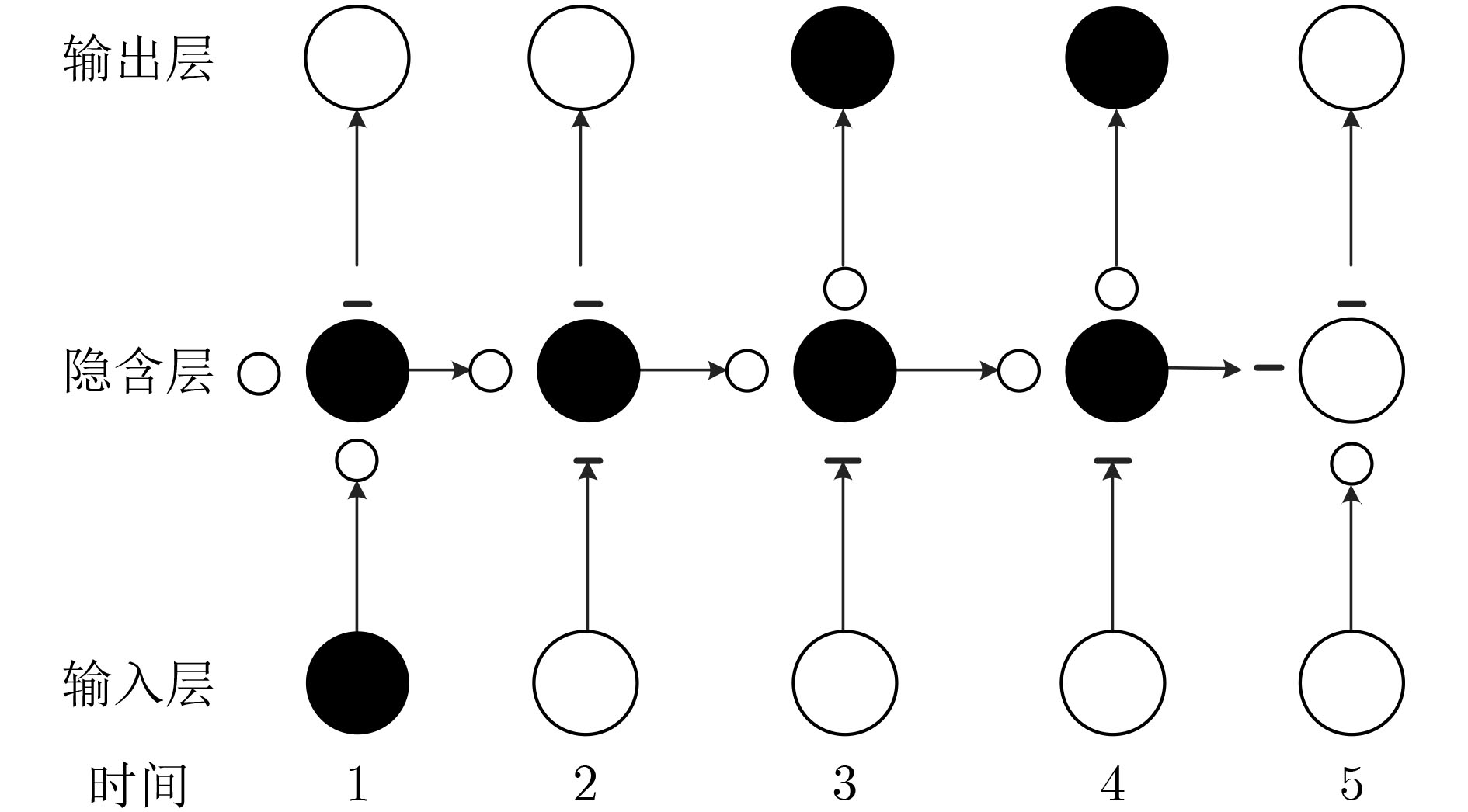
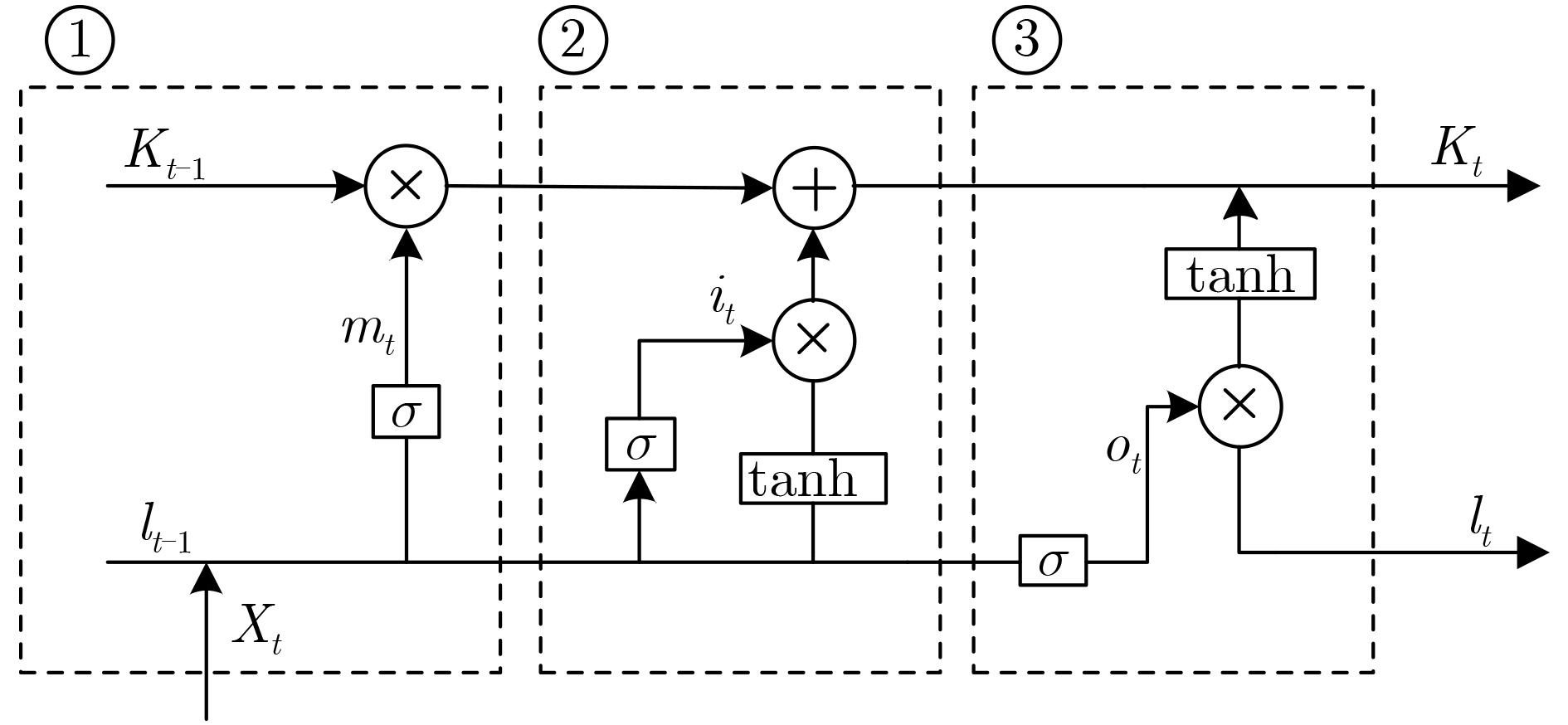
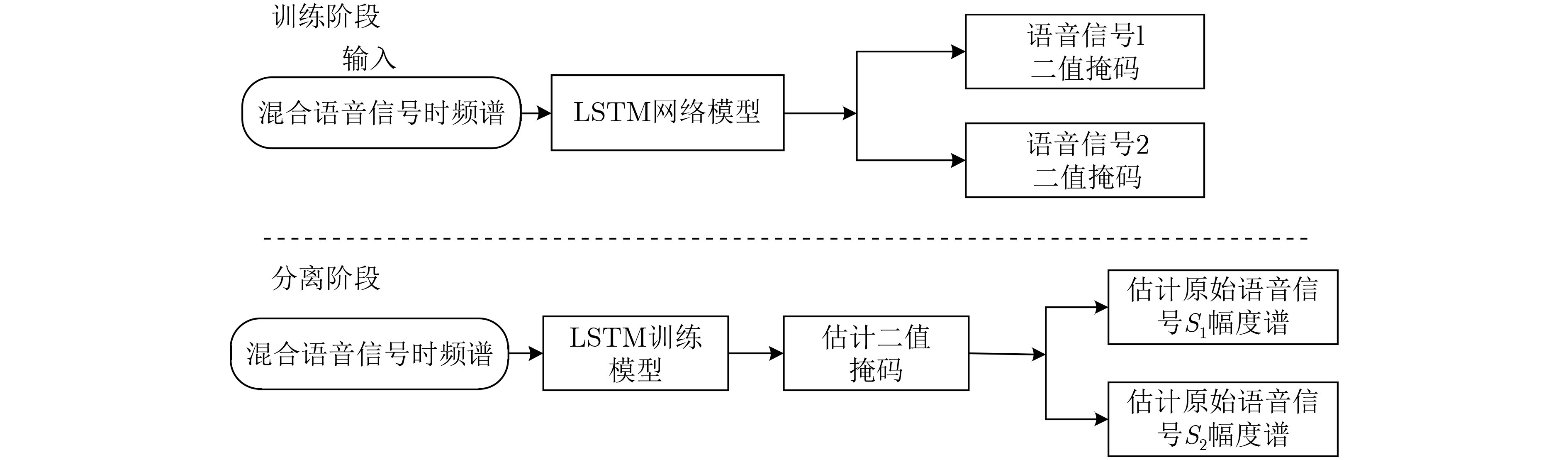
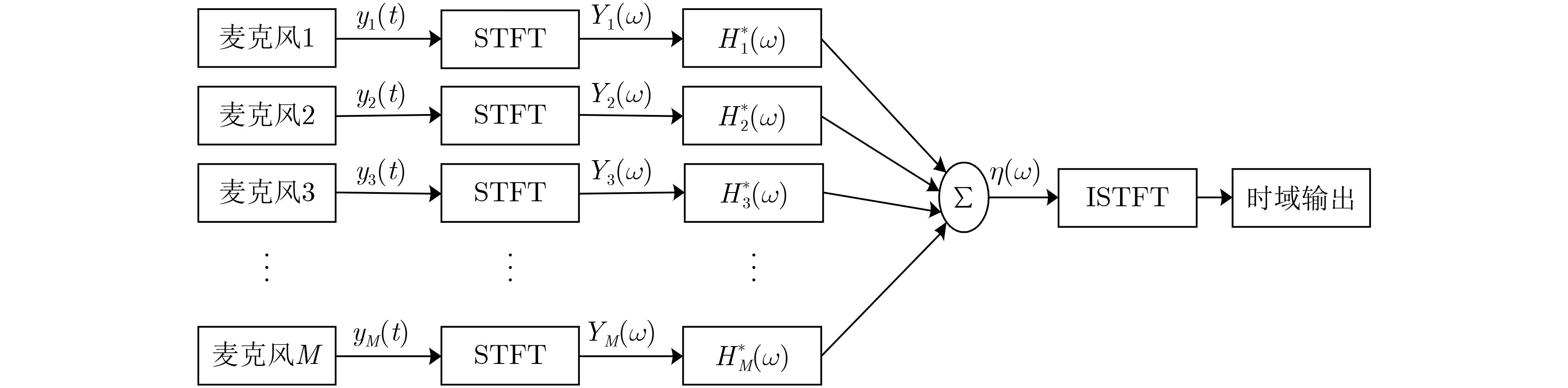
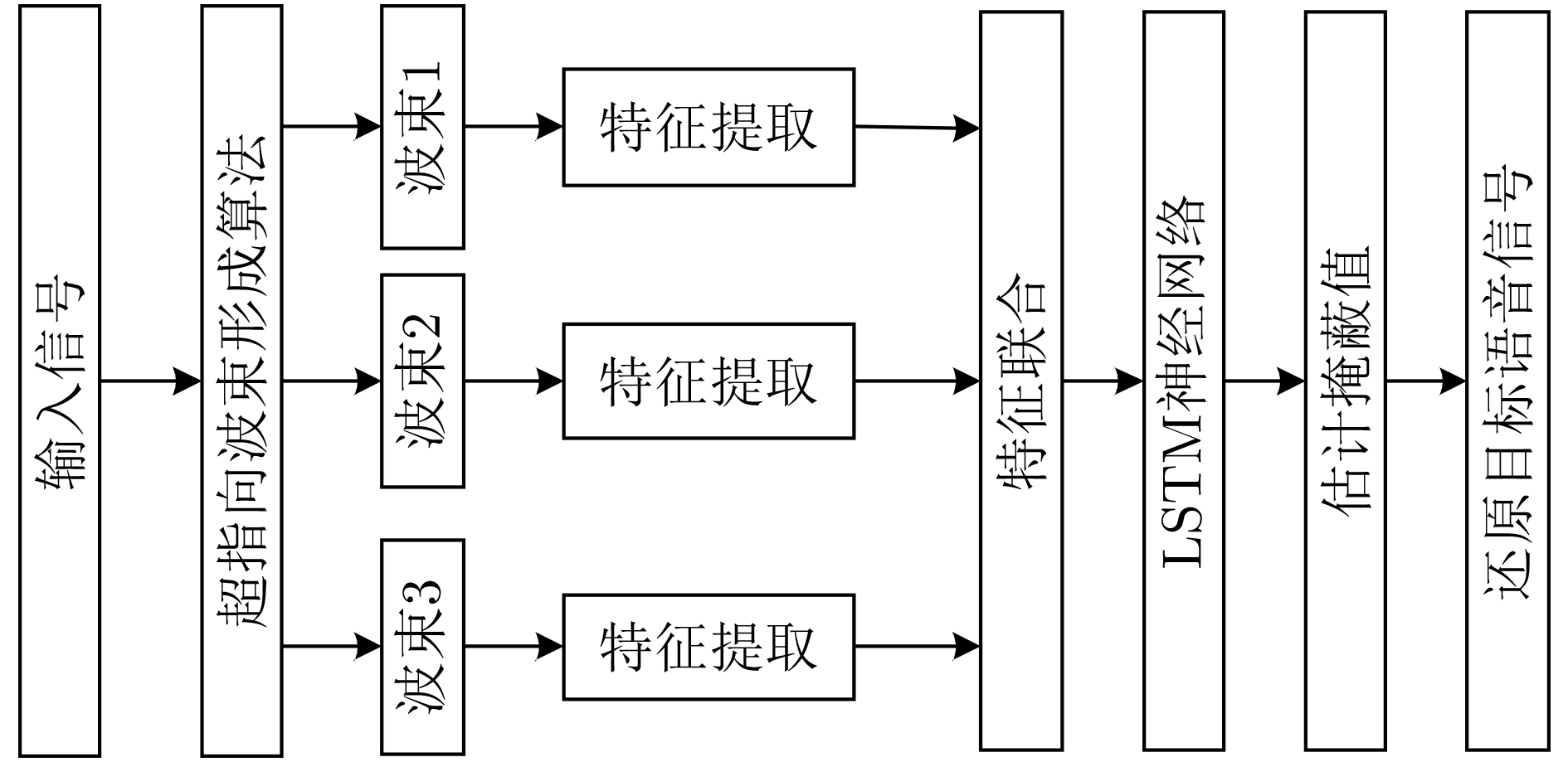
| Citation: | LAN Chaofeng, LIU Yan, ZHAO Hongyun, LIU Chundong. Research on Long Short-Term Memory Networks Speech Separation Algorithm Based on Beamforming[J]. Journal of Electronics & Information Technology, 2022, 44(7): 2531-2538. doi: 10.11999/JEIT210229

|

| [1] |
EPHRAT A, MOSSERI I, LANG O, et al. Looking to listen at the cocktail party: A speaker–independent audio–visual model for speech separation[J]. ACM Transactions on Graphics, 2008, 37(4): 109:1–109:11.
|
| [2] |
JONES G L and LITOVSKY R Y. A cocktail party model of spatial release from masking by both noise and speech interferers[J]. The Journal of the Acoustical Society of America, 2011, 130(3): 1463–1474. doi: 10.1121/1.3613928
|
| [3] |
XU Jiaming, SHI Jing, LIU Guangcan, et al. Modeling attention and memory for auditory selection in a cocktail party environment[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018.
|
| [4] |
黄雅婷, 石晶, 许家铭, 等. 鸡尾酒会问题与相关听觉模型的研究现状与展望[J]. 自动化学报, 2019, 45(2): 234–251.
HUANG Yating, SHI Jing, XU Jiaming, et al. Research advances and perspectives on the cocktail party problem and related auditory models[J]. Acta Automatica Sinica, 2019, 45(2): 234–251.
|
| [5] |
李娟. 基于ICA和波束形成的快速收敛的BSS算法[J]. 山西师范大学学报: 自然科学版, 2018, 32(4): 52–56.
LI Juan. A fast-convergence algorithm combining ICA and beamforming[J]. Journal of Shanxi Normal University:Natural Science Edition, 2018, 32(4): 52–56.
|
| [6] |
陈国良, 黄晓琴, 卢可凡. 改进的快速独立分量分析在语音分离系统中的应用[J]. 计算机应用, 2019, 39(S1): 206–209.
CHEN Guoliang, HUANG Xiaoqin, and LU Kefan. Application of improved fast independent component analysis in speech separation system[J]. Journal of Computer Applications, 2019, 39(S1): 206–209.
|
| [7] |
王昕, 蒋志翔, 张杨, 等. 基于时间卷积网络的深度聚类说话人语音分离[J]. 计算机工程与设计, 2020, 41(9): 2630–2635.
WANG Xin, JIANG Zhixiang, ZHANG Yang, et al. Deep clustering speaker speech separation based on temporal convolutional network[J]. Computer Engineering and Design, 2020, 41(9): 2630–2635.
|
| [8] |
崔建峰, 邓泽平, 申飞, 等. 基于非负矩阵分解和长短时记忆网络的单通道语音分离[J]. 科学技术与工程, 2019, 19(12): 206–210. doi: 10.3969/j.issn.1671-1815.2019.12.029
CUI Jianfeng, DENG Zeping, SHEN Fei, et al. Single channel speech separation based on non–negative matrix factorization and long short–term memory network[J]. Science Technology and Engineering, 2019, 19(12): 206–210. doi: 10.3969/j.issn.1671-1815.2019.12.029
|
| [9] |
陈修凯, 陆志华, 周宇. 基于卷积编解码器和门控循环单元的语音分离算法[J]. 计算机应用, 2020, 40(7): 2137–2141.
CHEN Xiukai, LU Zhihua, and ZHOU Yu. Speech separation algorithm based on convolutional encoder decoder and gated recurrent unit[J]. Journal of Computer Applications, 2020, 40(7): 2137–2141.
|
| [10] |
WANG Deliang and CHEN Jitong. Supervised speech separation based on deep learning: An overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702–1726. doi: 10.1109/TASLP.2018.2842159
|
| [11] |
刘文举, 聂帅, 梁山, 等. 基于深度学习语音分离技术的研究现状与进展[J]. 自动化学报, 2016, 42(6): 819–833.
LIU Wenju, NIE Shuai, LIANG Shan, et al. Deep learning based speech separation technology and its developments[J]. Acta Automatica Sinica, 2016, 42(6): 819–833.
|
| [12] |
WANG Yuxuan, NARAYANAN A, and WANG Deliang. On training targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1849–1858. doi: 10.1109/TASLP.2014.2352935
|
| [13] |
HUANG P S, KIM M, HASEGAWA–JOHNSON M, et al. Deep learning for monaural speech separation[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014: 1562–1566.
|
| [14] |
HUI Like, CAI Meng, GUO Cong, et al. Convolutional maxout neural networks for speech separation[C]. 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, United Arab Emirates. 2015: 24–27.
|
| [15] |
CHANDNA P, MIRON M, JANER J, et al. Monoaural audio source separation using deep convolutional neural networks[C]. The 13th International Conference, Grenoble, France, 2017: 258–266.
|
| [16] |
NIE Shuai, ZHANG Hui, ZHANG Xueliang, et al. Deep stacking networks with time series for speech separation[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014: 6667–6671.
|
| [17] |
GERS F A, SCHMIDHUBER J, and CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451–2471. doi: 10.1162/089976600300015015
|
| [18] |
梁尧, 朱杰, 马志贤. 基于深度神经网络的单通道语音分离算法[J]. 信息技术, 2018, 42(7): 24–27.
LIANG Yao, ZHU Jie, and MA Zhixian. A monaural speech separation algorithm based on deep neural networks[J]. Information Technology, 2018, 42(7): 24–27.
|
| [19] |
李文杰, 罗文俊, 李艺文, 等. 基于可分离卷积与LSTM的语音情感识别研究[J]. 信息技术, 2020, 44(10): 61–66.
LI Wenjie, LUO Wenjun, LI Yiwen, et al. Speech emotion recognition based on separable convolution and LSTM[J]. Information Technology, 2020, 44(10): 61–66.
|
| [20] |
WESTHAUSEN N L and MEYER B T. Dual–signal transformation LSTM network for real–time noise suppression[EB/OL]. https://arxiv.org/abs/2005.07551,2020.
|
| [21] |
GREZES F, NI Zhaoheng, TRINH V A, et al. Combining spatial clustering with LSTM speech models for multichannel speech enhancement[EB/OL]. https://arxiv.org/abs/2012.03388,2020.
|
| [22] |
LI Xiaofei and HORAUD R. Online monaural speech enhancement using delayed subband LSTM[EB/OL]. https://arxiv.org/abs/2005.05037, 2020.
|
| [23] |
潘超, 黄公平, 陈景东. 面向语音通信与交互的麦克风阵列波束形成方法[J]. 信号处理, 2020, 36(6): 804–815.
PAN Chao, HUANG Gongping, and CHEN Jingdong. Microphone array beamforming: An overview[J]. Journal of Signal Processing, 2020, 36(6): 804–815.
|
| [24] |
朱训谕, 潘翔. 基于麦克风线阵的语音增强算法研究[J]. 杭州电子科技大学学报: 自然科学版, 2020, 40(5): 30–33, 72.
ZHU Xunyu and PAN Xiang. Research on speech enhancement algorithm based on microphone linear array[J]. Journal of Hangzhou Dianzi University:Natural Science, 2020, 40(5): 30–33, 72.
|
| [25] |
KIM H S, KO H, BEH J, et al. Sound source separation method and system using beamforming technique[P]. USA Patent. 008577677B2, 2013.
|
| [26] |
ARAKI S, SAWADA H, and MAKINO S. Blind speech separation in a meeting situation with maximum SNR beamformers[C]. 2007 IEEE International Conference on Acoustics, Speech and Signal Processing–ICASSP’07, Honolulu, USA, 2007, 1: I–41–I–44.
|
| [27] |
SARUWATARI H, KURITA S, TAKEDA K, et al. Blind source separation combining independent component analysis and beamforming[J]. EURASIP Journal on Advances in Signal Processing, 2003, 2003: 569270. doi: 10.1155/S1110865703305104
|
| [28] |
WANG Lin, DING Heping, and YIN Fuliang. Speech separation and extraction by combining superdirective beamforming and blind source separation[M]. NAIK G and WANG Wenwu. Blind Source Separation. Heidelberg: Springer, 2014: 323–348.
|
| [29] |
XENAKI A, BOLDT J B, and CHRISTENSEN M G. Sound source localization and speech enhancement with sparse Bayesian learning beamforming[J]. The Journal of the Acoustical Society of America, 2018, 143(6): 3912–3921. doi: 10.1121/1.5042222
|
| [30] |
QIAN Kaizhi, ZHANG Yang, CHANG Shiyu, et al. Deep learning based speech beamforming[C]. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018: 5389–5393.
|
| [31] |
HIMAWAN I, MCCOWAN I, and LINCOLN M. Microphone array beamforming approach to blind speech separation[C]. The 4th International Workshop, Brno, The Czech Republic, 2007: 295–305.
|
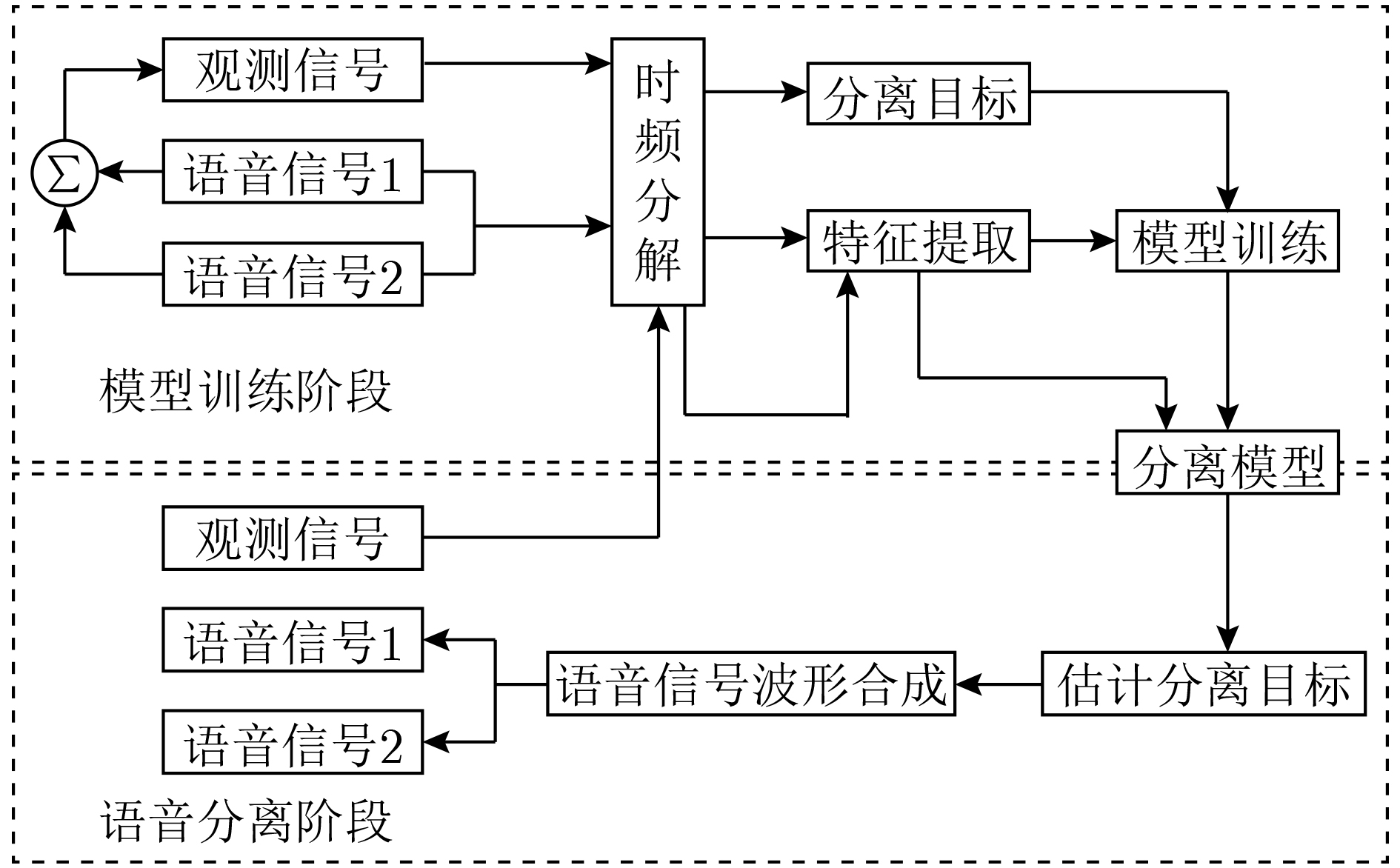
Figures(8) / Tables(1)



 DownLoad:
DownLoad: