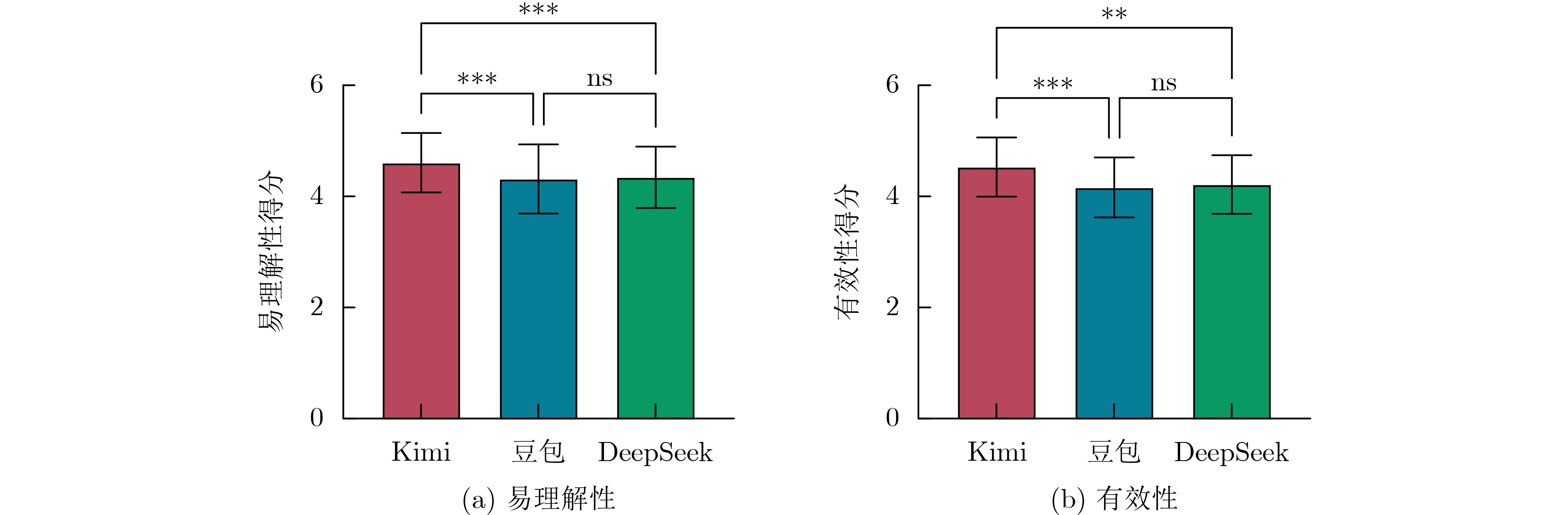
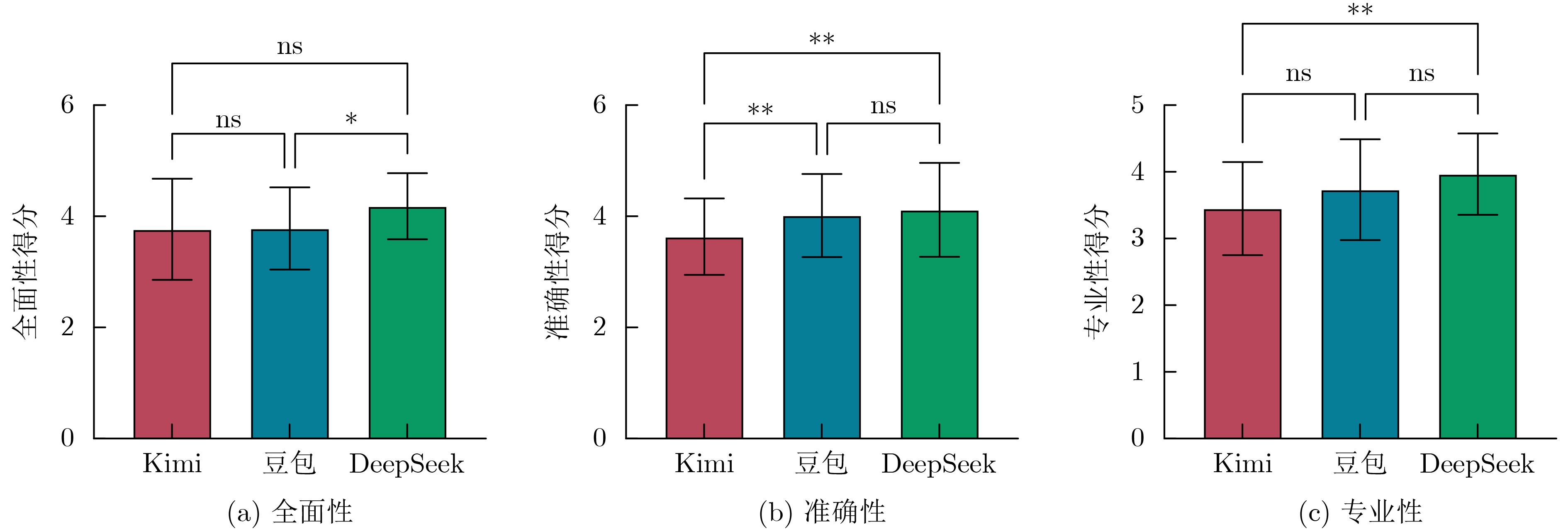
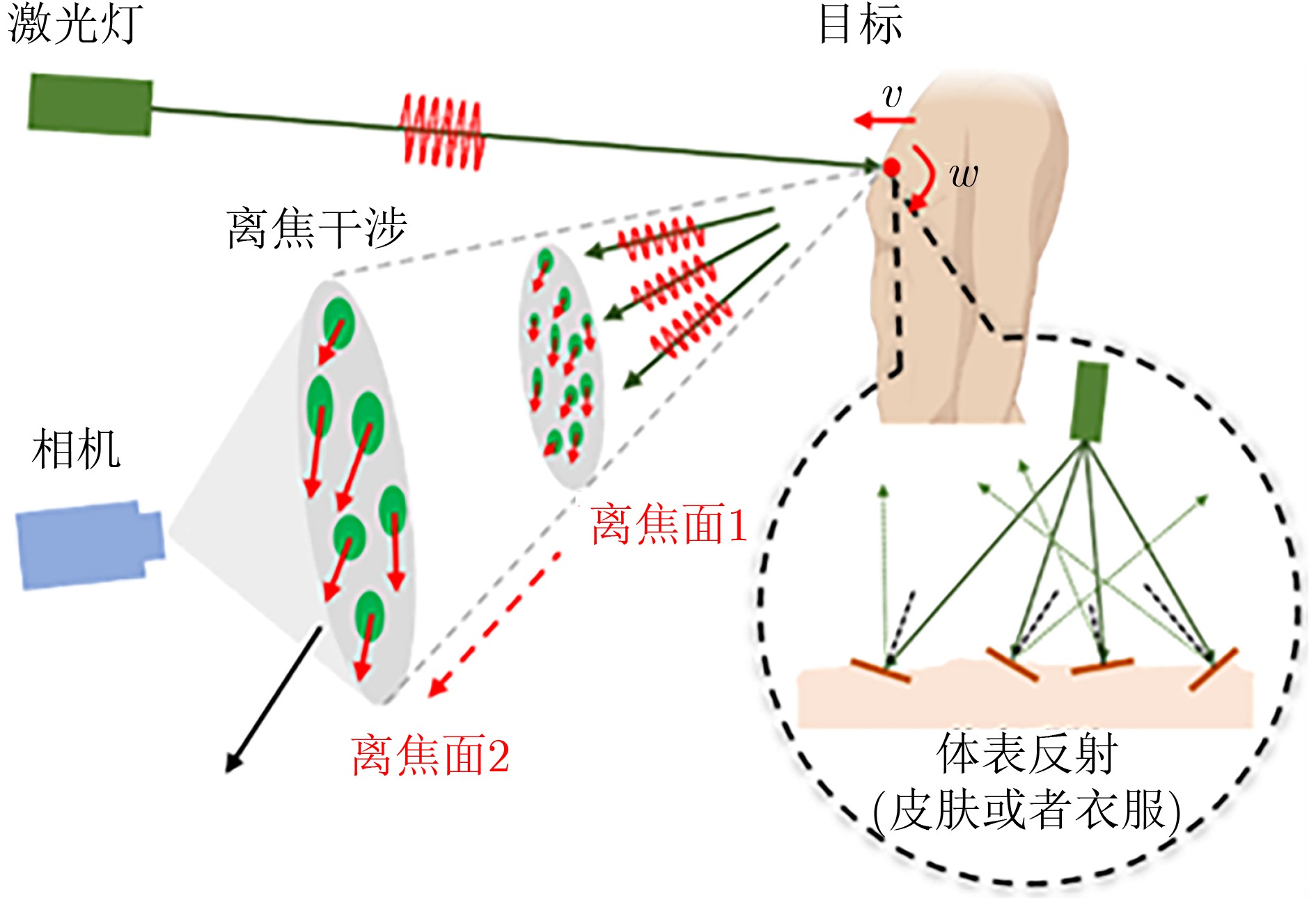
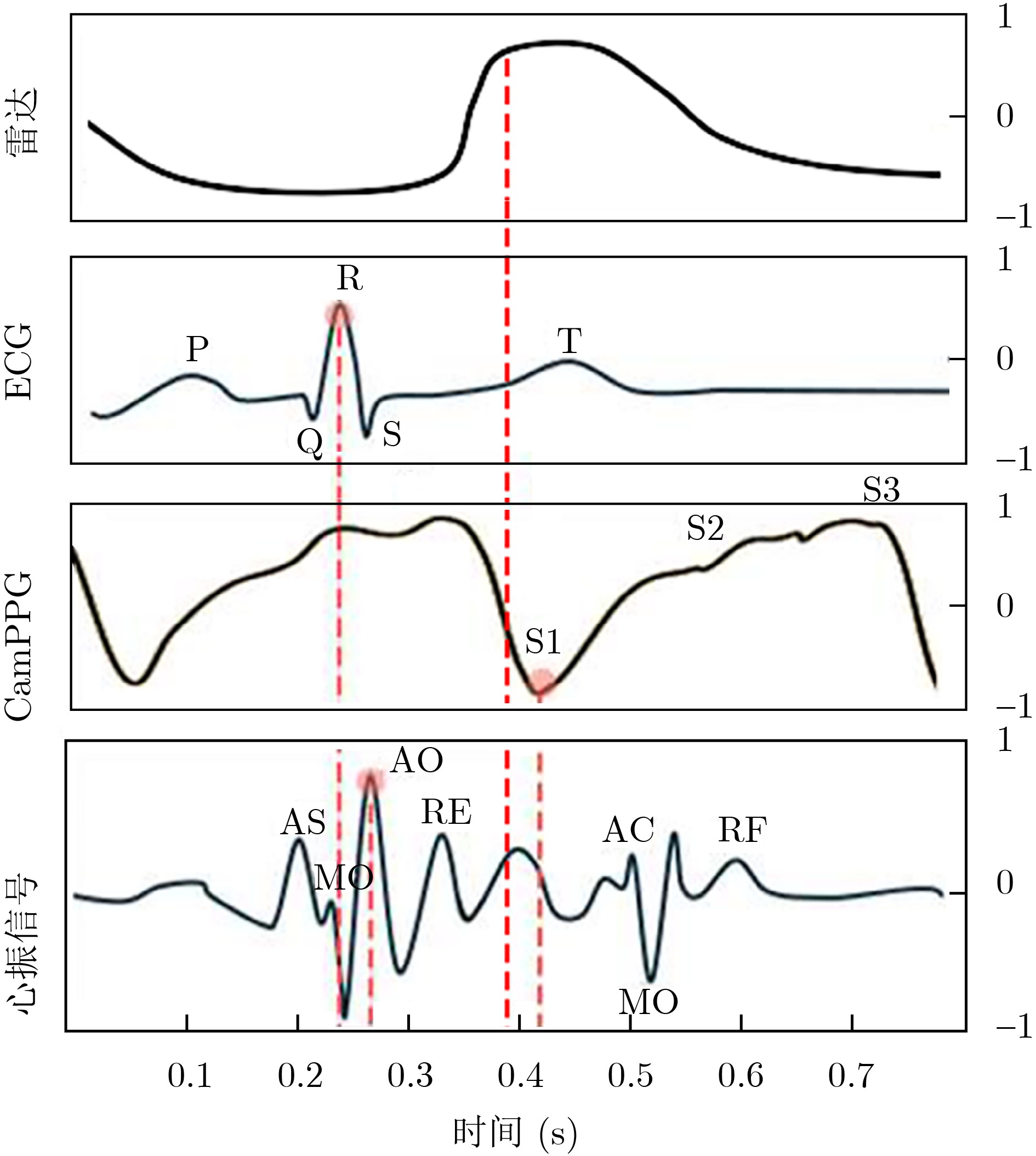
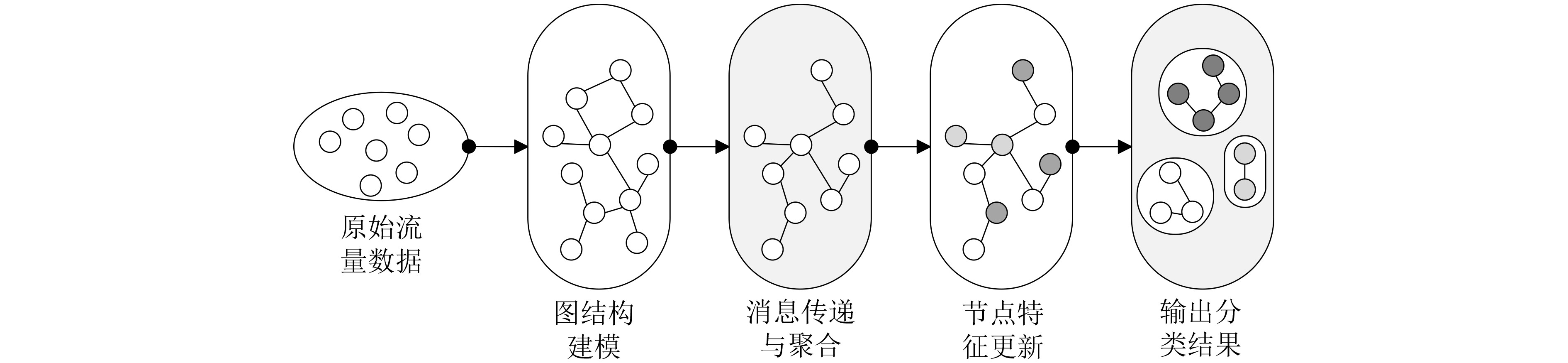
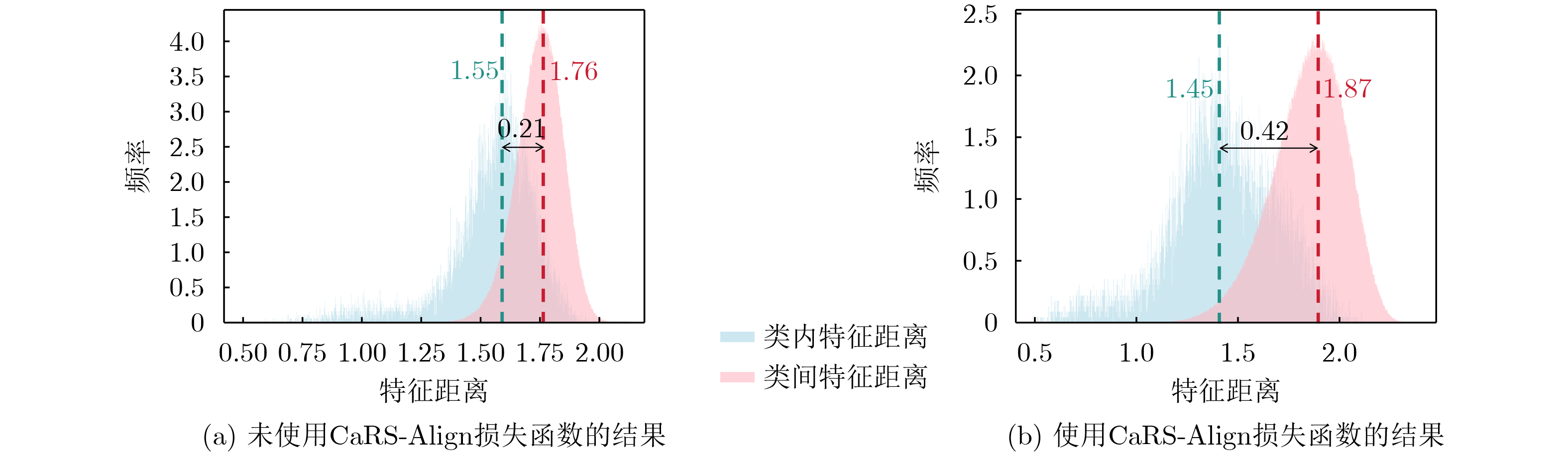
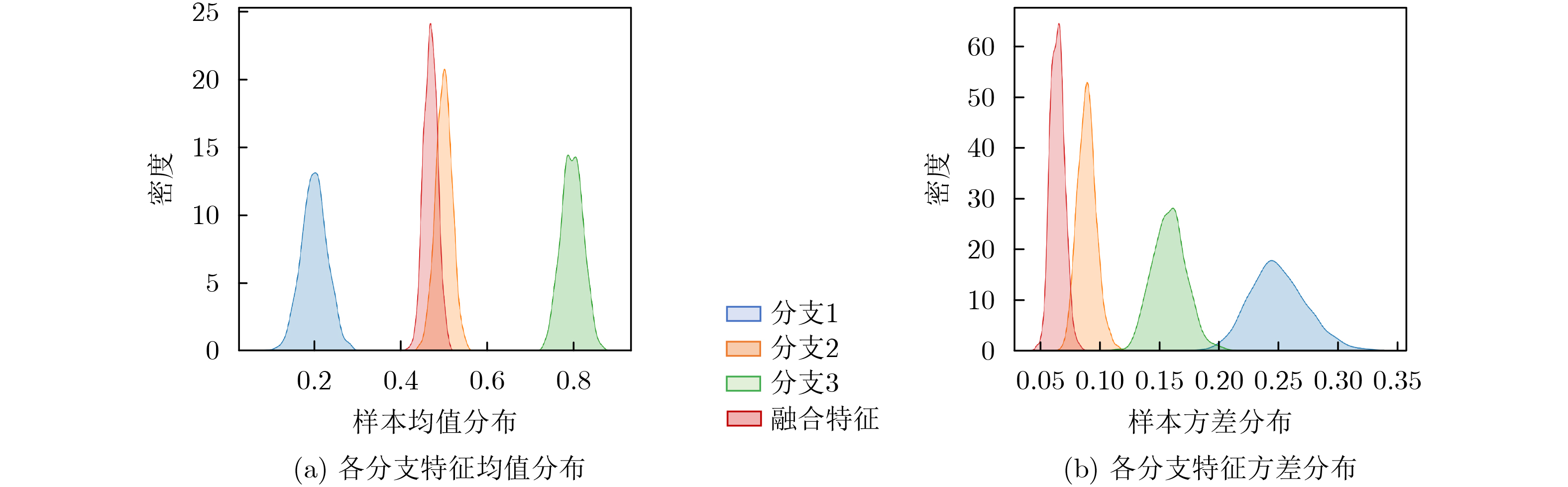
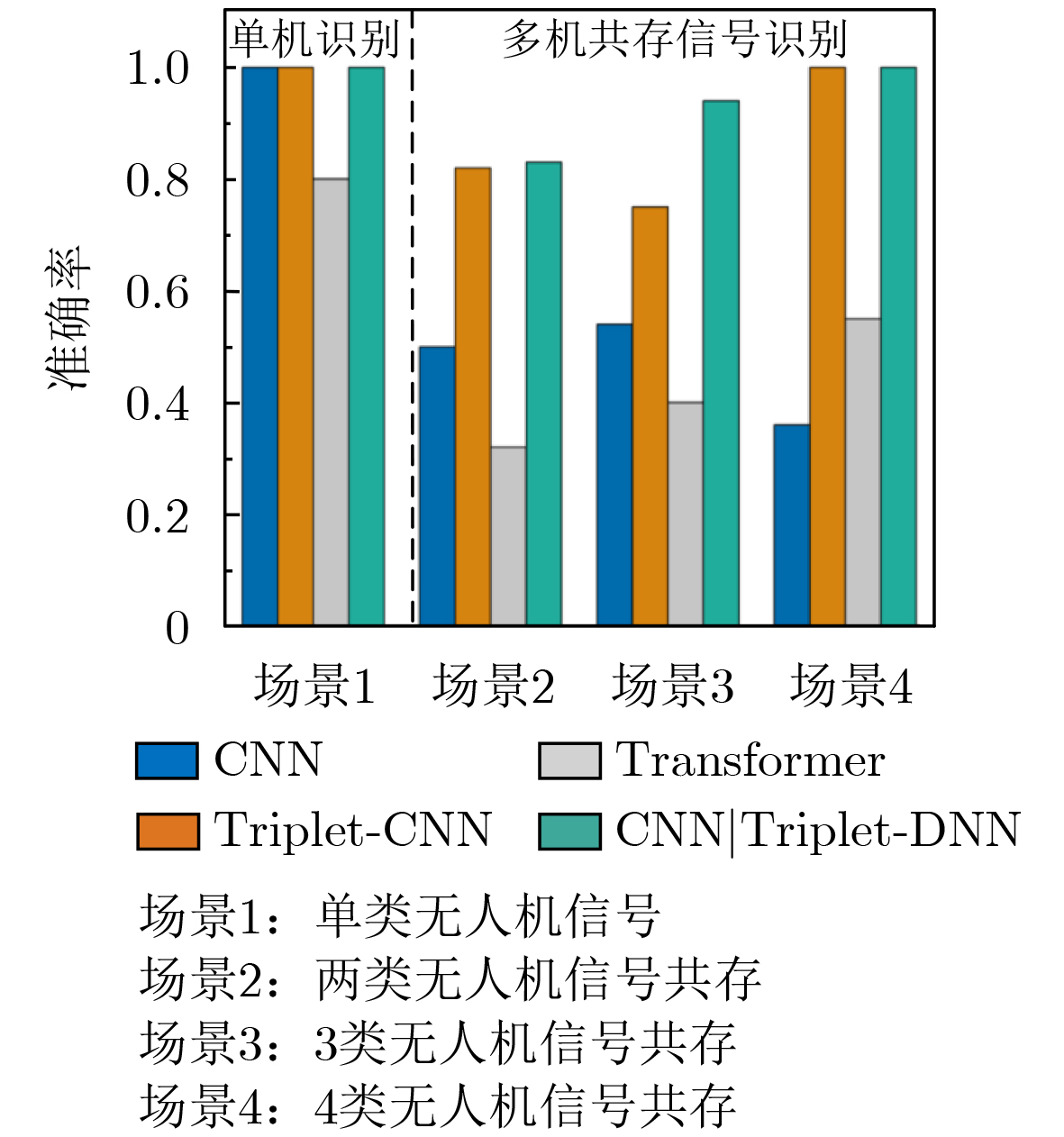
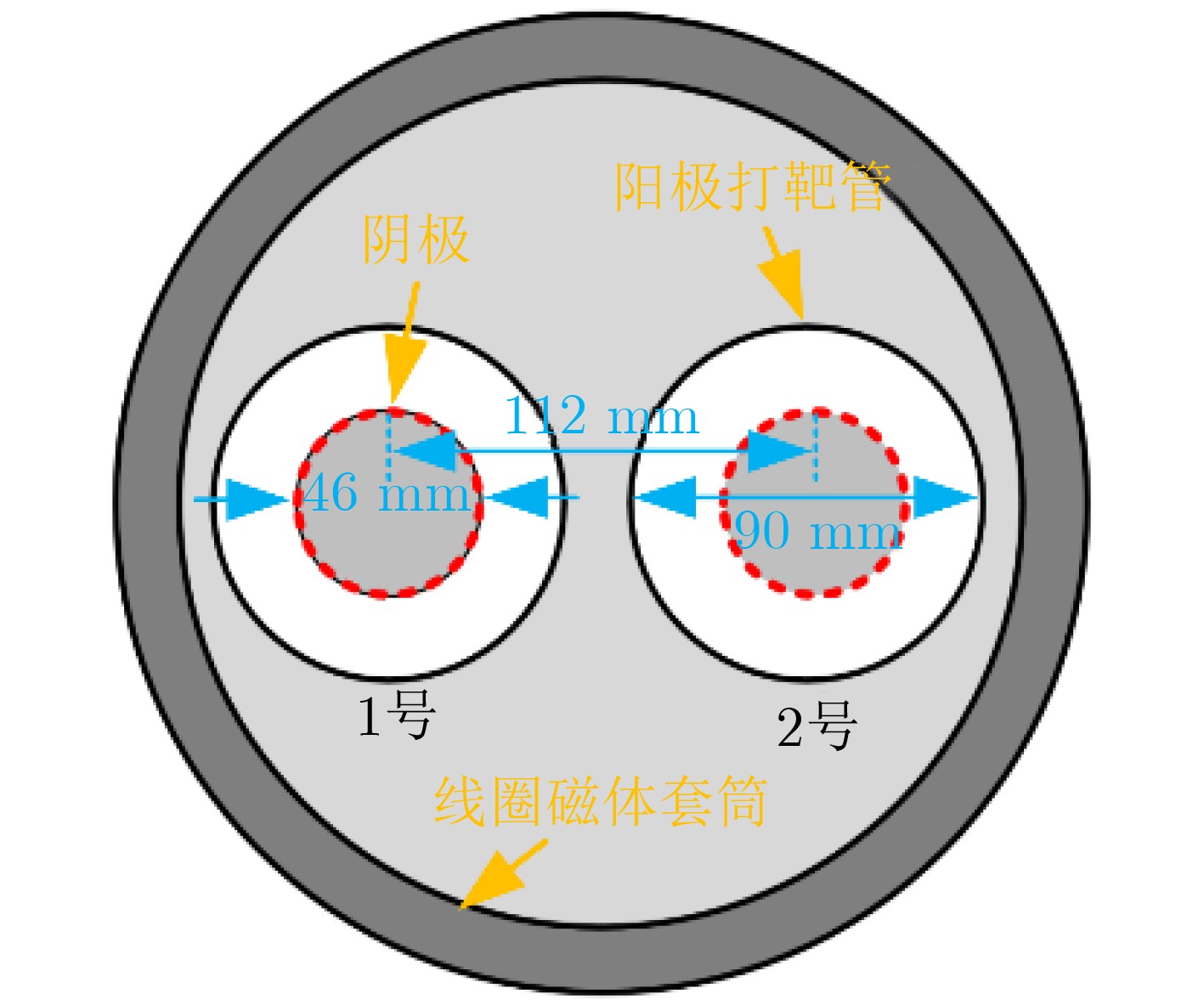
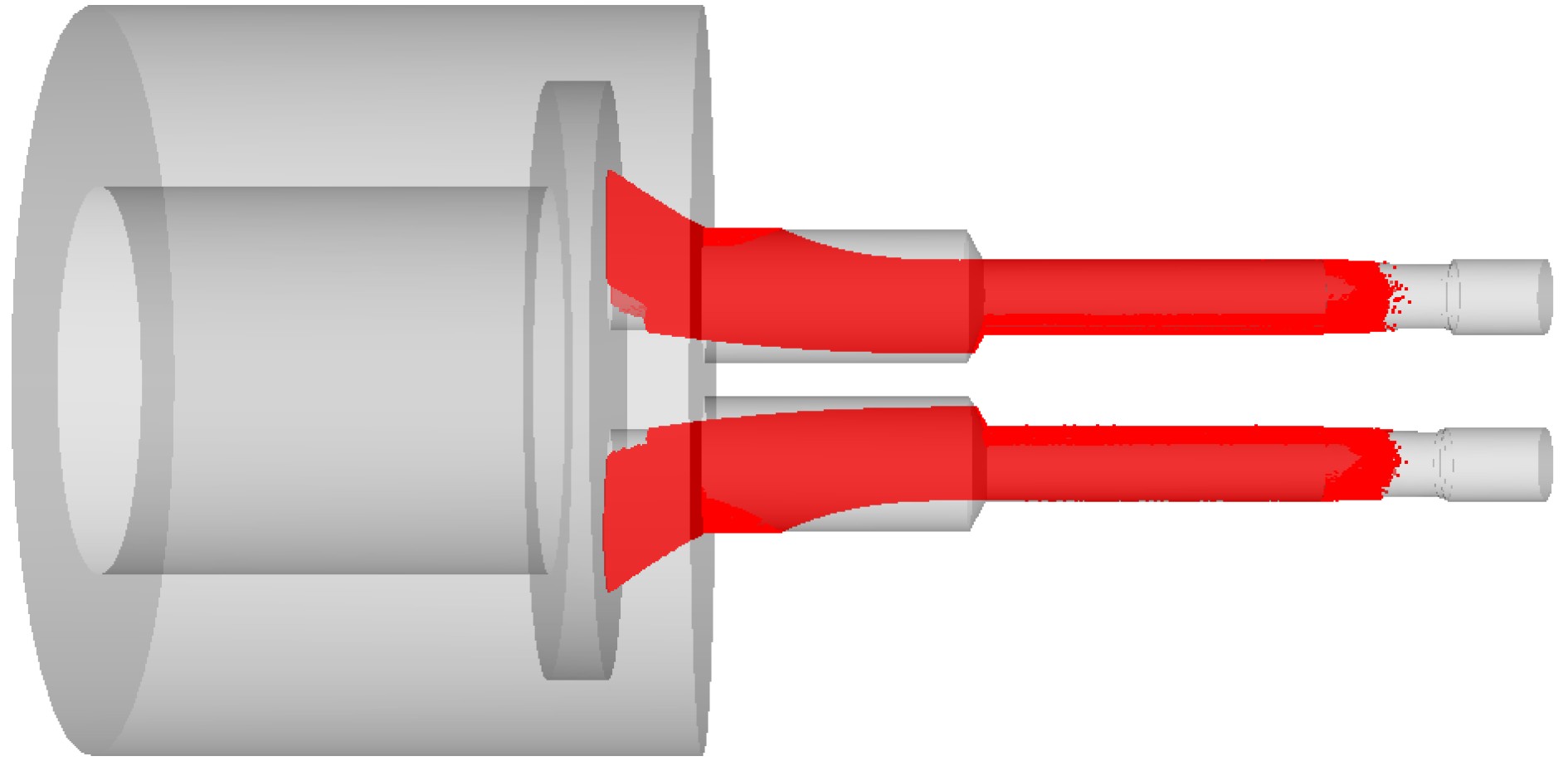
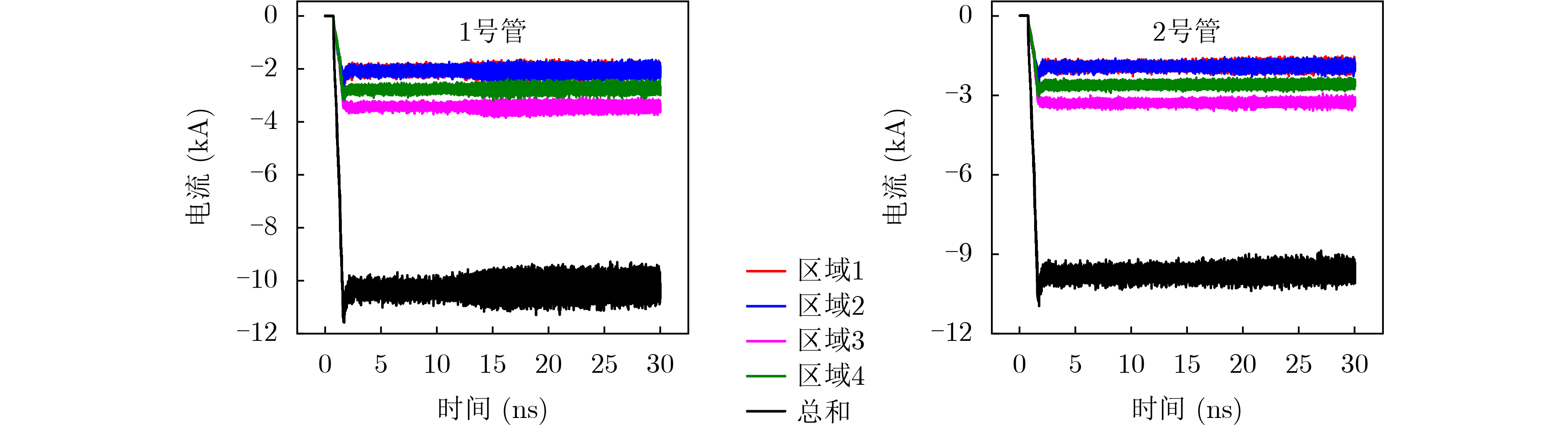
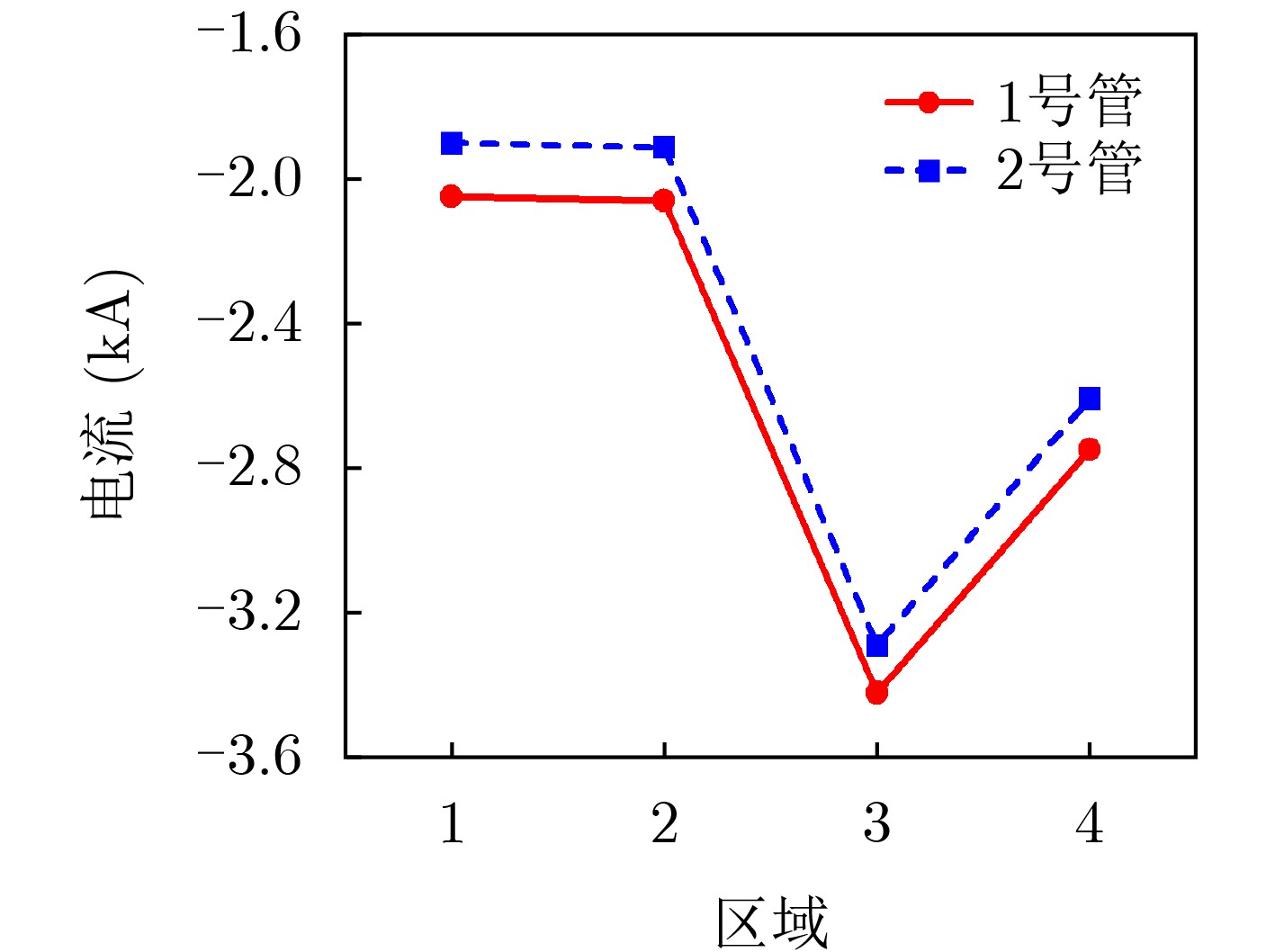
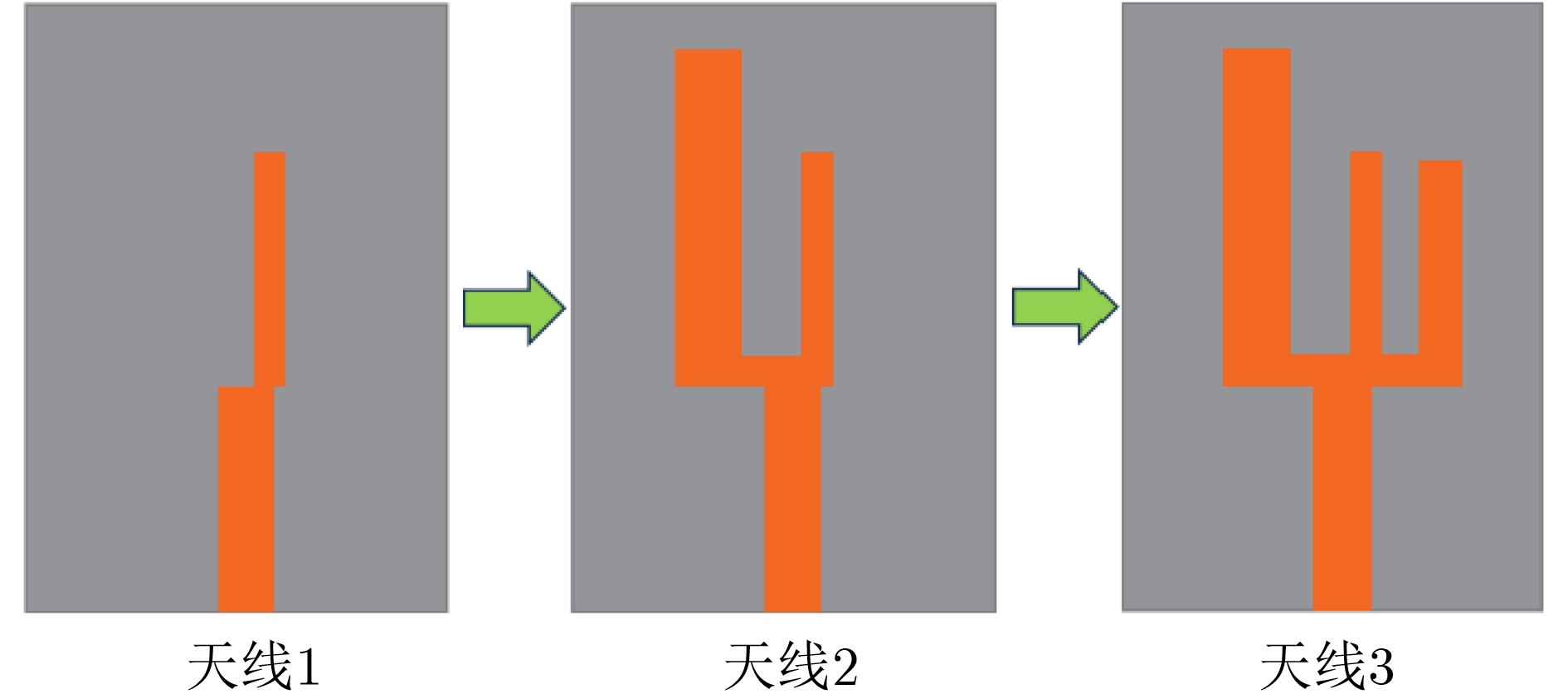
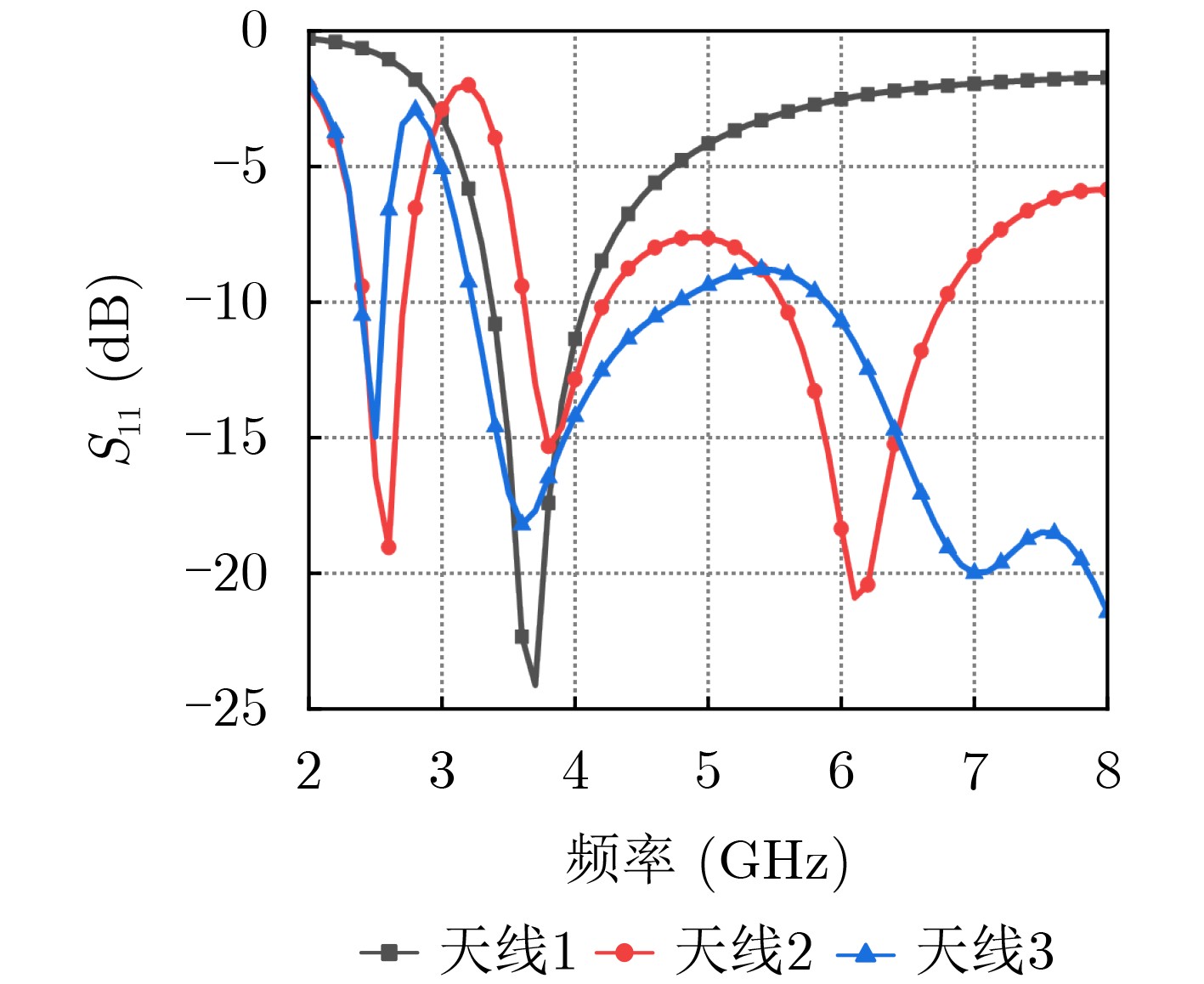
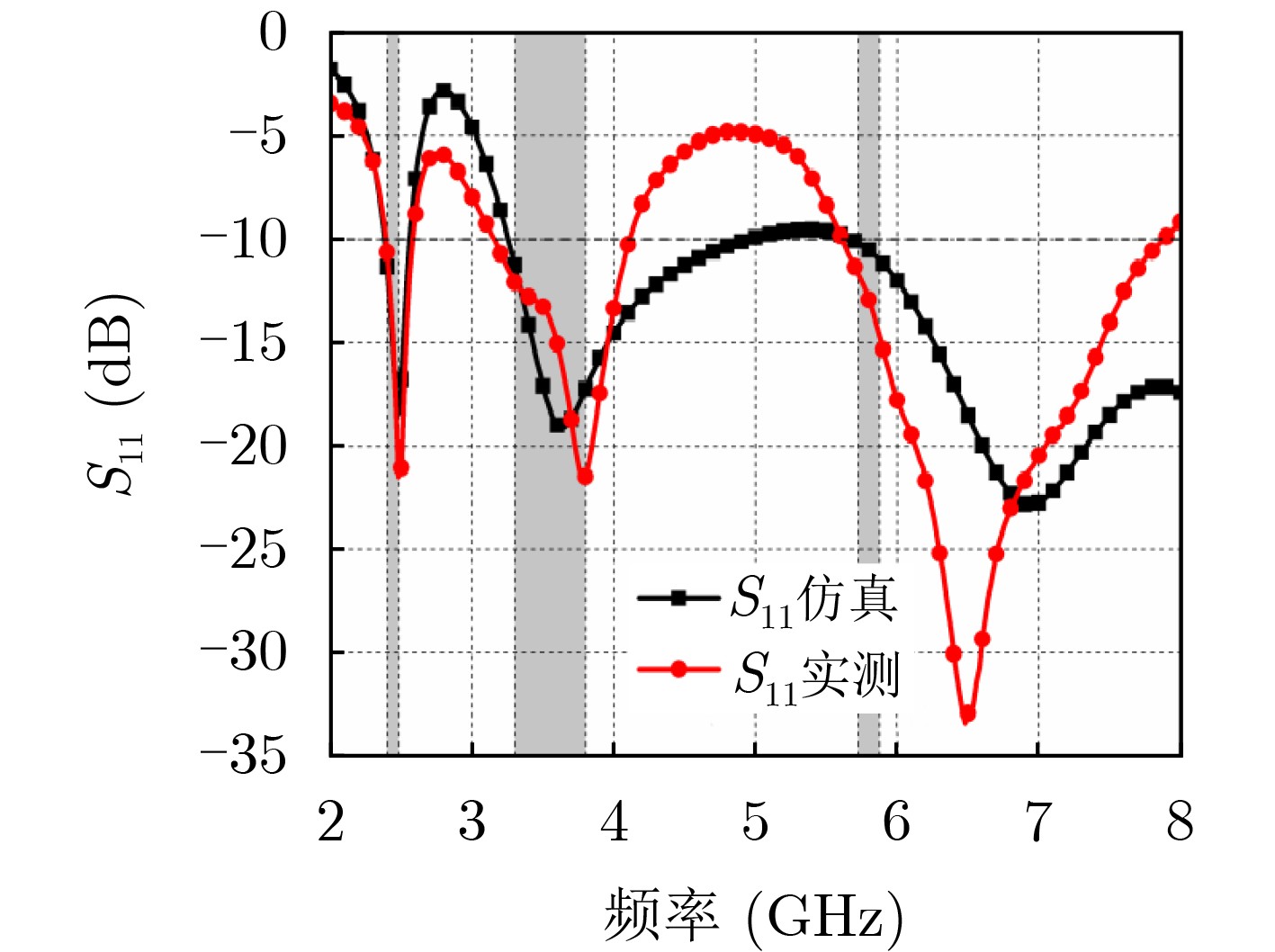
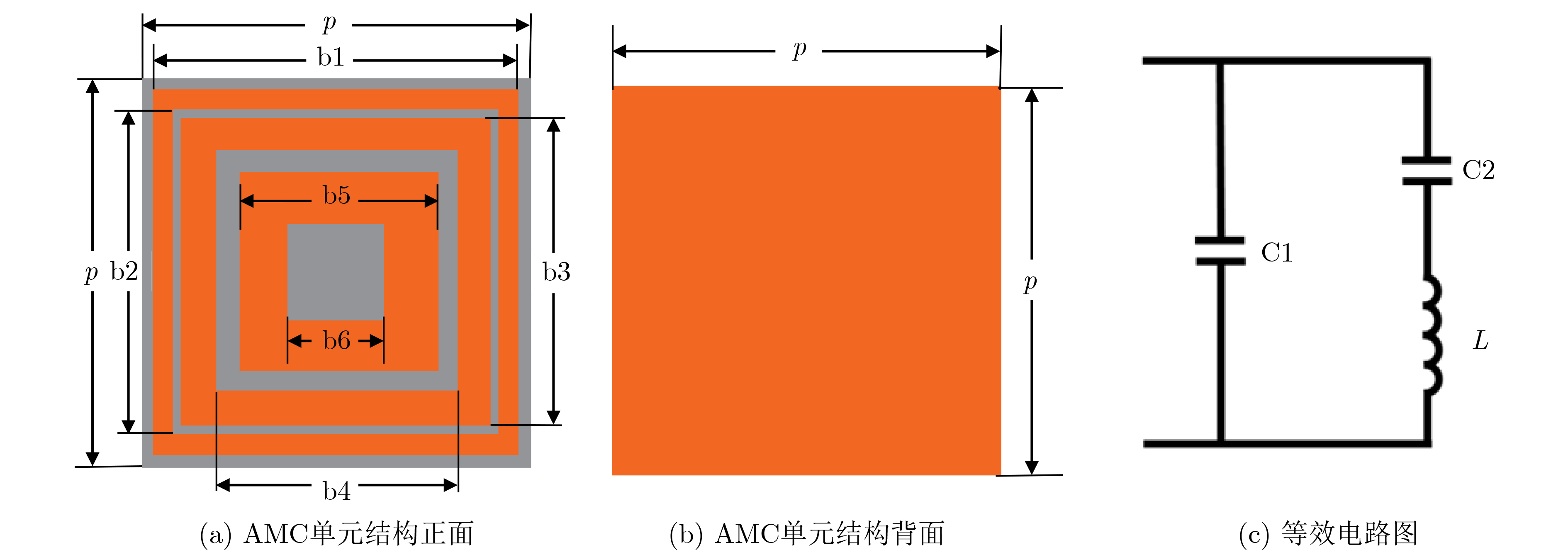
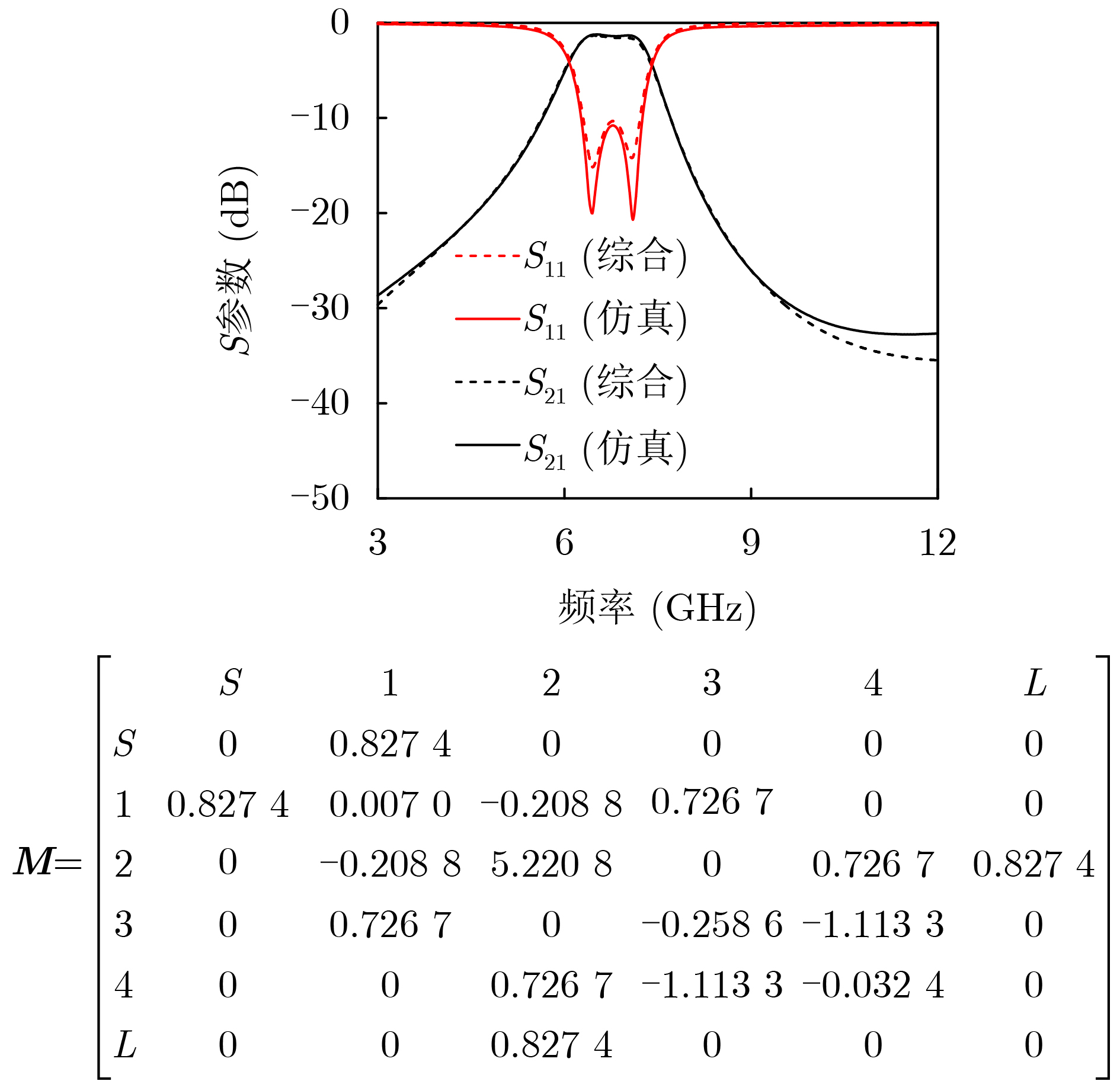
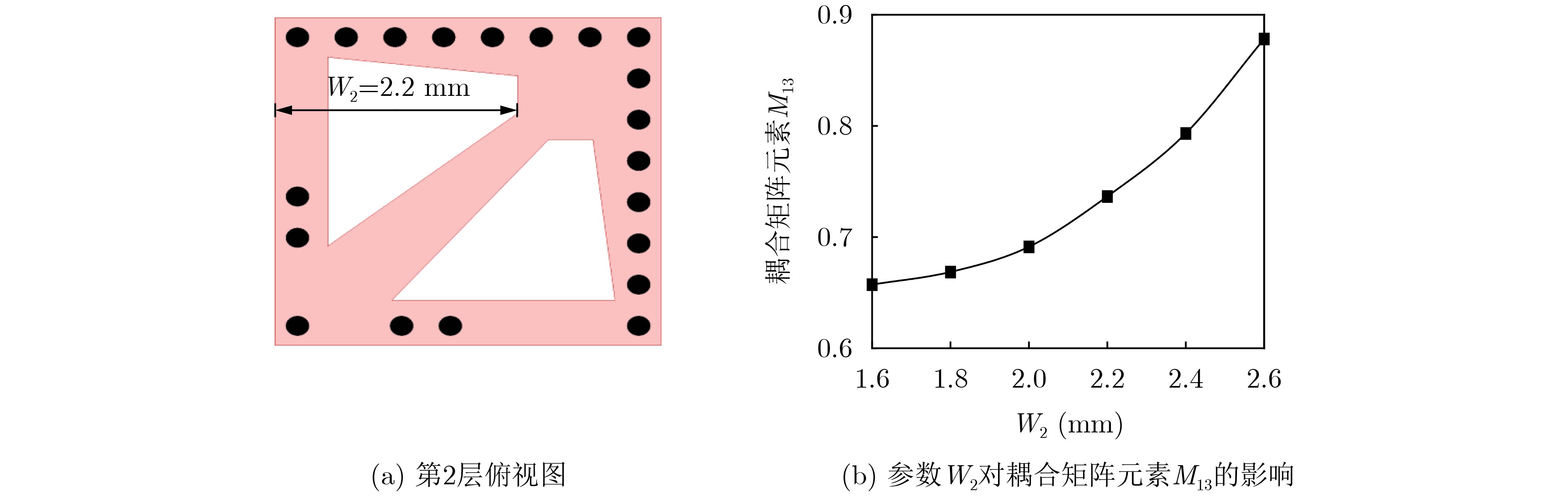
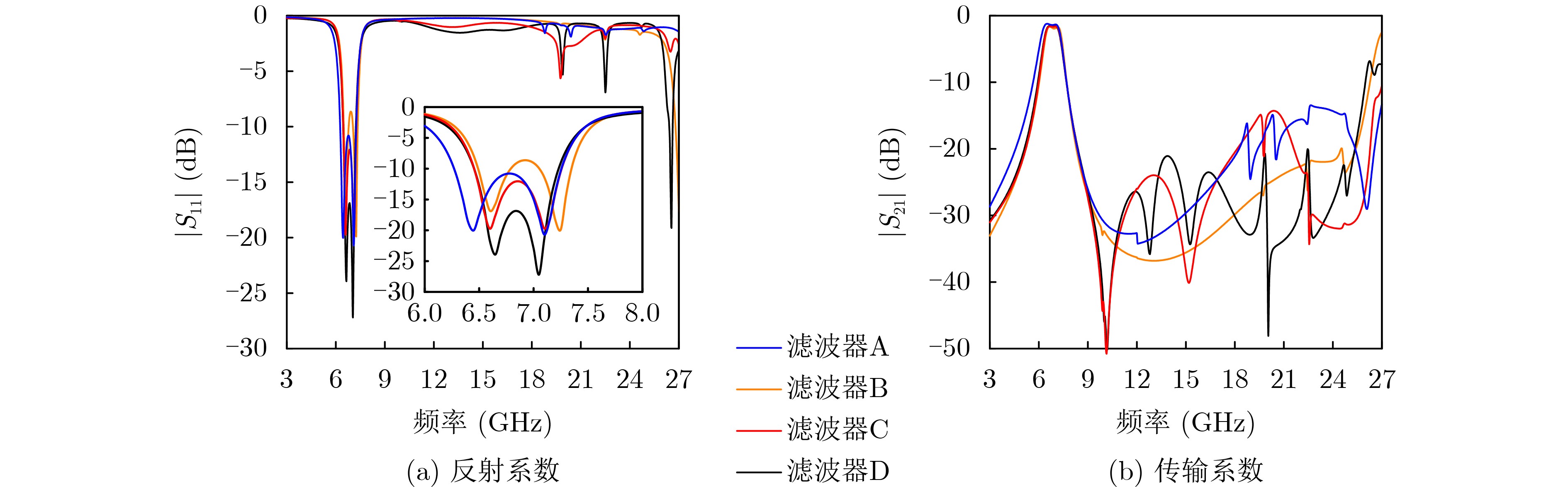
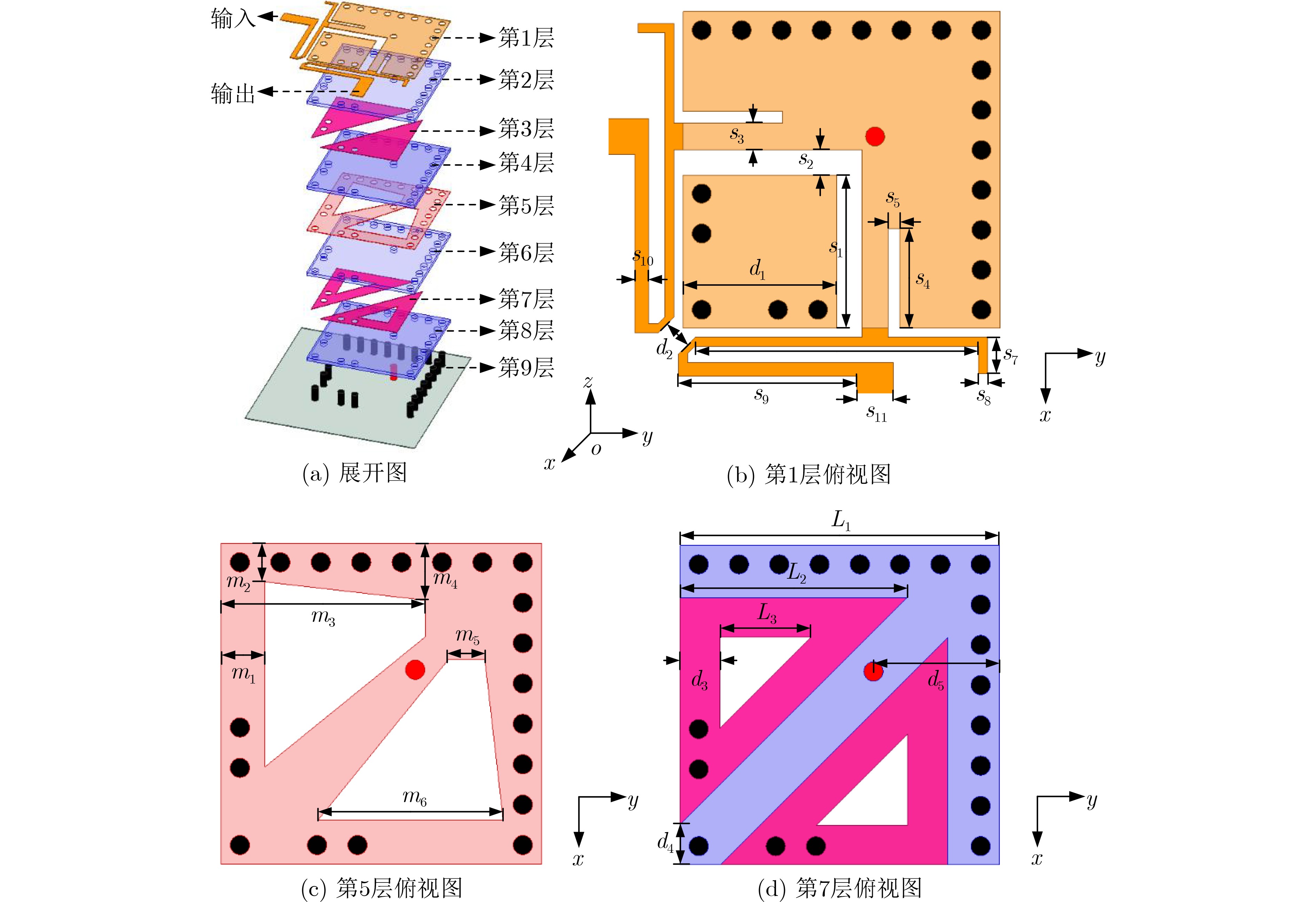
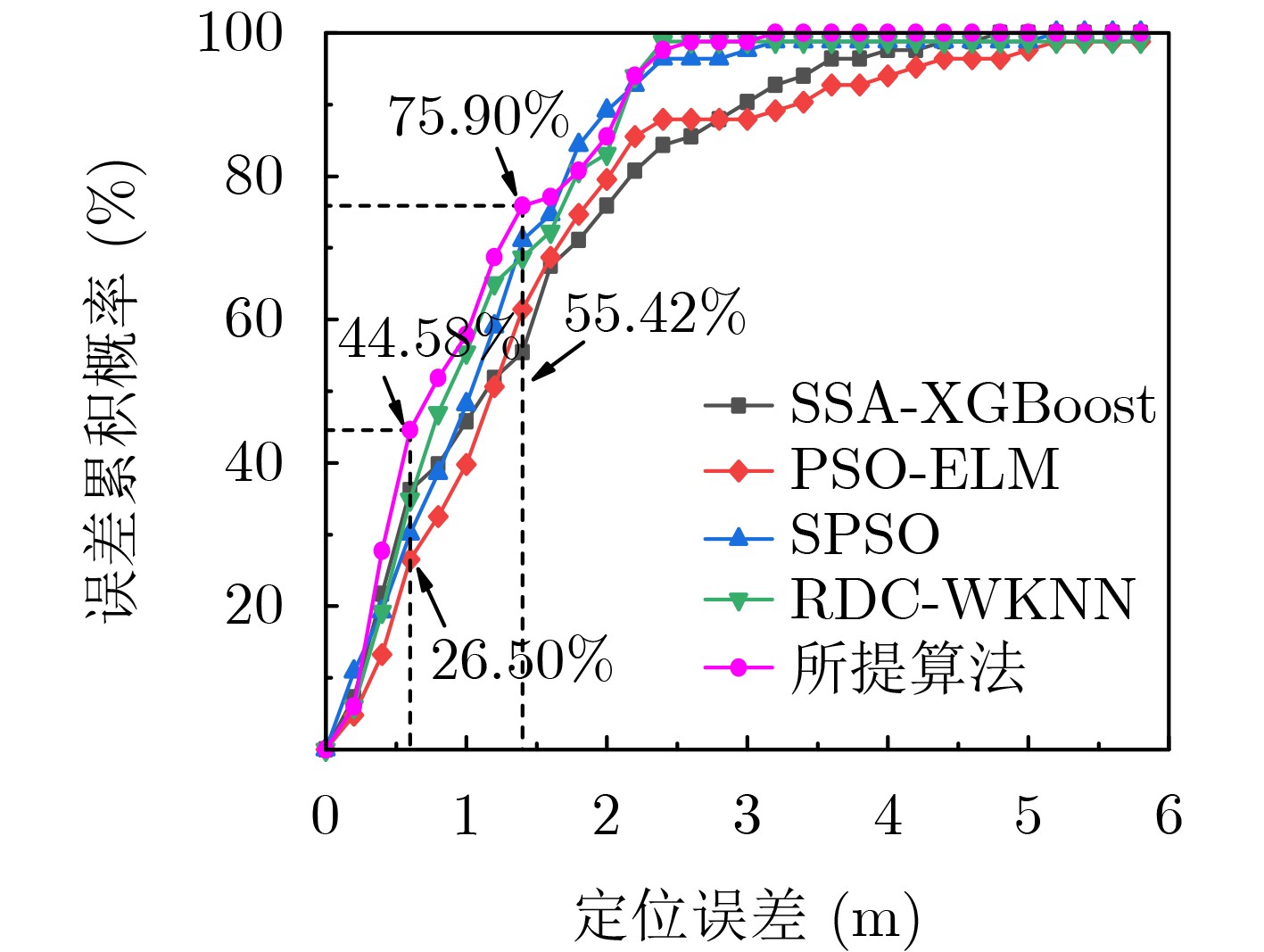
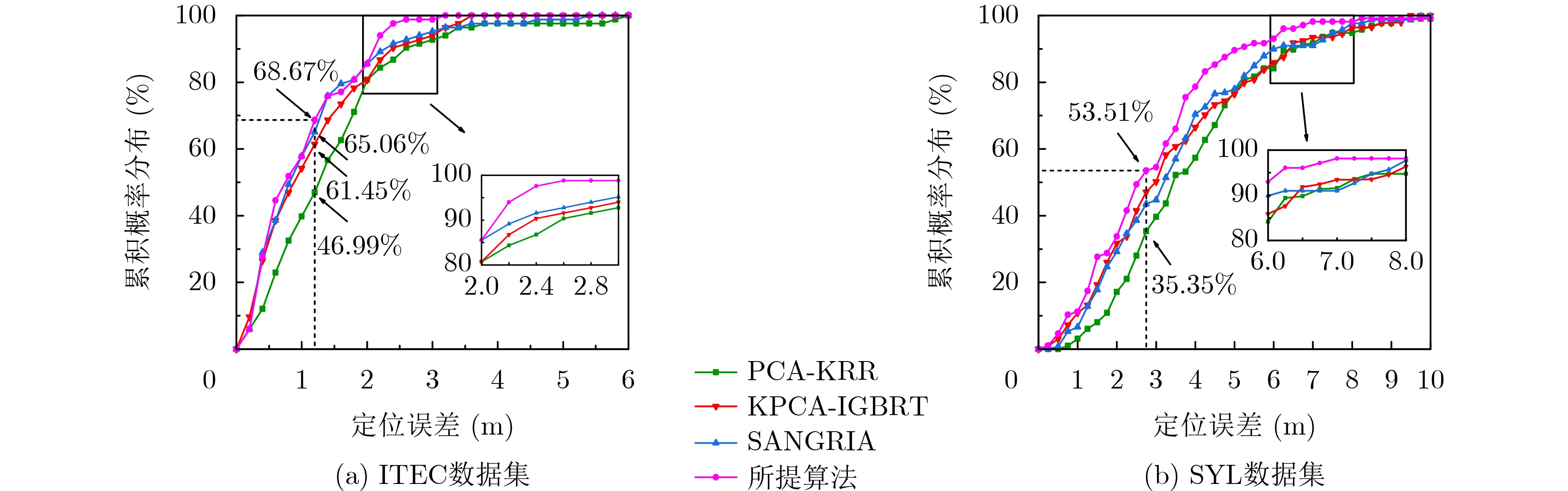
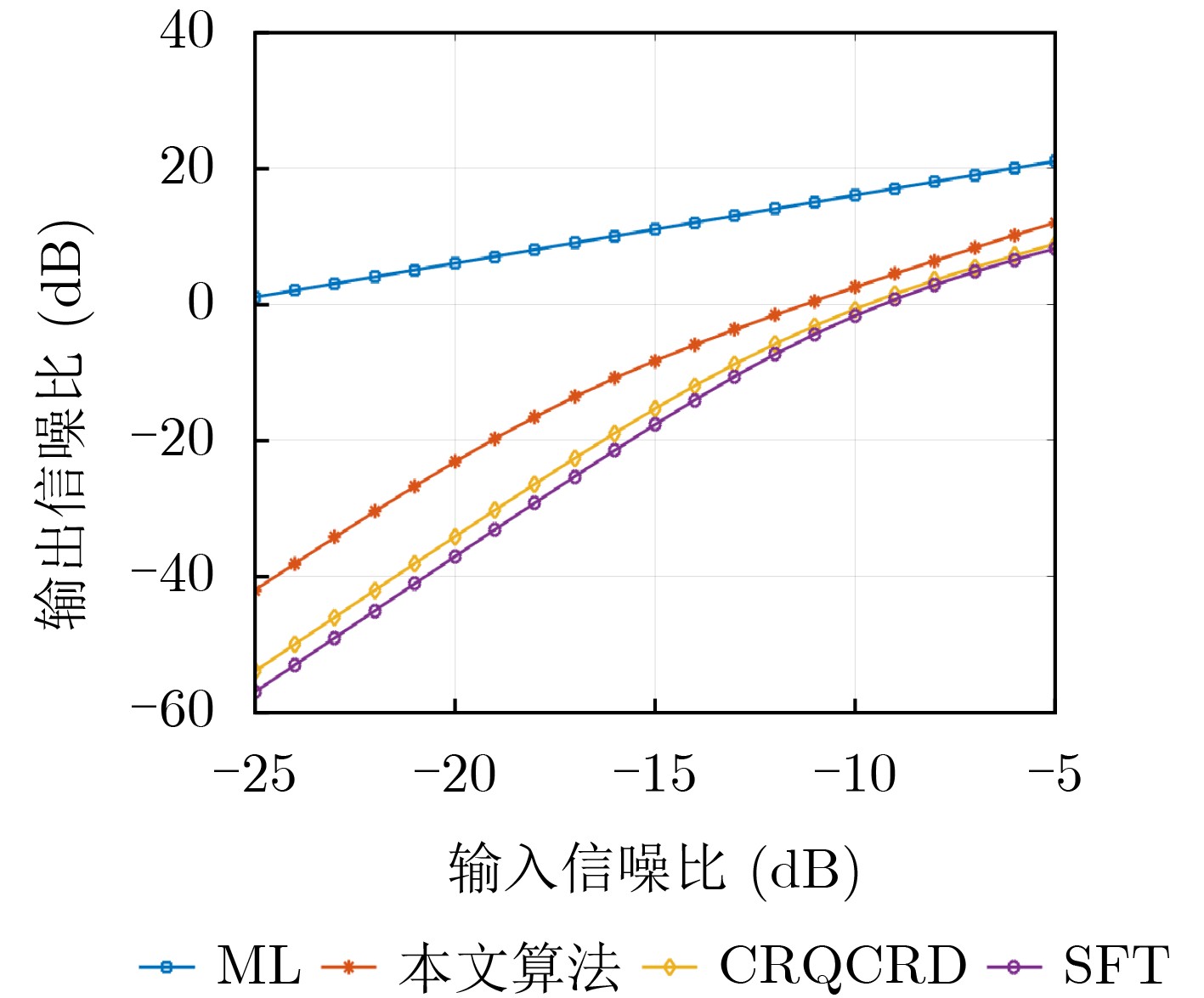
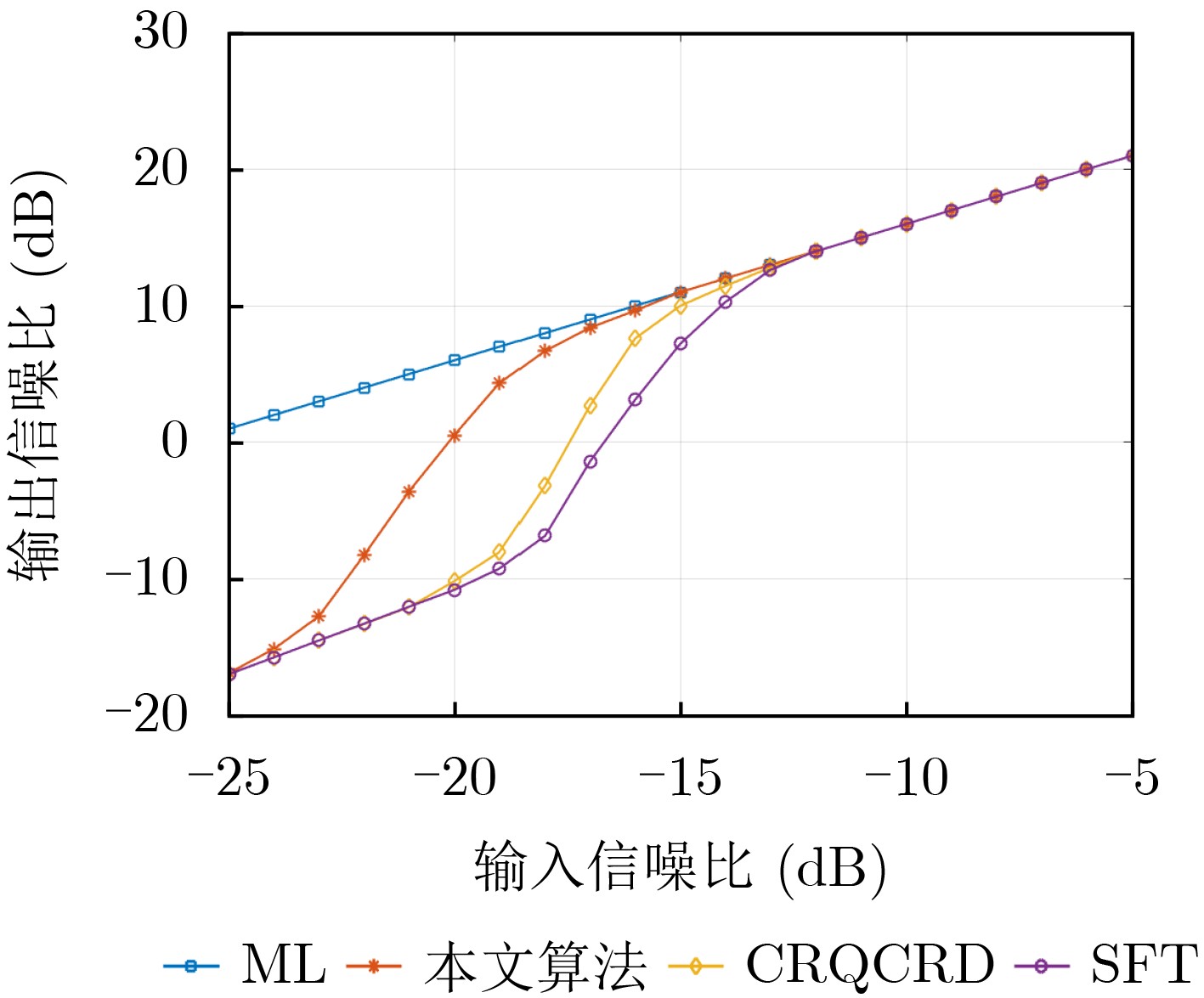
2026, 48(3): 1322-1332.
doi: 10.11999/JEIT251045
Abstract:
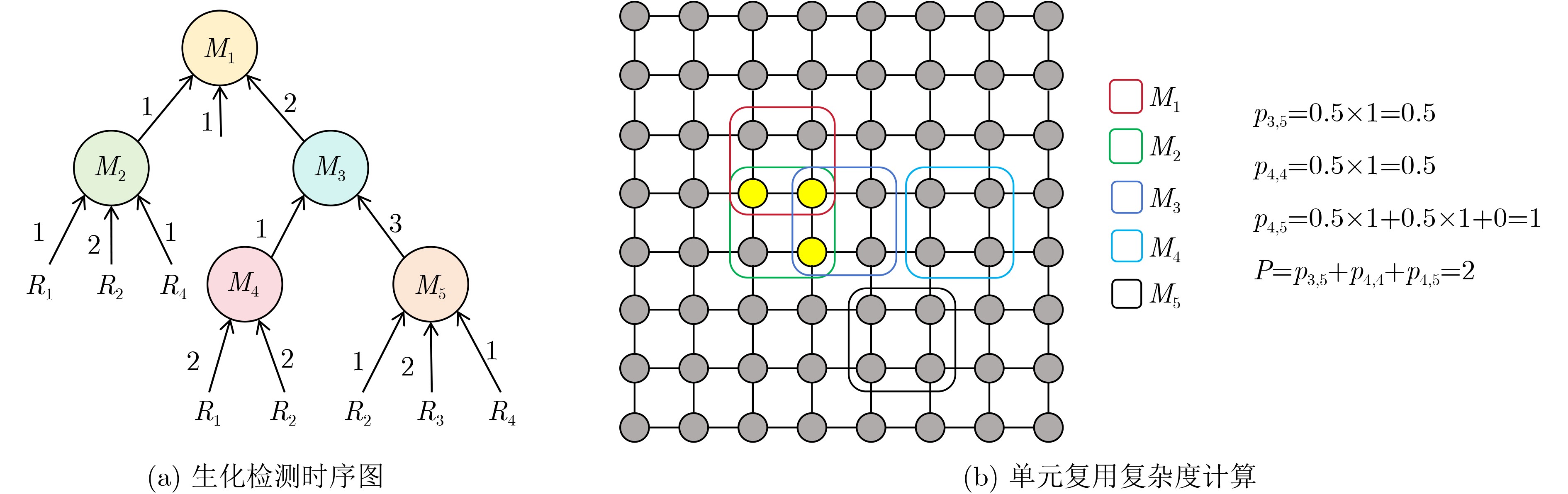
Objective Twisted Generalized Reed-Solomon (TGRS) codes have attracted considerable attention in coding theory due to their flexible structural properties. However, studies on their extended codes remain limited. Existing results indicate that only a small number of works examine extended TGRS codes, leaving gaps in the understanding of their error-correcting capability, duality properties, and applications. In addition, previously proposed parity-check matrix forms for TGRS codes lack clarity and do not cover all parameter ranges. In particular, the case h = 0 is not addressed, which limits applicability in scenarios requiring diverse parameter settings. Constructing non-Generalized Reed-Solomon (non-GRS) codes is of interest because such codes resist Sidelnikov-Shestakov and Wieschebrink attacks, whereas GRS codes are vulnerable. Maximum Distance Separable (MDS) codes, self-orthogonal codes, and almost self-dual codes are valued for their error-correcting efficiency and structural properties. MDS codes achieve the Singleton bound and are essential for distributed storage systems that require data reliability under node failures. Self-orthogonal and almost self-dual codes, due to their duality structures, are applied in quantum coding, secret sharing schemes, and secure multi-party computation. Accordingly, this paper aims to: (1) characterize the MDS and Almost MDS (AMDS) properties of double-twisted GRS codes \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document} and their extended codes \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v},{\boldsymbol{\infty}}) $\end{document}; (2) derive explicit and unified parity-check matrices for all valid parameter ranges, including h = 0; (3) establish non-GRS properties under specific parameter conditions; (4) provide necessary and sufficient conditions for self-orthogonality of the extended codes and almost self-duality of the original codes; and (5) construct a class of almost self-dual double-twisted GRS codes with flexible parameters for secure and reliable communication systems. Methods The study is based on algebraic coding theory and finite field methods. Explicit parity-check matrices are derived using properties of polynomial rings over \begin{document}$ {F}_{q} $\end{document}, Vandermonde matrix structures, and polynomial interpolation. The Schur product method is applied to determine non-GRS properties by comparing the dimensions of the Schur squares of the codes and their duals with those of GRS codes. Linear algebra and combinatorial techniques are used to characterize MDS and AMDS properties. Conditions are obtained by analyzing the nonsingularity of generator-matrix submatrices and solving systems involving symmetric sums of finite field elements. These conditions are expressed using the sets \begin{document}$ {S}_{k}(\boldsymbol{\alpha },{{\boldsymbol{\eta}} }) $\end{document},\begin{document}$ {L}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document}, and \begin{document}$ {D}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document}. Duality theory is used to study orthogonality. A code C is self-orthogonal if \begin{document}$ C\subseteq {C}^{\bot } $\end{document} and its generator matrix satisfies \begin{document}$ {\boldsymbol{G}}{{\boldsymbol{G}}}^{\rm T}=\boldsymbol{O} $\end{document}. For almost self-dual codes with odd length and dimension-(n–1)/2, this condition is combined with the structure of the dual code and symmetric sum relations of αi to obtain necessary and sufficient conditions. Results and Discussions For MDS and AMDS properties, the following results are obtained. The extended double-twisted GRS code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v},{\boldsymbol{\infty}}) $\end{document} is MDS if and only if \begin{document}$ 1\notin {S}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document} and \begin{document}$ 1\notin {L}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document}. The double-twisted GRS code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document} is AMDS if and only if \begin{document}$ 1\in {S}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document} and \begin{document}$ (0,1)\notin {D}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document}. The code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document}\begin{document}$ (0,1)\in {D}_{k}(\boldsymbol{\alpha },\boldsymbol{\eta }) $\end{document}. Unified parity-check matrices of \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document} and \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v},{\boldsymbol{\infty}}) $\end{document} are derived for all \begin{document}$ 0\leq h\leq k-1 $\end{document}, removing previous restrictions that exclude h = 0. For non-GRS properties, when \begin{document}$ k\geq 4 $\end{document} and \begin{document}$ n-k\geq 4 $\end{document}, both \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document} and its extended code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v},{\boldsymbol{\infty}}) $\end{document} are non-GRS for both \begin{document}$ 2k\geq n $\end{document} or \begin{document}$ 2k \lt n $\end{document}. This conclusion follows from the fact that the dimensions of their Schur squares exceed those of the corresponding GRS codes, which ensures resistance to Sidelnikov-Shestakov and Wieschebrink attacks. Regarding orthogonality, the extended code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v},{\boldsymbol{\infty}}) $\end{document} with \begin{document}$ h=k-1 $\end{document} is self-orthogonal under specific algebraic conditions. The code \begin{document}$ {C}_{k,\boldsymbol{h},{\boldsymbol{\eta }}}(\boldsymbol{\alpha },\boldsymbol{v}) $\end{document} with \begin{document}$ h=k-1 $\end{document} and \begin{document}$ n=2k+1 $\end{document} is almost self-dual if and only if there exists \begin{document}$ \lambda \in F_{q}^{*} $\end{document} such that \begin{document}$ \lambda {u}_{j}=v_{j}^{2} (j=1,2,\cdots ,2k+1) $\end{document} together with a symmetric sum condition on \begin{document}$ {\alpha }_{i} $\end{document} involving \begin{document}$ {\eta }_{1} $\end{document} and \begin{document}$ {\eta }_{2} $\end{document}. For odd prime power \begin{document}$ q $\end{document}, an almost self-dual code with parameters \begin{document}$[q-t-1,(q-t-2)/2 $\end{document}, \begin{document}$ \geq (q-t-2)/2] $\end{document} is constructed using the roots of \begin{document}$ m(x)=({x}^{q}-x)/f(x) $\end{document} where \begin{document}$ f(x)={x}^{t+1}-x $\end{document}. An example over \begin{document}$ {F}_{11} $\end{document} yields a \begin{document}$ [5,2,\geq 2] $\end{document} code. Conclusions The study advances the theory of double-twisted GRS codes and their extensions through five contributions: (1) complete characterization of MDS and AMDS properties using sets \begin{document}$ {S}_{k} $\end{document},\begin{document}$ {L}_{k} $\end{document},\begin{document}$ {D}_{k} $\end{document}; (2) unified parity-check matrices for all \begin{document}$ 0\leq h\leq k-1 $\end{document}; (3) non-GRS properties are established for \begin{document}$ k\geq 4 $\end{document}, ensuring resistance to known structural attacks; (4) necessary and sufficient conditions for self-orthogonal extended codes and almost self-dual original codes are obtained; (5) a flexible construction of almost self-dual double-twisted GRS codes is proposed. These results extend the theoretical understanding of TGRS-type codes and support the design of secure and reliable coding systems.