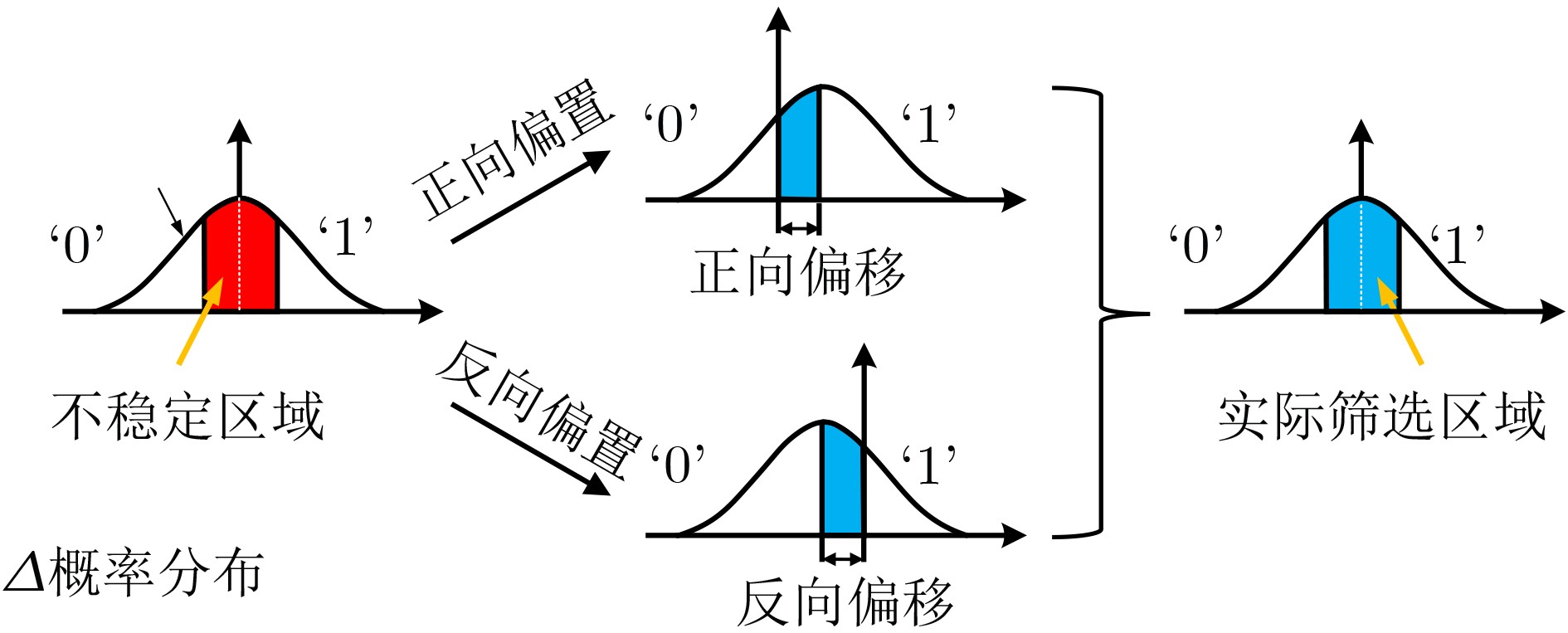
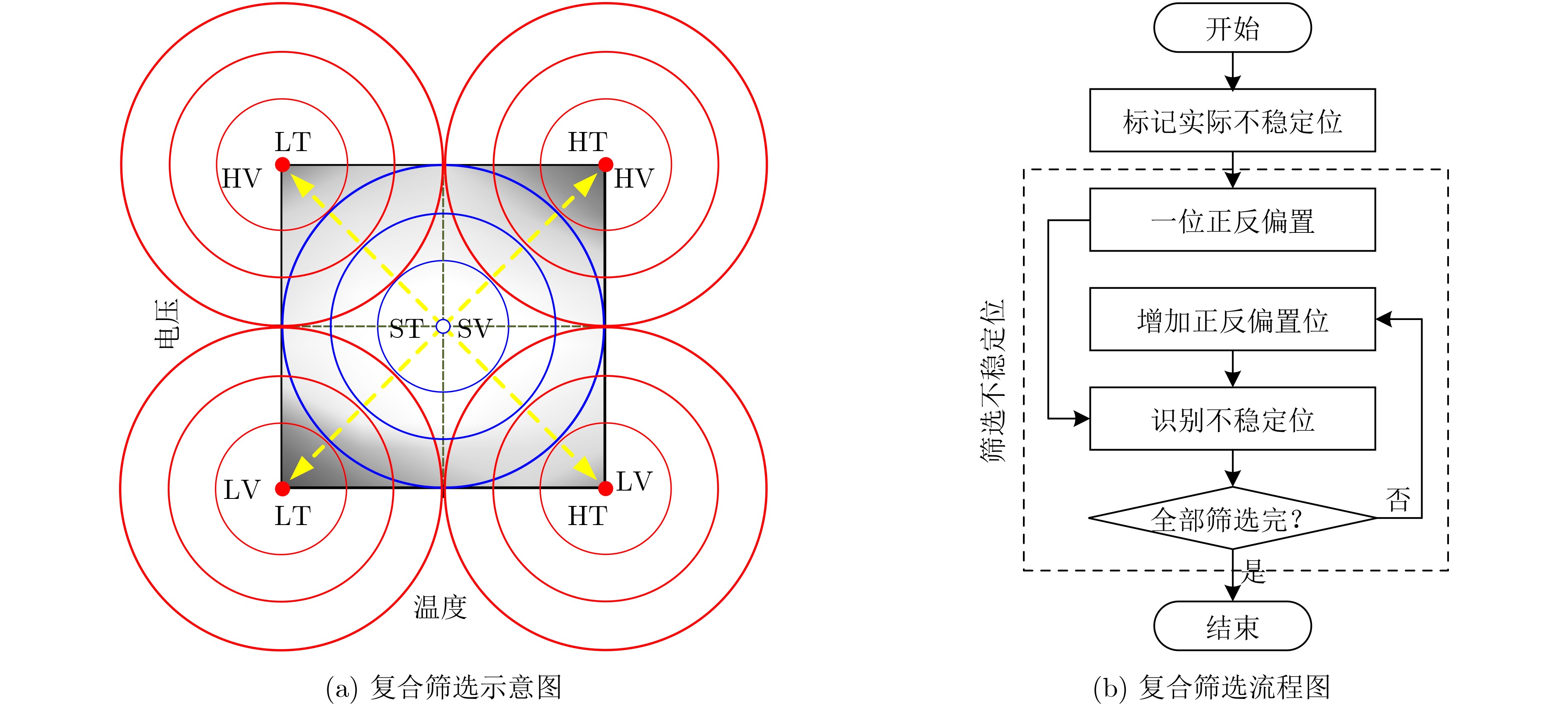
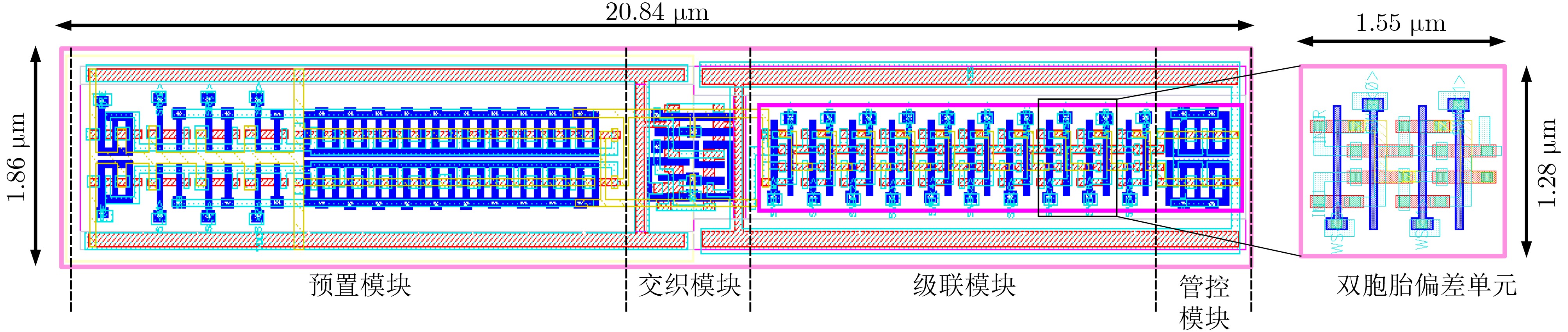
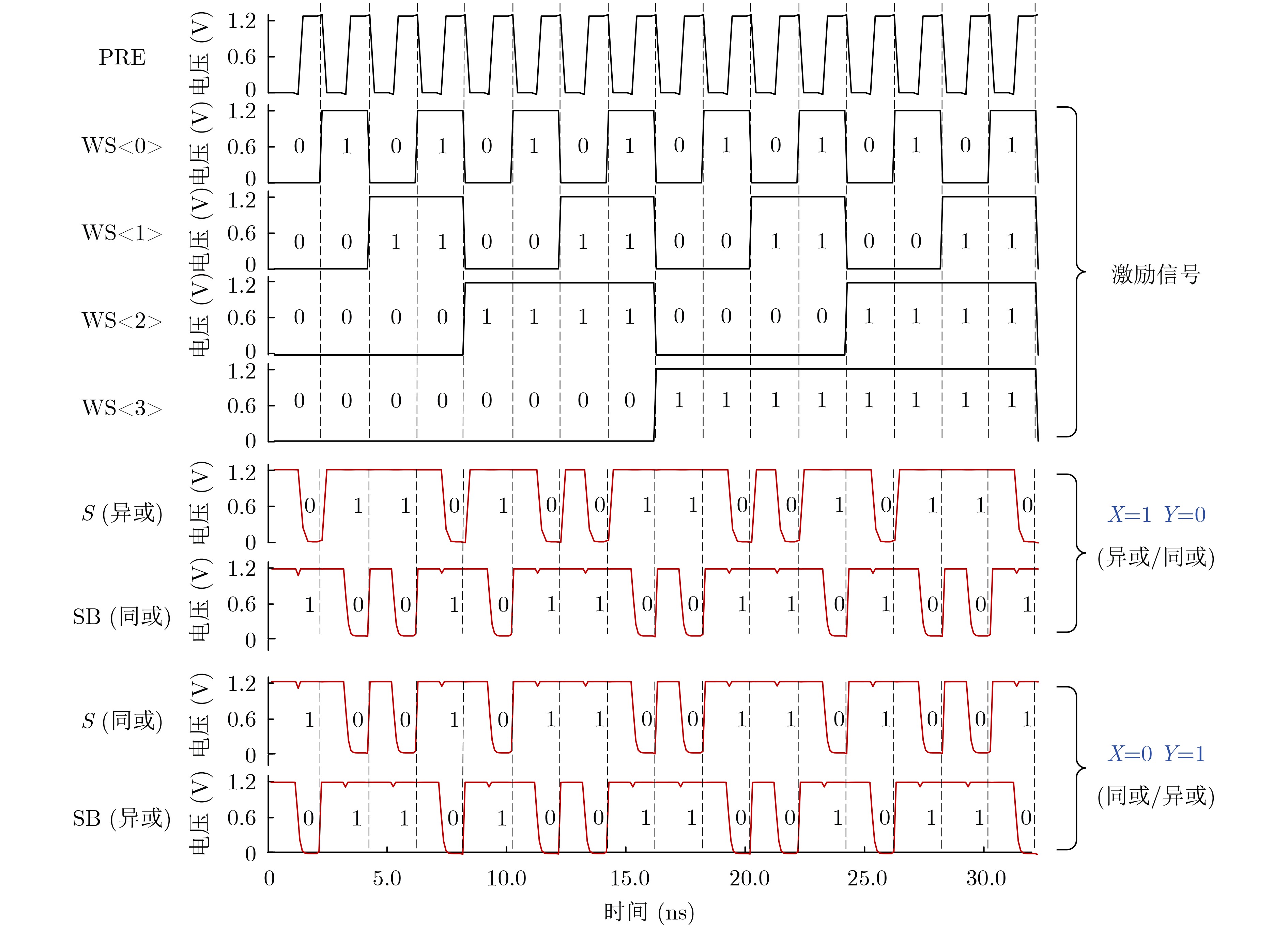
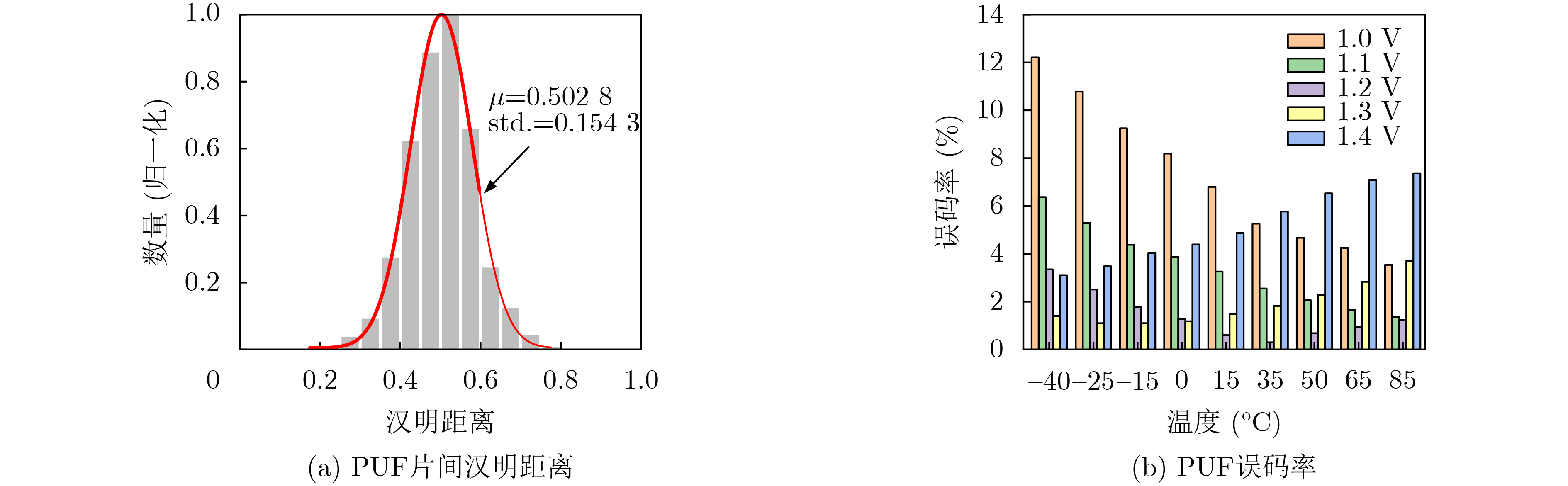
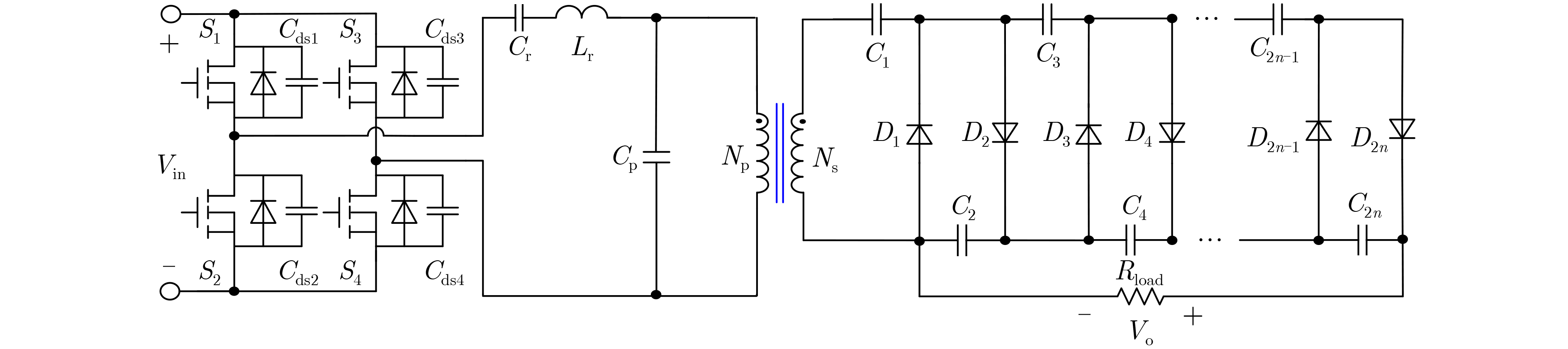
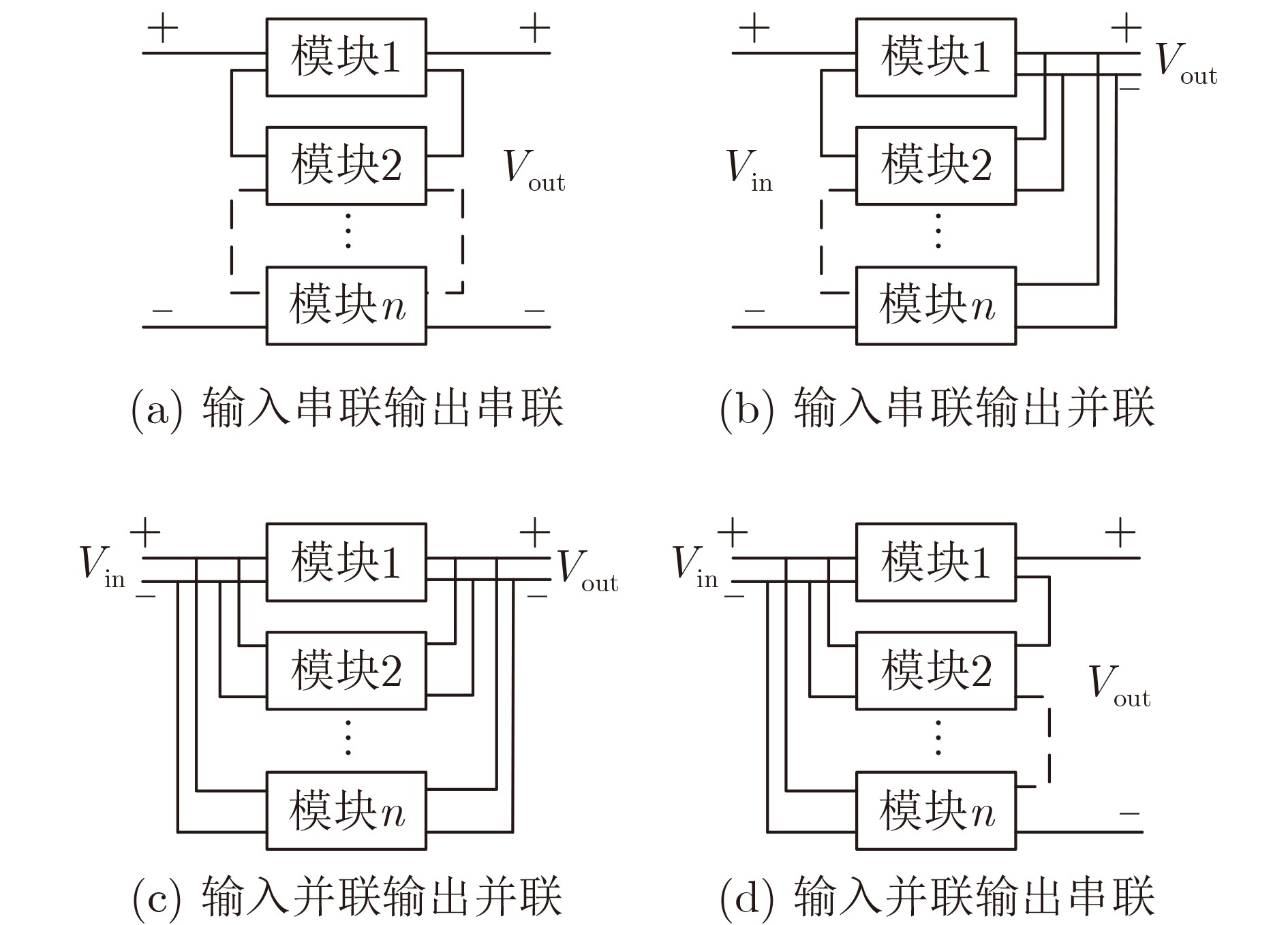
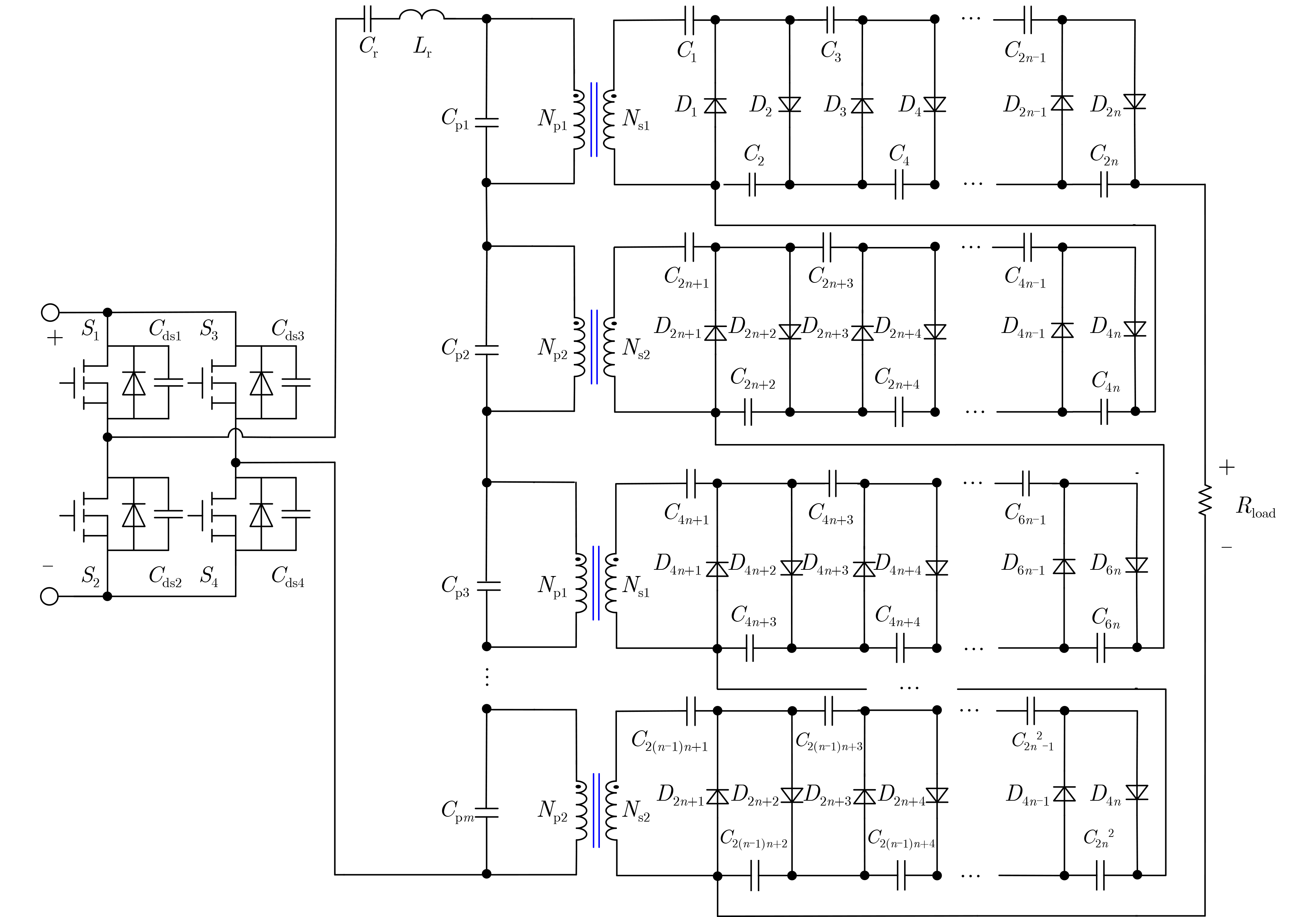
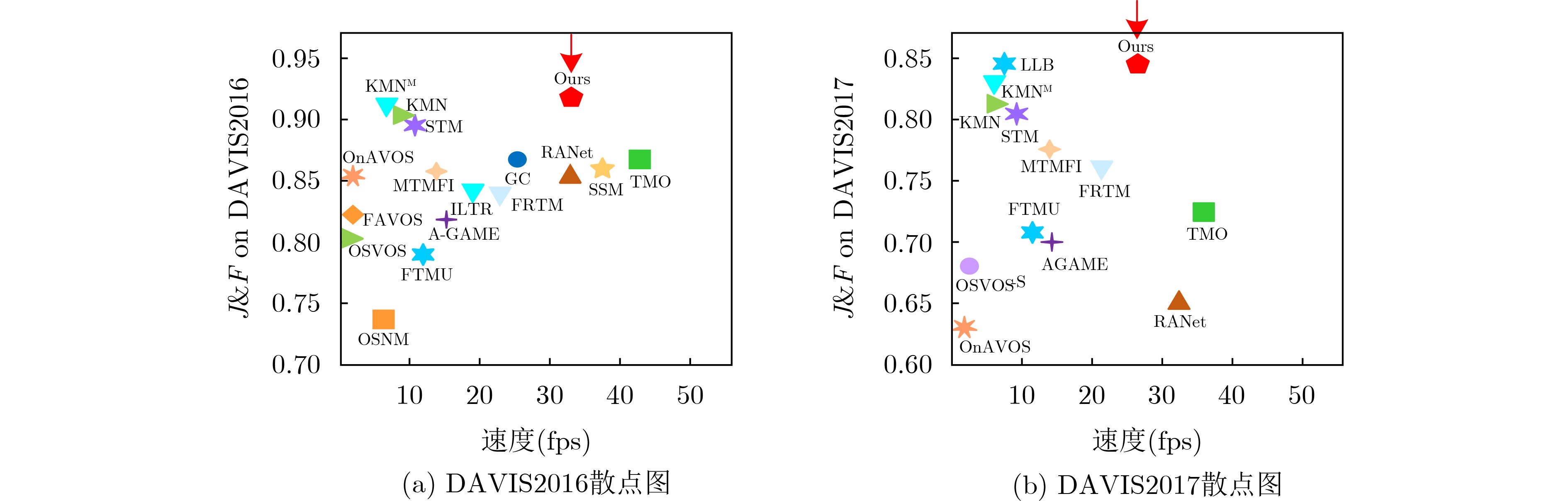
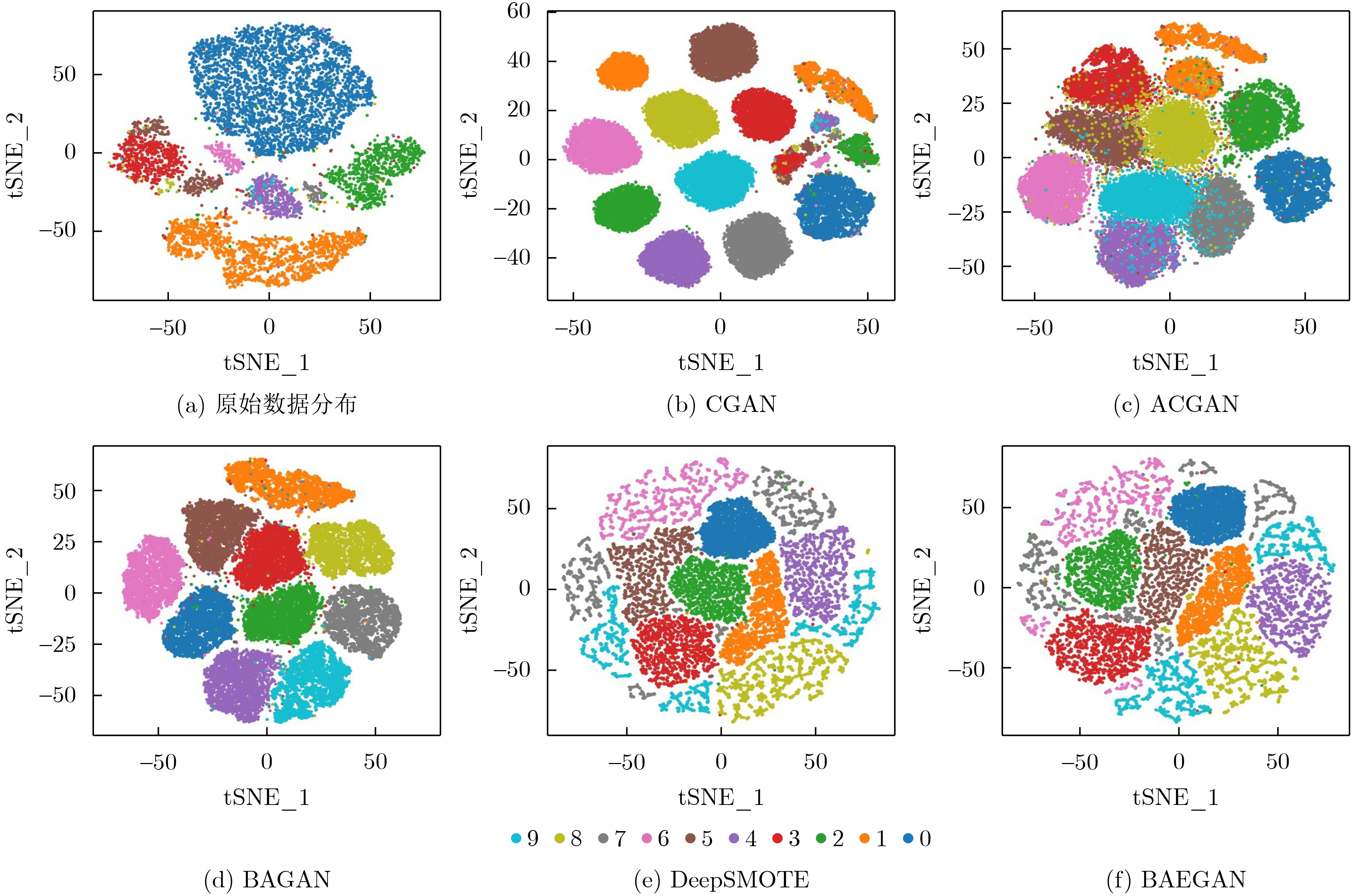
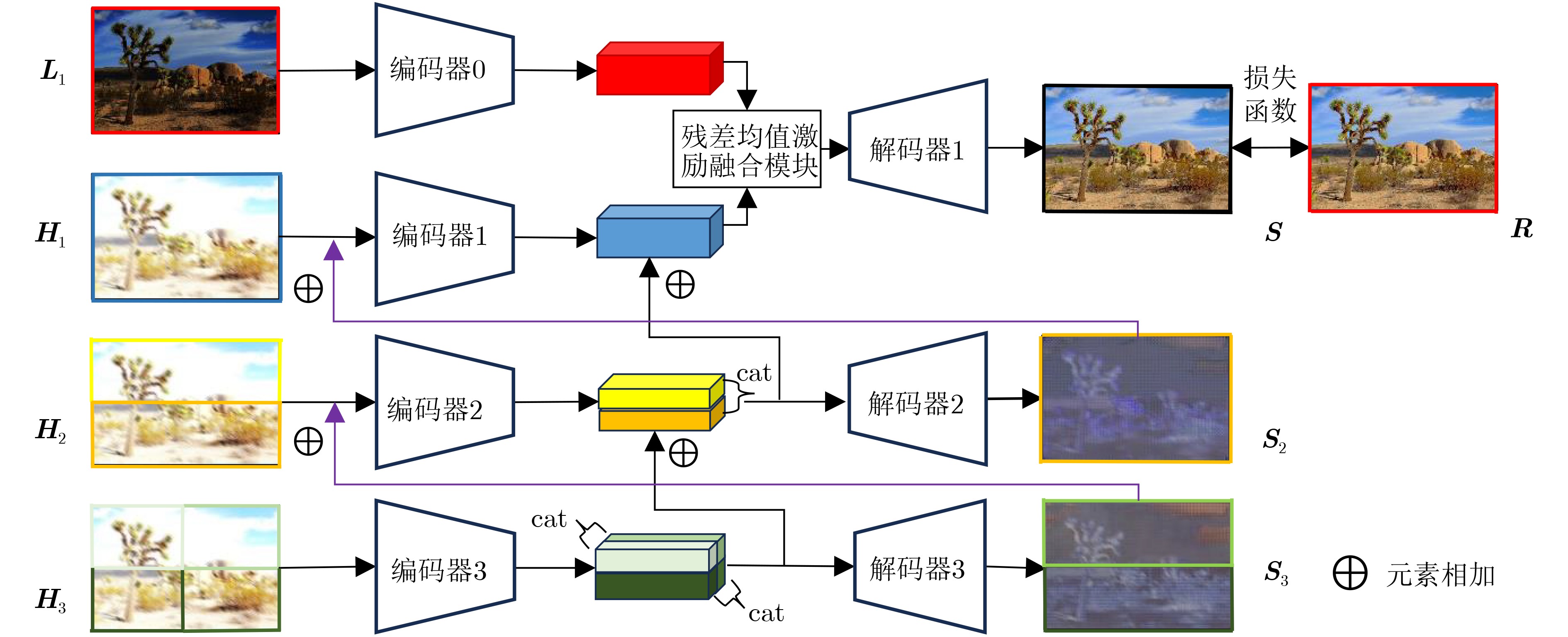
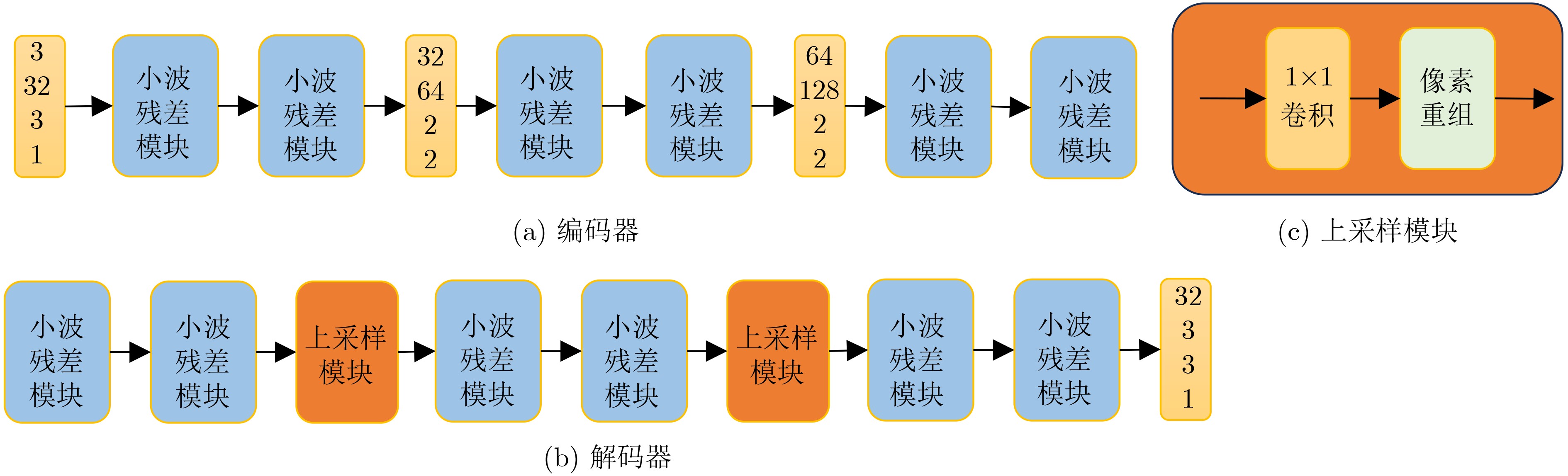
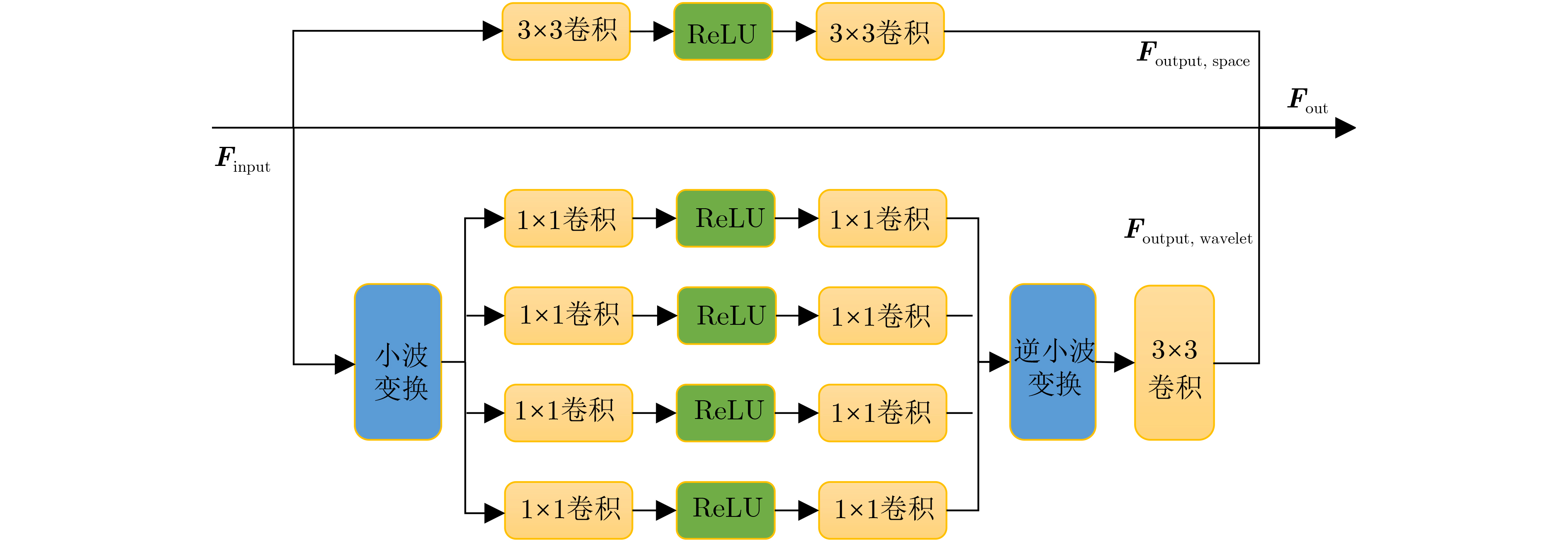
2024, 46(11): 4141-4150.
doi: 10.11999/JEIT240049
Abstract:
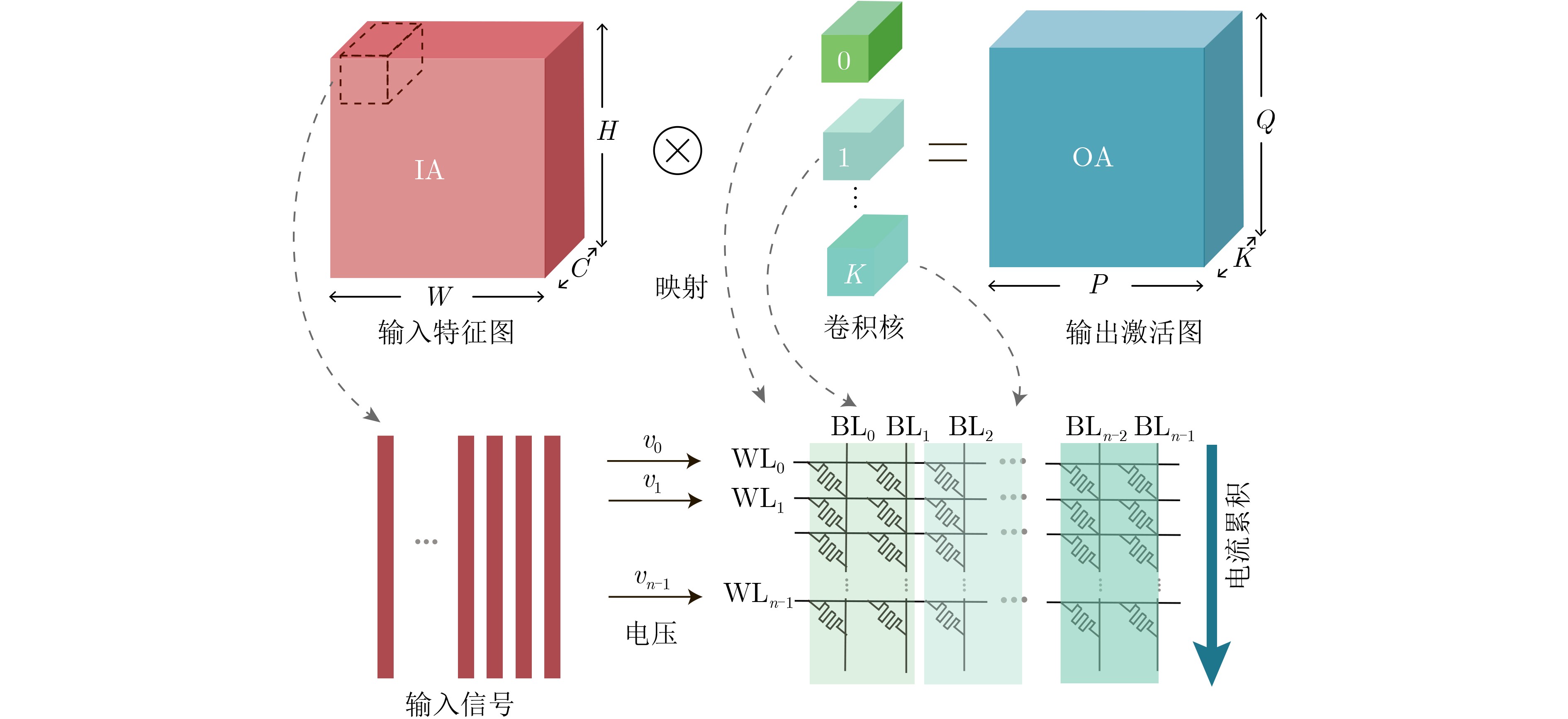
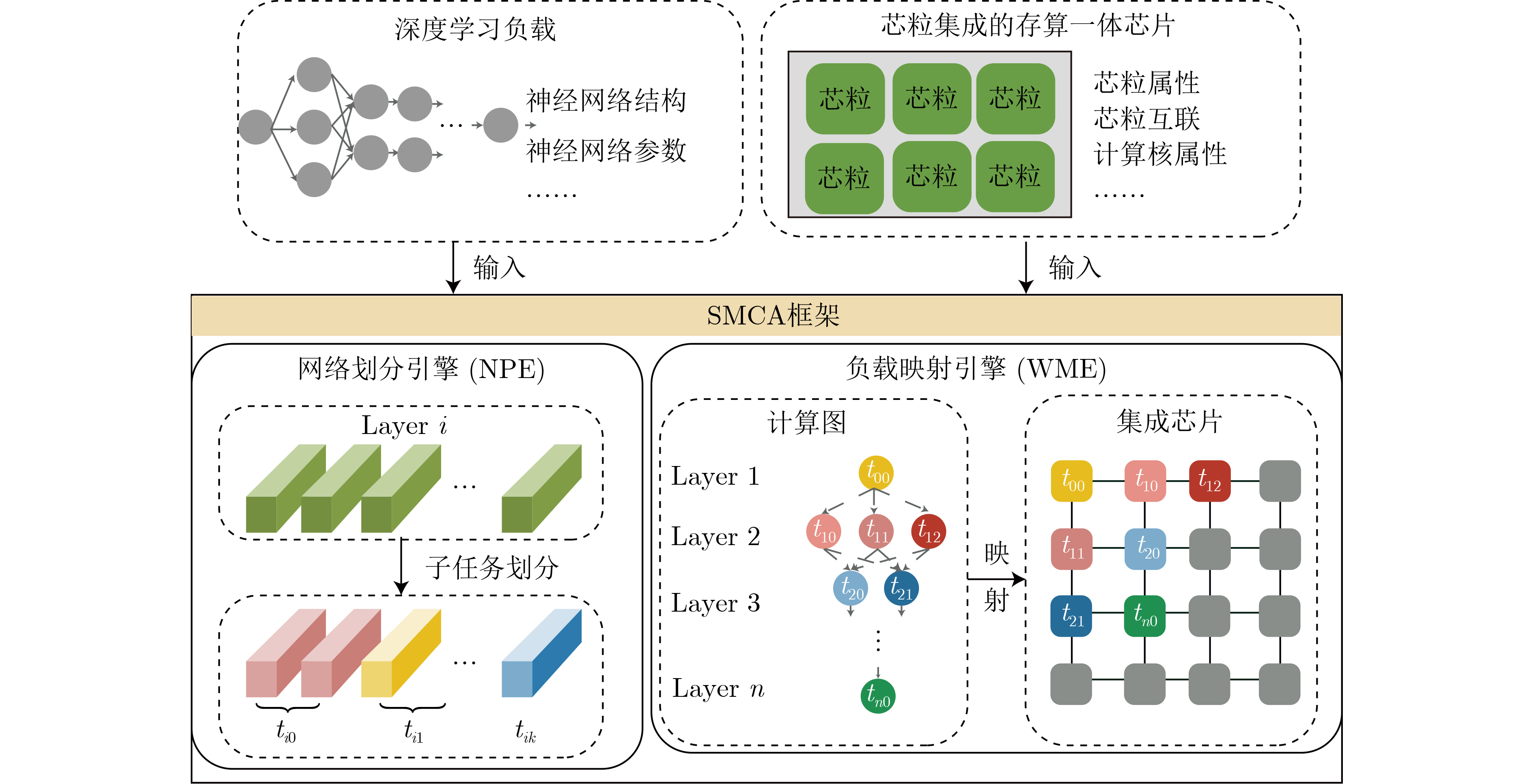
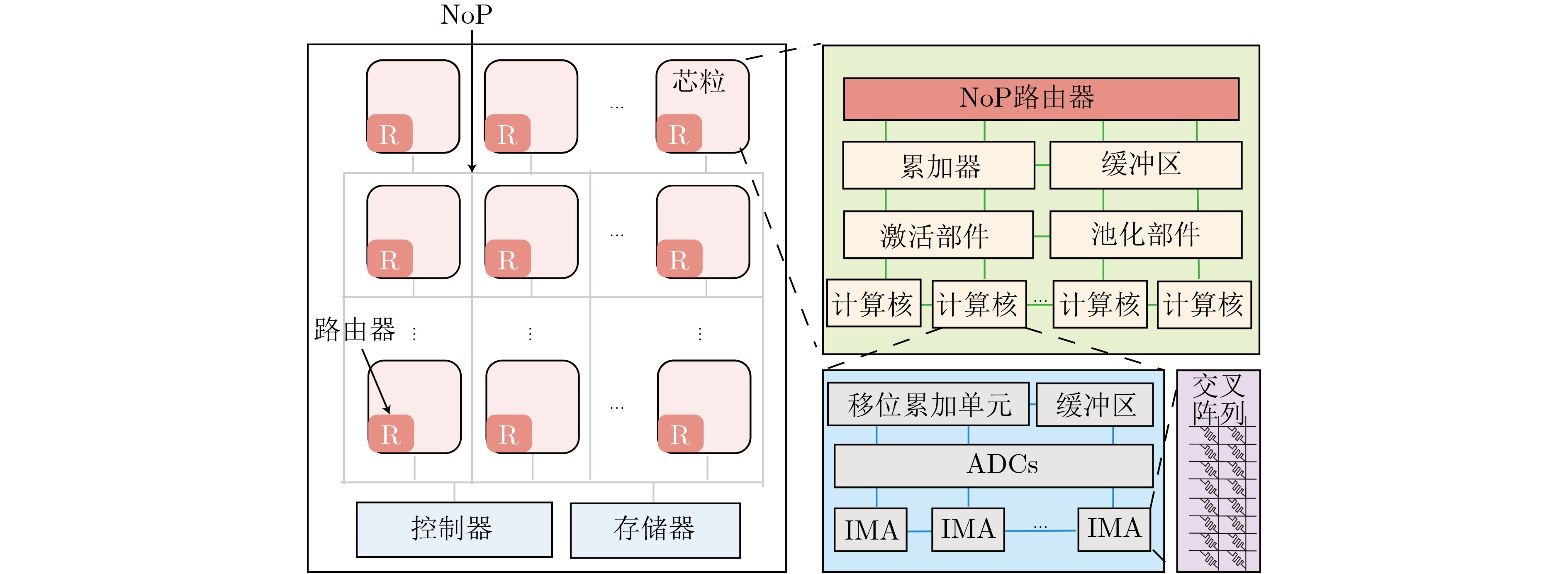
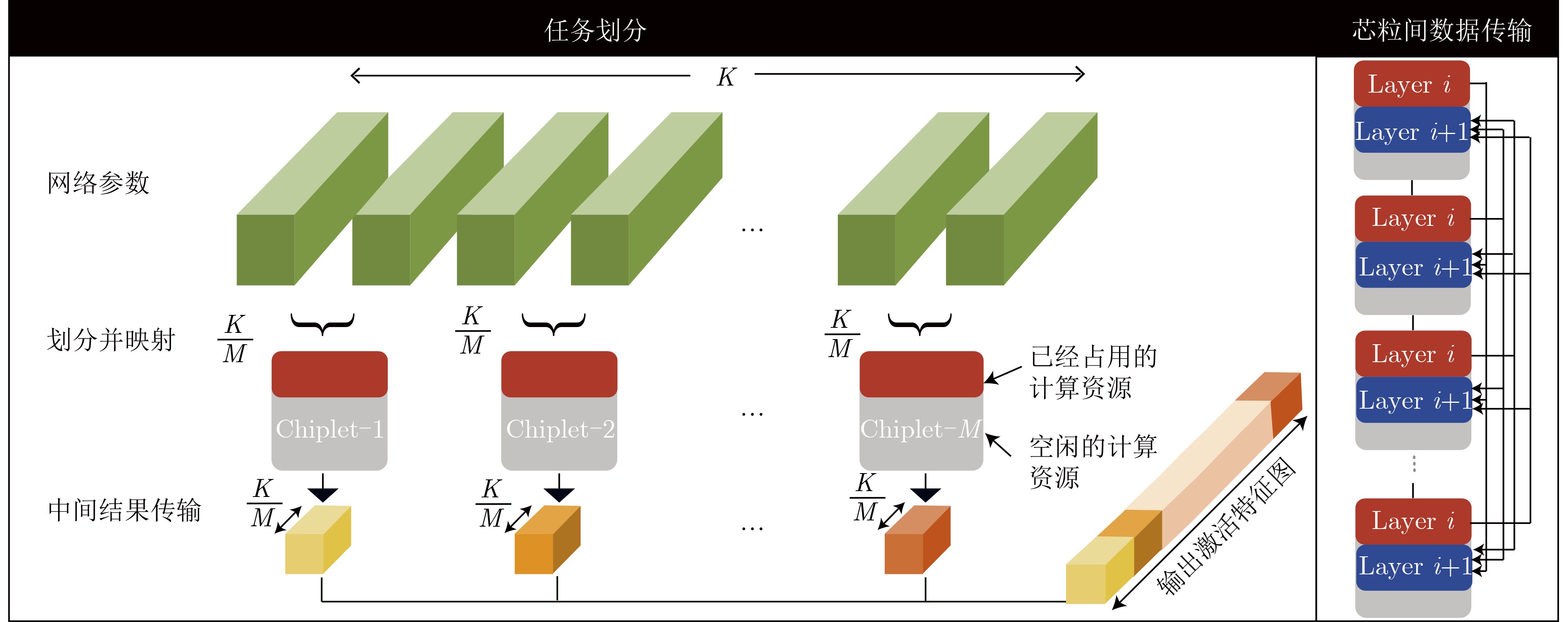
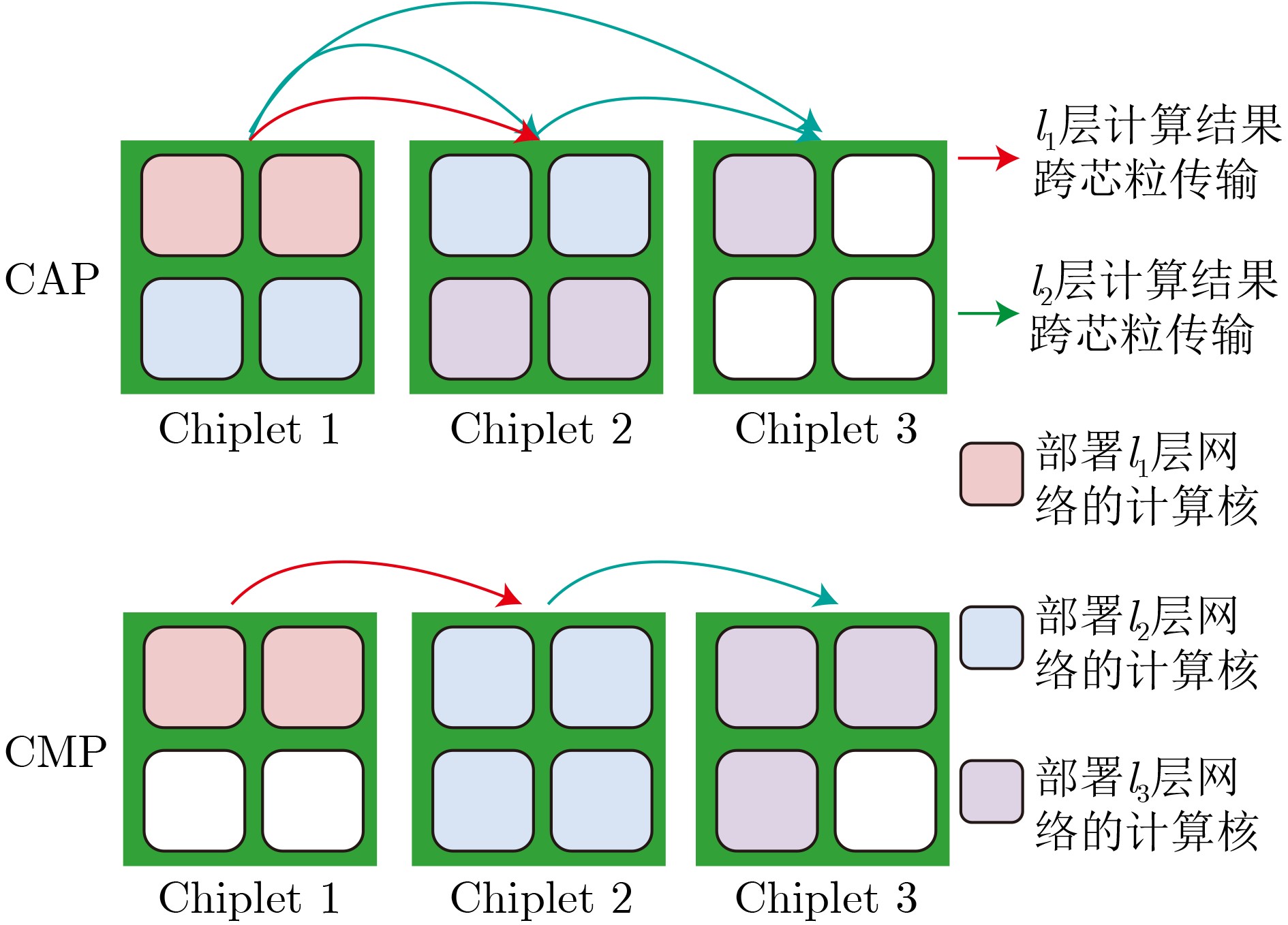
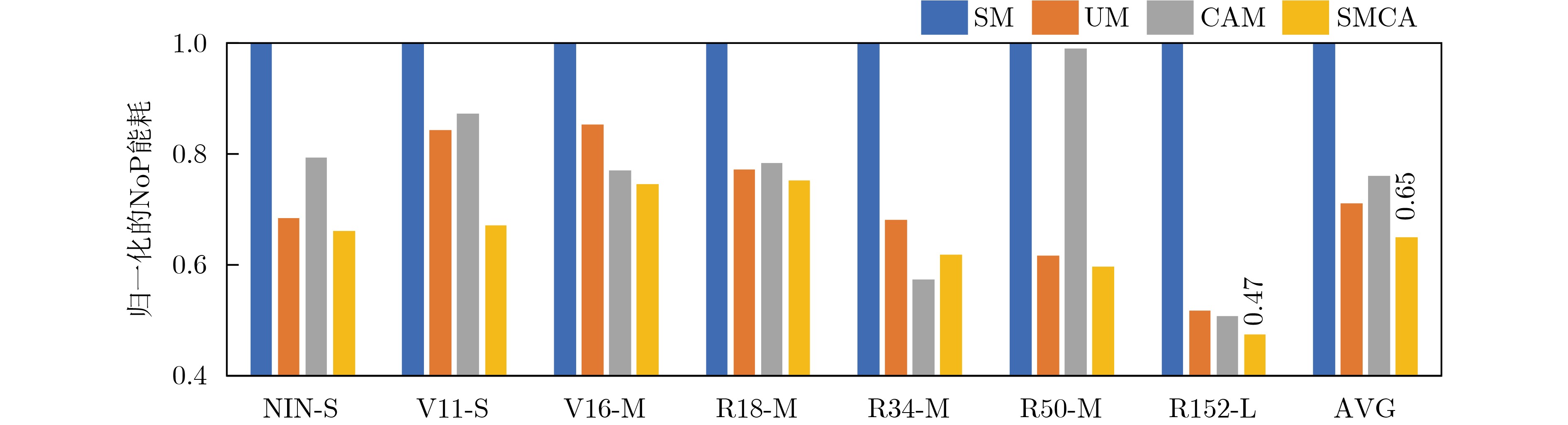
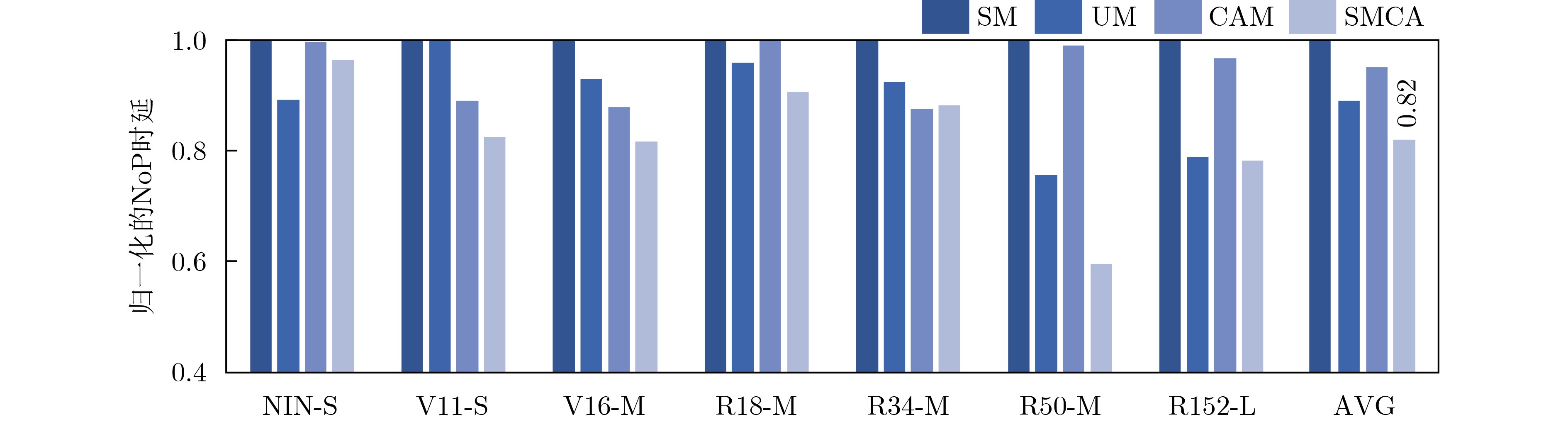
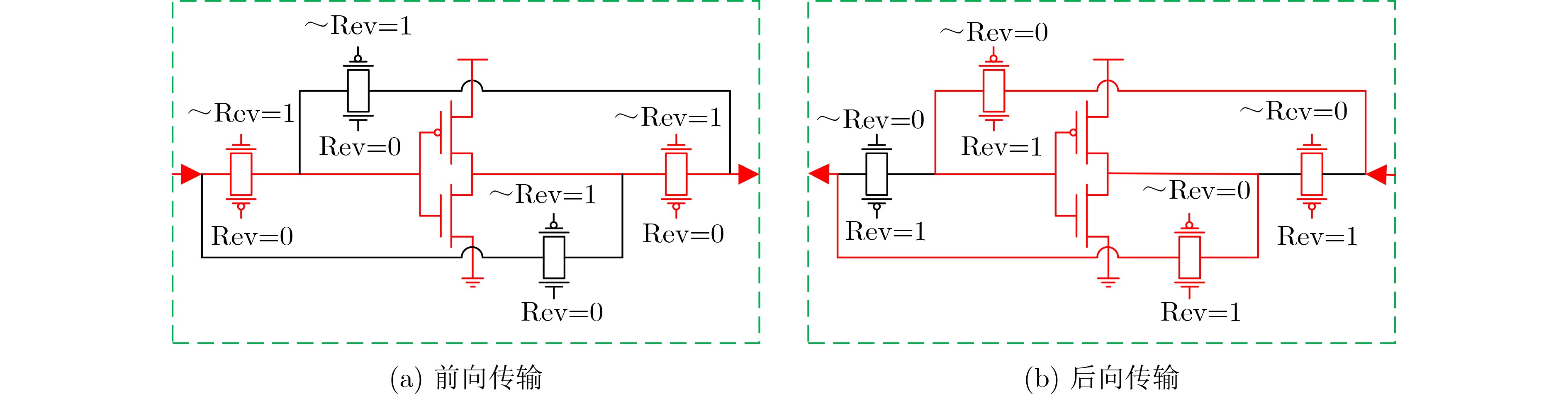
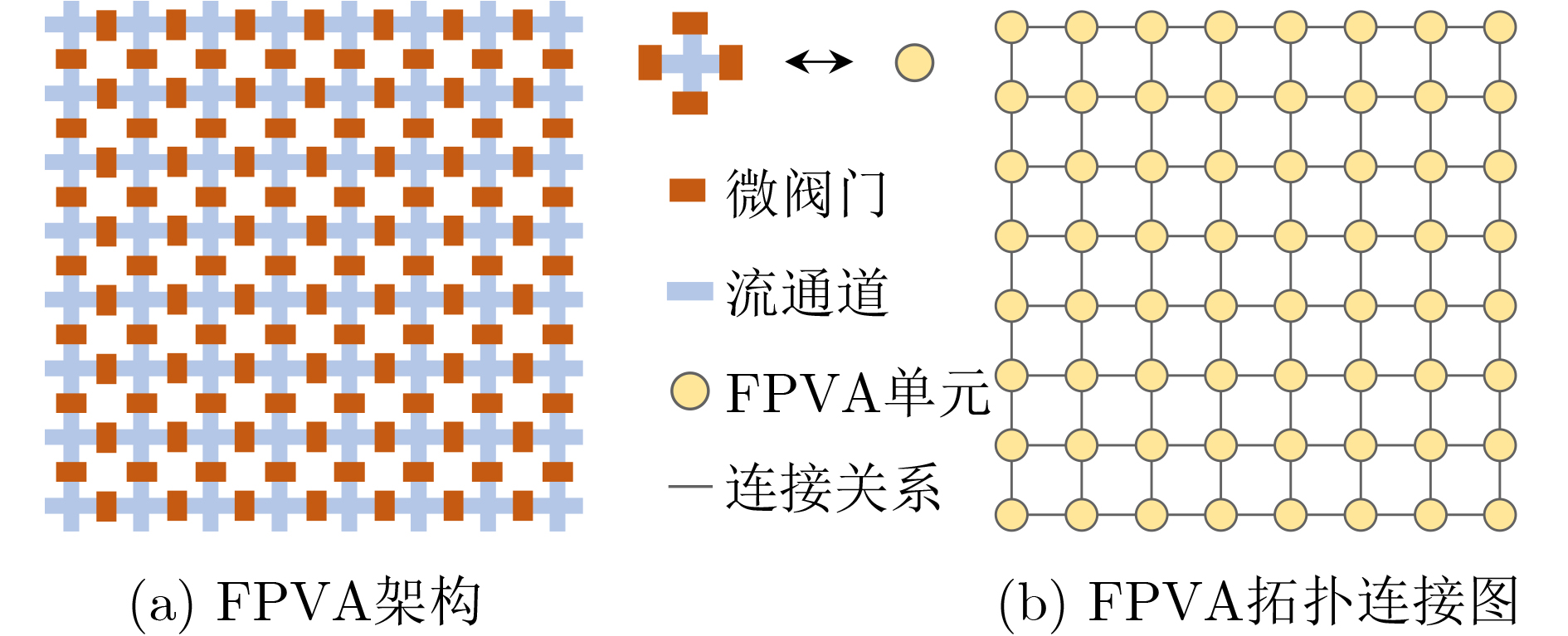
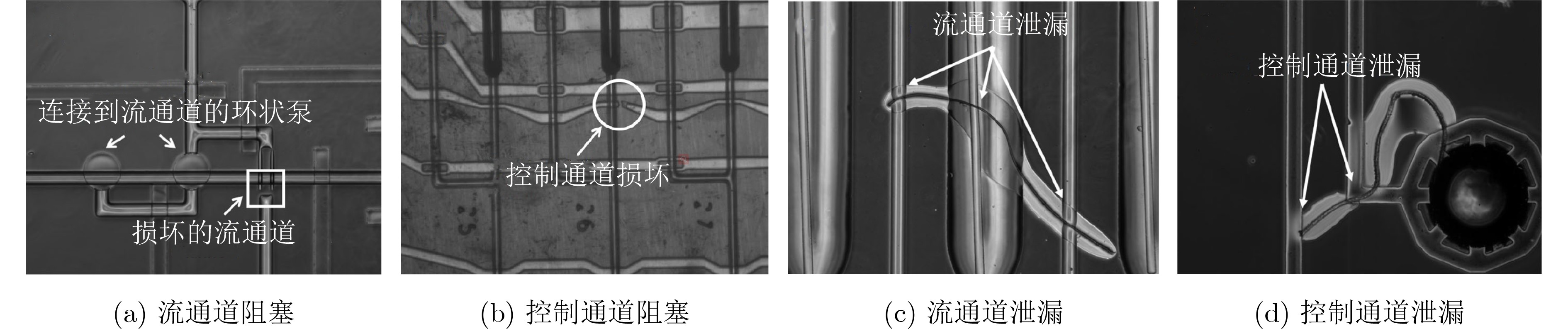
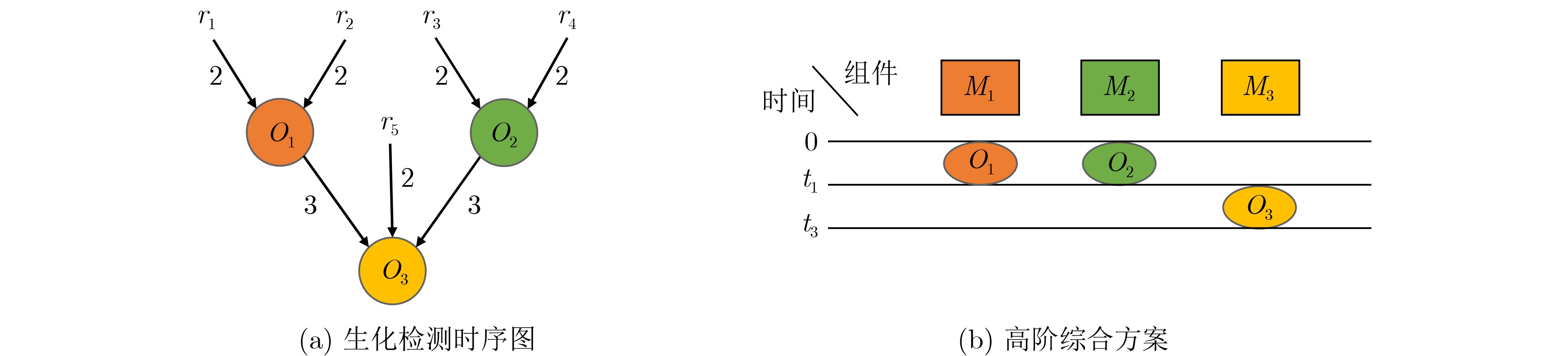
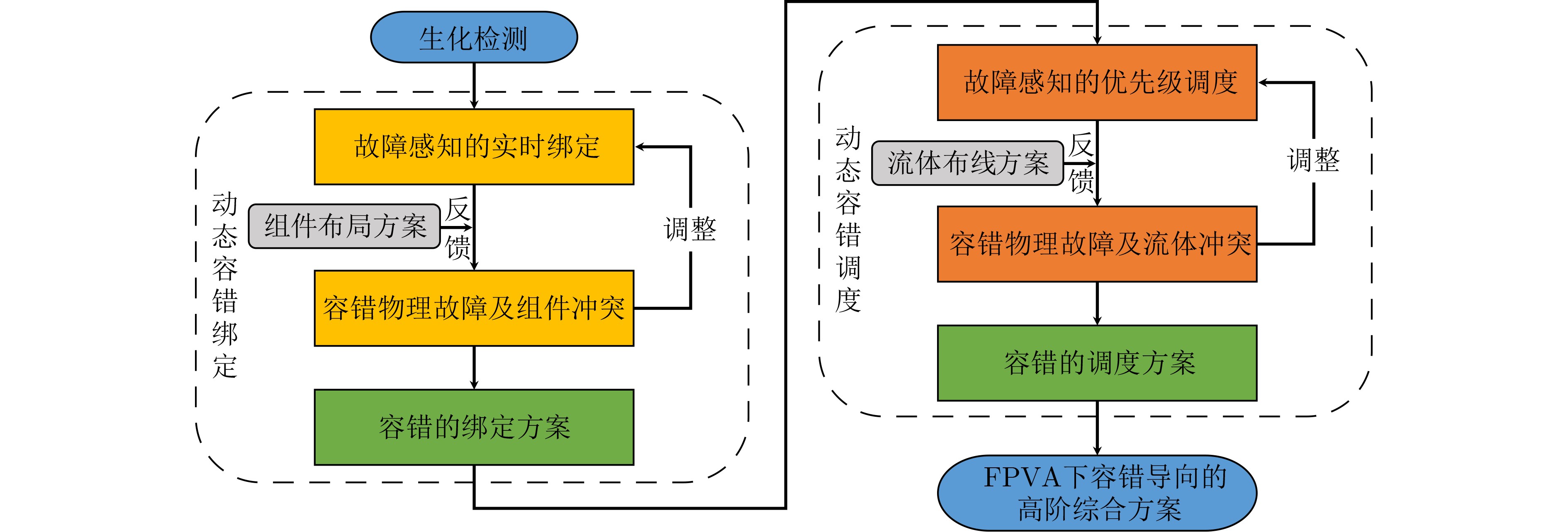
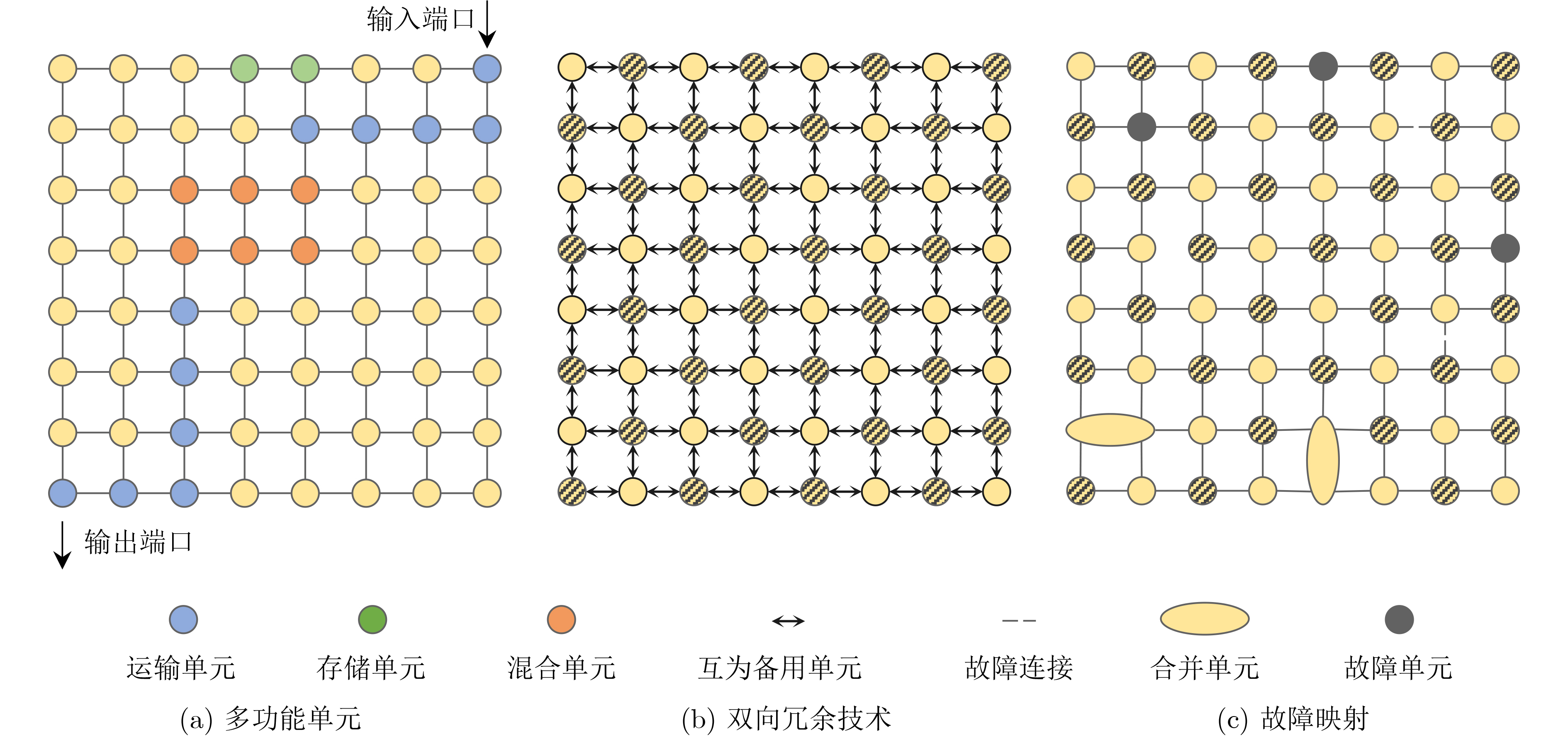
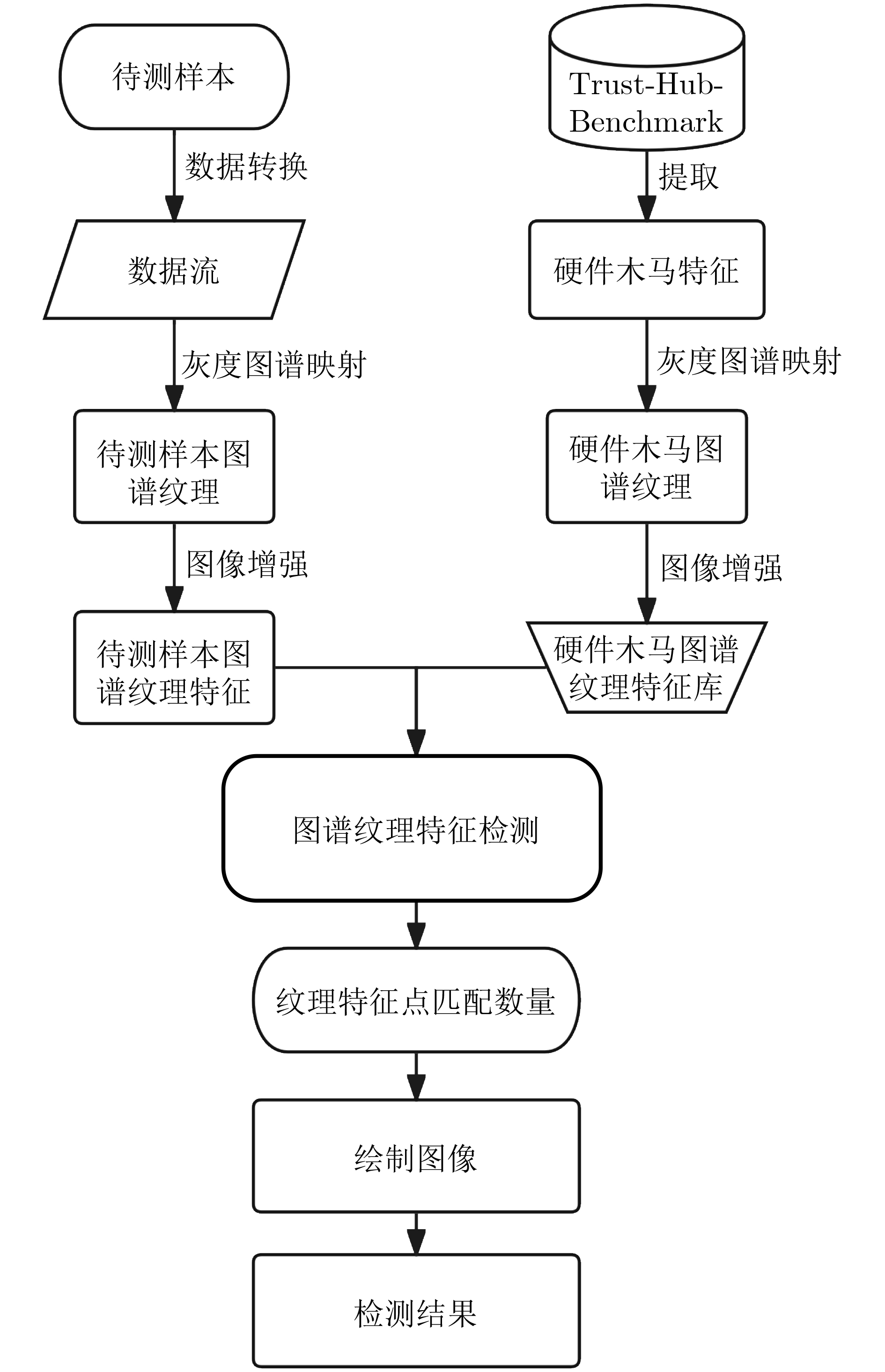
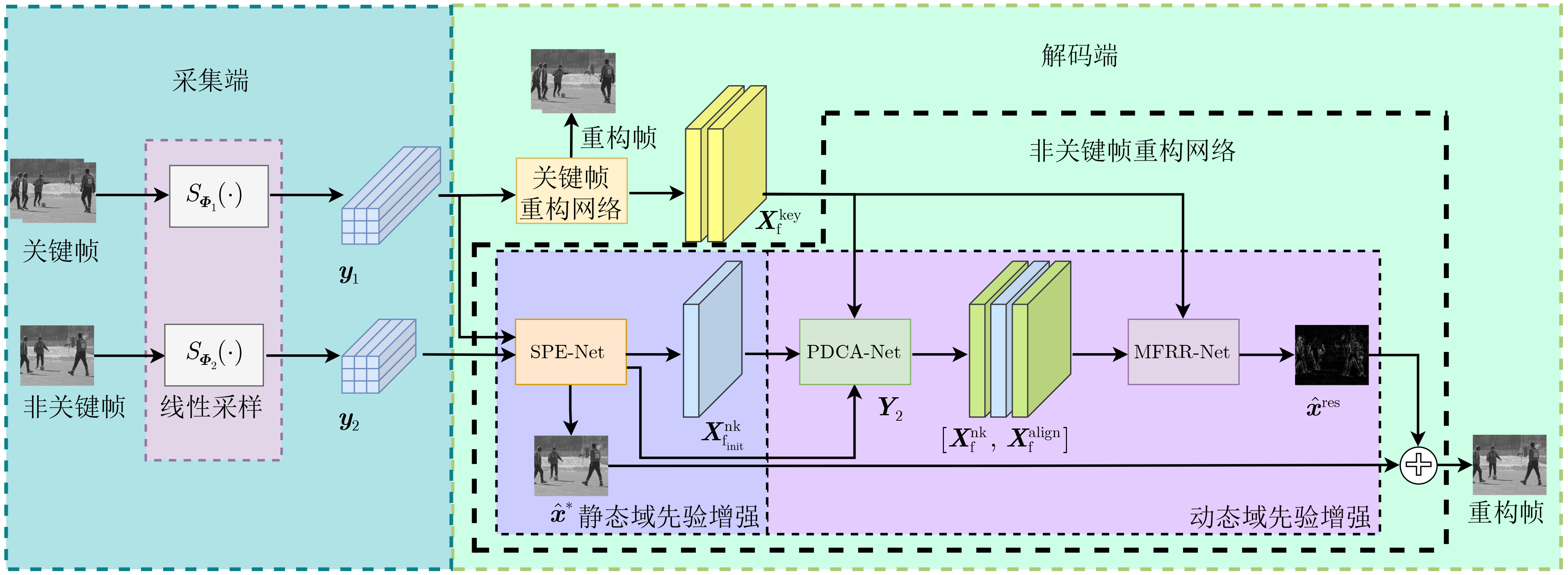
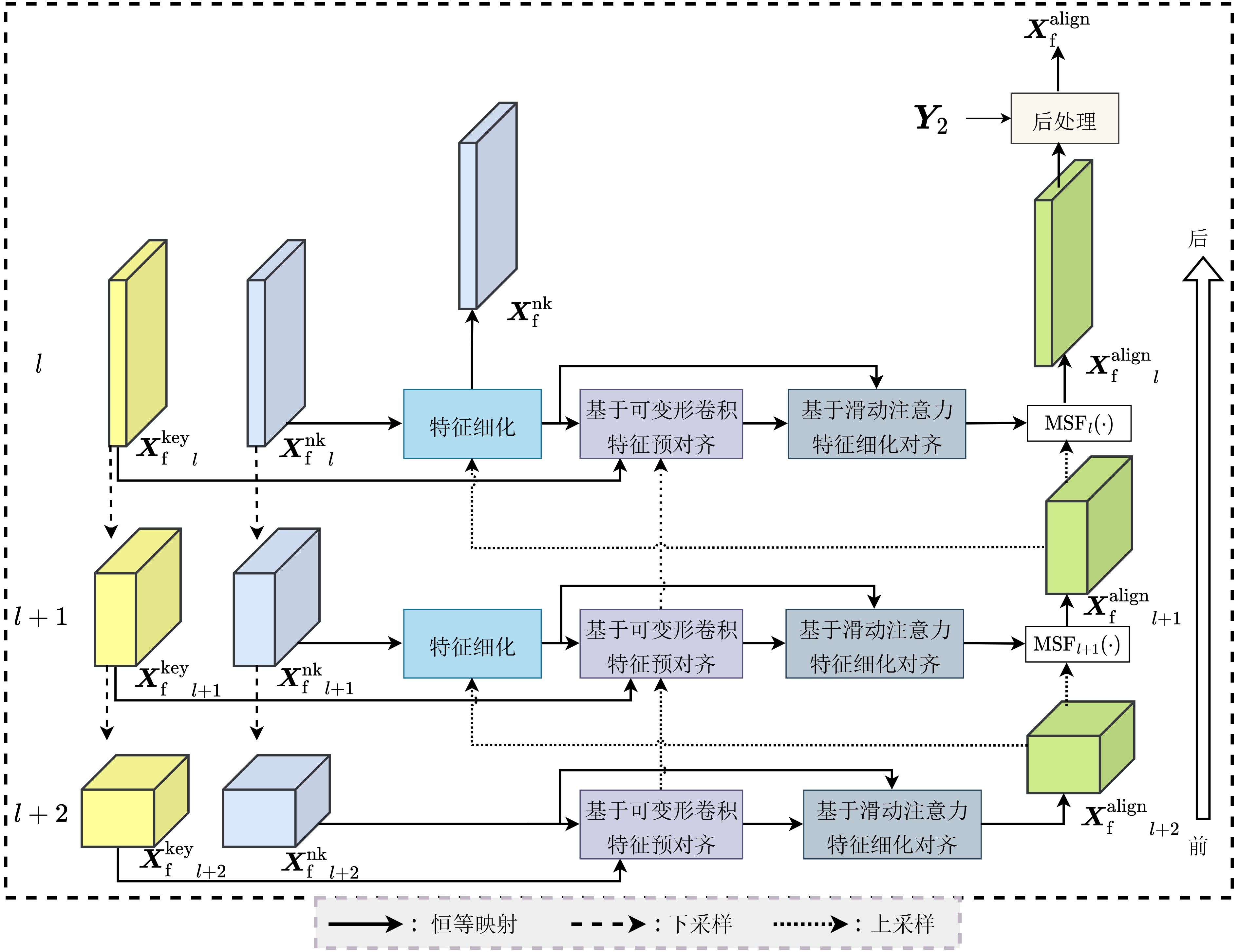
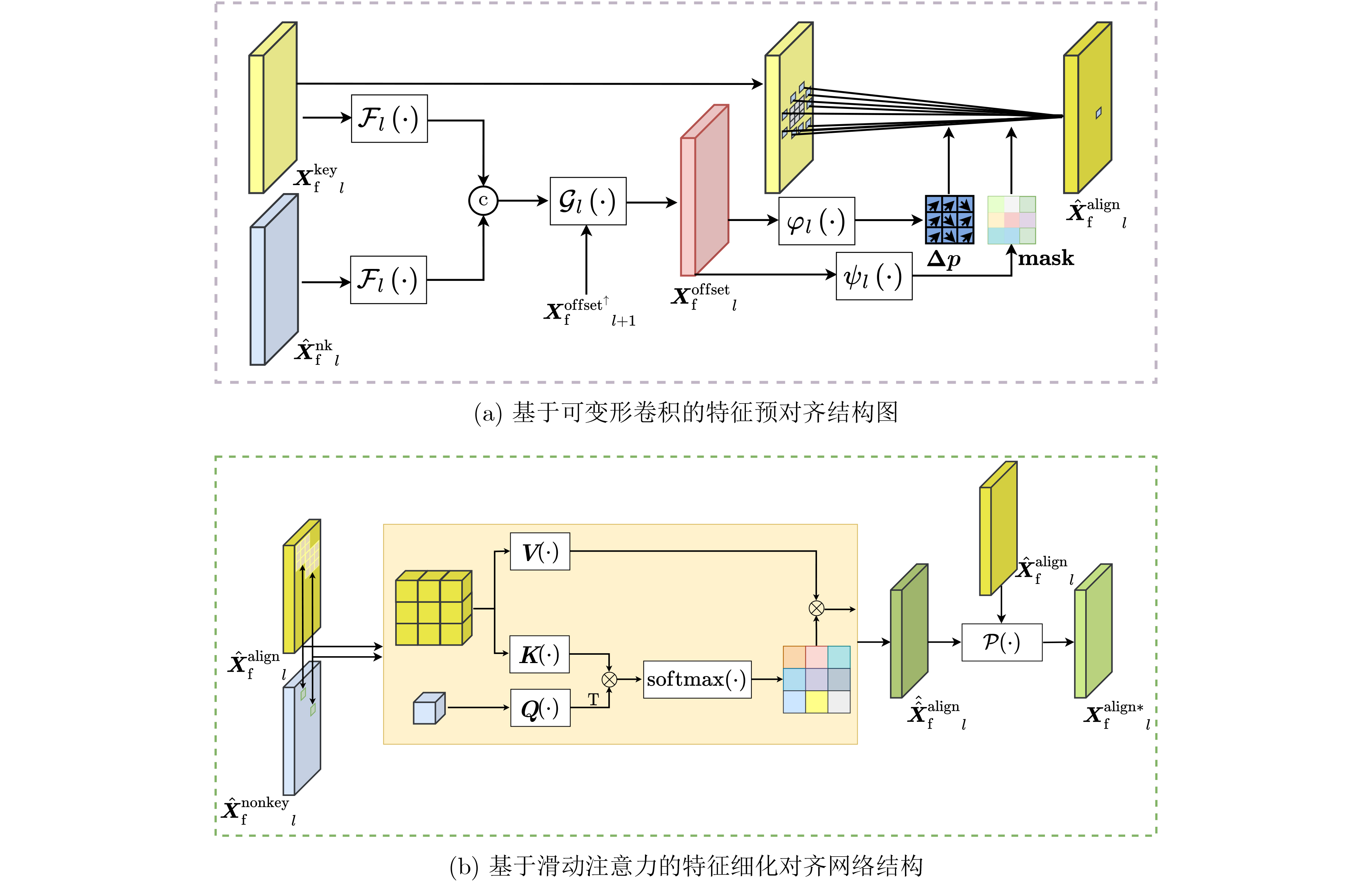
As a new generation of flow-based microfluidics, Fully Programmable Valve Array (FPVA) biochips have become a popular biochemical experimental platform that provide higher flexibility and programmability. Due to environmental and human factors, however, there are usually some physical faults in the manufacturing process such as channel blockage and leakage, which, undoubtedly, can affect the results of bioassays. In addition, as the primary stage of architecture synthesis, high-level synthesis directly affects the quality of sub-sequent design. The fault tolerance problem in the high-level synthesis stage of FPVA biochips is focused on for the first time in this paper, and dynamic fault-tolerant techniques, including a cell function conversion method, a bidirectional redundancy scheme, and a fault mapping method, are presented, providing technical guarantee for realizing efficient fault-tolerant design. By integrating these techniques into the high-level synthesis stage, a high-quality fault-tolerance-oriented high-level synthesis algorithm for FPVA biochips is further realized in this paper, including a fault-aware real-time binding strategy and a fault-aware priority scheduling strategy, which lays a good foundation for the robustness of chip architecture and the correctness of assay outcomes. Experimental results confirm that a high-quality and fault-tolerant high-level synthesis scheme of FPVA biochips can be obtained by the proposed algorithm, providing a strong guarantee for the subsequent realization of a fault-tolerant physical design scheme.