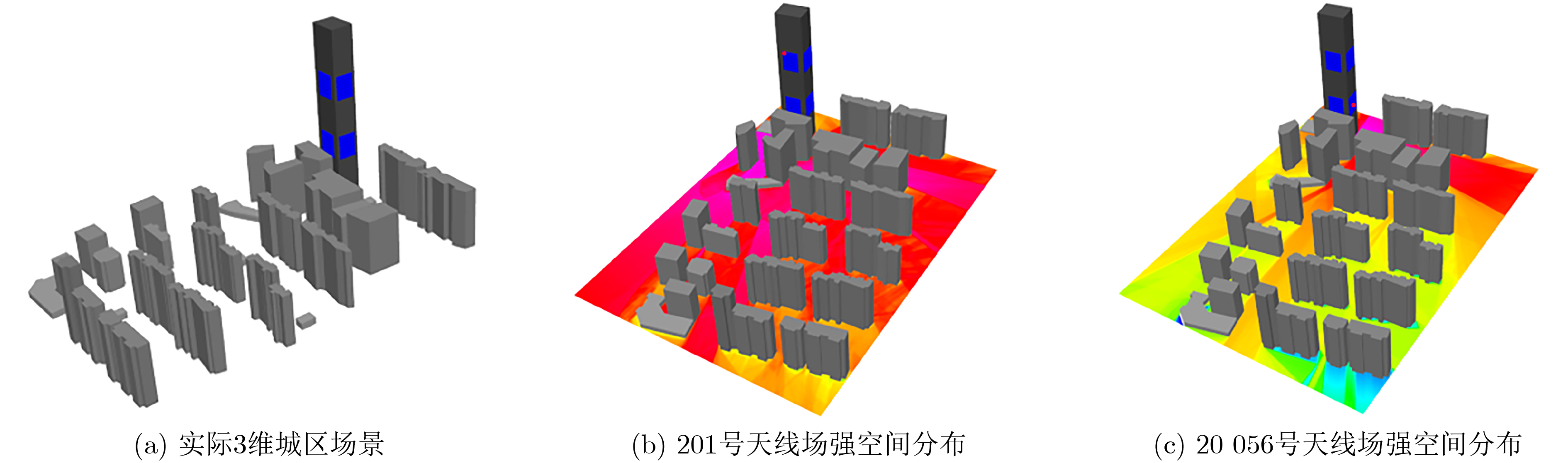
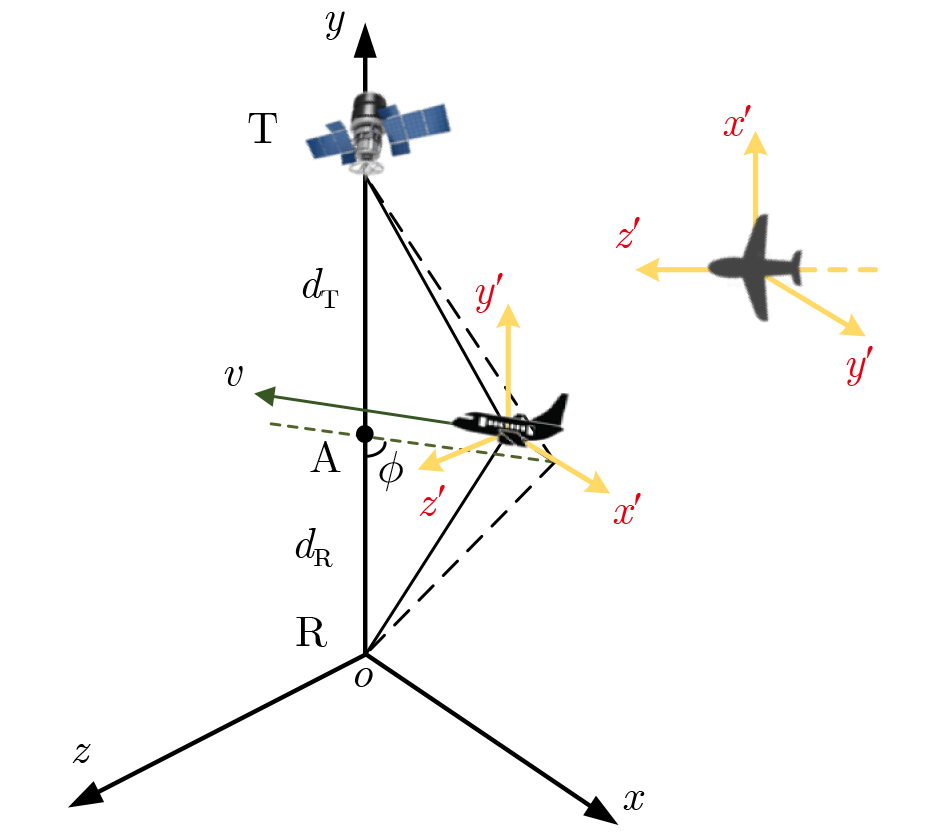
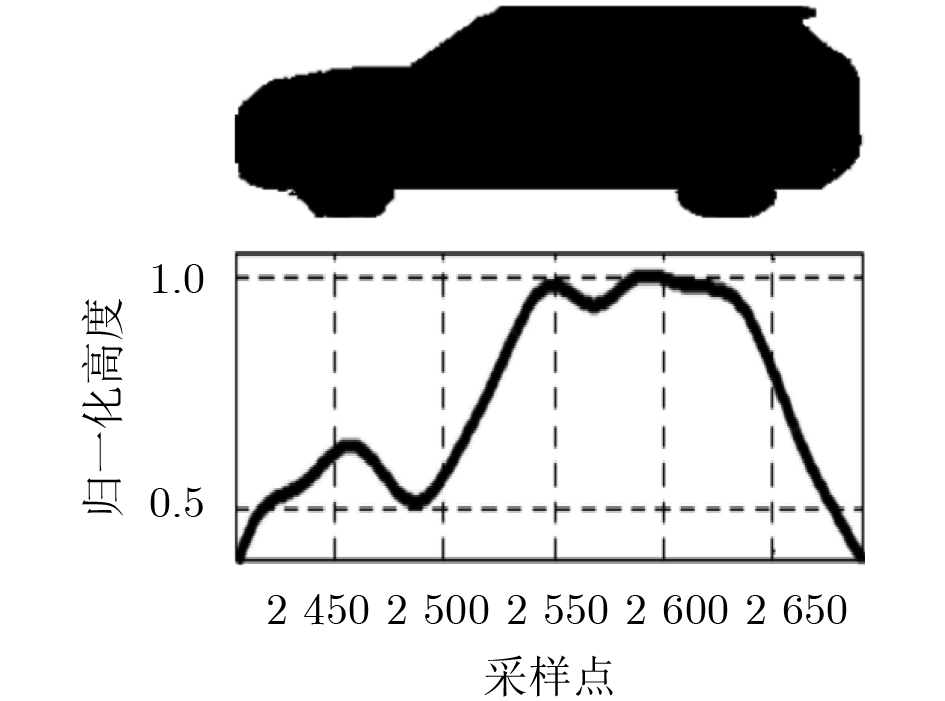
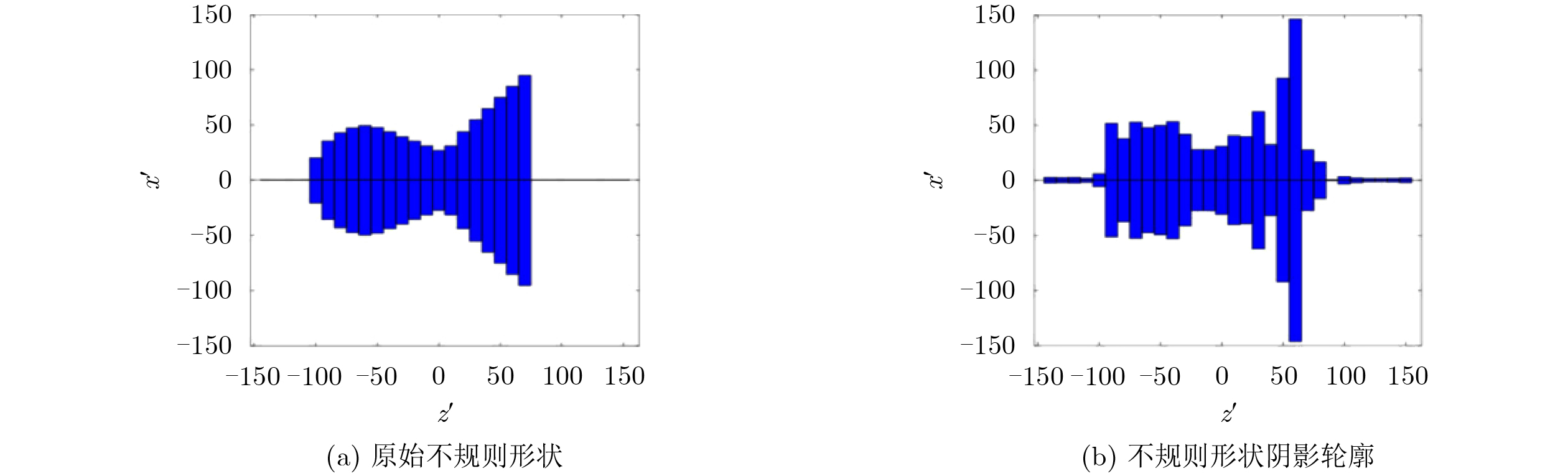
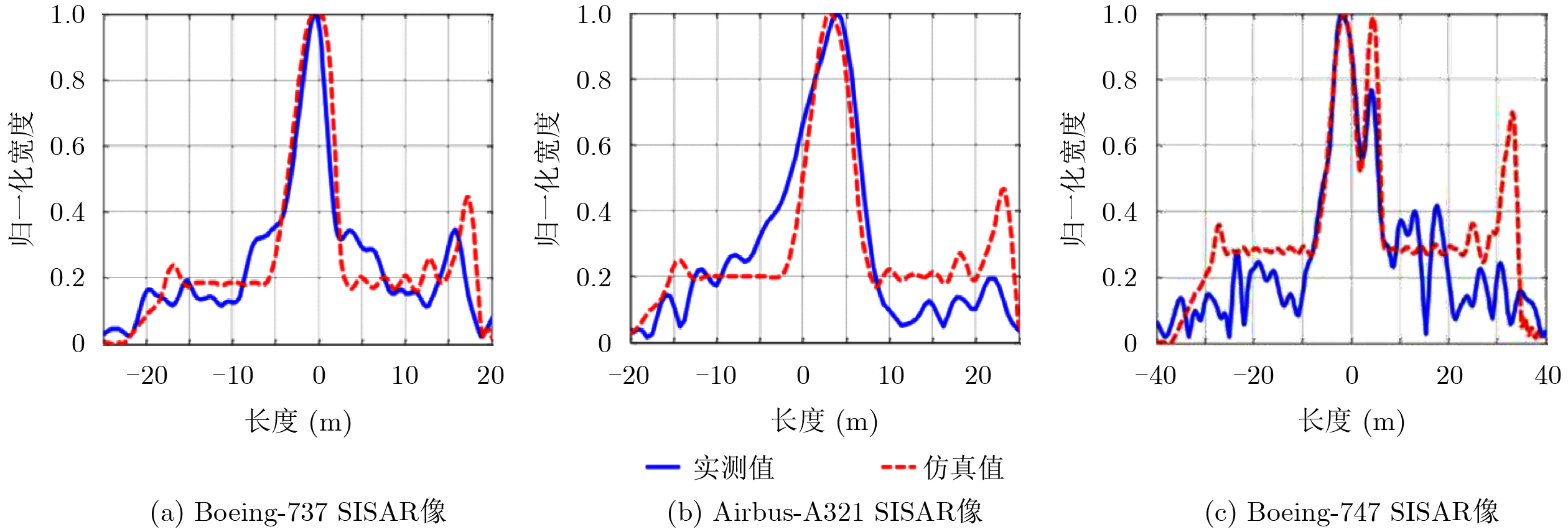
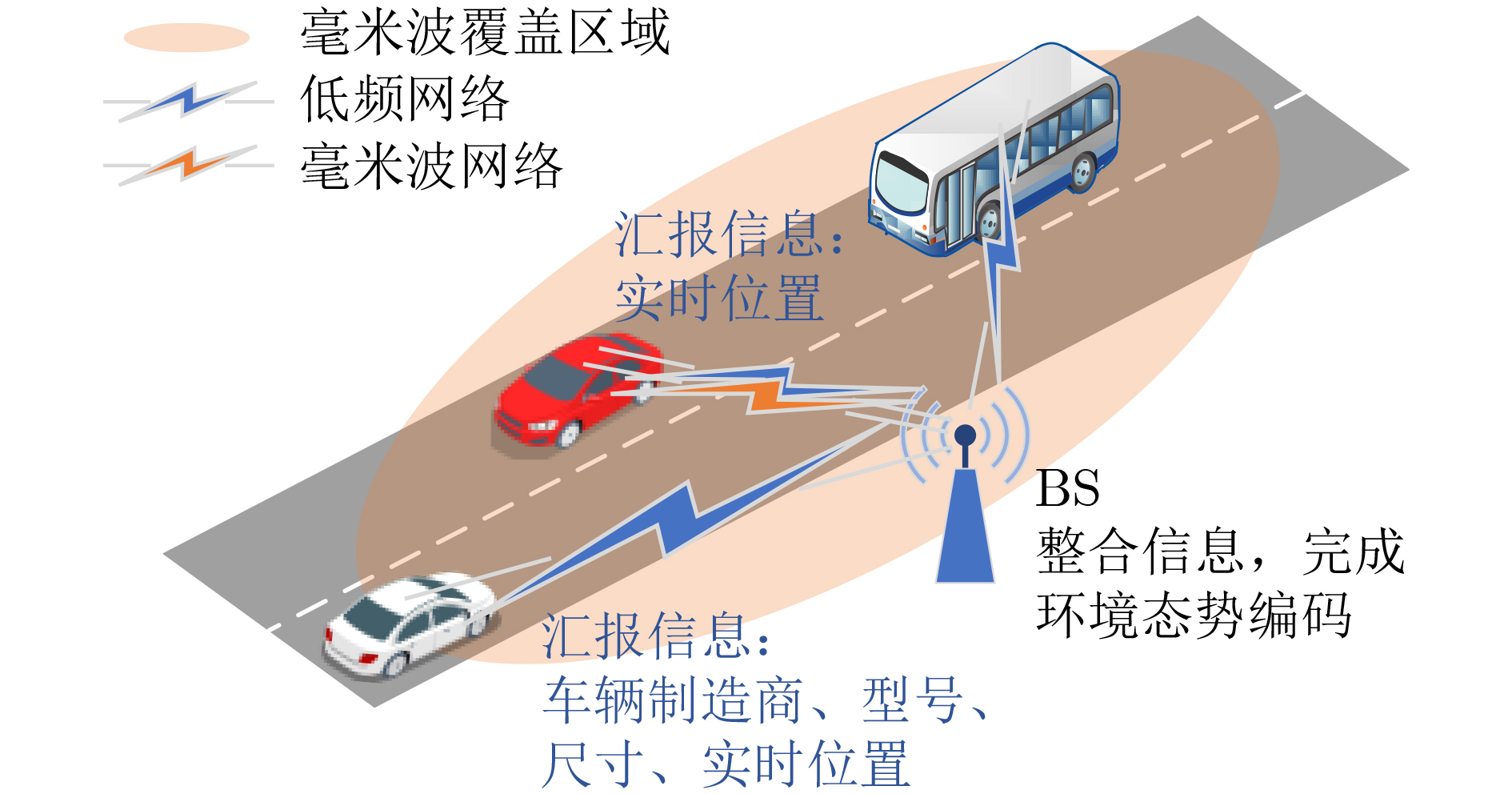
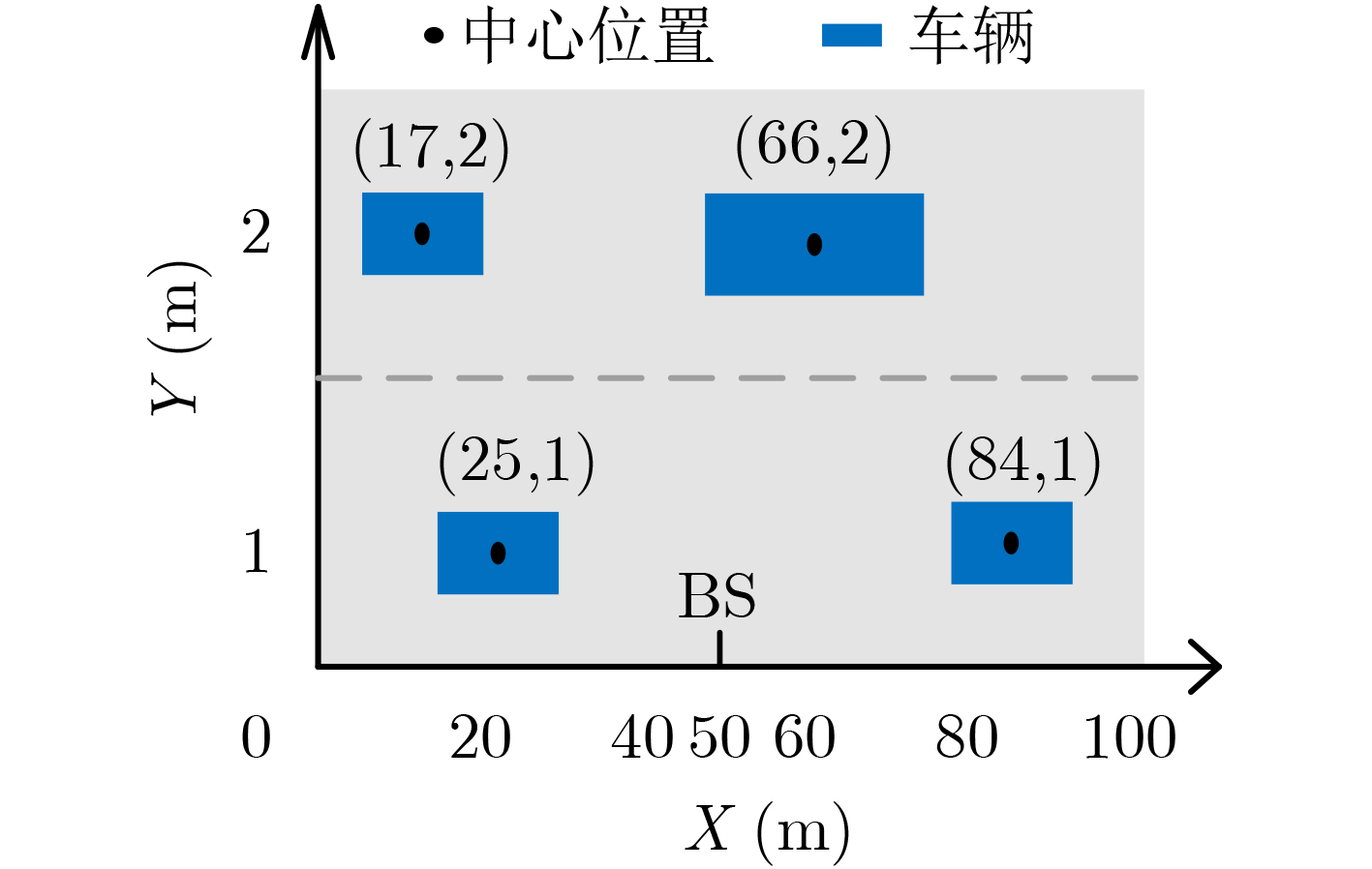
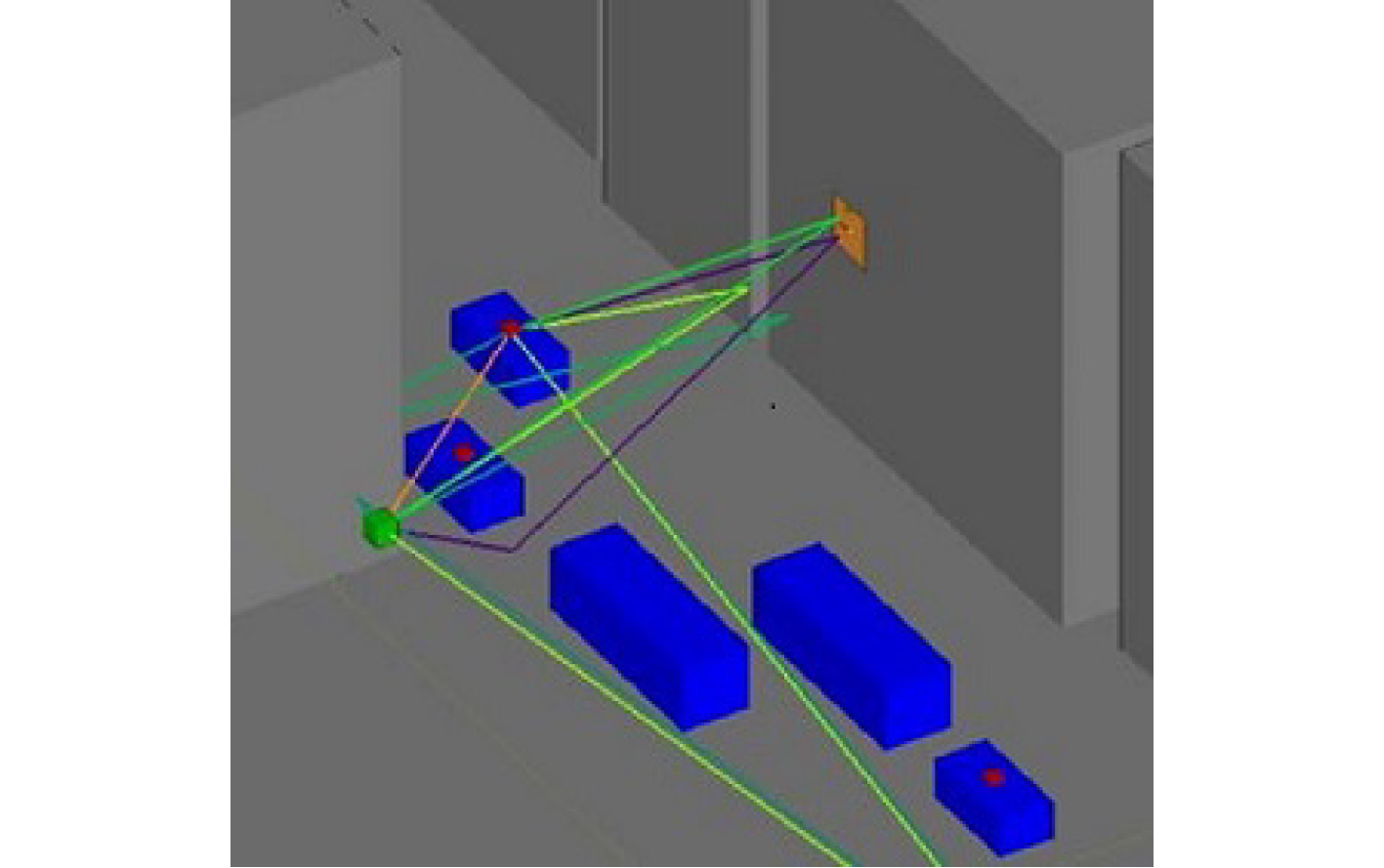
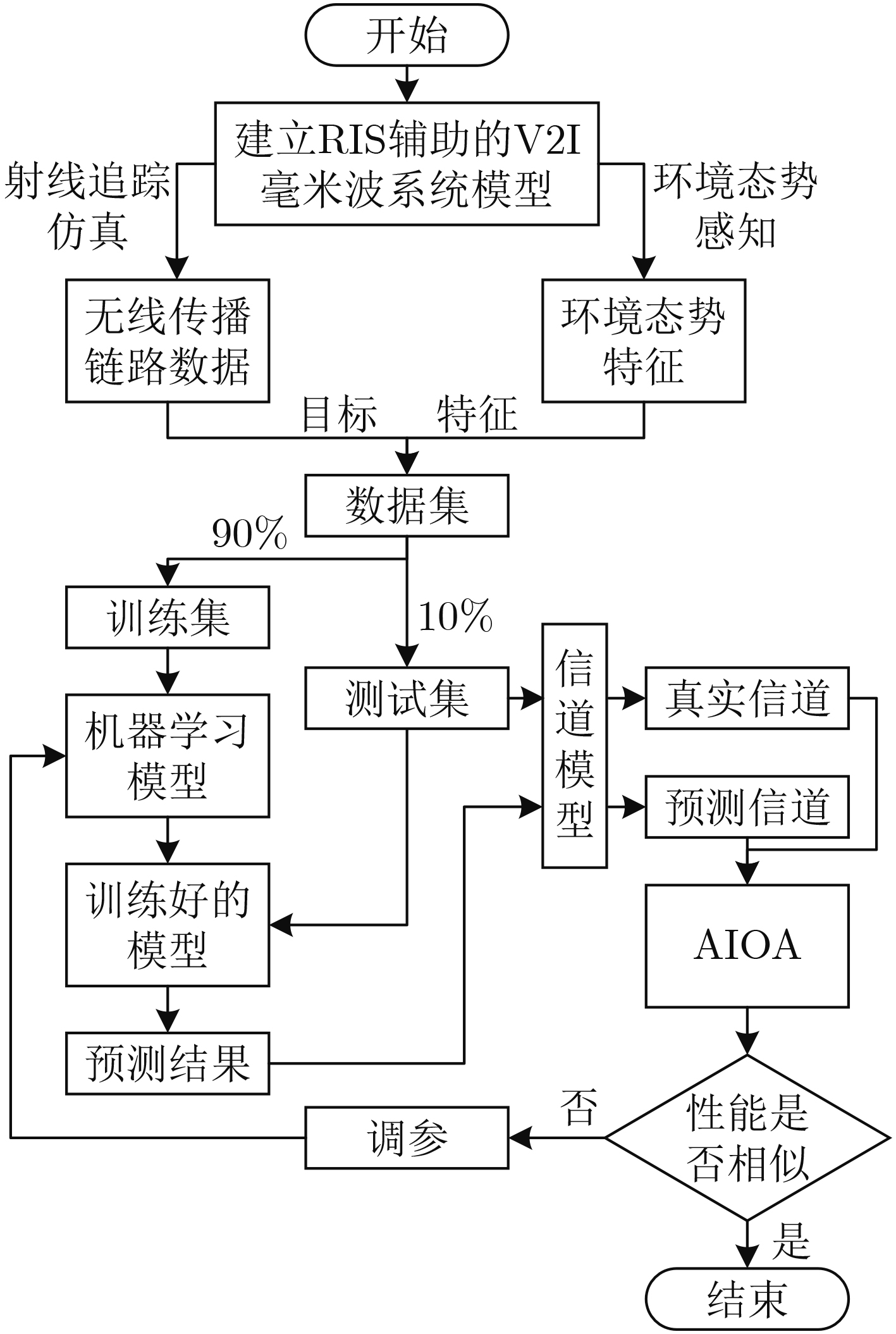
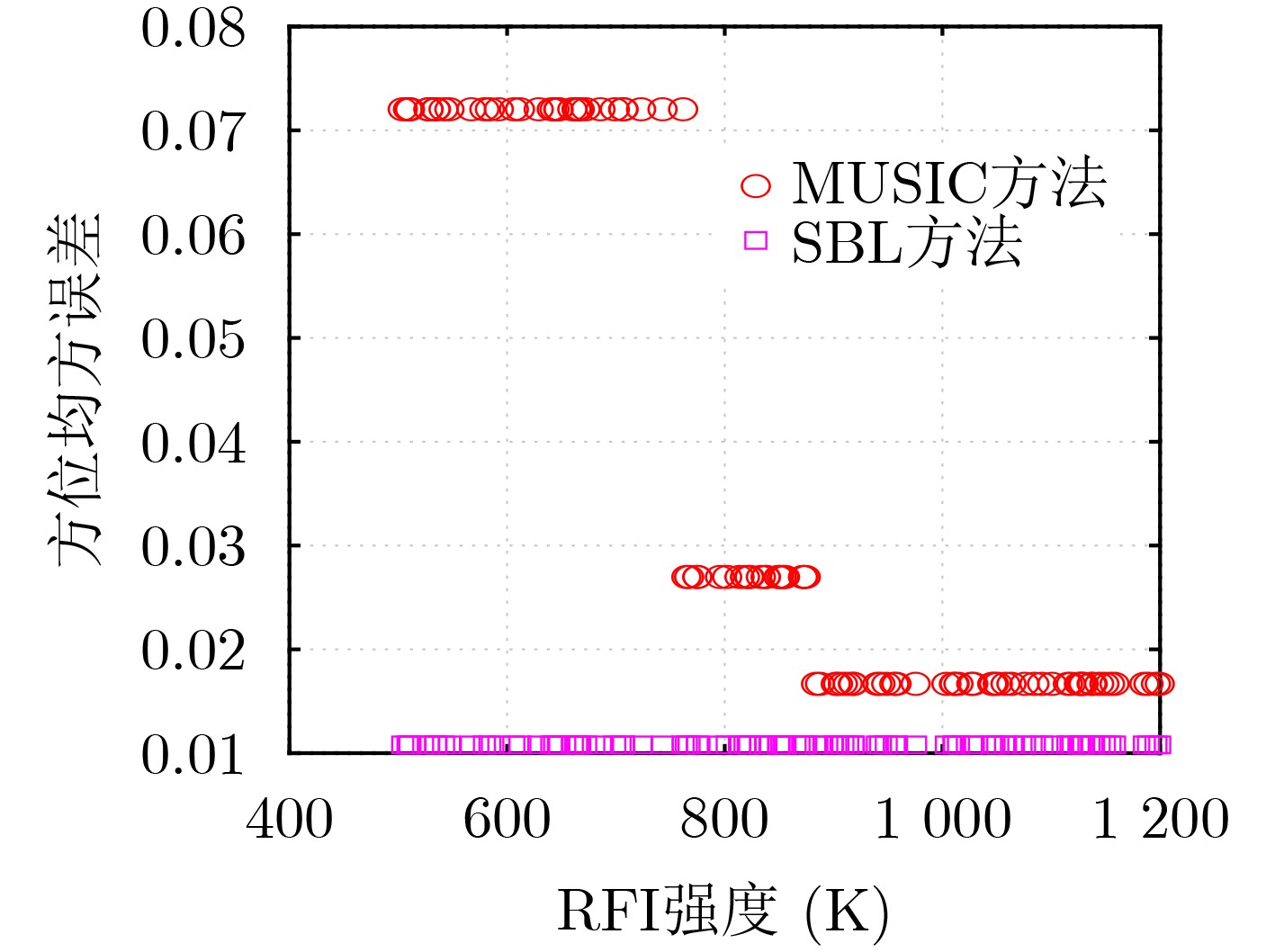
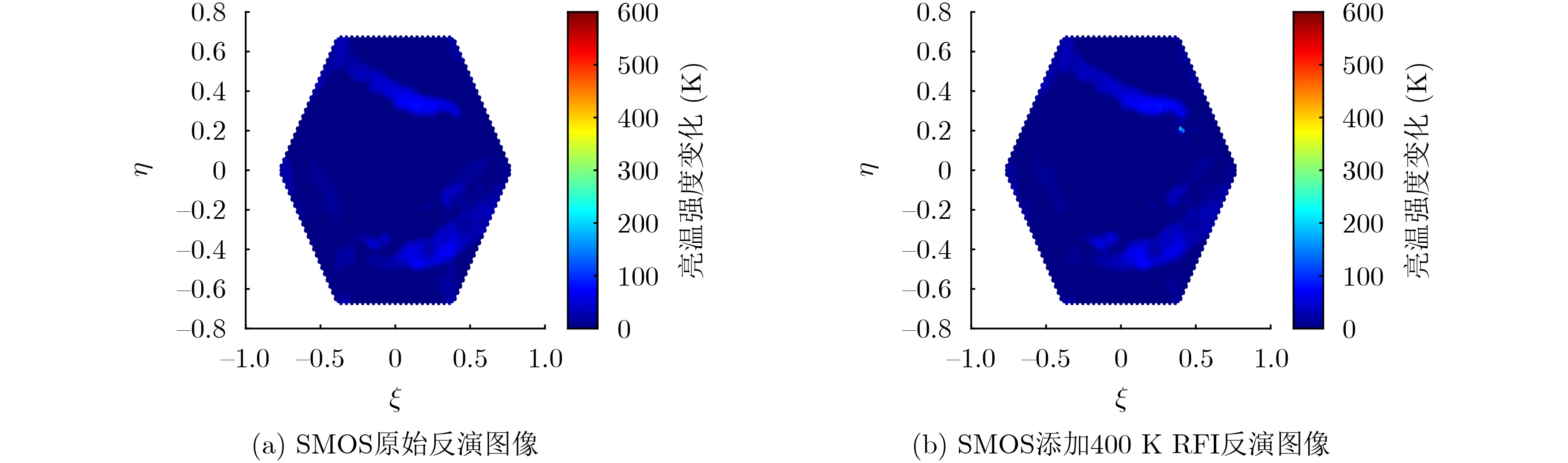
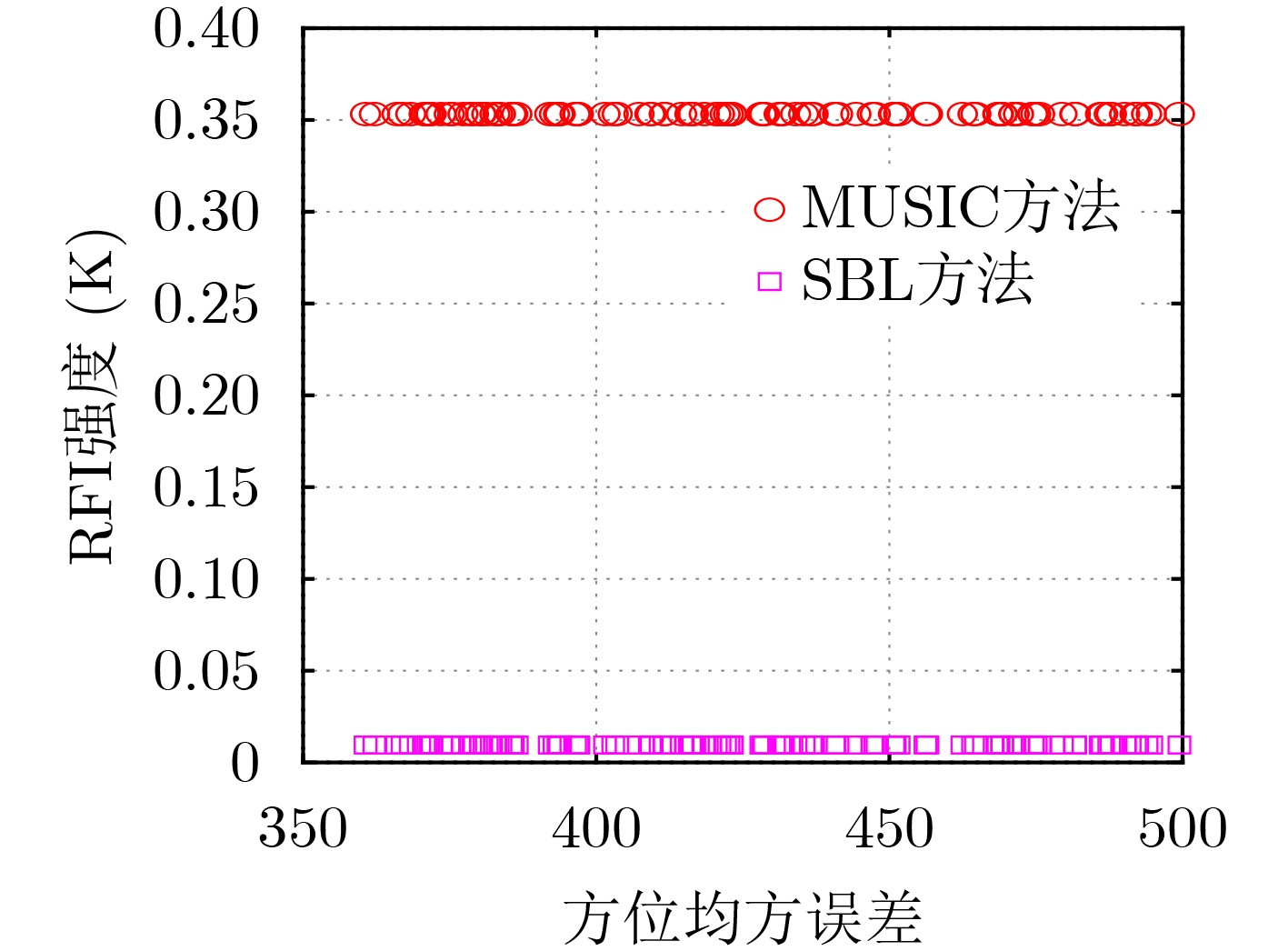
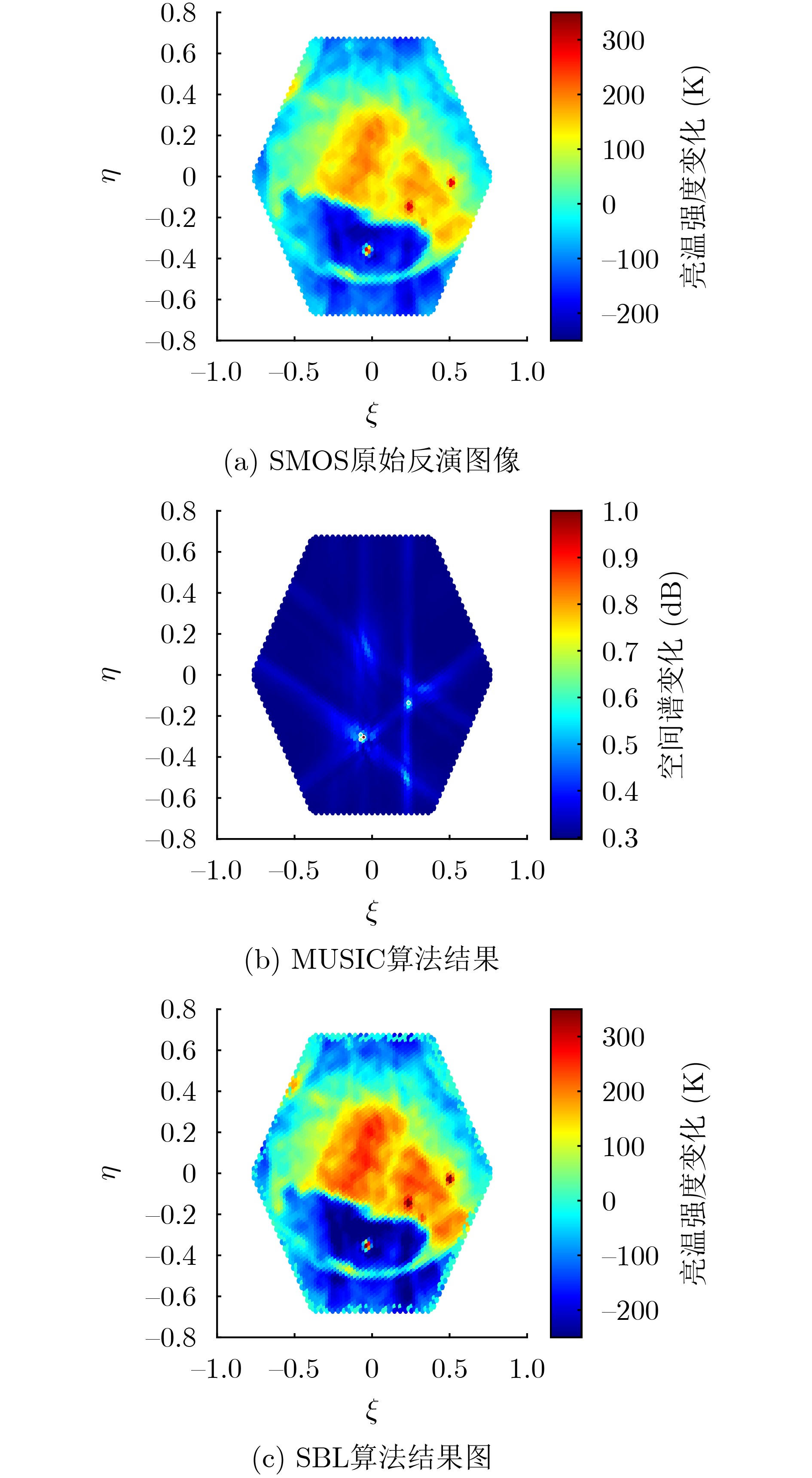
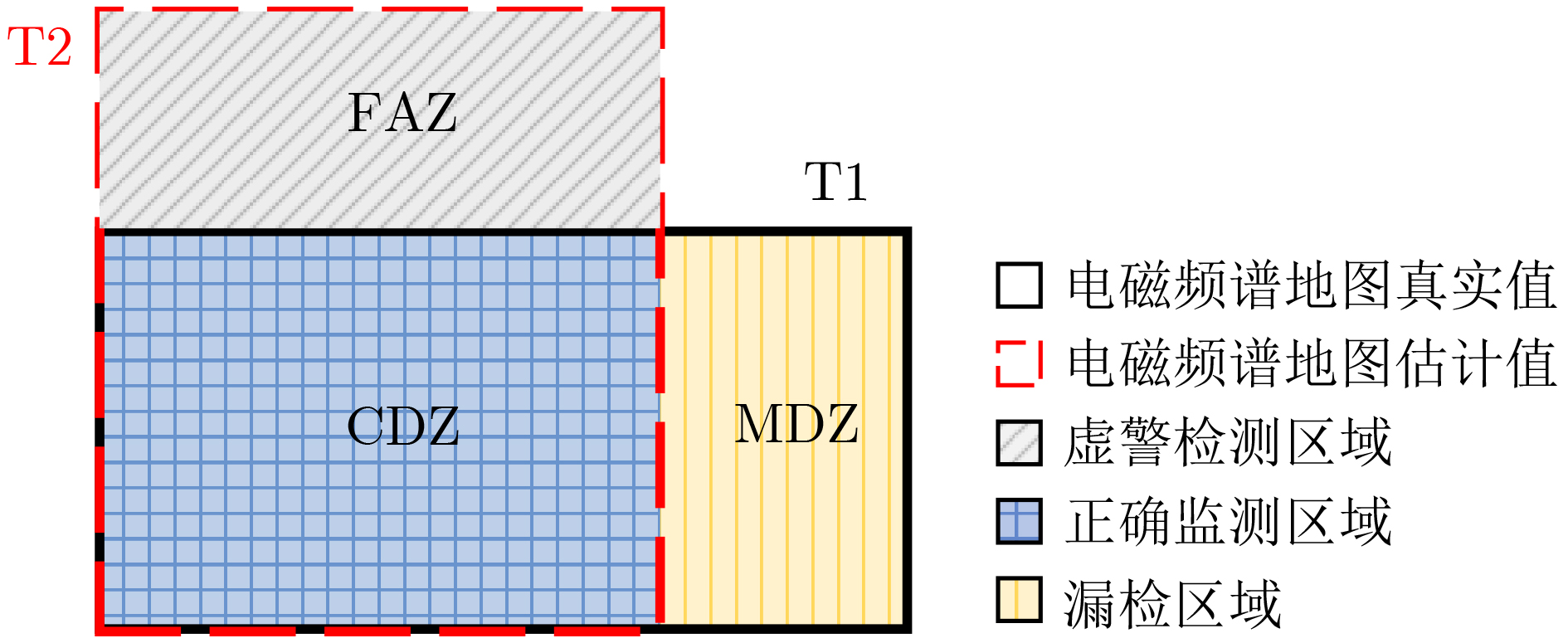
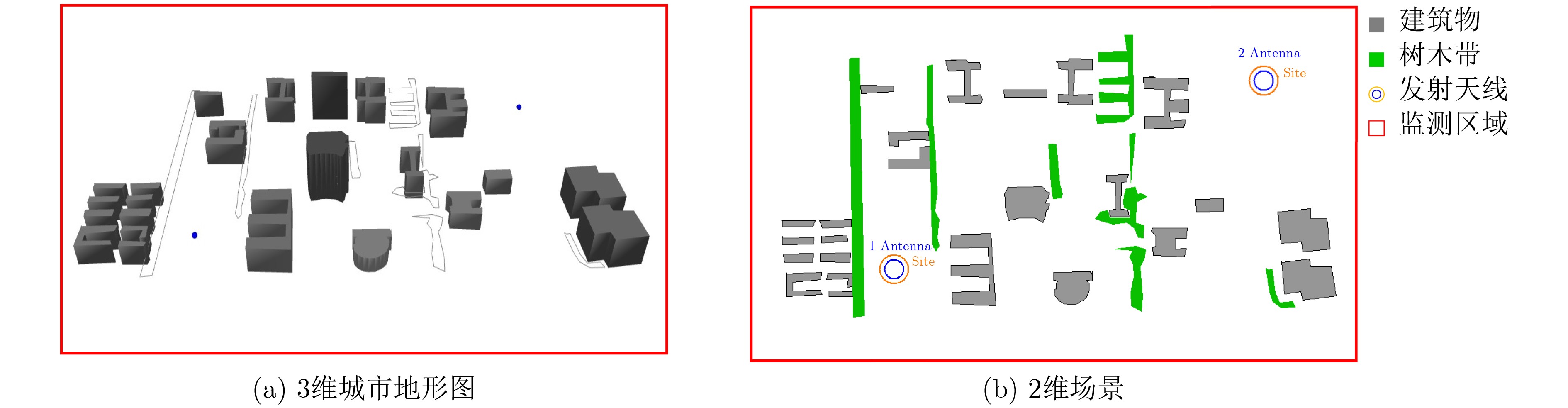
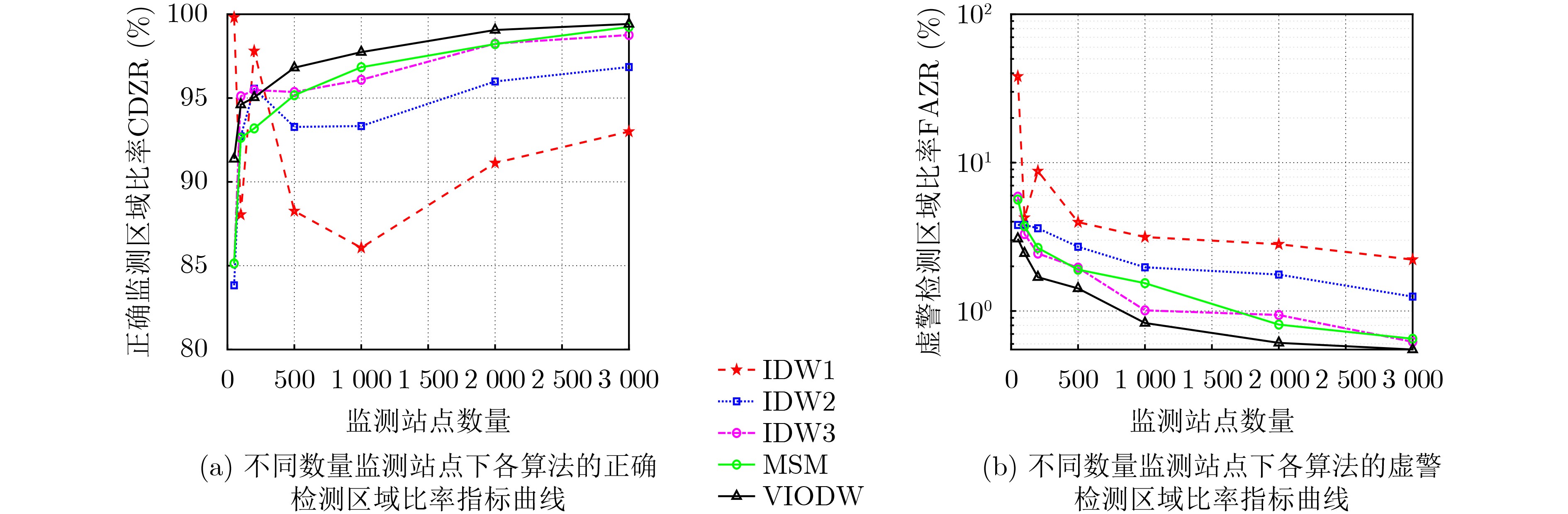
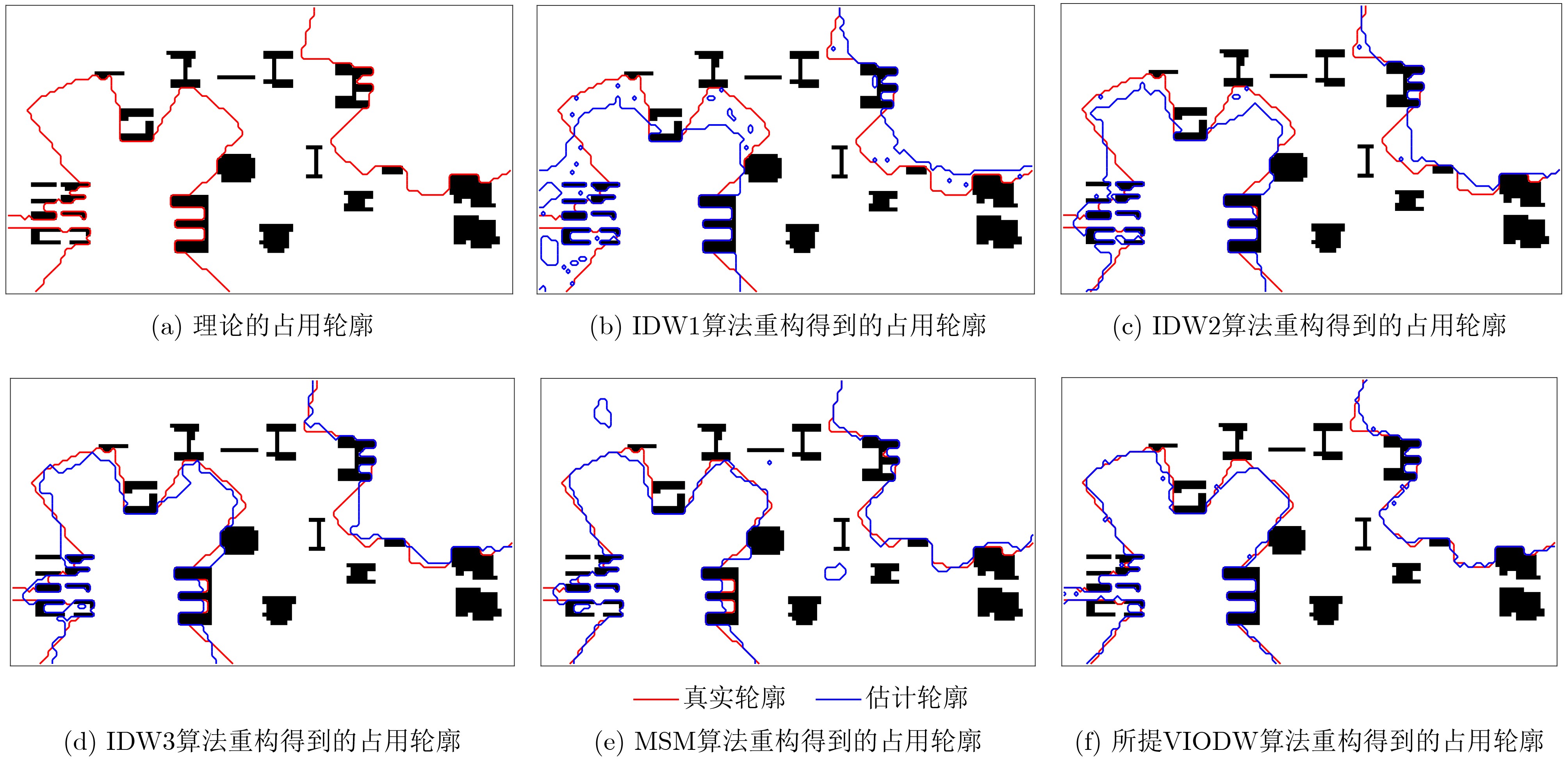
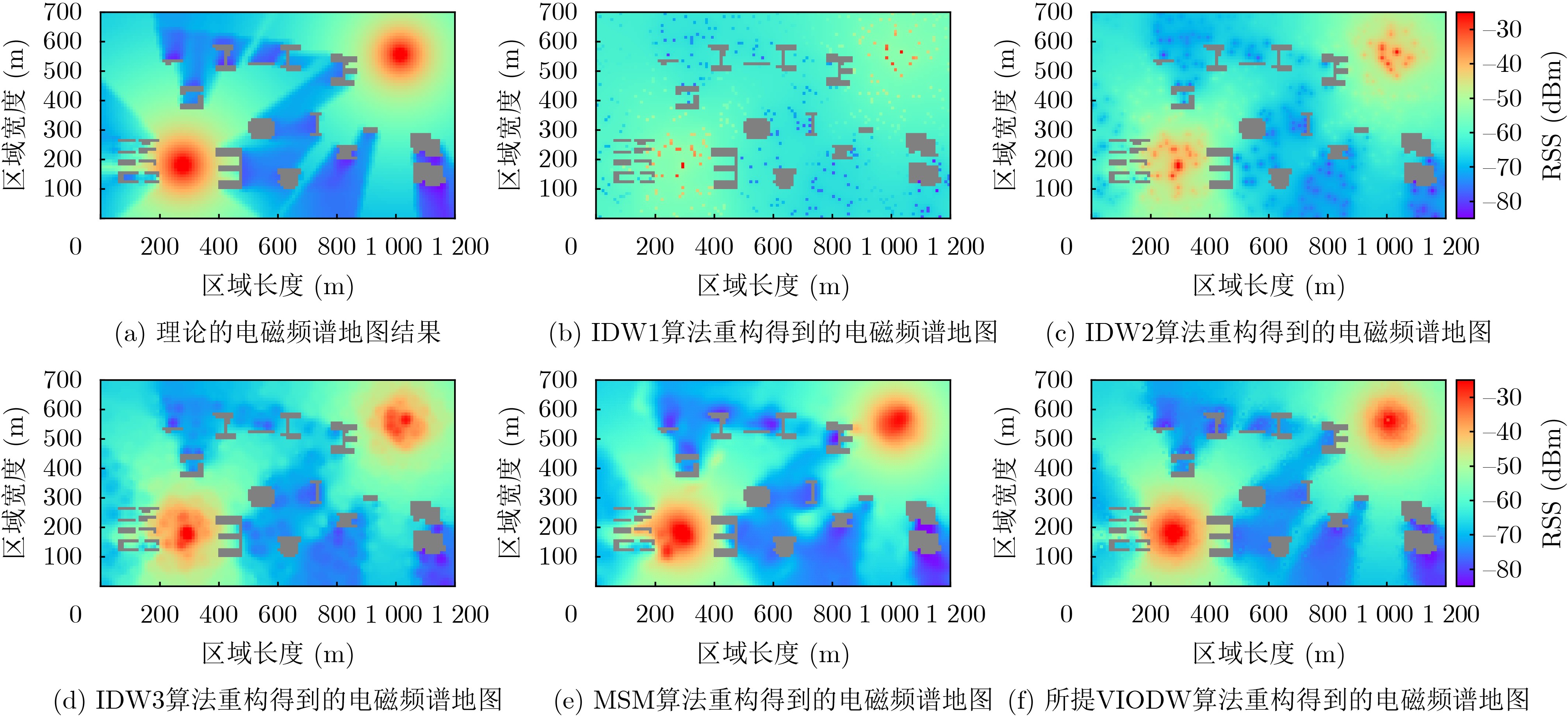
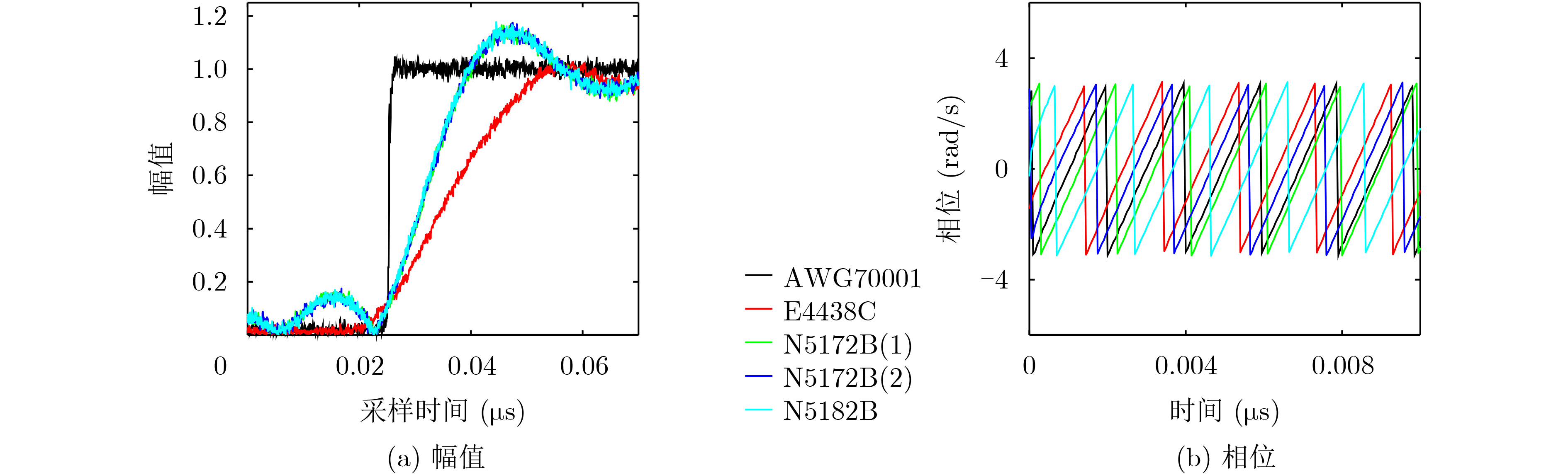
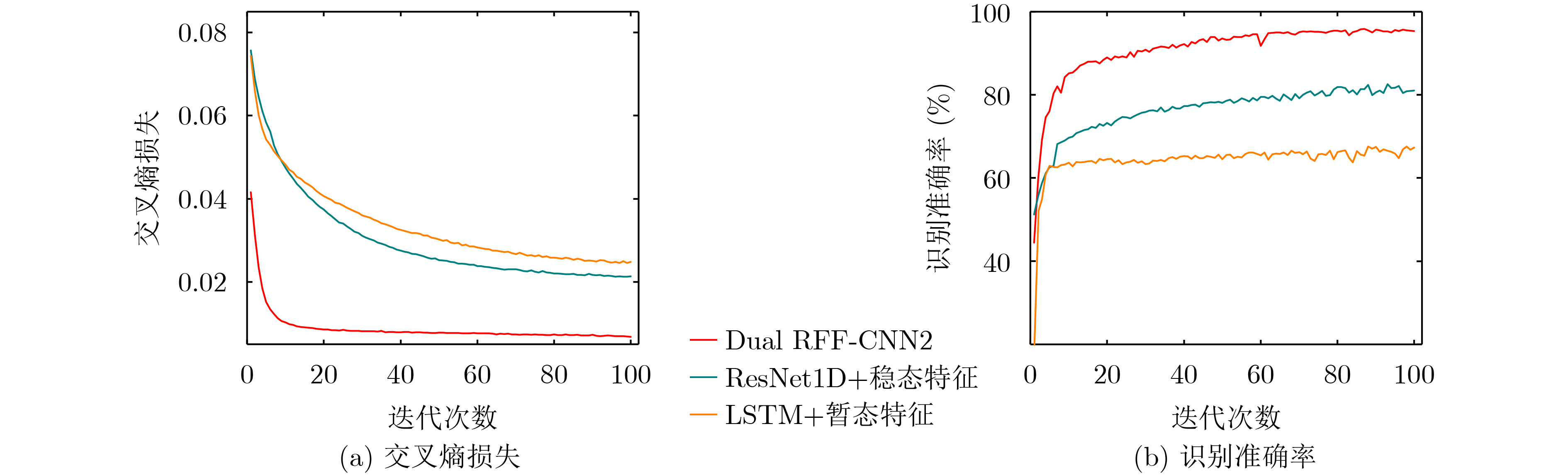
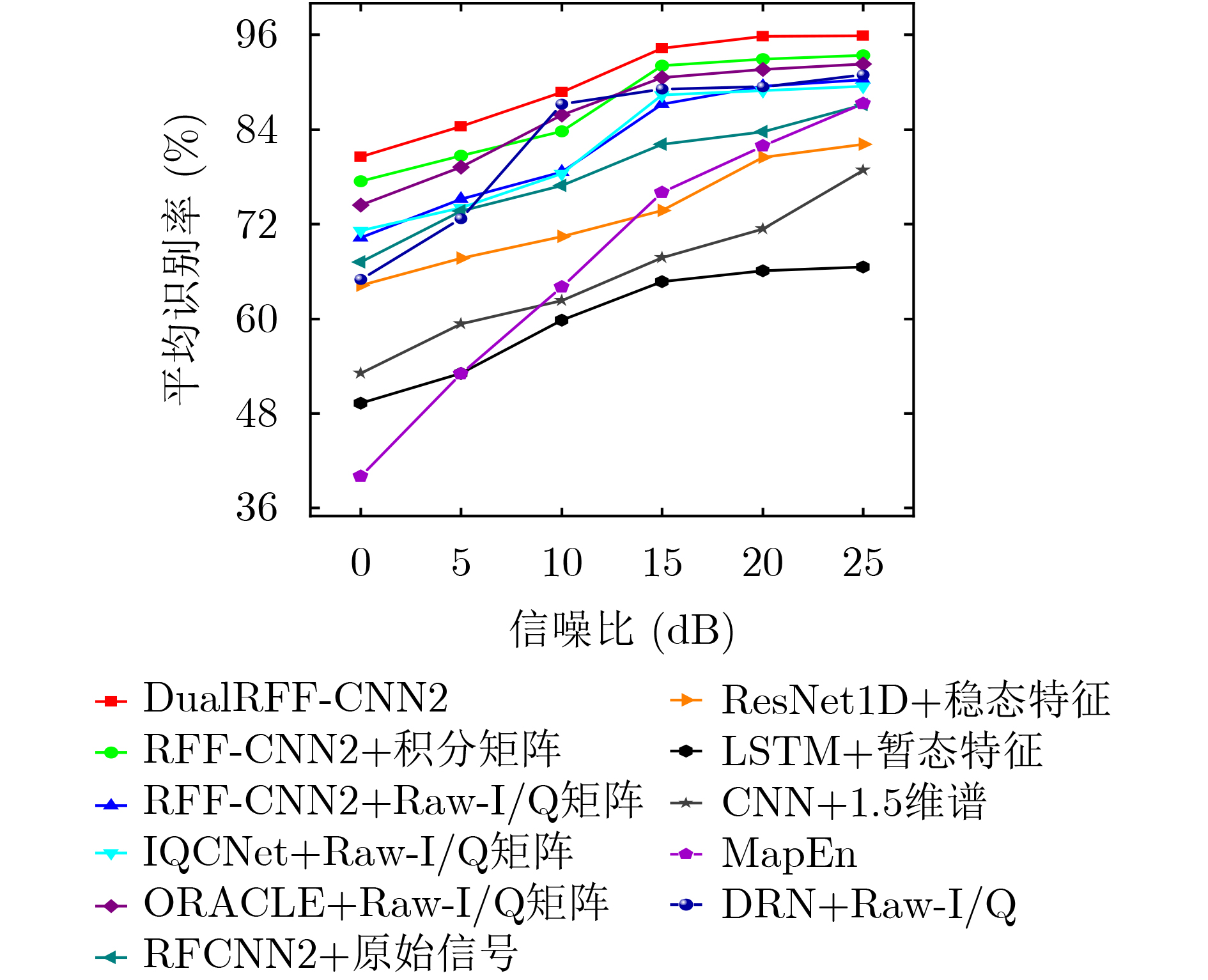
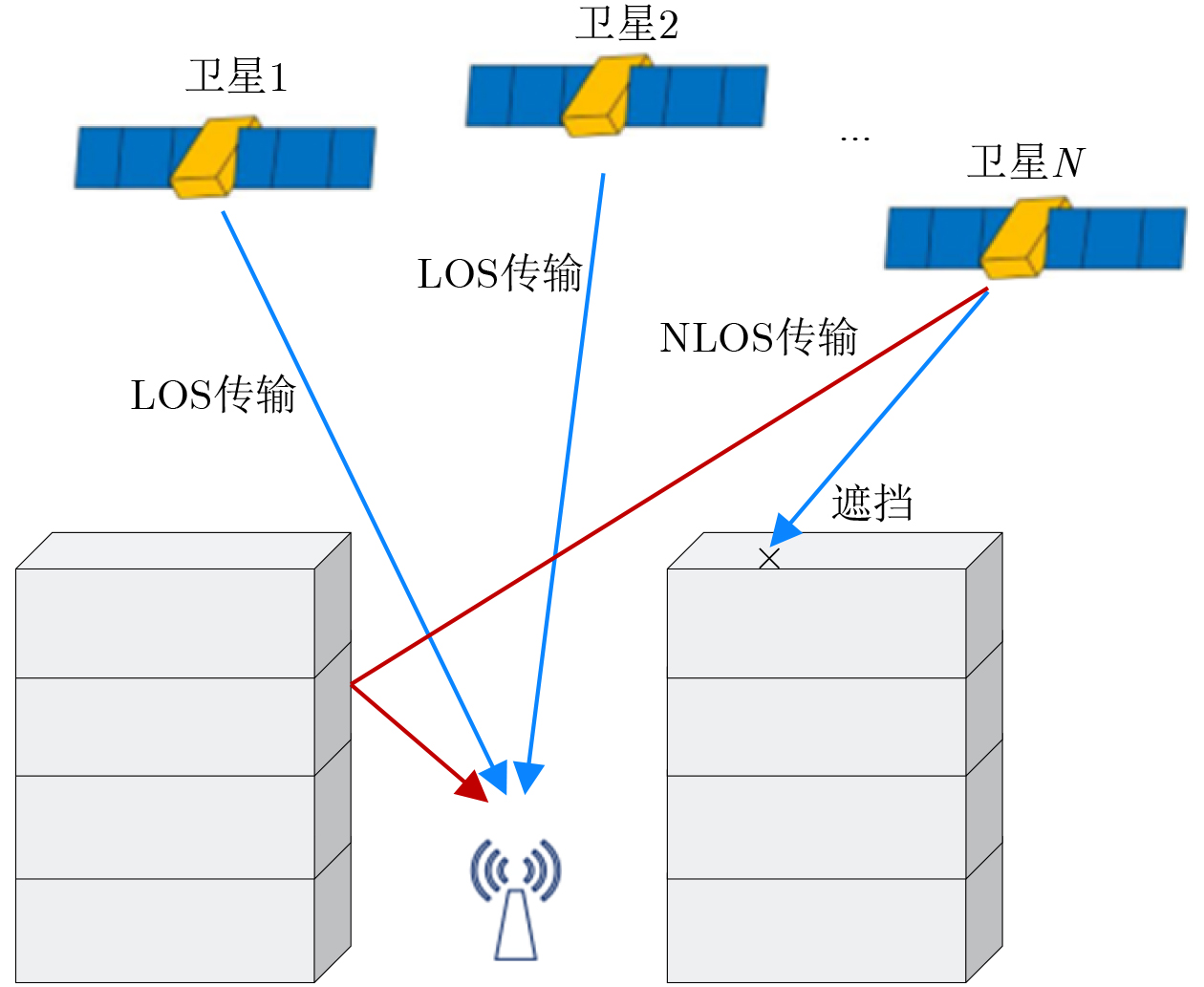
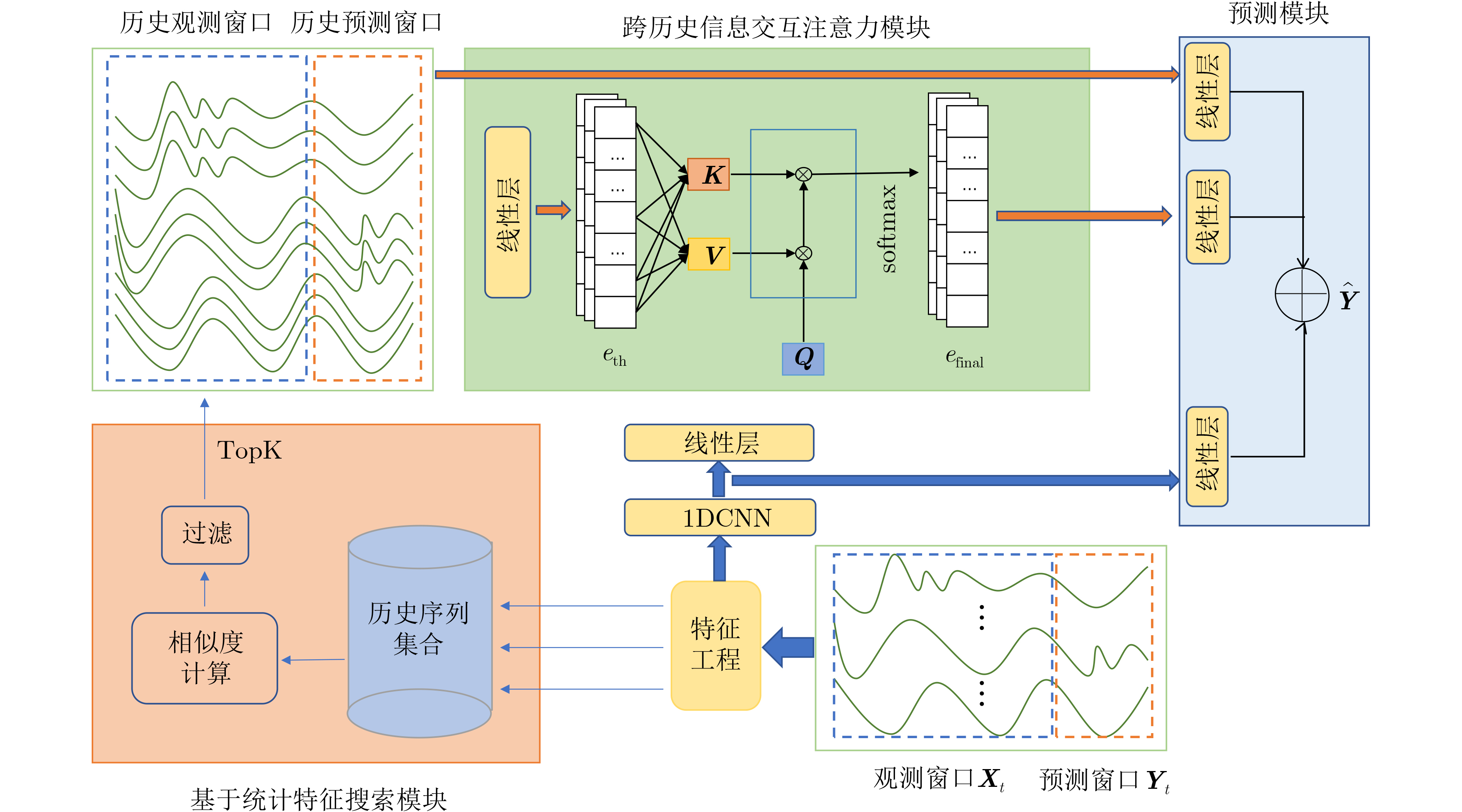
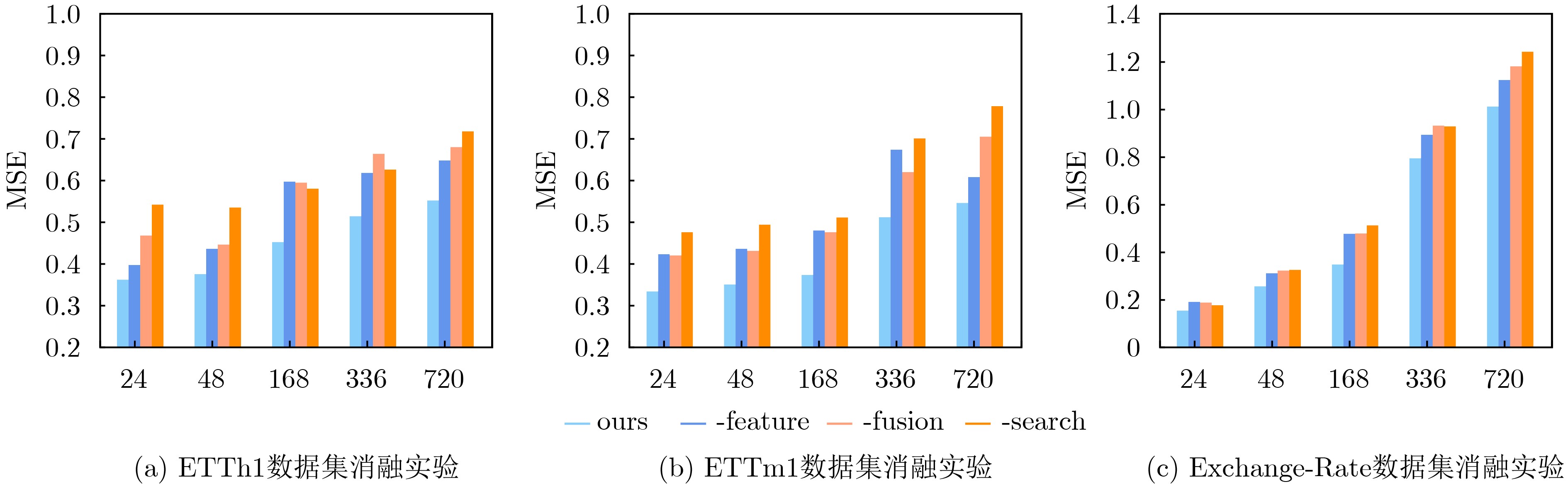
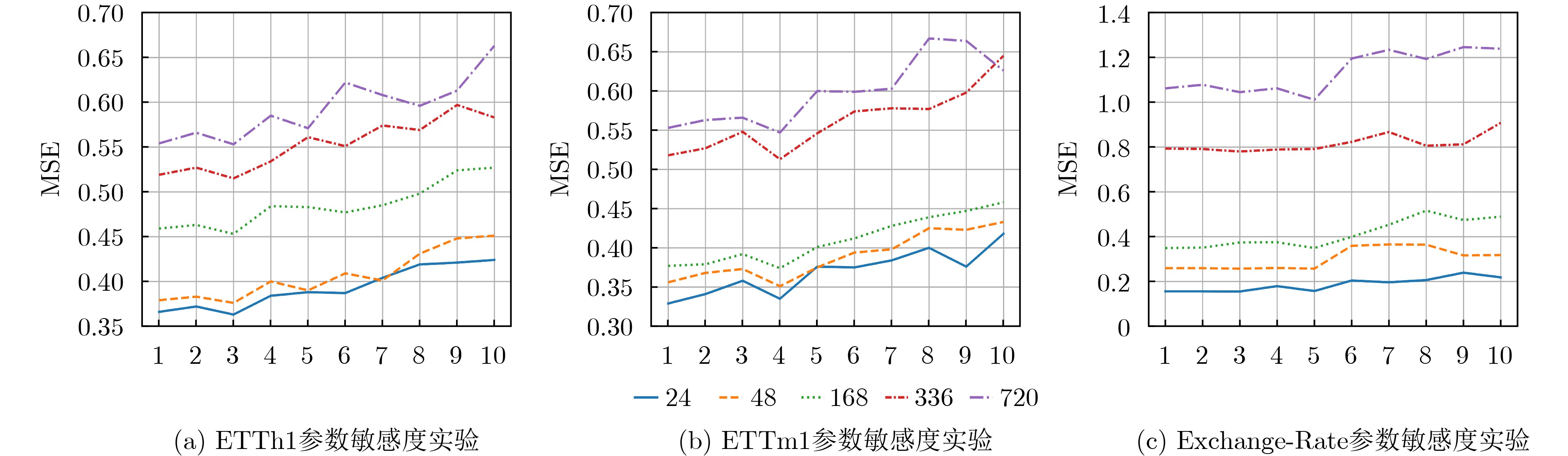
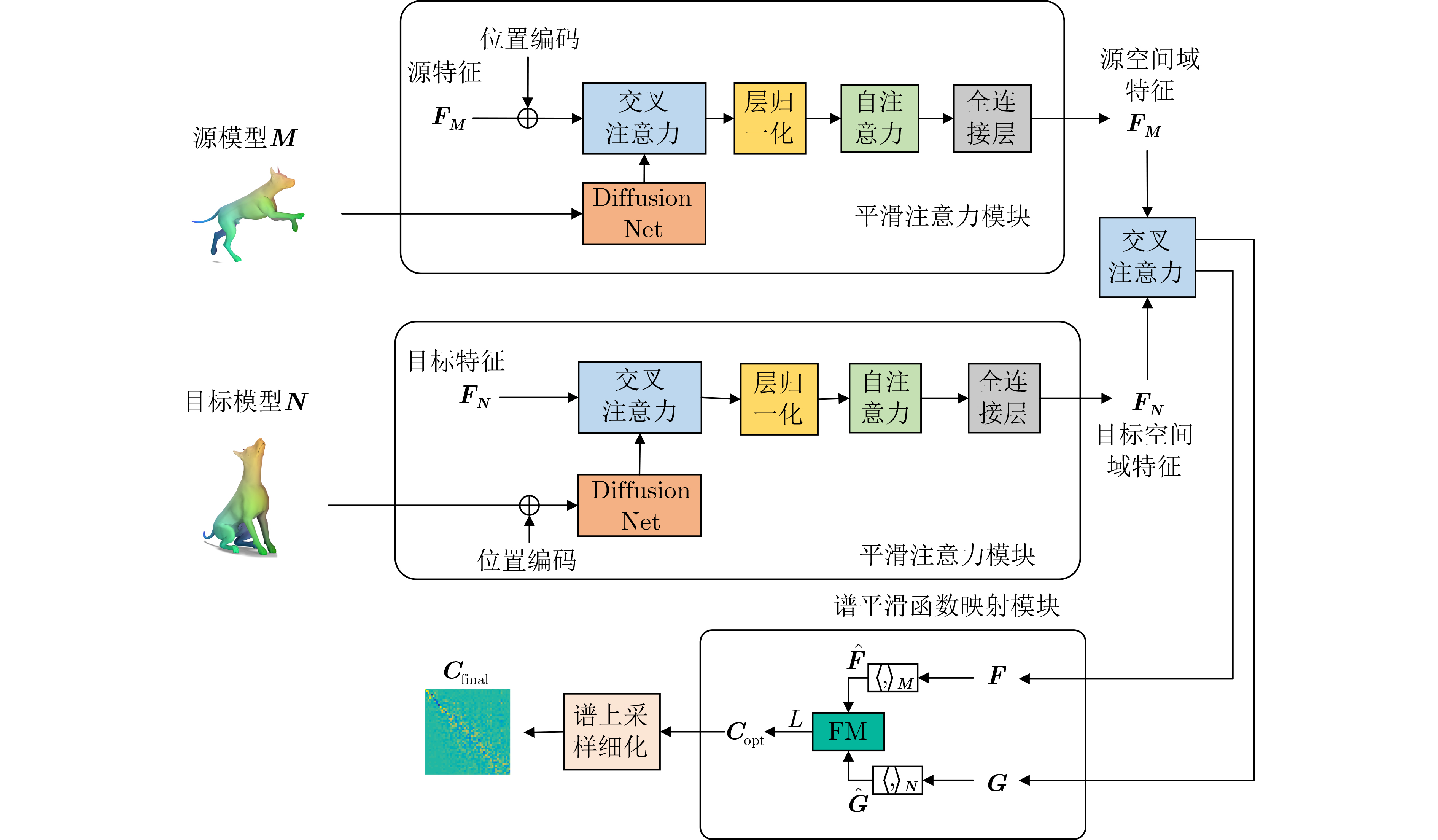
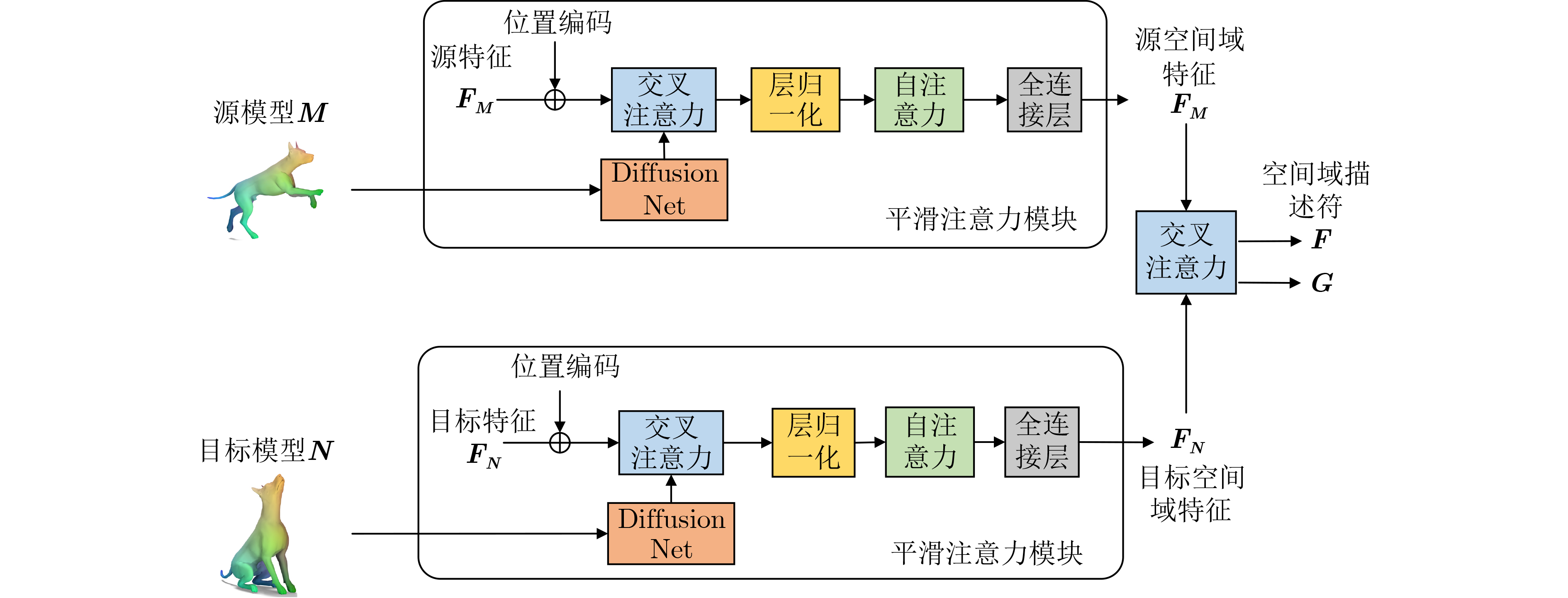
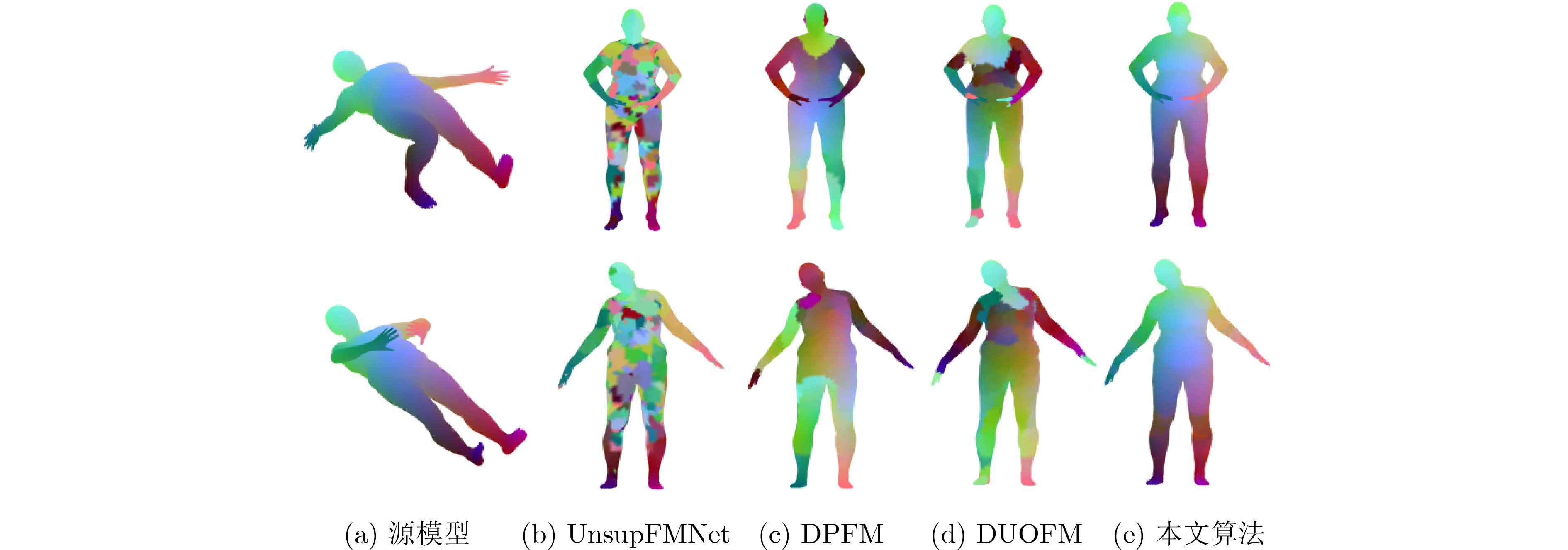
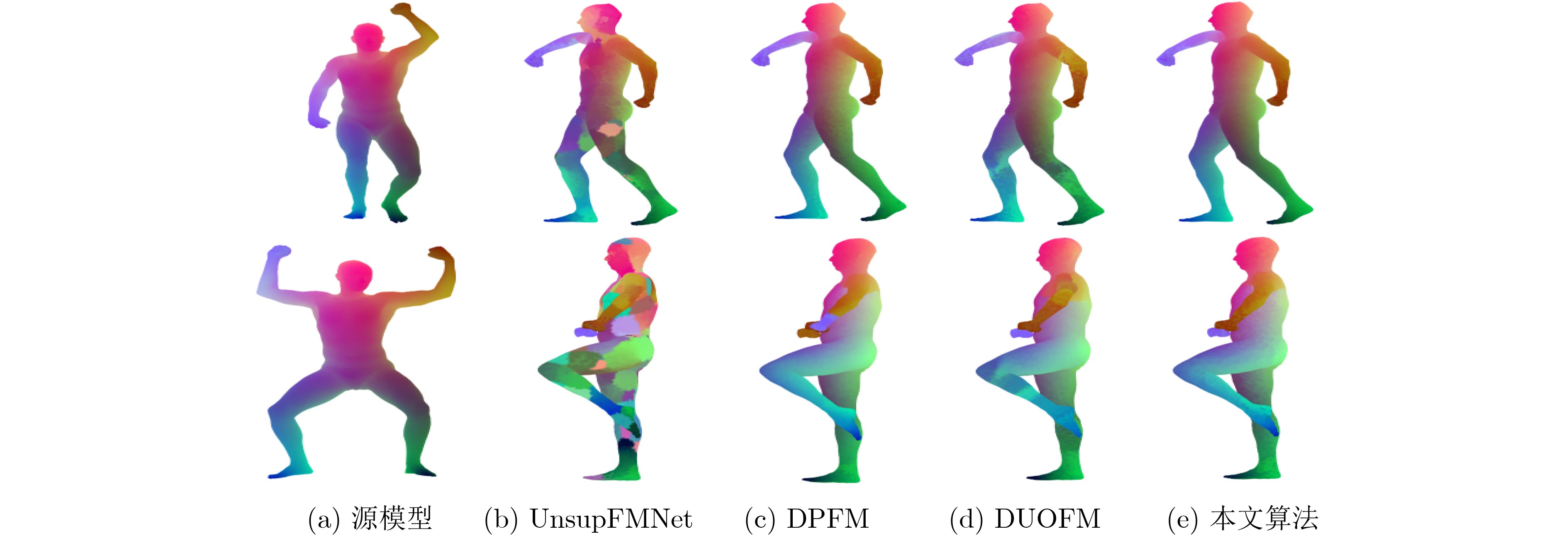
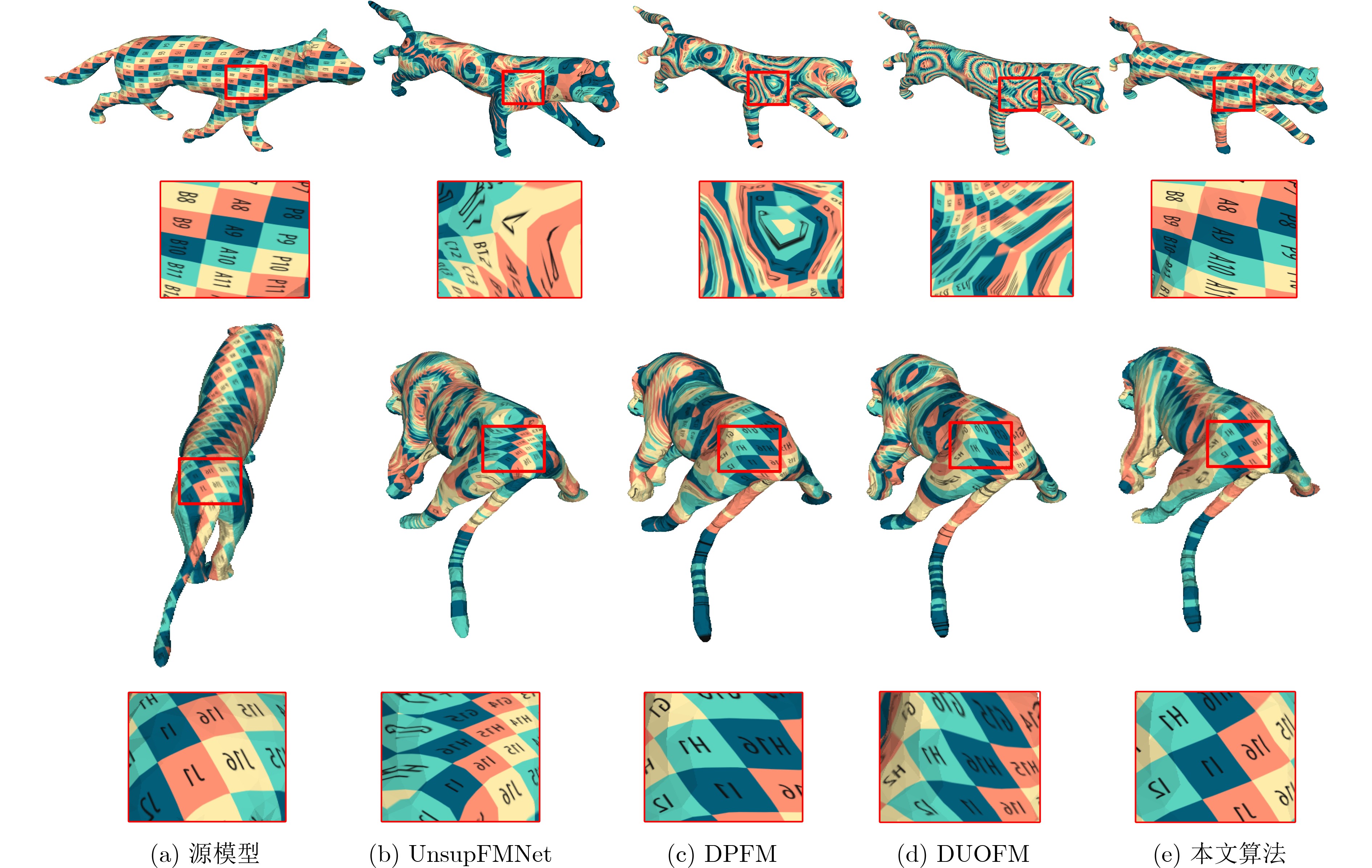
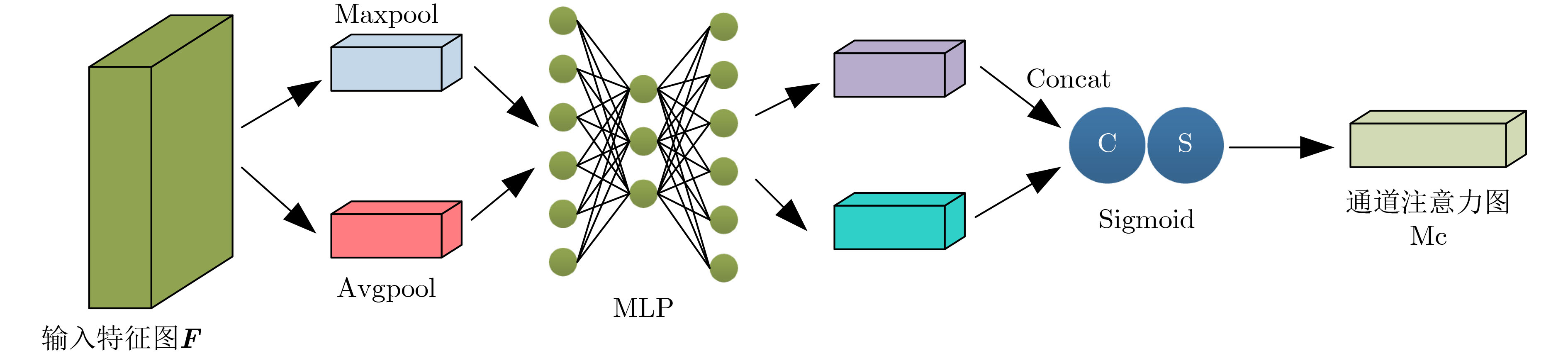
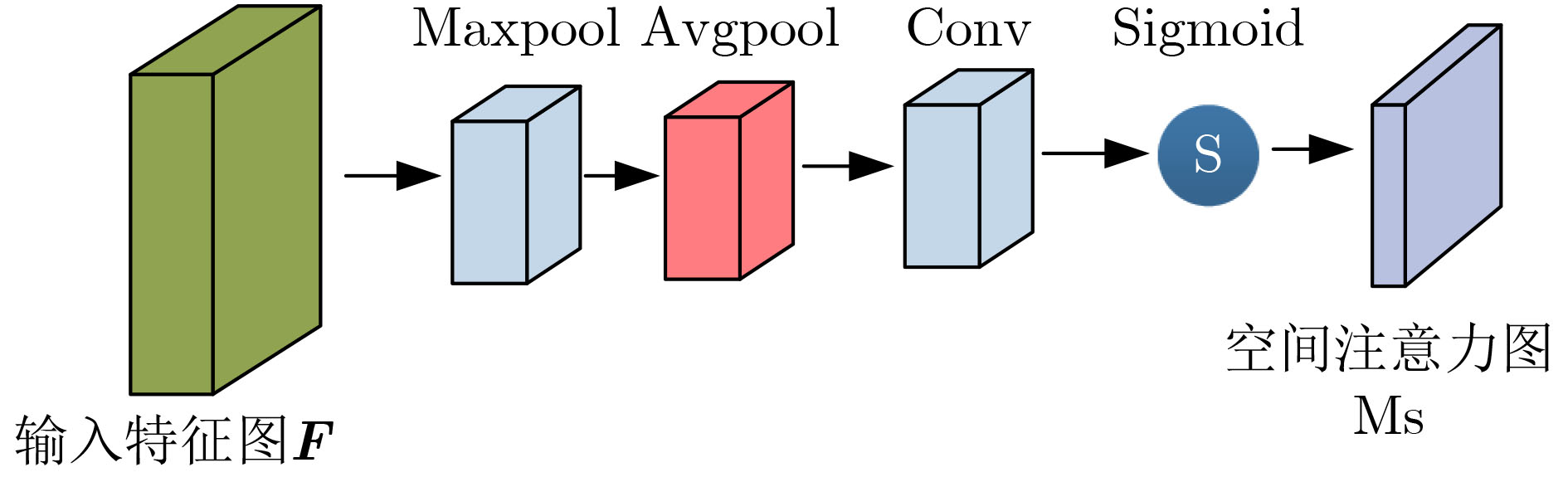
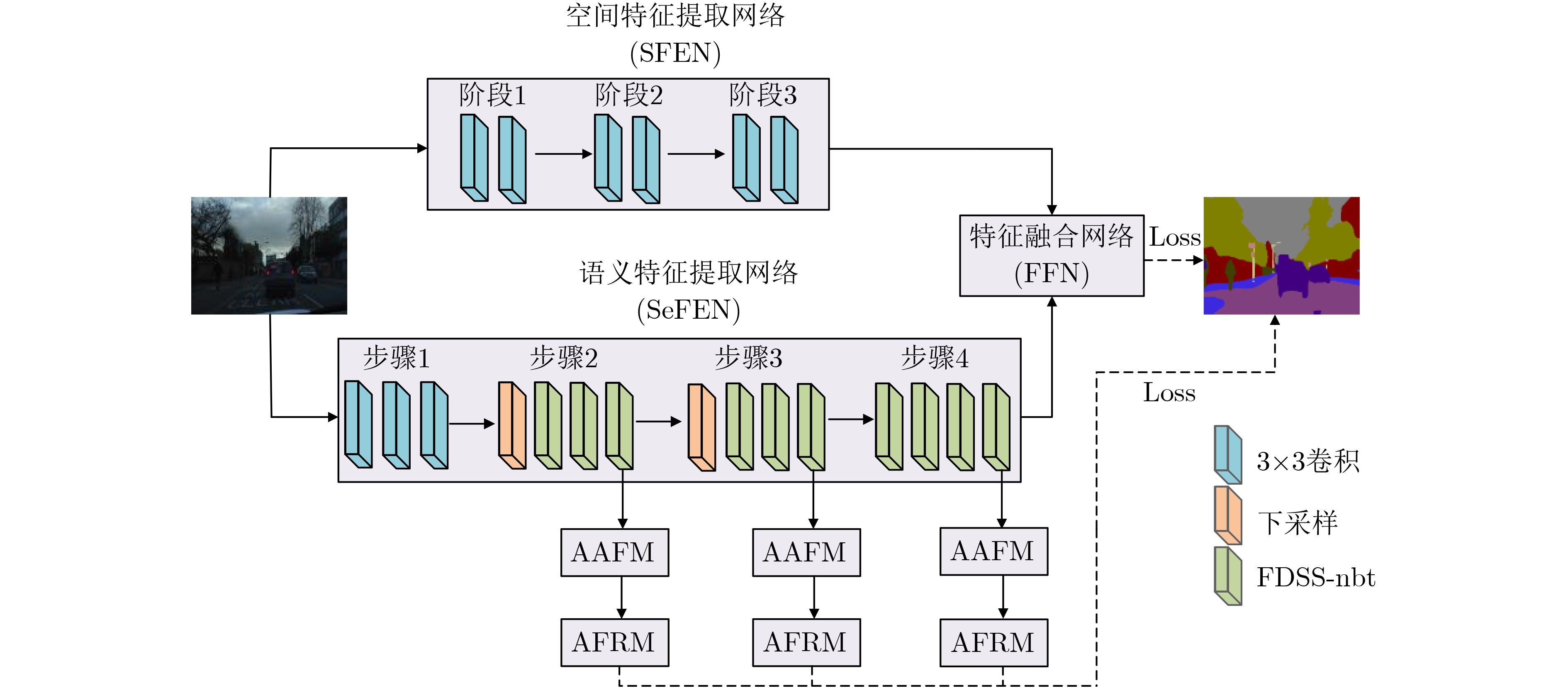
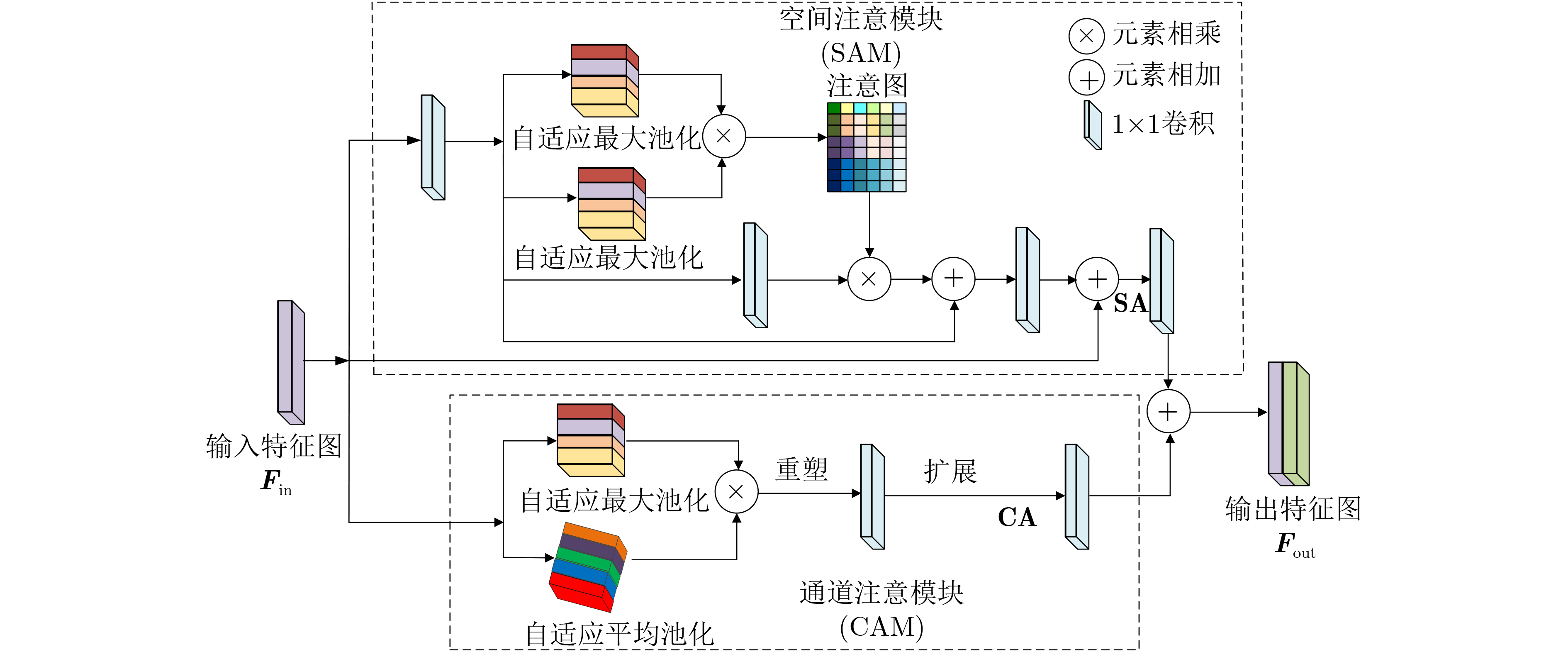
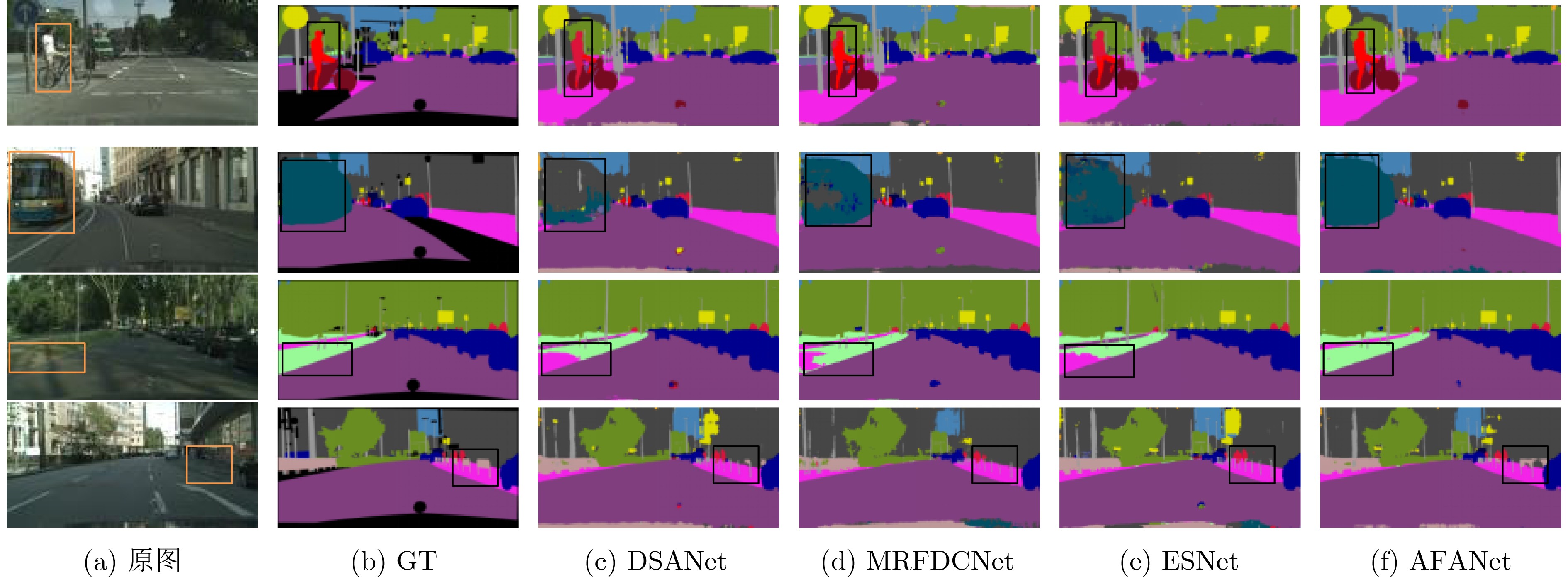
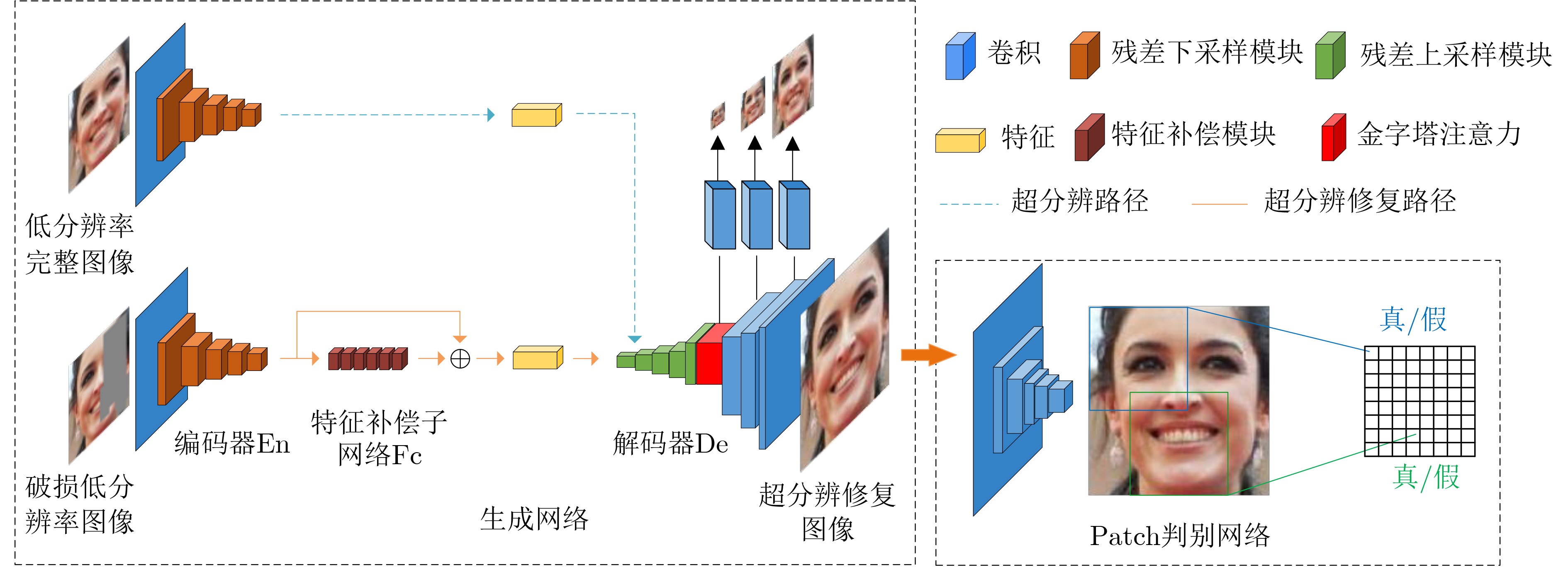
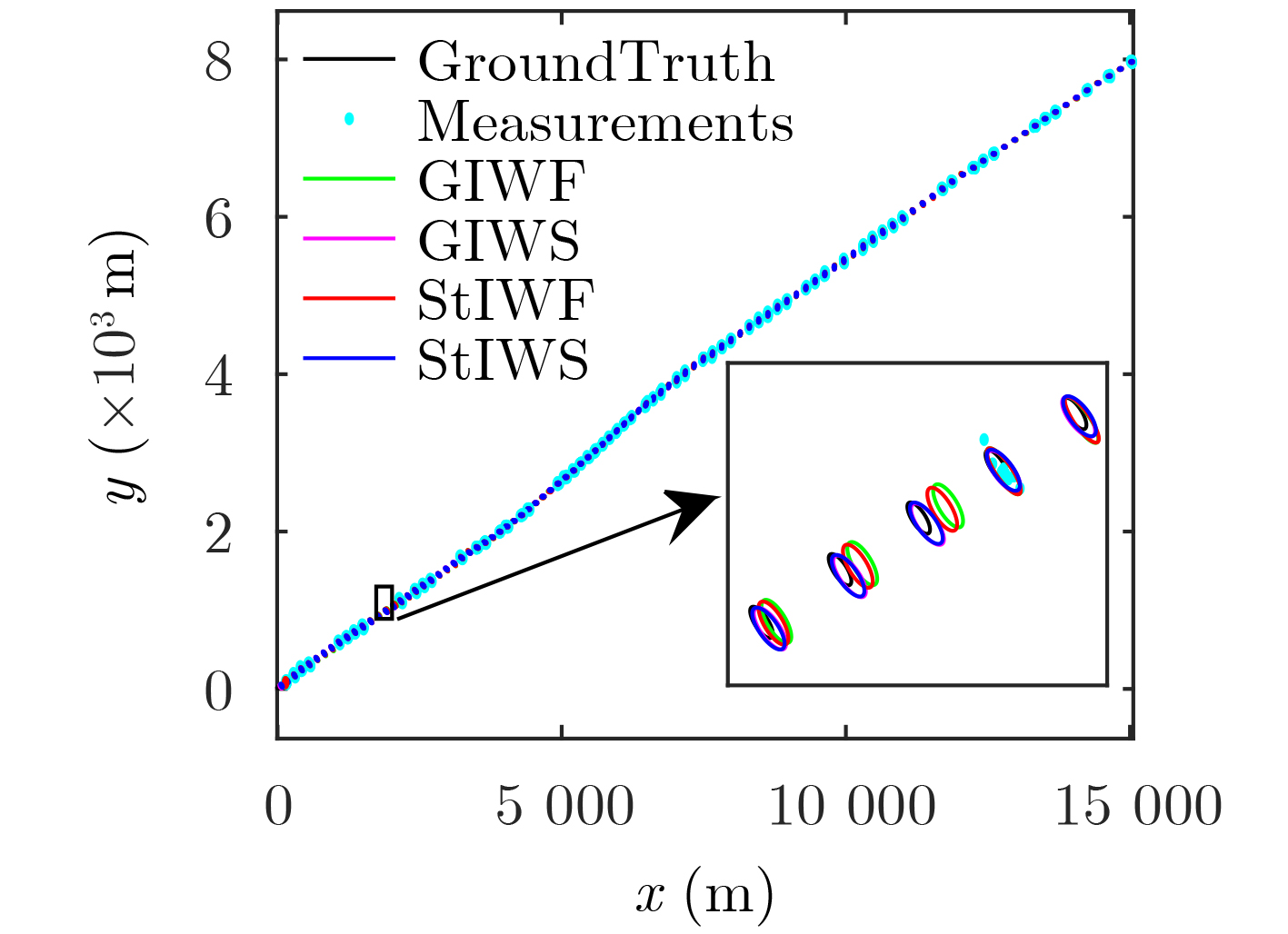
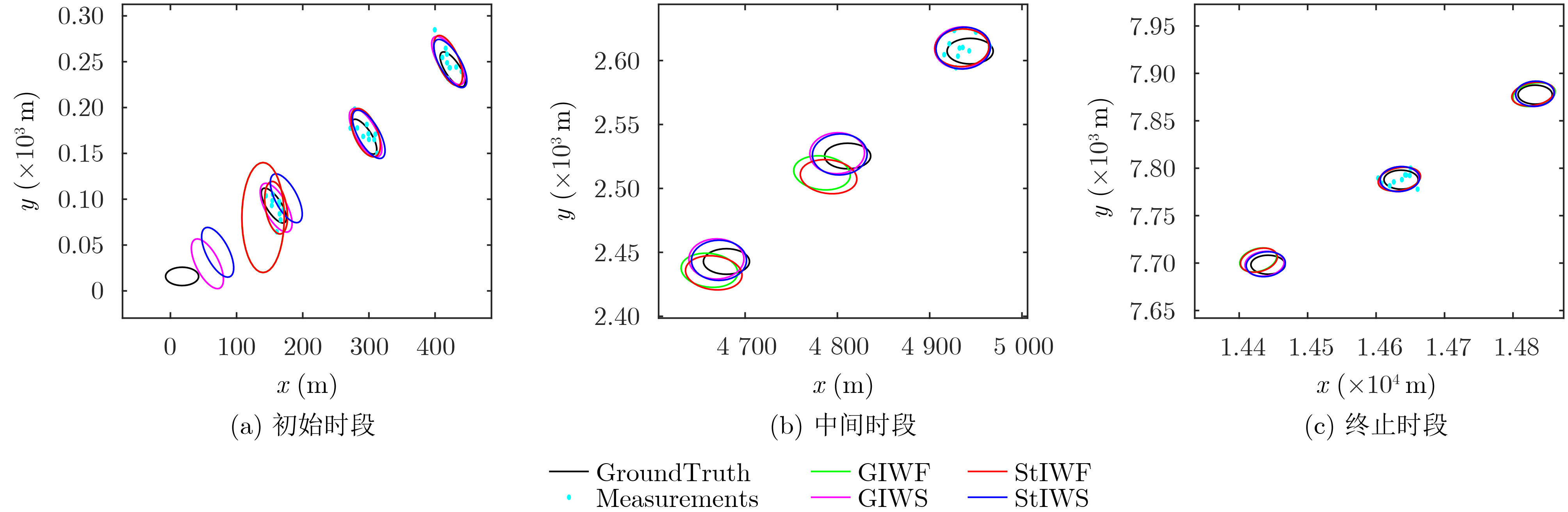
2024, 46(8): 3436-3444.
doi: 10.11999/JEIT231257
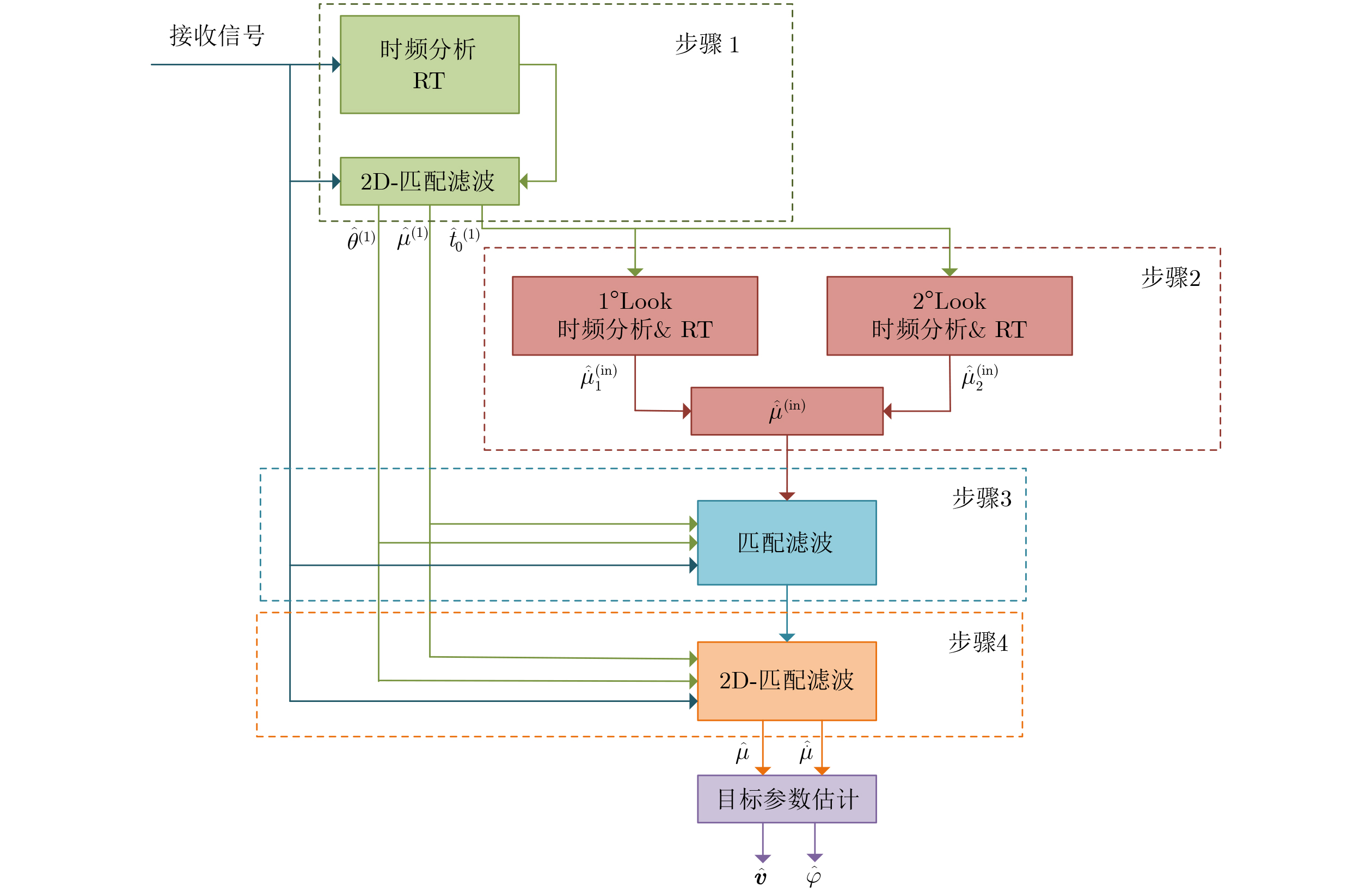
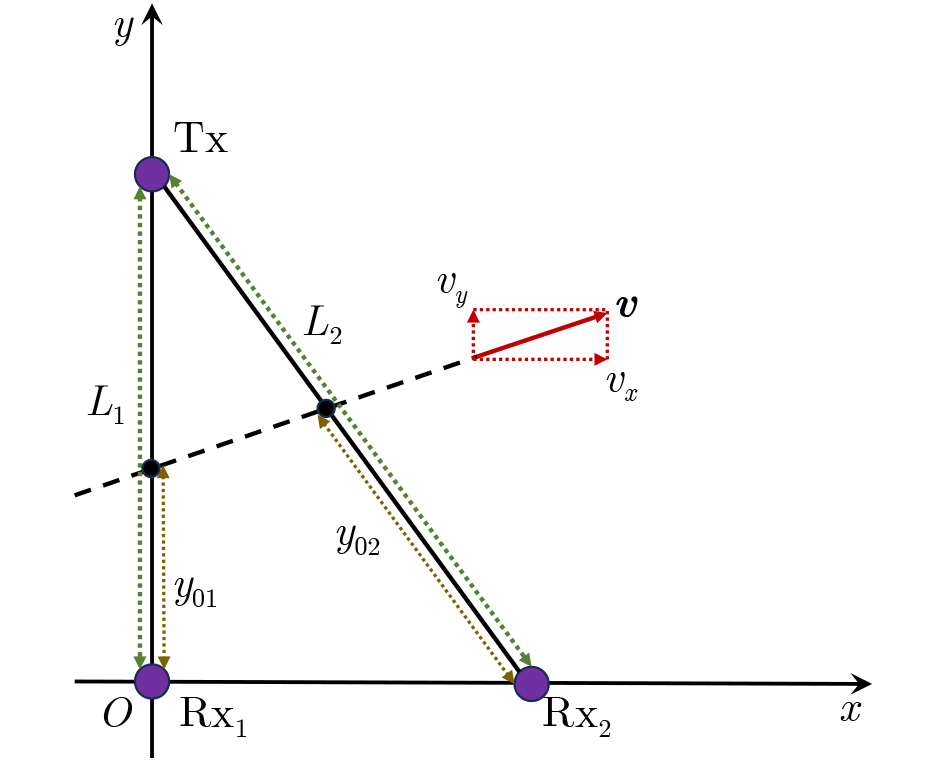
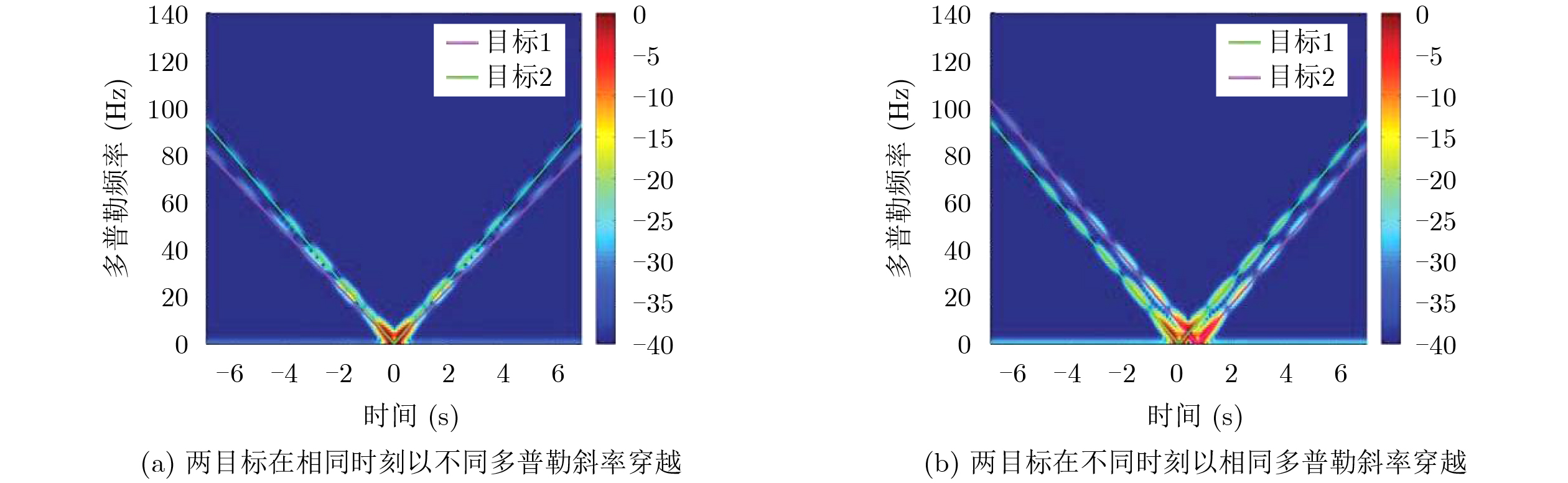
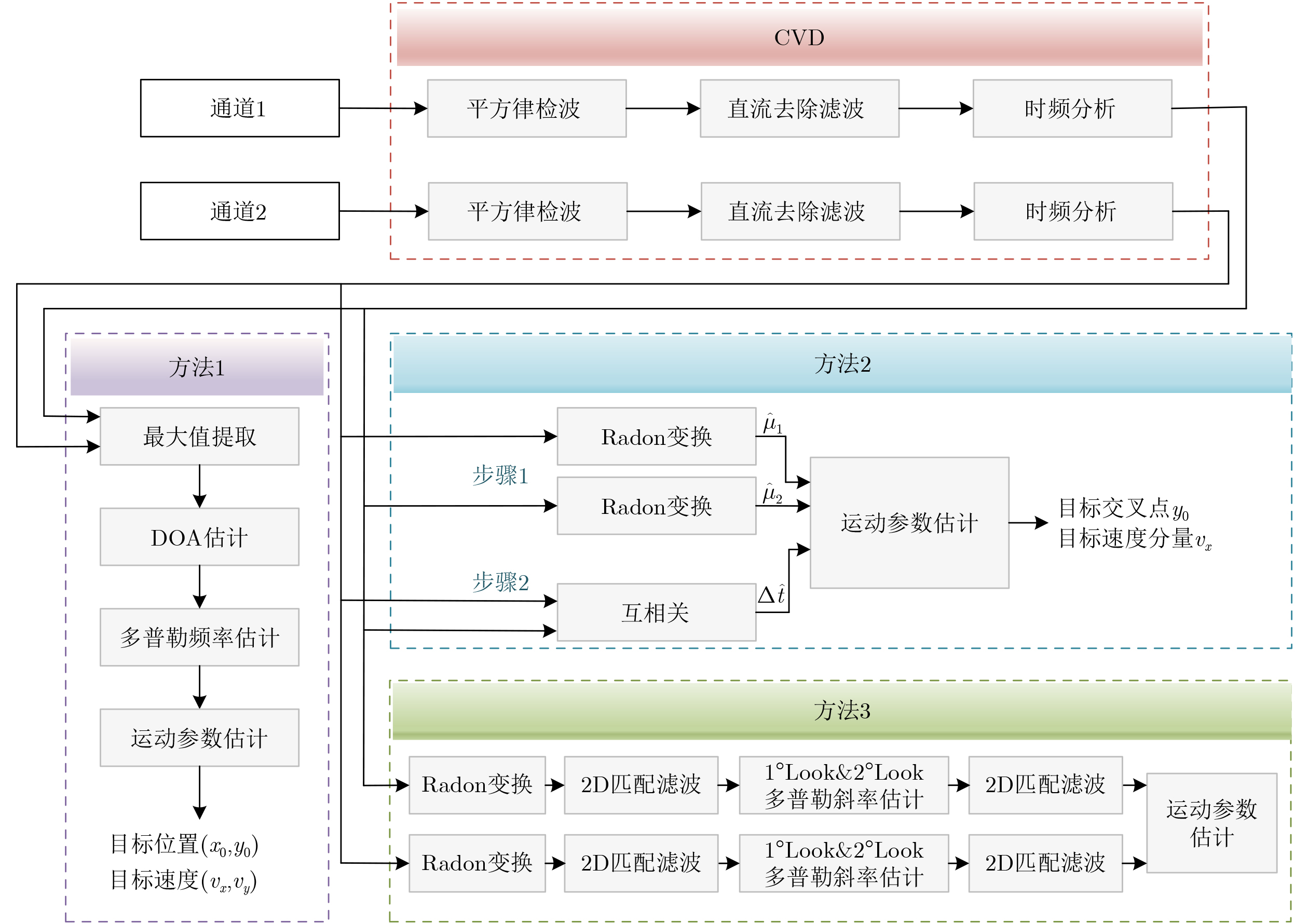
Abstract:
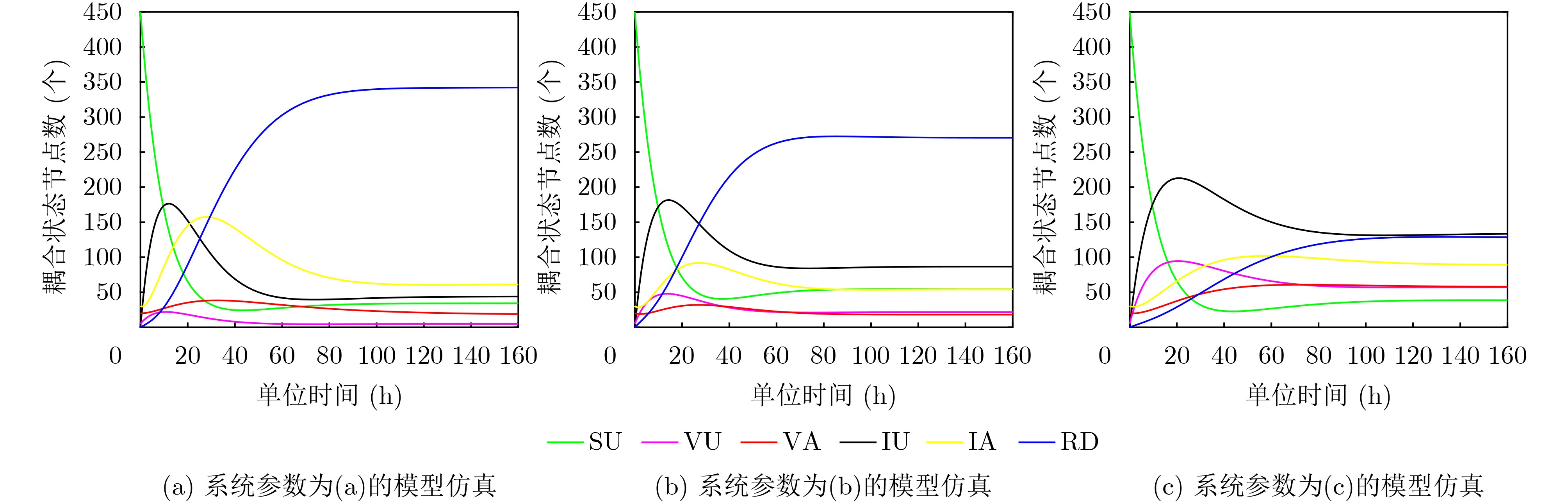
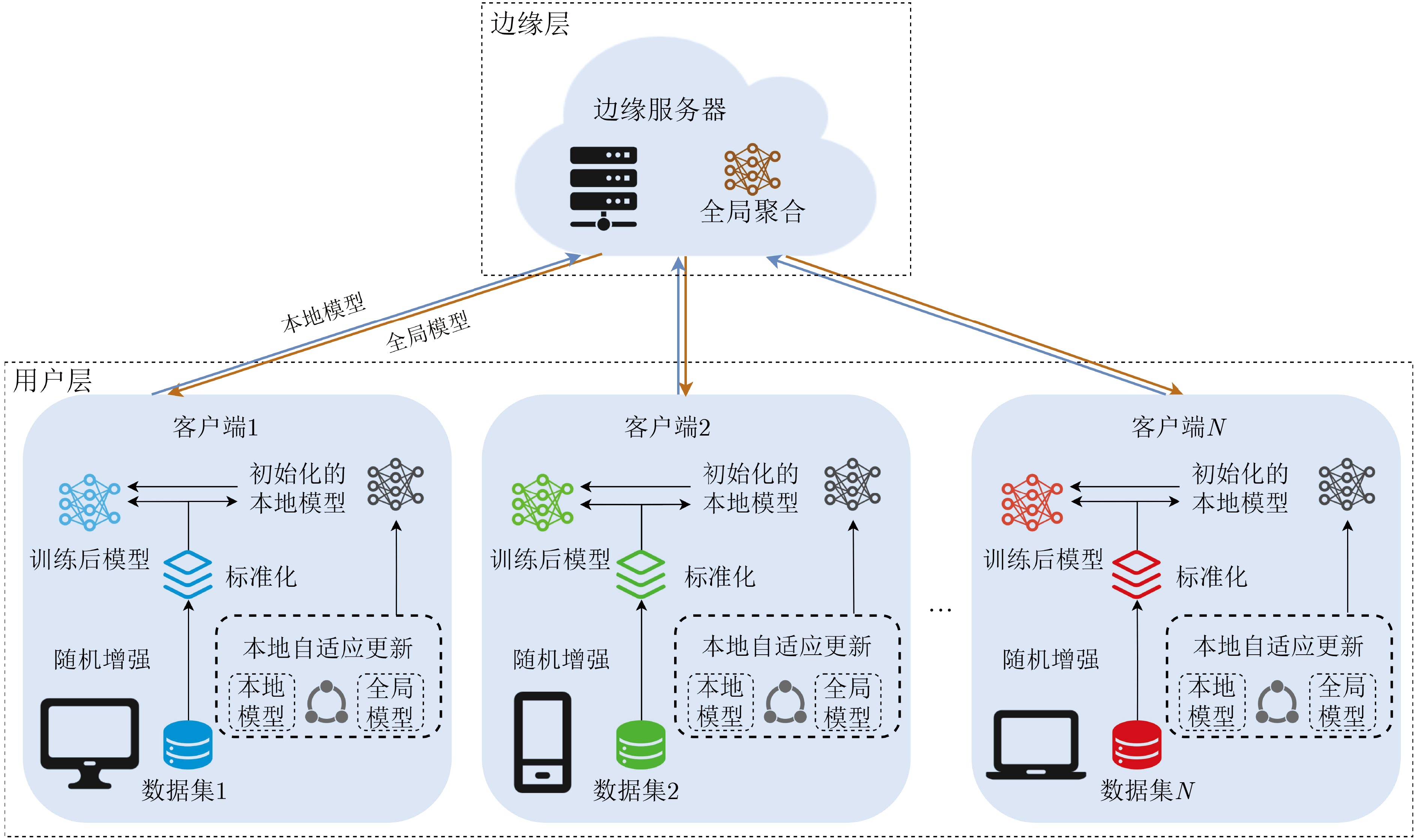
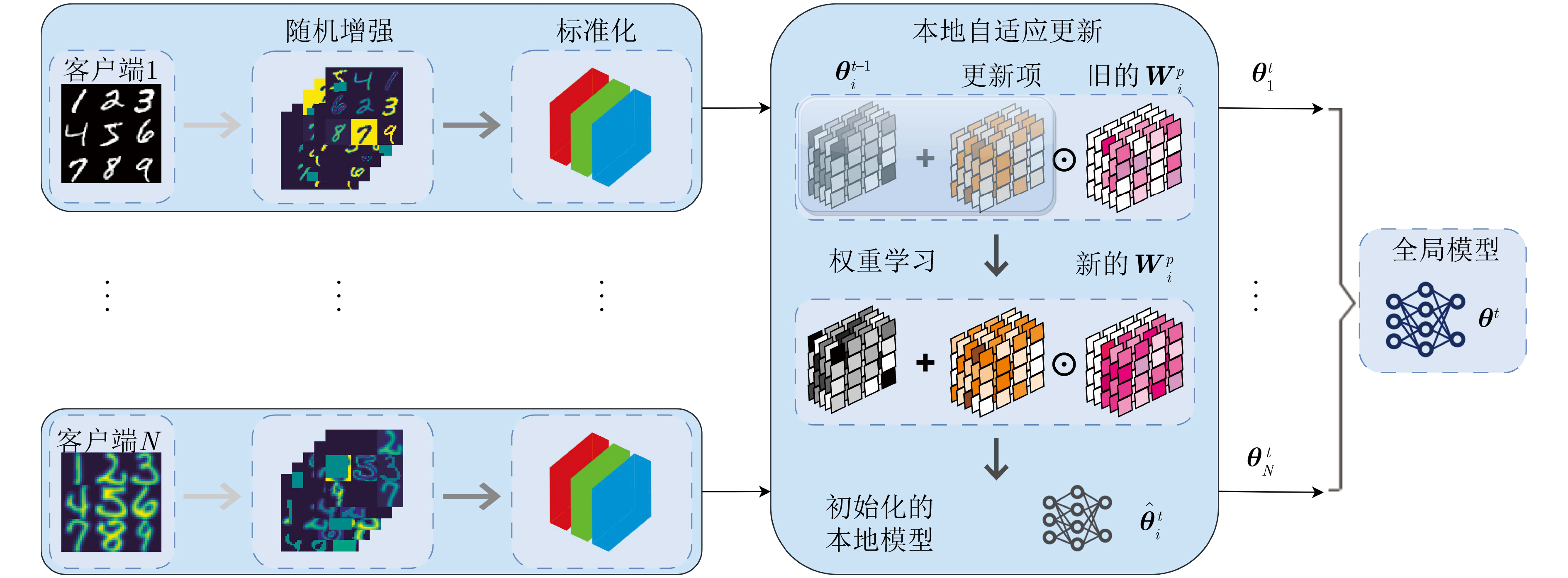
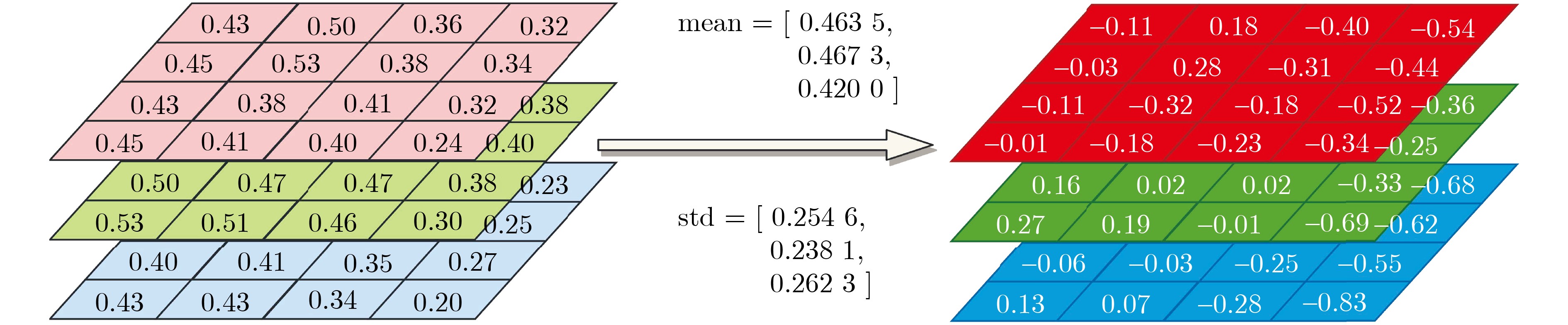
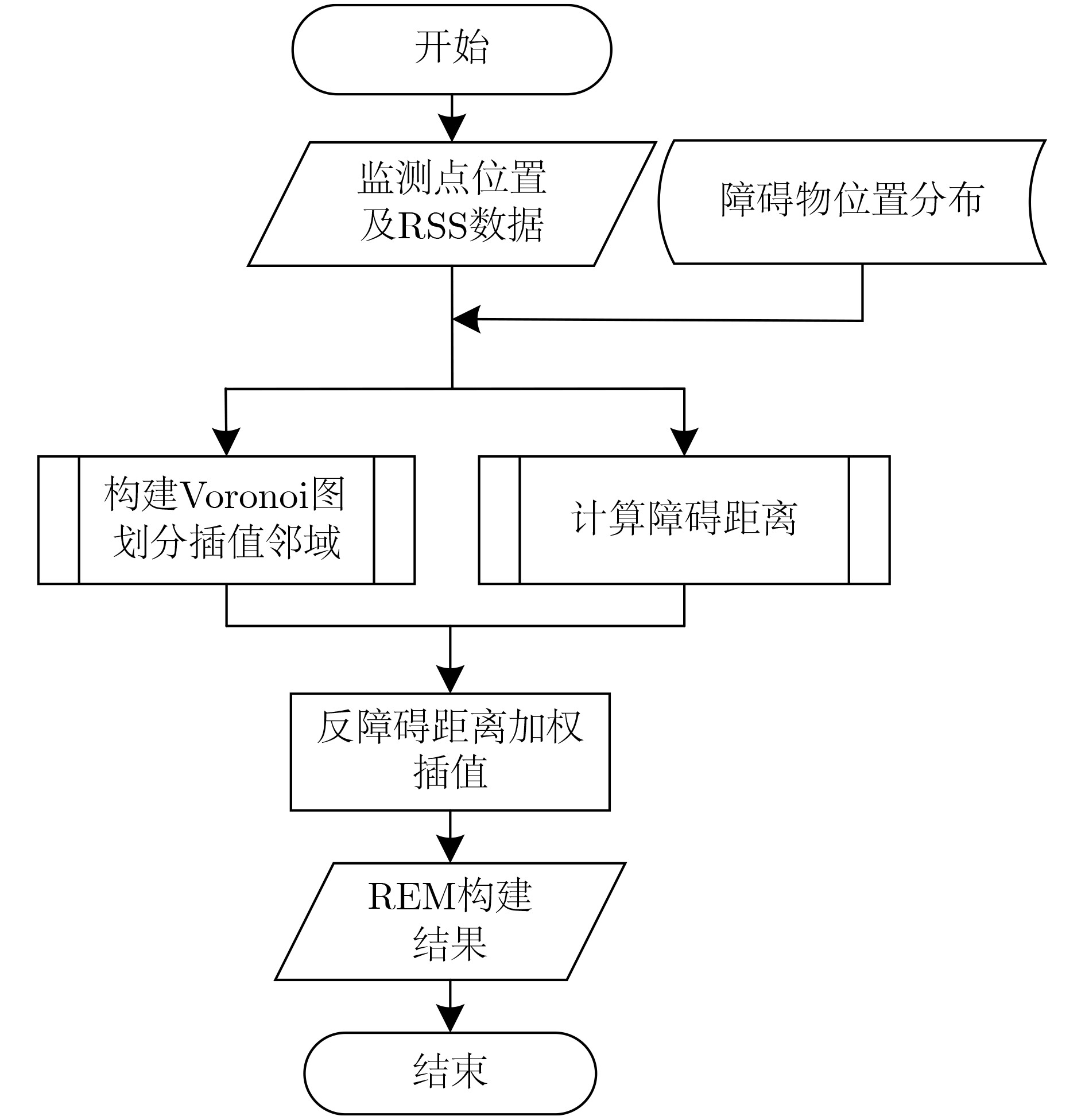
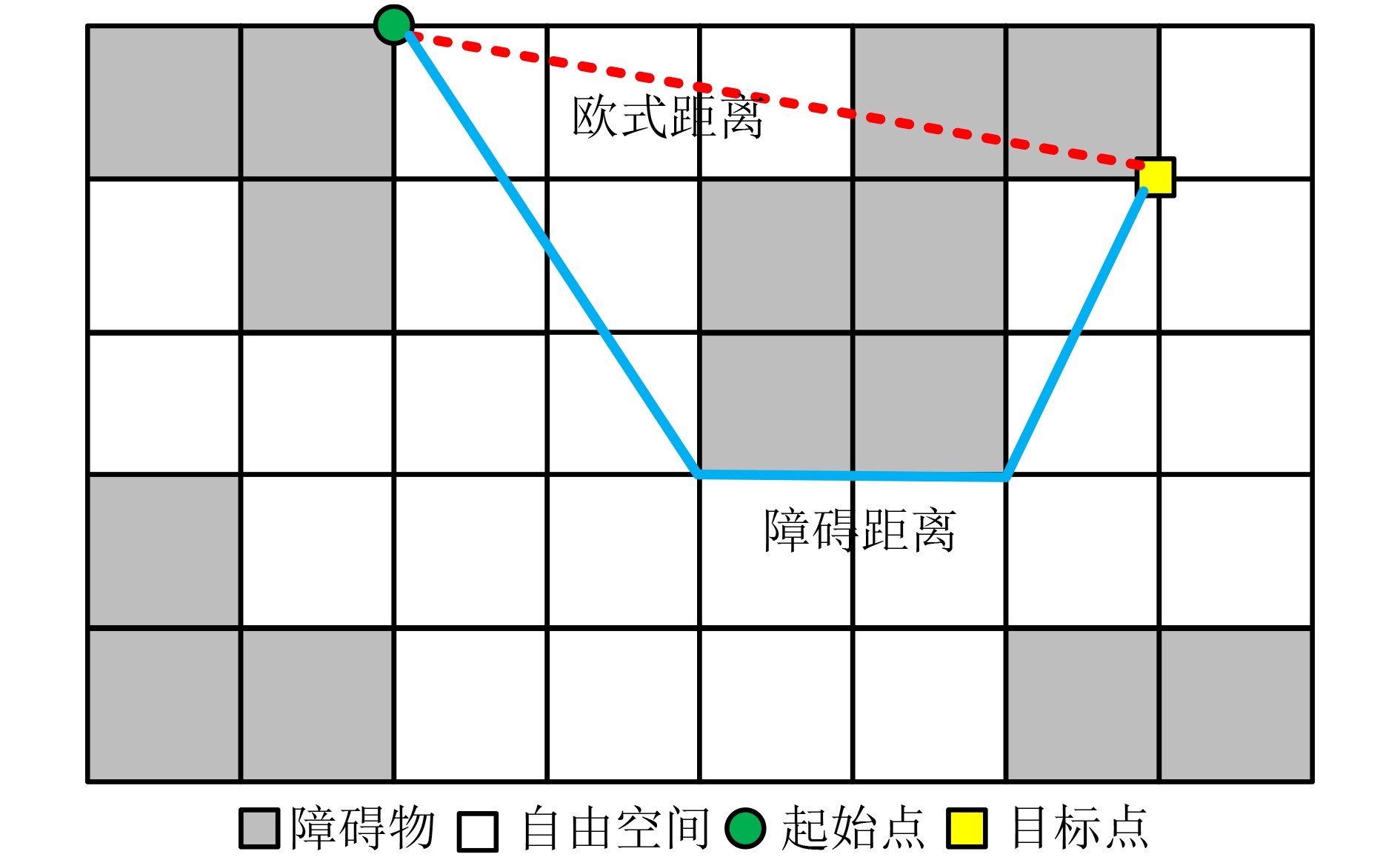
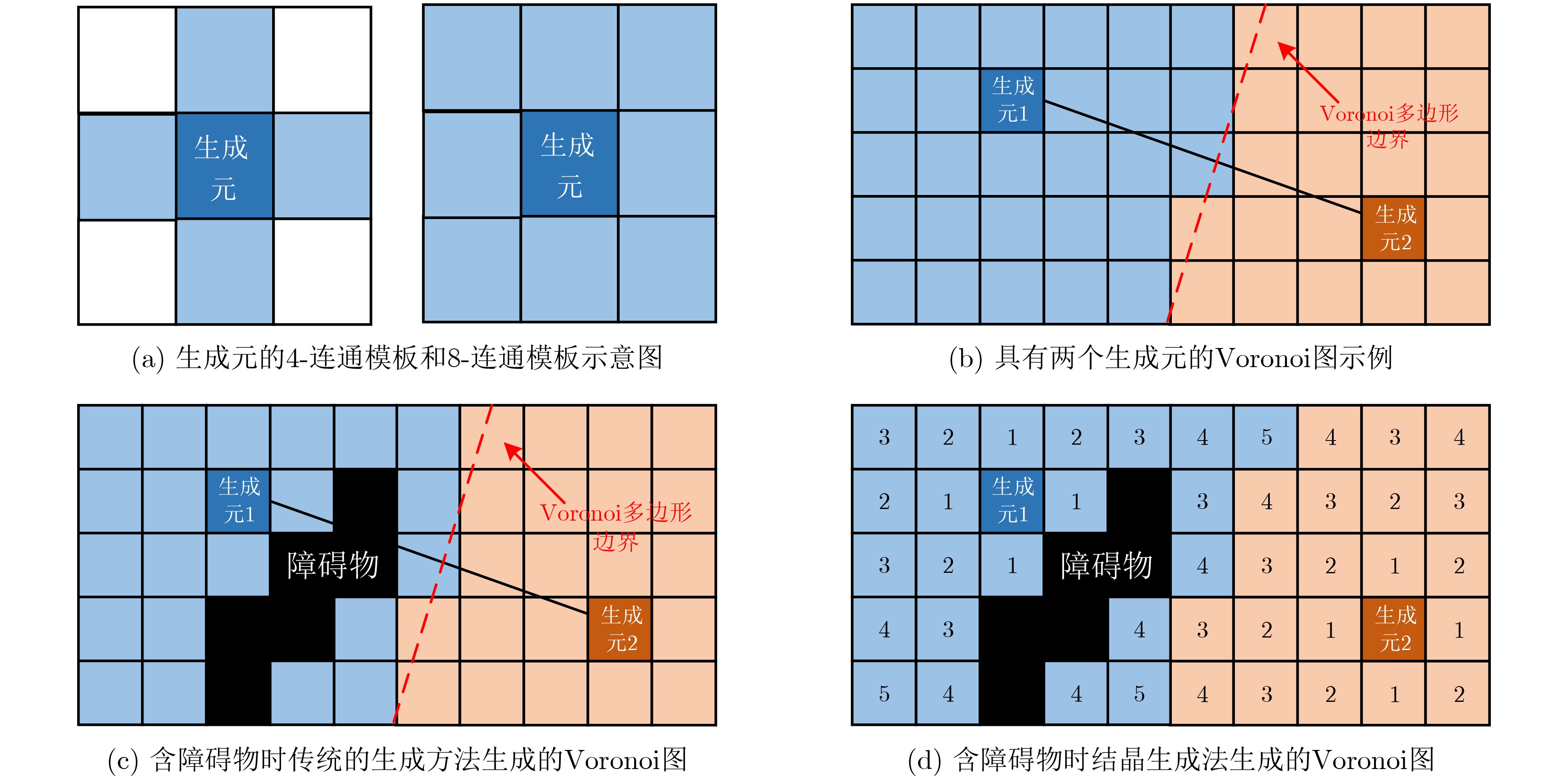
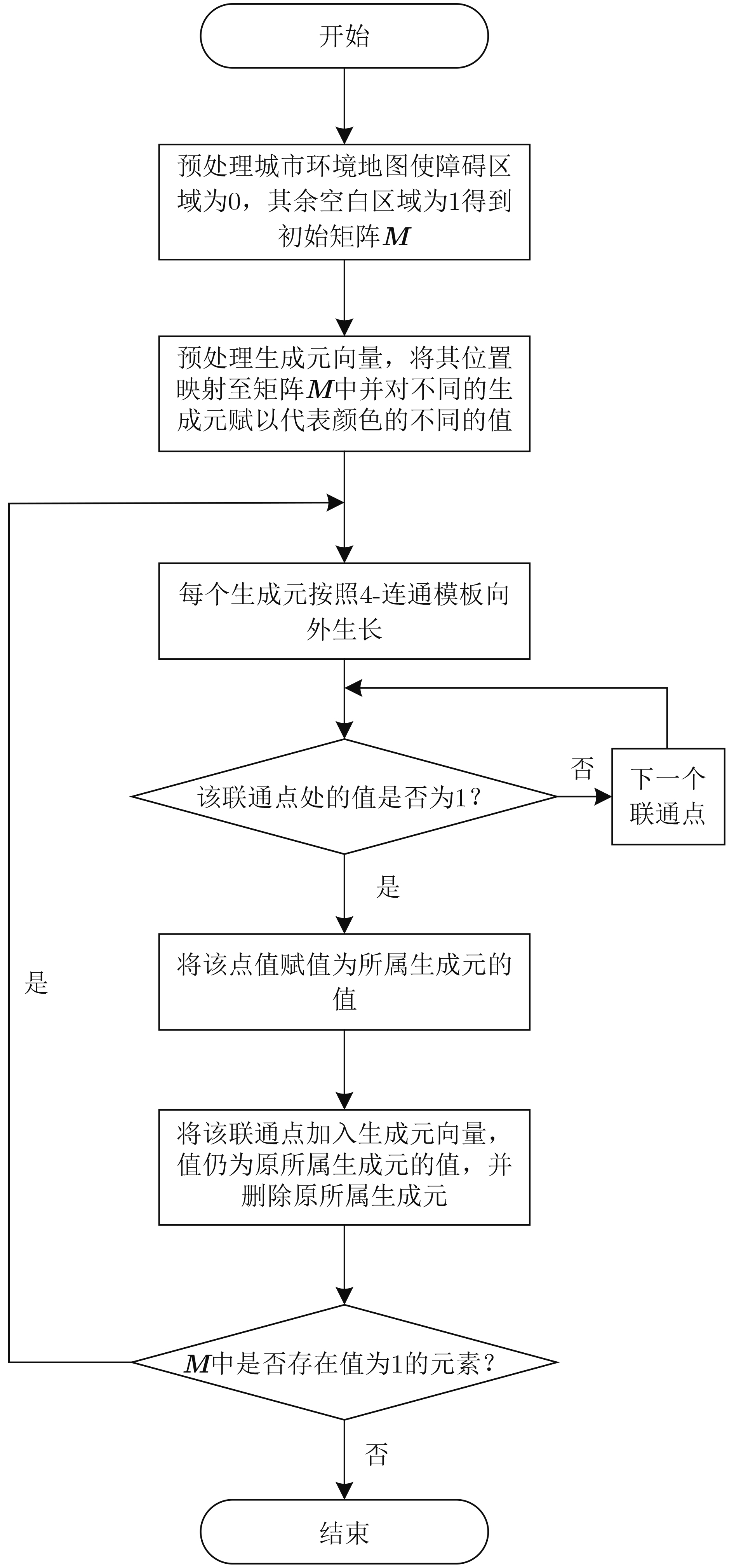
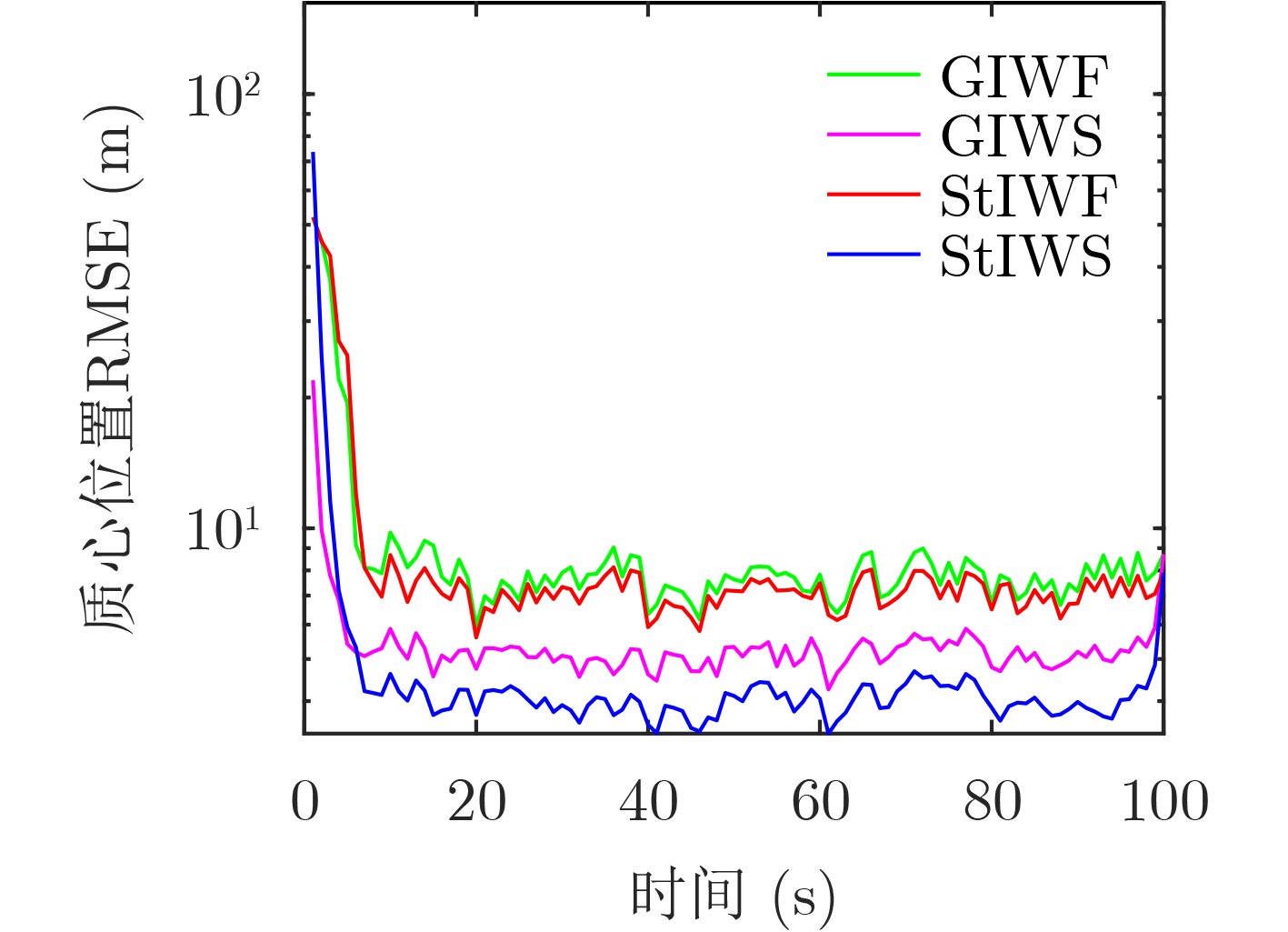
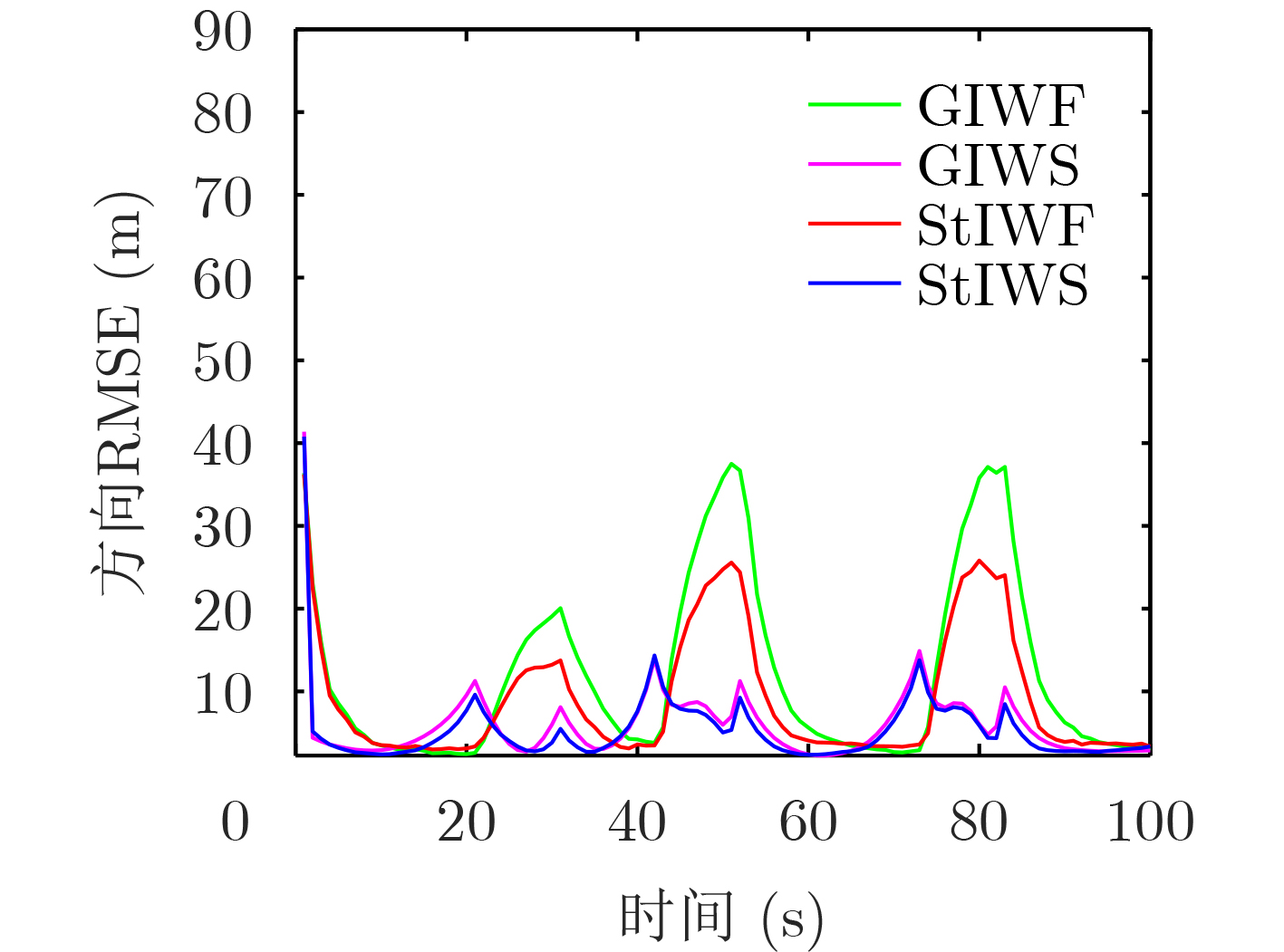
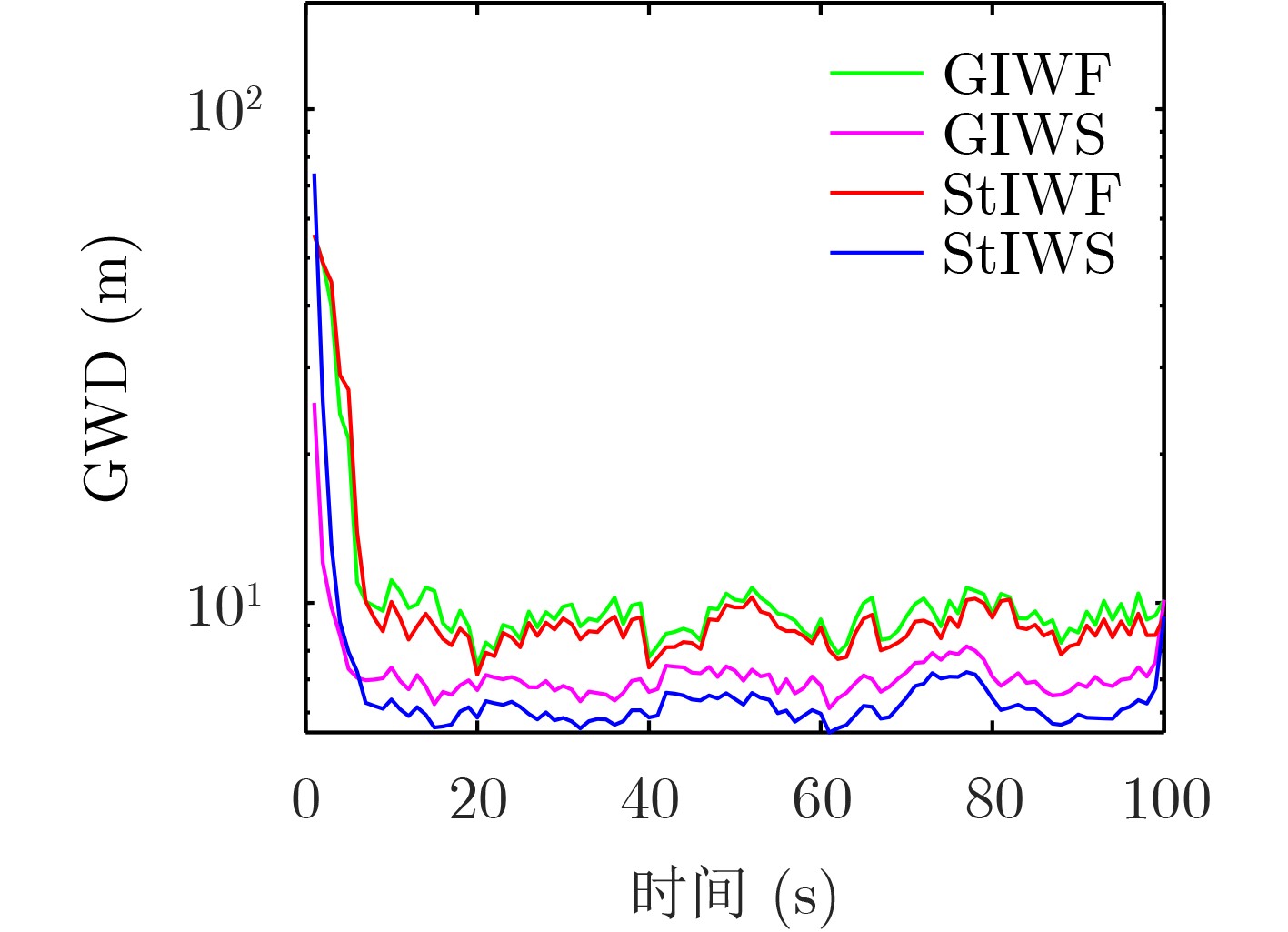
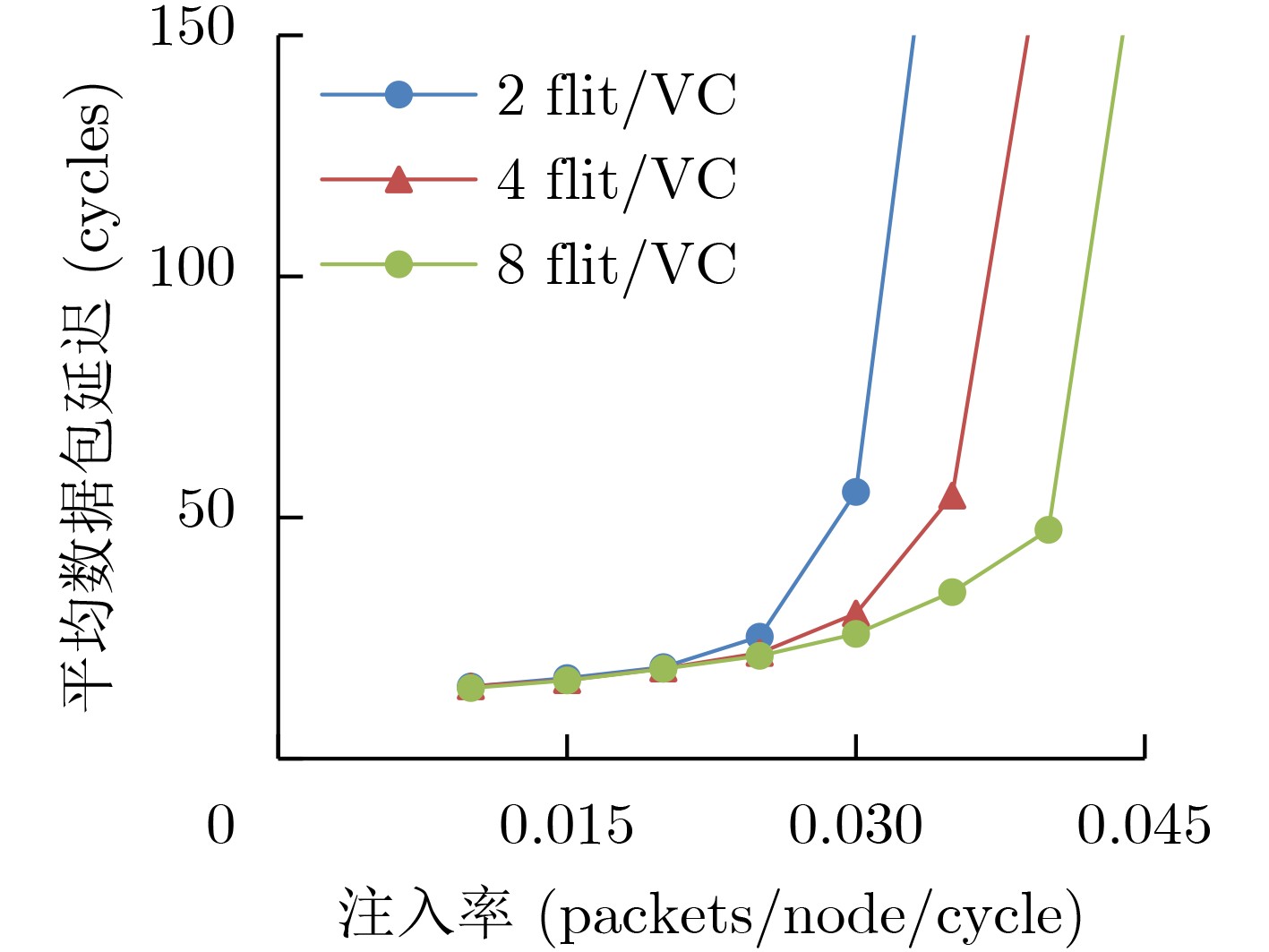
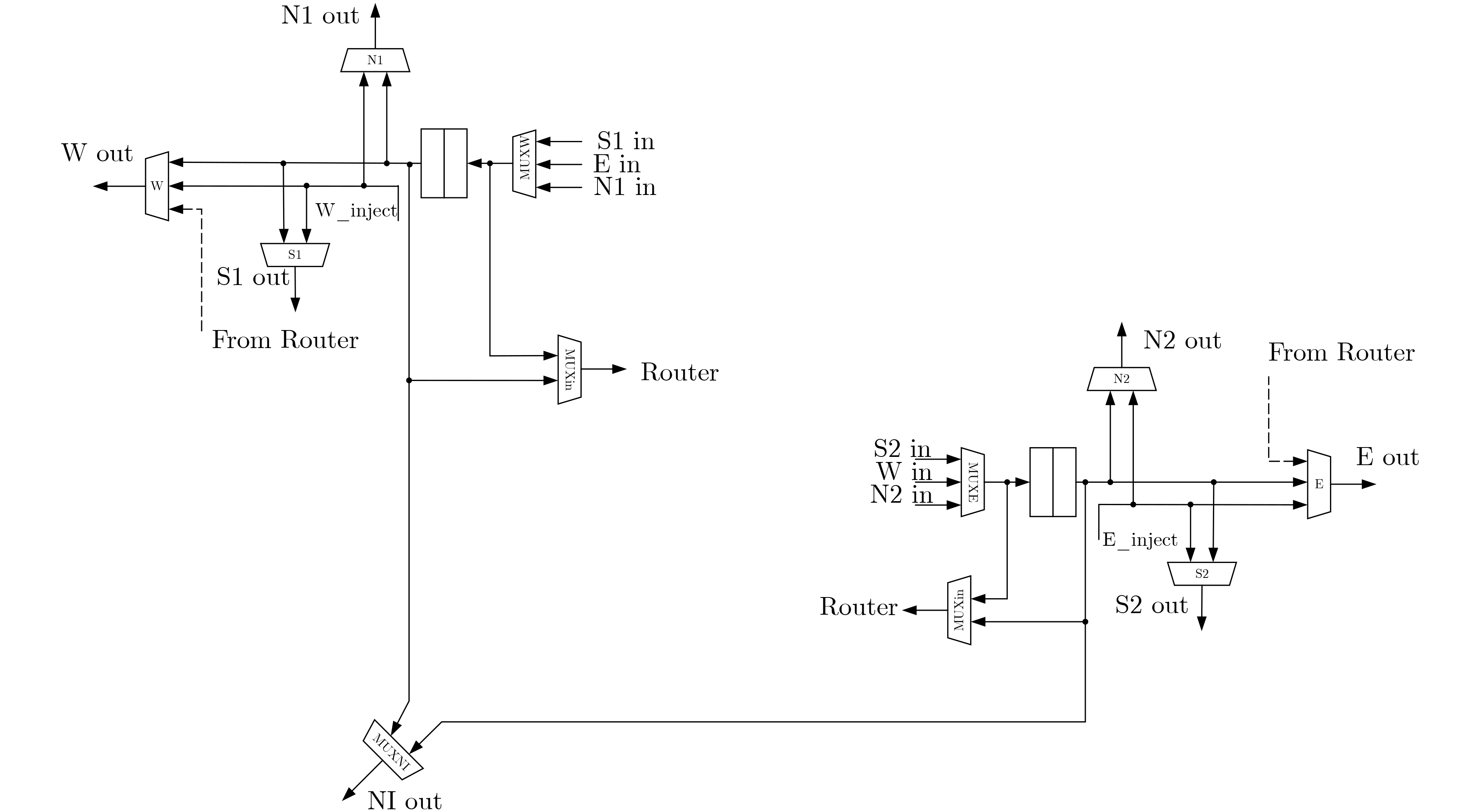
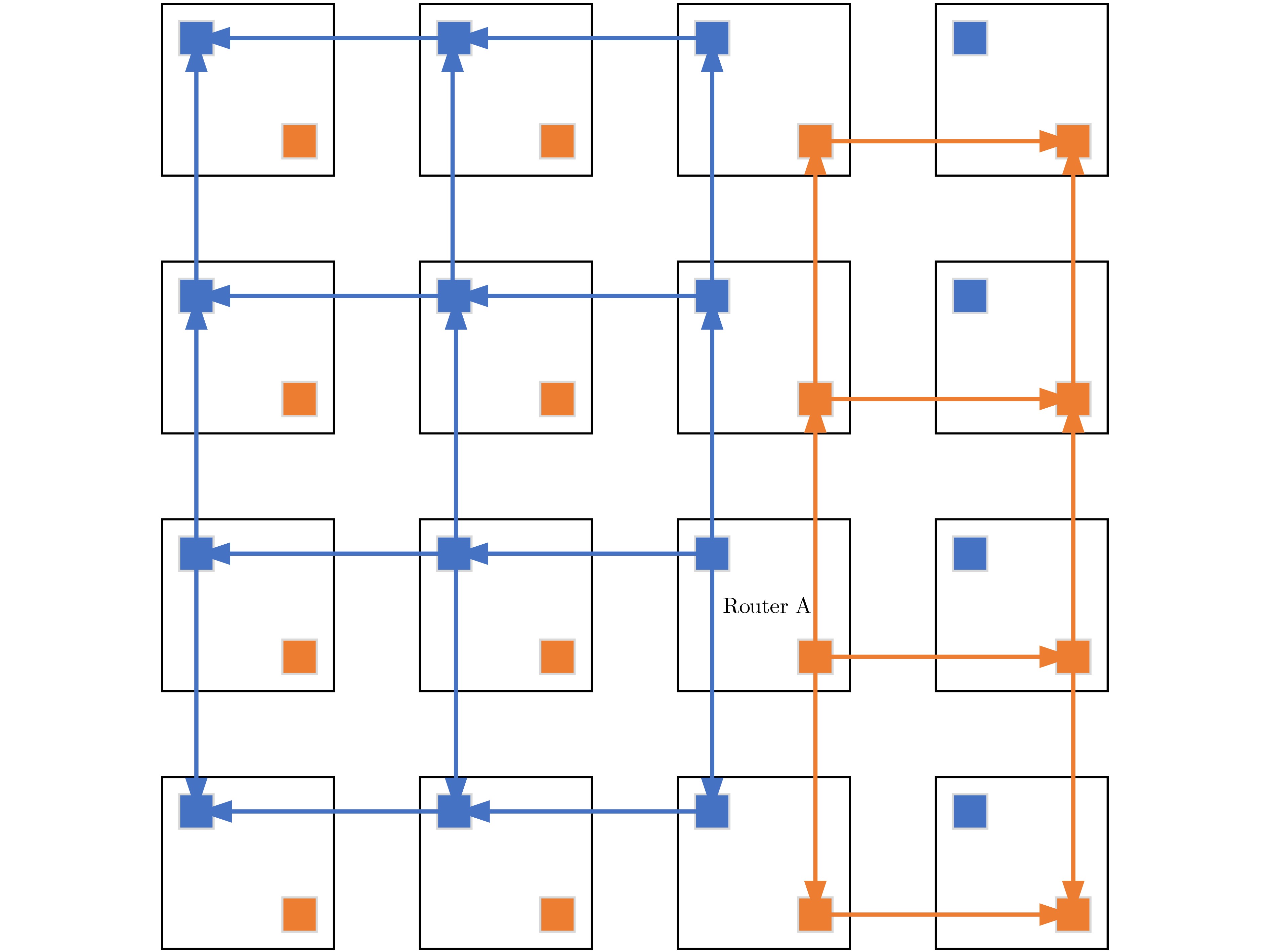
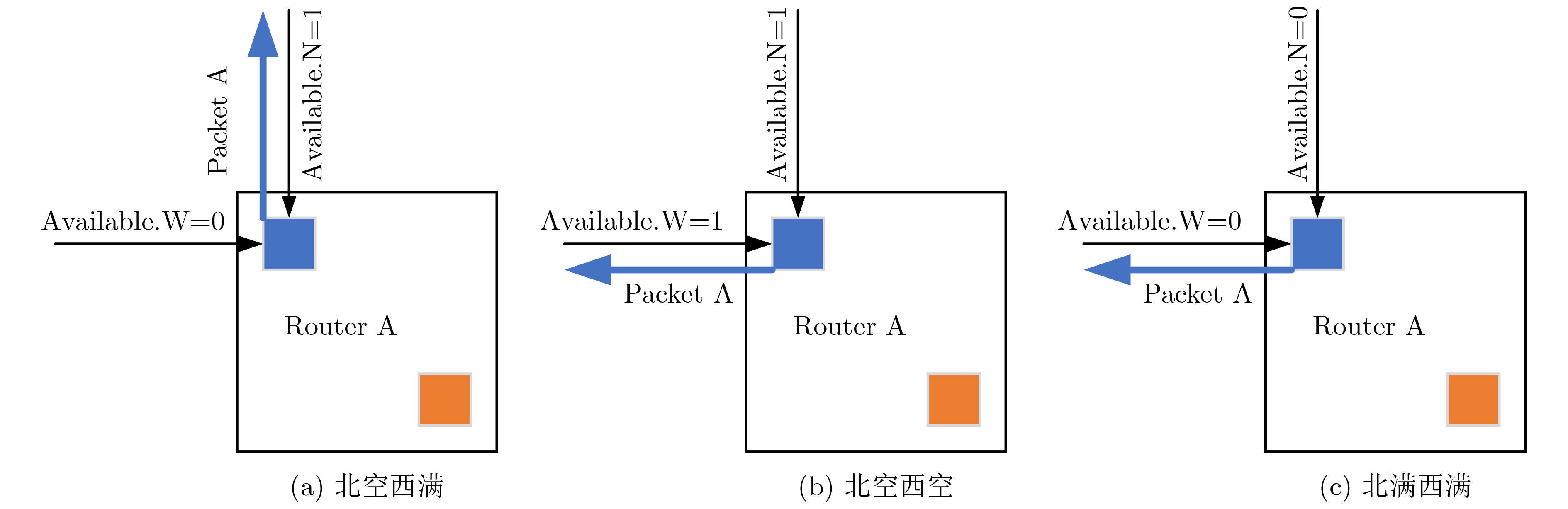
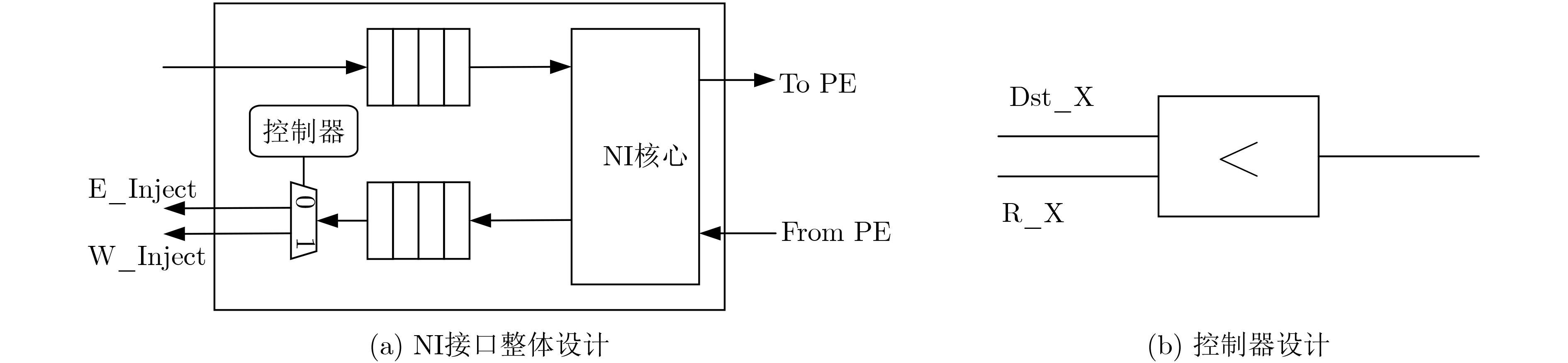
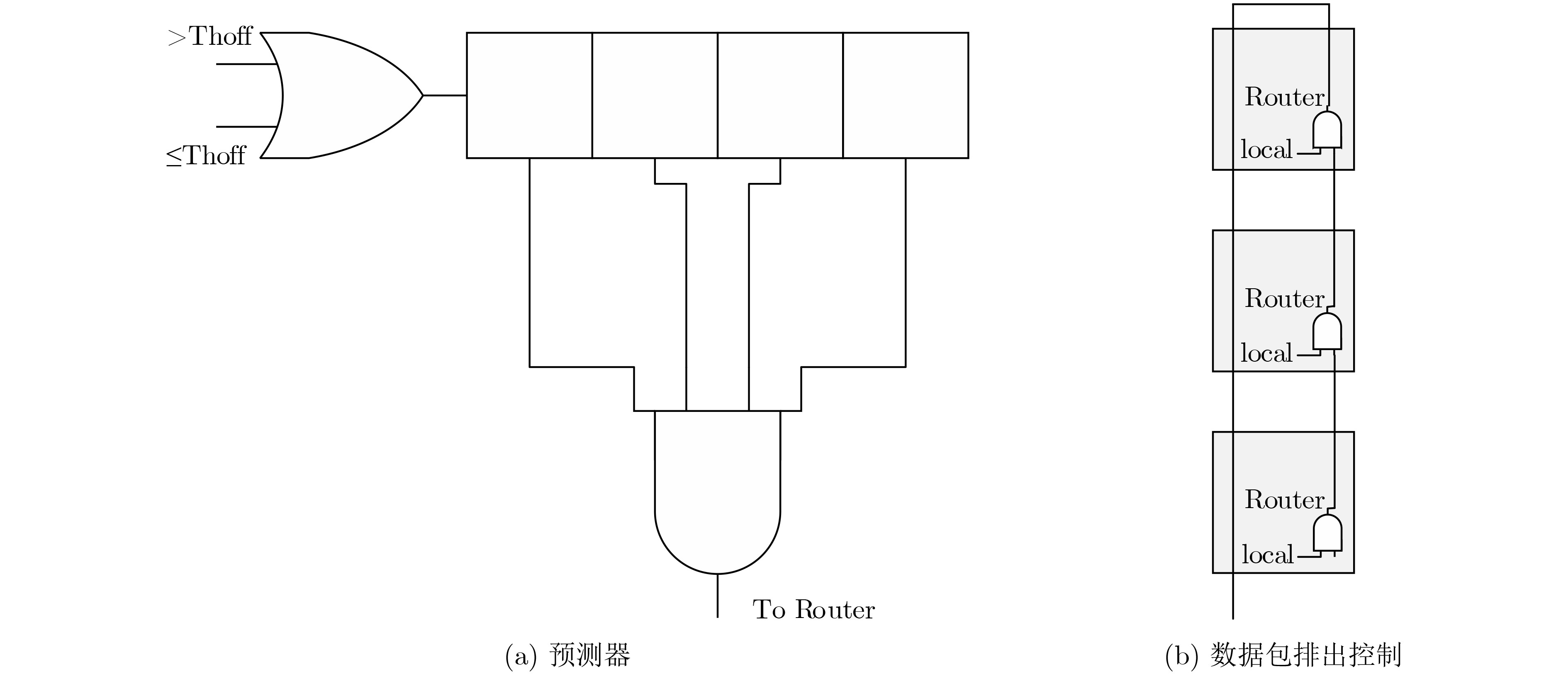
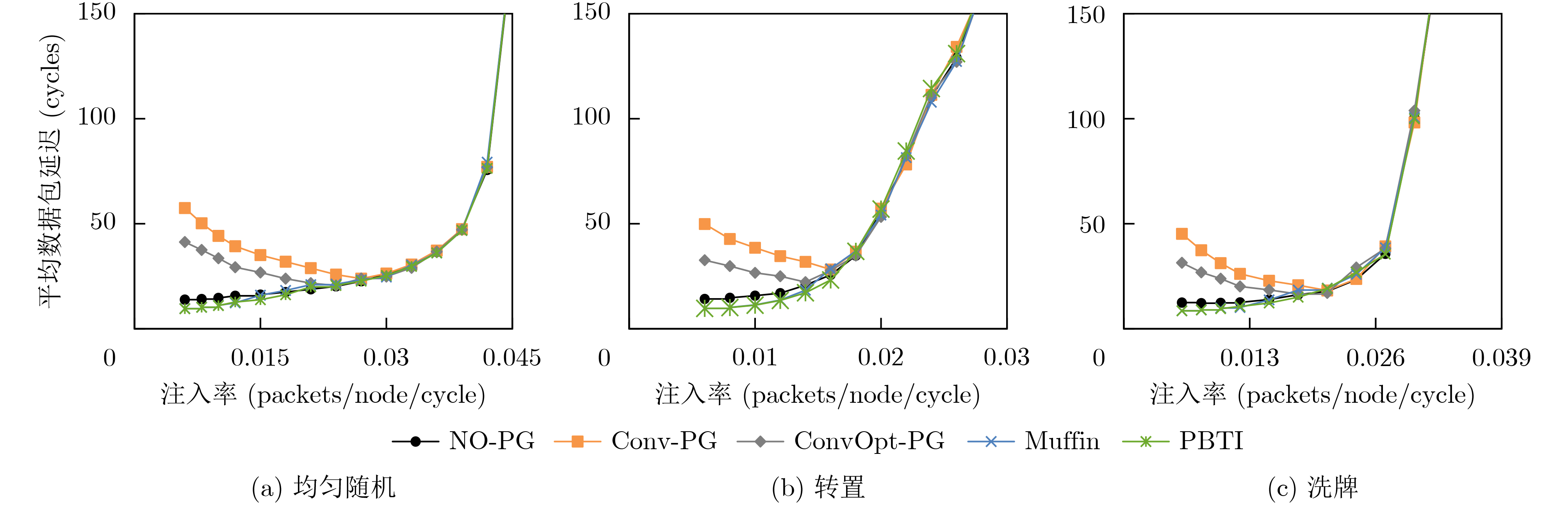
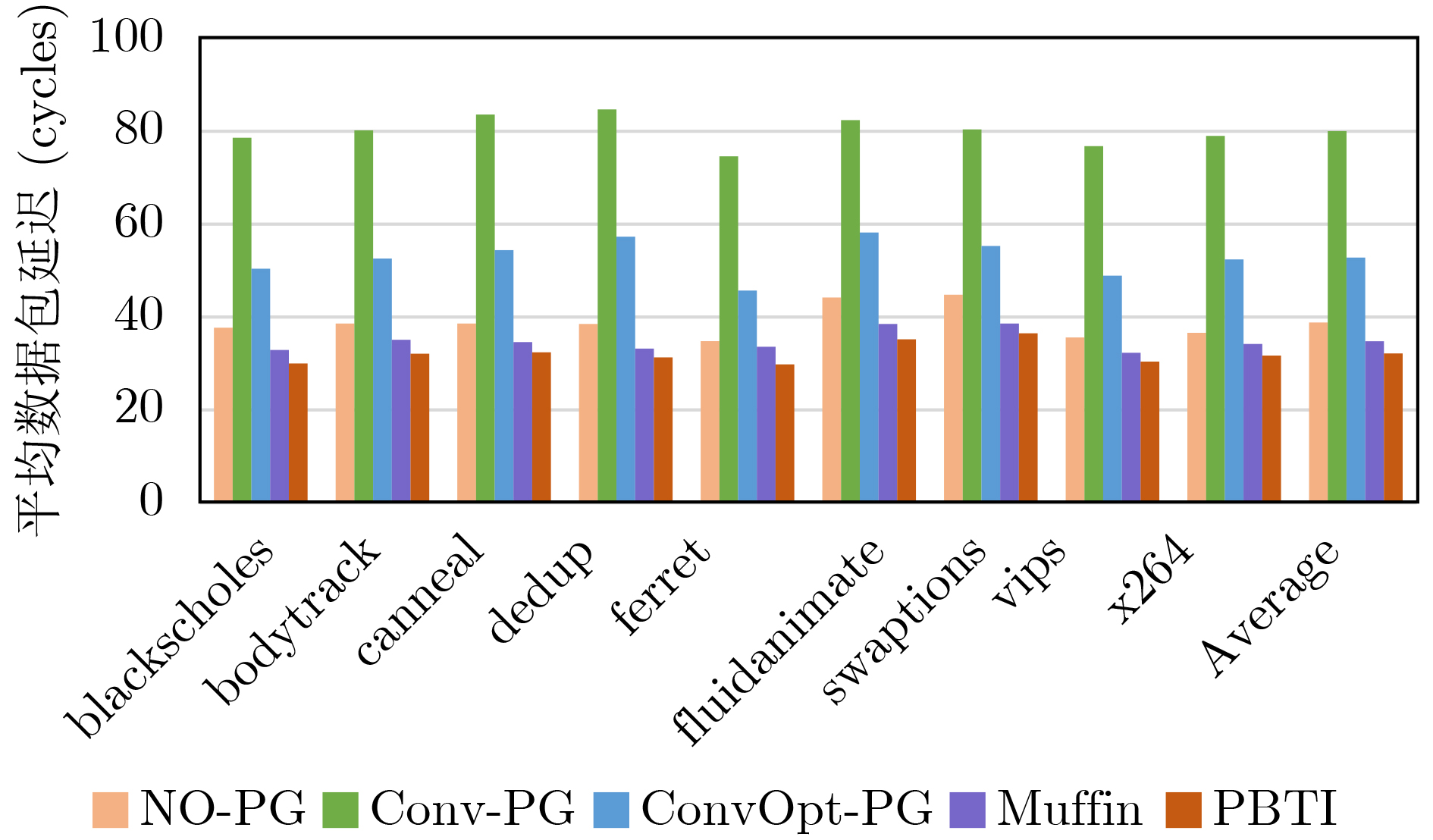
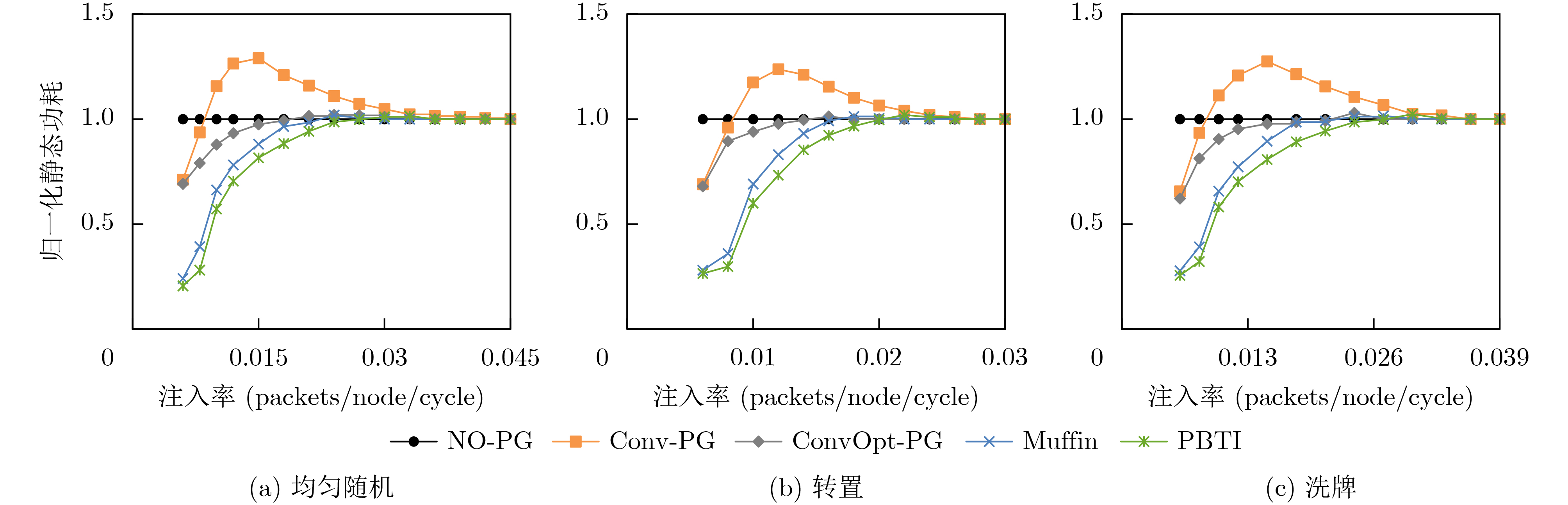
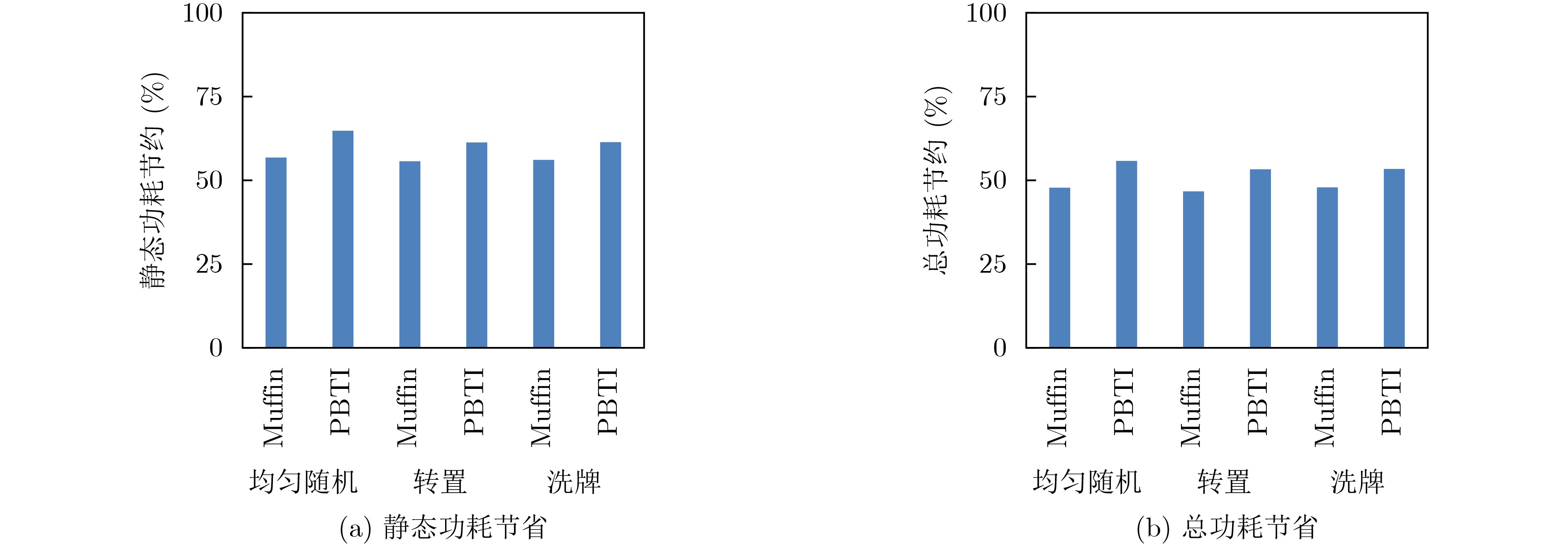
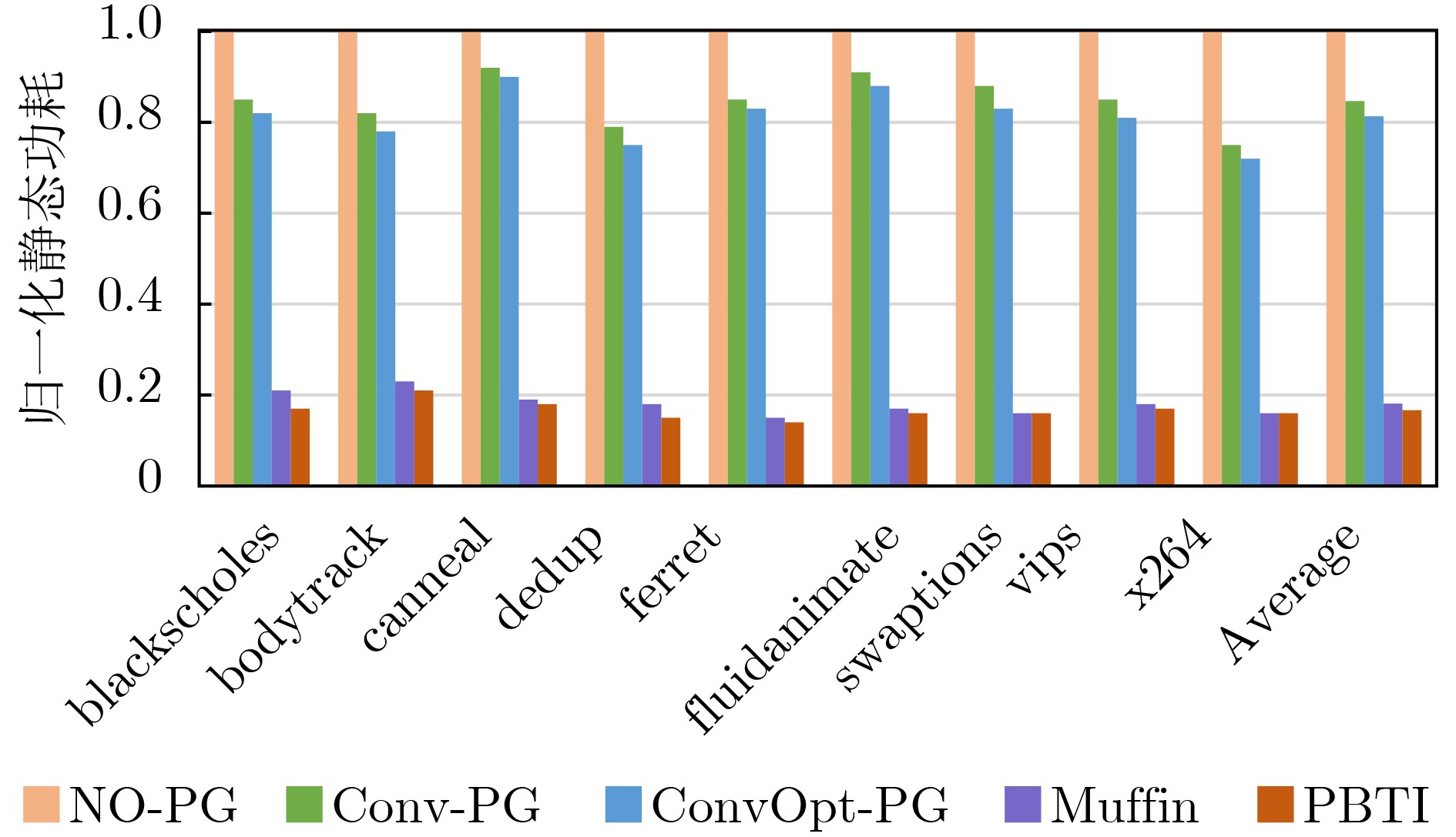
Static power consumption dominates the power overhead of Network-on-Chip (NoC) as the technology size shrinks. Power gating, a generalized power saving technique, turns off idle modules in NoCs to reduce static power consumption. However, the conventional power gating technique brings problems such as packet wake-up delay, break-even time, etc. To solve the above problems, the Partition Bypass Transmission Infrastructure (PBTI), which replaces the power gated router for packet transmission, is proposed in this paper, and a low-latency, low-power power gating scheme has been designed based upon this bypass mechanism. PBTI uses mutually independent bypasses to handle east-west packets separately, and uses common buffers within the bypasses to improve buffer utilization. PBTI can inject, transmit, and eject packets when the router is powered off. Packets can be transmitted from the source node to the destination node even if all routers in the network are power gated. When the traffic increases beyond the transmission capacity of PBTI, the routers perform a uniform wake-up in columns. Experimental results show that compared to the NoC without power gating, the scheme in this paper reduces 83.4% of static power consumption and 17.2% of packet delay, while adding only 6.2% additional area overhead. Compared to the conventional power gating scheme the power gated design in this paper achieves lower power consumption and delay, which is a significant advantage.