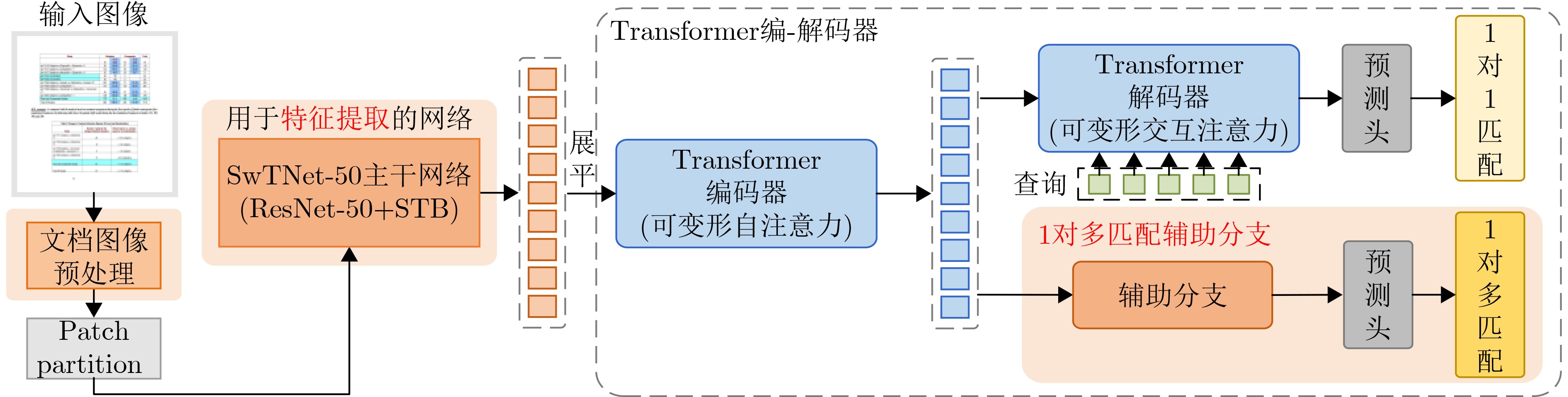
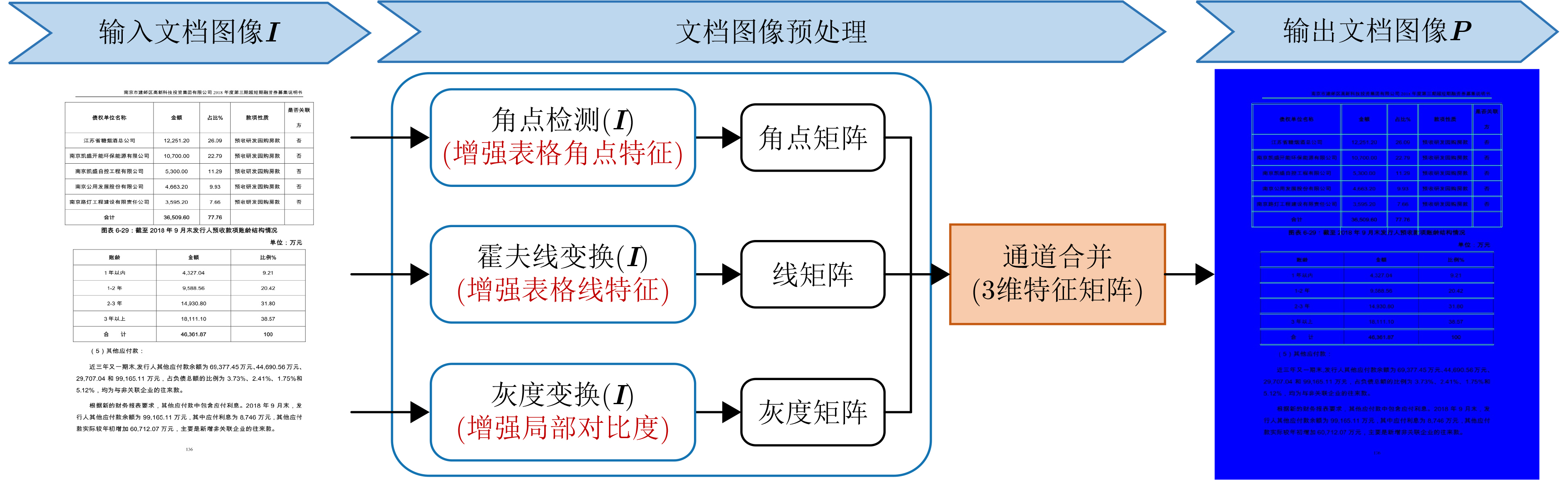
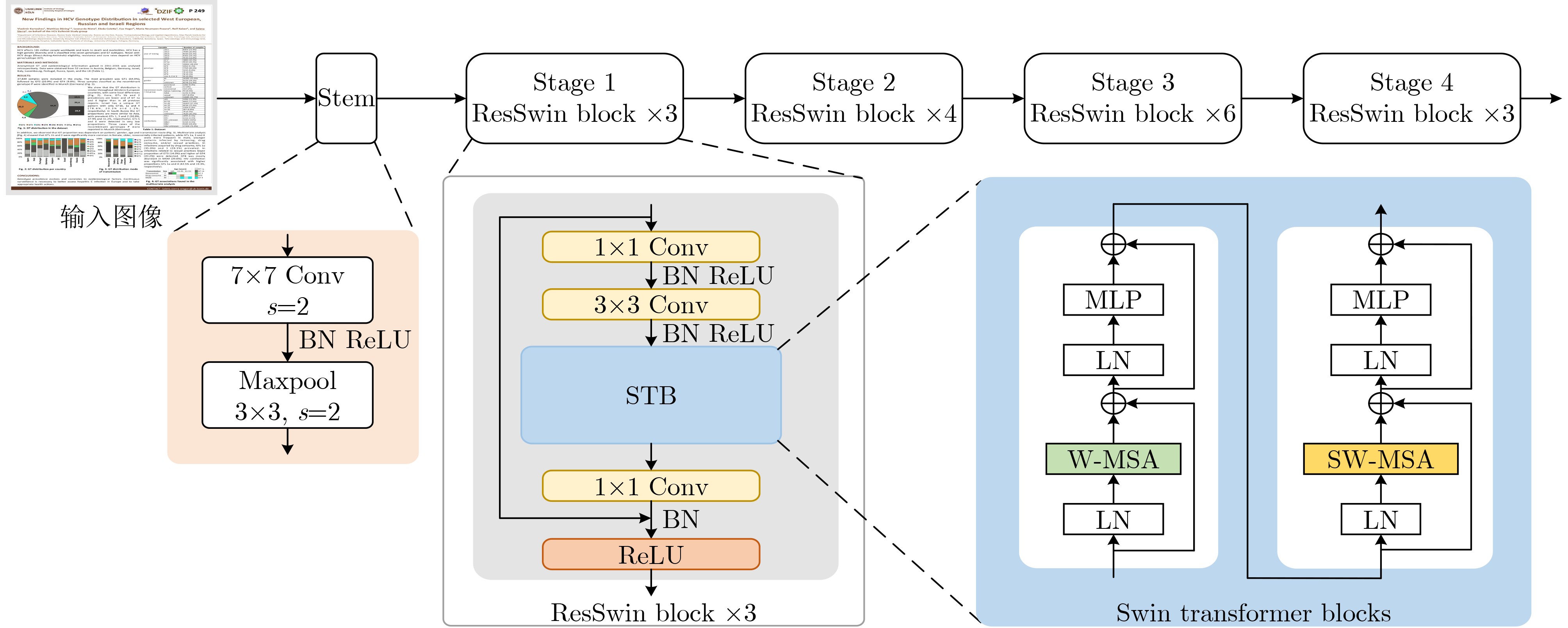
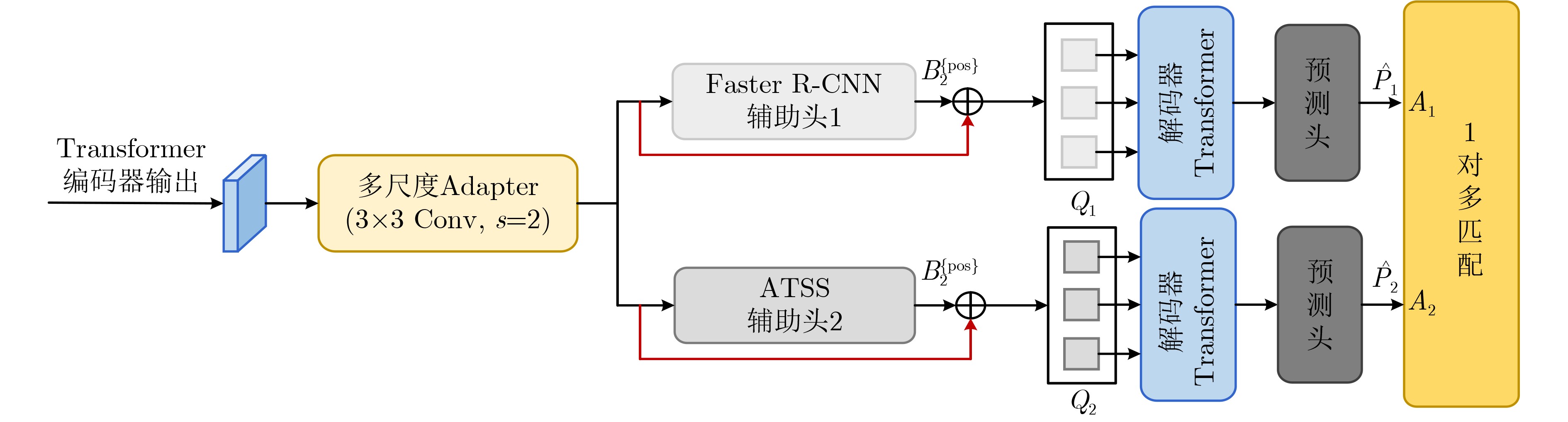
| Citation: | LU Di, YUAN Xuan. LGDNet: Table Detection Network Combining Local and Global Features[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4553-4562. doi: 10.11999/JEIT240428

|

| [1] |
高良才, 李一博, 都林, 等. 表格识别技术研究进展[J]. 中国图象图形学报, 2022, 27(6): 1898–1917. doi: 10.11834/jig.220152.
GAO Liangcai, LI Yibo, DU Lin, et al. A survey on table recognition technology[J]. Journal of Image and Graphics, 2022, 27(6): 1898–1917. doi: 10.11834/jig.220152.
|
| [2] |
WATANABE T, LUO Qin, and SUGIE N. Structure recognition methods for various types of documents[J]. Machine Vision and Applications, 1993, 6(2/3): 163–176. doi: 10.1007/BF01211939.
|
| [3] |
GATOS B, DANATSAS D, PRATIKAKIS I, et al. Automatic table detection in document images[C]. The Third International Conference on Advances in Pattern Recognition, Bath, UK, 2005: 609–618. doi: 10.1007/11551188_67.
|
| [4] |
KASAR T, BARLAS P, ADAM S, et al. Learning to detect tables in scanned document images using line information[C]. 2013 12th International Conference on Document Analysis and Recognition, Washington, USA, 2013: 1185–1189. doi: 10.1109/ICDAR.2013.240.
|
| [5] |
ANH T, IN-SEOP N, and SOO-HYUNG K. A hybrid method for table detection from document image[C]. 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 2015: 131–135. doi: 10.1109/ACPR.2015.7486480.
|
| [6] |
LEE K H, CHOY Y C, and CHO S B. Geometric structure analysis of document images: A knowledge-based approach[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1224–1240. doi: 10.1109/34.888708.
|
| [7] |
SCHREIBER S, AGNE S, WOLF I, et al. DeepDeSRT: Deep learning for detection and structure recognition of tables in document images[C]. 2017 14th IAPR International Conference on Document Analysis and Recognition, Kyoto, Japan, 2017: 1162–1167. doi: 10.1109/ICDAR.2017.192.
|
| [8] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031.
|
| [9] |
ARIF S and SHAFAIT F. Table detection in document images using foreground and background features[C]. 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 2018: 1–8. doi: 10.1109/DICTA.2018.8615795.
|
| [10] |
SIDDIQUI S A, MALIK M I, AGNE S, et al. DeCNT: Deep deformable CNN for table detection[J]. IEEE Access, 2018, 6: 74151–74161. doi: 10.1109/ACCESS.2018.2880211.
|
| [11] |
SUN Ningning, ZHU Yuanping, and HU Xiaoming. Faster R-CNN based table detection combining corner locating[C]. 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 2019: 1314–1319. doi: 10.1109/ICDAR.2019.00212.
|
| [12] |
CAI Zhaowei and VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA, 2018: 6154–6162. doi: 10.1109/CVPR.2018.00644.
|
| [13] |
PRASAD D, GADPAL A, KAPADNI K, et al. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, USA, 2020: 2439–2447. doi: 10.1109/CVPRW50498.2020.00294.
|
| [14] |
AGARWAL M, MONDAL A, and JAWAHAR C V. CDeC-Net: Composite deformable cascade network for table detection in document images[C]. 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 2021: 9491–9498. doi: 10.1109/ICPR48806.2021.9411922.
|
| [15] |
HUANG Yilun, YAN Qinqin, LI Yibo, et al. A YOLO-based table detection method[C]. 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 2019: 813–818. doi: 10.1109/ICDAR.2019.00135.
|
| [16] |
SHEHZADI T, HASHMI K A, STRICKER D, et al. Towards end-to-end semi-supervised table detection with deformable transformer[C]. The 17th International Conference on Document Analysis and Recognition-ICDAR 2023, San José, USA, 2023: 51–76. doi: 10.1007/978-3-031-41679-8_4.
|
| [17] |
ZHU Xizhou, SU Weijie, LU Lewei, et al. Deformable DETR: Deformable transformers for end-to-end object detection[C]. The 9th International Conference on Learning Representations, Vienna, Austria, 2021.
|
| [18] |
XIAO Bin, SIMSEK M, KANTARCI B, et al. Table detection for visually rich document images[J]. Knowledge-Based Systems, 2023, 282: 111080. doi: 10.1016/j.knosys.2023.111080.
|
| [19] |
SUN Peize, ZHANG Rufeng, JIANG Yi, et al. Sparse R-CNN: End-to-end object detection with learnable proposals[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 14449–14458. doi: 10.1109/CVPR46437.2021.01422.
|
| [20] |
CHEN Shoufa, SUN Peize, SONG Yibing, et al. DiffusionDet: Diffusion model for object detection[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 19773–19786. doi: 10.1109/ICCV51070.2023.01816.
|
| [21] |
ZHANG Hao, LI Feng, LIU Shilong, et al. DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection[EB/OL]. https://arxiv.org/abs/2203.03605, 2022.
|
| [22] |
ZONG Zhuofan, SONG Guanglu, and LIU Yu. DETRs with collaborative hybrid assignments training[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 6748–6758. doi: 10.1109/ICCV51070.2023.00621.
|
| [23] |
ABDALLAH A, BERENDEYEV A, NURADIN I, et al. TNCR: Table net detection and classification dataset[J]. Neurocomputing, 2022, 473: 79–97. doi: 10.1016/j.neucom.2021.11.101.
|
| [24] |
MONDAL A, LIPPS P, and JAWAHAR C V. IIIT-AR-13K: A new dataset for graphical object detection in documents[C]. The 14th IAPR International Workshop, DAS 2020, Wuhan, China, 2020: 216-230. doi: 10.1007/978-3-030-57058-3_16.
|
| [25] |
HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980–2988. doi: 10.1109/ICCV.2017.322.
|
Figures(11) / Tables(4)



 DownLoad:
DownLoad: