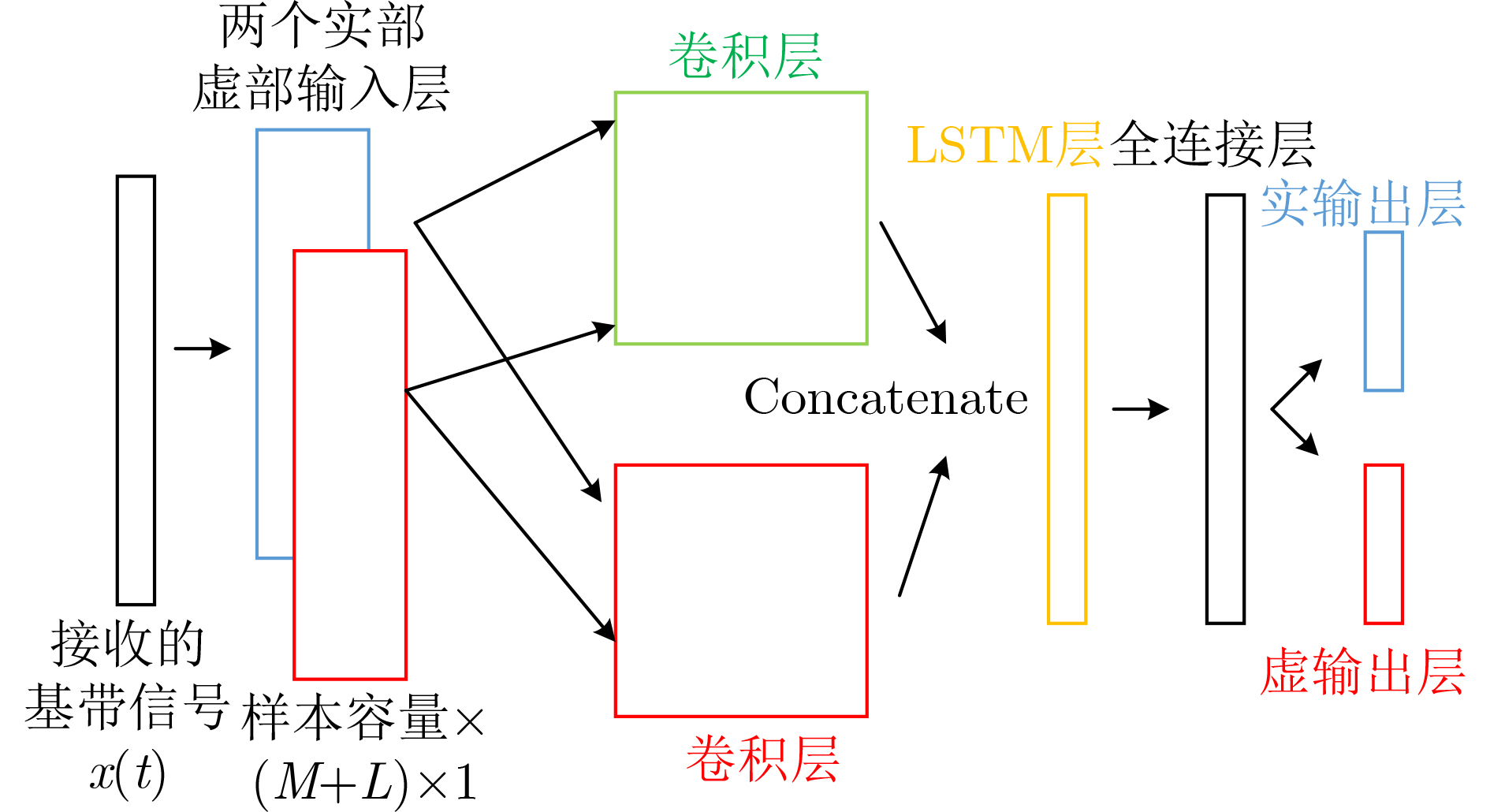
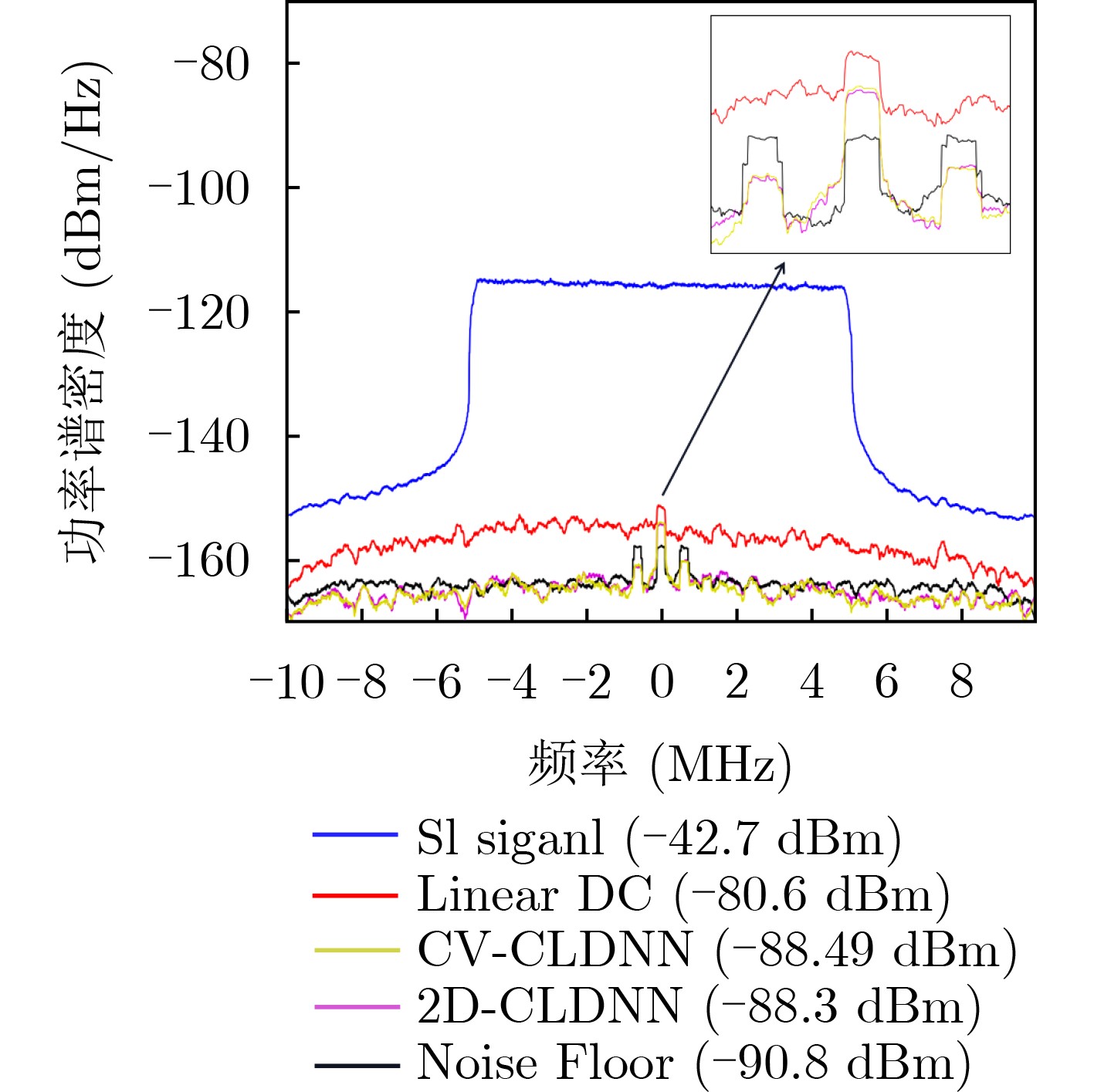
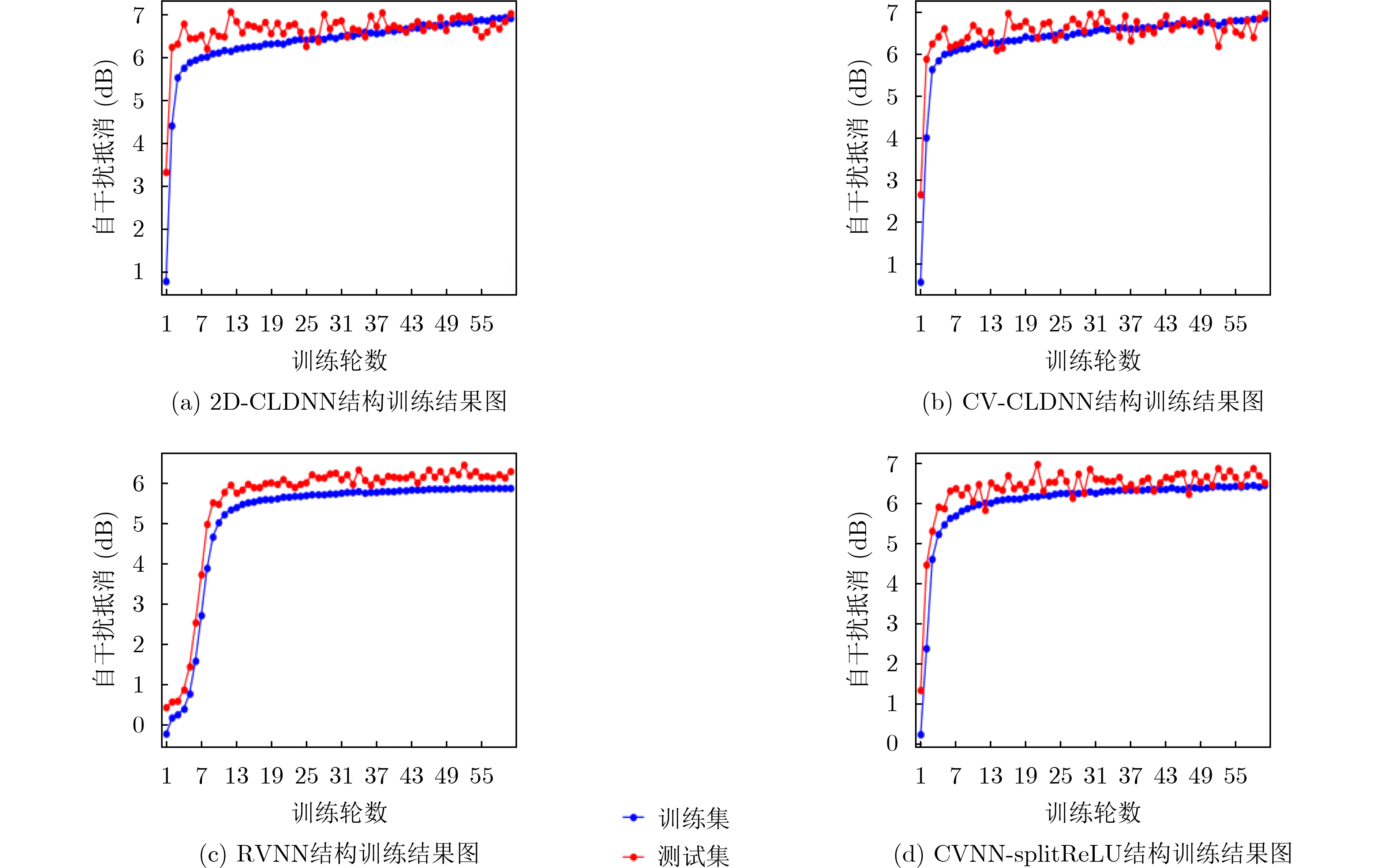
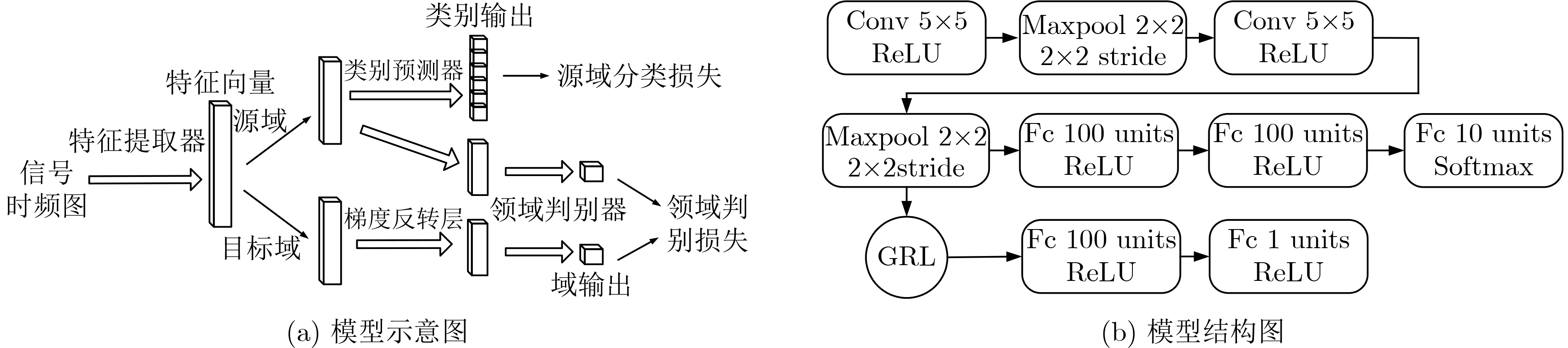
2022, 44(11): 4008-4017.
doi: 10.11999/JEIT211524
Abstract:
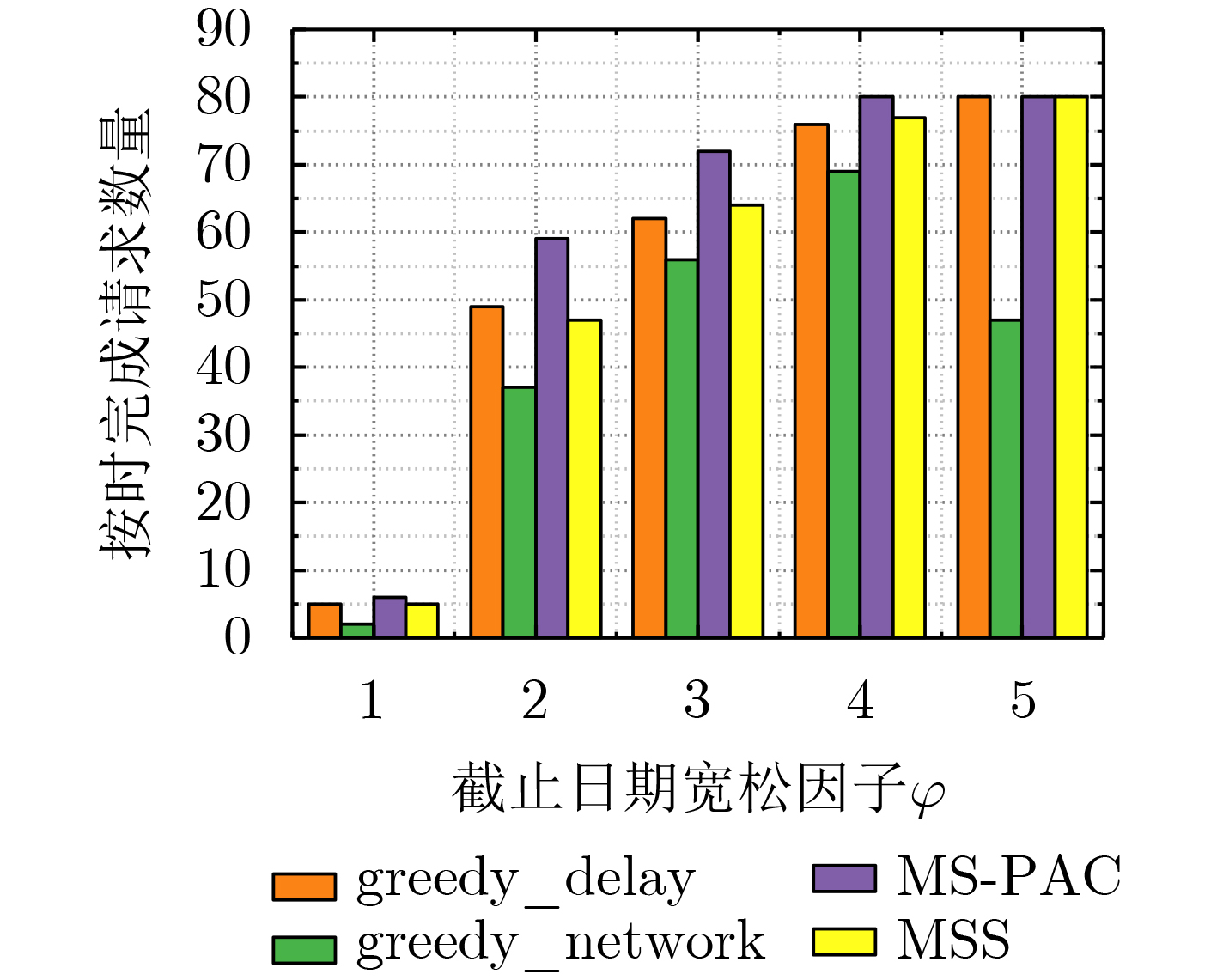
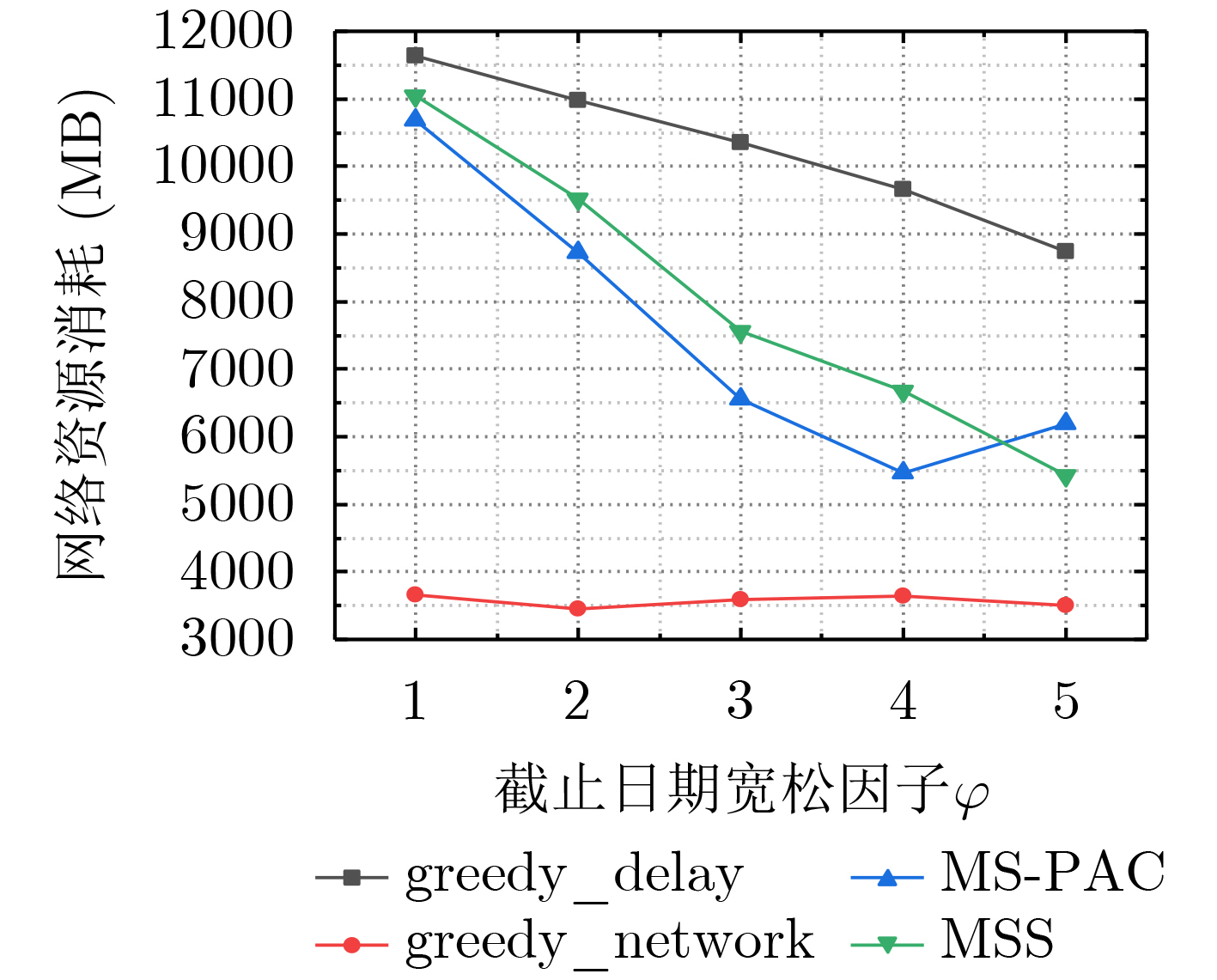
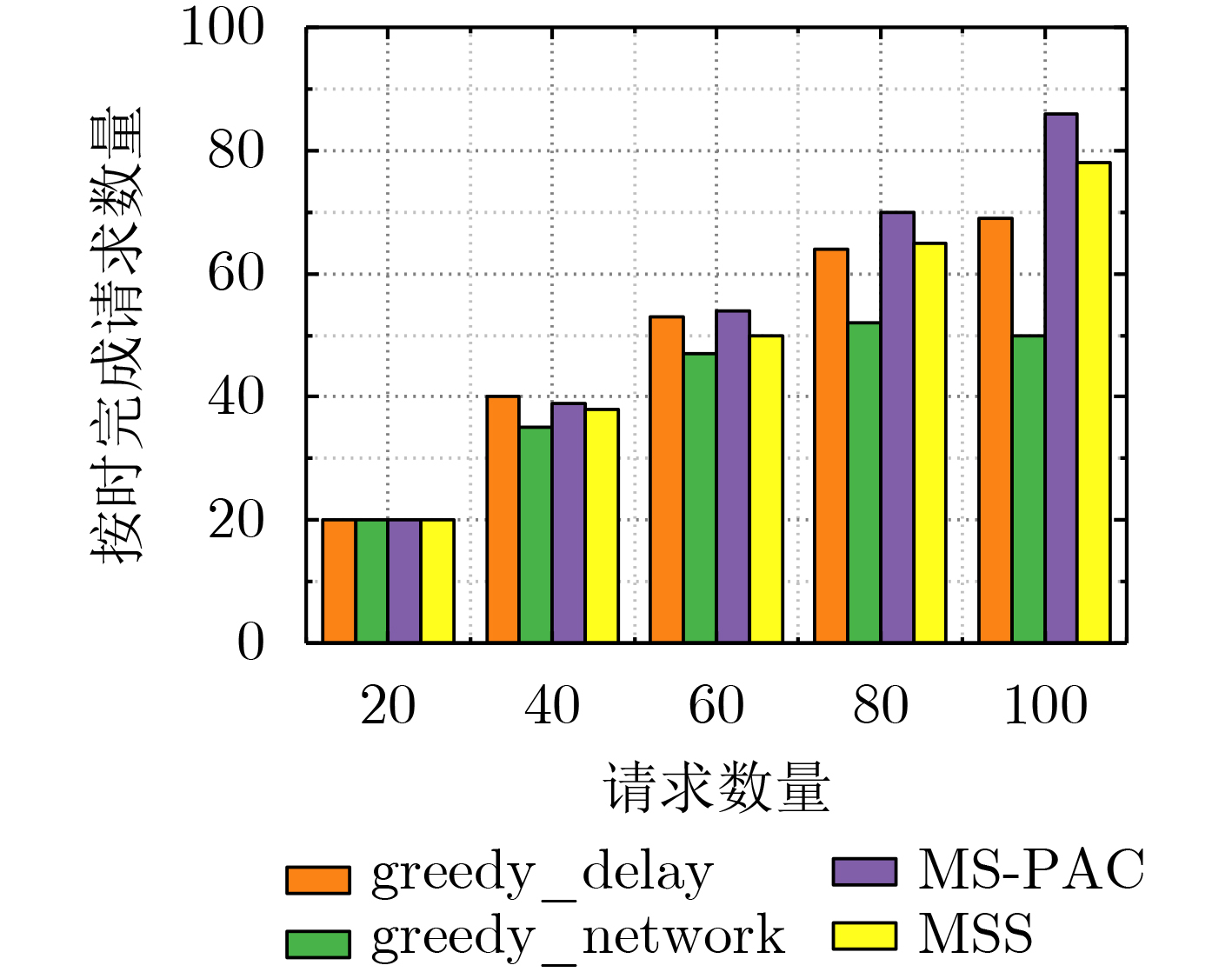
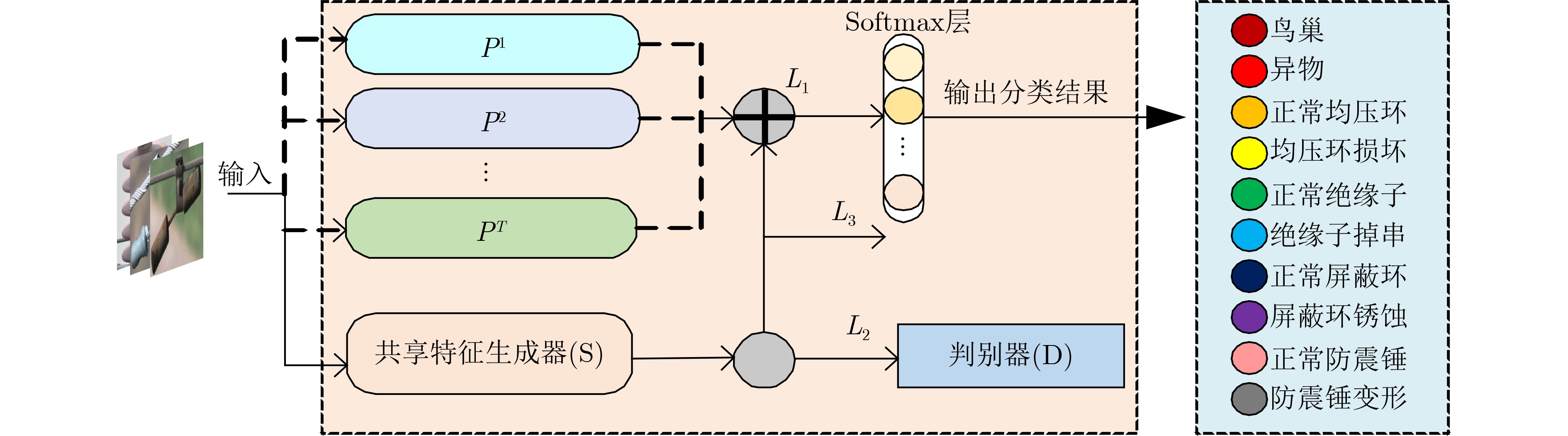
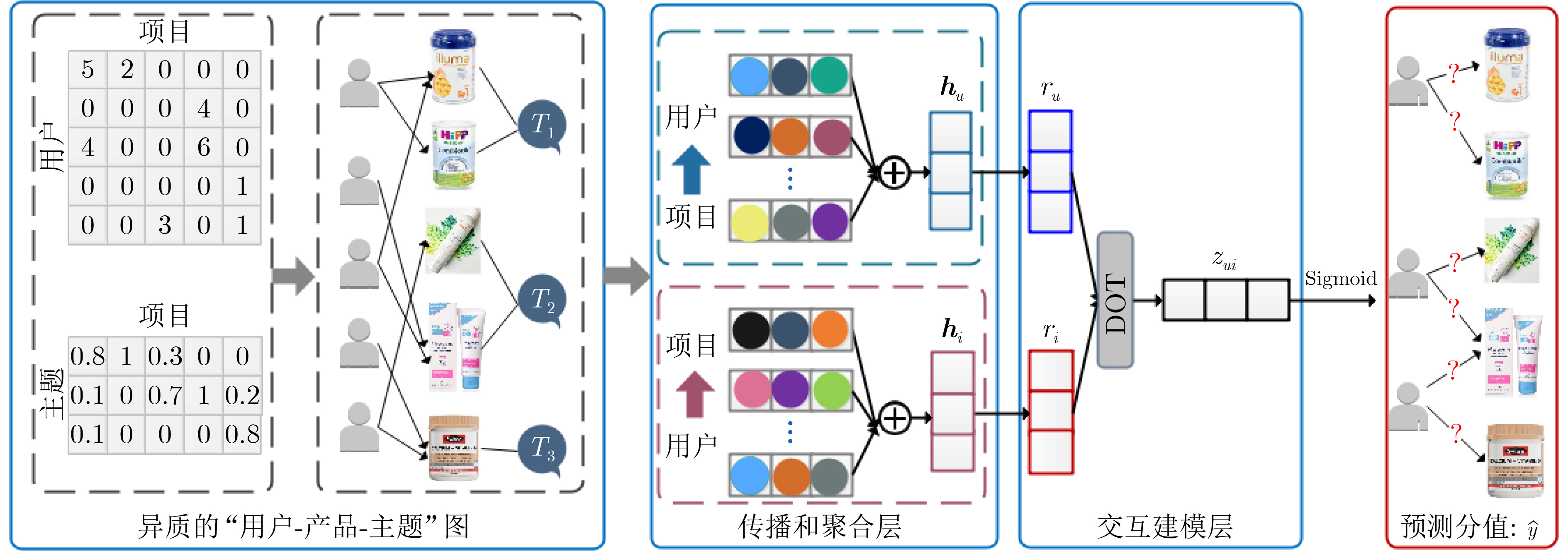
Cross-border e-commerce products recommendation has become one of the emerging researching topics in the field of e-commerce. Due to the diversity and complexity of e-commerce product information, the “user-item” correlation matrix is extremely sparse and the cold start problem is prominent. As a result, the traditional collaborative filtering model seems to be malfunctional. Meanwhile, the improved recommendation model based on collaborative filtering or matrix factorization only considers the explicit and implicit feedback information of the users to the products, while ignoring the graph structure information composed of users and items, so that the recommendation performance is difficult to meet the requirements of the platform and users. To tackle these issues, a recommender system of cross-border e-commerce based on heterogeneous graph neural network, named Heterogeneous Graph Neural network Recommender system (HGNR), is proposed in this paper. The model has two significant advantages: (1) the three-part graph is used as input, and high-quality information dissemination and aggregation are carried out on heterogeneous graphs through Graph Convolutional neural Network (GCN); (2) high-quality user and product representation vectors can be obtained, and realize the modeling of the complex interaction between users and products. Experimental results on real cross-border e-commerce order data sets show that HGNR not only owns the superior performance, but also can effectively improve the recommendation accuracy of cold-start users. Compared with nine baseline methods for recommendation, HGNR achieves improvements of at least 3.33%, 0.91%, and 0.54% on evaluation metrics of HitRate@10, Item-coverage@10 and MRR@10.