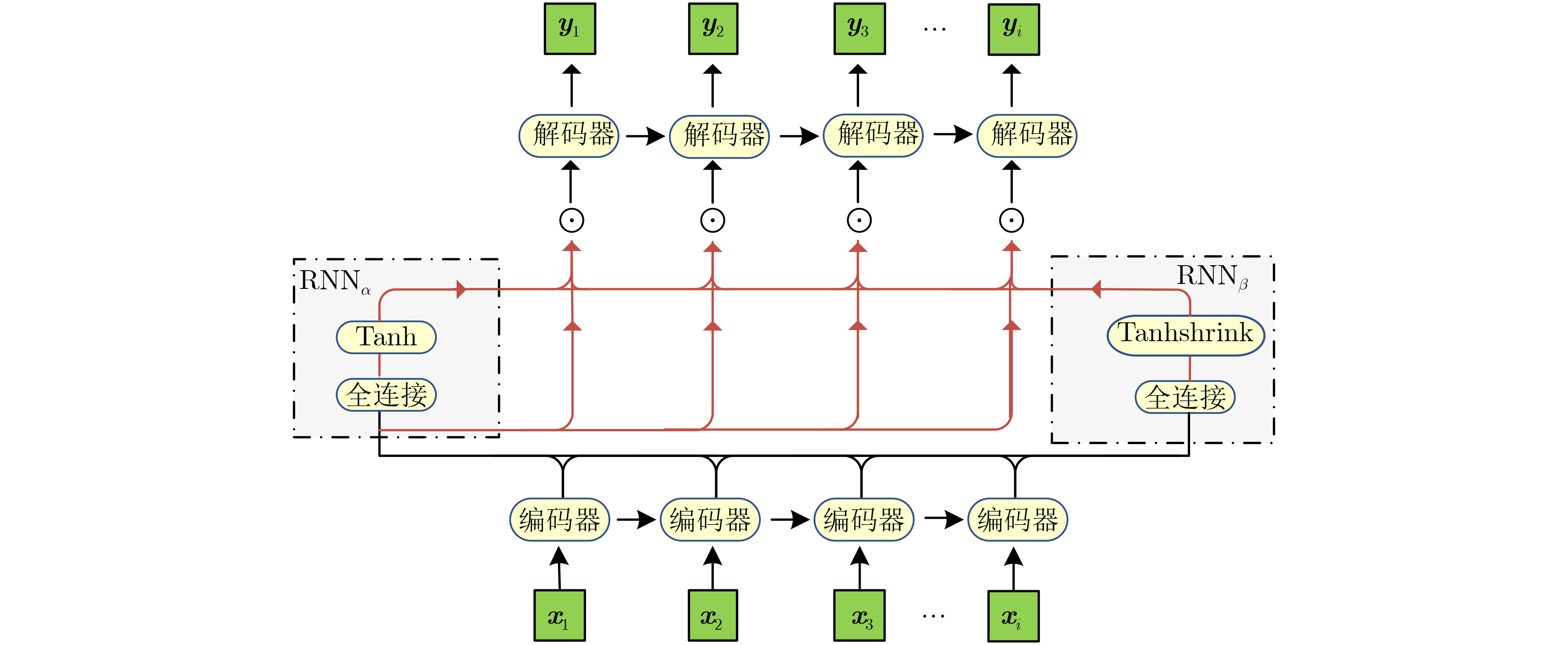
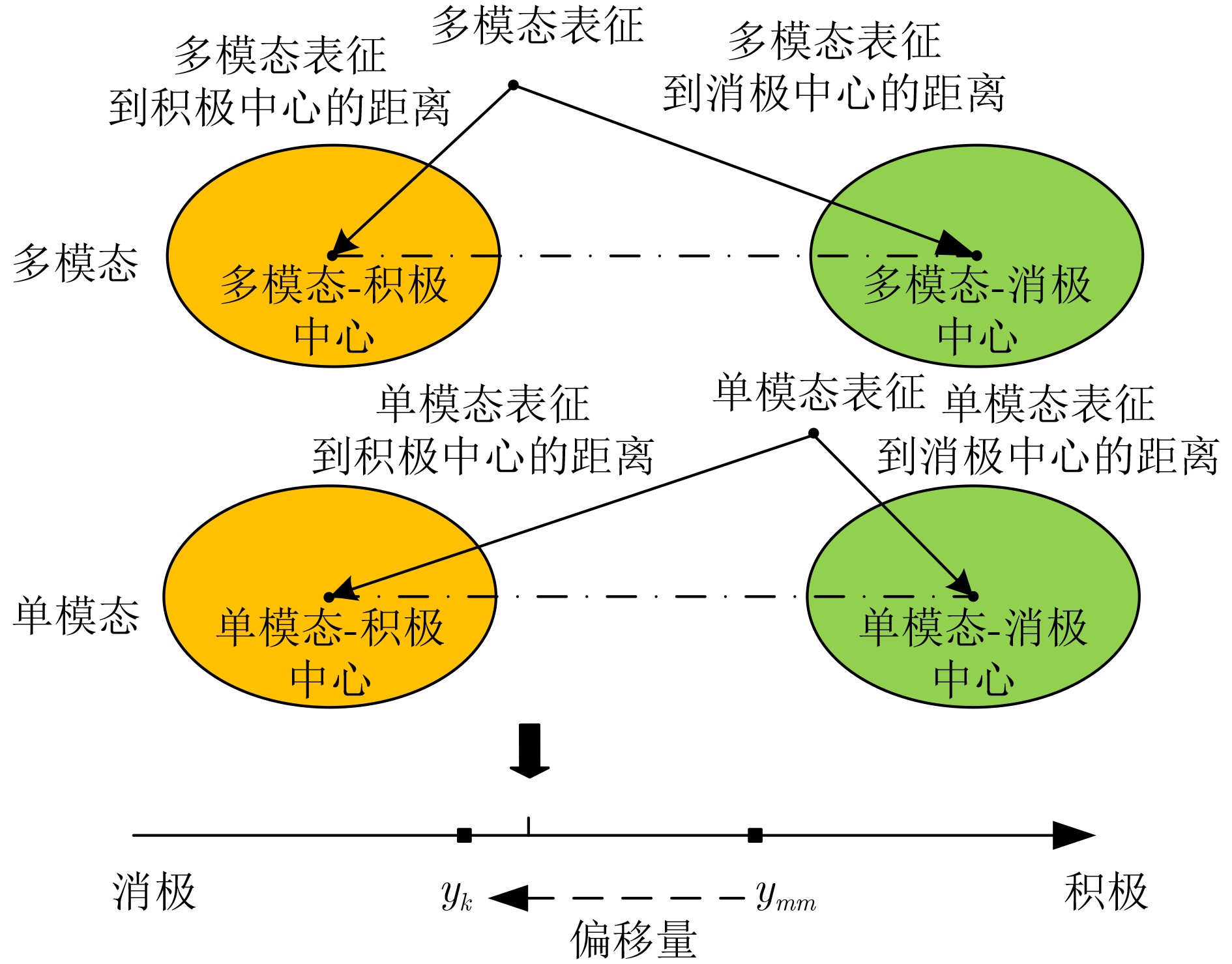
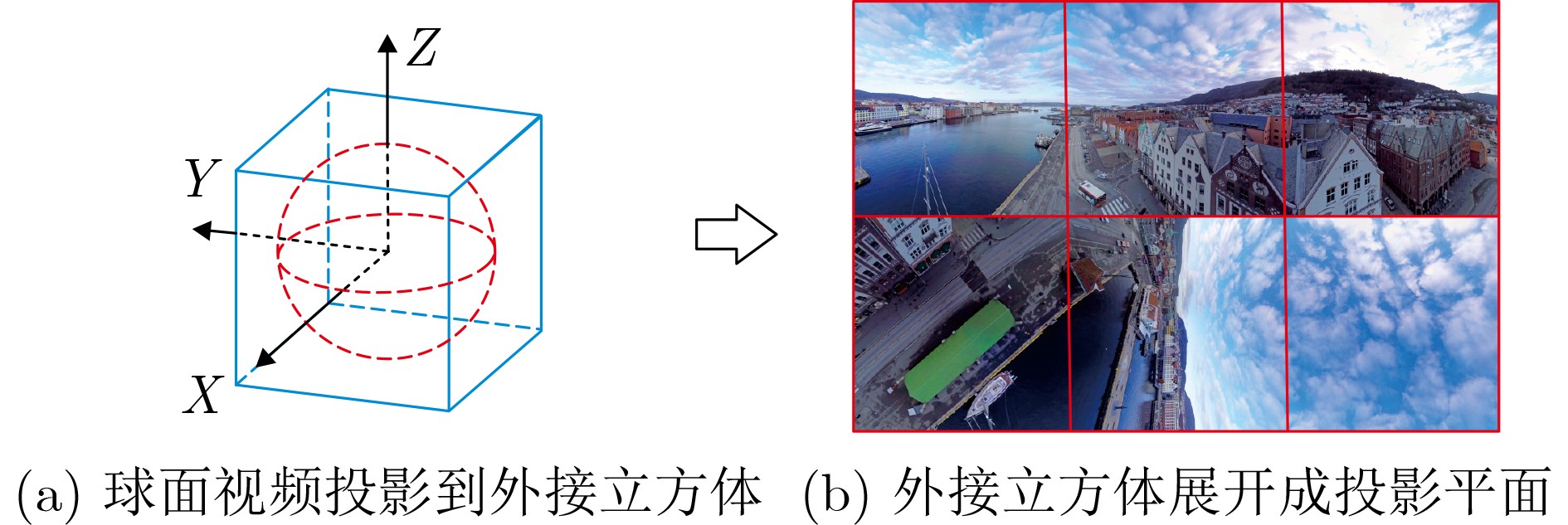
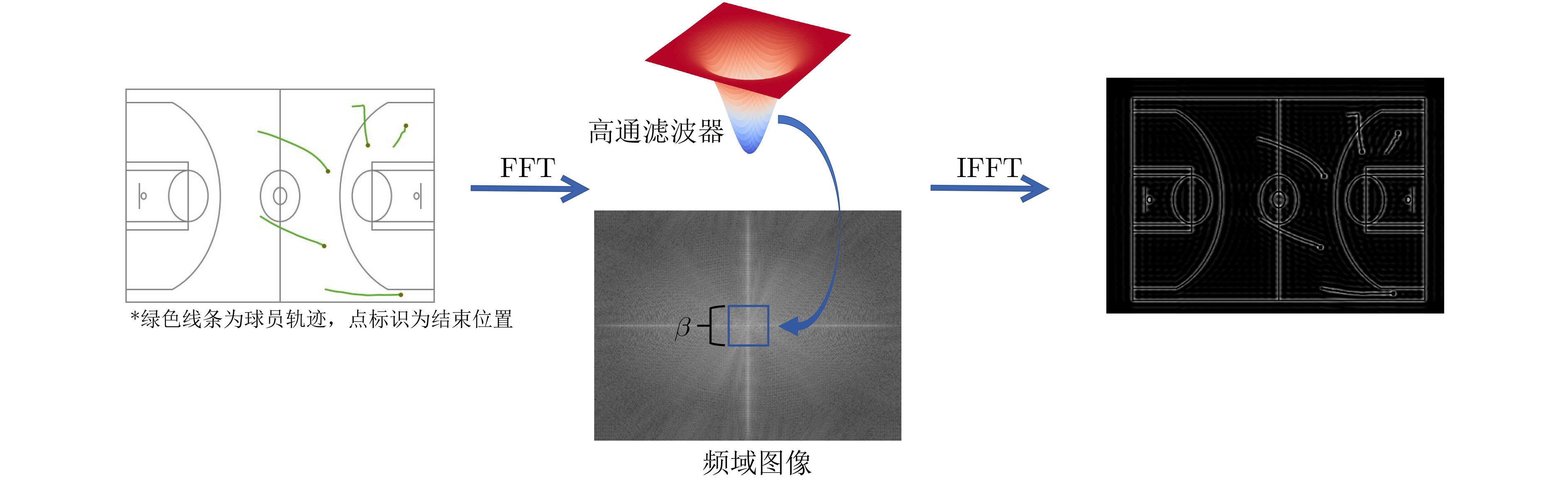
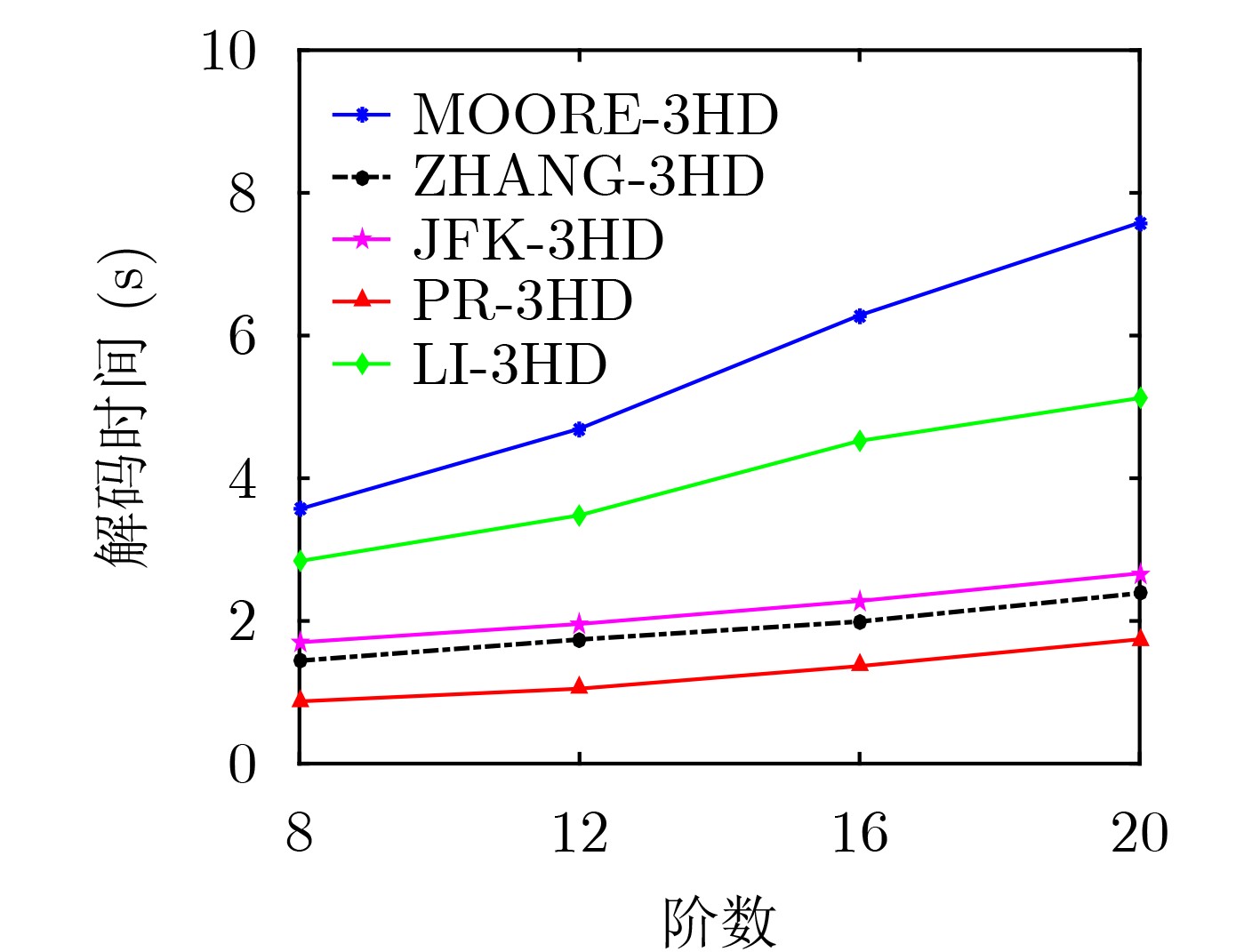
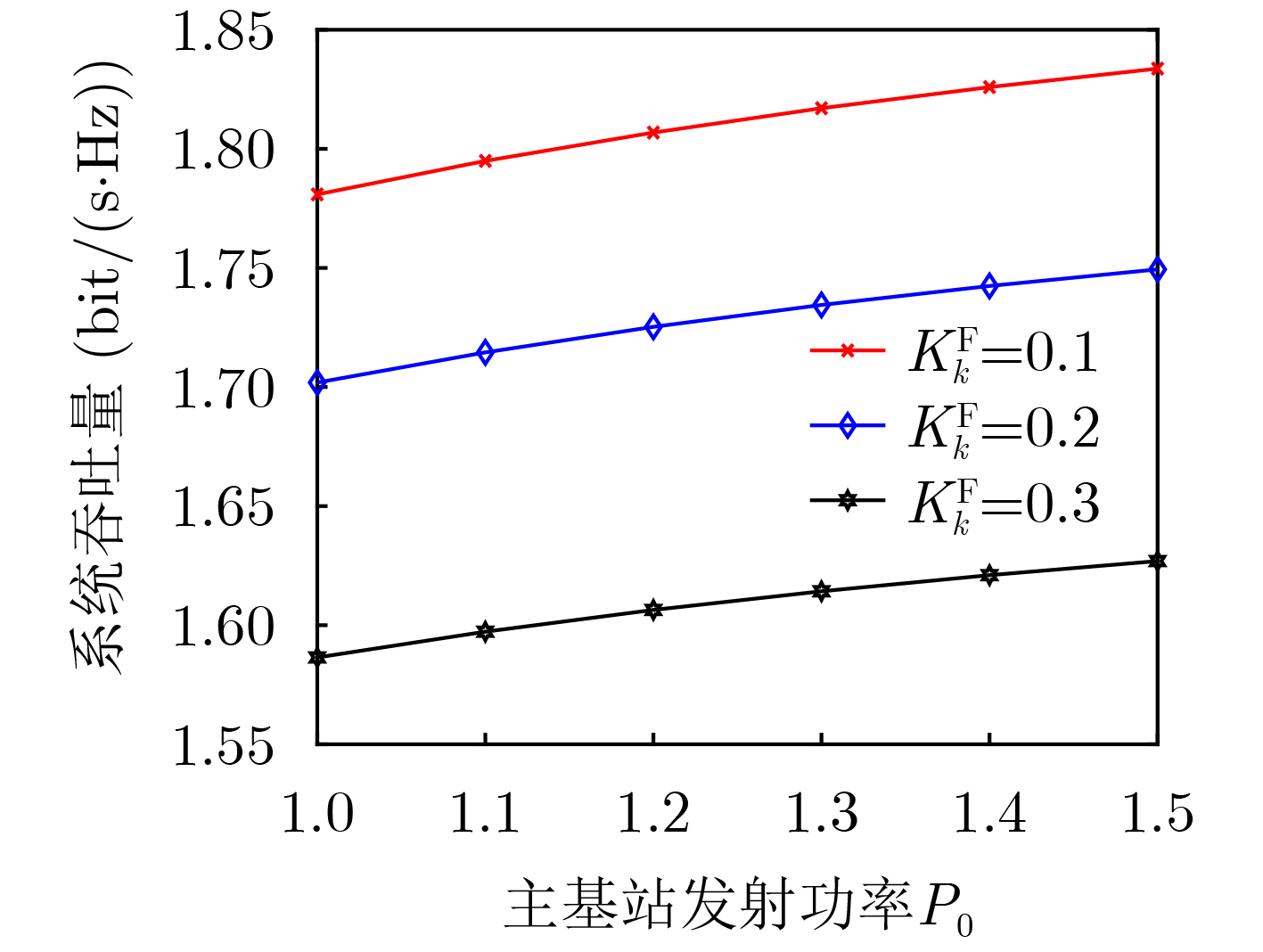
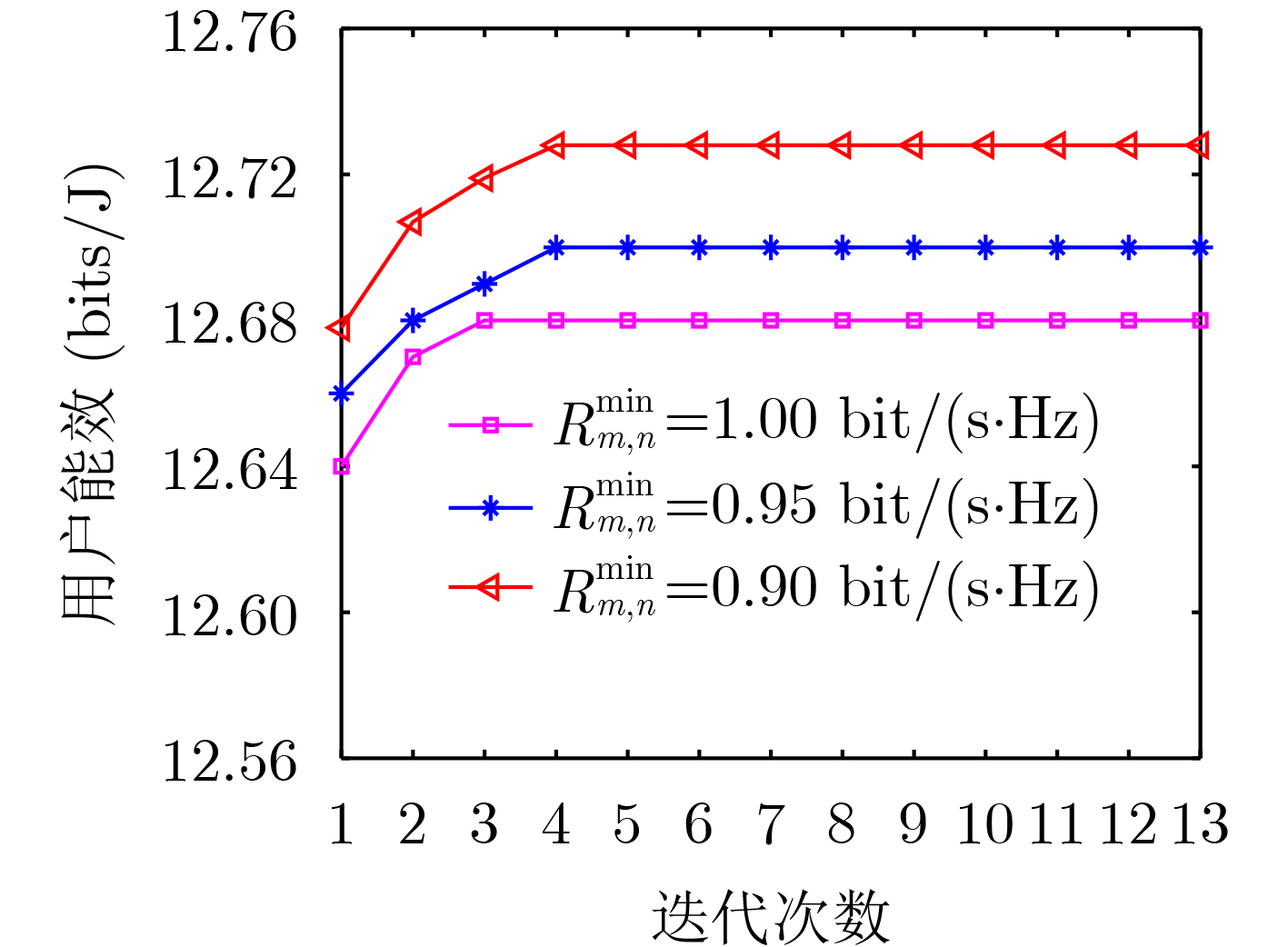
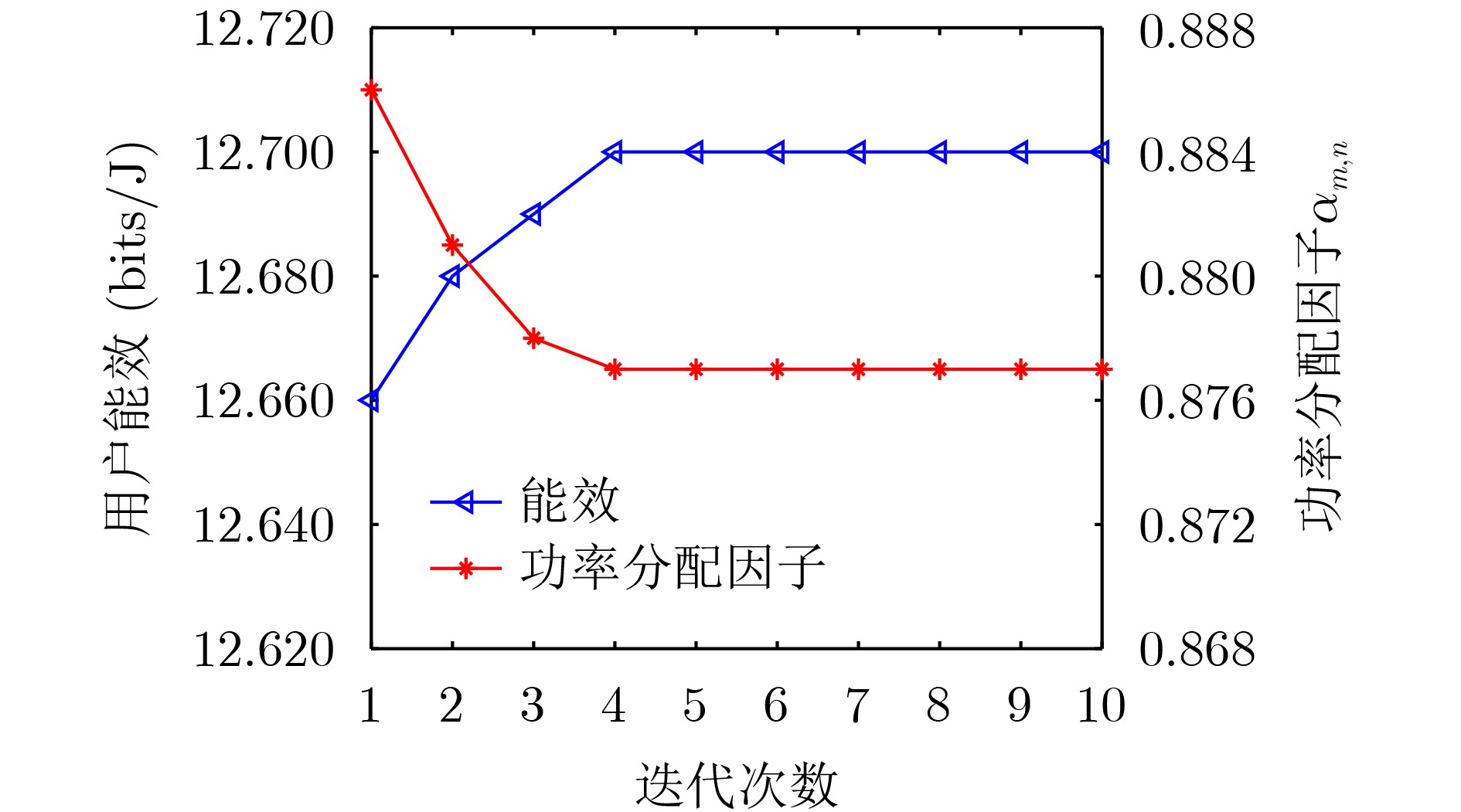
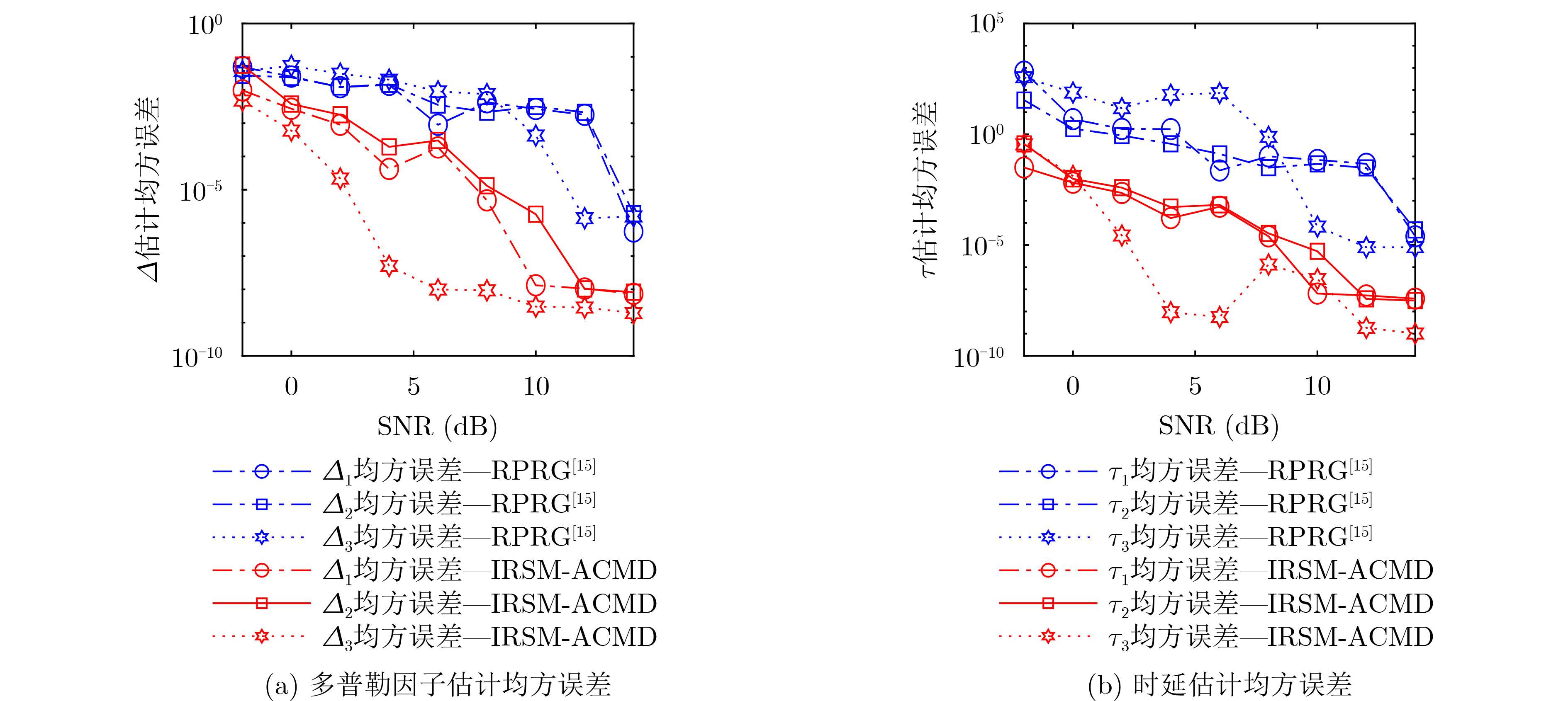
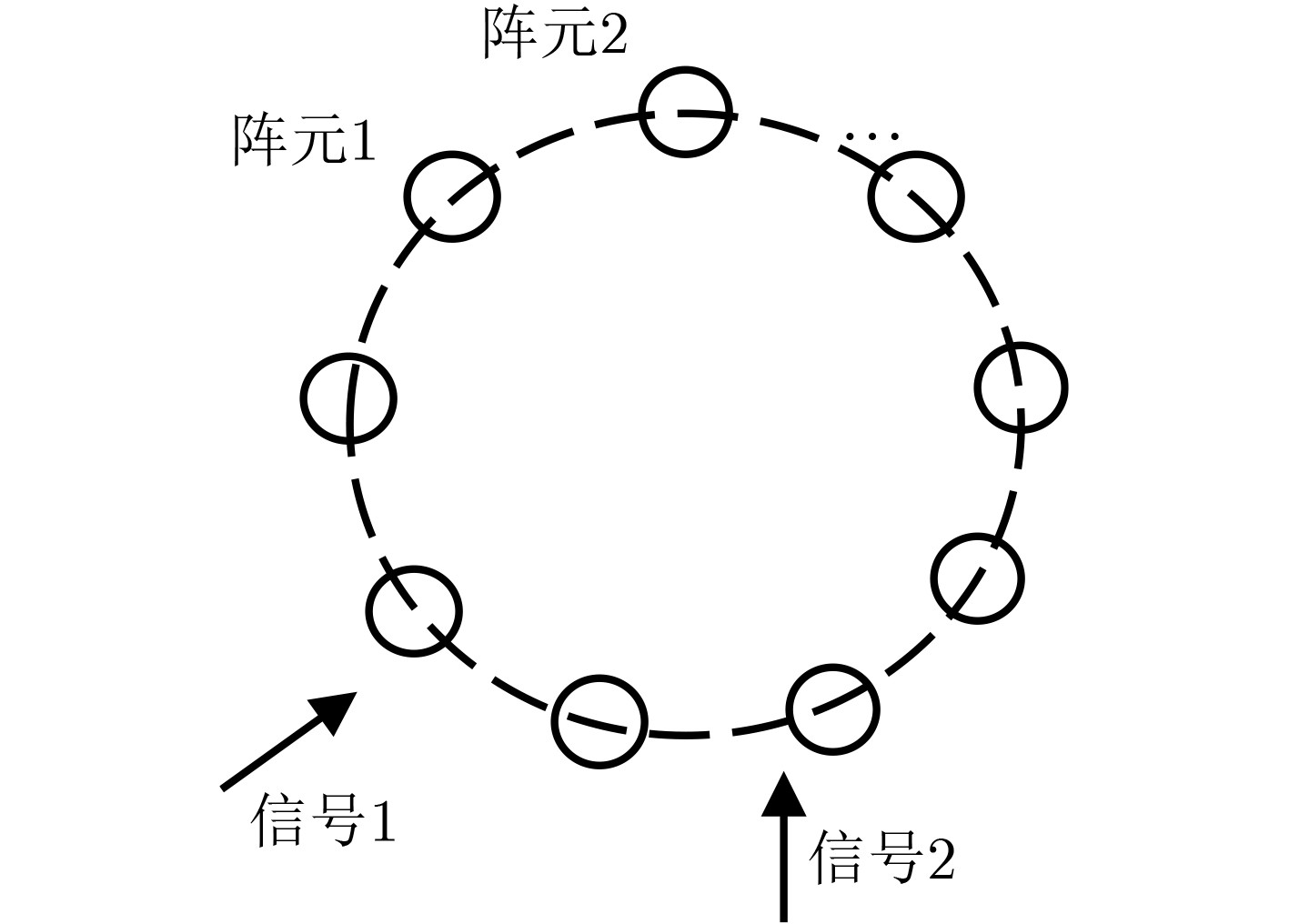
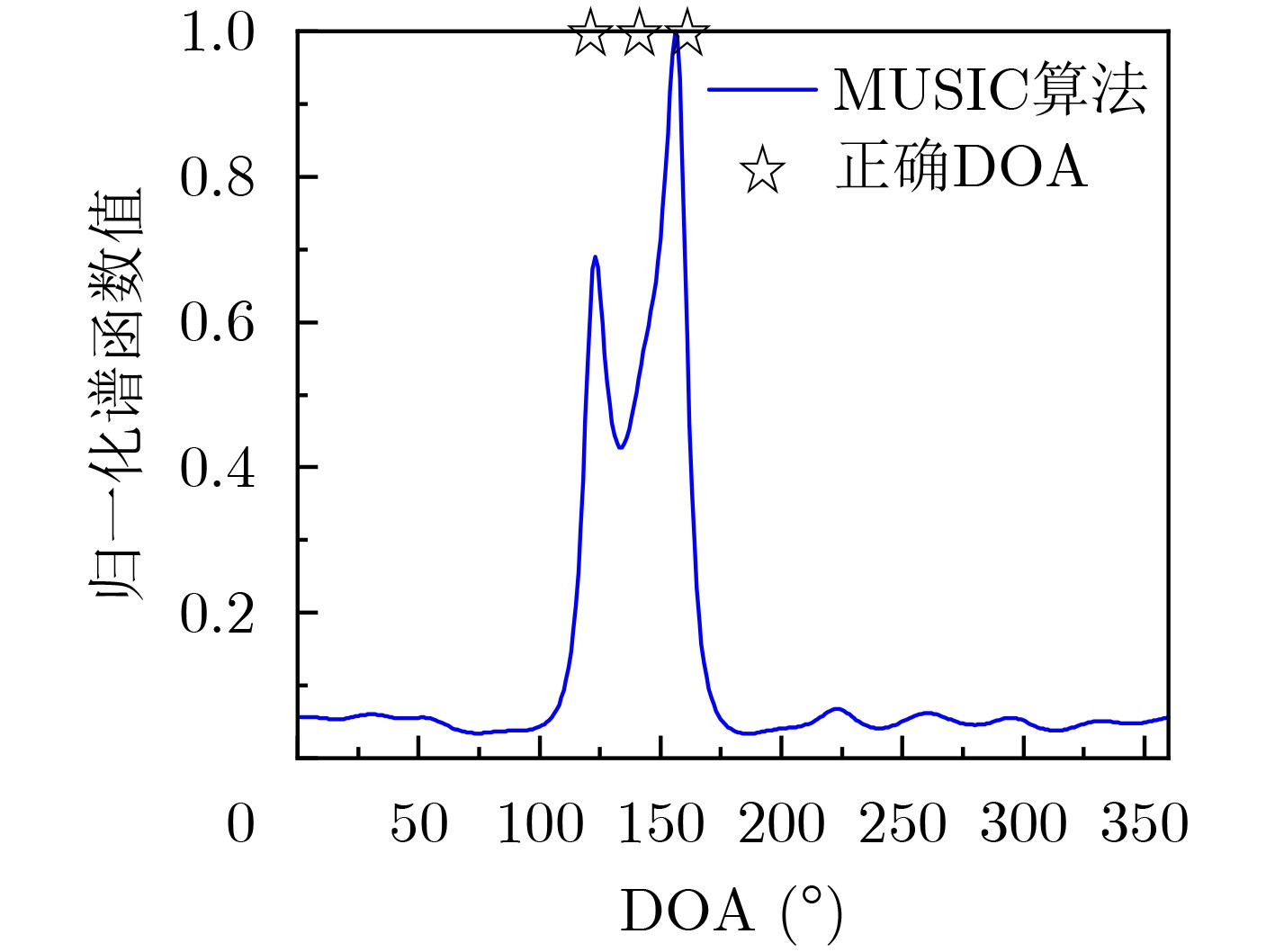
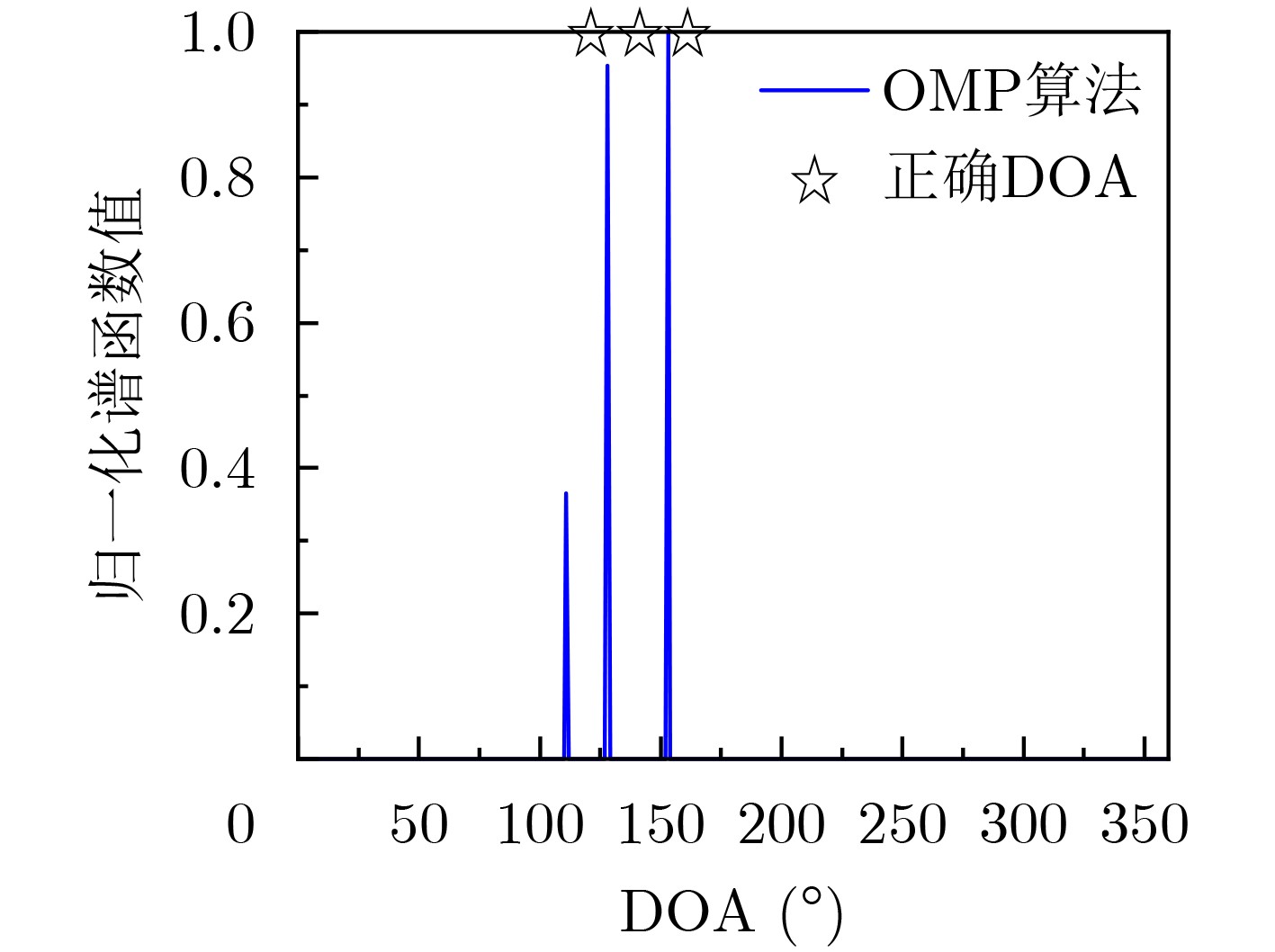
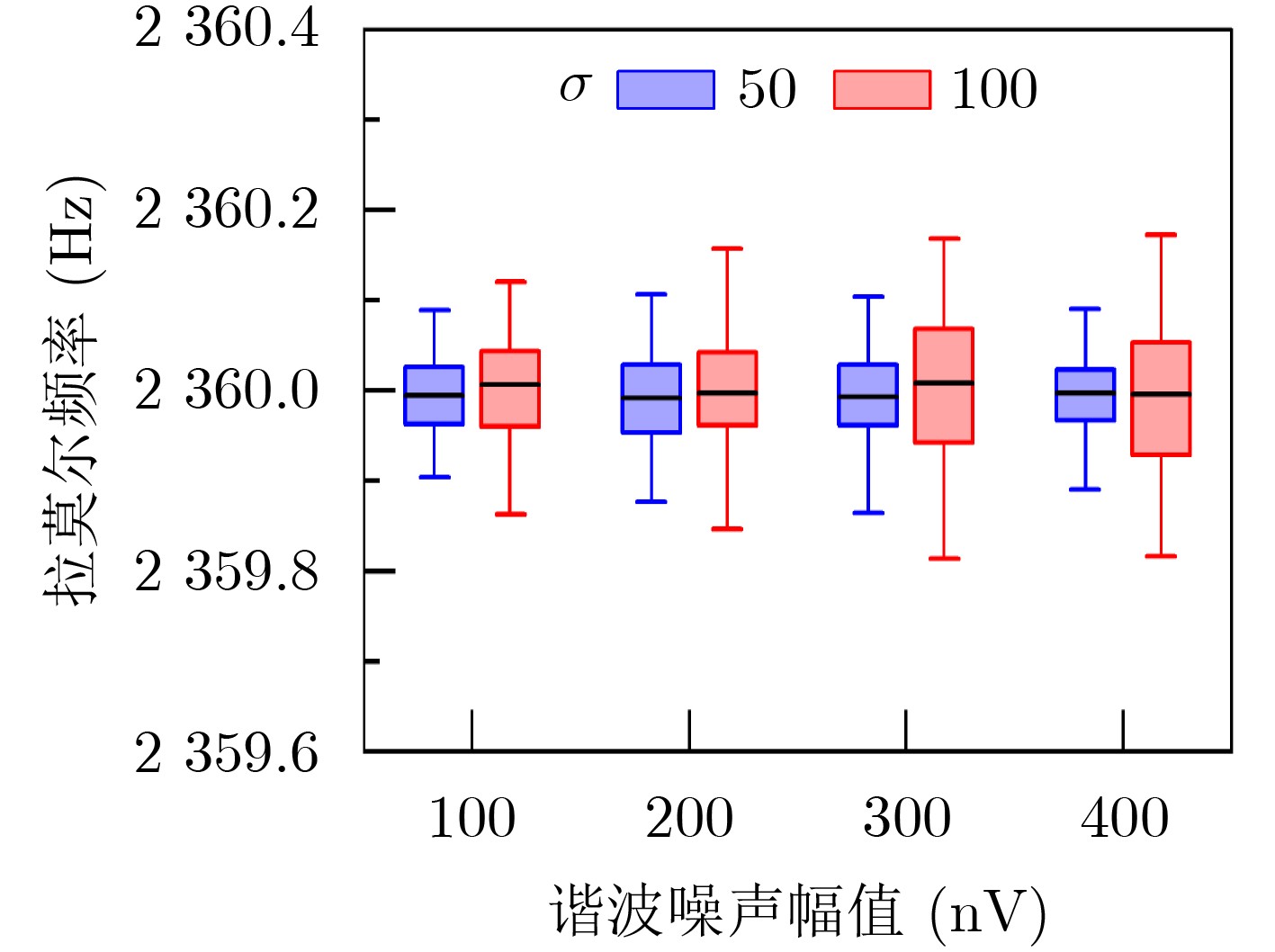
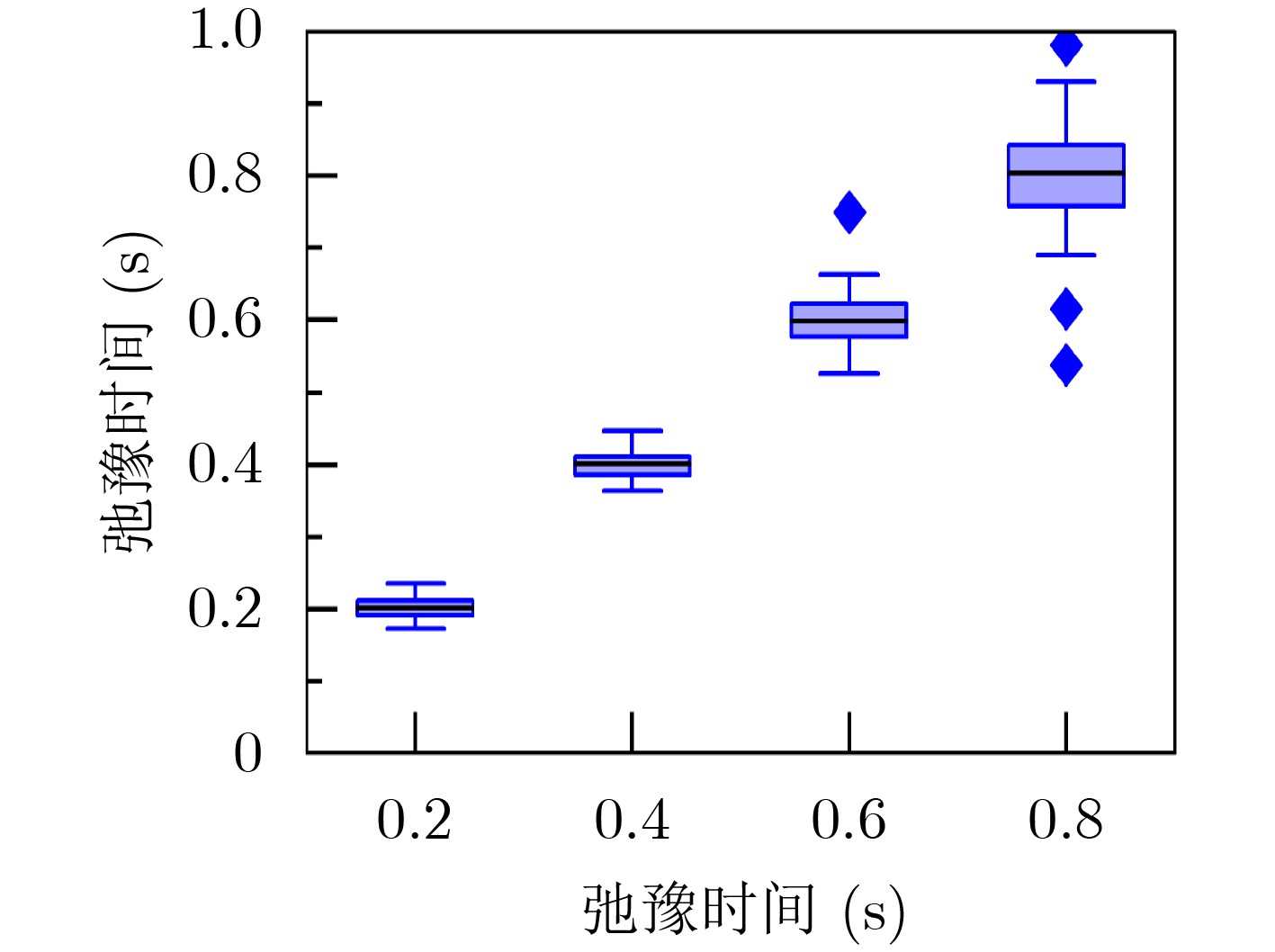
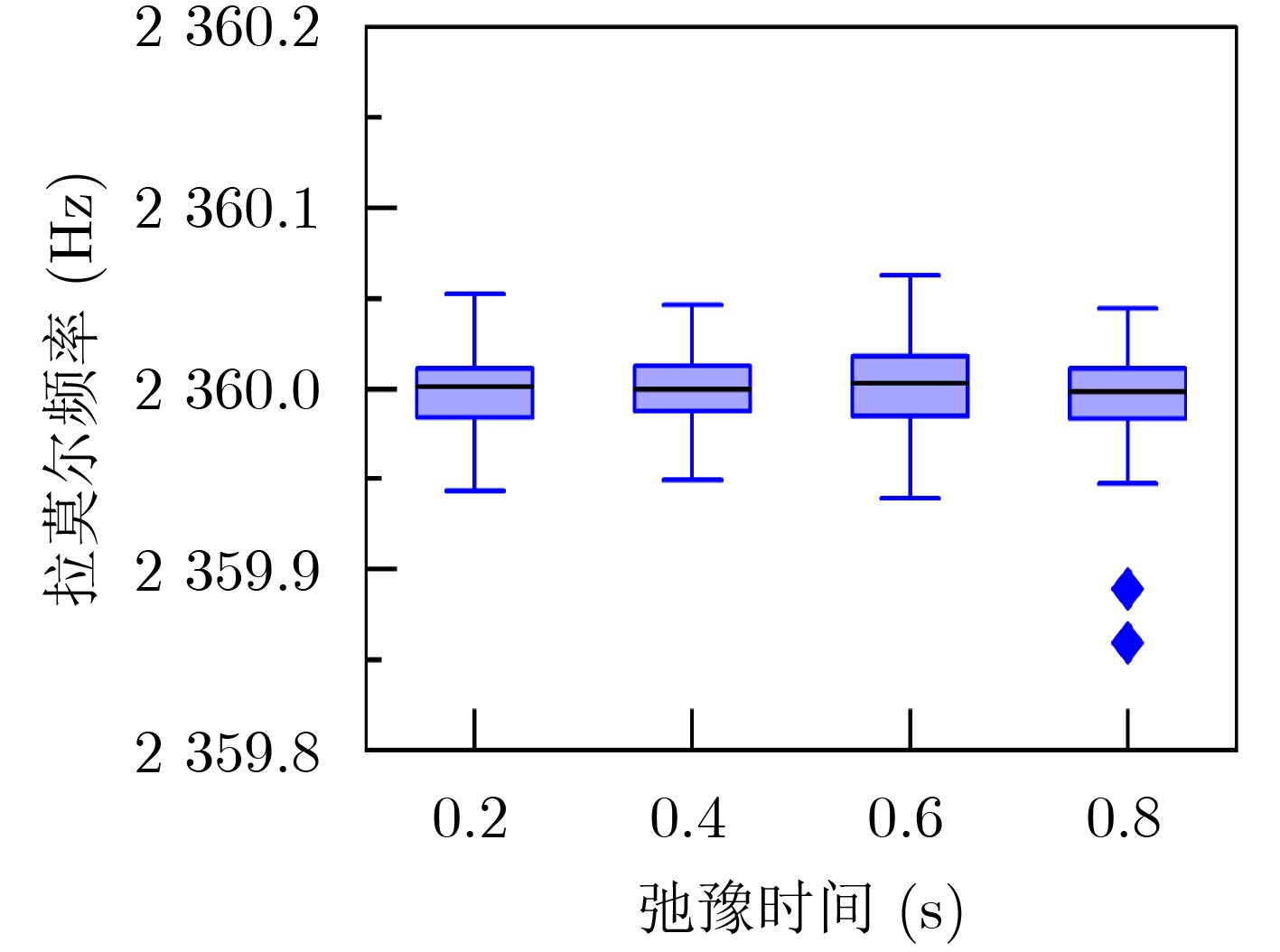
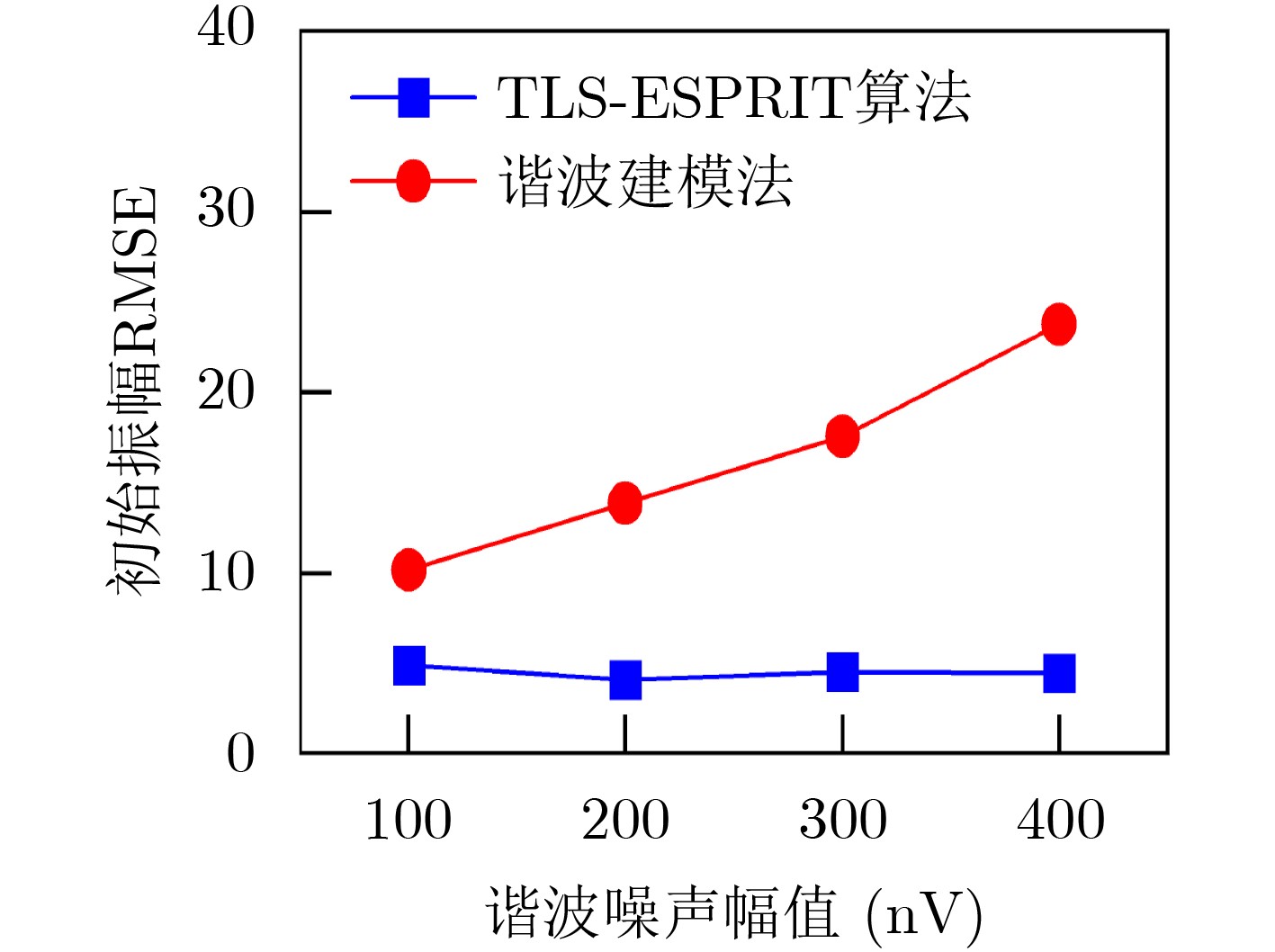
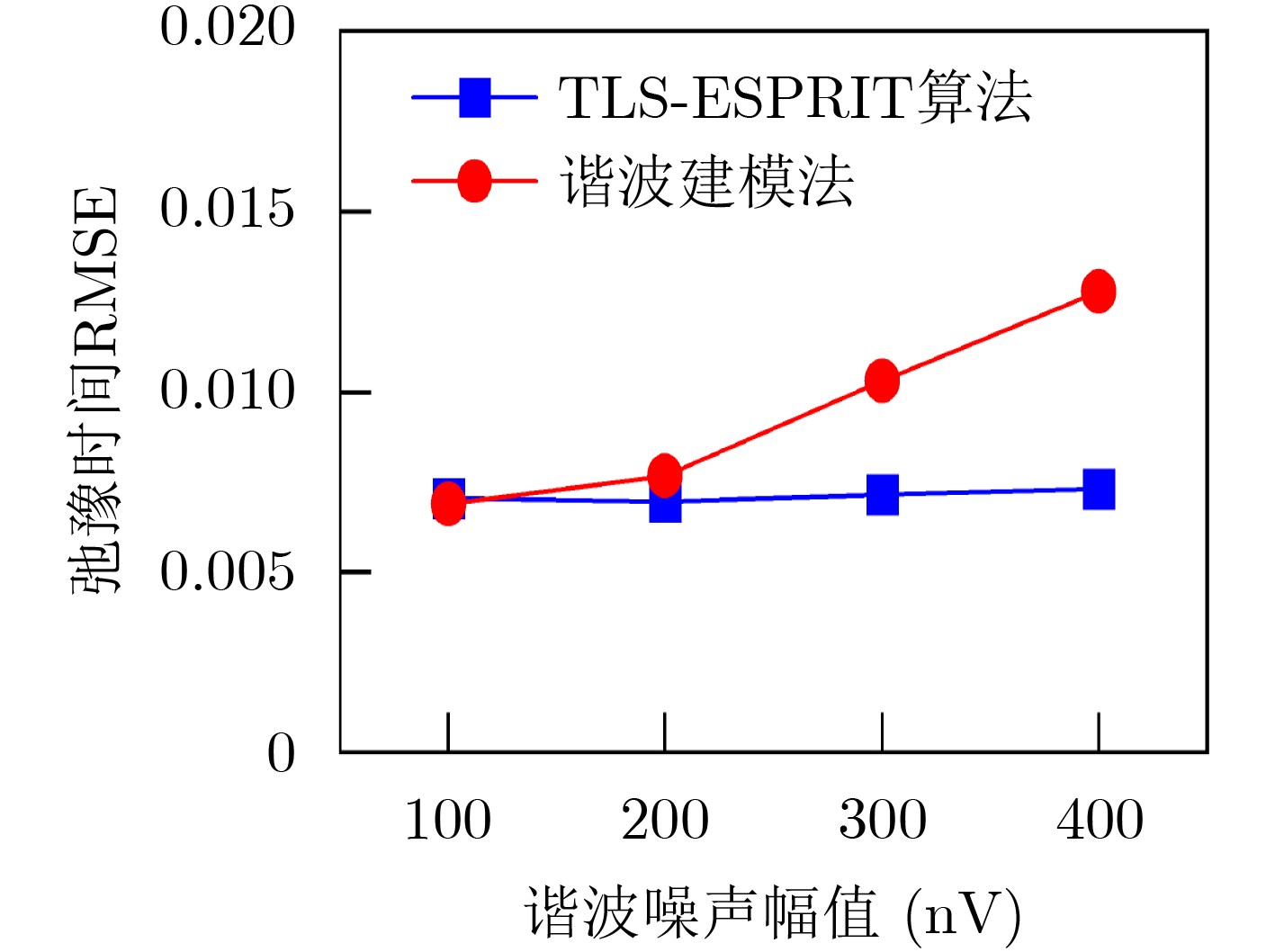
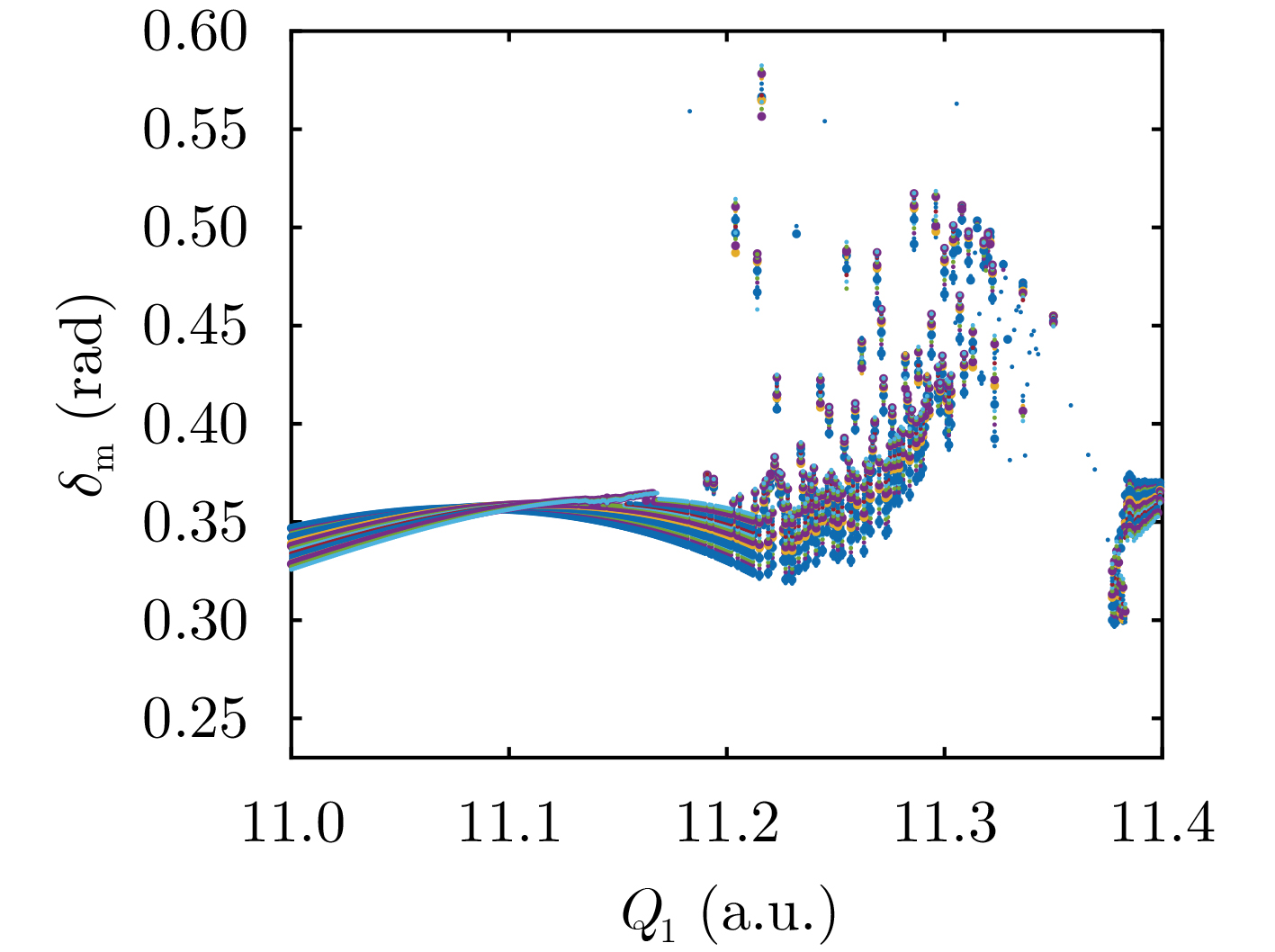
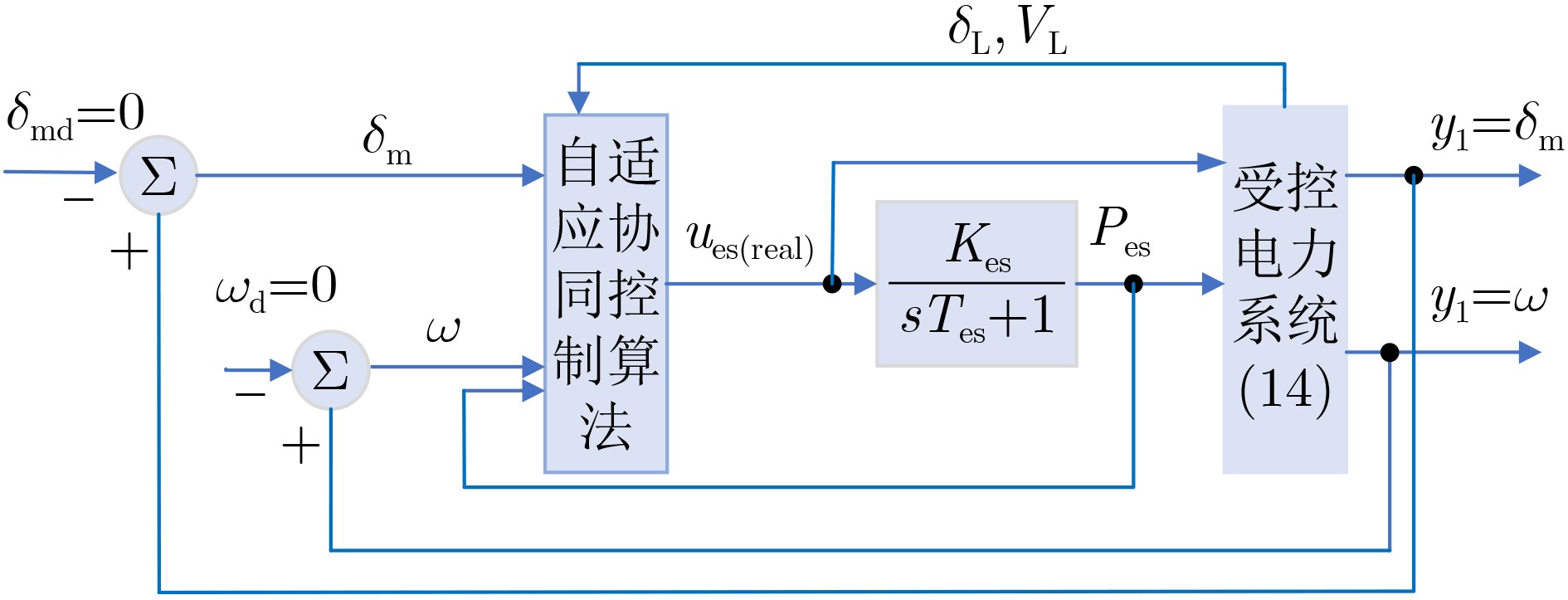
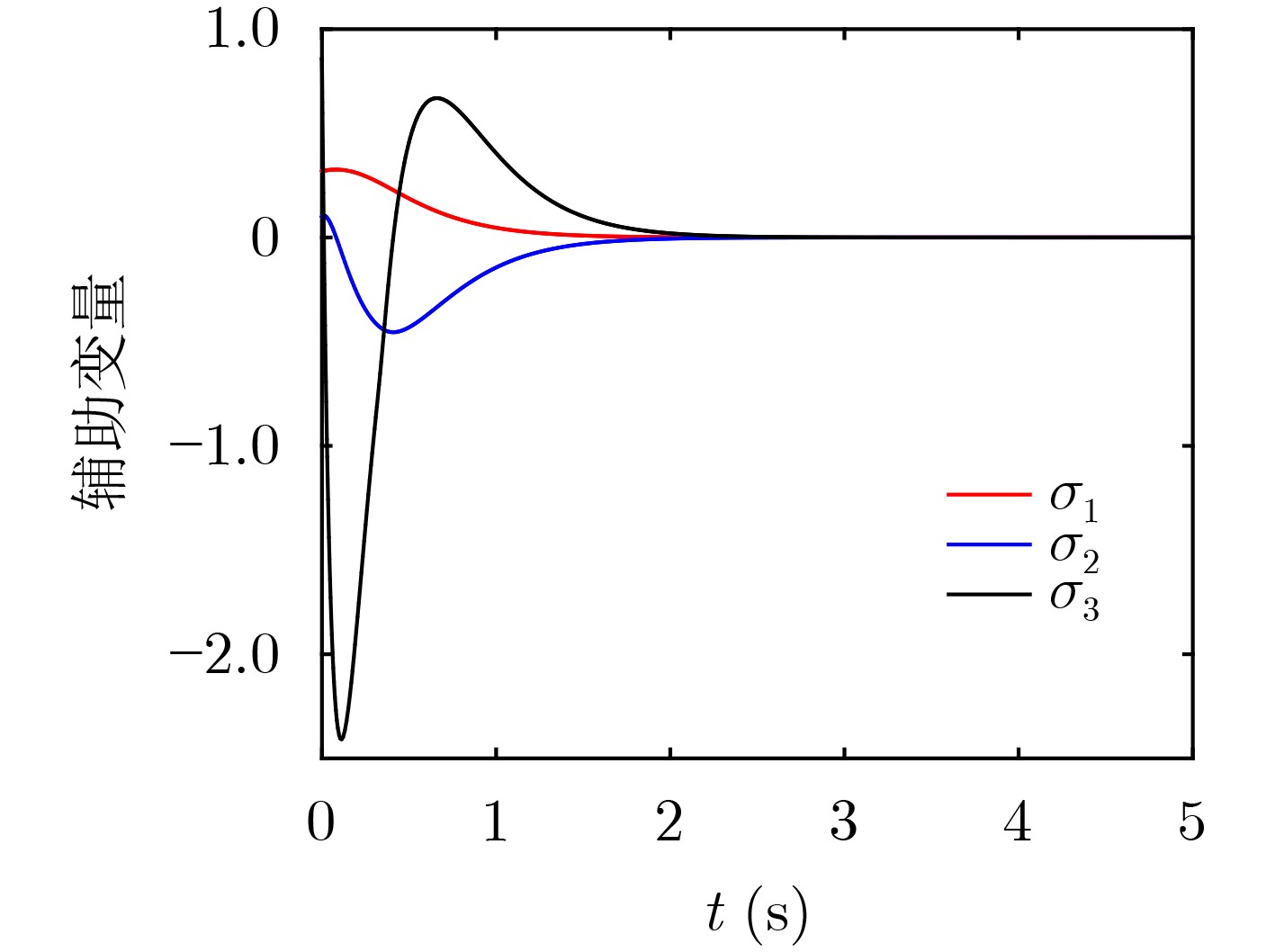
2024, 46(2): 408-427.
doi: 10.11999/JEIT230749
Abstract:
Artificial Intelligence(AI) develops in full swing with a great potential to surpass human, leading many people to believe that a singularity is imminent and that strong AI is about to be realized. This is a misconception of strong AI, because the core of strong AI is not whether it is powerful, but whether it has consciousness. In this article, firstly, the connotation of strong AI is explained, and the related problem of consciousness is discussed; Then, the ideas of Theory of Cognitive Relativity is elucidated, aimed at revealing the secret of consciousness, including the Principle of World’s Relativity, the Principle of Symbol’s Relativity, together with the relationships between world, language and mind. Subsequently, another new principle is expounded, namely the Principle of Consciousness’ Equivalence, to show the physical conditions required for arising of consciousness from matter, and to solve the hard problem of subjective experience or phenomenal consciousness, and to establish the fundamental theorem of cognition that conscious ability is limited by sensory ability with the upper bound of sensory capacity, and to analyze the possibility of where consciousness is as well as what self is. Finally, under the framework of the theory of cognitive relativity, a new creed for solving the puzzle of consciousness and a new guide for implementing machine consciousness are presented, with the future of strong AI envisioned.