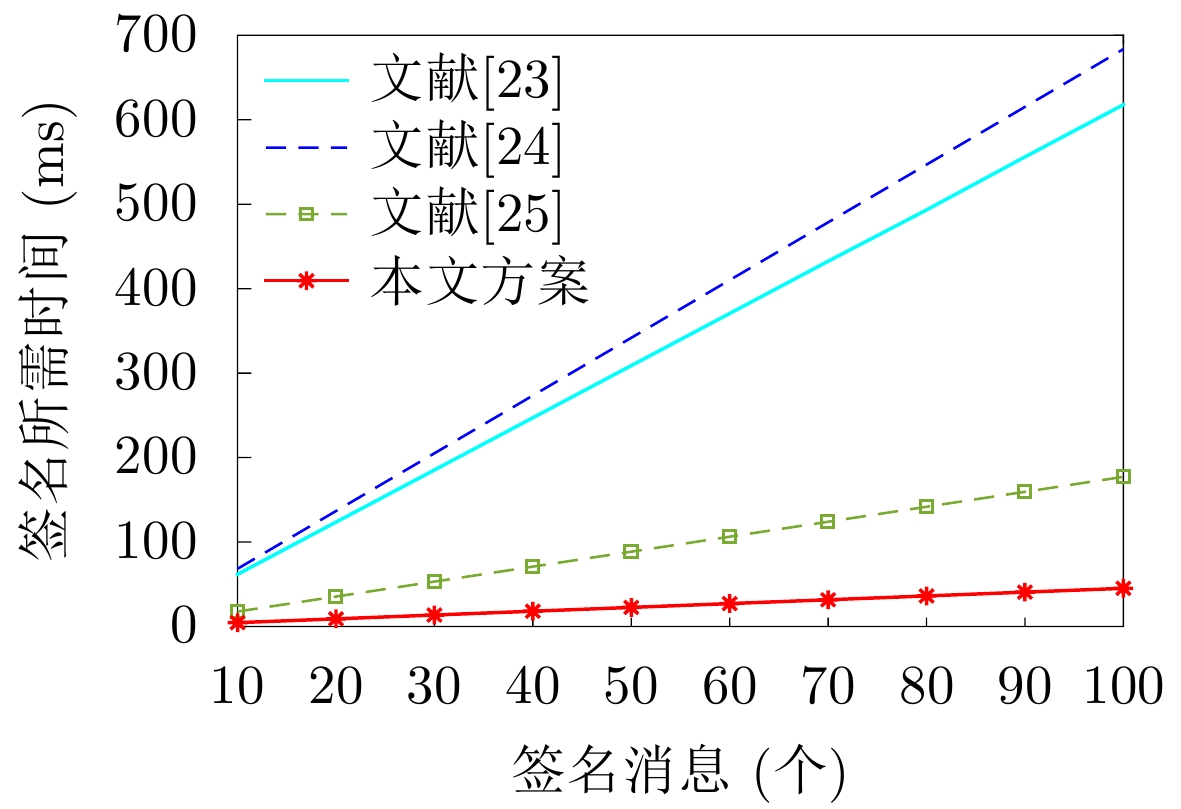
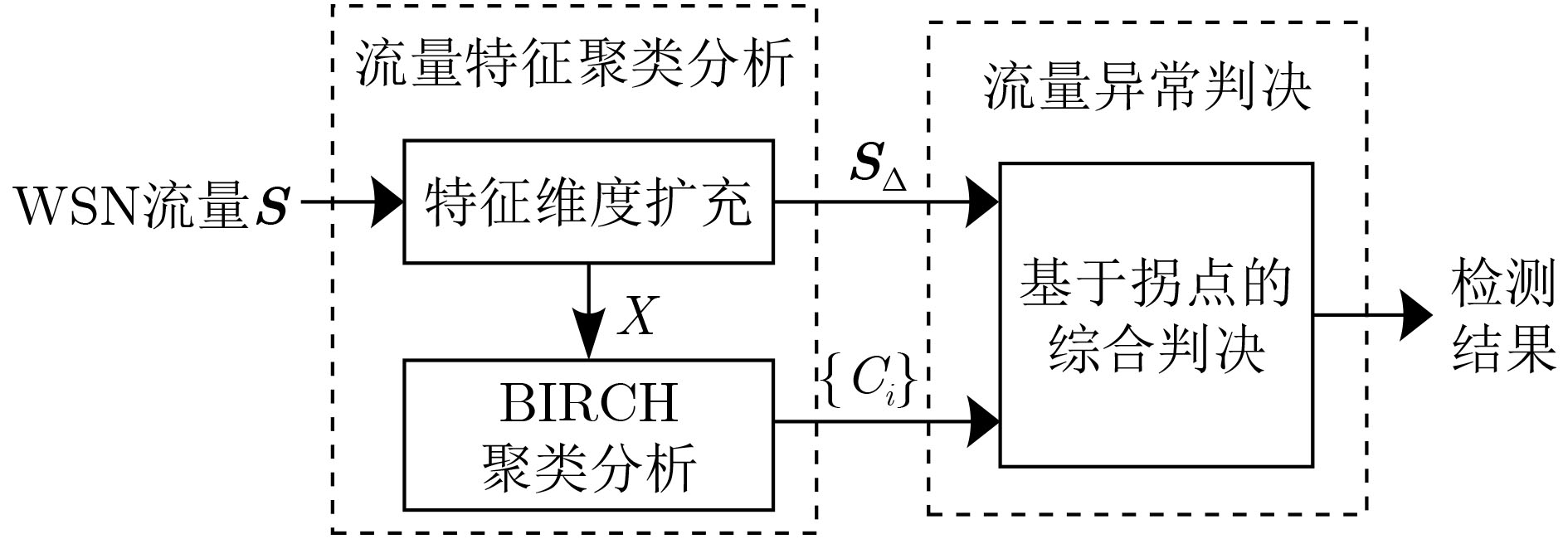
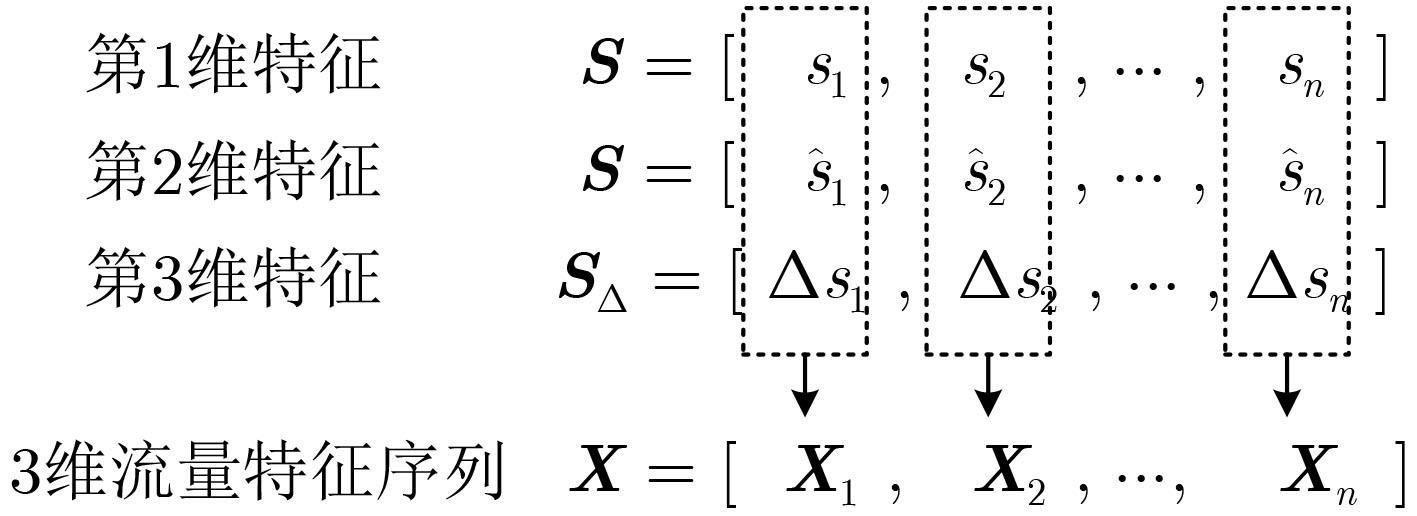
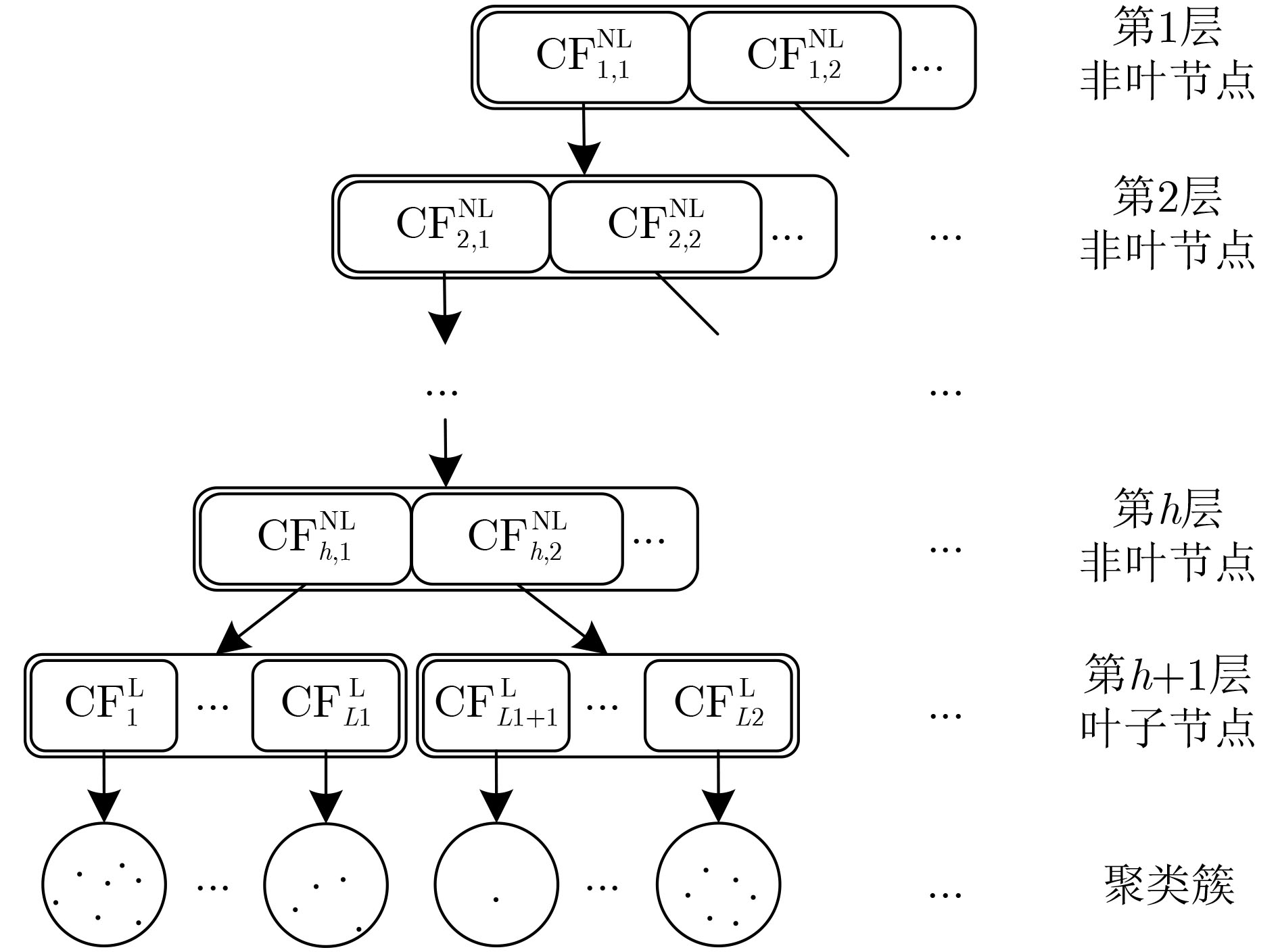
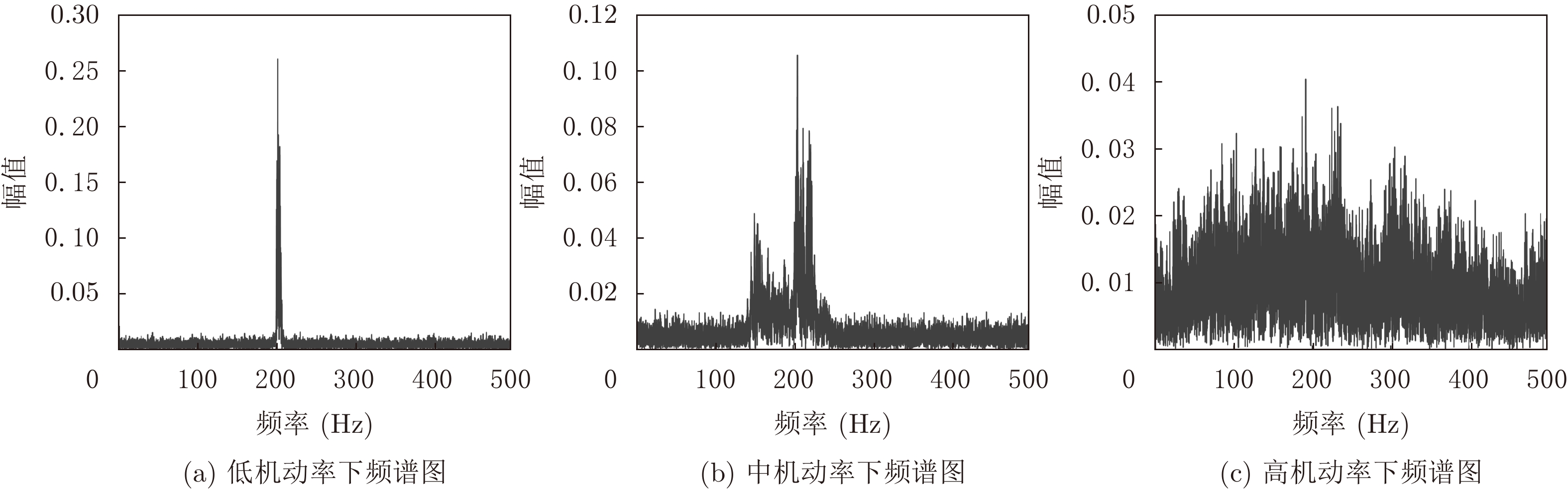
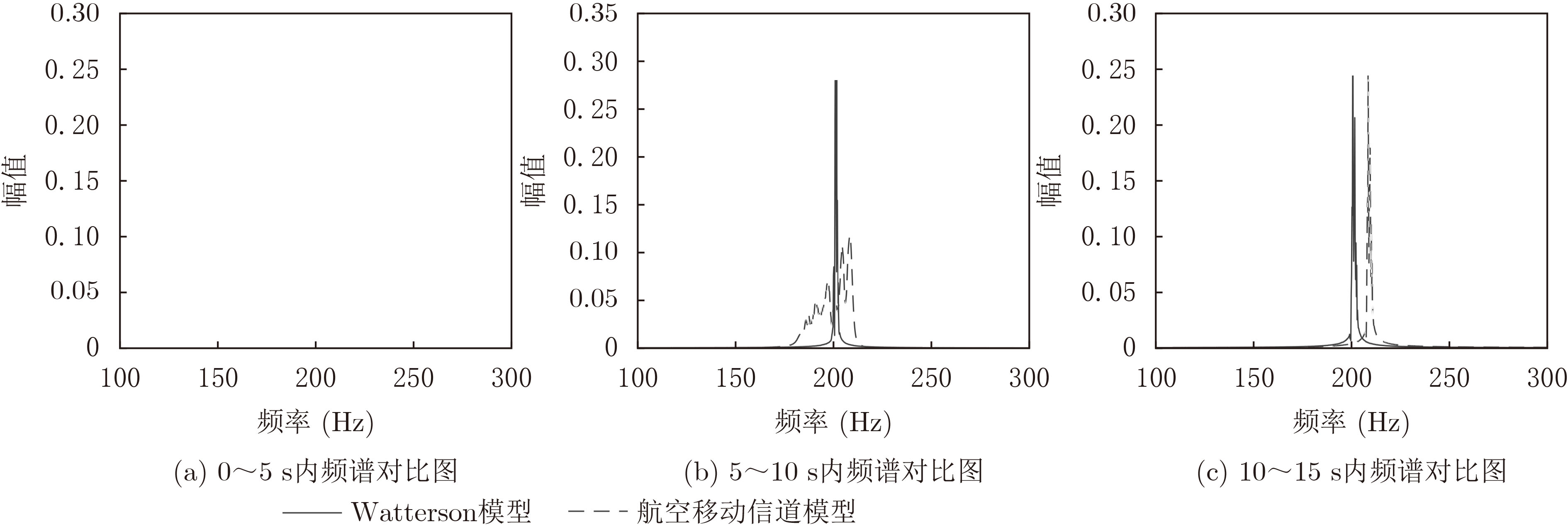
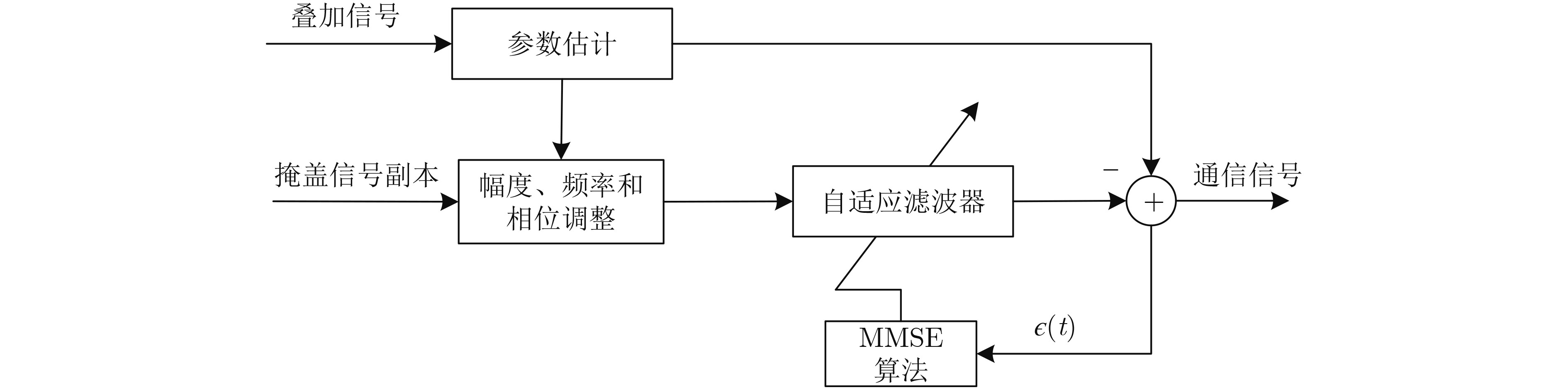
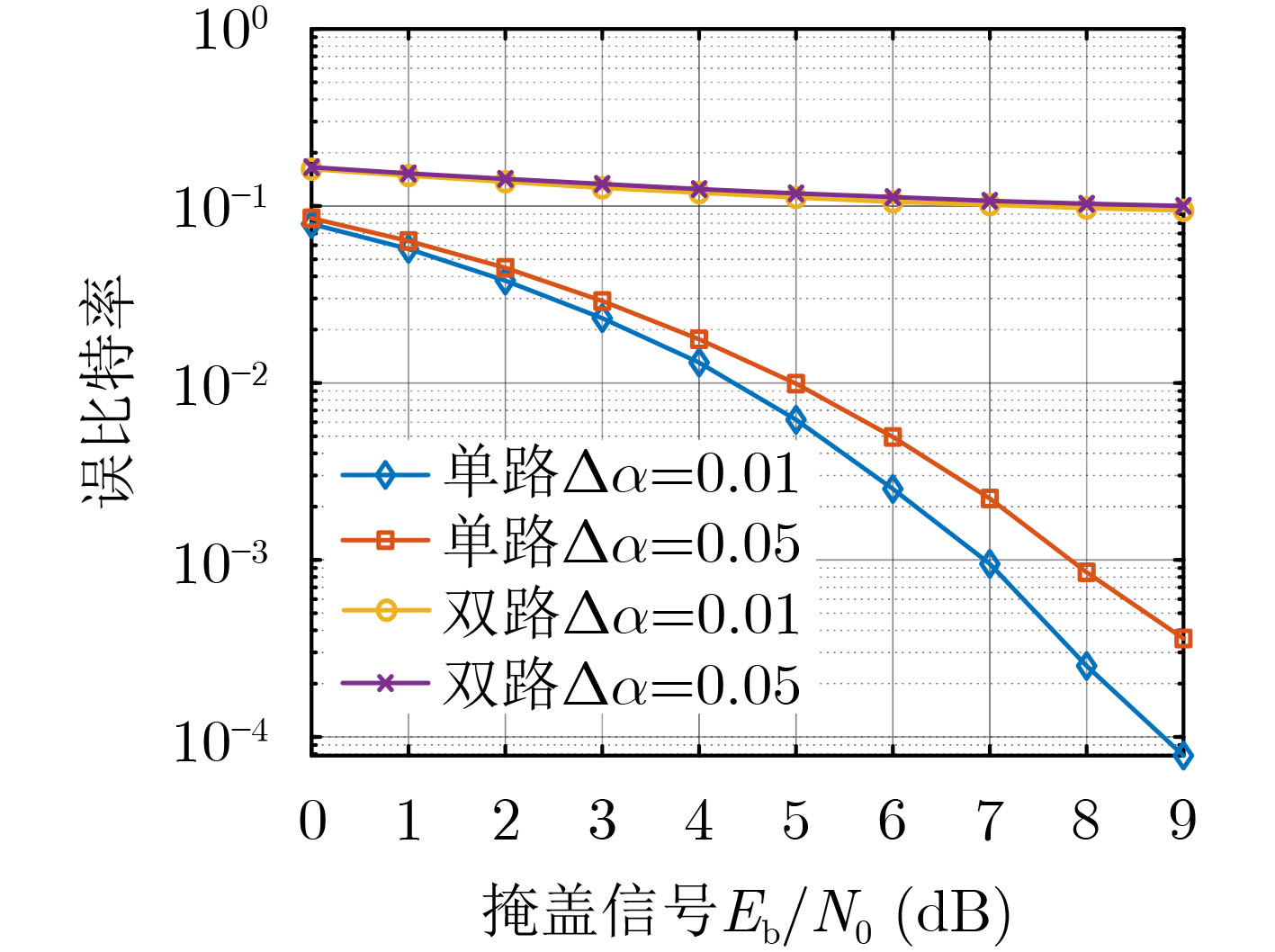
2022, 44(1): 78-88.
doi: 10.11999/JEIT210909
Abstract:
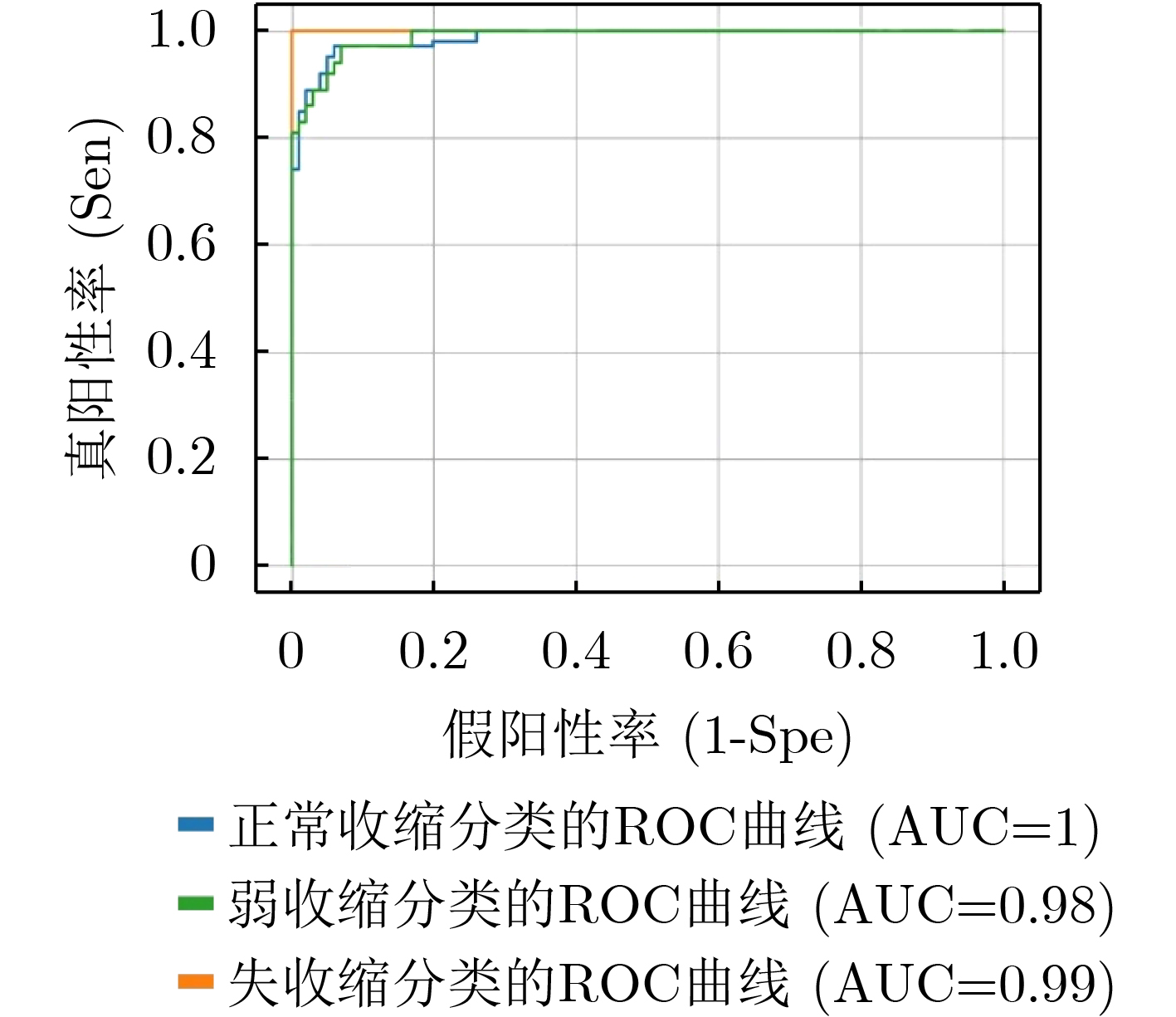
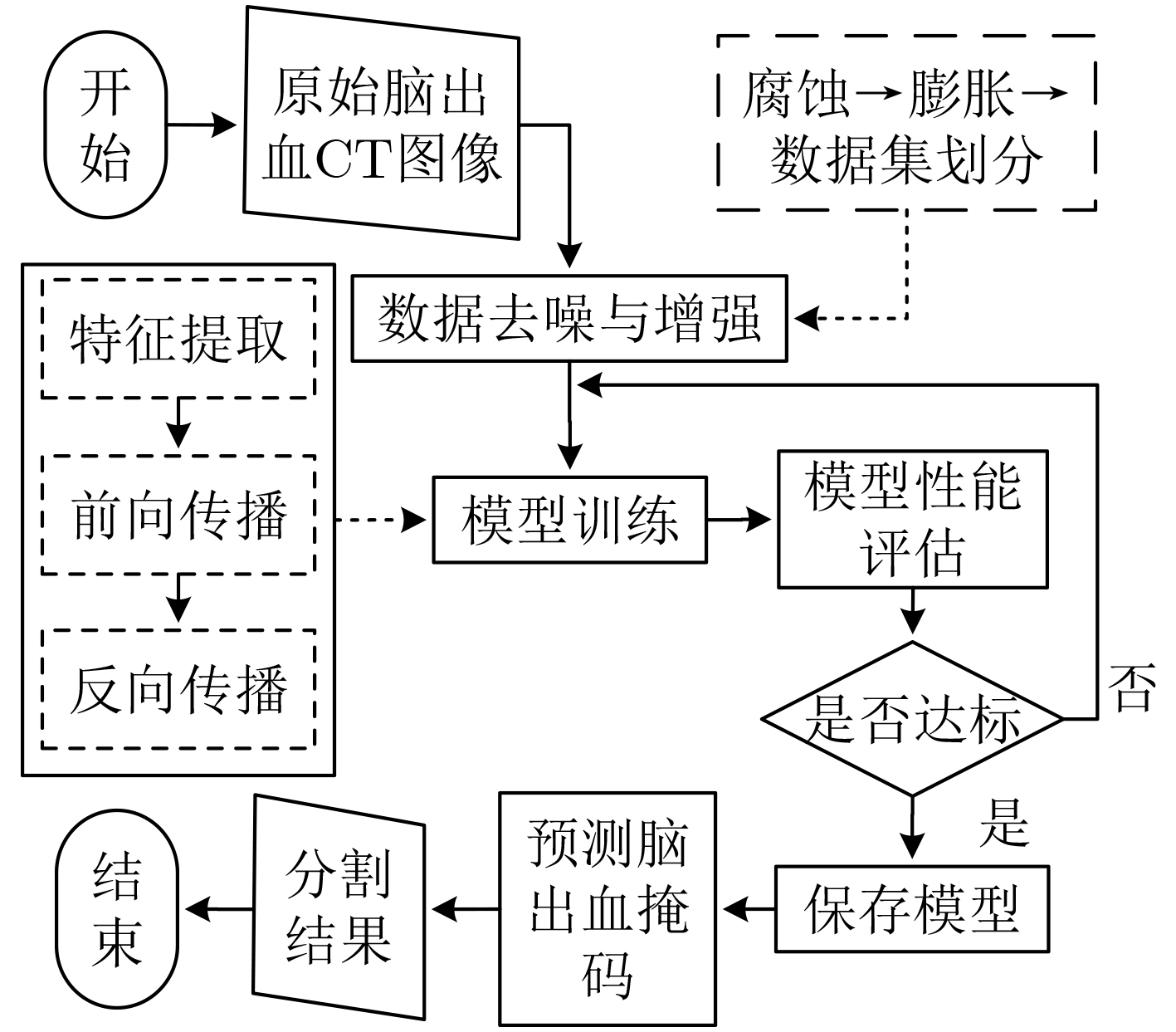
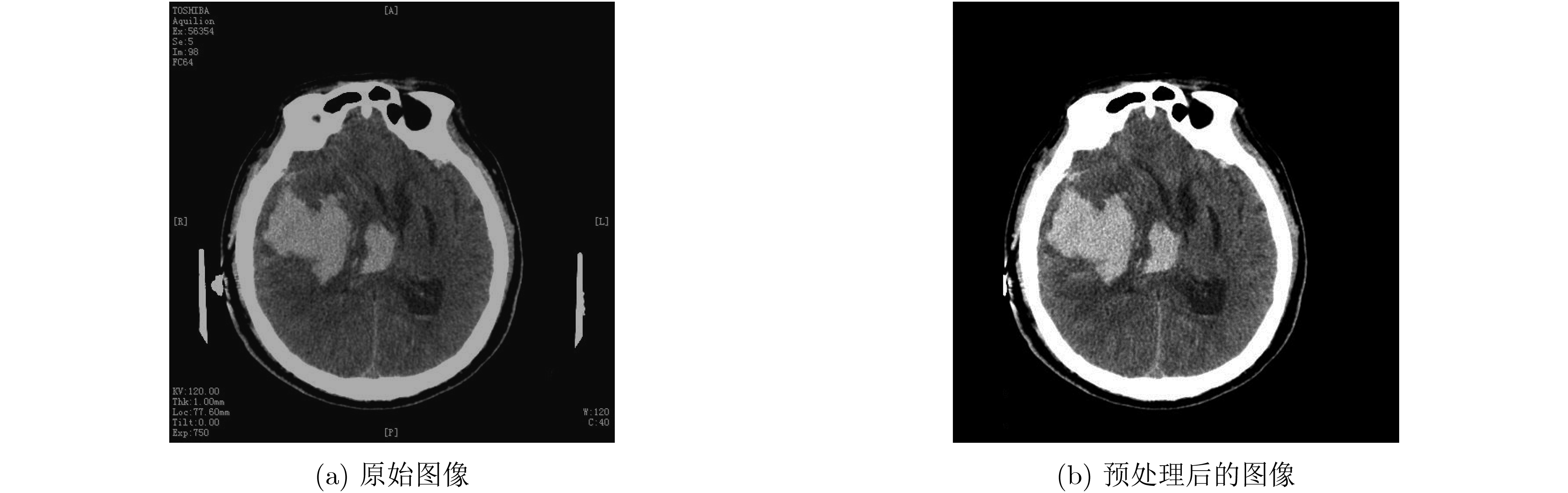
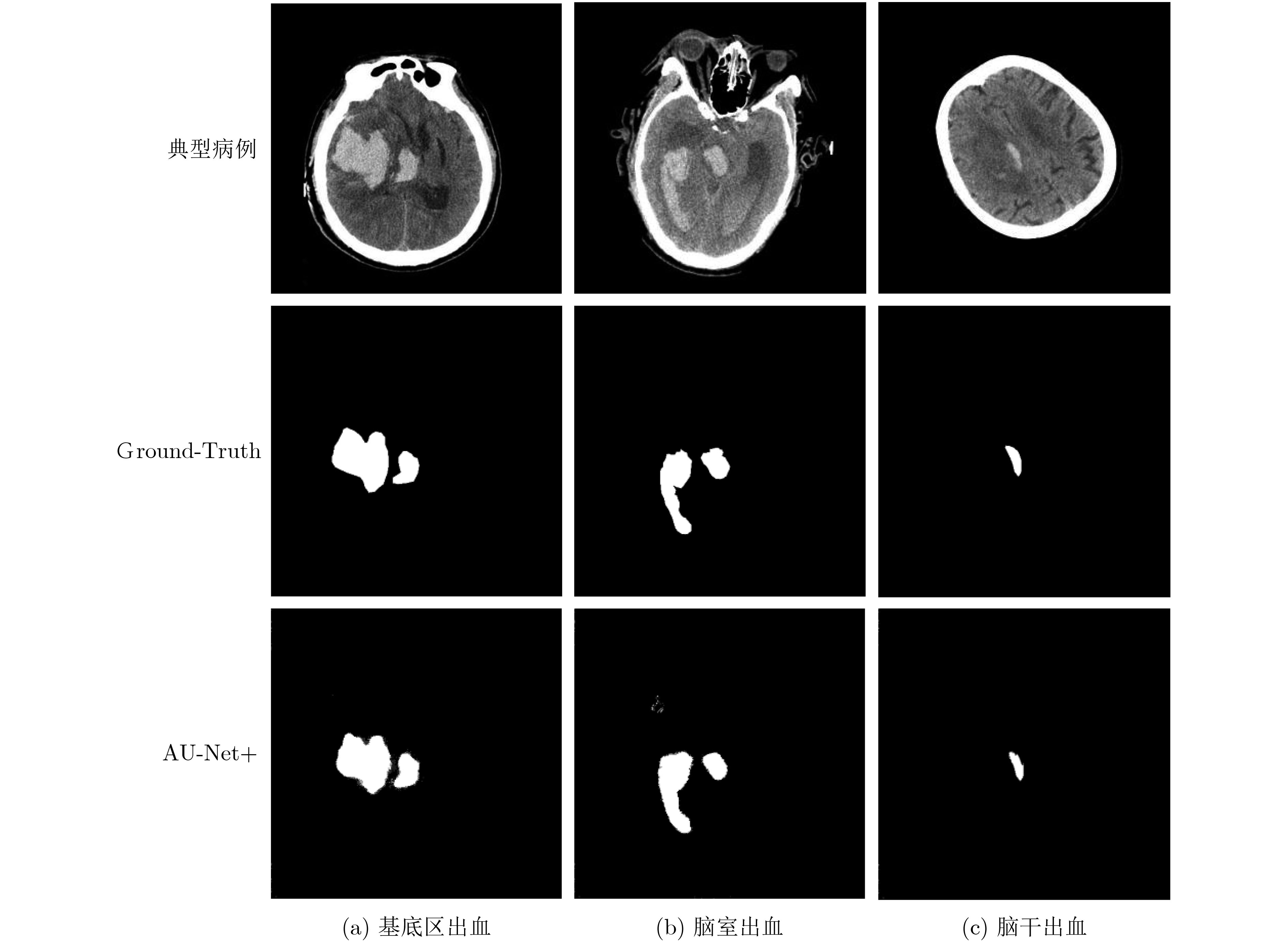
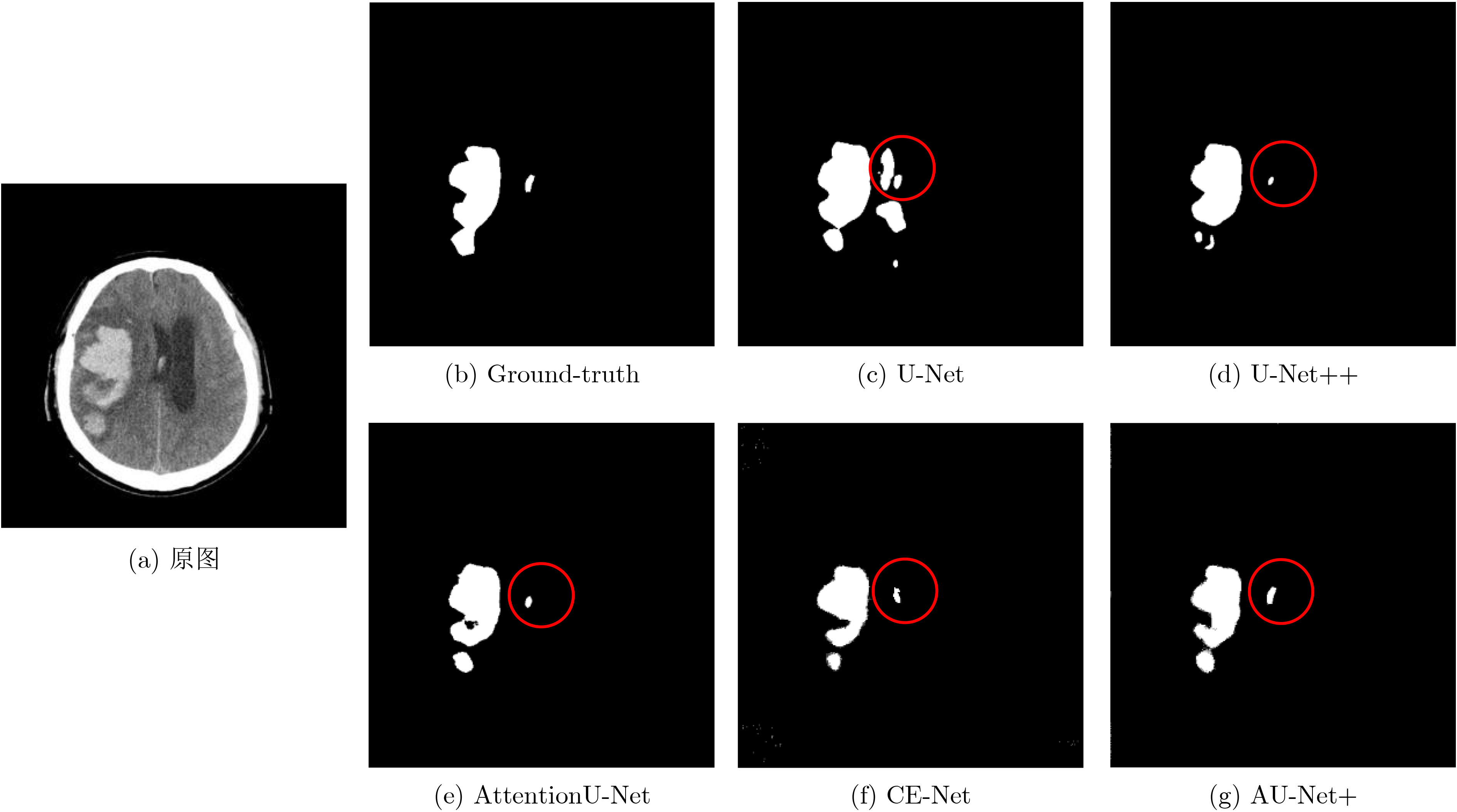
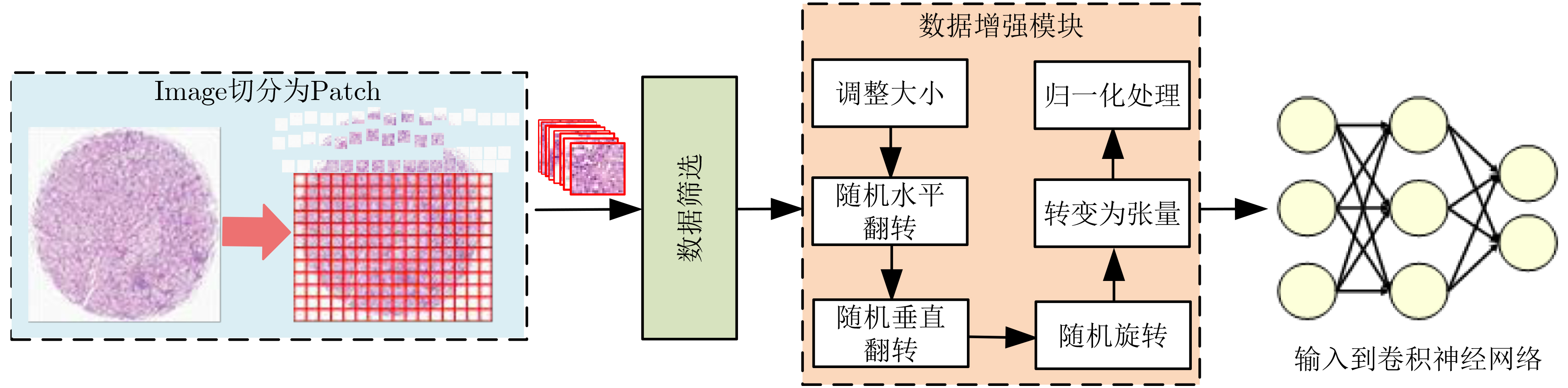
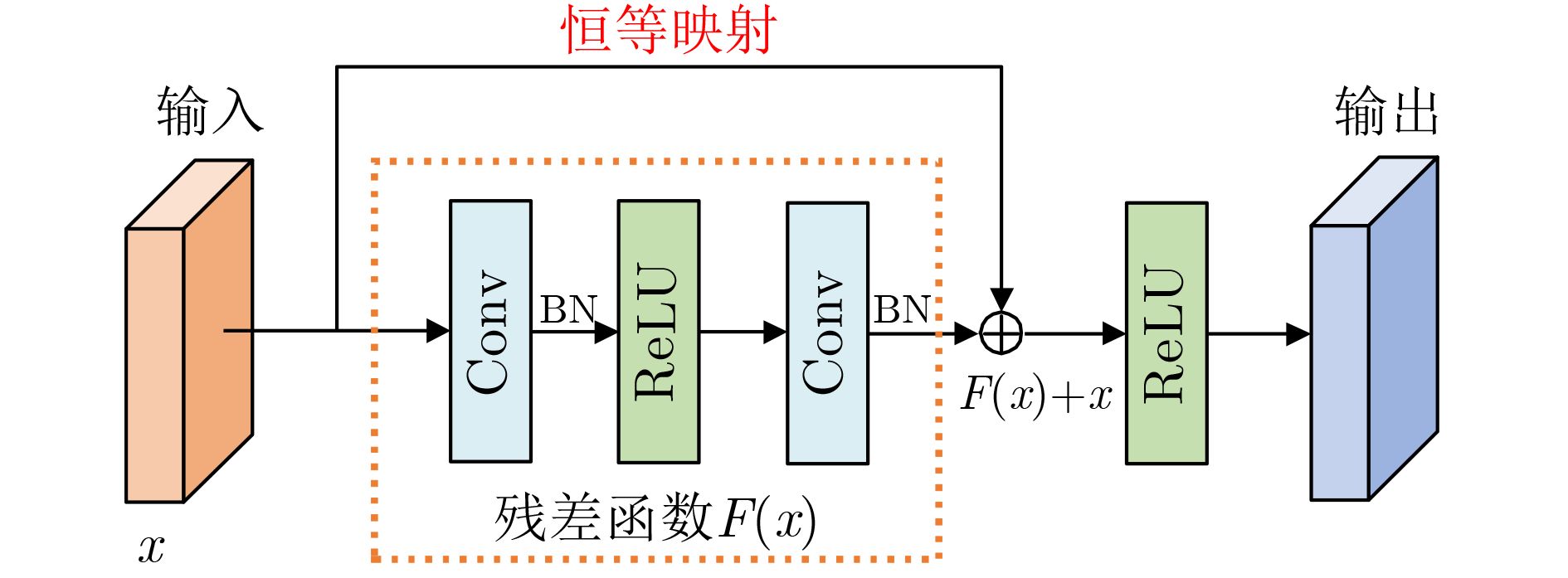
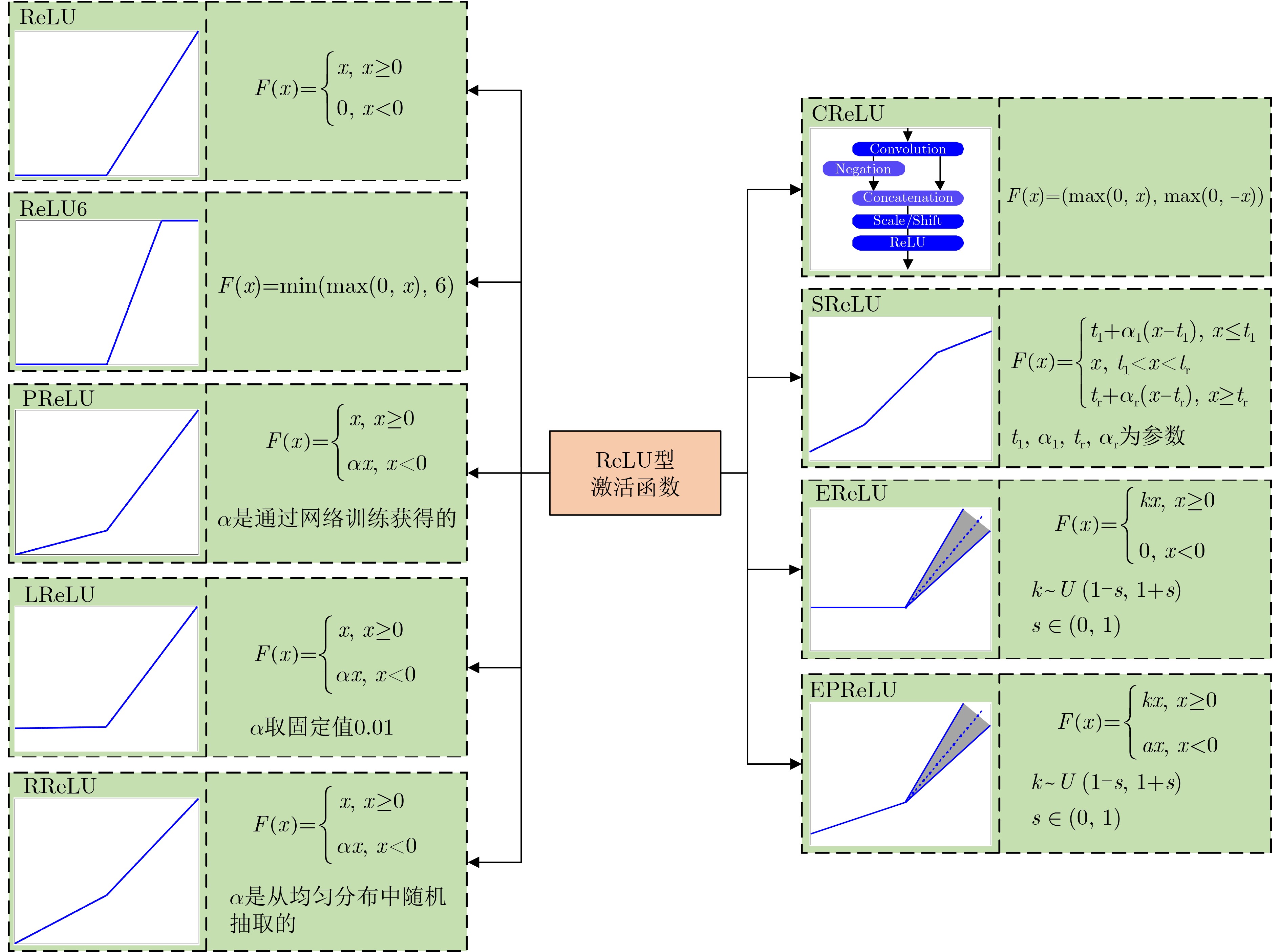
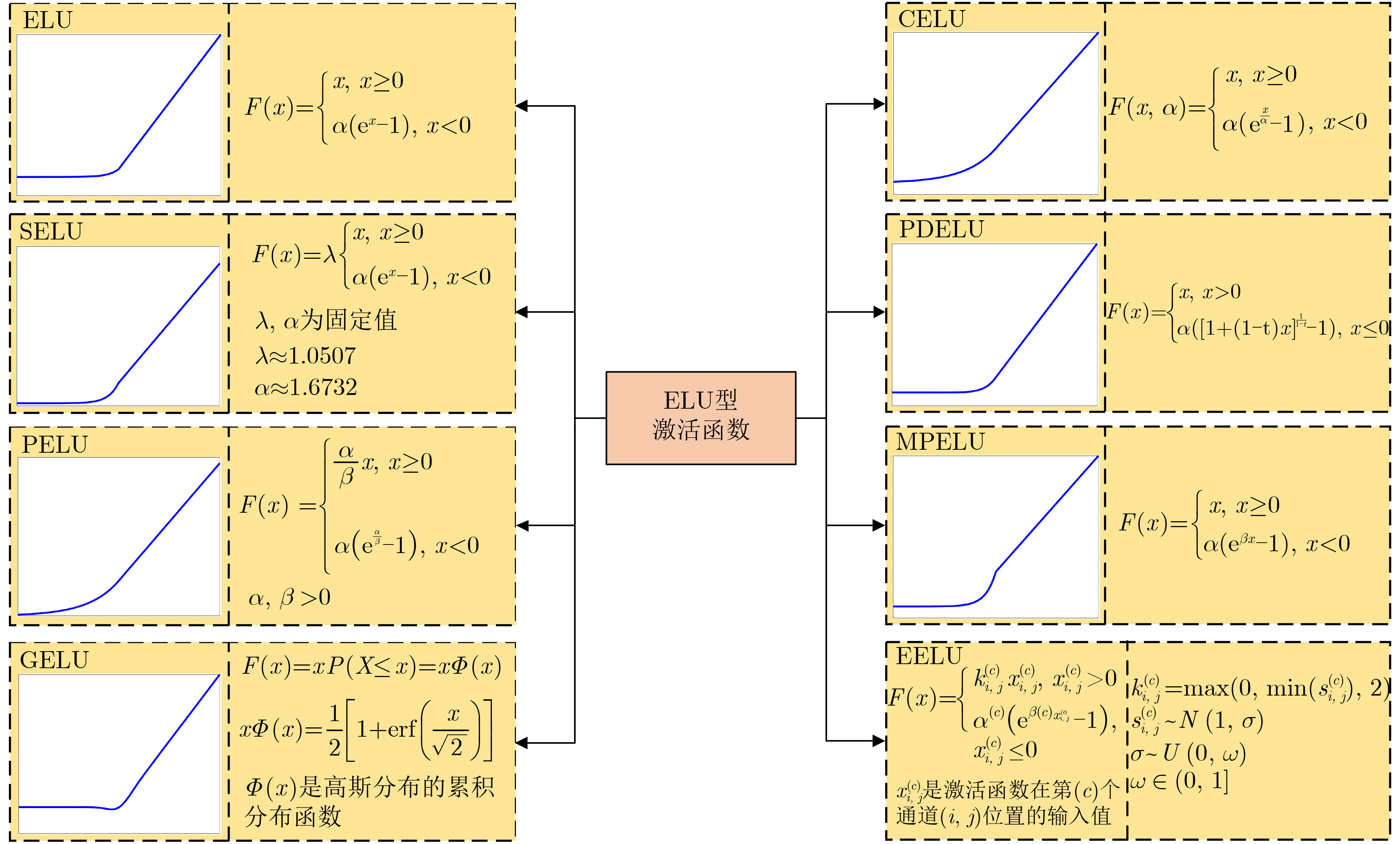
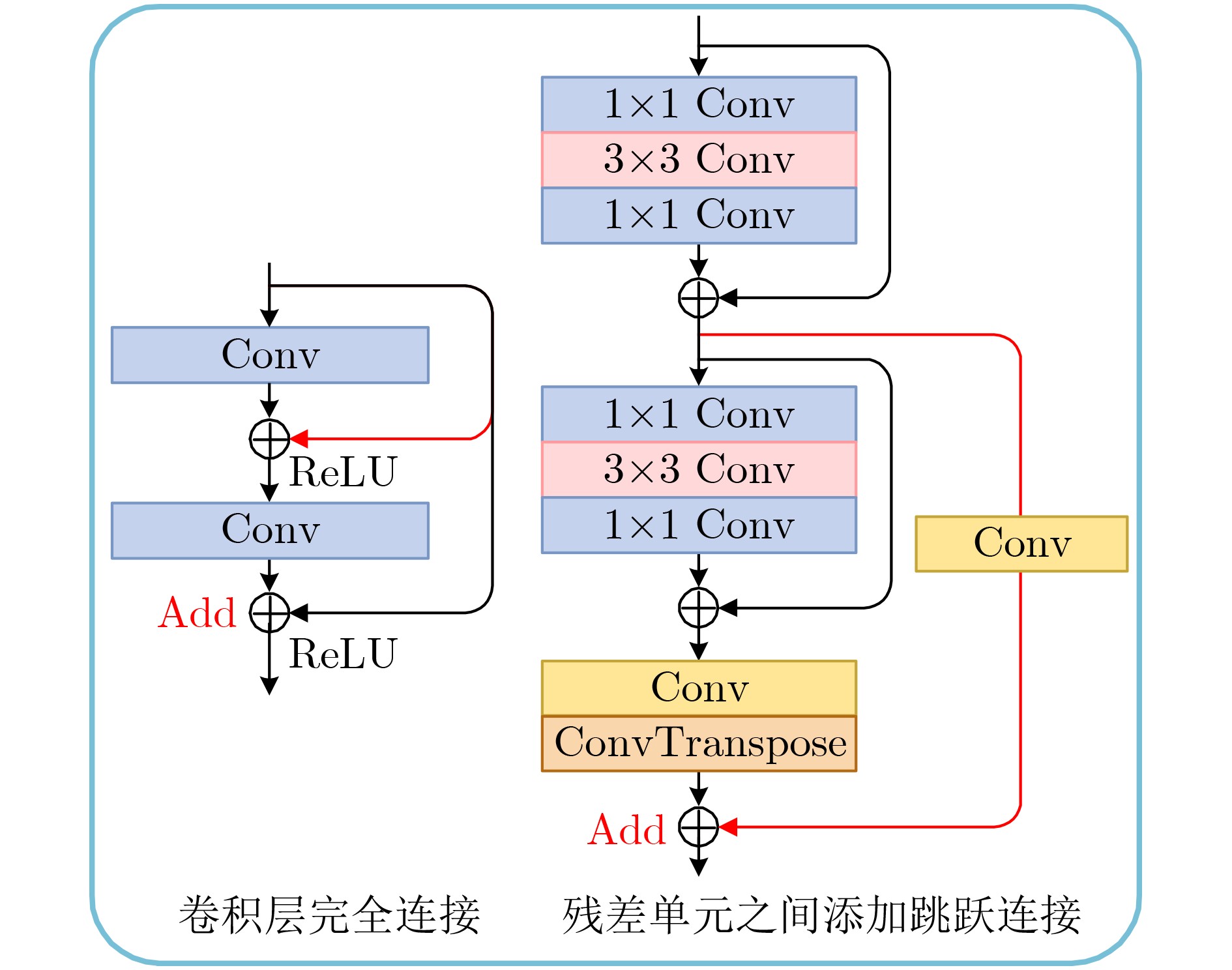
As the gold standard for the detection of Esophageal Motility Disorder(EMD), High-Resolution Manometry(HRM) is widely used in clinical tests to assist doctors in diagnosis. The amount of HRM images explodes with an increase in the prevalence rate, and the diagnostic process of EMD is complicated, both of which may lead to misdiagnosis of EMD in clinic. To improve the accuracy of the diagnosis of EMD, we hope to build a Computer Aided Diagnosis(CAD) system to assist doctors in analyzing HRM images automatically. Since the abnormality of esophageal contraction vigor is an important basis for diagnosis of EMD, in this paper, a Deep Learning(DL) model(PoS-ClasNet) is proposed to classify esophageal contraction vigor, which lays the foundation for machine to diagnose EMD instead of manual in the future. PoS-ClasNet, as a multi-task Convolutional Neural Network(CNN), is formed by PoSNet and S-ClassNet. The former is used to detect and extract swallowing frames in HRM images, while the latter identifies the type of contraction vigor based on esophageal swallowing characteristics. 4,000 expert-labeled HRM images are used for the experiment, among which the images of training set, verification set and test set accounted for 70%, 20% and 10%. On the test set, the classification accuracy of esophageal contraction vigor classifier PoS-ClasNet is as high as 93.25%, meanwhile the precision rate and the recall rate are 93.39% and 93.60% respectively. The experimental results show PoS-ClasNet can well adapt to the features of HRM image, with the outstanding accuracy and robustness in the task of intelligent diagnosis of esophageal contraction vigor. If the proposed model is used to assist doctors in clinical prevention, diagnosis and treatment, it will bring enormous social benefits.