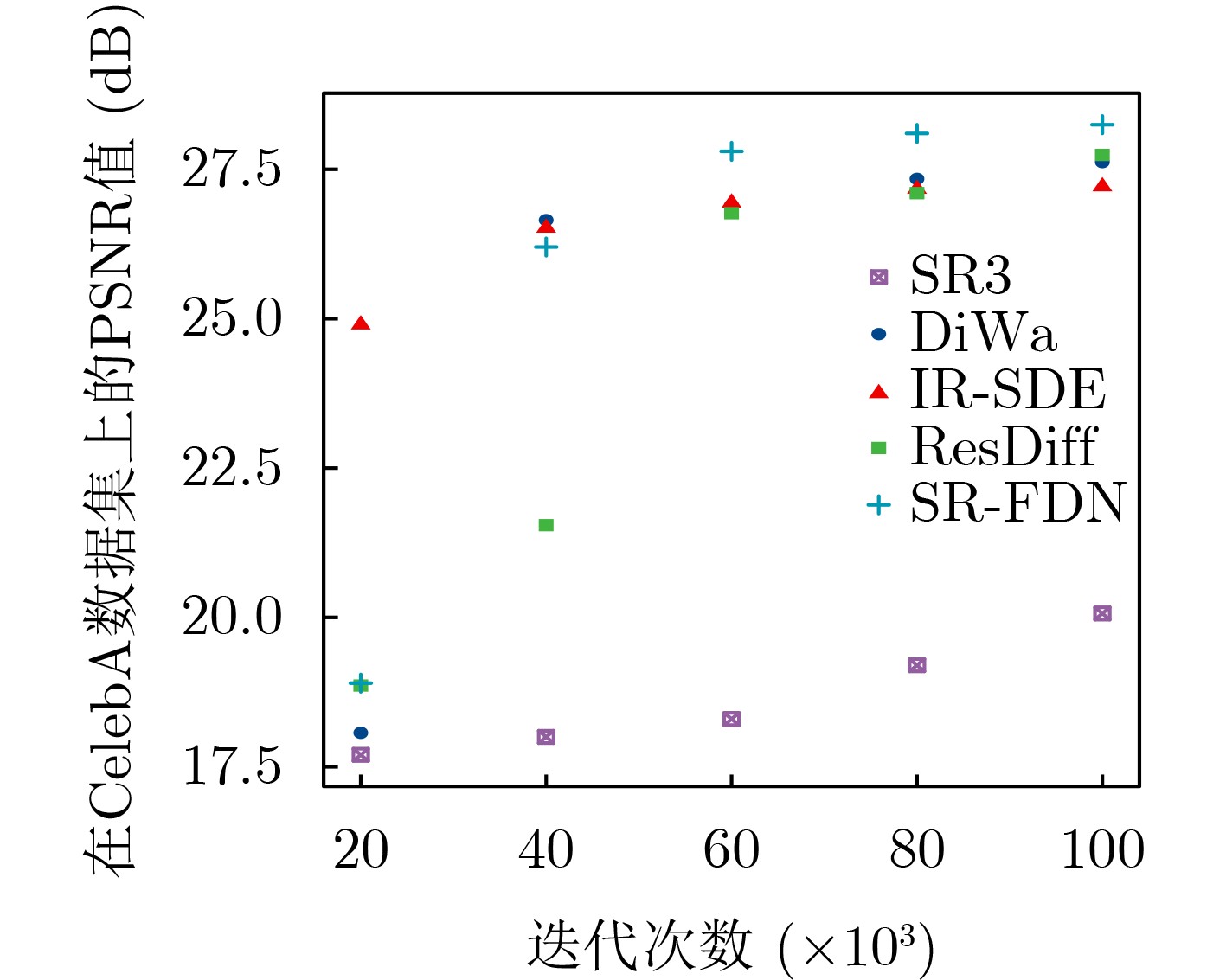
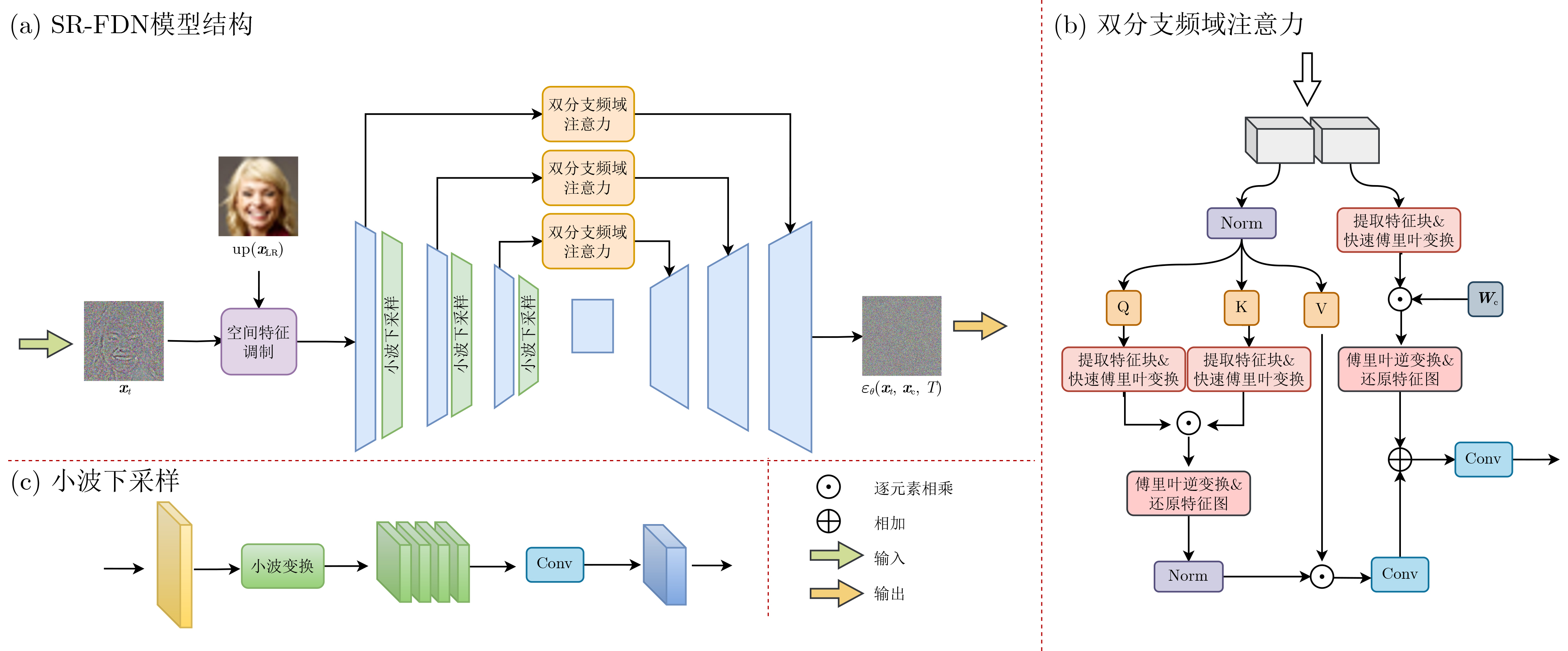
| Citation: | LI Xiumei, DING Linlin, SUN Junmei, BAI Huang. SR-FDN: A Frequency-Domain Diffusion Network for Image Detail Restoration in Super-Resolution[J]. Journal of Electronics & Information Technology, 2025, 47(10): 3941-3950. doi: 10.11999/JEIT250224

|

| [1] |
LIANG Jie, ZENG Hui, and ZHANG Lei. Details or artifacts: A locally discriminative learning approach to realistic image super-resolution[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5647–5656. doi: 10.1109/CVPR52688.2022.00557.
|
| [2] |
DONG Chao, LOY C C, HE Kaiming, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295–307. doi: 10.1109/TPAMI.2015.2439281.
|
| [3] |
MOSER B B, RAUE F, FROLOV S, et al. Hitchhiker's guide to super-resolution: Introduction and recent advances[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(8): 9862–9882. doi: 10.1109/TPAMI.2023.3243794.
|
| [4] |
YANG Qi, ZHANG Yanzhu, ZHAO Tiebiao, et al. Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction[J]. ISA Transactions, 2018, 82: 163–171. doi: 10.1016/j.isatra.2017.03.001.
|
| [5] |
SUN Long, PAN Jinshan, and TANG Jinhui. ShuffleMixer: An efficient ConvNet for image super-resolution[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1259.
|
| [6] |
ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 294–310. doi: 10.1007/978-3-030-01234-2_18.
|
| [7] |
程德强, 袁航, 钱建生, 等. 基于深层特征差异性网络的图像超分辨率算法[J]. 电子与信息学报, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179.
CHENG Deqiang, YUAN Hang, QIAN Jiansheng, et al. Image super-resolution algorithms based on deep feature differentiation network[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179.
|
| [8] |
HUANG Huaibo, HE Ran, SUN Zhenan, et al. Wavelet-SRNet: A wavelet-based CNN for multi-scale face super resolution[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1698–1706. doi: 10.1109/ICCV.2017.187.
|
| [9] |
LIANG Jingyun, CAO Jiezhang, SUN Guolei, et al. SwinIR: Image restoration using swin transformer[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 1833–1844. doi: 10.1109/ICCVW54120.2021.00210.
|
| [10] |
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 105–114. doi: 10.1109/CVPR.2017.19.
|
| [11] |
WANG Xintao, YU Ke, WU Shixiang, et al. ESRGAN: Enhanced super-resolution generative adversarial networks[C]. The 15th European Conference on Computer Vision Workshops, Munich, Germany, 2019: 63–79. doi: 10.1007/978-3-030-11021-5_5.
|
| [12] |
韩玉兰, 崔玉杰, 罗轶宏, 等. 基于密集残差和质量评估引导的频率分离生成对抗超分辨率重构网络[J]. 电子与信息学报, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.
HAN Yulan, CUI Yujie, LUO Yihong, et al. Frequency separation generative adversarial super-resolution reconstruction network based on dense residual and quality assessment[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.
|
| [13] |
任坤, 李峥瑱, 桂源泽, 等. 低分辨率随机遮挡人脸图像的超分辨率修复[J]. 电子与信息学报, 2024, 46(8): 3343–3352. doi: 10.11999/JEIT231262.
REN Kun, LI Zhengzhen, GUI Yuanze, et al. Super-resolution inpainting of low-resolution randomly occluded face images[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3343–3352. doi: 10.11999/JEIT231262.
|
| [14] |
WOLF V, LUGMAYR A, DANELLJAN M, et al. DeFlow: Learning complex image degradations from unpaired data with conditional flows[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 94–103. doi: 10.1109/CVPR46437.2021.00016.
|
| [15] |
HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574.
|
| [16] |
SONG Jiaming, MENG Chenlin, and ERMON S. Denoising diffusion implicit models[C]. The 9th International Conference on Learning Representations, Vienna, Austria, 2021.
|
| [17] |
LI Haoying, YANG Yifan, CHANG Meng, et al. SRDiff: Single image super-resolution with diffusion probabilistic models[J]. Neurocomputing, 2022, 479: 47–59. doi: 10.1016/j.neucom.2022.01.029.
|
| [18] |
SAHARIA C, HO J, CHAN W, et al. Image super-resolution via iterative refinement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 4713–4726. doi: 10.1109/TPAMI.2022.3204461.
|
| [19] |
MOSER B B, FROLOV S, RAUE F, et al. Waving goodbye to low-res: A diffusion-wavelet approach for image super-resolution[C]. The International Joint Conference on Neural Networks, Yokohama, Japan, 2024: 1–8. doi: 10.1109/IJCNN60899.2024.10651227.
|
| [20] |
LUO Ziwei, GUSTAFSSON F, ZHAO Zheng, et al. Image restoration with mean-reverting stochastic differential equations[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 957.
|
| [21] |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10674–10685. doi: 10.1109/CVPR52688.2022.01042.
|
| [22] |
SHANG Shuyao, SHAN Zhengyang, LIU Guangxing, et al. ResDiff: Combining CNN and diffusion model for image super-resolution[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 8975–8983. doi: 10.1609/aaai.v38i8.28746.
|
| [23] |
XU Guoping, LIAO Wentao, ZHANG Xuan, et al. Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation[J]. Pattern Recognition, 2023, 143: 109819. doi: 10.1016/j.patcog.2023.109819.
|
| [24] |
ZHANG Yutian, LI Xiaohua, and ZHOU Jiliu. SFTGAN: A generative adversarial network for pan-sharpening equipped with spatial feature transform layers[J]. Journal of Applied Remote Sensing, 2019, 13(2): 026507. doi: 10.1117/1.jrs.13.026507.
|
Figures(5) / Tables(7)



 DownLoad:
DownLoad: