

Static and Dynamic-domain Prior Enhancement Two-stage Video Compressed Sensing Reconstruction Network
-
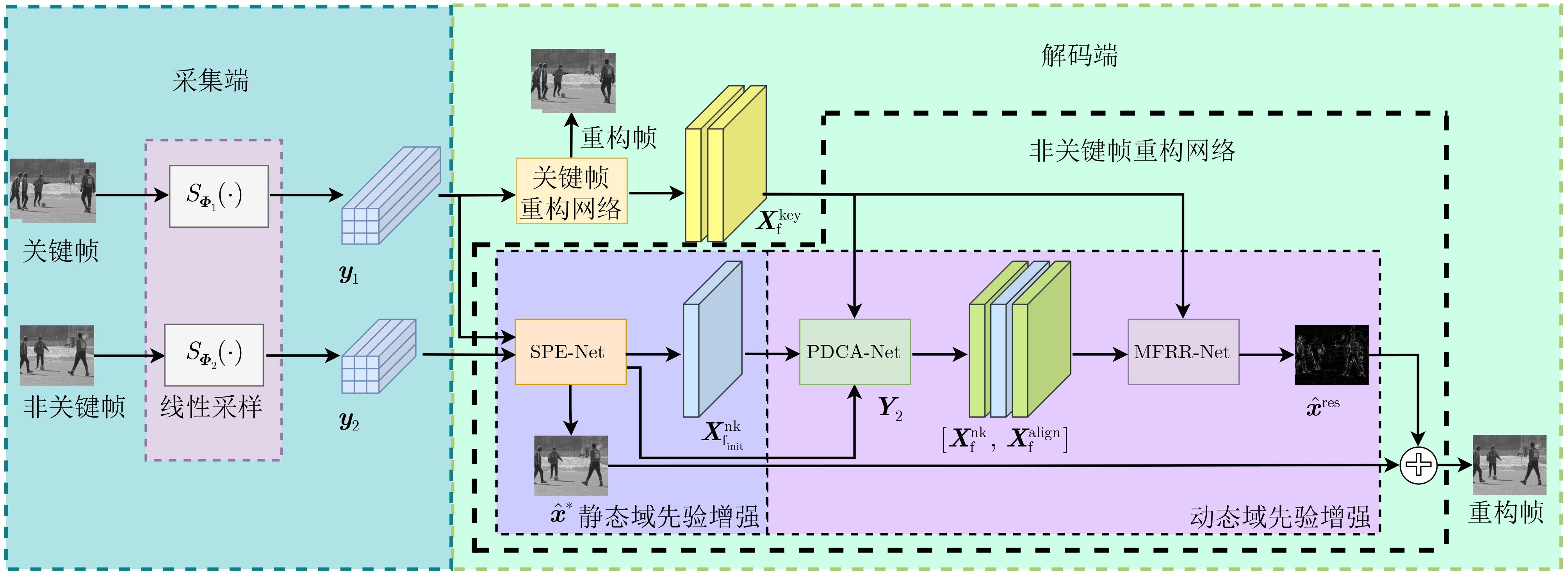
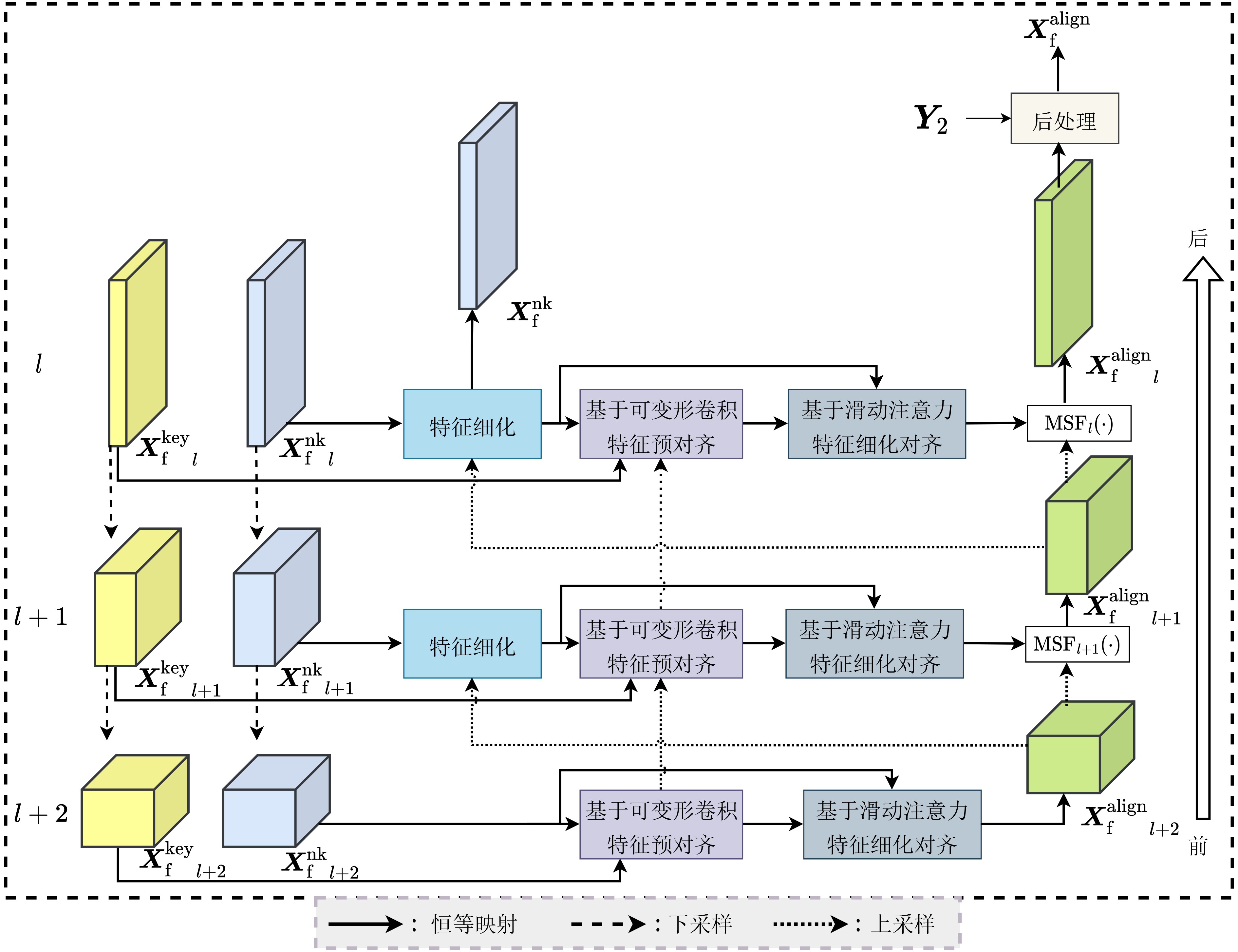
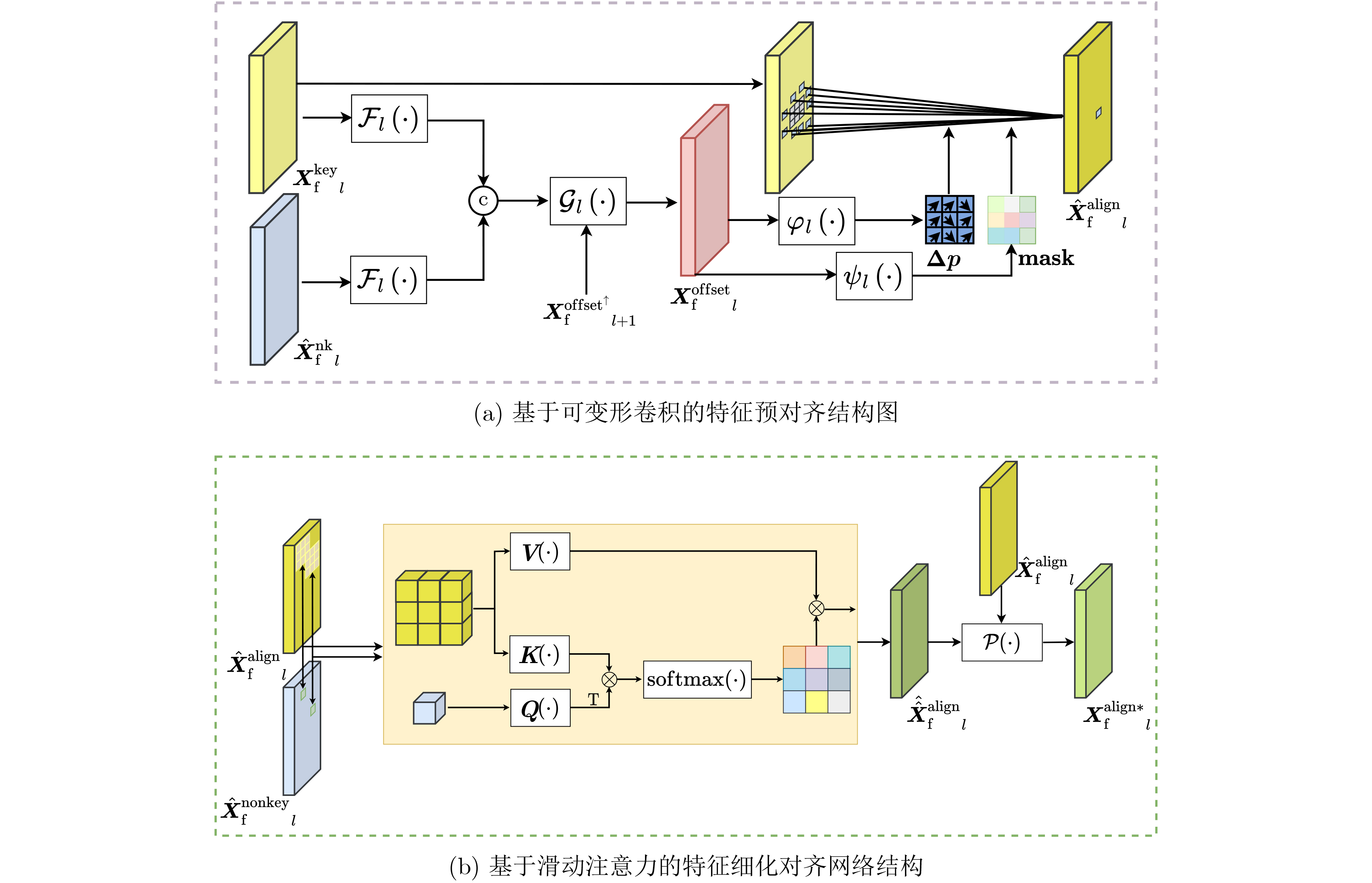
摘要: 视频压缩感知重构属于高度欠定问题,初始重构质量低与运动估计方式单一限制了帧间相关性的有效建模。为改善视频重构性能,该文提出静态与动态域先验增强两阶段重构网络(SDPETs-Net)。首先,提出利用参考帧测量值重构2阶静态域残差的策略,并设计相应的静态域先验增强网络(SPE-Net),为动态域先验建模提供可靠基础。其次,设计塔式可变形卷积联合注意力搜索网络(PDCA-Net),通过结合可变形卷积与注意力机制的优势,并构建塔式级联结构,有效地建模并利用动态域先验知识。最后,多特征融合残差重构网络(MFRR-Net)从多尺度提取并融合各特征的关键信息以重构残差,缓解两阶段耦合导致不稳定的模型训练,并抑制特征的退化。实验结果表明,在UCF101测试集下,与具有代表性的两阶段网络JDR-TAFA-Net相比,峰值信噪比(PSNR)平均提升3.34 dB,与近期的多阶段网络DMIGAN相比,平均提升0.79 dB。Abstract: Video compressed sensing reconstruction is a highly underdetermined problem, where the low-quality of initial reconstructed and the single-motion estimation approach limit the effective modeling of inter-frames correlations. To improve video reconstruction performance, the Static and Dynamic-domain Prior Enhancement Two-stage reconstruction Network (SDPETs-Net) is proposed. Firstly, a strategy of reconstructing second-order static-domain residuals using reference frame measurements is proposed, and a corresponding Static-domain Prior Enhancement Network (SPE-Net) is designed to provide a reliable basis for dynamic-domain prior modeling. Secondly, the Pyramid Deformable-convolution Combined with Attention-search Network (PDCA-Net) is designed, which combines the advantages of deformable-convolution and attention mechanisms, and a pyramid cascade structure is constructed to effectively model and utilize dynamic-domain prior knowledge. Lastly, the Multi-Feature Fusion Residual Reconstruction Network (MFRR-Net) extracts and fuses key information of each feature from multiple scales to reconstruct residues, alleviating the instability of model training caused by the coupling of the two stages and suppressing feature degradation. Simulation results show that the Peak Signal-to-Noise Ratio (PSNR) is improved by an average of 3.34 dB compared to the representative two-stage network JDR-TAFA-Net under the UCF101 test set, and by an average of 0.79 dB compared to the recent multi-stage network DMIGAN.
-
表 1 UCF101测试集重构性能对比PSNR(dB)/SSIM
$ {r}_{\mathrm{n}\mathrm{k}} $ CSVideoNet STM-Net Imr-Net JDRTAFA-Net DUMHAN DMIGAN 本文
SDPETs-Net$ 0.037 $ 26.87/0.81 32.50/0.93 33.40/— 33.14/0.94 35.37/— 35.86/— 36.36/0.96 $ 0.018 $ 25.09/0.77 31.14/0.91 31.90/— 31.63/0.91 33.70/— 34.23/— 35.01/0.95 $ 0.009 $ 24.23/0.74 29.98/0.89 30.51/— 30.33/0.89 32.11/— 32.65/— 33.75/0.94 平均值 25.40/0.77 31.21/0.91 31.94/— 31.70/0.91 33.73/— 34.25/— 35.04/0.95  下载: 导出CSV
下载: 导出CSV
表 2 QCIF序列重构性能对比PSNR(dB)($ {r}_{\mathrm{k}}=0.5 $,$ \mathrm{G}\mathrm{O}\mathrm{P}=8 $)
$ {r}_{\mathrm{n}\mathrm{k}} $ 算法
(网络)视频序列 平均值 Silent Ice Foreman Coastguard Soccer Mobile 0.01 RRS 21.25 20.72 18.51 21.16 21.42 15.24 19.72 SSIM-InterF-GSR 24.77 24.65 26.86 25.08 23.39 21.92 24.45 VCSNet-2 31.94 25.77 26.07 25.66 24.62 21.42 25.91 ImrNet 35.30 29.25 31.58 28.94 27.10 25.02 29.53 DUMHAN 37.25 31.69 34.46 31.63 28.37 29.28 32.11 本文SDPETs-Net 38.05 32.92 36.05 32.76 29.50 30.35 33.27 0.05 RRS 25.76 26.15 26.84 22.66 26.80 16.68 24.15 SSIM-InterF-GSR 33.68 28.81 33.18 28.09 27.65 22.99 29.07 VCSNet-2 34.52 29.51 29.75 27.01 28.62 22.79 28.70 ImrNet 38.07 33.76 36.03 30.80 31.81 27.55 33.00 DUMHAN 40.42 36.58 39.44 33.63 33.74 31.61 35.90 本文SDPETs-Net 41.09 37.98 40.82 34.31 34.85 32.36 36.90 0.1 RRS 33.95 31.09 35.17 27.34 29.74 20.00 29.55 SSIM-InterF-GSR 35.09 31.73 35.75 30.24 30.31 24.35 31.25 VCSNet-2 34.92 30.95 31.14 28.01 30.51 23.62 29.86 ImrNet 39.17 35.90 37.37 31.44 34.24 28.19 34.39 DUMHAN 41.73 38.66 41.68 34.73 36.40 32.48 37.61 本文SDPETs-Net 42.71 40.10 42.97 35.22 37.52 33.07 38.60
下载: 导出CSV
表 3 REDS4序列重构性能对比PSNR(dB)/SSIM
$ {r}_{\mathrm{n}\mathrm{k}} $ 序列 VCSNet-2 ImrNet STM-Net DUMHAN 本文SDPETs-Net 0.01 000 23.24/— 25.71/0.67 26.45/0.73 27.74/0.77 29.44/0.85 011 24.19/— 25.93/0.66 26.89/0.71 26.72/0.70 27.77/0.74 015 26.85/— 30.01/0.81 30.67/0.84 31.02/0.85 32.66/0.89 020 23.34/— 25.15/0.66 25.98/0.71 25.97/0.70 26.99/0.75 0.1 000 27.55/— 29.09/0.85 30.69/0.90 31.80/0.91 32.82/0.94 011 29.65/— 32.29/0.89 32.82/0.90 33.52/0.90 34.36/0.92 015 32.34/— 36.33/0.94 37.06/0.95 38.00/0.95 39.07/0.96 020 28.88/— 31.23/0.90 31.65/0.91 32.17/0.91 33.16/0.93
下载: 导出CSV
表 4 不同模型的空间与重构时间(GPU)与重构精度(PSNR(dB)/SSIM)对比
模型 参数量(M) 平均单帧重构时间(GPU)(s) 平均重构精度(PSNR(dB)/SSIM) ImrNet 8.69 0.03 31.94/— STM-Net 9.20 0.03 31.21/0.91 JDR-TAFA-Net 12.41 0.04 31.70/0.91 本文SDPETs-Net 7.44 0.04 35.04/0.95 本文SDPETs-Net 7.44 0.02(GOP并行) 35.04/0.95
下载: 导出CSV
表 5 静态域先验增强阶段的消融研究(PSNR(dB)/SSIM)
模型 设置 QCIF序列 平均值 SR MG Silent Ice Foreman Coastguard Soccer Mobile 基础 √ √ 36.71/0.97 31.42/0.94 34.04/0.94 31.19/0.88 28.20/0.76 27.82/0.92 31.56/0.90 1 √ × 36.32/0.96 31.09/0.94 33.14/0.92 30.14/0.85 27.99/0.74 26.78/0.90 30.91/0.89 2 × × 26.65/0.61 26.21/0.80 24.90/0.63 24.06/0.51 26.77/0.67 19.42/0.35 24.67/0.60
下载: 导出CSV
表 6 PDCA-Net消融实验对比(PSNR(dB)/SSIM)
模型 设置 REDS4序列 平均值 PA PP RA PC RF 000 011 015 020 基础 √ √ √ √ √ 31.74/0.91 32.17/0.87 36.99/0.95 31.00/0.89 32.98/0.90 1 √ √ √ √ × 31.56/0.91 31.92/0.87 36.78/0.94 30.81/0.88 32.77/0.90 2 √ √ √ × × 30.38/0.88 31.04/0.85 35.94/0.93 29.82/0.86 31.80/0.88 3 √ √ × × × 30.32/0.87 30.96/0.85 35.87/0.93 29.79/0.86 31.73/0.88 4 √ × × × × 30.08/0.87 30.80/0.84 35.65/0.93 29.67/0.86 31.55/0.87 5 × × × × × 29.38/0.84 30.55/0.84 35.19/0.92 29.40/0.85 31.13/0.86
下载: 导出CSV
-
[1] DONOHO D L. Compressed sensing[J]. IEEE Transactions on Information Theory, 2006, 52(4): 1289–1306. doi: 10.1109/TIT.2006.871582. [2] DO T T, CHEN Yi, NGUYEN D T, et al. Distributed compressed video sensing[C]. 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 2009: 1393–1396. doi: 10.1109/ICIP.2009.5414631. [3] KUO Yonghong, WU Kai, and CHEN Jian. A scheme for distributed compressed video sensing based on hypothesis set optimization techniques[J]. Multidimensional Systems and Signal Processing, 2017, 28(1): 129–148. doi: 10.1007/s11045-015-0337-4. [4] OU Weifeng, YANG Chunling, LI Wenhao, et al. A two-stage multi-hypothesis reconstruction scheme in compressed video sensing[C]. 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, USA, 2016: 2494–2498. doi: 10.1109/ICIP.2016.7532808. [5] ZHAO Chen, MA Siwei, ZHANG Jian, et al. Video compressive sensing reconstruction via reweighted residual sparsity[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(6): 1182–1195. doi: 10.1109/TCSVT.2016.2527181. [6] 和志杰, 杨春玲, 汤瑞东. 视频压缩感知中基于结构相似的帧间组稀疏表示重构算法研究[J]. 电子学报, 2018, 46(3): 544–553. doi: 10.3969/j.issn.0372-2112.2018.03.005.HE Zhijie, YANG Chunling, and TANG Ruidong. Research on structural similarity based inter-frame group sparse representation for compressed video sensing[J]. Acta Electronica Sinica, 2018, 46(3): 544–553. doi: 10.3969/j.issn.0372-2112.2018.03.005. [7] CHEN Can, WU Yutong, ZHOU Chao, et al. JsrNet: A joint sampling–reconstruction framework for distributed compressive video sensing[J]. Sensors, 2019, 20(1): 206. doi: 10.3390/s20010206. [8] SHI Wuzhen, LIU Shaohui, JIANG Feng, et al. Video compressed sensing using a convolutional neural network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(2): 425–438. doi: 10.1109/TCSVT.2020.2978703. [9] XU Kai and REN Fengbo. CSVideoNet: A real-time end-to-end learning framework for high-frame-rate video compressive sensing[C]. 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, USA, 2018: 1680–1688. doi: 10.1109/WACV.2018.00187. [10] XIA Kaiguo, PAN Zhisong, and MAO Pengqiang. Video compressive sensing reconstruction using unfolded LSTM[J]. Sensors, 2022, 22(19): 7172. doi: 10.3390/s22197172. [11] ZHANG Tong, CUI Wenxue, HUI Chen, et al. Hierarchical interactive reconstruction network for video compressive sensing[C]. 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10095587. [12] NEZHAD V A, AZGHANI M, and MARVASTI F. Compressed video sensing based on deep generative adversarial network[J]. Circuits, Systems, and Signal Processing, 2024, 43(8): 5048–5064. doi: 10.1007/s00034-024-02672-8. [13] LING Xi, YANG Chunling, and PEI Hanqi. Compressed video sensing network based on alignment prediction and residual reconstruction[C]. 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 2020: 1–6. doi: 10.1109/ICME46284.2020.9102723. [14] YANG Xin and YANG Chunling. Imrnet: An iterative motion compensation and residual reconstruction network for video compressed sensing[C]. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 2021: 2350–2354. doi: 10.1109/ICASSP39728.2021.9414534. [15] WEI Zhichao, YANG Chunling, and XUAN Yunyi. Efficient video compressed sensing reconstruction via exploiting spatial-temporal correlation with measurement constraint[C]. 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 2021: 1–6. doi: 10.1109/ICME51207.2021.9428203. [16] ZHOU Chao, CHEN Can, and ZHANG Dengyin. Deep video compressive sensing with attention-aware bidirectional propagation network[C]. 2022 15th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 2022: 1–5. doi: 10.1109/CISP-BMEI56279.2022.9980235. [17] 杨鑫, 杨春玲. 基于MAP的多信息流梯度更新与聚合视频压缩感知重构算法[J]. 电子学报, 2023, 51(11): 3320–3330. doi: 10.12263/DZXB.20220958.YANG Xin and YANG Chunling. MAP-based multi-information flow gradient update and aggregation for video compressed sensing reconstruction[J]. Acta Electronica Sinica, 2023, 51(11): 3320–3330. doi: 10.12263/DZXB.20220958. [18] YANG Xin and YANG Chunling. MAP-inspired deep unfolding network for distributed compressive video sensing[J]. IEEE Signal Processing Letters, 2023, 30: 309–313. doi: 10.1109/LSP.2023.3260707. [19] GU Zhenfei, ZHOU Chao, and LIN Guofeng. A temporal shift reconstruction network for compressive video sensing[J]. IET Computer Vision, 2024, 18(4): 448–457. doi: 10.1049/cvi2.12234. [20] 魏志超, 杨春玲. 时域注意力特征对齐的视频压缩感知重构网络[J]. 电子学报, 2022, 50(11): 2584–2592. doi: 10.12263/DZXB.20220041.WEI Zhichao and YANG Chunling. Video compressed sensing reconstruction network based on temporal-attention feature alignment[J]. Acta Electronica Sinica, 2022, 50(11): 2584–2592. doi: 10.12263/DZXB.20220041. [21] RANJAN A and BLACK M J. Optical flow estimation using a spatial pyramid network[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 2720–2729. doi: 10.1109/CVPR.2017.291. [22] CHAN K C K, WANG Xintao, YU Ke, et al. Understanding deformable alignment in video super-resolution[C]. 2021 35th AAAI Conference on Artificial Intelligence, 2021: 973–981. doi: 10.1609/aaai.v35i2.16181. [23] LIANG Ziwen and YANG Chunling. Feature-domain proximal high-dimensional gradient descent network for image compressed sensing[C]. 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 2023: 1475–1479. doi: 10.1109/ICIP49359.2023.10222347. [24] ZHU Xizhou, HU Han, LIN S, et al. Deformable ConvNets v2: More deformable, better results[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 9300–9308. doi: 10.1109/CVPR.2019.00953. [25] LIU Ze, HU Han, LIN Yutong, et al. Swin transformer V2: Scaling up capacity and resolution[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11999–12009. doi: 10.1109/CVPR52688.2022.01170. [26] HUANG Cong, LI Jiahao, LI Bin, et al. Neural compression-based feature learning for video restoration[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 5862–5871. doi: 10.1109/CVPR52688.2022.00578. [27] ARBELÁEZ P, MAIRE M, FOWLKES C, et al. Contour detection and hierarchical image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 898–916. doi: 10.1109/TPAMI.2010.161. [28] SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[EB/OL]. https://arxiv.org/abs/1212.0402, 2012. [29] NAH S, BAIK S, HONG S, et al. NTIRE 2019 challenge on video deblurring and super-resolution: Dataset and study[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, USA, 2019: 1996–2005. doi: 10.1109/CVPRW.2019.00251. -

 下载:
下载:





图(6) / 表(6)
计量
- 文章访问数: 790
- HTML全文浏览量: 488
- PDF下载量: 30
- 被引次数: 0
