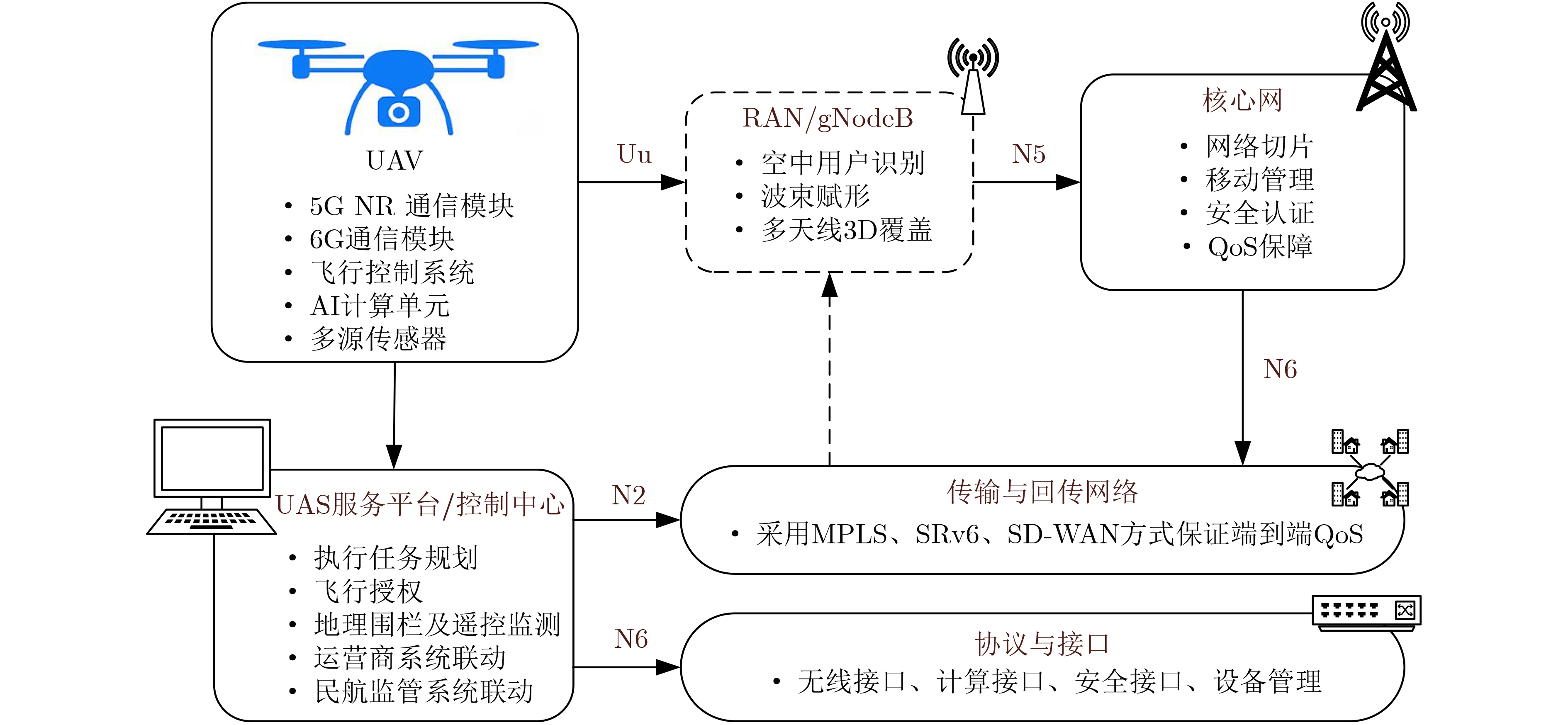
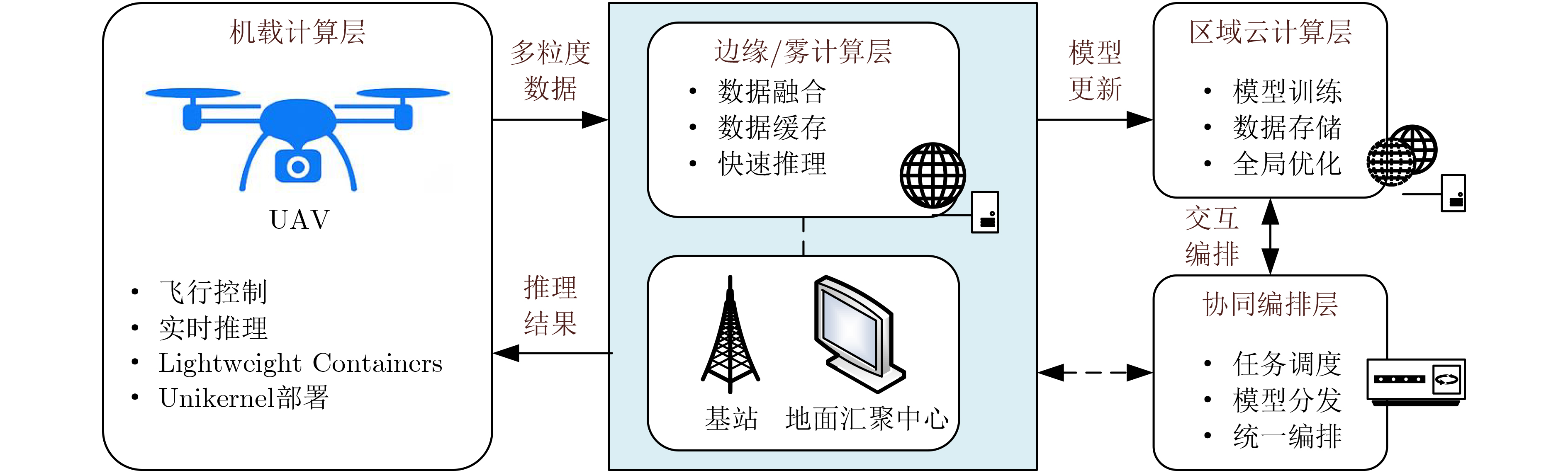
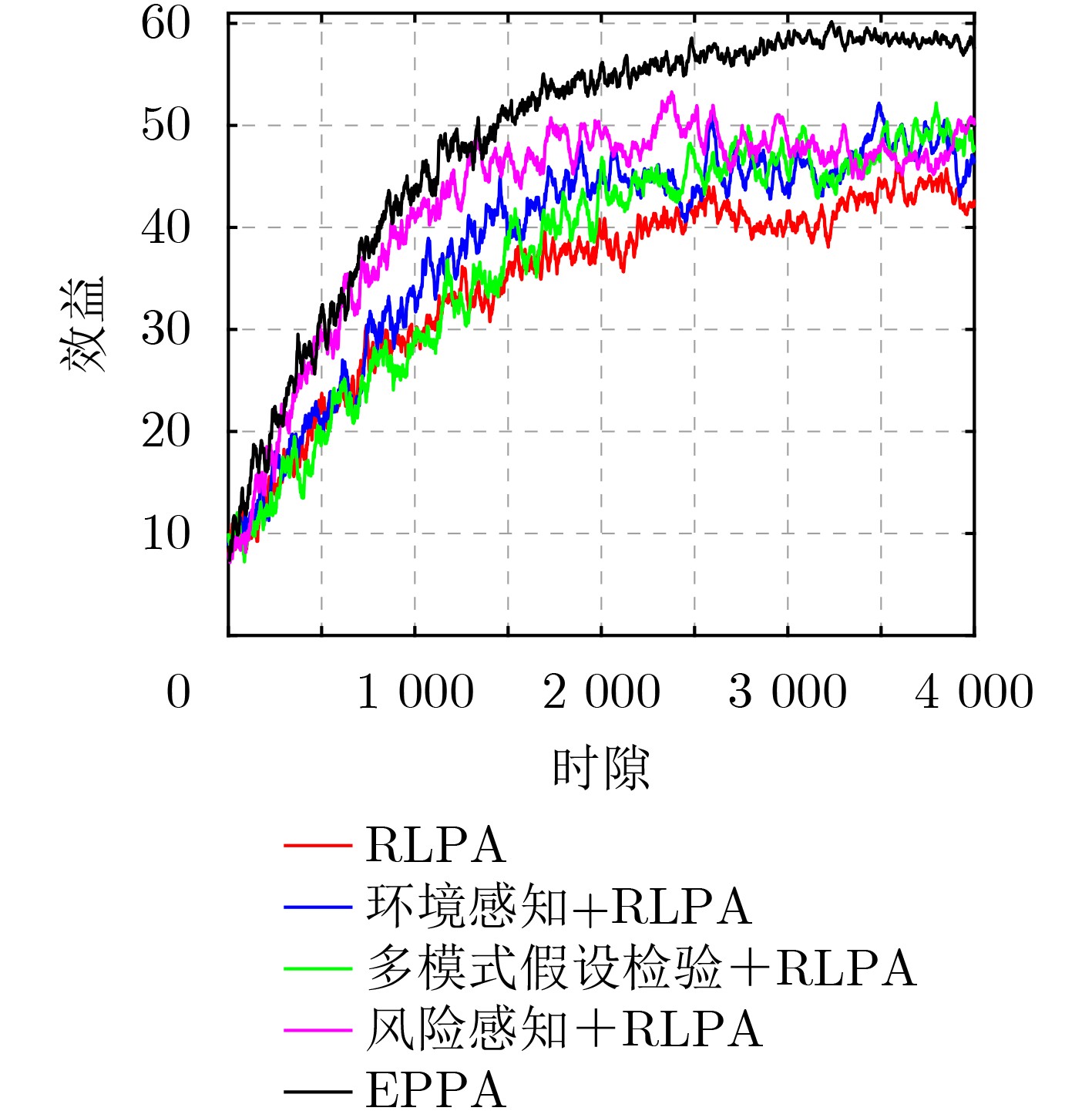
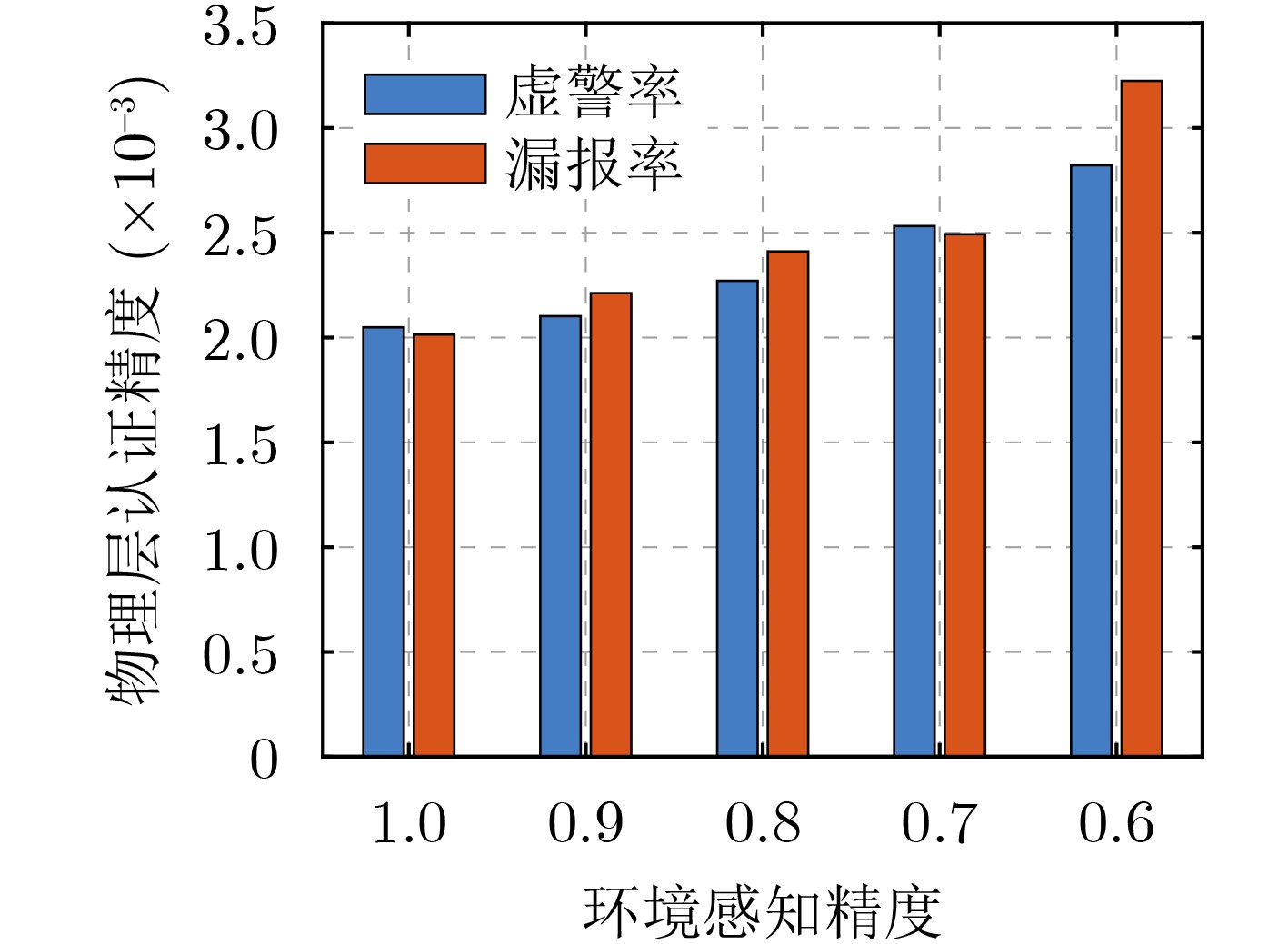
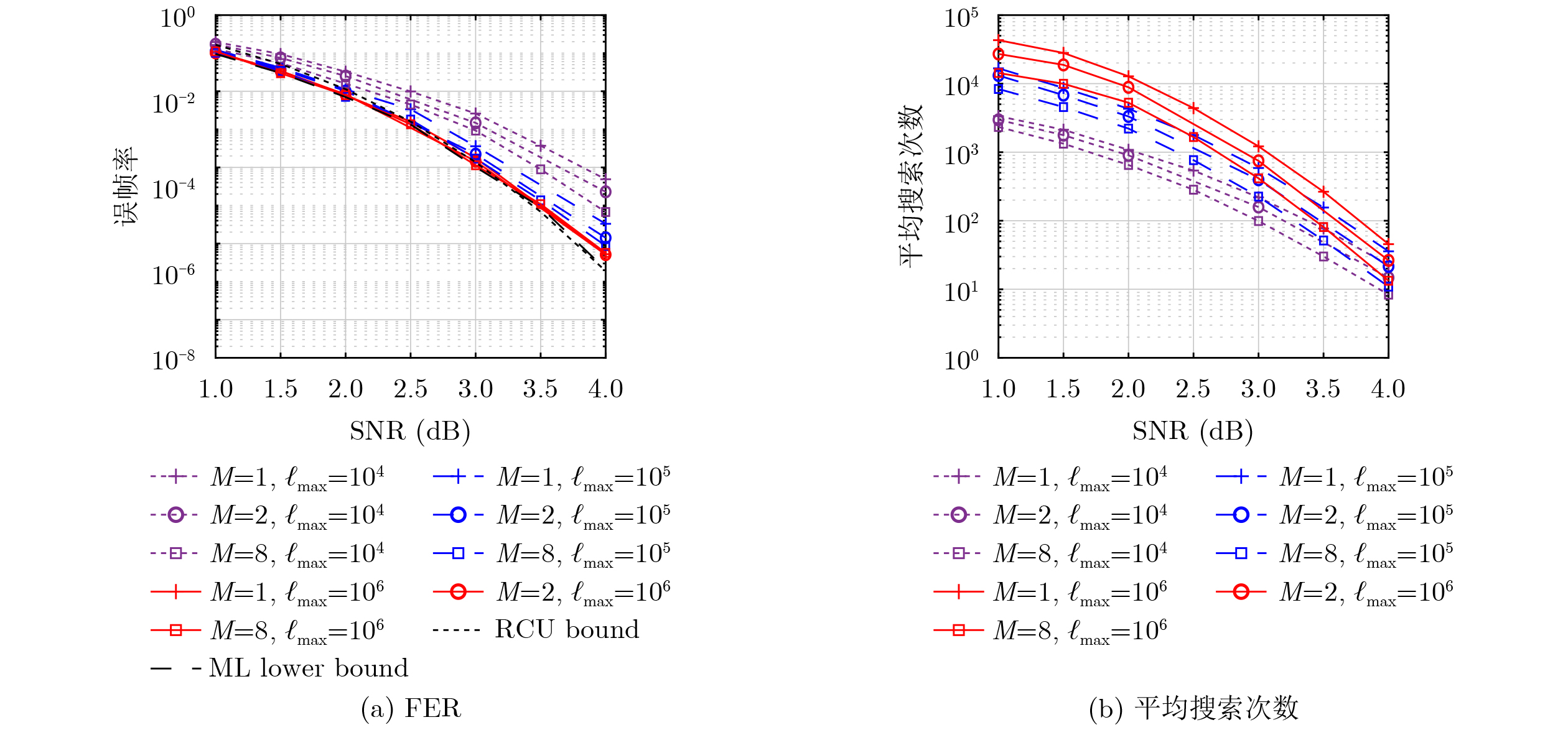
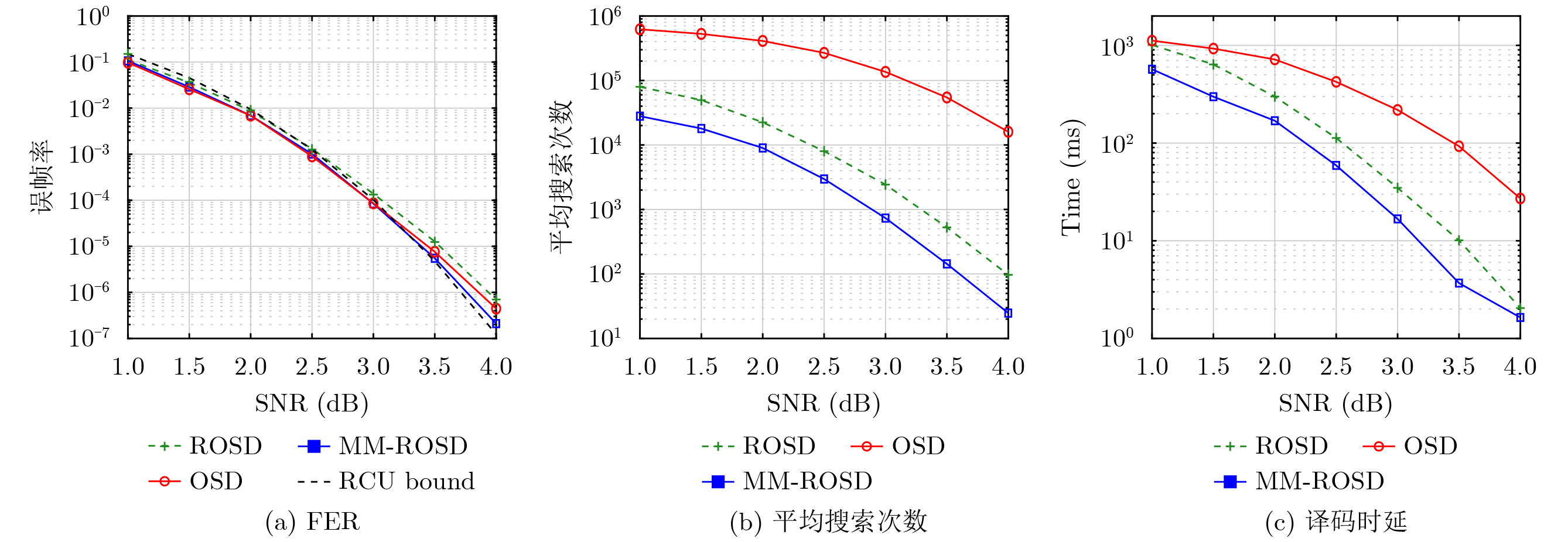
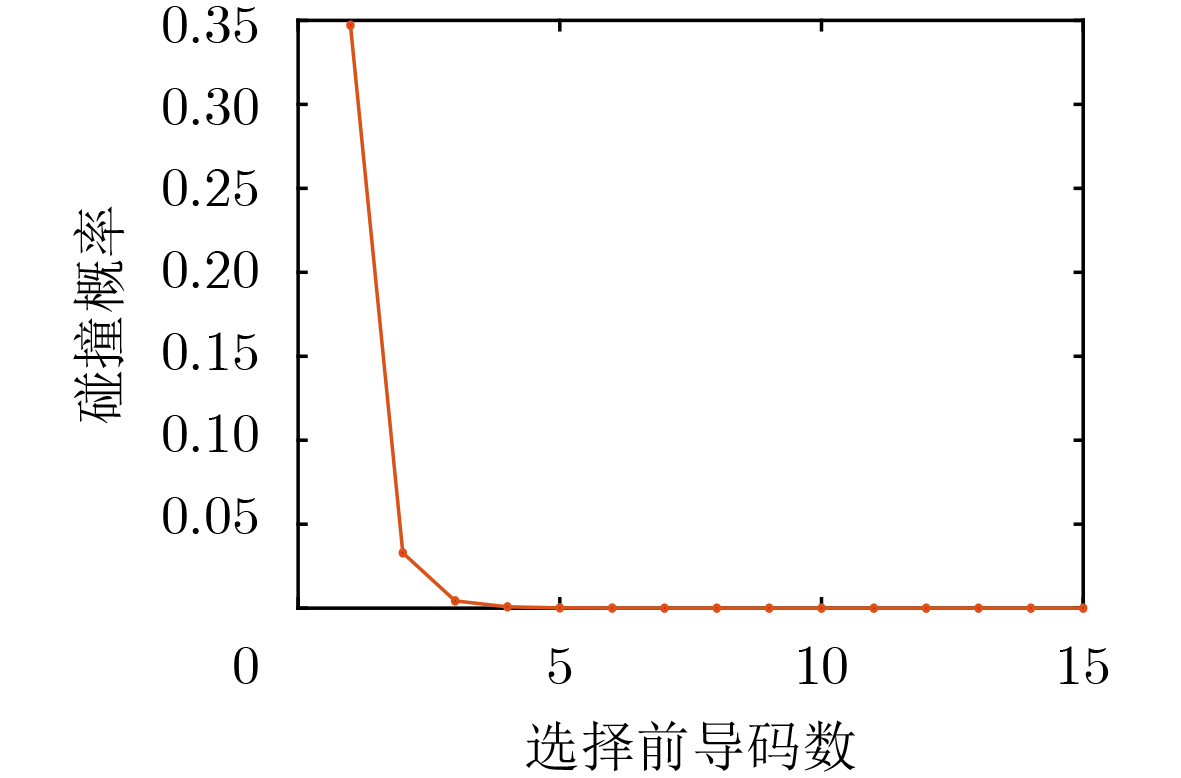
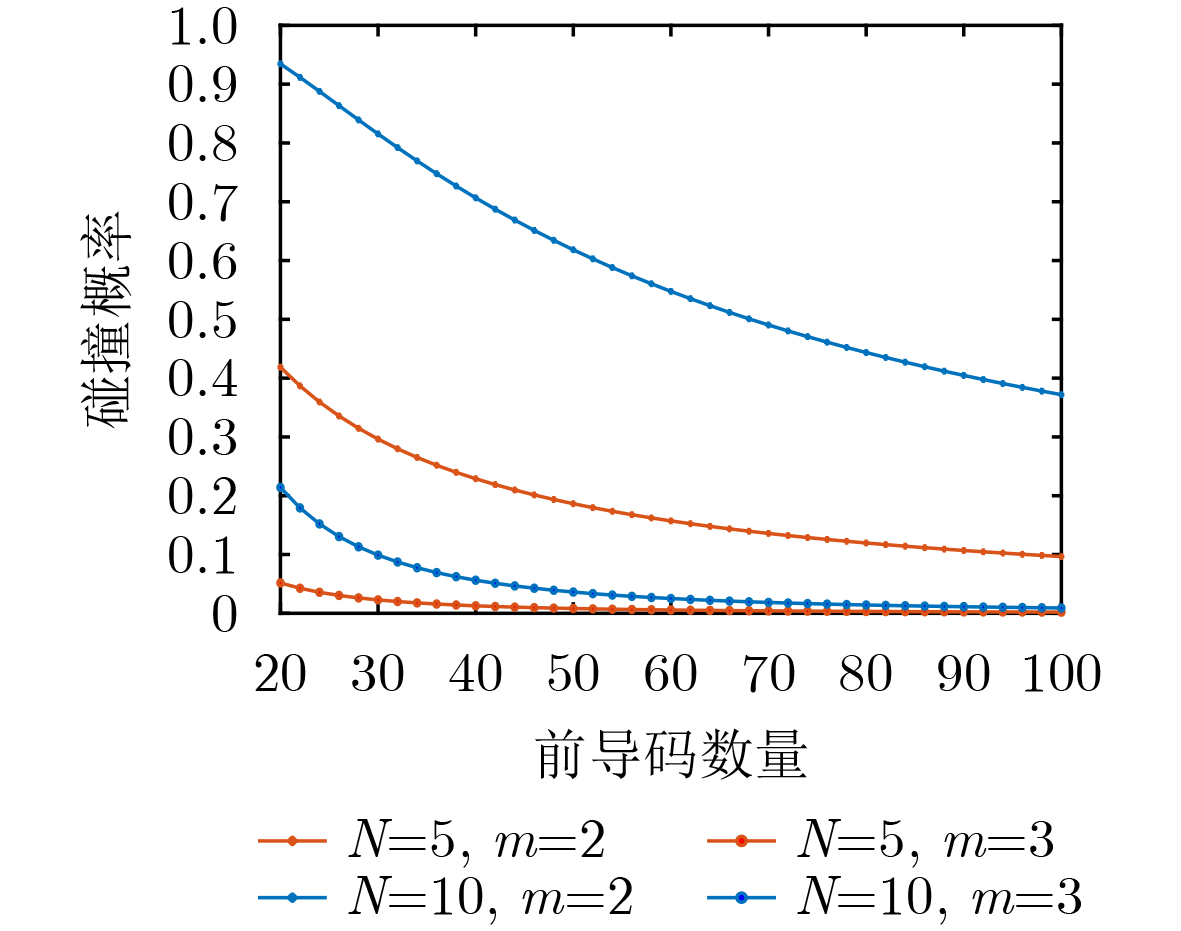
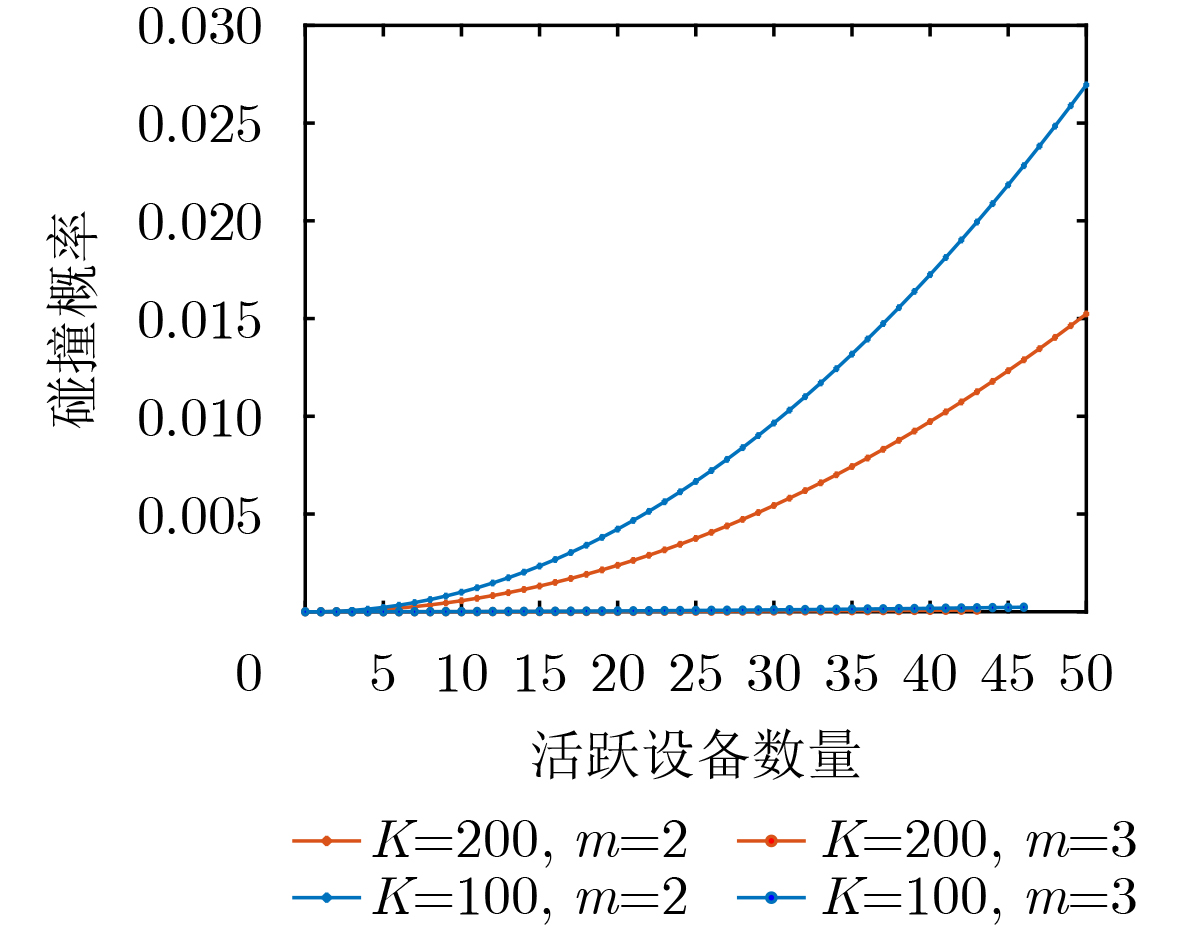
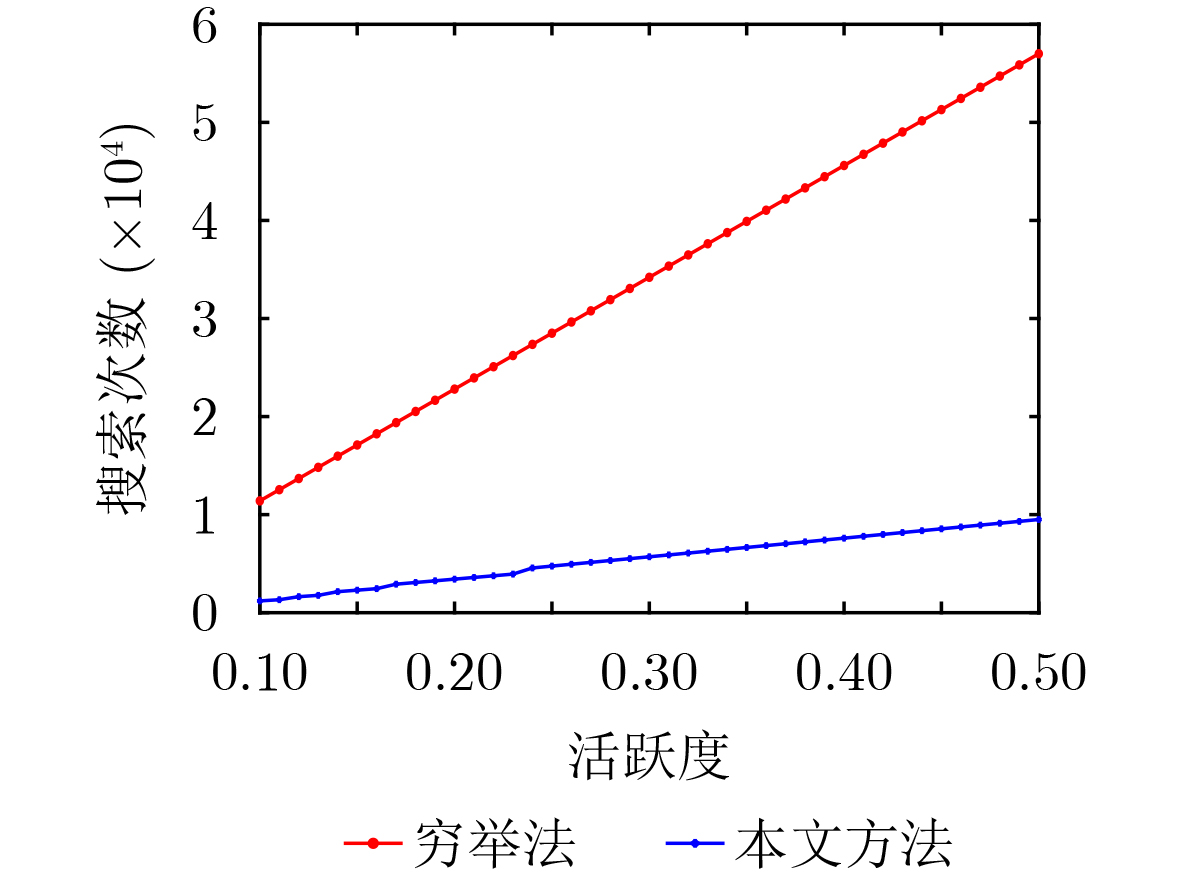
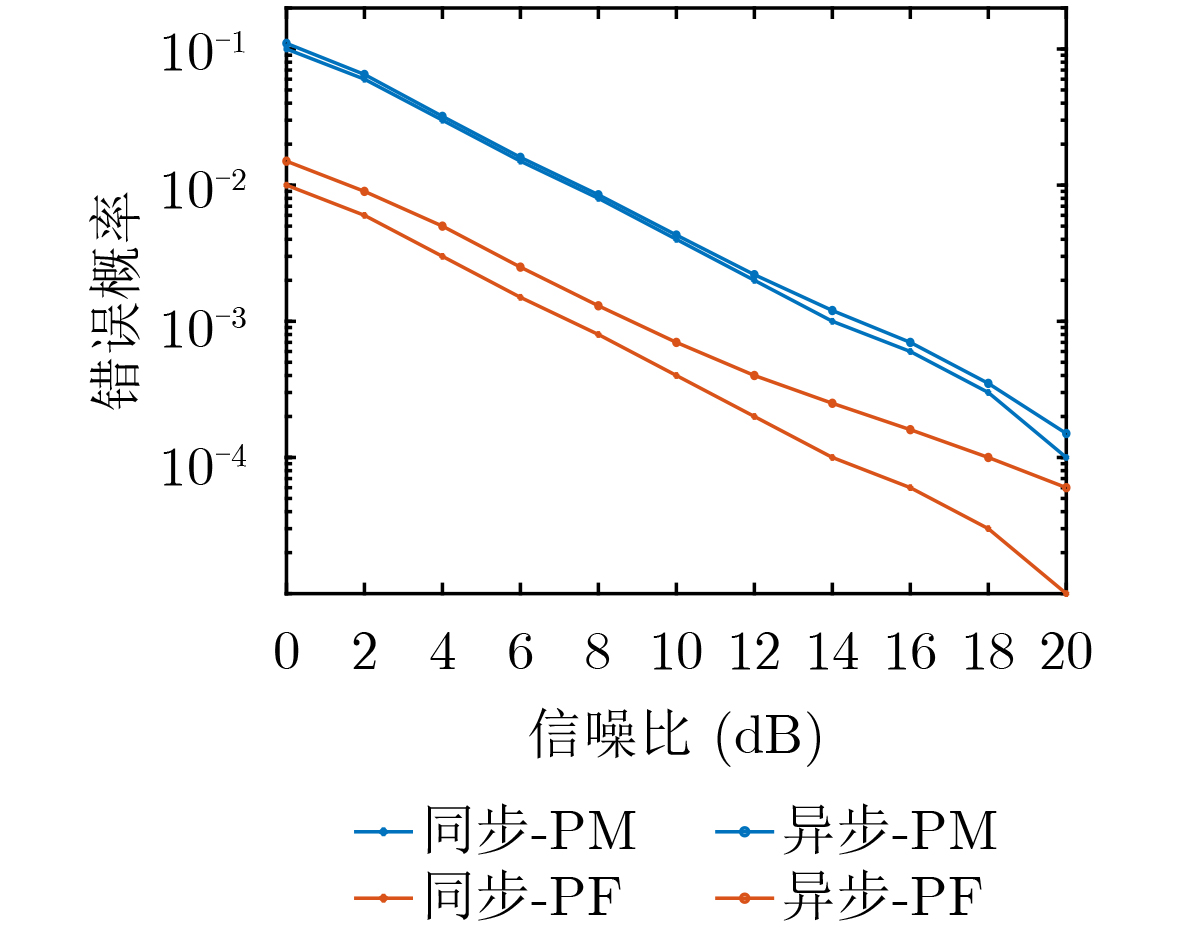
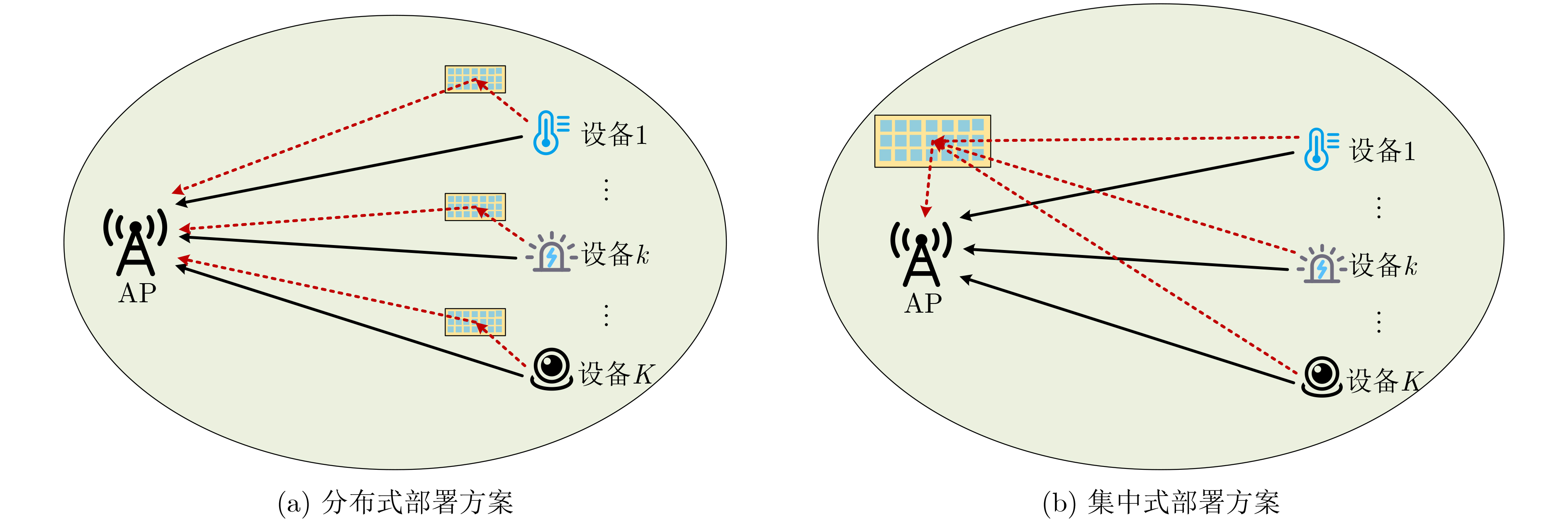
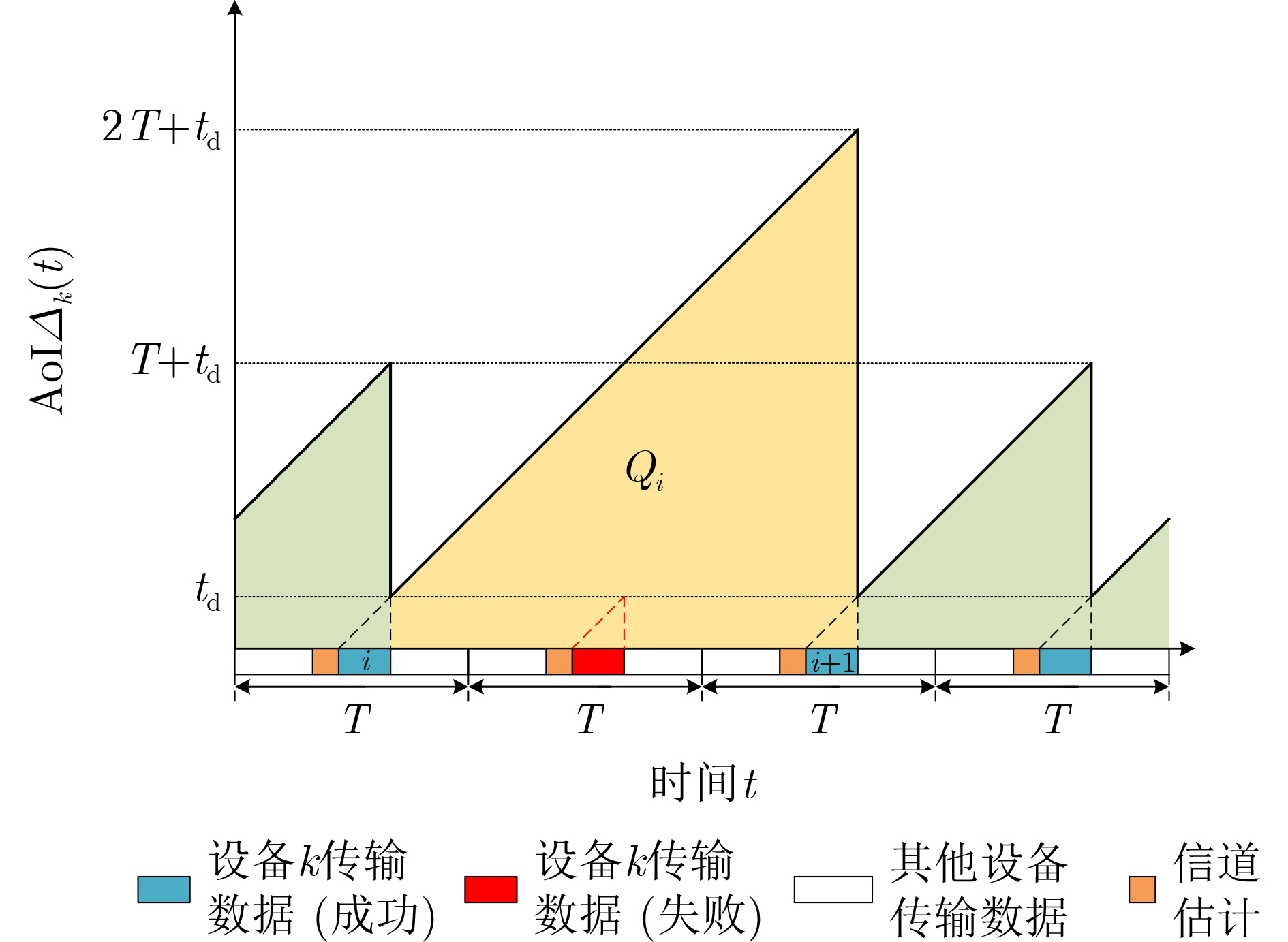
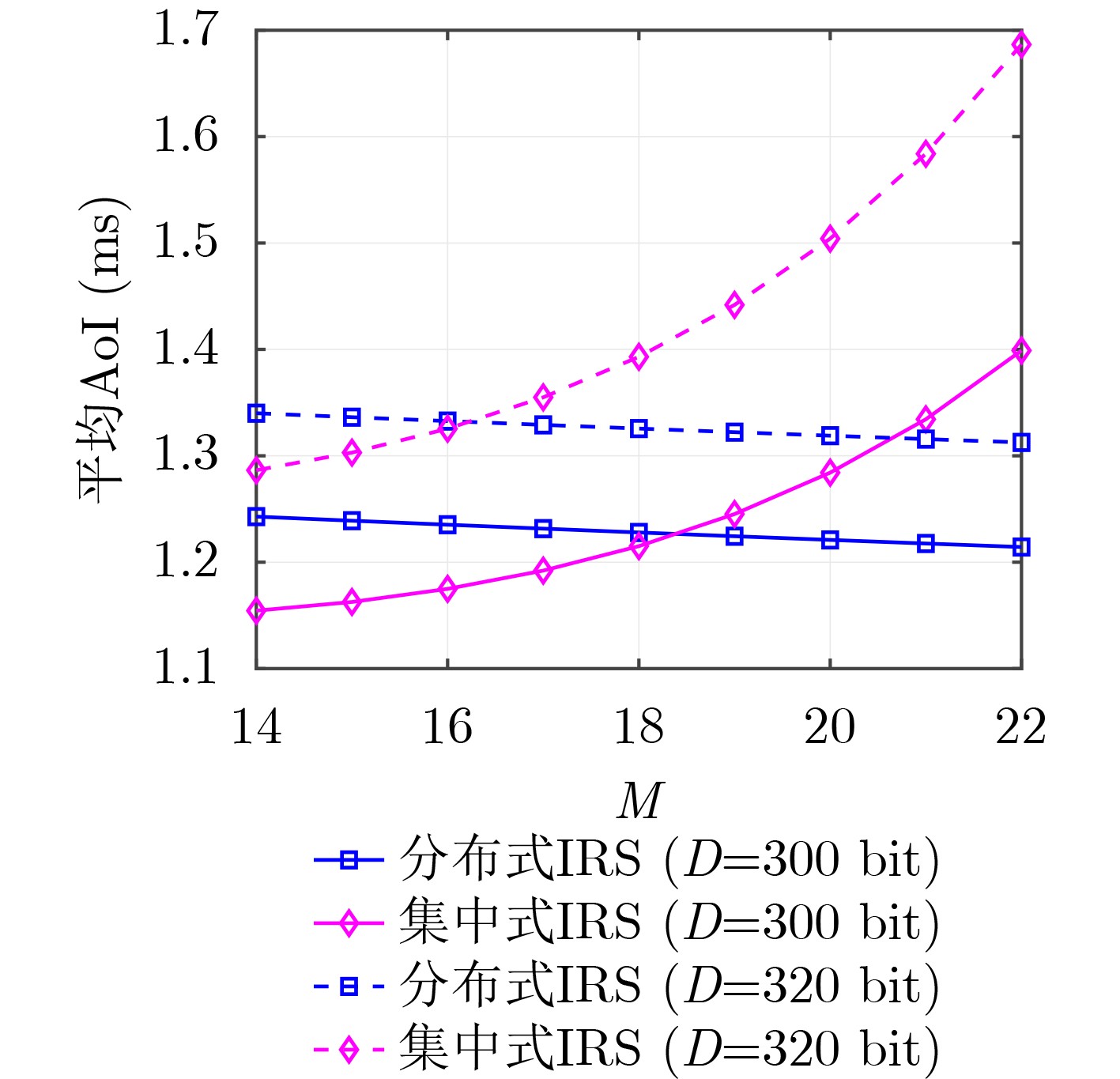
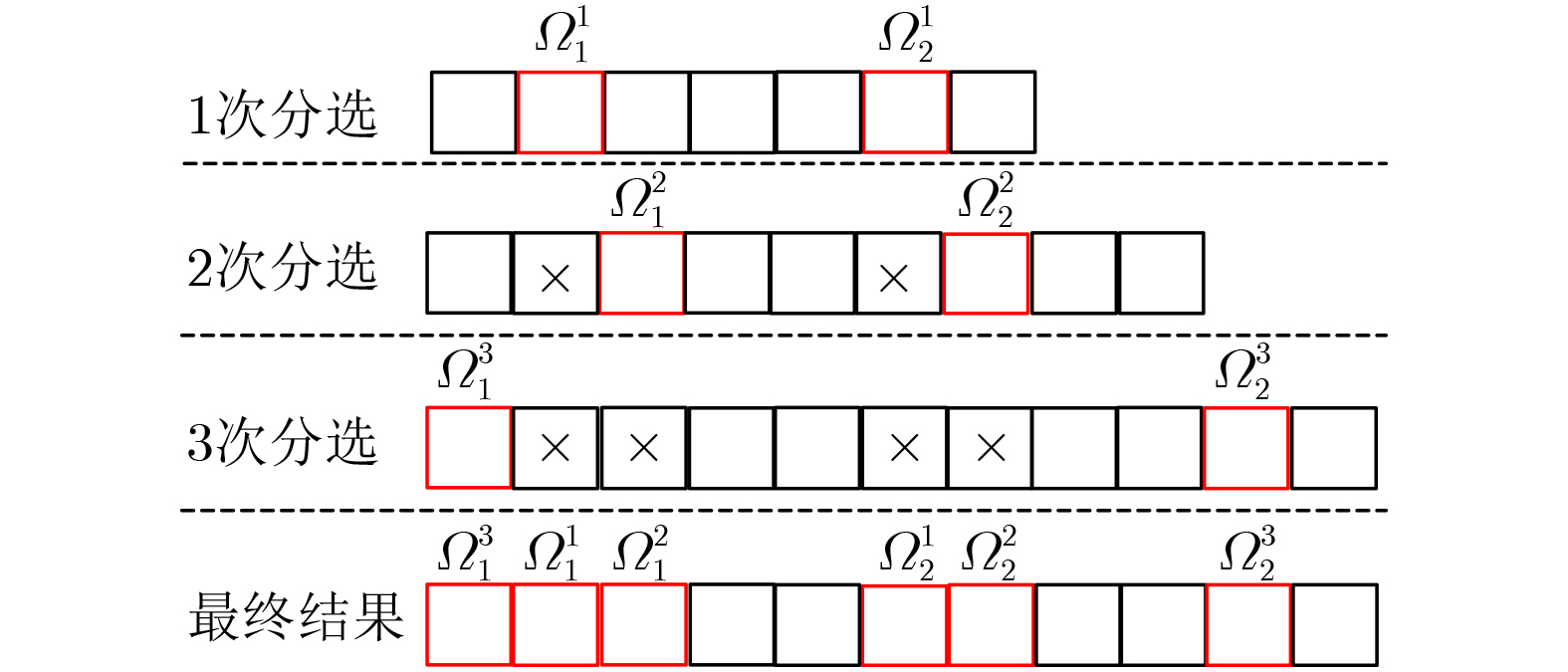
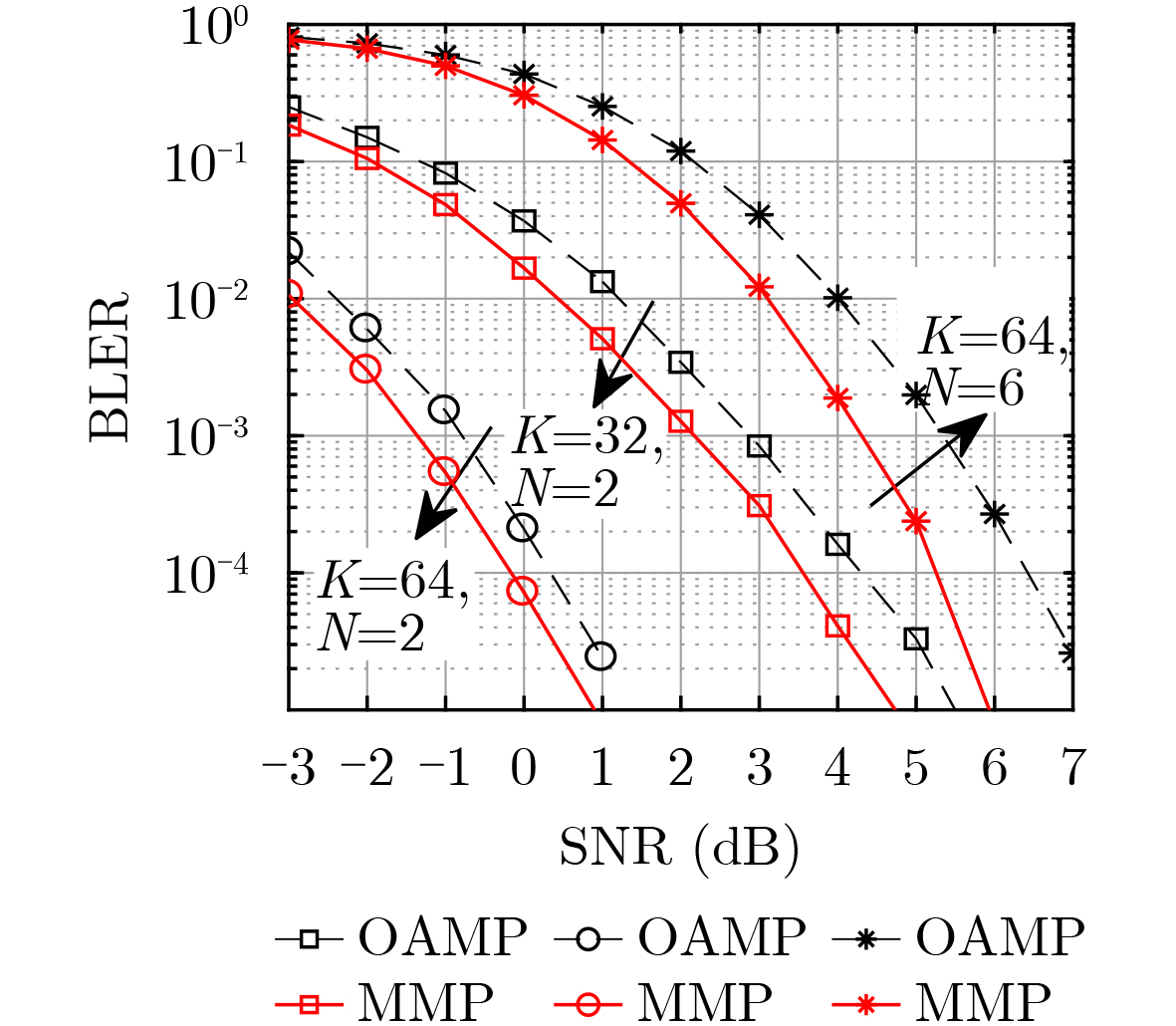
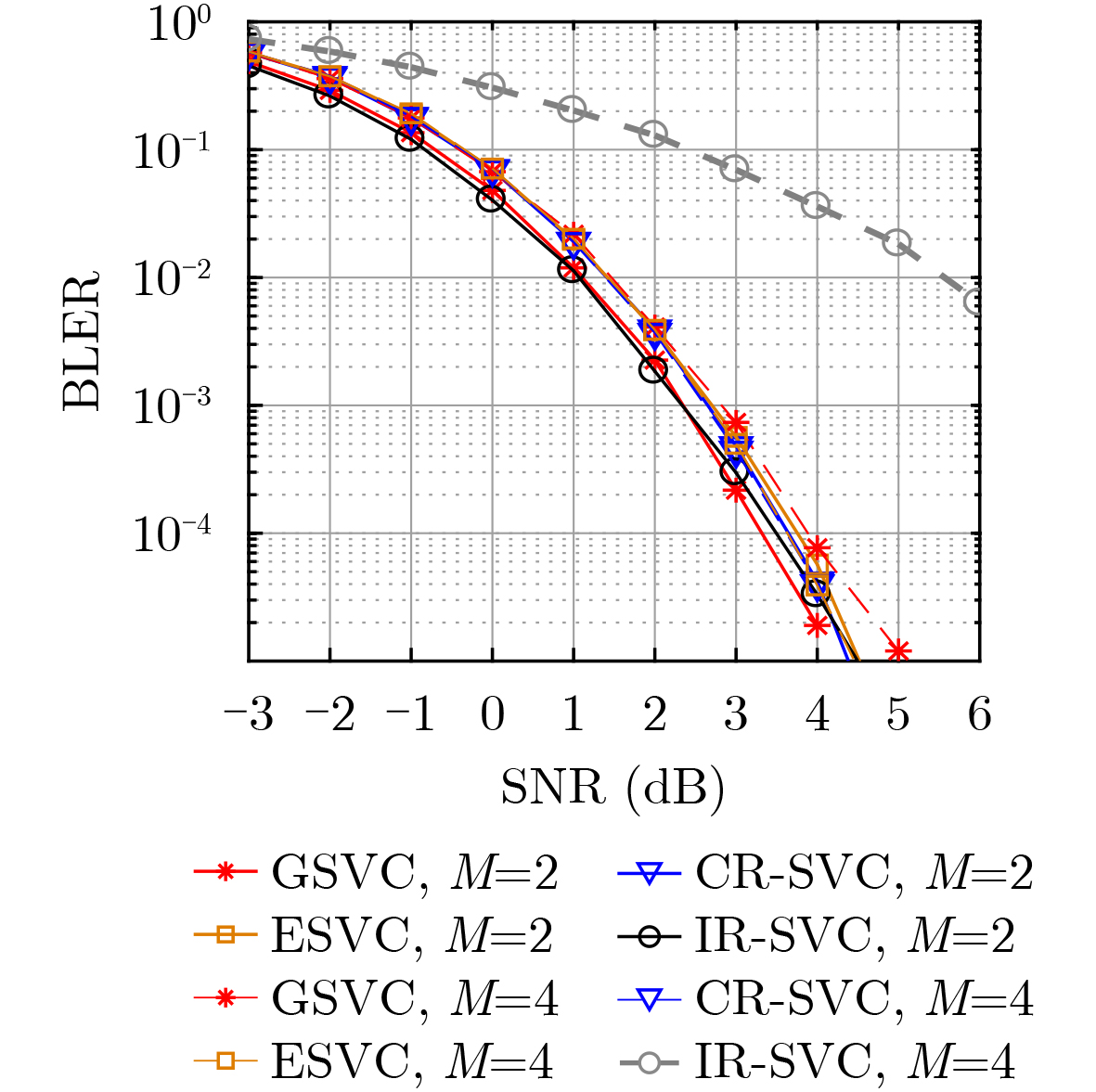
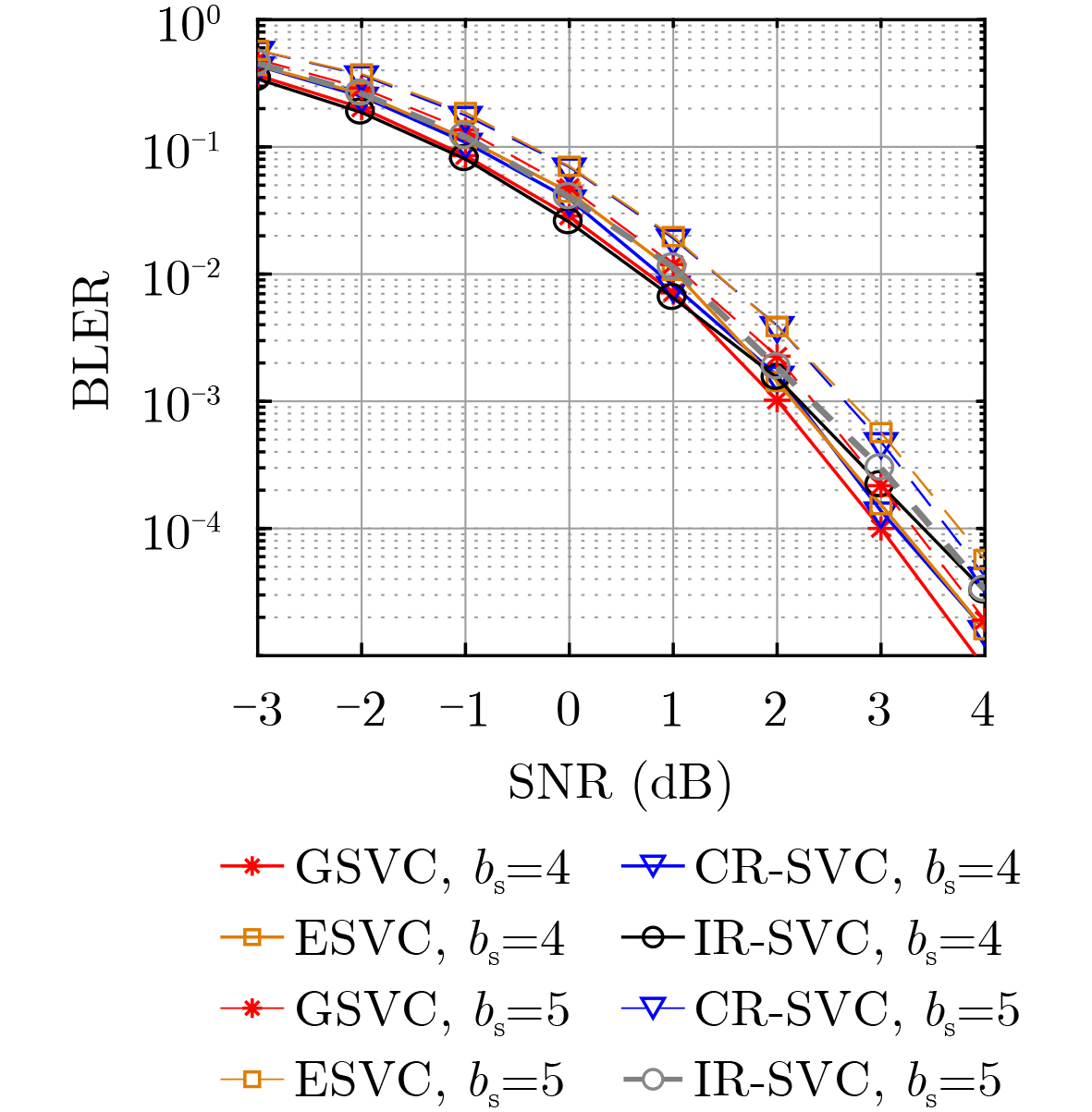
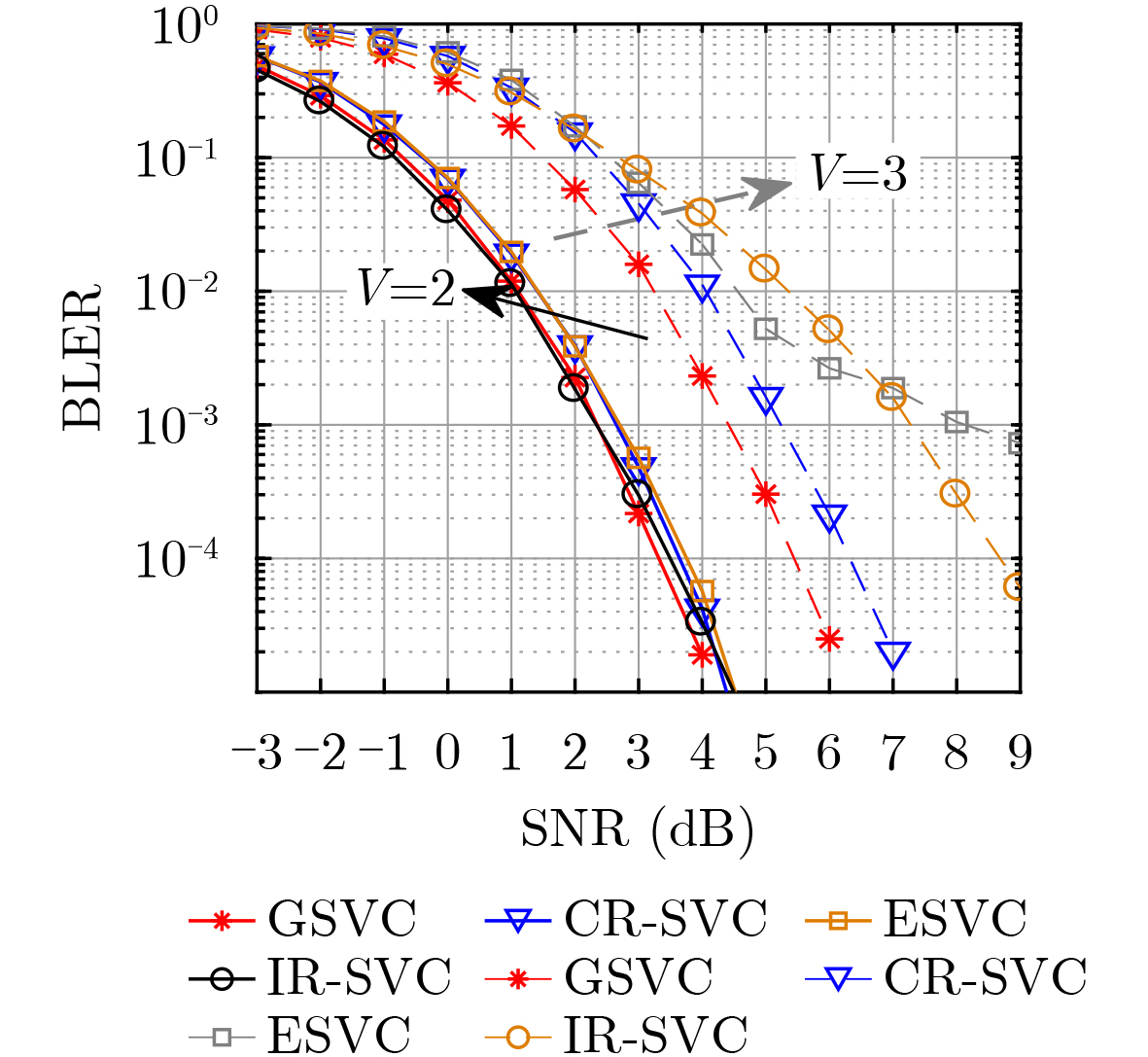
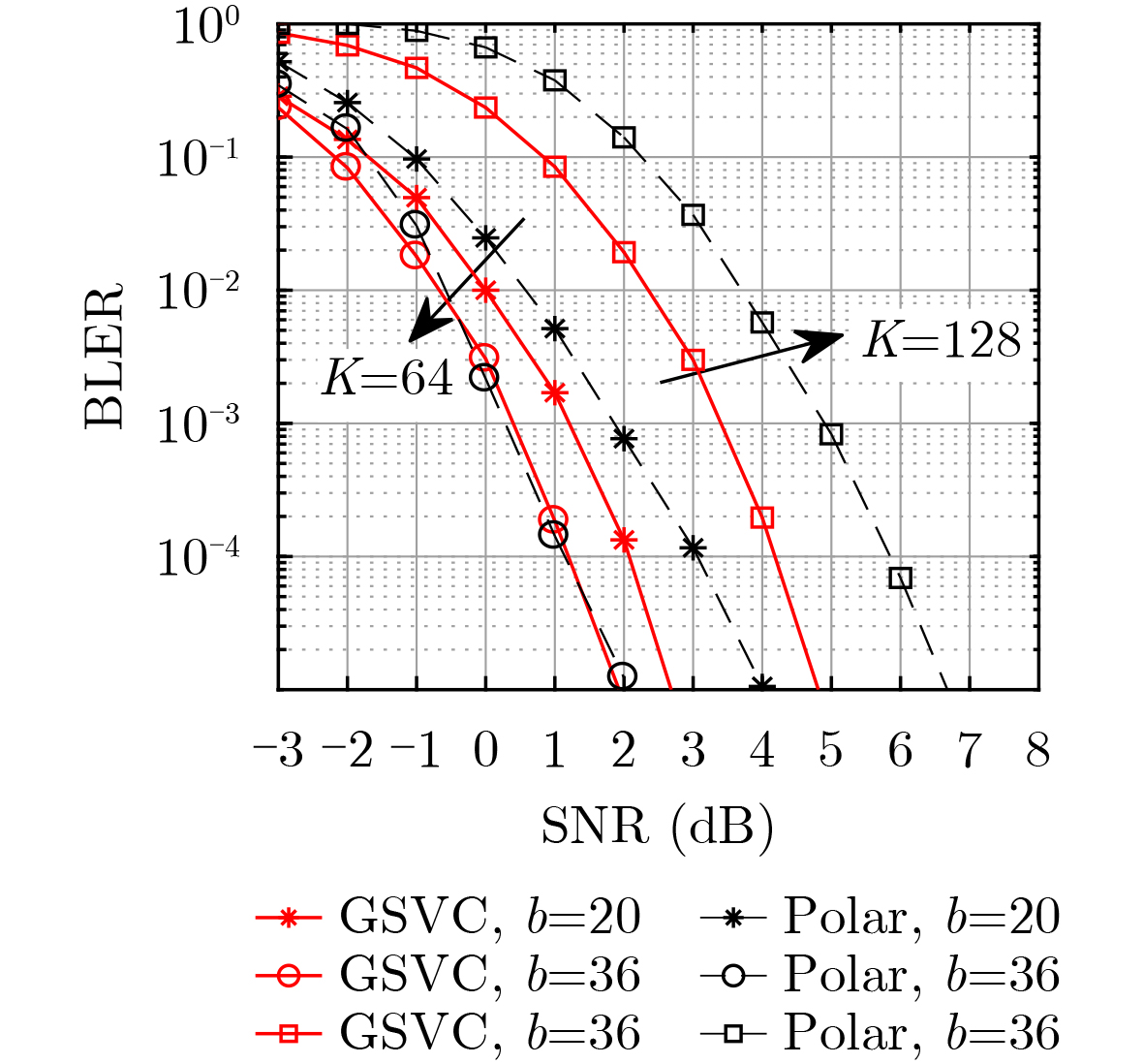
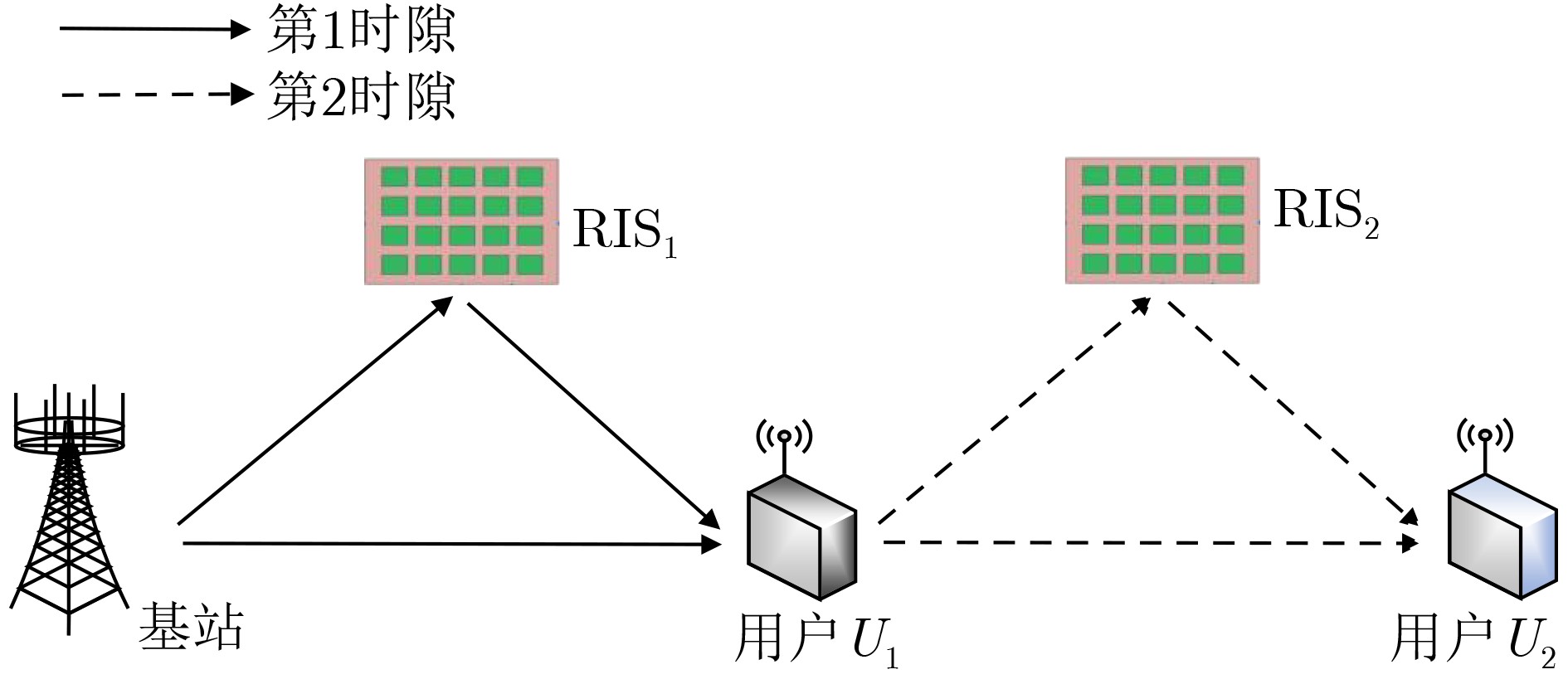
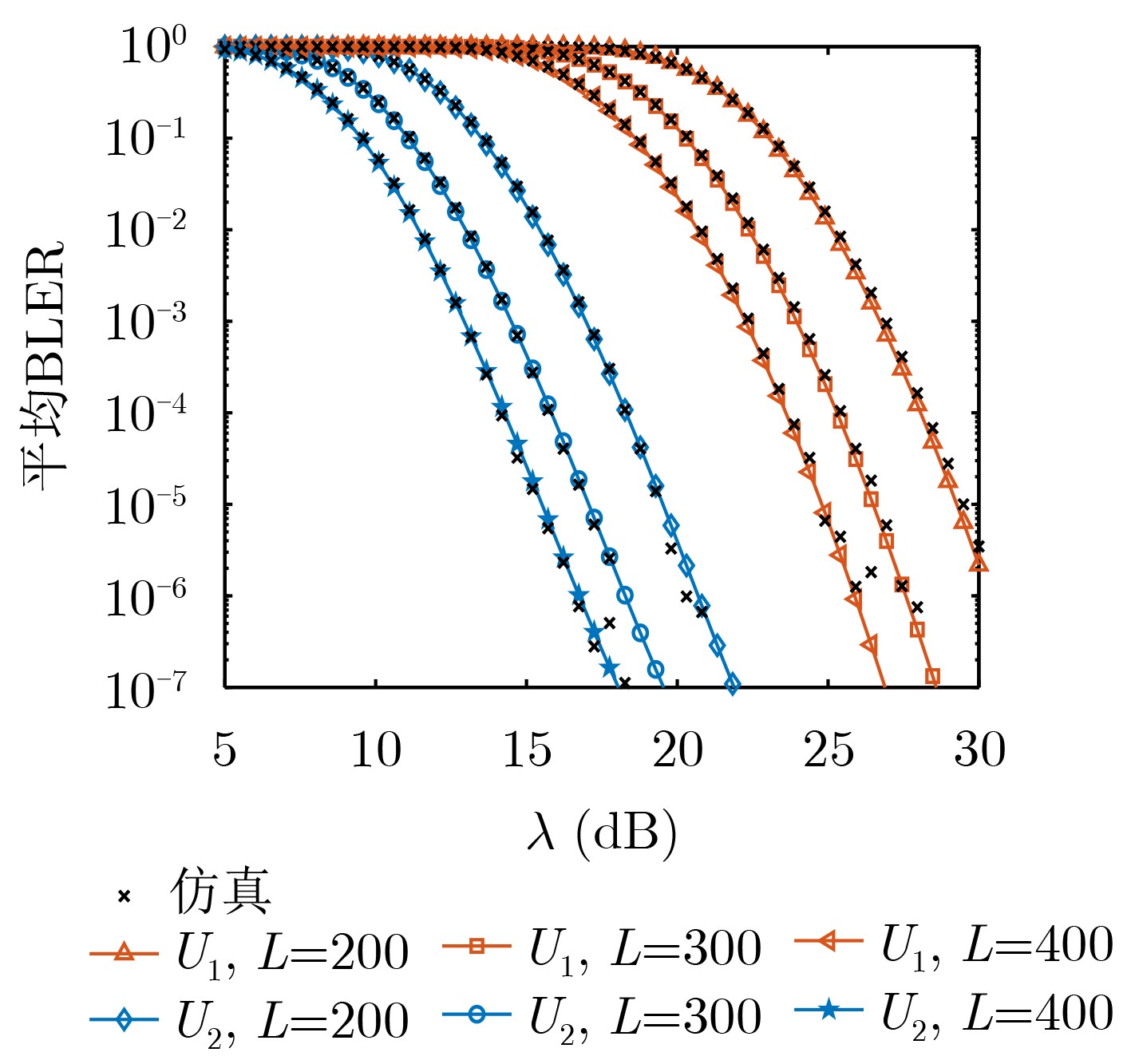
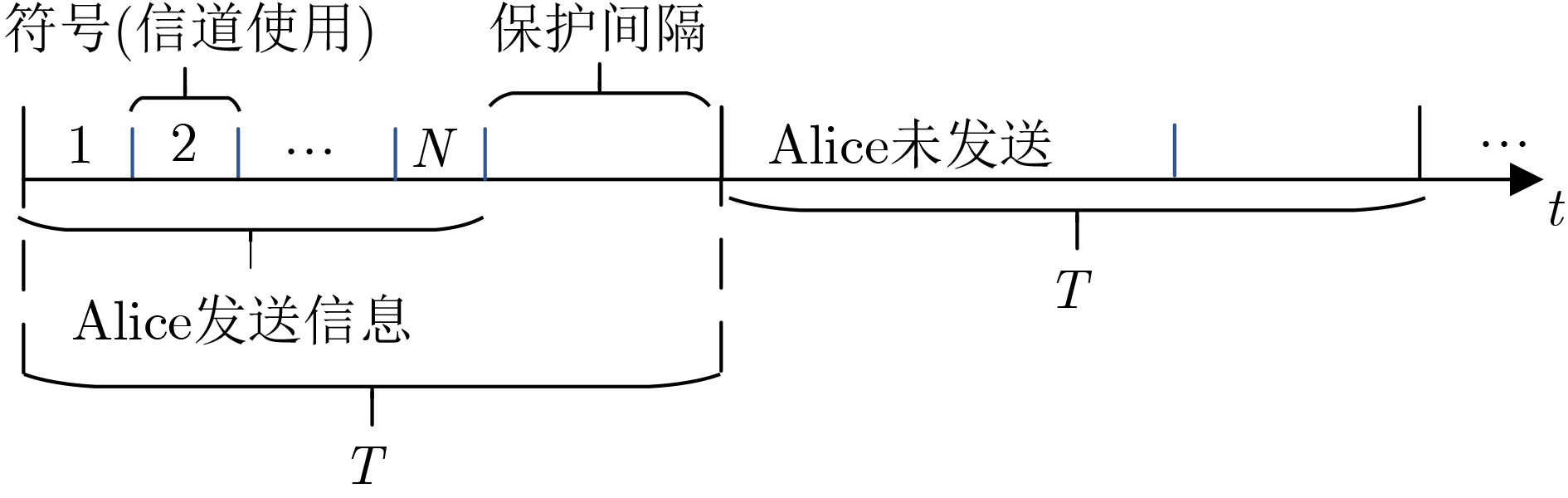
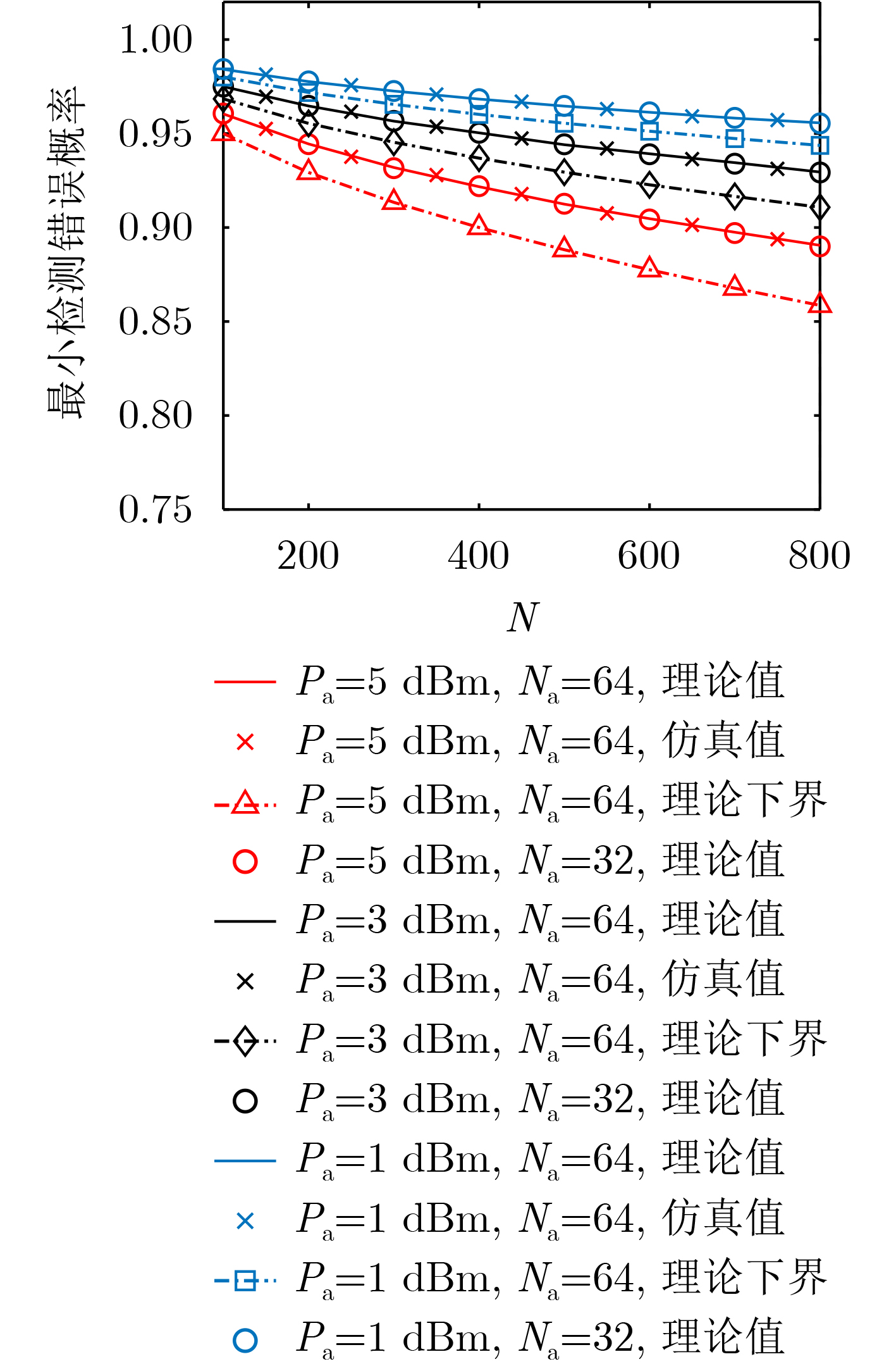
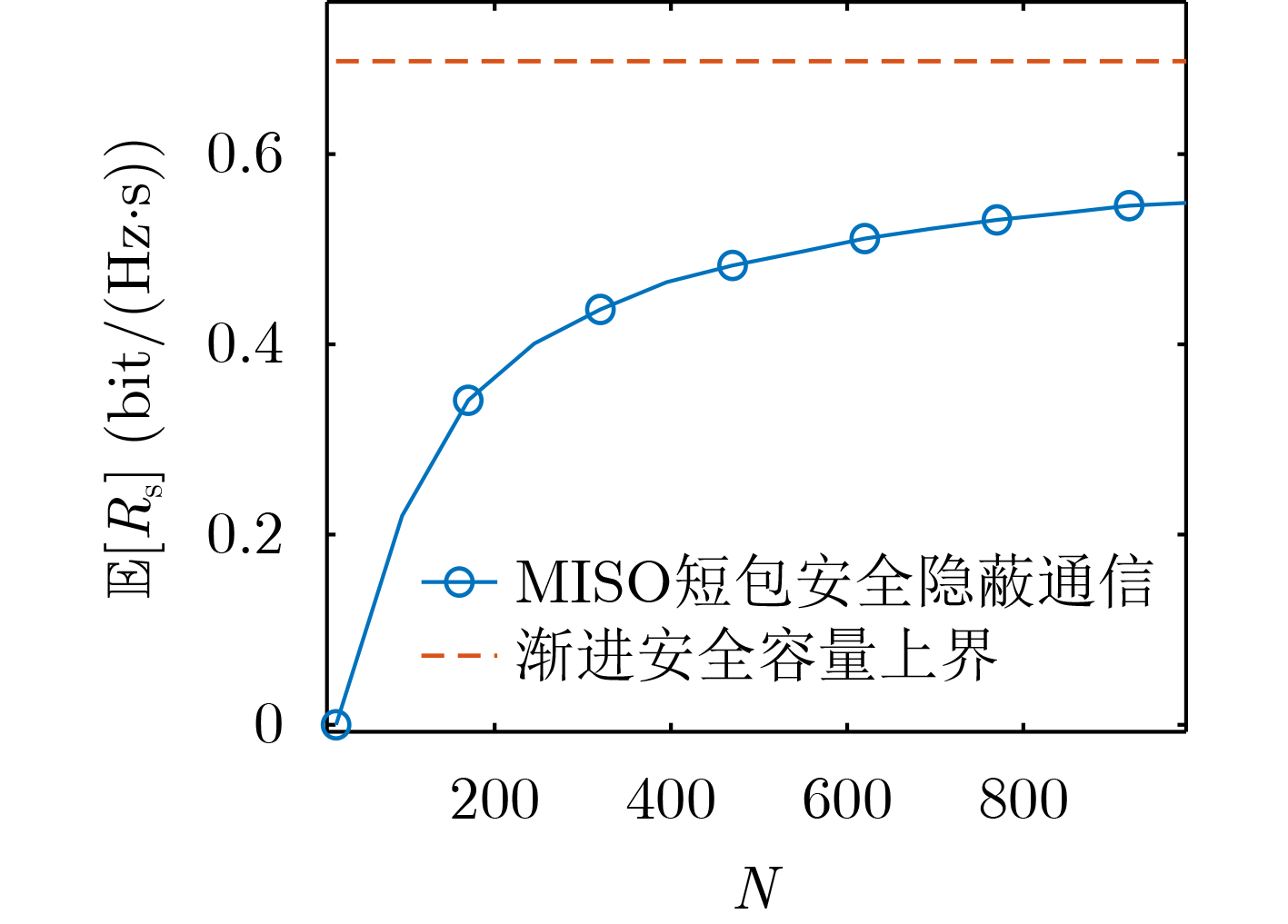
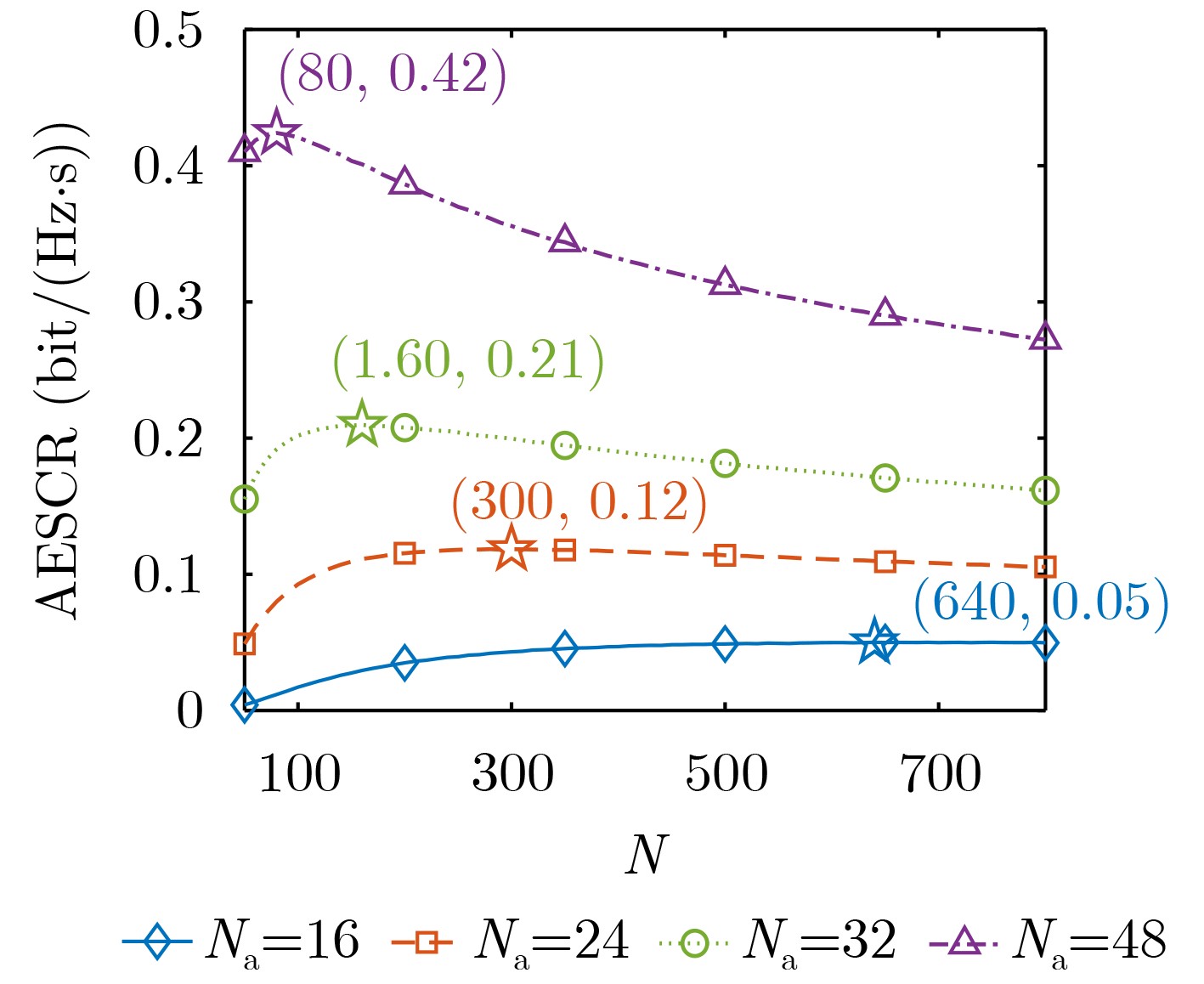
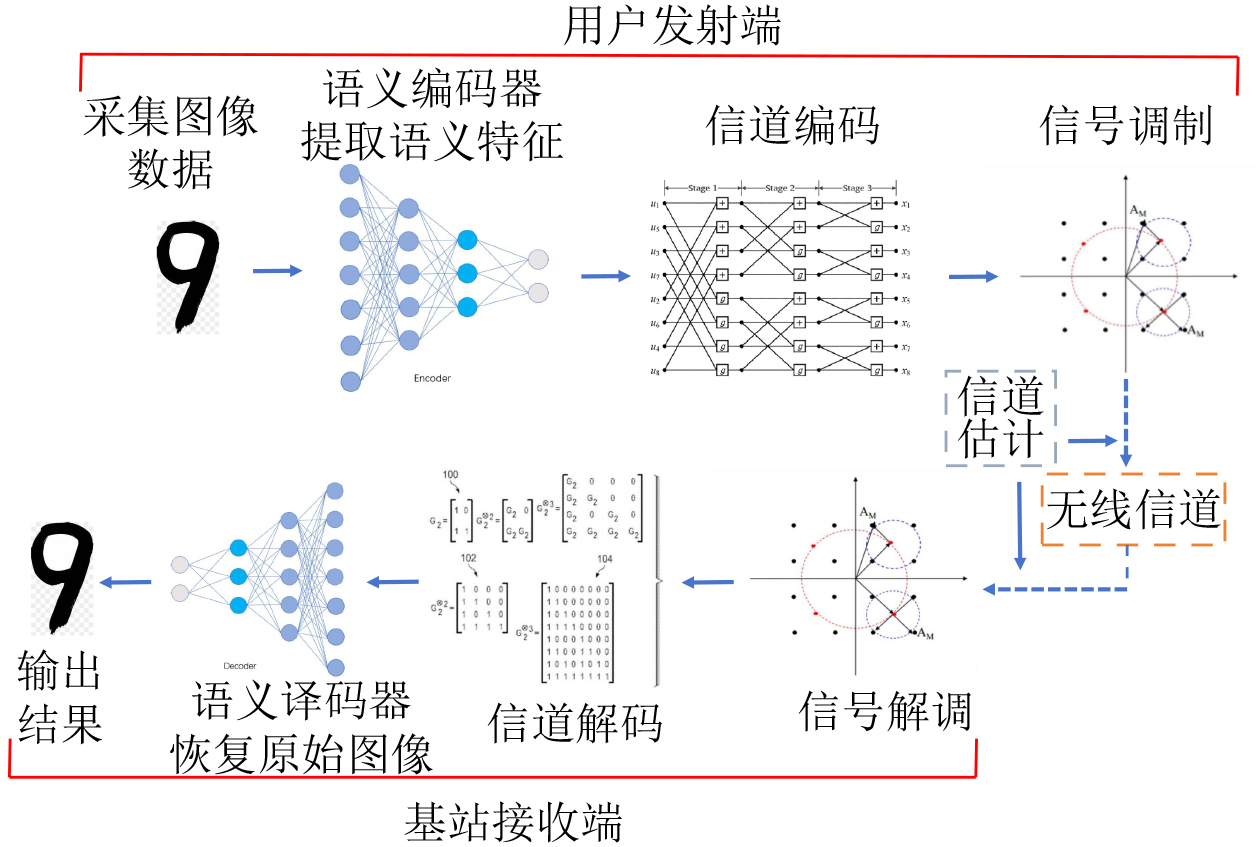
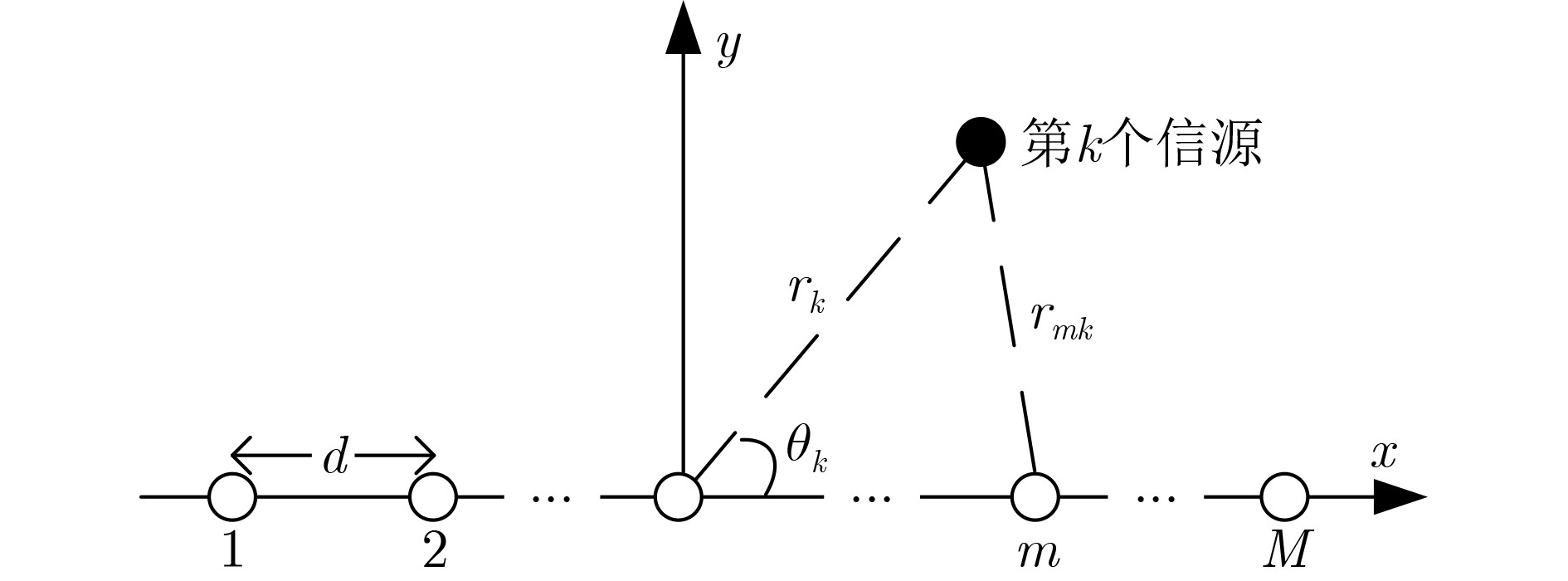
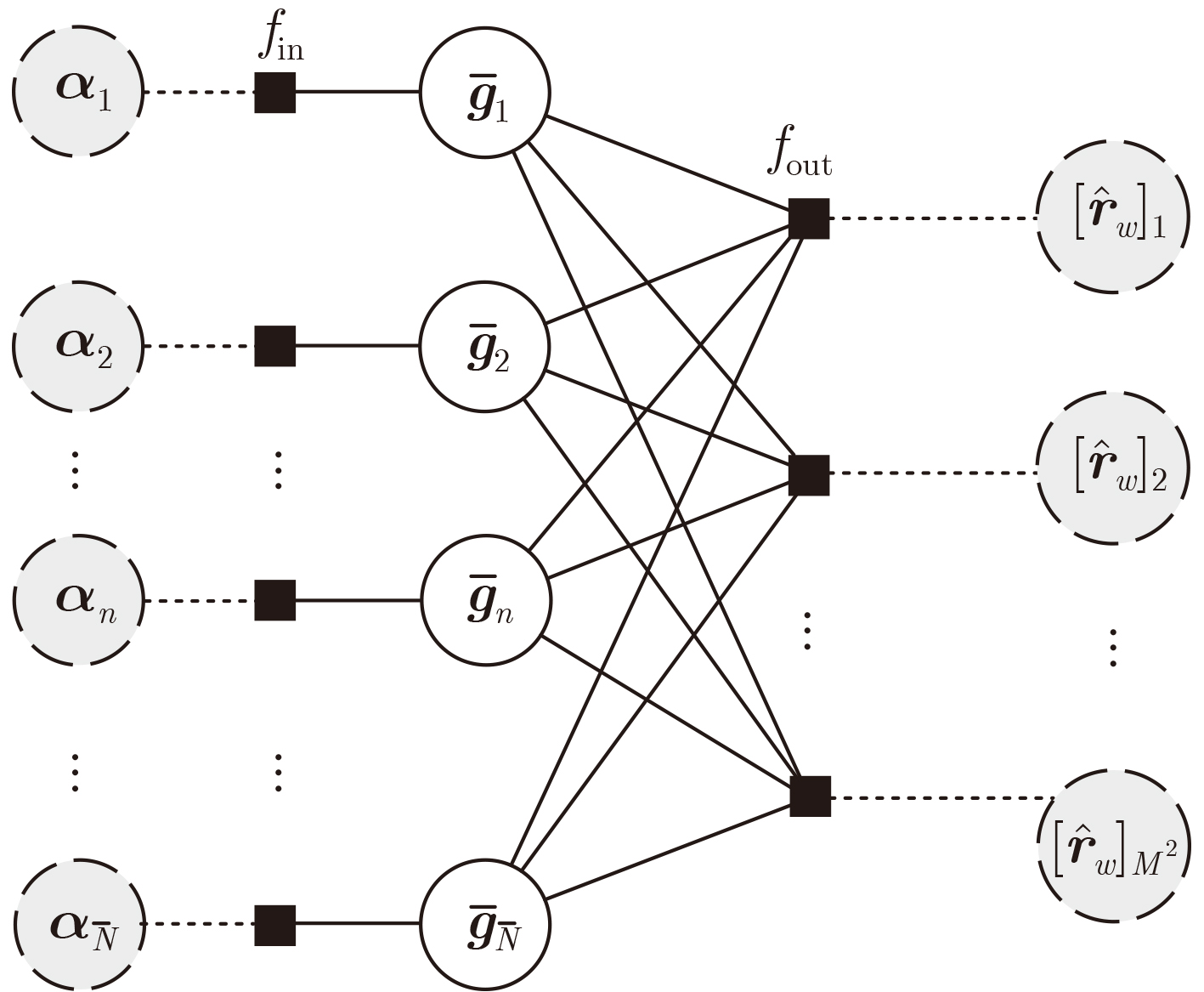
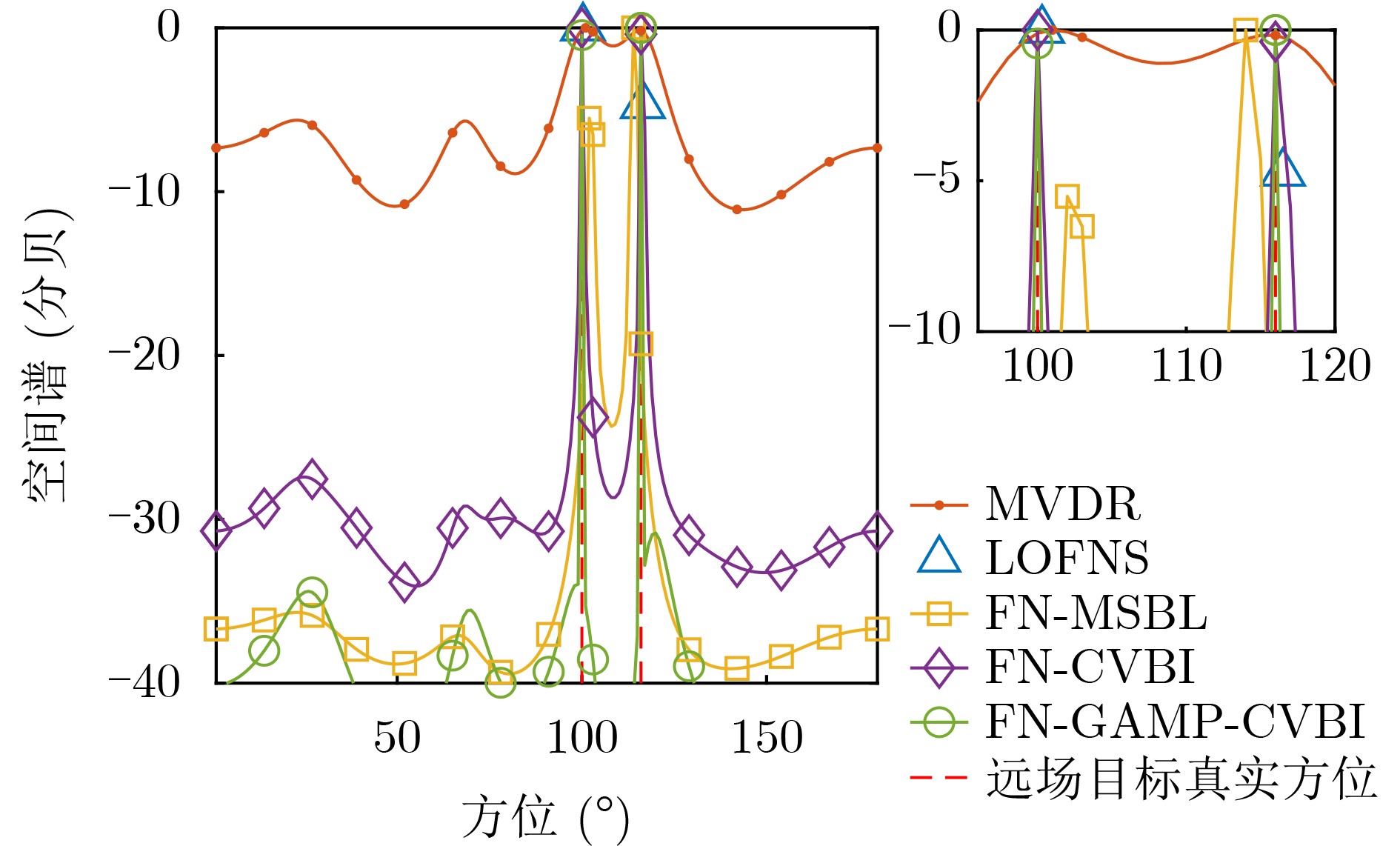
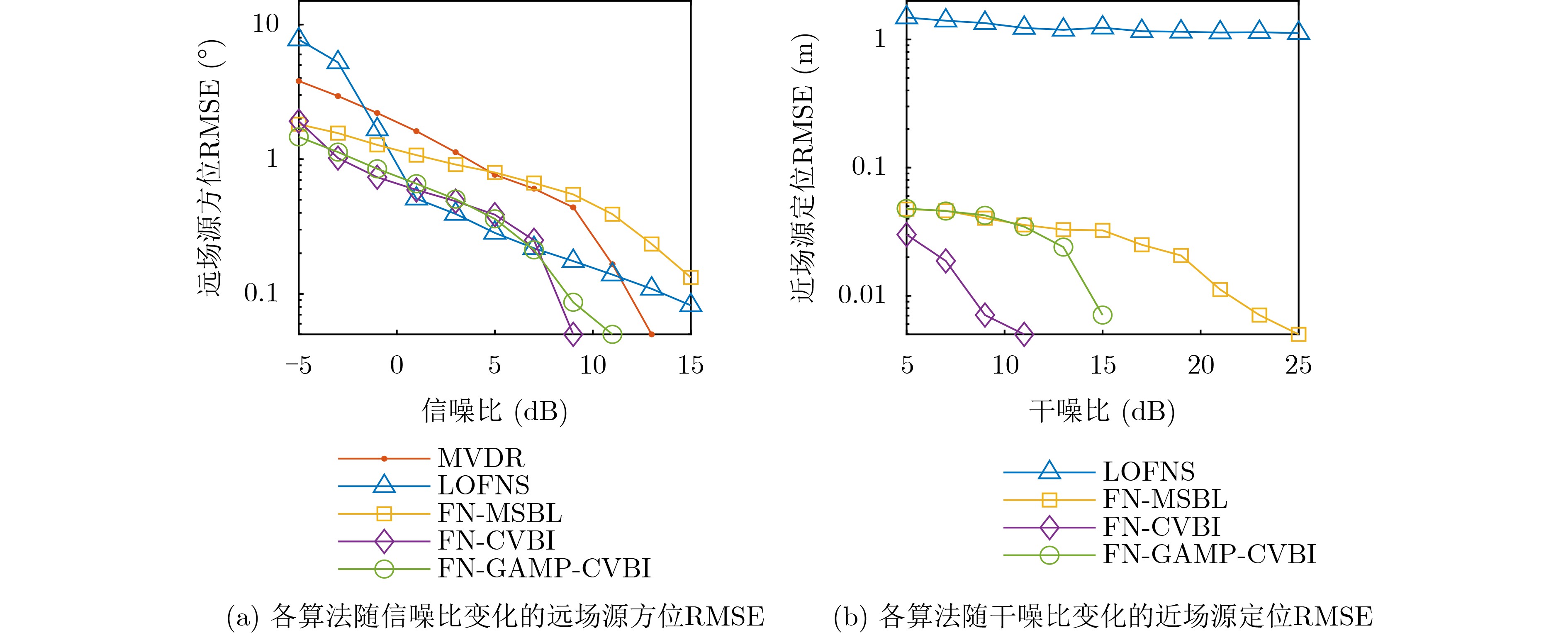
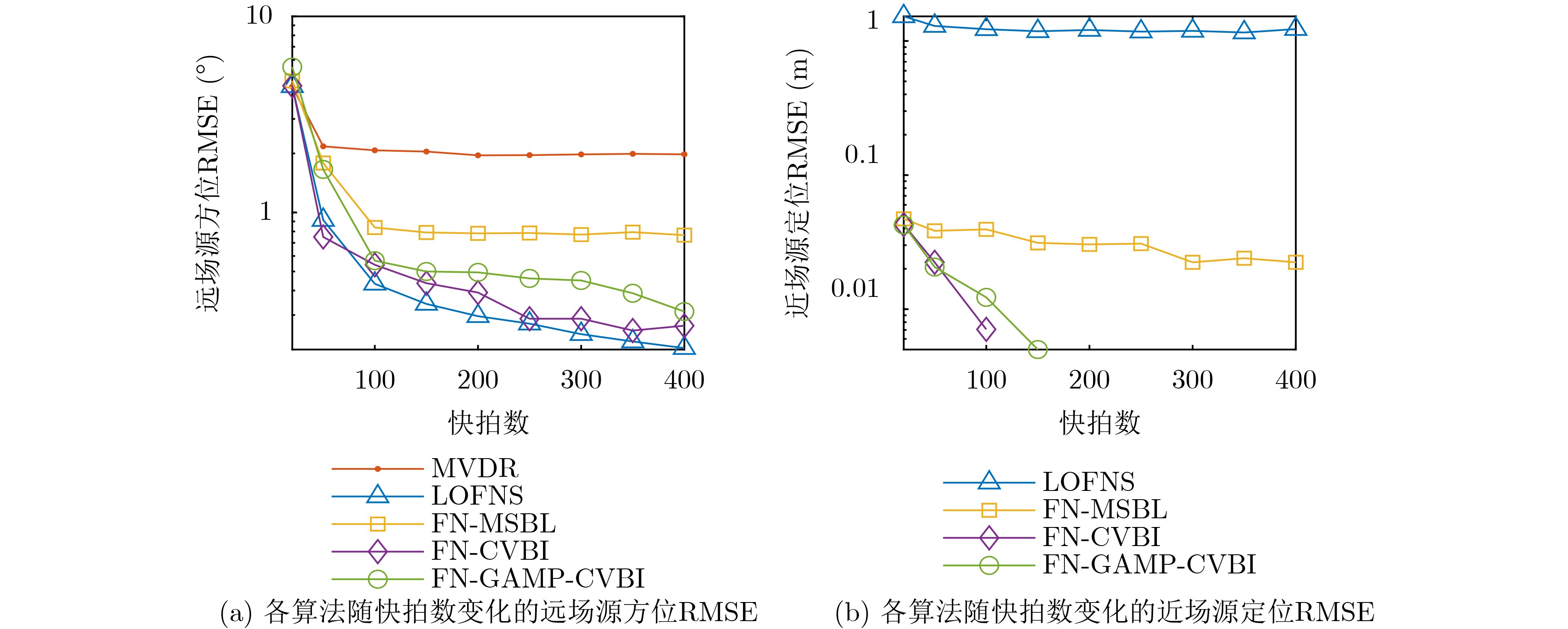
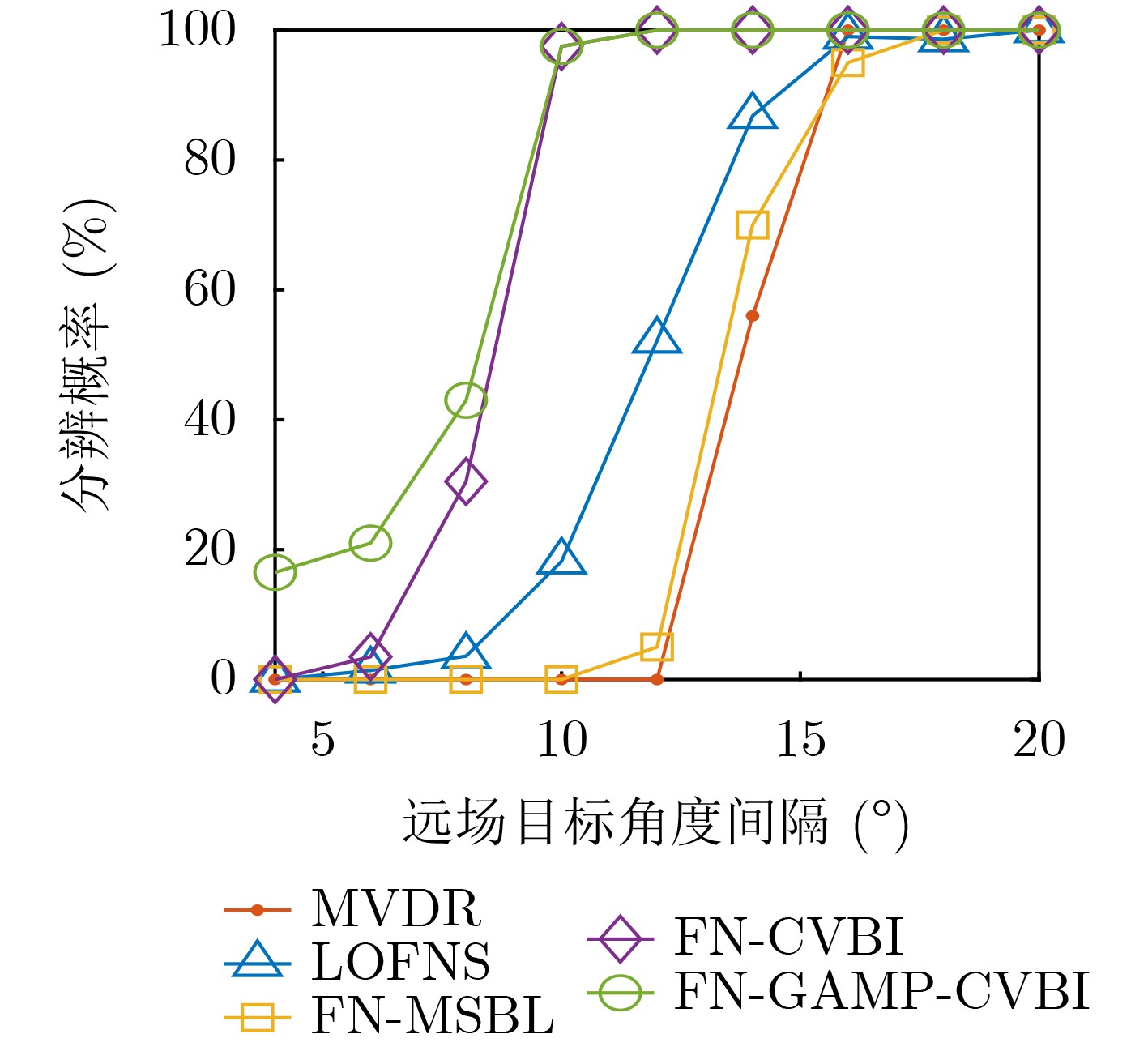
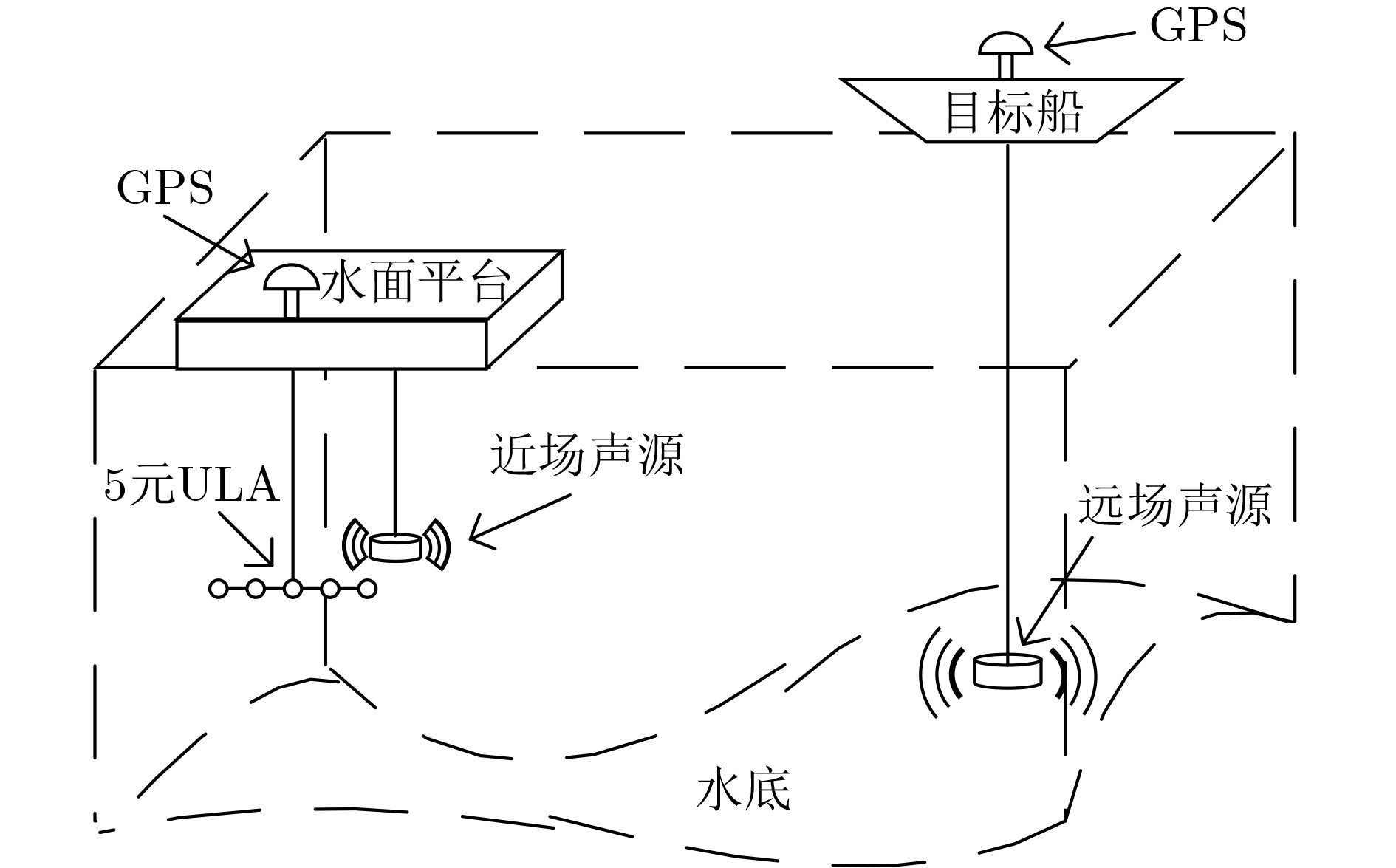
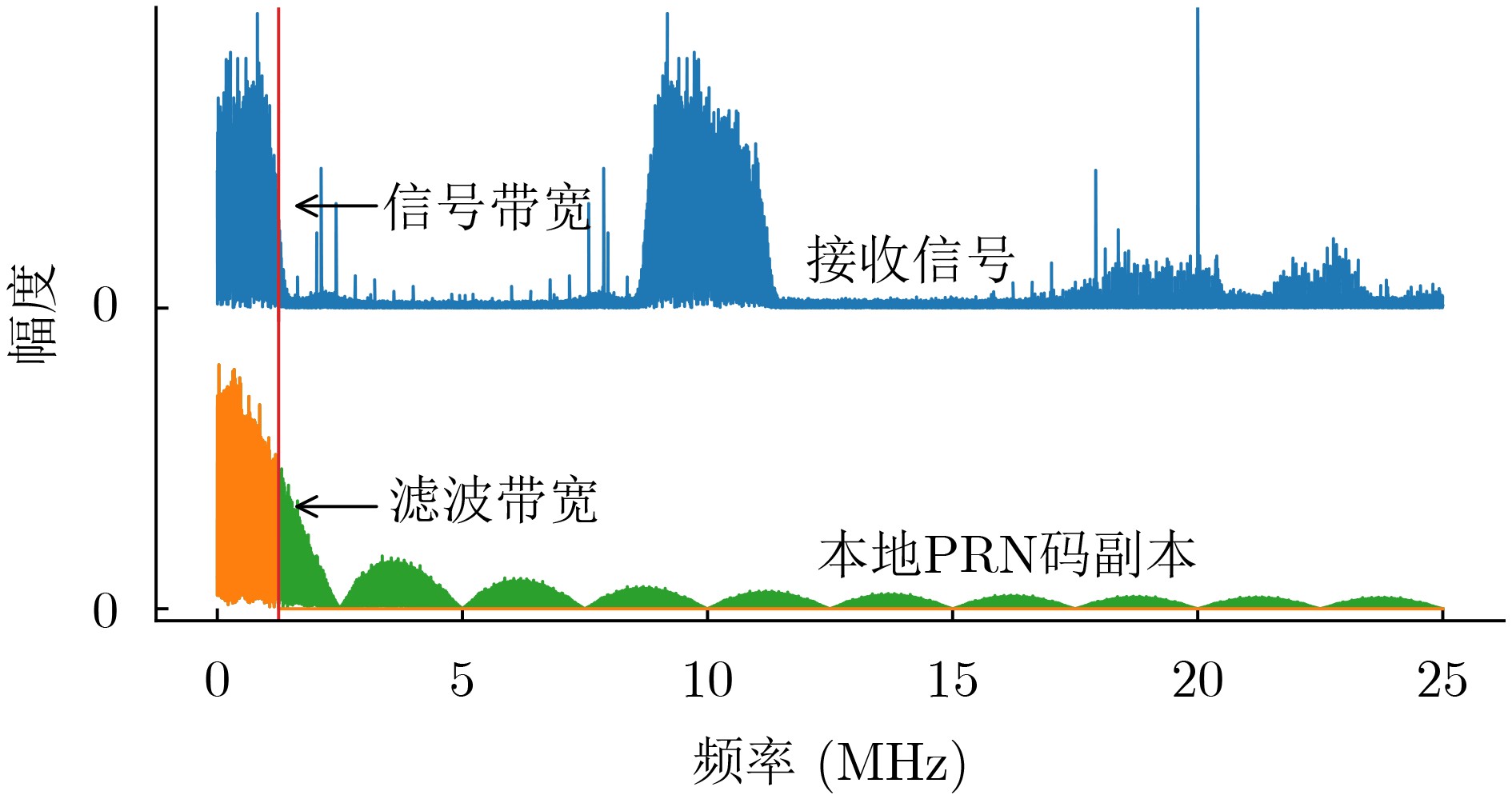
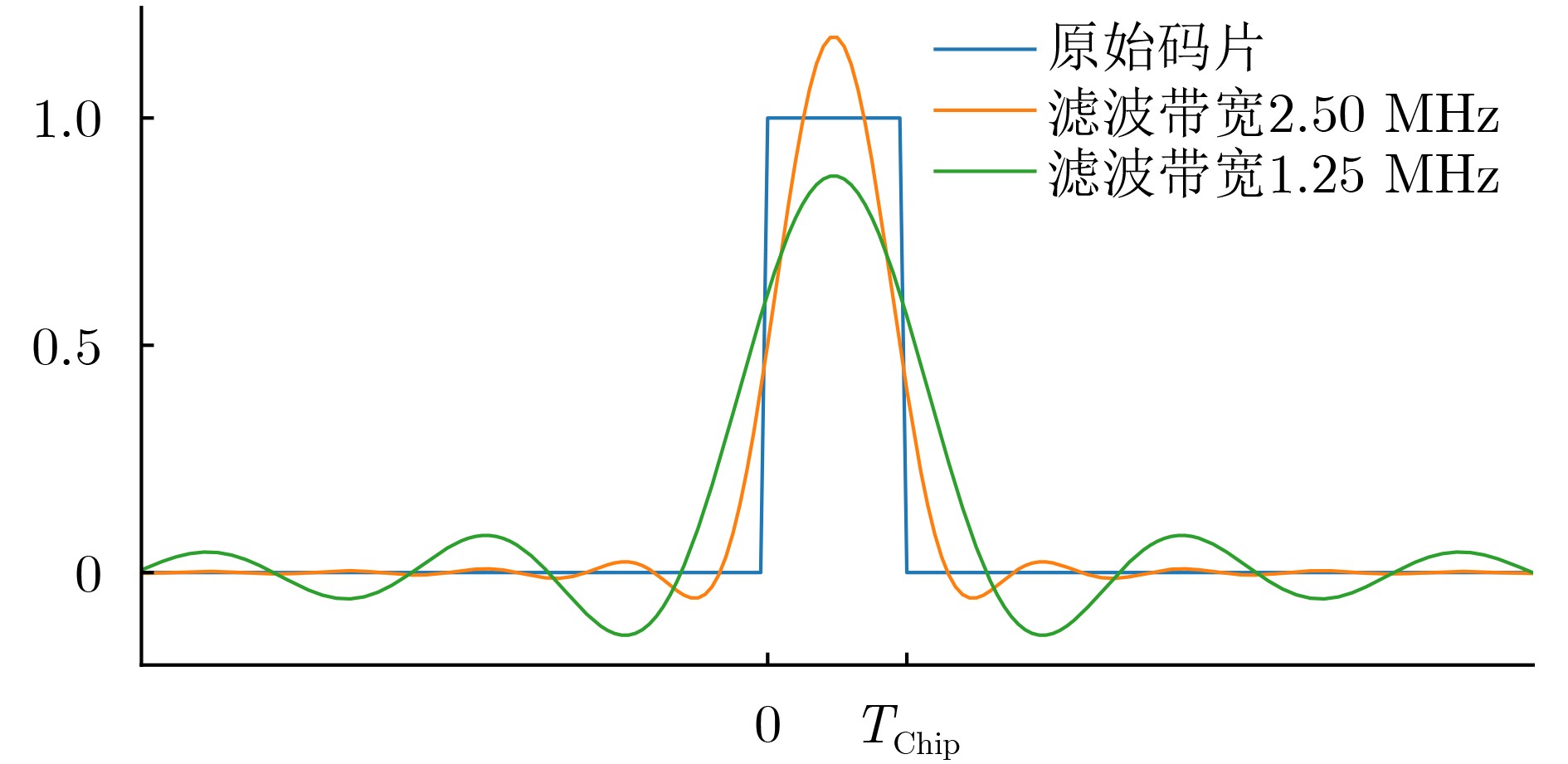
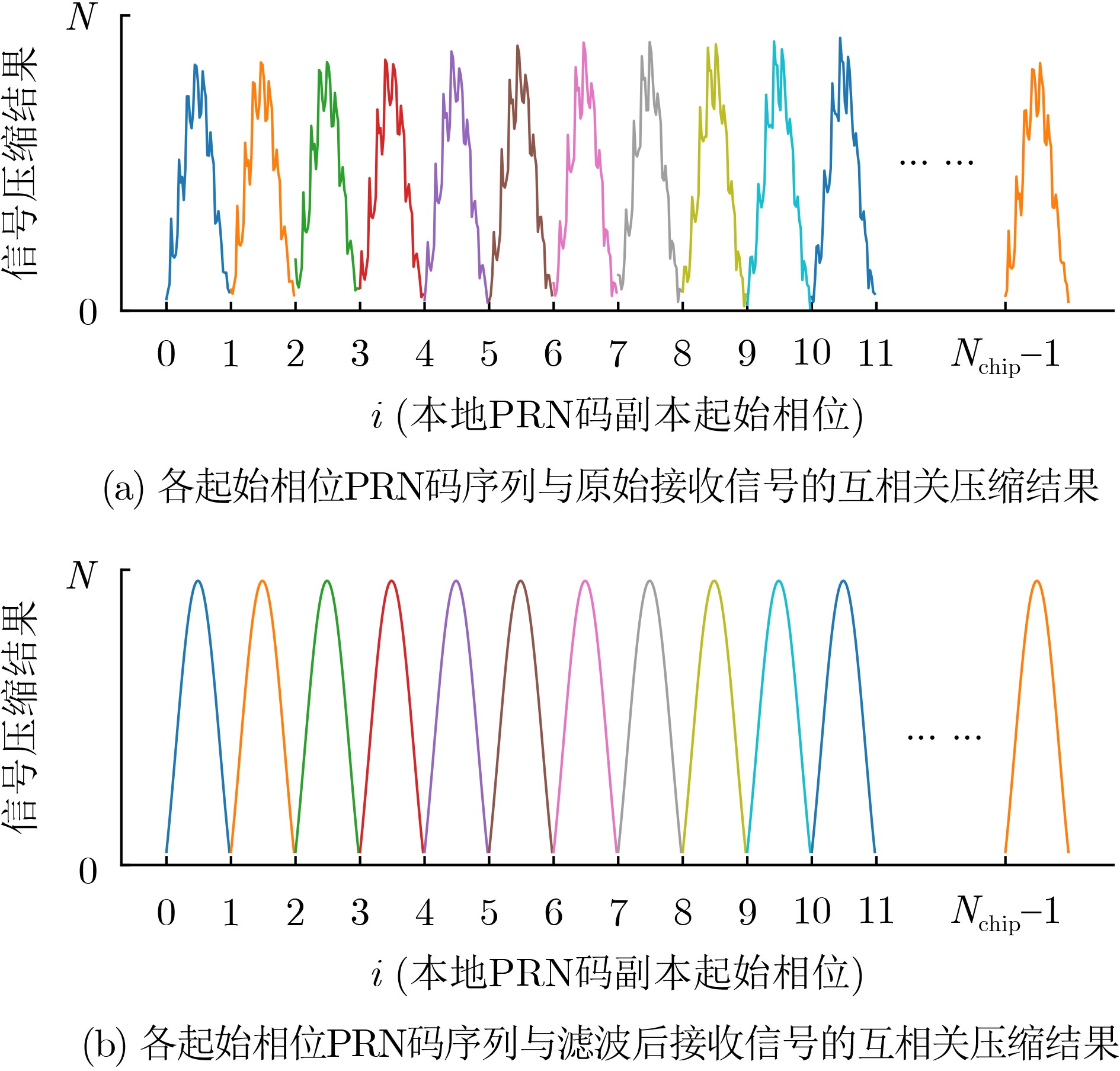
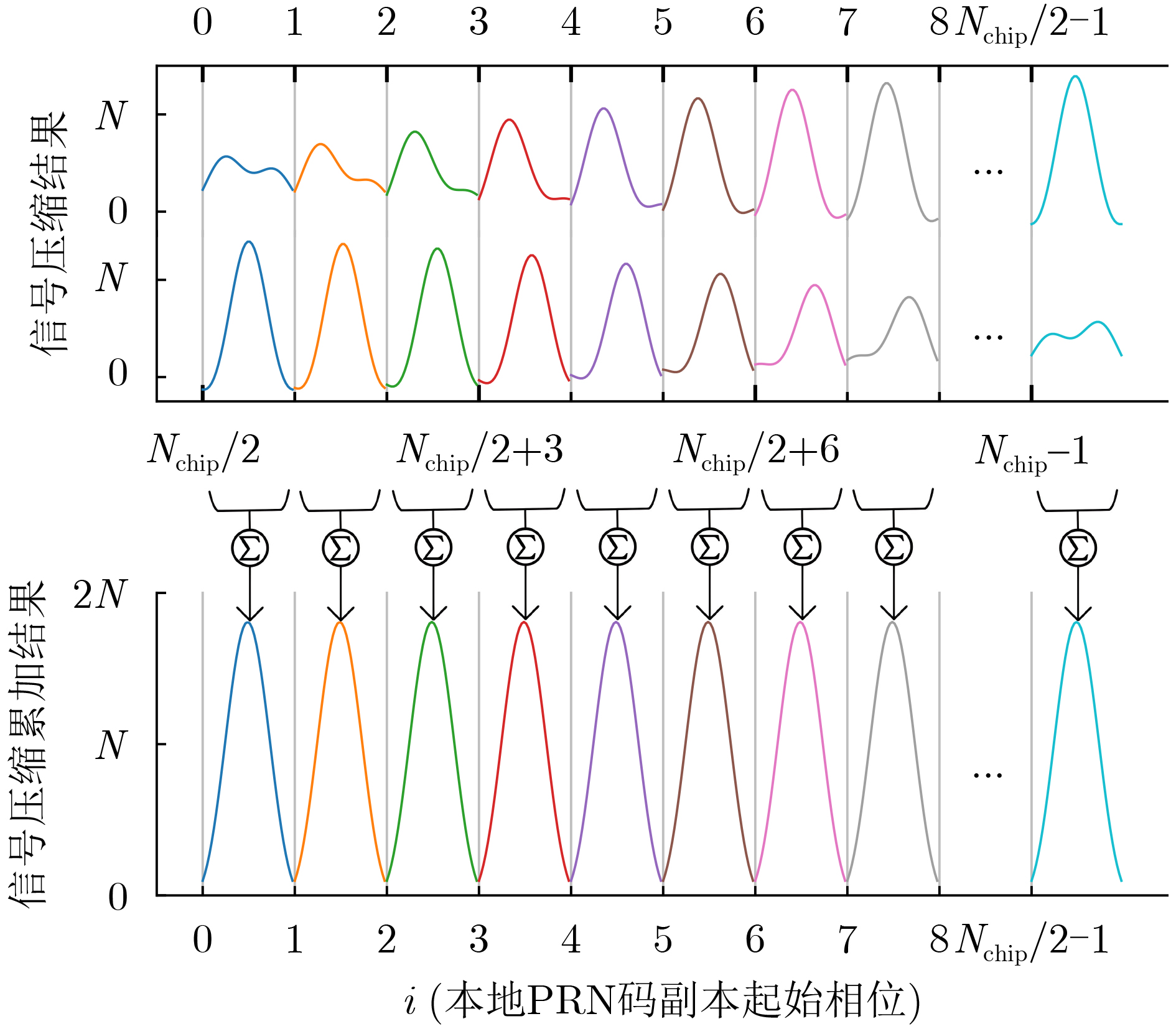
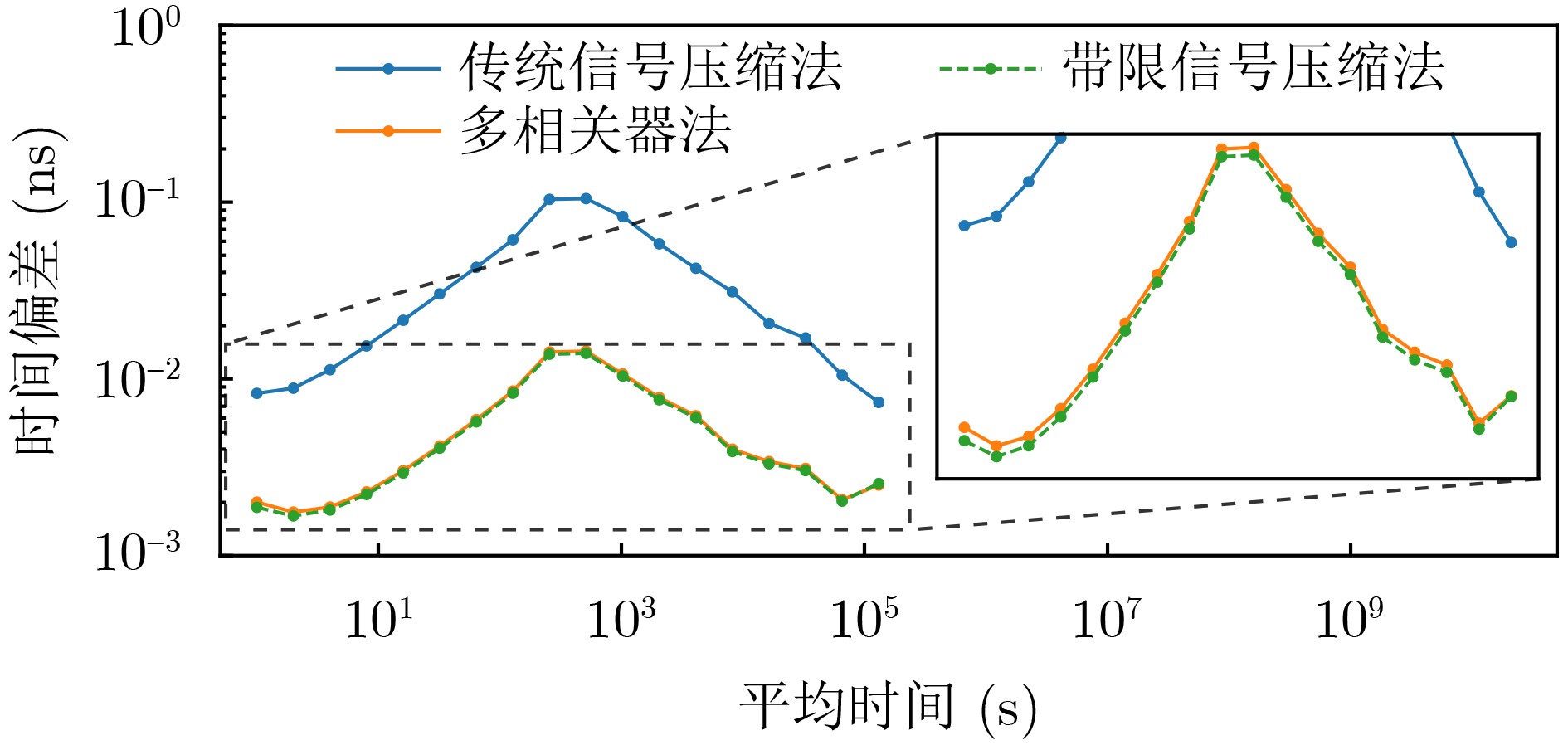
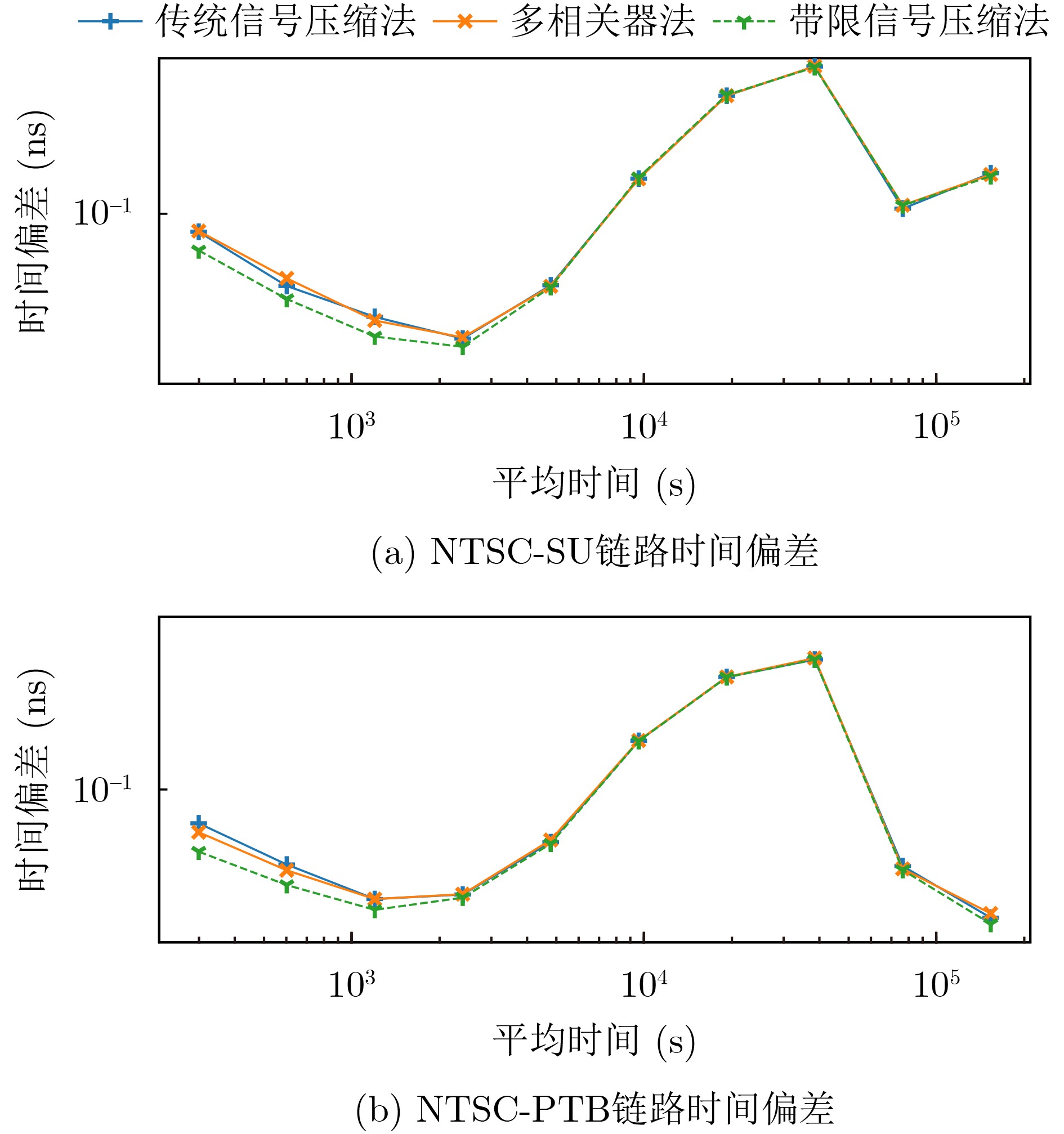
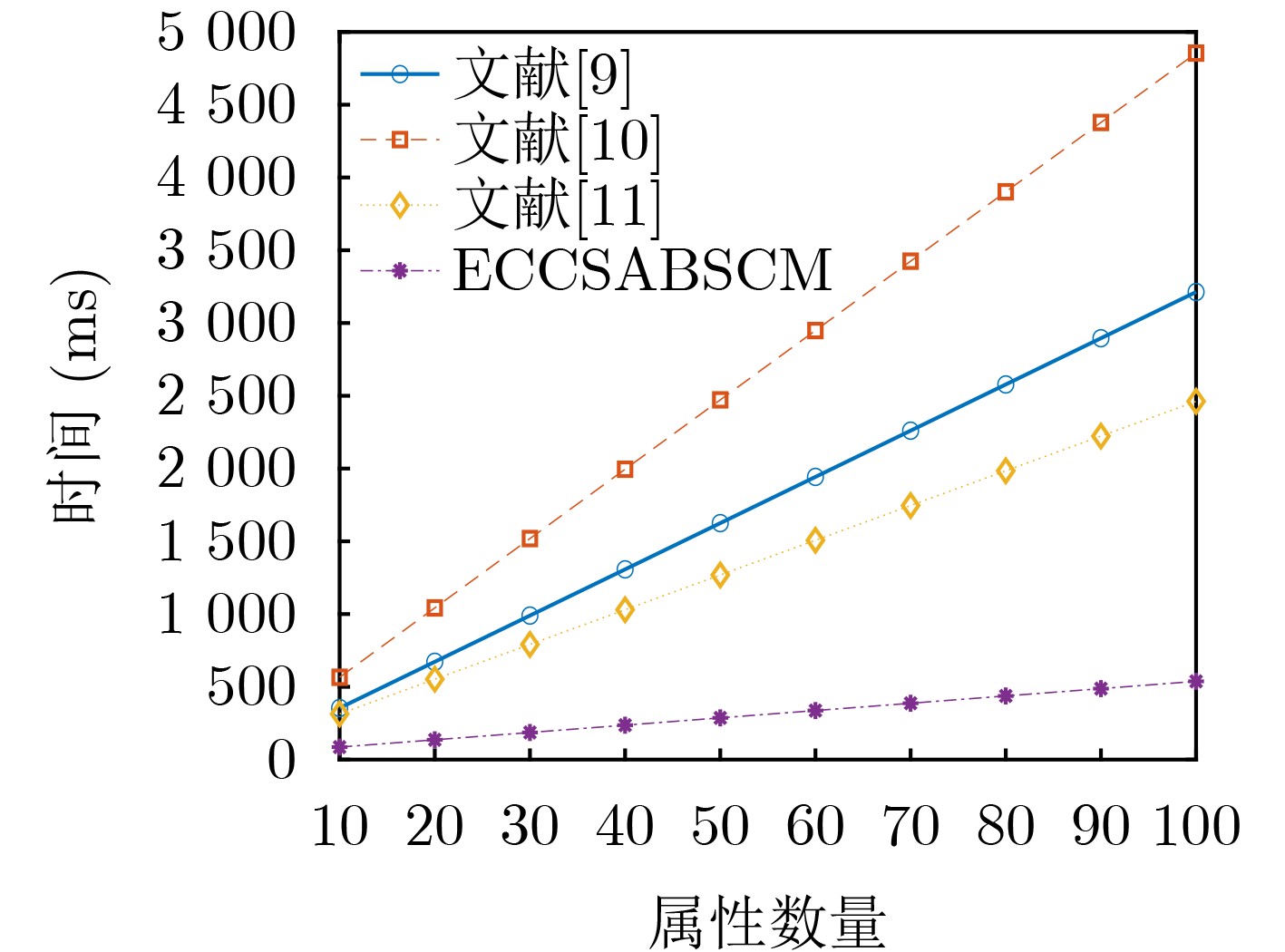
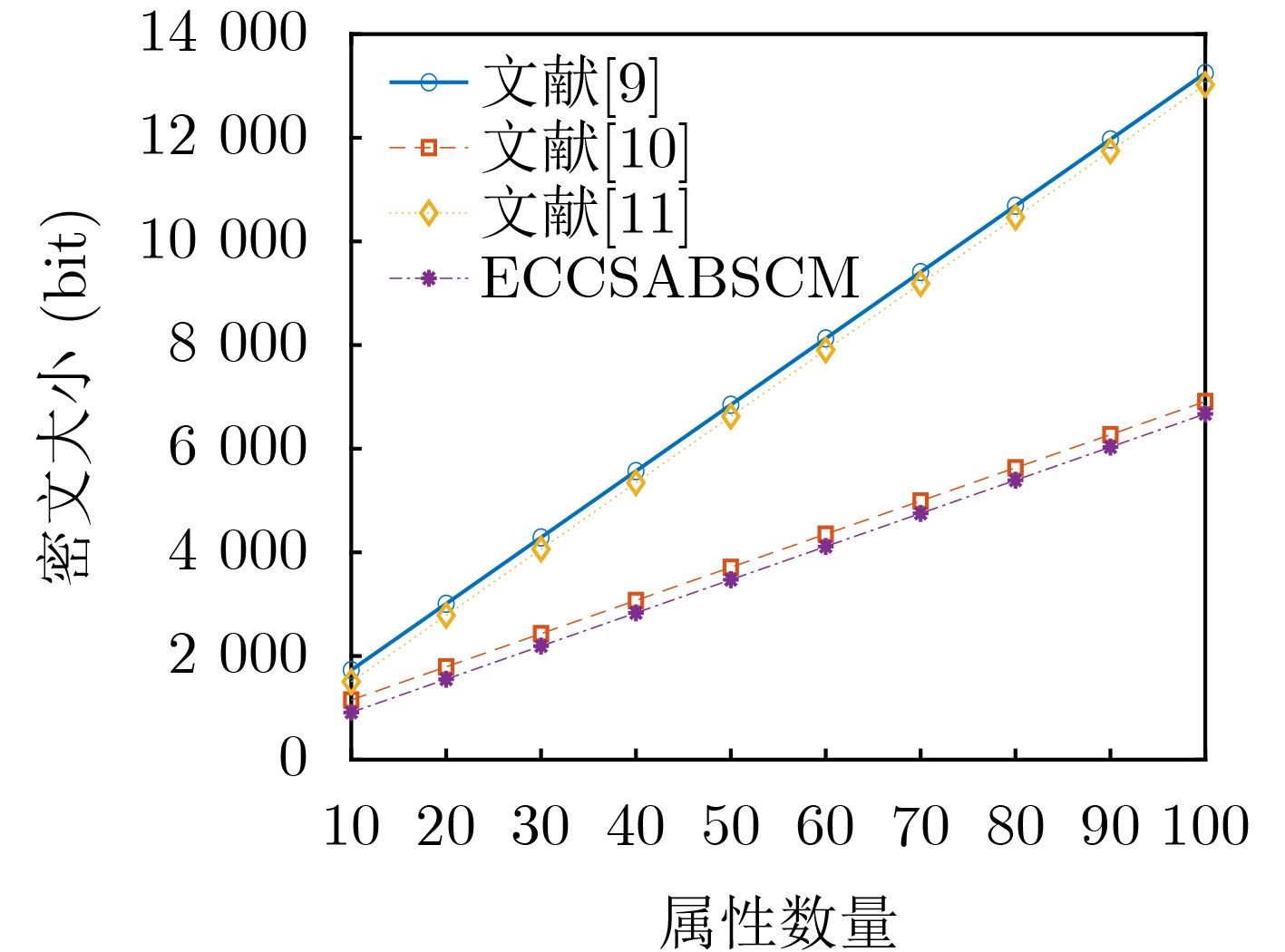
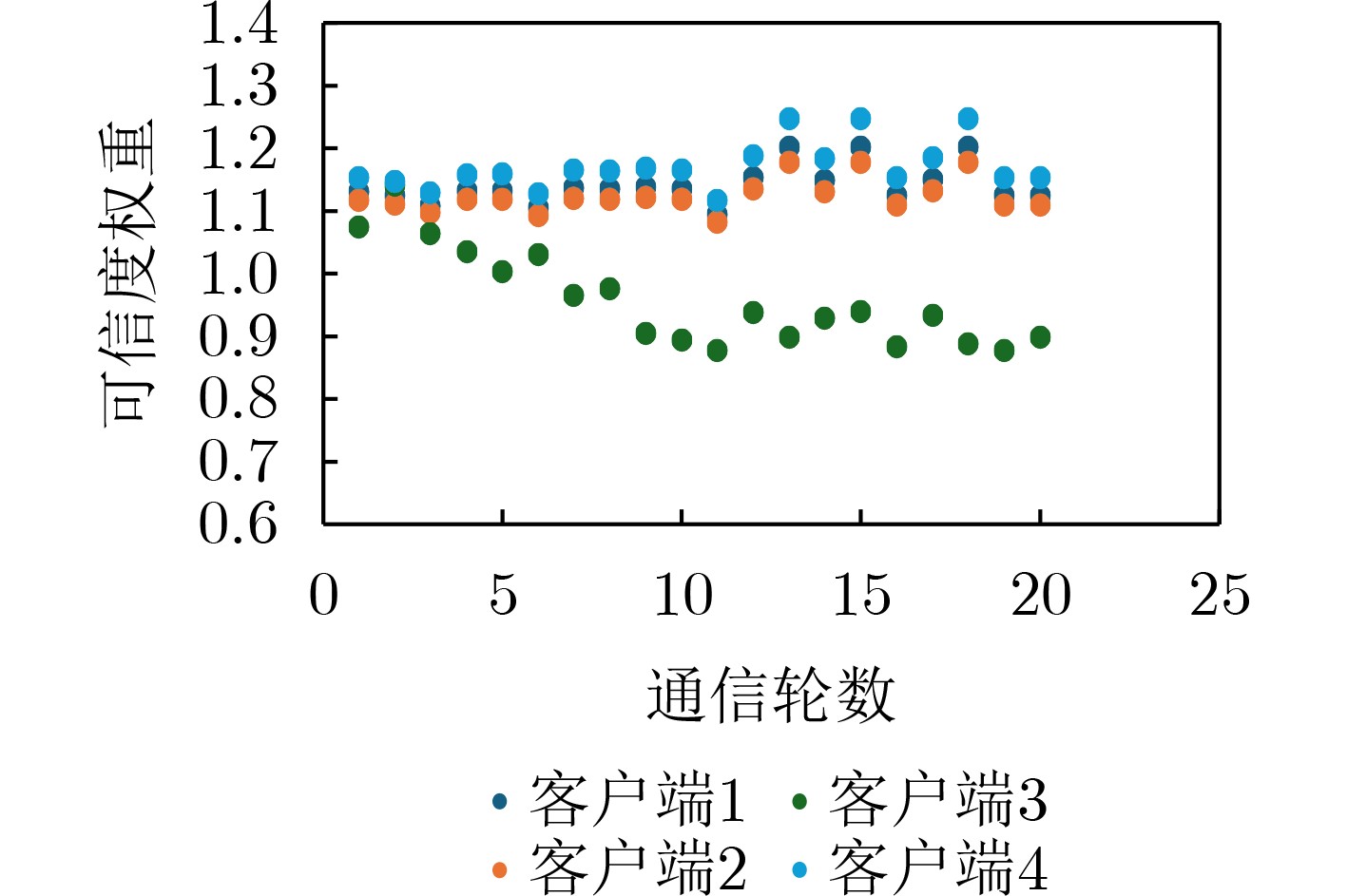
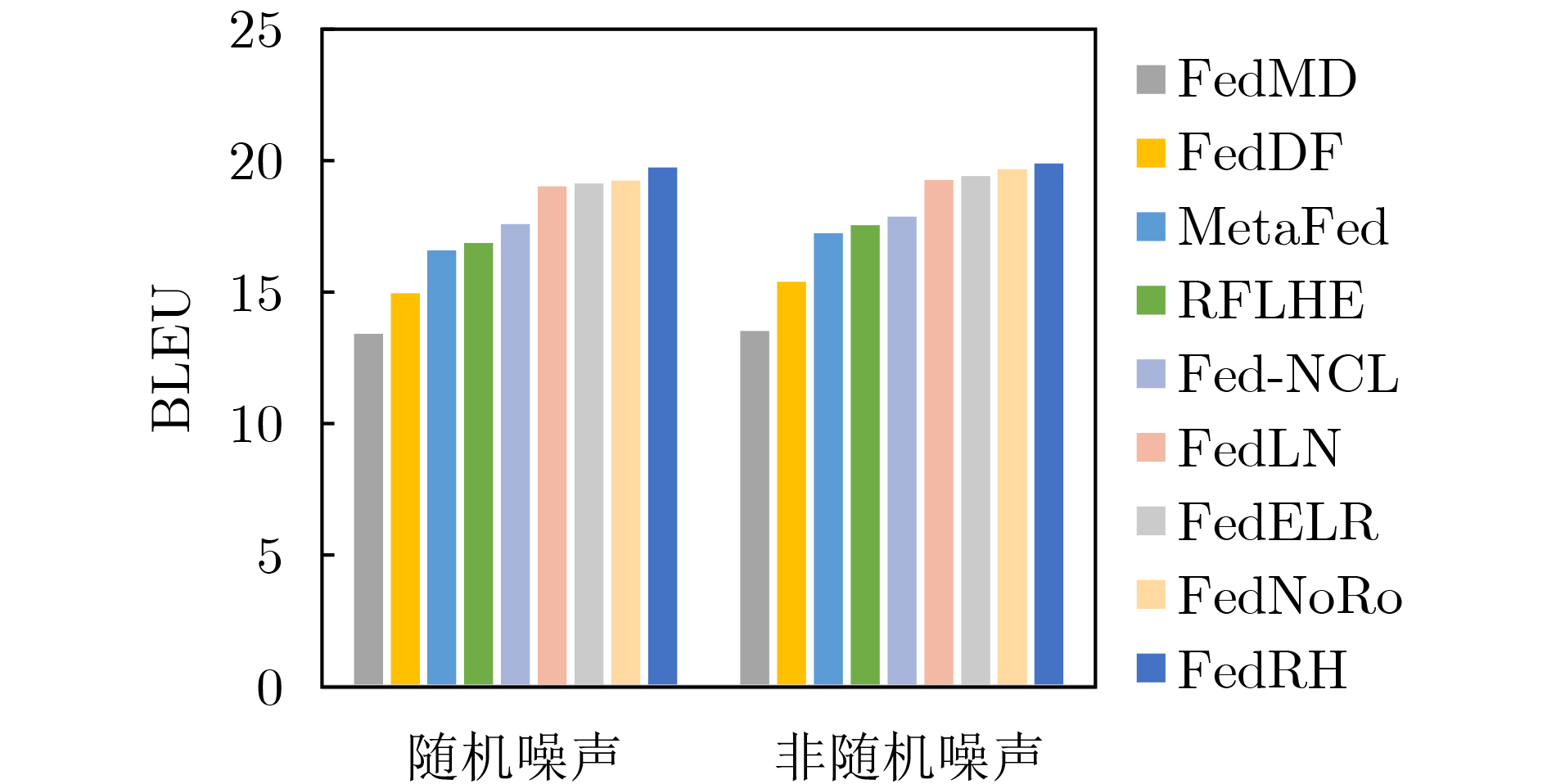
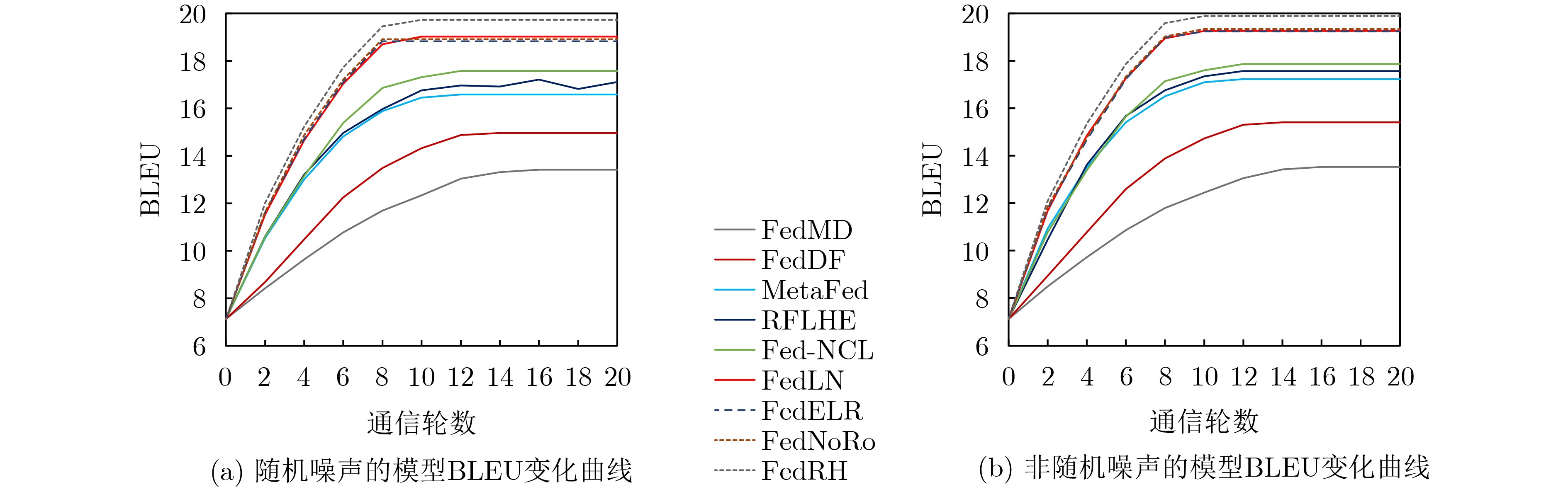
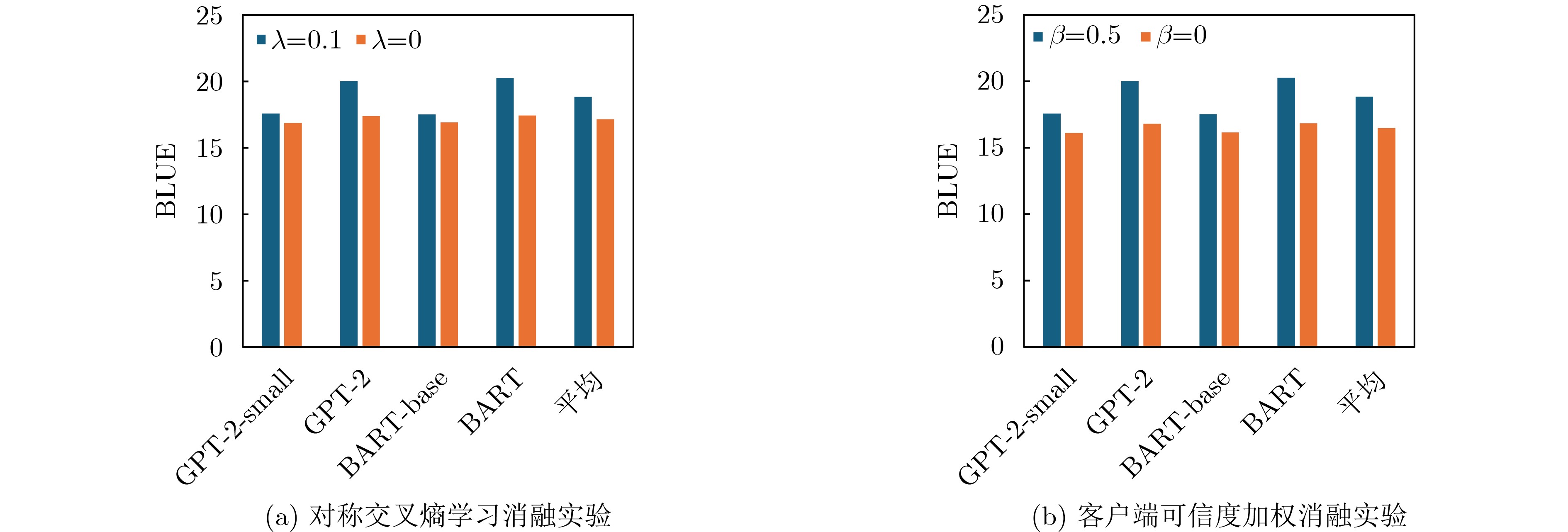
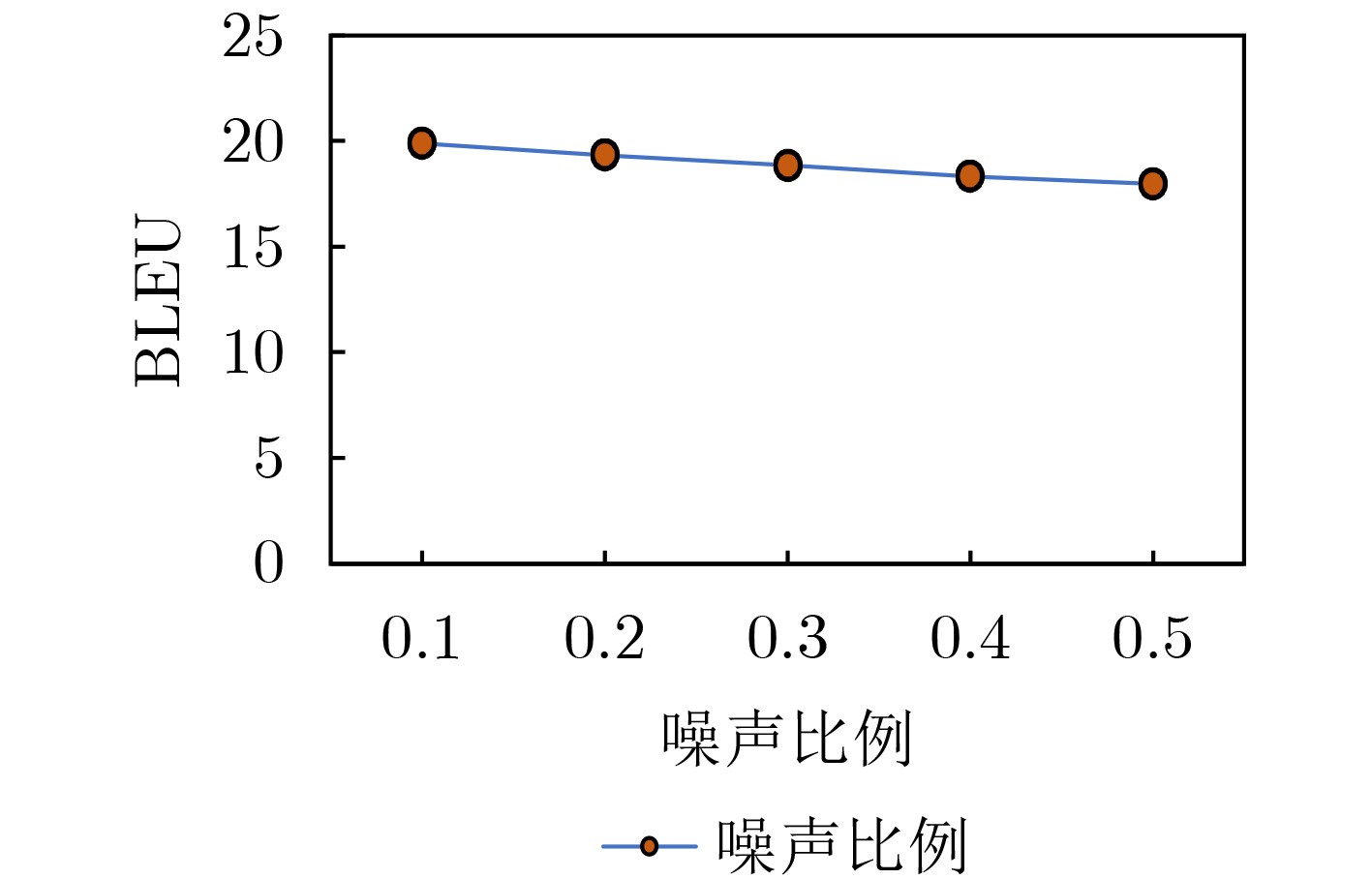
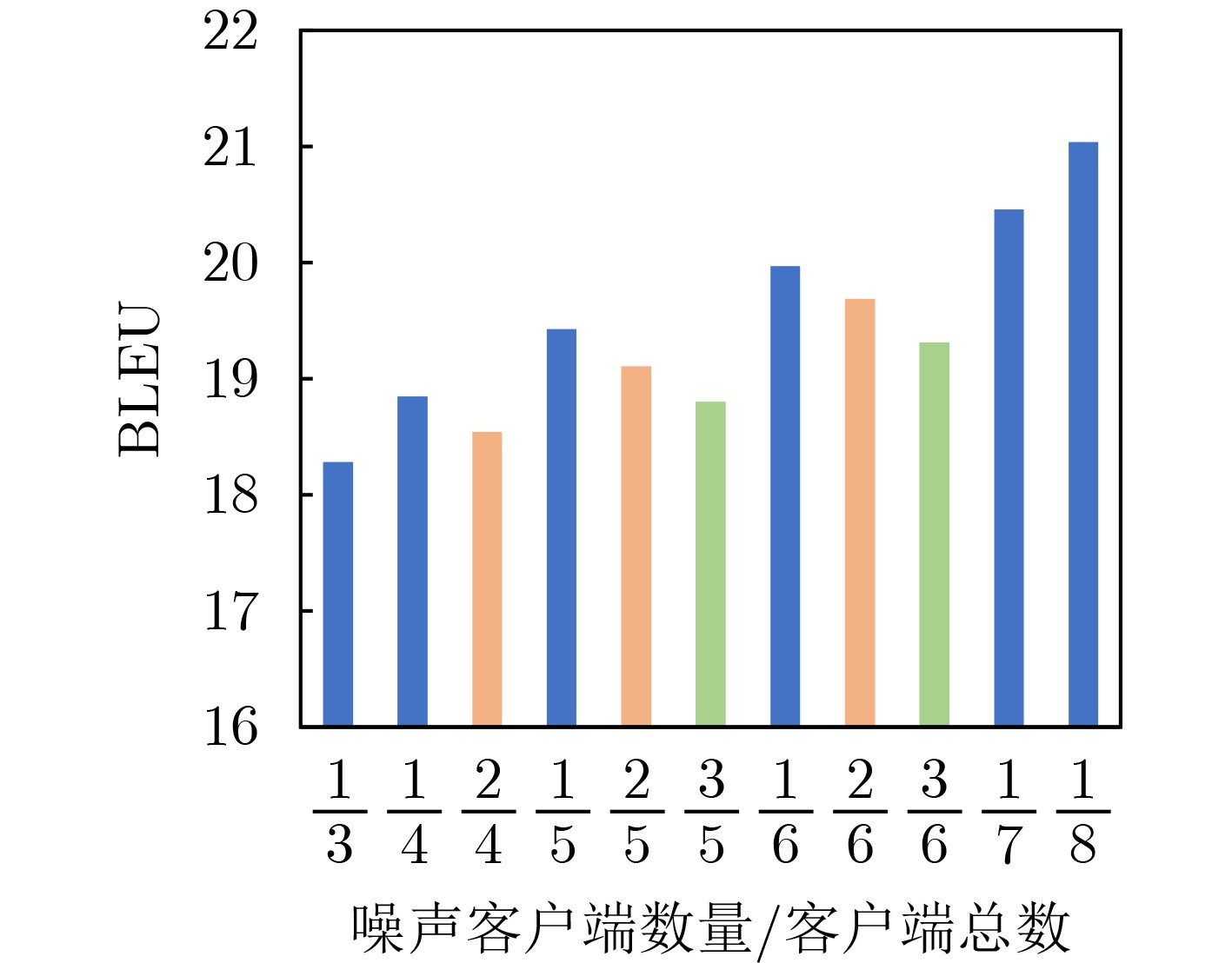
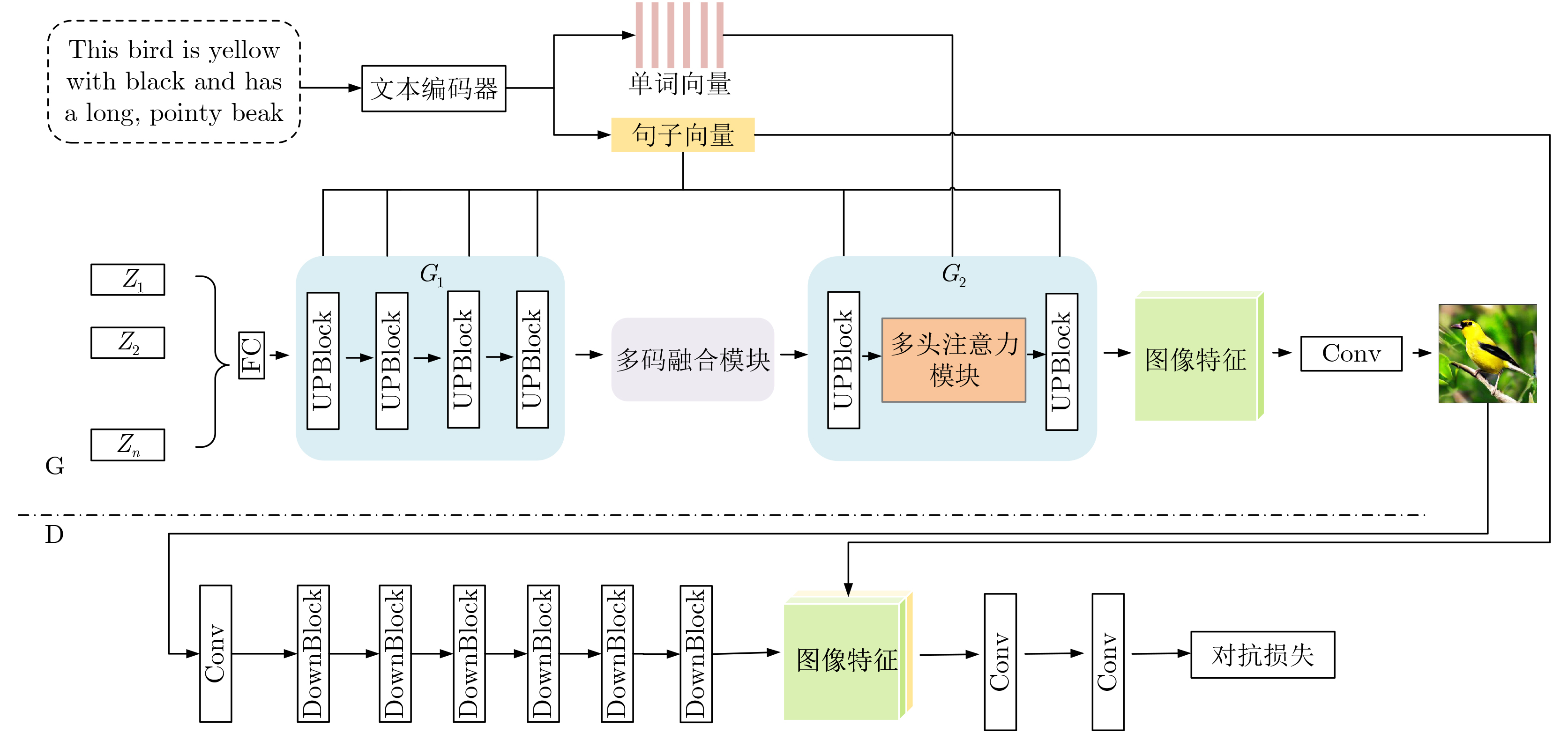
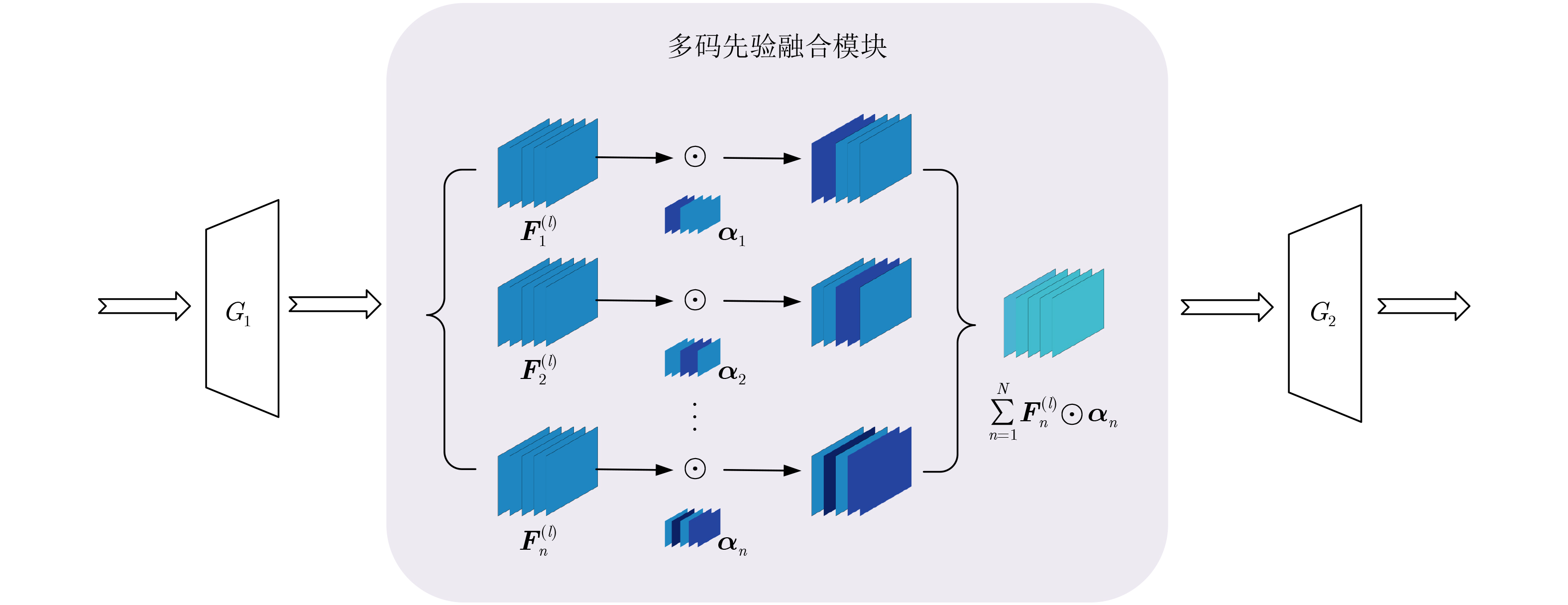
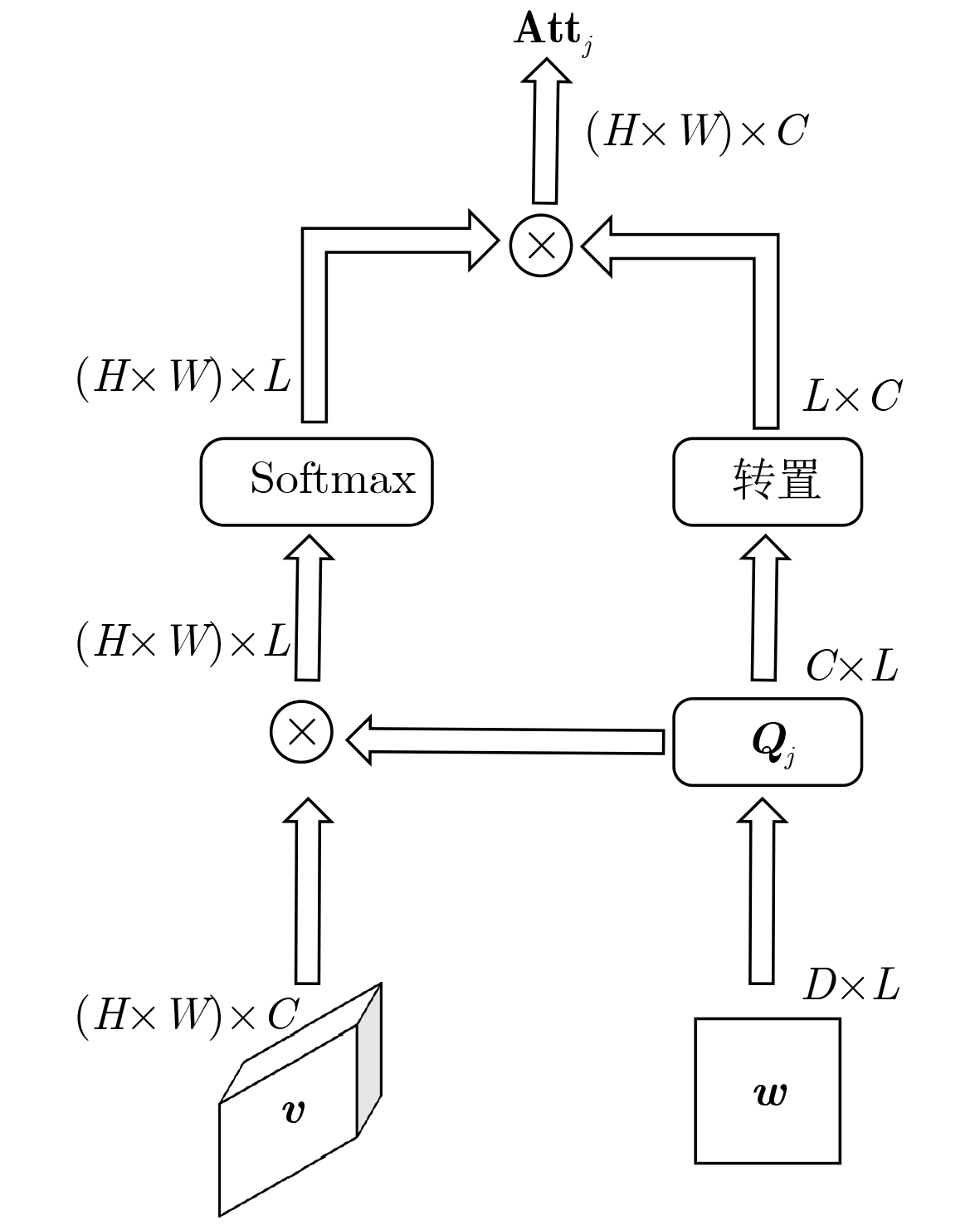
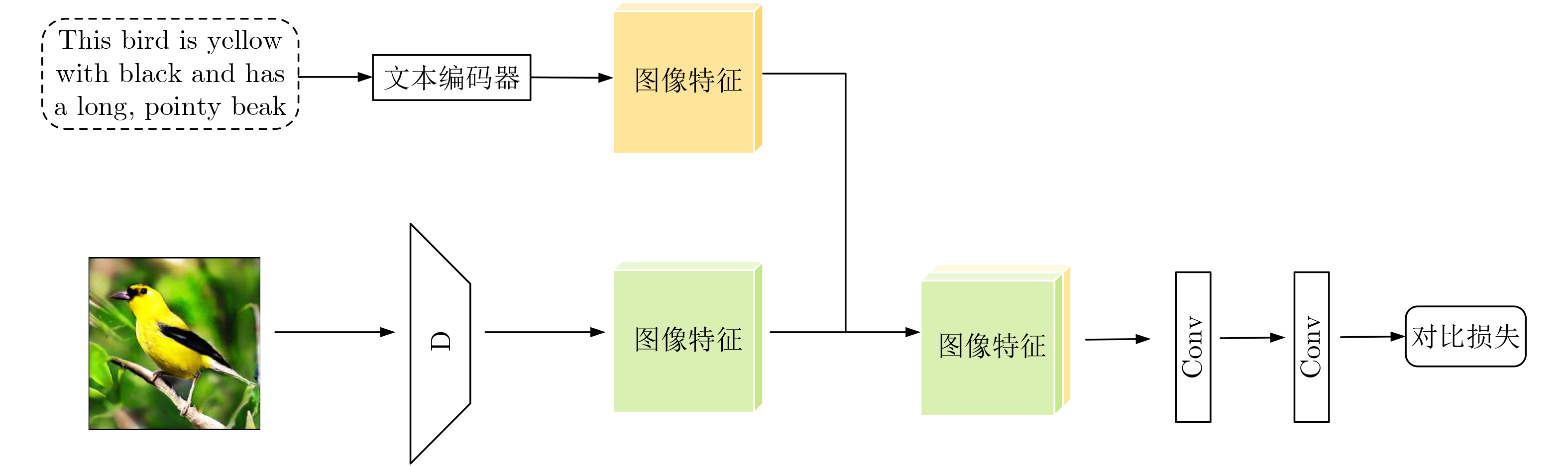
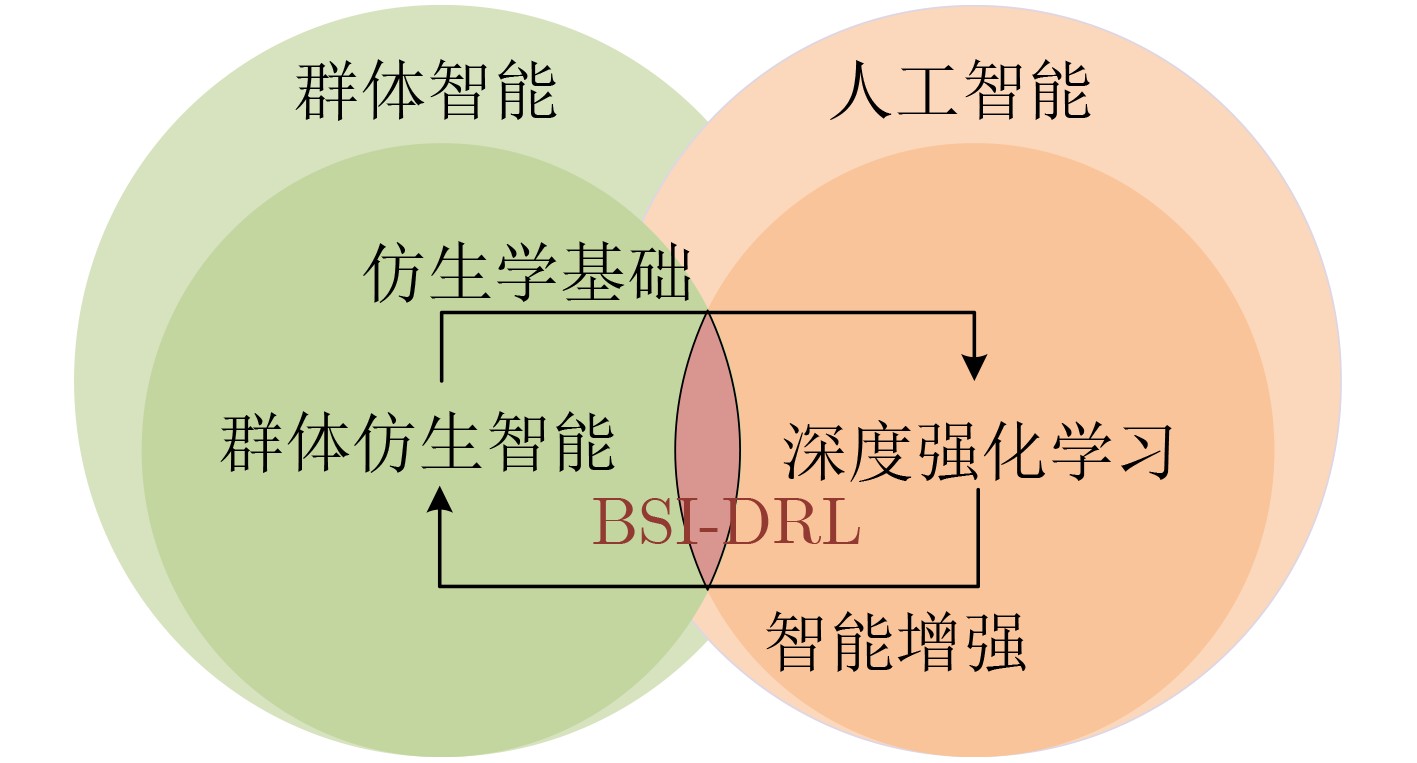
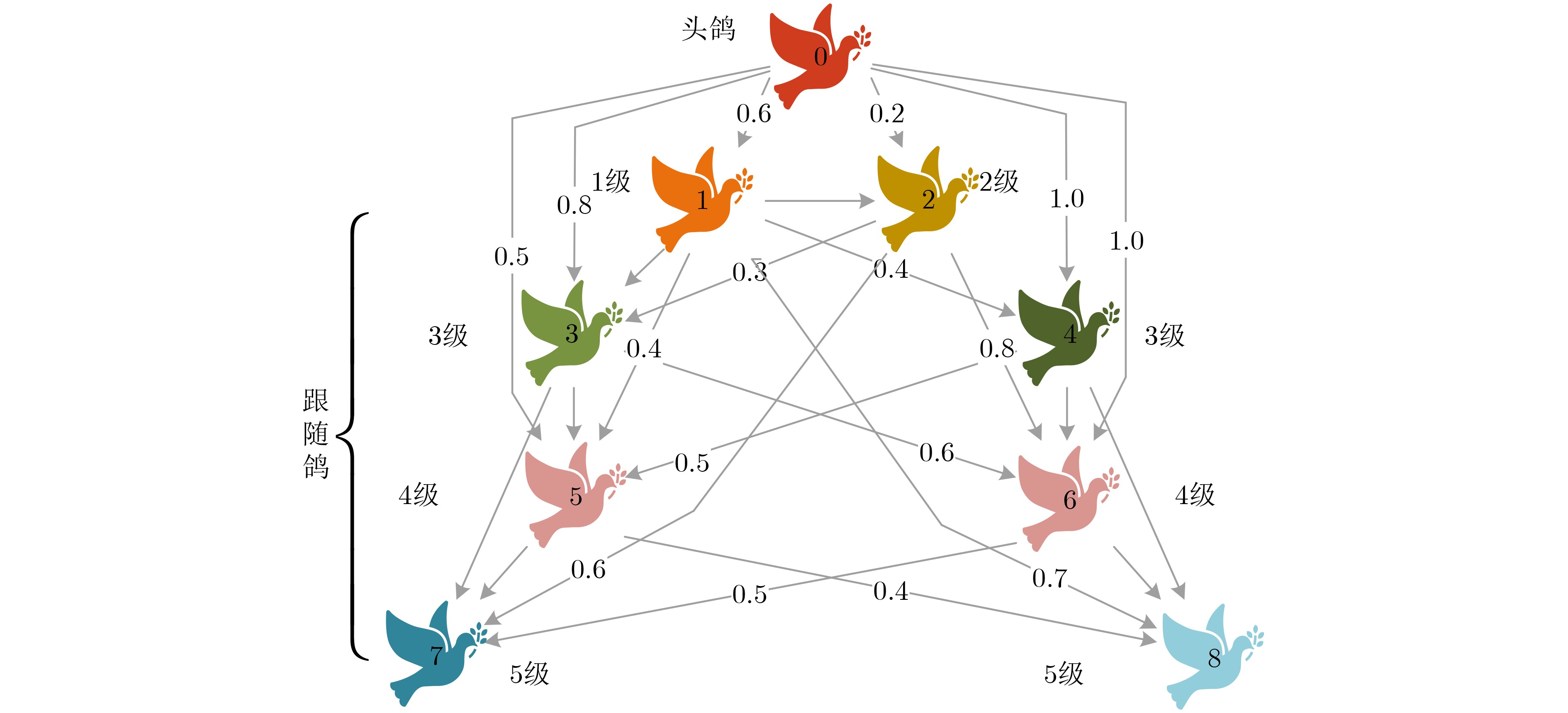
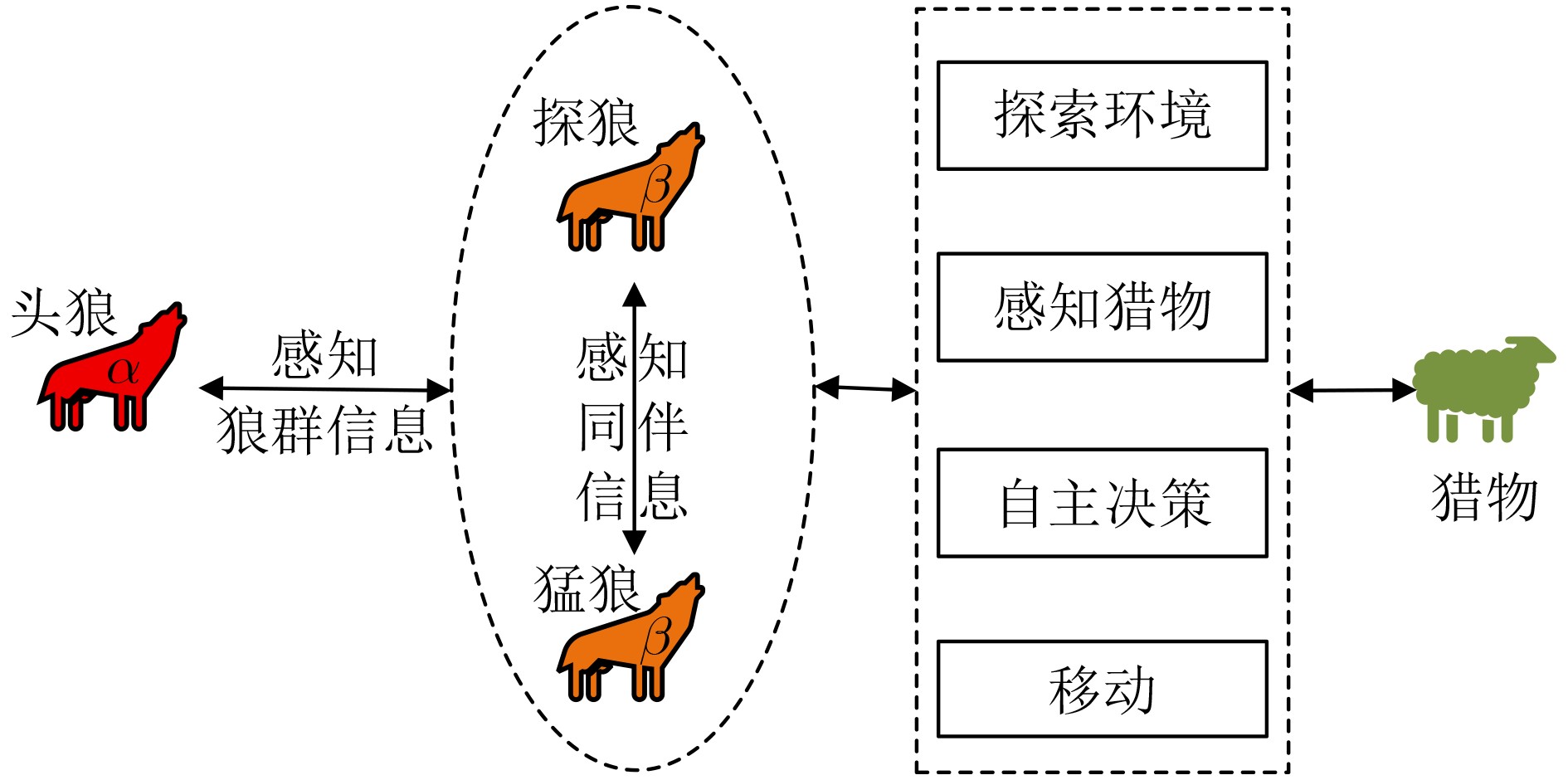
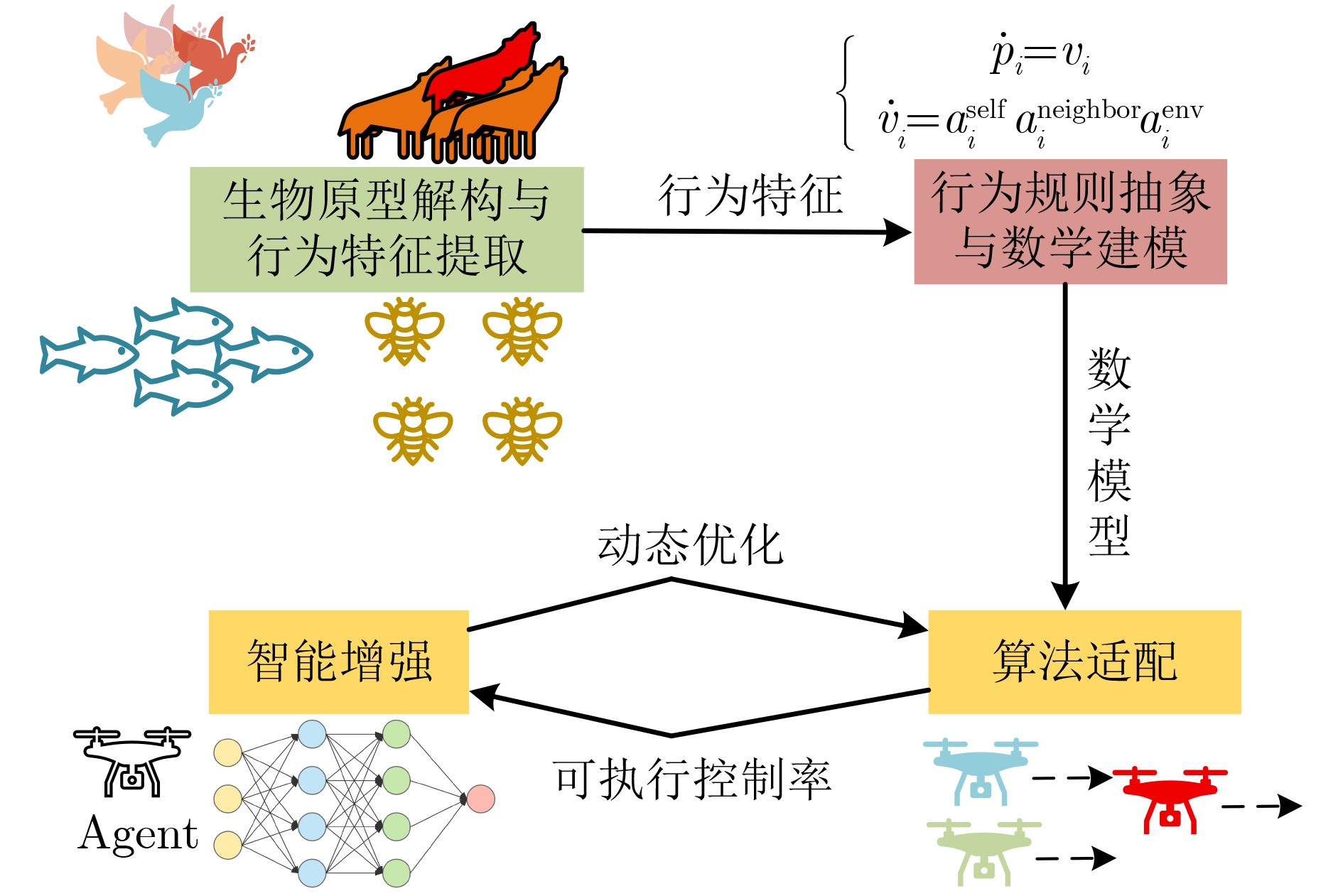
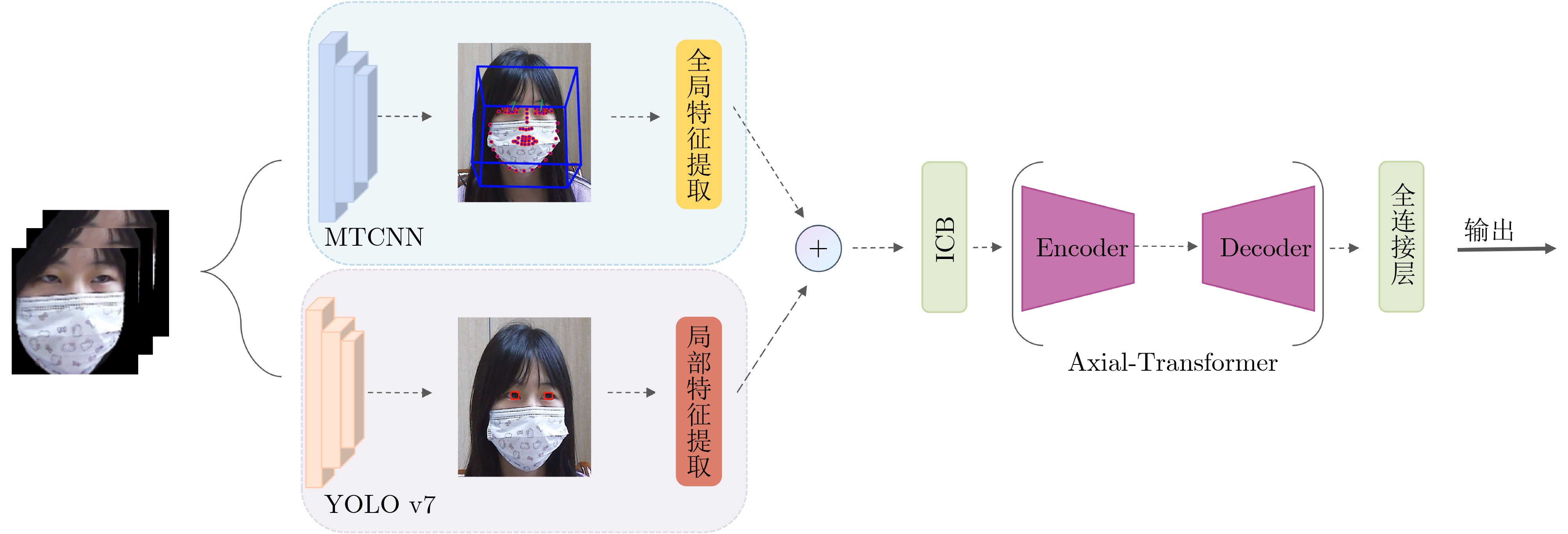
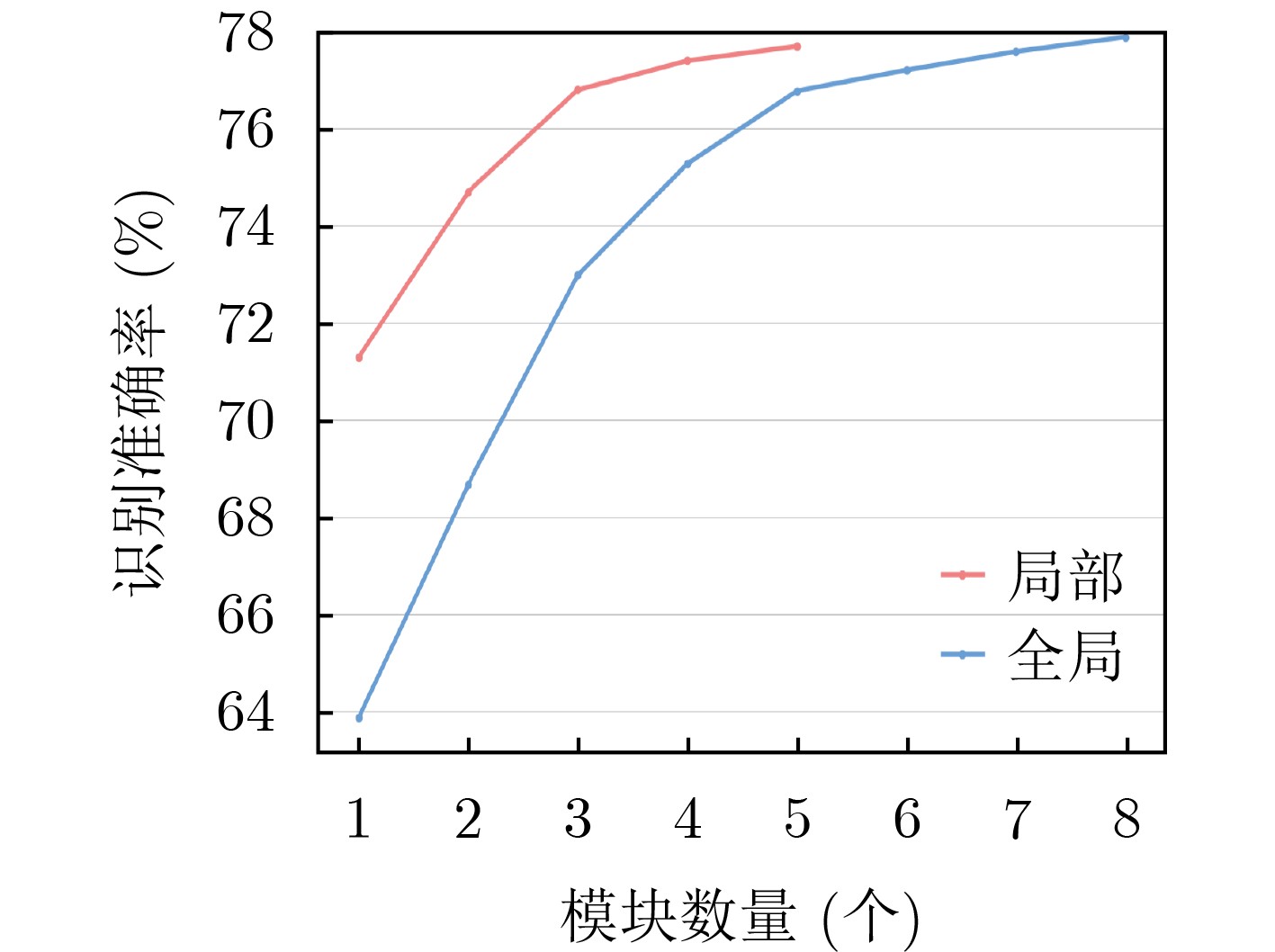
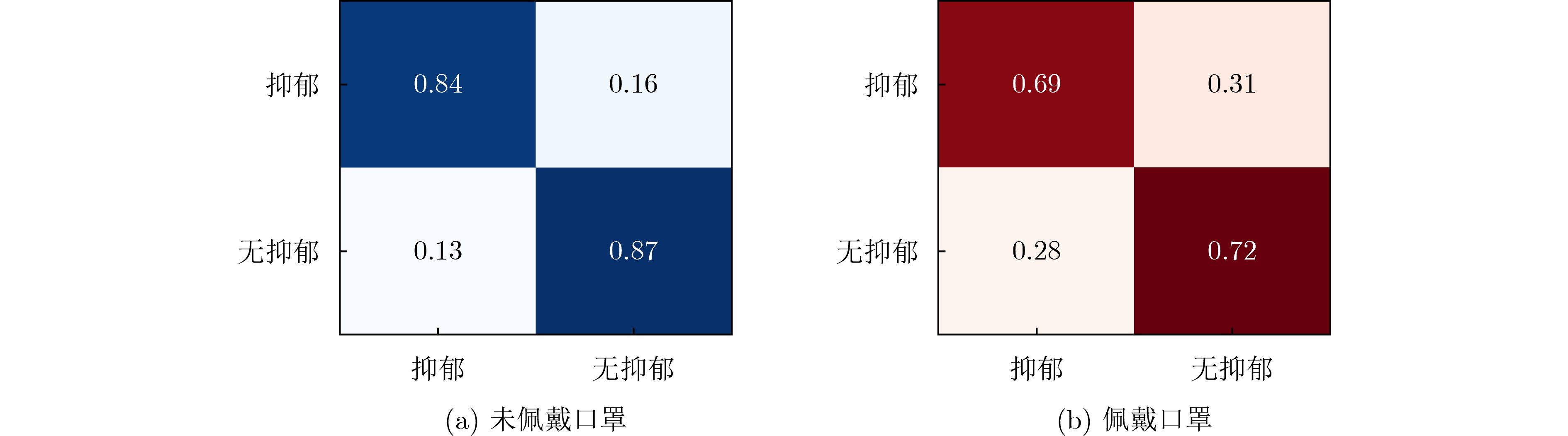
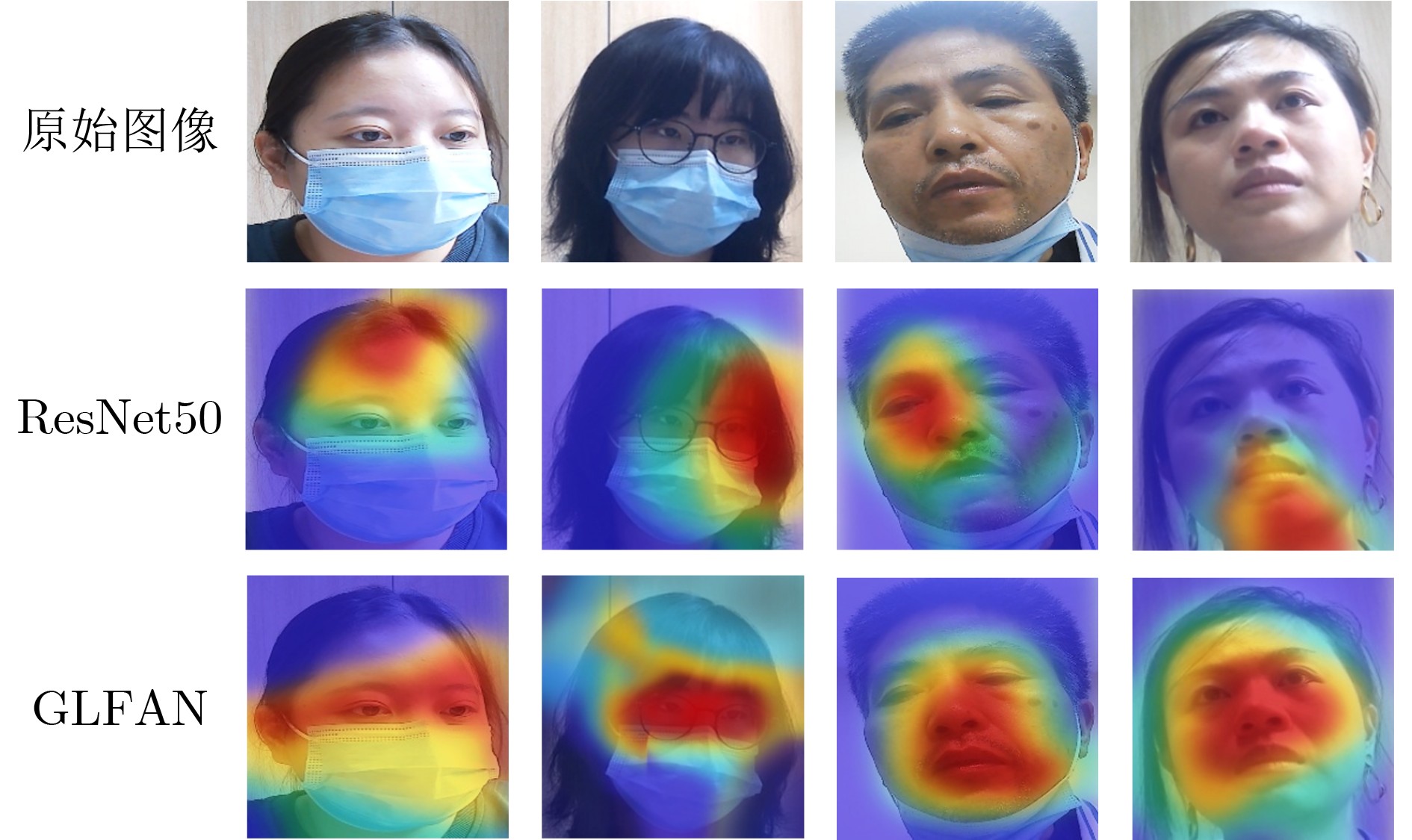
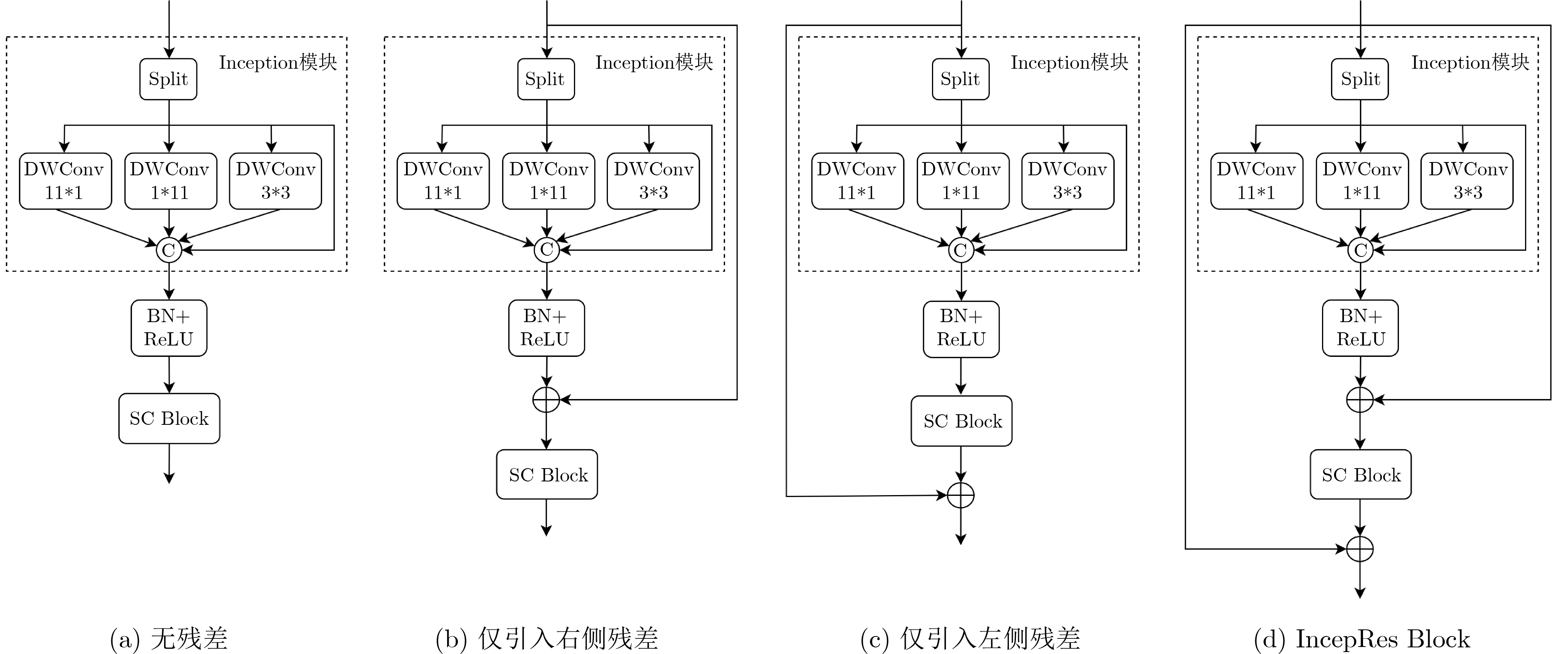
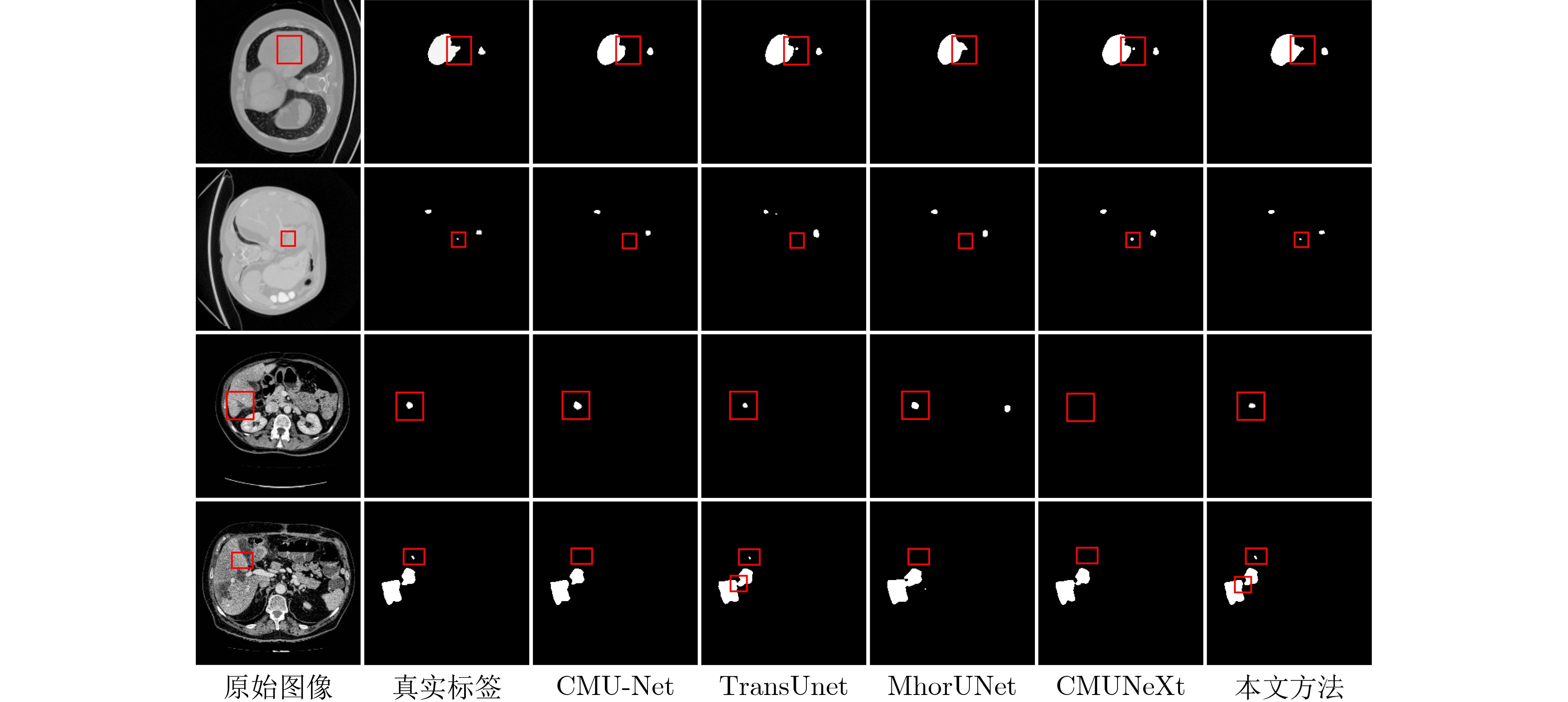
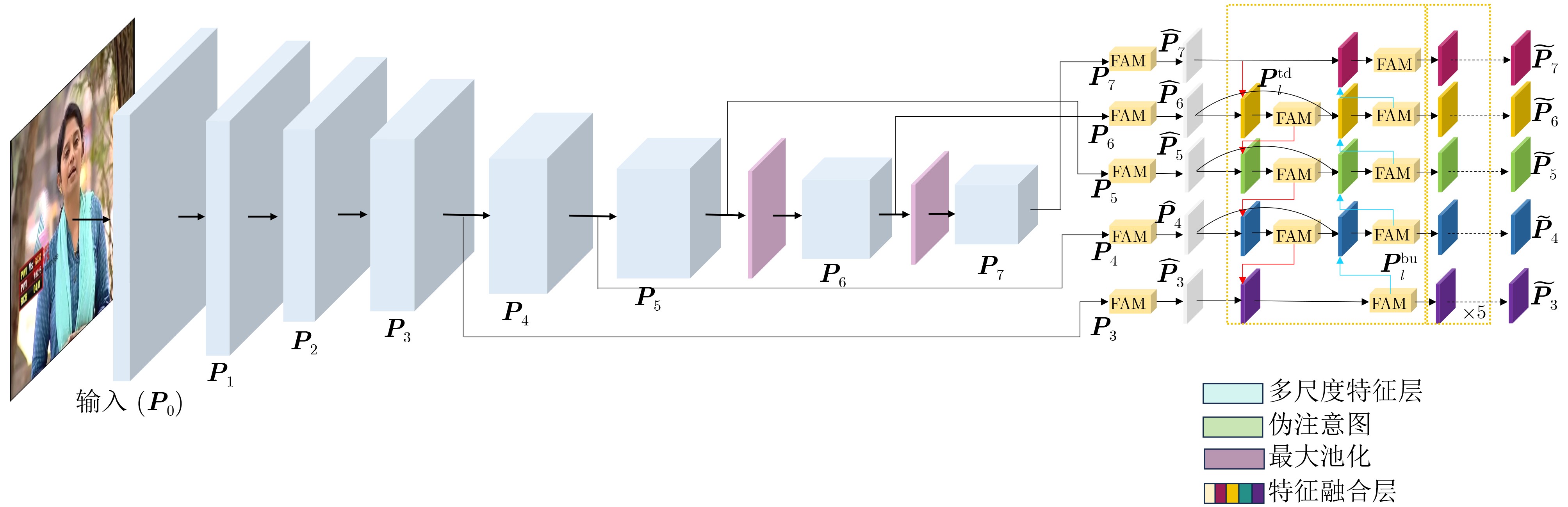
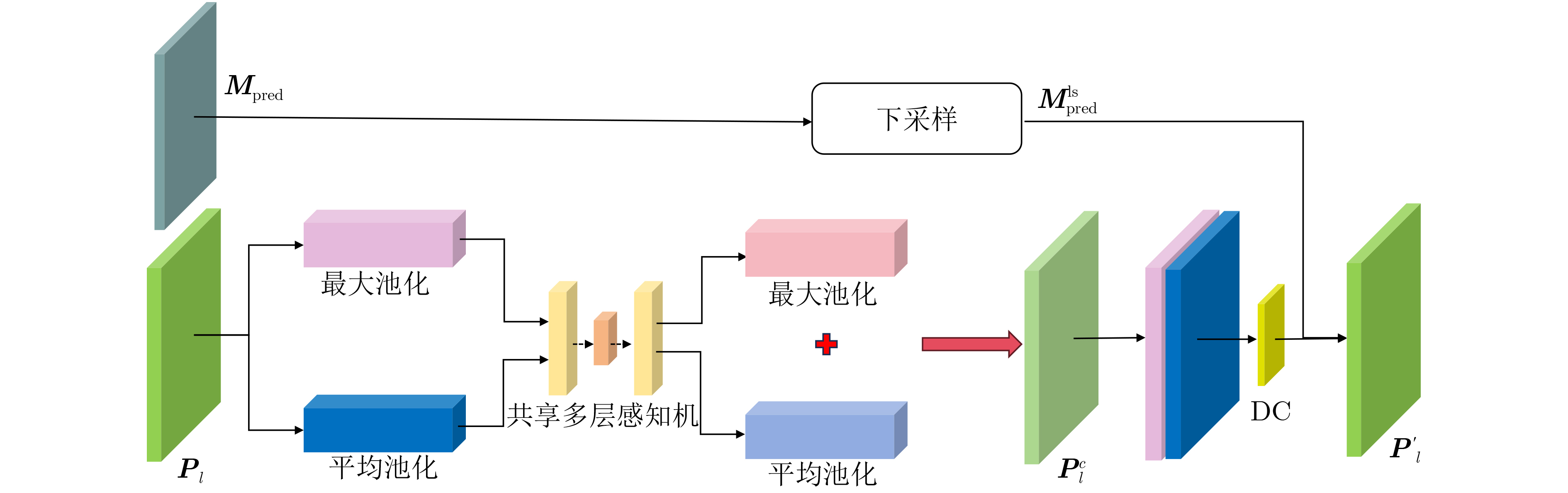
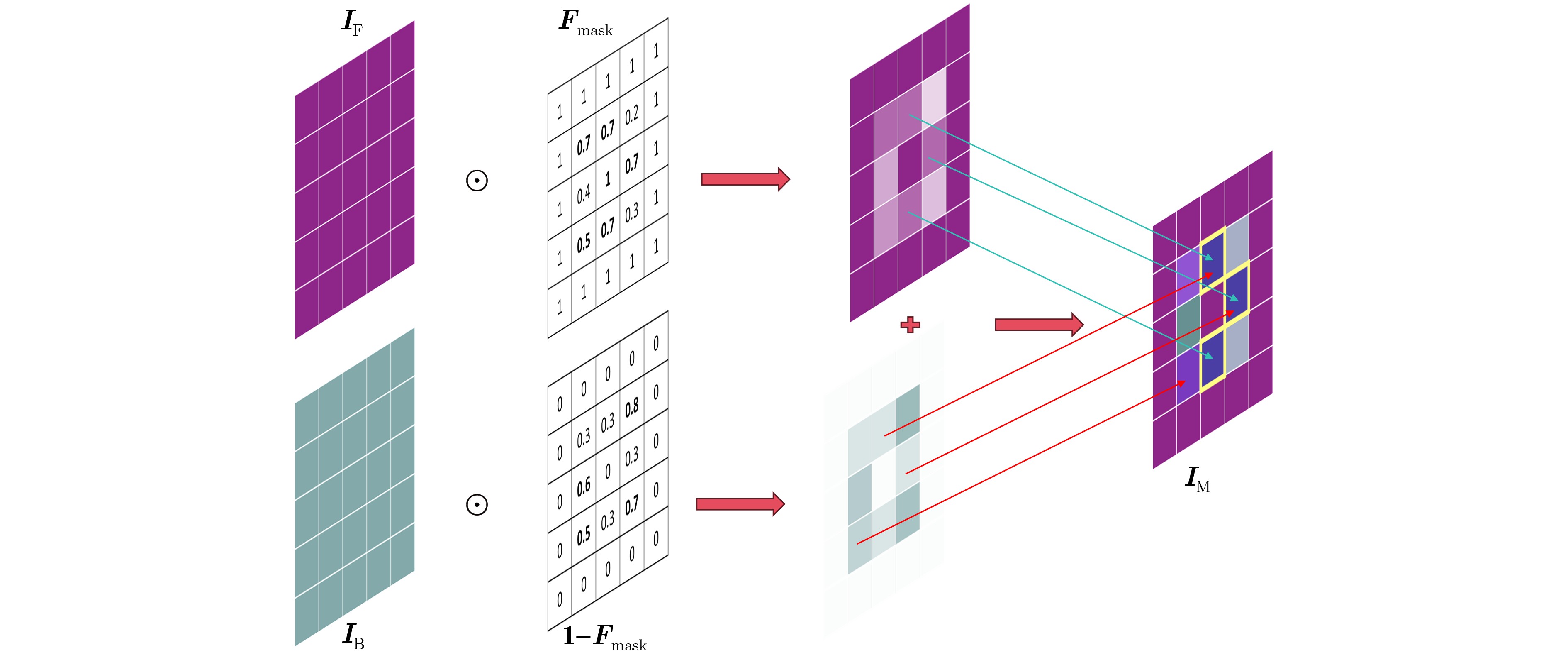
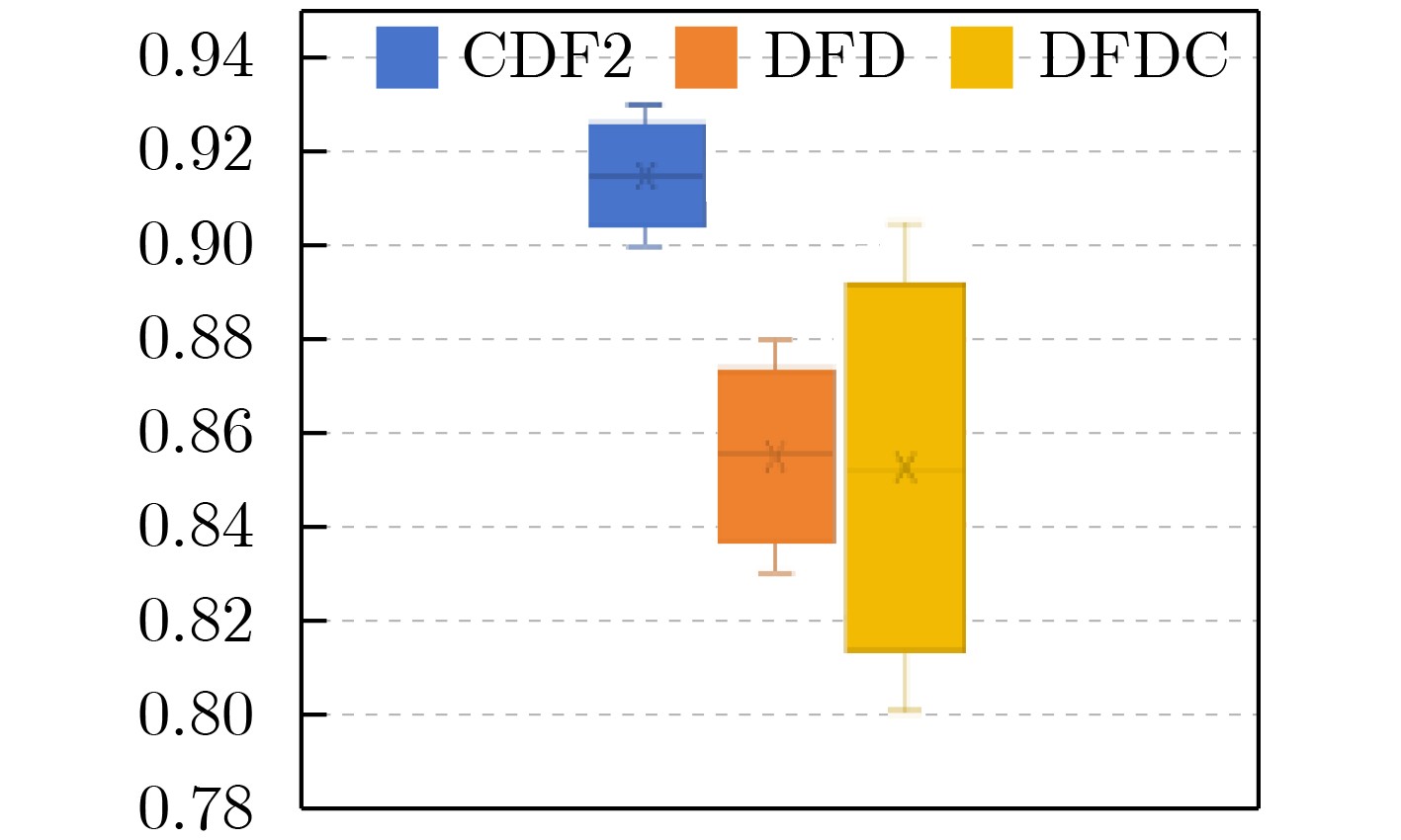
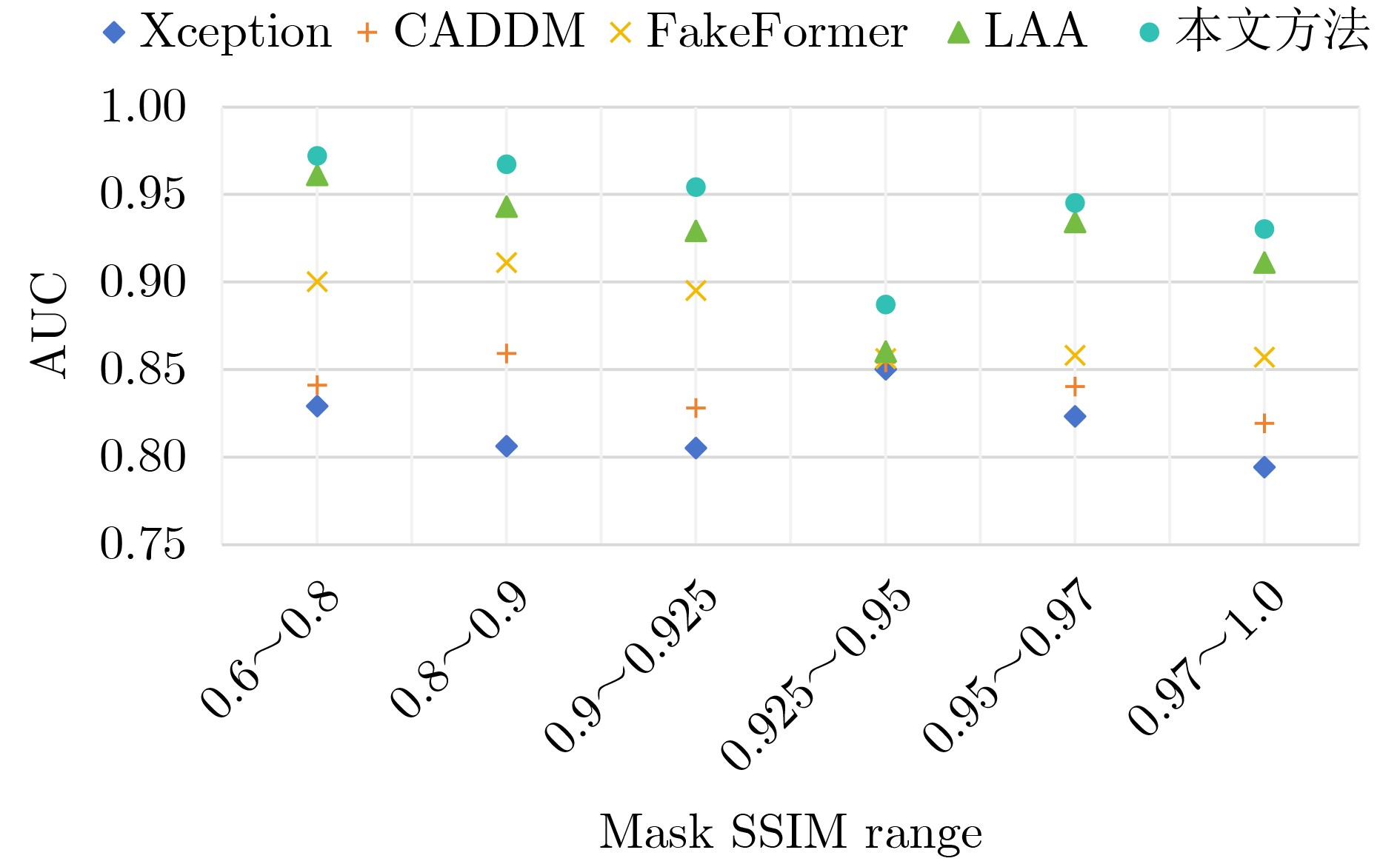
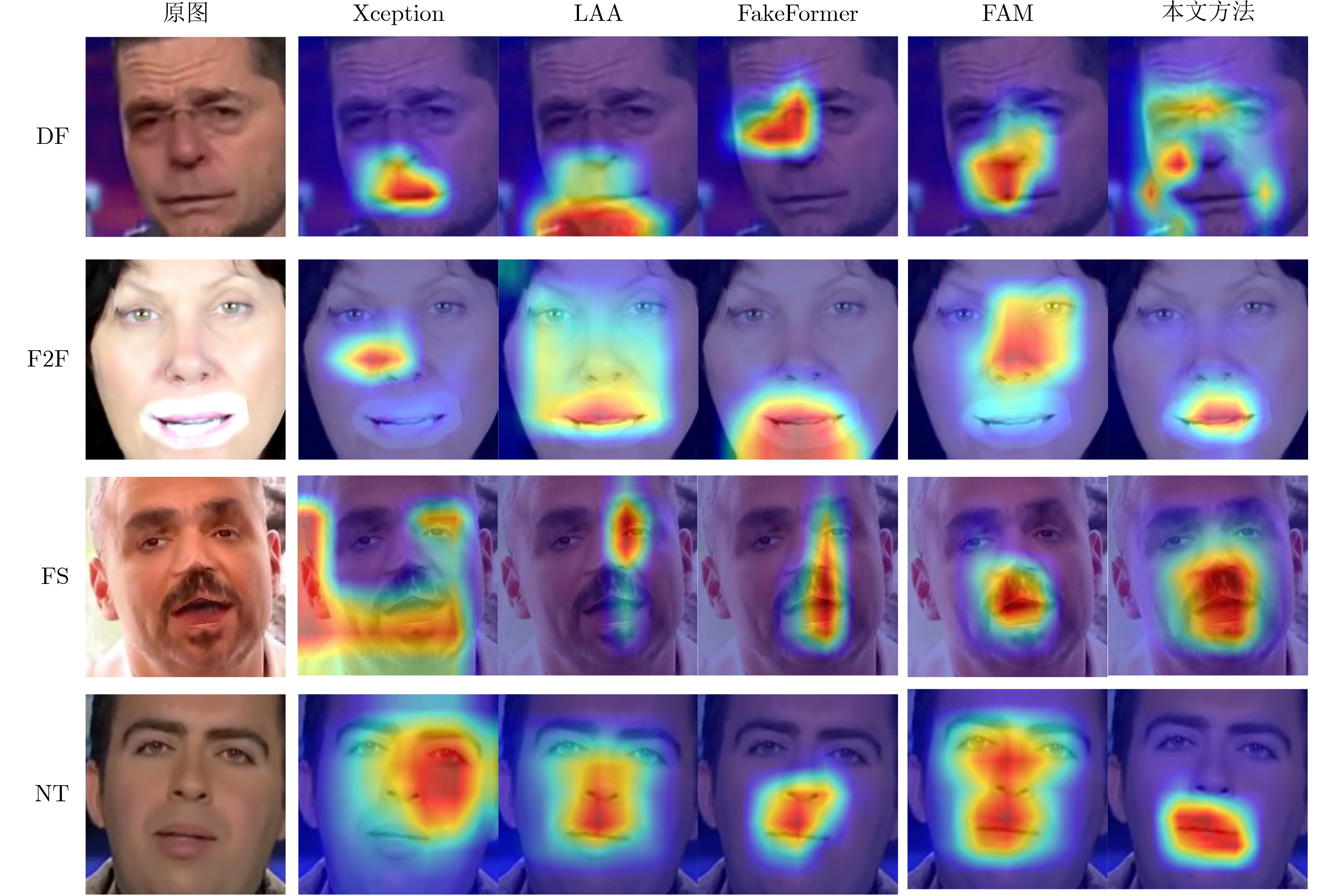
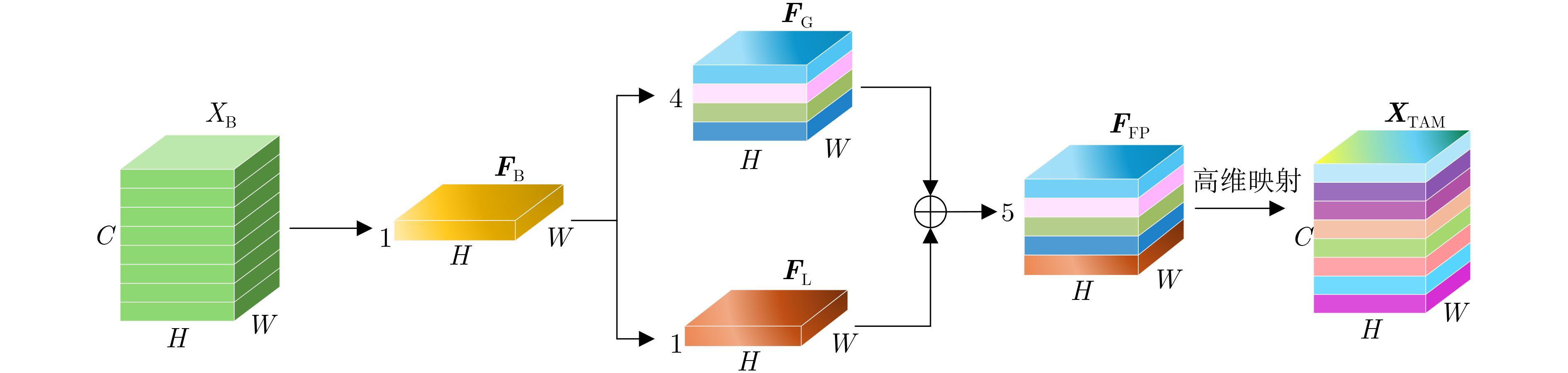
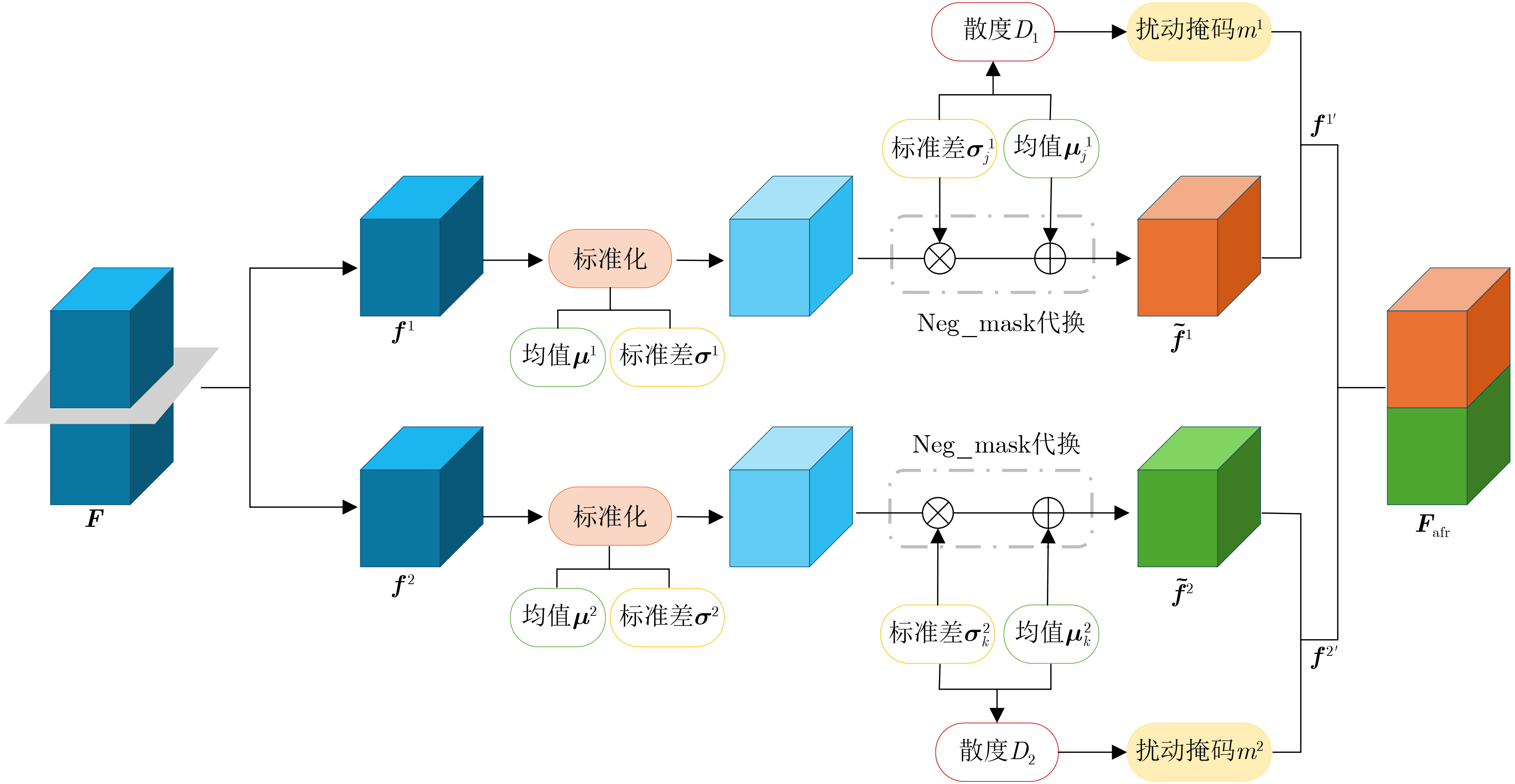
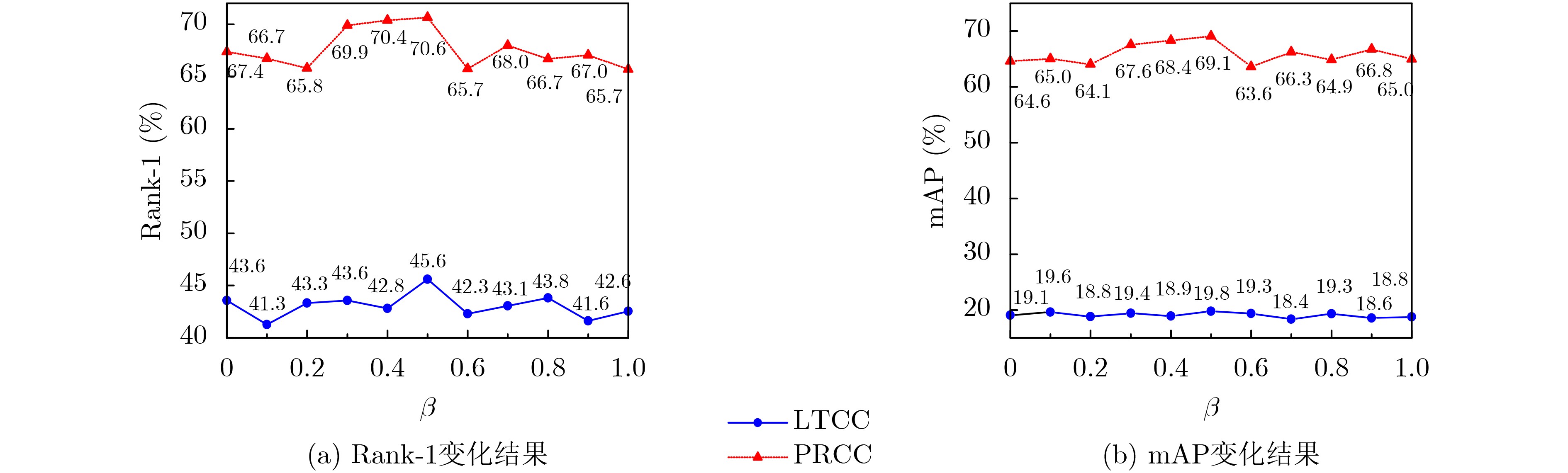
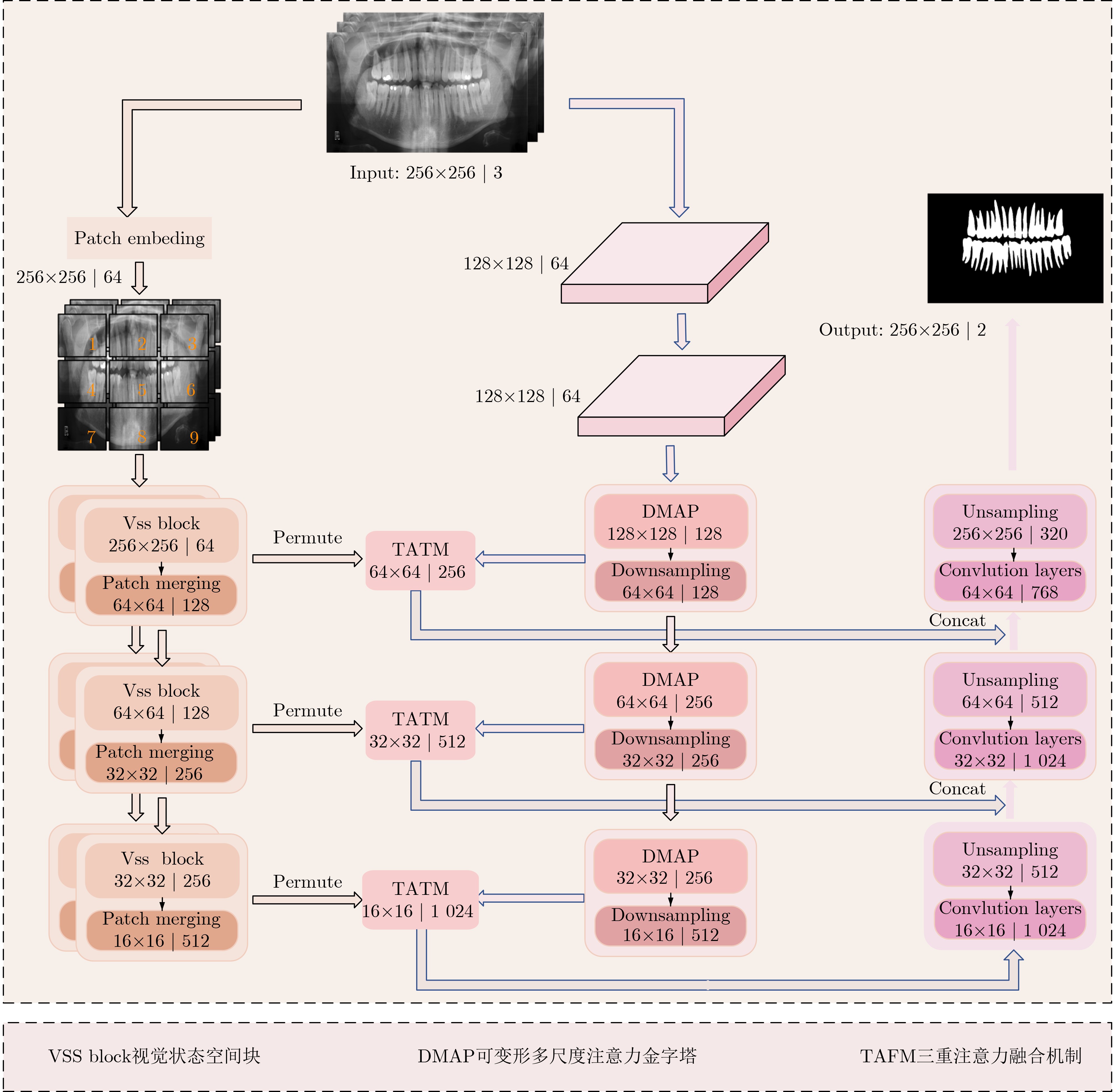
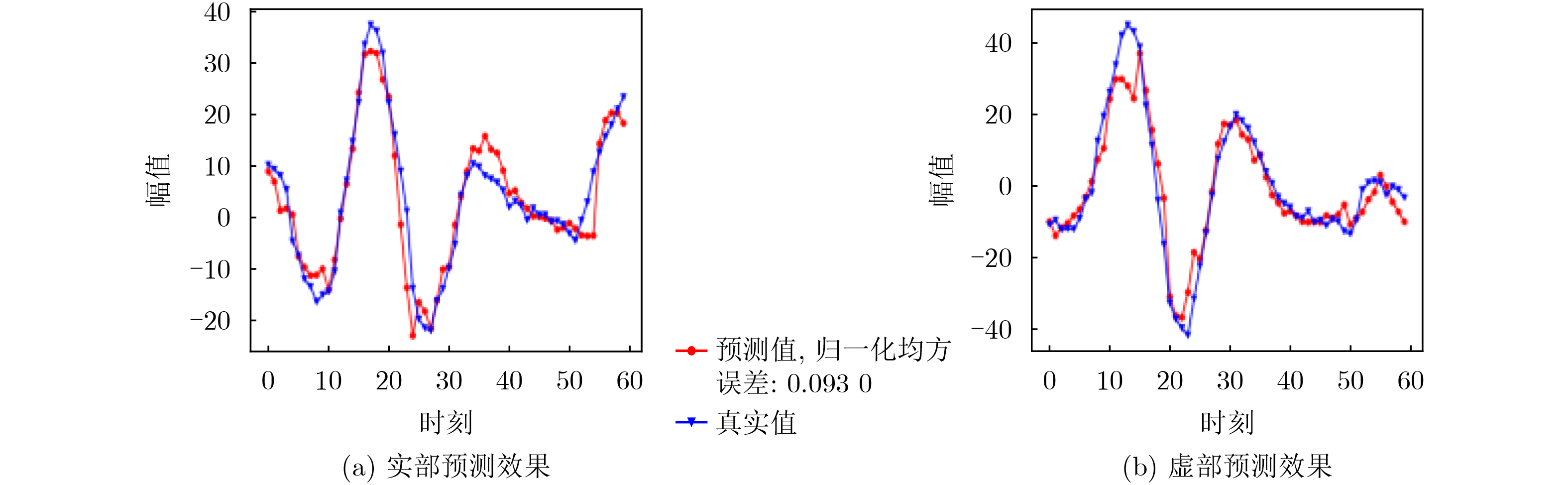
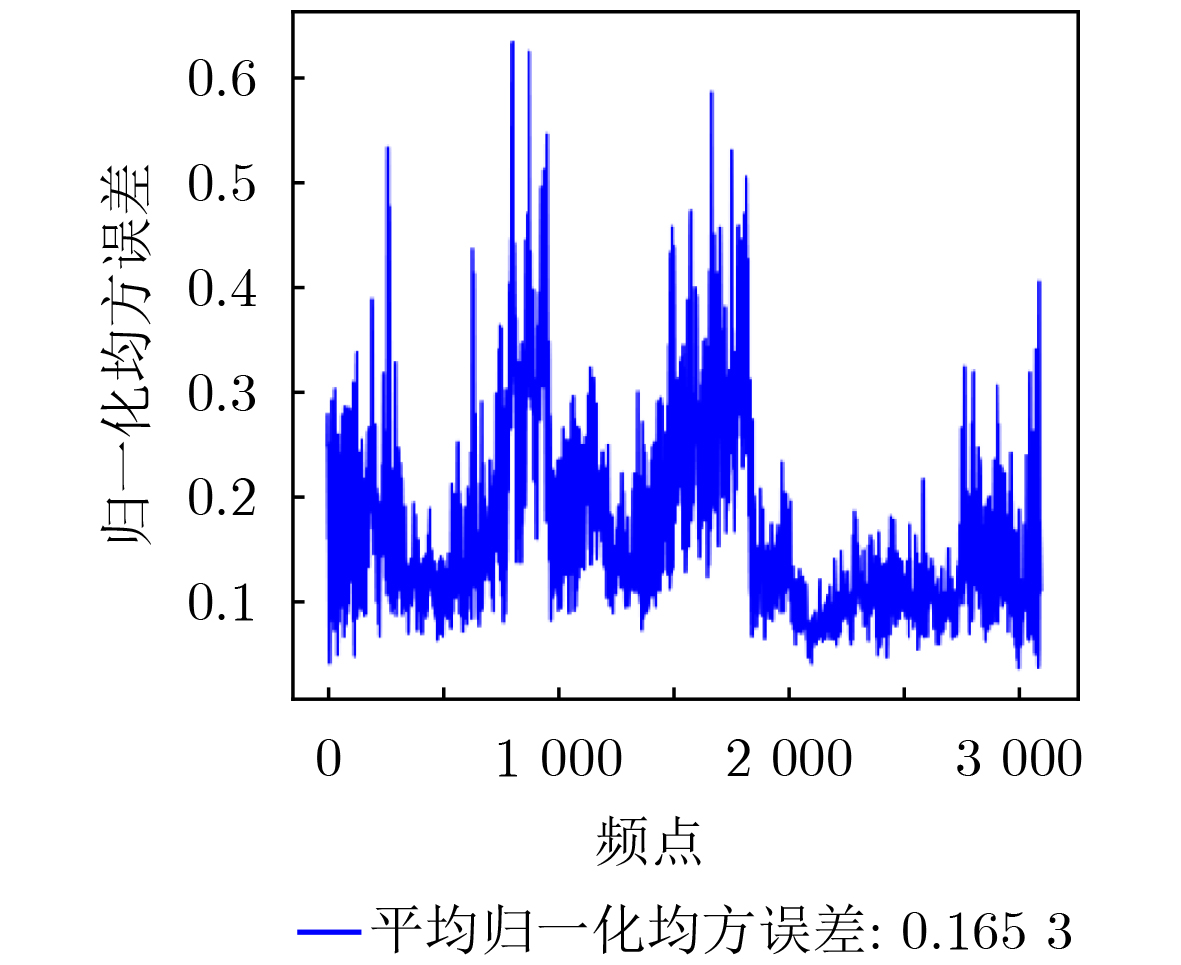
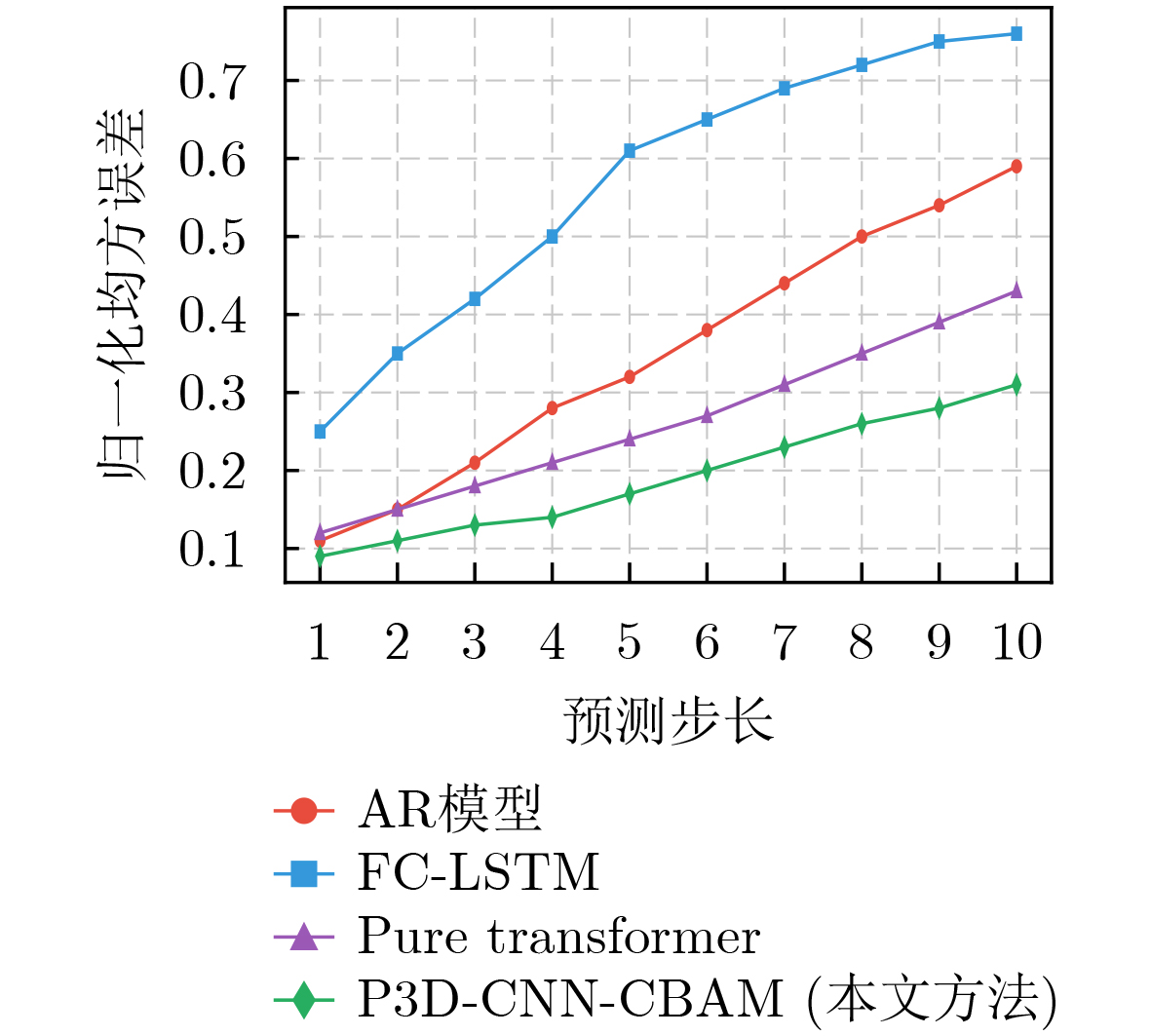
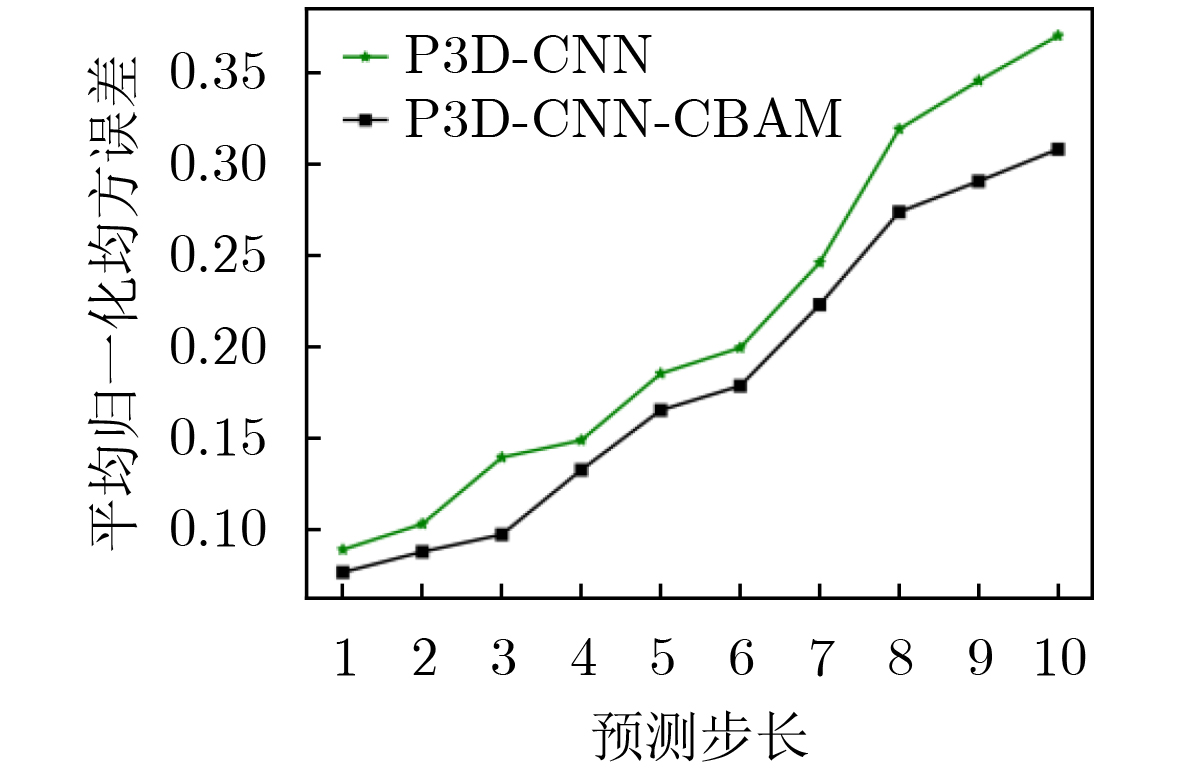
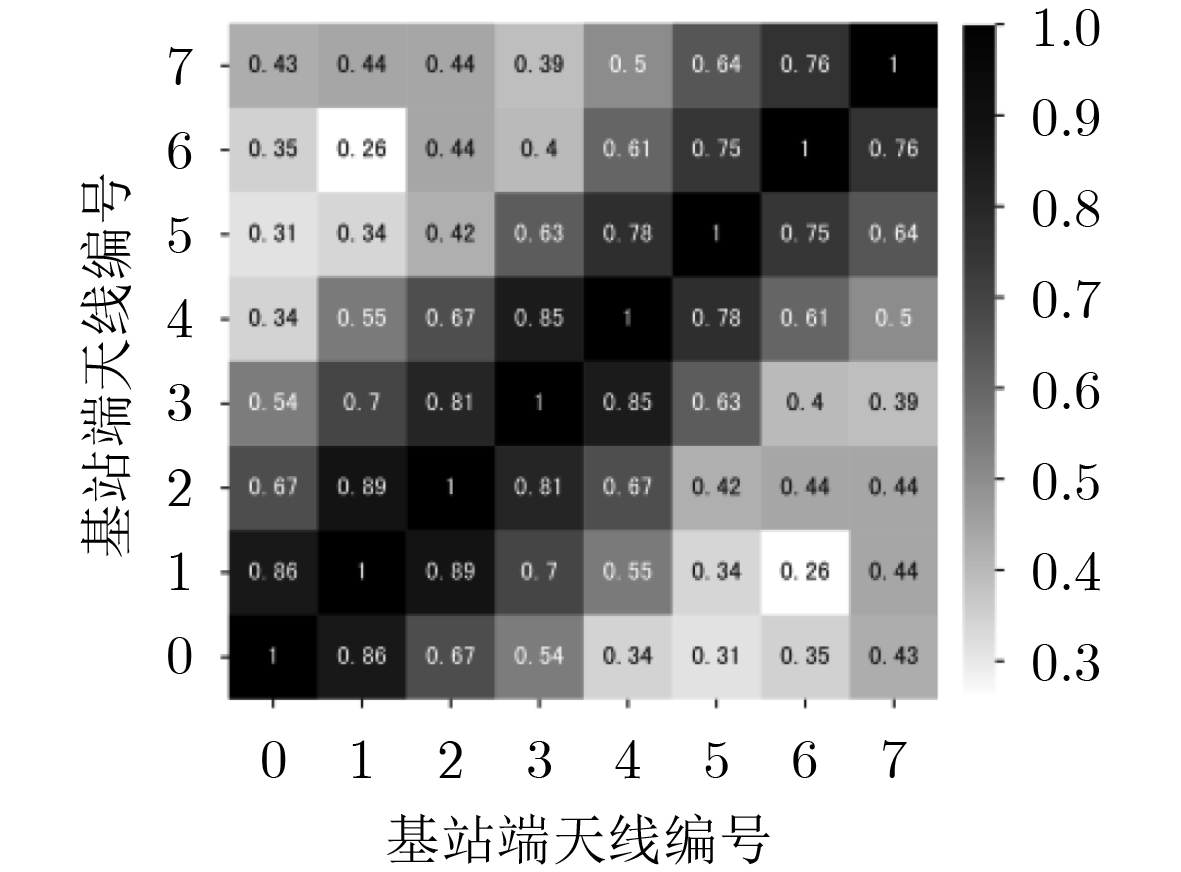
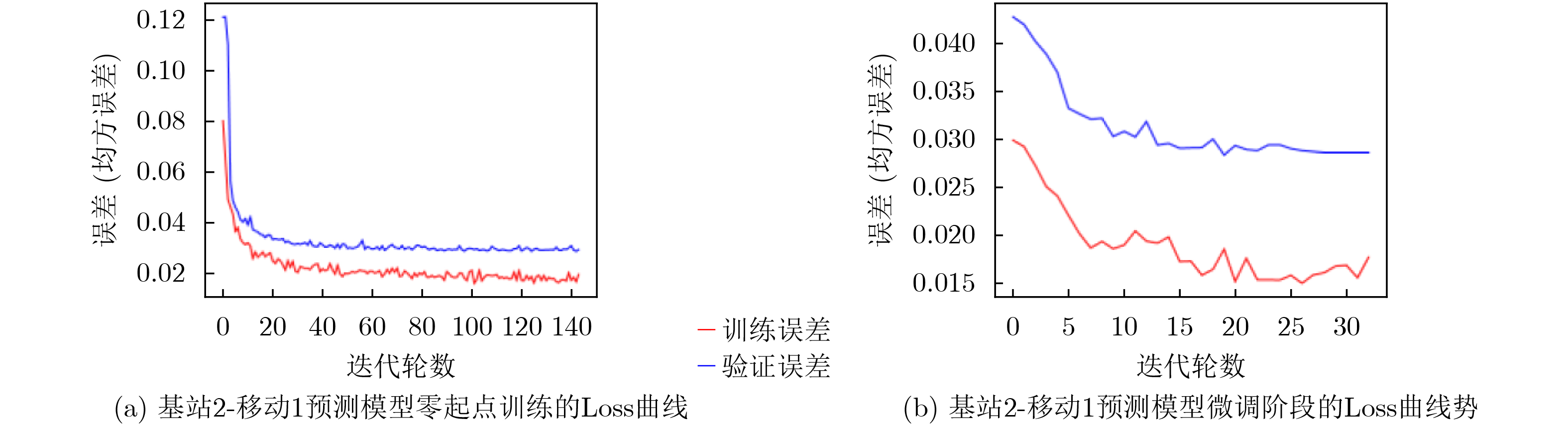
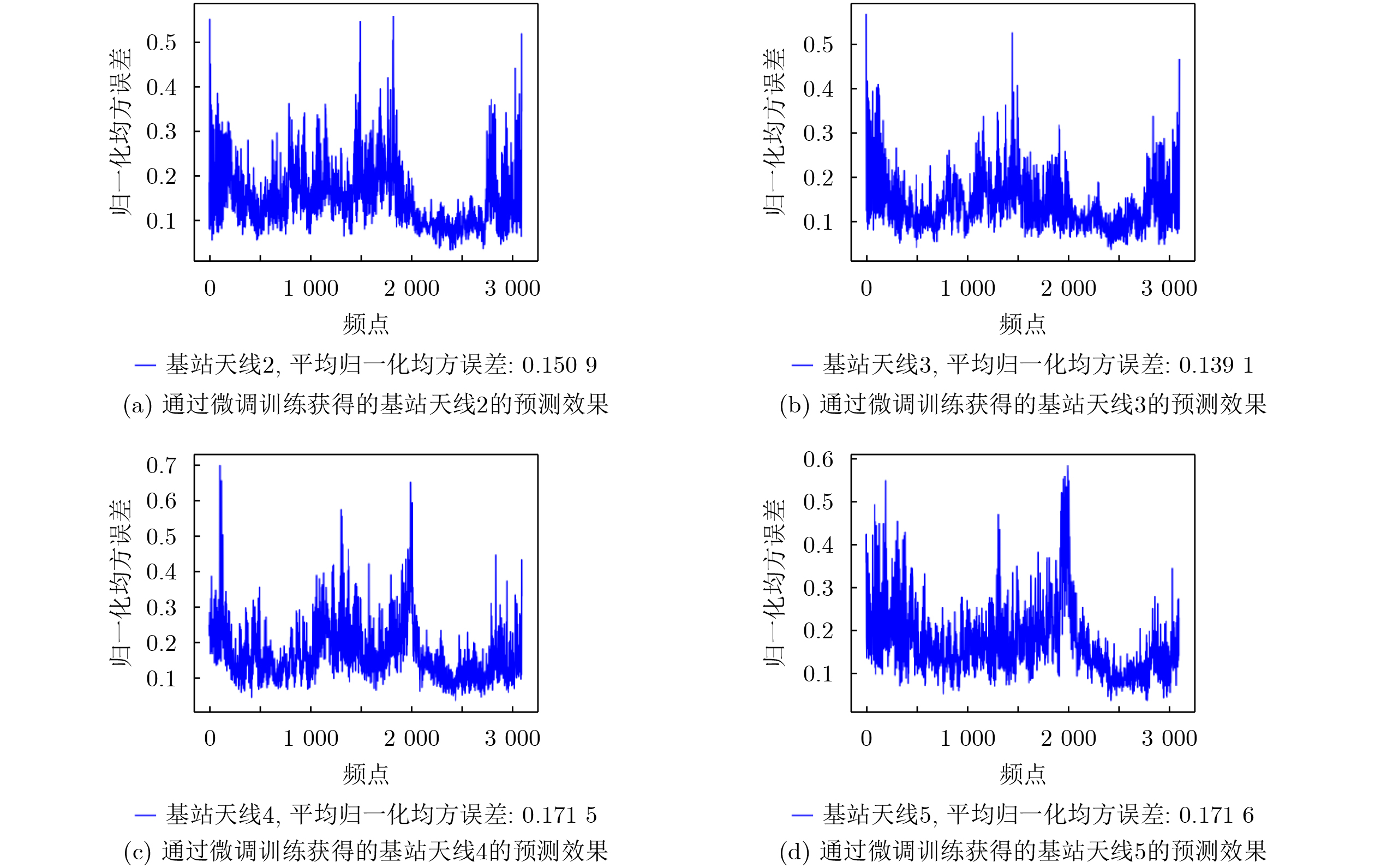
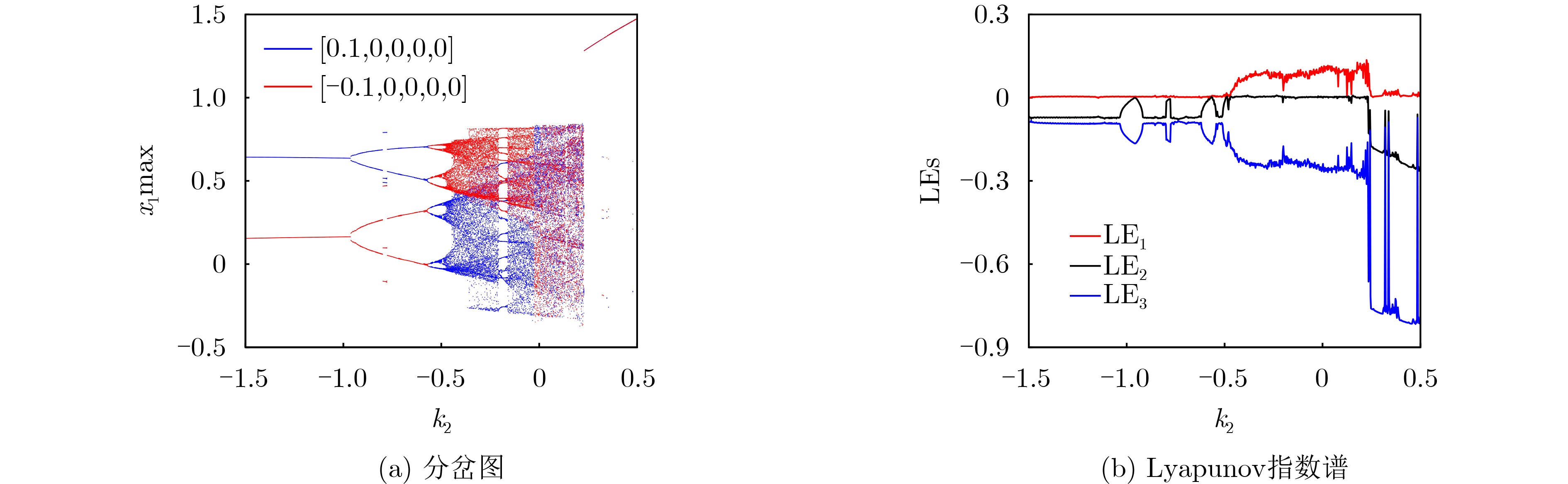
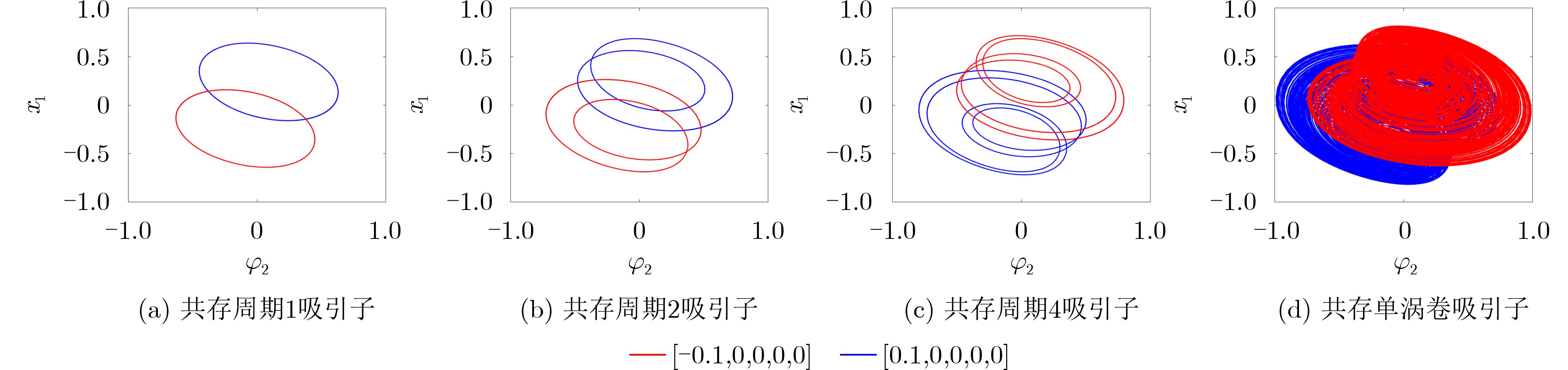
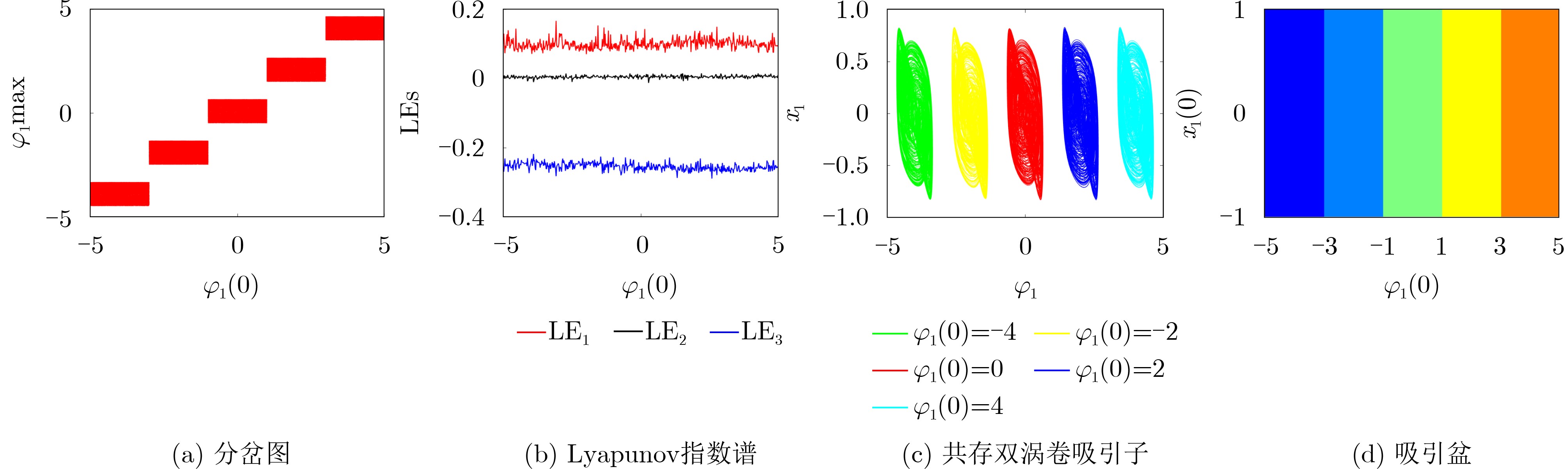
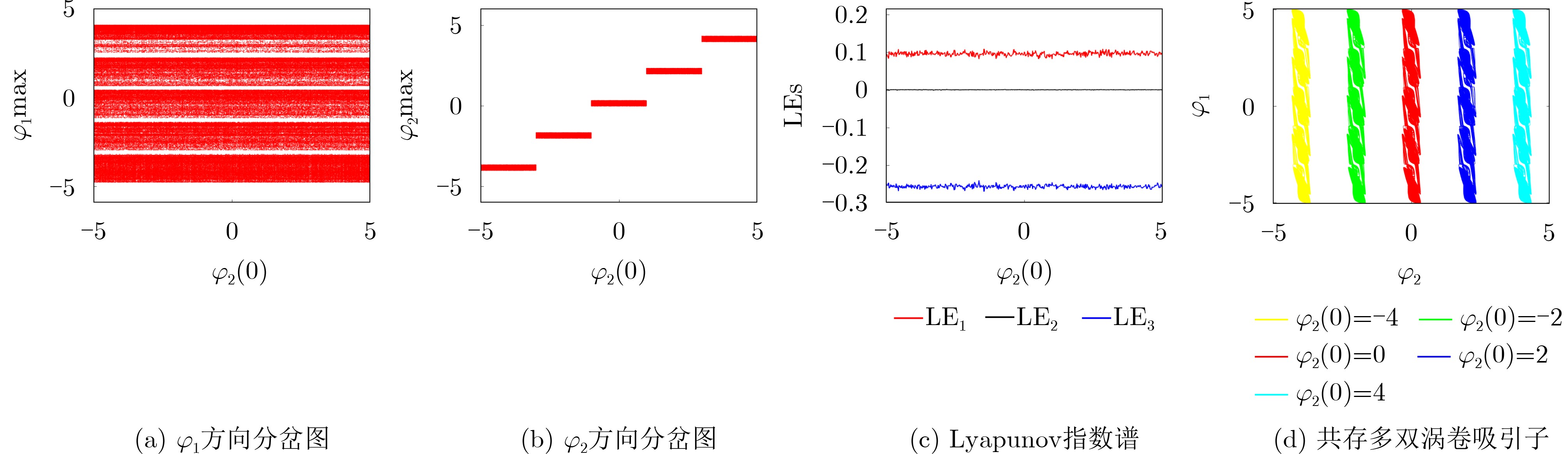
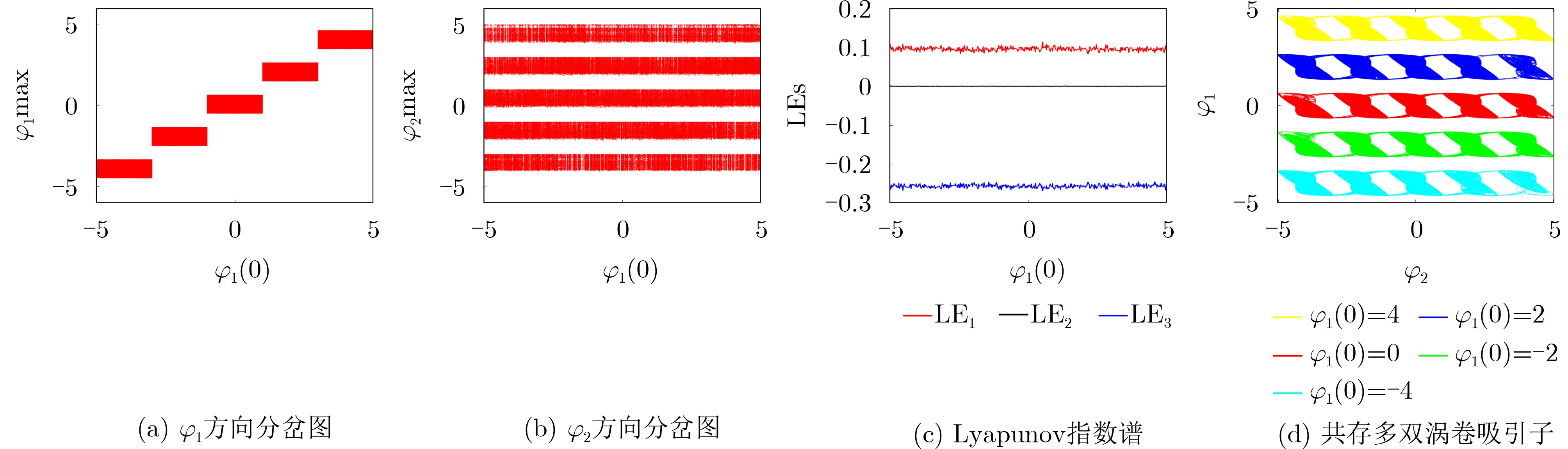
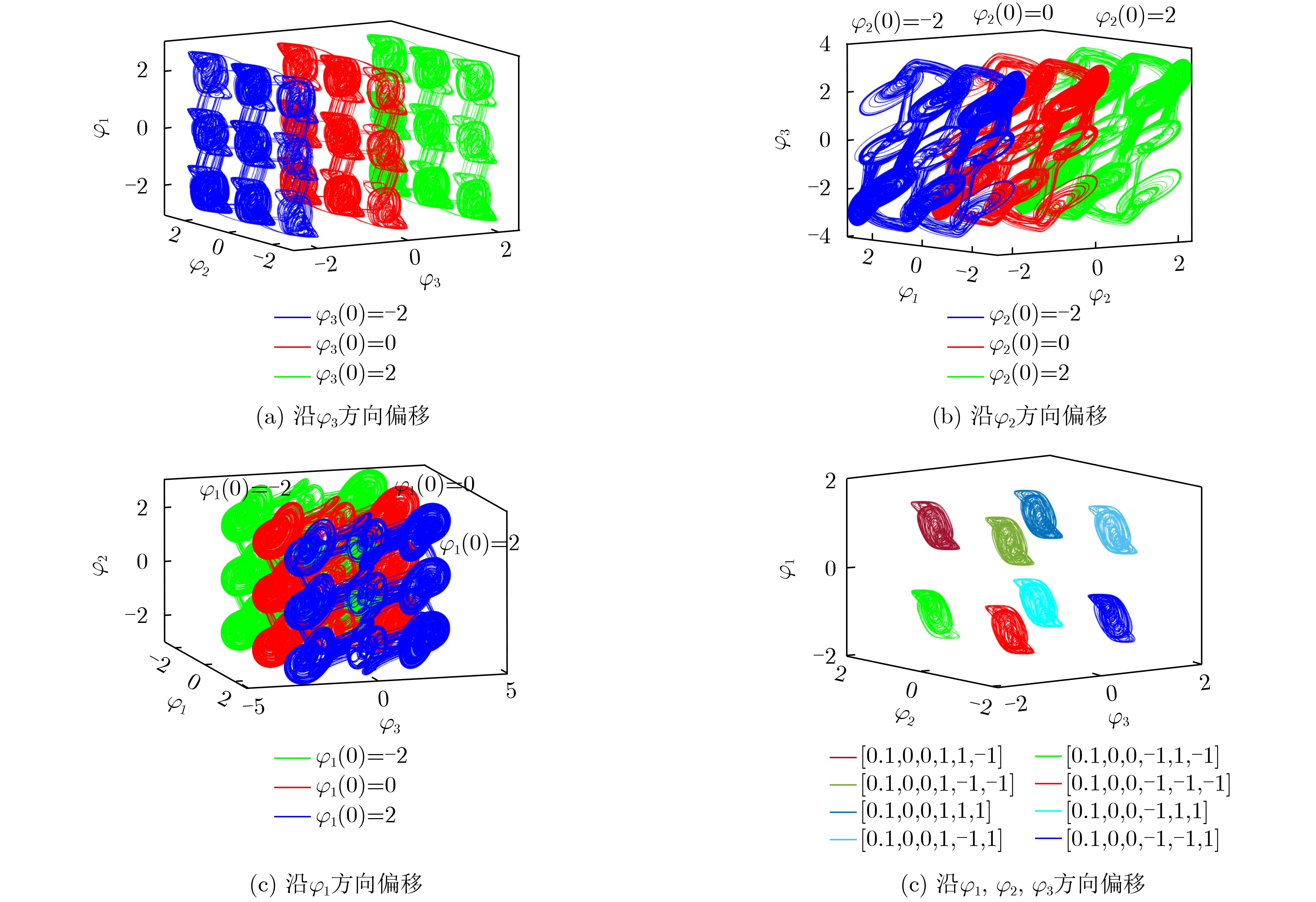
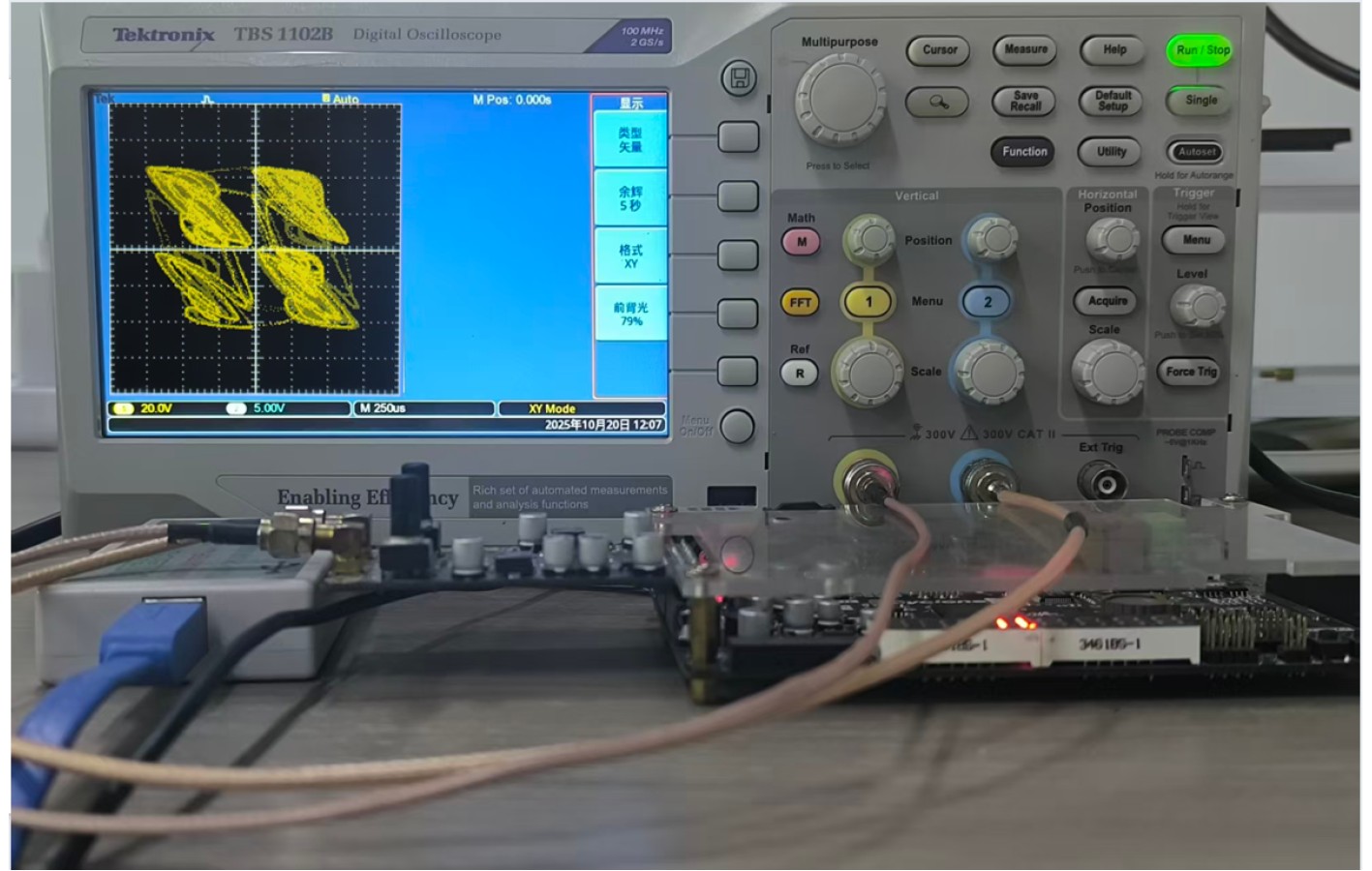
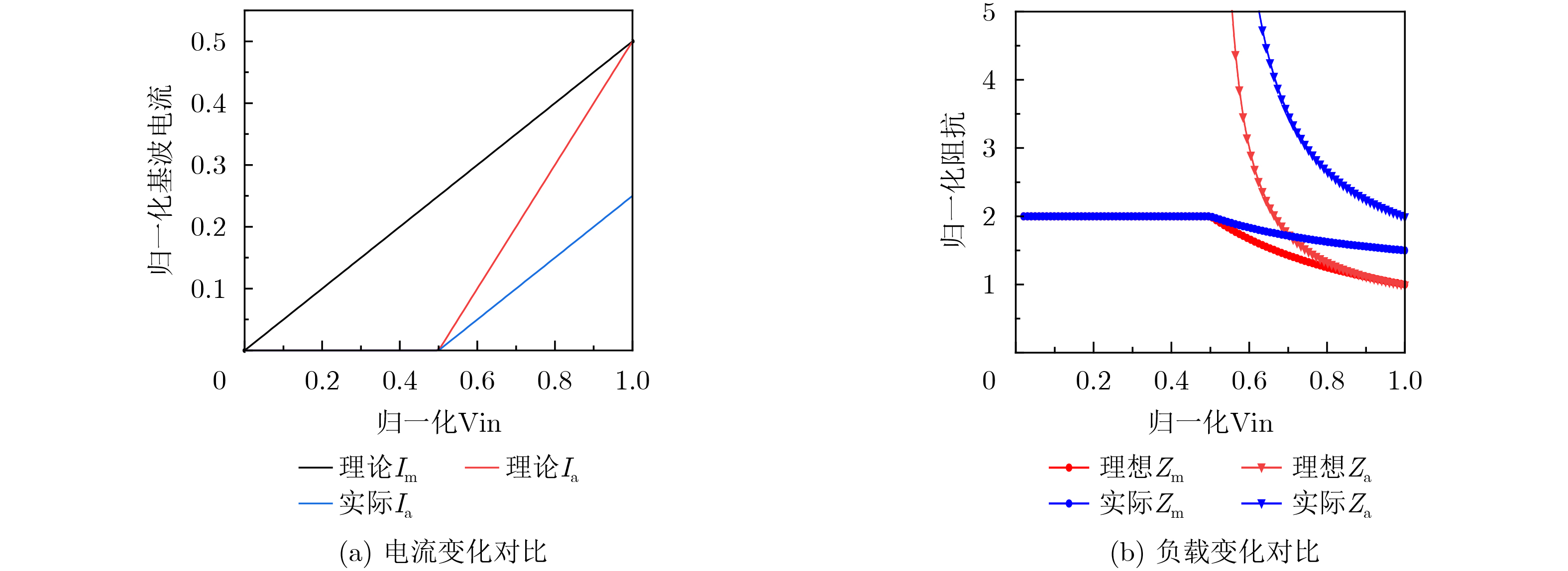
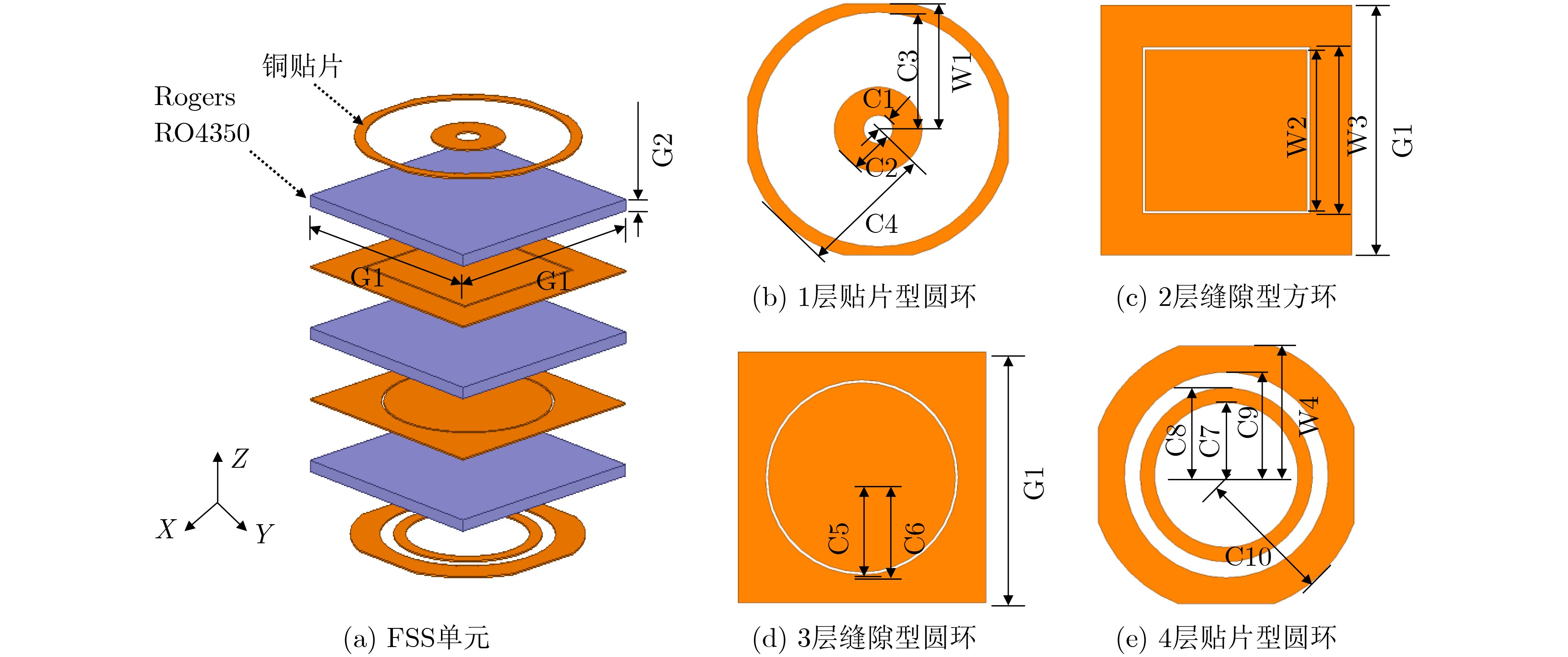
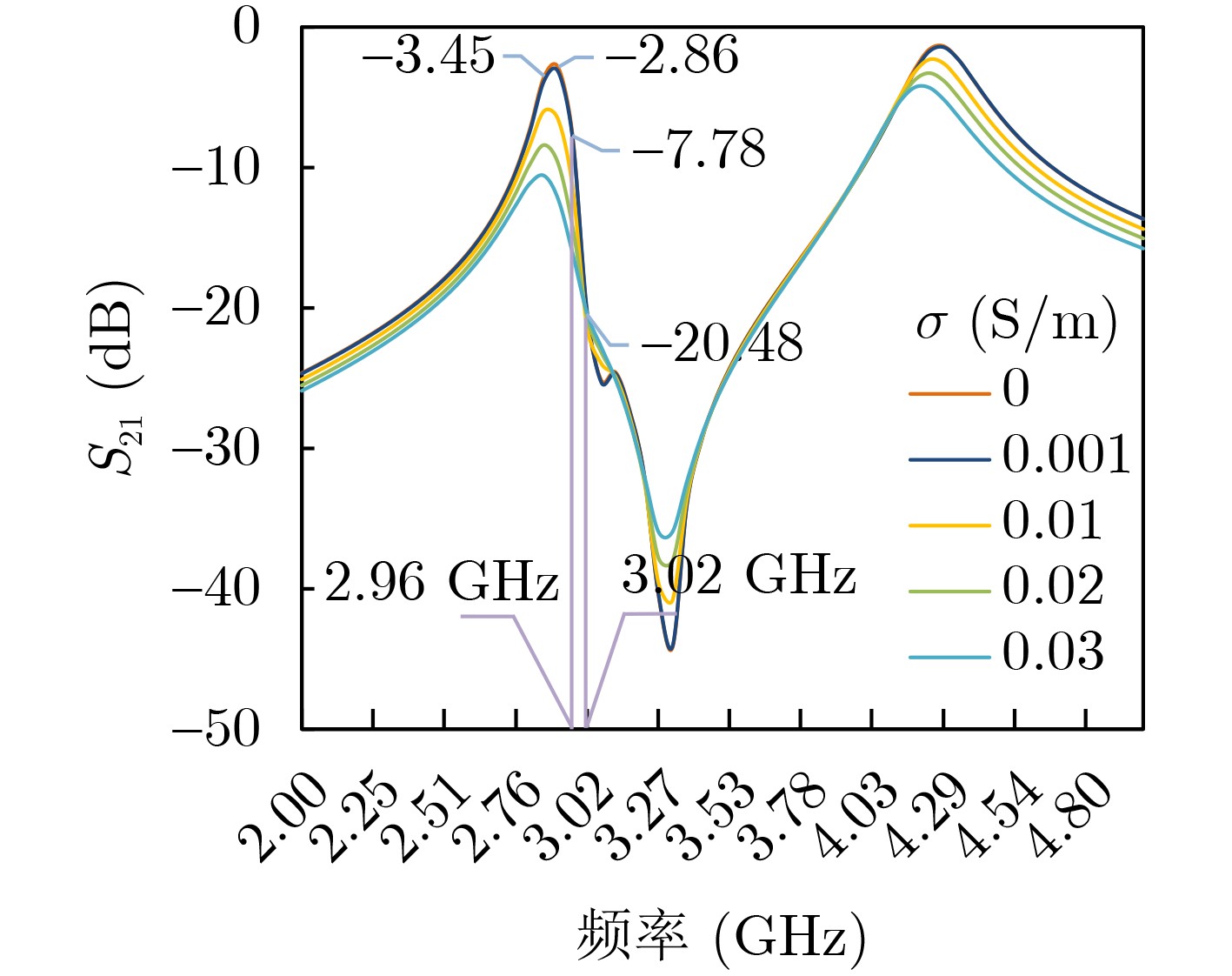
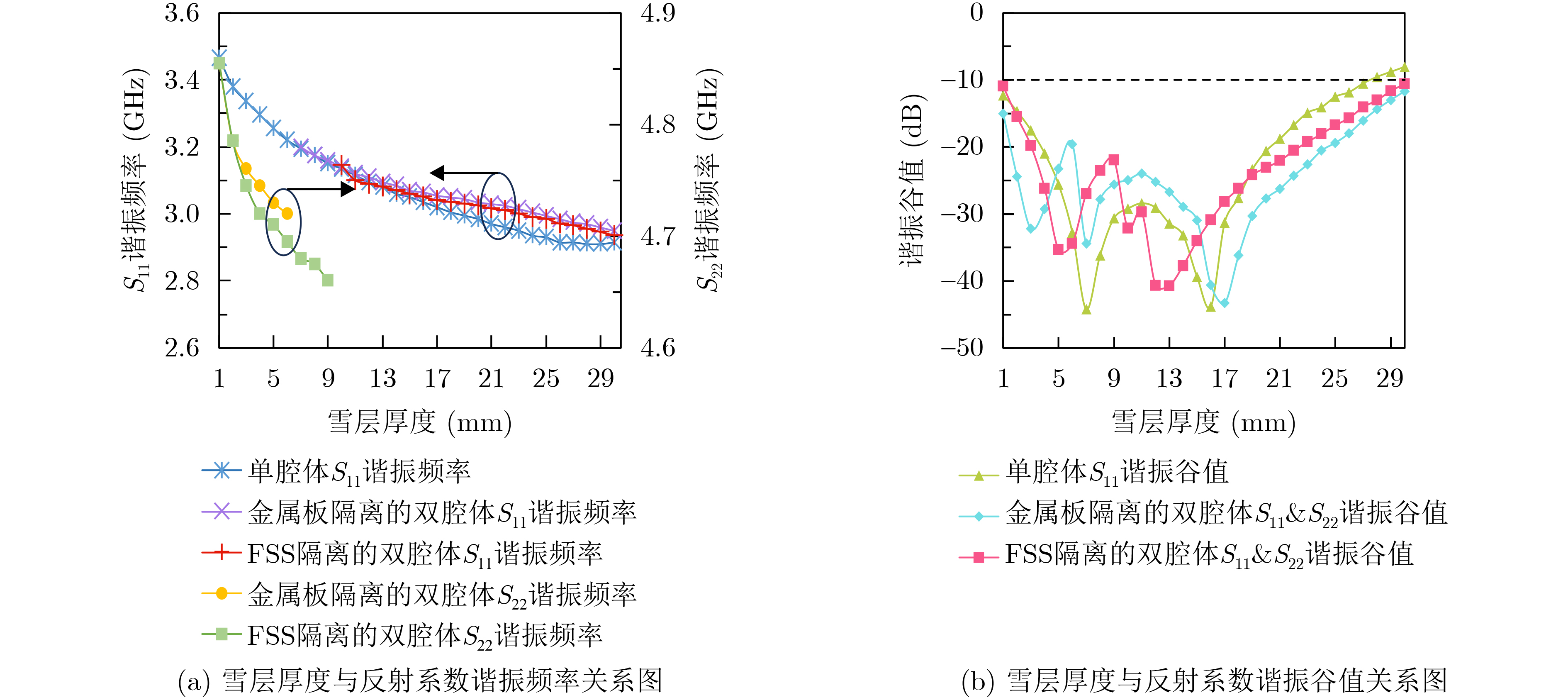
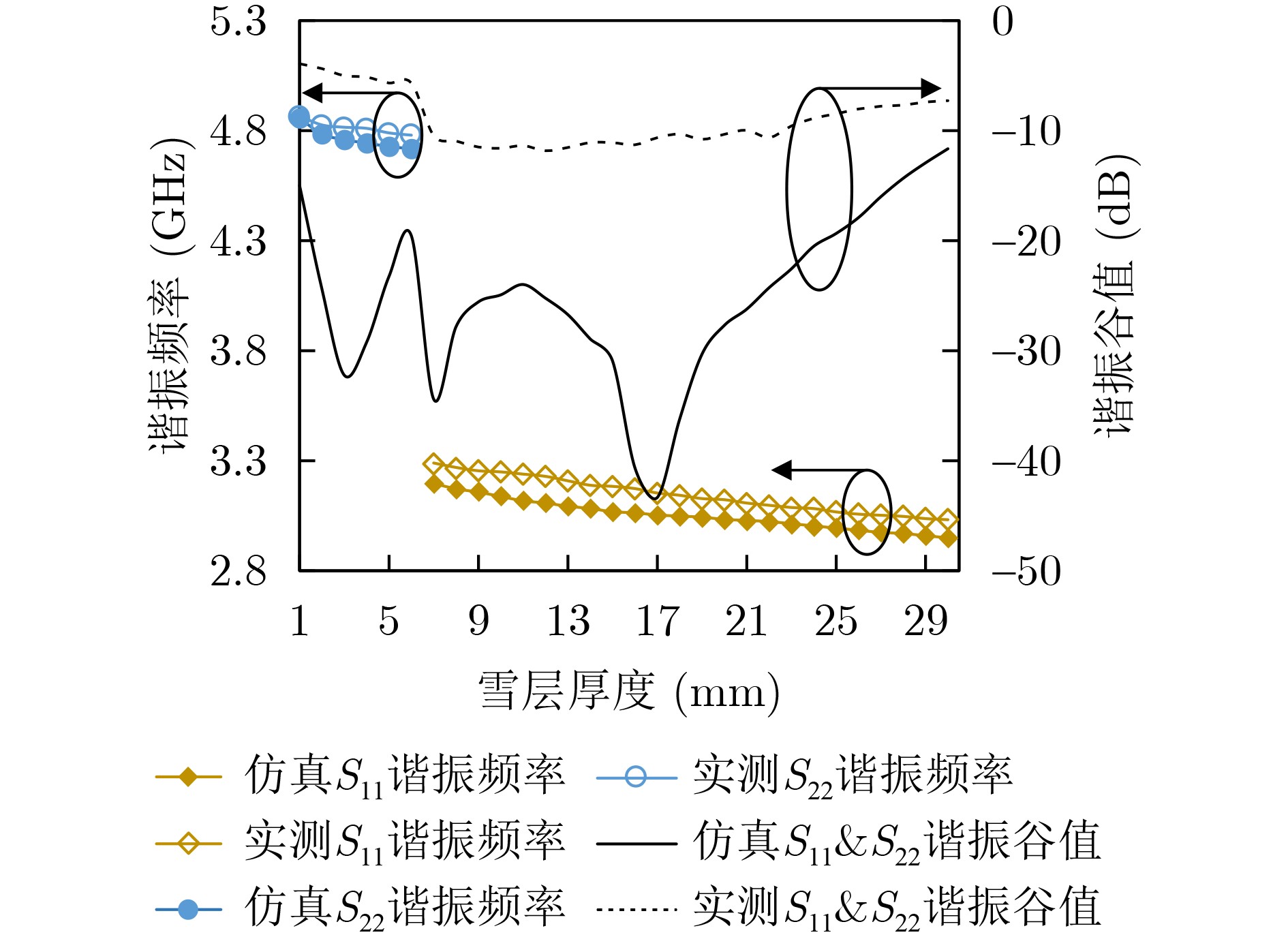
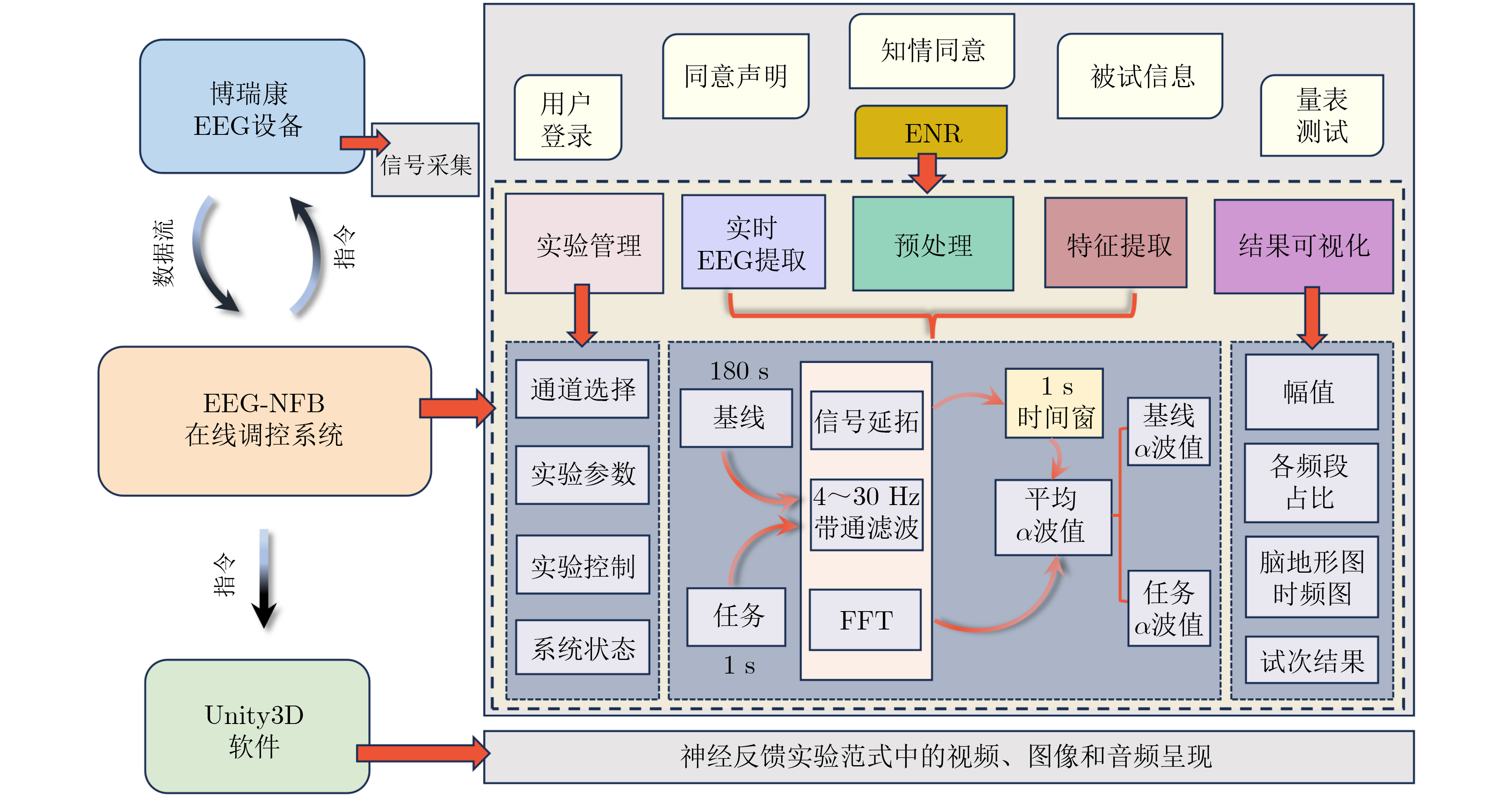
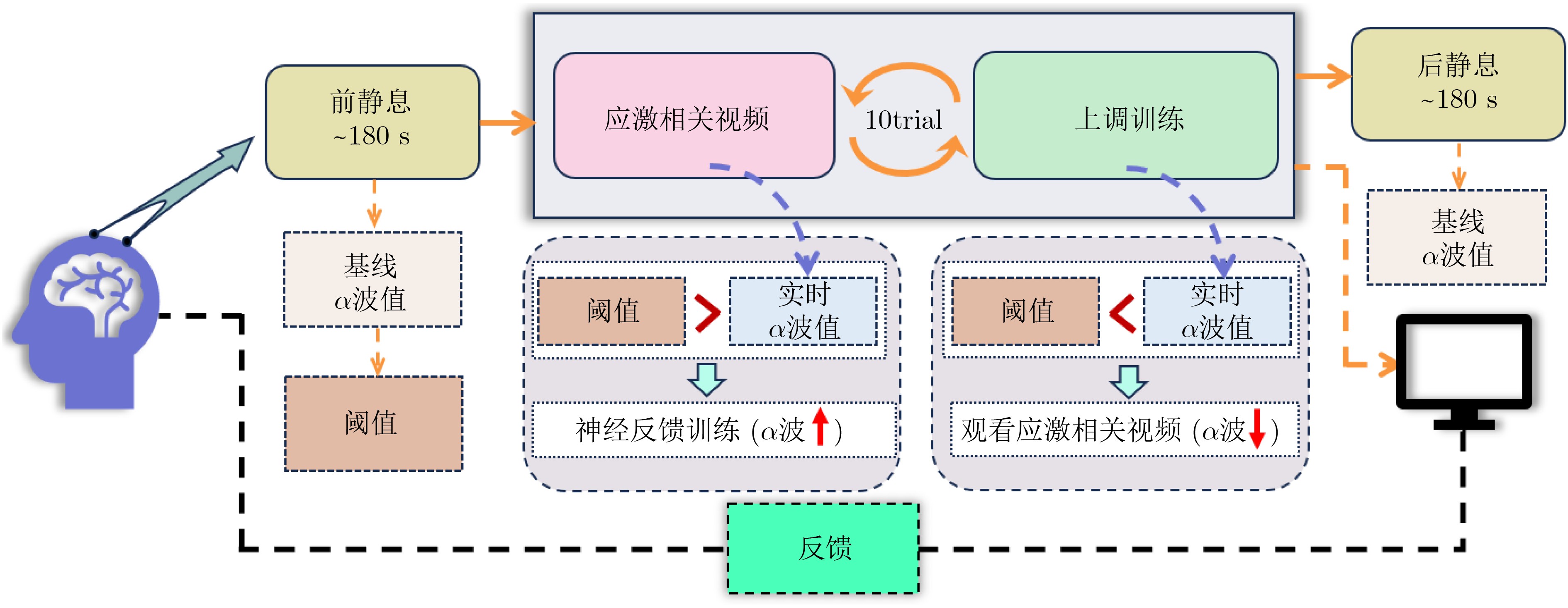
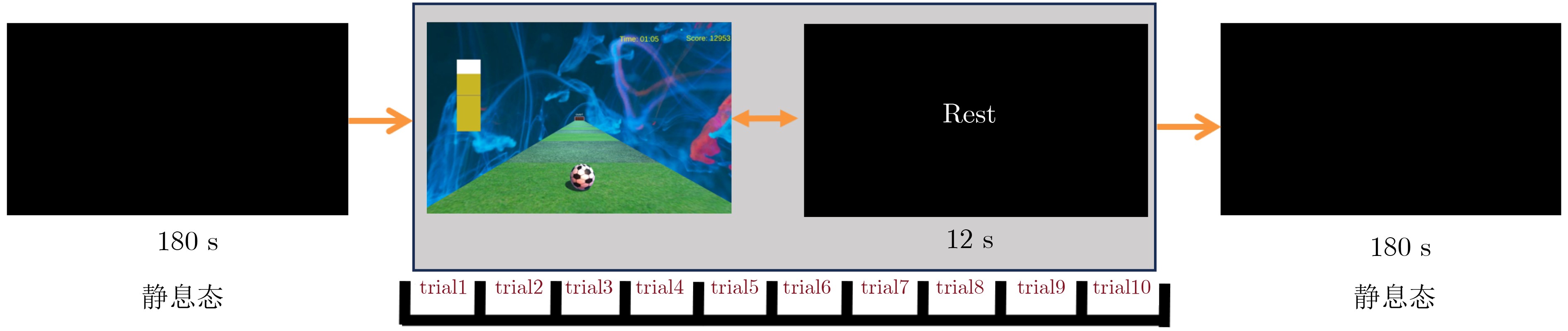
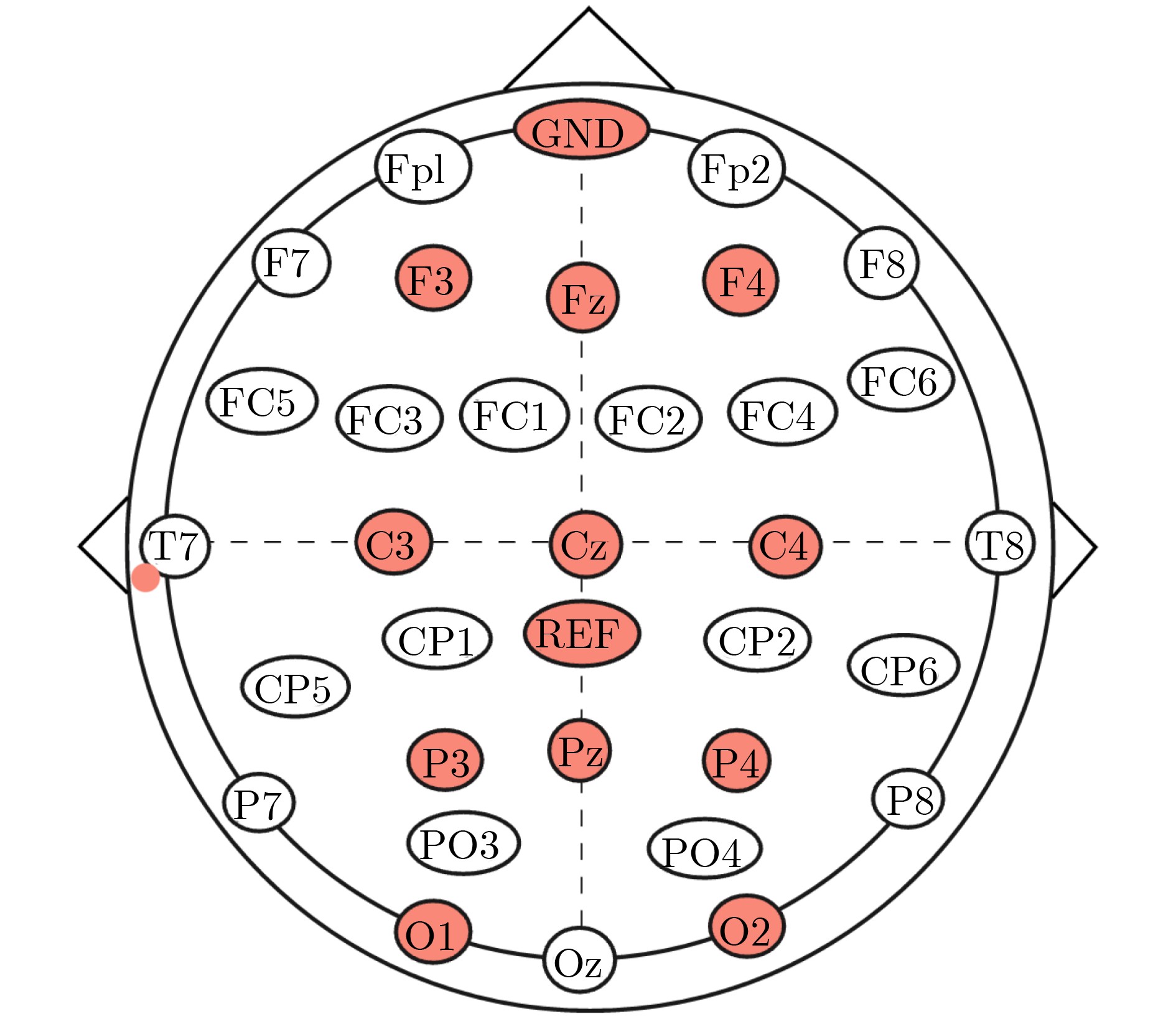
2026, 48(1): 404-416.
doi: 10.11999/JEIT250901
Abstract:
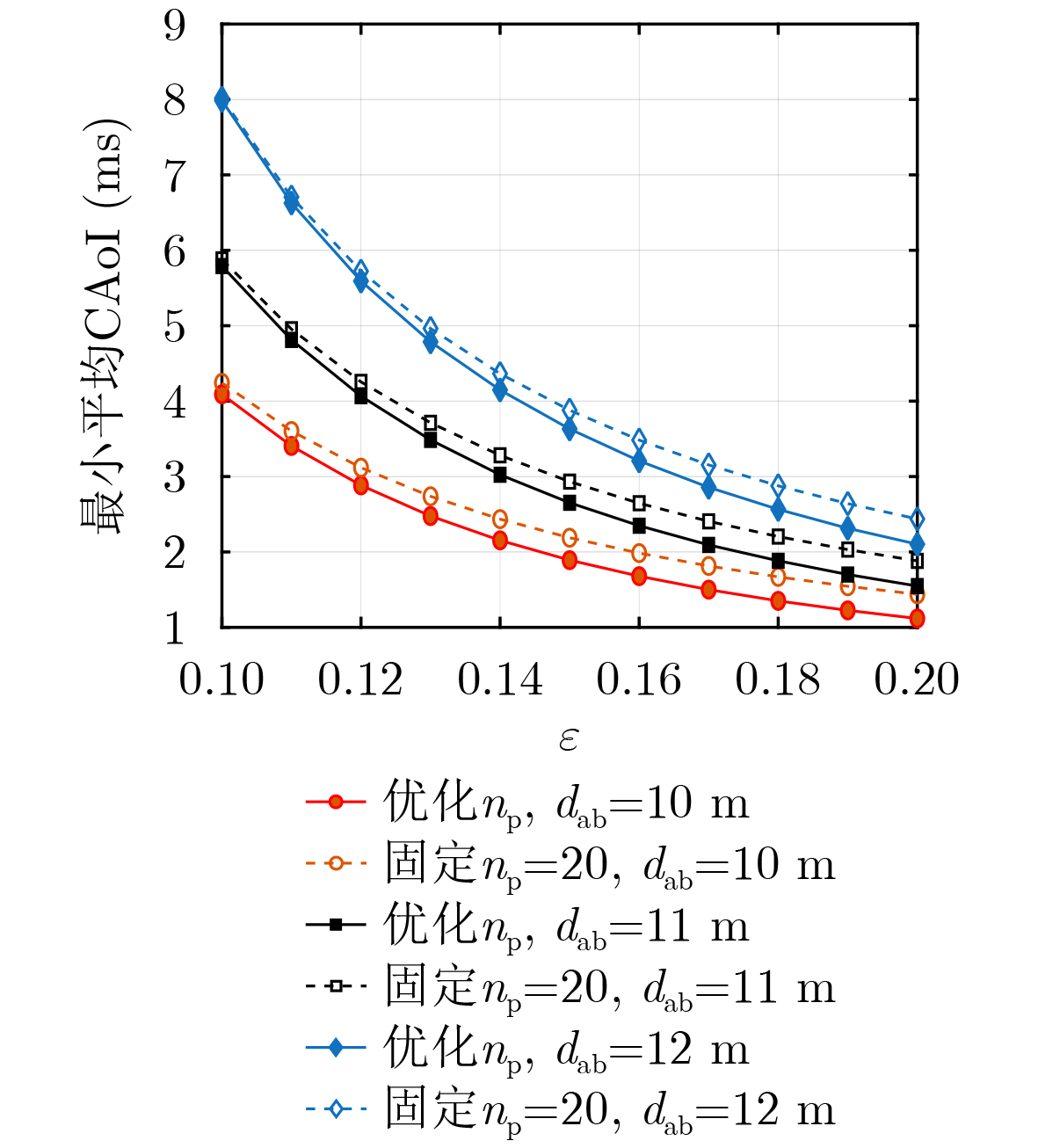
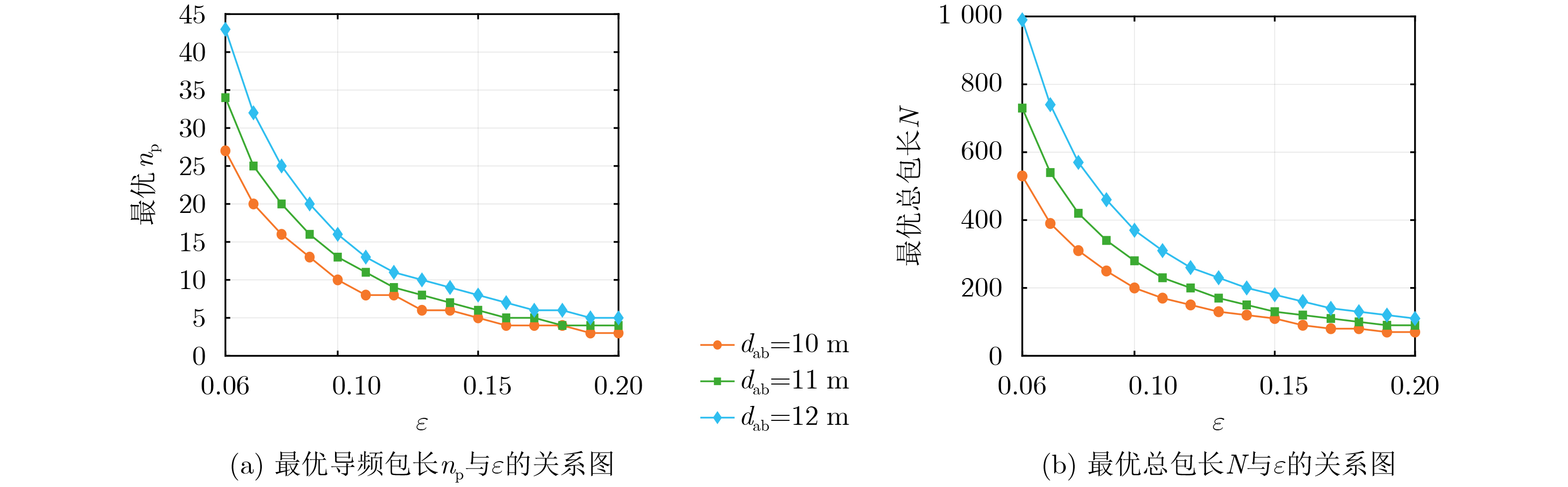
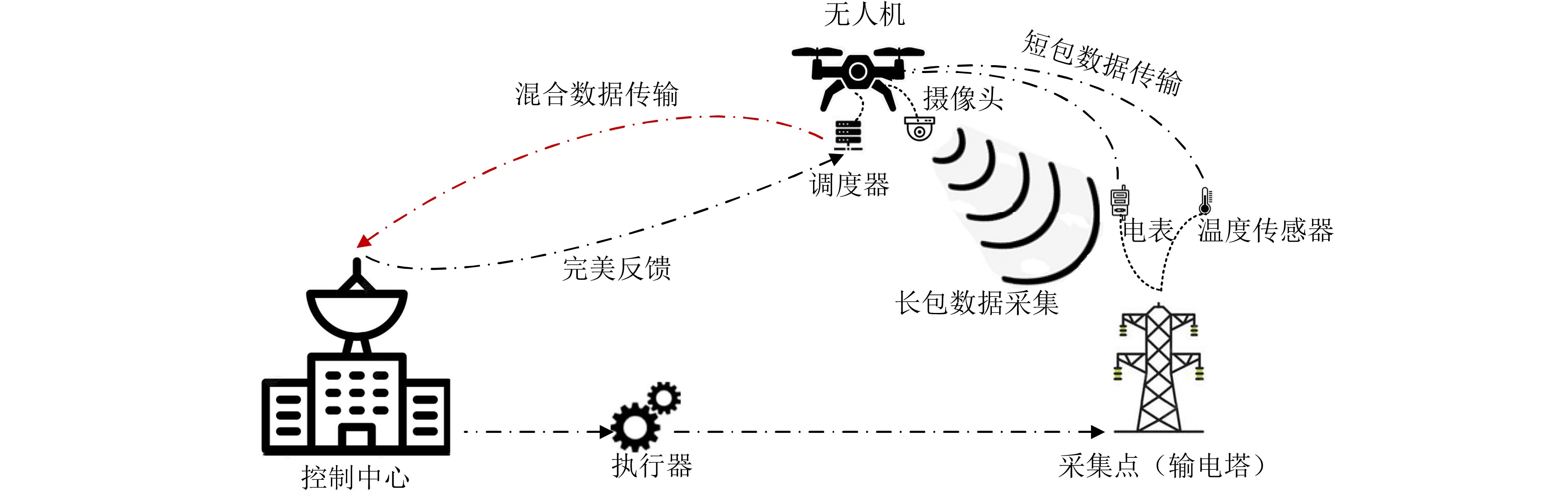
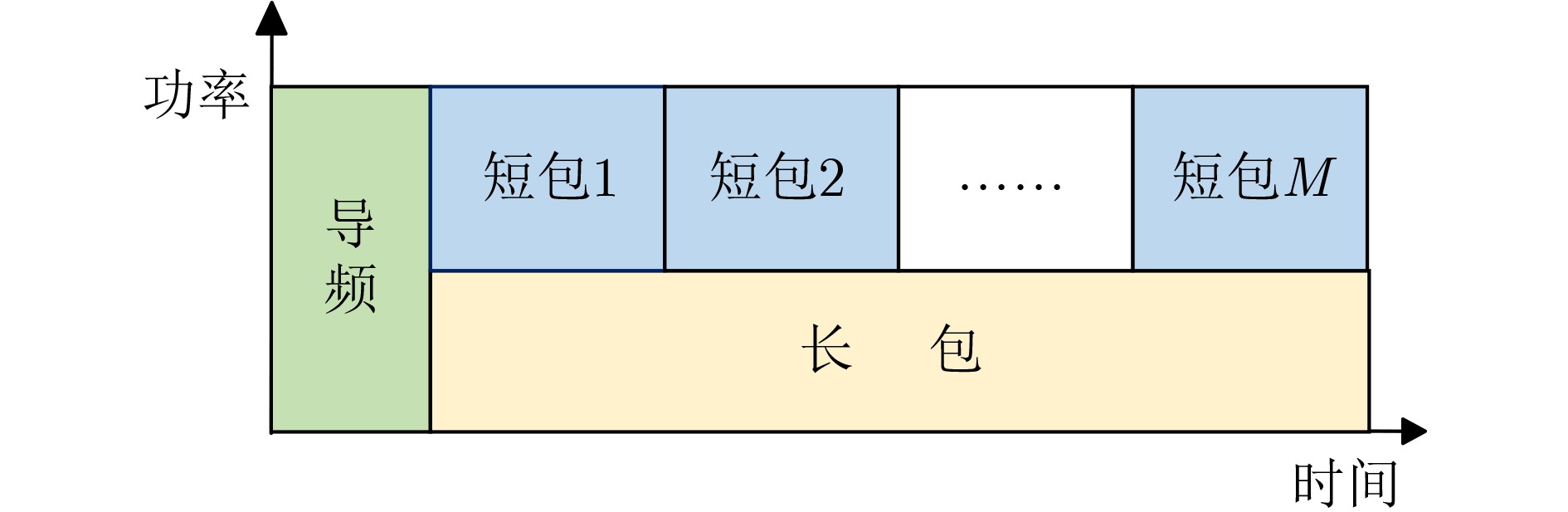
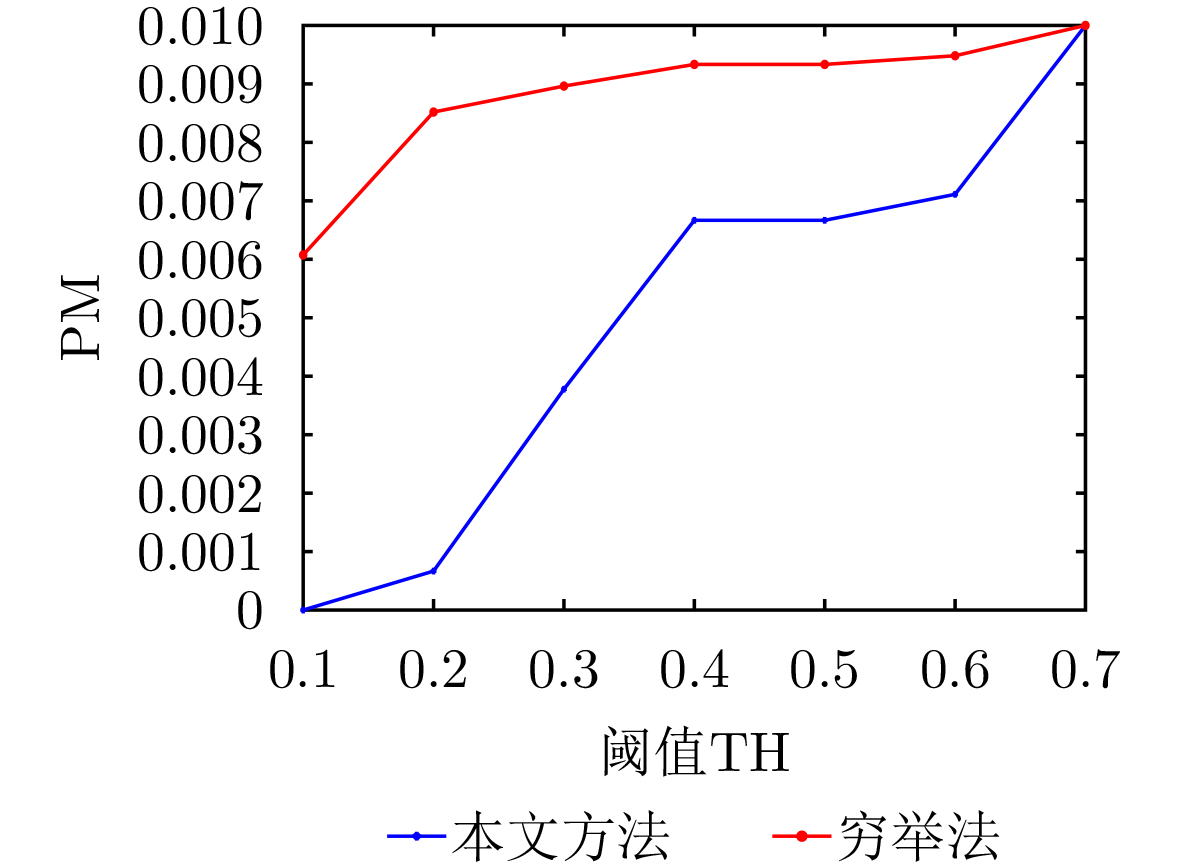
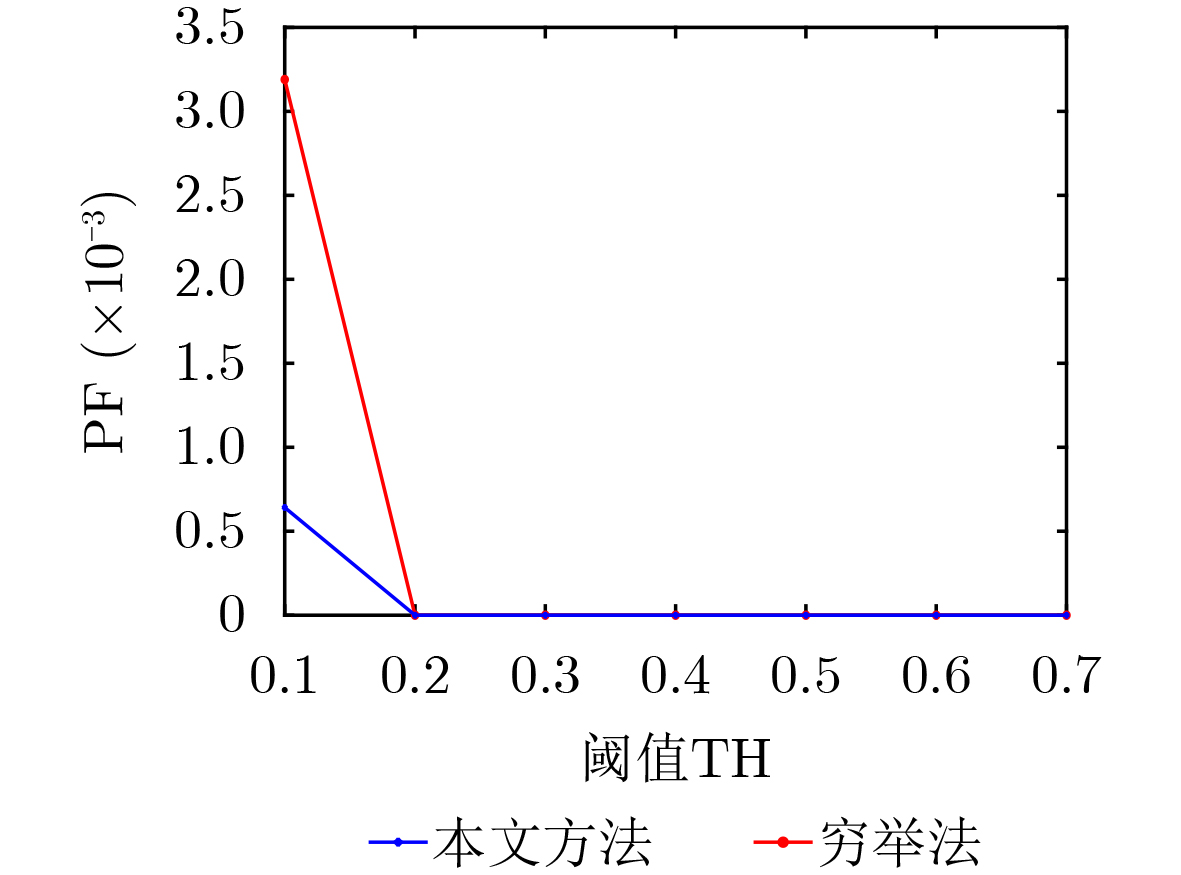
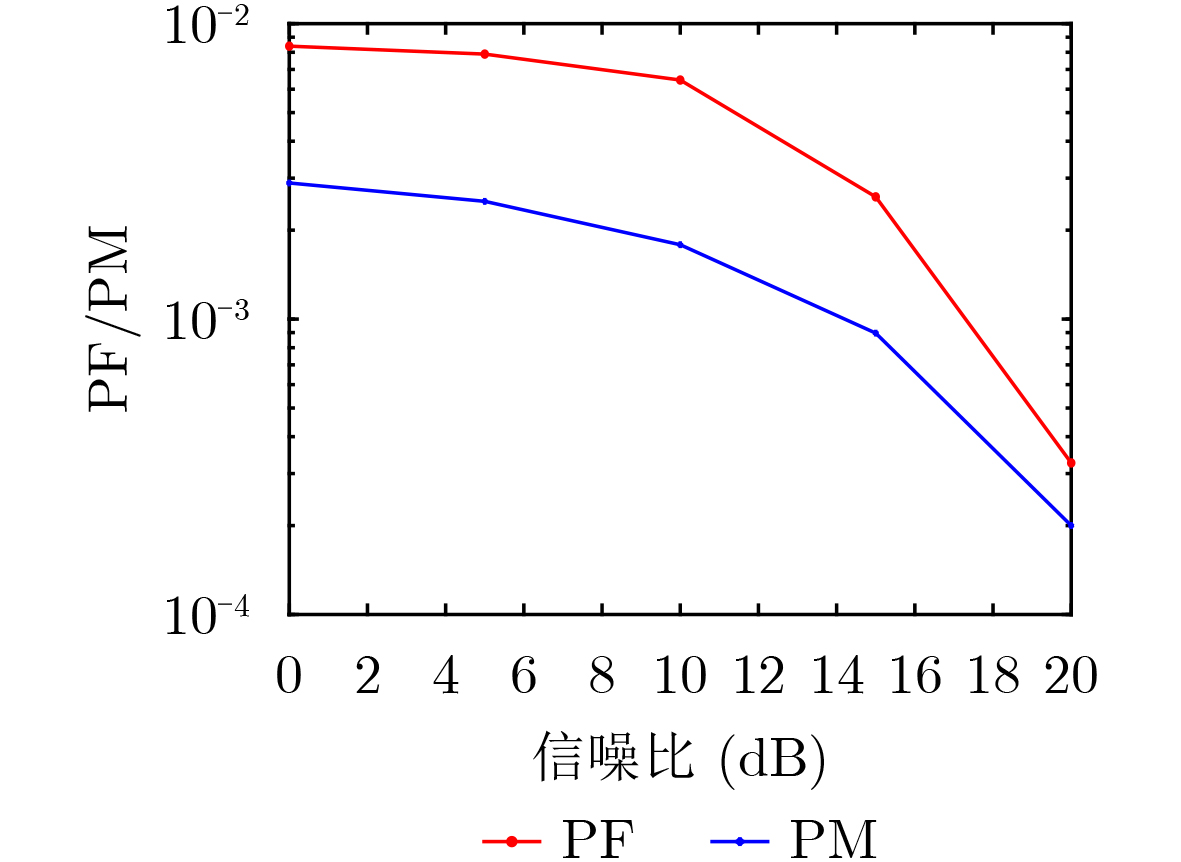
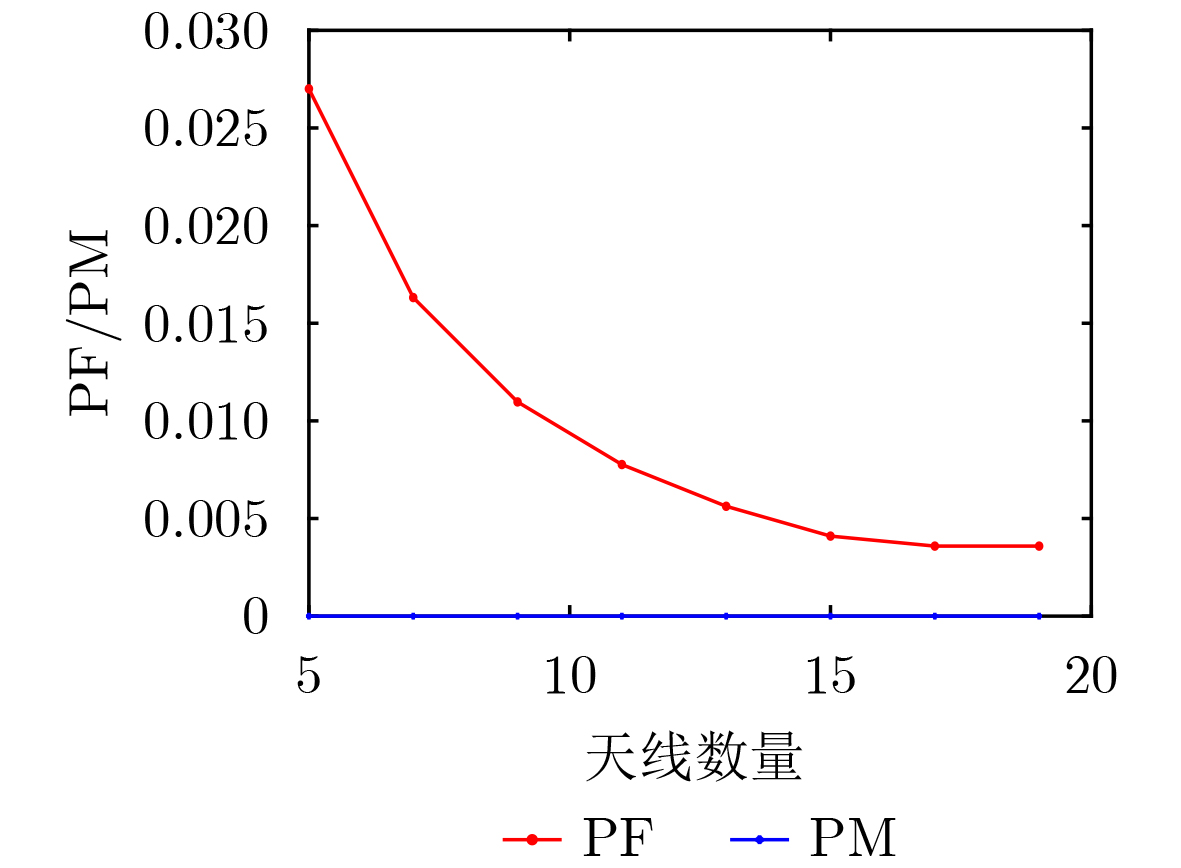
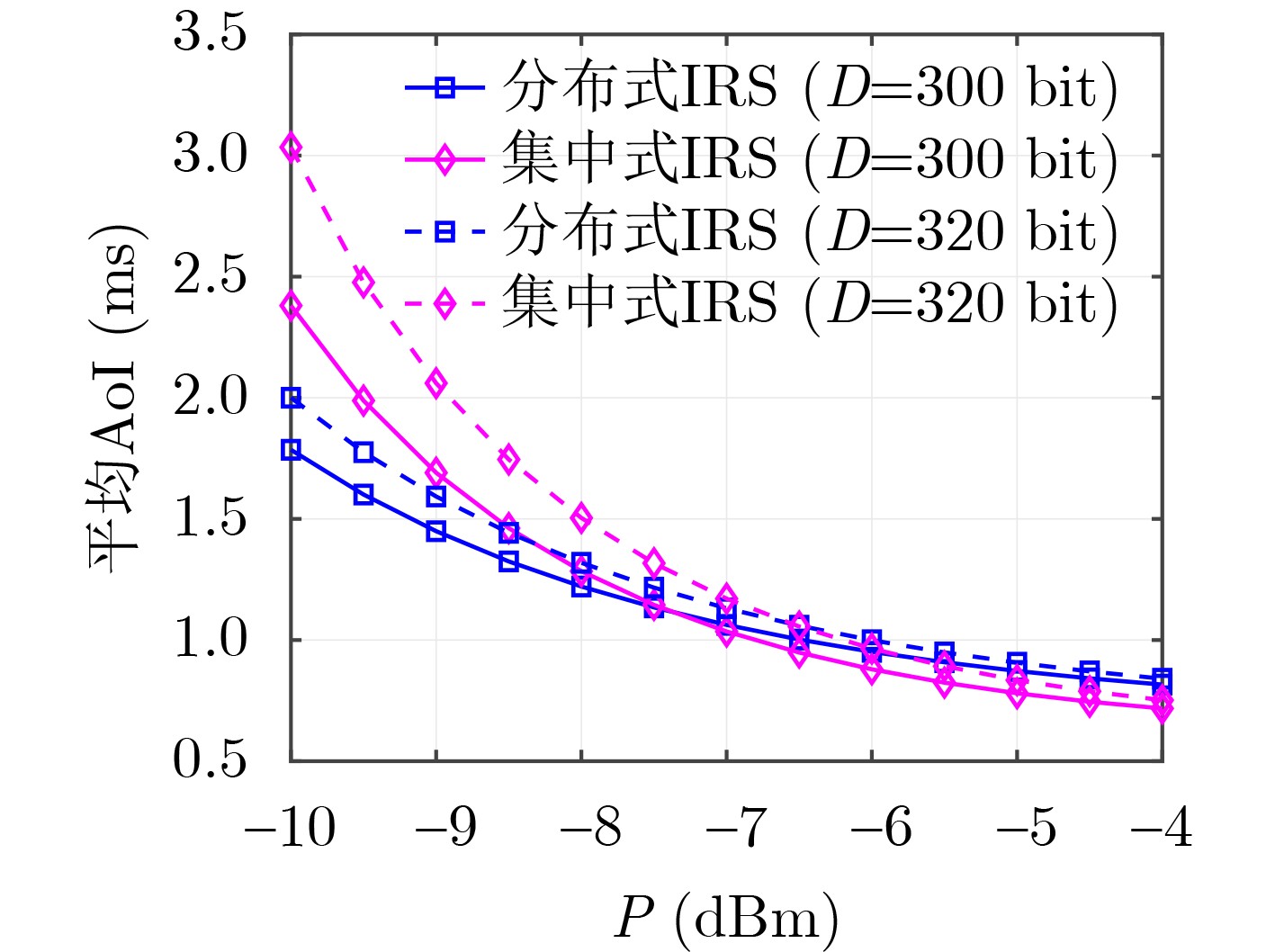
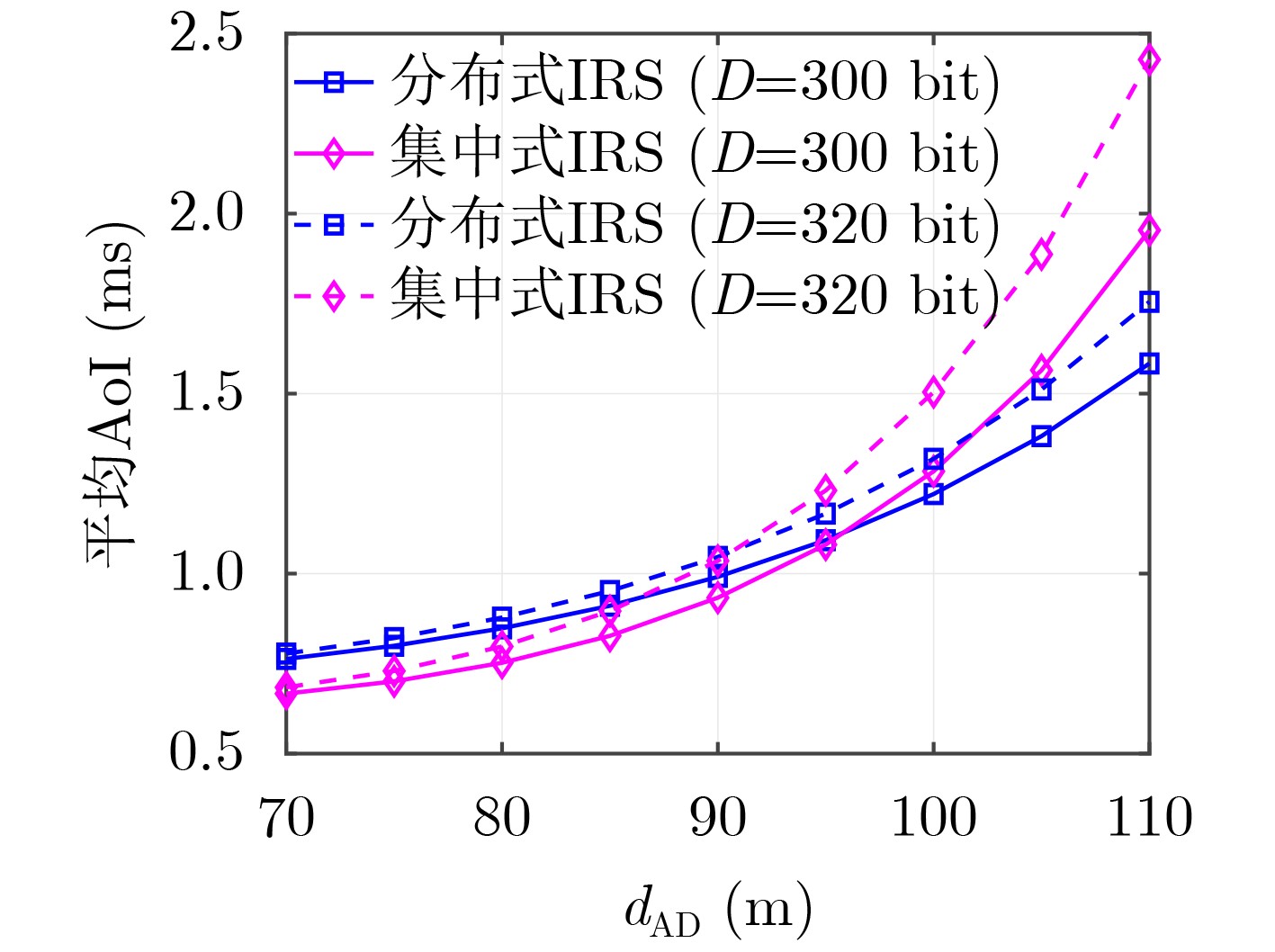
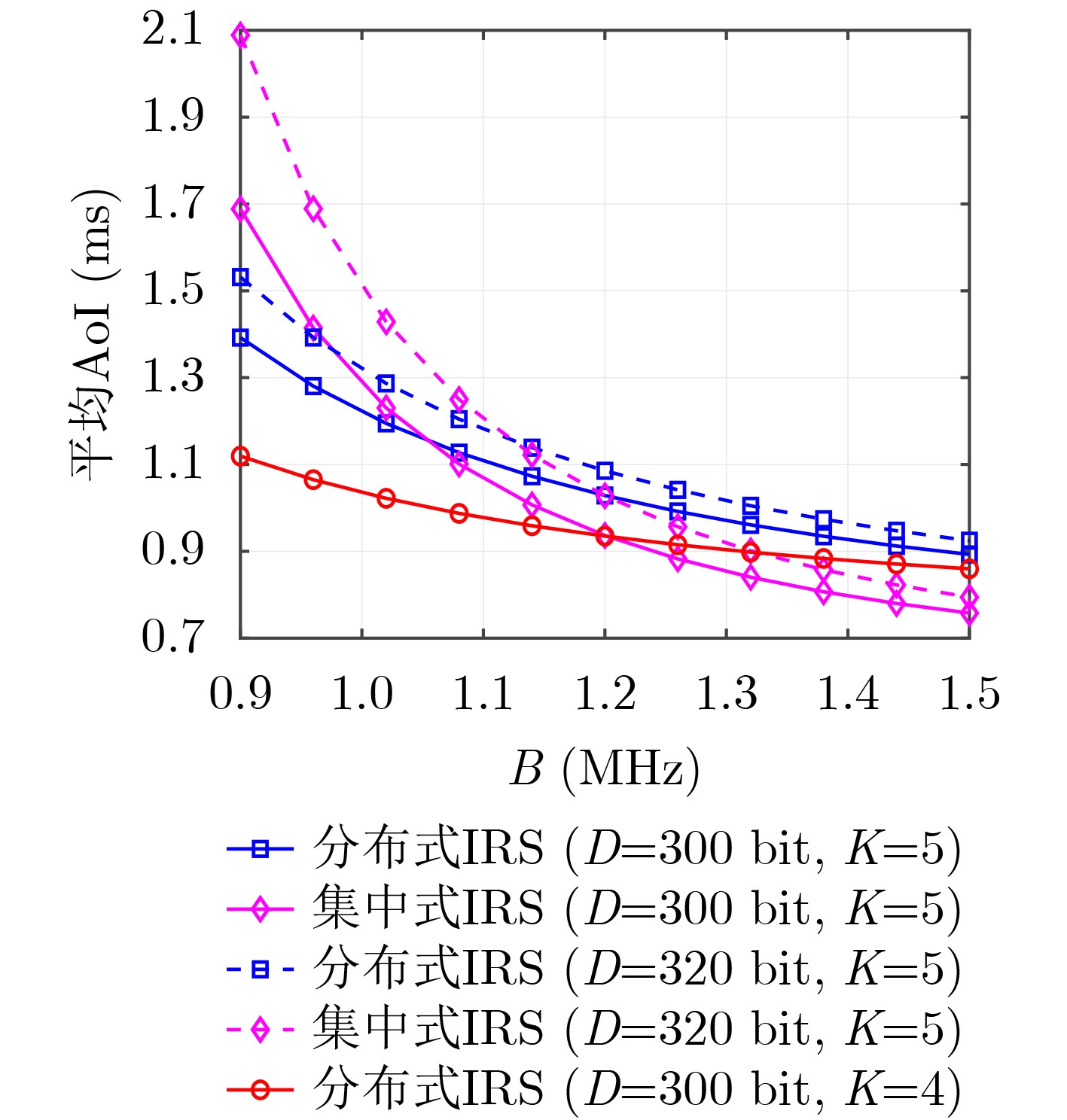
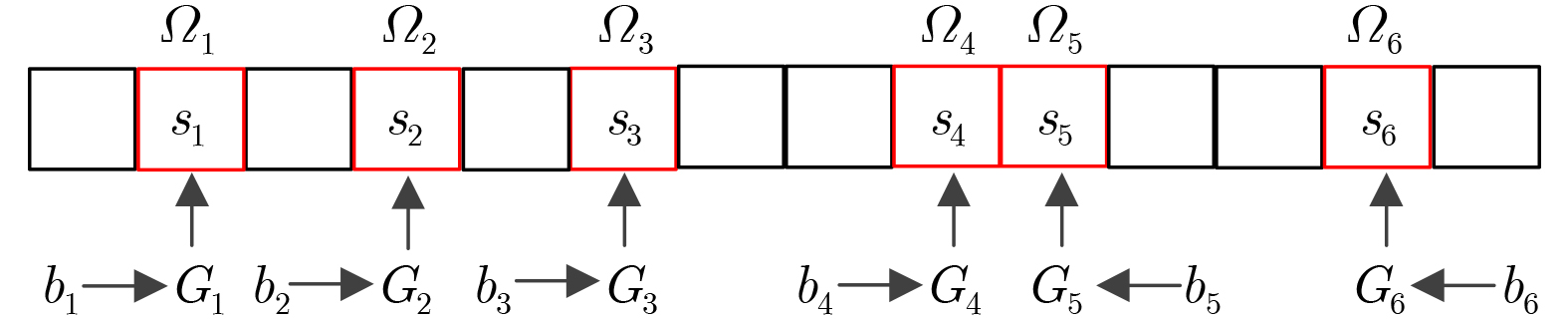
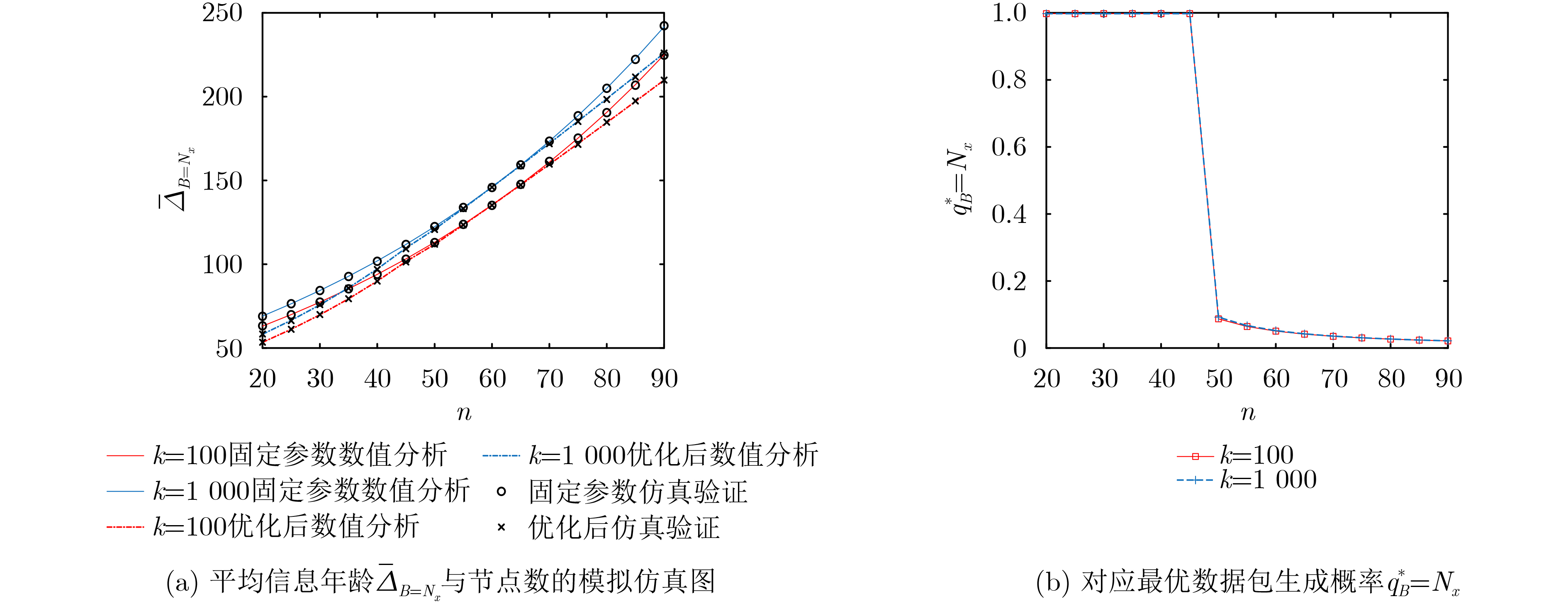
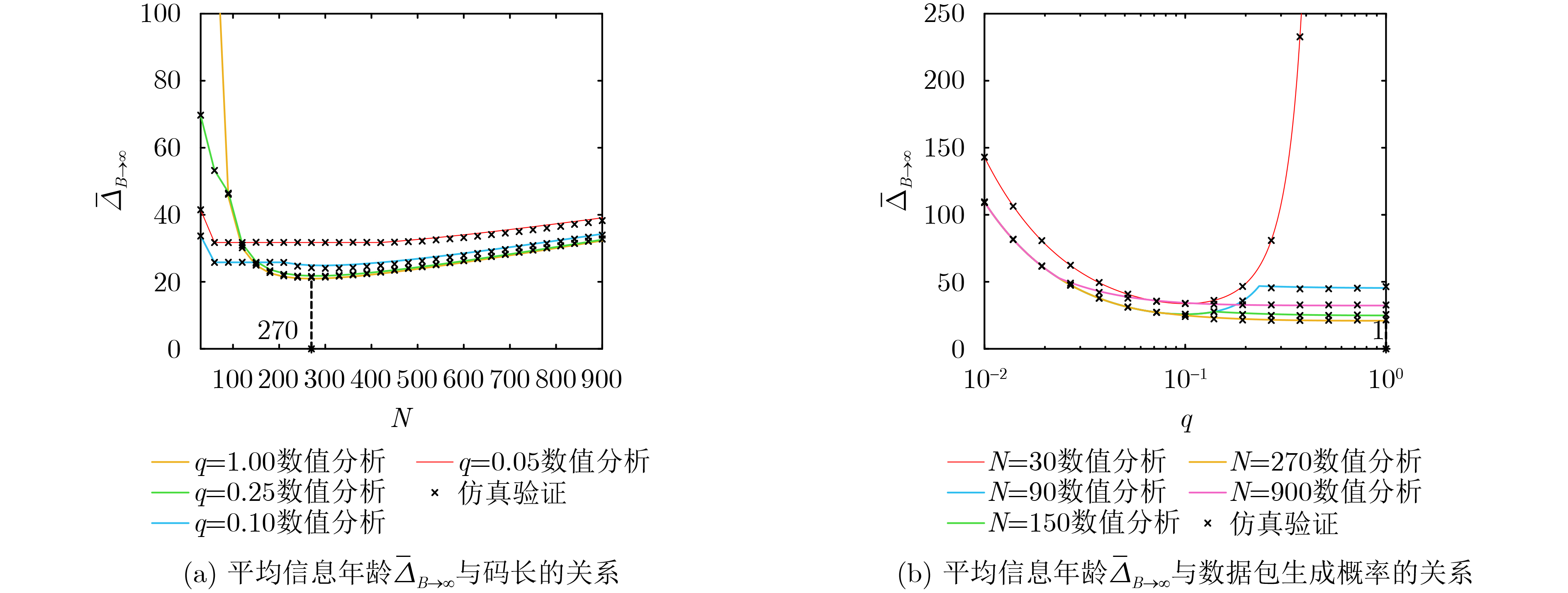
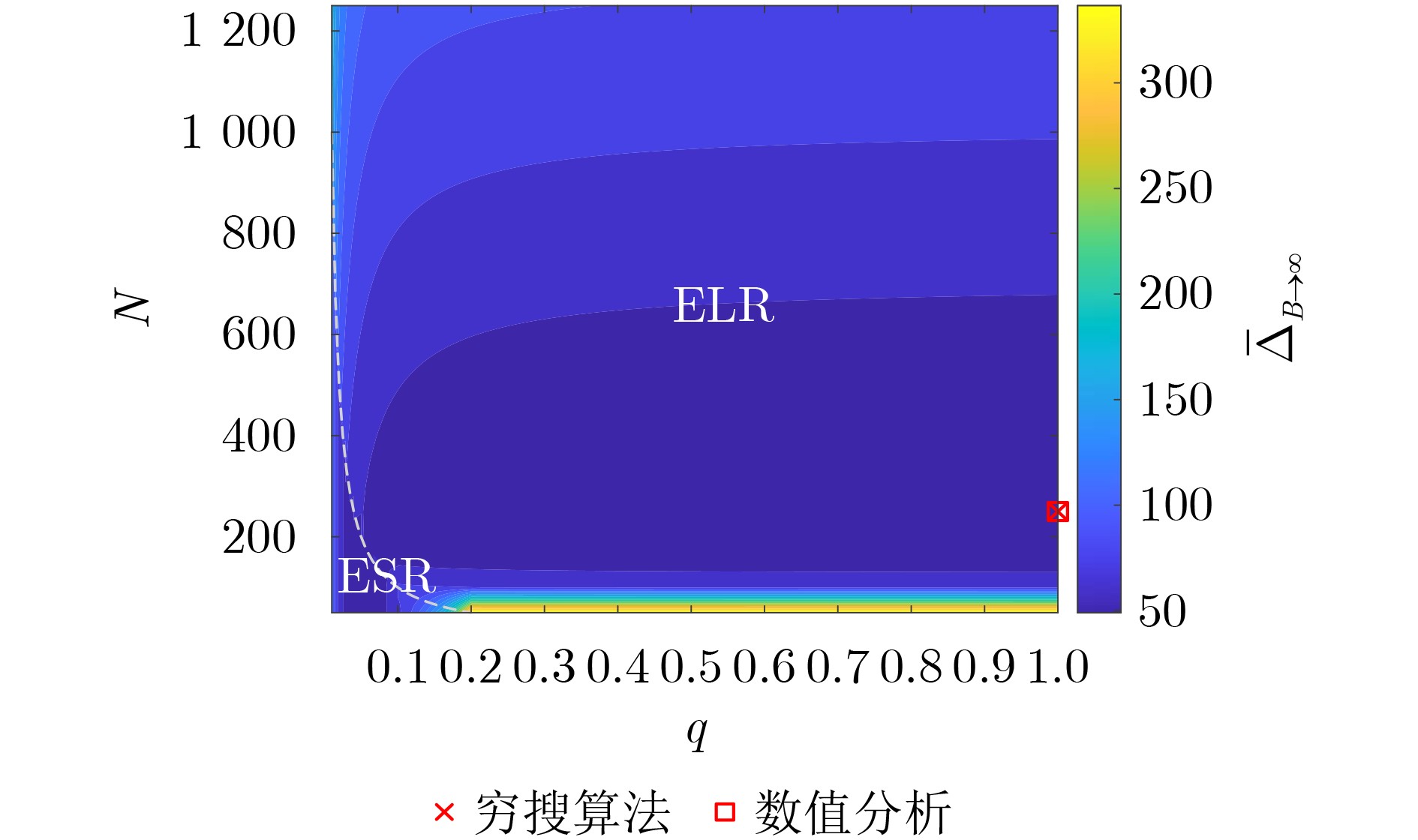
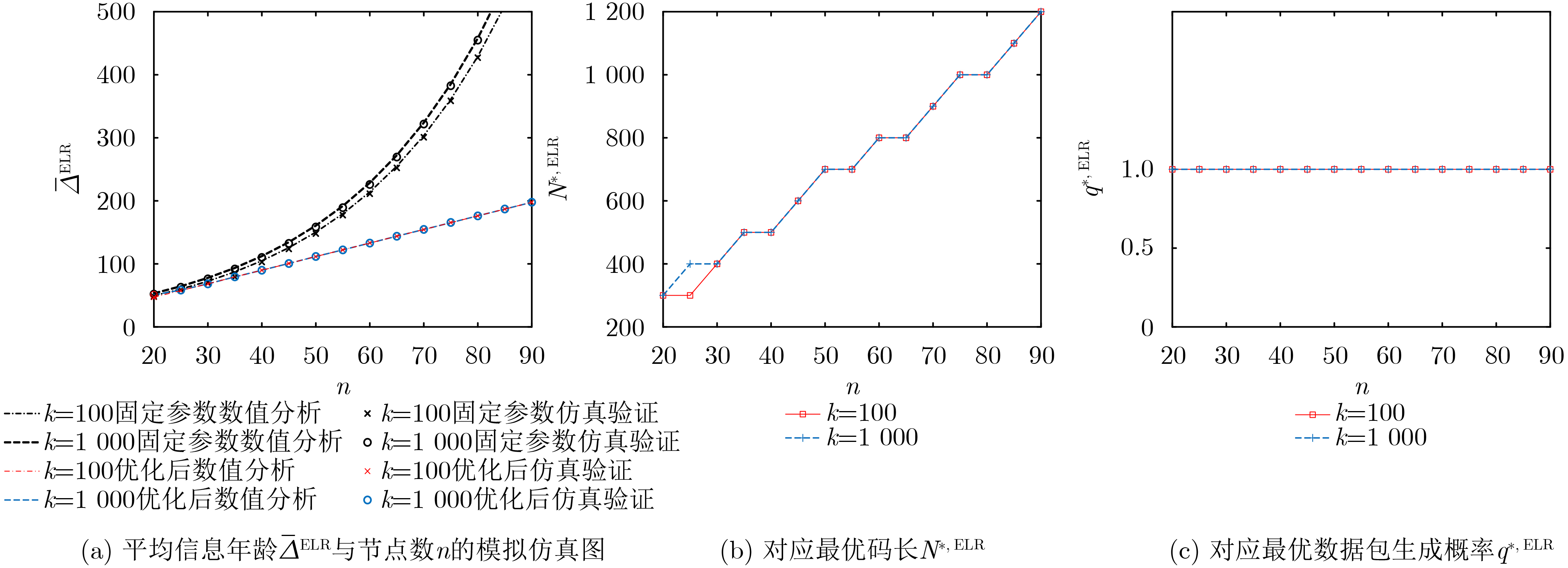
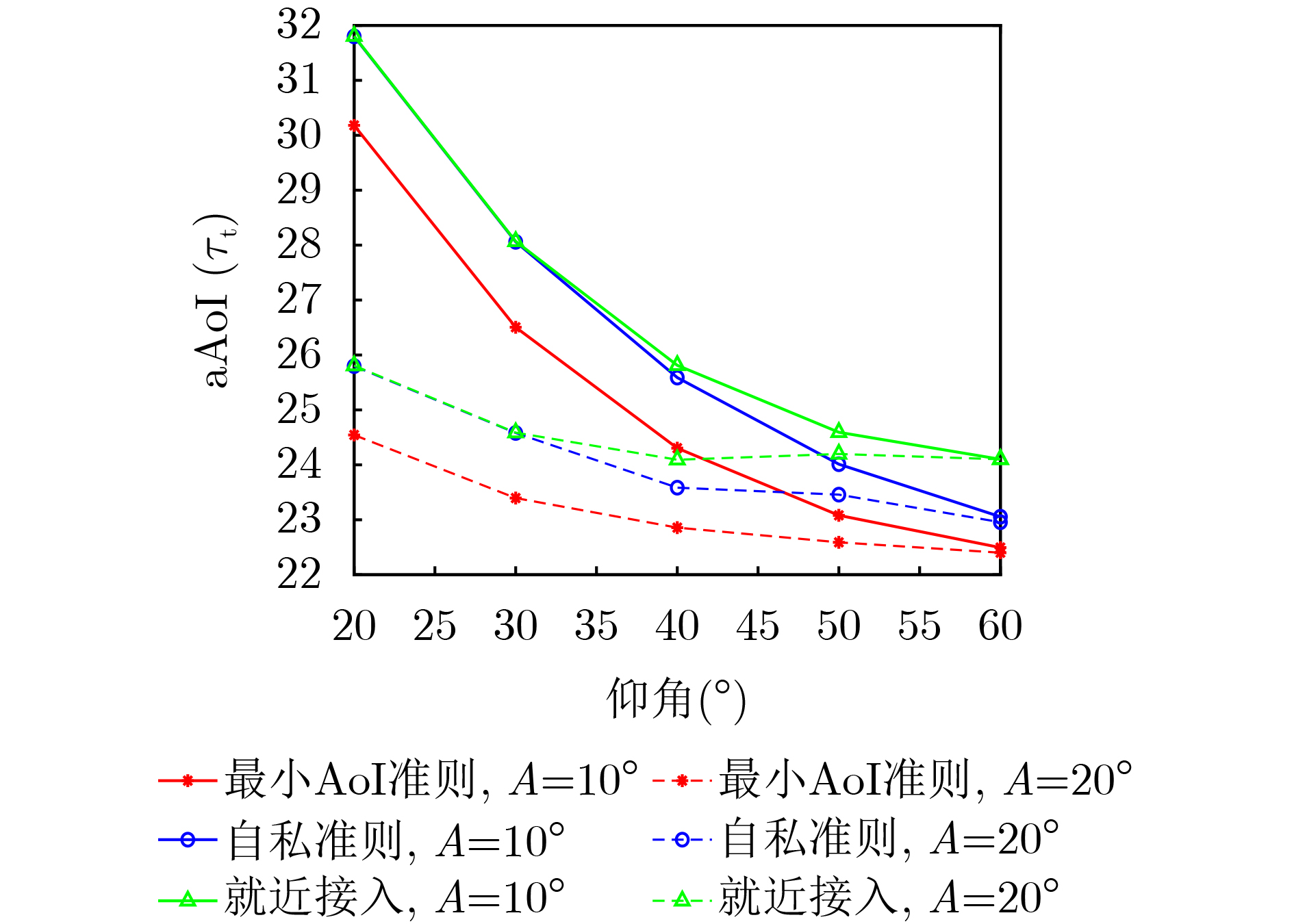
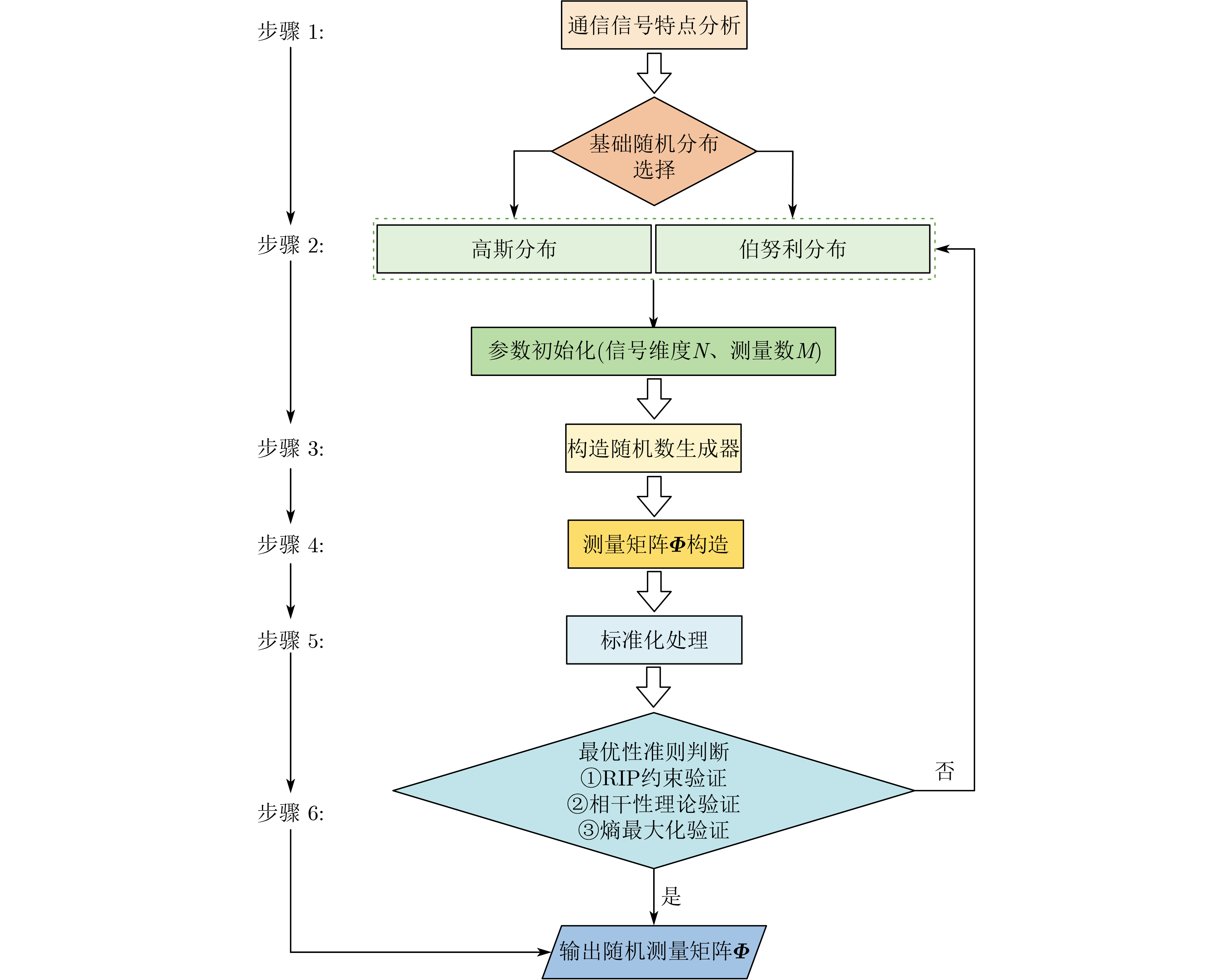
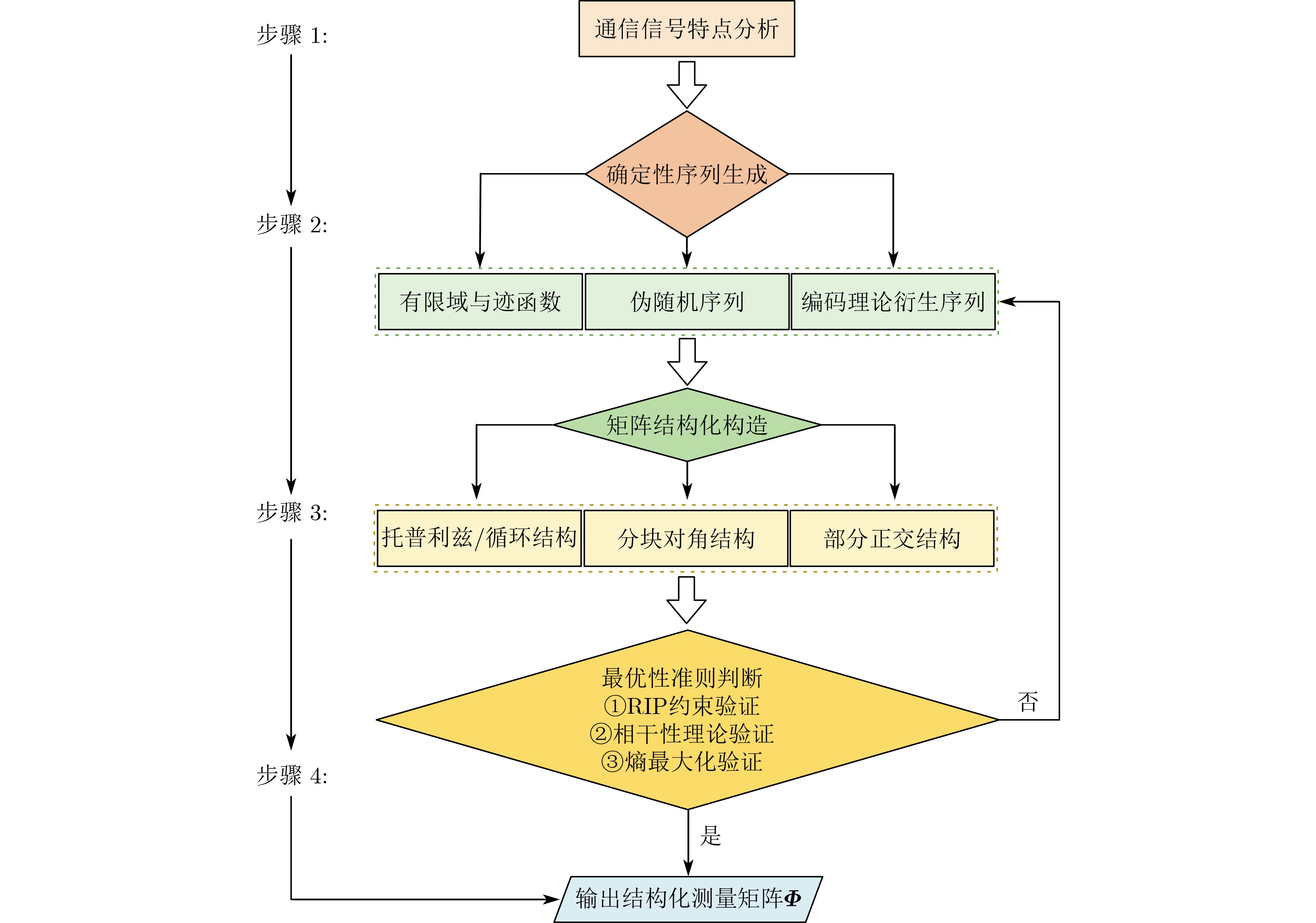
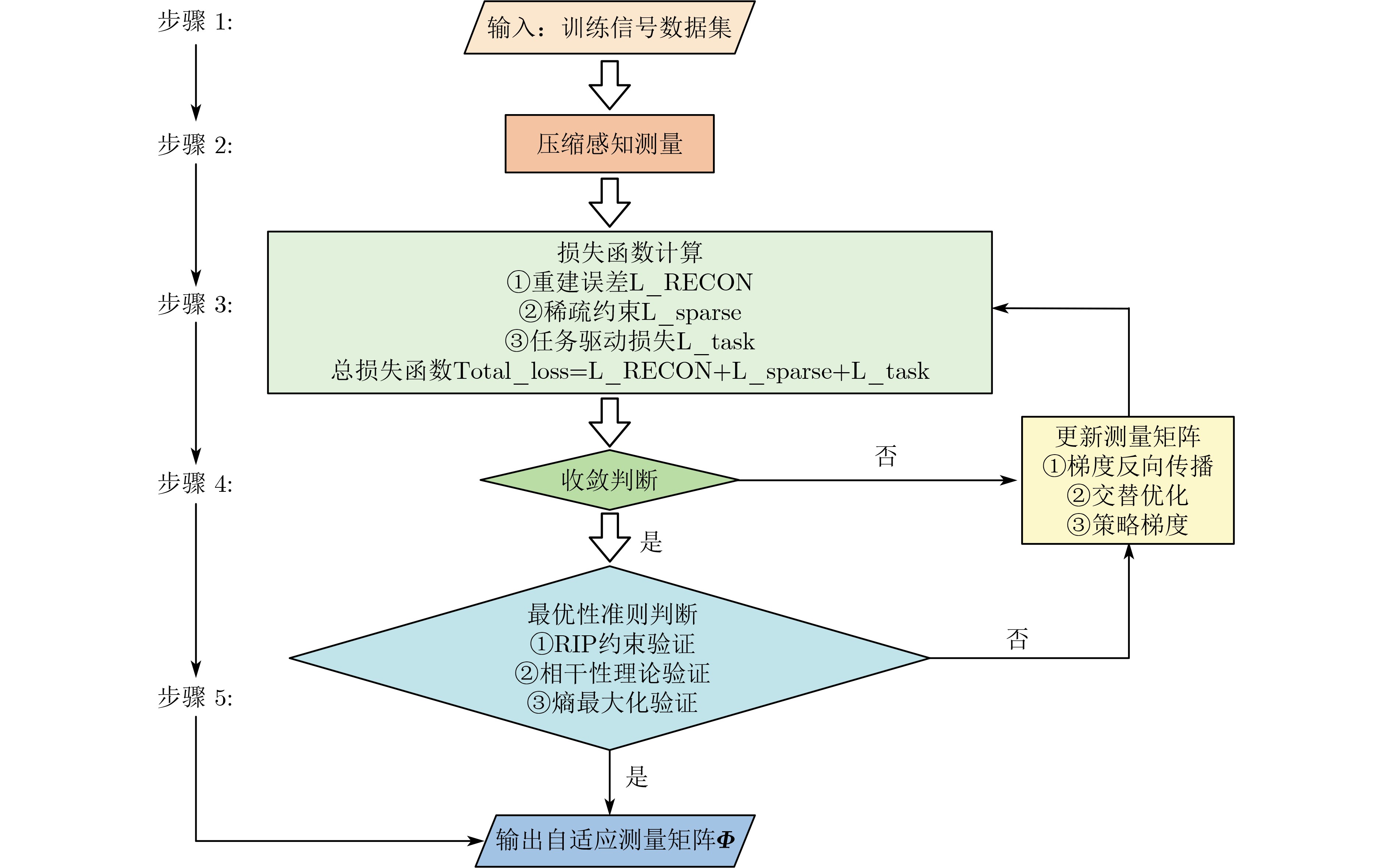
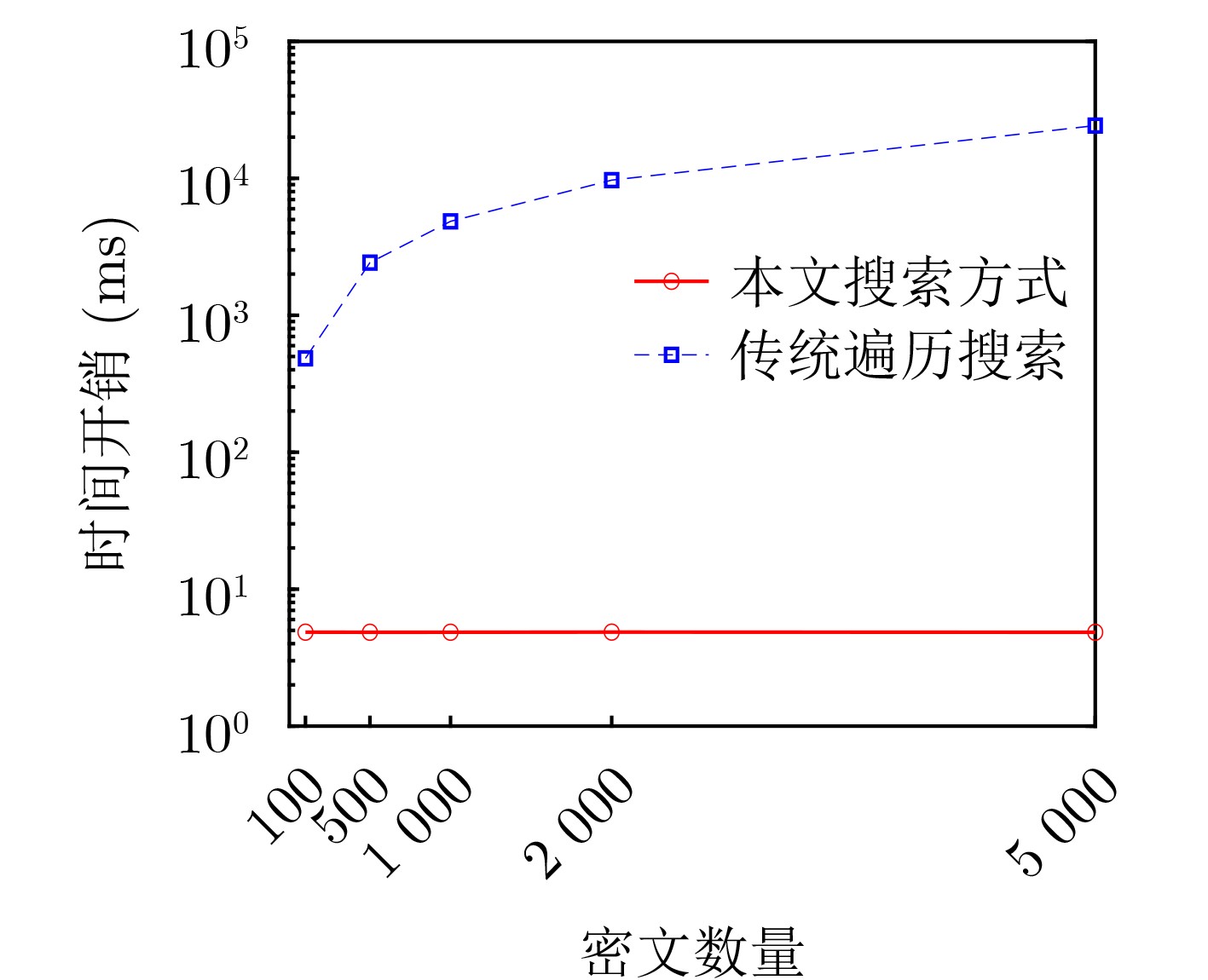
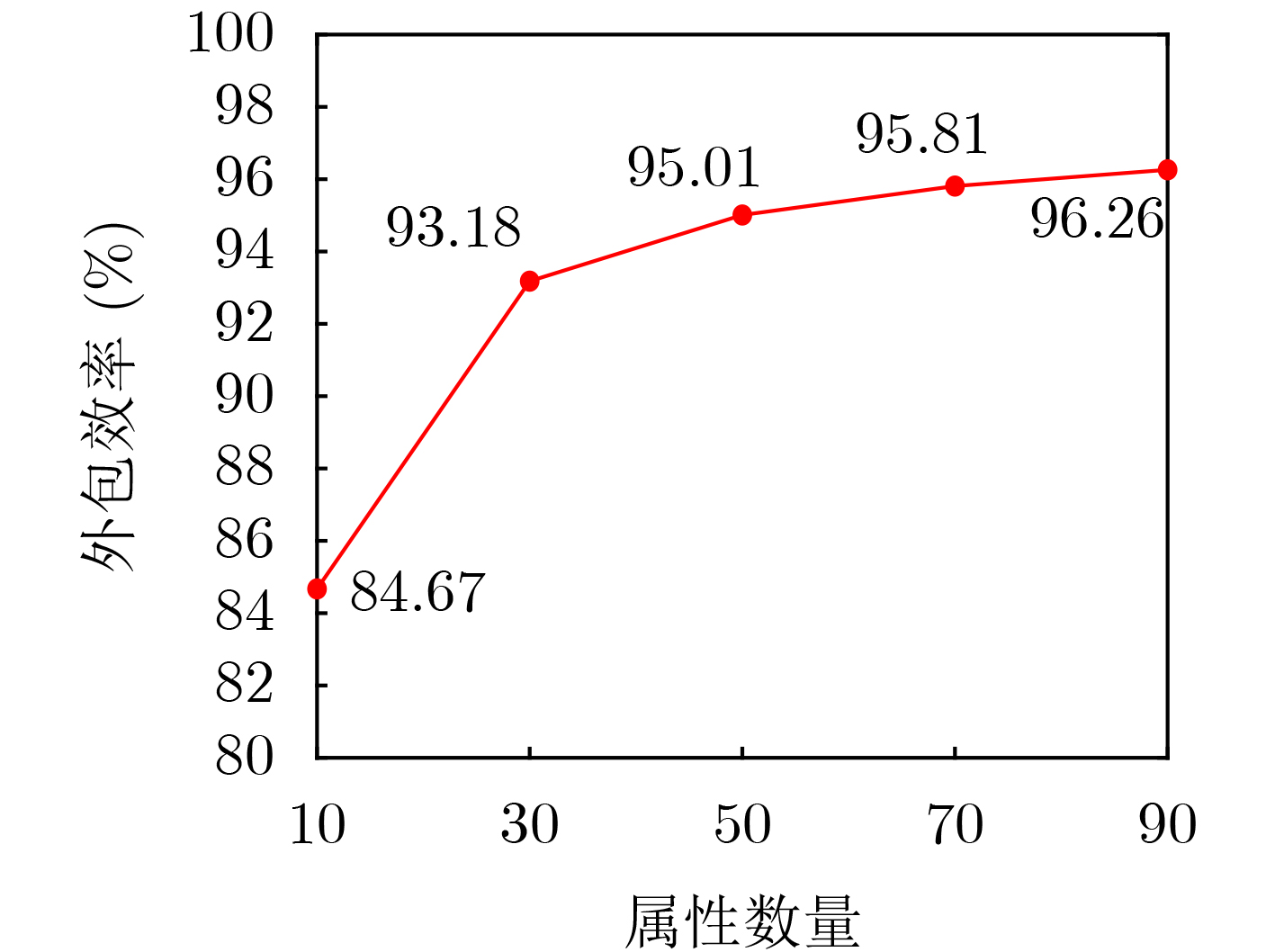
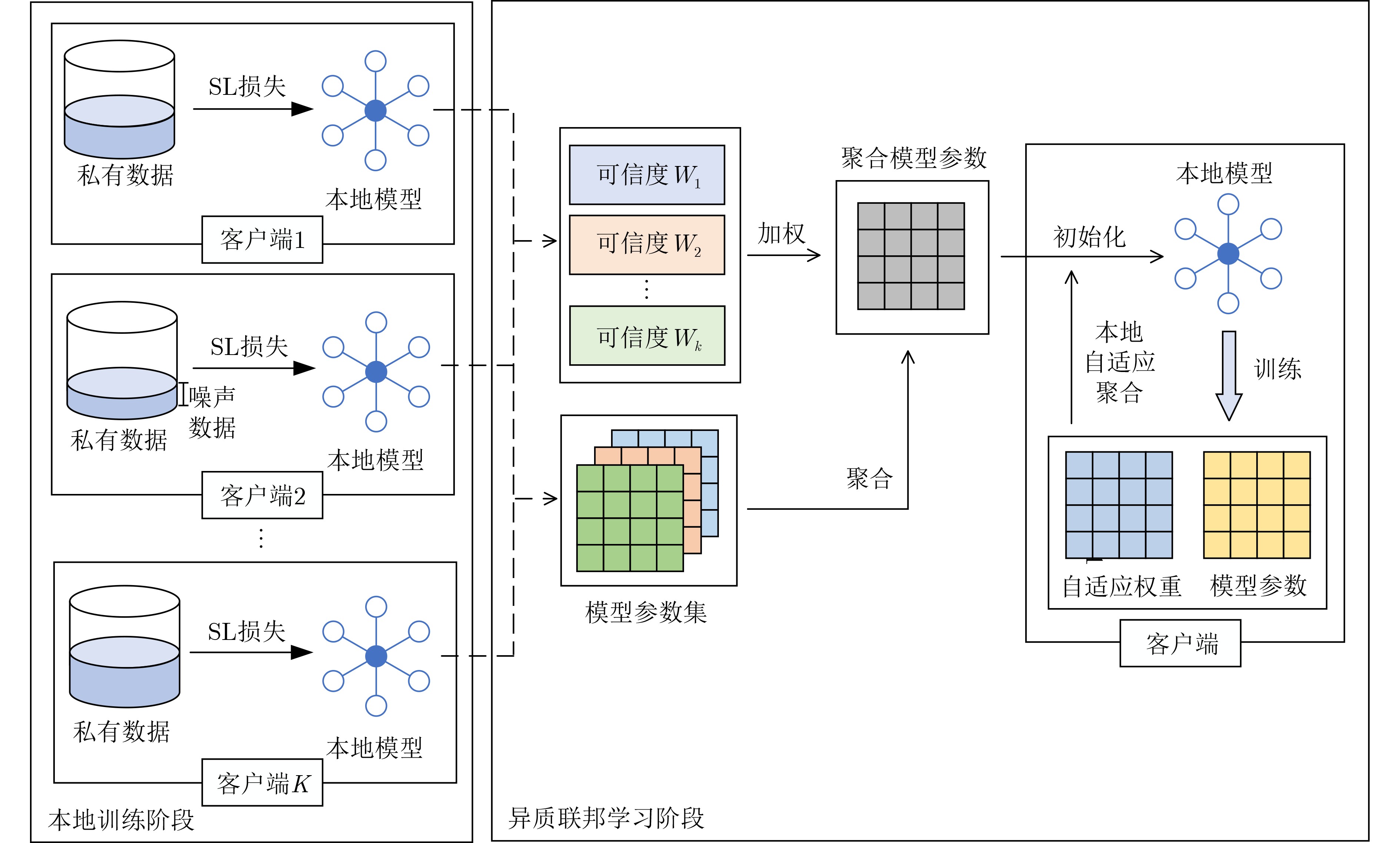
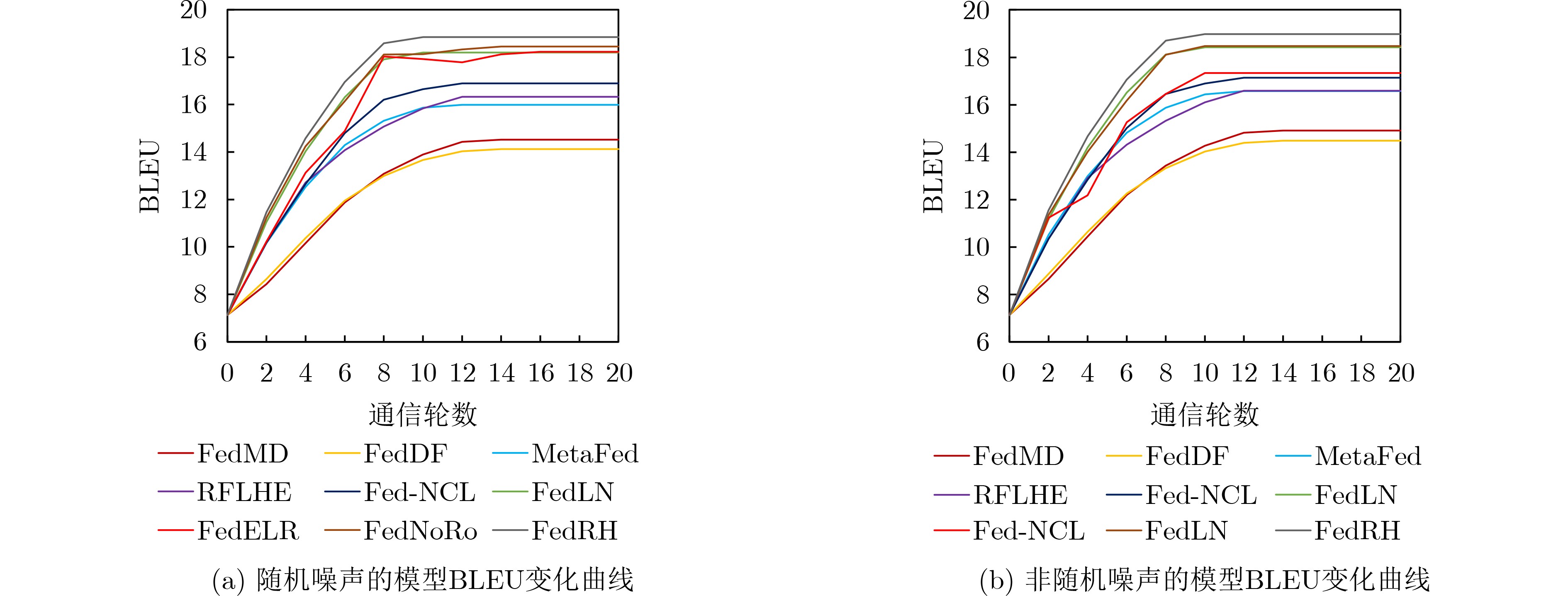
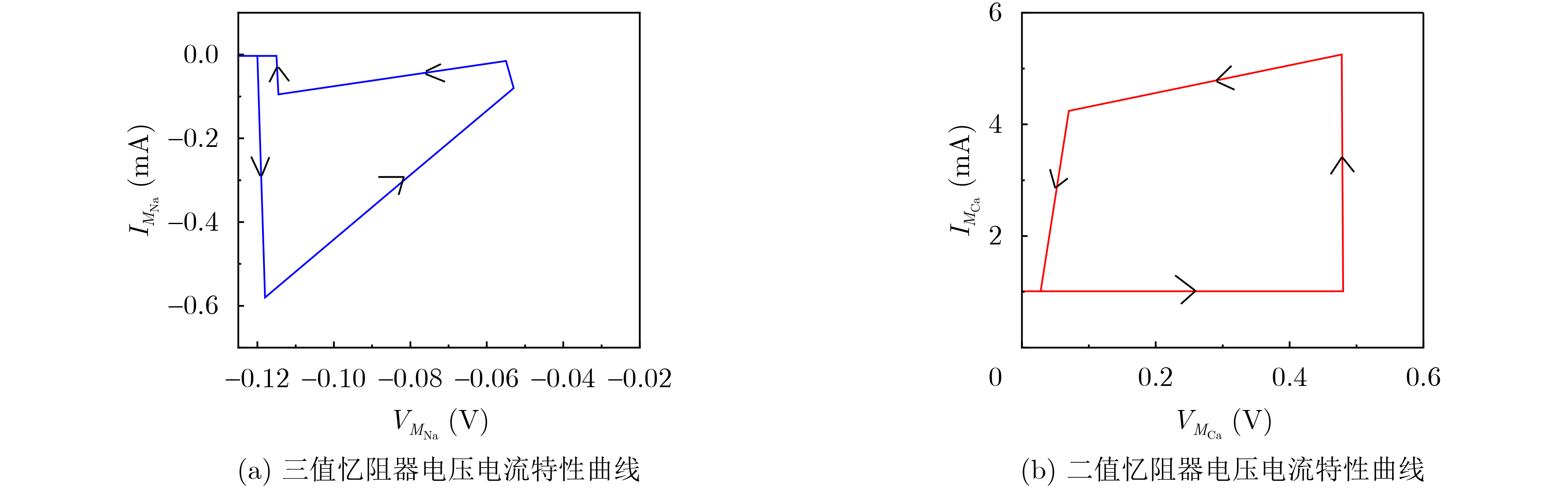
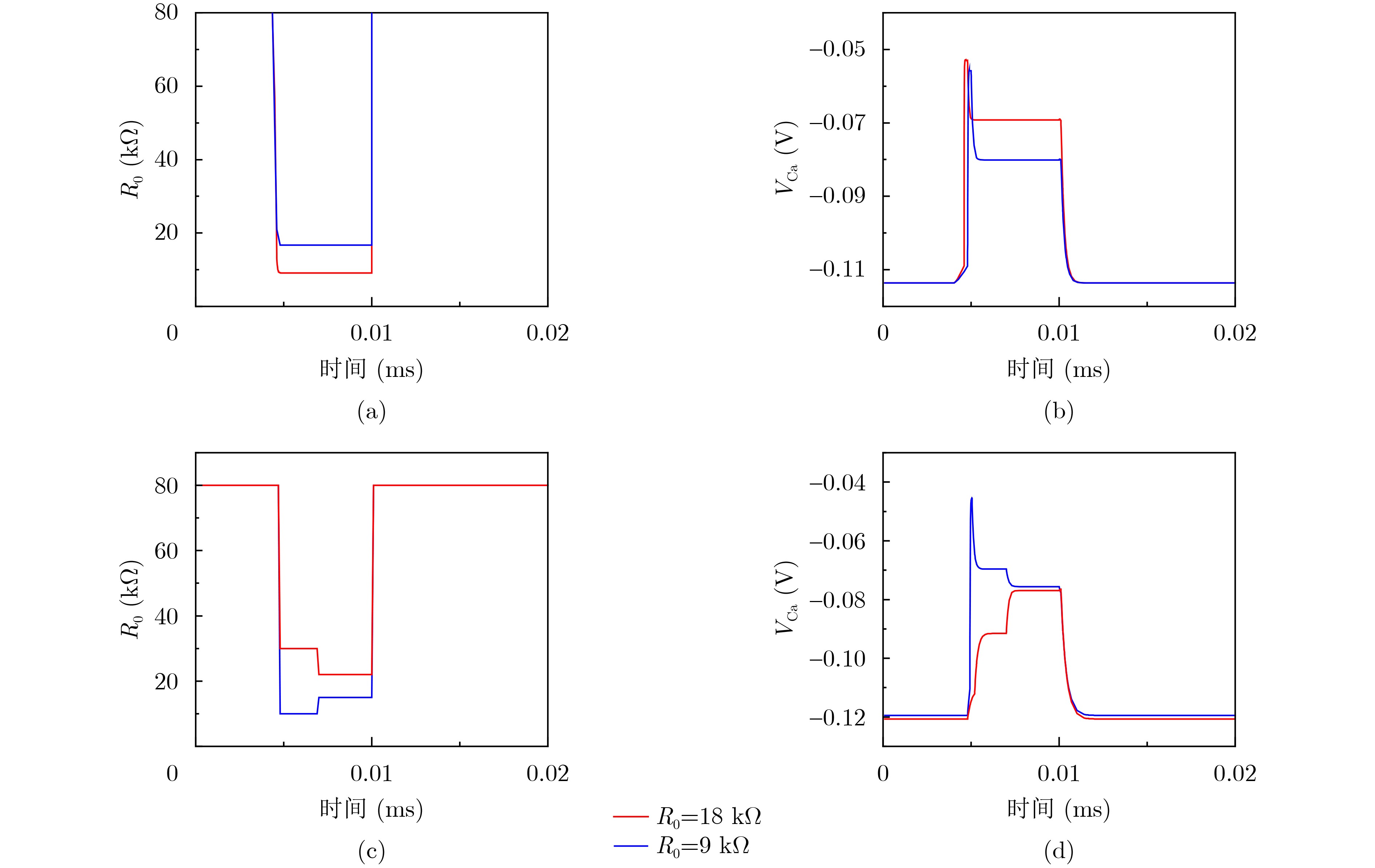
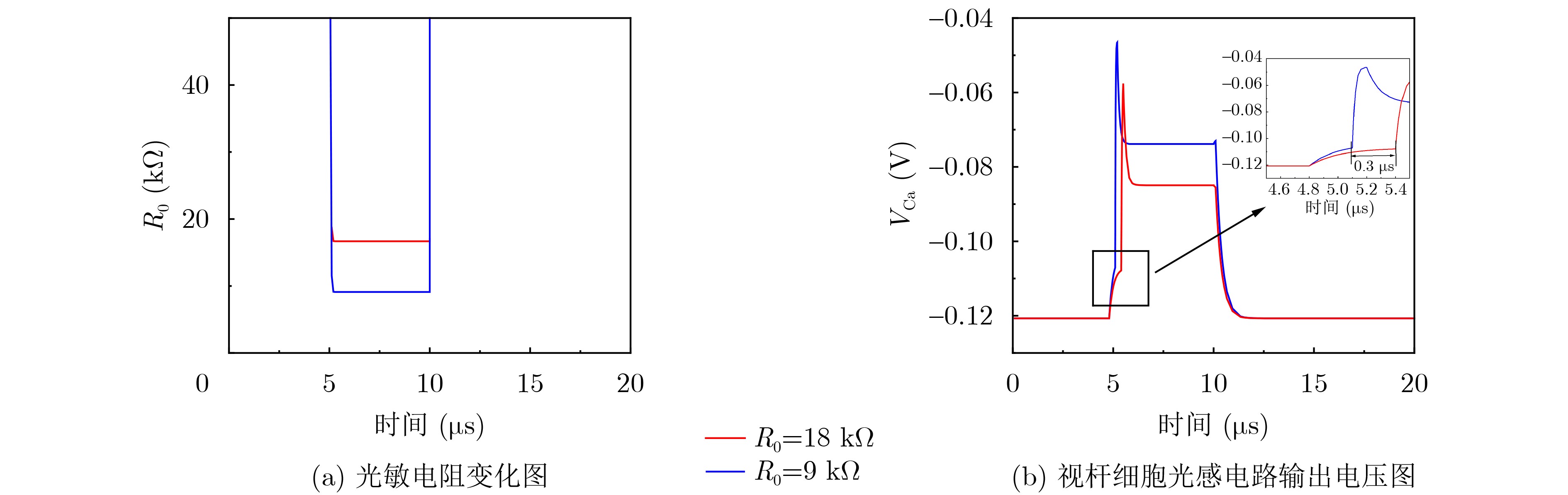
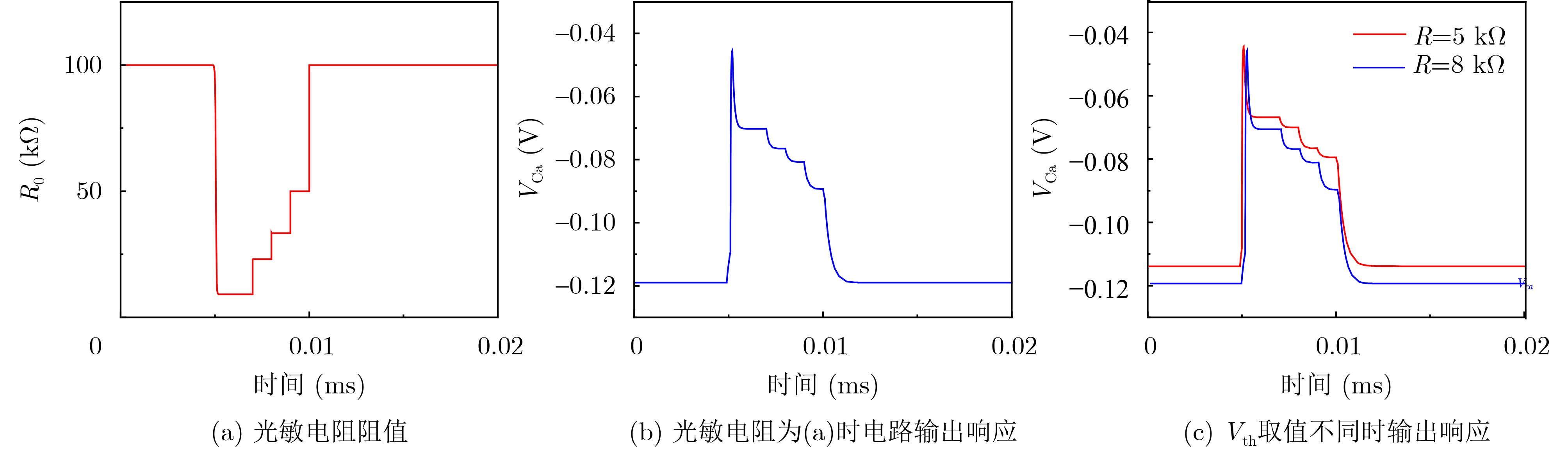
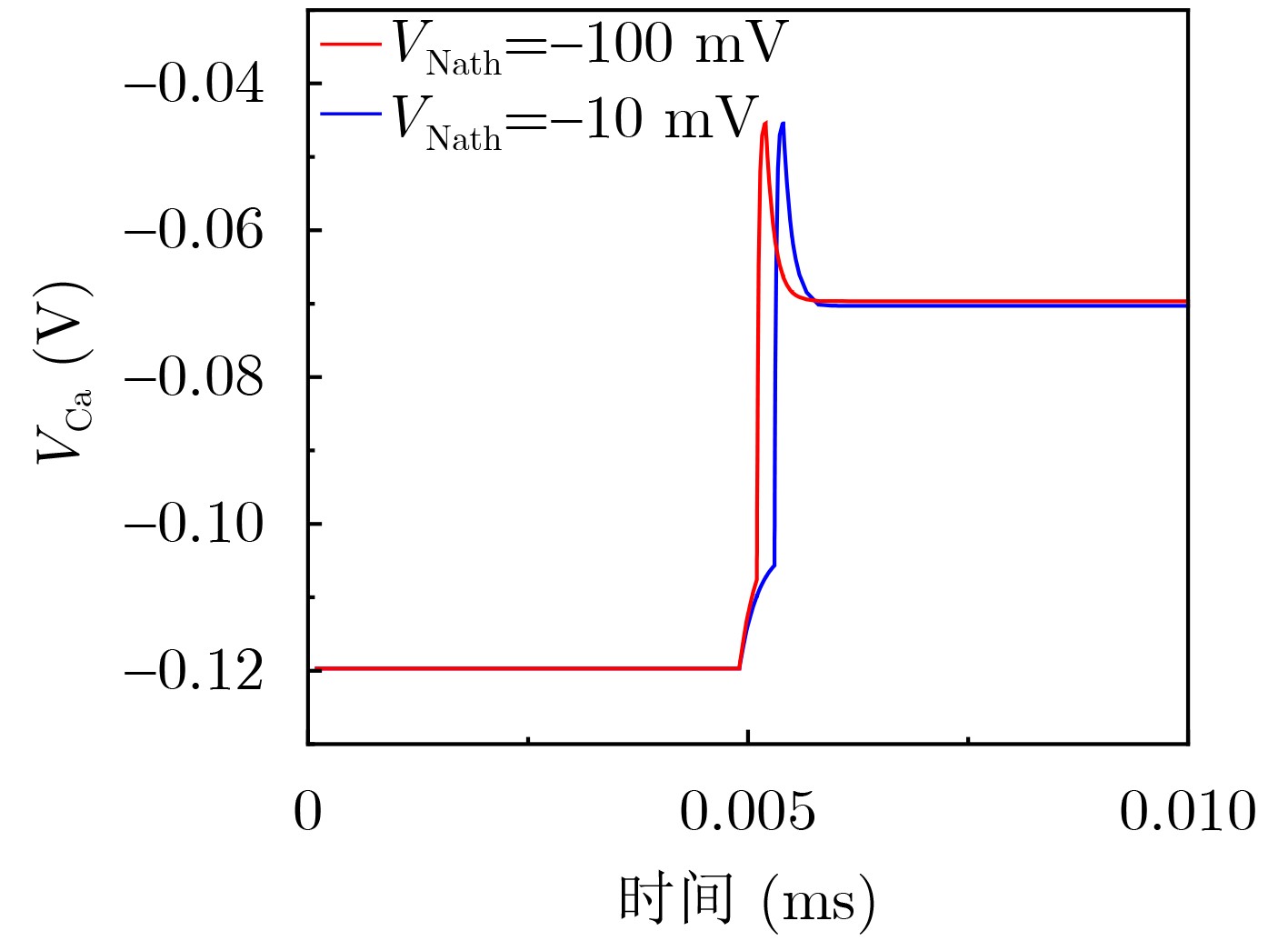
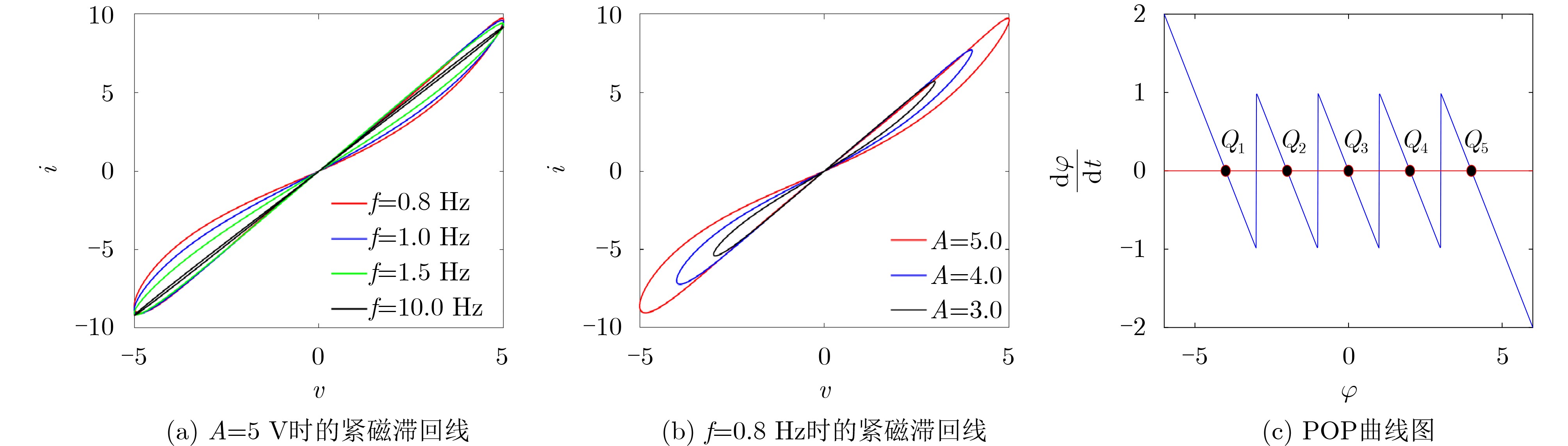
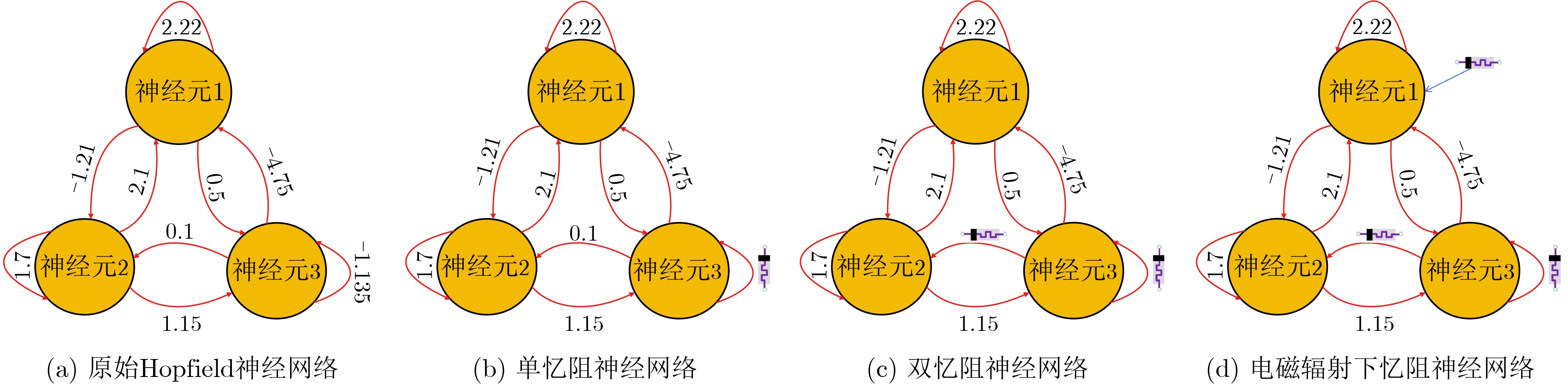
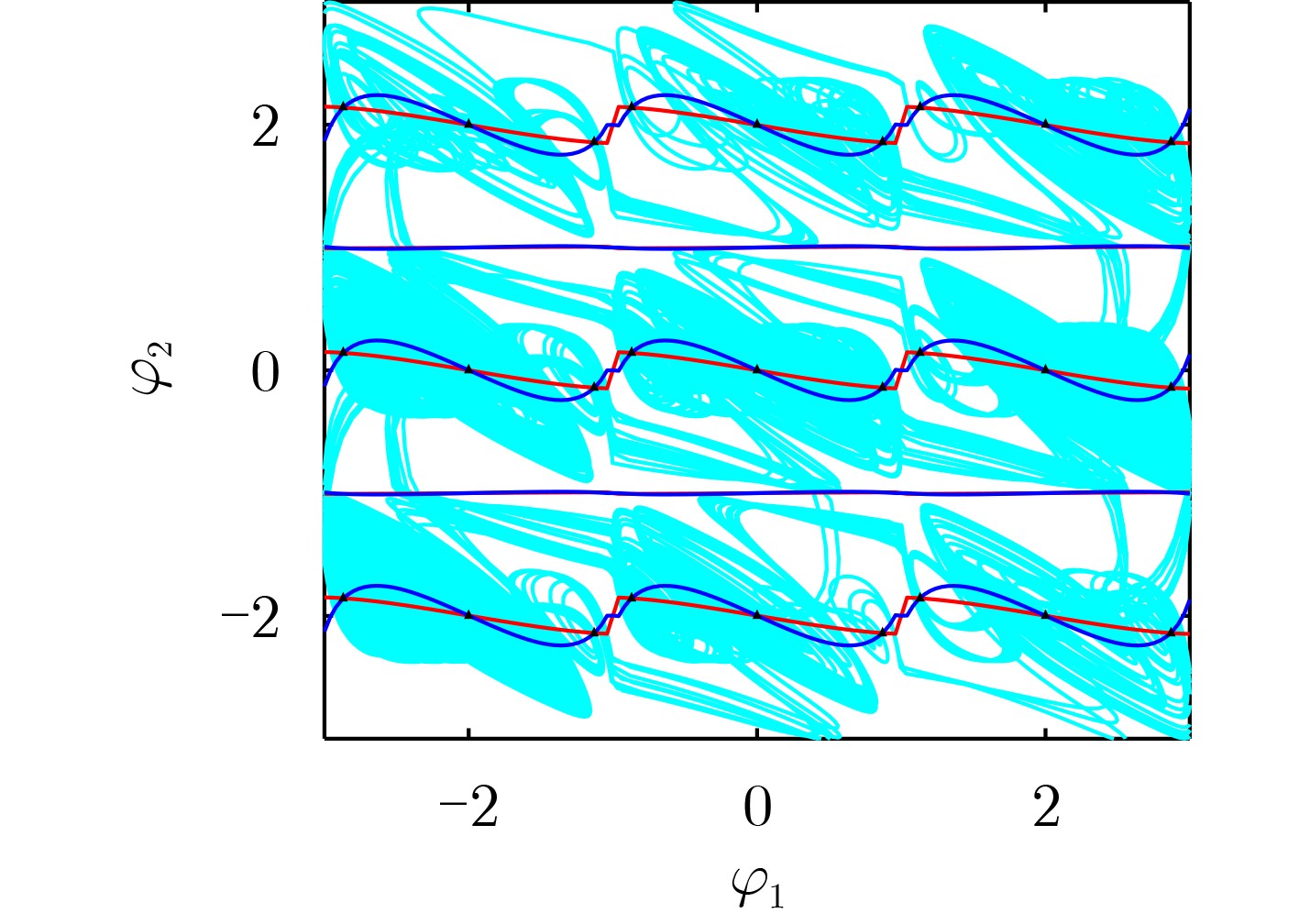
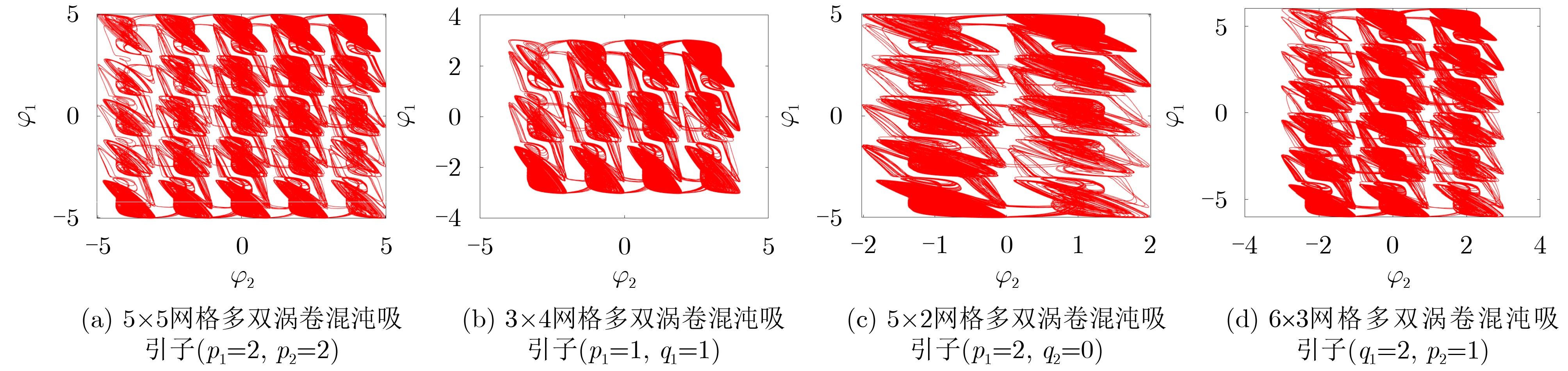
Objective Visual perception plays a critical role in artificial intelligence, robotics, and the Internet of Things. Although existing visual perception devices have achieved substantial progress, the widespread use of conventional CMOS circuit architectures still results in limitations such as slow sensing speed, complex structures, and high power consumption. In contrast, biological visual perception systems exhibit high response speed, low power consumption, and strong stability. Therefore, designing optical perception circuits inspired by biological visual systems has become an active research direction. Existing biologically inspired optical perception circuits are mainly based on the Leaky Integrate-and-Fire (LIF) model, which enables rapid and low-cost conversion of light intensity signals into spike signals. However, the LIF model only supports basic signal conversion and cannot adequately reproduce the working mechanisms and computational characteristics of biological visual neurons. Therefore, practical applications suffer from limited imaging quality, slow response, and weak adaptability. To address these issues, the structure and operating mechanism of human visual perception cells are investigated, a corresponding photosensing circuit is designed, and spiking camera schemes are proposed to achieve high-speed, low-power, and stable imaging. Methods The biological visual system provides valuable inspiration for bionic photosensing circuits due to its fast response, low power consumption, high stability, and strong adaptability. The biological mechanism of photoreceptor cells in the human visual system is analyzed from the perspective of ionic flow, and a mathematical photosensitivity model of rod cells is derived following the construction approach of the Hodgkin-Huxley (HH) model. Based on the closed states of ionic channels in rod cells, a memristor model is designed. Using the proposed memristor model and the mathematical model of photoreceptor cells, a rod-cell photosensing circuit is developed. Its adaptability, conversion speed, stability, and dynamic range are evaluated through simulation to verify effectiveness and bionic characteristics, and the results are compared with those of a photosensing circuit based on the LIF model. To further demonstrate practicality, the proposed rod-cell photosensing circuit is applied to a spiking camera, and its adaptability, speed, power consumption, error, and dynamic range are analyzed and compared with a spiking camera based on a simplified neuron photosensing circuit. Results and Discussions Based on the operating principles of photoreceptor cells in the human visual system, a photoreceptor cell model is proposed. Sodium-ion memristors and calcium-ion memristors are introduced to simulate sodium and calcium ion channels in photoreceptor cells, respectively, where the sodium-ion memristor is implemented as a tri-valued memristor. Using the proposed memristor model, a rod-cell photosensing circuit is designed. Under strong illumination, the circuit adapts to light intensity through resistance transitions of the sodium-ion memristor, reducing sensitivity and suppressing the influence of extreme illumination on normal lighting conditions, while maintaining fast conversion speed and a wide dynamic range. The rod-cell photosensing circuit is further combined with the signal conversion circuit to implement a spiking camera. Simulation results show that, compared with spiking cameras based on simplified neuron photosensing circuits and CMOS circuits, the imaging speed increases by 20% and 150%, respectively, while automatic adaptation to extreme illumination, low power consumption, high accuracy, and strong stability are achieved. Conclusions Inspired by the operating mechanisms of photoreceptor cells in the visual system, a mathematical model of rod cells and a corresponding memristor model are proposed, and a rod-cell photosensing circuit based on memristors is designed. The circuit reproduces the hyperpolarization and adaptive processes observed in rod-cell photosensing. Through capacitor charge-discharge behavior and memristor resistance transitions, optical signals are converted into voltage signals whose amplitudes vary with light intensity, with higher illumination producing higher voltage amplitudes. Automatic amplitude regulation under strong illumination is achieved, thereby suppressing the influence of extreme light conditions. Compared with simplified neuron photosensing circuits, the proposed rod-cell photosensing circuit provides faster conversion speed, a wide dynamic range from 50 to 5 000 lx, self-adaptation, and improved stability. An intelligent optical sensor array is further constructed, and a spiking camera is implemented by combining the photosensing circuit with a signal conversion circuit and a time-window function. Simulation results confirm clearer imaging under strong background illumination and effective high-speed imaging for both stationary and rapidly moving objects. Compared with spiking cameras based on simplified neuron photosensing circuits and CMOS circuits, imaging speed is improved by 20% and 150%, respectively, while low power consumption, small error, and strong anti-interference capability are maintained.