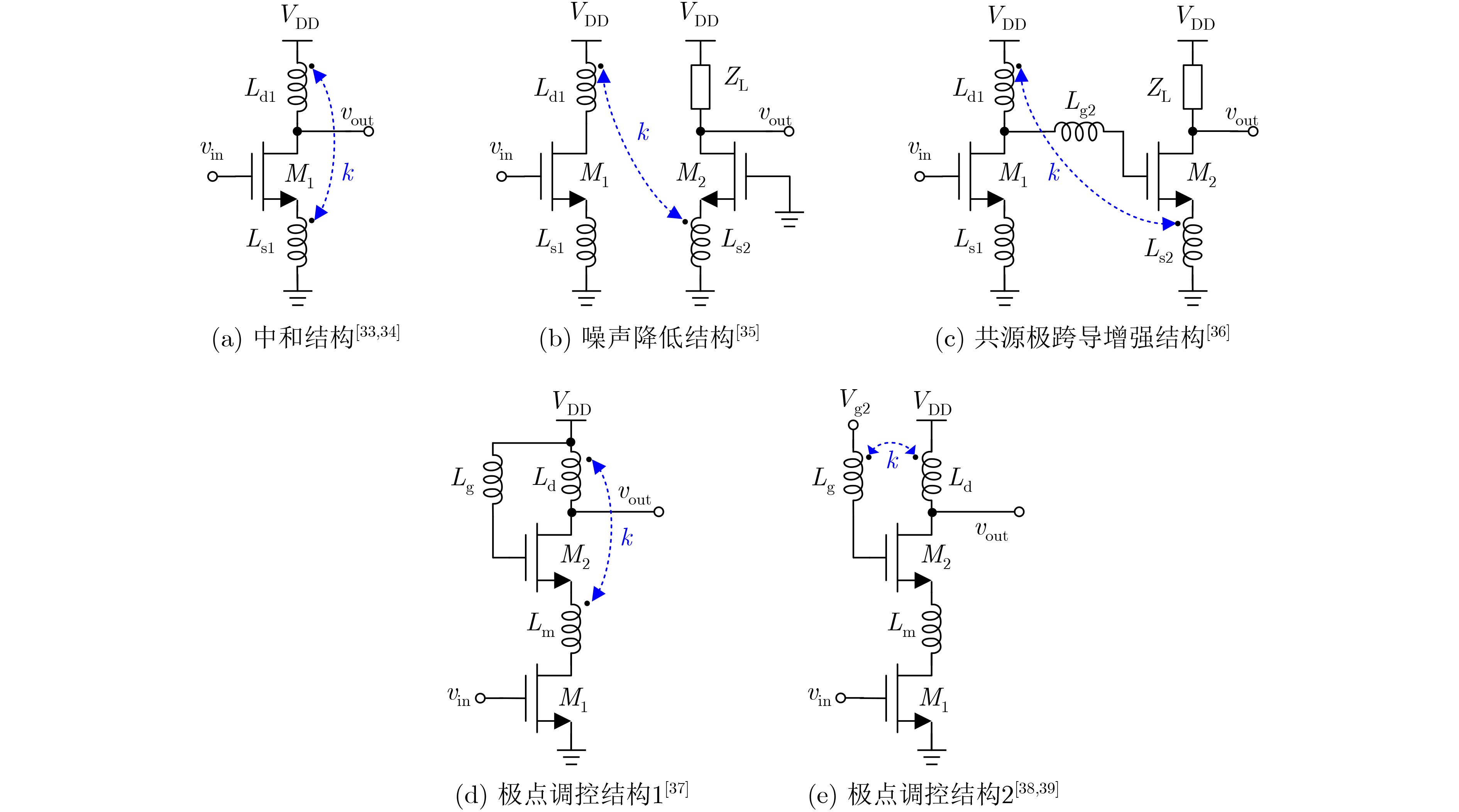
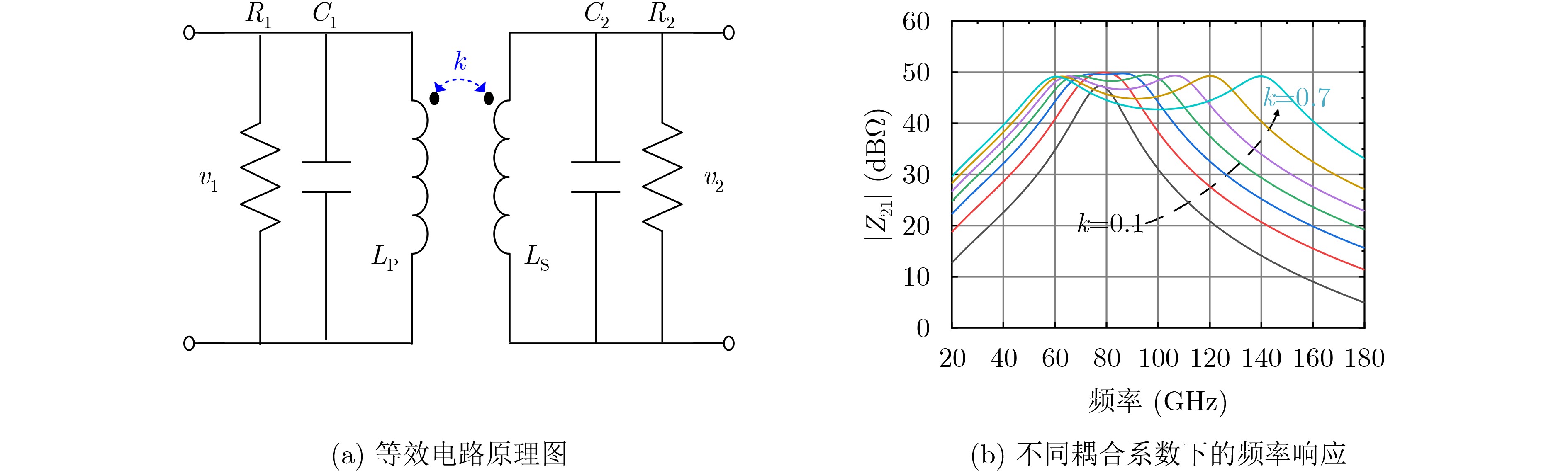
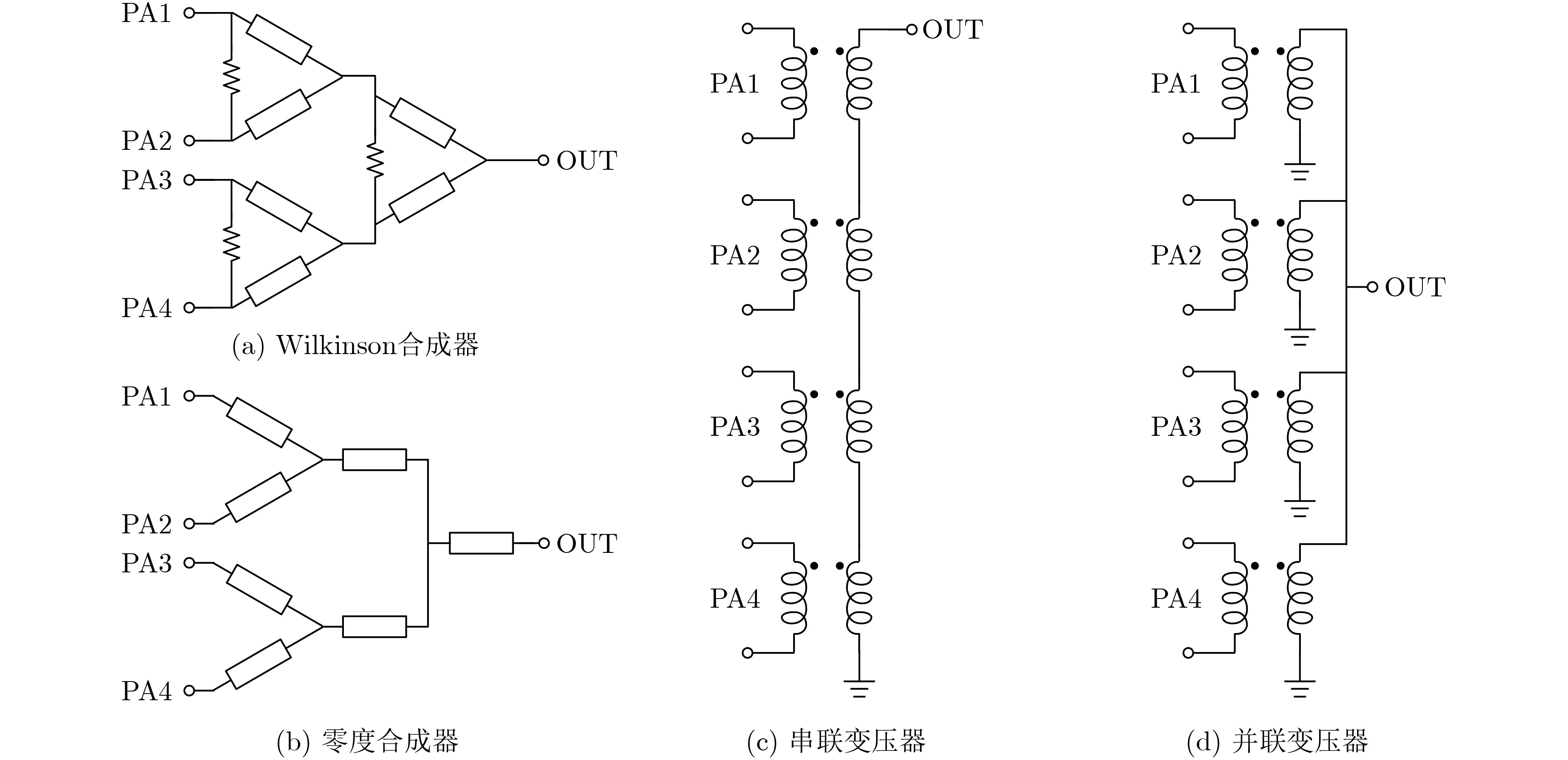
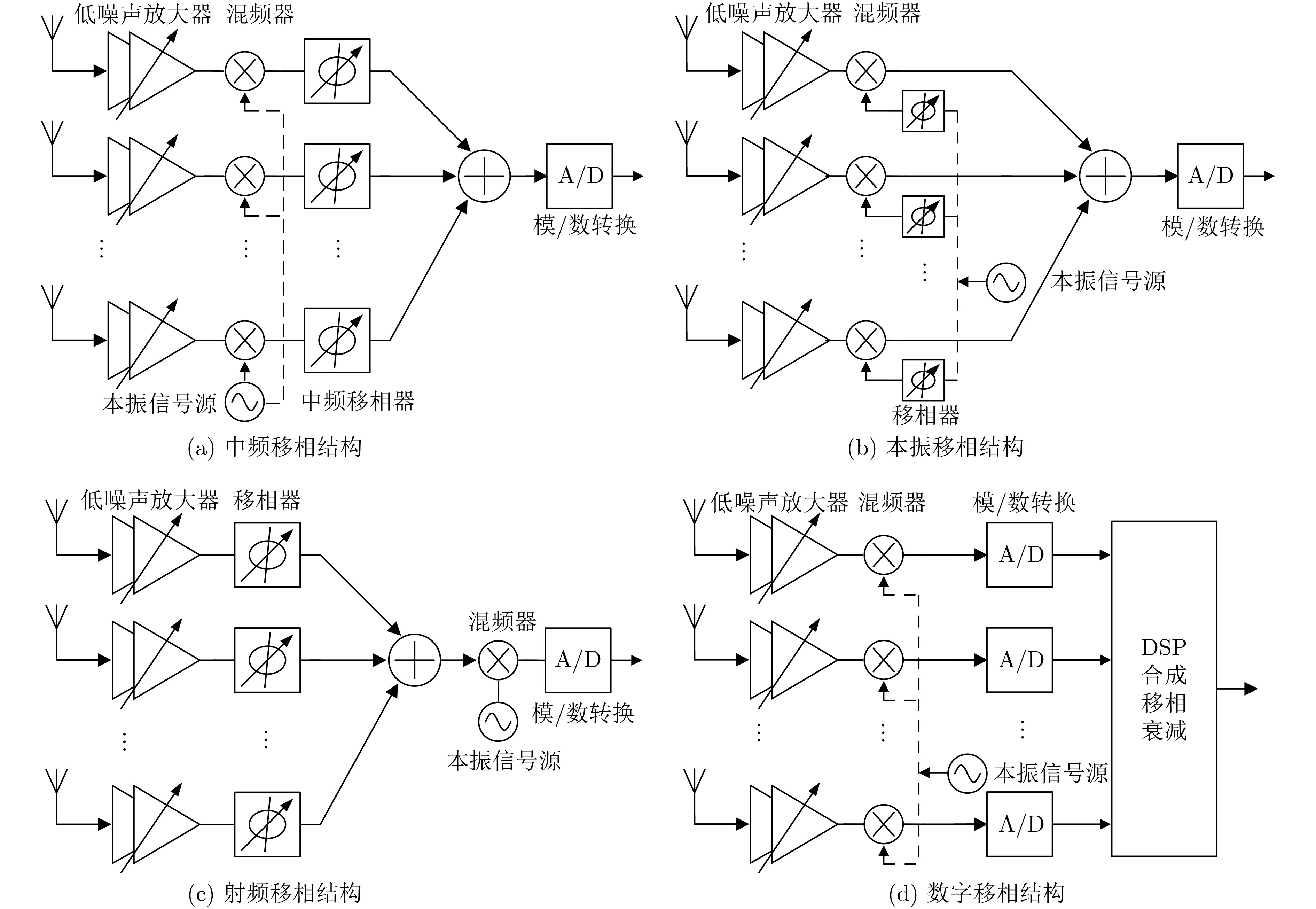
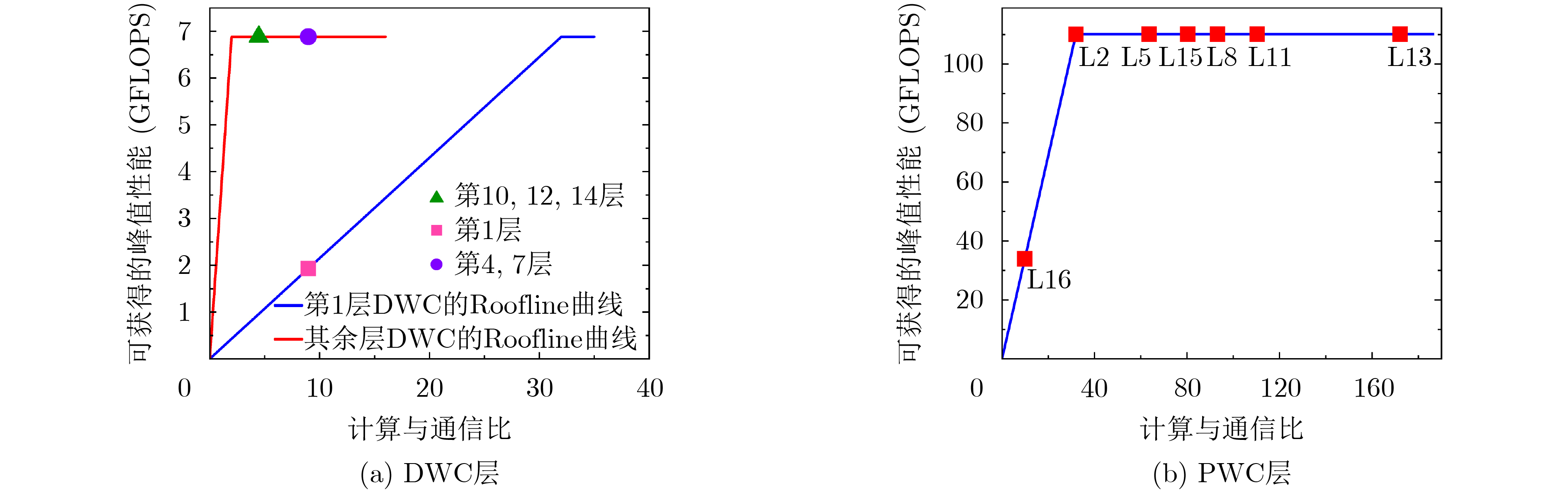
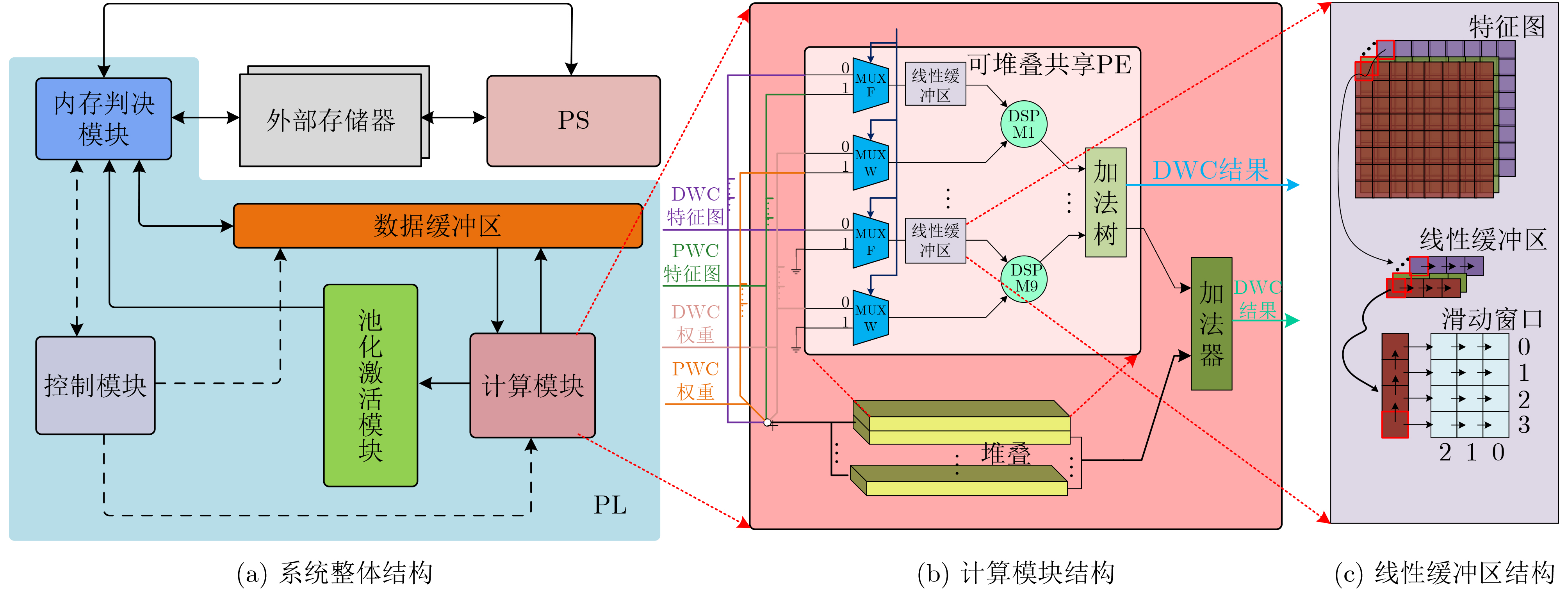
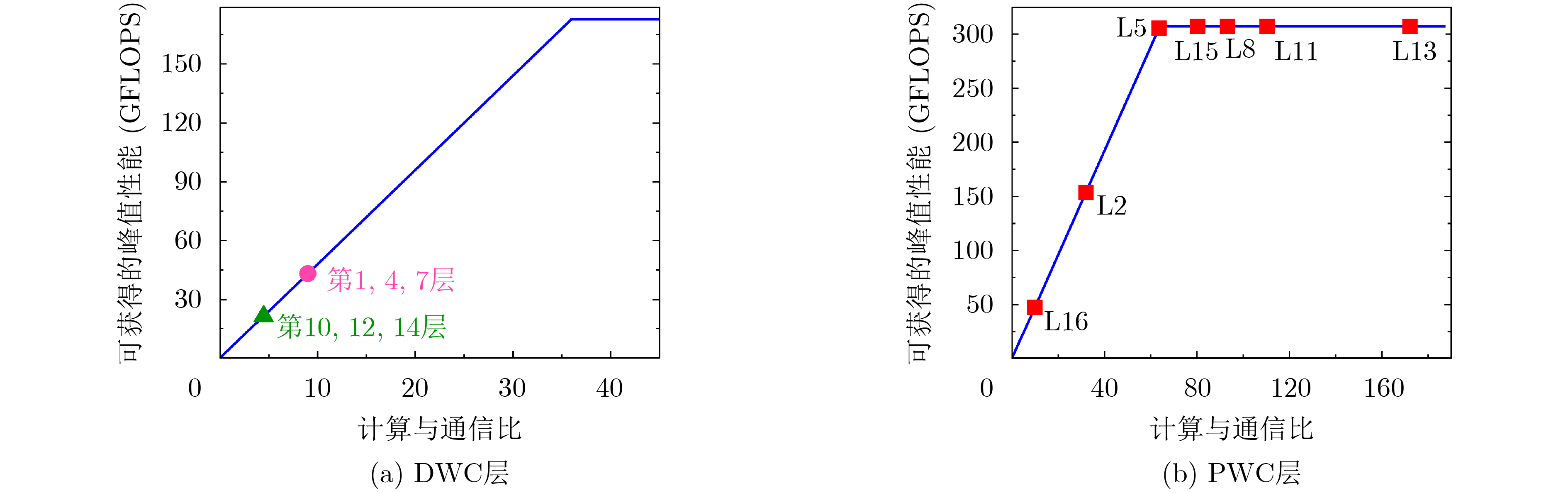
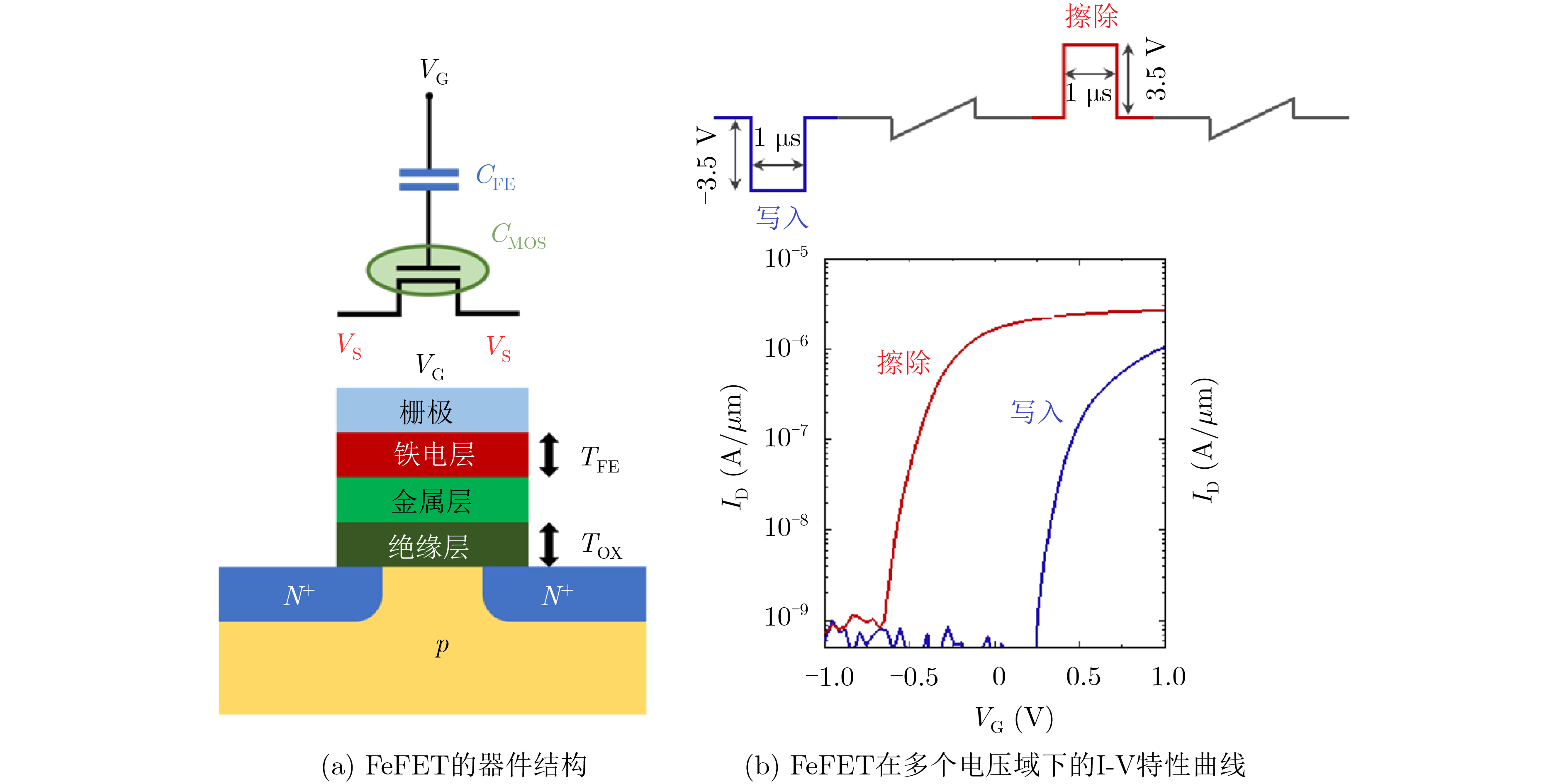
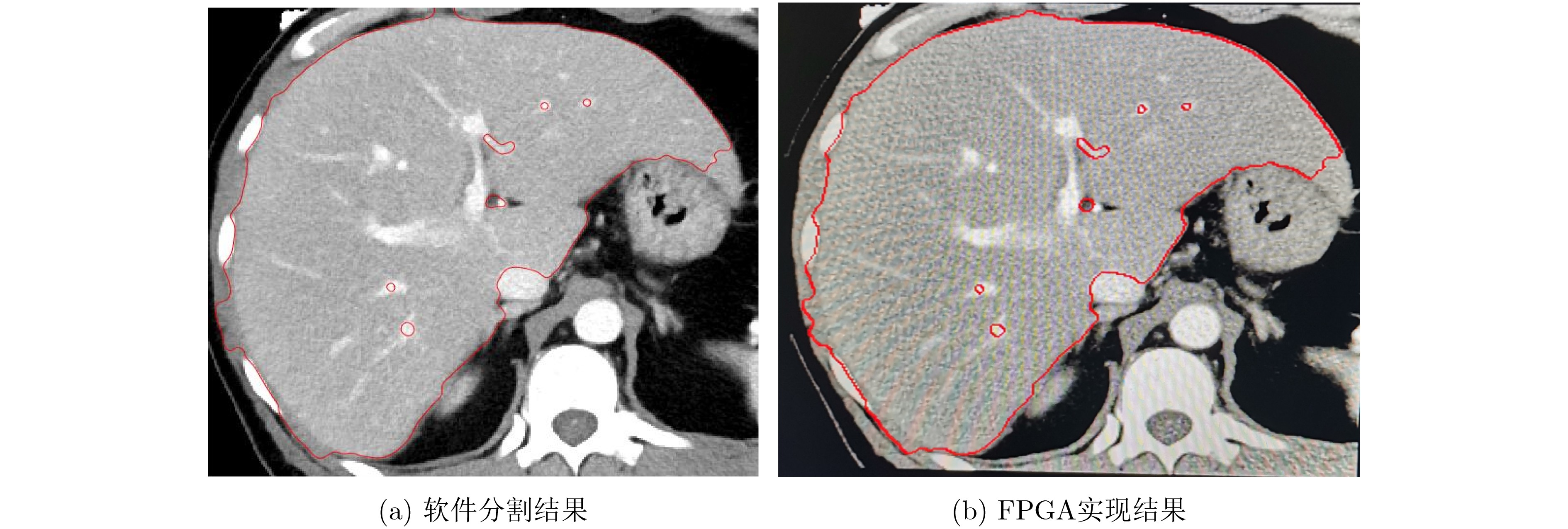
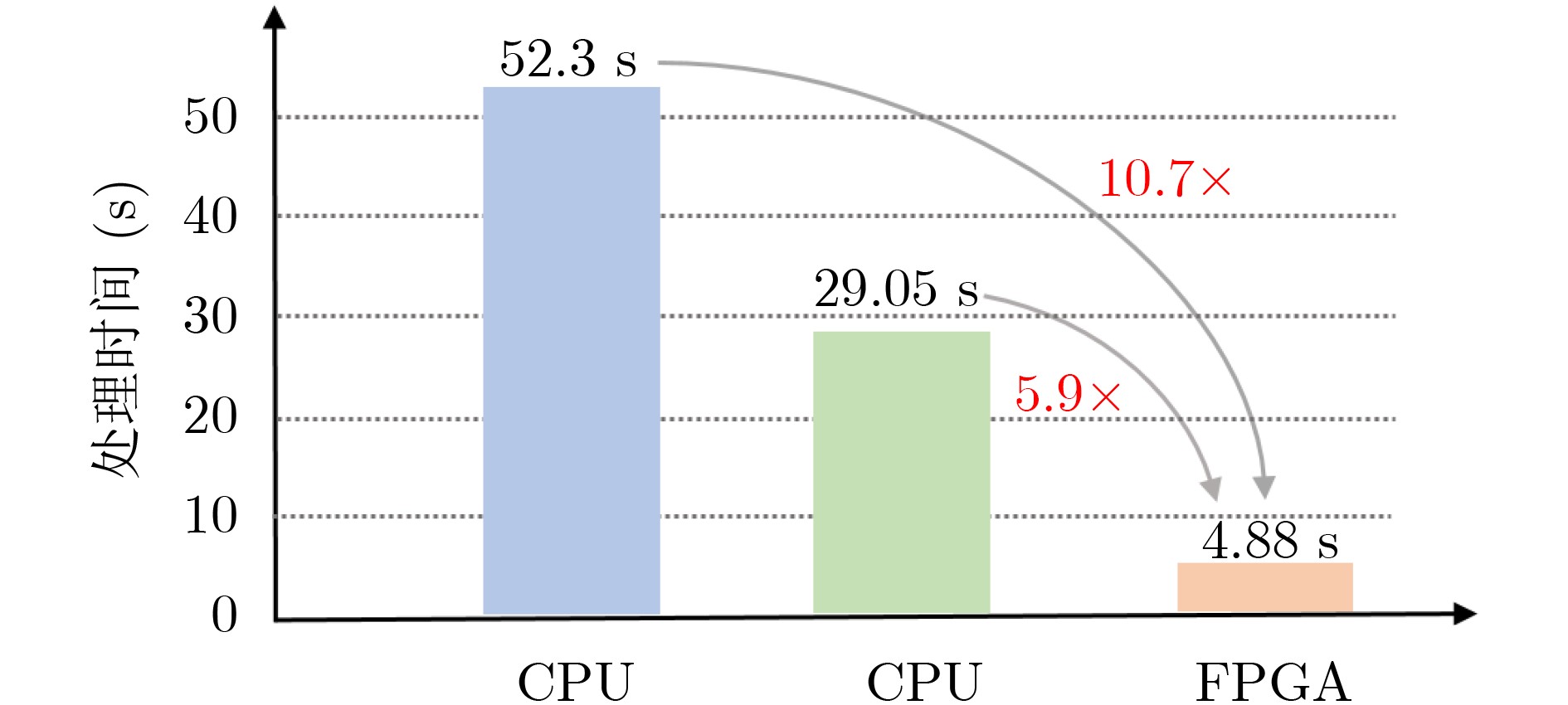
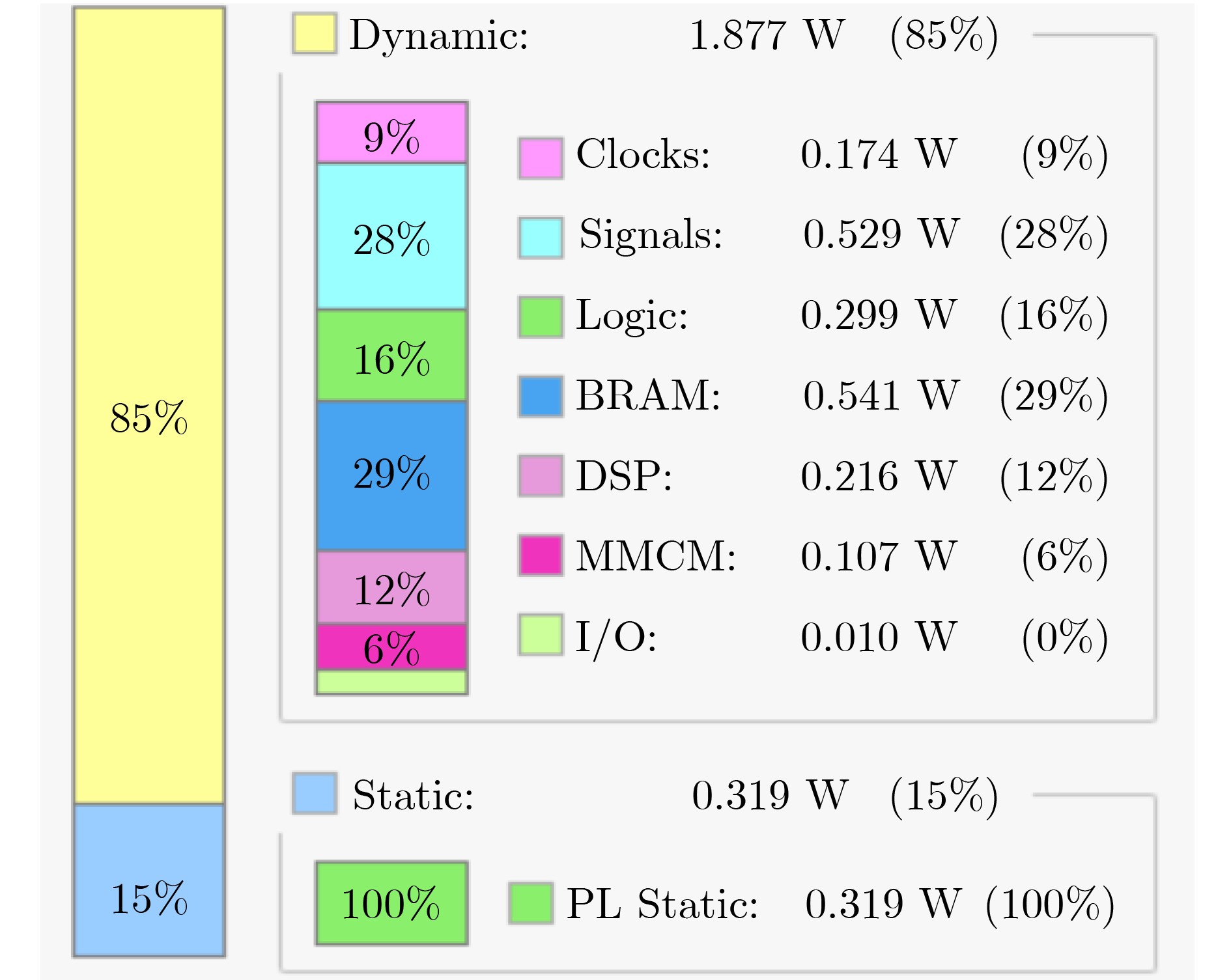
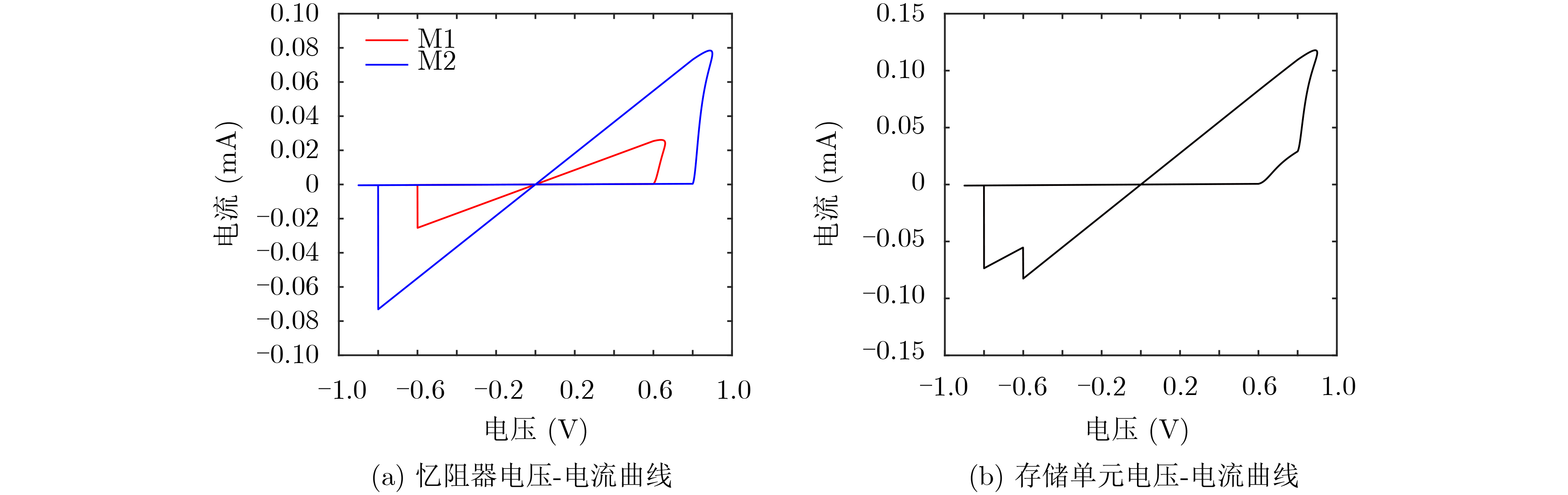
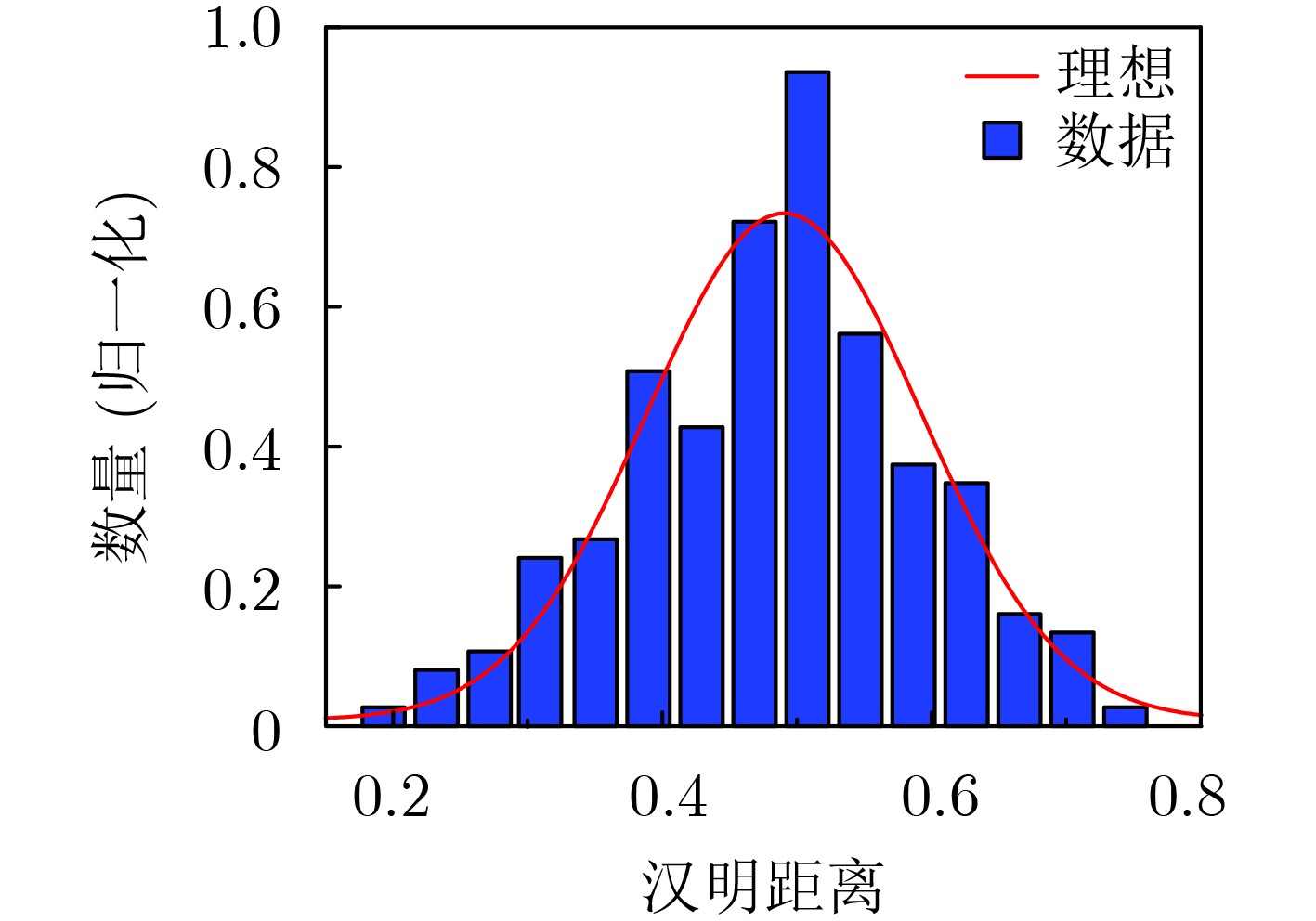
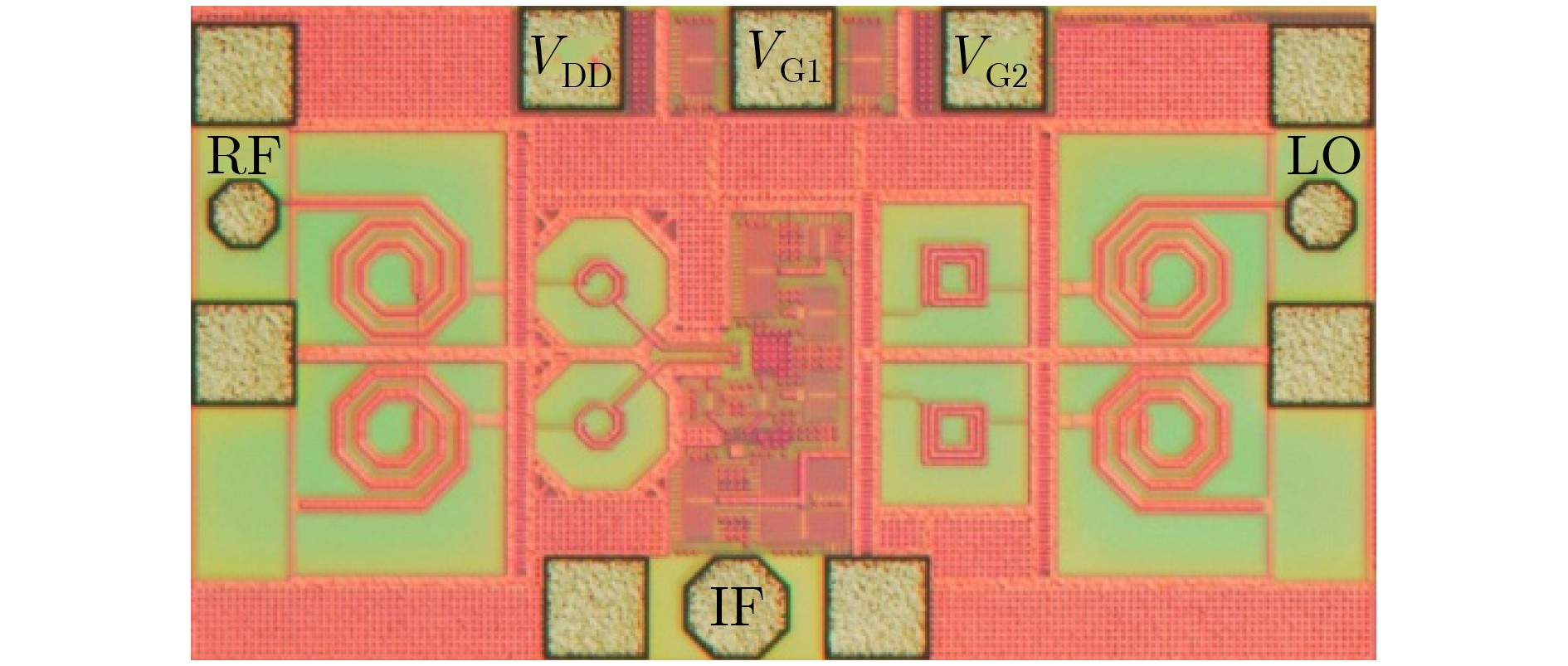
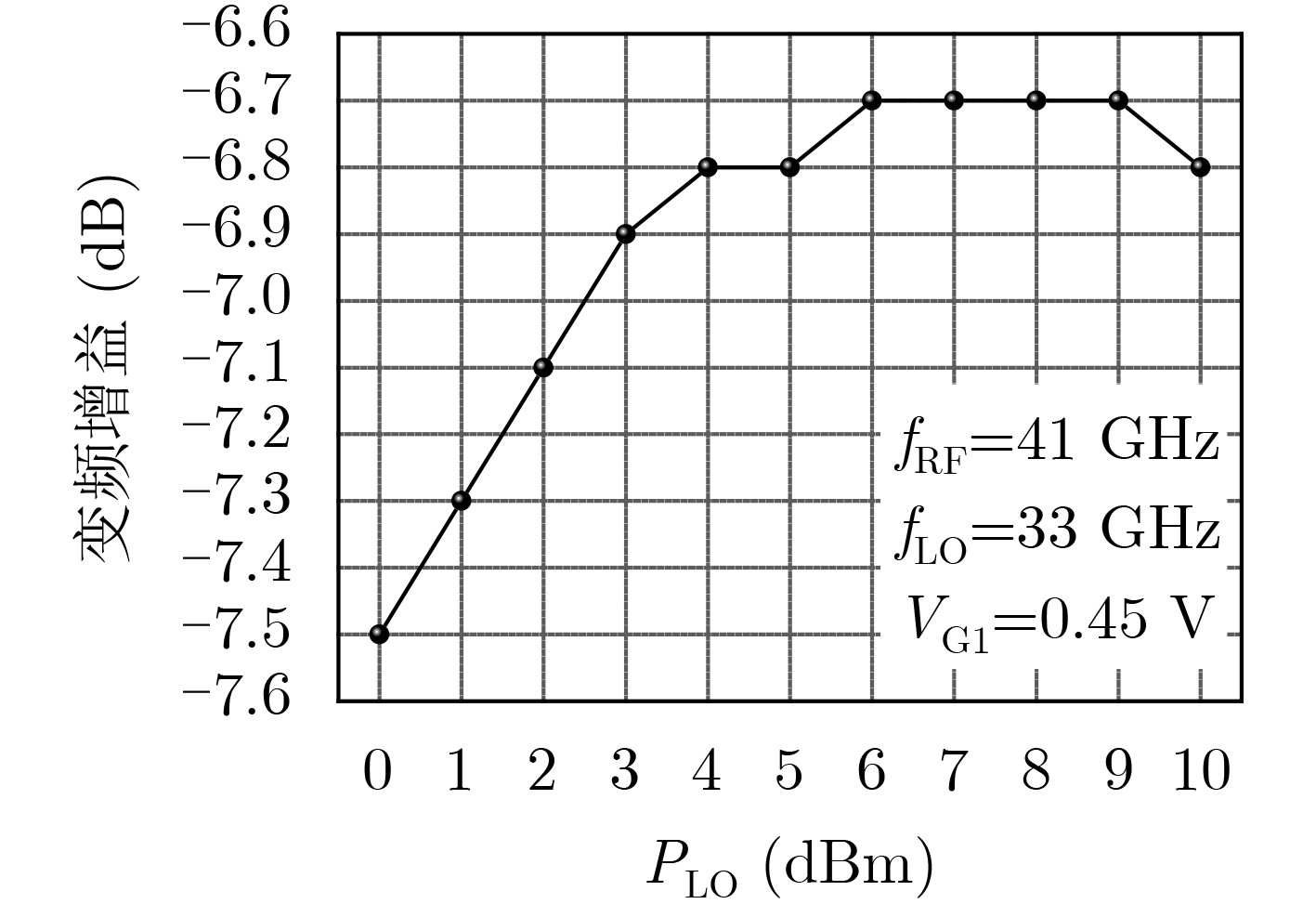
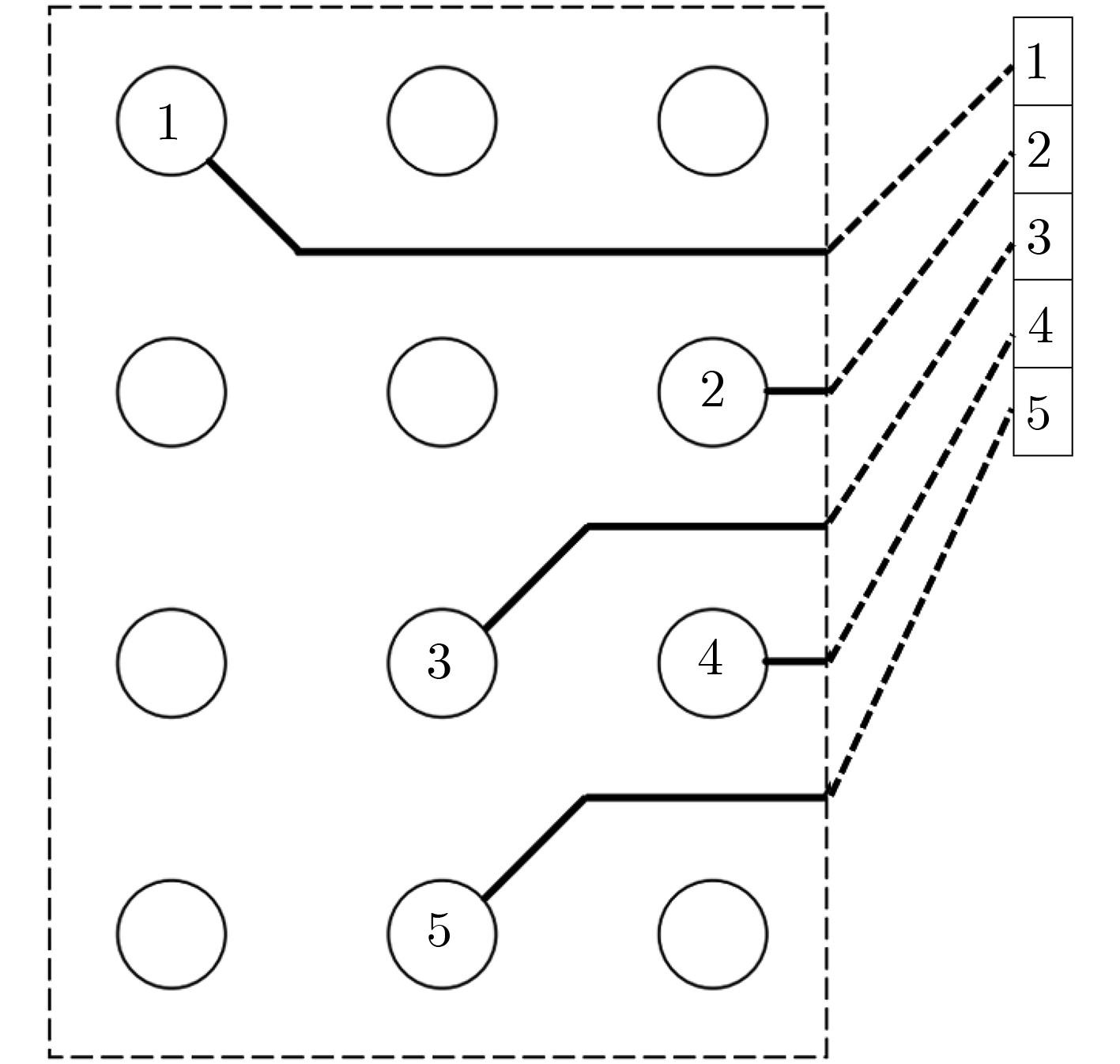
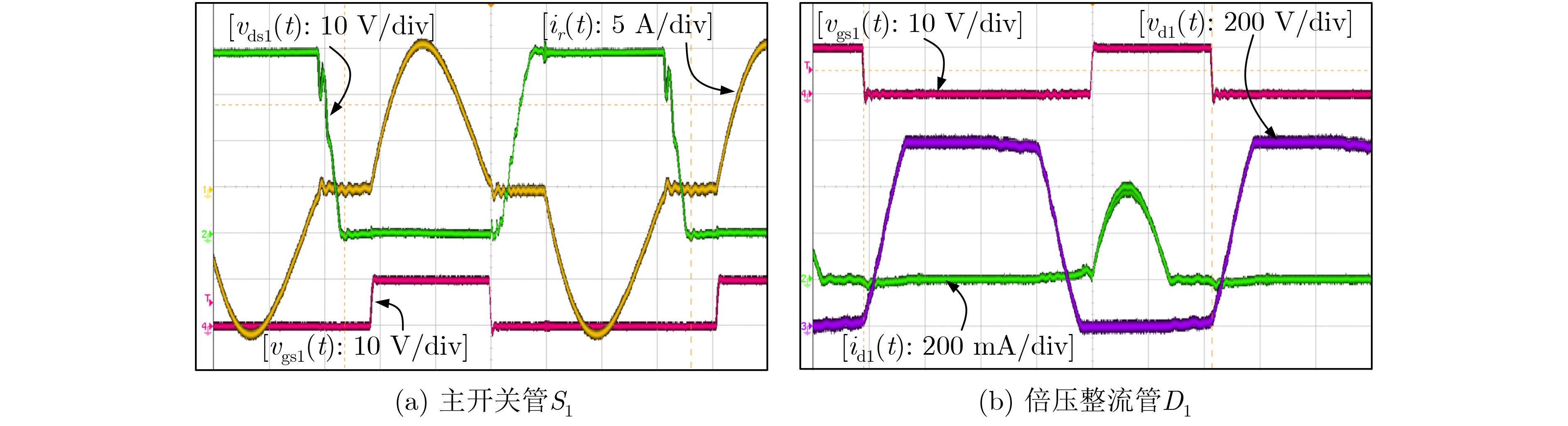
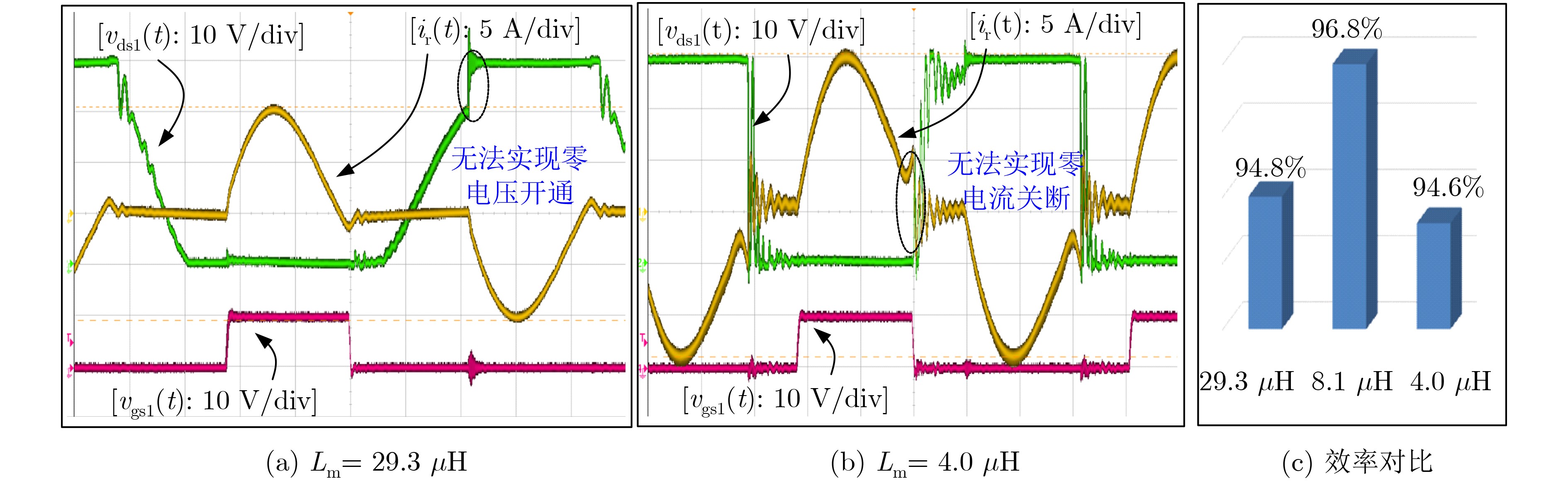
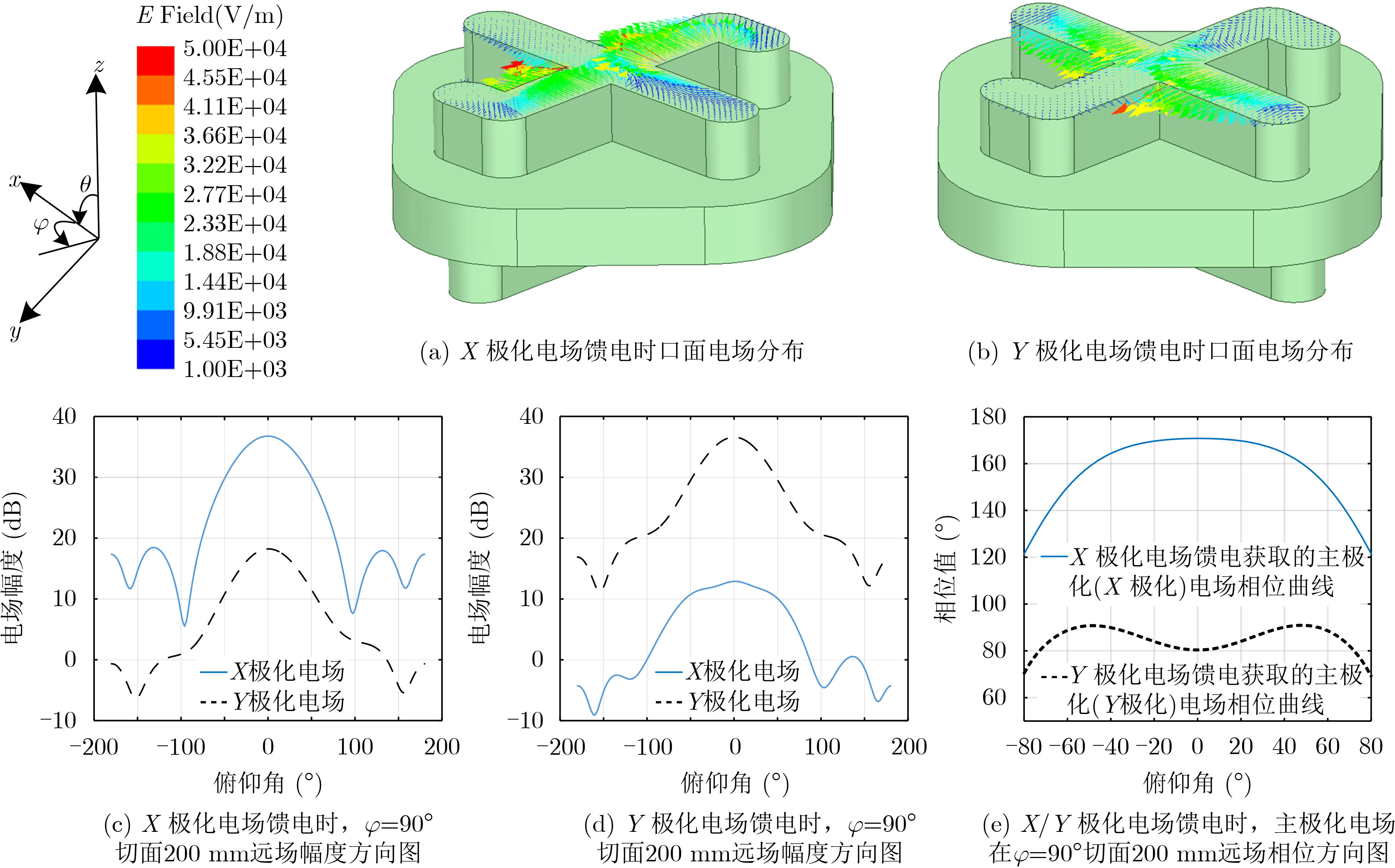
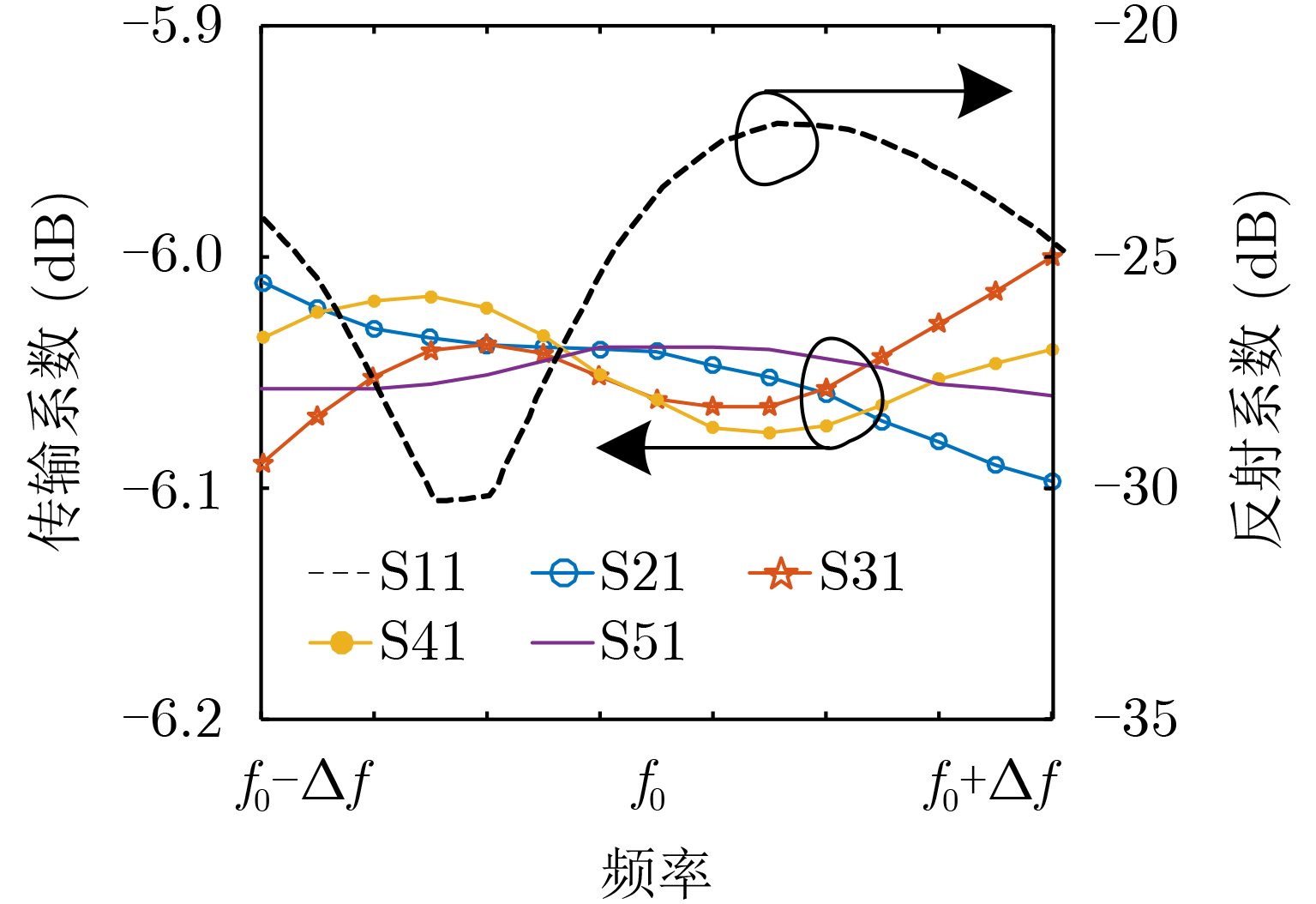
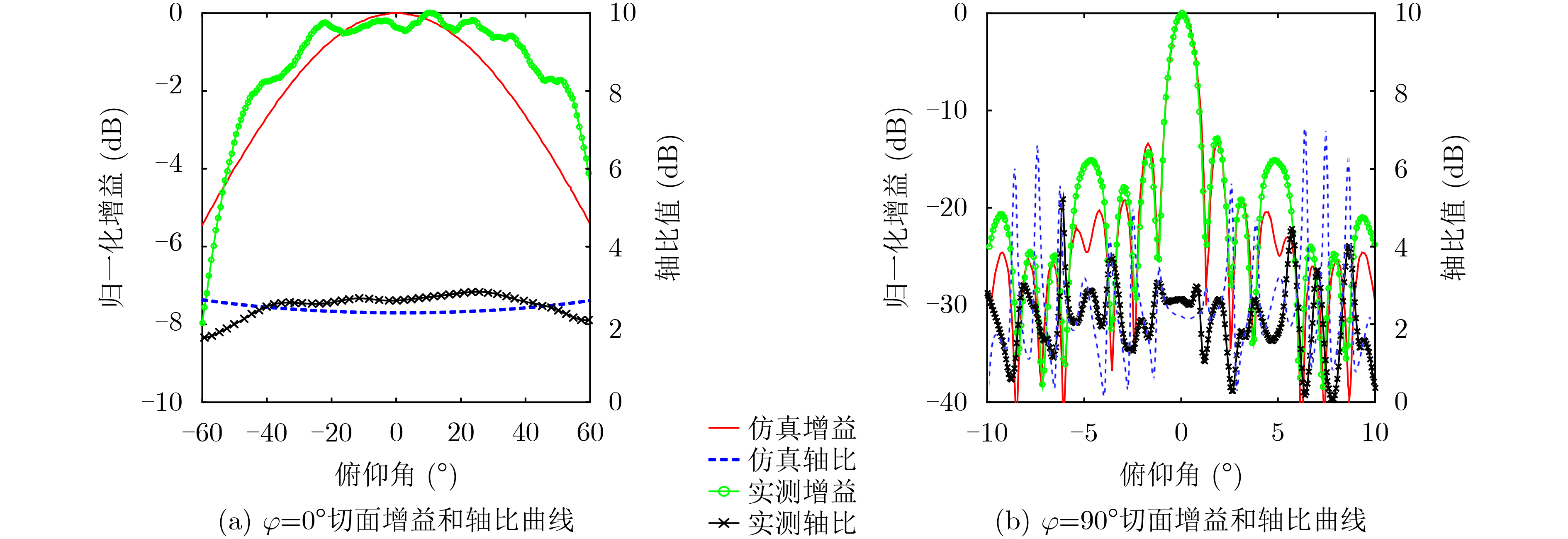
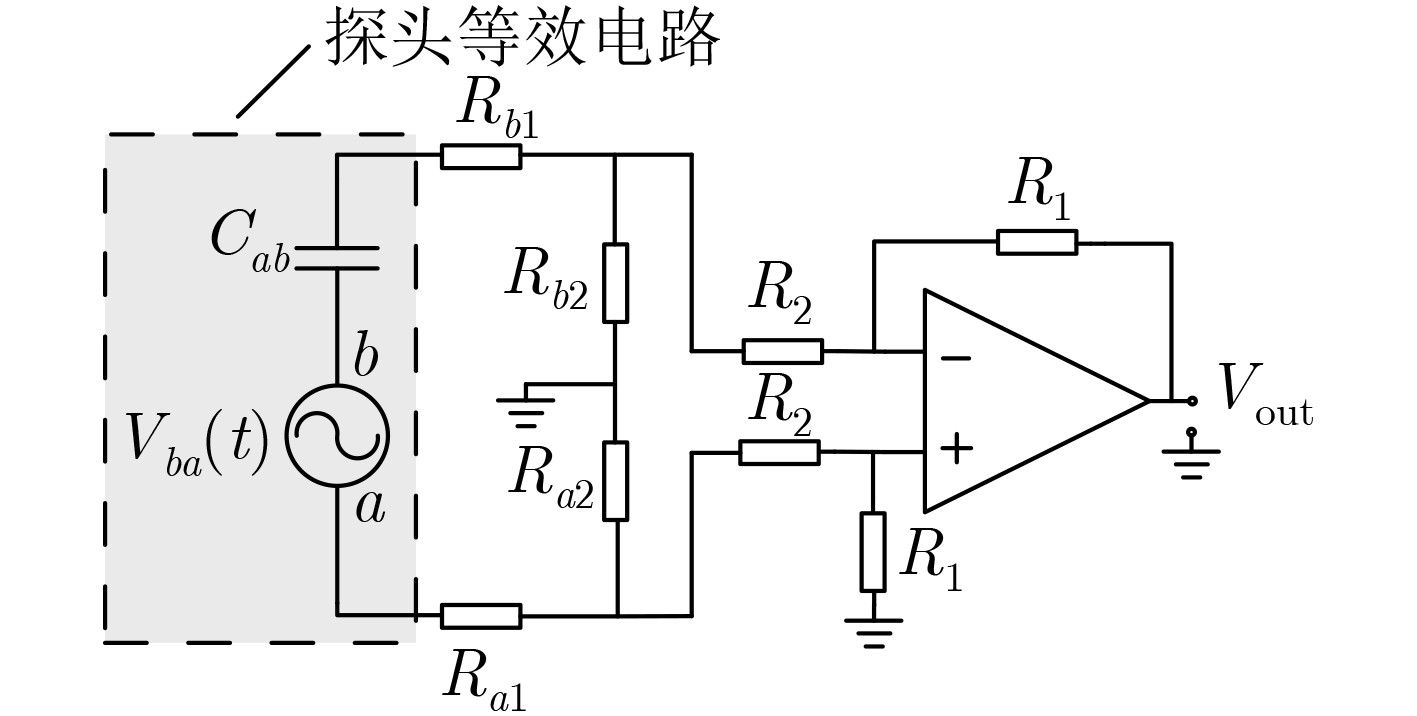
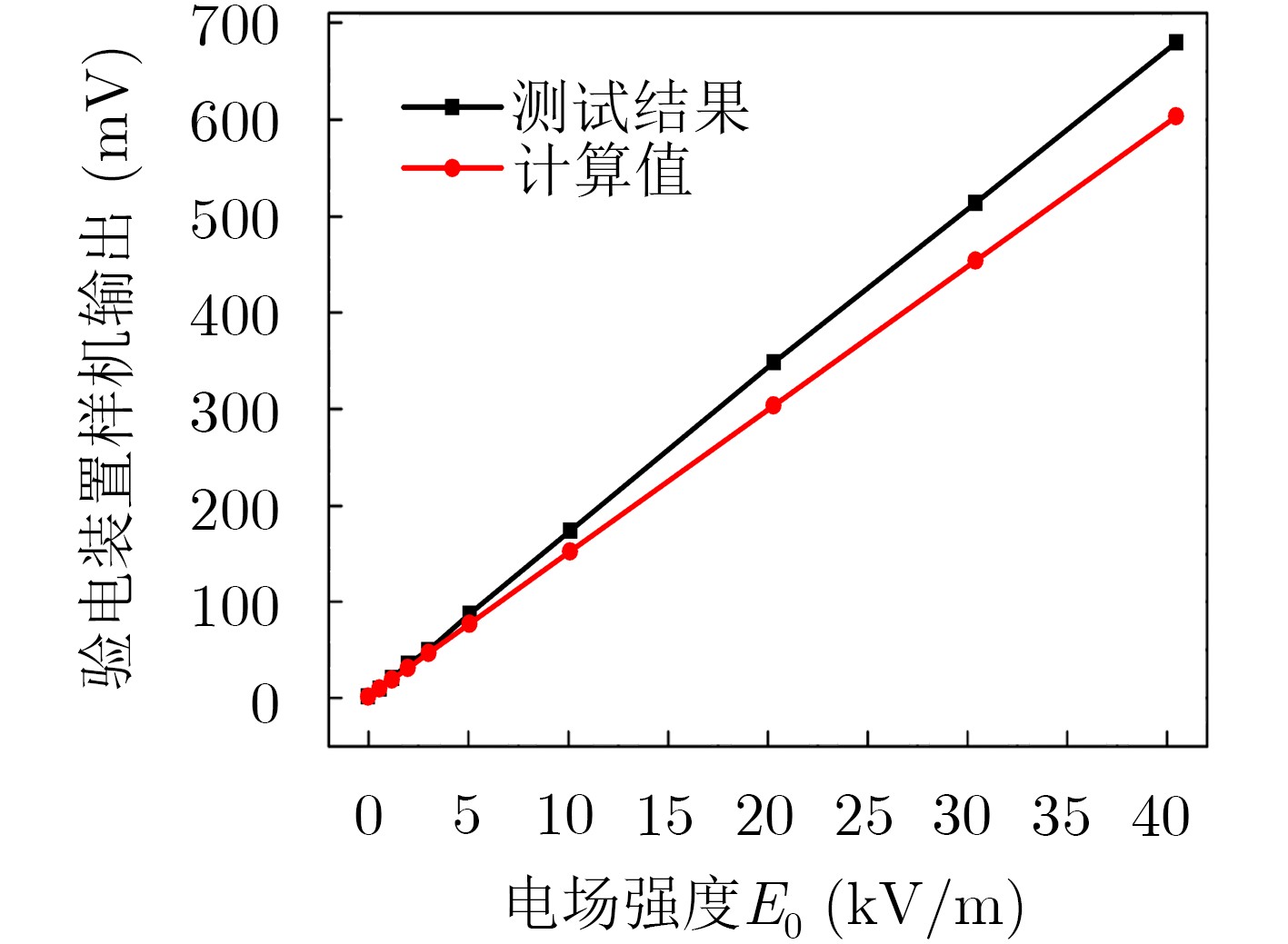
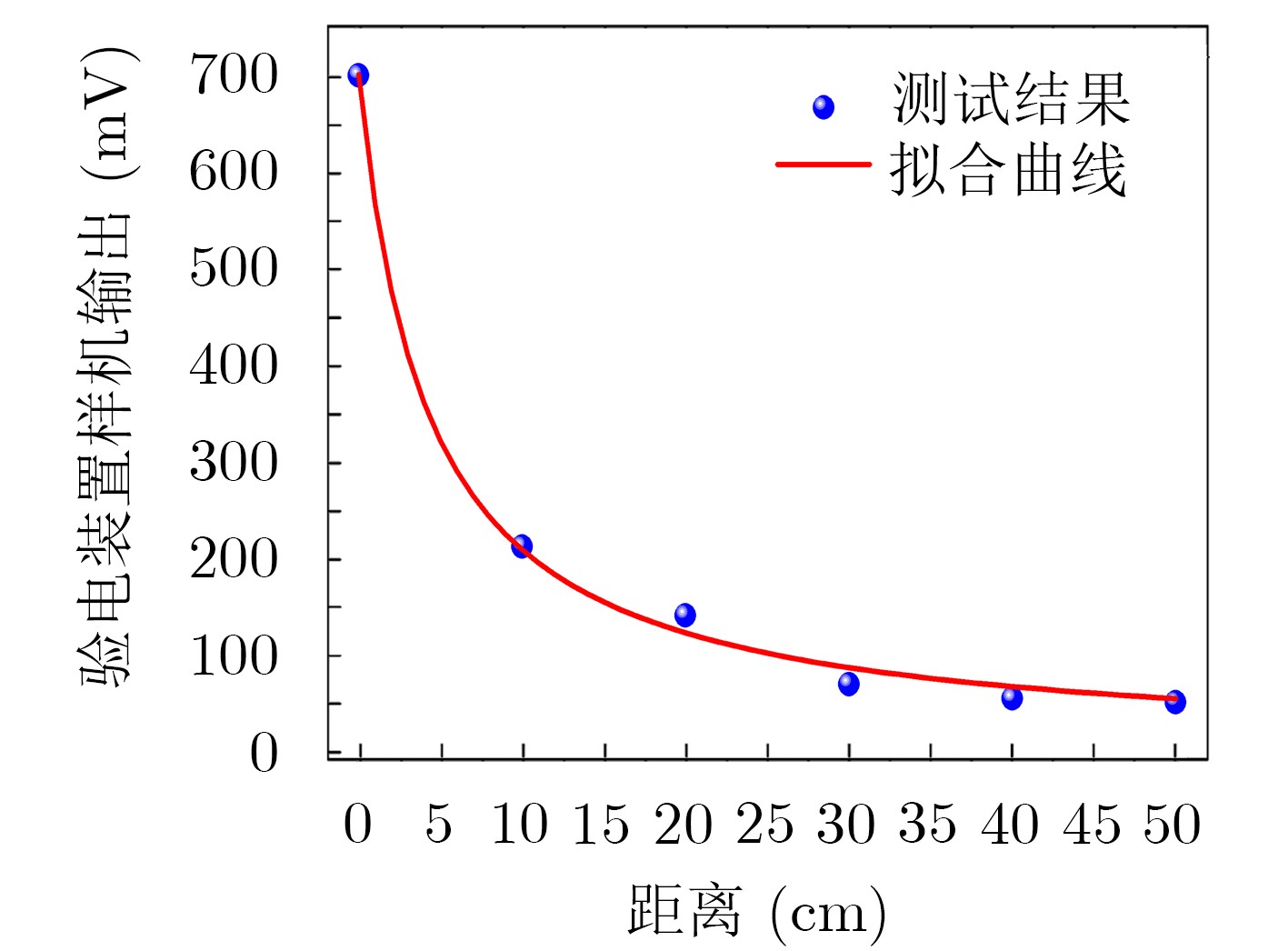
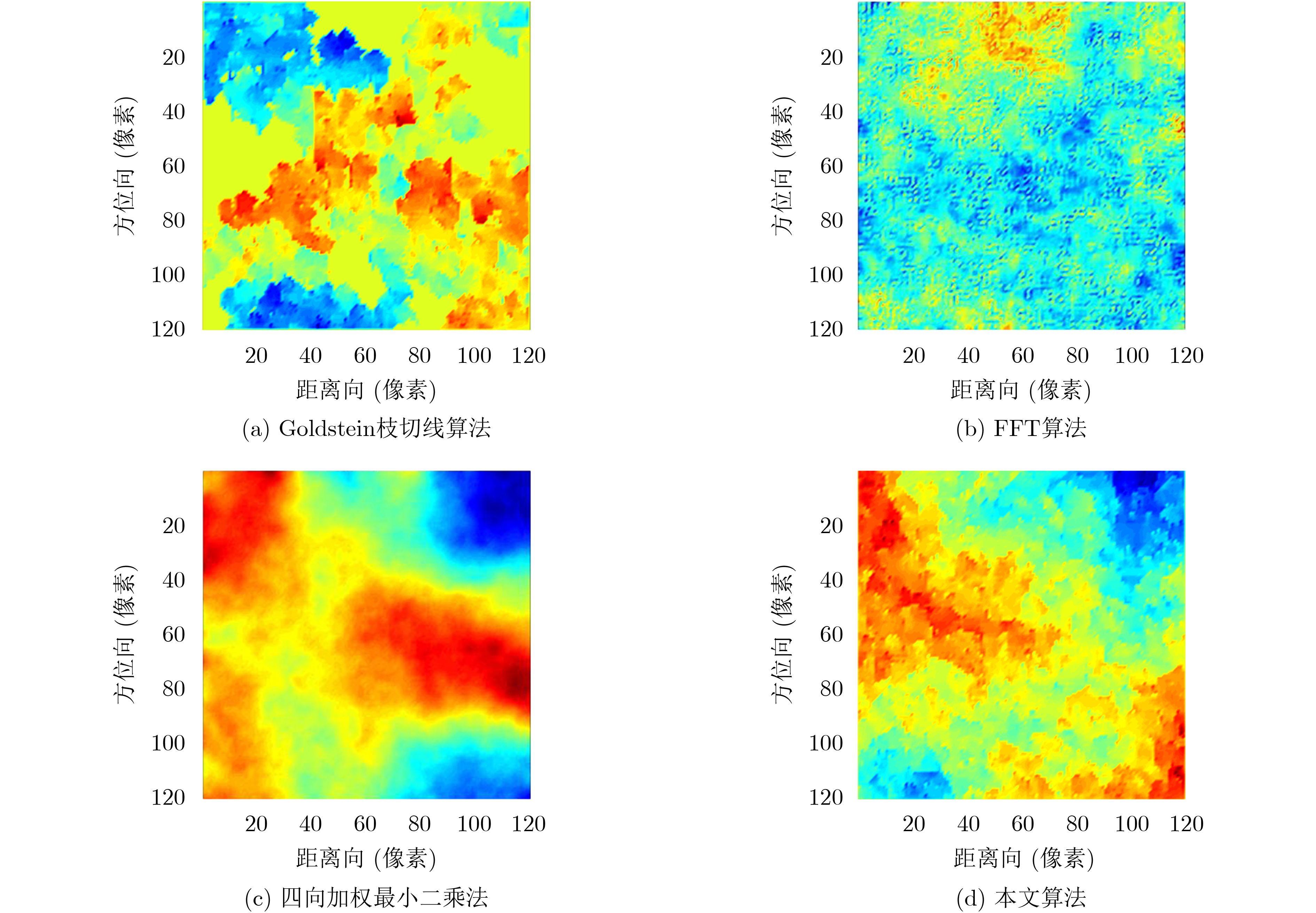
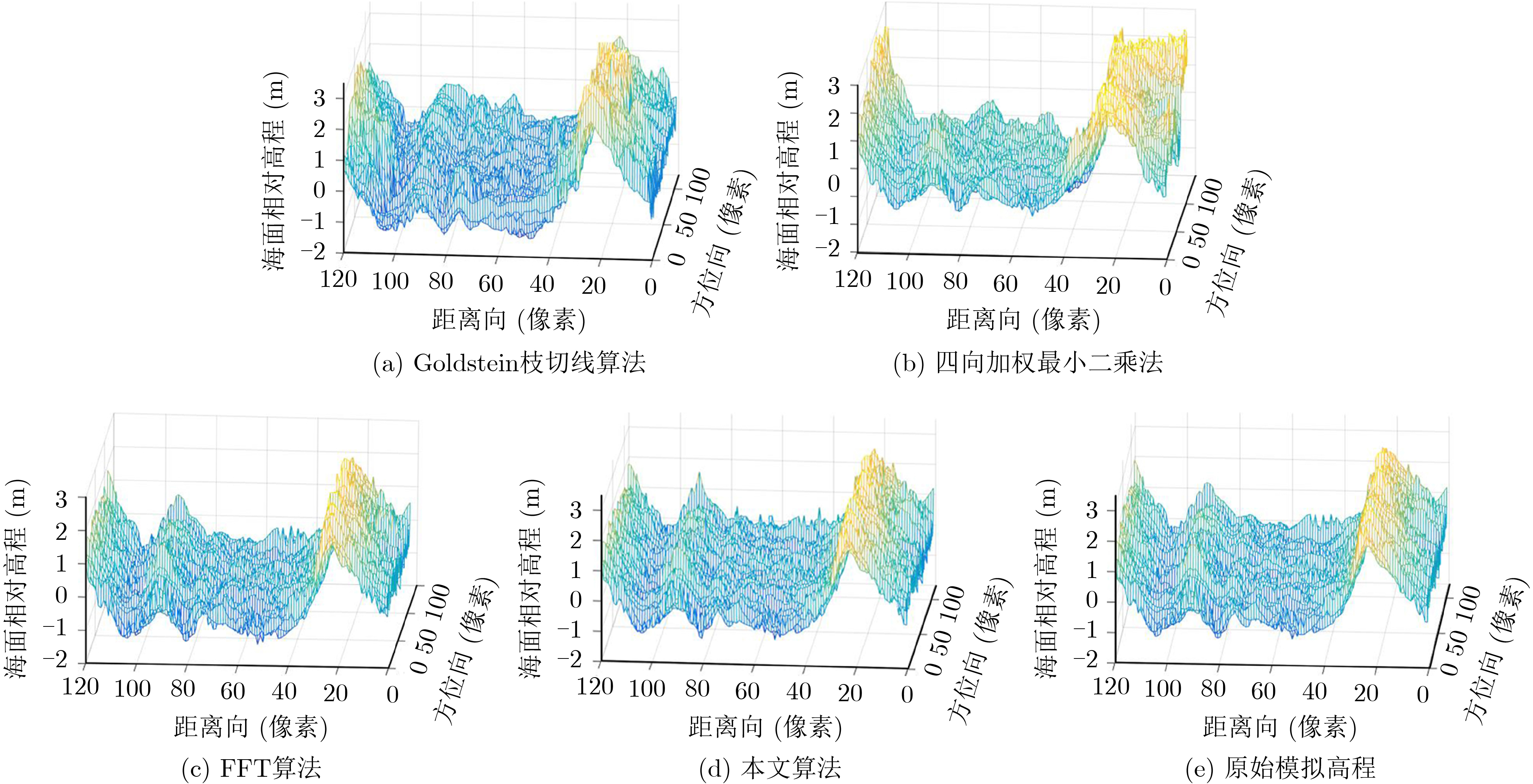
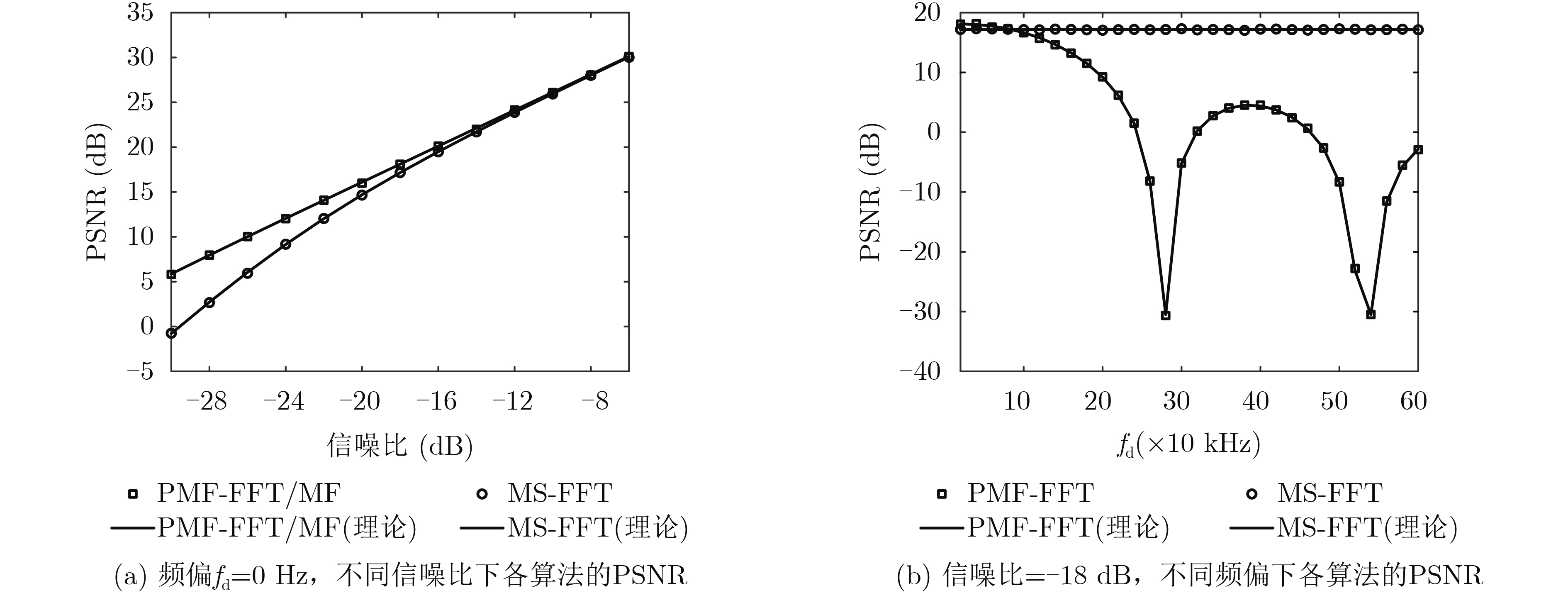
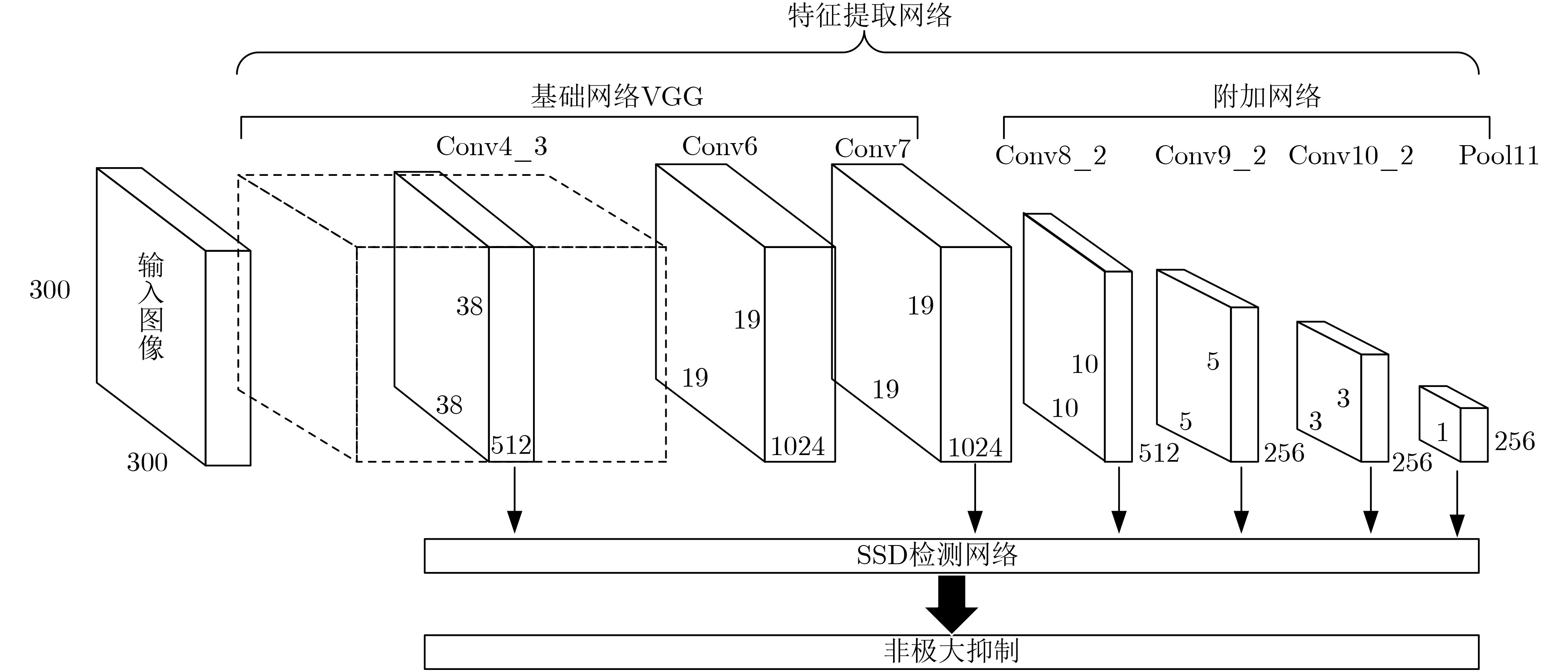
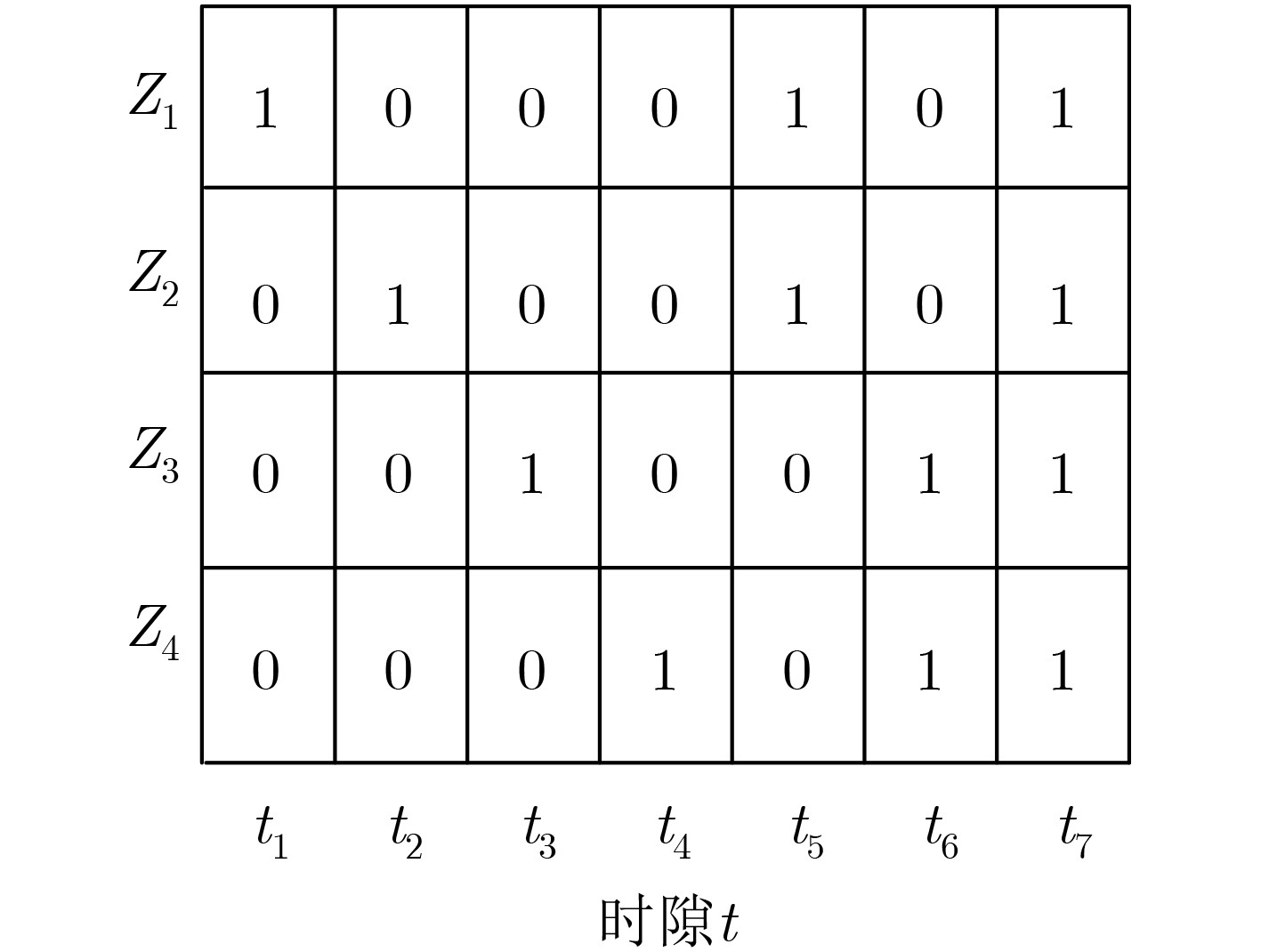
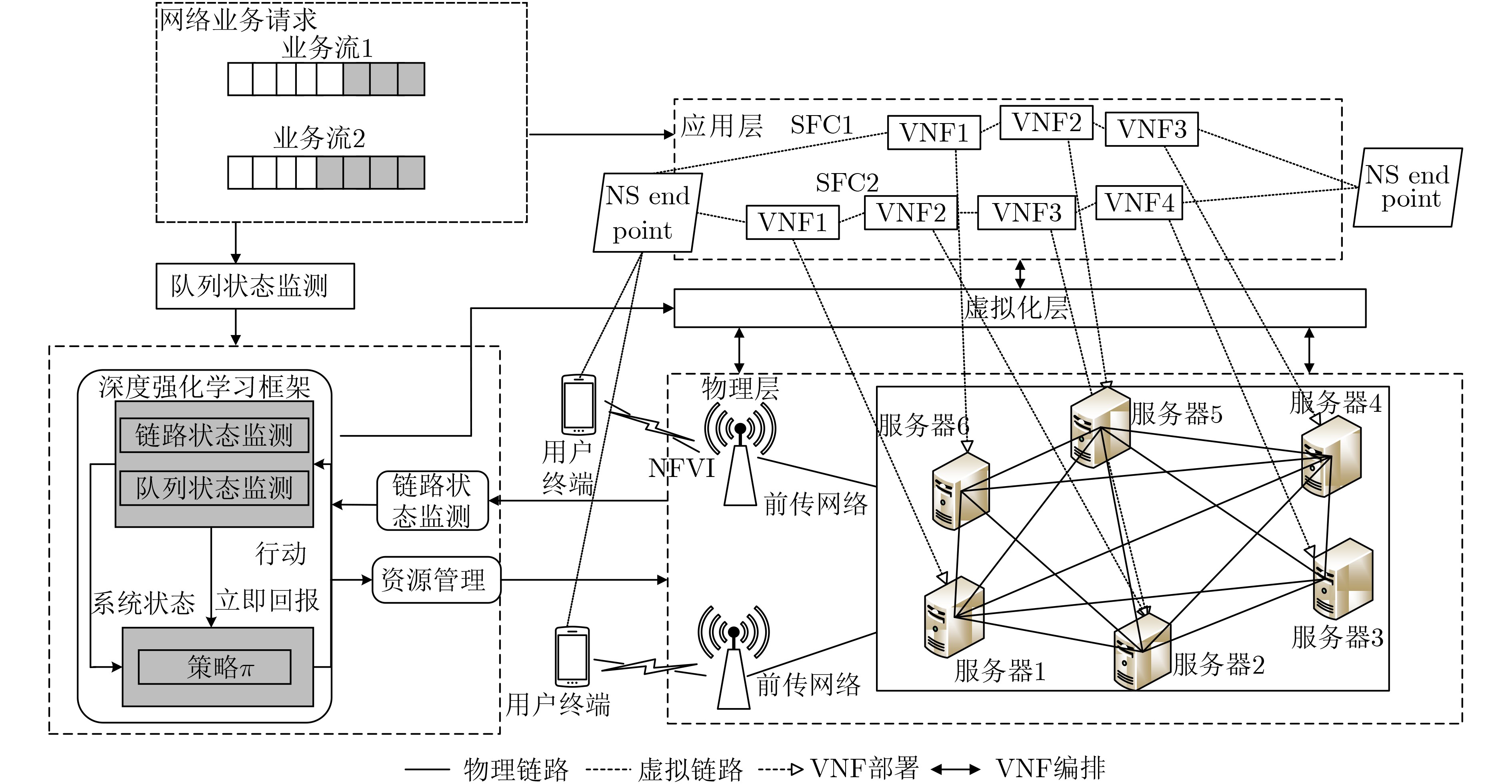
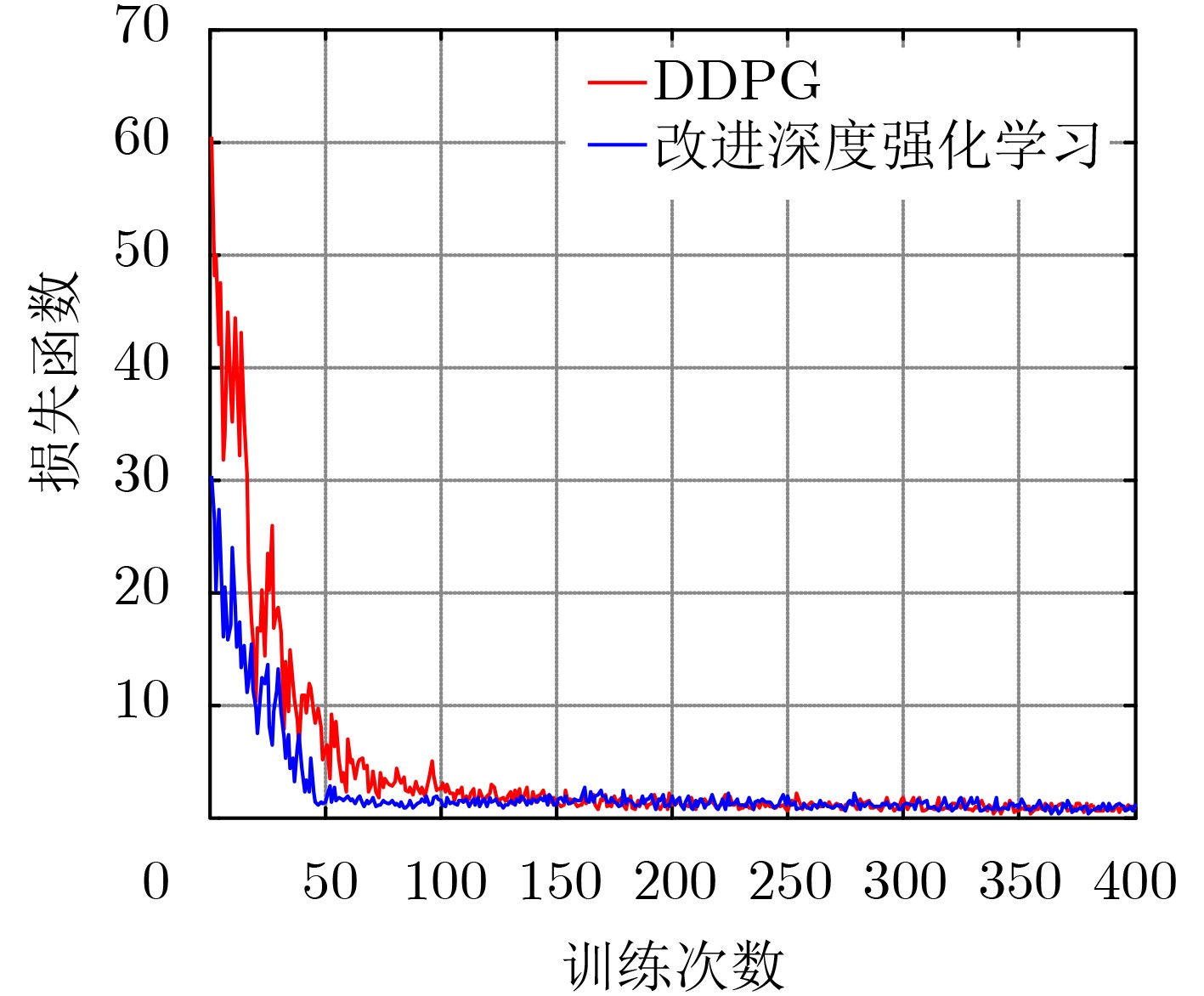
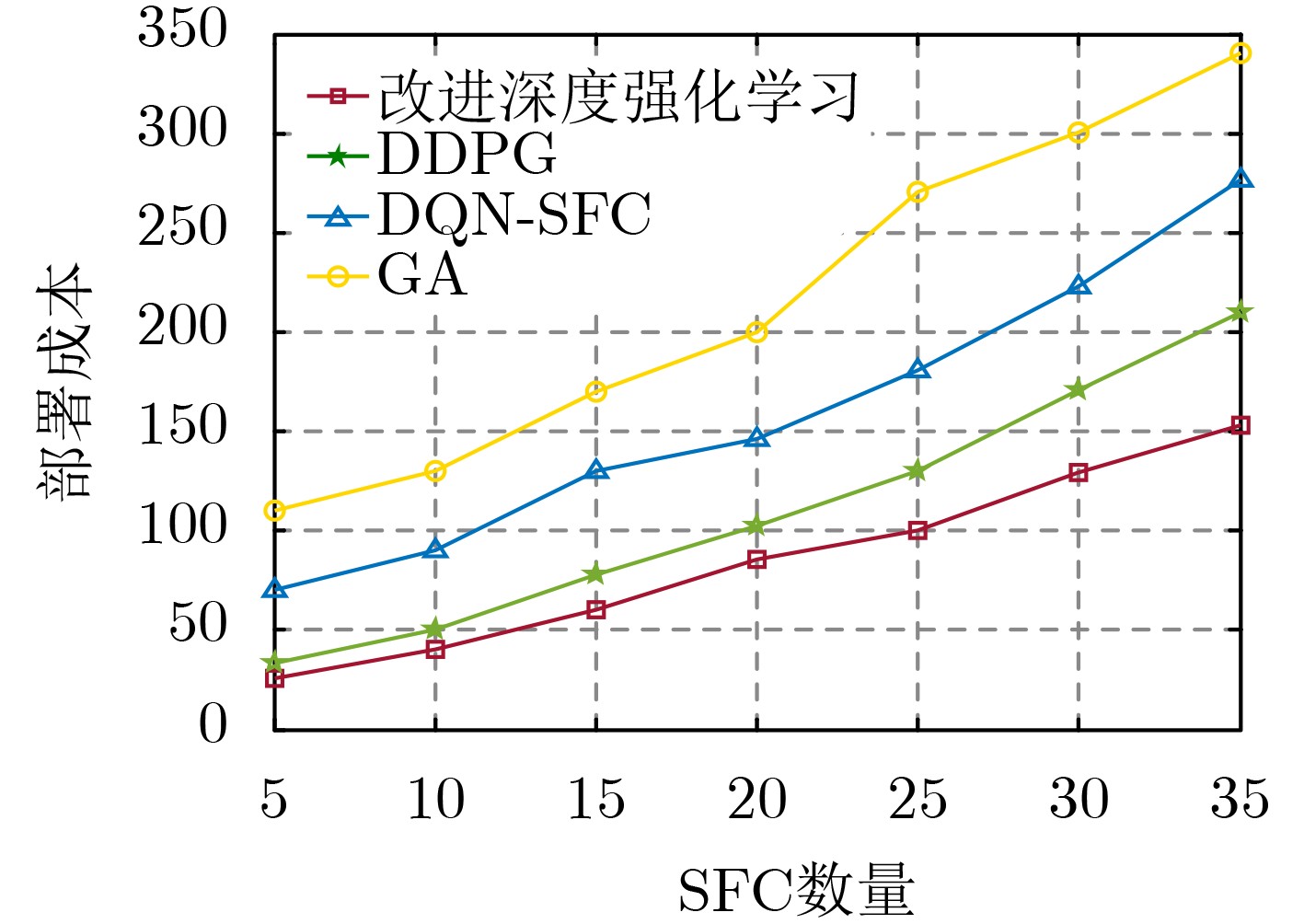
2021, 43(6): 1781-1788.
doi: 10.11999/JEIT191035
Abstract:
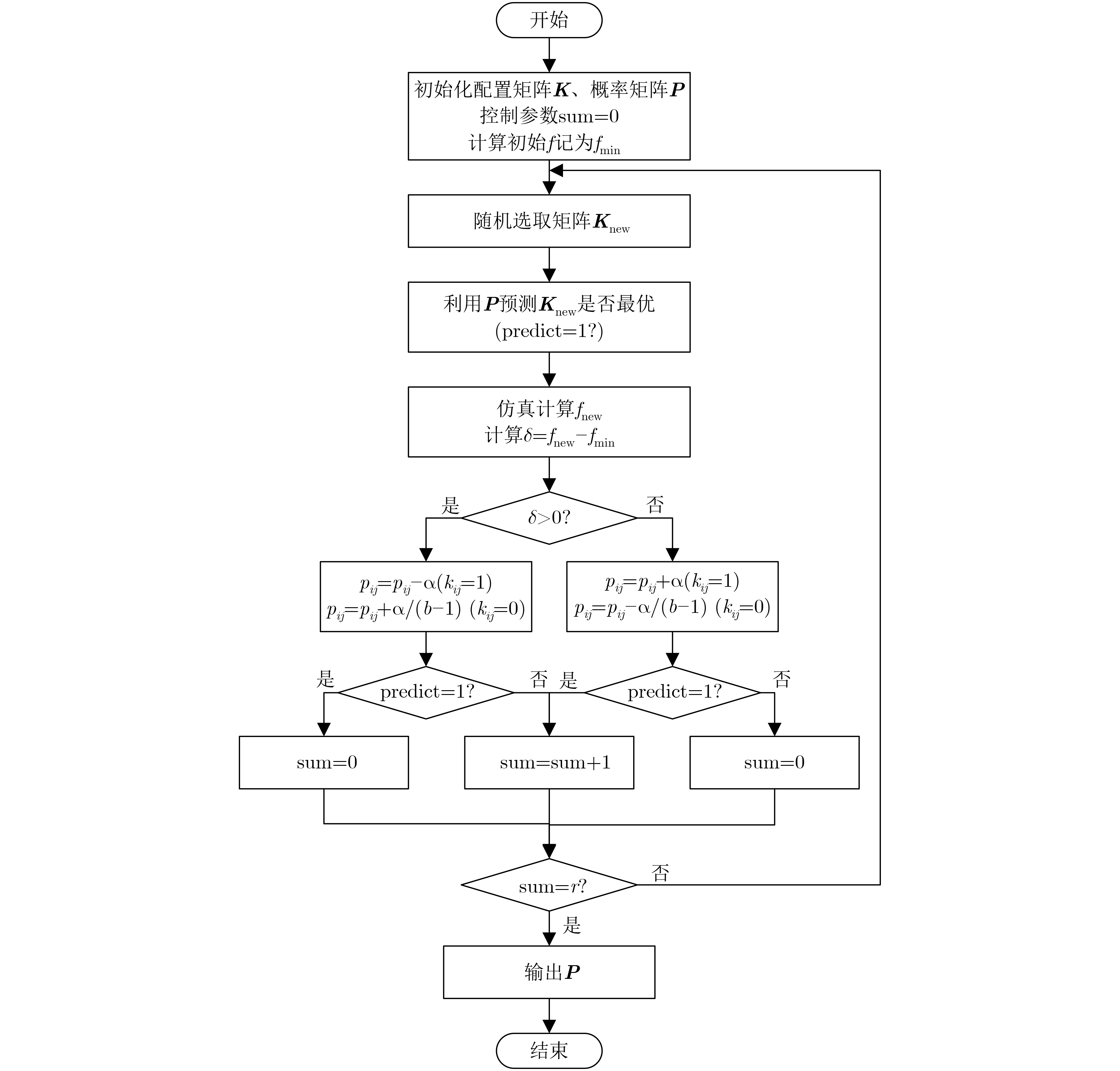
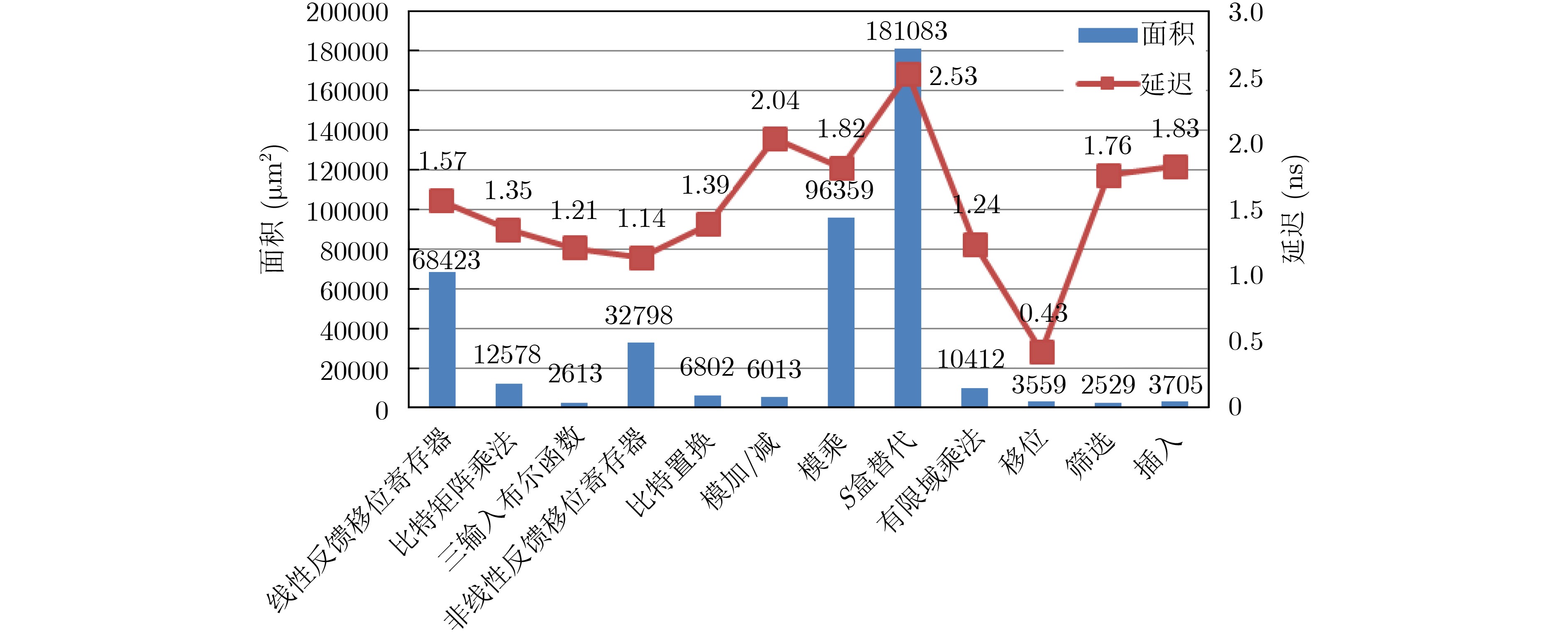
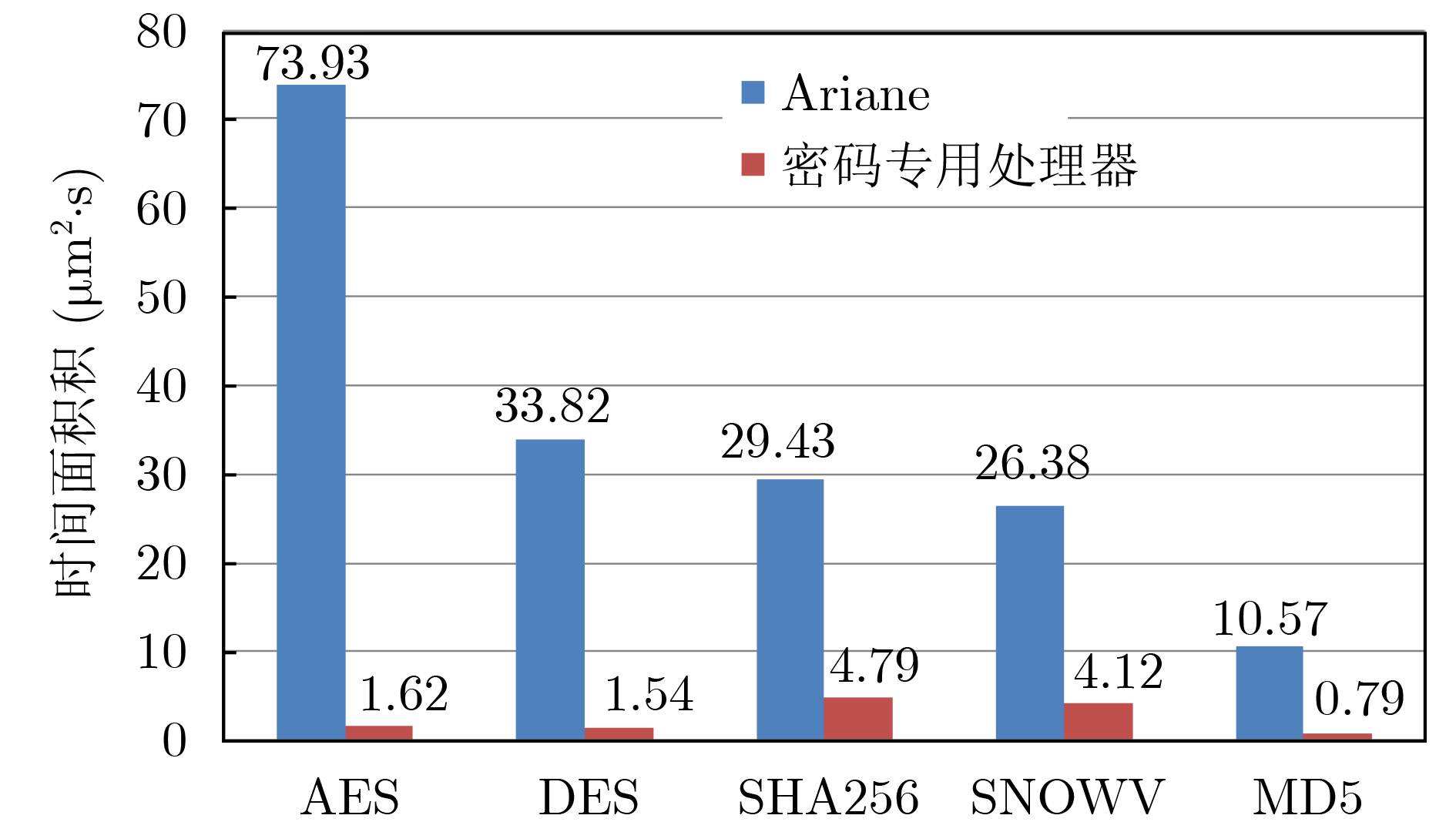
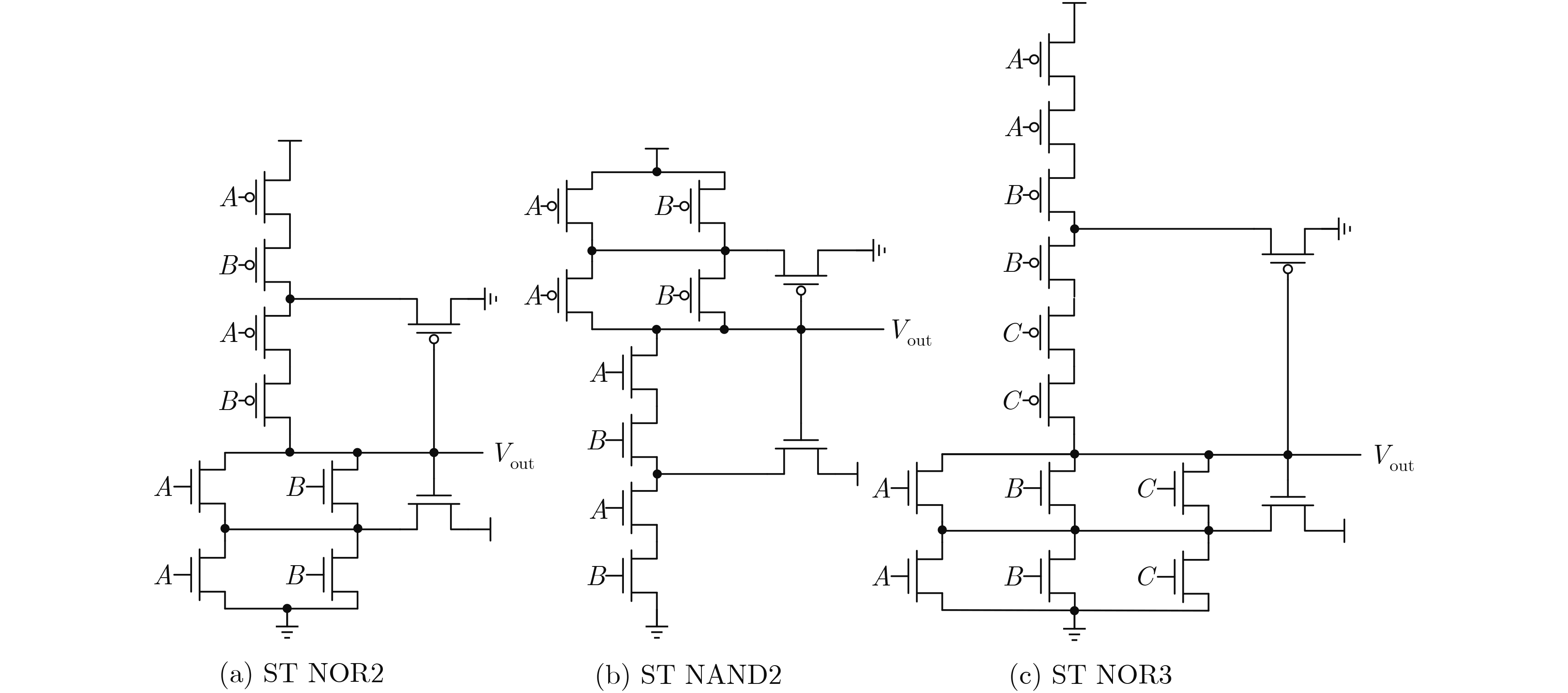
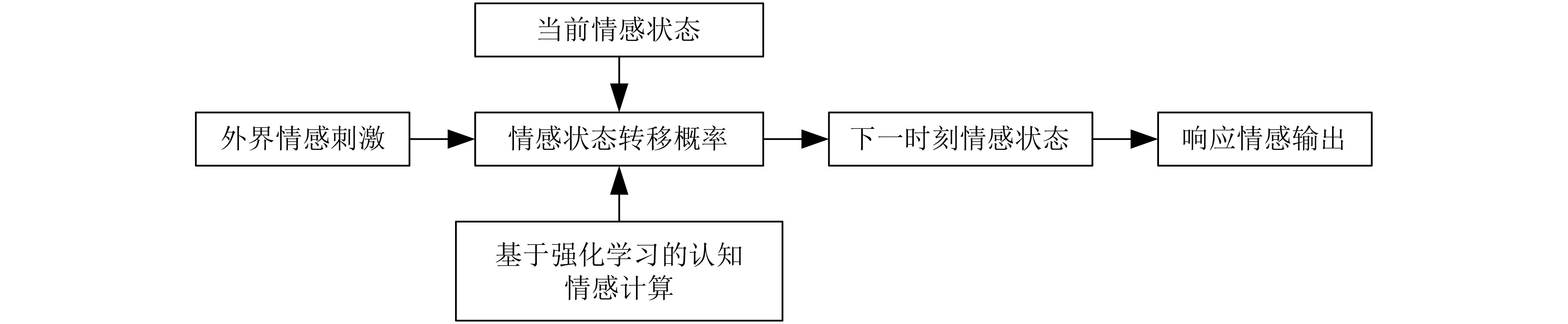
In order to enhance the cognitive emotional computing ability of robot, a cognitive emotional interaction model of robot based on reinforcement learning is proposed, which combines immediate feedback and long-term trend according to PAD(Pleasure-Arousal-Dominance) emotional space. Firstly, according to the psychology theory of interpersonal communication, the human emotion generation process is simulated to generate human-like emotions, and the three influencing factors of similarity, positivity and empathy are extracted. Secondly, the relationship between the response emotion+ state and the contexted long-term emotion state is established by using the global co-ordination feature of reinforcement learning, so as to model the robot emotion generation process. Then, three factors are incorporated into the model reward mechanism for the evaluate of the interactive emotion state, to update the model and get the optimal emotional strategy. Finally, the optimal emotional state corresponding to the obtained optimal emotional strategy is used to update the robot's emotional state transition probability, and based on the sentiment values of the six basic emotional states in space, them are mapped to continuous emotional space to get the optimal response emotional value of the robot. Subjective and objective comparison experiments show that the model in this paper can effectively increase the delicateness, continuity, positivity and empathy of the robot's emotional expression, and can effectively reduce the robot's dependence on external emotional stimuli, further improving the harmonious and friendly human-computer interaction.