

From Touch to Semantics: A Cross-Modal Framework for Zero-Shot Spiking Tactile Object Recognition
-
摘要: 触觉感知是机器人理解物体物理属性并实现精细交互的重要基础,在视觉受限或复杂场景中具有不可替代的作用。相比连续触觉信号,事件驱动的脉冲触觉以异步稀疏的方式编码接触动态变化,具备更高时间分辨率与能效优势。然而,受限于高采集成本与小样本规模,现有监督触觉识别方法在开放世界场景中面临显著泛化瓶颈。尽管零样本学习可缓解数据稀缺,但现有方法多依赖视觉辅助或人工粗粒度语义,难以适配脉冲触觉的复杂时空动态结构,且缺乏稳定的跨模态语义对齐机制。针对上述问题,该文提出一种面向脉冲触觉信号的零样本物体识别方法。首先,构建仿生脉冲图神经网络,对脉冲触觉时空演化进行建模,提取判别性且具生物可解释性的触觉表征;其次,引入大语言模型生成细粒度结构化触觉语义空间,并为各类别构建一致维度的语义原型;在此基础上,设计触觉到语义的正向映射与语义到触觉的反向重构,形成循环一致的跨模态对齐框架,从而提升对齐稳定性与未见类别泛化能力。在标准的零样本设定下,该文在脉冲触觉数据集上进行了系统实验评估,实验结果表明,该方法在平均类别准确率、Top-k准确率及语义对齐一致性等指标上均优于现有方法,验证了其在脉冲触觉零样本识别任务中的有效性与鲁棒性。该研究为脉冲触觉语义理解及开放环境下的机器人感知提供了新的技术路径。Abstract:
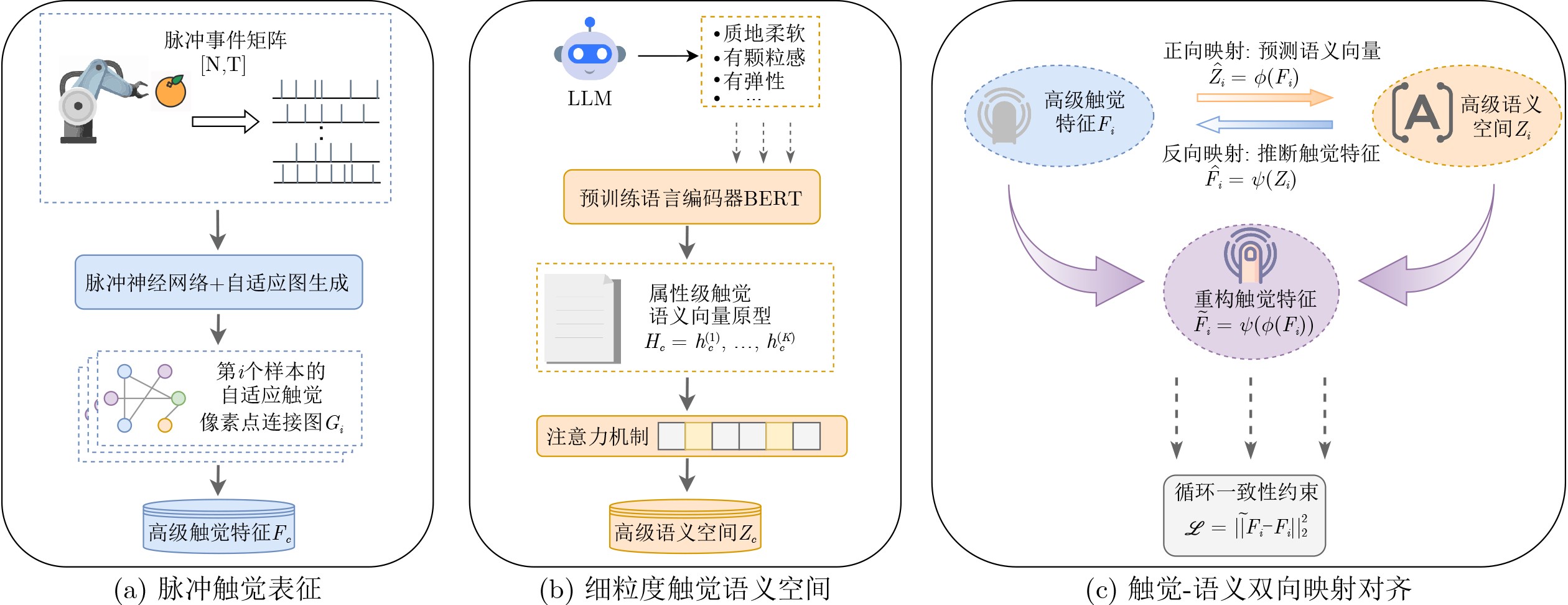
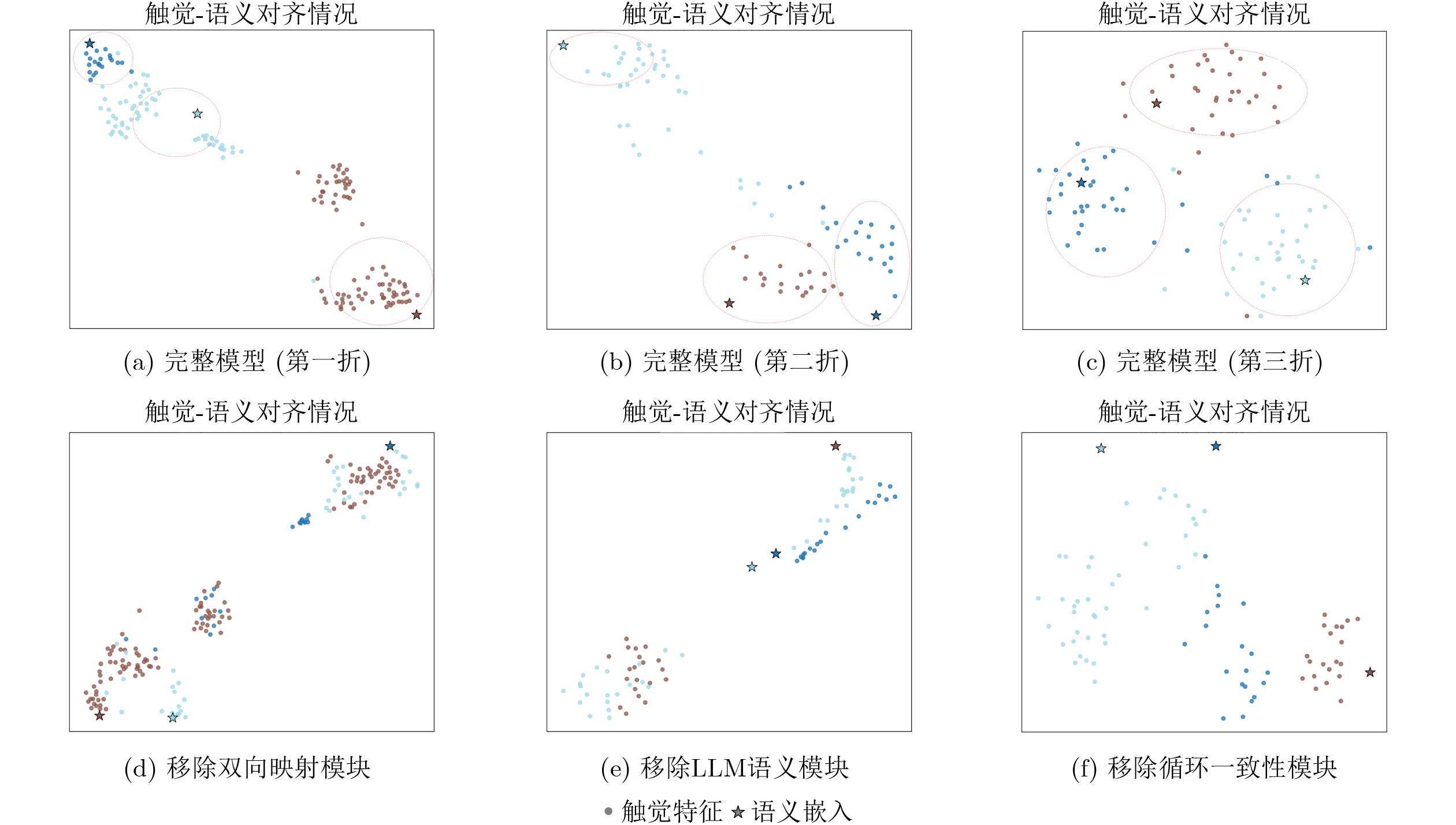
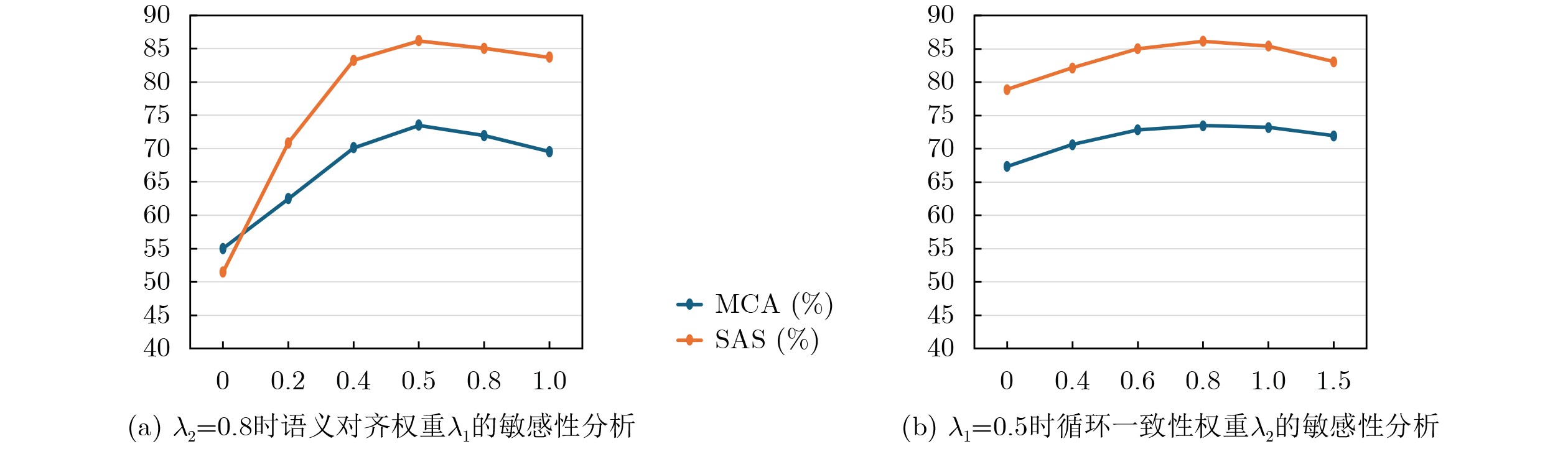
Objective Tactile perception enables robots to understand object properties and perform dexterous interactions. However, tactile data are costly to collect and difficult to scale, which limits conventional supervised learning in open-world scenarios. Zero-Shot Learning (ZSL) provides a promising solution by transferring knowledge from seen to unseen categories through semantic representations. Existing tactile ZSL methods either rely on auxiliary visual information or use manually designed attributes, which are often subjective and limited in generalization. Event-based spiking tactile signals are sparse and asynchronous, with rich spatiotemporal dynamics. These properties make semantic modeling more challenging. Systematic studies on zero-shot recognition for such data remain limited. To address these issues, this paper proposes a zero-shot object recognition framework for spiking tactile perception. The framework aims to bridge low-level tactile dynamics and high-level semantics in a scalable manner. Methods The proposed framework consists of three components ( Fig. 1 ): spiking tactile feature extraction, semantic prototype construction, and cross-modal tactile-semantic alignment. First, a biomimetic Spiking Graph Neural Network (SGNN) is used to model raw event-based spiking tactile signals. By integrating Leaky Integrate-and-Fire (LIF) neurons with graph-based message passing, the SGNN captures temporal firing dynamics and spatial relationships among tactile sensing units. It then generates discriminative and biologically interpretable high-level tactile embeddings. Second, instead of using manually annotated attributes, a Large Language Model (LLM) is used to generate structured, fine-grained, and extensible tactile attribute descriptions for each object category. These textual descriptions are encoded as continuous semantic vectors to form class-level semantic prototypes with consistent dimensionality across categories. This strategy supports flexible semantic expansion and avoids labor-intensive attribute engineering. Third, a bidirectional tactile-semantic alignment mechanism is designed to improve generalization to unseen categories. A forward mapping projects tactile embeddings into the semantic space for classification, whereas a reverse mapping reconstructs tactile features from semantic representations. A cycle-consistency constraint is imposed between the two mappings to preserve structural coherence and semantic stability across modalities. The overall framework is trained only on seen categories. During zero-shot inference, tactile embeddings of unseen samples are matched with their corresponding semantic prototypes in the shared embedding space.Results and Discussions The proposed method is evaluated on the Ev-Object event-based tactile dataset under a strict zero-shot setting, with disjoint seen and unseen category sets. Performance is assessed using Mean Class Accuracy (MCA), Top-k accuracy, and the Semantic Alignment Score (SAS). The proposed framework consistently outperforms representative tactile ZSL baselines across all metrics. It achieves an MCA of 73.48%, a Top-1 accuracy of 62.68%, and a Top-2 accuracy of 88.75%. Ablation studies show that removing the LLM semantic module, bidirectional mapping, or cycle-consistency constraint reduces recognition performance and semantic alignment quality. Removing the LLM semantic module causes a substantial decrease in MCA, which confirms the role of structured LLM-generated tactile semantics in knowledge transfer. Removing the bidirectional mapping or the cycle-consistency constraint also reduces performance, indicating that both components help maintain stable cross-modal alignment. The t-SNE visualization further shows that cycle-consistent alignment yields more compact intra-class clusters and clearer inter-class separation for unseen categories. Semantic prototypes are also better located near the centers of tactile feature clusters. These results indicate that combining biologically inspired spiking models with LLM-generated tactile semantics provides an effective solution for open-world tactile perception. Conclusions This paper presents a zero-shot object recognition framework for spiking tactile perception by integrating SGNN-based tactile representation with semantic prototypes. The proposed method addresses key limitations of existing tactile ZSL approaches by avoiding visual data and manual attribute design while effectively modeling the spatiotemporal dynamics of event-based spiking tactile signals. Experimental results under strict zero-shot settings confirm the effectiveness and robustness of the proposed framework. This work provides a strong baseline for zero-shot spiking tactile recognition and offers a principled path toward open-world tactile cognition in robotic systems. Future work will explore generalized zero-shot tactile perception, multimodal extensions, and real-world robotic deployment under noisy and dynamic sensing conditions. -
表 1 标准ZSL设置下不同方法在零样本脉冲触觉识别任务上的性能对比(%)
方法 基线类型 MCA Top-1 Acc Top-2 Acc ALE[28] 嵌入式ZSL (语言) 55.92 $ \pm $ 5.17 47.36 $ \pm $ 6.84 72.41 $ \pm $ 8.12 f-CLSWGAN[31] 生成式ZSL (语言) 58.74 $ \pm $ 6.23 50.21 $ \pm $ 7.55 76.89 $ \pm $ 7.33 zsl4ttr[11] 生成式ZSL (图像+语言) 61.35 $ \pm $ 5.88 52.63 $ \pm $ 6.92 79.05 $ \pm $ 6.74 UniT[32] 触觉表征学习 63.41 $ \pm $ 4.96 54.80 $ \pm $ 6.40 81.22 $ \pm $ 5.91 Octopi[33] 触觉-语言大模型 65.08 $ \pm $ 6.40 56.14 $ \pm $ 7.82 83.57 $ \pm $ 6.15 本文 嵌入式ZSL(语言) 73.48 $ \pm $ 4.35 62.68 $ \pm $ 7.81 88.75 $ \pm $ 6.47  下载: 导出CSV
下载: 导出CSV
表 2 关键模块的消融实验分析(%)
LLM语义 双向映射 循环一致性 MCA SAS × × × 31.57 30.24 × √ √ 56.12 52.78 √ × √ 54.98 51.46 √ √ × 71.35 78.92 √ √ √ 73.48 86.17
下载: 导出CSV
表 3 提示策略的消融实验分析(%)
策略 提示方式 MCA Top-1 Acc Top-2 Acc A 类别名基线 56.12 47.53 71.84 B 自由形式描述 68.94 58.26 81.33 C 结构化-3属性 71.51 60.17 84.60 D 结构化-5属性 73.48 62.68 88.75
下载: 导出CSV
-
[1] LI Baojiang, LI Liang, WANG Haiyan, et al. TVT-transformer: A tactile-visual-textual fusion network for object recognition[J]. Information Fusion, 2025, 118: 102943. doi: 10.1016/j.inffus.2025.102943. [2] LUO Shan, LEPORA N F, YUAN Wenzhen, et al. Tactile robotics: An outlook[J]. IEEE Transactions on Robotics, 2025, 41: 5564–5583. doi: 10.1109/TRO.2025.3608686. [3] ZHANG Yupo, LI Xiaoyu, FANG Senlin, et al. Multi-branch multi-scale channel fusion graph convolutional networks with transfer cost for robotic tactile recognition tasks[J]. IEEE Transactions on Automation Science and Engineering, 2025, 22: 11856–11868. doi: 10.1109/TASE.2025.3541339. [4] LI Liang, QIU Shengjie, LI Baojiang, et al. Object recognition based on tactile information: A generalized recognition network combining wavelet transform and transformer model for small sample datasets[J]. Information Sciences, 2025, 719: 122464. doi: 10.1016/j.ins.2025.122464. [5] UEDA S, HASHIMOTO A, HAMAYA M, et al. Visuo-tactile zero-shot object recognition with vision-language model[C]. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 2024: 7243–7250. doi: 10.1109/IROS58592.2024.10801766. [6] TAUNYAZOV T, SNG W, LIM B, et al. Event-driven visual-tactile sensing and learning for robots[C]. Robotics: Science and Systems XVI, Corvalis, USA, 2020. doi: 10.15607/RSS.2020.XVI.020. [7] 张铁林, 李澄宇, 王刚, 等. 适合类脑脉冲神经网络的应用任务范式分析与展望[J]. 电子与信息学报, 2023, 45(8): 2675–2688. doi: 10.11999/JEIT221459.ZHANG Tielin, LI Chengyu, WANG Gang, et al. Research advances and new paradigms for biology-inspired spiking neural networks[J]. Journal of Electronics & Information Technology, 2023, 45(8): 2675–2688. doi: 10.11999/JEIT221459. [8] YANG Jing, LIU Tingqing, REN Yaping, et al. AM-SGCN: Tactile object recognition for adaptive multichannel spiking graph convolutional neural networks[J]. IEEE Sensors Journal, 2023, 23(24): 30805–30820. doi: 10.1109/JSEN.2023.3329559. [9] NAG S, ZHU Xiatian, SONG Yizhe, et al. Zero-shot temporal action detection via vision-language prompting[C]. 17th European Conference on Computer Vision–ECCV, Tel Aviv, Israel, 2022: 681–697. doi: 10.1007/978-3-031-20062-5_39. [10] YANG Fengyu, FENG Chao, CHEN Ziyang, et al. YANG Fengyu, FENG Chao, CHEN Ziyang, et al. Binding touch to everything: Learning unified multimodal tactile representations[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 26330–26343. doi: 10.1109/CVPR52733.2024.02488. [11] CAO Guanqun, JIANG Jiaqi, BOLLEGALA D, et al. Multimodal zero-shot learning for tactile texture recognition[J]. Robotics and Autonomous Systems, 2024, 176: 104688. doi: 10.1016/j.robot.2024.104688. [12] MERIBOUT M, TAKELE N A, DEREGE O, et al. Tactile sensors: A review[J]. Measurement, 2024, 238: 115332. doi: 10.1016/j.measurement.2024.115332. [13] GUO Fangming, YU Fangwen, LI Mingyan, et al. Event-driven tactile sensing with dense spiking graph neural networks[J]. IEEE Transactions on Instrumentation and Measurement, 2025, 74: 2508113. doi: 10.1109/TIM.2025.3541787. [14] HU Jiarui, ZHOU Yanmin, WANG Zhipeng, et al. X-Tacformer: Spatio-tempral attention model for tactile recognition[C]. 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 2024: 9638–9644. doi: 10.1109/ICRA57147.2024.10610365. [15] 杨静, 吉晓阳, 李少波, 等. 具有正则化约束的脉冲神经网络机器人触觉物体识别方法[J]. 电子与信息学报, 2023, 45(7): 2595–2604. doi: 10.11999/JEIT220711.YANG Jing, JI Xiaoyang, LI Shaobo, et al. Spiking neural network robot tactile object recognition method with regularization constraints[J]. Journal of Electronics & Information Technology, 2023, 45(7): 2595–2604. doi: 10.11999/JEIT220711. [16] POURPANAH F, ABDAR M, LUO Yuxuan, et al. A review of generalized zero-shot learning methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 4051–4070. doi: 10.1109/TPAMI.2022.3191696. [17] CAO Weipeng, WU Yuhao, SUN Yixuan, et al. A review on multimodal zero-shot learning[J]. WIREs Data Mining and Knowledge Discovery, 2023, 13(2): e1488. doi: 10.1002/widm.1488. [18] FOTEINOPOULOU N M and PATRAS I. EmoCLIP: A vision-language method for zero-shot video facial expression recognition[C]. 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkiye, 2024: 1–10. doi: 10.1109/FG59268.2024.10581982. [19] ZHONG Shaohong, ALBINI A, MAIOLINO P, et al. TactGen: Tactile sensory data generation via zero-shot sim-to-real transfer[J]. IEEE Transactions on Robotics, 2025, 41: 1316–1328. doi: 10.1109/TRO.2024.3521967. [20] LIU Huaping, SUN Fuchun, FANG Bin, et al. Cross-modal zero-shot-learning for tactile object recognition[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(7): 2466–2474. doi: 10.1109/TSMC.2018.2818184. [21] BI T, SFERRAZZA C, and D’ANDREA R. Zero-shot sim-to-real transfer of tactile control policies for aggressive swing-up manipulation[J]. IEEE Robotics and Automation Letters, 2021, 6(3): 5761–5768. doi: 10.1109/LRA.2021.3084880. [22] MIRZA M J, KARLINSKY L, LIN Wei, et al. Meta-prompting for automating zero-shot visual recognition with LLMs[C]. 18th European Conference on Computer Vision-ECCV, Milan, Italy, 2025: 370–387. doi: 10.1007/978-3-031-72627-9_21. [23] NAGAR A, JAISWAL S, and TAN C. Zero-shot visual reasoning by vision-language models: Benchmarking and analysis[C]. 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 2024: 1–8. doi: 10.1109/IJCNN60899.2024.10650020. [24] LIU Cheng, WANG Chao, PENG Yan, et al. ZVQAF: Zero-shot visual question answering with feedback from large language models[J]. Neurocomputing, 2024, 580: 127505. doi: 10.1016/j.neucom.2024.127505. [25] YELENOV A, UMURBEKOV I, KENZHEBEK D, et al. Zero-shot reasoning with haptic and visual feedback in vision-language-action robotic manipulation[C]. The CLAWAR 2025 Conference on AI Enabled Robotic Loco-Manipulation, Yokohama, Japan, 2025: 205–216. doi: 10.1007/978-3-032-09427-8_20. [26] BOULENGER V, MARTEL M, BOUVET C, et al. Feeling better: Tactile verbs speed up tactile detection[J]. Brain and Cognition, 2020, 142: 105582. doi: 10.1016/j.bandc.2020.105582. [27] MILLER T M, BLANKENBURG F, and PULVERMÜLLER F. Language, but not music, shapes tactile perception[J]. Language and Cognition, 2025, 17: e53. doi: 10.1017/langcog.2025.10006. [28] AKATA Z, PERRONNIN F, HARCHAOUI Z, et al. Label-embedding for attribute-based classification[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 819–826. doi: 10.1109/CVPR.2013.111. [29] CHI Wei, ZHANG Ying, ZHANG Xiaolu, et al. MA-SGNN: A multi-view adaptive spiking graph neural network for event-based tactile recognition[C]. 2025 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Wuhan, China, 2025: 2088–2093. doi: 10.1109/BIBM66473.2025.11355976. [30] 曹毅, 吴伟官, 李平, 等. 基于时空特征增强图卷积网络的骨架行为识别[J]. 电子与信息学报, 2023, 45(8): 3022–3031. doi: 10.11999/JEIT220749.CAO Yi, WU Weiguan, LI Ping, et al. Skeleton action recognition based on spatio-temporal feature enhanced graph convolutional network[J]. Journal of Electronics & Information Technology, 2023, 45(8): 3022–3031. doi: 10.11999/JEIT220749. [31] XIAN Yongqin, LORENZ T, SCHIELE B, et al. Feature generating networks for zero-shot learning[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5542–5551. doi: 10.1109/CVPR.2018.00581. [32] XU Zhengtong, UPPULURI R, ZHANG Xinwei, et al. UniT: Data efficient tactile representation with generalization to unseen objects[J]. IEEE Robotics and Automation Letters, 2025, 10(6): 5481–5488. doi: 10.1109/LRA.2025.3559835. [33] YU S, LIN K, XIAO Anxing, et al. Octopi: Object property reasoning with large tactile-language models[C]. Robotics: Science and Systems, Delft, Netherlands, 2024. -

 下载:
下载:


图(3) / 表(3)
计量
- 文章访问数: 247
- HTML全文浏览量: 121
- PDF下载量: 9
- 被引次数: 0
