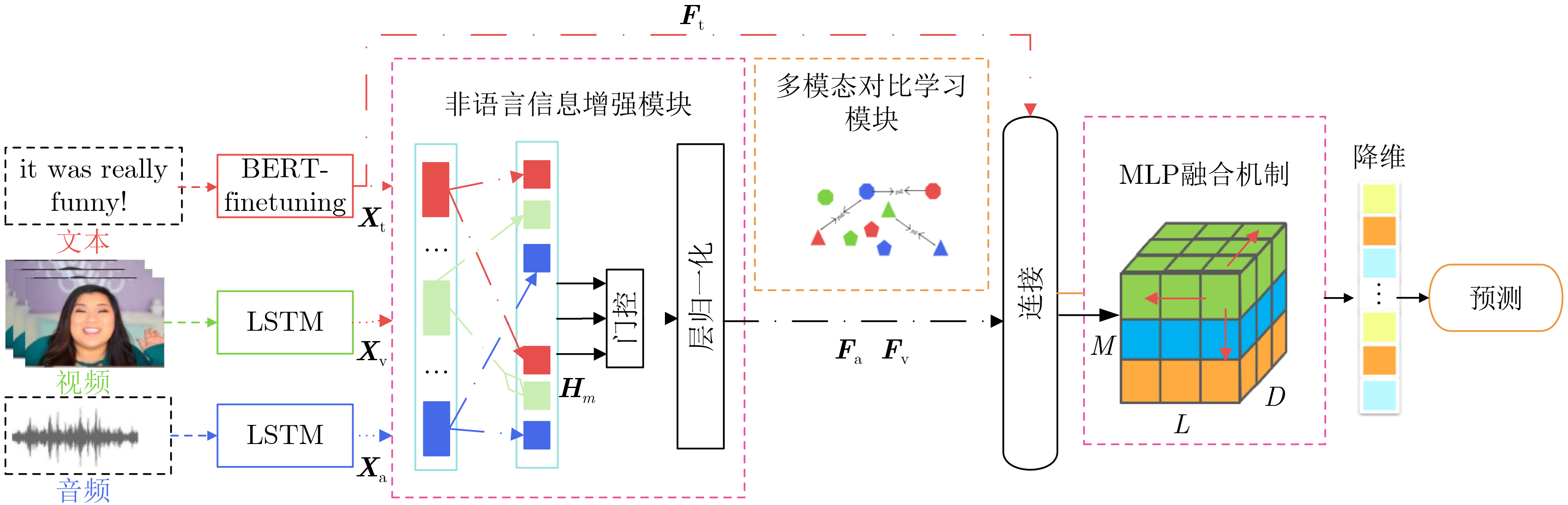
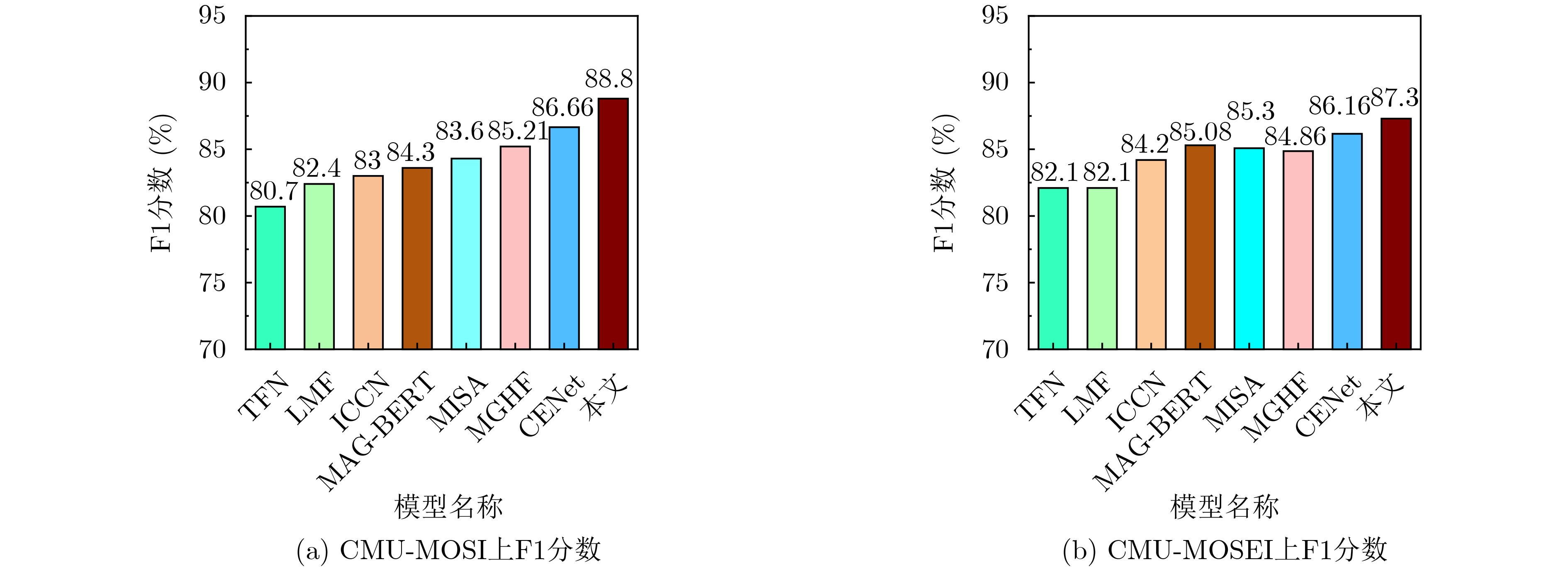
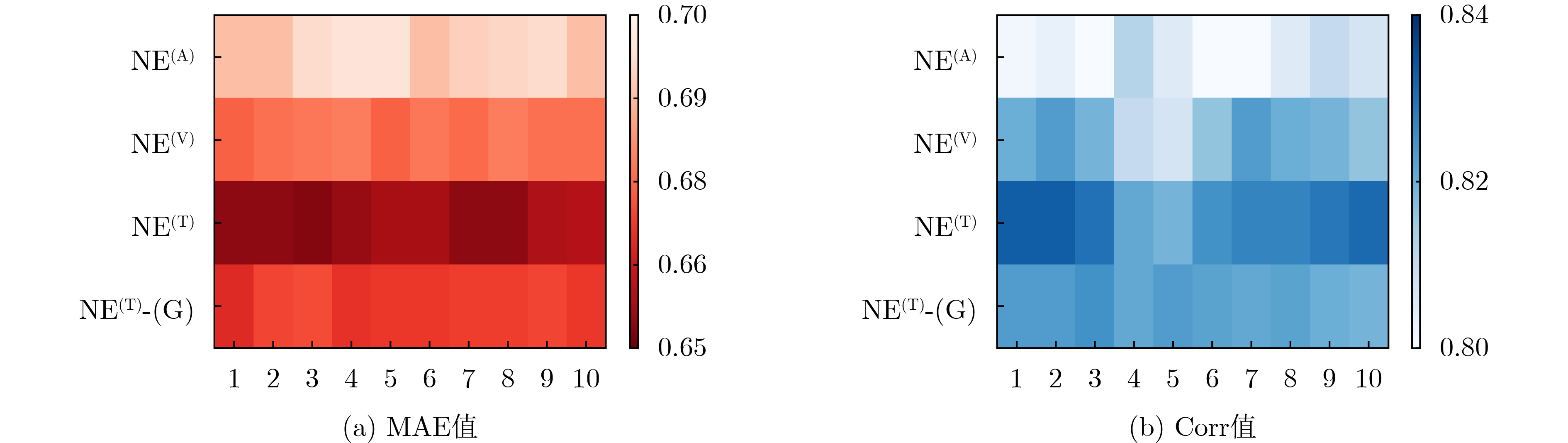
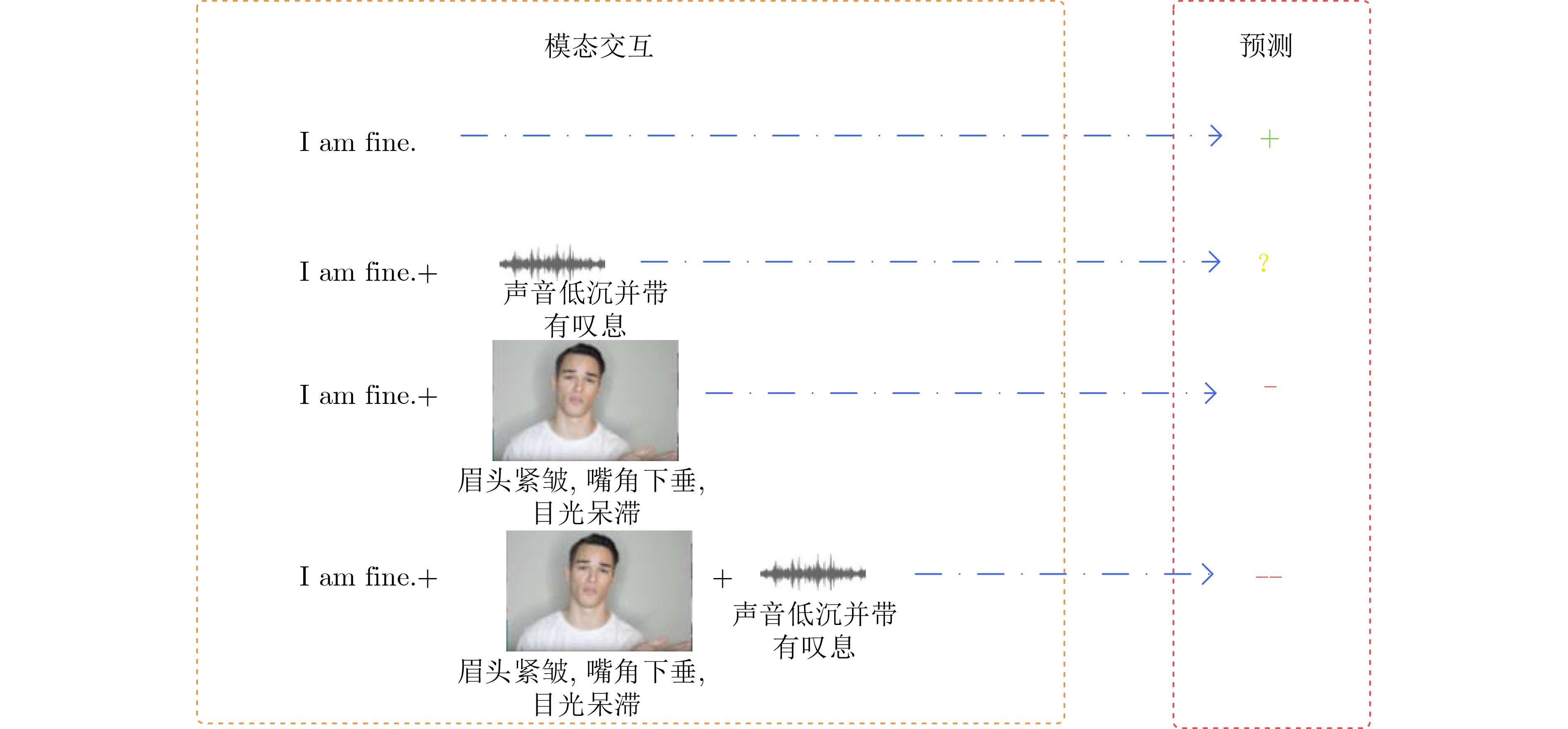
| Citation: | LIU Jia, SONG Hong, CHEN Dapeng, WANG Bin, ZHANG Zengwei. A Multimodal Sentiment Analysis Model Enhanced with Non-verbal Information and Contrastive Learning[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3372-3381. doi: 10.11999/JEIT231274

|

| [1] |
李霞, 卢官明, 闫静杰, 等. 多模态维度情感预测综述[J]. 自动化学报, 2018, 44(12): 2142–2159. doi: 10.16383/j.aas.2018.c170644.
LI Xia, LU Guanming, YAN Jingjie, et al. A survey of dimensional emotion prediction by multimodal cues[J]. Acta Automatica Sinica, 2018, 44(12): 2142–2159. doi: 10.16383/j.aas.2018.c170644.
|
| [2] |
丁永刚, 李石君, 付星, 等. 面向时序感知的多类别商品方面情感分析推荐模型[J]. 电子与信息学报, 2018, 40(6): 1453–1460. doi: 10.11999/JEIT170938.
DING Yonggang, LI Shijun, FU Xing, et al. Temporal-aware multi-category products recommendation model based on aspect-level sentiment analysis[J]. Journal of Electronics & Information Technology, 2018, 40(6): 1453–1460. doi: 10.11999/JEIT170938.
|
| [3] |
李紫荆, 陈宁. 基于图神经网络多模态融合的语音情感识别模型[J]. 计算机应用研究, 2023, 40(8): 2286–2291,2310. doi: 10.19734/j.issn.1001-3695.2023.01.0002.
LI Zijing and CHEN Ning. Speech emotion recognition based on multi-modal fusion of graph neural network[J]. Application Research of Computers, 2023, 40(8): 2286–2291,2310. doi: 10.19734/j.issn.1001-3695.2023.01.0002.
|
| [4] |
ZHENG Jiahao, ZHANG Sen, WANG Zilu, et al. Multi-channel weight-sharing autoencoder based on cascade multi-head attention for multimodal emotion recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 2213–2225. doi: 10.1109/TMM.2022.3144885.
|
| [5] |
FU Yahui, OKADA S, WANG Longbiao, et al. Context- and knowledge-aware graph convolutional network for multimodal emotion recognition[J]. IEEE MultiMedia, 2022, 29(3): 91–100. doi: 10.1109/MMUL.2022.3173430.
|
| [6] |
NGUYEN D, NGUYEN D T, ZENG Rui, et al. Deep auto-encoders with sequential learning for multimodal dimensional emotion recognition[J]. IEEE Transactions on Multimedia, 2022, 24: 1313–1324. doi: 10.1109/TMM.2021.3063612.
|
| [7] |
吕卫, 韩镓泽, 褚晶辉, 等. 基于多模态自注意力网络的视频记忆度预测[J]. 吉林大学学报:工学版, 2023, 53(4): 1211–1219. doi: 10.13229/j.cnki.jdxbgxb.20210842.
LÜ Wei, HAN Jiaze, CHU Jinghui, et al. Multi-modal self-attention network for video memorability prediction[J]. Journal of Jilin University:Engineering and Technology Edition, 2023, 53(4): 1211–1219. doi: 10.13229/j.cnki.jdxbgxb.20210842.
|
| [8] |
陈杰, 马静, 李晓峰, 等. 基于DR-Transformer模型的多模态情感识别研究[J]. 情报科学, 2022, 40(3): 117–125. doi: 10.13833/j.issn.1007-7634.2022.03.015.
CHEN Jie, MA Jing, LI Xiaofeng, et al. Multi-modal emotion recognition based on DR-Transformer model[J]. Information Science, 2022, 40(3): 117–125. doi: 10.13833/j.issn.1007-7634.2022.03.015.
|
| [9] |
MA Hui, WANG Jian, LIN Hongfei, et al. A transformer-based model with self-distillation for multimodal emotion recognition in conversations[J]. IEEE Transactions on Multimedia, 2023: 1–13. doi: 10.1109/TMM.2023.3271019.
|
| [10] |
WU Yujin, DAOUDI M, and AMAD A. Transformer-based self-supervised multimodal representation learning for wearable emotion recognition[J]. IEEE Transactions on Affective Computing, 2024, 15(1): 157–172. doi: 10.1109/TAFFC.2023.3263907.
|
| [11] |
YANG Kailai, ZHANG Tianlin, ALHUZALI H, et al. Cluster-level contrastive learning for emotion recognition in conversations[J]. IEEE Transactions on Affective Computing, 2023, 14(4): 3269–3280. doi: 10.1109/TAFFC.2023.3243463.
|
| [12] |
WANG Min, CAO Donglin, LI Lingxiao, et al. Microblog sentiment analysis based on cross-media bag-of-words model[C]. International Conference on Internet Multimedia Computing and Service, Xiamen, China, 2014: 76–80. doi: 10.1145/2632856.2632912.
|
| [13] |
ZADEH A, CHEN Minghai, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]. The Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 1103–1114. doi: 10.18653/v1/D17-1115.
|
| [14] |
LIU Zhun, SHEN Ying, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2247–2256. doi: 10.18653/v1/P18-1209.
|
| [15] |
TSAI Y H H, BAI Shaojie, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 6558–6569. doi: 10.18653/v1/P19-1656.
|
| [16] |
韩虎, 吴渊航, 秦晓雅. 面向方面级情感分析的交互图注意力网络模型[J]. 电子与信息学报, 2021, 43(11): 3282–3290. doi: 10.11999/JEIT210036.
HAN Hu, WU Yuanhang, and QIN Xiaoya. An interactive graph attention networks model for aspect-level sentiment analysis[J]. Journal of Electronics & Information Technology, 2021, 43(11): 3282–3290. doi: 10.11999/JEIT210036.
|
| [17] |
SUN Hao, WANG Hongyi, LIU Jiaqing, et al. CubeMLP: An MLP-based model for multimodal sentiment analysis and depression estimation[C]. The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 2022: 3722–3729. doi: 10.1145/3503161.3548025.
|
| [18] |
. HAZARIKA D, ZIMMERMANN R, and PORIA S. MISA: Modality-invariant and -specific representations for multimodal sentiment analysis[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 1122–1131. doi: 10.1145/3394171.3413678.
|
| [19] |
蔡宇扬, 蒙祖强. 基于模态信息交互的多模态情感分析[J]. 计算机应用研究, 2023, 40(9): 2603–2608. doi: 10.19734/j.issn.1001-3695.2023.02.0050.
CAI Yuyang and MENG Zuqiang. Multimodal sentiment analysis based on modal information interaction[J]. Application Research of Computers, 2023, 40(9): 2603–2608. doi: 10.19734/j.issn.1001-3695.2023.02.0050.
|
| [20] |
DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, USA, 2019: 4171–4186. doi: 10.18653/v1/N19-1423.
|
| [21] |
WANG Di, LIU Shuai, WANG Quan, et al. Cross-modal enhancement network for multimodal sentiment analysis[J]. IEEE Transactions on Multimedia, 2023, 25: 4909–4921. doi: 10.1109/TMM.2022.3183830.
|
| [22] |
HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735.
|
| [23] |
ZADEH A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2236–2246. doi: 10.18653/v1/P18-1208.
|
| [24] |
WANG Yaoting, LI Yuanchao, LIANG P P, et al. Cross-attention is not enough: Incongruity-aware dynamic hierarchical fusion for multimodal affect recognition[EB/OL]. https://doi.org/10.48550/arXiv.2305.13583, 2023.
|
| [25] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.
|
| [26] |
MAI Sijie, ZENG Ying, ZHENG Shuangjia, et al. Hybrid contrastive learning of tri-modal representation for multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2023, 14(3): 2276–2289. doi: 10.1109/TAFFC.2022.3172360.
|
| [27] |
ZADEH A, ZELLERS R, PINCUS E, et al. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages[J]. IEEE Intelligent Systems, 2016, 31(6): 82–88. doi: 10.1109/MIS.2016.94.
|
| [28] |
QI Qingfu, LIN Liyuan, ZHANG Rui, et al. MEDT: Using multimodal encoding-decoding network as in transformer for multimodal sentiment analysis[J]. IEEE Access, 2022, 10: 28750–28759. doi: 10.1109/ACCESS.2022.3157712.
|
| [29] |
GANDHI A, ADHVARYU K, PORIA S, et al. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions[J]. Information Fusion, 2023, 91: 424–444. doi: 10.1016/j.inffus.2022.09.025.
|
| [30] |
SUN Zhongkai, SARMA P, SETHARES W, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 8992–8999. doi: 10.1609/aaai.v34i05.6431.
|
| [31] |
RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained transformers[C/OL]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 2359–2369. doi: 10.18653/v1/2020.acl-main.214.
|
| [32] |
QUAN Zhibang, SUN Tao, SU Mengli, et al. Multimodal sentiment analysis based on cross-modal attention and gated cyclic hierarchical fusion networks[J]. Computational Intelligence and Neuroscience, 2022, 2022: 4767437. doi: 10.1155/2022/4767437.
|
| [33] |
ZOU Wenwen, DING Jundi, and WANG Chao. Utilizing BERT intermediate layers for multimodal sentiment analysis[C]. IEEE International Conference on Multimedia and Expo (ICME), Taipei, China, 2022: 1–6. doi: 10.1109/ICME52920.2022.9860014.
|
Figures(6) / Tables(3)



 DownLoad:
DownLoad: