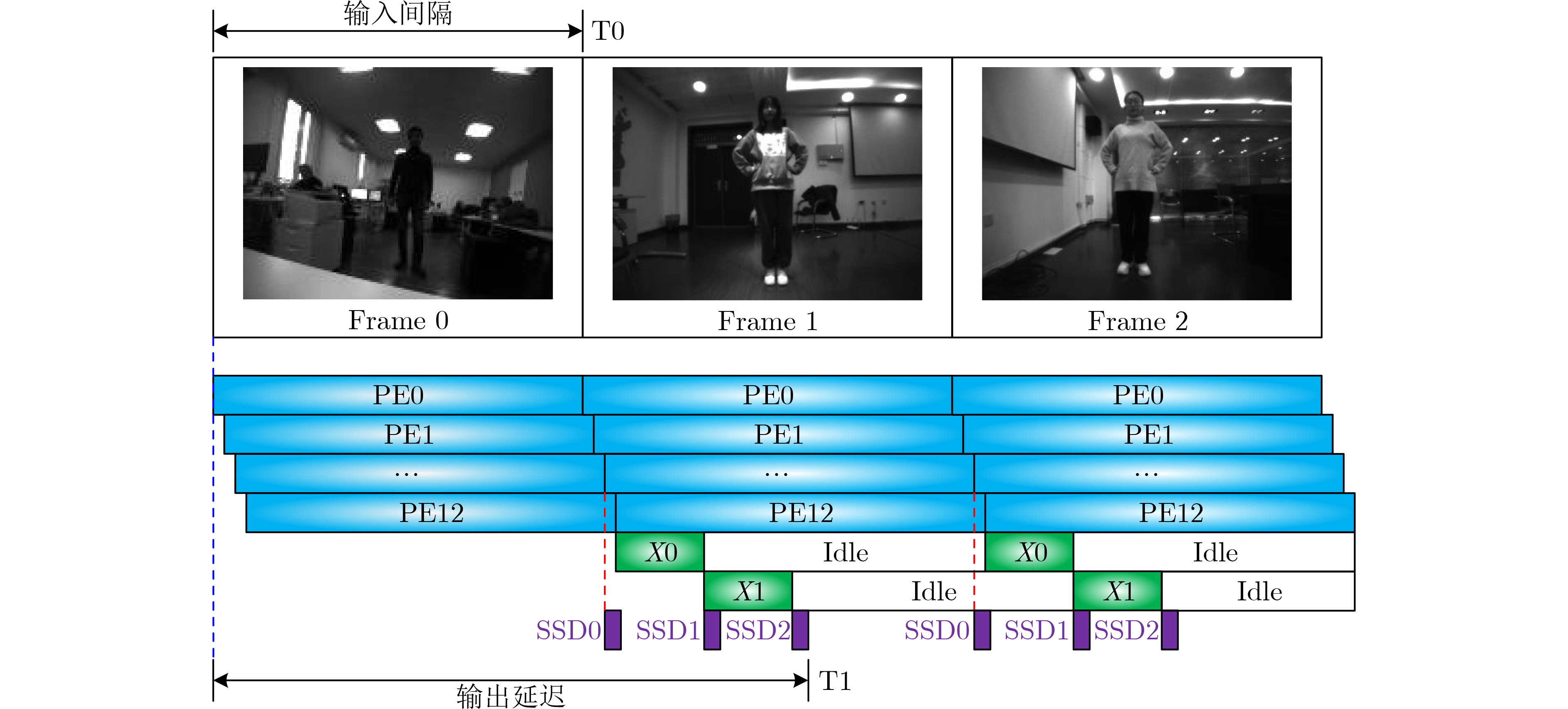
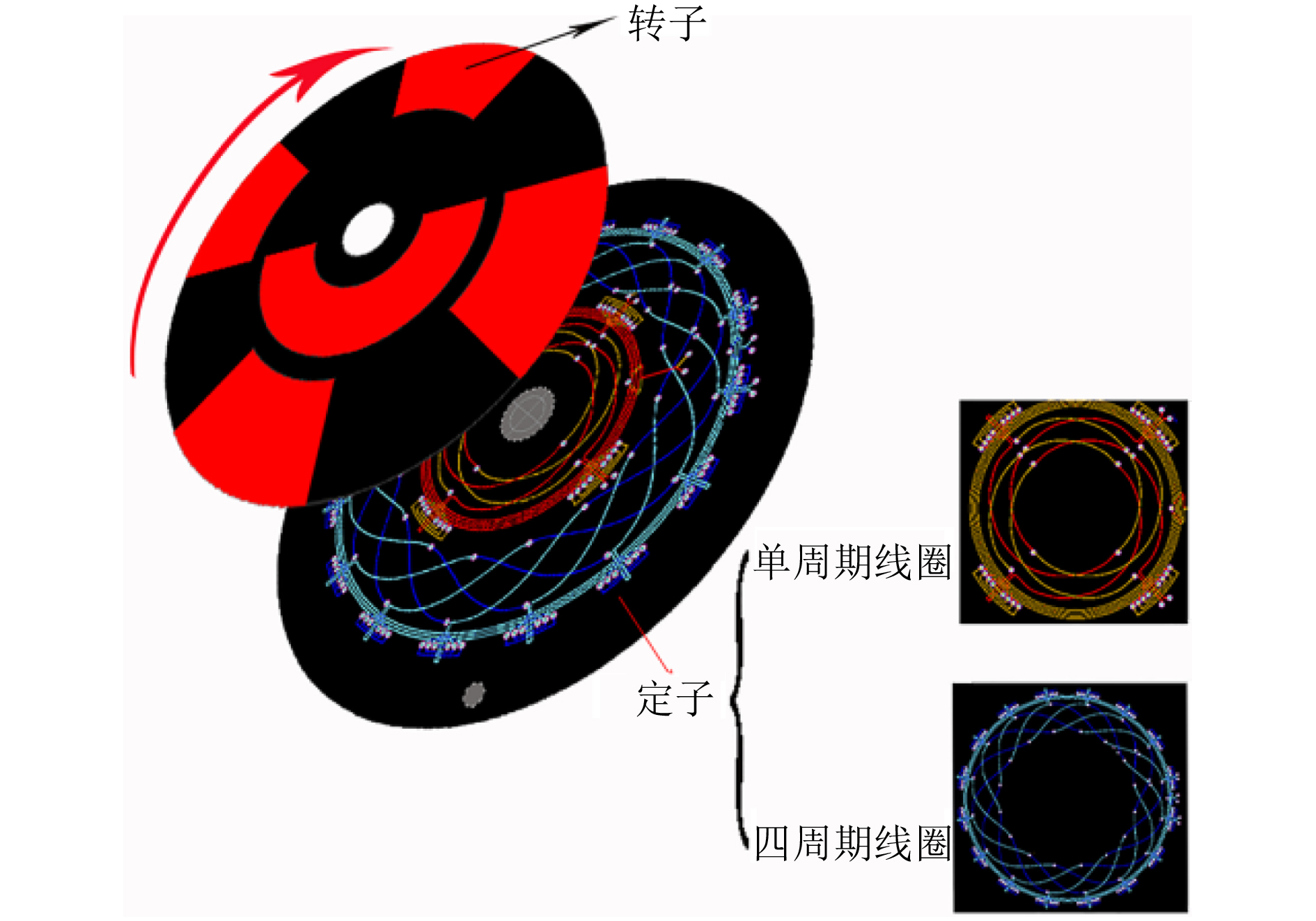
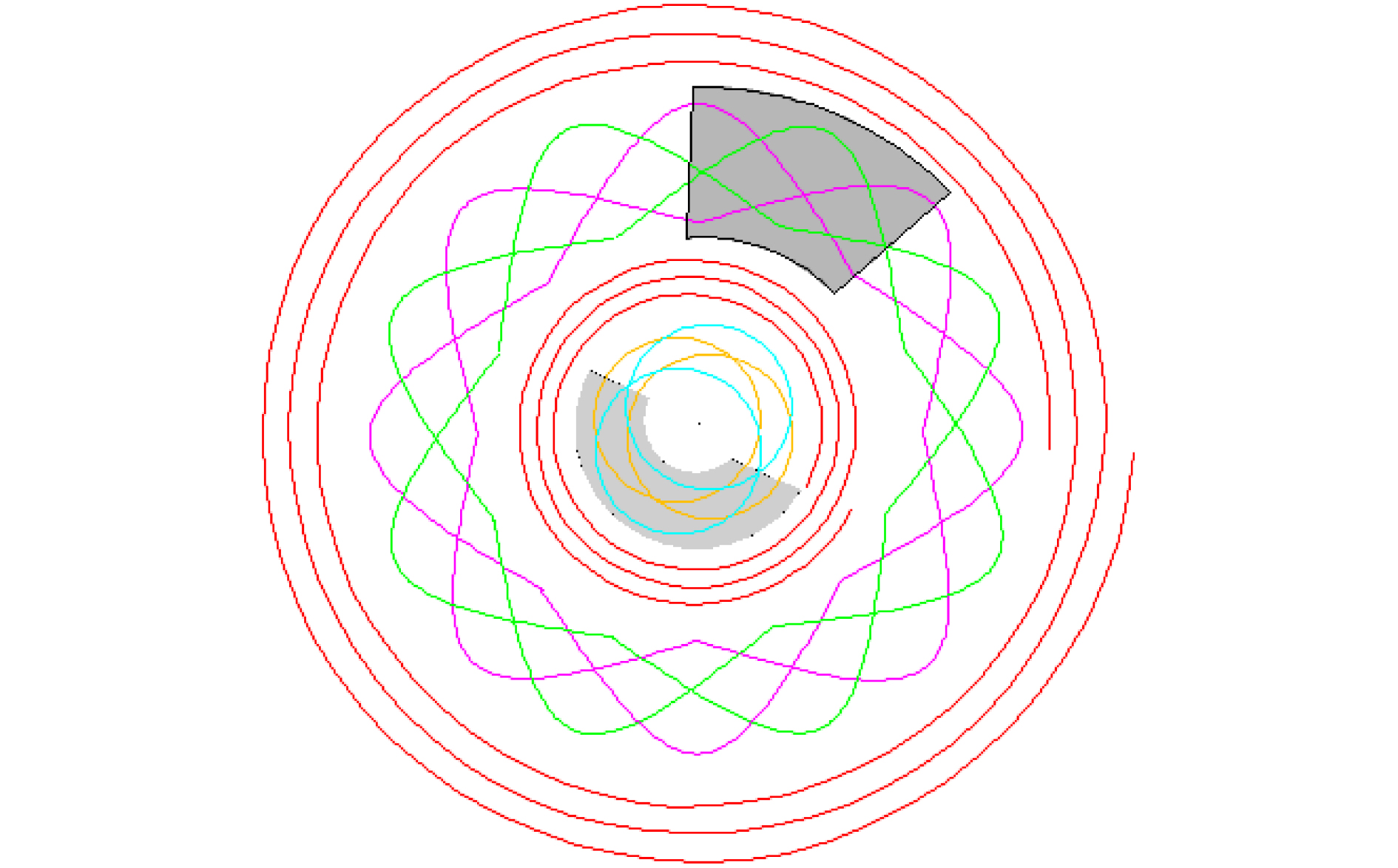
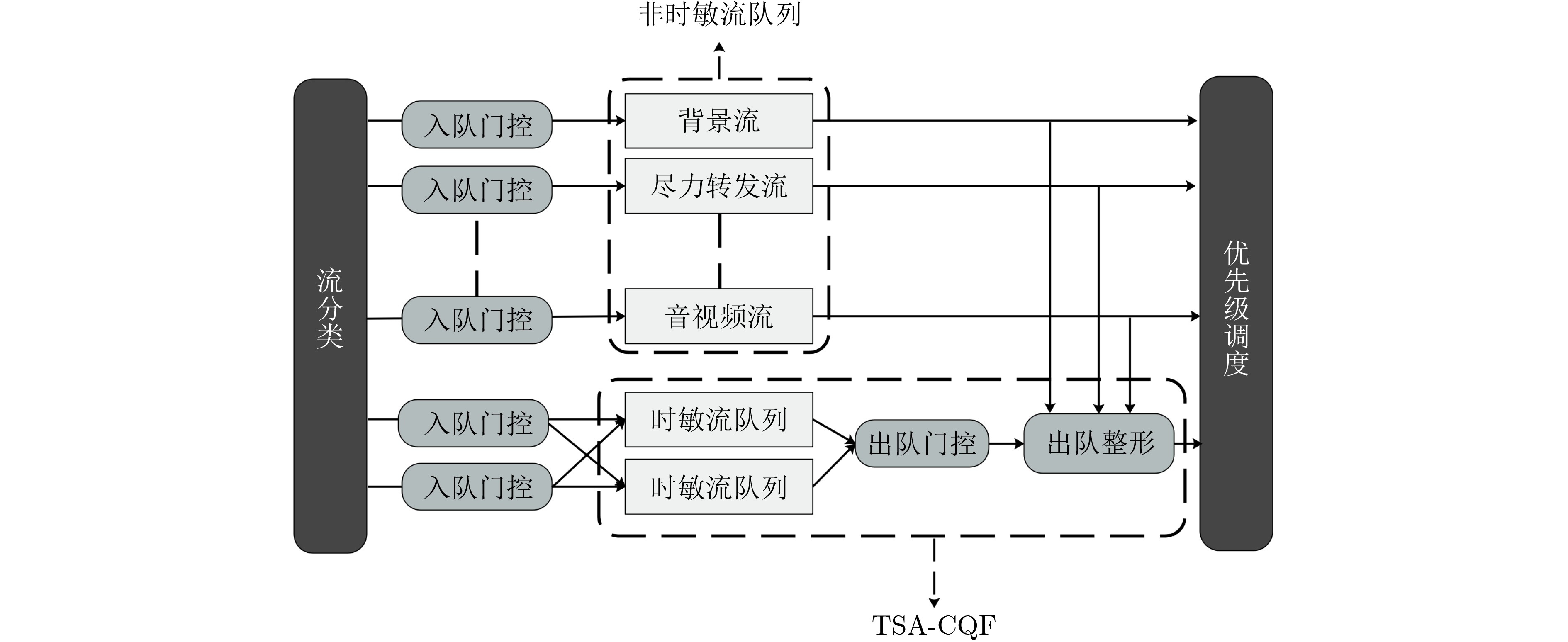
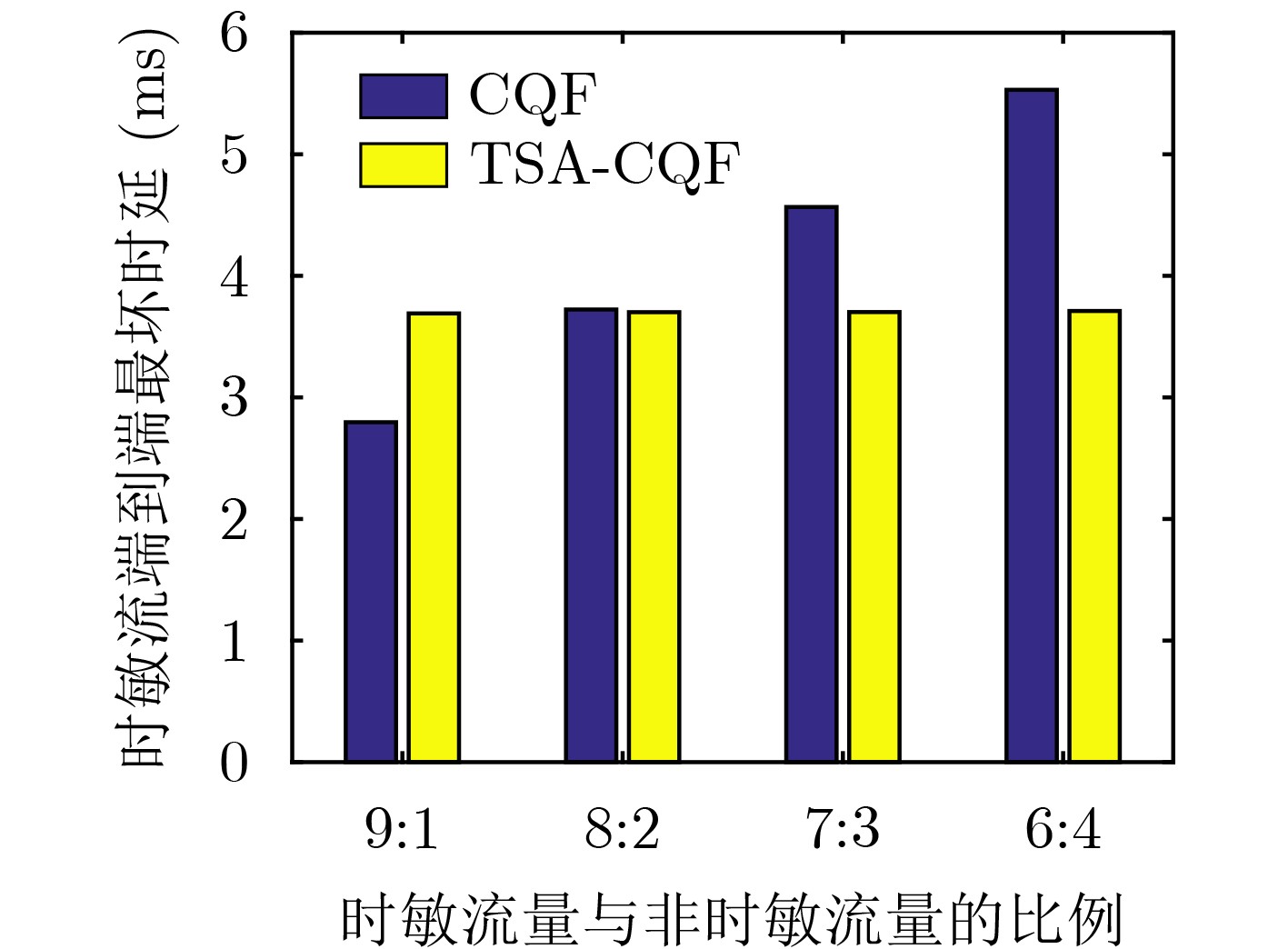
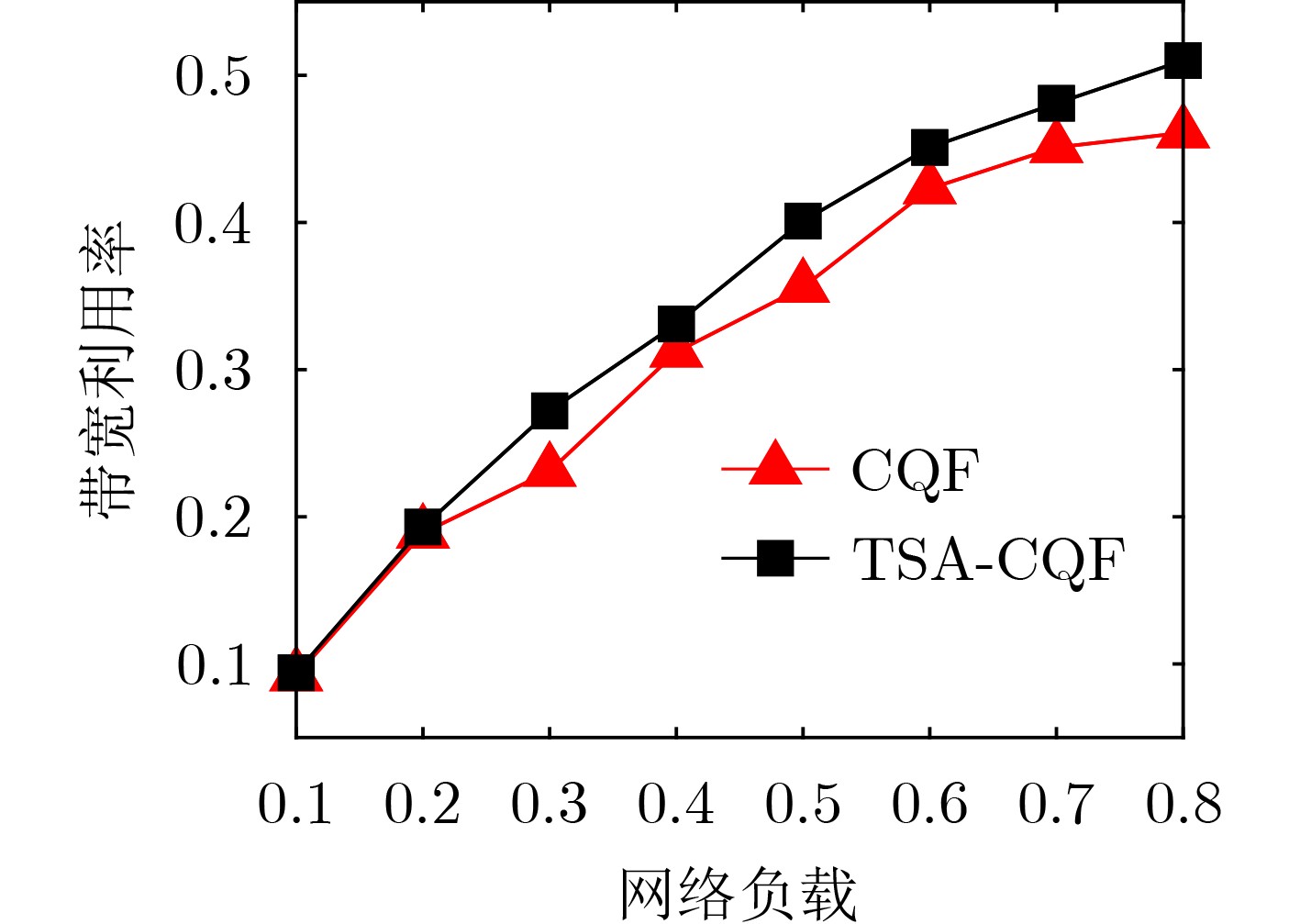
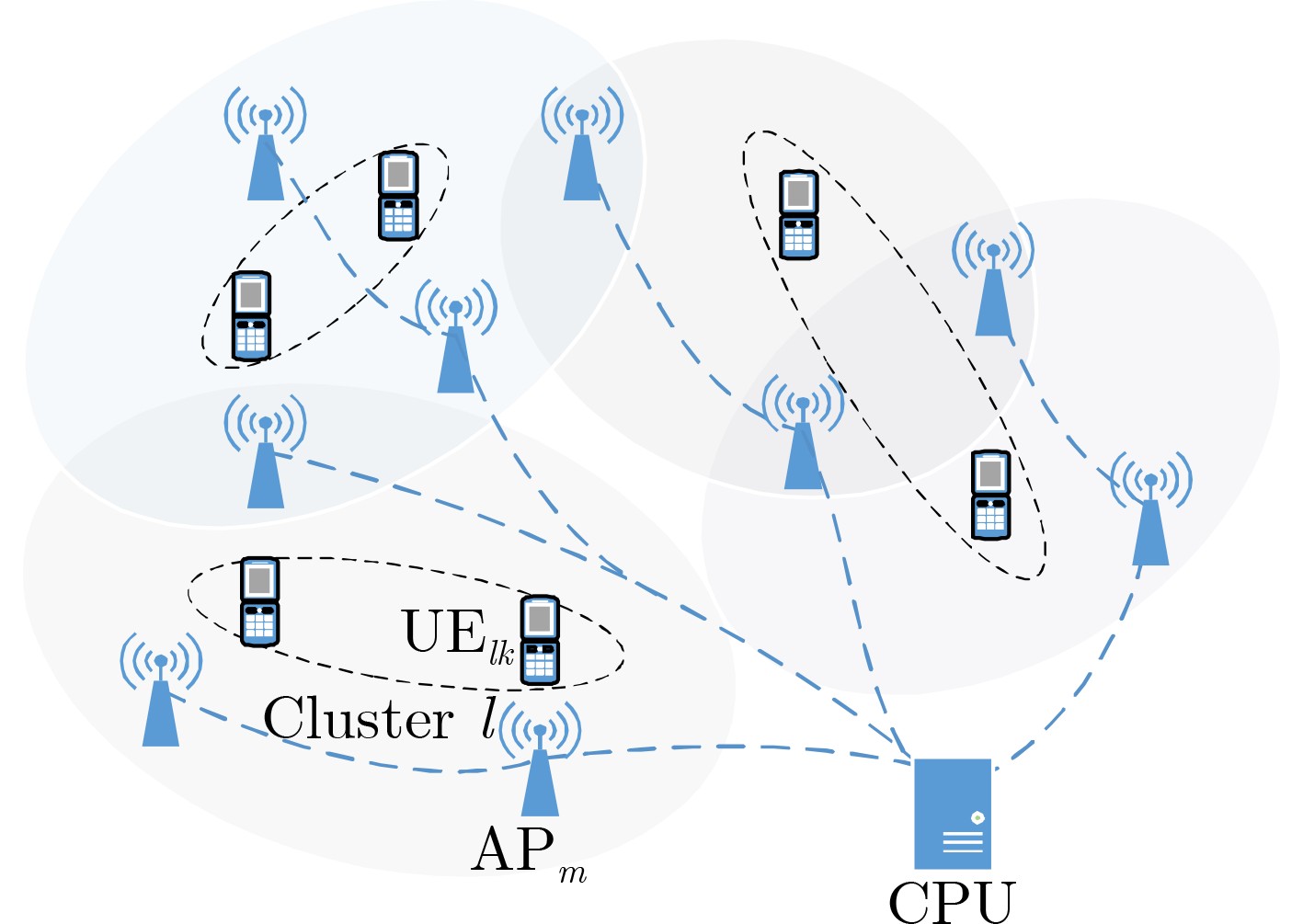
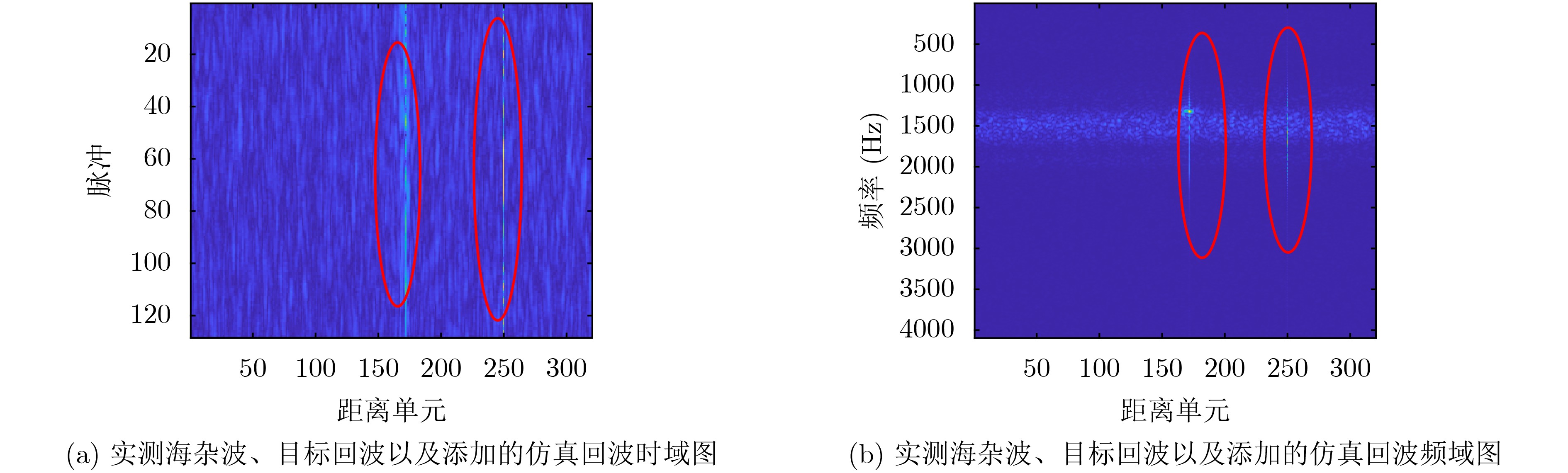
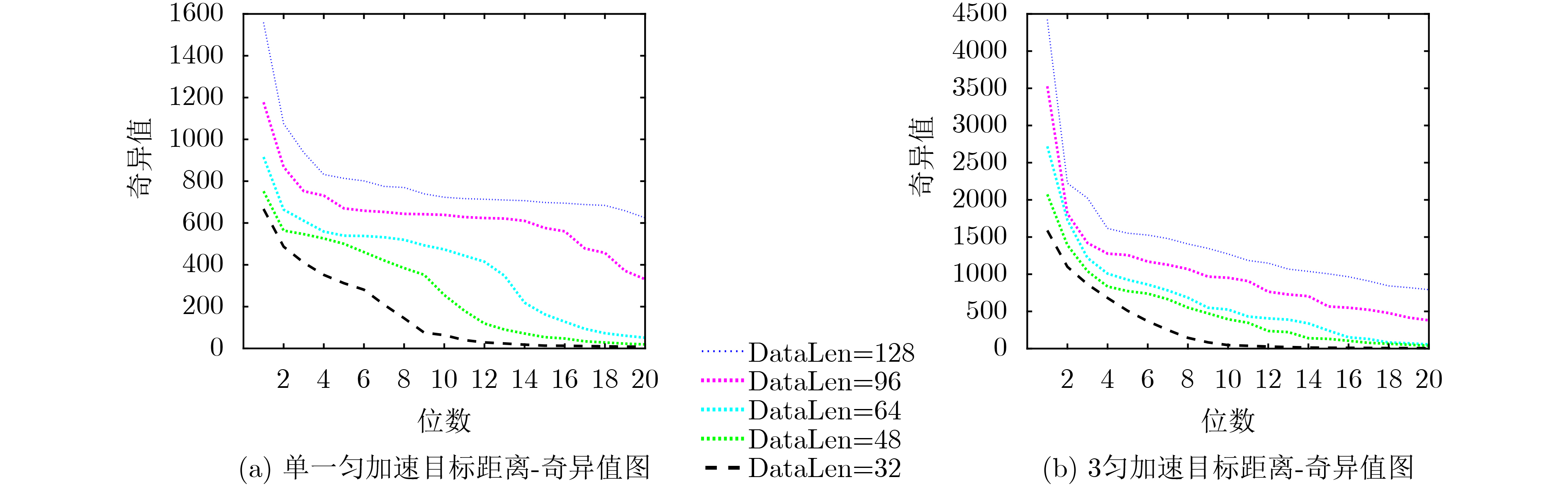
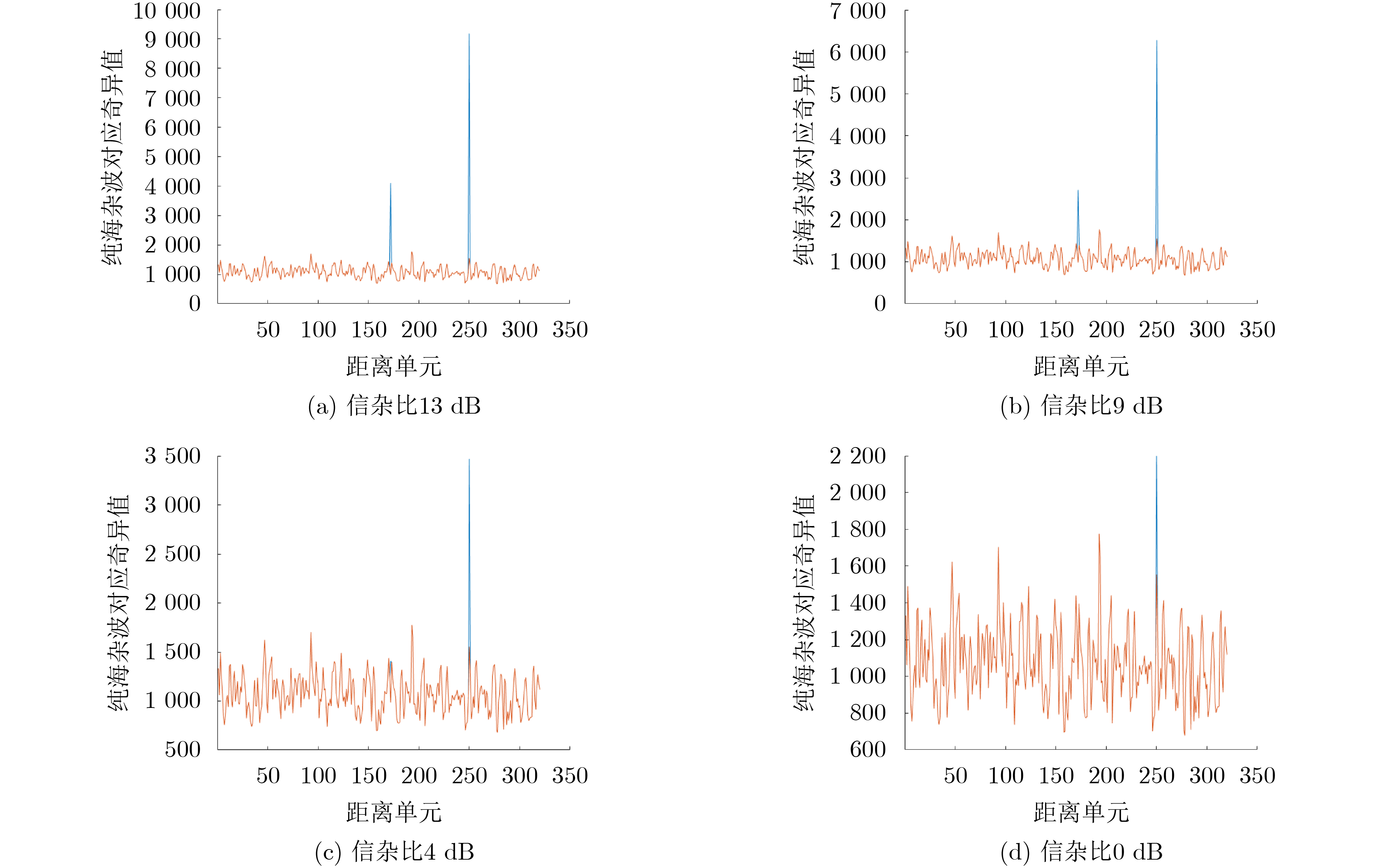
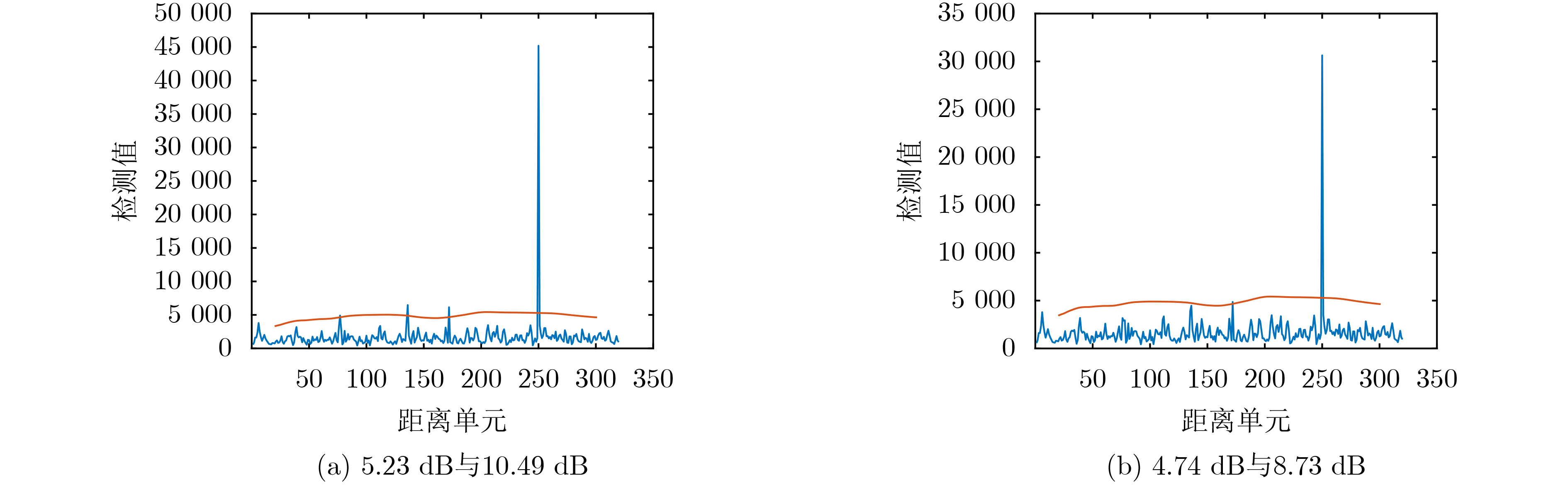
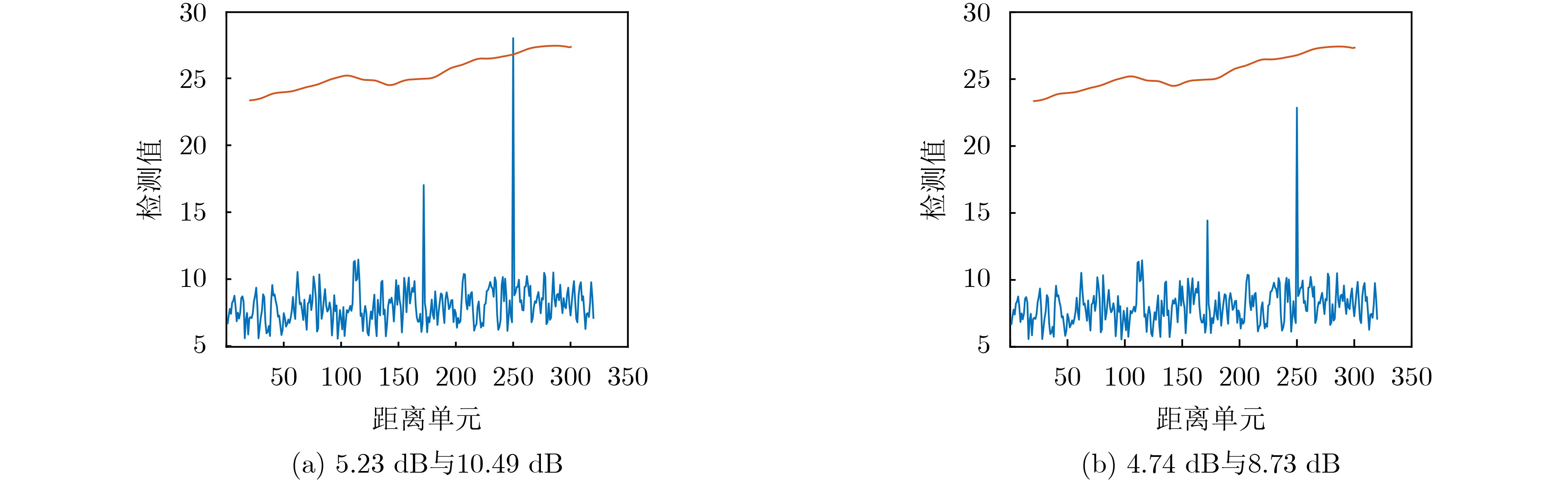
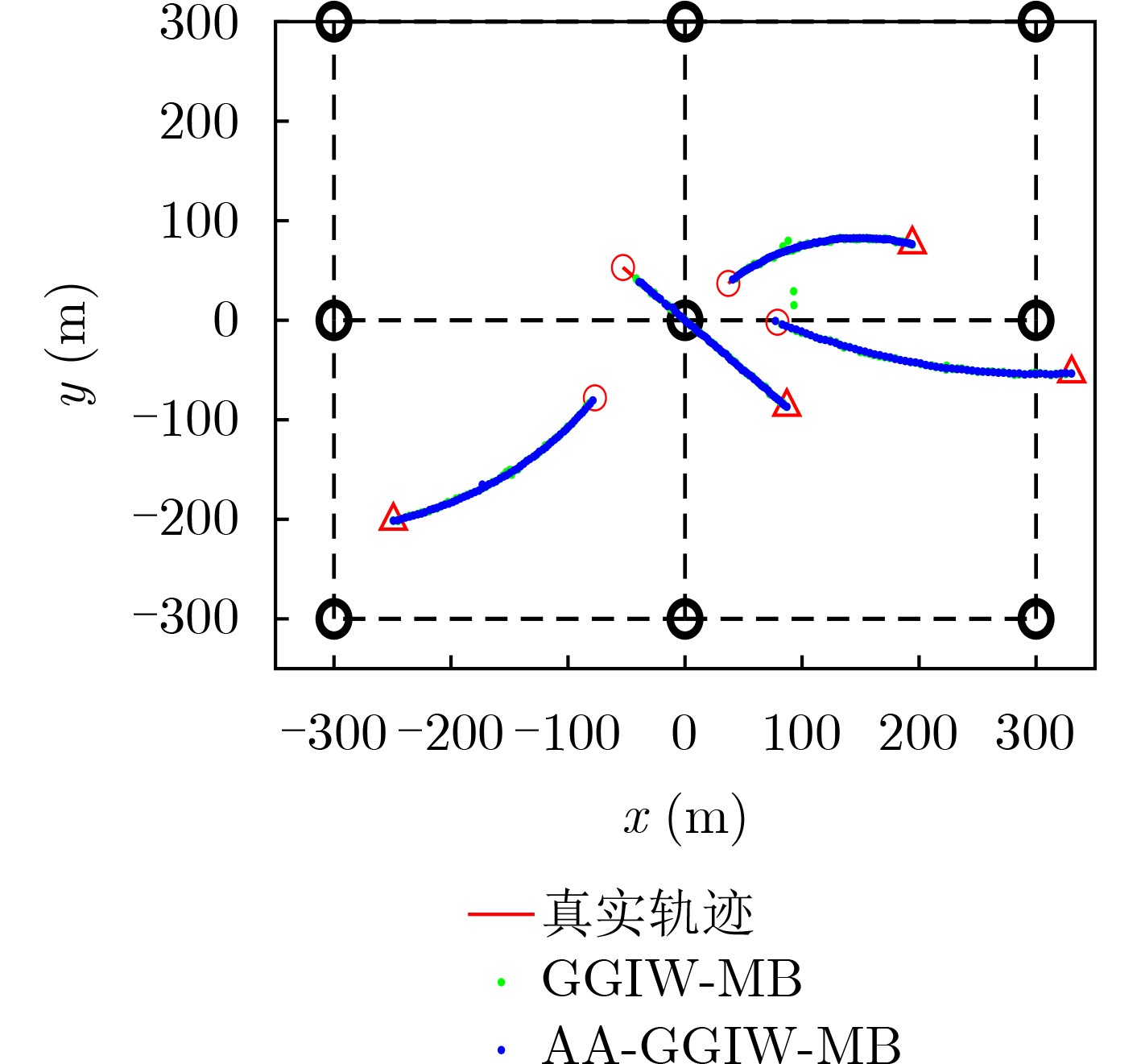
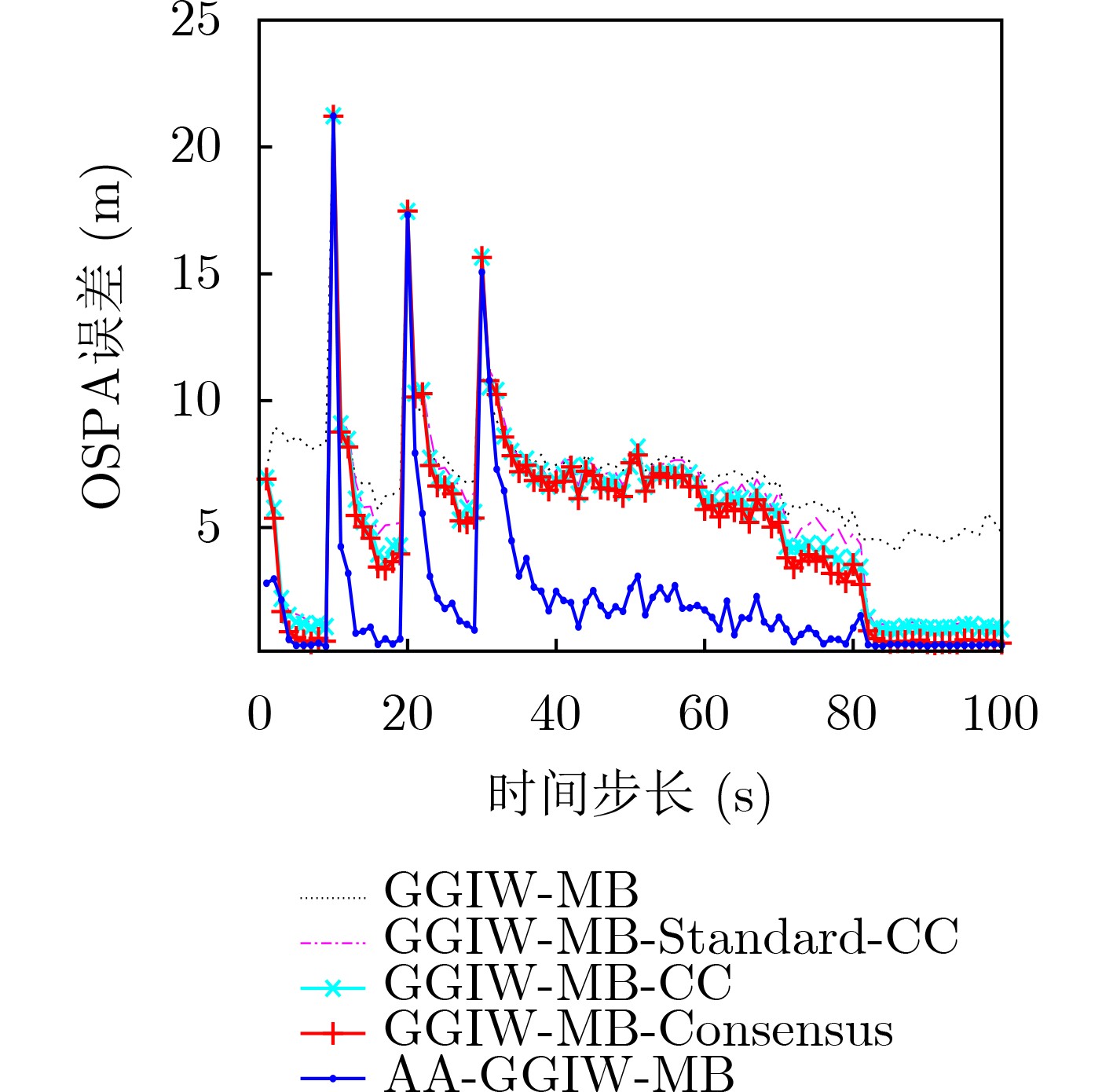
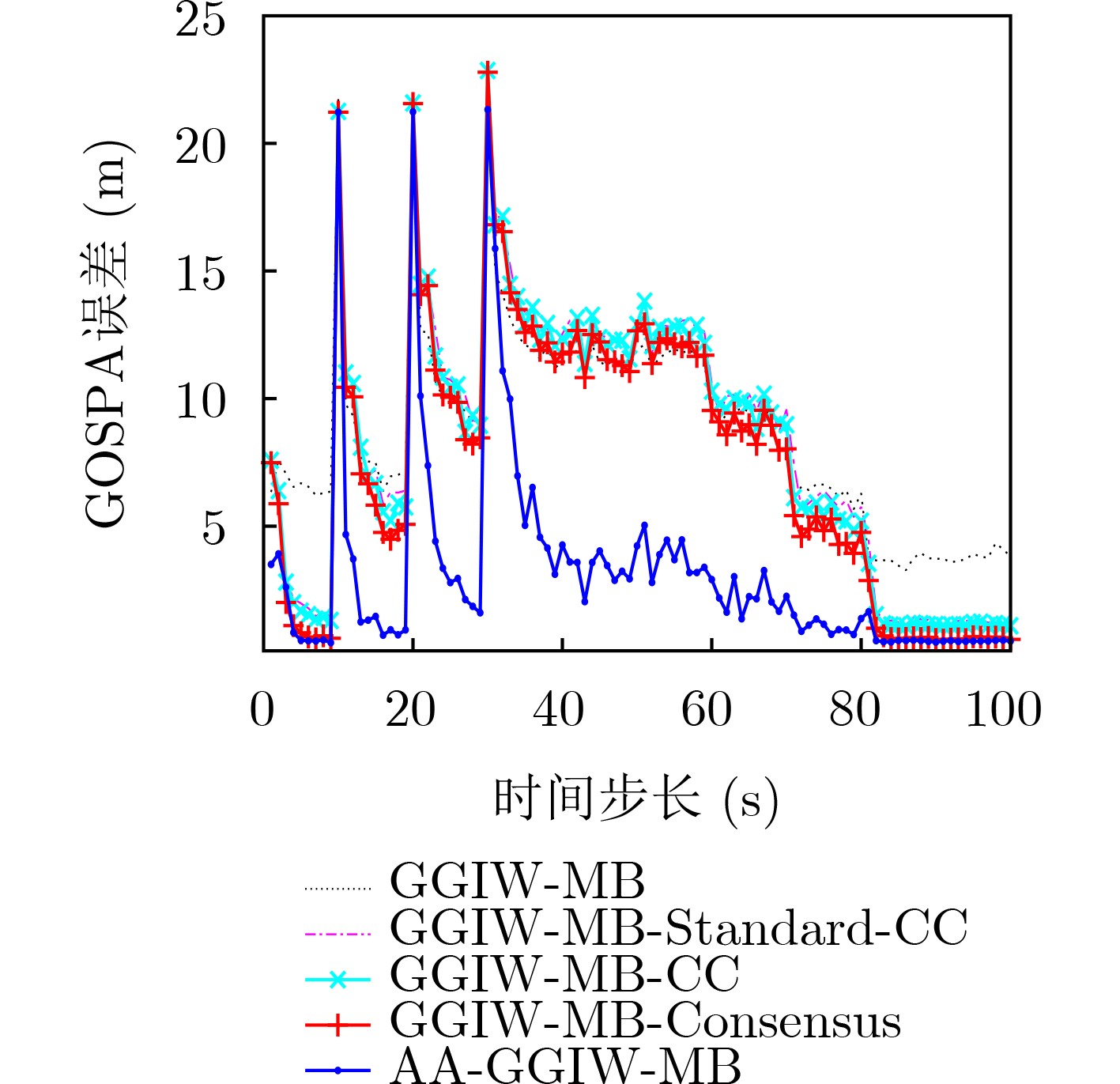
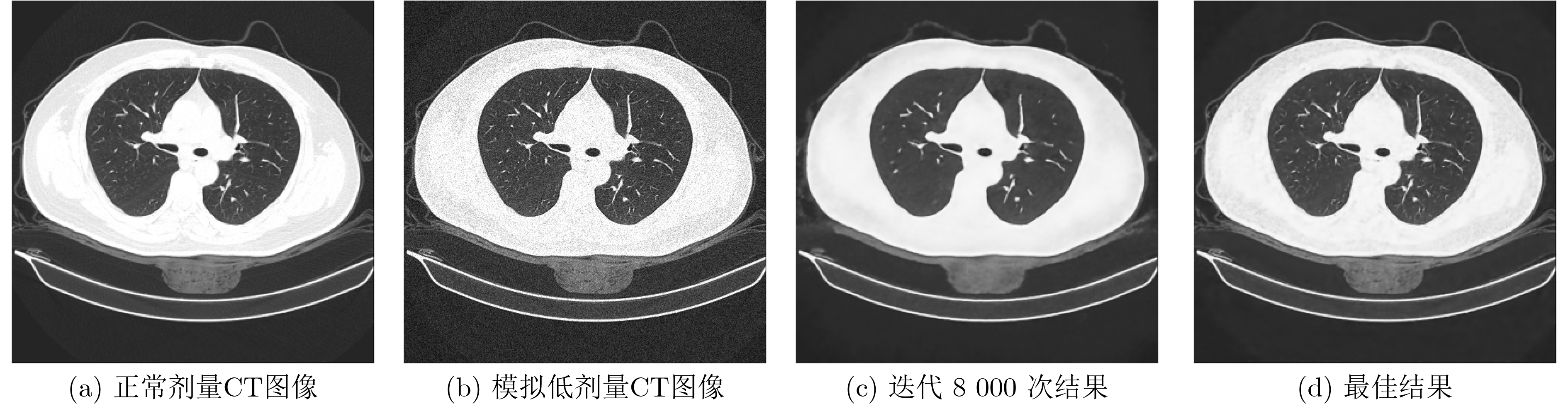
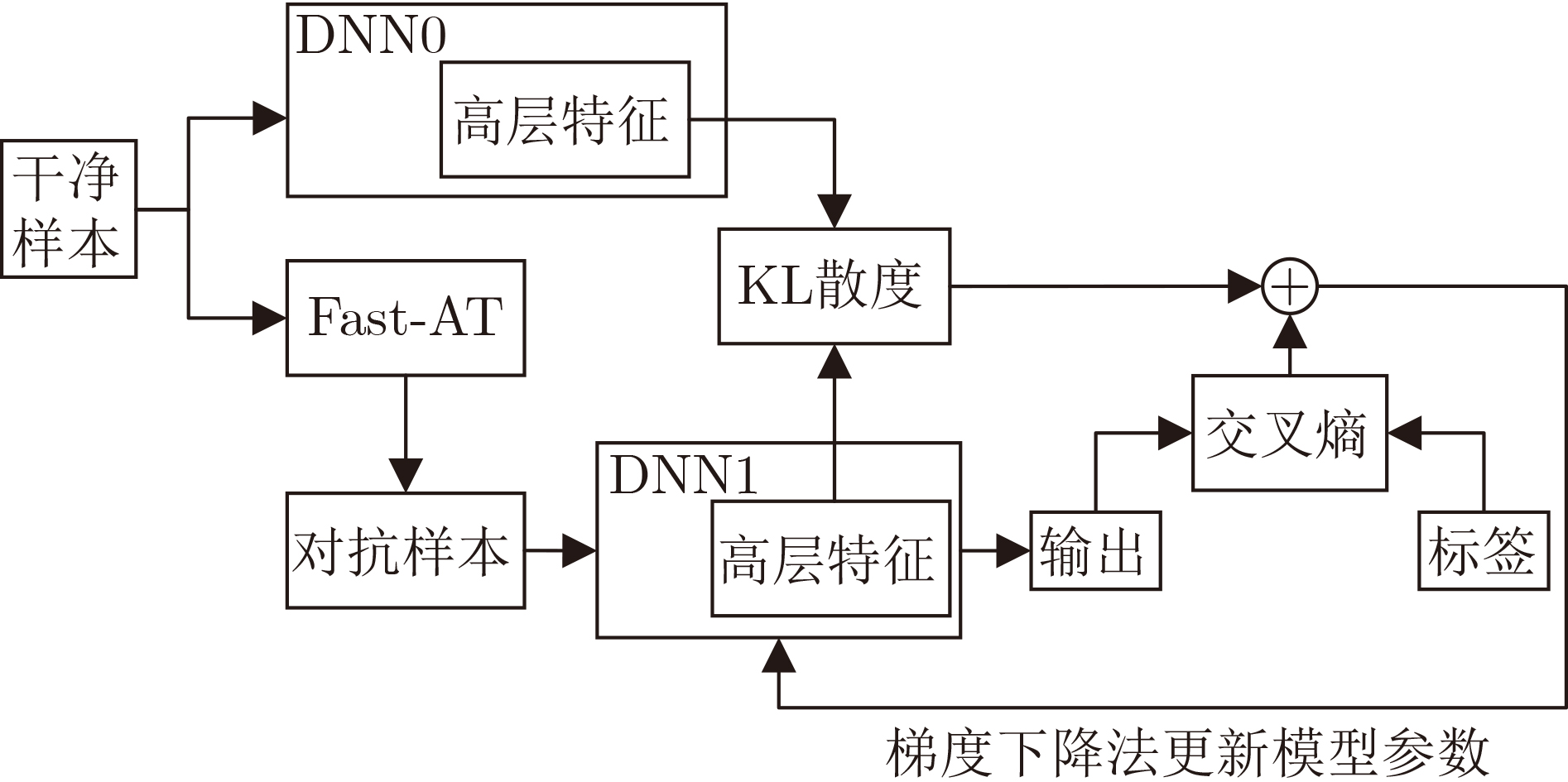
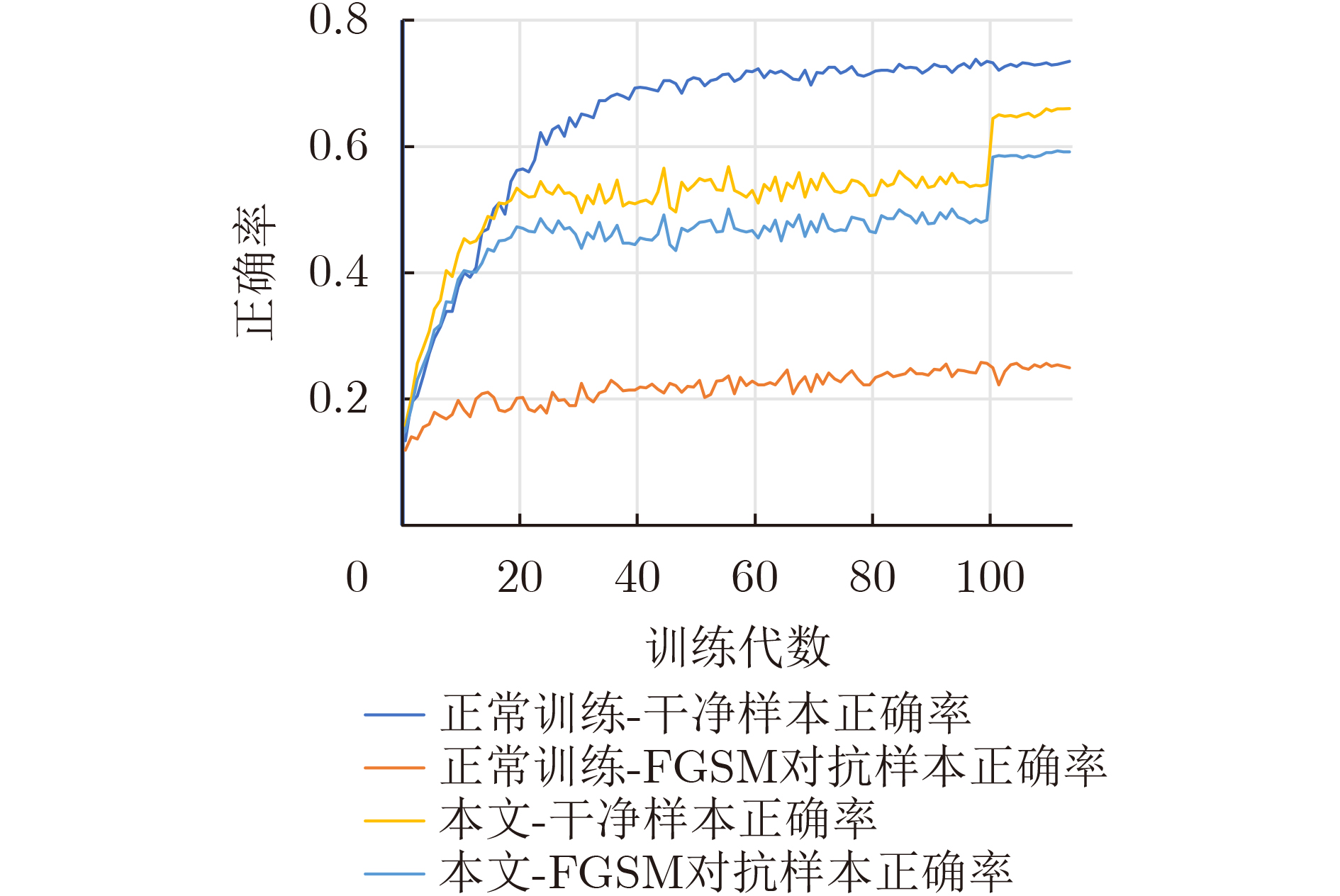
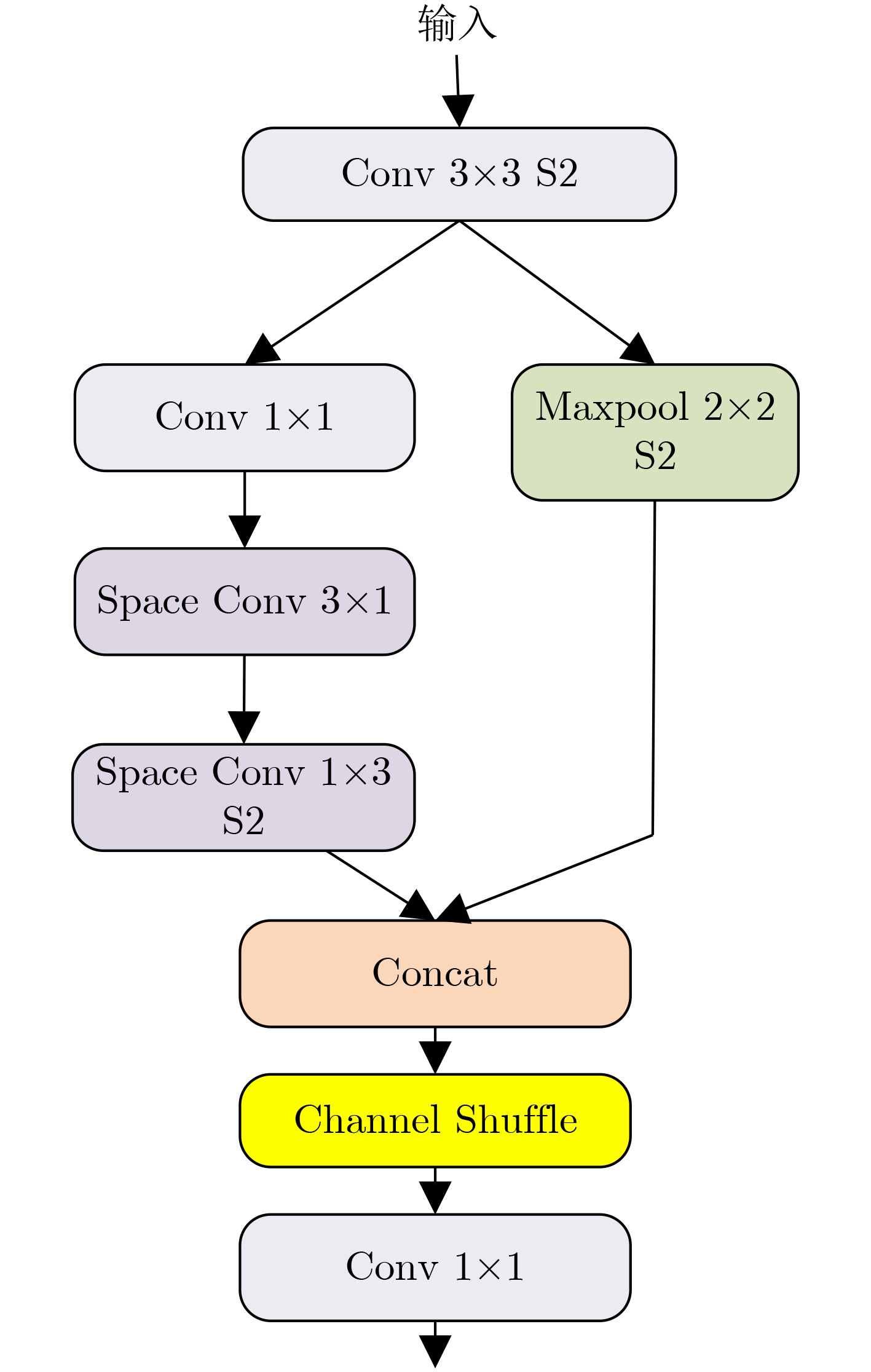
2023, 45(6): 2205-2215.
doi: 10.11999/JEIT220413
Abstract:
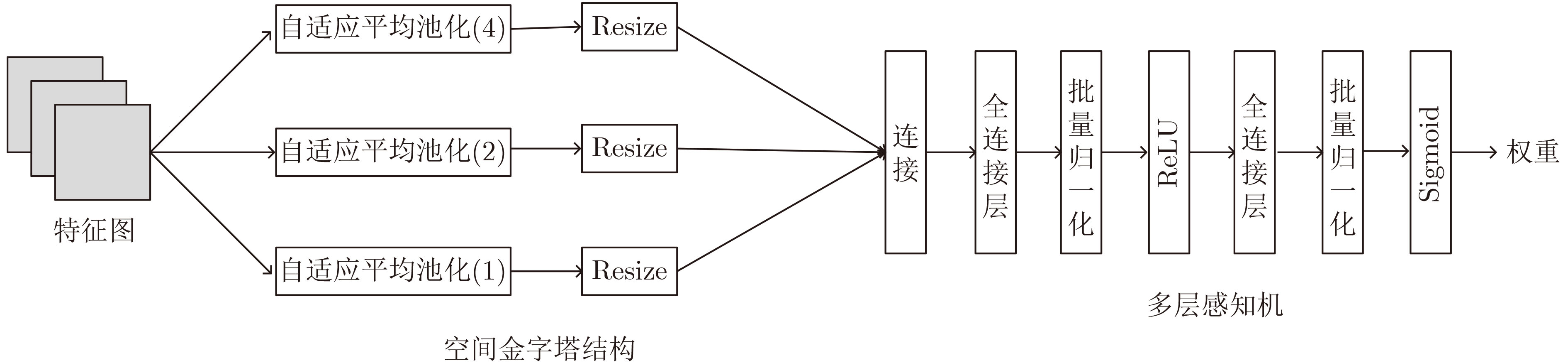
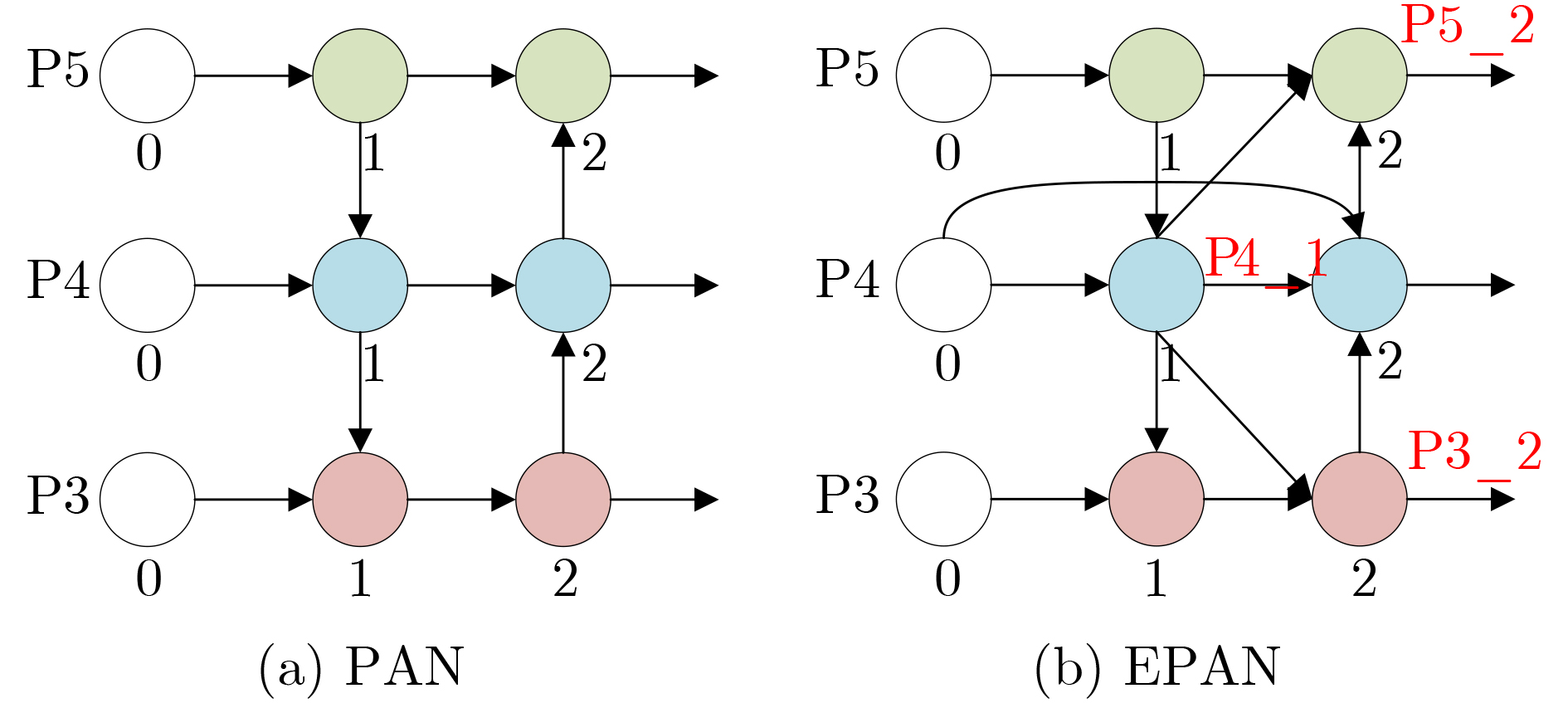
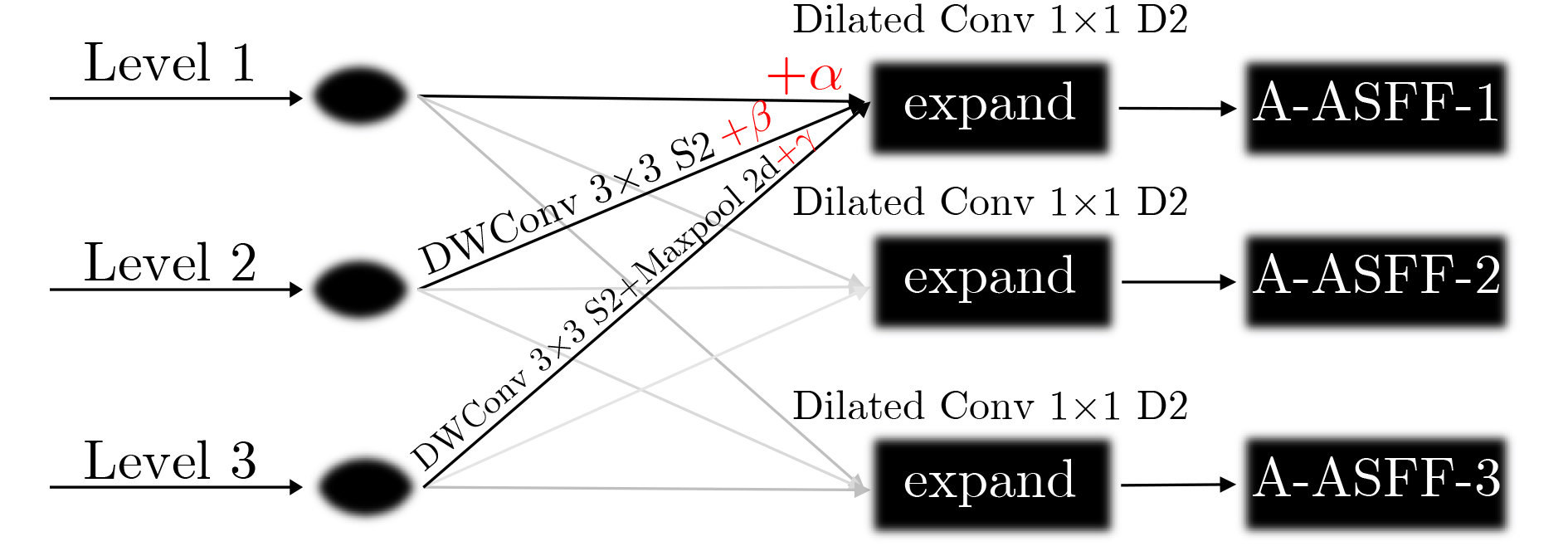
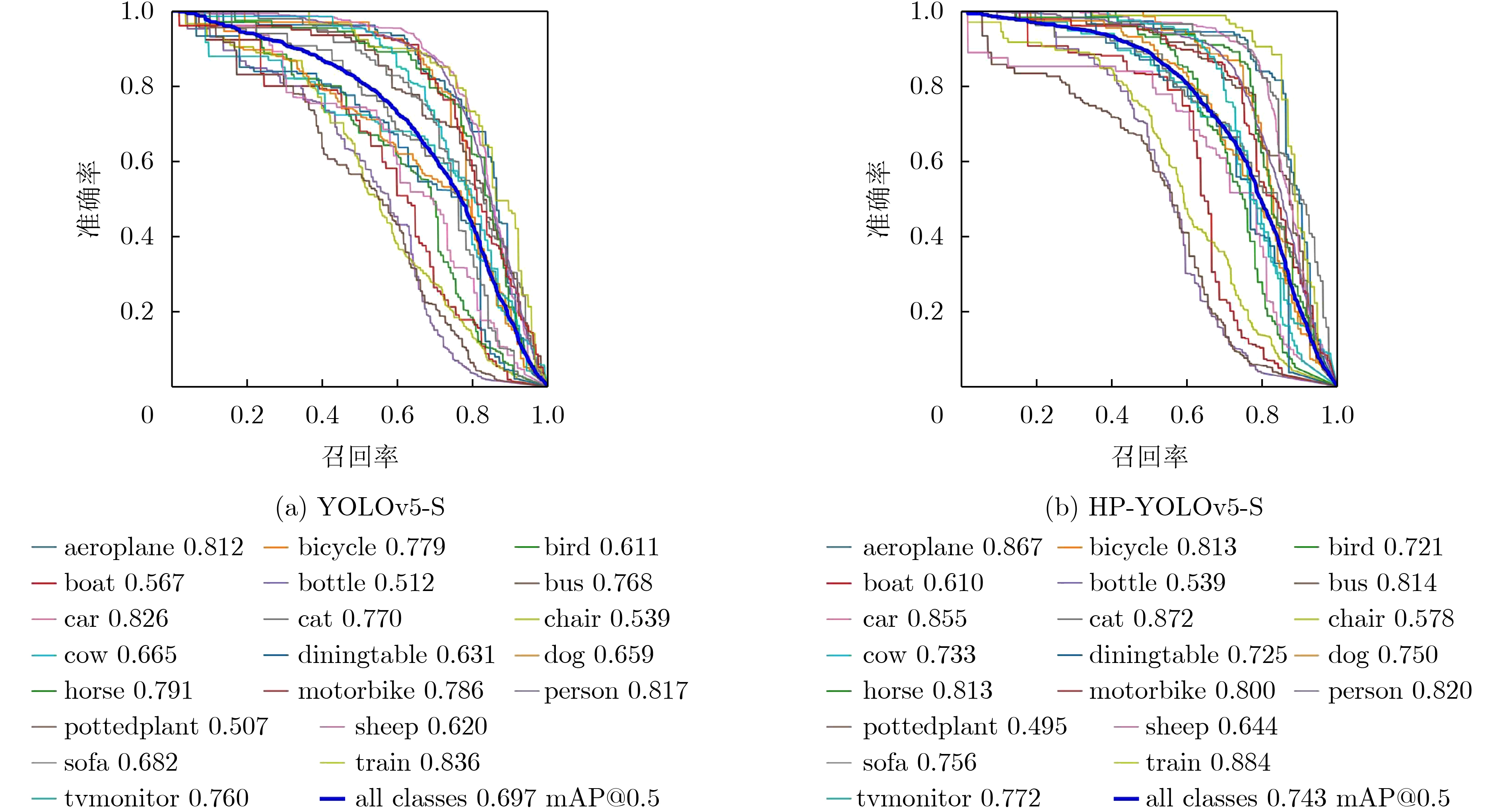
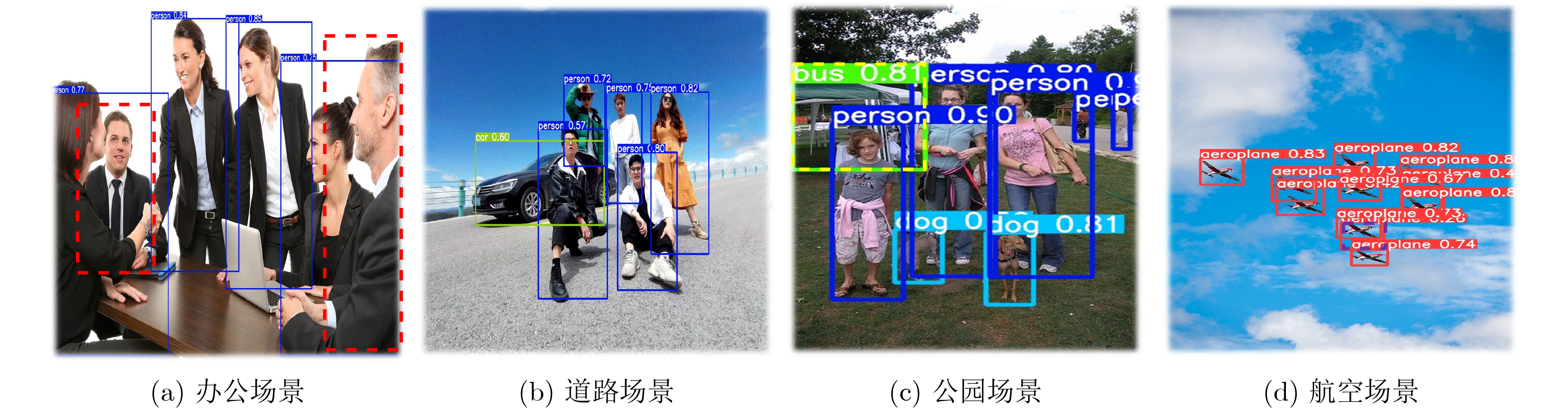
Considering the problems of imbalanced comprehensive performance of the current deep learning single-stage detection algorithms and difficult deployment in embedded devices, one High-Performance object detection algorithm for embedded platforms is proposed in this paper. Based on the You Only Look Once v5 (YOLOv5) network, in the backbone network part of the improved algorithm firstly, the original focus module and original Cross Stage Partial Darknet are replaced by a designed space stem block and an improved ShuffleNetv2, respectively. The kernel size of Space Pyramid Pooling (SPP) is reduced to lighten the backbone network. Secondly, in the neck, an Enhanced Path Aggregation Network (EPAN) based on Path Aggregation Network (PAN) design is adopted, a P6 large target output layer is added, and the feature extraction ability of the network is improved. And then, in the head, an Adaptive-Atrous Spatial Feature Fusion (A-ASFF) based on Adaptive Spatial Feature Fusion (ASFF) is used to replace the original detection head, the object scale change problem is solved, and the detection accuracy is greatly improved with a small amount of additional overhead. Finally, in the function section, a Complete Intersection over Union (CIoU) loss function is replaced by the Efficient Intersection over Union (EIoU), a HardSwish activation function is replaced by a Sigmoid weighted Linear Unit (SiLU), and model synthesis ability has been improved. The experimental results show that compared to YOLOv5-S, the mAP@.5 and mAP@.5:95 of the same version of the algorithm proposed in this paper are increased by 4.6% and 6.3% while the number of parameters and the computational complexity are reduced by 43.5% and 12.0%, respectively. Using the original model and the TensorRT accelerated model for speed evaluation on the Jetson Nano platform, the inference latency is reduced by 8.1% and 9.8%, respectively. The comprehensive indicators of many excellent object detection networks and their friendliness to embedded platforms are surpassed by the algorithm proposed in this paper and the practical meaning is generated.