| Citation: | XUE Peiyun, DAI Shutao, BAI Jing, GAO Xiang. Emotion Recognition with Speech and Facial Images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4542-4552. doi: 10.11999/JEIT240087

|

| [1] |
KUMARAN U, RADHA RAMMOHAN S, NAGARAJAN S M, et al. Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN[J]. International Journal of Speech Technology, 2021, 24(2): 303–314. doi: 10.1007/s10772-020-09792-x.
|
| [2] |
韩虎, 范雅婷, 徐学锋. 面向方面情感分析的多通道增强图卷积网络[J]. 电子与信息学报, 2024, 46(3): 1022–1032. doi: 10.11999/JEIT230353.
HAN Hu, FAN Yating, and XU Xuefeng. Multi-channel enhanced graph convolutional network for aspect-based sentiment analysis[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1022–1032. doi: 10.11999/JEIT230353.
|
| [3] |
CORNEJO J and PEDRINI H. Bimodal emotion recognition based on audio and facial parts using deep convolutional neural networks[C]. Proceedings of the 18th IEEE International Conference On Machine Learning And Applications, Boca Raton, USA, 2019: 111–117. doi: 10.1109/ICMLA.2019.00026.
|
| [4] |
O’TOOLE A J, CASTILLO C D, PARDE C J, et al. Face space representations in deep convolutional neural networks[J]. Trends in Cognitive Sciences, 2018, 22(9): 794–809. doi: 10.1016/j.tics.2018.06.006.
|
| [5] |
CHEN Qiupu and HUANG Guimin. A novel dual attention-based BLSTM with hybrid features in speech emotion recognition[J]. Engineering Applications of Artificial Intelligence, 2021, 102: 104277. doi: 10.1016/J.ENGAPPAI.2021.104277.
|
| [6] |
PAN Bei, HIROTA K, JIA Zhiyang, et al. A review of multimodal emotion recognition from datasets, preprocessing, features, and fusion methods[J]. Neurocomputing, 2023, 561: 126866. doi: 10.1016/j.neucom.2023.126866.
|
| [7] |
LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791.
|
| [8] |
HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735.
|
| [9] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.
|
| [10] |
KIM B K, LEE H, ROH J, et al. Hierarchical committee of deep CNNs with exponentially-weighted decision fusion for static facial expression recognition[C]. Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle Washington, USA, 2015: 427–434. doi: 10.1145/2818346.2830590.
|
| [11] |
TZIRAKIS P, TRIGEORGIS G, NICOLAOU M A, et al. End-to-end multimodal emotion recognition using deep neural networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1301–1309. doi: 10.1109/JSTSP.2017.2764438.
|
| [12] |
SAHOO S and ROUTRAY A. Emotion recognition from audio-visual data using rule based decision level fusion[C]. Proceedings of 2016 IEEE Students’ Technology Symposium, Kharagpur, India, 2016: 7–12. doi: 10.1109/TechSym.2016.7872646.
|
| [13] |
WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11534–11542. doi: 10.1109/CVPR42600.2020.01155.
|
| [14] |
CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1251–1258. doi: 10.1109/CVPR.2017.195.
|
| [15] |
LIVINGSTONE S R and RUSSO F A. The Ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English[J]. PLoS One, 2018, 13(5): e0196391. doi: 10.1371/journal.pone.0196391.
|
| [16] |
WANG Yongjin and GUAN Ling. Recognizing human emotional state from audiovisual signals[J]. IEEE Transactions on Multimedia, 2008, 10(5): 936–946. doi: 10.1109/TMM.2008.927665.
|
| [17] |
MARTIN O, KOTSIA I, MACQ B, et al. The eNTERFACE’ 05 audio-visual emotion database[C]. Proceedings of the 22nd International Conference on Data Engineering Workshops, Atlanta, USA, 2006: 8. doi: 10.1109/ICDEW.2006.145.
|
| [18] |
VIJAYAN D M, ARUN A V, GANESHNATH R, et al. Development and analysis of convolutional neural network based accurate speech emotion recognition models[C]. Proceedings of the 19th India Council International Conference, Kochi, India, 2022: 1–6. doi: 10.1109/INDICON56171.2022.10040174.
|
| [19] |
AGGARWAL A, SRIVASTAVA A, AGARWAL A, et al. Two-way feature extraction for speech emotion recognition using deep learning[J]. Sensors, 2022, 22(6): 2378. doi: 10.3390/s22062378.
|
| [20] |
ZHANG Limin, LI Yang, ZHANG Yueting, et al. A deep learning method using gender-specific features for emotion recognition[J]. Sensors, 2023, 23(3): 1355. doi: 10.3390/s23031355.
|
| [21] |
KANANI C S, GILL K S, BEHERA S, et al. Shallow over deep neural networks: A empirical analysis for human emotion classification using audio data[M]. MISRA R, KESSWANI N, RAJARAJAN M, et al. Internet of Things and Connected Technologies. Cham: Springer, 2021: 134–146. doi: 10.1007/978-3-030-76736-5_13.
|
| [22] |
FALAHZADEH M R, FARSA E Z, HARIMI A, et al. 3D convolutional neural network for speech emotion recognition with its realization on Intel CPU and NVIDIA GPU[J]. IEEE Access, 2022, 10: 112460–112471. doi: 10.1109/ACCESS.2022.3217226.
|
| [23] |
FALAHZADEH M R, FAROKHI F, HARIMI A, et al. Deep convolutional neural network and gray wolf optimization algorithm for speech emotion recognition[J]. Circuits, Systems, and Signal Processing, 2023, 42(1): 449–492. doi: 10.1007/s00034-022-02130-3.
|
| [24] |
HARÁR P, BURGET R, and DUTTA M K. Speech emotion recognition with deep learning[C]. Proceedings of the 4th International Conference on Signal Processing and Integrated Networks, Noida, India, 2017: 137–140. doi: 10.1109/SPIN.2017.8049931.
|
| [25] |
SLIMI A, HAFAR N, ZRIGUI M, et al. Multiple models fusion for multi-label classification in speech emotion recognition systems[J]. Procedia Computer Science, 2022, 207: 2875–2882. doi: 10.1016/j.procs.2022.09.345.
|
| [26] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
| [27] |
MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: Practical guidelines for efficient CNN architecture design[C]. Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 116–131. doi: 10.1007/978-3-030-01264-9_8.
|
| [28] |
SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4510–4520. doi: 10.1109/CVPR.2018.00474.
|
| [29] |
MIDDYA A I, NAG B, and ROY S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities[J]. Knowledge-Based Systems, 2022, 244: 108580. doi: 10.1016/j.knosys.2022.108580.
|
| [30] |
LUNA-JIMÉNEZ C, KLEINLEIN R, GRIOL D, et al. A proposal for multimodal emotion recognition using aural transformers and action units on RAVDESS dataset[J]. Applied Sciences, 2021, 12(1): 327. doi: 10.3390/app12010327.
|
| [31] |
BOUALI Y L, AHMED O B, and MAZOUZI S. Cross-modal learning for audio-visual emotion recognition in acted speech[C]. Proceedings of the 6th International Conference on Advanced Technologies for Signal and Image Processing, Sfax, Tunisia, 2022: 1–6. doi: 10.1109/ATSIP55956.2022.9805959.
|
| [32] |
MOCANU B and TAPU R. Audio-video fusion with double attention for multimodal emotion recognition[C]. Proceedings of the 14th Image, Video, and Multidimensional Signal Processing Workshop, Nafplio, Greece, 2022: 1–5. doi: 10.1109/IVMSP54334.2022.9816349.
|
| [33] |
WOZNIAK M, SAKOWICZ M, LEDWOSINSKI K, et al. Bimodal emotion recognition based on vocal and facial features[J]. Procedia Computer Science, 2023, 225: 2556–2566. doi: 10.1016/j.procs.2023.10.247.
|
| [34] |
PAN Bei, HIROTA K, JIA Zhiyang, et al. Multimodal emotion recognition based on feature selection and extreme learning machine in video clips[J]. Journal of Ambient Intelligence and Humanized Computing, 2023, 14(3): 1903–1917. doi: 10.1007/s12652-021-03407-2.
|
| [35] |
TANG Guichen, XIE Yue, LI Ke, et al. Multimodal emotion recognition from facial expression and speech based on feature fusion[J]. Multimedia Tools and Applications, 2023, 82(11): 16359–16373. doi: 10.1007/s11042-022-14185-0.
|
| [36] |
CHEN Luefeng, WANG Kuanlin, LI Min, et al. K-means clustering-based kernel canonical correlation analysis for multimodal emotion recognition in human-robot interaction[J]. IEEE Transactions on Industrial Electronics, 2023, 70(1): 1016–1024. doi: 10.1109/TIE.2022.3150097.
|
| [37] |
CHEN Guanghui and ZENG Xiaoping. Multi-modal emotion recognition by fusing correlation features of speech-visual[J]. IEEE Signal Processing Letters, 2021, 28: 533–537. doi: 10.1109/LSP.2021.3055755.
|
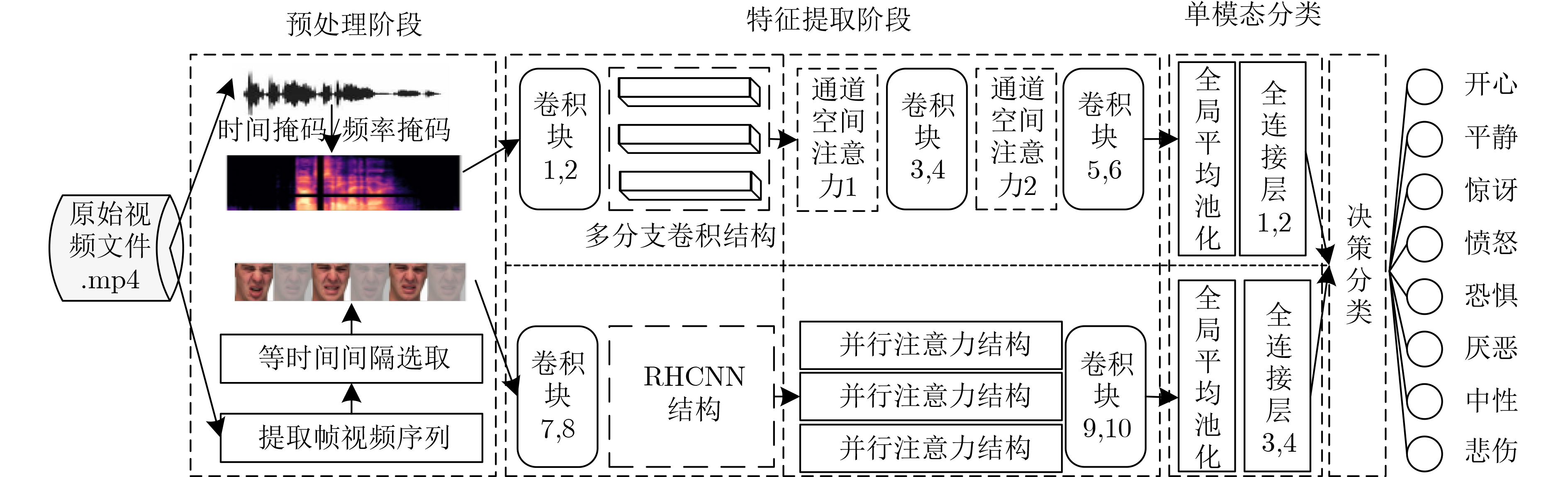
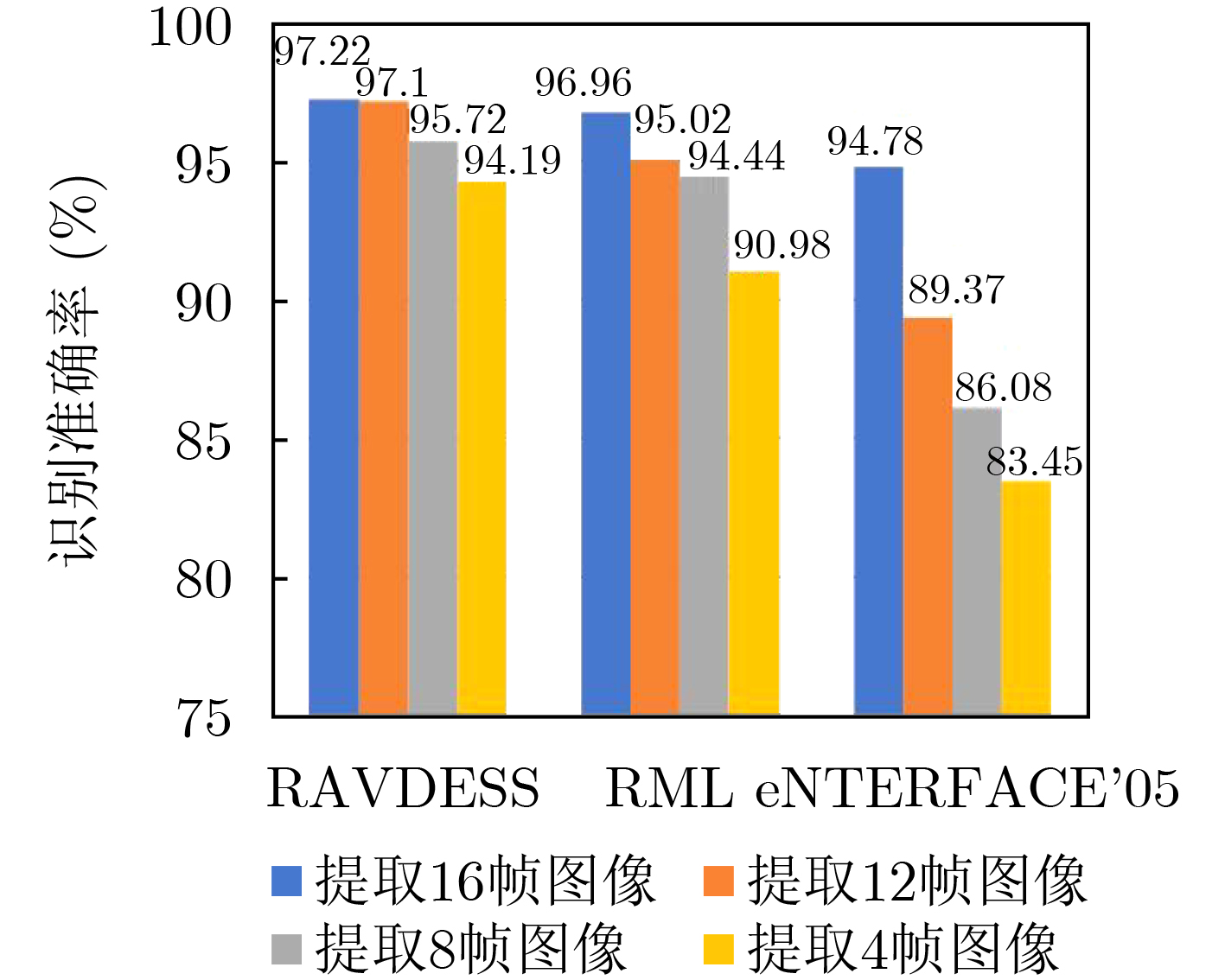
Figures(11) / Tables(6)



 DownLoad:
DownLoad: