

Deep Network for Joint Multi-exposure Fusion and Image Deblur
-
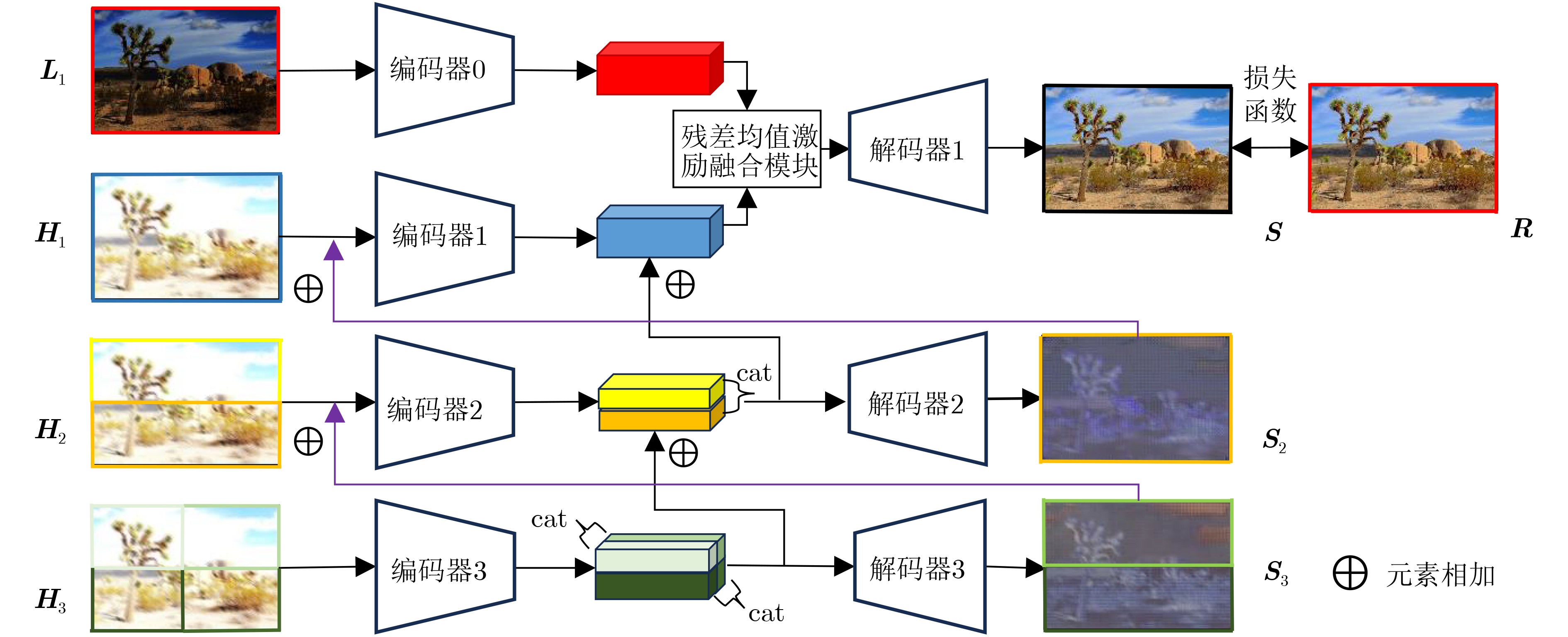
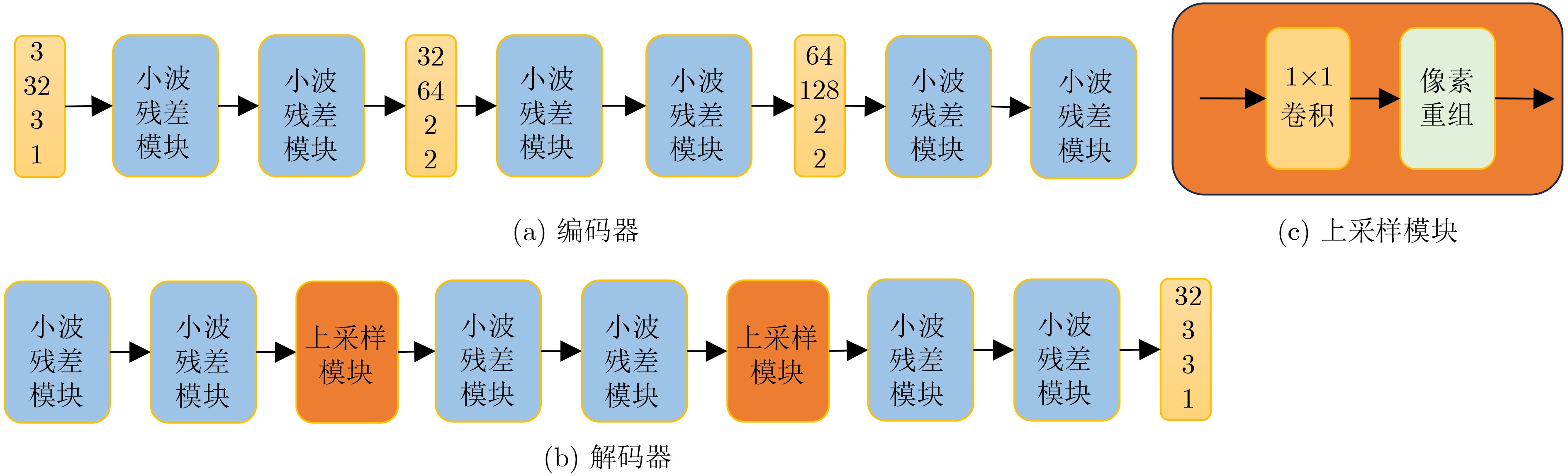
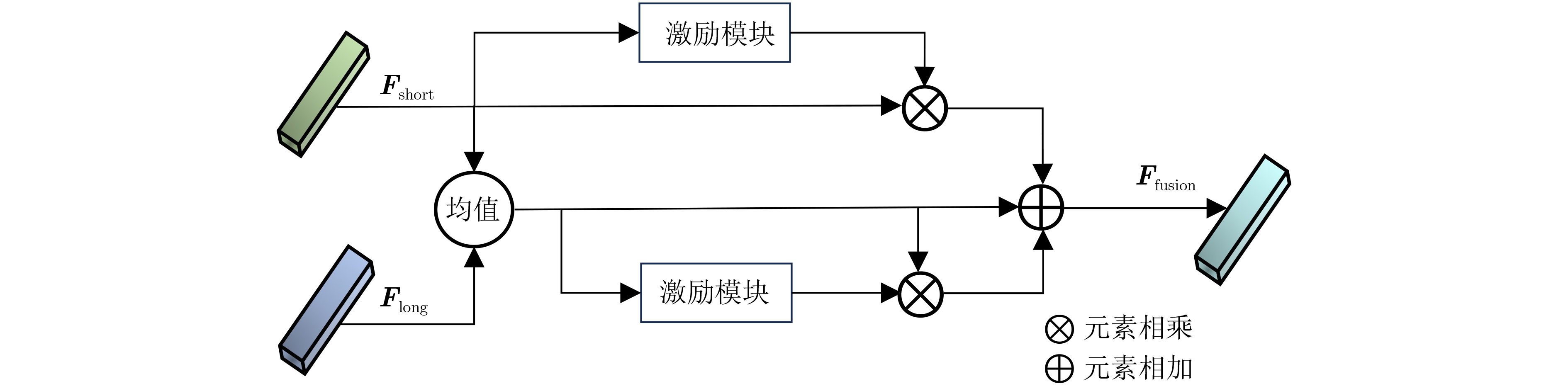
摘要: 多曝光图像融合可提高图像的动态范围,从而获取高质量的图像。对于在像自动驾驶等快速运动场景中获得的模糊的长曝光图像,利用通用的图像融合方法将其直接与低曝光图像融合得到的图像质量并不高。目前暂缺乏对带有运动模糊的长曝光和短曝光图像的端到端融合方法。基于此,该文提出一种联合多曝光融合和图像去模糊的深度网络(DF-Net)端到端地解决带有运动模糊的长短曝光图像融合问题。该方法提出一种结合小波变换的残差模块用于构建编码器和解码器,其中设计单个编码器对短曝光图像进行特征提取,构建基于编码器和解码器的多级结构对带有模糊的长曝光图像进行特征提取,设计残差均值激励融合模块进行长短曝光特征的融合,最后通过解码器重建图像。由于缺少基准数据集,创建了基于数据集 SICE 的带有运动模糊的多曝光融合数据集,用于模型的训练与测试。最后,从定性和定量的角度将所设计的模型和方法和其他先进的图像去模糊和多曝光融合的分步优化方法进行了实验对比,验证了该文的模型和方法对带有运动模糊的多曝光图像融合的优越性。并在移动车辆上采集到的多曝光数据组上进行验证,结果显示了所提方法解决实际问题的有效性。Abstract: Multi-exposure image fusion is used to enhance the dynamic range of images, resulting in higher-quality outputs. However, for blurred long-exposure images captured in fast-motion scenes, such as autonomous driving, the image quality achieved by directly fusing them with low-exposure images using generalized fusion methods is often suboptimal. Currently, end-to-end fusion methods for combining long and short exposure images with motion blur are lacking. To address this issue, a Deblur Fusion Network (DF-Net) is proposed to solve the problem of fusing long and short exposure images with motion blur in an end-to-end manner. A residual module combined with wavelet transform is proposed for constructing the encoder and decoder, where a single encoder is designed for the feature extraction of short exposure images, a multilevel structure based on encoder and decoder is built for feature extraction of long exposure images with blurring, a residual mean excitation fusion module is designed for the fusion of the long and short exposure features, and finally the image is reconstructed by the decoder. Due to the lack of a benchmark dataset, a multi-exposure fusion dataset with motion blur based on the dataset SICE is created for model training and testing. Finally, the designed model and method are experimentally compared with other state-of-the-art step-by-step optimization methods for image deblurring and multi-exposure fusion from both qualitative and quantitative perspectives to verify the superiority of the model and method in this paper for multi-exposure image fusion with motion blur. The validation is also conducted on a multi-exposure dataset acquired from a moving vehicle, and the effectiveness of the proposed method in solving practical problems is demonstrated by the results.
-
Key words:
- Multi-exposure image fusion /
- Image deblurring /
- Wavelet transform /
- Feature fusion
-
表 1 DF-Net与Deblur+MEF策略下最优方法在PSNR和SSIM上的比较
方法组合 DPE-MEF [15] IFCNN [16] MEFNet[17] U2fusion[18] PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM DMPHN [12] 18.012 0 0.822 6 19.470 0 0.813 5 16.630 0 0.746 0 18.075 9 0.700 9 MIMO-UNet [13] 18.138 9 0.835 7 19.803 2 0.835 5 17.026 8 0.774 8 18.269 2 0.716 1 DeepRFT [14] 19.052 9 0.912 8 20.517 4 0.906 0 18.154 6 0.870 8 18.760 7 0.752 9 DF-Net PSNR = 21.712 6 SSIM = 0.924 6  下载: 导出CSV
下载: 导出CSV
表 2 DF-Net与MEF+Deblur策略下最优方法在PSNR和SSIM上的比较
方法组合 DPE-MEF [15] IFCNN[16] MEFNet[17] U2fusion[18] PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM DMPHN [12] 18.273 4 0.799 8 19.701 4 0.856 4 18.415 5 0.778 1 17.449 2 0.605 0 MIMO-UNet [13] 20.089 6 0.873 1 20.187 9 0.876 1 18.601 4 0.797 1 19.563 0 0.815 0 DeepRFT[14] 19.913 3 0.871 6 19.704 0 0.885 9 18.779 3 0.819 1 19.918 2 0.809 6 DF-Net PSNR = 21.712 6 SSIM = 0.924 6
下载: 导出CSV
表 4 模块消融实验比较
小波残差模块 RMEFB PSNR SSIM 实验1 × × 21.216 1 0.912 4 实验2 × √ 21.352 1 0.917 2 实验3 √ × 21.602 4 0.919 6 DF-Net √ √ 21.712 6 0.924 6
下载: 导出CSV
-
[1] LI Shutao and KANG Xudong. Fast multi-exposure image fusion with median filter and recursive filter[J]. IEEE Transactions on Consumer Electronics, 2012, 58(2): 626–632. doi: 10.1109/TCE.2012.6227469. [2] MERTENS T, KAUTZ J, and VAN REETH F. Exposure fusion[C]. The 15th Pacific Conference on Computer Graphics and Applications, Maui, USA, 2007: 382–390. doi: 10.1109/PG.2007.17. [3] ZHANG Hao and MA Jiayi. IID-MEF: A multi-exposure fusion network based on intrinsic image decomposition[J]. Information Fusion, 2023, 95: 326–340. doi: 10.1016/j.inffus.2023.02.031. [4] LI Jiawei, LIU Jinyuan, ZHOU Shihua, et al. Learning a coordinated network for detail-refinement multiexposure image fusion[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(2): 713–727. doi: 10.1109/TCSVT.2022.3202692. [5] KIM T H, AHN B, and LEE K M. Dynamic scene deblurring[C]. 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2013: 3160–3167. doi: 10.1109/ICCV.2013.392. [6] 杨爱萍, 李磊磊, 张兵, 等. 基于轻量化渐进式残差网络的图像快速去模糊[J]. 电子与信息学报, 2022, 44(5): 1674–1682. doi: 10.11999/JEIT210298.YANG Aiping, LI Leilei, ZHANG Bing, et al. Fast image deblurring based on the lightweight progressive residual network[J]. Journal of Electronics & Information Technology, 2022, 44(5): 1674–1682. doi: 10.11999/JEIT210298. [7] TSAI F J, PENG Y T, LIN Y Y, et al. Stripformer: Strip transformer for fast image deblurring[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 146–162. doi: 10.1007/978-3-031-19800-7_9. [8] CHEN Liangyu, CHU Xiaojie, ZHANG Xiangyu, et al. Simple baselines for image restoration[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 17–33. doi: 10.1007/978-3-031-20071-7_2. [9] ZAMIR S W, ARORA A, KHAN S, et al. Multi-stage progressive image restoration[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 14821–14831. doi: 10.1109/CVPR46437.2021.01458. [10] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/CVPR.2018.00745. [11] SODANO M, MAGISTRI F, GUADAGNINO T, et al. Robust double-encoder network for RGB-D panoptic segmentation[C]. 2023 IEEE International Conference on Robotics and Automation, London, UK, 2023: 4953–4959. doi: 10.1109/ICRA48891.2023.10160315. [12] ZHANG Hongguang, DAI Yuchao, LI Hongdong, et al. Deep stacked hierarchical multi-patch network for image deblurring[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5978–5986. doi: 10.1109/CVPR.2019.00613. [13] CHO S J, JI S W, HONG J P, et al. Rethinking coarse-to-fine approach in single image deblurring[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 4641–4650. doi: 10.1109/ICCV48922.2021.00460. [14] MAO Xintian, LIU Yiming, LIU Fengze, et al. Intriguing findings of frequency selection for image deblurring[C]. Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 1905–1913. doi: 10.1609/aaai.v37i2.25281. [15] HAN Dong, LI Liang, GUO Xiaojie, et al. Multi-exposure image fusion via deep perceptual enhancement[J]. Information Fusion, 2022, 79: 248–262. doi: 10.1016/j.inffus.2021.10.006. [16] ZHANG Yu, LIU Yu, SUN Peng, et al. IFCNN: A general image fusion framework based on convolutional neural network[J]. Information Fusion, 2020, 54: 99–118. doi: 10.1016/j.inffus.2019.07.011. [17] MA Kede, DUANMU Zhengfang, ZHU Hanwei, et al. Deep guided learning for fast multi-exposure image fusion[J]. IEEE Transactions on Image Processing, 2020, 29: 2808–2819. doi: 10.1109/TIP.2019.2952716. [18] XU Han, MA Jiayi, JIANG Junjun, et al. U2Fusion: A unified unsupervised image fusion network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 502–518. doi: 10.1109/TPAMI.2020.3012548. -

 下载:
下载:











图(12) / 表(4)
计量
- 文章访问数: 1104
- HTML全文浏览量: 475
- PDF下载量: 72
- 被引次数: 0
