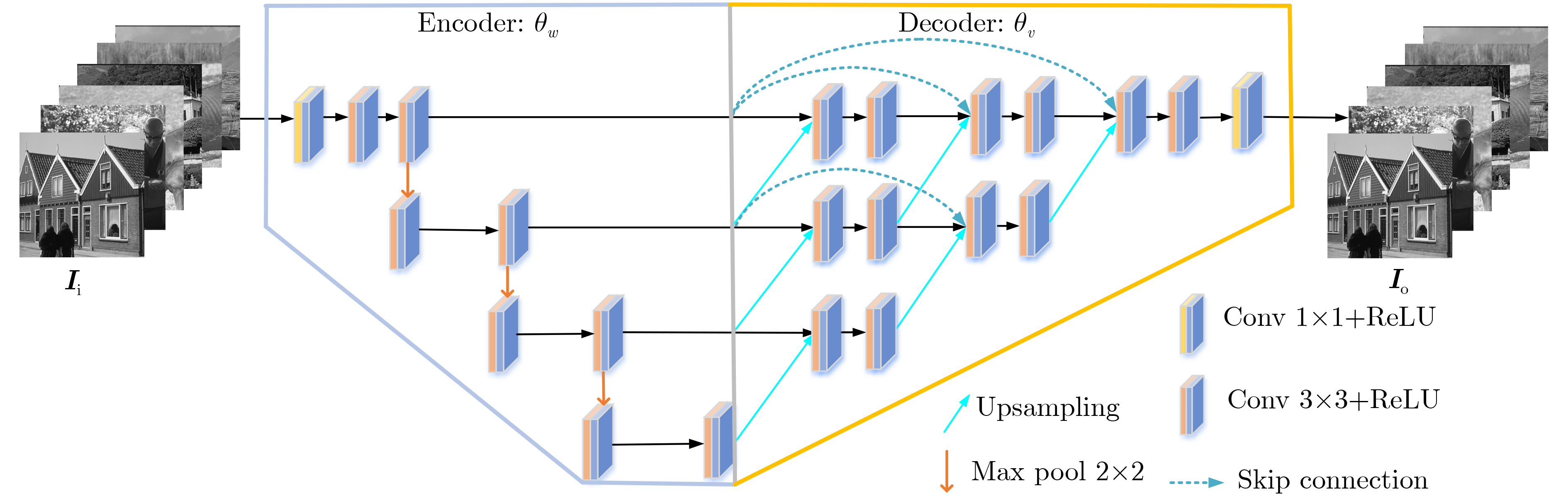
| Citation: | XU Shaoping, ZHOU Changfei, XIAO Jian, TAO Wuyong, DAI TianYu. A Fusion Network for Infrared and Visible Images Based on Pre-trained Fixed Parameters and Deep Feature Modulation[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3305-3313. doi: 10.11999/JEIT231283

|

| [1] |
CHANG Zhihao, FENG Zhixi, YANG Shuyuan, et al. AFT: Adaptive fusion transformer for visible and infrared images[J]. IEEE Transactions on Image Processing, 2023, 32: 2077–2092. doi: 10.1109/TIP.2023.3263113.
|
| [2] |
WU Xin, HONG Danfeng, and CHANUSSOT J. UIU-Net: U-Net in U-Net for infrared small object detection[J]. IEEE Transactions on Image Processing, 2023, 32: 364–376. doi: 10.1109/TIP.2022.3228497.
|
| [3] |
TANG Linfeng, YUAN Jiteng, ZHANG Hao, et al. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware[J]. Information Fusion, 2022, 83/84: 79–92. doi: 10.1016/j.inffus.2022.03.007.
|
| [4] |
冯鑫, 张建华, 胡开群, 等. 基于变分多尺度的红外与可见光图像融合[J]. 电子学报, 2018, 46(3): 680–687. doi: 10.3969/j.issn.0372-2112.2018.03.025.
FENG Xin, ZHANG Jianhua, HU Kaiqun, et al. The infrared and visible image fusion method based on variational multiscale[J]. Acta Electronica Sinica, 2018, 46(3): 680–687. doi: 10.3969/j.issn.0372-2112.2018.03.025.
|
| [5] |
RAM PRABHAKAR K, SAI SRIKAR V, and BABU R V. DeepFuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 4714–4722. doi: 10.1109/ICCV.2017.505.
|
| [6] |
LI Hui and WU Xiaojun. DenseFuse: A fusion approach to infrared and visible images[J]. IEEE Transactions on Image Processing, 2019, 28(5): 2614–2623. doi: 10.1109/TIP.2018.2887342.
|
| [7] |
ZHANG Hao, XU Han, XIAO Yang, et al. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity[C]. The Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, USA, 2020: 12797–12804. doi: 10.1609/AAAI.V34I07.6975.
|
| [8] |
MA Jiayi, YU Wei, LIANG Pengwei, et al. FusionGAN: A generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11–26. doi: 10.1016/j.inffus.2018.09.004.
|
| [9] |
MA Jiayi, XU Han, JIANG Junjun, et al. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion[J]. IEEE Transactions on Image Processing, 2020, 29: 4980–4995. doi: 10.1109/TIP.2020.2977573.
|
| [10] |
LI Jing, HUO Hongtao, LI Chang, et al. AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks[J]. IEEE Transactions on Multimedia, 2021, 23: 1383–1396. doi: 10.1109/TMM.2020.2997127.
|
| [11] |
XU Han, MA Jiayi, JIANG Junjun, et al. U2Fusion: A unified unsupervised image fusion network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 502–518. doi: 10.1109/TPAMI.2020.3012548.
|
| [12] |
LIANG Jingyun, CAO Jiezhang, SUN Guolei, et al. SwinIR: Image restoration using swin transformer[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops, Montreal, Canada, 2021: 1833–1844. doi: 10.1109/ICCVW54120.2021.00210.
|
| [13] |
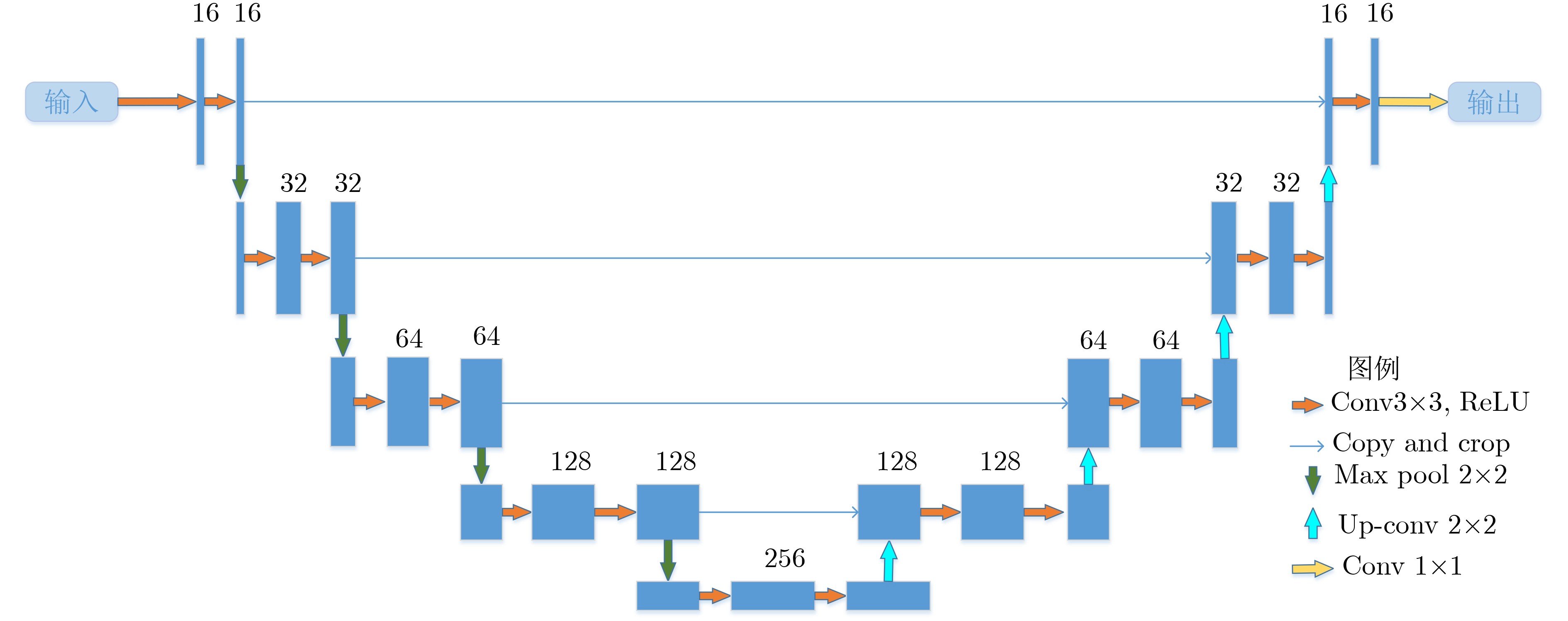
RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28.
|
| [14] |
WEI Yanyan, ZHANG Zhao, WANG Yang, et al. DerainCycleGAN: Rain attentive cycleGAN for single image deraining and rainmaking[J]. IEEE Transactions on Image Processing, 2021, 30: 4788–4801. doi: 10.1109/TIP.2021.3074804.
|
| [15] |
ZHANG Yuyang, XU Shibiao, WU Baoyuan, et al. Unsupervised multi-view constrained convolutional network for accurate depth estimation[J]. IEEE Transactions on Image Processing, 2020, 29: 7019–7031. doi: 10.1109/TIP.2020.2997247.
|
| [16] |
KRISTAN M, LEONARDIS A, MATAS J, et al. The eighth visual object tracking VOT2020 challenge results[C]. European Conference on Computer Vision, Glasgow, UK, 2020: 547–601. doi: 10.1007/978-3-030-68238-5_39.
|
| [17] |
MA Jiayi, CHEN Chen, LI Chang, et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31: 100–109. doi: 10.1016/j.inffus.2016.02.001.
|
| [18] |
LIU Yu, CHEN Xun, WARD R K, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882–1886. doi: 10.1109/LSP.2016.2618776.
|
| [19] |
KUMAR B K S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform[J]. Signal, Image and Video Processing, 2013, 7(6): 1125–1143. doi: 10.1007/s11760-012-0361-x.
|
| [20] |
MA Jiayi, TANG Linfeng, XU Meilong, et al. STDFusionNet: An infrared and visible image fusion network based on salient target detection[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 1–13. doi: 10.1109/TIM.2021.3075747.
|
| [21] |
LIU Jinyuan, FAN Xin, HUANG Zhanbo, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5792–5801. doi: 10.1109/CVPR52688.2022.00571.
|
| [22] |
HUANG Zhanbo, LIU Jinyuan, FAN Xin, et al. ReCoNet: Recurrent correction network for fast and efficient multi-modality image fusion[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 539–555. doi: 10.1007/978-3-031-19797-0_31.
|
| [23] |
TANG Wei, HE Fazhi, and LIU Yu. YDTR: Infrared and visible image fusion via Y-shape dynamic transformer[J]. IEEE Transactions on Multimedia, 2023, 25: 5413–5428. doi: 10.1109/TMM.2022.3192661.
|
| [24] |
TANG Wei, HE Fazhi, LIU Yu, et al. DATFuse: Infrared and visible image fusion via dual attention transformer[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(7): 3159–3172. doi: 10.1109/TCSVT.2023.3234340.
|
| [25] |
蔺素珍, 韩泽. 基于深度堆叠卷积神经网络的图像融合[J]. 计算机学报, 2017, 40(11): 2506–2518. doi: 10.11897/SP.J.1016.2017.02506.
LIN Suzhen and HAN Ze. Images fusion based on deep stack convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(11): 2506–2518. doi: 10.11897/SP.J.1016.2017.02506.
|
| [26] |
SHEIKH H R and BOVIK A C. Image information and visual quality[J]. IEEE Transactions on Image Processing, 2006, 15(2): 430–444. doi: 10.1109/TIP.2005.859378.
|
| [27] |
ASLANTAS V and BENDES E. A new image quality metric for image fusion: The sum of the correlations of differences[J]. AEU-International Journal of Electronics and Communications, 2015, 69(12): 1890–1896. doi: 10.1016/j.aeue.2015.09.004.
|
Figures(4) / Tables(4)



 DownLoad:
DownLoad: