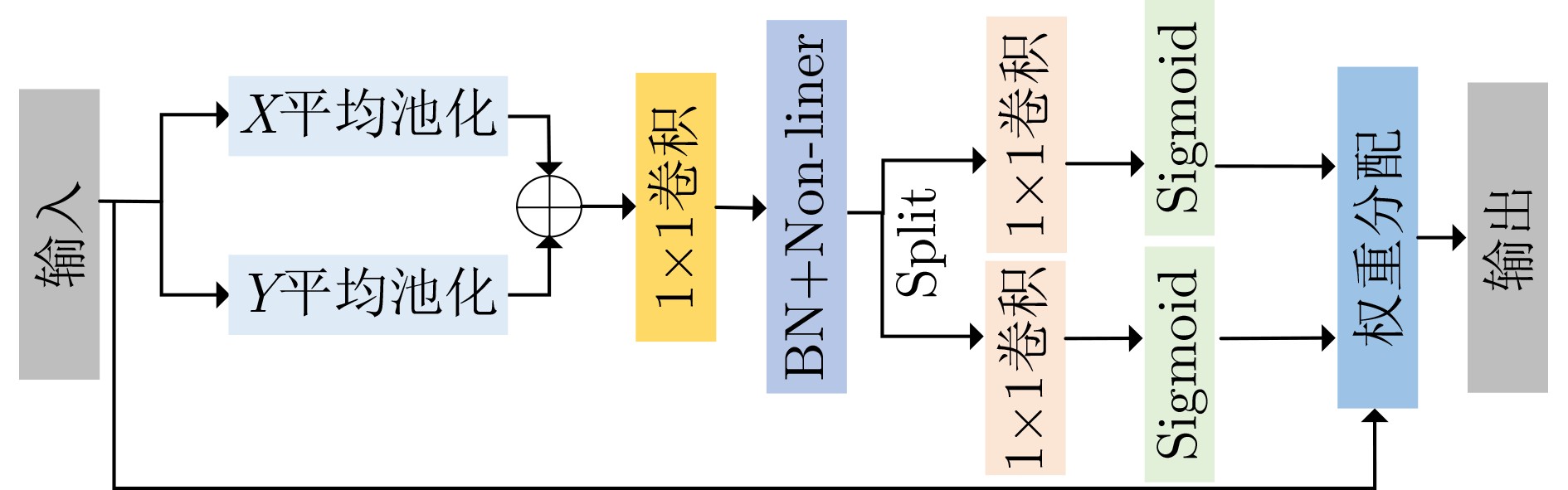
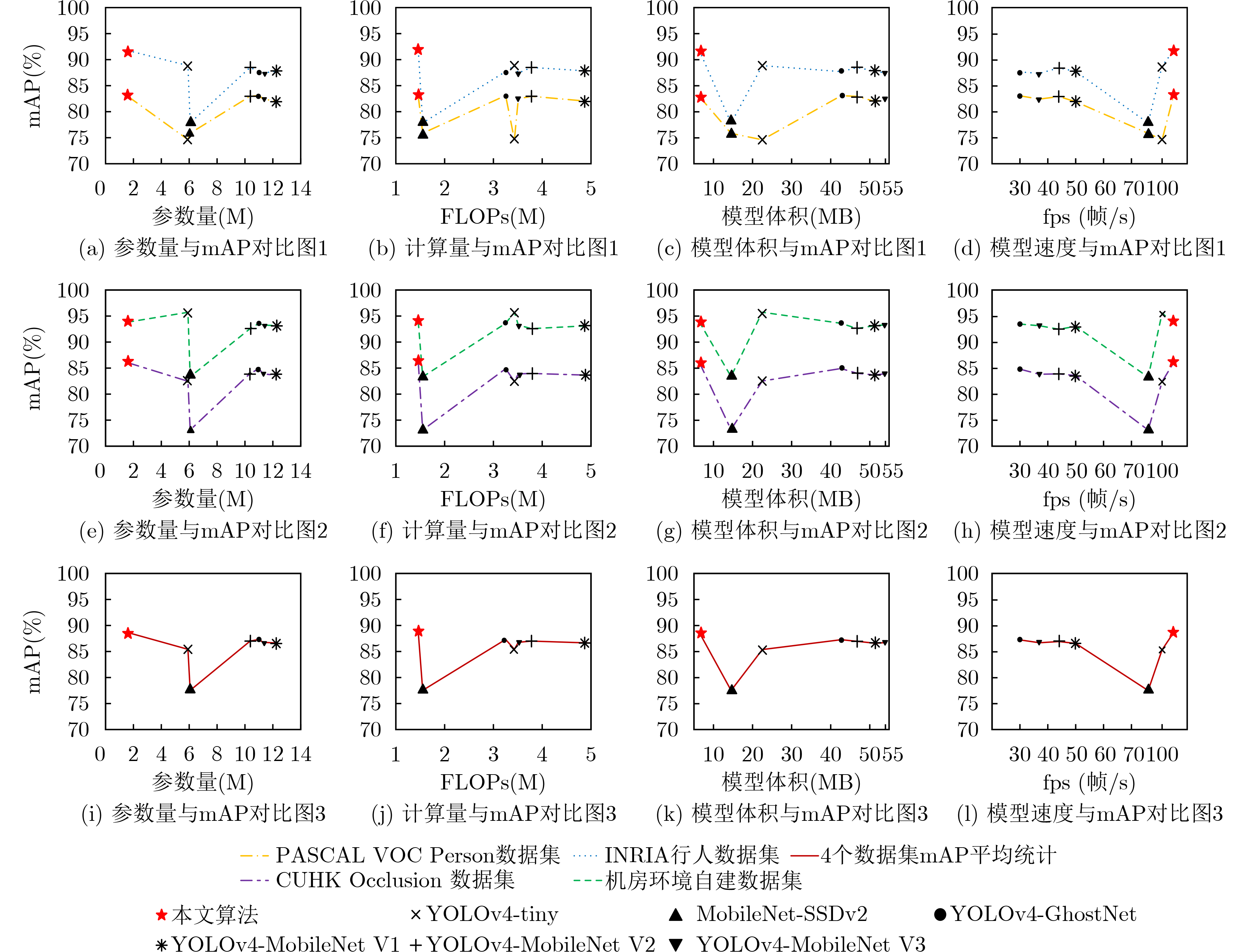
| Citation: | ZHAO Feng, LI Yongheng, LI Jing, LIU Hanqiang. Lightweight Indoor Personnel Detection Algorithm Based on Improved YOLOv4-tiny[J]. Journal of Electronics & Information Technology, 2022, 44(11): 3815-3824. doi: 10.11999/JEIT220241

|

| [1] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587.
|
| [2] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788.
|
| [3] |
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37.
|
| [4] |
TAN Mingxing, PANG Ruoming, and LE Q V. Efficientdet: Scalable and efficient object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10778–10787.
|
| [5] |
LIU Wei, LIAO Shengcai, HU Weidong, et al. Learning efficient single-stage pedestrian detectors by asymptotic localization fitting[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 643–659.
|
| [6] |
张明伟, 蔡坚勇, 李科, 等. 基于DE-YOLO的室内人员检测方法[J]. 计算机系统应用, 2020, 29(1): 203–208. doi: 10.15888/j.cnki.csa.007240
ZHANG Mingwei, CAI Jianyong, LI Ke, et al. Indoor personnels detection method based on DE-YOLO[J]. Computer Systems &Applications, 2020, 29(1): 203–208. doi: 10.15888/j.cnki.csa.007240
|
| [7] |
董小伟, 韩悦, 张正, 等. 基于多尺度加权特征融合网络的地铁行人目标检测算法[J]. 电子与信息学报, 2021, 43(7): 2113–2120. doi: 10.11999/JEIT200450
DONG Xiaowei, HAN Yue, ZHANG Zheng, et al. Metro pedestrian detection algorithm based on multi-scale weighted feature fusion network[J]. Journal of Electronics &Information Technology, 2021, 43(7): 2113–2120. doi: 10.11999/JEIT200450
|
| [8] |
苏杨, 卢翔, 李琨, 等. 基于轻量深度学习网络的机房人物检测研究[J]. 工业仪表与自动化装置, 2021(1): 100–103. doi: 10.3969/j.issn.1000-0682.2021.01.024
SU Yang, LU Xiang, LI Kun, et al. Research on computer room human detection based on lightweight deep learning network[J]. Industrial Instrumentation &Automation, 2021(1): 100–103. doi: 10.3969/j.issn.1000-0682.2021.01.024
|
| [9] |
WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. Scaled-YOLOv4: Scaling cross stage partial network[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13024–13033.
|
| [10] |
BOCHKOVSKIY A, WANG C Y, and LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. https://arxiv.org/abs/2004.10934v1, 2020.
|
| [11] |
HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: More features from cheap operations[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1577–1586.
|
| [12] |
ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6848–6856.
|
| [13] |
YU F, KOLTUN V, and FUNKHOUSER T. Dilated residual networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 636–644.
|
| [14] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184
|
| [15] |
HOU Qibin, ZHOU Daquan, and FENG Jiashi. Coordinate attention for efficient mobile network design[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13708–13717.
|
| [16] |
SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4510–4520.
|
| [17] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824
|
| [18] |
GHIASI G, LIN T Y, and LE Q V. DropBlock: A regularization method for convolutional networks[C]. The 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 10750–10760.
|
| [19] |
EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4
|
| [20] |
DALAL N and TRIGGS B. Histograms of oriented gradients for human detection[C]. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, USA, 2005: 886–893.
|
| [21] |
OUYANG Wanli and WANG Xiaogang. A discriminative deep model for pedestrian detection with occlusion handling[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3258–3265.
|
| [22] |
CHIU Y C, TSAI C Y, RUAN M D, et al. Mobilenet-SSDv2: An improved object detection model for embedded systems[C]. 2020 International Conference on System Science and Engineering, Kagawa, Japan, 2020: 1–5.
|
| [23] |
LIU Jie and LIU Lizhi. Helmet wearing detection based on YOLOv4-MT[C]. Proceedings of the 2021 4th International Conference on Robotics, Control and Automation Engineering, Wuhan, China, 2021: 1–5.
|
| [24] |
FANG Lifa, WU Yanqiang, LI Yuhua, et al. Ginger seeding detection and shoot orientation discrimination using an improved YOLOv4-LITE network[J]. Agronomy, 2021, 11(11): 2328. doi: 10.3390/agronomy11112328
|
| [25] |
WANG Shengying, CHEN Tao, LV Xinyu, et al. Forest fire detection based on lightweight Yolo[C]. The 2021 33rd Chinese Control and Decision Conference, Kunming, China, 2021: 1560–1565.
|
| [26] |
WANG Huixuan, GE Huayong, and LI Muxian. PFG-YOLO: A safety helmet detection based on YOLOv4[C]. The 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference, Xi'an, China, 2021: 1242–1246.
|
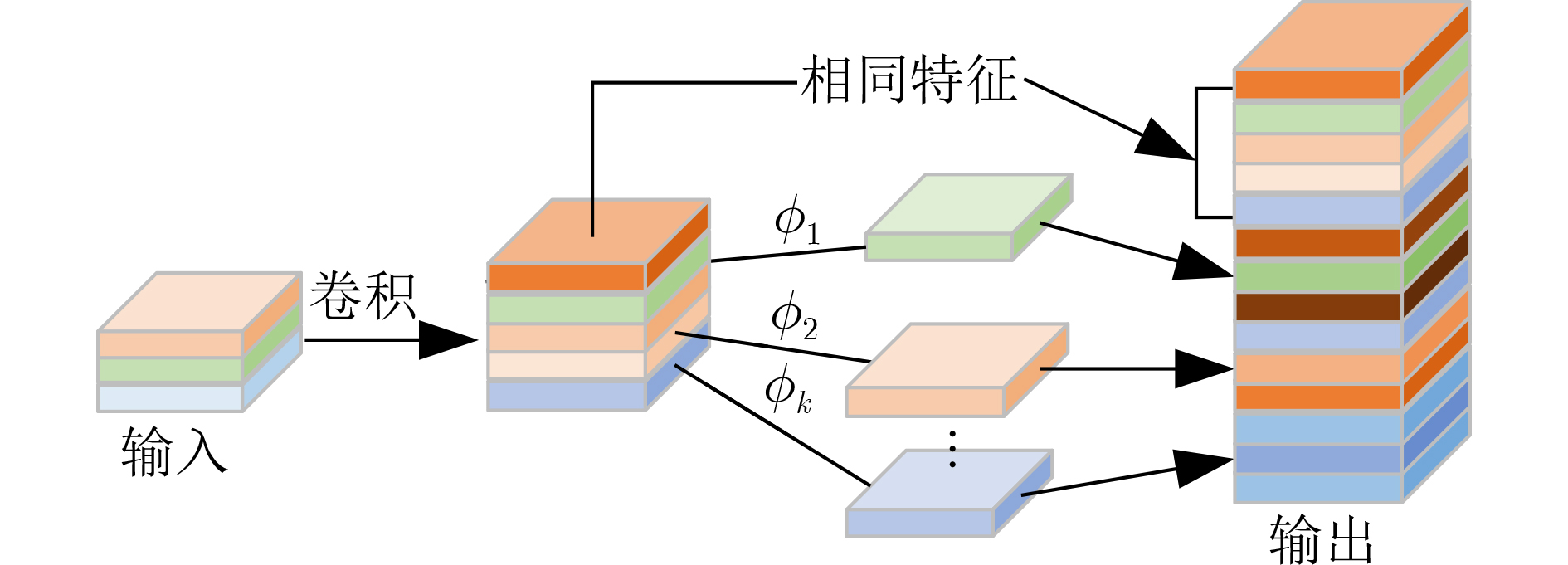
Figures(9) / Tables(5)



 DownLoad:
DownLoad: