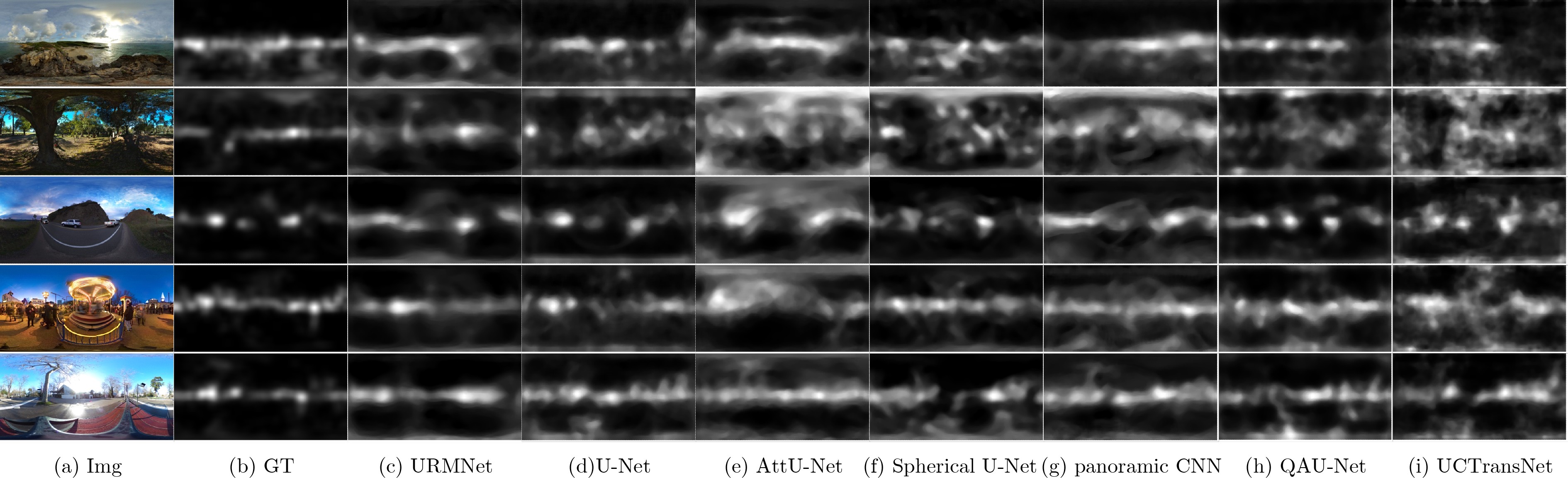
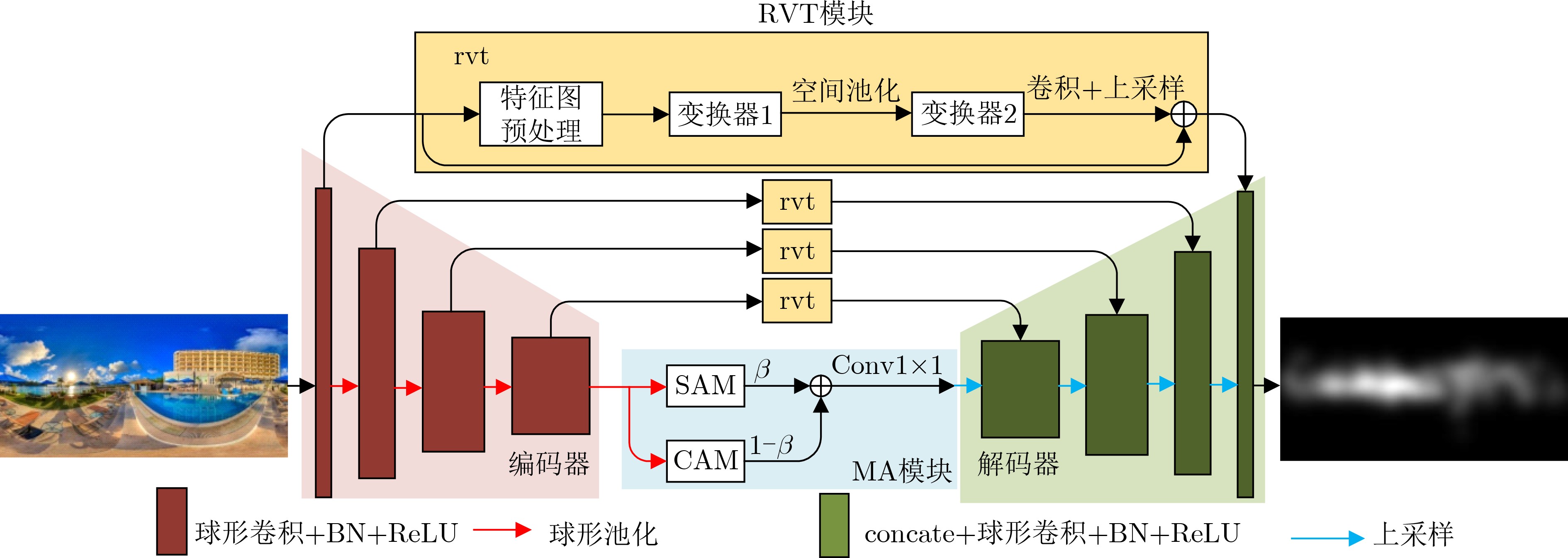
| Citation: | CHEN Xiaolei, ZHANG Pengcheng, LU Yubing, CAO Baoning. Saliency Detection of Panoramic Images Based on Robust Vision Transformer and Multiple Attention[J]. Journal of Electronics & Information Technology, 2023, 45(6): 2246-2255. doi: 10.11999/JEIT220684

|

| [1] |
刘政怡, 段群涛, 石松, 等. 基于多模态特征融合监督的RGB-D图像显著性检测[J]. 电子与信息学报, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297
LIU Zhengyi, DUAN Quntao, SHI Song, et al. RGB-D image saliency detection based on multi-modal feature-fused supervision[J]. Journal of Electronics &Information Technology, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297
|
| [2] |
WEN Anzhou. Real-time panoramic multi-target detection based on mobile machine vision and deep learning[J]. Journal of Physics:Conference Series, 2020, 1650: 032113. doi: 10.1088/1742-6596/1650/3/032113
|
| [3] |
ZHANG Ziheng, XU Yanyu, YU Jingyi, et al. Saliency detection in 360° videos[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 504–520.
|
| [4] |
COORS B, CONDURACHE A P, and GEIGER A. SphereNet: Learning spherical representations for detection and classification in omnidirectional images[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 525–541.
|
| [5] |
MARTÍN D, SERRANO A, and MASIA B. Panoramic convolutions for 360° single-image saliency prediction[C/OL]. The Fourth Workshop on Computer Vision for AR/VR, 2020: 1–4.
|
| [6] |
DAI Feng, ZHANG Youqiang, MA Yike, et al. Dilated convolutional neural networks for panoramic image saliency prediction[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020: 2558–2562.
|
| [7] |
MONROY R, LUTZ S, CHALASANI T, et al. SalNet360: Saliency maps for omni-directional images with CNN[J]. Signal Processing:Image Communication, 2018, 69: 26–34. doi: 10.1016/j.image.2018.05.005
|
| [8] |
DAHOU Y, TLIBA M, MCGUINNESS K, et al. ATSal: An attention Based Architecture for Saliency Prediction in 360° Videos[M]. Cham: Springer, 2021: 305–320.
|
| [9] |
ZHU Dandan, CHEN Yongqing, ZHAO Defang, et al. Saliency prediction on omnidirectional images with attention-aware feature fusion network[J]. Applied Intelligence, 2021, 51(8): 5344–5357. doi: 10.1007/s10489-020-01857-3
|
| [10] |
CHAO Fangyi, ZHANG Lu, HAMIDOUCHE W, et al. A multi-FoV viewport-based visual saliency model using adaptive weighting losses for 360° images[J]. IEEE Transactions on Multimedia, 2020, 23: 1811–1826. doi: 10.1109/tmm.2020.3003642
|
| [11] |
XU Mai, YANG Li, TAO Xiaoming, et al. Saliency prediction on omnidirectional image with generative adversarial imitation learning[J]. IEEE Transactions on Image Processing, 2021, 30: 2087–2102. doi: 10.1109/tip.2021.3050861
|
| [12] |
GUTIÉRREZ J, DAVID E J, COUTROT A, et al. Introducing un salient360! Benchmark: A platform for evaluating visual attention models for 360° contents[C]. The 2018 Tenth International Conference on Quality of Multimedia Experience, Cagliari, Italy, 2018: 1–3.
|
| [13] |
MAO Xiaofeng, QI Gege, CHEN Yuefeng, et al. Towards robust vision transformer[J]. arXiv: 2105.07926, 2021.
|
| [14] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.
|
| [15] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021.
|
| [16] |
RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241.
|
| [17] |
OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention u-net: Learning where to look for the pancreas[J]. arXiv: 1804.03999, 2018.
|
| [18] |
HONG Luminzi, WANG Risheng, LEI Tao, et al. Qau-Net: Quartet attention U-Net for liver and liver-tumor segmentation[C]. 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, China, 2021: 1–6.
|
| [19] |
WANG Haonan, CAO Peng, WANG Jiaqi, et al. UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(3): 2441–2249. doi: 10.1609/aaai.v36i3.20144
|
| [20] |
CORNIA M, BARALDI L, SERRA G, et al. Predicting human eye fixations via an LSTM-based saliency attentive model[J]. IEEE Transactions on Image Processing, 2018, 27(10): 5142–5154. doi: 10.1109/tip.2018.2851672
|
| [21] |
LOU Jianxun, LIN Hanhe, MARSHALL D, et al. TranSalNet: Towards perceptually relevant visual saliency prediction[J]. arXiv: 2110.03593, 2021.
|
Figures(9) / Tables(7)



 DownLoad:
DownLoad: