| Citation: | XU Yongjun, CAO Qi, WAN Yangliang, ZHOU Jihua, ZHAO Tao, CHEN Qianbin. Robust Secure Resource Allocation Algorithm for Heterogeneous Networks with Hardware Impairments[J]. Journal of Electronics & Information Technology, 2023, 45(1): 243-253. doi: 10.11999/JEIT211123

|

| [1] |
XU Yongjun, GUI Guan, GACANIN H, et al. A survey on resource allocation for 5G heterogeneous networks: Current research, future trends, and challenges[J]. IEEE Communications Surveys & Tutorials, 2021, 23(2): 668–695. doi: 10.1109/COMST.2021.3059896
|
| [2] |
LIU Xilong and ANSARI N. Green relay assisted D2D communications with dual batteries in heterogeneous cellular networks for IoT[J]. IEEE Internet of Things Journal, 2017, 4(5): 1707–1715. doi: 10.1109/JIOT.2017.2717853
|
| [3] |
KHALILI A, AKHLAGHI S, TABASSUM H, et al. Joint user association and resource allocation in the uplink of heterogeneous networks[J]. IEEE Wireless Communications Letters, 2020, 9(6): 804–808. doi: 10.1109/LWC.2020.2970696
|
| [4] |
FANG Fang, ZHANG Haijun, CHENG Julian, et al. Energy-efficient resource allocation for downlink non-orthogonal multiple access network[J]. IEEE Transactions on Communications, 2016, 64(9): 3722–3732. doi: 10.1109/TCOMM.2016.2594759
|
| [5] |
CUMANAN K, DING Zhiguo, SHARIF B, et al. Secrecy rate optimizations for a MIMO secrecy channel with a multiple-antenna eavesdropper[J]. IEEE Transactions on Vehicular Technology, 2014, 63(4): 1678–1690. doi: 10.1109/TVT.2013.2285244
|
| [6] |
AHMED M, LI Yong, ZHUO Yinxiao, et al. Secrecy ensured socially aware resource allocation in device-to-device communications underlaying HetNet[J]. IEEE Transactions on Vehicular Technology, 2019, 68(5): 4933–4948. doi: 10.1109/TVT.2019.2890879
|
| [7] |
MA Hui, CHENG Julian, and WANG Xianfu. Proportional fair secrecy beamforming for MISO heterogeneous cellular networks with wireless information and power transfer[J]. IEEE Transactions on Communications, 2019, 67(8): 5659–5673. doi: 10.1109/TCOMM.2019.2910260
|
| [8] |
LI Bin, FEI Zesong, and CHU Zheng. Optimal transmit beamforming for secure SWIPT in a two-tier HetNet[J]. IEEE Communications Letters, 2017, 21(11): 2476–2479. doi: 10.1109/LCOMM.2017.2734759
|
| [9] |
LI Bin, FEI Zesong, CHU Zheng, et al. Secure transmission for heterogeneous cellular networks with wireless information and power transfer[J]. IEEE Systems Journal, 2018, 12(4): 3755–3766. doi: 10.1109/JSYST.2017.2713881
|
| [10] |
LIU Zhixin, WANG Sainan, LIU Yang, et al. Robust secure transmission and power transfer in heterogeneous networks with confidential information[J]. IEEE Transactions on Vehicular Technology, 2020, 69(10): 11192–11205. doi: 10.1109/TVT.2020.3008349
|
| [11] |
ZHANG Bo, LI Bin, HUANG Kaizhi, et al. Robust secrecy energy efficiency optimization for wireless powered heterogeneous networks using distributed ADMM algorithm[J]. IEEE Access, 2019, 7: 116277–116294. doi: 10.1109/ACCESS.2019.2935798
|
| [12] |
BJÖRNSON E, HOYDIS J, KOUNTOURIS M, et al. Massive MIMO systems with non-ideal hardware: Energy efficiency, estimation, and capacity limits[J]. IEEE Transactions on Information Theory, 2014, 60(11): 7112–7139. doi: 10.1109/TIT.2014.2354403
|
| [13] |
XU Yongjun, XIE Hao, and HU R Q. Max-min beamforming design for heterogeneous networks with hardware impairments[J]. IEEE Communications Letters, 2021, 25(4): 1328–1332. doi: 10.1109/LCOMM.2020.3044936
|
| [14] |
XU Yongjun, LI Guoquan, YANG Yang, et al. Robust resource allocation and power splitting in SWIPT enabled heterogeneous networks: A robust minimax approach[J]. IEEE Internet of Things Journal, 2019, 6(6): 10799–10811. doi: 10.1109/JIOT.2019.2941897
|
| [15] |
MANSUKHANI J and RAY P. Censored spectrum sharing strategy for MIMO systems in cognitive radio networks[J]. IEEE Transactions on Wireless Communications, 2019, 18(12): 5500–5510. doi: 10.1109/TWC.2019.2936839
|
| [16] |
WANG Shaowei, SHI Weijia, and WANG Chonggang. Energy-efficient resource management in OFDM-based cognitive radio networks under channel uncertainty[J]. IEEE Transactions on Communications, 2015, 63(9): 3092–3102. doi: 10.1109/TCOMM.2015.2452251
|
| [17] |
HAN Dongsheng, LI Shijie, PENG Yuefeng, et al. Energy sharing-based energy and user joint allocation method in heterogeneous network[J]. IEEE Access, 2020, 8: 37077–37086. doi: 10.1109/ACCESS.2020.2975293
|
| [18] |
徐勇军, 谷博文, 杨洋, 等. 基于不完美CSI的D2D通信网络鲁棒能效资源分配算法[J]. 电子与信息学报, 2021, 43(8): 2189–2198. doi: 10.11999/JEIT200587
XU Yongjun, GU Bowen, YANG Yang, et al. Robust energy-efficient resource allocation algorithm in D2D communication networks with imperfect CSI[J]. Journal of Electronics &Information Technology, 2021, 43(8): 2189–2198. doi: 10.11999/JEIT200587
|
| [19] |
BEN-TAL A, EL GHAOUI L, and NEMIROVSKI A. Robust Optimization[M]. Princeton: Princeton University Press, 2009.
|
| [20] |
DINKELBACH W. On nonlinear fractional programming[J]. Management Science, 1967, 13(7): 492–498. doi: 10.1287/mnsc.13.7.492
|
| [21] |
PAPANDRIOPOULOS J and EVANS J S. SCALE: A low-complexity distributed protocol for spectrum balancing in multiuser DSL networks[J]. IEEE Transactions on Information Theory, 2009, 55(8): 3711–3724. doi: 10.1109/TIT.2009.2023751
|
| [22] |
BOYD S and VANDENBERGHE L. Convex Optimization[M]. Cambridge: Cambridge University Press, 2004.
|
| [23] |
李国权, 徐勇军, 陈前斌. 基于干扰效率多蜂窝异构无线网络最优基站选择及功率分配算法[J]. 电子与信息学报, 2020, 42(4): 957–964. doi: 10.11999/JEIT190419
LI Guoquan, XU Yongjun, and CHEN Qianbin. Interference efficiency-based base station selection and power allocation algorithm for multi-cell heterogeneous wireless networks[J]. Journal of Electronics &Information Technology, 2020, 42(4): 957–964. doi: 10.11999/JEIT190419
|
| [24] |
GUO Shengjie and ZHOU Xiangwei. Robust resource allocation with imperfect channel estimation in NOMA-based heterogeneous vehicular networks[J]. IEEE Transactions on Communications, 2019, 67(3): 2321–2332. doi: 10.1109/TCOMM.2018.2885999
|
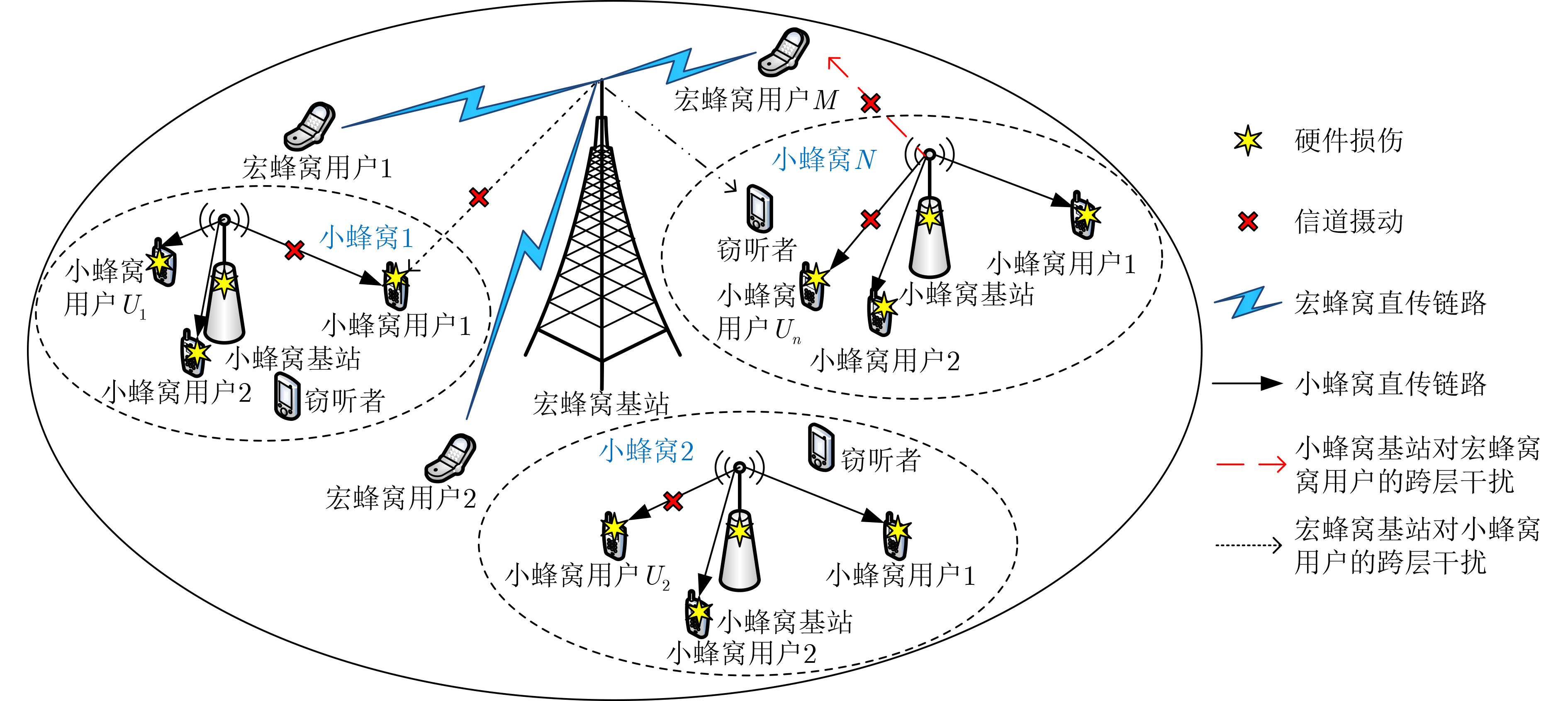
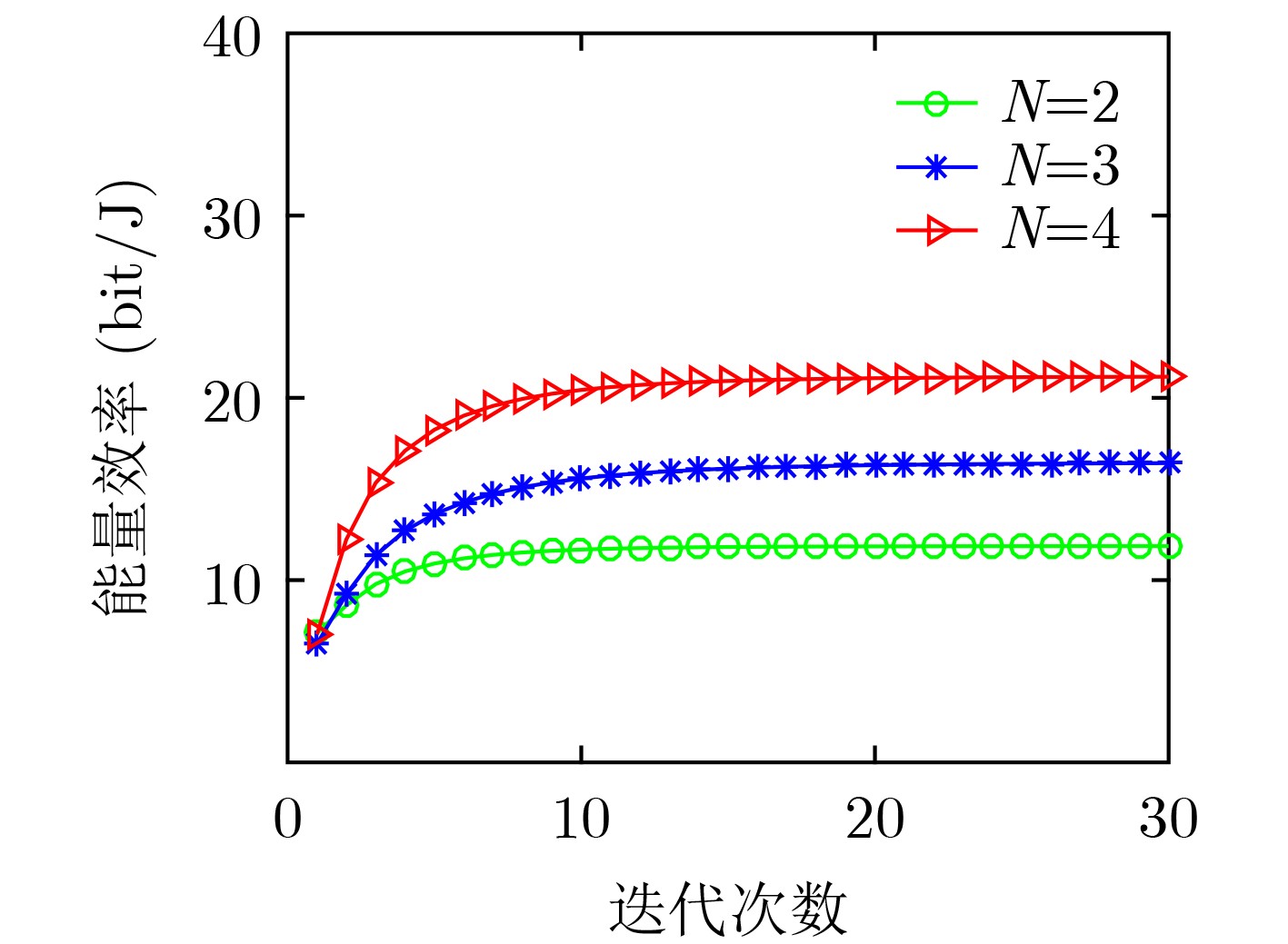
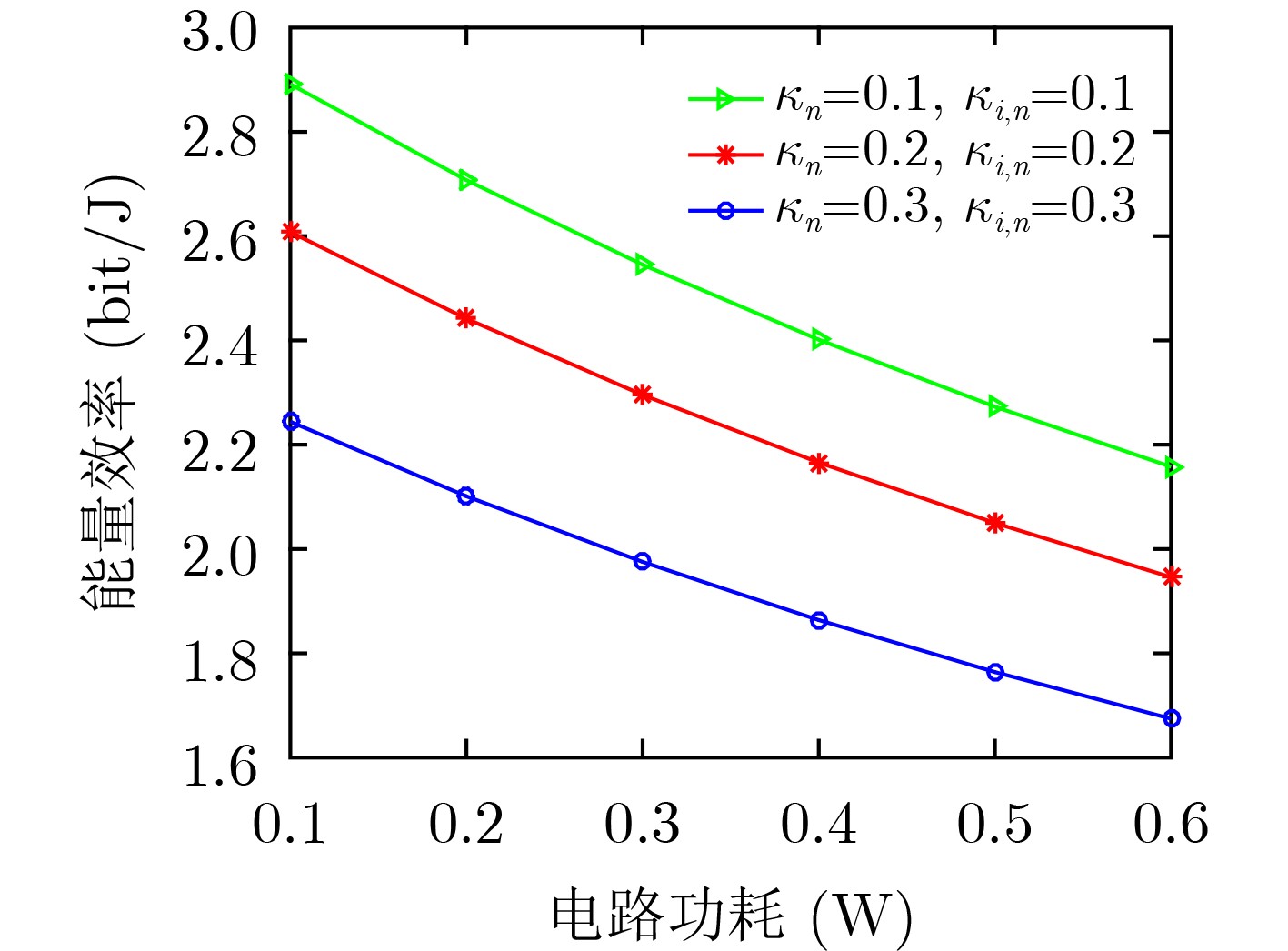
Figures(8) / Tables(1)



 DownLoad:
DownLoad: