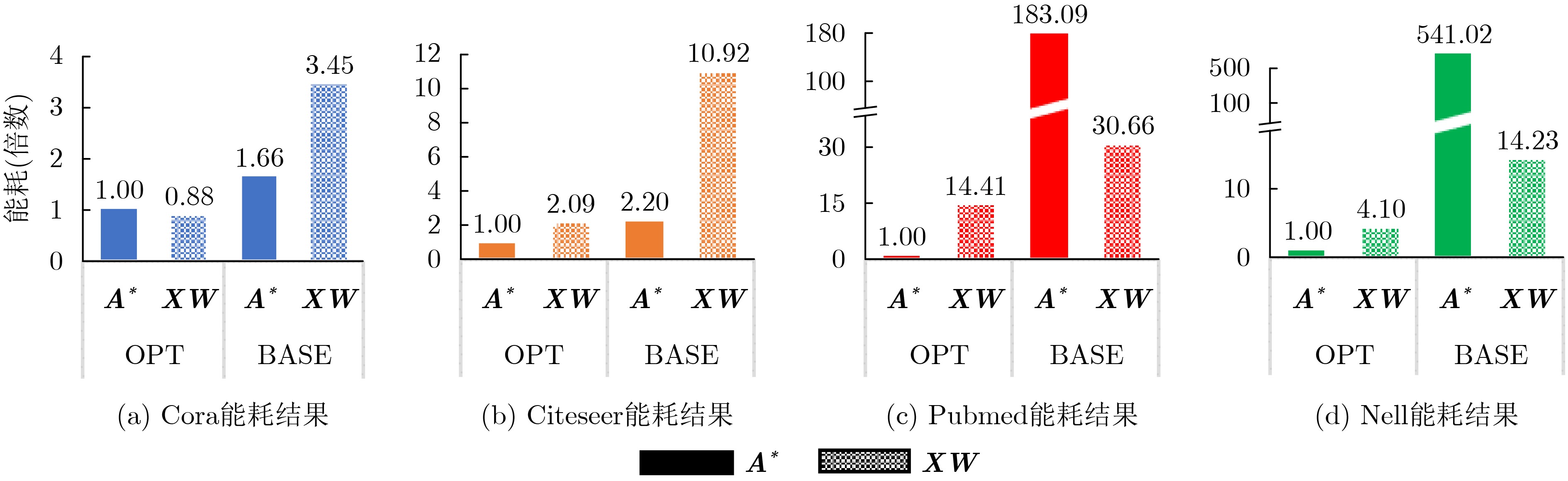
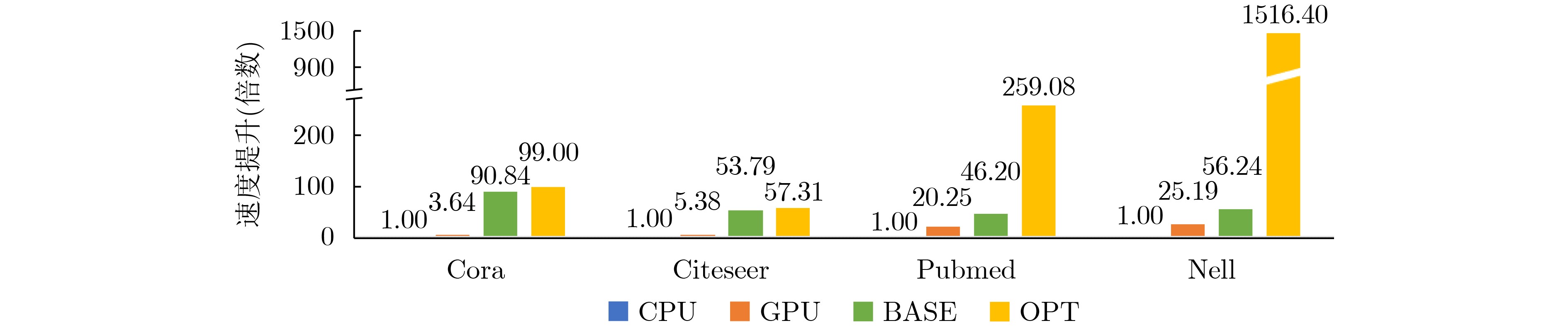
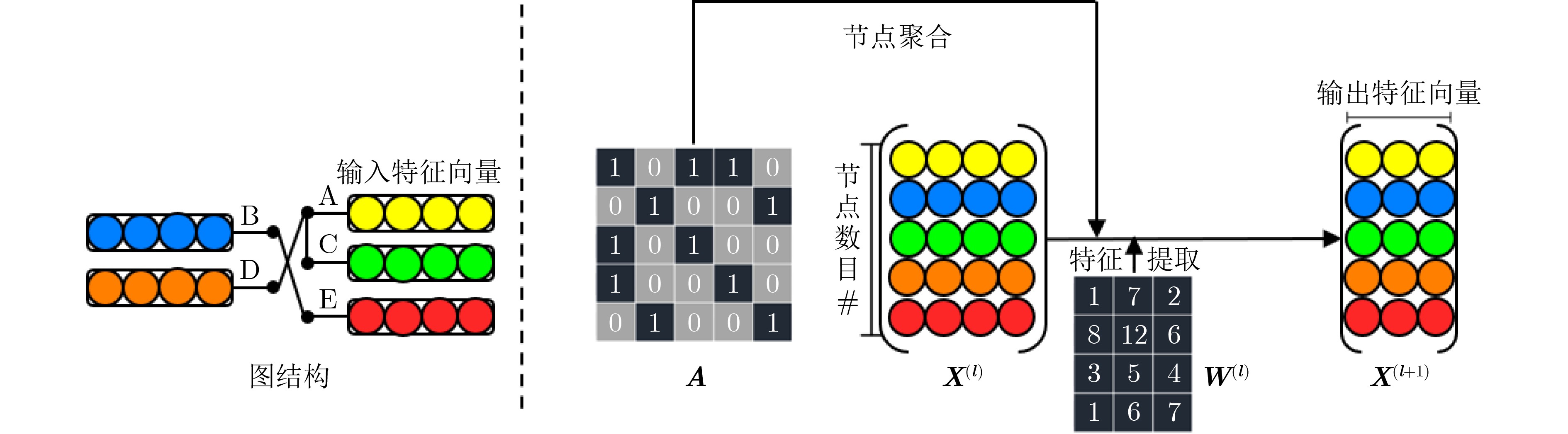
| Citation: | LI Bing, WU Kangjun, WANG Jing, LI Sen, GAO Lan, ZHANG Weigong, NI Tianming. Design of Graph Convolutional Network Accelerator Based on Resistive Random Access Memory[J]. Journal of Electronics & Information Technology, 2023, 45(1): 106-115. doi: 10.11999/JEIT211435

|

| [1] |
KIPF T N and WELLING M. Semi-supervised classification with graph convolutional networks[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [2] |
PARK H W, PARK S, and CHONG M. Conversations and medical news frames on twitter: Infodemiological study on COVID-19 in South Korea[J]. Journal of Medical Internet Research, 2020, 22(5): e18897. doi: 10.2196/18897
|
| [3] |
SHI Chence, XU Minkai, ZHU Zhaocheng, et al. GraphAF: A flow-based autoregressive model for molecular graph generation[C]. The 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [4] |
YAN Mingyu, DENG Lei, HU Xing, et al. HyGCN: A GCN accelerator with hybrid architecture[C]. 2020 IEEE International Symposium on High Performance Computer Architecture, San Diego, USA, 2020: 15–29.
|
| [5] |
GENG Tong, LI Ang, SHI Runbin, et al. AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing[C]. The 53rd Annual IEEE/ACM International Symposium on Microarchitecture, Athens, Greece, 2020: 922–936.
|
| [6] |
LIANG Shengwen, WANG Ying, LIU Cheng, et al. EnGN: A high-throughput and energy-efficient accelerator for large graph neural networks[J]. IEEE Transactions on Computers, 2021, 70(9): 1511–1525. doi: 10.1109/TC.2020.3014632
|
| [7] |
WONG H S P, LEE H Y, YU Shimeng, et al. Metal–oxide RRAM[J]. Proceedings of the IEEE, 2012, 100(6): 1951–1970. doi: 10.1109/JPROC.2012.2190369
|
| [8] |
SHAFIEE A, NAG A, MURALIMANOHAR N, et al. ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars[C]. The ACM/IEEE 43rd Annual International Symposium on Computer Architecture, Seoul, Korea, 2016: 14–26.
|
| [9] |
TANG Shibin, YIN Shouyi, ZHENG Shixuan, et al. AEPE: An area and power efficient RRAM crossbar-based accelerator for deep CNNs[C]. The IEEE 6th Non-Volatile Memory Systems and Applications Symposium, Hsinchu, China, 2017: 1–6.
|
| [10] |
CHI Ping, LI Shuangchen, XU Cong, et al. PRIME: A novel processing-in-memory architecture for neural network computation in ReRAM-based main memory[C]. The ACM/IEEE 43rd Annual International Symposium on Computer Architecture, Seoul, Korea, 2016: 27–39.
|
| [11] |
YANG T H, CHENG H Y, YANG C L, et al. Sparse ReRAM engine: Joint exploration of activation and weight sparsity in compressed neural networks[C]. The 46th Annual International Symposium on Computer Architecture, Phoenix, USA, 2019: 236–249.
|
| [12] |
SONG Linghao, ZHUO Youwei, QIAN Xuehai, et al. GraphR: Accelerating graph processing using ReRAM[C]. 2018 IEEE International Symposium on High Performance Computer Architecture, Vienna, Austria, 2018: 531–543.
|
| [13] |
CHALLAPALLE N, RAMPALLI S, SONG Linghao, et al. GaaS-X: Graph analytics accelerator supporting sparse data representation using crossbar architectures[C]. The 47th Annual International Symposium on Computer Architecture, Valencia, Spain, 2020: 433–445.
|
| [14] |
DAI Guohao, HUANG Tianhao, WANG Yu, et al. GraphSAR: A sparsity-aware processing-in-memory architecture for large-scale graph processing on ReRAMs[C]. The 24th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 2019: 120–126.
|
| [15] |
WANG Zhao, GUAN Yijin, SUN Guangyu, et al. GNN-PIM: A processing-in-memory architecture for graph neural networks[C]. The 13th Conference on Advanced Computer Architecture, Kunming, China, 2020: 73–86.
|
| [16] |
HE Yintao, WANG Ying, LIU Cheng, et al. TARe: Task-adaptive in-situ ReRAM computing for graph learning[C]. The 58th ACM/IEEE Design Automation Conference, San Francisco, USA, 2021: 577–582.
|
| [17] |
WU Zonghan, PAN Shirui, CHEN Fengwen, et al. A comprehensive survey on graph neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4–24. doi: 10.1109/TNNLS.2020.2978386
|
| [18] |
SEN P, NAMATA G, BILGIC M, et al. Collective classification in network data[J]. AI Magazine, 2008, 29(3): 93. doi: 10.1609/aimag.v29i3.2157
|
| [19] |
CARLSON A, BETTERIDGE J, KISIEL B, et al. Toward an architecture for never-ending language learning[C]. The 24th AAAI Conference on Artificial Intelligence, Atlanta, America, 2010: 1306–1313.
|
| [20] |
SONG Linghao, QIAN Xuehai, LI Hai, et al. PipeLayer: A pipelined ReRAM-based accelerator for deep learning[C]. 2017 IEEE International Symposium on High Performance Computer Architecture, Austin, USA, 2017: 541–552.
|
| [21] |
ZHU Zhenhua, SUN Hanbo, QIU Kaizhong, et al. MNSIM 2.0: A behavior-level modeling tool for memristor-based neuromorphic computing systems[C]. The 2020 on Great Lakes Symposium on VLSI, Beijing, China, 2020: 83–88.
|
| [22] |
FEY Y and LENSSEN J E. Fast graph representation learning with PyTorch geometric[EB/OL]. https://arxiv.org/abs/1903.02428v3, 2019.
|
| [23] |
ABOU-RJEILI A and KARYPIS G. Multilevel algorithms for partitioning power-law graphs[C]. The 20th IEEE International Parallel & Distributed Processing Symposium, Rhodes, Greece, 2006: 10.
|
Figures(10) / Tables(2)



 DownLoad:
DownLoad: