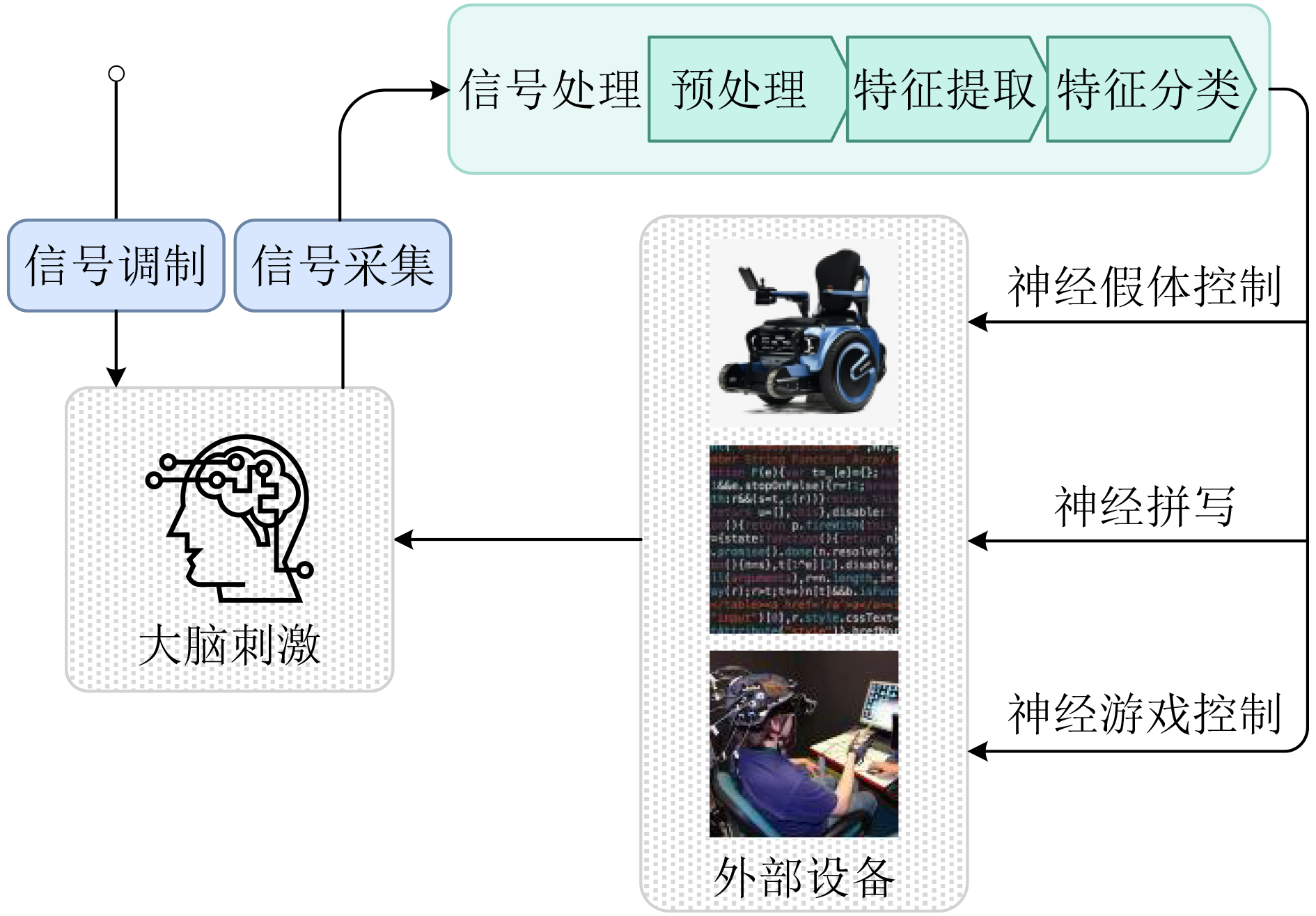
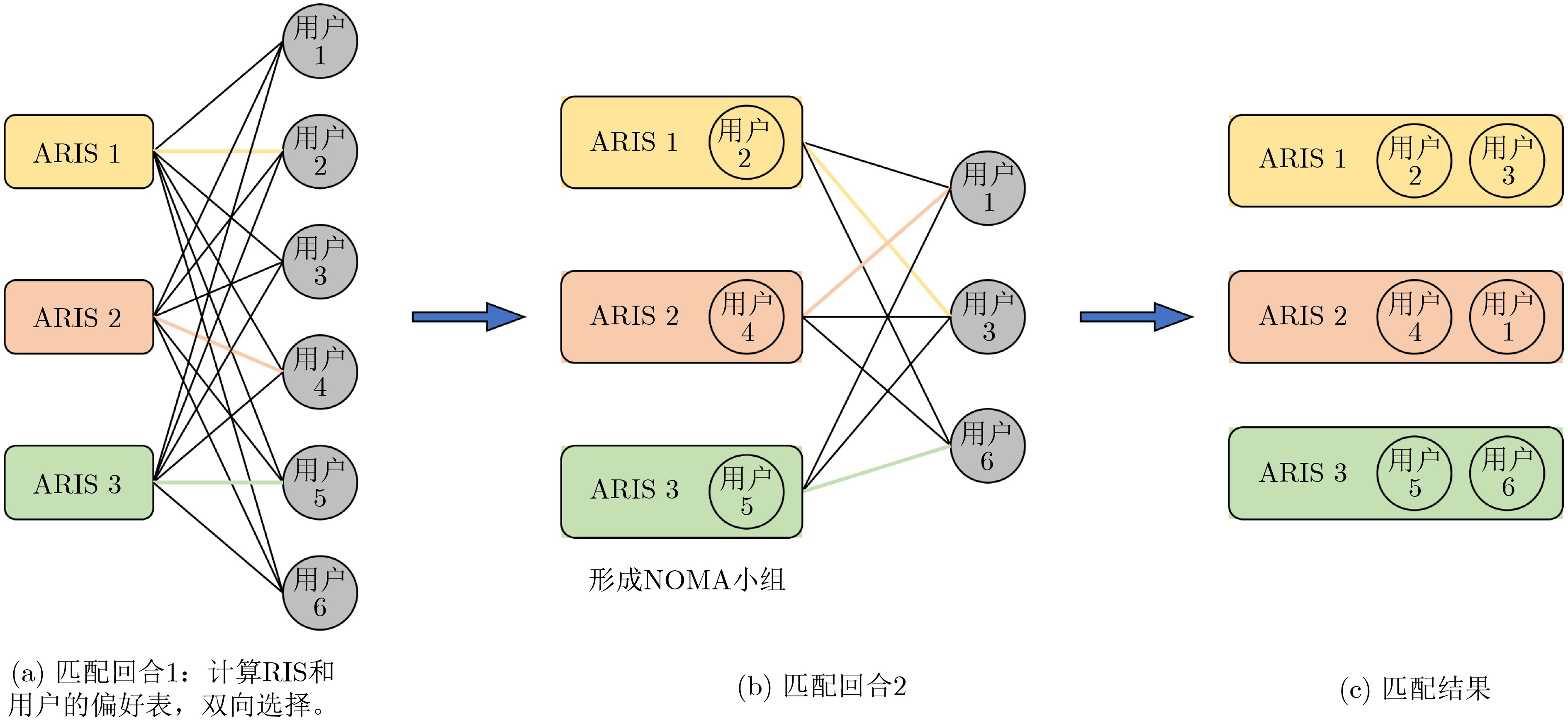
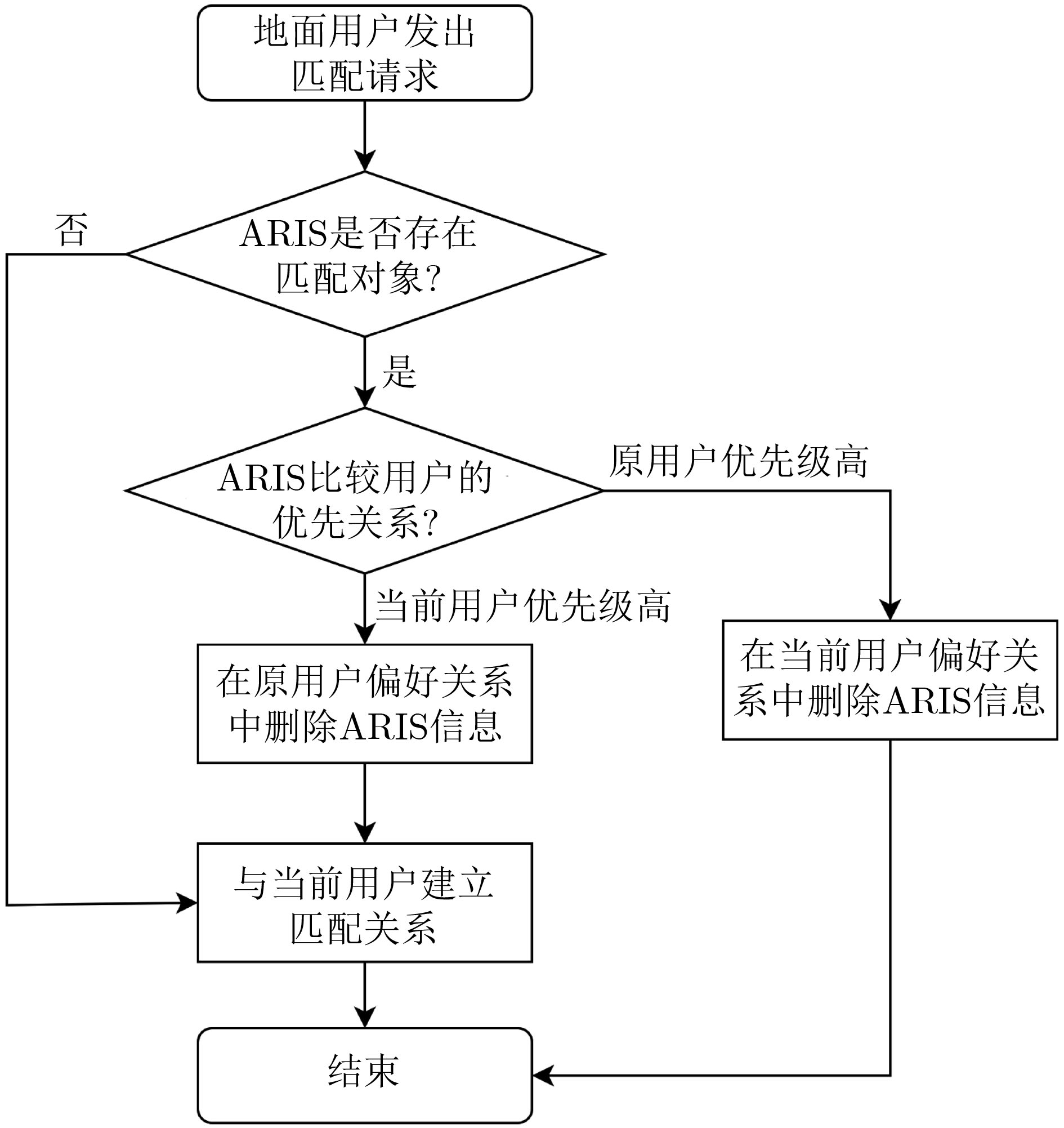
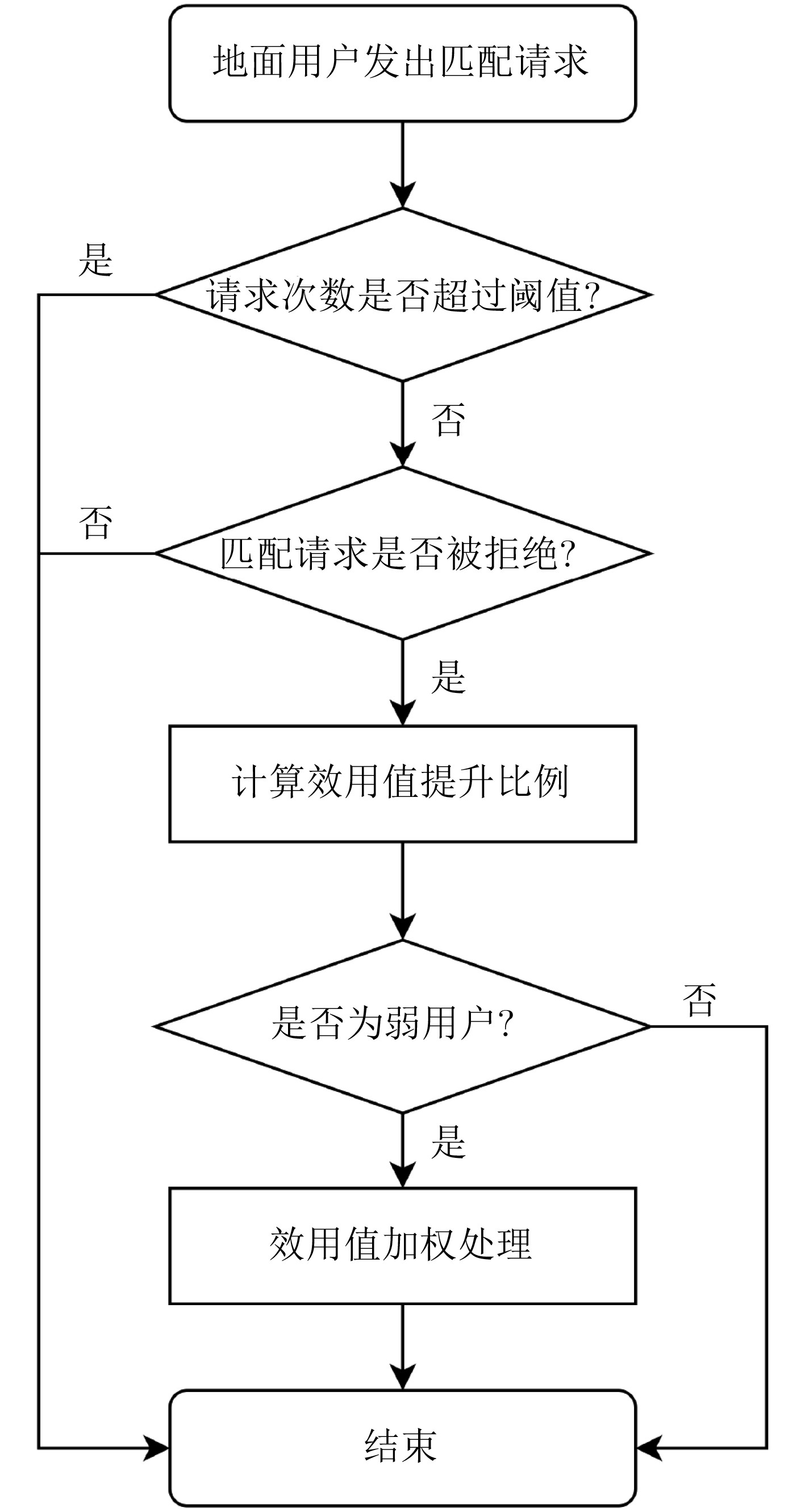
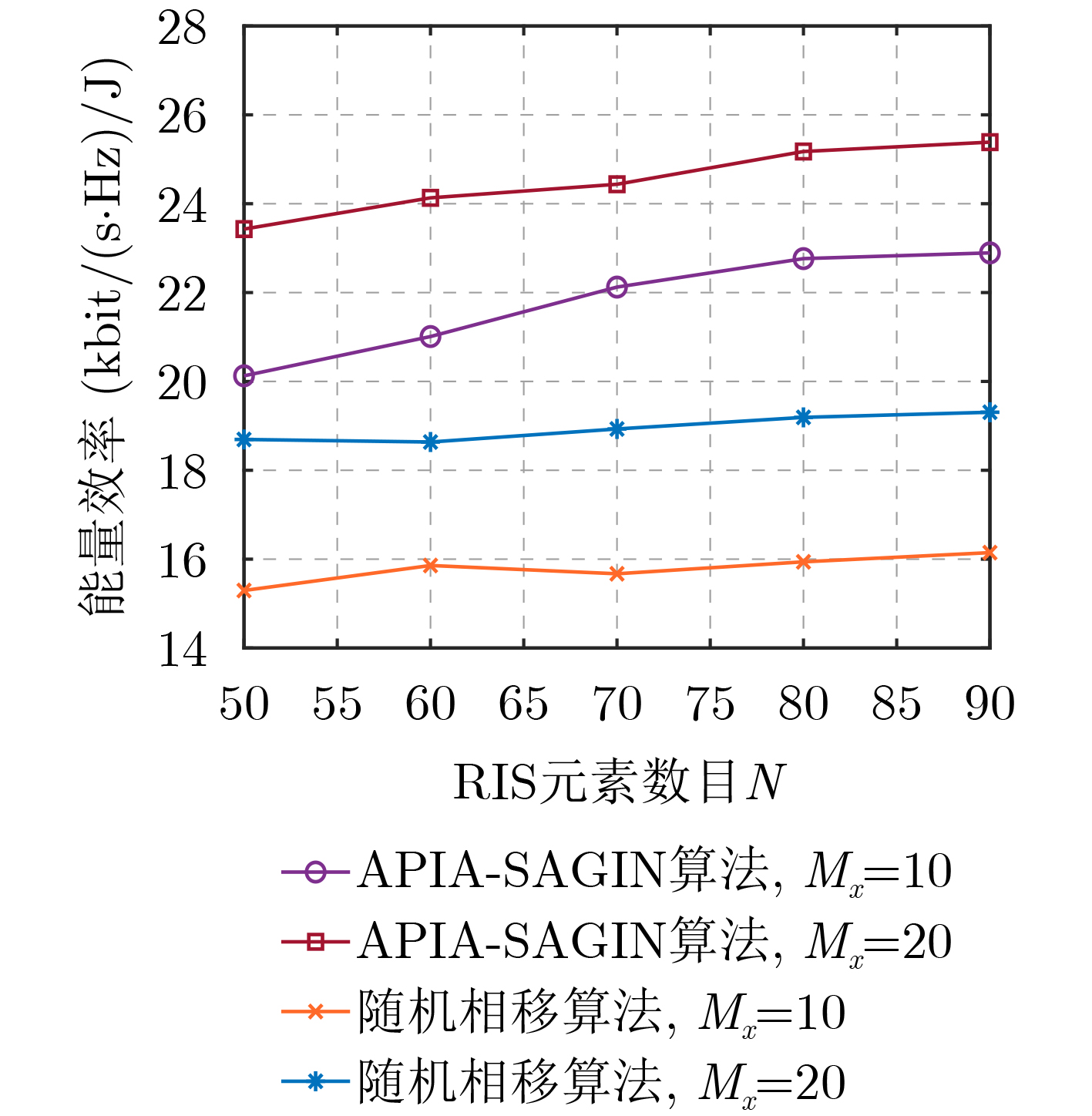
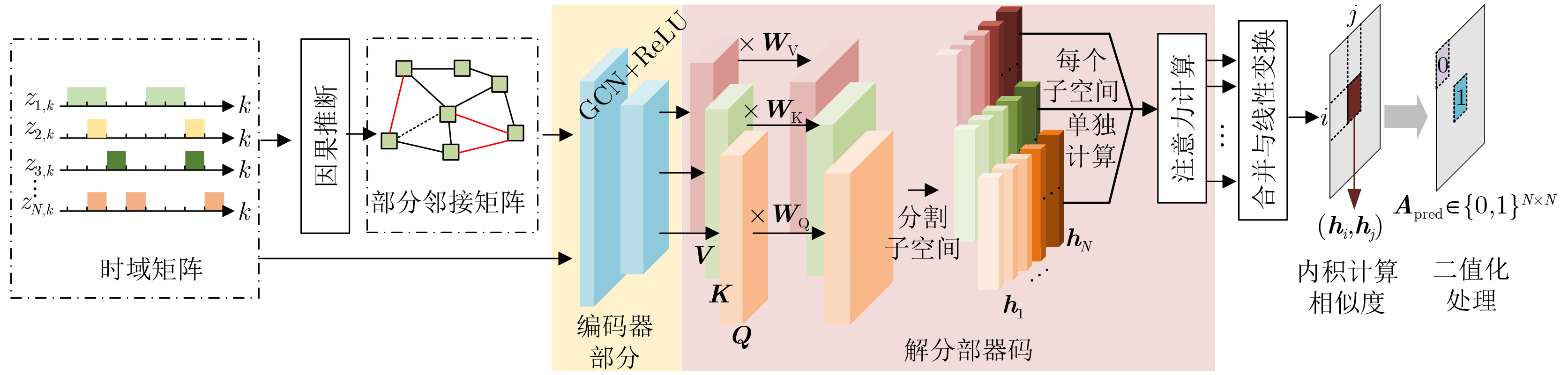
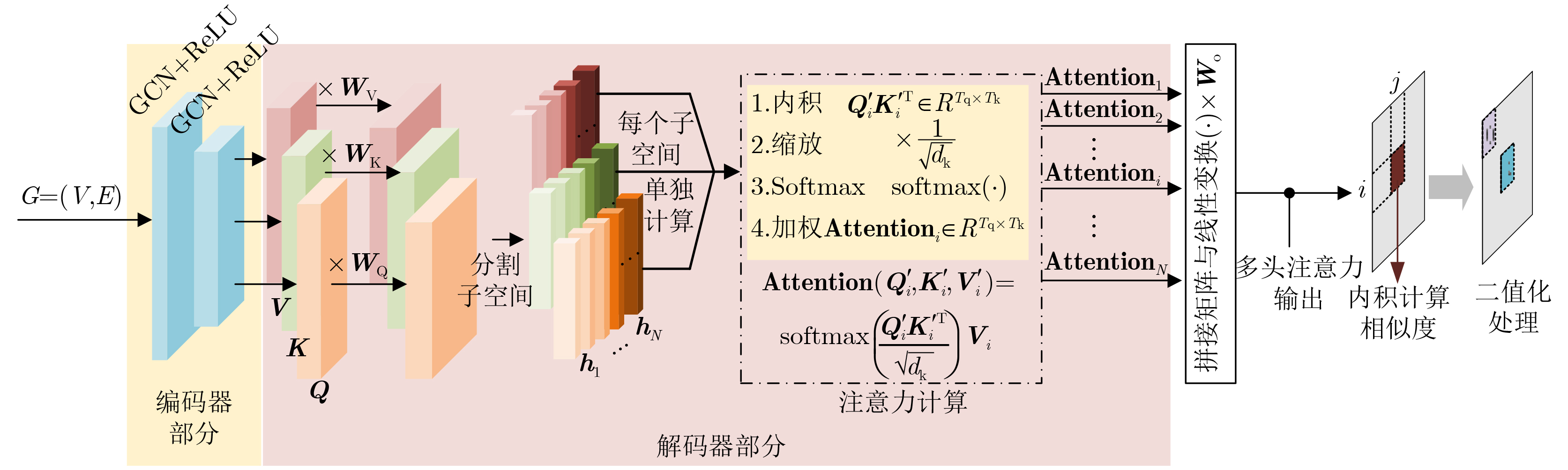
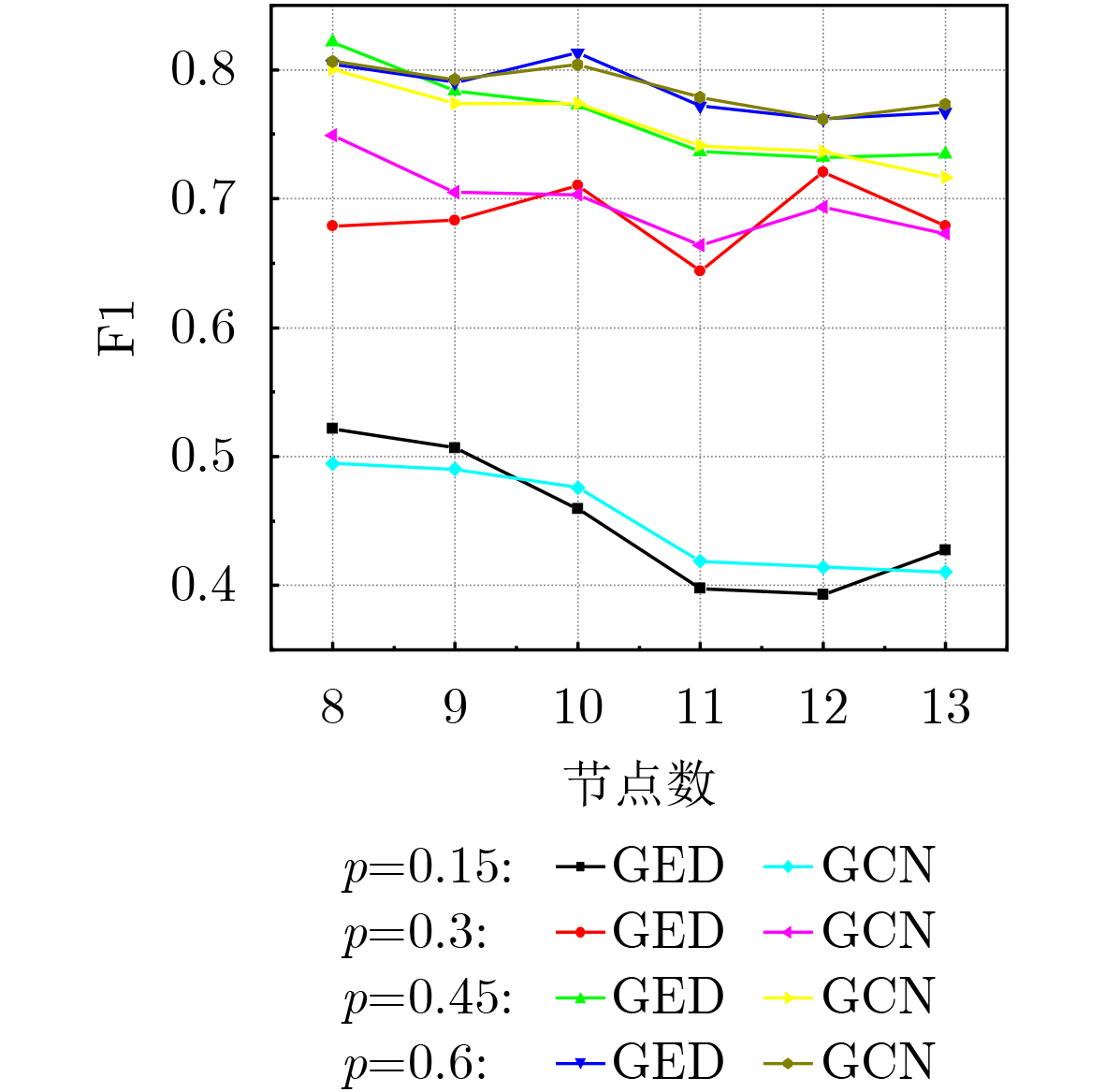
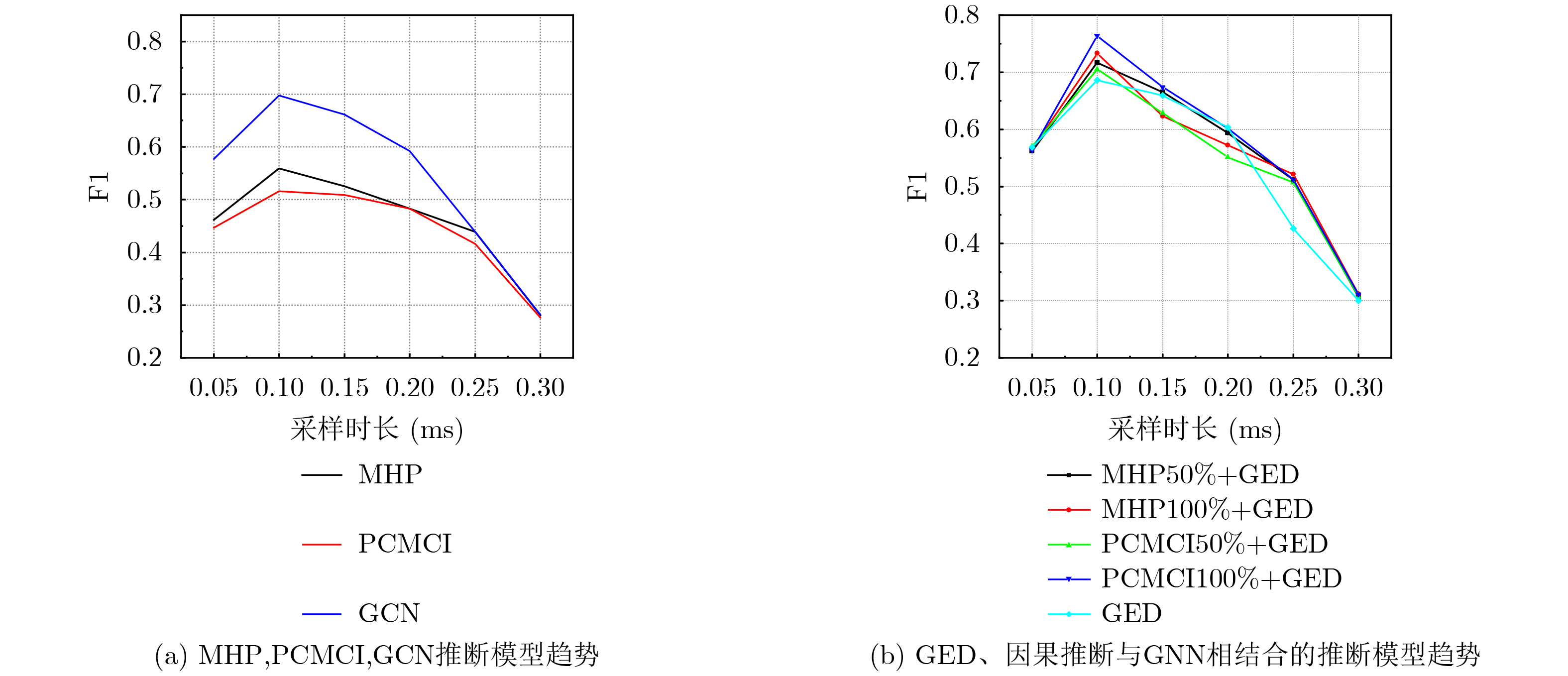
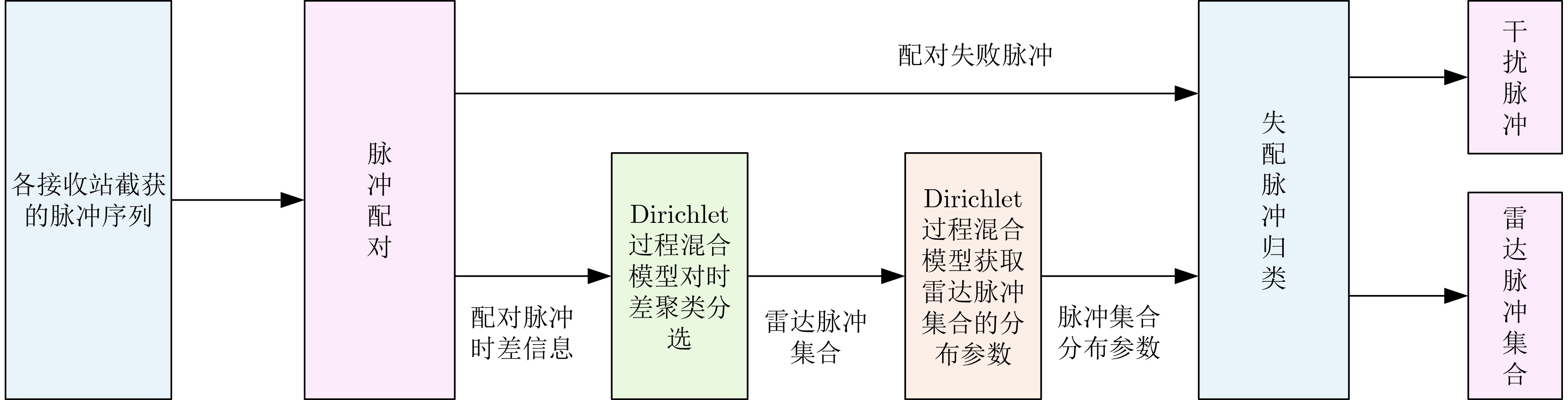
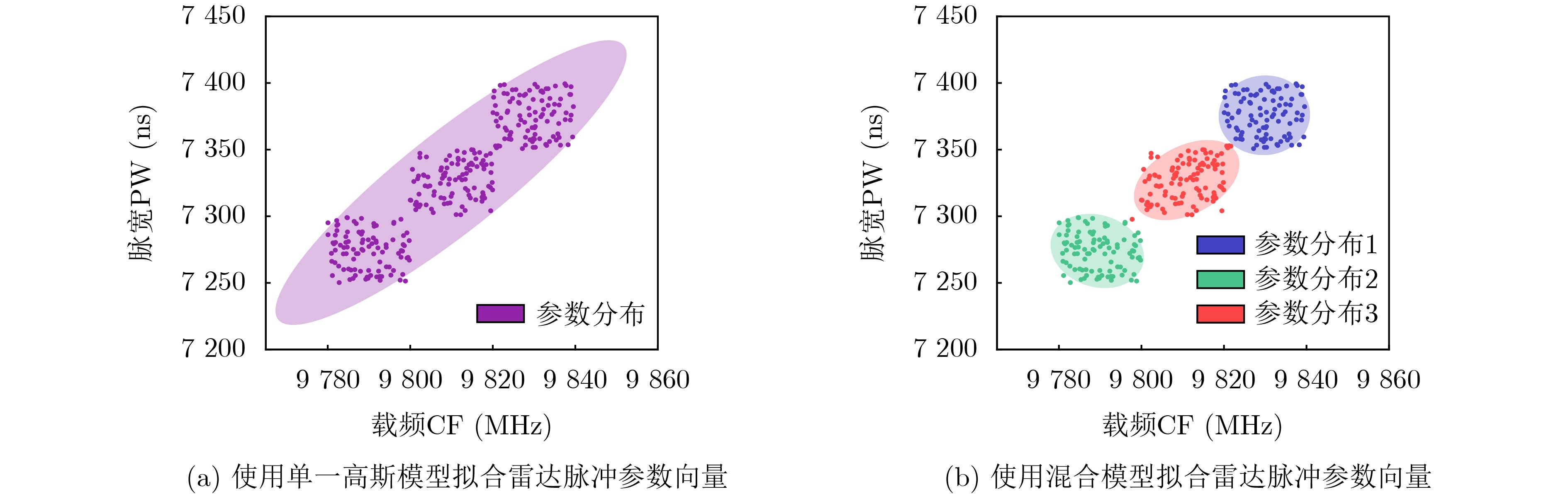
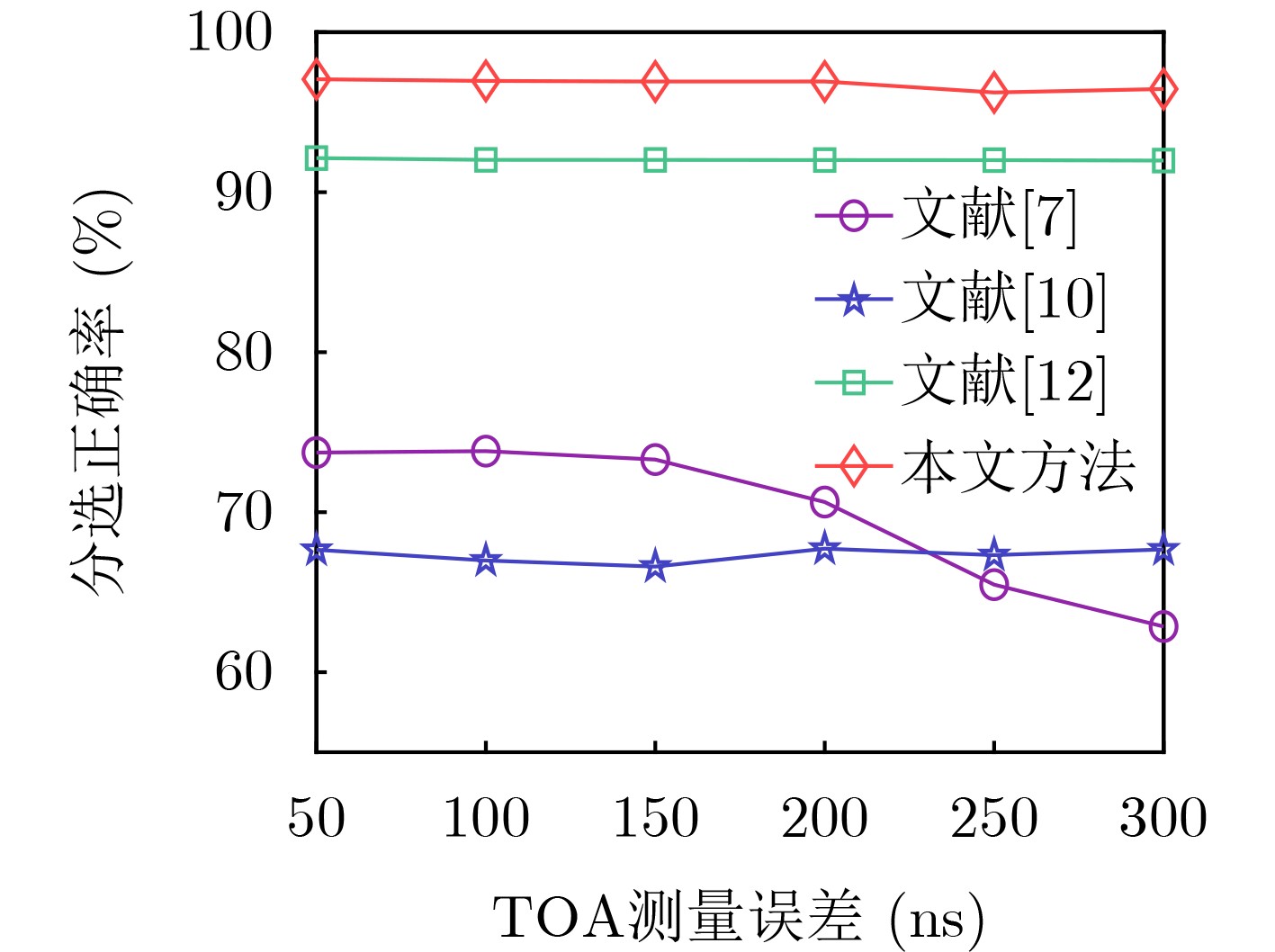
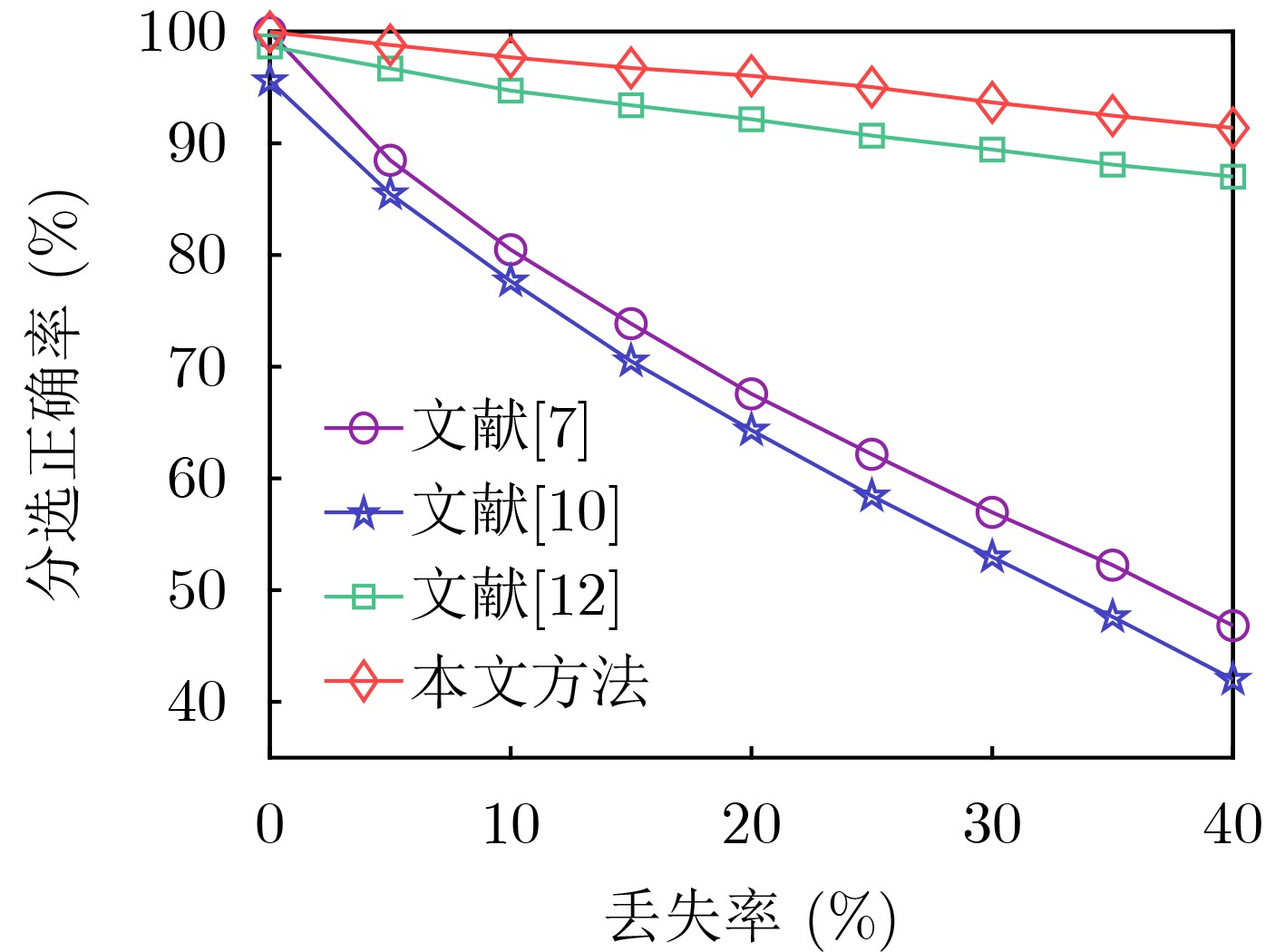
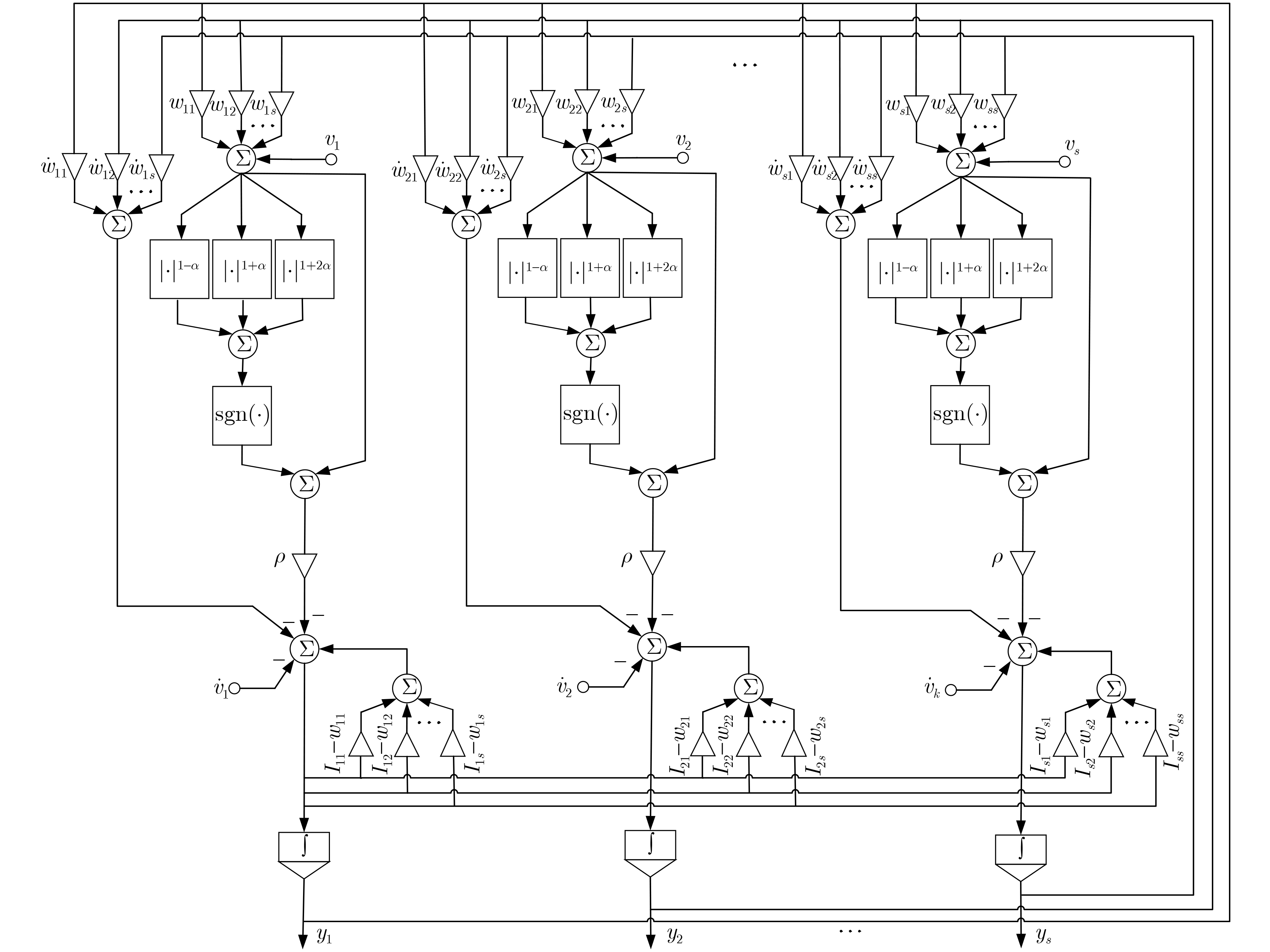
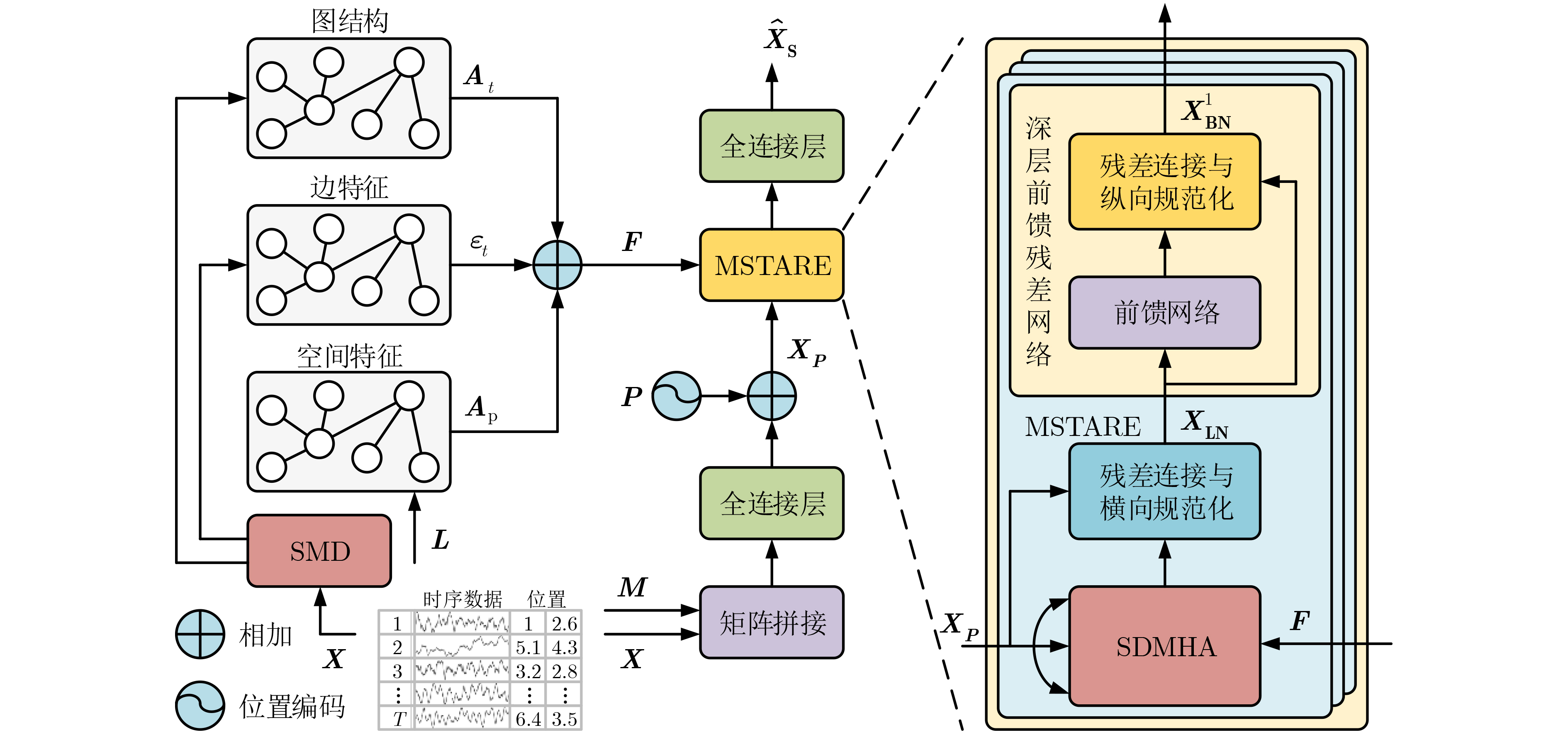
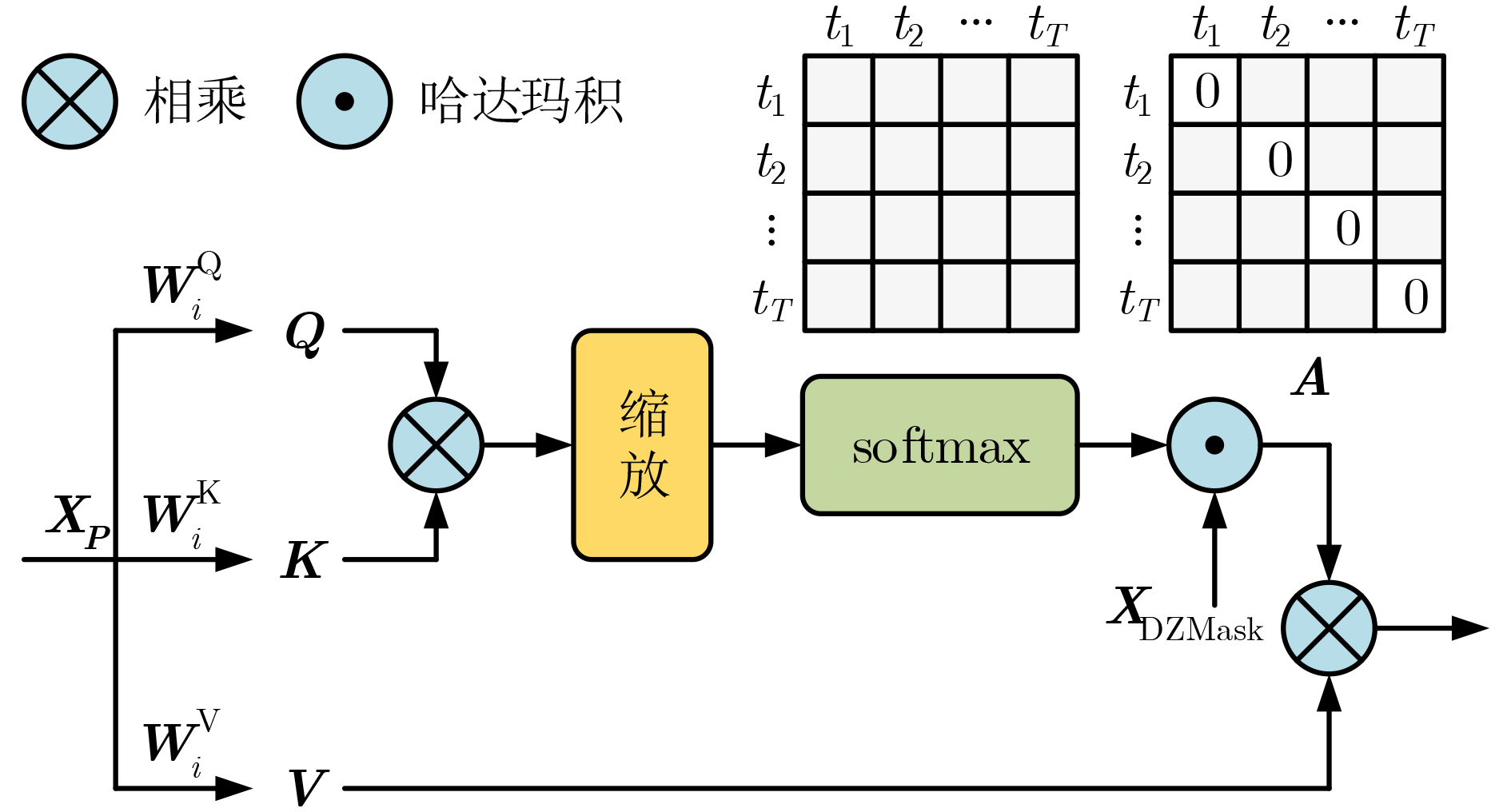
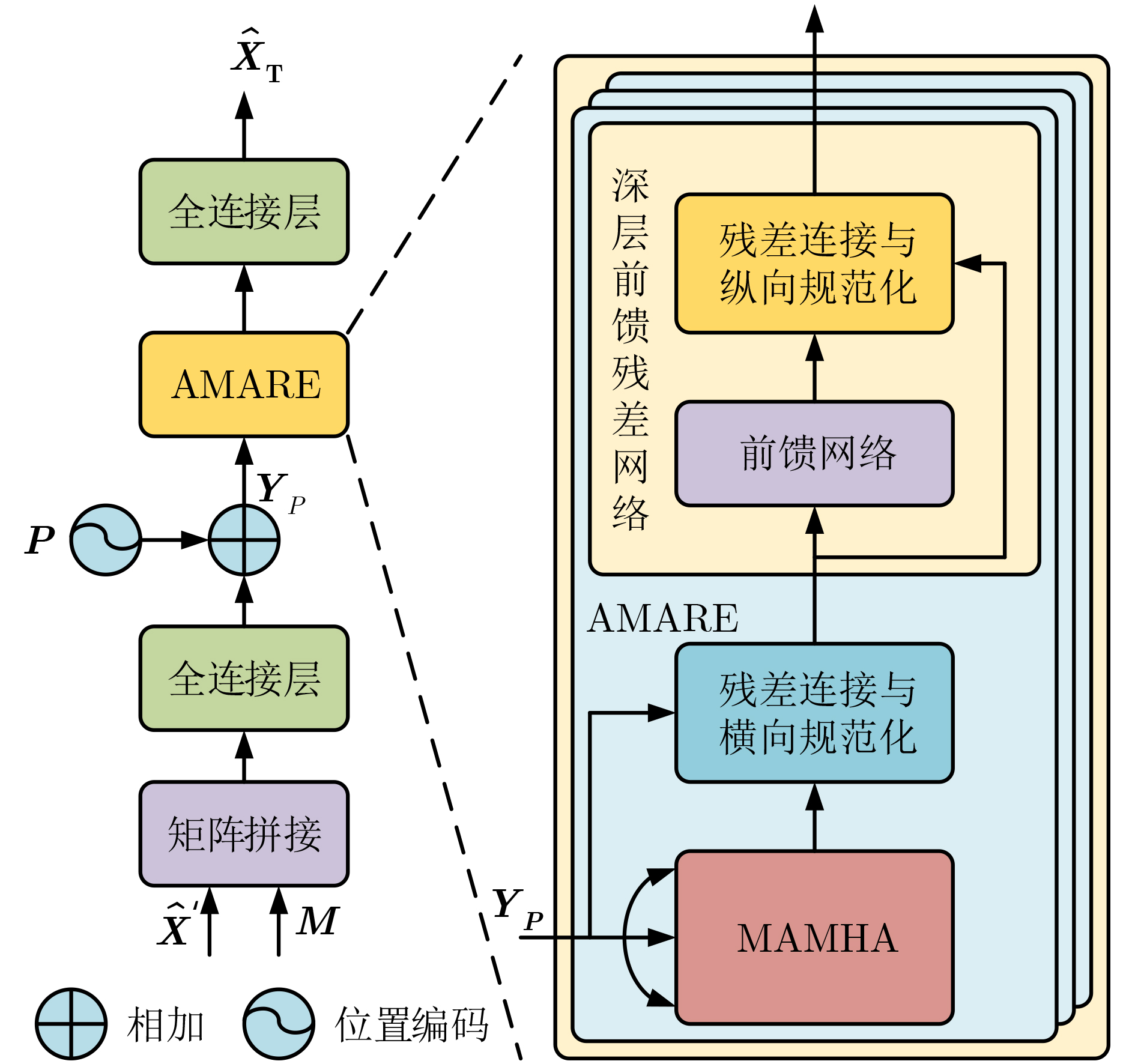
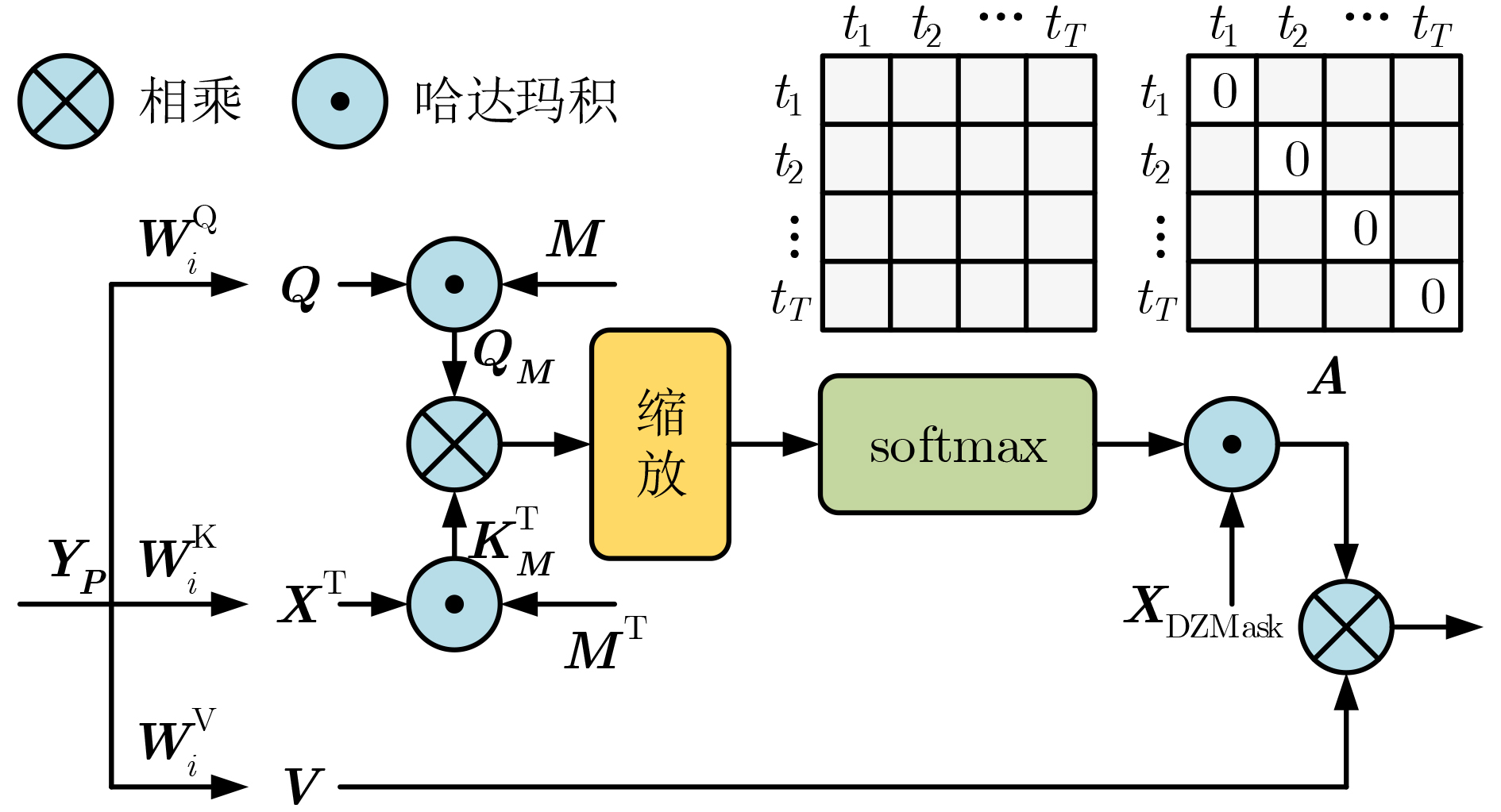
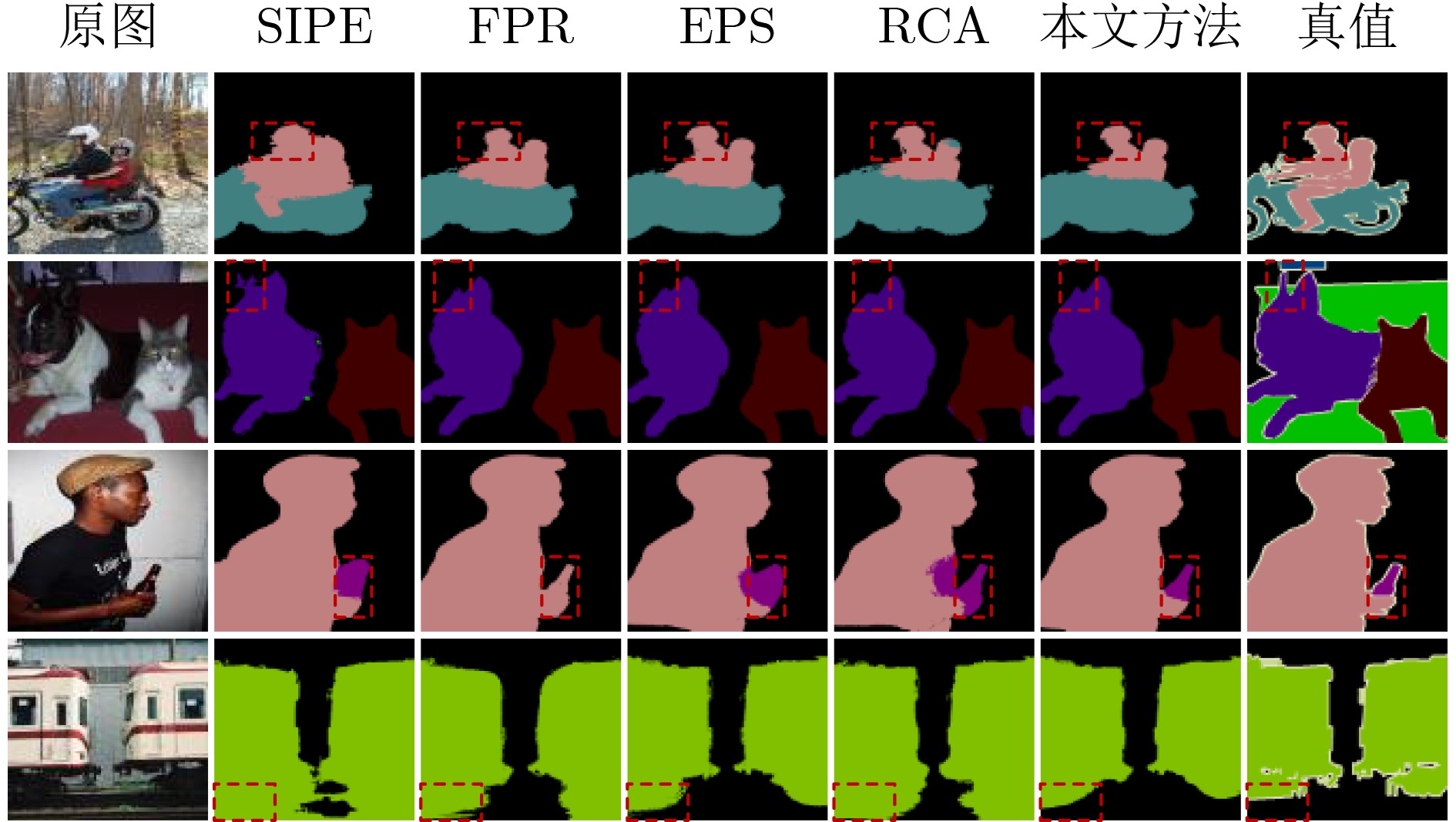
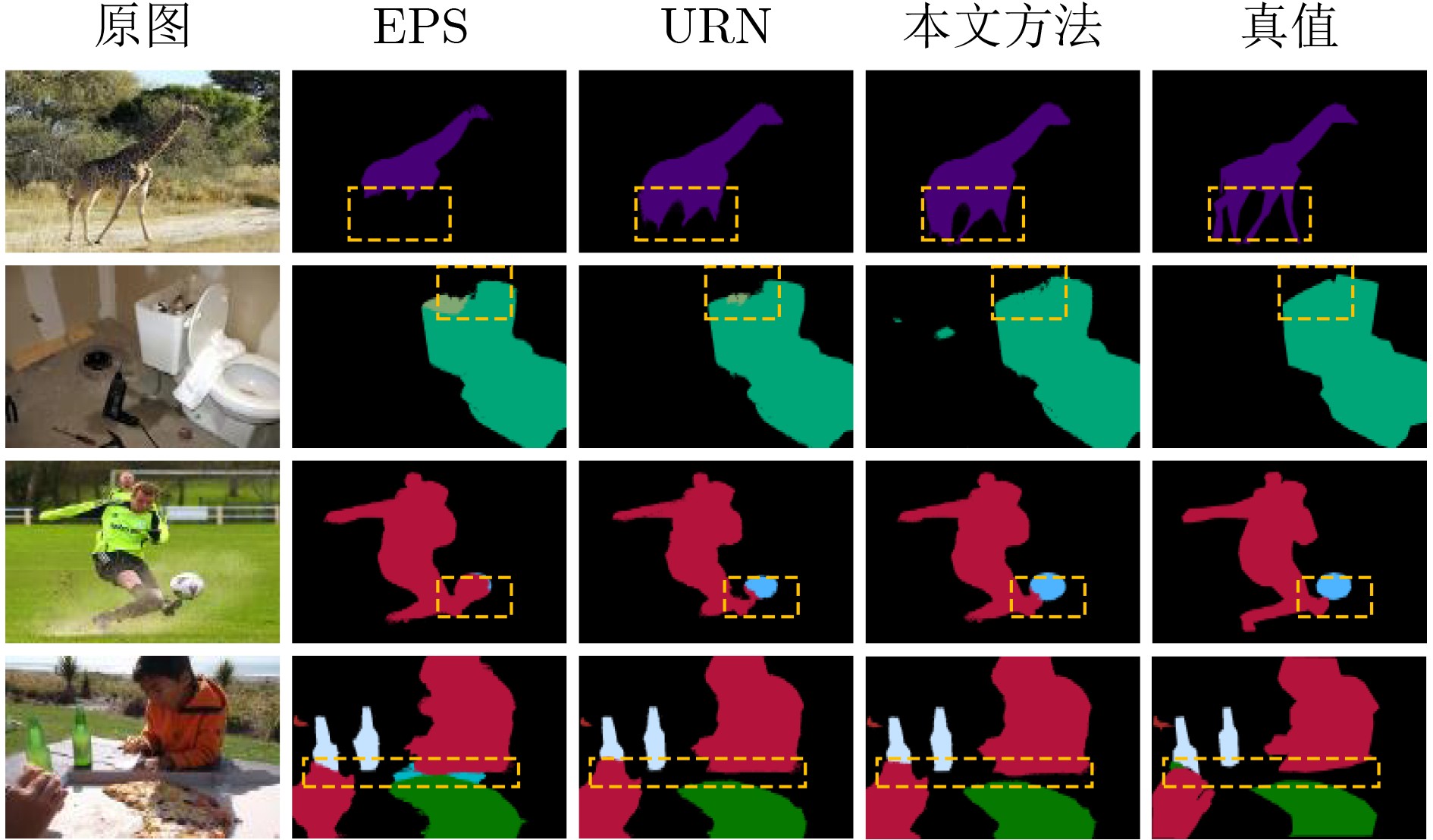
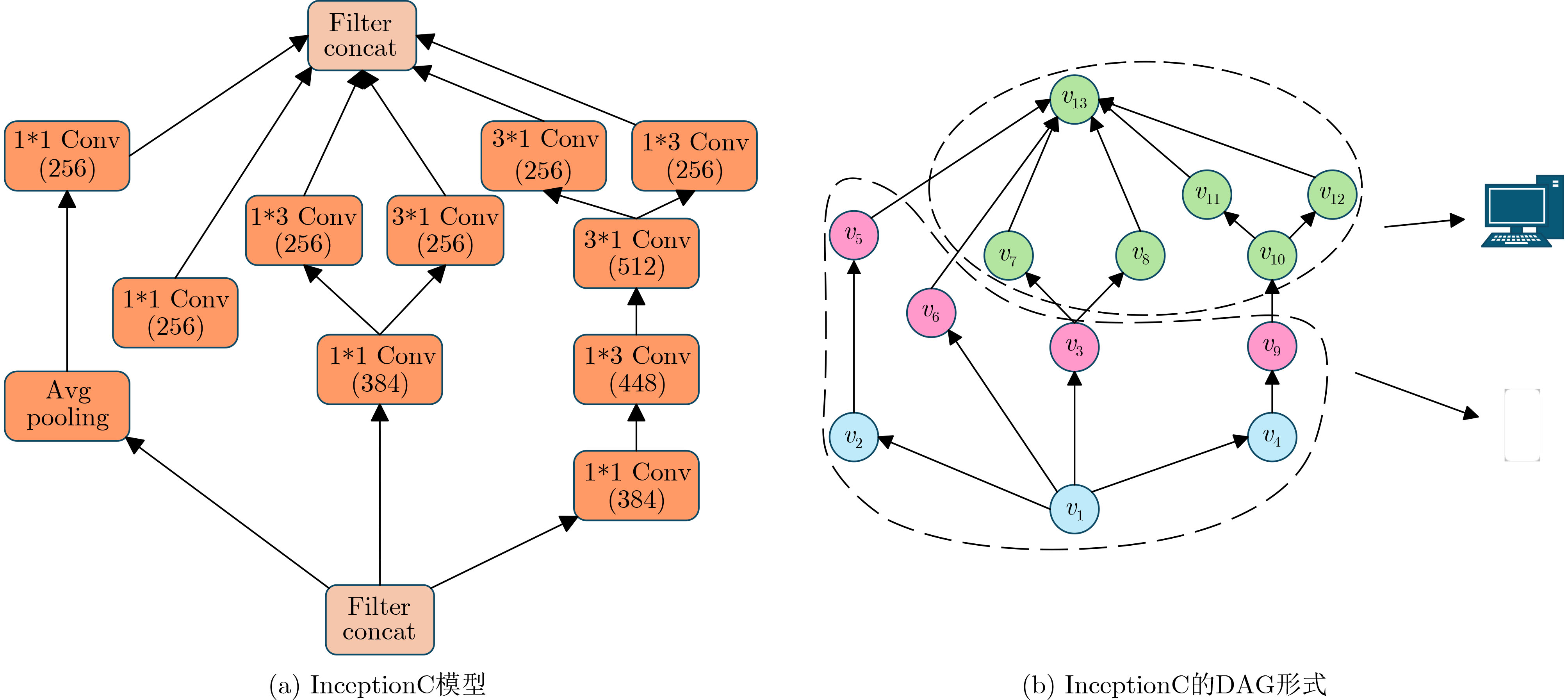
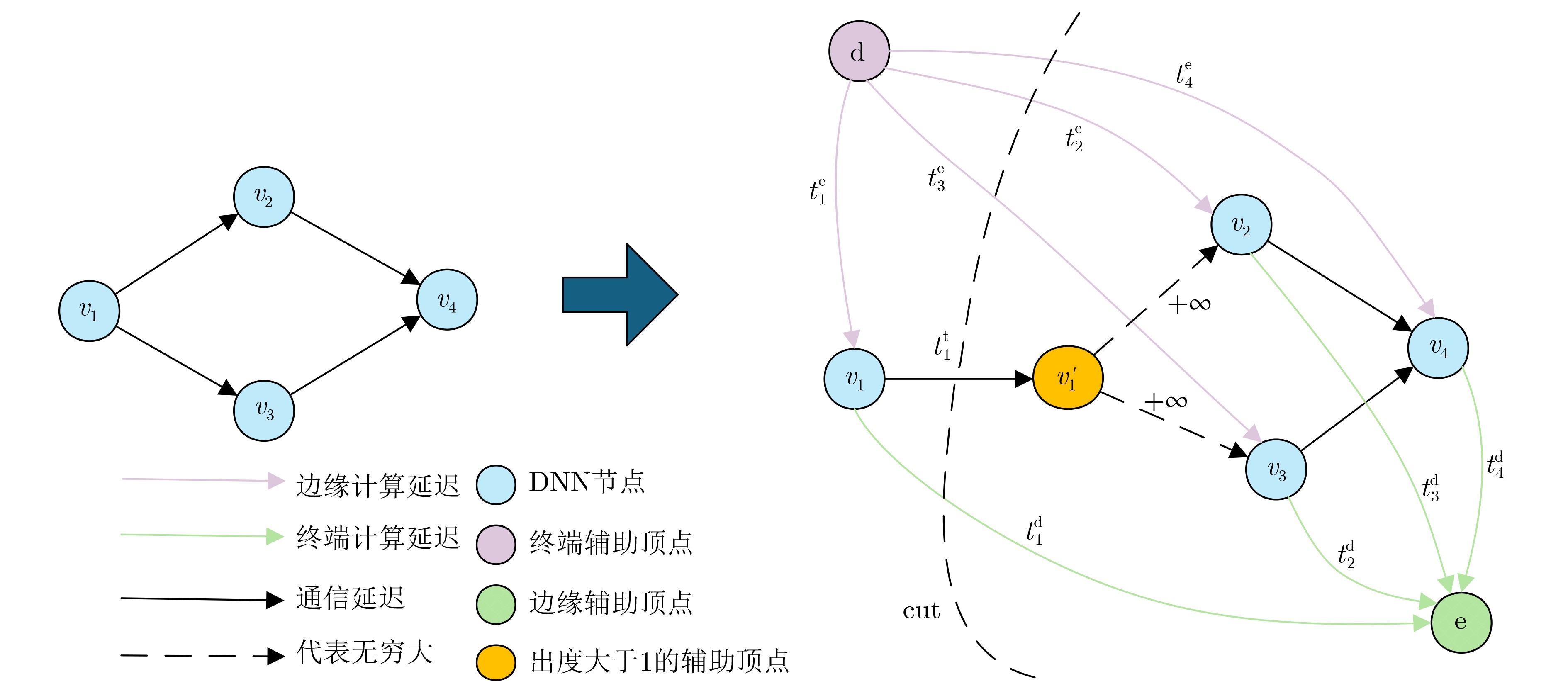
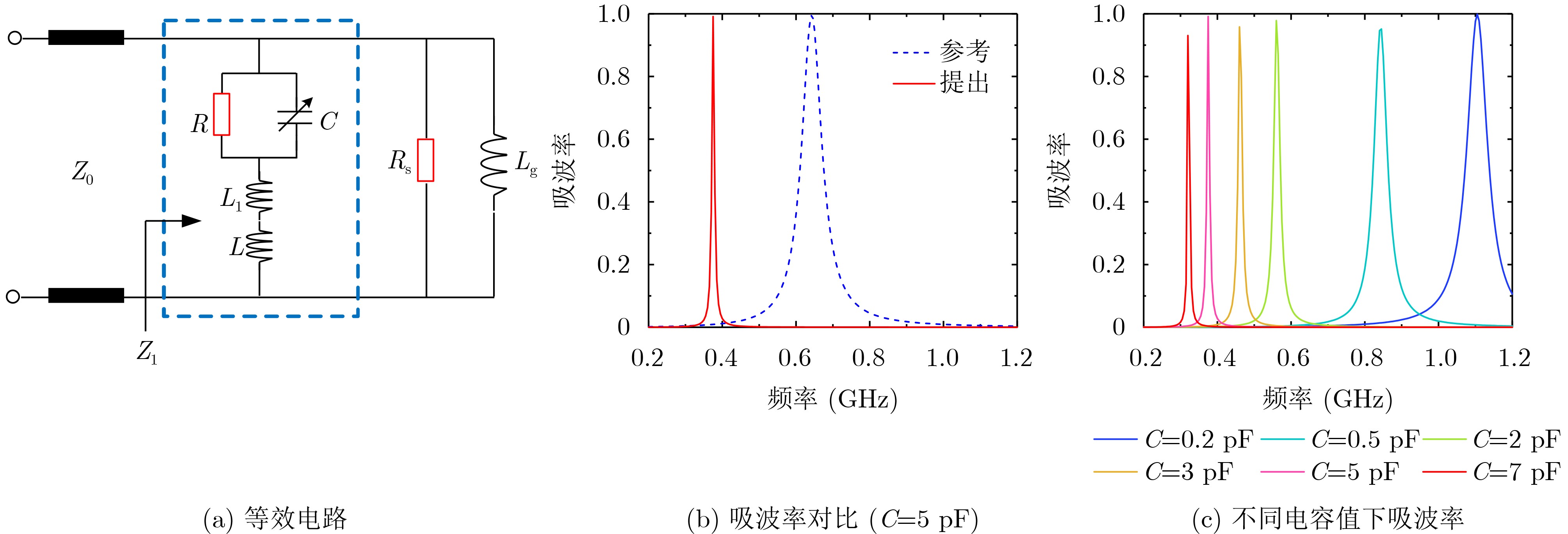
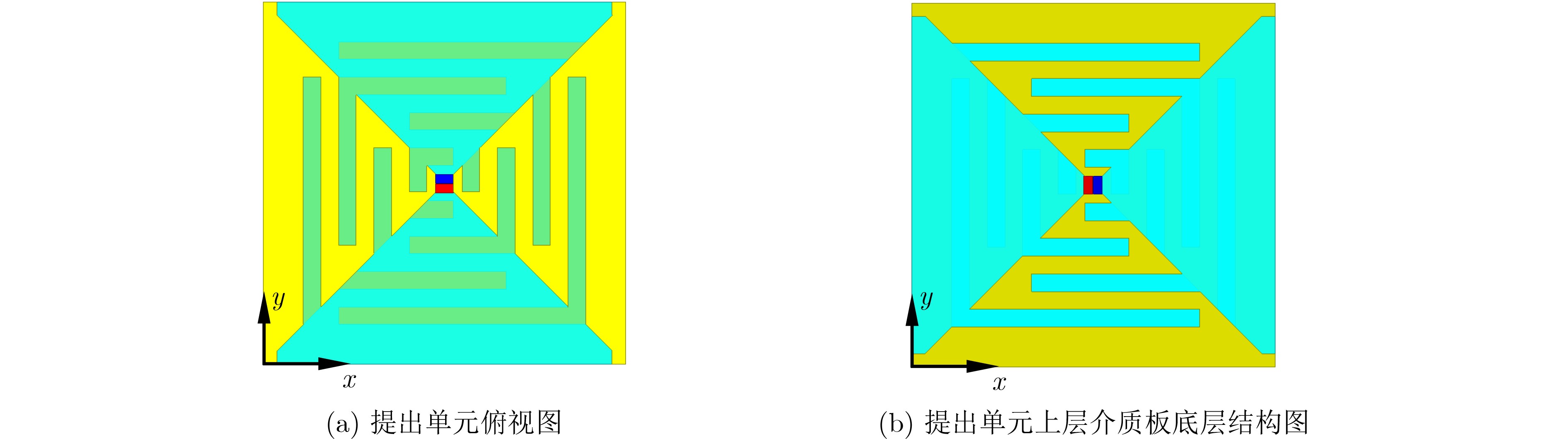
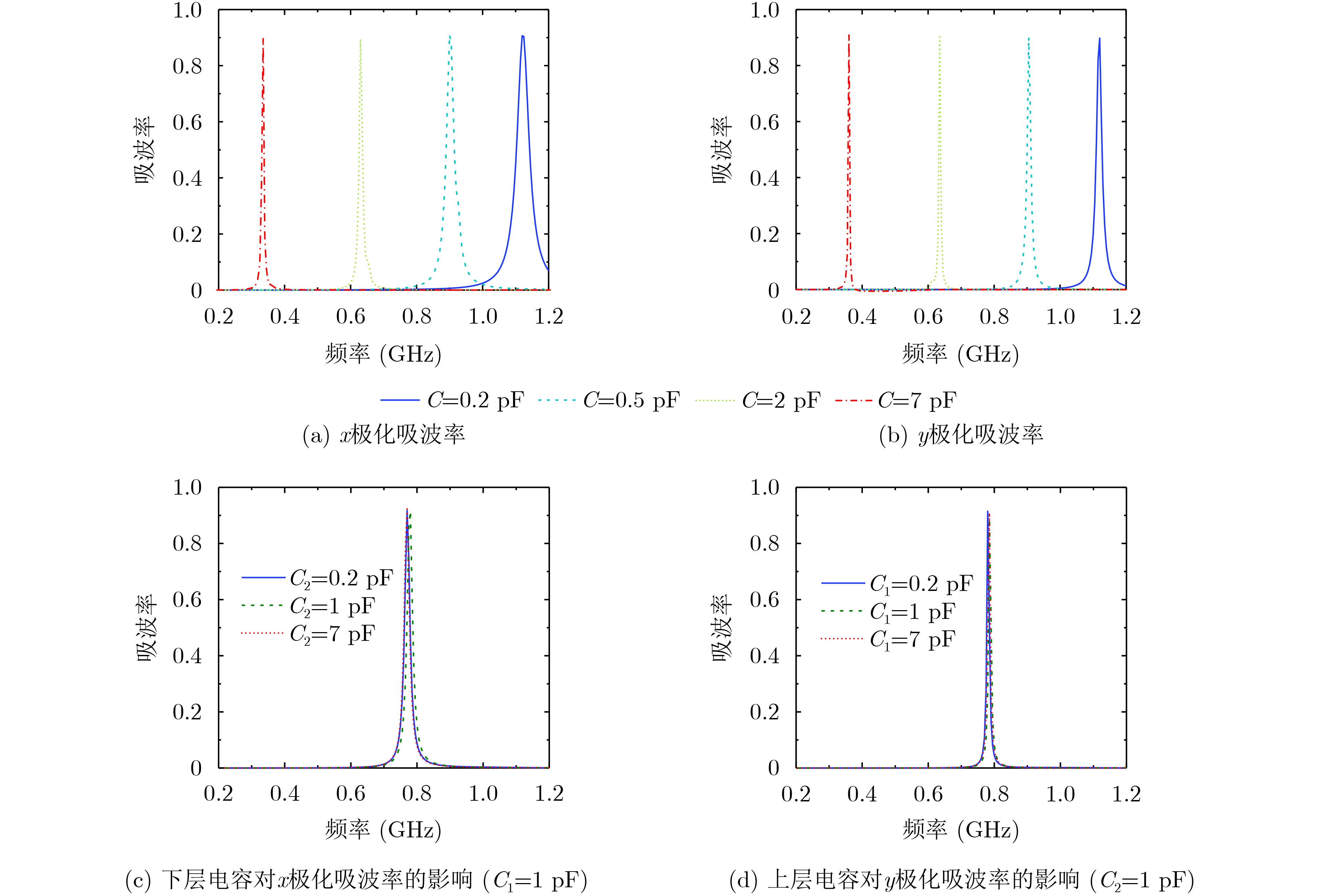
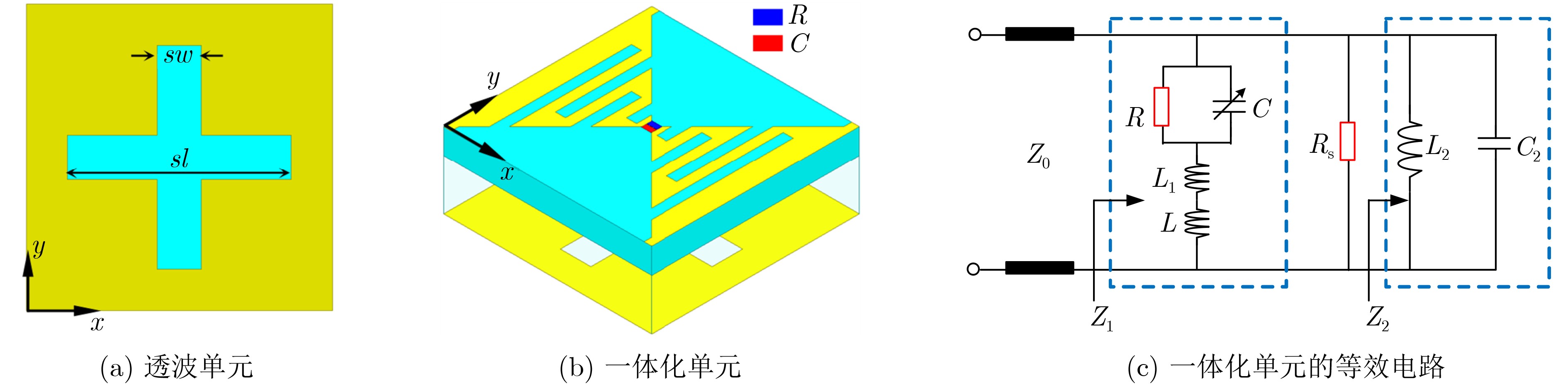
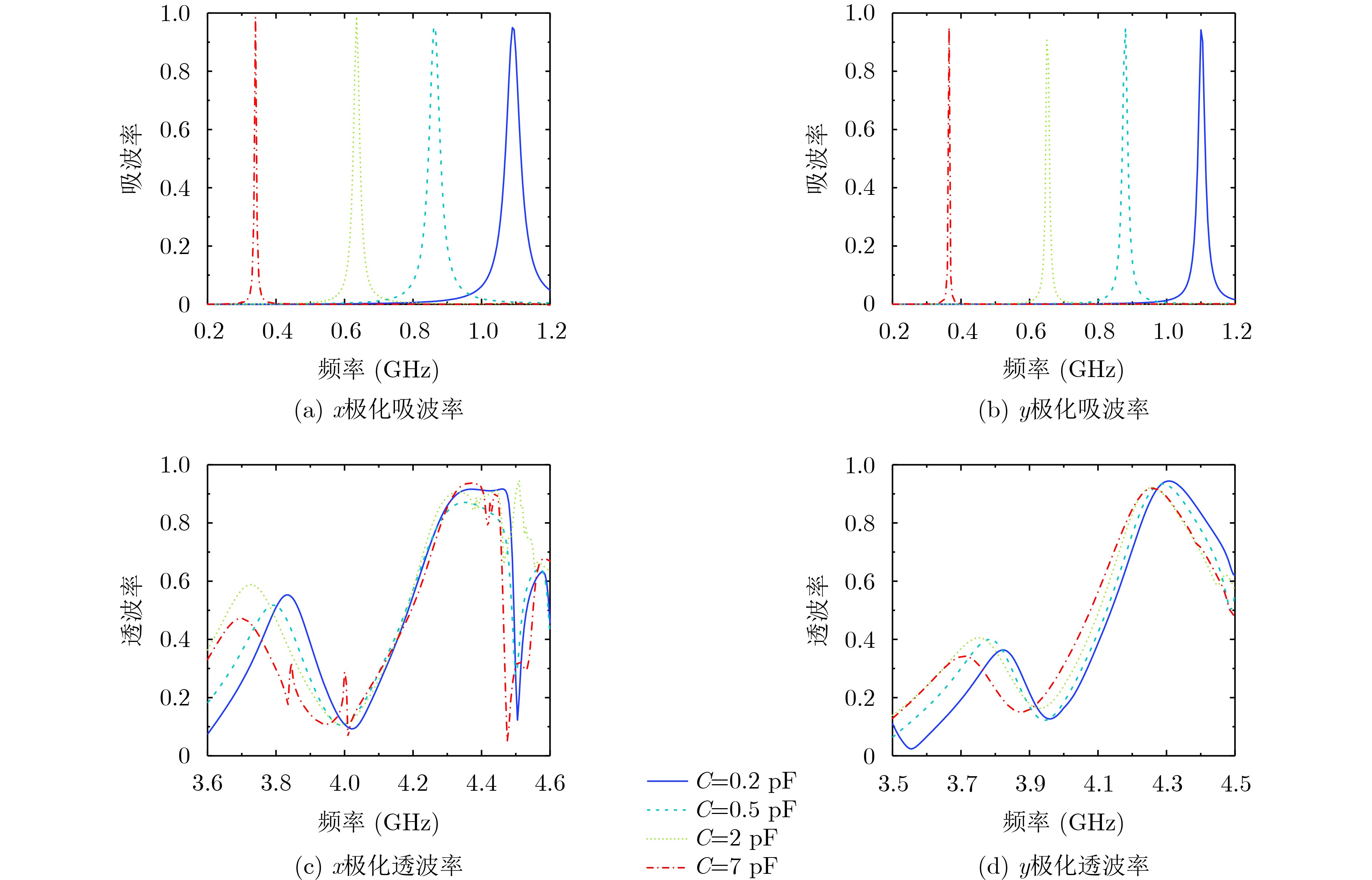
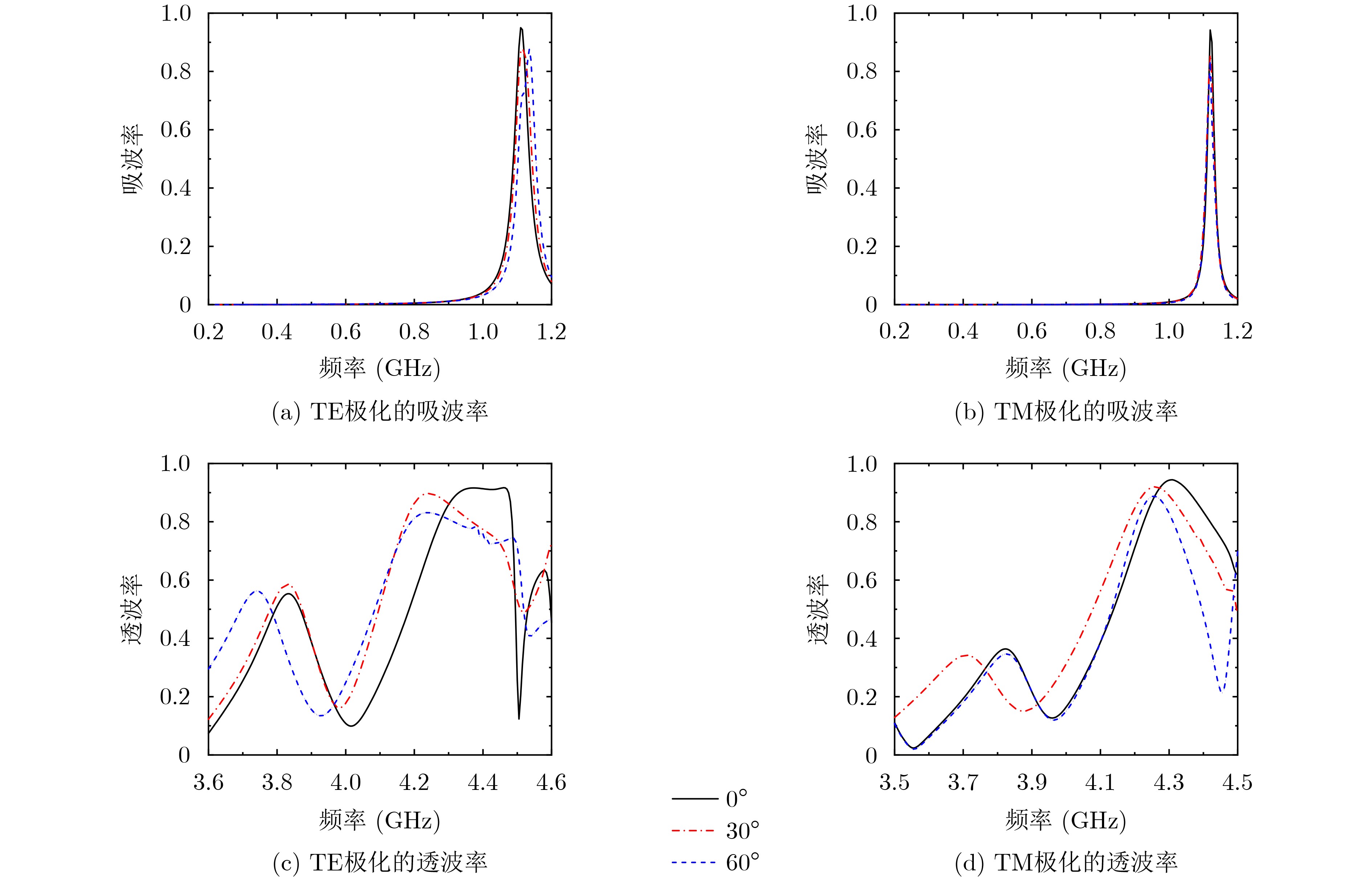
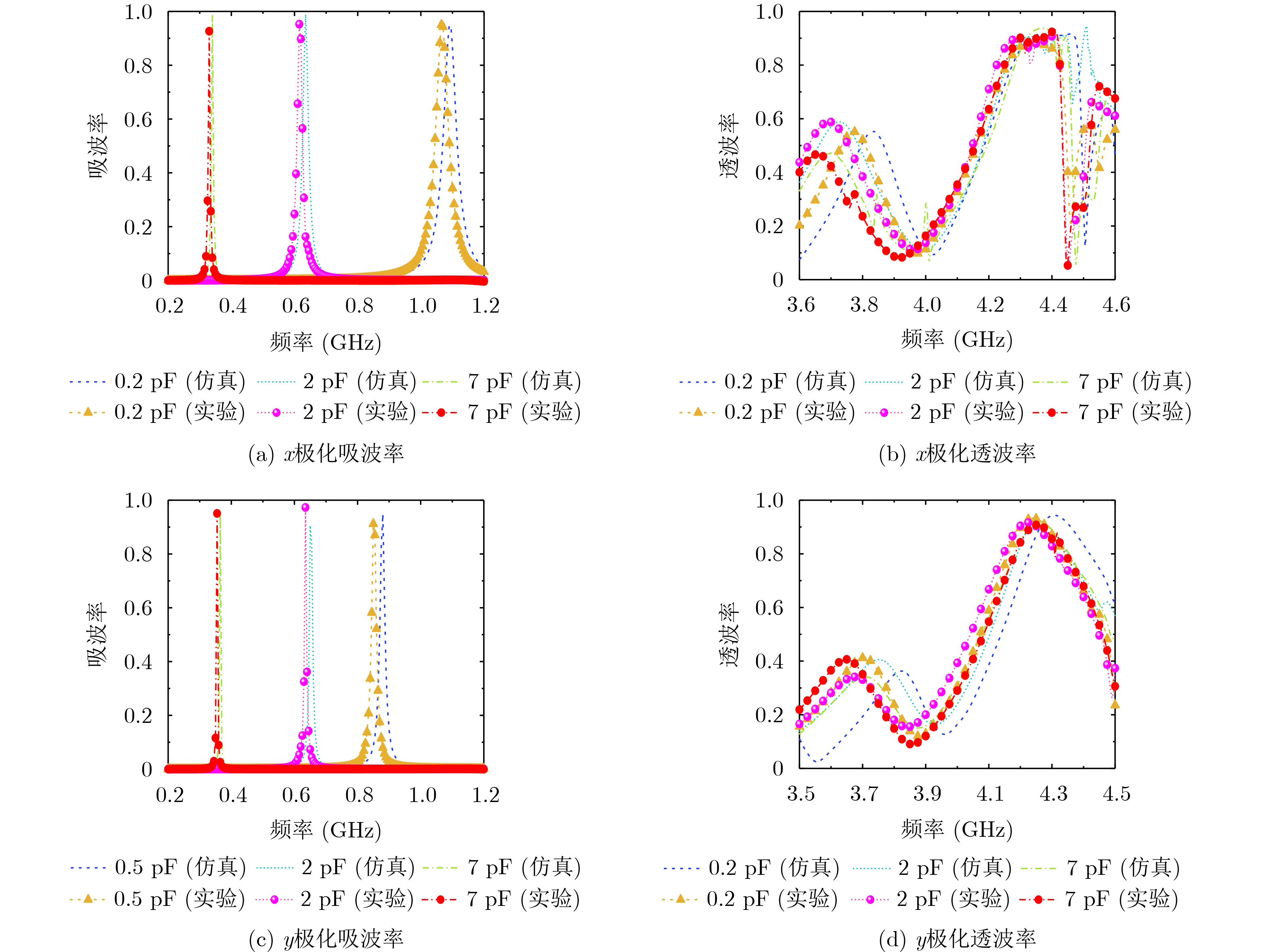
2025, 47(10): 3632-3645.
doi: 10.11999/JEIT250026
Abstract:
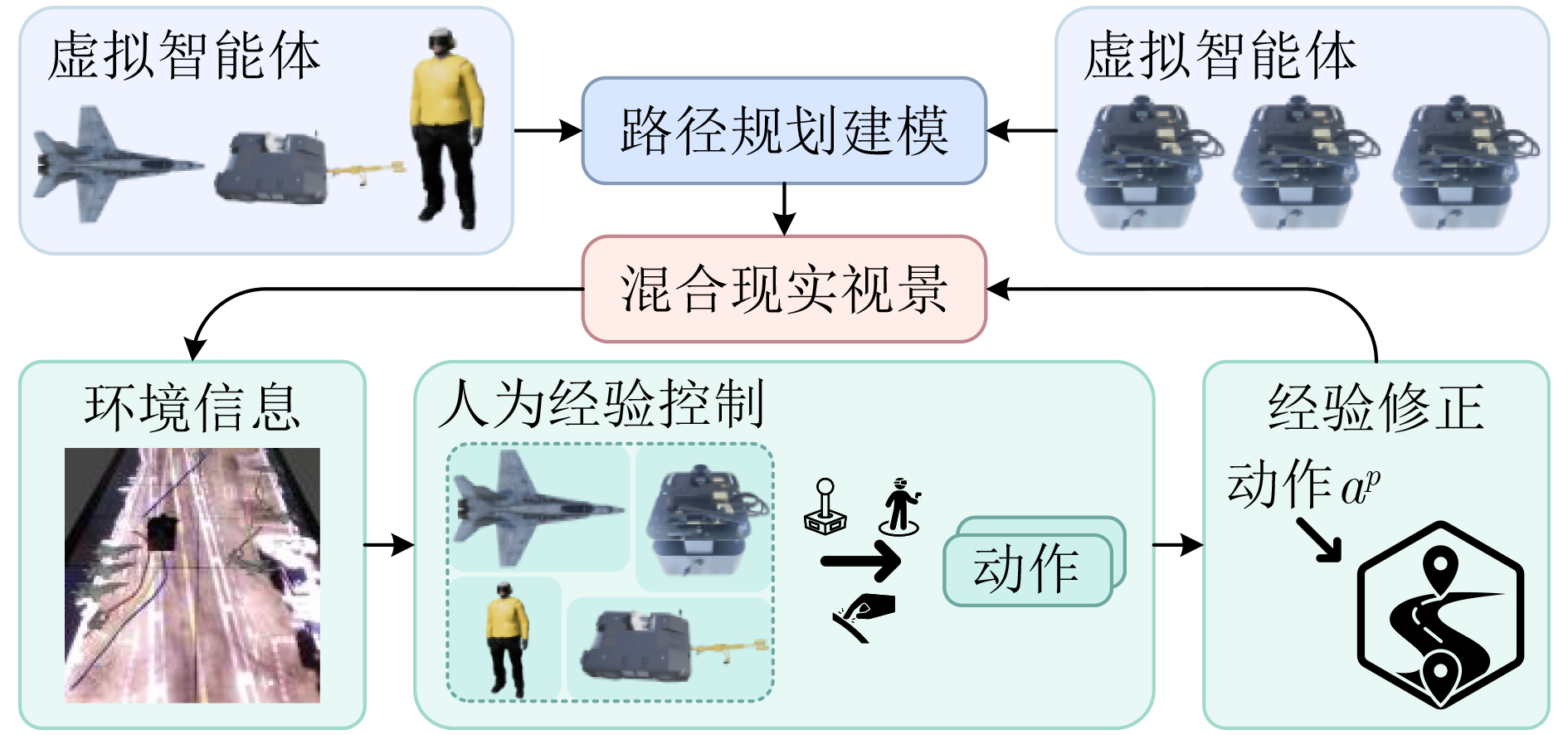
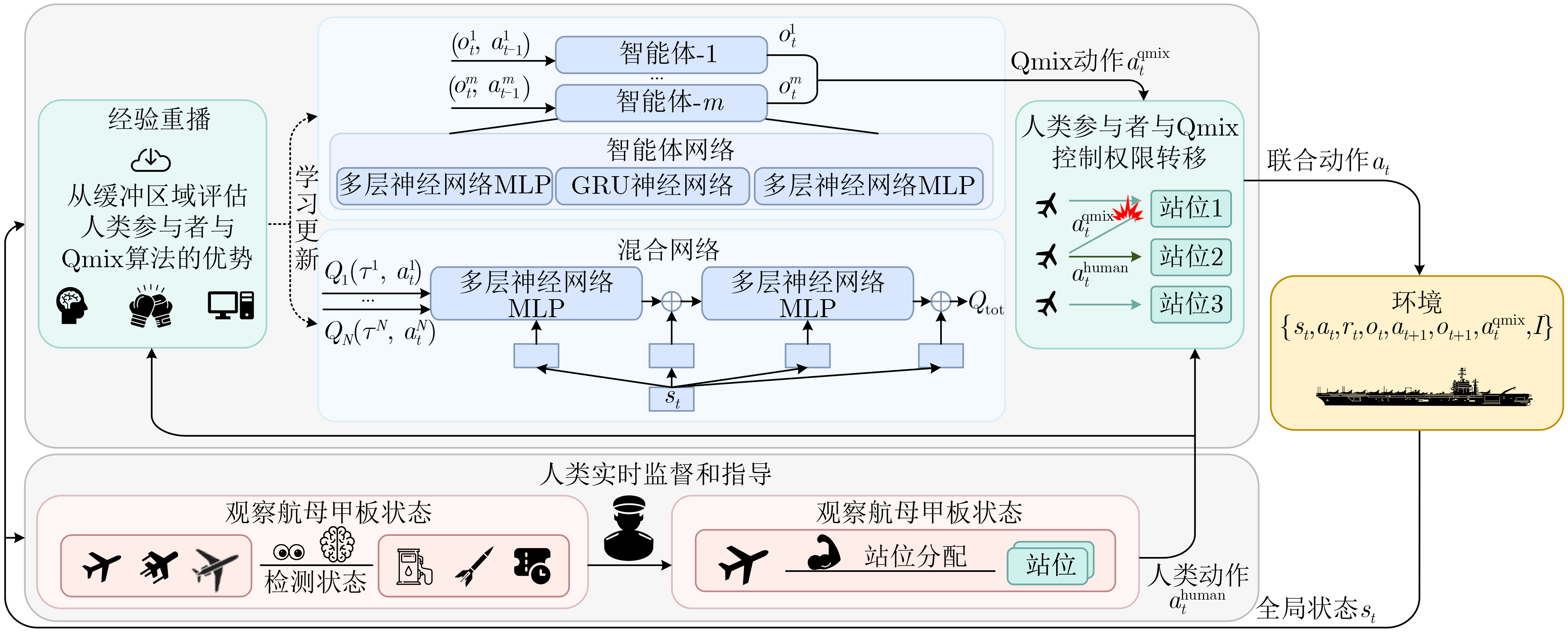
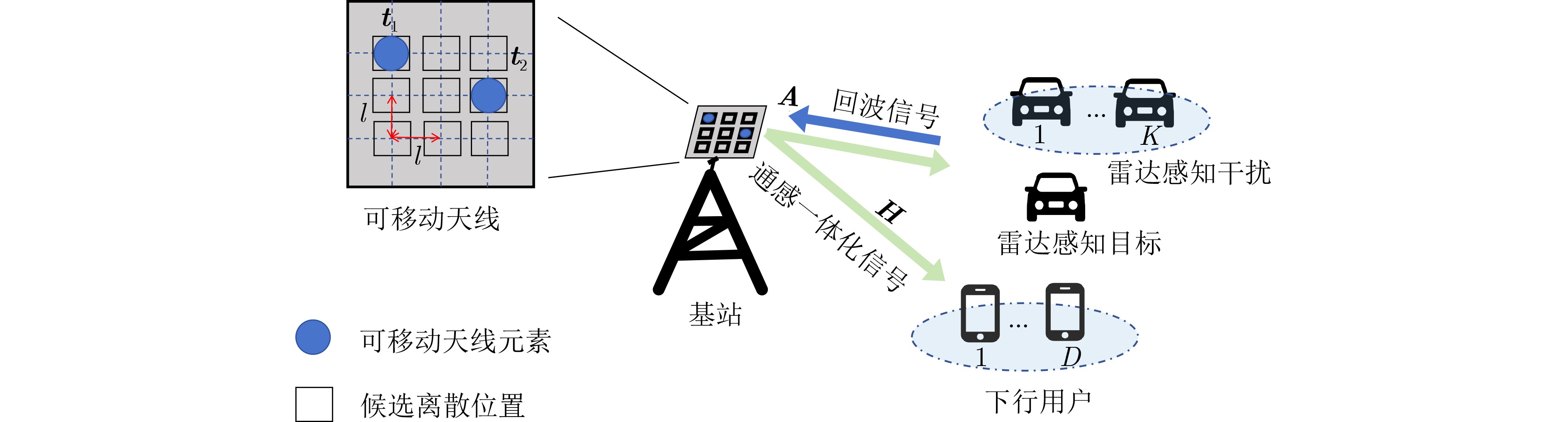
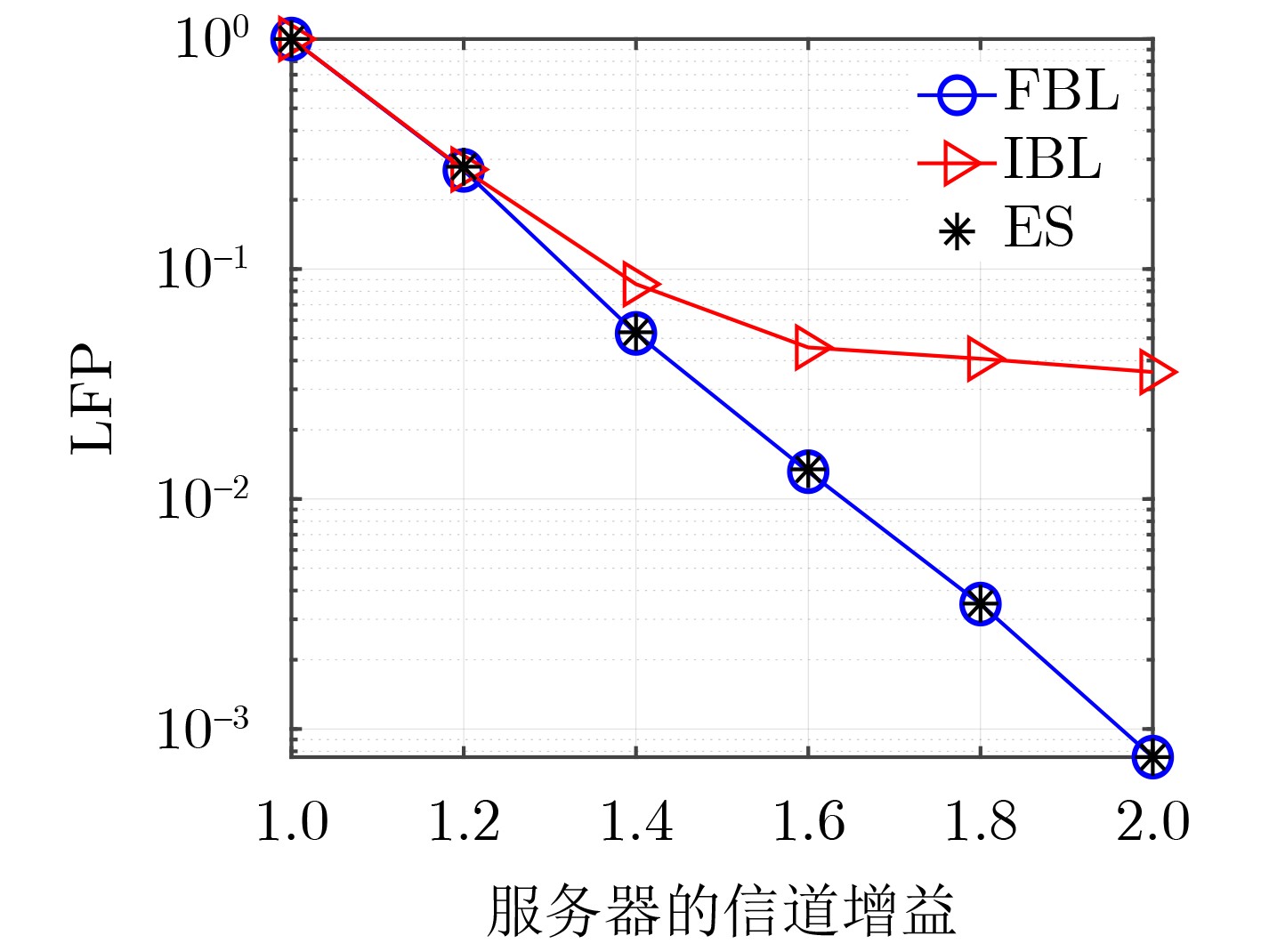
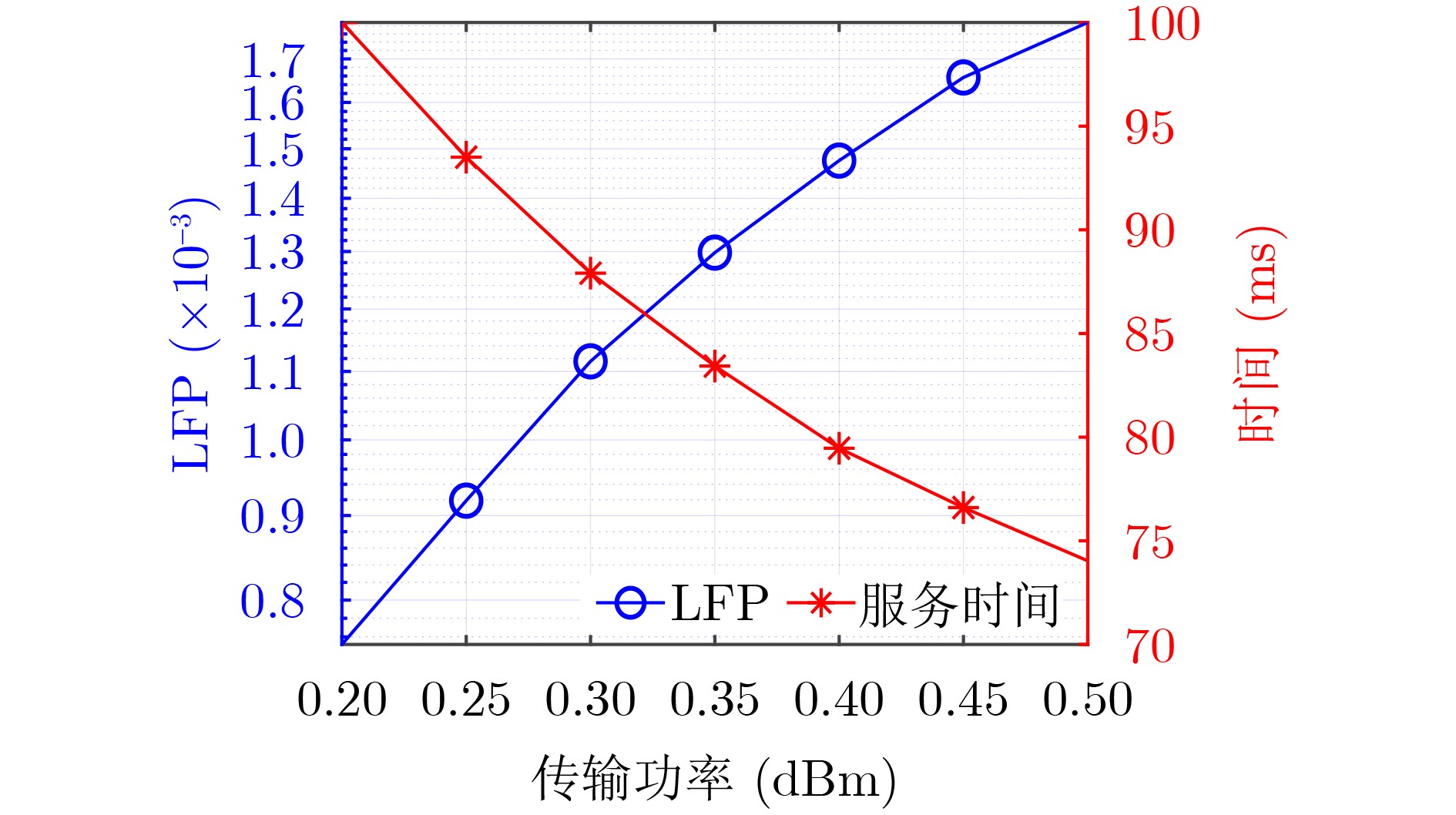
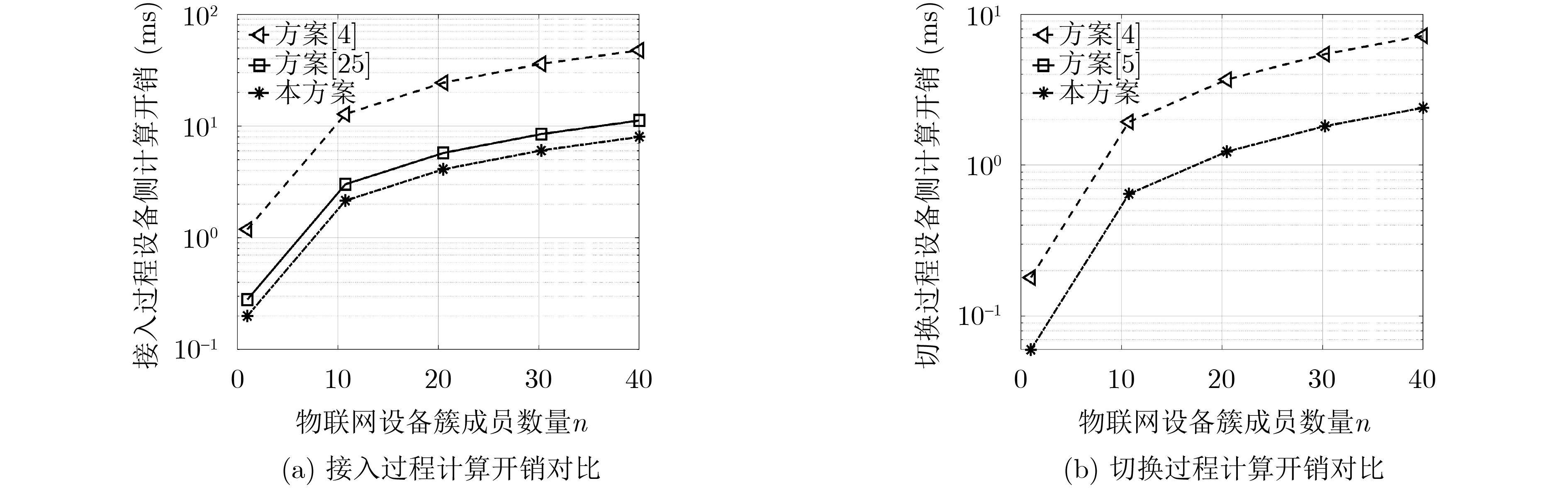
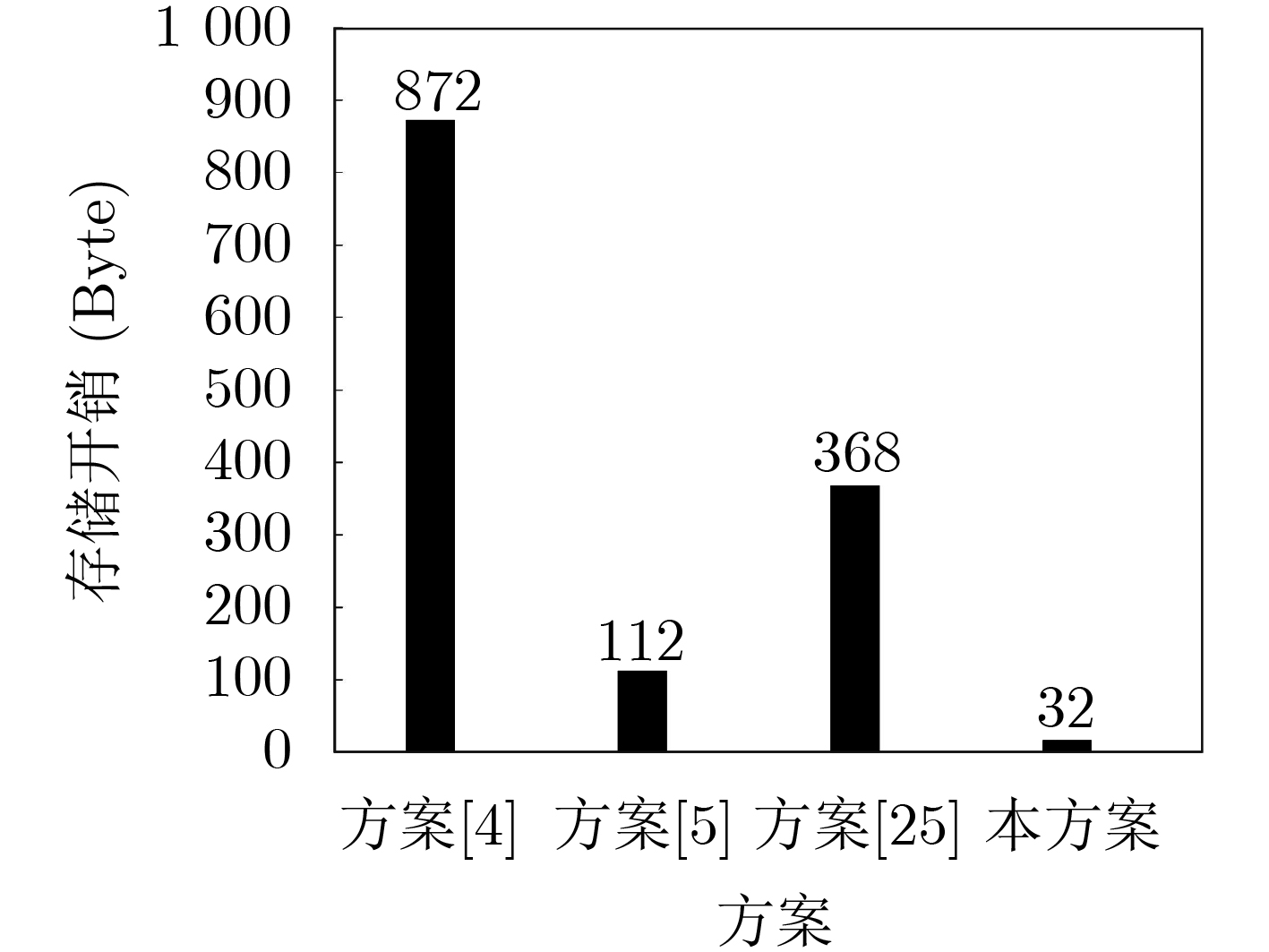
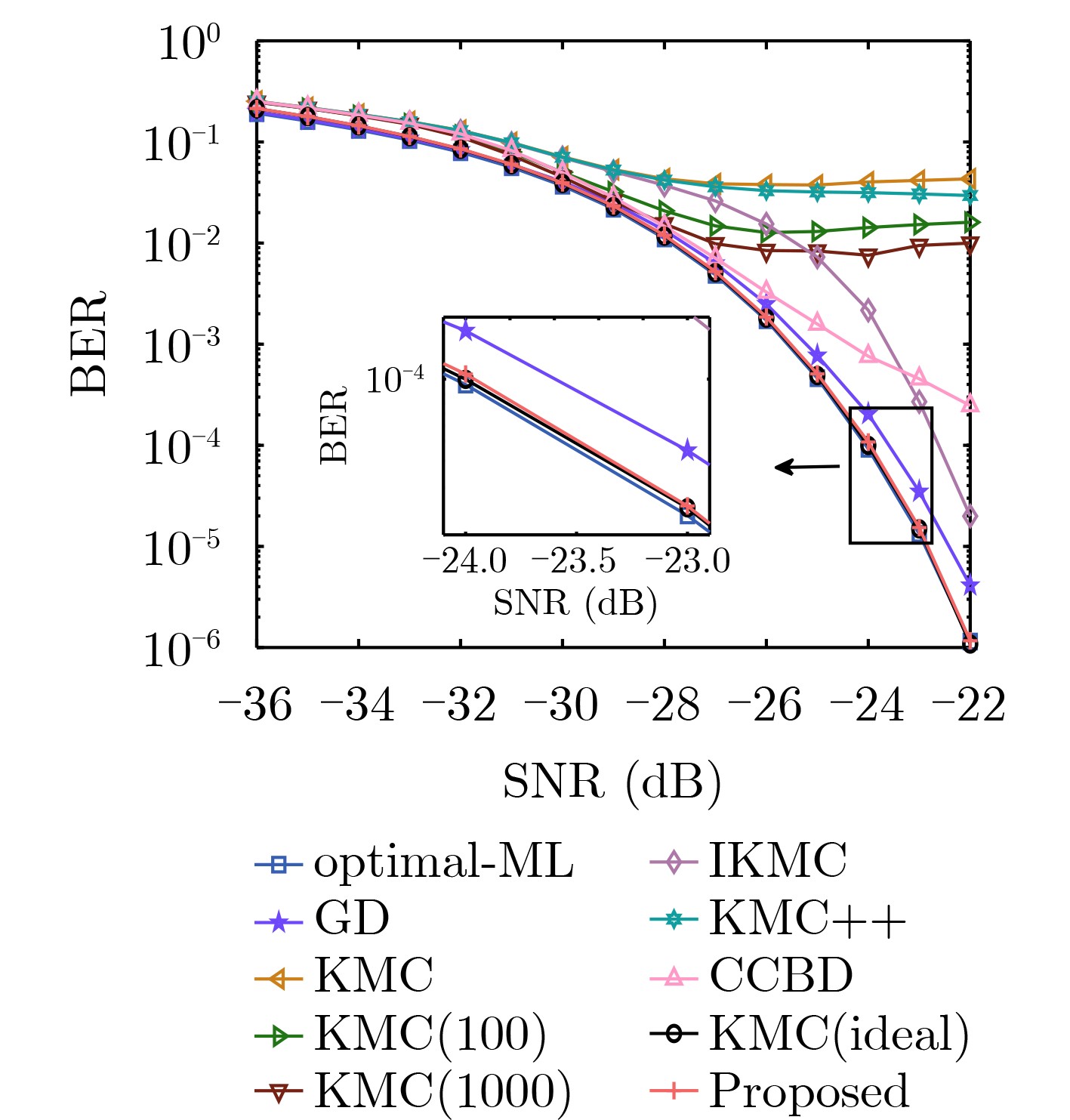
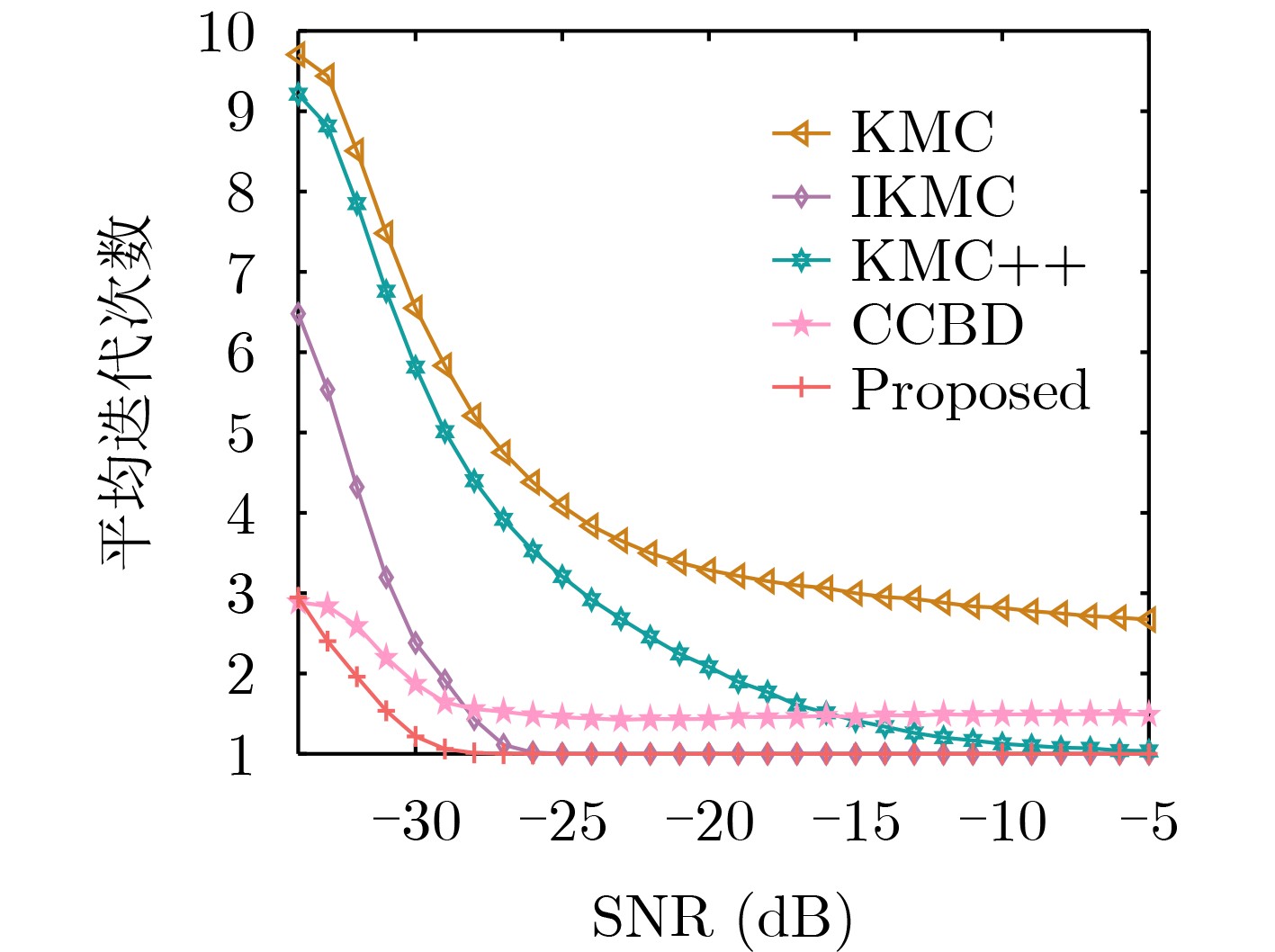
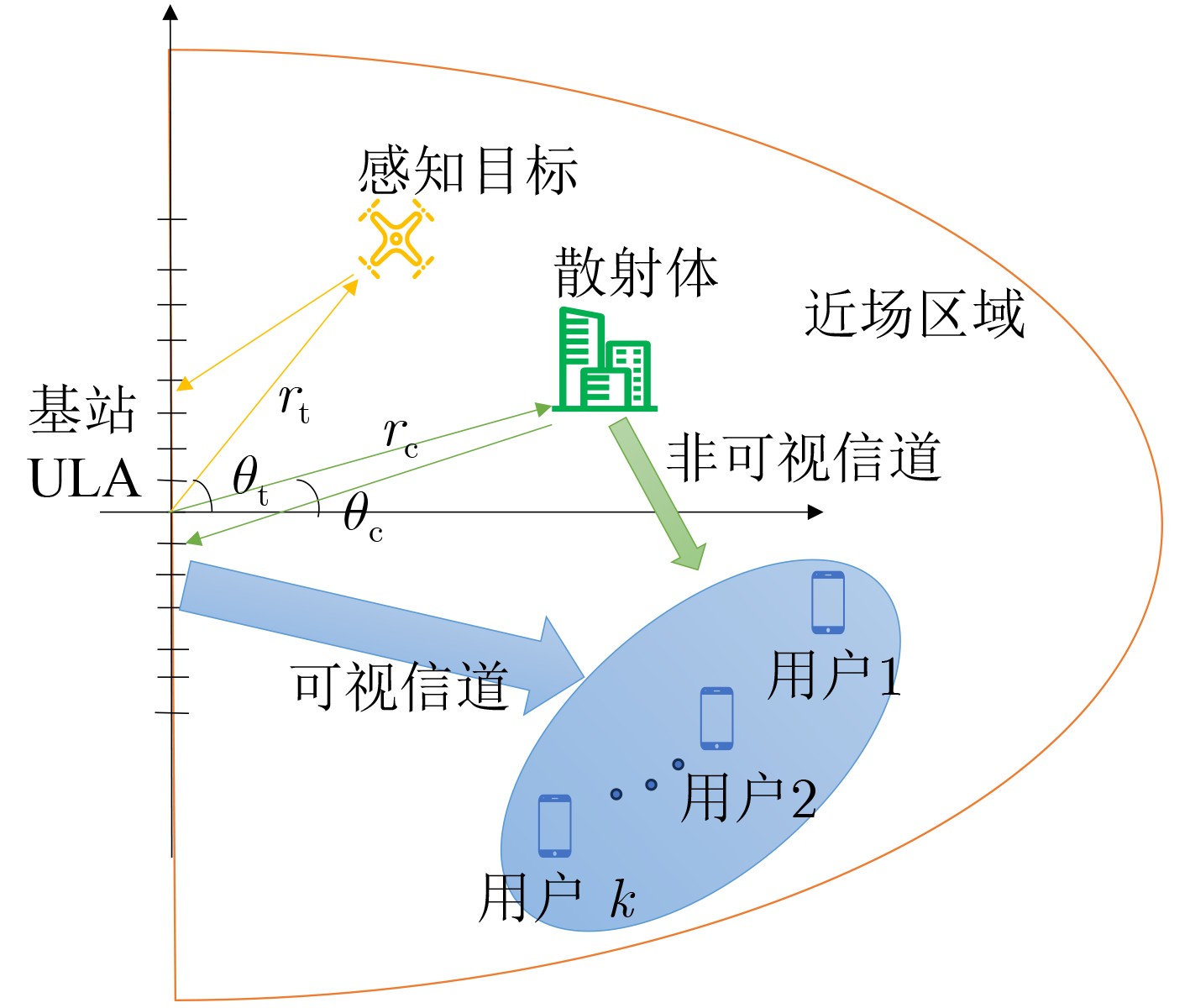
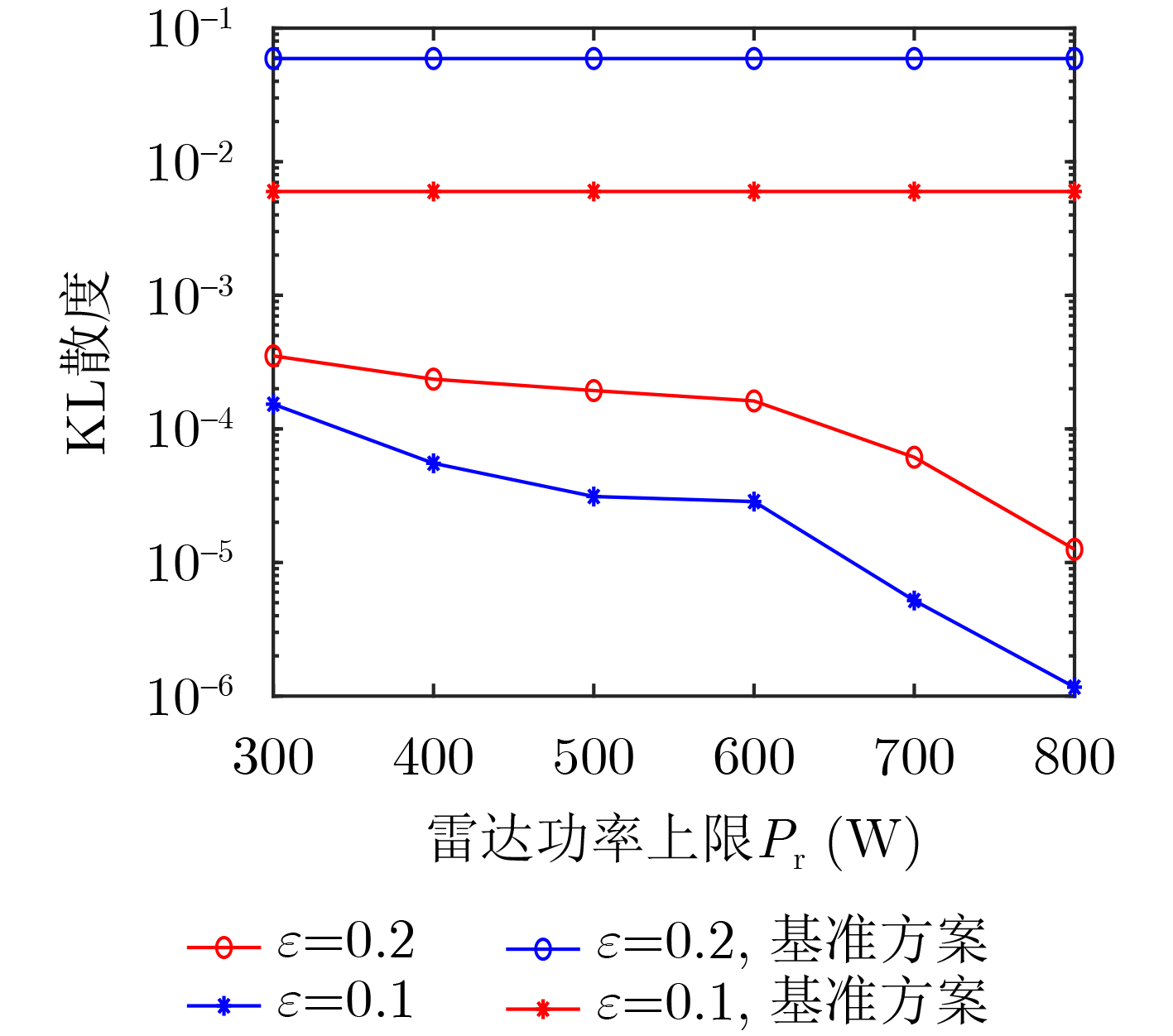
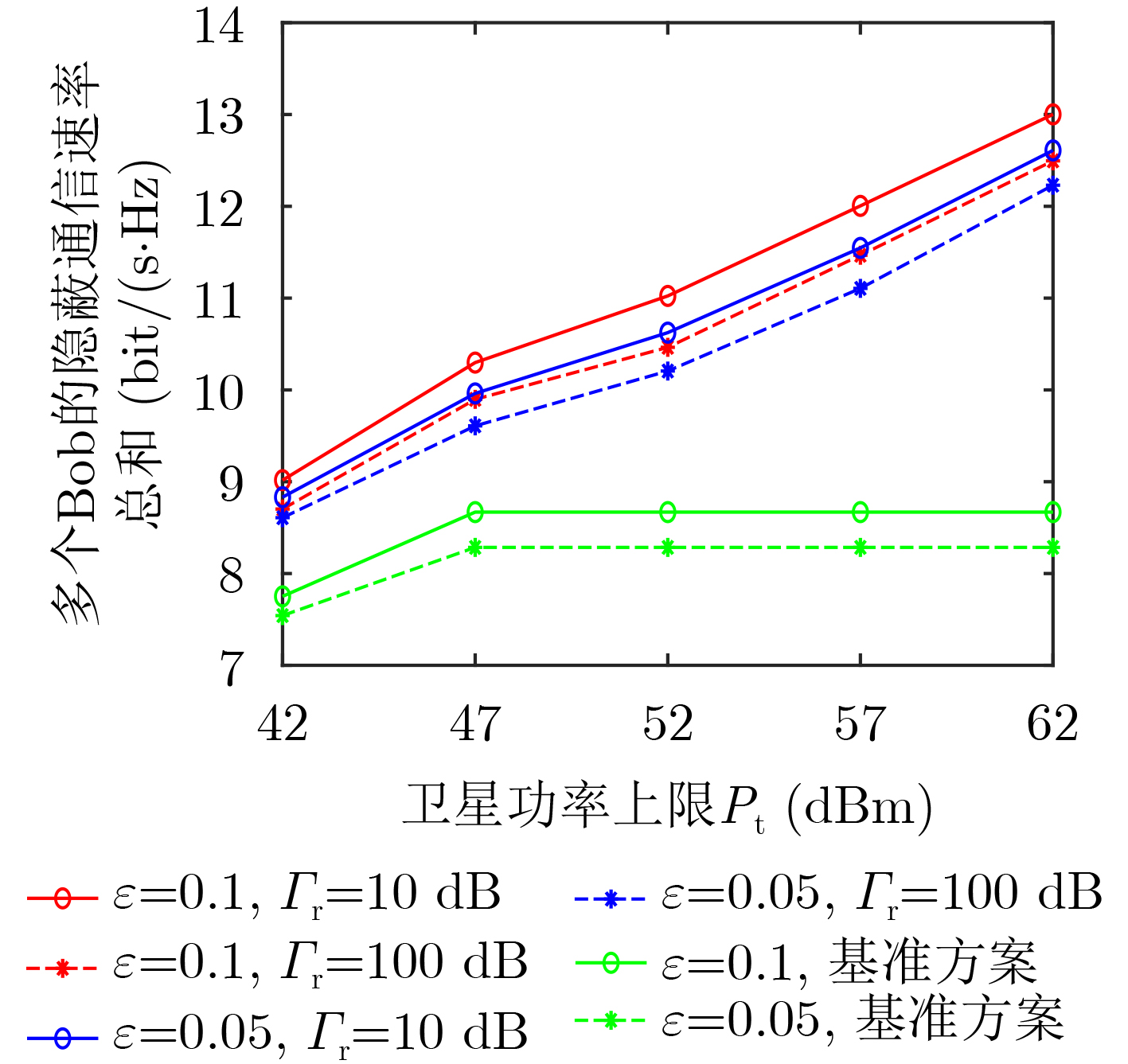
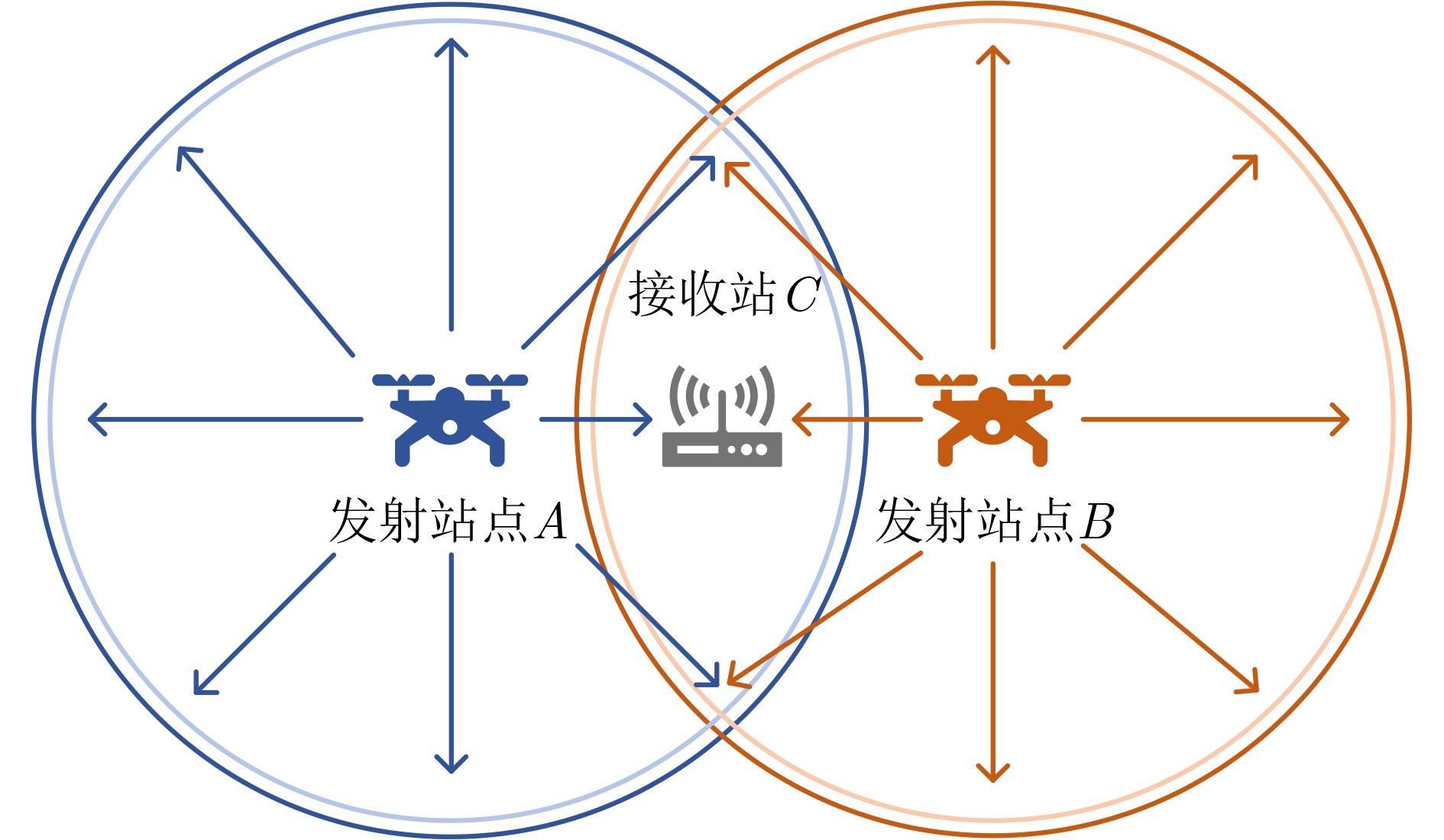
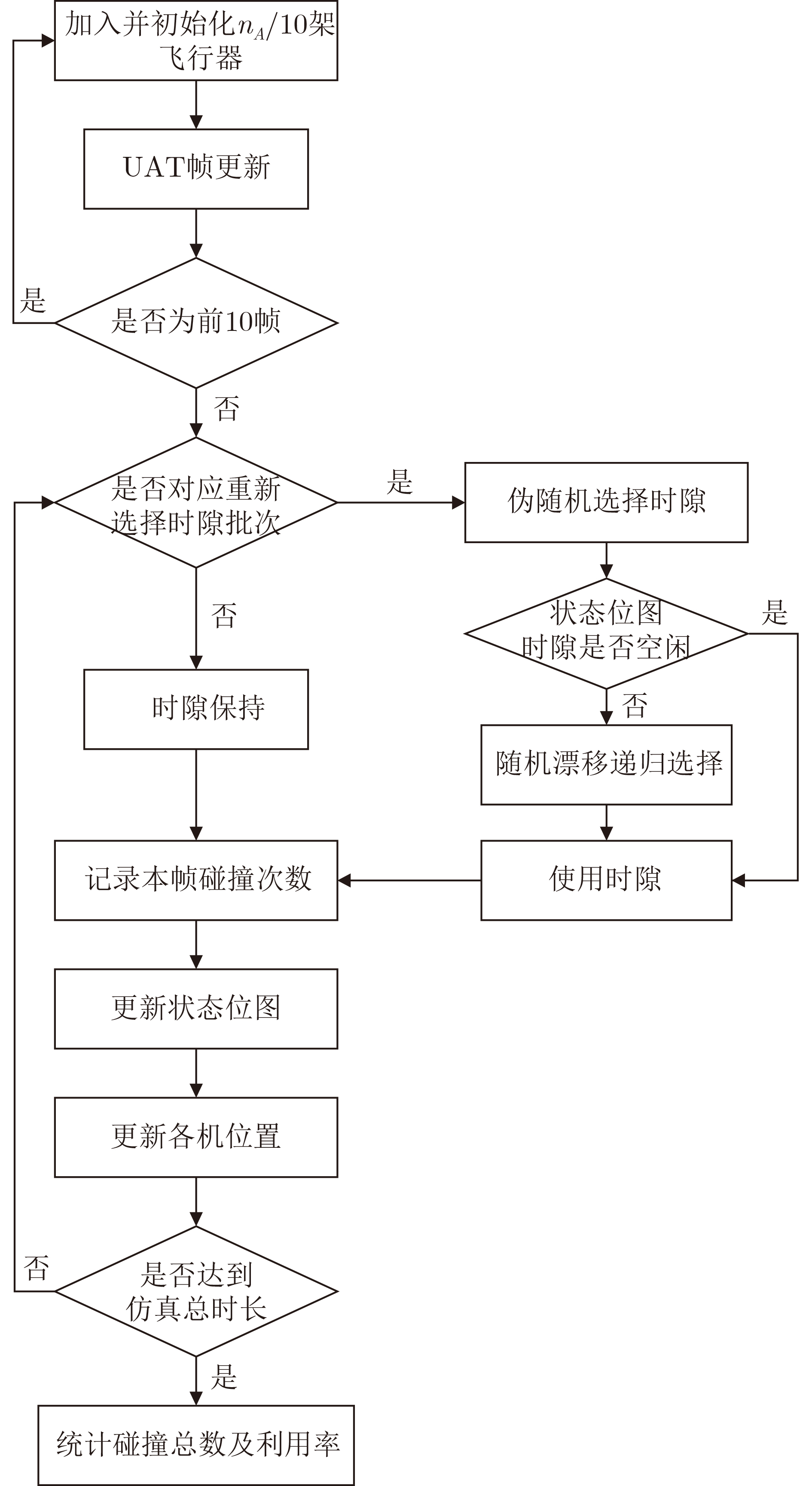
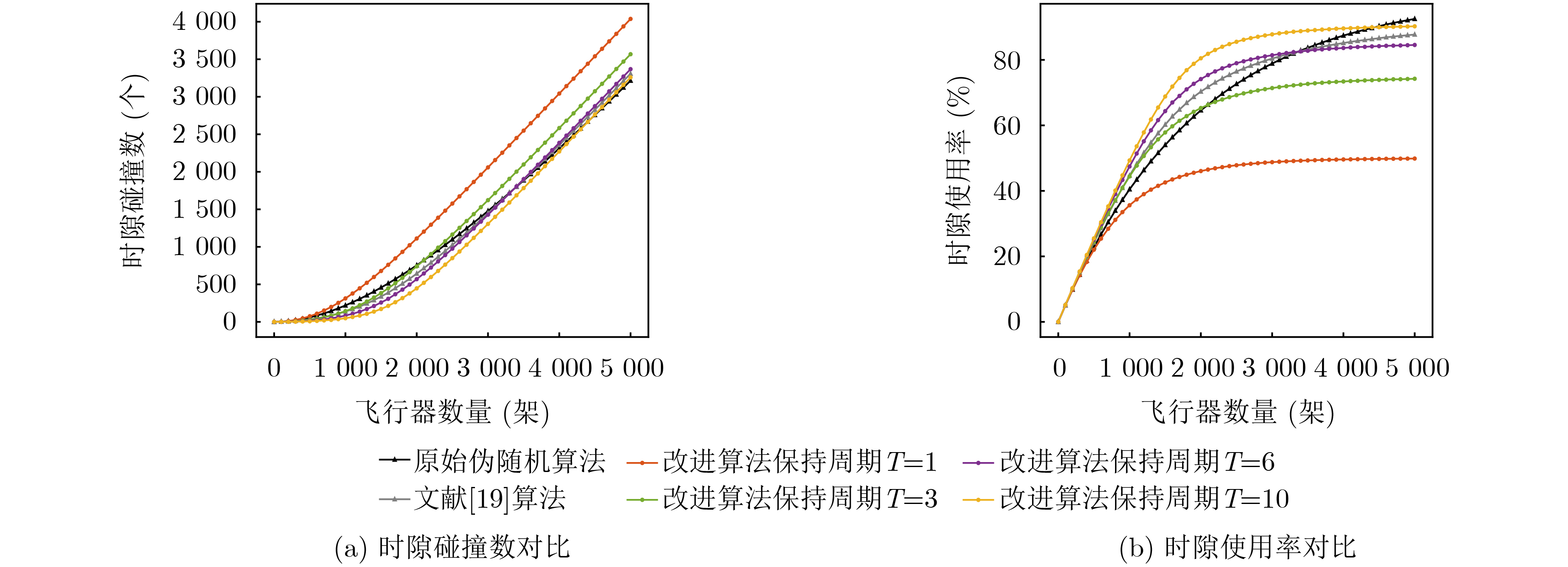
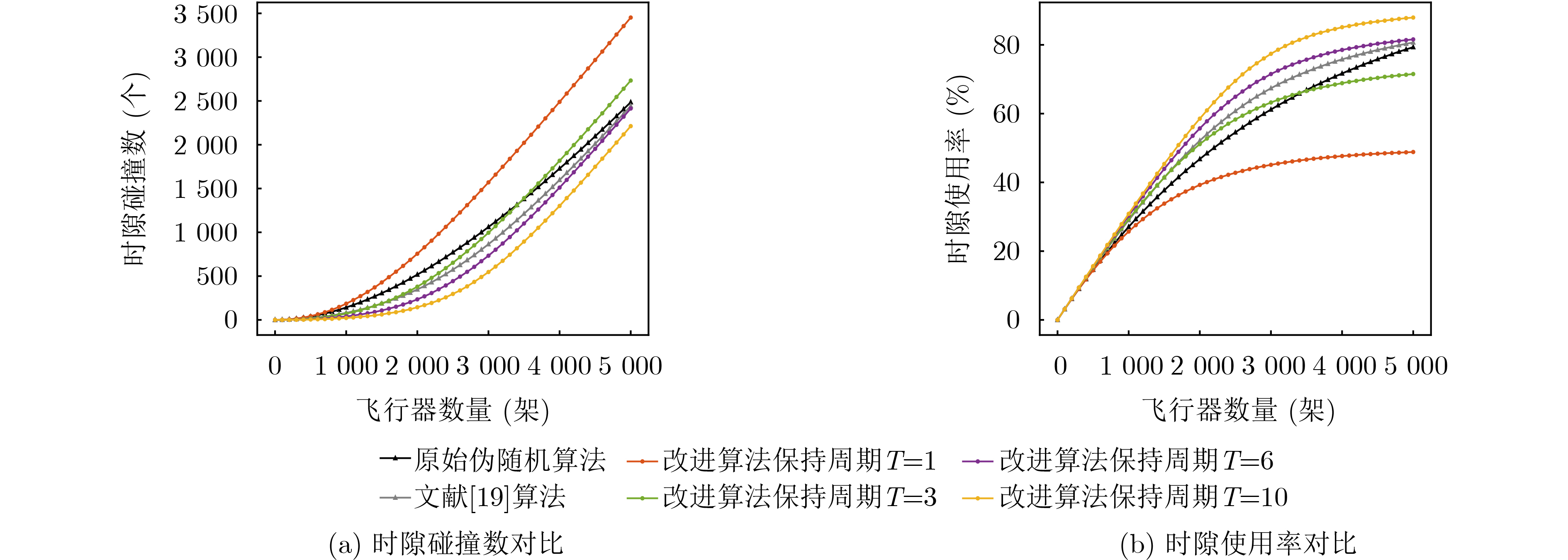
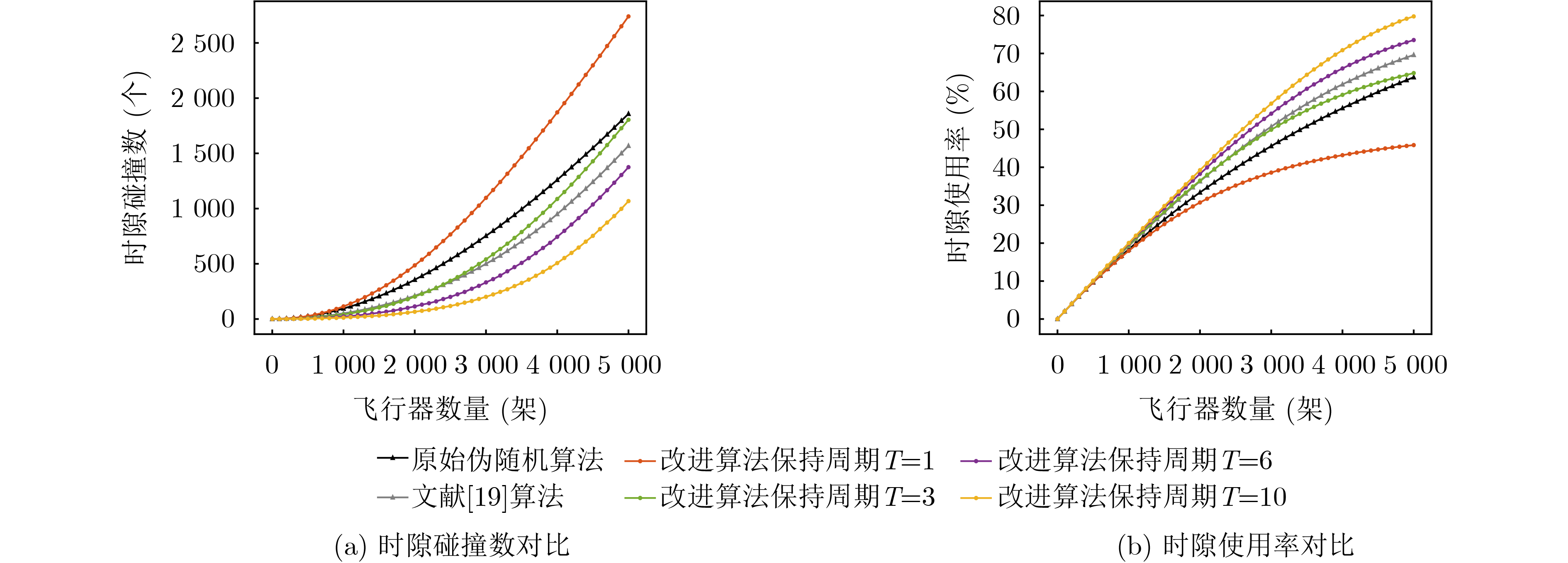
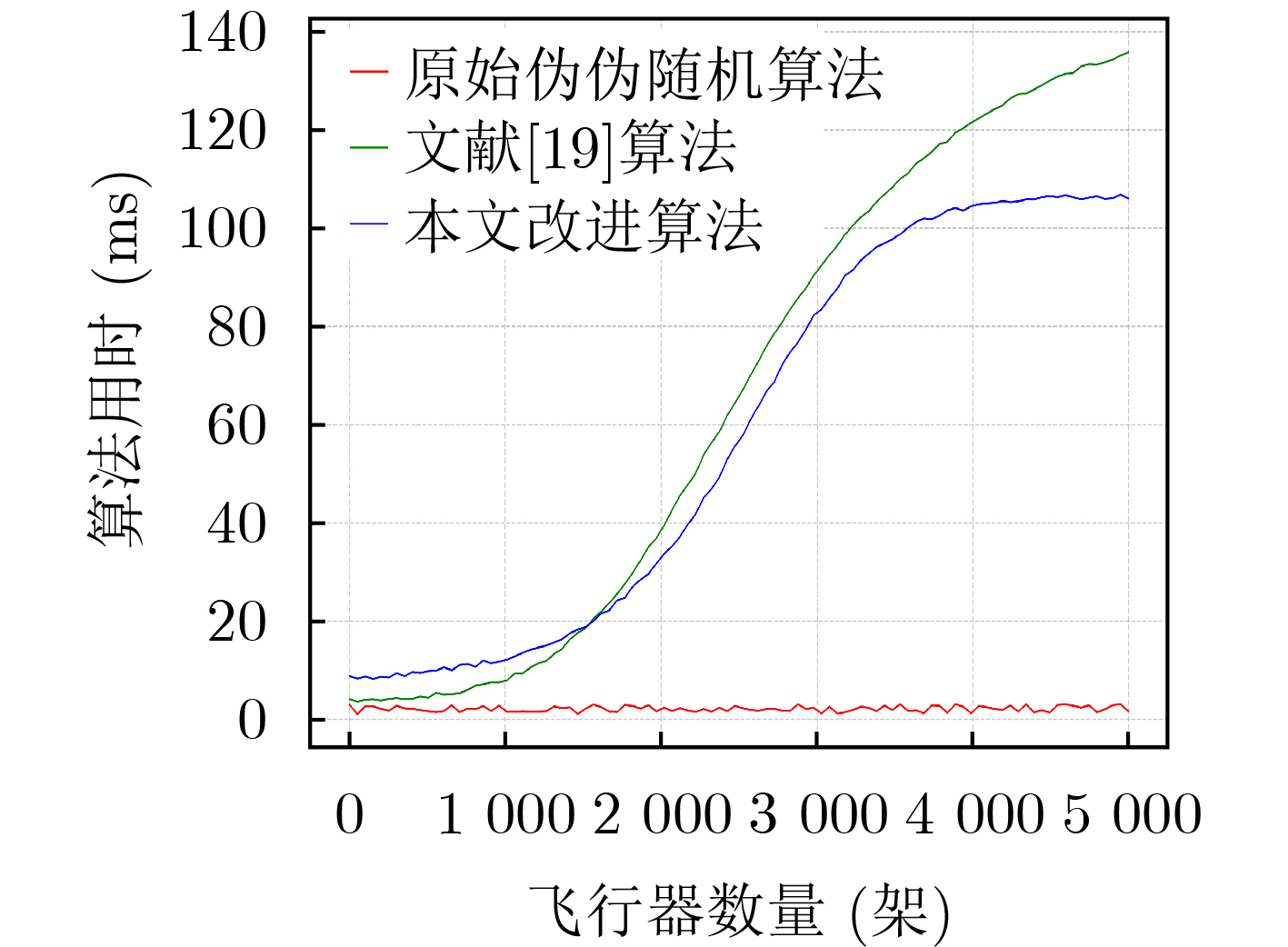
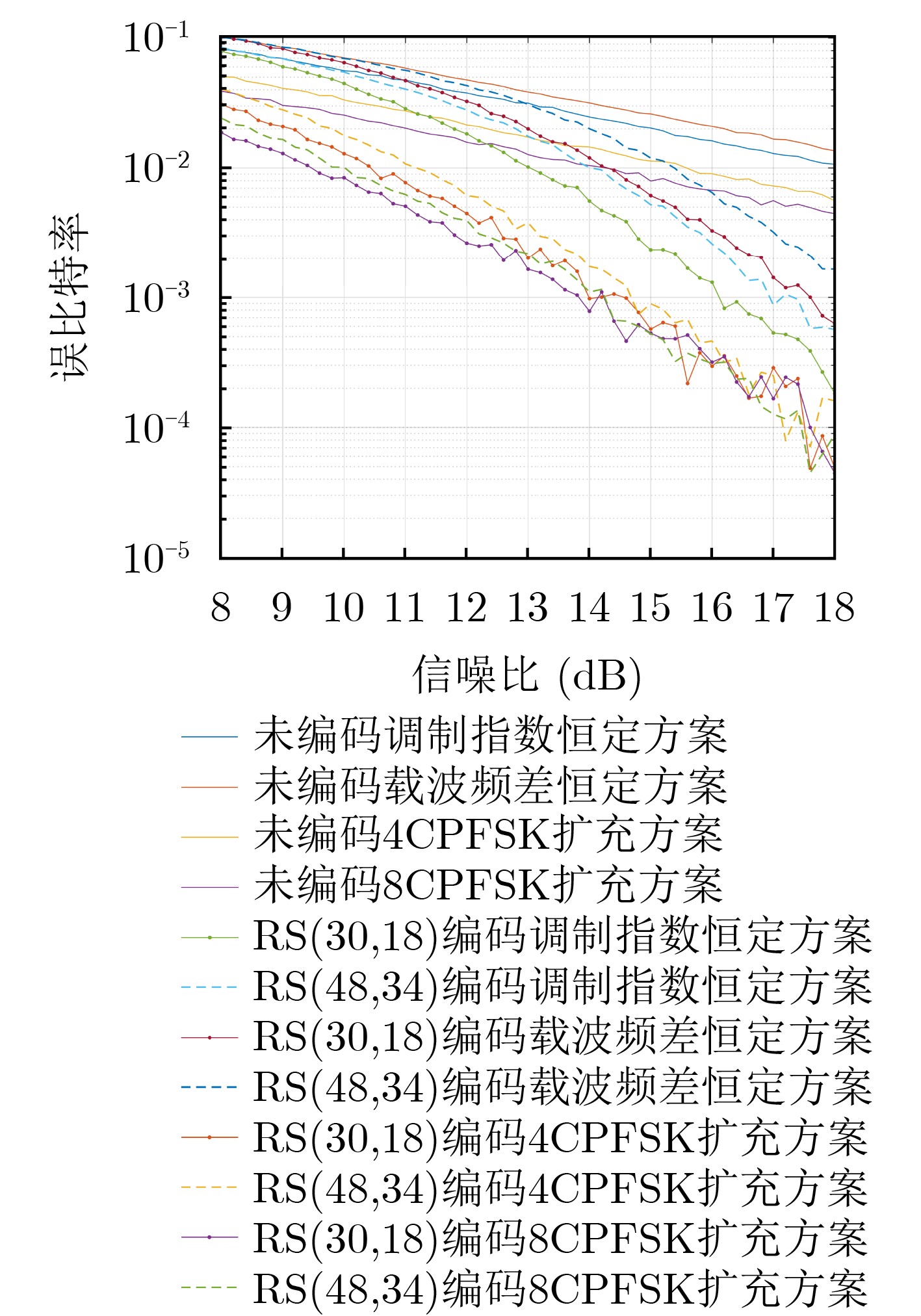
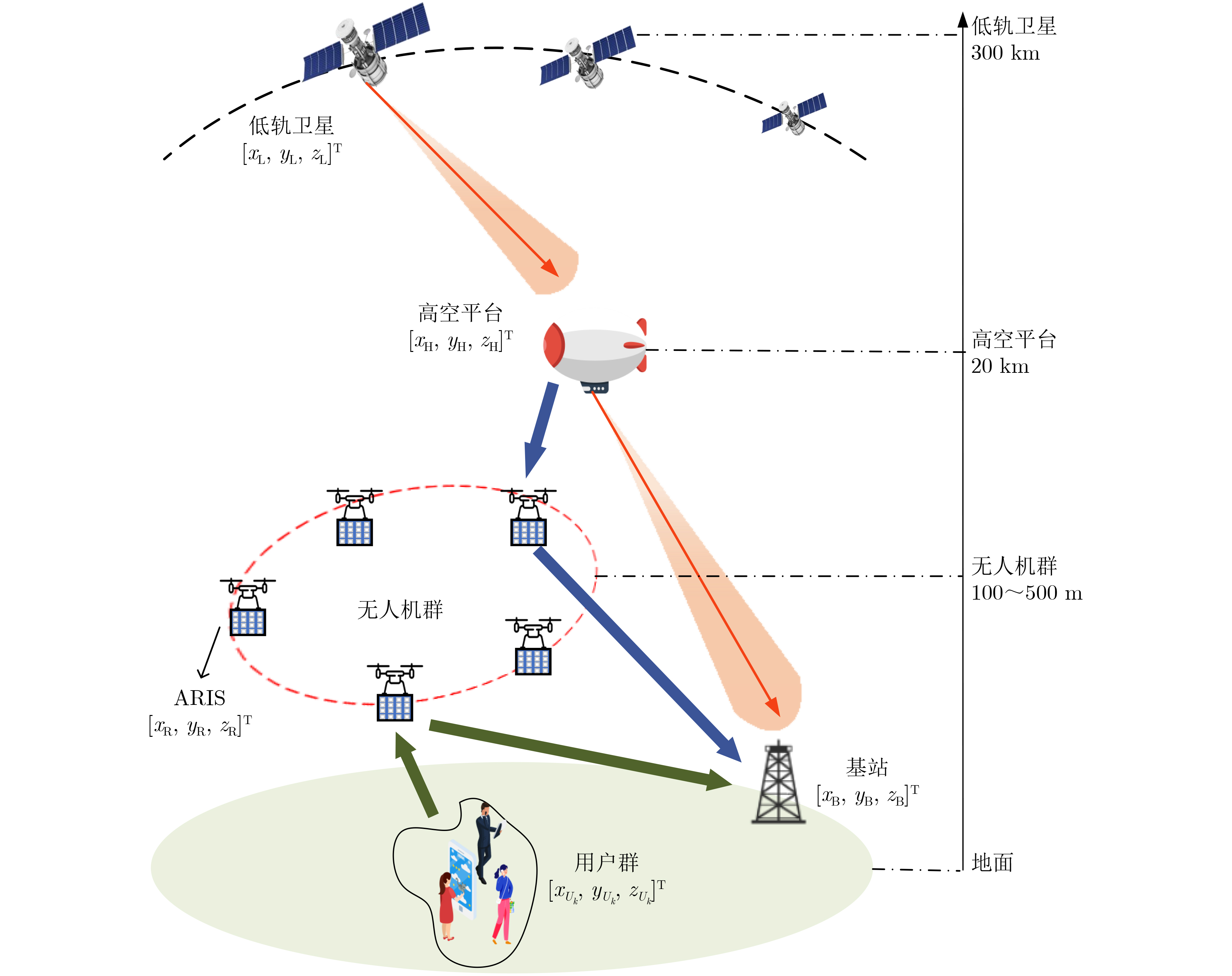
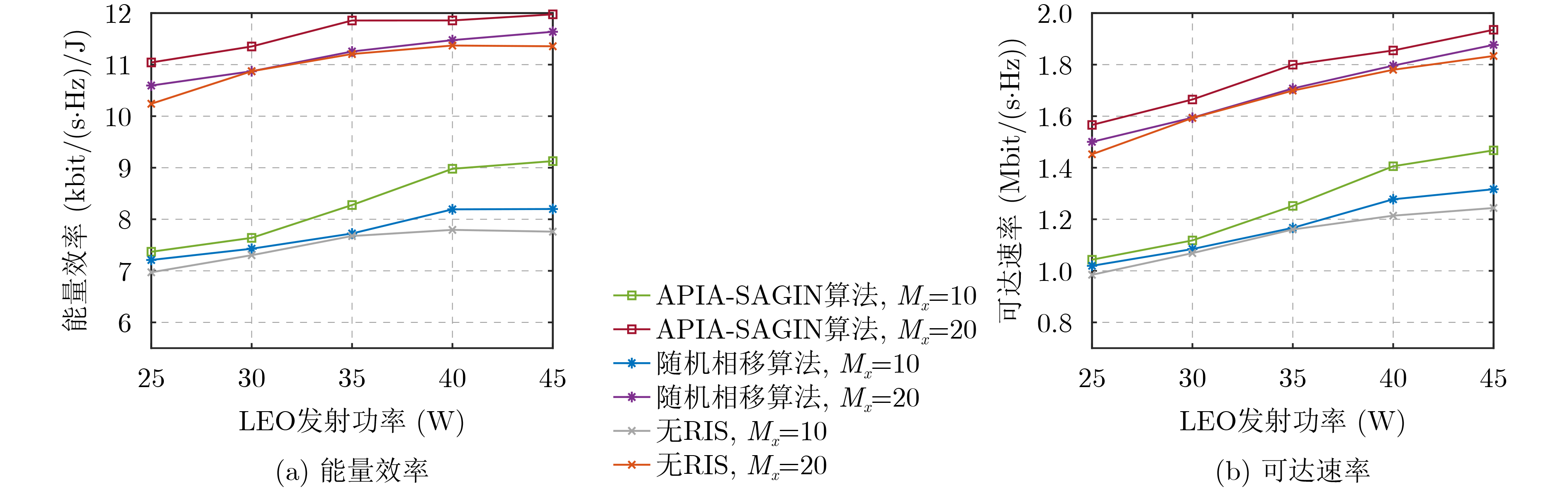
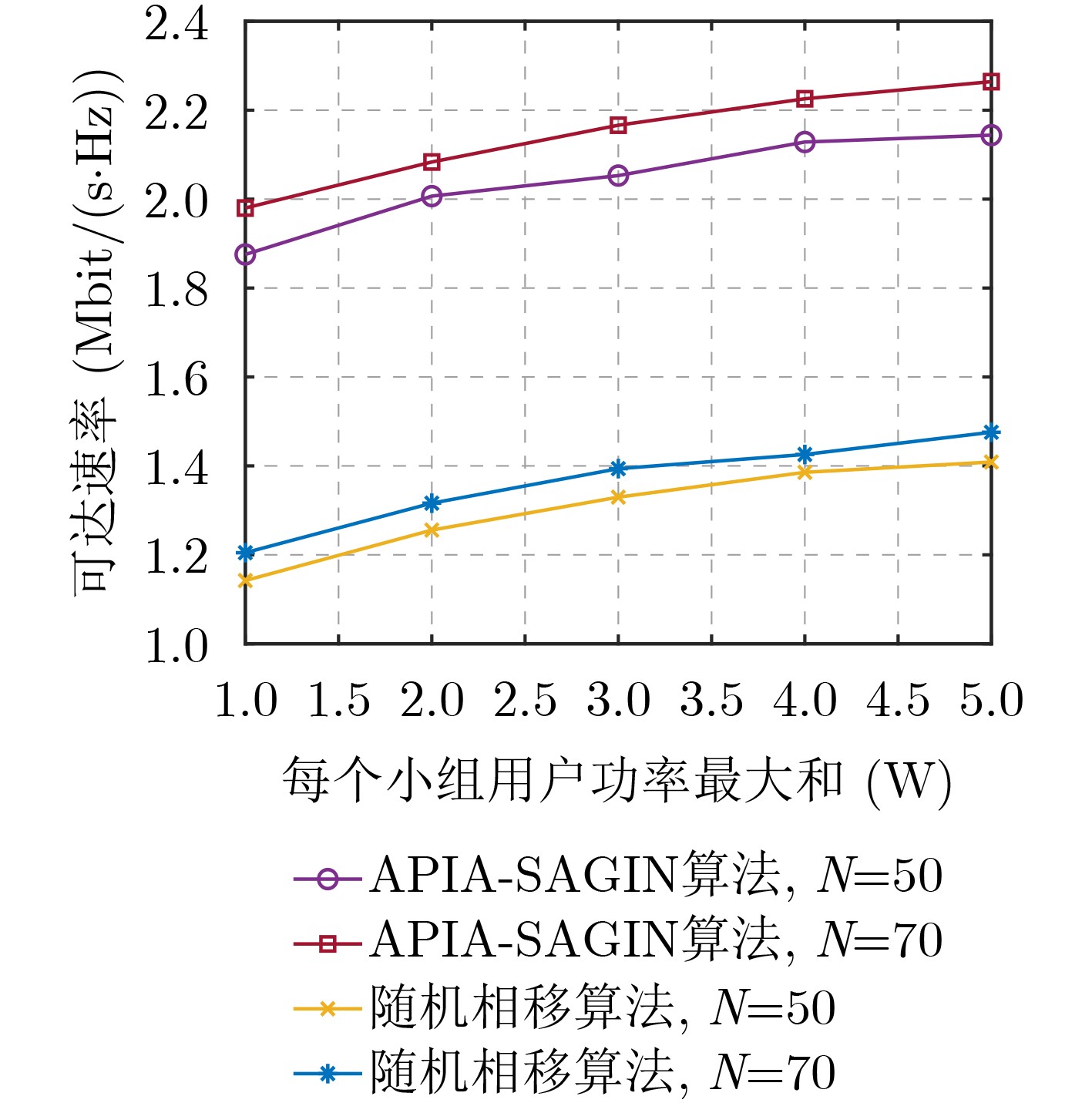
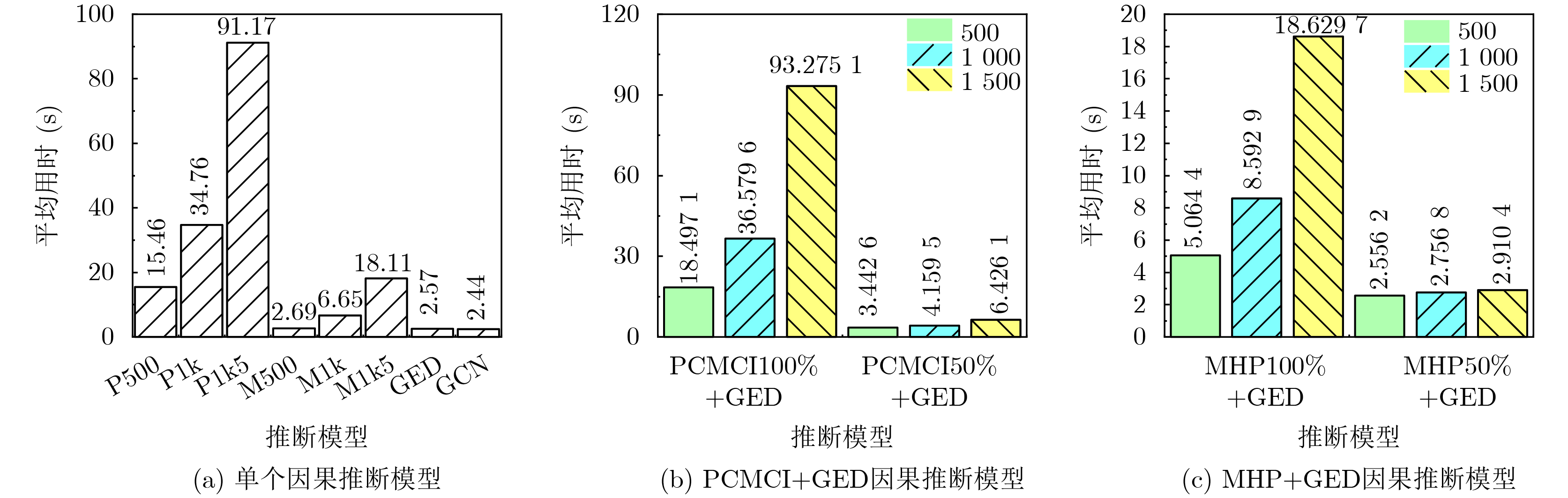
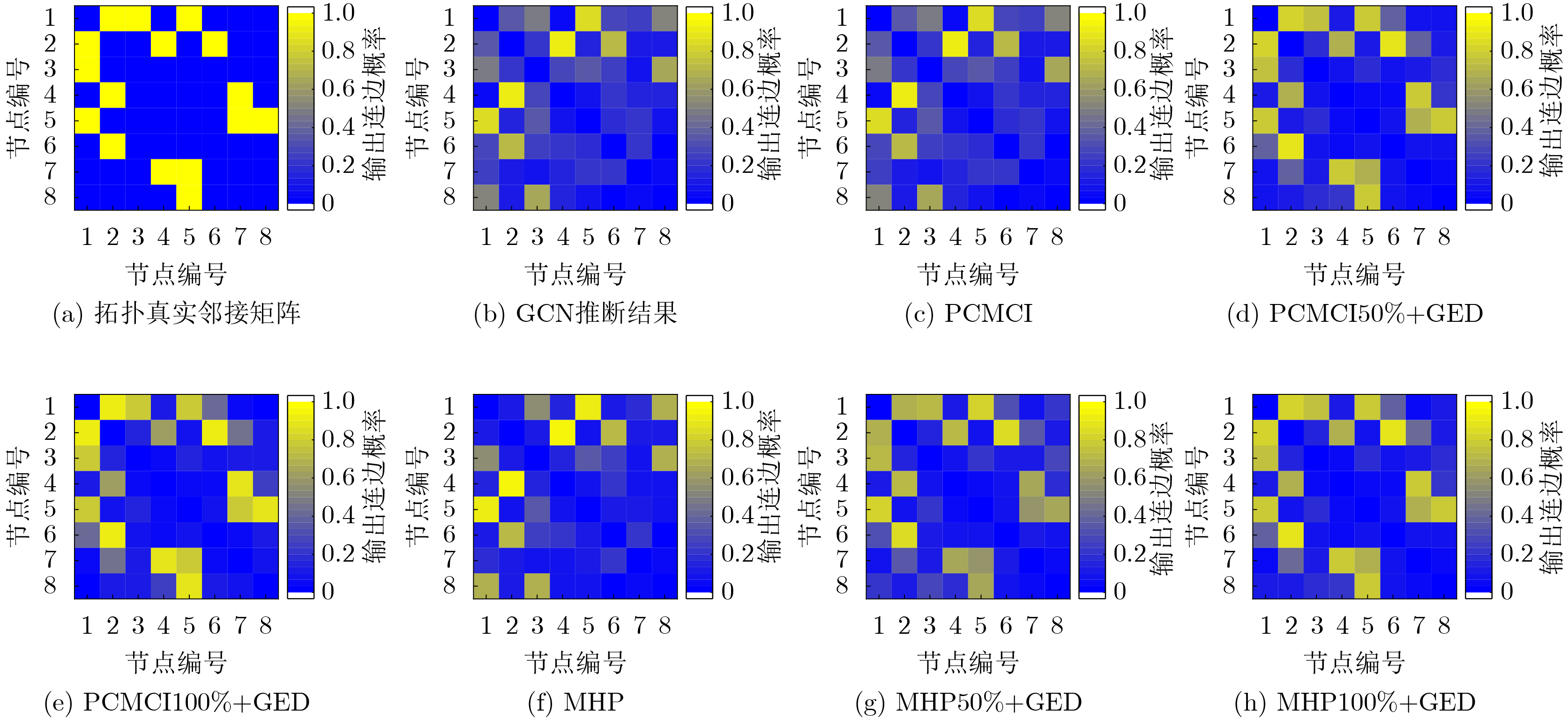
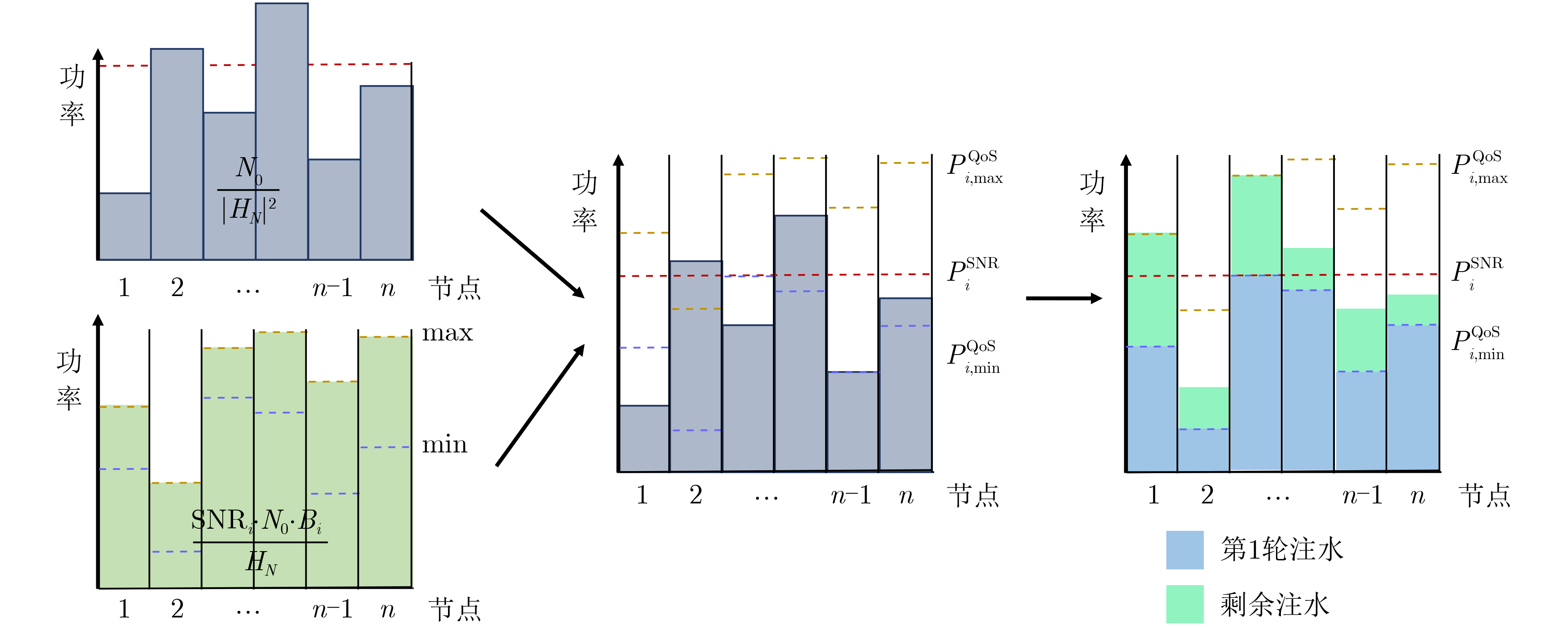
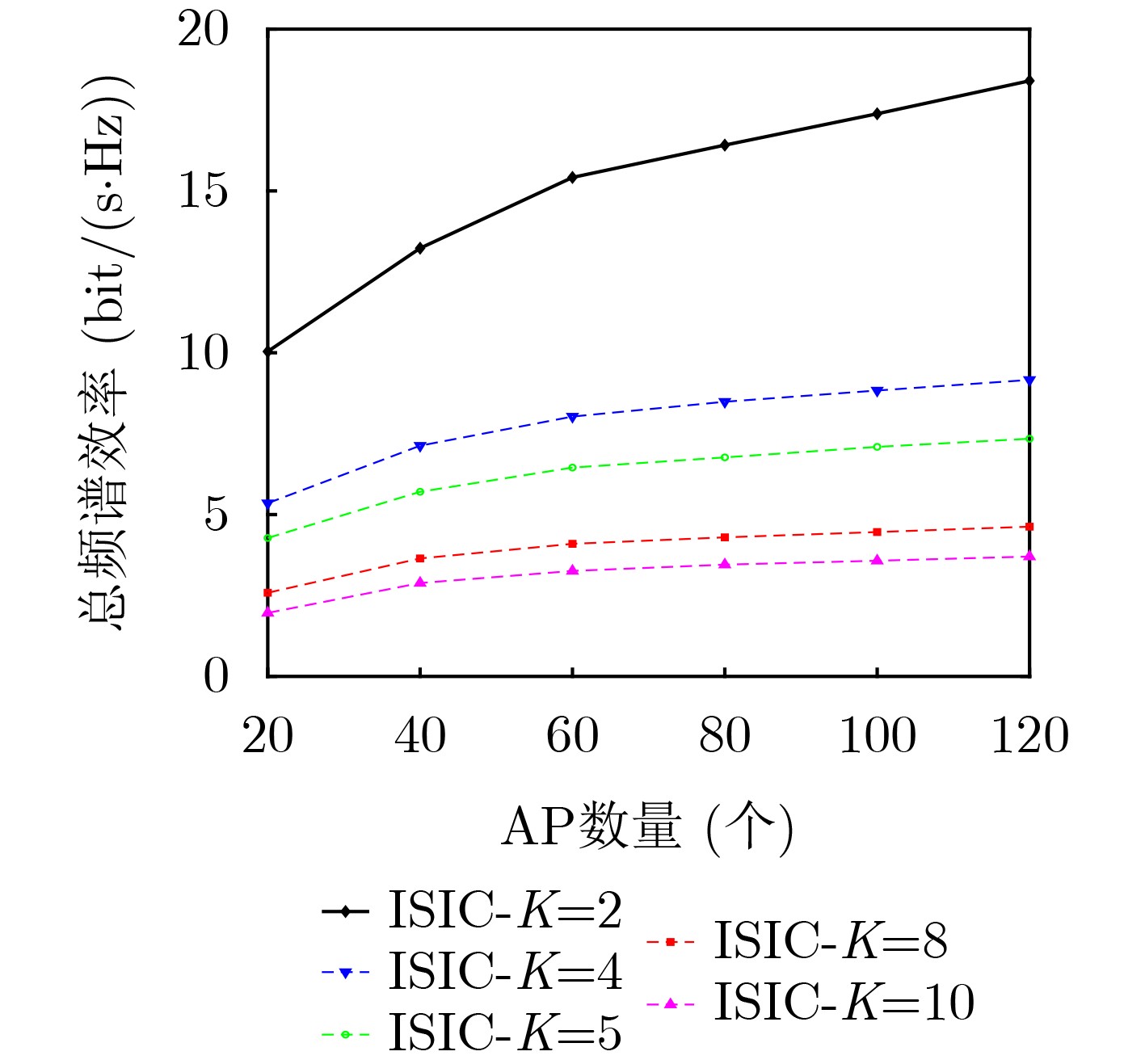
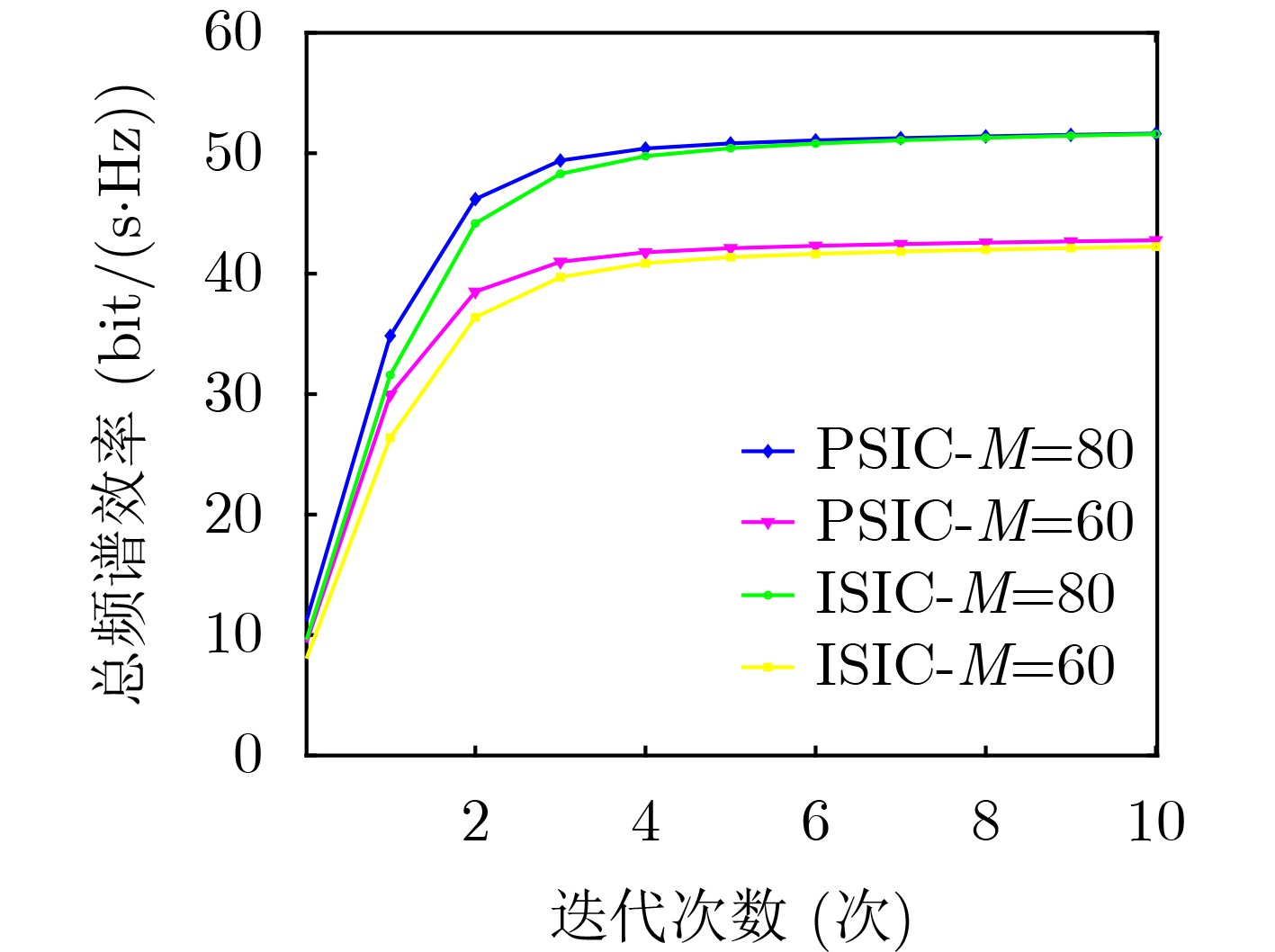
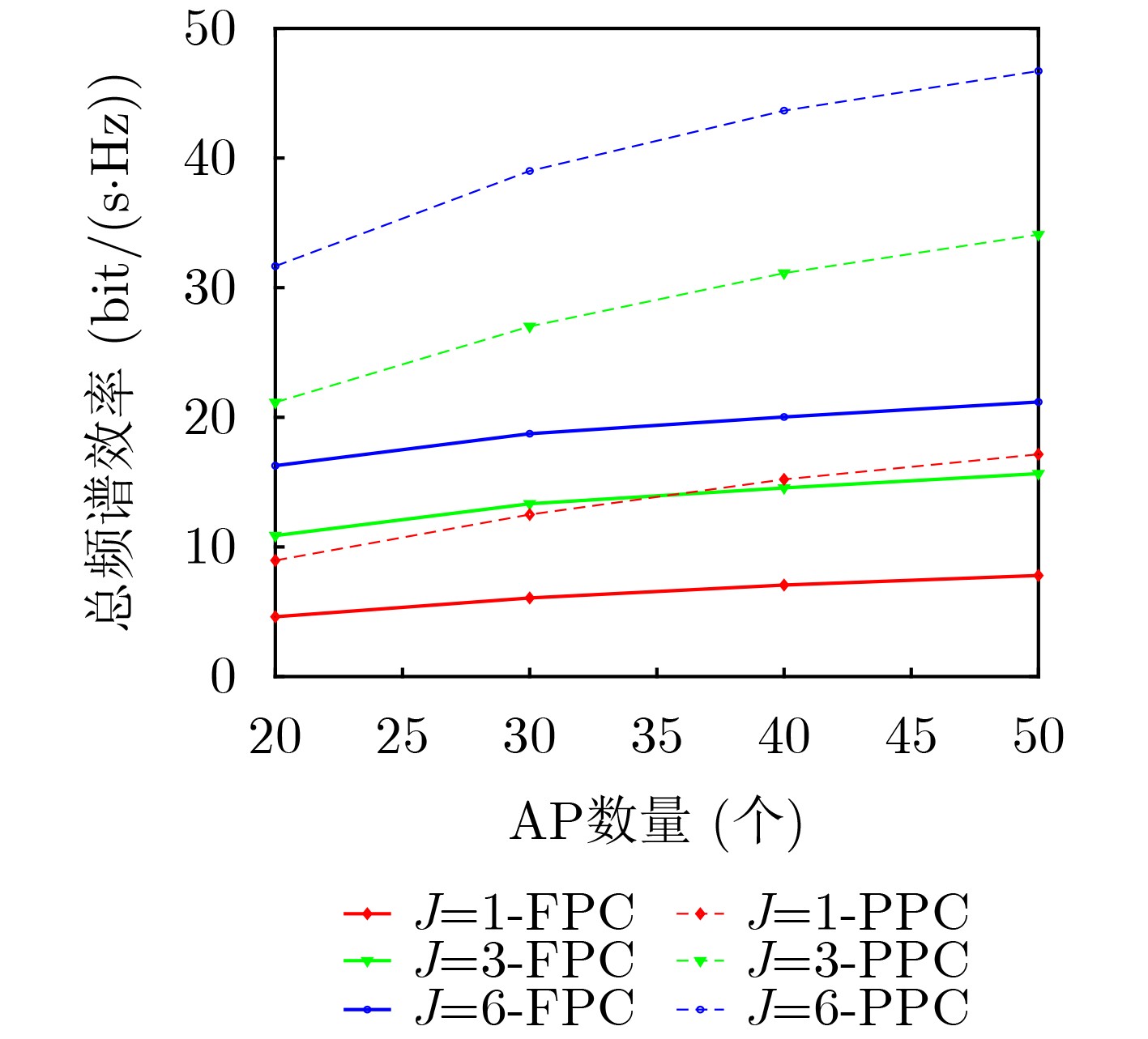
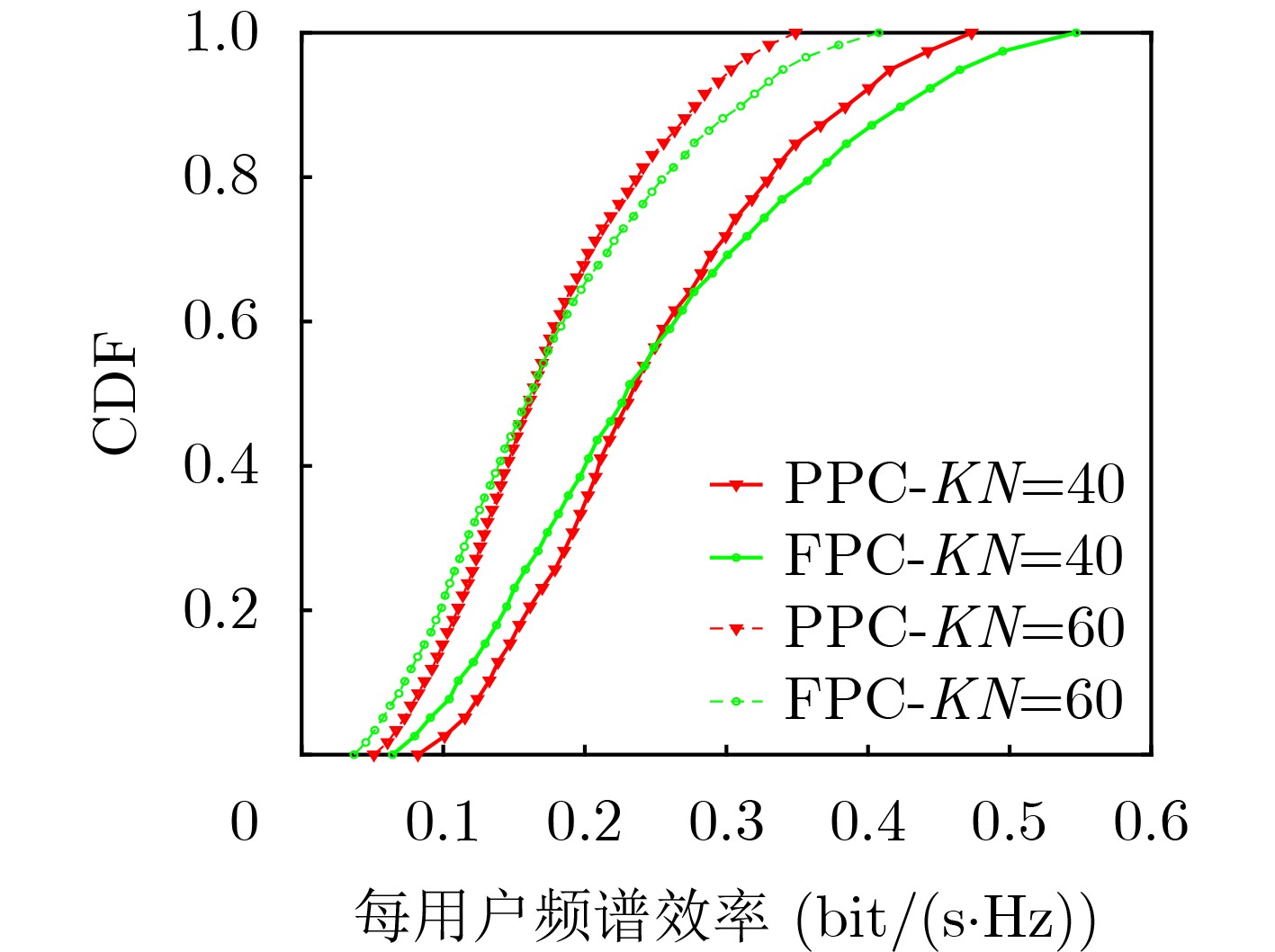
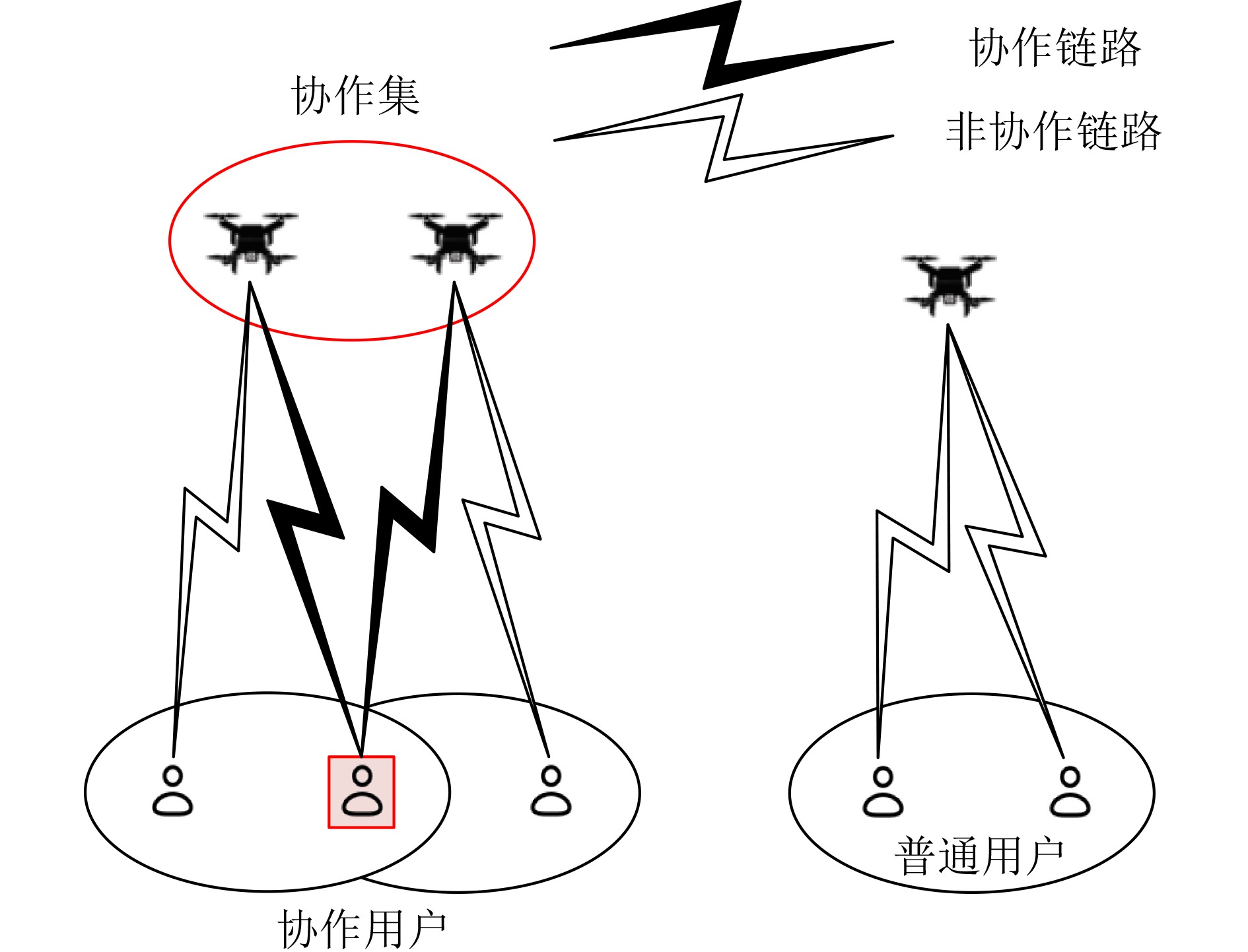
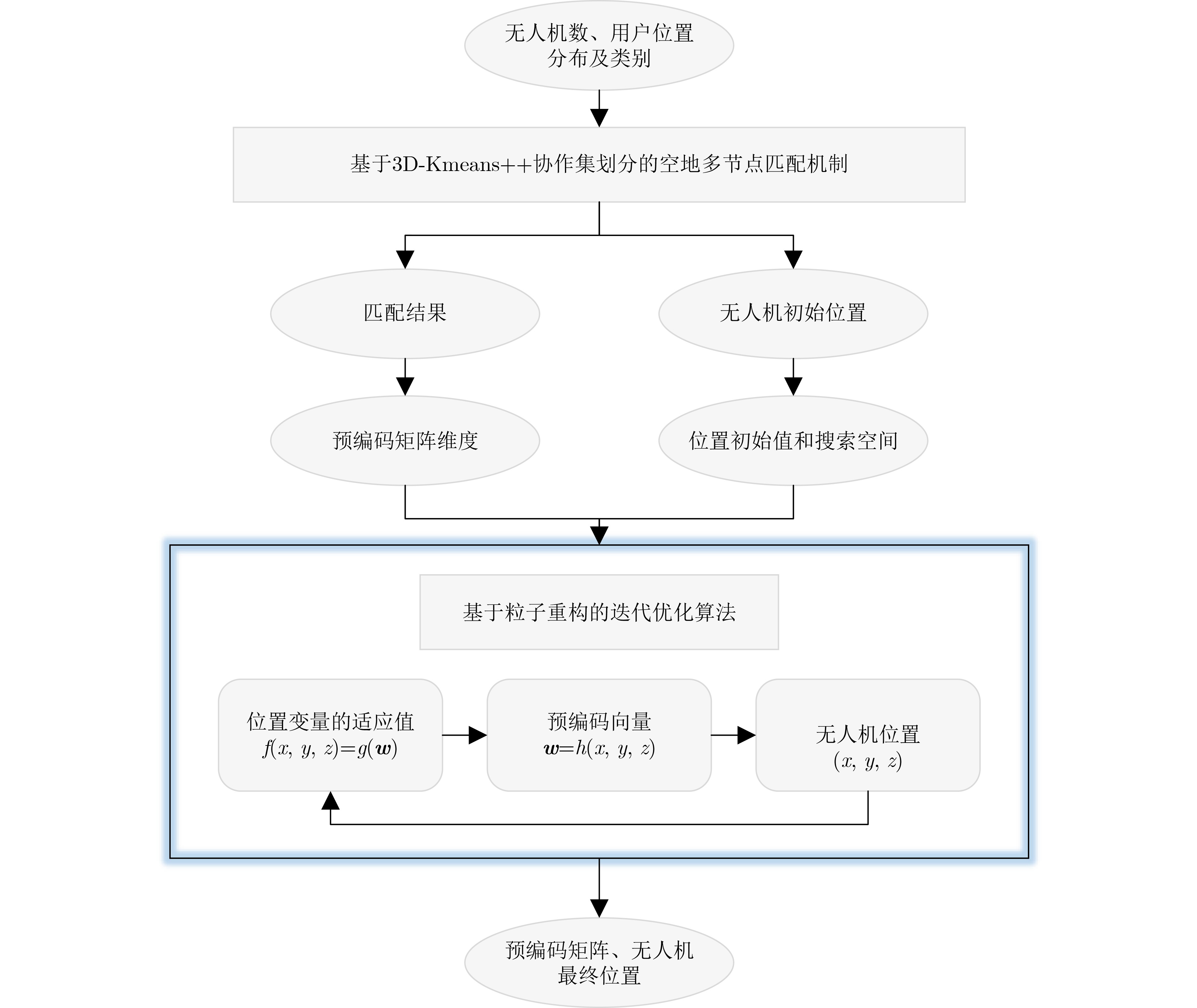
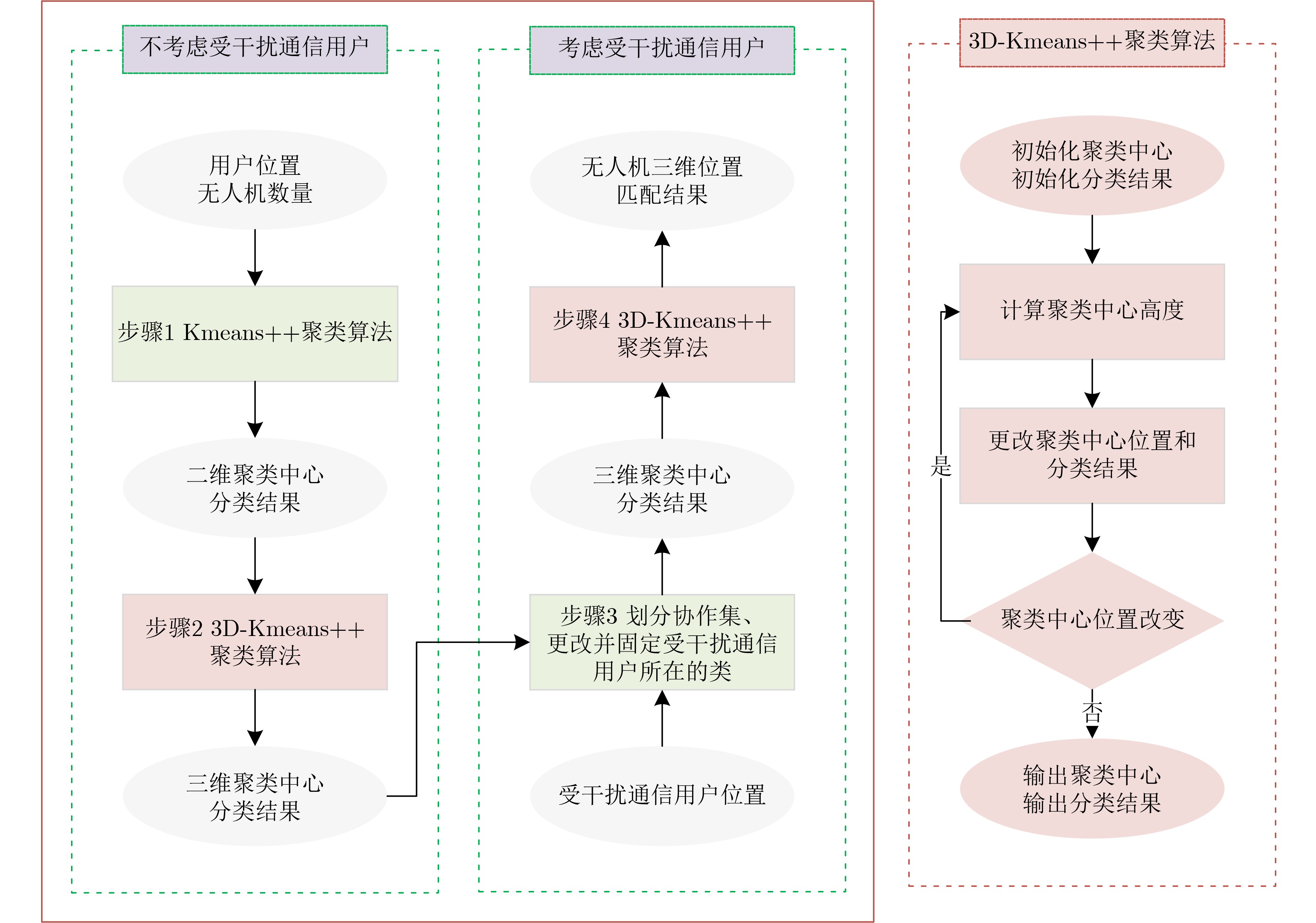
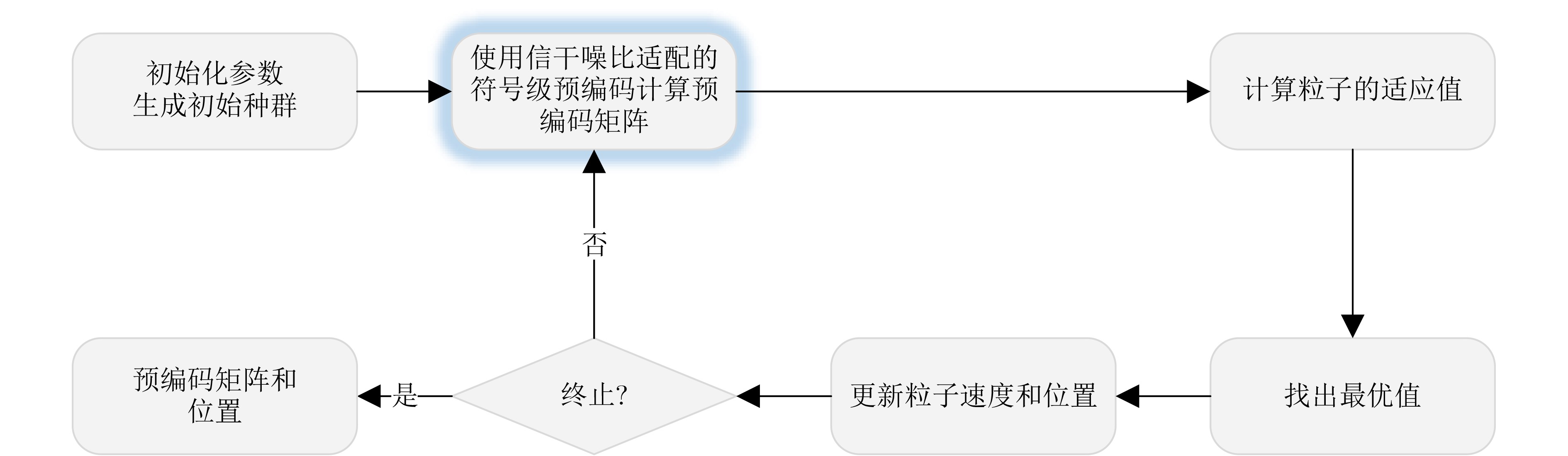
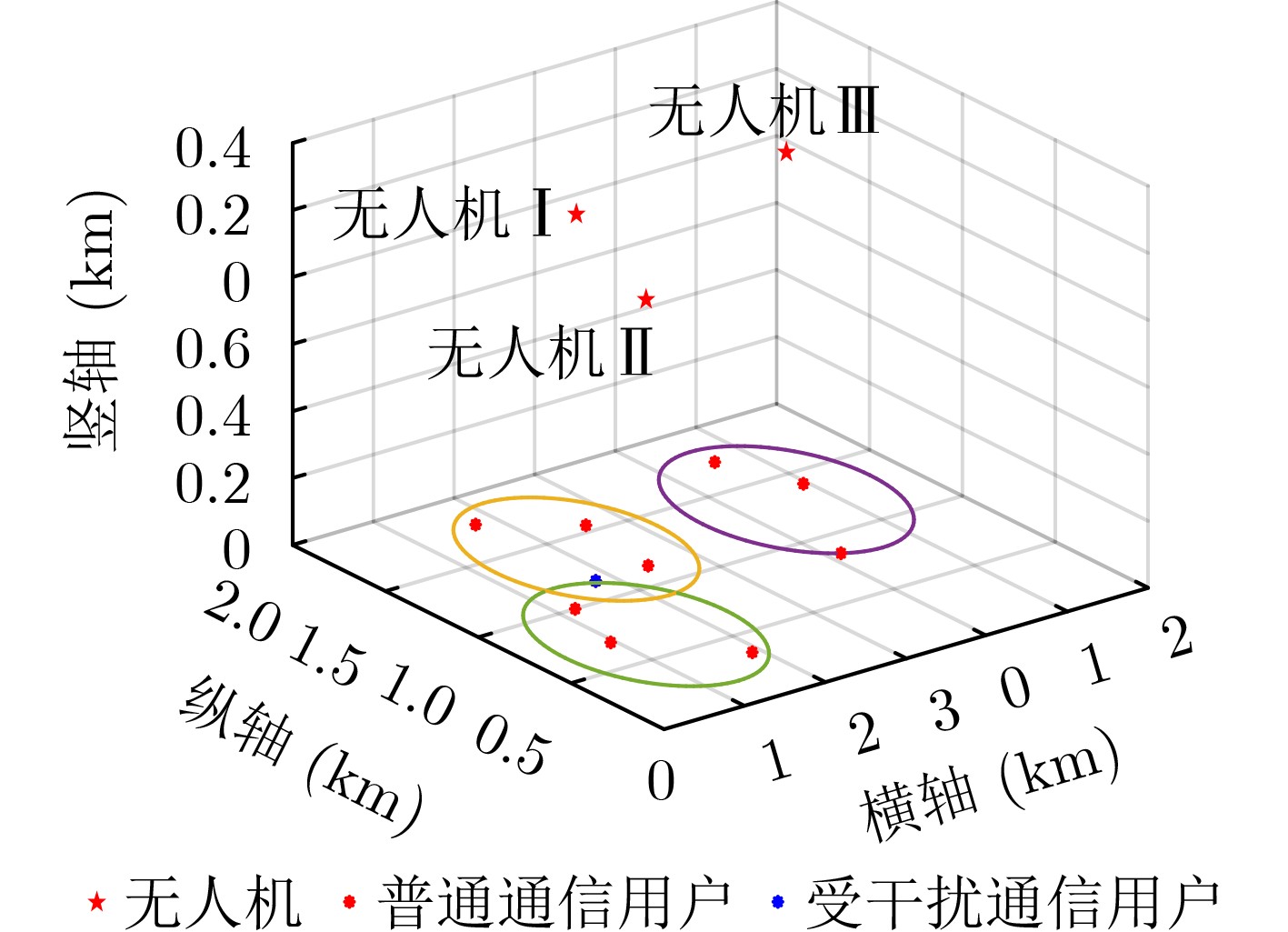
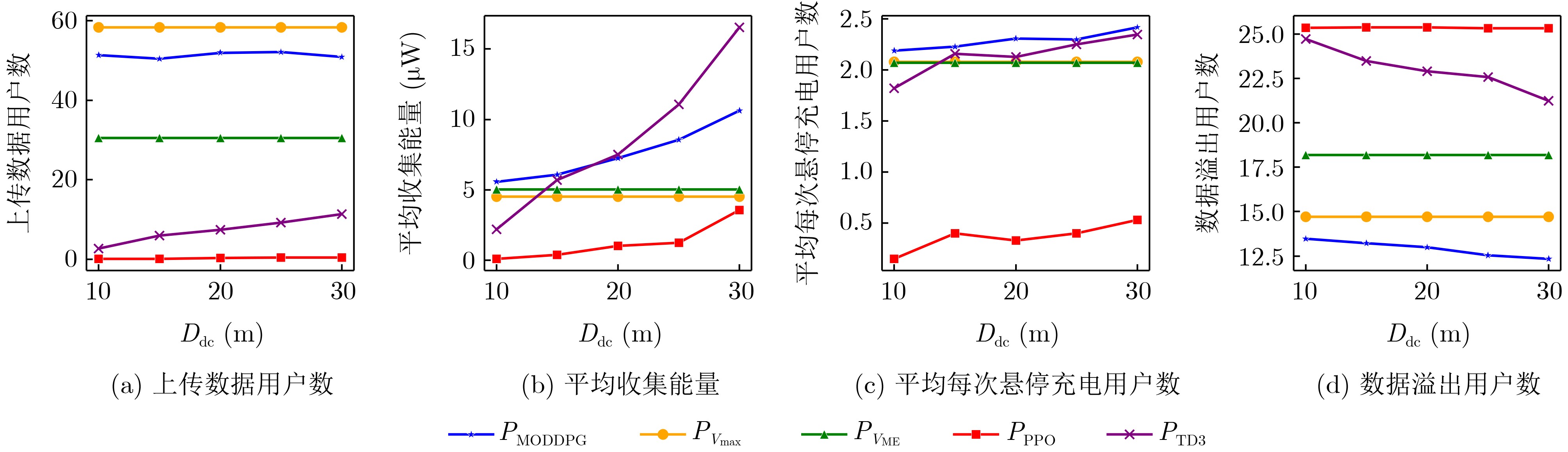
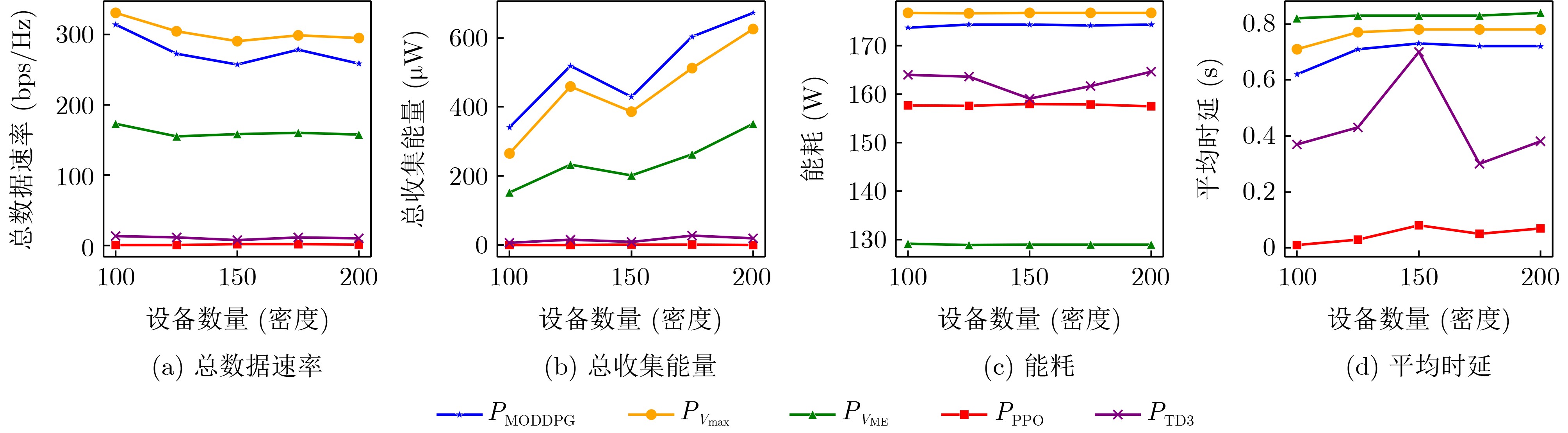
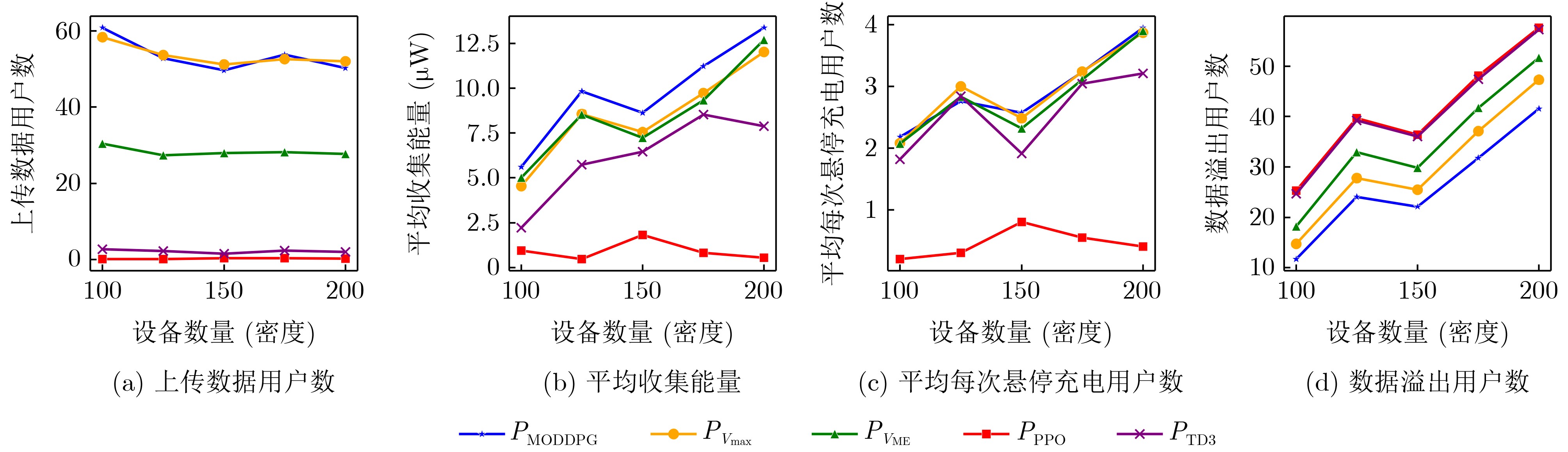
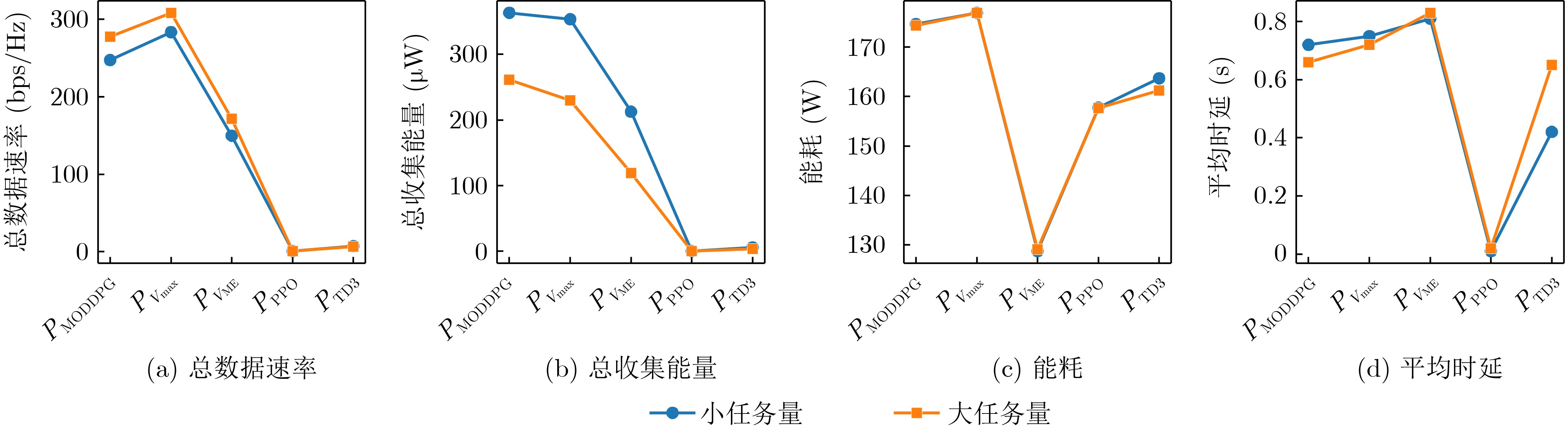
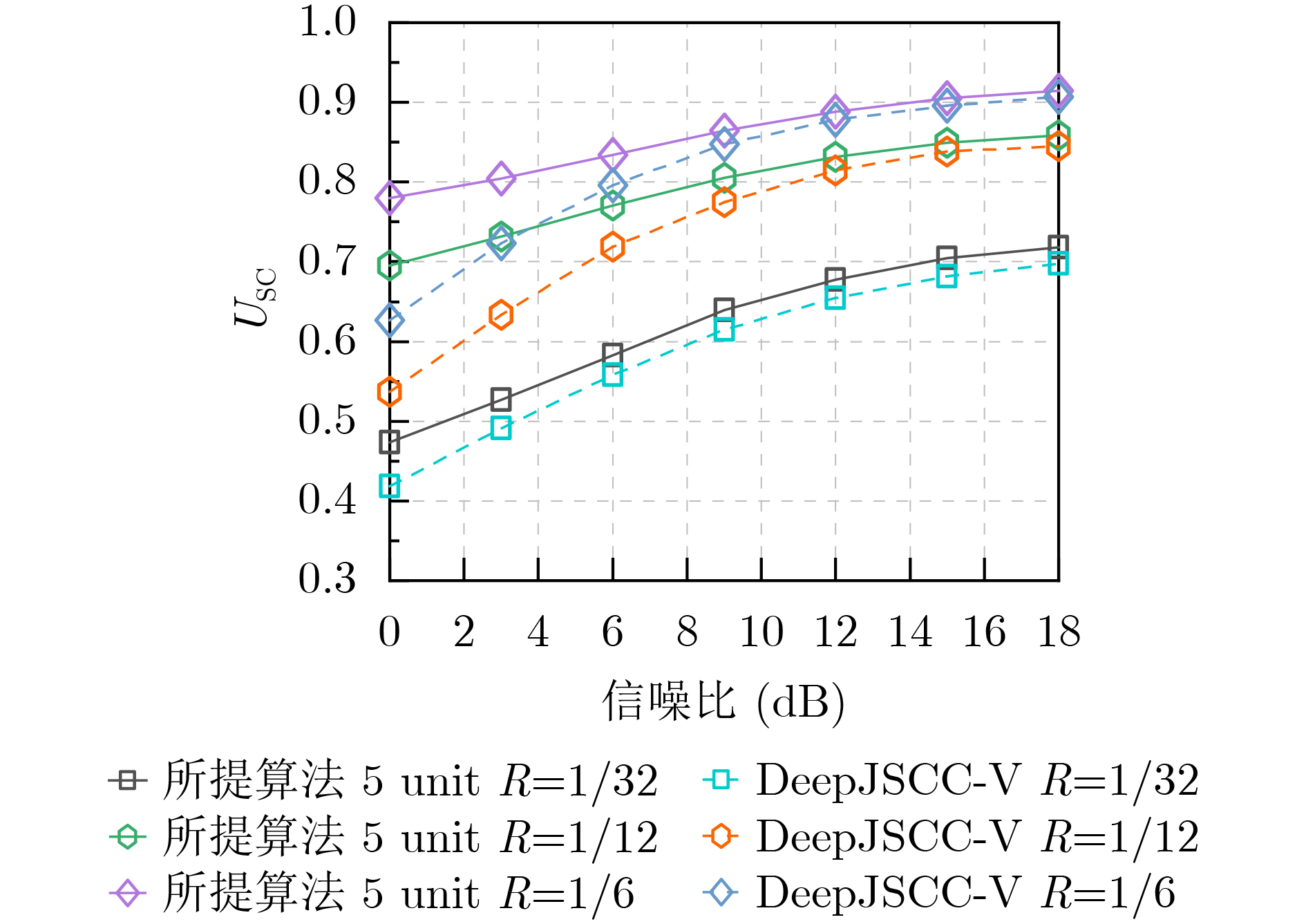
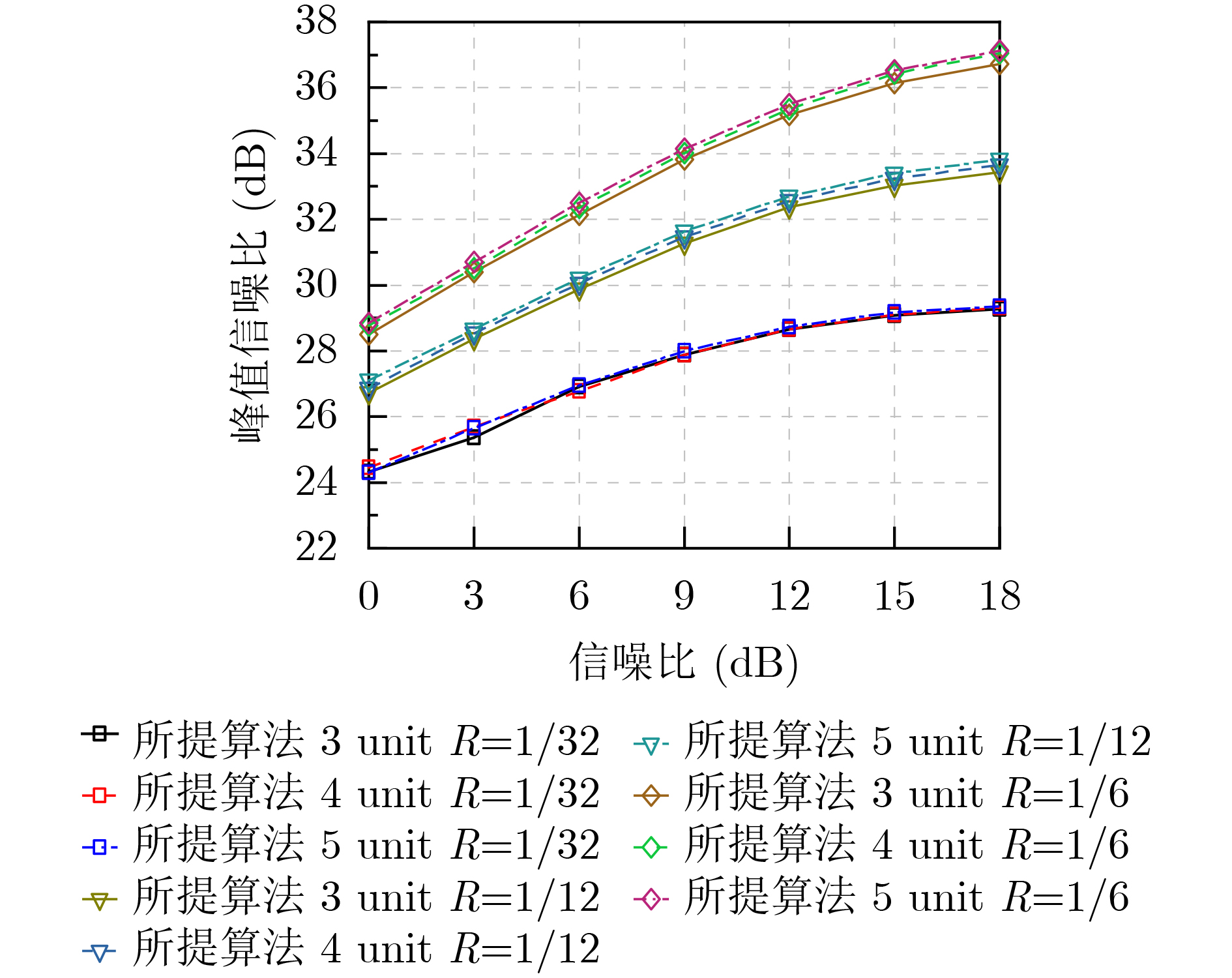
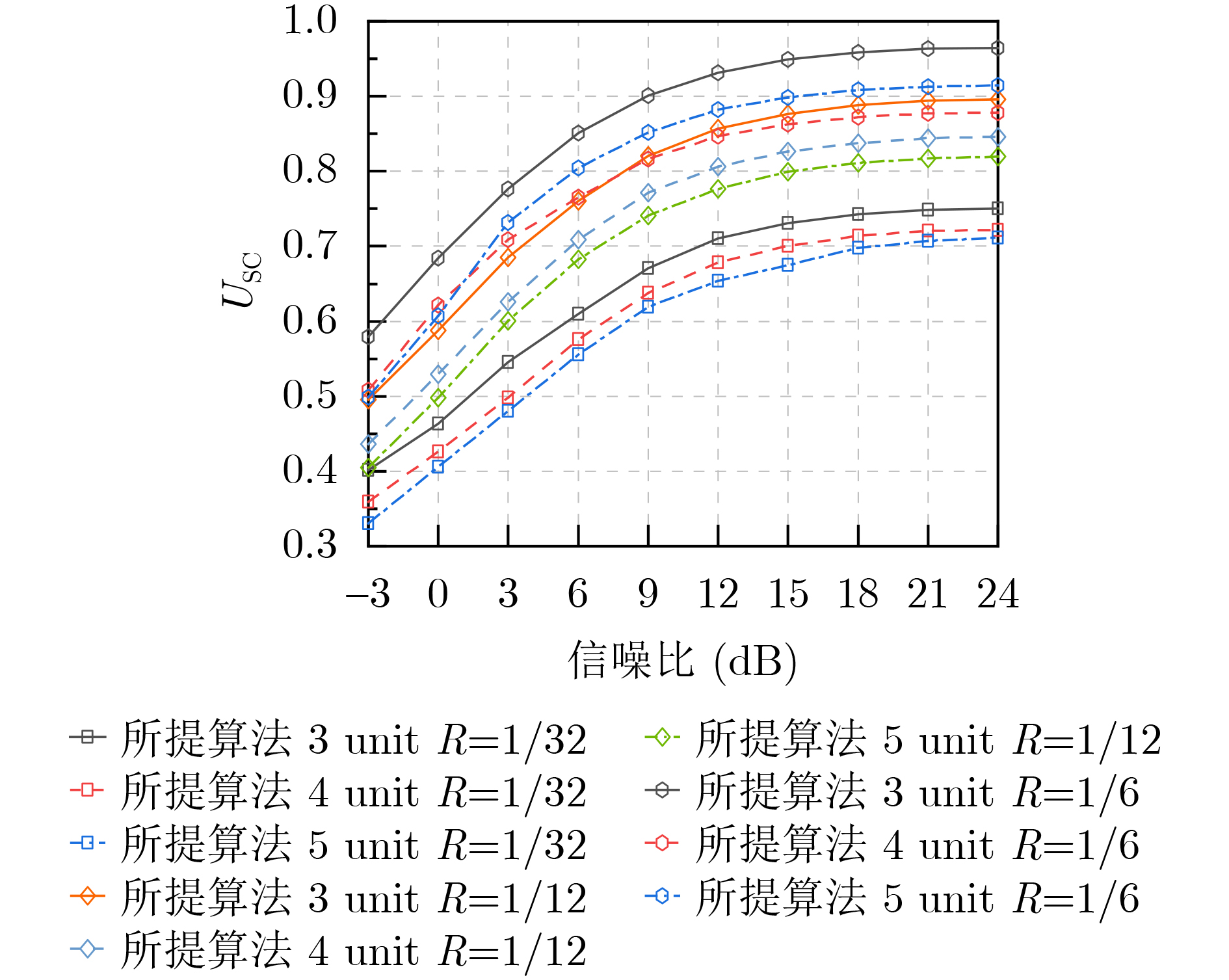
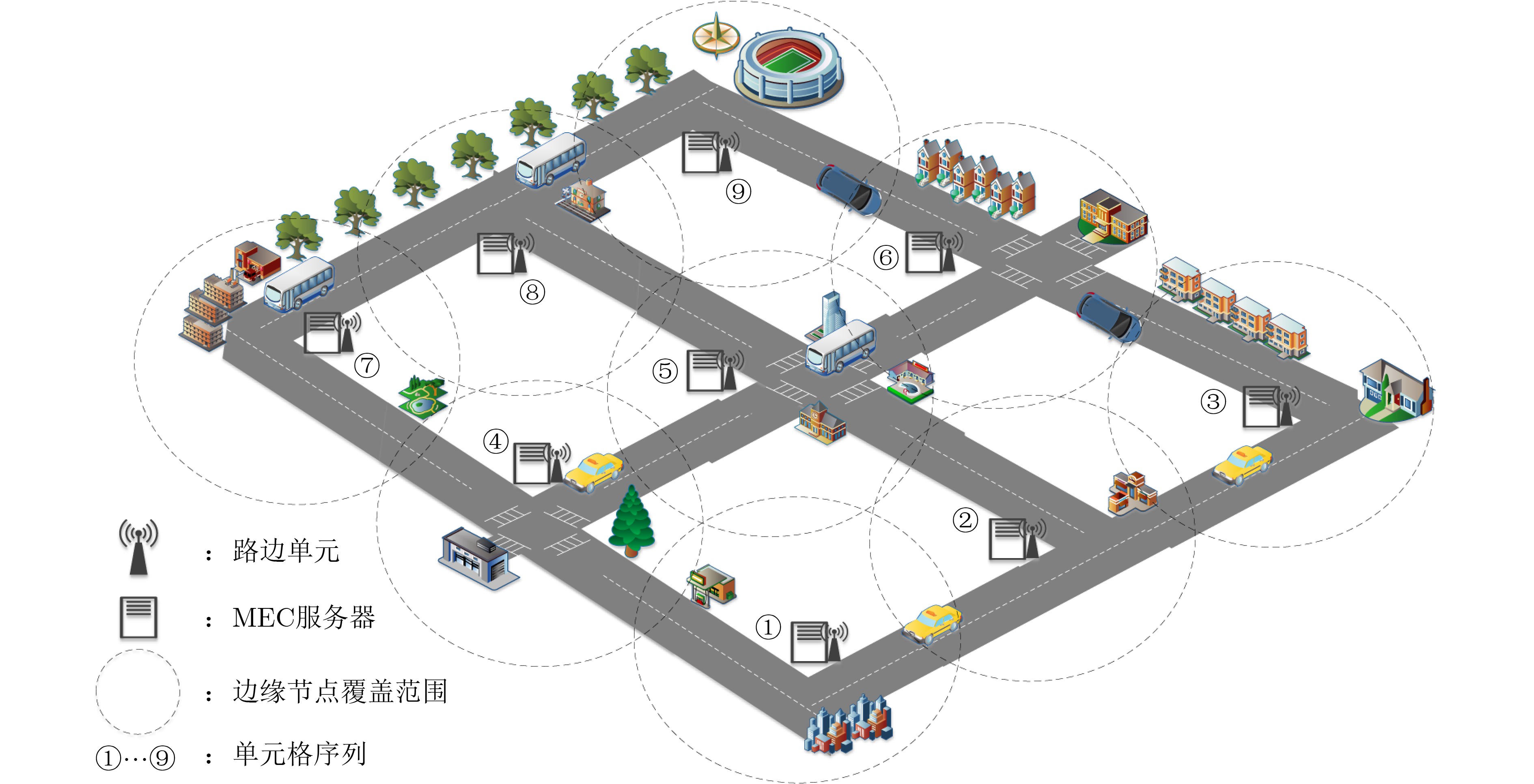
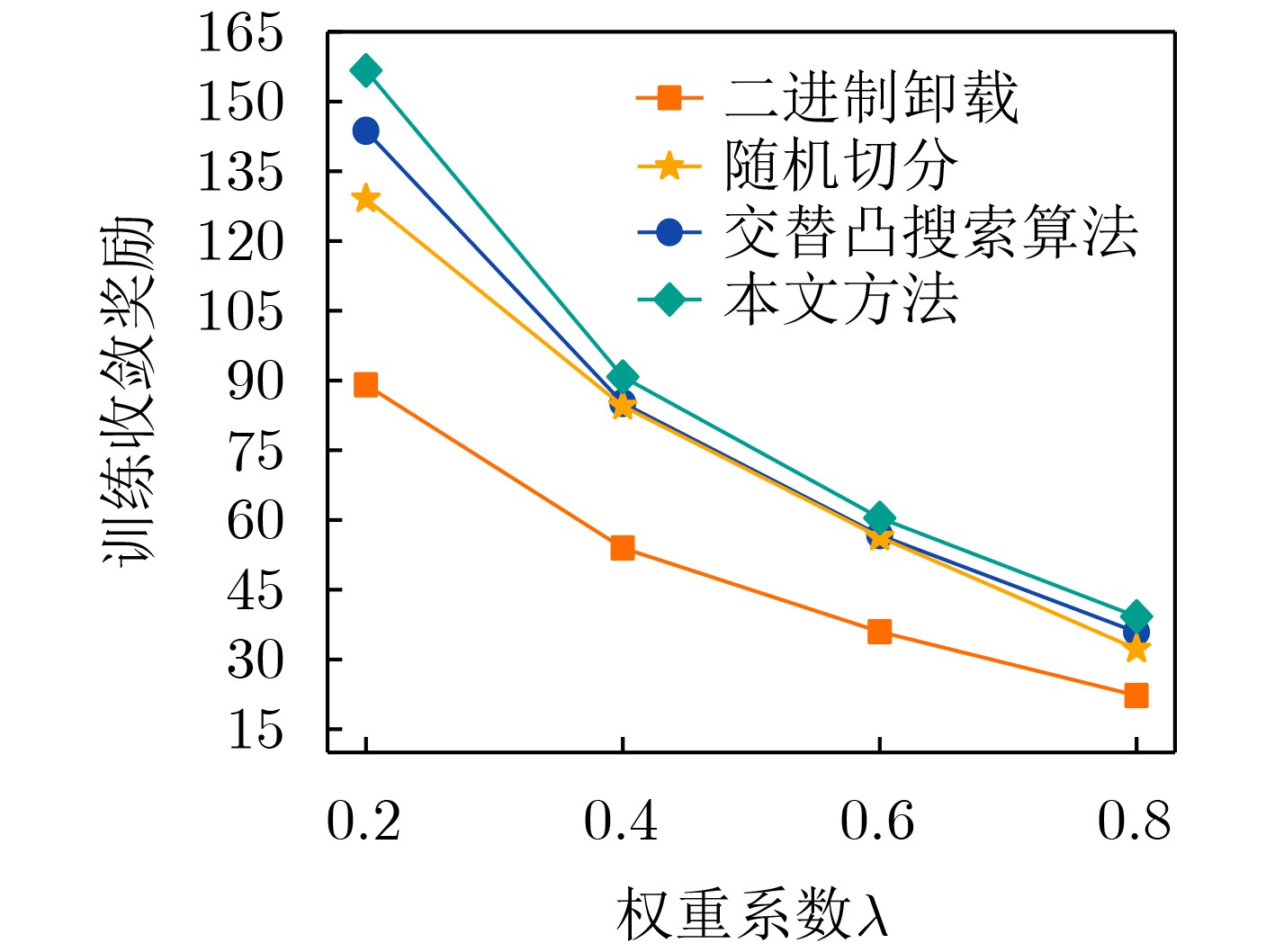
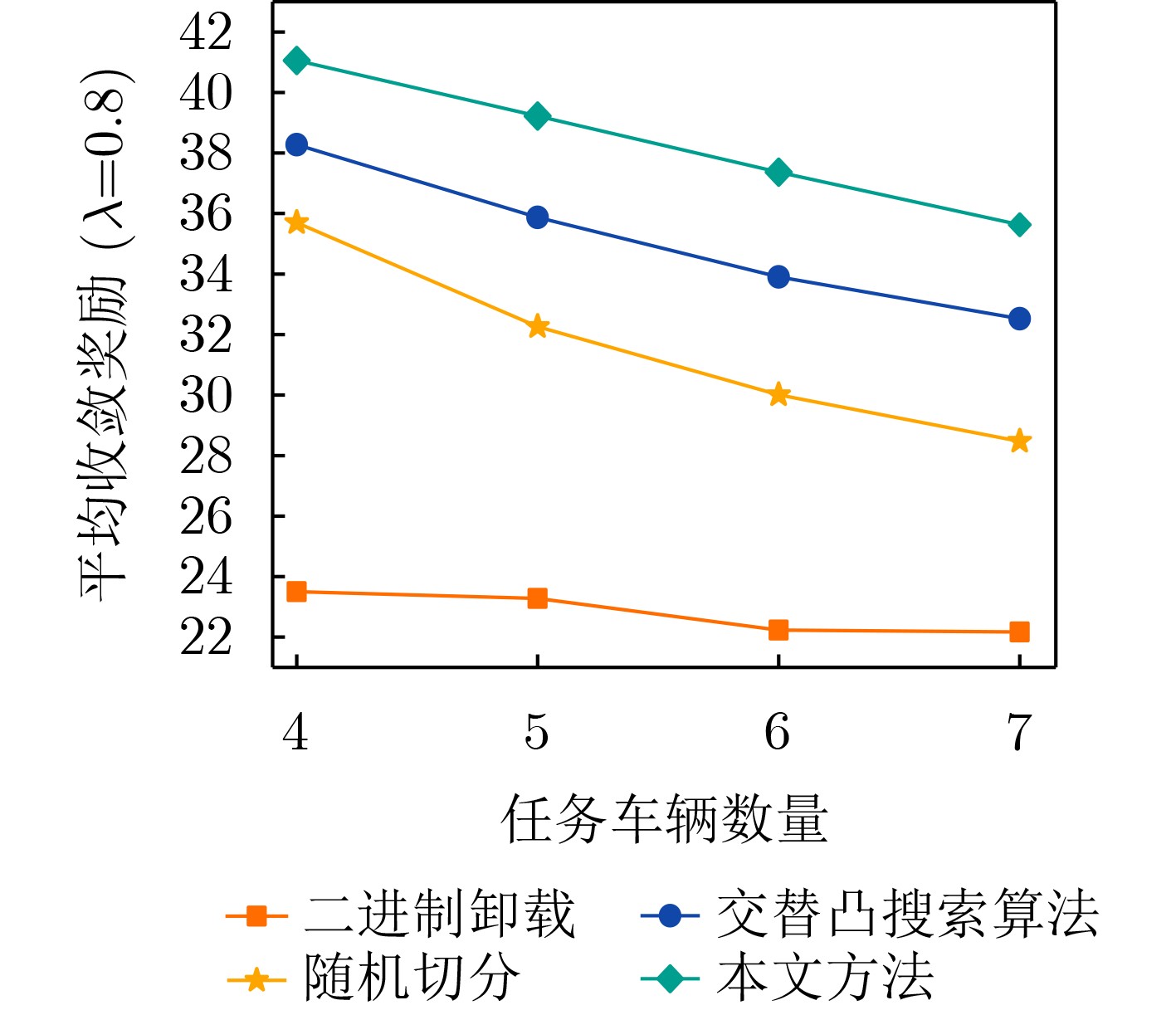
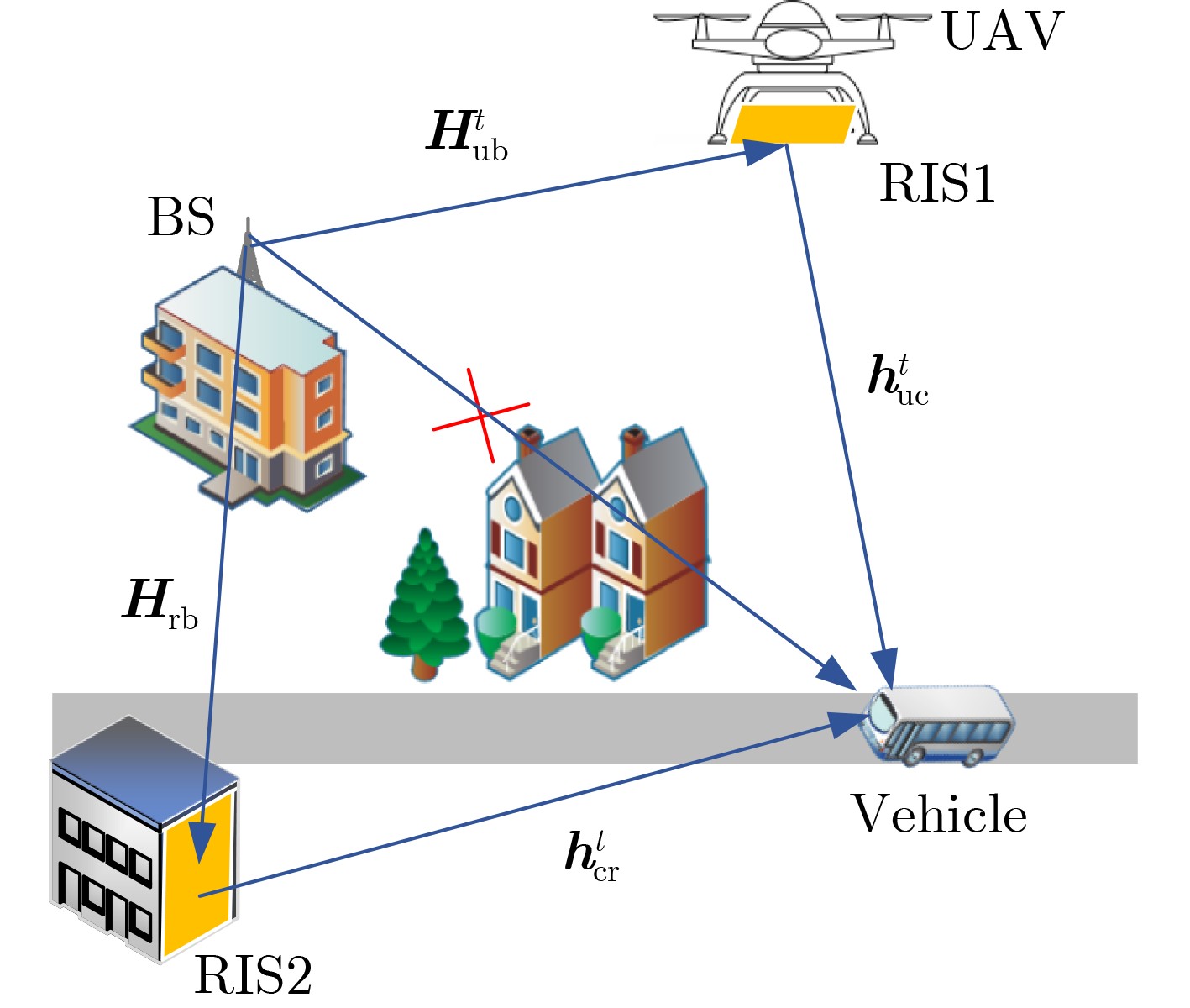
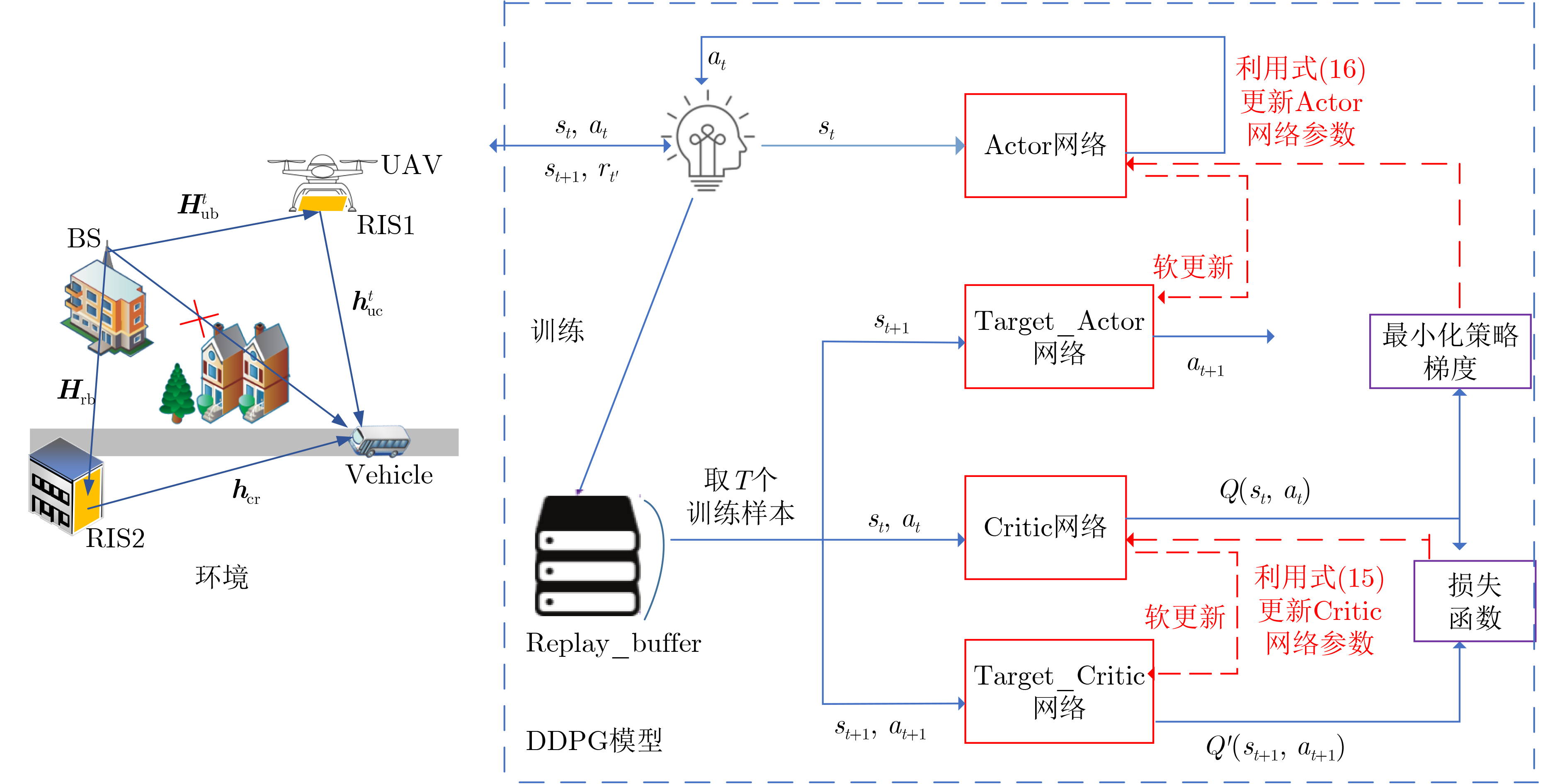
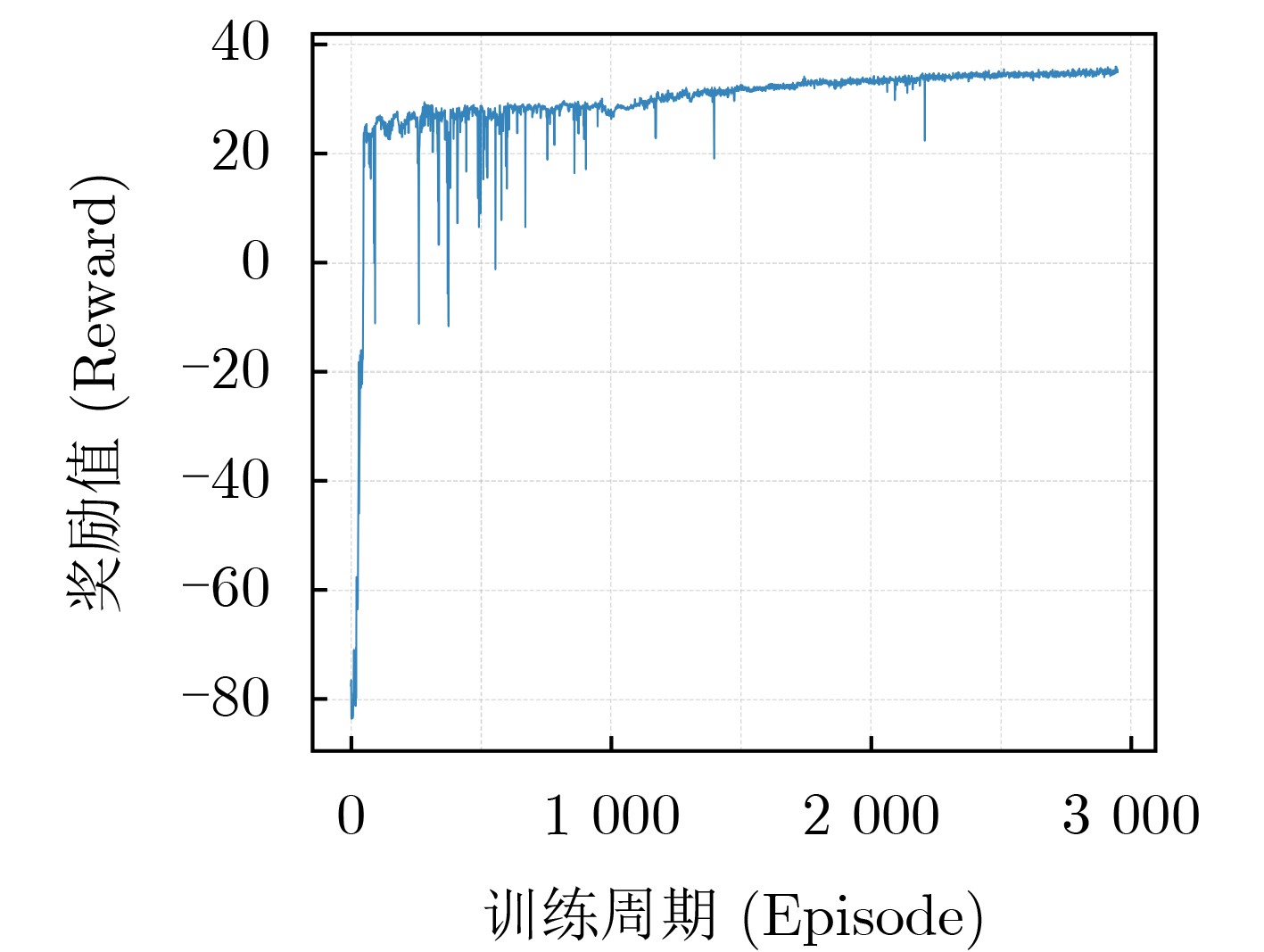
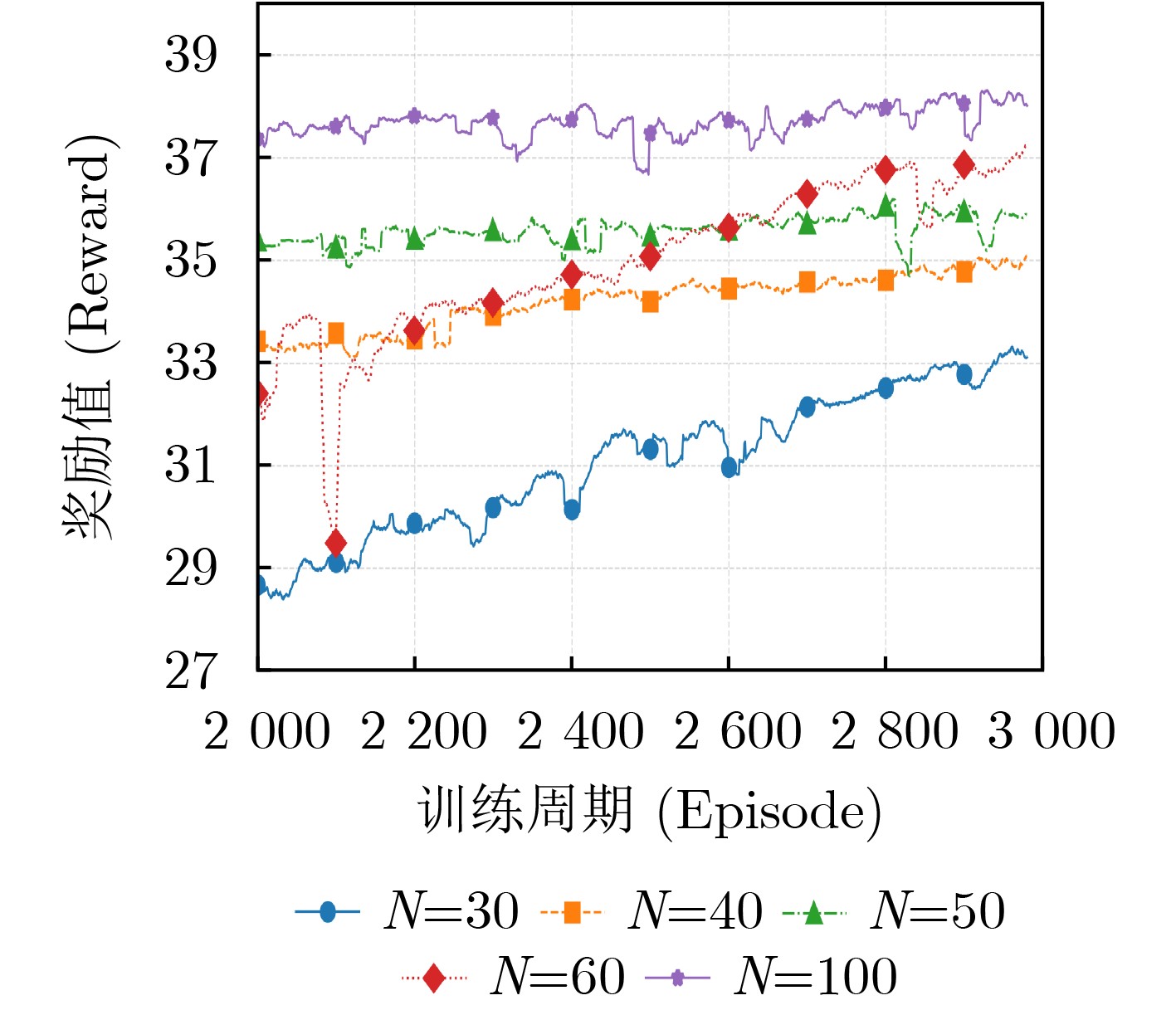
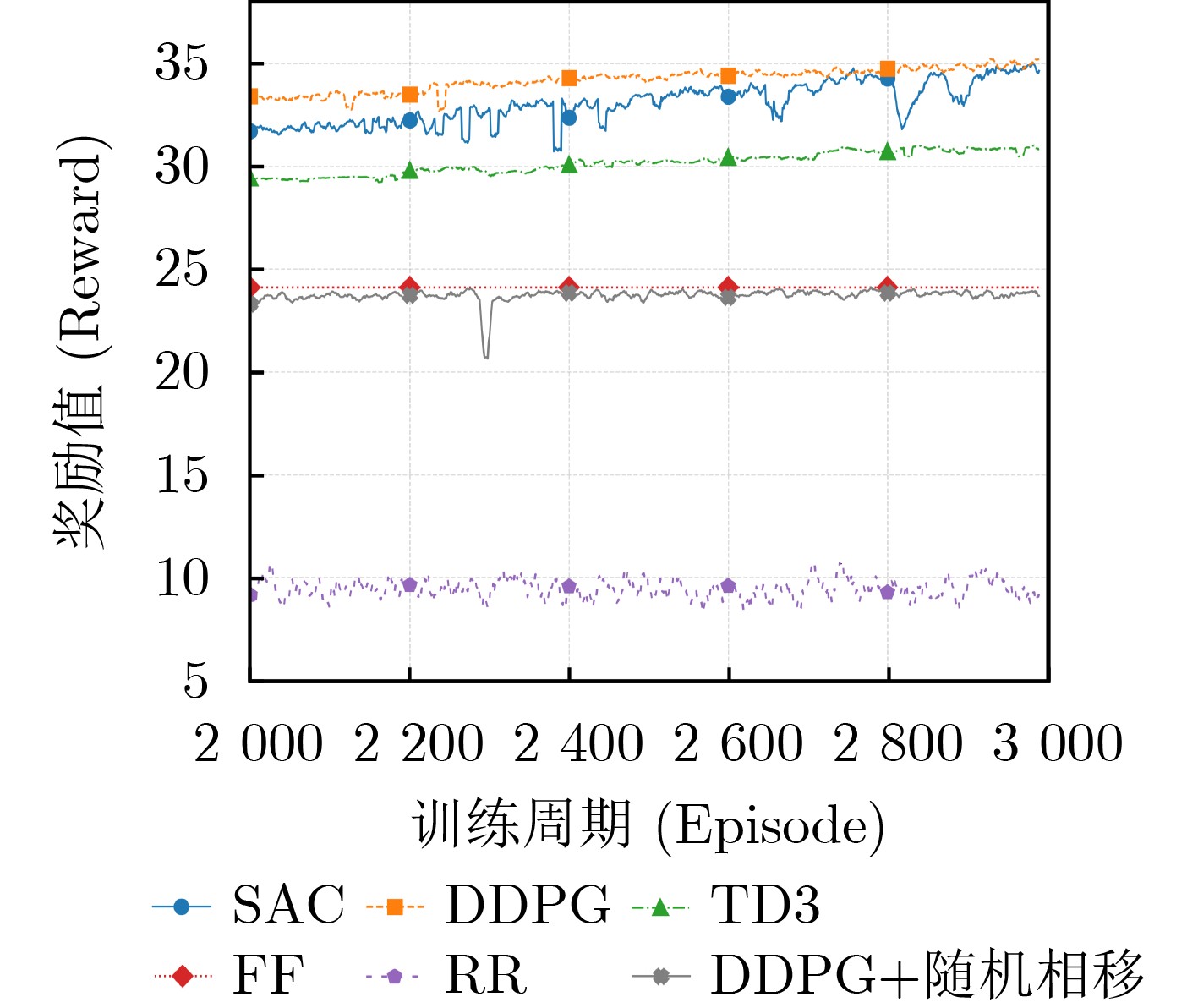
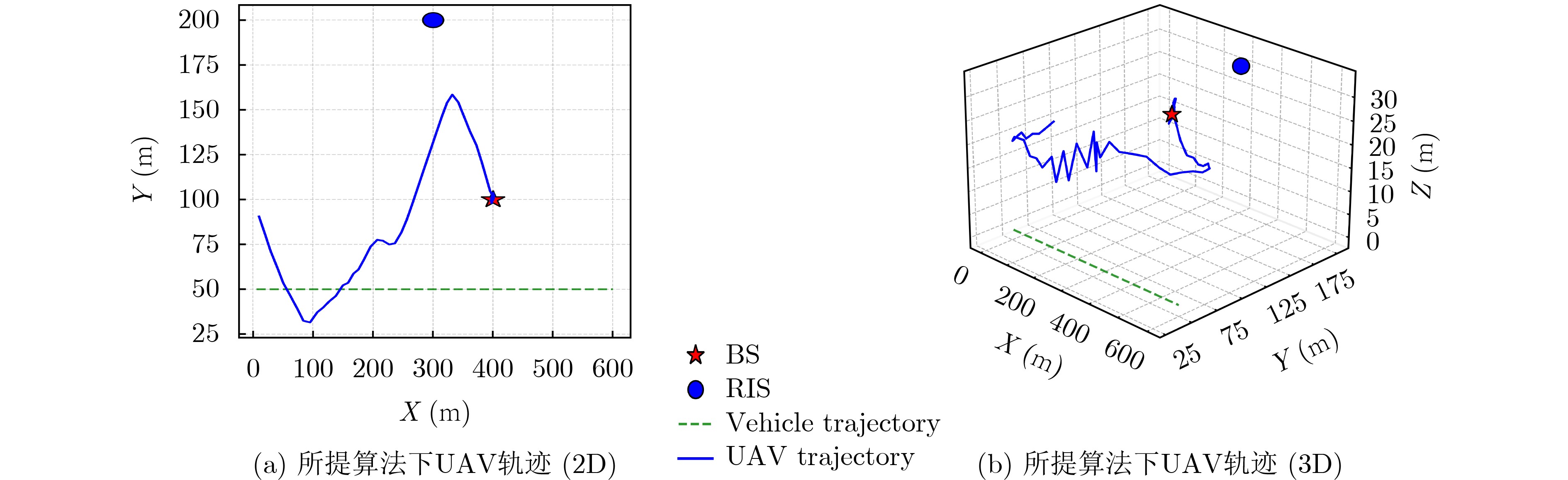
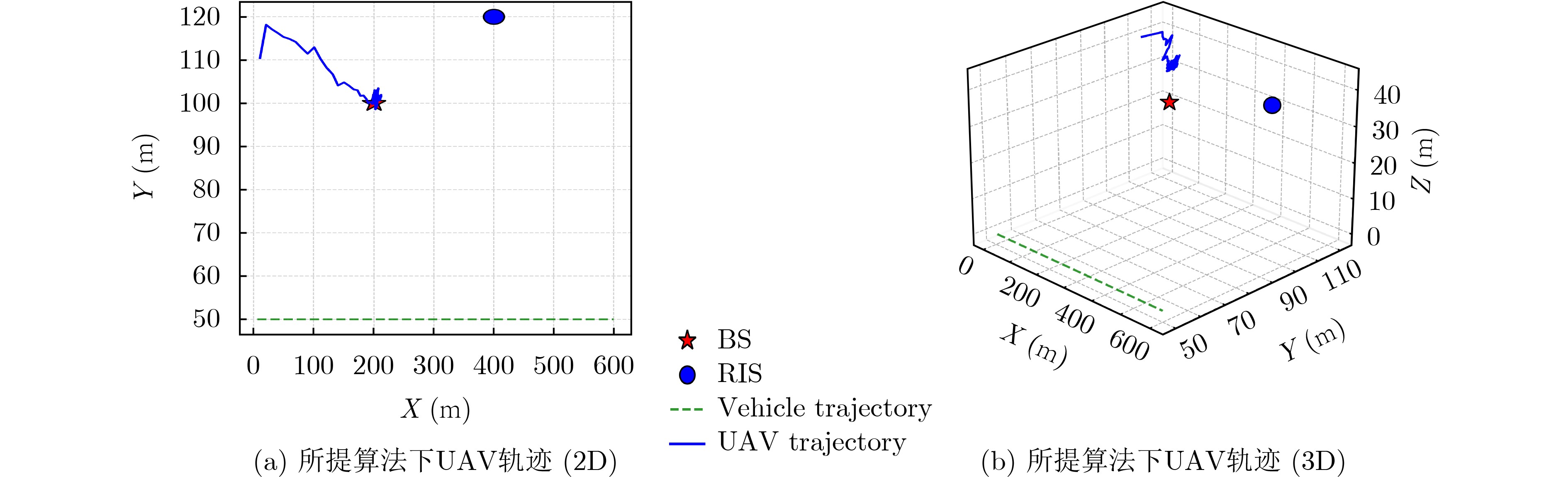
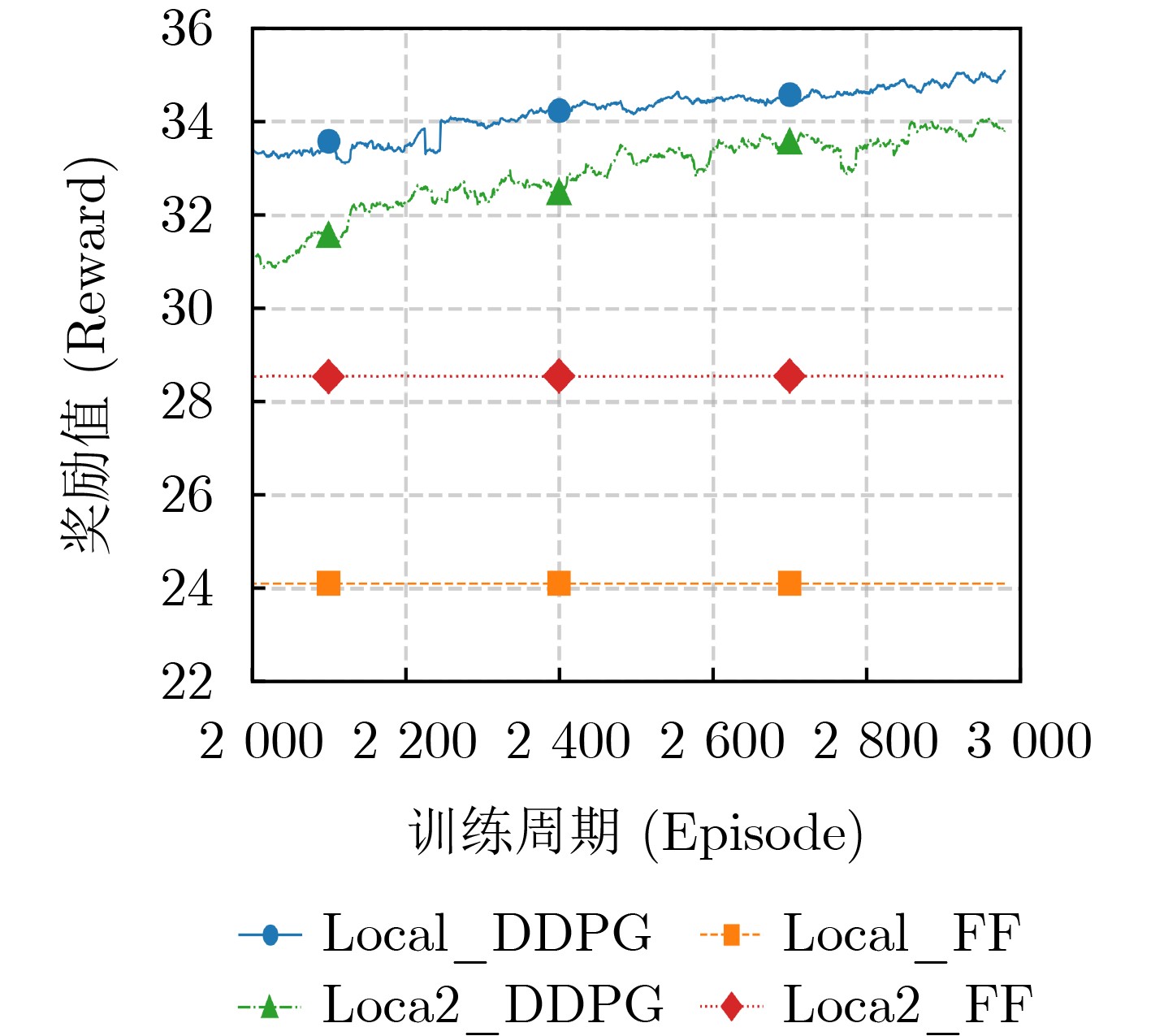
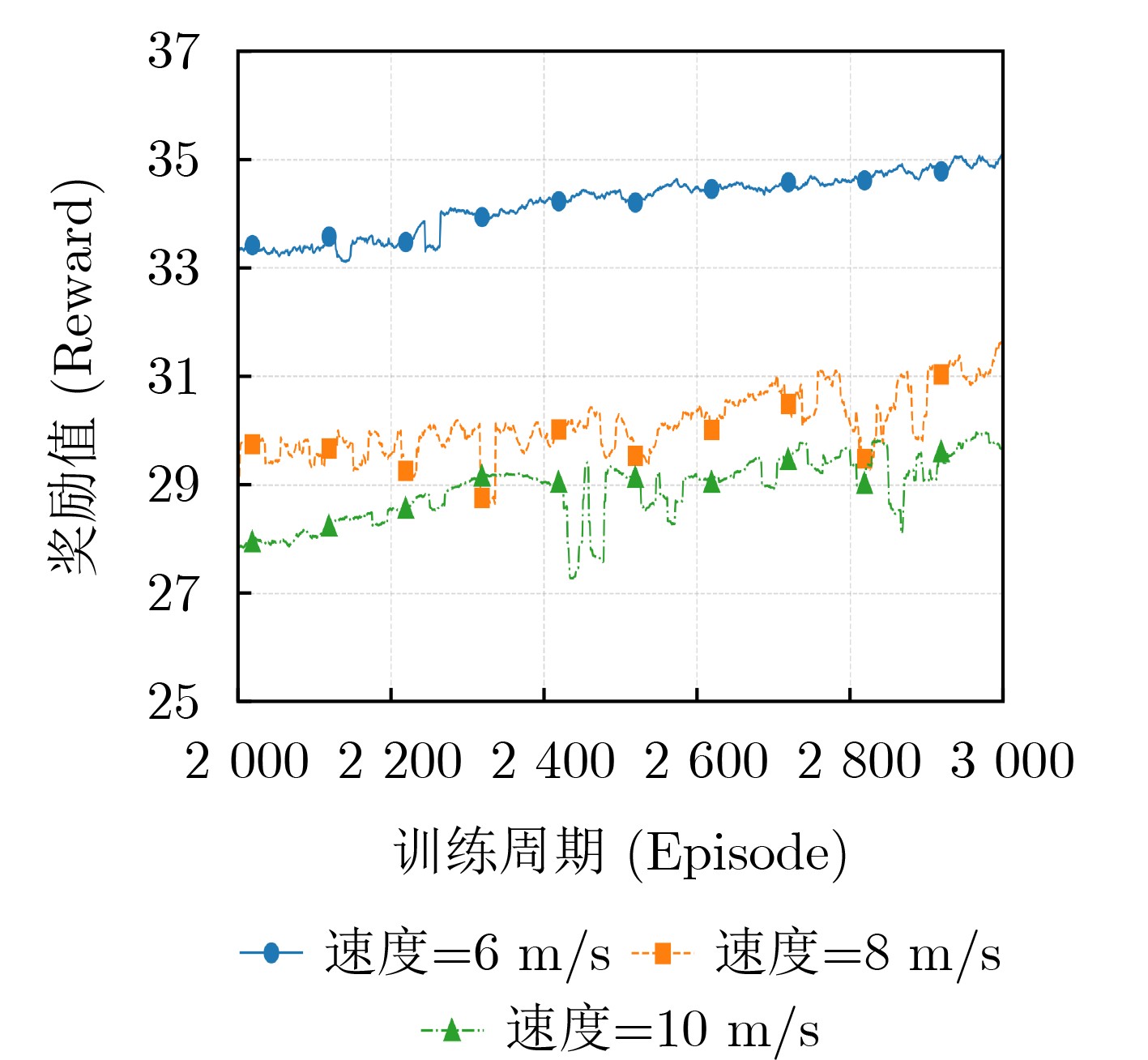
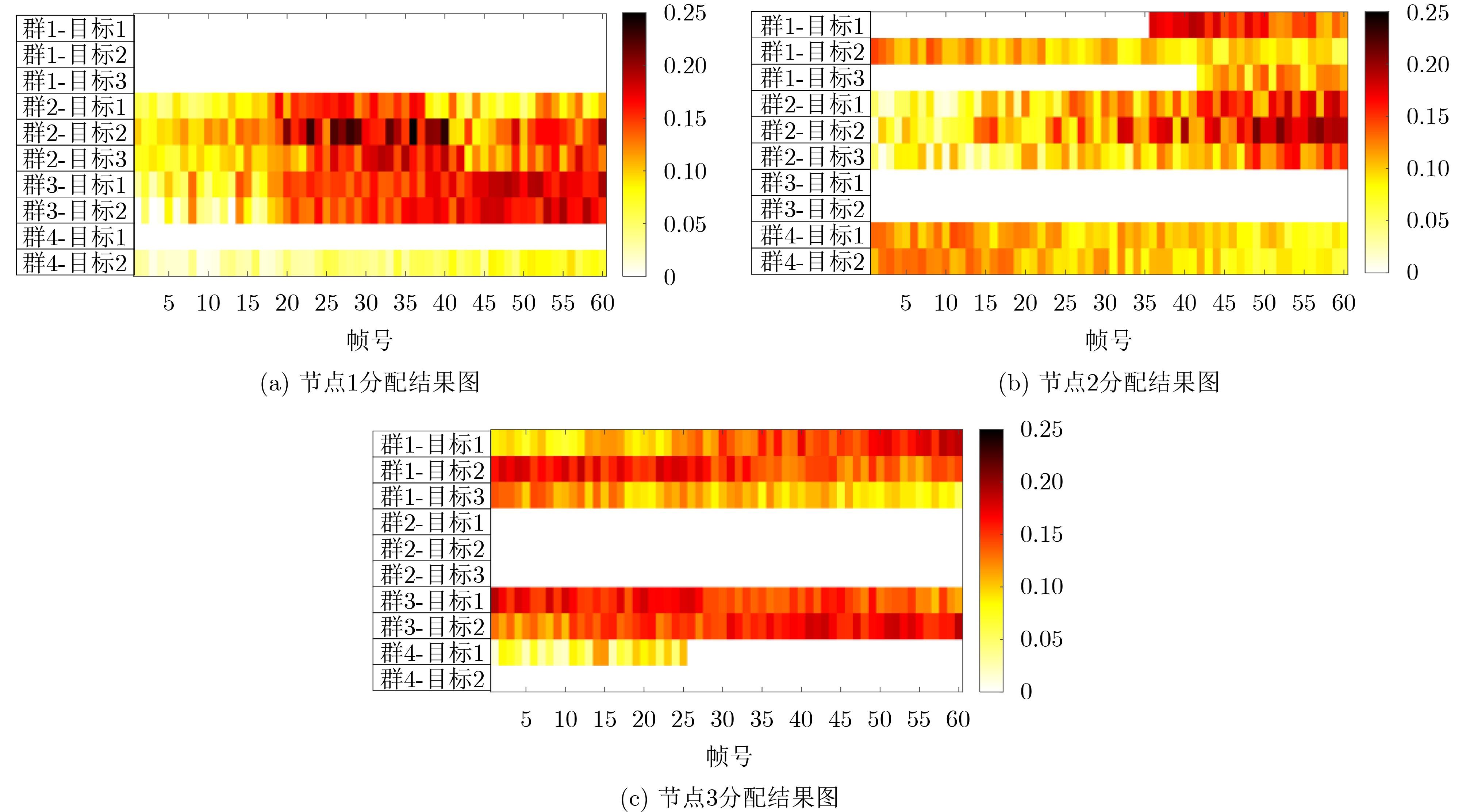
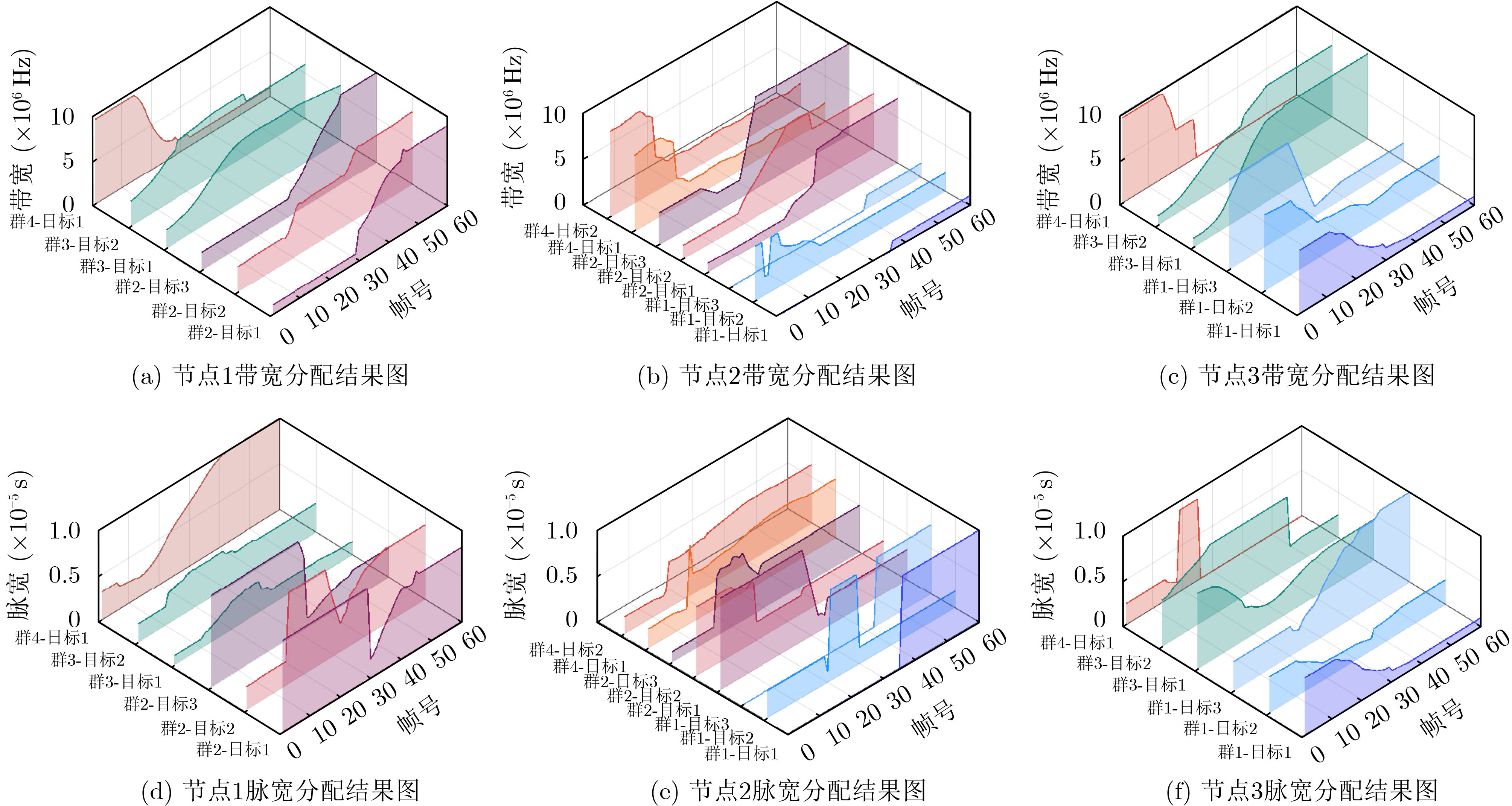
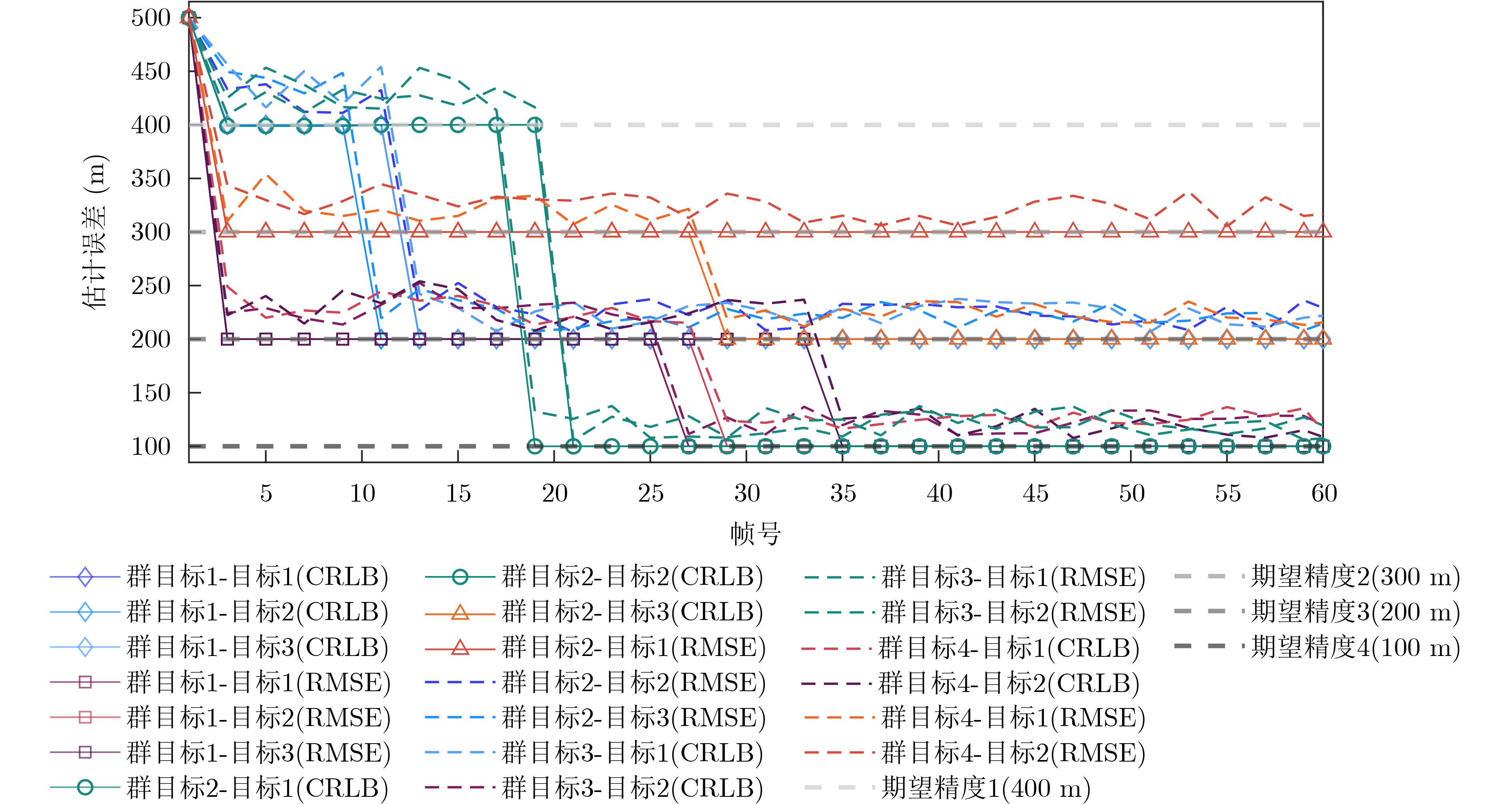
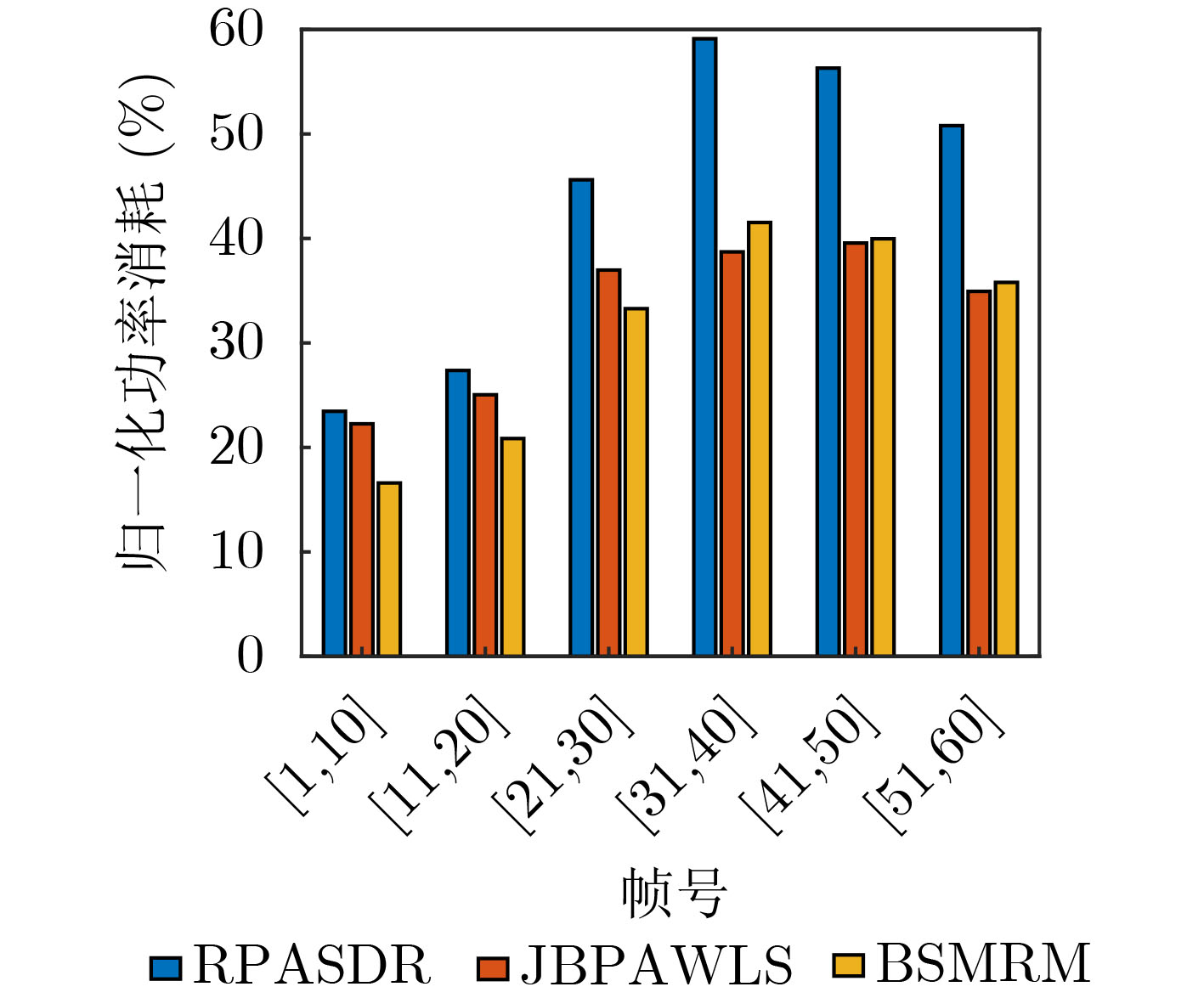
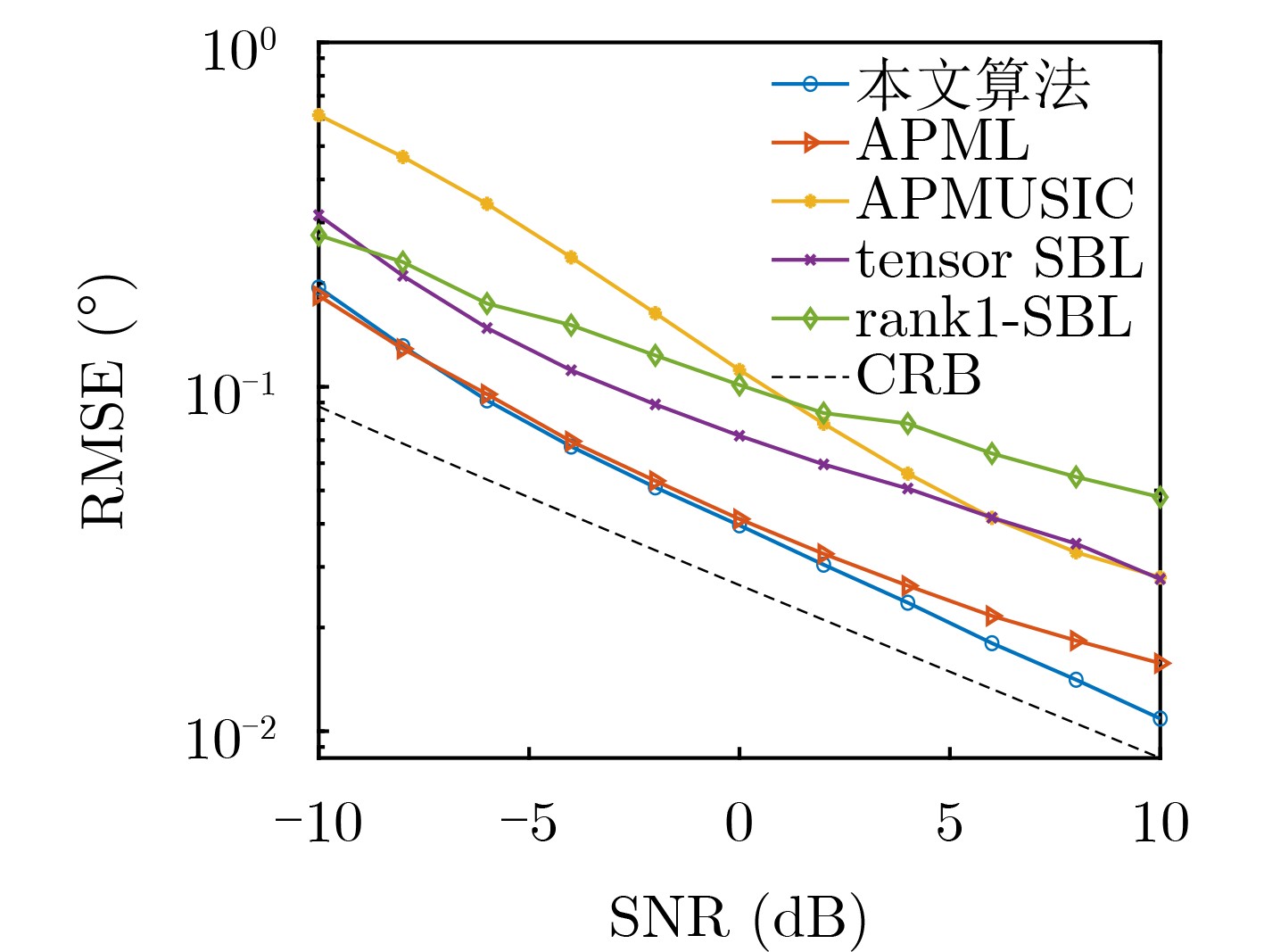
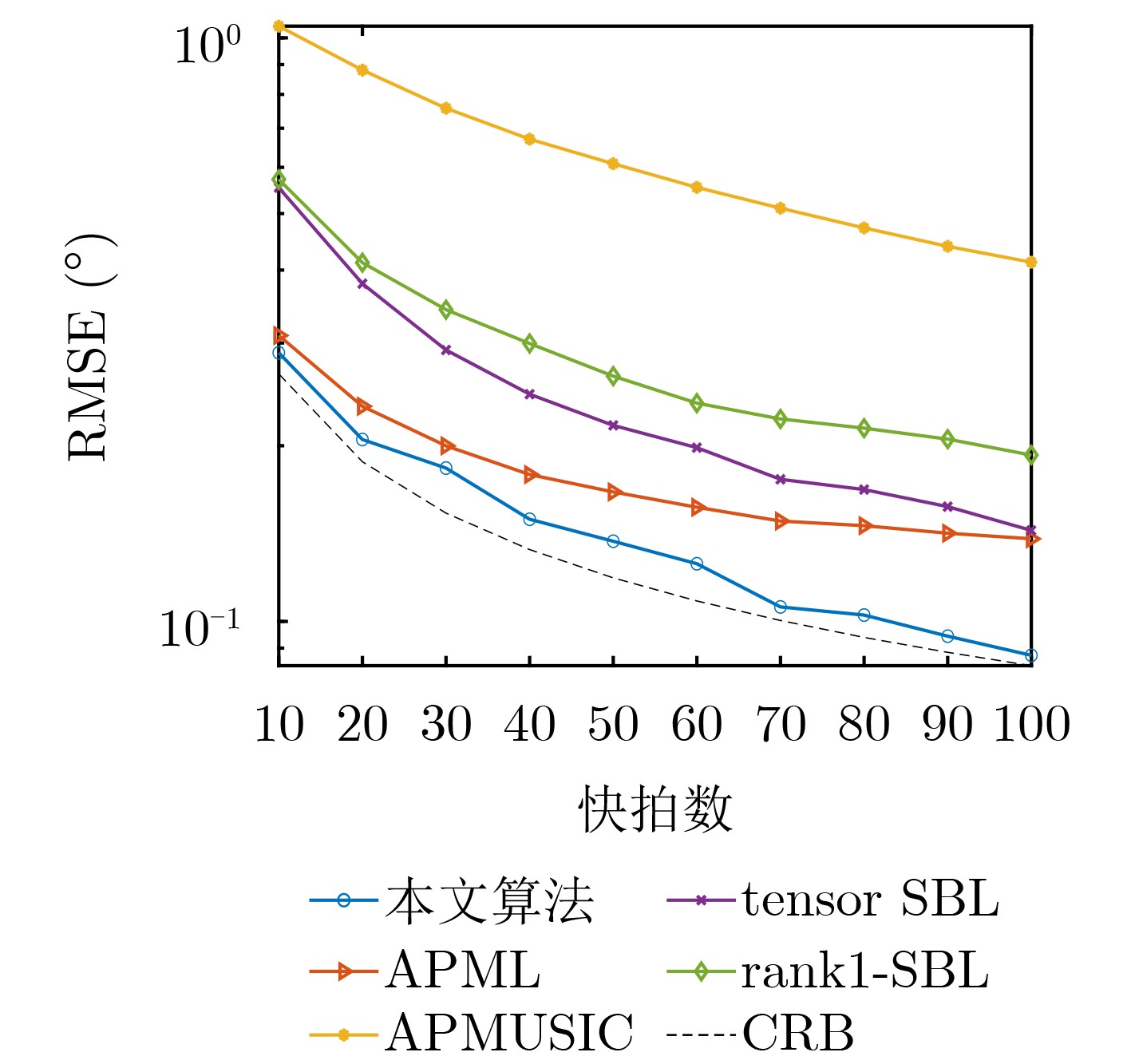
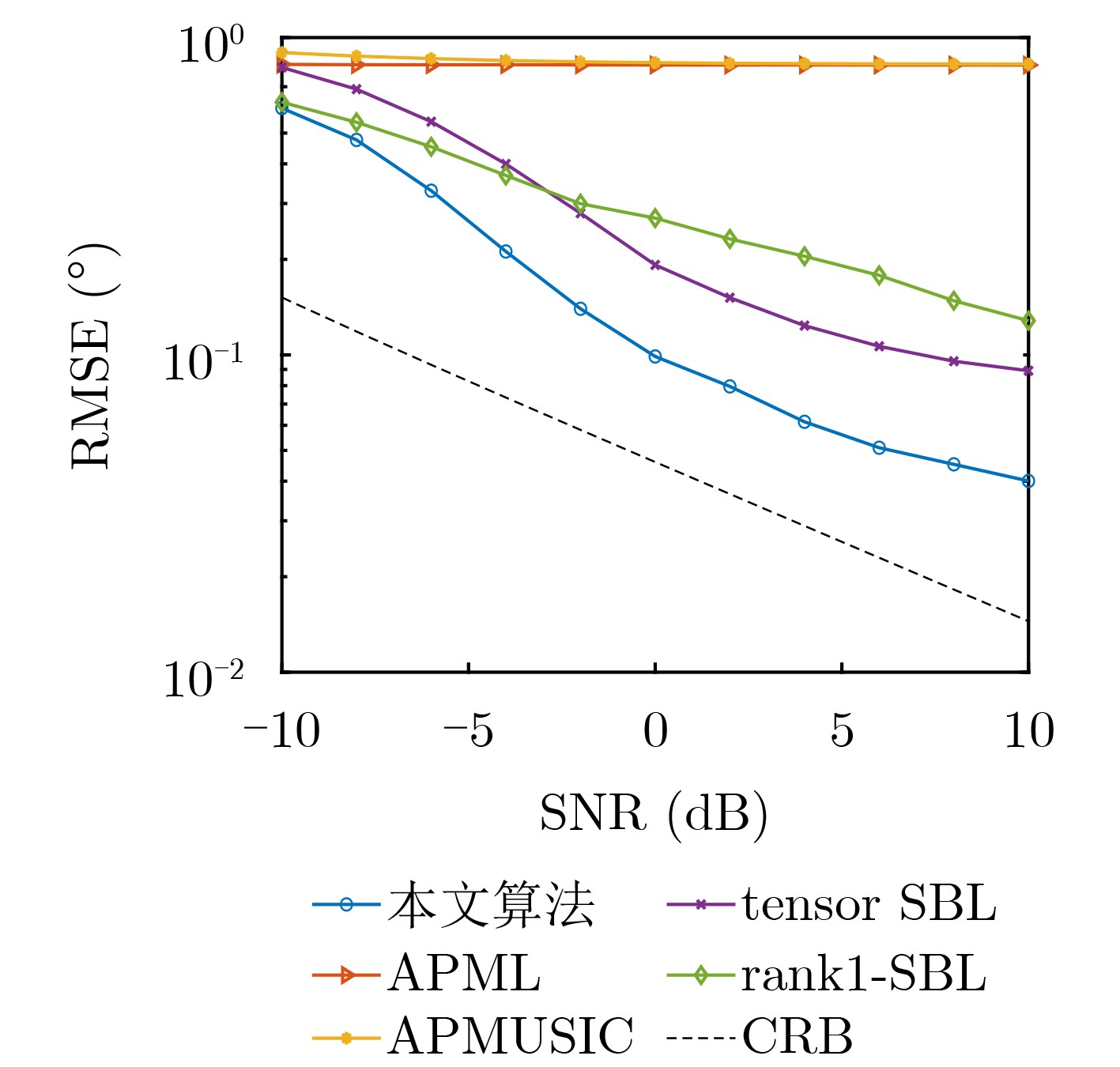
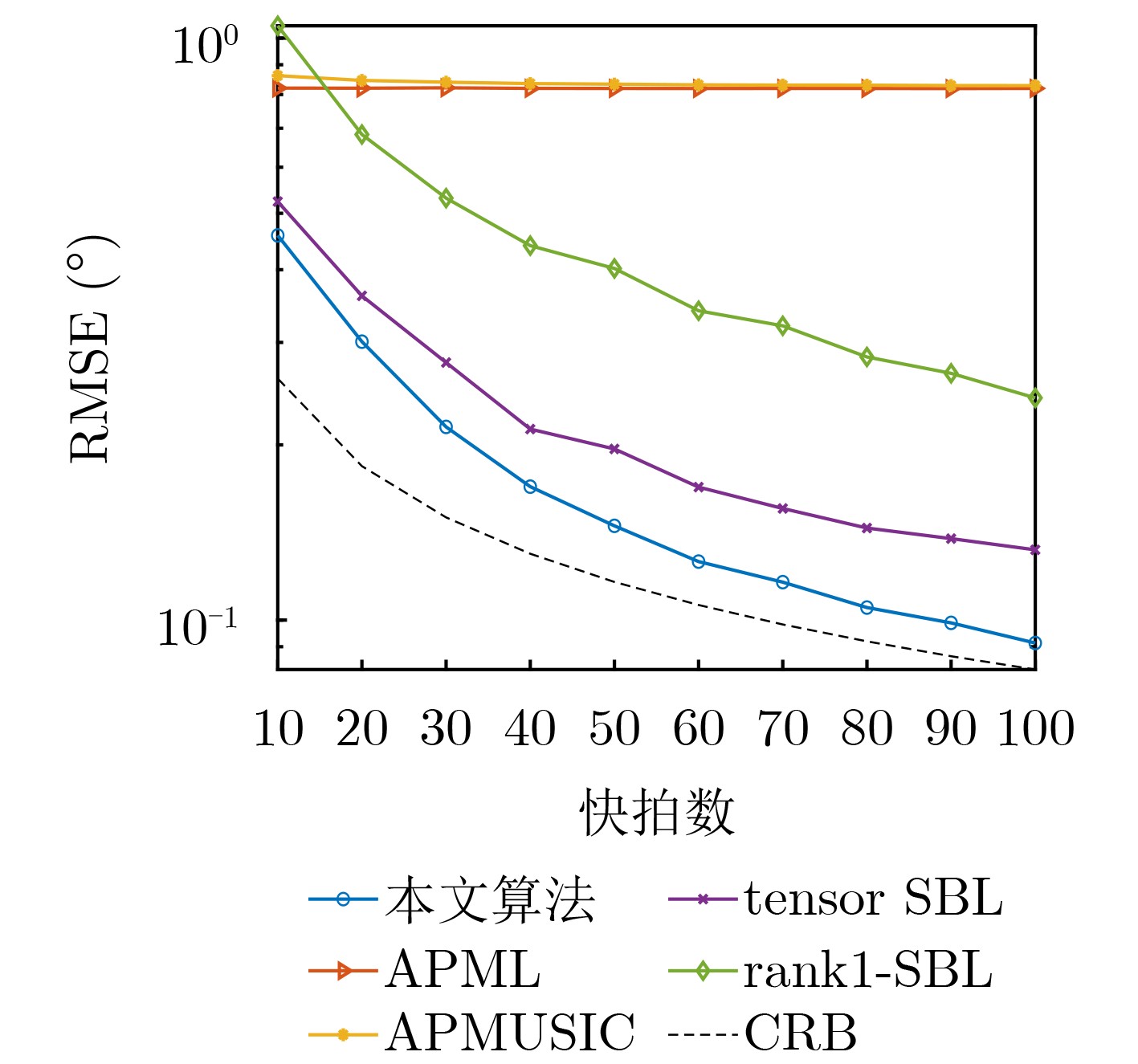
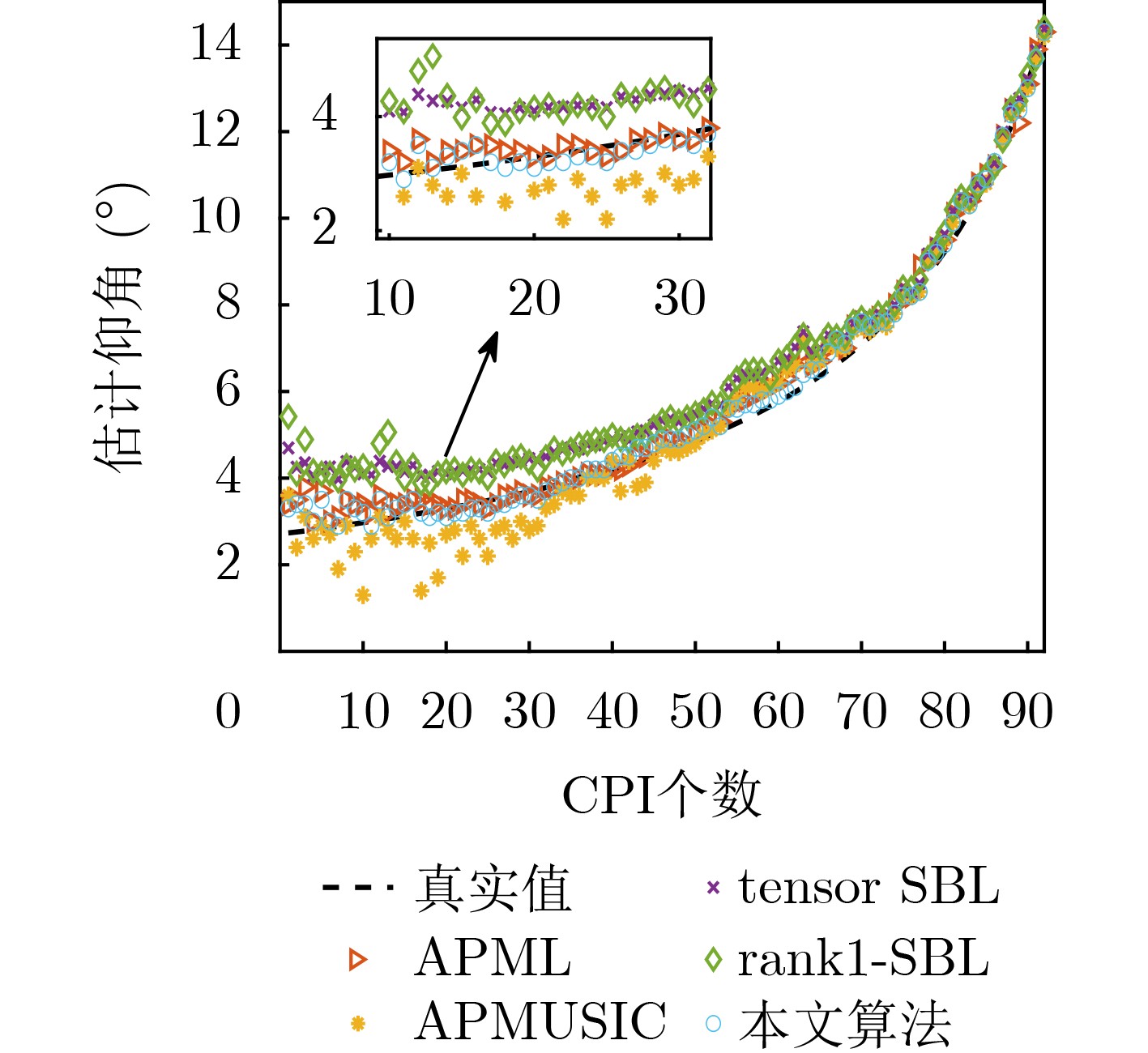
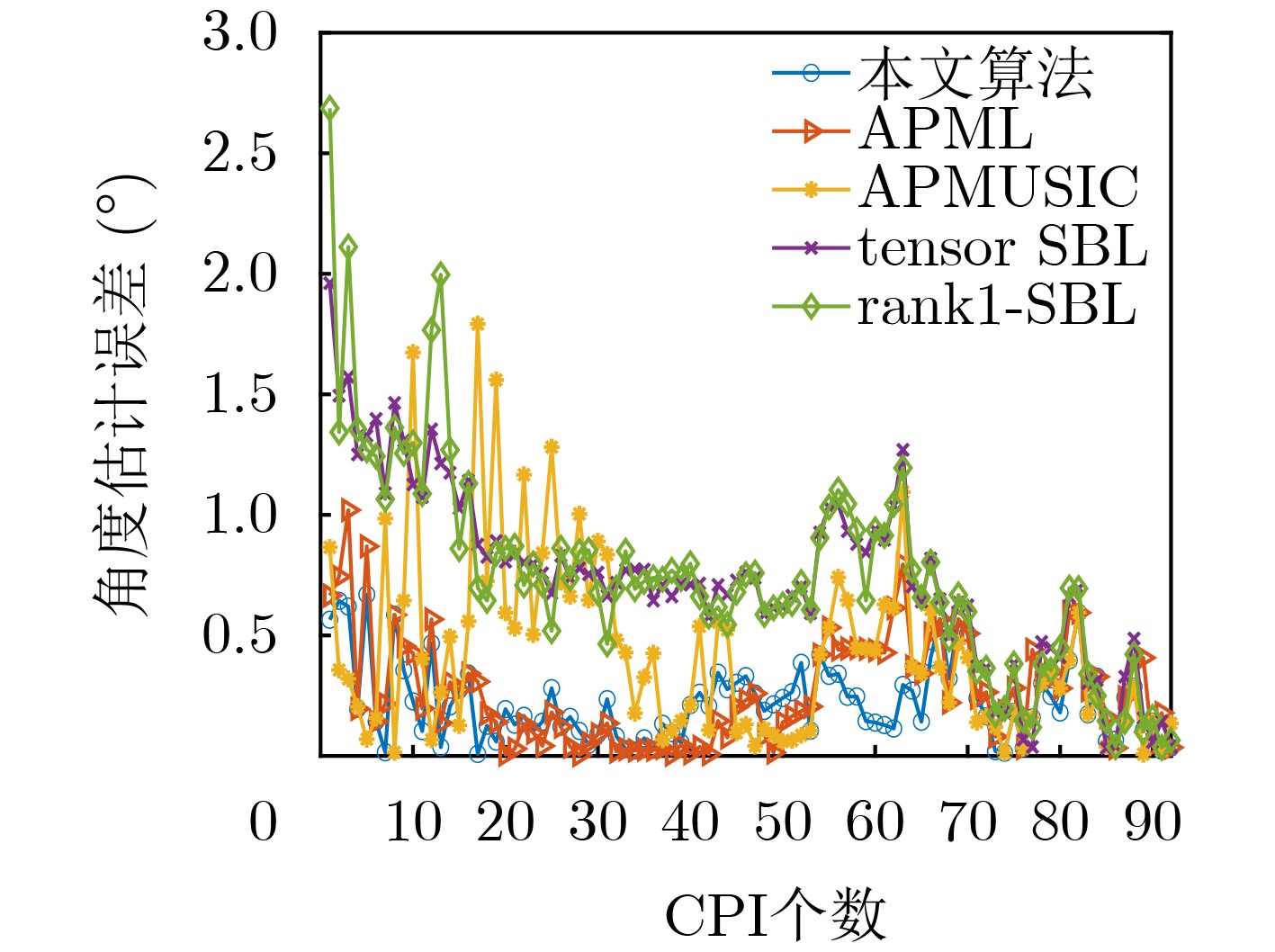
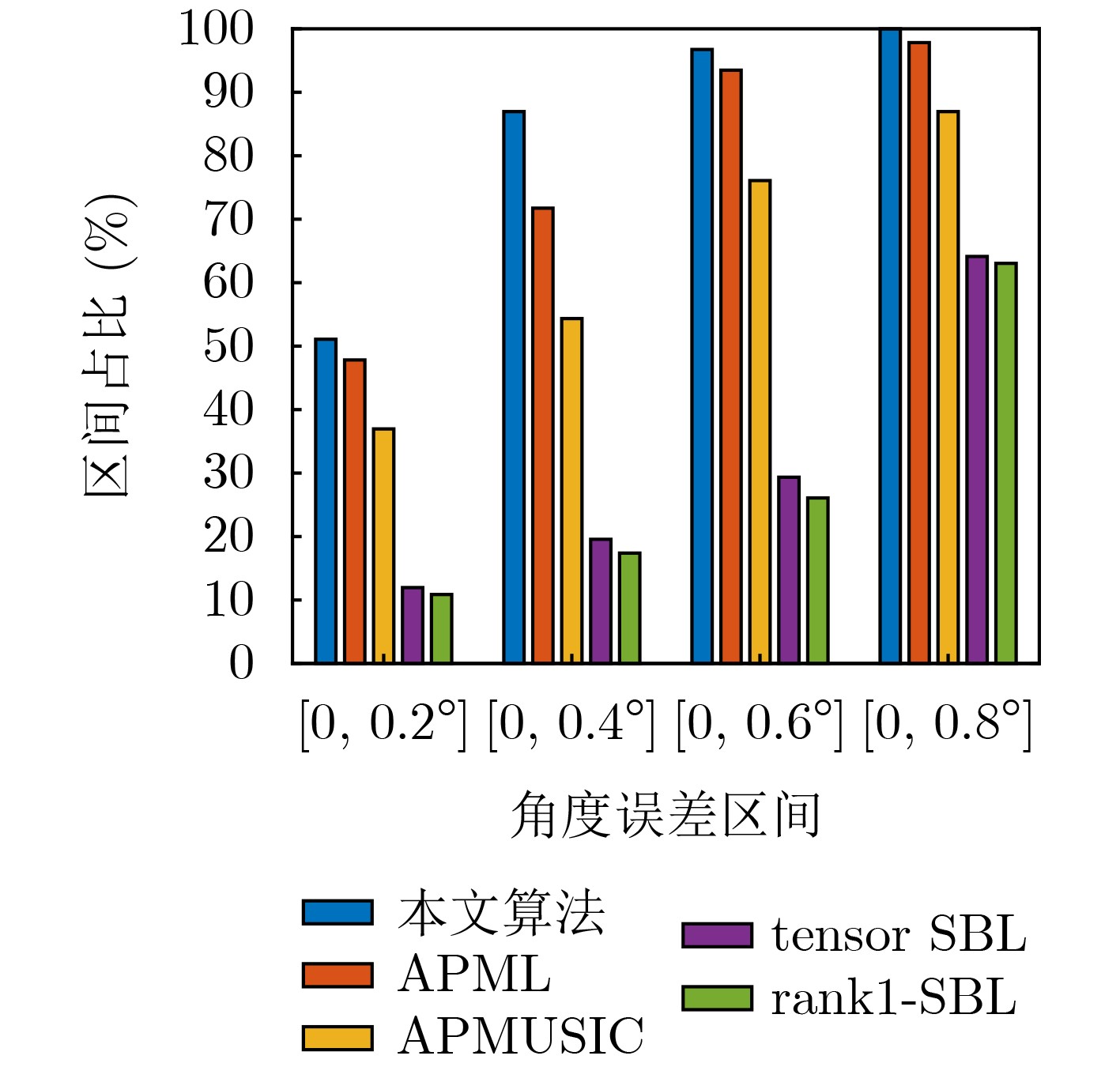
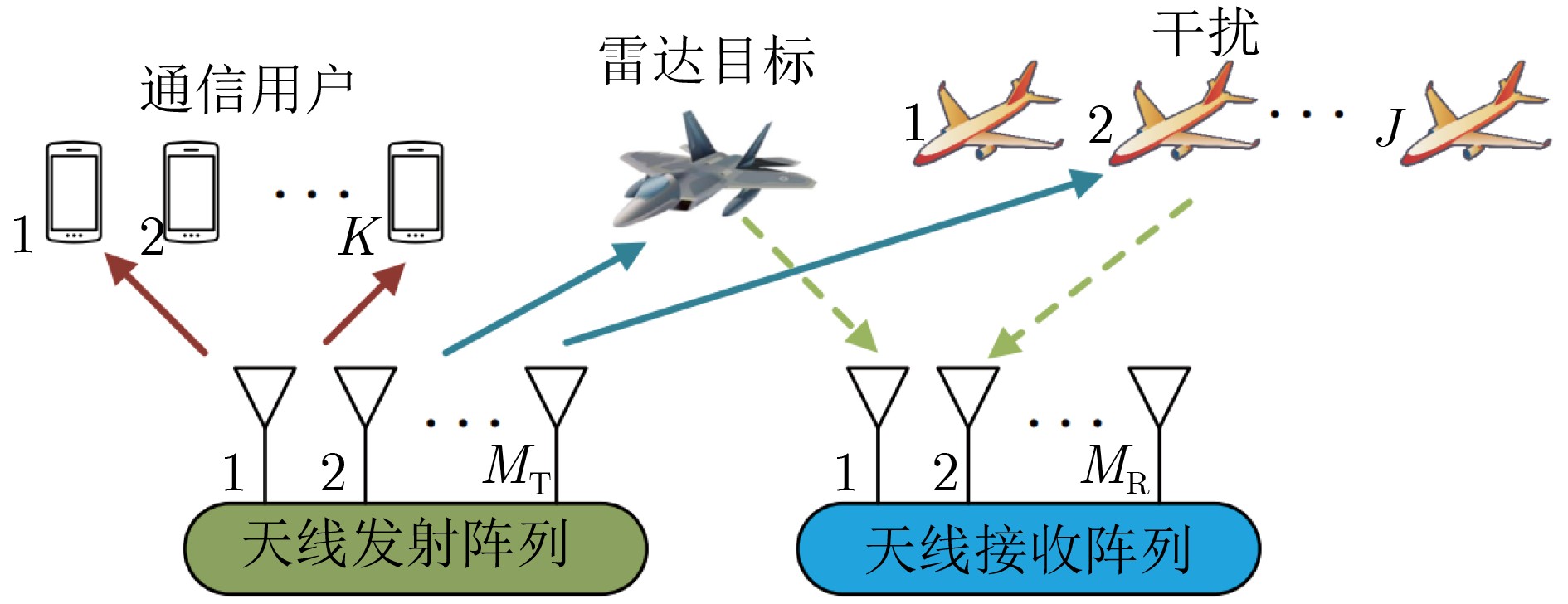
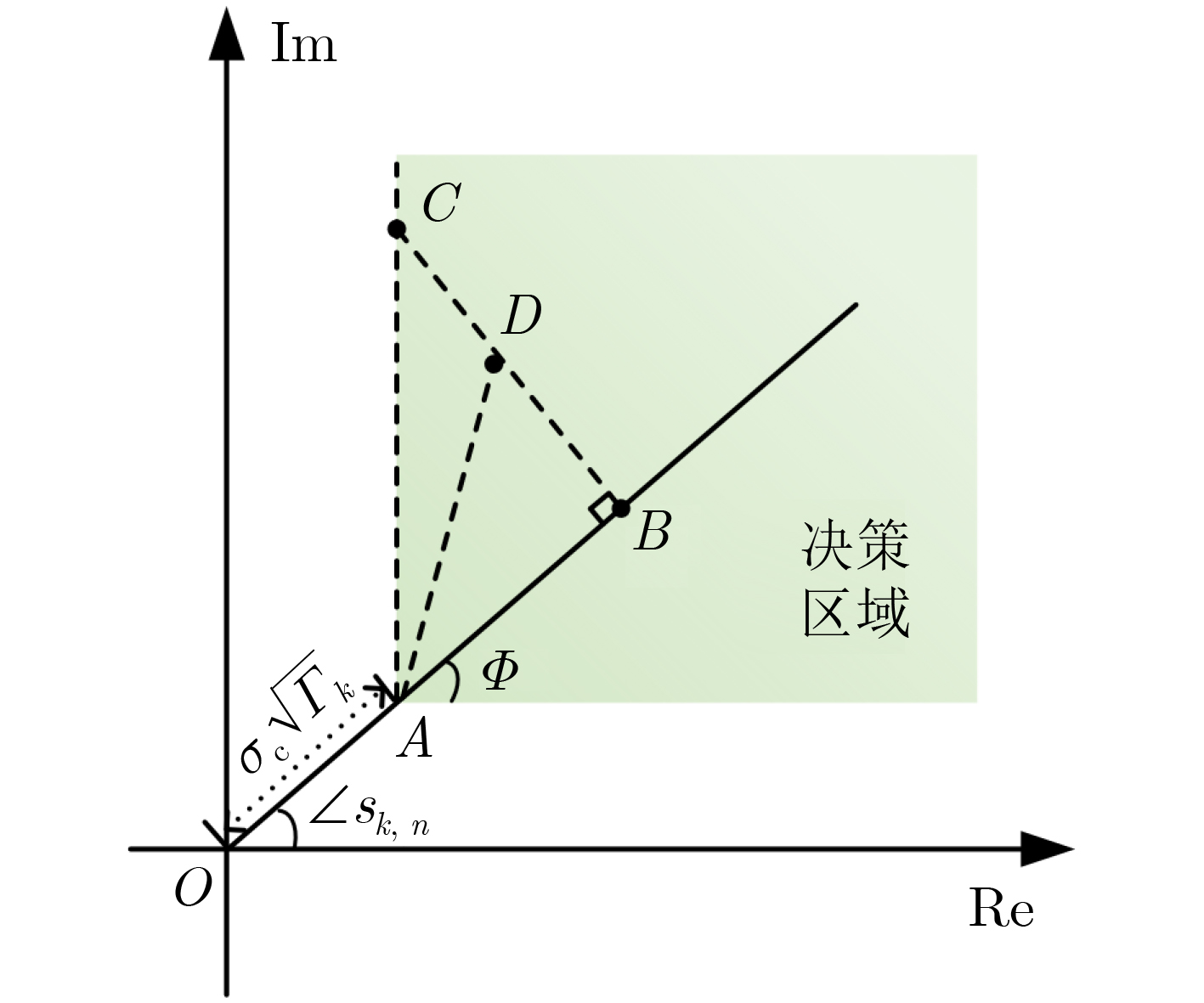
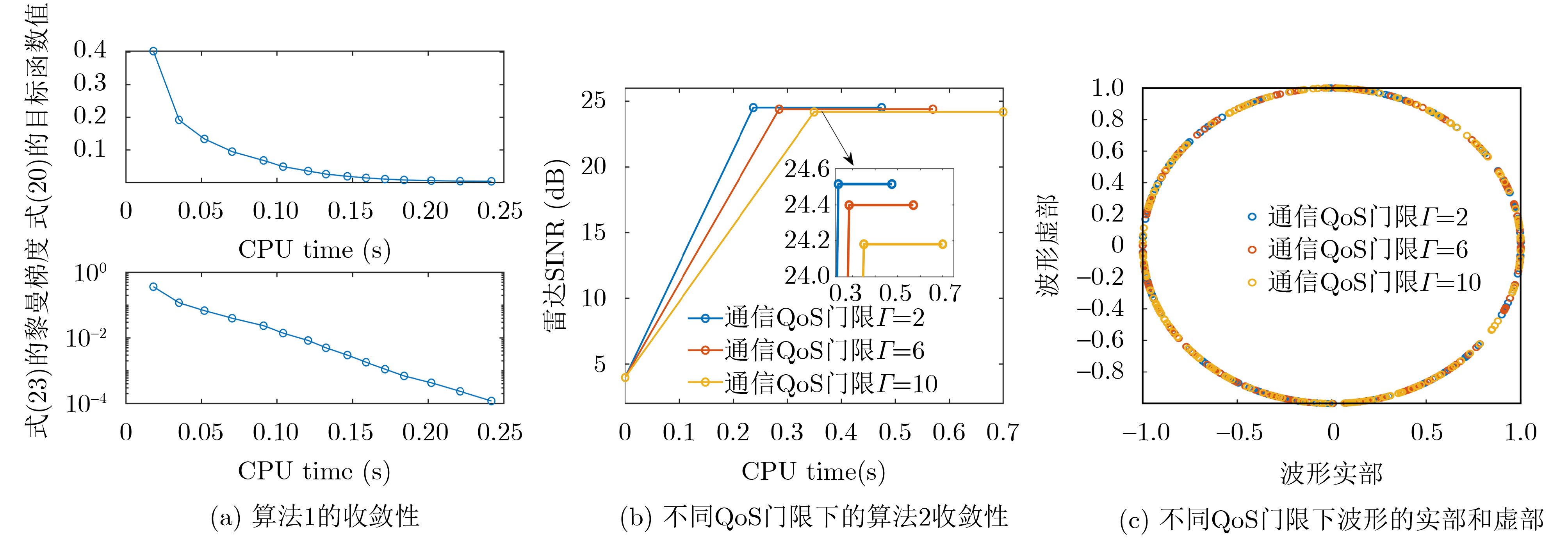
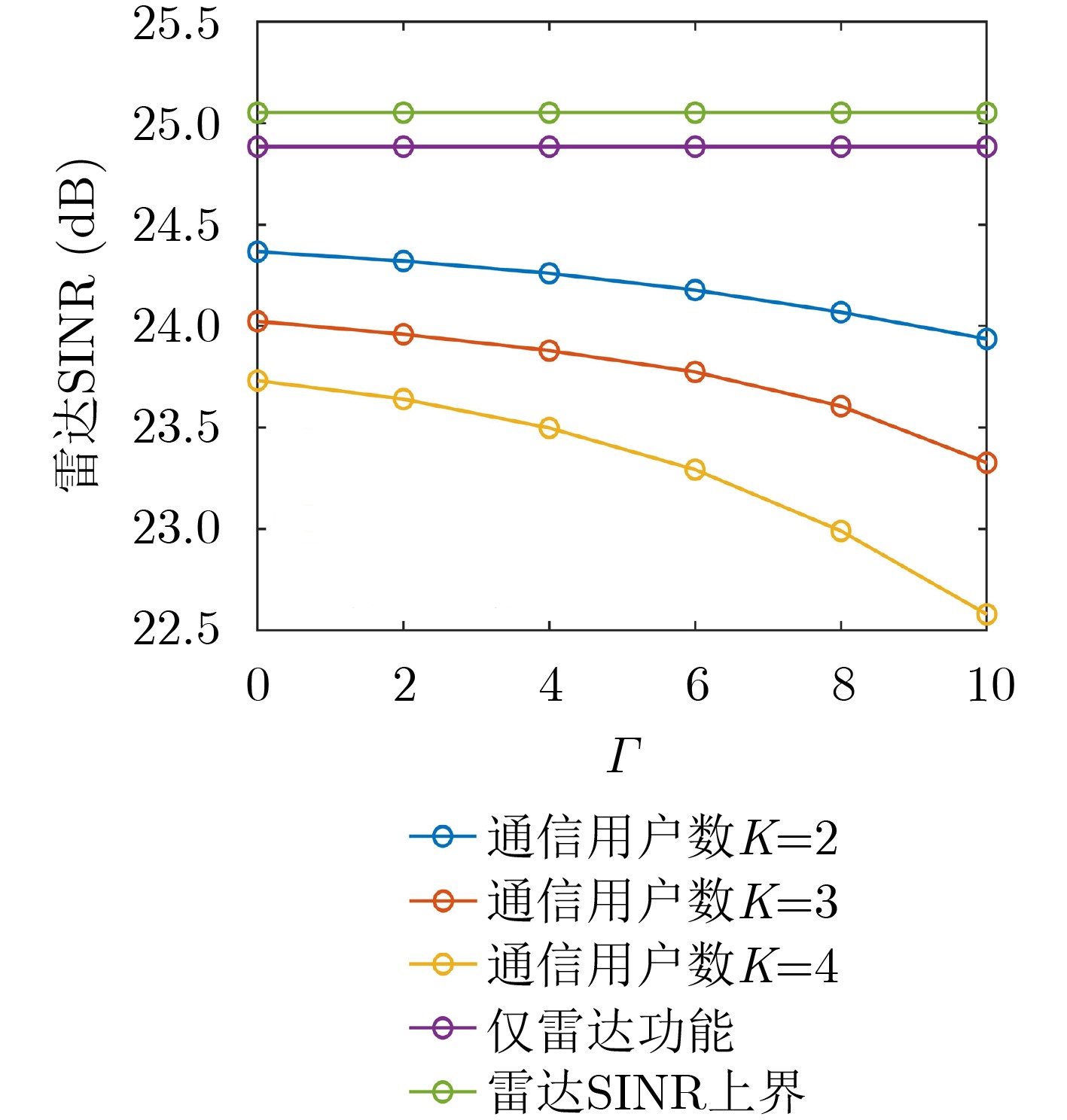
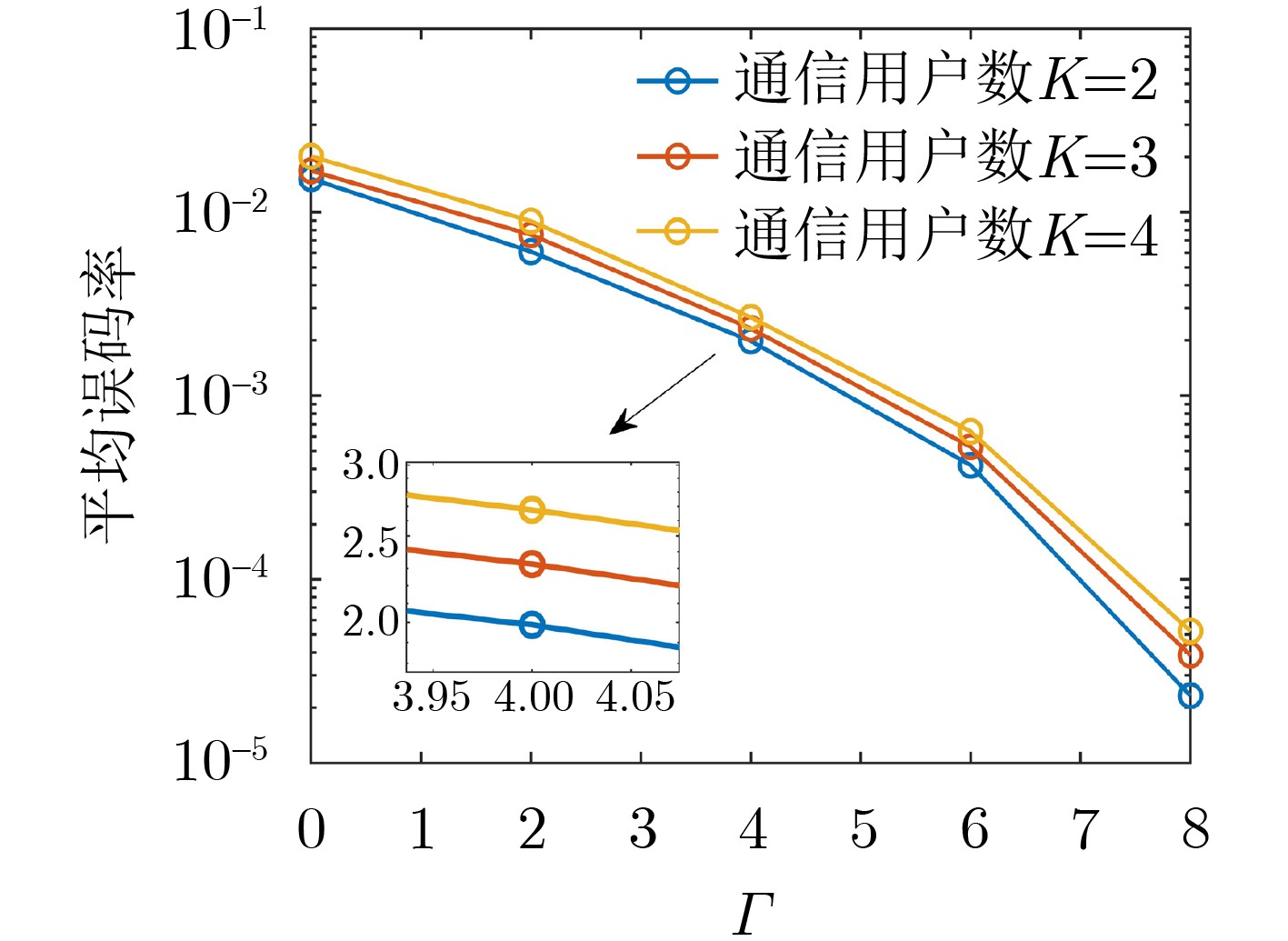
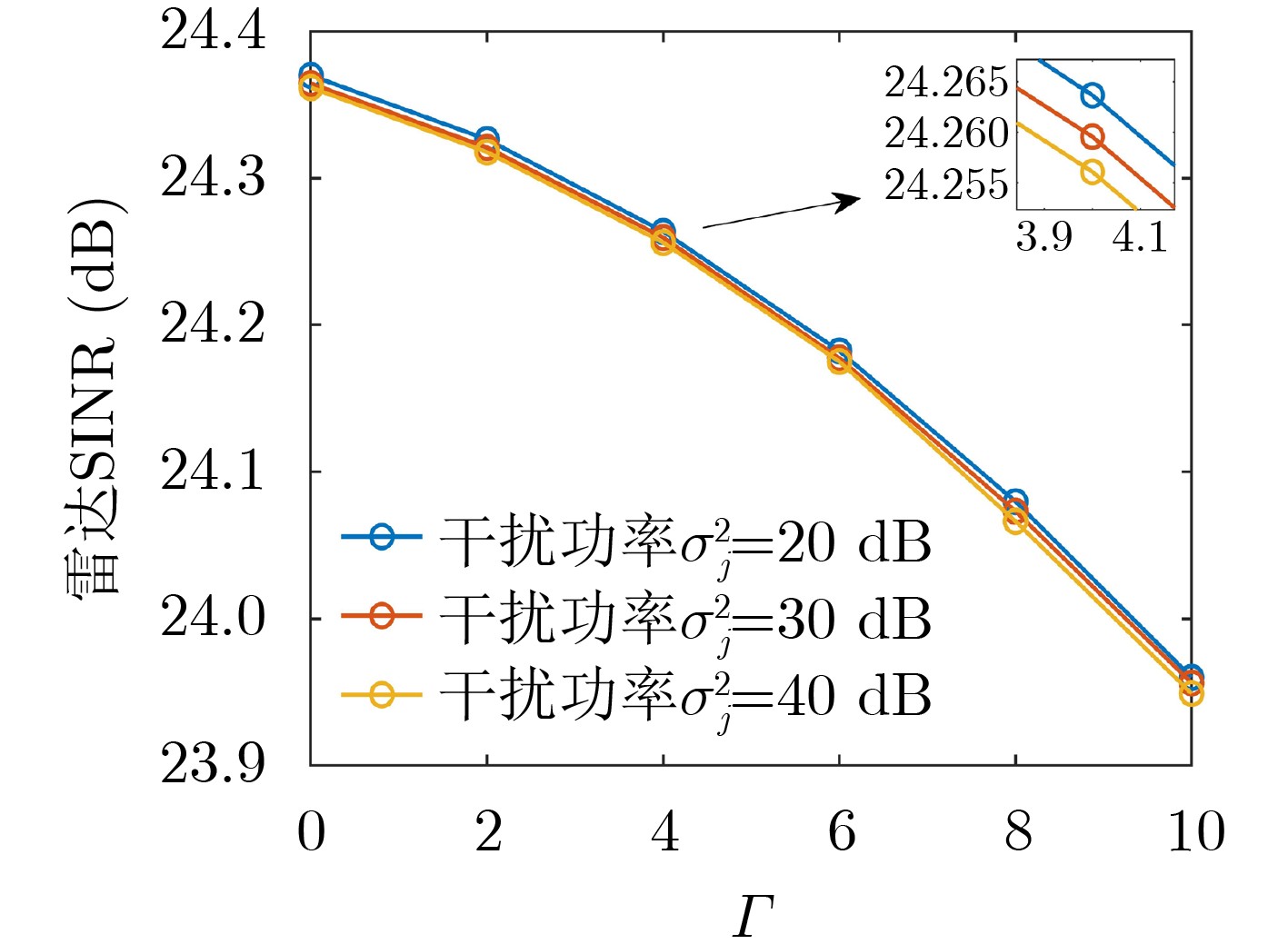
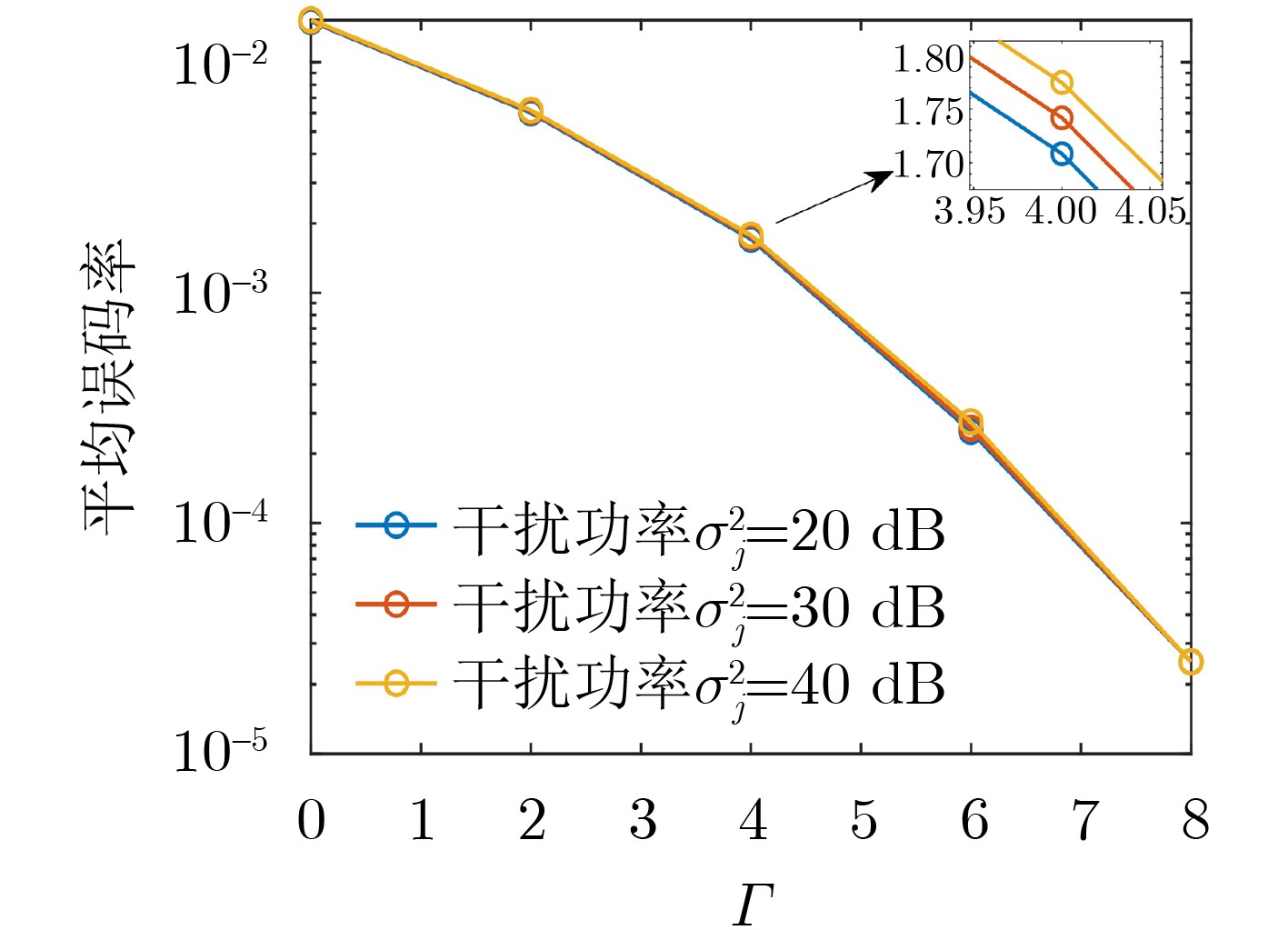
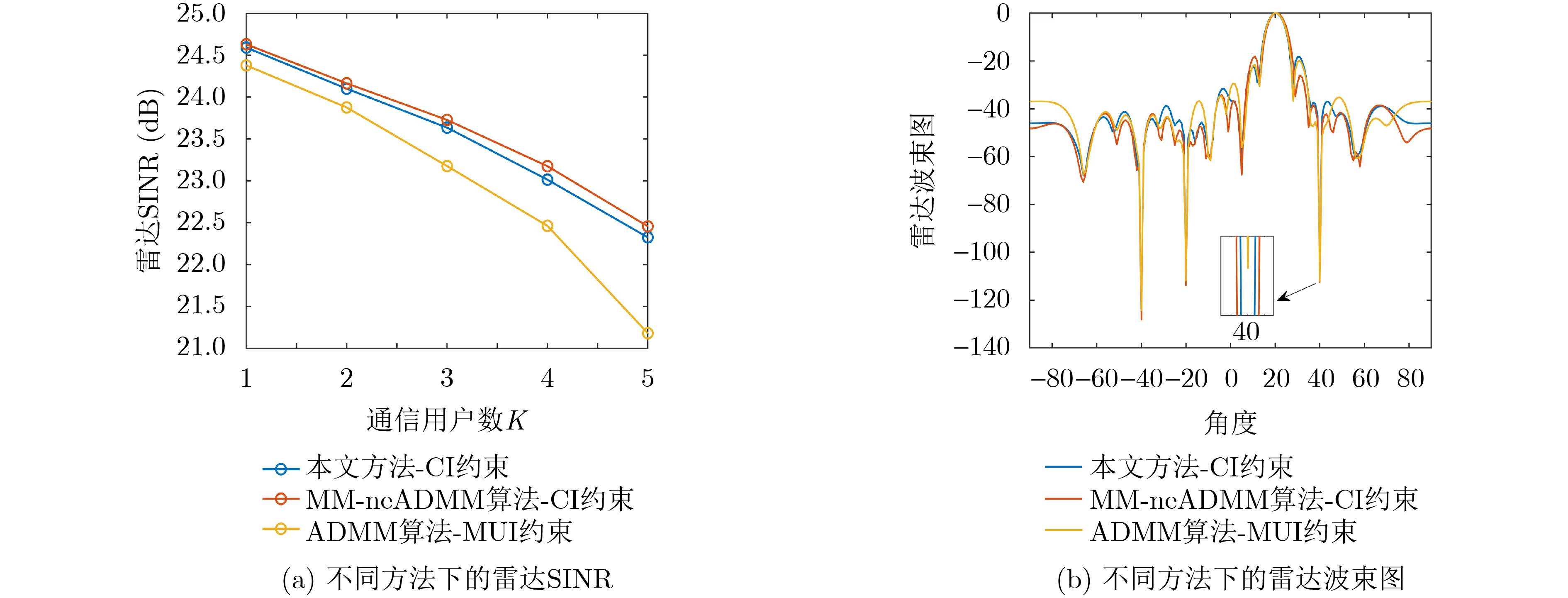
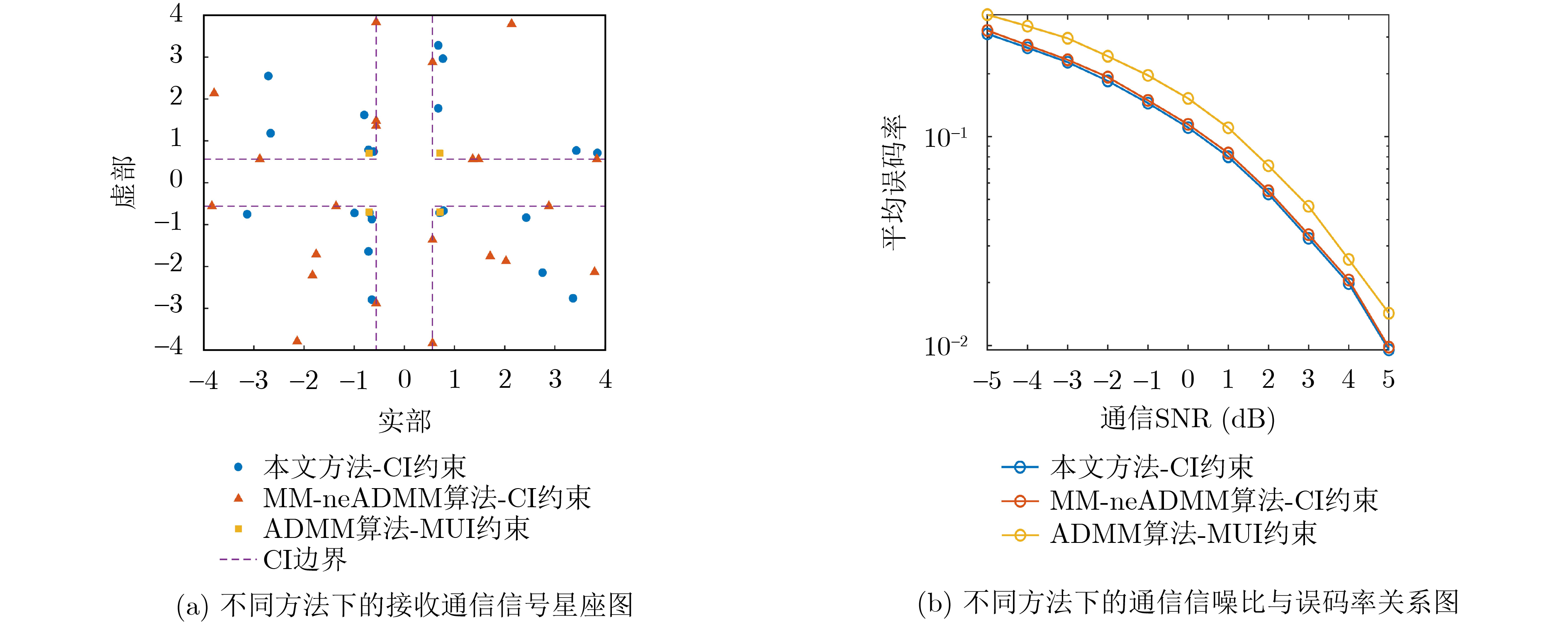
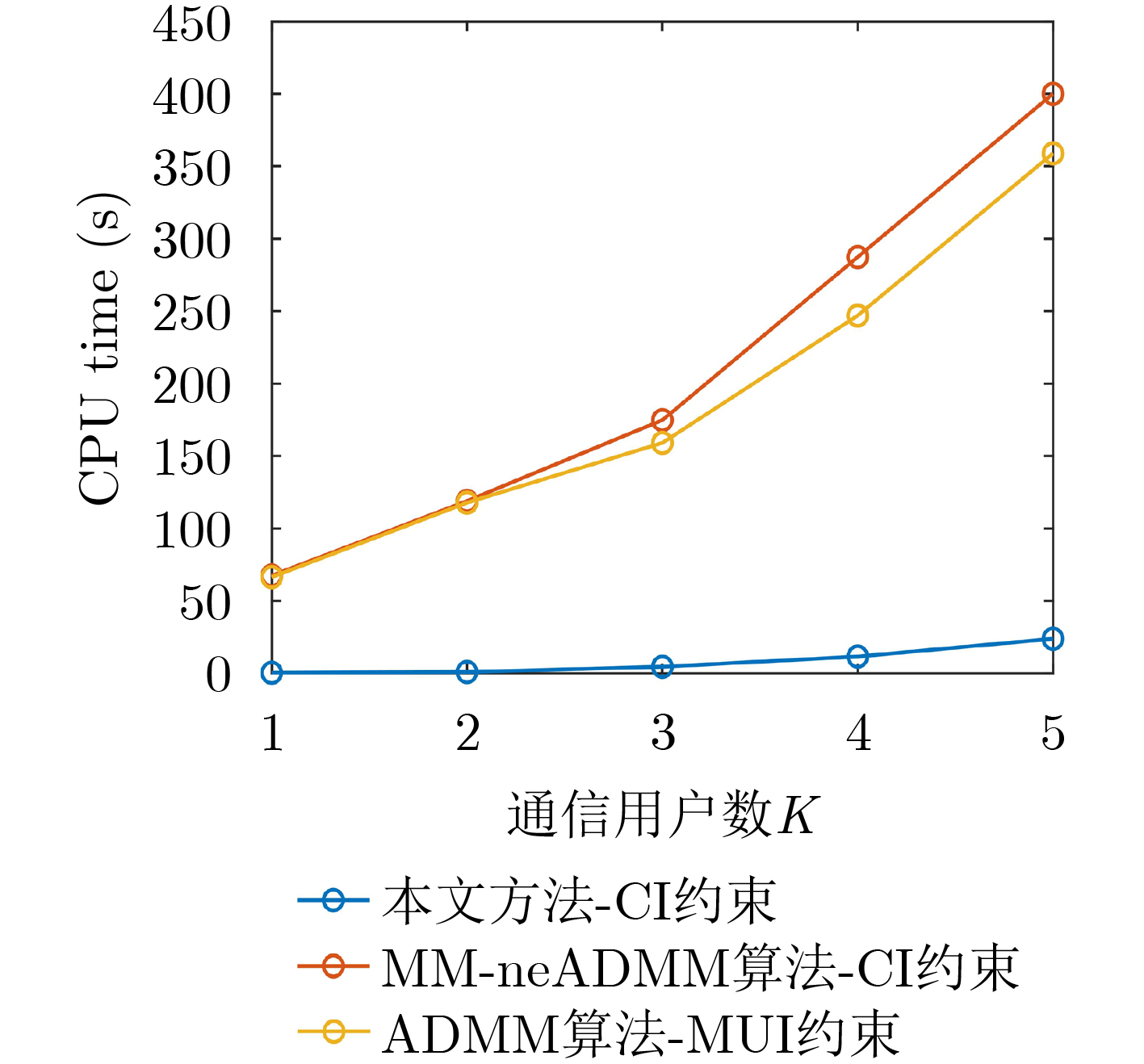
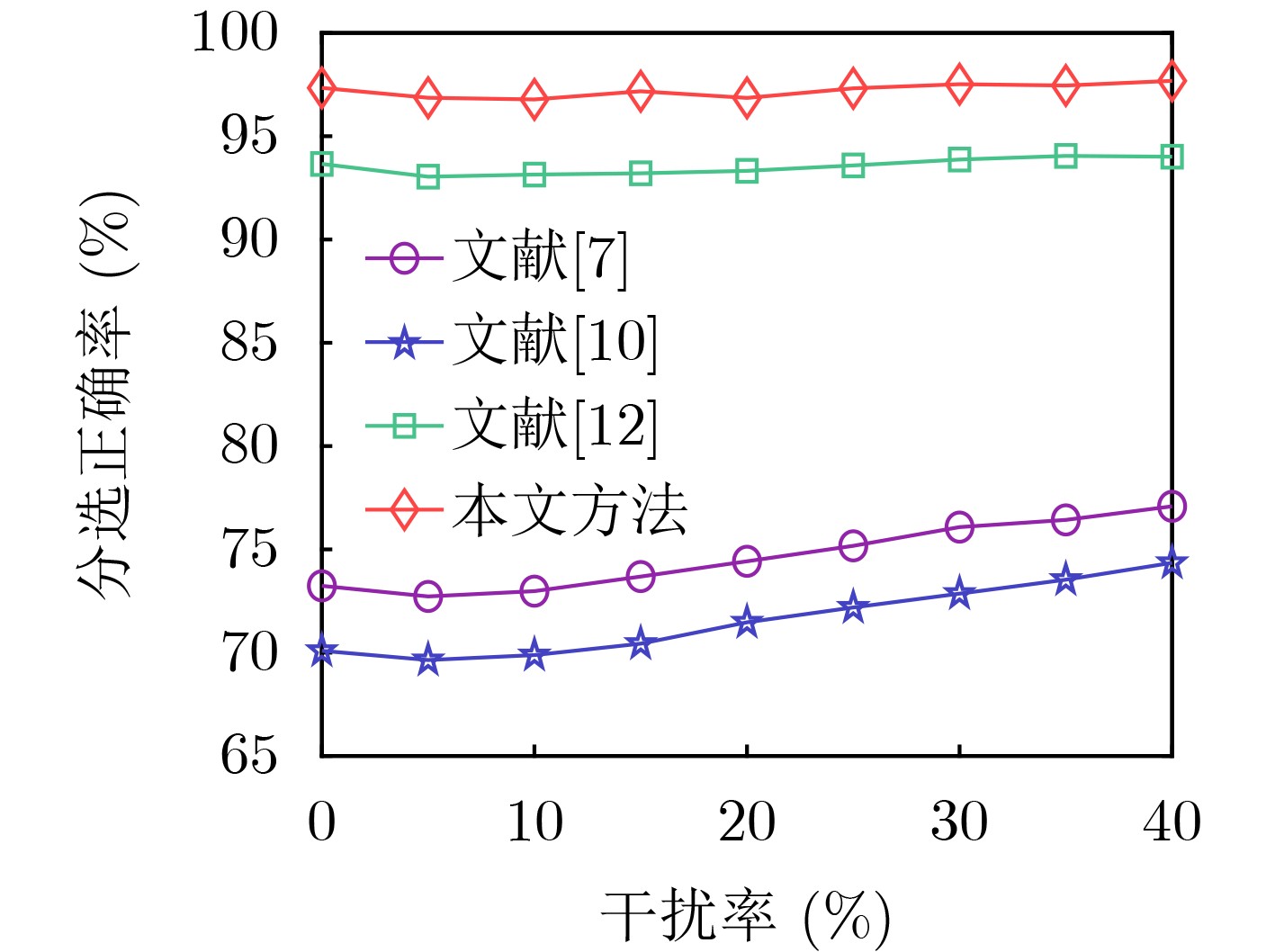
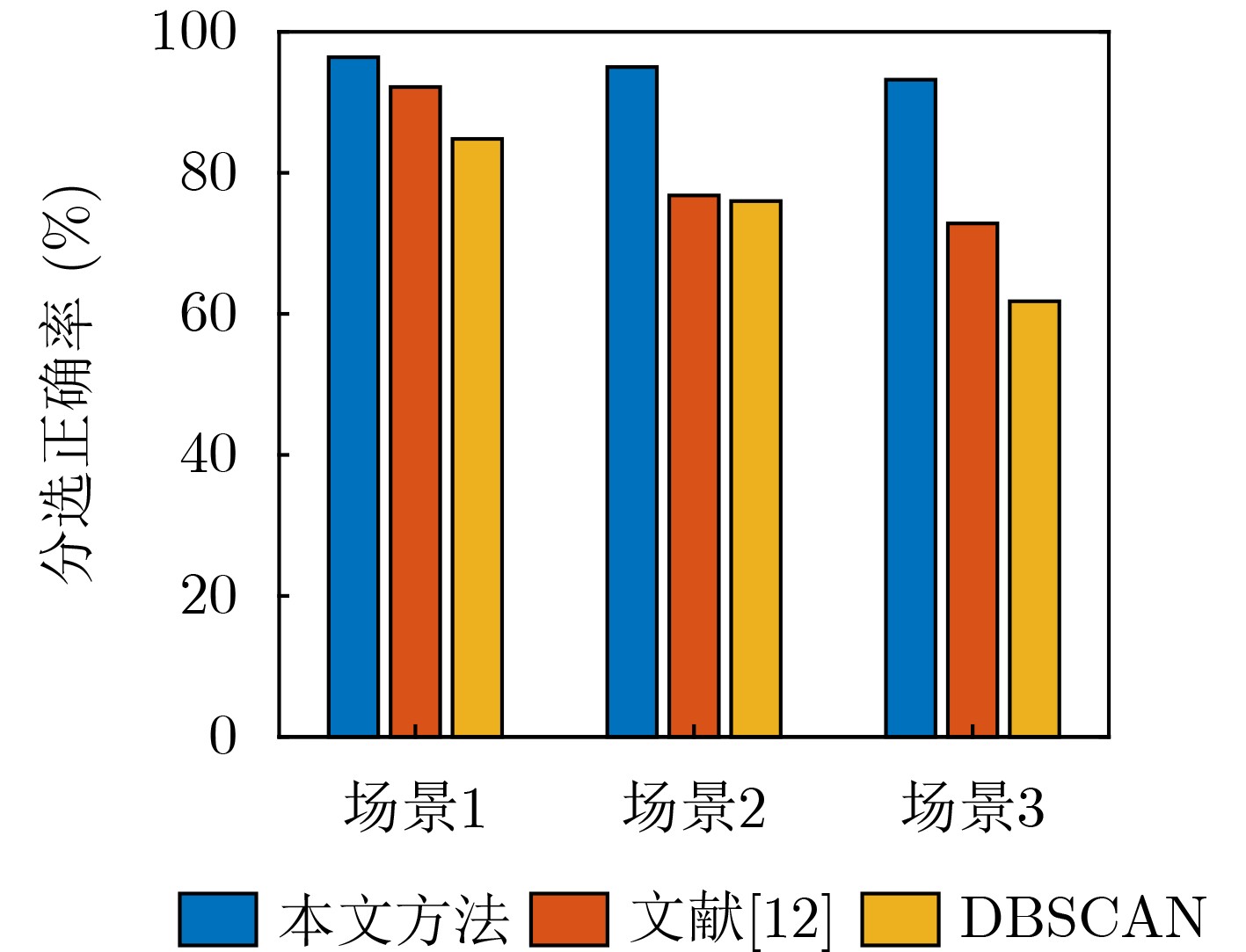
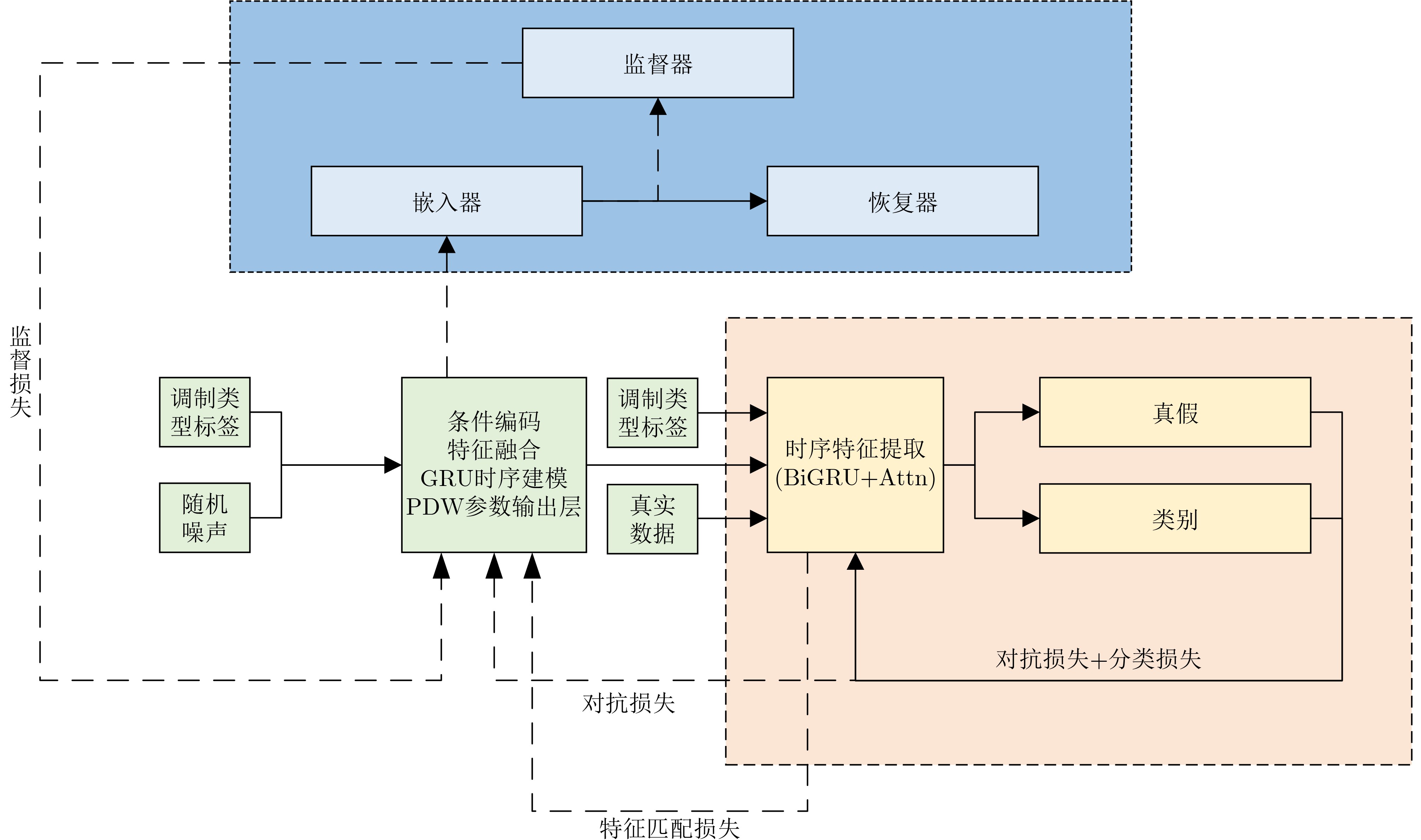
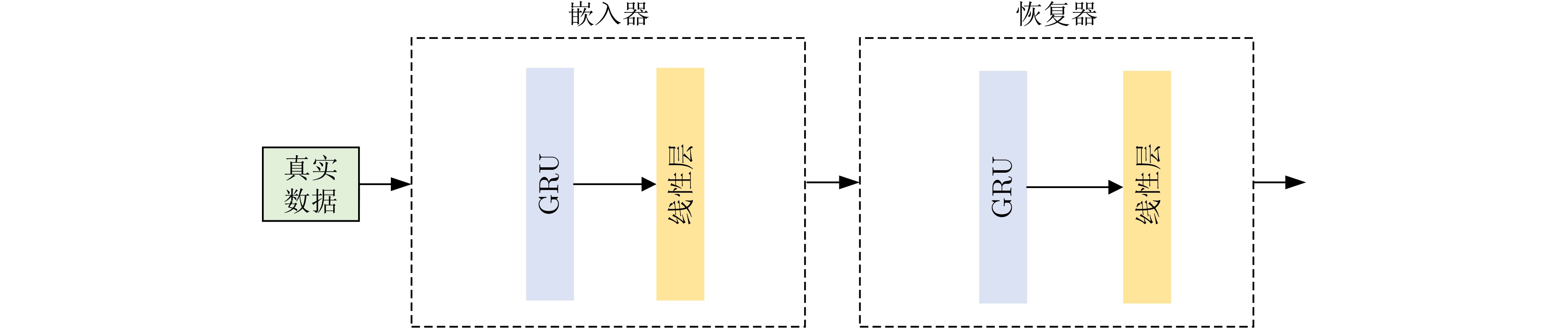
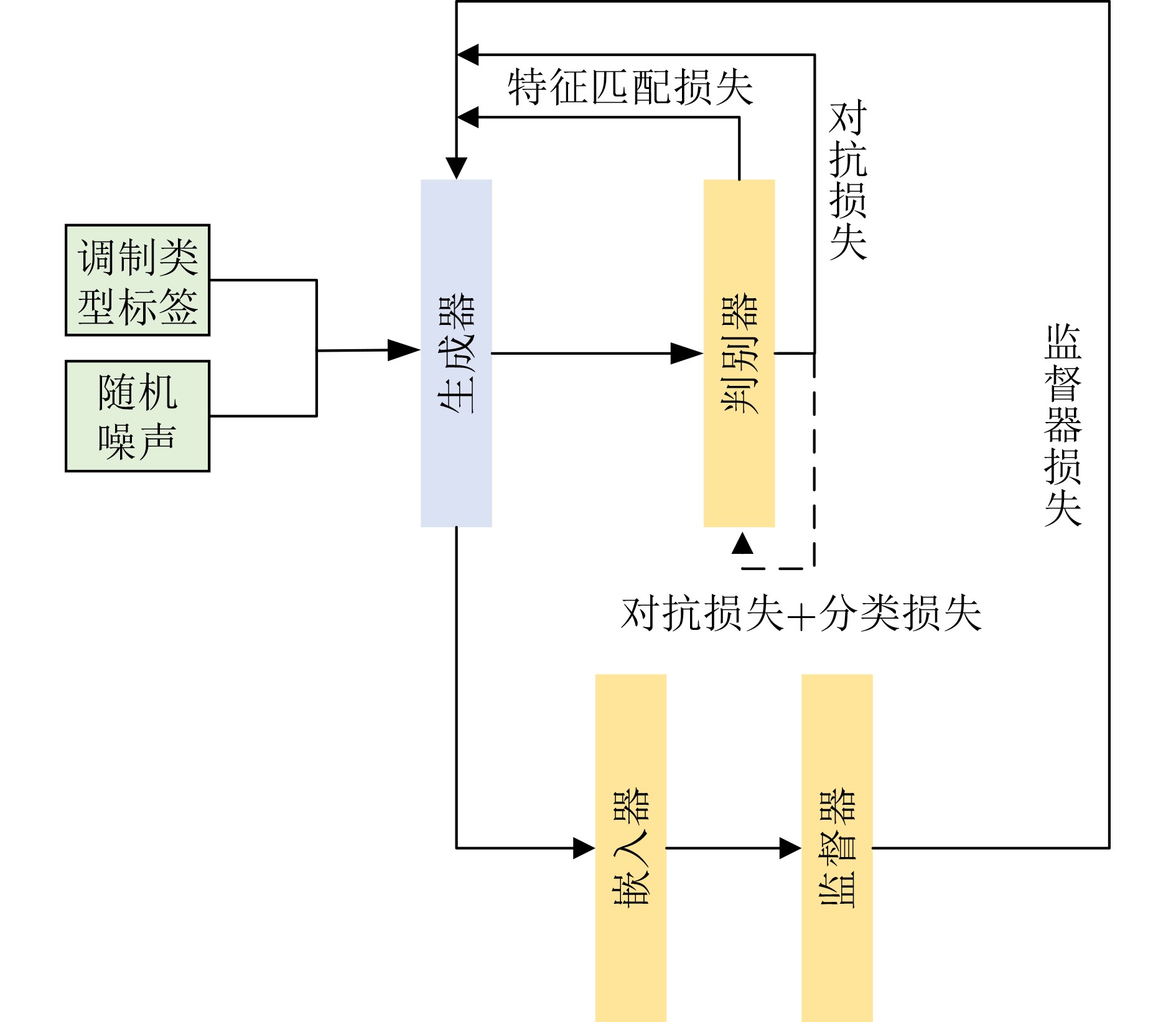
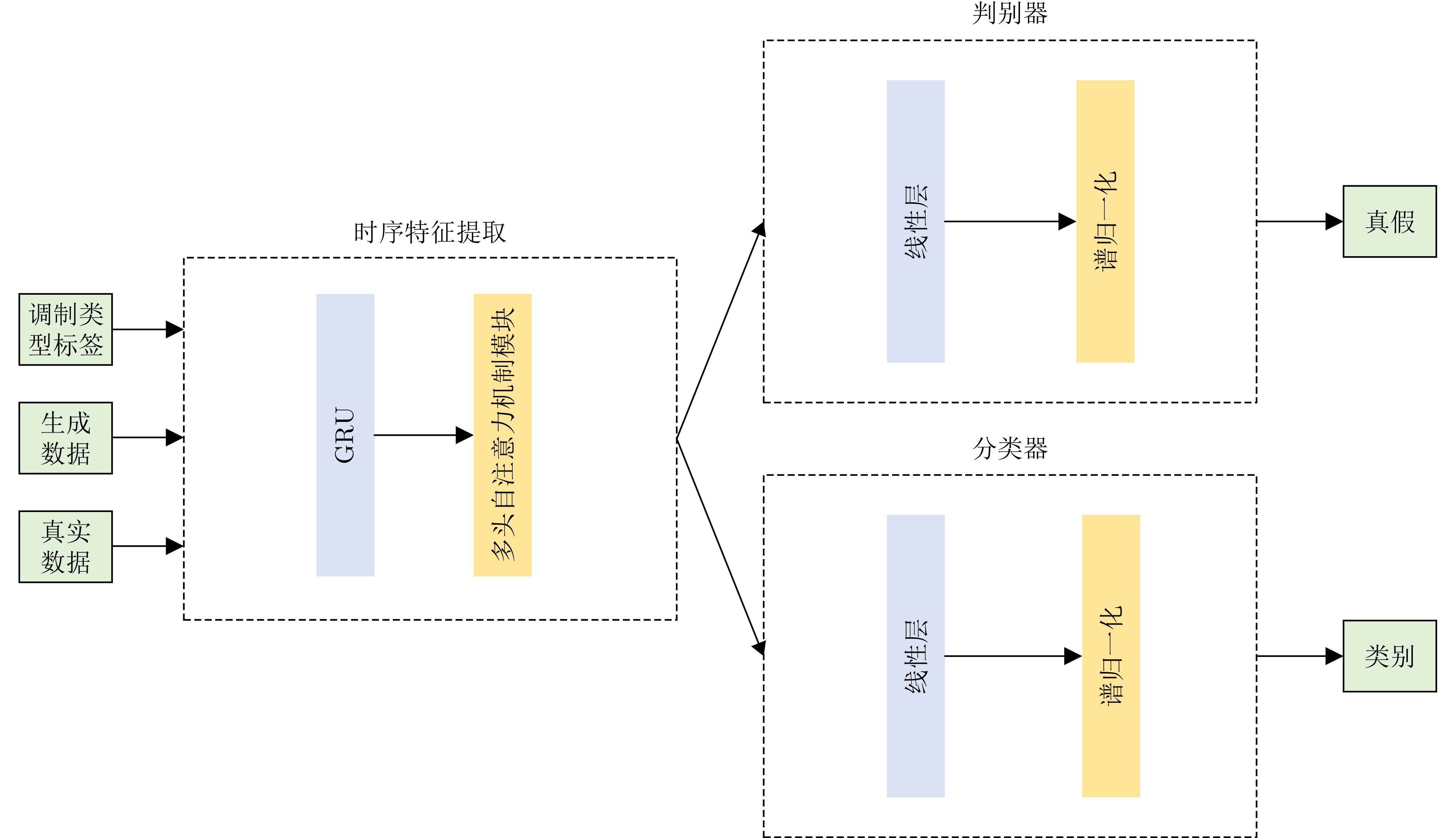
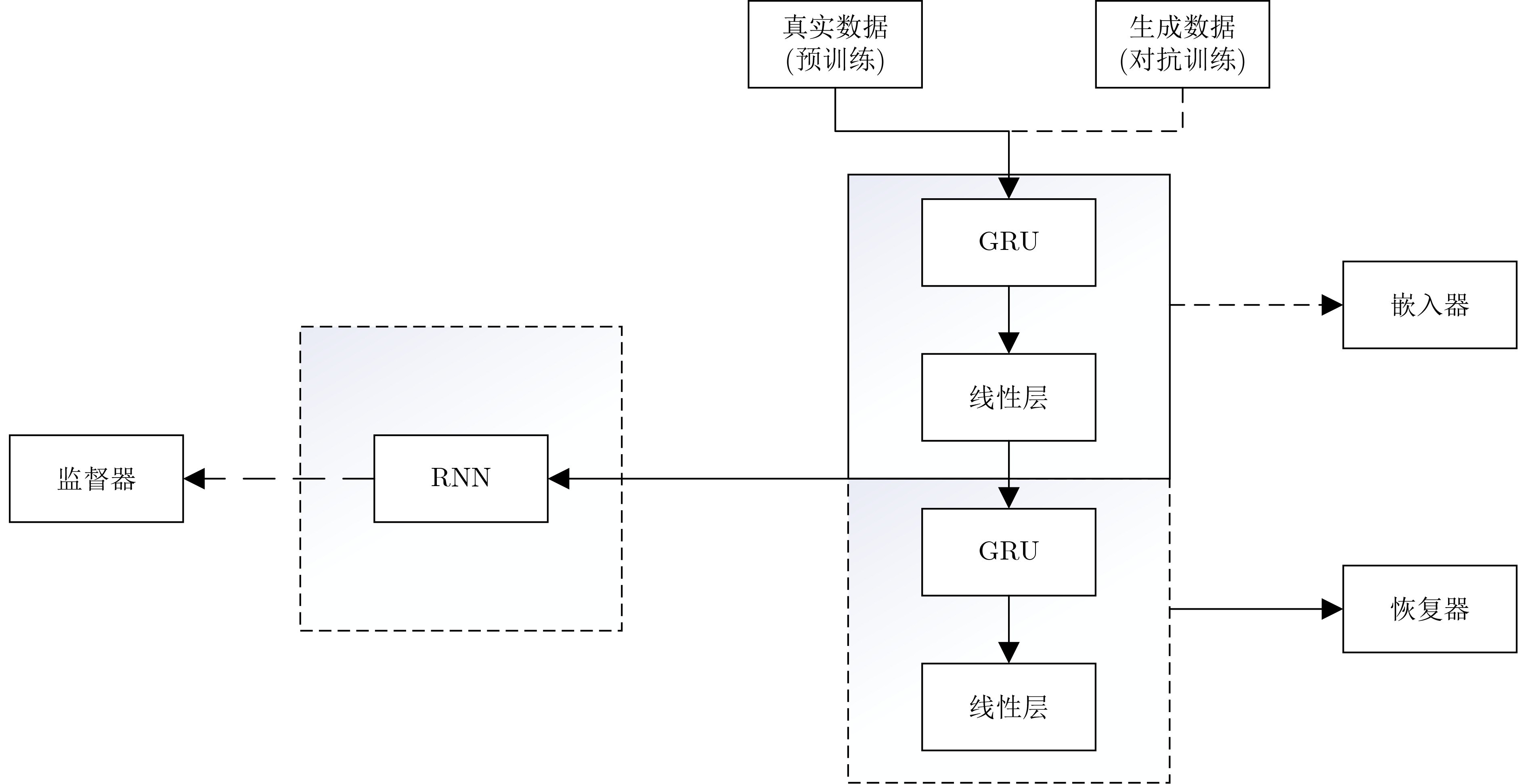
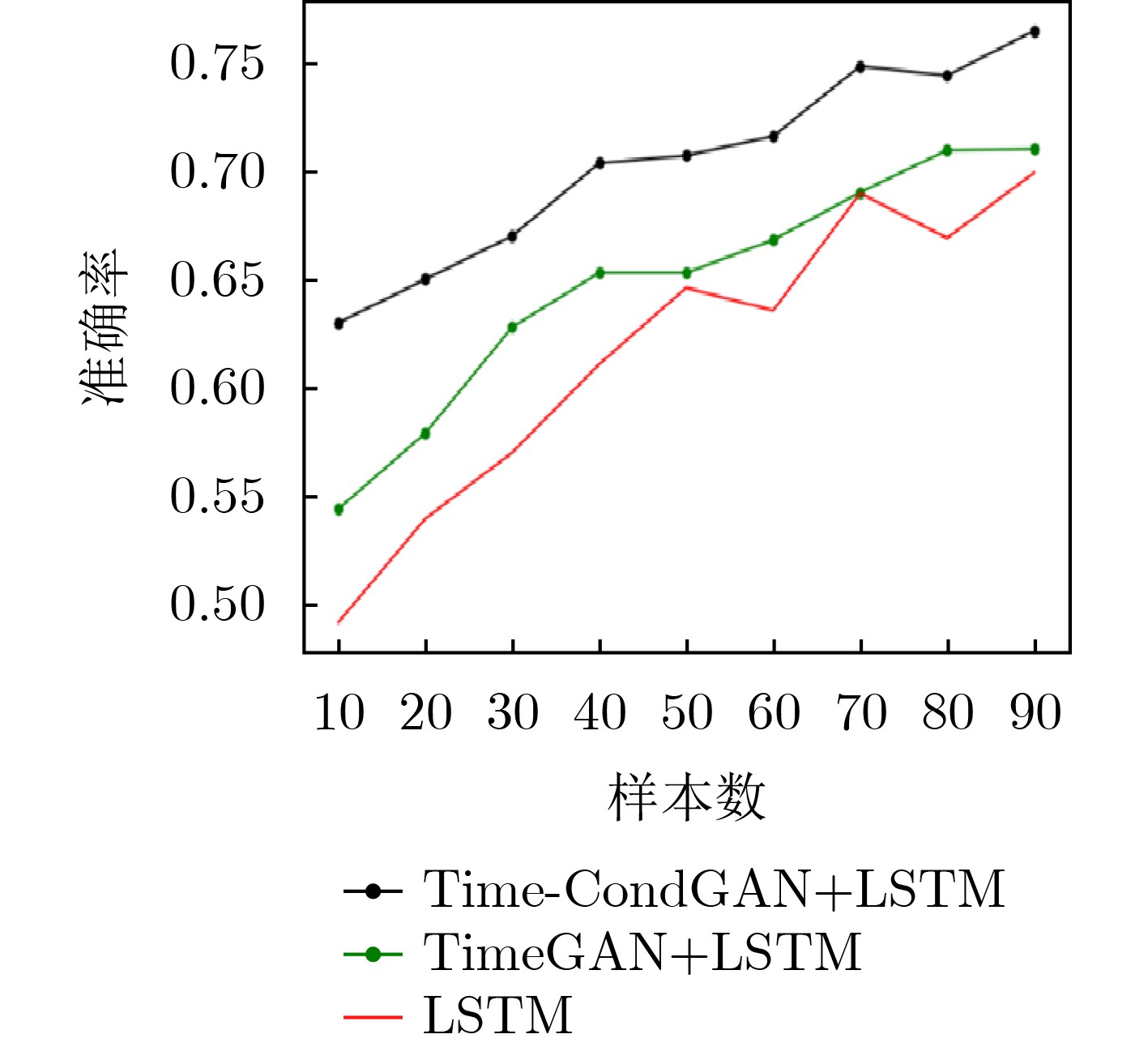
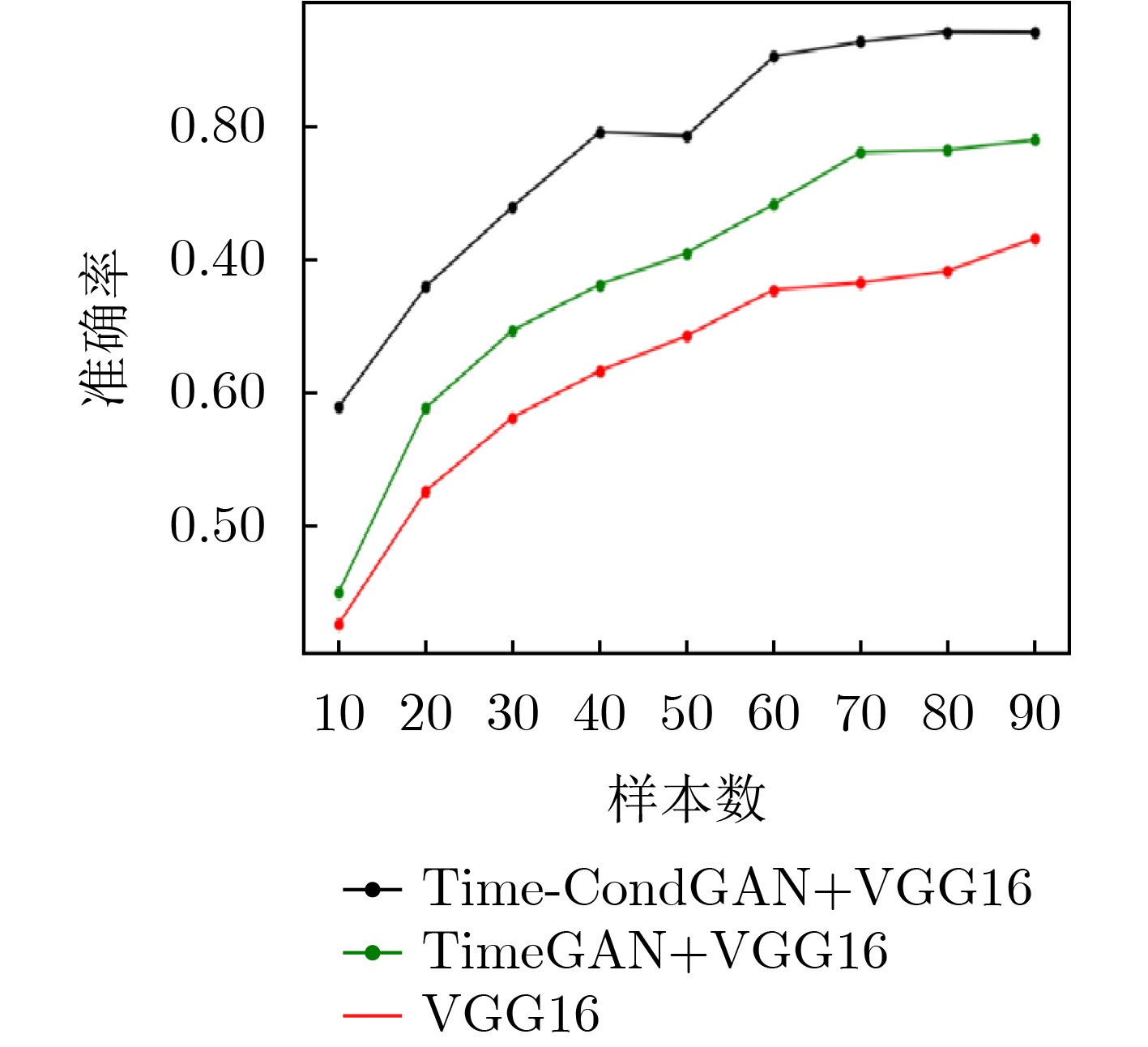
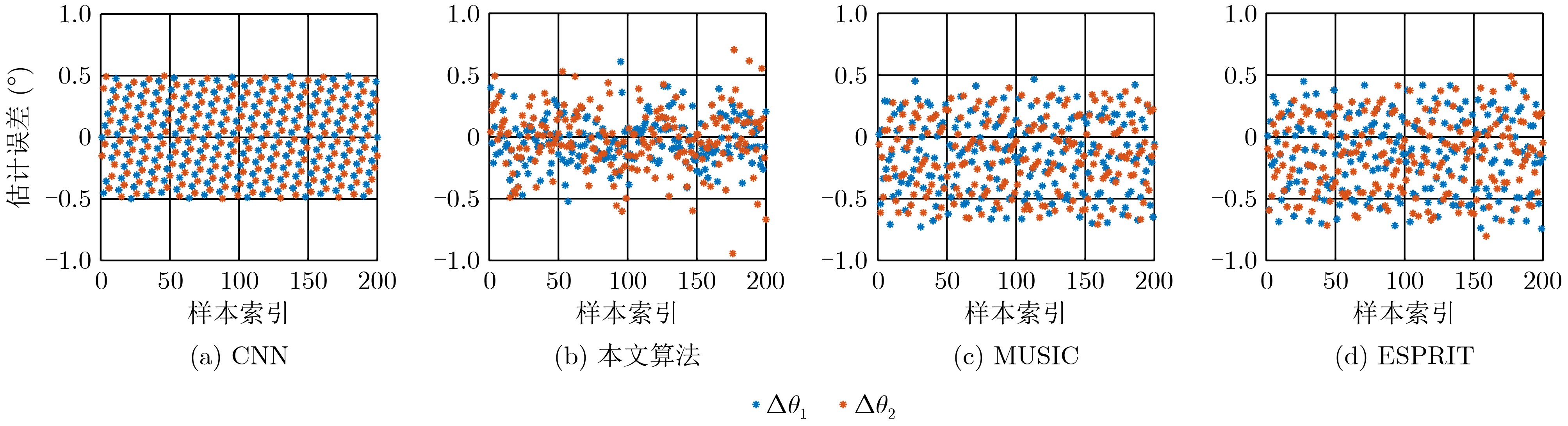
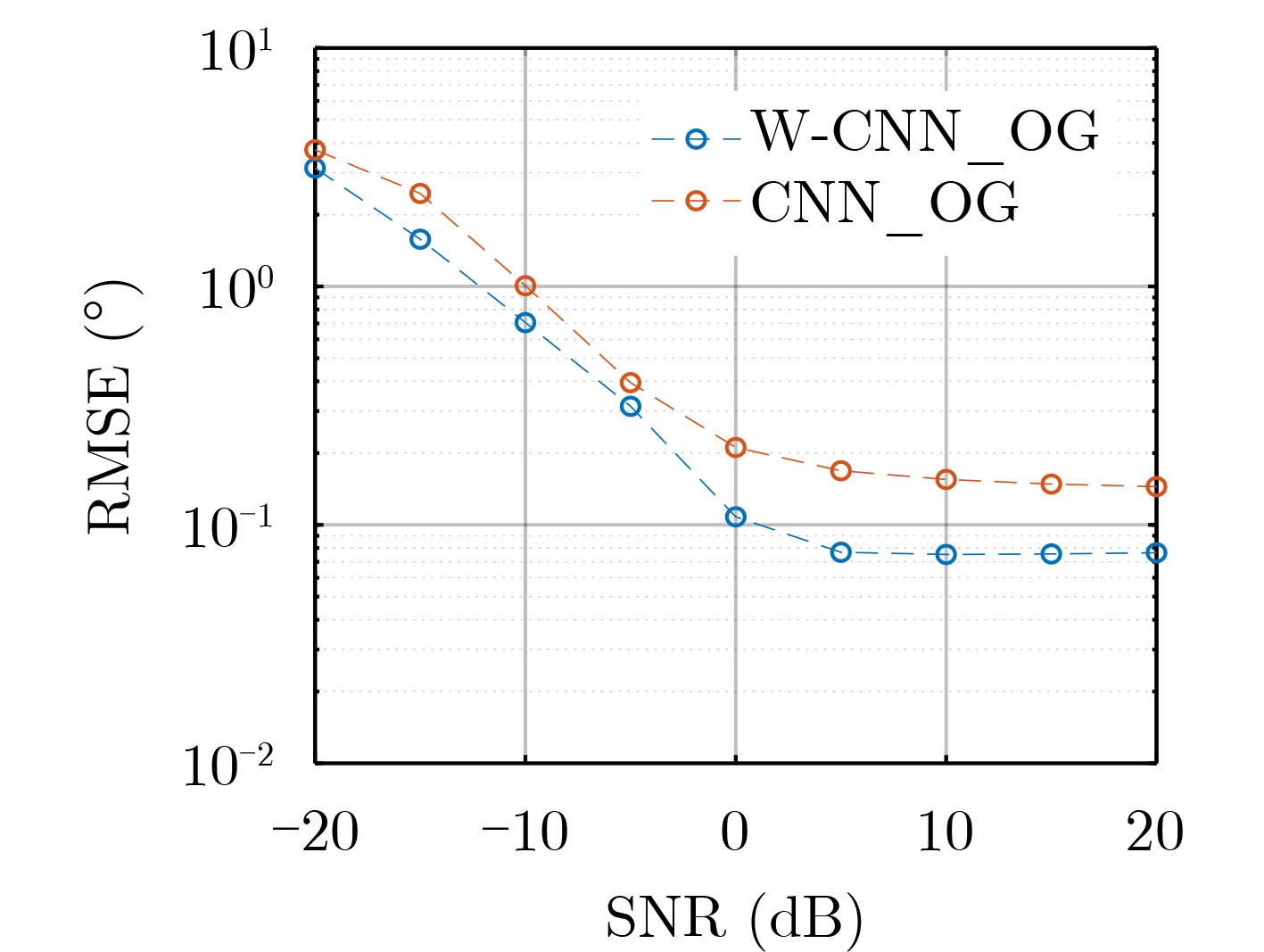
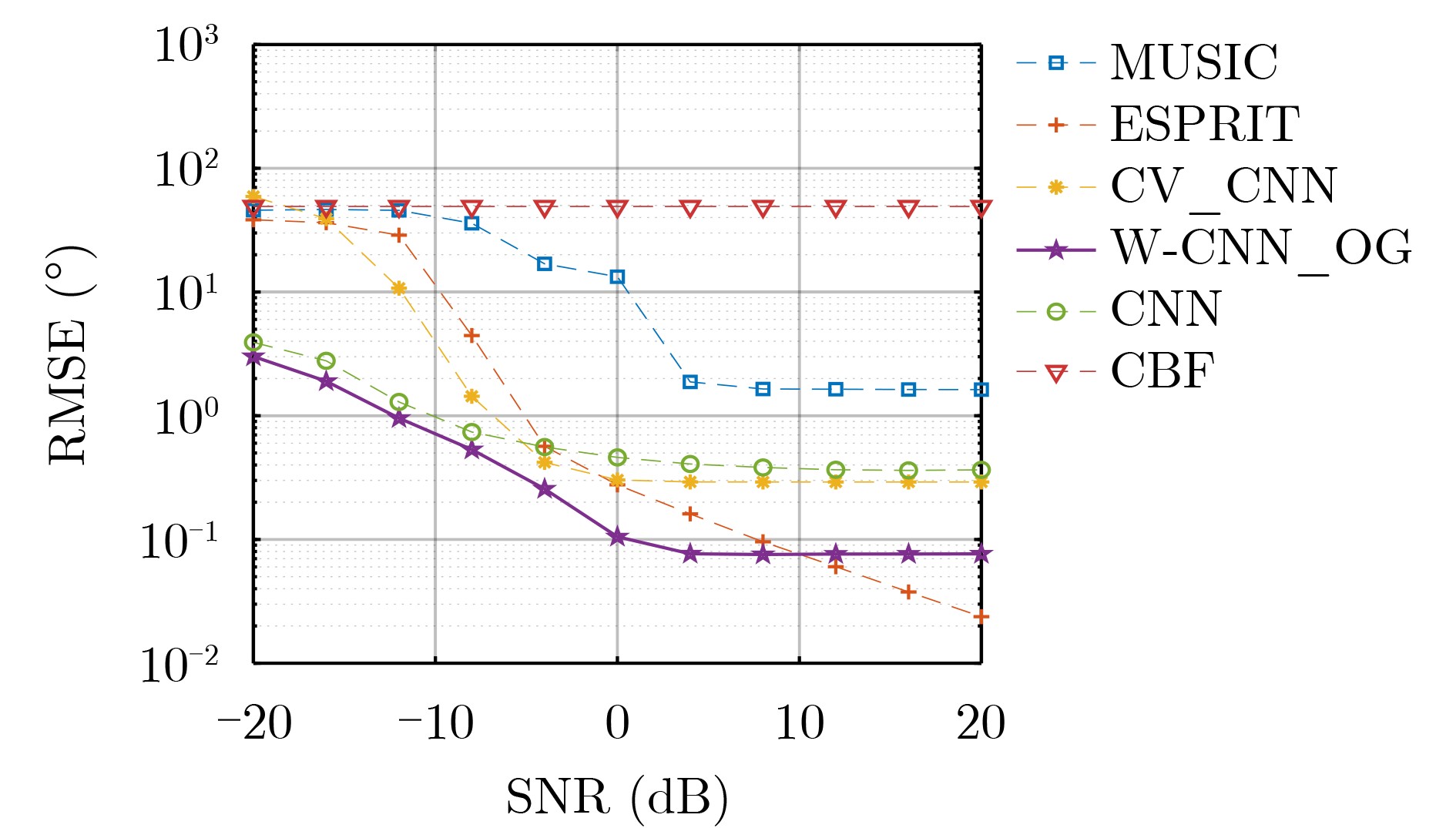
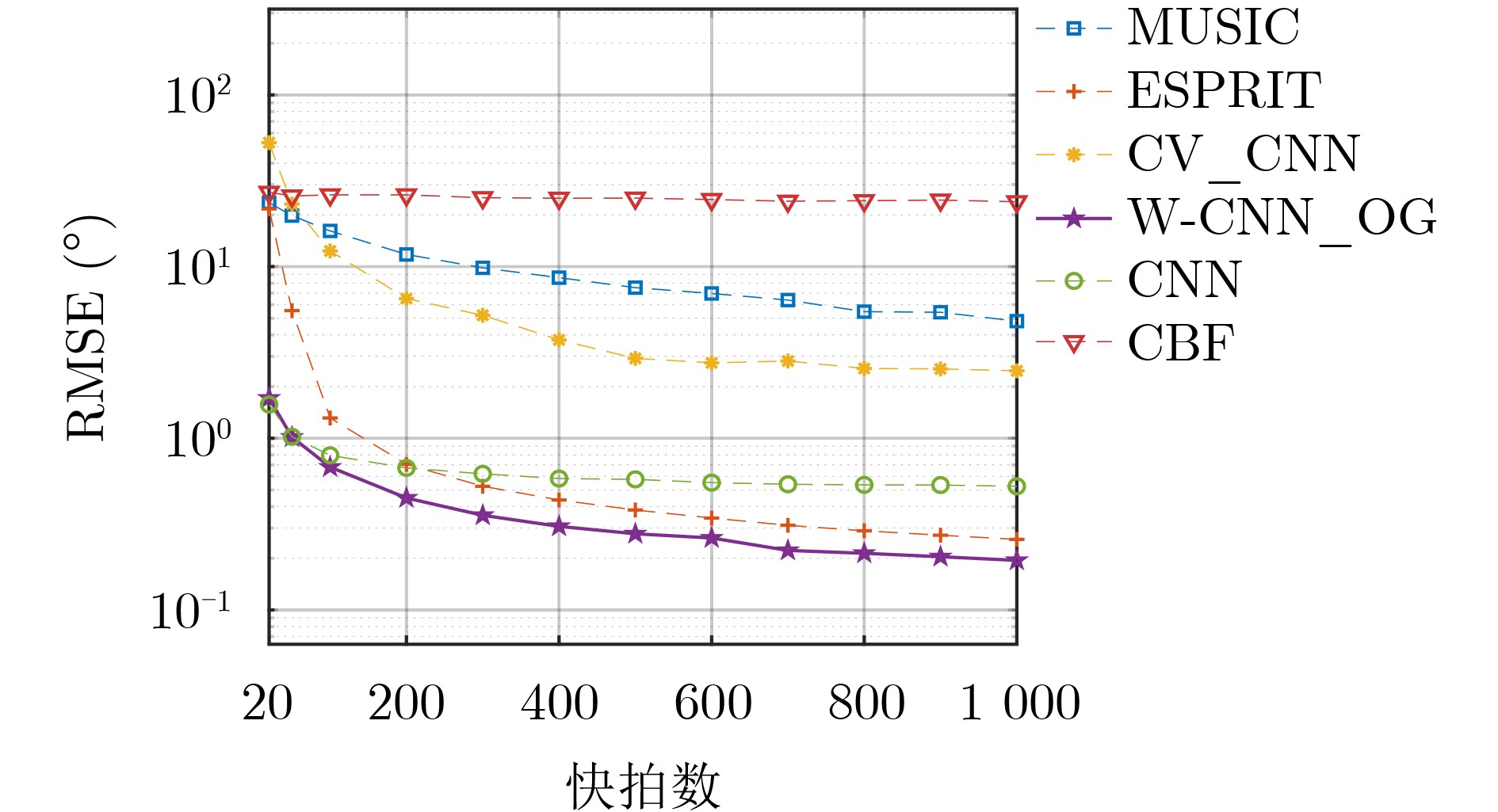
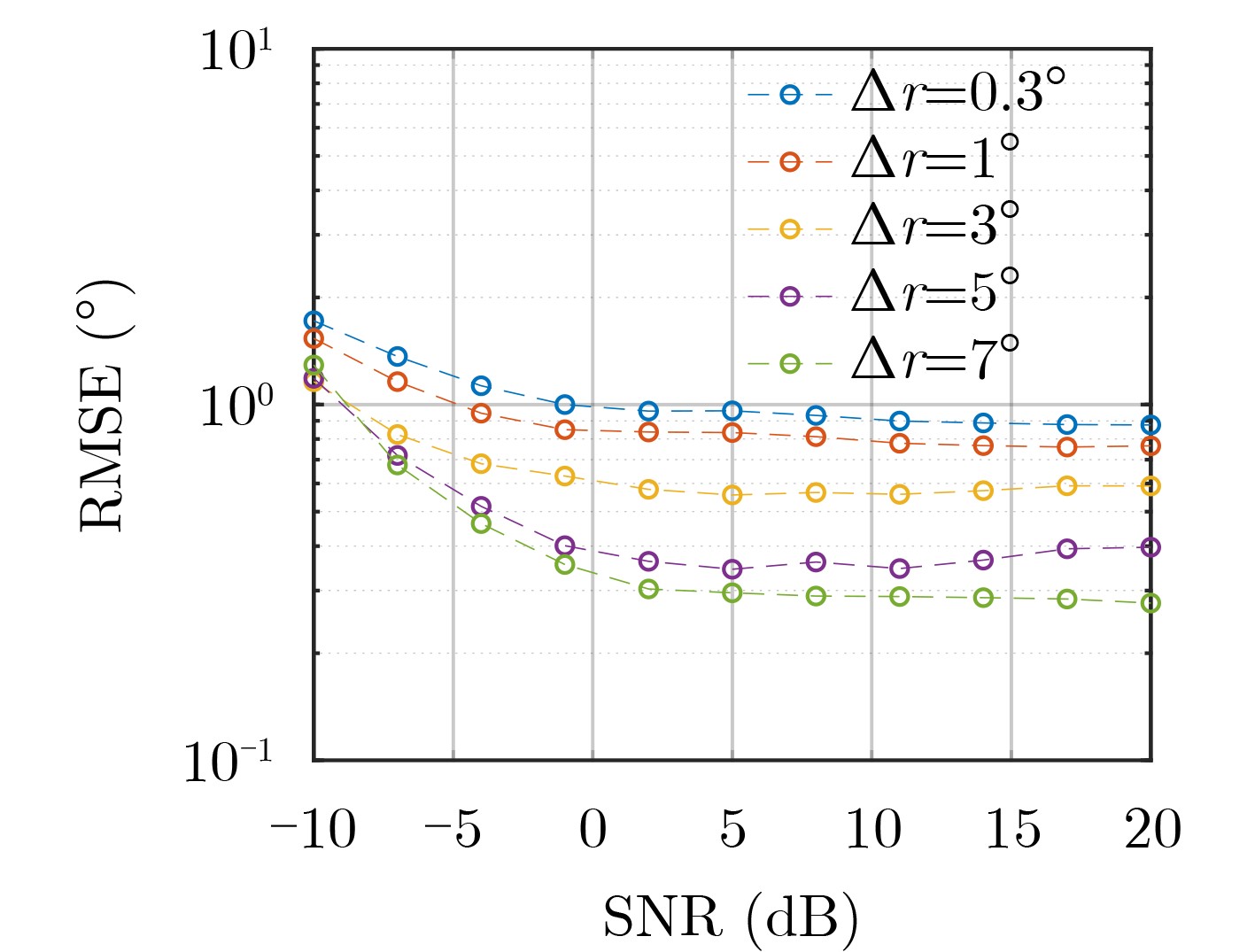
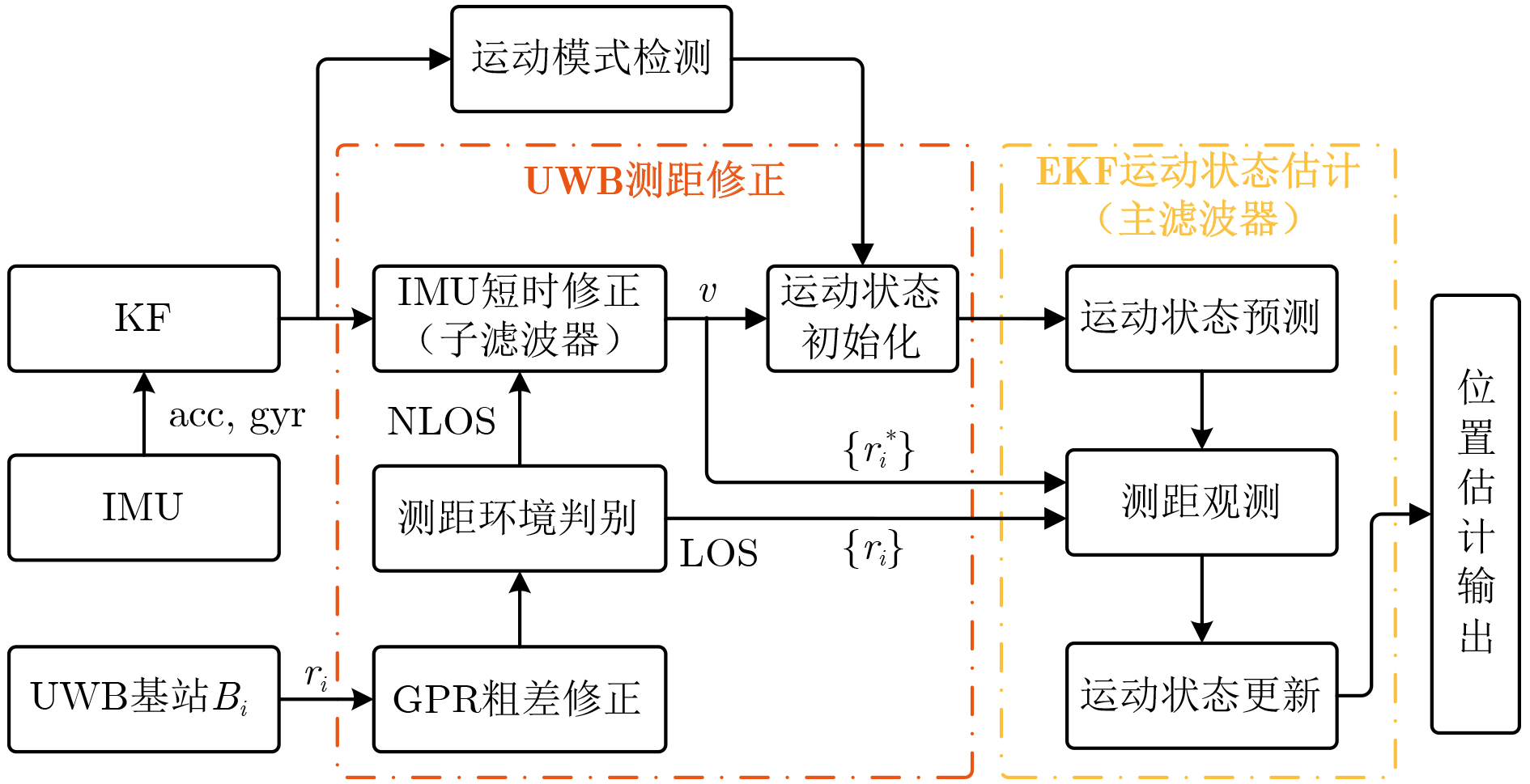
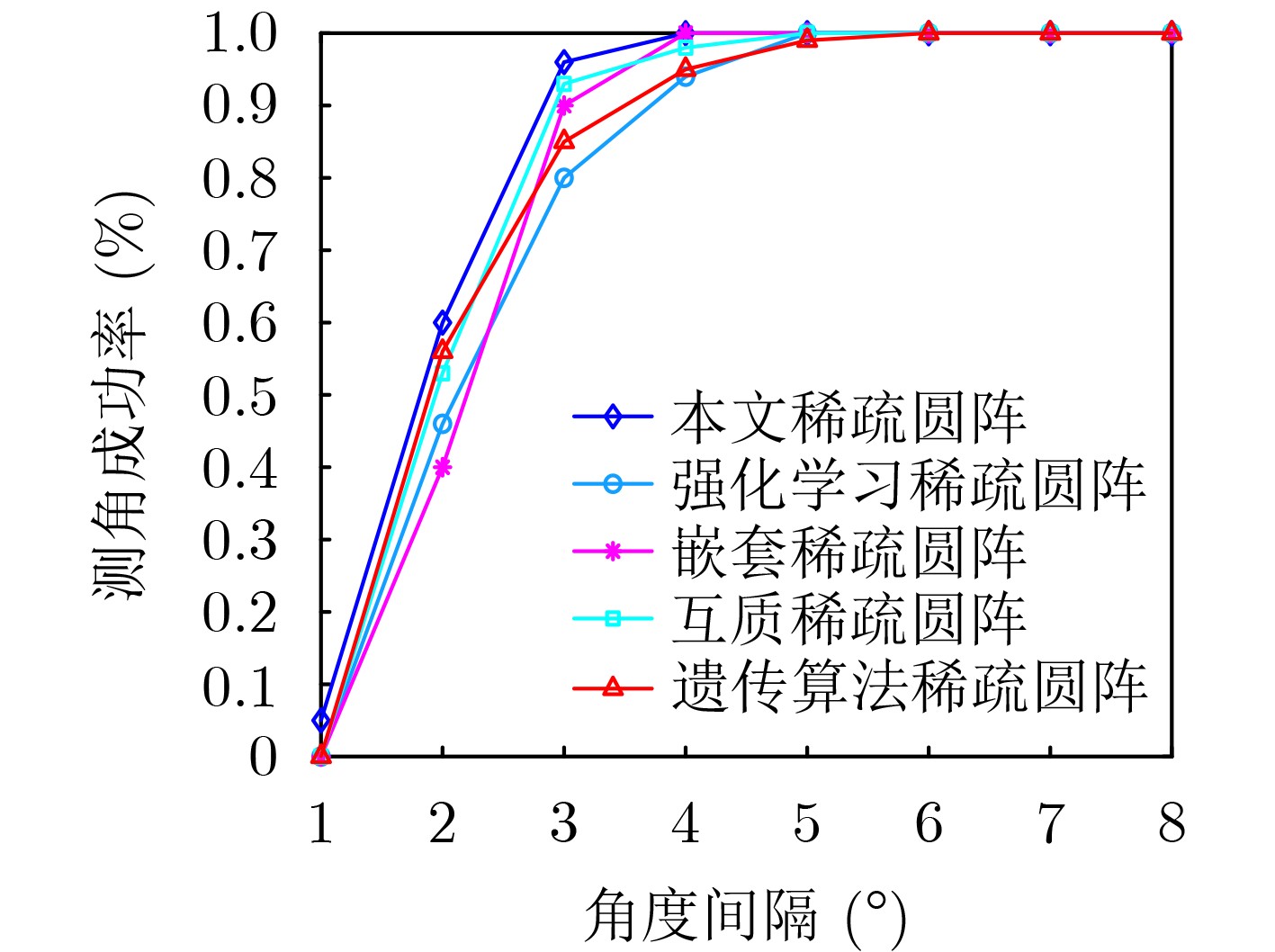
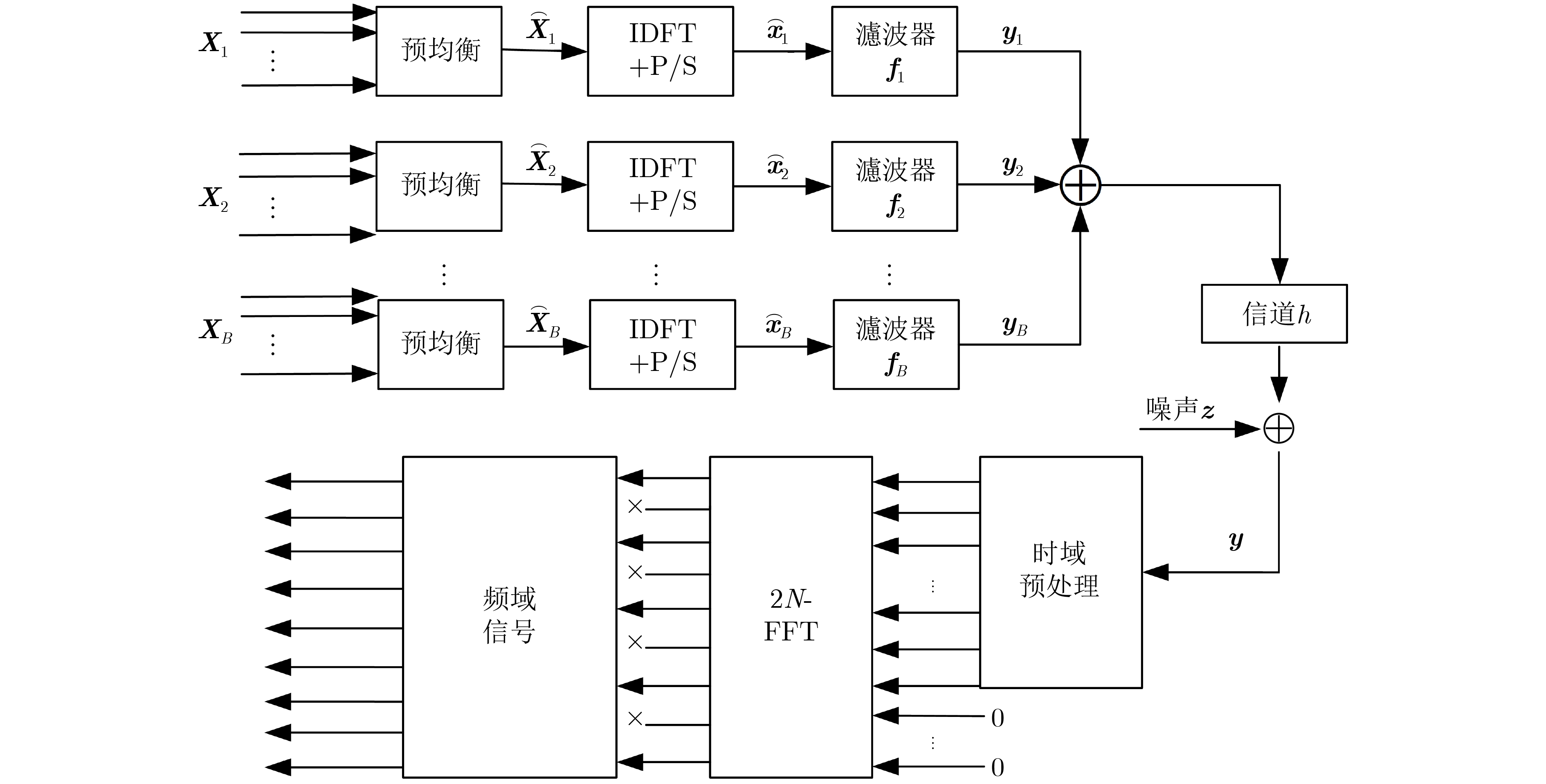
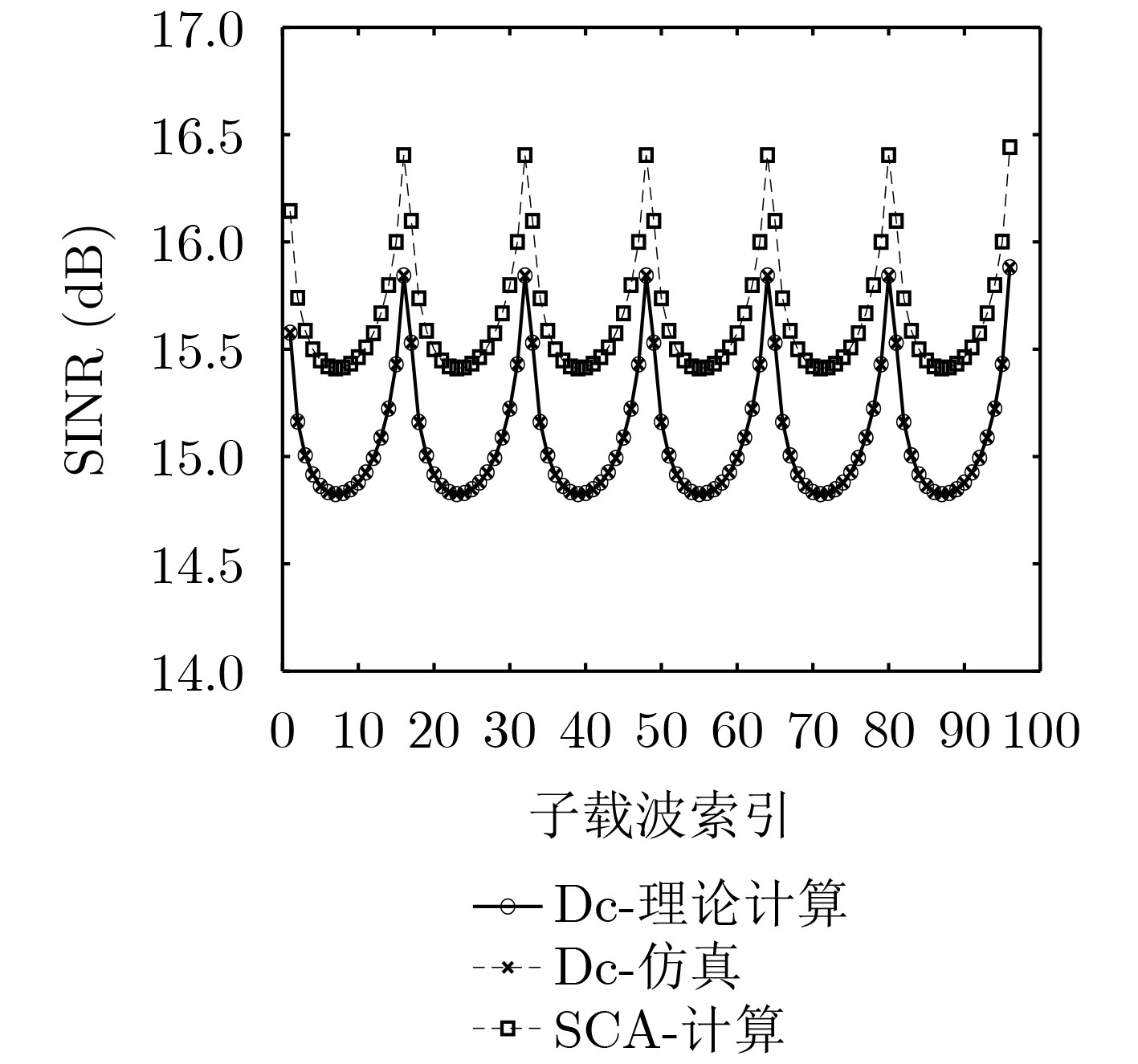
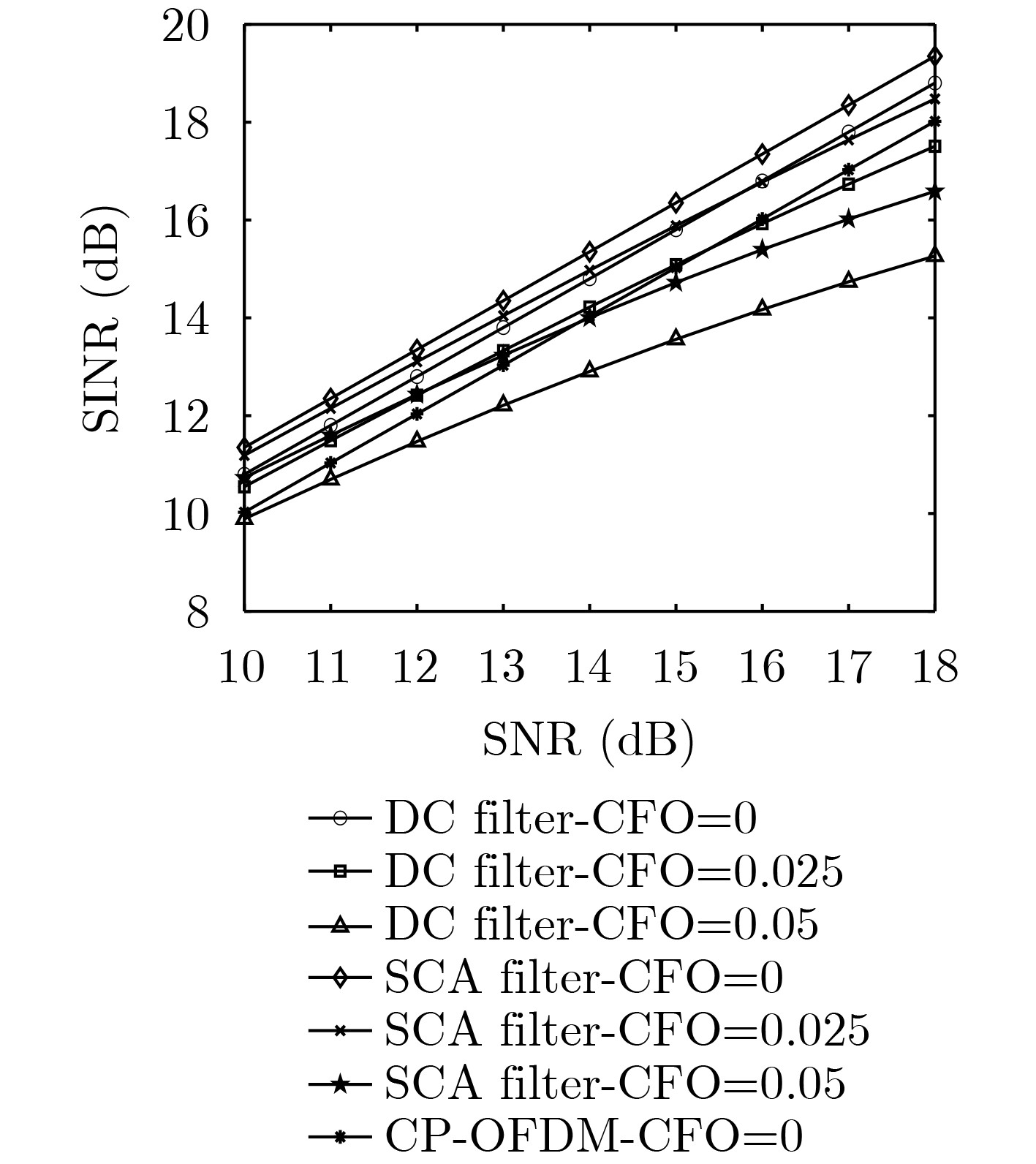
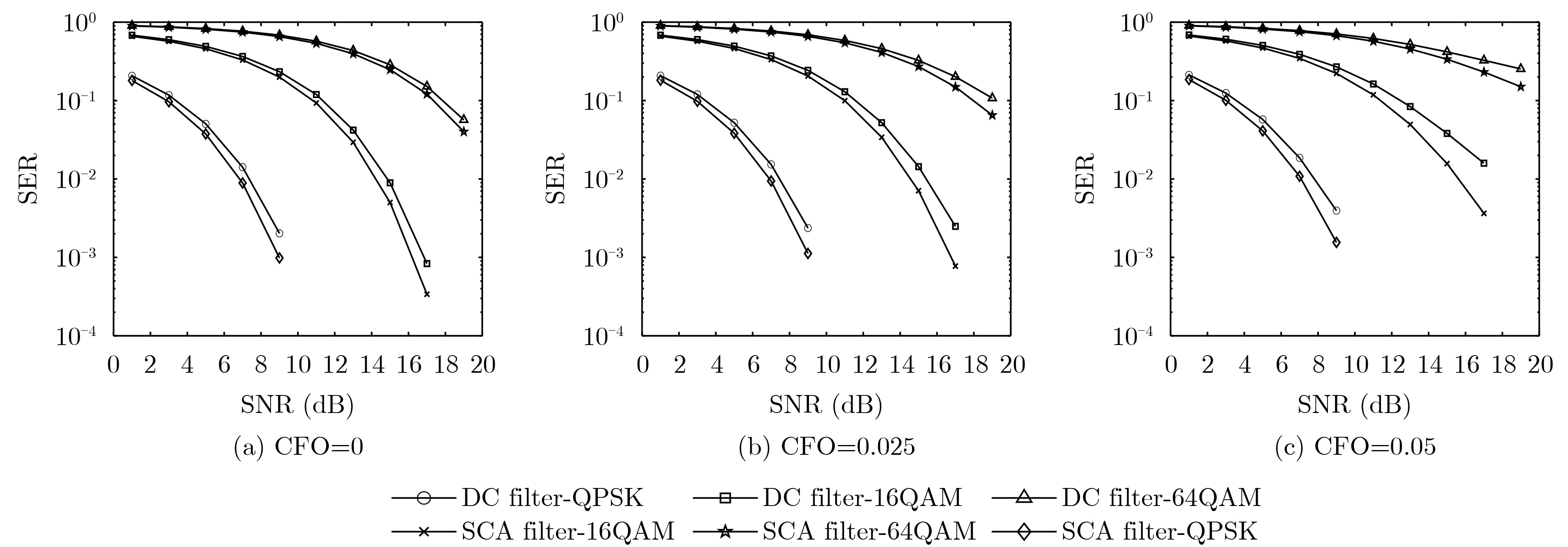
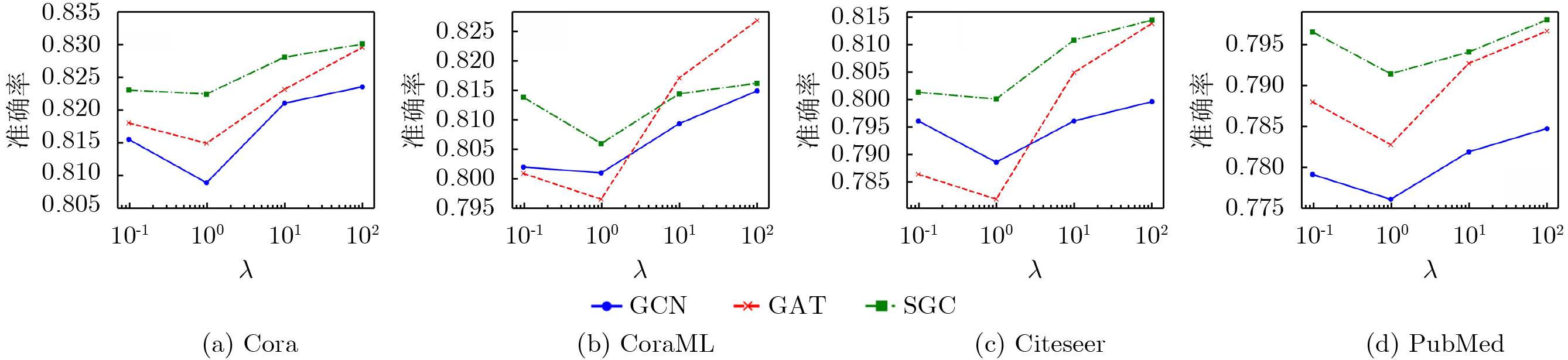
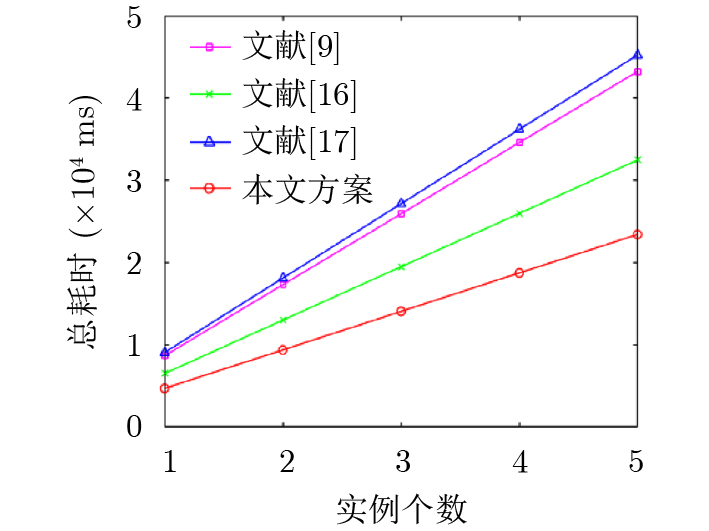
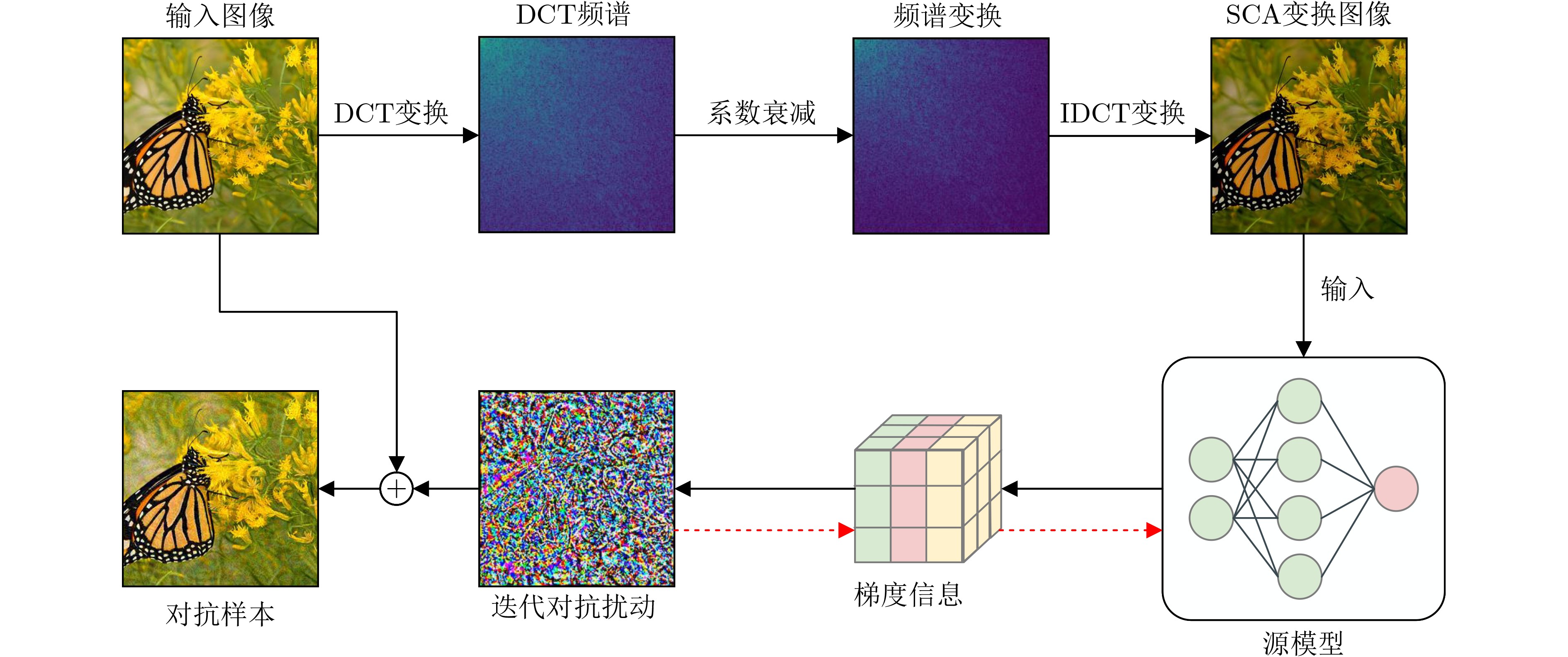
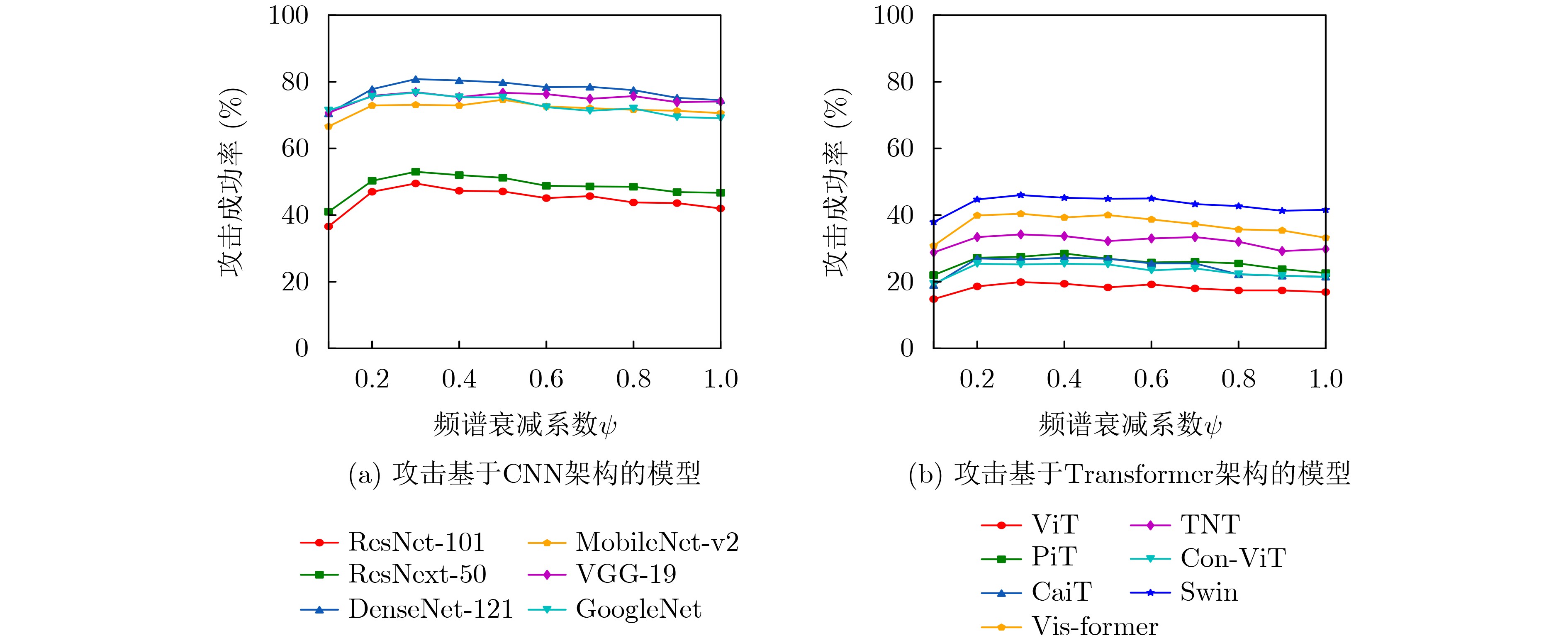
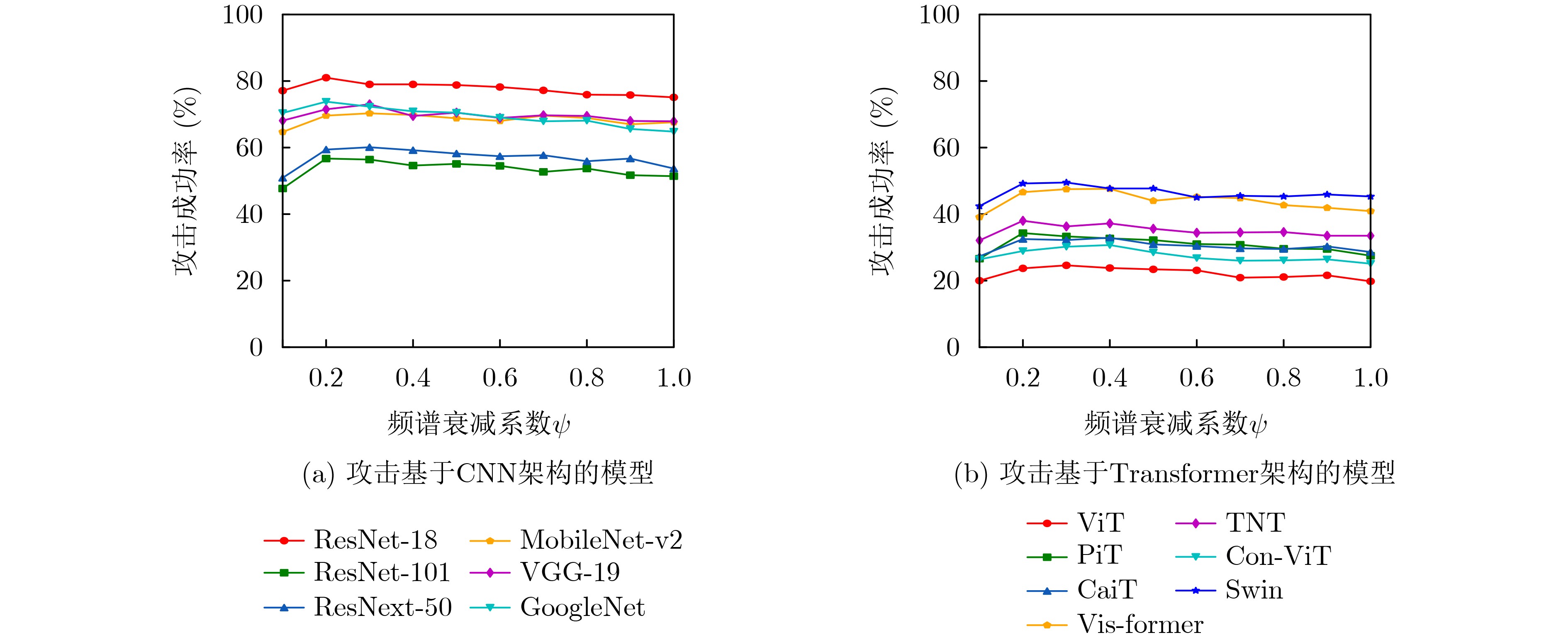
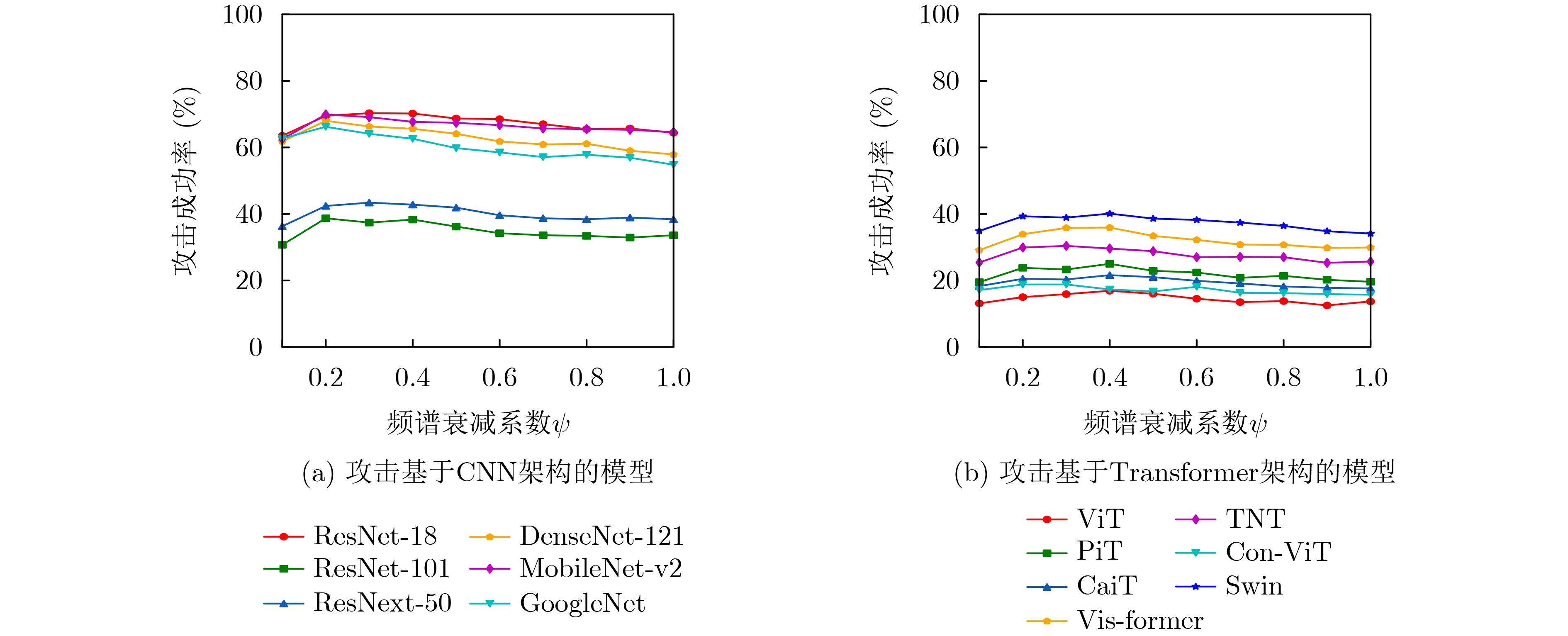
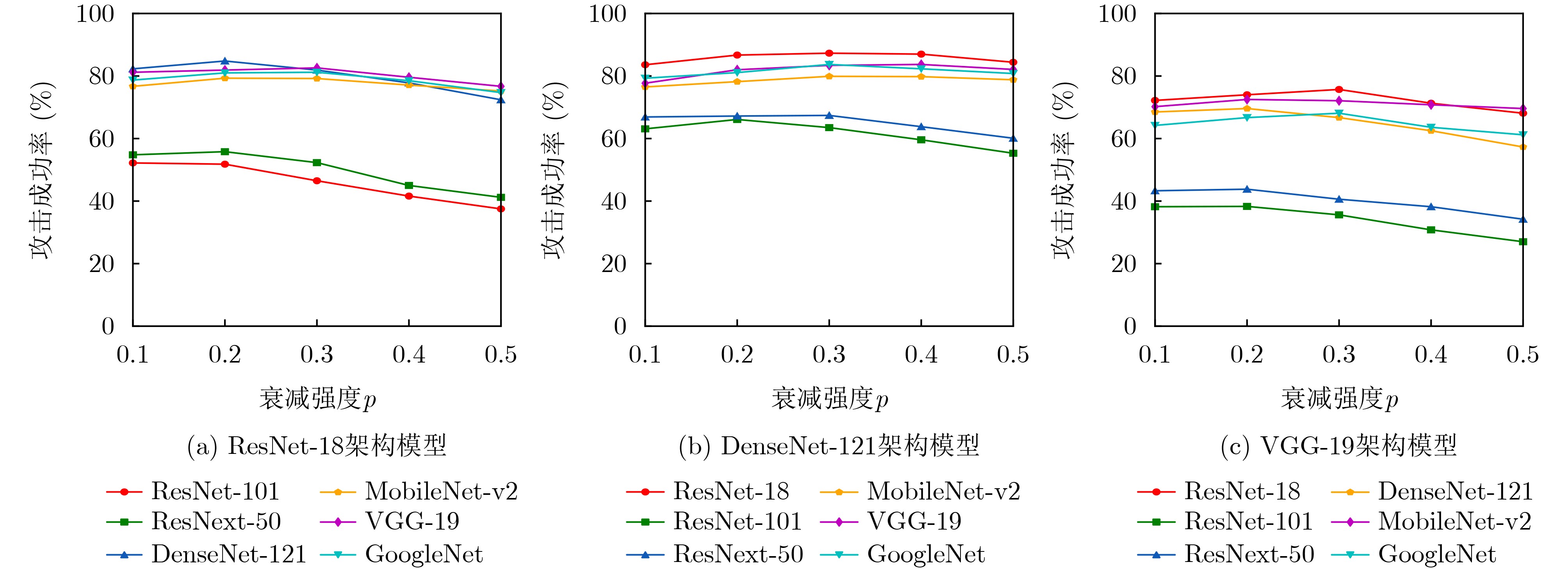
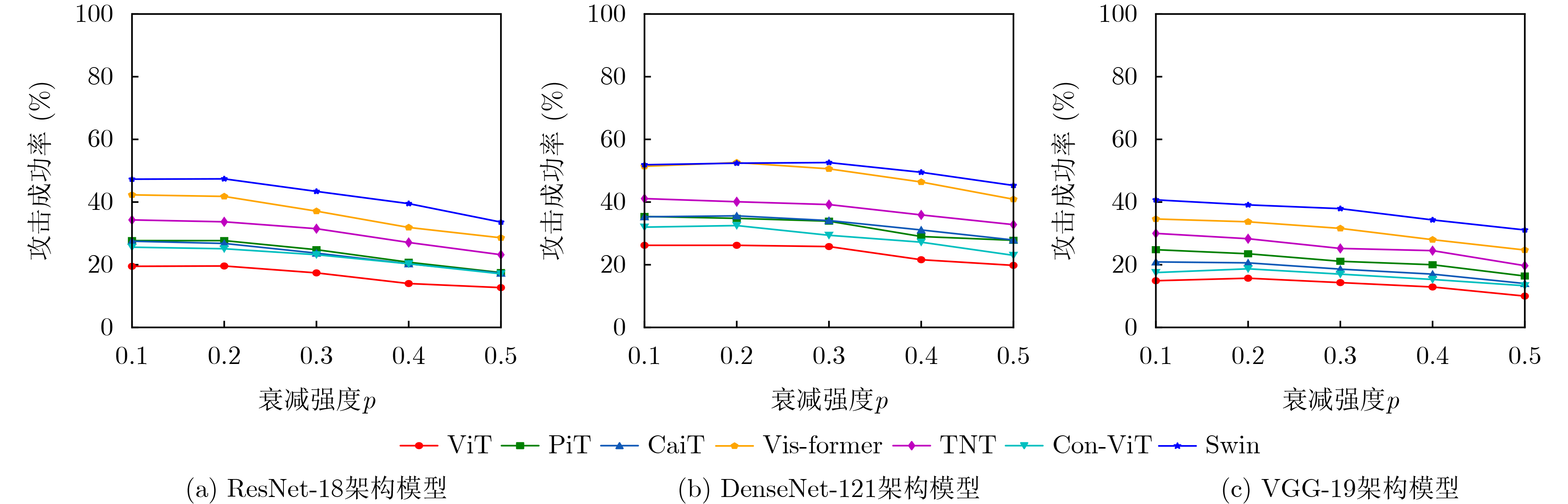
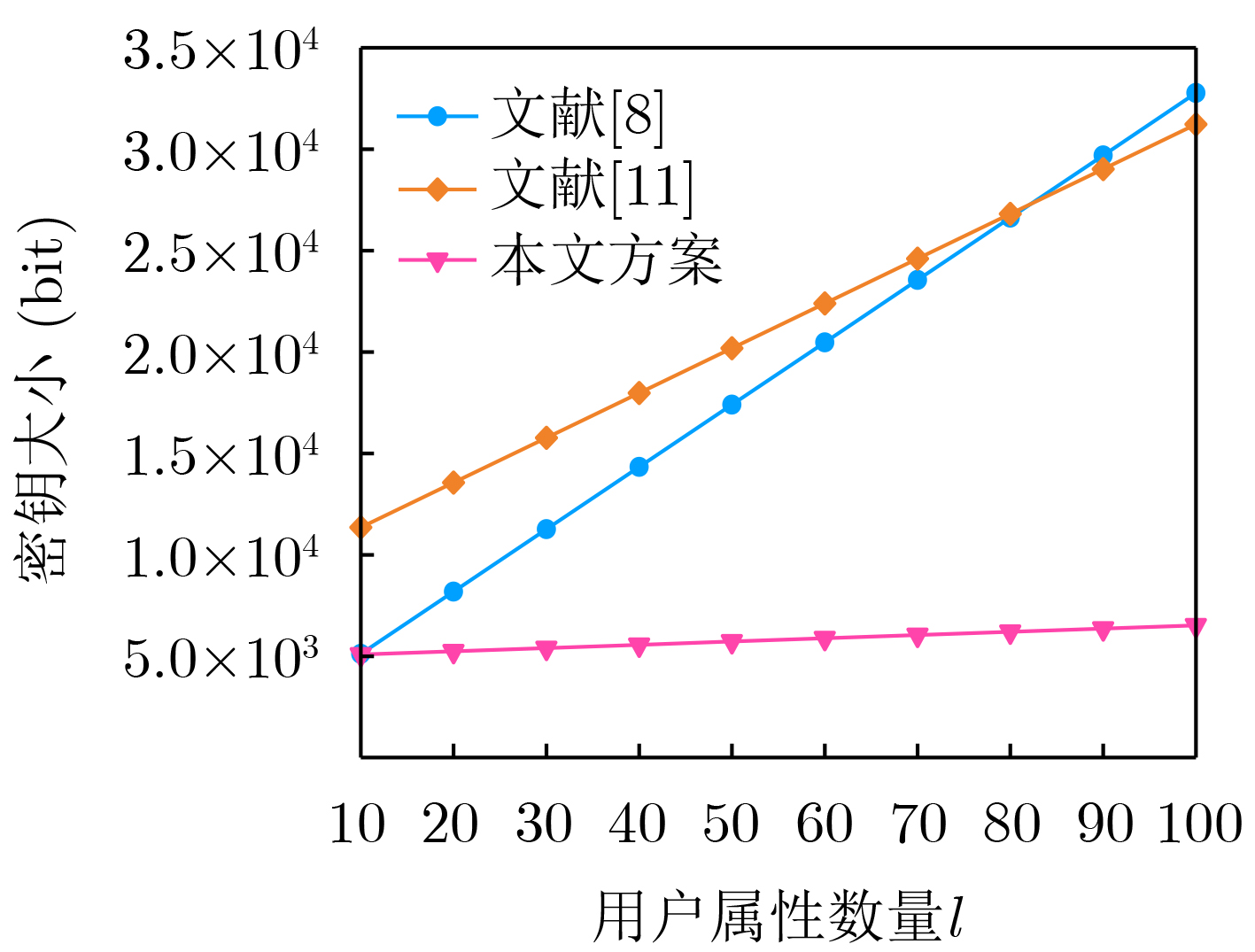
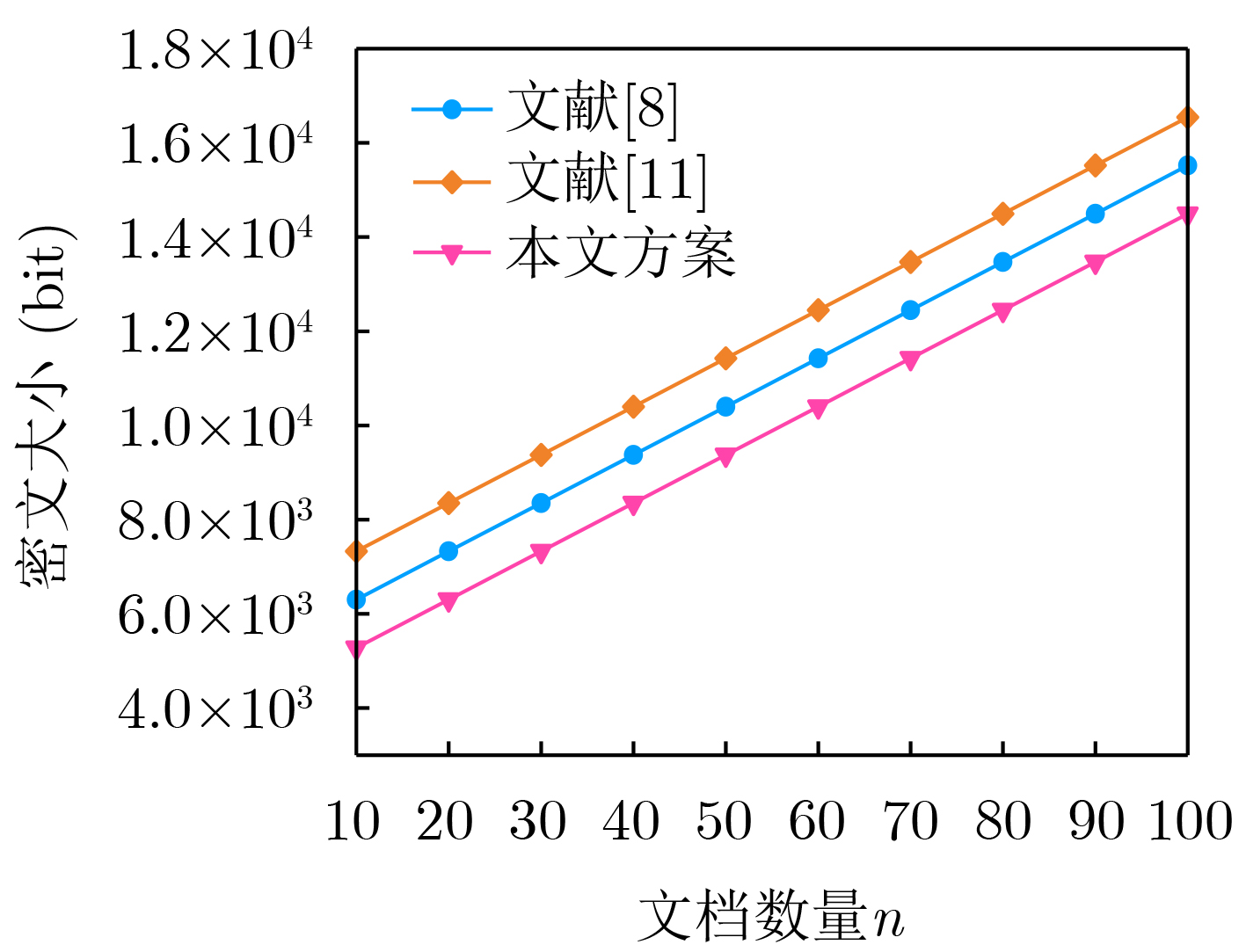
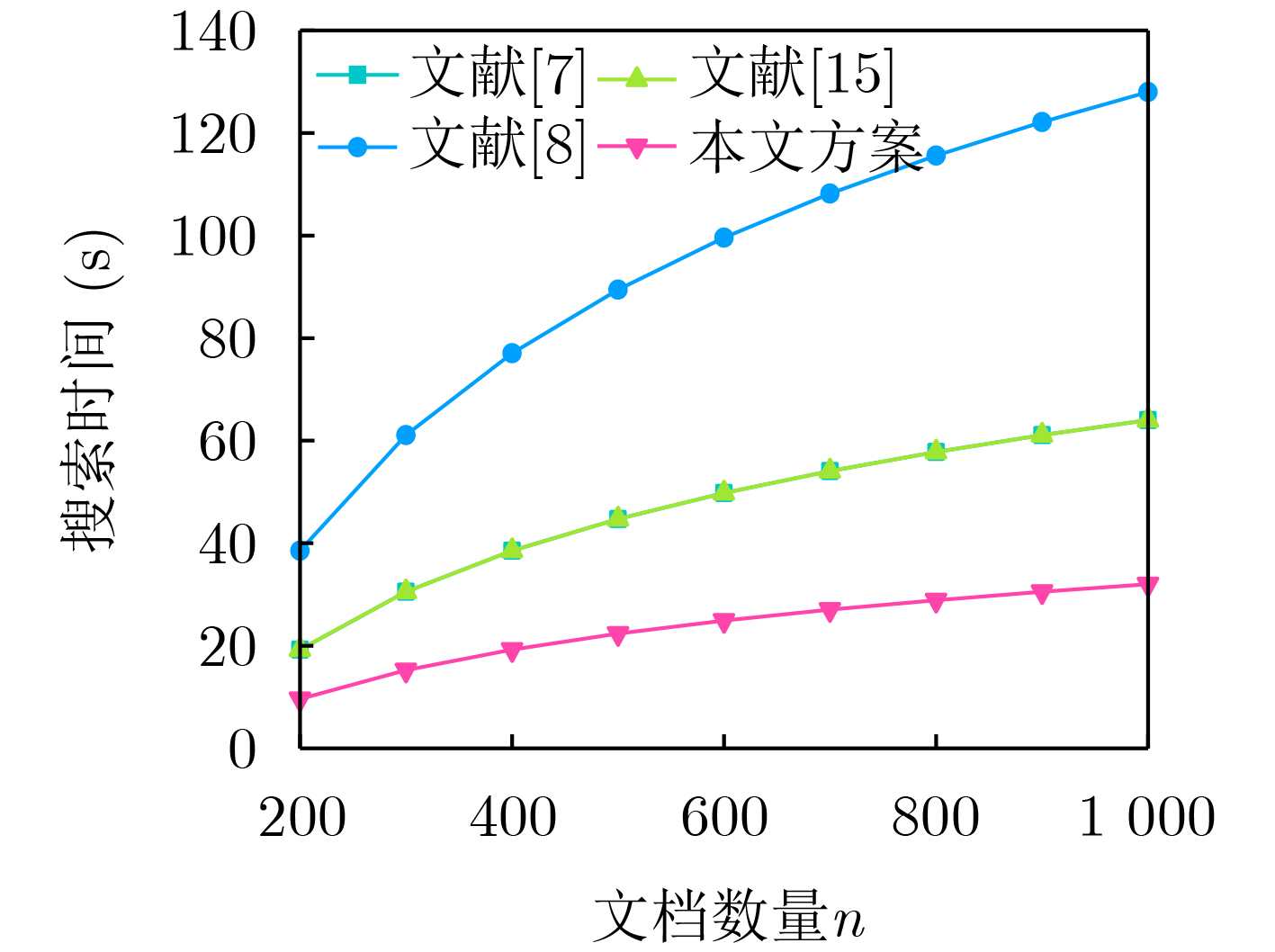
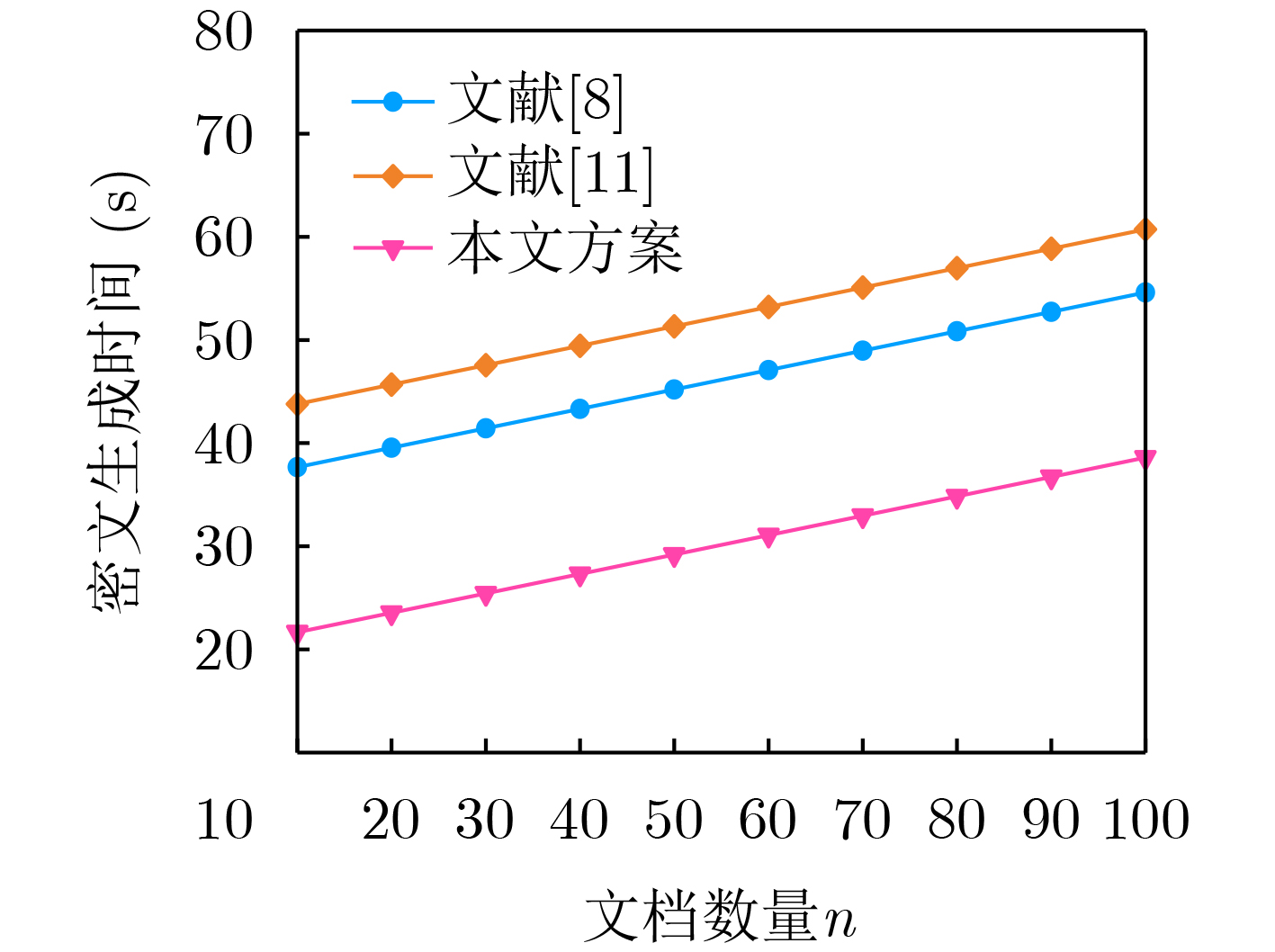
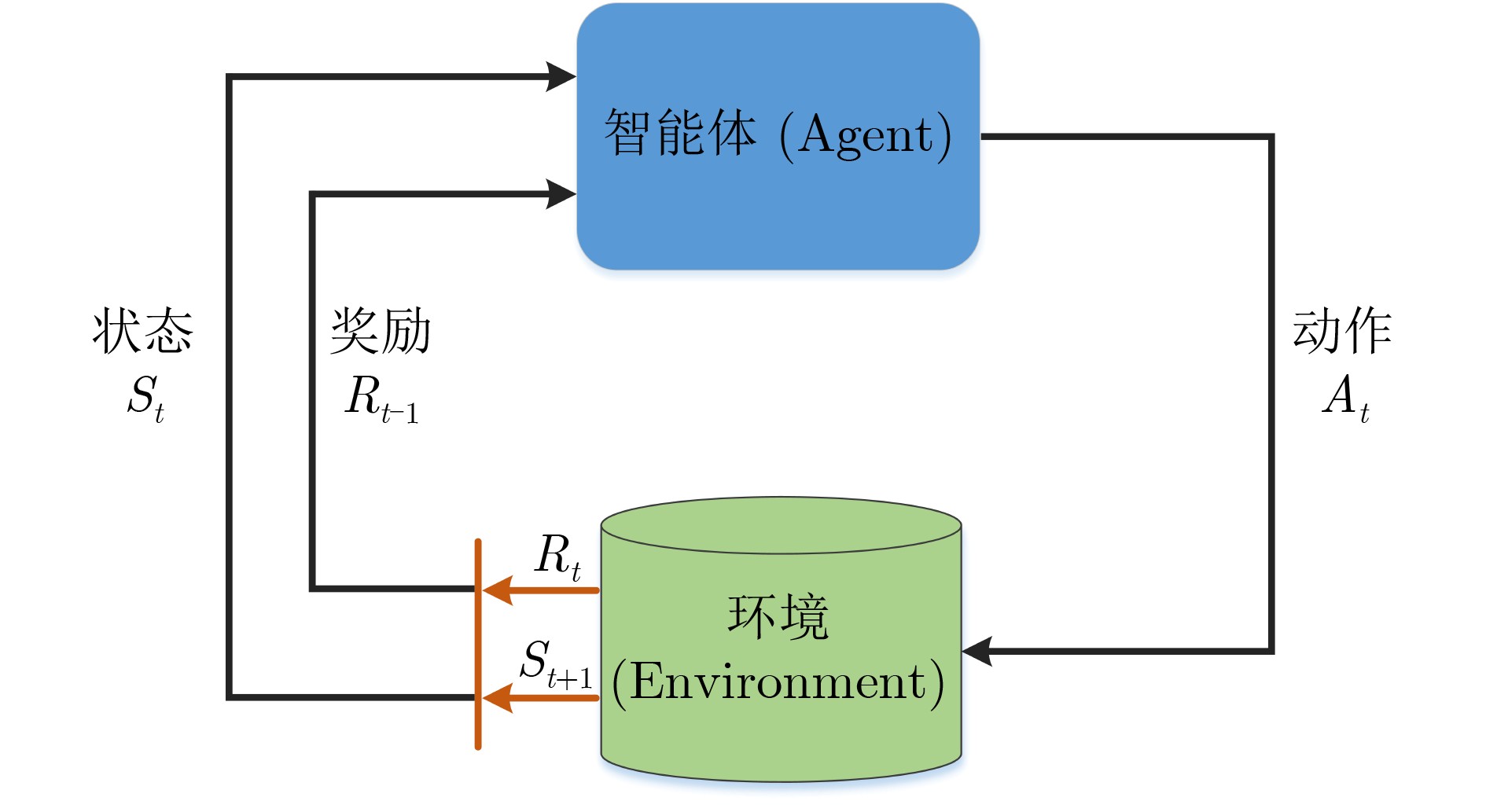
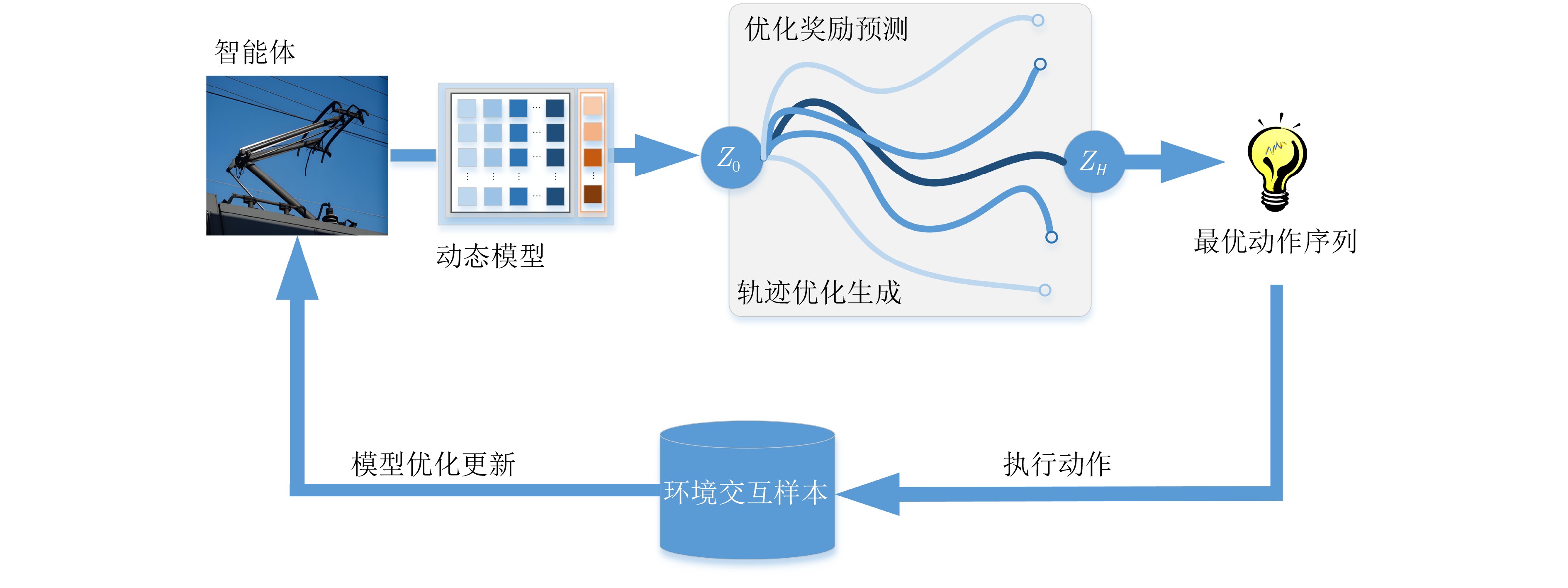
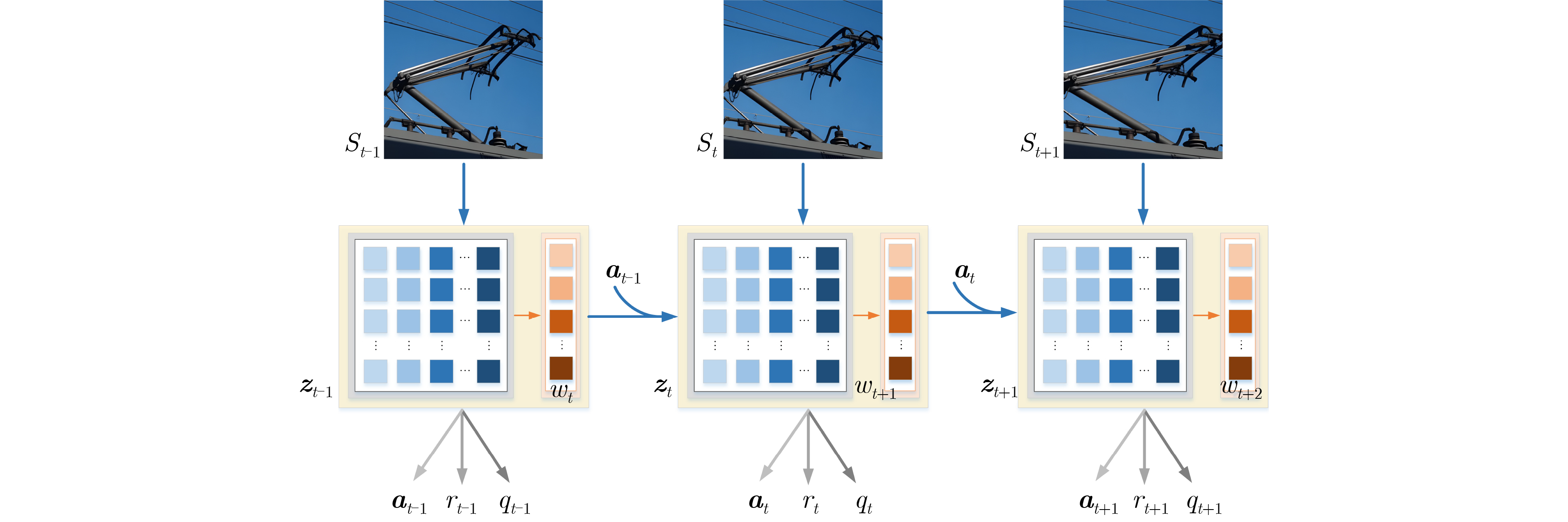
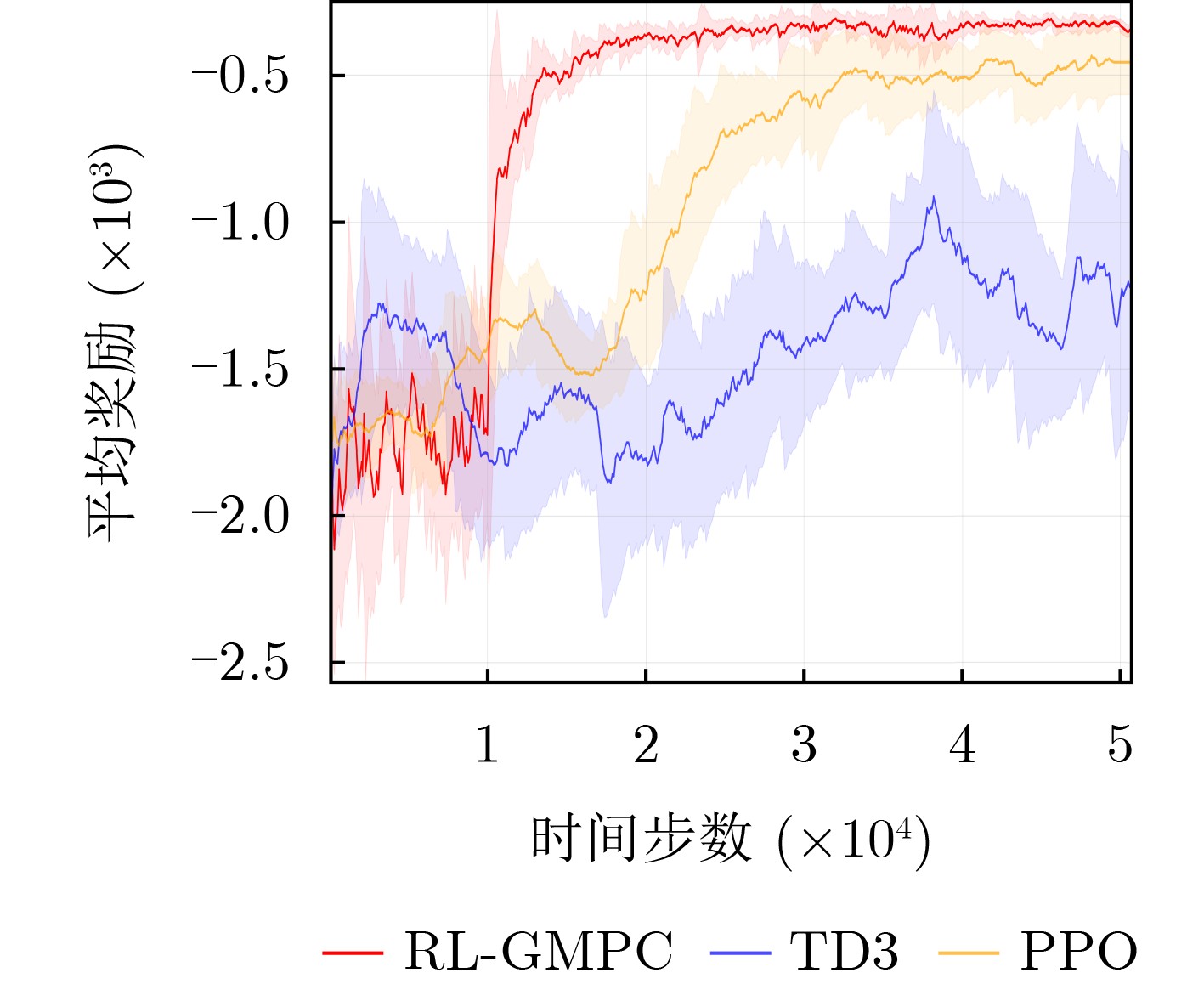
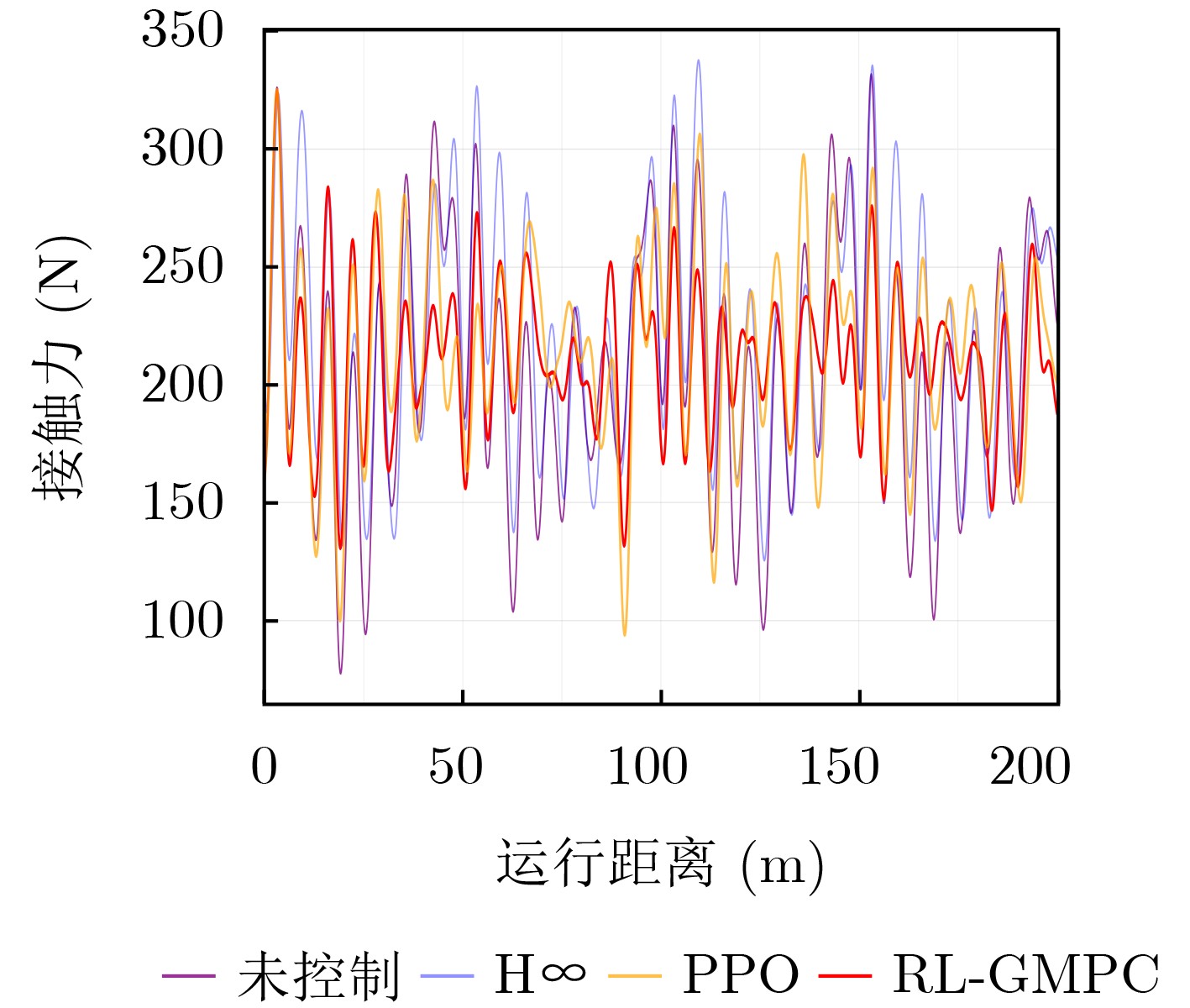
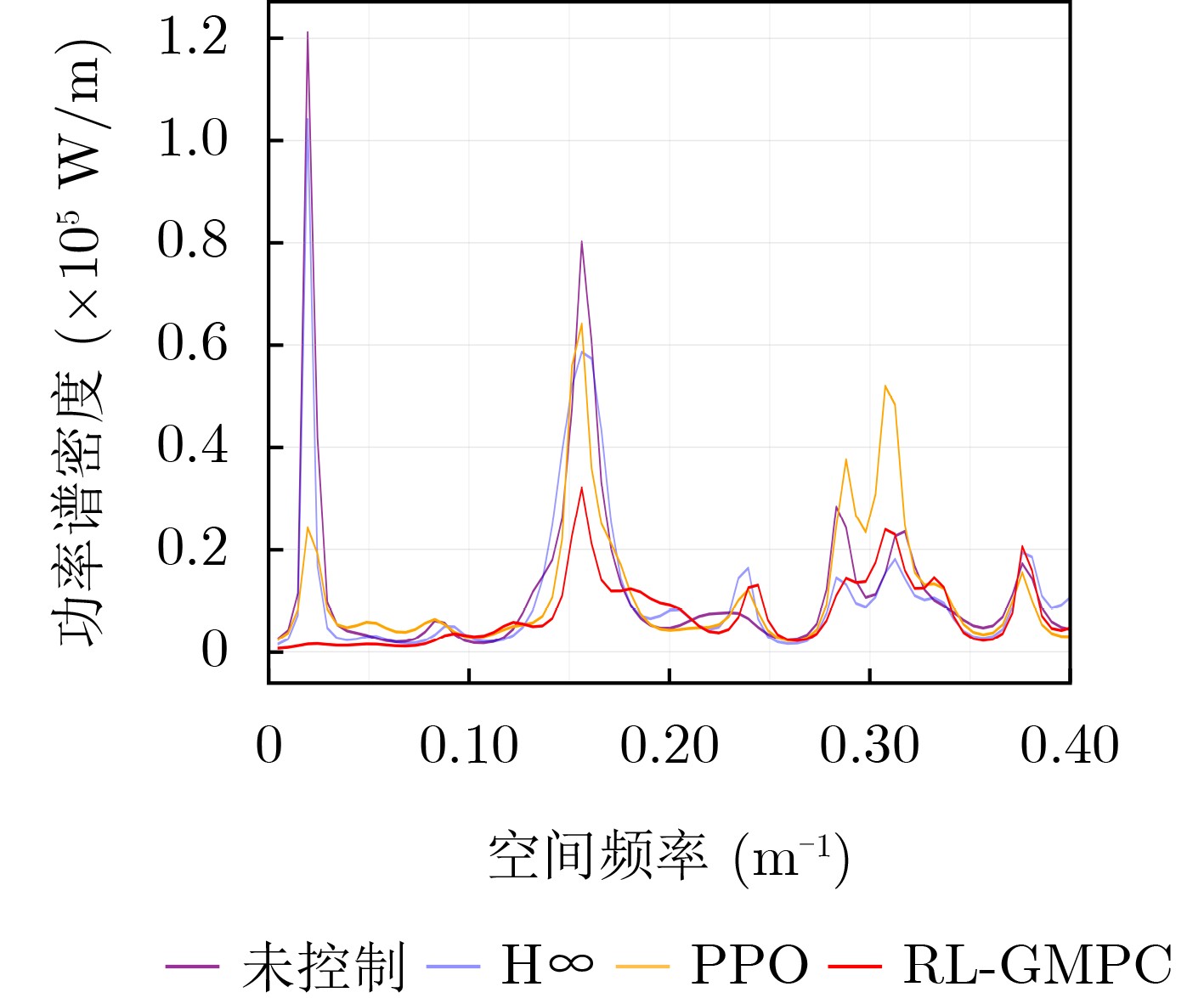
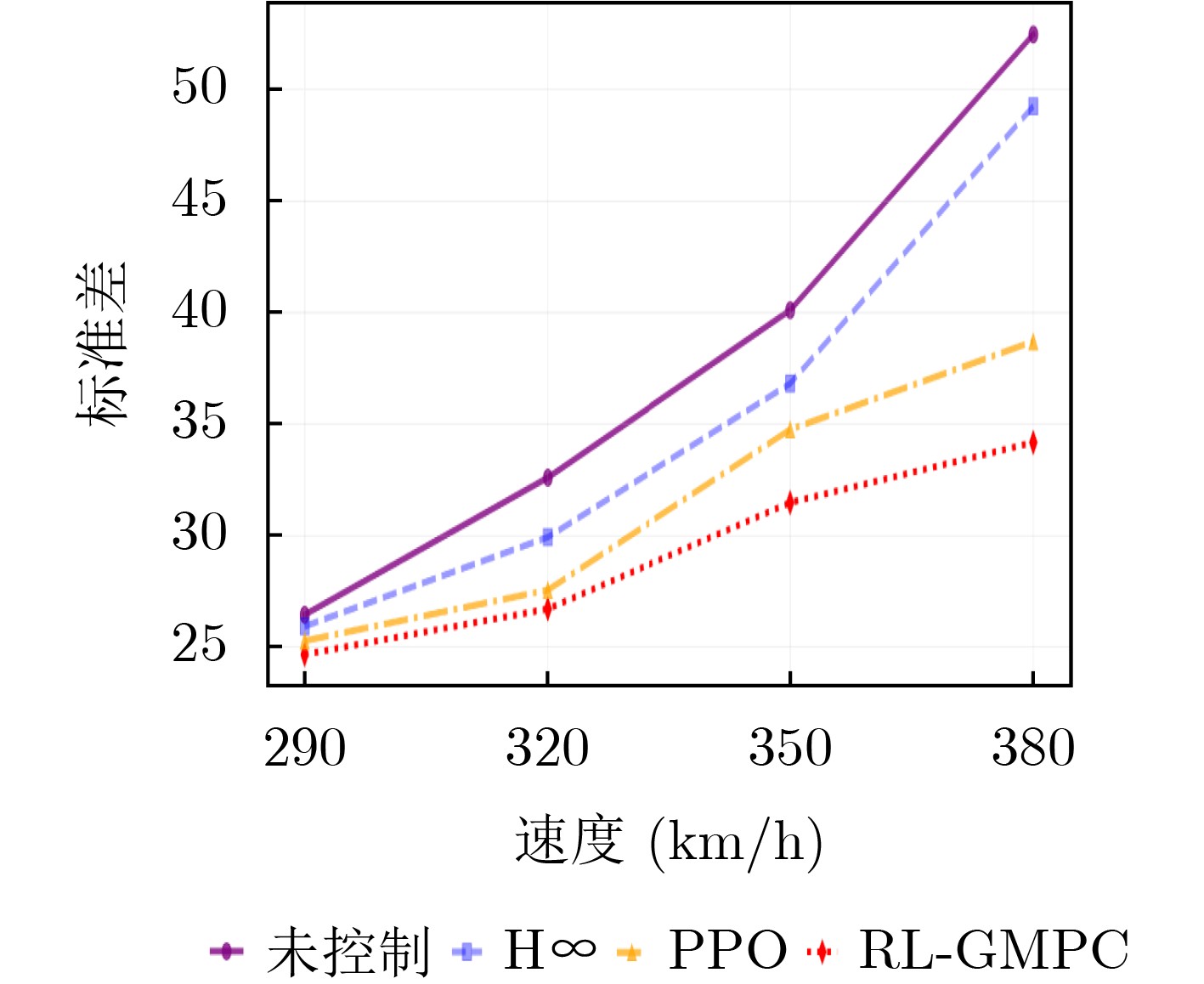
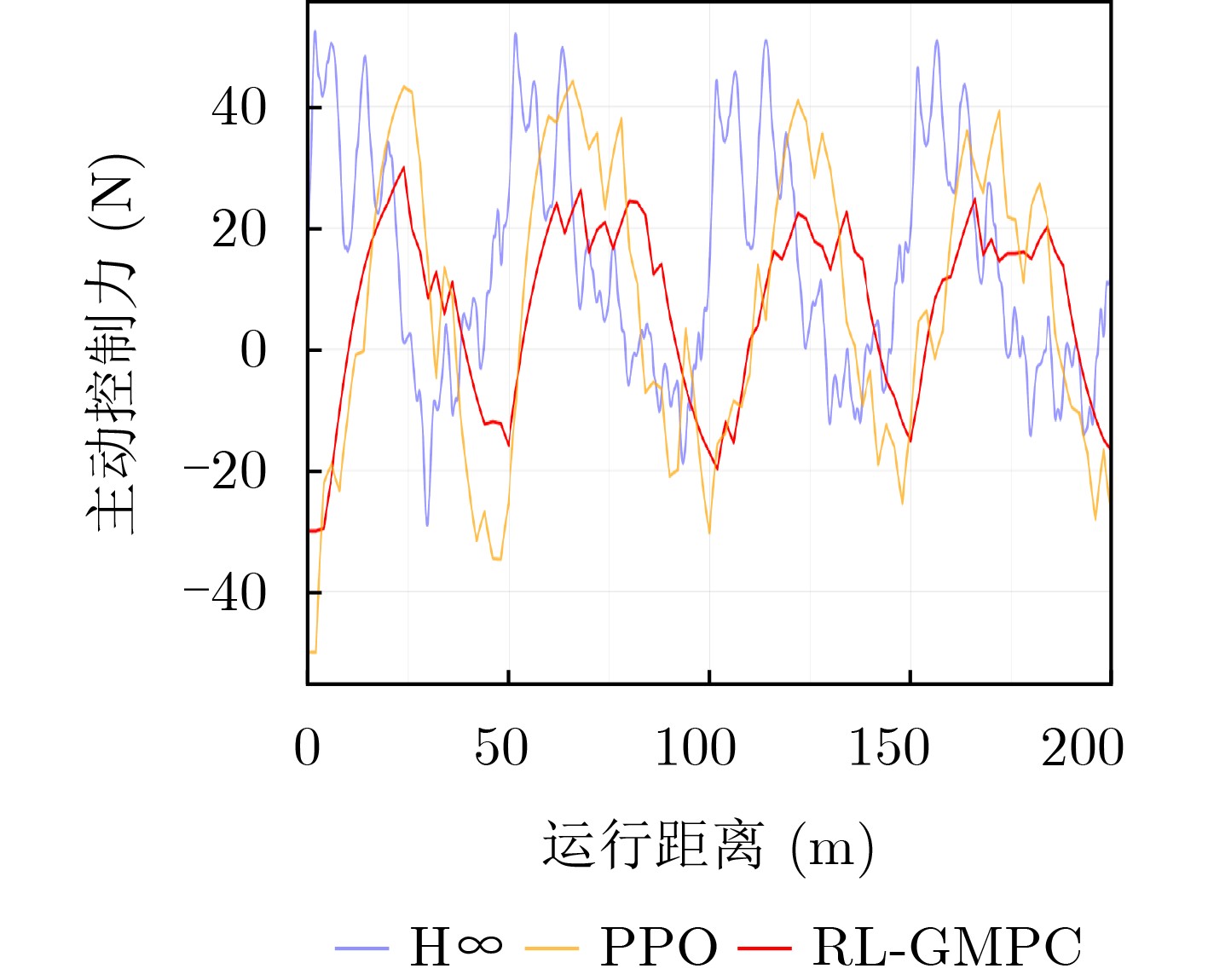
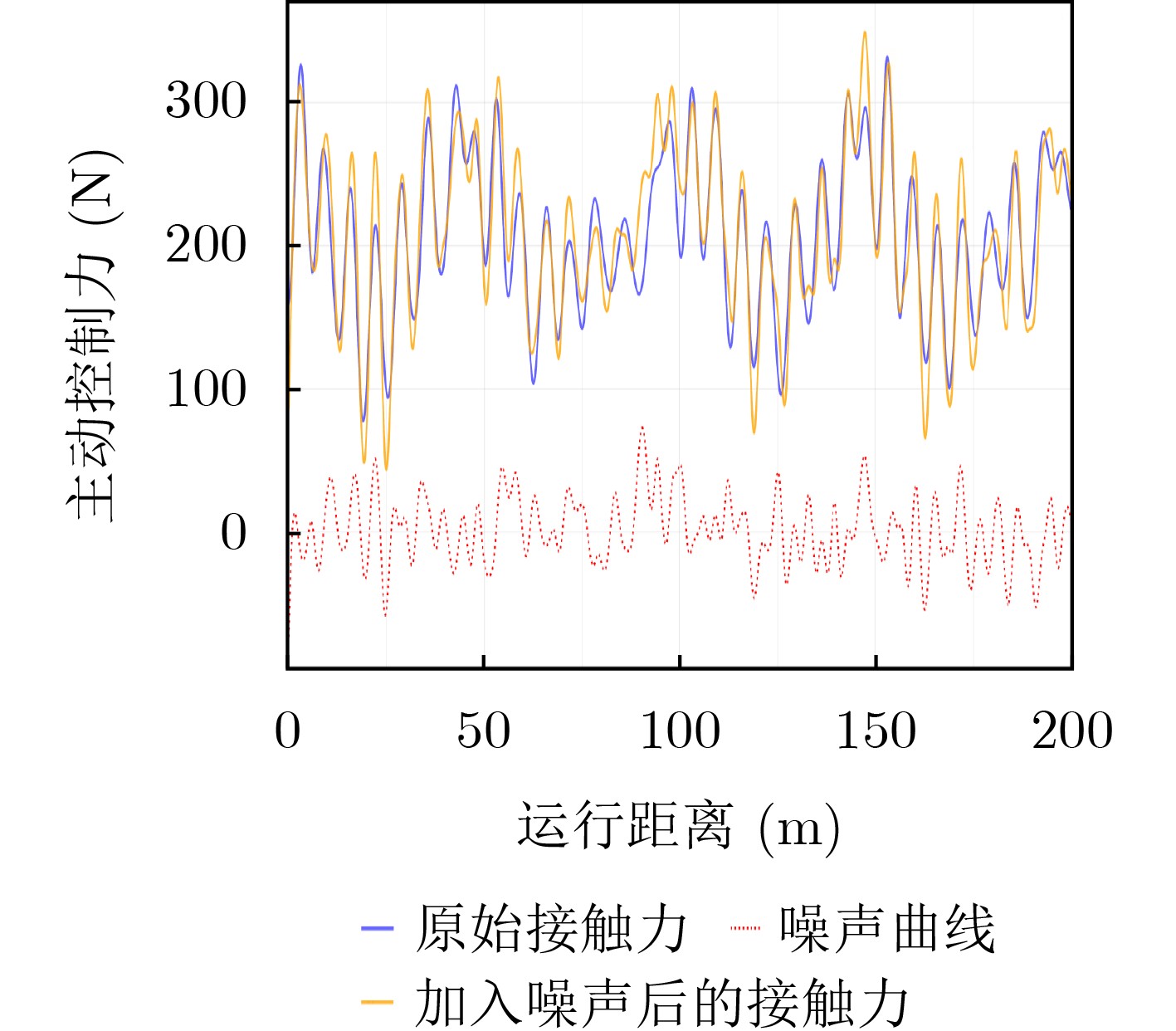
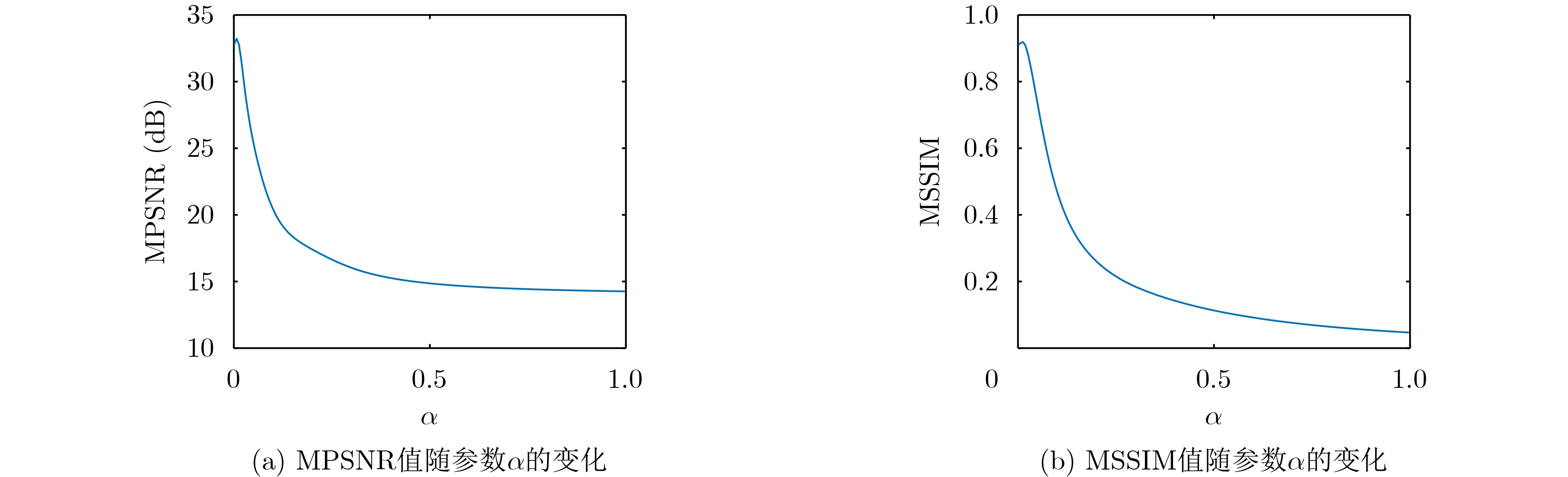
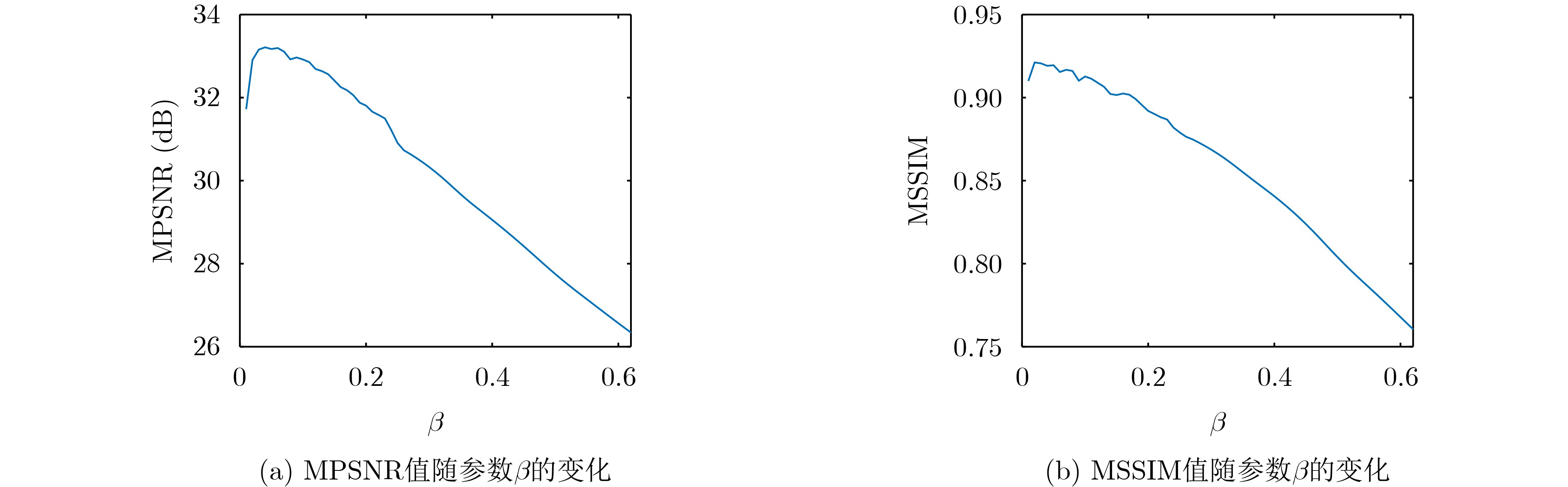
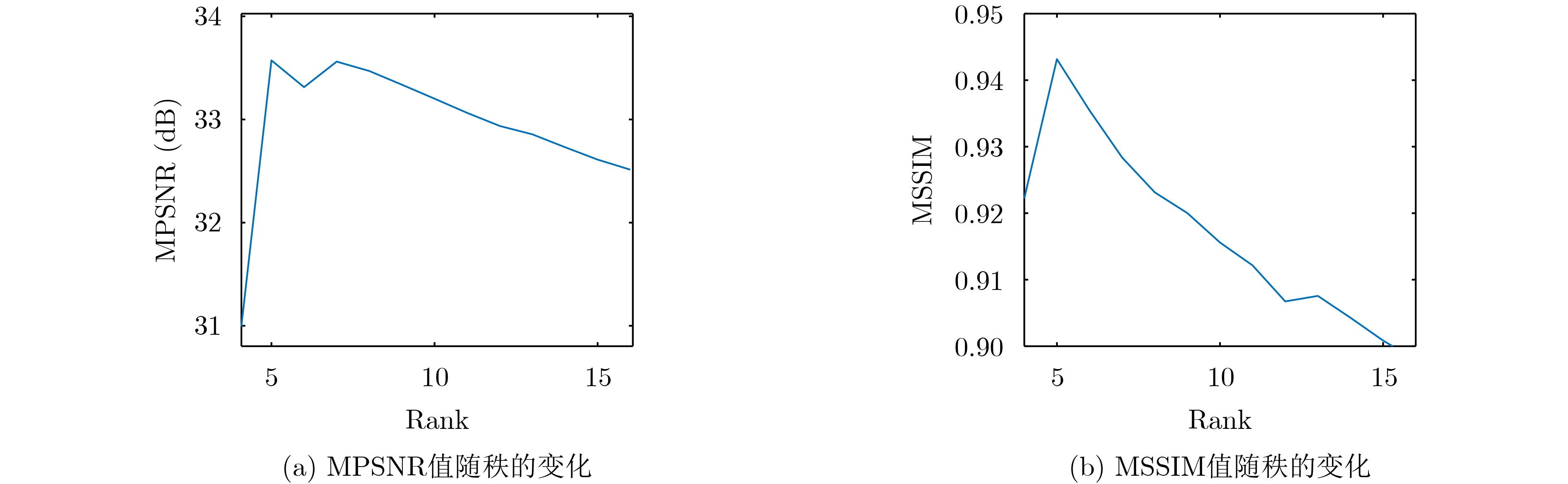
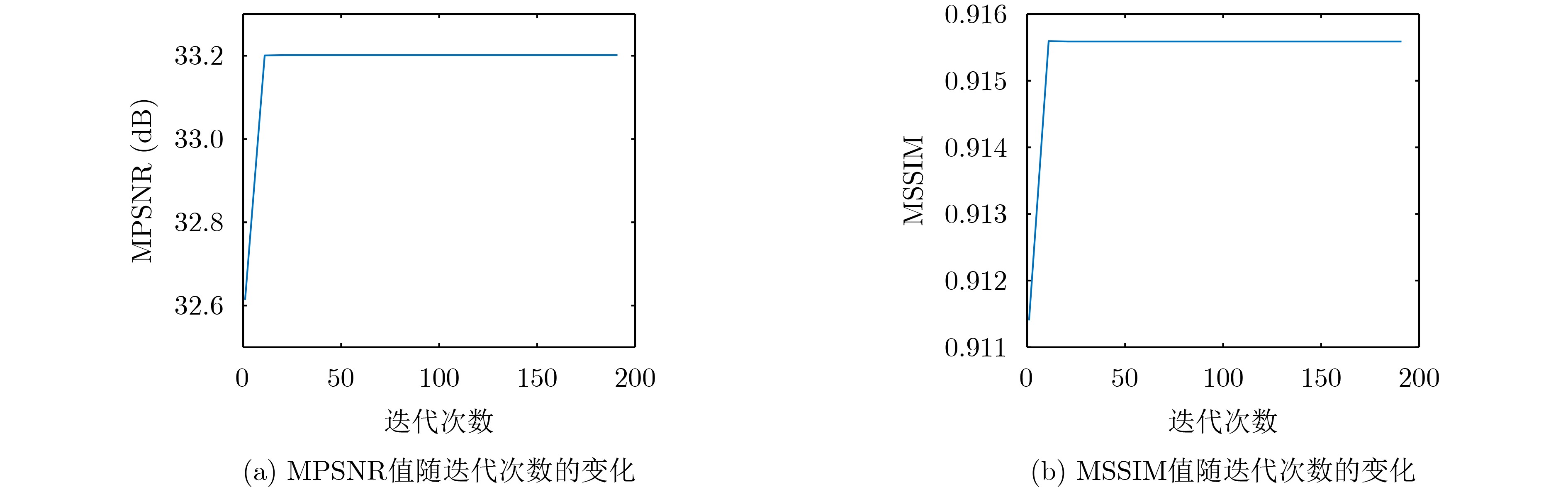
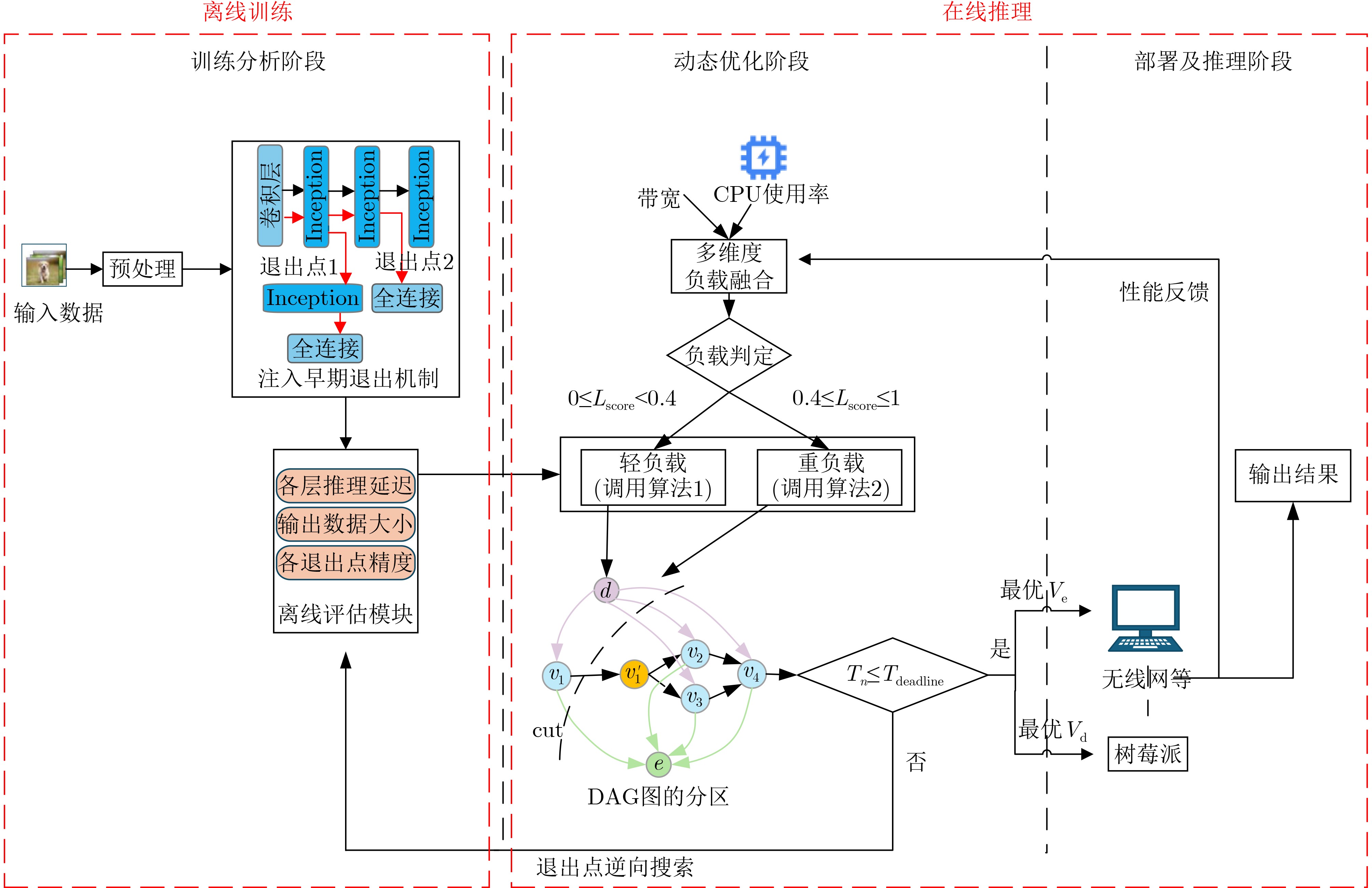
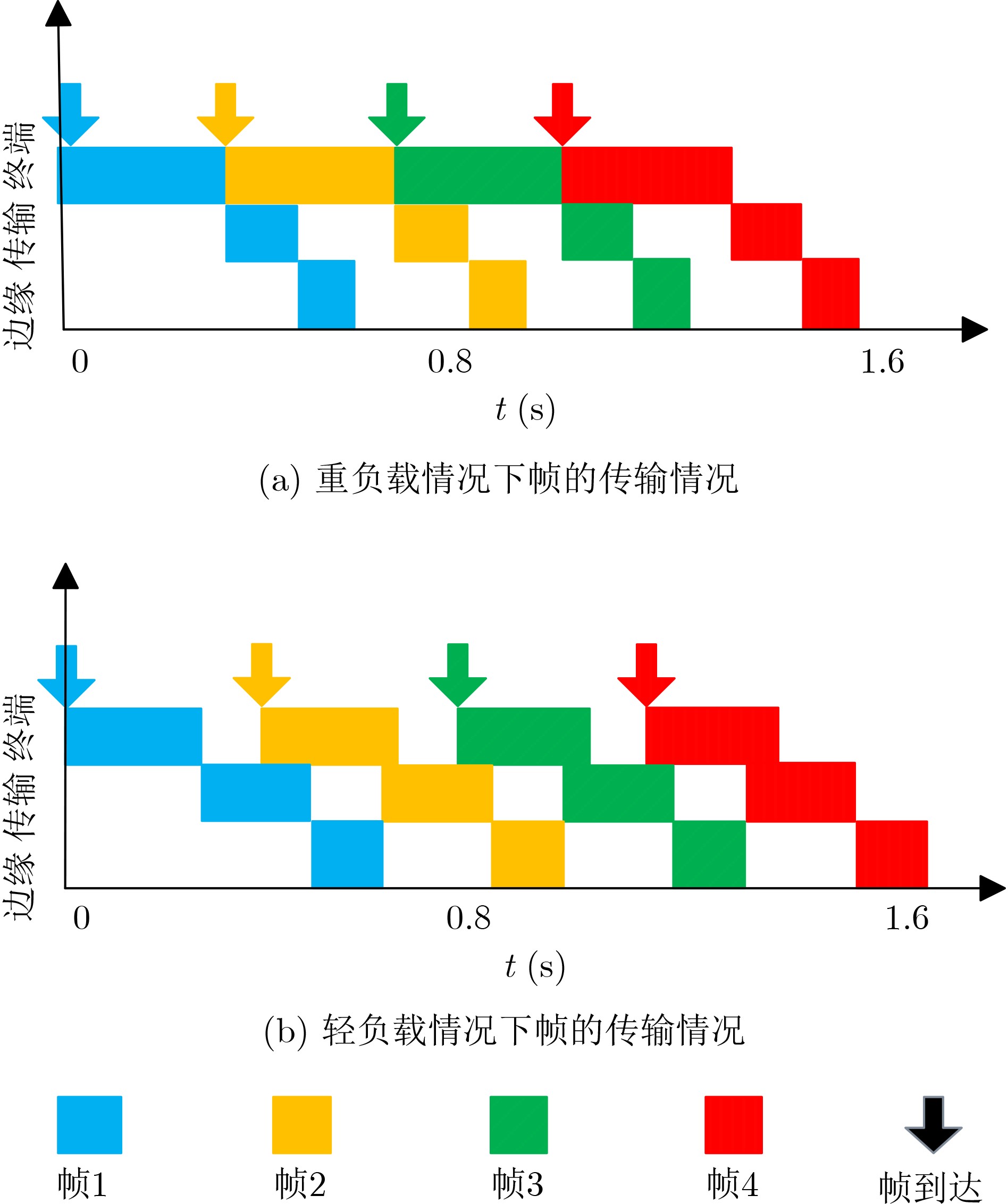
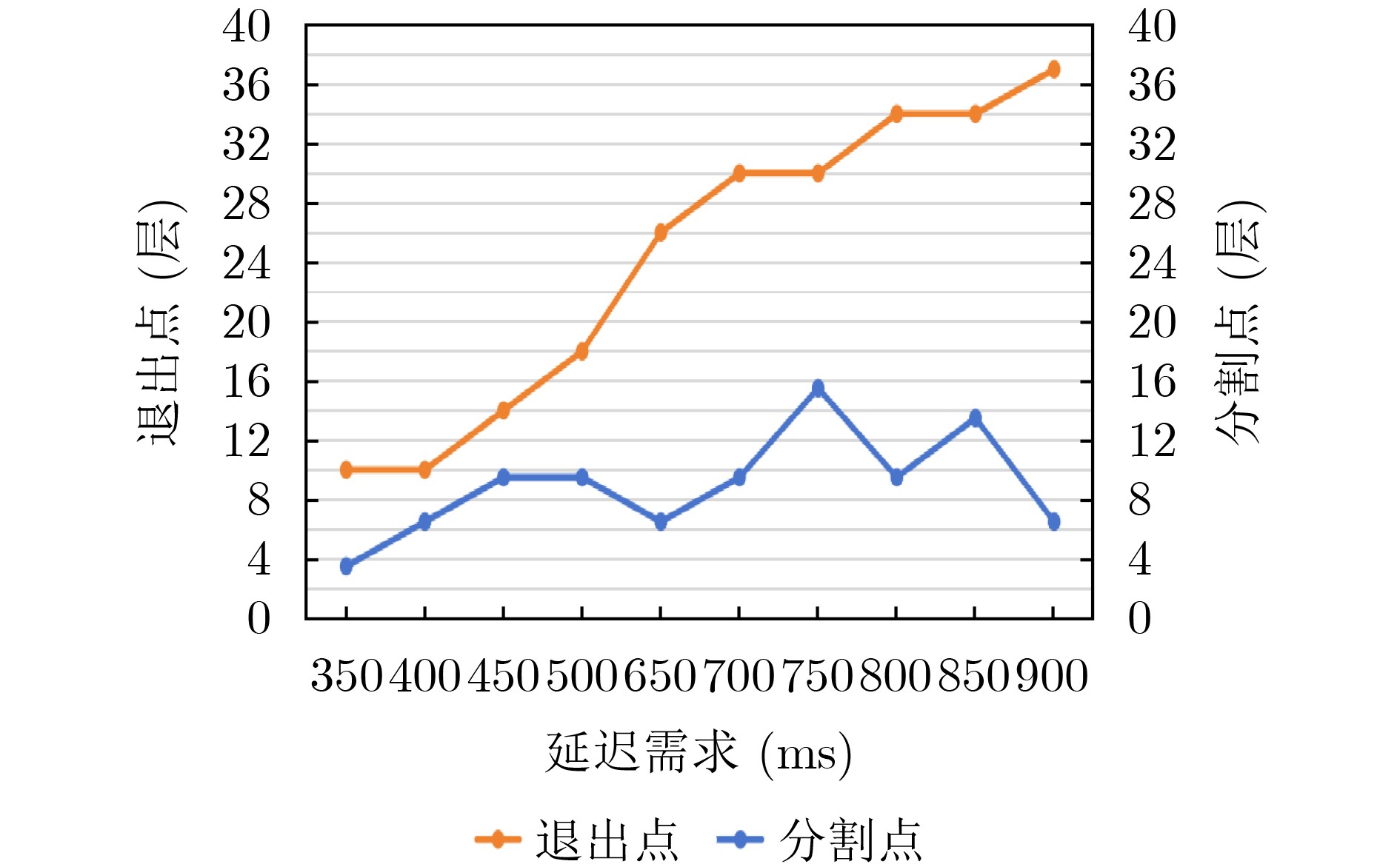
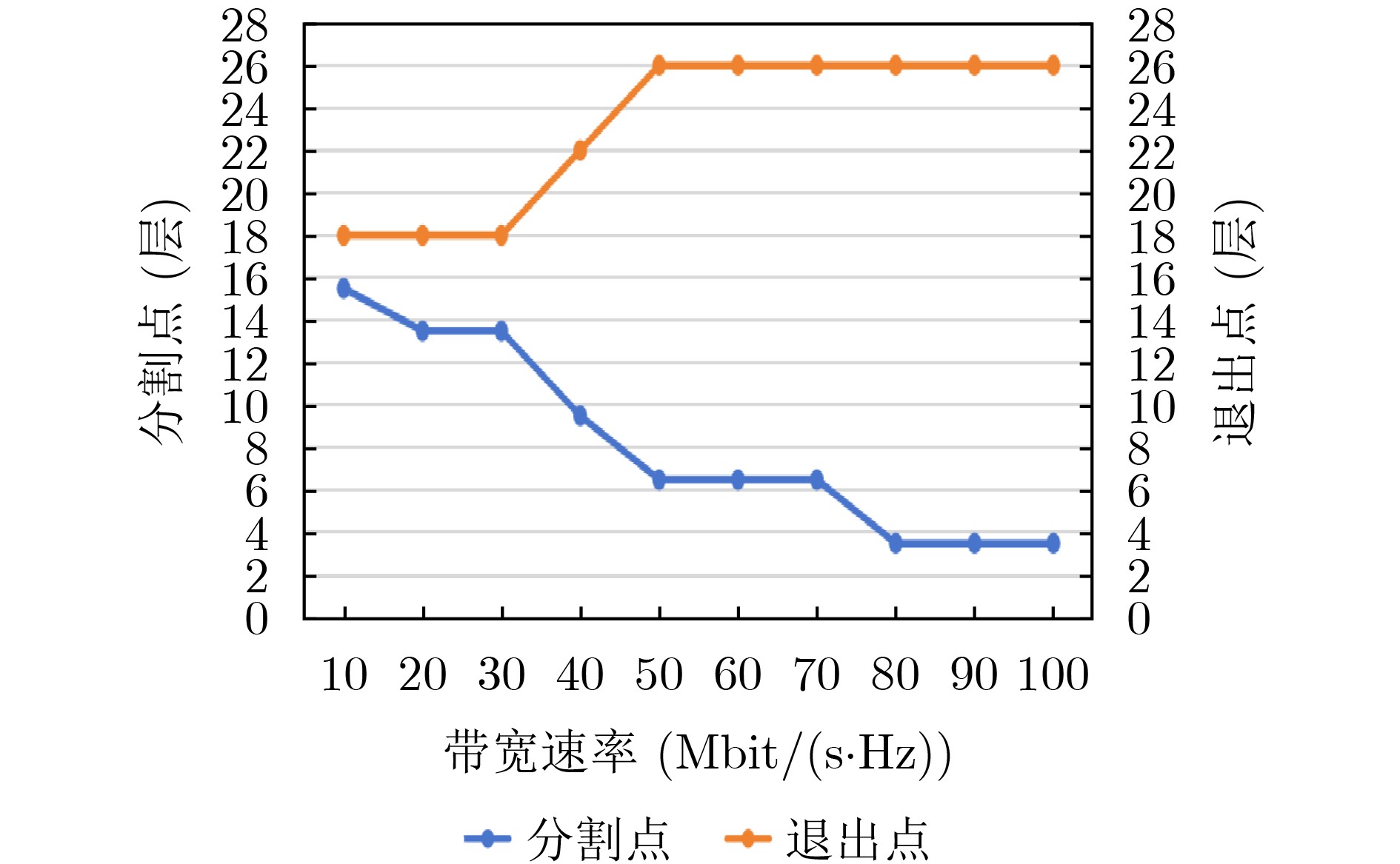
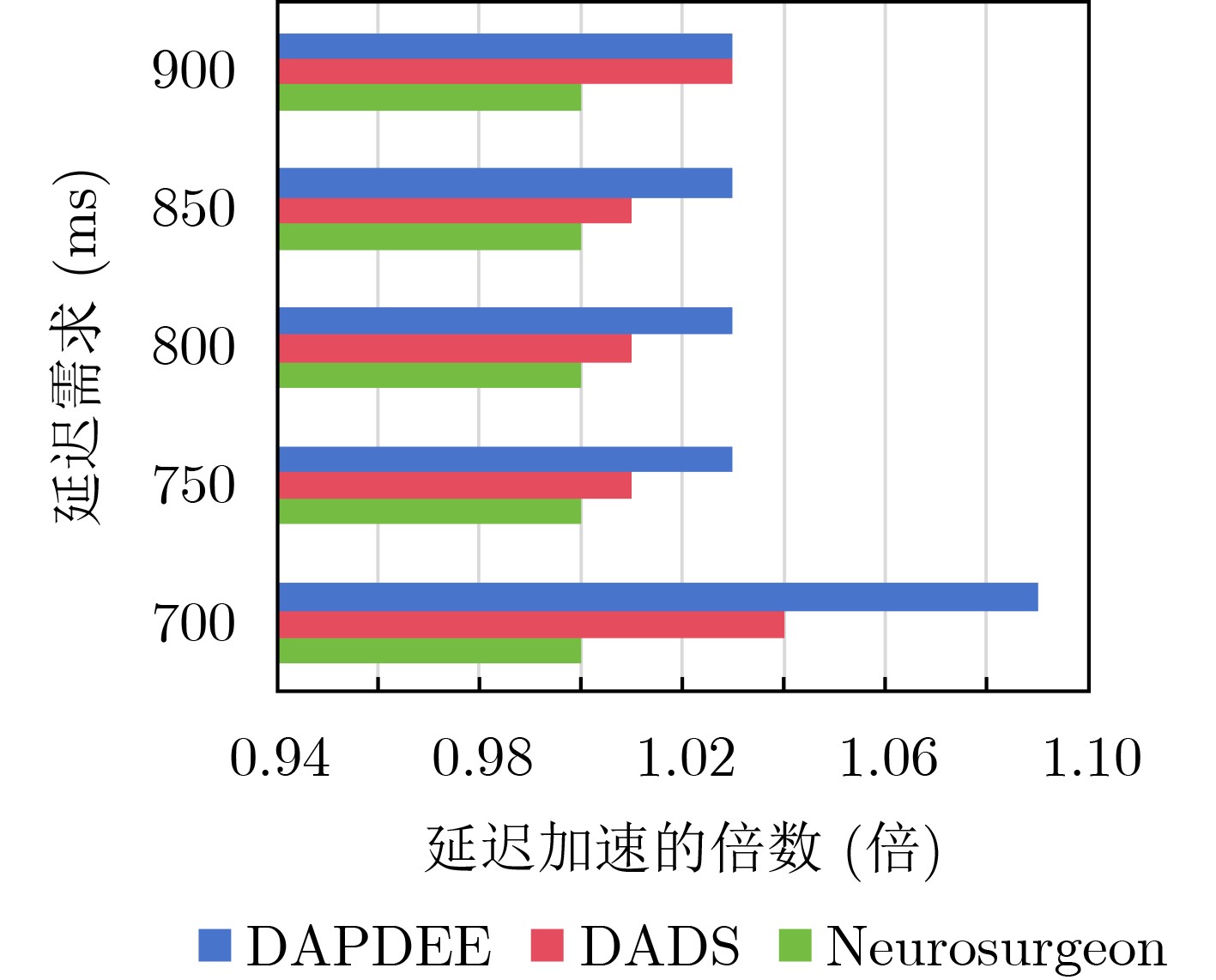
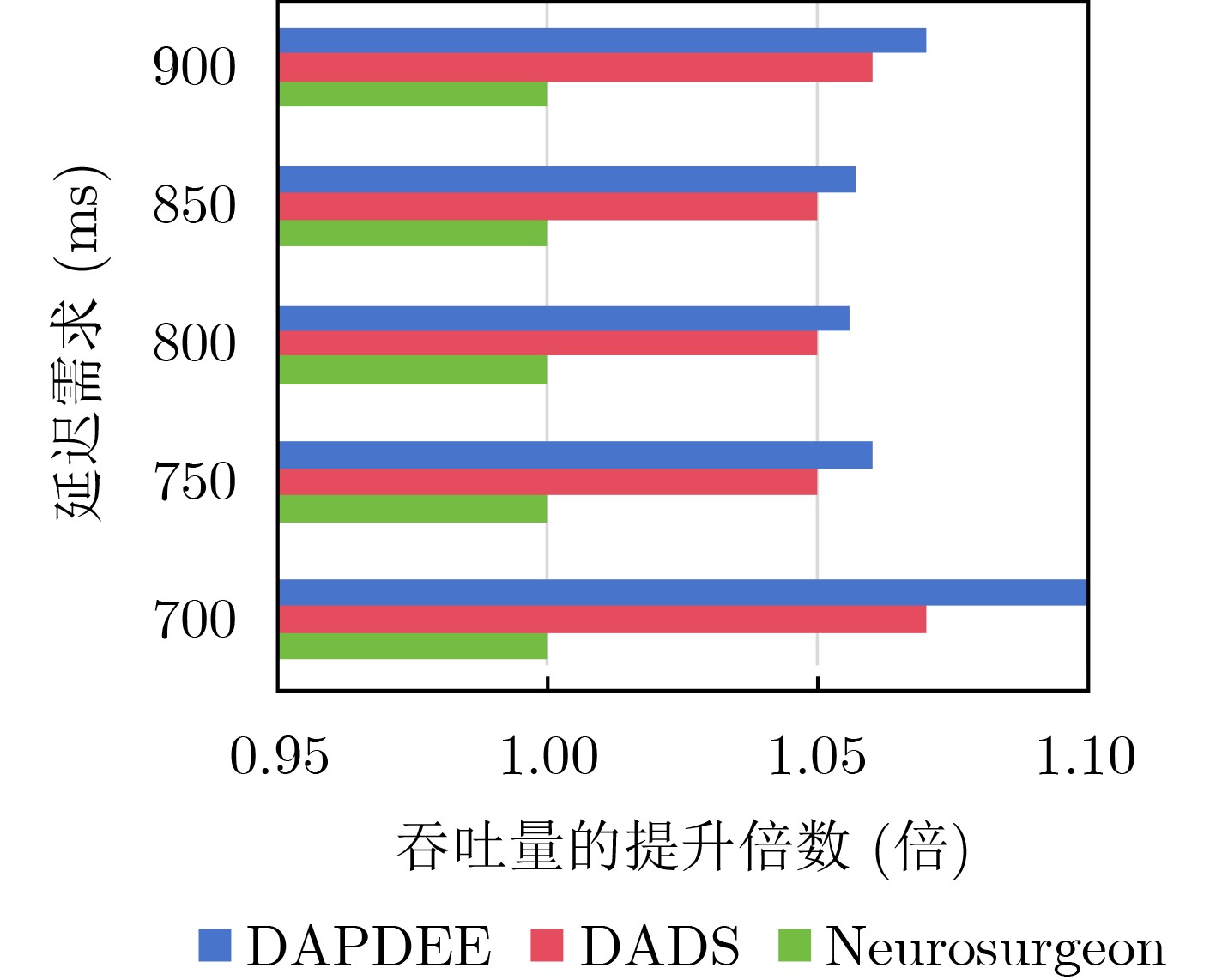
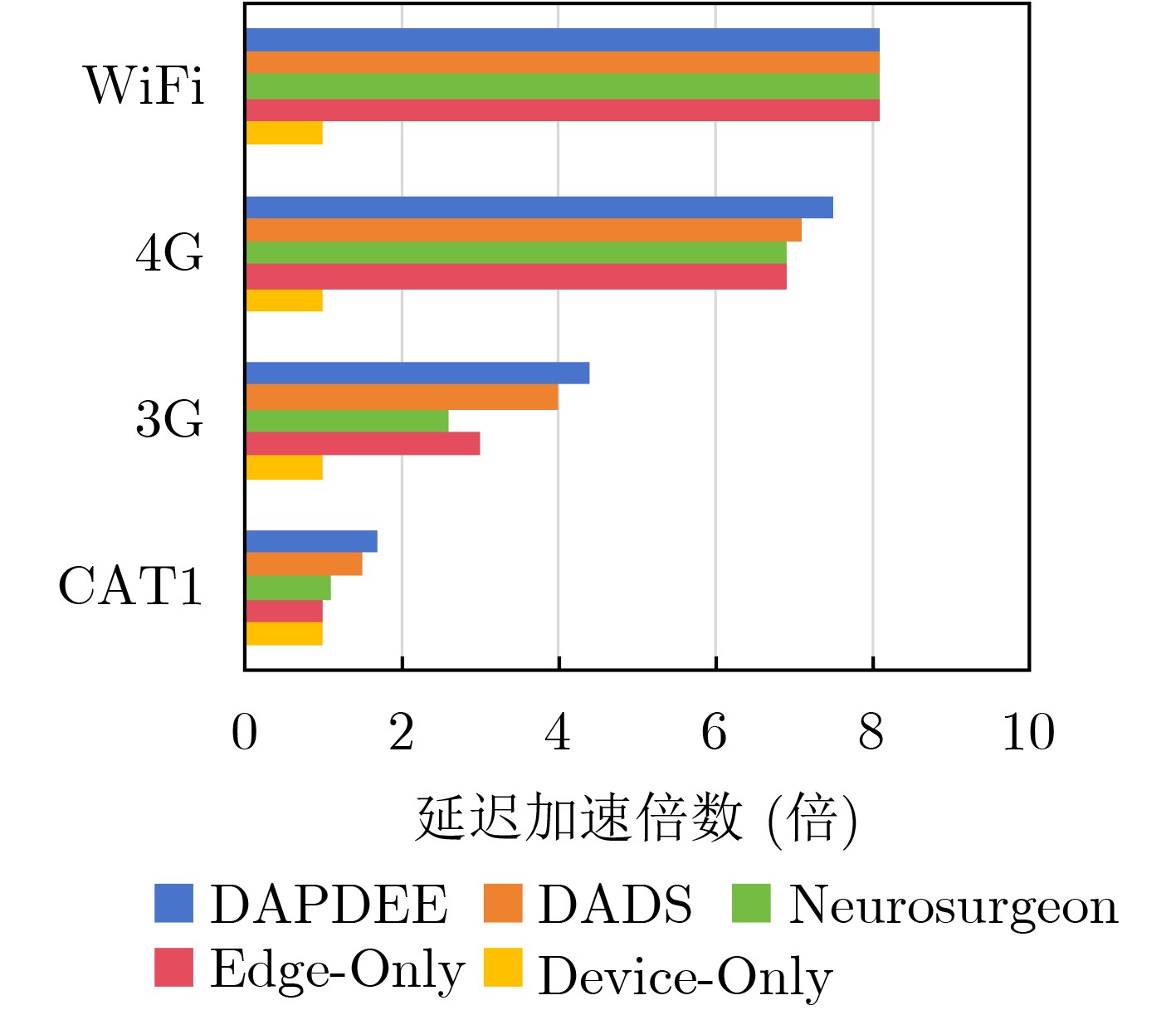
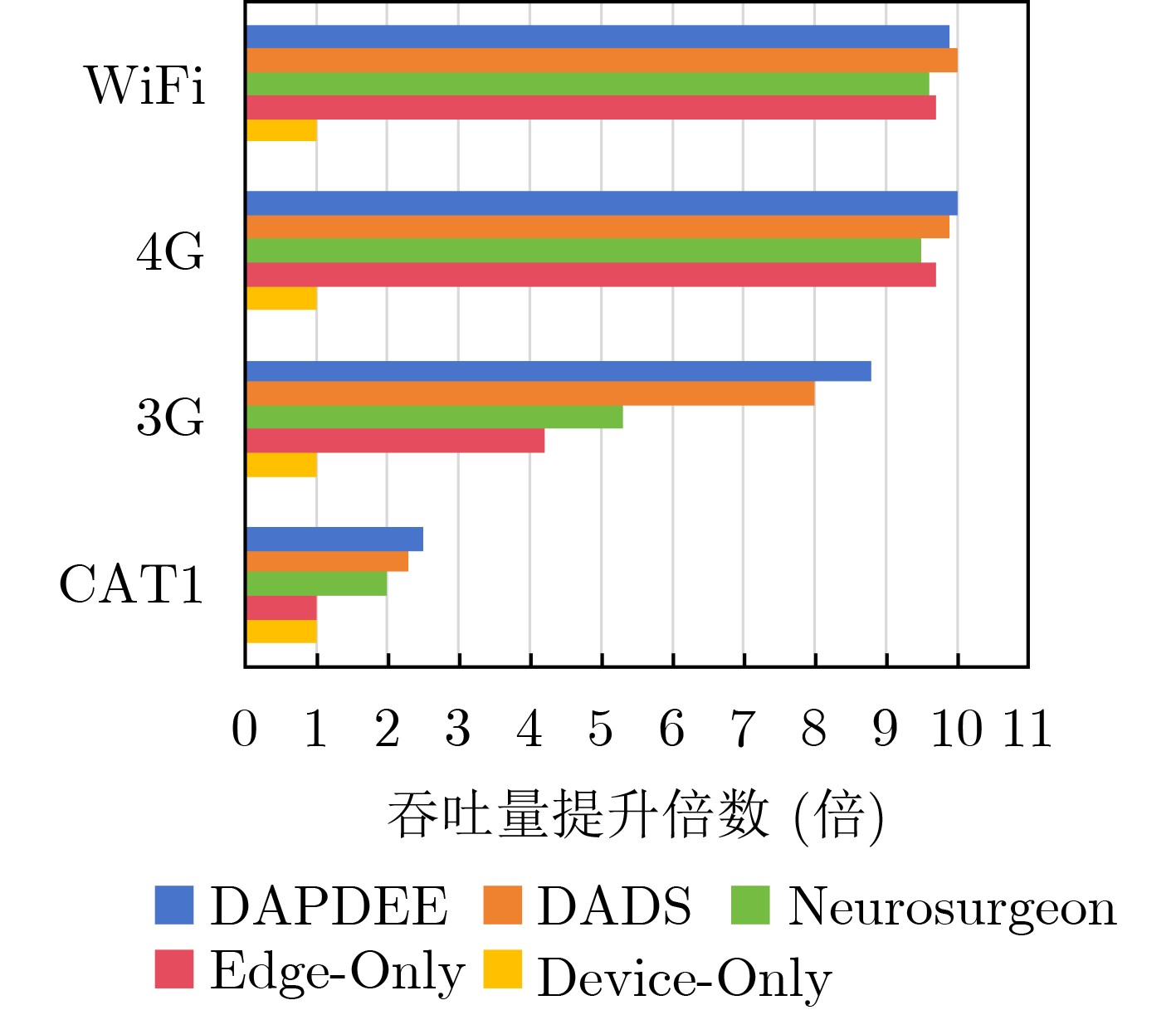
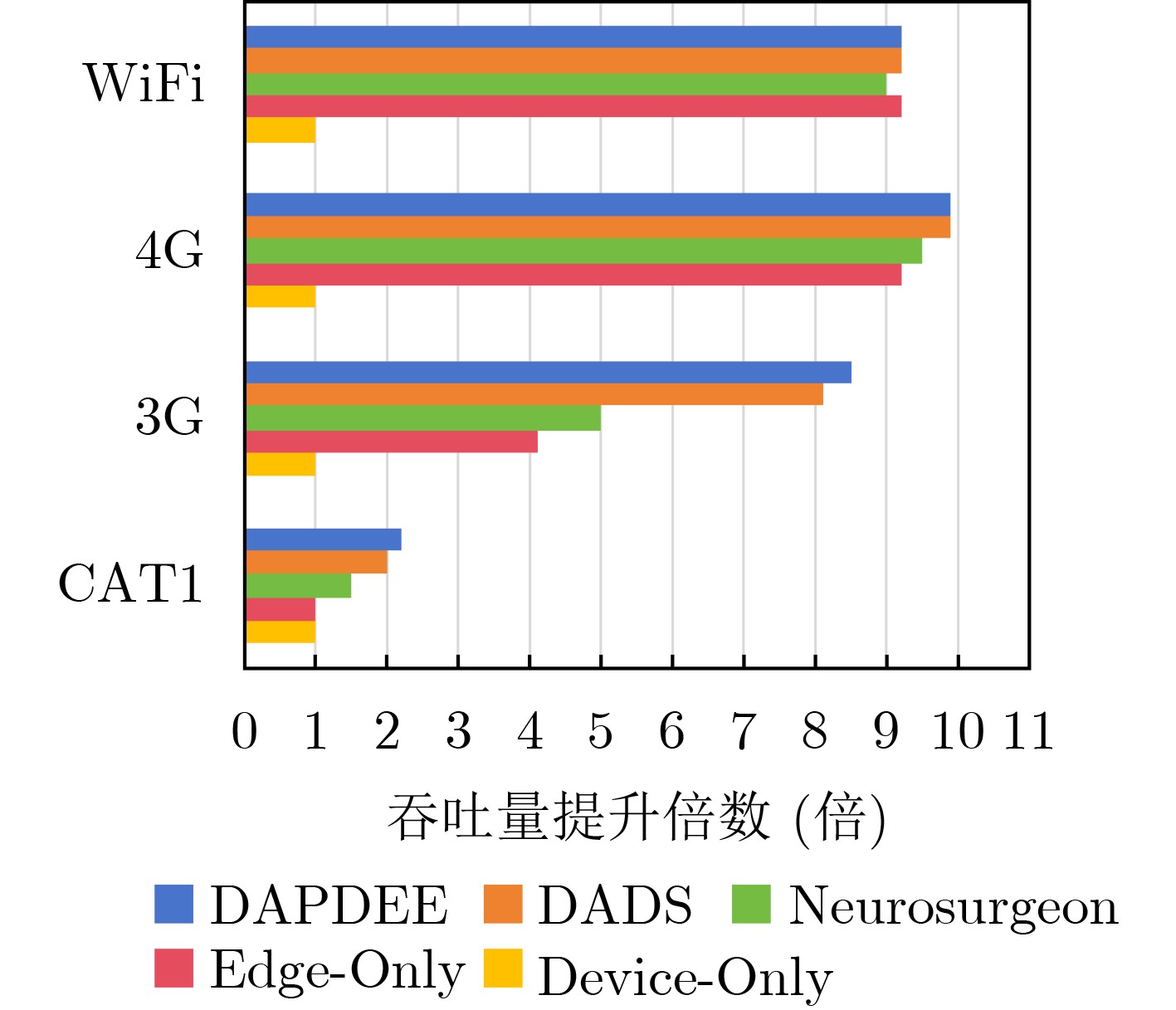
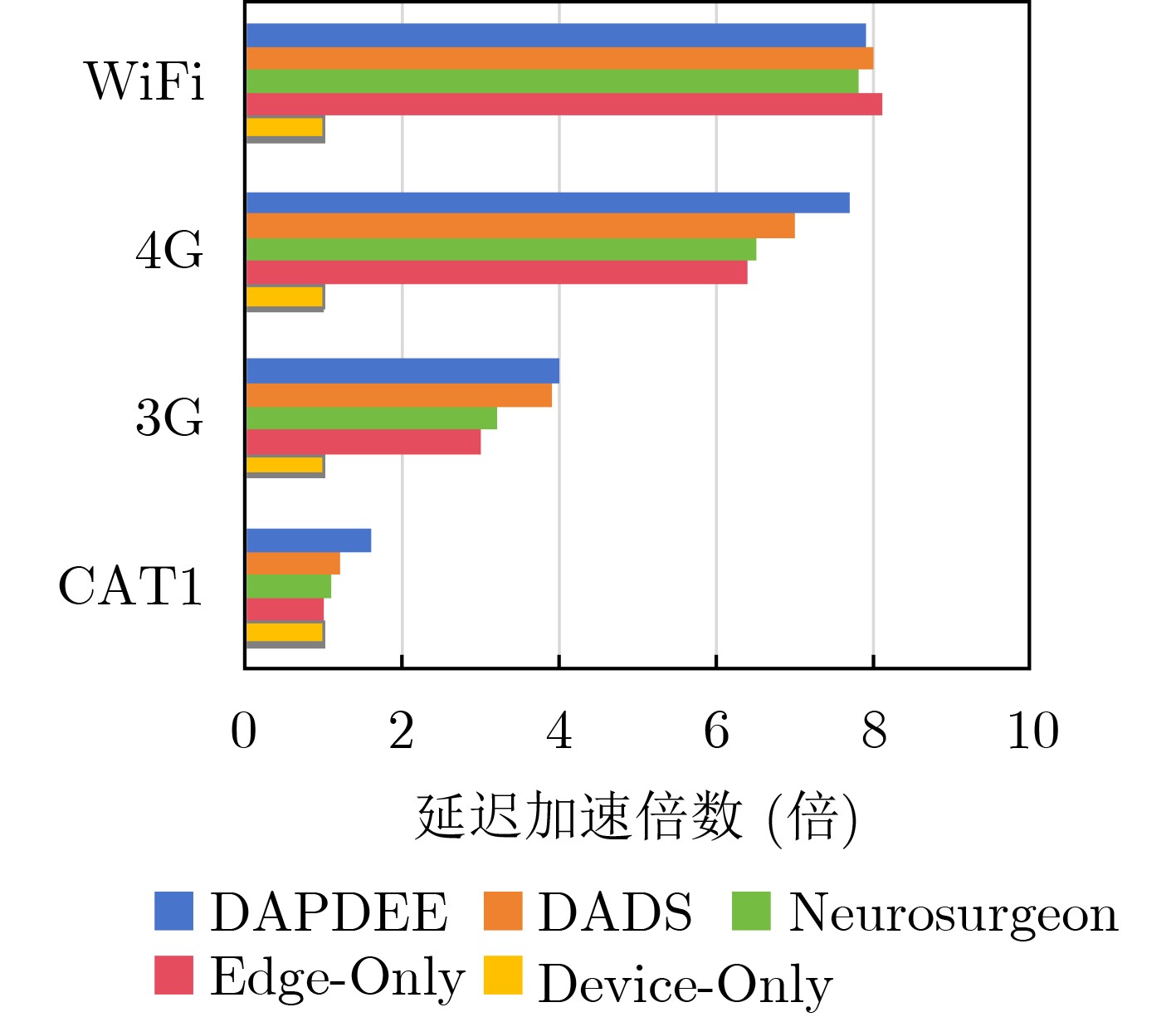
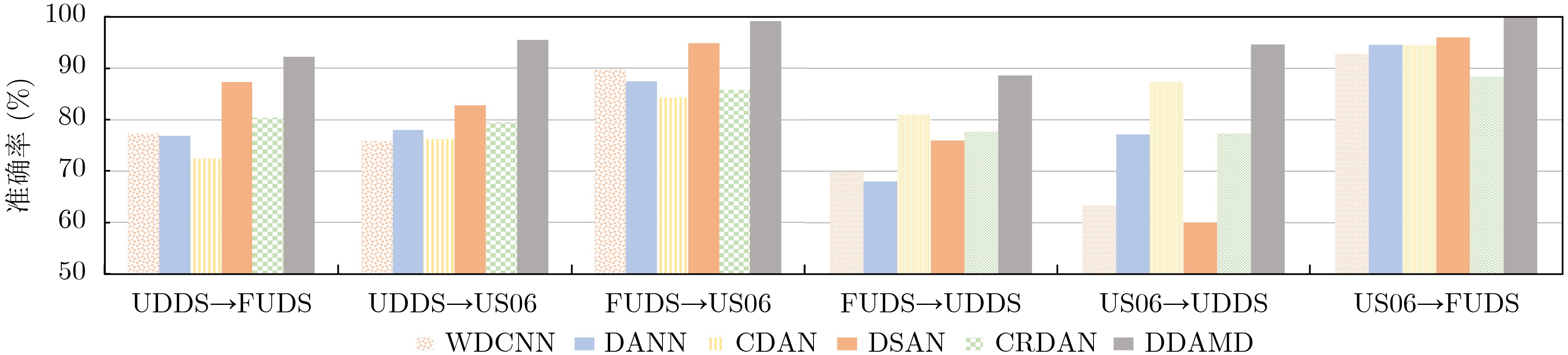
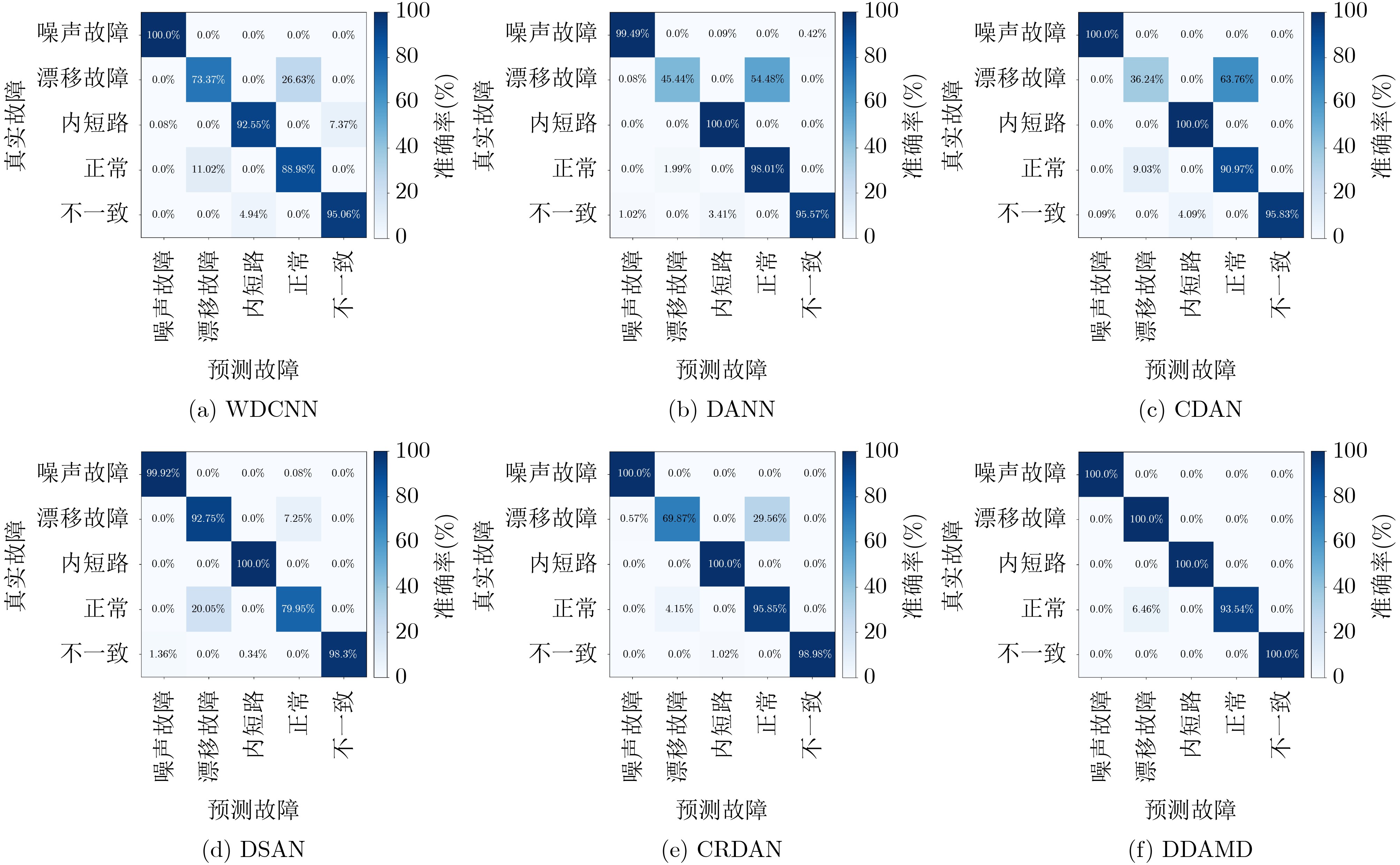
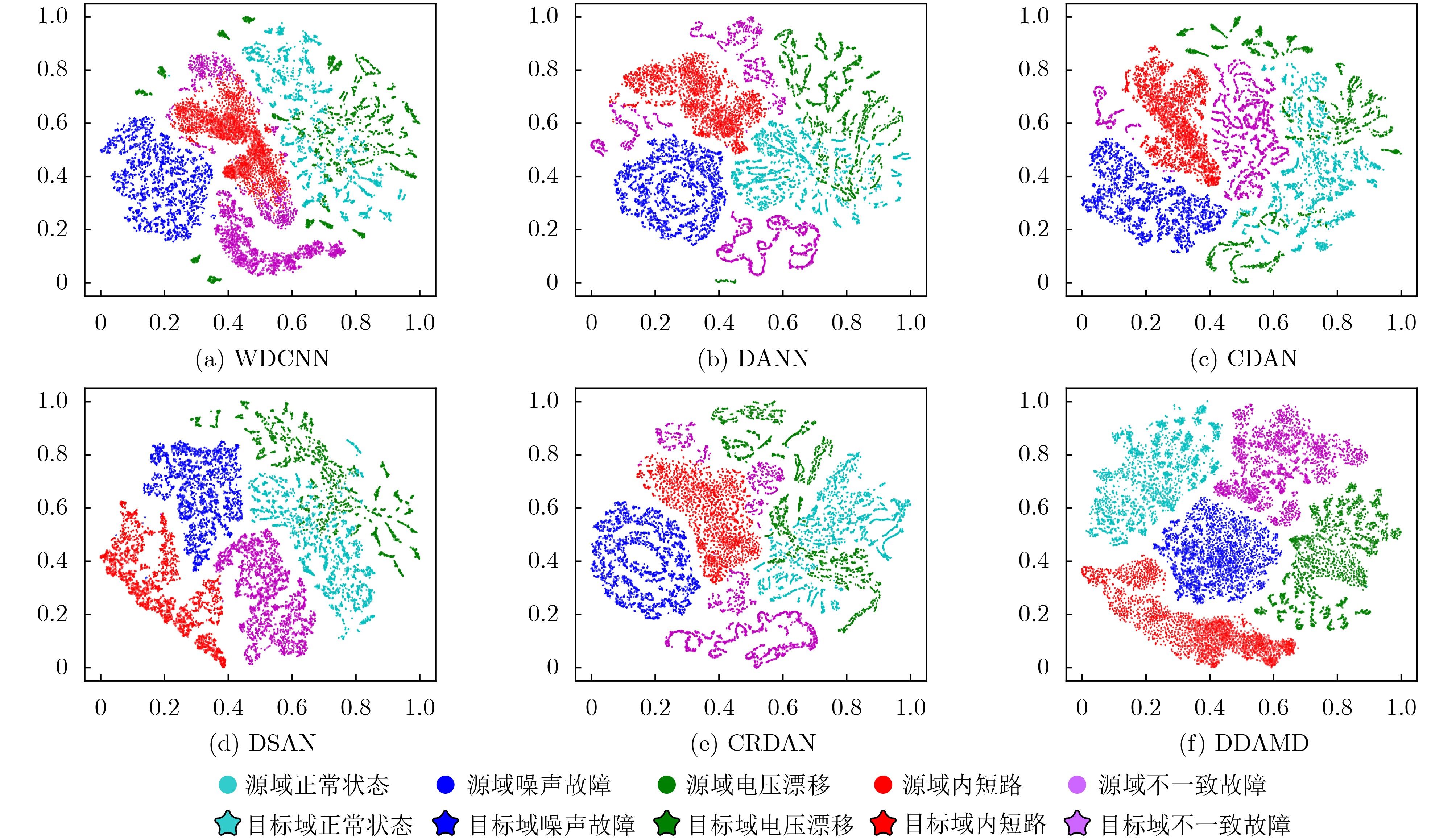
Objective With the rapid growth of data volume at the edge of the Internet of Things (IoT), traditional centralized computing architectures are inadequate to meet real-time processing requirements. Due to the limited computing and storage capabilities of IoT devices, data overflow frequently occurs when handling large volumes of information. Meanwhile, the reliance on battery power exacerbates energy shortages, further hindering continuous operation and data processing. Unmanned Aerial Vehicles (UAVs), with their flexible deployment capabilities, are increasingly being integrated into distributed computing environments to improve IoT data processing efficiency. However, the stochastic and dynamic nature of IoT user demands presents significant challenges for existing resource scheduling schemes, which struggle to effectively coordinate UAV deployments. Moreover, most studies focus on single-objective optimization, making it difficult to simultaneously balance energy harvesting, energy consumption, system latency, and data transmission rates under complex environmental conditions. To address these challenges, this paper proposes an optimization framework for a UAV-assisted, wireless-powered Mobile Edge Computing (MEC) system based on an improved Multi-Objective Deep Deterministic Policy Gradient (MODDPG) algorithm. The proposed method jointly optimizes task offloading, energy harvesting, flying energy consumption, and system latency, enhancing the overall performance and feasibility of IoT systems. Methods This paper designs a UAV-assisted, wireless-powered MEC system model, where the UAV follows a “fly-hover-communicate” protocol and operates in full-duplex mode during hovering to simultaneously perform data collection and energy transmission. The system model integrates a propulsion energy consumption model and a nonlinear energy harvesting model, formulating a multi-objective optimization problem based on task generation, energy state, and wireless channel conditions of IoT devices. To address this optimization problem, an improved MODDPG algorithm is proposed. A multi-dimensional reward function is constructed to maximize the data transmission rate and total harvested energy while minimizing system energy consumption and task offloading latency within a unified reinforcement learning framework. The agent continuously interacts with the dynamic environment to optimize the UAV’s flight trajectory, task offloading ratio, and energy transmission strategy. The proposed method is implemented and validated through extensive simulations conducted on the Python platform under various experimental settings. Results and Discussions To evaluate the performance of the proposed algorithm, comparative experiments are conducted against four other control strategies. The impact of different data collection coverage radii on the proposed strategy is analyzed (Fig. 3, Fig. 4). In terms of total data transmission rate, the \begin{document}${P_{\rm{MODDPG}}}$\end{document} strategy consistently ranks second to the maximum throughput strategy across all coverage settings, while significantly outperforming the other three strategies (Fig. 3(a)). Regarding total harvested energy, \begin{document}${P_{\rm{MODDPG}}}$\end{document} achieves the highest energy collection in all scenarios, with performance improving as the coverage radius increases (Fig. 3(b)), demonstrating its capability to enhance energy transmission coverage and system efficiency. In terms of system energy consumption, the \begin{document}${P_{{V_{\max }}}}$\end{document} strategy exhibits the highest energy usage, whereas \begin{document}${P_{\rm{MODDPG}}}$\end{document} effectively controls flight energy consumption, maintaining significantly lower energy usage compared to high-speed flying strategies (Fig. 3(c)). For average latency, \begin{document}${P_{\rm{MODDPG}}}$\end{document} achieves lower latency than the \begin{document}$P_{V_{\max}} $\end{document} strategy and the \begin{document}$P_{V_{\mathrm{ME}}} $\end{document} strategy method in most cases (Fig. 3(d)). In terms of service performance, \begin{document}${P_{\rm{MODDPG}}}$\end{document} demonstrates superior results across multiple metrics, including the number of uploading users, average harvested energy, average number of charged users per hovering instance, and the number of users experiencing data overflow, with particularly significant advantages in energy collection and reducing data overflow rates. (Fig. 4(a), Fig. 4(b), Fig. 4(c), Fig. 4(d)). In experiments with varying IoT device densities (Fig. 5, Fig. 6), \begin{document}${P_{\rm{MODDPG}}}$\end{document} exhibits strong environmental adaptability. As device density increases and resource competition intensifies, \begin{document}${P_{\rm{MODDPG}}}$\end{document} intelligently optimizes flight paths and resource scheduling, maintaining high data transmission rates and energy harvesting levels while effectively suppressing system latency and data overflow. Furthermore, simulation results under different task load scenarios (small and large tasks) (Fig. 7) indicate that \begin{document}${P_{\rm{MODDPG}}}$\end{document} can flexibly adjust its strategy based on task load variations, maximizing resource utilization. Even under heavy load conditions, the proposed algorithm maintains superior data rates, energy harvesting efficiency, and system stability, effectively coping with dynamic traffic variations. Notably, \begin{document}${P_{\rm{MODDPG}}}$\end{document} not only delivers outstanding optimization performance but also demonstrates significantly faster convergence during training compared to traditional methods such as Proximal Policy Optimization (PPO) and TD3. Overall,\begin{document}${P_{\rm{MODDPG}}}$\end{document} outperforms existing strategies in multi-objective optimization, system energy efficiency enhancement, task scheduling flexibility, and environmental adaptability. Conclusions This paper addresses the critical challenges of energy limitations, data overflow, and high latency in IoT environments by proposing an optimization framework for a UAV-assisted wireless-powered MEC system, which integrates UAV, MEC, and Wireless Power Transfer (WPT) technologies. In the proposed system, IoT devices’ data upload demands are updated in real time, with the UAV sequentially accessing each device based on the priority of its demands using a "fly-hover-communicate" protocol. An improved MODDPG algorithm, based on deep reinforcement learning, is introduced to jointly optimize data transmission rate, energy harvesting, energy consumption, and system latency. Training results demonstrate that, under all optimization scenarios, the proposed scheme consistently achieves the highest total harvested energy while simultaneously balancing the other three optimization objectives. Compared to other baseline strategies, the proposed method exhibits better adaptability by dynamically adjusting to environmental changes and varying device priorities, ultimately achieving coordinated multi-objective optimization and superior performance across different conditions. Future research will focus on extending this work to address multi-UAV cooperative task allocation, resource management, energy harvesting coordination, and multi-UAV trajectory planning.