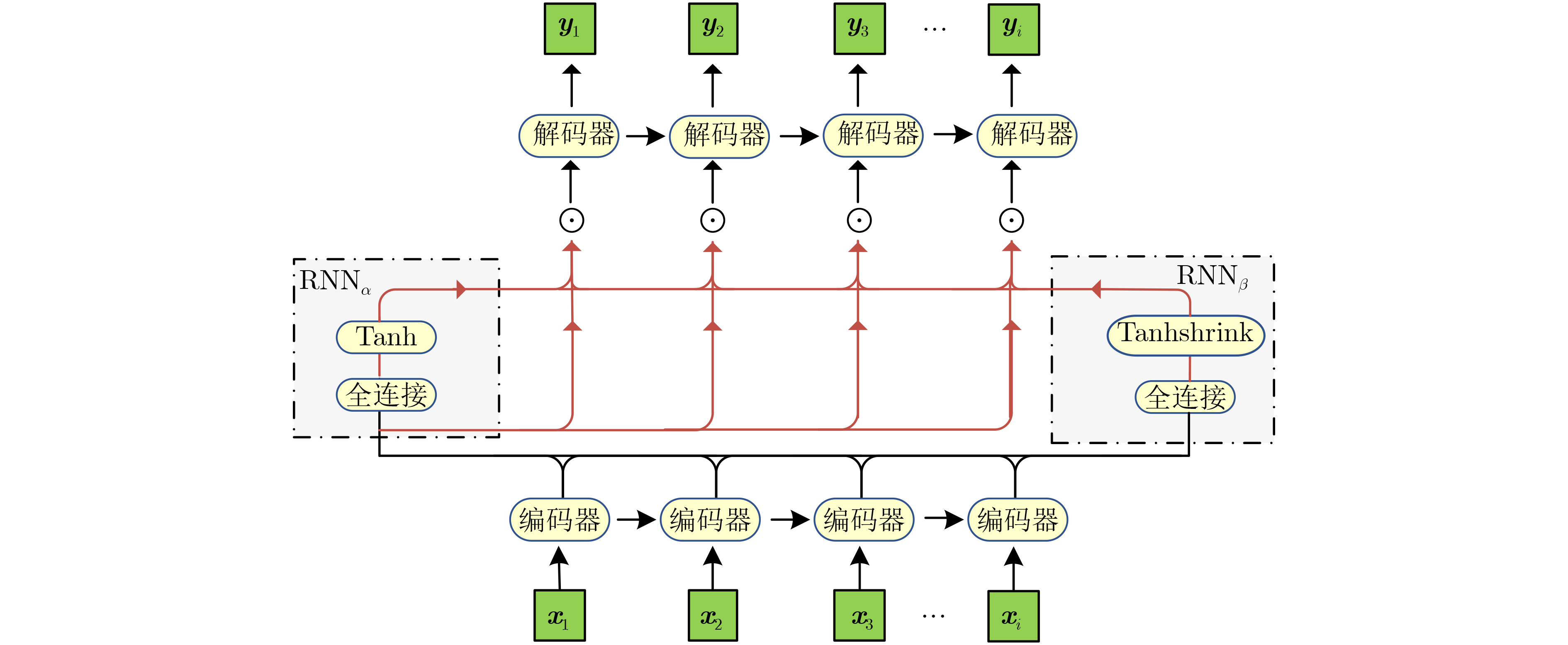
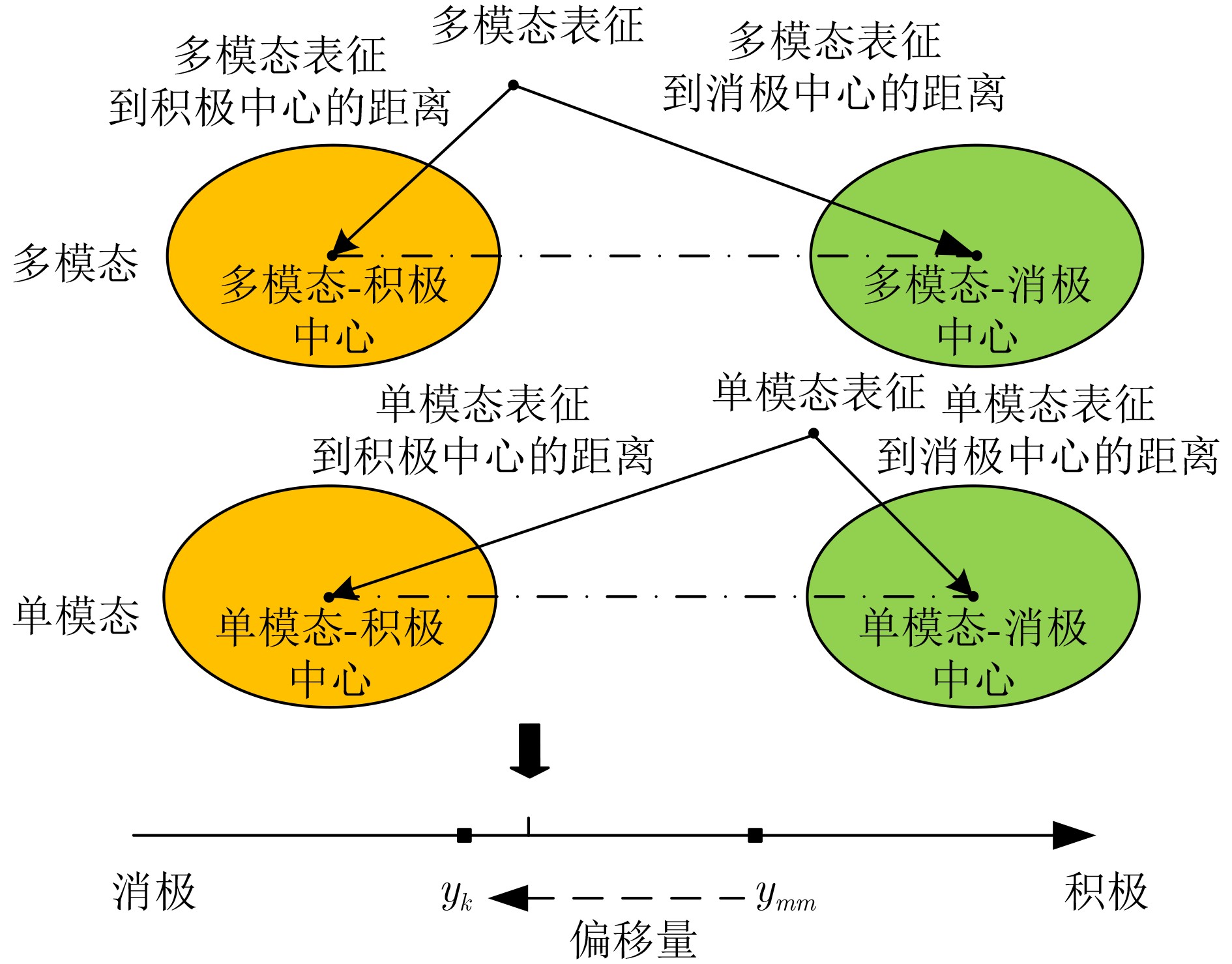
| Citation: | SUN Qiang, WANG Shuyu. Self-supervised Multimodal Emotion Recognition Combining Temporal Attention Mechanism and Unimodal Label Automatic Generation Strategy[J]. Journal of Electronics & Information Technology, 2024, 46(2): 588-601. doi: 10.11999/JEIT231107

|

| [1] |
曾子明, 孙守强, 李青青. 基于融合策略的突发公共卫生事件网络舆情多模态负面情感识别[J]. 情报学报, 2023, 42(5): 611–622. doi: 10.3772/j.issn.1000-0135.2023.05.009.
ZENG Ziming, SUN Shouqiang, and LI Qingqing. Multimodal negative sentiment recognition in online public opinion during public health emergencies based on fusion strategy[J]. Journal of the China Society for Scientific and Technical Information, 2023, 42(5): 611–622. doi: 10.3772/j.issn.1000-0135.2023.05.009.
|
| [2] |
姚鸿勋, 邓伟洪, 刘洪海, 等. 情感计算与理解研究发展概述[J]. 中国图象图形学报, 2022, 27(6): 2008–2035. doi: 10.11834/jig.220085.
YAO Hongxun, DENG Weihong, LIU Honghai, et al. An overview of research development of affective computing and understanding[J]. Journal of Image and Graphics, 2022, 27(6): 2008–2035. doi: 10.11834/jig.220085.
|
| [3] |
KUMAR P and RAMAN B. A BERT based dual-channel explainable text emotion recognition system[J]. Neural Networks, 2022, 150: 392–407. doi: 10.1016/j.neunet.2022.03.017.
|
| [4] |
曾义夫, 蓝天, 吴祖峰, 等. 基于双记忆注意力的方面级别情感分类模型[J]. 计算机学报, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845.
ZENG Yifu, LAN Tian, WU Zufeng, et al. Bi-memory based attention model for aspect level sentiment classification[J]. Chinese Journal of Computers, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845.
|
| [5] |
BAKHSHI A, HARIMI A, and CHALUP S. CyTex: Transforming speech to textured images for speech emotion recognition[J]. Speech Communication, 2022, 139: 62–75. doi: 10.1016/j.specom.2022.02.007.
|
| [6] |
黄程韦, 赵艳, 金赟, 等. 实用语音情感的特征分析与识别的研究[J]. 电子与信息学报, 2011, 33(1): 112–116. doi: 10.3724/SP.J.1146.2009.00886.
HUANG Chengwei, ZHAO Yan, JIN Yun, et al. A study on feature analysis and recognition of practical speech emotion[J]. Journal of Electronics & Information Technology, 2011, 33(1): 112–116. doi: 10.3724/SP.J.1146.2009.00886.
|
| [7] |
杨杨, 詹德川, 姜远, 等. 可靠多模态学习综述[J]. 软件学报, 2021, 32(4): 1067–1081. doi: 10.13328/j.cnki.jos.0061670.
YANG Yang, ZHAN Dechuan, JIANG Yuan, et al. Reliable multi-modal learning: A survey[J]. Journal of Software, 2021, 32(4): 1067–1081. doi: 10.13328/j.cnki.jos.0061670.
|
| [8] |
韩卓群. 基于多模态融合的情感识别技术研究与实现[D]. [硕士论文], 山东大学, 2022. doi: 10.27272/d.cnki.gshdu.2022.004451.
HAN Zhuoqun. Research and implementation of emotion recognition technology based on multimodal fusion[D]. [Master dissertation], Shandong University, 2022. doi: 10.27272/d.cnki.gshdu.2022.004451.
|
| [9] |
ZADEH A, CHEN Minghai, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]. Proceedings of 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 1103–1114. doi: 10.18653/v1/D17-1115.
|
| [10] |
LIU Zhun, SHEN Ying, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2247–2256. doi: 10.18653/v1/P18-1209.
|
| [11] |
MAI Sijie, HU Haifeng, and XING Songlong. Modality to modality translation: An adversarial representation learning and graph fusion network for multimodal fusion[C]. Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 164–172. doi: 10.1609/aaai.v34i01.5347.
|
| [12] |
WU Yang, LIN Zijie, ZHAO Yanyan, et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Virtual, 2021: 4730–4738. doi: 10.18653/v1/2021.findings-acl.417.
|
| [13] |
YU Wenmeng, XU Hua, MENG Fanyang, et al. CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 2020: 3718–3727. doi: 10.18653/v1/2020.acl-main.343.
|
| [14] |
ZADEH A A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2236–2246. doi: 10.18653/v1/P18-1208.
|
| [15] |
BALTRUŠAITIS T, AHUJA C, and MORENCY L P. Multimodal machine learning: A survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423–443. doi: 10.1109/TPAMI.2018.2798607.
|
| [16] |
赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479–1503. doi: 10.3778/j.issn.1673-9418.2112081.
ZHAO Xiaoming, YANG Yijiao, and ZHANG Shiqing. Survey of deep learning based multimodal emotion recognition[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1479–1503. doi: 10.3778/j.issn.1673-9418.2112081.
|
| [17] |
KAUR R and KAUTISH S. Multimodal sentiment analysis: A survey and comparison[M]. Information Resources Management Association. Research Anthology on Implementing Sentiment Analysis Across Multiple Disciplines. IGI Global, 2022: 1846–1870. doi: 10.4018/978-1-6684-6303-1.ch098.
|
| [18] |
KAUR R and KAUTISH S. Multimodal sentiment analysis: A survey and comparison[J]. International Journal of Service Science Management Engineering and Technology, 2019, 10(2): 38–58. doi: 10.4018/IJSSMET.2019040103.
|
| [19] |
ZHANG J, XING L, TAN Z, et al. Multi-head attention fusion networks for multi-modal speech emotion recognition[J]. Computers & Industrial Engineering, 2022, 168: 108078. doi: doi: 10.1016/j.cie.2022.108078.
|
| [20] |
GHOSAL D, AKHTAR S, CHAUHAN D, et al. Contextual inter-modal attention for multi-modal sentiment analysis[C]. Proceedings of 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018: 3454–3466. doi: 10.18653/v1/D18-1382.
|
| [21] |
MAI Sijie, HU Haifeng, and XING Songlong. Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing[C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 481–492. doi: 10.18653/v1/P19-1046.
|
| [22] |
MAI Sijie, XING Songlong, and HU Haifeng. Locally confined modality fusion network with a global perspective for multimodal human affective computing[J]. IEEE Transactions on Multimedia, 2020, 22(1): 122–137. doi: 10.1109/TMM.2019.2925966.
|
| [23] |
HE Jiaxuan, MAI Sijie, and HU Haifeng. A unimodal reinforced transformer with time squeeze fusion for multimodal sentiment analysis[J]. IEEE Signal Processing Letters, 2021, 28: 992–996. doi: 10.1109/LSP.2021.3078074.
|
| [24] |
王汝言, 陶中原, 赵容剑, 等. 多交互图卷积网络用于方面情感分析[J]. 电子与信息学报, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459.
WANG Ruyan, TAO Zhongyuan, ZHAO Rongjian, et al. Multi-interaction graph convolutional networks for aspect-level sentiment analysis[J]. Journal of Electronics & Information Technology, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459.
|
| [25] |
DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. Proceedings of 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2019: 4171–4186. doi: 10.18653/v1/N19-1423.
|
| [26] |
SIRIWARDHANA S, KALUARACHCHI T, BILLINGHURST M, et al. Multimodal emotion recognition with transformer-based self supervised feature fusion[J]. IEEE Access, 2020, 8: 176274–176285. doi: 10.1109/ACCESS.2020.3026823.
|
| [27] |
YU Wenmeng, XU Hua, YUAN Ziqi, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[C]. Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2021: 10790–10797. doi: 10.1609/aaai.v35i12.17289.
|
| [28] |
WANG Di, GUO Xutong, TIAN Yumin, et al. TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis[J]. Pattern Recognition, 2023, 136: 109259. doi: 10.1016/j.patcog.2022.109259.
|
| [29] |
ZENG Yufei, LI Zhixin, TANG Zhenjun, et al. Heterogeneous graph convolution based on In-domain Self-supervision for Multimodal Sentiment Analysis[J]. Expert Systems with Applications, 2023, 213: 119240. doi: 10.1016/j.eswa.2022.119240.
|
| [30] |
HWANG Y and KIM J H. Self-supervised unimodal label generation strategy using recalibrated modality representations for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Dubrovnik, Croatia, 2023: 35–46. doi: 10.18653/v1/2023.findings-eacl.2.
|
| [31] |
CHOI E, BAHADORI M T, KULAS J A, et al. RETAIN: An interpretable predictive model for healthcare using reverse time attention mechanism[C]. Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 3512–3520.
|
| [32] |
WANG Yansen, SHEN Ying, LIU Zhun, et al. Words can shift: Dynamically adjusting word representations using nonverbal behaviors[C]. Proceedings of 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 7216–7223. doi: 10.1609/aaai.v33i01.33017216.
|
| [33] |
PHAM H, LIANG P P, MANZINI T, et al. Found in translation: Learning robust joint representations by cyclic translations between modalities[C]. Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 6892–6899. doi: 10.1609/aaai.v33i01.33016892.
|
| [34] |
TSAI Y H H, BAI Shaojie, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]. Proceedings of the 57th Association for Computational Linguistics, Florence, Italy, 2019: 6558. doi: 10.18653/v1/P19-1656.
|
| [35] |
RAHMAN W, HASAN K, LEE S, et al. Integrating multimodal information in large pretrained transformers[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 2020: 2359–2369. doi: 10.18653/v1/2020.acl-main.214.
|
| [36] |
ZHAO Xianbing, CHEN Yixin, CHEN Yiting, et al. HMAI-BERT: Hierarchical multimodal alignment and interaction network-enhanced BERT for multimodal sentiment analysis[C]. Proceedings of 2022 IEEE International Conference on Multimedia and Expo, Taipei, China, 2022: 1–6. doi: 10.1109/ICME52920.2022.9859747.
|
| [37] |
HAZARIKA D, ZIMMERMANN R, and PORIA S. MISA: Modality-invariant and-specific representations for multimodal sentiment analysis[C]. Proceedings of the 28th ACM International Conference on Multimedia, Seattle, United States, 2020: 1122–1131. doi: 10.1145/3394171.3413678.
|
| [38] |
HAN Wei, CHEN Hui, and PORIA S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis[C]. Proceedings of Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 9180–9192. doi: 10.18653/v1/2021.emnlp-main.723.
|
| [39] |
YU Yakun, ZHAO Mingjun, QI Shiang, et al. ConKI: Contrastive knowledge injection for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Toronto, Canada, 2023: 13610–13624. doi: 10.18653/v1/2023.findings-acl.860.
|
| [40] |
XIE Jinbao, WANG Jiyu, WANG Qingyan, et al. A multimodal fusion emotion recognition method based on multitask learning and attention mechanism[J]. Neurocomputing, 2023, 556: 126649. doi: 10.1016/j.neucom.2023.126649.
|
| [41] |
YANG Bo, SHAO Bo, WU Lijun, et al. Multimodal sentiment analysis with unidirectional modality translation[J]. Neurocomputing, 2022, 467: 130–137. doi: 10.1016/j.neucom.2021.09.041.
|
| [42] |
LAI Songning, HU Xifeng, LI Yulong, et al. Shared and private information learning in multimodal sentiment analysis with deep modal alignment and self-supervised multi-task learning[J]. arXiv preprint arXiv: 2305.08473, 2023.
|
| [43] |
YANG Bo, WU Lijun, ZHU Jinhua, et al. Multimodal sentiment analysis with two-phase multi-task learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2015–2024. doi: 10.1109/TASLP.2022.3178204.
|

Figures(4) / Tables(10)



 DownLoad:
DownLoad: