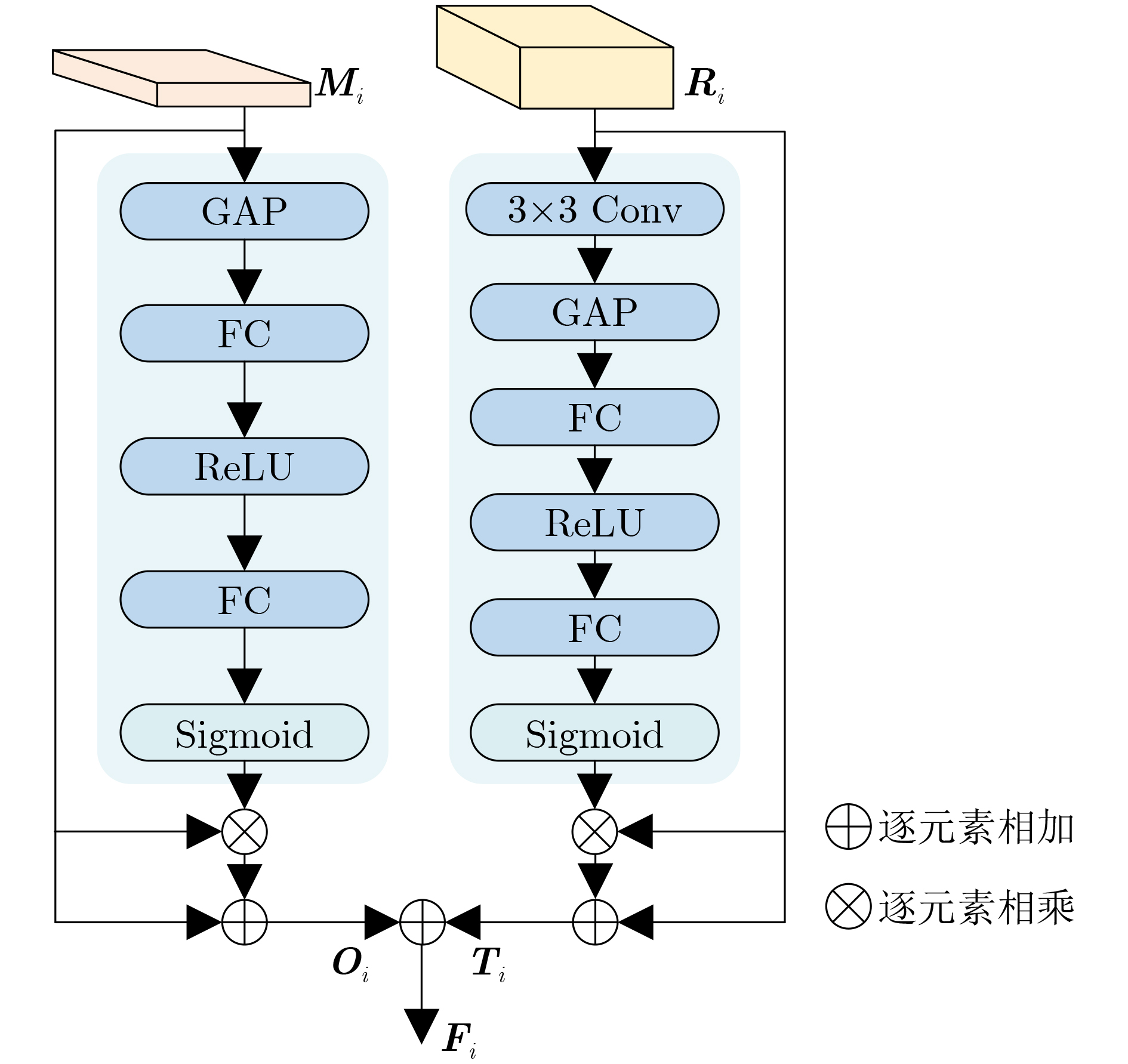
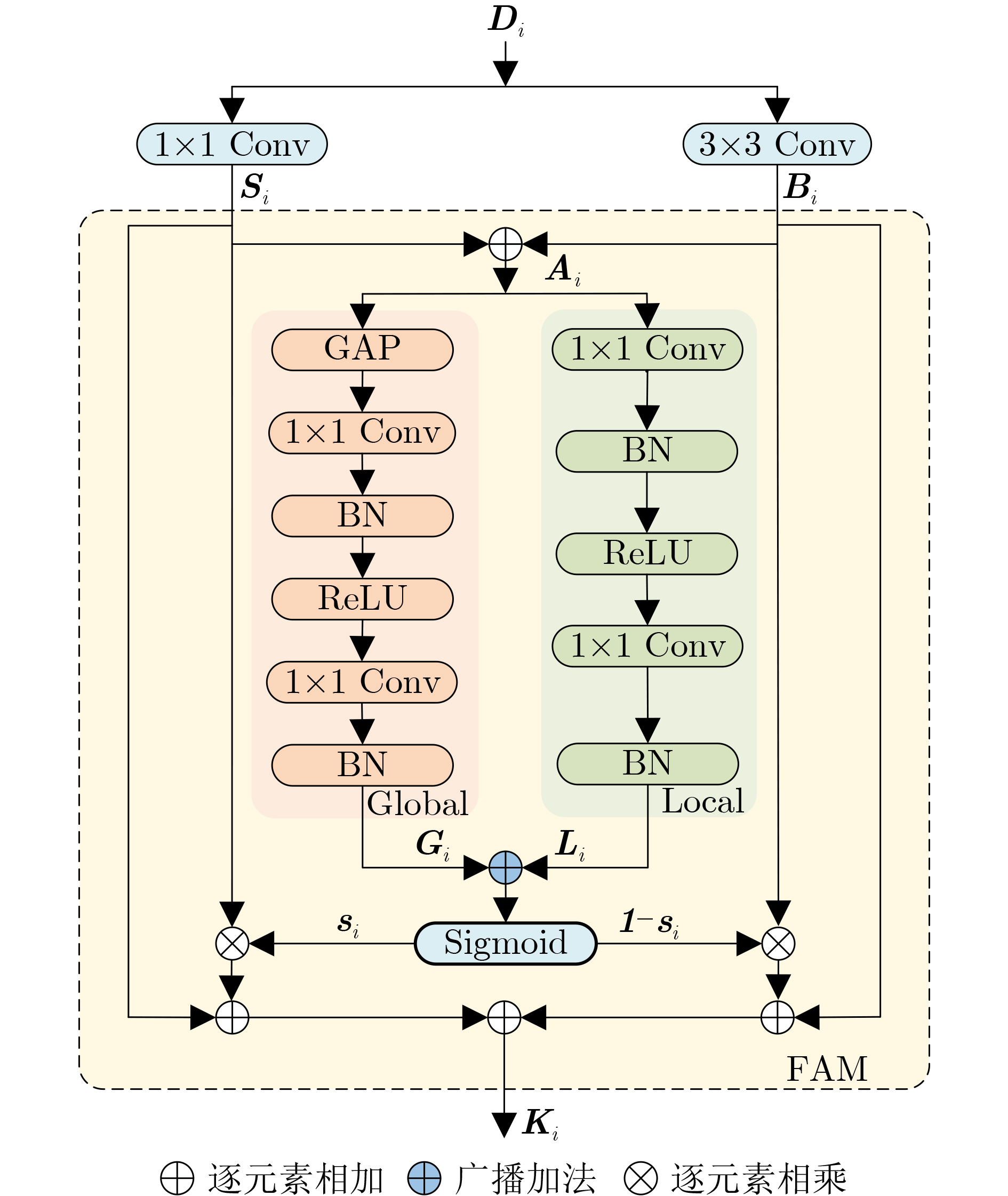
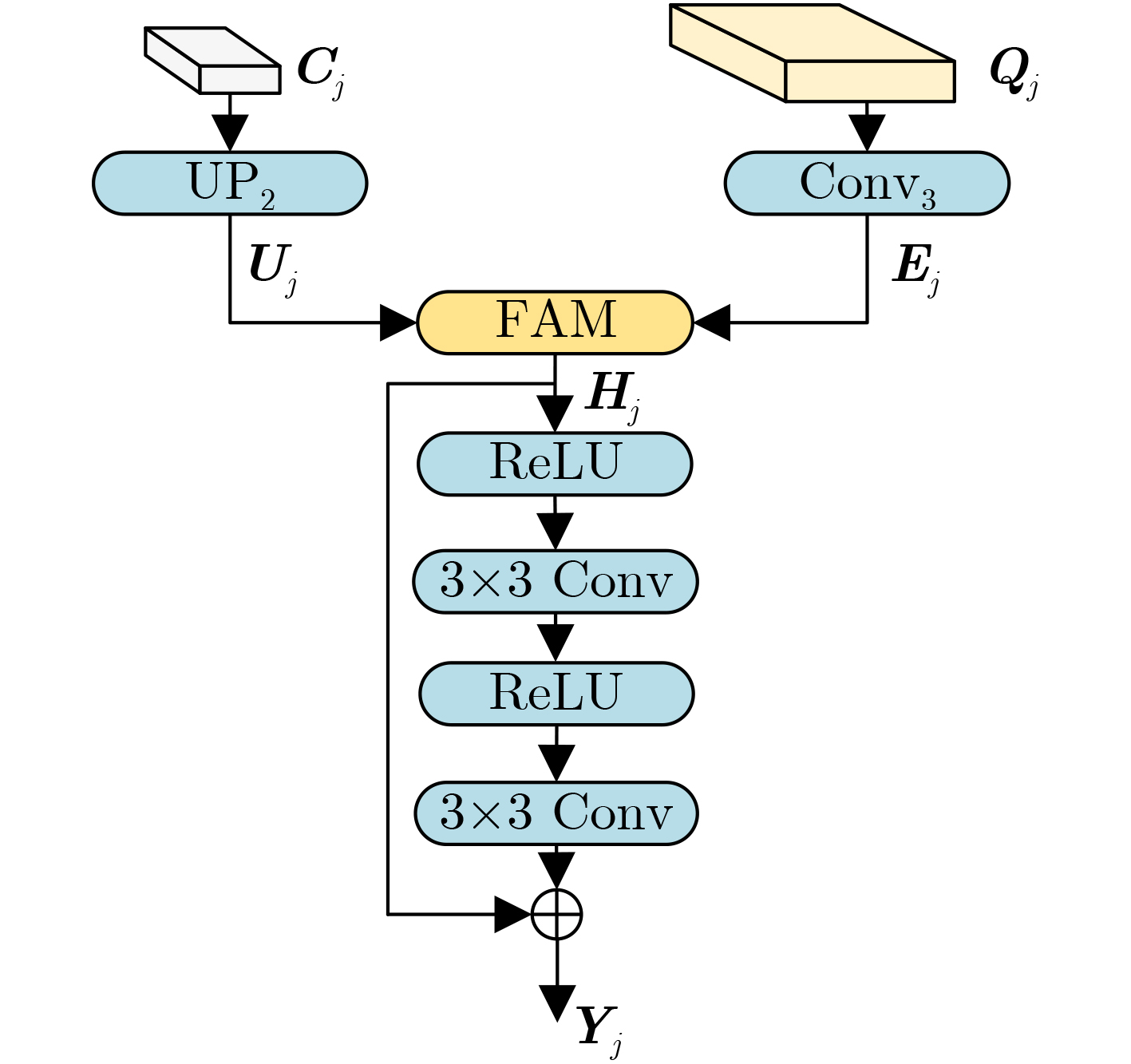
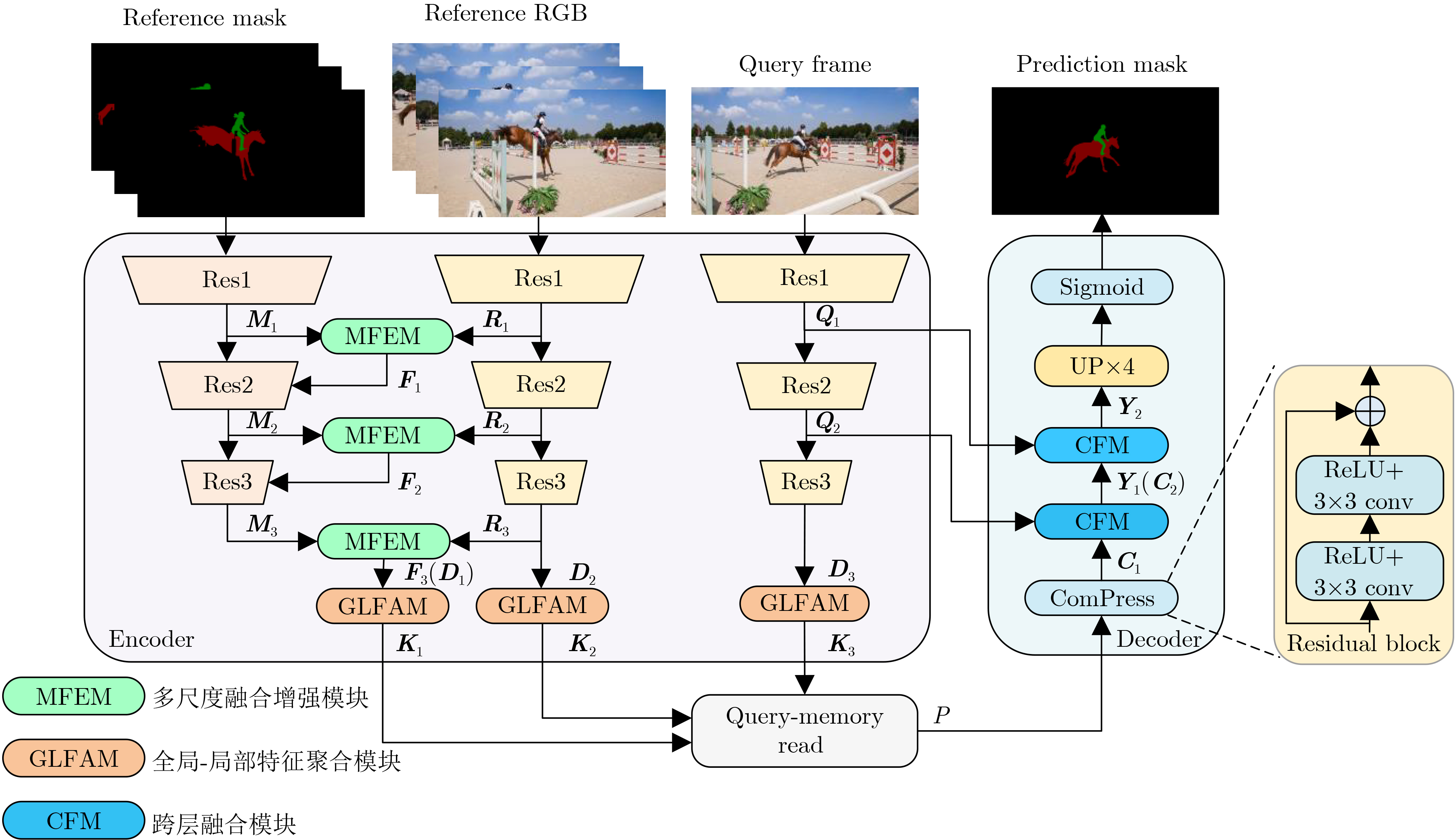
| Citation: | HOU Zhiqiang, DONG Jiale, MA Sugang, WANG Chenxu, YANG Xiaobao, WANG Yunchen. Video Object Segmentation Algorithm Based on Multi-scale Feature Enhancement and Global-Local Feature Aggregation[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4198-4207. doi: 10.11999/JEIT231394

|

| [1] |
ERDÉLYI A, BARÁT T, VALET P, et al. Adaptive cartooning for privacy protection in camera networks[C]. 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea (South), 2014: 44–49. doi: 10.1109/AVSS.2014.6918642.
|
| [2] |
WANG Wenguan, SHEN Jianbing, PORIKLI F, et al. Semi-supervised video object segmentation with super-trajectories[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 985–998. doi: 10.1109/TPAMI.2018.2819173.
|
| [3] |
SALEH K, HOSSNY M, and NAHAVANDI S. Kangaroo vehicle collision detection using deep semantic segmentation convolutional neural network[C]. 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 2016: 1–7. doi: 10.1109/DICTA.2016.7797057.
|
| [4] |
LU Xiankai, WANG Wenguan, SHEN Jianbing, et al. Learning video object segmentation from unlabeled videos[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 8957–8967. doi: 10.1109/CVPR42600.2020.00898.
|
| [5] |
CAELLES S, MANINIS K K, PONT-TUSET J, et al. One-shot video object segmentation[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5320–5329. doi: 10.1109/CVPR.2017.565.
|
| [6] |
CHENG H K, TAI Y W, and TANG C K. Modular interactive video object segmentation: Interaction-to-mask, propagation and difference-aware fusion[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5555–5564. doi: 10.1109/CVPR46437.2021.00551.
|
| [7] |
VOIGTLAENDER P and LEIBE B. Online adaptation of convolutional neural networks for video object segmentation[C]. British Machine Vision Conference 2017, London, UK, 2017.
|
| [8] |
OH S W, LEE J Y, SUNKAVALLI K, et al. Fast video object segmentation by reference-guided mask propagation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7376–7385. doi: 10.1109/CVPR.2018.00770.
|
| [9] |
徐金东, 赵甜雨, 冯国政, 等. 基于上下文模糊C均值聚类的图像分割算法[J]. 电子与信息学报, 2021, 43(7): 2079–2086. doi: 10.11999/JEIT200263.
XU Jindong, ZHAO Tianyu, FENG Guozheng, et al. Image segmentation algorithm based on context fuzzy C-means clustering[J]. Journal of Electronics & Information Technology, 2021, 43(7): 2079–2086. doi: 10.11999/JEIT200263.
|
| [10] |
杭昊, 黄影平, 张栩瑞, 等. 面向道路场景语义分割的移动窗口变换神经网络设计[J]. 光电工程, 2024, 51(1): 230304. doi: 10.12086/oee.2024.230304.
HANG Hao, HUANG Yingping, ZHANG Xurui, et al. Design of swin transformer for semantic segmentation of road scenes[J]. Opto-Electronic Engineering, 2024, 51(1): 230304. doi: 10.12086/oee.2024.230304.
|
| [11] |
OH S W, LEE J Y, XU Ning, et al. Video object segmentation using space-time memory networks[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 9225–9234. doi: 10.1109/ICCV.2019.00932.
|
| [12] |
LUITEN J, VOIGTLAENDER P, and LEIBE B. PReMVOS: Proposal-generation, refinement and merging for video object segmentation[C]. 14th Asian Conference on Computer Vision, Perth, Australia, 2019: 565–580. doi: 10.1007/978-3-030-20870-7_35.
|
| [13] |
PERAZZI F, KHOREVA A, BENENSON R, et al. Learning video object segmentation from static images[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3491–3500. doi: 10.1109/CVPR.2017.372.
|
| [14] |
JOHNANDER J, DANELLJAN M, BRISSMAN E, et al. A generative appearance model for end-to-end video object segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA: 2019: 8945–8954. doi: 10.1109/CVPR.2019.00916.
|
| [15] |
LI Yu, SHEN Zhuoran, and SHAN Ying. Fast video object segmentation using the global context module[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 735–750. doi: 10.1007/978-3-030-58607-2_43.
|
| [16] |
SEONG H, HYUN J, and KIM E. Kernelized memory network for video object segmentation[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 629–645. doi: 10.1007/978-3-030-58542-6_38.
|
| [17] |
SEONG H, HYUN J, and KIM E. Video object segmentation using Kernelized memory network with multiple kernels[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2595–2612. doi: 10.1109/TPAMI.2022.3163375.
|
| [18] |
KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015.
|
| [19] |
ZHU Wencheng, LI Jiahao, LU Jiwen, et al. Separable structure modeling for semi-supervised video object segmentation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(1): 330–344. doi: 10.1109/TCSVT.2021.3060015.
|
| [20] |
CHO S, LEE M, LEE S, et al. Treating motion as option to reduce motion dependency in unsupervised video object segmentation[C]. The IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 5129–5138. doi: 10.1109/WACV56688.2023.00511.
|
| [21] |
ROBINSON A, LAWIN F J, DANELLJAN M, et al. Learning fast and robust target models for video object segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7404–7413. doi: 10.1109/CVPR42600.2020.00743.
|
| [22] |
MEI Jianbiao, WANG Mengmeng, LIN Yeneng, et al. TransVOS: Video object segmentation with transformers[J]. arXiv: 2106.00588, 2021. doi: 10.48550/arXiv.2106.00588.
|
| [23] |
GAO Bocong, ZHAO Yuqian, ZHANG Fan, et al. Video object segmentation based on multi-level target models and feature integration[J]. Neurocomputing, 2022, 492: 396–407. doi: 10.1016/j.neucom.2022.04.042.
|
| [24] |
徐凯, 李国荣, 洪德祥, 等. 结合在线归纳和直推推理的快速视频目标分割方法[J]. 计算机学报, 2022, 45(10): 2117–2132. doi: 10.11897/SP.J.1016.2022.02117.
XU Kai, LI Guorong, HONG Dexiang, et al. A fast video object segmentation method based on inductive learning and transductive reasoning[J]. Chinese Journal of Computers, 2022, 45(10): 2117–2132. doi: 10.11897/SP.J.1016.2022.02117.
|
| [25] |
MANINIS K K, CAELLES S, CHEN Yuhua, et al. Video object segmentation without temporal information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(6): 1515–1530. doi: 10.1109/TPAMI.2018.2838670.
|
| [26] |
YANG Linjie, WANG Yanran, XIONG Xuehan, et al. Efficient video object segmentation via network modulation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6499–6507. doi: 10.1109/CVPR.2018.00680.
|
| [27] |
CHENG Jingchun, TSAI Y H, HUNG W C, et al. Fast and accurate online video object segmentation via tracking parts[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7415–7424. doi: 10.1109/CVPR.2018.00774.
|
| [28] |
WANG Ziqin, XU Jun, LIU Li, et al. RANet: Ranking attention network for fast video object segmentation[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 3977–3986. doi: 10.1109/ICCV.2019.00408.
|
| [29] |
SUN Mingjie, XIAO Jimin, LIM E G, et al. Fast template matching and update for video object tracking and segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10788–10796. doi: 10.1109/CVPR42600.2020.01080.
|
| [30] |
LAN Meng, ZHANG Jing, ZHANG Lefei, et al. Learning to learn better for video object segmentation[C]. The AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 1205–1212. doi: 10.1609/aaai.v37i1.25203.
|
Figures(7) / Tables(3)



 DownLoad:
DownLoad: