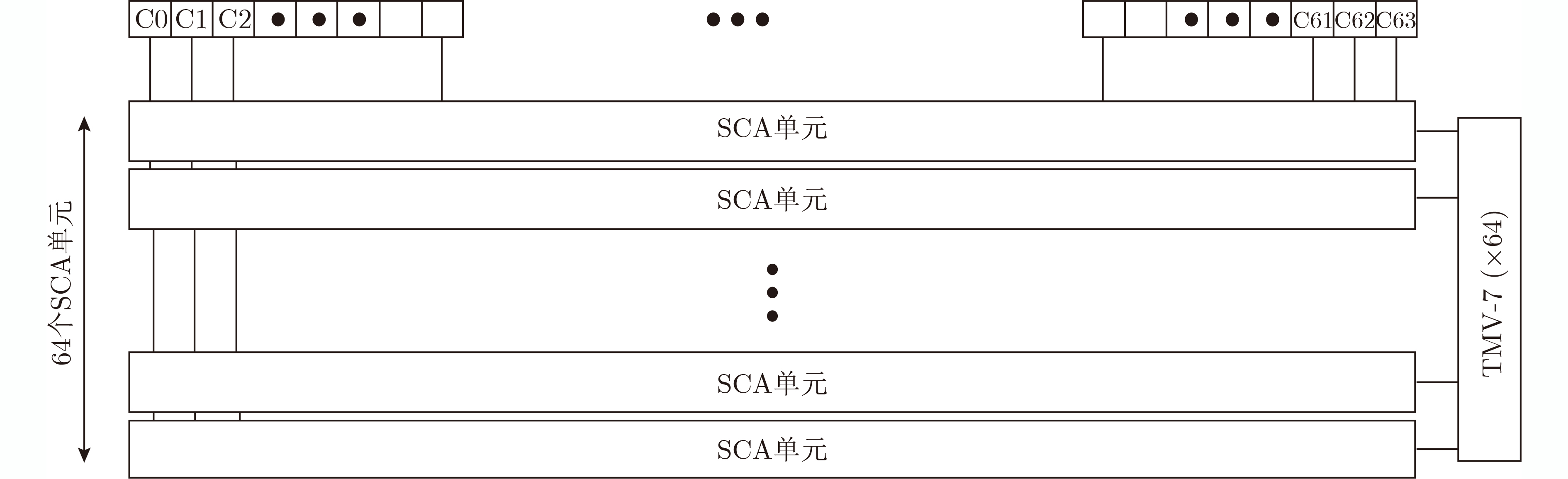
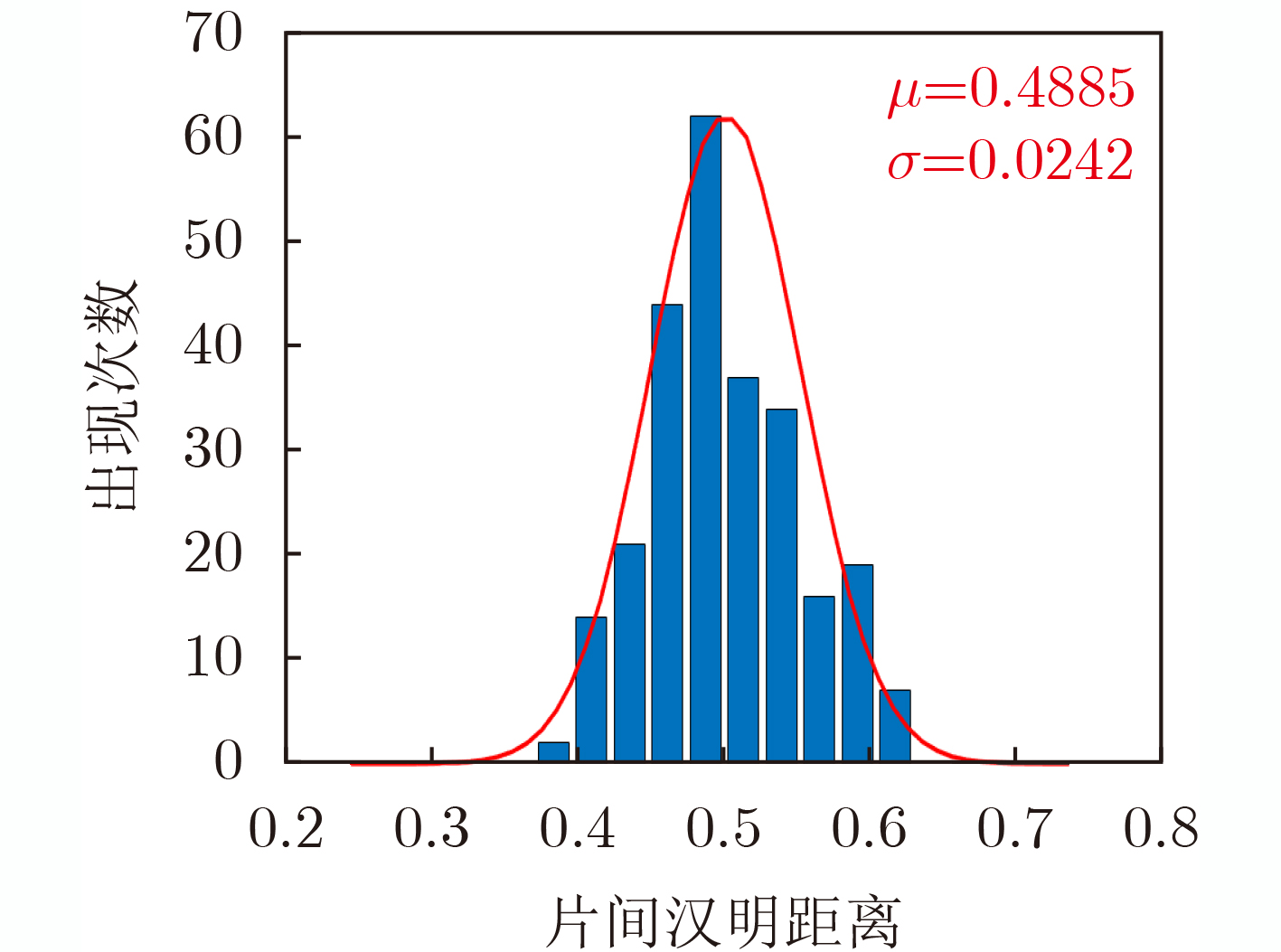
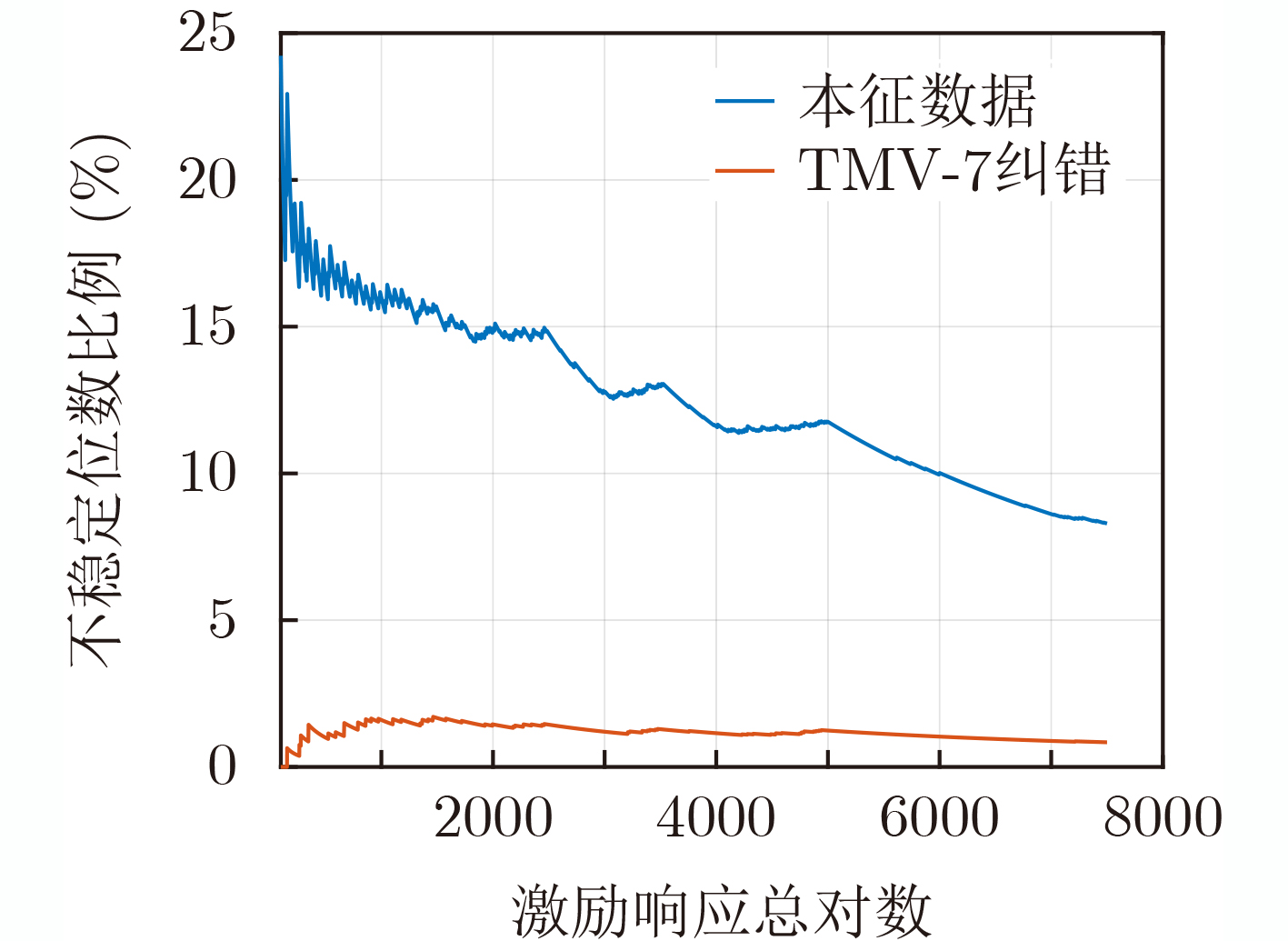
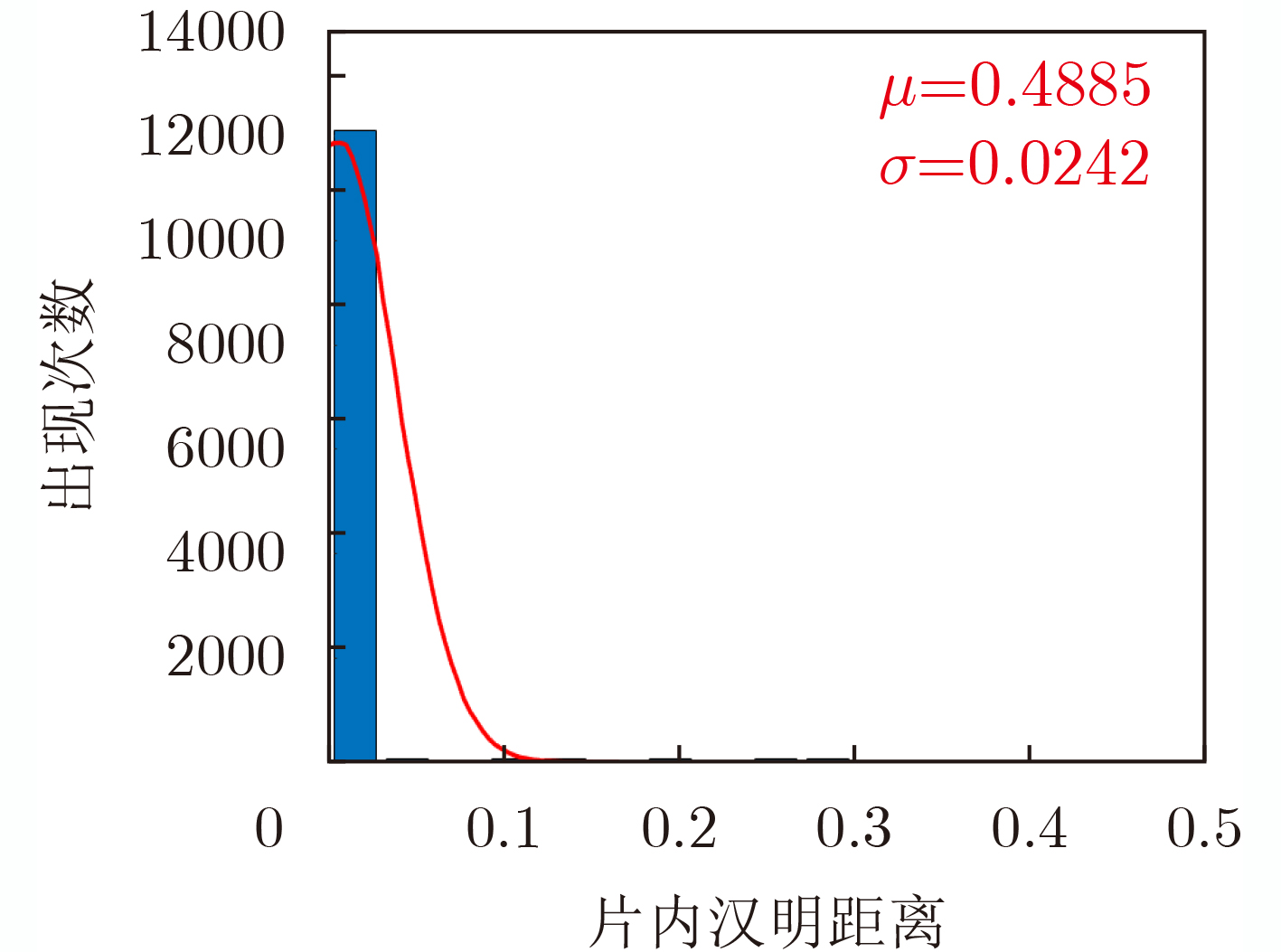
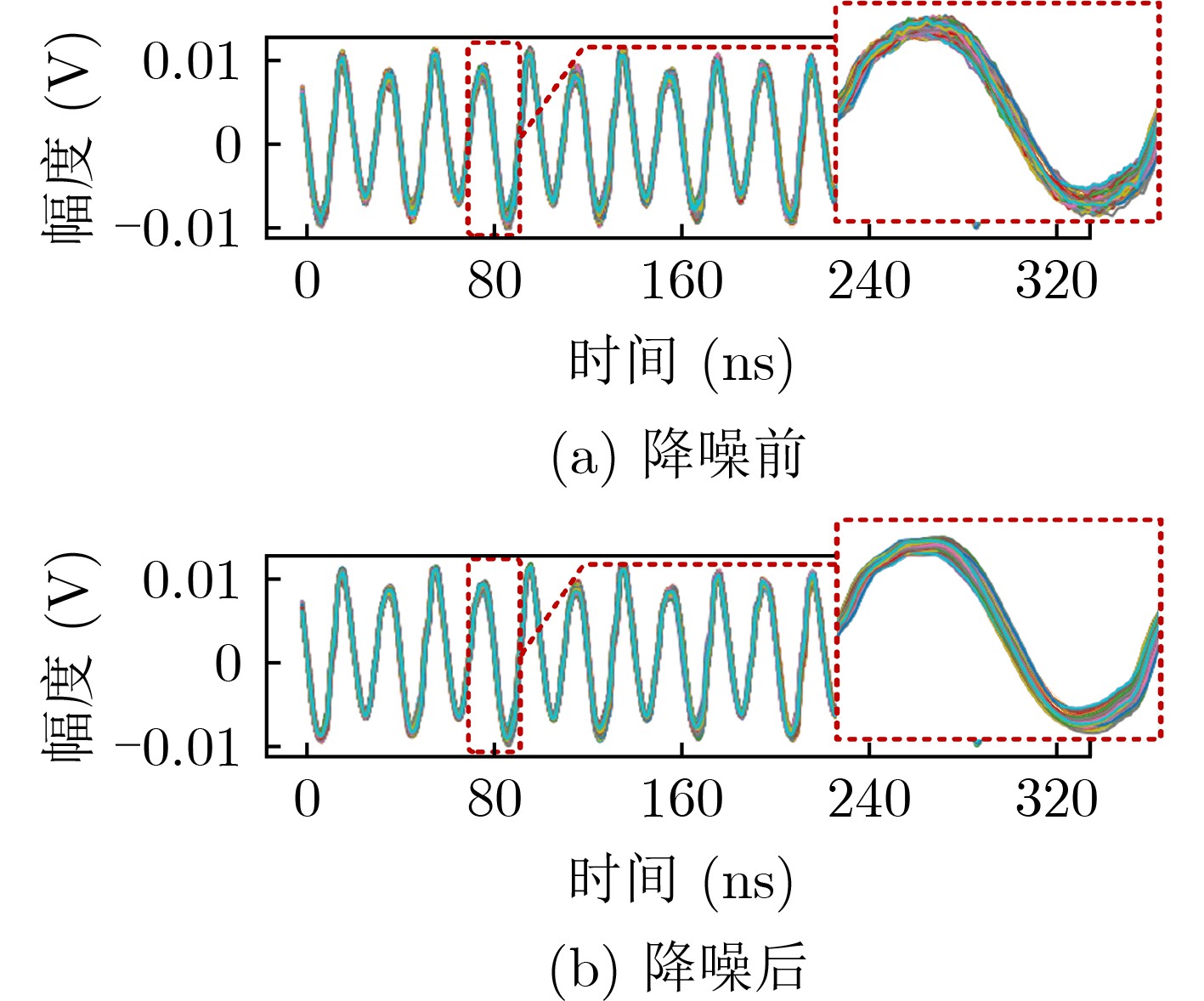
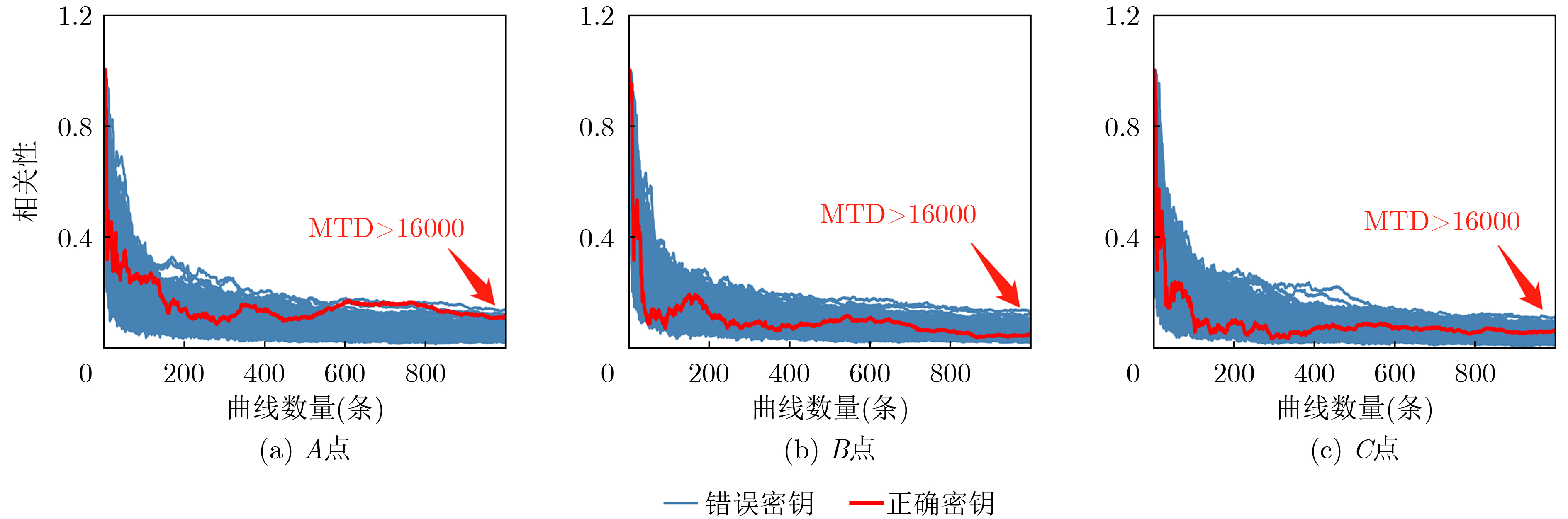
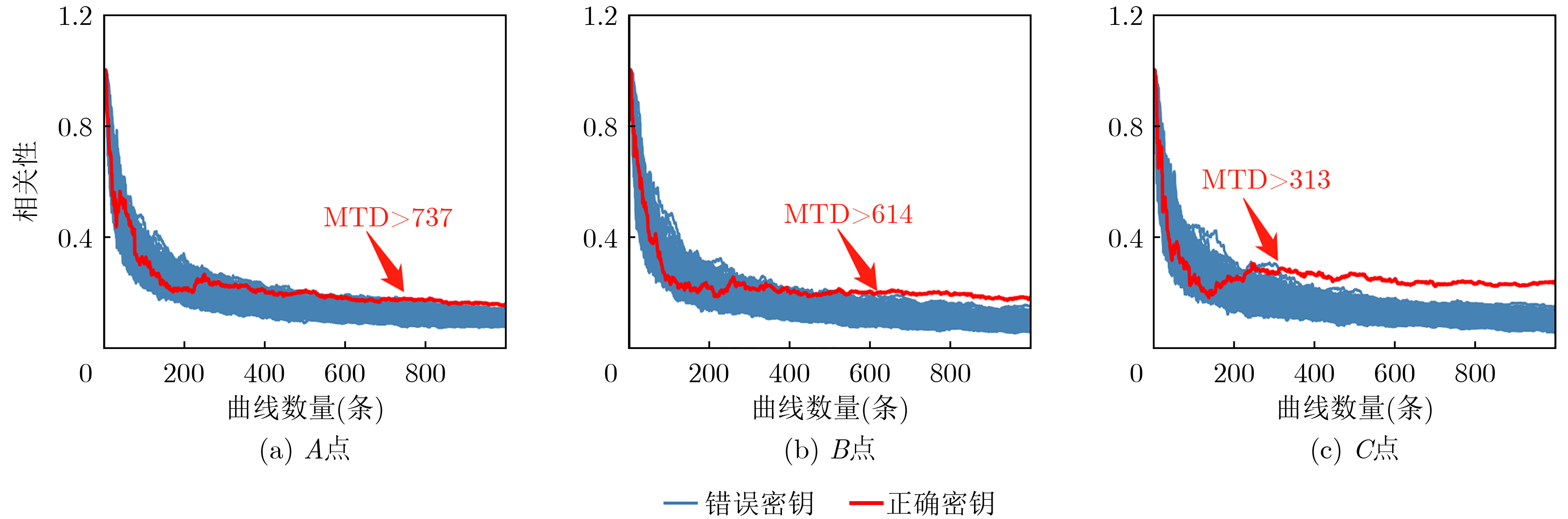
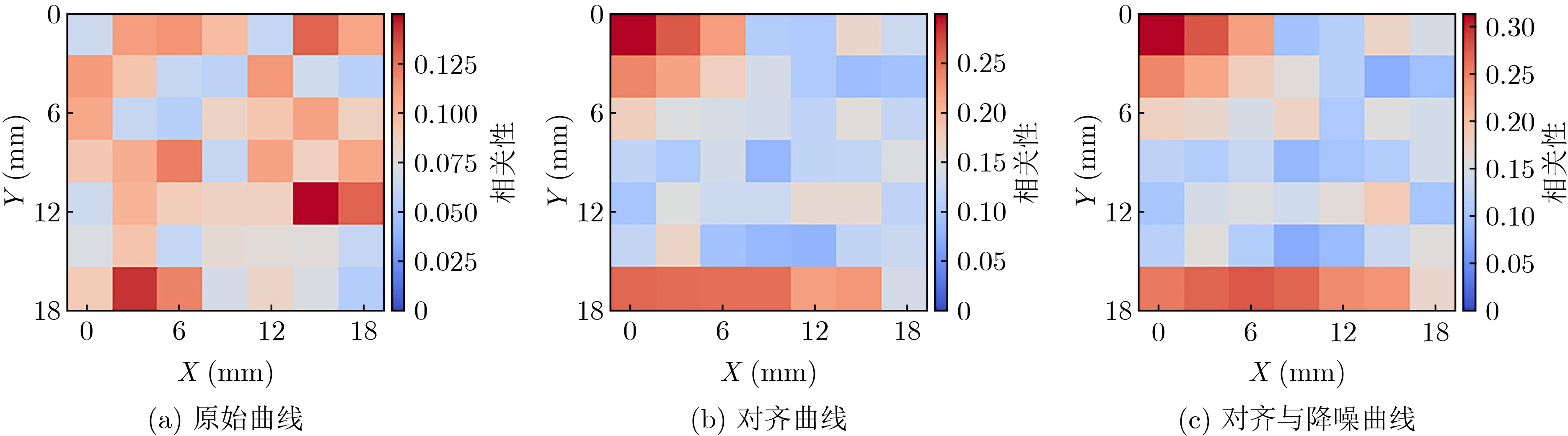
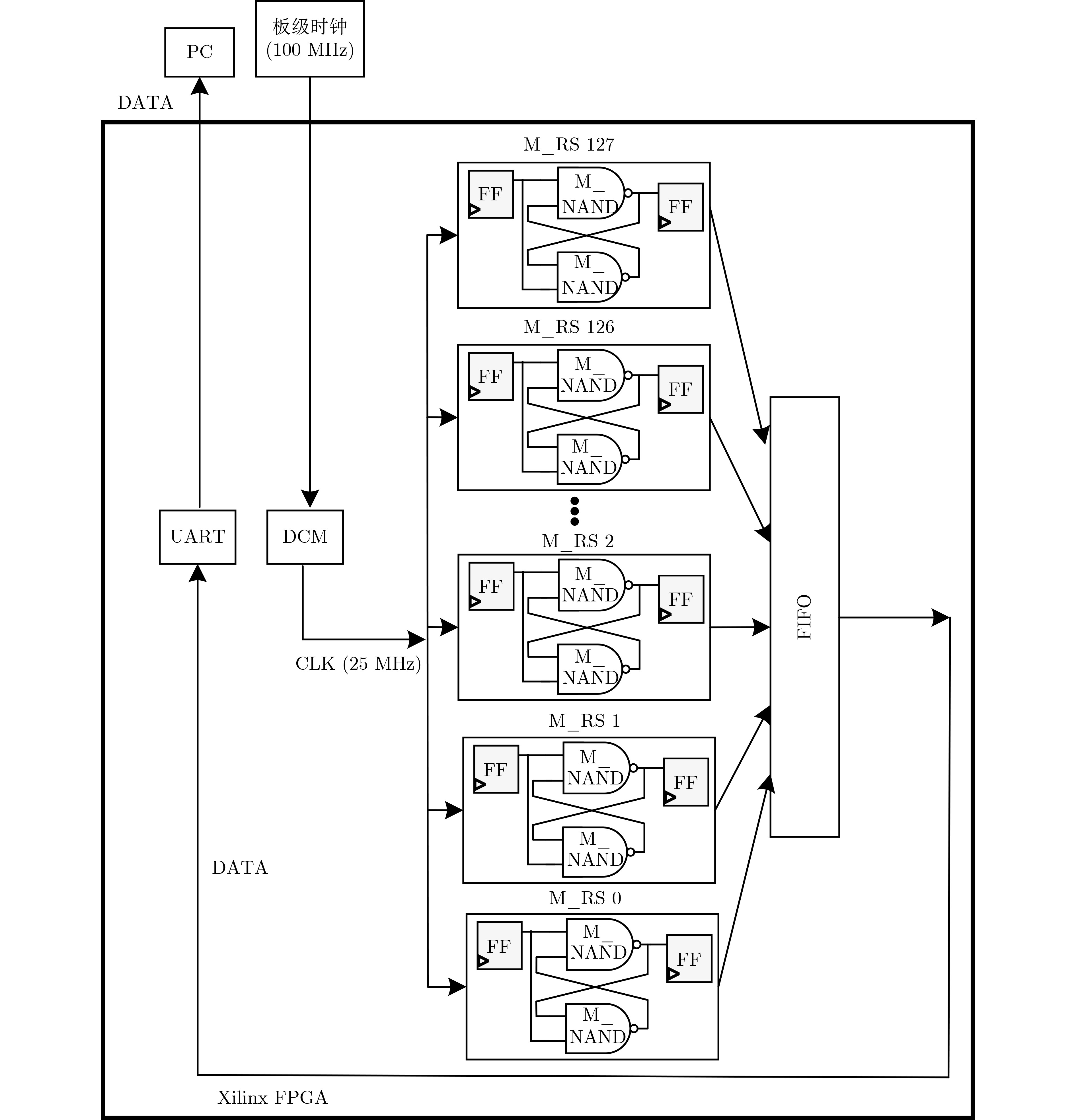
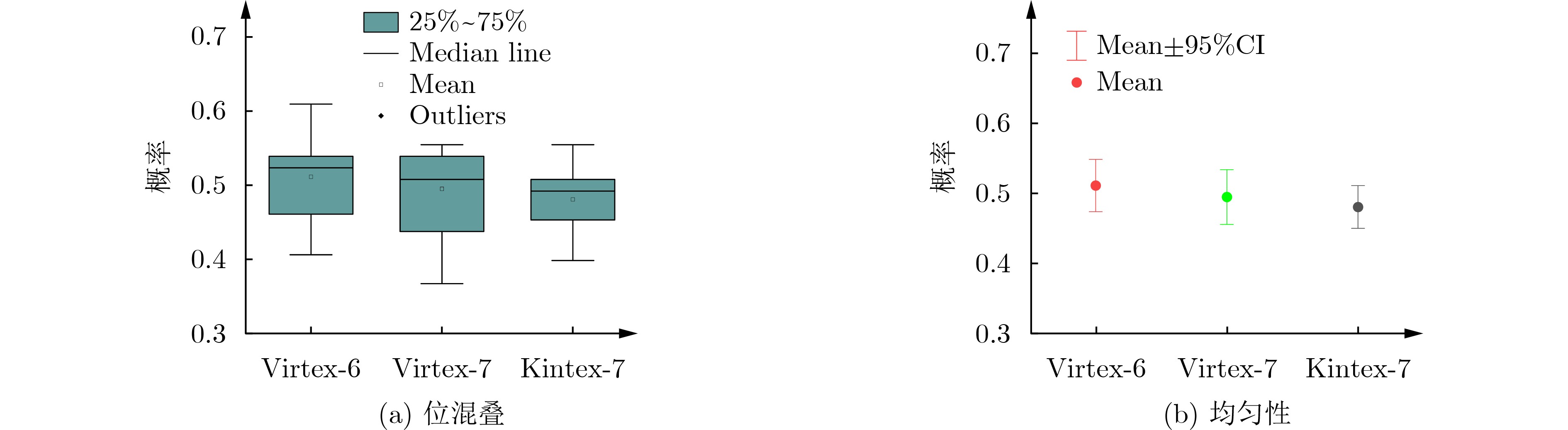
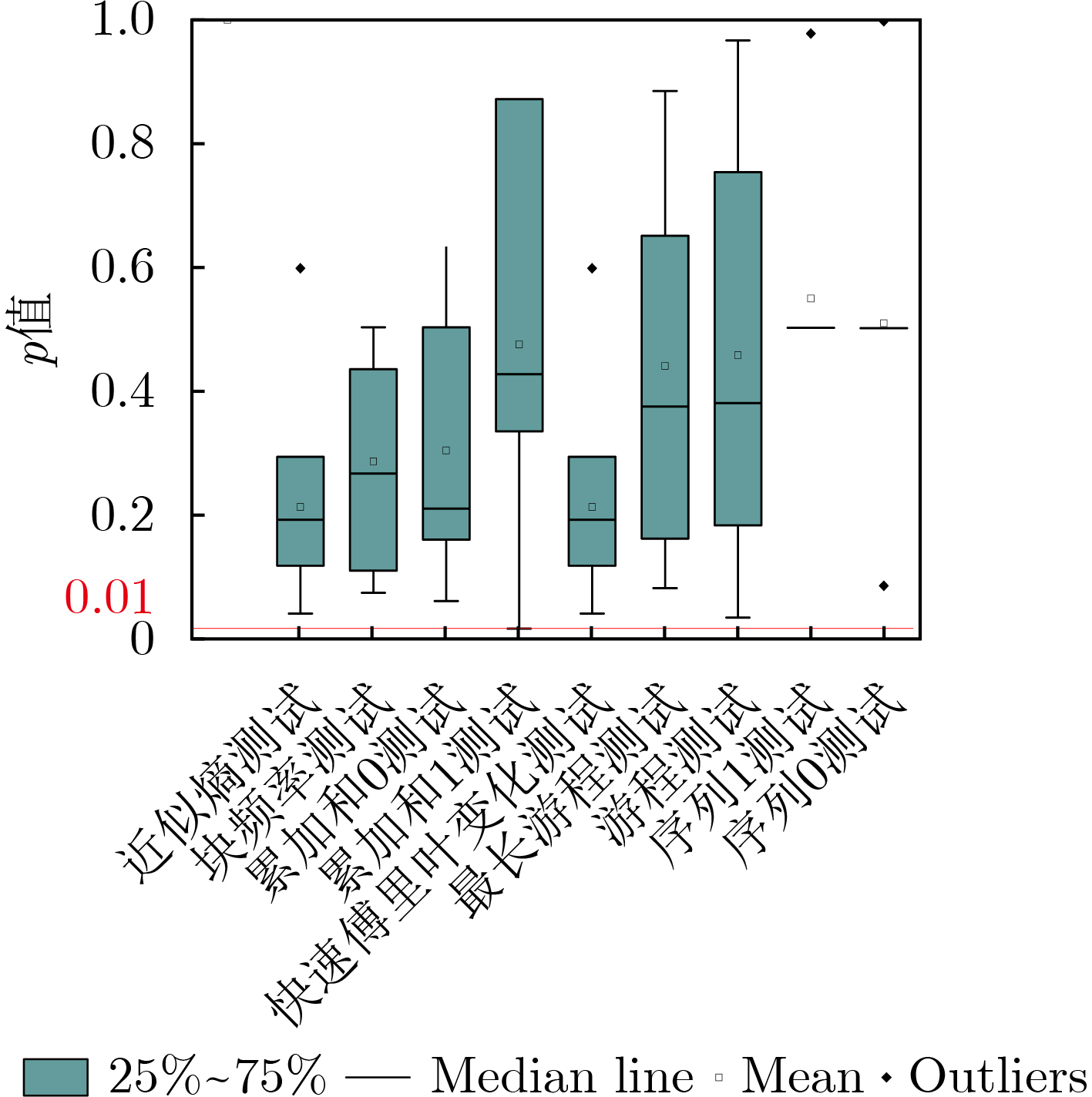
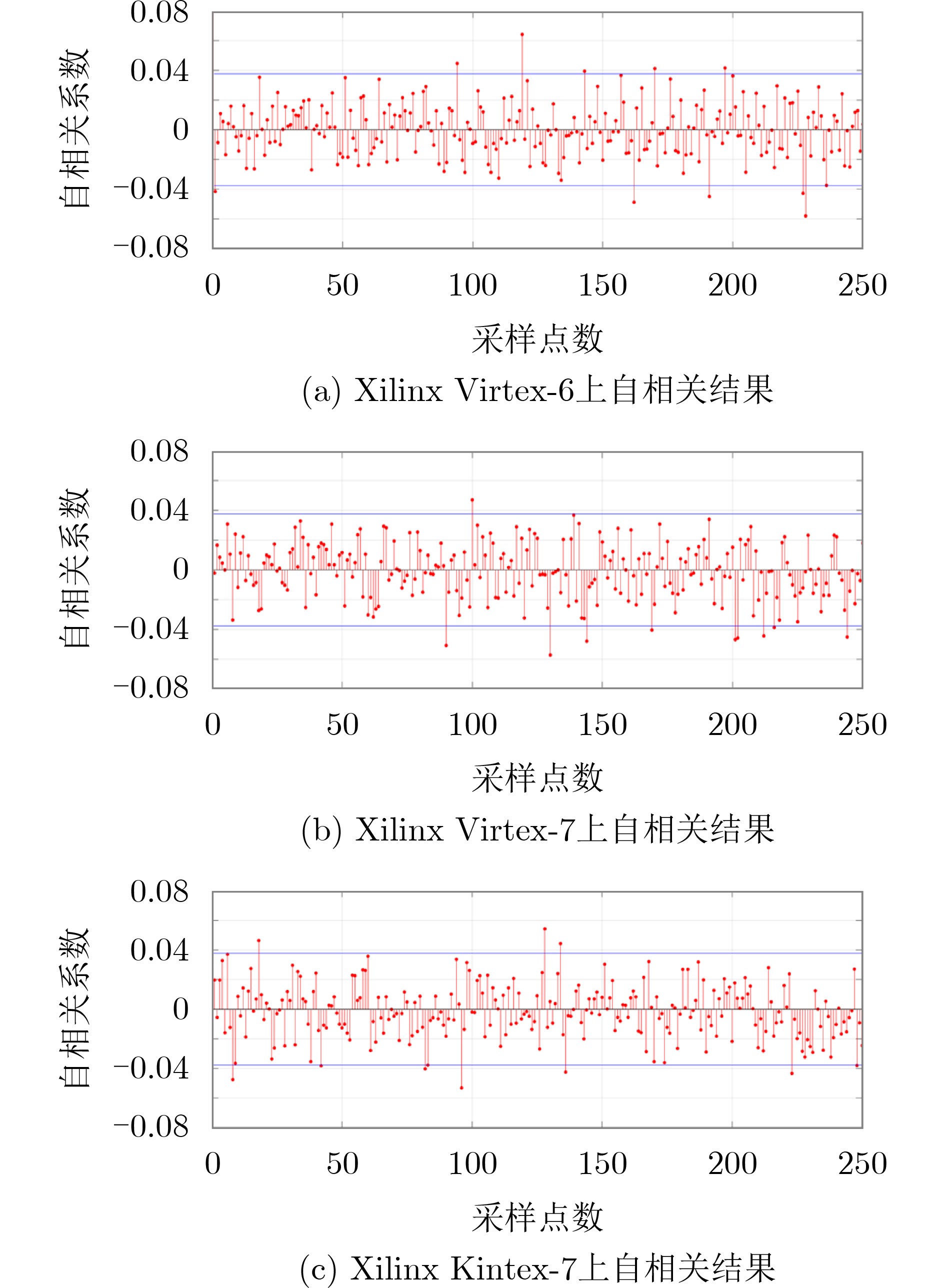
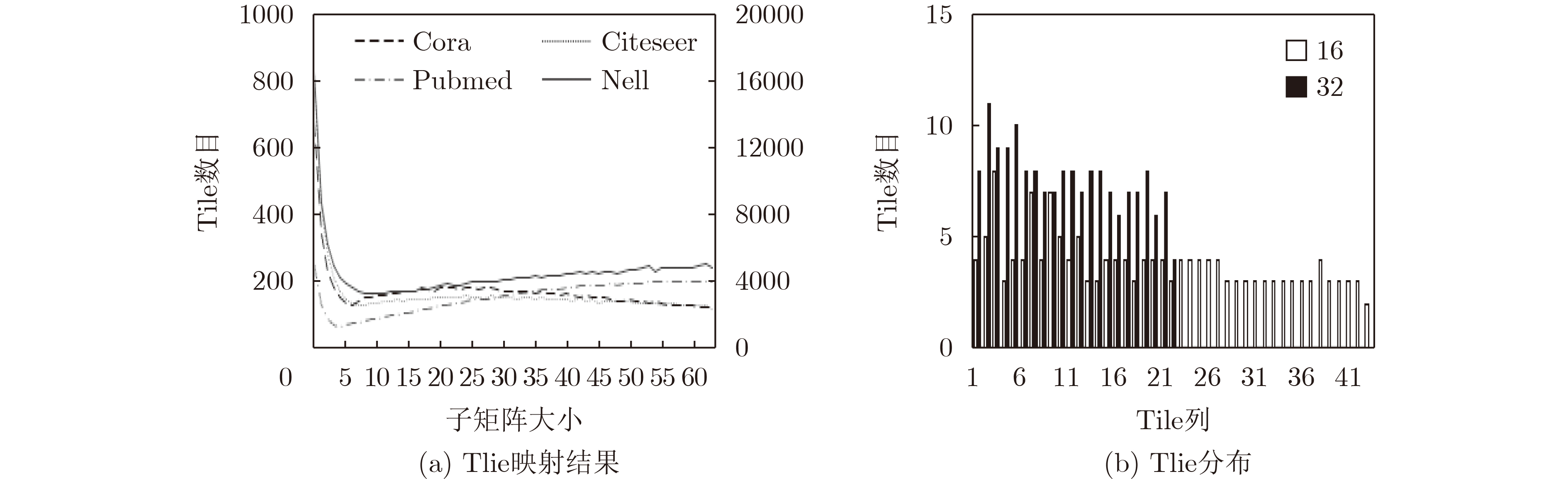
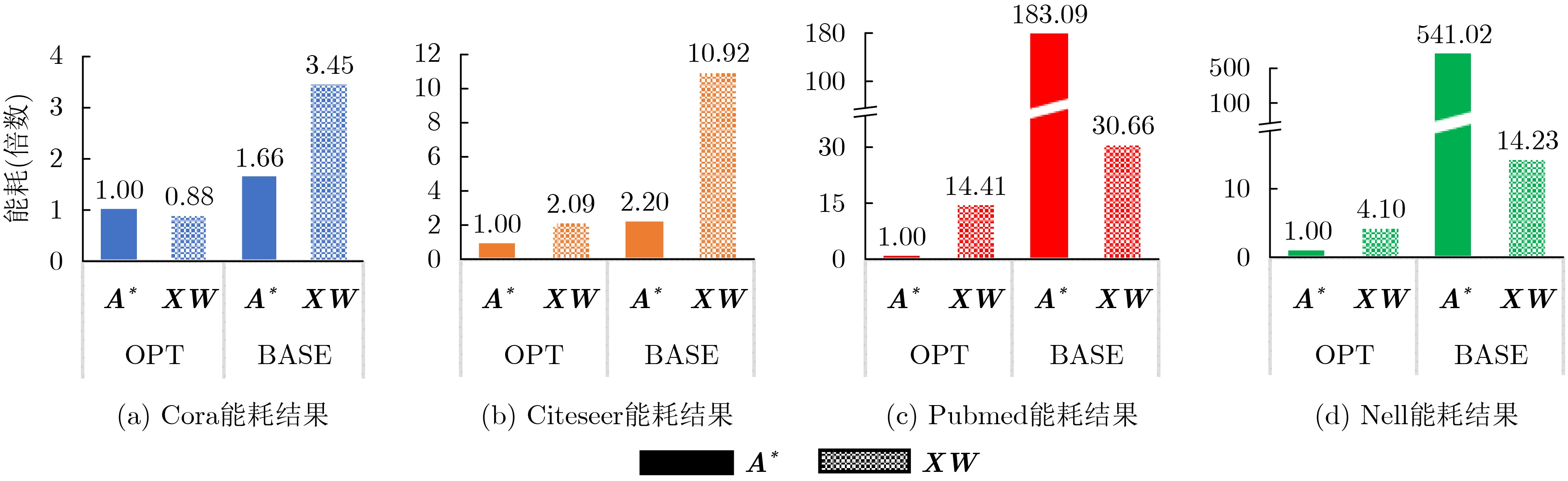
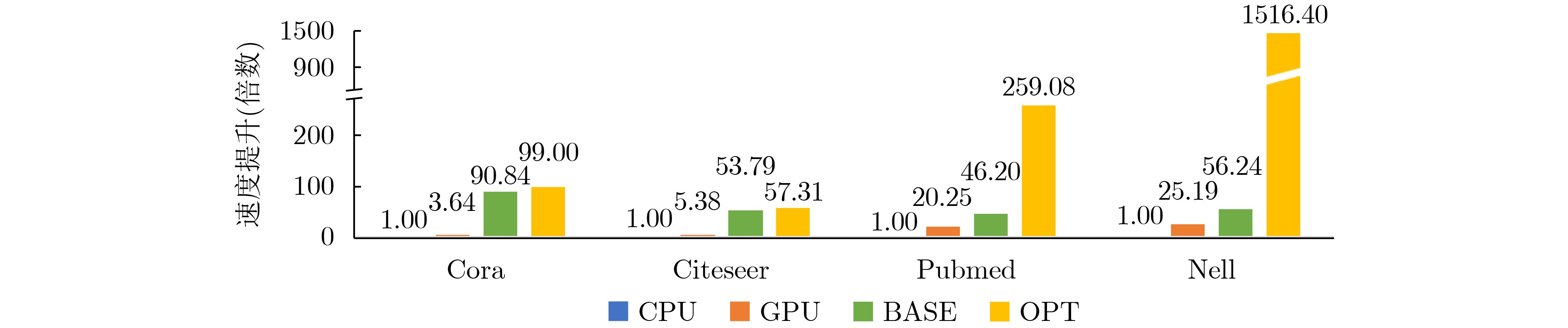
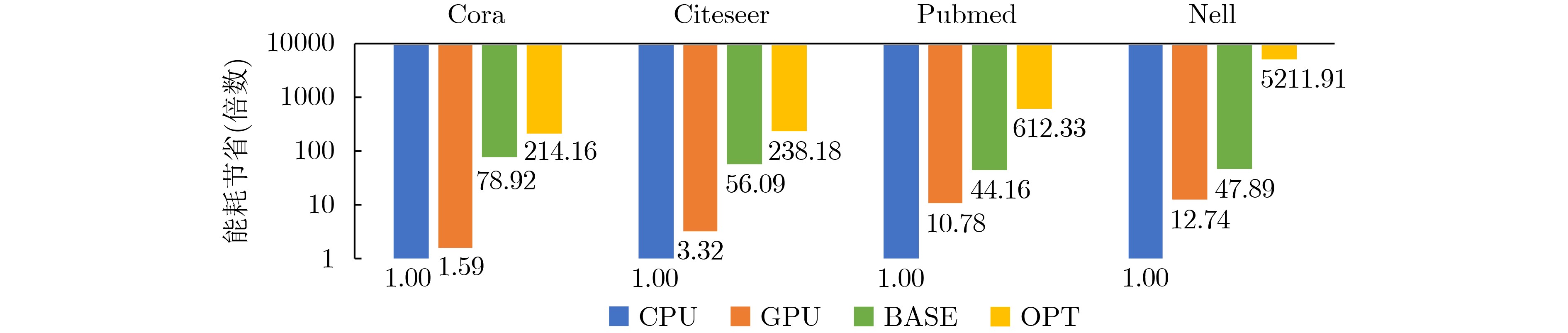
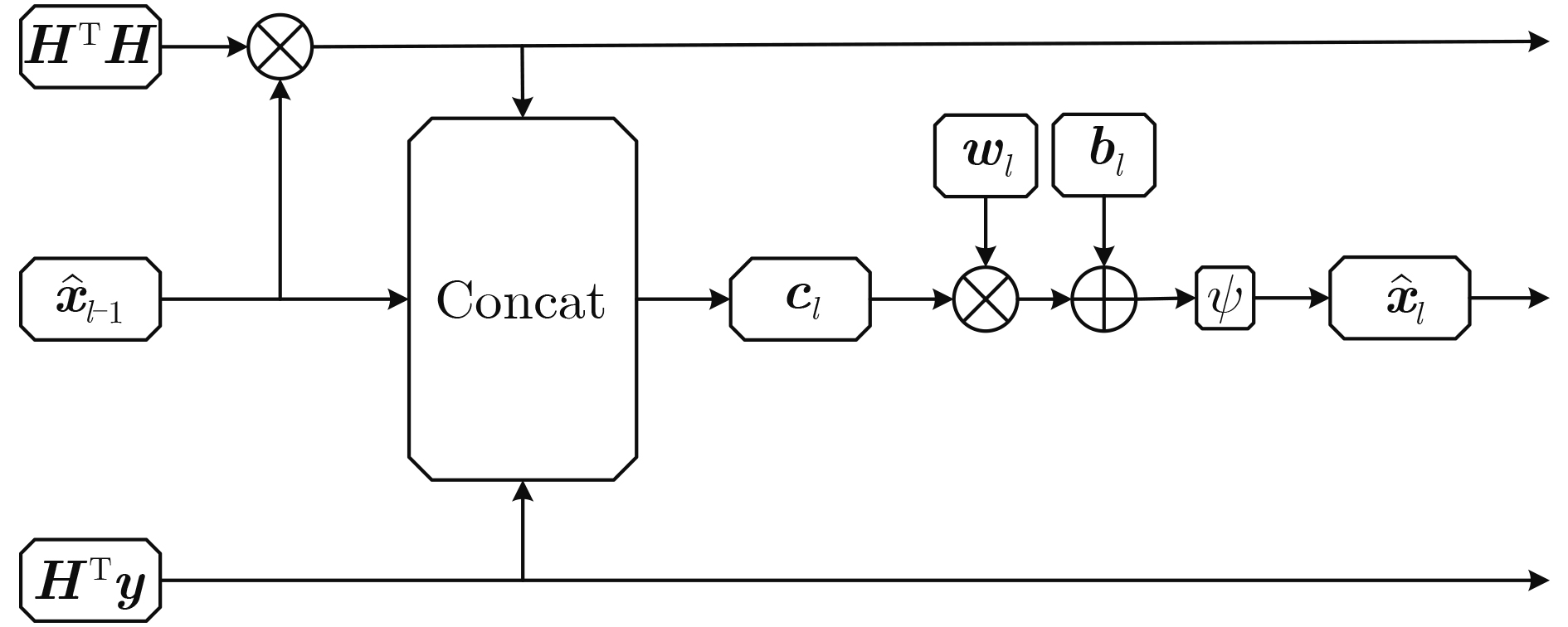
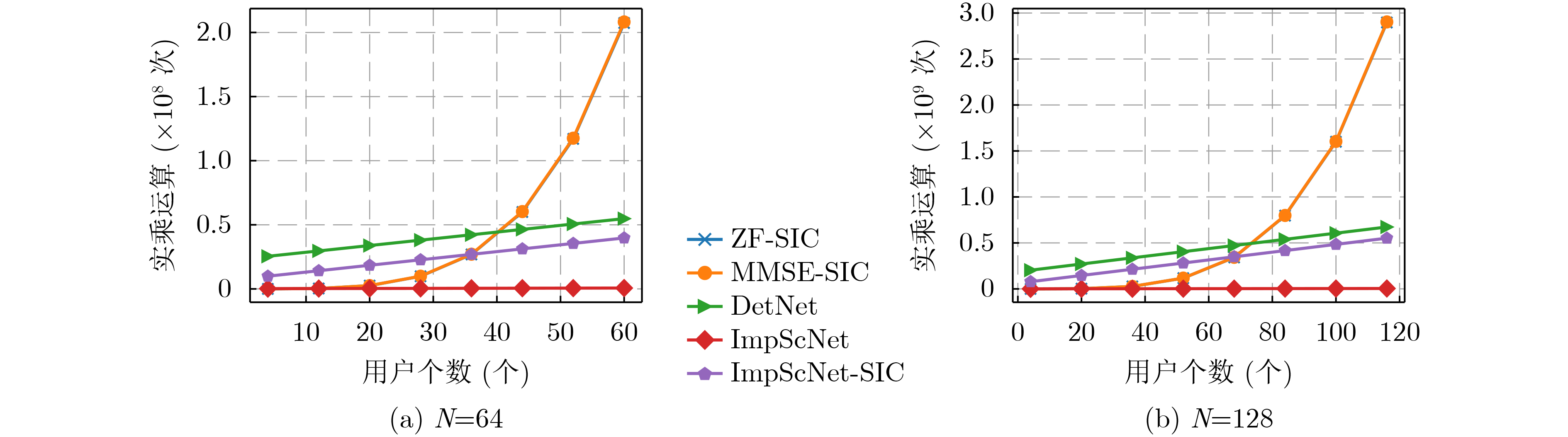
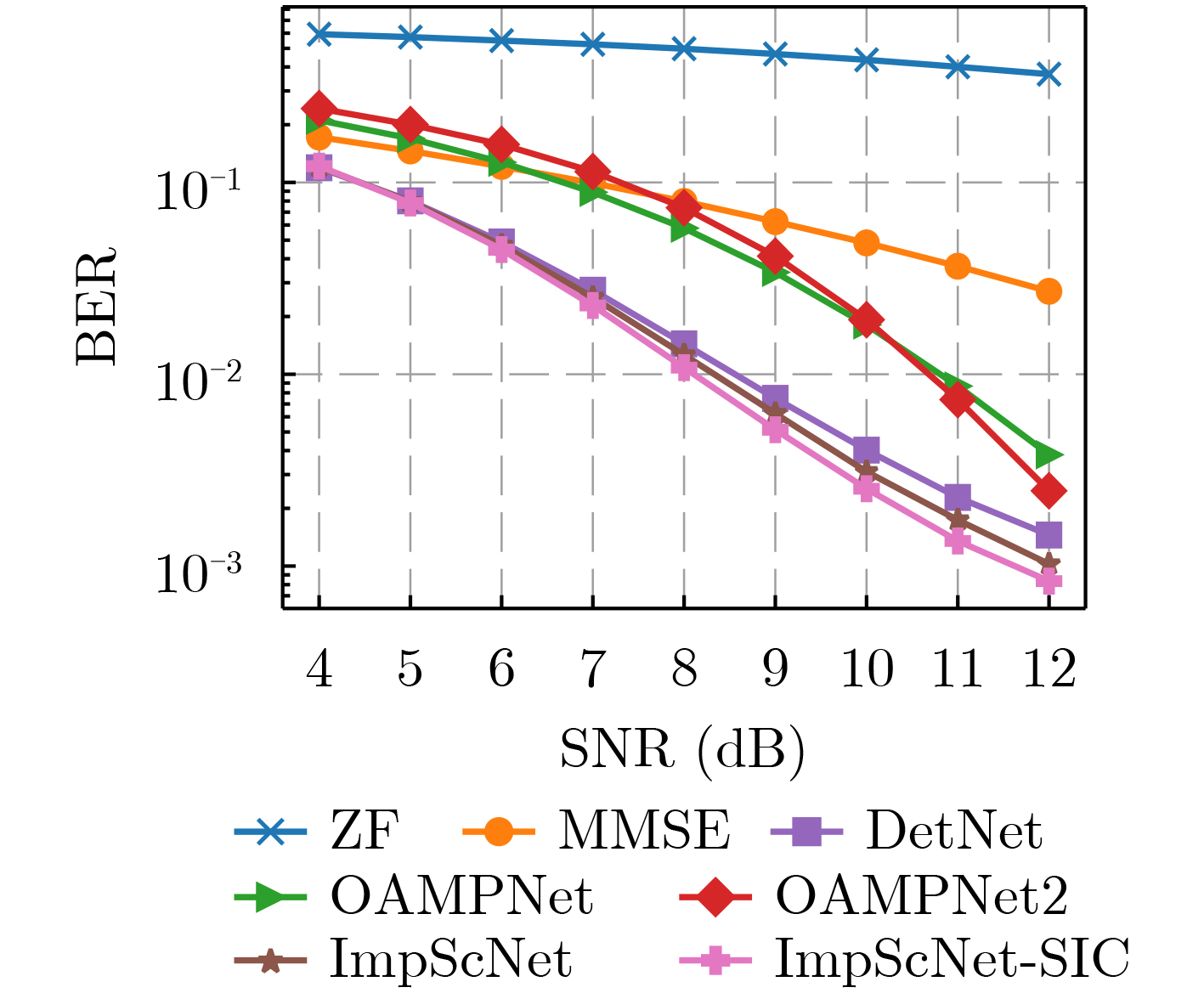
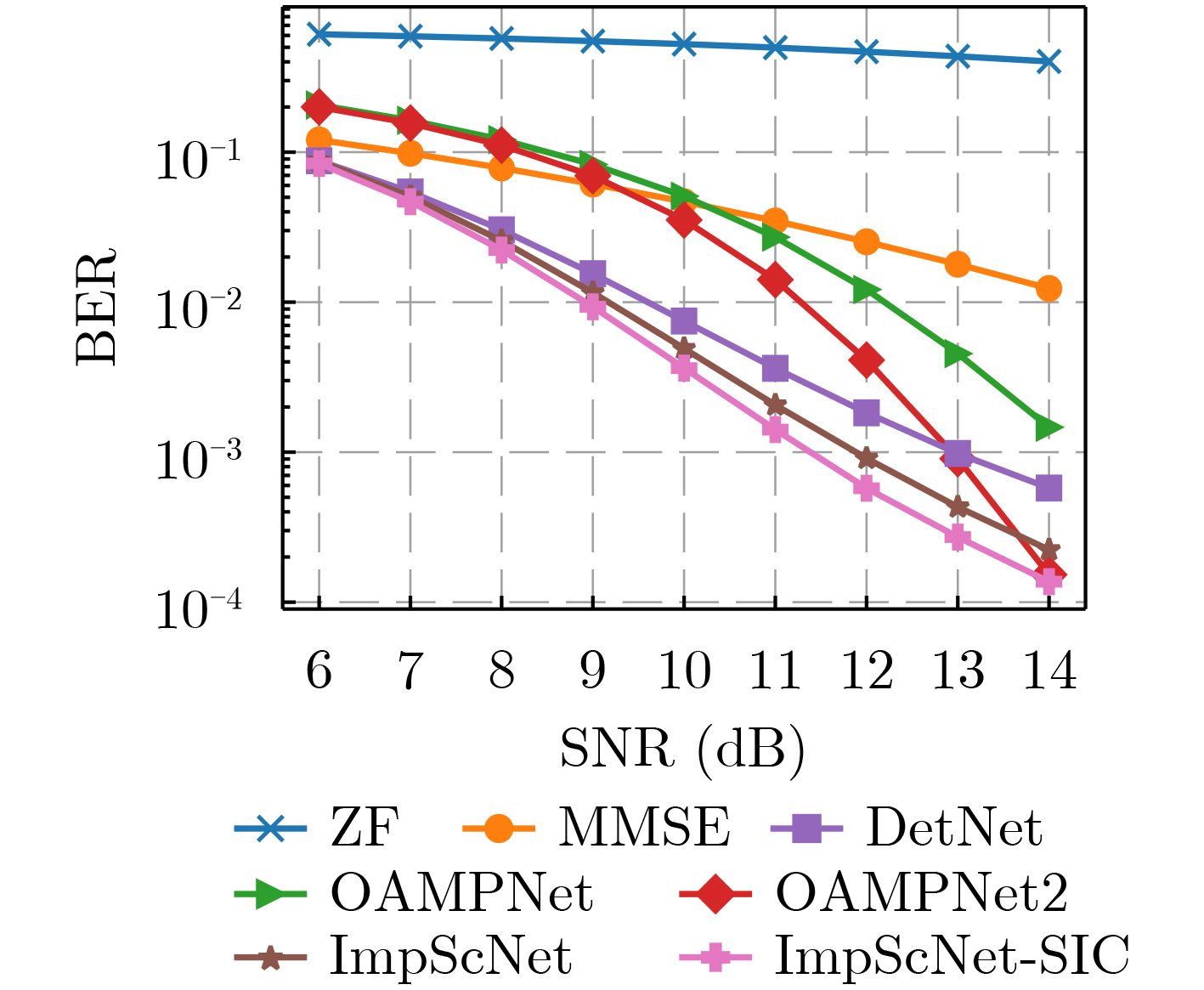
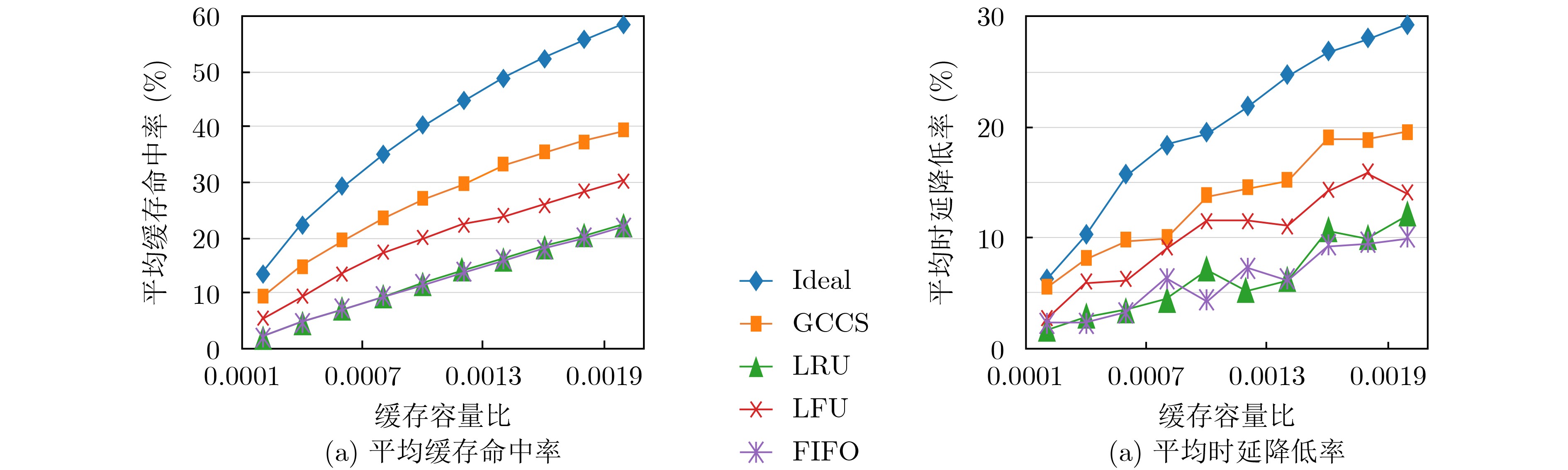
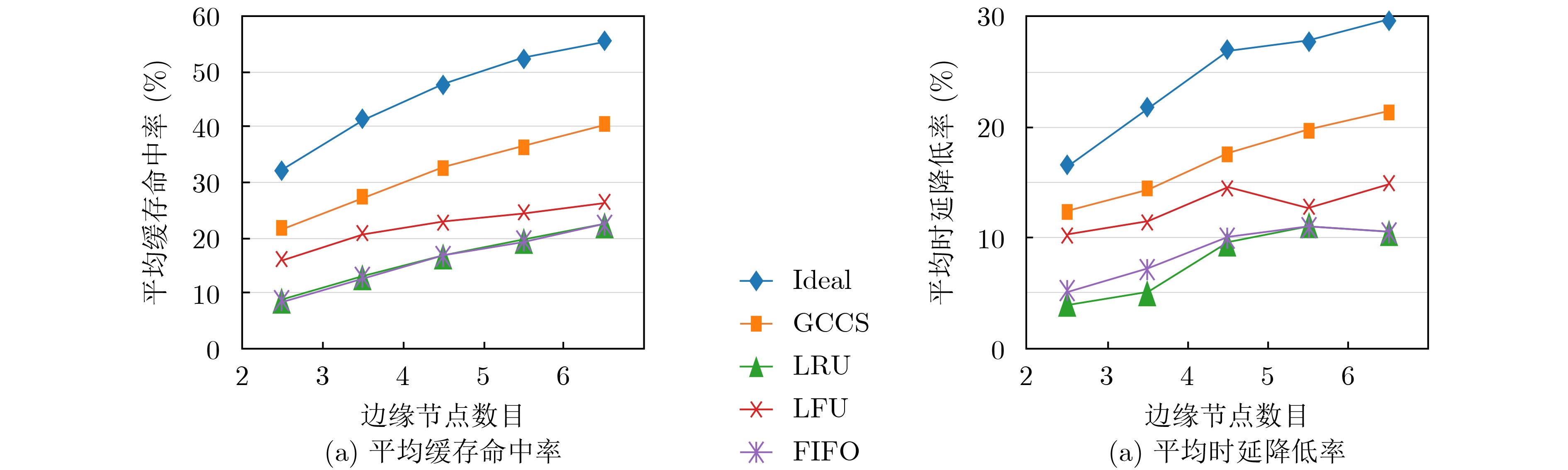
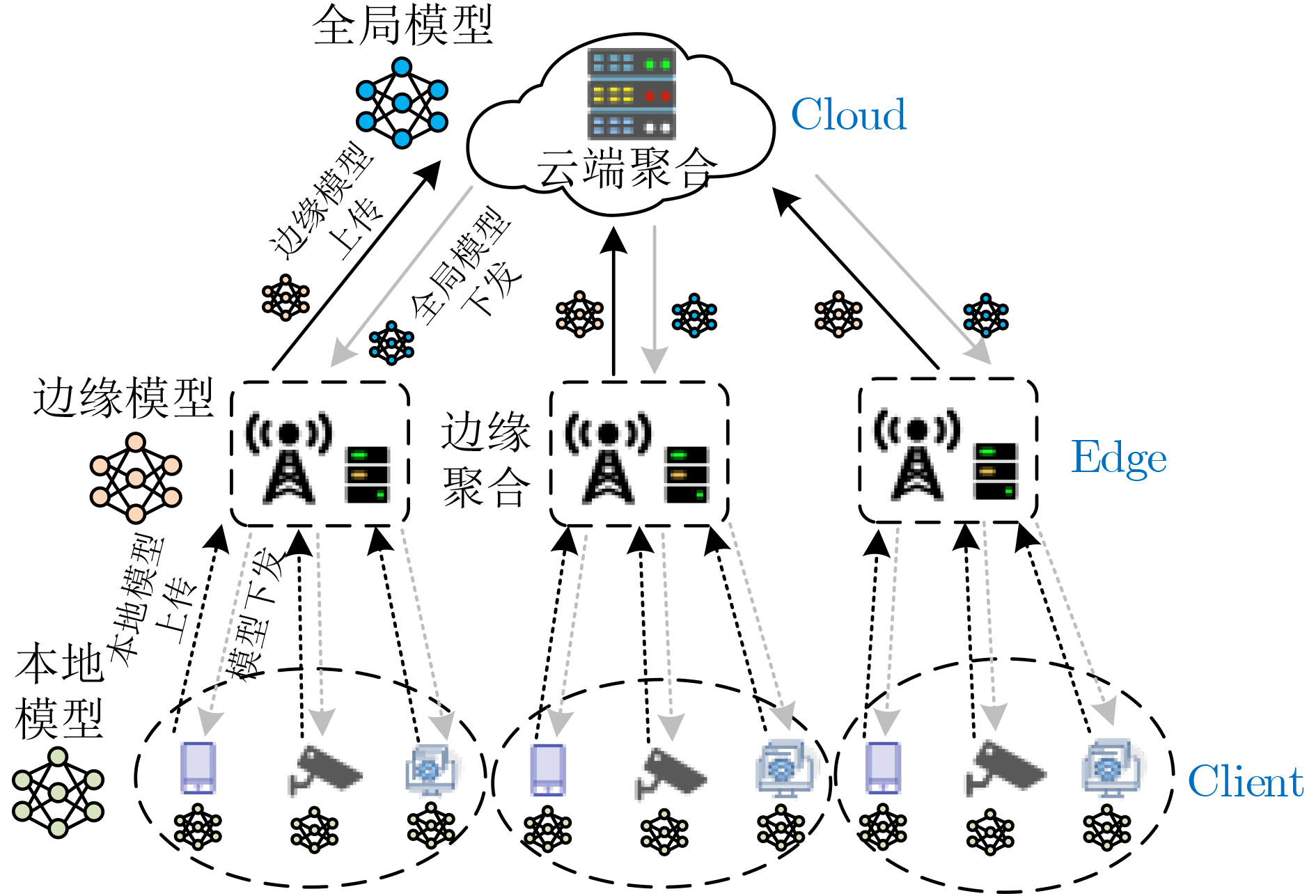
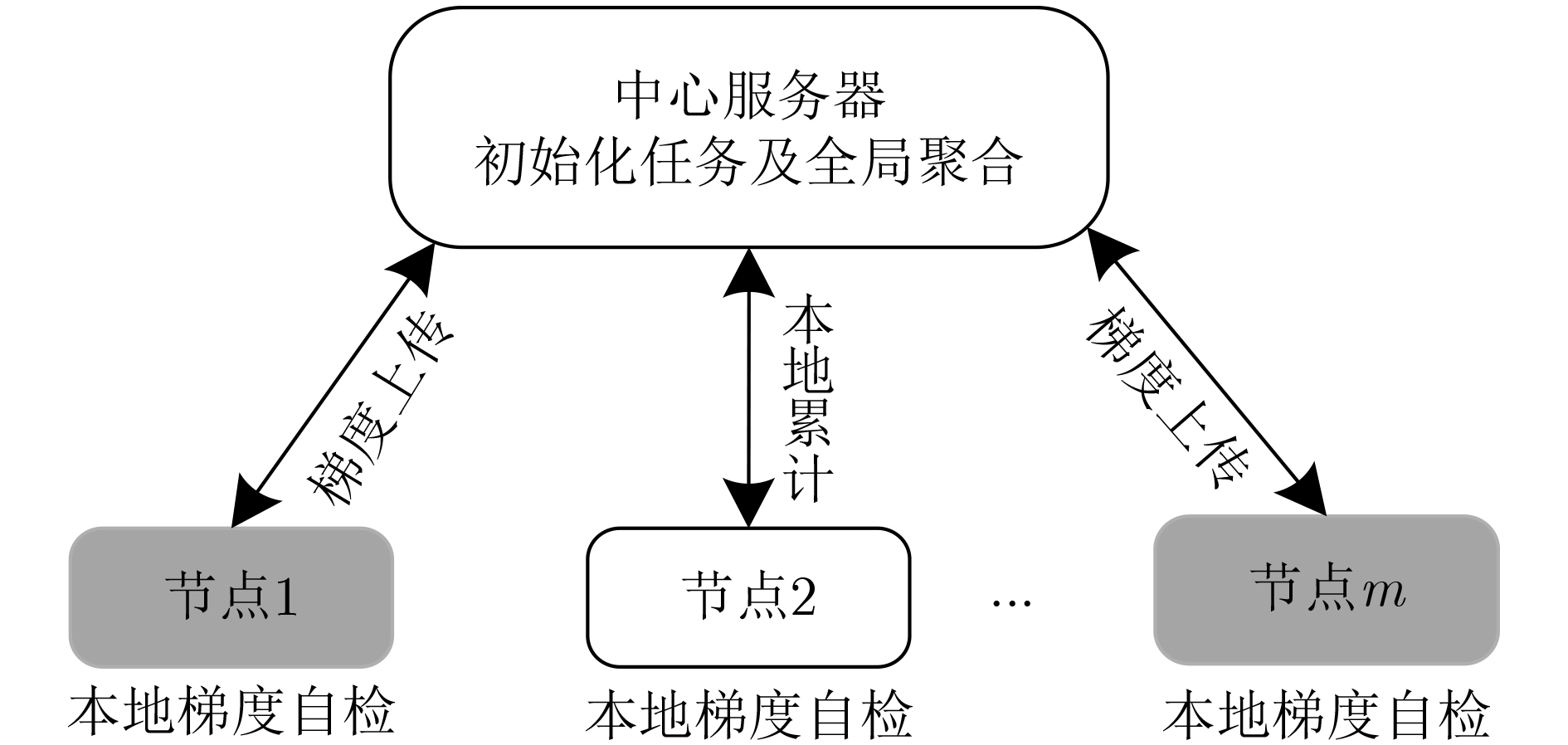
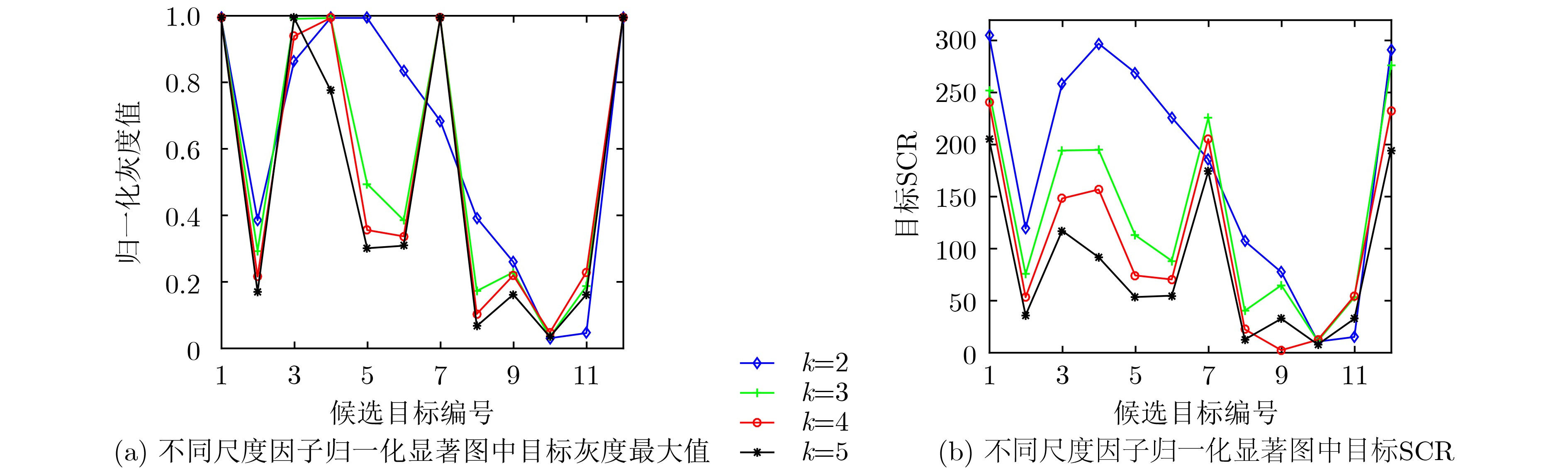
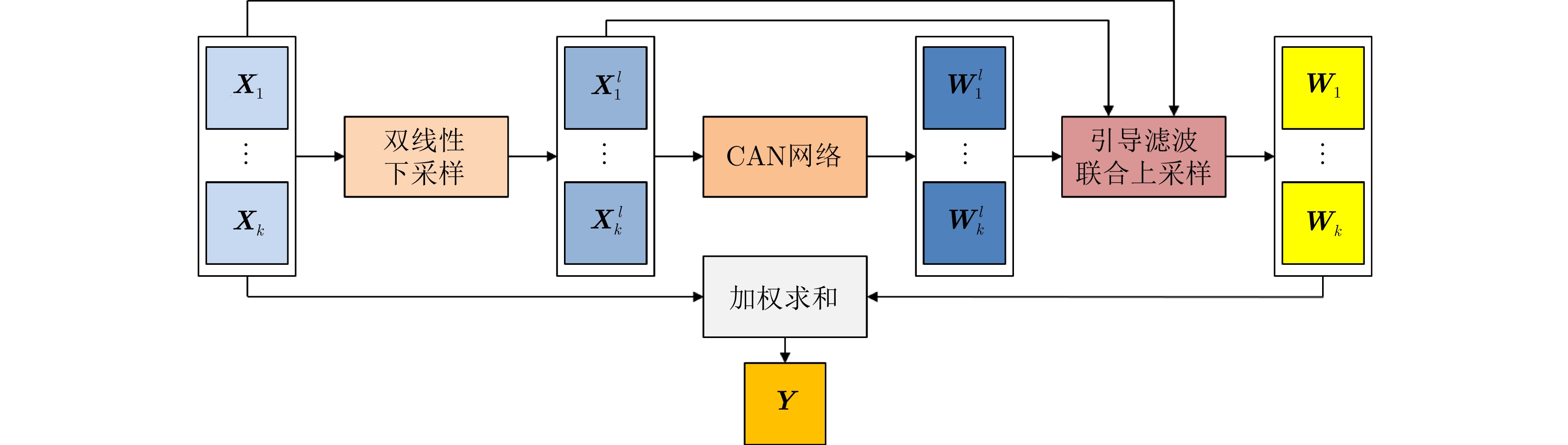
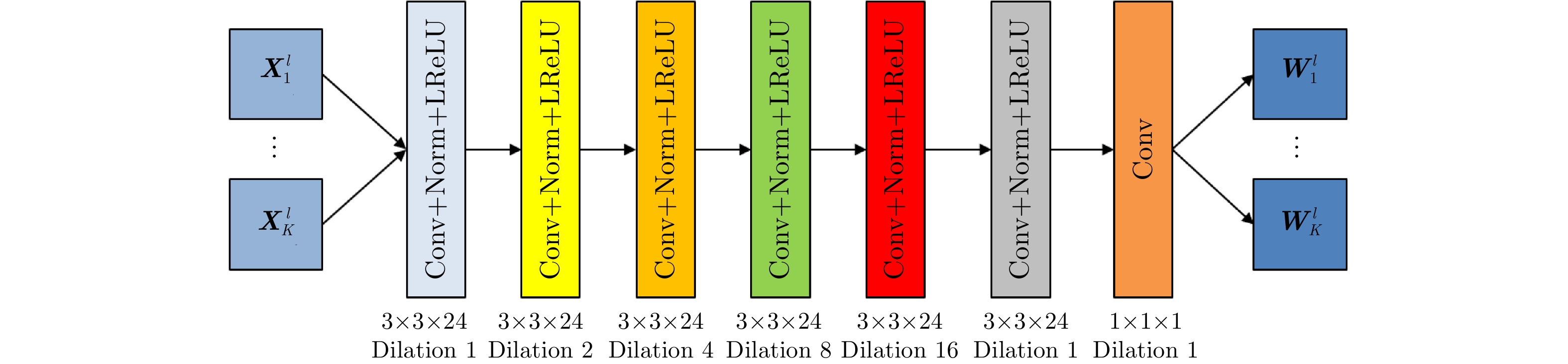
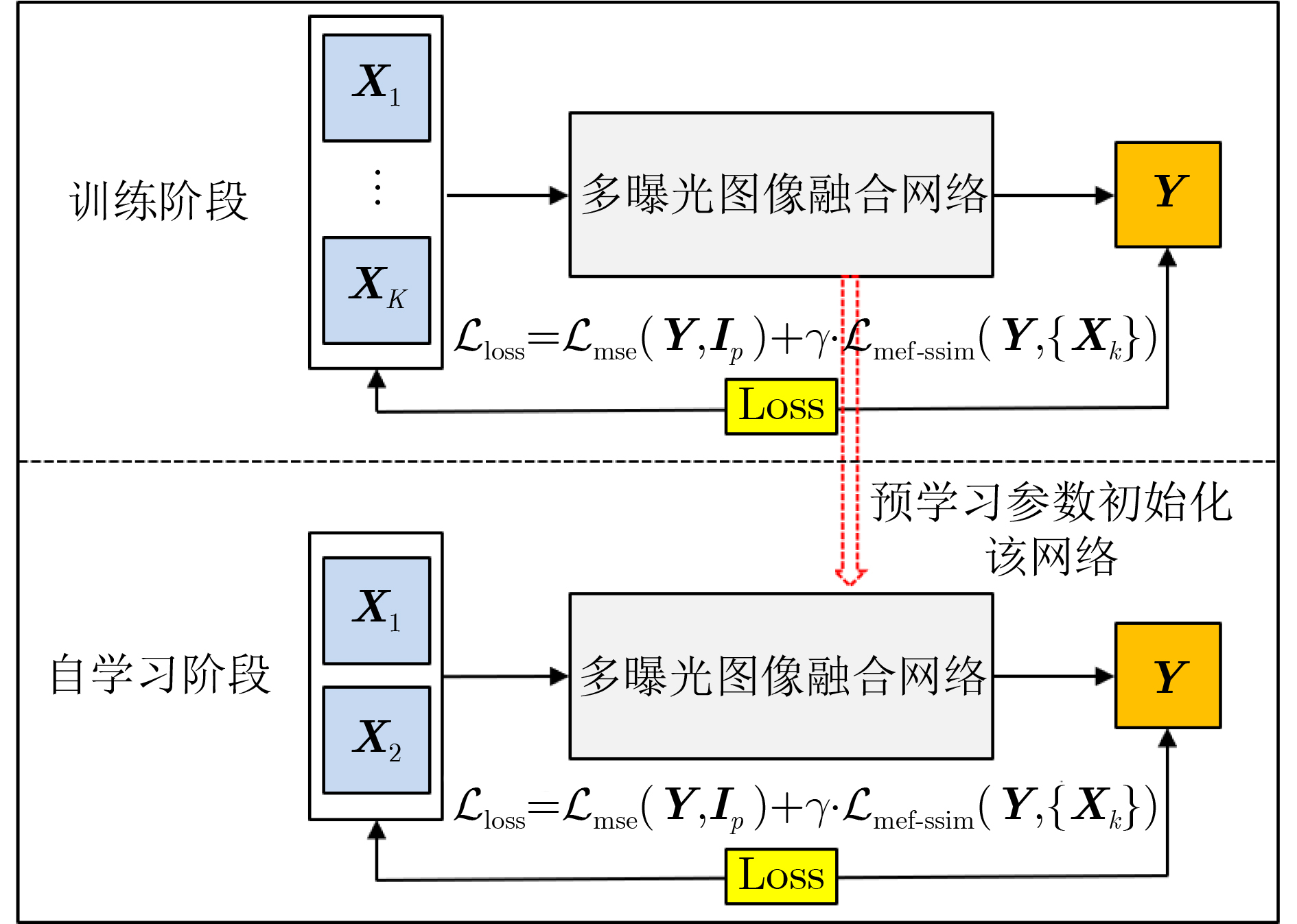
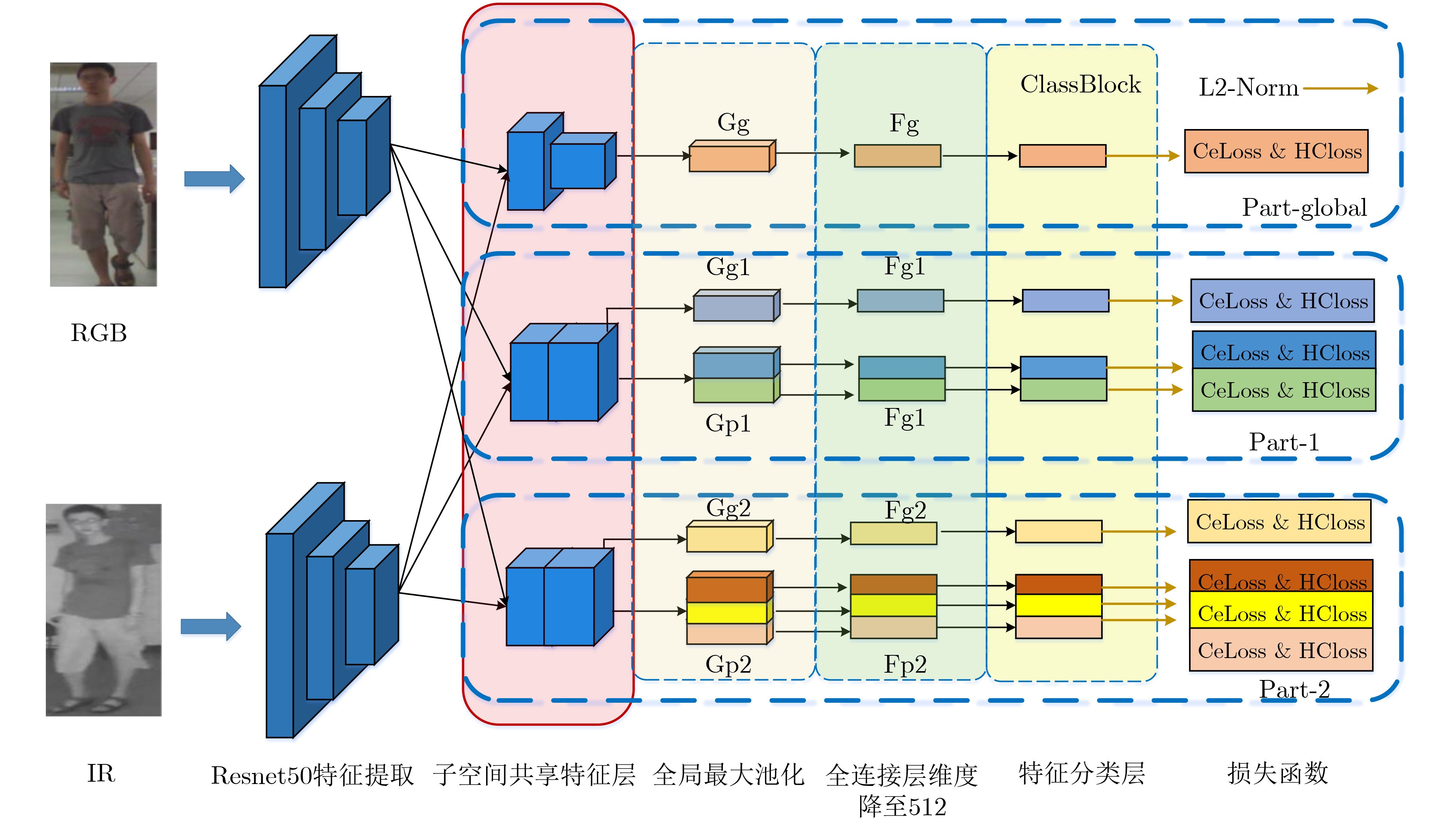
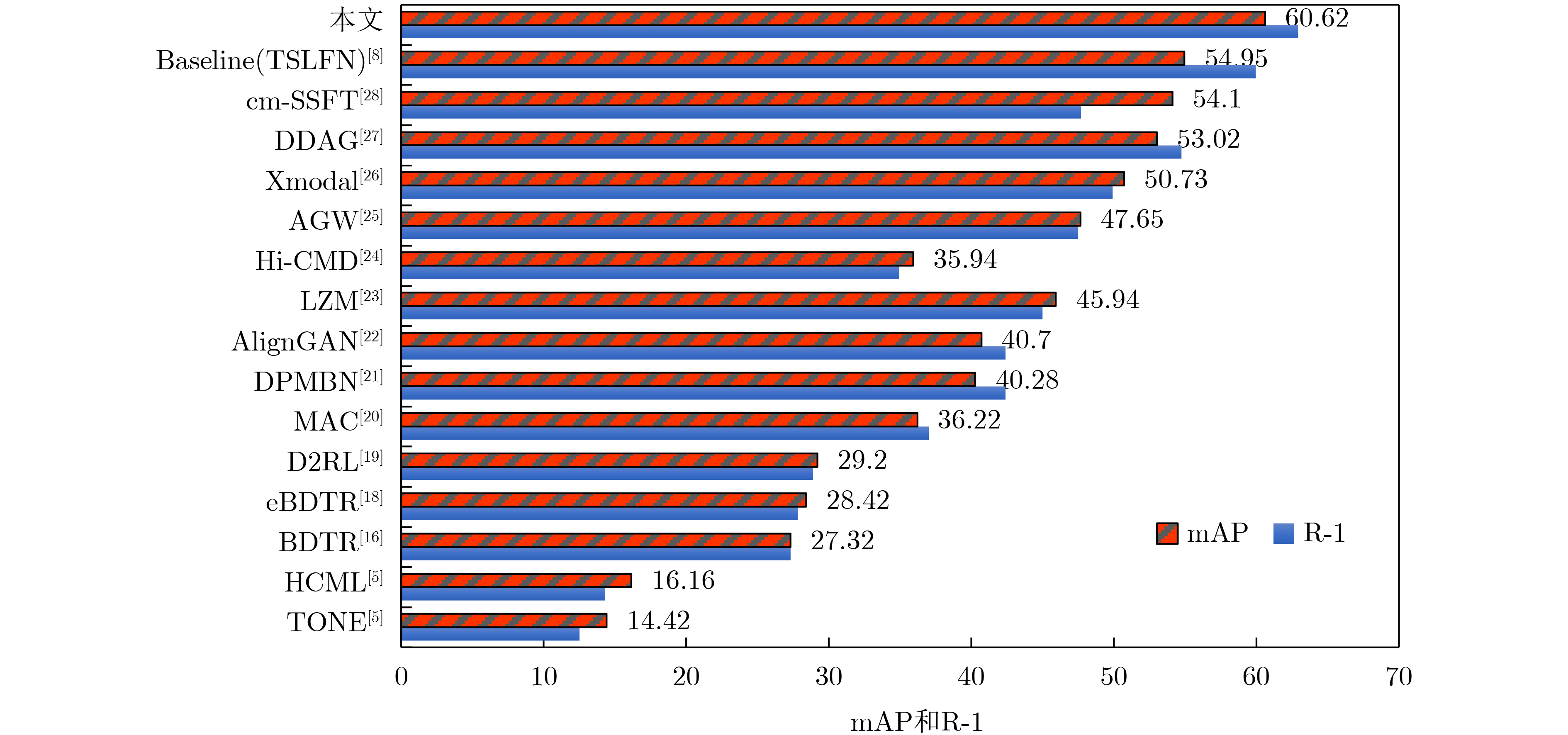
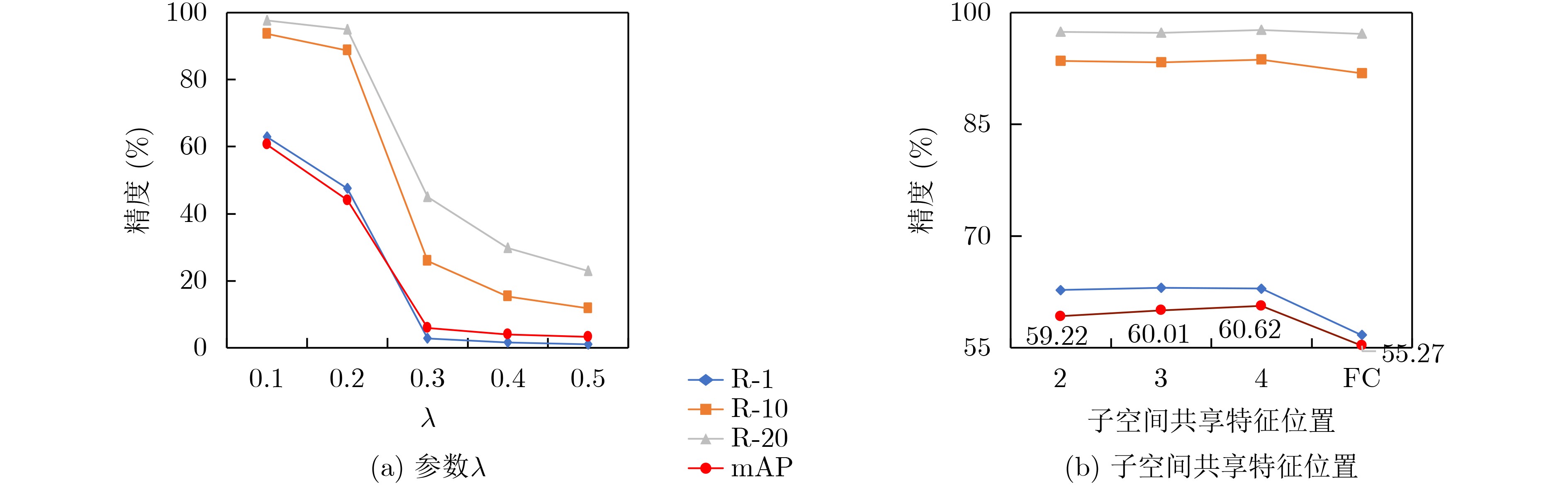
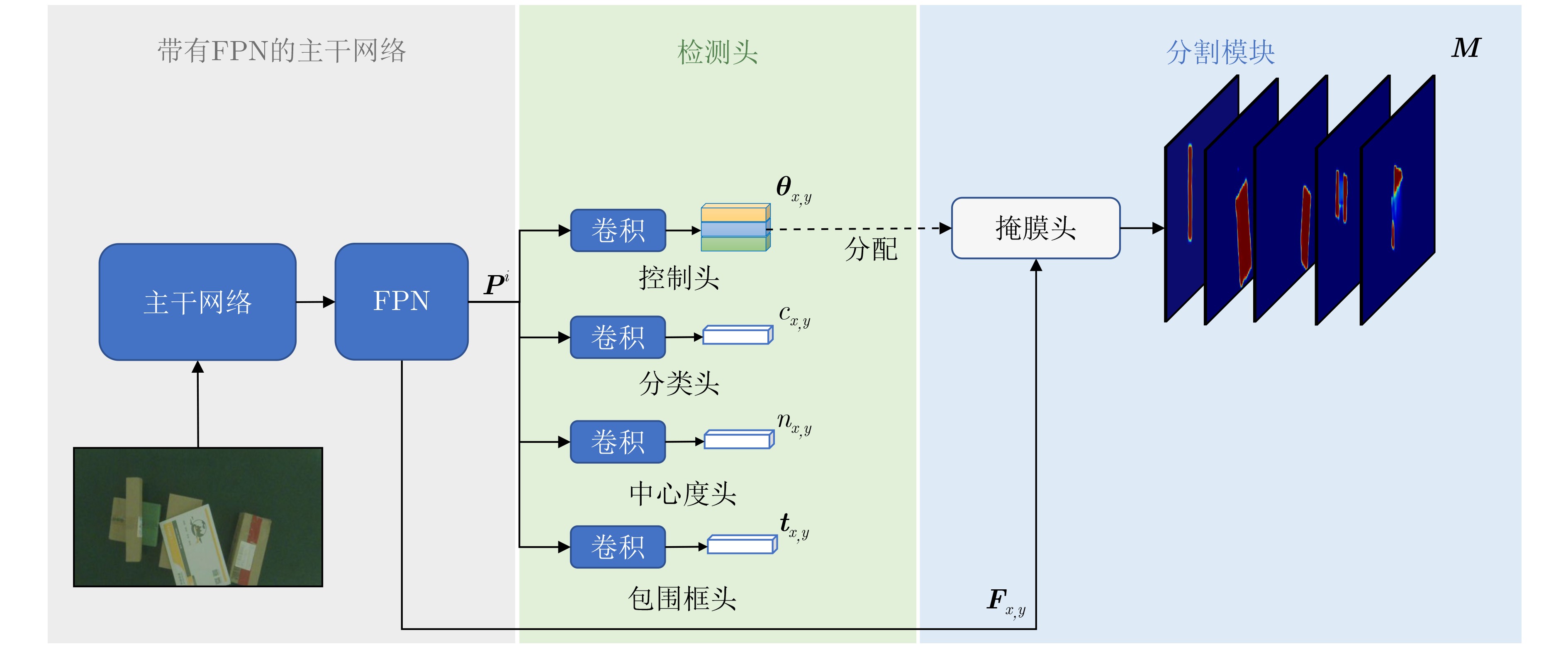
2023, 45(1): 371-382.
doi: 10.11999/JEIT211185
Abstract:
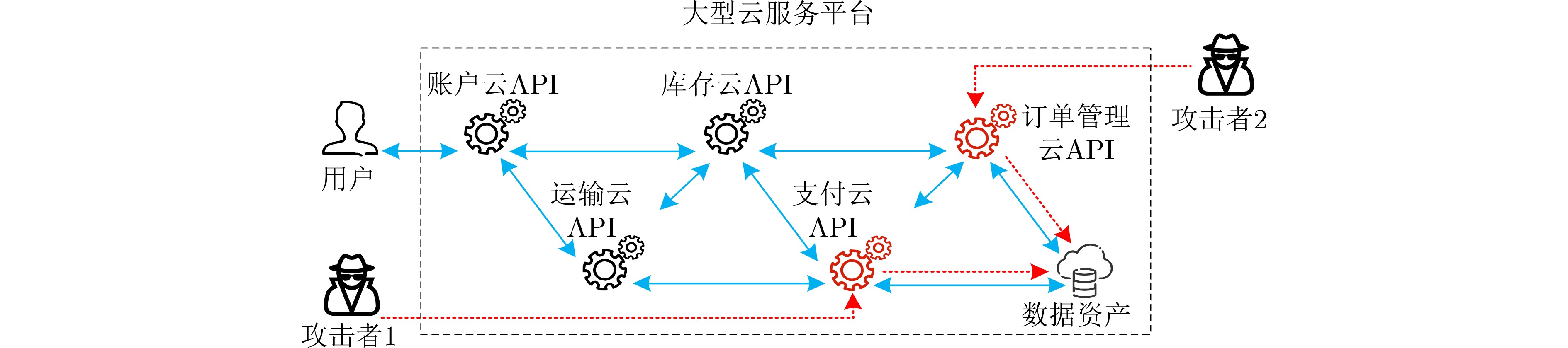
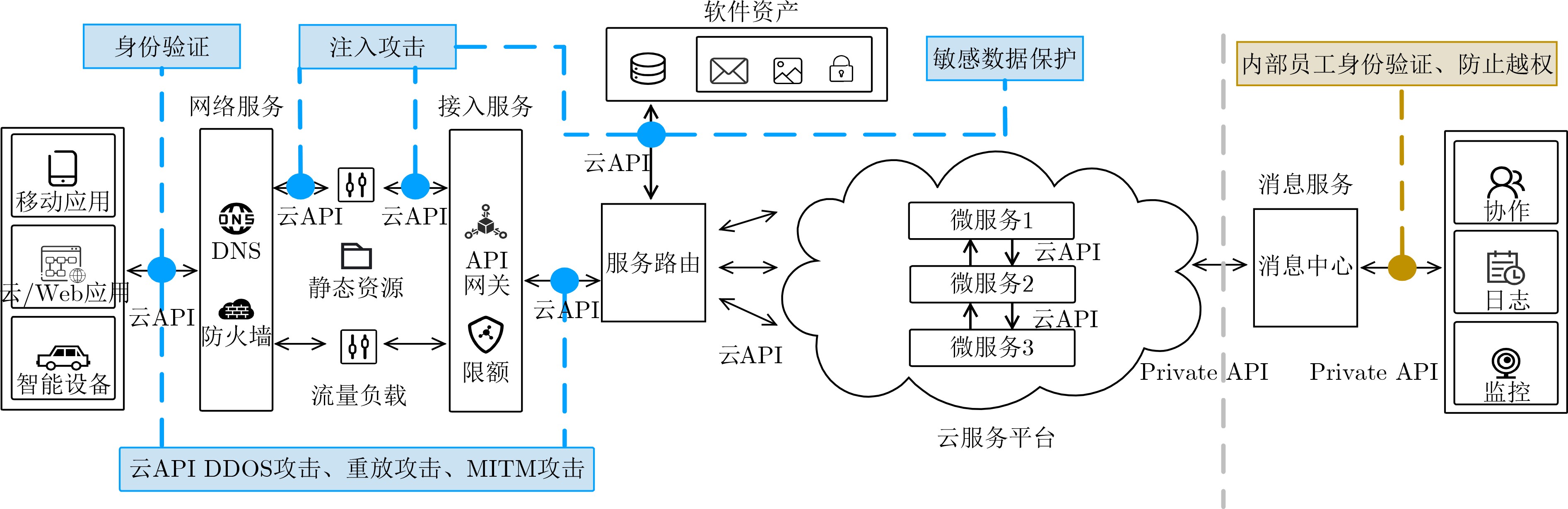
In the cloud era, cloud Application Programming Interface (API) is the best carrier for service delivery, capability replication and data output. However, cloud API increases the exposure and attack surface of cloud application while opening up services and data. Through data hijacking, traffic analysis and other technologies, attackers can obtain the key resources of the target cloud API, so as to identify the identity and behavior of users, or even directly cause the paralysis of the underlying system. Currently, there are many types of attacks against cloud APIs, and their threats and protection methods are different. However, the existing researches lack a systematic summary for cloud API attack and protection methods. In this paper, a detail survey on the threats and protection methods faced by cloud API is conducted. Firstly, the evolution and the classification of cloud API are analyzed. The vulnerability of cloud API and the importance of cloud API security research are then discussed. Furthermore, a systematical cloud API security research framework is proposed, which covers six aspects: identity authentication, cloud API Distributed Denial of Service (DDoS) attack protection, replay attack protection, Man-In-The-Middle (MITM) attack protection, injection attack protection and sensitive data protection. In addition, the necessity of Artificial Intelligence (AI) protection for cloud API is discussed. Finally, the future challenges and development trends of cloud API protection are presented.