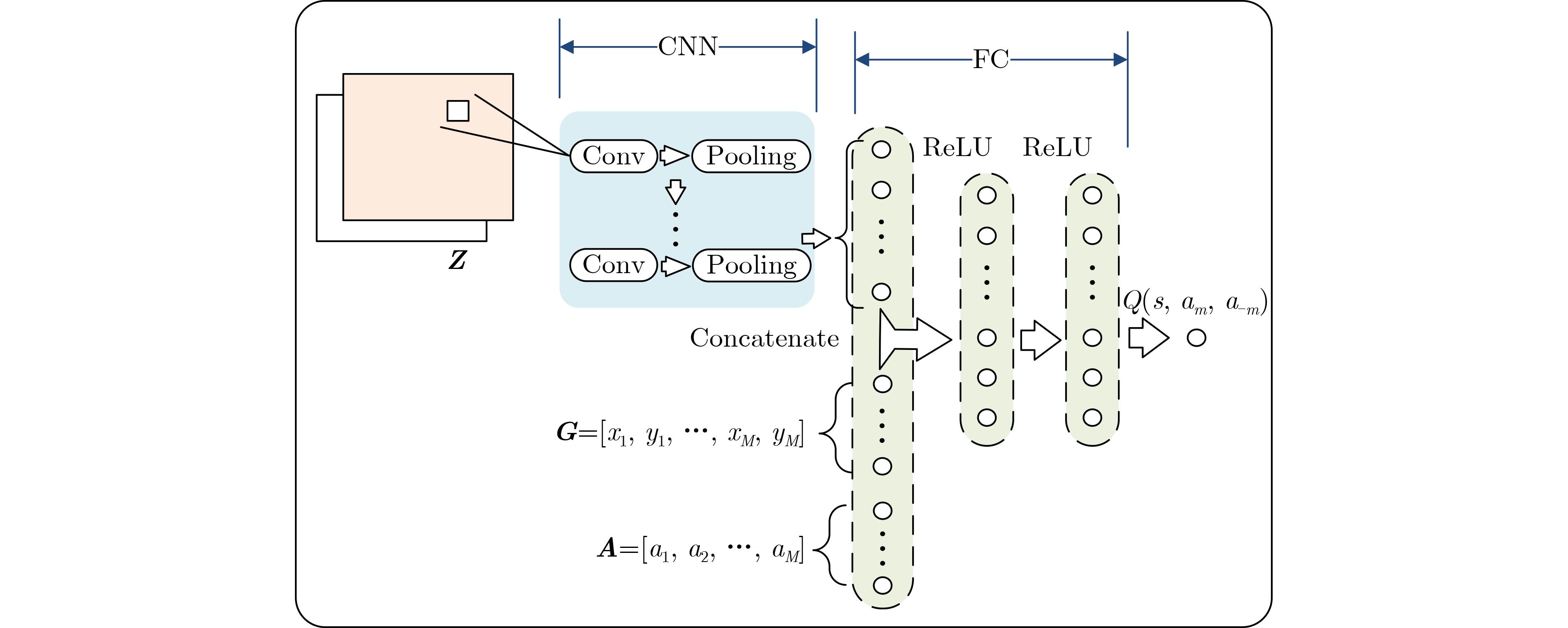
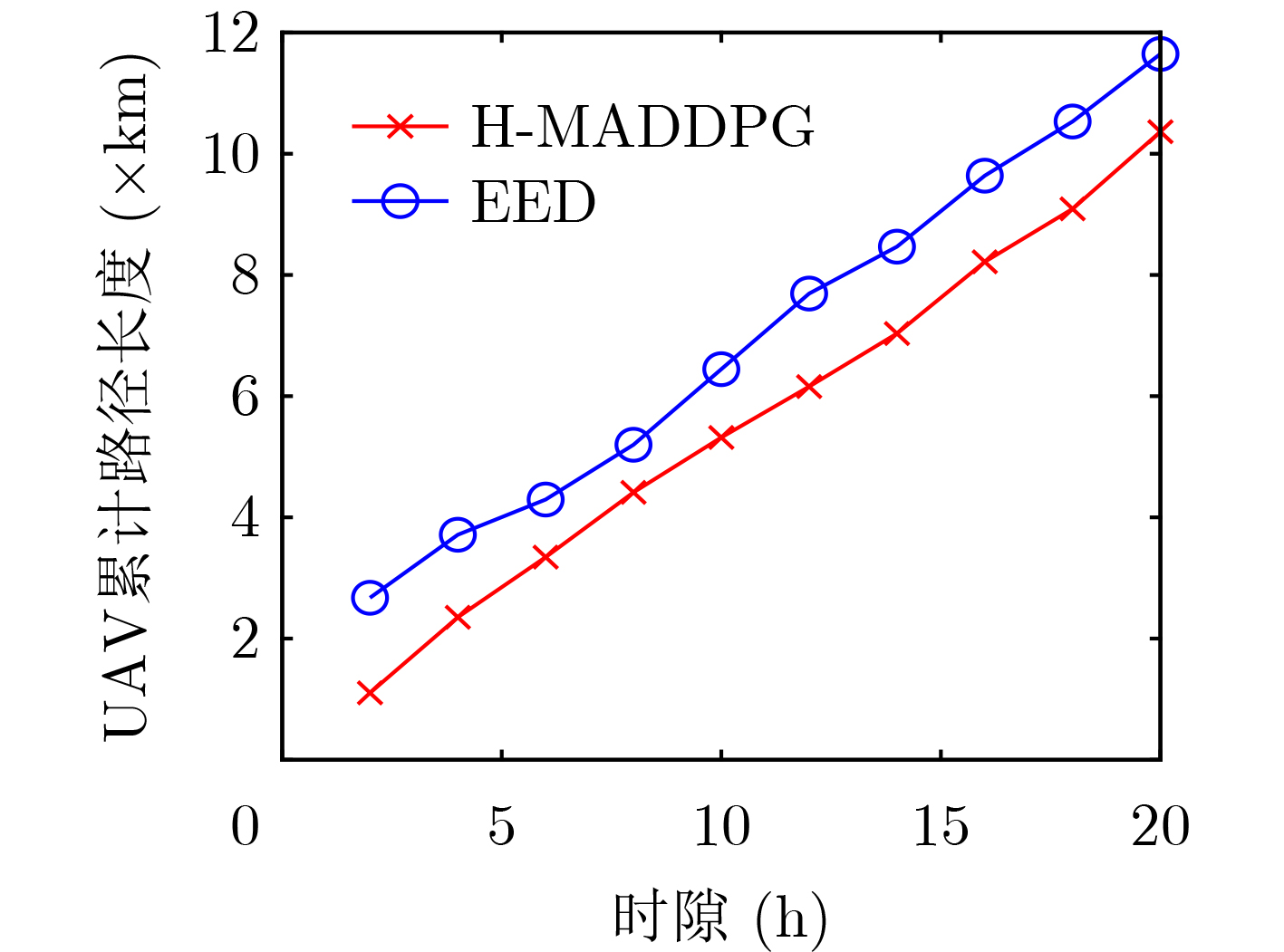
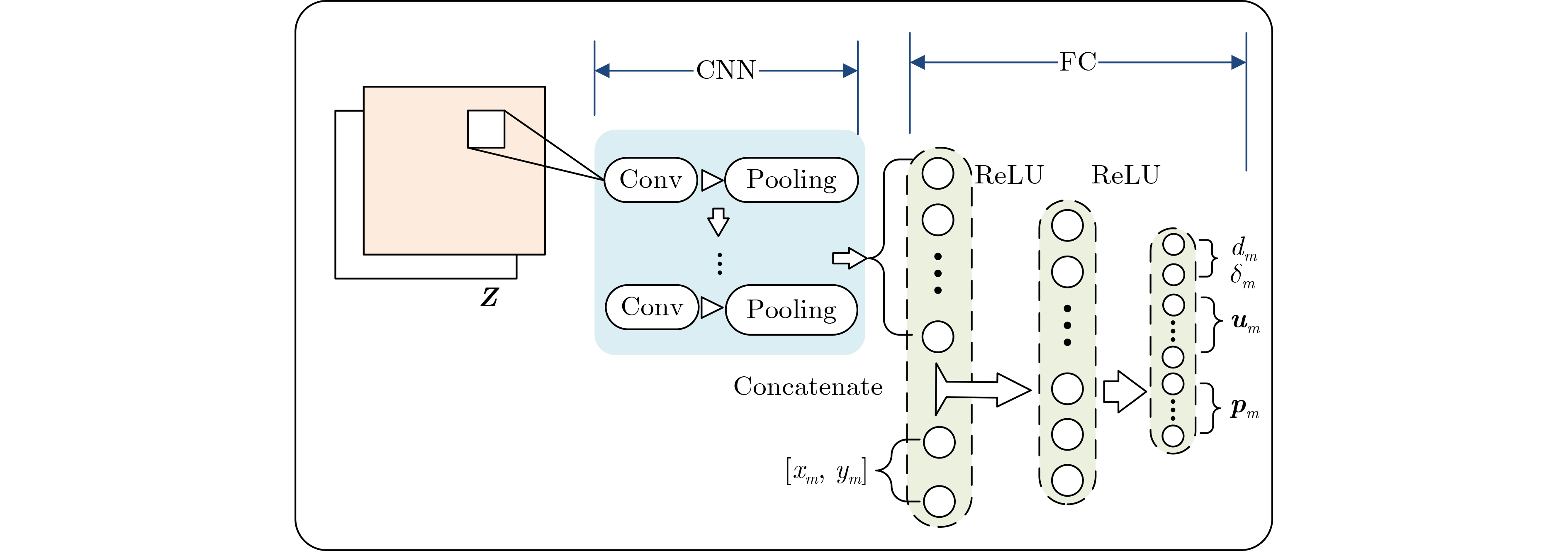
| Citation: | TANG Lun, LI Zhixuan, PU Hao, WANG Zhiping, CHEN Qianbin. A Dynamic Pre-Deployment Strategy of UAVs Based on Multi-Agent Deep Reinforcement Learning[J]. Journal of Electronics & Information Technology, 2023, 45(6): 2007-2015. doi: 10.11999/JEIT220513

|

| [1] |
SAAD W, BENNIS M, and CHEN Mingzhe. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems[J]. IEEE Network, 2020, 34(3): 134–142. doi: 10.1109/MNET.001.1900287
|
| [2] |
陈新颖, 盛敏, 李博, 等. 面向6G的无人机通信综述[J]. 电子与信息学报, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789
CHEN Xinying, SHENG Min, LI Bo, et al. Survey on unmanned aerial vehicle communications for 6G[J]. Journal of Electronics &Information Technology, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789
|
| [3] |
WANG Qian, CHEN Zhi, LI Hang, et al. Joint power and trajectory design for physical-layer secrecy in the UAV-aided mobile relaying system[J]. IEEE Access, 2018, 6: 62849–62855. doi: 10.1109/ACCESS.2018.2877210
|
| [4] |
ZHANG Guangchi, WU Qingqing, CUI Miao, et al. Securing UAV communications via joint trajectory and power control[J]. IEEE Transactions on Wireless Communications, 2019, 18(2): 1376–1389. doi: 10.1109/TWC.2019.2892461
|
| [5] |
GAO Ying, TANG Hongying, LI Baoqing, et al. Joint trajectory and power design for UAV-enabled secure communications with no-fly zone constraints[J]. IEEE Access, 2019, 7: 44459–44470. doi: 10.1109/ACCESS.2019.2908407
|
| [6] |
ZHANG Shuhang, ZHANG Hongliang, HE Qichen, et al. Joint trajectory and power optimization for UAV relay networks[J]. IEEE Communications Letters, 2018, 22(1): 161–164. doi: 10.1109/LCOMM.2017.2763135
|
| [7] |
YANG Gang, DAI Rao, and LIANG Yingchang. Energy-efficient UAV backscatter communication with joint trajectory design and resource optimization[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 926–941. doi: 10.1109/TWC.2020.3029225
|
| [8] |
LIU C H, CHEN Zheyu, TANG Jian, et al. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach[J]. IEEE Journal on Selected Areas in Communications, 2018, 36(9): 2059–2070. doi: 10.1109/JSAC.2018.2864373
|
| [9] |
ZHAO Nan, CHENG Yiqiang, PEI Yiyang, et al. Deep reinforcement learning for trajectory design and power allocation in UAV networks[C]. 2020 IEEE International Conference on Communications, Dublin, Ireland, 2020: 1–6.
|
| [10] |
WANG Liang, WANG Kezhi, PAN Cunhua, et al. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing[J]. IEEE Transactions on Mobile Computing, 2022, 21(10): 3536–3550.
|
| [11] |
CHEN Xiaming, JIN Yaohui, QIANG Siwei, et al. Analyzing and modeling spatio-temporal dependence of cellular traffic at city scale[C]. 2015 IEEE International Conference on Communications, London, the United Kingdom, 2015: 3585–3591.
|
| [12] |
ZHANG Chuanting, ZHANG Haixia, QIAO Jingping, et al. Deep transfer learning for intelligent cellular traffic prediction based on cross-domain big data[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(6): 1389–1401. doi: 10.1109/JSAC.2019.2904363
|
| [13] |
唐伦, 蒲昊, 汪智平, 等. 基于注意力机制ConvLSTM的UAV节能预部署策略[J]. 电子与信息学报, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368
TANG Lun, PU Hao, WANG Zhiping, et al. Energy-efficient predictive deployment strategy of UAVs based on ConvLSTM with attention mechanism[J]. Journal of Electronic &Information Technology, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368
|
| [14] |
OSBORNE M J. An Introduction to Game Theory[M]. London: Oxford University Press, 2003: 8–10.
|
| [15] |
SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 2018: 324–326.
|
| [16] |
ZHANG Qianqian, SAAD W, BENNIS M, et al. Predictive deployment of UAV base stations in wireless networks: Machine learning meets contract theory[J]. IEEE Transactions on Wireless Communications, 2021, 20(1): 637–652. doi: 10.1109/TWC.2020.3027624
|
| [17] |
YIN Sixing and YU R F. Resource allocation and trajectory design in UAV-Aided cellular networks based on multiagent reinforcement learning[J]. IEEE Internet of Things Journal, 2022, 9(4): 2933–2943. doi: 10.1109/JIOT.2021.3094651
|
Figures(7) / Tables(4)



 DownLoad:
DownLoad: