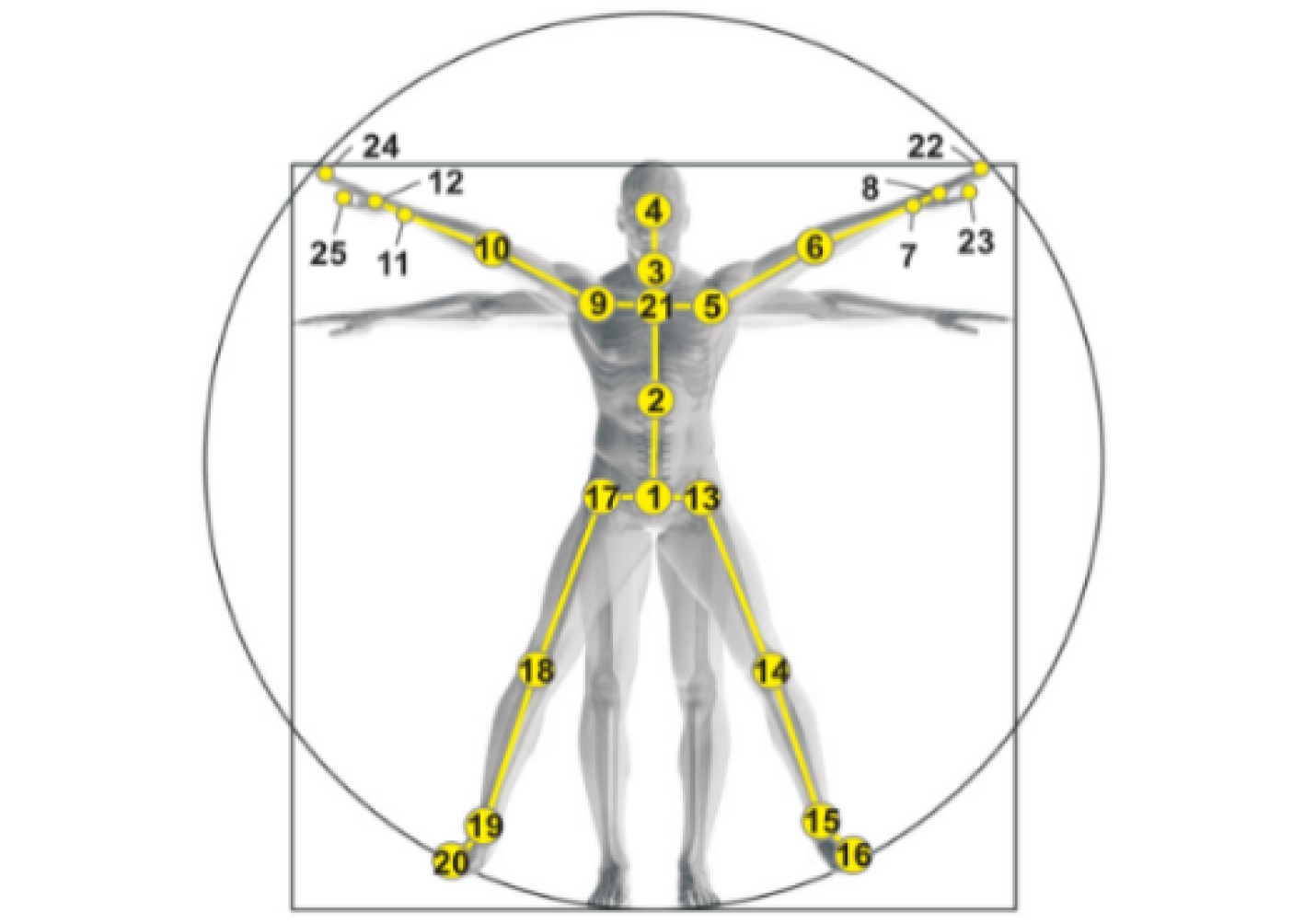
| Citation: | Yun LIU, Panpan XUE, Hui LI, Chuanxu WANG. A Review of Action Recognition Using Joints Based on Deep Learning[J]. Journal of Electronics & Information Technology, 2021, 43(6): 1789-1802. doi: 10.11999/JEIT200267

|

| [1] |
吴培良, 杨霄, 毛秉毅, 等. 一种视角无关的时空关联深度视频行为识别方法[J]. 电子与信息学报, 2019, 41(4): 904–910. doi: 10.11999/JEIT180477
WU Peiliang, YANG Xiao, MAO Bingyi, et al. A perspective-independent method for behavior recognition in depth video via temporal-spatial correlating[J]. Journal of Electronics &Information Technology, 2019, 41(4): 904–910. doi: 10.11999/JEIT180477
|
| [2] |
朱煜, 赵江坤, 王逸宁, 等. 基于深度学习的人体行为识别算法综述[J]. 自动化学报, 2016, 42(6): 848–857. doi: 10.16383/j.aas.2016.c150710
ZHU Yu, ZHAO Jiangkun, WANG Yining, et al. A review of human action recognition based on deep learning[J]. Acta Automatica Sinica, 2016, 42(6): 848–857. doi: 10.16383/j.aas.2016.c150710
|
| [3] |
罗会兰, 王婵娟, 卢飞. 视频行为识别综述[J]. 通信学报, 2018, 39(6): 169–180. doi: 10.11959/j.issn.1000-436x.2018107
LUO Huilan, WANG Chanjuan, and LU Fei. Survey of video behavior recognition[J]. Journal on Communications, 2018, 39(6): 169–180. doi: 10.11959/j.issn.1000-436x.2018107
|
| [4] |
张会珍, 刘云麟, 任伟建, 等. 人体行为识别特征提取方法综述[J]. 吉林大学学报: 信息科学版, 2020, 38(3): 360–370.
ZHANG Huizhen, LIU Yunlin, REN Weijian, et al. Human behavior recognition feature extraction method: A survey[J]. Journal of Jilin University:Information Science Edition, 2020, 38(3): 360–370.
|
| [5] |
ZHU Fan, SHAO Ling, XIE Jin, et al. From handcrafted to learned representations for human action recognition: A survey[J]. Image and Vision Computing, 2016, 55(2): 42–52. doi: 10.1016/j.imavis.2016.06.007
|
| [6] |
ZHANG Zhengyou. Microsoft kinect sensor and its effect[J]. IEEE Multimedia, 2012, 19(2): 4–10. doi: 10.1109/MMUL.2012.24
|
| [7] |
YAN Yichao, XU Jingwei, NI Bingbing, et al. Skeleton-aided articulated motion generation[C]. The 25th ACM International Conference on Multimedia, Mountain View, USA, 2017: 199–207. doi: 10.1145/3123266.3123277.
|
| [8] |
HAN Fei, REILY B, HOFF W, et al. Space-time representation of people based on 3D skeletal data: A review[J]. Computer Vision and Image Understanding, 2017, 158: 85–105. doi: 10.1016/j.cviu.2017.01.011
|
| [9] |
XIA Lu, CHEN C C, and AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 20–27.
|
| [10] |
WENG Junwu, WENG Chaoqun, and YUAN Junsong. Spatio-temporal Naive-Bayes nearest-neighbor (ST-NBNN) for skeleton-based action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Tianjin, China, 2017: 4171–4180.
|
| [11] |
LI Bo, DAI Yuchao, CHENG Xuelian, et al. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN[C]. 2017 IEEE International Conference on Multimedia & Expo Workshops, Hong Kong, China, 2017: 4171–4180. doi: 10.1109/ICMEW.2017.8026282.
|
| [12] |
KIM T S and REITER A. Interpretable 3D human action analysis with temporal convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1623–1631. dio: 10.1109/CVPRW. 2017.207.
|
| [13] |
LI Chao, ZHONG Qiaoyong, XIE Di, et al. Skeleton-based action recognition with convolutional neural networks[C]. 2017 IEEE International Conference on Multimedia & Expo Workshops, Hong Kong, China, 2017: 597–600. doi: 10.1109/ICMEW.2017.8026285.
|
| [14] |
LIU Mengyuan, LIU Hong, and CHEN Chen. Enhanced skeleton visualization for view invariant human action recognition[J]. Pattern Recognition, 2017, 68: 346–362. doi: 10.1016/j.patcog.2017.02.030
|
| [15] |
KE Qiuhong, AN Senjian, BENNAMOUN M, et al. SkeletonNet: Mining deep part features for 3-D action recognition[J]. IEEE Signal Processing Letters, 2017, 24(6): 731–735. doi: 10.1109/LSP.2017.2690339
|
| [16] |
KE Qiuhong, BENNAMOUN M, AN Senjian, et al. A new representation of skeleton sequences for 3D action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3288–3297.
|
| [17] |
LE T M, INOUE N, and SHINODA K. A fine-to-coarse convolutional neural network for 3D human action recognition[J]. arXiv preprint arXiv: 1805.11790, 2018.
|
| [18] |
LI Chao, ZHONG Qiaoyong, XIE Di, et al. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation[J]. arXiv preprint arXiv: 1804.06055, 2018.
|
| [19] |
刘庭煜, 陆增, 孙毅锋, 等. 基于三维深度卷积神经网络的车间生产行为识别[J]. 计算机集成制造系统, 2020, 26(8): 2143–2156.
LIU Tingyu, LU Zeng, SUN Yifeng, et al. Working activity recognition approach based on 3D deep convolutional neural network[J]. Computer Integrated Manufacturing Systems, 2020, 26(8): 2143–2156.
|
| [20] |
姬晓飞, 秦琳琳, 王扬扬. 基于RGB和关节点数据融合模型的双人交互行为识别[J]. 计算机应用, 2019, 39(11): 3349–3354. doi: 772/j.issn.1001-9081.2019040633
JI Xiaofei, QIN Linlin, and WANG Yangyang. Human interaction recognition based on RGB and skeleton data fusion model[J]. Journal of Computer Applications, 2019, 39(11): 3349–3354. doi: 772/j.issn.1001-9081.2019040633
|
| [21] |
YAN An, WANG Yali, LI Zhifeng, et al. PA3D: Pose-action 3D machine for video recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7922–7931. doi: 10.1109/CVPR.2019.00811.
|
| [22] |
CAETANO C, BRÉMOND F, and SCHWARTZ W R. Skeleton image representation for 3D action recognition based on tree structure and reference joints[C]. The 32nd SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 2019: 16–23.
|
| [23] |
CAETANO C, SENA J, BRÉMOND F, et al. SkeleMotion: A new representation of skeleton joint sequences based on motion information for 3D action recognition[C]. The 16th IEEE International Conference on Advanced Video and Signal Based Surveillance, Taipei, China, 2019: 1–8. doi: 10.1109/AVSS.2019.8909840.
|
| [24] |
LI Yanshan, XIA Rongjie, LIU Xing, et al. Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 1066–1071. doi: 10.1109/ICME.2019.00187.
|
| [25] |
YANG Fan, WU Yang, SAKTI S, et al. Make skeleton-based action recognition model smaller, faster and better[C]. The ACM Multimedia Asia, Beijing, China, 2019: 1–6. doi: 10.1145/3338533.3366569.
|
| [26] |
SHAHROUDY A, LIU Jun, NG T T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115.
|
| [27] |
LIU Jun, SHAHROUDY A, XU Dong, et al. Spatio-temporal LSTM with trust gates for 3D human action recognition[C]. The European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 816–833. doi: 10.1007/978-3-319-46487-9_50.
|
| [28] |
LIU Jun, SHAHROUDY A, XU Dong, et al. Skeleton-based action recognition using spatio-temporal LSTM network with trust gates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(12): 3007–3021. doi: 10.1109/TPAMI.2017.2771306
|
| [29] |
LIU Jun, WANG Gang, HU Ping, et al. Global context-aware attention LSTM networks for 3D action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1647–1656. doi: 10.1109/CVPR.2017.391.
|
| [30] |
LIU Jun, WANG Gang, DUAN Lingyun, et al. Skeleton-based human action recognition with global context-aware attention LSTM networks[J]. IEEE Transactions on Image Processing, 2018, 27(4): 1586–1599.
|
| [31] |
ZHENG Wu, LI Lin, ZHANG Zhaoxiang, et al. Relational network for skeleton-based action recognition[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 826–831.
|
| [32] |
LI Shuai, LI Wanqing, COOK C, et al. Independently recurrent neural network (IndRNN): Building a longer and deeper RNN[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5457–5466. doi: 10.1109/CVPR.2018.00572.
|
| [33] |
王佳铖, 鲍劲松, 刘天元, 等. 基于工件注意力的车间作业行为在线识别方法[J/OL]. 计算机集成制造系统, 2020: 1–13. http://kns.cnki.net/kcms/detail/11.5946.TP.20200623.1501.034.html.
WANG Jiacheng, BAO Jinsong, LIU Tianyuan, et al. Online method for worker operation recognition based on the attention of workpiece[J/OL]. Computer Integrated Manufacturing Systems, 2020: 1–13. http://kns.cnki.net/kcms/detail/11.5946.TP.20200623.1501.034.html.
|
| [34] |
YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[J]. arXiv preprint arXiv: 1801.07455, 2018.
|
| [35] |
SHI Lei, ZHANG Yifan, CHENG Jia, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 12026–12035.
|
| [36] |
LI M, CHEN Siheng, CHEN Xu, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3595–3603.
|
| [37] |
GAO Xiang, HU Wei, TANG Jiaxiang, et al. Optimized skeleton-based action recognition via sparsified graph regression[C]. The 27th ACM International Conference on Multimedia, New York, USA, 2019: 601–610.
|
| [38] |
LI Chaolong, CUI Zhen, ZHENG Wenming, et al. Spatio-temporal graph convolution for skeleton based action recognition[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 247–254.
|
| [39] |
TANG Yansong, TIAN Yi, LU Jiwen, et al. Deep progressive reinforcement learning for skeleton-based action recognition[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5323–5332.
|
| [40] |
SONG Yifan, ZHANG Zhang, and WANG Liang. Richly activated graph convolutional network for action recognition with incomplete skeletons[C]. 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 1–5. doi: 10.1109/ICIP.2019.8802917.
|
| [41] |
PENG Wei, HONG Xiaopeng, CHEN Haoyu, et al. Learning graph convolutional network for skeleton-based human action recognition by neural searching[J]. arXiv preprint arXiv: 1911.04131, 2019.
|
| [42] |
WU Cong, WU Xiaojun, and KITTLER J. Spatial residual layer and dense connection block enhanced spatial temporal graph convolutional network for skeleton-based action recognition[C]. 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 2019: 1–5.
|
| [43] |
SHI Lei, ZHANG Yifan, CHENG Jian, et al. Skeleton-based action recognition with directed graph neural networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7912–7921.
|
| [44] |
LI Maosen, CHEN Siheng, CHEN Xu, et al. Symbiotic graph neural networks for 3D skeleton-based human action recognition and motion prediction[J]. arXiv preprint arXiv: 1910.02212, 2019.
|
| [45] |
YANG Hongye, GU Yuzhang, ZHU Jianchao, et al. PGCN-TCA: Pseudo graph convolutional network with temporal and channel-wise attention for skeleton-based action recognition[J]. IEEE Access, 2020, 8: 10040–10047. doi: 10.1109/ACCESS.2020.2964115
|
| [46] |
WU Felix, ZHANG Tianyi, DE SOUZA JR A H, et al. Simplifying graph convolutional networks[J]. arXiv preprint arXiv: 1902.07153, 2019.
|
| [47] |
CHEN Jie, MA Tengfei, and XIAO Cao. FastGCN: Fast learning with graph convolutional networks via importance sampling[J]. arXiv preprint arXiv: 1801.10247, 2018.
|
| [48] |
ZHANG Pengfei, LAN Cuiling, XING Junliang, et al. View adaptive neural networks for high performance skeleton-based human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1963–1978. doi: 10.1109/TPAMI.2019.2896631
|
| [49] |
HU Guyue, CUI Bo, and YU Shan. Skeleton-based action recognition with synchronous local and non-local spatio-temporal learning and frequency attention[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 1216–1221.
|
| [50] |
SI Chenyang, JING Ya, WANG Wei, et al. Skeleton-based action recognition with spatial reasoning and temporal stack learning[C]. The European Conference on Computer Vision, Munich, Germany, 2018: 103–118.
|
| [51] |
SI Chenyang, CHEN Wentao, WANG Wei, et al. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1227–1236. doi: 10.1109/CVPR.2019.00132.
|
| [52] |
GAO Jialin, HE Tong, ZHOU Xi, et al. Focusing and diffusion: Bidirectional attentive graph convolutional networks for skeleton-based action recognition[J]. arXiv preprint arXiv: 1912.11521, 2019.
|
| [53] |
ZHANG Pengfei, LAN Cuiling, ZENG Wenjun, et al. Semantics-guided neural networks for efficient skeleton-based human action recognition[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020. doi: 10.1109/CVPR42600.2020.00119.
|
| [54] |
XIE Chunyu, LI Ce, ZHANG Baochang, et al. Memory attention networks for skeleton-based action recognition[C]. The 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 2018.
|
| [55] |
WENG Junwu, LIU Mengyuan, JIANG Xudong, et al. Deformable pose traversal convolution for 3D action and gesture recognition[C]. The European Conference on Computer Vision, Munich, Germany, 2018: 768–775. doi: 10.1007/978-3-030-01234-2_9.
|
| [56] |
WANG Jiang, LIU Zicheng, WU Ying, et al. Mining actionlet ensemble for action recognition with depth cameras[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 1290–1297. doi: 10.1109/CVPR.2012.6247813.
|
| [57] |
YUN K, HONORIO J, CHATTOPADHYAY D, et al. Two-person interaction detection using body-pose features and multiple instance learning[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 28–35. doi: 10.1109/CVPRW.2012.6239234.
|
| [58] |
OREIFEJ O and LIU Zicheng. HON4D: Histogram of oriented 4D normals for activity recognition from depth sequences[C]. 2013 IEEE conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 716–723. doi: 10.1109/CVPR.2013.98.
|
| [59] |
SEIDENARI L, VARANO V, BERRETTI S, et al. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, USA, 2013: 479–485.
|
| [60] |
WEI Ping, ZHAO Yibiao, ZHENG Nanning, et al. Modeling 4D human-object interactions for event and object recognition[C]. 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2013: 3272–3279.
|
| [61] |
YU Gang, LIU Zicheng, and YUAN Junsong. Discriminative orderlet mining for real-time recognition of human-object interaction[C]. The Asian Conference on Computer Vision, Singapore, 2014: 50–65. doi: 10.1007/978-3-319-16814-2_4.
|
| [62] |
WANG Jiang, NIE Xiaohan, XIA Yin, et al. Cross-view action modeling, learning, and recognition[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2649–2656. doi: 10.1109/CVPR.2014.339.
|
| [63] |
RAHMANI H, MAHMOOD A, HUYNH D Q, et al. HOPC: Histogram of oriented principal components of 3D pointclouds for action recognition[C]. The European Conference on Computer Vision, Zurich, Switzerland, 2014: 742–757. doi: 10.1007/978-3-319-10605-2_48.
|
| [64] |
CHEN Chen, JAFARI R, and KEHTARNAVAZ N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor[C]. 2015 IEEE International Conference on Image Processing, Quebec, Canada, 2015: 168–172.
|
| [65] |
HU Jianfang, ZHENG Weishi, LAI Jianhuang, et al. Jointly learning heterogeneous features for RGB-D activity recognition[C]. 2015 IEEE conference on Computer Vision and Pattern Recognition, Boston, America, 2015: 5344–5352.
|
| [66] |
RAHMANI H, MAHMOOD A, HUYNH D, et al. Histogram of oriented principal components for cross-view action recognition[J]. IEEE transactions on Pattern Analysis and Machine Intelligence, 2016, 38(12): 2430–2443. doi: 10.1109/TPAMI.2016.2533389
|
| [67] |
XU Ning, LIU Anan, NIE Weizhi, et al. Multi-modal & multi-view & interactive benchmark dataset for human action recognition[C]. The 23rd ACM International Conference on Multimedia, Brisbane, Australia, 2015: 1195–1198.
|
| [68] |
KAY W, CARREIRA J, SIMONYAN K, et al. The kinetics human action video dataset[J]. arXiv preprint arXiv: 1705.06950, 2017.
|
| [69] |
LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873
|
| [70] |
MARSZALEK M, LAPTEV I, and SCHMID C. Actions in context[C]. 2019 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 2391–2396. doi: 10.1109/CVPR.2009.5206557.
|
| [71] |
KUEHNE H, JUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556-2563. doi:10.1007/978-3-642-33374-3_41 .
|
| [72] |
CAO Zhe, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 7291–7299. doi: 10.1109/CVPR.2017.143.
|
| [73] |
SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[J]. arXiv preprint arXiv: 1212.0402, 2012.
|
| [74] |
HAN Jungong, SHAO Ling, XU Dong, et al. Enhanced computer vision with microsoft kinect sensor: A review[J]. IEEE Transactions on Cybernetics, 2013, 43(5): 1318–1334. doi: 10.1109/TCYB.2013.2265378
|
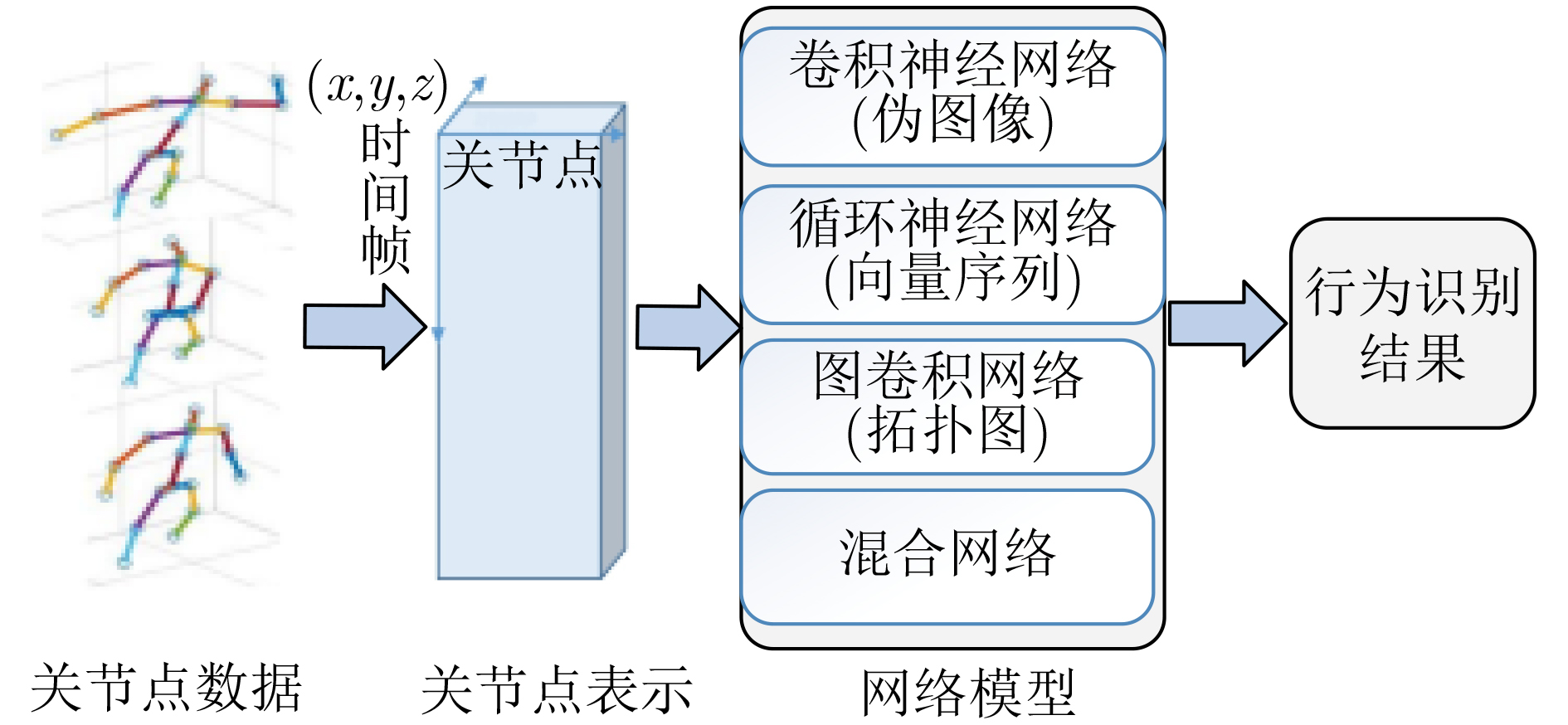
Figures(10) / Tables(6)



 DownLoad:
DownLoad: