

Recent Advances in Remote Sensing Image-Text Retrieval Driven by Vision-Language Foundation Models
-
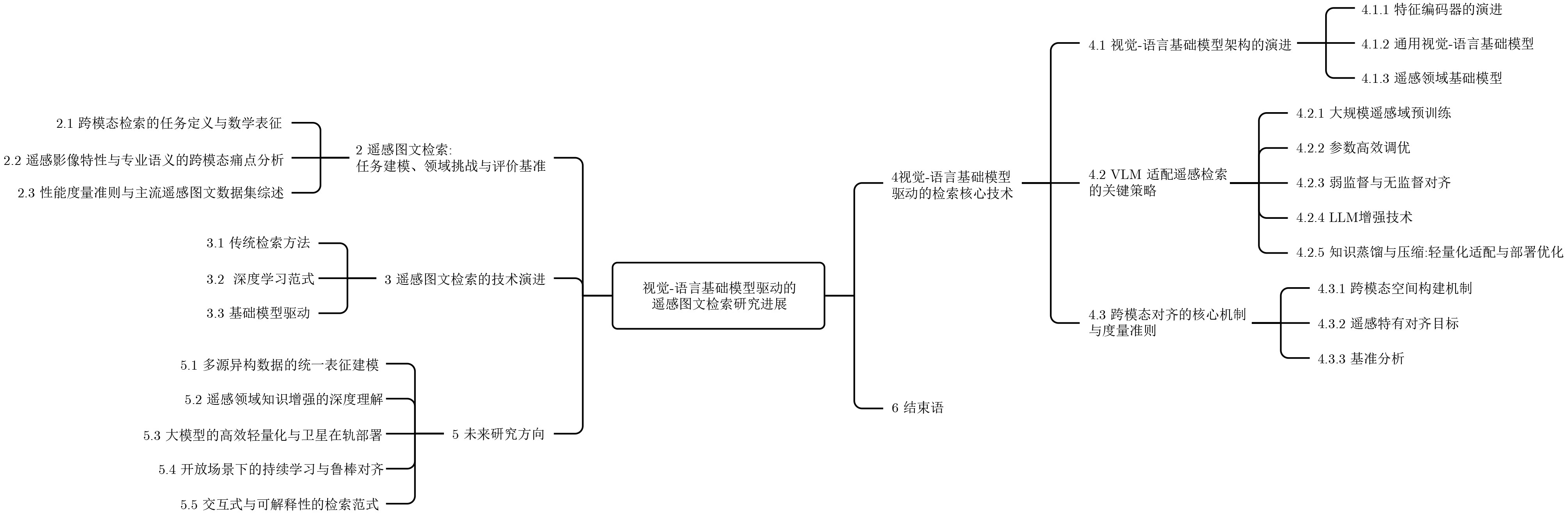
摘要: 遥感图文检索(RS-ITR)通过建立遥感影像与自然语言描述之间的跨模态语义关联,为海量地理空间数据的语义理解与智能检索提供了重要支撑。随着高分辨率对地观测数据持续积累,复杂场景、多尺度结构、专业语义表达及标注稀缺等因素,使传统手工特征方法和常规深度跨模态模型在语义建模、跨场景泛化和开放环境适应方面受到明显制约。围绕视觉-语言基础模型(VLM)驱动的遥感图文检索研究,该文系统梳理了任务建模、领域挑战、评价基准与技术演进脉络,重点归纳了模型架构范式、遥感领域适配策略和跨模态语义对齐机制,并结合代表性数据集、典型方法及性能比较总结了当前研究进展。分析表明,视觉-语言基础模型在缓解语义鸿沟、提升零样本迁移能力和增强复杂语义理解方面展现出显著优势,但多源异构数据统一建模、地理知识增强、开放场景持续学习以及轻量化部署仍是该方向亟待突破的关键问题。相关综述可为遥感多模态信息理解、跨模态检索模型设计及工程应用提供系统参考。Abstract:
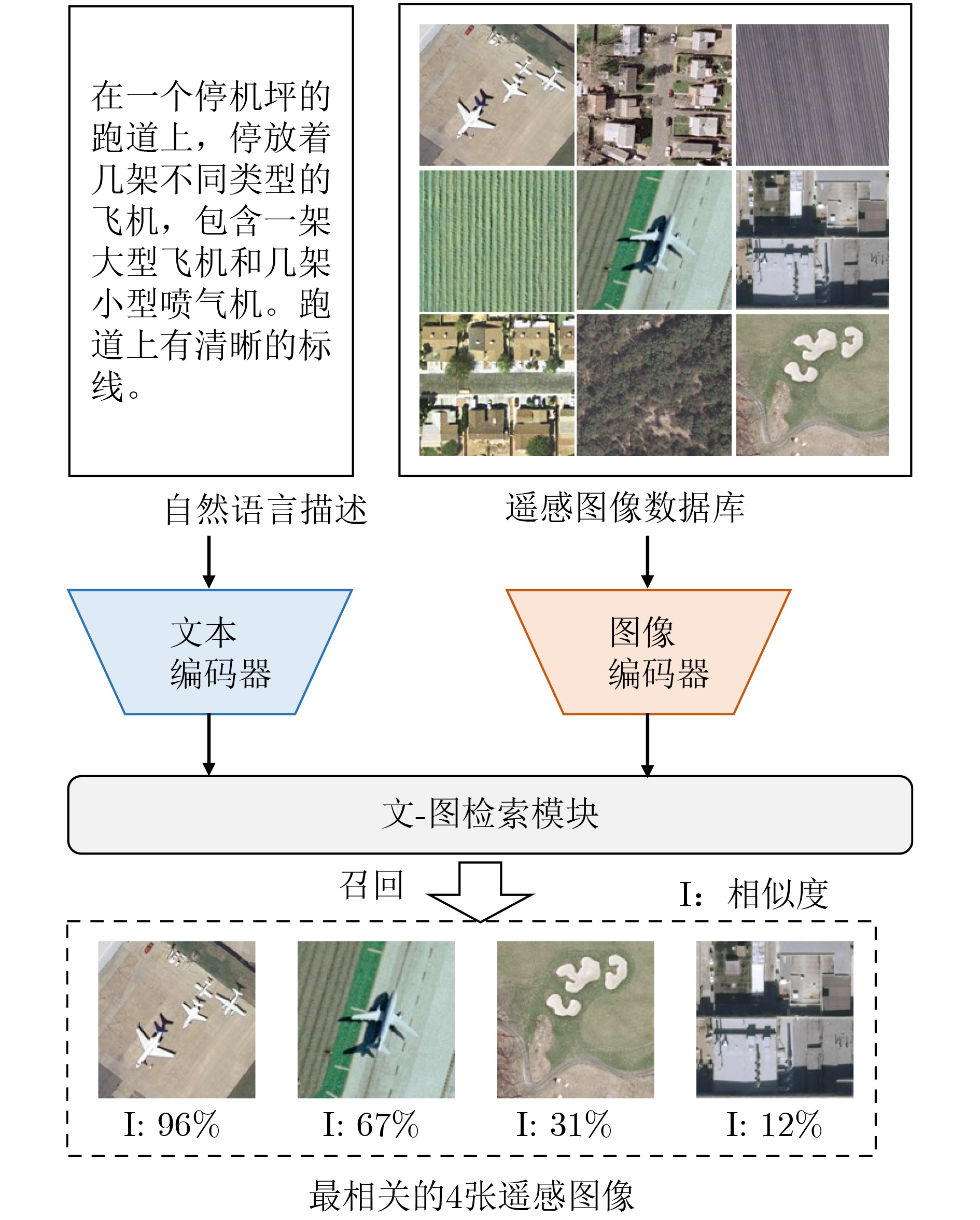
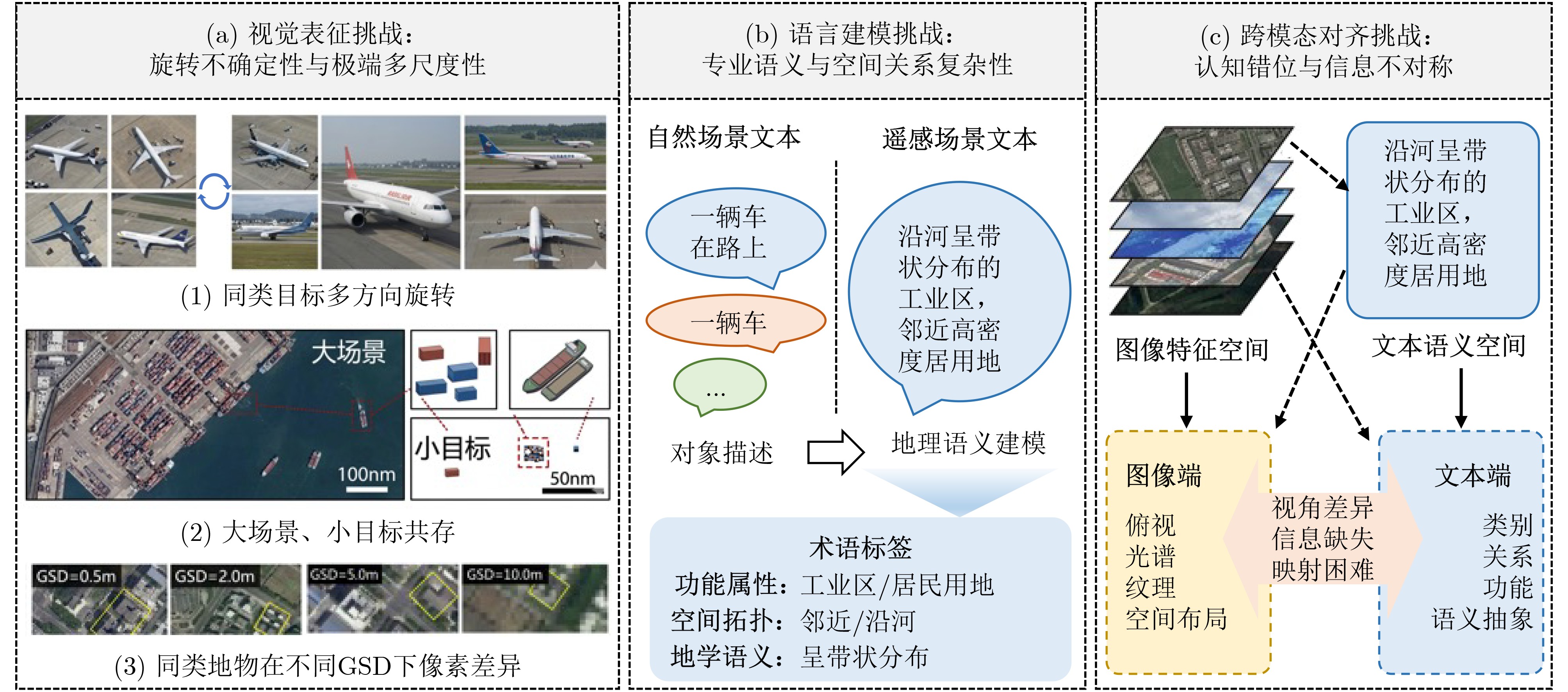
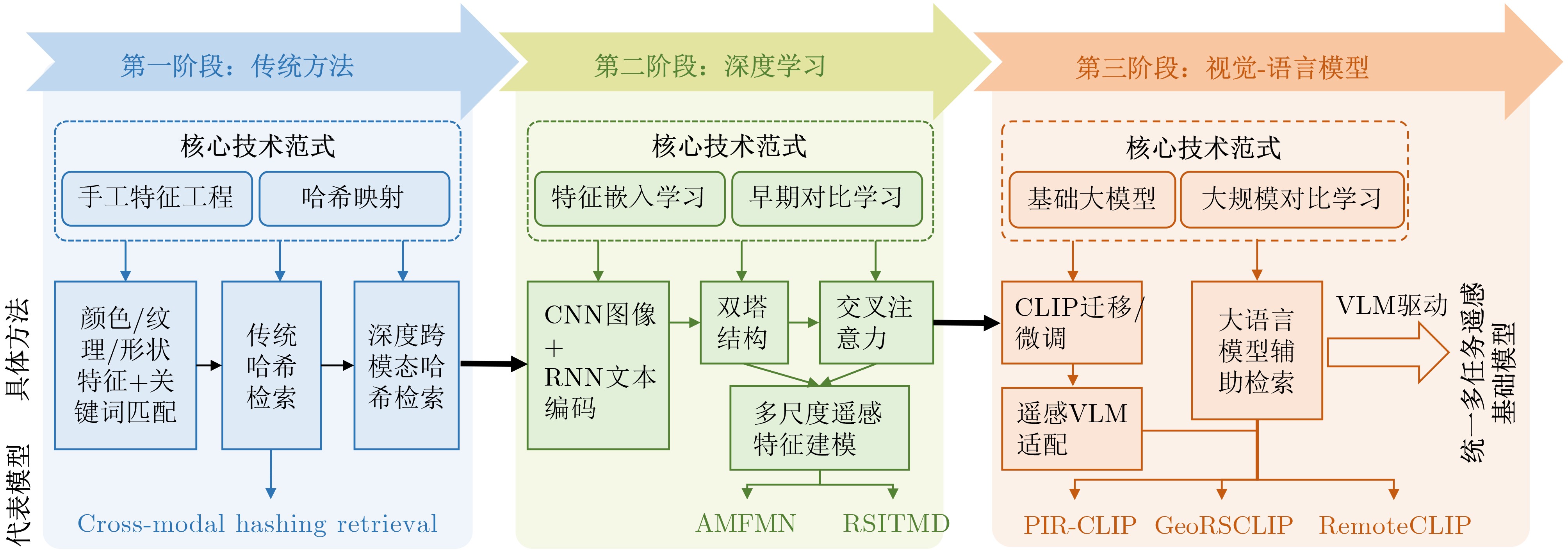
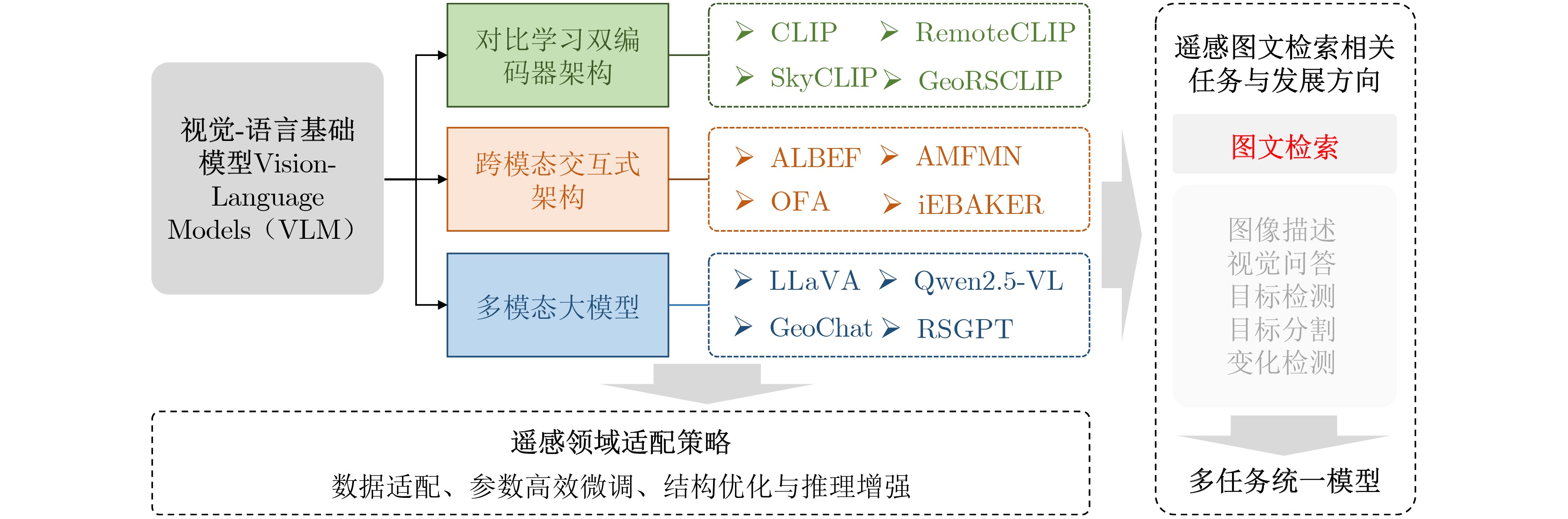
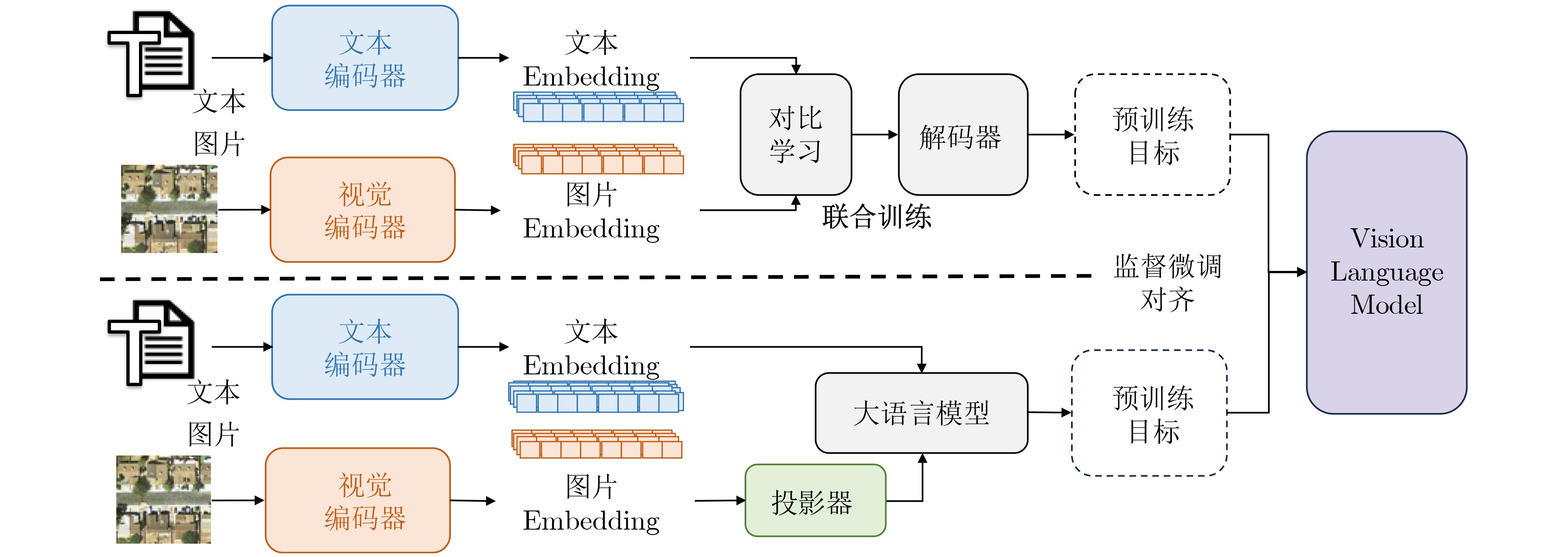
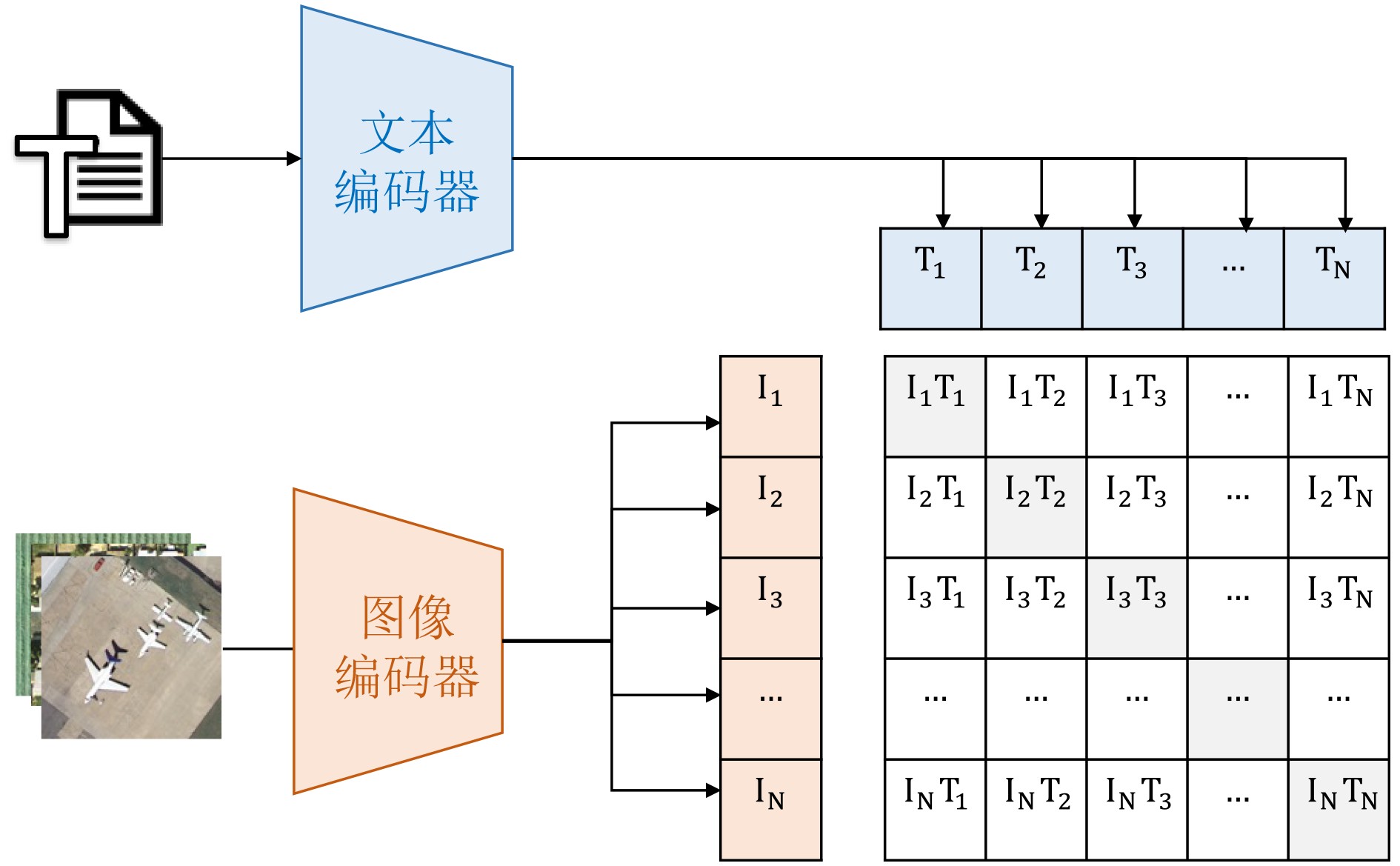
Significance Remote Sensing Image-Text Retrieval (RS-TIR) connects large-scale Earth observation imagery with natural-language queries and has become an important interface for geospatial intelligence systems. Compared with conventional content-based retrieval, RS-TIR allows users to search for scenes, objects, spatial layouts, and functional regions through semantic descriptions rather than handcrafted visual cues. This capability is increasingly needed in natural resource monitoring, urban governance, disaster response, environmental assessment, and on-demand retrieval from rapidly growing satellite archives. However, RS-TIR remains challenging. Remote sensing imagery is captured from nadir or near-nadir perspectives, shows strong rotation invariance, and contains extreme scale variation, ranging from tiny vehicles to large airports. It also requires domain-specific semantic descriptions, such as land-use attributes, spatial distributions, and geoscientific relations. Meanwhile, high-quality image-text annotations remain limited relative to the scale of remote sensing data. These properties widen the cross-modal semantic gap between images and language and limit the generalization ability of traditional cross-modal retrieval methods. Against this background, this review examines how Vision-Language Foundation Models (VLMs) reshape RS-ITR through large-scale contrastive pre-training, stronger transferable representations, and more flexible multimodal interaction mechanisms. It also explains why remote sensing adaptation is needed and why a focused synthesis of architectures, datasets, alignment mechanisms, and future directions is timely for this field. Progress The technical development of RS-ITR is reviewed from three complementary perspectives. First, this review summarizes the domain-specific challenges that shape the task, including visually isotropic topology with extreme scale variation, professional and fine-grained textual semantics, and the compounded cross-modal semantic gap between overhead imagery and natural-language descriptions ( Fig. 3 ). The overall survey structure is then presented to show the logical progression from task formulation to future challenges (Fig. 1 ). From a methodological perspective, RS-ITR has evolved from handcrafted visual descriptors and shallow semantic mapping to deep representation learning, and then to VLM-driven paradigms with stronger generalization and zero-shot transfer capability (Fig. 4 ,Table 2 ). Early methods rely on color, texture, shape, and hash-based retrieval. However, they struggle to model high-level geospatial semantics and complex scene composition. Deep learning methods improve retrieval by learning joint embedding spaces, adopting dual-encoder or interaction-based architectures, and using multi-scale feature fusion and region-aware matching. These methods improve semantic consistency, but they still depend heavily on labeled data and often show limited robustness in open or cross-sensor scenarios. Second, this review summarizes the benchmark ecosystem used to evaluate these methods. Representative datasets range from small-scale test sets, such as Sydney-Caption and UCM-Caption, to mainstream benchmarks, such as RSICD and RSITMD, and recent large-scale training resources, such as RS5M and SkyScript (Table 1 ). These datasets show a clear transition from small manually annotated corpora to web-scale or automatically generated image-text pairs. This transition supports domain pre-training and large model adaptation. Third, this review analyzes the core VLM techniques that now drive progress in RS-ITR. The model spectrum and representative architecture families are systematically summarized, including contrastive dual-encoder models, multimodal interaction models, and remote sensing foundation models integrated with large language models (Fig. 5 ,Fig. 6 ,Table 3 ). Domain adaptation routes are further grouped into continued remote sensing pre-training, parameter-efficient transfer learning, adapter-based tuning, prompt learning, and instruction tuning. At the semantic alignment level, this review focuses on contrastive joint embedding, fine-grained multi-scale alignment, and the use of remote sensing priors, such as spatial topology and geolocation. Performance comparisons on RSICD and RSITMD show that remote sensing VLMs, especially RemoteCLIP, GeoRSCLIP, iEBAKER, and LRSCLIP, yield consistent gains in mean Recall (mR) and overall retrieval robustness (Table 4). In parallel, this review tracks the extension of retrieval capability into unified multi-task remote sensing models, in which retrieval, grounding, segmentation, and reasoning begin to share a common multimodal representation space.Conclusions Several conclusions are drawn from the comparative analysis. First, VLMs establish a dominant paradigm for RS-ITR because they narrow the cross-modal semantic gap and improve transferability across datasets and scenes. Second, no single architecture is universally optimal. Dual-encoder models remain attractive for large-scale retrieval because of their efficiency, whereas interaction-based or instruction-enhanced models provide finer semantic alignment at a higher computational cost. Third, domain adaptation is indispensable. Continued pre-training on remote sensing image-text corpora, parameter-efficient tuning, and prompt-based adaptation consistently outperform direct reuse of internet-trained VLMs. This finding indicates that remote sensing imagery differs too strongly from natural-image distributions for generic pre-training alone to be sufficient. Fourth, the most effective recent methods do not improve performance through scale alone. They also exploit remote sensing-specific information, including multi-scale structures, foreground objects, explicit keyword reasoning, and spatial priors. Finally, this review shows that the field is shifting from isolated retrieval models toward more general geospatial multimodal systems. Retrieval is no longer treated only as a matching task. It is also becoming a key capability that supports question answering, instruction following, knowledge augmentation, and coordinated reasoning in remote sensing applications. Prospects Future research is expected to advance in four closely related directions. The first direction is the unified representation of multi-source heterogeneous data, especially the integration of optical imagery with Synthetic Aperture Radar (SAR), hyperspectral data, thermal infrared observations, and multi-temporal acquisitions. The second direction is knowledge-enhanced retrieval, in which geospatial priors, land-use rules, remote sensing terminology, and external knowledge bases are incorporated into multimodal alignment and retrieval-augmented reasoning. The third direction is lifelong and open-world learning. Real deployment requires models to remain reliable under seasonal variation, sensor updates, regional domain shifts, cloud contamination, and newly emerging categories, while avoiding catastrophic forgetting. The fourth direction is efficiency and deployability. Practical remote sensing systems often operate under tight computational budgets. Therefore, lightweight tuning, sparse computation, token reduction, model compression, and on-orbit and edge inference will become increasingly important. Interactive and explainable retrieval is also likely to gain importance. It allows analysts to refine queries through dialogue and inspect the image regions or semantic cues that support retrieval decisions. Overall, continued progress in data construction, domain adaptation, semantic alignment, and efficient multimodal modeling is expected to make RS-ITR a more robust infrastructure capability for Earth observation applications. -
表 1 典型遥感图文检索数据集
数据集 图片数量 图像尺寸 描述模式/标注方式 类别 Sydney-Caption[29] 613 500 × 500 每张图像5句描述 核心测试基准 UCM-Caption[30] 2100 256 × 256 每张图像5句描述 核心测试基准 RSICD[31] 10,921 224 × 224 每张图像1–5句描述 核心测试基准 RSITMD[32] 4743 256 × 256 每张图像5句描述 + 细粒度关键词 核心测试基准 NWPU-Caption[33,34] 31,500 256 × 256 每张图像5句描述 大规模预训练/训练数据 RSICap[35] 2585 512 × 512 每张图像1句高质量人工标注描述 生成式/指令微调数据 RS5M[36] 5M 全分辨率 关键词过滤 + BLIP-2生成 大规模预训练/训练数据 SkyScript[37] 5.2M 全分辨率 自动生成 + CLIP 过滤 大规模预训练/训练数据 MMRS-1M subset[38] 1M 全分辨率 多任务指令跟随 生成式/指令微调数据 GeoLangBind-2M subset[39] 2M 全分辨率 数据集整合 + 自动生成 大规模预训练/训练数据 Git-10M[40] 10M 全分辨率 自动生成 + 数据清洗 大规模预训练/训练数据  下载: 导出CSV
下载: 导出CSV
表 2 遥感图文检索技术演进
技术阶段 核心思想 技术特点 优势 局限 传统方法 手工特征+关键词匹配 低层视觉描述 结构简单、计算开销低、
具有一定可解释性难以表达高层语义,
存在明显语义鸿沟深度学习方法 表征学习 学习图文共享嵌入空间 语义表达能力增强,
可实现端到端训练依赖大规模标注数据,
跨场景泛化能力有限视觉语言基础模型 大规模预训练 VLM构建统一跨模态语义空间 泛化能力强,支持零样本迁移 存在领域分布差异,需遥感适配 VLM扩展与多任务
统一模型统一语义表示 将检索、检测、分割等任务
纳入统一框架任务协同、共享表示、
增强场景理解能力计算复杂度高,
模型规模与训练成本较大
下载: 导出CSV
表 3 典型视觉-语言模型与遥感基础模型对比
模型 基础网络 训练数据 训练策略 应用领域 CLIP[9] ResNets、ViT WIT(WebImageText) 对比学习 通用 Flamingo[58] NFNet、Transformer COCO、OKVQA、VQAv2、MSVDQA Gated Cross-Attention+
Perceiver Resampler通用 ALBEF[79] BERT、ViT COCO 和 Visual Genome 对比学习 通用 BLIP[80] BERT 、 ViT COCO、Visual Genome、Conceptual Captions 对比学习 通用 LLaVA[81] Vicuna、CLIP ScienceQA、CC-595K、
LLaVA-Instruct-158KProjector+Instruction Tuning 通用 Qwen2.5-VL[83] ViT、Qwen2.5 多个数据集 动态分辨率预训练+
多阶段指令微调通用 GPT-4V[84] 未公开 多个数据集 未公开 通用 Gemini[85] 未公开 多个数据集 未公开 通用 RemoteCLIP[10] ViT-14 10 个数据集 MAE 遥感 RSGPT[35] InstructBLIP 图像+文本描述+指令 文本监督 遥感 GeoChat[88] LLaVA1.5 318k 个指令对的RS数据集 LoRA 微调 遥感 EarthPT[89] Unsupervised Multitask Learners ClearSky 自回归 遥感 DINO-MM[90] Self-supervised Multitask Learners 多个数据集 蒸馏+对比 遥感 SkySense[91] ViT 多个数据集 冻结+微调 遥感 RingMo[92] ViT 多个数据集 MAE+PIMask 遥感 RSPrompter[93] SAM WHU, NWPU, SSDD 冻结+微调 遥感 SpectralGPT[94] ViT fMoW/BigEarthNetS2 MAE+3DMask 遥感
下载: 导出CSV
表 4 遥感VLM检索性能比较
方法 年份 模型参数量(M) 预训练数据规模(million) 微调方式 RSICD Dataset RSITMD Dataset PIR[62] 2023 161 5.00 视觉指令微调 23.48 39.09 RemoteCLIP[10] 2024 428 0.83 持续预训练 35.02 50.68 GeoRSCLIP[36] 2024 151 5.00 参数高效微调 38.26 52.43 SkyCLIP[37] 2024 428 2.60 持续预训练/零样本迁移 19.97 30.58 iEBAKER[110] 2025 151 0.20 直接微调 43.41 55.65 LRSCLIP[11] 2025 367 2.00 全量微调 48.34 65.04
下载: 导出CSV
-
[1] ZHANG Lefei and ZHANG Liangpei. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities[J]. IEEE Geoscience and Remote Sensing Magazine, 2022, 10(2): 270–294. doi: 10.1109/MGRS.2022.3145854. [2] SUN Ziheng, SANDOVAL L, CRYSTAL-ORNELAS R, et al. A review of earth artificial intelligence[J]. Computers & Geosciences, 2022, 159: 105034. doi: 10.1016/j.cageo.2022.105034. [3] CHAUDHURI U, BANERJEE B, BHATTACHARYA A, et al. CMIR-NET: A deep learning based model for cross-modal retrieval in remote sensing[J]. Pattern Recognition Letters, 2020, 131: 456–462. doi: 10.1016/j.patrec.2020.02.006. [4] XU Lingxin, WANG Luyao, ZHANG Jinzhi, et al. A review of cross-modal image-text retrieval in remote sensing[J]. Remote Sensing, 2025, 17(24): 3995. doi: 10.3390/rs17243995. [5] MANDAL D, CHAUDHURY K N, and BISWAS S. Generalized semantic preserving hashing for n-label cross-modal retrieval[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2633–2641. doi: 10.1109/CVPR.2017.282. [6] YUAN Zhiqiang, ZHANG Wenkai, TIAN Changyuan, et al. Remote sensing cross-modal text-image retrieval based on global and local information[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5620616. doi: 10.1109/TGRS.2022.3163706. [7] ZHANG Jingqi, JI Jiaqi, RU Huiying, et al. A global-local dual-stream collaborative enhancement model for cross-modal image and text retrieval in remote sensing scenarios[J]. AIP Advances, 2025, 15(8): 085009. doi: 10.1063/5.0280560. [8] PAN Jiancheng, MA Qing, and BAI Cong. A prior instruction representation framework for remote sensing image-text retrieval[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 611–620. doi: 10.1145/3581783.3612374. [9] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, Virtual Event, 2021: 8748–8763. [10] LIU Fan, CHEN Delong, GUAN Zhangqingyun, et al. RemoteCLIP: A vision language foundation model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5622216. doi: 10.1109/TGRS.2024.3390838. [11] CHEN Weizhi, DENG Yupeng, JIN Wei, et al. DGTRSD and DGTRSCLIP: A dual-granularity remote sensing image–text dataset and vision–language foundation model for alignment[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 29113–29130. doi: 10.1109/JSTARS.2025.3625958. [12] YANG Xiaoyu, LI Chao, WANG Zhiming, et al. Remote sensing cross-modal text-image retrieval based on attention correction and filtering[J]. Remote Sensing, 2025, 17(3): 503. doi: 10.3390/rs17030503. [13] GUAN Jihong, SHU Yulou, LI Wengen, et al. PR-CLIP: Cross-modal positional reconstruction for remote sensing image-text retrieval[J]. Remote Sensing, 2025, 17(13): 2117. doi: 10.3390/rs17132117. [14] WANG Yijing, TANG Xu, MA Jingjing, et al. Cross-modal remote sensing image-text retrieval via context and uncertainty-aware prompt[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(6): 11384–11398. doi: 10.1109/TNNLS.2024.3458898. [15] HOXHA G, ANGYAL O, and DEMIR B. Self-supervised cross-modal text-image time series retrieval in remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5639115. doi: 10.1109/TGRS.2025.3601393. [16] WANG Tianshi, LI Fengling, ZHU Lei, et al. Cross-modal retrieval: A systematic review of methods and future directions[J]. The IEEE, 2024, 112(11): 1716–1754. doi: 10.1109/JPROC.2024.3525147. [17] BALTRUŠAITIS T, AHUJA C, and MORENCY L P. Multimodal machine learning: A survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423–443. doi: 10.1109/TPAMI.2018.2798607. [18] NGIAM J, KHOSLA A, KIM M, et al. Multimodal deep learning[C]. The 28th International Conference on Machine Learning, Bellevue, USA, 2011: 689–696. [19] KIROS R, SALAKHUTDINOV R, and ZEMEL R S. Unifying visual-semantic embeddings with multimodal neural language models[J]. arXiv preprint arXiv: 1411.2539, 2014. doi: 10.48550/arXiv.1411.2539. [20] 刘扬, 付征叶, 郑逢斌. 高分辨率遥感影像目标分类与识别研究进展[J]. 地球信息科学学报, 2015, 17(9): 1080–1091. doi: 10.3724/SP.J.1047.2015.01080.LIU Yang, FU Zhengye, and ZHENG Fengbin. Review on high resolution remote sensing image classification and recognition[J]. Journal of Geo-Information Science, 2015, 17(9): 1080–1091. doi: 10.3724/SP.J.1047.2015.01080. [21] XIA Guisong, BAI Xiang, DING Jian, et al. DOTA: A large-scale dataset for object detection in aerial images[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3974–3983. doi: 10.1109/CVPR.2018.00418. [22] 周月敏, 周翔. 中国高分辨率对地观测系统共性应用技术规范体系框架研究[J]. 地球信息科学学报, 2018, 20(9): 1298–1305. doi: 10.12082/dqxxkx.2018.180144.ZHOU Yuemin and ZHOU Xiang. The system framework of technical standards for common applications in China high-resolution earth observation system[J]. Journal of Geo-Information Science, 2018, 20(9): 1298–1305. doi: 10.12082/dqxxkx.2018.180144. [23] LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296–307. doi: 10.1016/j.isprsjprs.2019.11.023. [24] 佃袁勇, 方圣辉, 姚崇怀. 多尺度分割的高分辨率遥感影像变化检测[J]. 遥感学报, 2016, 20(1): 129–137. doi: 10.11834/jrs.20165074.DIAN Yuanyong, FANG Shenghui, and YAO Chonghuai. Change detection for high-resolution images using multilevel segment method[J]. Journal of Remote Sensing, 2016, 20(1): 129–137. doi: 10.11834/jrs.20165074. [25] ZHU Xiaoxiang, TUZEL O, MOU Lichao, et al. Deep learning in remote sensing: A comprehensive review and list of resources[J]. IEEE Geoscience and Remote Sensing Magazine, 2017, 5(4): 8–36. doi: 10.1109/MGRS.2017.2762307. [26] 袁翔, 程塨, 李戈, 等. 遥感影像小目标检测研究进展[J]. 中国图象图形学报, 2023, 28(6): 1662–1684. doi: 10.11834/jig.221202.YUAN Xiang, CHENG Gong, LI Ge, et al. Progress in small object detection for remote sensing images[J]. Journal of Image and Graphics, 2023, 28(6): 1662–1684. doi: 10.11834/jig.221202. [27] ZHAO Beigeng. A systematic survey of remote sensing image captioning[J]. IEEE Access, 2021, 9: 154086–154111. doi: 10.1109/ACCESS.2021.3128140. [28] LI Xiang, WEN Congcong, HU Yuan, et al. Vision-language models in remote sensing: Current progress and future trends[J]. IEEE Geoscience and Remote Sensing Magazine, 2024, 12(2): 32–66. doi: 10.1109/MGRS.2024.3383473. [29] QU Bo, LI Xuelong, TAO Dacheng, et al. Deep semantic understanding of high resolution remote sensing image[C]. Proceedings of International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 2016: 1–5. doi: 10.1109/CITS.2016.7546397. [30] YANG Yi and NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]. The 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, USA, 2010: 270–279. doi: 10.1145/1869790.1869829. [31] LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183–2195. doi: 10.1109/TGRS.2017.2776321. [32] YUAN Zhiqiang, ZHANG Wenkai, FU Kun, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4404119. doi: 10.1109/TGRS.2021.3078451. [33] CHENG Gong, HAN Junwei, and LU Xiaoqiang. Remote sensing image scene classification: Benchmark and state of the art[J]. The IEEE, 2017, 105(10): 1865–1883. doi: 10.1109/JPROC.2017.2675998. [34] CHENG Qimin, HUANG Haiyan, XU Yuan, et al. NWPU-captions dataset and MLCA-Net for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5629419. doi: 10.1109/TGRS.2022.3201474. [35] HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: A remote sensing vision-language model and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 224: 272–286. doi: 10.1016/j.isprsjprs.2025.03.028. [36] ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision-language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154. [37] WANG Zhecheng, PRABHA R, HUANG Tianyuan, et al. WANG Zhecheng, PRABHA R, HUANG Tianyuan, et al. SkyScript: A large and semantically diverse vision-language dataset for remote sensing[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024. 5805–5813. doi: 10.1609/aaai.v38i6.28393. [38] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5917820. doi: 10.1109/TGRS.2024.3409624. [39] XIONG Zhitong, WANG Yi, YU Weikang, et al. GeoLangBind: Unifying earth observation with agglomerative vision-language foundation models[J]. arXiv preprint arXiv: 2503.06312, 2025. doi: 10.48550/arXiv.2503.06312. [40] LIU Chenyang, CHEN Keyan, ZHAO Rui, et al. Text2Earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model[J]. IEEE Geoscience and Remote Sensing Magazine, 2025, 13(3): 238–259. doi: 10.1109/MGRS.2025.3560455. [41] RUI Yong, HUANG T S, and CHANG S F. Image retrieval: Current techniques, promising directions, and open issues[J]. Journal of Visual Communication and Image Representation, 1999, 10(1): 39–62. doi: 10.1006/jvci.1999.0413. [42] DATCU M, DASCHIEL H, PELIZZARI A, et al. Information mining in remote sensing image archives: System concepts[J]. IEEE Transactions on Geoscience and Remote Sensing, 2003, 41(12): 2923–2936. doi: 10.1109/TGRS.2003.817197. [43] MIKRIUKOV G, RAVANBAKHSH M, and DEMIR B. Unsupervised contrastive hashing for cross-modal retrieval in remote sensing[C]. International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022: 4463–4467. doi: 10.1109/ICASSP43922.2022.9746251. [44] MIKRIUKOV G, RAVANBAKHSH M, and DEMIR B. Deep unsupervised contrastive hashing for large-scale cross-modal text-image retrieval in remote sensing[J]. arXiv preprint arXiv: 2201.08125, 2022. doi: 10.48550/arXiv.2201.08125. [45] 郑富中, 张海粟, 张雄, 等. 遥感图像跨模态语义检索技术与应用[J]. 指挥与控制学报, 2026, 12(1): 21–30. doi: 10.20278/j.jc2.2096-0204.2023.0126.ZHENG Fuzhong, ZHANG Haisu, ZHANG Xiong, et al. Remote sensing cross-modal semantic retrieval technology and application[J]. Journal of Command and Control, 2026, 12(1): 21–30. doi: 10.20278/j.jc2.2096-0204.2023.0126. [46] DASCHIEL H and DATCU M. Information mining in remote sensing image archives: System evaluation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2005, 43(1): 188–199. doi: 10.1109/TGRS.2004.838374. [47] SMEULDERS A W M, WORRING M, SANTINI S, et al. Content-based image retrieval at the end of the early years[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(12): 1349–1380. doi: 10.1109/34.895972. [48] CHENG Gong and HAN Junwei. A survey on object detection in optical remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 117: 11–28. doi: 10.1016/j.isprsjprs.2016.03.014. [49] O’SHEA K and NASH R. An introduction to convolutional neural networks[J]. arXiv preprint arXiv: 1511.08458, 2015. doi: 10.48550/arXiv.1511.08458. [50] SHERSTINSKY A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network[J]. Physica D: Nonlinear Phenomena, 2020, 404: 132306. doi: 10.1016/j.physd.2019.132306. [51] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000– 6010. [52] FROME A, CORRADO G S, SHLENS J, et al. DeViSE: A deep visual-semantic embedding model[C]. The 27th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2013: 2121–2129. [53] GUO Mao, YUAN Yuan, and LU Xiaoqiang. Deep cross-modal retrieval for remote sensing image and audio[C]. The 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 2018: 1–7. doi: 10.1109/PRRS.2018.8486338. [54] WANG Liwei, LI Yin, and LAZEBNIK S. Learning deep structure-preserving image-text embeddings[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 5005–5013. doi: 10.1109/CVPR.2016.541. [55] ZHU Zicong, KANG Jian, DIAO Wenhui, et al. SIRS: Multitask joint learning for remote sensing foreground-entity image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5625615. doi: 10.1109/TGRS.2024.3402216. [56] LI Chunyuan, GAN Zhe, YANG Zhengyuan, et al. Multimodal foundation models: From specialists to general-purpose assistants[J]. Foundations and Trends in Computer Graphics and Vision, 2024, 16(1/2): 1–214. doi: 10.1561/0600000110. [57] WANG Wenhui, BAO Hangbo, DONG Li, et al. Image as a foreign language: BEiT pretraining for vision and vision-language tasks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 19175–19186. doi: 10.1109/cvpr52729.2023.01838. [58] ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: A visual language model for few-shot learning[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1723. [59] JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C/OL]. The 38th International Conference on Machine Learning, Virtual Event, 2021: 4904–4916. [60] WORTSMAN M, ILHARCO G, KIM J W, et al. Robust fine-tuning of zero-shot models[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 7949–7961. doi: 10.1109/CVPR52688.2022.00780. [61] PELEG A, SINGH N D, and HEIN M. Advancing compositional awareness in CLIP with efficient fine-tuning[J]. arXiv preprint arXiv: 2505.24424, 2025. doi: 10.48550/arXiv.2505.24424. [62] PAN Jiancheng, MA Muyuan, MA Qing, et al. PAN Jiancheng, MA Muyuan, MA Qing, et al. PIR: Remote sensing image-text retrieval with prior instruction representation learning[J]. arXiv preprint arXiv: 2405.10160, 2024. doi: 10.48550/arXiv.2405.10160. [63] GAO Peng, GENG Shijie, ZHANG Renrui, et al. CLIP-adapter: Better vision-language models with feature adapters[J]. International Journal of Computer Vision, 2024, 132(2): 581–595. doi: 10.1007/s11263-023-01891-x. [64] ZHANG Renrui, ZHANG Wei, FANG Rongyao, et al. Tip-Adapter: Training-free adaption of CLIP for few-shot classification[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 493–510. doi: 10.1007/978-3-031-19833-5_29. [65] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022, 130(9): 2337–2348. doi: 10.1007/s11263-022-01653-1. [66] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Conditional prompt learning for vision-language models[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16795–16804. doi: 10.1109/CVPR52688.2022.01631. [67] 王懿婧, 唐旭, 韩硕, 等. 遥感跨模态图文检索: 关键技术与挑战[J]. 遥感学报, 2026, 30(2): 262–278. doi: 10.11834/jrs.20255437.WANG Yijing, TANG Xu, HAN Shuo, et al. Remote sensing cross-modal image-text retrieval: Key technologies and challenges[J]. National Remote Sensing Bulletin, 2026, 30(2): 262–278. doi: 10.11834/jrs.20255437. [68] 付琨, 卢宛萱, 刘小煜, 等. 遥感基础模型发展综述与未来设想[J]. 遥感学报, 2024, 28(7): 1667–1680. doi: 10.11834/jrs.20233313.FU Kun, LU Wanxuan, LIU Xiaoyu, et al. A comprehensive survey and assumption of remote sensing foundation modal[J]. National Remote Sensing Bulletin, 2024, 28(7): 1667–1680. doi: 10.11834/jrs.20233313. [69] LIU Jiaqi, FU Ronghao, SUN Lang, et al. SkyMoE: A vision-language foundation model for enhancing geospatial interpretation with mixture of experts[C]. The 40th AAAI Conference on Artificial Intelligence, Singapore, Singapore, 2026: 7168–7178. doi: 10.1609/aaai.v40i9.37653. [70] WANG Peijin, HU Huiyang, TONG Boyuan, et al. RingmoGPT: A unified remote sensing foundation model for vision, language, and grounded tasks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5611320. doi: 10.1109/TGRS.2024.3510833. [71] HU Huiyang, WANG Peijin, FENG Yingchao, et al. RingMo-Agent: A unified remote sensing foundation model for multi-platform and multi-modal reasoning[J]. arXiv preprint arXiv: 2507.20776, 2025. doi: 10.48550/arXiv.2507.20776. [72] BI Hanbo, FENG Yingchao, TONG Boyuan, et al. RingMoE: Mixture-of-modality-experts multi-modal foundation models for universal remote sensing image interpretation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026, 48(4): 4388–4405. doi: 10.1109/TPAMI.2025.3643453. [73] ZHANG Zilun, SHEN Haozhan, ZHAO Tiancheng, et al. GeoRSMLLM: A multimodal large language model for vision-language tasks in geoscience and remote sensing[J]. arXiv preprint arXiv: 2503.12490, 2025. doi: 10.48550/arXiv.2503.12490. [74] WANG Junjue, XUAN Weihao, QI Heli, et al. DisasterM3: A remote sensing vision-language dataset for disaster damage assessment and response[C]. The 39th International Conference on Neural Information Processing Systems, San Diego, USA, 2025. [75] 张帅豪, 潘志刚. 遥感大模型: 综述与未来设想[J]. 遥感技术与应用, 2025, 40(1): 1–13. doi: 10.11873/j.issn.1004-0323.2025.1.0001.ZHANG Shuaihao and PAN Zhigang. Remote sensing large models: Review and future prospects[J]. Remote Sensing Technology and Application, 2025, 40(1): 1–13. doi: 10.11873/j.issn.1004-0323.2025.1.0001. [76] LI L H, YATSKAR M, YIN D, et al. VisualBERT: A simple and performant baseline for vision and language[J]. arXiv preprint arXiv: 1908.03557, 2019. doi: 10.48550/arXiv.1908.03557. [77] CHEN Y C, LI Linjie, YU Licheng, et al. UNITER: UNiversal image-TExt representation learning[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 104–120. doi: 10.1007/978-3-030-58577-8_7. [78] WANG Peng, YANG An, MEN Rui, et al. OFA: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 23318–23340. [79] LI Junnan, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: Vision and language representation learning with momentum distillation[C]. The 35th International Conference on Neural Information Processing Systems, Virtual Event, 2021: 742. [80] LI Junnan, LI Dongxu, XIONG Caiming, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 12888–12900. [81] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1516. [82] DAI Wenliang, LI Junnan, LI Dongxu, et al. InstructBLIP: Towards general-purpose vision-language models with instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 2142. [83] BAI Shuai, CHEN Keqin, LIU Xuejing, et al. Qwen2.5-VL technical report[J]. arXiv preprint arXiv: 2502.13923, 2025. doi: 10.48550/arXiv.2502.13923. [84] YANG Zhengyuan, LI Linjie, LIN K, et al. The dawn of LMMs: Preliminary explorations with GPT-4V(ision)[J]. arXiv preprint arXiv: 2309.17421, 2023. doi: 10.48550/arXiv.2309.17421. [85] Gemini Team Google. Gemini: A family of highly capable multimodal models[J]. arXiv preprint arXiv: 2312.11805, 2023. doi: 10.48550/arXiv.2312.11805. [86] CHEN Xi, WANG Xiao, CHANGPINYO S, et al. PaLI: A jointly-scaled multilingual language-image model[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023. [87] PENG Zhiliang, WANG Wenhui, DONG Li, et al. Kosmos-2: Grounding multimodal large language models to the world[J]. arXiv preprint arXiv: 2306.14824, 2023. doi: 10.48550/arXiv.2306.14824. [88] KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: Grounded large vision-language model for remote sensing[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 27831–27840. doi: 10.1109/CVPR52733.2024.02629. [89] SMITH M J, FLEMING L, and GEACH J E. EarthPT: A time series foundation model for earth observation[J]. arXiv preprint arXiv: 2309.07207, 2024. doi: 10.48550/arXiv.2309.07207. [90] WANG Yi, ALBRECHT C M, and ZHU Xiaoxiang. Self-supervised vision transformers for joint SAR-optical representation learning[C]. The IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 2022: 139–142. doi: 10.1109/IGARSS46834.2022.9883983. [91] GUO Xin, LAO Jiangwei, DANG Bo, et al. SkySense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 27662–27673. doi: 10.1109/CVPR52733.2024.02613. [92] SUN Xian, WANG Pengjing, LU Wanxuan, et al. RingMo: A remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5612822. doi: 10.1109/TGRS.2022.3194732. [93] CHEN Keyan, LIU Chenyang, CHEN Hao, et al. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4701117. doi: 10.1109/TGRS.2024.3356074. [94] HONG Danfeng, ZHANG Bing, LI Xuyang, et al. SpectralGPT: Spectral remote sensing foundation model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5227–5244. doi: 10.1109/TPAMI.2024.3362475. [95] YUAN Yuan, ZHAN Yang, and XIONG Zhitong. Parameter-efficient transfer learning for remote sensing image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5619014. doi: 10.1109/TGRS.2023.3308969. [96] GENG Shijie, YUAN Jianbo, TIAN Yu, et al. HiCLIP: Contrastive language-image pretraining with hierarchy-aware attention[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023. [97] SUNG Y L, CHO J, and BANSAL M. VL-ADAPTER: Parameter-efficient transfer learning for vision-and-language tasks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5217–5227. doi: 10.1109/CVPR52688.2022.00516. [98] LU Haoyu, HUO Yuqi, YANG Guoxing, et al. UniAdapter: Unified parameter-efficient transfer learning for cross-modal modeling[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024. [99] HINTON G, VINYALS O, and DEAN J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv: 1503.02531, 2015. doi: 10.48550/arXiv.1503.02531. [100] LERNER P, FERRET O, and GUINAUDEAU C. Cross-modal retrieval for knowledge-based visual question answering[C]. The 46th European Conference on Information Retrieval on Advances in Information Retrieval, Glasgow, UK, 2024: 421–438. [101] CEPEDA V V, NAYAK G K, and SHAH M. GeoCLIP: Clip-inspired alignment between locations and images for effective worldwide geo-localization[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 379. [102] WEN Congcong, LIN Yiting, QU Xiaokang, et al. Remote sensing retrieval-augmented generation: Bridging remote sensing imagery and comprehensive knowledge with a multimodal dataset and retrieval-augmented generation model[J]. IEEE Geoscience and Remote Sensing Magazine, 2026, 14(2): 85–103. doi: 10.1109/MGRS.2025.3645852. [103] WEI Chen, ZHANG Yiwei, GUAN Xi, et al. GeoAI for driving risk assessment via vision-language models: A knowledge guided RAG system and dual evaluation[C]. The 8th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery (GeoAI '25), Minneapolis, USA, 2025: 161–173. doi: 10.1145/3764912.3770832. [104] XU Wenjia, YU Zijian, MU Boyang, et al. RS-Agent: Automating remote sensing tasks through intelligent agents[J]. arXiv preprint arXiv: 2406.07089, 2024. doi: 10.48550/arXiv.2406.07089. [105] SHAO Run, LI Ziyu, ZHANG Zhaoyang, et al. Asking like Socrates: Socrates helps VLMs understand remote sensing images[J]. arXiv preprint arXiv: 2511.22396, 2025. doi: 10.48550/arXiv.2511.22396. [106] RUSAK E, REIZINGER P, JUHOS A, et al. InfoNCE: Identifying the gap between theory and practice[C]. The 28th International Conference on Artificial Intelligence and Statistics, Mai Khao, Thailand, 2025: 4159–4167. [107] WANG Jianren, FANG Zhaoyuan, and ZHAO Hang. AlignNet: A unifying approach to audio-visual alignment[C]. The IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, USA, 2020: 3298–3306. doi: 10.1109/WACV45572.2020.9093345. [108] AKSAN E and HILLIGES O. STCN: Stochastic temporal convolutional networks[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [109] JAYASUMANA S, RAMALINGAM S, VEIT A, et al. Rethinking FID: Towards a better evaluation metric for image generation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 9307–9315. doi: 10.1109/CVPR52733.2024.00889. [110] ZHANG Yan, JI Zhong, MENG Changxu, et al. iEBAKER: Improved remote sensing image-text retrieval framework via eliminate before align and keyword explicit reasoning[J]. Expert Systems with Applications, 2026, 296: 128968. doi: 10.1016/j.eswa.2025.128968. -

 下载:
下载:


图(7) / 表(4)
计量
- 文章访问数: 451
- HTML全文浏览量: 234
- PDF下载量: 44
- 被引次数: 0
