

Intelligent Resource Allocation Algorithm Based on Outdated CSI for Multi-Node URLLC
-
摘要: 工业物联网(IIoT)往往具有节点数量多、通信可靠性与时延要求严格等特点。大规模节点导致信道状态信息(CSI)反馈开销大,难以实时获取。然而,基于过期CSI的资源分配,往往需要以冗余的发射功率、码长等资源配置来保障通信的可靠性,严重制约了系统能效。针对该问题,该文以最大化能效为目标,提出一种基于连续凸近似(SCA)辅助深度强化学习(DRL)的功率码长联合分配算法。首先,基于SCA算法对功率和码长进行预分配,获得具有物理可解释性的基准解;进而,以基准解为先验信息,设计基于双延迟深度确定性策略梯度(TD3)的DRL算法进行增量式优化。仿真表明,所提算法能有效应对信道动态变化,显著提升系统能效。Abstract:
Objective Ultra-Reliable and Low-Latency Communications (URLLC) is widely used in Industrial Internet of Things (IIoT) systems. However, in mobile industrial scenarios such as transportation and inspection, instantaneous Channel State Information (CSI) is difficult to obtain because of feedback overhead. Resource allocation decisions therefore need to be made using outdated CSI. This mismatch restricts system energy efficiency. Traditional convex optimization methods have difficulty addressing this problem. Classical Deep Reinforcement Learning (DRL) algorithms also have limited convergence stability and policy performance under the stringent latency and reliability constraints of URLLC. To address these challenges, this paper considers a multi-node URLLC system under outdated CSI in dynamic scenarios. An energy-efficiency maximization problem is formulated under the Finite BlockLength (FBL) regime, with communication latency and reliability constraints. An efficient and stable algorithm is then designed for joint power and blocklength allocation. Methods A Successive Convex Approximation (SCA)-assisted DRL framework is proposed to maximize energy efficiency under outdated CSI. First, an SCA-based algorithm is developed to obtain a pre-allocation solution for transmit power and blocklength. This solution is feasible and physically interpretable, but relatively conservative. Based on this baseline, a Twin Delayed Deep Deterministic policy gradient (TD3) algorithm is used for incremental refinement through interaction with the dynamic environment. This process reduces the conservatism of SCA. The SCA solution is used as prior knowledge in the state representation. Node location information is also incorporated into the state space. These designs narrow the policy search space and enable the DRL agent to better capture large-scale channel characteristics and system dynamics under outdated CSI. Learning efficiency and stability are therefore improved. Results and Discussions The proposed algorithm is evaluated through simulations and compared with three benchmark algorithms: an SCA-based optimization algorithm, a TD3 algorithm without SCA guidance, and a TD3 algorithm without node location information. The results show that the proposed method outperforms all benchmarks in convergence stability and system energy efficiency. In the training phase ( Fig. 3 ), the average reward of the proposed algorithm increases steadily and converges stably. By contrast, removing node location information leads to lower rewards and stronger fluctuations. Removing SCA guidance causes the algorithm to converge to a much lower reward level. These results confirm the roles of SCA-based prior guidance and location-aware state representation in improving training stability. In the actual operation stage (Fig. 4 ), the proposed algorithm achieves high and stable energy efficiency and outperforms all comparison algorithms. Under outdated CSI, DRL-based methods can obtain higher energy efficiency than conservative optimization methods when transmission succeeds. However, removing node location information reduces energy efficiency, and removing SCA guidance increases transmission failures. These results verify the effectiveness of both designs in improving energy efficiency and maintaining policy feasibility. The effects of key system parameters are also examined. For basic resource parameters, a moderate increase in the blocklength budget (Fig. 5 ) or power budget (Fig. 6 ) improves system energy efficiency. For reliability constraints (Fig. 7 ), the reliability requirement should be set according to service requirements to avoid resource waste. Finally, the average energy efficiency under different numbers of nodes and different numbers of neurons in the TD3 network is analyzed (Fig. 8 ). The results provide guidance for algorithm configuration and network-scale design.Conclusions This paper addresses energy-efficient resource allocation for multi-node URLLC systems with outdated CSI by integrating SCA and DRL. In the proposed framework, a TD3-based DRL algorithm is guided by an SCA reference solution, and node location information is incorporated into the state representation. This optimization-learning dual-driven framework combines the interpretability and feasibility of model-based optimization with the adaptivity of data-driven learning. Simulation results show that the proposed method achieves higher energy efficiency than SCA-based optimization and conventional TD3 while satisfying URLLC latency and reliability constraints. The SCA reference solution improves policy stability and effectiveness under outdated CSI. Node location information further supports efficient decision-making. This work focuses on a single-cell multi-node scenario under Time Division Multiple Access (TDMA). Practical issues such as multi-cell interference, cooperative scheduling among multiple base stations, and more complex mobility patterns are not considered. Future work will extend the proposed framework to multi-cell and multi-agent scenarios and test its applicability under more severe CSI imperfections. -
1 资源预分配算法流程
初始化:初始化可行局部点$ ({\mathbf{m}}^{0},{\mathbf{p}}^{0}) $,$ \tau =0 $ 迭代: (1) 围绕函数$ {F}^{\tau }(\mathbf{m},\mathbf{p}) $构建局部问题(LP) (2) 通过椭球法求解凸问题(LP):初始化椭球,每次迭代中,构
造分离超平面,更新椭球,直至误差小于阈值,得到局部最优解
$ ({\mathbf{m}}^{\ast },{\mathbf{p}}^{\ast }) $(3) If 目标函数的性能提升小于阈值:结束迭代,返回
$ (\left\lceil {\mathbf{m}}^{\ast }\right\rceil ,{\mathbf{p}}^{\ast }) $Else:$ ({\mathbf{m}}^{\tau +1},{\mathbf{p}}^{\tau +1})=({\mathbf{m}}^{\ast },{\mathbf{p}}^{\ast }) $,$ \tau =\tau +1 $,回到(1)  下载: 导出CSV
下载: 导出CSV
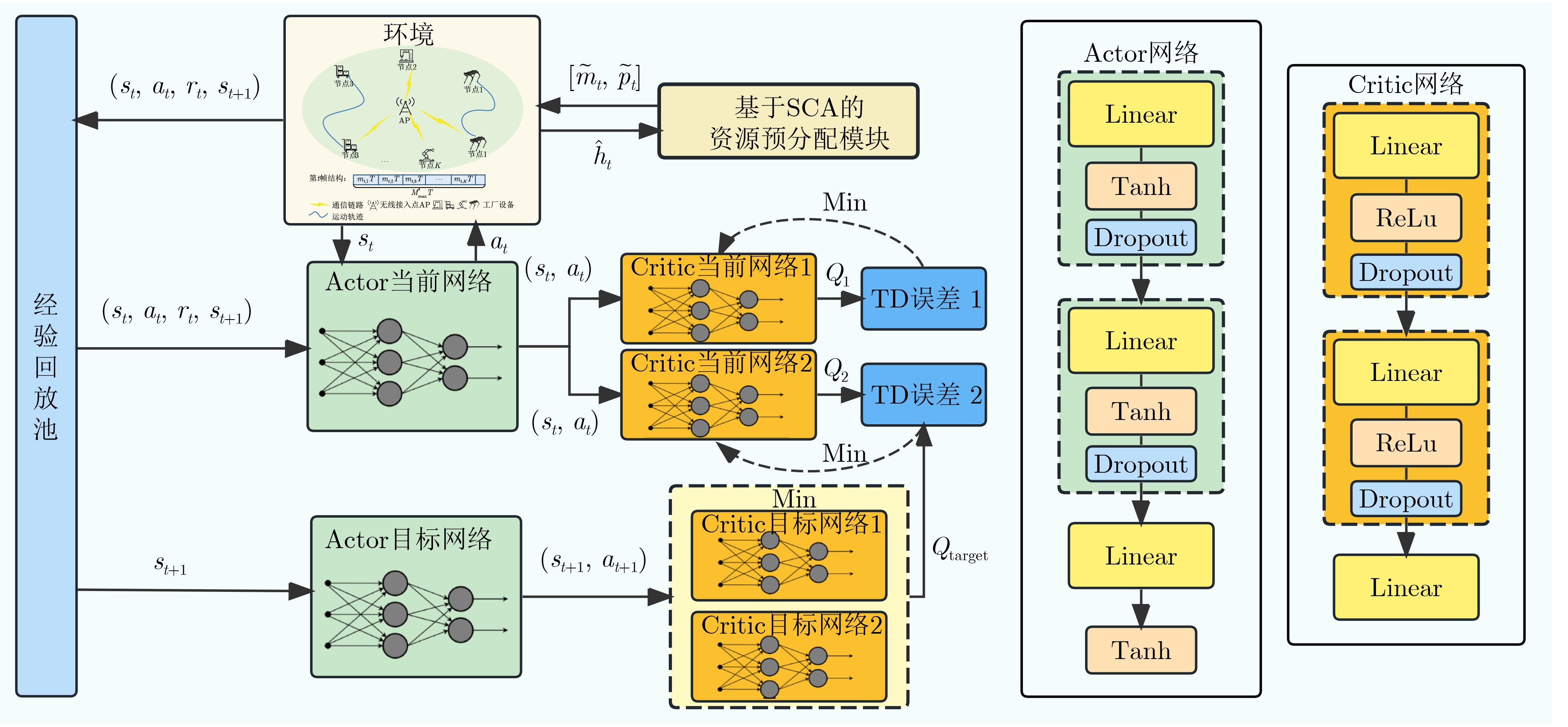
2 基于SCA辅助DRL的功率码长联合分配算法流程
初始化Actor当前网络$ \mu $和两个Critic当前网络$ {Q}_{1} $,$ {Q}_{2} $的网络参数$ {\mathbf{\theta }}_{\mu } $,$ {\mathbf{\theta }}_{1} $,$ {\mathbf{\theta }}_{2} $,以及对应的目标网络参数$ {\mathbf{\theta }}_{{{\mu }_{\text{target}}}} $,$ {\mathbf{\theta }}_{\text{target},1} $,$ {\mathbf{\theta }}_{\text{target},2} $ 初始化经验回放池$ \mathcal{R} $,学习率$ l $、折扣因子$ \delta $、探索噪声$ {\chi }_{t} $、软更新系数$ \xi $和延迟更新间隔$ \kappa $ (1) For 每一训练回合 do (2) 重置环境,获取初始状态$ {\mathbf{s}}_{0} $ (3) For 时间步$ t=1\rightarrow {T}_{0} $ do (4) 根据算法1预分配所有节点的功率和码长,得到$ \left({\mathbf{\tilde{m}}}_{t},{\mathbf{\tilde{p}}}_{t}\right) $ (5) 根据Actor网络和探索噪声$ {\chi }_{t} $生成动作$ {\mathbf{a}}_{t}=\mu \left({\mathbf{s}}_{t}\right)+{\chi }_{t} $ (6) 环境执行$ {\mathbf{a}}_{t} $,反馈奖励$ {r}_{t} $,进入下一个状态$ {\mathbf{s}}_{t+1} $,存储 $ \left({\mathbf{s}}_{t},{\mathbf{a}}_{t},{r}_{t},{\mathbf{s}}_{t+1}\right) $到$ \mathcal{R} $中 (7) 从$ \mathcal{R} $中随机采样一批经验样本训练Actor当前网络和Critic当前网络 (8) If $ t\text{mod}\kappa =0 $then 更新Actor当前网络$ \mu $,软更新目标网络参数: $ {\mathbf{\theta }}_{{{\mu }_{\text{target}}}}\leftarrow \xi {\mathbf{\theta }}_{\mu }+\left(1-\xi \right){\mathbf{\theta }}_{{{\mu }_{\text{target}}}} $,$ {\mathbf{\theta }}_{\text{target},i}\leftarrow \xi {\mathbf{\theta }}_{i}+\left(1-\xi \right){\mathbf{\theta }}_{\text{target},i} $,$ i=1,2 $ (9) 输出:收敛后的功率码长联合分配策略
下载: 导出CSV
表 1 通信系统仿真参数
参数名称 符号 数值 噪声谱密度 $ \sigma _{k}^{2} $ $ 1\times {10}^{-7} $ 数据包大小 $ {D}_{k} $ $ 100\ \text{bits} $ 每个调制符号传输时长 $ T $ $ 1\text{ ms} $ 莱斯因子 $ {K}_{\text{R}} $ $ 5 $ 莱斯信道参考距离 $ {d}_{0} $ $ 1.0\text{ m} $ 莱斯信道路径损耗指数 $ a $ $ 2.2 $ 莱斯信道参考信道增益 $ {g}_{0} $ $ 1\times {10}^{-3} $
下载: 导出CSV
表 2 TD3网络训练超参数
参数名称 符号 数值 学习率 $ l $ $ 0.0001 $ 折扣因子 $ \delta $ $ 0.99 $ 探索噪声的标准差 $ \sigma $ $ 0.2 $ 软更新系数 $ \xi $ $ 0.005 $ 延迟更新间隔 $ \kappa $ $ 2 $ 批量大小 $ B $ $ 256 $ 回合最大时间步 $ {T}_{0} $ $ 1000 $ 缩放因子 $ \alpha $ $ 100 $ 正常数偏置项 $ \beta $ $ 100 $
下载: 导出CSV
-
[1] 张明强, 马晓聪, 杨雅娟, 等. 工业物联网智能感知-传输-控制融合: 关键技术与未来展望[J]. 电子与信息学报, 2025, 47(10): 3410–3425. doi: 10.11999/JEIT250305.ZHANG Mingqiang, MA Xiaocong, YANG Yajuan, et al. Integrating intelligent sensing, transmission, and control for industrial IoT networks: Key technologies and future directions[J]. Journal of Electronics & Information Technology, 2025, 47(10): 3410–3425. doi: 10.11999/JEIT250305. [2] TALLAT R, HAWBANI A, WANG Xingfu, et al. Navigating industry 5.0: A survey of key enabling technologies, trends, challenges, and opportunities[J]. IEEE Communications Surveys & Tutorials, 2024, 26(2): 1080–1126. doi: 10.1109/COMST.2023.3329472. [3] HAQUE E, TARIQ F, KHANDAKER M R A, et al. A comprehensive survey of 5G URLLC and challenges in the 6G era[EB/OL]. https://arxiv.org/abs/2508.20205, 2025. [4] 胡钰林, 喻鑫岚, 高伟, 等. 低时延工业物联网中移动边缘计算的安全性与可靠性联合优化[J]. 电子与信息学报, 2025, 47(10): 3492–3504. doi: 10.11999/JEIT250262.HU Yulin, YU Xinlan, GAO Wei, et al. Security and reliability-optimal offloading for mobile edge computing in low-latency industrial IoT[J]. Journal of Electronics & Information Technology, 2025, 47(10): 3492–3504. doi: 10.11999/JEIT250262. [5] LIAQ M, SHARIF S, ZEADALLY S, et al. Utilization of machine learning in future wireless networks for resource optimization: A survey[J]. Ad Hoc Networks, 2025, 178: 103983. doi: 10.1016/j.adhoc.2025.103983. [6] DONG Yun, ZHANG Liyuan, LIN Zijian, et al. Multiuser covert terahertz communication with outdated CSI and data exception[J]. Transactions on Emerging Telecommunications Technologies, 2025, 36(7): e70184. [7] WAN Xiaoyu, LI Ershun, WANG Zhengqiang, et al. Energy-efficient resource allocation for multicarrier NOMA systems with imperfect CSI[C]. 2021 IEEE 4th International Conference on Electronic Information and Communication Technology, Xi’an, China, 2021: 823–827. doi: 10.1109/ICEICT53123.2021.9531322. [8] HUANG Jie, YU Tao, YANG Fan, et al. AoI-aware resource allocation with interference avoidance for ultradense industrial internet of things networks[J]. IEEE Internet of Things Journal, 2024, 11(17): 28787–28797. doi: 10.1109/JIOT.2024.3403849. [9] TEJA P R, DUBEY K, and DUBEY R. 2DRL: Cognitive D2D control under imperfect CSI via adaptive deep reinforcement learning[J]. International Journal of Networked and Distributed Computing, 2026, 14(1): 6. doi: 10.1007/s44227-025-00081-0. [10] POLYANSKIY Y, POOR H V, and VERDU S. Channel coding rate in the finite blocklength regime[J]. IEEE Transactions on Information Theory, 2010, 56(5): 2307–2359. doi: 10.1109/TIT.2010.2043769. [11] 胡钰林, 肖志成, 徐浩. 有限码长域下针对多用户大规模MIMO系统速率优化的高效功率分配算法[J]. 电子与信息学报, 2025, 47(1): 35–47. doi: 10.11999/JEIT240241.HU Yulin, XIAO Zhicheng, and XU Hao. Efficient power allocation algorithm for throughput optimization of multi-user massive MIMO systems in finite blocklength regime[J]. Journal of Electronics & Information Technology, 2025, 47(1): 35–47. doi: 10.11999/JEIT240241. [12] MUGISHA R, MAHMOOD A, ABEDIN S F, et al. Joint power and blocklength allocation for energy-efficient ultra- reliable and low- latency communications[C]. 2021 17th International Symposium on Wireless Communication Systems, Berlin, Germany, 2021: 1–6. doi: 10.1109/ISWCS49558.2021.9562249. [13] PRADHAN A, DAS S, and PIRAN J. Blocklength optimization and power allocation for energy-efficient and secure URLLC in industrial IoT[J]. IEEE Internet of Things Journal, 2024, 11(6): 9420–9431. doi: 10.1109/JIOT.2023.3324379. [14] SHI Ningzhe, ZHANG Yu, and ZHOU YiqingSHI Ningzhe, ZHANG Yu, and ZHOU Yiqing. Deep reinforcement learning based subchannel selection and power allocation in wireless networks with imperfect CSI[C]. 2023 IEEE 97th Vehicular Technology Conference2023 IEEE 97th Vehicular Technology Conference, Florence, Italy, 2023: 1–5. doi: 10.1109/VTC2023-Spring57618.2023.10199481. [15] FUJIMOTO S, HOOF H, and MEGER D. Addressing function approximation error in actor-critic methods[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 1587–1596. [16] GAO Wei, ZHENG P, HU Yulin, et al. A novel link adaptation approach for URLLC: A DRL-based method with OLLA[C]. 2024 IEEE Wireless Communications and Networking Conference, Dubai, United Arab Emirates, 2024: 1–6. doi: 10.1109/WCNC57260.2024.10570645. [17] SAMPAIO L and LANDAU L T N. Spatially and temporally correlated channel estimation and detection for comparator network-aided MIMO receivers with 1-bit ADCs[J]. EURASIP Journal on Advances in Signal Processing, 2025, 2025(1): 34. doi: 10.1186/s13634-025-01238-3. [18] ZHAO Yizhen, GAO Wei, ZHU Yao, et al. ZHAO Yizhen, GAO Wei, ZHU Yao, et al. Energy efficiency maximization for multi-node IoT networks operating with finite blocklength codes[C]. 2024 19th International Symposium on Wireless Communication Systems, Rio de Janeiro, Brazil, 2024: 1–6. doi: 10.1109/ISWCS61526.2024.10639049. [19] GIWA O, SHOCK J, TOIT J D, et al. Optimisation of resource allocation in heterogeneous wireless networks using deep reinforcement learning[EB/OL]. https://arxiv.org/abs/2509.25284, 2026. -










图(8) / 表(4)
计量
- 文章访问数: 164
- HTML全文浏览量: 52
- PDF下载量: 26
- 被引次数: 0
 下载:
下载:
