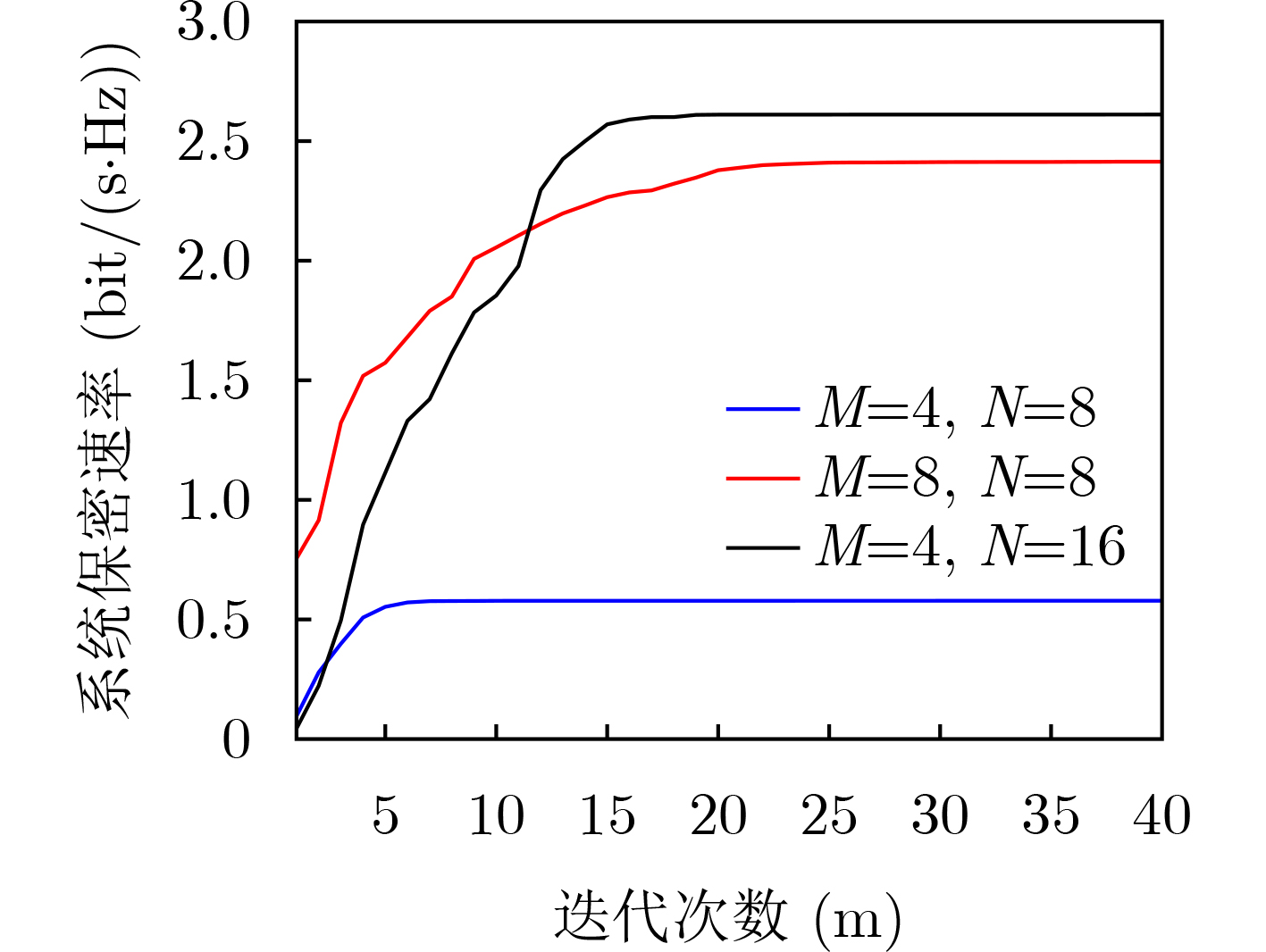
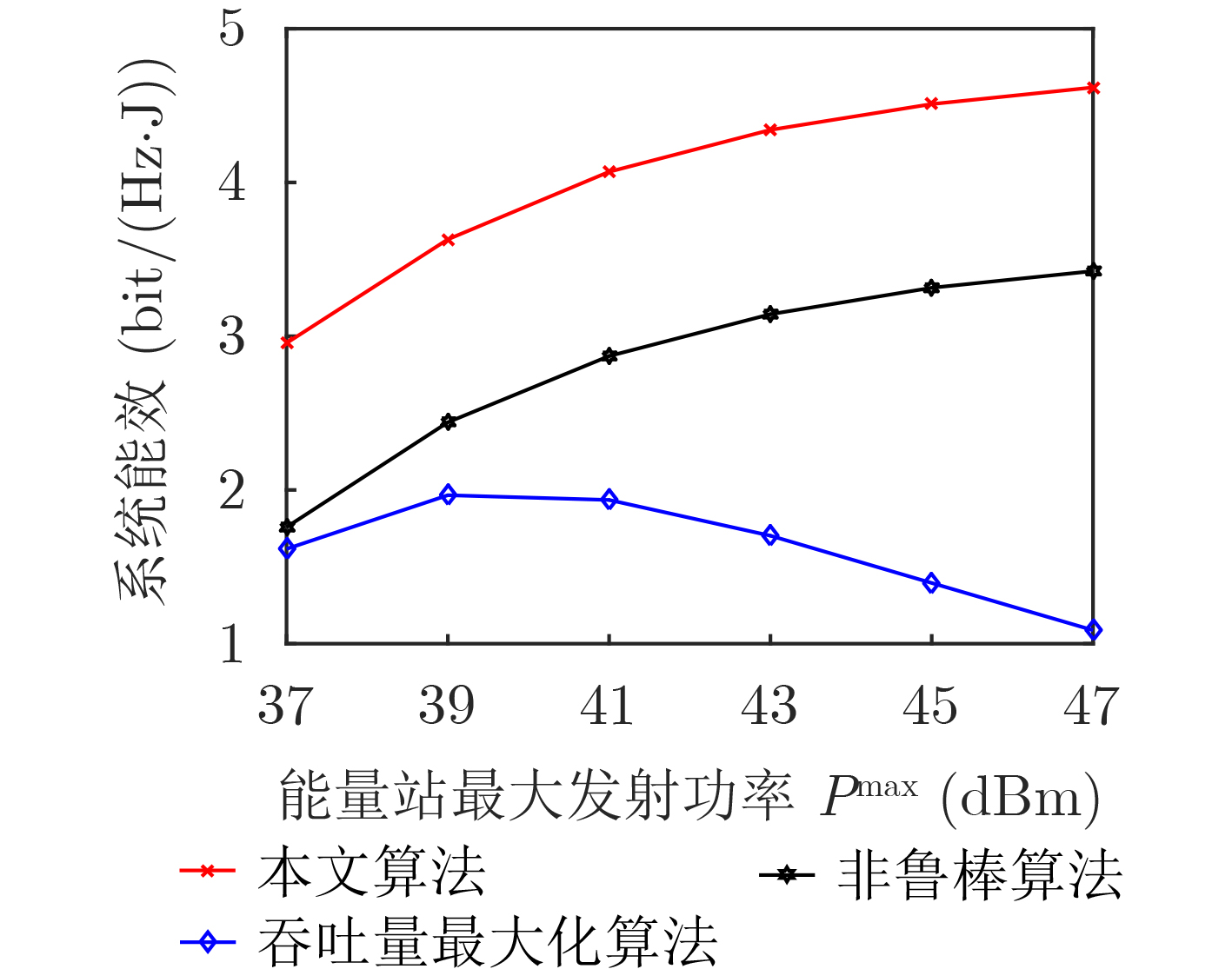
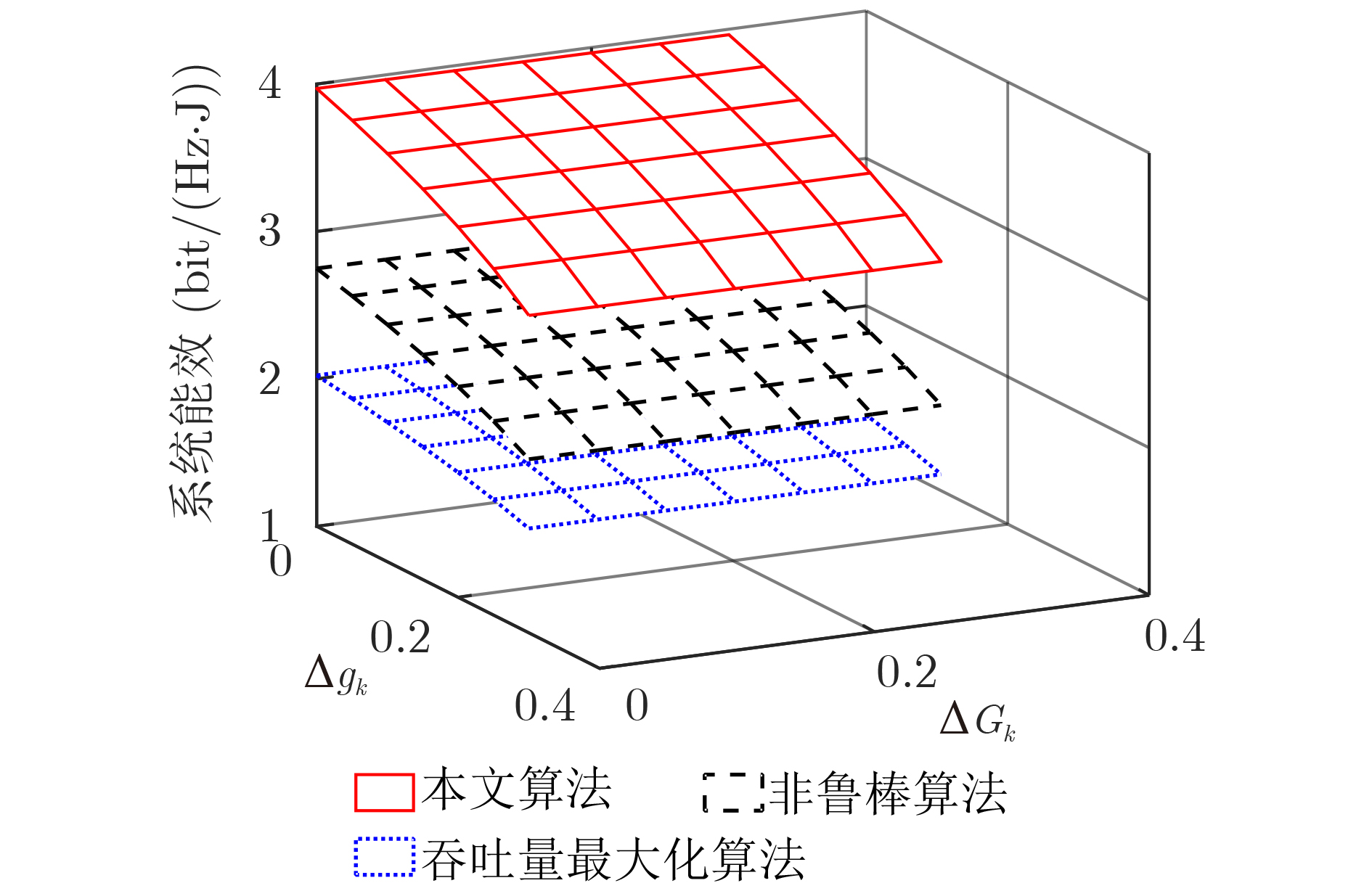
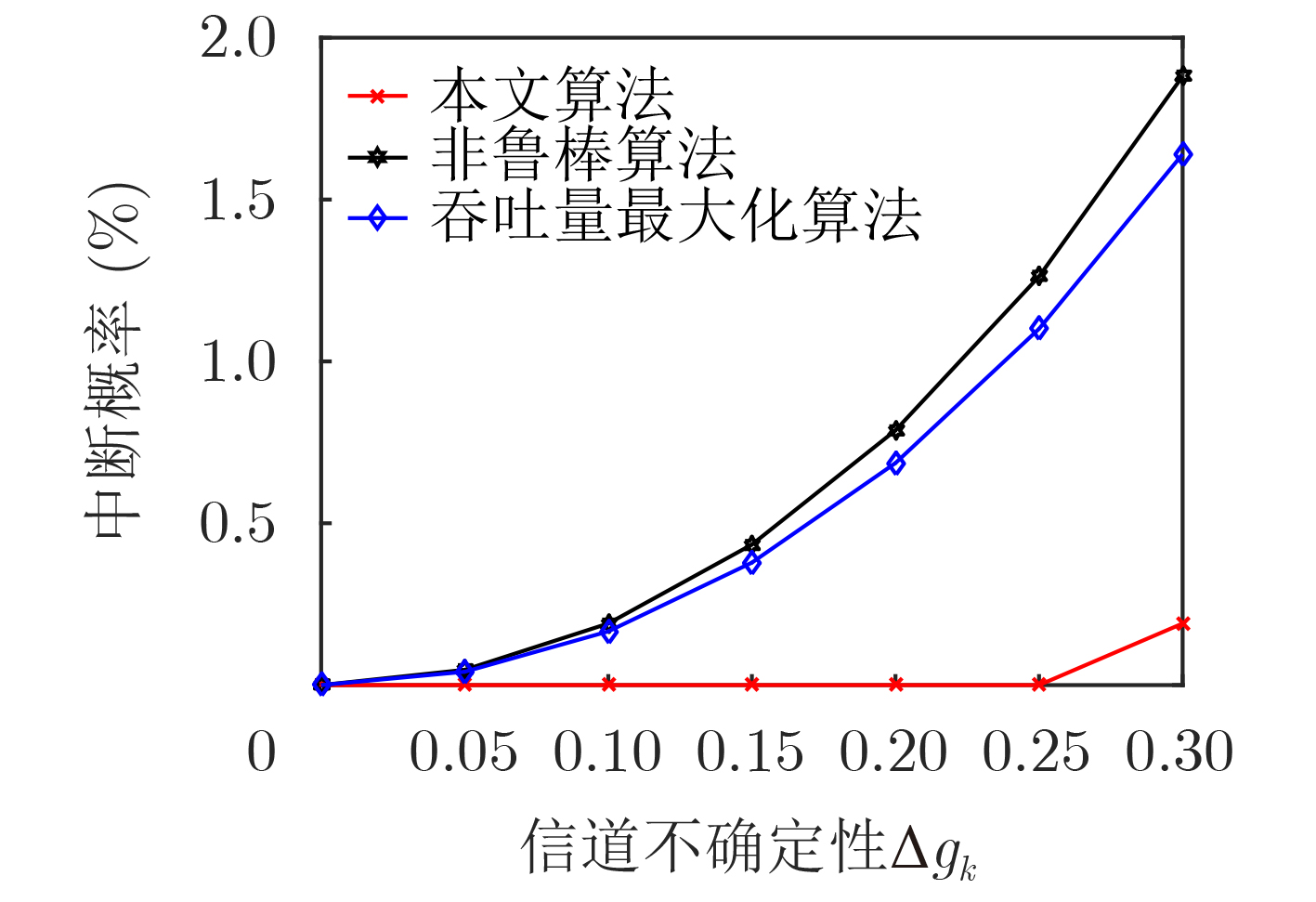
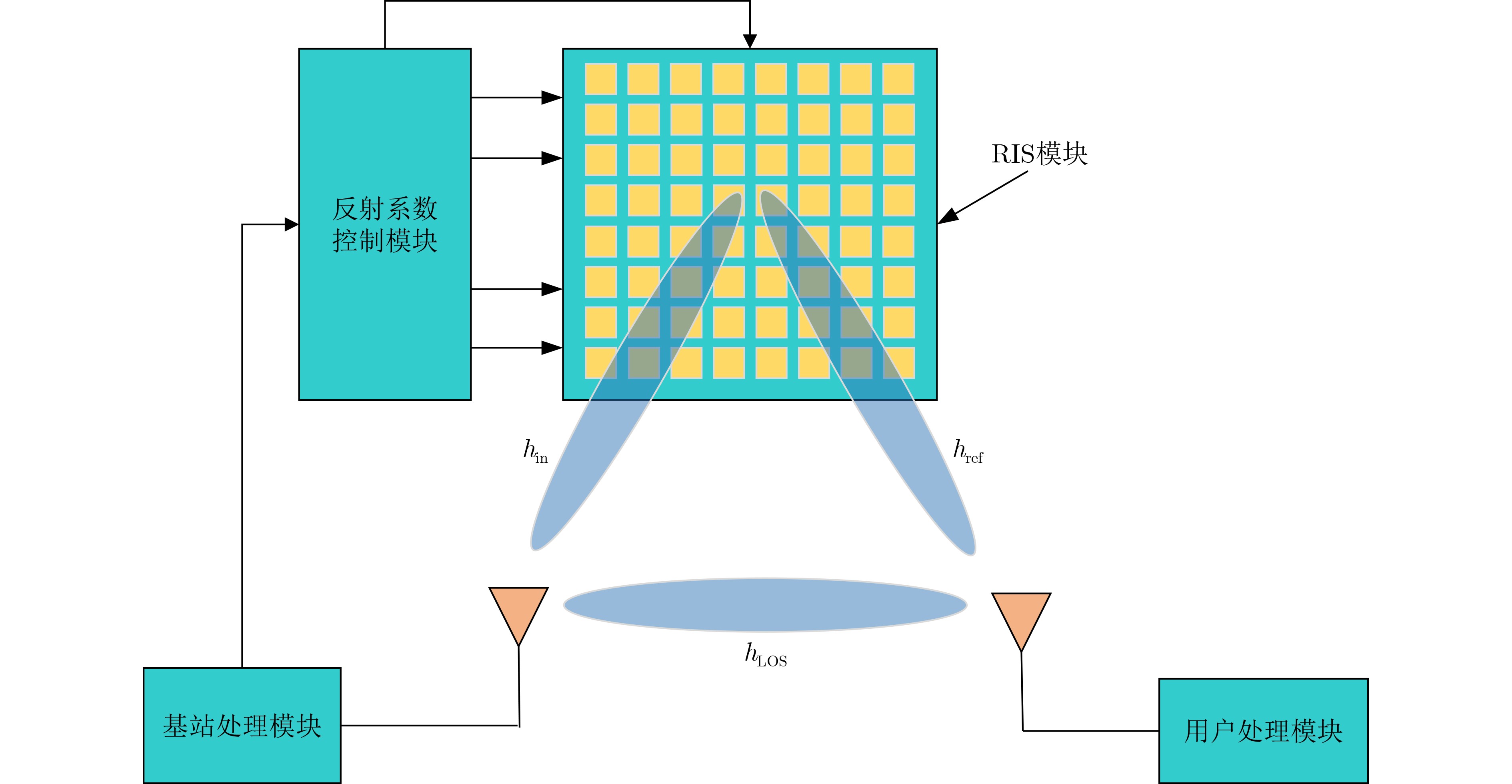
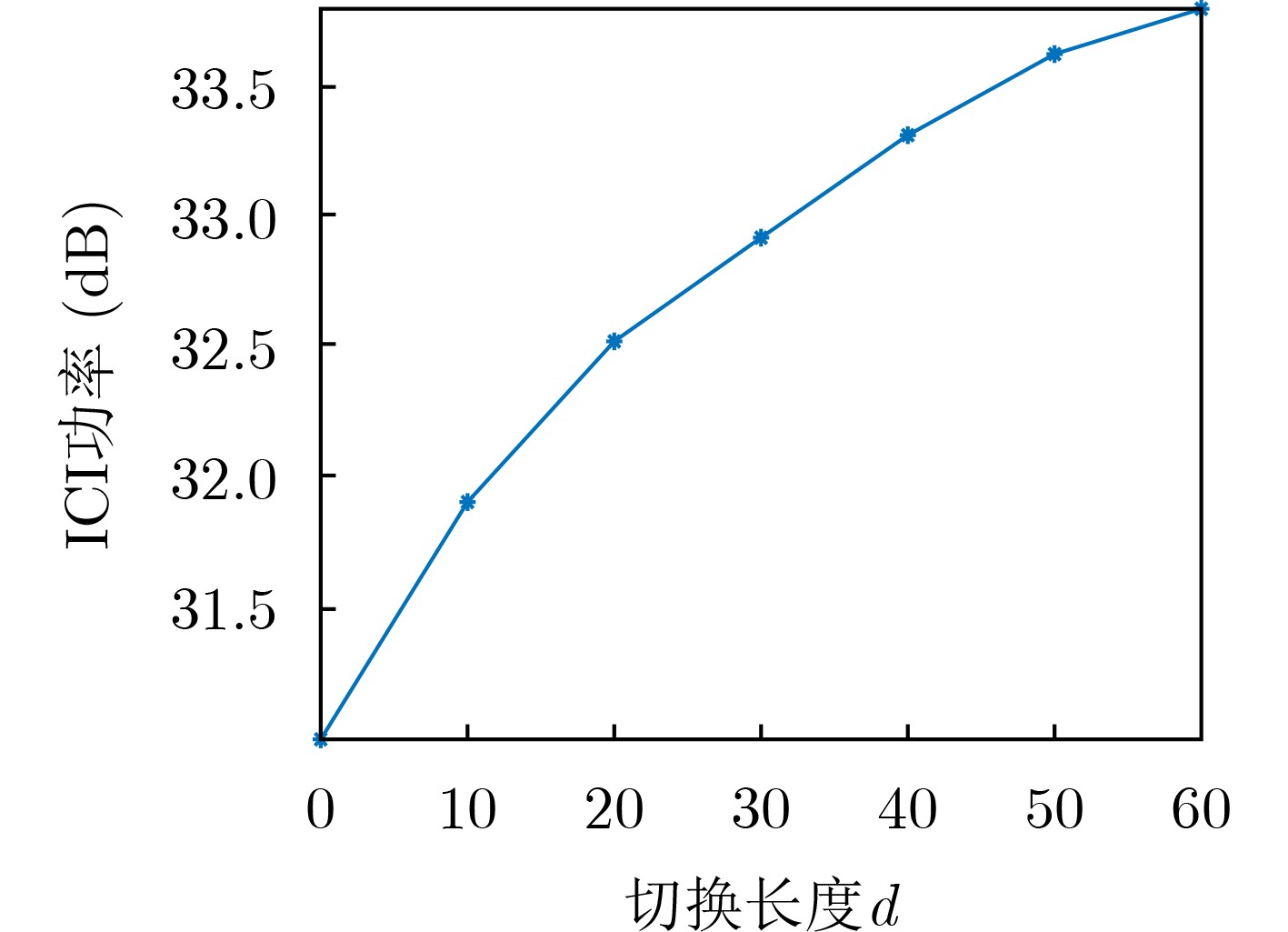
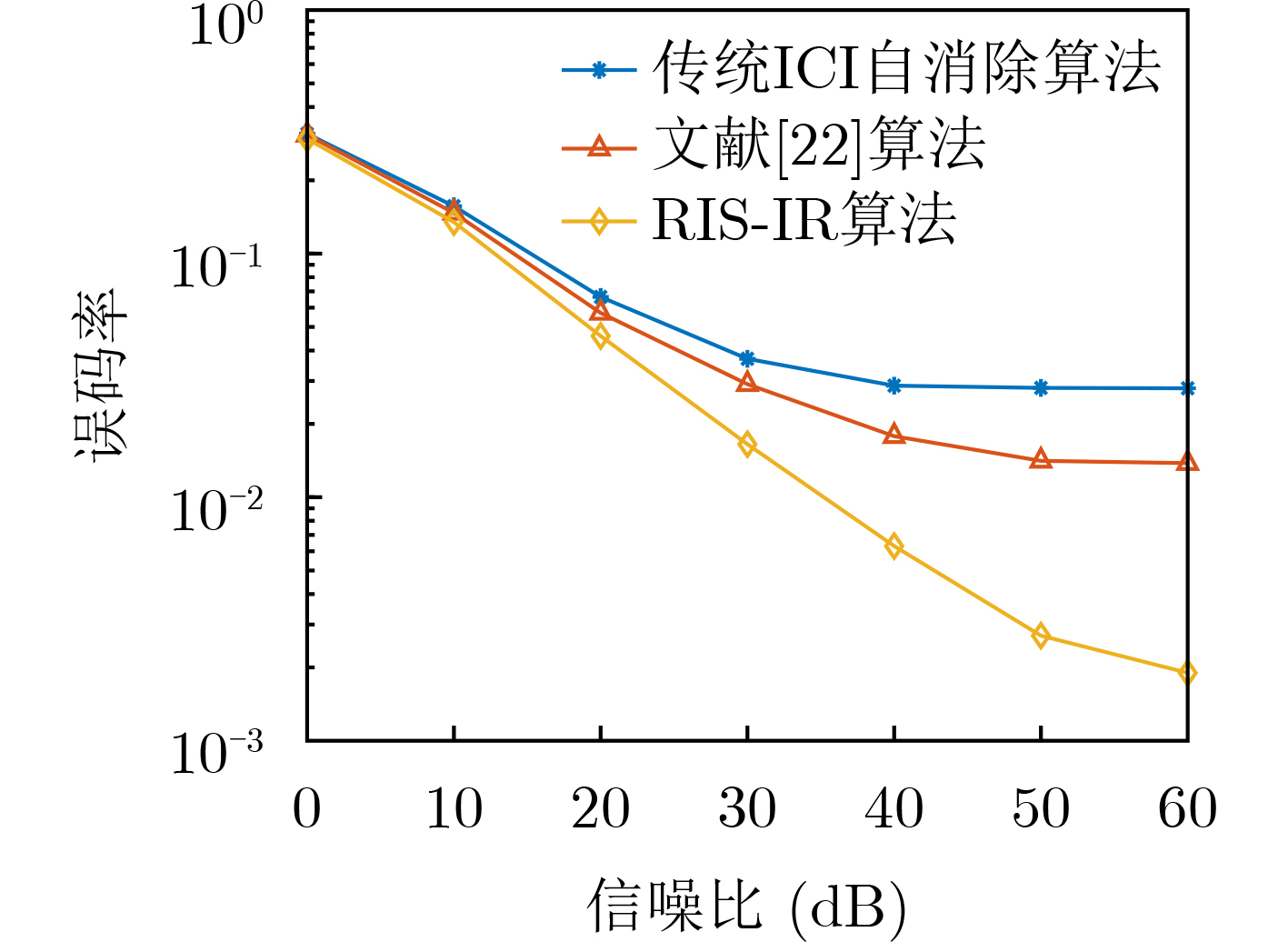
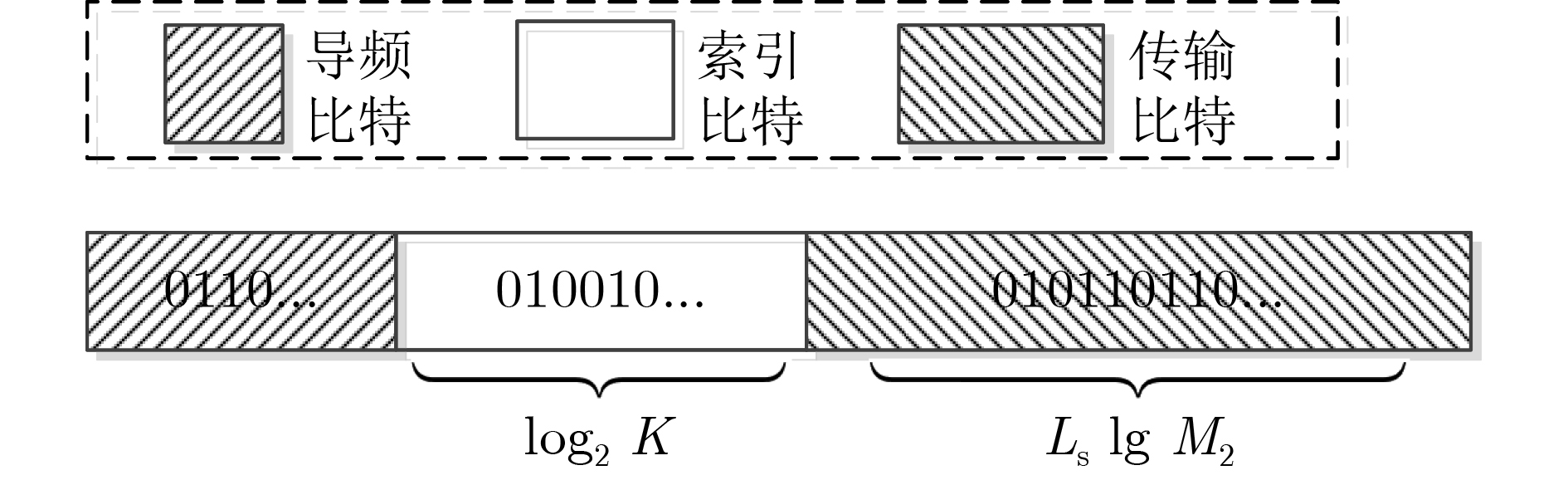
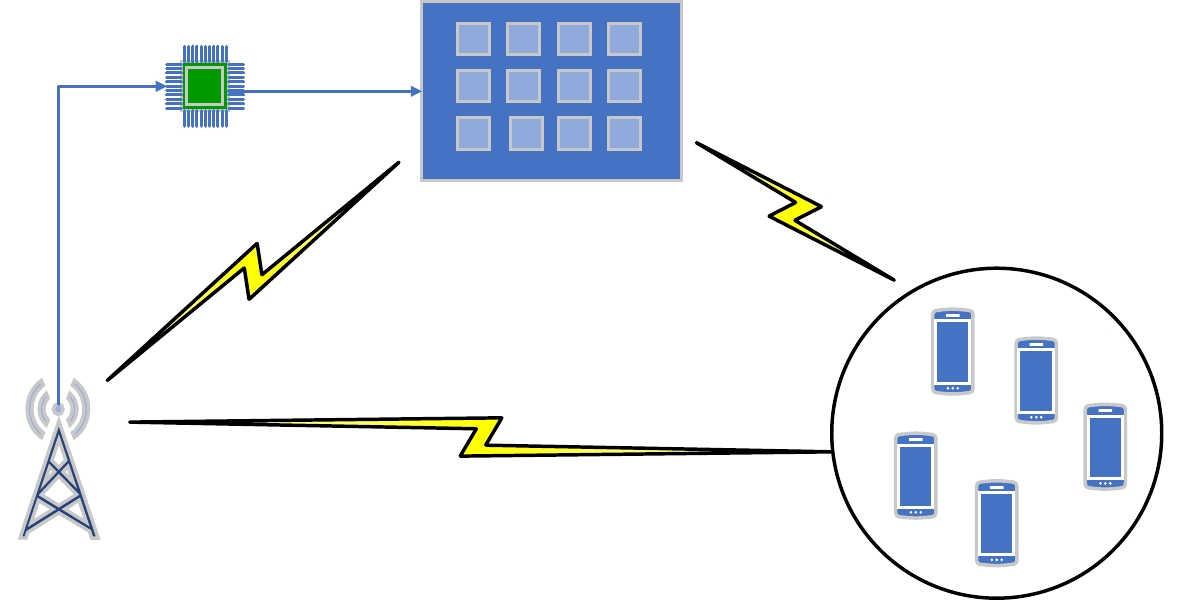
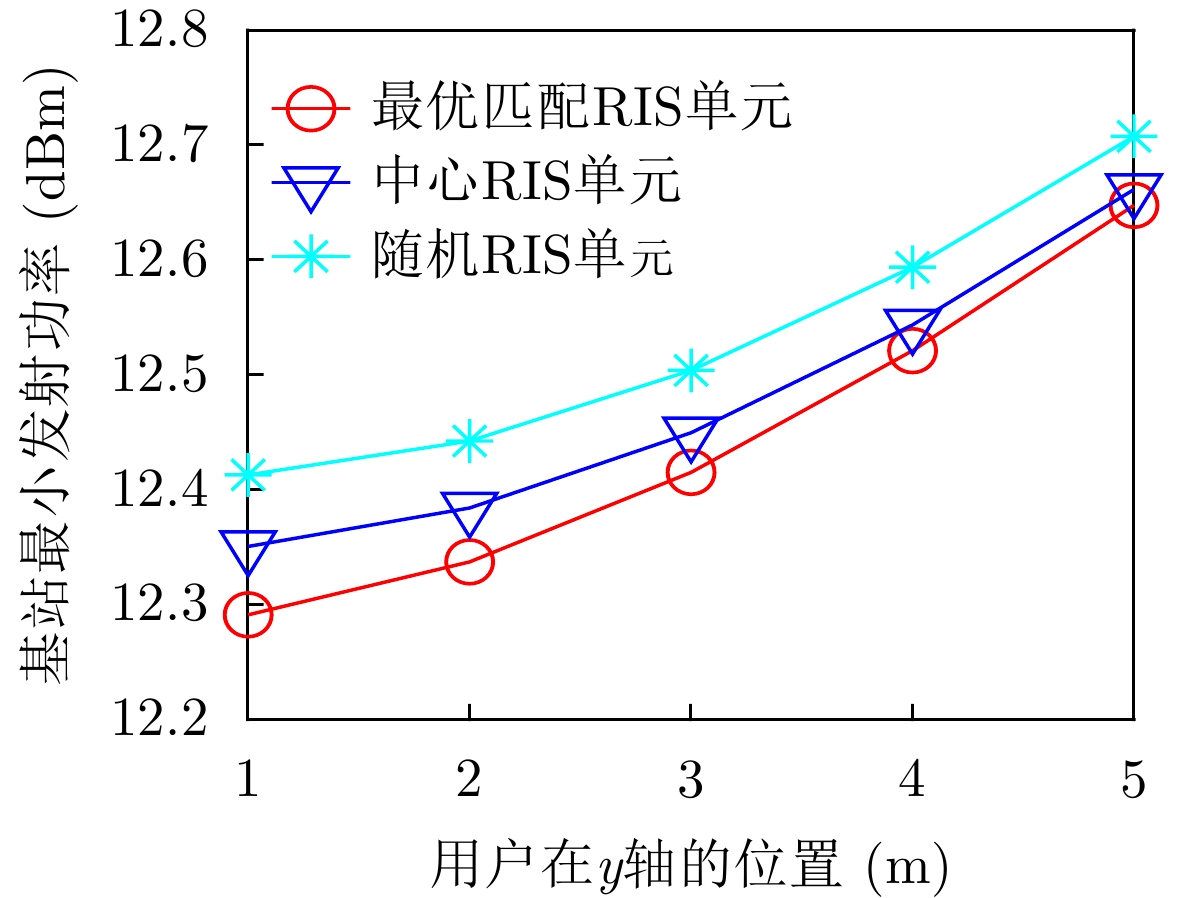
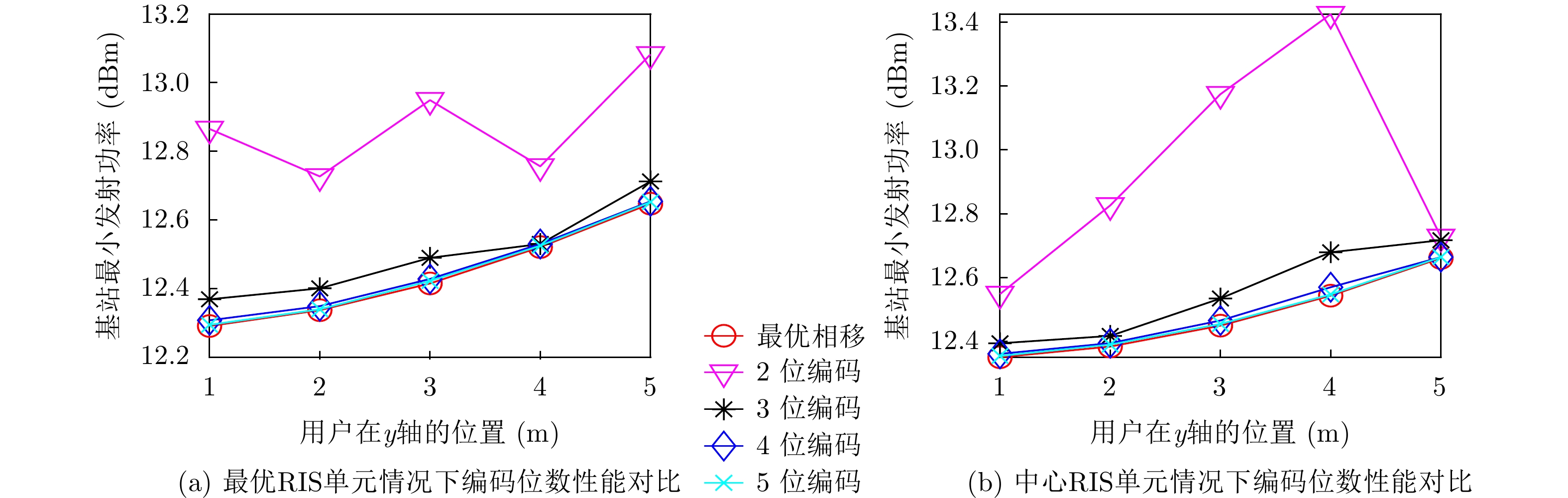
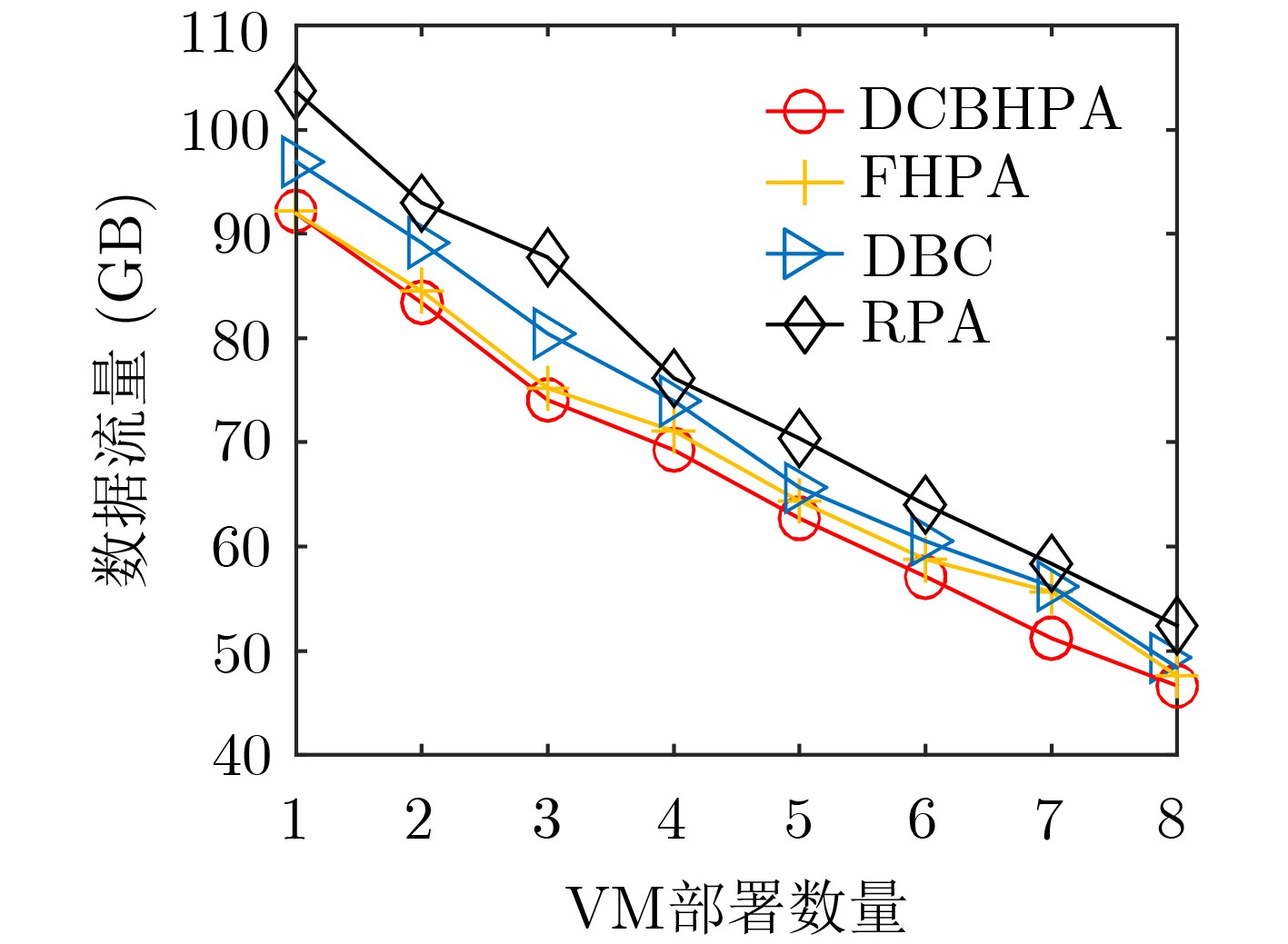
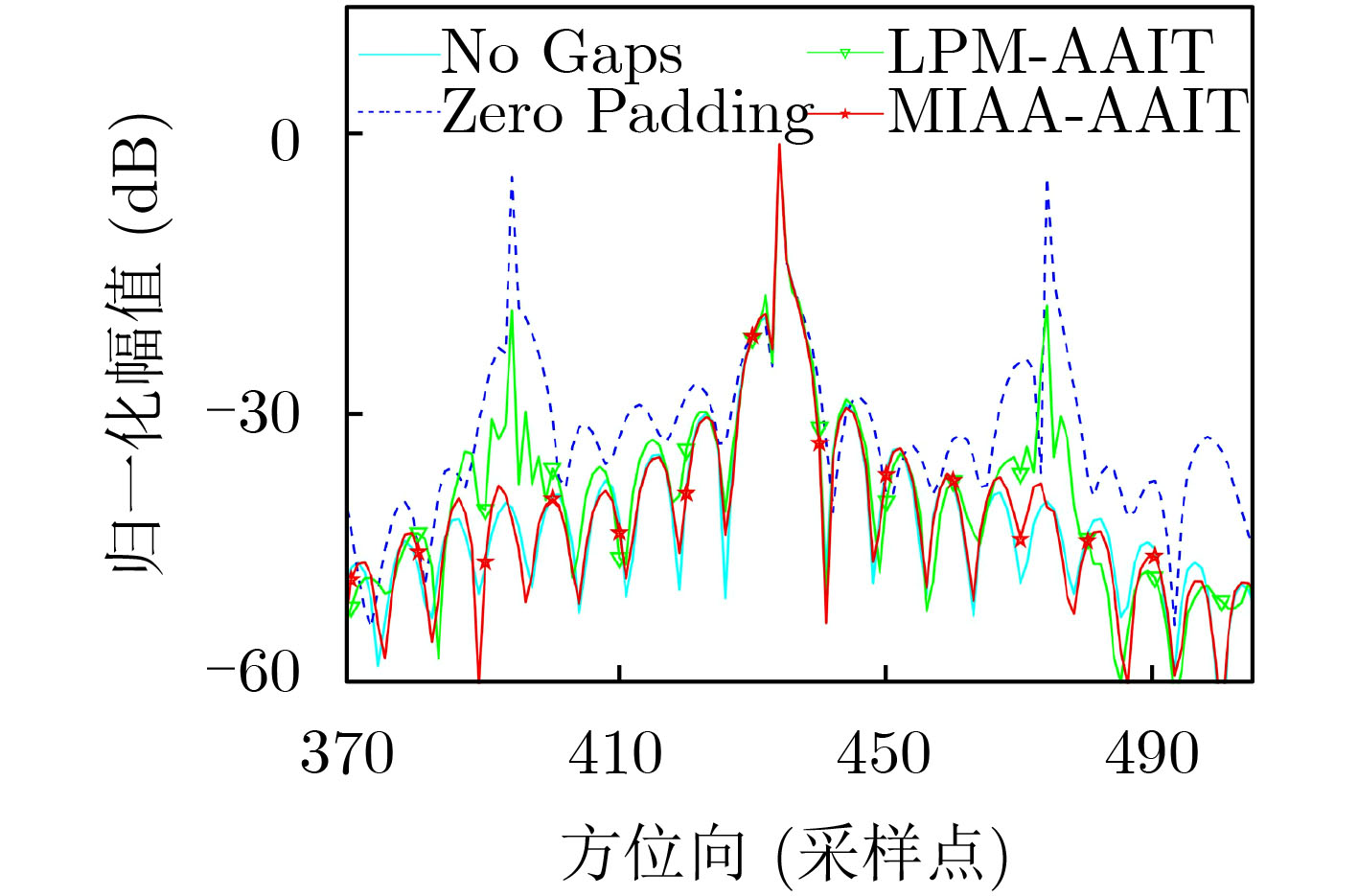
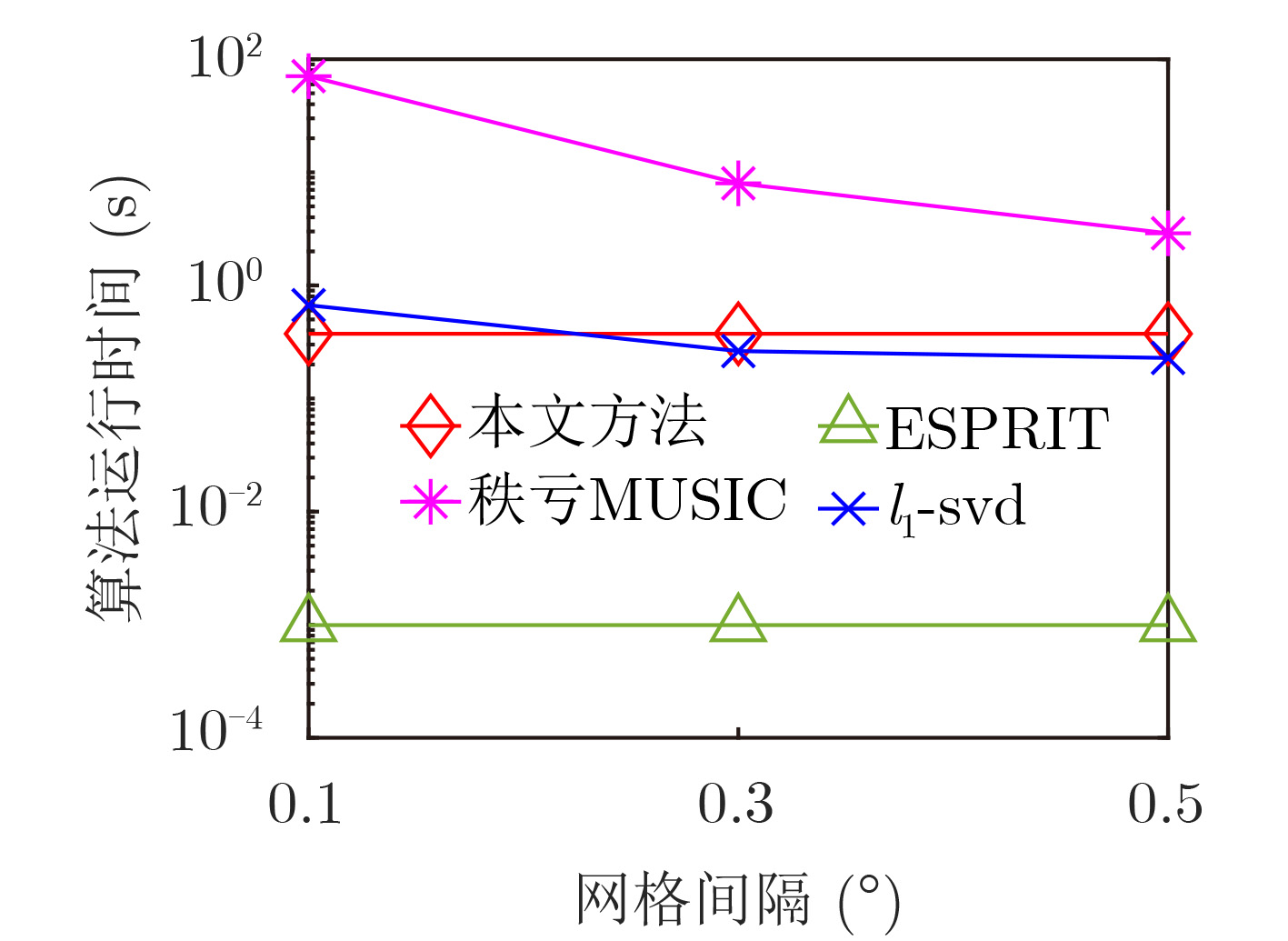
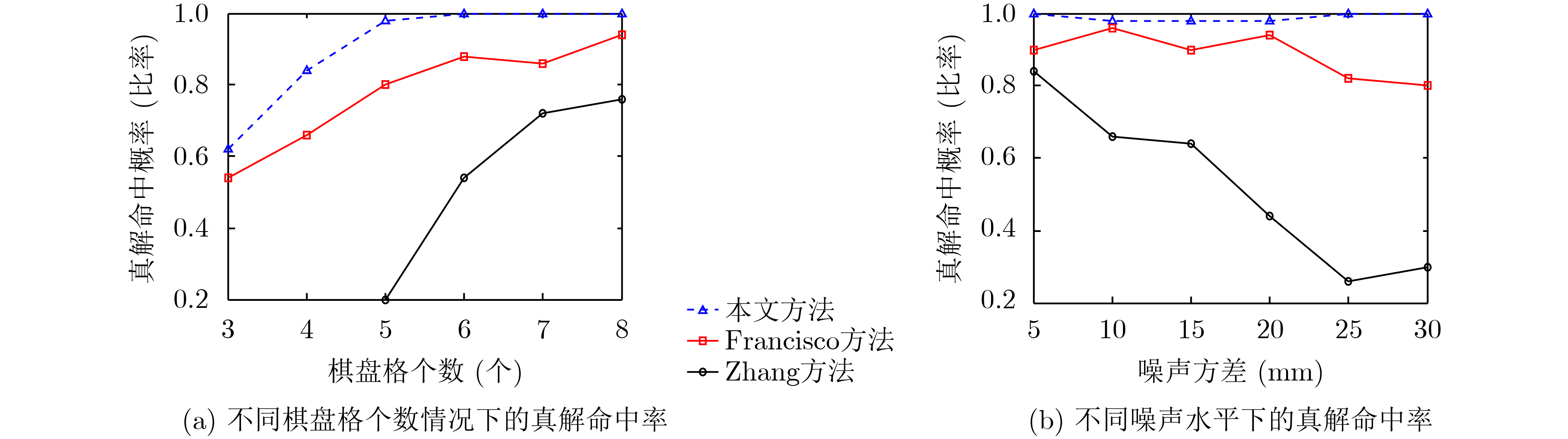
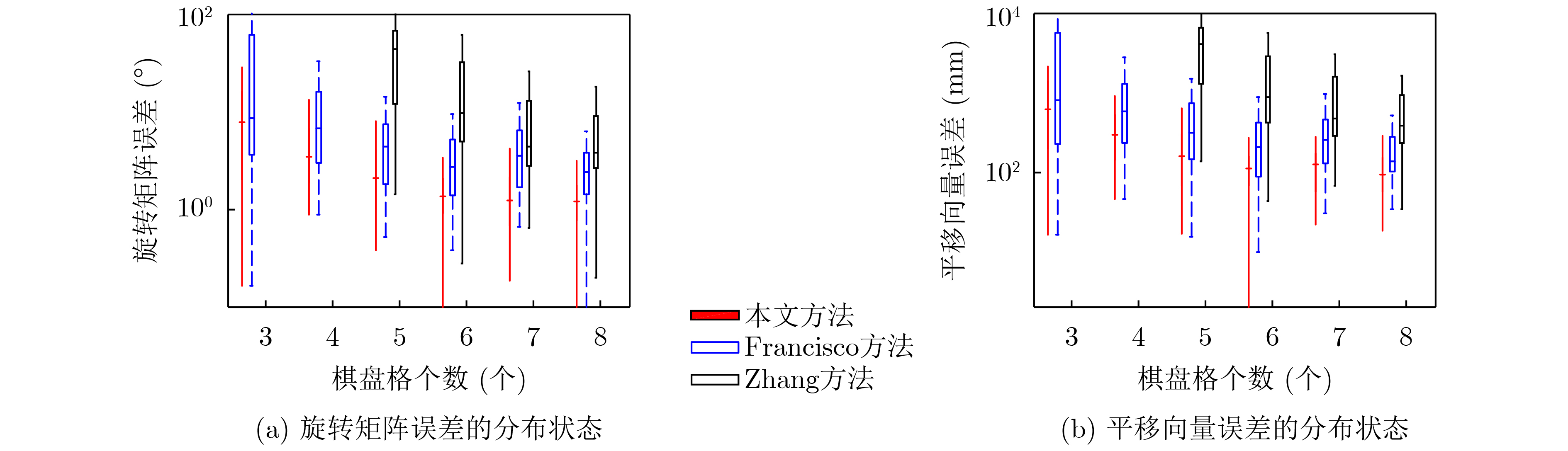
2022, 44(7): 2531-2538.
doi: 10.11999/JEIT210229
Abstract:
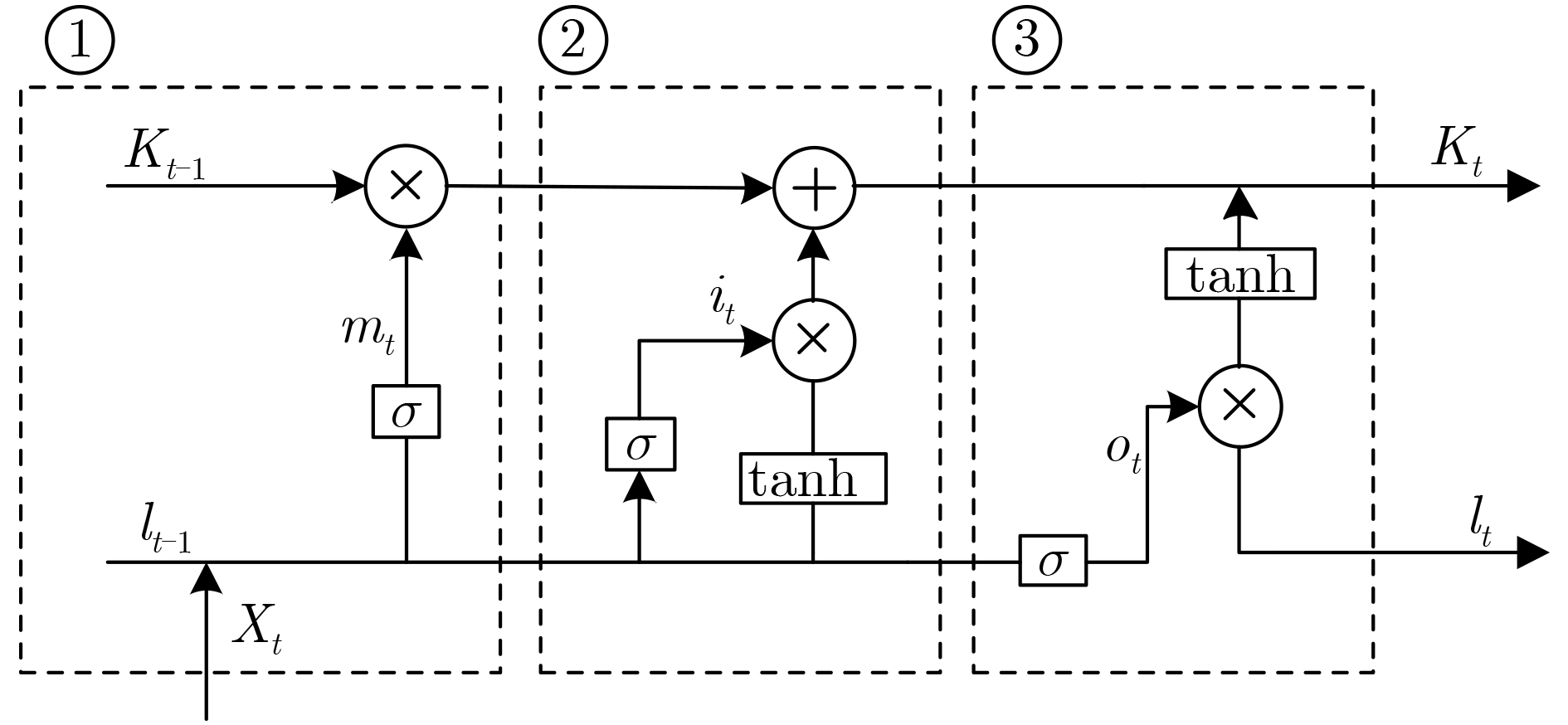
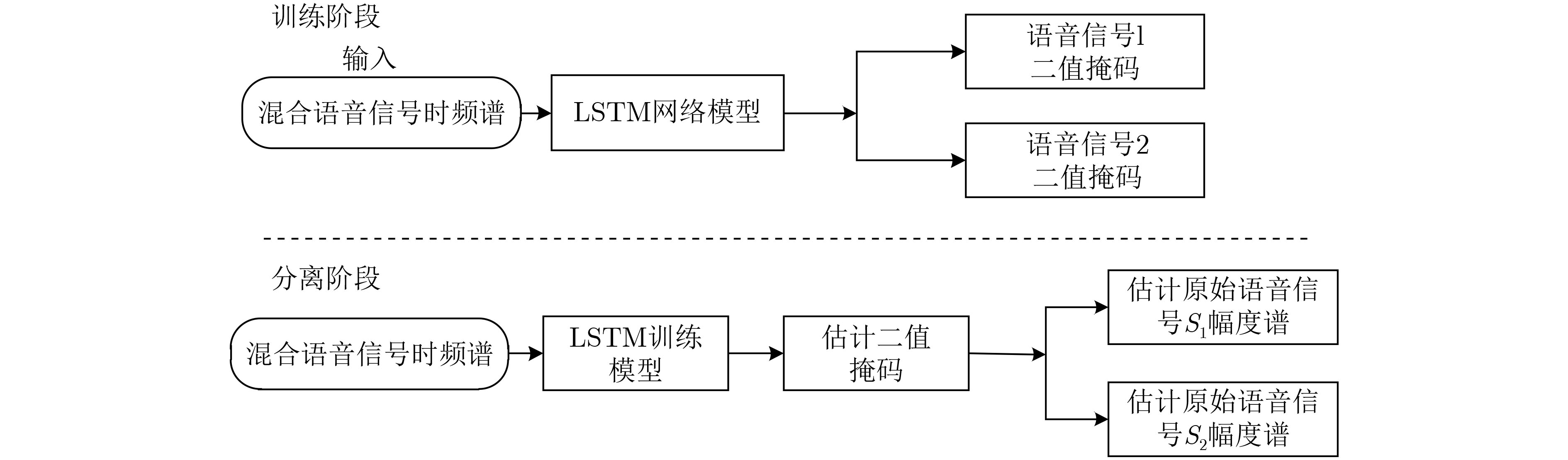
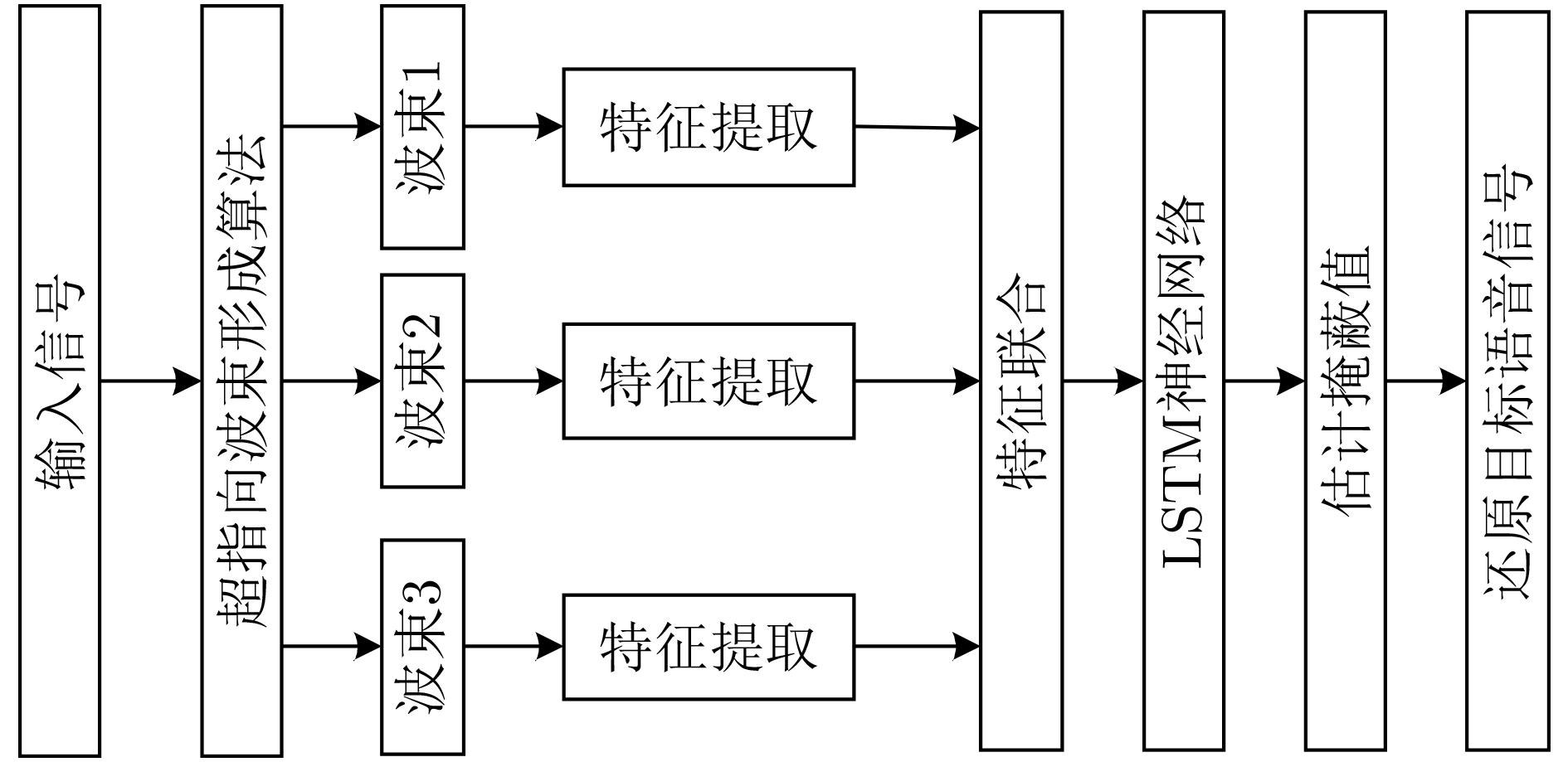
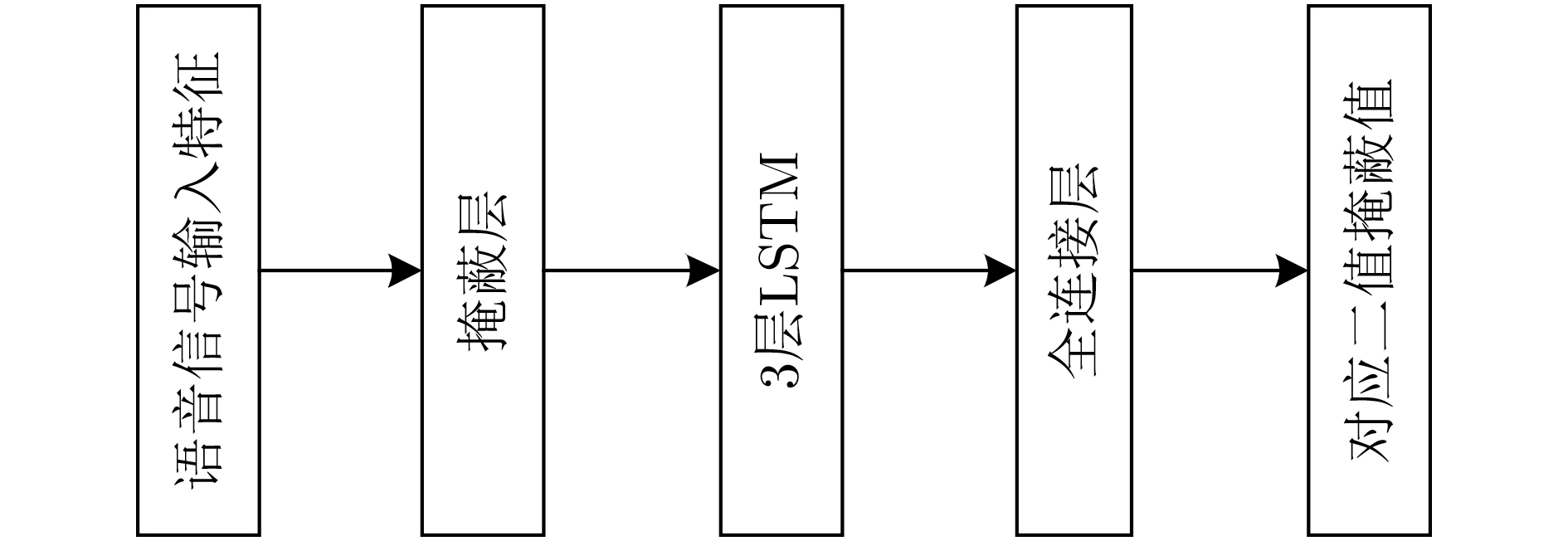
In the field of speech separation using deep learning, the Recurrent Neural Network (RNN) is commonly used for speech separation, but the network model has a gradient descent problem in the separation process, and the separation result is not ideal. Considering this problem, this paper uses Long Short-Term Memory (LSTM) network to explore the signal separation, which makes up for the deficiency of RNN network. The separation of multi-channel vocal signals is more complicated, and most of the separation methods used at this stage are based on the spectrum mapping method, and the spatial information of the voice signal is not effectively used. In response to this problem, this paper combines the beamforming algorithm and the LSTM network to propose a beamforming LSTM algorithm. The voice files of three speakers are randomly selected from the TIMIT voice library, and the super-pointing beamforming algorithm is used to obtain beams in three different directions. The spectral amplitude characteristics in each beam are extracted, and a neural network is constructed to predict the masking value. The to-be-separated speech signal spectrum is obtained. and the time-domain signal is constructed, and the speech separation is realized. The algorithm makes full use of the spatial characteristics of the speech signal and the signal frequency domain characteristics. The effect of speech separation in different directions is verified through experiments. Compared with the IBM-LSTM network, at 60-degree direction, this algorithm improves Perceptual Evaluation of Speech Quality (PESQ) by 0.59, Short-Time Objective Intelligibility (STOI) index by 0.06, and Signal to Noise Ratio (SNR) by 1.13 dB. At the other two reverse directions, the experimental results also prove that the algorithm has better separation performance than the IBM-LSTM algorithm and the RNN algorithm.