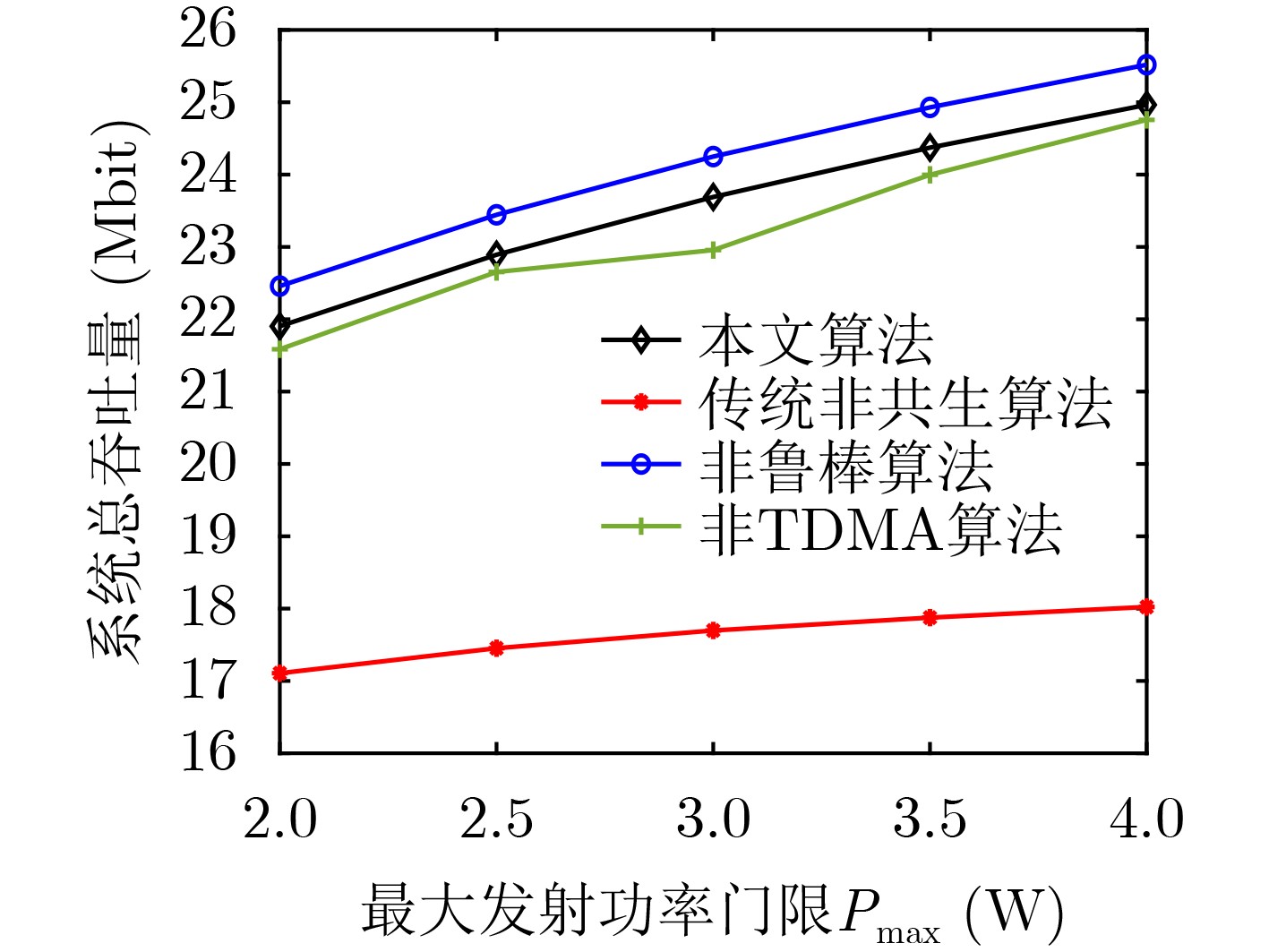
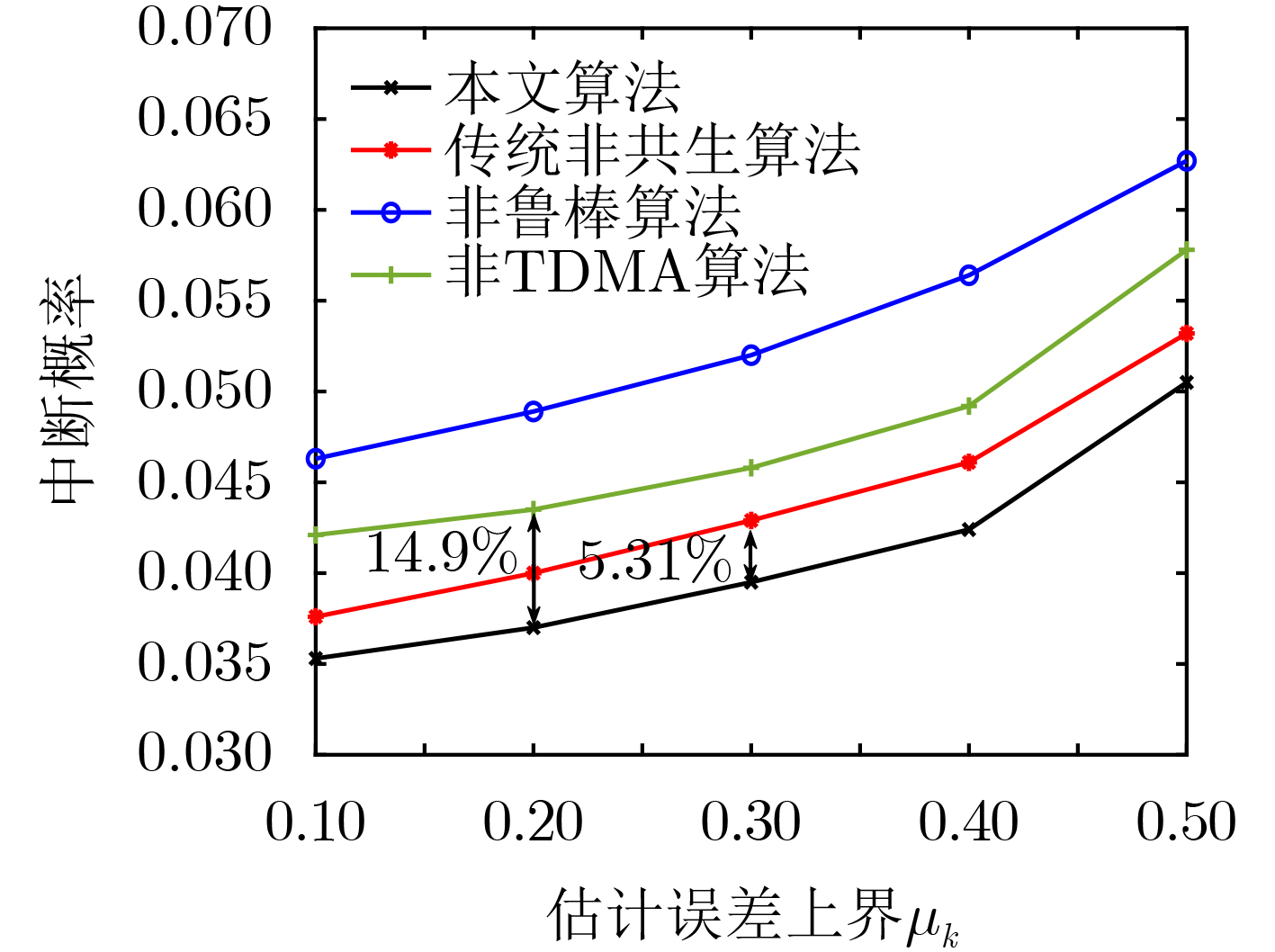
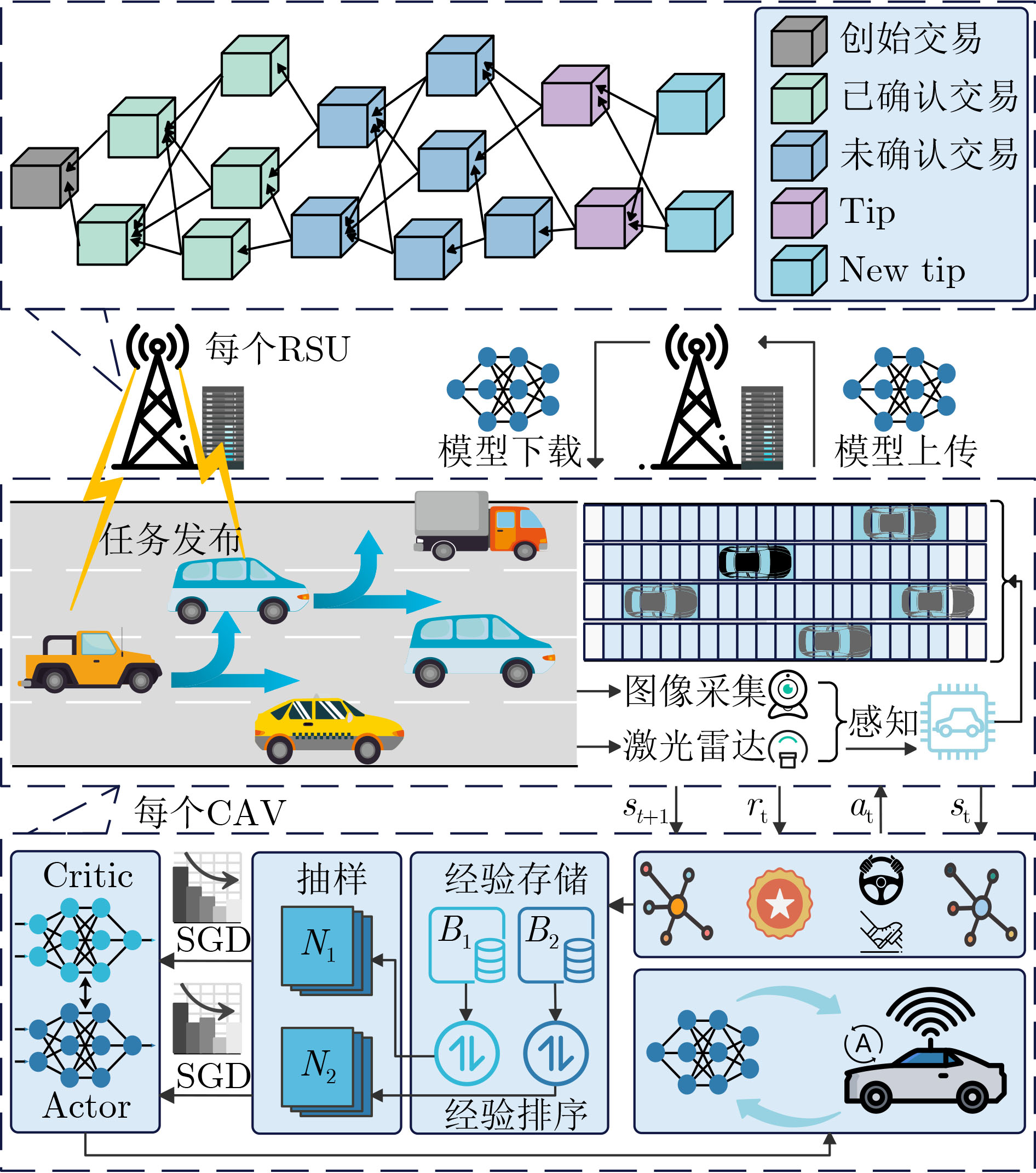
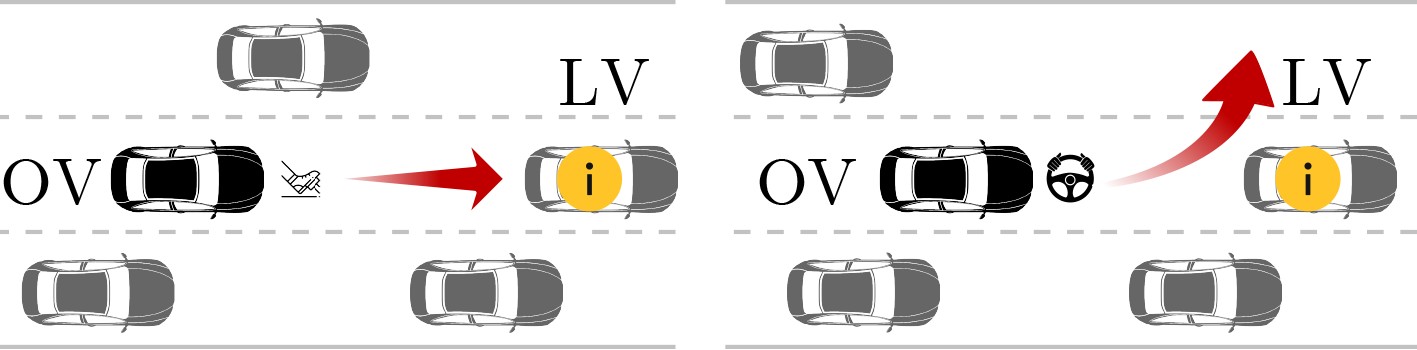
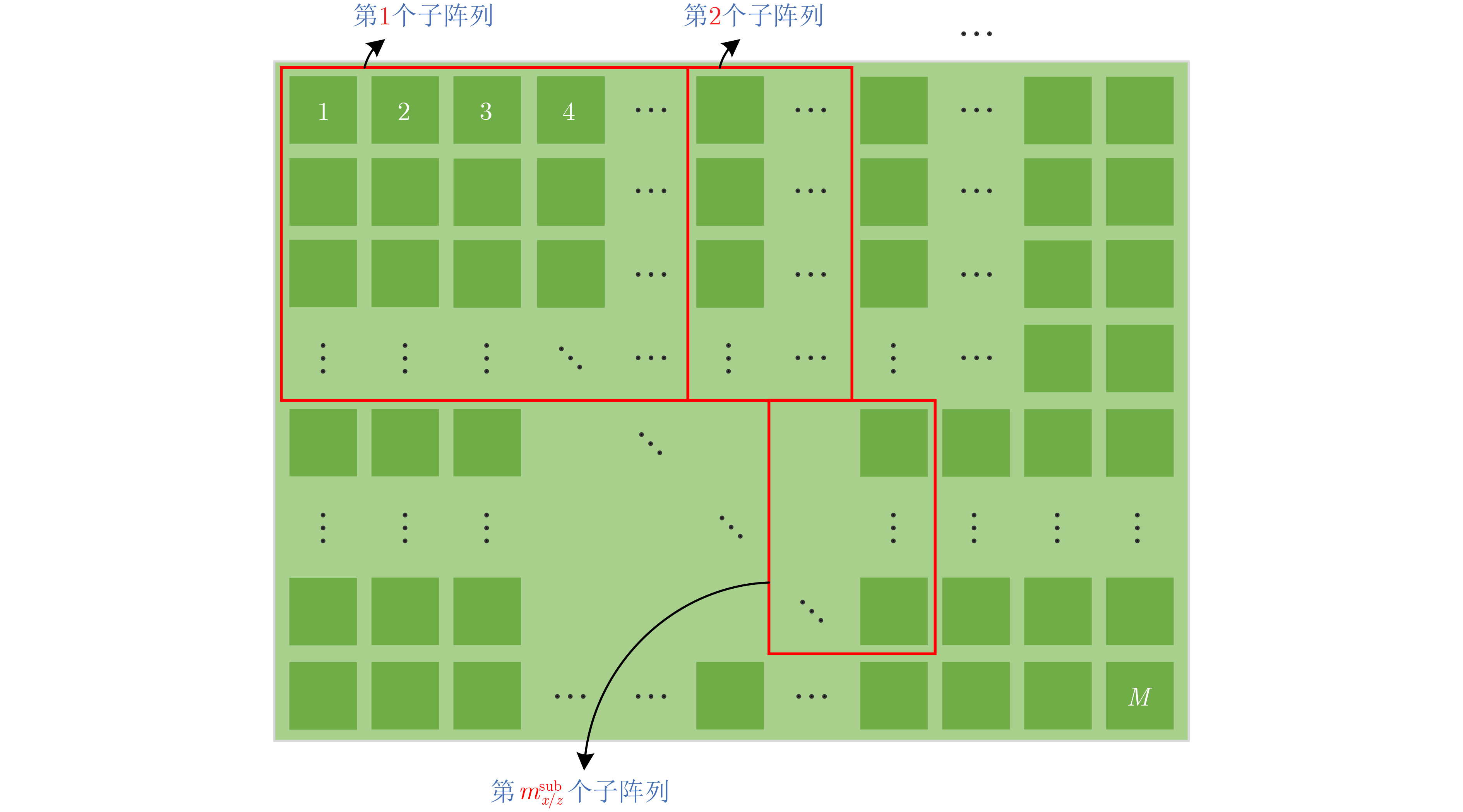
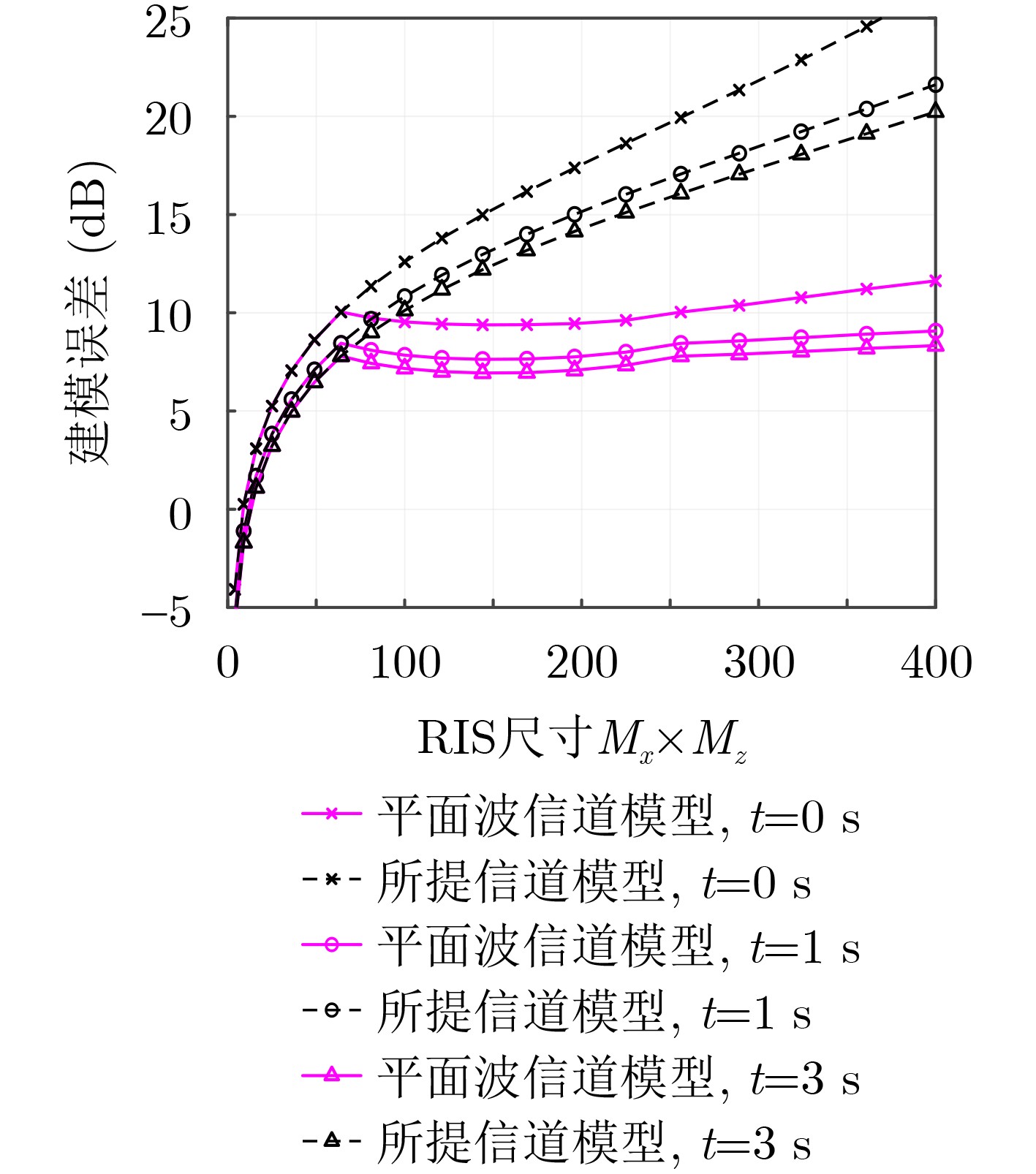
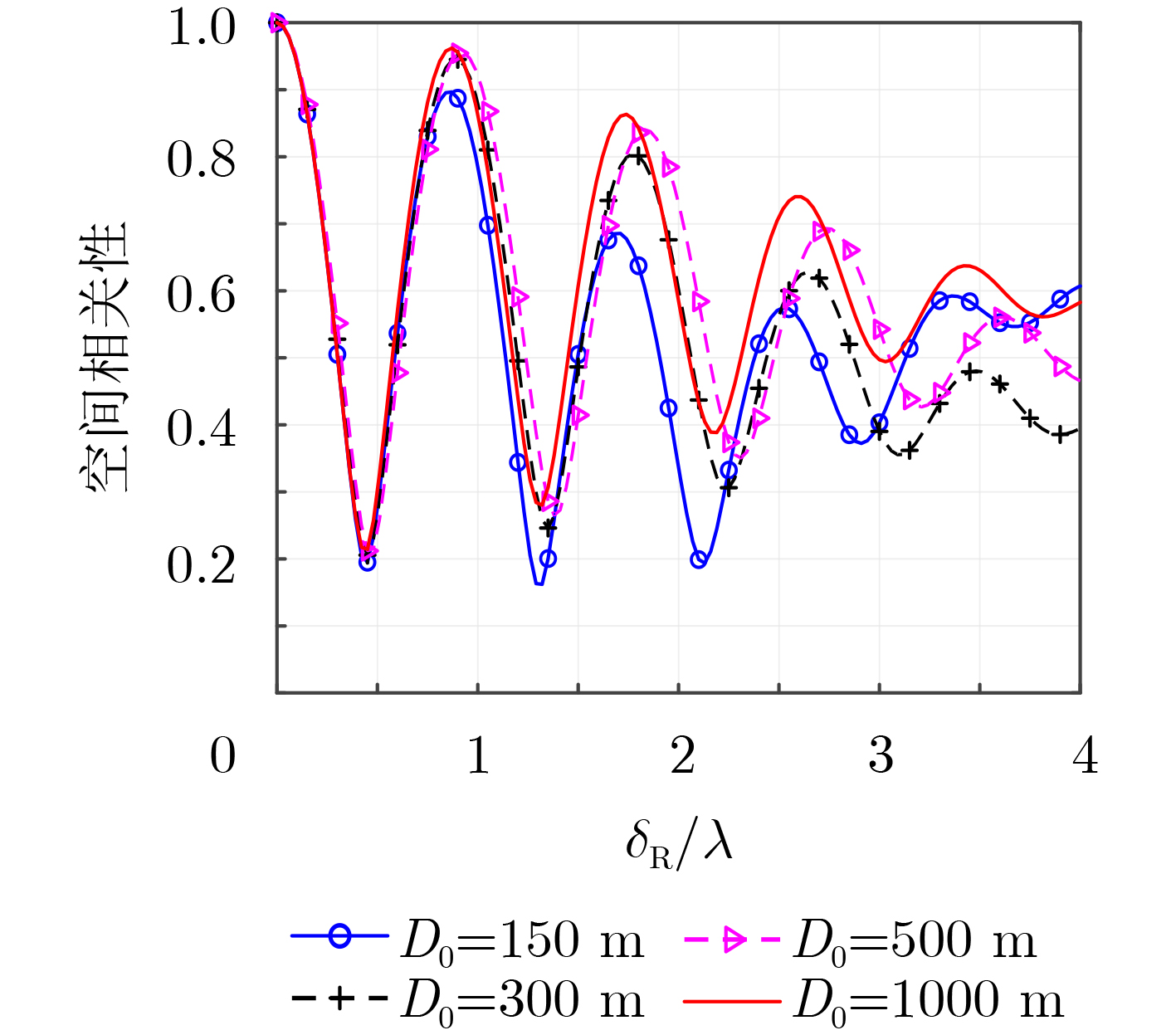
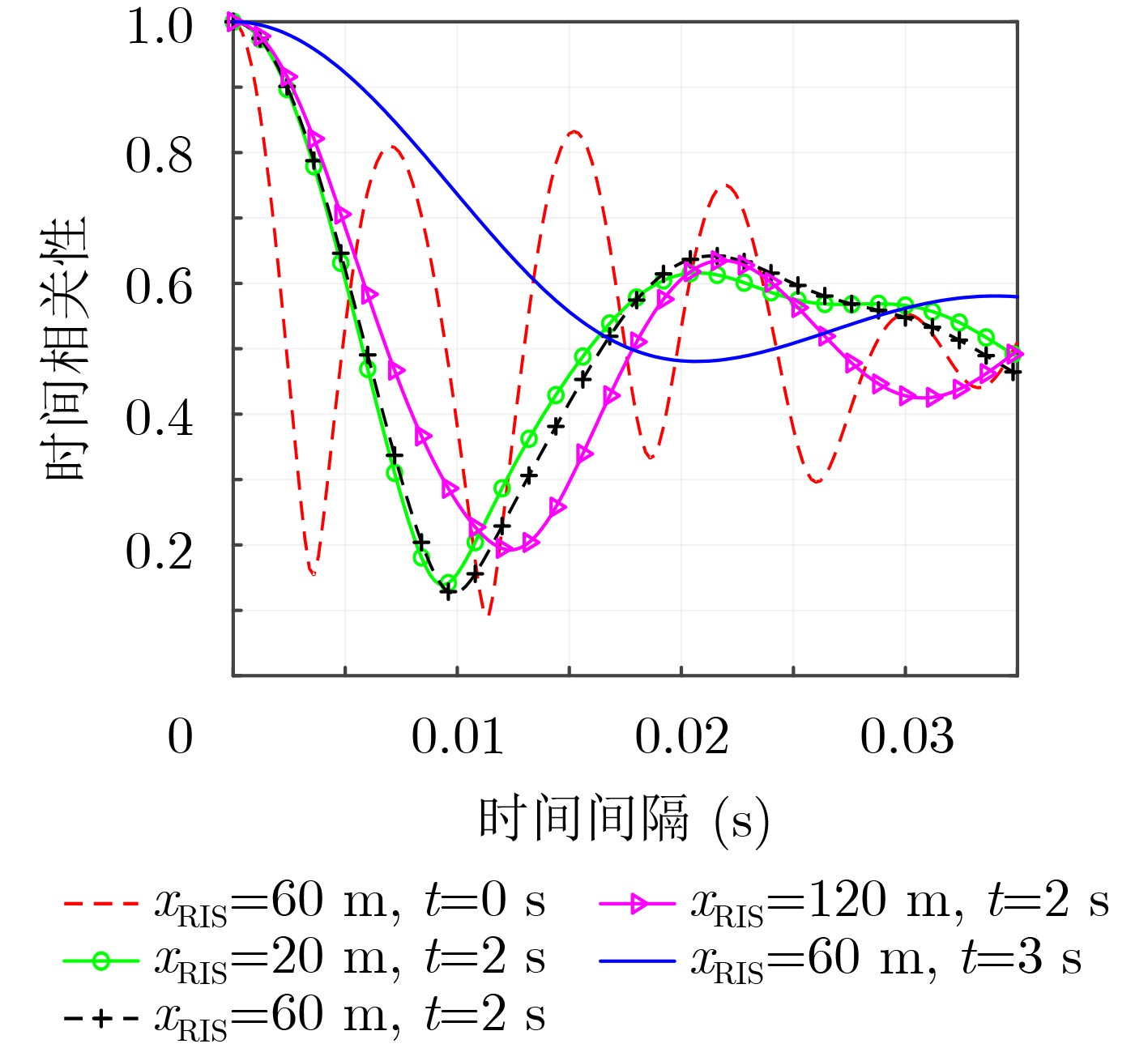
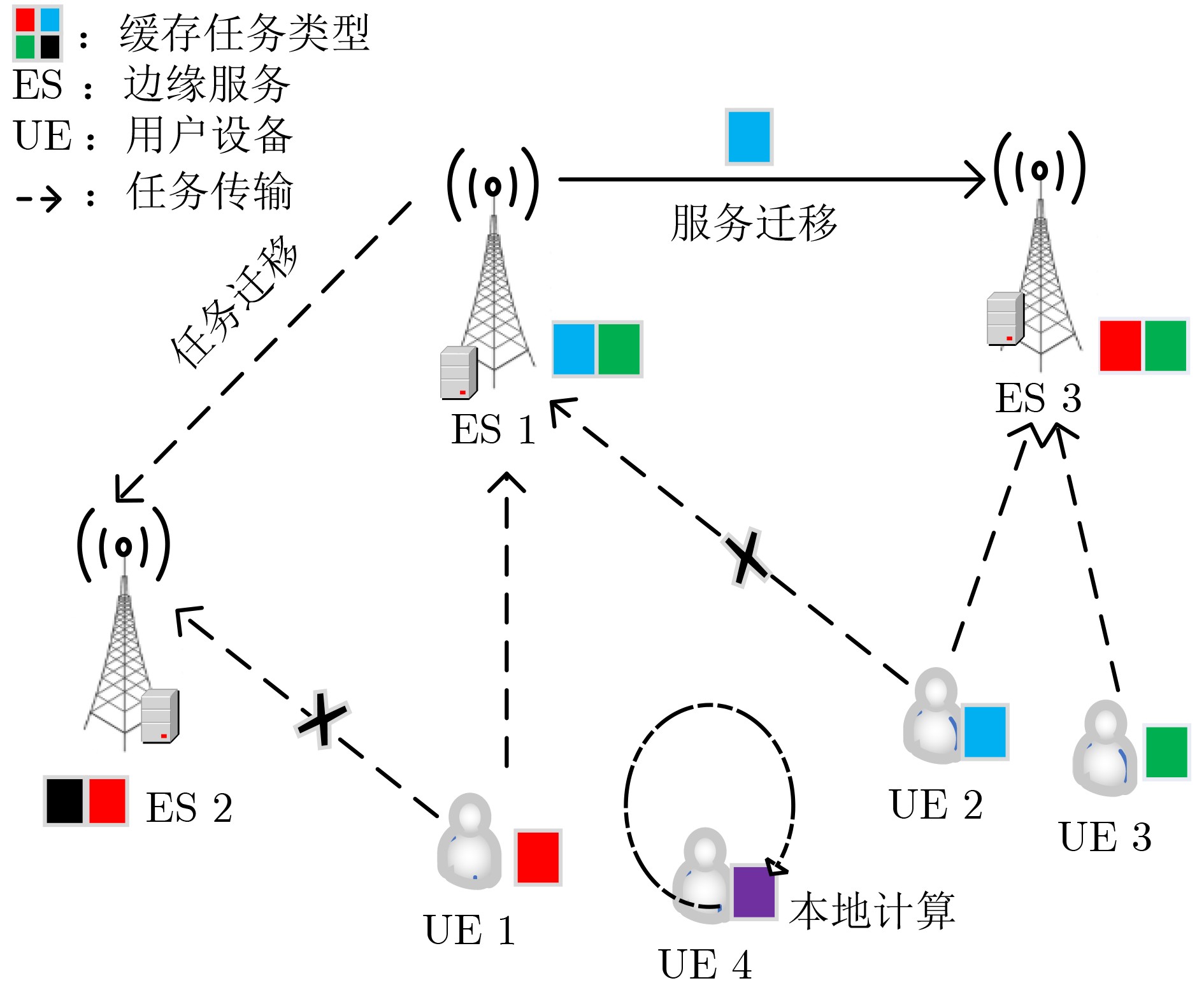
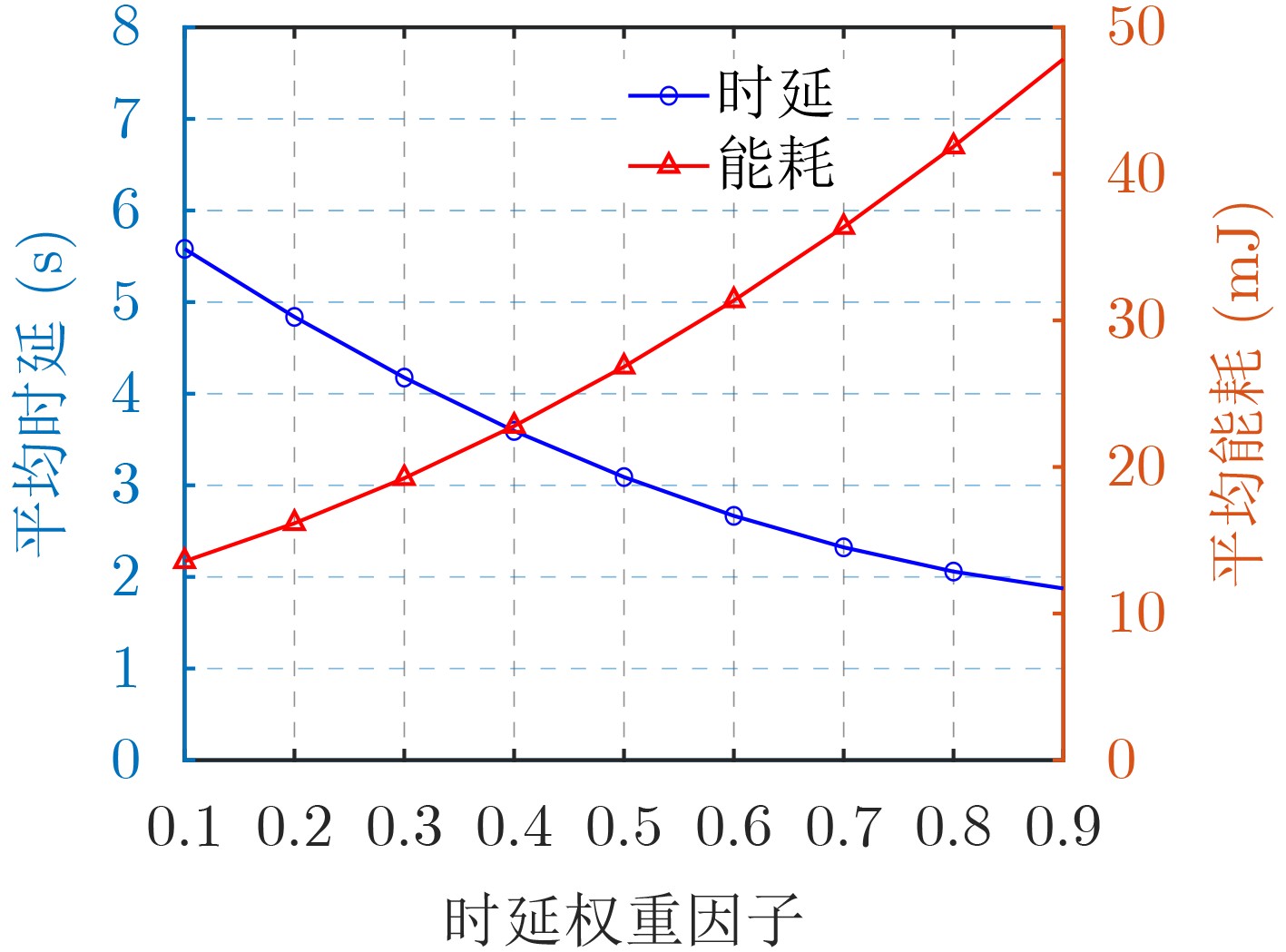
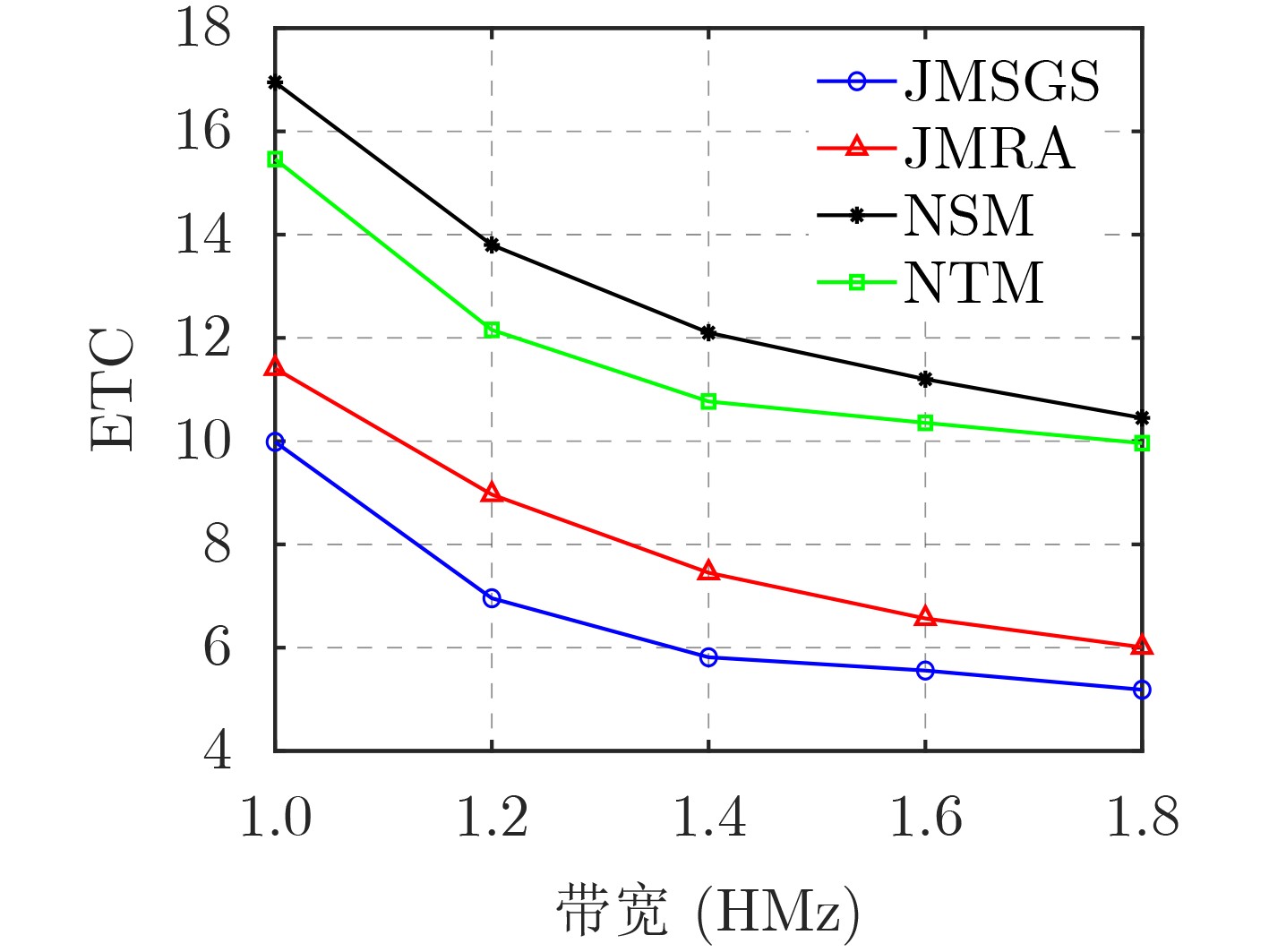
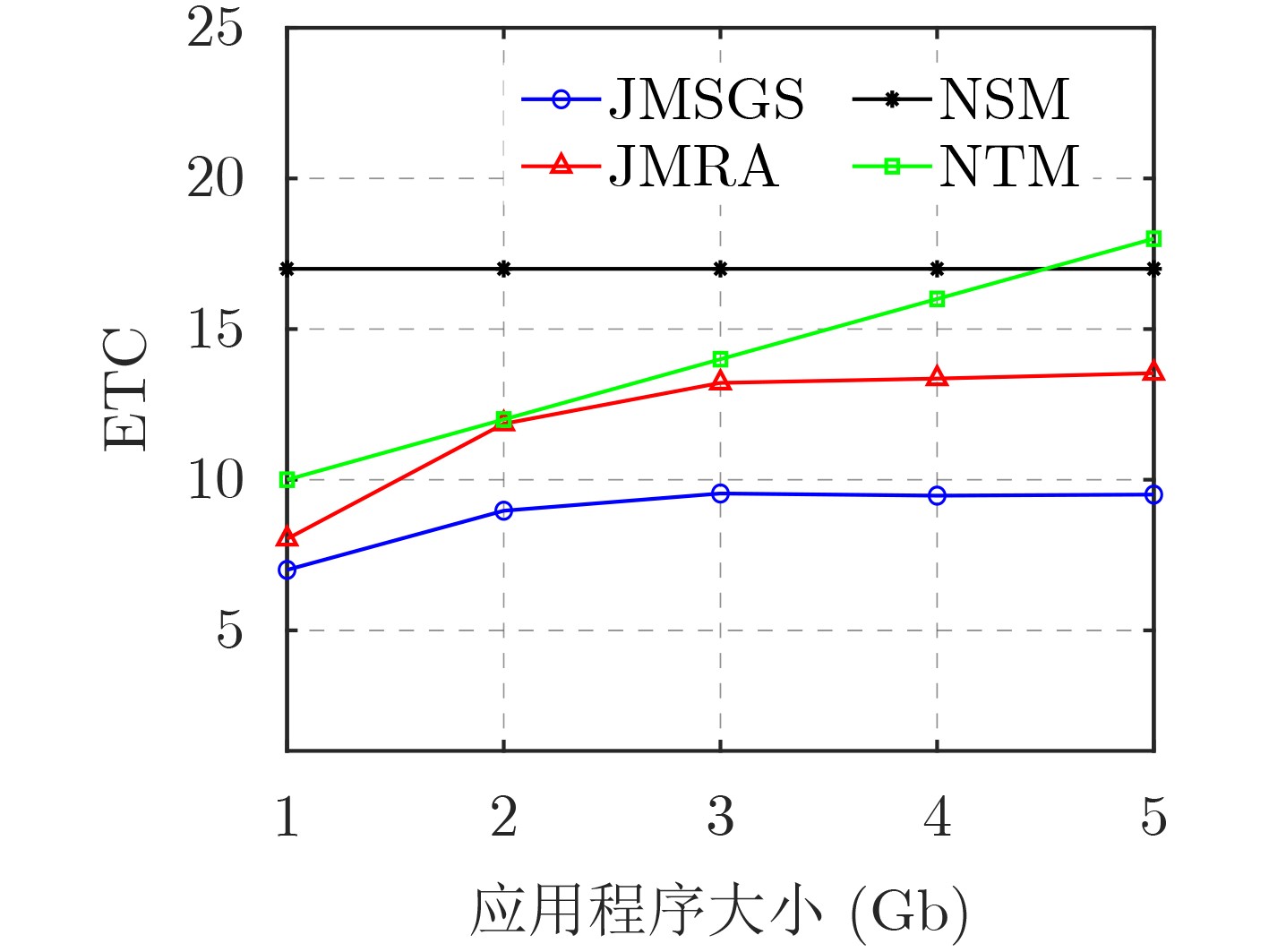
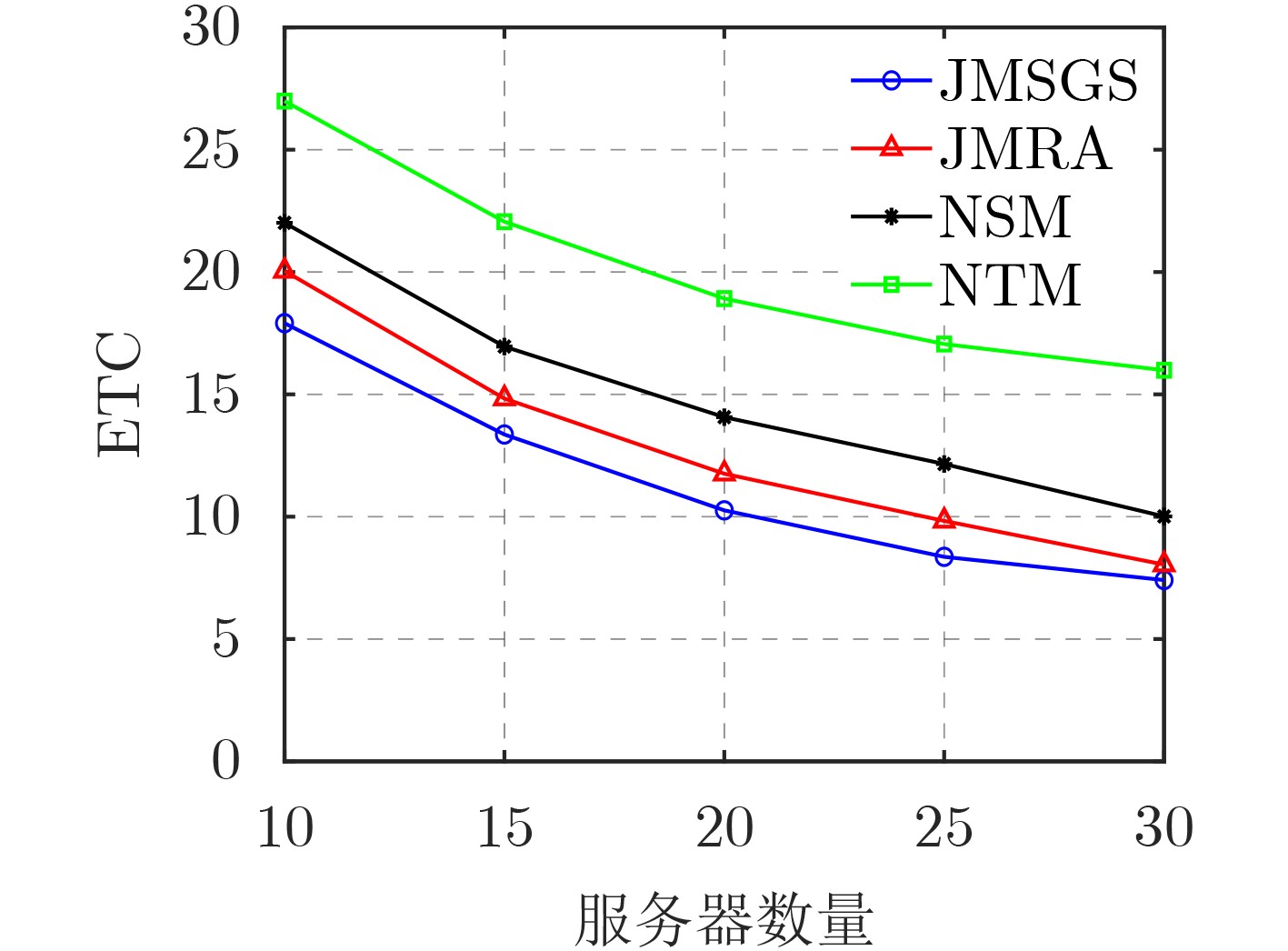
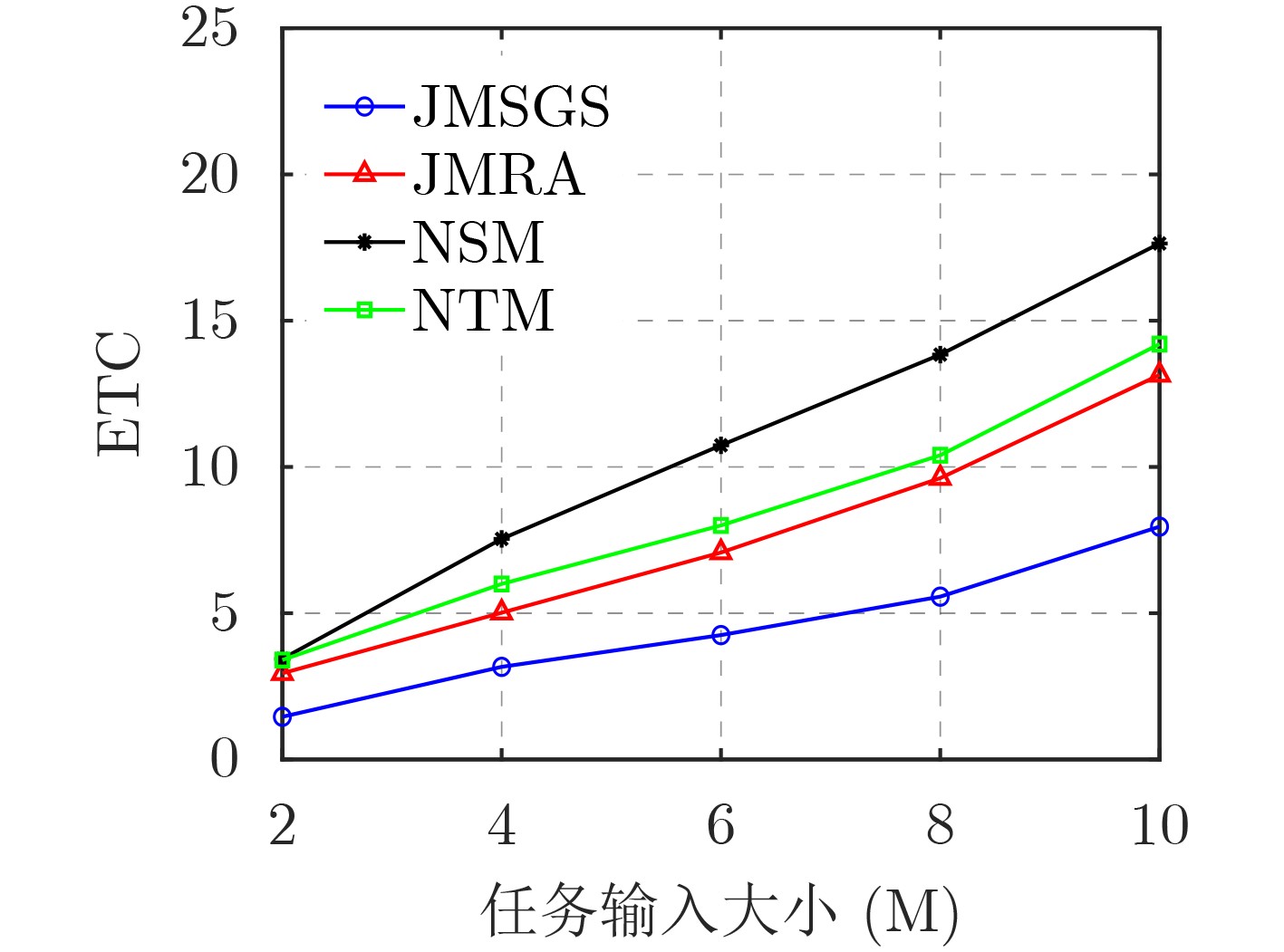
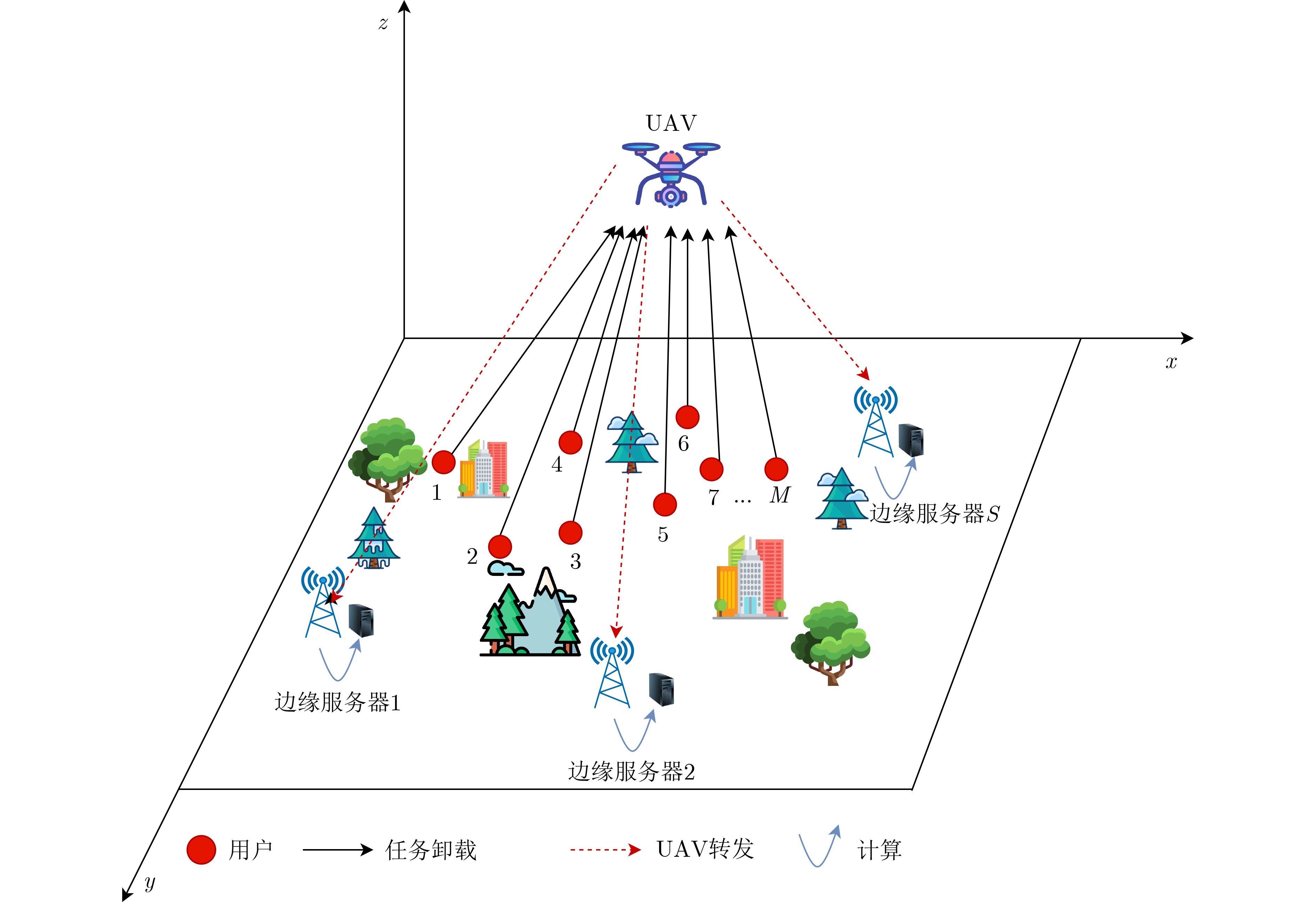
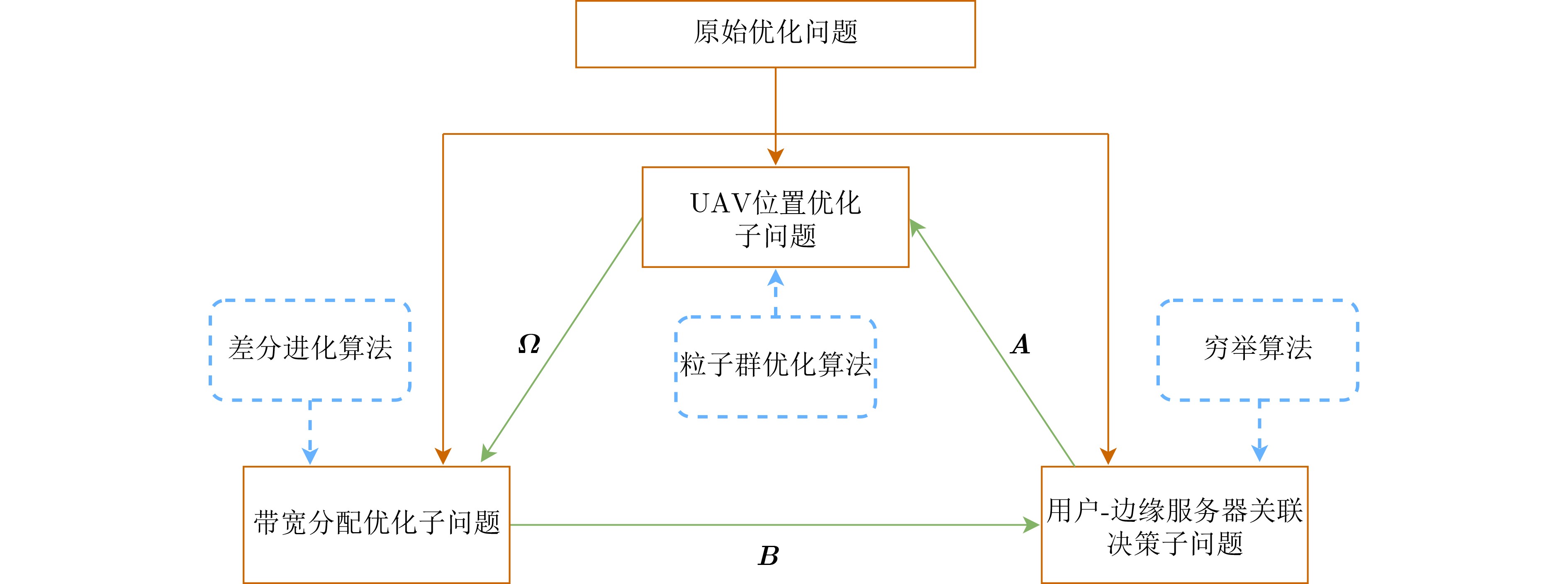
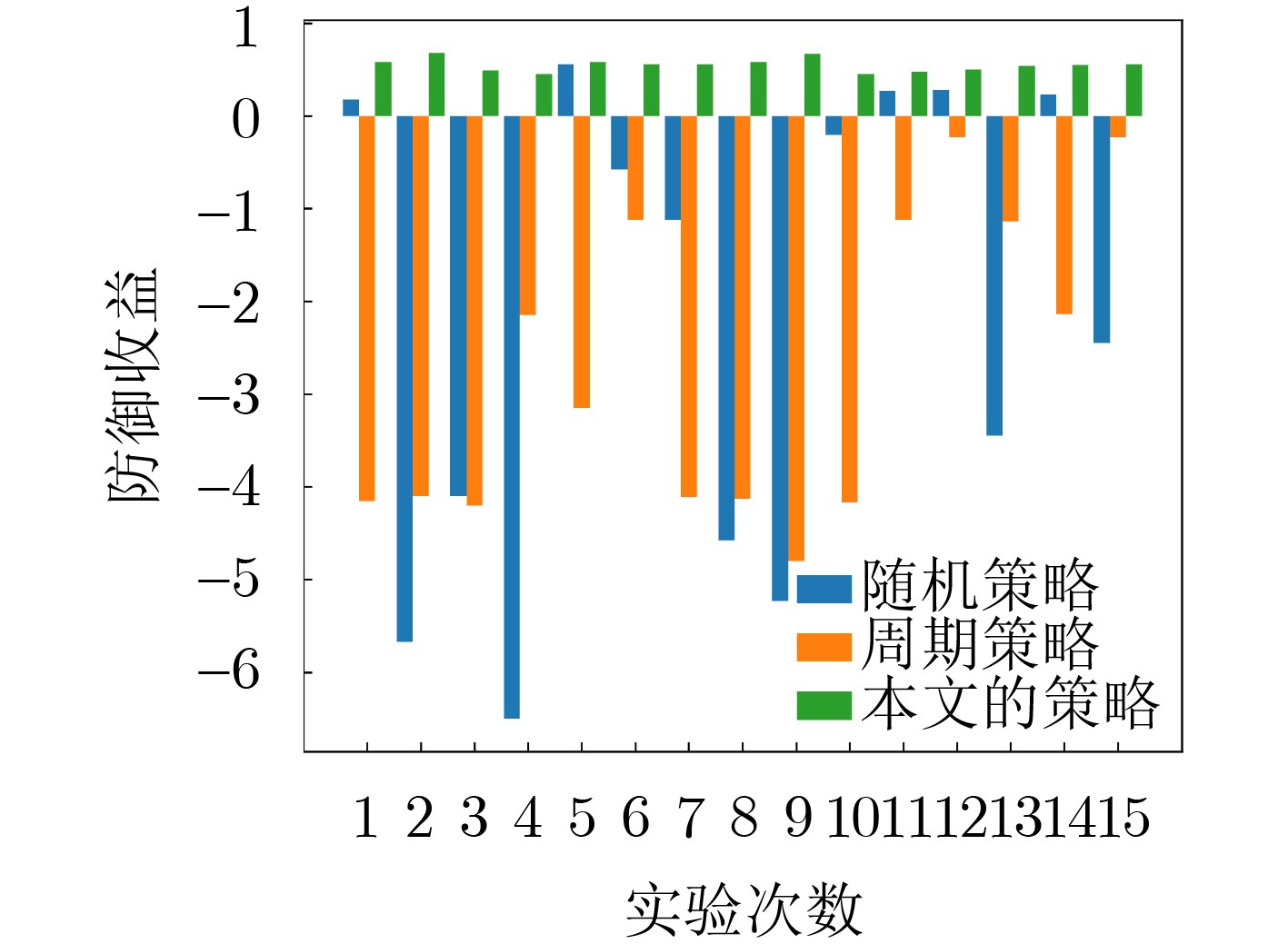
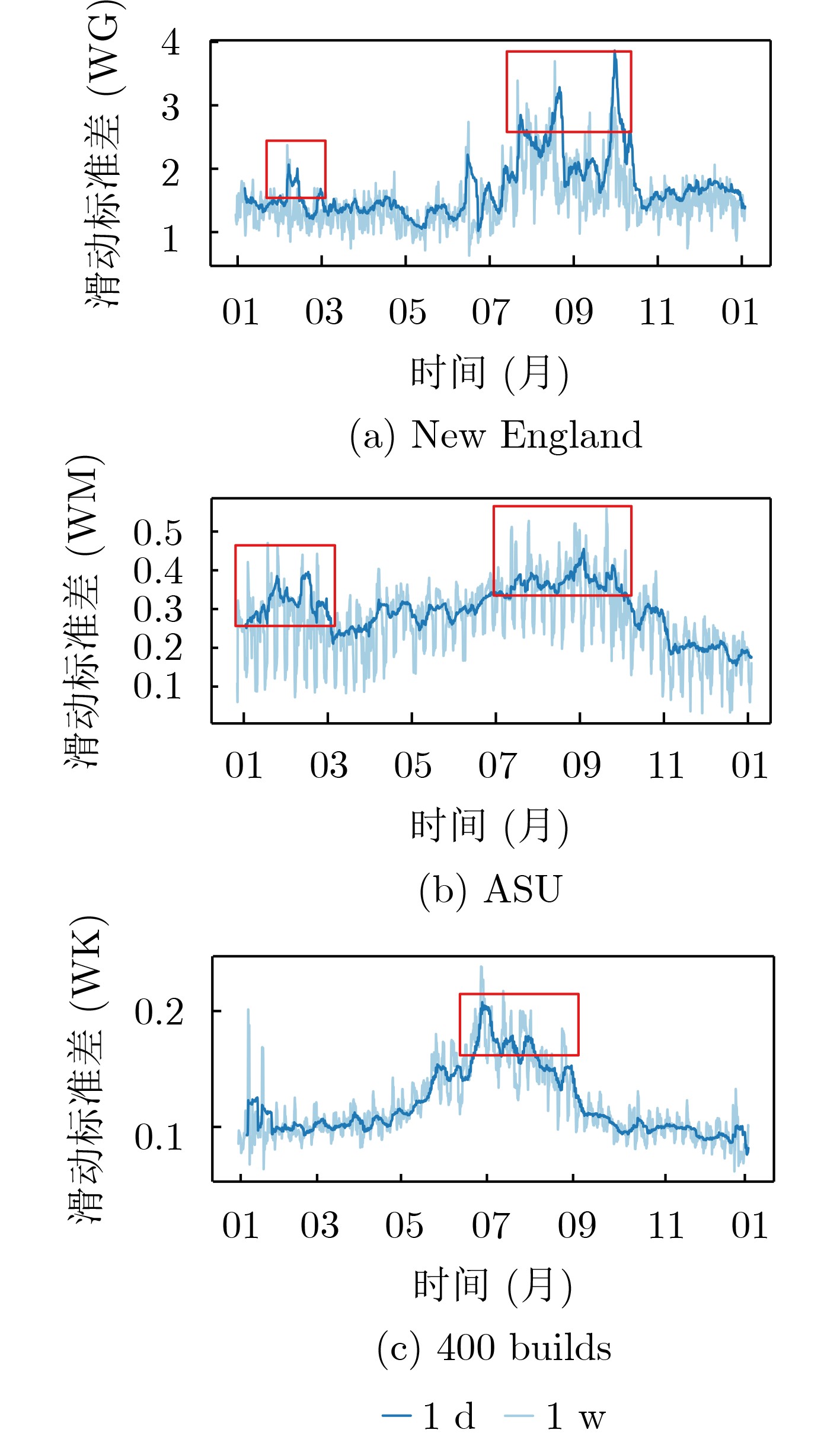
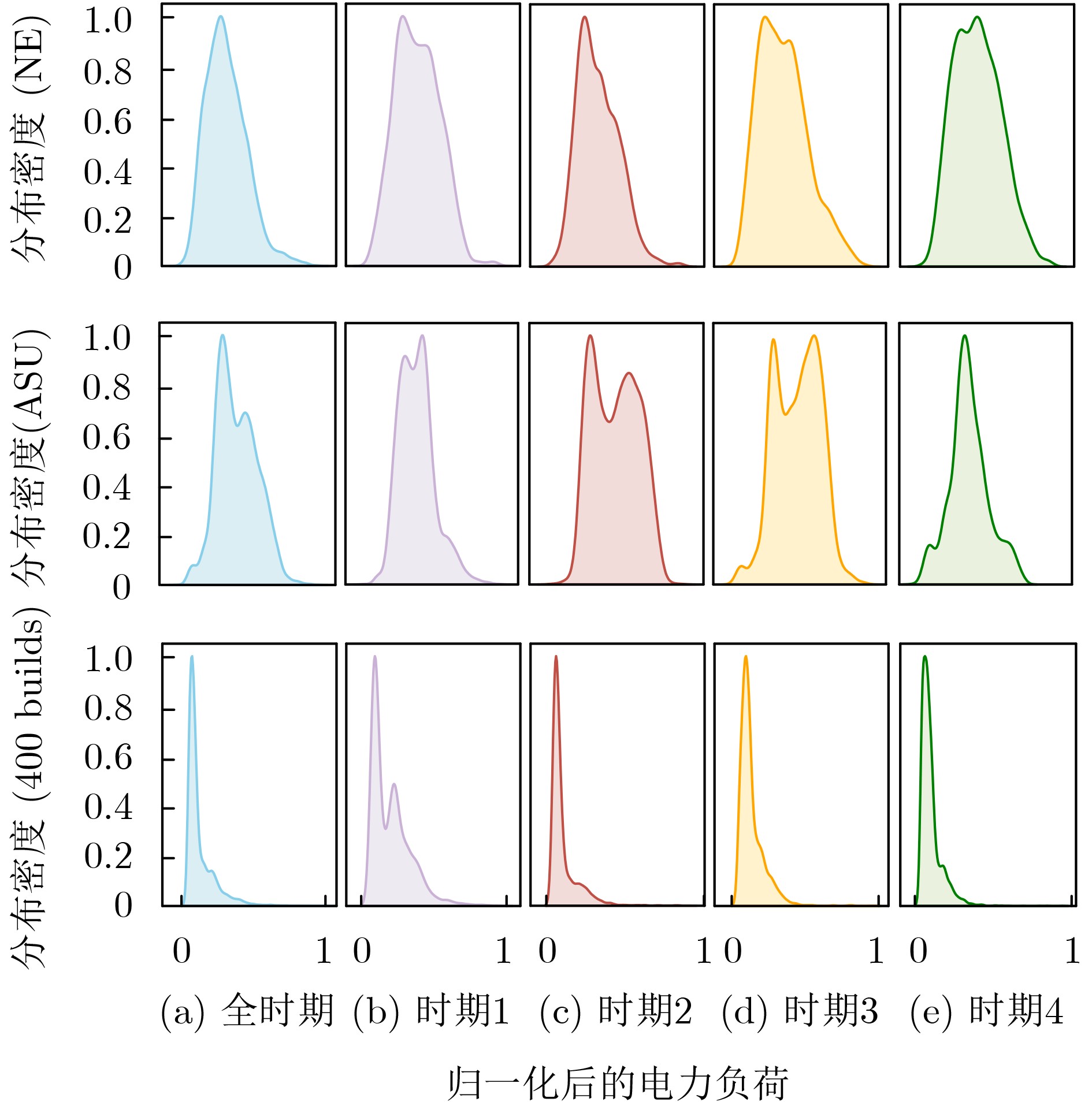
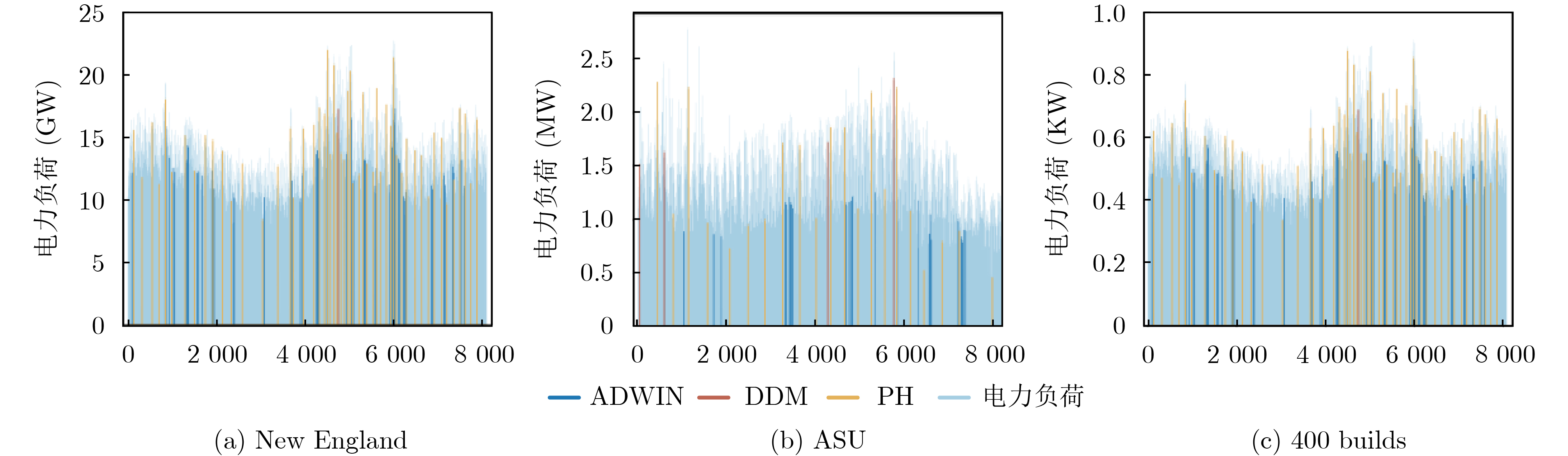
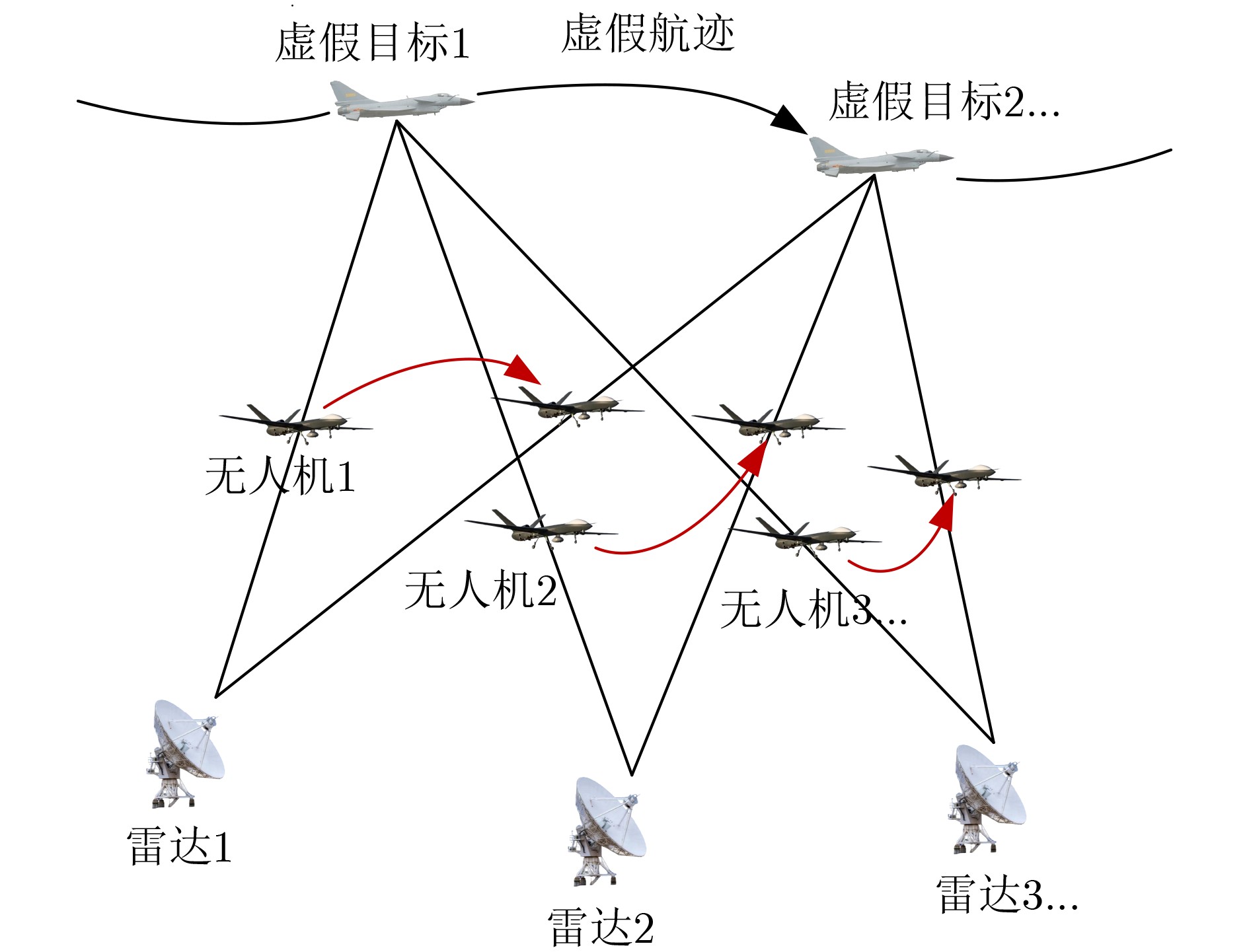
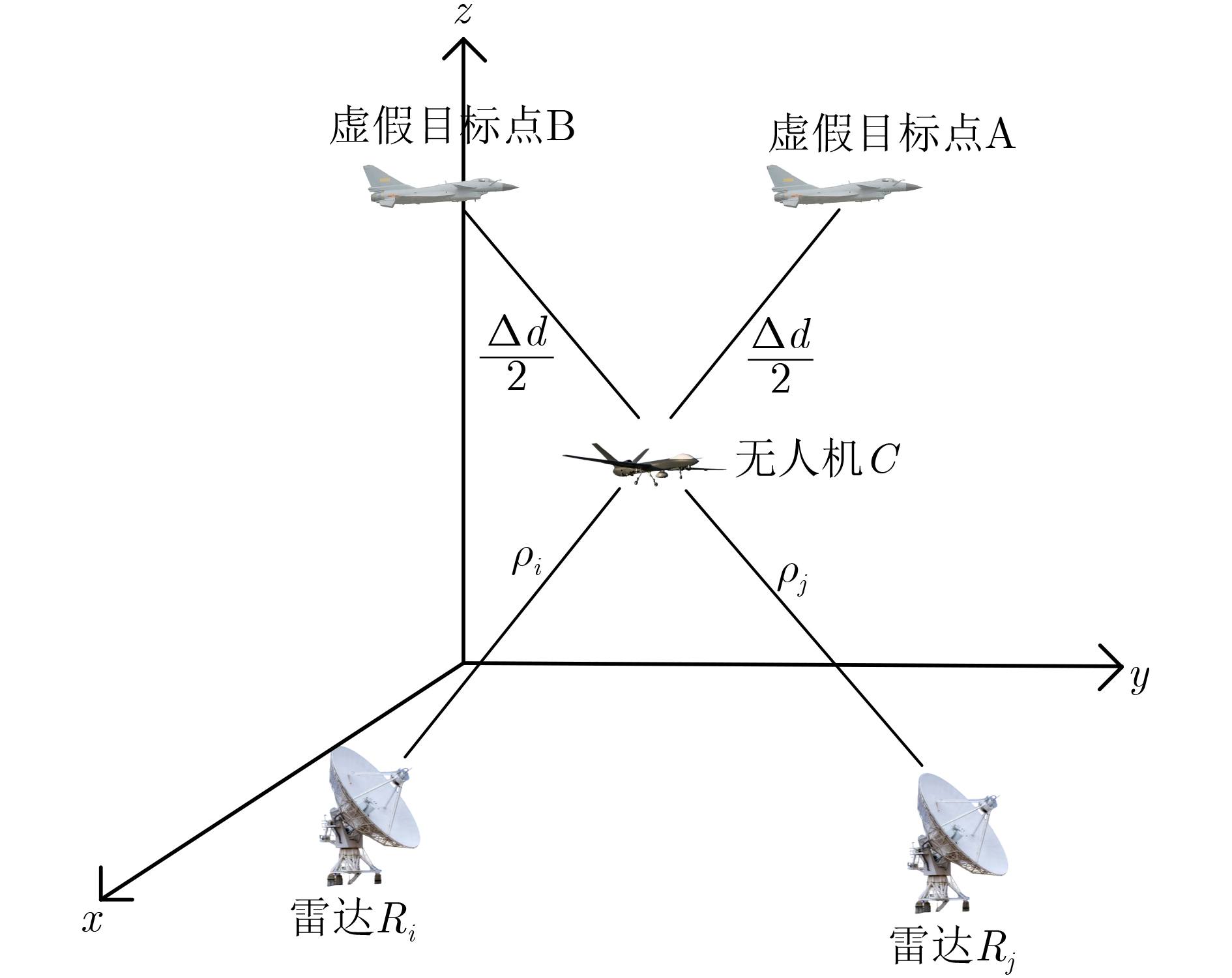
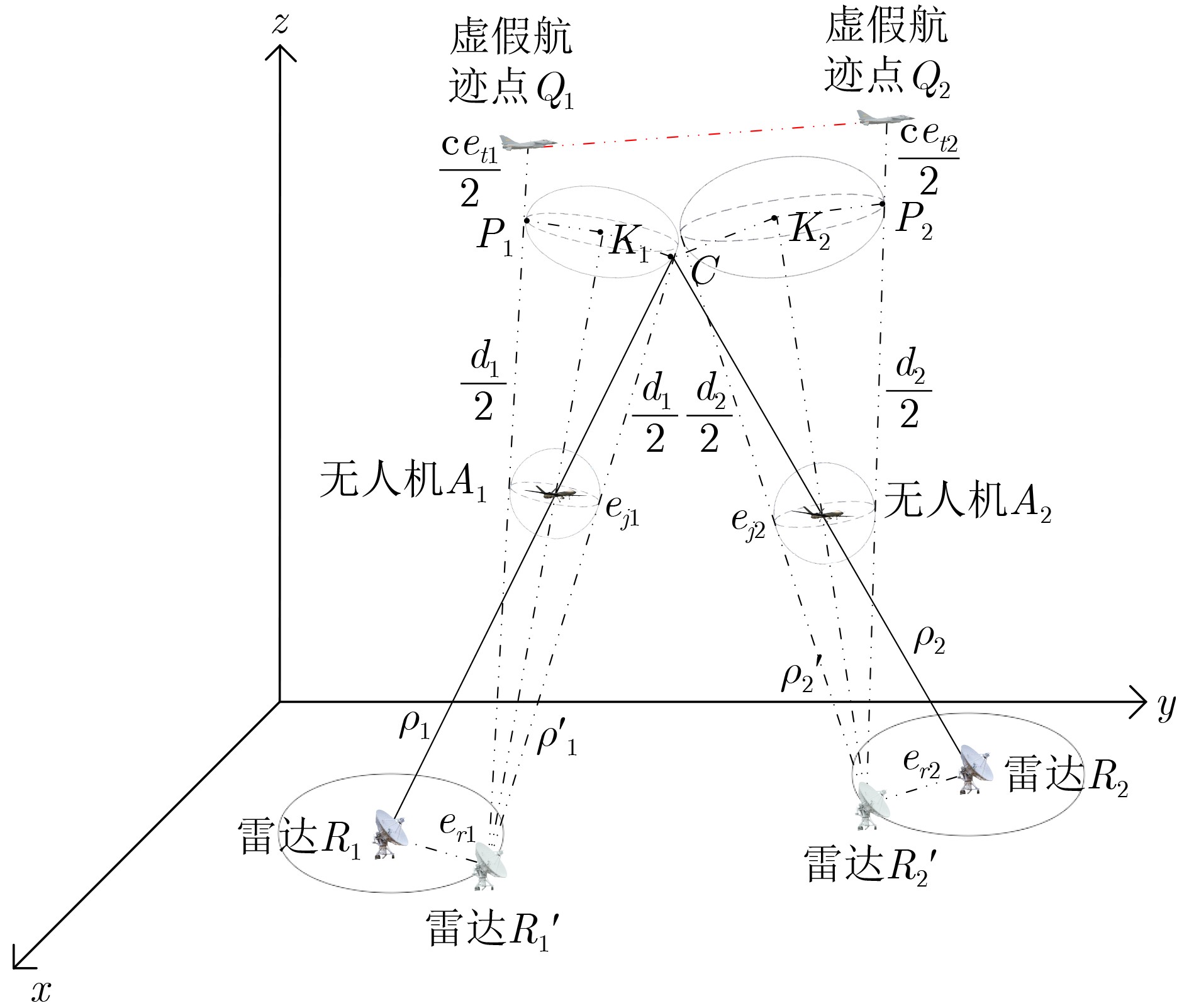
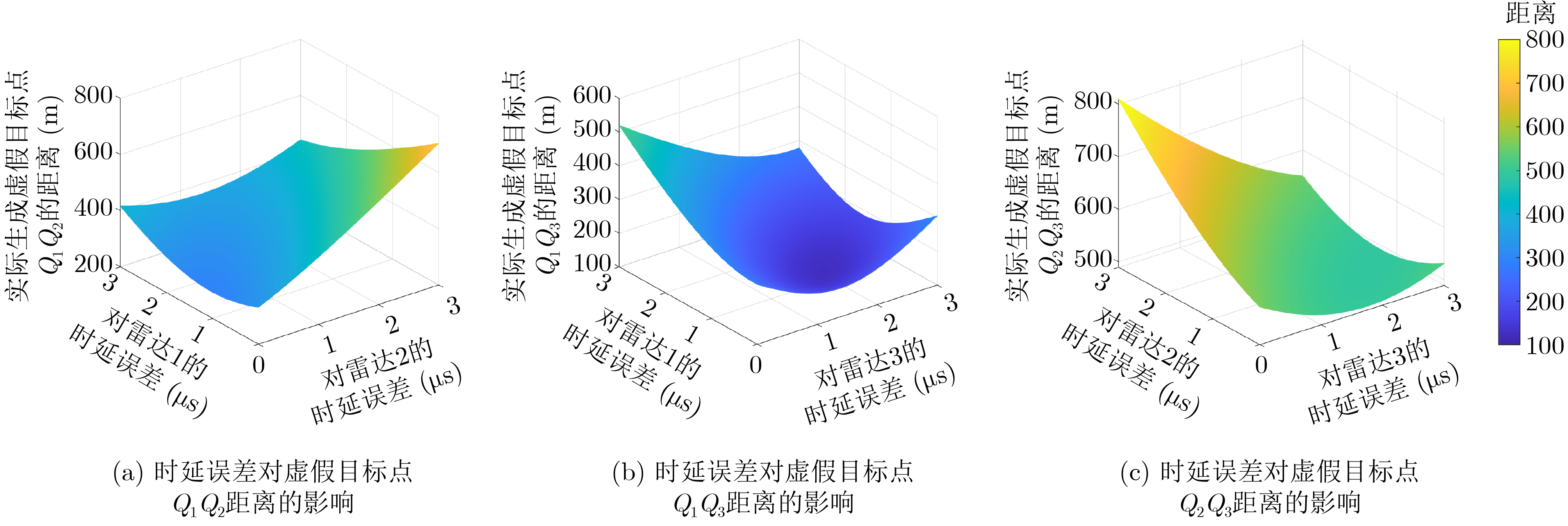
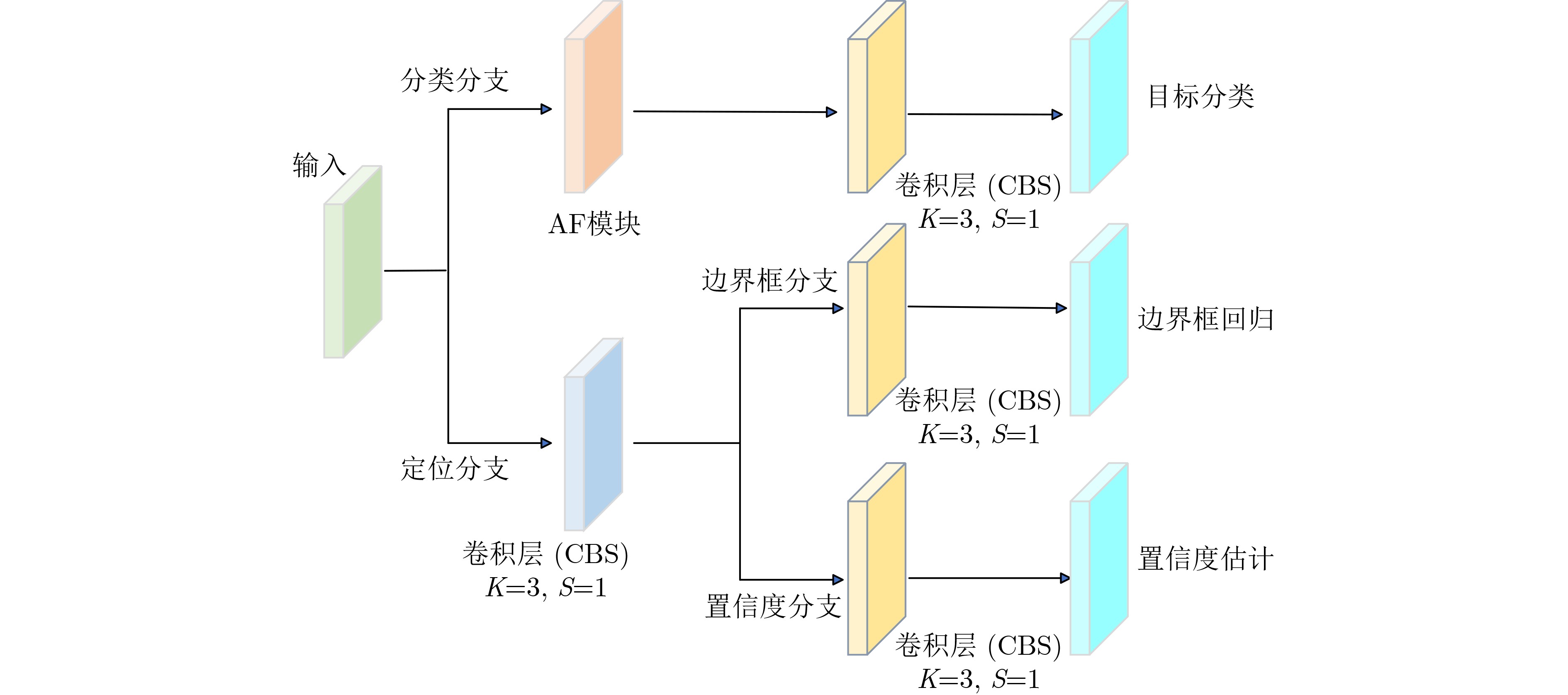
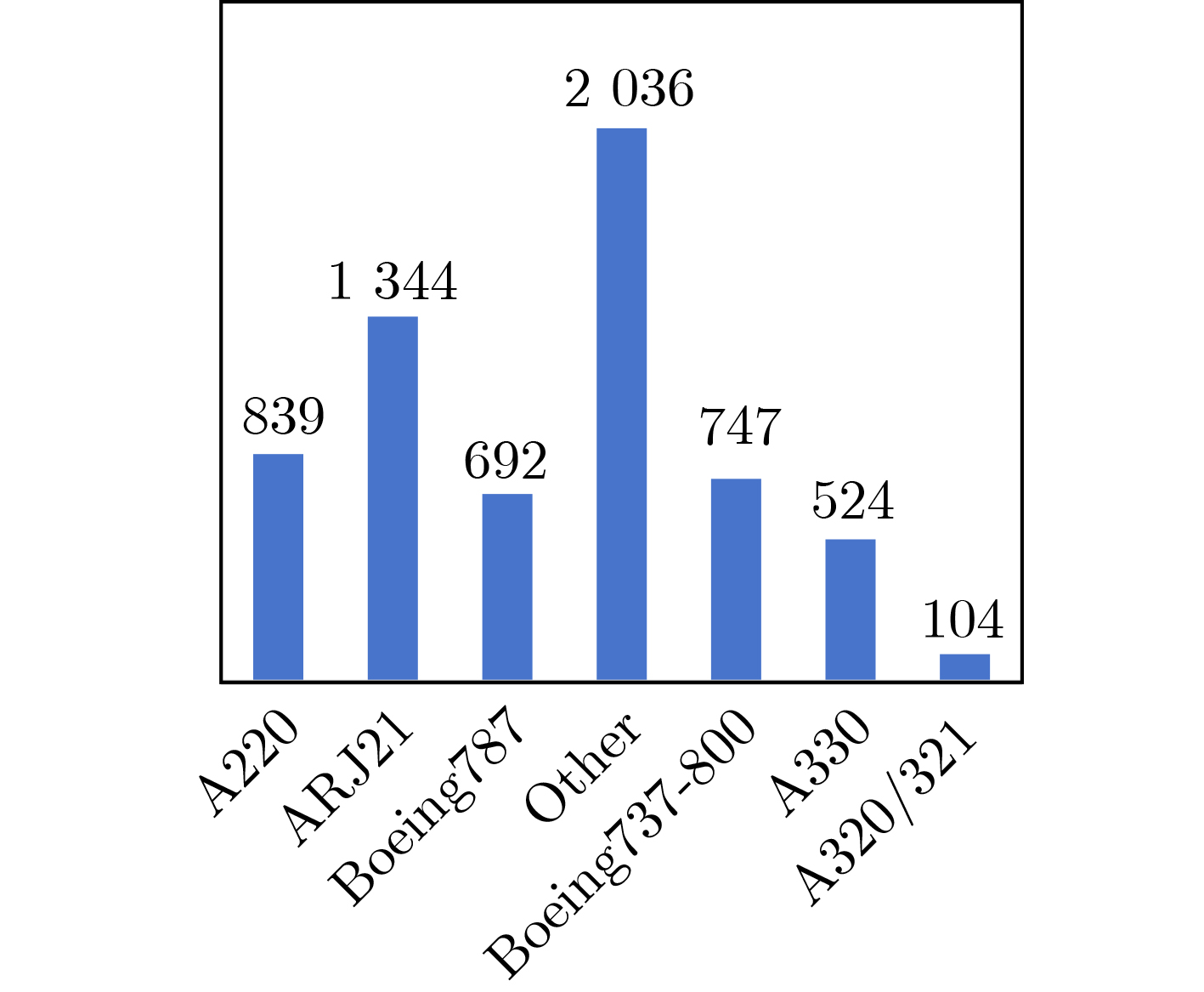
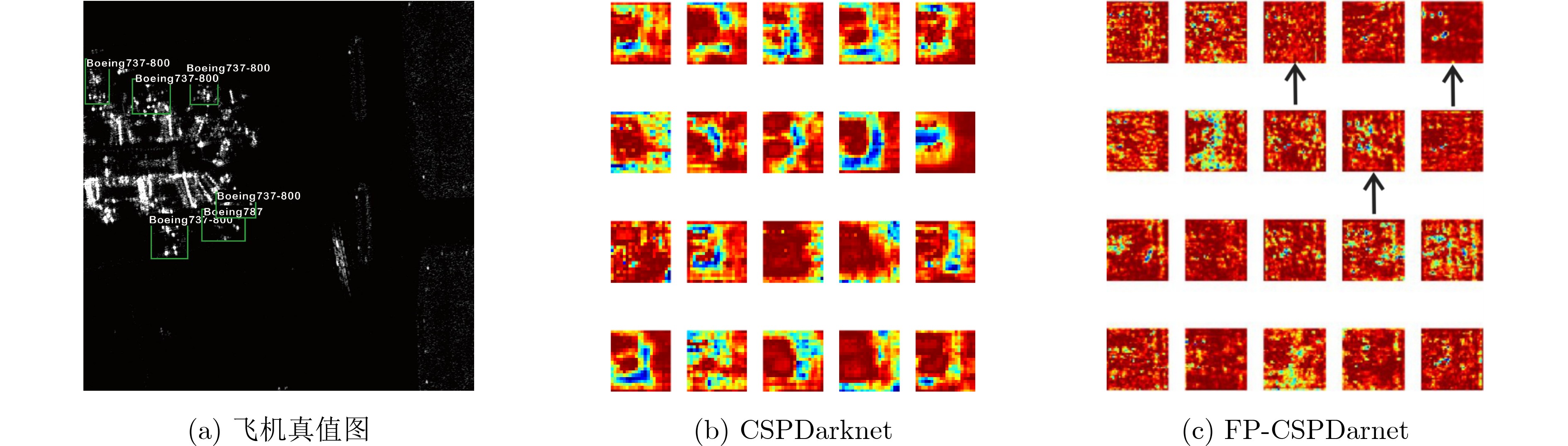
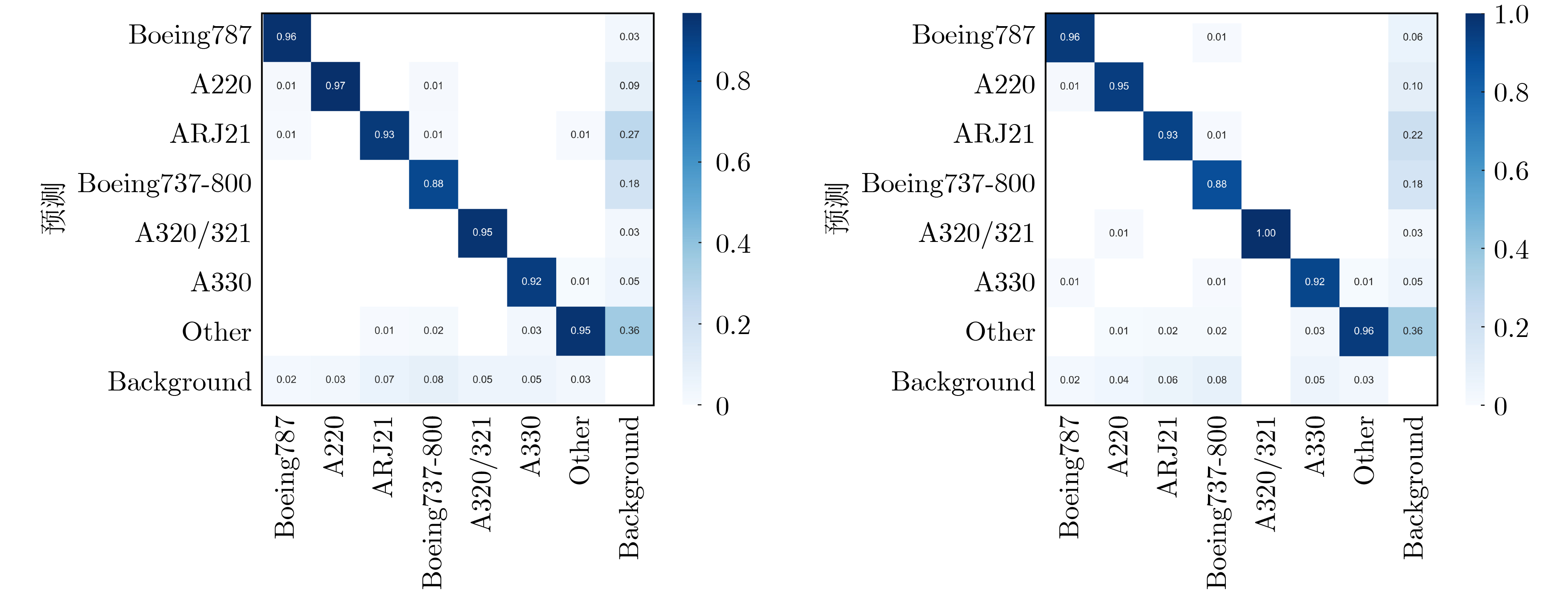
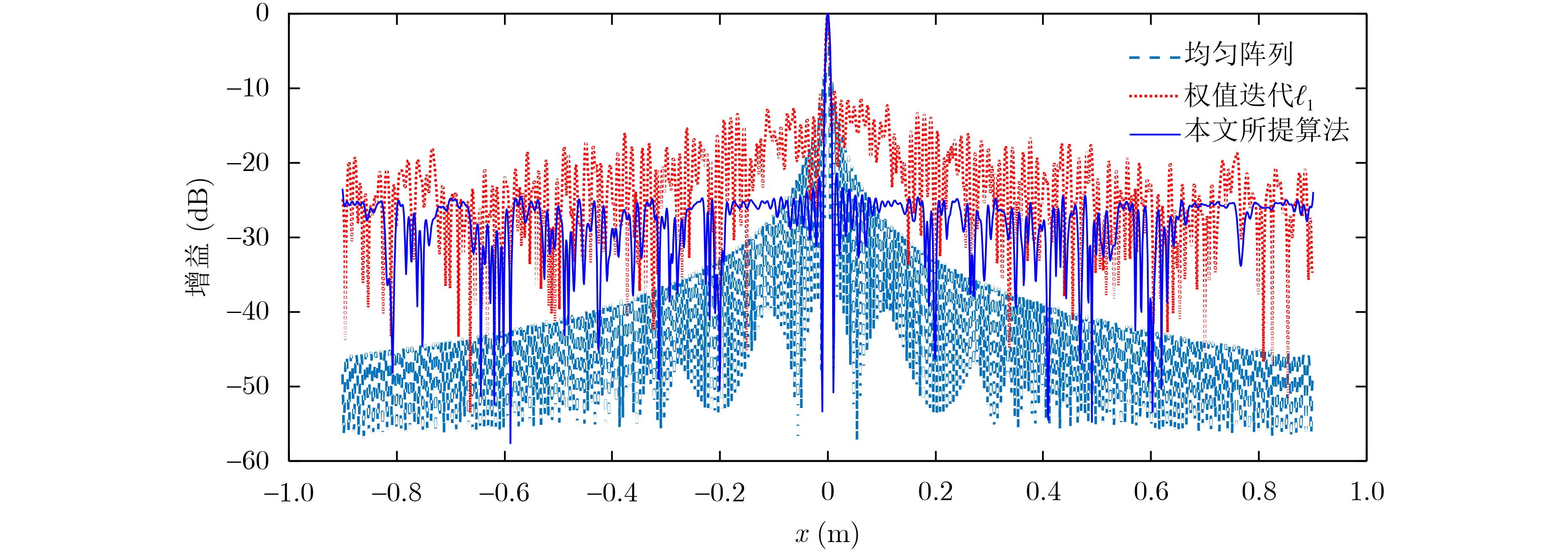
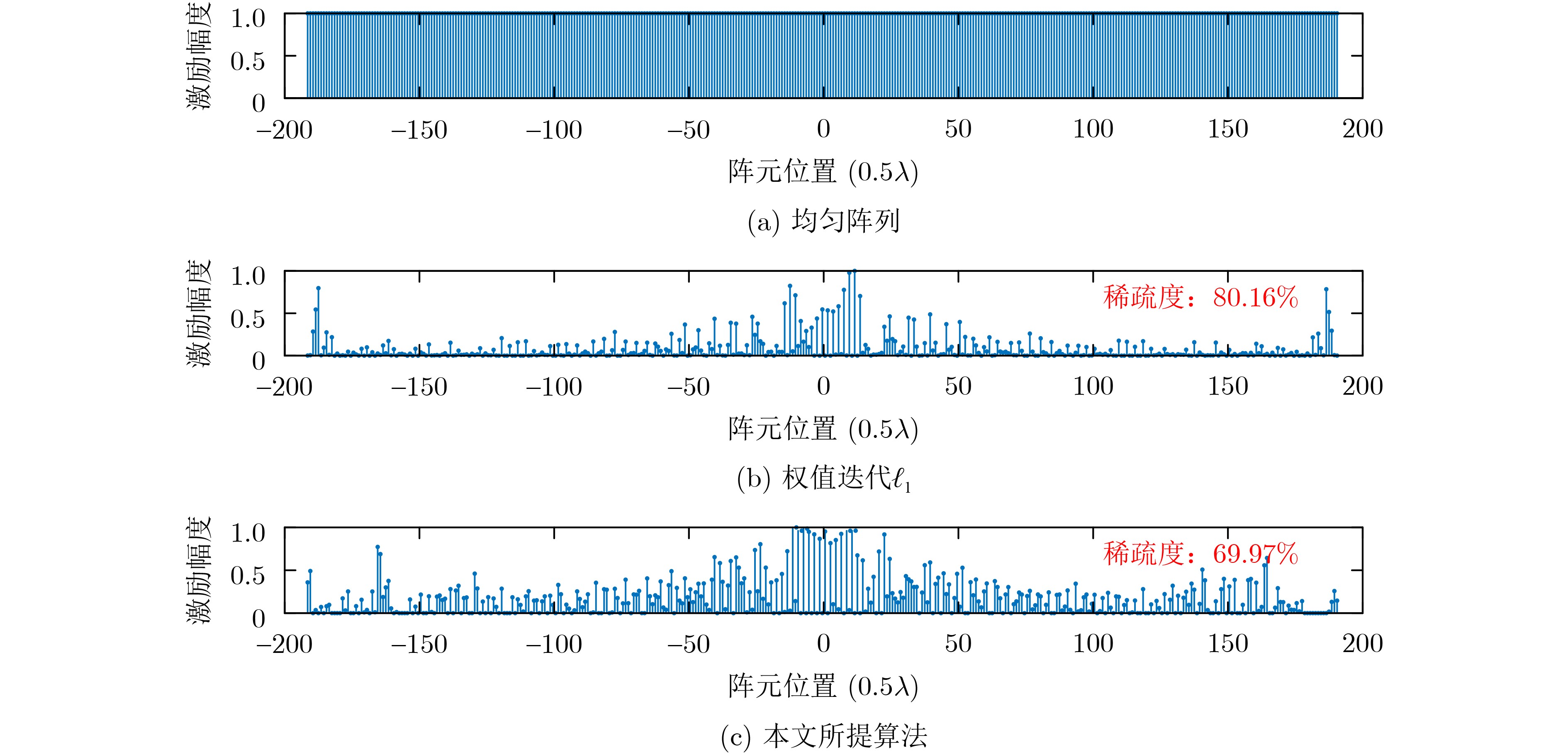
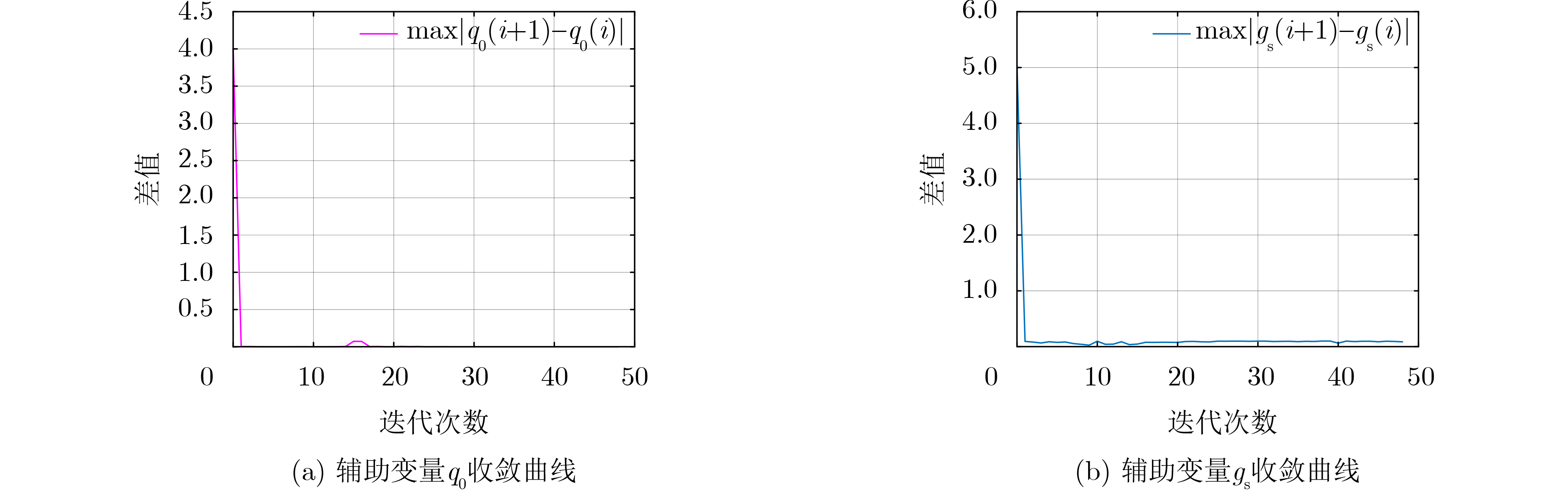
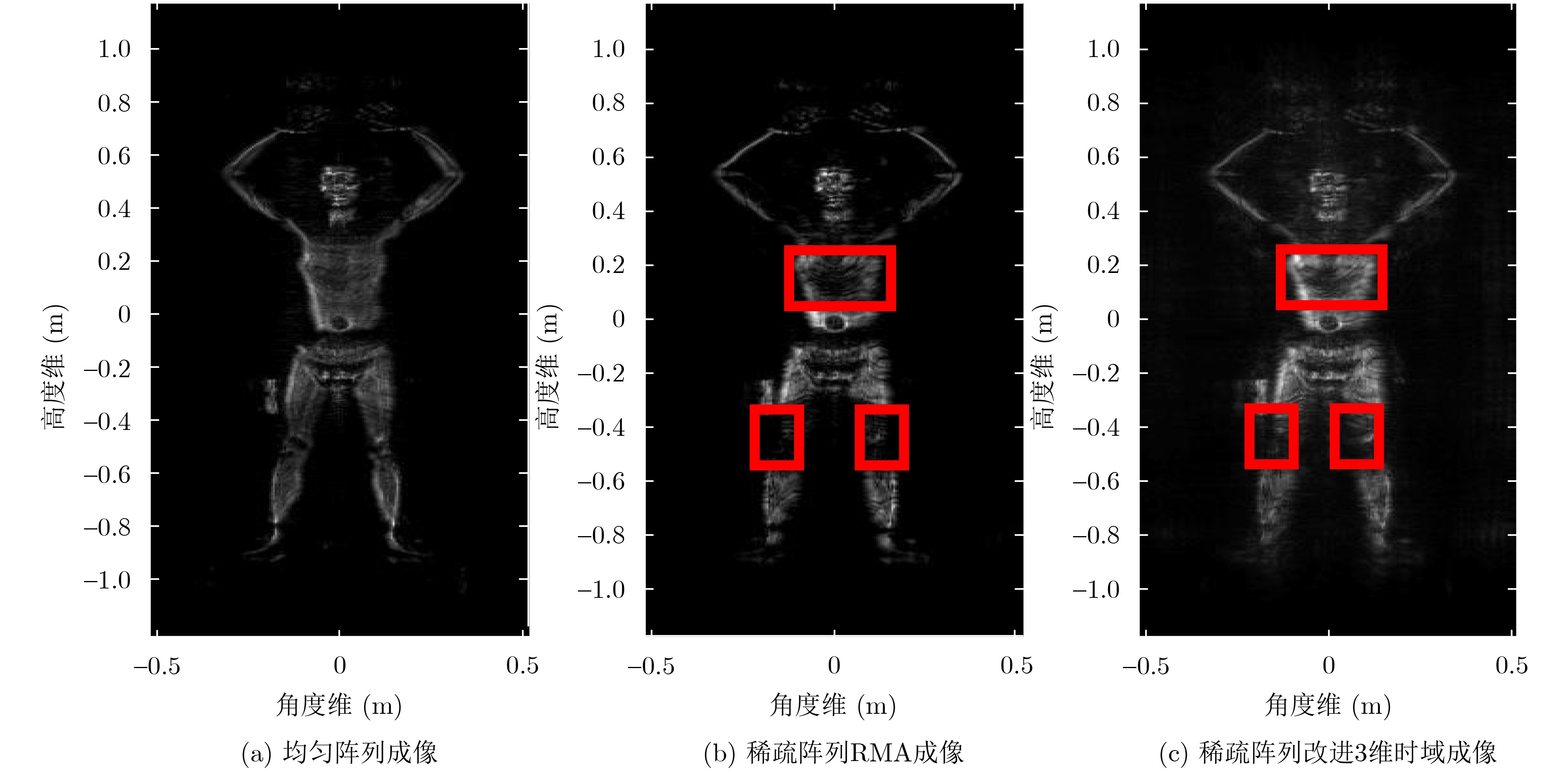
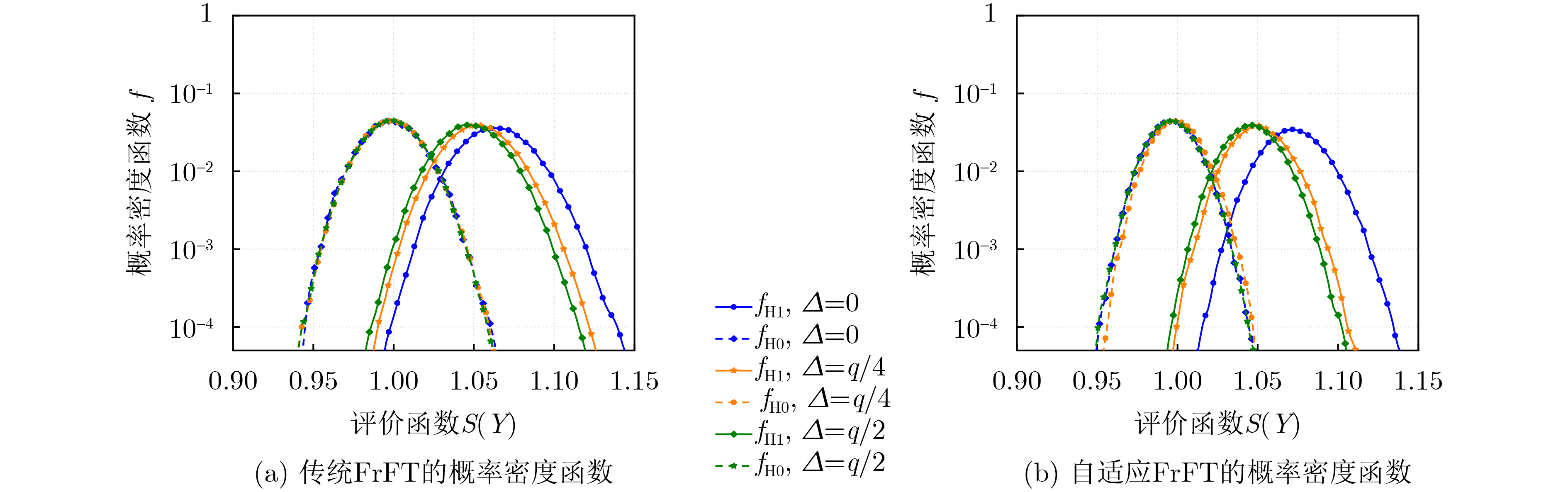
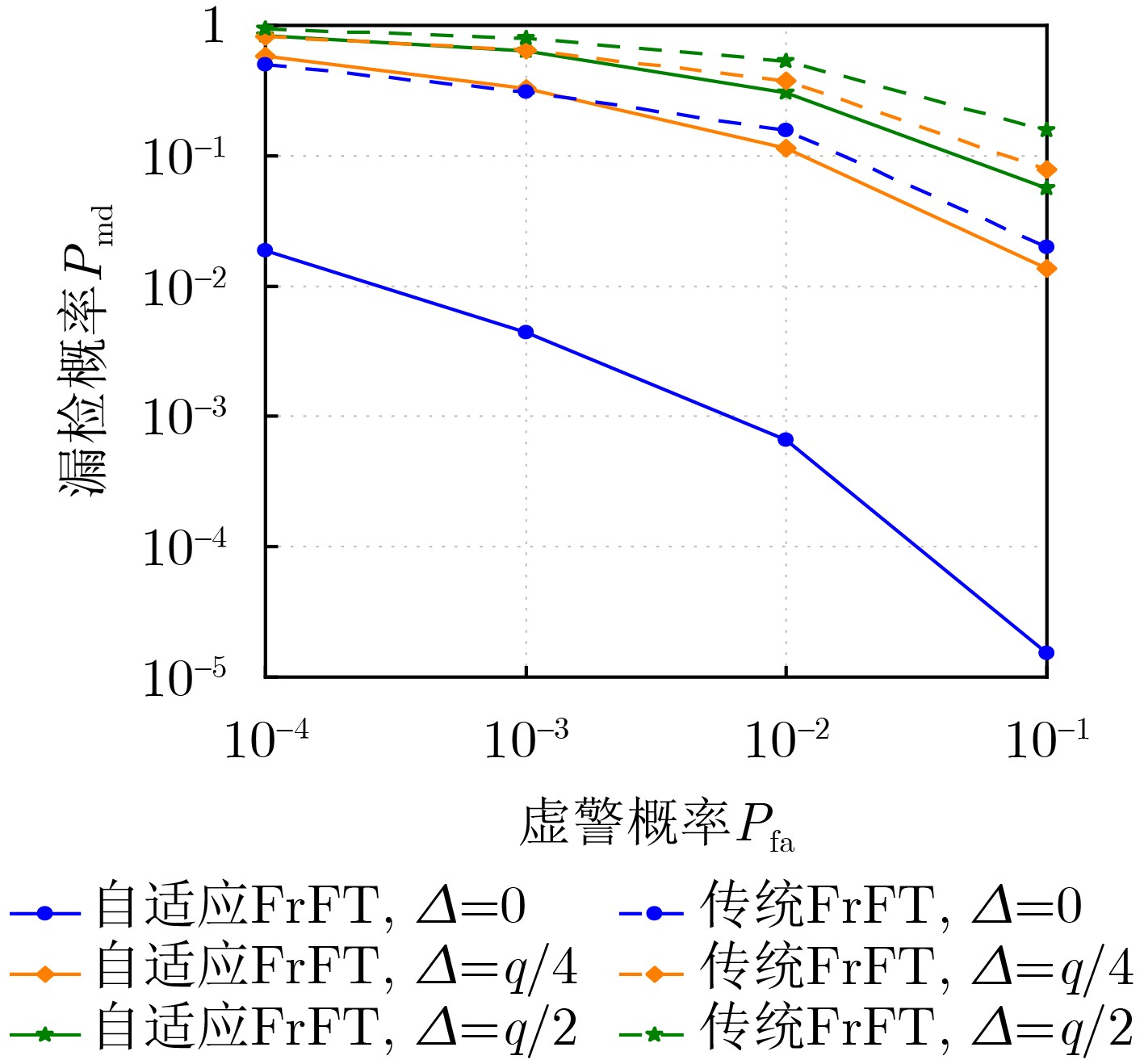
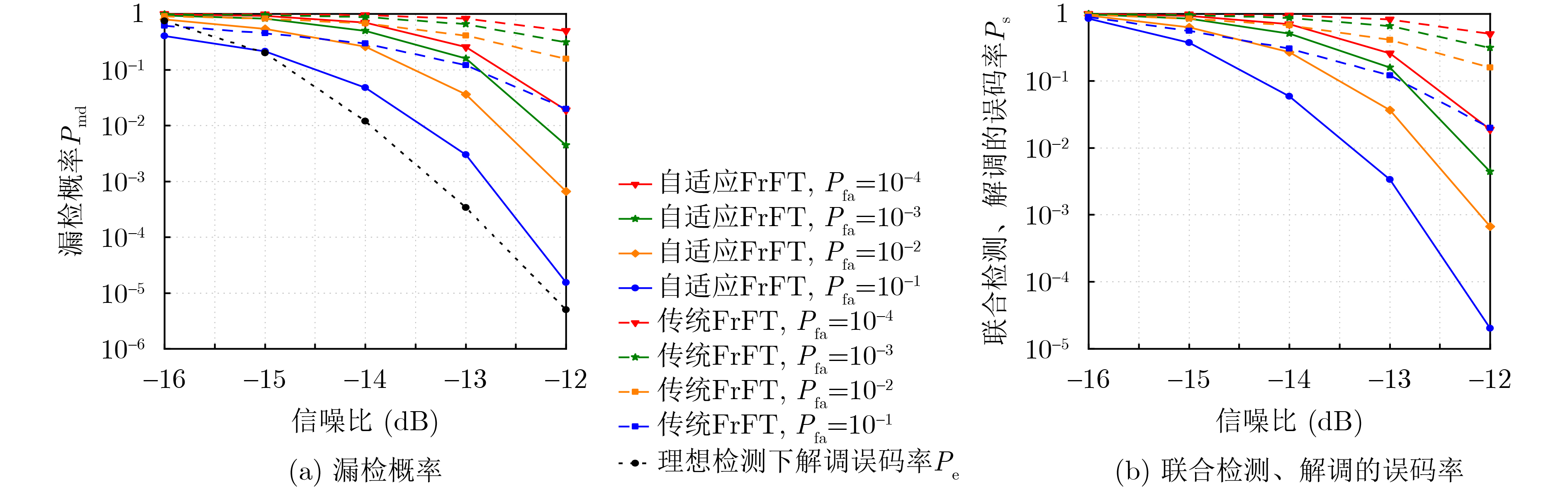
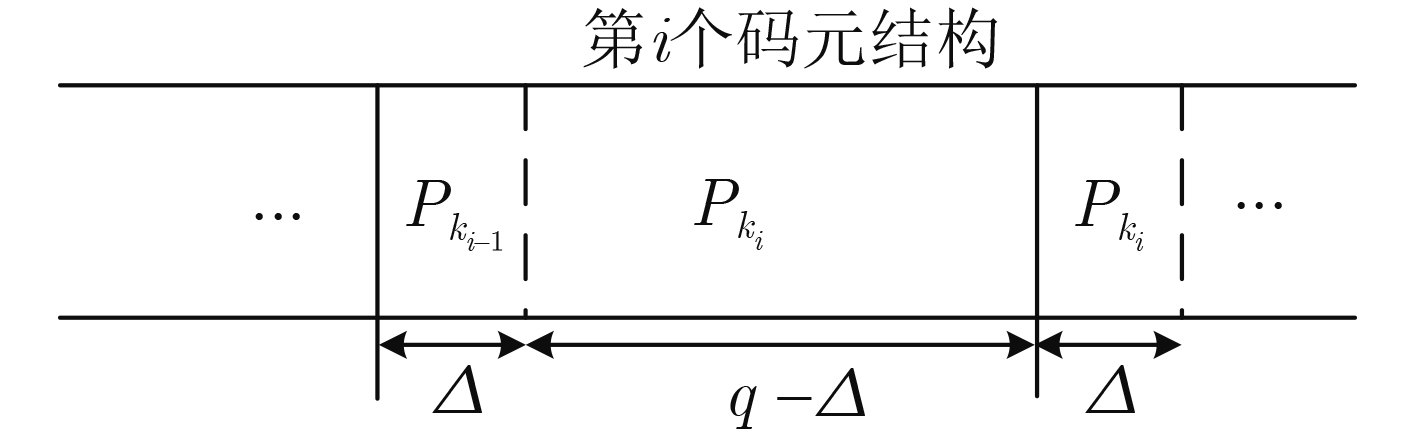
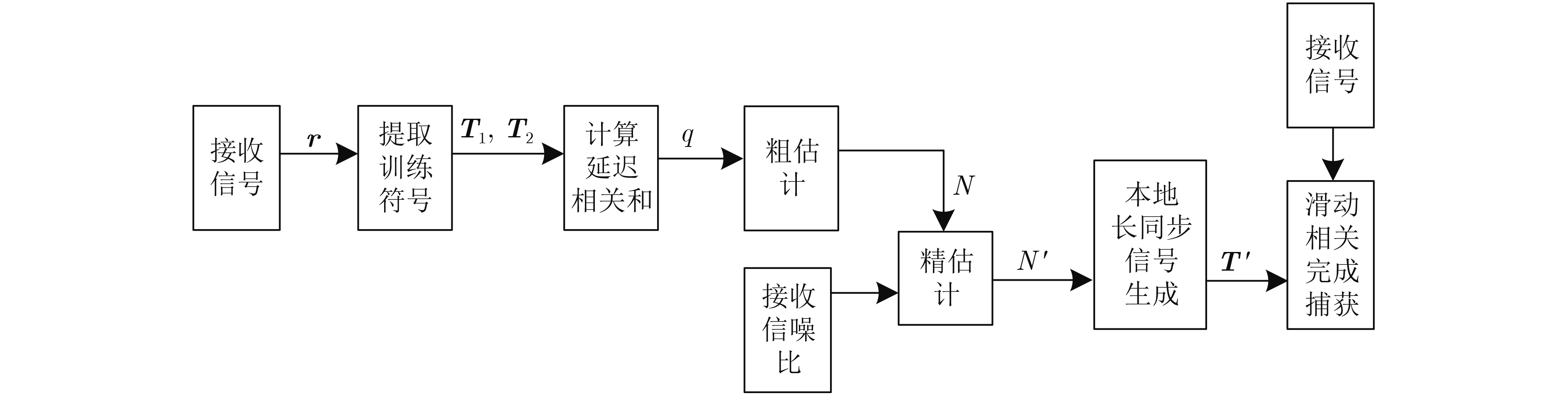
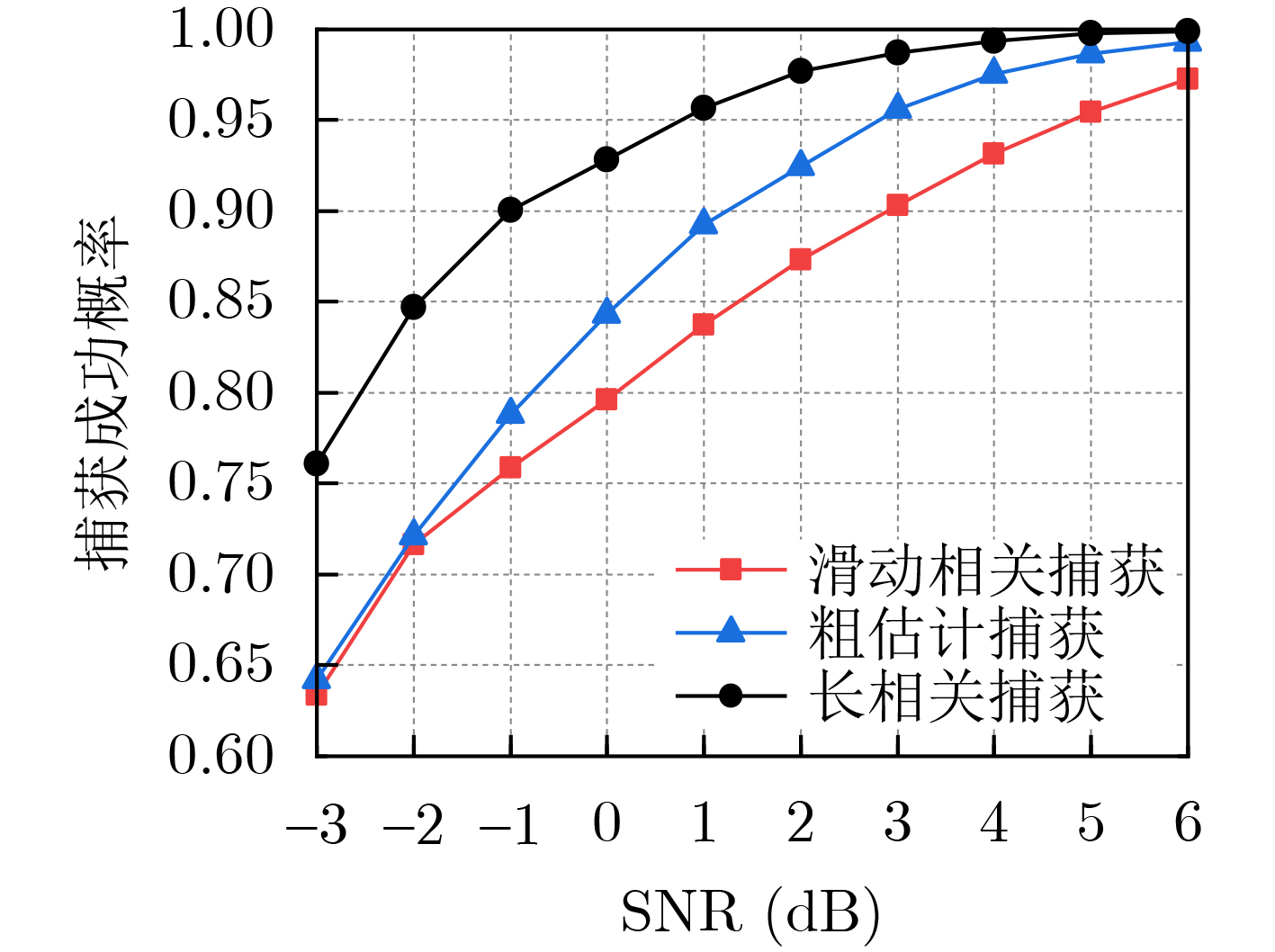
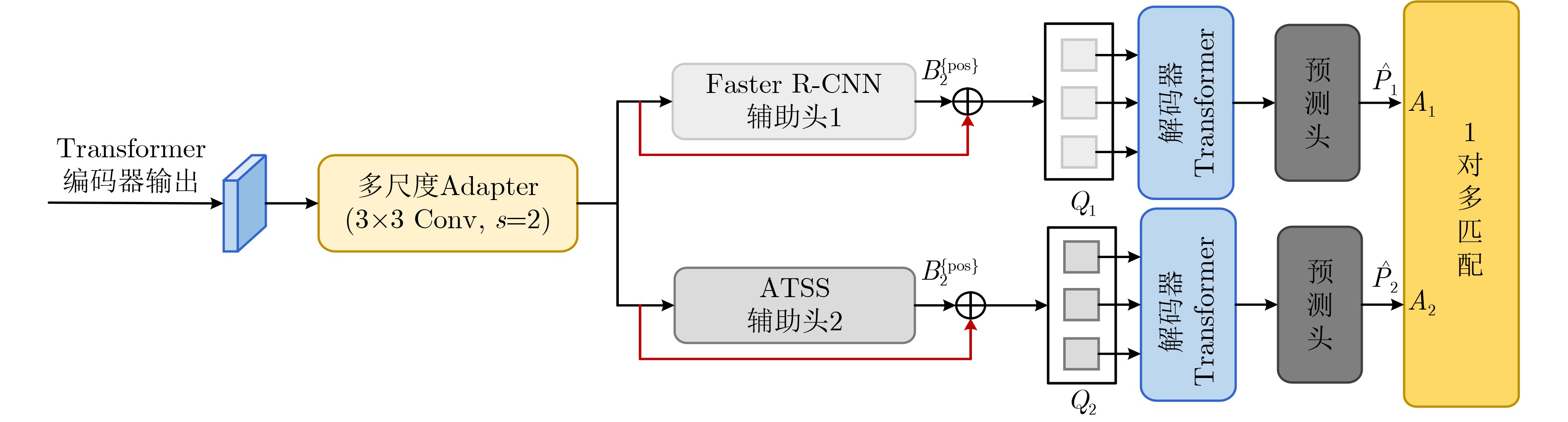
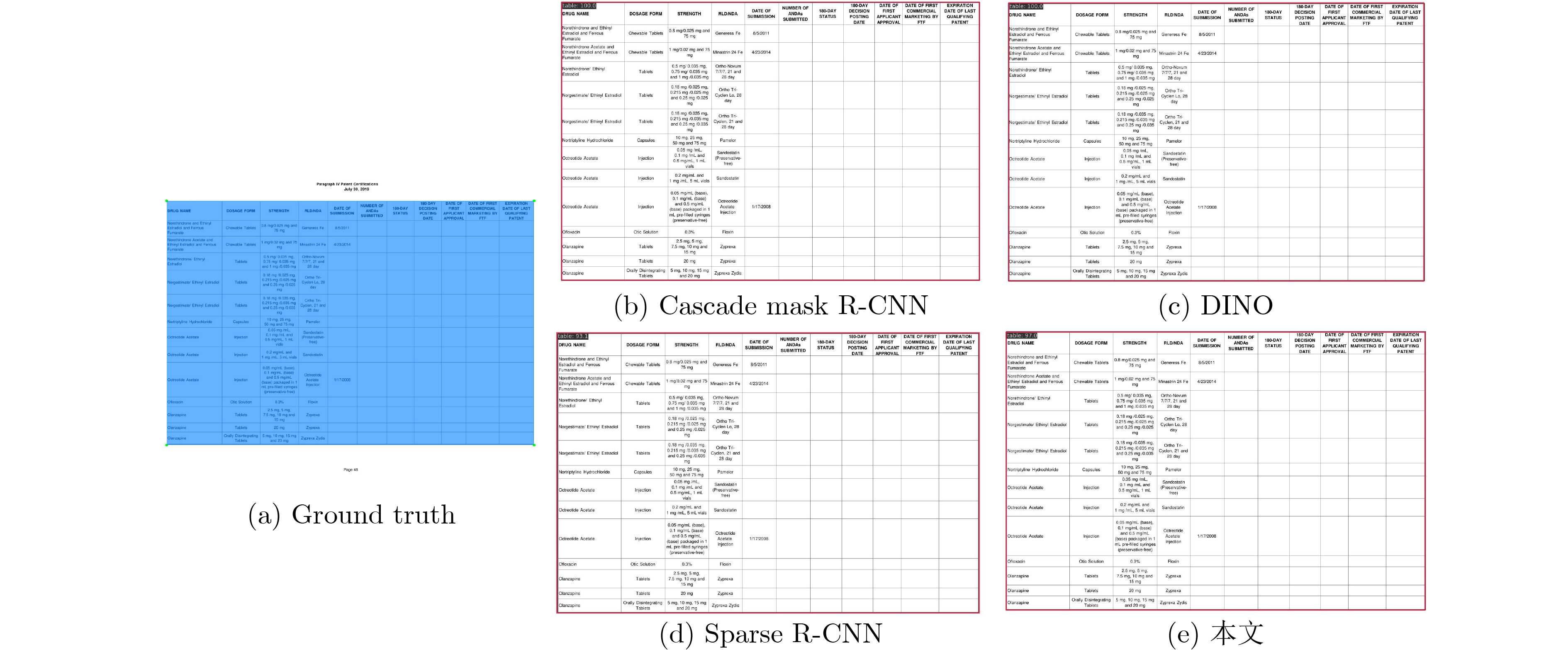
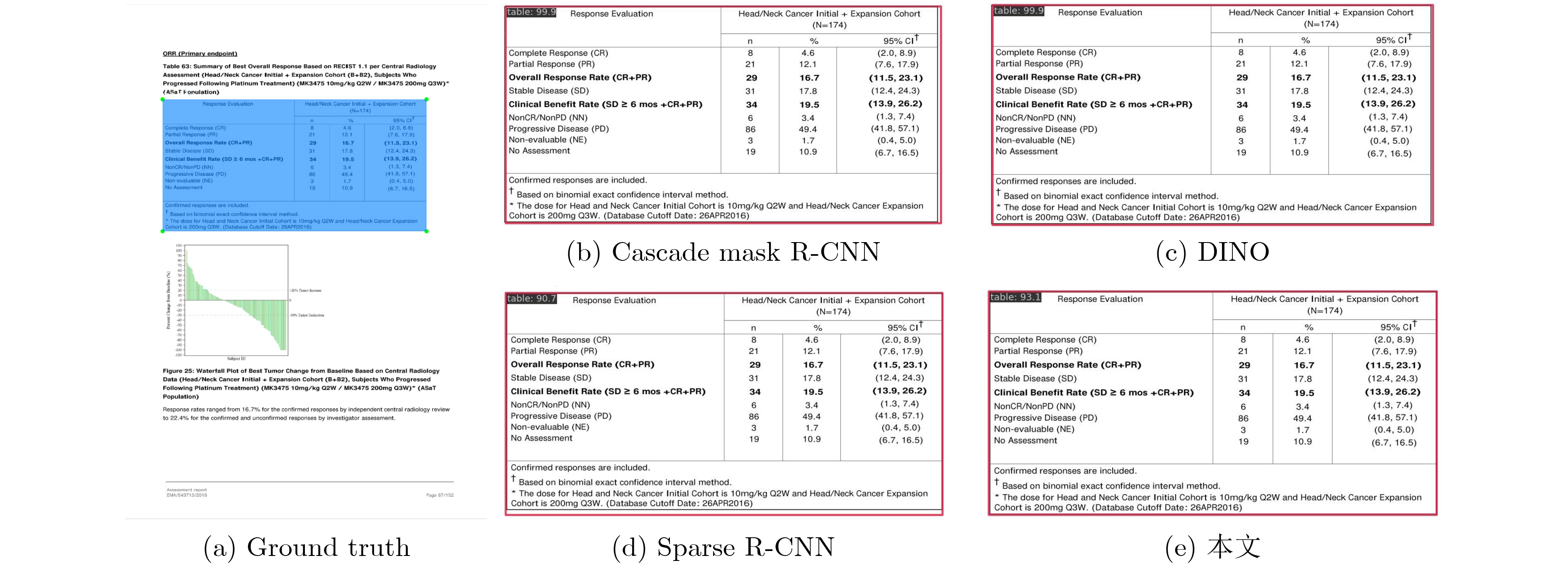
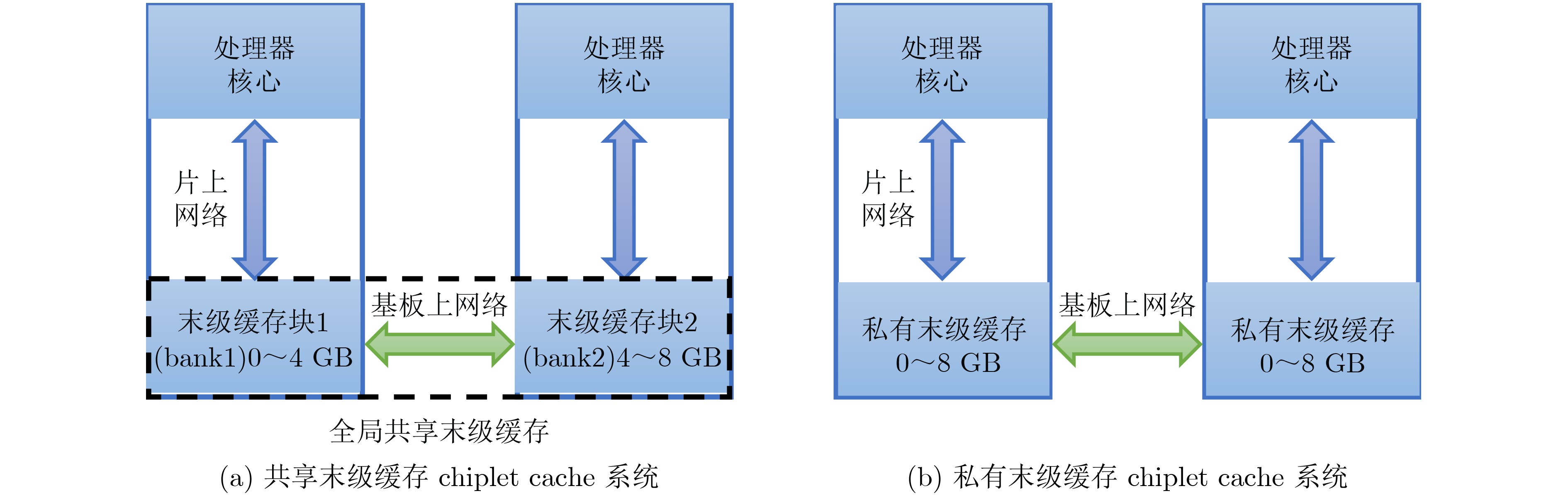
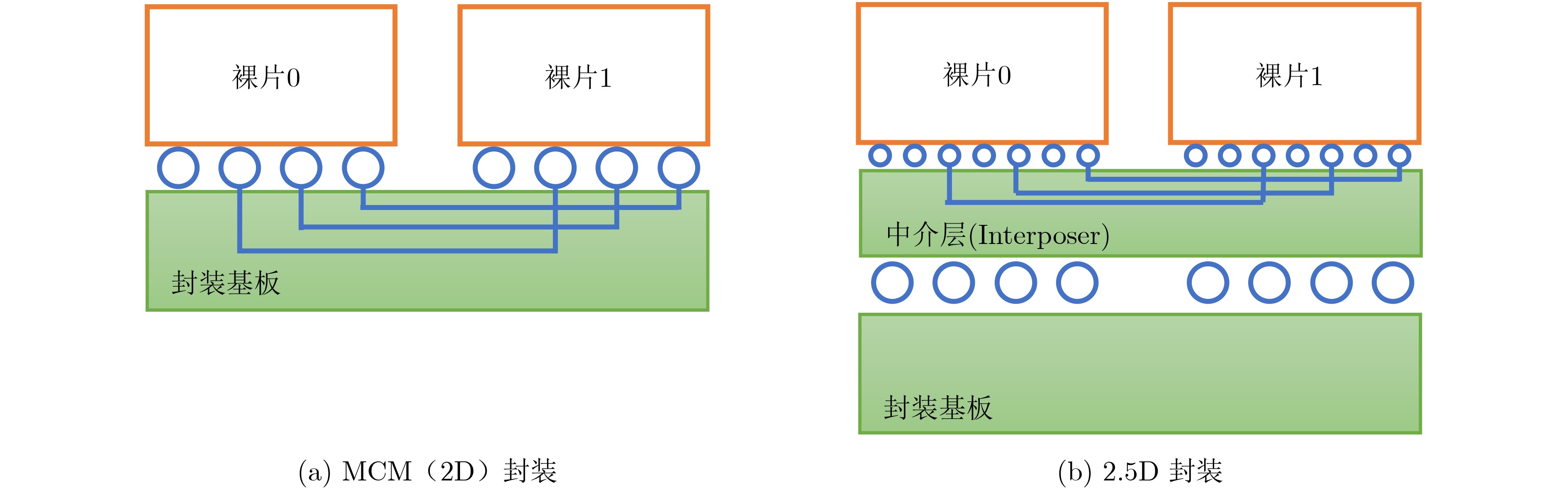
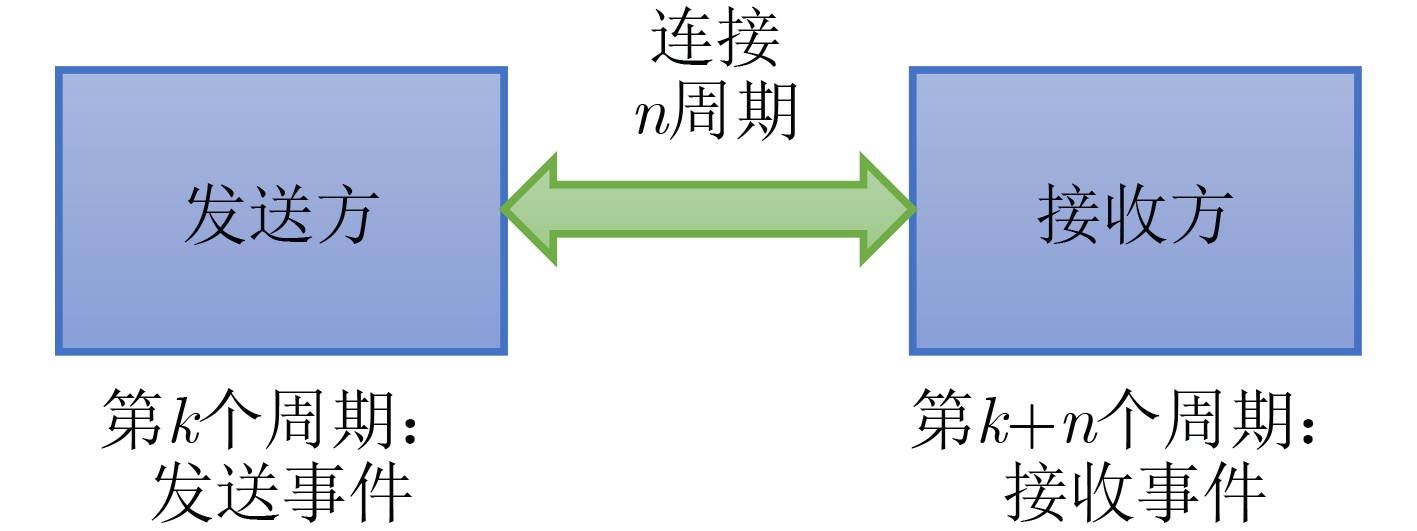
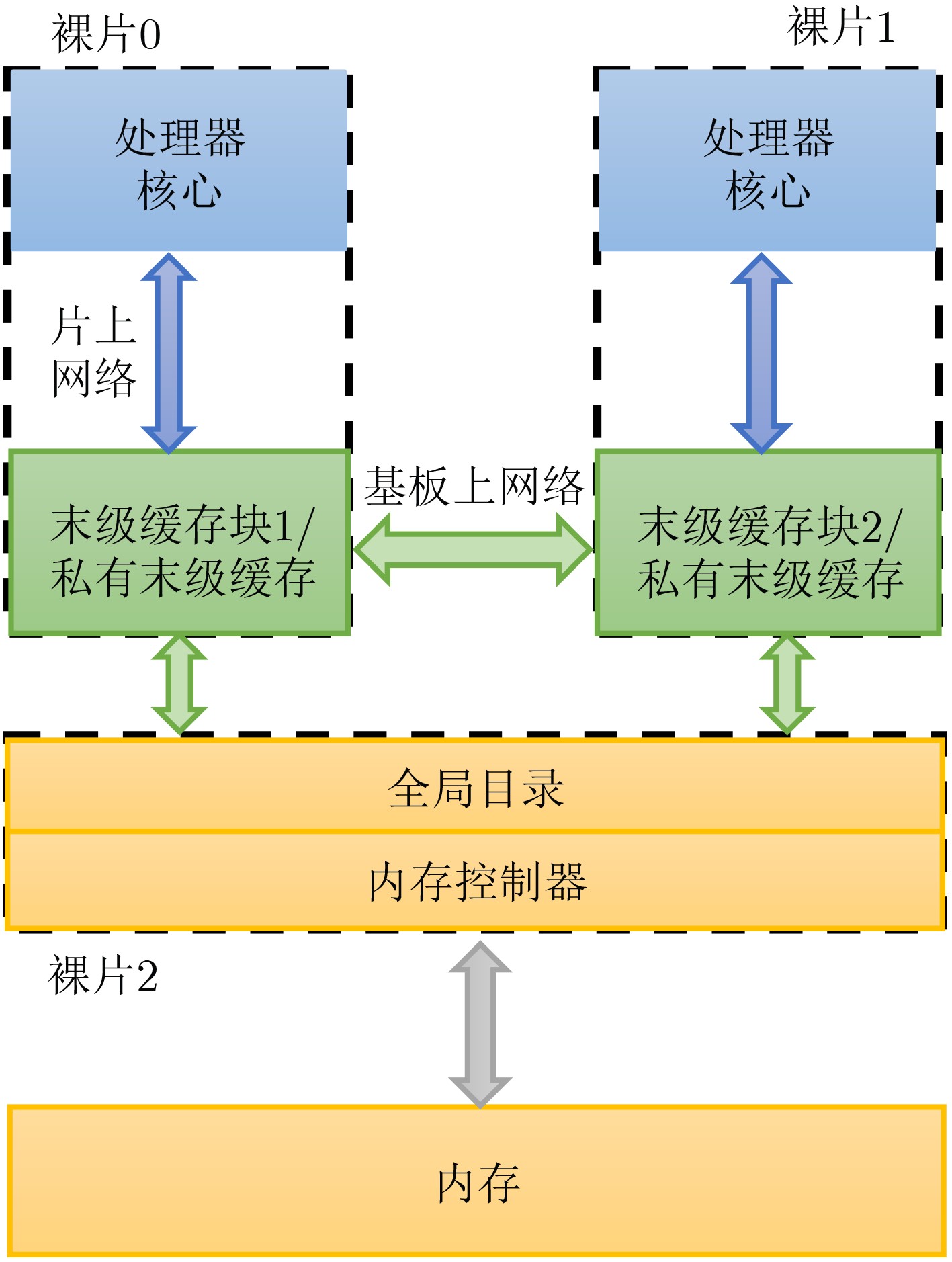
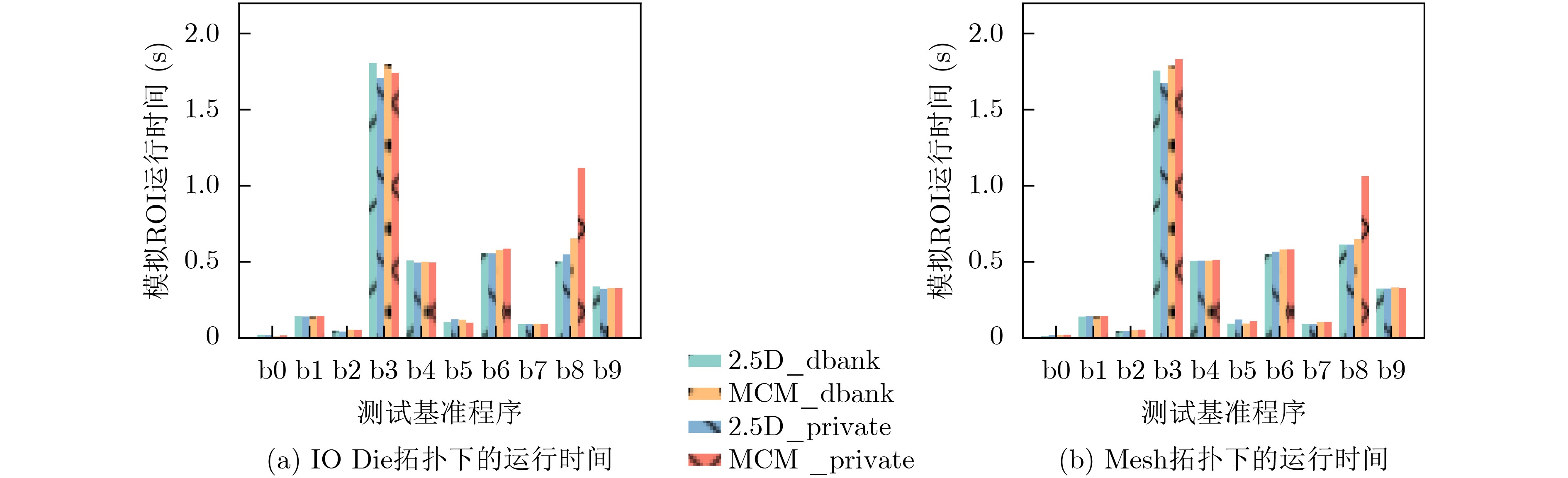
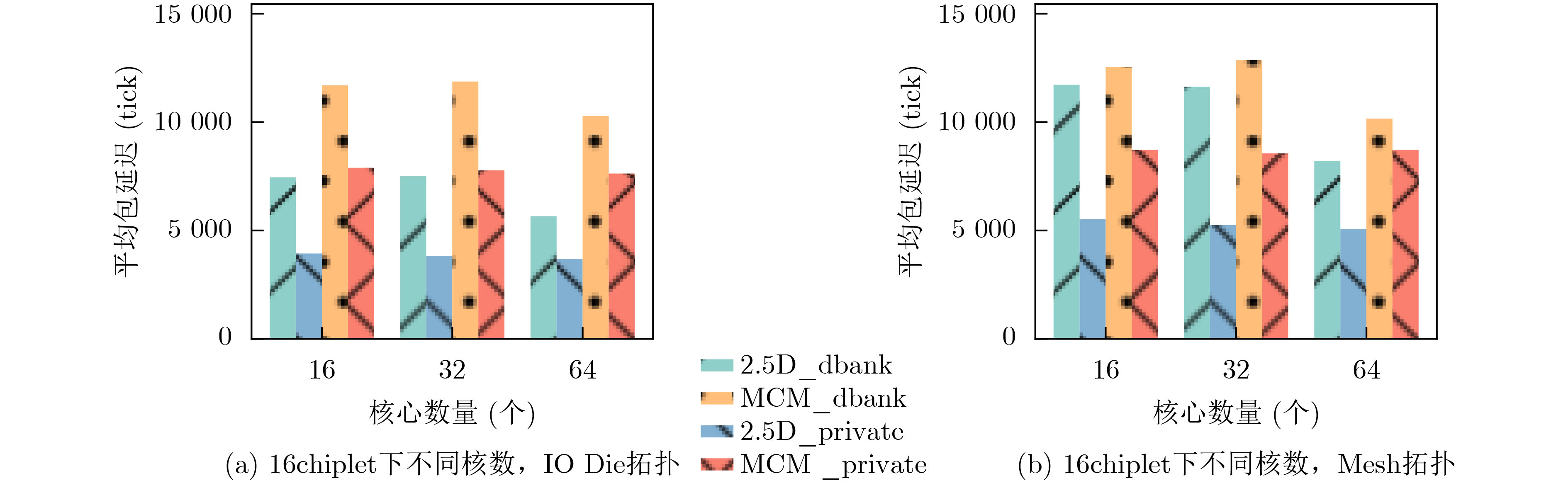
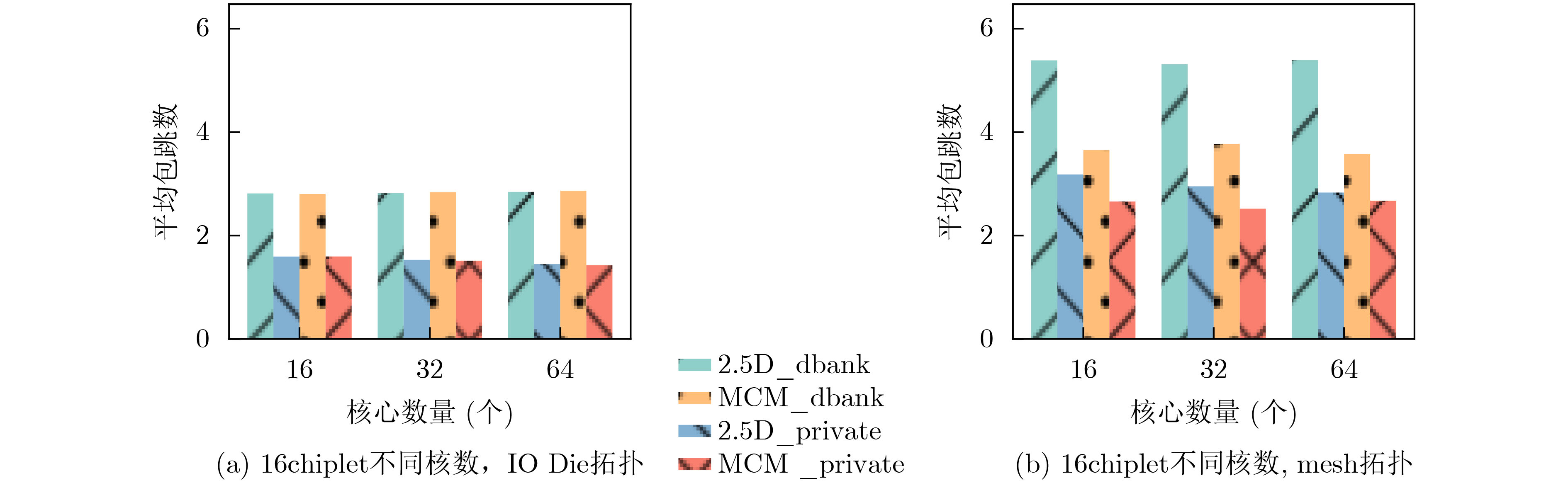
2024, 46(12): 4542-4552.
doi: 10.11999/JEIT240087
Abstract:
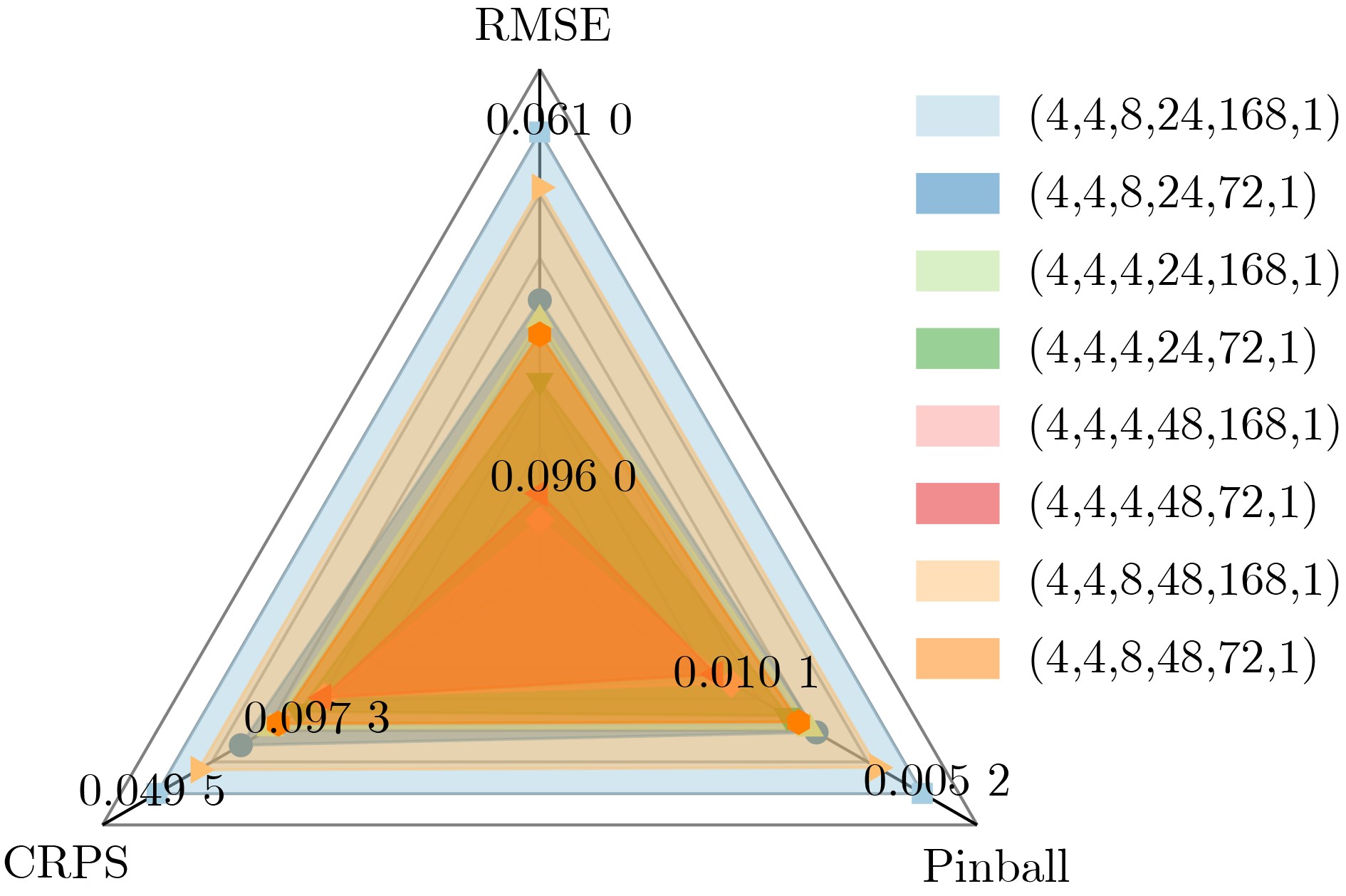
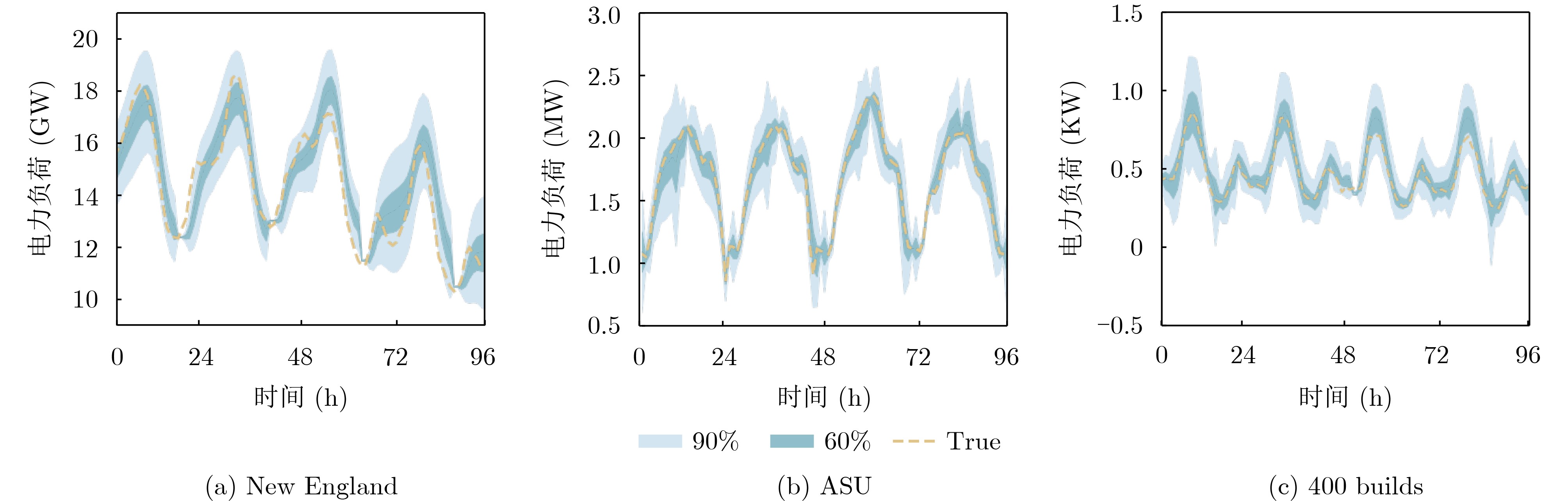
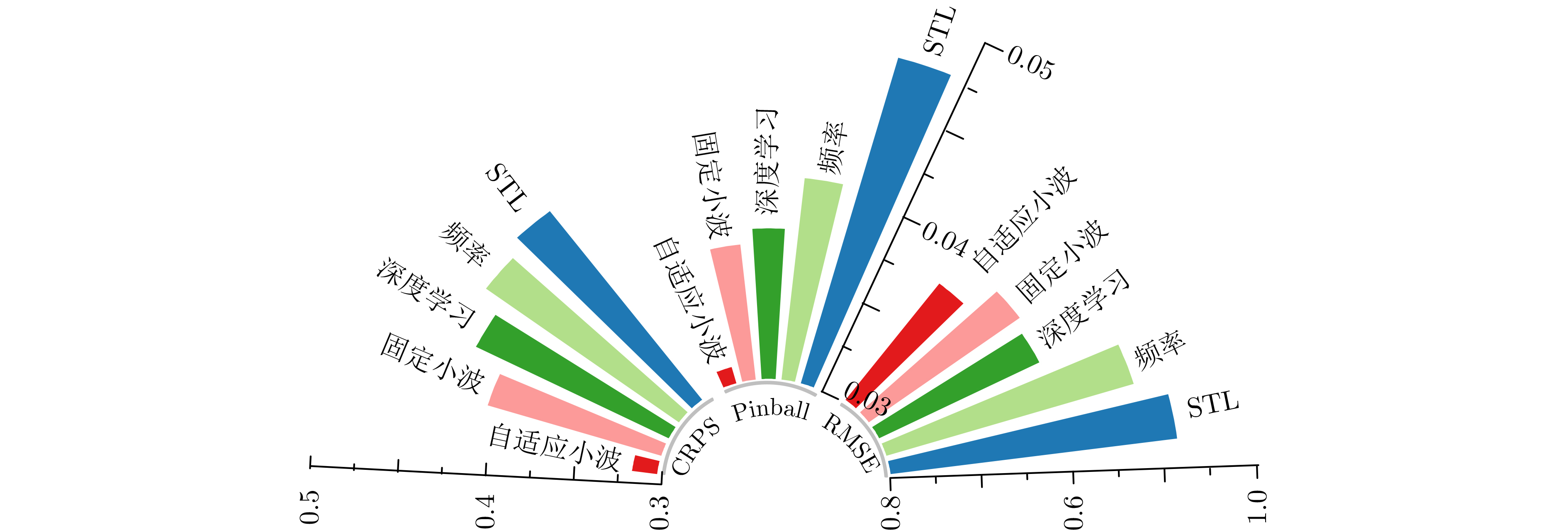
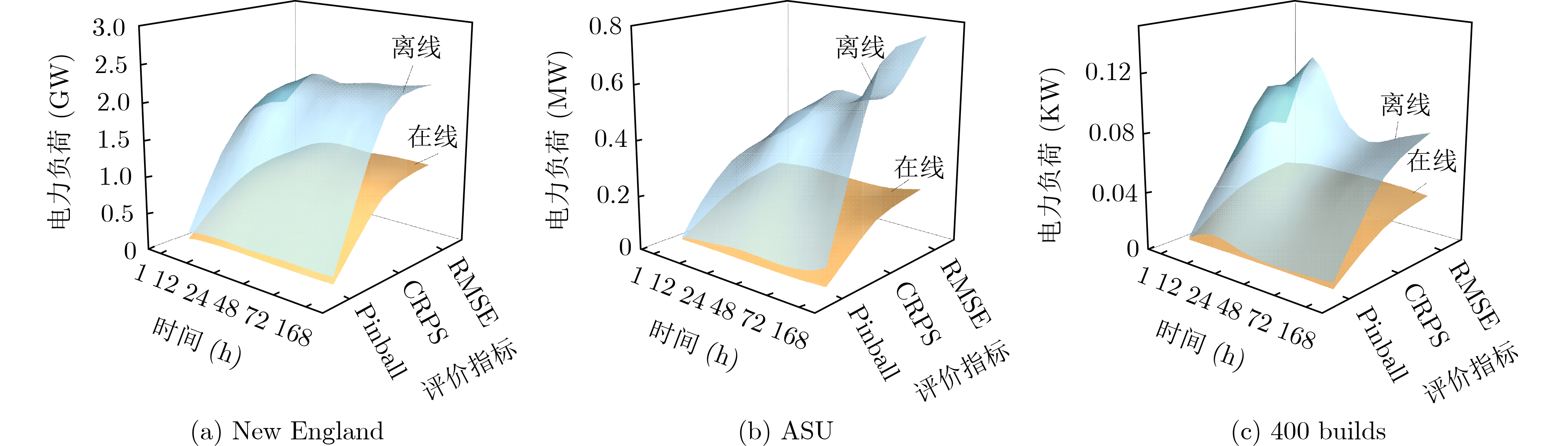
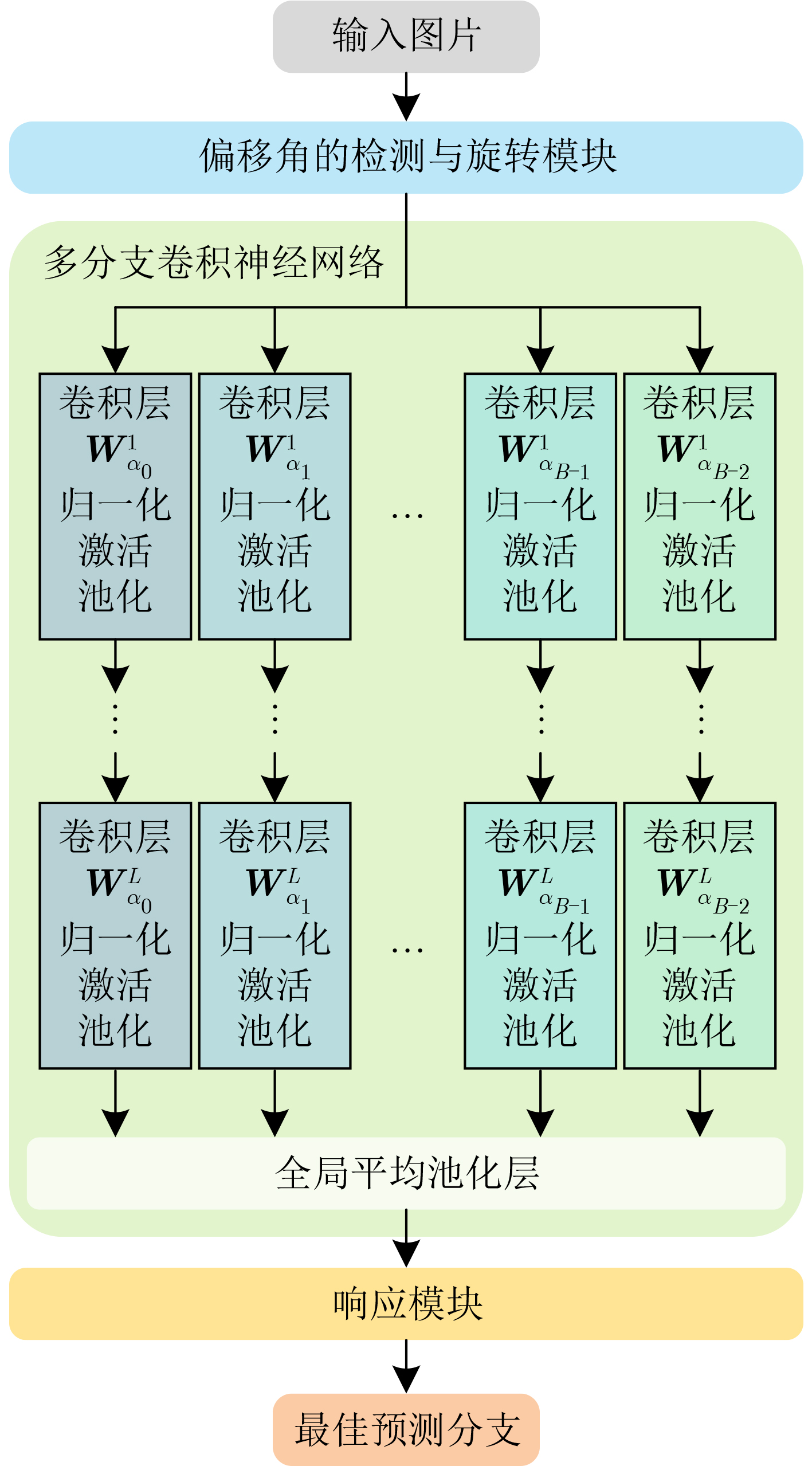
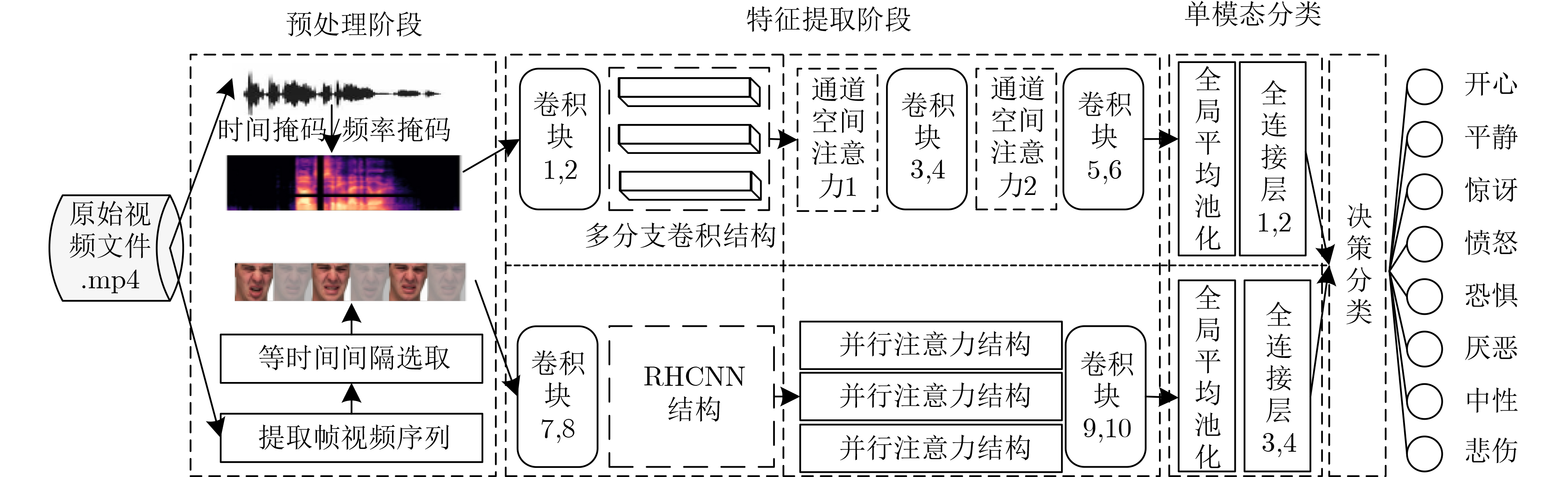
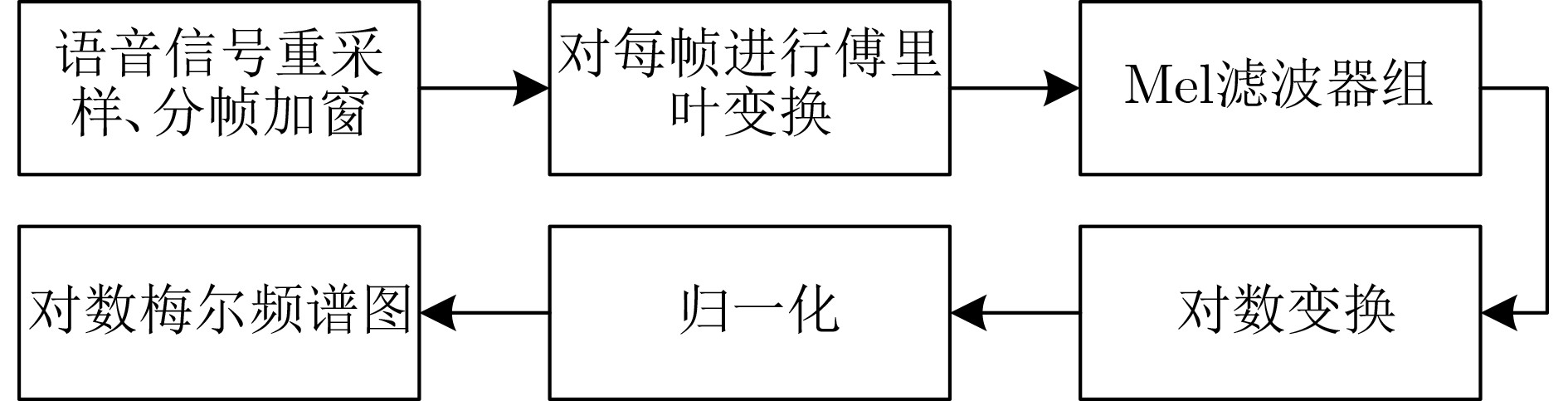
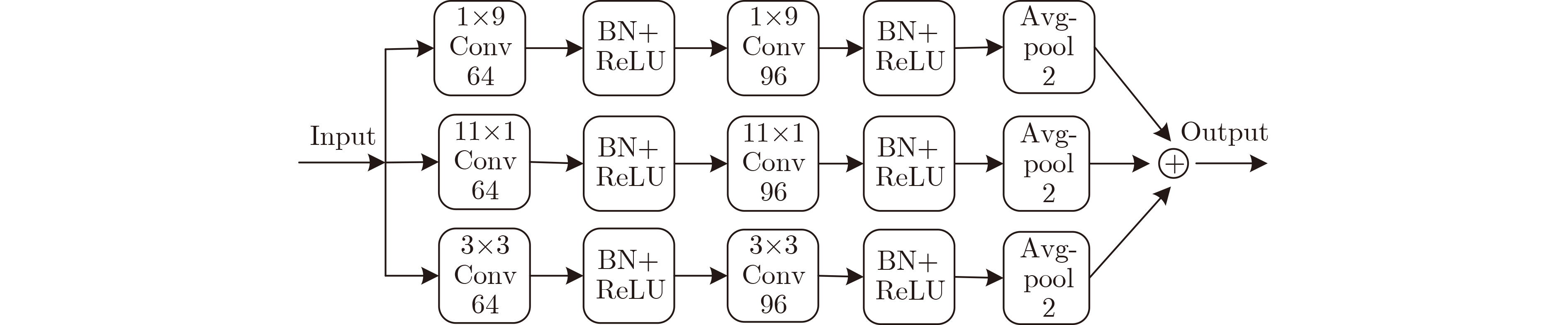
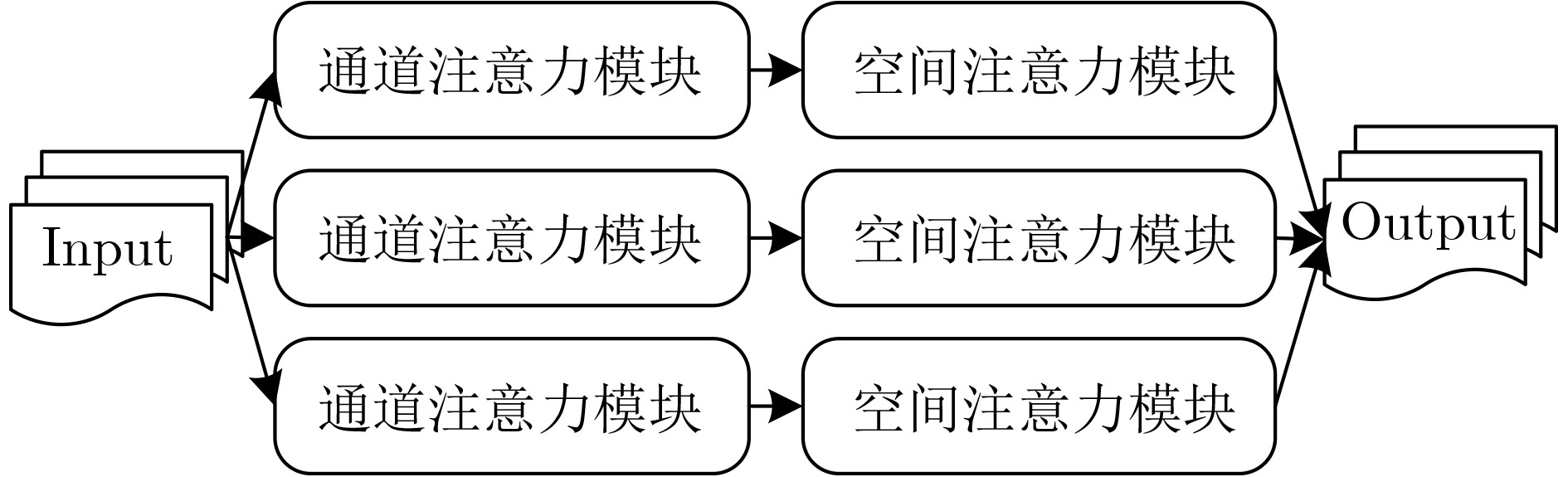
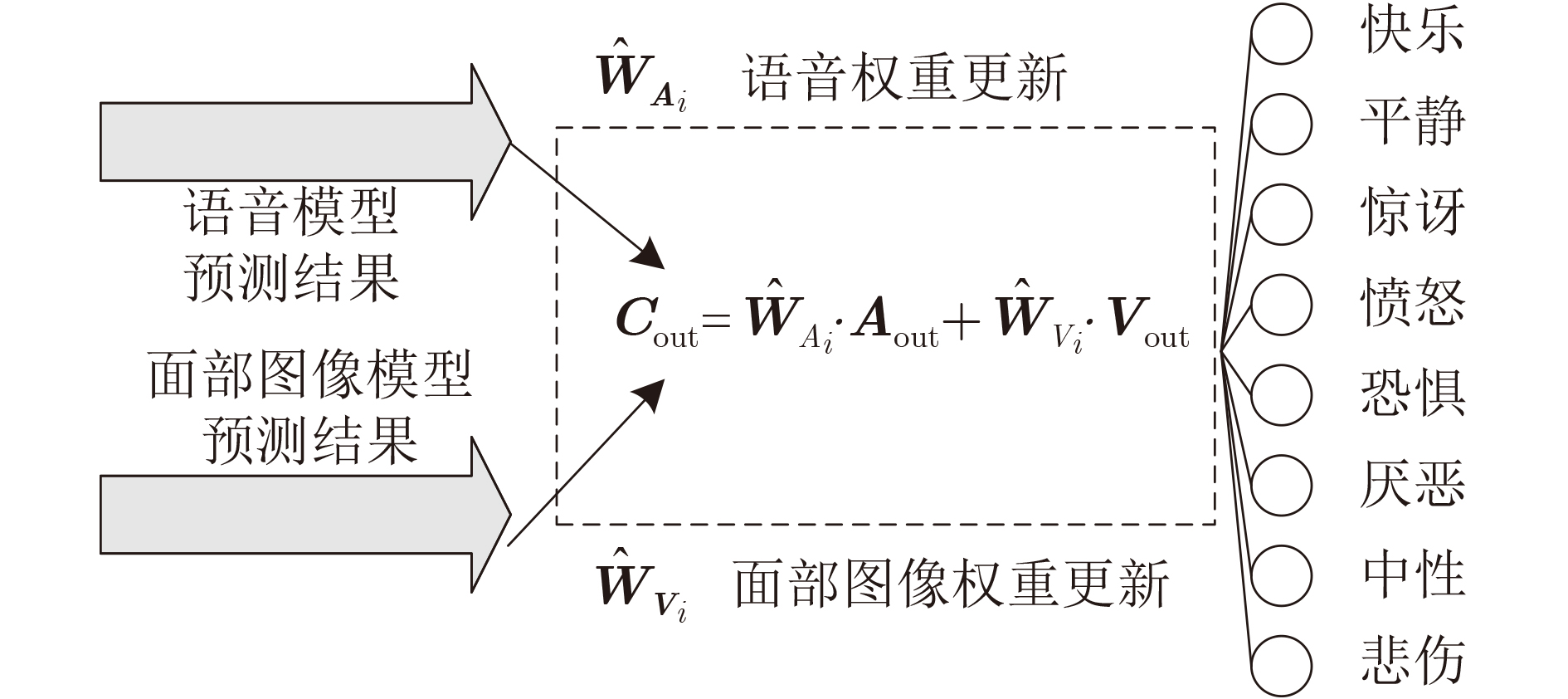
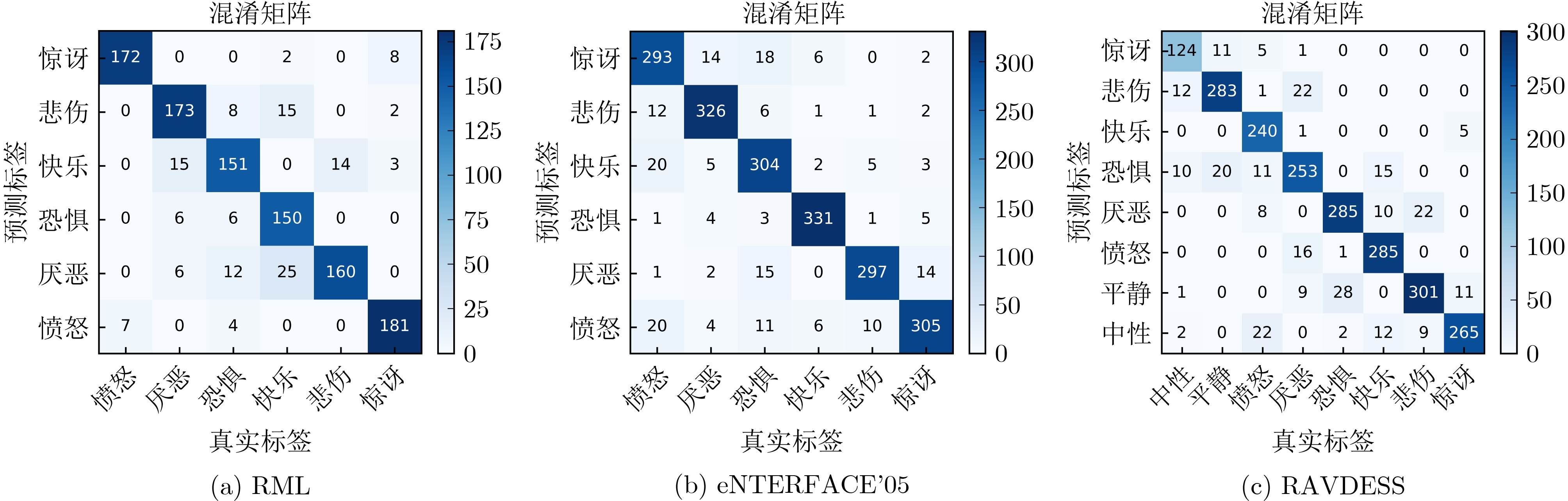
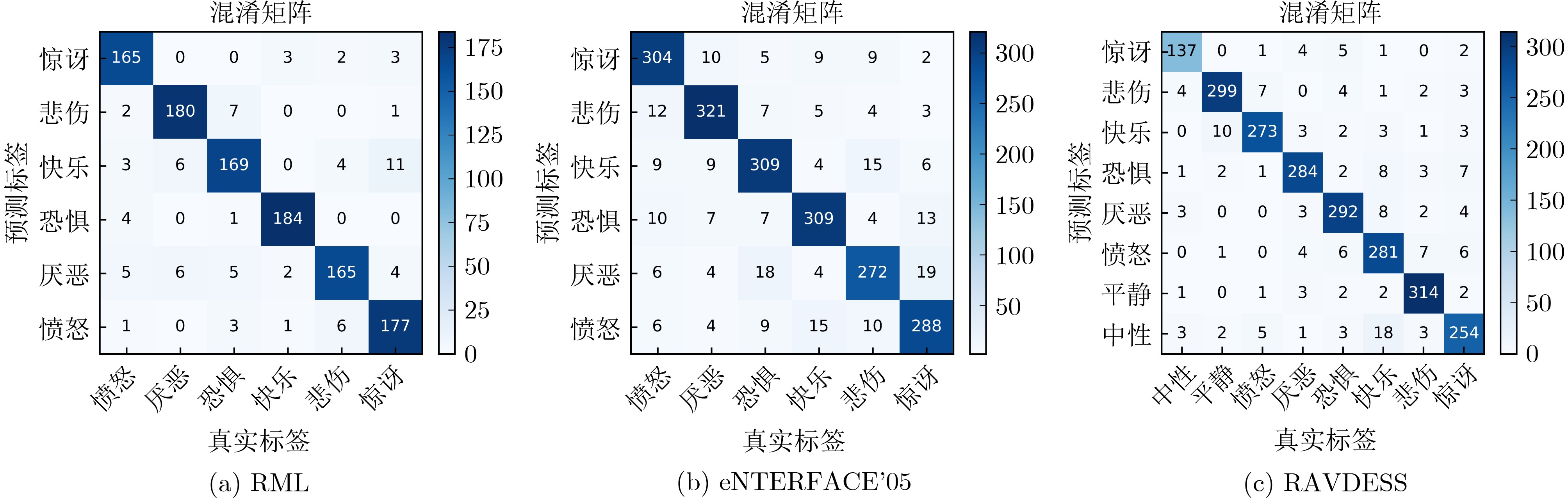
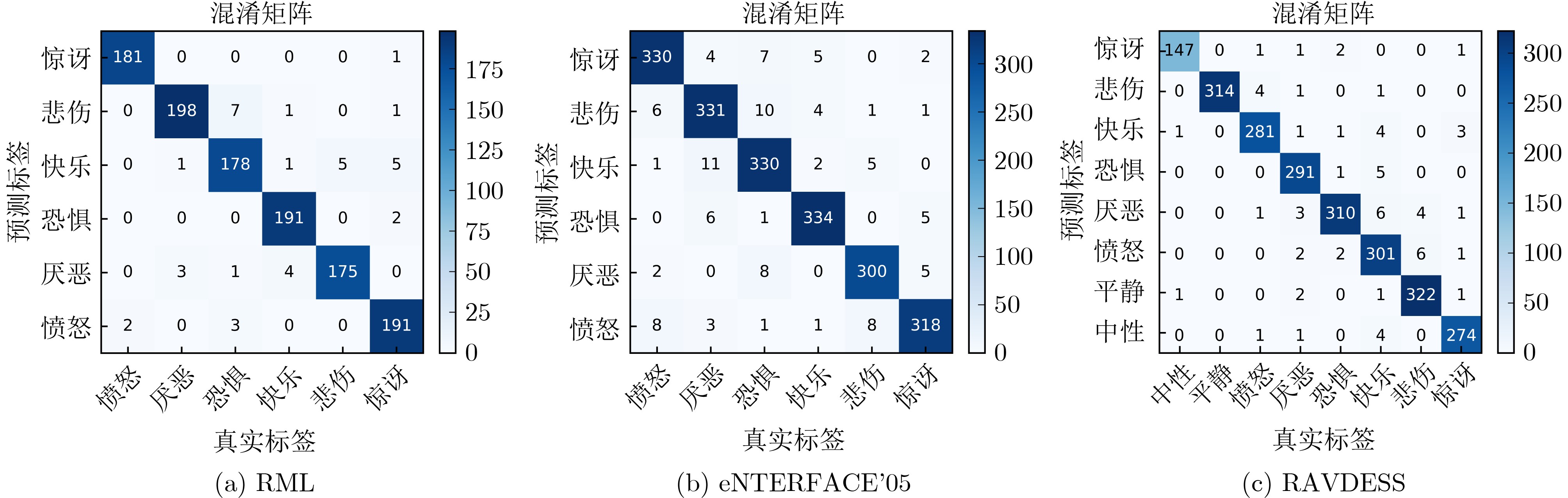
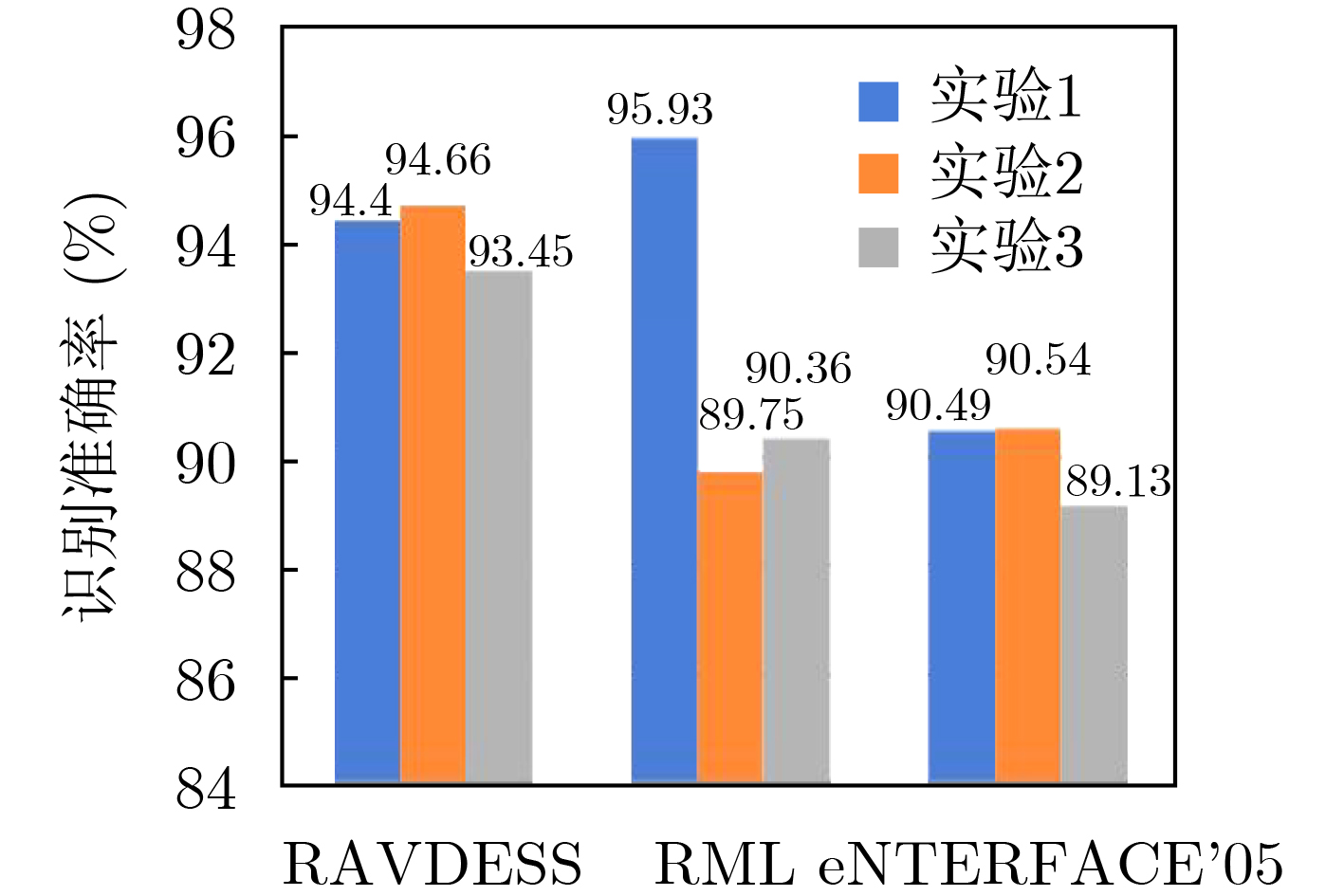
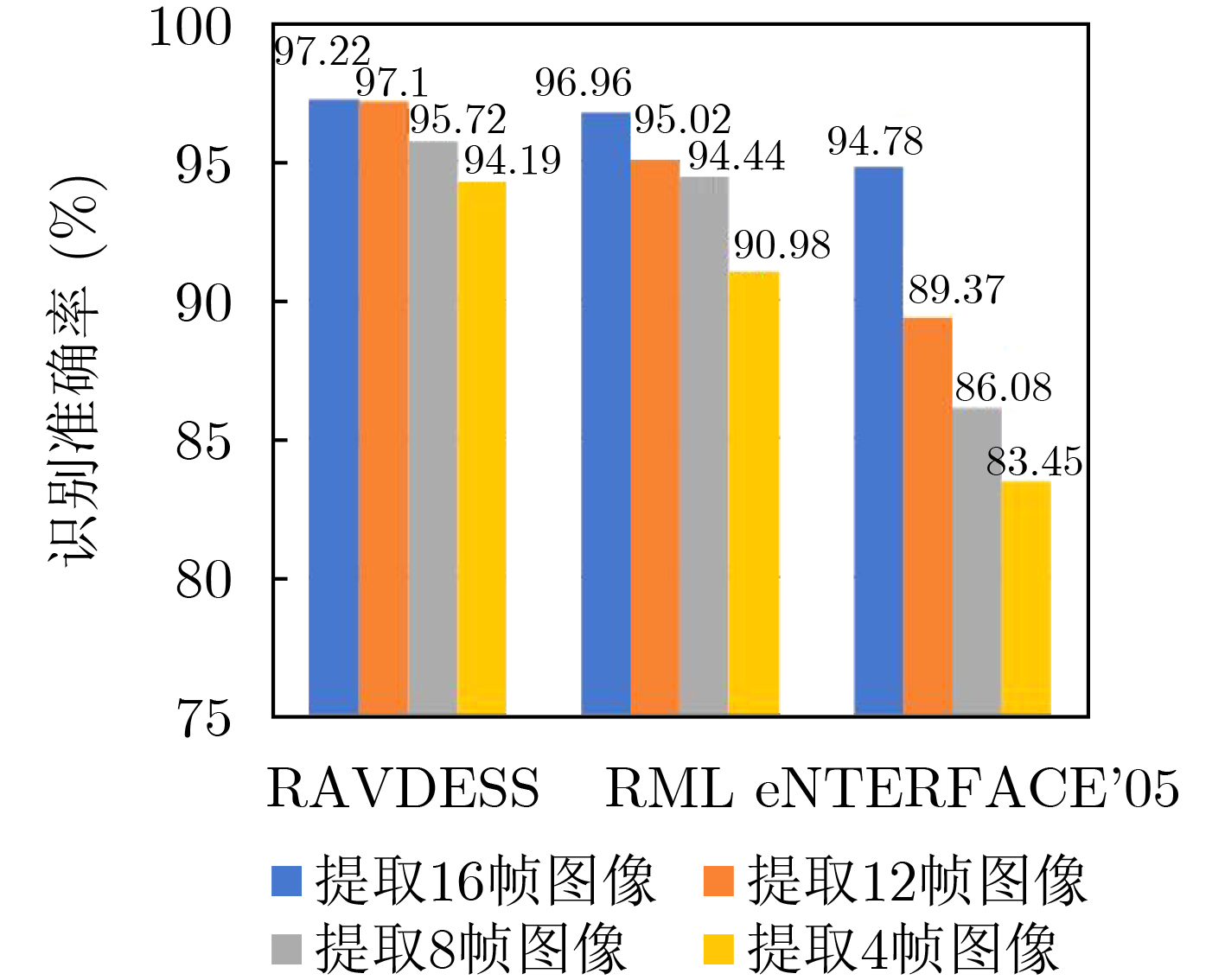
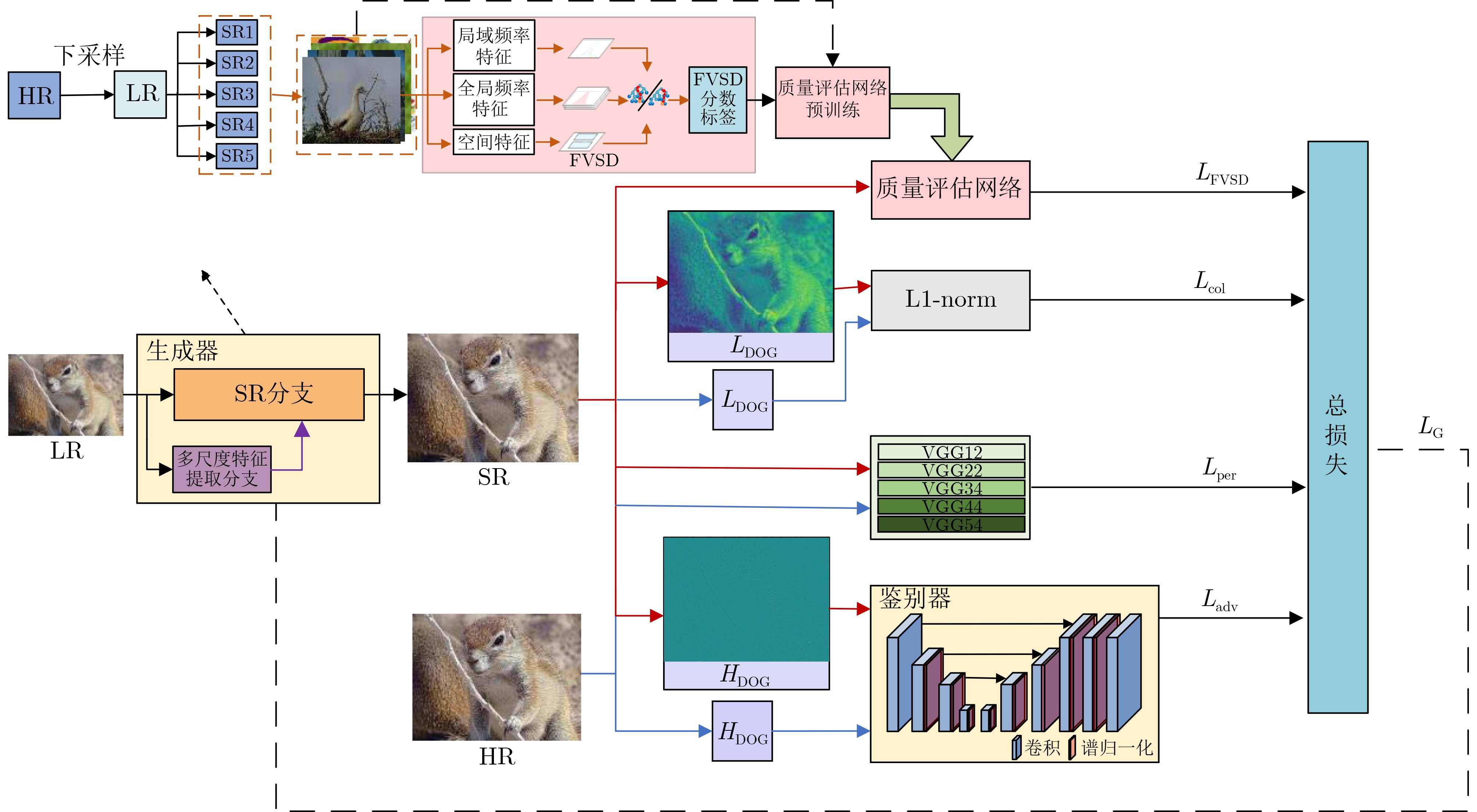
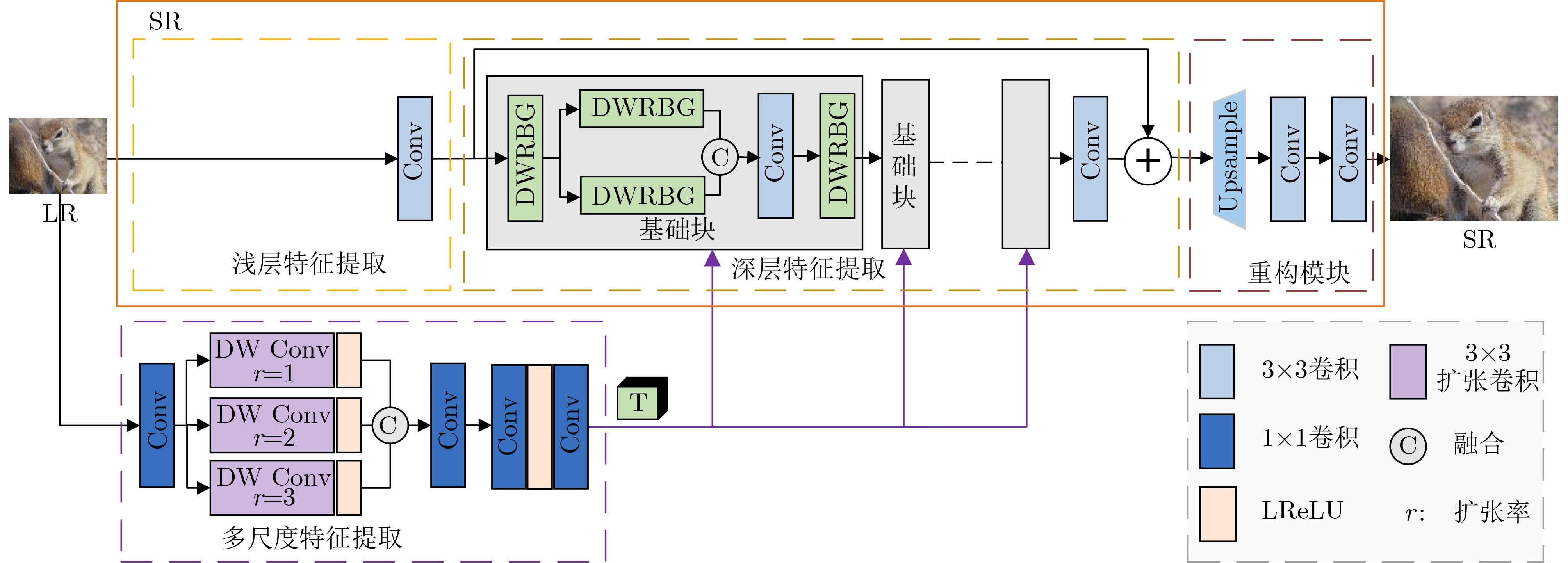
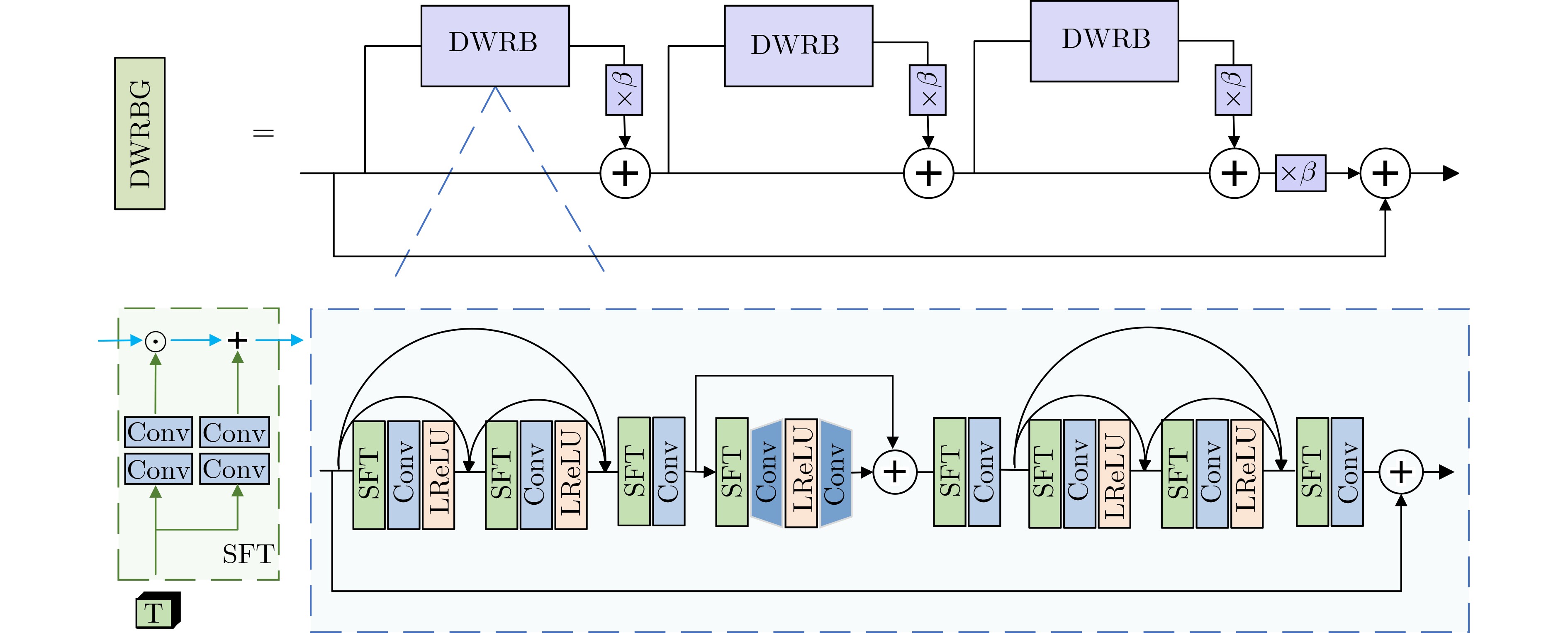
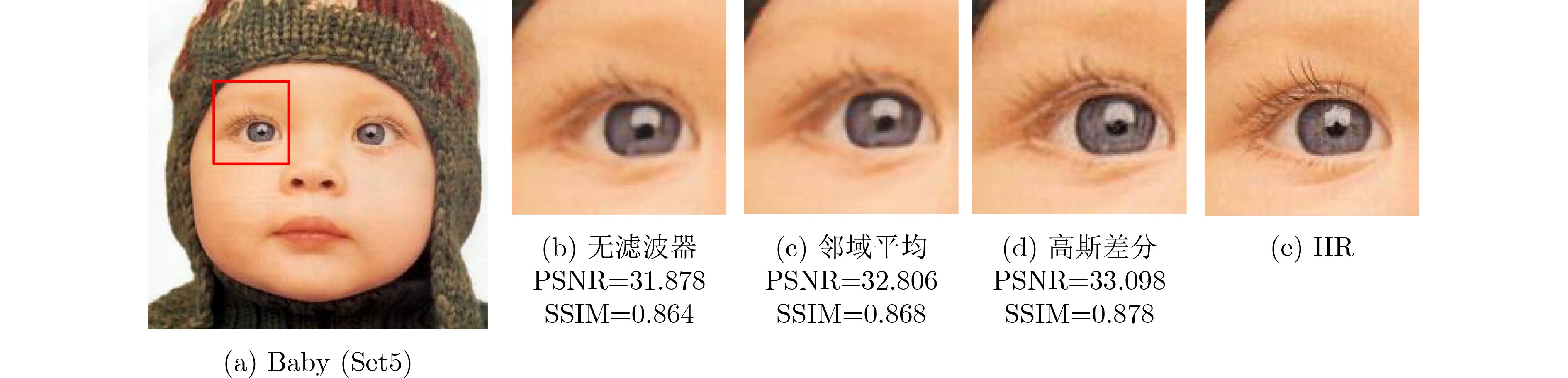
In order to improve the accuracy of emotion recognition models and solve the problem of insufficient emotional feature extraction, this paper conducts research on bimodal emotion recognition involving audio and facial imagery. In the audio modality, a feature extraction model of a Multi-branch Convolutional Neural Network (MCNN) incorporating a channel-space attention mechanism is proposed, which extracts emotional features from speech spectrograms across time, space, and local feature dimensions. For the facial image modality, a feature extraction model using a Residual Hybrid Convolutional Neural Network (RHCNN) is introduced, which further establishes a parallel attention mechanism that concentrates on global emotional features to enhance recognition accuracy. The emotional features extracted from audio and facial imagery are then classified through separate classification layers, and a decision fusion technique is utilized to amalgamate the classification results. The experimental results indicate that the proposed bimodal fusion model has achieved recognition accuracies of 97.22%, 94.78%, and 96.96% on the RAVDESS, eNTERFACE’05, and RML datasets, respectively. These accuracies signify improvements over single-modality audio recognition by 11.02%, 4.24%, and 8.83%, and single-modality facial image recognition by 4.60%, 6.74%, and 4.10%, respectively. Moreover, the proposed model outperforms related methodologies applied to these datasets in recent years. This illustrates that the advanced bimodal fusion model can effectively focus on emotional information, thereby enhancing the overall accuracy of emotion recognition.