

Constructions of Splitting Authentication Codes Based on Group Divisible Design
-
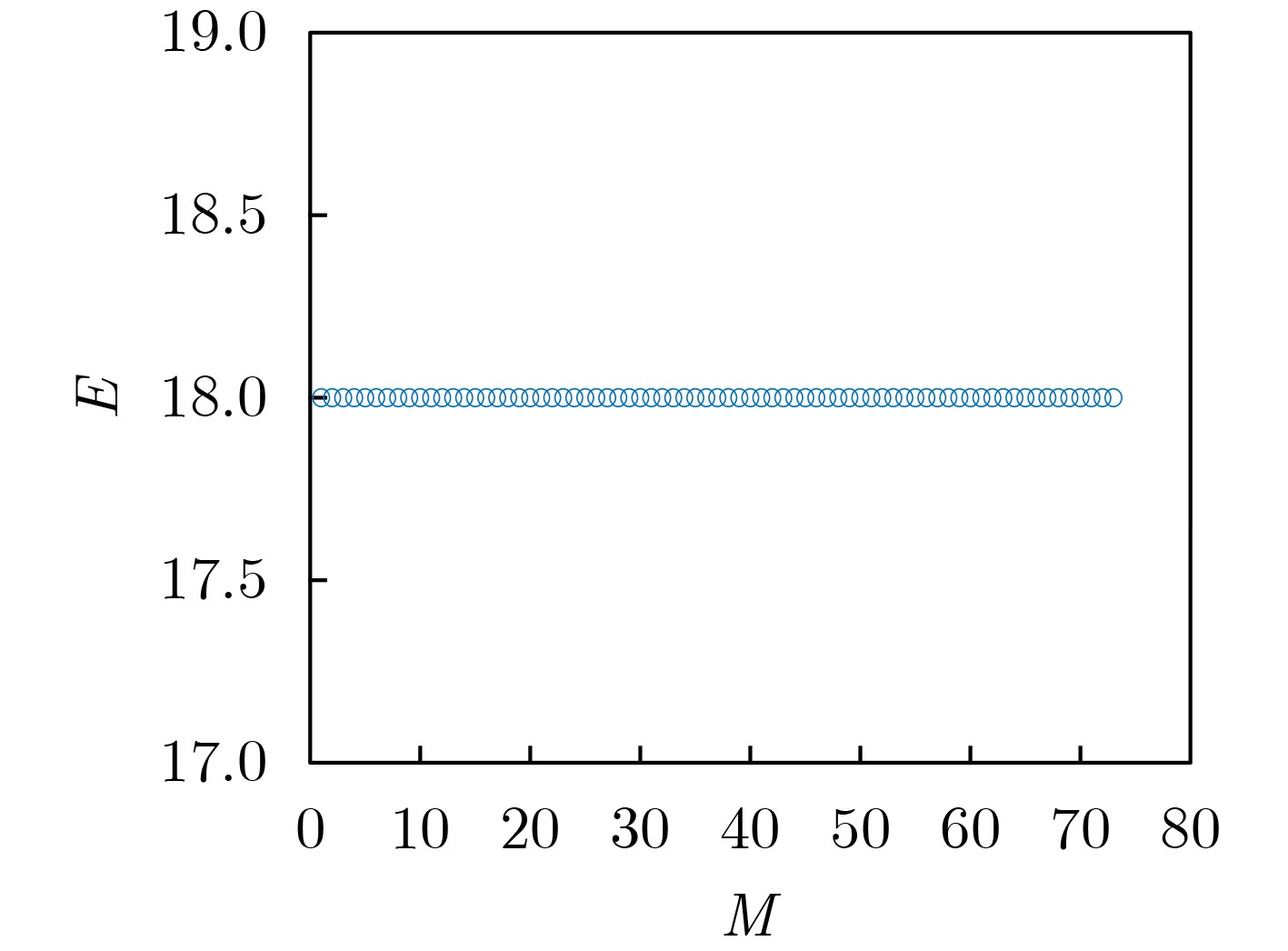
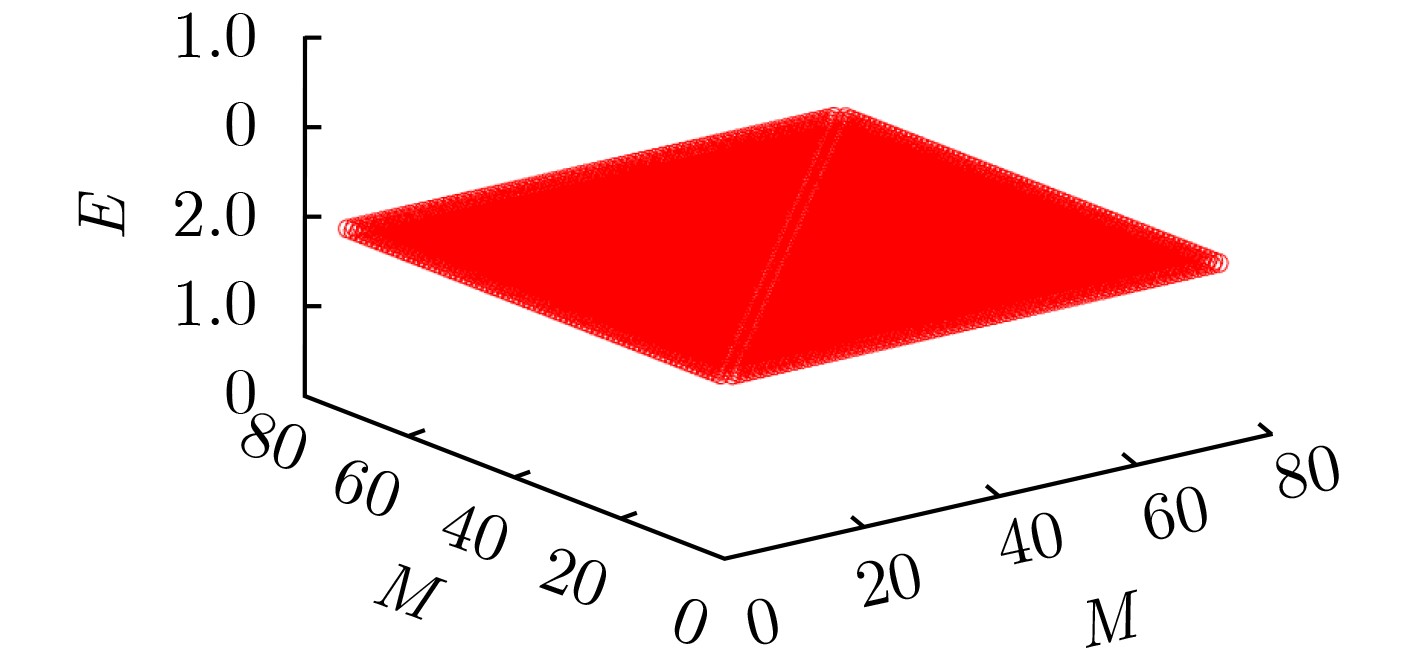
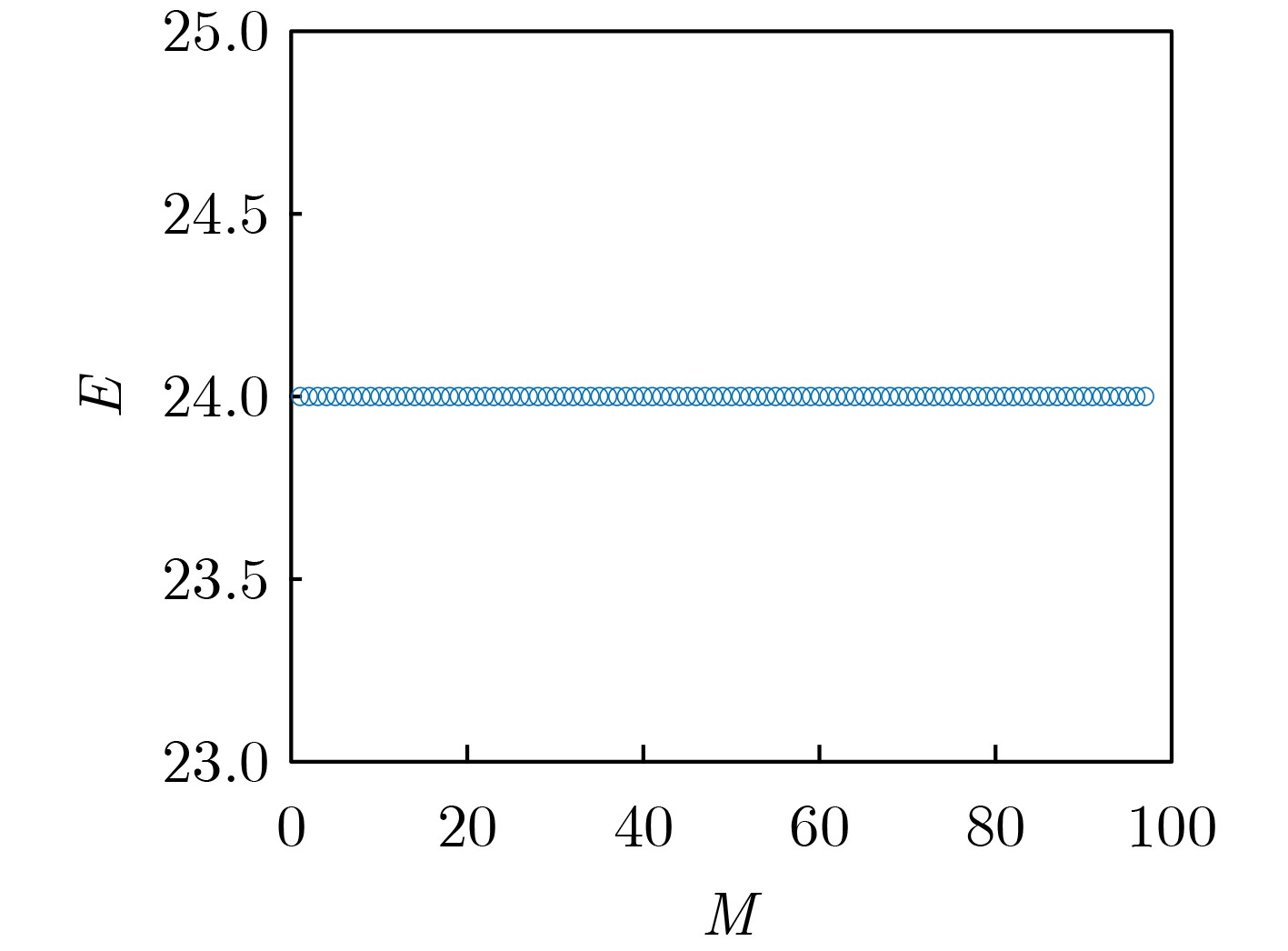
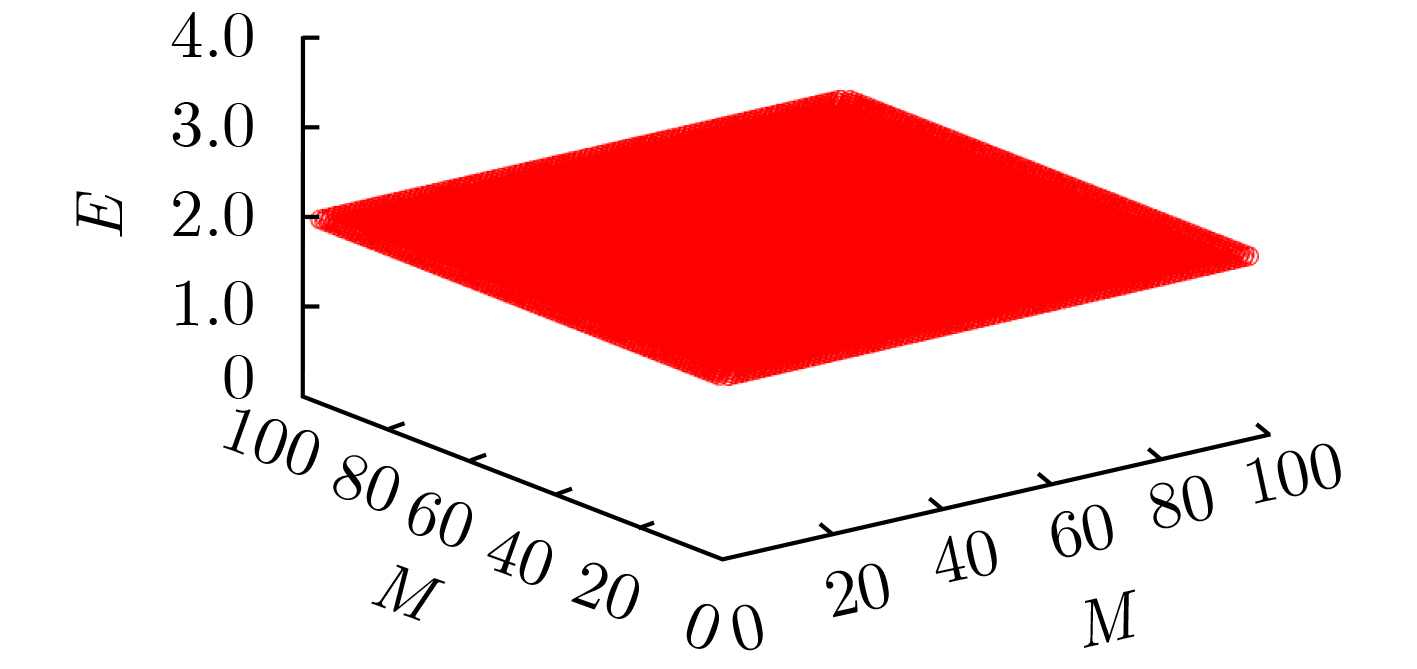
摘要: 分裂认证码是研究带仲裁的认证码的一种重要手段,相对无分裂认证码而言,分裂认证码大大提高了编码规则的利用率,该文主要通过可分组设计构造分裂认证码。首先给出了通过可分组设计(GDD)构造分裂认证码的定理,利用可分组设计构造可裂可分组设计,再由可裂可分组设计构造可裂平衡不完全区组设计(BIBD),进而得到分裂认证码;验证在该文给定的条件下,通过可分组设计构造分裂认证码的可行性,在此基础上设计了一种可裂设计,构造了一组分裂认证码。计算所构造的分裂认证码的信源个数、编码规则个数、消息个数和假冒攻击成功概率及替代攻击成功概率等参数,并证明所构造的分裂认证码为最优分裂认证码。给出所构造的分裂认证码的具体例子,计算其假冒攻击成功概率、替代攻击成功概率,通过模拟仿真验证构造的合理性,并验证其满足最优性。Abstract: Splitting authentication codes are an important method to study authentication codes with arbitration. Splitting authentication codes have a higher utilization rate of encoding rules than non-splitting authentication codes. Splitting authentication codes are constructed through group divisible design in this article. Firstly, a theorem for constructing splitting authentication codes is given. The theorem uses Group Divisible Design (GDD) to construct a splitting-GDD, and then a splitting-Balanced Incomplete Block Design (BIBD) by splitting-GDD is constructed, and then a splitting authentication code is obtained; Secondly, the feasibility of constructing splitting authentication codes through GDD under the conditions given in this article is verified. Then a splitting design is given and a splitting authentication codes based on GDD is constructed; Thirdly, the number of sources, the number of encoding rules, the number of messages of the splitting authentication code, the impersonation attack probability and the substitution attack probability are calculated, then this article proves that the constructed splitting authentication code is an optimal splitting authentication code; Finally, a concrete example of the constructed splitting authentication code is given, the successful impersonation attack probability and the successful substitution attack probability are calculated, the rationality of construction is verified by simulation, and verifies that it satisfies the optimality.
-
表 1 分裂认证码的示例
$ {s}_{1} $ $ {s}_{2} $ $ {e}_{1} $ $ \left\{{m}_{1}, \,{m}_{2}\right\} $ $ \left\{{m}_{3}, \,{m}_{5}\right\} $ $ {e}_{2} $ $ \left\{{m}_{2}, \,{m}_{3}\right\} $ $ \left\{{m}_{4}, \,{m}_{6}\right\} $ $ {e}_{3} $ $ \left\{{m}_{3}, \,{m}_{4}\right\} $ $ \left\{{m}_{5}, \,{m}_{7}\right\} $ $ {e}_{4} $ $ \left\{{m}_{4}, \,{m}_{5}\right\} $ $ \left\{{m}_{6}, \,{m}_{8}\right\} $ $ {e}_{5} $ $ \left\{{m}_{5}, \,{m}_{6}\right\} $ $ \left\{{m}_{7}, \,{m}_{9}\right\} $ $ {e}_{6} $ $ \left\{{m}_{6}, \,{m}_{7}\right\} $ $ \left\{{m}_{8}, \,{m}_{1}\right\} $ $ {e}_{7} $ $ \left\{{m}_{7}, \,{m}_{8}\right\} $ $ \left\{{m}_{9}, \,{m}_{2}\right\} $ $ {e}_{8} $ $ \left\{{m}_{8}, \,{m}_{9}\right\} $ $ \left\{{m}_{1}, \,{m}_{3}\right\} $ $ {e}_{9} $ $ \left\{{m}_{9}, \,{m}_{1}\right\} $ $ \left\{{m}_{2}, \,{m}_{4}\right\} $  下载: 导出CSV
下载: 导出CSV
表 2 2-分裂认证码
$ \left(\mathrm{3,73,219}\right) $ $ {s}_{1} $ $ {s}_{2} $ $ {s}_{3} $ $ {e}_{1} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{25},{m}_{26}\} $ $ \{{m}_{49},{m}_{50}\} $ $ {e}_{2} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{27},{m}_{28}\} $ $ \{{m}_{51},{m}_{52}\} $ $ {e}_{3} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{29},{m}_{30}\} $ $ \{{m}_{53},{m}_{54}\} $ $ {e}_{4} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{31},{m}_{30}\} $ $ \{{m}_{55},{m}_{56}\} $ $ {e}_{5} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{33},{m}_{30}\} $ $ \{{m}_{57},{m}_{58}\} $ $ {e}_{6} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{35},{m}_{30}\} $ $ \{{m}_{59},{m}_{60}\} $ $ {e}_{7} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{37},{m}_{30}\} $ $ \{{m}_{61},{m}_{62}\} $ $ {e}_{8} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{39},{m}_{30}\} $ $ \{{m}_{63},{m}_{64}\} $ $ {e}_{9} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{41},{m}_{30}\} $ $ \{{m}_{65},{m}_{66}\} $ $ {e}_{10} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{43},{m}_{30}\} $ $ \{{m}_{67},{m}_{68}\} $ $ {e}_{11} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{45},{m}_{30}\} $ $ \{{m}_{69},{m}_{70}\} $ $ {e}_{12} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{47},{m}_{30}\} $ $ \{{m}_{71},{m}_{72}\} $ $ {e}_{13} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{3},{m}_{5}\} $ $ \{{m}_{13},{m}_{21}\} $ $ {e}_{14} $ $ \{{m}_{6},{m}_{7}\} $ $ \{{m}_{8},{m}_{10}\} $ $ \{{m}_{18},{m}_{1}\} $ $ {e}_{15} $ $ \{{m}_{14},{m}_{15}\} $ $ \{{m}_{16},{m}_{18}\} $ $ \{{m}_{1},{m}_{9}\} $ $ {e}_{16} $ $ \{{m}_{22},{m}_{23}\} $ $ \{{m}_{24},{m}_{1}\} $ $ \{{m}_{9},{m}_{17}\} $ $ {e}_{17} $ $ \{{m}_{24},{m}_{73}\} $ $ \{{m}_{1},{m}_{3}\} $ $ \{{m}_{11},{m}_{19}\} $ $ {e}_{18} $ $ \{{m}_{73},{m}_{1}\} $ $ \{{m}_{2},{m}_{4}\} $ $ \{{m}_{12},{m}_{20}\} $ $ \cdots $ $ \cdots $ $ \cdots $ $ \cdots $
下载: 导出CSV
表 3
$ 2- $ 分裂认证码$ \left(\mathrm{3,97,388}\right) $ $ {s}_{1} $ $ {s}_{2} $ $ {s}_{3} $ $ {e}_{1} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{33},{m}_{34}\} $ $ \{{m}_{65},{m}_{66}\} $ $ {e}_{2} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{35},{m}_{36}\} $ $ \{{m}_{67},{m}_{68}\} $ $ {e}_{3} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{37},{m}_{38}\} $ $ \{{m}_{69},{m}_{70}\} $ $ {e}_{4} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{39},{m}_{40}\} $ $ \{{m}_{71},{m}_{72}\} $ $ {e}_{5} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{41},{m}_{42}\} $ $ \{{m}_{73},{m}_{74}\} $ $ {e}_{6} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{43},{m}_{44}\} $ $ \{{m}_{75},{m}_{76}\} $ $ {e}_{7} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{45},{m}_{46}\} $ $ \{{m}_{77},{m}_{78}\} $ $ {e}_{8} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{47},{m}_{48}\} $ $ \{{m}_{79},{m}_{80}\} $ $ {e}_{9} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{49},{m}_{50}\} $ $ \{{m}_{81},{m}_{82}\} $ $ {e}_{10} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{51},{m}_{52}\} $ $ \{{m}_{83},{m}_{84}\} $ $ {e}_{11} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{53},{m}_{54}\} $ $ \{{m}_{85},{m}_{86}\} $ $ {e}_{12} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{55},{m}_{56}\} $ $ \{{m}_{87},{m}_{88}\} $ $ {e}_{13} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{57},{m}_{58}\} $ $ \{{m}_{89},{m}_{90}\} $ $ {e}_{14} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{59},{m}_{60}\} $ $ \{{m}_{91},{m}_{92}\} $ $ {e}_{15} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{61},{m}_{62}\} $ $ \{{m}_{93},{m}_{94}\} $ $ {e}_{16} $ $ \{{m}_{1},{m}_{2}\} $ $ \{{m}_{63},{m}_{64}\} $ $ \{{m}_{95},{m}_{96}\} $ $ {e}_{17} $ $ \{{m}_{97},{m}_{2}\} $ $ \{{m}_{1},{m}_{15}\} $ $ \{{m}_{12},{m}_{26}\} $ $ {e}_{18} $ $ \{{m}_{1},{m}_{18}\} $ $ \{{m}_{10},{m}_{20}\} $ $ \{{m}_{14},{m}_{31}\} $ $ {e}_{19} $ $ \{{m}_{25},{m}_{9}\} $ $ \{{m}_{1},{m}_{11}\} $ $ \{{m}_{5},{m}_{20}\} $ $ {e}_{20} $ $ \{{m}_{5},{m}_{22}\} $ $ \{{m}_{14},{m}_{24}\} $ $ \{{m}_{18},{m}_{1}\} $ $ {e}_{21} $ $ \{{m}_{24},{m}_{17}\} $ $ \{{m}_{97},{m}_{1}\} $ $ \{{m}_{7},{m}_{19}\} $ $ {e}_{22} $ $ \{{m}_{18},{m}_{11}\} $ $ \{{m}_{27},{m}_{28}\} $ $ \{{m}_{1},{m}_{13}\} $ $ {e}_{23} $ $ \{{m}_{6},{m}_{32}\} $ $ \{{m}_{15},{m}_{18}\} $ $ \{{m}_{22},{m}_{1}\} $ $ {e}_{24} $ $ \{{m}_{1},{m}_{11}\} $ $ \{{m}_{3},{m}_{29}\} $ $ \{{m}_{8},{m}_{30}\} $ $ \cdots $ $ \cdots $ $ \cdots $ $ \cdots $
下载: 导出CSV
-
[1] GILBERT E N, MACWILLIAMS F J, and SLOANE N J A. Codes which detect deception[J]. The Bell System Technical Journal, 1974, 53(3): 405–424. doi: 10.1002/j.1538-7305.1974.tb02751.x [2] SIMMONS G J. Authentication Theory/Coding Theory[M]. BLAKLEY G R, CHAUM D. Advances in Cryptology: Proceedings of CRYPTO 84. Berlin Heidelberg: Springer-Verlag, 1985: 411–431. [3] 王永传, 杨义先. 分裂认证码与纠错码[J]. 通信保密, 1999(1): 64–66.WANG Yongchuan and YANG Yixian. Spliting authentication codes with and error-correcting codes[J]. Information Security and Communications Privacy, 1999(1): 64–66. [4] OGATA W, KUROSAWA K, STINSON D R, et al. New combinatorial designs and their applications to authentication codes and secret sharing schemes[J]. Discrete Mathematics, 2004, 279(1/3): 383–405. [5] GE Gennian, MIAO Ying, and WANG Lihua. Combinatorial constructions for optimal splitting authentication codes[J]. Discrete Mathematics, 2005, 18(4): 663–678. [6] 刘金龙, 许宗泽. CARTESIAN认证码的原理及构造[J]. 电子与信息学报, 2008, 30(1): 93–95.LIU Jinlong and XU Zongze. On the theory and construction of CARTESIAN authentication codes[J]. Journal of Electronics &Information Technology, 2008, 30(1): 93–95. [7] 裴定一. 消息认证码[M]. 合肥: 中国科学技术大学出版社, 2009.PEI Dingyi. Message Authentication Codes[M]. Hefei: China University of science and Technology Press, 2009. [8] WANG Jinhua and SU Renwang. Further results on the existence of splitting BIBDs and application to authentication codes[J]. Acta Applicandae Mathematicae, 2010, 109(3): 791–803. doi: 10.1007/s10440-008-9346-8 [9] LIANG Miao, JI Lijun, and ZHANG Jingcai. Some new classes of 2-fold optimal or perfect splitting authentication codes[J]. Cryptography and Communications, 2017, 9(3): 407–430. doi: 10.1007/s12095-015-0179-9 [10] LI Mingchao, LIANG Miao, DU Beiliang, et al. A construction for optimal c-splitting authentication and secrecy codes[J]. Designs, Codes and Cryptography, 2018, 86(8): 1739–1755. doi: 10.1007/s10623-017-0421-x [11] COLBOURN C J and DINITZ J H. Handbook of Combinatorial Designs[M]. Boca Raton: CRC Press, 1996. [12] 沈灏. 组合设计理论[M]. 上海: 上海交通大学出版社, 2008.SHEN Hao. Theory of Combinatorial Designs[M]. Shanghai: Shanghai Jiao Tong University Press, 2008. [13] SAURABH S and SINHA K. Some new resolvable group divisible designs[J/OL]. Communications in Statistics-Theory and Methods, 2020. doi: 10.1080/03610926.2020.1817487. [14] FORBES A D. Group divisible designs with block size four and type g ub1(gu/2)1[J]. Graphs and Combinatorics, 2020, 36(6): 1687–1703. doi: 10.1007/s00373-020-02213-5 [15] ABEL R J R, BUNJAMIN Y A, and COMBE D. Some new group divisible designs with block size 4 and two or three group sizes[J]. Journal of Combinatorial Designs, 2020, 28(8): 614–628. doi: 10.1002/jcd.21719 [16] XU Hengzhou, YU Zhongyang, FENG Dan, et al. New construction of partial geometries based on group divisible designs and their associated LDPC codes[J]. Physical Communication, 2020, 39: 100970. doi: 10.1016/j.phycom.2019.100970 [17] HUANG Yupei, LIU Chiaan, CHANG Y, et al. A family of group divisible designs with arbitrary block sizes[J]. Taiwanese Journal of Mathematics, 2019, 23(6): 1291–1302. [18] HUBER M. Combinatorial bounds and characterizations of splitting authentication codes[J]. Cryptography and Communications, 2010, 2(2): 173–185. doi: 10.1007/s12095-010-0020-4 [19] VISHNU V I and PUTHALI H B. Techniques for validating and sharing secrets[P]. USA, Patent, 20120159645, 2012. [20] 王晨宇, 汪定, 王菲菲, 等. 面向多网关的无线传感器网络多因素认证协议[J]. 计算机学报, 2020, 43(4): 683–700. doi: 10.11897/SP.J.1016.2020.00683WANG Chenyu, WANG Ding, WANG Feifei, et al. Multi-factor user authentication scheme for multi-gateway wireless sensor networks[J]. Chinese Journal of Computers, 2020, 43(4): 683–700. doi: 10.11897/SP.J.1016.2020.00683 [21] LI Zengpeng, WANG Ding, and MORAIS E. Quantum-safe round-optimal password authentication for mobile devices[J/OL]. IEEE Transactions on Dependable and Secure Computing, 2020. doi: 10.1109/TDSC.2020.3040776. [22] WANG Chenyu, WANG Ding, XU Guoai, et al. Efficient privacy-preserving user authentication scheme with forward secrecy for industry 4.0[J/OL]. Science China (Information Sciences). https://kns.cnki.net/kcms/detail/11.5847.TP.20210820.1521.008.html, 2021. -


 下载:
下载:








图(4) / 表(4)
计量
- 文章访问数: 1188
- HTML全文浏览量: 850
- PDF下载量: 67
- 被引次数: 0
